某厂大模型(两个字)启动离职脱敏,核心成员需要强制签署,想离职必须提前3个月同步公司。
在大厂日爆那里看到一则消息,如题。
感觉相当夸张,说明 AI 已经发展到无论是薪酬、制度、还是规则,都跟传统互联网完全不一样了。
另外,从大家反馈的面试来看。
AI 的浓度越来越高,传统的 Java 后端八股比例在逐渐下降,有 7/3 分的趋势。
今天就带着大家过一遍高频的 AI Agent 面试题。

所有回答基于我们的 PaiCLI 来展开,这是一个用 Java 写的 AI Coding Agent,类似 Claude Code。
content
01、你在 Agent 项目中具体做了什么?
老王开门见山:“先整体介绍一下,你在这个项目里负责了哪些模块?”
我说:“PaiCLI 经历了 21 个版本迭代,从最初的 ReAct 一路做到了支持 Multi-Agent 的可交付产品。我主要负责了三块核心工作。”
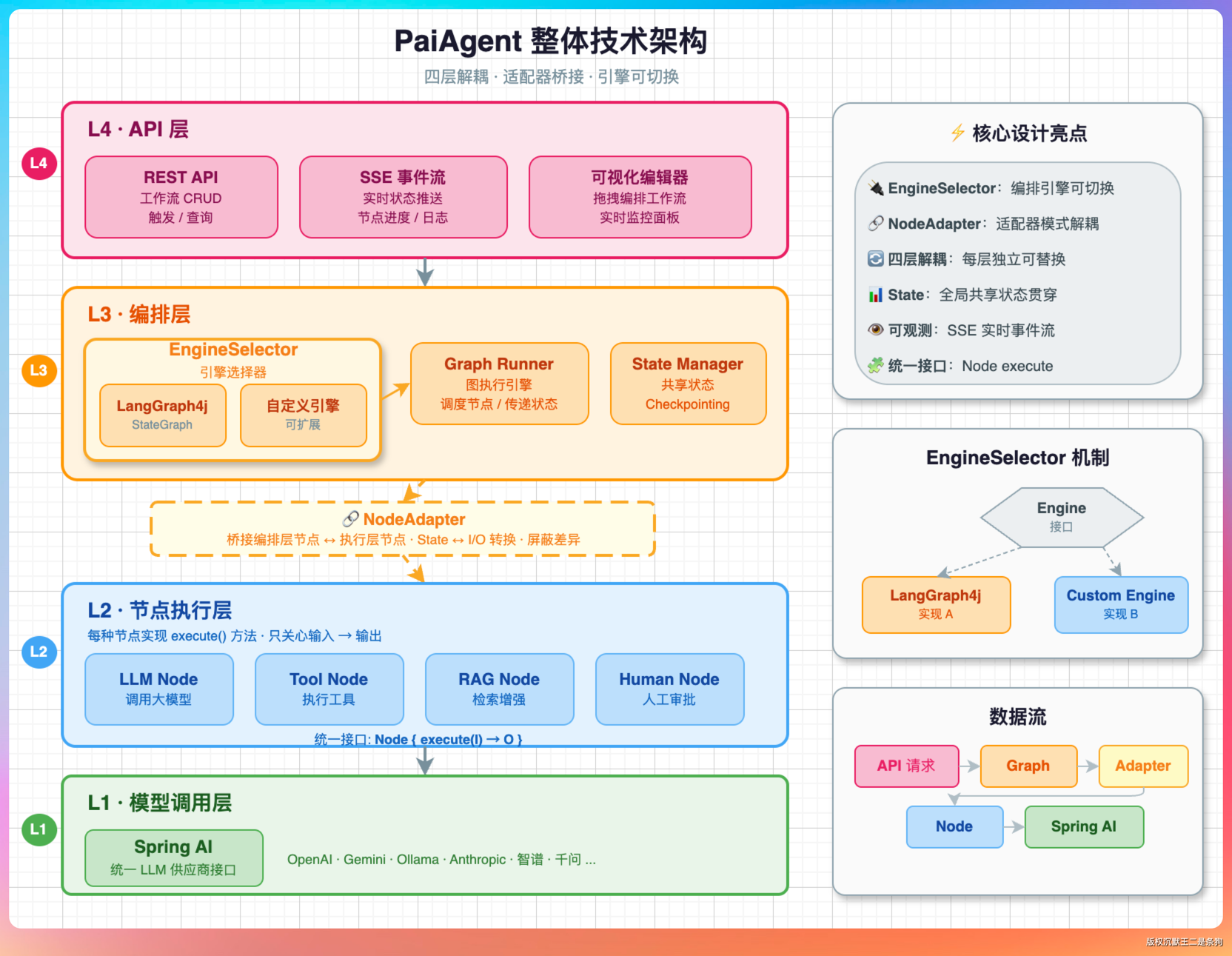
第一块是 Agent 引擎。
