我花两天读完 Claude Code 压缩机制源码,整理了这份四阶段管线全解析
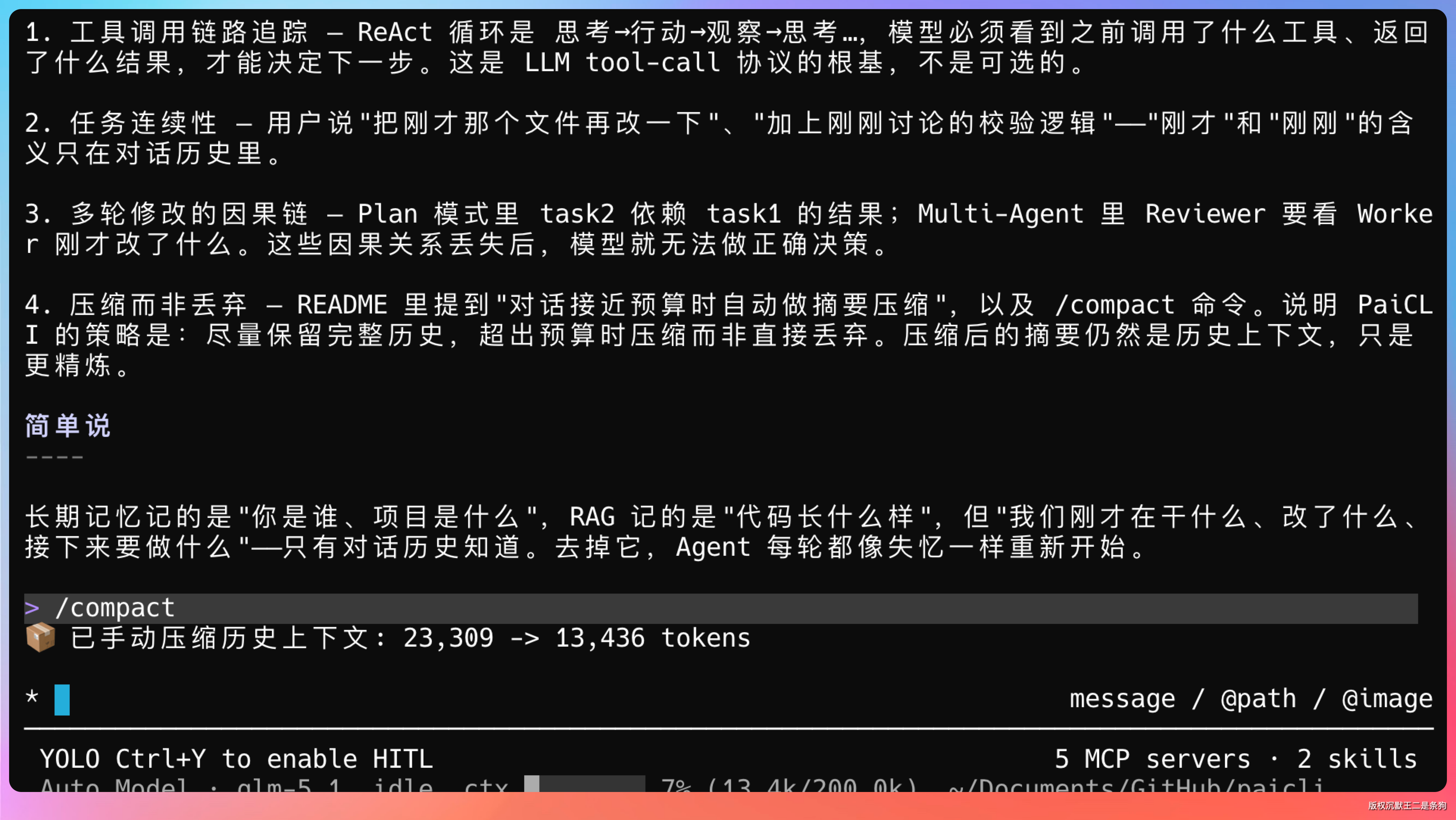
大家好,我是二哥呀。
很多小伙伴在催 AI Agent 的面渣逆袭,其实我已经在写了,其中一部分也整理到进阶之路上了,大家通过 AI Agent 的菜单进去就可以看到。
只是还没有整理成面渣逆袭的风格。
先争取每天给大家积累一篇素材,后面再统一整理,Claude Code 的八股应该是不会过时的。这篇我们来讲 Claude Code 的压缩机制。
- 什么时候压缩?
- 压缩的时候保留什么丢弃什么?
- 压缩完成之后怎么恢复工作状态?
为了讲清楚,我花了两天时间把 compact 目录下的十几个源码文件从头到尾读了一遍。从最轻量的规则裁剪,到 LLM 驱动的结构化摘要,再到熔断机制和兜底方案,每一层都有明确的触发条件和退出策略。
系好安全带,我们粗粗粗发~
01、为什么需要压缩?
