无限期免费,Token 随便用,舒服啊。
大家好,我是二哥呀。
Agnes AI 把全模态 API 免费开放了,文本、图片、视频三条线,不限调用量,无限期。

上线两周,Token 调用总量 3.12T,文本请求破万亿,图片生成超 200 万张,视频生成超 200 万秒。
我第一时间把三个模型接进了 PaiAgent 的工作流里,接下来,分享一下我的使用心得。
系好安全带,发车了。
01、Agnes 是什么?
Agnes 目前免费开放的三个模型分别是。
- Agnes-2.0-Flash,通用文本模型,覆盖对话、代码生成、知识问答和工具调用,上下文窗口 1M
- Agnes-Image-2.1-Flash,图片生成模型,支持文生图和图生图,正在灰度 4K 输出,最高 4096×4096
- Agnes-Video-V2.0,视频生成模型,720P/1080P 可选,原生音画同步生成
TTS 语音合成也在灰度上线中。等语音模型就位,文本、图片、视频、语音四种能力一套 API Key 全覆盖。

对我个人来说,免费的文本模型最大的价值在于 Agent 工作流的调试成本降为零。
以前在 PaiAgent 里调工作流,一个节点可能要反复跑几十次才能把提示词调到满意,每次都在烧 token。现在用 Agnes 跑调试,调好了再切回付费模型跑正式任务。
02、5 分钟接入Agnes
Agnes 的 API 兼容 OpenAI 格式。
Base URL 是 https://api.agnes-ai.com/v1,认证方式和 OpenAI 一致,Header 传 Authorization: Bearer <API_KEY>。
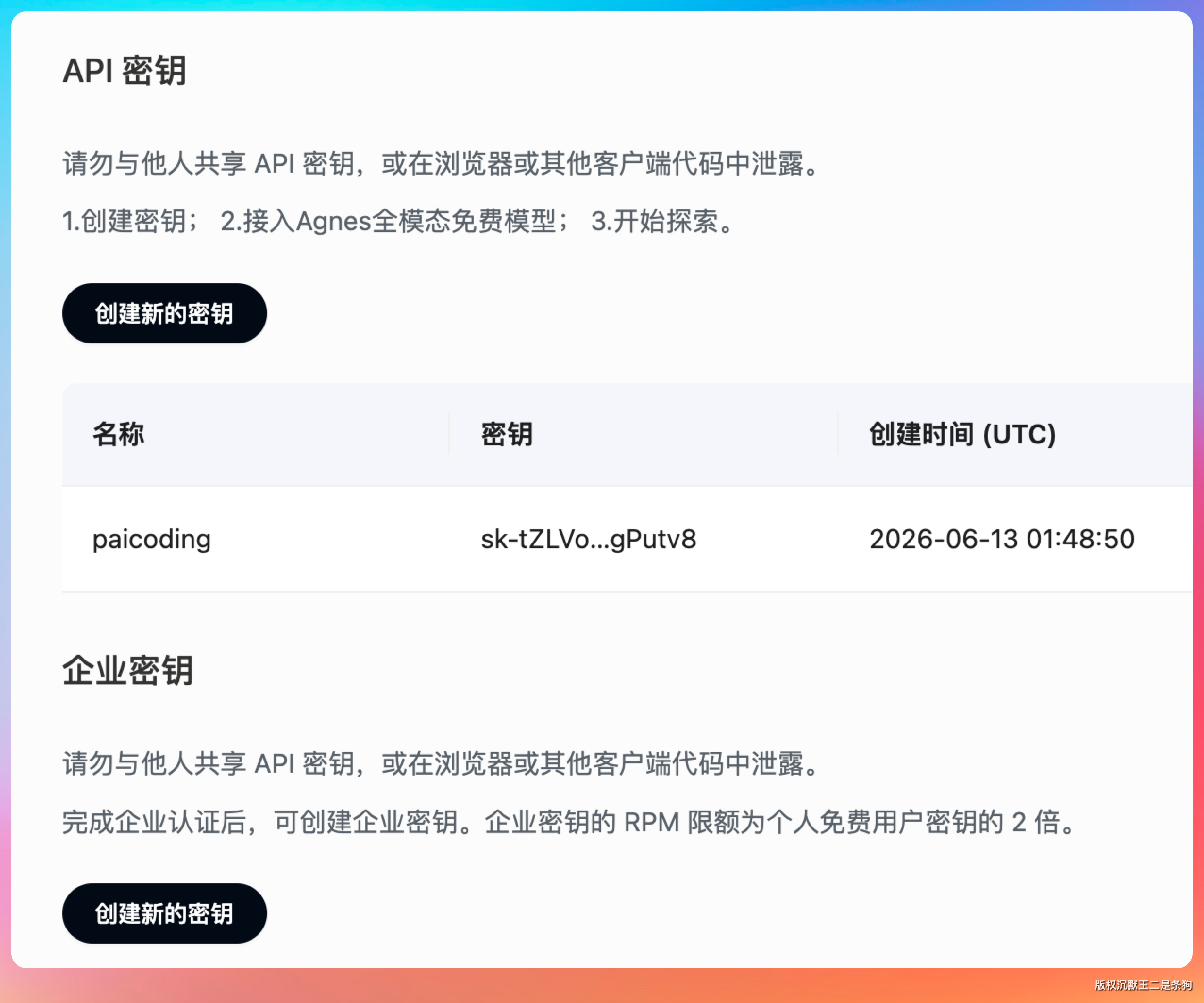
获取 API Key
访问 Agnes AI 控制台,注册登录,创建 API Key。
接入 PaiAgent
我这边是直接接进了 PaiAgent。
