深入理解Claude Code:CLAUDE.md、Hooks、Skills、Subagents
大家好,我是二哥呀。
为了彻底掌握Claude Code,我还特意从0到1撸了一个PaiCLI。
Claude Code 是目前除了Codex 之外,最牛逼的 Agent Harness 了。
对国产模型的支持比Codex更友好。所以如果你使用的是国产模型,Claude Code就是最好的选择。
它有自己的上下文管理策略、Rules、Hooks、Skills 和 Subagent 委派机制。
这篇内容就从 Claude Code 官方文档出发,结合我们的 PaiCLI 实战项目,拆解 Claude Code 的上下文、CLAUDE.md、Hooks、Skills、Subagent 的内部机制。
https://code.claude.com/docs/zh-CN/how-claude-code-works
01、上下文窗口里到底装了什么
可能有小伙伴认为 Claude Code 的上下文就是“我说了什么、它回了什么”。实际上,对话历史只是上下文窗口里七类内容的其中一种。
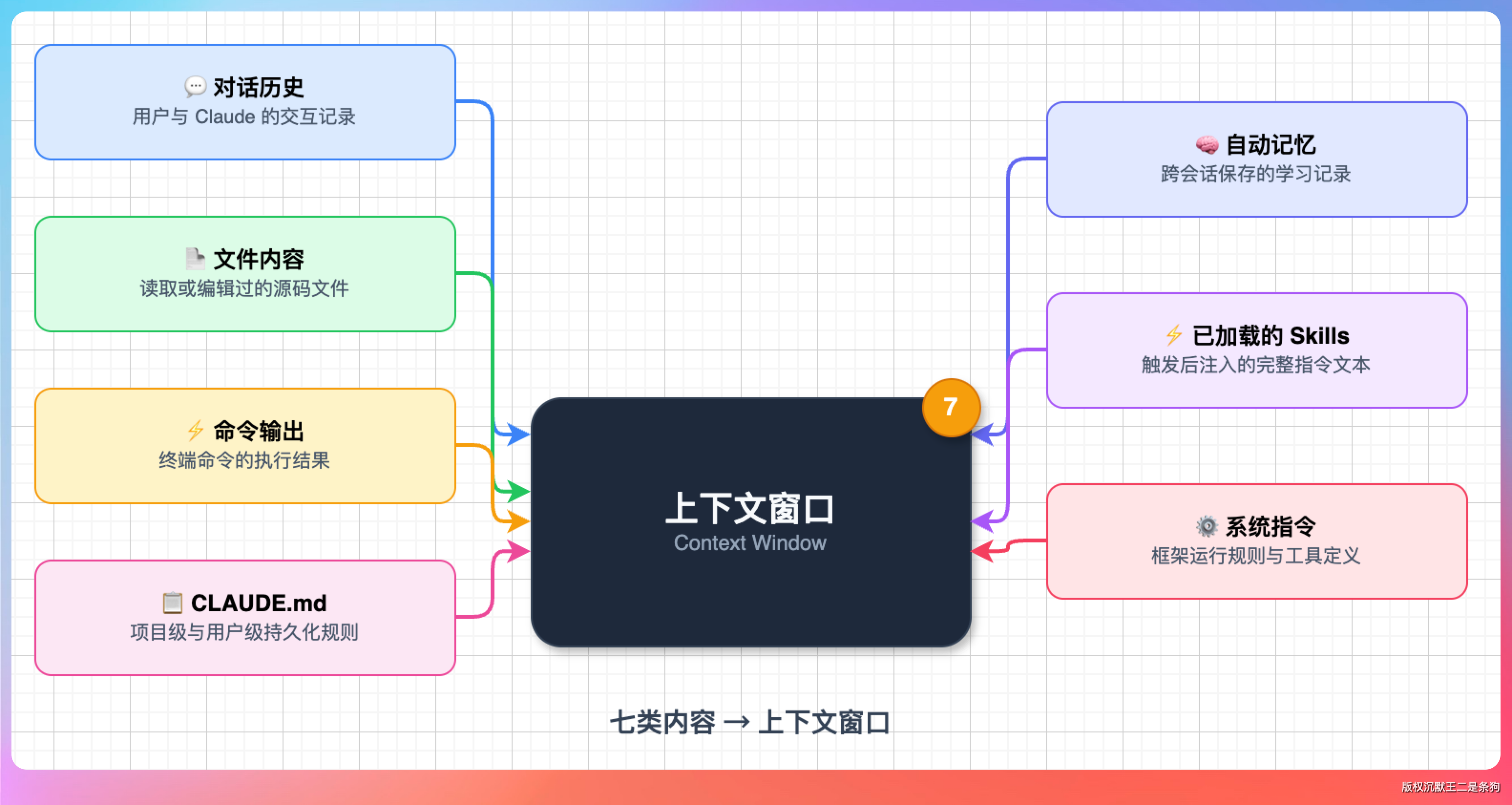
- 对话历史,用户和 Claude 之间的交互记录
- 文件内容,Claude 读取或编辑过的源码文件
- 命令输出,终端命令的执行结果
- CLAUDE.md,项目级的持久化规则
- 自动记忆,Claude 跨会话保存的学习记录
- 已加载的 Skills,被触发后注入的完整指令文本
- 系统指令,Claude Code 框架本身的运行规则和工具定义
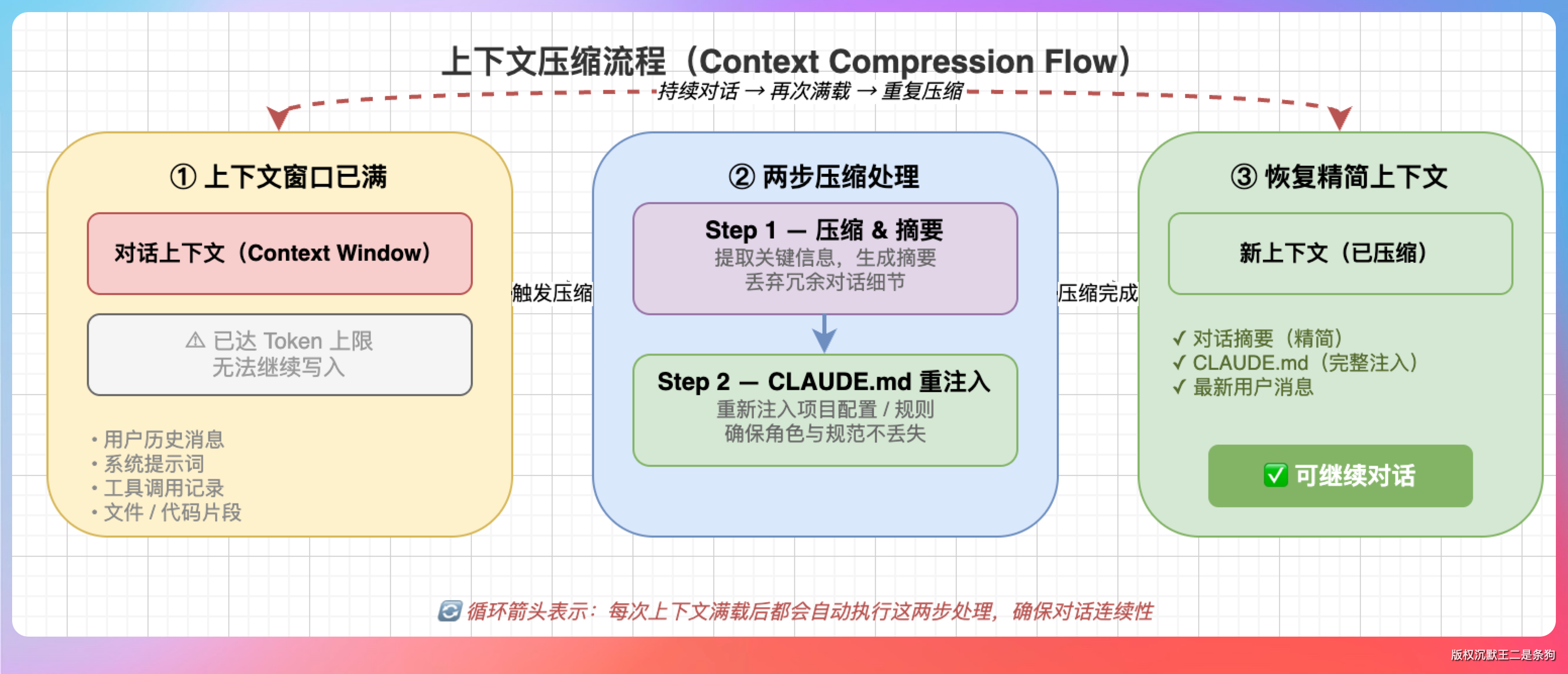
上下文满了怎么办?
