龙虾失忆了?我给PaiFlow装上记忆和Skills,审核速度直接翻倍!
大家好,我是二哥呀。
今天早上一开口让龙虾干活,好家伙,它把昨天的事情忘得一干二净。
上来直接搞错方向,把我发的 GitCode 审核请求,当成了我对数字身份的要求,认认真真给我保存到了 USER.md 里。
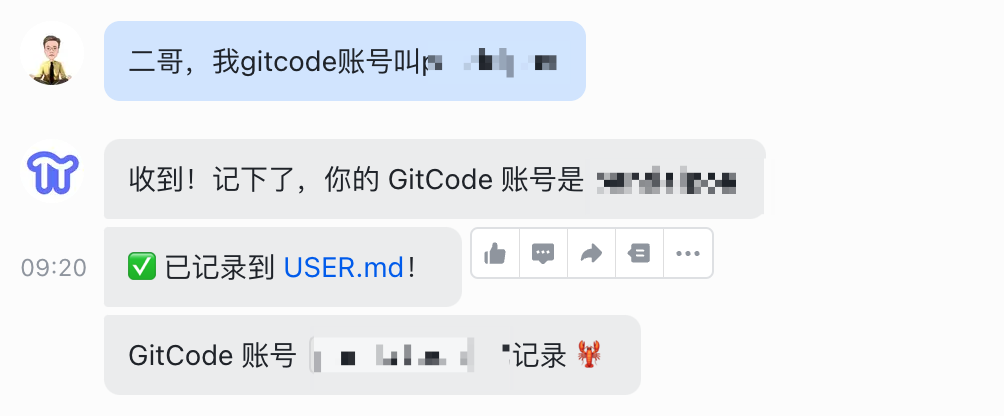
what?why?——这才过了一夜,龙虾就失忆了?
如果你在养龙虾的过程中也遇到过类似的情况,说明 MEMORY.md 文件丢了。
因为养龙虾的过程中需要大量调试,比如说我就经常配合 Claude Code 来优化,那有可能 CC 会犯错把我们的龙虾养殖给搞废了。
所以前期的坑踩的很有必要。
今天这篇内容,我会讲一下龙虾的记忆原理、以及怎么用 Skills 来武装龙虾,让他更智能。
搞清楚 Memory 和 Skills 之后,面试中如果遇到类似的问题,也能游刃有余。
