打饭时我问老板:“DeepSeek-V4、Claude Opus 4.7 都 1M 上下文窗口了,都塞进去不就行了?”没等老板开口,打饭阿姨听完就直摇头。。
大家好,我是二哥呀。
先问一个问题,你觉得上下文窗口是越大越好吗?
换句话说,上下文窗口是 200k token的时候你感觉聪明还是 1M 的时候?
答案可能会让很多小伙伴失望。
窗口越大,管不好反而越容易翻车。
今天这篇内容,咱们就把 Claude Code 上下文管理的完整体系拆解开来。
从 Context 到 Compaction 压缩,从 /compact 命令到子代理隔离,每一层机制是怎么配合的,怎么用才能让 CC 在长对话里始终保持高水准。
系好安全带,我们粗粗粗发~
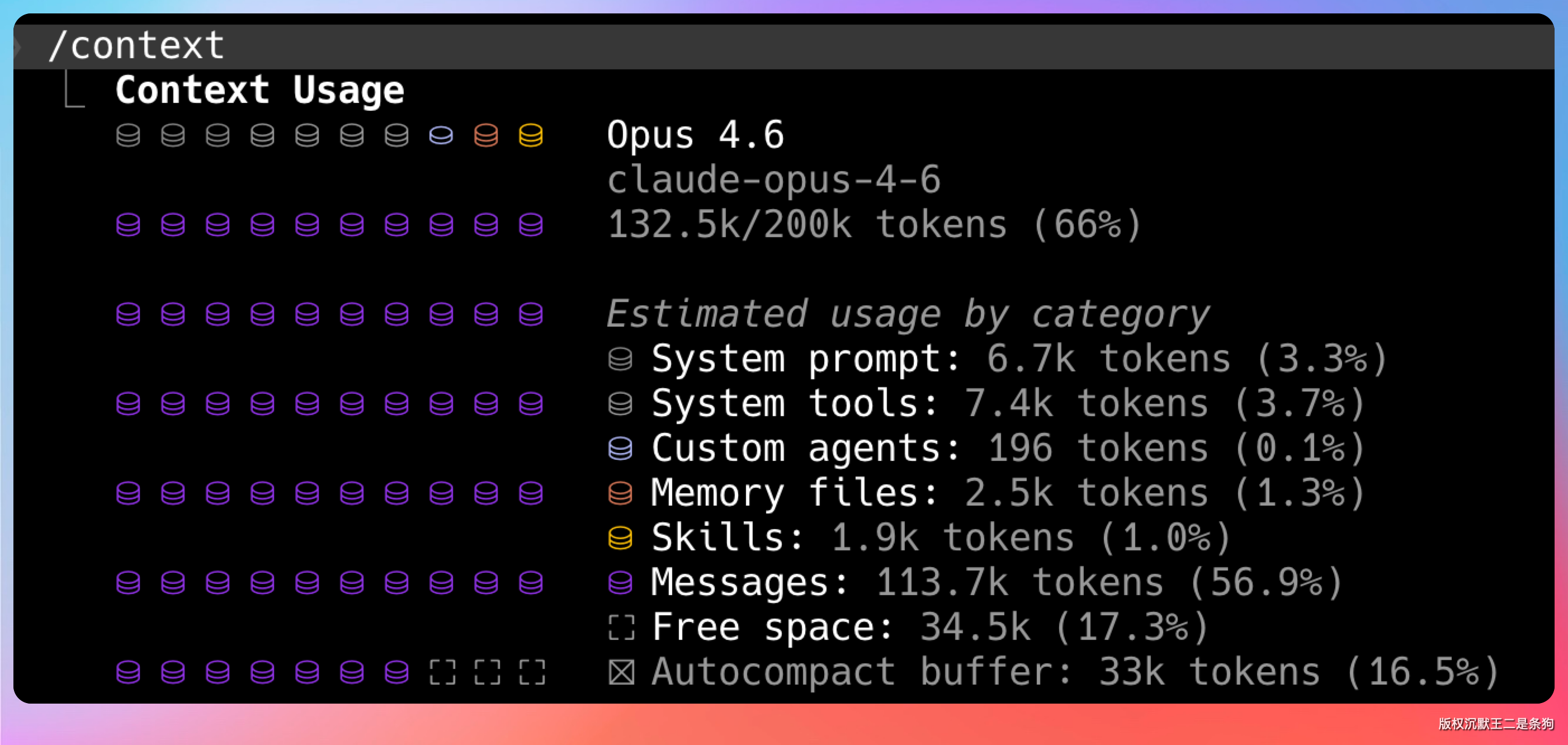
01、1M Token 到底有多大?
1M Token 大约等于 75 万个英文单词,换算成中文大概是 50 万字。
什么概念呢?
《三体》三部曲加起来 88 万字,1M Token 差不多能装下其中的两本。

我现在处理文本的时候,仍然用的是 Opus 4.6 也就是 200k token,只有在编码的时候才会用 Opus 4.7。
随着大模型版本的迭代,下一代的 LLM 应该都会往 1M 上下文窗口发展。
但 1M 不是万能解药。
Anthropic 的 CPO Jon Bell 在 2026 年 4 月透露过一个数据:1M 窗口上线后,自动压缩事件只减少了 15%。
为什么只有 15%?
