给 Agent 接入 MCP,支持 stdio 和 Streamable HTTP。
大家好,我是二哥呀。
上一期我们给 PaiCLI 加上了联网能力,搜索和抓取都有了。但这些工具都是我们自己实现的。
如果想让 Agent 操作本地文件系统呢?
或者读取 GitHub 仓库呢?
难到每个需求都要自己写一遍?
不用。MCP 可以用来干这个。
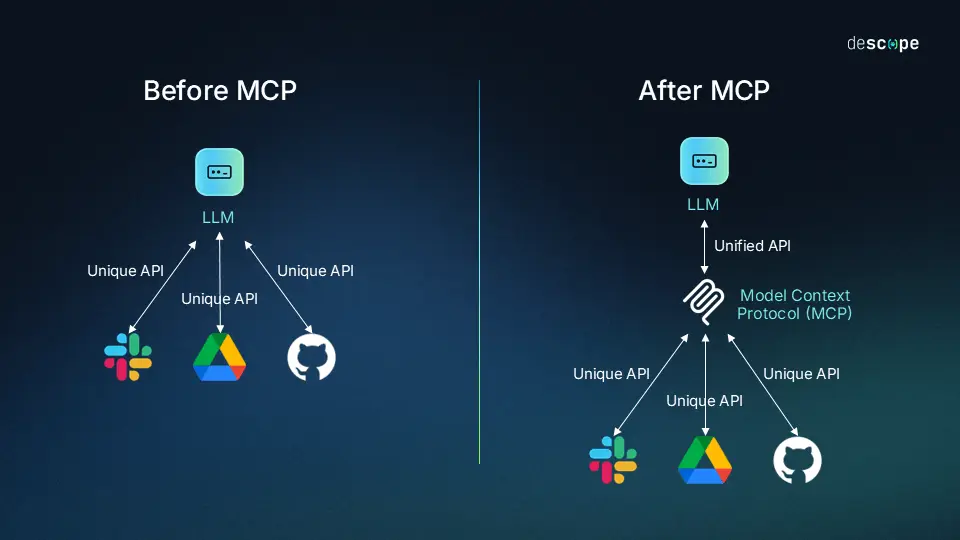
MCP 全称 Model Context Protocol,翻译过来叫做模型上下文协议。一句话概括:它是一个让 Agent 接入第三方工具的标准协议。
有了 MCP,别人写好的工具(比如文件操作、GitHub 读取、数据库查询),我们的 Agent 不用写一行代码就能直接用。
当然了,配置还是需要配置的。😄
这一期,我们就来给 PaiCLI 接上 MCP。
01、先看效果
老规矩,先看接上 MCP 之后 PaiCLI 能干什么,再聊怎么实现。
在没有配置 MCP 之前,启动 PaiCLI 会看到这样的提示:
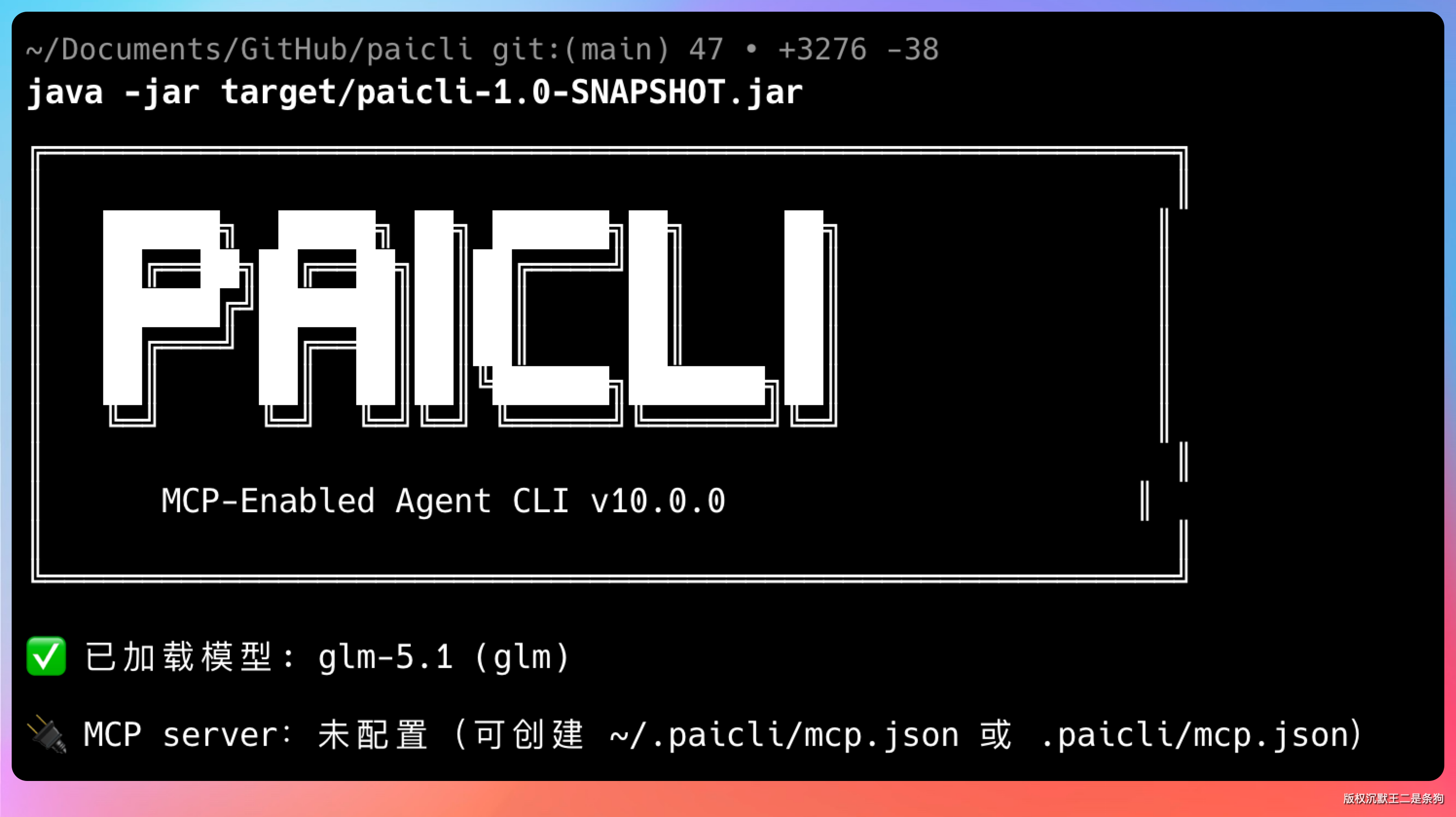
🔌 MCP server:未配置。意思是 MCP 已经就绪了,只需要我们告诉它要连哪些 server。
这次我们来接入两个 MCP server。
第一个是 Claude 官方提供的 filesystem,一个基于 stdio 的本地文件操作工具,支持读写文件、搜索文件、列目录等等。
stdio啥意思,我们后面会讲。
第二个是智谱提供的 zread,一个基于 Streamable HTTP 的远程工具,可以读取 GitHub 仓库的文件内容和目录结构。