实现了 ReAct 模式的主循环,包括 LLM 调用、工具执行、上下文管理这一整套流程。Agent 每次循环都要做预算检查、上下文压缩、工具调度,这些机制都是我设计和实现的。
第二块是 LLM 多模型接入。
我写了一套 OpenAI 兼容的抽象客户端,基于 OkHttp3 做 SSE 流式解析,支持智谱、DeepSeek、阶跃星辰、Kimi 四个国产模型的无缝切换。每个模型有自己的特殊处理,比如智谱支持 prompt caching,DeepSeek 支持 1M 上下文窗口。
第三块是 tool use 和 MCP 集成。
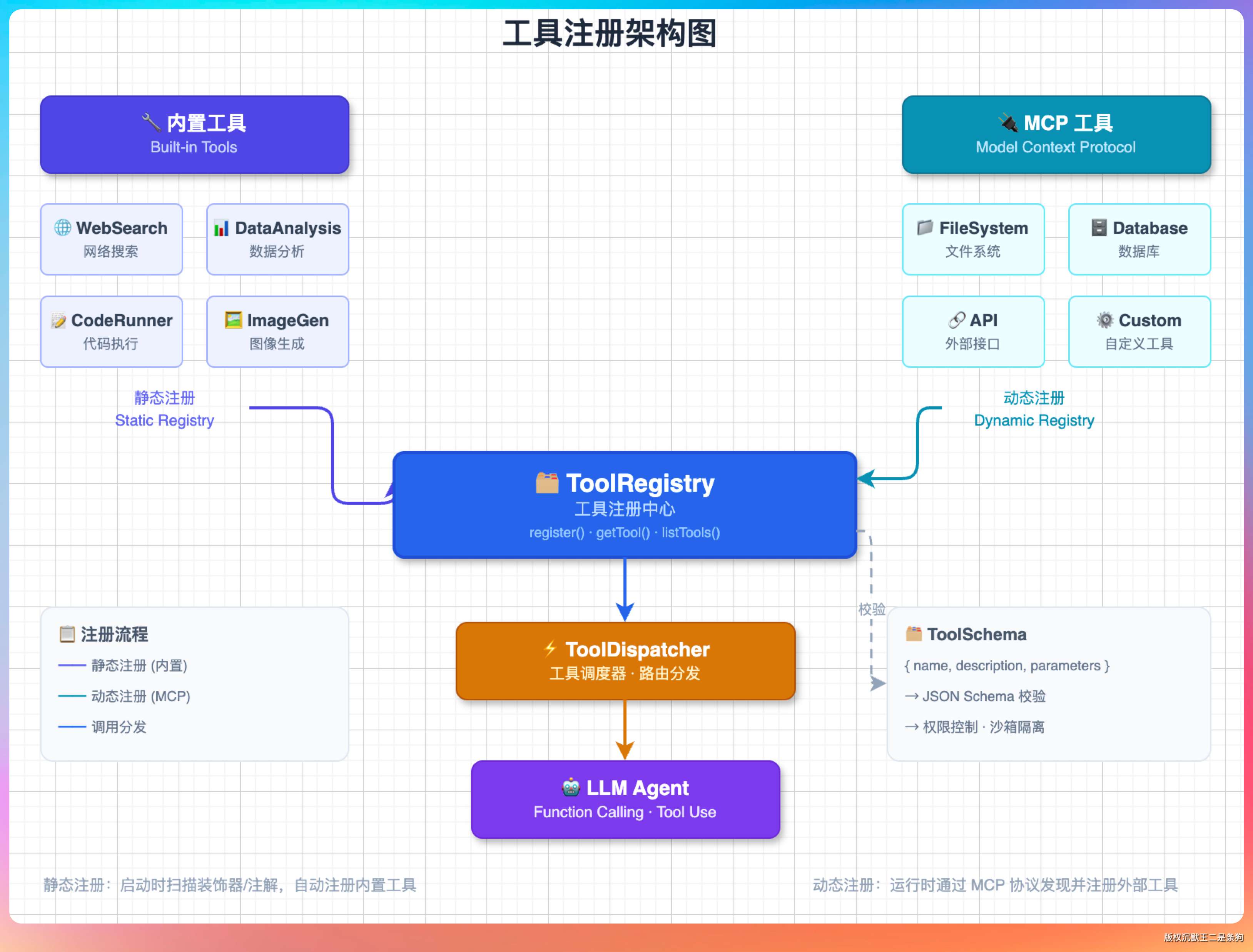
内置了 11 个核心工具,像文件读写、命令执行、代码搜索、网页抓取这些,同时支持动态接入 MCP Server 的外部工具。
02、Agent 的循环执行是怎么设计的?
老王来了兴趣:“你们的 ReAct 循环具体怎么设计的?”
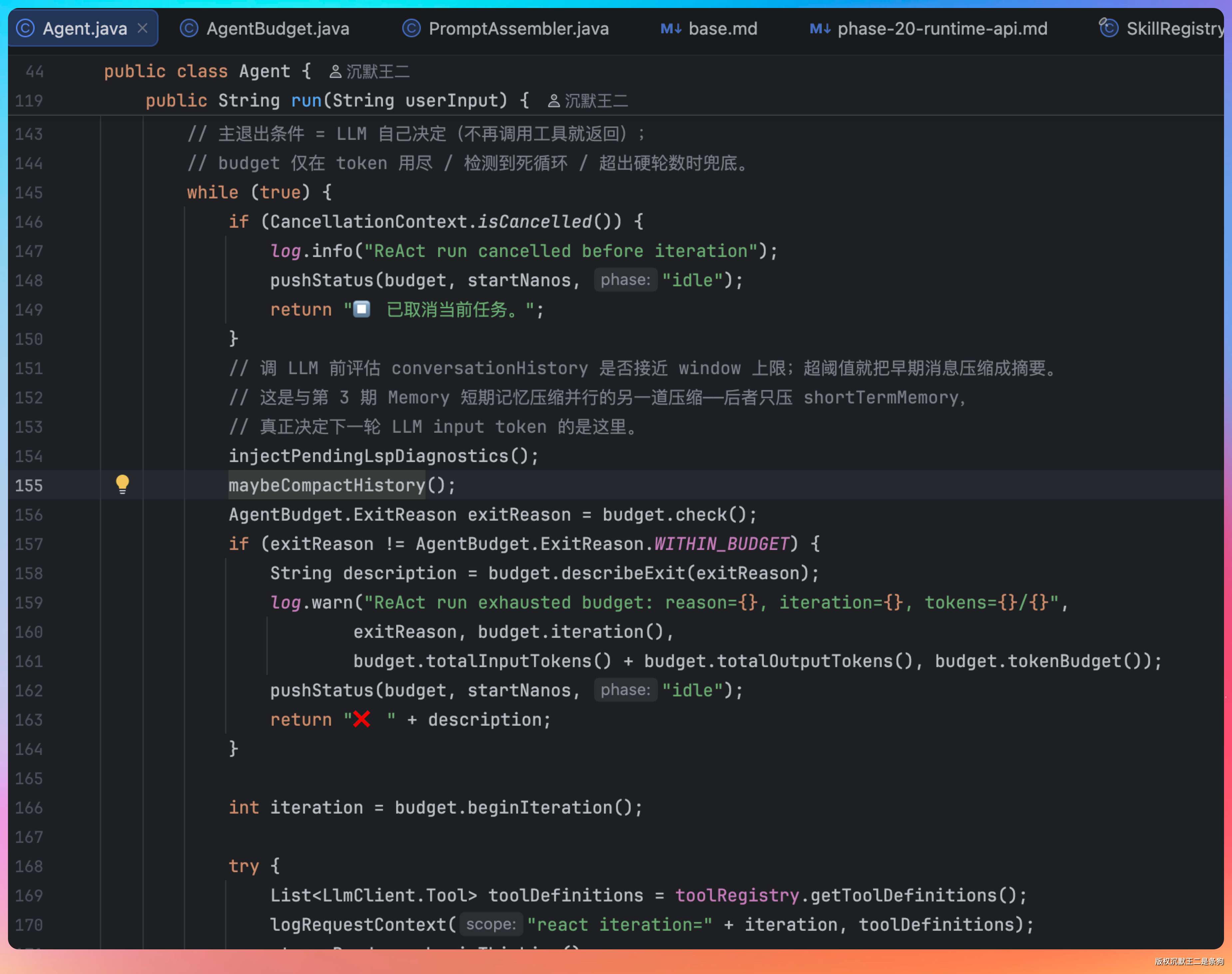