因为真正的问题不在窗口大小,而在上下文质量。
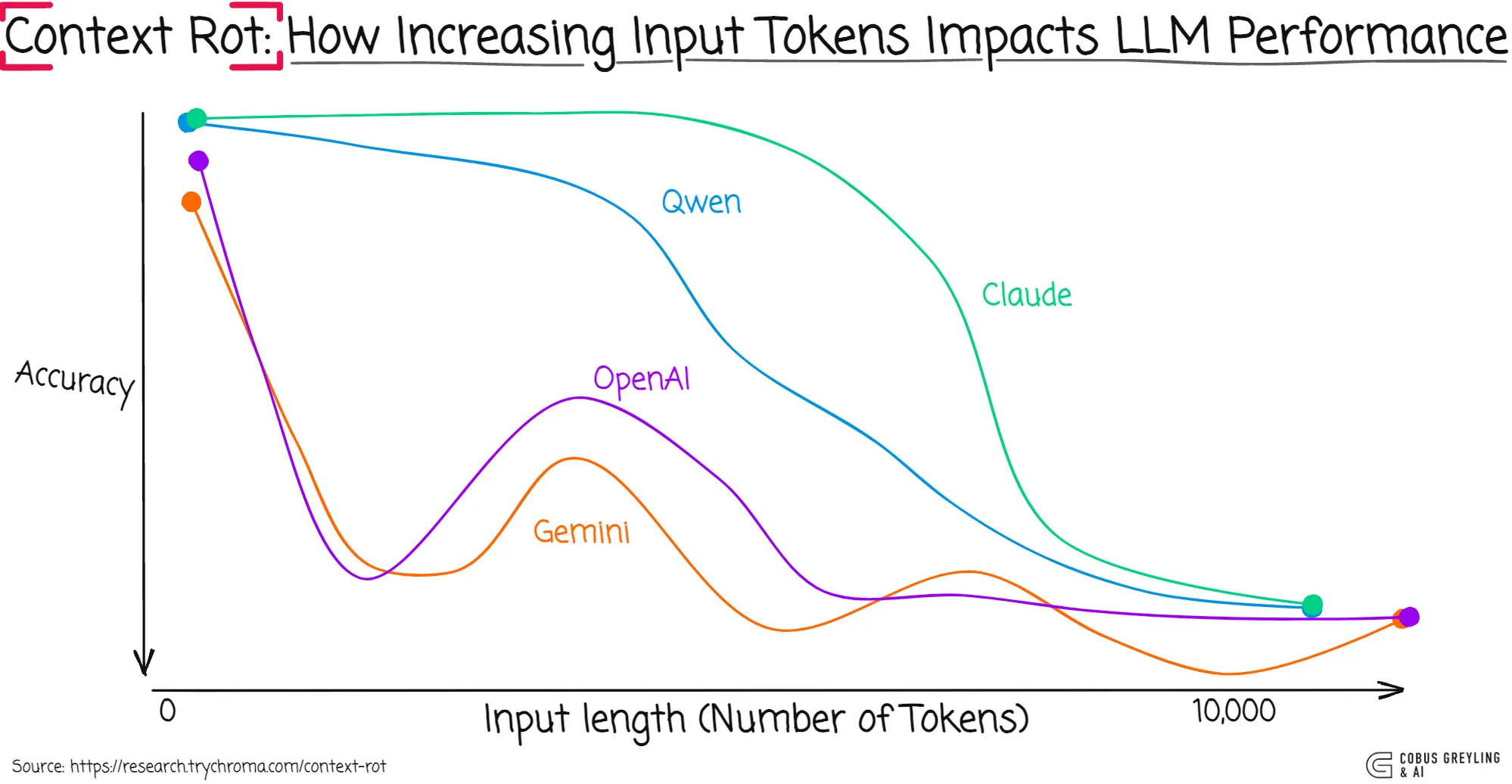
02、Context Rot 是什么?
