我测了 Qoder Experts 整整一天,Agent 专家团真的牛。
大家好,我是二哥呀。
Qoder V0.8 发布了 Experts Mode,大号我拿 PaiGit 做了增量功能测试(issue和Wiki),Experts Mode 的表现让我有点上瘾。
但增量开发本质上还是在已有代码上修改,心里还有个疑问没有解开:如果是从零开始搭一个全新模块,Experts Mode 还能稳住吗?
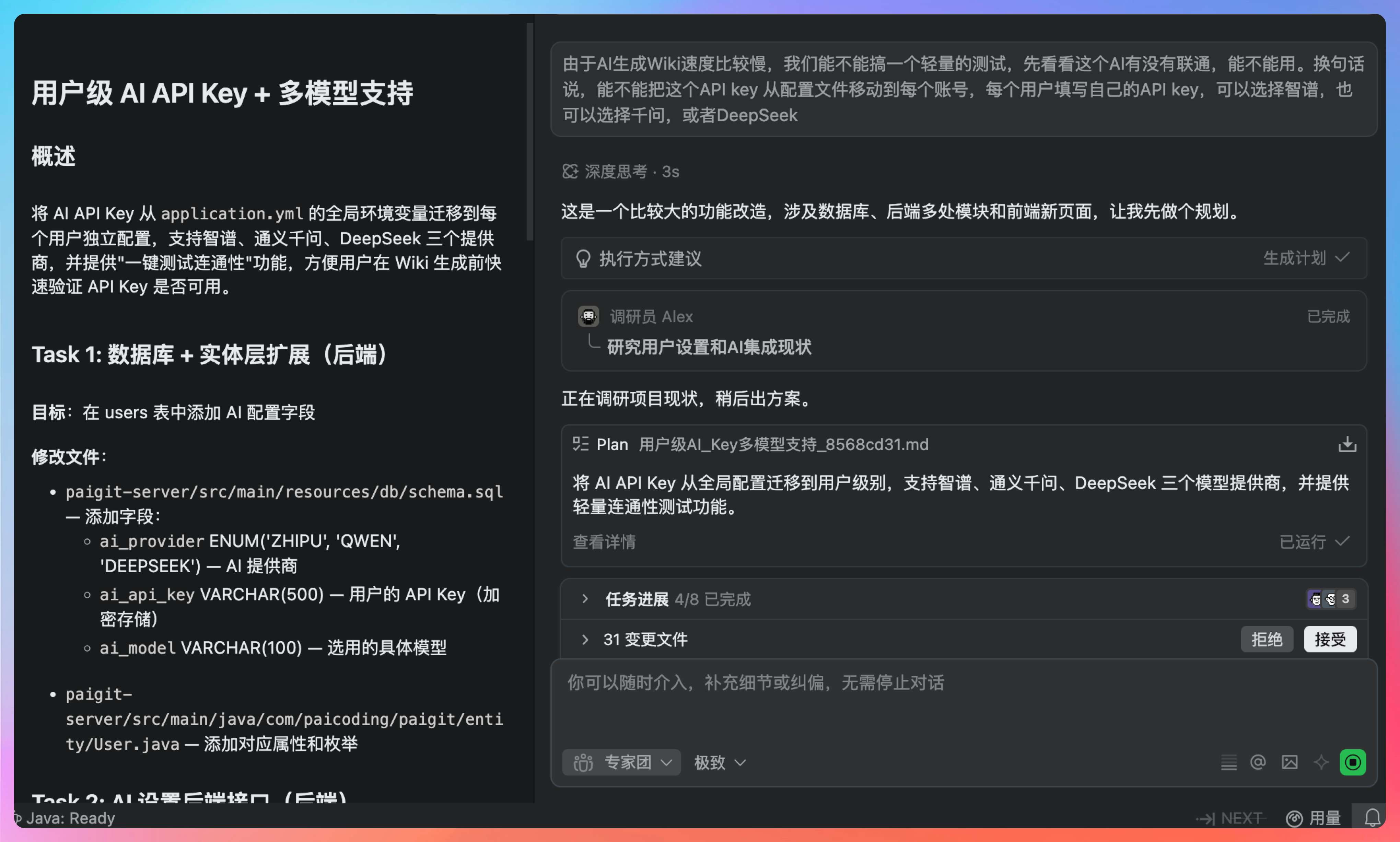
于是我这次换了一个更有挑战性的任务——让 PaiAgent 开发一个大模型 API key 接入功能,给每个用户使用,这样在使用 Wiki 功能的时候,就可以用自己的套餐。
典型的从 0.1 到一的全栈开发任务,拿来考验 Experts Mode 再合适不过。
全篇内容非常肝,系好安全带,我们发车。滴滴滴,出发啦。
01、从零开发的挑战
增量开发有个天然优势:现有代码就是最好的参考。
AI 可以看着 Issue 模块学怎么设计实体,看着 Wiki 模块学怎么写 Controller,照葫芦画瓢就能完成八成。即使某个地方出了偏差,改起来代价也不大。
但从零开发不一样。
没有参考,意味着 AI 需要自己从头决定:数据库表怎么设计、API 路径怎么规划、前后端接口怎么约定、哪些逻辑要放在数据库层保证原子性、哪些要在应用层处理。每一个决策都可能影响后续,一旦架构选错,后期返工成本极高。
注意,每次有新的需求,Qoder 的 Experts Mode 都会先让调查员 Alex 进来深入调查一番。
看看有哪些基础设施可以用,免得伤筋动骨。
我故意在需求里没有说清楚这些细节,想看看 Experts Mode 自己能不能发现并处理这些。
这个问题在软件工程里叫“需求模糊性处理”。优秀的架构师会在设计初期就识别出这些模糊点,并主动澄清。
大部分 AI 工具在面对模糊需求时要么胡猜,要么卡住不动。
我想看看 Qoder 的 Leader Agent 会怎么处理。
从结果来看,Qoder 处理的非常不错。
更重要的是,这类任务其实特别适合拿来测 Agent 的真实水平。
为什么?
因为它不是那种“改个按钮颜色”“加个接口字段”的轻量活,而是一个典型的跨层改造:数据库、后端服务、外部模型调用、前端设置页、权限校验、异常提示、回归验证,全都要动。任何一个环节理解不到位,最后都可能表现成“功能看起来做完了,但其实不能上线”。
所以我这次盯的,已经不是单个 Agent 会不会写代码,而是整套 Experts Mode 能不能同时做到三件事:
- 第一,能不能把模糊需求补全成一套可执行方案
- 第二,能不能在多人并行的情况下保持接口和实现一致
- 第三,能不能在交付前自己把坑踩一遍,而不是把问题留给我收尾
如果这三件事都能做到,那它的价值就不只是“帮我省点时间”,而是真的开始接近一个有组织能力的 AI 开发团队。
02、启动 Experts Mode
打开 Qoder,新建一个会话,切换到【专家团】,也就是 Experts Mode,输入需求:
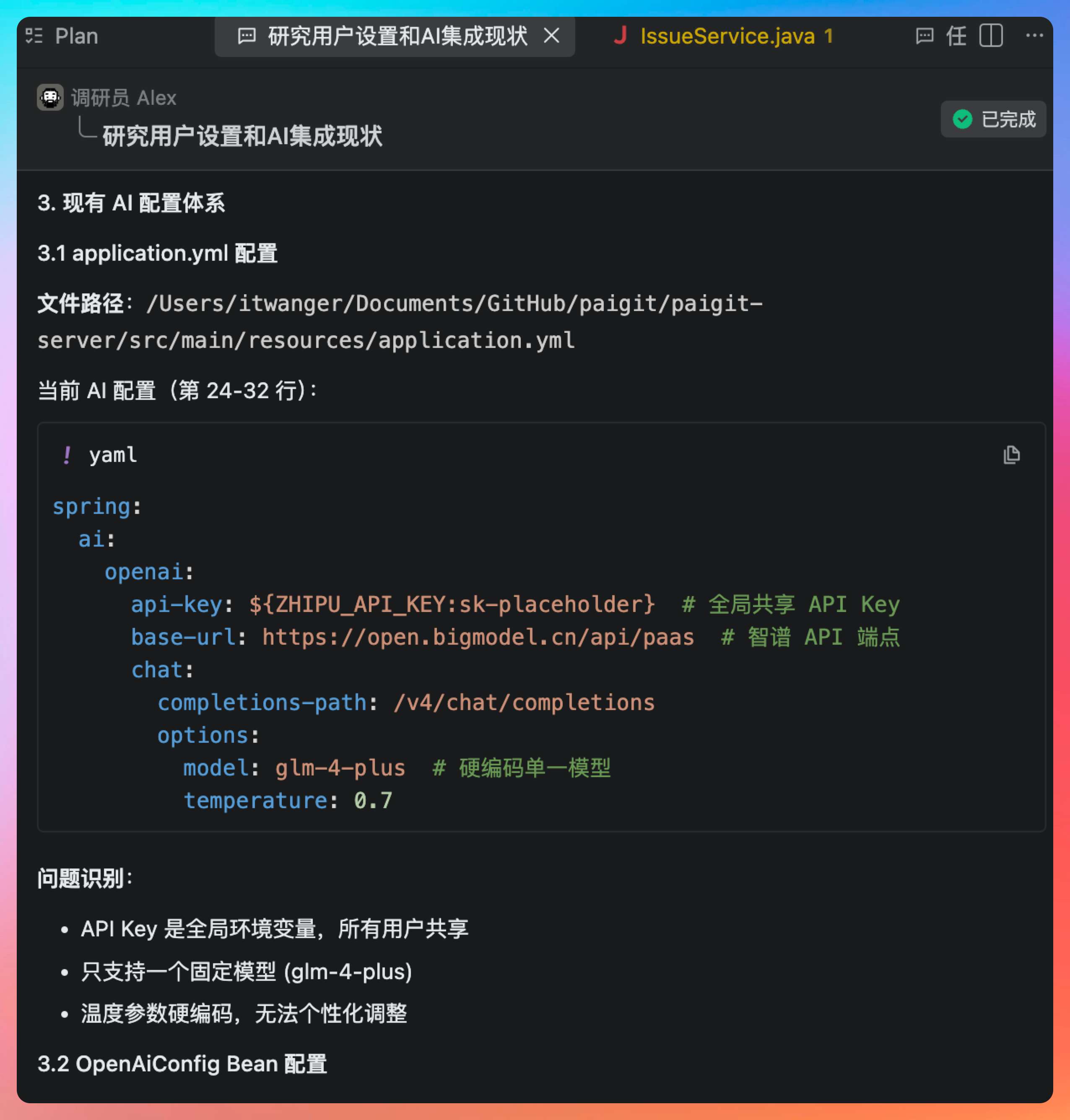
由于 AI 生成 Wiki 速度比较慢,我们能不能搞一个轻量的测试,先看看这个 AI 有没有联通,能不能用。换句话说,能不能把这个 API key 从配置文件移动到每个账号,每个用户填写自己的 API key,可以选择智谱,也可以选择千问,或者 DeepSeek
输入完成,按下回车,Leader Agent 开始工作。
这一步是我最感兴趣的:面对一个全新模块,它会怎么拆解?