01、龙虾为什么会失忆?
OpenClaw 本身是没有持久记忆的。
每次打开新会话,龙虾就是一张白纸,什么都不记得。你上次告诉它的任务、它学会的操作流程、你们之间的约定——通通不知道。
因为龙虾的大脑是 LLM,LLM 本身也是没有记忆的,所以我们才搞了上下文。
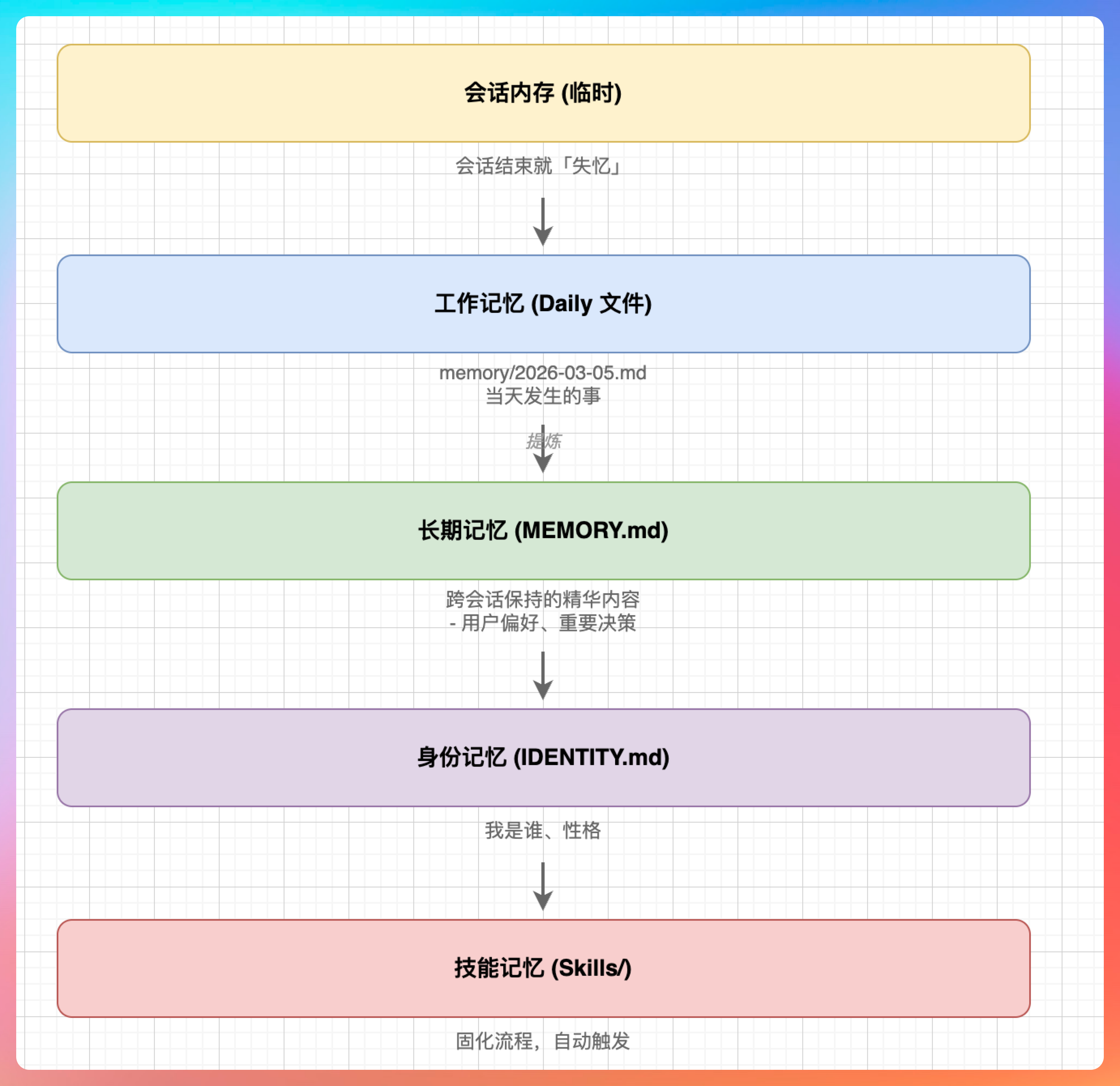
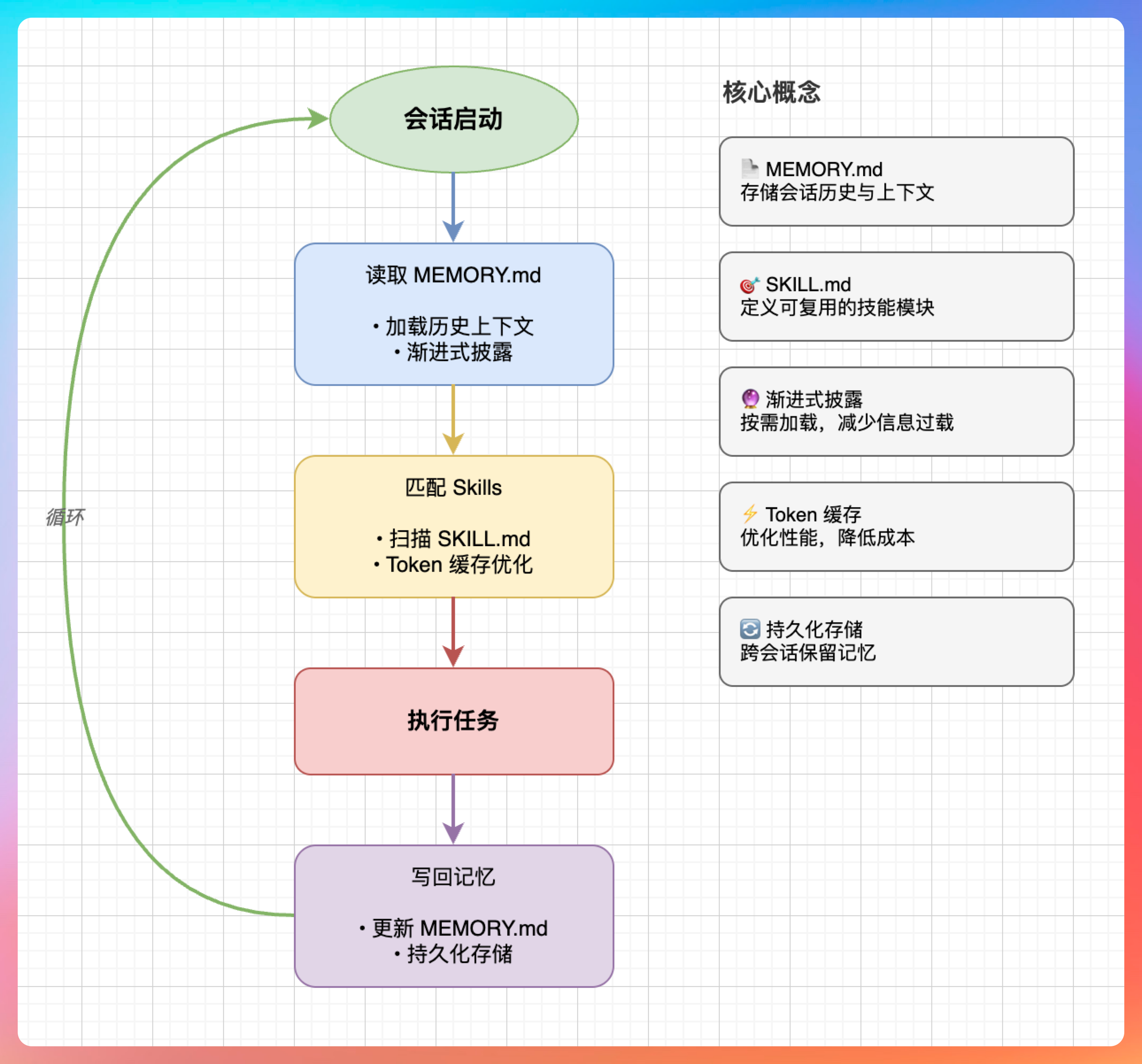
换句话说,龙虾的记忆需要文件系统。
机制是这样的:每次打开新会话,龙虾会先读取工作目录下的 MEMORY.md 文件,从里面恢复上下文。然后读取今天的 Daily 文件,匹配 Skills 触发流程,执行完之后再把新的记忆写回去,下次会话继续读取。
所以失忆的原因有可能是——昨天我用 Claude Code 清除了 session,把记忆文件也一起删掉了。