简单说就是:
随着上下文越来越长,模型的注意力被分散到太多 Token 上,对当前任务的理解反而在下降。
具体表现在。
你让 CC 改一个 Bug,它前面已经读了 20 个文件、跑了 30 条命令,上下文里塞满了各种中间结果。到最后真正要改代码的时候,它突然“忘了”之前分析出来的结果。
宝玉大佬分享过一个很形象的比喻:1M 上下文就像你有一张能放 1000 本书的桌子,但同一时间你真正能看到还是眼前那几本。桌子越大,找书的时间反而越长,注意力越分散。
这就引出了一个反直觉的结论。
上下文不是越多越好,而是越精准越好。
Claude Code 的上下文管理体系,本质上就是在解决这个问题:怎么在一个巨大的窗口里,始终让模型“看到”最相关的信息。
03、Compaction 压缩机制
Compaction 是 Claude Code 上下文管理的核心武器。
它的设计目标很明确,在上下文快要溢出之前,把不重要的历史信息压缩成摘要,腾出空间给新内容。
但实际的实现比想象中复杂得多,分了四个阶段。
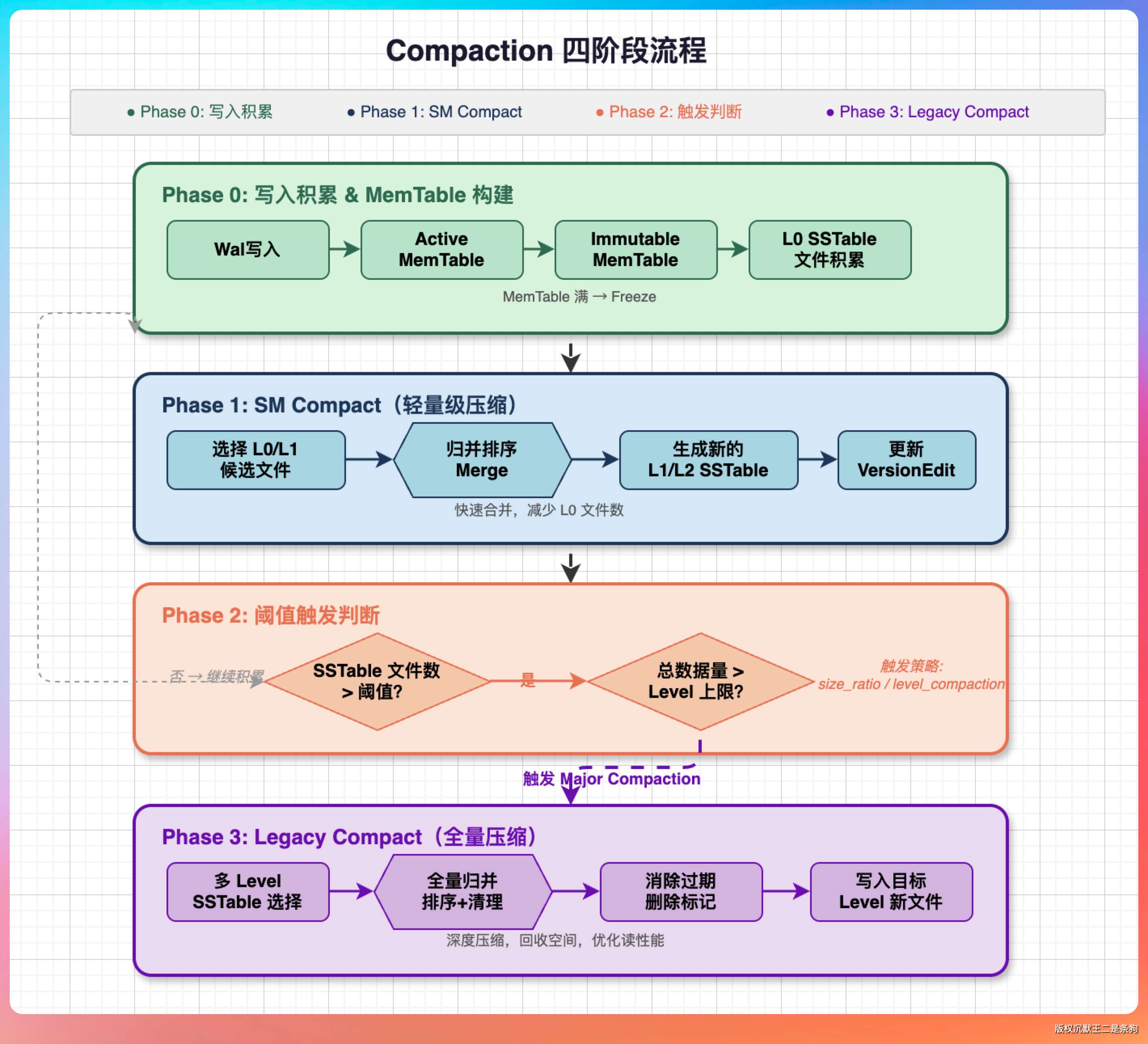
预处理
CC 在每次对话之前,先计算当前上下文的 Token 使用率。如果某些工具返回的结果特别长,比如 grep 搜出了 500 行代码,它会在原地做一次“微压缩”,把完整结果替换成摘要,保留关键行和行号。
这一步不需要调用模型,纯规则处理。
自动压缩决策
当 Token 使用率超过约 83.5% 的时候,自动触发宏压缩。
这里有两条路径:
第一条是会话记忆压缩。
它的思路是把“提取摘要”和“执行压缩”拆成两个独立的系统。CC 在后台持续运行一个增量笔记系统,每当 Agent 做了一个重要决策、读了一个关键文件、或者得到了一个重要结论,它就悄悄把这些信息记到一份 Markdown 笔记里。等到需要压缩的时候,直接拿这份笔记当摘要,再保留最近几轮的原始对话。
第二条是 摘要压缩。
会话记忆压缩如果因为某些原因失败了(比如笔记系统出了问题),就回退到传统的 LLM 摘要模式。让模型重新读一遍上下文,生成一份结构化的摘要,包含:当前目标、已完成的工作、做过的决策、涉及的文件、下一步计划。
趁早拦截。
