AI Infra超级周期,这六个方向你必须知道
大家好,我是二哥呀。
2025年初DeepSeek的走红,让越来越多人意识到一个关键点:大模型的竞争,早就不只是模型本身的事了,训练和推理过程中的工程优化同样至关重要。
周末我研究了朱亦博老师的一篇技术帖,深受启发,我把亦博老师总结的AI Infra六大重点方向,用咱们程序员能听懂的方式给大家讲讲。
说实话,这六个方向如果啃论文的话,真的挺烧脑。但理解了这些,你就能明白为什么2026年AI Infra会成为超级周期,以及咱们Java程序员和AI开发者到底该往哪个方向发力。好,我们直接来逐个拆解。
01、分布式推理:让模型跑得更快
要理解分布式推理,得先搞懂两个基本概念。混合专家模型MoE是由门控网络和若干专家模型组成的,门控网络负责选择合适的专家来处理问题,不同专家擅长不同领域,关键特性是"稀疏激活",也就是处理单个请求时只激活少数专家。
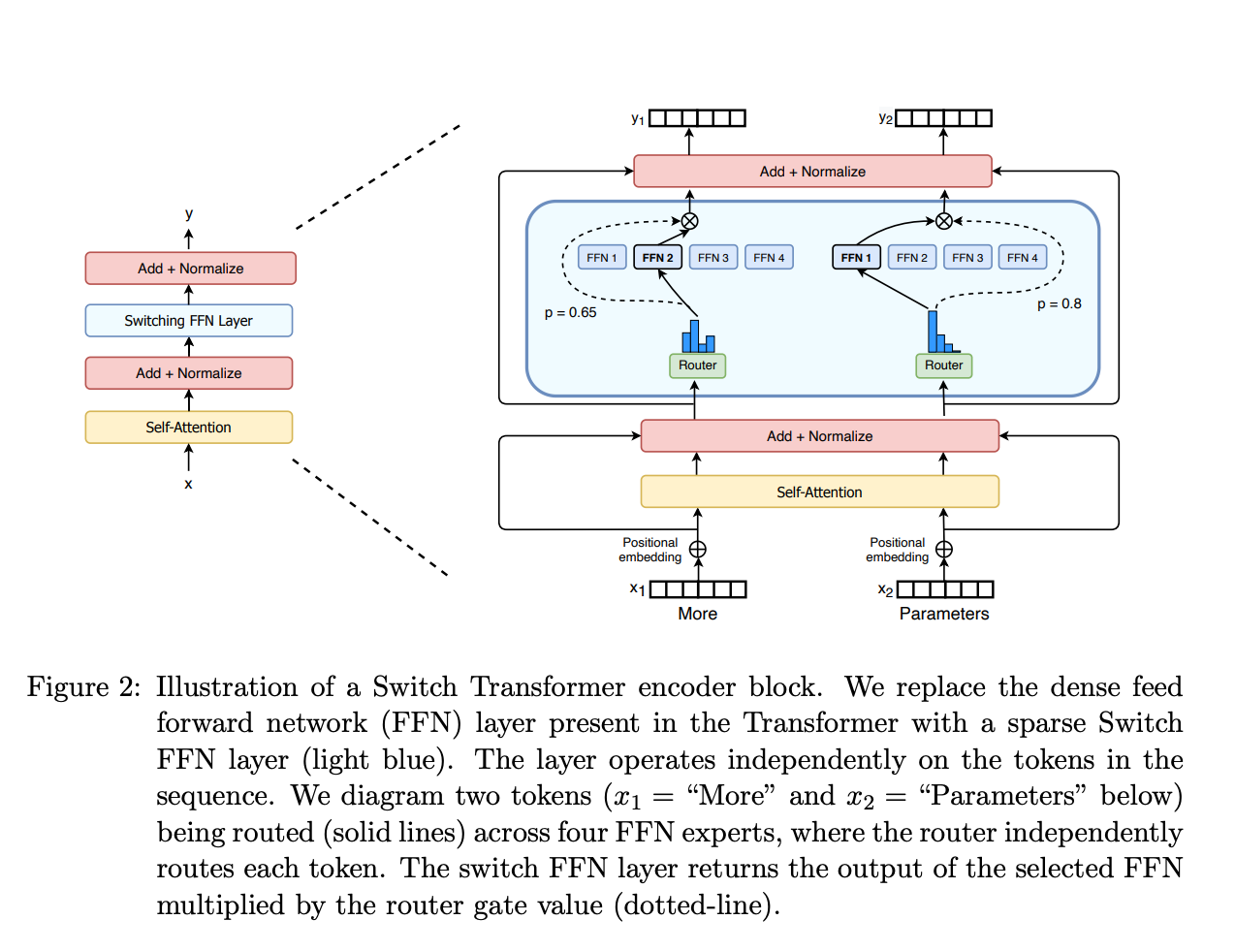