Claude Code 的处理策略分两步。
第一步,清除较早的工具调用输出,文件读取结果、命令执行结果这些占空间大但时效性低的内容会被优先移除。
第二步,对整段对话历史做摘要压缩,把具体的措辞、数值、代码片段浓缩成概要。
压缩的后果是信息丢失。
在对话第三轮强调过的规则、第五轮讨论过的架构决策,经过压缩后很可能变成一句模糊的总结。这就是长对话里 Claude“遗忘”指令的真实原因。
解决方案很明确。
需要跨轮次持久生效的规则,不要写在对话里,写进 CLAUDE.md。
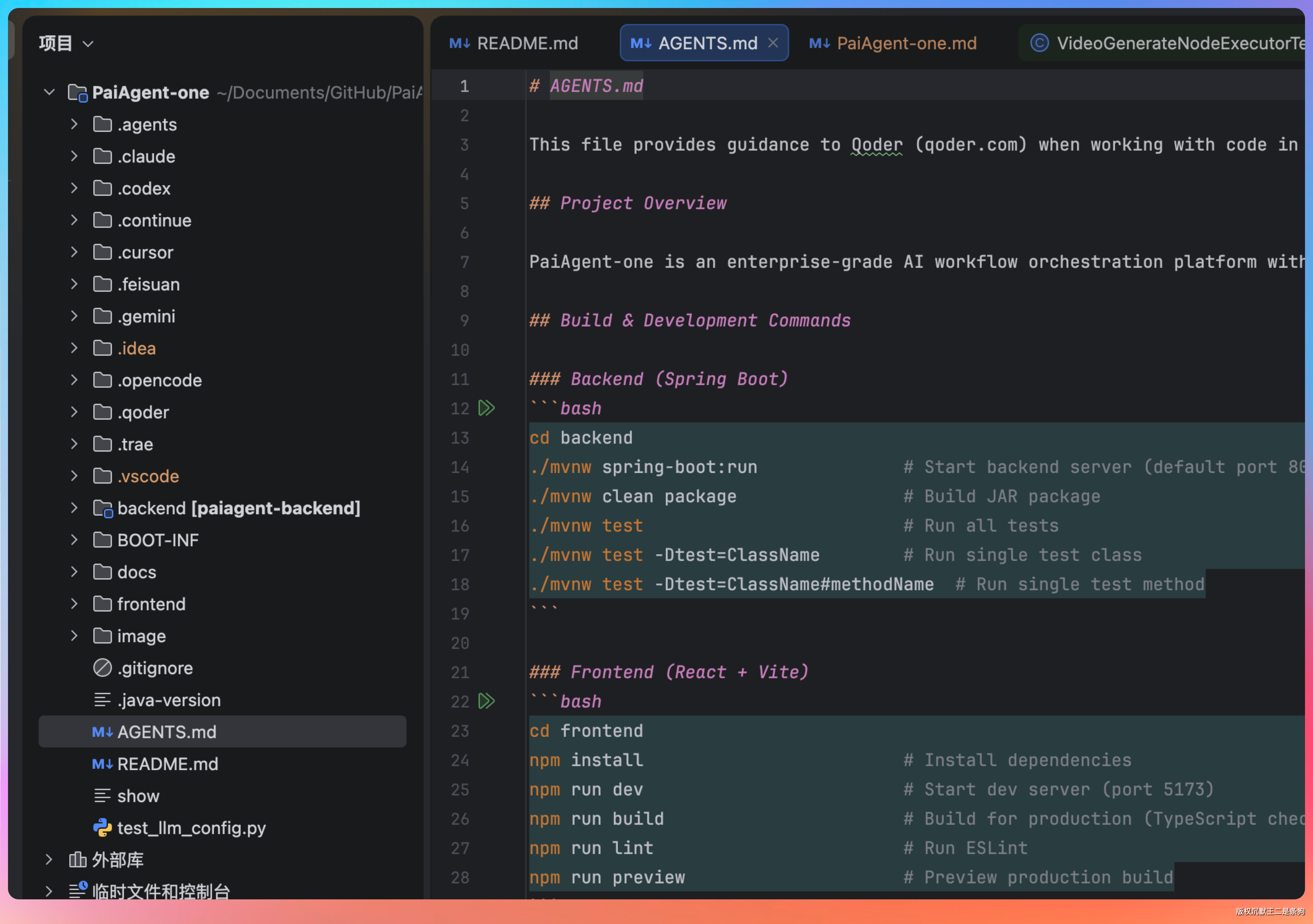
Codex 是 AGENTS.md。
CLAUDE.md 的内容在每次压缩后都会被重新注入上下文,不受摘要压缩的影响。也可以在 CLAUDE.md 里加一个“压缩指令”章节,告诉 Claude 压缩时哪些信息必须保留。
另一个有效手段是 /compact 命令,主动触发压缩并指定保留焦点,比如 /compact 聚焦在 API 变更上。
自动记忆也是跨会话持久化的一环。
它存储在 ~/.claude/projects/ 目录下,每次新会话启动时加载 MEMORY.md 的前 200 行或 25KB。
与 CLAUDE.md 不同的是,自动记忆由 Claude 自己写入,记录的是它在工作中学到的模式和偏好。但自动记忆的加载量远小于 CLAUDE.md,更适合存放细碎的经验信息,不适合承载核心的项目规则。
每个新的 Claude Code 会话都从一个全新的上下文窗口开始,历史对话不会自动带过来。
跨会话传递信息只有两条通道,CLAUDE.md 和自动记忆。
切记:需要长期生效的规则,写进 CLAUDE.md 而不是对话里。
可以这么说,CLAUDE.md 是上下文里最重要的持久化内容,它的加载机制决定了规则能不能被 Claude Code 看到。
02、CLAUDE.md 的加载机制
Claude Code 启动时会从四个位置按顺序查找并加载 CLAUDE.md。
| 层级 | 位置 | 共享范围 |
|---|---|---|
| 托管策略 | /Library/Application Support/ClaudeCode/CLAUDE.md | 组织内所有用户 |
| 用户级 | ~/.claude/CLAUDE.md | 所有项目通用 |
| 项目级 | ./CLAUDE.md 或 ./.claude/CLAUDE.md | 通过 Git 共享给团队 |
| 本地级 | ./CLAUDE.local.md(被 gitignore) | 仅限本机使用 |
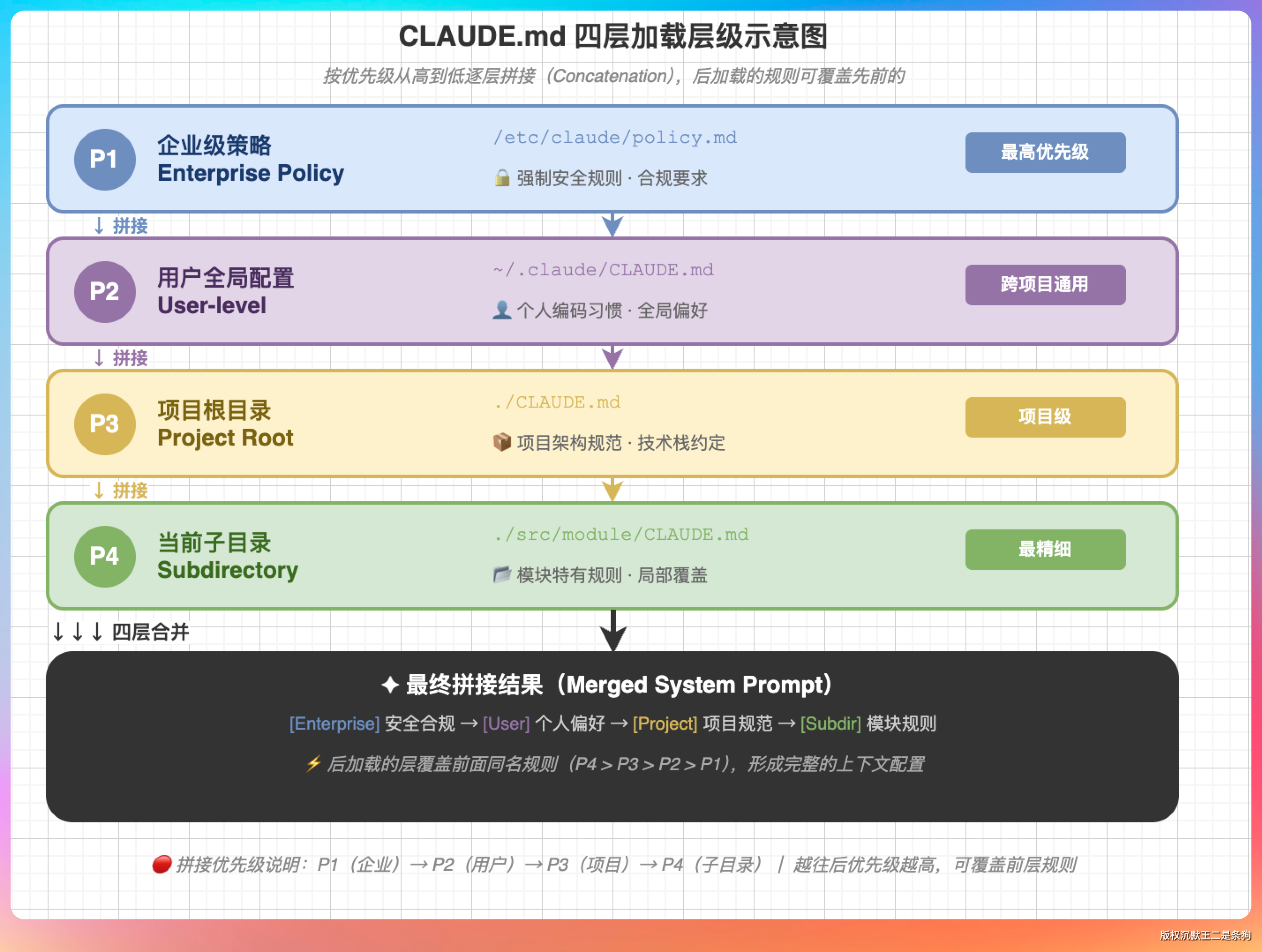
这里有一个重要的设计决策,四层文件是拼接的,不是覆盖的。
所有层级的内容从文件系统根目录到当前工作目录的顺序全部串联在一起,统统注入上下文窗口。CLAUDE.local.md 在每个层级的 CLAUDE.md 之后追加。
拼接意味着什么?