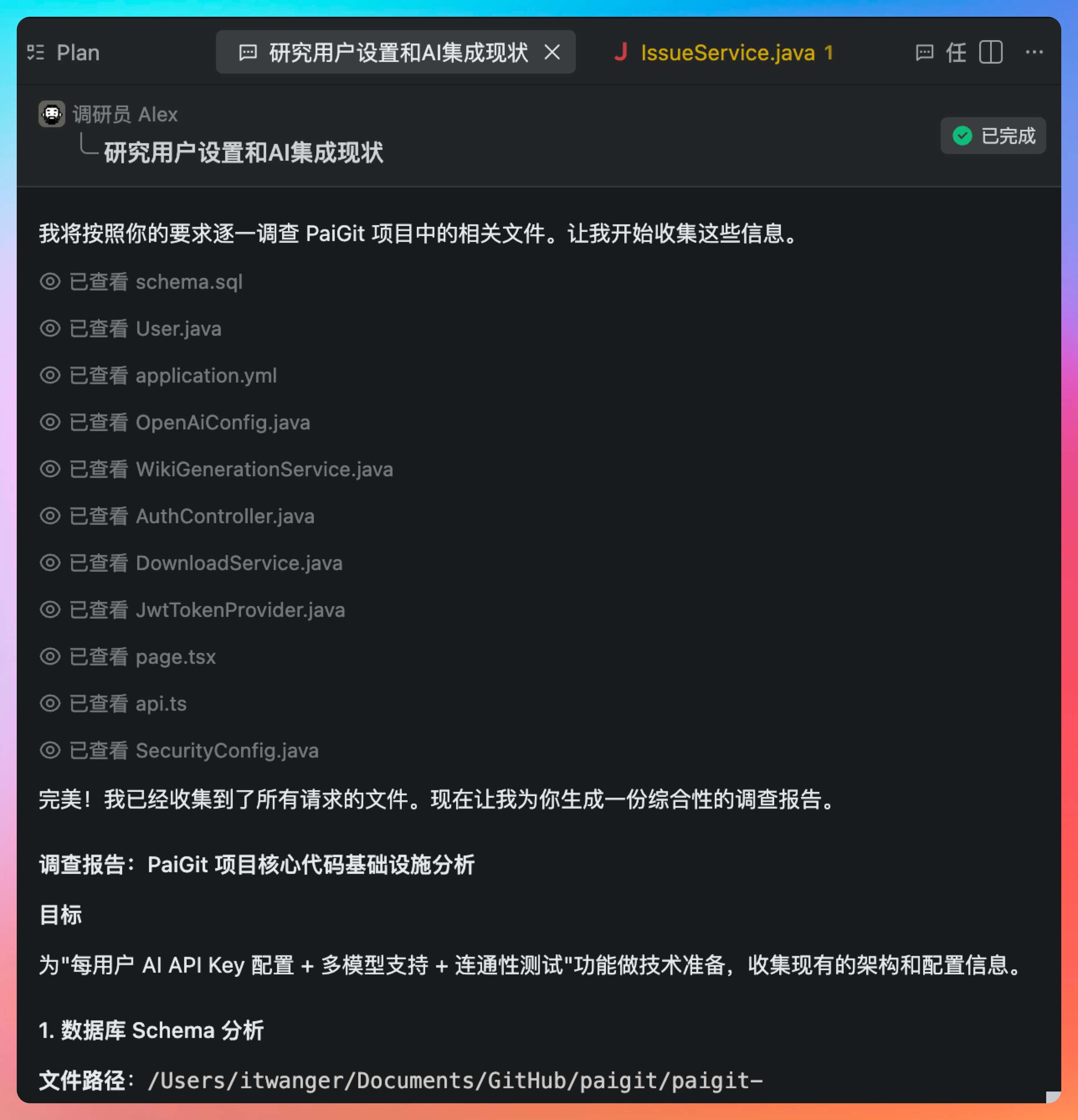
等了大概 15 秒,研究员 Alex 就把事情给调研清楚了。
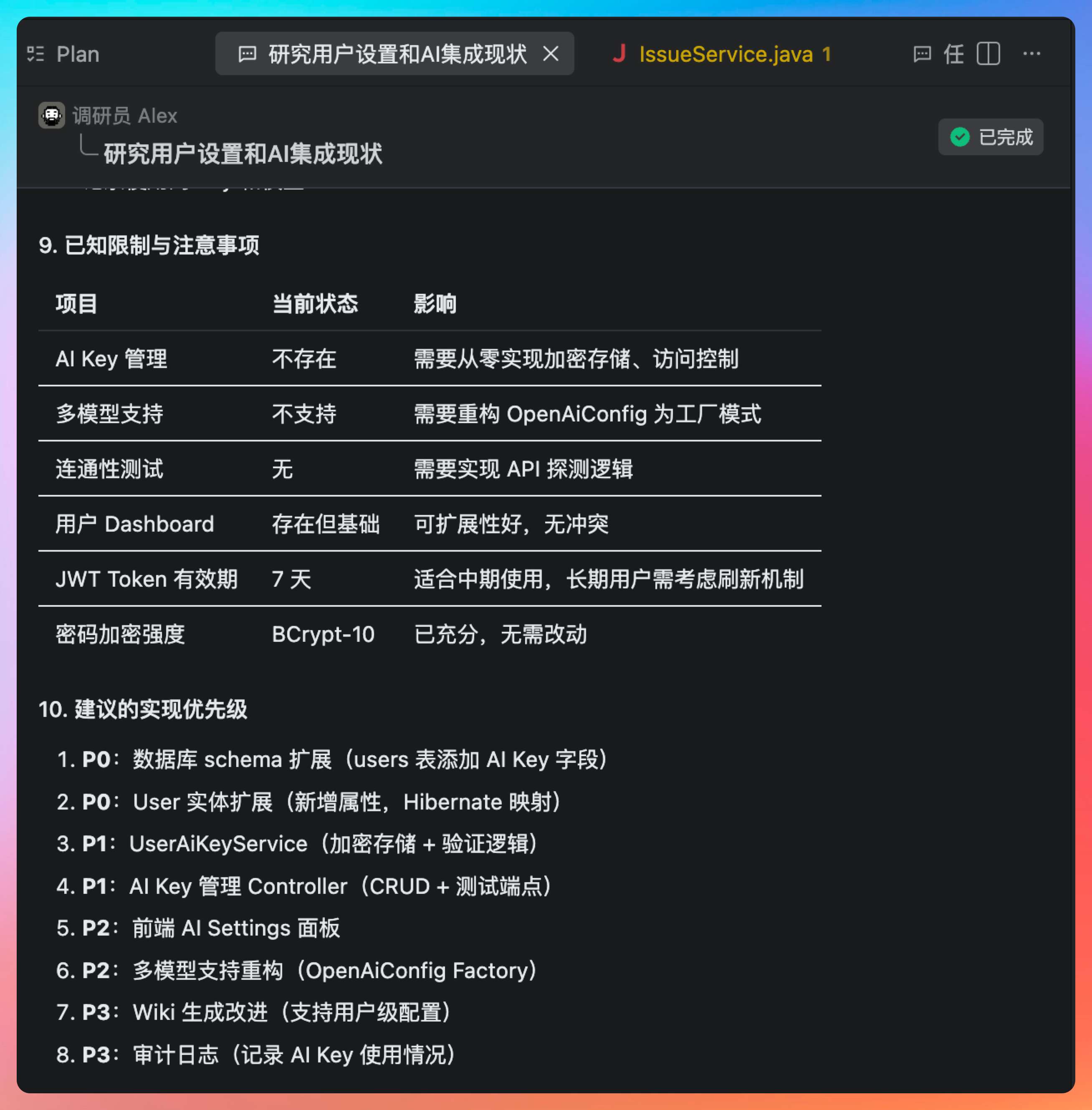
一共八个阶段,两个 P0,两个 P1,两个 P2,两个 P3:
- P0:数据库 schema 扩展(users 表添加 AI Key 字段)
- P0:User 实体扩展(新增属性,Hibernate 映射)
- P1:UserAiKeyService(加密存储 + 验证逻辑)
- P1:AI Key 管理 Controller(CRUD + 测试端点)
- P2:前端 AI Settings 面板
- P2:多模型支持重构(OpenAiConfig Factory)
- P3:Wiki 生成改进(支持用户级配置)
- P3:审计日志(记录 AI Key 使用情况)
这种优先级分级的思路非常专业。
P0 是阻塞性的基础工作,没有数据库字段和实体扩展,后续所有功能都无法开展。P1 是核心功能,包括加密存储和 API 接口,这是用户能感知到的主要价值。P2 是体验优化,前端面板和配置工厂让功能更完整。P3 是增值功能,审计日志对于企业级应用很重要,但对于 MVP 版本可以延后。
接着,出了一份 plan 计划。
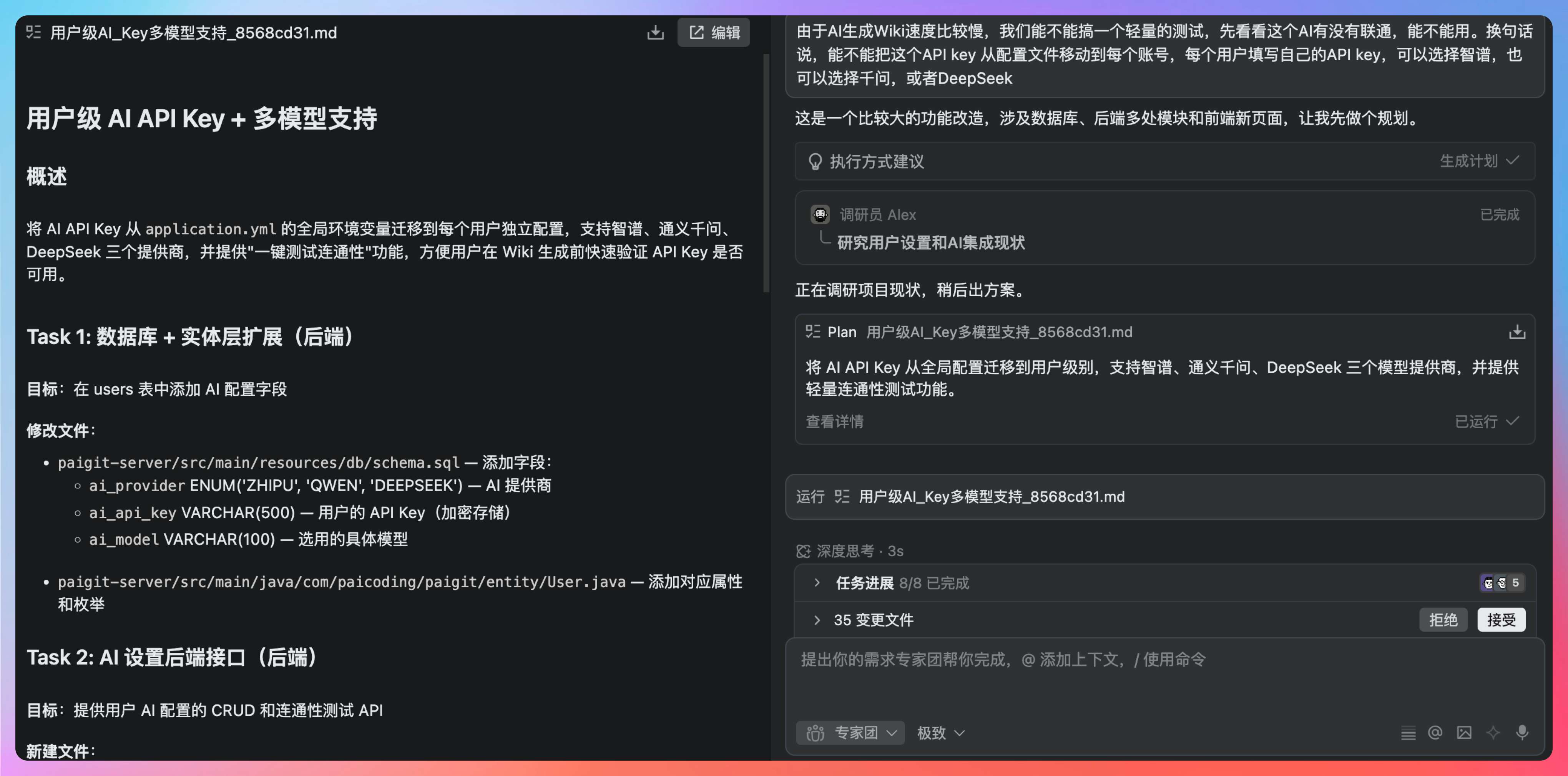
功能就是我们前面提到的。
将 AI API Key 从 application.yml 的全局环境变量迁移到每个用户独立配置,支持智谱、通义千问、DeepSeek 三个提供商,并提供一键测试连通性功能,方便用户在 Wiki 生成前快速验证 API Key 是否可用。