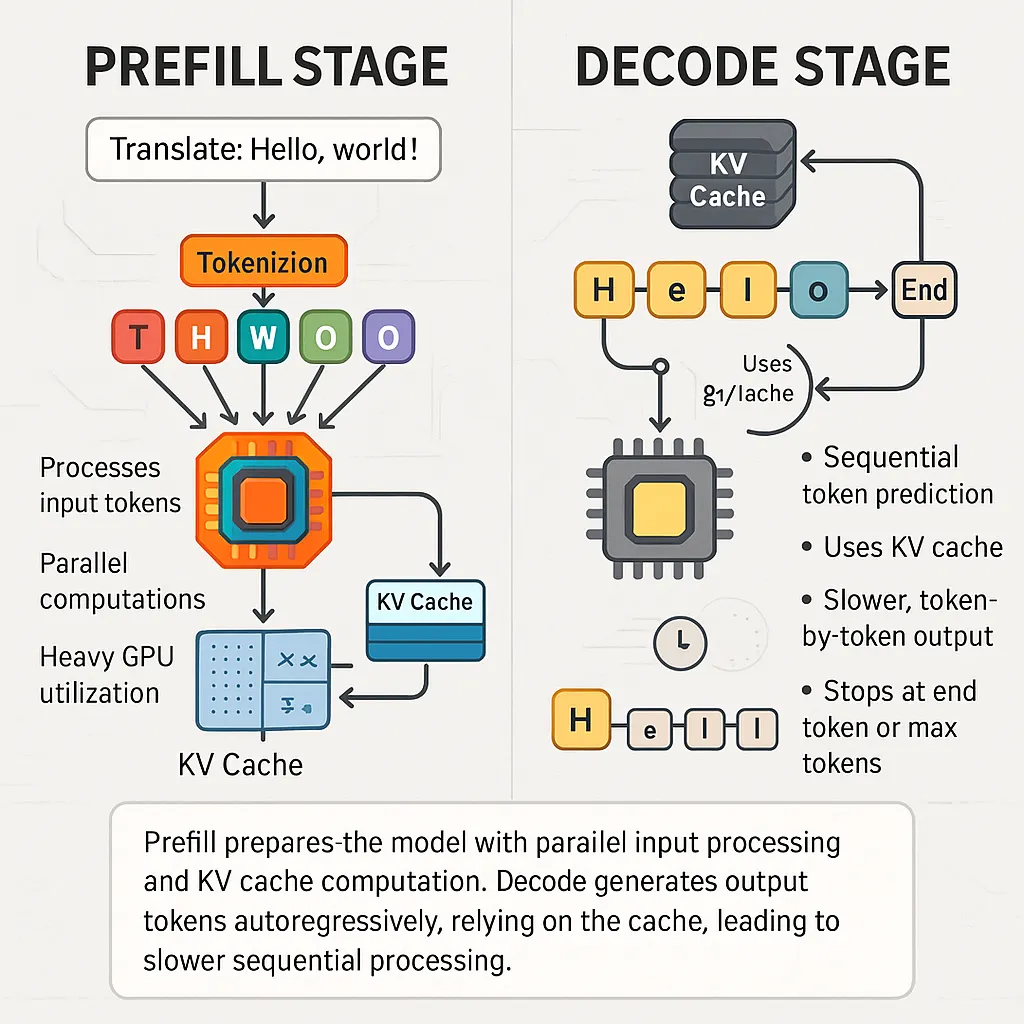
自回归仅解码架构是模型生成文本的方式,推理分为prefill和decode两个阶段。
prefill将输入转换为K、V并生成首个token,decode则是基于已有K、V逐词生成输出。这两个阶段对资源的需求完全不同,prefill是计算密集型,decode是访存密集型。
看懂了这两个基础,就能理解现在主流的优化思路了。
既然不同阶段资源需求不同,那就把它们拆开部署,这就是PD分离的由来。
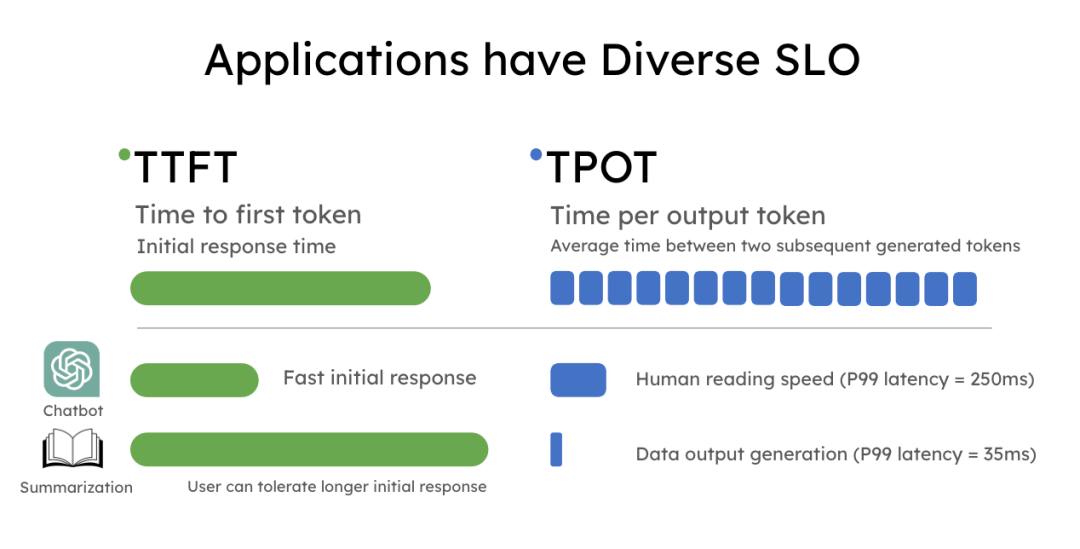
DistServe论文首次提出这个概念,把prefill和decode分别部署在不同设备上,或者同一设备的不同GPU上,这样就避免了相互干扰,可以独立优化TTFT(首个token响应时间)和TPOT(后续平均token生成时间)这两个核心指标。
你可能会问,这样拆开部署有什么好处呢?