我说:“其实很简单,核心就是一个 while(true) 循环,退出条件由 LLM 自己决定。”
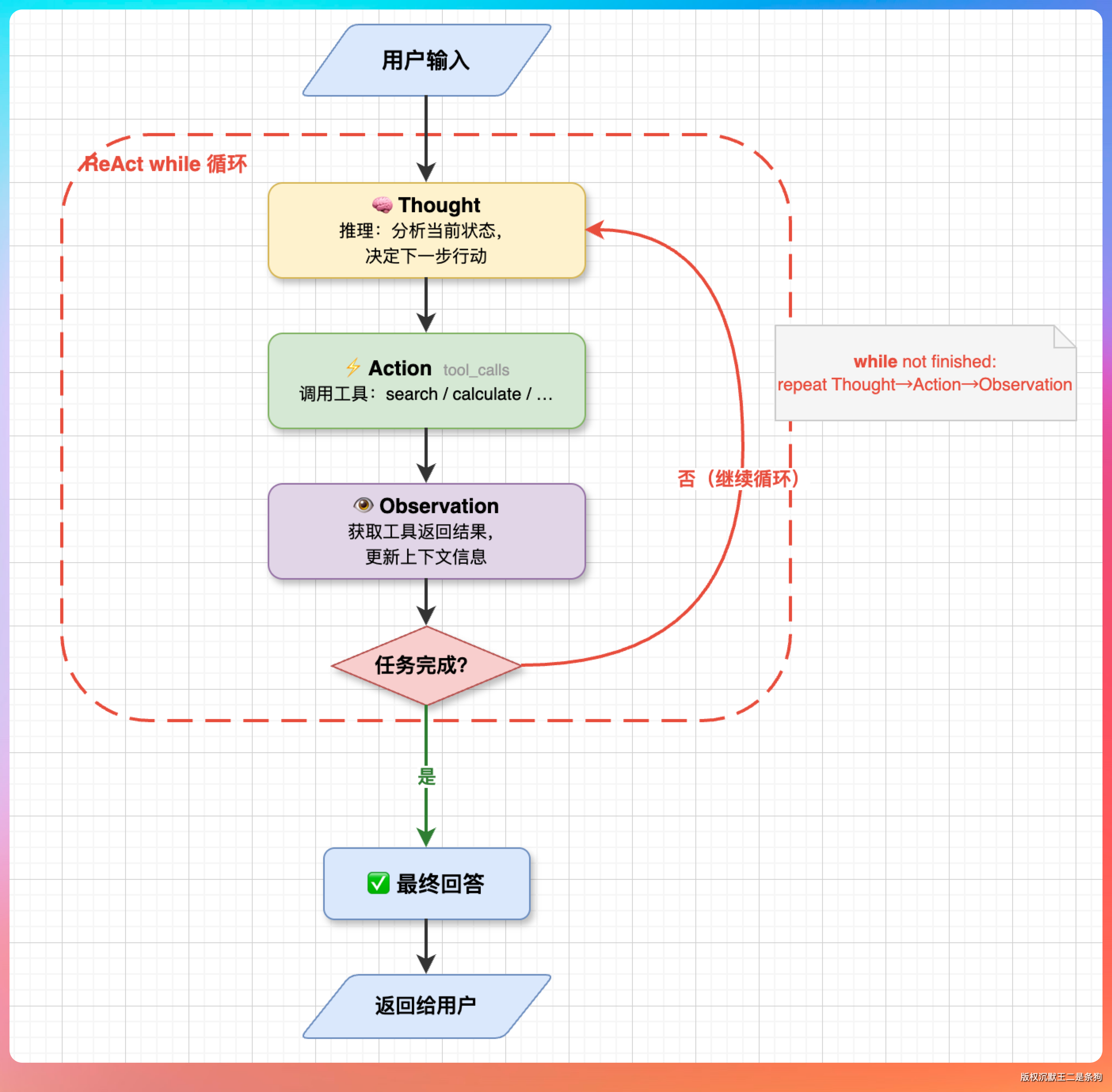
每次循环做四件事。
- 第一步,检查预算,看 token 用了多少、迭代了多少轮,如果超了就强制退出。
- 第二步,检查上下文是否需要压缩。
- 第三步,把对话历史和工具定义一起发给 LLM。
- 第四步,看 LLM 的返回,如果有 tool_calls,就执行工具,把结果塞回对话历史,进入下一轮循环;如果没有 tool_calls,说明 LLM 认为任务完成了,直接返回最终答案。
老王追问:“退出由 LLM 自己决定,那万一 LLM 陷入死循环怎么办?反复调同一个工具,停不下来。”
我说:“有兜底策略。我们会跟踪两个指标,一个是累计的 token 消耗,默认上限是模型最大上下文窗口的 80%;二是循环迭代次数,有个上限值。任何一个指标超标,都会直接跳出循环返回提示给用户。”
03、是框架内置的工具调用还是 Prompt 控制输出?
