想学 OpenClaw?这条 GitHub 学习路线最省时间
大家好,我是二哥呀。
身边几个同事都在折腾 OpenClaw,可你真问一句“它到底强在哪”,很多人就卡住了。
仓库 Star 点了,文档也翻了几页,脑子里还是一团乱,这种感觉我太懂了。
这次咱们换个思路,不去一头扎进源码里硬啃,而是按“仓库首页,看官方文档,看 Gateway,看 Workspace,看 Multi-Agent,再看 Tools 和扩展”的顺序,把 OpenClaw 的 GitHub 仓库过一遍。
先把结论摆这儿:OpenClaw 真正有意思的,不是某一个命令,也不是某一个插件,而是它把“聊天入口、代理运行时、工作区记忆、工具调用、多 Agent 路由”串成了一条完整链路。
我会把我认为最省时间的一条学习路线拆给你,顺手把哪些页面值得看,哪些地方可以先跳过,也都说清楚。
01、看仓库首页这三个信号
很多人学开源项目,最容易犯的一个错就是太着急。
仓库一打开,马上切到 packages、apps、docs,想从目录结构里直接推导全局设计。
说实话,这个动作对于 OpenClaw 这种项目不太划算。
因为它不是一个单纯的前端项目,也不是一个只会收发消息的机器人项目,它横跨了 CLI、Gateway、聊天渠道、工作区文件、Agent 运行时、插件、工具系统。

你一开始就钻源码,脑子里很难有地图。
我建议第一步只看三个信号。
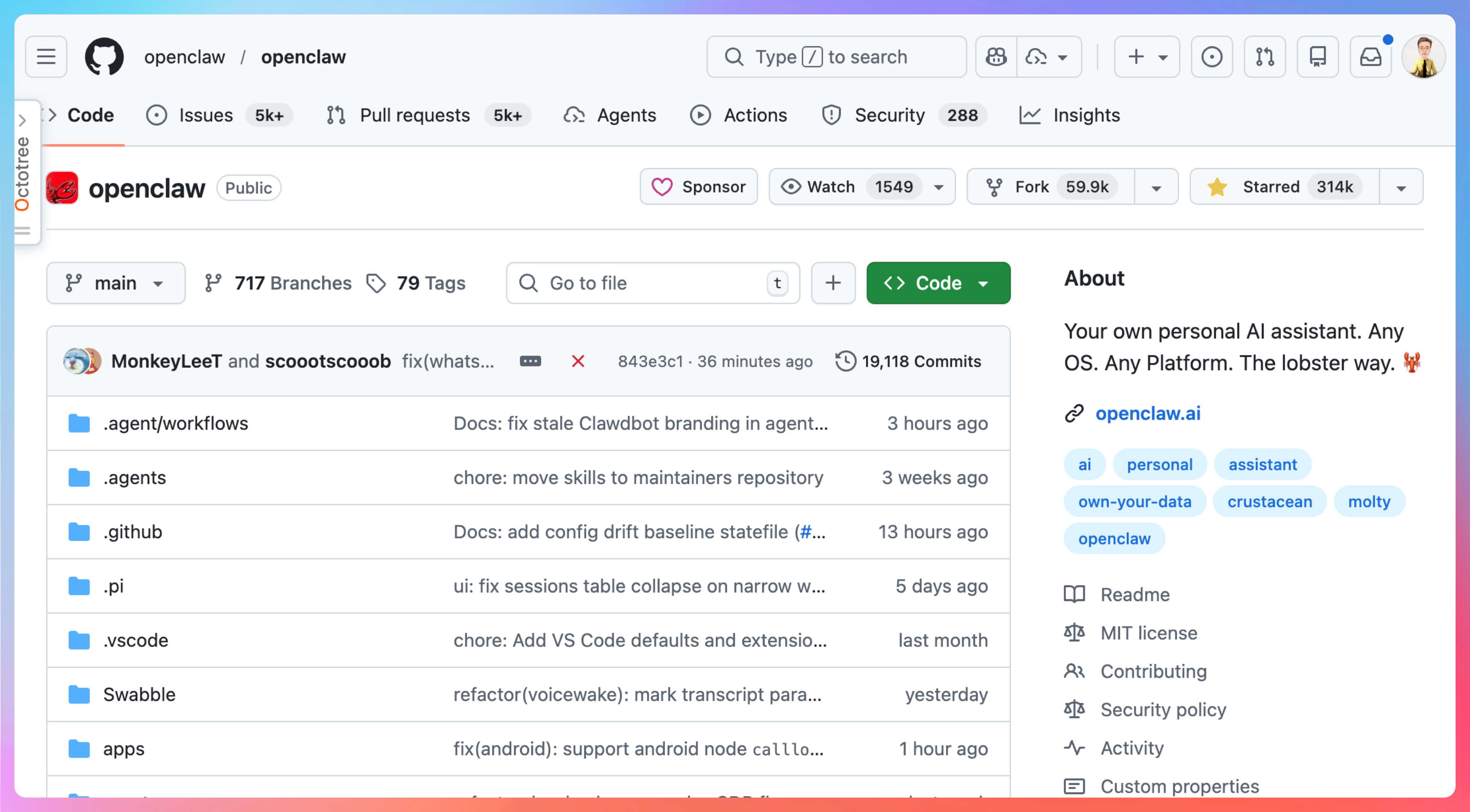
