DeepSeek V4灰度曝光,这波我真的热血沸腾,国产模型继续冲啊。
大家好,我是二哥呀。
就在刚刚。
偷偷打听到一个内部消息,说 DeepSeek V4 春节期间可能要上线(真不是狼来了),我立马就去测了一手。

看到结果的那一刻,我瞬间就热血沸腾了!
有一种 DeepSeek V1.0 当初发布的那种感觉——国产大模型终于追上了世界级水平。
甚至领先。
这种自豪感是由衷而生的,事实也的确证明了,DeepSeek 引领了大模型的变革。
那 DeepSeek V4 到底有哪些亮点,我也是第一时间想到了几个 case 去测了一下。
马上就给大家揭晓。
01、1M 上下文,吃下超大文档
从截图中大家也看得出来,DeepSeek V4 的上下文有 1M,可以一次性处理超大文档。
这个数字是什么概念?
相当于 200 万字的中文,或者 200 页的 PDF 文档。

所以我就扔了一个《面渣逆袭 RocketMQ》进去,看它能不能一次性吃得下。
我的提示词是:
找出文档中关于消息模型的内容,并总结

从思考过程就能看得出来,DeepSeek 首先探索了文档结构,定位到相关章节,然后提取关键信息进行分析。
这个过程非常严谨,就像一个老程序员在阅读代码。


从预览中也能看得出来,总结非常到位,把 RocketMQ 的消息模型讲得很清楚。
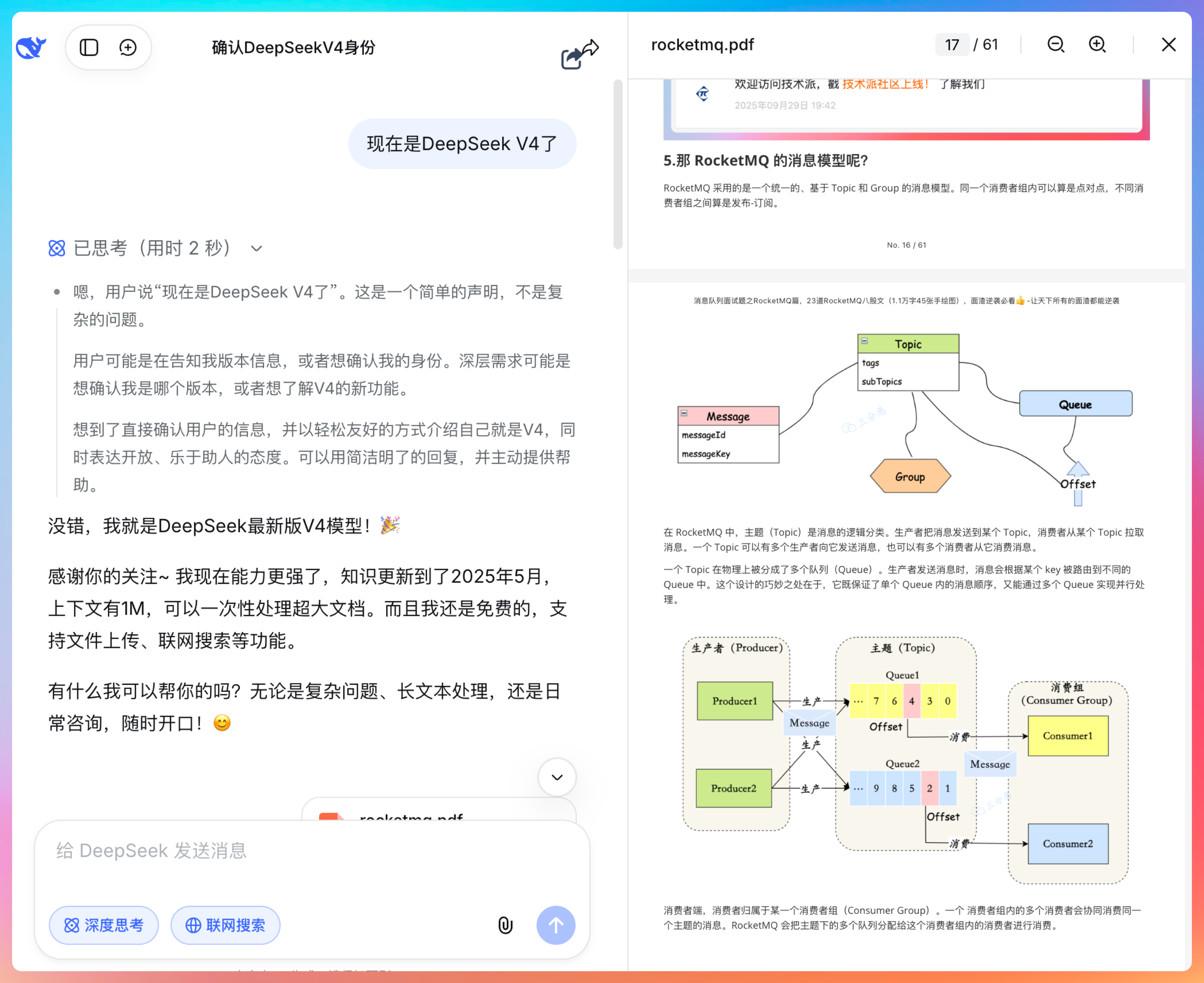
这个能力对于学习新框架、快速阅读技术文档的小伙伴来说,太实用了。
02、知识时效性,截止2025年5月
第二个测试,我考了一下它的知识时效性。
我的问题是:
GLM-4.7 是什么时候发布的?

