面试官:“你连个Agent项目都没有也好意思投简历?”我反驳:“LangGraph4J、Function Calling不算?”面试官:“我错了。”
老王发量很多,且阳光自信,一看就是刚入职没两年的热血青年,但确实有面试官的威严。
这是我的第一场面试,说不紧张那是不可能的。
但提前已经和同频道的宿友互面了两周,面对老王的压力,自认为能扛得住。😄
“我看你简历上连个Agent项目都没有,你难道不知道现在是AI时代吗?”老王第一次张嘴就开始给压力。

我倒是一点都没怂:“LangGraph4J+SpringAI做的这个工作流编排就是啊,王哥,你仔细看。”
“你小子,挺能被压力嘛,我就是测试一下你的心态。”老王一下子和蔼了起来,我们之间的感情好像升温了一般,空气也变得微妙了起来~
“王哥,你继续,我对 PaiAgent这个项目还是自信的,一手Vibe Coding完成的,在GitHub上也有快200 star 了。”
https://github.com/itwanger/PaiAgent
content
01、LangGraph4j 中的 State 是干什么用的?
“先聊聊 State,你们项目里 LangGraph4j 的 State 是怎么用的?”
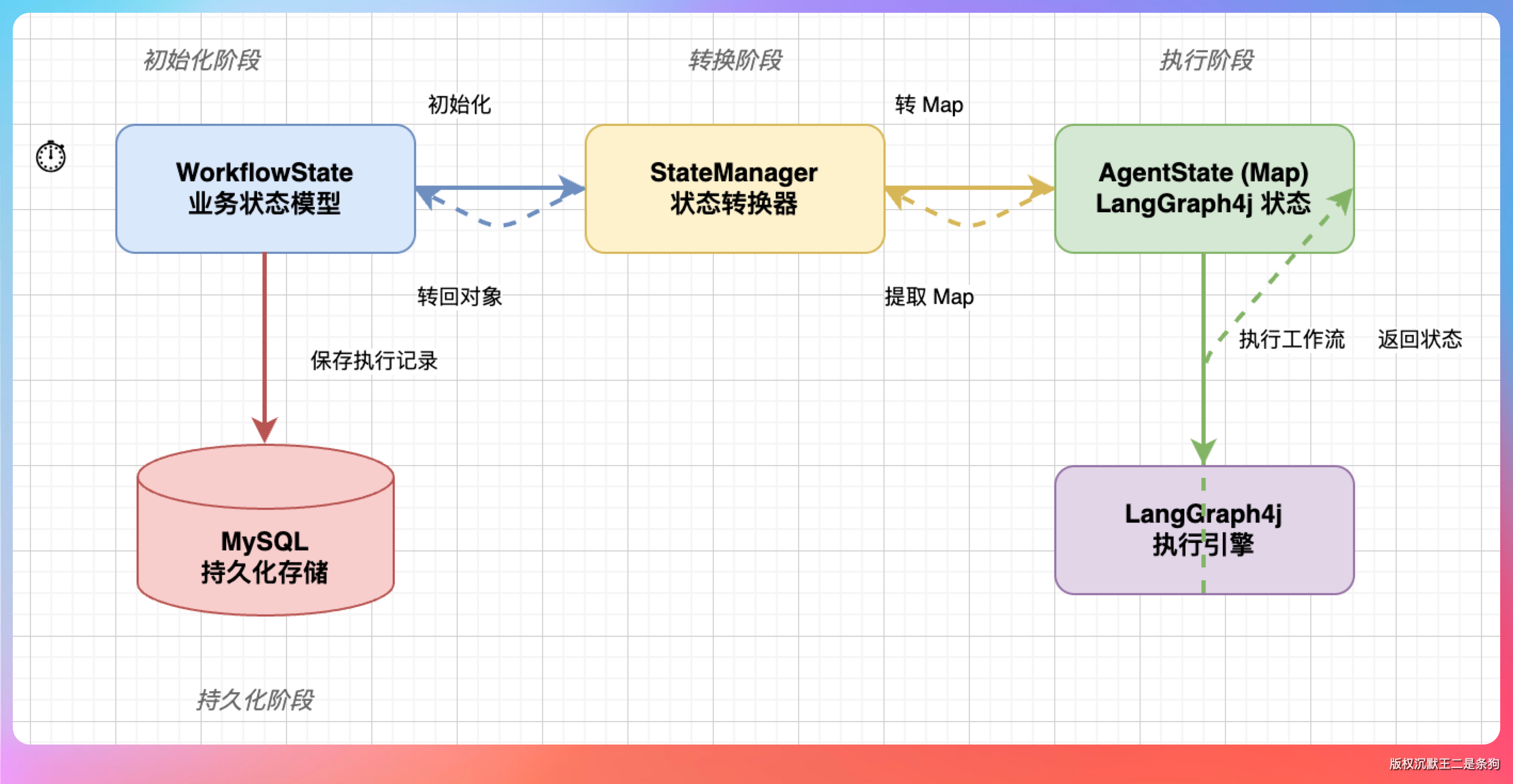
我说:“王哥,State 在 LangGraph4j 里是整个工作流的‘记忆中枢’。”
你可以把它理解成一个贯穿所有节点的数据背包——每个节点执行完,都把结果往这个背包里塞一份,下一个节点从背包里拿上一个节点的输出来用。
在 PaiAgent 里,我们设计了一个 WorkflowState 类,里面有几个核心字段:
@Data
public class WorkflowState {
private String currentNodeId;
private Map<String, Object> globalContext = new HashMap<>();
private Map<String, NodeOutput> nodeOutputs = new HashMap<>();
private String status = "RUNNING";
private String errorMessage;
private Long startTime;
private String inputData;
}currentNodeId 记录当前执行到哪个节点了,nodeOutputs 存每个节点的执行结果,globalContext 用来放跨节点的共享数据。
不过实际实现中,我们并没有直接把 WorkflowState 塞进 LangGraph4j 的 StateGraph。
LangGraph4j 要求用 AgentState,底层其实是一个 Map<String, Object>。所以我们在 StateManager 里做了一层转换——初始化的时候把 inputData、currentInput、nodeOutputs、status 这些字段放到一个 Map 里,传给 LangGraph4j:
public Map<String, Object> initializeState(String inputData) {
Map<String, Object> state = new HashMap<>();
state.put("inputData", inputData);
Map<String, Object> currentInput = new HashMap<>();
currentInput.put("input", inputData);
state.put("currentInput", currentInput);
state.put("nodeOutputs", new HashMap<>());
state.put("status", "RUNNING");
state.put("startTime", System.currentTimeMillis());
return state;
}老王点头:“那 WorkflowState 和 AgentState 之间是什么关系?”
我说:“WorkflowState 是我们自己定义的业务模型,方便序列化和持久化。AgentState 是 LangGraph4j 框架的状态模型。StateManager 负责两者之间的转换,初始化时 WorkflowState 转 Map 给 LangGraph4j,执行完再从 Map 提取回 WorkflowState 用来保存执行记录。”
老王又追了一句:“那节点执行失败了,State 里怎么处理?”
我说:“NodeAdapter 里有错误处理逻辑。如果某个节点抛了异常,会把 State 的 status 设为 FAILED,errorMessage 记录具体的报错信息。LangGraphWorkflowEngine 在收到最终状态后,通过 stateManager.isSuccessful(finalState) 检查 status 字段,只有 SUCCESS 或 RUNNING 才算正常结束。FAILED 状态会触发 WORKFLOW_COMPLETE 事件带上失败信息,同时这条执行记录也会以 FAILED 状态写入数据库,方便后续排查。”
“整个 State 的生命周期就是:初始化 -> 节点依次更新 -> 最终状态持久化。每个环节出了问题都有兜底。”
02、节点之间的图是怎么构建的?参数怎么传递?
老王继续追问:“图的构建过程讲讲,你们的 GraphBuilder 具体做了哪些事?”
我说:“GraphBuilder 做三件事,加节点、加边、设入口出口。”
先创建一个 StateGraph<AgentState>,然后遍历工作流配置里的所有节点,逐个用 NodeAdapter 适配成 AsyncNodeAction,注册到图里:
public CompiledGraph<AgentState> buildGraph(WorkflowConfig config,
Consumer<ExecutionEvent> eventCallback) throws Exception {
StateGraph<AgentState> graph = new StateGraph<>(AgentState::new);
addNodes(graph, config.getNodes(), eventCallback);
addEdges(graph, config.getEdges());
setEntryAndExit(graph, config.getNodes(), config.getEdges());
return graph.compile();
}入口和出口的识别也讲究——不是硬编码的,而是通过边的拓扑关系动态查找。没有入边的节点就是入口,没有出边的节点就是出口:
private WorkflowNode findEntryNode(List<WorkflowNode> nodes, List<WorkflowEdge> edges) {
for (WorkflowNode node : nodes) {
boolean hasIncomingEdge = edges.stream()
.anyMatch(edge -> edge.getTarget().equals(node.getId()));
if (!hasIncomingEdge) return node;
}
return null;
}找到入口后,加一条 StateGraph.START -> entryNode 的边;找到出口后,加一条 exitNode -> StateGraph.END 的边。
老王问:“那参数传递呢?A 节点输出的数据,B 节点怎么拿到?”