第一个信号是热度和更新频率。截止 2026 年 3 月 15 日,我看到 OpenClaw 的 GitHub 仓库已经超过 314k Star,最新 release 是 v2026.3.13-1,发布时间是 2026 年 3 月 14 日。
这说明生态已经很大,而且更新没停。学这种项目,别想着一口气把源码看完,先抓主干更划算。
第二个信号是 README 给你的第一印象。README 不是给你凑篇幅的,它其实在告诉你项目方最希望你怎么理解这个项目。
如果一个项目首页一直在强调模型参数、底层框架、性能数据,那它的核心卖点通常在那里。
OpenClaw 不一样,它首页和官方站点反复强调的是 Gateway、渠道接入、Agent、Tools、Workspace、Dashboard。这就意味着,你学习的时候也应该从这些概念往下压,而不是反过来。
第三个信号是官方文档目录是不是清晰。OpenClaw 这点做得挺好,文档并不是一团散沙。
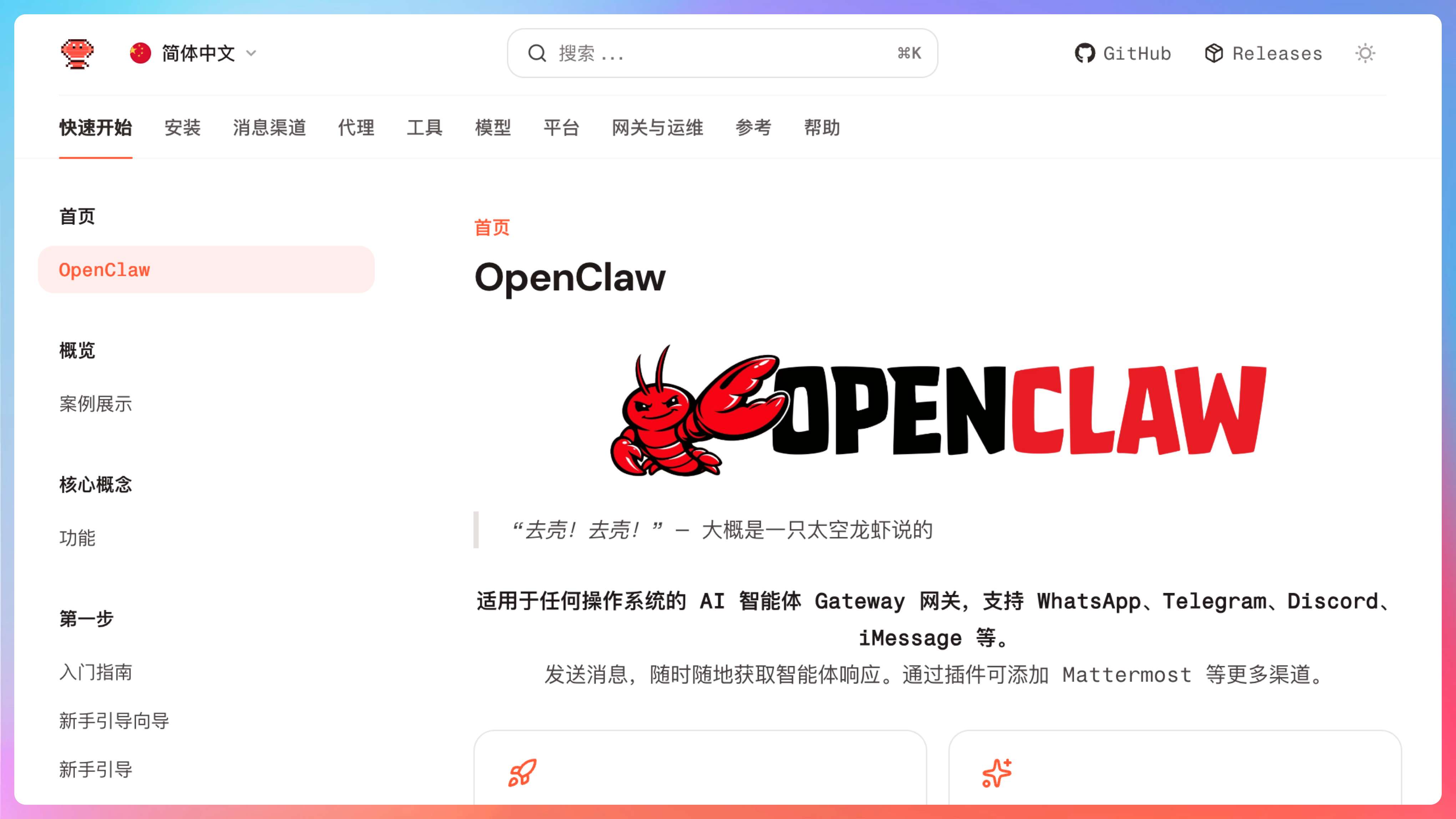
你会看到 Getting Started、Agent Workspace、Agent Runtime、Multi-Agent Routing、Channels、Tools 这些页面被拆得很清楚。说白了,它已经在替你划重点了。很多人学仓库学半天,其实是没把项目方已经搭好的学习路线利用起来。
所以第一步不要急着 clone,先盯着仓库首页问自己三个问题:这个项目现在活不活跃?项目方最想让我先理解什么?官方有没有替我准备好学习地图?这三个问题答清楚了,后面的路会顺很多。
02、照着官方文档把它跑起来
如果你问我,学习 OpenClaw 的第一天最该做什么,我的答案不是读源码,而是“跑通最小闭环”。
