面试官:RAG 不用向量数据库,用 MySQL 硬扛?我:100 万向量不是很轻松?
老王透明的茶杯里,泡满了枸杞,我就瞅了一眼,少说也有 100 颗。
没等我回过来神,老王就直入主题:“你做 RAG 检索用的什么数据库?”
“MySQL。”
老王差点没把刚抿到嘴里的水喷到我帅气的脸上:“就 MySQL?向量检索你用 MySQL?”
“咋了王哥,MySQL 不配拥有向量吗?100 万条 chunk 我照样给它安排得明明白白。”
看老王气急败坏的样子,我笑了:“王哥,逗逗你啦,活跃活跃气氛嘛,这下我不紧张了。向量这块我用的是 ElasticSearch 了,既能做语义,又能做关键字存储,混合检索轻松搞定。😄”
老王真是个好人啊,愣是没生气,仍然和颜悦色。问出了下一题:“你这个 RAG 系统,检索精确率怎么评估的?具体怎么测试?”
(内心 OS:这下面试有了,天底下所有的面试官都能像老王一样就好了呀。)
PS:以下题目来自派聪明 RAG 项目的真实面试题目,如上图所示,阿里飞猪一面。
content
01、检索精确率怎么评估的?具体怎么测试?
我说:“王哥,我在派聪明 RAG 里专门做过一轮评估。”
“评估检索质量,业界常用的指标有三个:精确率(Precision)、召回率(Recall)和 MRR(Mean Reciprocal Rank)。”
精确率看的是检索出来的文档里有多少是真正相关的。比如检索返回了 10 个 chunk,其中 7 个和问题相关,精确率就是 70%。
召回率看的是所有相关文档里,有多少被检索出来了。比如知识库里一共有 15 个相关 chunk,检索返回了 7 个,召回率就是 46.7%。
MRR 看的是第一个正确结果的排名,排名越靠前分越高。用户最关心的其实是“第一条结果是不是我要的”,MRR 就是衡量这个的。

具体怎么测试呢?
“我的做法是构建一个评估数据集。”
“先标注 200 到 500 组 QA 对,每组包含一个问题和对应的标准答案 chunk。然后把这些问题批量放到检索模块,拿到返回结果,和标注结果做对比,算上面三个指标。”
“派聪明 RAG 上线前我们跑了一轮评估,精确率从最初的 68% 优化到了 89%,主要靠两个手段:一个是换了更好的 embedding 模型,另一个是加了重排模型对检索结果做二次排序。”
老王追问:“重排模型用的哪个?”
“用的 bge-reranker-v2-m3,这个模型对中文语义的理解比较好,而且推理速度能接受,P95 延迟在 50ms 以内。”
老王点点头:“评估体系搭得还可以。”
02、上传文件的数量上限多少?
老王接着问:“上传文件的数量上限是多少?文件大小多少?”
我说:“这个要分两层来说——业务层限制和系统层限制。”
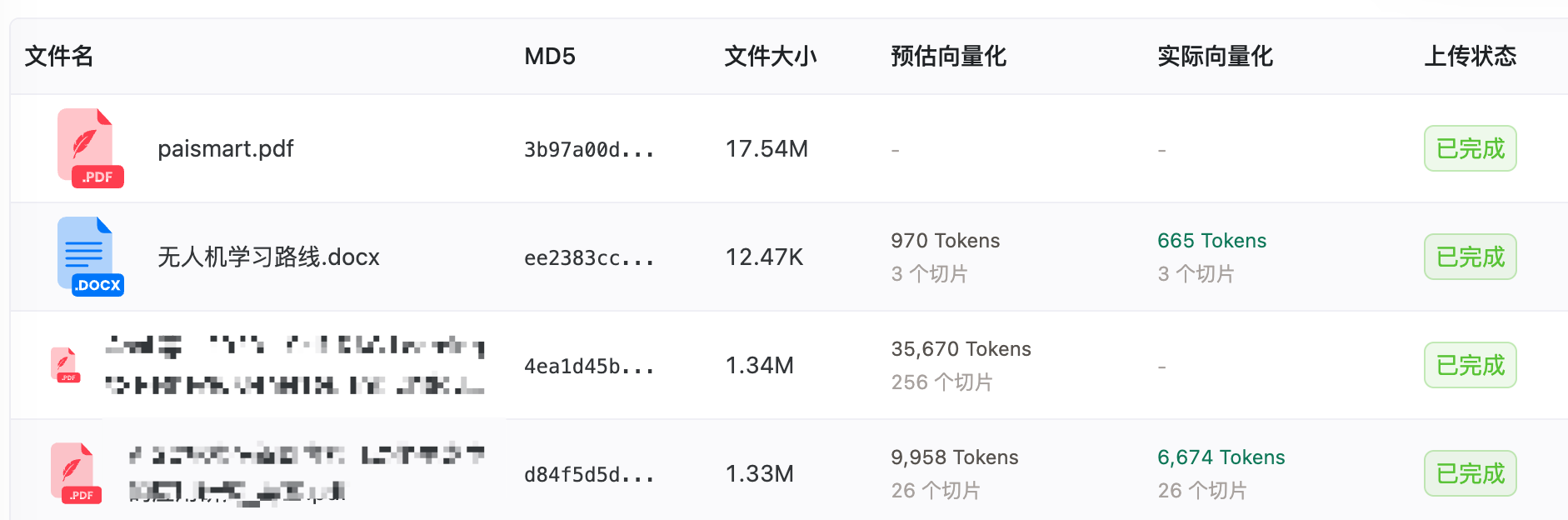
“业务层面,我们限制单次上传不超过 20 个文件,单文件不超过 50MB。大部分用户上传的是 PDF 和 Word,50MB 基本覆盖了 99% 的文档。”

“系统层面,真正的瓶颈在文档解析和向量化。一个 50MB 的 PDF 可能有几百页,解析成文本、切分成 chunk、逐个向量化,整个流程下来可能要几分钟。如果用户一次上传 20 个这种大文件,后台任务队列会堆积。”
“所以我做了异步处理。用户上传后立刻返回成功,后台用 Kafka 慢慢消化。前端有个进度条,处理完了会通知用户。”
老王追问:“如果有人恶意上传大量垃圾文件呢?”
“做了限流。按用户维度限制每天上传总量不超过 500MB,按 IP 维度限制并发上传数,以及做了每天的 Embedding 额度限制。另外文件类型也做了白名单,只允许 PDF、Word、TXT、Markdown 这几种。”

03、如果文档数量百万级应该怎么办?