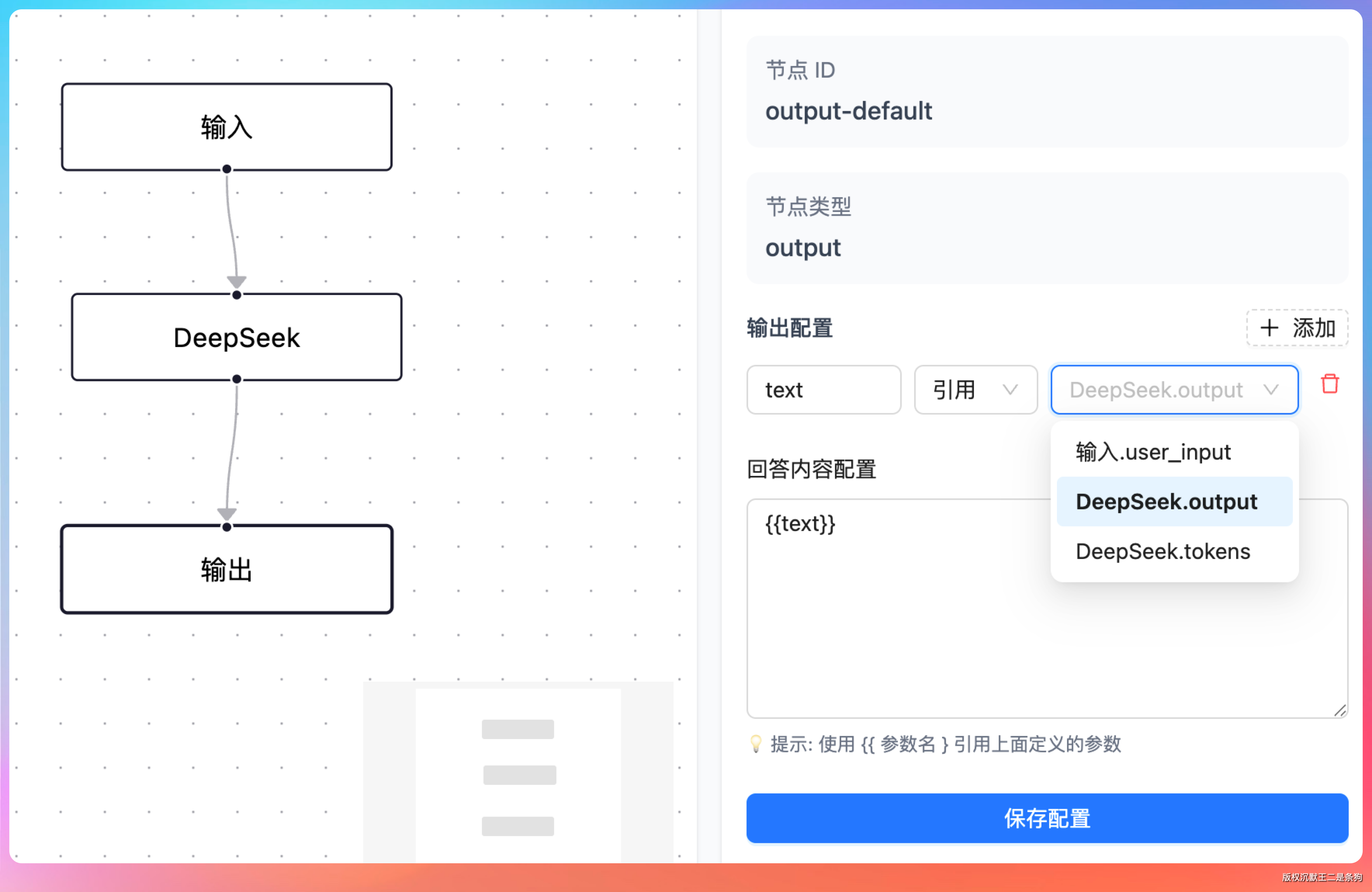
我说:“靠 State 里的 currentInput 字段。NodeAdapter 里有这么一段逻辑,每个节点执行完,把输出写到 nodeOutputs 里存档,同时更新 currentInput 为当前节点的输出:
newStateData.put("nodeOutputs", nodeOutputs);
newStateData.put("currentInput", output);
newStateData.put("currentNodeId", node.getId());下一个节点拿到的 currentInput,就是上一个节点的输出。如果某个节点需要跨过中间节点去引用更上游的数据,就从 nodeOutputs 里按节点 ID 查。”
老王又问:“如果是第一个节点呢?没有上游节点怎么办?”
我说:“第一个节点的 currentInput 在 StateManager 初始化时就设好了,{"input": "用户原始输入"}。所以第一个节点拿到的就是用户输入。”
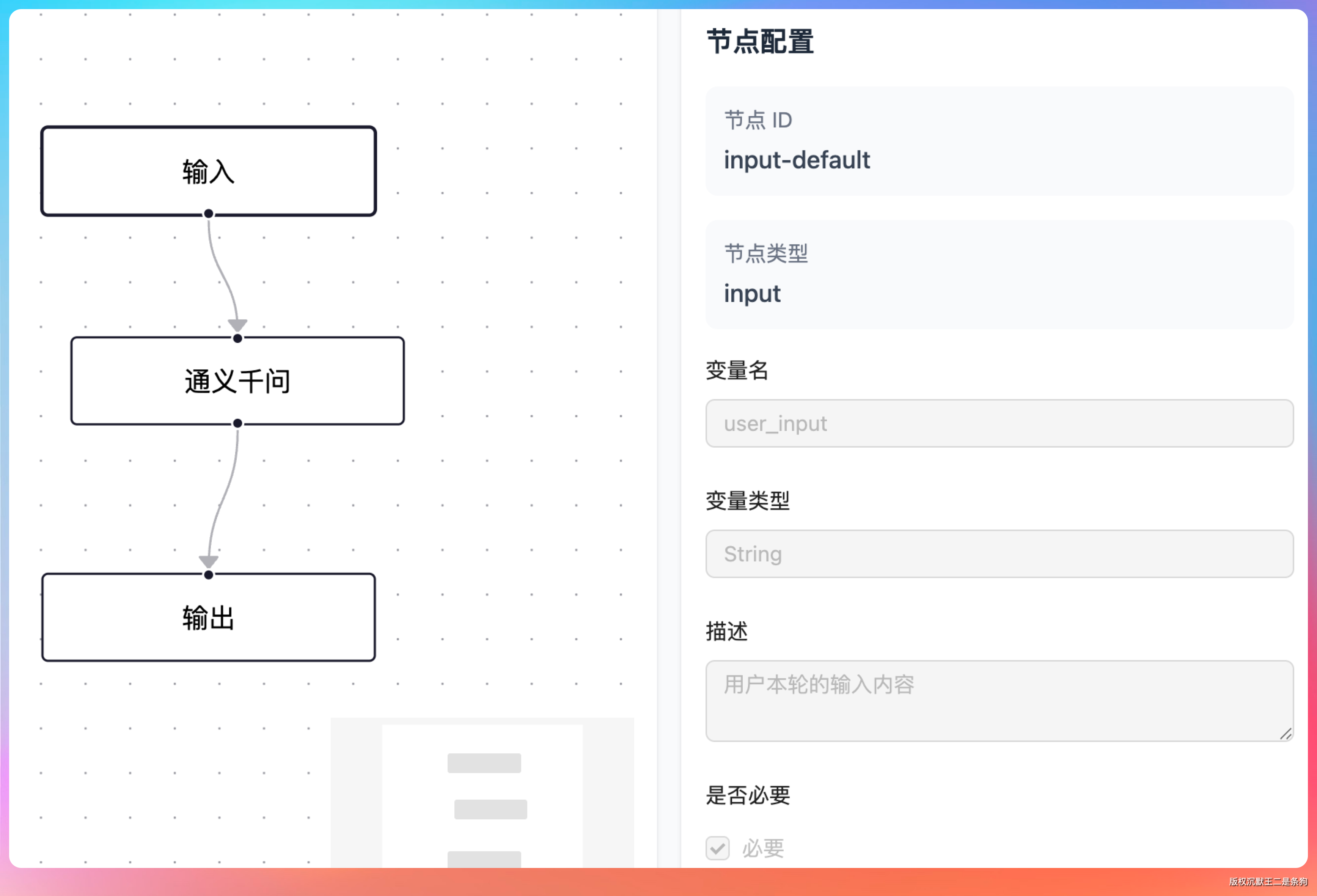
除了这种链式传递,我们的 Prompt 模板还支持 {{variable}} 语法做变量替换。
PromptTemplateService 会根据 inputParams 配置,区分 input(静态值)和 reference(引用上游节点输出)两种类型来填充变量。
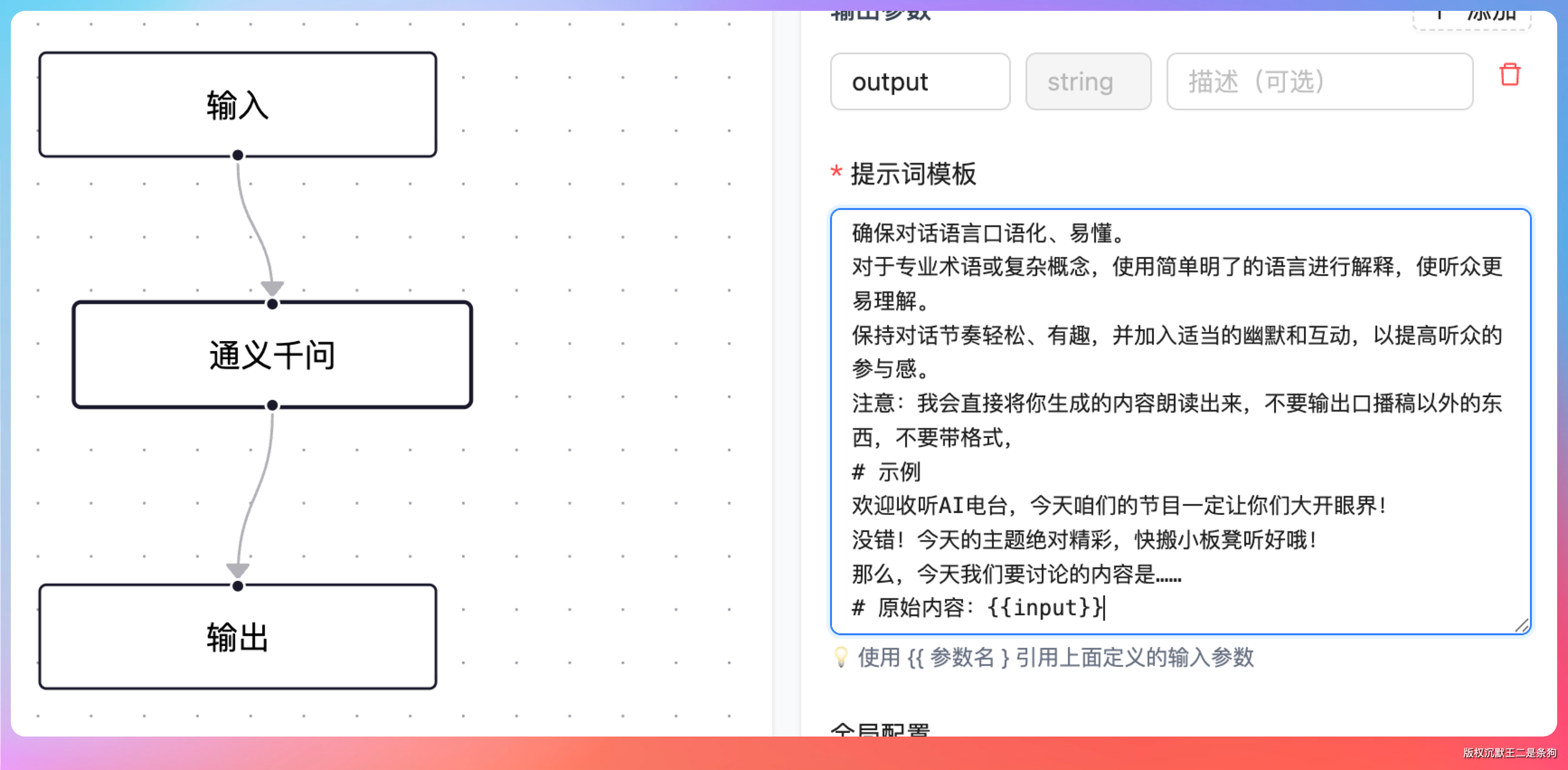
比如配置了 referenceNode: "node_llm1.analysis",就会去 currentInput 里找 analysis 字段的值填进模板。
03、支持哪些节点类型?
老王问:“你们系统支持多少种节点?”
我说:“目前支持 8 种。”
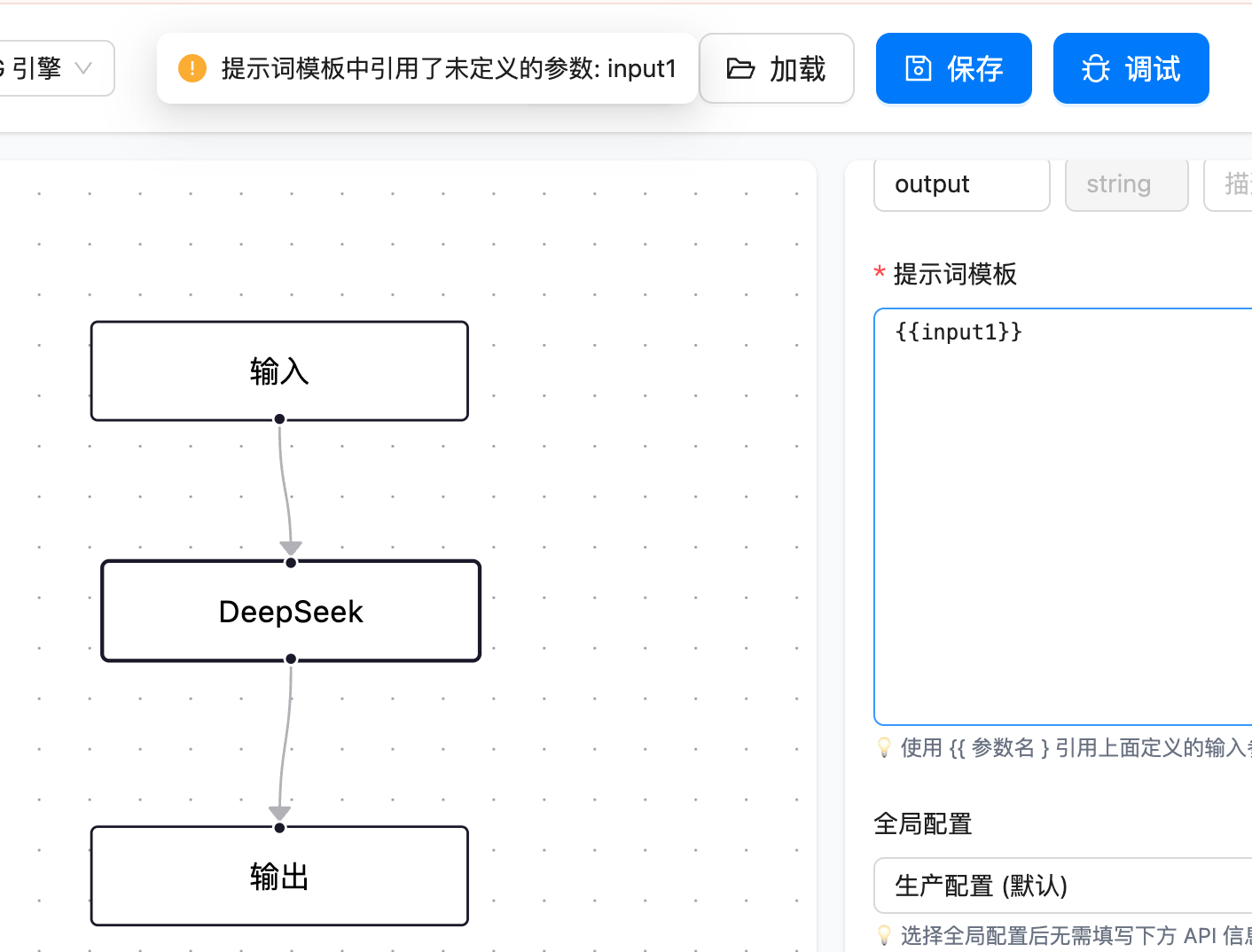
input 和 output 是两个基础节点,负责数据的入口和出口。中间的处理节点有 5 种 LLM 节点——openai、deepseek、qwen、zhipu、aiping,都继承自同一个 AbstractLLMNodeExecutor 基类。还有一个 TTS 语音合成节点。
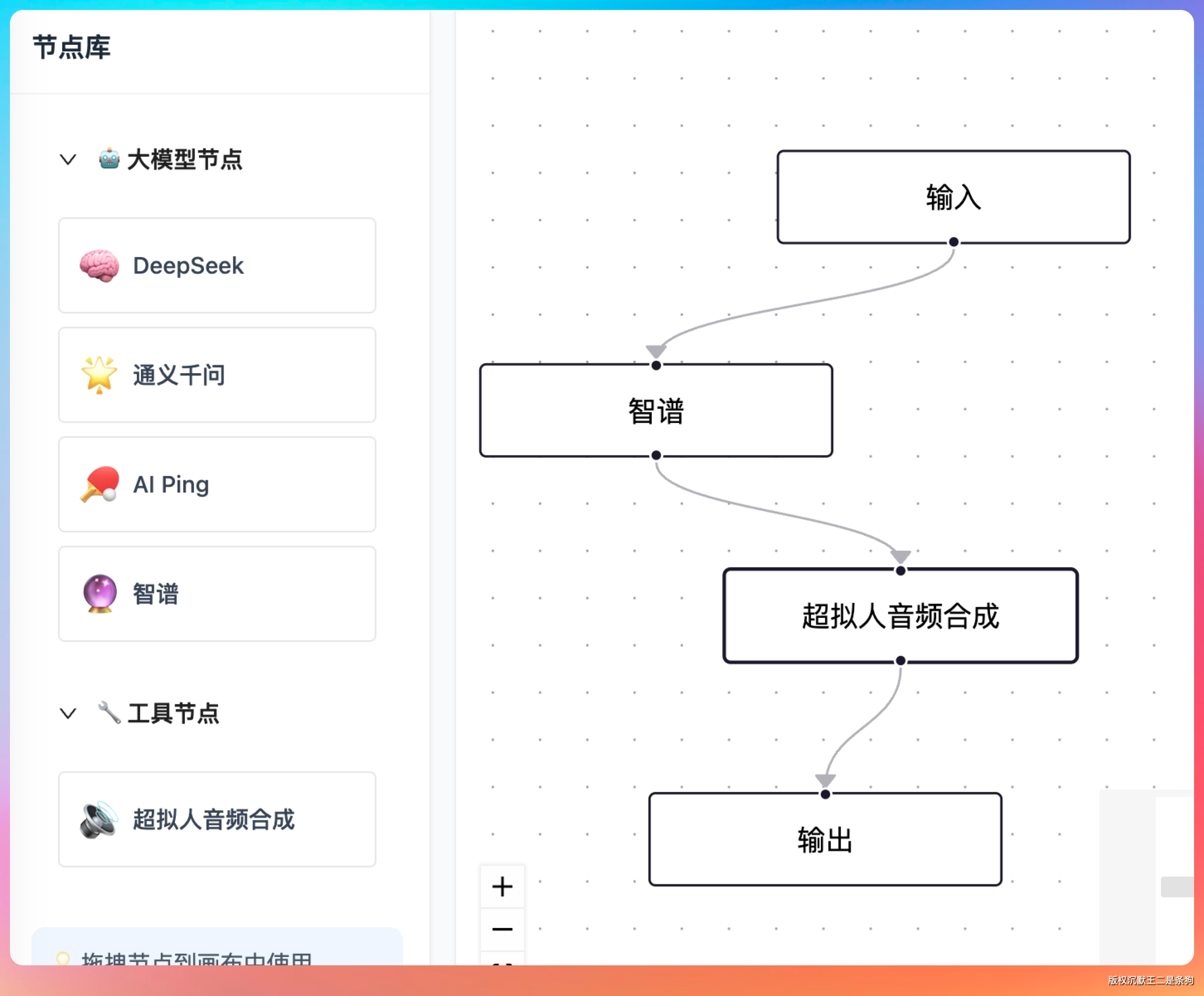
这里有个设计亮点——LLM 节点的模板方法模式。我们把配置提取、模板替换、API 调用、输出构建这些通用流程全部封装在 AbstractLLMNodeExecutor 里,5 个 LLM 子类只需要实现一个 getNodeType() 方法:
public class OpenAINodeExecutor extends AbstractLLMNodeExecutor {
@Override