因为你只有真的跑起来一次,后面再去看文档和代码,脑子里才有画面。
否则很多词你都认识,放在一起就是一片雾。什么叫 onboarding,什么叫 workspace,什么叫 channel,什么叫 gateway,什么叫 dashboard,文字看着都懂,但没有实际体验,你很难把它们连起来。
OpenClaw 的官方 Getting Started 给得很直接,一条安装命令,再接 onboarding 或 setup,基础流程就能带起来。
官方站点还给了默认控制面板地址和最基本的运行方式。项目方把最短路径已经铺好了,你先走通一遍,比你看十篇二手教程都管用。
我自己的建议是,第一天只做下面这几件事:
安装 OpenClaw
运行 onboard 或 setup
启动 gateway
打开 dashboard
接入一个你最熟悉的聊天渠道只要你走完这条链路,你马上就会明白,OpenClaw 不是一个“在终端里陪你聊天”的小工具,它更像一个常驻在你机器上的 AI 调度中枢。
你发来的消息,会先进入 Gateway,然后找到对应的 Agent 和 Session,再按当前工作区上下文去调用工具,最后把结果回到原来的聊天渠道里。
这一层感受很关键,因为它会直接改变你看仓库的方式。没有跑通之前,你会觉得这个仓库很散。跑通之后再回头看,就会发现这些目录其实都在服务同一件事:让一个能动手的 Agent 长时间、稳定地工作。
别嫌这一步“没有技术含量”。很多人看仓库看不明白,不是因为脑子不够用,而是因为顺序错了。先跑起来,再回头看设计,你会轻松很多。
03、Gateway 这根主骨架
OpenClaw 最容易被低估的地方,就是 Gateway。
