Leader 说 Skills 就是 Prompt 换皮,我不信,花一周做了个能自动过验证码的浏览器自动化 Skill,结果他偷偷给我绩效打了 A
大家好,我是二哥呀。
必须推荐一个,最近一直在用,GitHub 上有 1.4K Star 的开源项目,名叫 BrowserAct。
专门为 AI Agent 打造的浏览器自动化 CLI 工具。
https://github.com/browser-act/skills
它和普通的无头 Chrome 封装最大的区别在于:专门解决 Agent 被网站拦截的问题。
三层突破体系,层层递进:
- 环境层:stealth 反检测浏览器 + 指纹伪装 + 动态代理 + Session/Cookie/Profile 隔离。大部分场景在这一层就解决了,根本不会触发验证。
- 执行层:solve-captcha 自动解决常见验证码,stealth-extract 一条命令提取受保护页面内容,全程无人值守。
- 人机交互层:remote-assist 生成远程链接,手机或任意设备上接管浏览器,完成短信验证码、扫码登录等必须人工参与的步骤。人操作完,Agent 继续原来的会话,不需要从头开始。
三种浏览器模式覆盖不同场景:stealth 反检测、chrome 复用登录态、chrome-direct 零配置控制当前 Chrome。
50+ 命令,支持 Claude Code、Cursor、Codex CLI、Gemini CLI 等主流 AI Agent。
我实际跑了几个场景,效果确实让我有点惊喜。
比如说直接在Agent里用知乎搜索 AI Agent 的 TOP10 热门帖子。
嘎嘎嘎的好用。
01、安装 BrowserAct
最简单的方式是直接跟 Agent 说“帮我安装 BrowserAct:https://github.com/browser-act/skills/tree/main/browser-act”,Agent 会自动完成全部安装流程。