“你们用了 Spring AI 吗?工具调用的逻辑是框架帮你做的,还是自己写的?”老王接着问。
我说:“没用 Spring AI,全部自己写的。”
PaiCLI 定义了一个 LlmClient 接口作为 LLM 调用的抽象层,底下有一个基类,基于 OkHttp3 实现了 OpenAI 兼容协议的 SSE 流式请求。
工具调用的流程也是我们自己解析的。
LLM 返回的 SSE 流里,tool_calls 是分片到达的,一个工具调用的 id、name、arguments 可能分散在多个 SSE event 里。
我们回把这些碎片存起来,等流结束后组装成完整的 ToolCall 对象。
老王问:“为什么不用 Spring AI?自己造轮子不怕维护成本高吗?”
我说:“主要 PaiCLI 是命令行工具,启动速度很重要,Spring AI 太重了,也没必要,毕竟现在都是 AI Coding,基本上不存在实现不了的。”
04、System Prompt 是怎么设计的?
老王话锋一转:“聊聊你们的系统提示词设计,一次性写死还是动态拼装的?”
我说:“动态拼装的,而且是分层组装。”
我们有一个 PromptAssembler,负责把系统提示词从多个 Markdown 文件里拼起来。
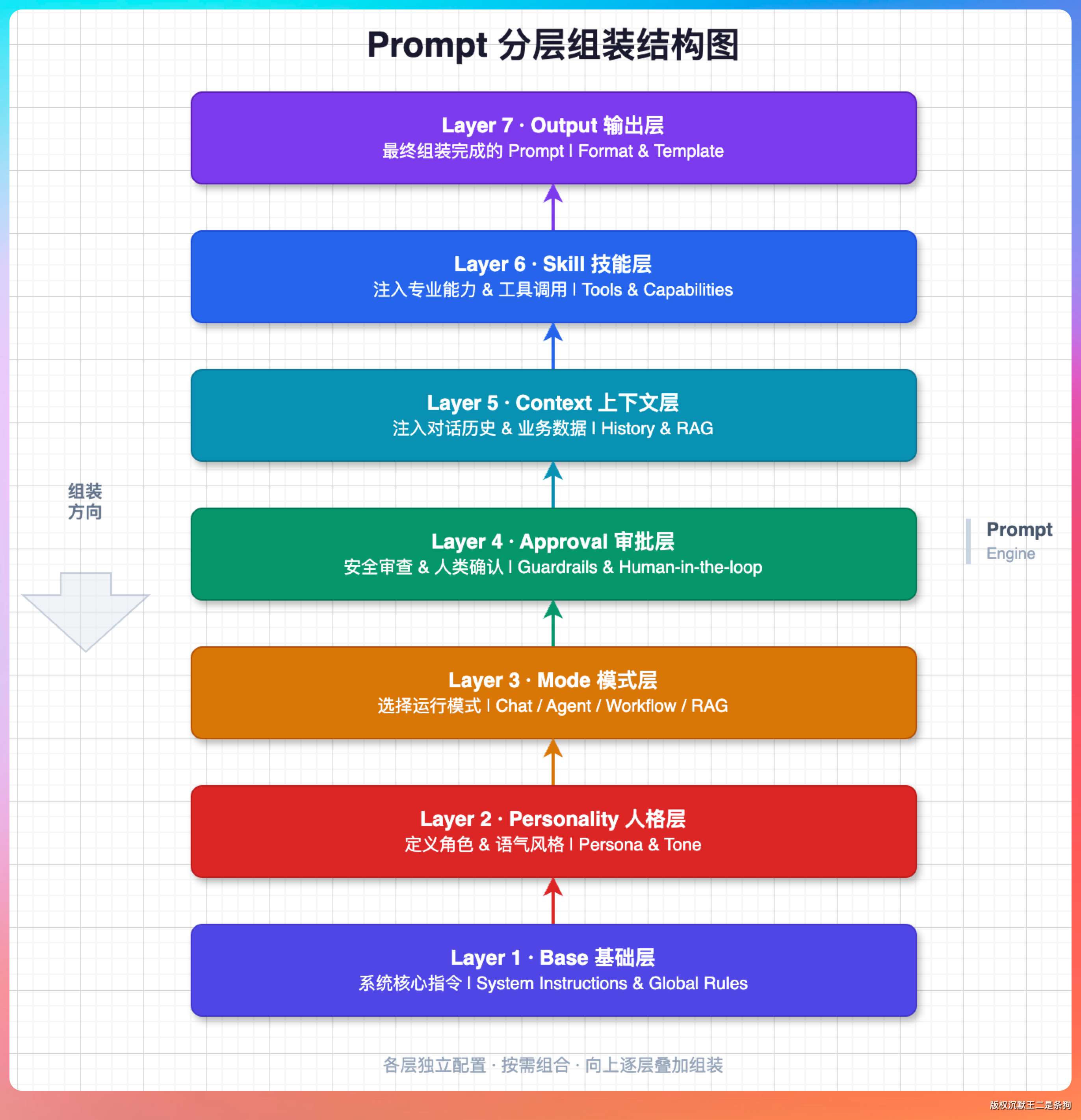
整个提示词分成 7 层:
- 第一层是 base.md,定义了 PaiCLI 的身份,比如“你是 PaiCLI,一个智能编程 Agent”,还有语言要求“用中文回复”,以及所有可用工具的列表和使用策略。
- 第二层是性格设定,目前用的是 calm.md,定义冷静理性的风格。
- 第三层是模式指令,ReAct 模式、Plan 模式、Multi-Agent 模式各有一个 Markdown 文件,告诉模型当前应该以什么方式工作。
- 第四层是审批策略,控制哪些工具需要用户确认才能执行。
- 第五层是动态上下文,包括记忆摘要和外部上下文源。
- 第六层是 Skill 索引,把启用的 Skill 描述注入进去。
- 第七层是上下文管理指令和协作协议。
老王追问:“提示词文件放在哪?用户能自定义吗?”