假设用户级 CLAUDE.md 写了“使用四个空格缩进”,项目级 CLAUDE.md 又写了“使用两个空格缩进”,两条规则会同时存在于上下文里。
Claude 需要自行判断哪条优先,判断错了就表现为“规则没生效”。排查规则不生效的问题时,先检查各层级 CLAUDE.md 之间有没有冲突,往往比改 Prompt 有效得多。
官方建议每个 CLAUDE.md 文件控制在 200 行以内,指令要具体到可以验证。
03、Hooks 的强制拦截机制
CLAUDE.md 是建议。Claude 读了规则会在决策时参考,但不保证每次都遵守,它有自己的判断,有时候认为某条规则在当前场景下不适用就会跳过。
如果某些规则必须执行,比如“提交前必须跑 lint”、“禁止 force push 到 main 分支”、“所有写入操作必须经过审批”,就需要 Hooks 来强制拦截。
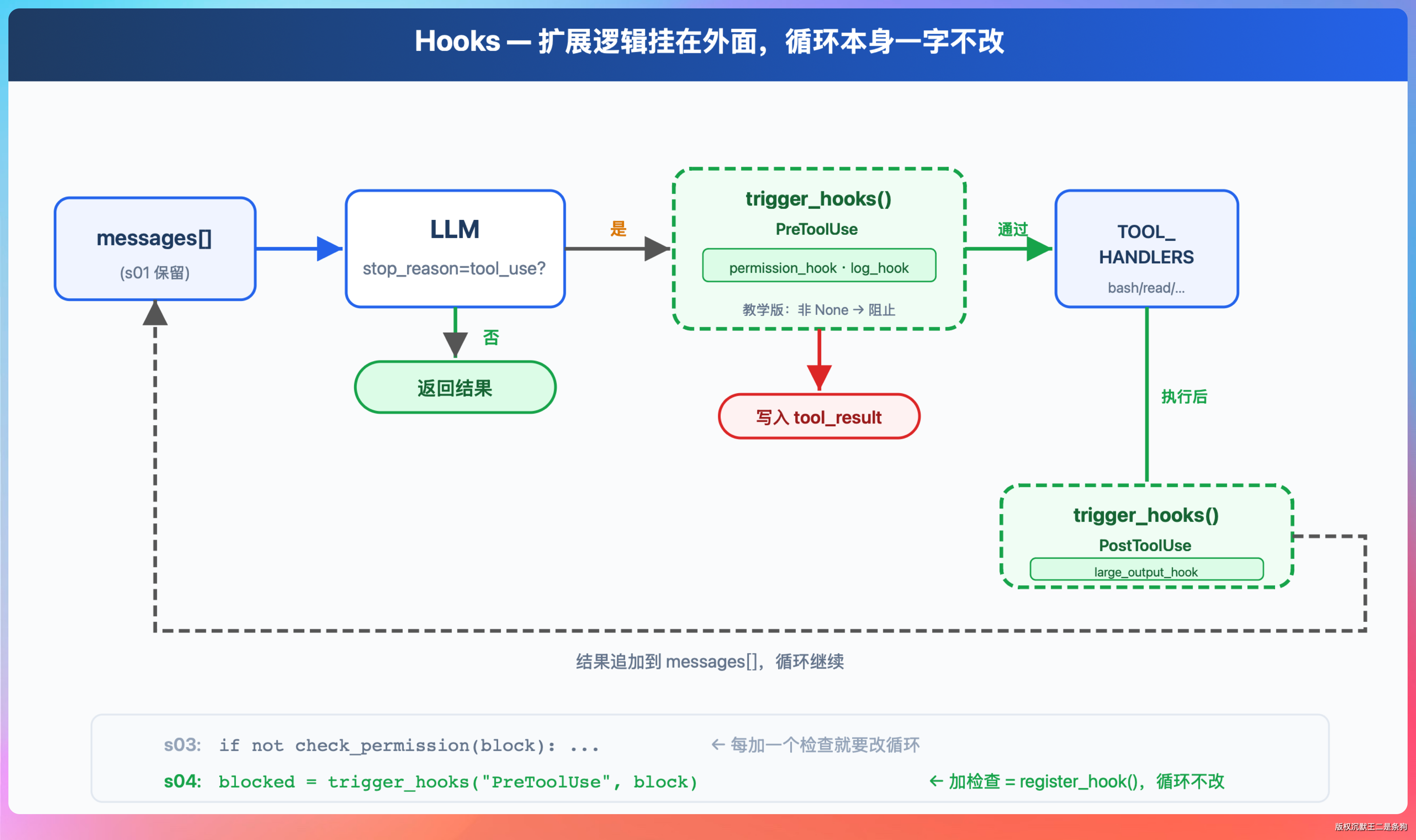
Hooks 是用户定义的钩子程序,绑定在 Claude Code 生命周期的特定节点上自动执行。
和 CLAUDE.md 的“请遵守”不同,Hooks 的逻辑是“不满足条件就阻断操作”,Claude 没有跳过的余地。
Hooks 的结构是三层嵌套。
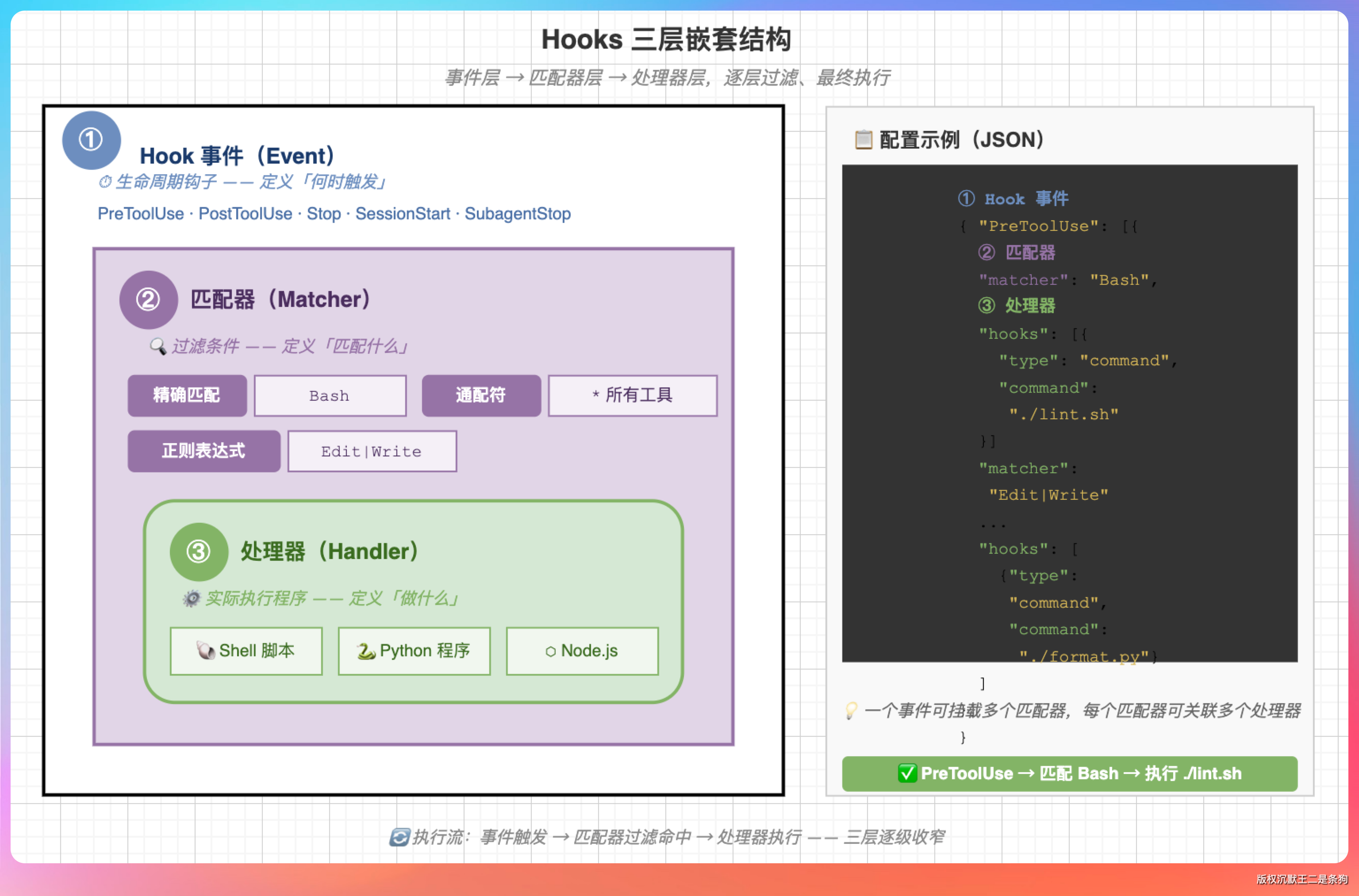
处理器有五种类型,覆盖不同的校验场景。
- command 执行 Shell 命令,最常用。比如提交前自动跑格式化检查,或者在文件写入前校验内容是否符合安全规范
- http 发送 POST 请求到指定 URL,用于通知外部系统或触发 CI 流水线
- mcp_tool 调用已连接的 MCP 服务器上的工具,把 MCP 生态的能力引入生命周期钩子
- prompt 把问题抛给 Claude 模型做是非判断,用于需要语义理解的动态审查场景
- agent 派出一个 Subagent 做复杂的多步校验,目前还在实验阶段
五种类型里最常用的是 command,它通过退出码控制行为。
返回 0 表示校验通过,操作继续执行;返回 2 表示阻断,操作被禁止并把标准错误输出作为错误信息展示给 Claude;其他返回码表示非阻断性错误,记录到日志但不阻止操作。