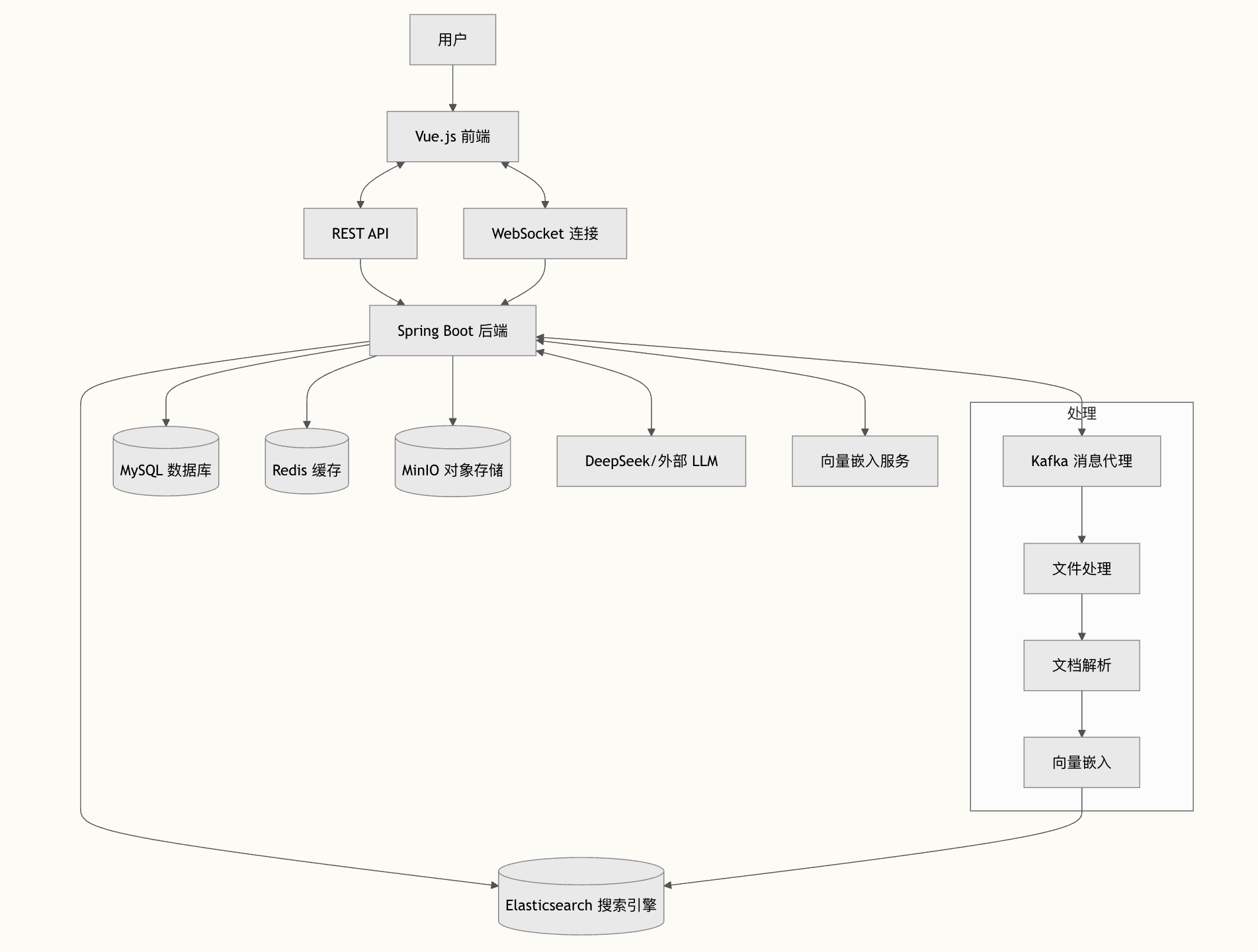
老王靠在椅子上,表情变得认真了:“如果文档数量到了百万级,存储和检索怎么设计?压力很大怎么办?”
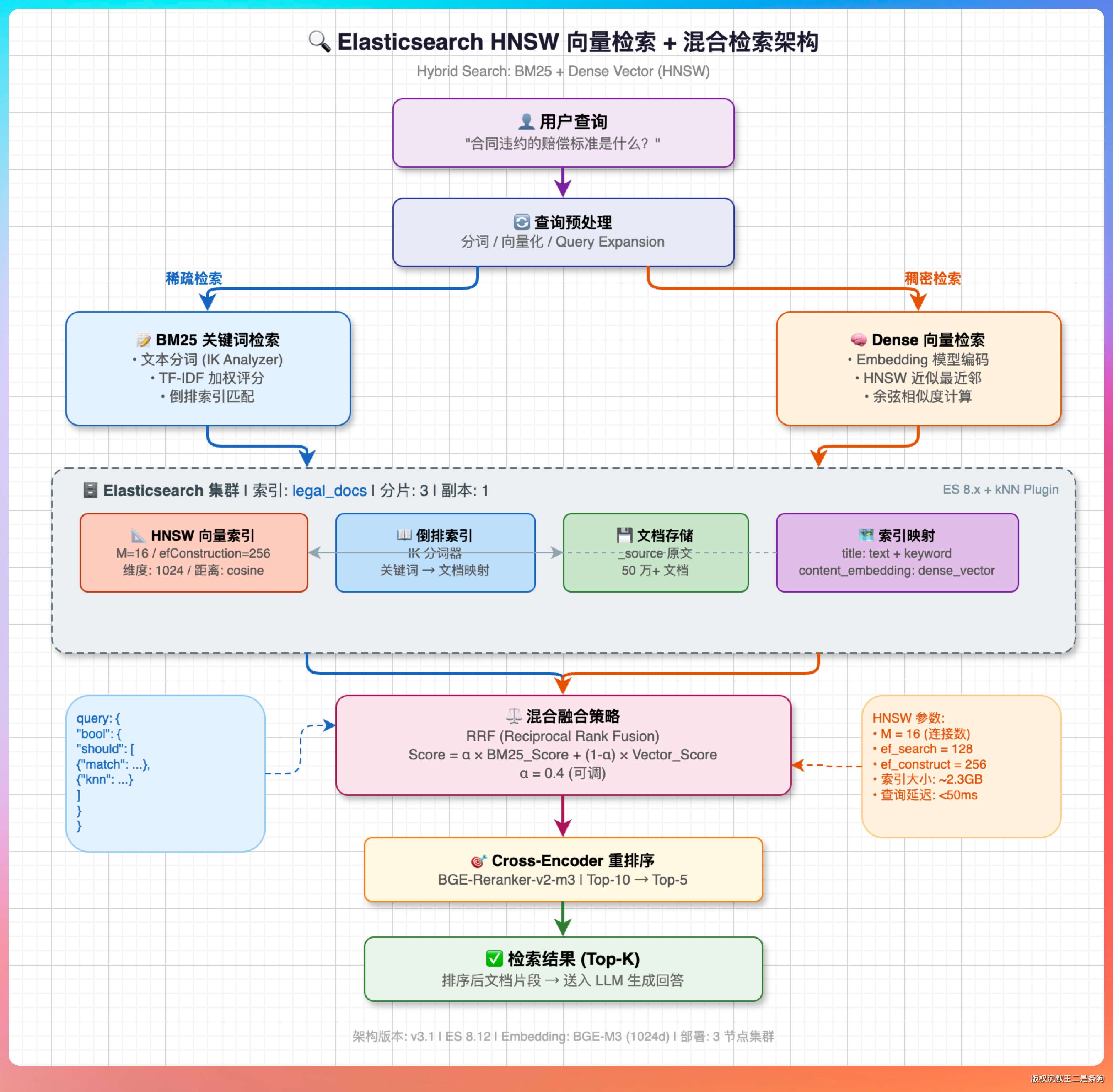
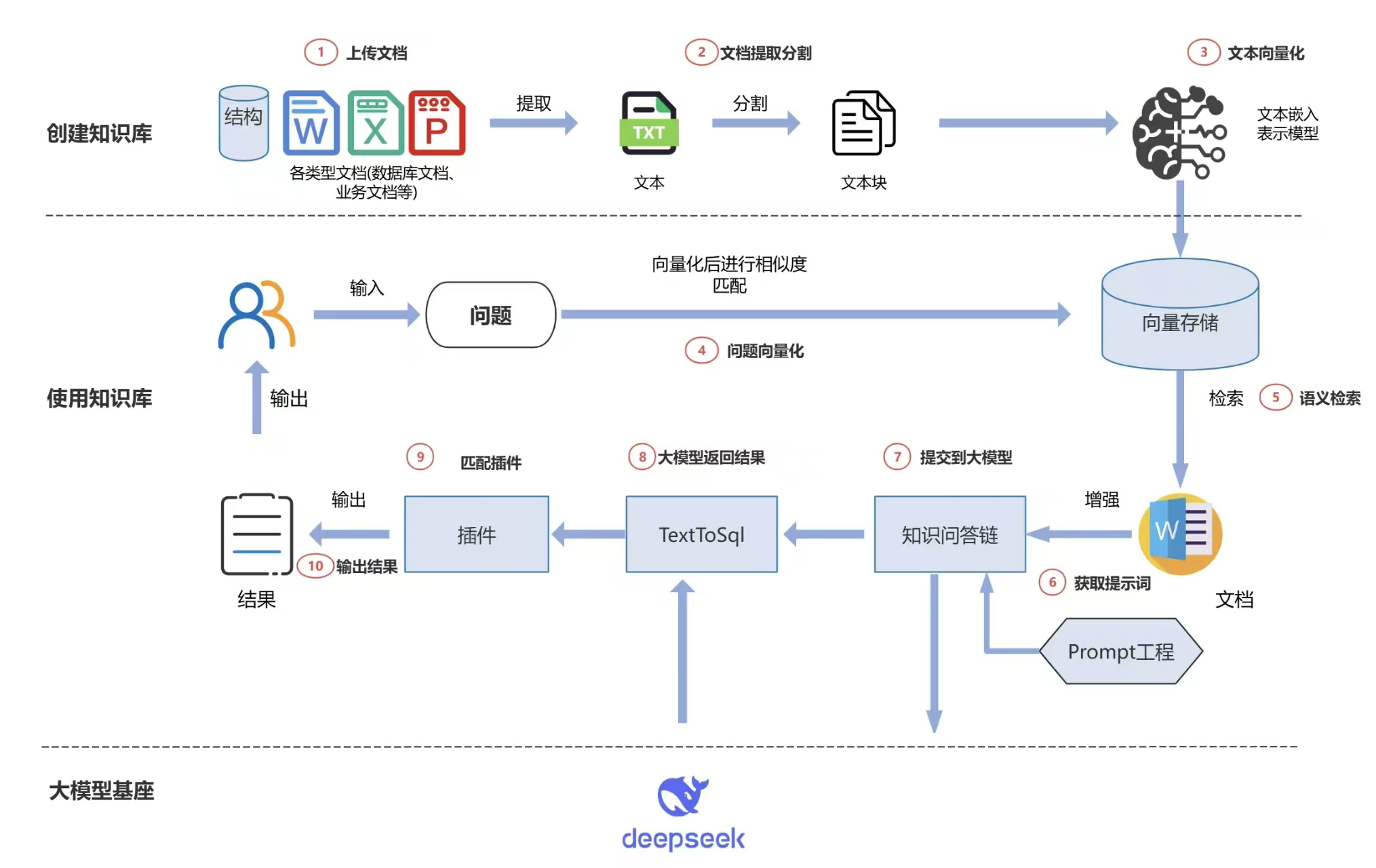
“这个问题要分层来看。派聪明的架构是 MySQL 存文档元数据,ElasticSearch 存向量和关键词,两者配合。”
存储层怎么设计?
“先说 MySQL。MySQL 存的是文档元数据——文件名、文件路径、上传时间、文档分类、所属用户这些。不存向量,向量数据全在 ES 里。所以 MySQL 这边没有大字段,存储压力很小,百万级文档也就是几 GB 的数据量,单表就能扛住。”
“如果真要优化,可以按业务分库。比如法律文档一个库、技术文档一个库。或者冷热分离,超过 6 个月没被访问的文档归档到冷存储。但这个量级目前用不上。”
“真正的存储大头在 ES。百万级文档,假设每个文档平均切成 50 个 chunk,那就是 5000 万条 chunk。每条 chunk 存一个 2048 维向量,光向量数据就是 5000 万 × 2048 × 4 字节 ≈ 400GB。”
“ES 的存储优化有几个思路。第一,用稠密向量索引。ES 8.x 之后支持 HNSW 索引,向量检索不需要暴力遍历,建了索引之后检索速度能提升 10 倍以上。第二,冷热分层。ES 支持把热数据放 SSD,冷数据放 HDD,检索性能和存储成本可以兼顾。”