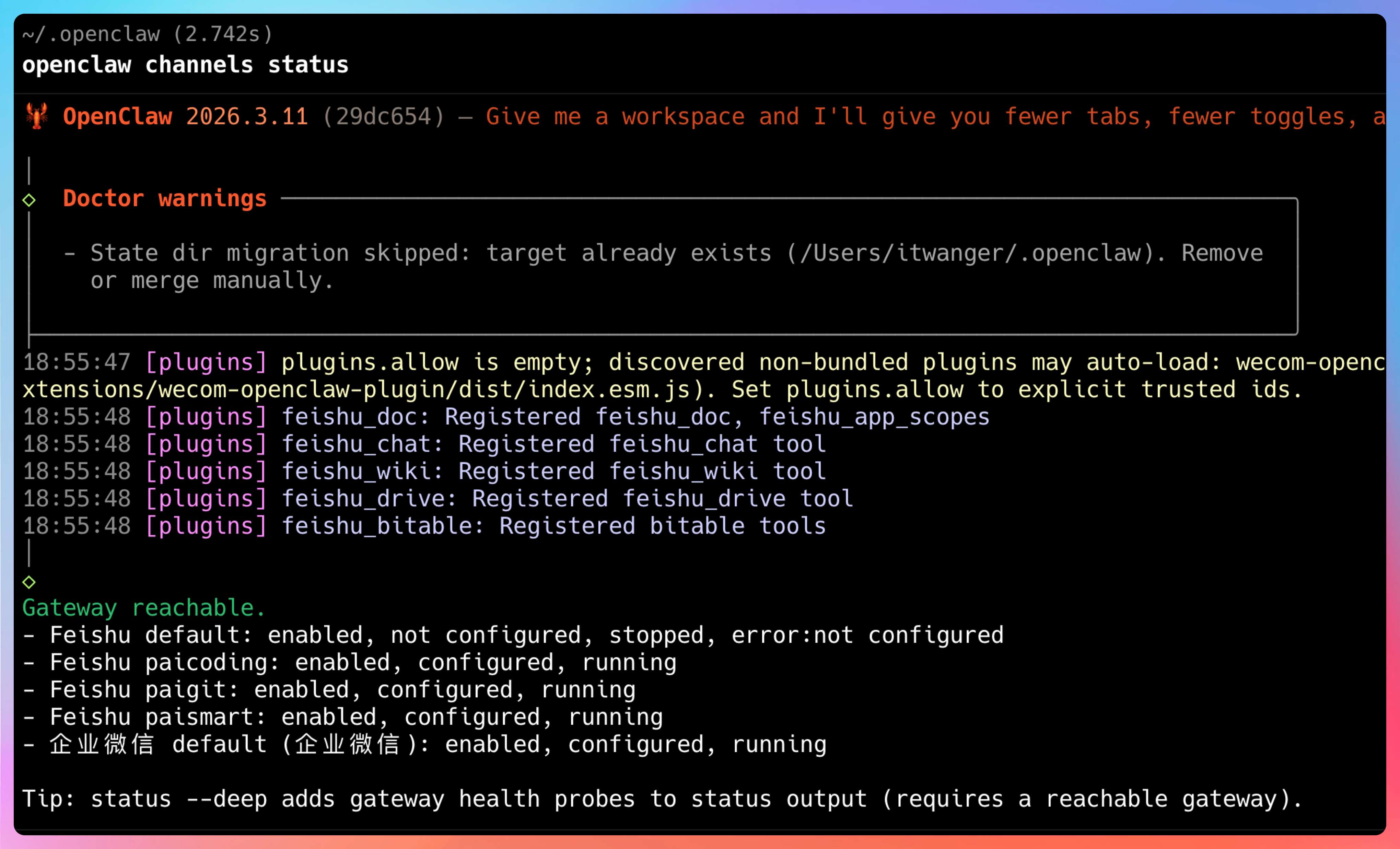
很多人第一次接触它,会把注意力放在“它能接飞书”“它能接 Telegram”“它能接 Discord”“它有一个 Web 控制台”这些表层能力上。可你只要去看一眼官方文档,就会发现项目方自己讲得非常明确:Gateway 才是整个系统的单一事实来源。会话、路由、渠道连接、节点、控制界面,很多核心状态都围着它转。
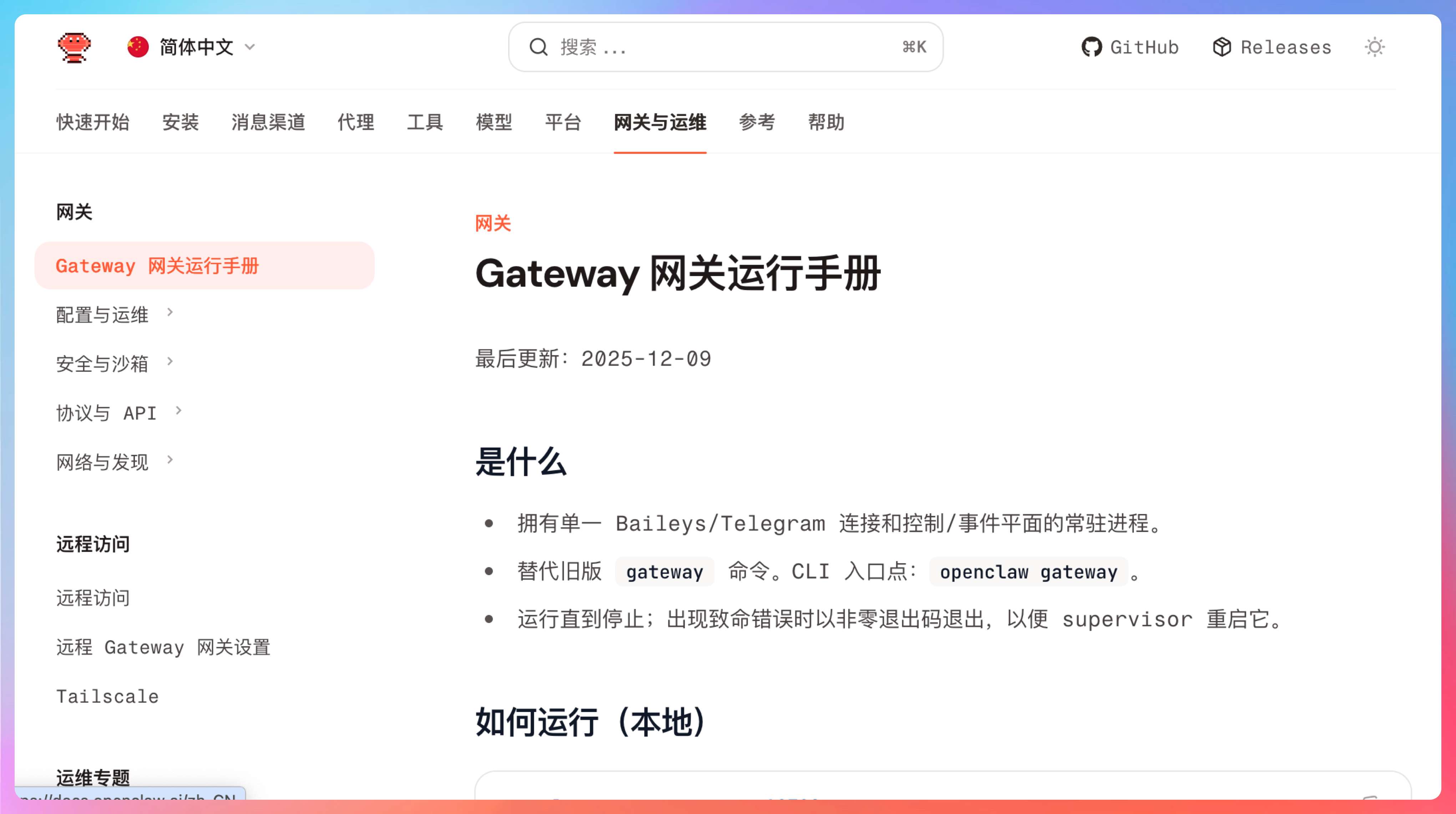
把这句话记住,你学习仓库的主线就出来了。
OpenClaw 不是“很多机器人插件拼起来”的感觉,它更像一套有中枢的操作系统。聊天渠道只是入口,Dashboard 只是可视化界面,真正决定消息怎么走、上下文归到哪里、回复回到哪个地方、哪个 Agent 来接这条消息的,是 Gateway 的路由逻辑。
你甚至可以先不看代码,只在脑子里记住这张图:
消息入口
-> Gateway
-> Agent / Session / Workspace
-> Tools
-> 返回原聊天渠道这也是为什么我建议第三步一定要去看 Gateway、Channel Routing、Session 相关文档。等你把这一层搞明白,再去看仓库里的渠道插件、Agent 配置、会话存储位置,就不再是零碎知识点了,而是一套完整系统里的零件。
顺着这个思路,你甚至能反过来理解很多设计选择。
为什么它能一边接聊天软件,一边保留长期上下文?为什么一个 Gateway 能挂多个渠道?为什么控制台能看到会话和节点状态?因为这些能力,本来就不是后补上去的,而是围着 Gateway 这根主骨架长出来的。