Opus 4.6 默认的上下文窗口是 200K token,Opus 4.7/4.8 扩展到了 1M token。
200K 已经很大了,大概能装下 15 万个中文字。
但使用过Claude Code的小伙伴都知道,上下文的增长速度远超想象。
每次 Claude Code 执行一个工具调用(读文件、搜索、运行命令),返回的结果都会被完整记录在对话历史里。
更麻烦的是 Context Rot(上下文退化)。窗口越大,模型的注意力越分散,容易“忘记”早期的关键指令,或者把中间某次失败的尝试和最终的修复方案搞混。
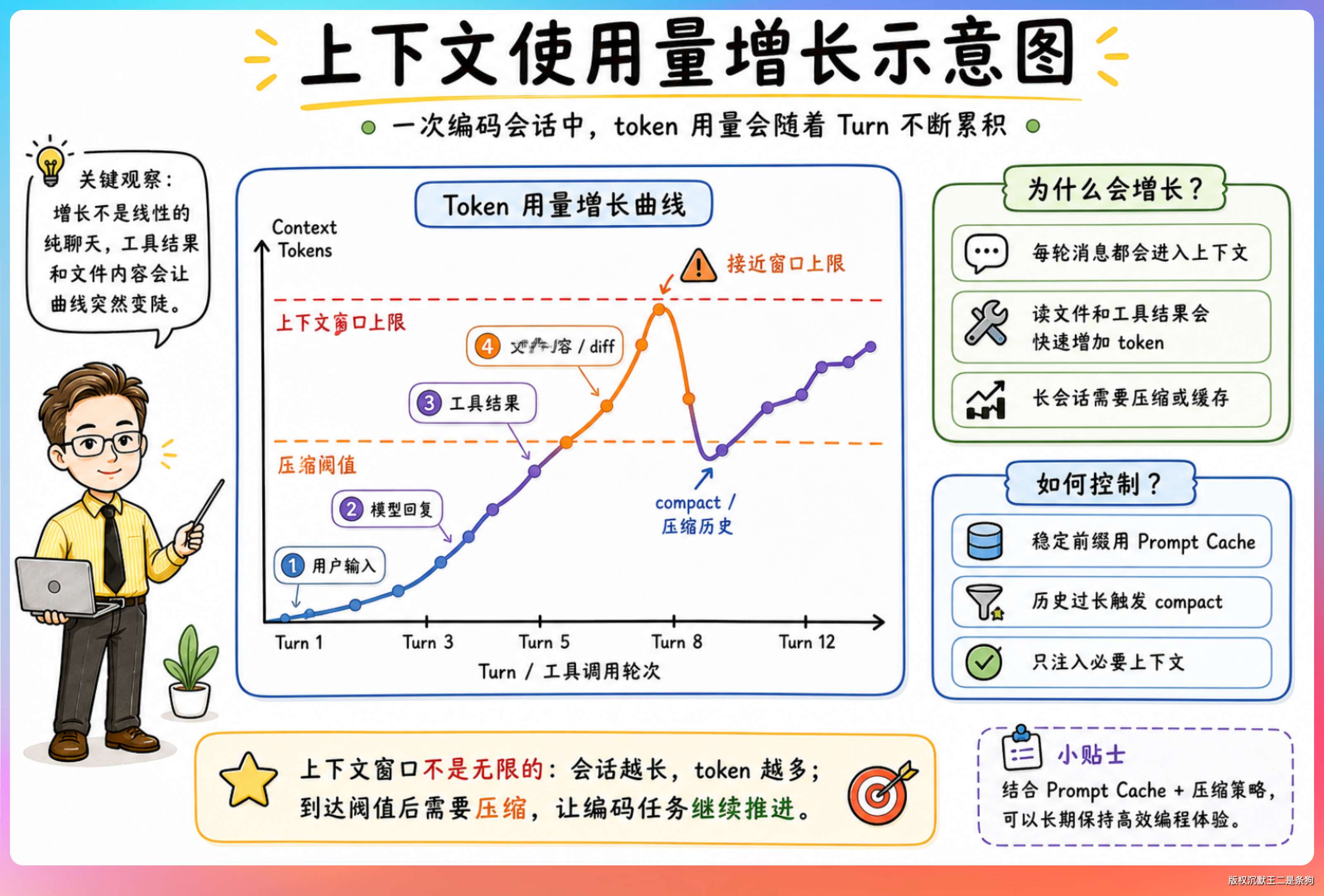
所以压缩是必须的,它是保证 Claude Code 在长会话中持续可用的核心机制。
02、压缩机制的四个阶段
我从源码里整理出了完整的流程:
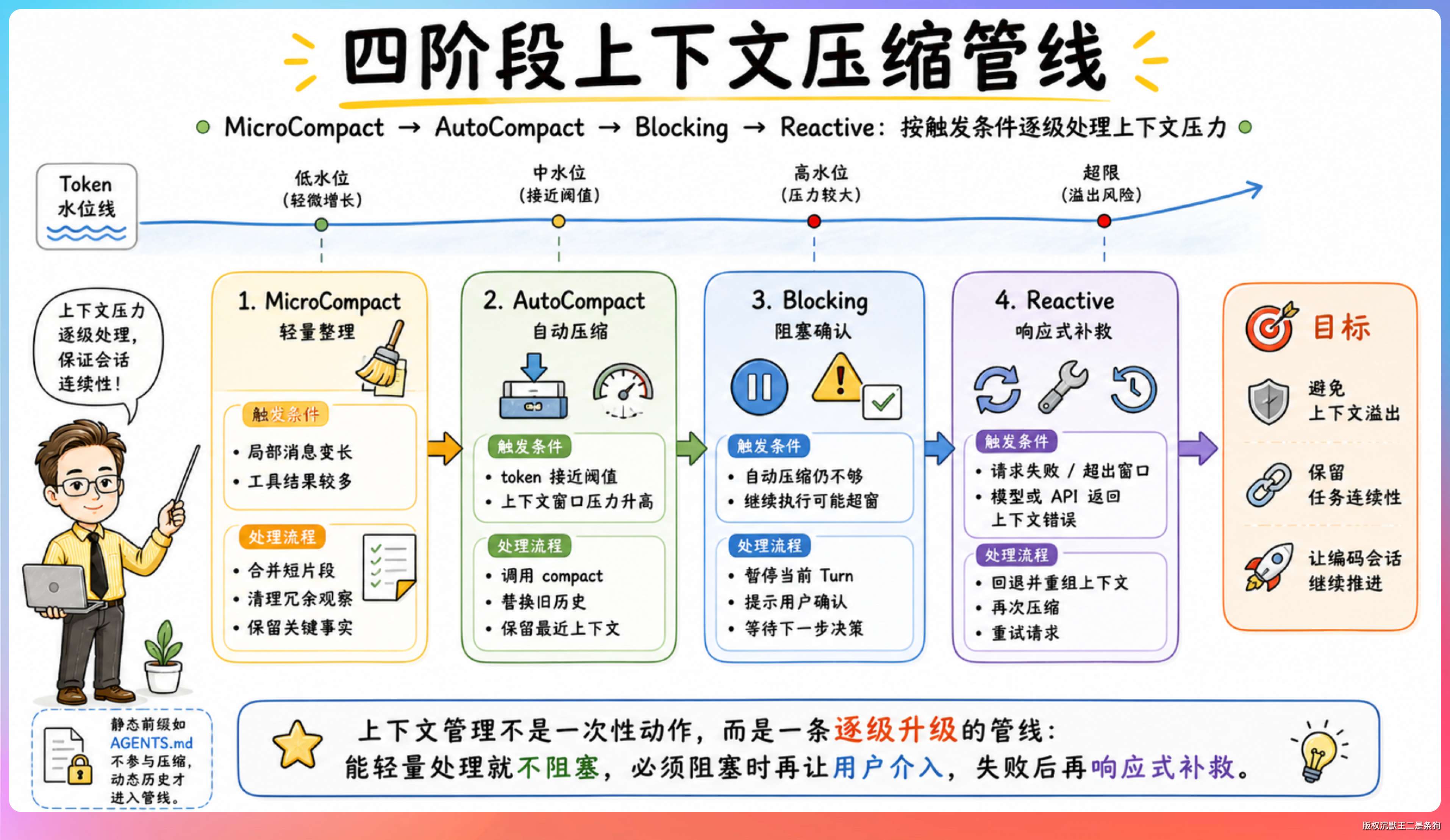
第一阶段:微压缩(MicroCompaction)。静默预处理,规则驱动,不调用 LLM。对工具返回结果做原地裁剪,去掉冗余输出。
第二阶段:自动压缩(AutoCompaction)。LLM 驱动,当上下文用量超过阈值时,用一个独立的 LLM 调用生成结构化摘要,替换整段对话历史。
第三阶段:阻塞限制(Blocking Limit)。上下文接近极限时,直接拒绝发送请求,防止 API 返回 413 错误。
第四阶段:响应式兜底(Reactive Fallback)。如果前三阶段都没能控制住上下文大小,在实际收到 prompt_too_long 错误后,执行最激进的压缩:逐条删除最旧的消息。
03、静默预处理
MicroCompaction 在每次 API 调用之前运行,不调用 LLM,不生成摘要,只做一件事:裁剪工具返回结果。
源码里定义了一个“可压缩工具”名单:
const COMPACTABLE_TOOLS = new Set<string>([
FILE_READ_TOOL_NAME,
...SHELL_TOOL_NAMES,
GREP_TOOL_NAME,
GLOB_TOOL_NAME,
WEB_SEARCH_TOOL_NAME,
WEB_FETCH_TOOL_NAME,
FILE_EDIT_TOOL_NAME,
FILE_WRITE_TOOL_NAME,
])这些工具的共同特点是返回结果很长。一次文件读取可能返回几百行代码,一次 grep 搜索可能匹配几十个文件的上百行结果。但这些结果在模型处理完之后,完整的返回值就没什么用了。模型已经根据搜索结果找到了目标文件,已经根据文件内容做了修改,保留完整的历史输出只会浪费空间。