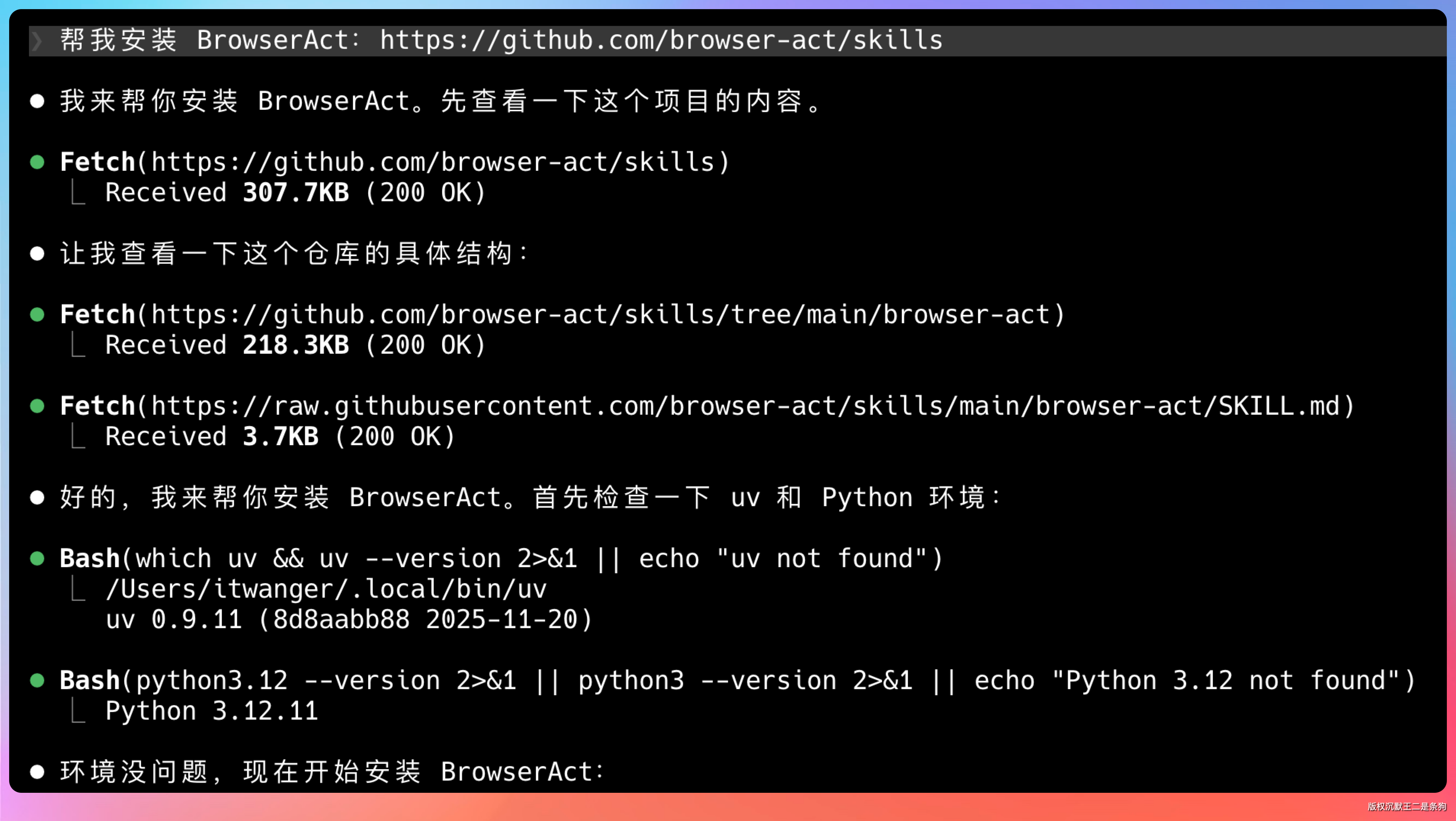
安装过程会自动检测 Agent 环境,从 GitHub 拉取 Skill 文件,完成后显示安装路径和支持的 Agent 列表。
我这里用的是Claude Code演示,你也可以用 Codex 等 Agent 工具。
装完之后可以通过 get-skills core 拿到完整的命令指南和环境状态。
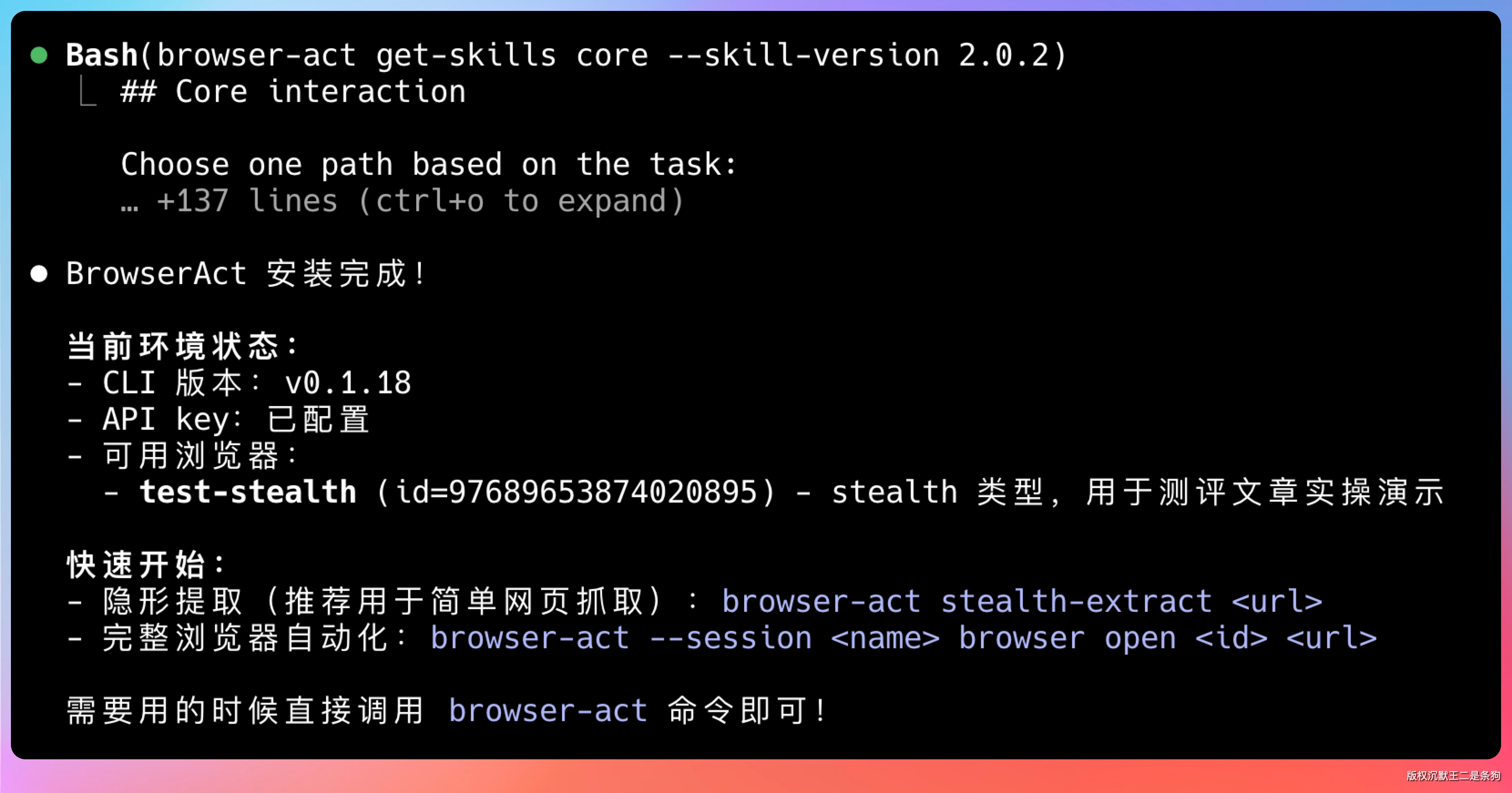
需要注意的是,stealth 浏览器和动态代理功能需要 API Key,直接按照 Agent 的提示操作,点击链接授权一下即可。

授权完成后就可以猛猛干活了。
02、一条命令抓小红书
装好之后,可以先试试 stealth-extract。这个命令的定位是“高级版 WebFetch”,用反检测浏览器打开目标 URL,等 JavaScript 渲染完成后提取内容,一条命令搞定。
拿 httpbin.org 做了个热身测试,直接跟 Agent 说:
用 stealth-extract 提取 https://httpbin.org/headers 的内容Agent 自动调用 BrowserAct,返回的结果如下所示:
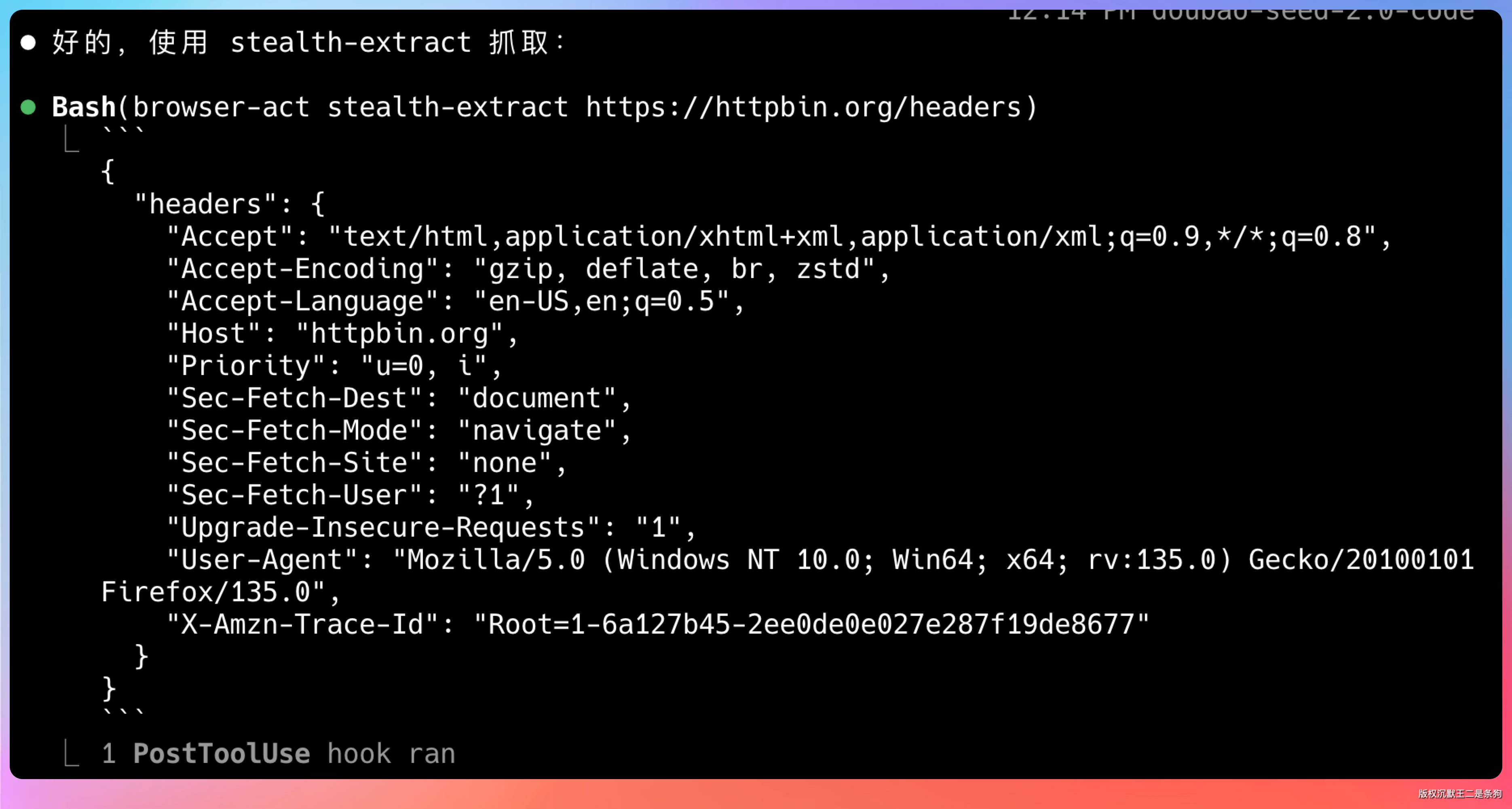
注意看 User-Agent:Windows NT 10.0 + Firefox/135.0。
我的电脑是 macOS + Chrome,但 stealth-extract 发出去的请求完全伪装成了 Windows 上的 Firefox。不是简单地改个 UA 字符串,而是整套请求头都是一致的:Sec-Fetch-Dest、Sec-Fetch-Mode 这些指纹字段全部匹配 Firefox 的行为模式。

热身完毕,上难度。
小红书的访问限制是出了名的严格,用 curl 直接抓小红书,拿到的全是混淆后的 JavaScript 代码:
curl -s https://www.xiaohongshu.com/explore | head -20
# 返回:一坨 <script> 标签和混淆的 JS,没有任何实际内容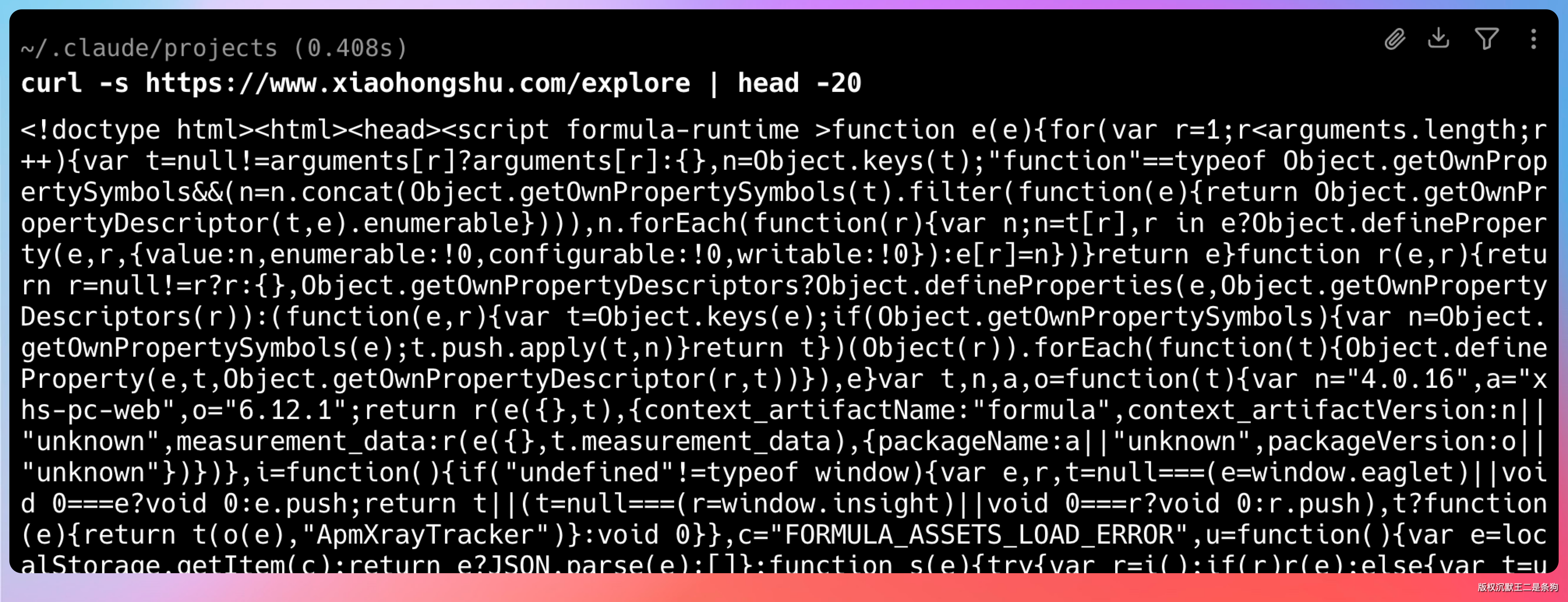
换成 BrowserAct,跟 Agent 说:
帮我提取小红书 Explore 页面的内容:https://www.xiaohongshu.com/exploreAgent 会调用 stealth-extract,直接拿到小红书首页的完整推荐内容,频道分类、笔记标题、作者名、互动数据全都有:
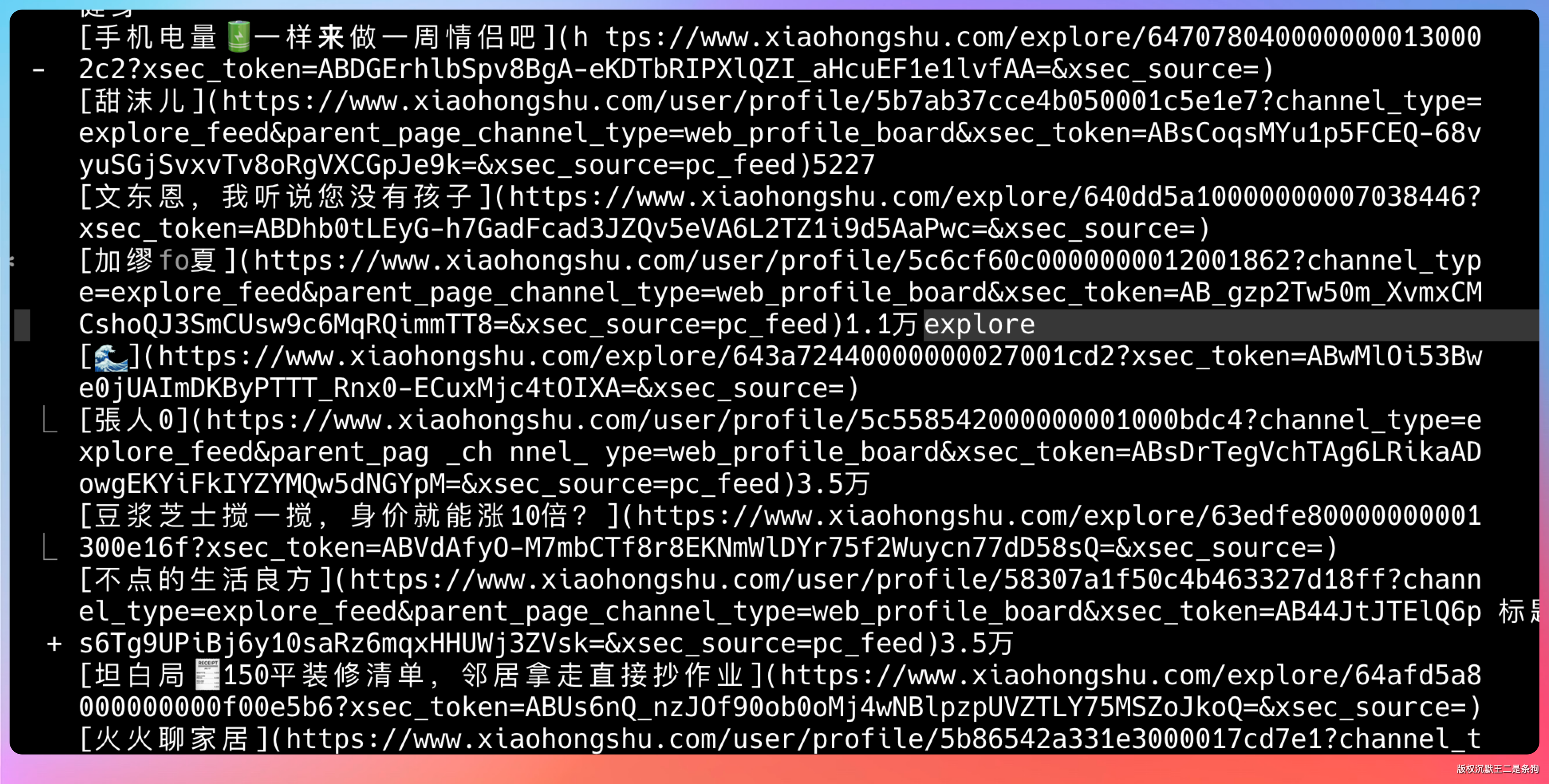
连每条笔记的详情链接、作者主页链接也一起返回了。
而且页面顶部的频道分类(推荐、穿搭、美食、彩妆...)也完整提取出来了。
一条命令,不需要打开浏览器、不需要管理 Session、不需要写一行代码。
给个 URL,stealth-extract 就能帮我们搞定指纹伪装、JavaScript 渲染、内容提取等全部流程。
这里说一下 stealth-extract 和 WebFetch 的本质区别。
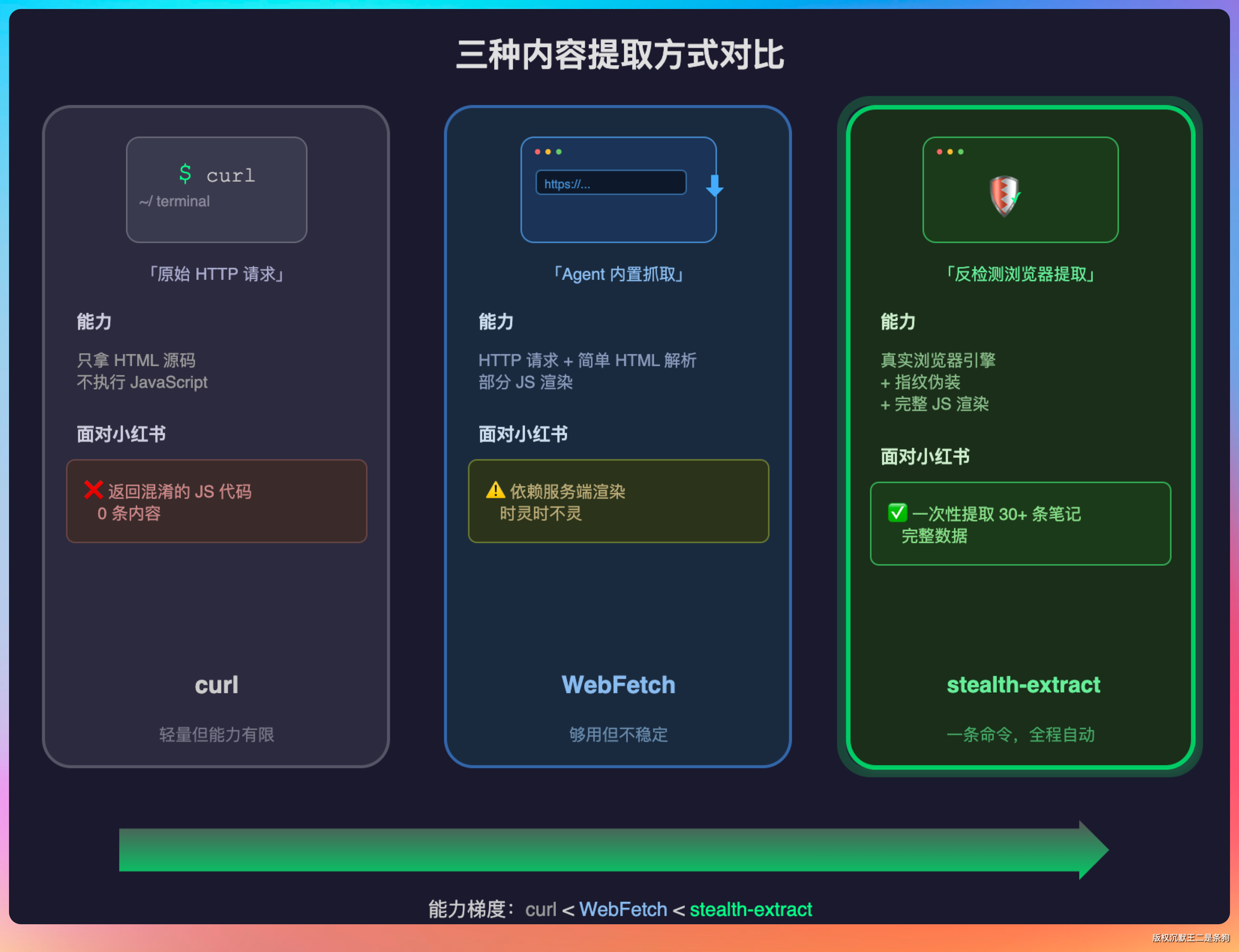
WebFetch 是 Agent 自带的网页抓取工具,底层走的是 HTTP 请求加上简单的 HTML 解析。碰到需要 JavaScript 渲染的页面,WebFetch 有时候能拿到内容(依赖服务端渲染),但很多时候是拿不到的。
stealth-extract 是真的启动了一个反检测浏览器,等页面完全渲染完毕再提取,所以动态渲染的内容、懒加载的数据、需要 JavaScript 执行后才出现的元素,全都能拿到。
再说 curl,直接 HTTP 请求拿到的是原始 HTML 源码,动态渲染的内容拿不到。
三者的能力梯度如下:
curl < WebFetch < stealth-extract
能用轻量工具搞定的场景当然优先用轻量工具,但碰到有访问限制的网站,stealth-extract 是唯一能打的选项。
对于那些只需要”拿内容不需要交互”的场景,stealth-extract 是效率最高的方式。而且 stealth-extract 会对抓取到的内容做清洗,给到用户干净的数据,节省 token。
还能通过自然语言指定输出格式,比如:
用 stealth-extract 提取这个页面,输出 Markdown 格式:https://news.ycombinator.com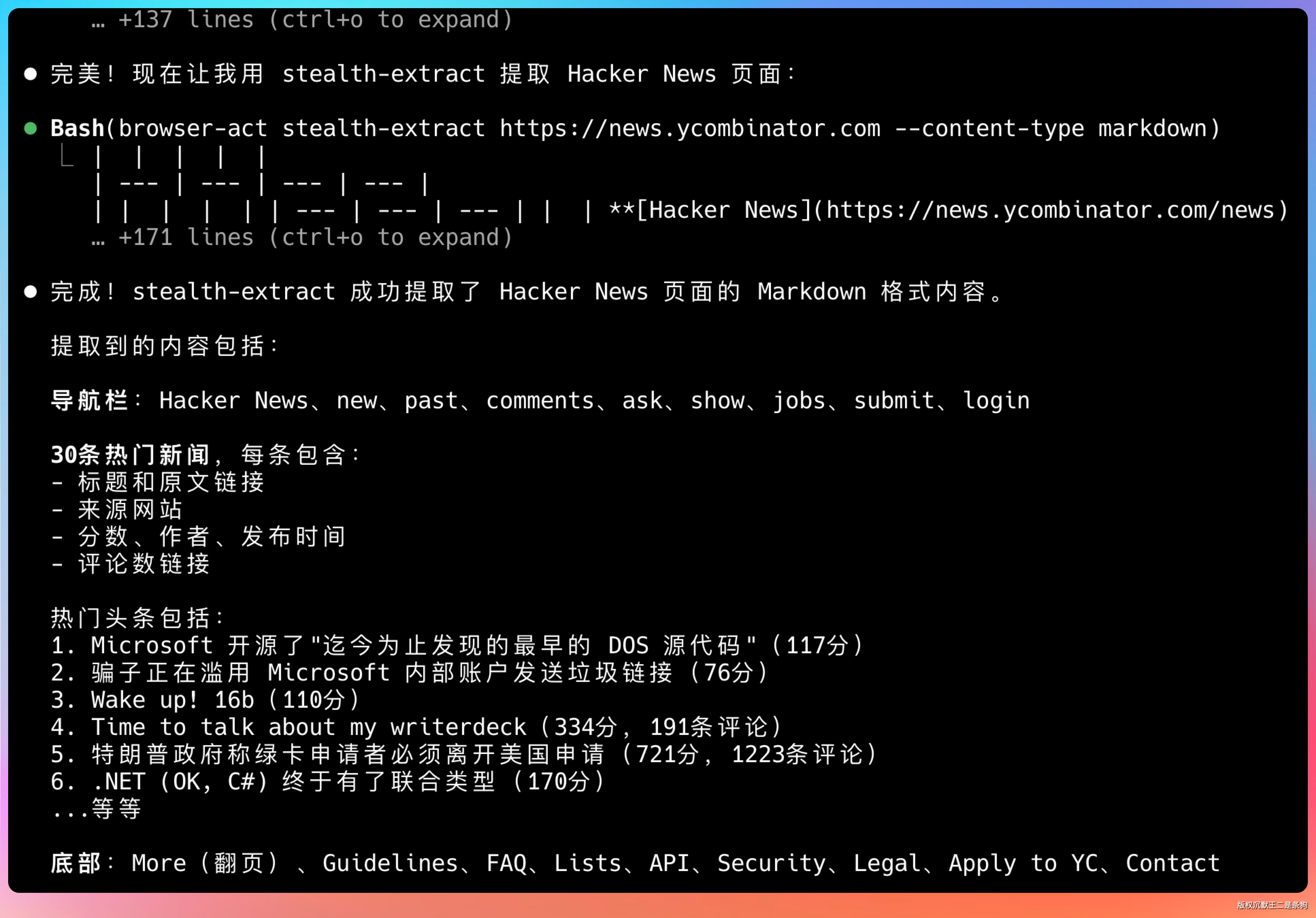
Agent 会自动加上 --content-type markdown 参数。多个 URL 可以并行跑,每次调用都是独立的,没有 Session 冲突的问题。
03、stealth 浏览器
stealth-extract 适合“拿了就走”的场景。但如果需要交互操作,比如登录、点击、填表单、翻页,像人一样操作,就得创建 stealth 浏览器。
比 Browser Use 更强大,后面我会演示。
值得一提的是,stealth 浏览器是运行在本机的浏览器,你托管的账号信息安全地留在本地,不会上传到任何第三方服务器。而且它还支持指纹浏览器多账号扩展能力,特别适合养号场景。
跟 Agent 说一句就行:
帮我创建一个 stealth 浏览器,然后打开 bot.sannysoft.com 做反检测测试
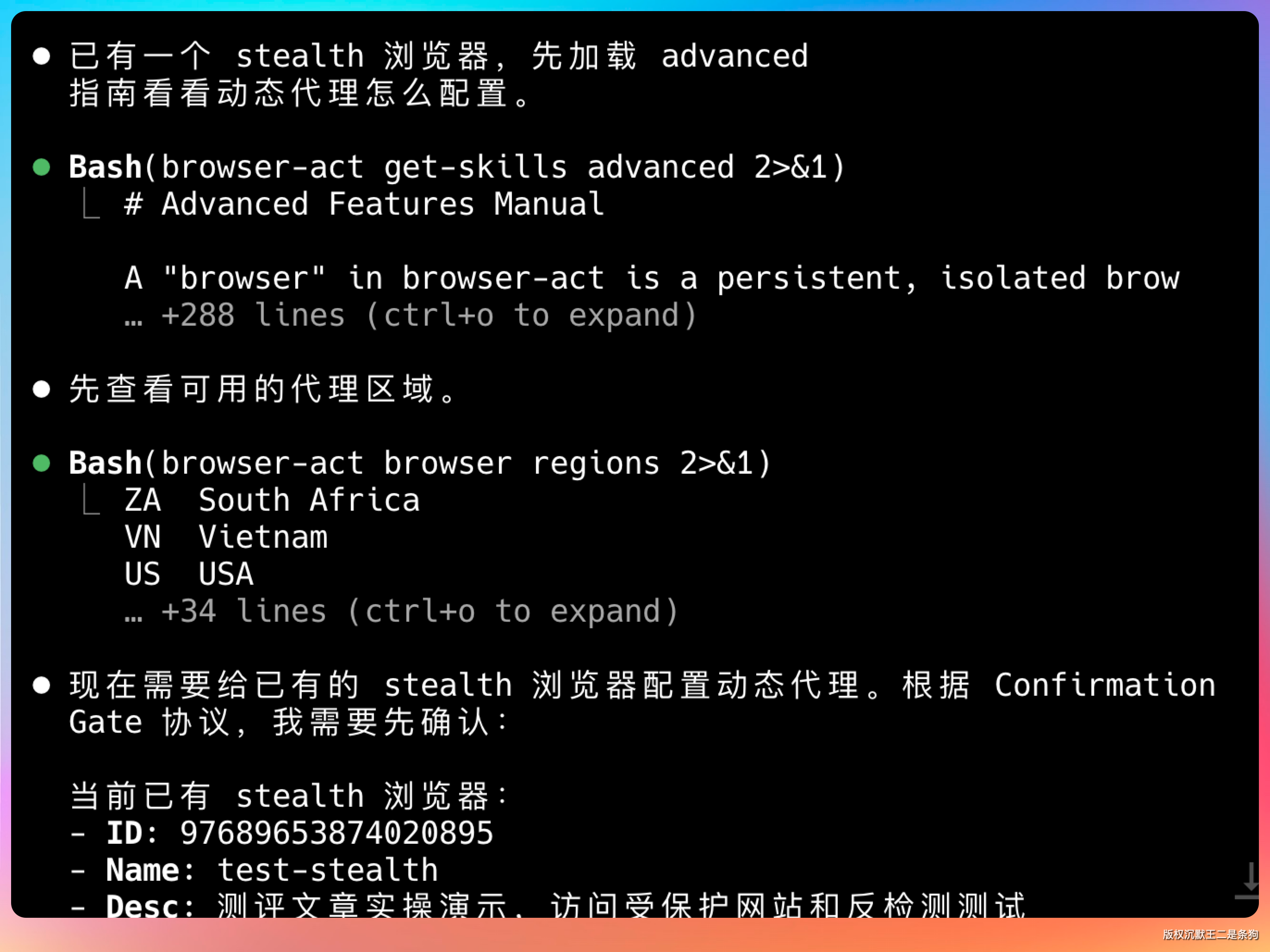
BrowserAct 有一个 Confirmation Gate 机制:创建浏览器、删除数据、导入 Profile 这些敏感操作,必须经过用户明确批准才能执行,所以不用担心安全问题。
headed 模式会让浏览器带界面运行,可以实时看到 Agent 在操作什么。