我说:“有三级加载优先级。第一级是 JAR 包里内置的 resources/prompts/ 目录,这是默认值。第二级是用户目录 ~/.paicli/prompts/,用户可以在这里覆盖默认提示词。第三级是项目目录 .paicli/prompts/,优先级最高,适合团队级别的定制。这个设计参考了 Claude Code 的 CLAUDE.md 机制,让不同项目可以有不同的 Agent 行为。”
05、调用 LLM 的全过程
“从用户输入到最终返回,整个 LLM 调用过程说一遍。”老王这次要听全流程。
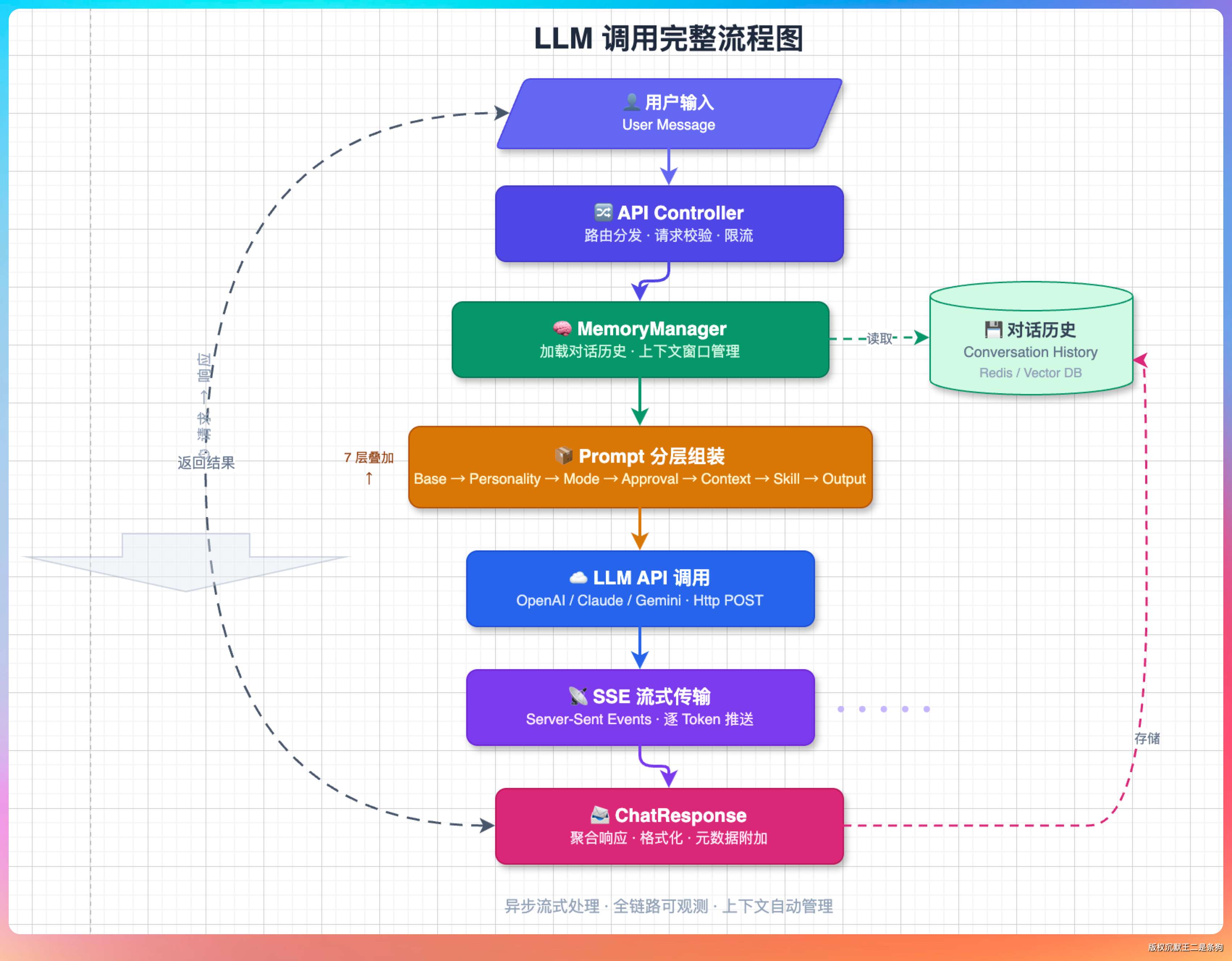
第一步,用户输入进来后,构建上下文。我们会从短期记忆里提取和当前问题相关的信息,拼进系统提示词的动态上下文。
memoryManager.addUserMessage(userInput);
String memoryContext = memoryManager.buildContextForQuery(
userInput, contextProfile.memoryContextTokens()
);
updateSystemPromptWithMemory(memoryContext);第二步,把用户消息加入对话历史。如果消息里有图片引用(比如截图路径),会把图片转成 base64 编码的 ContentPart,和文本一起打包。
第三步,进入 ReAct 循环。先检查是否需要压缩上下文,再检查预算。
第四步,构建 HTTP 请求。
把对话历史和工具定义序列化成 OpenAI 格式的 JSON。messages 数组里每条消息带 role 和 content,tools 数组里每个工具带 name、description 和 parameters 的 JSON Schema。
第五步,发送请求并解析 SSE 流。
OkHttp3 建立长连接,逐行读取 data: 开头的事件。每个事件里的 delta 可能包含三种信息:reasoning_content(思考过程)、content(回复内容)、tool_calls(工具调用)。三个字段通过 StreamRenderer 实时渲染给用户。
第六步,流结束后组装 ChatResponse,包含完整的 content、reasoning、toolCalls 列表、token 统计。
第七步,回到 Agent 循环,决定是执行工具还是返回结果。
老王追问:“你提到实时渲染,思考过程和回复内容是怎么区分的?”
我说:“靠 SSE 事件里的字段名。DeepSeek 和智谱的深度思考模式会在 delta 里返回 reasoning_content 字段,普通回复走 content 字段。PaiCLI 内部维护了两个状态,用来控制终端输出的格式。思考过程会用折叠面板的样式展示,不会和最终回复混在一起。”
(内心 OS:这题我太熟了,流式渲染那块我调了三天才搞定各种边界情况🥲)
06、Tool 什么时候发给 LLM,什么时候执行?
老王接着往下挖:“工具定义什么时候发给模型的?是注册时就发了,还是每次请求都发?”