根据论文实验数据和大规模推理服务的实践来看,同样的资源,PD分离确实能承载更多请求,或者为相同请求提供更优的响应速度。说真的,这个优化思路在工程实践中效果很明显。
但PD分离也不是完美的,特别是在混合长度请求的场景下,会出现生产者-消费者失衡的问题。
预填充实例处理速度和解码实例消费速度不匹配,导致部分实例资源利用率过低或过载。于是DOPD论文提出了动态调整P、D实例的策略,通过资源监控、请求路由、KV通信等组件实现自动扩缩容,这个在负载波动大的场景下尤其有效。
进一步的优化思路是,既然prefill和decode可以分离,那decode阶段的注意力模块和前馈网络模块能不能也分离呢?
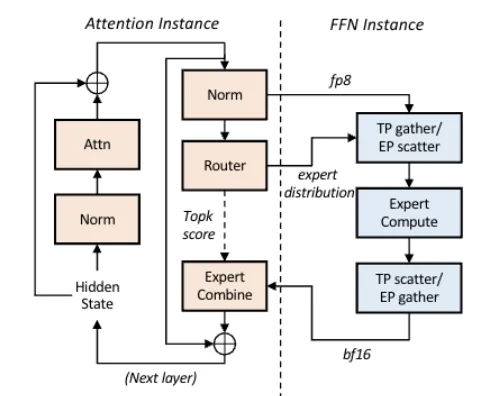
Step-3模型论文提出的AFD架构就是这个思路,将访存密集型的Attention模块和计算密集型的FFN模块部署在不同设备上。
实验数据显示,用H20部署Attention实例,H800部署FFN实例,既能提升效率又能降低硬件成本,甚至FFN部分可以考虑国产化硬件,打破对高端GPU的单一依赖。
再来看看MoE模型的跨机部署问题。主流大模型比如DeepSeek V3系列有约1.4万个专家模型,单卡或单台服务器根本承载不了。
MoE模型的稀疏激活特性意味着每次输入只激活少量专家,未激活的专家算力处于闲置状态。同时跨机部署时的GPU通信如果用NCCL这种传统通信库,效率很低,因为NCCL擅长全量密集通信,而MoE只需要按需传输。
DeepSeek开源的DeepEP通信库就是专门为MoE稀疏通信设计的,支持原生FP8精度通信,具备通信-计算重叠能力。腾讯网络平台部门在此基础上结合TRMT技术进行优化,大幅提升了在RoCE网络下的效率。讲真,这种针对性的优化在工程实践中价值巨大。