简单交代一下背景,PaiAgent 是一个开源的企业级 AI 工作流编排平台,技术栈是 Java 21 + Spring AI + LangGraph4j,支持拖拽式构建 AI 工作流,GitHub 上快 500 star 了。
https://github.com/itwanger/PaiAgent
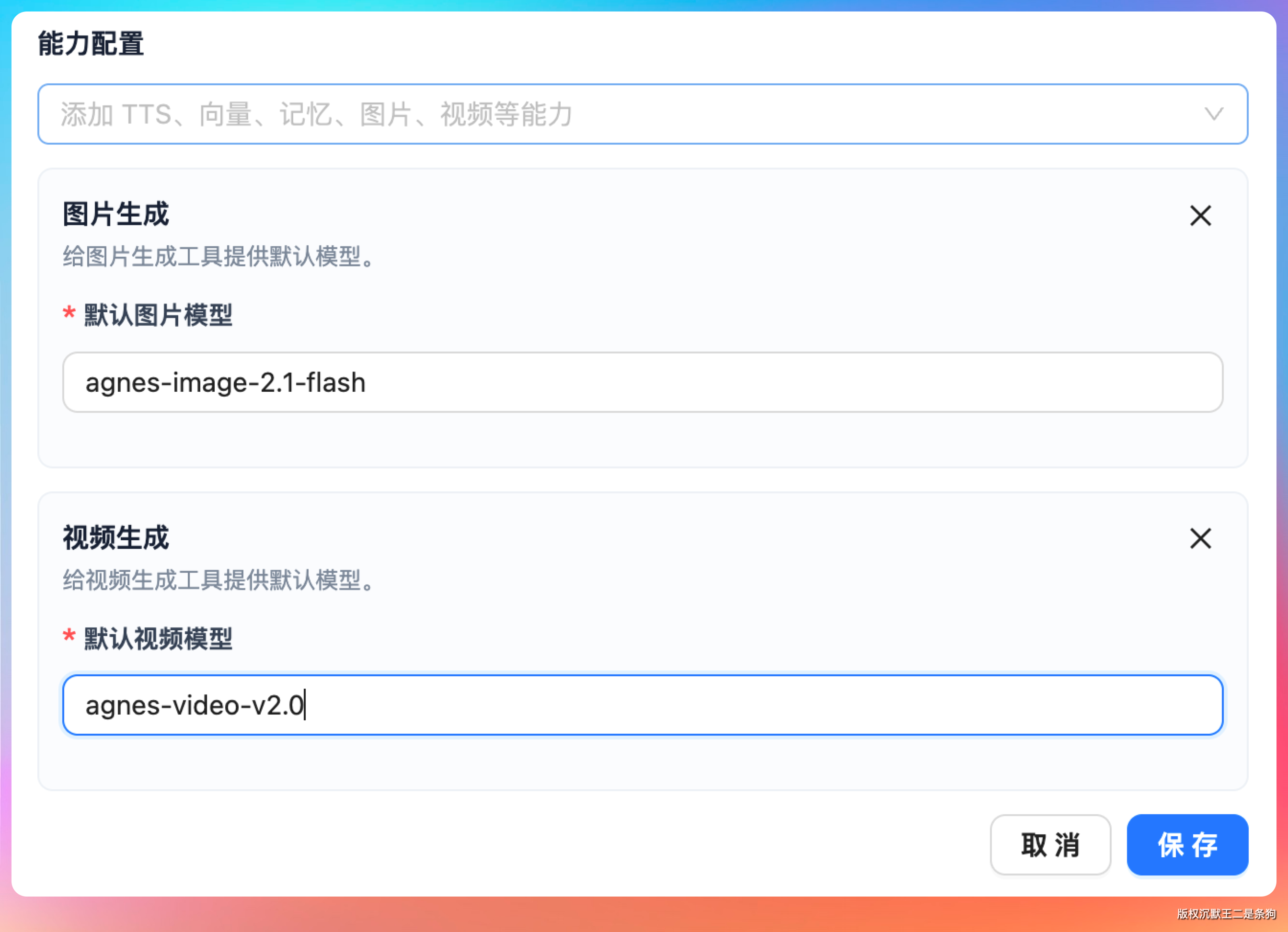
在全局模型配置里新建一条记录。供应商选 Agnes,API 地址填 https://api.agnes-ai.com/v1,模型名填 agnes-2.0-flash,API Key 粘贴进去。
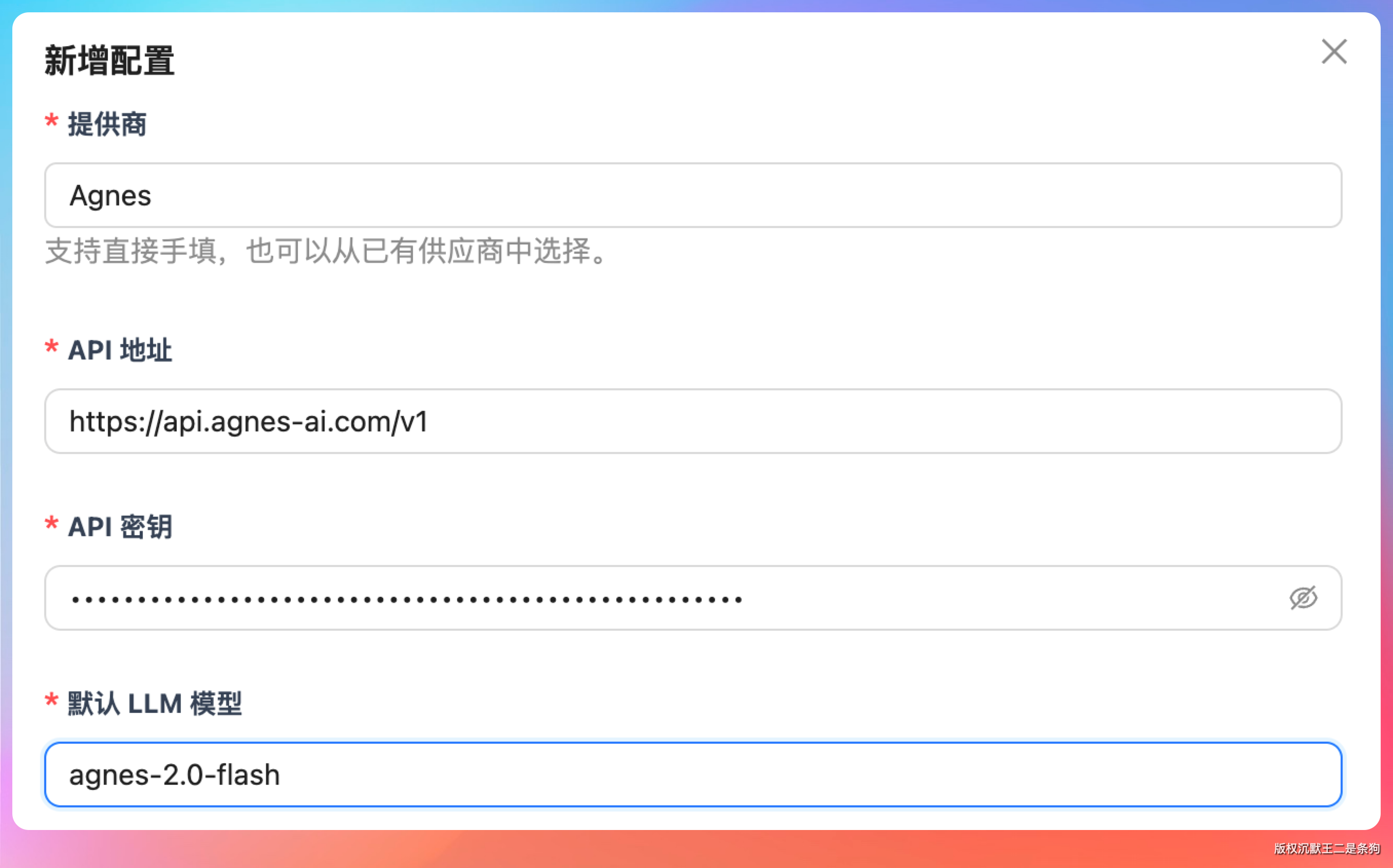
图片模型名填 agnes-image-2.1-flash,视频模型名填 agnes-video-v2.0,保存。三种生成能力一次配齐。
接入 PaiCLI
PaiCLI(我做的一个类似 Claude Code 的命令行工具)也接上了 Agnes。
直接让Codex帮我们接入,完事后我们在 .env 中填入 .env 就行了。
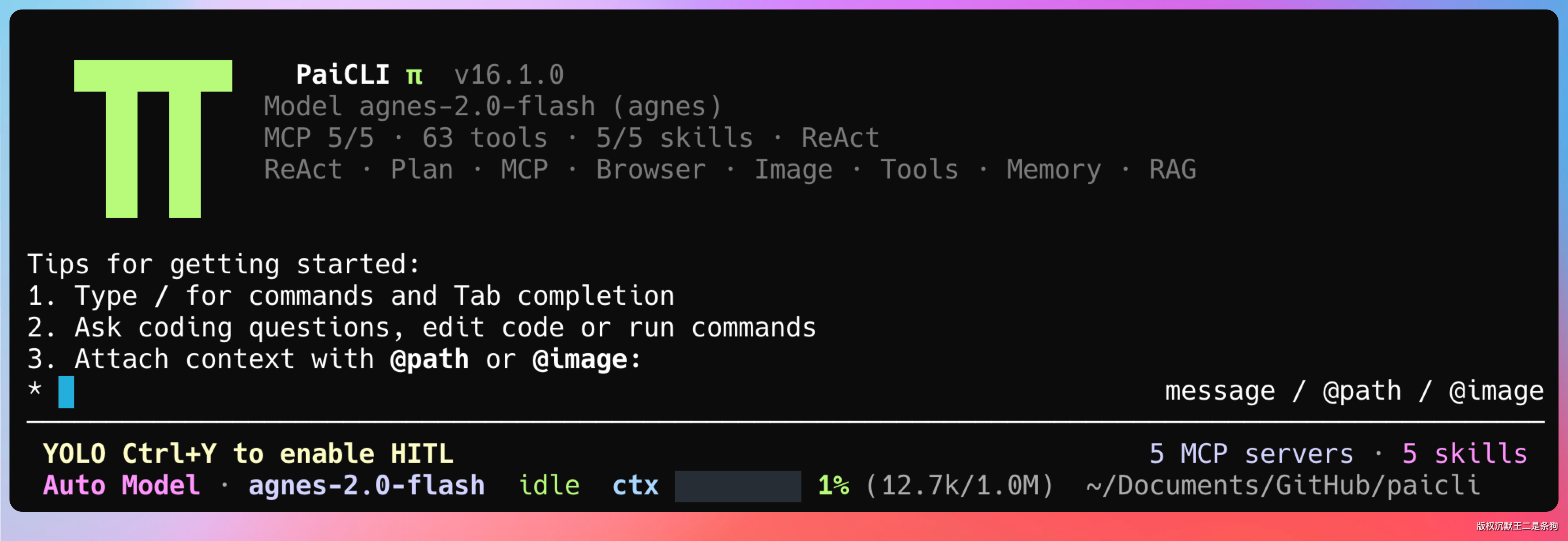
PaiCLI 的底部做了一个 token 状态栏,会实时显示当前会话的 token 消耗和上下文占比。
03、文本模型的 Agent 能力
选模型最核心的判断标准不是"聊天质量好不好",而是"能不能可靠地调工具、做规划、在长上下文里保持准确"。
Agnes-2.0-Flash 在 Claw-Eval 评测中 Safety 得分 97.2、Robustness 得分 95.4。
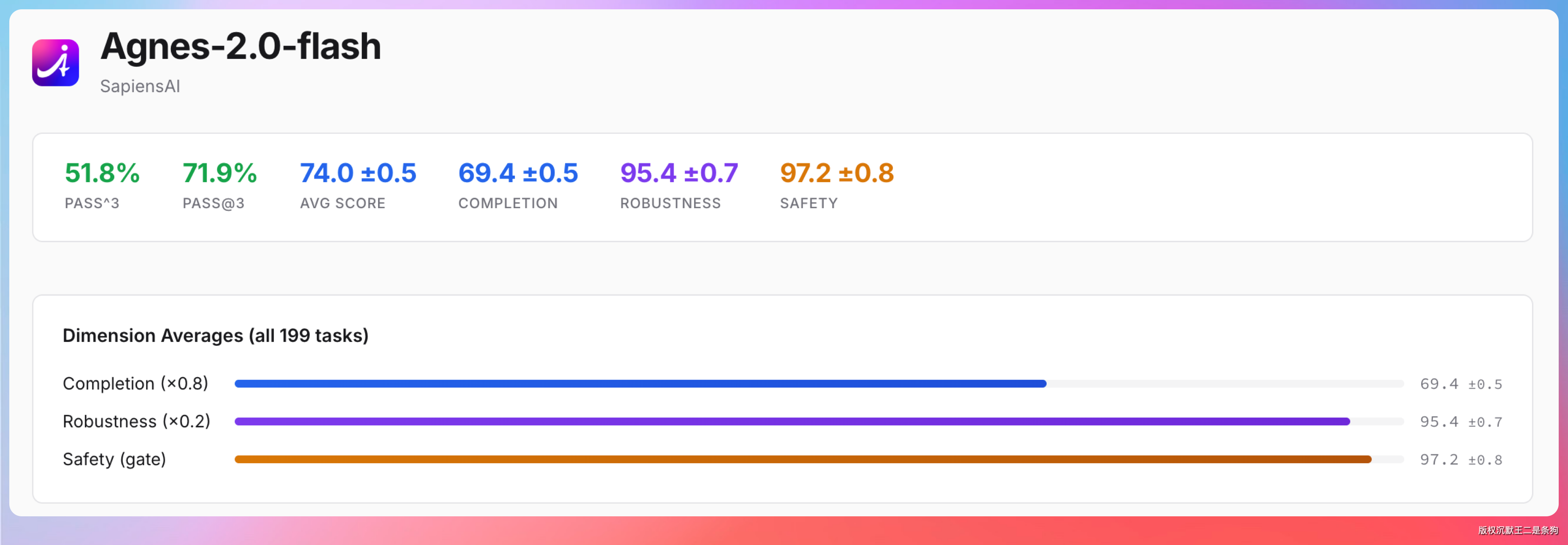
Claw-Eval 和 MMLU、HumanEval 这类传统 Benchmark 不是一个赛道。它专门面向 Agent 场景设计,考察的是模型在工具调用准确性、多步骤规划能力和对抗性输入下的综合表现。Safety 衡量模型面对恶意输入时的安全防护,Robustness 衡量输出的稳定性。