我说:“每次请求都发。”
在 ReAct 循环里,调用 LLM 之前,都会从 ToolRegistry 拿一份最新的工具定义列表:
List<LlmClient.Tool> toolDefinitions = toolRegistry.getToolDefinitions();
LlmClient.ChatResponse response = llmClient.chat(
conversationHistory, toolDefinitions, streamRenderer
);这样做的好处是,如果中途用户通过 /mcp 命令加载了新的 MCP Server,新注册的工具在下一轮循环就能被 LLM 感知到。
工具的注册发生在构造阶段。内置工具在构造方法里逐一注册,read_file、write_file、execute_command、glob_files、grep_code 这些。每个工具由四个部分组成:名称、描述、参数的 JSON Schema、执行函数。
tools.put("read_file", new Tool(
"read_file",
"读取文件内容(仅限项目根目录之内)",
createParameters(
new Param("path", "string", "文件路径", true),
new Param("offset", "integer", "起始行号", false),
new Param("limit", "integer", "最多读取多少行", false)
),
args -> {
Path safe = pathGuard.resolveSafe(args.get("path"));
return readFileForTool(safe, args);
}
));MCP 工具是动态注册的。
用户启动 MCP Server 后,ToolRegistry 的 registerMcpTool() 方法把外部工具注册到同一个 Map 里,命名空间用 mcp__{server}__{tool} 格式隔离。
老王追问:“那执行呢?一个请求返回多个 tool_calls,是串行还是并行?”
我说:“看数量。如果只有一个 tool_call,直接在当前线程执行。如果有多个,开线程池并行跑,最多 4 个并发。”
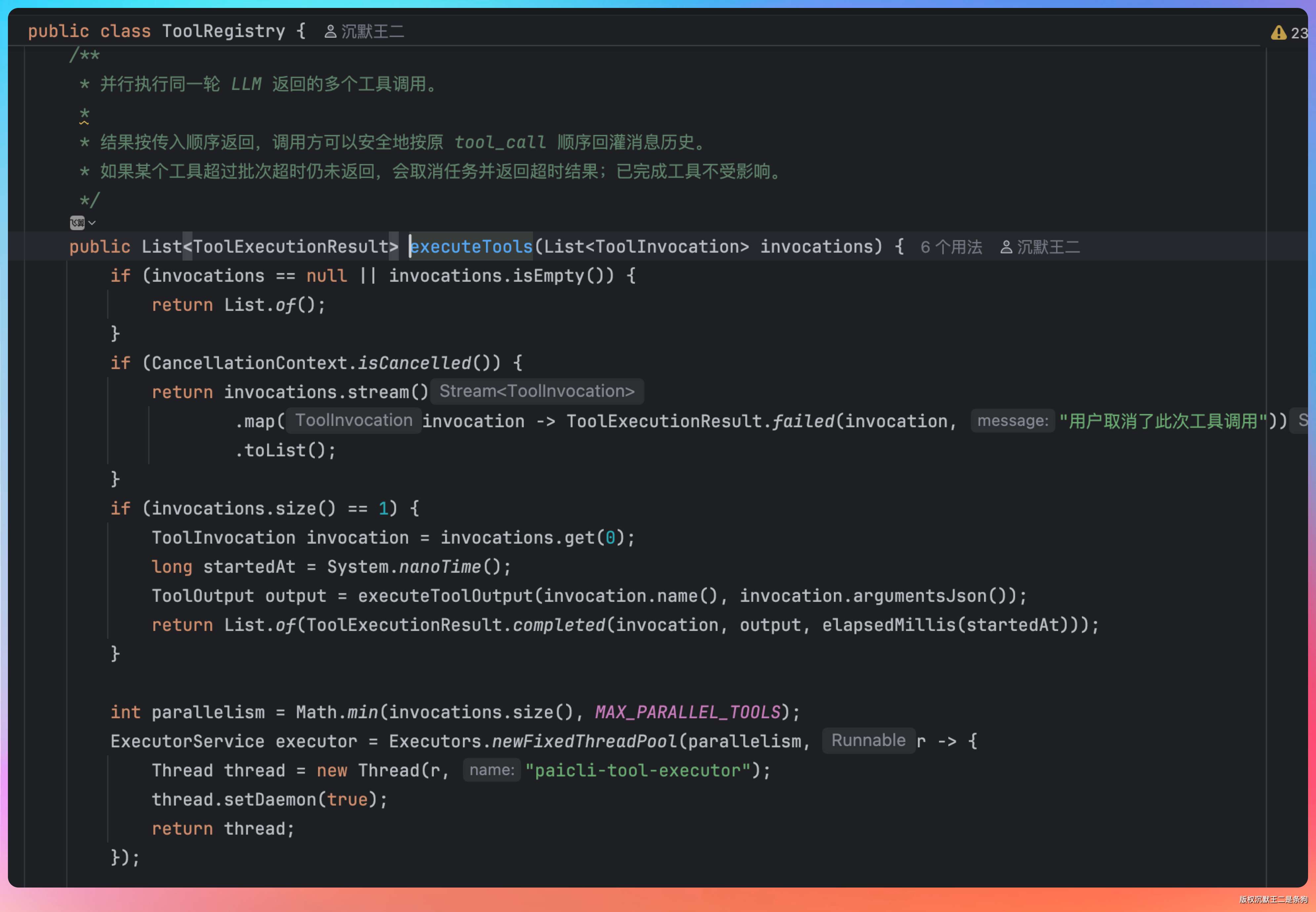
并行执行有两个超时保护:单个命令 60 秒超时,整个工具批次 90 秒超时。如果某个工具超时了,对应的 Future 会被取消,返回 TimedOut 状态,不影响其他工具的结果。
07、返回结果怎么知道该调用哪个 Tool?