配置文件放在 ~/.paicli/mcp.json,内容长这样:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "${PROJECT_DIR}"]
},
"zread": {
"type": "http",
"url": "https://open.bigmodel.cn/api/mcp/zread/mcp",
"headers": {
"Authorization": "Bearer your_api_key"
}
}
}
}
好,我们的 PaiCLI Agent 就同时接入了两种 MCP:一种是 stdio 传输(filesystem),另一种是 Streamable HTTP 传输(zread)。
重新启动 PaiCLI,输入提示词:
读一下 itwanger/paicoding 仓库根目录的 README,给我讲讲它在做什么
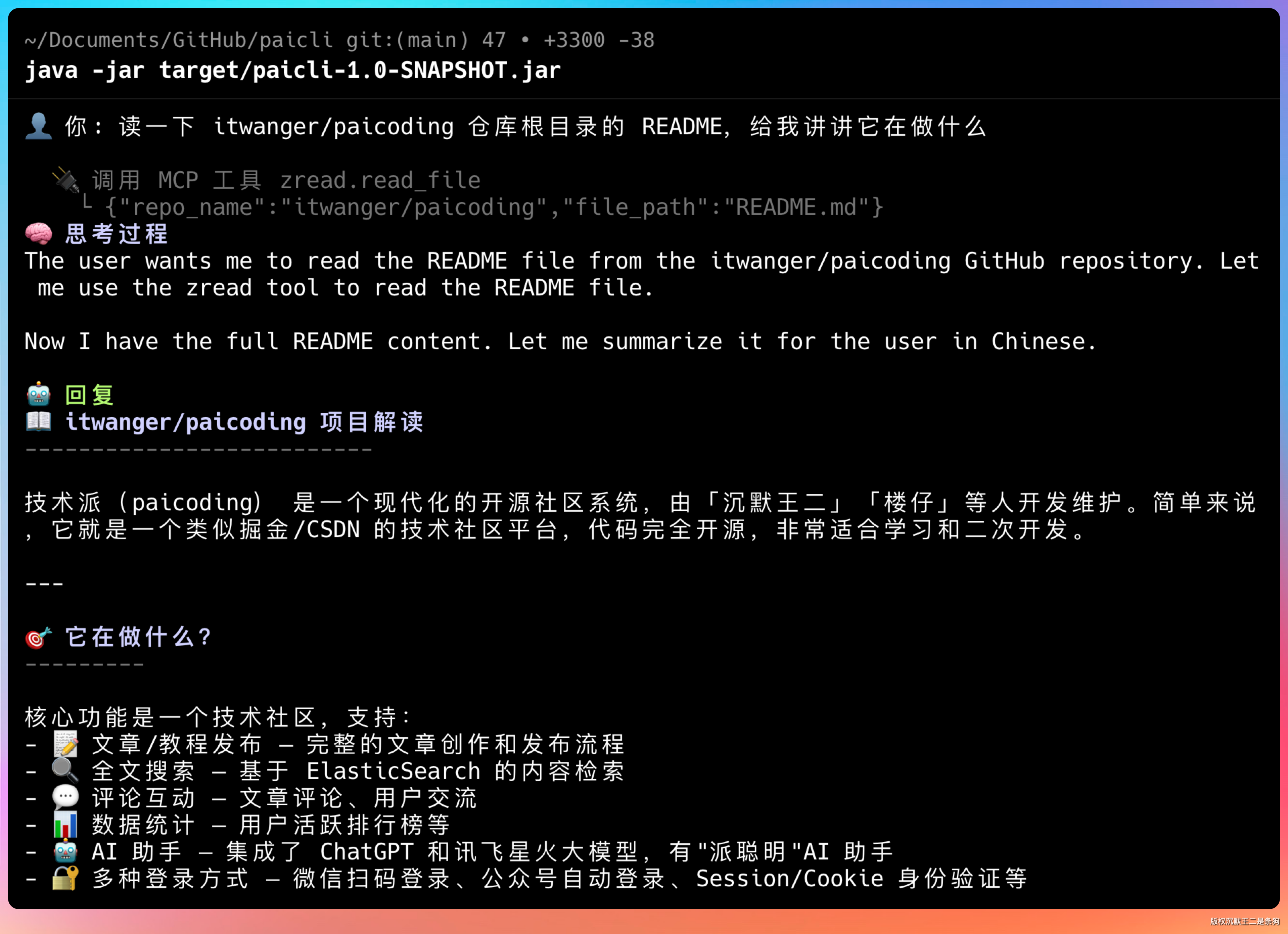
Agent 自动调用了 zread.read 这个 MCP 工具,去 GitHub 上抓取了 README 的内容,然后给出了总结。
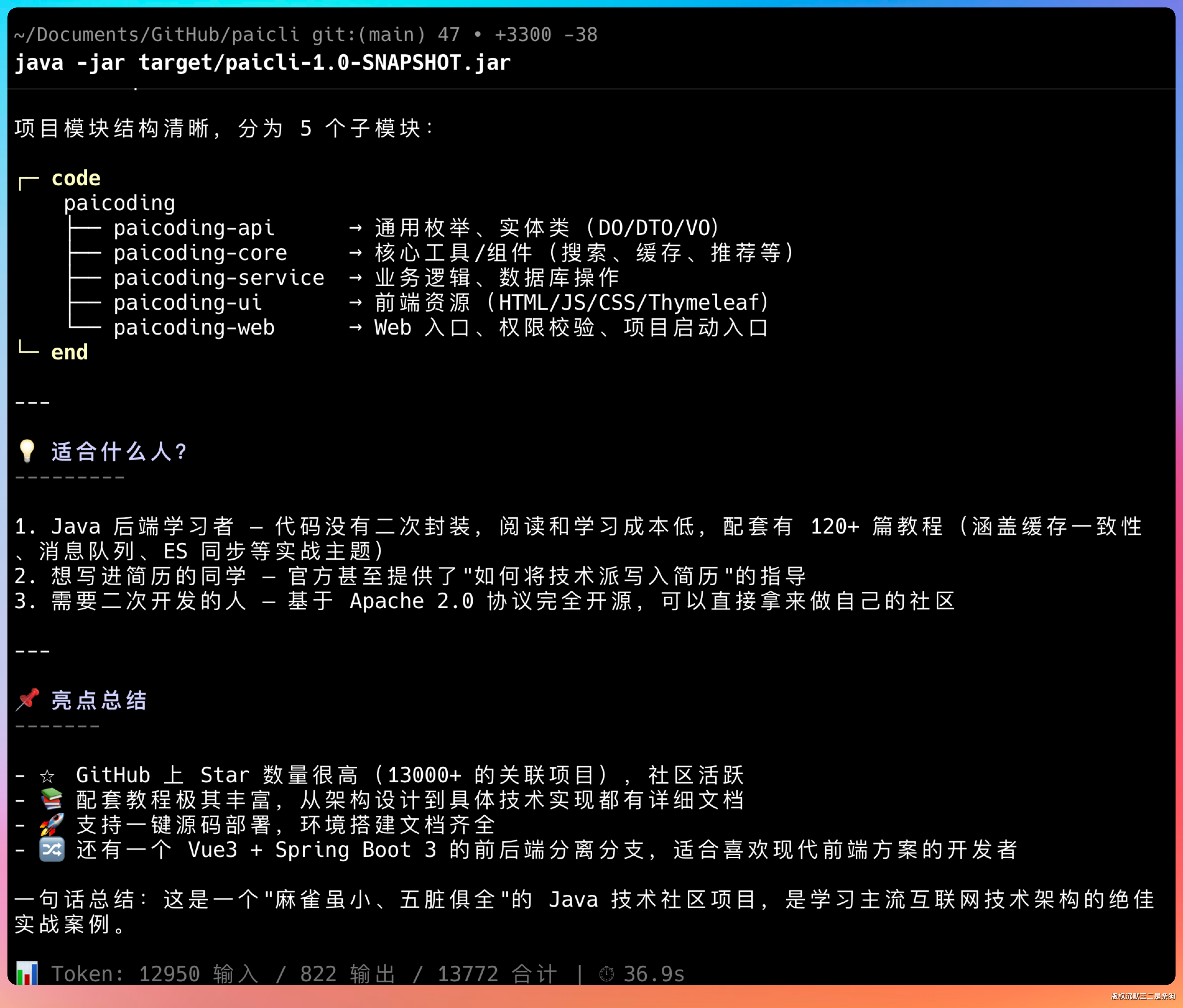
再试试 zread.get_repo_structure,输入提示词:我想看 src 目录的完整树状结构,包括所有子目录和文件。
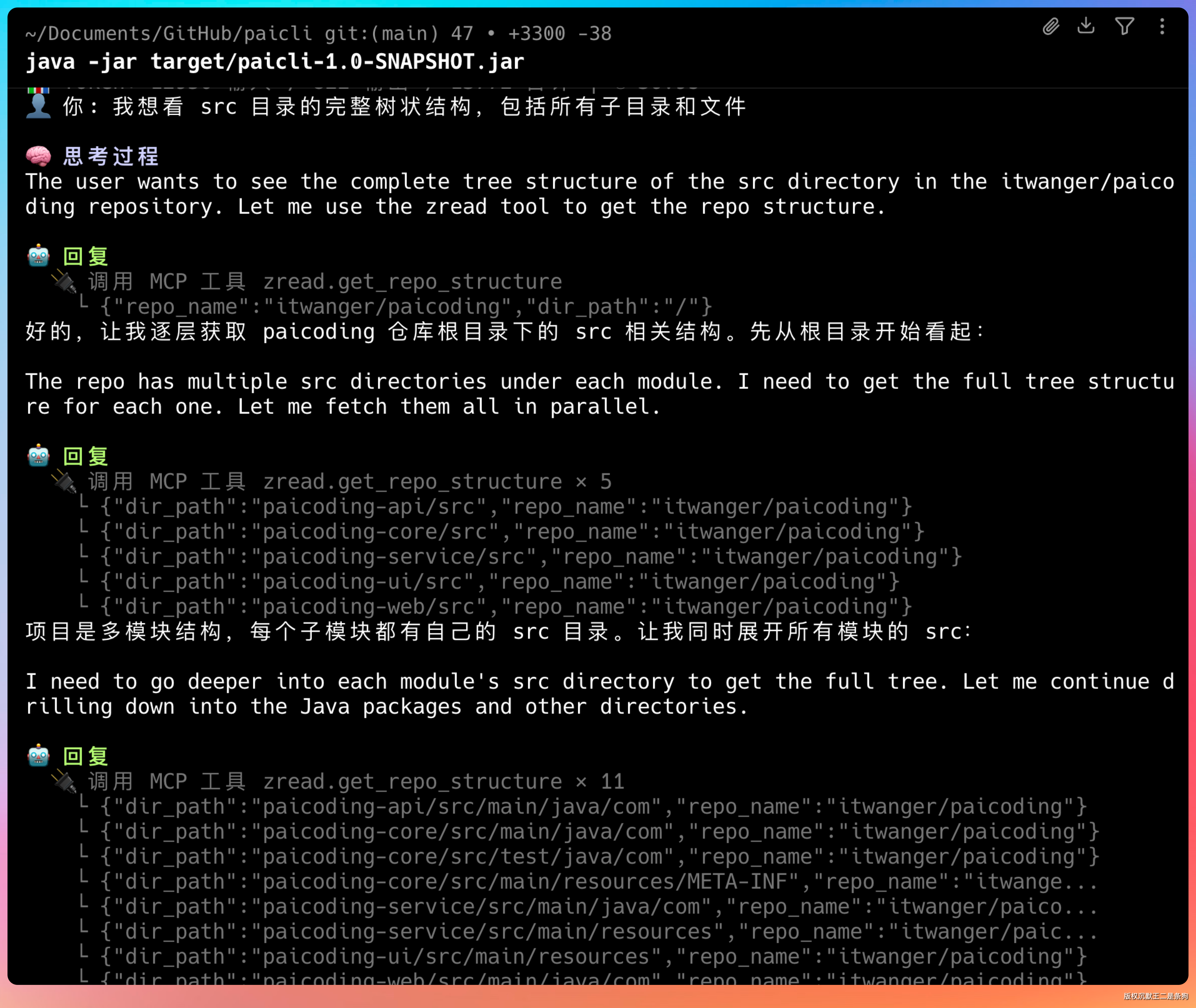
整个仓库的目录结构一目了然。你也可以试试其他提示词:
- 搜一下 itwanger/paicli 这个仓库的官方文档,看看 MCP 是怎么集成的?