Hook 事件覆盖了 Claude Code 的完整生命周期。
- 会话级别有
SessionStart和SessionEnd; - 每轮对话级别有
UserPromptSubmit(用户输入提交时)和Stop(Claude 完成回复时); - 工具调用级别有
PreToolUse(调用工具前)和PostToolUse(调用工具后)。 - 此外还有
SubagentStart、TaskCreated、FileChanged、PreCompact等更细粒度的事件,总共超过 20 种。
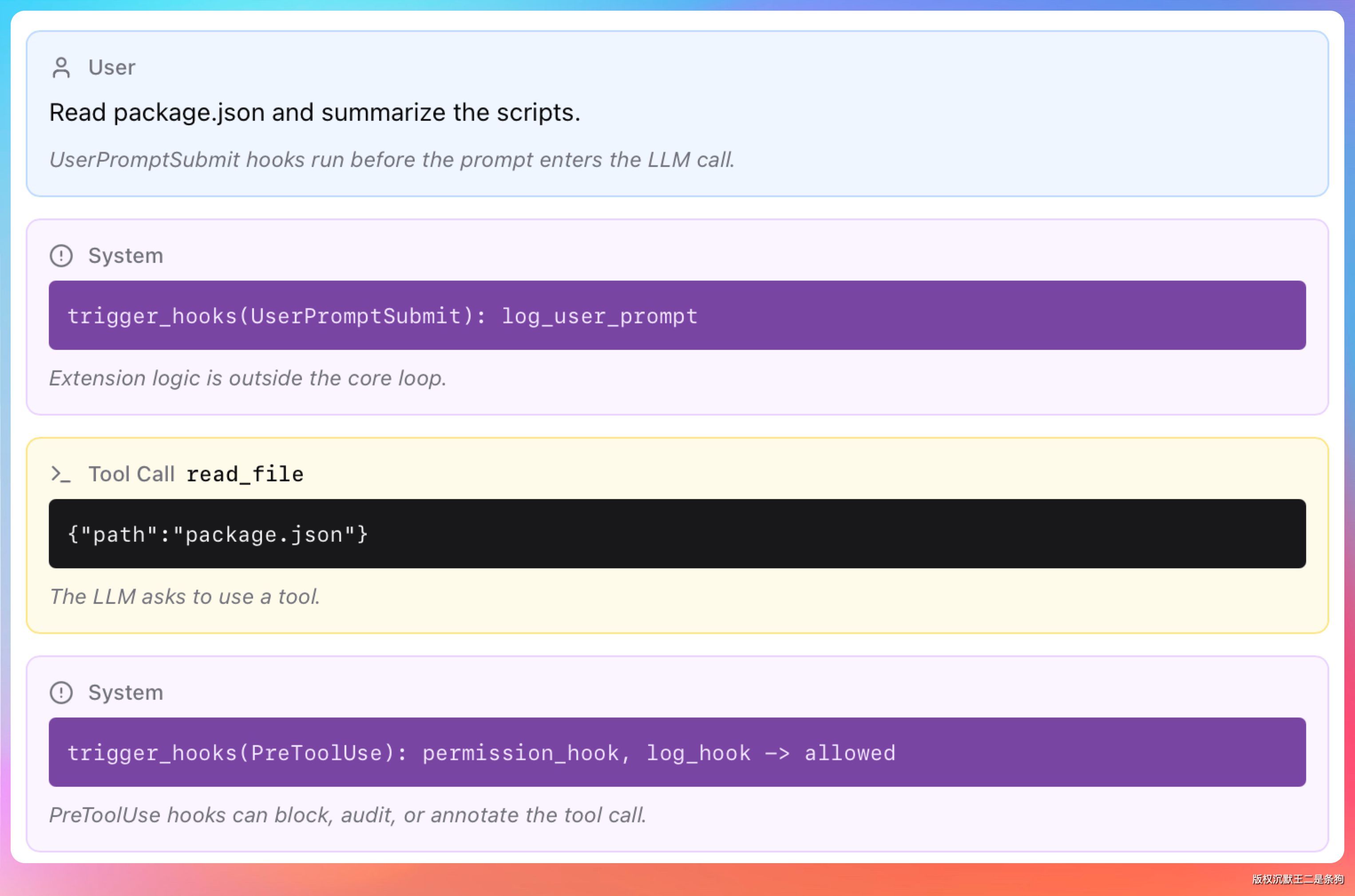
最值得深入了解的是 PreToolUse 事件。它在 Claude 调用任何工具之前触发,Hook 可以返回 permissionDecision 字段来控制权限。
allow直接放行,不弹确认deny直接拒绝,操作被阻止ask弹出确认提示,让用户决定defer交给默认权限逻辑处理
除了权限控制,PreToolUse 的 Hook 还可以通过 updatedInput 字段修改工具的输入参数。
这意味着可以在 Claude 执行命令之前自动改写命令内容,比如强制给所有 git commit 命令加上签名参数,或者在文件写入前自动追加版权声明。
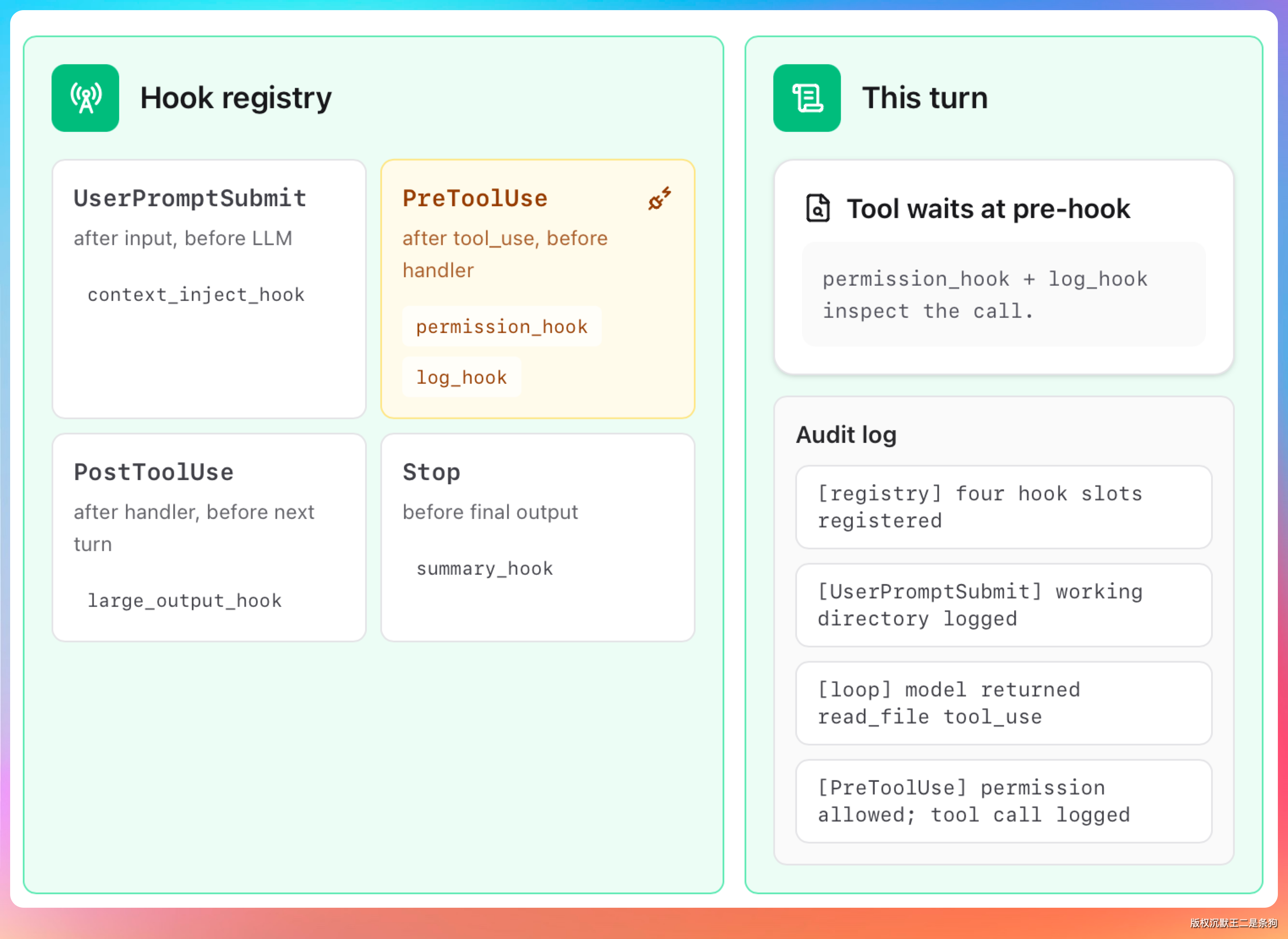
Hooks 的配置位置和 CLAUDE.md 的层级类似,用户级放在 ~/.claude/settings.json,项目级放在 .claude/settings.json,本地级放在 .claude/settings.local.json。
默认超时是 600 秒(command/http/mcp_tool 类型),prompt 类型 30 秒,agent 类型 60 秒。
还有一个实用功能是异步 Hook。在 Hook 配置里加上 "async": true,Hook 会在后台执行,不阻塞 Claude 的操作流程。
如果加上 "asyncRewake": true,后台 Hook 返回退出码 2 时会向 Claude 发送一条系统提醒,通知它有异步校验未通过。这个机制适合耗时较长的检查,比如远程代码扫描服务。