最后规划了 5 个任务。

- Task 1: 数据库 + 实体层扩展(后端)
- Task 2: AI 设置后端接口(后端)
- Task 3: Wiki 生成服务改造(后端)
- Task 4: 前端 AI 设置面板
- Task 5: 验证
这种任务拆解能力体现了 Leader Agent 对软件工程最佳实践的理解。
Task 1 和 Task 2 是独立的后端开发,可以并行;Task 3 依赖 Task 2 的接口定义;Task 4 前端依赖 Task 2 的 API;Task 5 验证依赖所有前面的任务。这种依赖关系的识别,让并行开发成为可能,也避免了无效的阻塞等待。
这种能力不是简单的“读代码”,而是真正的“架构理解”。
而且这里还有一个很多人第一次用多 Agent 工具时容易忽略的点:Leader Agent 的价值,不在于它会不会写某一段代码,而在于它能不能把“正确的工作顺序”定下来。
软件开发最怕的不是某个任务做慢了,而是顺序错了。数据库还没定,前端就先写表单;接口协议没定,测试就先录脚本;最后大家都很忙,但忙出来的是一堆返工。
这次 Qoder 给我的观感是,它不是在机械地把任务分给 5 个 Agent,而是在先判断依赖,再安排并行。这个差别非常大。前者只是“多开几个窗口”,后者才是“像个 Tech Lead 一样组织战斗”。
03、五个专家同时开工
调研完毕后,三个后端工程师、一个前端工程师和一个测试工程师开始并行工作。
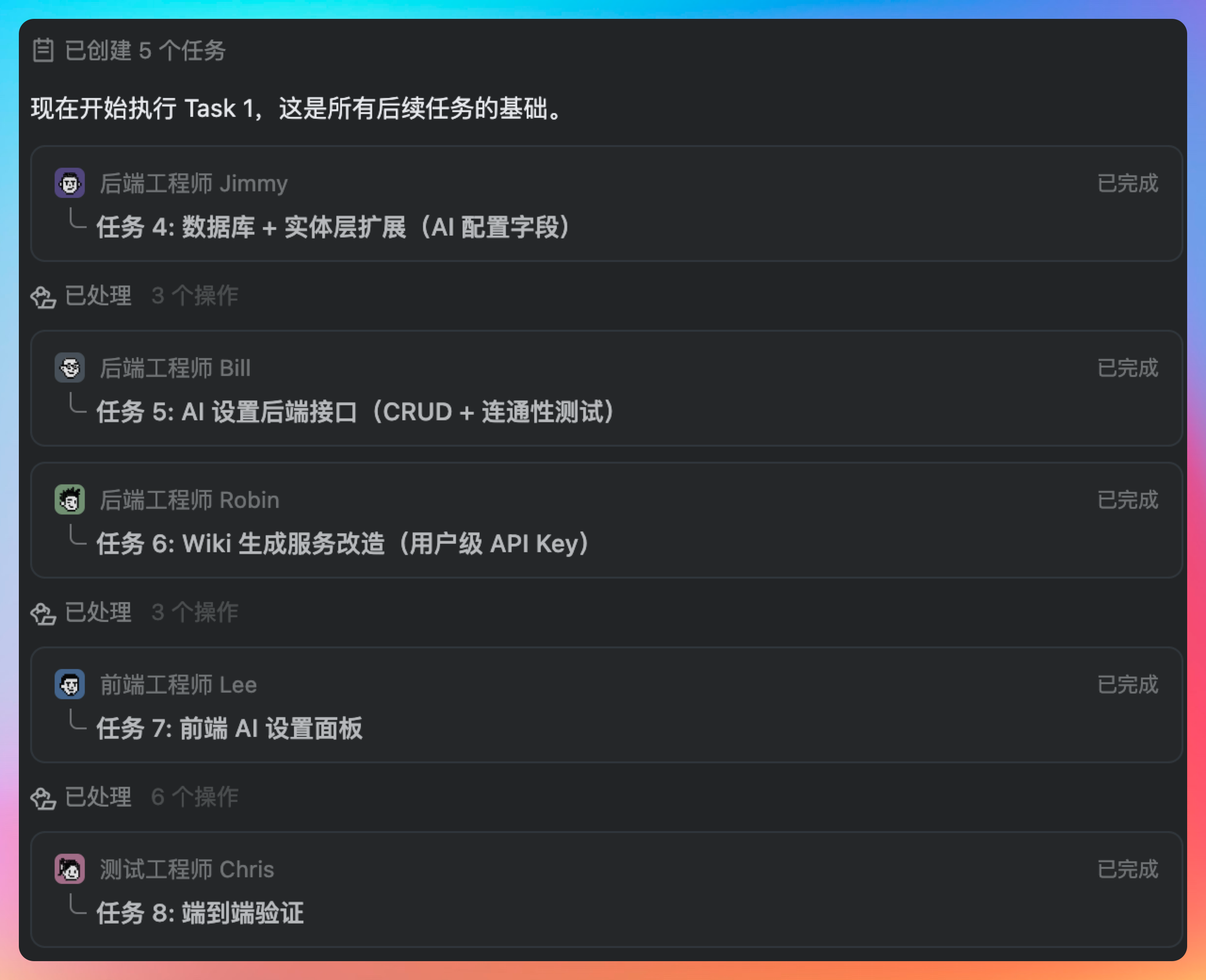
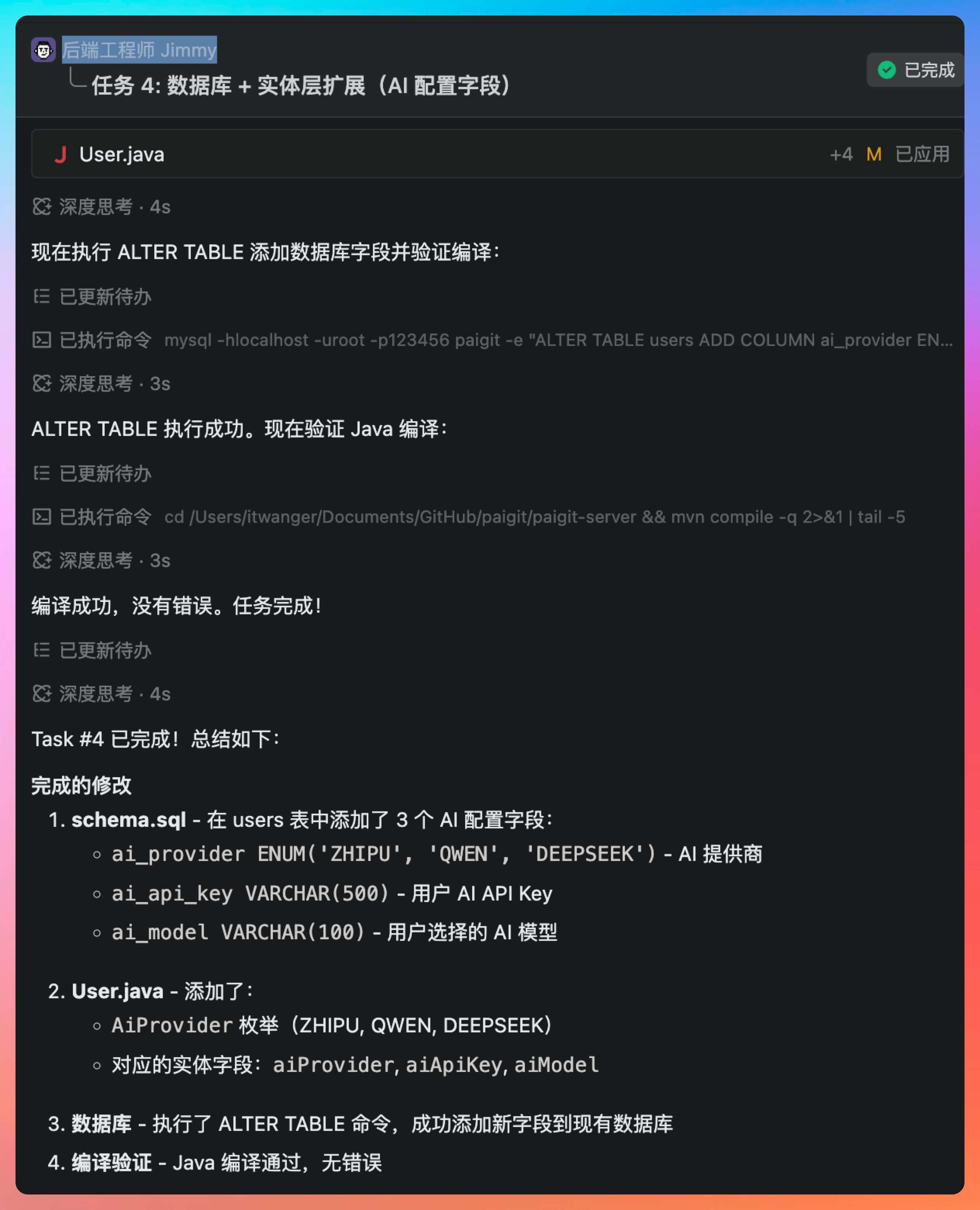