- 看看 itwanger/paicoding 仓库整体的目录结构
接下来测试 Claude 官方的 filesystem MCP。
最好清一下上下文 /clear。
输入提示词:把 README.md 第 3 行那句“对标 Claude Code”改成“对标 Claude Code 作者为沉默王二”。
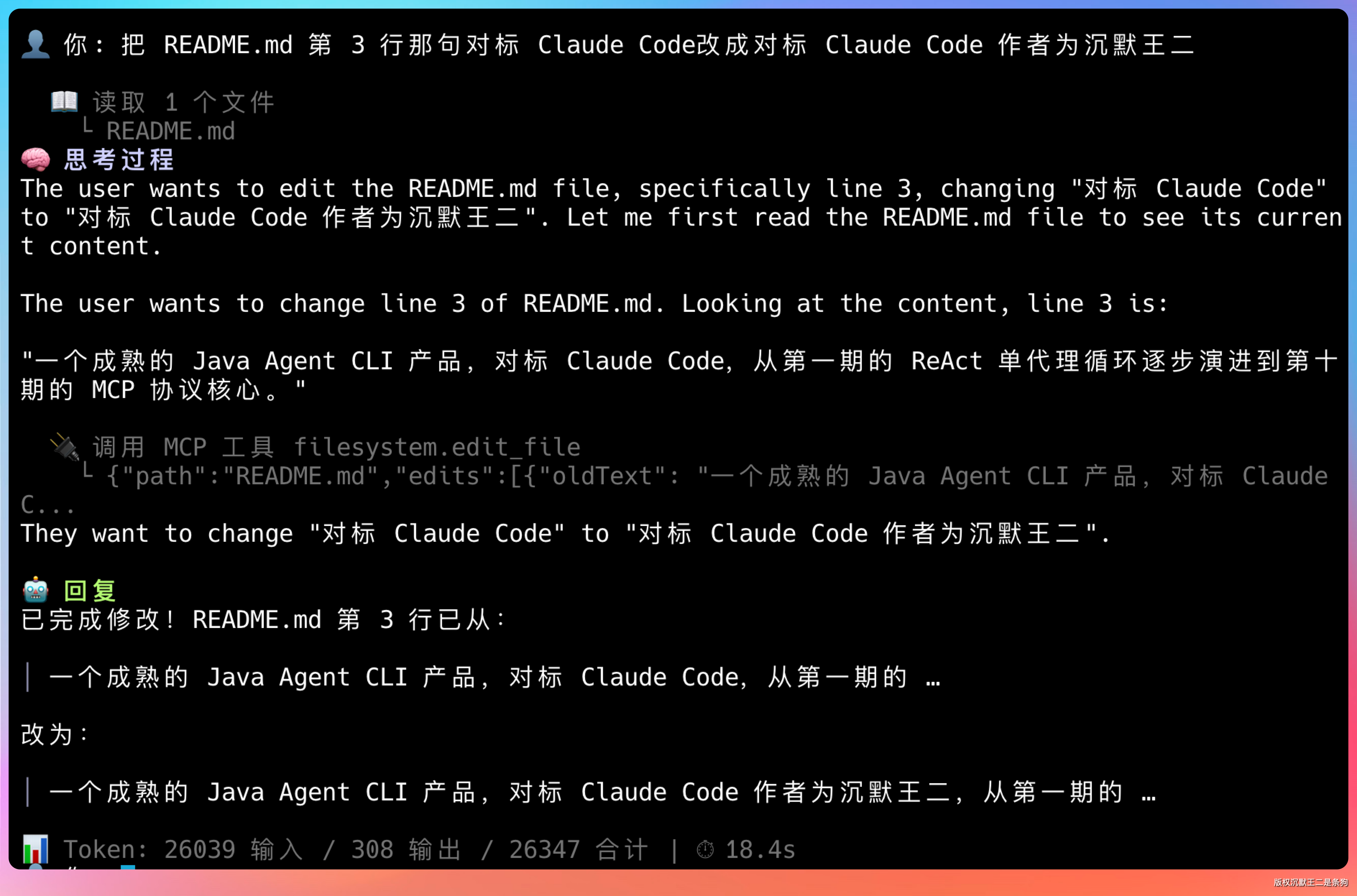
这里能看到 Agent 调用了 MCP 工具 filesystem.edit_file,直接修改了本地文件。
回到仓库里验证一下,改动确实生效了。
再比如调用 filesystem.search_files,在整个仓库里搜文件名带 Manager 的 Java 文件。
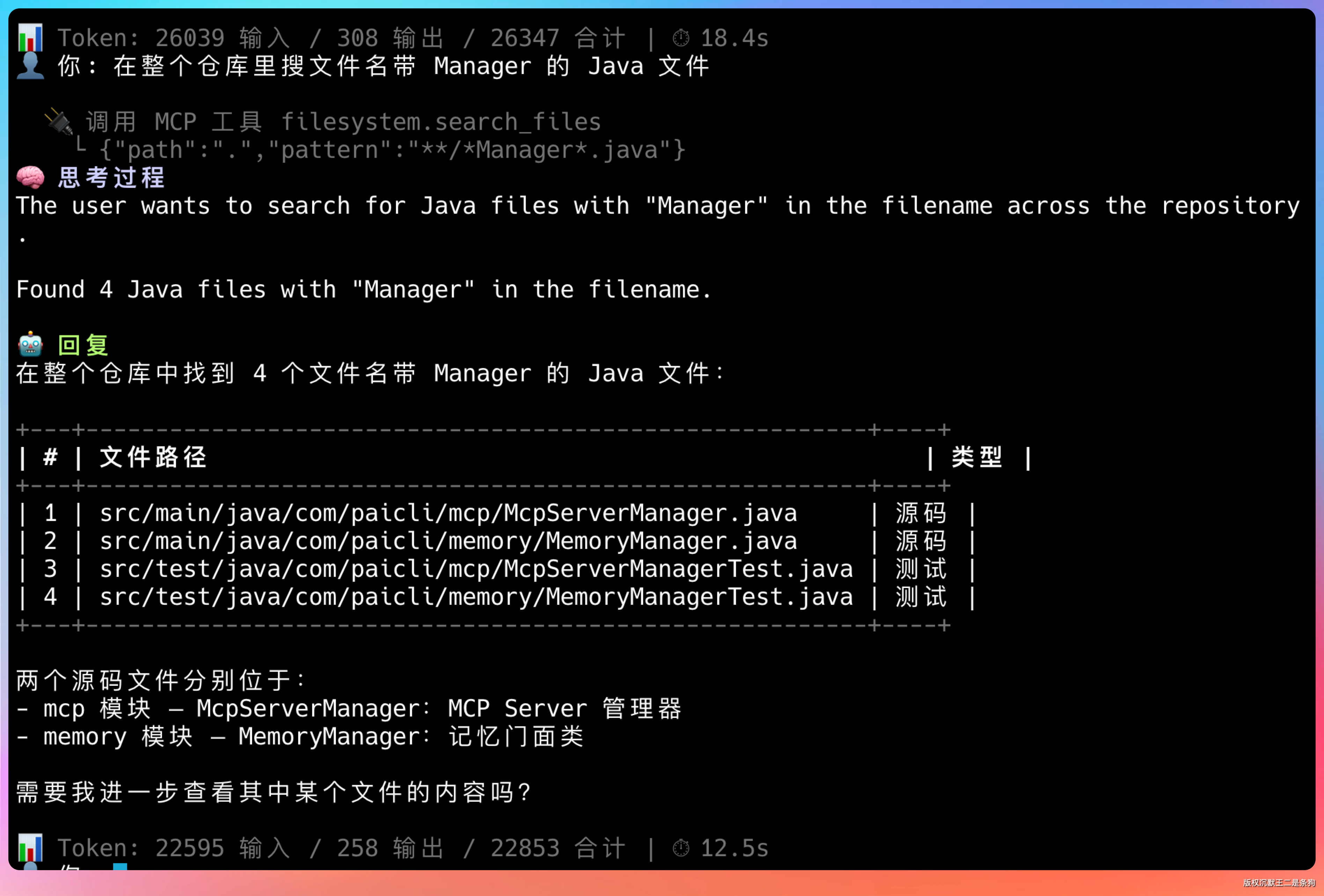
两种 MCP 都跑通了。
Agent 不需要知道工具的实现细节,只要 MCP server 提供了工具描述,Agent 就能根据用户意图自动选择调用。
这就是 MCP 最大的价值:工具的开发者和 Agent 的开发者可以完全解耦。filesystem 的作者不需要知道 PaiCLI 是怎么实现的,PaiCLI 也不需要知道 filesystem 内部是怎么读写文件的。双方只要遵循 MCP 协议,就能无缝对接。
02、MCP 到底是什么
效果看完了,现在来硬核一把,把 MCP 的技术细节掰开揉碎给大家讲清楚。
JSON-RPC 2.0 协议
MCP 的底层通信协议是 JSON-RPC 2.0。
不是 HTTP REST,不是 gRPC,就是最朴素的 JSON-RPC。
JSON-RPC 很简单,一个请求长这样:
{"jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": {}}一个响应长这样:
{"jsonrpc": "2.0", "id": 1, "result": {"tools": [...]}}id 用来配对请求和响应。客户端发 id=1 的请求,服务端回 id=1 的响应,这样即使多个请求并发,也不会搞混。
还有一种叫通知(notification),没有 id 字段,服务端不需要回复:
{"jsonrpc": "2.0", "method": "notifications/initialized", "params": {}}为什么选 JSON-RPC 而不是 REST?