CLAUDE.md 管方向,Hooks 管纪律。
04、Skills 的触发机制
CLAUDE.md 每次会话都加载,Skills 是按需加载的。
一个 Skill 的完整指令只有在被触发后才进入上下文窗口,平时只有一行描述挂在索引清单里。
这是 Skills 和 CLAUDE.md 最根本的区别,也是 Skills 存在的意义——把不常用但需要时很关键的能力从常驻上下文里拿掉,给日常对话腾出空间。
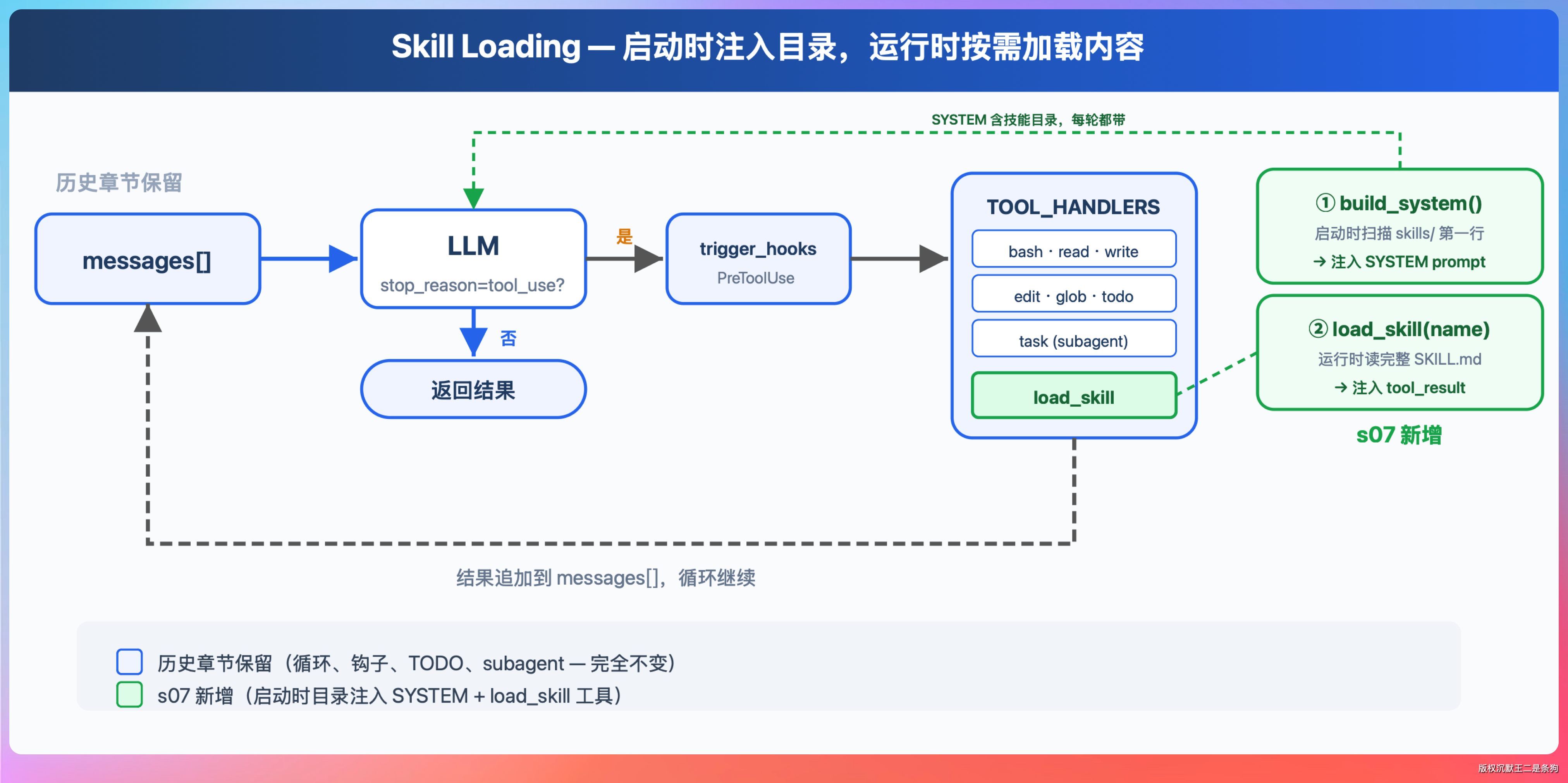
Skill 的触发分三步。
- 第一步,Claude Code 启动时收集所有 Skill 的名称和描述文本,拼成一张索引清单注入上下文。
- 第二步,每轮对话时 Claude 扫一遍这张清单,判断当前任务是否和某个 Skill 匹配。
- 第三步,匹配上了才发起调用,这时候 SKILL.md 的全文才被加载进上下文。
注意第一步的含义。
Claude 做匹配决策时看到的只有索引清单里的描述,看不到 SKILL.md 的正文。描述文本写得不到位,Claude 从头到尾都不知道这个 Skill 的存在。正文写得再精妙也没用,因为模型在决定“要不要调用”的那一刻,根本没有机会看到正文。
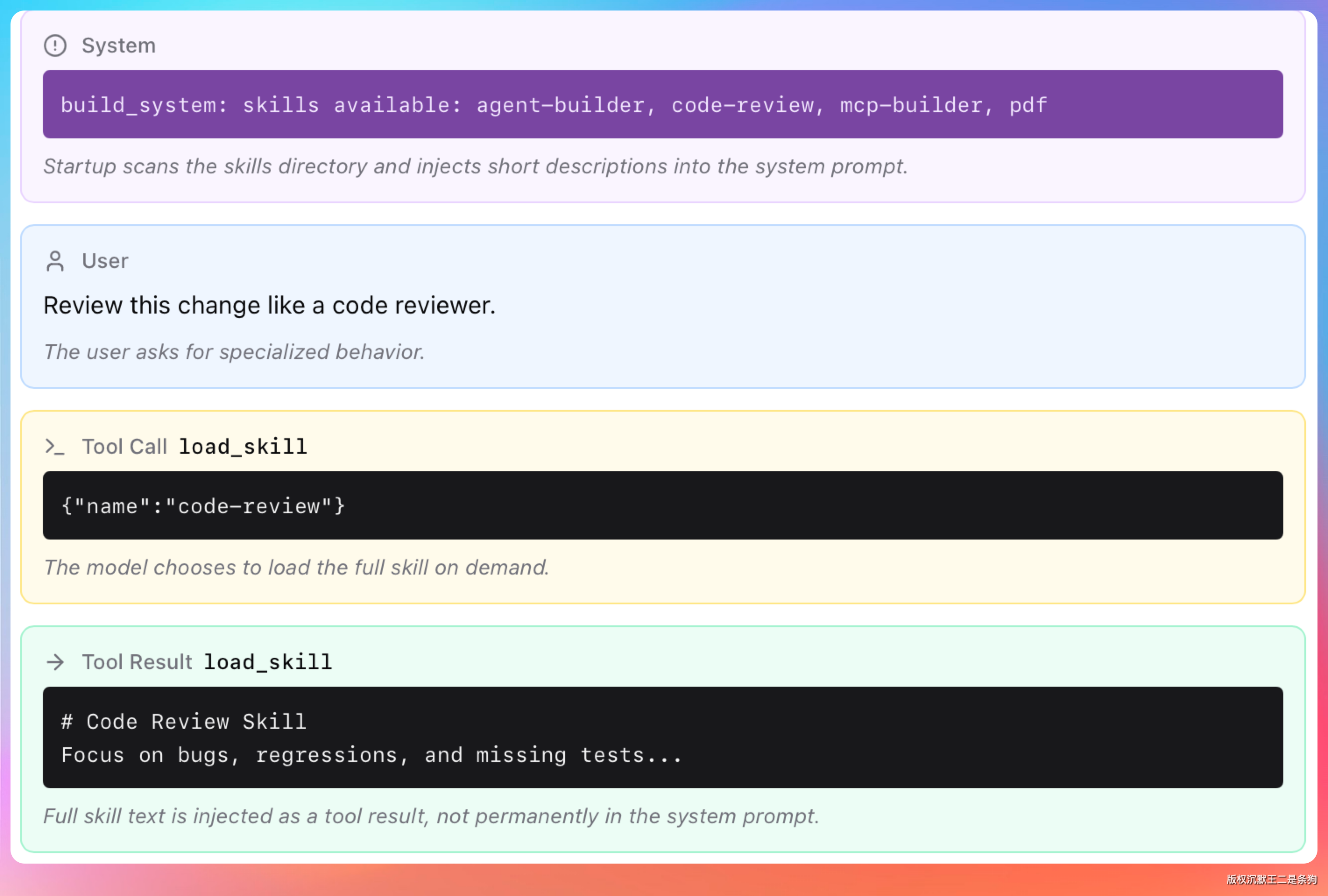
索引清单有严格的预算限制。
整张清单只允许占用上下文窗口的 1%,由 skillListingBudgetFraction 参数控制。
单个 Skill 的描述文本(description 加 when_to_use 字段合计)最多 1536 个字符,由 maxSkillDescriptionChars 参数控制。超出 1536 字符的部分会被截断。在第 1537 个字符之后写的触发条件和使用场景,模型压根看不到。
Skill 被触发加载后,它的内容会一直留在当前会话里,不会因为开启新一轮对话而消失。但上下文压缩时 Skill 也会被处理。