protected String getNodeType() { return "openai"; }
}以前 5 个节点加起来 800 多行代码,重构之后每个就 10 行左右。NodeExecutorFactory 用 Spring 的依赖注入自动收集所有 NodeExecutor 实现,按 getSupportedNodeType() 注册到 Map 里,运行时按类型取:
@Component
public class NodeExecutorFactory {
private final Map<String, NodeExecutor> executors = new HashMap<>();
@Autowired
public NodeExecutorFactory(List<NodeExecutor> executorList) {
for (NodeExecutor executor : executorList) {
executors.put(executor.getSupportedNodeType(), executor);
}
}
}至于 LangGraph4j 的 START 和 END 节点,那不是业务节点,是框架层面用来标记图的起点和终点的虚拟节点。
GraphBuilder 在设置入口时加 StateGraph.START -> entryNode 的边,设置出口时加 exitNode -> StateGraph.END 的边,框架就知道从哪开始执行、到哪结束。
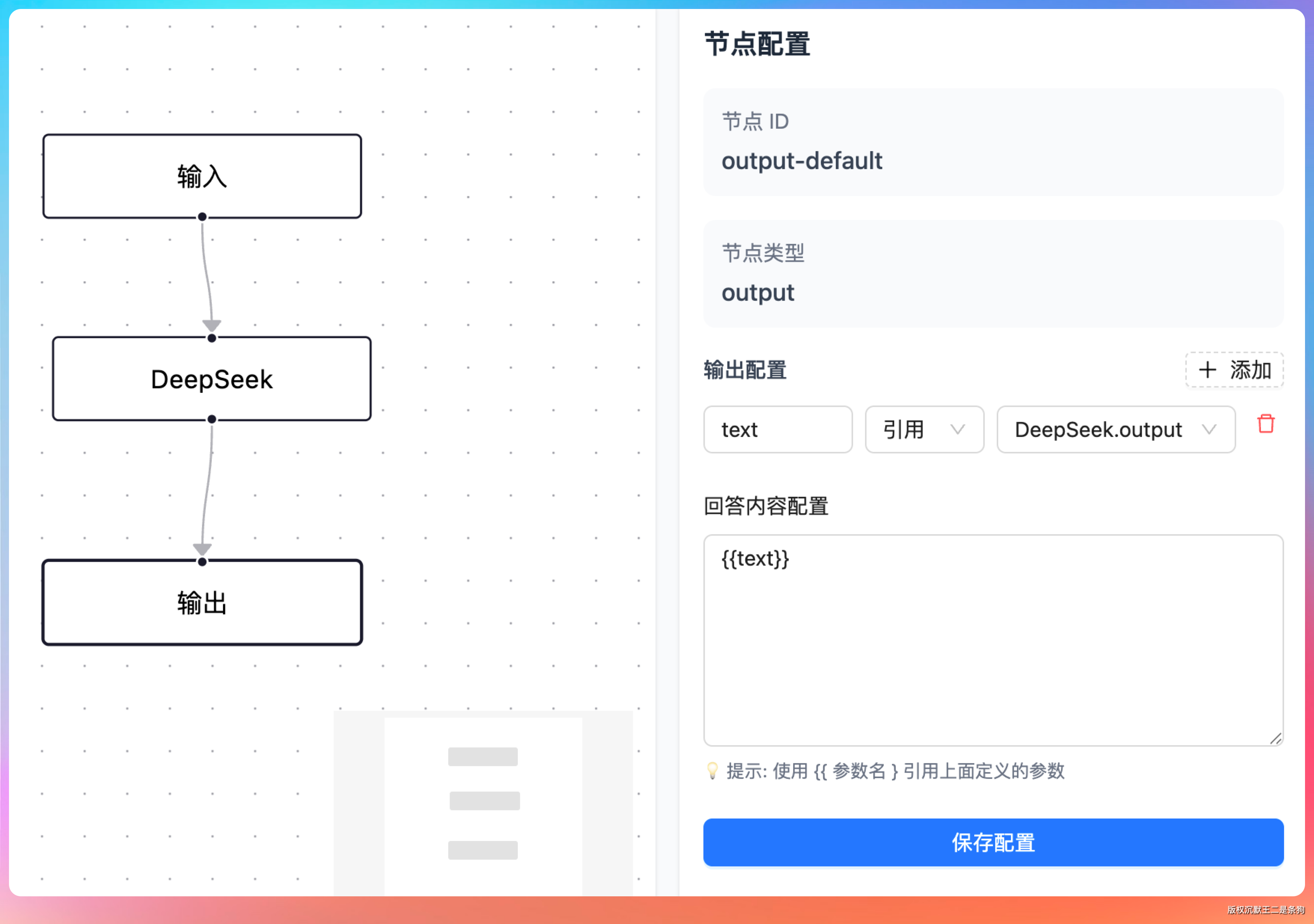
这里还有一个设计细节——NodeAdapter 适配器模式。LangGraph4j 要求每个节点是一个 AsyncNodeAction<AgentState>,但我们已有的节点执行器是 NodeExecutor 接口。
NodeAdapter 的作用就是做桥接,把 NodeExecutor.execute(node, input, callback) 包装成 LangGraph4j 需要的异步 Lambda 形式。
这样原有的 NodeExecutor 代码一行不改,就能接入 LangGraph4j 框架。老引擎用 DAG 拓扑排序直接调 NodeExecutor,新引擎通过 NodeAdapter 间接调,两条路复用同一套执行器。
老王点头:“那如果我要新增一种节点类型,比如搜索节点,改动量大吗?”
我说:“非常小。实现 NodeExecutor 接口,写一个类注册到 Spring 容器里就行。NodeExecutorFactory 自动发现,NodeAdapter 自动适配,GraphBuilder 不用改一行代码。这就是策略模式 + 工厂模式的好处,新增节点类型的改动完全封闭在新类内部,对已有代码零侵入。”
04、工具插件的定义和 Function Calling 一致吗?
老王话锋一转:“你们的工具插件怎么定义的?跟 OpenAI 的 Function Calling 是什么关系?”