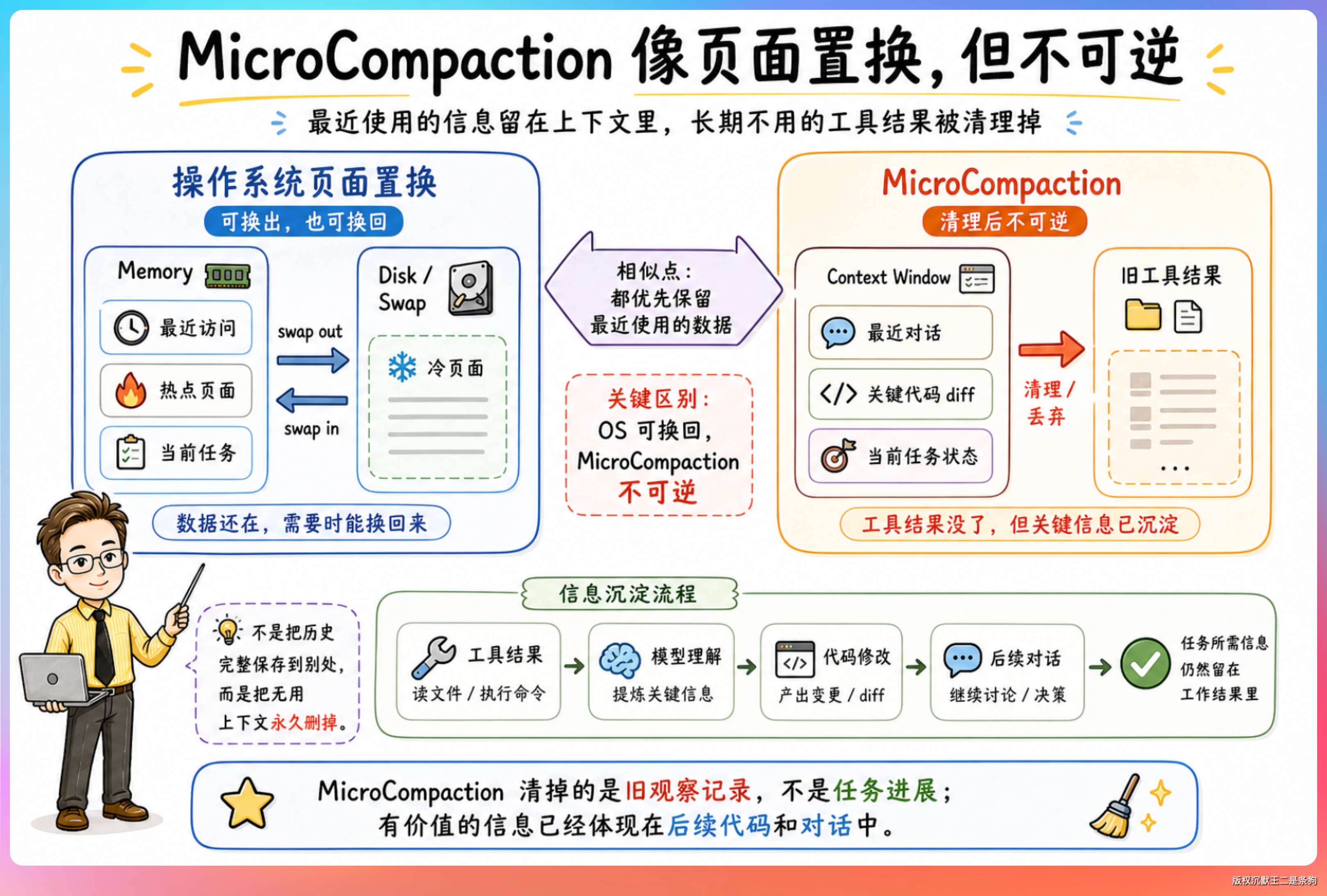
MicroCompaction 的处理方式是在消息列表中原地替换,把旧的 tool_result 内容截断或替换成占位文本 [Old tool result content cleared]。模型看不到完整的历史工具输出,但最近的工具结果会保留。
这个设计和操作系统的页面置换算法有点像:最近使用的数据留在内存里,长时间没被访问的数据交换出去。
区别在于,操作系统换出去的数据还能换回来,而 MicroCompaction 是不可逆的,清理掉的工具结果就真的没了。不过这没关系,因为模型需要的信息已经体现在后续的代码修改和对话内容里了。
基于时间间隔的清理
MicroCompaction 还有一个基于时间的触发机制,配置在 timeBasedMCConfig.ts 里:
const TIME_BASED_MC_CONFIG_DEFAULTS: TimeBasedMCConfig = {
enabled: false,
gapThresholdMinutes: 60,
keepRecent: 5,
}这里需要先科普一下 Prompt Cache 的概念。每次你和 Claude Code 交互,系统都要把完整的对话历史发送给 Anthropic 的 API。Prompt Cache 机制允许服务端缓存已经处理过的上下文前缀,下一次请求如果前缀没变,就不需要重新计算。这样既省时间又省钱(缓存命中的 token 计费只有原价的十分之一)。
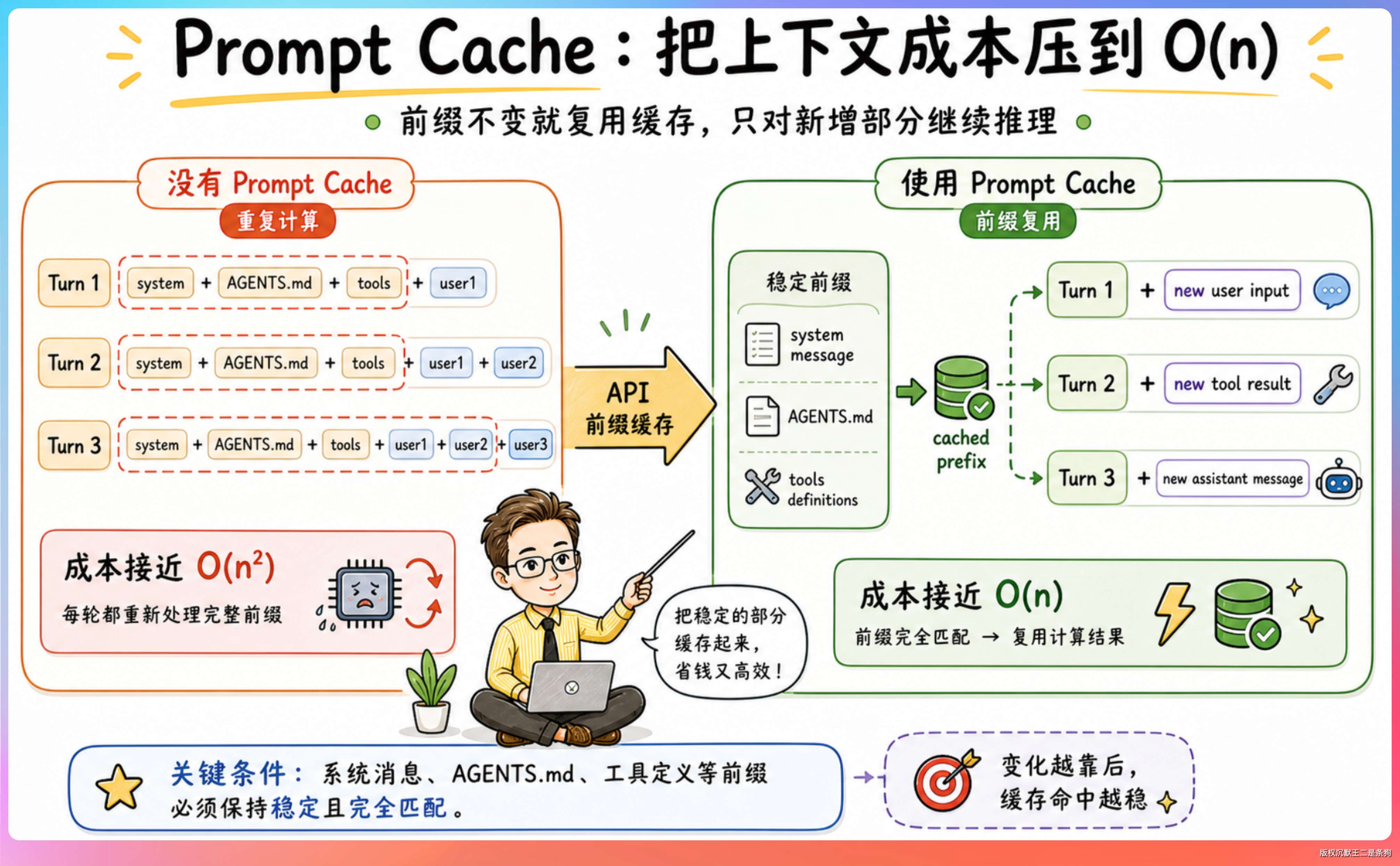
但是 Prompt Cache 有 TTL(过期时间)。
Anthropic 的 Prompt Caching 默认 TTL 是 5 分钟,也支持 1 小时 TTL;Claude Code 是否使用 1 小时 TTL,会受到用户资格、Provider 和配置开关的影响。
源码里 MicroCompaction 把阈值设成 60 分钟,是为了在服务端缓存基本可以确定已经过期时再清理旧工具结果,避免为了清理而主动破坏本来还能命中的缓存。这样做的意义是:缓存已经冷掉时,下一次请求本来就要重新发送和计算前缀,那就先把旧工具结果瘦身,减少重新发送的数据量。