检索层怎么优化?
“检索这块,ES 天然支持向量检索和关键词检索,混合检索直接搞定。压力大的话有几个优化思路。”
“第一,先过滤再向量搜索。用户的查询通常带有元数据条件,比如‘帮我找法律相关的文档’。先在 ES 里用 term 查询把候选集缩小,再做向量相似度计算,计算量就小多了。”
“第二,调整 HNSW 参数。ES 的 HNSW 索引有两个关键参数:m(每层的邻居数)和 ef_search(检索时的候选数)。m 越大索引越准但占用内存越多,ef_search 越大检索越准但越慢。我们实测下来 m=16、ef_search=100 在准确率和延迟之间是比较好的平衡。”
“第三,缓存热门查询。很多 RAG 系统 80% 的查询集中在 20% 的热门问题上。把这些问题的检索结果缓存在 Redis 里,命中率能到 40% 以上,直接省掉向量计算。”
老王追问:“2048 维的向量,检索延迟能接受吗?”
“2048 维确实比 1024 维慢一点,但差异没想象中大。HNSW 索引的检索复杂度是 O(log N),和维度关系不大。我们压测下来,5000 万条 2048 维向量,P99 延迟在 100ms 以内,完全可以接受。”
老王点点头:“ES 存向量 + MySQL 存元数据,这个架构是对的。”
04、文档上传时候切片大小设置的多少?
老王继续追问:“文档上传时候切片大小设置的多少?为什么这么设置?为什么不用 1MB 或者 10MB?”
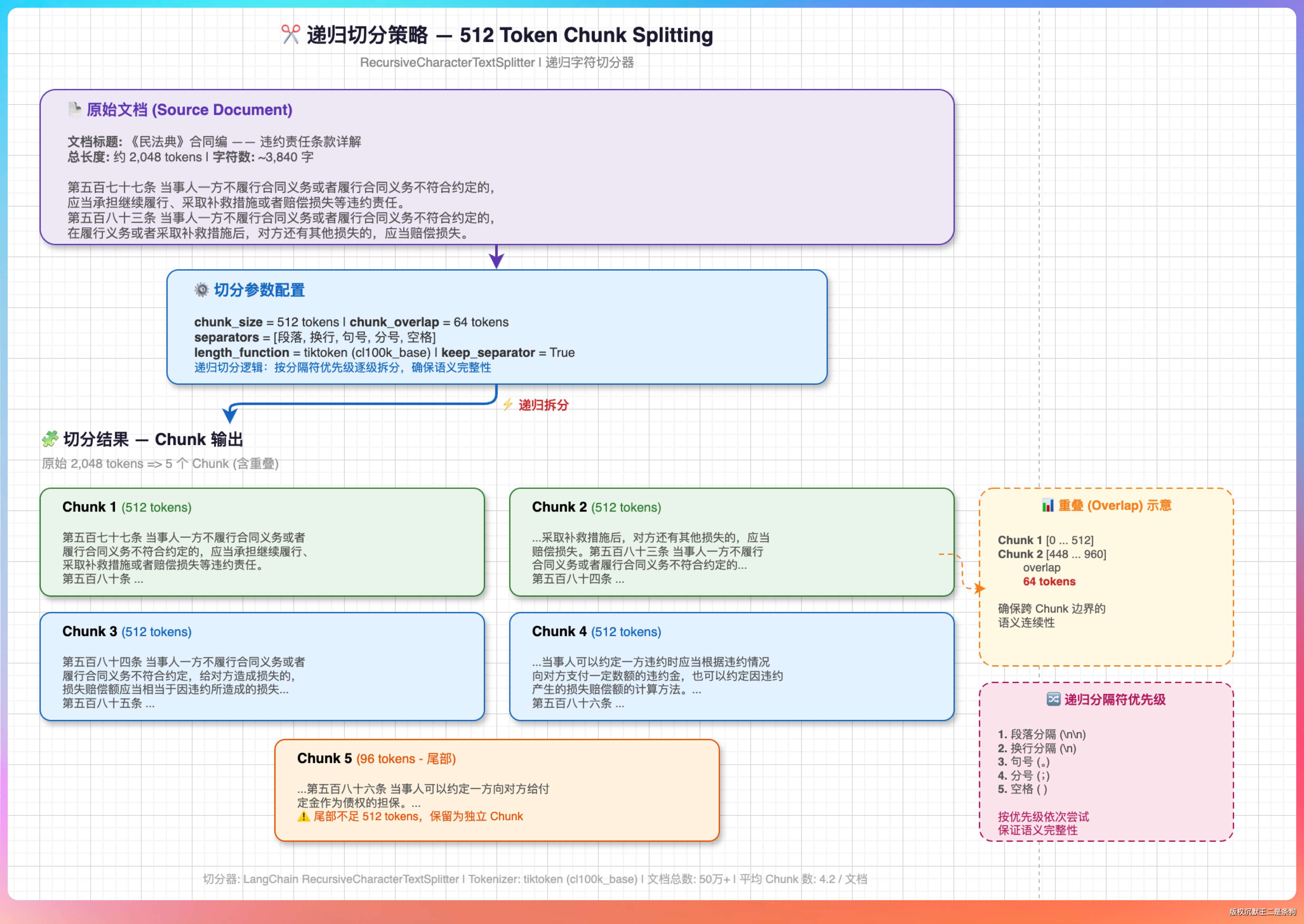
我说:“我们的 chunk 大小设的是 512 个 token,overlap 是 64 个 token。”
为什么是 512?
“第一,检索精度。我们用的通义 text-embedding-v4 模型,虽然最大支持 8192 token 输入,输出 2048 维向量,但实测下来 chunk 越长,语义越分散,embedding 的区分度反而下降。512 token 是我们在精确率和信息量之间反复调参后找到的最优值。”
“第二,语义完整性。太小的 chunk(比如 100 token)容易把一句完整的话切断,检索出来的内容缺乏上下文,模型理解不了。太大的 chunk(比如 2000 token)包含的主题太多,检索精度下降——一个 chunk 里聊了三个话题,到底是因为哪个话题被检索出来的?”
“第三,token 预算。大模型的上下文窗口是有限的。如果每个 chunk 太大,能塞进去的 chunk 数量就少。512 token 的 chunk,一次检索返回 5 个,加上 prompt 模板,总共不到 4000 token,给生成留了足够空间。”
老王追问:“为什么不用 1MB 或者 10MB?”
“因为 chunk 的单位应该是 token,不是字节。1MB 的文本大约 50 万字,那已经不是 chunk 了,那是整本书。10MB 更离谱。”
“说到底,切片的目的是把长文档拆成‘语义单元’,每个单元表达一个相对独立的主题。这个粒度和存储大小无关,和语义有关。按字节切跟按句号切一样不靠谱,只有按语义切才有意义。”
“我们后来还做了一个优化——递归切分。先按段落切,如果段落超过 512 token 再按句子切。这样尽量保证每个 chunk 都是完整的段落或者完整的几个句子,不会把一句话从中间劈开。”
老王满意地点了点头。
05、多机部署怎么做?
老王画风一转:“多机部署考虑过吗?需要改进哪里?”
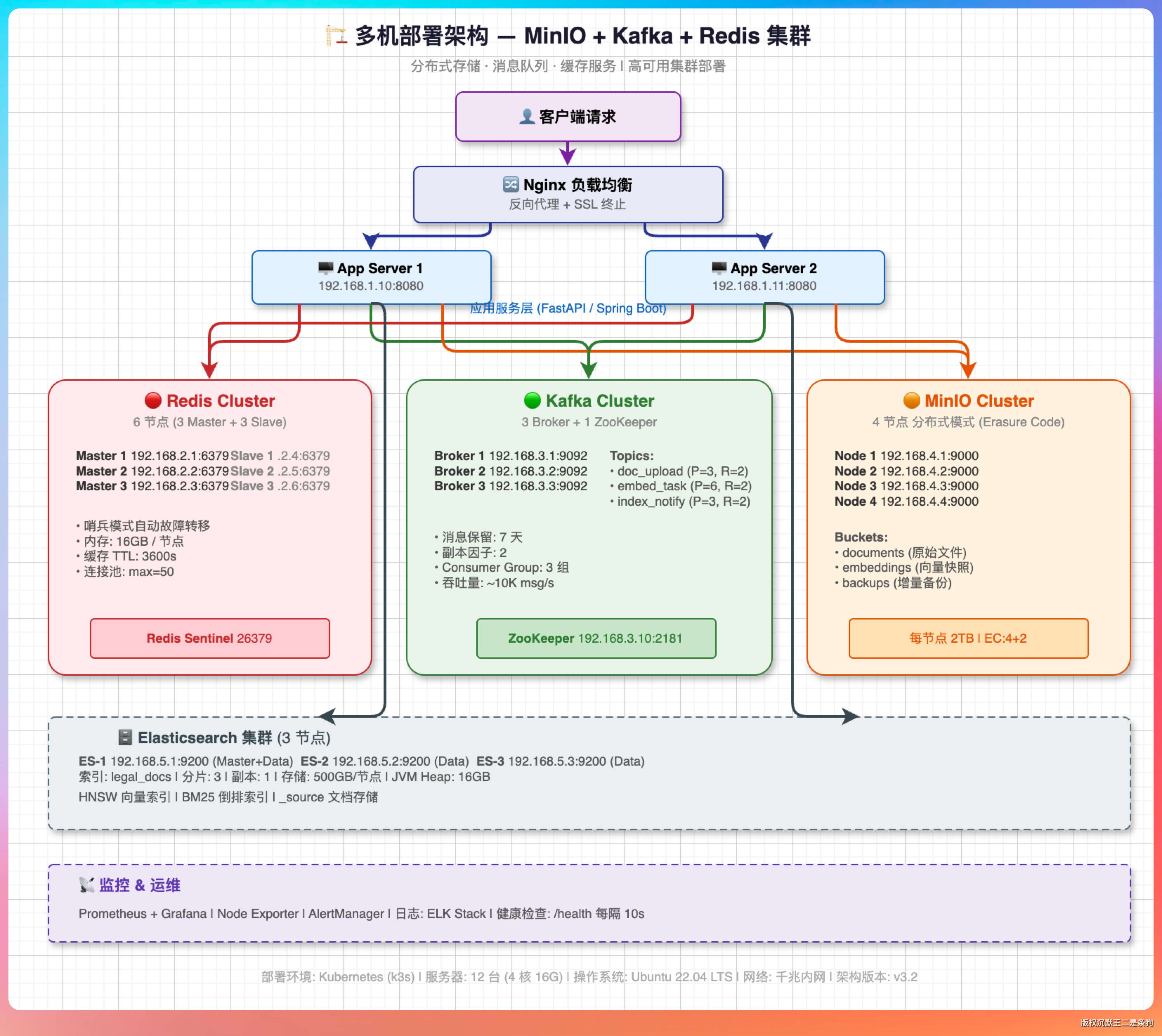
我说:“考虑过,但派聪明 RAG 目前还是单机部署,因为业务量还没到需要多机的程度。不过架构设计的时候已经考虑了扩展性。”
“如果要做多机部署,主要考虑三个地方。”
“第一个是文件存储。我们已经用了 MinIO 做对象存储,多机环境下天然支持共享访问,这块不用改。”
“第二个是任务队列。文档解析和向量化是异步任务,我们已经用了 Kafka,多台机器可以消费同一个 topic,天然支持多机。但要注意 partition 的分配策略,确保任务不会被重复消费。”
“第三个是 Session 管理。Session 要从本地存储迁移到 Redis,实现 Session 共享。”
06、水平扩展怎么做?
老王紧跟着问:“怎么做到水平扩展?”
我说:“水平扩展的核心是无状态。只要服务是无状态的,挂再多的机器都行,前面加个负载均衡就完事。”
“RAG 系统里有三类服务:文档上传服务、检索服务、生成服务。”
“检索服务天然是无状态的——接收一个 query,去数据库里搜,返回结果。任何一台机器都能处理,不依赖本地状态。生成服务也是无状态的——接收 prompt,调大模型 API,返回结果。”
“文档上传服务稍微复杂一点,因为涉及文件落盘和异步任务。但我们文件存 MinIO、任务走 Kafka,所以它也是无状态的。”
“因此水平扩展的改造重点就是把状态外置——文件存 MinIO、任务存 Kafka、Session 存 Redis、数据存 MySQL。服务本身不保存任何状态,随时可以扩缩容。”
07、哪些接口是无状态的?
老王接着问:“有哪些接口是无状态的?”
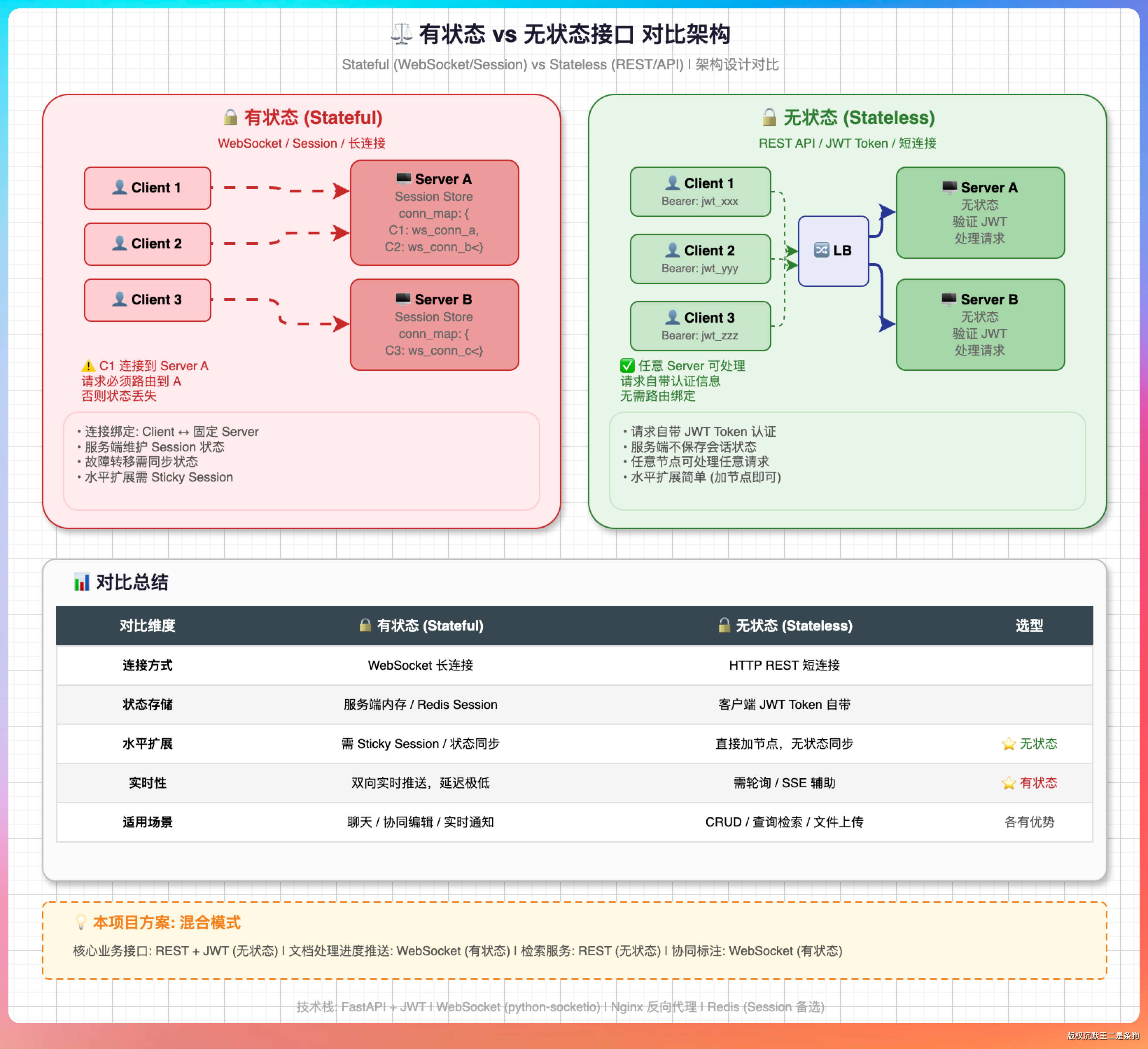
“搜索接口是无状态的。输入 query,返回检索结果,不依赖任何本地状态。”
“生成接口是无状态的。输入 prompt + context,调 LLM API,返回生成结果。”
“文档列表查询接口是无状态的。读 MySQL,返回数据。”
“健康检查接口是无状态的。返回 OK 就完事。”
“有状态的主要是两个:文件上传接口(如果文件存本地的话)和 WebSocket 连接(因为 WebSocket 是长连接,连接状态绑定在具体的服务器实例上)。”
08、视频音频怎么做 RAG 检索?
老王突然换了个方向:“视频音频怎么检索?语音转文字花费很高怎么解决?”
我说:“视频音频 RAG 的核心思路是先把它们转成文本或者其他可向量化的表示,再走传统 RAG 的流程。”
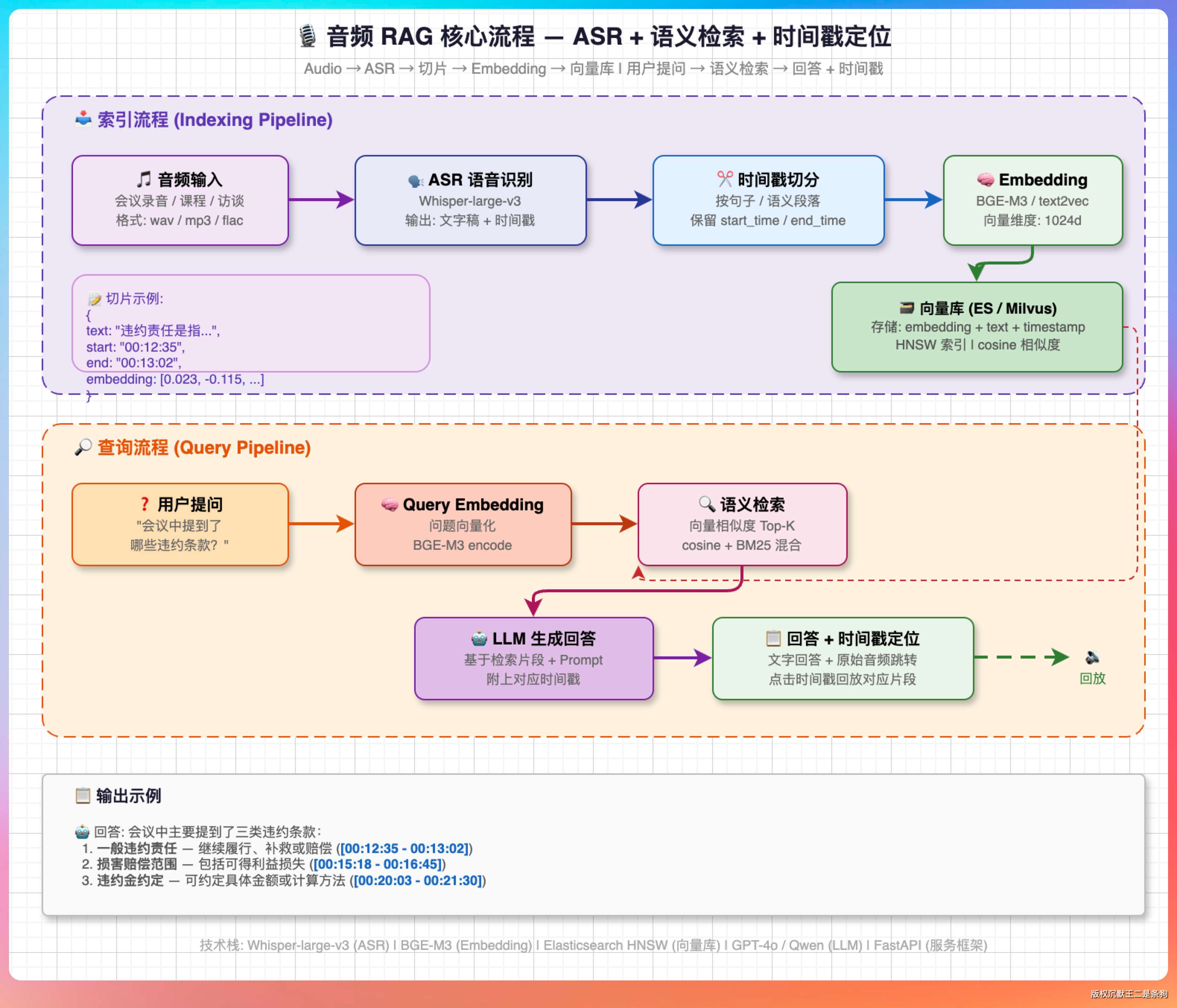
核心流程是这样的:把音频通过 ASR(自动语音识别)转成文字稿,文字稿按时间戳切分成片段,每个片段做 Embedding 向量化存到向量库里。
用户提问的时候做语义检索,找到最相关的文字片段,然后基于这些片段生成回答,同时返回对应的时间戳。
ASR 模型的选择有几个主流方向。开源的可以用 Whisper(OpenAI 开源的,效果非常好,支持多语言)、FunASR(阿里开源的中文 ASR)、SenseVoice(阿里最新开源的多模态语音模型)。
商用 API 可以用阿里云语音识别、腾讯云 ASR、火山引擎 ASR 这些。Whisper 是综合性价比最高的选择,自己部署成本不高,效果接近商用 API。
这个方案适合纯音频场景,比如播客检索、客服通话分析、会议录音问答。视频场景如果不需要画面信息也可以用这个方案,把视频里的音轨提取出来做 ASR 就行。
如果视频里的画面信息很重要,比如教学视频里的板书、商品视频里的展示、监控视频里的事件,那纯 ASR 就不够了,需要把画面信息也利用起来。
核心流程是这样的:把视频按一定频率抽帧(比如每秒抽一帧或每个关键帧抽一张),用多模态 Embedding 模型把每一帧图像转成向量,存到向量库里。用户提问的时候用同一个多模态 Embedding 模型把问题向量化(多模态模型可以同时处理文本和图像),做语义检索找到最相关的视频帧,然后基于这些帧的时间戳定位到视频片段。
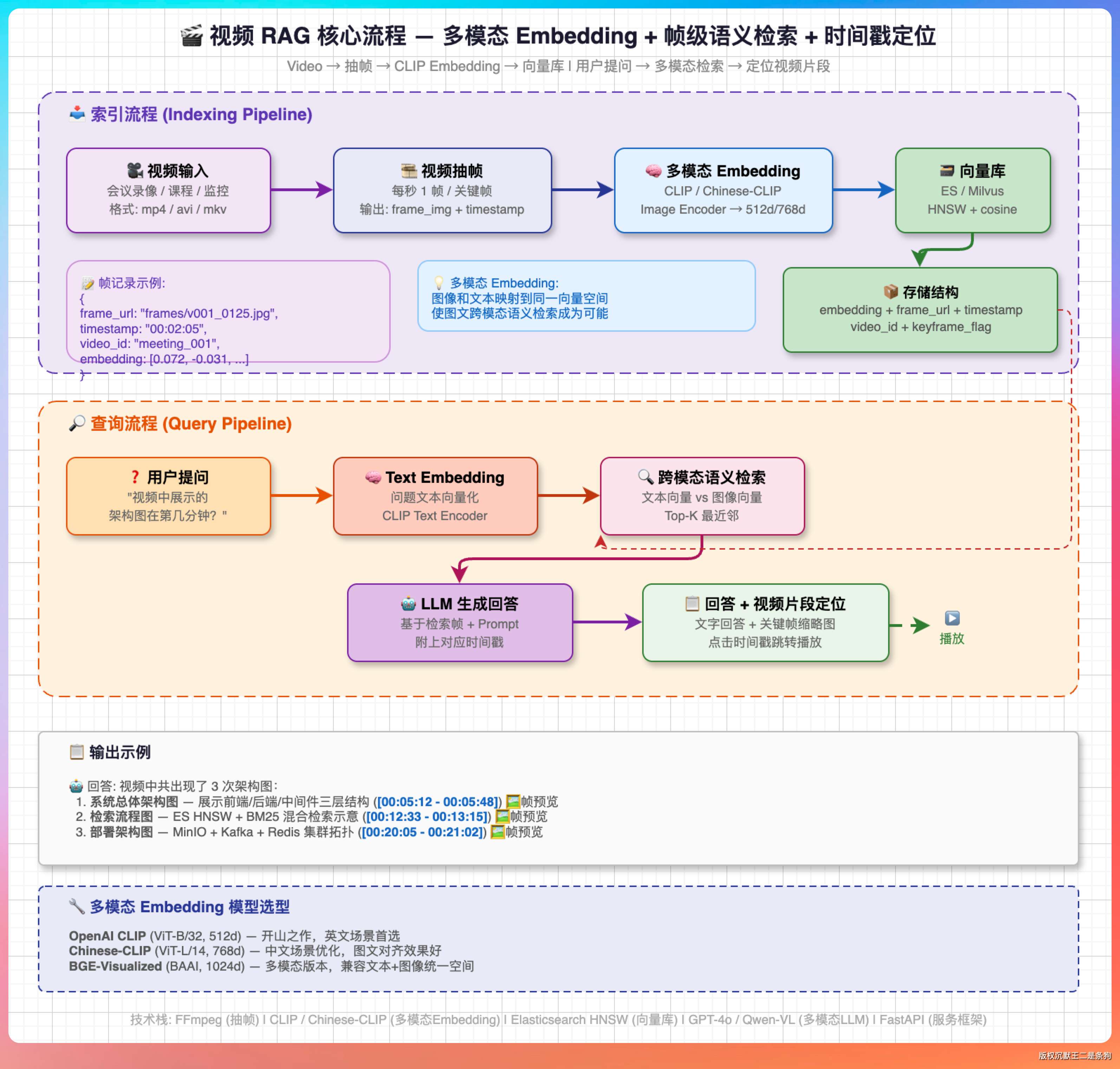
多模态 Embedding 模型的选择主要是 CLIP 系列。OpenAI 的 CLIP 是开山之作,中文场景下可以用 Chinese-CLIP 或者 BGE-M3 的多模态版本。
这个方案的好处是能利用画面信息,缺点是计算成本高,因为视频帧的数量通常很大。一个一小时的视频按每秒一帧抽就是 3600 帧,每帧都要做 Embedding 和存储,对资源消耗比较大。
有没有多模态方案?
最新的趋势是用视觉大模型直接理解视频内容生成结构化描述。比如用 Qwen-VL、InternVL、GPT-4V 这类模型,把视频片段送进去让模型生成详细的文字描述(包括画面内容、人物动作、场景变化),然后把这些描述按时间戳切分做向量化检索。

这个方案的好处是描述质量非常高,因为视觉大模型能理解画面里的语义关系,不只是单纯的图像 Embedding。坏处是成本高,每段视频都要调用大模型生成描述,处理速度慢,token 消耗大。
09、为什么用 WebSocket
老王问了最后一个问题:“为什么用 WebSocket?WebSocket 多服务器怎么部署?”
“SSE 是单向的,服务端往客户端推数据,客户端只能被动接收。大部分 AI 产品用 SSE 就够了,因为场景就是‘我问你答’,服务端流式吐 token,客户端渲染就完事。”
“但 RAG 场景有一个关键需求——客户端需要主动中断生成。用户问了一个问题,大模型还在吐 token,用户一看方向不对,想点‘停止生成’。SSE 做不到优雅中断,客户端只能关闭整个连接再重新建连。WebSocket 是双向通信,客户端随时可以发一条 stop 消息给服务端,服务端收到后立刻停止生成,连接还在,下一轮对话直接复用。”
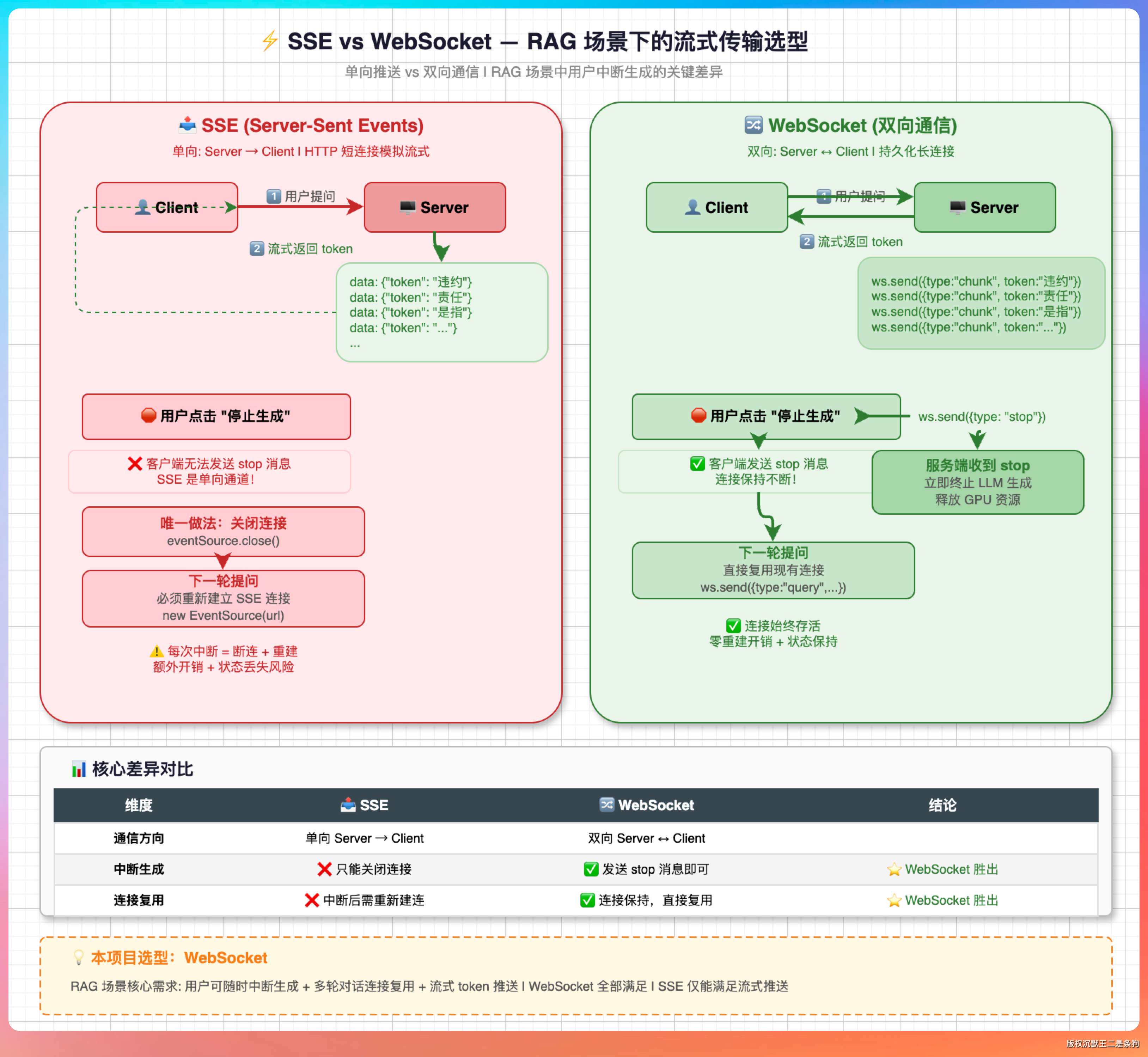
“另外,RAG 的处理流程比较长——文档检索 → 结果重排 → prompt 拼装 → 大模型生成,整个链条可能要好几秒。用 WebSocket 可以在每个阶段给前端推进度,比如‘正在检索...’、‘正在生成...’,客户端也可以在任何阶段发消息取消任务,交互体验比 SSE 灵活很多。”
老王追问:“WebSocket 多服务器怎么部署?”
“WebSocket 是长连接,用户 A 连到了服务器 1,后续所有消息都得发给服务器 1,不能发给服务器 2——因为服务器 2 上没有这条连接。”
“解决方案有两种。”
“第一种是粘性会话(Sticky Session)。在负载均衡器(比如 Nginx)上配置,让同一个用户的请求始终路由到同一台服务器。配置很简单,Nginx 加一行 ip_hash 就行。缺点是某台服务器挂了,上面的所有连接都断了。”
“第二种是消息广播。多台服务器之间用 Redis Pub/Sub 或者消息队列做消息同步。服务器 1 收到要推送给用户 A 的消息,先发布到 Redis 频道,所有服务器都订阅这个频道,持有用户 A 连接的那台服务器负责推送。这种方案更优雅,服务器挂了用户重连到其它服务器就行。”
“派聪明 RAG 目前用的是第一种,因为简单,够用。如果后续要做高可用,会切到第二种。”
resume
很多小伙伴做完 RAG 项目,简历上就写个“基于 LLM 实现了一个 RAG 问答系统”,一句话带过。面试官看完心想:谁不会写这一句话啊。
简历要写得有区分度,得让面试官看完就想追问。我给大家一个参考模板:
项目名称:派聪明 RAG 智能问答系统
项目简介:基于 Spring Boot + MySQL + Redis 构建的企业级 RAG 系统,支持多格式文档上传、智能切片、向量化检索和大模型流式问答,已在技术社区实际部署运行。
技术栈:Spring Boot、MySQL、Redis、Kafka、ElasticSearch、MinIO、text-embedding-v4(Embedding,2048 维)、bge-reranker-v2-m3(重排)、WebSocket
核心职责:
- 设计并实现文档切片引擎,采用 512 token 递归切分策略,结合段落感知和句子边界检测,检索精确率从 68% 提升到 89%
- 基于 ES HNSW 向量索引 + 混合检索架构,支撑百万级 chunk 的语义检索,2048 维向量 P99 延迟控制在 100ms 以内
- 引入 bge-reranker-v2-m3 重排模型对检索结果做二次排序,Top-5 命中率提升 23%,MRR 从 0.61 提升到 0.78
- 设计 WebSocket + Redis Pub/Sub 的流式推送架构,支持多服务器部署下的实时消息同步和连接高可用
- 构建异步文档处理流水线(Kafka + MinIO),实现文件上传、解析、向量化的全流程异步化,单日处理能力达 5000+ 文档
ending
写到这里,想跟正在准备 AI 面试的小伙伴说几句掏心窝子的话。
不要刻意追求 Agent,不要总觉得 RAG 已经过时了,实际上如果深扒的话,RAG 能涉及很多底层的原理。
AI 时代,人心很浮躁,技术迭代的速度也很快。
就像 OpenClaw,已经要被爱马仕 Agent 取代了。
但底层的原理,大家都是一样的。
不要让自己一直在追求新的路上,而是要真正沉下心去,扣一些核心原理。
也只有这样,你才能真正的驾驭这个 AI 时代。