02、面向Tile的开发语言:让算子优化更简单
高性能训练或推理的内核优化,一直是一件很精细化的工作。
要精确定义thread、block、grid如何调度,各种硬件的tensor计算核心如何使用,各级缓存如何访问。传统的优化方式都是针对硬件特性的精细化设计加上复杂的调优手段,核心目的是高效处理数据来提升算子或模型的整体效率。
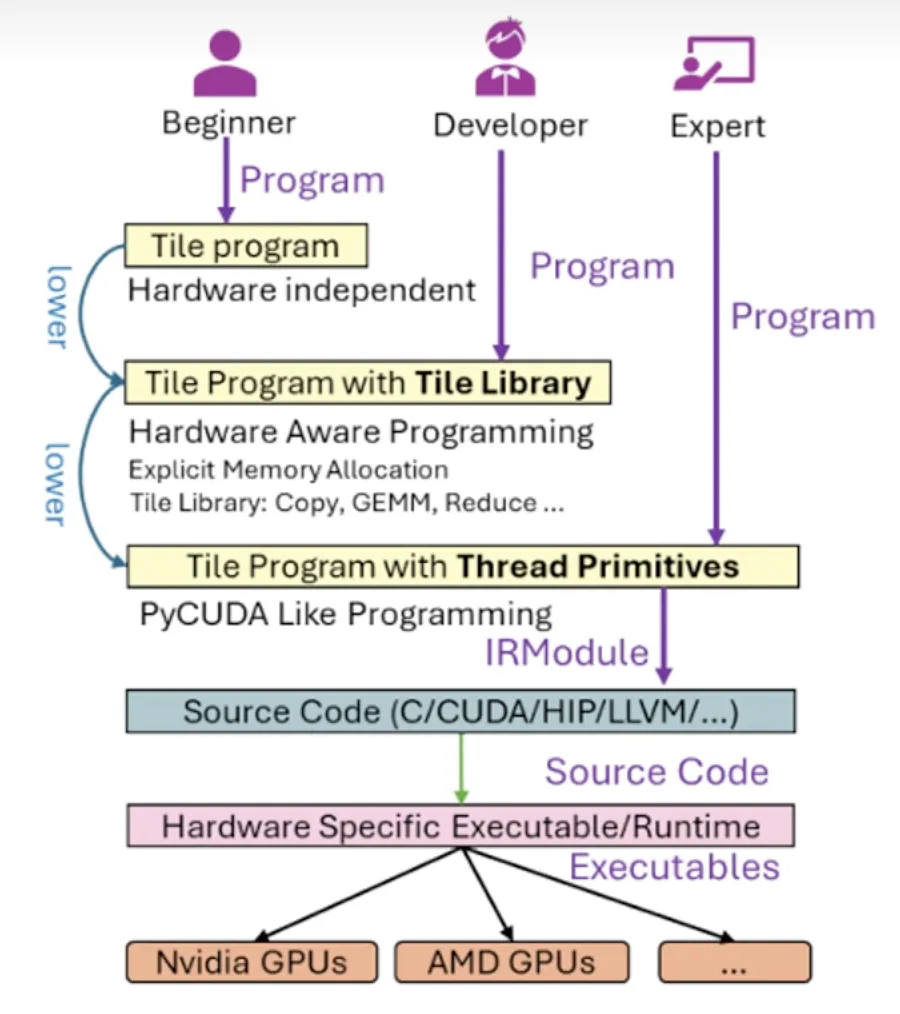
那问题来了,能不能有一种开发语言,让开发者只聚焦于数据流开发,不用过多关注底层调度呢?TileLang就是这个方向的技术探索。
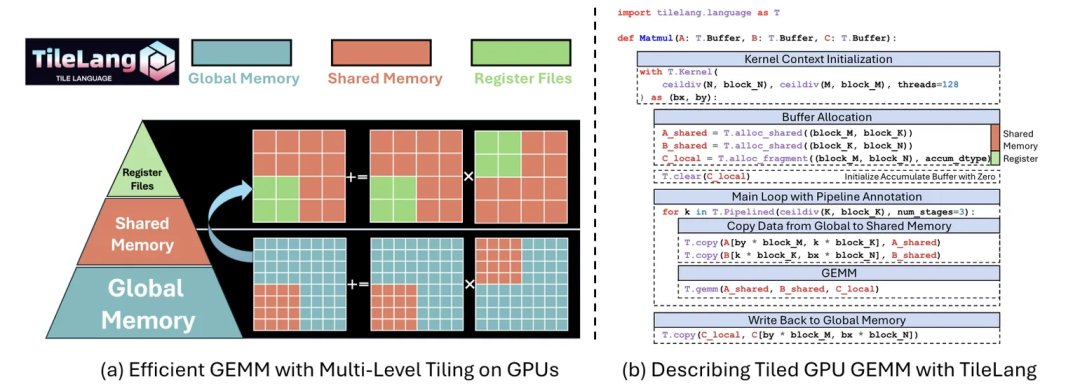
TileLang是一种将数据流与调度逻辑彻底解耦的语言,开发者只需专注数据流逻辑,调度策略交给编译器完成。
论文中给出了一个矩阵乘法的例子,仅需简洁的几种矩阵定义、内存分配、流水线定义和算子调用,就实现了矩阵乘法运算。
这种语言提供了三个层级的编程方式。入门版只描述数据块和计算逻辑,其余硬件实现细节和优化全部由编译器完成。进阶版可以调用一些封装的算子,兼顾开发效率和灵活性。精细版则可以进行精细化的线程级开发,适用于极致性能优化场景。这三个层级还可以混合使用。
根据论文实验数据,TileLang可以用少量代码提供更优的模型效率。值得一提的是,DeepSeek V3.2官方文档中也明确说明,部分算子采用TileLang进行了重构。这一点特别能说明这个技术的实用价值。
03、RL训推分离:解决训练和推理的资源矛盾