keepRecent: 5 表示保留最近 5 个可压缩工具的结果,更早的全部替换成 [Old tool result content cleared]。这个数字的选择也经过了考量:太少可能清掉模型还需要的信息,太多起不到节省的效果。5 是一个经验值。
MicroCompaction 最大的优势是零成本:不消耗 API 调用,不产生额外的 token 费用,纯规则处理,速度极快。它不会影响对话的语义完整性,只是把模型已经“消化”过的冗余数据清理掉。
04、自动压缩
MicroCompaction 只清理工具返回结果,AutoCompaction 则要把整段对话历史重写成一份摘要。
触发阈值
AutoCompaction 的触发条件在 autoCompact.ts 里定义:
const MAX_OUTPUT_TOKENS_FOR_SUMMARY = 20_000
export function getEffectiveContextWindowSize(model: string): number {
const reservedTokensForSummary = Math.min(
getMaxOutputTokensForModel(model),
MAX_OUTPUT_TOKENS_FOR_SUMMARY,
)
let contextWindow = getContextWindowForModel(model, getSdkBetas())
return contextWindow - reservedTokensForSummary
}
export const AUTOCOMPACT_BUFFER_TOKENS = 13_000计算过程分两步。
第一步,算出有效上下文窗口。200K 的窗口要预留 20,000 token 给压缩摘要的输出(这个数字来自 p99.99 的统计:压缩摘要输出的 99.99 分位数是 17,387 token)。所以有效窗口是 180,000 token。
第二步,在有效窗口基础上再减去 13,000 token 的安全缓冲。最终的自动压缩阈值是 167,000 token,大约占原始 200K 窗口的 83.5%。
也就是说,当你的对话消耗了 167K token 的时候,Claude Code 会自动触发压缩。这个阈值大约是原始窗口的 83.5%,留了足够的空间给压缩操作本身。
如果你用的是 1M 上下文窗口的模型(比如加了 [1m] 后缀的 Opus 4.8),有效窗口是 980K,自动压缩阈值在 967K 左右,也就是说你可以用到 96.7% 才触发压缩。