我说:“我们的工具插件定义和 OpenAI Function Calling 的规范是一致的。”
在 PaiAgent 里,工具插件通过 Spring AI 的 FunctionCallback 接口实现。拿 LoadSkillReferenceFunction 举例:
public class LoadSkillReferenceFunction implements FunctionCallback {
@Override
public String getName() { return "load_skill_reference"; }
@Override
public String getDescription() {
return "加载指定技能的参考文档内容...";
}
@Override
public String getInputTypeSchema() {
return """
{
"type": "object",
"properties": {
"skill_name": { "type": "string", "description": "技能名称" },
"reference_name": { "type": "string", "description": "参考文档名称" }
},
"required": ["skill_name", "reference_name"]
}
""";
}
@Override
public String call(String functionInput) {
// 解析参数,加载reference文件
}
}getName() 对应 Function Calling 的 name 字段,getDescription() 对应 description,getInputTypeSchema() 返回的就是标准的 JSON Schema,和 OpenAI 的 parameters 定义完全一致。
注册到 ChatClient 也很直接。ChatClientFactory 创建 ChatClient 时,把 FunctionCallback 列表传进去:
builder.defaultFunctions(functions.toArray(new FunctionCallback[0]));Spring AI 在调用大模型时会自动把这些函数描述序列化成 OpenAI Function Calling 的格式发给模型。
模型返回 tool_calls,Spring AI 再自动调用对应的 call() 方法,把结果喂回模型继续生成。我们在 AbstractLLMNodeExecutor 里还加了最大迭代次数限制,防止模型陷入无限函数调用循环:
private static final int MAX_FUNCTION_ITERATIONS = 5;05、OpenAI 兼容和 Response 有什么区别?