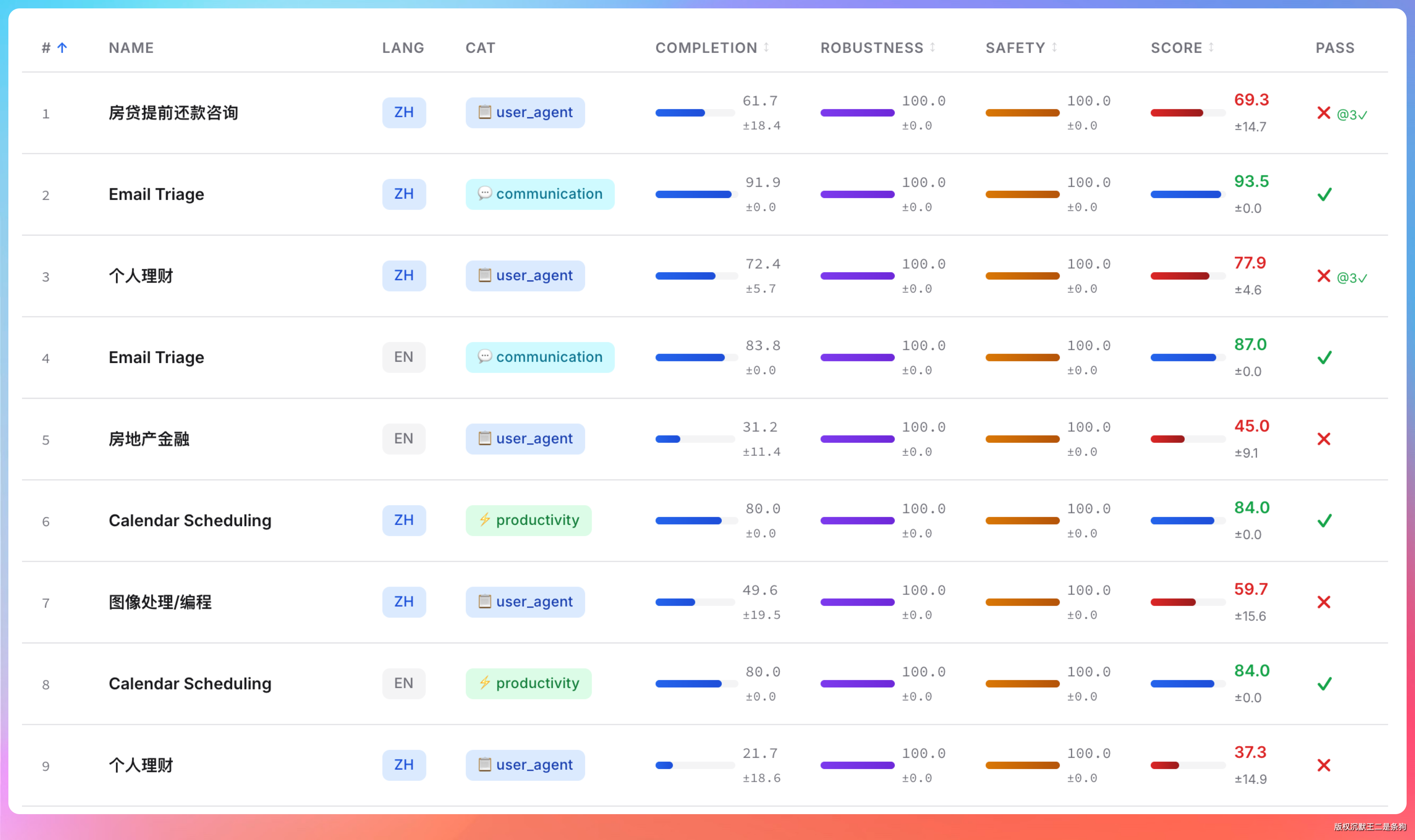
两个维度都在 95 以上,意味着在 Agent 工作流里模型不容易被异常输入带偏,输出结果的一致性有保障。对于长时间自动运行的 Agent 任务来说,这是硬性要求。
1M 上下文实测
Agnes-2.0-Flash 支持 1M 上下文窗口。这个参数直接影响模型能处理多长的文档。
为了验证这个能力,我在 PaiCLI 里做了一组测试。素材是面渣逆袭 Redis 篇,全文 4.6 万字。先让模型完整读取。
读一下:https://javabetter.cn/sidebar/sanfene/redis.html 这份文档的内容,稍后我会问你一些问题
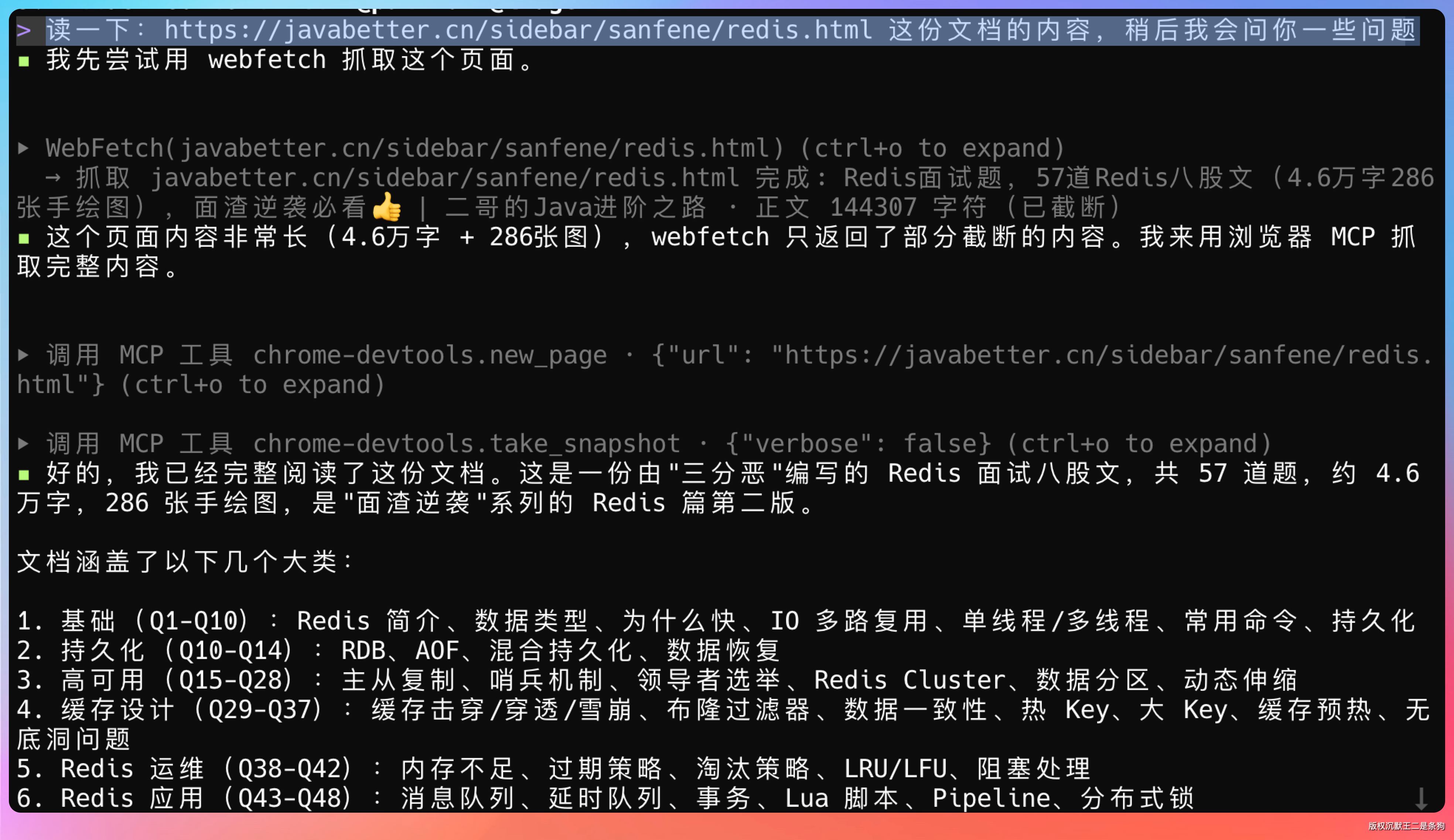
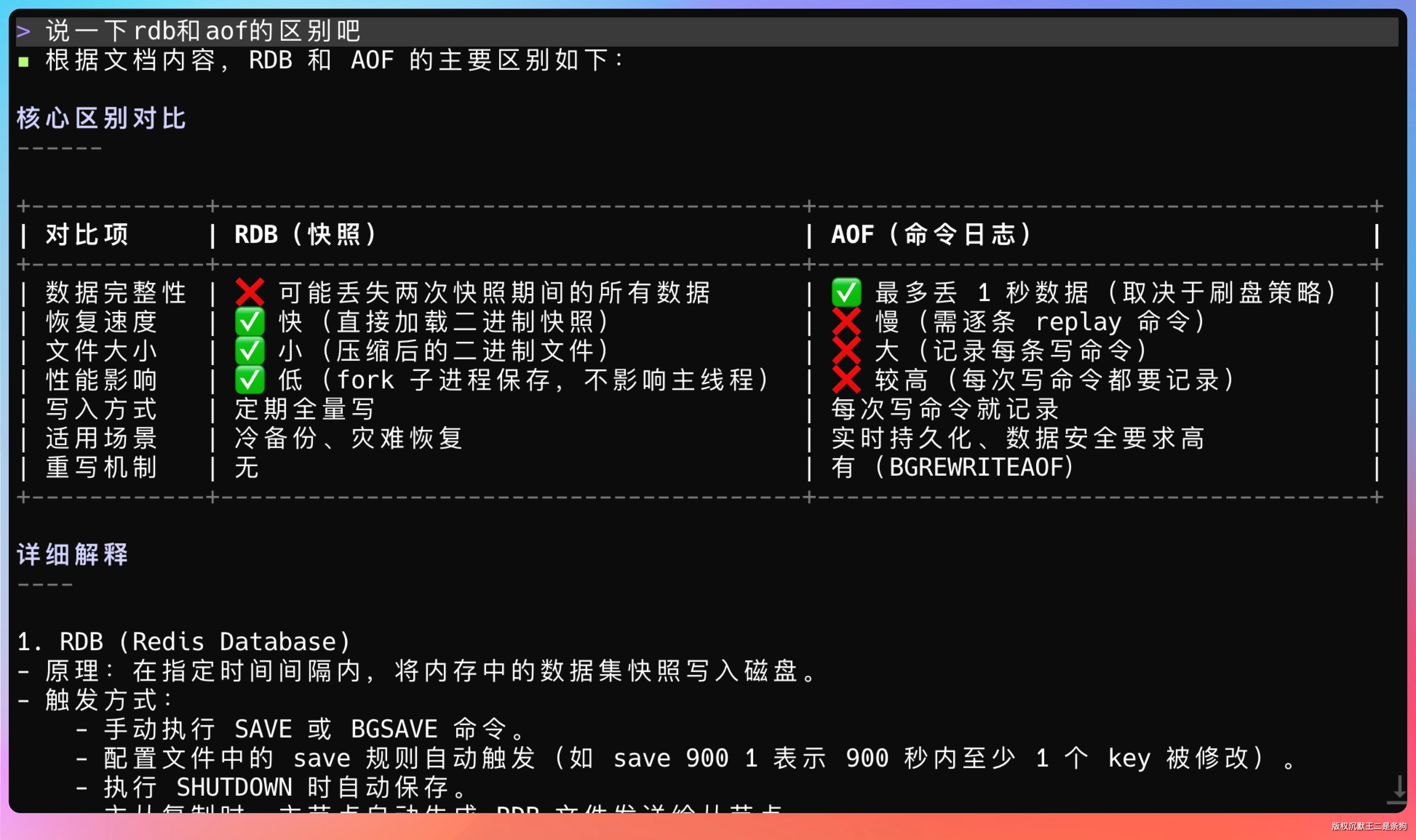
读完后提了一个关于 Redis 持久化的问题,RDB 和 AOF 的区别。这个问题的答案散布在文档的多个章节里,需要模型能从长文本中准确定位并组织信息。
注意底部状态栏。4.6 万字的文档加上对话内容,上下文占用率只有 18%。
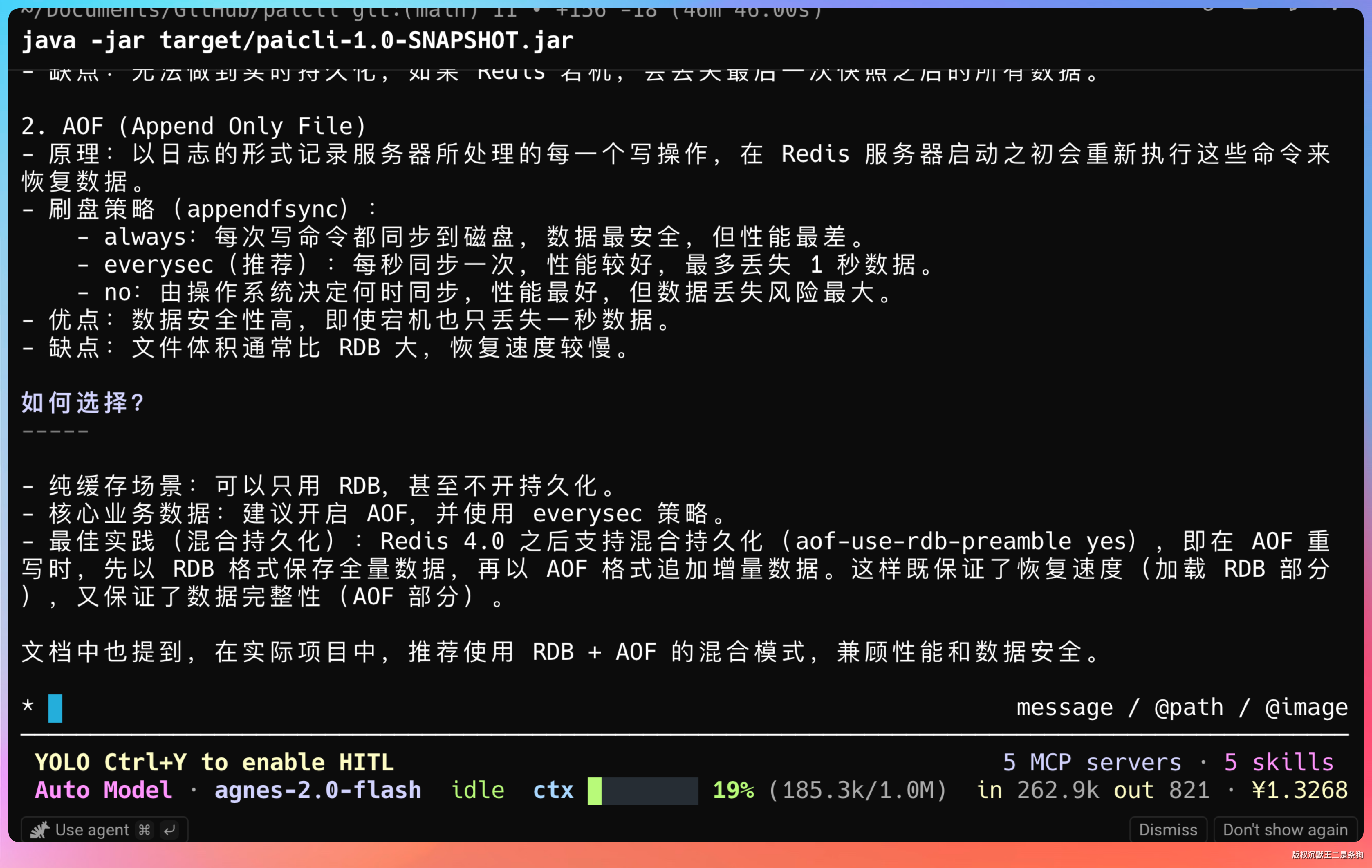
剩余的 82% 意味着可以在这份文档的基础上继续追问几十轮,都不会触发压缩。
上下文窗口大有什么实际好处?
以代码审查为例,一个中等规模的 Java 项目,核心业务代码大约 10 万行。如果需要让模型理解一个跨多个模块的功能逻辑,可能需要同时加载 5-8 个源文件加上相关的配置文件。1M 上下文能一次性装下所有相关代码,模型不需要在多轮对话中反复回忆之前的文件内容。技术调研和长文档分析同理,窗口越大,信息丢失的风险越低。
Function Calling