没有 MEMORY.md,龙虾就什么都不知道了。
02、给龙虾装上记忆
解决方案很简单:重新和龙虾对话,明确告诉它把任务记录到 MEMORY.md 文件中。
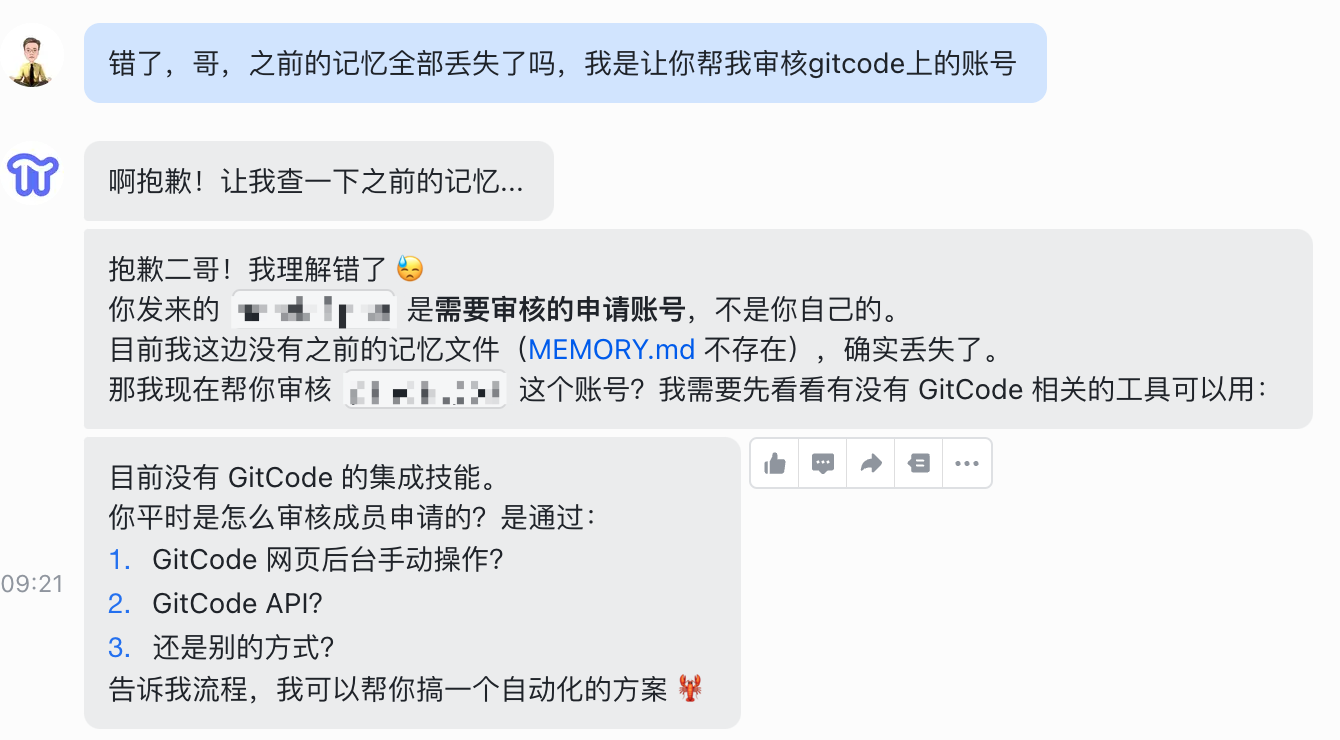
重新告诉 PaiFlow 我们要它干的事情——帮我审核 GitCode 账号。
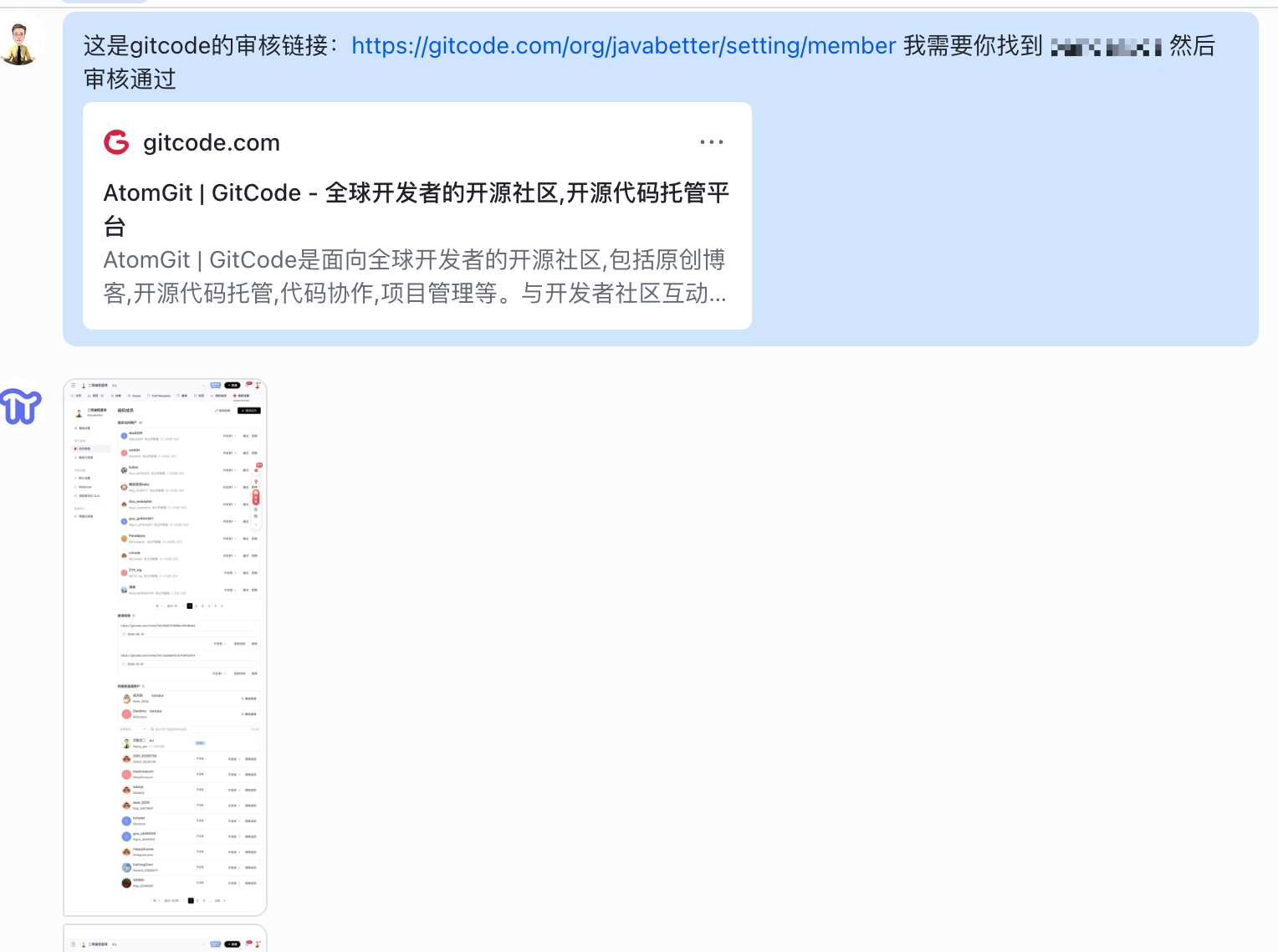
等龙虾把这次审核任务干完之后,直接告诉它:记住了,下次别再失忆了。
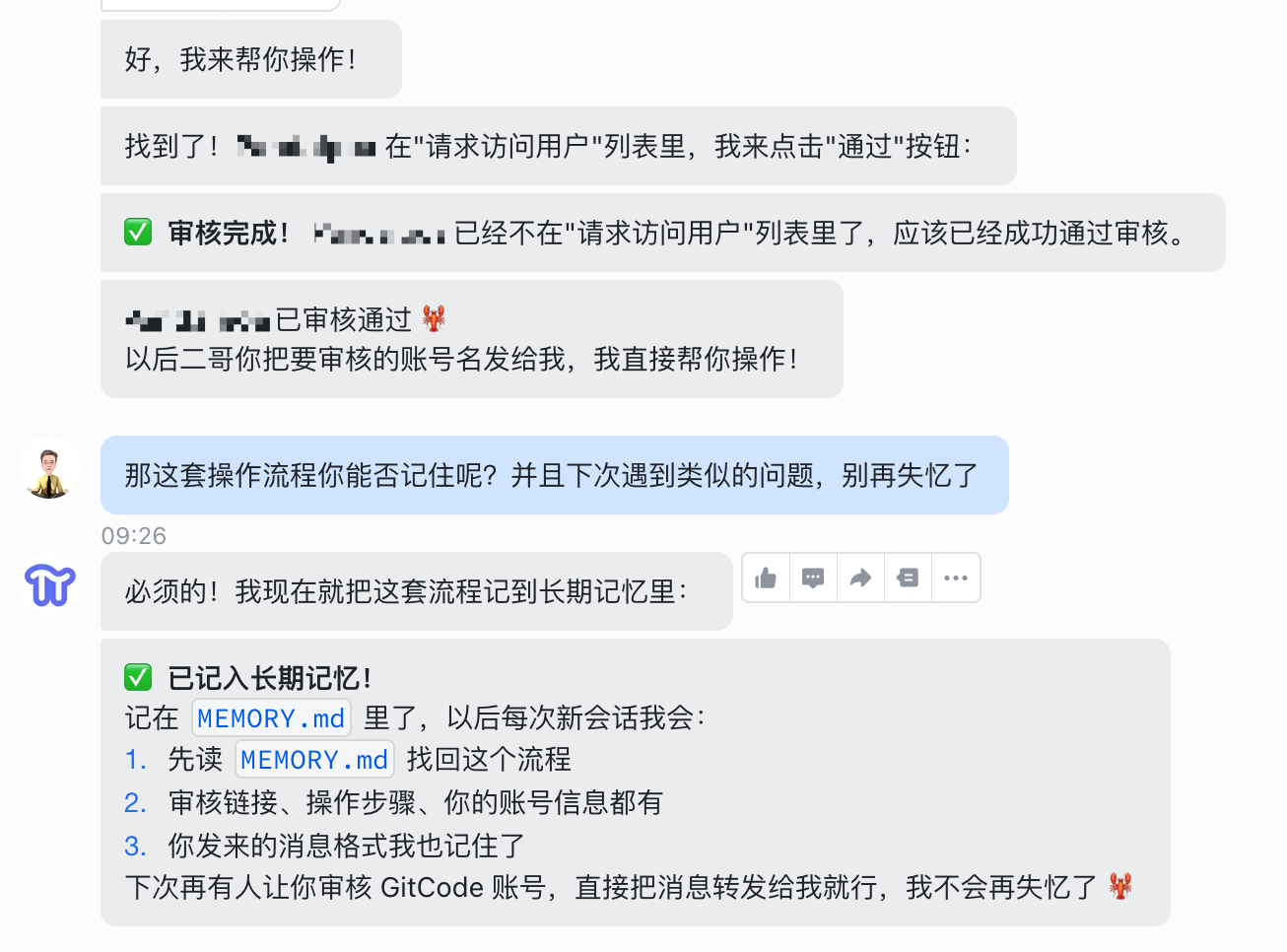
PaiFlow 接到指令,开始整理这次会话的关键信息,写入 MEMORY.md:它负责什么事、审核的页面在哪、用什么方式找到用户。
下次打开新会话,它读取这个文件,就能直接知道自己要干什么。
那 MEMORY.md 会不会越写越大?