老王接着问:“你们接入了 OpenAI、DeepSeek、通义千问好几家模型,这些厂商的 API 不一样吧?怎么统一的?”
我说:“靠 OpenAI 兼容协议。”
现在主流的国产模型厂商——DeepSeek、通义千问、智谱——基本都提供了 OpenAI 兼容的 API 接口。也就是说请求格式都是 /v1/chat/completions,请求体的 messages、model、temperature 这些字段结构一样。差异主要在 base_url 和 api_key。
在 PaiAgent 里,ChatClientFactory 统一用 OpenAiApi + OpenAiChatModel 来创建客户端:
private ChatModel createOpenAICompatibleModel(String apiUrl, String apiKey,
String model, Double temperature) {
OpenAiApi openAiApi = new OpenAiApi(apiUrl, apiKey);
OpenAiChatOptions options = OpenAiChatOptions.builder()
.model(model)
.temperature(temperature)
.build();
return new OpenAiChatModel(openAiApi, options);
}不管你传进来的是 https://api.openai.com/v1、https://api.deepseek.com/v1 还是 https://dashscope.aliyuncs.com/compatible-mode/v1,都走同一套代码。
工厂方法的 switch 里,openai、deepseek、qwen 三种类型都指向 createOpenAICompatibleModel。
老王追问:“那 Response 呢?各家返回的格式也完全一致吗?”
我说:“大部分字段一致,比如 choices[0].message.content 的结构是一样的。
但有些细节会有差异,比如 token 统计字段,有的叫 usage.prompt_tokens,有的叫 usage.input_tokens。还有流式返回的 SSE 格式,个别厂商在 finish_reason 的枚举值上会有差异。”
“Spring AI 帮我们屏蔽了这些差异,它在 OpenAiChatModel 里做了标准化处理。我们从 ChatResponse 里拿到的 metadata.getUsage() 已经是统一格式了,不需要自己处理不同厂商的差异。”
老王接着问:“那你们是怎么实现运行时动态切换模型的?不重启服务就能换?”
我说:“对,完全是动态的。ChatClientFactory 每次调用都是 new OpenAiApi(apiUrl, apiKey) 创建新实例,不是 Spring 单例注入的。每个节点可以配不同的 apiUrl 和 model,比如第一个节点用 DeepSeek 做初步分析,第二个节点用 GPT 做精细加工。都在工作流配置的 JSON 里定义,运行时读配置动态创建 ChatClient。你在前端拖拽编辑器里改个模型名字,下次执行就生效了。”
这种设计的好处是灵活,坏处是每次请求都创建新的 ChatClient 实例,有一定的开销。不过对于工作流这种低频调用场景,这点开销完全可以接受。如果后续要做高并发的在线推理,可能需要加个连接池。
06、如何确保喂给大模型的参数完全符合格式要求?
老王问了一个很实际的问题:“配置里的参数各种各样,你怎么保证传给大模型的请求不会因为参数格式问题报错?”
我说:“三道防线。”
第一道是 validateResolvedConfig。节点执行前,先检查 apiUrl、apiKey、model 三个必填字段是否为空:
private void validateResolvedConfig(LLMNodeConfig config) {
if (isBlank(config.getApiUrl()) || isBlank(config.getApiKey()) || isBlank(config.getModel())) {
throw new IllegalArgumentException(
String.format("%s 节点缺少有效的模型配置", getNodeType().toUpperCase()));
}
}第二道是全局配置优先机制。节点配置里有一个 configId 字段,如果填了,就从数据库读取 LLMGlobalConfig,用经过验证的全局配置覆盖节点级配置。这避免了每个节点都手动填 apiUrl 和 apiKey 带来的出错风险。只有全局配置不存在时,才回退到节点自身的配置。
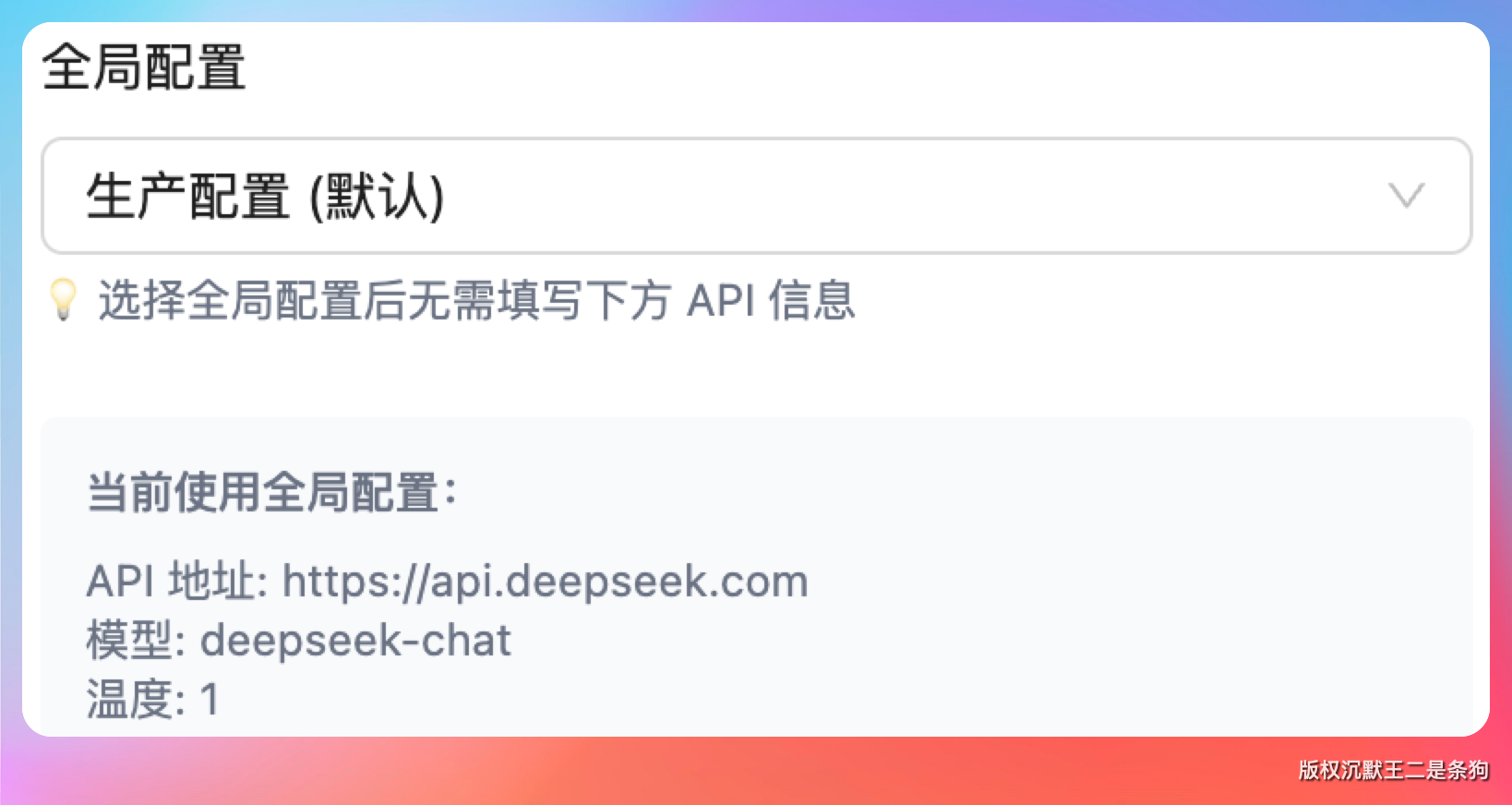
第三道是 PromptTemplateService 的模板变量兜底。如果模板里有 {{variable}} 但对应的参数找不到值,不会报错,而是替换成空字符串。
这样即使上游节点没有输出预期的字段,Prompt 也不会包含未解析的 {{}} 标记——虽然结果可能不太理想,但至少不会让大模型 API 报 400。
另外,temperature 字段我们默认设了 0.7,trimString 方法会对所有字符串参数做 trim 处理,去掉前后空格,防止配置界面拷贝粘贴时带进来的空白字符。
老王问:“你们有没有遇到过参数格式导致的真实线上问题?”
我说:“遇到过。有一次用户在 apiUrl 末尾多粘了一个斜杠,Spring AI 拼接路径的时候变成了双斜杠,直接 404。后来我们在 trimString 基础上又加了 URL 末尾斜杠的去除逻辑。还有一次 apiKey 里混进了换行符,肉眼看不出来,但请求头里就多了个 \n,服务端直接拒绝认证。”
07、TTS 参数规范性如何保证?
老王问:“你们还做了 TTS 语音合成,音色和文本这些参数是怎么校验的?”