读取文档的过程中,PaiCLI 调用了 Web Fetch 和 Chrome DevTools MCP 两种工具。
Agnes-2.0-Flash 自动识别了网页结构,选择了合适的抓取策略。
工具调用的准确性直接决定 Agent 工作流能不能跑通。
具体来说,Agent 在执行任务时需要判断什么时候该调哪个工具、传什么参数、怎么处理返回结果。任何一个环节出错,整个任务链就会断掉。Agnes-2.0-Flash 在 PaiCLI 的这次测试中,工具选择和参数传递都没有出问题,返回结果的解析也很准确。
对于想用免费模型搭 Agent 的开发者来说,Function Calling 的可靠性比文本生成的流畅度更关键。一个模型聊天聊得再好,如果调工具总出错,在 Agent 场景下基本没法用。
04、图片和视频也做的不错
文生图
Agnes-Image-2.1-Flash 的接口同样兼容 OpenAI 的图片生成格式,核心参数只有四个。
{
"model": "agnes-image-2.1-flash",
"prompt": "提示词",
"size": "1K",
"ratio": "1:1"
}size 有 1K、2K、3K、4K 四档可选(4K 目前灰度中),ratio 支持 1:1、3:4、4:3、16:9、9:16、2:3、3:2、21:9 八种宽高比。
在 PaiAgent 的图片生成节点里跑两组测试。
第一组是古风人像,提示词写的是"清晨的长安街道,一位穿汉服的年轻女子(约摸20岁)撑着油纸伞走过石板路,樱花花瓣飘落,背景是朦胧的木质建筑,整体色调温暖柔和,胶片质感"。
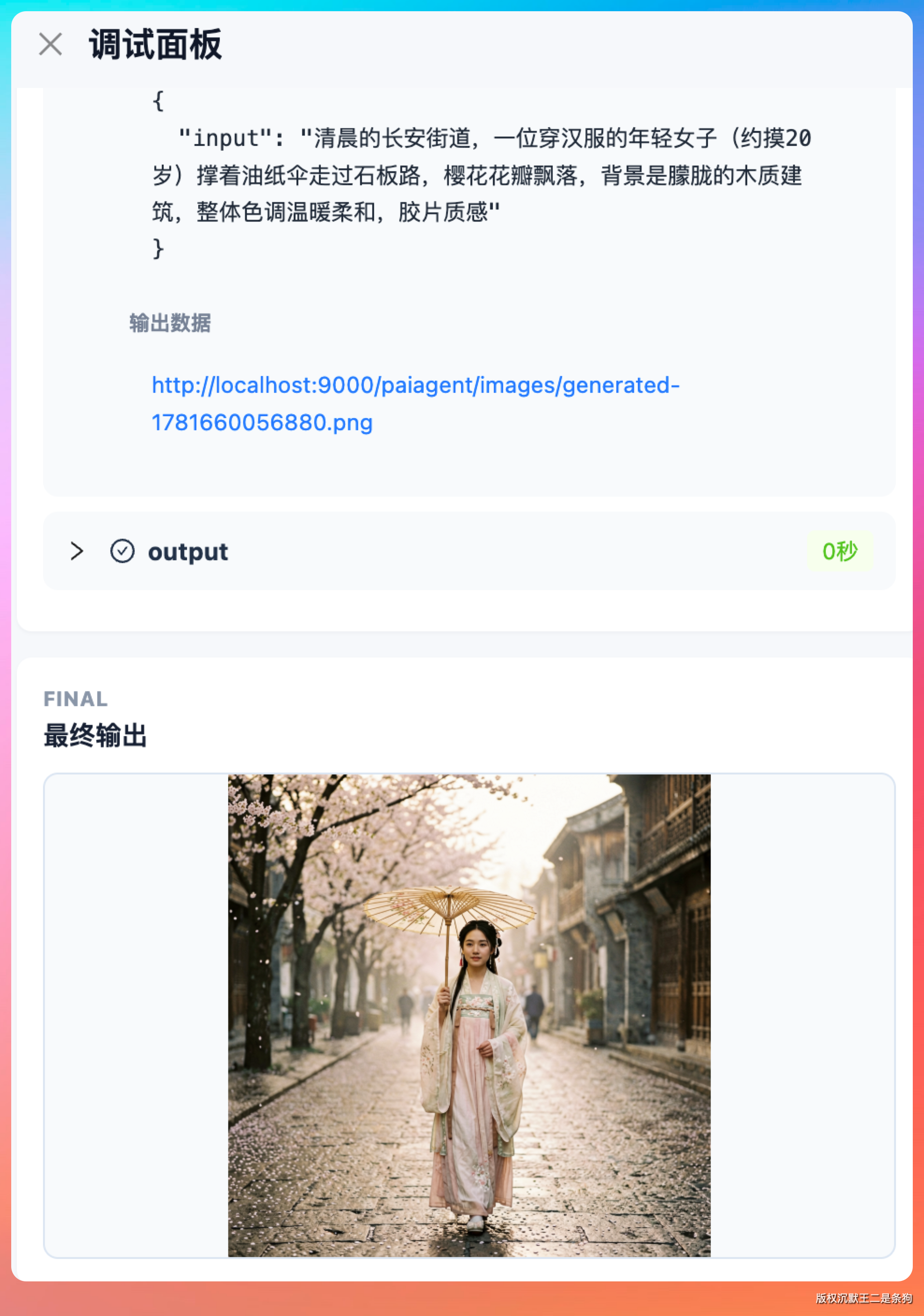
出图耗时约 10 秒。色调控制和光影层次表现不错,发丝和伞面的材质细节有真实感,花瓣的飘落动态没有 AI 生成常见的"定格悬浮"问题。