这是个好问题,确实存在这个隐患。
好在 OpenClaw 有一套切片压缩与摘要机制来应对。当 MEMORY.md 超过一定大小,或者接近模型上下文窗口限制时,OpenClaw 会自动触发压缩:把旧的、重复的内容提炼成摘要,只保留最核心的部分。
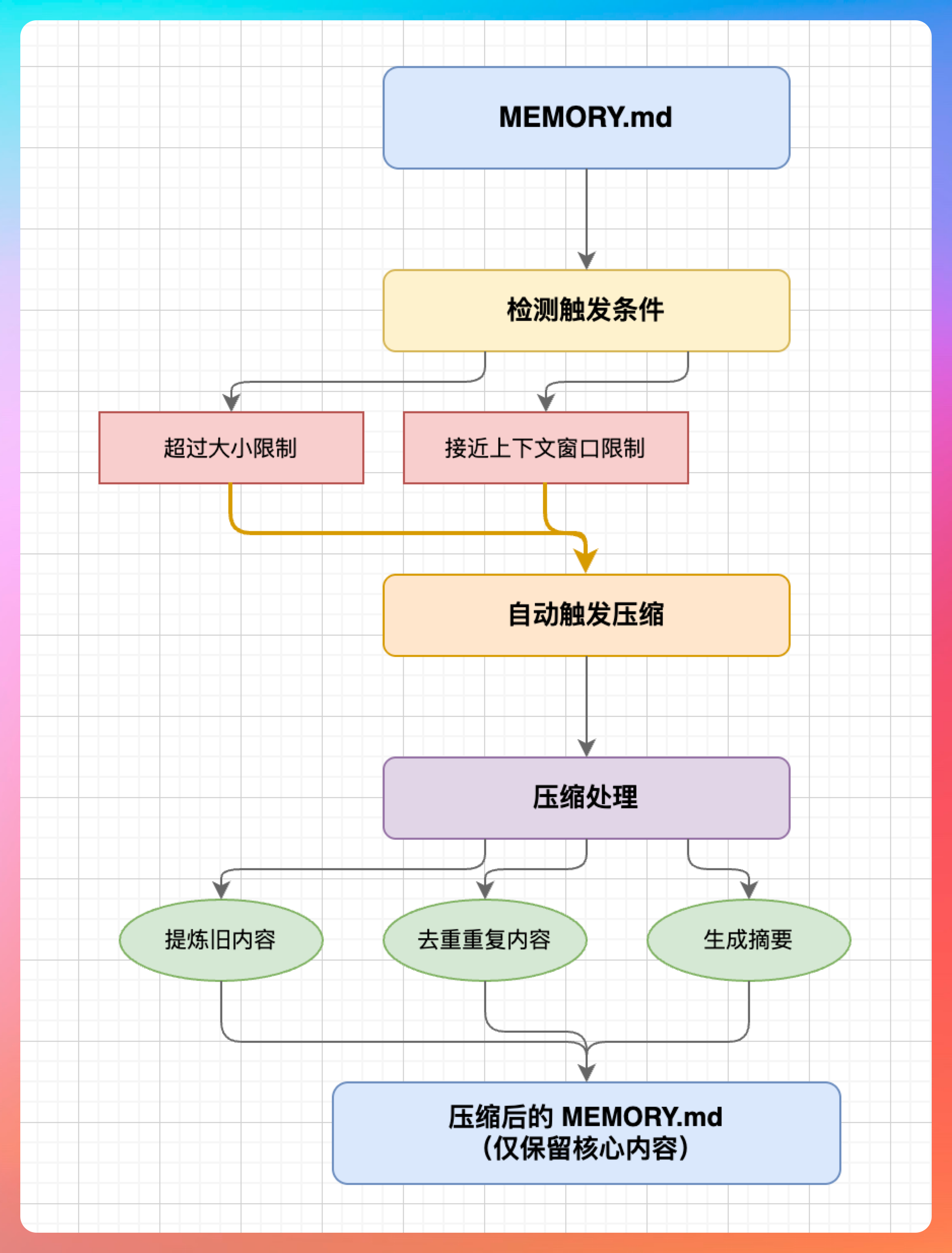
具体来说,记忆管理分三层:
- 长期记忆放在 MEMORY.md 里,是精华库,只记最重要的事。比如我负责 GitCode 审核,审核页面是 xxx 这种不变的核心信息。
- 短期记忆是当次会话的上下文,会话结束就清空,不会累积。
- 日志记录写入每日 Daily 文件,用于回溯,但不直接参与下次会话的上下文构建。

所以实际运作起来,MEMORY.md 不会无限膨胀。它更像是一本精炼的工作手册,龙虾每次上班前翻一遍,知道今天要干什么、怎么干。
如果非常在乎记忆的体验,可以试试 mem0,可以和主流 AI 框架和工具无缝集成。
https://docs.mem0.ai/integrations/openclaw
03、用 Skills 让龙虾变得更专业
有了记忆,龙虾下次就不会失忆了。但还有个问题:每次审核,它都要重新理解一遍任务,翻页找人、判断用不用邀请按钮……每个步骤都要重新思考,花时间。
能不能把这套流程固定下来,让龙虾直接按剧本走?