我说:“TTS 这块坑不少,我们在参数规范性上下了功夫。”
先说音色。我们用的是阿里百炼的 qwen3-tts-flash 模型,它支持的音色是一个枚举列表——Cherry、Ethan、Serena 这些。
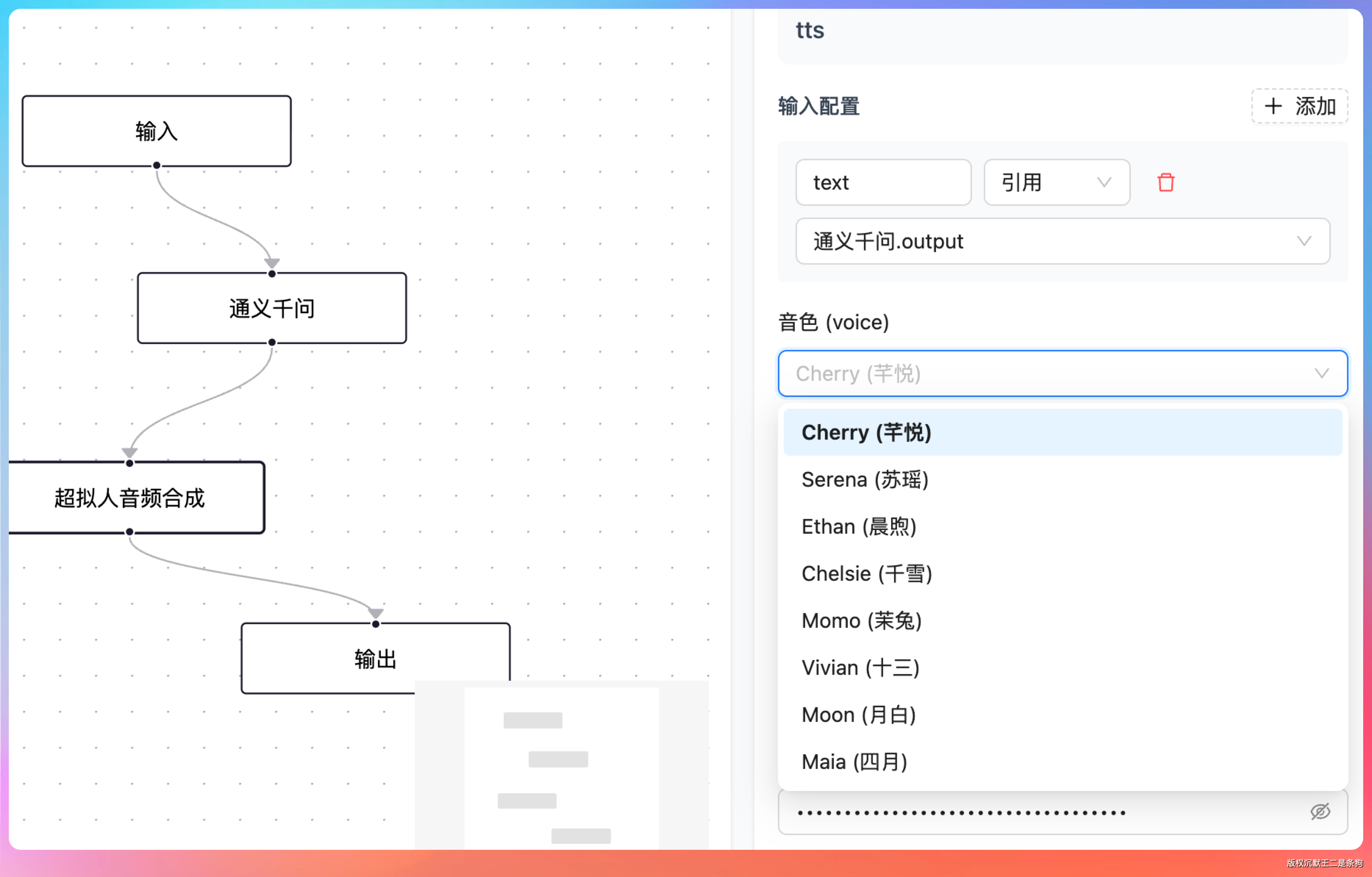
用户在前端选的是中文名或英文名字符串,到后端需要转成 SDK 的枚举类型。我们写了一个 convertVoice 方法做转换,如果传了一个不存在的音色名,不会直接报错,而是降级到默认的 CHERRY:
private AudioParameters.Voice convertVoice(String voiceStr) {
try {
return AudioParameters.Voice.valueOf(voiceStr.toUpperCase());
} catch (IllegalArgumentException e) {
log.warn("未知音色: {}, 使用默认音色 CHERRY", voiceStr);
return AudioParameters.Voice.CHERRY;
}
}再说文本。阿里百炼 TTS API 对单次输入有长度限制——UTF-8 编码不能超过 600 字节。一段中文,三个字节一个字符,600 字节也就 200 个汉字左右。
我们设了一个 MAX_TTS_INPUT_LENGTH = 400 字符的上限,然后在 splitText 方法里做分段:
private List<String> splitText(String text, int maxLength) {
// ...
while (end > start) {
String candidate = text.substring(start, end);
int byteLength = candidate.getBytes(StandardCharsets.UTF_8).length;
if (byteLength <= 600) {
// 尝试在标点符号处断句
int lastPunctuation = findLastPunctuation(text, start, end);
if (lastPunctuation > start) {
end = lastPunctuation + 1;
}
chunks.add(candidate);
break;
}
end -= 10; // 超长就往回缩
}
}分割逻辑做了两个关键处理:一是按 UTF-8 字节数而不是字符数来判断是否超限,因为中英文混排时字符数和字节数差异很大;二是优先在标点符号(句号、感叹号、问号等)处断句,让每个片段都是完整的句子,不会在词语中间截断。
08、TTS 如何保证音色一致性和参数稳定性?
老王继续追:“分段之后,多个片段分别调用 TTS API,怎么保证最后合成的音频音色是统一的?”
我说:“这个问题说到点子上了。核心策略有三个。”
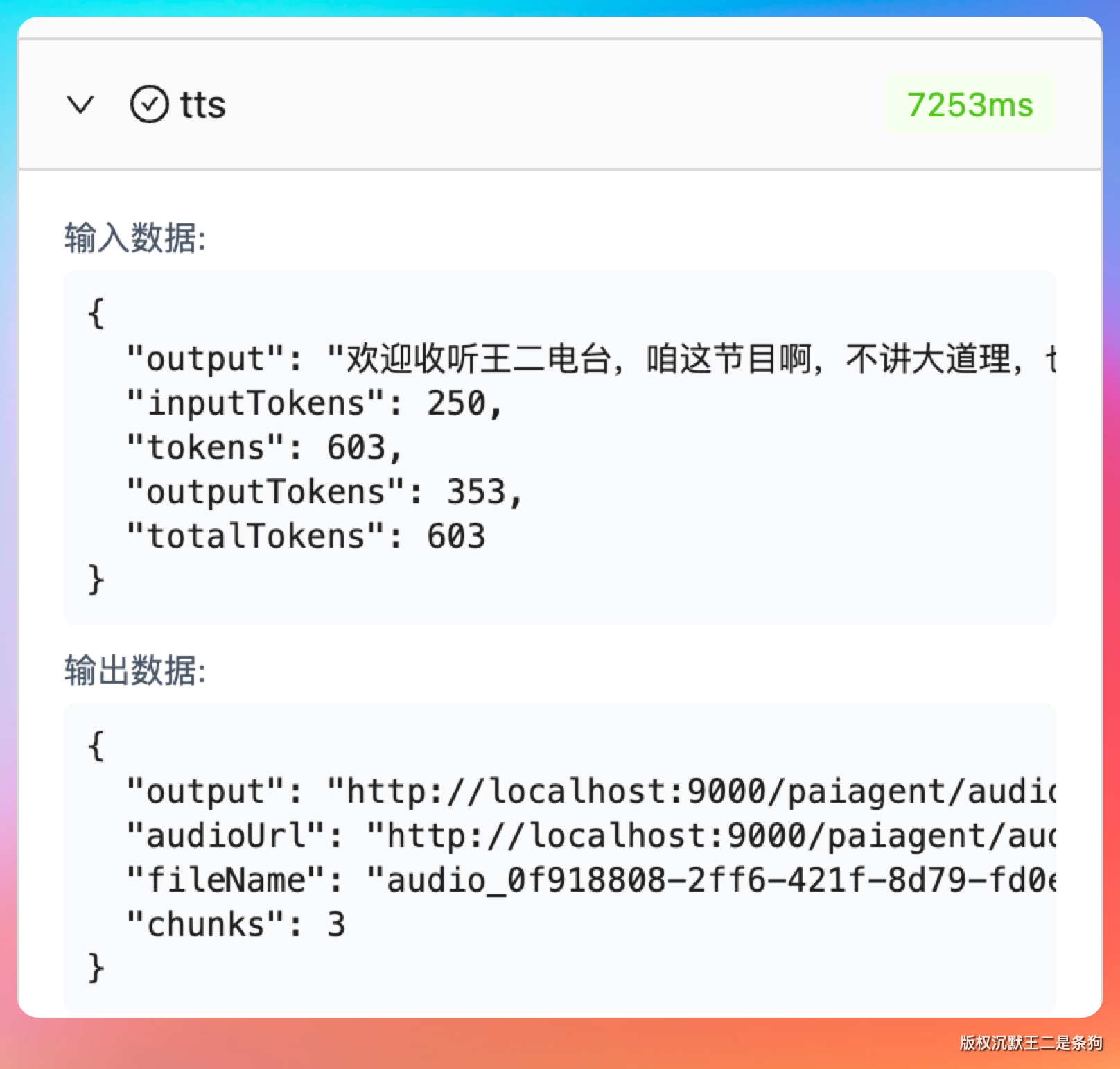
第一个是参数固化。所有分段共用同一组 TTS 参数——相同的 model、voice、languageType。这些参数在节点配置时就确定了,不会因为分段而改变。每个片段的 API 调用构建的参数都一样:
MultiModalConversationParam param = MultiModalConversationParam.builder()
.apiKey(apiKey)
.model(model)
.text(chunk)
.voice(voice)
.languageType(languageType)
.build();变的只有 text 字段,voice 和 model 是固定的。
第二个是并行处理 + 有序合并。我们用 CompletableFuture.supplyAsync 并行调用多个 TTS 请求,但最后合并音频的时候是按原始顺序拼接的:
// 并行请求
List<CompletableFuture<byte[]>> futures = new ArrayList<>();
for (int i = 0; i < textChunks.size(); i++) {
futures.add(CompletableFuture.supplyAsync(() -> { ... }));
}