强化学习训练使用的数据集,是由模型推理产生,或者模型推理产生加人工标注产生的。如果把训练任务和生成数据集的推理任务部署在同一集群上,部署难度和调度难度确实比较低,但会带来几个明显问题。
训练和推理两个阶段的优化思路完全不同,耦合在一起优化难度极大且会相互影响。训练和推理对硬件的需求也不同,无法通过异构硬件部署提升性价比。训练或推理各自过程中如果出现异常,会影响到对方环节。
解决方案还是老思路,把两个阶段解耦开来独立优化。但训推分离的实践又会出现新问题,推理的输出可能经过Agent复杂的处理逻辑,训练和推理流程间的时序依赖关系很容易造成"气泡"式的算力资源浪费。
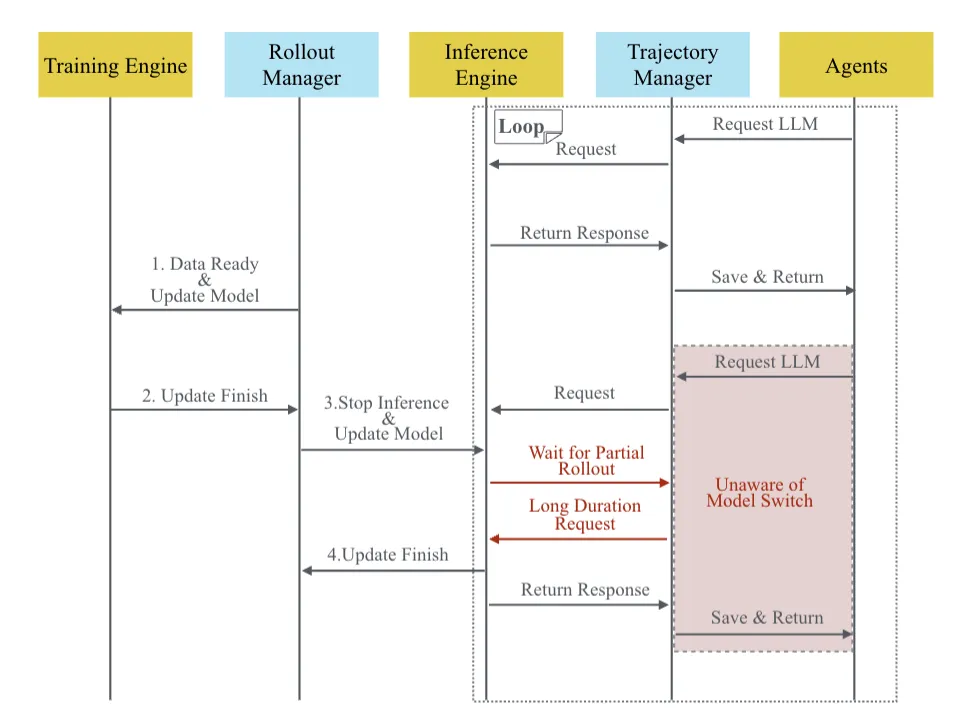
SeamlessFlow论文针对第一个问题设计了一个数据交互平面,介于Agent和LLM之间,核心是"轨迹管理器",把Agent调用LLM的全过程以及全部输入输出精准记录,保障一致性,同时这个过程对Agent完全透明。
针对第二个问题,SeamlessFlow给出了一个巧妙的解决方案,不在分离和一体中做抉择,而是选择灵活的资源调度方式。通过标签机制给资源分配任务,某些资源可以按需灵活执行推理或训练阶段的任务,从而消除计算资源气泡。
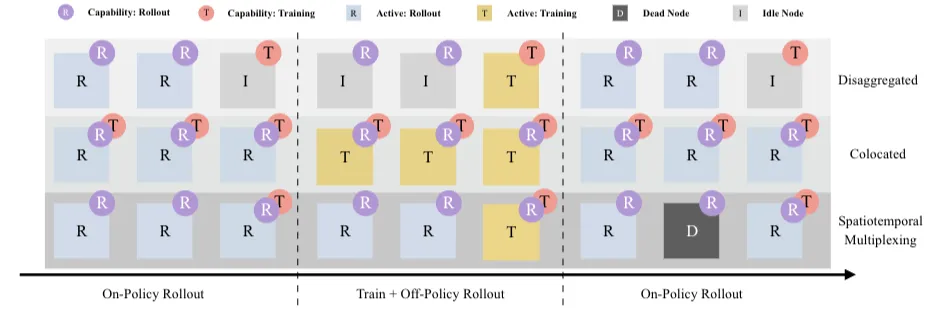
这种设计思路在工程实践中真的很有启发性,不是非黑即白的选择,而是根据实际情况灵活调度。
04、模型-系统的协同设计:从优化到设计
几乎所有的模型训练或推理优化思路,都是基于模型的特点来针对性优化。那如果在模型设计的时候就结合更高性价比的硬件去设计呢?