后端工程师 Jimmy 负责任务 1:数据库 + 实体层扩展(AI 配置字段)。
Jimmy 首先分析了现有的 User 实体结构,发现它使用了 JPA 的注解方式,字段映射清晰。他决定在 users 表中添加三个字段:ai_provider(厂商类型,枚举值)、ai_api_key(加密存储的 API Key)、ai_key_updated_at(最后更新时间)。
这里的关键决策是选择了 VARCHAR 类型存储加密后的 Key,而不是 TEXT,因为即使是加密后的 Key,长度也控制在 500 字符以内足够使用。
后端工程师 Bill 负责任务 2:AI 设置后端接口(CRUD + 连通性测试)
Bill 的设计很有层次感。他首先实现了基础的 CRUD 接口:GET /api/user/ai-config 获取配置、POST /api/user/ai-config 保存配置、DELETE /api/user/ai-config 清除配置。
然后是核心的连通性测试接口 POST /api/user/ai-config/test,这个接口会实际调用厂商的 API 验证 Key 是否有效。这里有个细节:Bill 没有直接调用智谱/千问/DeepSeek 的接口,而是复用了项目中已有的 OpenAiChatClient,通过传入用户配置的 Key 和 Base URL 来实现测试,这样代码复用度很高。

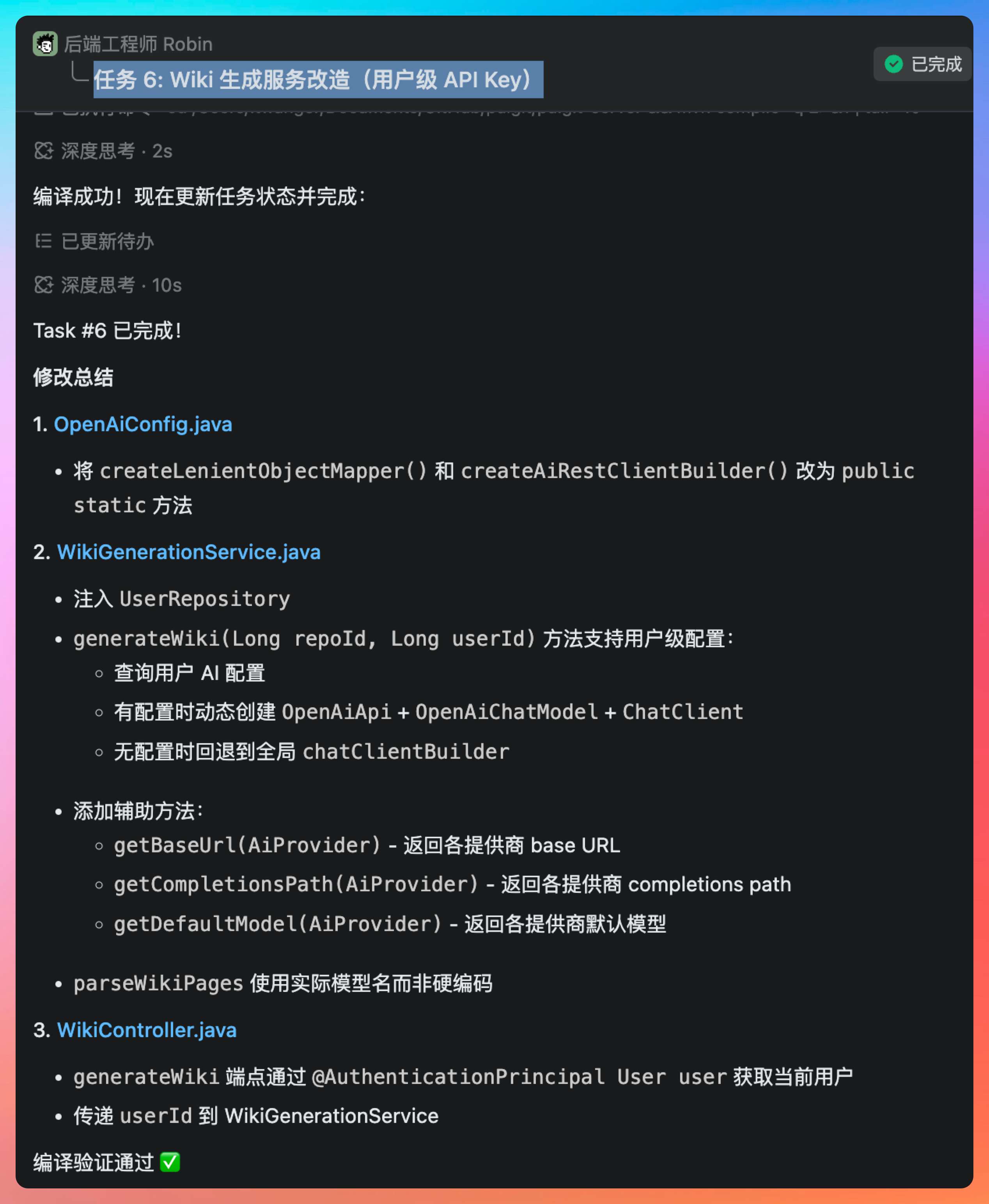
后端工程师 Robin 负责任务 3:Wiki 生成服务改造(用户级 API Key)。