如果 Token 使用率超过了 88.5%,CC 会直接给一个 413 错误,拦截请求不让它发出去。因为这时候即使发出去了,API 那边大概率也会返回超限错误。
事后恢复。
万一 API 真的返回了 413 错误,CC 还有两个兜底策略。
- 一个叫 Context Collapse,排水式清理,把最老的对话直接丢弃。
- 另一个叫 Reactive Compact,紧急压缩,用最激进的方式把上下文压到安全线以下。
整个四阶段的设计思路很像现实中的防洪体系。日常保持水位(微压缩)、超过警戒线排水(会话记忆压缩)、接近堤坝上限拦截(413 拦截)、决口了紧急抢修(Reactive Compact)。
04、/compact 命令
理解了 Compaction 的底层机制,再来看怎么在实际使用中主动管理上下文。

/compact 是最常用的命令。
在终端里直接输入 /compact,CC 会立即触发一次压缩,把当前的对话历史总结成摘要,然后用摘要替换原始对话继续工作。
另外,/compact 后面可以跟自定义指令,告诉 CC 压缩时该保留什么、丢弃什么。
/compact 重点保留数据库Schema变更和API端点设计,调试过程可以丢弃这一招在实际开发中特别实用。
比如我们在做一个复杂的数据库重构,前面花了大量上下文在调试 Migration 脚本,后面要开始写 API 层的代码了。这时候 /compact 一下,把调试细节压缩掉,只保留 Schema 设计的结论,上下文立刻就清爽了,模型的注意力也能集中到接下来的 API 开发上。
另一个命令是 /clear,和 /compact 的区别在于:
/compact是有损压缩,模型自动总结;/clear是完全清空,你自己决定带什么信息进新会话。
什么时候用 /clear 呢?
当你要开始一个完全不同的任务时。比如前面在做后端 API,现在要切到前端页面,两个任务之间没有什么关联。这时候 /clear 比 /compact 更干净,因为 /compact 的摘要里可能还残留着后端的信息,干扰前端的开发。
还有一个很多人不知道的环境变量:CLAUDE_CODE_AUTO_COMPACT_WINDOW。
export CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000设置这个变量后,不管你的实际窗口多大(1M 也好),CC 都会在接近 20 万 Token 时自动触发压缩。
建议:在 60-70% 的时候主动 /compact,比等到 83.5% 被动触发效果好得多。
因为主动压缩时上下文还比较干净,生成的摘要质量高。被动触发时往往已经塞满了各种中间结果,压出来的摘要容易丢关键信息。
05、CLAUDE.md
聊完了动态的上下文管理,再说一个静态的但极其重要的机制,CLAUDE.md。
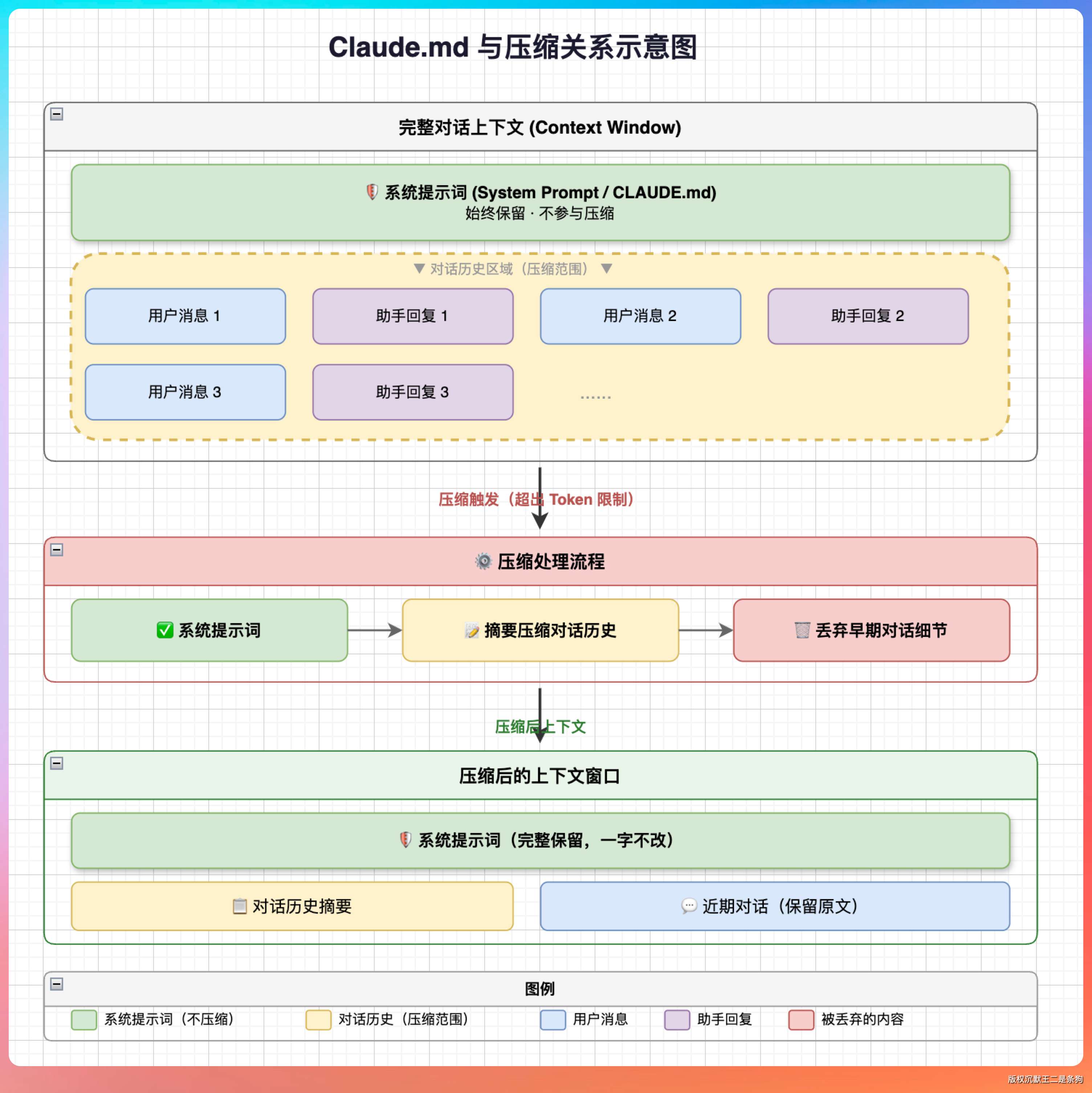
CLAUDE.md 是 Claude Code 的项目配置文件,放在项目根目录下。CC 每次启动新会话时,会自动把 CLAUDE.md 的内容注入到系统提示词里。
千万别把 CLAUDE.md 当成一个普通的配置文件,写几条“用 Java”、“用LangGraph4J”之类的规则就完事了。
如果你从上下文管理的角度来理解它,CLAUDE.md 实际上是一个 L1 缓存,它确保了每次会话开始时,模型就已经“知道”了项目的核心背景,不需要再花上下文去重新发现。
举个例子。
我的 paicoding 项目的 CLAUDE.md 里写了项目的基本要求。CC 每次帮我写代码的时候,不需要再问“技术栈”、“代码规约”,这些信息已经在上下文的最前面了。
这就是 CLAUDE.md 在上下文管理中的价值。

把高频重复的信息前置,减少每次会话的信息获取成本。
还有一个进阶用法:CLAUDE.md 里的规则在压缩后不会丢失。
因为它是系统提示词的一部分,Compaction 只压缩对话历史,不动系统提示词。所以你的代码规范、安全策略、项目约定,即使经历了多次压缩,也始终存在。
06、Sub-agent
Claude Code 还有一个上下文管理的大招,Sub-agent。
当你让 CC 执行一个复杂任务时,它可以派出 Sub-agent 去完成具体的子任务。每个 Sub-agent 都有自己独立的上下文窗口,做完之后只把最终结果返回给主 Agent。
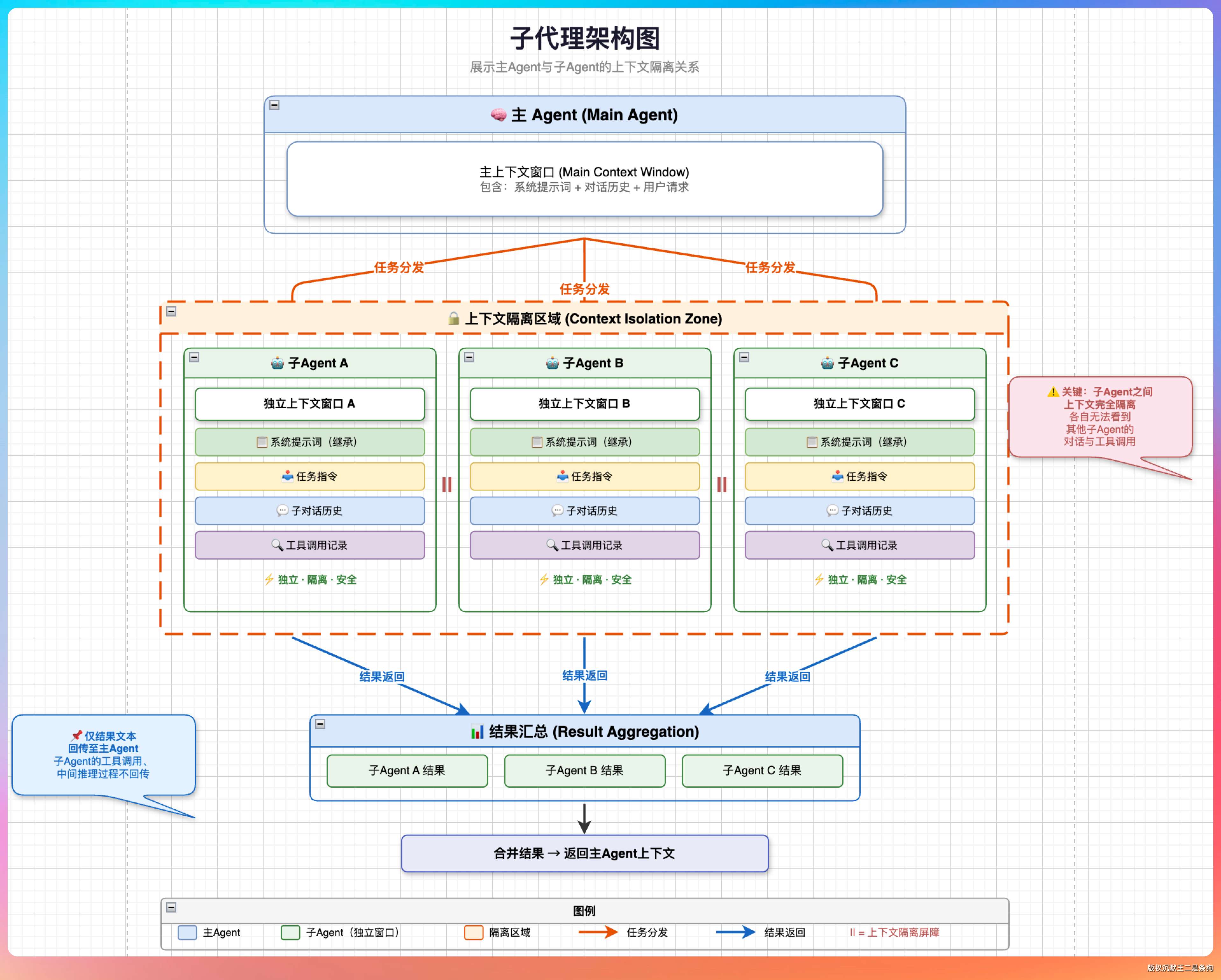
这意味着什么?