Step-3模型就是在模型-系统协同设计的思路下设计完成的。
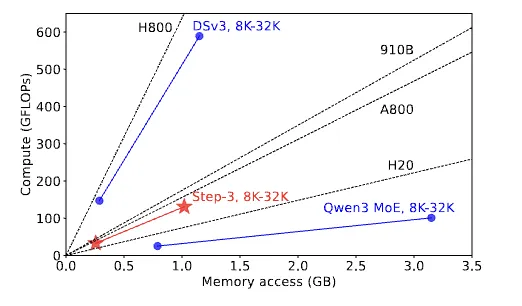
Step-3论文提出了"算术强度"的概念,即和显存交互平均每个字节所需要运算的次数。算术强度和Attention模块的设计有关,和batch size、上下文长度这些参数无关。
同时GPU硬件的算力和显存带宽也是固定的,硬件的算力-带宽比也是固定的。
当模型的算术强度高于硬件的roofline时,硬件算力成为瓶颈,反之则内存带宽成为瓶颈。在设计模型的Attention模块时,算术强度应尽可能接近主流硬件的roofline,这样整体效率才较优。这个设计思路真的很精妙。
量化方案的设计也需要考虑。针对Attention模块,如果采用不同精度的量化,模型的算术强度会发生变化。Step-3模型无论算术强度是提升还是降低,都有可以匹配的硬件可用,这种灵活性在模型-系统协同设计时特别重要。
MoE模型与系统架构的联合设计也需要考虑多方面因素。在AFD架构下,如果BatchSize过大,网络传输耗时增大从而增大TPOT。因此做模型设计时,需要综合设计模型和系统,让模型的稀疏度、隐状态值、层数与卡型、网络带宽和期望TPOT值进行合理的设计与匹配。
这种协同设计的思路,比起单纯优化,更能在源头上提升效率。
05、Agent Infra:贾维斯离我们还有多远
关于Agent Infra,这块内容现在真的是热火朝天。先来看主流Agent框架的对比,GitHub上热度前五的框架各有特点。
AutoGPT适合各类通用任务,完全自主执行任务,但复杂任务场景下前后文一致性和成本效率是问题。LangGraph适合可明确拆解任务步骤的场景,灵活的多步骤控制和易调试是优势,但自主性有限。
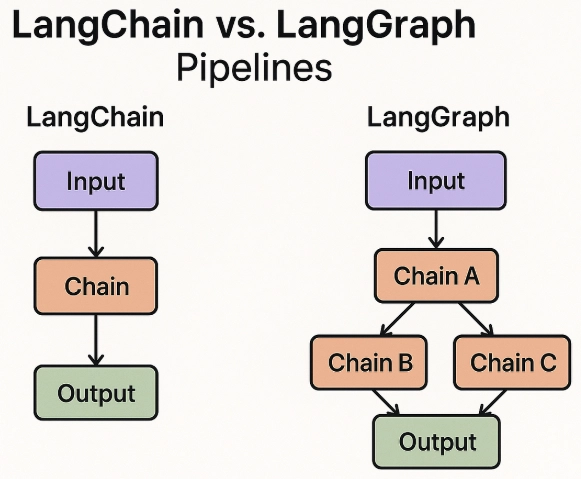
Workflow和Agent的选择也很关键。Workflow适合任务步骤确定、条件有限的流程,通过预设路径执行任务。