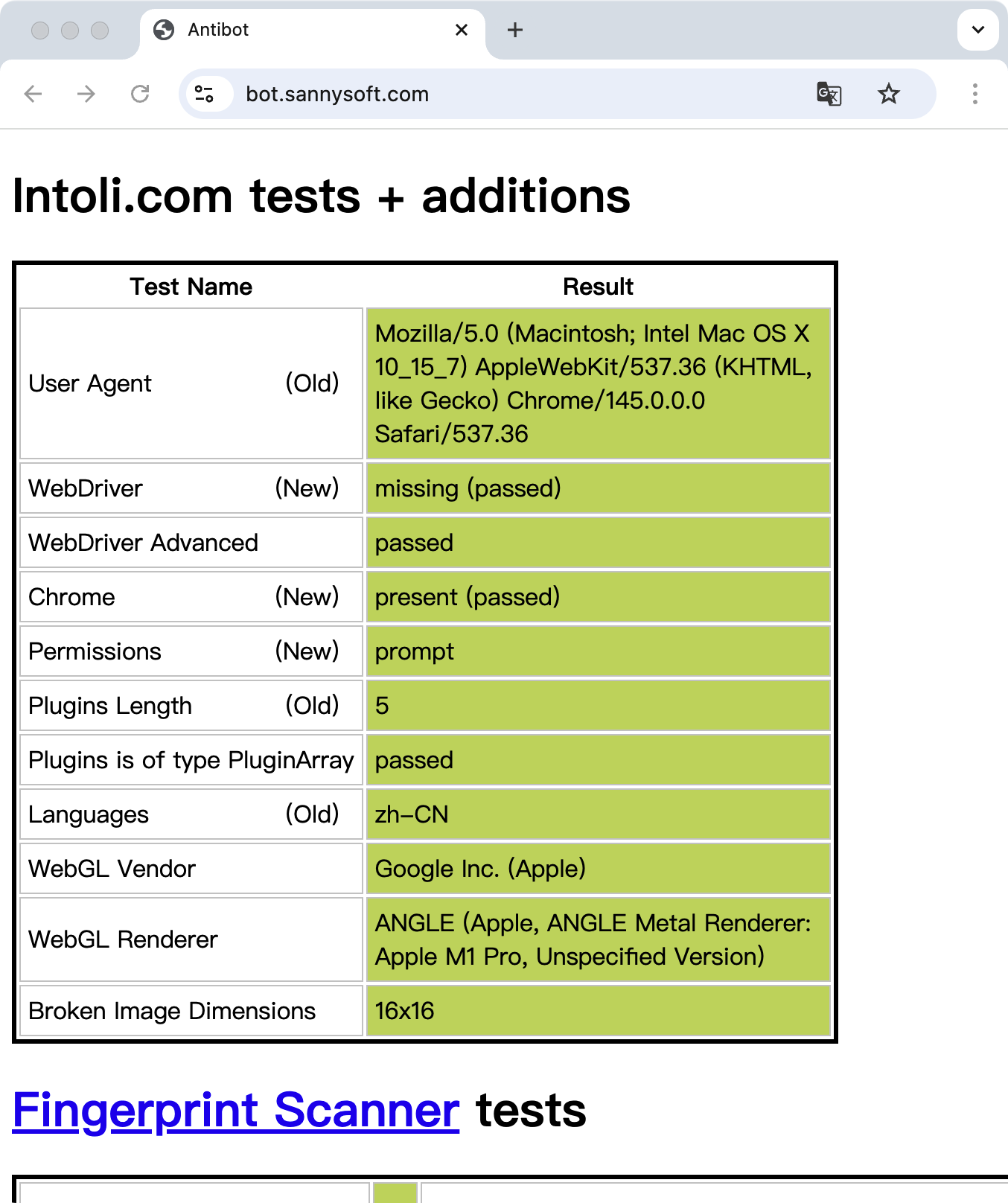
检测结果拿到了。
| 检测项 | 结果 |
|---|---|
| User Agent | 正常浏览器 UA(passed) |
| WebDriver | missing(passed) |
| WebDriver Advanced | passed |
| Chrome 对象 | present(passed) |
| Permissions | prompt |
| Plugins 数量 | 5 |
| Plugins 类型 | PluginArray(passed) |
18 项检测,全部 ok。

做过浏览器自动化的小伙伴应该知道,普通的无头浏览器在 WebDriver 这一项上就会直接返回 present 而不是 missing,更别提 Selenium 检测、Chrome 调试工具检测这些。BrowserAct 的 stealth 模式在所有维度上都处理到位了。
知乎搜索必须登录才能看到内容,这个用过的小伙伴应该知道,直接用Agent是很难直接做到这一点的。
这正好是 stealth 浏览器 + remote-assist 的用武之地。
跟 Agent 说:
用 stealth 浏览器打开知乎,搜索 AI Agent,如果需要登录就给我一个远程链接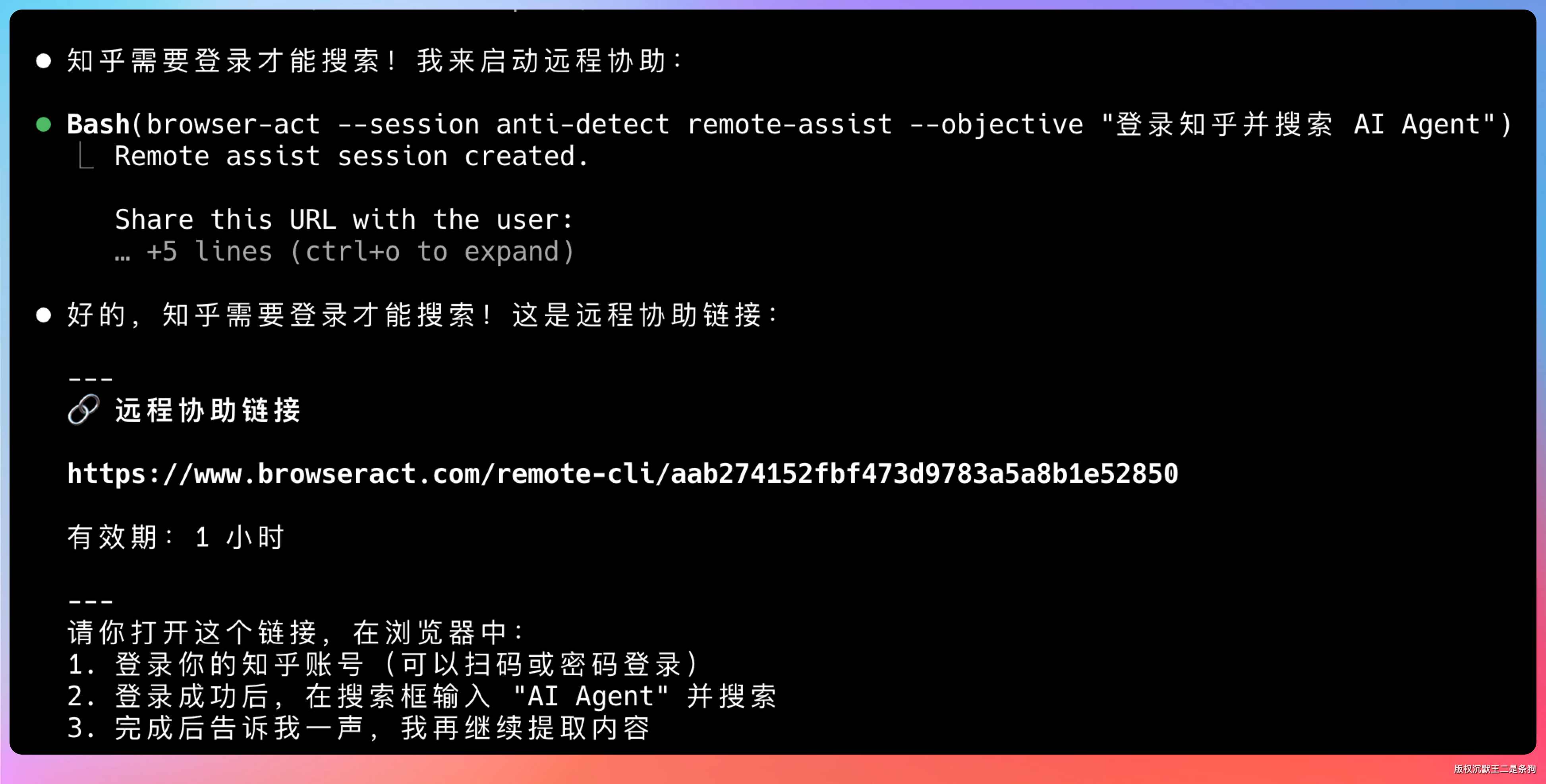
Agent 打开知乎搜索页,发现需要登录,自动启动 remote-assist 发一个链接。
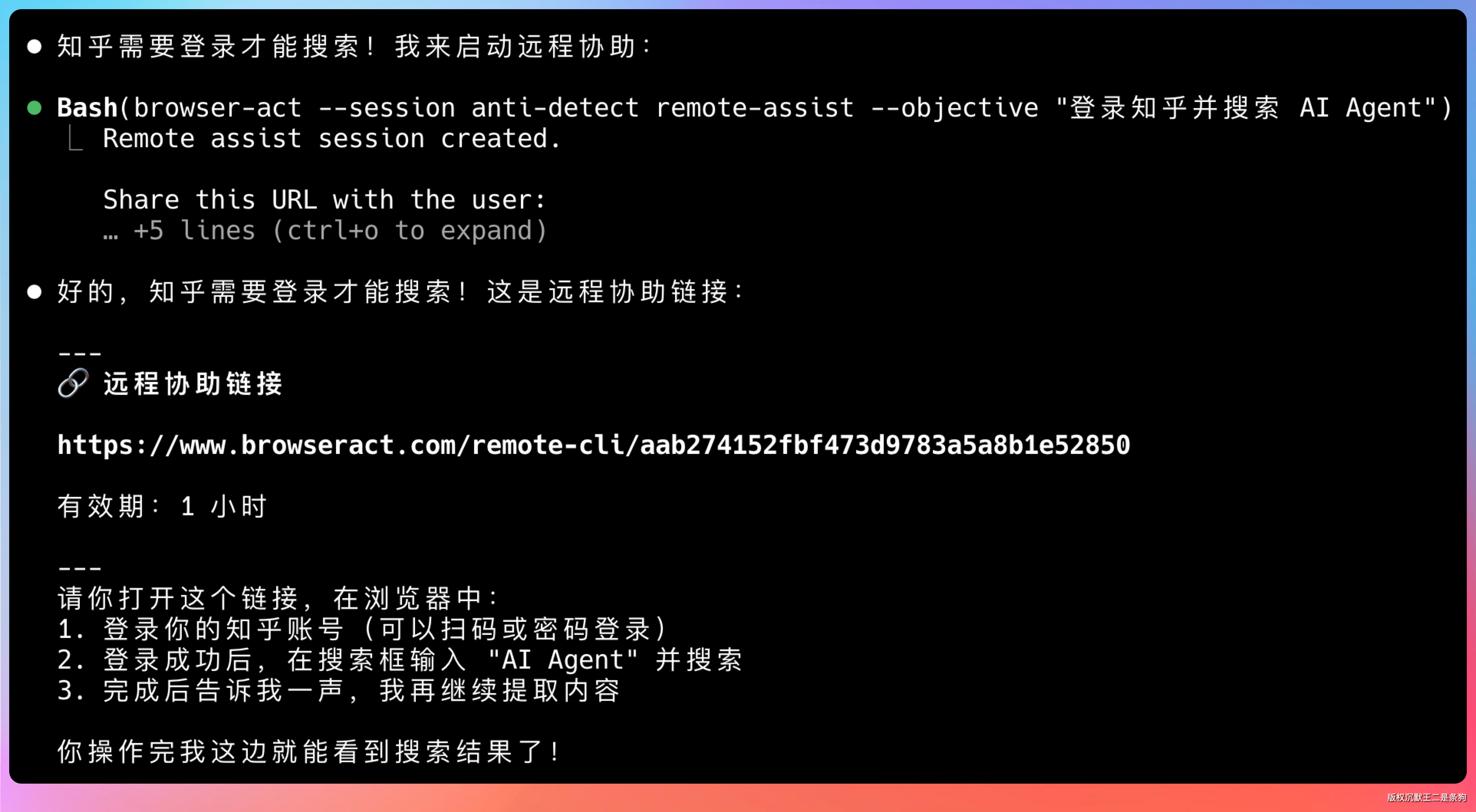
我们打开链接,扫码登录知乎,Agent 拿到登录态之后继续搜索提取。
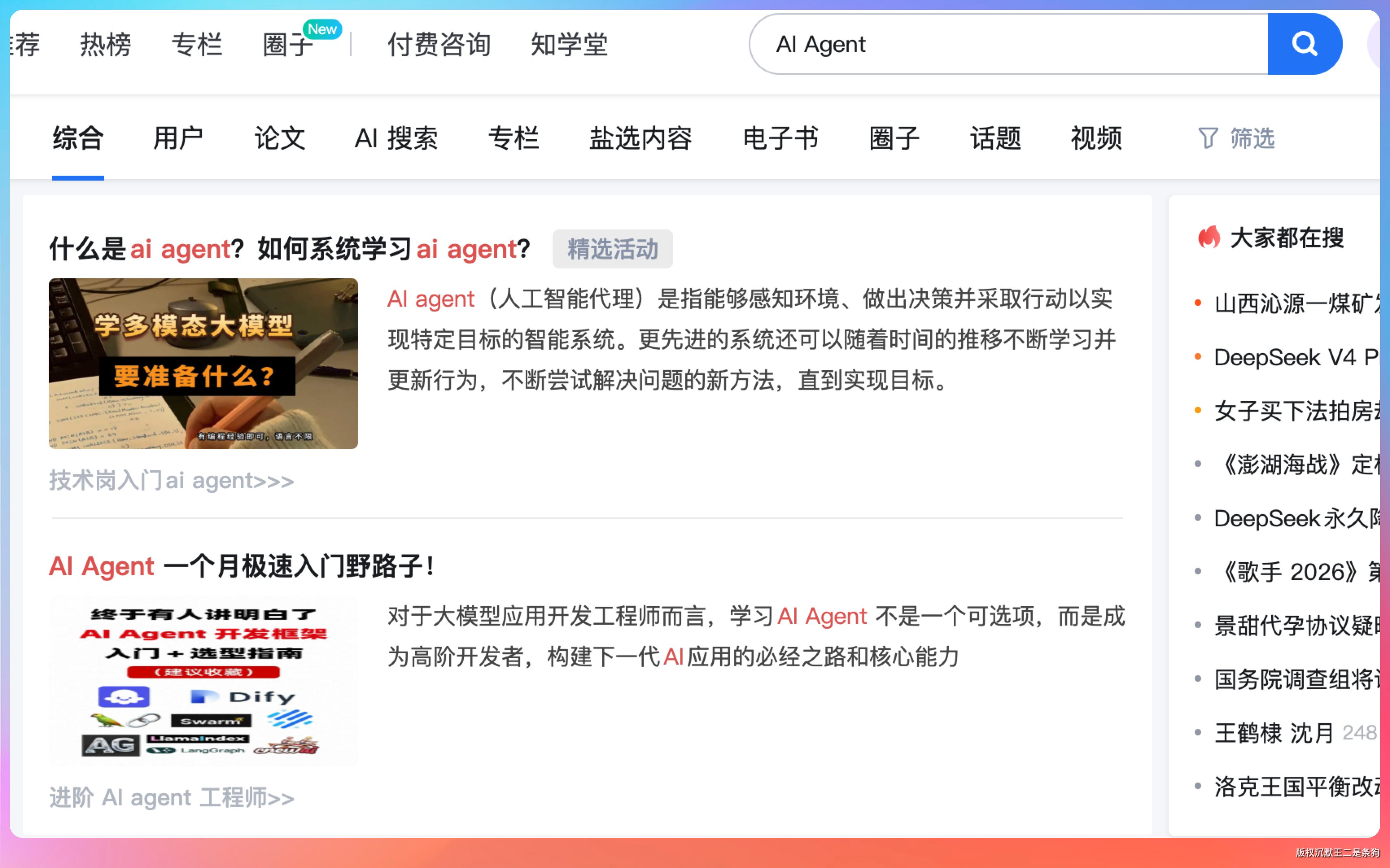
整个过程我们只需要花 10 秒钟扫个码,剩下的全是 Agent 在做。
看,结果拿到了,是不是贼方便。