中间过程不会污染主 Agent 的上下文。
举一个真实场景。我让 CC 帮我做竞品调研,同时分析 Dify、Coze、FastGPT 三个平台。如果不用 Sub-agent,CC 要在主上下文里依次打开三个平台的文档、读取内容、整理信息,三个平台的信息全部堆在一起,上下文很容易爆炸。
用了 Sub-agent 之后,CC 派出三个 Sub-agent,每个负责一个平台。每个 Sub-agent 在自己的窗口里完成调研,最后只把一份精炼的对比结果交回来。主 Agent 的上下文里只多了一份结果报告,干净又卫生。
在 Claude Code 里触发 Sub-agent 不需要特殊命令,CC 会根据任务的复杂度和独立性自动决定是否拆分。
对于涉及多个独立模块的任务,优先使用 Sub-agent 并行处理。07、Memory 系统
上面说的 Compaction、/compact、CLAUDE.md、Sub-agent,都是单次会话内的上下文管理。
还有一种信息需要跨会话保留,CC 为此设计了 Memory 系统。
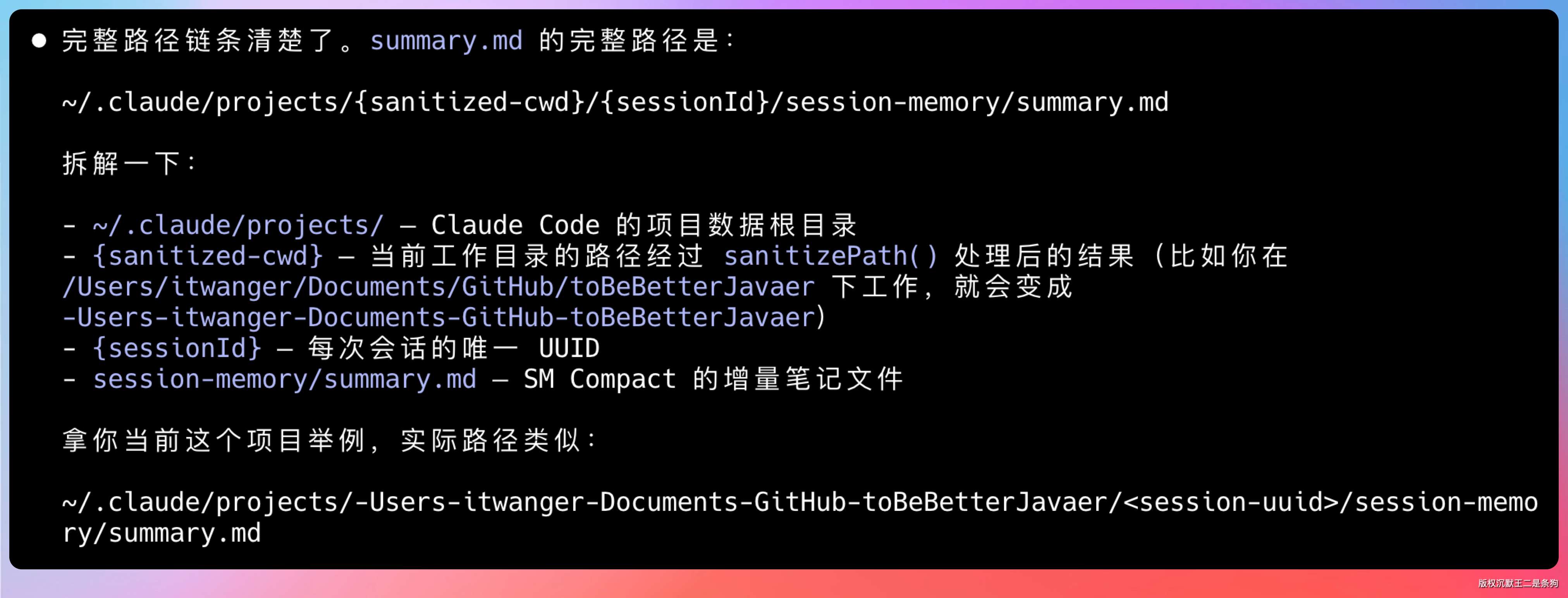