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
// 按顺序取结果
for (CompletableFuture<byte[]> future : futures) {
audioChunks.add(future.get());
}第三个是 WAV 格式合并。多个音频片段合并时,我们取第一个片段的 44 字节 WAV 头作为最终文件的头部,后续片段只拼接数据部分(跳过各自的 WAV 头),最后更新文件头里的 fileSize 和 dataSize 字段:
byte[] header = Arrays.copyOf(firstChunk, 44);
mergedStream.write(header);
for (byte[] chunk : audioChunks) {
if (chunk.length > 44) {
mergedStream.write(chunk, 44, chunk.length - 44);
}
}
// 更新 WAV 头的 fileSize 和 dataSize这样保证了合并后的音频文件格式正确,音色一致。最终文件上传到 MinIO,返回一个可访问的 URL。
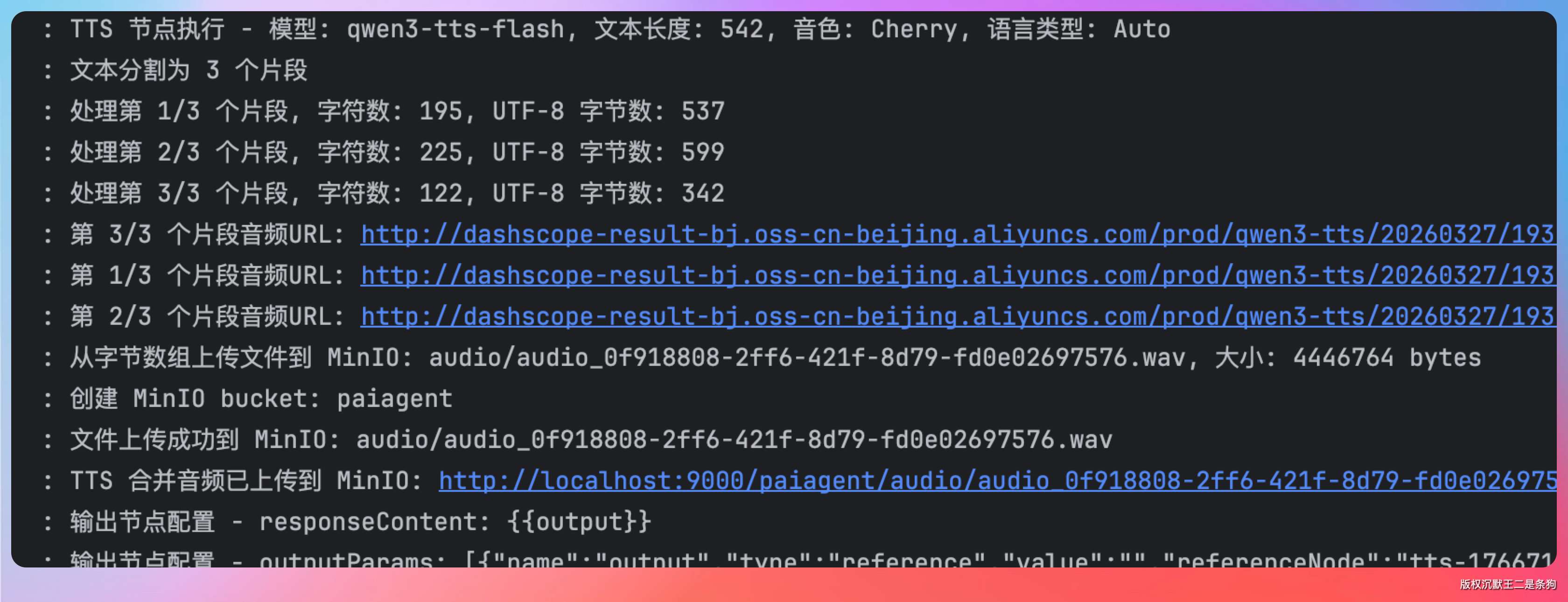
老王追问:“如果某个片段 TTS 调用失败了呢?”
我说:“CompletableFuture 会抛 RuntimeException,上层捕获后触发 NODE_ERROR 事件,整个工作流标记为 FAILED。目前没有做单片段重试,这是后续可以优化的点,比如加一个 RetryTemplate,对单片段失败做 3 次重试,重试间隔指数递增,这样偶发的网络抖动就不会导致整个 TTS 任务失败了。”
09、项目中的 Skill 和 MCP 逻辑
老王问:“你简历上写了 Skill 机制,讲讲这是什么东西?”
我说:“Skill 在 PaiAgent 里是一套‘预置最佳实践指南’机制。”
你可以理解为,每个 Skill 就是一个专业领域的知识包——比如'短视频脚本生成'、'技术文章写作'、'客服话术'。它不是代码逻辑,而是一个结构化的 Markdown 文件,告诉大模型在这个场景下应该怎么做、用什么模板、参考什么样例。
技术实现上,SkillRegistry 在应用启动时自动加载所有 Skill:
@PostConstruct
public void init() {
// 先从classpath加载
int classpathLoaded = loadFromClasspath();
if (classpathLoaded > 0) return;
// 回退到文件系统
loadFromFileSystem();
}每个 Skill 目录下有一个 SKILL.md 主文件,还可以有 reference/ 子目录放参考文档。SkillLoader 负责解析 YAML frontmatter 提取 name 和 description,正文内容作为指南。
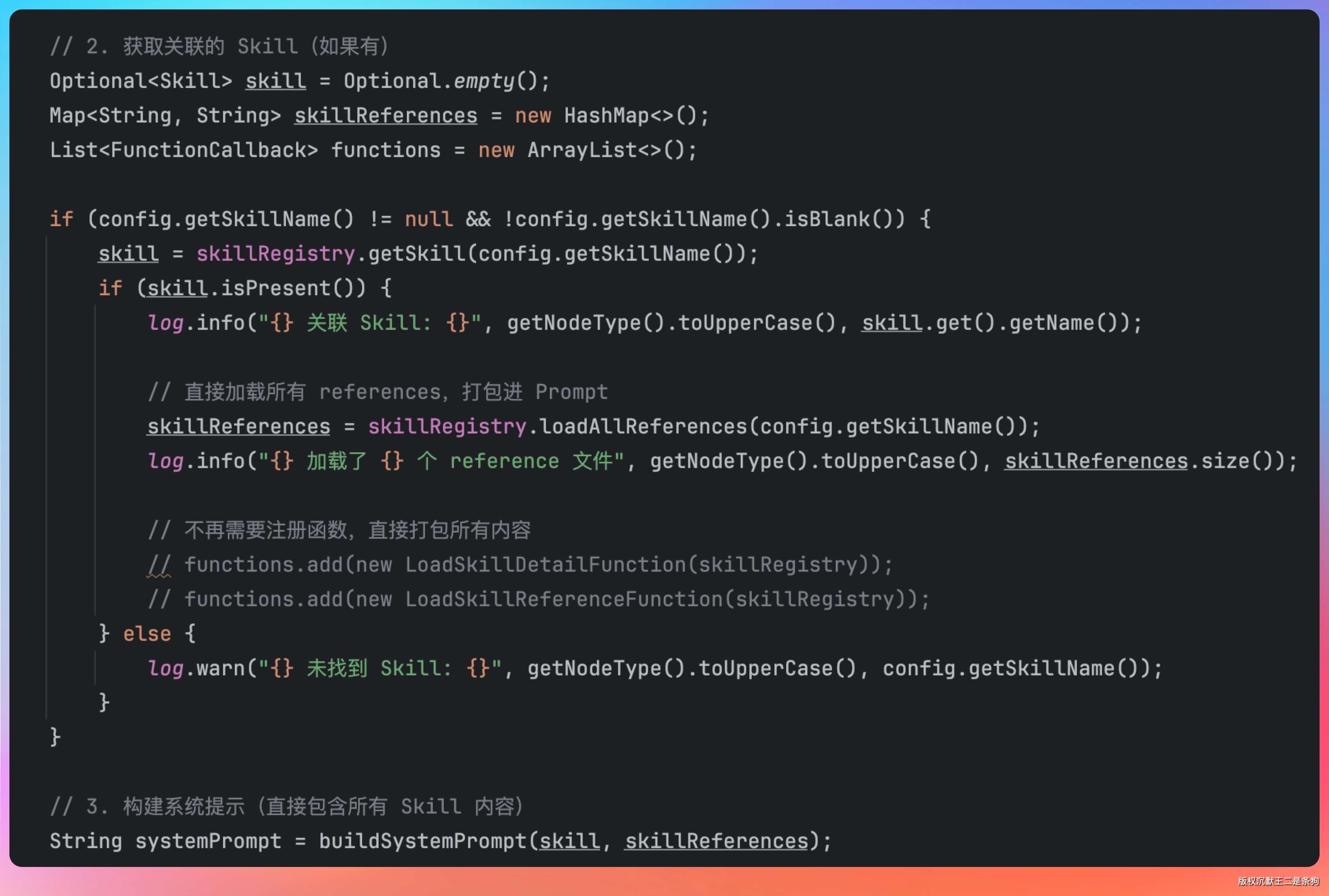
当 LLM 节点配置了 skillName 时,AbstractLLMNodeExecutor 会从 SkillRegistry 加载对应 Skill 的完整内容和所有 reference 文件,打包进系统提示词:
if (config.getSkillName() != null && !config.getSkillName().isBlank()) {
skill = skillRegistry.getSkill(config.getSkillName());
if (skill.isPresent()) {
skillReferences = skillRegistry.loadAllReferences(config.getSkillName());
}
}
String systemPrompt = buildSystemPrompt(skill, skillReferences);buildSystemPrompt 调用 Skill 的 getFullExecutionPrompt 方法,把技能描述、指南内容、所有参考文档一次性拼进系统提示词。这样大模型在生成回复时,就有了完整的专业知识上下文。
老王追问:“那 Skill 的加载性能怎么样?每次请求都要读文件吗?”