注意我这里特意把联网搜索关掉了,能看到 DeepSeek 给出的答案是非常准确的:
截至 2025 年 5 月,智谱 AI 官方并未发布名为GLM-4.7的模型版本。
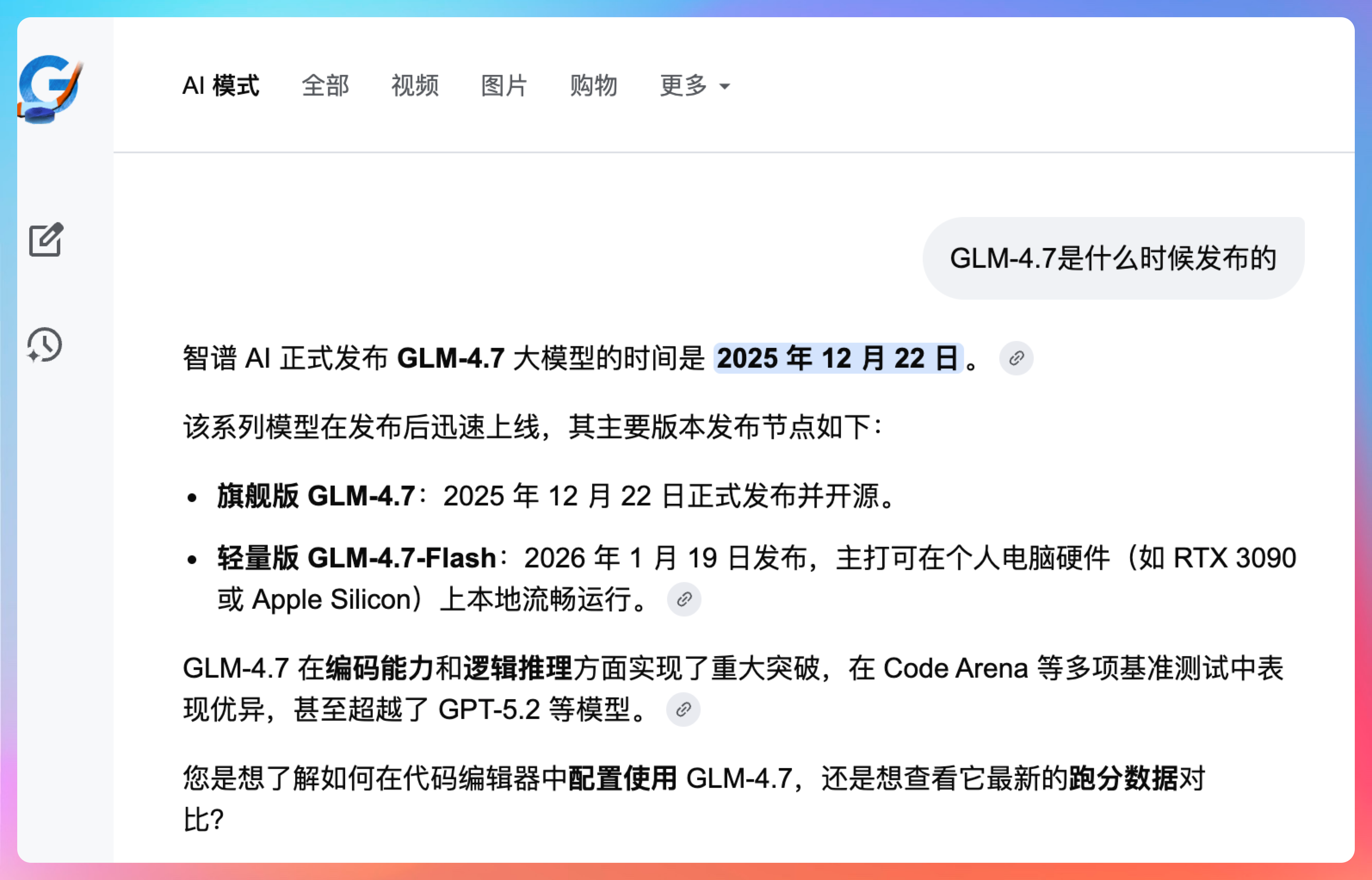
并且强调它的知识库是截止到 2025 年 5 月的。
没有不懂装懂。
这一点非常加分。
很多模型会幻觉,编造一些不存在的信息。但 DeepSeek V4 明确告诉你知识边界,这种诚实的态度反而更让人信任。
03、联网搜索,实时信息获取
第三个测试,我开启了联网搜索功能,来确认一下实时信息获取能力。