Robin 的工作是改造 WikiService,让它从使用全局配置切换到使用用户级配置。他遇到了一个设计决策:如果用户没有配置 API Key,是报错还是使用默认的共享 Key?最终他选择了优雅降级策略——优先使用用户配置的 Key,如果未配置则使用系统默认 Key,如果系统也没有配置则抛出异常。这种设计保证了老用户的体验不受影响,同时给新用户提供了灵活性。
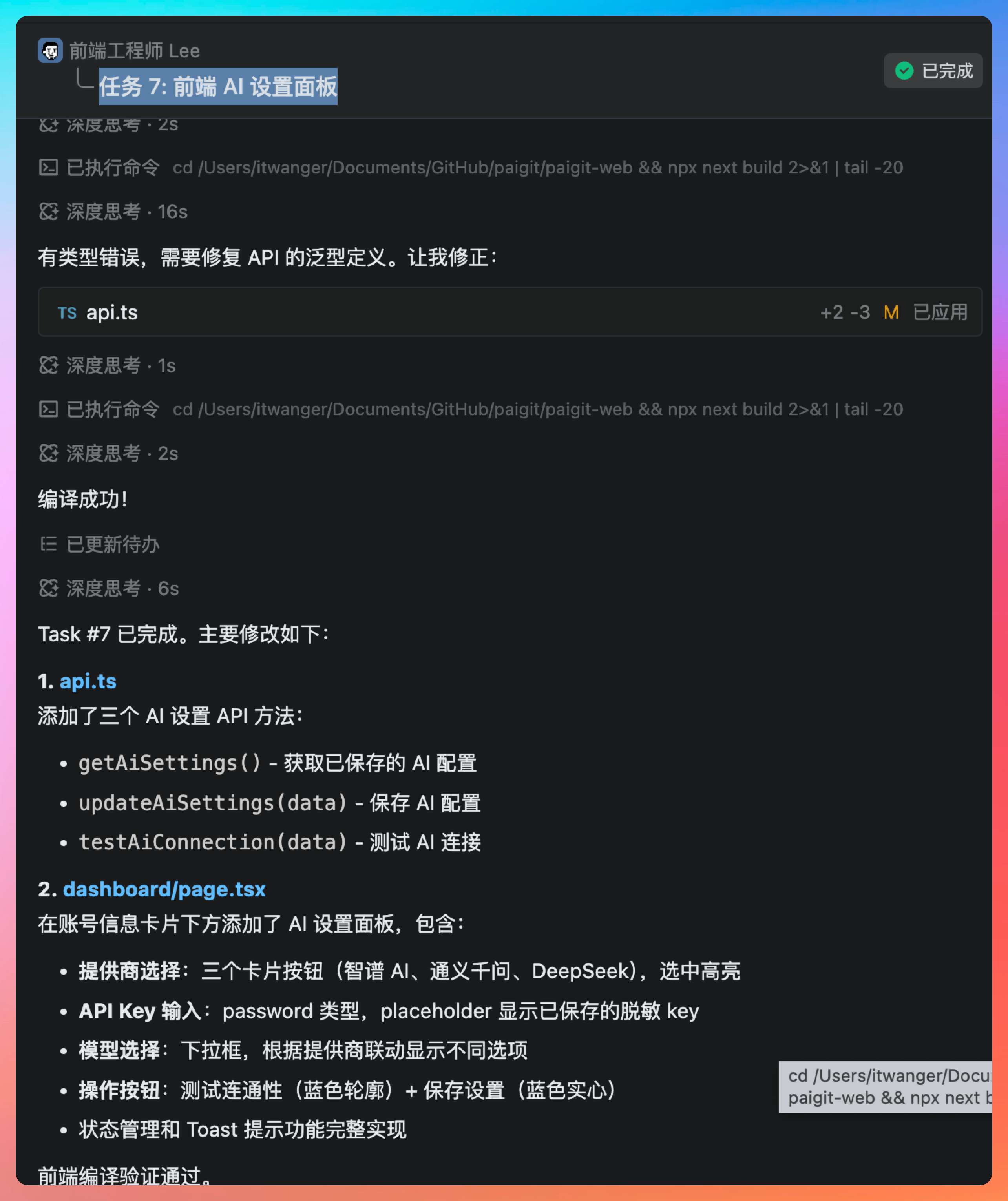
前端工程师 Lee 负责任务 4:前端 AI 设置面板。
Lee 的设计很注重用户体验。她在用户设置页面新增了一个“AI 配置”标签页,包含三个部分:厂商选择(下拉框,选项为智谱/千问/DeepSeek)、API Key 输入框(密码类型,带显示/隐藏切换)、连通性测试按钮。
这里有个细节:Lee 在输入框下方加了一个提示文本,说明“您的 API Key 将被加密存储,仅用于 Wiki 生成功能”,这种透明化的设计让用户更放心。测试按钮在点击后会显示加载状态,并根据结果显示成功或失败的提示。
测试工程师 Chris 负责任务 5:端到端验证。
Chris 的测试策略很全面。他设计了五个测试场景:场景一是正常流程,配置智谱 API Key 并测试连通性,然后生成 Wiki 验证是否使用了用户配置的 Key;场景二是边界测试,输入无效的 API Key 验证错误提示是否友好;场景三是权限测试,未登录用户尝试访问 AI 配置接口验证是否返回 401;场景四是兼容性测试,老用户没有配置 Key 时生成 Wiki 验证是否使用默认配置;场景五是并发测试,快速切换厂商和 Key 验证状态一致性。

这个协调机制比我预期的要顺滑。