我说:“不用。SkillRegistry 在应用启动时一次性加载所有 Skill 到内存,存在 ConcurrentHashMap 里。reference 文件第一次读取后也会缓存。后续请求直接从内存取,不走文件 I/O。ConcurrentHashMap 保证了多线程安全,多个工作流并行执行时不会有并发问题。”
10、Skill 的渐进式引用是什么机制?
老王问:“你说的渐进式引用是啥意思?大模型怎么知道该用哪个 Skill?”
我说:“渐进式引用(Progressive Disclosure)是我们最初设计 Skill 体系时的一个理念。”
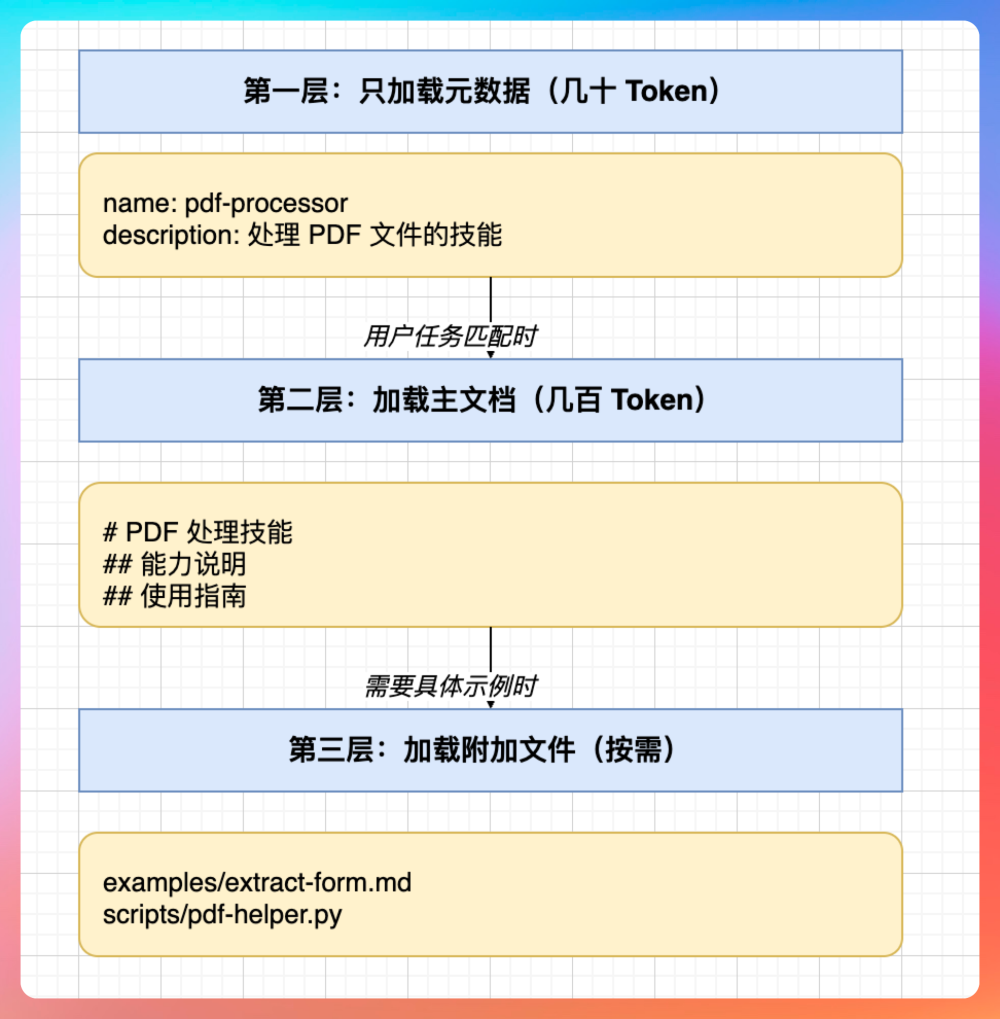
最初的设想是分三个阶段:
第一阶段,系统提示词里只放 Skill 的摘要——名称和描述。大模型看到当前任务和某个 Skill 的描述匹配,觉得需要用它。
第二阶段,大模型通过 Function Calling 调用 load_skill_detail 函数,加载 Skill 的完整指南内容(SKILL.md 正文)。
第三阶段,大模型根据指南中提到的参考文档列表,再调用 load_skill_reference 函数,按需加载具体的模板和样例。
这两个函数我们都实现了——LoadSkillDetailFunction 和 LoadSkillReferenceFunction,都是标准的 FunctionCallback。大模型通过 Function Calling 自主决定什么时候加载、加载哪个文档。
但在实际使用中,我们发现这种方式有个问题,多轮函数调用增加了延迟和 token 消耗,而且有时候模型会“忘记”去调用这些函数。所以当前的实现做了简化,改成直接全量加载:
// 直接加载所有 references,打包进 Prompt
skillReferences = skillRegistry.loadAllReferences(config.getSkillName());
// 不再需要注册函数,直接打包所有内容
// functions.add(new LoadSkillDetailFunction(skillRegistry));
// functions.add(new LoadSkillReferenceFunction(skillRegistry));代码里你能看到被注释掉的函数注册。现在的策略是一次性把 Skill 完整内容和所有 reference 打包进系统提示词,牺牲一些 token 换取更稳定的执行效果。
老王问:“那渐进式引用还有什么意义?”
我说:“在 Skill 规模小的时候,全量加载没问题。但如果一个 Skill 有几十个 reference 文件、几万字的内容,全塞进系统提示词就会撑爆上下文窗口。那时候渐进式引用的价值就体现出来了,只加载当前任务需要的那部分,按需加载。函数调用的基础设施我们已经写好了,随时可以切回去。”
11、使用 Skill 时如何解决上下文窗口限制问题?
老王问了最后一个问题:“你刚才说 Skill 内容全量打包进系统提示词,那上下文窗口不够用怎么办?”
先说现状。我们用的模型大多支持 128K 甚至更大的上下文窗口。
一个 Skill 的 SKILL.md 加几个 reference,一般在 5000-15000 token 左右,对于 128K 来说绰绰有余。加上用户输入、节点间传递的数据、函数描述,总共也就占用 20-30K token,还有很大的余量。
但如果场景变复杂——比如一个节点配了 Skill,用户输入又特别长(比如一篇万字文章要翻译),或者工作流链条很长、每个节点都往 State 里塞大量数据——上下文就可能吃紧。

我们目前的应对策略有几个:
一是输出裁剪。每个节点的输出只保留关键字段,不会把整个 LLM 响应(包括 token 统计这些元数据)都传给下游。
二是 reference 的分文件管理。Skill 的参考文档拆成多个小文件,而不是一个大文件。这样即使要切回渐进式加载,也能做到精细控制。
三是 SkillRegistry 的缓存机制。用 ConcurrentHashMap 缓存已加载的 reference 内容,避免重复读取文件系统。虽然不直接解决上下文问题,但减少了 I/O 开销。
private final Map<String, Map<String, String>> referenceCache = new ConcurrentHashMap<>();未来如果真遇到上下文不够的场景,有几个方向可以做:一是切回渐进式引用,让模型按需加载 reference;二是对 Skill 内容做摘要压缩,只保留当前任务相关的段落;三是引入 RAG,把 Skill 内容向量化存储,检索时只返回最相关的片段。不过说实话,目前 128K 的窗口对于绝大多数工作流场景来说足够用了。
老王听完沉默了几秒:“你什么时候能来上班?”
我说:“明天吧,我回去准备一下我帅气的衣服,哦不,下周一吧,我回去请大家吃个饭庆祝下🎉”