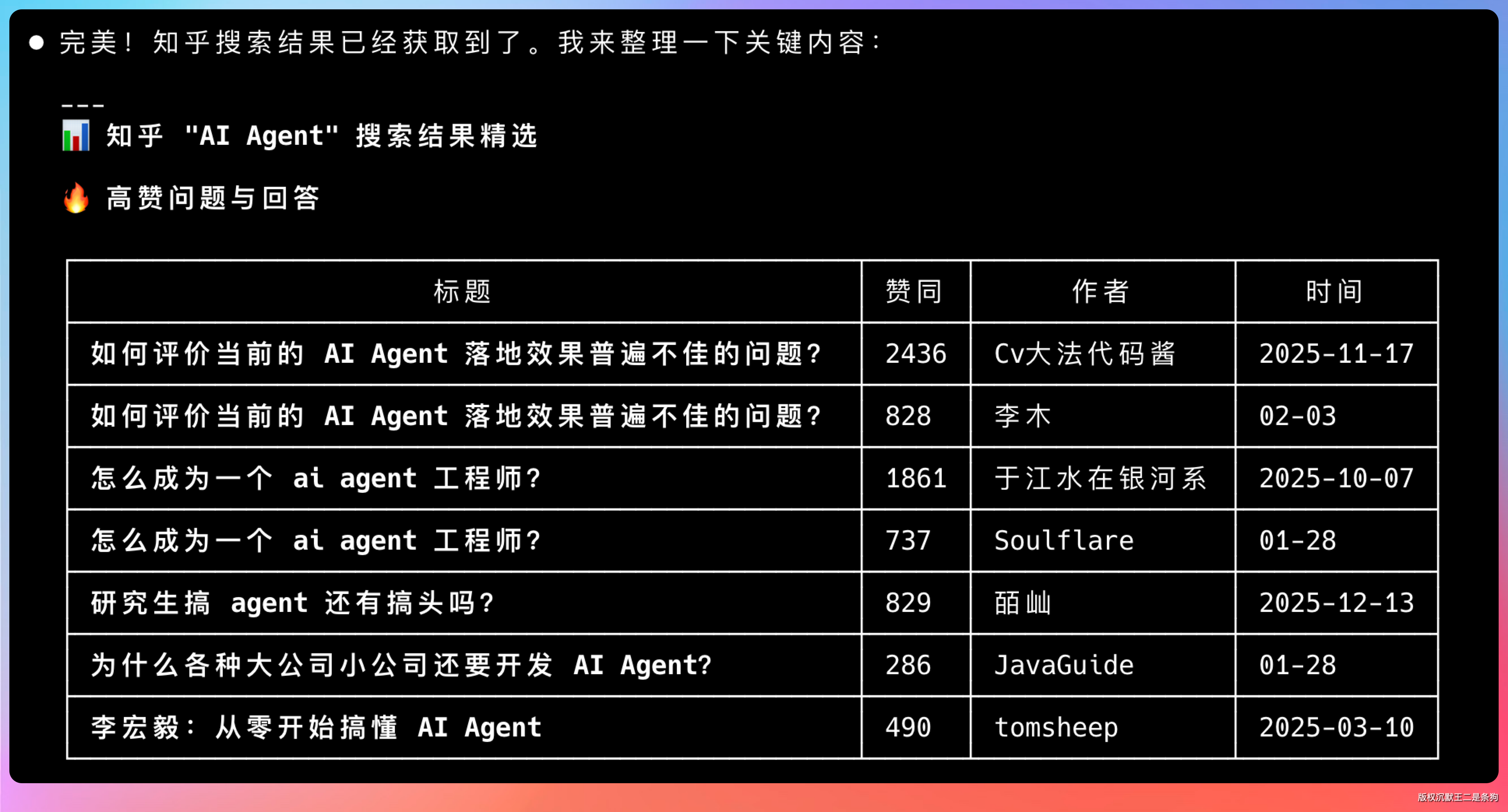
04、搜 AI 博主的 Agent 内容
大家都知道,微信生态的内容是不允许外部浏览器搜索的,比如说谷歌搜索和百度。
那假设我们要做 AI Agent 方向的竞品调研,想看看最近关注的 AI 博主都在公众号上发表了哪些内容。
BrowserAct 可以做得到。
跟 Agent 说:
用 stealth-extract 搜一下关于 AI Agent 的最新文章,比如说苍何、JavaGuide、沉默王二这些博主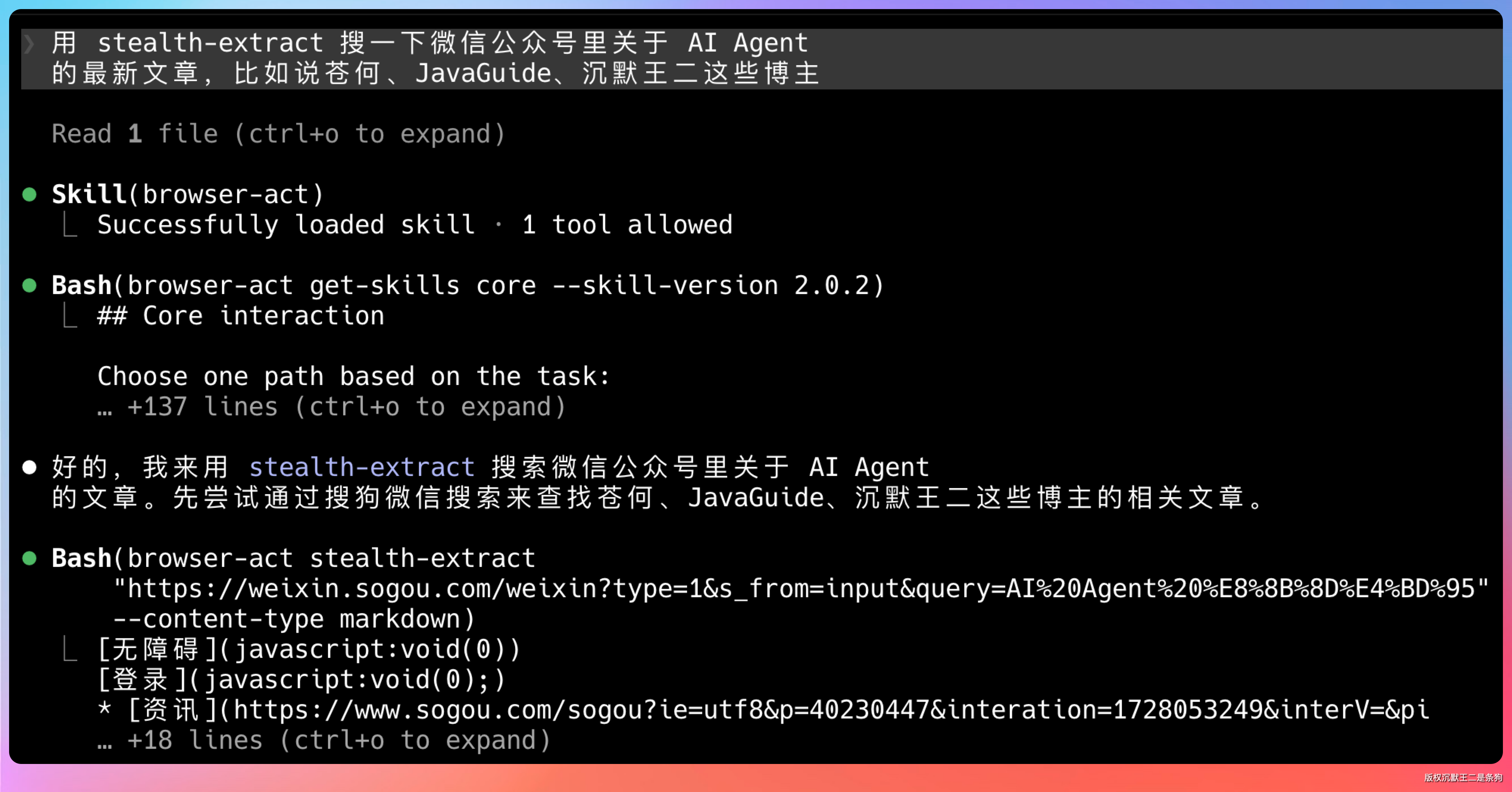
Agent 会调用 stealth-extract,通过搜狗搜索返回完整的文章列表,标题、摘要、公众号名、发布时间全都有。
比如搜“AI Agent 苍何”:

搜“AI Agent JavaGuide”:

搜“AI Agent 沉默王二”:

还可以用 full browser 模式查看完整的内容。

如果想翻页看更多结果,也是自然语言搞定:
翻到第 2 页,继续提取文章列表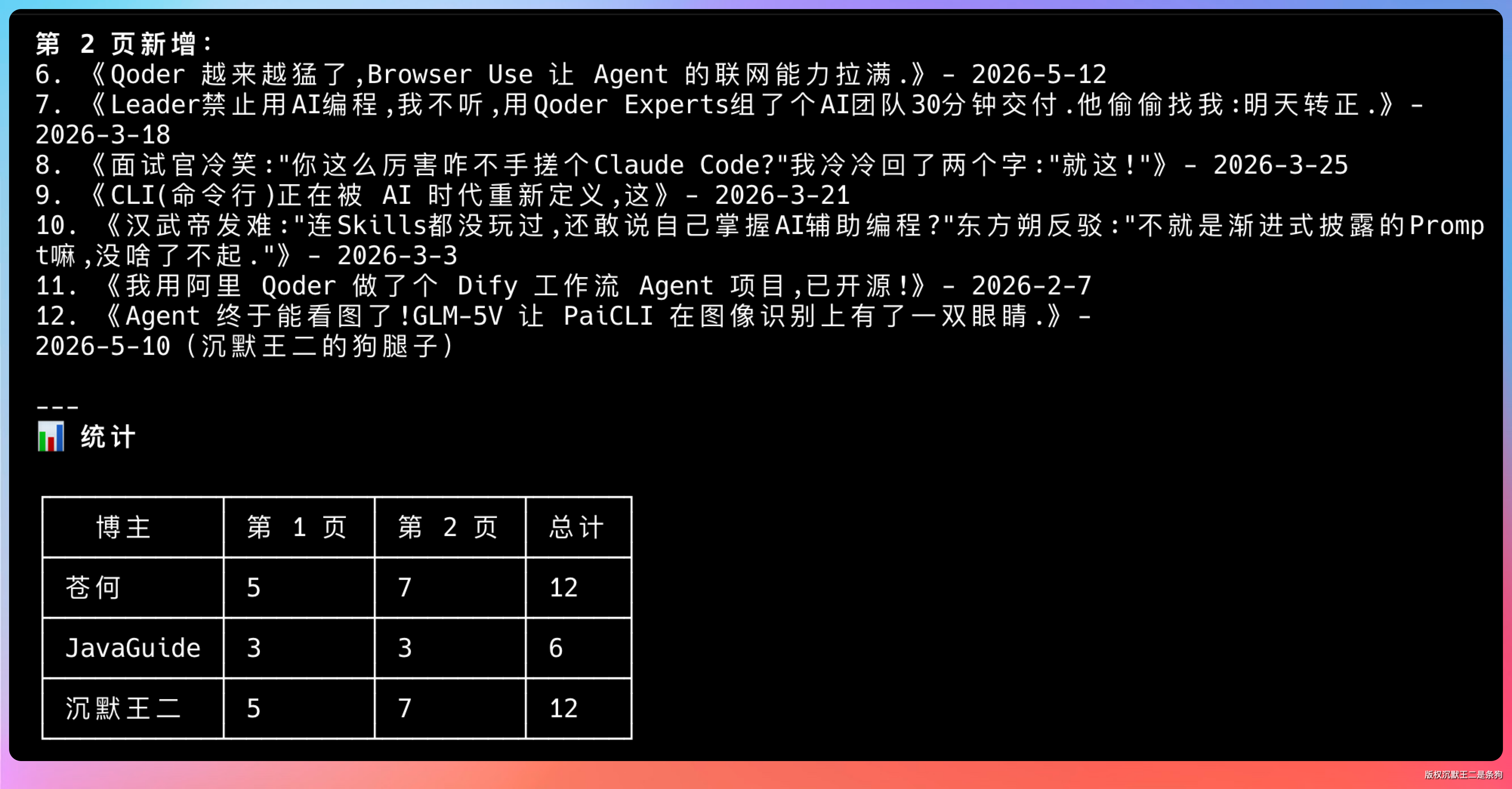
Agent 会自动走 Open → State → Interact → Verify 循环:找到翻页按钮点击,等页面稳定后重新提取。
这个场景的价值在于:公众号的文章在微信生态之外很难批量获取,搜狗搜索是少数入口之一,但它对自动化访问有频率限制。
stealth-extract 的反检测能力让这件事变得简单无比。
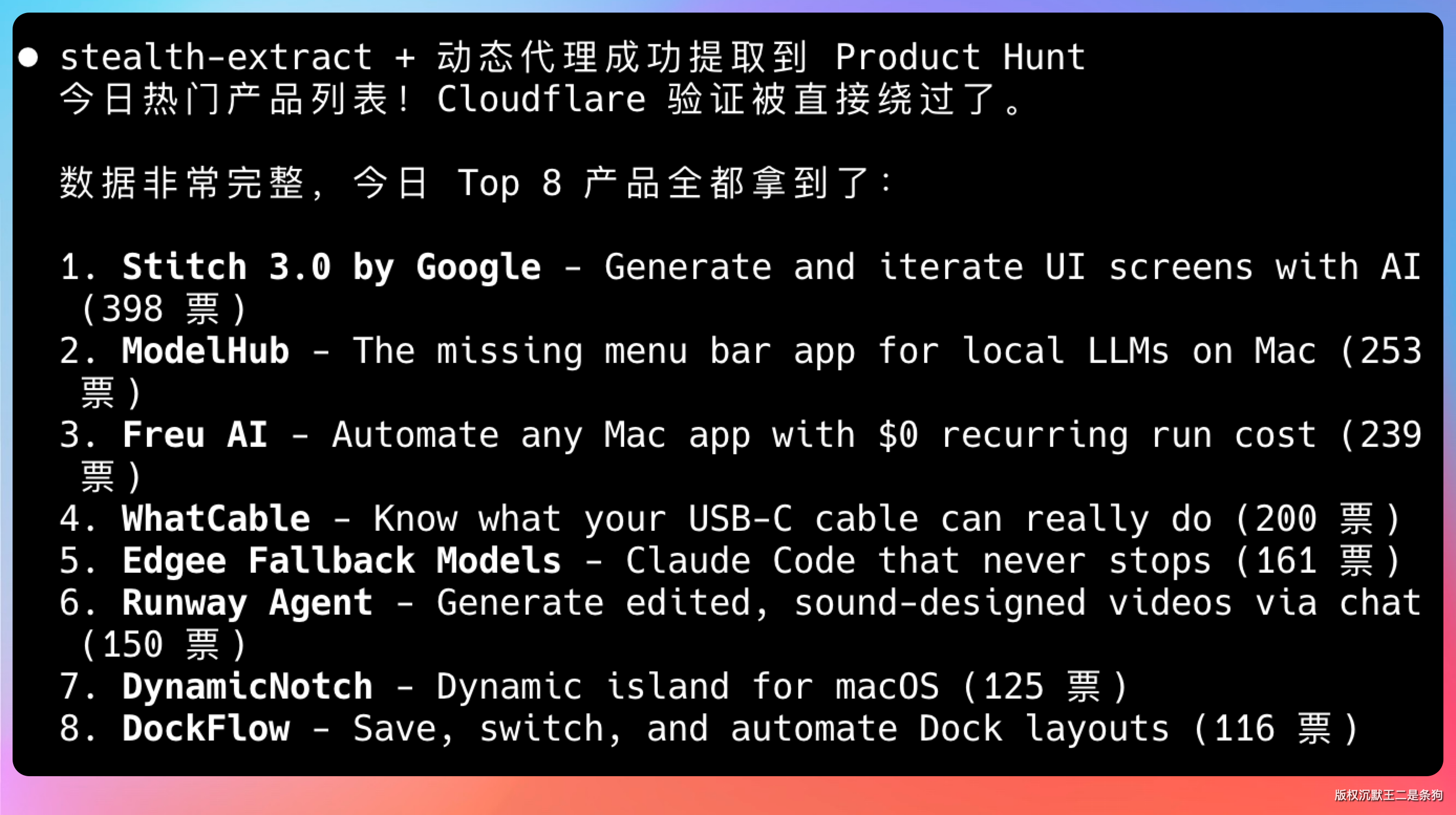
如果是大型数据采集场景,还可以把 stealth 浏览器和动态代理结合使用。比如批量提取 YouTube 视频信息、Product Hunt 产品数据这类海外平台,动态代理会自动轮换 IP,配合 stealth 浏览器的指纹伪装,即使高频访问也不容易被限制。适合需要持续、大量采集数据的业务场景。