04、学会 OpenClaw 的关键
如果说 Gateway 解决的是“消息怎么走”,那 Workspace 解决的就是“Agent 为什么会越用越像你的人”。

这一点,我觉得也是 OpenClaw 最值得普通开发者学习的地方。因为太多 AI 产品,把个性化都压在 prompt 里,或者压在某个设置面板里,结果就是看起来方便,用起来很脆。今天换个机器,明天换个会话,很多东西就散了。
OpenClaw 的做法更像一个长期经营的工作区。官方文档把这个概念讲得非常直接:Workspace 是 Agent 的家,是它默认的工作目录,也是它最重要的上下文来源。这里面常见的文件包括 AGENTS.md、SOUL.md、USER.md、IDENTITY.md、TOOLS.md,还有可选的 MEMORY.md 和 memory/ 目录。
说白了,OpenClaw 并不是只想做一个“会回消息的机器人”,它想做的是一个能长期共事的 AI 助手。
你的行为规则写在 AGENTS.md,你的性格边界在 SOUL.md,你对用户的理解在 USER.md,你对本地工具和环境的说明在 TOOLS.md。这些文件不是花架子,它们会直接影响 Agent 每次运行时看到的上下文。
所以你真想学这个仓库,第四步一定别只盯着 prompt 技巧。你应该去研究这些工作区文件到底各自负责什么,哪些信息适合进 AGENTS.md,哪些适合进 TOOLS.md,哪些记忆应该放到 MEMORY.md。这才是 OpenClaw 和很多“一次性 AI 助手”真正拉开差距的地方。