不过 Anthropic 也发现 1M 窗口下自动压缩事件只减少了 15%(远低于预期),说明大多数长会话的上下文增长并不是线性的,即使窗口大了 5 倍,该压缩的时候还是会压缩。
压缩流程
触发压缩后,Claude Code 的执行步骤如下:
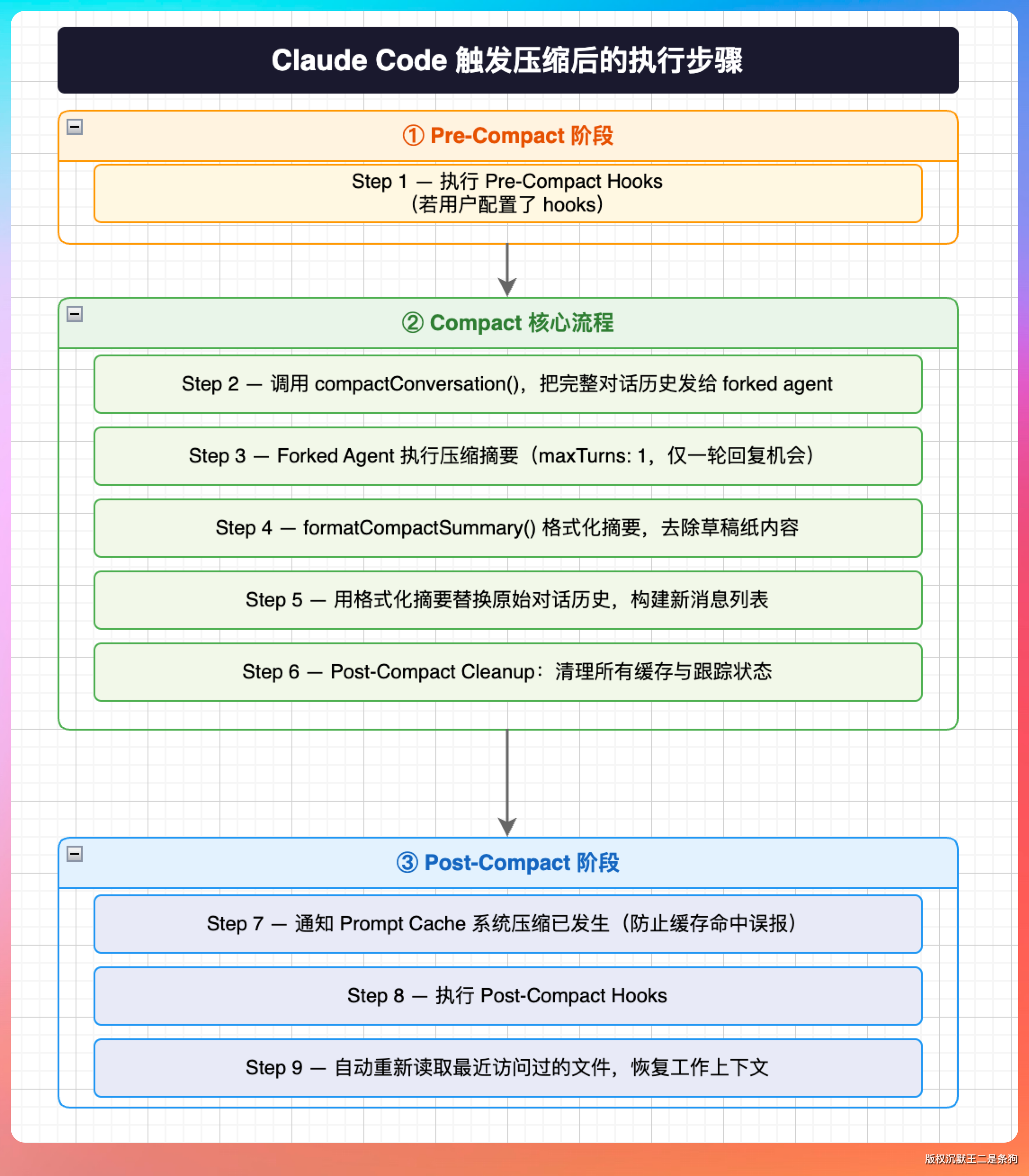
- 先执行压缩前钩子(Pre-Compact Hooks,如果用户在配置中设置了 hooks 的话)
- 调用
compactConversation函数,把整段对话历史发给一个独立的 forked agent - 这个 forked agent 是一个专门用来做压缩的 LLM 实例,它只有一轮机会(
maxTurns: 1),必须在一次回复中完成摘要 - 拿到摘要后,用
formatCompactSummary函数做格式化处理,去掉草稿纸内容 - 用格式化后的摘要替换原始对话历史,构建新的消息列表
- 执行压缩后清理(Post-Compact Cleanup),清理所有缓存和跟踪状态
- 通知 Prompt Cache 系统压缩已经发生(防止缓存命中检测误报)
- 执行压缩后钩子(Post-Compact Hooks)
- 自动重新读取最近访问过的文件,恢复工作上下文
压缩期间会在终端显示一条提示消息,告诉你正在压缩。整个过程通常需要十几秒到半分钟,取决于对话历史的长度。
两条压缩路径
源码里实际有两条压缩路径:
路径一:会话记忆压缩(Session Memory Compact)。如果开启了会话记忆功能,Claude Code 会在后台持续做增量笔记。压缩时直接用这些笔记作为摘要,而不需要重新让 LLM 通读整段对话。
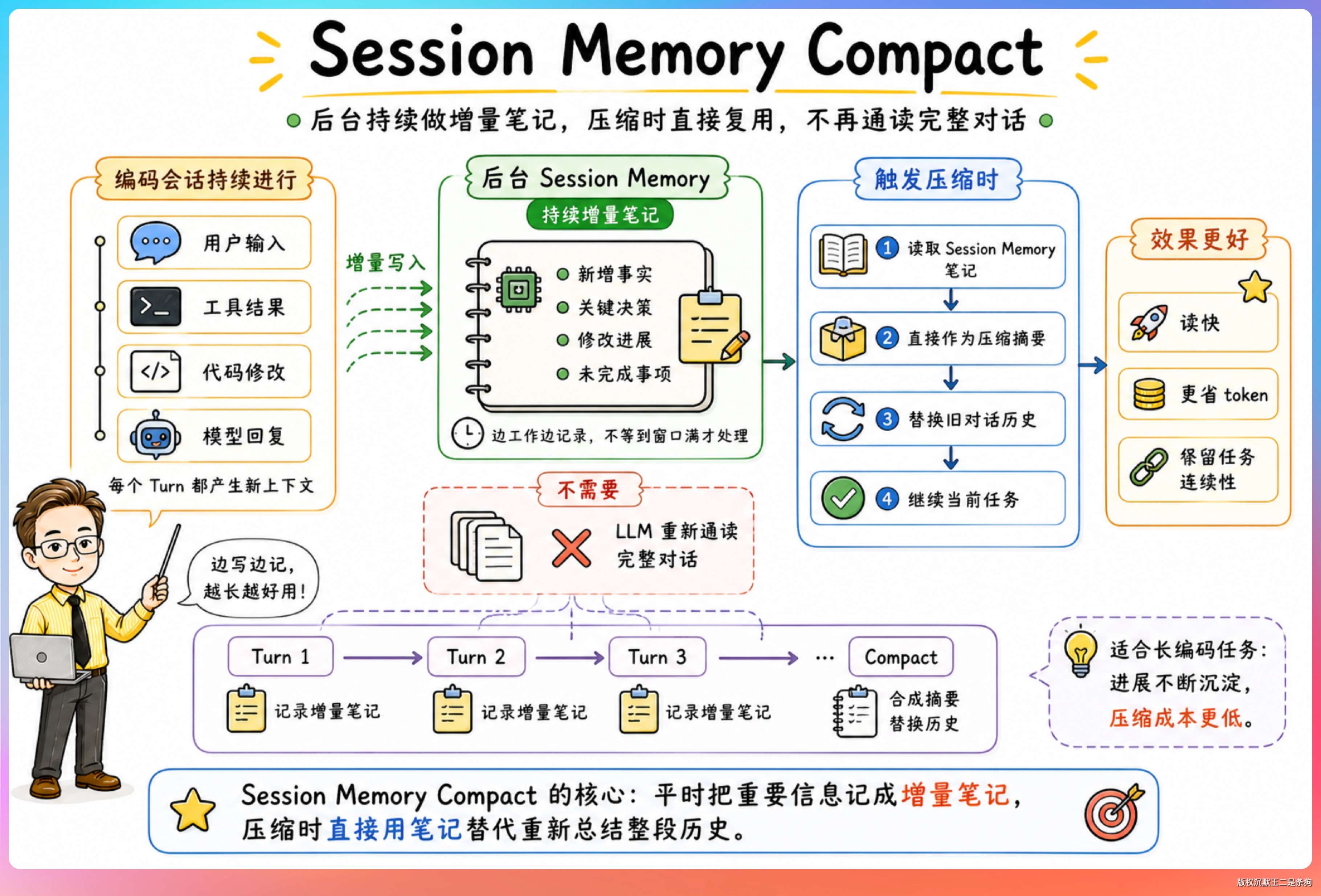
export const DEFAULT_SM_COMPACT_CONFIG: SessionMemoryCompactConfig = {
minTokens: 10_000,
minTextBlockMessages: 5,
maxTokens: 40_000,
}这条路径的好处是速度快,因为笔记已经在后台生成好了,压缩时直接拿来用。
配置里的三个参数分别控制了压缩后保留的最小 token 数(10,000)、最少保留的消息数(5 条有文本内容的消息)和最大 token 数(40,000)。
也就是说,即使有会话记忆,也不会把最近的消息全部丢掉,至少保留 5 条最近的对话和 10K token 的内容。