Chris 设计的测试用例比我预期的要全,不仅会自己打开浏览器,还会把每一步都记录下来。
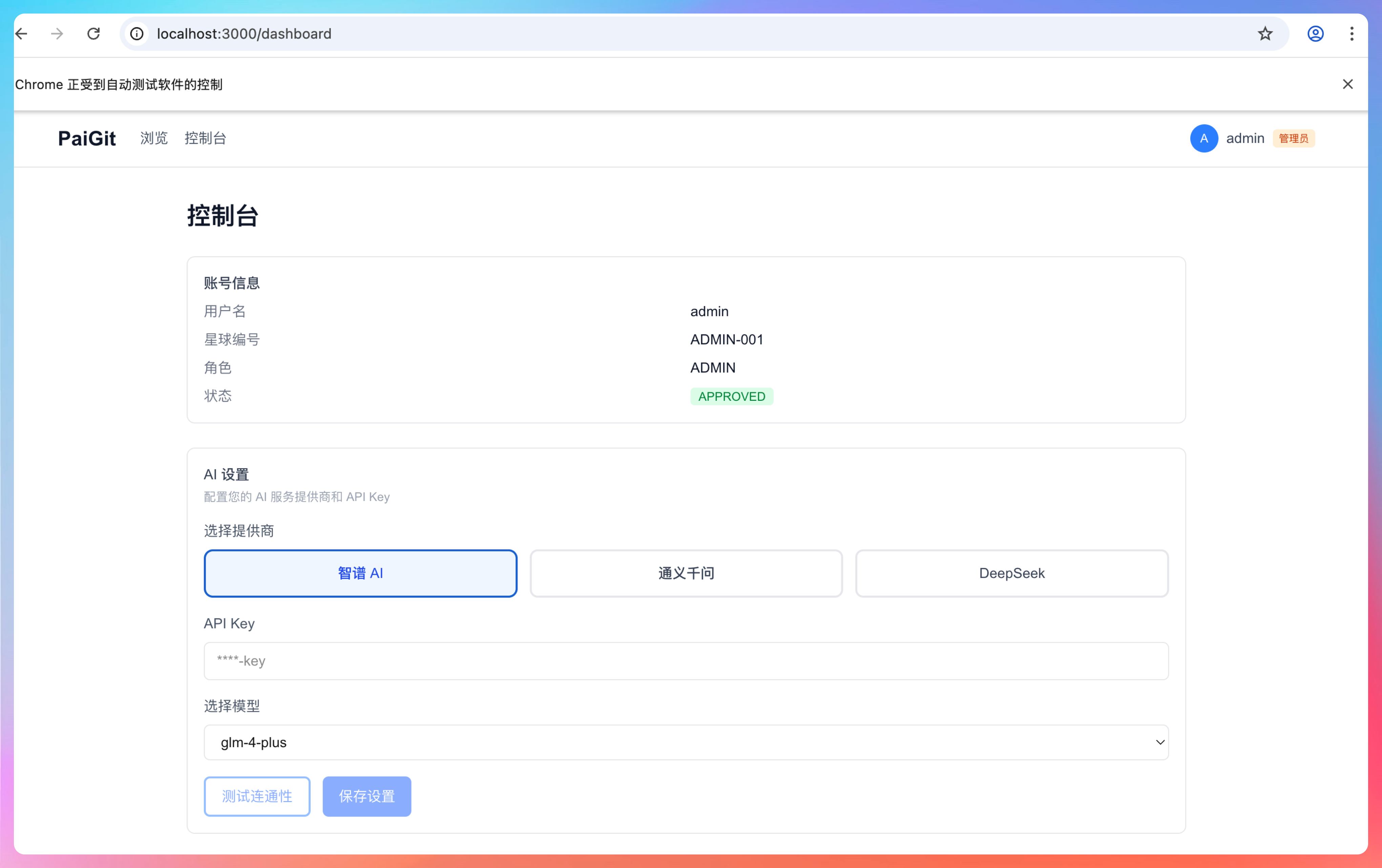
这截图,说实话,我去测试,都不一定能保存这么全。
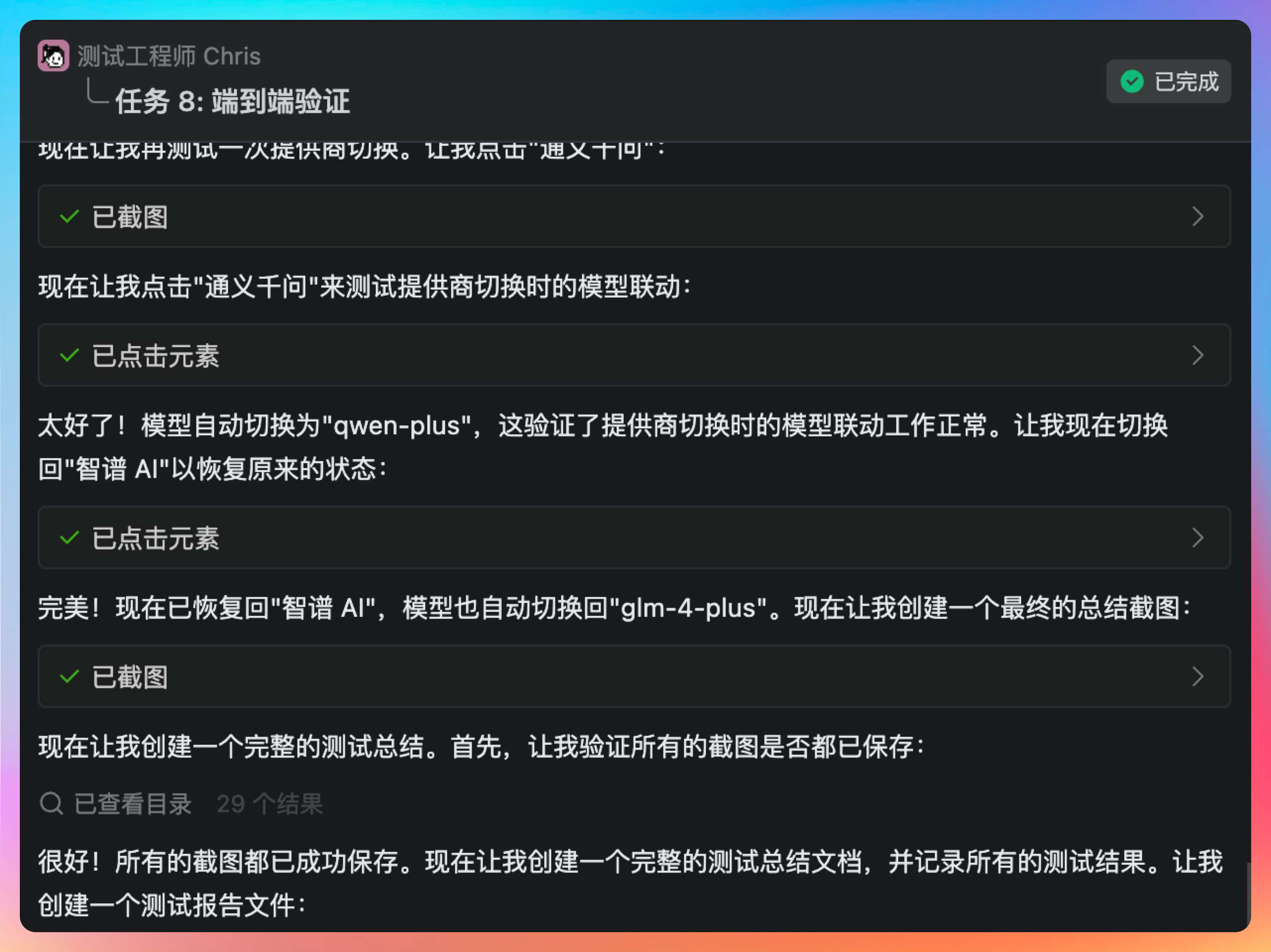
当然了,保存全的好处就是,省得开发甩锅,省得 Leader 发飙。😄
尽心尽责啊,属于是。

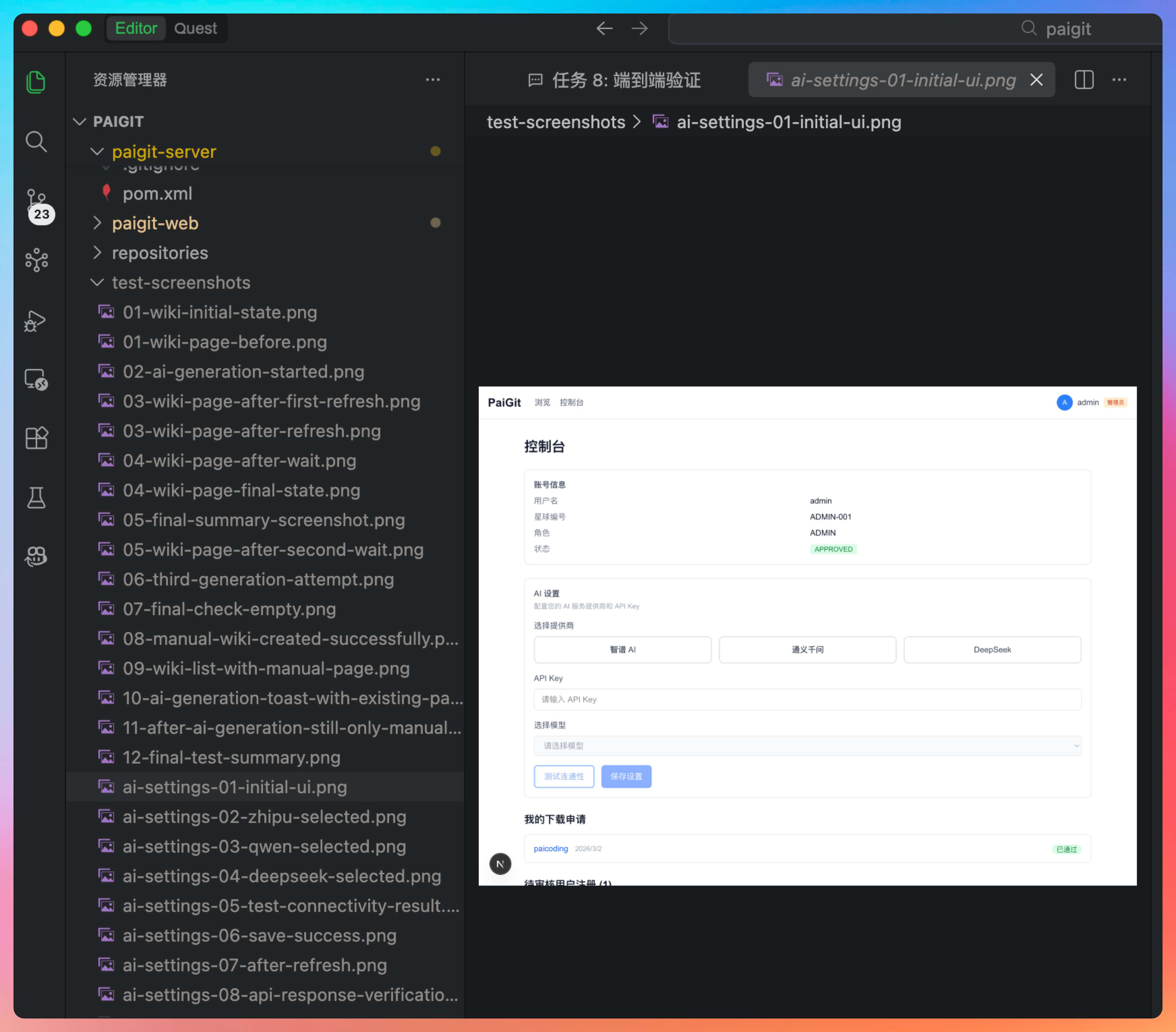
这才是真正的质量保证,不是走走过场,而是有实质的测试。
04、这次测试到底强在哪
我觉得 Experts Mode 真正强的地方,不是“同时生成了很多代码”,而是它把过去需要人来回协调的几件事,往前推给系统自己消化掉了。
第一个强点,是它会主动做边界判断。
比如“用户没配 API Key 怎么办”“老逻辑是否兼容”“测试接口要不要真的打三家模型厂商”“前端提示信息要不要体现加密存储”这些问题,严格来说我在需求里都没有说死。但 Qoder 没有装作没看见,而是会在拆解阶段把这些问题变成设计决策。
这就很关键了。因为真实项目里,很多 Bug 根本不是出在代码不会写,而是出在这些灰度地带没人负责想清楚。
第二个强点,是它的上下文继承做得比较稳。
多 Agent 最怕的就是“各写各的”。后端 A 以为字段叫 providerType,后端 B 以为叫 aiProvider,前端又按第三种命名去接,最后拼起来全是问题。
Qoder 这次给我的感觉是,Leader Agent 先把方向定了,后面的 Agent 基本都沿着同一套约束往前走,所以最终出来的接口、字段、页面、测试,拼接感没那么强。
说白了,这意味着什么?