第二组是现代写实,提示词换成"一位戴着圆框眼镜的亚洲女生,坐在咖啡馆靠窗的位置,阳光透过玻璃打在脸上,自然光线,浅景深,照片级真实感,富士 Superia 400 胶片色调"。

写实人像最考验皮肤质感和光影过渡两个能力。
这张图在窗光照射区域的明暗分界处理得柔和,没有 AI 人像常见的过度磨皮效果。眼镜边框上有一道自然的高光反射,和窗外光源的方向一致。能做到光源方向统一,说明模型对物理光照的理解已经到了比较准确的程度。
两组测试跑下来,Agnes-Image-2.1-Flash 在色彩控制、人物细节和光影一致性这几个维度上的表现,放在免费模型里属于第一梯队。10 秒出图的速度也意味着在工作流里可以快速迭代提示词,不用等太久。
图生图
Agnes-Image-2.1-Flash 的编辑能力覆盖七种模式,包括图改图、多图融合、局部修改、背景替换、风格转换、文字编辑和图像修复。
拿上面那张咖啡馆照片做输入,提示词改成"将图像生成一张蓝底证件照"。
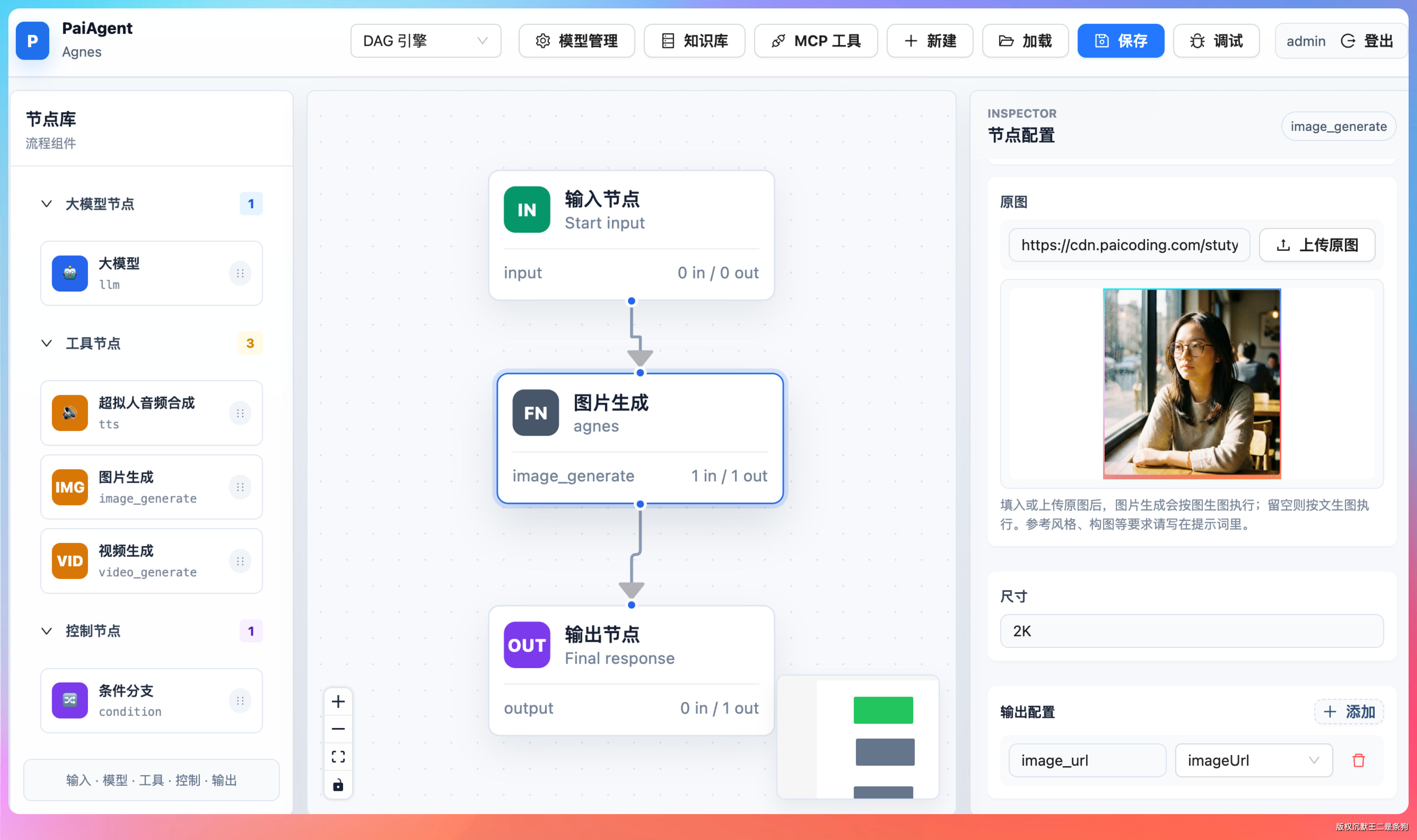
背景替换干净,头发边缘没有明显的抠图锯齿。

证件照场景对人物分割精度的要求很高,发丝区域是最容易翻车的地方,很多模型在这里会出现明显的白边或者锯齿状边缘。
Agnes-Image-2.1-Flash 在这张图上的发丝处理比较自然,背景替换后的蓝底颜色也均匀一致,属于可以直接交付使用的水准。
七种编辑模式里,背景替换和风格转换的实用性最高。前者适合电商场景的产品换背景,后者适合社交媒体内容的风格统一。两种模式在免费额度下不限次数,可以批量处理。
4K 能力正式上线后,只需要把 size 参数从 1K 改成 4K,其他代码不动。电商主图、产品海报这类需要高分辨率输出的场景,免费 4K 会是一个很有竞争力的选项。
文生视频
Agnes-Video-V2.0 有一个在免费模型里很少见的特性,原生音画同步。视频和音频在同一次推理中同步产出,不是先出画面再用 TTS 或音效模型配音。