用 stealth 浏览器 + 动态代理,打开 Product Hunt 首页,提取今日热门产品列表
full browser 模式被 Cloudflare 拦住了,但 stealth-extract + 动态代理一条命令直接穿透。
05、三种浏览器模式怎么选
实测过程中我把三种浏览器模式都摸了一遍,总结一下各自的适用场景。

- stealth 模式:反检测浏览器 + 指纹伪装 + 代理轮换,专门应对有访问限制的网站。支持无头模式下依然保持反检测能力,普通的 headless Chrome 做不到这一点。适合批量采集、匿名访问、竞品监控这类场景。
- chrome 模式:把本地 Chrome 的 Profile 导入到一个独立环境里运行。好处是能复用已有的登录态,适合需要登录态但不想手动登录的场景。
- chrome-direct 模式:直接控制当前正在运行的 Chrome。零配置,天然带所有登录态和插件。
06、BrowserAct Forge
BrowserAct 还有一个配套工具叫 Skill Forge。
定位是把跑通的网站操作流程生成一个可复用的 Skill 文件,后续同类任务直接调用,不再需要 Agent 从零摸索页面。
安装命令:
帮我安装 browser-act-skill-forge,Skill 地址:https://github.com/browser-act/skills/tree/main/browser-act-skill-forge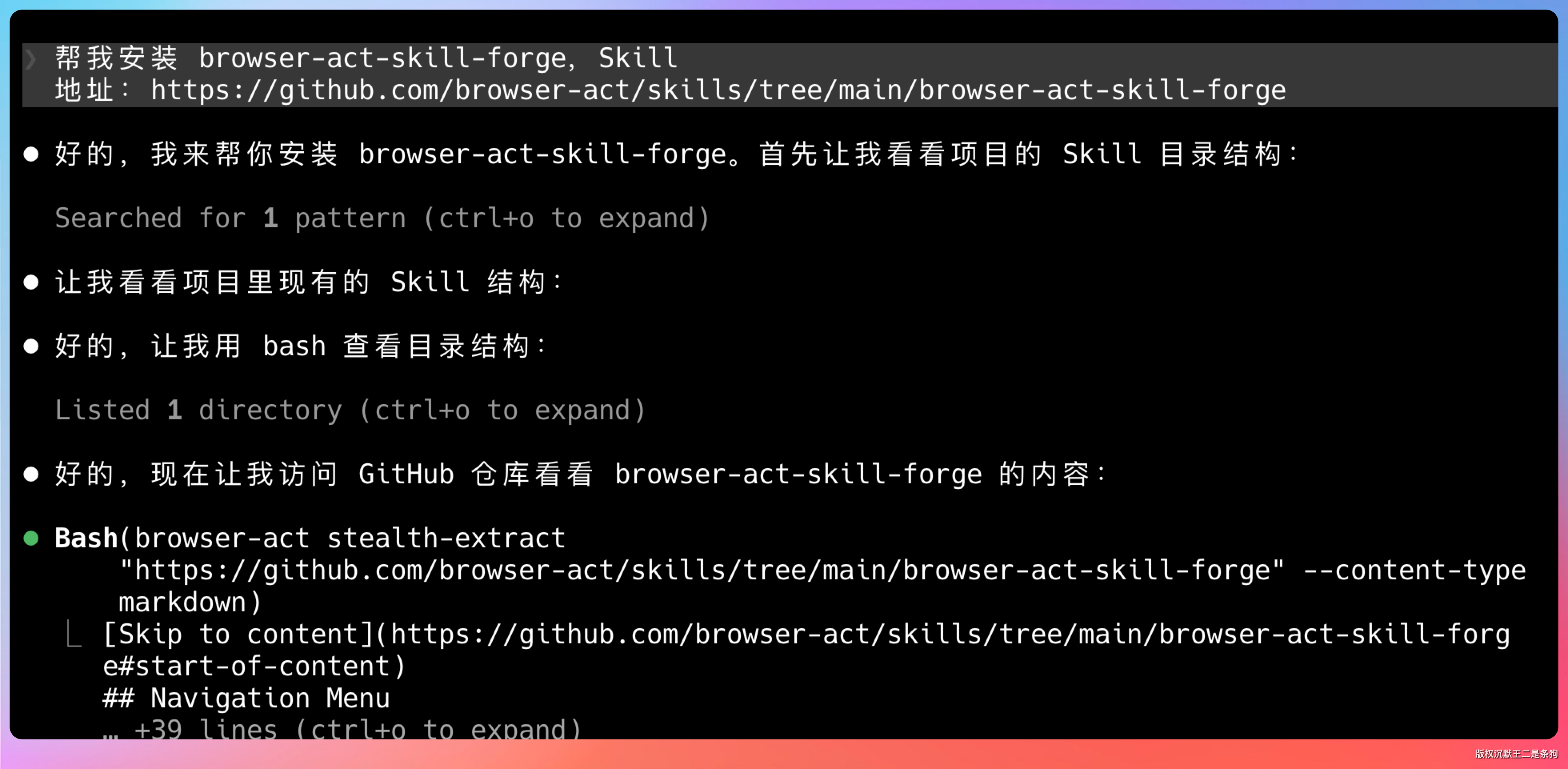
然后告诉 Agent 想做什么:
我需要到知乎上执行搜索,帮我沉淀一个稳定可复用的 SkillSkill Forge 会自动分析网站结构,尝试找到最合适的方法(比如发现可用 API),结合 DOM 操作,生成标准化的 Skill。
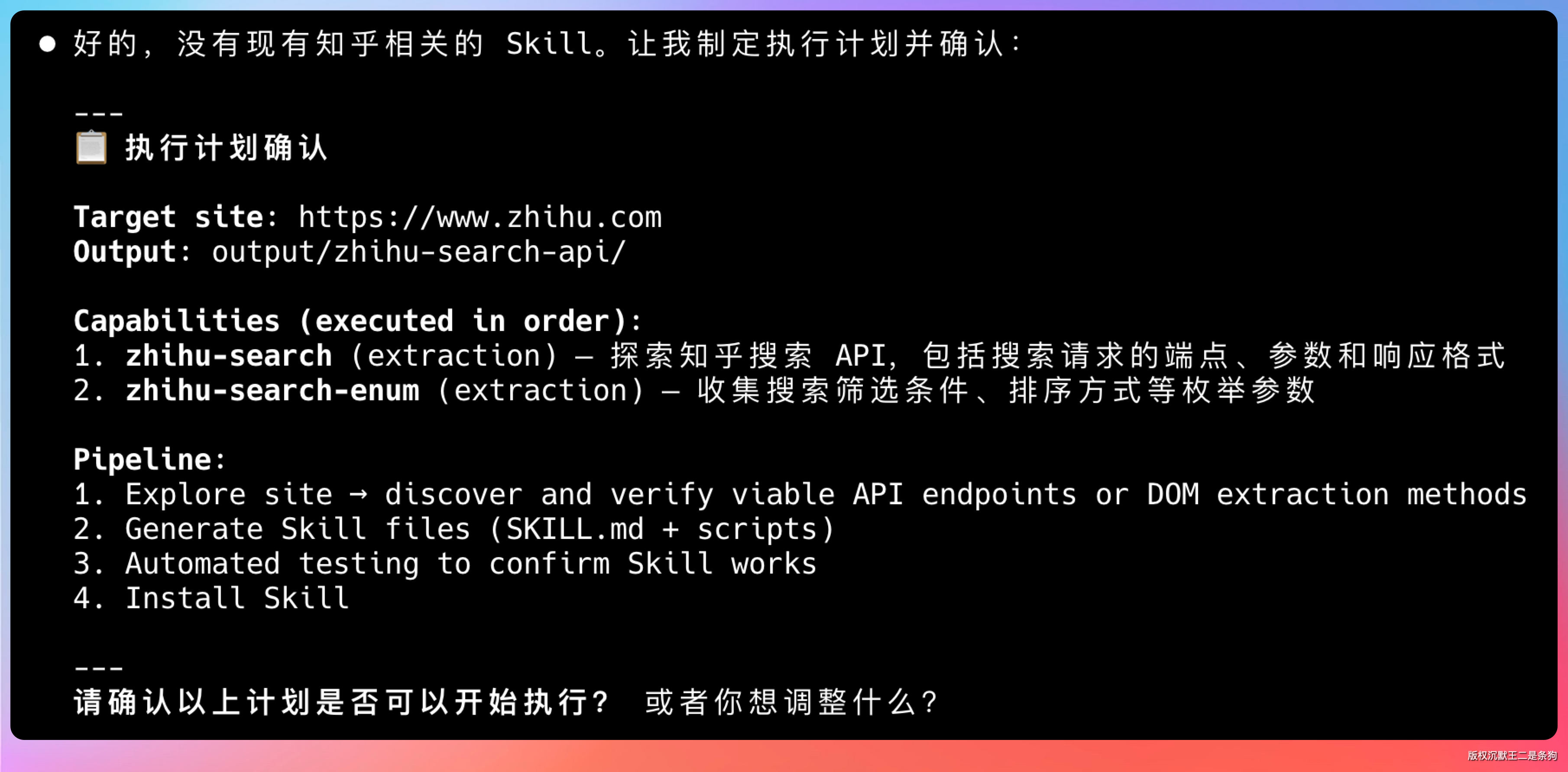