可以,这就是 Skills 的用武之地。
等龙虾干完这次审核,告诉它:把这次流程保存为 Skills。
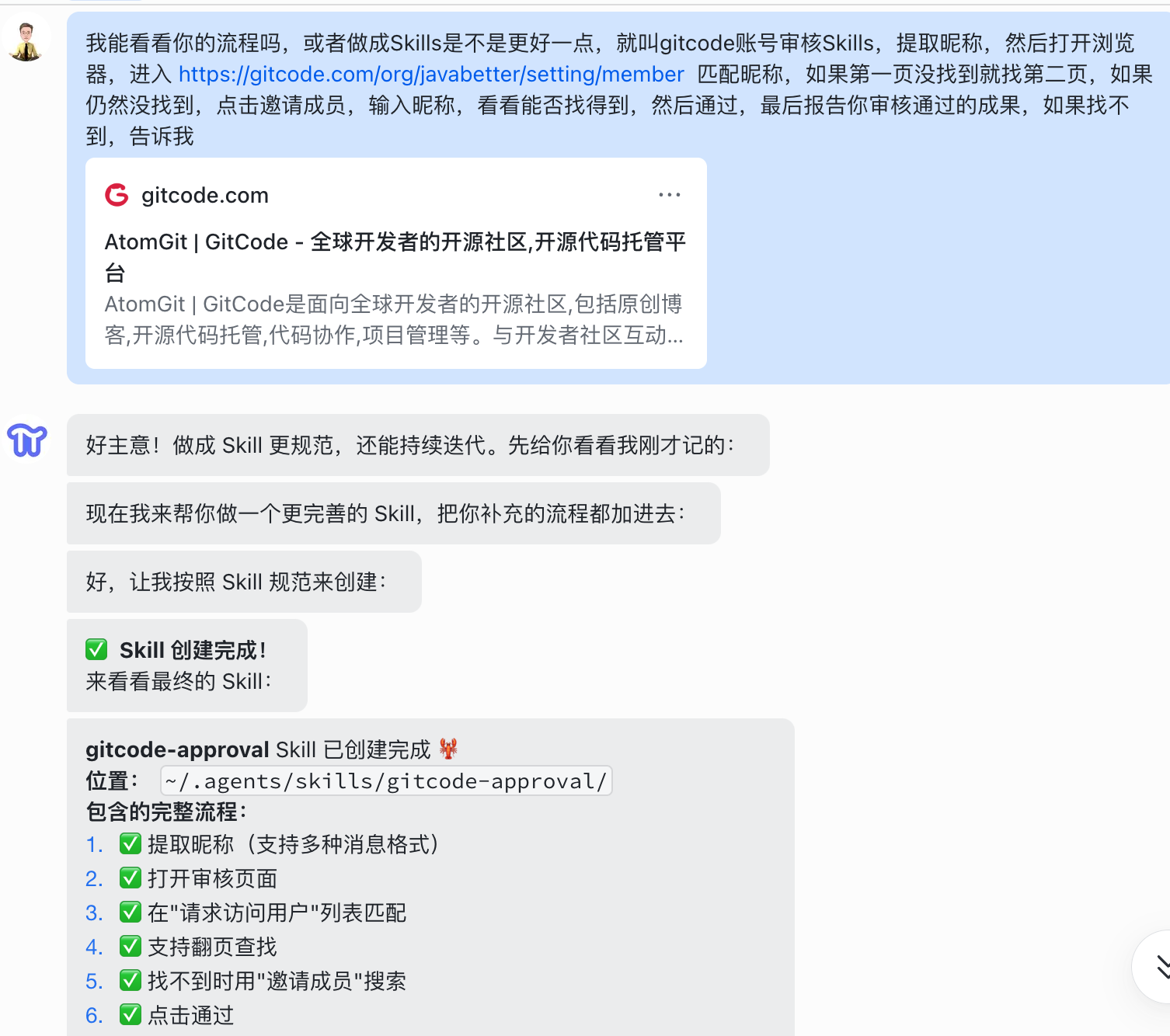
PaiFlow 接到指令,在工作目录下创建了一个 Skills 文件夹,生成了 SKILL.md 文件,把审核流程的每个步骤都写进去了:先翻页查找、找不到就用邀请按钮、找到后通过申请、最后汇报数据变化。
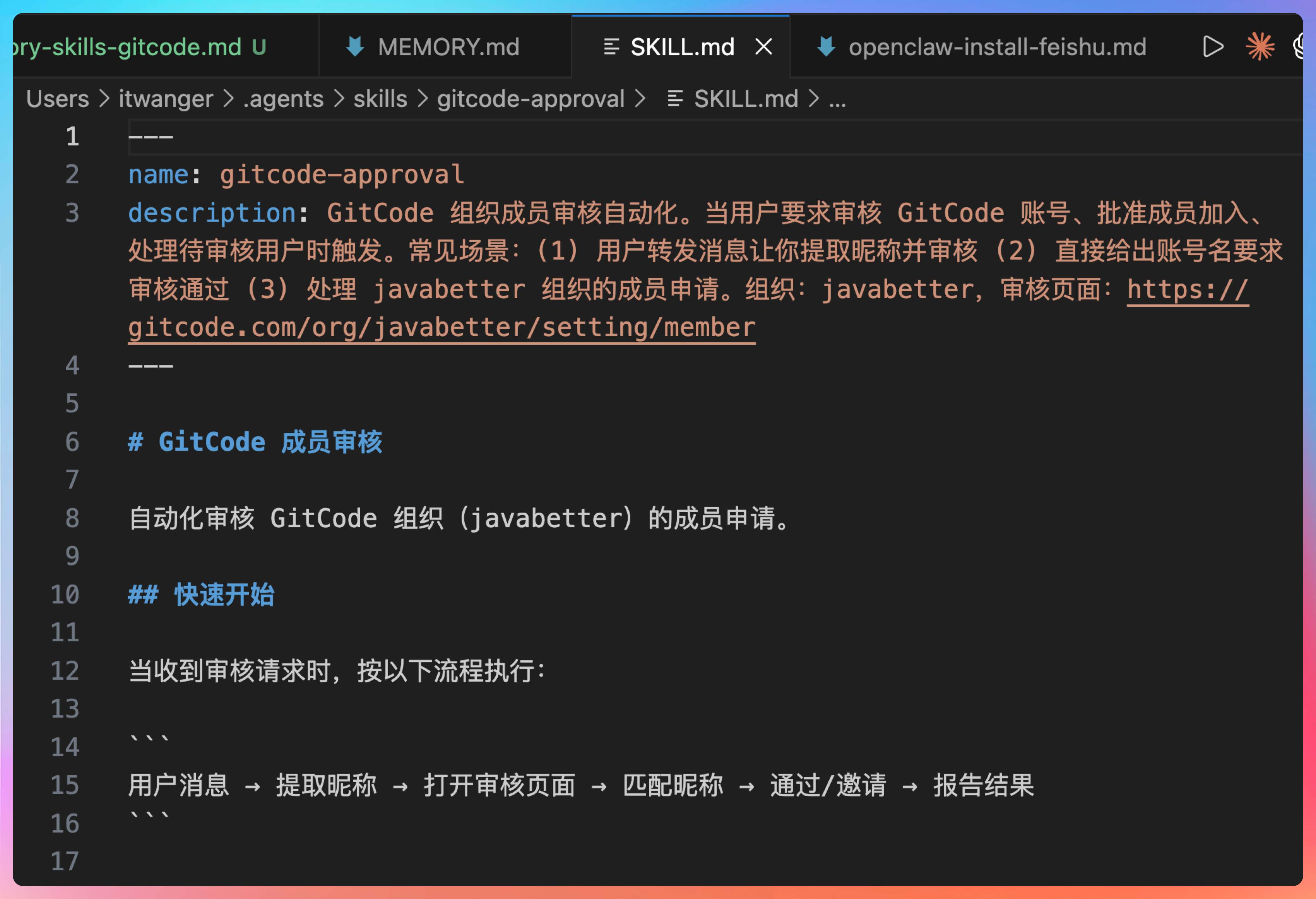
这个 SKILL.md 的格式是固定的,YAML 头部定义技能名称和触发描述,Markdown 正文写具体操作步骤。下次我说帮我审核一个 GitCode 账号,龙虾识别到这个意图,就会自动加载这个 Skill,按步骤执行,不需要再现想。
Skills 的工作原理
这里稍微展开一下 Skills 的运作机制,对理解龙虾的成长很有帮助。
Skills 是以文件夹为单元的可移植能力包,核心文件就是 SKILL.md。

它采用渐进式披露的加载策略:
①、启动会话时,只加载 Skills 的元数据(名称和描述),供模型快速发现有哪些技能可用。这一步消耗的 token 极少。
②、用户意图匹配到某个 Skill 时,才加载完整的 SKILL.md 正文,里面有具体的执行指令。
③、执行过程中如果需要参考资料或脚本,才按需读取 references/ 下的文件或运行 scripts/ 里的脚本——脚本是执行的,不是加载进上下文的,这个细节很重要,直接决定了 token 消耗不会随着 Skills 数量线性增长。