Memory 系统是一个基于文件的持久化存储,默认在 ~/.claude/projects/<项目路径>/memory/ 目录下。
它支持四种类型的记忆:用户偏好(user)、行为反馈(feedback)、项目状态(project)、外部引用(reference)。
和 Compaction 不同的是,Memory 不是自动触发的。
CC 会在对话中发现值得长期保留的信息时,主动写入 Memory 文件。比如你说“我希望写代码的时候注释能详细一点”,它会把这个偏好存进 memory/feedback_semicolons.md,下次新会话开始时自动加载。
- CLAUDE.md 存的是项目级别的硬规则,整个团队共享,会提交到 Git。
- Memory 存的是个人级别的软偏好,只在本地生效,不提交。
从上下文管理的角度来看,Memory 解决的是一个根本问题,信息的生命周期管理。
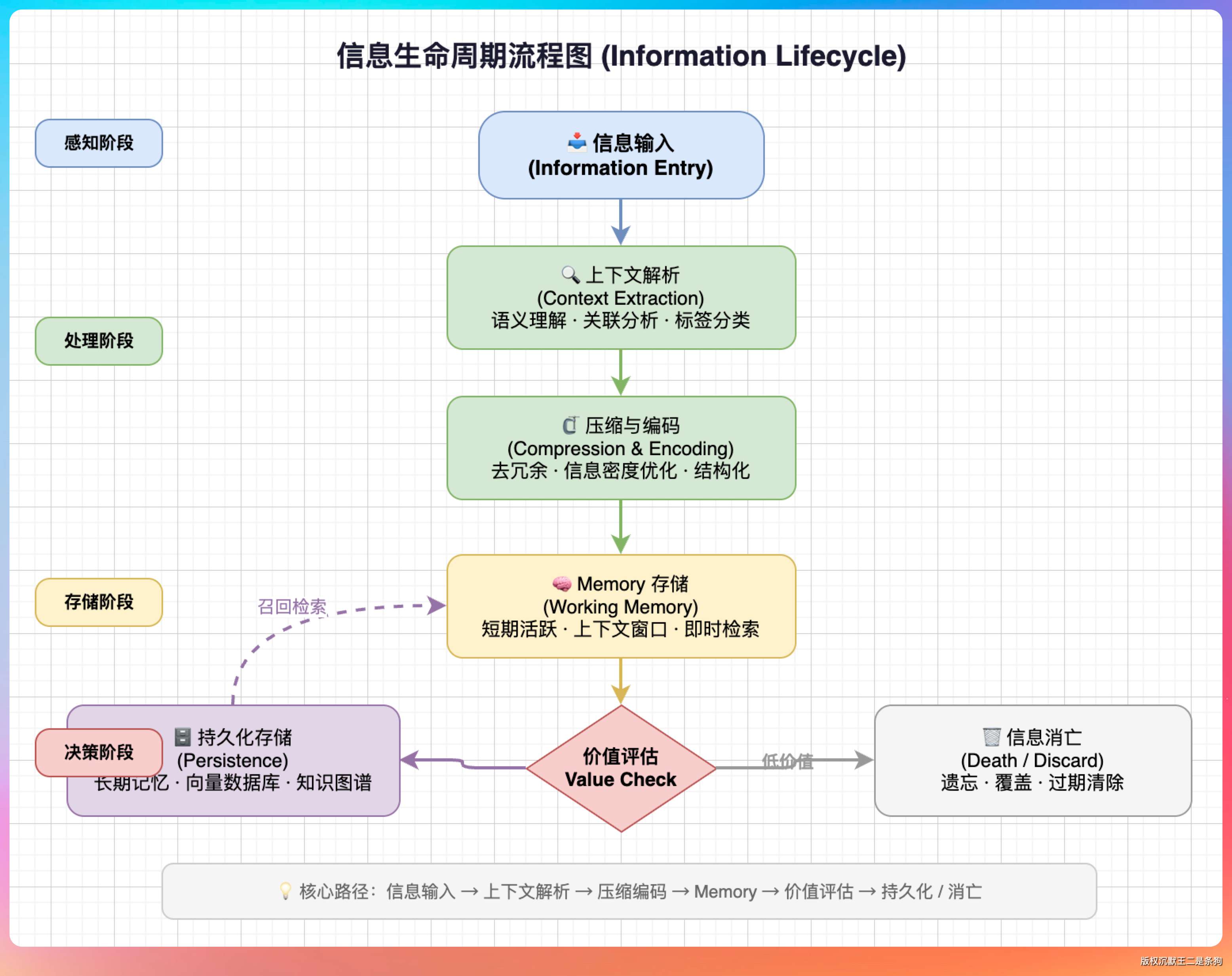
一条信息在 CC 的系统里,会经历这样的旅程:
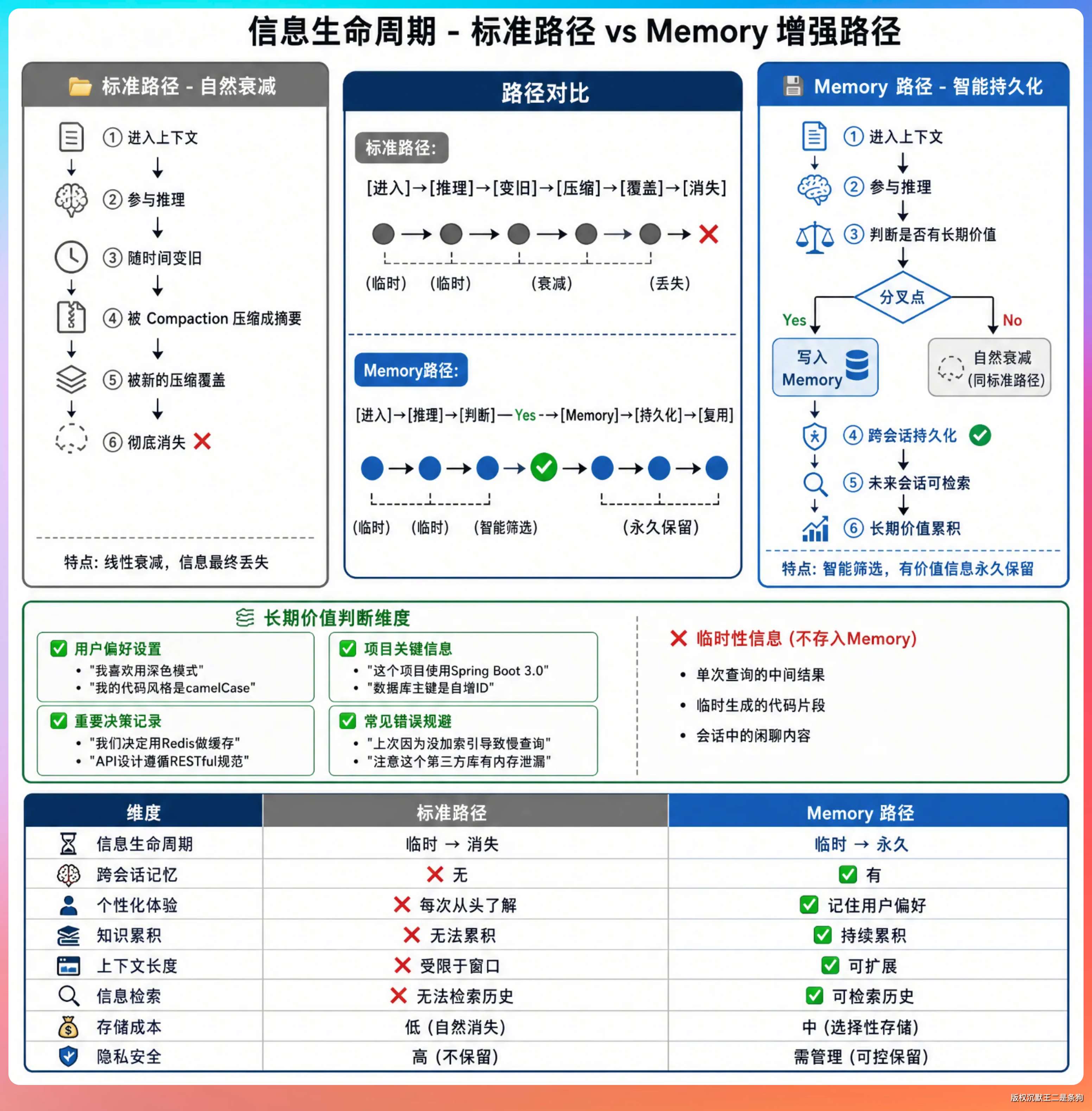
进入上下文 → 参与推理 → 随时间变旧 → 被 Compaction 压缩成摘要 → 被新的压缩覆盖 → 彻底消失Memory 在这条路径上插了一个分叉:
进入上下文 → 参与推理 → 判断是否有长期价值 → 是 → 写入 Memory → 跨会话持久化
→ 否 → 自然衰减08、四条建议
第一,手动 /compact 比自动触发好。
在完成一个逻辑阶段后主动压缩(比如调试完 Bug、写完一个模块),压出来的摘要比 83.5% 被动触发时的质量高得多。因为你能控制压缩的时机和重点。
第二,把重要规则放 CLAUDE.md 而不是对话开头。
对话开头的指令在压缩后可能丢失,CLAUDE.md 里的内容是压缩安全区,永远不会被干掉。
第三,复杂任务拆成 Sub-agent。
如果一个任务涉及多个独立的子任务(调研多个竞品、重构多个模块、测试多个场景),让 CC 用 Sub-agent 并行处理,而不是在一个上下文里串行。
第四,/compact 后面记得要加指令。
不要裸跑 /compact,告诉它该保留什么、该丢弃什么。否则它会用默认策略压缩,可能保留了你不需要的调试日志,却丢了你后面要用的设计决策。