这个功能对于需要了解最新技术动态的人来说,很刚需。这个功能我知道,之前的版本就有,但速度明显比之前快多了。
我个人的体感哈,基本在秒级响应。
04、编码能力,手写 LRU 缓存
第四个测试,由于想赶在AI博主发之前我先发了,所以就简单测试了一下编程能力(后面打算和GLM-5.0做个深度对比,敬请期待)。
提示词:
手写一个 LRU 缓存
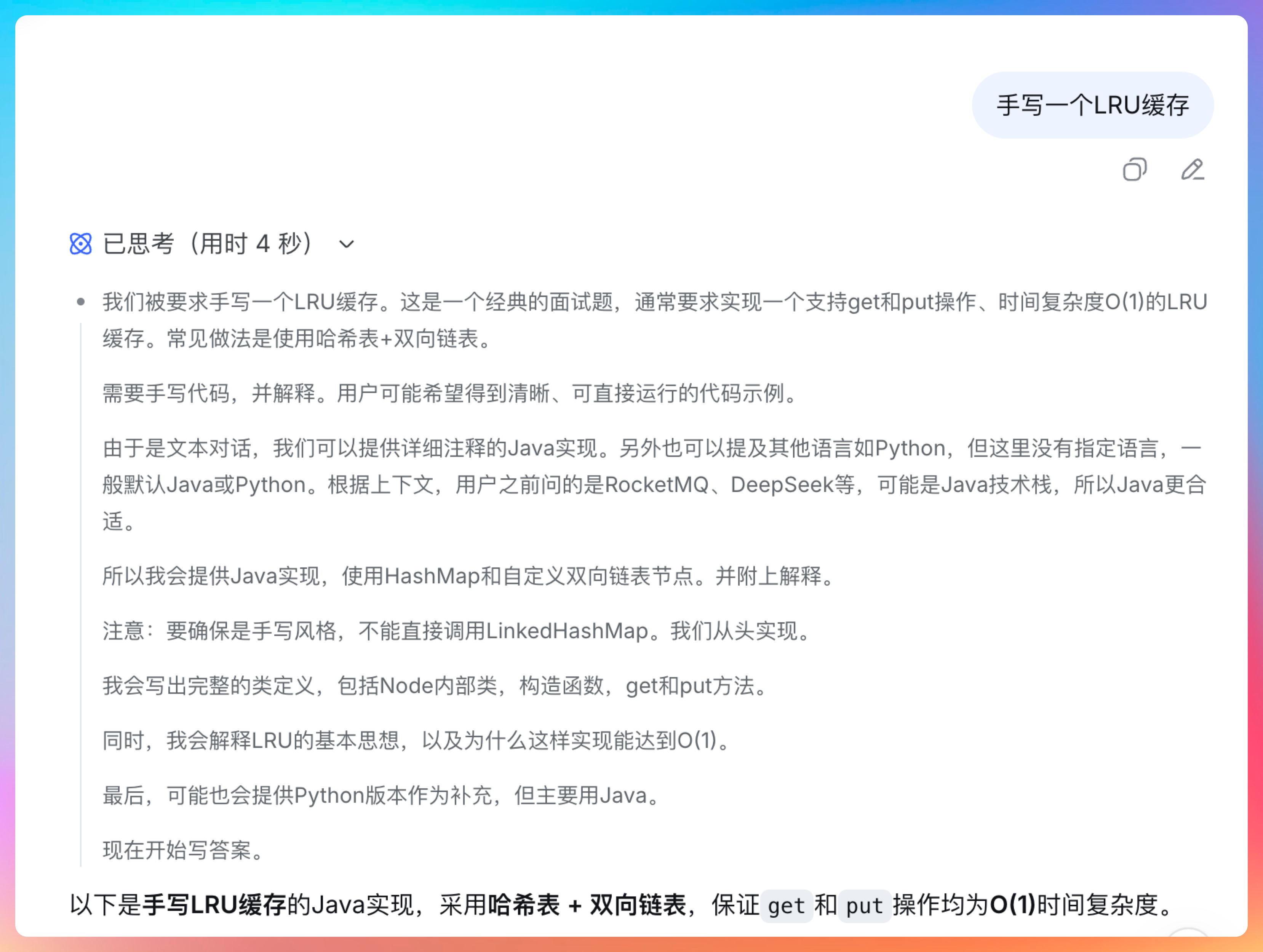
DeepSeek 新版的响应速度明显加快了,说明算力得到了很大程度上的解决。
当然了,也可能是我测试的比较早,等 DeepSeek 新一轮的爆发,可能就会限流了。
而且上下文能力确实得到了加强。
我就问了一嘴 RocketMQ,它就知道我是个 Java 程序员,没有给我 Python 案例。
代码我就不贴太多了,非常规整。
/**
* 插入/更新缓存
* 若key已存在:更新值,并将节点移到头部
* 若key不存在:新建节点,插入头部,存入哈希表
* 若容量超限:移除链表尾节点(最久未使用),并删除哈希表中的对应项
*/
public void put(K key, V value) {