“模型返回一堆 JSON,你怎么把它和具体的工具函数对应上?”老王问。
我说:“关键在 tool_calls 里的 name 字段。”
LLM 返回的每个 tool_call 有三个核心字段:id(唯一标识)、function.name(工具名称)、function.arguments(参数 JSON)。name 就是我们注册工具时用的那个名字,比如 read_file、execute_command。
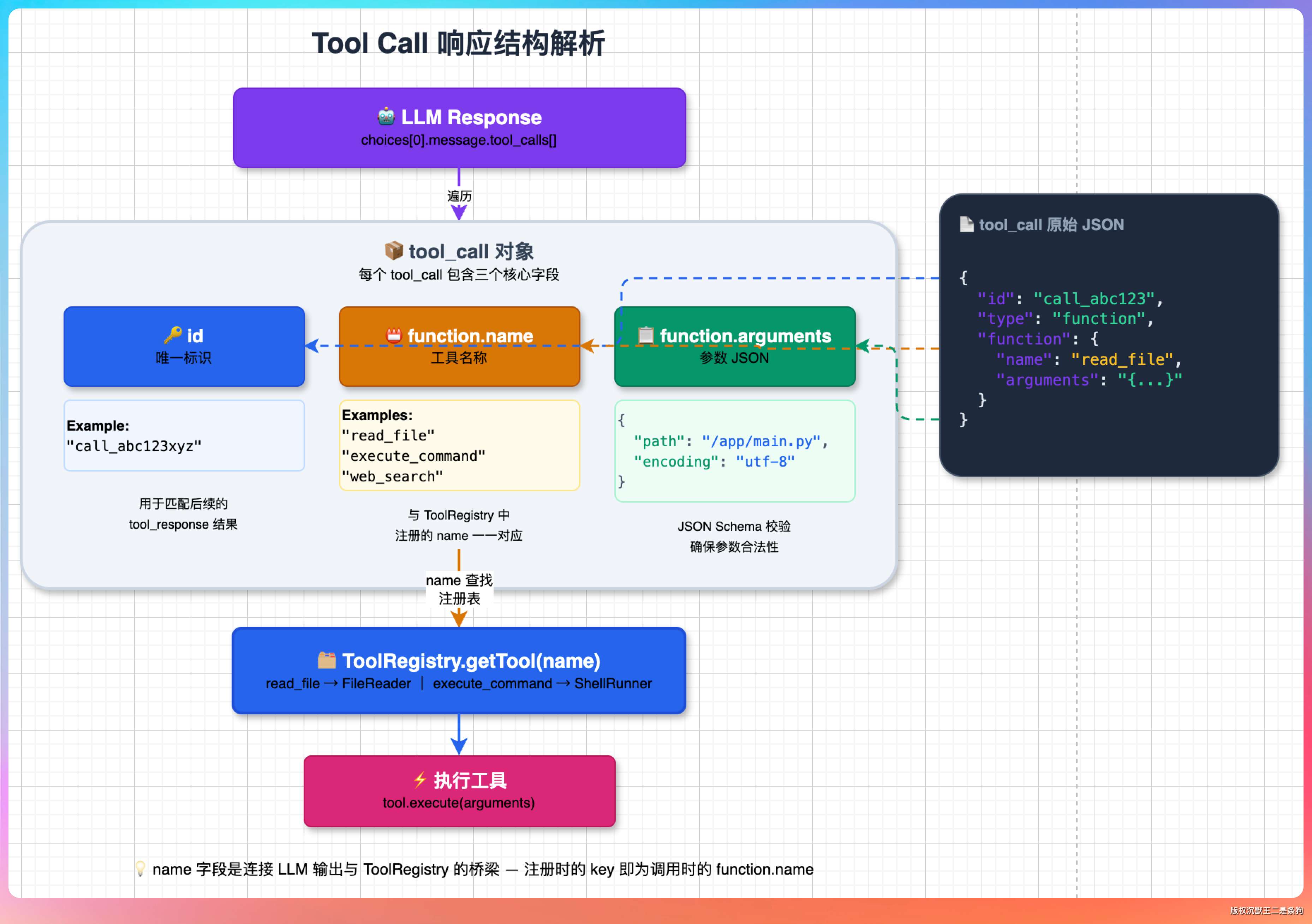
SSE 流式场景下,这三个字段不是一次到齐的。一个 tool_call 的信息可能分散在多个 SSE event 里,name 和 arguments 都是逐片段到达的。所以我们会按 index 累积。
流结束后,再组装成 ToolCall 列表。每个 ToolCall 带着完整的 name 和 arguments。
然后根据 name 去 ToolRegistry 的 Map 里查找对应的执行函数,把 arguments 的 JSON 字符串解析成参数 Map,传给工具函数执行。执行完的结果连带 id 一起包装成 tool 类型的消息,塞回对话历史,让 LLM 知道每个工具调用的结果对应哪个请求。
for (ToolExecutionResult toolResult : toolResults) {
conversationHistory.add(
LlmClient.Message.tool(toolResult.id(), toolResult.result())
);
}老王追问:“如果模型返回了一个不存在的工具名呢?比如幻觉出来一个 ‘delete_database’?”
我说:“如果找不到对应的 key,就返回一个错误信息,‘未知工具:delete_database’。这条错误信息会作为 tool 消息塞回对话历史,LLM 看到之后通常会自我纠正,换一个正确的工具重试。我们在 base.md 的系统提示词里也明确列出了所有可用工具的名称,减少幻觉的概率。”
(内心 OS:嘿嘿嘿,老王,这种细节的追问都难不住我🤣)
08、记忆压缩方式,怎么生成摘要?
老王最后一题:“你前面提到了上下文压缩,具体怎么做的?怎么生成摘要?”