Claude Code 的压缩机制对 Skill 做了特殊保护,压缩后会重新注入每个 Skill 的前 5000 个 token,所有 Skill 的重新注入总预算是 25000 个 token,按最近使用时间排序保留。如果一次会话里触发了太多 Skill,最早使用的 Skill 在压缩后就不再保留了。
一个标准的 Skill 目录长这样。
my-skill/
SKILL.md # 主文件,包含 frontmatter 和指令正文
references/ # 参考资料,加载时自动引入
scripts/ # 可执行脚本,供 Claude 调用
examples/ # 示例输出SKILL.md 的 frontmatter 里有几个值得关注的字段。
disable-model-invocation设为true可以防止 Claude 自动加载这个 Skill,只能通过用户手动输入斜杠命令触发,适合那些只在特定场景使用的重量级 Skill。allowed-tools可以指定 Skill 激活时 Claude 可以免权限使用的工具列表,减少频繁的权限确认弹窗。model可以覆盖当前会话的模型,让某个 Skill 使用更强或更经济的模型执行。context: fork可以让 Skill 在一个独立的 Subagent 上下文里运行,避免 Skill 的大量输出污染主上下文。
SKILL.md 还支持动态内容注入。
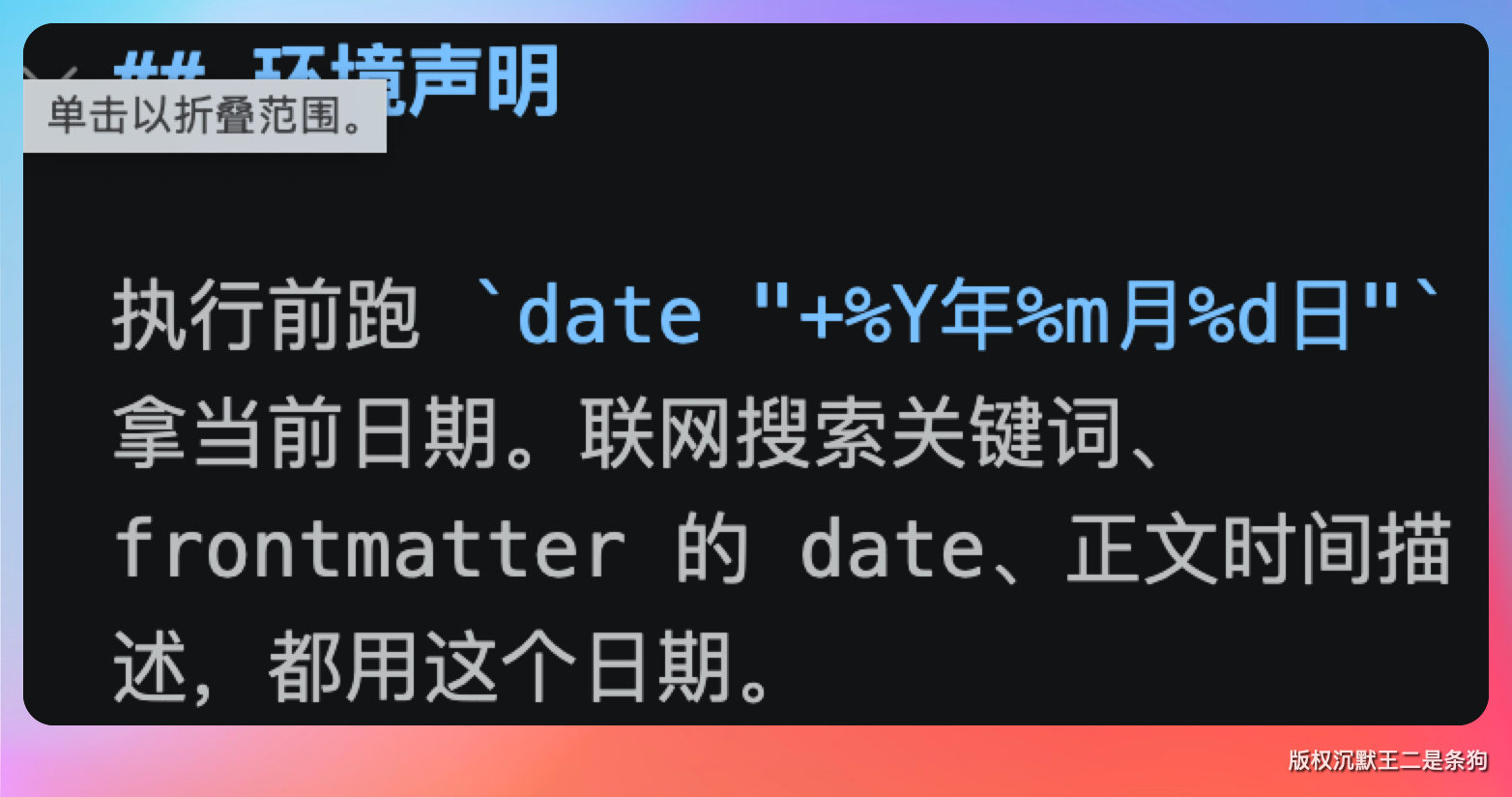
用 !`<command>` 语法可以在加载时执行 Shell 命令,把命令输出替换到 Skill 正文里。
比如 !`date "+%Y年%m月%d日"` 会在每次加载时自动插入当前日期。这个能力让 Skill 可以感知运行时的环境状态,不需要手动更新内容。
Skill 的优先级也有讲究。
同名 Skill 在不同位置定义时,优先级从高到低依次是企业托管策略 > 个人级(~/.claude/skills/)> 项目级(.claude/skills/)> 插件级。高优先级的同名 Skill 会覆盖低优先级的。
05、Subagent 的上下文隔离
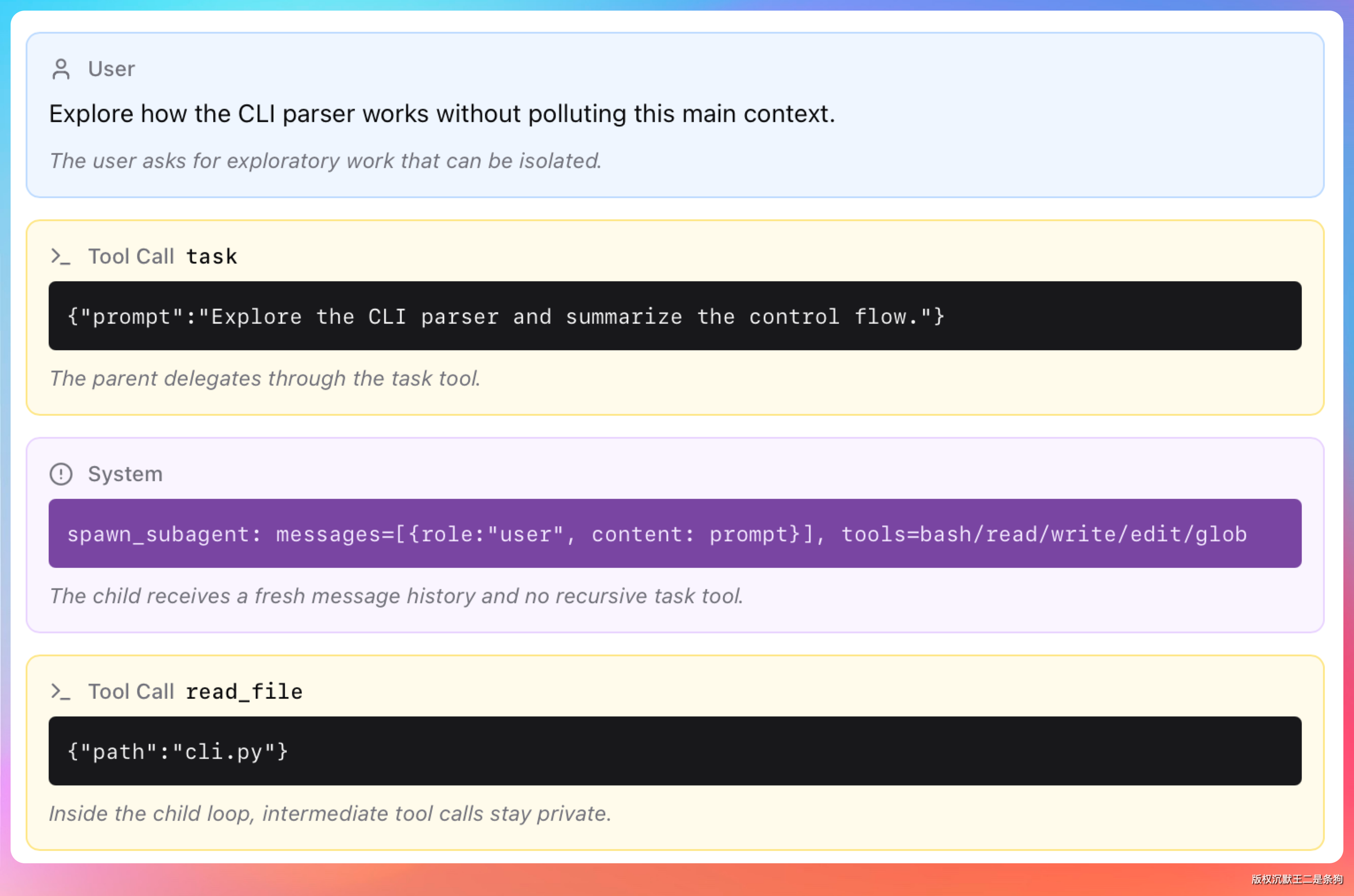
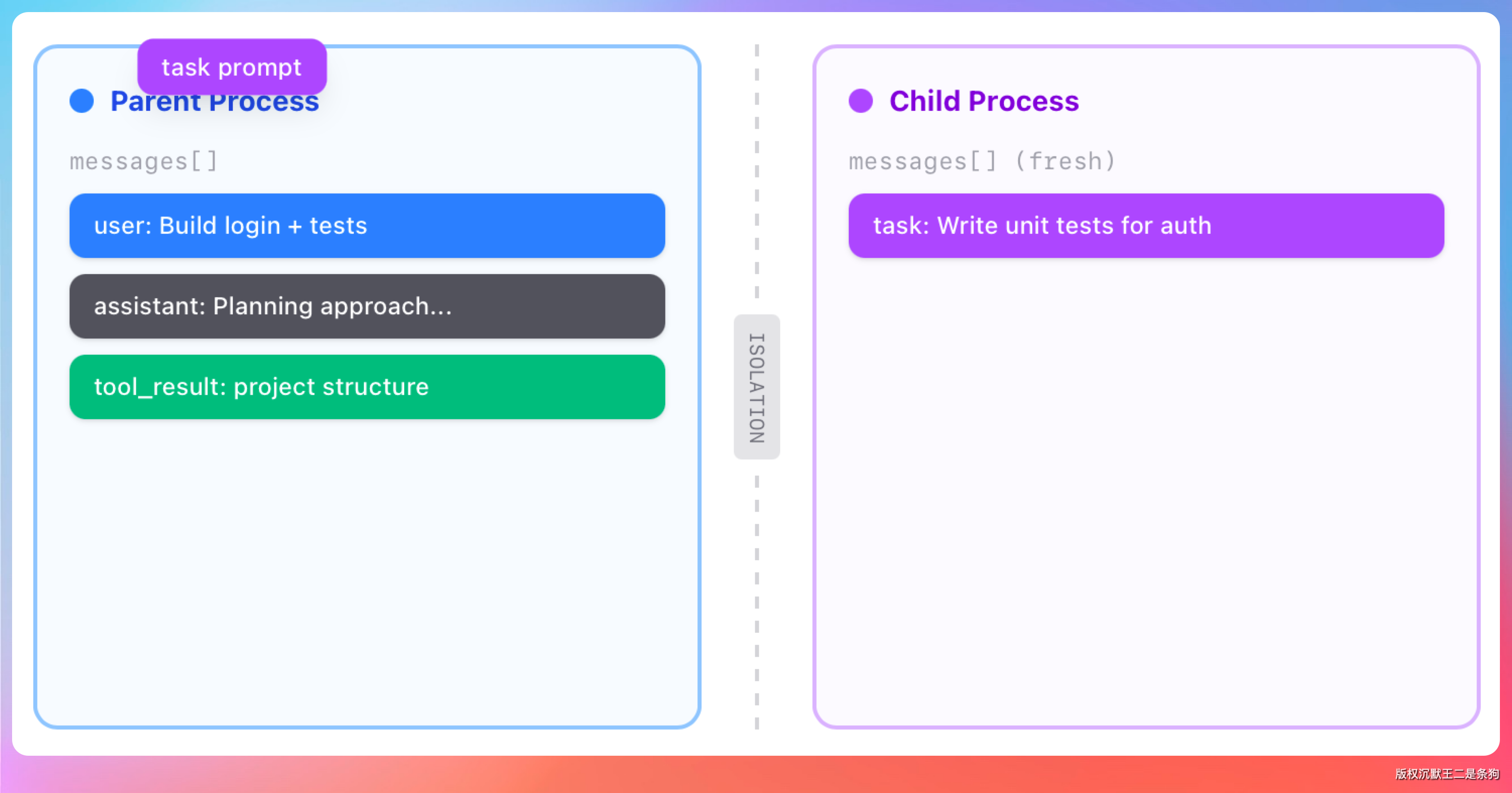