Agent适合任务步骤无固定分支,需要在对话上下文里做决策、需要跨工具动态组合的场景。
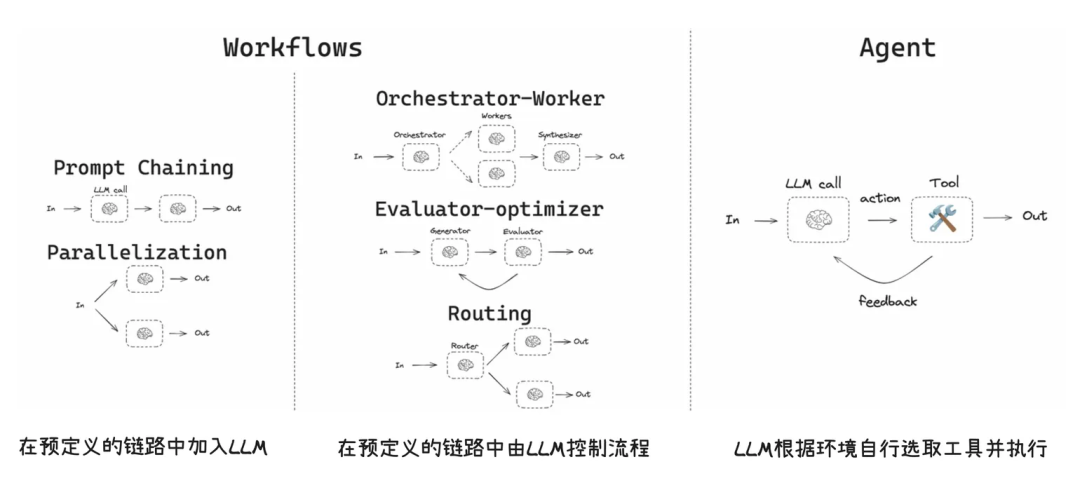
MCP技术标准也是Agent应用开发的新范式。MCP是一个标准协议,定义了AI应用与外部工具和数据源的交互标准。
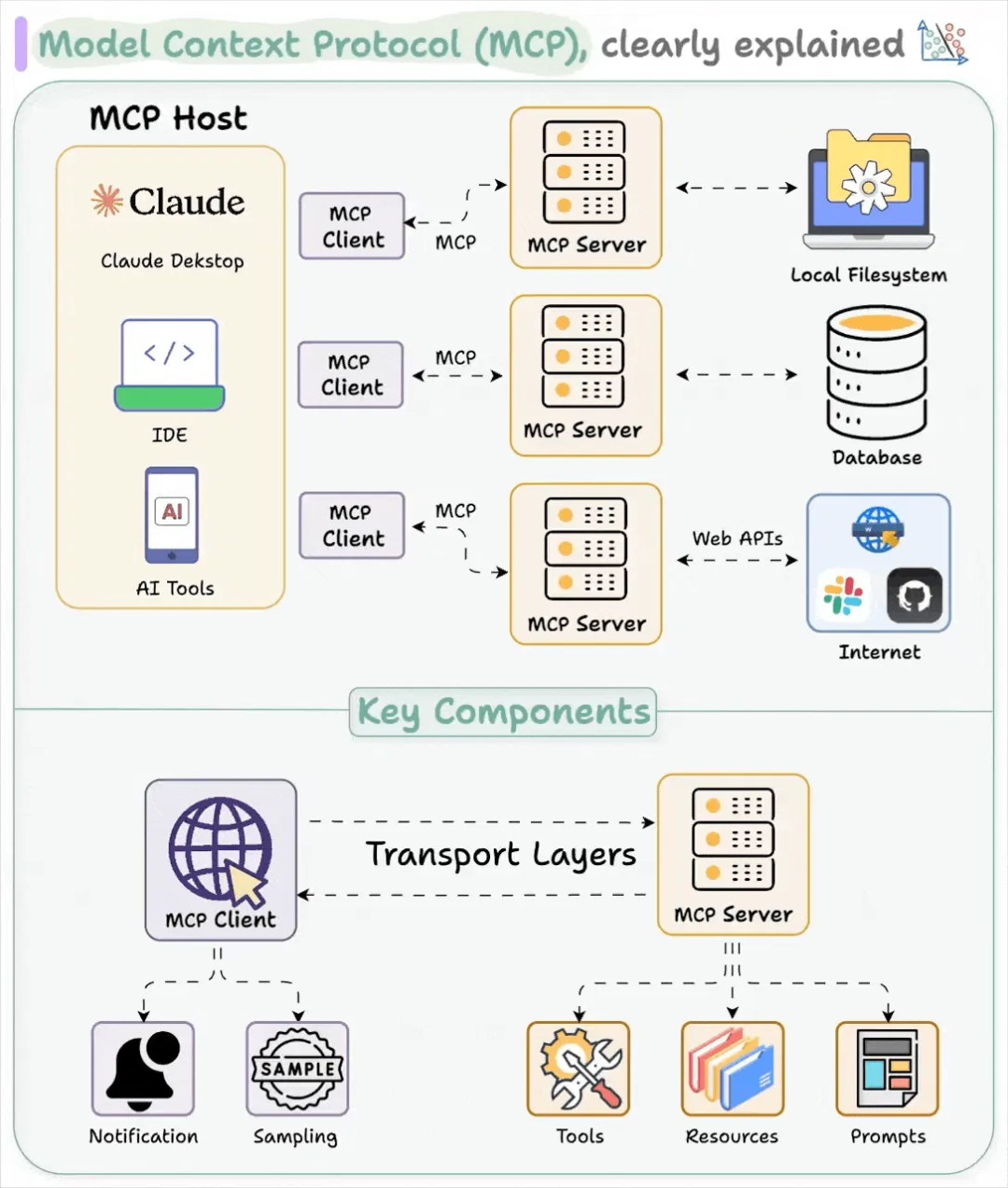
MCP的组件包括MCP Server、MCP Client和MCP Host。相比FunctionCalling,MCP采用标准协议与接口,生态更好。
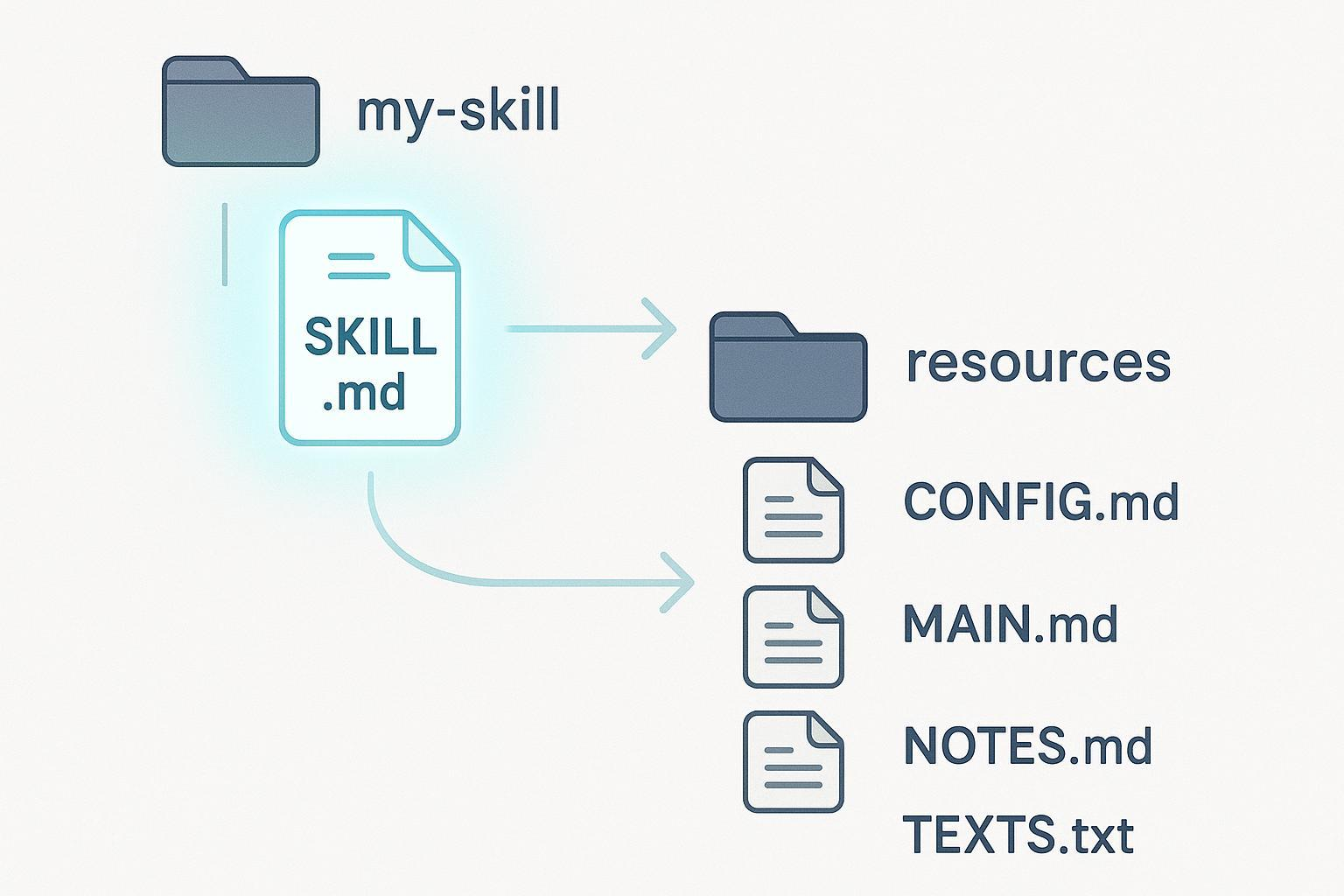
Skills与MCP是构建Agent的两个重要技术标准,Skills管"教方法",MCP管"用什么做"。
Skills是封装专业知识、SOP流程和判断逻辑的模块,MCP是标准化连接协议,赋予Agent操作真实世界数据的能力。两者在架构性能、部署维护、安全特性和适用场景上各有优劣。
但Skills也存在安全陷阱。按需激活机制可能导致语义劫持和幽灵指令,Scripts目录中的恶意脚本可能利用Agent调用的Bash权限执行危险操作,不安全配置可能导致隐密后门。这些安全问题在开发和使用Agent时都需要特别注意。
当前成熟的Docker容器、传统虚拟机和Serverless都不太适合承载Agent业务。容器技术本质上是进程级隔离,在多租户环境下存在安全风险。传统虚拟机的启动时延问题让用户无法忍受。Serverless的状态保持问题会导致巨大的I/O开销和延迟。
腾讯云的最佳实践给出了几个关键技术要求。强隔离与安全性,Agent生成的代码不可信,必须防止逃逸。长程任务稳定性,任务可能运行很长时间,连接断开不能导致任务失败。状态管理与持久化,运行过程中的数据在Crash后能否恢复。可观测性与审计,必须知道Agent在沙箱里到底干了什么。
腾讯云通过Cube沙箱技术实现80ms服务交付,MVM快照加镜像预热技术消除冷启动,独立Guest Kernel硬隔离,Serverless架构不请求无资源消耗,暂停恢复机制实现零闲置成本。这些技术手段在工程实践中效果显著。