05、Multi-Agent 才是它最值钱的地方
说实话,我一开始也以为 OpenClaw 最香的是“接各种聊天工具”。后来越看越觉得,真正值钱的还是它把 Multi-Agent 做成了系统能力,而且文档和配置思路都很完整。
官方 Multi-Agent Routing 文档写得很清楚,一个 Agent 不是一个名字那么简单,而是一整个独立的“脑子”:自己的 Workspace,自己的 agentDir,自己的会话存储,自己的认证资料,自己的技能目录,自己的行为规则。
换句话说,你不是在“给同一个机器人加皮肤”,你是在同一个 Gateway 下面养多只彼此隔离的小龙虾。
这套设计的好处很直接。很多原本容易搅在一起的东西,被它硬生生拆开了。一个 Agent 负责 coding,一个 Agent 负责飞书群消息,一个 Agent 负责日常提醒,一个 Agent 负责内容整理。每个 Agent 都有自己的工作区、自己的渠道绑定、自己的路由规则、自己的历史会话。系统会清爽很多,排查问题也容易。
更重要的是,官方把路由优先级也讲得明明白白。消息到底进哪个 Agent,不是模型“脑补”决定的,而是 bindings 按 peer、accountId、channel、默认 Agent 这样的顺序去匹配。这一点特别工程化,也特别值得学。因为只要是做过线上系统的人都知道,最怕那种“看起来聪明,实际不可控”的路由逻辑。
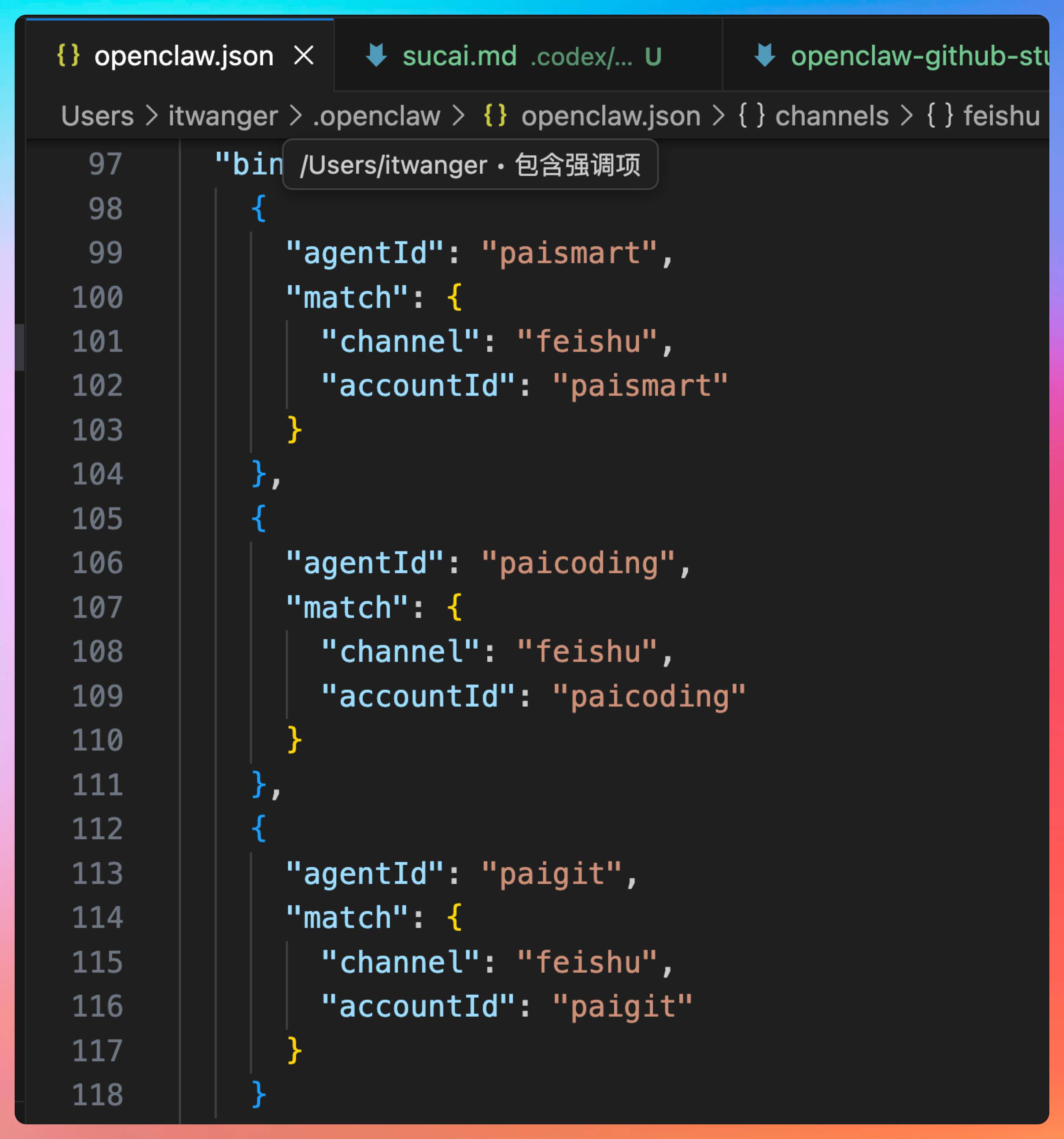