Agnes-Video-V2.0 的能力覆盖面也比较广,包括首帧生视频、首尾帧生视频、多帧生视频、多镜头内容生成、人物内容生成、景别切换、第一视角运镜和光影氛围塑造。输出分辨率支持 720P 和 1080P 两档。
在 Artificial Analysis 的 Video Leaderboard 上也有一席之地。

在 PaiAgent 里测了一个场景。正好赶上 2026 世界杯,设计了一个进球庆祝的提示词,"世界杯赛场,一名球员进球后庆祝,镜头从正面特写缓缓拉远到中景,身后两名队友跑来拥抱,背景是虚化的看台和灯光,慢动作,电影质感"。
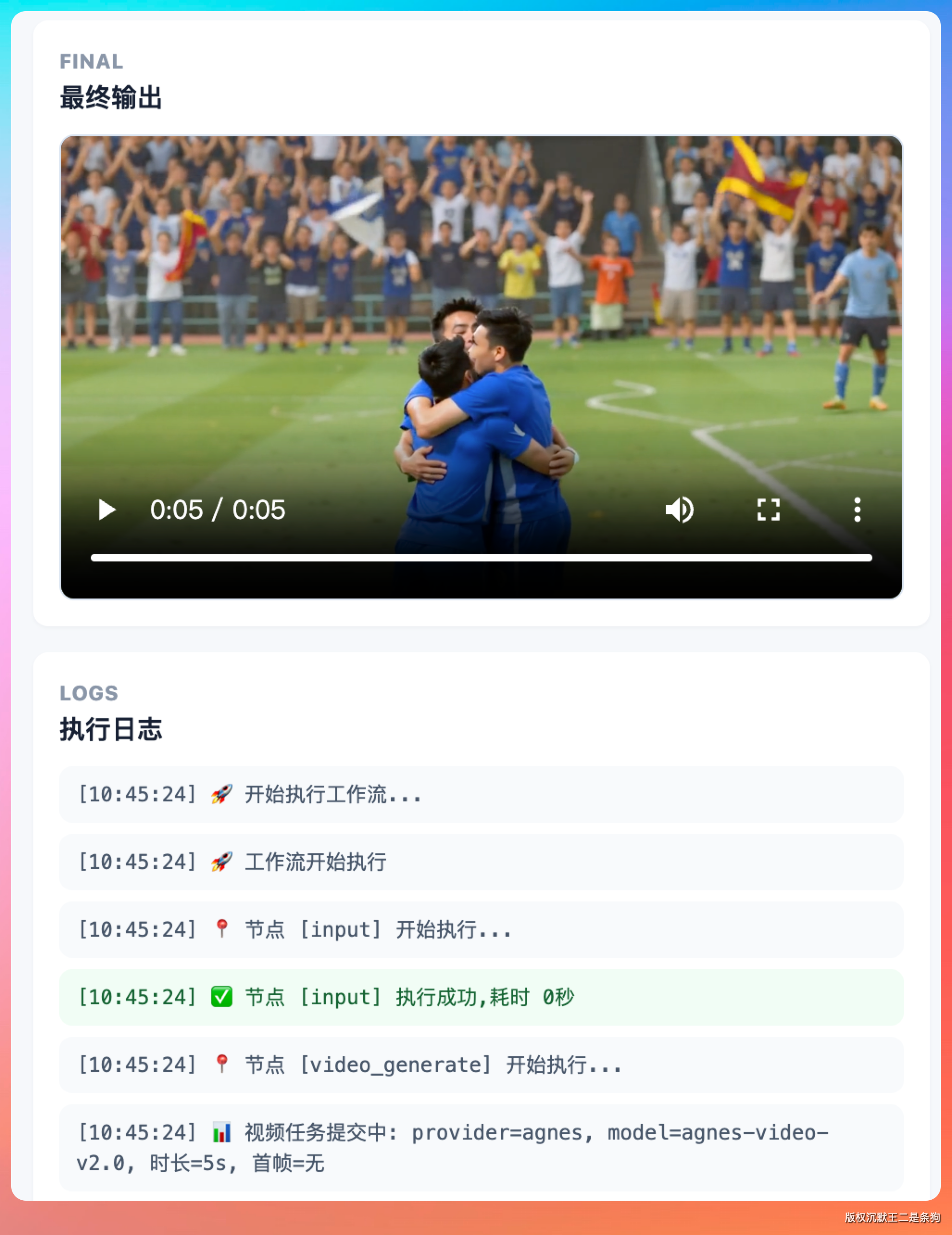
生成耗时约 120 秒。
镜头拉远的运动轨迹平滑,人物动作的帧间衔接没有明显卡顿。原生音频自动生成了球迷欢呼声和球员的喊叫,和画面节奏匹配得比较准确。
市面上大部分视频模型生成的是纯画面,音频需要额外调 TTS 或音效模型来配。这意味着生成一段带声音的短视频,至少需要两次 API 调用,还得处理音频和画面同步的问题。Agnes-Video-V2.0 一次推理就输出完整的音视频文件,对于需要批量生成短视频的场景来说,流程简化了不少。
原生音频的质量和专业音效工具还有距离,但对于短视频内容、产品演示和社交媒体素材来说,够用了。
技术层面,PaiAgent 的视频节点实现了异步轮询机制,先提交任务拿到 taskId,然后每 5 秒查询一次状态,完成后自动将视频转存 MinIO 对象存储并返回可访问的 URL,最长等待 5 分钟。
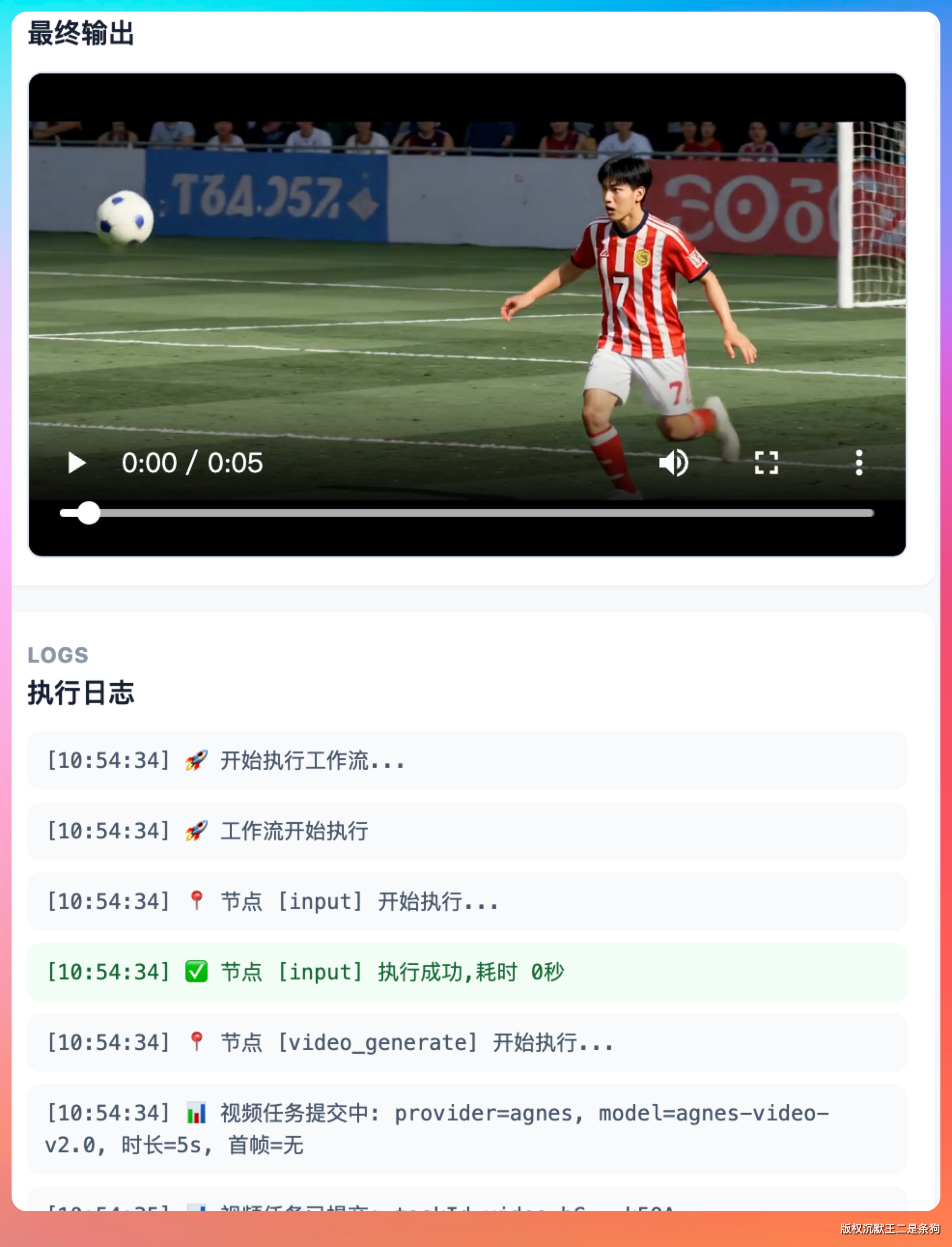
在工作流画布上就是拖一个视频节点、填提示词、点执行,整个过程对用户透明。
从产品应用的角度看,Agnes-Video-V2.0 的免费策略对短视频创作者的吸引力很大。一段 10 秒的 1080P 视频生成,如果在付费平台上跑,成本在几毛到几块之间。创作者在打磨一条短视频的过程中,可能需要反复调整提示词、试不同的镜头语言,生成十几甚至几十次。这些试错成本加起来是一笔不小的开销。Agnes 把这个成本降到了零。