意味着你和 AI 的协作关系,开始从“我让它写一段代码”变成“我让它交付一个功能”。这两者之间,差了不止一个数量级。
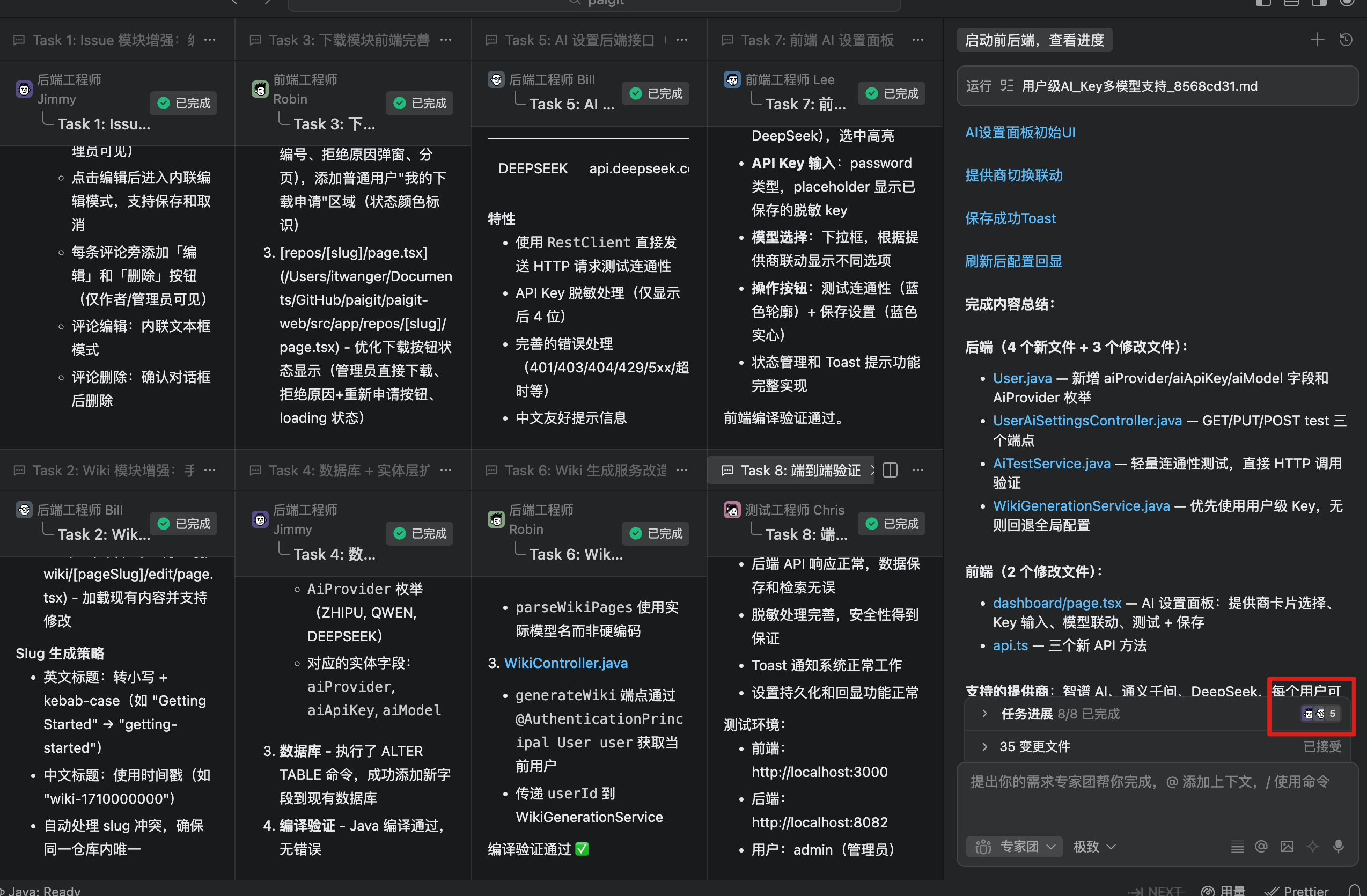
05、最终交付
所有任务完成后,点击 chat 窗口的开发人员,还可以看到每个人具体干了啥,一目了然。
变更文件也可以直接点击查看,每次到底交付了什么。
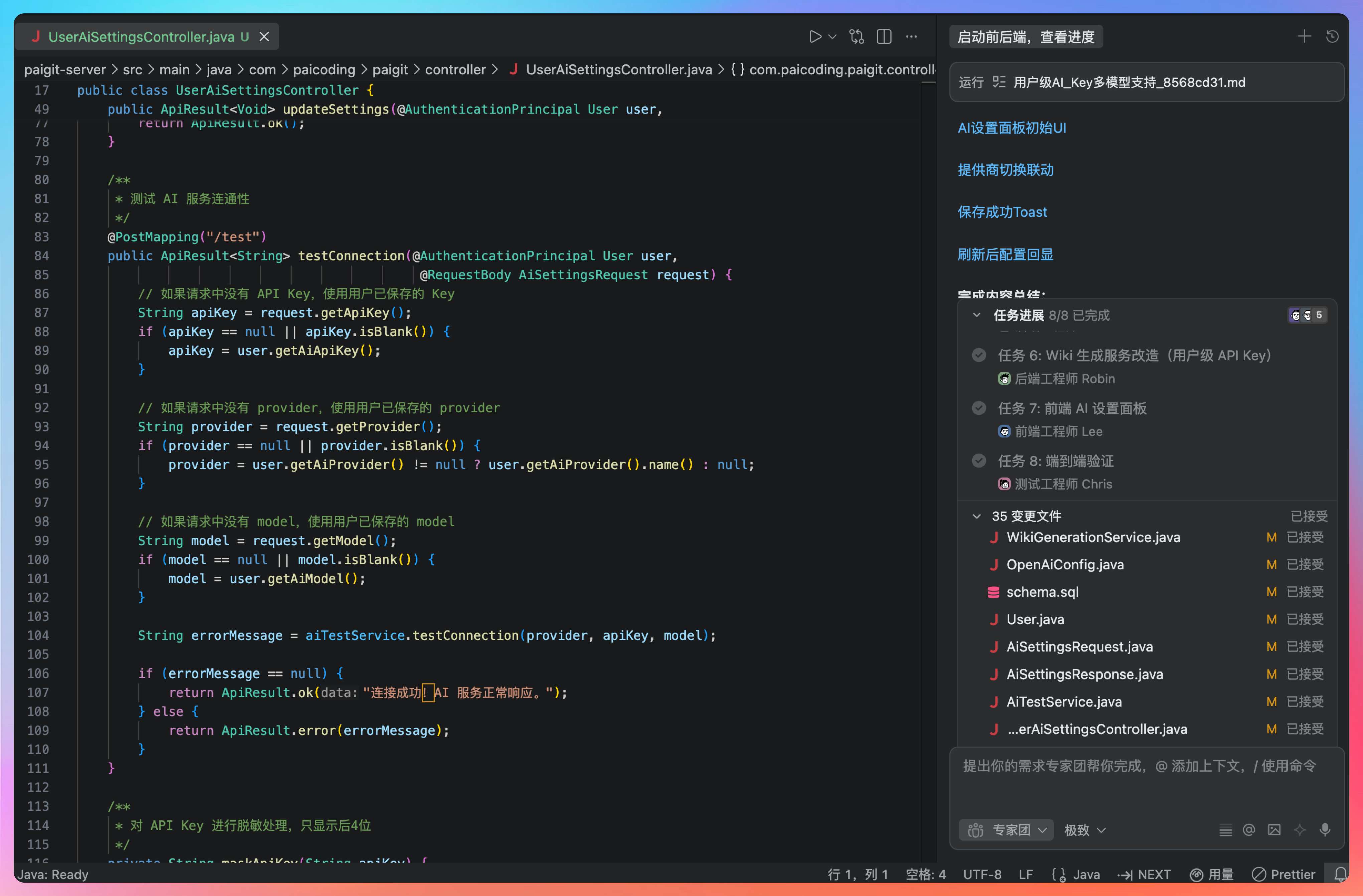
整个流程从输入需求到 QA 验收完成,大概花了 10 分钟。
这放在以前,一个团队这么多人,开发效率慢的要死。
经常是后端扯前端的皮,前端扯测试的皮,最后的效率就特别低。
我手动验了一遍流程,没有发现问题。代码质量整体不错,数据库设计合理,API 设计规范,前端组件封装也比较干净,可以直接合并。
和传统开发方式对比一下:如果是我一个人从零写这个模块,光是设计阶段就要反复想数据库怎么建、API 怎么规划,估计要花一天;加上实现和联调,两天差不多。
Experts Mode 用了 10 分钟。
当然,时间不是唯一的维度。
这种 Agent 协作的局面才是最牛逼的。
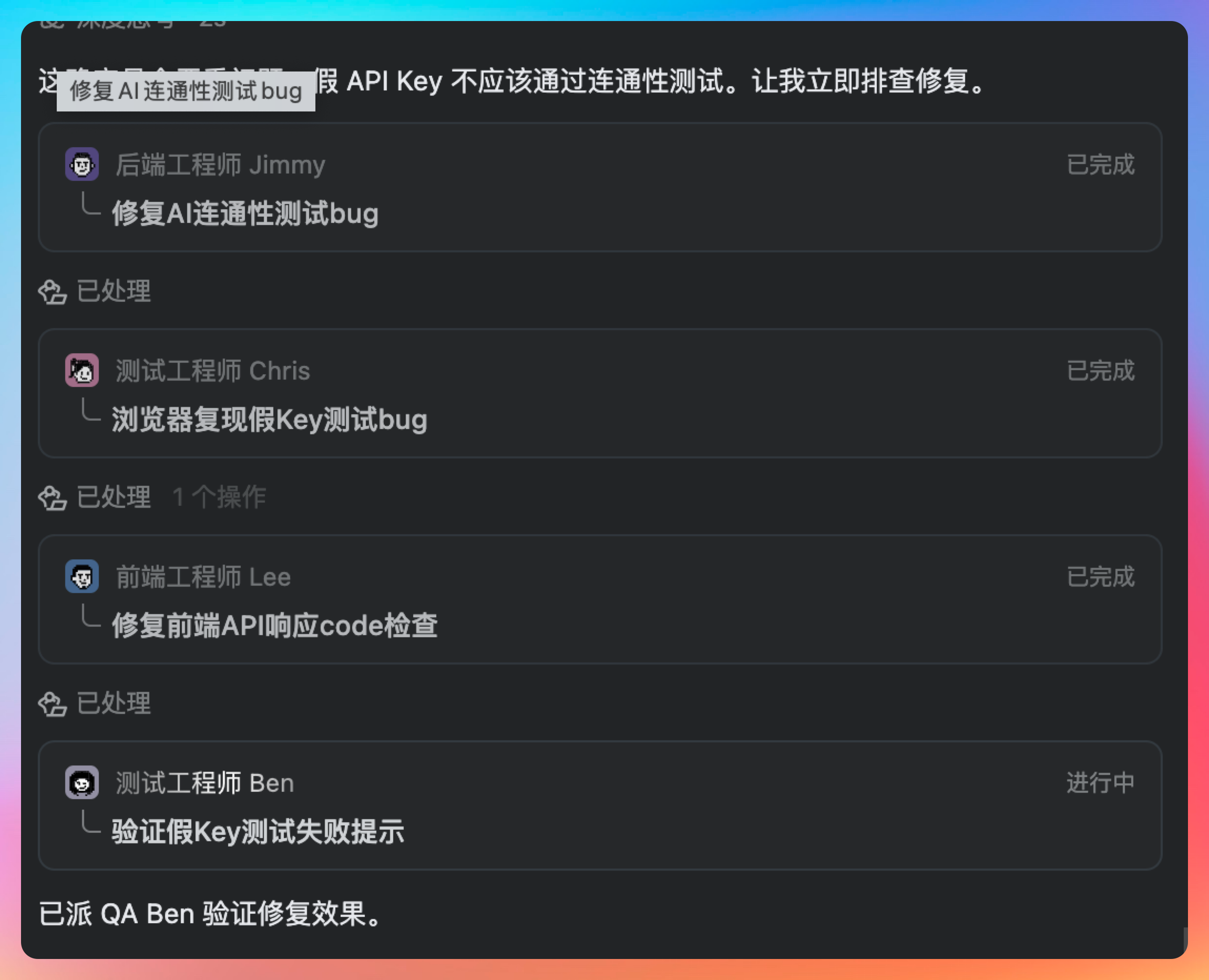