所以当你已经把单 Agent 跑通以后,下一步最值得看的,不是去抄别人那份超长配置,而是去理解一个问题:为什么 OpenClaw 要把 Agent、Workspace、Session、AccountId、Binding 这些概念拆得这么细?你把这层想明白,以后你自己设计 Agent 系统时,也会下意识避开很多坑。
06、最后才去翻代码
到这一步,你再回去看 GitHub 仓库,感觉就完全不一样了。
以前你看到 apps、packages、docs、skills 这些目录,可能会觉得杂。现在你知道它们各自服务哪条主线,阅读成本会低很多。我的建议是,最后把注意力放在三个地方。
第一个地方是 Tools 文档和相关实现。OpenClaw 官方现在把 browser、canvas、cron、sessions、gateway、web_search 这些能力都当成一等工具来讲,而不是零散外挂。
这个思路很重要,因为它意味着 Agent 的能力边界是可组合、可控制、可审计的。你以后做自己的 Agent 项目时,这种“把工具系统提成平台层能力”的设计很有参考价值。
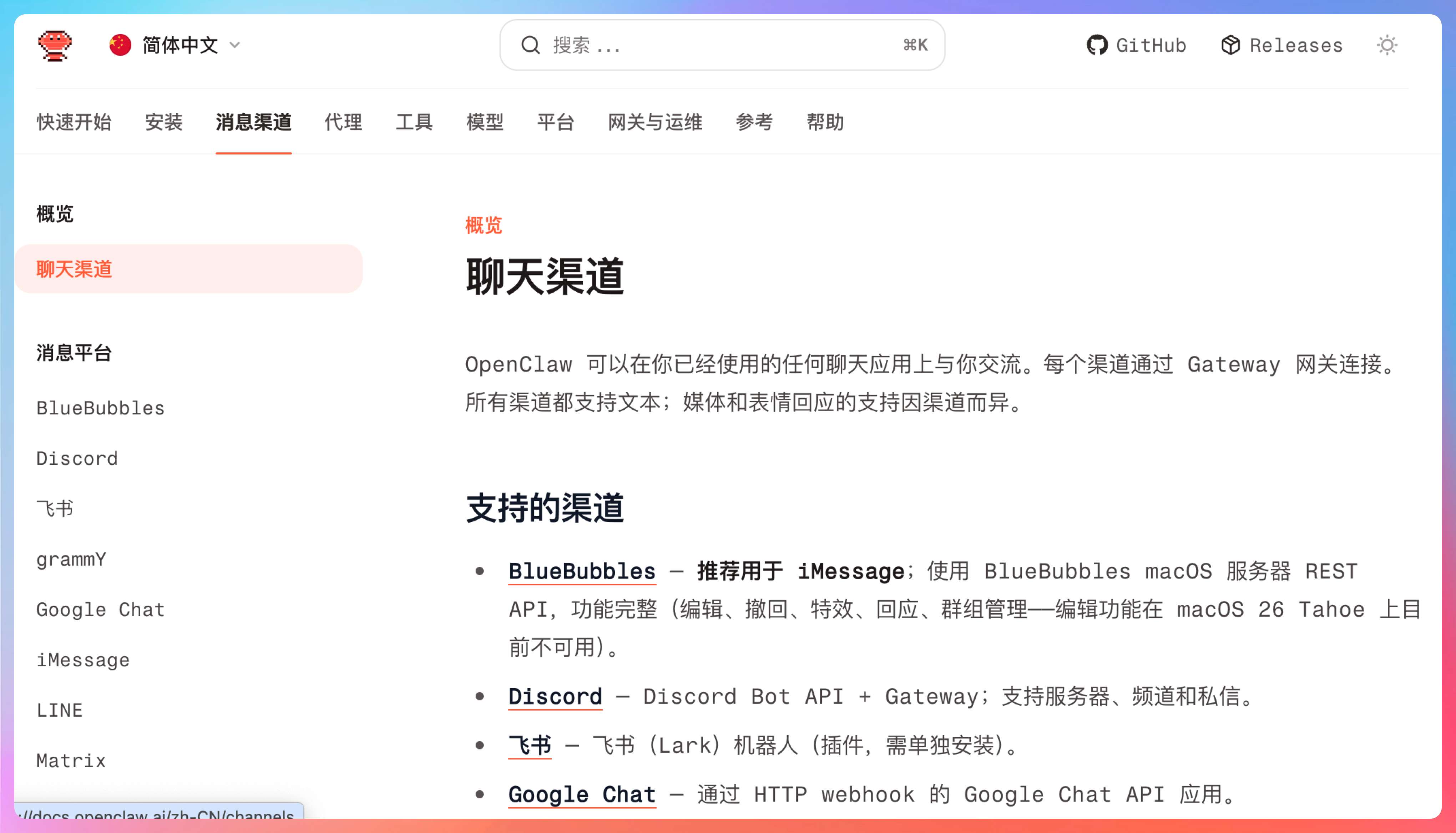
第二个地方是 Channels。你不一定每个都用,但至少要挑一个你熟悉的渠道去读。因为渠道层最能帮助你理解 OpenClaw 是怎么把“聊天消息”映射成“可持续运行的系统输入”的。飞书、Telegram、Discord 这些看上去只是入口不同,背后其实都要过 Gateway、Session、Routing 这套骨架。
第三个地方是 CONTRIBUTING 和 Issues。很多人学开源项目,只会看 README,不看社区协作。其实对于 OpenClaw 这种更新快、生态大的仓库,PR、Issue、文档变更、版本发布记录,往往比死盯某个文件更能帮助你理解项目的演化方向。你会知道哪些能力刚加上,哪些概念最近被重写,哪些设计已经稳定了。