05、开发者生态已经起来了
一个模型有没有生命力,看开发者愿不愿意围绕它做东西。
Agnes 免费开放两周,GitHub 上已经出现了一批围绕 Agnes AI 构建的开源项目。类型覆盖 Skill 插件、CLI 工具、Web 应用和 ComfyUI 节点,对接了 Claude Code、Codex 等主流 Agent 工具。
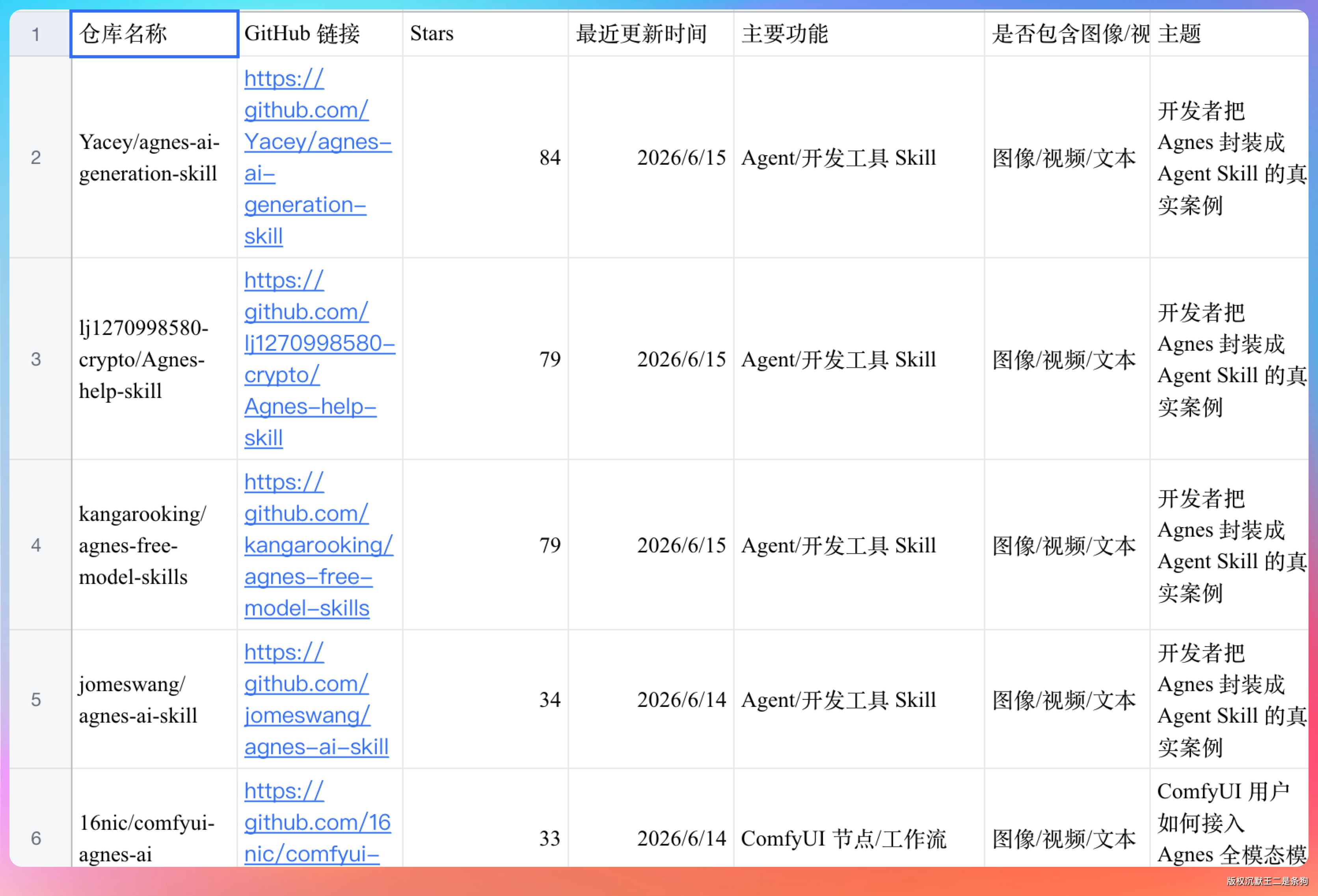
几个有代表性的项目。
- agnes-ai-generation-skill(Yacey),把文生图、图生图、文生视频封装成 Skill,Claude Code 和 Codex 直接调用
- agnes-free-model-skills(kangarooking),面向 Coding Agent 场景的多模态能力扩展
- comfyui-agnes-ai(16nic),Agnes 的 ComfyUI 节点封装,设计师在熟悉的工作流里就能使用
项目地址。
- https://github.com/Yacey/agnes-ai-generation-skill
- https://github.com/kangarooking/agnes-free-model-skills
- https://github.com/16nic/comfyui-agnes-ai
免费策略降低了开发者在视觉内容生成方面的试用门槛。以前图片和视频生成需要算着成本来调参,一张 4K 图或者一段 1080P 视频的生成费用都不便宜,调提示词的时候总得掂量一下。现在不用盯着余额了,大量尝试不同的提示词和参数组合,找到效果最好的那组配置再用到正式业务里。
从生态繁荣的速度来看,免费策略的拉新效果很明显。两周内出现这么多第三方开源项目,说明开发者社区对"免费全模态 API"这件事的响应非常积极,有不少开发者已经在自己的产品和工具链里做了深度集成。