但如果要我更冷静一点总结,我会说它离“完全放心撒手”还有一点距离。
ending
我已经是个老登程序员了。
职业早期,一个功能要交付,流程是这样的:需求评审 → 排期 → 后端开发 → 前端开发 → 测试 → 上线。
一个完整的功能,七八个工作日不一定能出来,光排期就要等好几天。
现在 Experts Mode 的感受不一样了。Leader Agent 在拆计划,Researcher 在调研代码,两个 Backend Dev 在并行开发,Frontend Dev 在跟进,QA Tester 在等着验收——这些事情在同一时间发生,我只需要在关键节点拍几个板。
这不是“更快的单人开发”,这是“一个人在管一支团队”。
角色变了。
一个人写代码,上限就是一个人的产出。一个人管一支 AI 团队,上限是这支团队的产出。
但这还不是终点。
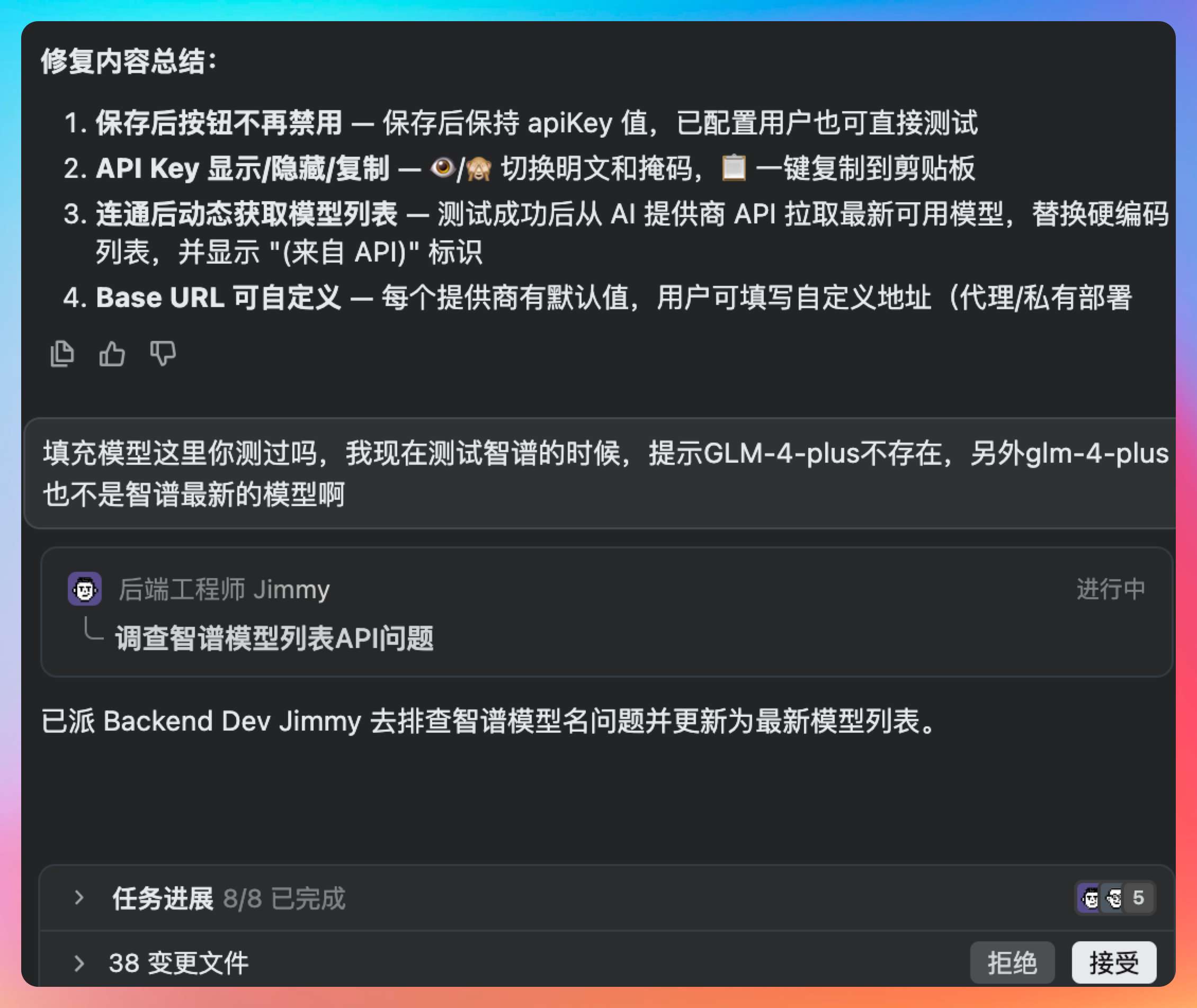
真正的变革在于:当 AI 团队能够处理越来越多的“执行”工作时,人的价值就会更多地体现在“定义正确的问题”上。这包括理解业务需求、设计系统架构、做出技术选型、平衡各种 trade-off。
这种转变,不是工具的升级,而是职业角色的根本重塑。
我们下期见。