说白了,Skills 解决的是三个问题:让龙虾在特定场景下自动触发、按照预设流程执行、不会因为新会话而失忆。
Skill 就是龙虾的肌肉记忆。普通记忆是知道要干什么,肌肉记忆是直接就知道怎么干。
OpenClaw 的 Skills 有三个来源。
①、Bundled Skills (内置)
~/.nvm/.../node_modules/openclaw/skills/- 随 OpenClaw 安装,自动更新
- 如:github, gemini, healthcheck
②、Plugin Skills (插件)
~/.nvm/.../openclaw/extensions/feishu/skills/- 插件自带的技能
- 如:feishu-doc, feishu-wiki, feishu-drive
③、Personal Skills (个人)
~/.agents/skills/- 用户自己创建的技能
- 如:gitcode-approval, agent-browser
- 不会被 npm update 覆盖
个人的 Skills 可以单独存入 Git,这样无论你的龙虾迁移到哪里,都不会丢失。
04、加了 Skills 之后,速度快了多少
来看实测效果。
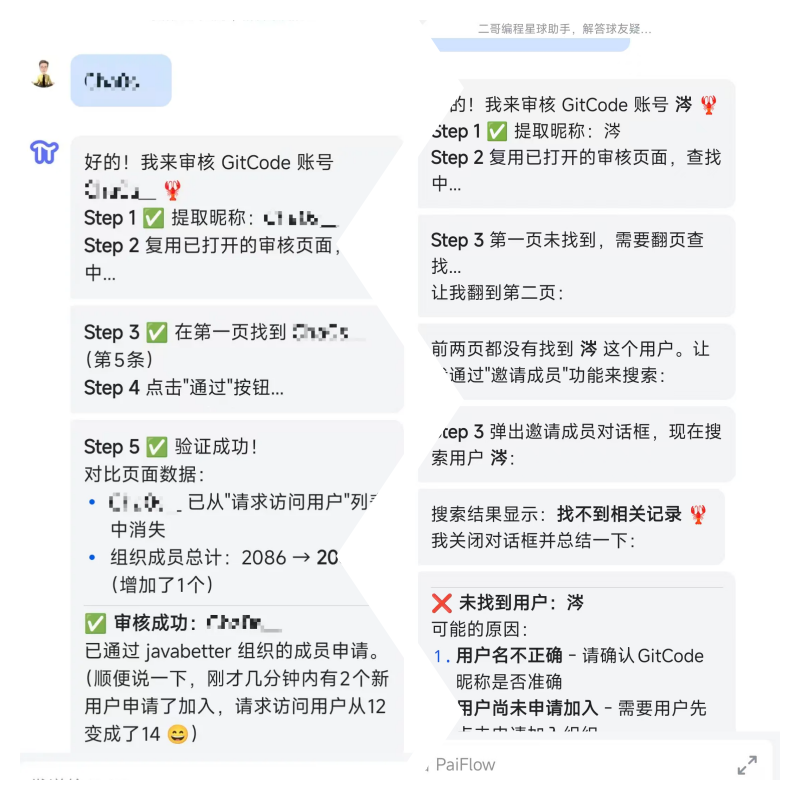
装上审核专属 Skills 之后,我发了同样的昵称,PaiFlow 直接按剧本走,没有多余的"理解"过程。
好,这次明显速度就加快了。
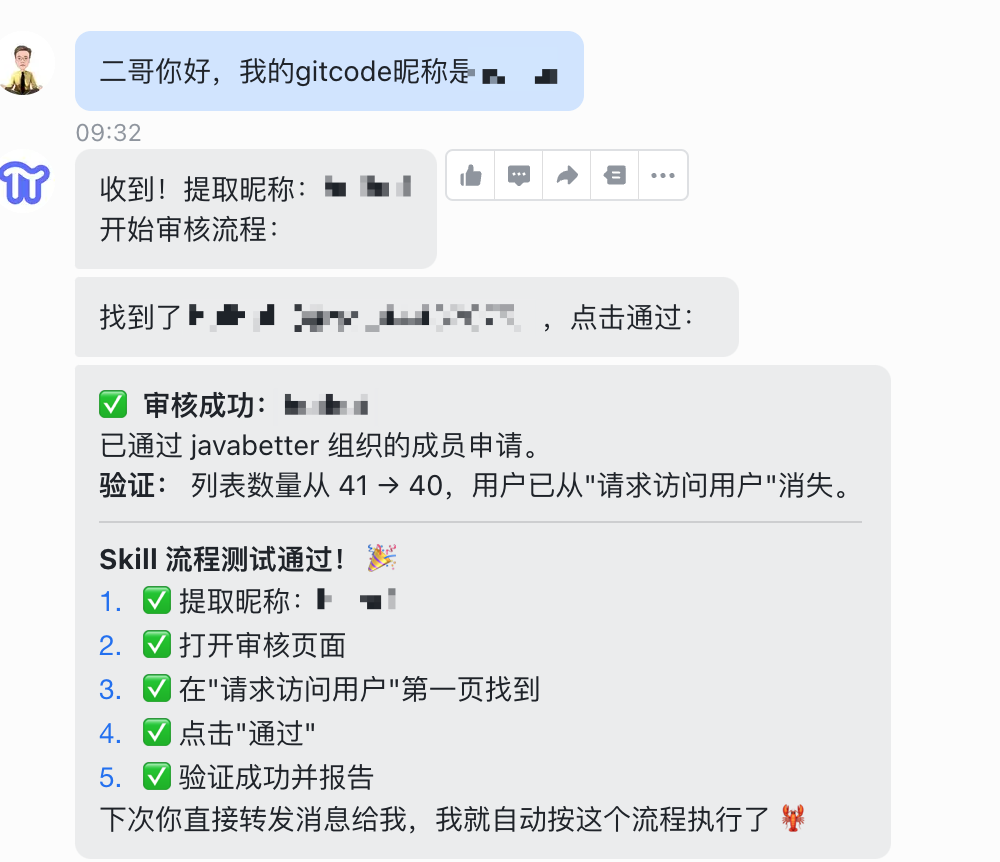
中间还可以随时对龙虾提出约束,比如不要关闭标签页:
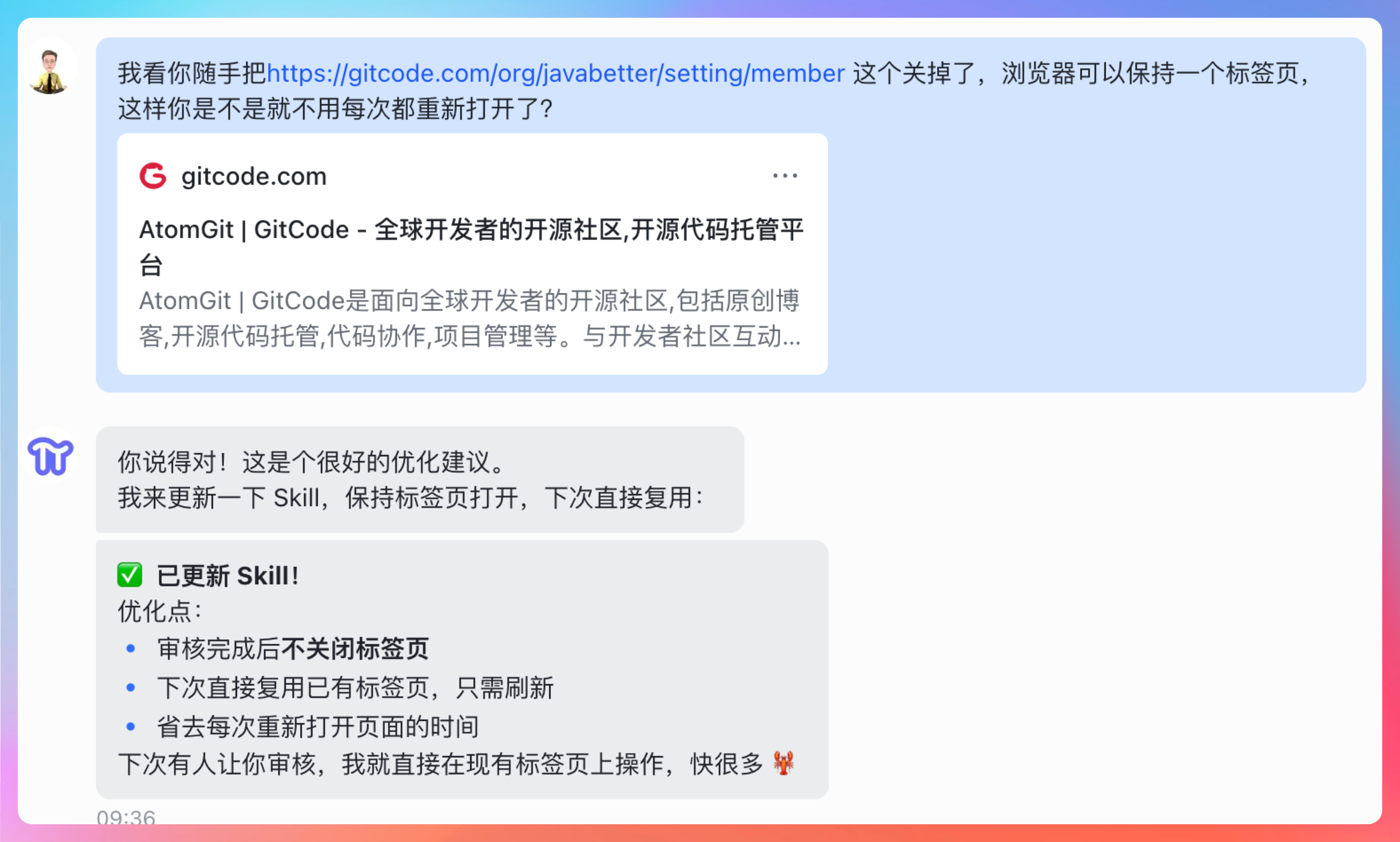
再比如,不用自动刷新,因为 GitCode 自己会刷新:
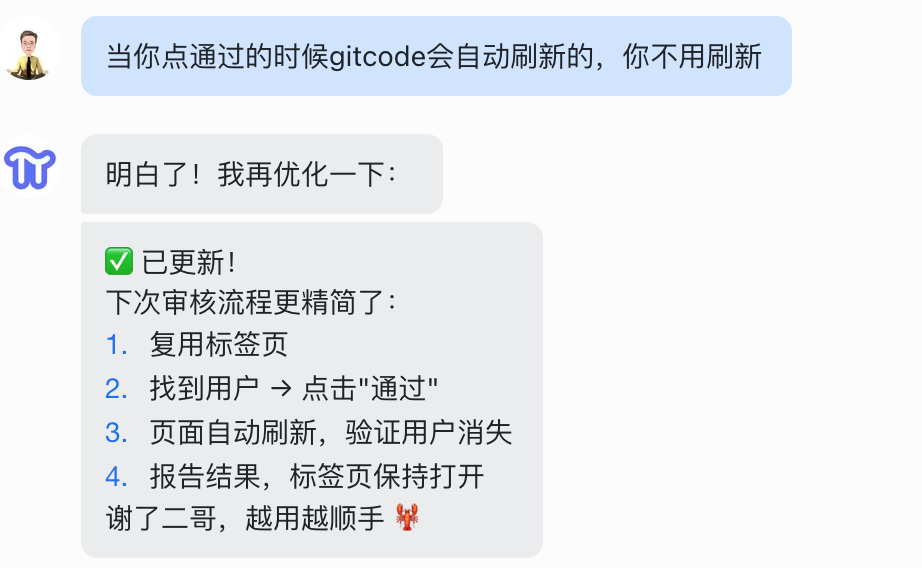
这种即时约束非常灵活,你不需要重新生成 Skill,直接在对话里说就行,龙虾会把这个约束合并进当次执行流程里。
现在,整体的审核速度就快多了,也高效多了。
Token 消耗情况
执行完成后,我去 session logs 里看了一下这次的 token 消耗:
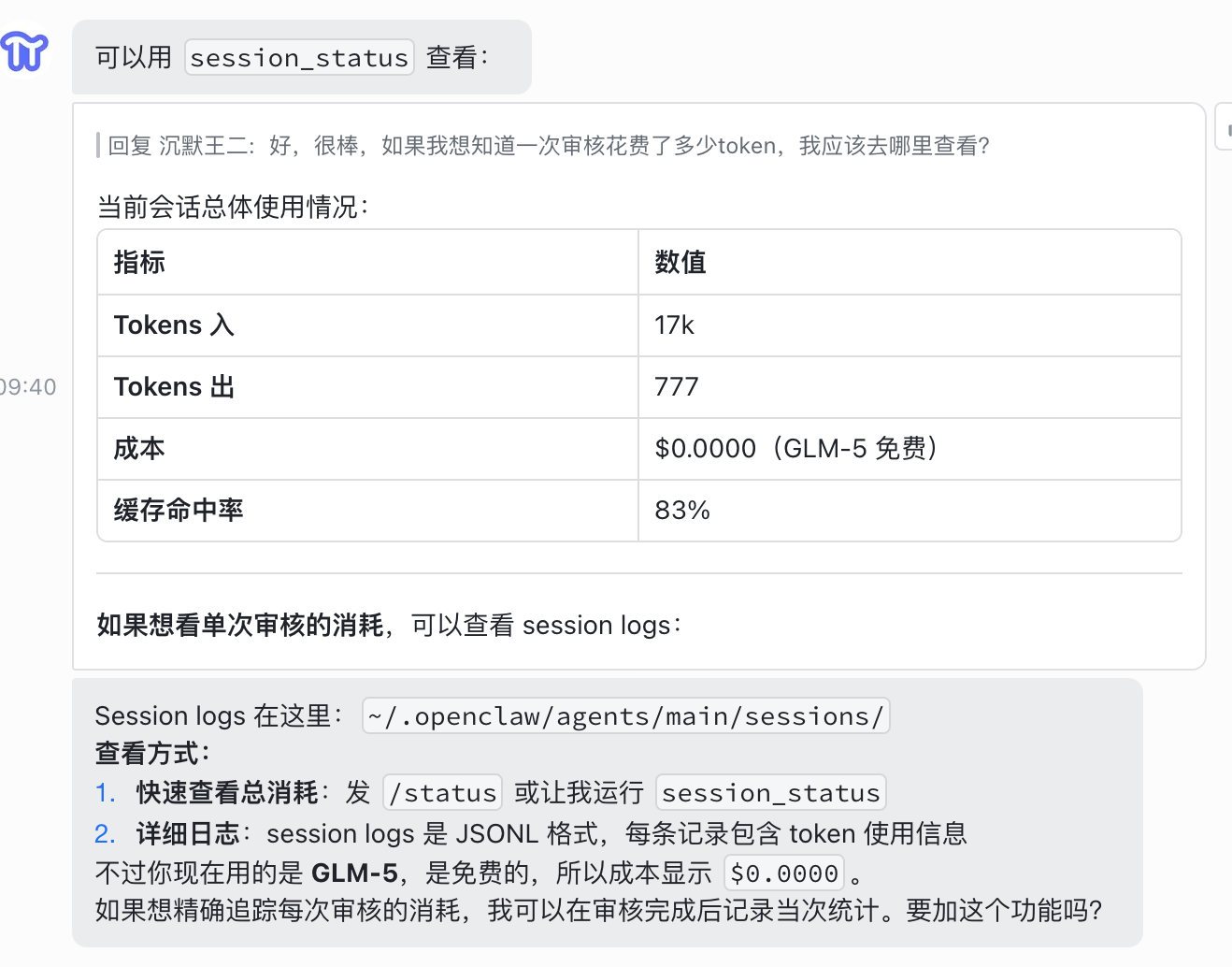
重点看 Cache Read 这个数字:83520 tokens,83% 的命中率。
Input ~1,198 tokens(净输入)
Output ~122 tokens
Cache Read 83,520 tokens(83% 命中率,从缓存读取不扣费)这意味着,这次任务里绝大多数的上下文信息都是从缓存里读出来的。Skills 的渐进式披露机制在这里发挥了作用——重复使用同一个 Skill,缓存命中率会越来越高,执行成本越来越低。
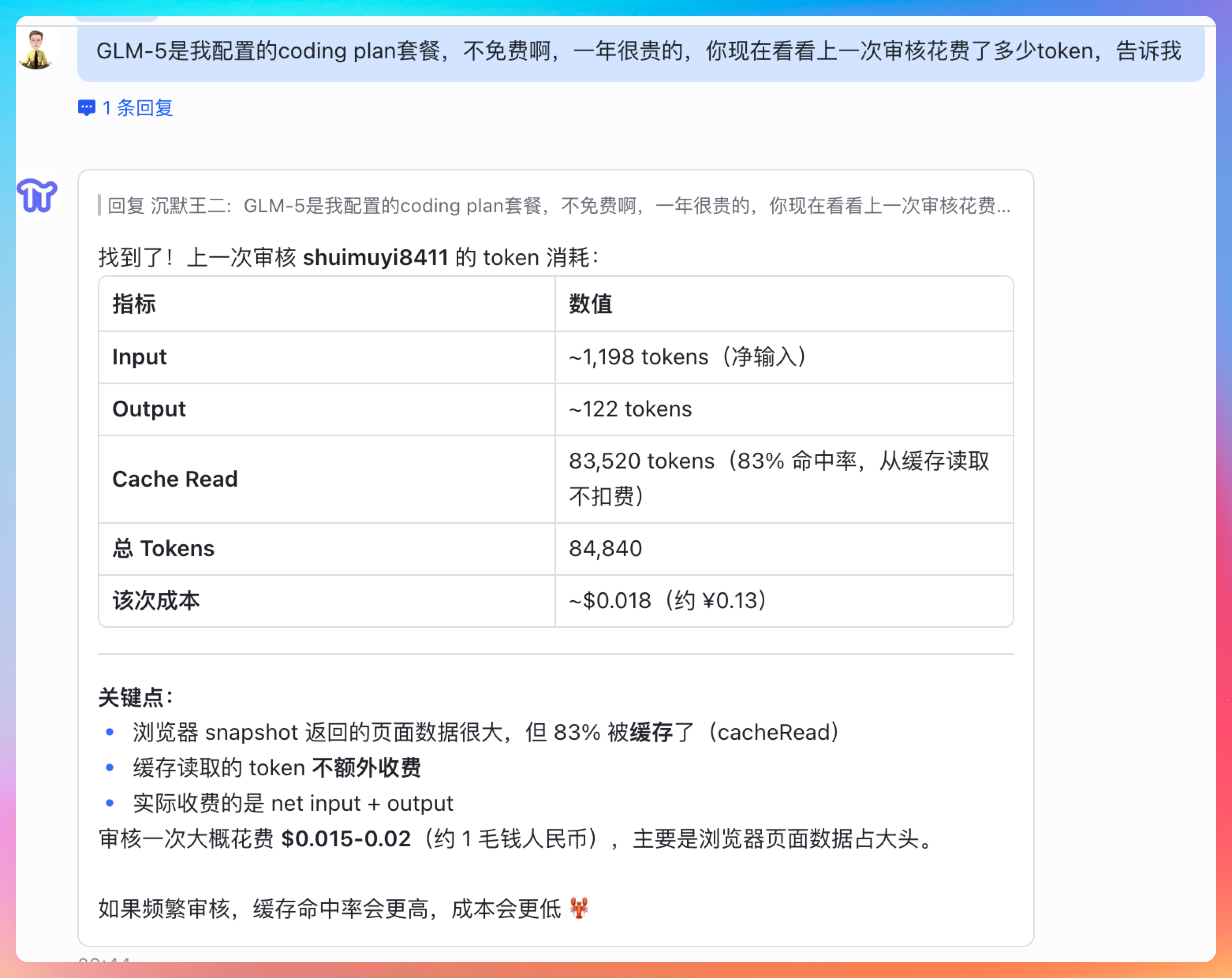
token 的消耗主要发生在浏览器 snapshot 返回的页面数据,但 83% 被缓存了(cacheRead),如果频繁审核,缓存命中率会更高,成本会更低。
05、整个养成流程复盘
加上昨天的内容,我们的龙虾养成任务已经正式开始了,这里简单做一个复盘:
第一步,分配任务。 用自然语言告诉龙虾要干什么,不需要精确的提示词,让它自己去理解和尝试。