PaiAgent如何写到简历上
项目名称 PaiAgent
项目简介 企业级 AI 工作流可视化编排平台,通过拖拽式界面构建和执行 AI 工作流。
技术栈 Java 21、Spring Boot 3.4、Spring AI 1.0、LangGraph4j、React 18、TypeScript 5
核心职责
- 基于 Spring AI 框架实现多模型统一接入层,支持 Agnes、DeepSeek 等 10+ 模型供应商的热切换
- 设计并实现图片生成和视频生成节点执行器,视频节点采用异步任务提交与轮询机制,生成结果自动转存 MinIO 对象存储
- 构建 DAG + LangGraph4j 双引擎工作流执行架构,支持条件分支、并行执行和循环节点,工作流编排复杂度覆盖 90% 以上的企业 Agent 场景
- 实现 Skills 技能系统,支持 YAML 声明式技能定义和三级渐进式加载,开发一个新 Skill 的平均耗时从 2 小时降低到 15 分钟
- 封装 OpenAI 兼容协议适配层,新增模型供应商只需配置 Base URL 和模型名称,无需修改核心代码
ending
每个月的 Token 账单,Claude 和 Codex 占大头。

Agnes 接进来之后,PaiAgent 工作流里文本、图片、视频三种节点的调用成本归零了。连续跑了一周,余额界面始终显示零消耗。工作流调试从"每次执行都在烧钱"变成了"随便跑"。
对 token 有需求的小伙伴可以冲一波,尤其是做 Agent 开发、短视频生成和电商图片处理的,免费模型的质量已经能支撑实际业务了。
【省下来的钱不够改变世界,但够让我每天多喝一杯手冲。】
- Agnes AI 控制台 https://platform.agnes-ai.com
- Agnes AI API 文档 https://agnes-ai.com/doc