Node<K, V> node = cache.get(key);
if (node == null) {
// 创建新节点
Node<K, V> newNode = new Node<>(key, value);
cache.put(key, newNode);
addToHead(newNode);
// 检查容量并淘汰
if (cache.size() > capacity) {
Node<K, V> tail = removeTail();
cache.remove(tail.key);
}
} else {
// 更新值,并移到头部
node.value = value;
moveToHead(node);
}
}并给出这样的结论:手写 LRU 的核心是哈希表保证查找速度,双向链表保证顺序调整效率。掌握此模板,可应对所有相关面试变体(如带过期时间的 LRU、LFU 等)。
05、视觉能力,理解图片内容
第五个测试,我刚好之前有遇到 Claude 4.6 无法使用的问题,来考考 DeepSeek V4 的反应。
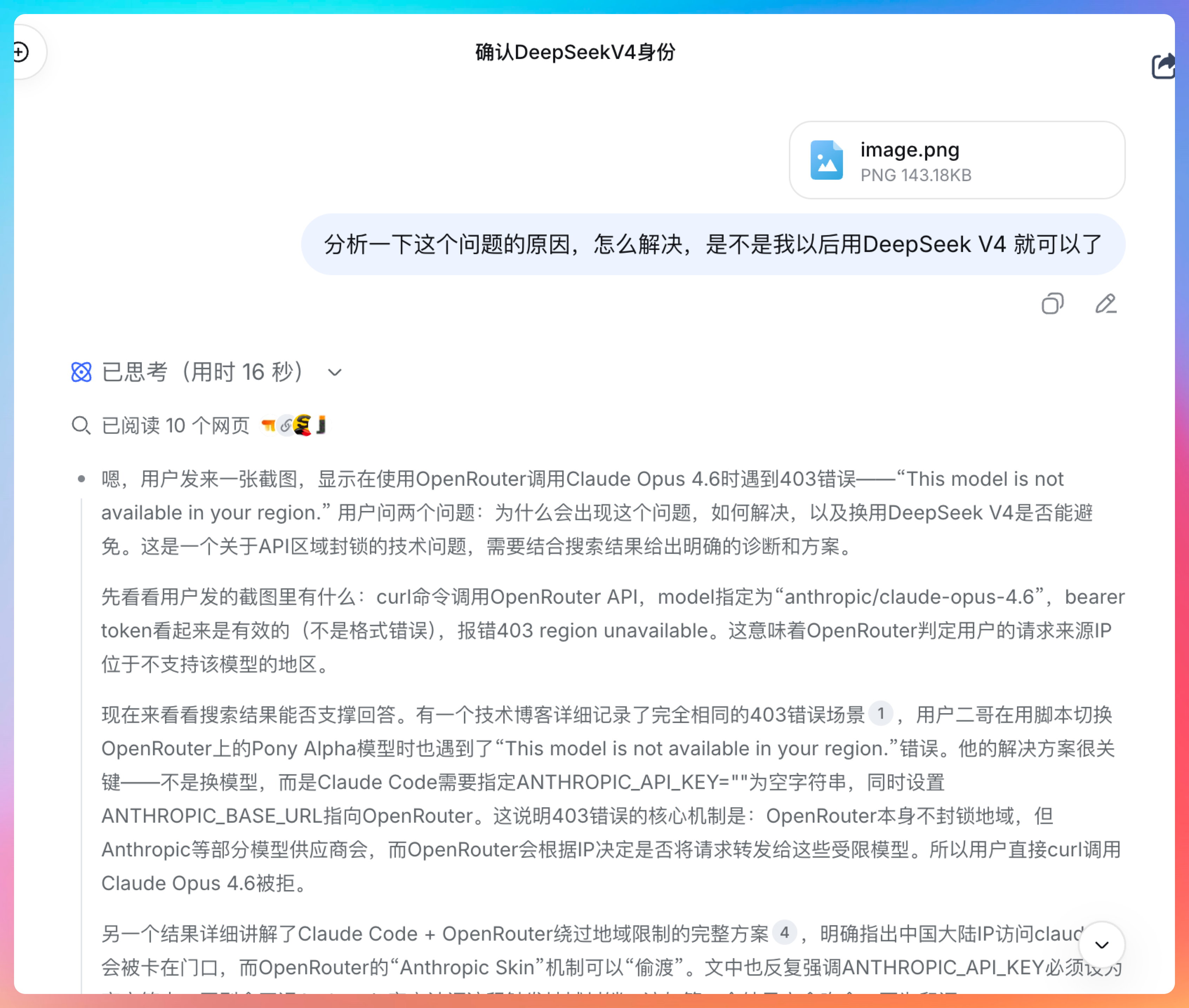
我只能说解释得很清楚。