我说:“在每次 LLM 调用前触发。”
检查逻辑很简单,先估算当前对话历史的 token 数,如果低于阈值(默认是模型最大上下文窗口的 90%),什么都不做。超过阈值了,就启动压缩。
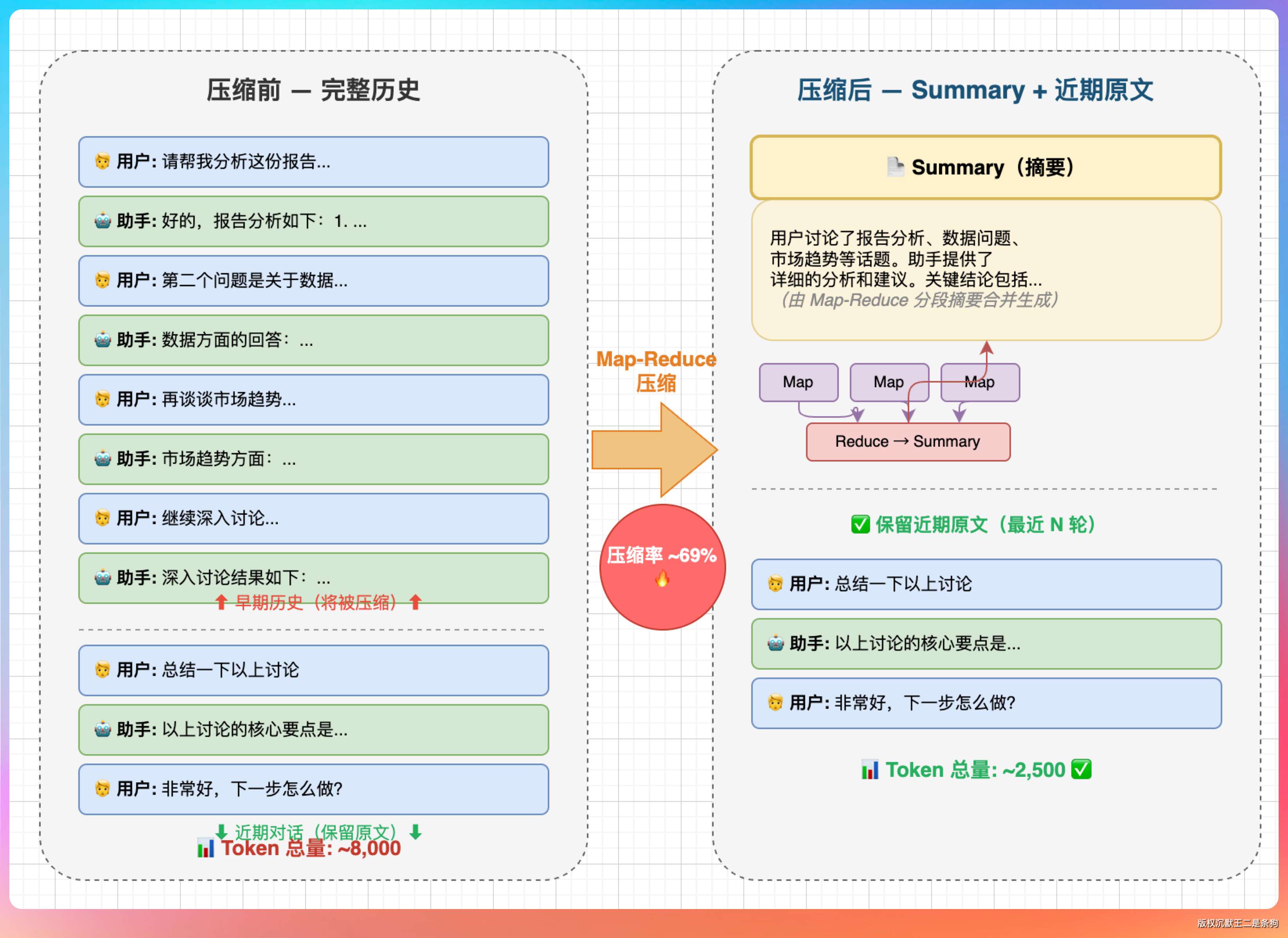
压缩不是全量压缩,而是按“轮次”分割。
保留最近 3 轮用户对话不动,把更早的对话拿出来生成摘要。分割点必须落在 user 消息的边界上,不能把一组 tool_call 和 tool_result 拆开,否则 LLM 无法理解。
拿到要压缩的消息后,调用 LLM 生成摘要。
摘要提示词是精心设计的,要求保留四类关键信息:用户的核心诉求、Agent 已完成的操作、达成的共识、未解决的问题。
private static final String SUMMARY_PROMPT = """
请把下面的对话历史压缩成简明摘要,保留:
1. 用户提出的关键诉求与目标
2. Agent 已经完成的关键操作(哪些工具调用了什么、返回了什么核心结果)
3. 已经达成的共识或结论
4. 仍未解决的问题或待办
不要复述每条原文,不要列举所有工具调用,不要保留无关闲聊。
输出 1-3 段中文,不要用列表,不要加任何前缀或元描述。
""";摘要生成后,重建对话历史。
结构是:系统提示词 → 一条 user 消息,装压缩摘要 → 一条 assistant 消息,内容是“好的,我已了解之前的上下文,请继续。” → 最近 3 轮原始对话。
assistant 消息是协议层面的约定。OpenAI 兼容协议要求 user 和 assistant 消息交替出现,不能有两条连续的 user 消息。加这条“确认收到”的 assistant 消息,是为了保证消息序列的合法性。
老王追问:“摘要的输入有长度限制吗?如果要压缩的对话本身就有几万字呢?”
我说:“有的,限制在 6 万字符。超过这个长度的部分会被截断,只取前 6 万字符送去生成摘要。这是为了防止摘要请求本身超出 LLM 的上下文窗口。实际使用中,3 轮保留 + 90% 触发阈值的组合下,需要压缩的内容一般在 2-3 万字符,很少触及这个上限。”
老王追问:“压缩之后 token 能降多少?”
我说:“一般能压到原来的 20%-30%。比如压缩前 8 万 token,压缩后大概 2-3 万。摘要本身通常只有几百到一千多 token,加上保留的最近 3 轮原始对话,总量会下降很多。日志里会打印压缩前后的 token 数和消息数对比,方便观察效果。”
如何写到简历上?
AI编程助手|Agent开发|PaiCLI 2026-03 ~ 至今
项目简介:基于 Java 的 AI Coding Agent 命令行工具,对标 Claude Code,支持 ReAct、Plan-and-Execute、Multi-Agent 三种执行模式,接入智谱、DeepSeek、阶跃星辰、Kimi 等国产大模型。
技术栈:Java 17、OkHttp3、Jackson、JLine3、MCP Protocol
核心职责:
- 设计并实现 ReAct 主循环引擎,基于 LLM 自主决策的 while(true) 架构,集成预算管理(token/迭代双维度),实现自动上下文压缩。
- 基于 OkHttp3 + SSE 实现 OpenAI 兼容的多模型接入层,支持 ToolCall 分片累积解析。
- 内置 11 个核心工具 + MCP 动态扩展,支持多工具并行执行(最大 4 并发)、超时保护和有序结果返回。
- 实现 7 层系统提示词组装架构,支持 JAR 内置 → 用户级 → 项目级三级覆盖,实现模式切换和上下文动态注入。
- 设计上下文压缩机制,按用户轮次分割、LLM 生成摘要、保留最近 3 轮原始对话,token 压缩率达 70%-80%,解决长对话场景下的上下文溢出问题。