Subagent 是一个拥有独立上下文窗口的助手。
主 Agent 把任务委派过去,Subagent 在自己的窗口里完成工作,可能读几十个文件、跑多条命令、搜索整个代码库,最终只把结论返回给主 Agent。
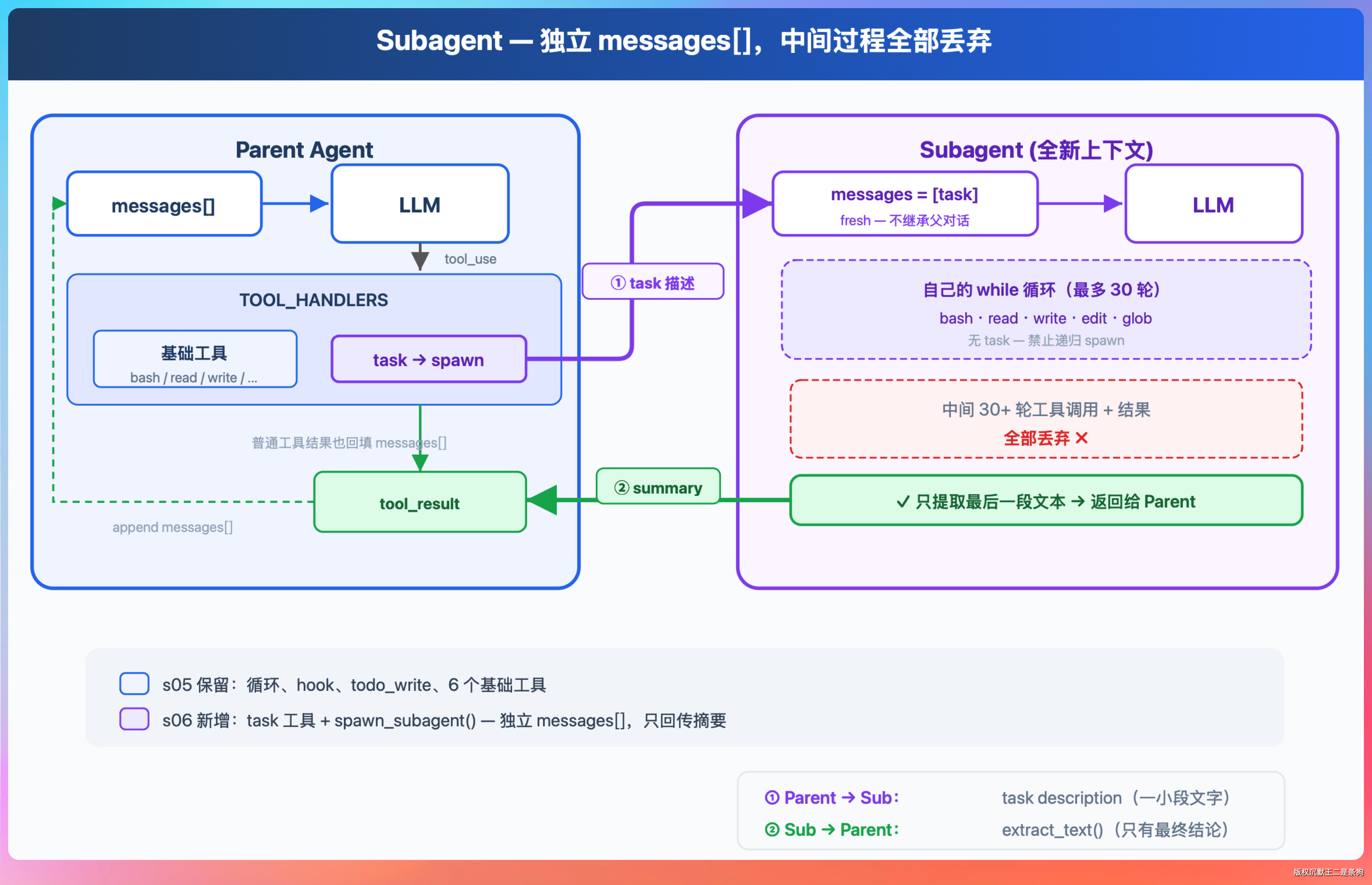
中间产生的全部过程数据留在 Subagent 自己的窗口里,主上下文一个字节都不多占。
Claude Code 内置了三种 Subagent,各有分工。
| 类型 | 模型 | 可用工具 | 用途 |
|---|---|---|---|
| Explore | Haiku(快速模型) | 只读,无写入和编辑权限 | 文件发现、代码搜索、代码库探索 |
| Plan | 继承主模型 | 只读,无写入和编辑权限 | 方案调研、架构规划 |
| General-purpose | 继承主模型 | 全部工具 | 复杂研究、多步操作、代码修改 |
一个重要的设计细节。
Explore 和 Plan 两种 Subagent 启动时会跳过 CLAUDE.md 和 Git 状态的加载。
它们用一个干净的上下文开始工作,目的是让响应速度更快、上下文利用率更高。只有 General-purpose 类型会加载完整的 CLAUDE.md 和 Git 状态信息。
这个选择是一种权衡。
Explore 和 Plan 主要做信息收集和分析,不需要遵守项目的代码规范和提交约定,跳过 CLAUDE.md 不会造成质量问题;General-purpose 需要修改代码和执行命令,必须了解项目规则才能产出合格的结果。
实际使用中怎么选?
搜索代码、查找文件定义、浏览目录结构这类只需要读不需要写的探索性工作,交给 Explore,它会用 Haiku 模型,运行快、成本低。
需要综合分析代码库来制定方案的任务,交给 Plan,它继承主模型的推理能力但不会误改文件。需要实际动手改代码、跑命令的复杂子任务,交给 General-purpose,它拥有全部工具权限。
每层 Subagent 的对话记录独立存储在 ~/.claude/projects/{project}/{sessionId}/subagents/ 目录下,默认保留 30 天后自动清理。