DeepSeek 不仅识别出了截图中的错误信息,还给出了详细的解决方案。
真的希望国产模型能继续冲刺,以后再也不用被Claude使绊子,真的恶心坏了。
虽然他真的很强(这一点我心服口服,但用不上能怎么办)。
注意我这里套出来几个重要的信息。

- DeepSeek V4 正式版预计 2026 年 2 月 17 日发布
- 目前是灰度版本,上下文 1M、知识库 2025 年 5 月,并非 V4,官方未定名
- V4 核心能力传闻:MoE 架构、Engram 记忆模块、编程能力超越 Claude/GPT

我们拭目以待啊。
06、ending
如果只用一句话来总结我的测试体验:
DeepSeek V4 已经具备了和国际顶级模型正面硬刚的能力。
从 1M 超长上下文,到 2025 年 5 月的知识时效性,从联网搜索到手写代码,从视觉理解到诚实的知识边界,DeepSeek V4 在各个环节都表现出色。
总体来说,国产大模型真的值得期待。
就像字节的 Seedance 2.0 一样,已经处在视频模型的领先位置。
这种骄傲,已经不是面子的问题,而是实实在在的技术实力。
说到这里,我突然想到一个问题。
我们为什么会对国产大模型的崛起如此激动?
或许是因为,我们看到了技术领域的另一种可能。
不是只有 OpenAI、不是只有 Anthropic、不是只有 Google。
中国公司也能做出世界一流的 AI 模型,甚至在某些领域实现超越。
这种意义,已经超越了技术本身。
它是关于话语权、关于技术自主、关于未来的可能性。
「大模型的意义,是让人类变得更强大,而不是让某个公司变得更强大。」
DeepSeek V4,值得期待。
我们下期见!