不过会话记忆压缩目前还是实验功能,需要特定的配置才能开启。从源码来看,它的优先级高于全量对话摘要,系统会先尝试会话记忆压缩路径,只有在 Session Memory 为空、内容不足或者功能未开启时,才回退到标准路径。
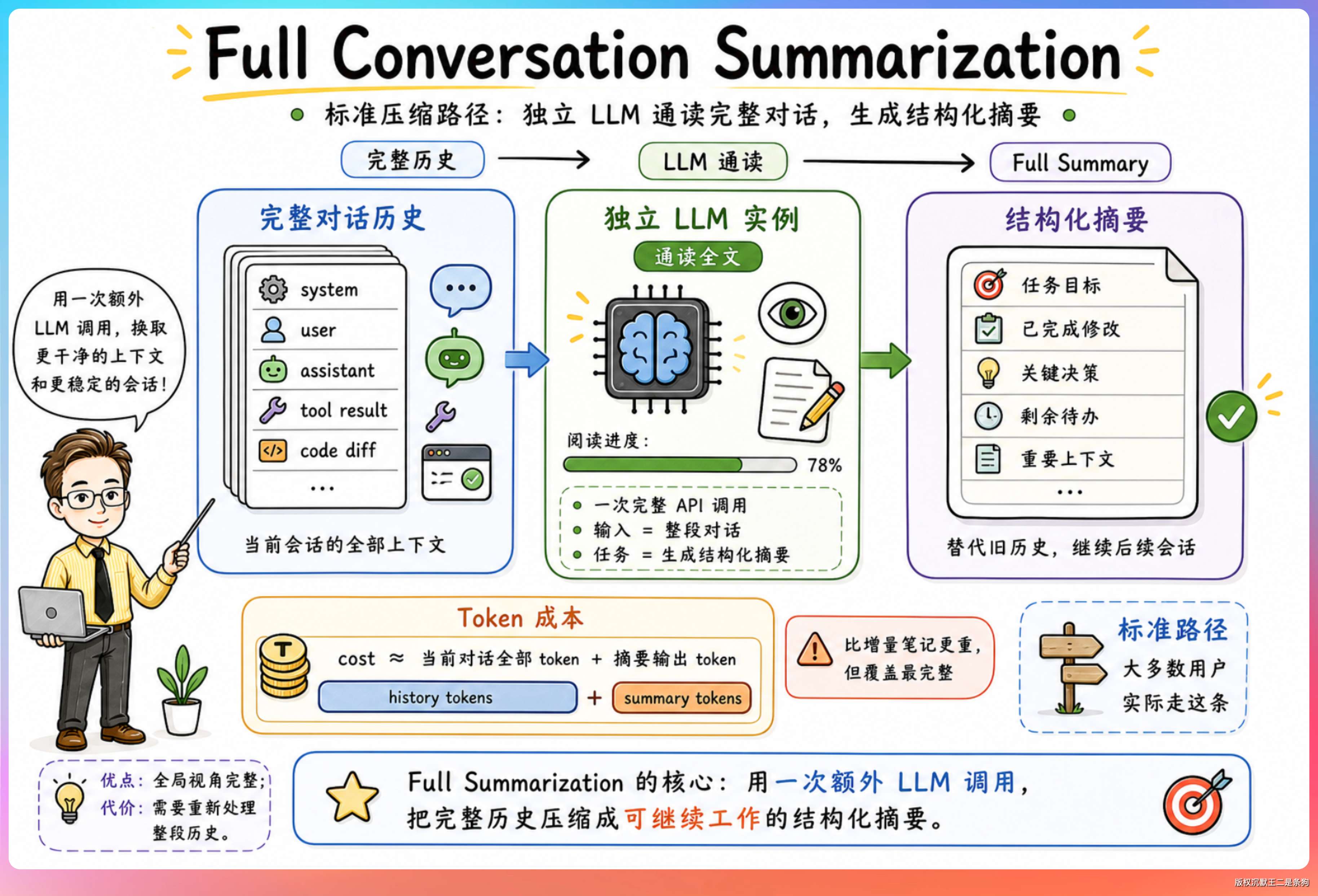
路径二:全量对话摘要(Full Conversation Summarization)。标准路径,也是目前大多数用户实际走的路径。把整段对话发给一个独立的 LLM 实例,让它通读全文后生成一份完整的结构化摘要。这个过程需要一次完整的 API 调用,消耗的 token 数约等于当前对话的全部 token 加上摘要输出的 token。
05、压缩提示词
压缩效果好不好,全看压缩提示词(Compaction Prompt)写得怎么样。这个 Prompt 定义在 prompt.ts 里,是整套压缩机制最核心的部分。
防止工具调用
Prompt 开头是一段极其严格的“禁止调用工具”声明:
const NO_TOOLS_PREAMBLE = `CRITICAL: Respond with TEXT ONLY. Do NOT call any tools.
- Do NOT use Read, Bash, Grep, Glob, Edit, Write, or ANY other tool.
- You already have all the context you need in the conversation above.
- Tool calls will be REJECTED and will waste your only turn — you will fail the task.
- Your entire response must be plain text: an <analysis> block followed by a <summary> block.
`压缩操作是一个独立的 forked agent(分叉智能体),它和主会话共享相同的工具集。
为什么要共享?
因为 Anthropic 的 Prompt Cache 是按照请求的“前缀”来匹配的,工具集是前缀的一部分。如果压缩用的 forked agent 去掉了工具集,cache key 就对不上了,无法复用主会话积累的缓存。
但这带来了一个副作用。