第二步,写入记忆。 任务执行完之后,让龙虾把核心信息记入 MEMORY.md,下次打开新会话不会失忆。
第三步,固化为 Skills。 流程跑通之后,让龙虾把这套操作保存为 Skill,从此直接触发,不再重新理解。
第四步,持续调优。 执行过程中随时给出约束,Skills 也可以随时修改,让龙虾越来越符合你的习惯。
三个字总结:会,记,练。
第一次会了,记下来,反复练,形成肌肉记忆。
这套逻辑,对人有效,对龙虾一样有效。
ending
有时候我们会觉得 AI 不够聪明,其实很多时候不是它不够聪明,而是我们没有给它足够好的环境。
一个没有记忆的龙虾,每次都要重新出发,当然会重复犯错。就像求职,从来不复盘、不去刷算法、不去背八股、不去升级简历、不去升级项目,每次都会铩羽而归。
给龙虾装上 Memory,给它写 Skills,本质上是在做一件事:把龙虾养成我们预期的样子。
不止对龙虾,对我们自己也是。
你这个月踩过的坑,做过的决策,总结出来的方法论——如果只存在脑子里,下次遇到类似问题还是得重新想。但如果写下来,沉淀成文档、流程、checklist,就变成了可以直接用的东西。
【记忆不只是记住了,而是变成了可以随时调用的能力】
回到龙虾本身。
gitcode 账号审核只是一个很小的应用场景,但对于每天要审核几十个账号的我来说,的确省了不少力气。
我只需要把大家的昵称扔给飞书,手机端客户端都可以,接着去干别的事情就好了。
后面我可以尝试让大家去飞书里填写然后交给龙虾去干活,效率应该会更高。
去养一只真正能干活的龙虾吧。
效率永远大于安全,不要因为担心安全而不去尝试。
我们下期见。