自定义 Subagent 的方式是在 .claude/agents/ 目录下创建 Markdown 文件。YAML 头部声明名称、描述、可用工具、使用的模型等属性,正文部分是系统提示词。
---
name: code-reviewer
description: Reviews code for quality and best practices
tools: Read, Glob, Grep
model: sonnet
---
You are a code reviewer...这个定义让主 Agent 在需要代码审查时可以委派给 code-reviewer,后者只有只读工具不会误改代码,用 Sonnet 模型运行更快也更便宜。
还可以通过 skills 字段预加载特定 Skill,通过 mcpServers 字段给 Subagent 配置独立的 MCP 服务器,这些服务器在 Subagent 启动时连接、结束时断开,不占主上下文的工具定义空间。
还有一种特殊的 Fork Subagent,通过 /fork 命令或 context: fork 配置启用。

Fork Subagent 继承主 Agent 的完整对话历史,不用重新解释背景信息,适合需要在已有讨论基础上做深入分支探索的场景。
比如讨论到一半想让另一个模型评估当前方案是否可行,Fork 一个 Subagent 出来,它直接从当前讨论的上下文继续,不需要重新描述背景。Fork Subagent 和主 Agent 共享 Prompt 缓存,不会重复消耗缓存配额。
ending
上下文是 Claude Code 的工作记忆,容量有限。
CLAUDE.md 管方向,Hooks 管纪律,Skills 管专业,Subagent 管分工。
五个机制各守边界,又在每一轮对话里彼此协作。
很多人花大量时间打磨 Prompt 的措辞,但决定 Claude Code 能不能持续稳定产出的,从来不是某一句话写得多巧妙,而是对这五个机制的配置质量和理解深度。
【把时间花在理解工具的运作方式上,比花在猜测工具的脾气上,回报大得多。】
我们下棋见。