模型看到工具集就会有“调用工具”的冲动。比如说模型会判断“我需要读一下某个文件才能写出准确的摘要”,然后尝试调用 Read 工具。
由于 maxTurns: 1 的限制,工具调用会被直接拒绝,但这一轮的文本输出也没了,压缩直接失败。
所以 Anthropic 的解决方案是把“禁止调用工具”放在 Prompt 的最前面,用大写加粗的语气明确告诉模型:你只有一次机会,如果浪费在工具调用上就彻底失败了。
这段话还加了首尾呼应,Prompt 末尾有个 NO_TOOLS_TRAILER 再次提醒:
const NO_TOOLS_TRAILER =
'\n\nREMINDER: Do NOT call any tools. Respond with plain text only — ' +
'an <analysis> block followed by a <summary> block. ' +
'Tool calls will be rejected and you will fail the task.'两阶段输出
压缩提示词要求模型输出两个 XML 块:
<analysis> 块:思考过程的草稿纸。模型按时间顺序分析每条消息,记录用户意图、技术决策、代码细节、错误和修复方案。
<summary> 块:正式摘要,包含 9 个固定章节:
- Primary Request and Intent:用户的核心需求和意图
- Key Technical Concepts:涉及的技术概念和框架
- Files and Code Sections:操作过的文件、代码片段、修改记录
- Errors and Fixes:遇到的错误和修复方案
- Problem Solving:解决的问题和正在排查的问题
- All User Messages:所有非工具结果的用户消息(原文)
- Pending Tasks:待完成的任务
- Current Work:压缩前正在做什么
- Optional Next Step:下一步计划
<analysis> 块在摘要生成后会被 formatCompactSummary 函数直接删除。
export function formatCompactSummary(summary: string): string {
let formattedSummary = summary
formattedSummary = formattedSummary.replace(
/<analysis>[\s\S]*?<\/analysis>/,
'',
)
// ...