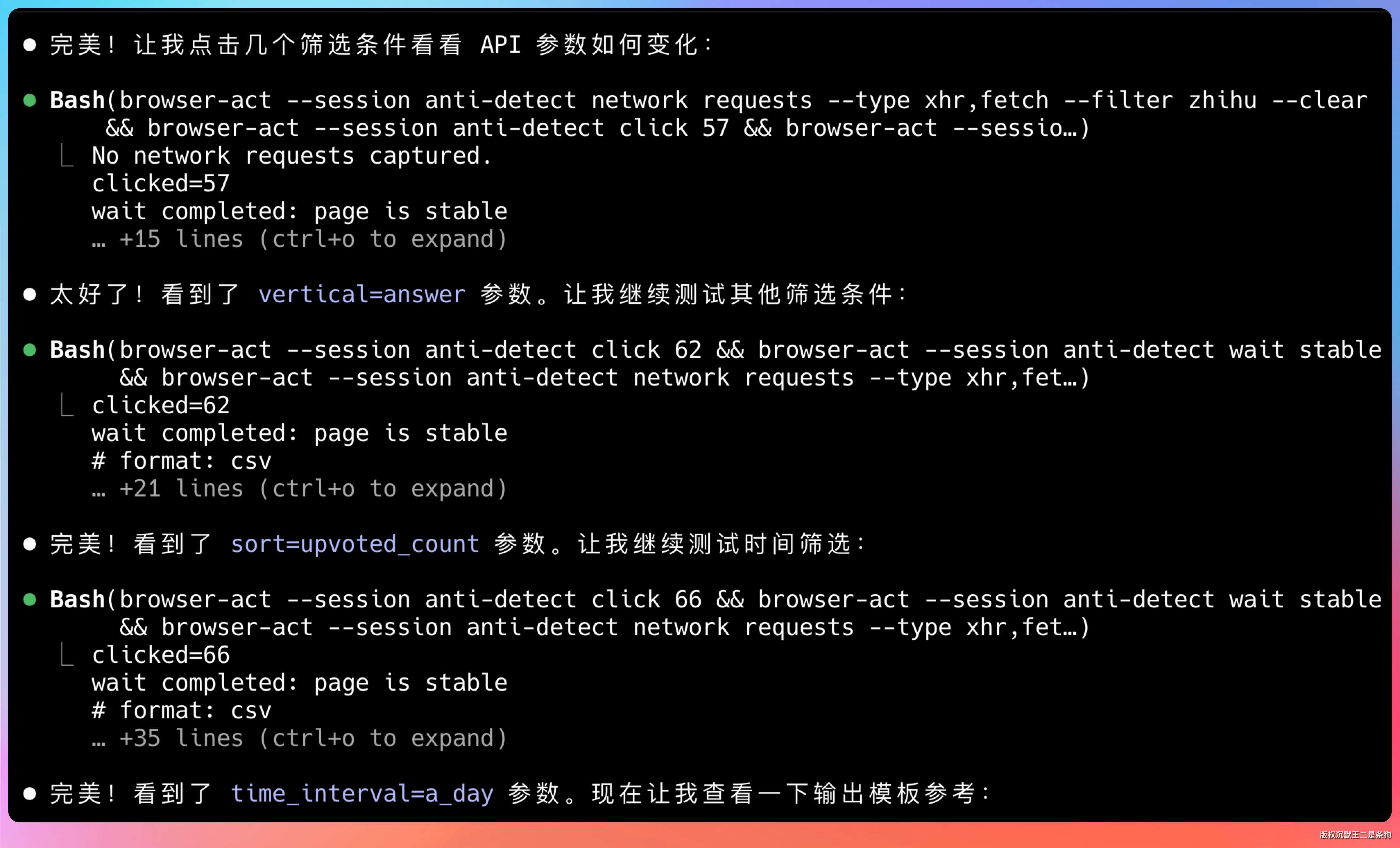
而且做好的 Skill 可以分享给同事或团队成员。
比如你花半小时搞定了一个复杂网站的数据采集流程,生成一个 Skill 发给同事,同事一行命令安装直接就能用。把“我已经跑通的网站能力”变成别人也能直接调用的协作资产,爽歪歪啊。
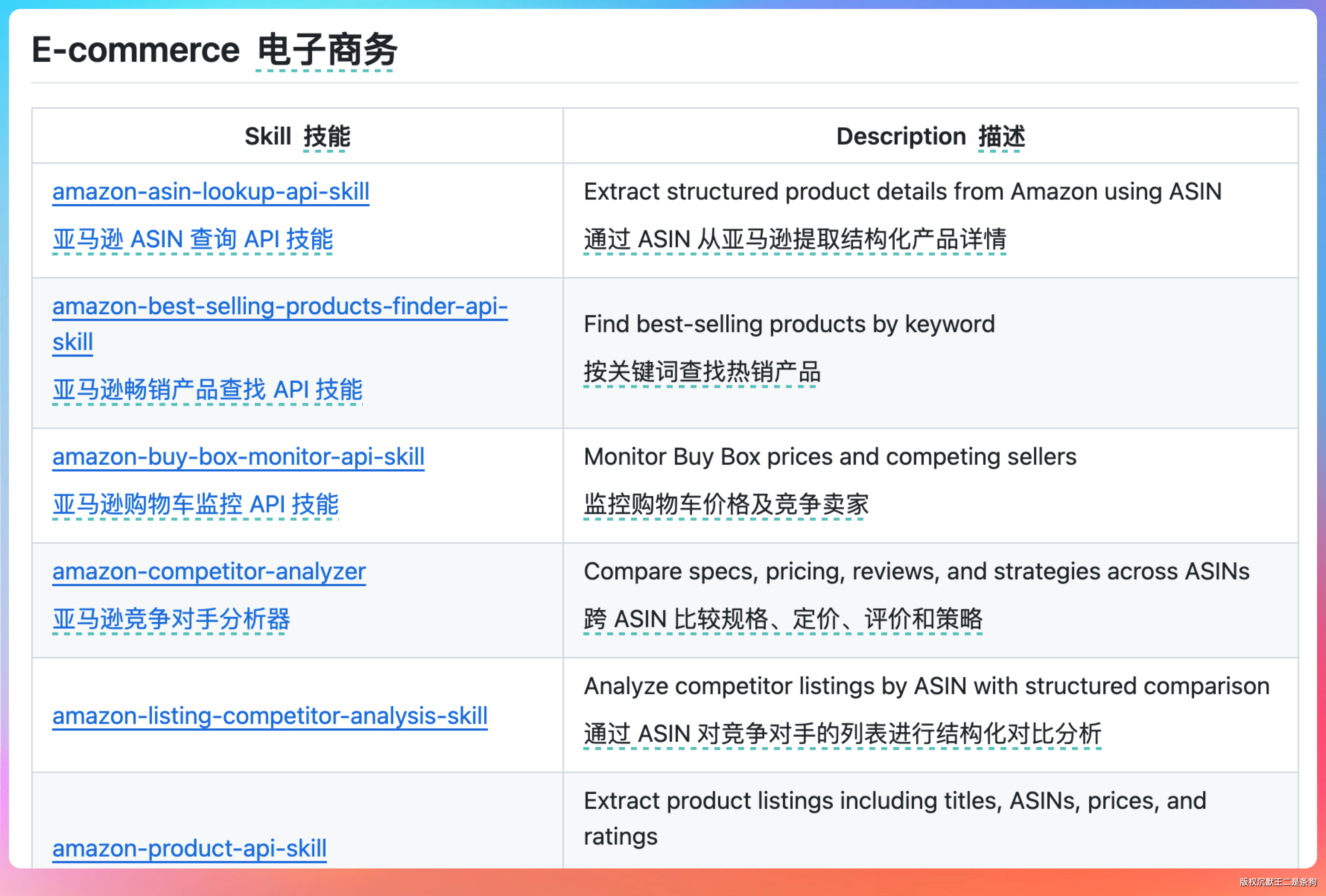
BrowserAct 团队用 Skill Forge 已经生成了 30 多个现成的 Skill,覆盖 Amazon、Google Maps、YouTube、Reddit、微信、知乎等平台,装上就能跑。
07、和 agent-browser 对比
我之前用的浏览器自动化工具是 agent-browser(web-access Skill 里的 CDP Proxy 方案)。
基础能力方面两者没有太大差异,但在突破访问限制这件事上 BrowserAct 显然更强大:
| 功能 | BrowserAct | agent-browser |
|---|---|---|
| 基础浏览器操作 | ✅ | ✅ |
| 截图和数据提取 | ✅ | ✅ |
| Cookie / Session 管理 | ✅ | ✅ |
| 反检测浏览器 | ✅ | ❌ |
| 验证码自动解决 | ✅ | ❌ |
| 动态代理 | ✅ | ❌ |
| 人机协作(remote-assist) | ✅ | ❌ |
| 通用内容提取(stealth-extract) | ✅ | ❌ |
1.4K Star,MIT 协议,免费开源。
如果大家也在用 Claude Code 或者 Codex CLI 做浏览器自动化,经常被网站拦截的话,可以试试。
帮我安装 BrowserAct:https://github.com/browser-act/skills【工具的价值不是功能多,而是在我们最需要的地方,确确实实能顶上去。】
我们下期见。