因为 MCP 的通信不是资源导向的(不存在“某个工具的 URL”),而是过程调用导向的——“我要调用某个方法,传这些参数”。
JSON-RPC 天然适合这种场景,协议头尾加起来也就几个字段,解析起来比 HTTP REST 简单很多。
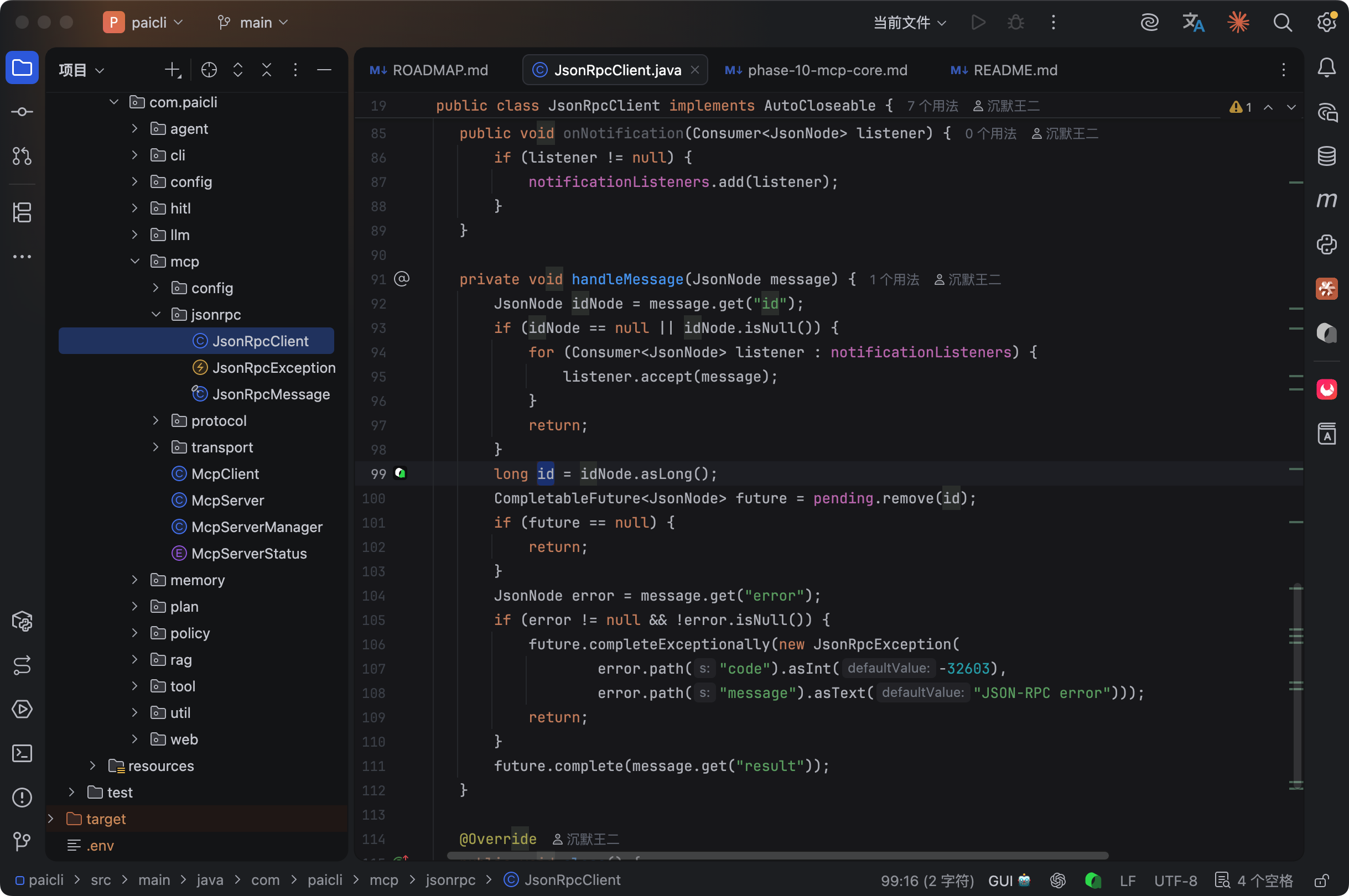
PaiCLI 手写了一个 JsonRpcClient,大概 120 行代码。用 AtomicLong 生成递增 ID,用 ConcurrentHashMap<Long, CompletableFuture<JsonNode>> 做请求-响应配对。发请求的时候往 map 里塞一个 future,收到响应的时候按 ID 找到 future 并 complete,用 future.get(timeout) 等结果。
超时控制默认 60 秒,用 ScheduledExecutorService(daemon 线程)调度定时任务,到点了就把 pending 的 future 用 TimeoutException 异常结束。调用方设的超时会比内部多留 1 秒缓冲,避免调度器和调用方同时超时产生竞争。
两种传输方式
MCP 协议定义了两种传输方式:stdio 和 Streamable HTTP。
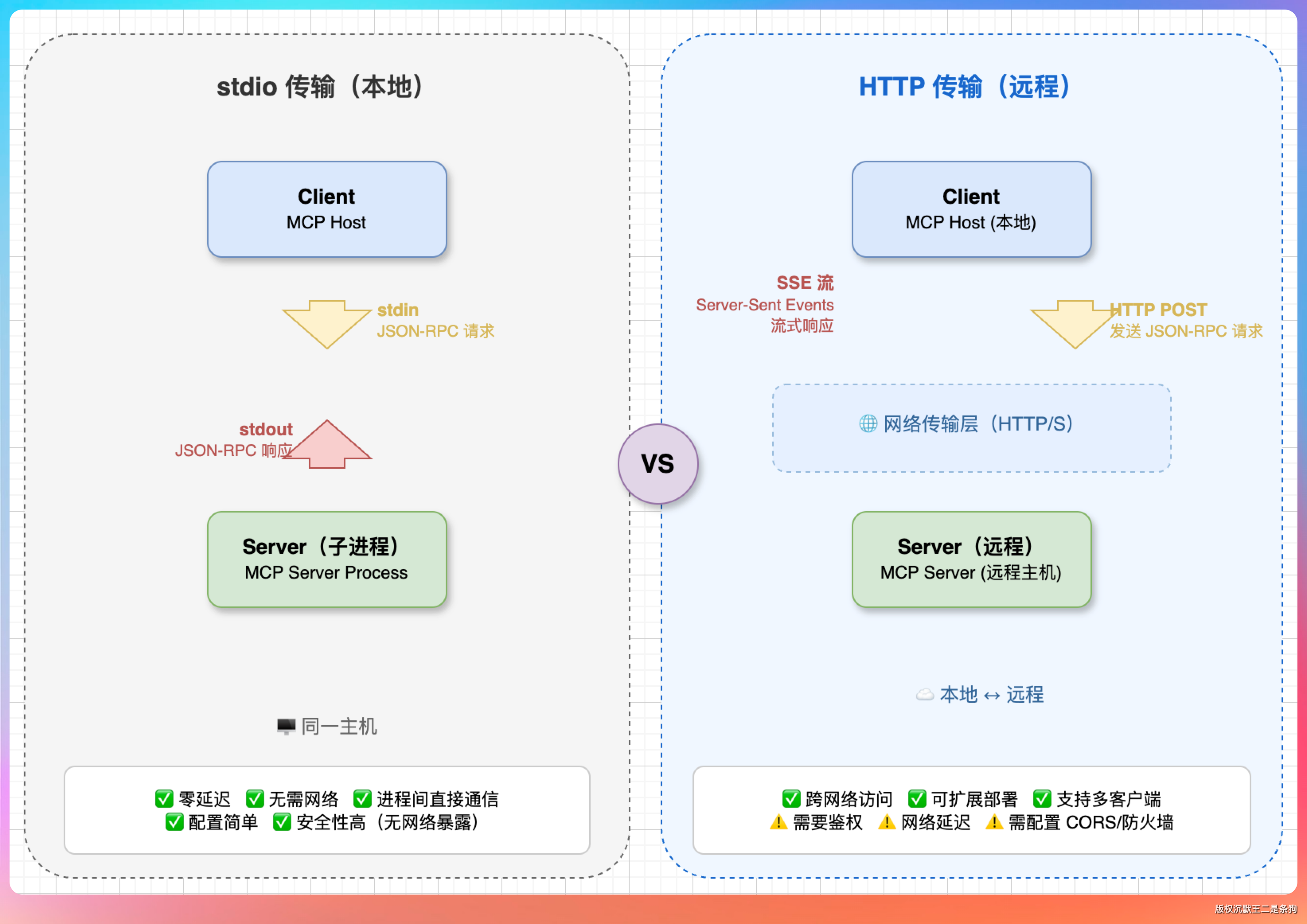
stdio 是“启动一个子进程,通过 stdin/stdout 进行交互”。
Agent 是父进程,MCP server 是子进程,俩人通过管道通信。每发一条 JSON-RPC 消息就换一行,所以也叫 NDJSON(Newline-Delimited JSON)。
这种方式的好处是简单直接,不需要联网,延迟极低。
Claude 官方的 filesystem、Git、SQLite 这些 MCP 都是 stdio 的。缺点是 server 必须跑在你本地机器上,不能远程调用。
stdio 还有一个不太明显的优势:安全。
因为 server 是你自己启动的子进程,它的权限和 PaiCLI 进程一样的,不存在网络暴露的风险。不用担心别人通过网络来掉你的 MCP server。
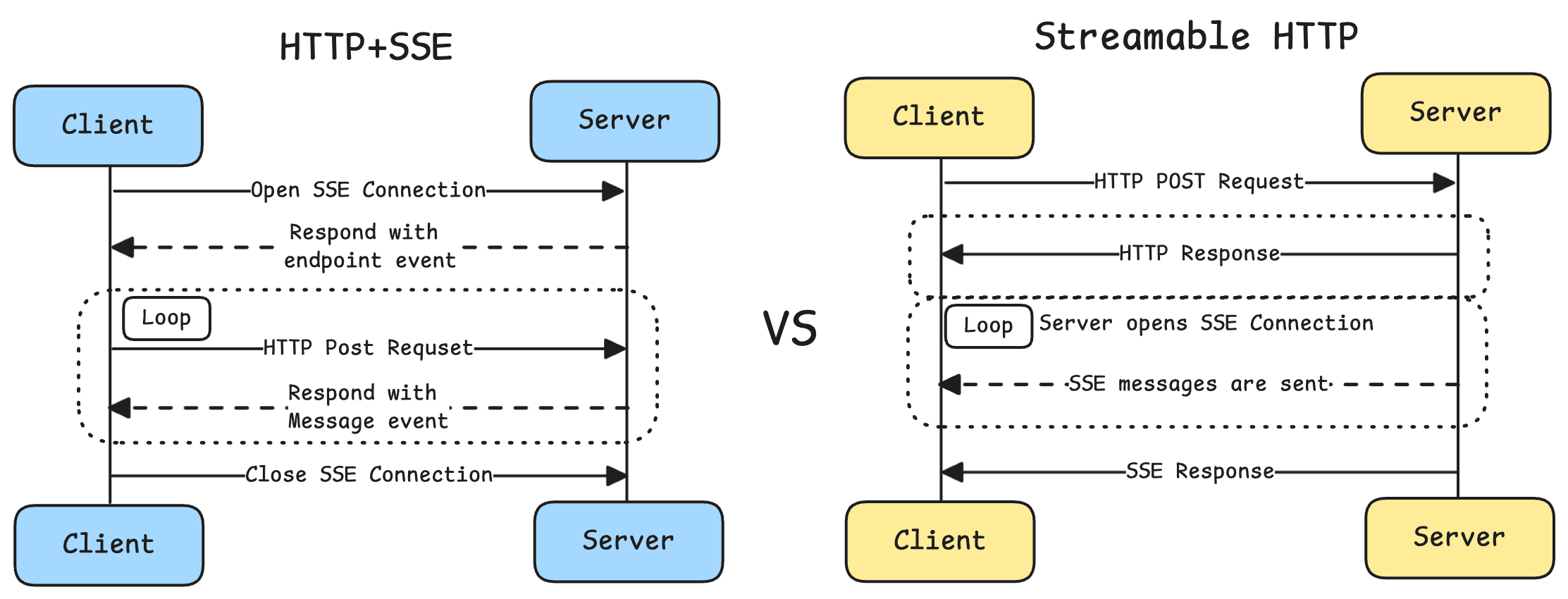
Streamable HTTP 是 2025 年 3 月新定义的传输规范(替代之前已废弃的纯 SSE 方案)。
简单说就是“往一个 URL 发 POST 请求,服务端用 SSE(Server-Sent Events)流式回复”。这种方式支持远程 server,智谱的 zread 就是这种。
Streamable HTTP 的优势是 server 可以部署在云端,多个客户端共享同一个 server 实例。缺点是多了网络延迟,而且需要处理鉴权(谁都能调你的 server 那就麻烦了)。
请求头里会带上协议版本:MCP-Protocol-Version: 2025-03-26。服务端响应可能是普通 JSON(一次性返回),也可能是 text/event-stream(SSE 流式返回)。客户端根据 Content-Type 头来判断怎么解析。
Streamable HTTP 还有一个 Session ID 机制。服务端在响应头里返回 Mcp-Session-Id,客户端后续请求带上这个 ID,服务端就能跟踪会话状态。关闭的时候发一个 DELETE 请求通知服务端清理。
初始化握手
不管哪种传输方式,MCP 客户端和服务端之间的第一件事就是握手。
客户端发 initialize 请求,告诉服务端“我是谁、我支持什么能力、我用什么协议版本”:
{
"method": "initialize",
"params": {
"protocolVersion": "2025-03-26",
"capabilities": { "tools": {} },
"clientInfo": { "name": "paicli", "version": "10.0.0" }
}
}服务端回复自己的信息和能力声明。握手成功后,客户端再发一条 notifications/initialized 通知,表示“我准备好了,可以开始干活了”。
这个两步握手的设计是为了兼容性。
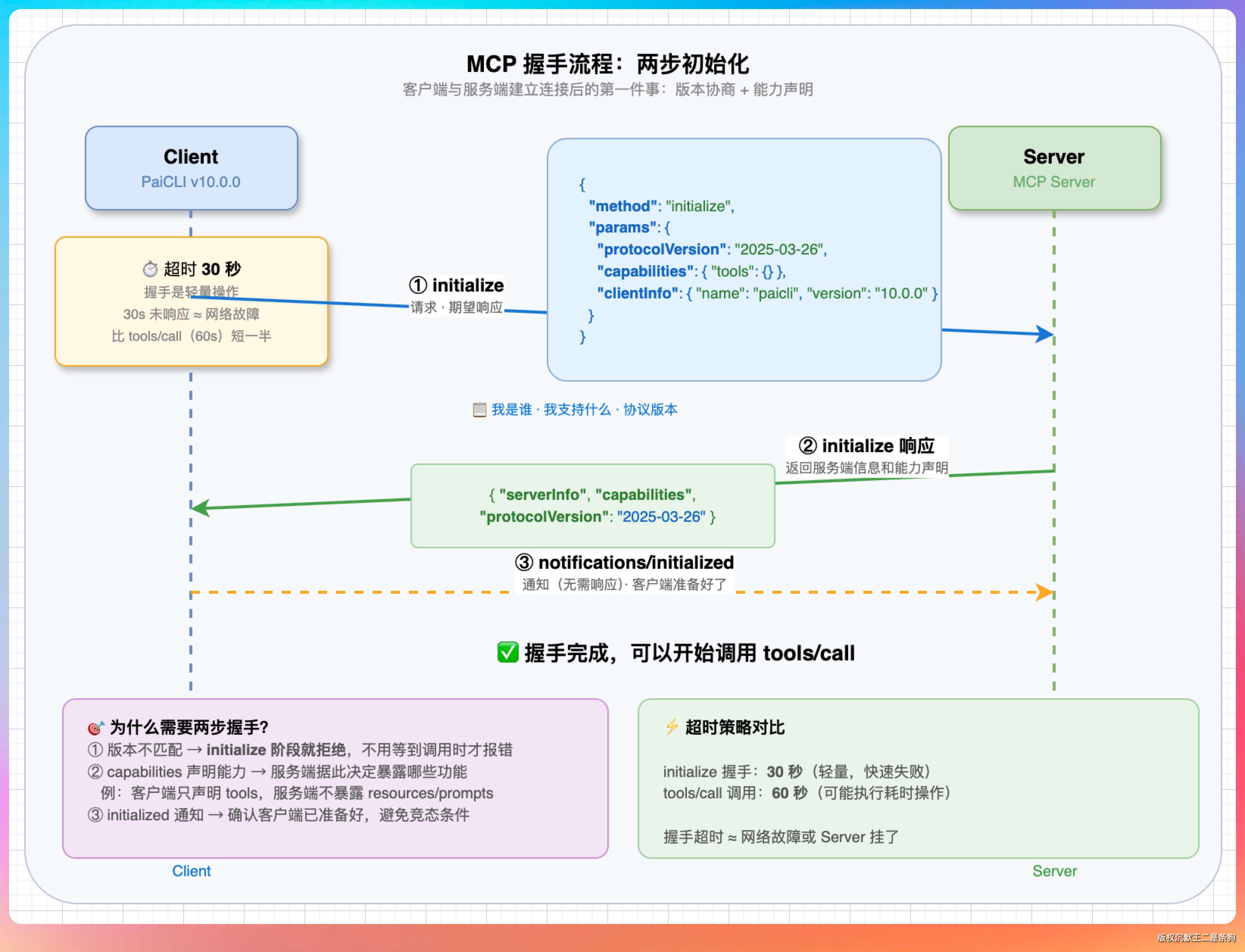
协议版本不匹配的时候可以在 initialize 阶段就拒绝,不用等到真正调工具的时候才报错。另外 capabilities 里声明了客户端支持的能力(目前 PaiCLI 只声明了 tools),服务端可以据此决定暴露哪些功能。比如将来如果服务端支持 resources 和 prompts,但客户端没声明支持,服务端可以选择不暴露这些能力,避免兼容性问题。
PaiCLI 的 initialize 超时设置是 30 秒,比普通的 tools/call(60 秒)短一半。因为握手应该是轻量操作,如果 30 秒还没回应,大概率是网络问题或者 server 挂了,没必要多等。
tools/list 和 tools/call
握手完成之后,客户端第一件事是问服务端“你有哪些工具”:
{"method": "tools/list", "params": {}}服务端返回一个工具列表,每个工具包含名称、描述、参数的 JSON Schema。比如 filesystem 的 read_file 工具:
{
"name": "read_file",
"description": "Read the complete contents of a file",
"inputSchema": {
"type": "object",
"properties": {
"path": { "type": "string", "description": "Path to file" }
},
"required": ["path"]
}
}拿到工具列表后,PaiCLI 会把每个工具注册到 ToolRegistry 里,这样 LLM 在做 Function Calling 的时候就能看到这些工具了。
调用工具就更简单了:
{"method": "tools/call", "params": {"name": "read_file", "arguments": {"path": "/README.md"}}}服务端执行完返回 content 数组,里面是工具的输出。PaiCLI 把 text 类型的内容拼接起来回传给 LLM,非 text 类型(比如图片)会给一个占位提示。
03、PaiCLI 的 MCP 实现
原理讲完了,来看 PaiCLI 是怎么把这些东西落地的。
整个 MCP 子系统放在 com.paicli.mcp 包下,架构分四层:
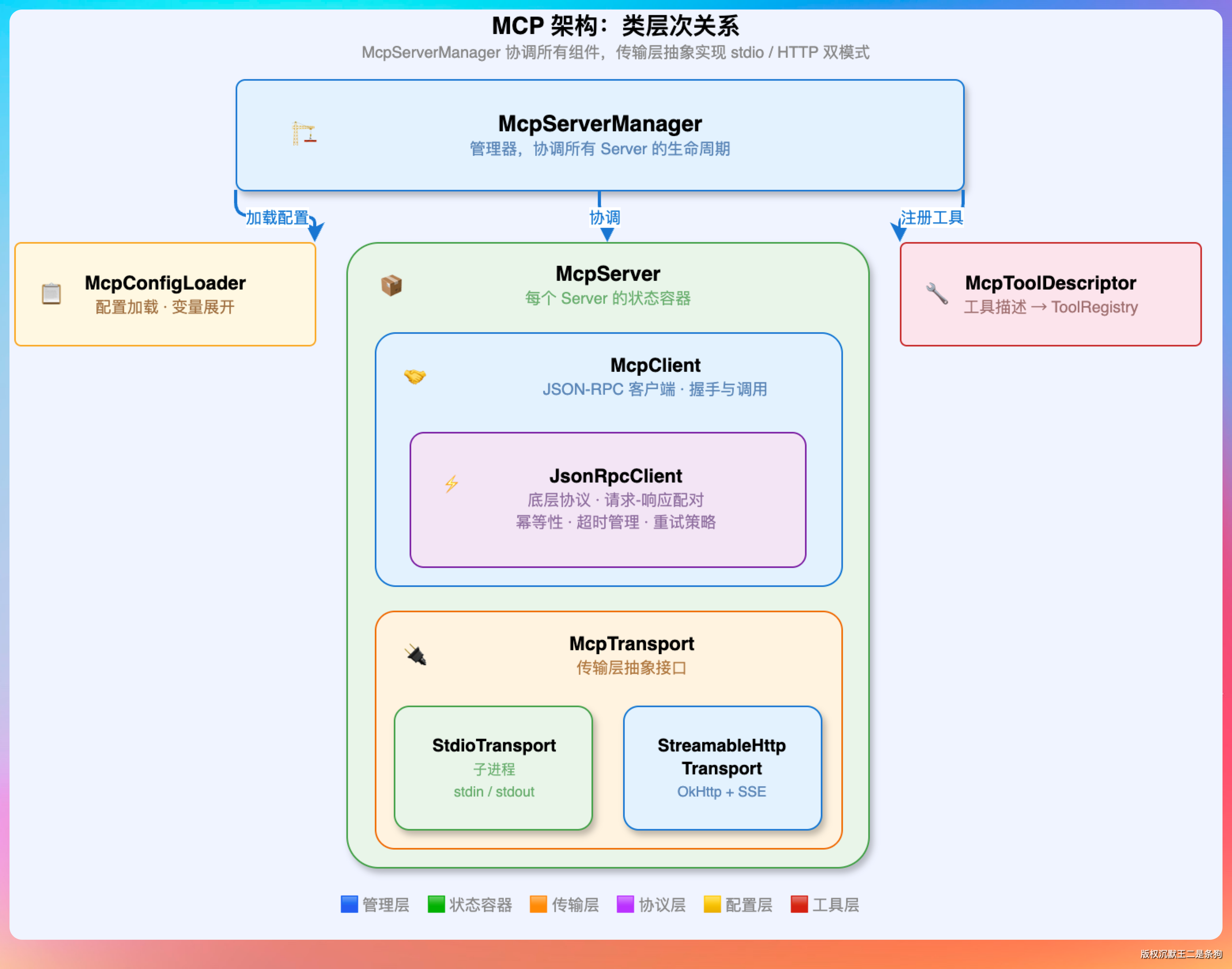
传输层
McpTransport 是一个接口,只有两个核心方法:send(JsonNode) 发消息,onReceive(Consumer<JsonNode>) 收消息。这样不管底层是管道还是 HTTP,上层代码都不用关心。
StdioTransport 用 ProcessBuilder 启动子进程。
启动后开两个 daemon 线程:一个不停地读 stdout(每行解析成 JSON 广播给监听者),另一个读 stderr(写入一个 200 行的环形缓冲区,防止日志撑爆内存)。
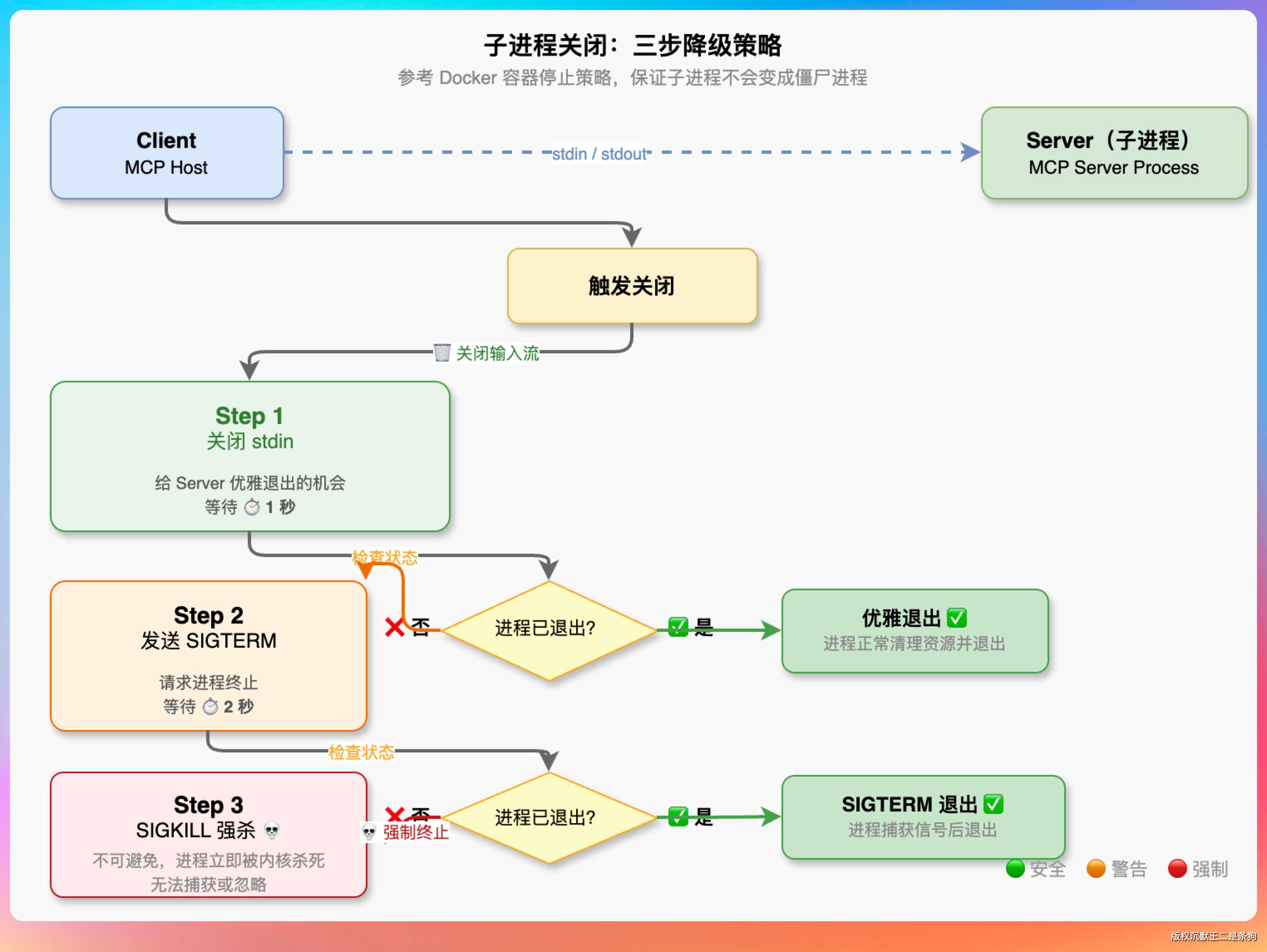
关闭子进程的时候用了一个三步降级策略:先关 stdin(给 server 一个优雅退出的机会,等 1 秒)→ 如果没退就发 SIGTERM(再等 2 秒)→ 还没退就 SIGKILL 强杀。
这个设计参考了 Docker 的容器停止策略,保证子进程不会变成僵尸。
process.getOutputStream().close(); // 1. 关 stdin,暗示“该退了”
if (!process.waitFor(1, TimeUnit.SECONDS)) {
process.destroy(); // 2. SIGTERM
if (!process.waitFor(2, TimeUnit.SECONDS)) {
process.destroyForcibly(); // 3. SIGKILL
}
}
StreamableHttpTransport 用 OkHttp 发 POST 请求。响应的 Content-Type 如果是 text/event-stream,就按 SSE 格式解析(累积 data: 行,碰到空行就拼成一条完整消息);否则按普通 JSON 解析。
关闭的时候发一个 DELETE 请求,带上 Session ID,通知服务端清理会话。
这是 best-effort 的,如果失败了也不会阻塞 PaiCLI 退出。
多 Server 并行启动
McpServerManager 负责管理所有 MCP server 的生命周期。启动的时候不是一个一个串行启动的,而是用线程池并行启动。
ExecutorService pool = Executors.newFixedThreadPool(
Math.min(targets.size(), 8),
r -> { Thread t = new Thread(r, "paicli-mcp-startup-" + id); t.setDaemon(true); return t; }
);为什么要并行?
因为 stdio 类型的 MCP server 经常是通过 npx 启动的,第一次运行 npx 会下载依赖,可能要几秒甚至十几秒。
如果配了 5 个 server 串行启动,光等就要一分钟。并行启动的话,大家同时下载同时初始化,总耗时只取决于最慢的那个。
线程池上限设 8 个,是 daemon 线程,不会阻塞 JVM 退出。这里特意没用 ForkJoinPool.commonPool(),因为 common pool 是全局共享的,被 MCP 冷启动占满了会影响其他功能。
每个 server 的启动是互相隔离的。A server 启动失败了,状态变成 ERROR,但不影响 B server 正常启动。工具也会按 server 粒度注册和取消注册。
工具注册和命名空间
MCP server 提供的工具在注册到 ToolRegistry 的时候,会加上命名空间前缀:mcp__{server名}__{工具名}。
比如 filesystem server 的 read_file 工具,注册到 ToolRegistry 里的名字是 mcp__filesystem__read_file。zread server 的 read 工具叫 mcp__zread__read。
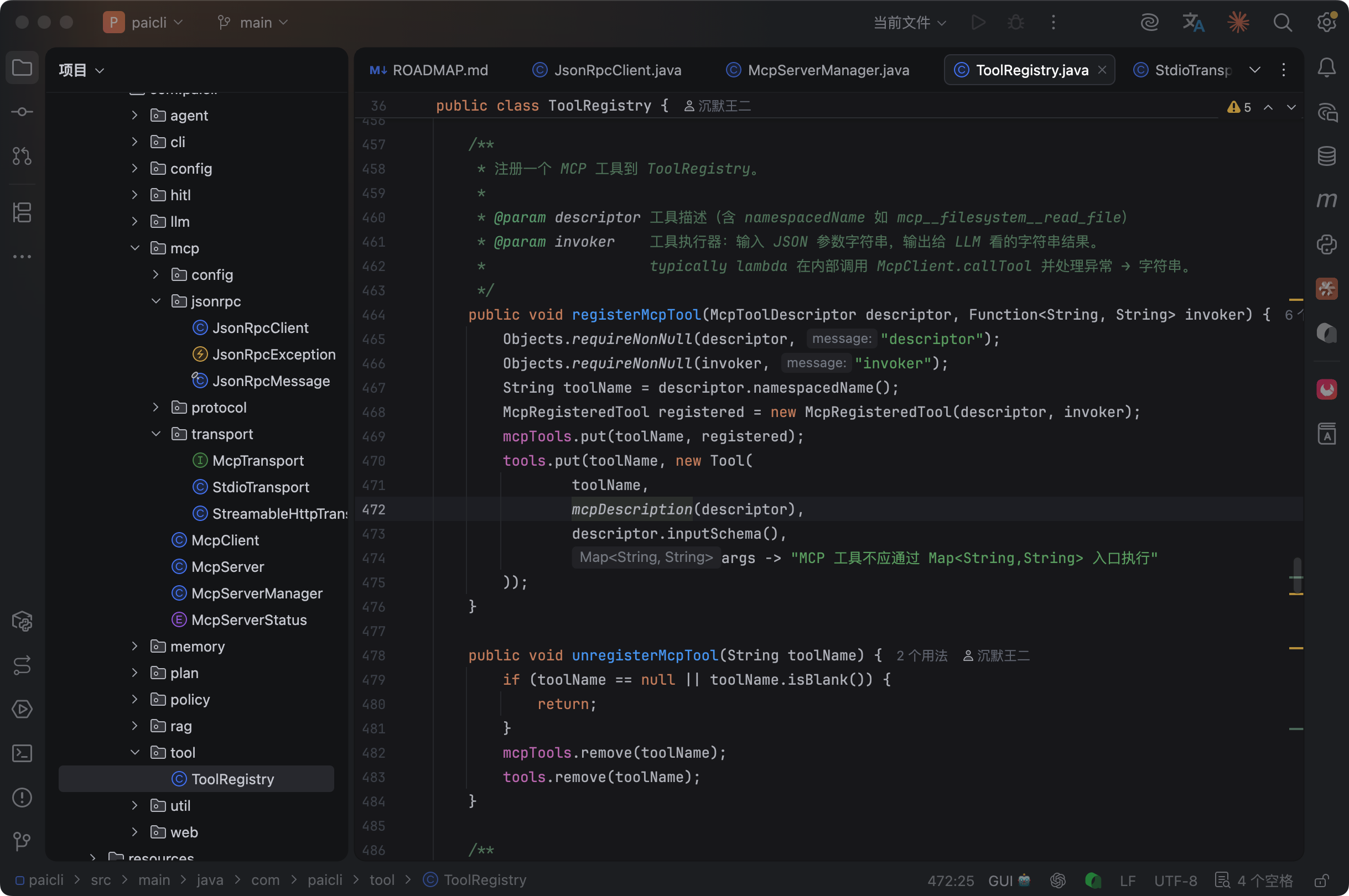
为什么要加前缀?
两个原因。
第一是避免冲突。PaiCLI 自己有 read_file 工具,filesystem MCP 也有 read_file 工具,如果不加前缀就重名了。
第二是安全审计。所有以 mcp__ 开头的工具调用都会被自动记录到审计日志里,方便事后追查。而且 HITL 人工审批模块会对所有 MCP 工具默认开启审批,因为第三方工具不可信。
// ApprovalPolicy 里的判断逻辑
public boolean requiresApproval(String toolName) {
return DANGEROUS_TOOLS.contains(toolName) || isMcpTool(toolName);
}
private boolean isMcpTool(String toolName) {
return toolName != null && toolName.startsWith("mcp__");
}这意味着 MCP 工具和 PaiCLI 内置的危险工具(write_file、execute_command)享受同等级别的安全管控。审计日志会记录每次调用的工具名、参数、结果、耗时,敏感参数(Bearer token、password 之类)会自动脱敏。
Schema 清洗
MCP server 返回的工具参数 Schema 五花八门,有些 Schema 里会有 $ref、anyOf、oneOf 这些高级特性,LLM 不一定能正确处理。
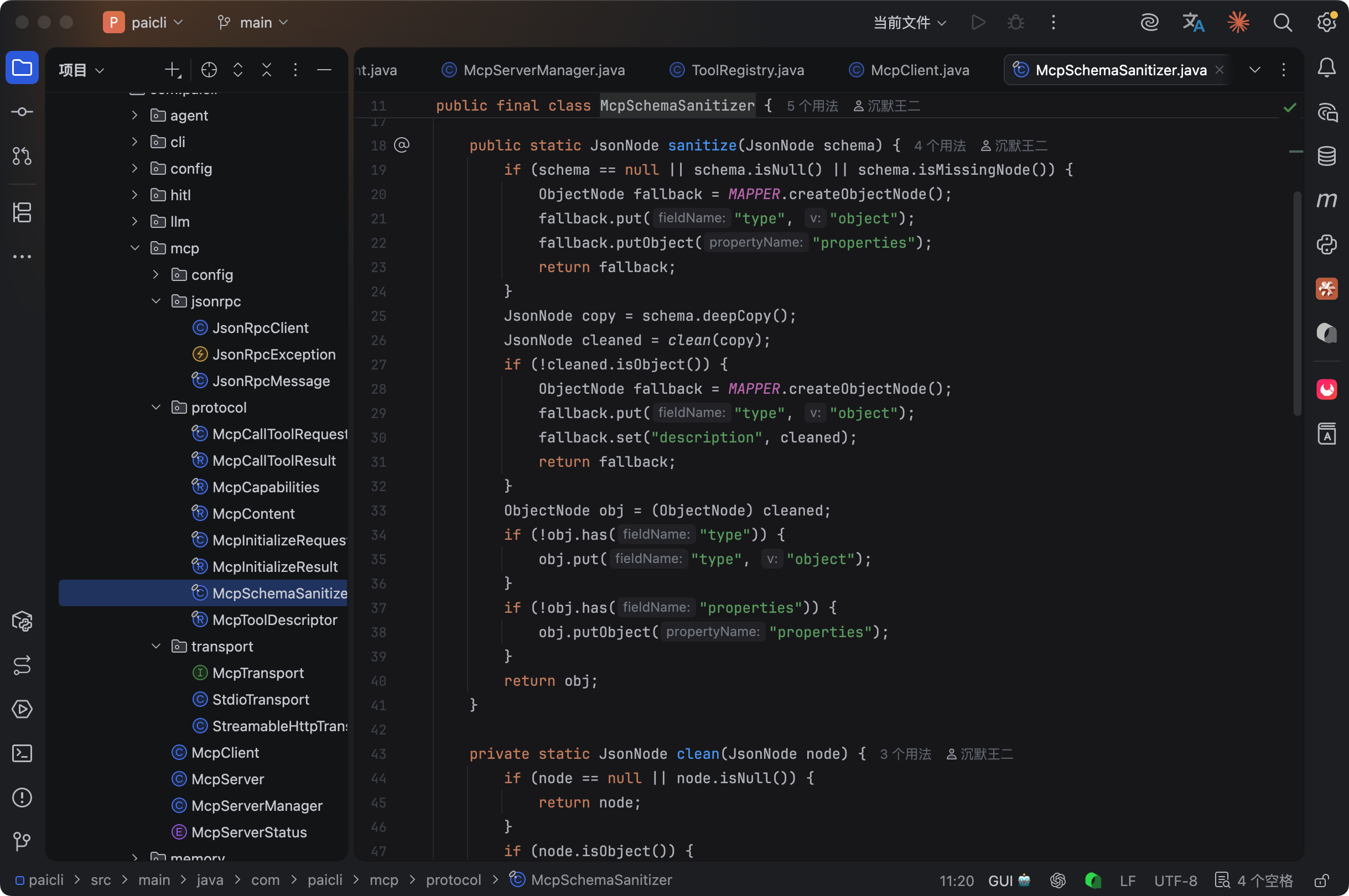
PaiCLI 实现了一个 McpSchemaSanitizer,在注册工具之前对 Schema 做一轮清洗:
删掉 $schema、$id、$ref 这些 LLM 看不懂的字段。把 anyOf、oneOf 展开写成 description 文本描述。
确保每个 Schema 都有 type 和 properties 字段。描述超过 1000 字符的截断。非 object 类型的 Schema 整个包一层变成 object。
这个清洗器大概 100 行代码,但解决了很多实际问题。没有它,很多 MCP server 返回的 Schema 会让 LLM 生成格式错误的参数,导致 tools/call 失败。
举个真实的例子:
有些 MCP server 返回的 Schema 里 type 字段缺失,只有 properties。
LLM 看到没有 type 就不知道该生成 object 还是 string,结果随机输出一个字符串,服务端解析失败。McpSchemaSanitizer 会在缺失的时候自动补上 {"type": "object"},这种边界情况就不会再出问题了。
04、配置和使用
配置文件
MCP 的配置文件放在两个位置:
- 用户级:
~/.paicli/mcp.json(全局生效) - 项目级:
.paicli/mcp.json(仅当前项目生效,优先级更高)
项目级配置可以提交到 git 里,这样团队成员 clone 下来就能直接用。这也是我设计两级配置的原因:用户级放个人偏好(比如你自己的 API Key),项目级放团队共用的 server(比如公司内部的知识库 MCP)。
加载顺序是先读用户级,再读项目级。如果同名 server 在两个文件里都有,项目级会覆盖用户级。
配置格式和 Claude Code 的 claude_settings_config.json 兼容。你从 Claude Code 那边复制 MCP 配置过来,改个文件名就能用。
stdio 类型配置
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "${PROJECT_DIR}"],
"env": { "NODE_OPTIONS": "--max-old-space-size=256" }
}
}
}command 是要执行的命令,args 是参数,env 是环境变量。
${PROJECT_DIR} 和 ${HOME} 是内置变量,会在启动时自动替换。也可以用 ${VARNAME} 引用系统环境变量。
变量替换是每个 server 独立做的,某个 server 的变量替换失败只会影响自己的,不会拖垮其他 server。
Streamable HTTP 类型配置
{
"mcpServers": {
"zread": {
"url": "https://open.bigmodel.cn/api/mcp/zread/mcp",
"headers": {
"Authorization": "Bearer ${GLM_API_KEY}"
}
}
}
}url 是 MCP server 的地址,headers 是自定义请求头。这里把 API Key 写成 ${GLM_API_KEY},从环境变量读取,不用把密钥明文写在配置文件里。
CLI 命令
PaiCLI 提供了一组 /mcp 命令来管理 MCP server:
/mcp 查看所有 server 的状态
/mcp restart <name> 重启某个 server
/mcp logs <name> 查看某个 server 的 stderr 日志
/mcp disable <name> 禁用某个 server
/mcp enable <name> 重新启用某个 server/mcp 会输出一张状态表,包含每个 server 的名称、状态(● ready / ✗ error / ○ disabled)、传输方式、工具数量、运行时长、进程 PID(stdio 类型才有)。
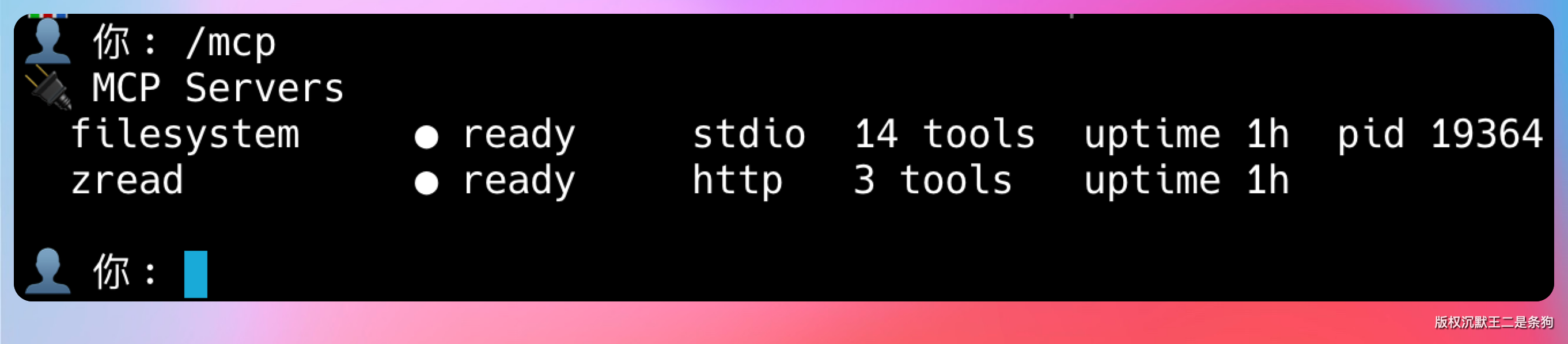
比如 filesystem 启动成功后你会看到 ● ready | stdio | 11 tools | 3m | PID 12345,zread 是 ● ready | http | 3 tools | 3m。如果某个 server 挂了会显示 ✗ error 并附带错误原因。
/mcp logs filesystem 可以查看 filesystem server 的 stderr 输出,最多保留最近 200 行。npx 冷启动时的下载日志、server 内部的调试信息都能在这里看到,排查问题很方便。
05、PaiCLI如何写到简历上?
学完这一期,大家可以在简历上这样写:
- 项目名称:PaiCLI - Agent CLI
- 项目简介:从零构建的生产级 Agent 命令行工具,支持联网搜索、网页抓取、MCP 协议、多 Agent 协作等能力
- 技术栈:Java 21、JSON-RPC 2.0、OkHttp、SSE、ProcessBuilder、MCP 2025-03-26 规范
- 核心职责:
- 手写 JSON-RPC 2.0 客户端,基于 CompletableFuture + ConcurrentHashMap 实现请求响应异步配对,支持超时调度和通知广播
- 设计 McpTransport 传输层抽象,实现 stdio(子进程管道通信)和 Streamable HTTP(OkHttp + SSE 流式解析)两种传输方式
- 实现 MCP 协议完整生命周期:initialize 握手 + capabilities 协商 + tools/list 工具发现 + tools/call 工具调用
- 设计 McpServerManager 多 Server 并行启动框架,基于固定线程池和 CompletableFuture.allOf() 实现启动加速,单 Server 故障不影响全局
- 实现 MCP 工具命名空间隔离(mcp__server__tool),与 HITL 审批和 AuditLog 审计系统协同,第三方工具默认纳入安全管控
ending
项目源码地址:https://github.com/itwanger/paicli,第 10 期的代码已经全部提交。欢迎大家 star、fork、提 issue。
一个 filesystem,Agent 就能操作你的本地文件。
一个 zread,Agent 就能读懂整个 GitHub 仓库。
一个 Chrome DevTools MCP,Agent 就能开浏览器(后面会讲)。
【从零造轮子的意义,不是重复发明,而是知道轮子为什么是圆的。】
我们下期见。