所以顺序一定别反。先首页,再上手,再架构,再工作区,再多 Agent,最后才是代码和社区。这么学,OpenClaw 对你来说就不再是一堆目录,而是一张越来越清晰的地图。
ending
写到这里,我还是想劝一句,别把学 OpenClaw 这件事搞得太苦。
很多人一看到大仓库就本能紧张,觉得必须先把目录背下来,把源码啃穿,把每个配置项都看懂,才算“学会”。可真实情况往往不是这样。
一个项目值不值得你学,不在于它有多少文件,而在于它有没有一套清晰的方法,帮你把复杂度收住。
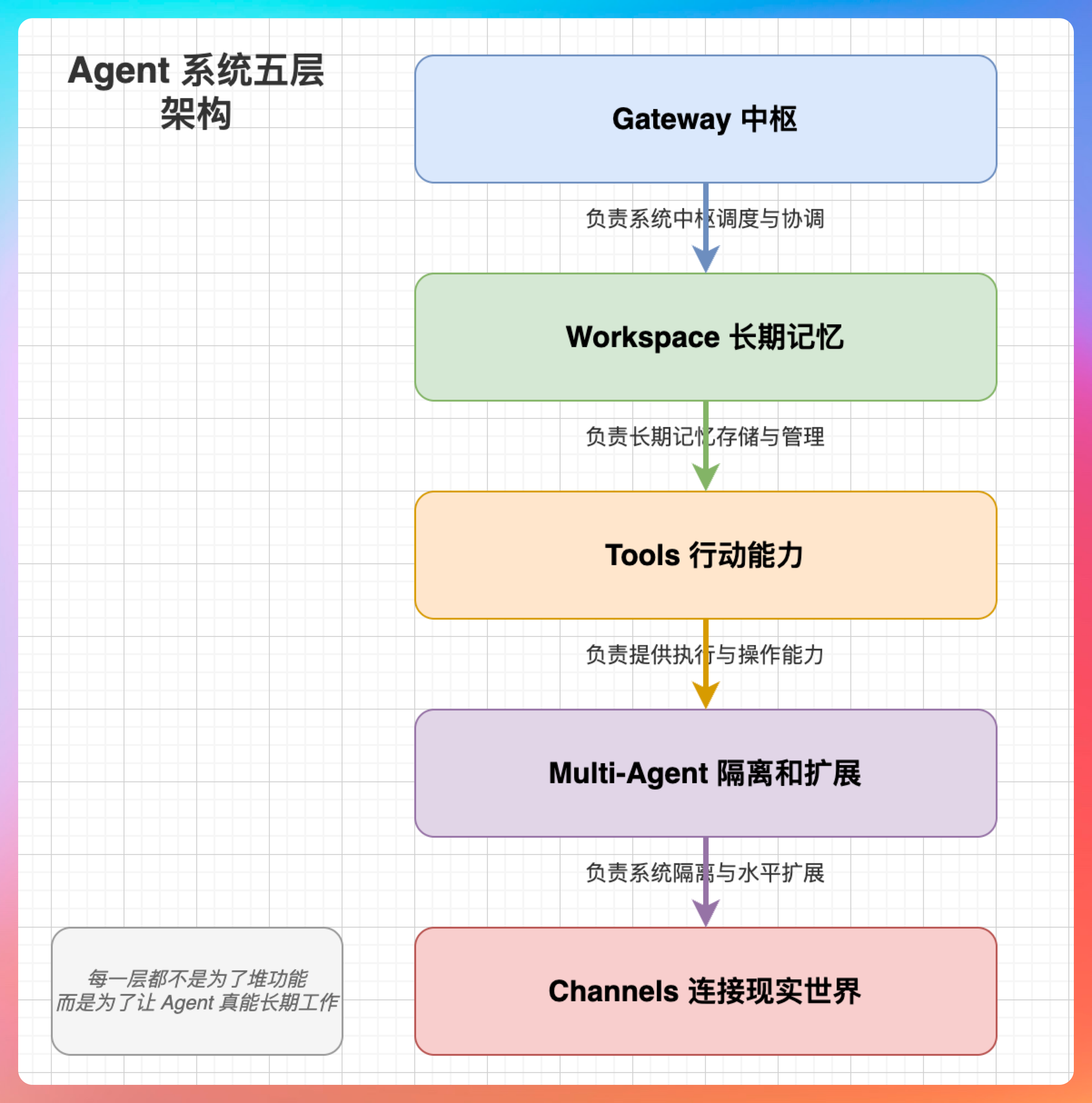
Gateway 负责中枢,Workspace 负责长期记忆,Tools 负责行动能力,Multi-Agent 负责隔离和扩展,Channels 负责连接现实世界。每一层都不是为了堆功能,而是为了让 Agent 真能长期工作。
所以我一直觉得,这个仓库很适合拿来学习。你不一定要照搬它的实现,也不一定明天就自己写一个 OpenClaw,但只要把这套思路吃透一点,对你理解 AI Agent、工具调用、长期记忆、工作区设计、多 Agent 架构,都会有帮助。
所以别再把“学仓库”理解成“把所有代码看完”了。先跑起来,先找到主骨架,先知道作者想解决什么问题,再去翻实现细节。这样学,不容易累,也更容易真的学进去。
说到底,GitHub 上最值钱的不是那个 Star 数,而是你有没有借着这个仓库,把自己的理解往前推一点。