06、超节点形态的硬件基础设施:通信效率的终极追求
训练、推理的跨卡、跨机通信现在已经是刚需,相较于RDMA,GPU之间的专有通信通道更为高效。超节点的核心就是让更多的卡可以通过专有通信通道进行互通,形成一个高效的超大GPU域。

NVIDIA的Vera Rubin NVL144单域包括144颗Rubin GPU,支持FP4,单域带宽高达260TBps。
在推理场景中,模型上下文长度的增长对算力的需求是平方级增长,对显存的需求是线性增长,结合PD分离、Attention-FFN分离等部署思路,对卡间通信带宽的需求极大。更大规模的NVlink高带宽域将为超长上下文模型的推理服务提供更有利的基础设施环境。
NVIDIA官方技术博客提到,面对未来1M上下文长度的模型即将成为主流的趋势,采用Rubin架构加NVL144超节点以PD分离方式部署推理服务将成为最佳实践。不仅NVIDIA,多家异构计算硬件厂商也都在规划更单大规模GPU、TPU高带宽域的超节点形态基础设施。
ending
相较于2024年,2025年相同参数量的模型能力已经有了超过十倍的差异,这些进步是模型、系统、数据等多方面综合进步的结果。2025年的工程和系统工作,整体方向是更精细化的设计和优化,而非一味追求"超级硬件"和"超级集群"。
2026年,系统的优化工作将会更加精细化,进一步探索基于低成本硬件的极致性价比。
而工程重点发展方向应该在AI Agent Infra,因为所有模型、工程相关工作的进步全部是服务于AI应用真正的落地。"贾维斯"何时会来到我们身边,我想这应该不远了。
对于我们Java程序员和AI开发者来说,理解这些AI Infra的发展方向,能帮助我们更好地把握技术趋势,在职业发展上做出更明智的选择。
分布式推理、TileLang这类开发语言、RL训推分离、模型-系统协同设计、Agent Infra、超节点硬件,这六个方向每个都值得深入研究。
参考资料: