刚刚!Codex官方发声:Codex原生支持其他模型。
大家好,我是二哥呀。
这不。Codex 负责人 Tibo 发话了,Codex、以及 CLI 和 SDK 原生支持任何开源模型了,不限于 GPT-5.5。
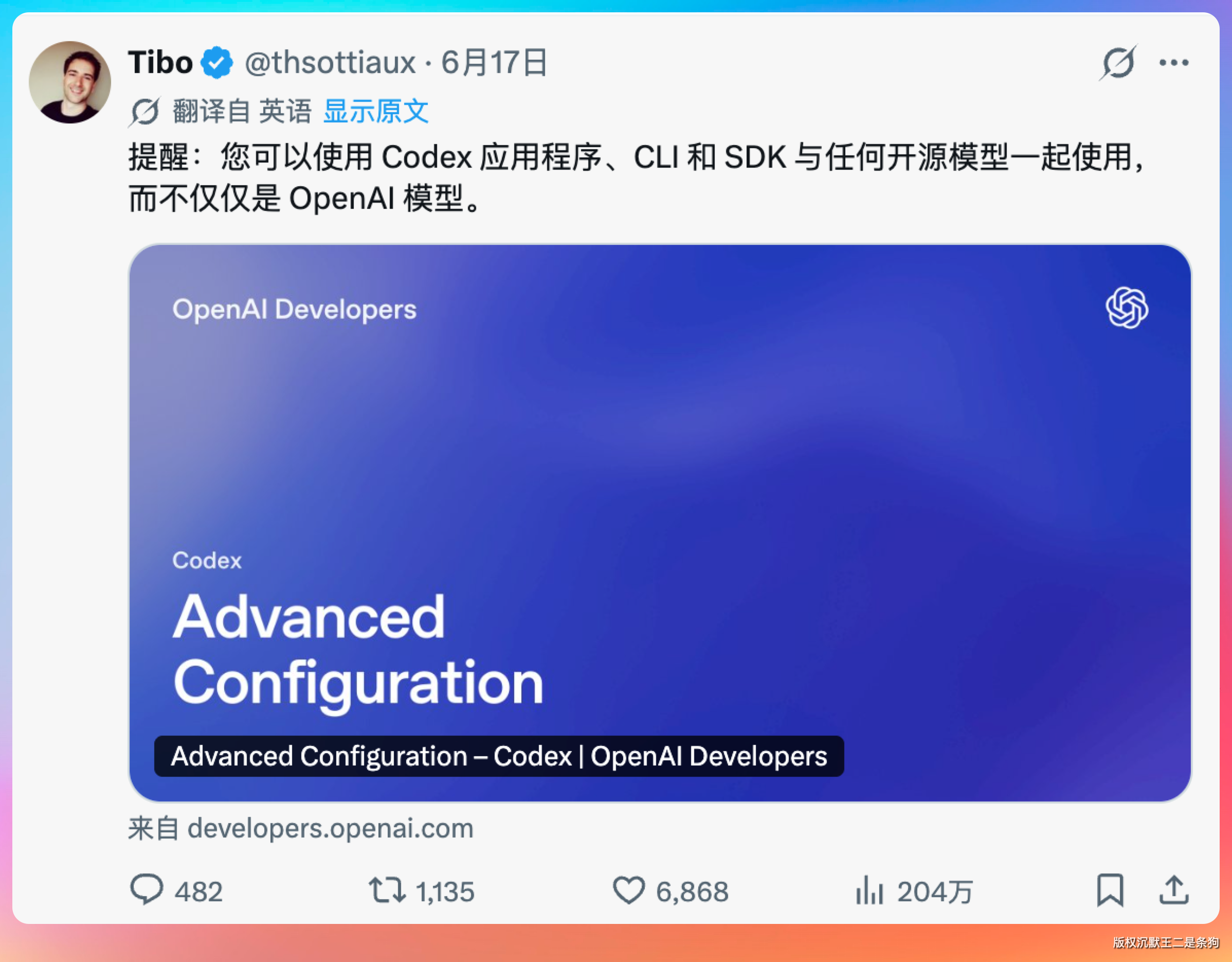
这对我们国内用户是大大的利好啊。
这就意味着我们可以放心大胆的给Codex 接入其他国产模型,比如说 DeepSeek V4 Flash 和 Step 3.7 Flash。
这波,必须得给 OpenAI 点个大大的赞。
要知道,Codex和Claude Code就是目前最顶级的Agent工具。
没他们俩,我现在是真干不了一点活了。

01、Codex的模型自由
Codex 的官方文档里也有明确说明,可以将 Codex 指向任何支持 Chat Completions 或 Responses API 的模型。
并且强调,对 Chat Completions API 的支持已弃用,并将在未来版本的 Codex 中移除。

这个要求就会卡掉一批暂不支持 Responses API 的模型,比如说 DeepSeek V4。
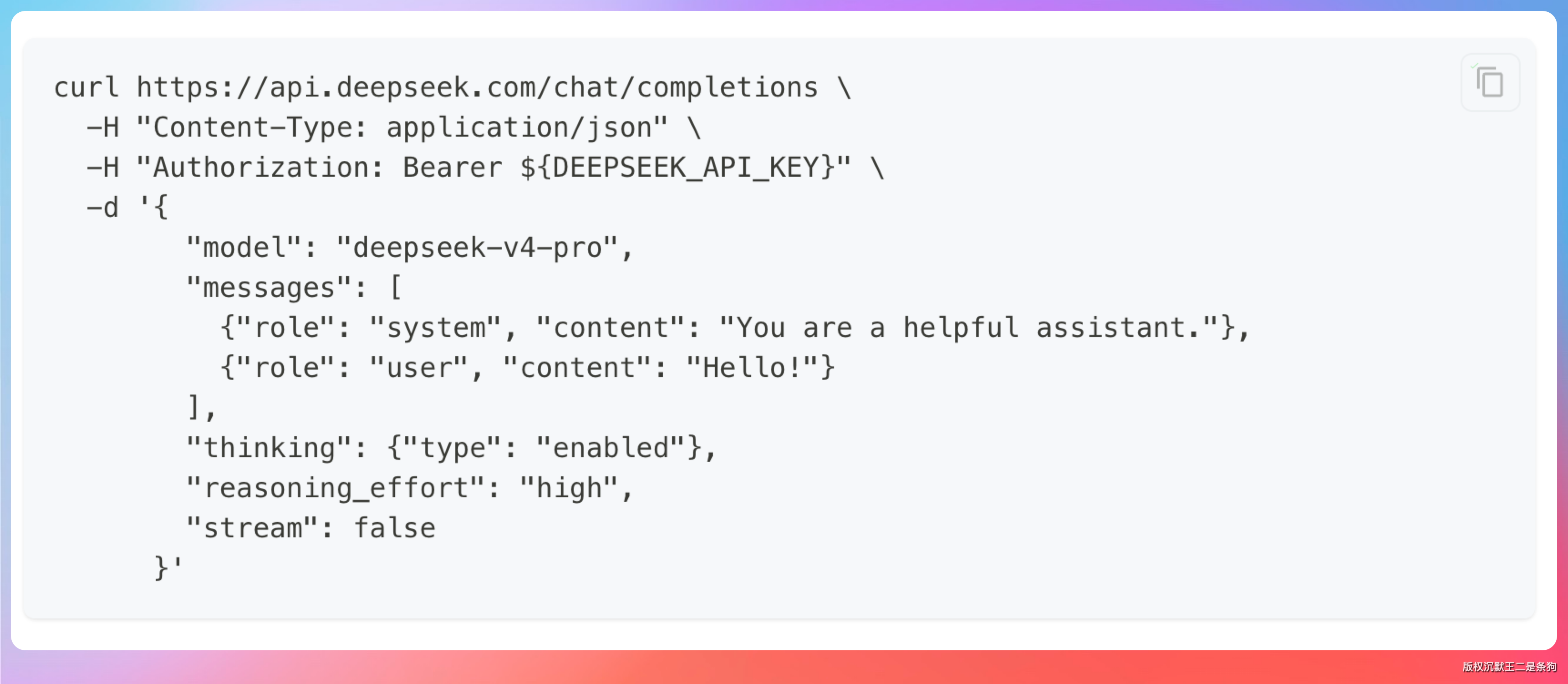
那如果想要Codex支持 DeepSeek V4,就需要做一个中间代理做个协议转换。我的开源项目PaiSwitch就实现了。

当然了,如果模型本身兼容了 Responses API,那就直接接入就行了,Step 3.7 Flash 就是这样,成为首批原生适配 Codex 的非 OpenAI 模型。

配置方式有两种。
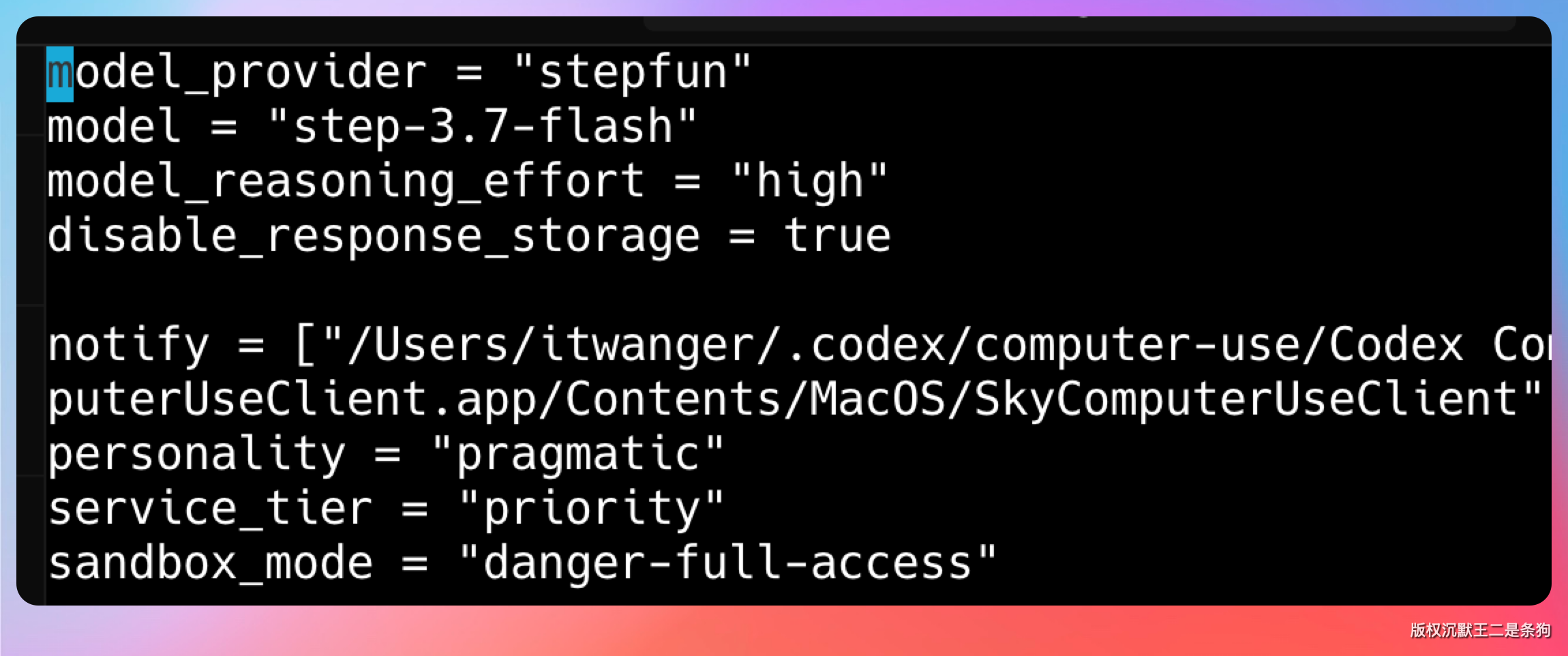
第一种,直接改配置文件。Codex 的配置在 ~/.codex/config.toml,写入 model_providers 块即可。Step 3.7 Flash 因为原生支持 Responses API,配置很简单。
model_provider = "stepfun"
model = "step-3.7-flash"
model_reasoning_effort = "high"
[model_providers.stepfun]
name = "StepFun"
base_url = "https://api.stepfun.com/v1"
wire_api = "responses"第二种,用 PaiSwitch 或者 CC-Switch。前者是我做的一个模型控制台,选好模型、填入 API key 后,可以一键写入 Codex 的 config.toml 和 auth.json。
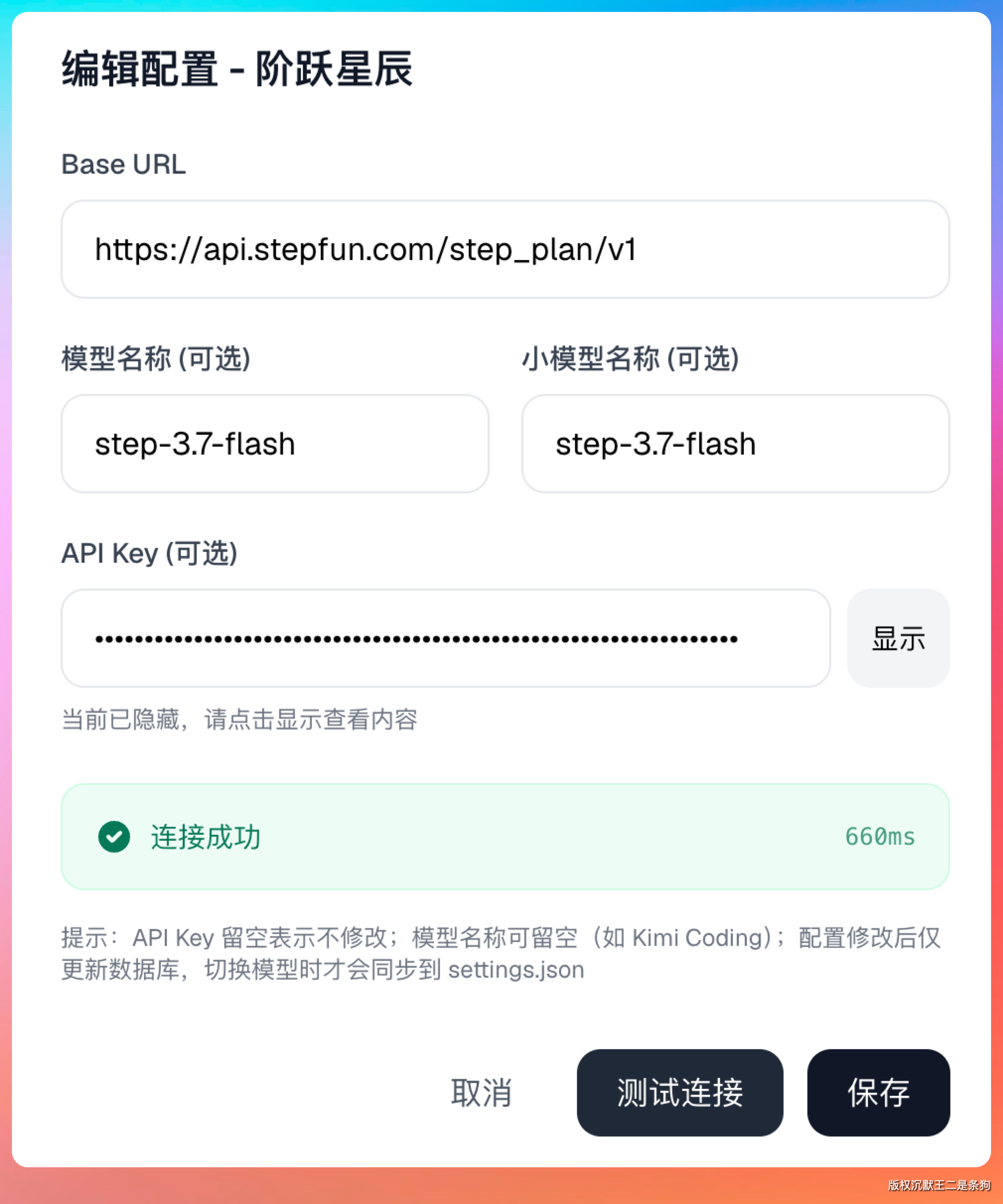
它内置了协议代理,DeepSeek 这种只支持 Chat Completions 的模型,PaiSwitch 会自动做 Responses API 到 Chat Completions 的转换。
当然了,不管是CC-Switch 还是 PaiSwitch,背后其实都是改的配置文件,原理是一样的。
不管怎么说,Codex 能把模型层解耦出来,等于放弃了模型锁定带来的短期粘性,换取了一个更大的可能,成为一个只负责 Agent 调度和跨模型协作的中立平台。
真的很open啊。
搞定 Codex 的国产模型配置后,我们来做一个横评,看看 DeepSeek V4 Flash 和 Step 3.7 Flash 在 Coding Agent、Search Agent、Tool-use Agent 三个场景下的表现。
02、参数对比
先把 DeepSeek V4 Flash 和 Step 3.7 Flash 参数摆出来对比一下。
| 维度 | DeepSeek V4 Flash | Step 3.7 Flash |
|---|---|---|
| 发布日期 | 2026 年 4 月 24 日 | 2026 年 5 月 29 日 |
| 总参数量 | 284B | 198B(含 1.8B ViT 视觉编码器) |
| 活跃参数量 | 13B | 11B |
| 架构 | MoE + CSA/HCA 混合注意力 | MoE(288 专家 × top-8)+ 滑窗/全局混合注意力 |
| 上下文窗口 | 1M tokens | 256K tokens |
| 最大输出 | 384K tokens | 256K tokens |
| 多模态 | 否 | 是(原生视觉) |
| 开源协议 | MIT | Apache 2.0 |
两个模型走的技术路线截然不同。
DeepSeek V4 Flash 在注意力机制上做了激进压缩。官方提到的核心是 token-wise compression + DSA(DeepSeek Sparse Attention),在 1M 上下文长度下显著降低计算和显存开销。284B 总参数、13B 活跃参数,用 FP4 量化 MoE 专家层,模型文件大约 160GB。
它的核心竞争力是“同样的活干完,硬件资源用得更少”。
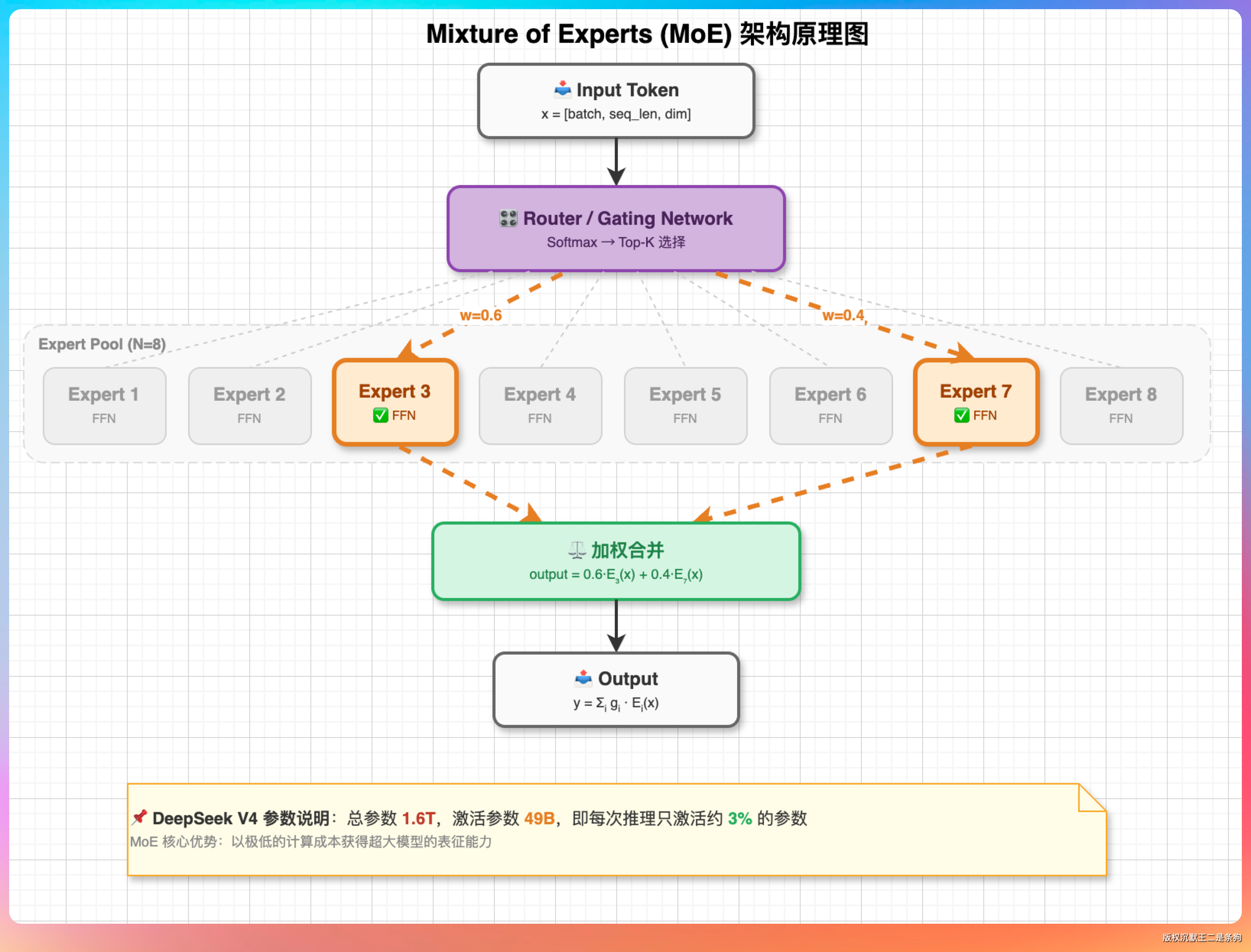
Step 3.7 Flash 的思路是为 Agent 任务做专项优化。198B 参数里嵌入了一个 1.8B 参数的 ViT 视觉编码器,原生支持截图、设计稿、图表等视觉输入,视觉理解能力直接进 Agent 工作流,而不是作为单独的功能模块。
45 层语言层里有 42 层是路由 MoE 层,每层 288 个专家取 top-8 激活,加上 3-way Multi-Token Prediction,推理速度最高到 400 tokens/s。
DeepSeek V4 Flash 默认 1M 上下文,Step 3.7 Flash 是 256K。
03、写代码谁更利索
同一个 prompt 发给两个模型,各自独立生成代码,直接对比产出质量。
由于 Codex 切换模型后需要重启才能加载新的模型,所以这里我直接用 PaiCLI 来跑,我自己 Vibe Coding 出来的一个 Claude Code。
直接 /model 一键切换,非常方便。
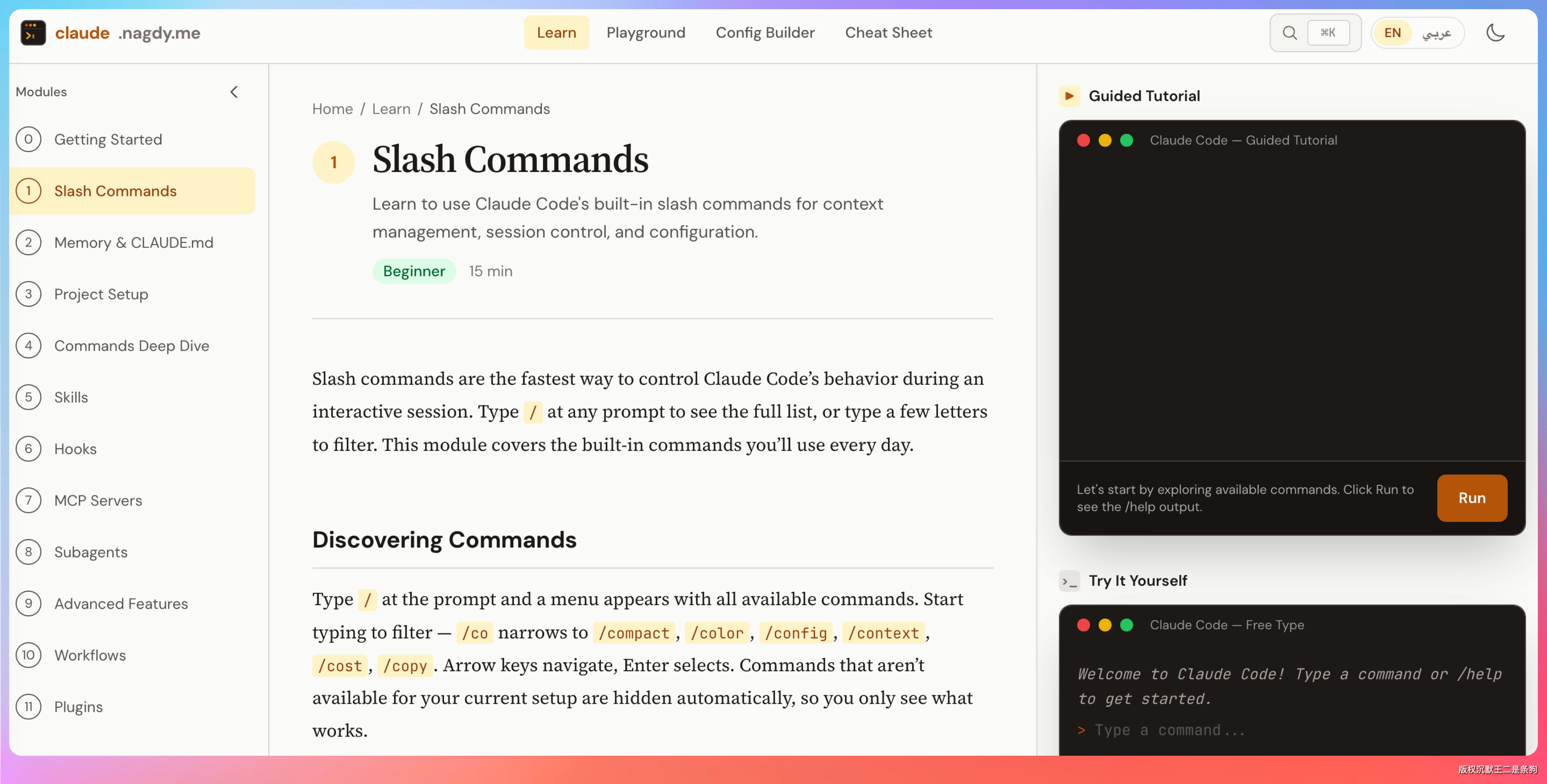
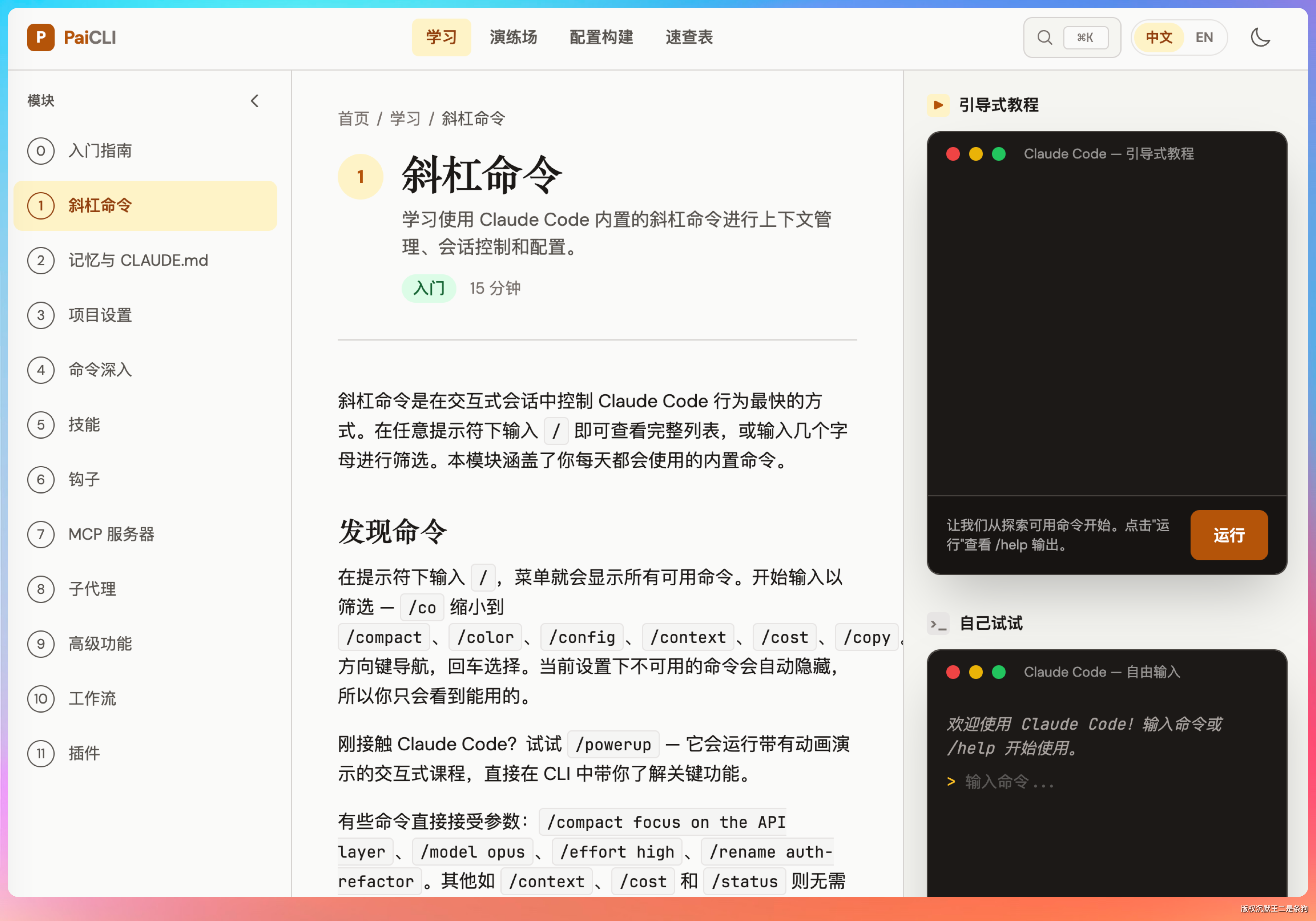
我选了一个有一定复杂度的前端项目:在demo-step目录下,复刻 https://claude.nagdy.me/learn/slash-commands/ 这个网站,做成中文的,要求1:1还原。
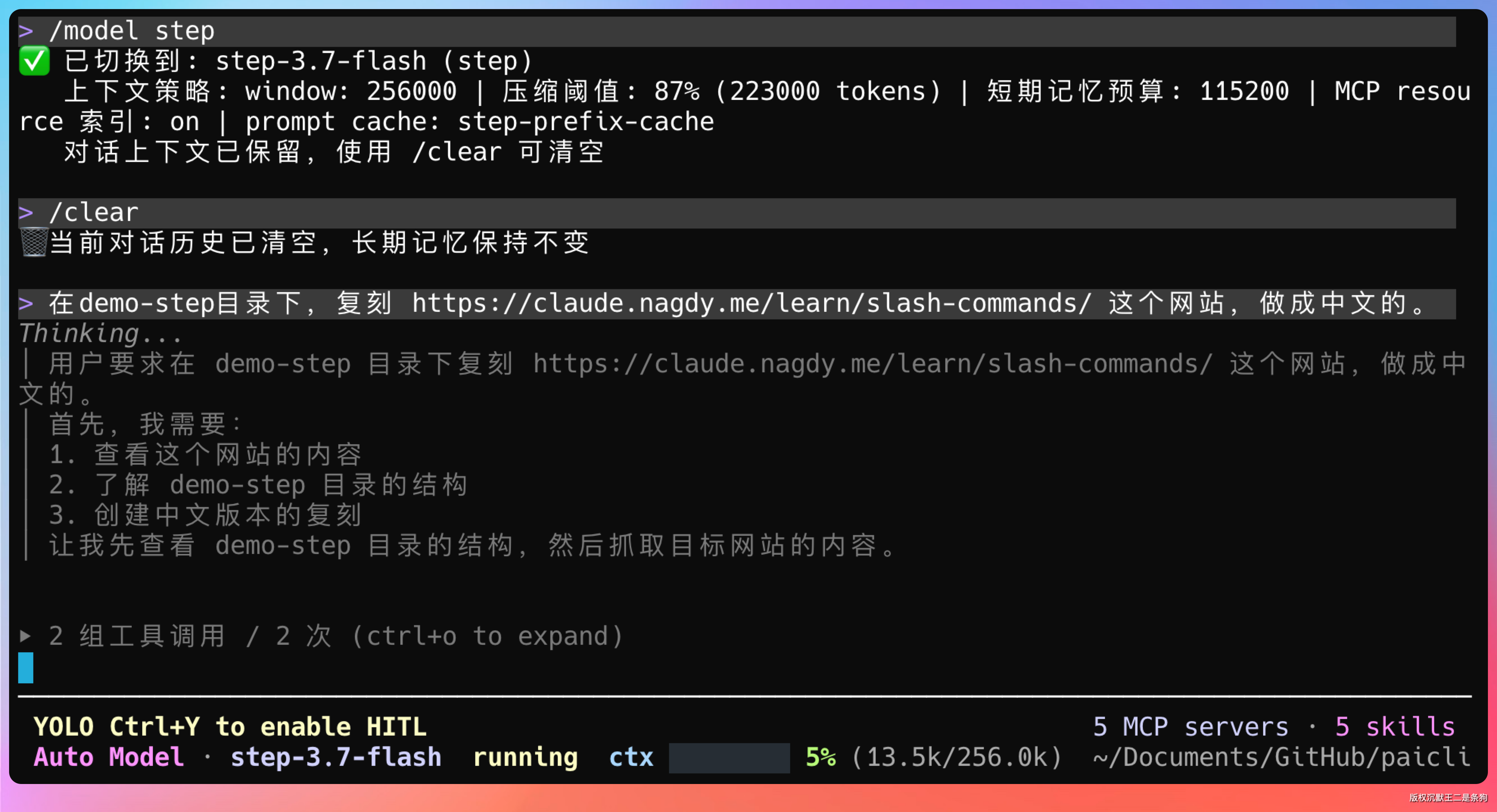
这个网站要求三栏布局(左侧导航 + 中间教程内容 + 右侧仿终端交互演示),包含命令分类卡片、workflow 模板、选择题测验组件,以及右侧终端的逐字打字动画效果。最终输出一个能直接在浏览器打开的 HTML 文件。
这个任务的综合性比较强。
既要写 HTML 结构和 CSS 样式,又要写 JS 交互逻辑(打字动画、测验反馈、导航高亮),还要在视觉设计上做到位(暖白底色、橙色主色调、圆角卡片、monospace 命令标签)。
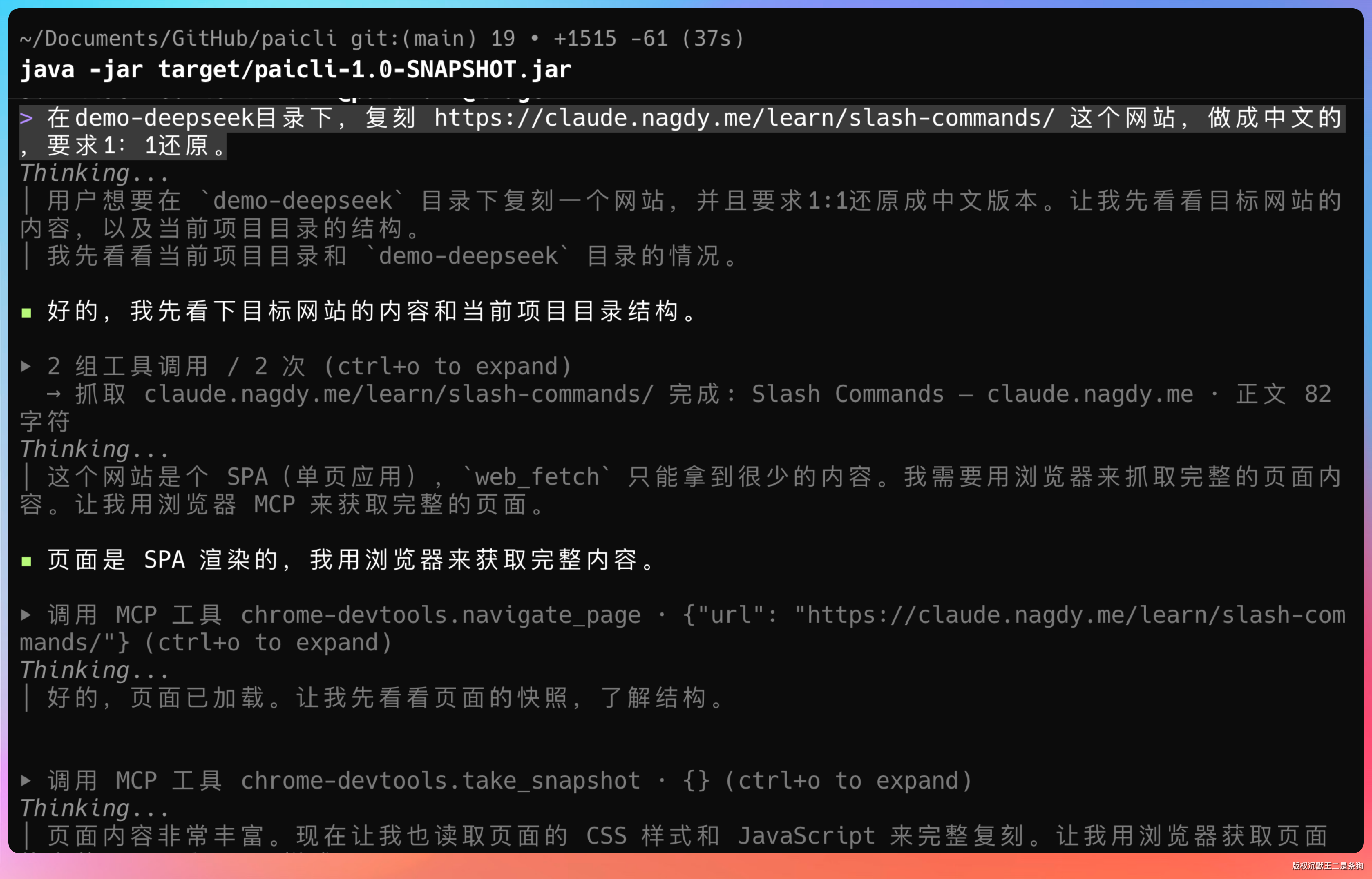
DeepSeek V4 Flash 的表现
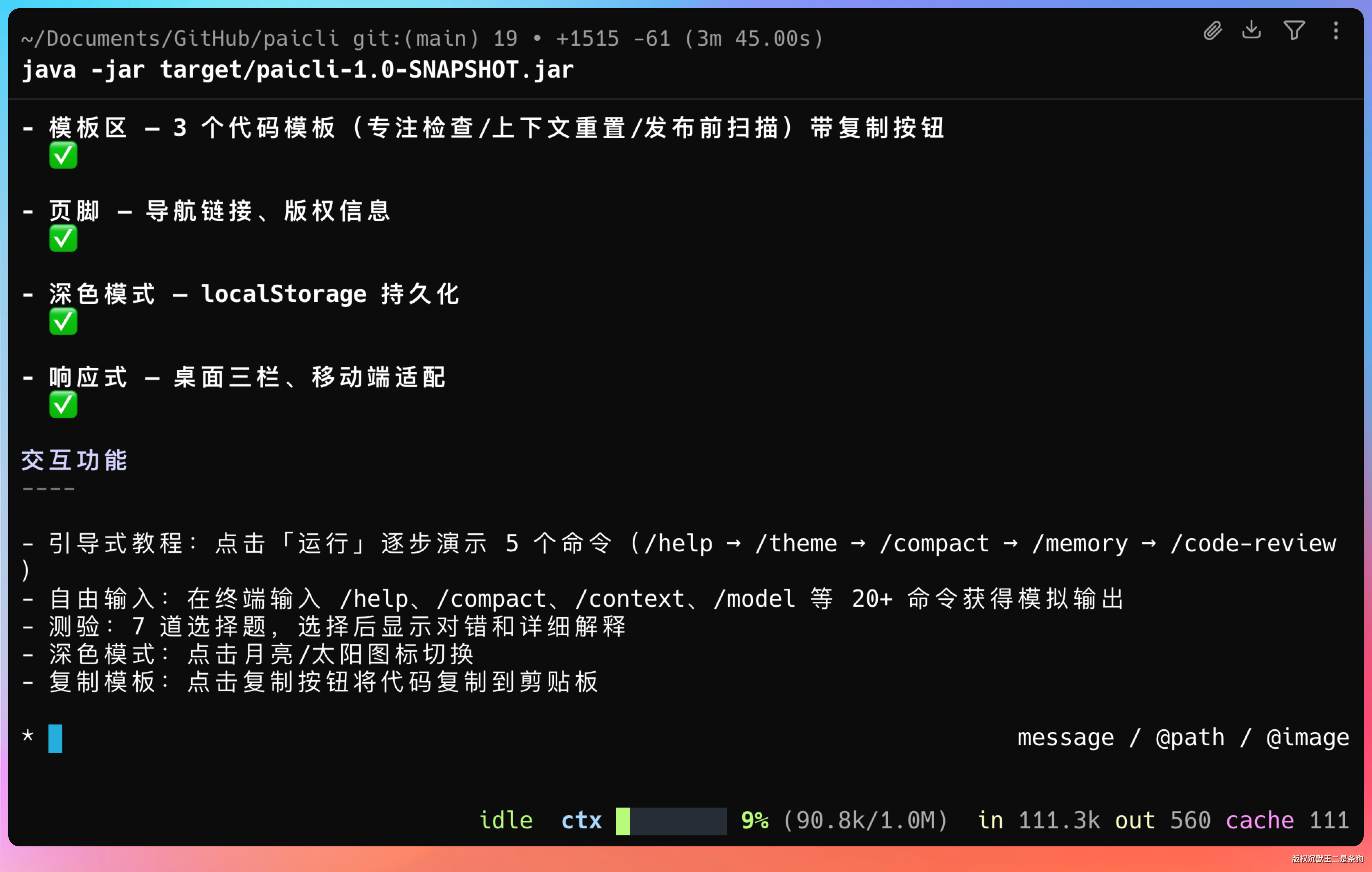
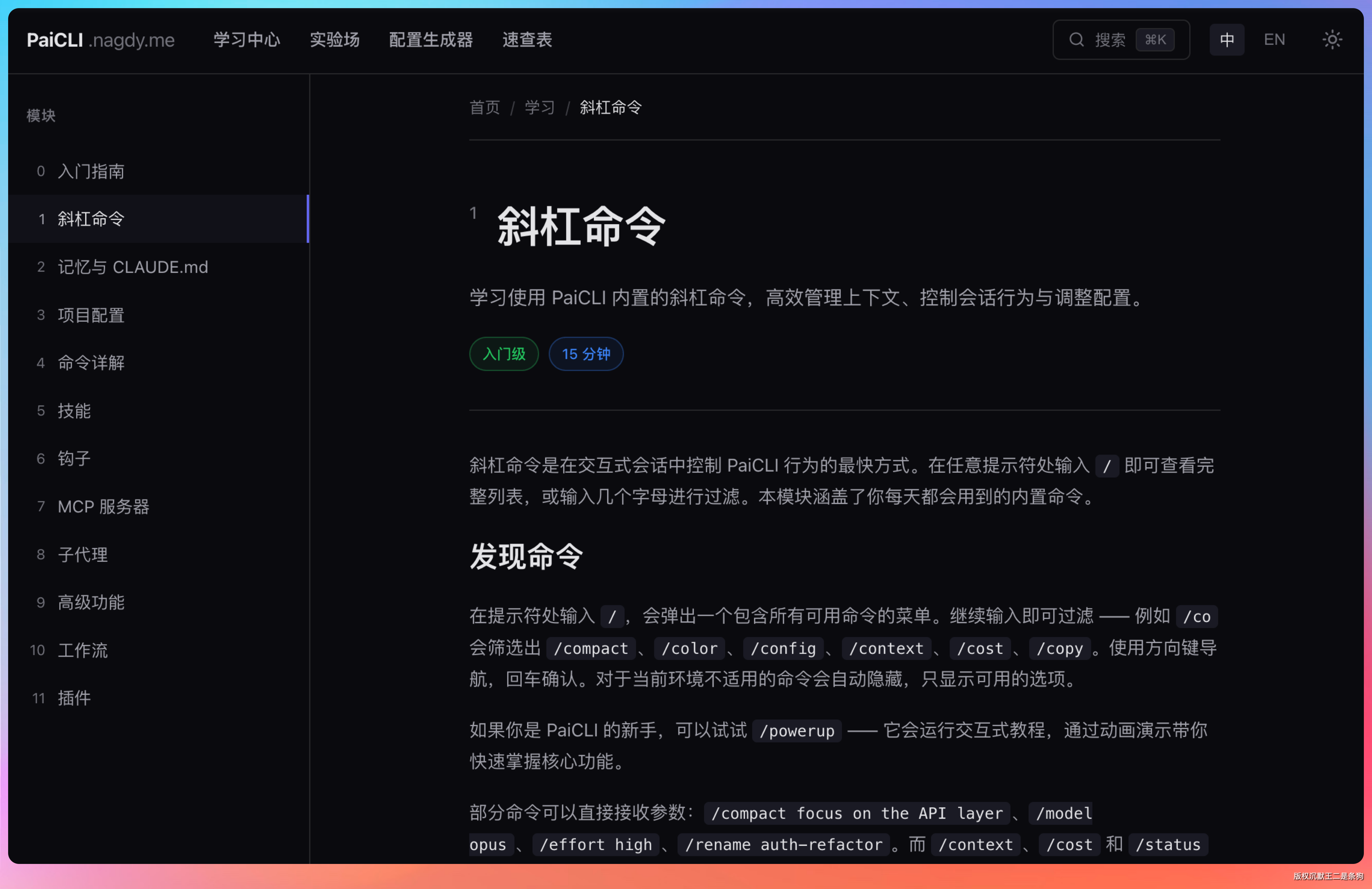
Step 3.7 Flash 的表现
直接上对比数据:
| 维度 | DeepSeek V4 Flash | Step 3.7 Flash |
|---|---|---|
| 端到端用时 | 约 38 秒 | 约 42 秒 |
| 总 token 消耗 | 约 15K tokens | 约 22K tokens |
| 工具调用次数 | 12 次 | 14 次 |
| 三栏布局还原 | 结构基本正确,但右侧终端区域样式偏差较大 | 三栏比例、间距与原站高度一致 |
| 打字动画效果 | 未实现逐字打字动画 | 完整还原逐字打字 + 光标闪烁效果 |
| 配色还原度 | 主色调偏差明显,卡片圆角和阴影缺失 | 暖白底色、橙色主色调、圆角卡片均还原到位 |
| 交互逻辑完整度 | 测验组件缺少反馈提示 | 选择题测验、导航高亮、命令分类卡片交互完整 |
从结果上看,Step 3.7 Flash 在还原度上更接近原网站。布局、配色、动画三个维度都做到了接近 1:1 的复刻。
另外,从 PaiCLI 的运行过程也能看得出来,Agent在完成任务的过程中,调用了很多工具,比如说 StepSearch。
StepSearch 是阶跃星辰提供的一个联网搜索工具。
再比如说调用Chrome Devtools MCP,用来通过Chrome浏览器直接打开目标网站。
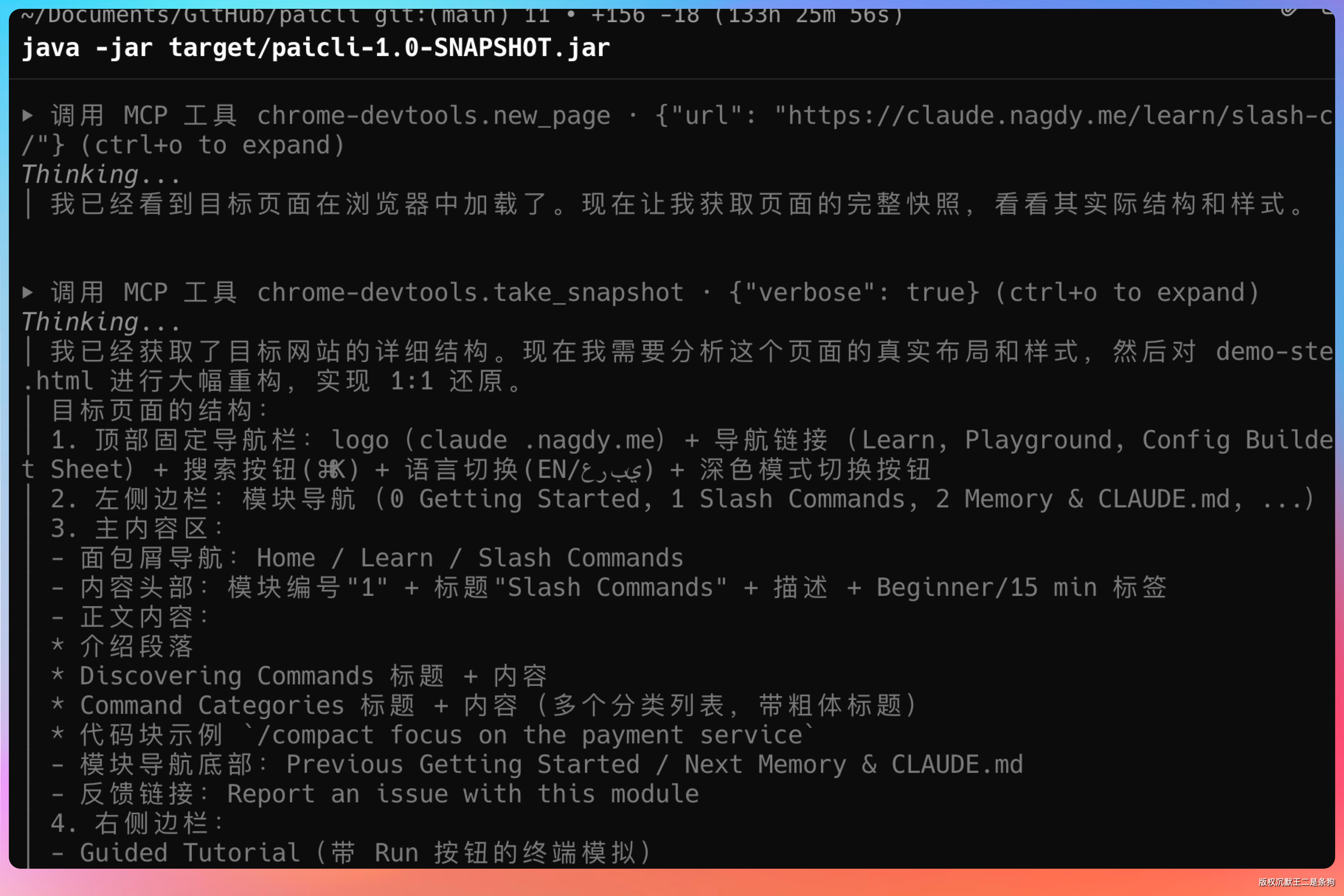
注意 take_snapshot,可以用来提取网页的结构和文字信息(如无障碍树、DOM 树和 UID),生成便于大模型理解的纯文本数据。
整个过程涉及到了很多步骤(搜索→读取→提取→生成等等),但Step 3.7 Flash的表现一直非常稳定。
04、多模态工作流体验
前面测的是纯代码生成,这一节我们换个方向,看看 Step 3.7 Flash 在多模态工作流里的表现。
这里测试的不是单纯的图像生成能力,而是 Agent 编排【理解 → 调度 → 生成】整条链路的能力。
Step 3.7 Flash 内置了 1.8B 参数的 ViT 视觉编码器,可以直接在 Agent 工作流里读图、理解图、再基于理解结果调度下游任务,这是 DeepSeek V4 Flash 目前做不到的(纯文本模型)。
这次我们用 PaiAgent 来跑,先测试文生图。prompt 是”一位戴着圆框眼镜的亚洲女生,坐在咖啡馆靠窗的位置,阳光透过玻璃打在脸上,自然光线,浅景深,照片级真实感,富士 Superia 400 胶片色调”。
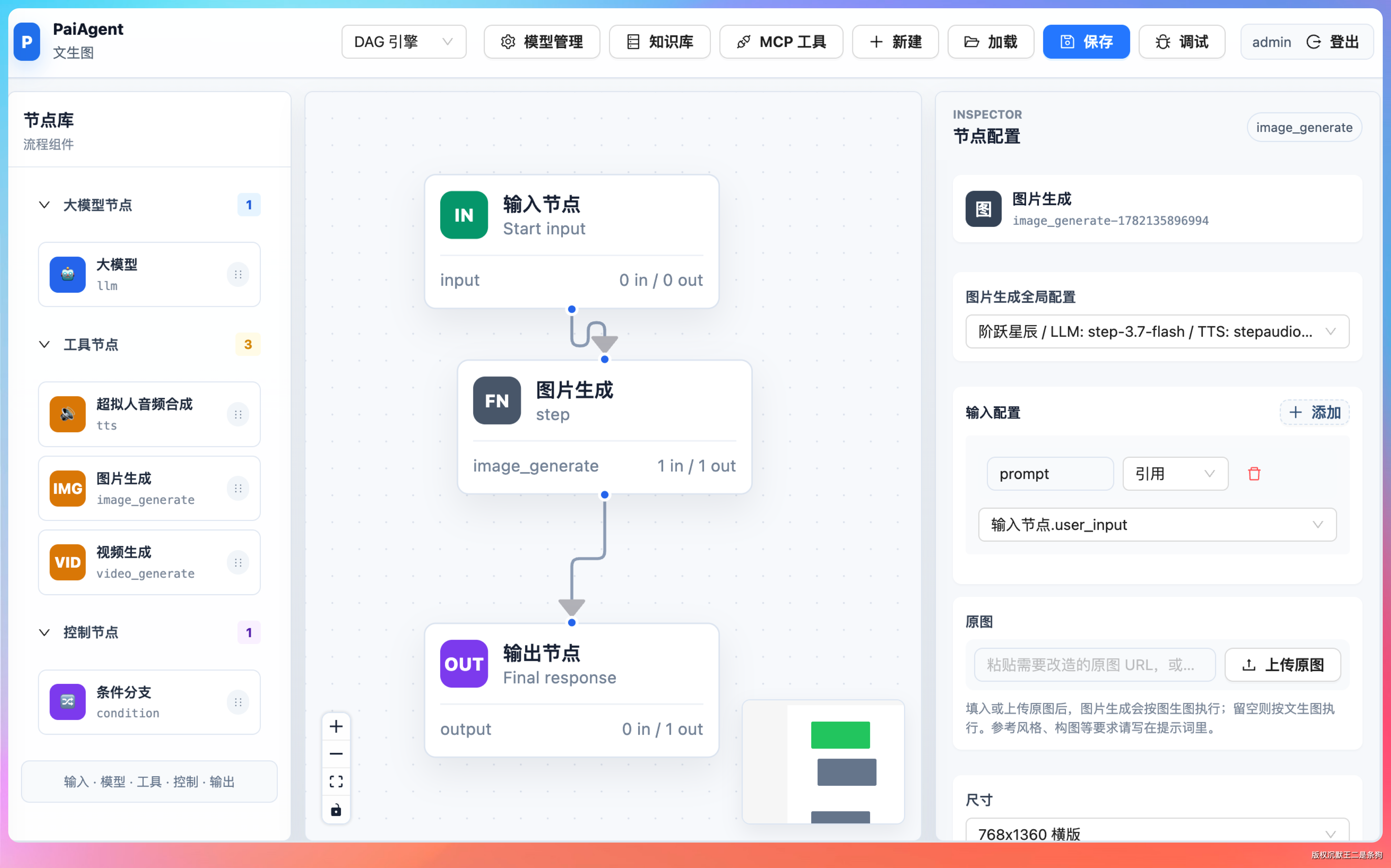
结果如下所示:

光影、肤色、眼镜反光都处理得很自然,几乎看不出 AI 生成的痕迹。
接下来才是重点。
我们把刚才生成的咖啡馆照片作为输入,让 Step 3.7 Flash 读图后生成一张证件照。
这个任务的关键在于:模型需要先理解原图中的人物特征(五官、发型、眼镜款式),再将人物从复杂背景中提取出来,最后按照证件照规范重新生成。
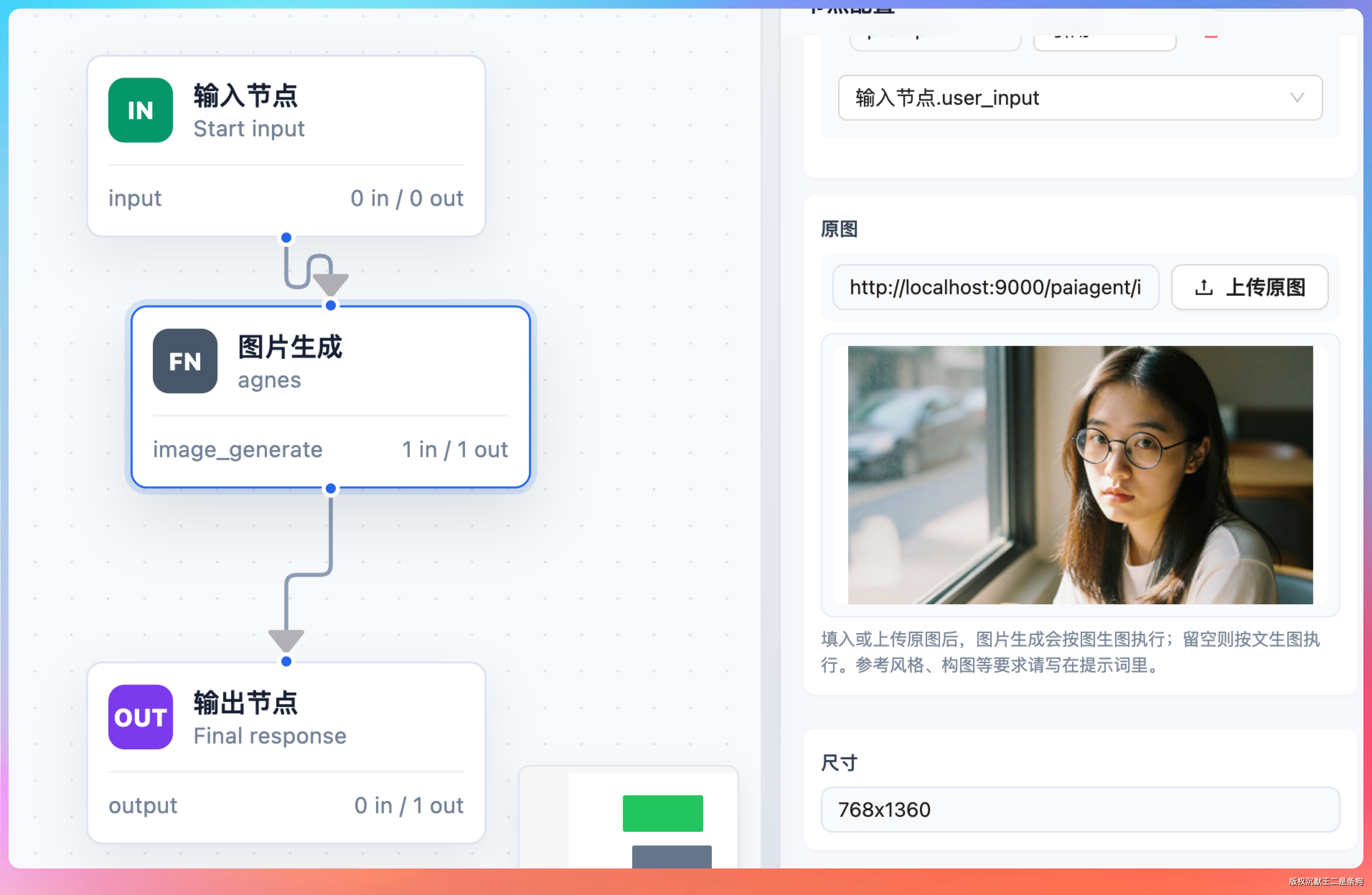

出来的结果背景替换得很干净,人物边缘没有明显的毛边,五官特征也保持了一致。
整个流程是:文生图 → 读图理解 → 证件照生成,Step 3.7 Flash 一条链路走完,中间不需要切换模型或手动中转。
这就是原生视觉能力进 Agent 工作流的优势。
05、选型建议
高频、简单的代码辅助任务(补全、简单修改、格式化、代码解释),选 DeepSeek V4 Flash。
成本极低,1M 上下文处理大文件没有压力,单轮推理能力(GPQA Diamond 88.1%)足够应对这类场景。
复杂的 Agent 工作流(涉及多步推理、工具编排、搜索综合、跨文件修改),选 Step 3.7 Flash。
端到端稳定性更好,首次通过率省下的重试成本可以部分抵消单价差距。原生多模态能力是额外的加分项,截图理解 → 代码生成这种流程,它能一条龙走完,DeepSeek 目前做不到。
需要接入 Codex 的场景,Step 3.7 Flash 有 Responses API 原生支持的优势,直连不需要中间网关,延迟更低。DeepSeek V4 Flash 需要通过 PaiSwitch 的协议代理做转换,多一跳但功能上不受影响。
ending
就目前来说,Codex 和Claude Code 就是最好的两个 Agent,不止于编码。
两个都可以接入国产模型,这一点对于我们国内用户来说,可以说真的非常友好了。
当然了,要想和Codex做到完美结合,还需要国产模型尽早支持 Responses API,并且各个 tool call 的调用尽量保持一致。
就目前来说,Step 3.7 Flash 在这方面做的不错,是首批原生适配 Codex 的非 OpenAI 模型,表现也很稳定。
【选模型跟选工具一个道理。不是看参数谁最多,是看谁干完活最利索。】