}也就是说,analysis 只是一个“草稿纸”,让模型先把思路理清楚,提高最终摘要的质量,但草稿本身不会占用后续的上下文空间。
这在提示词工程里是一个经典技巧,叫做“drafting scratchpad pattern”(草稿本模式)。让模型先在一个临时空间里做分析和推理,但只保留最终结论。和 Chain-of-Thought 有点像,但区别在于 CoT 的思考过程通常会保留在输出中,而 drafting scratchpad 会在后处理阶段被主动删除。
部分压缩
除了全量压缩,还有一种部分压缩(Partial Compact)。当对话里已经存在之前的压缩摘要时,不需要重新压缩整段对话,只需要压缩摘要之后的新增部分。
源码里定义了两个方向:
from方向:只压缩最近的消息,保留早期上下文up_to方向:压缩到某个点为止,后续消息保留
部分压缩的好处是压缩范围更小,LLM 需要处理的输入更少,速度更快,消耗的 token 也更少。
06、阻塞限制
自动压缩不是万能的。如果压缩后上下文仍然超标,或者 LLM 调用本身失败了,后面还有两道防线。
阻塞限制(Blocking Limit)
在有效上下文窗口的基础上,只保留 3,000 token 的缓冲:
export const MANUAL_COMPACT_BUFFER_TOKENS = 3_000当上下文用量超过 有效窗口 - 3,000 token(大约 88.5%)时,Claude Code 直接拒绝发送 API 请求。这比收到 413 错误再处理要好很多,413 错误意味着请求已经发出去了,浪费了一次 API 调用。
断路器(Circuit Breaker)
这是源码里我最喜欢的一个设计。
const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3断路器的逻辑很简单:连续失败 3 次后,停止自动压缩的重试。因为如果连续 3 次都失败了,说明上下文可能处于一种无法通过压缩恢复的状态(比如单条消息就超过了限制),继续重试只会浪费资源。
兜底方案
当 API 实际返回了 prompt_too_long 错误时,响应式兜底会执行最激进的压缩:按 drainage 策略逐条删除最旧的消息。
07、消息分组策略
压缩时需要决定哪些消息可以被“打包”在一起处理。grouping.ts 里实现了基于 API 轮次的消息分组。
export function groupMessagesByApiRound(messages: Message[]): Message[][] {
const groups: Message[][] = []
let current: Message[] = []
let lastAssistantId: string | undefined
for (const msg of messages) {
if (
msg.type === 'assistant' &&
msg.message.id !== lastAssistantId &&
current.length > 0
) {
groups.push(current)
current = [msg]
} else {
current.push(msg)
}
if (msg.type === 'assistant') {
lastAssistantId = msg.message.id
}
}
if (current.length > 0) {
groups.push(current)
}
return groups
}分组的边界不是“用户发了一条新消息”,而是“出现了一个新的 assistant message ID”。
为什么?
源码注释里解释了:在 SDK 和 API 调用场景中,整个工作负载可能只有一条用户消息,但 agent 会执行几十轮工具调用。如果按用户消息分组,整个会话就是一个组,没法做增量压缩。按 API 轮次分组,可以精细到每一轮 tool_use → tool_result 的配对。
08、压缩后的恢复机制
压缩完成后,Claude Code 不是直接把摘要扔给模型就完事了。还有一套完整的恢复机制。
压缩后清理(Post-Compact Cleanup)
postCompactCleanup.ts 里列出了压缩后需要重置的所有状态:
export function runPostCompactCleanup(querySource?: QuerySource): void {
resetMicrocompactState()
// Reset context collapse (main thread only)
// Clear getUserContext cache
resetGetMemoryFilesCache('compact')
clearSystemPromptSections()
clearClassifierApprovals()
clearSpeculativeChecks()
clearBetaTracingState()
clearSessionMessagesCache()
}包括:MicroCompaction 状态、CLAUDE.md 和 Memory 文件缓存、系统提示词分段、工具权限的预检查结果等。
重置确保压缩后的“新会话”不会被旧状态污染。比如 Memory 文件缓存如果不清理,压缩后模型看到的 Memory 可能是过时的版本。
有一项特意不清理
源码注释里有一段特别的说明:
We intentionally do NOT clear invoked skill content here. Skill content must survive across multiple compactions so that createSkillAttachmentIfNeeded() can include the full skill text in subsequent compaction attachments.
Skill 的内容在压缩后不会被清理。
因为 Skill 是用户主动加载的专业技能包,如果压缩时丢掉了,后续的对话就失去了这些专业指导。Skill 内容会被重新注入到压缩后的上下文中,确保跨压缩的连续性。
Sub-agent 的隔离问题
压缩后清理还处理了一个微妙的并发问题。Claude Code 的 Sub-agent 和主线程运行在同一个进程中,共享模块级别的状态。如果 Sub-agent 触发了压缩并重置了状态,会把主线程的状态也破坏掉。
解决方案是通过 querySource 参数判断:只有主线程的压缩才重置模块级状态,Sub-agent 的压缩跳过这些全局重置。
const isMainThreadCompact =
querySource === undefined ||
querySource.startsWith('repl_main_thread') ||
querySource === 'sdk'文件自动重读
压缩完成后,Claude Code 会自动重新读取最近访问过的文件(最多 5 个,每个文件上限 5K token,总预算 50K token)。这样模型在压缩后不需要手动 re-read 刚才在看的代码,可以直接继续工作。
09、手动压缩和环境变量
除了自动触发,Claude Code 还提供了手动压缩的方式。
/compact 命令
在对话中输入 /compact 可以手动触发压缩。还支持自定义指令:
/compact focus on the database migration code自定义指令会被追加到 Compaction Prompt 的末尾:
export function getCompactPrompt(customInstructions?: string): string {
let prompt = NO_TOOLS_PREAMBLE + BASE_COMPACT_PROMPT
if (customInstructions && customInstructions.trim() !== '') {
prompt += `\n\nAdditional Instructions:\n${customInstructions}`
}
prompt += NO_TOOLS_TRAILER
return prompt
}手动 /compact 和自动压缩不是同一种触发逻辑。
自动压缩依赖上下文用量阈值,默认会在有效窗口减去 13,000 token 缓冲后触发;手动 /compact 则由用户主动发起,可以在任何合适的时间提前执行。源码里的 MANUAL_COMPACT_BUFFER_TOKENS = 3_000 更准确地说是接近极限时给手动压缩保留的缓冲空间,不是“手动压缩的触发阈值”。
实际使用中,我建议在以下几个时间点手动执行 /compact:
- 探索阶段结束,准备开始编码之前
- 完成一个里程碑之后
- 上下文用量到 60%-70% 的时候
- 任务方向发生重大转变时
CLAUDE.md 中的压缩指令
除了命令行参数,还可以在 CLAUDE.md 里添加持久的压缩指令:
## Compact Instructions
When summarizing the conversation focus on typescript code changes
and also remember the mistakes you made and how you fixed them.Compaction Prompt 会自动读取 CLAUDE.md 中的这些指令,作为 Additional Instructions 附加到摘要提示词中。