Agent 终于能开浏览器了!Chrome DevTools MCP 接入全解析
大家好,我是二哥呀。
做了联网搜索,做了 MCP,我发现 PaiCLI 还有一个问题,Agent “看不见”一些固有生态的内容,比如说微信的内容。
直接用 web_fetch 去读微信的内容,是读不到的,因为微信生态的内容,外部的搜索引擎无能为力。
还有一些动态渲染的网页内容,抓回来的 HTML 里几乎没有内容。
以及想让 Agent 填表单、截图、看看控制台报错等,更是想都别想。
这一期,我们来接入 Google 官方的 Chrome DevTools MCP,让 PaiCLI 从“能调工具的 Agent”进化成“能开浏览器的 Agent”。
能导航页面、点击元素、填表单、拿 DOM 快照、看网络请求。
看完这一篇,大家就会明白一套完整的浏览器接入方案是怎么设计的,从启动体验到人工审批,从提示词策略到多模态边界,每一步都有讲究。
有了 Chrome Devtools MCP 后,Agent 就可以主动 fallback 到浏览器 MCP:调 mcp__chrome-devtools__new_page 打开页面,等文章容器加载完,再调 take_snapshot 拿 DOM 文本快照,最后总结输出。
Agent 可以主动去打开浏览器,能力就有了大幅提升。
01、Chrome DevTools MCP 是什么
Chrome DevTools 是 Google 官方提供的一个 MCP 工具。
一共有 28 个工具,按功能分八类。
导航有 6 个:navigate_page 开链接、new_page 建新标签页、select_page 切换标签、close_page 关页面、list_pages 看开了哪些标签、wait_for 等指定元素或文本出现。
模拟用户动作有:click 点元素、fill 填单个输入框、fill_form 一次性填整个表单、type_text 模拟键盘输入、press_key 按快捷键、hover 悬停、drag 拖拽、handle_dialog 处理弹窗、upload_file 传文件。
还有 take_snapshot 拿 DOM 文本、take_screenshot 截图、evaluate_script 执行 JavaScript、list_console_messages 看浏览器控制台报错等等。
为什么选官方的 Chrome DevTools MCP,而不是 Playwright 或者 Puppeteer?
三个原因。
第一,Google 官方出品,不需要我们再维护一套浏览器驱动。
第二,支持 --isolated=true 模式,每次启动用临时 user-data-dir,不占用用户的日常 Chrome profile。
第三,原生支持 --browser-url 参数,可以复用已打开的 Chrome,为后面的 CDP 会话复用打下基础。
02、CDP 原理与消息流转
Chrome DevTools MCP 能操控浏览器,靠的是 CDP 协议。
CDP 全称 Chrome DevTools Protocol,是 Chromium 团队提供的一套远程调试协议。
我们平时在 Chrome 里按 F12 打开开发者工具,DevTools 面板和浏览器之间通信用的就是这套协议。只不过 DevTools 面板是给人用的,而 CDP 是给应用程序用的,比如说 Agent。
CDP 的通信方式是 WebSocket。
Chrome 启动的时候加一个 --remote-debugging-port=9222 参数,就会在 9222 端口开一个 WebSocket 服务。外部程序连上这个 WebSocket,就能发命令、接收事件,实现双向实时通信。
具体建立连接的过程是这样的:
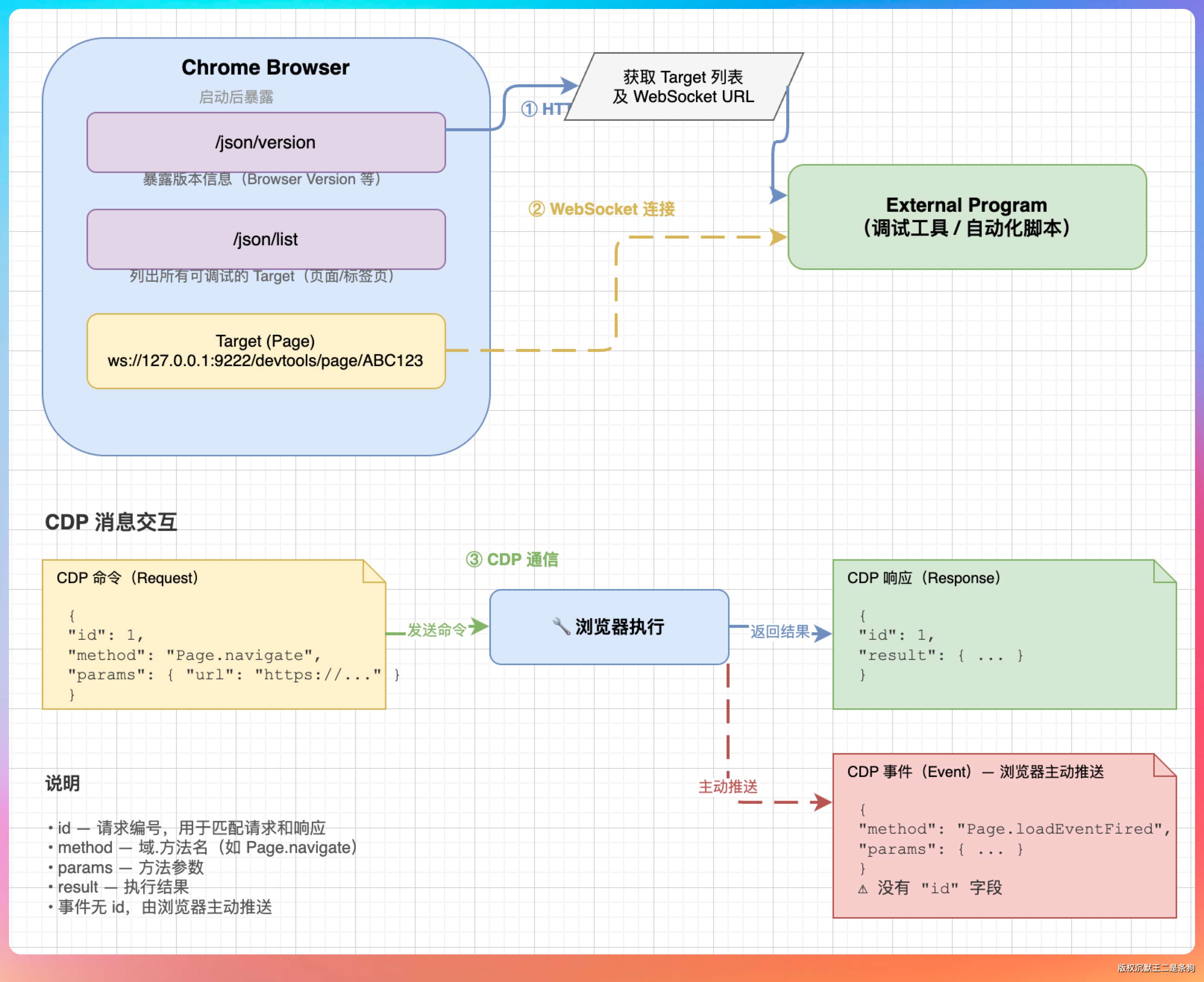
Chrome 启动后,先在 /json/version 端点暴露版本信息,再在 /json/list 端点列出所有可调试的页面(CDP 里叫 target)。
每个 target 都有一个 WebSocket URL,格式类似 ws://127.0.0.1:9222/devtools/page/ABC123。外部程序拿到这个 URL 后建立 WebSocket 连接,然后就可以发 CDP 命令了。
每条 CDP 命令都是一个 JSON 消息,包含 id(请求编号)、method(域.方法名)、params(参数)。浏览器执行完之后返回一个同样带 id 的 JSON 响应,包含 result(结果)。如果是事件通知,浏览器主动推过来的消息里没有 id,而是带 method 和 params,比如 Page.loadEventFired。
chrome-devtools-mcp 的 Puppeteer 把这套底层的 WebSocket 收发都封装好了。
Agent 调 MCP 工具的时候,不需要自己拼 JSON 消息,也不需要管理 WebSocket 连接。Puppeteer 内部还处理了消息的序列号、超时重发、连接断开后的自动重连,这些脏活累活 Agent 一概不用操心。

CDP 把浏览器的能力分成了很多个“域”(Domain),每个域负责一类功能。
Page 域管导航和页面生命周期,DOM 域管元素查询和属性修改,Runtime 域管 JavaScript 执行,Network 域管请求拦截和流量监控,Input 域管鼠标和键盘的模拟操作,Target 域管标签页的创建和切换。
我们日常在 DevTools 里做的所有事情,背后都是这些域的方法调用。
chrome-devtools-mcp 内部就是通过 Puppeteer 封装了这些 CDP 调用。
它的架构是分层的:MCP Server 层处理 JSON-RPC 请求和会话管理,Tool Adapter 层把 MCP 工具调用映射到 CDP 域方法或 Puppeteer API,Chrome Runtime 层真正执行浏览器操作,Data Collection 层把结果序列化返回给 Agent。
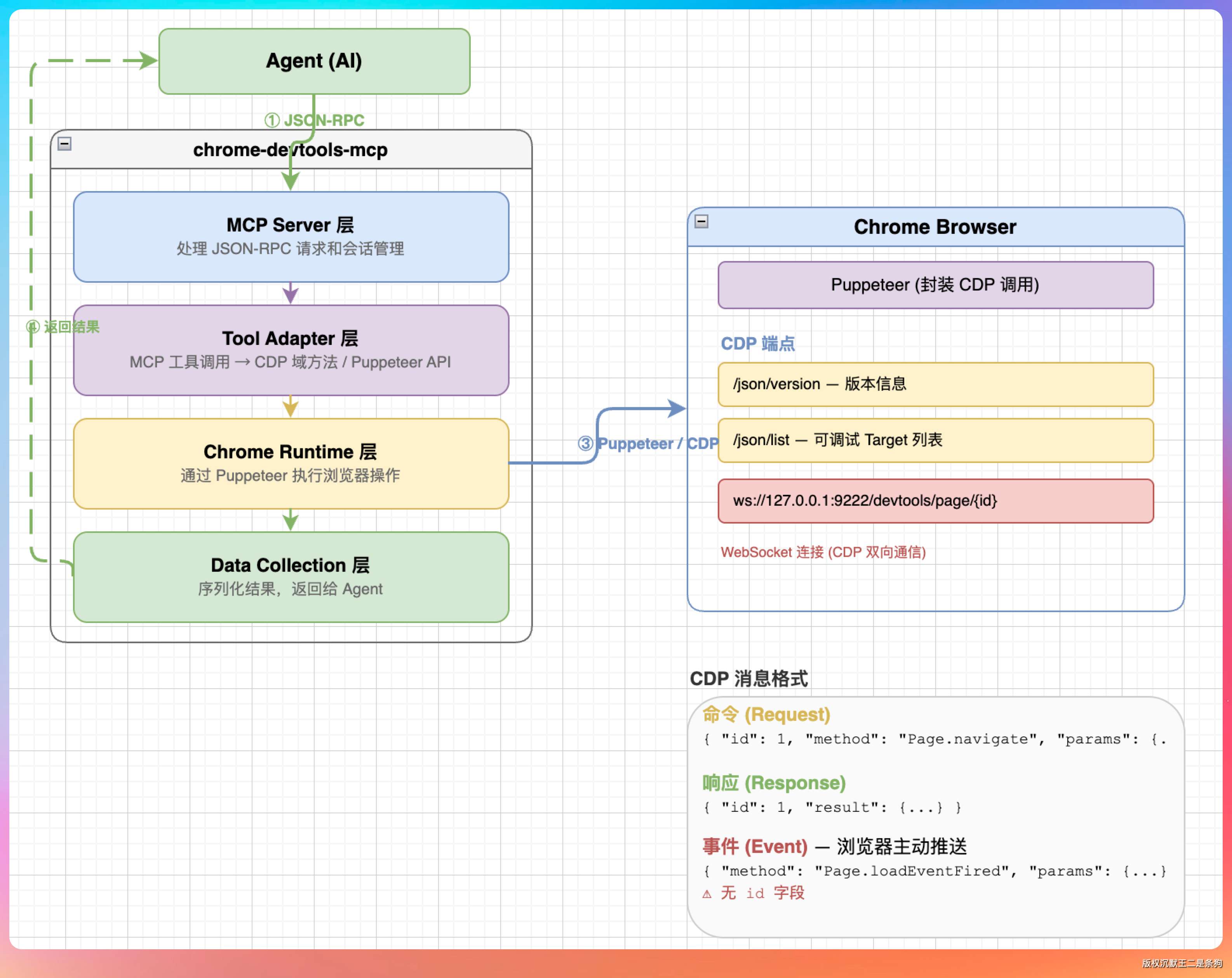
常用的工具和 CDP 域的对应关系大致是这样的:navigate_page 和 new_page 走 Page 域,click、fill、type_text、press_key 走 Input 域,evaluate_script 走 Runtime 域,take_screenshot 走 Page 域的 captureScreenshot 方法。
而 take_snapshot 比较特殊,它走的是 Accessibility 域,拿到的是页面的可访问性树(Accessibility Tree),这是浏览器为了辅助功能(比如屏幕阅读器)维护的一份结构化文本表示,比原始 HTML 更干净,比截图更可读。
Agent 调 navigate_page 时,请求路径是这样的:
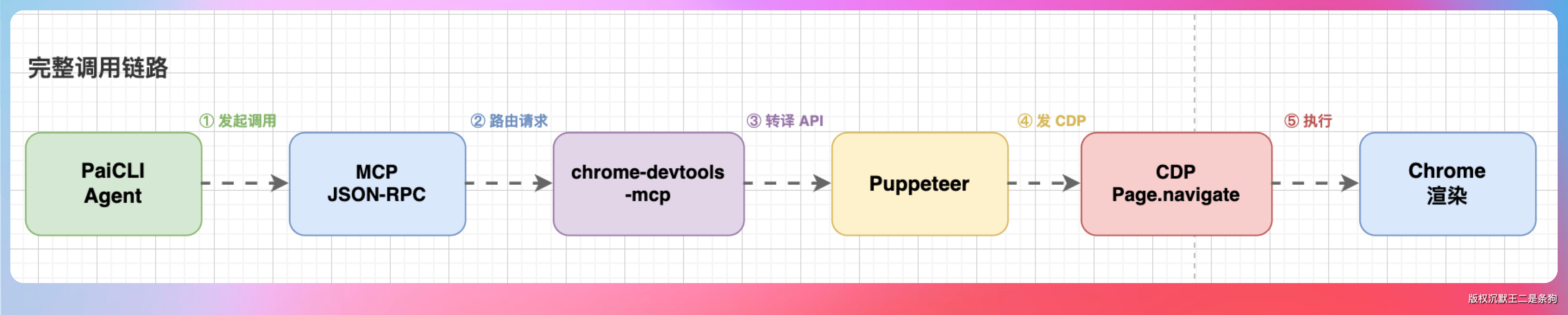
再比如 take_snapshot,它走的是 CDP 的 Accessibility 域或者 DOM 域,把页面的可访问性树或者 DOM 结构提取成纯文本,直接返回给 LLM 阅读。
而 take_screenshot 走的是 CDP 的 Page.captureScreenshot,返回的是 PNG 图片的二进制数据。
整个消息流是双向的。
Agent 发命令给浏览器,浏览器也会主动推事件回来。比如页面加载完成会推 Page.loadEventFired,网络请求完成会推 Network.requestWillBeSent。
chrome-devtools-mcp 内部会订阅这些事件,配合 wait_for 工具让 Agent 能等特定条件出现再继续操作。
理解了 CDP 这一层,后面再看 chrome-devtools-mcp 的工具设计就很好懂了:每个工具其实就是对一组 CDP 方法的高级封装,加上了参数校验、错误处理和结果格式化,让 Agent 不需要直接跟 CDP 的底层细节打交道。
03、默认接入与启动体验
chrome-devtools 在 PaiCLI 里是默认 enabled 的。
~/.paicli/mcp.json 如果不存在,启动时会自动创建一份默认模板,里面就包含 chrome-devtools 的配置:
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": ["-y", "chrome-devtools-mcp@latest", "--isolated=true"]
}
}
}
--isolated=true 告诉 server 每次启动都用一个全新的临时用户数据目录,不要去碰用户日常的 Chrome 书签、历史、Cookie。
这个隔离机制值得展开说一说。
--isolated=true 的底层原理是每次启动 Chrome 的时候,Puppeteer 会创建一个操作系统临时目录下的子目录作为 --user-data-dir,比如 /tmp/puppeteer-dev_profile-abc123。
这个目录里存的是浏览器的所有本地数据:Cookie、localStorage、sessionStorage、IndexedDB、缓存、登录态。浏览器关闭之后,这个临时目录会被自动清理掉,不留痕迹。
隔离的好处是:Agent 在浏览器里做的所有操作,不会污染用户日常的 Chrome。即使 Agent 访问了恶意网站,Cookie 被篡改了,关掉浏览器就什么都清了。
但隔离也有代价:登录态没法共用。
如果你让 Agent 登录了某个网站,下次再开浏览器,登录态没了,又得重新登录。
这正是之后我们要解决的问题:用 --browser-url 参数连接到用户日常打开的 Chrome,复用已有的登录状态。--browser-url 的用法是 --browser-url=http://127.0.0.1:9222,直接连上一个已经打开的 Chrome 实例,不走 isolated 模式。
另外,macOS 用户首次运行可能会碰到系统权限弹窗。
Chrome 在 isolated 模式下启动时,macOS 可能会请求“辅助功能”或“屏幕录制”权限,这是操作系统级别的安全策略,必须手动点允许,否则 Chrome 启动会失败。如果碰到启动超时,先检查一下系统偏好设置里有没有待审批的权限请求。
可以用 /mcp disable chrome-devtools 随时关闭。
当然了,默认 enabled 会让 PaiCLI 首次启动特别慢。
为了减轻用户的等待焦虑,McpServerManager.startAll() 里另起了一个 daemon 进度来打印线程,每 5 秒检查一次还没 ready 的 server,把等待时长实时打印出来:
🔌 启动 MCP server(5 个)...
✓ filesystem stdio 14 工具 1.2s
⏳ chrome-devtools stdio 启动中...(首次需拉包 + 启动 Chrome)
✓ zread http 3 工具 0.8s
⏳ chrome-devtools stdio 启动中...(已等待 12s)
✓ chrome-devtools stdio 28 工具 18.5s
5/5 就绪,共 60 个 MCP 工具
04、从 mcp.json 到工具注册
前面讲了 CDP 原理和启动体验,这一节我们把整个接入路径从配置到工具注册串起来,看看 PaiCLI 内部到底做了什么。
第一步,读取配置。
Main.java 启动时会检测 ~/.paicli/mcp.json 是否存在。
如果文件不存在,就用默认模板创建一份,里面包含 chrome-devtools 的配置。如果文件已经存在但缺 chrome-devtools 条目,只打印一行提示,不会擅自改用户的配置文件。
第二步,启动 server 进程。
McpServerManager.startAll() 遍历 mcpServers 里所有非 disabled 的条目,对每个 server 启动一个子进程。
chrome-devtools 的 command 是 npx,args 是 ["-y", "chrome-devtools-mcp@latest", "--isolated=true"]。
npx 会先在本地缓存里找,找不到就从 npm 拉取,然后执行。这就是首次启动特别慢的原因。
第三步,MCP 握手。
子进程起来之后,McpClient.initialize() 发送 JSON-RPC initialize 请求,等 server 回复 capabilities。
第四步,拉取工具列表。
chrome-devtools server 在 capabilities 里声明了 tools 能力,PaiCLI 就调 tools/list 拿到 28 个工具的 schema 定义,每个工具包含名称、描述和参数格式。
第五步,注册到 ToolRegistry。
28 个工具按 mcp__{server}__{tool} 的格式注册,比如 mcp__chrome-devtools__navigate_page、mcp__chrome-devtools__take_snapshot。
这些工具跟内置工具和之前注册的其他 MCP 工具在同一个 Registry 里统一管理,HITL 审批、AuditLog 记录一个都不少。
有一点值得说:chrome-devtools-mcp 的浏览器不是连接时就启动的。
它是在 Agent 第一次调用浏览器相关工具时,才会自动拉起 Chrome 实例。这意味着如果用户只是启动了 PaiCLI 但没让 Agent 操作浏览器,Chrome 进程是不会出现的,不占用资源。
05、系统提示词升级
光把工具注册进去还不够,得让 Agent 知道什么时候用浏览器、什么时候用 web_fetch。
否则 Agent 遇到微信内容还是先去调 web_fetch,失败之后再重试,很浪费 token 和时间。
于是我们在系统提示词里加了「web_fetch vs 浏览器 MCP」决策表:Agent.SYSTEM_PROMPT、PlanExecuteAgent.EXECUTION_PROMPT、SubAgent.WORKER_PROMPT。
这套提示词相当于给 Agent 写了一份“浏览器操作手册”。
06、场景实测
代码写完了,Prompt 也调好了,该上手验证了。
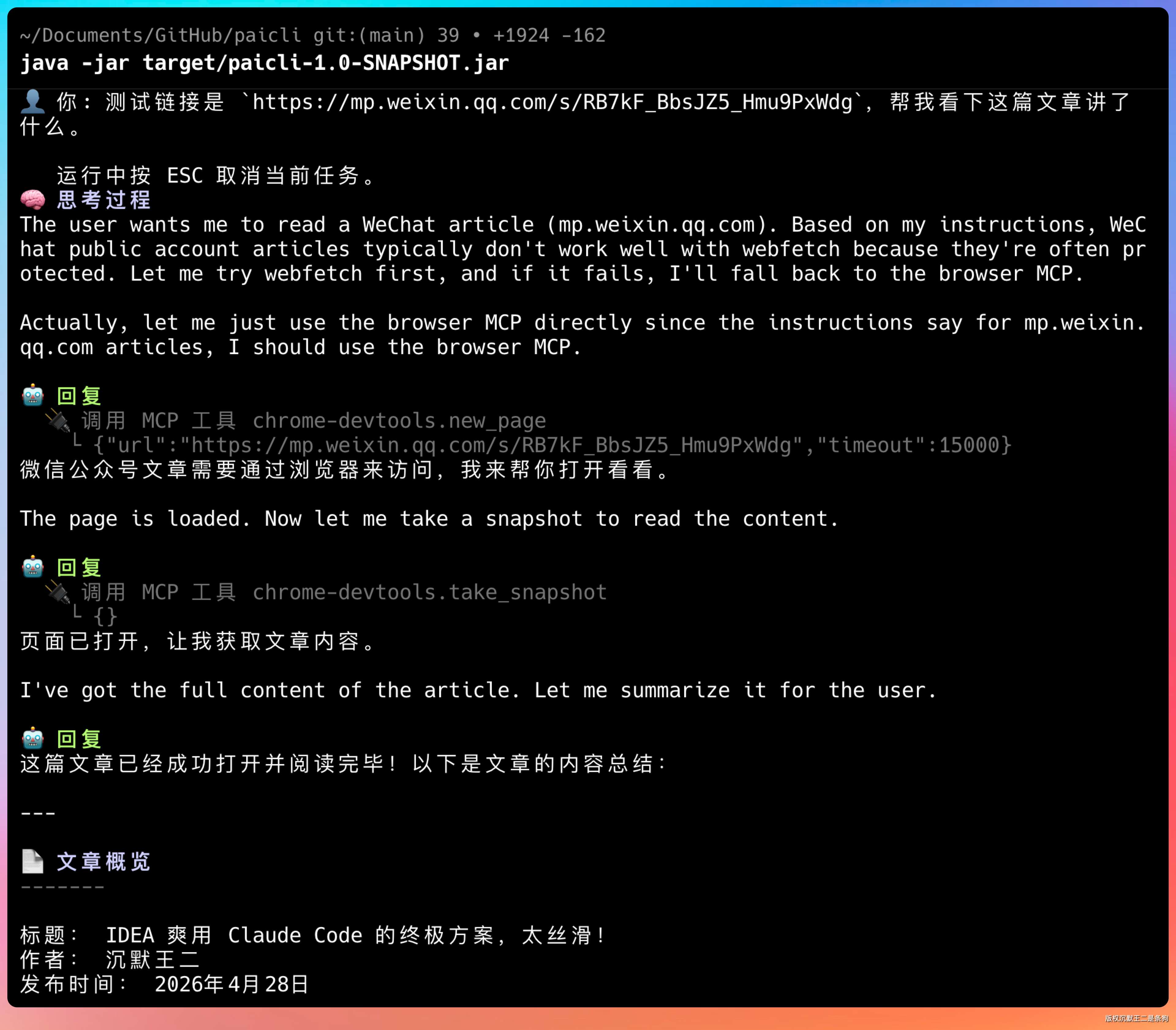
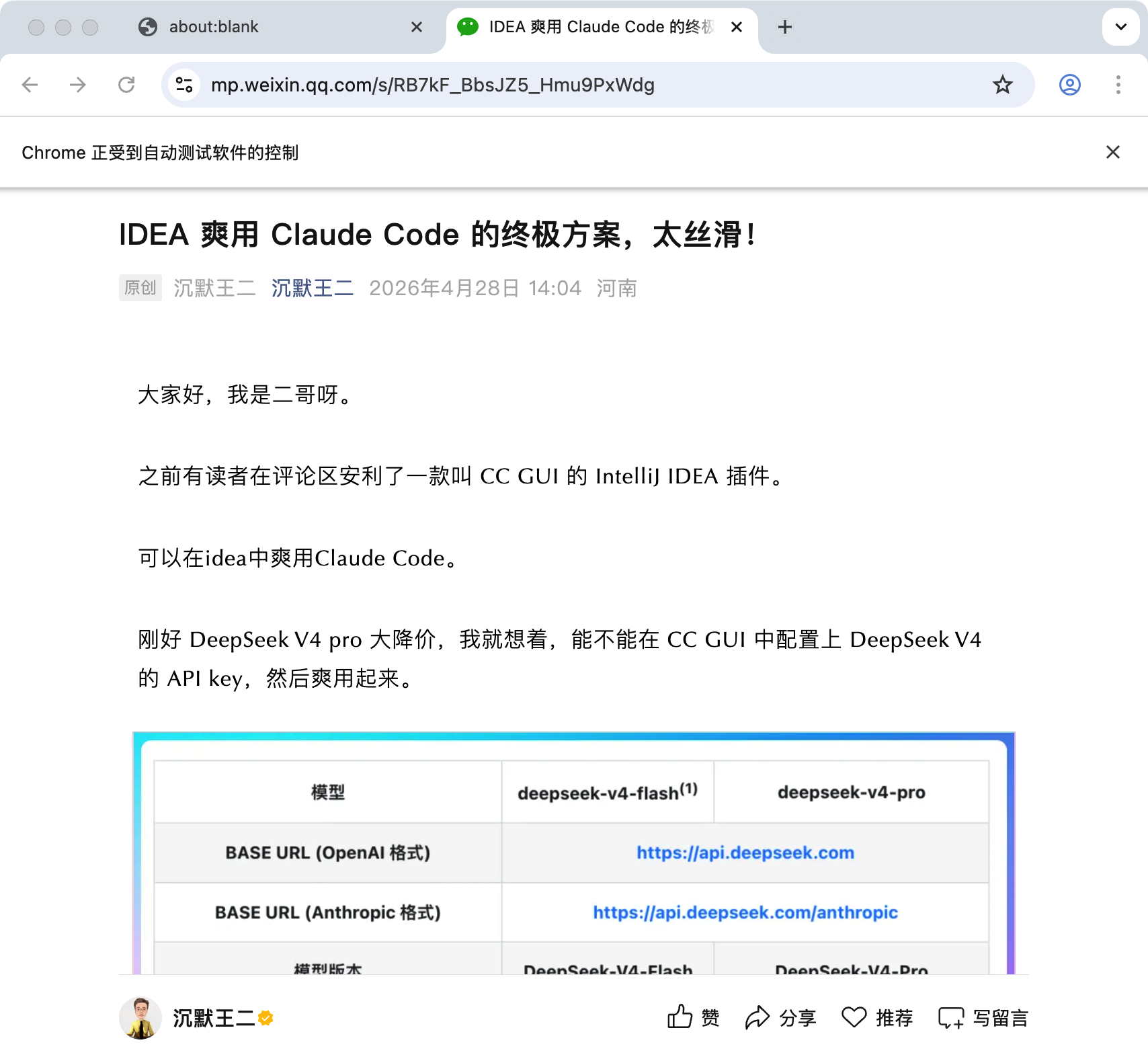
提示词:测试链接是 https://mp.weixin.qq.com/s/RB7kF_BbsJZ5_Hmu9PxWdg,帮我看下这篇文章讲了什么。
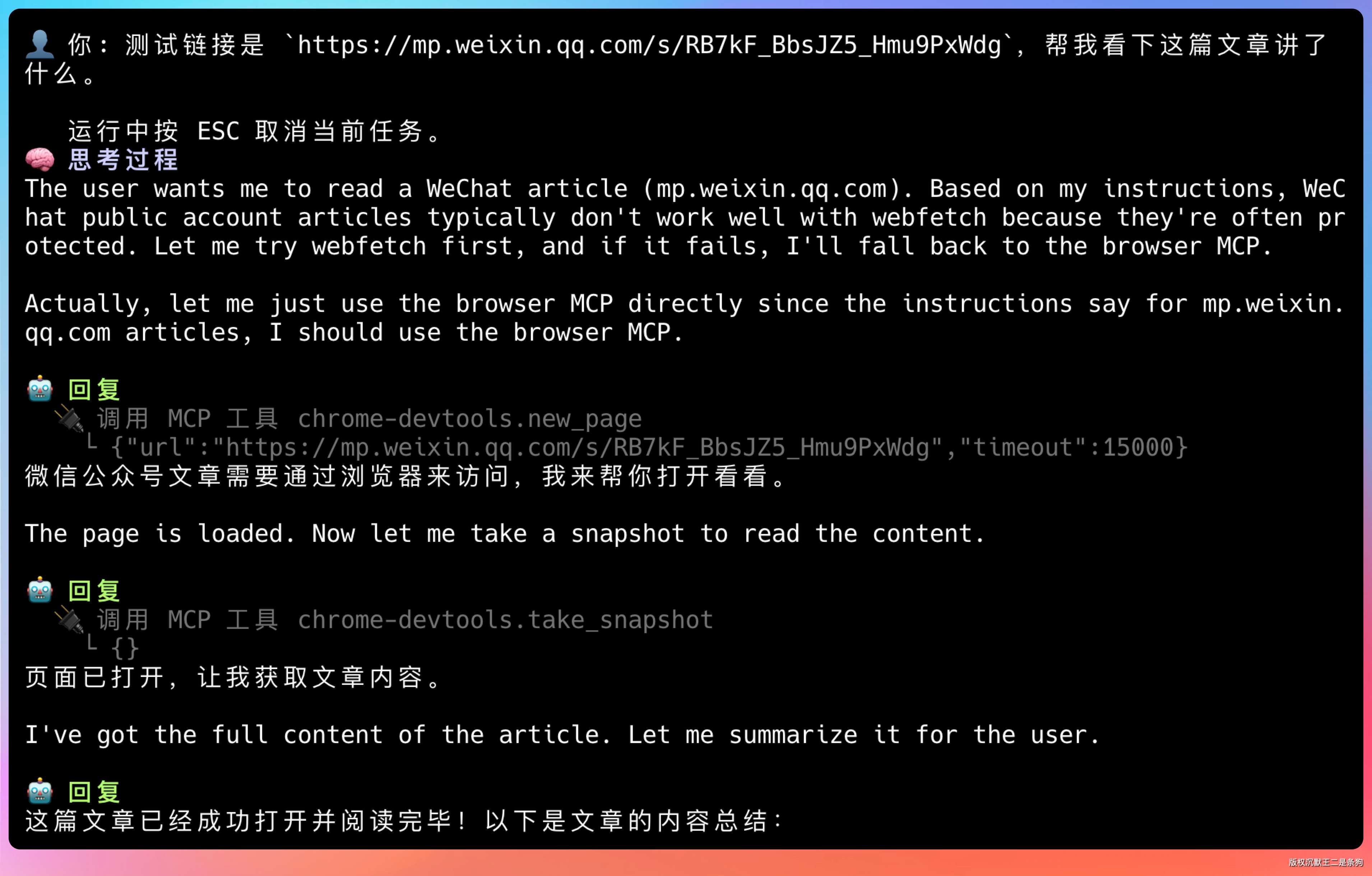
从 llm 的思考过程就能看得出来,用户想要阅读微信生态的内容,我会先尝试用 web_fetch,如果不行,我会使用 Chrome 的 MCP。
实际上,提示词里已经讲了,阅读微信生态的内容需要用浏览器的 MCP,所以直接调用了 mcp__chrome-devtools__new_page,然后等内容加载后,通过 take_snapshot 去拿正文的 DOM,最后总结输出。
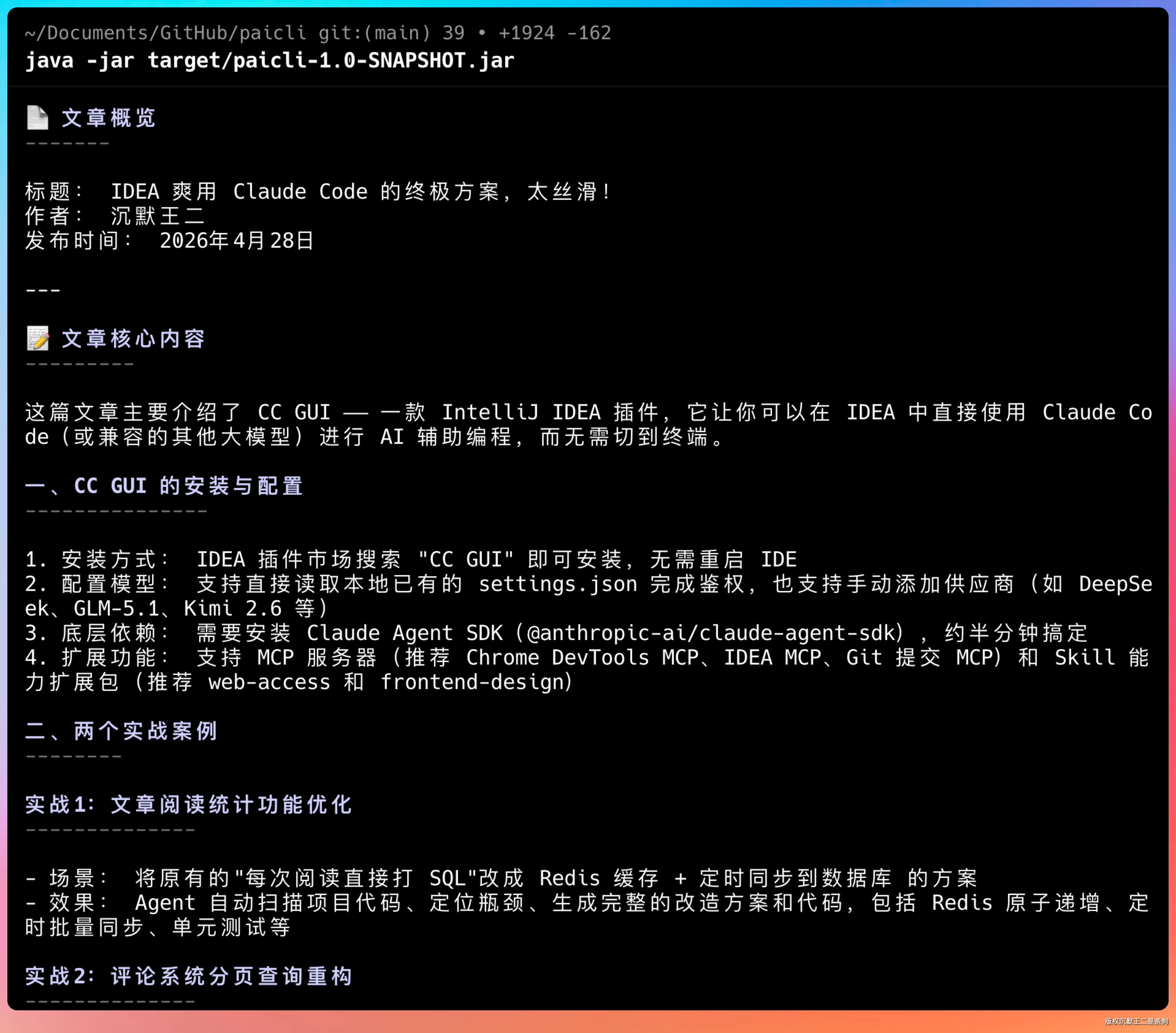
完全没问题。
并且确实新开了一个 Chrome 去阅读这篇内容。
第二个提示词是:截图看一下 paicoding.com 的首页
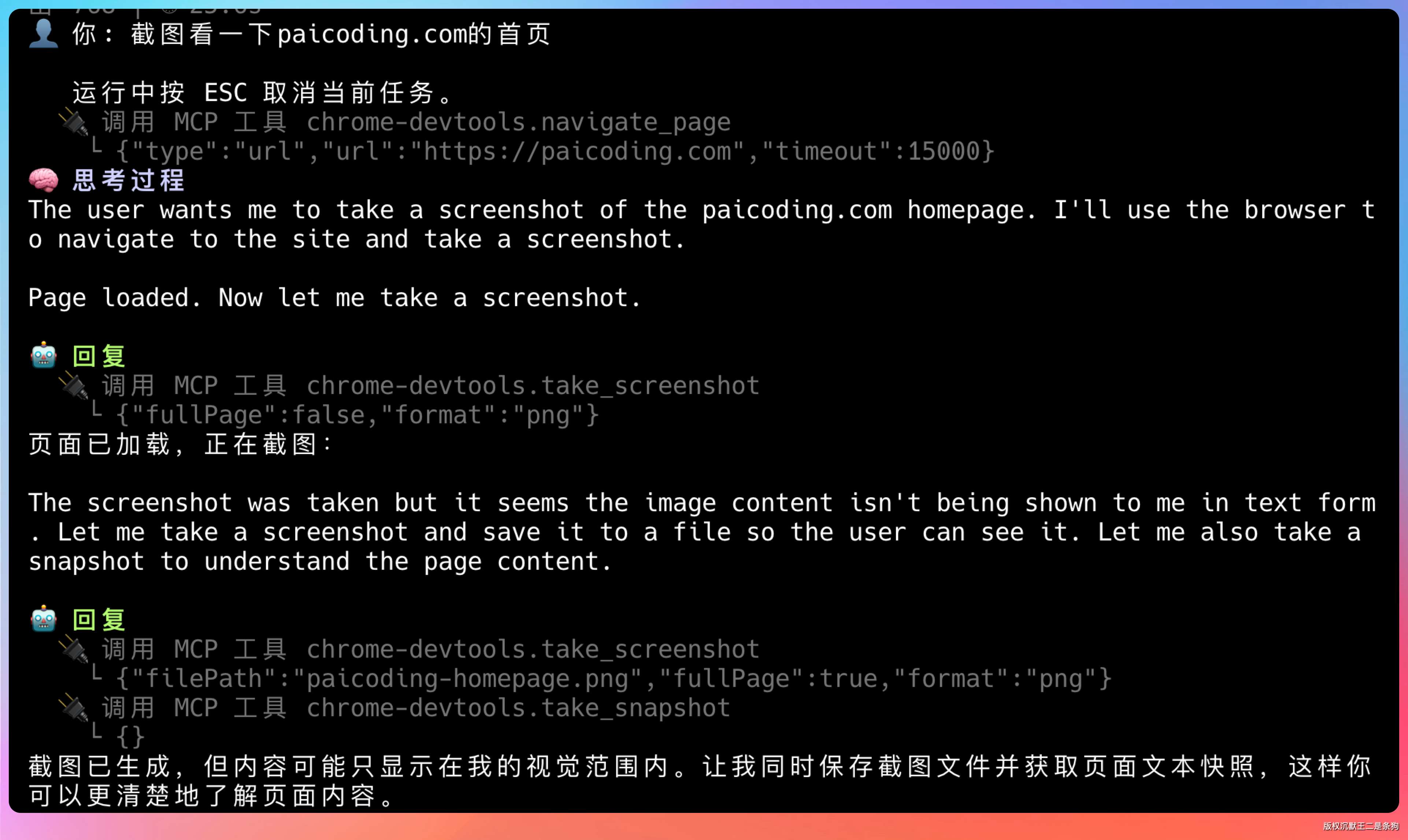
这时候会调用 MCP 工具 chrome-devtools.take_screenshot,然后再传给 llm 去读内容。
项目的根目录确实也能看到截图。
07、PaiCLI 如何写到简历上
项目名称:PaiCLI — Browser-Capable Agent CLI
项目简介:基于 Java 实现的 AI Agent 命令行工具,接入 Chrome DevTools MCP server,使 Agent 具备完整浏览器自动化能力,覆盖导航、输入、DOM 快照、截图、网络请求监控等 28 个工具。
技术栈:Java 21、MCP Protocol、Chrome DevTools Protocol、JSON-RPC 2.0、ConcurrentHashMap、CompletableFuture
核心职责:
- 接入 chrome-devtools-mcp,设计
--isolated=true安全隔离策略,实现 mcp.json 自动模板创建 - 设计 web_fetch → 浏览器 MCP 自动 fallback 机制,当 web_fetch 因 SPA / 反爬墙 / 客户端渲染返回空正文时,Agent 自动切换到 Chrome DevTools MCP 通过 take_snapshot 拿取 DOM 文本,覆盖微信公众号、知乎专栏、掘金等 web_fetch 不可达场景
- 设计 MCP server 启动进度打印线程,每 5 秒刷新未就绪 server 等待时长