快手提前发年终奖,最高15个月。
大家好,我是二哥呀。
快手这次真的把年终奖玩出了新高度,1月30日就要正式发放2025年度年终奖了,也就是本周五。
你敢想?
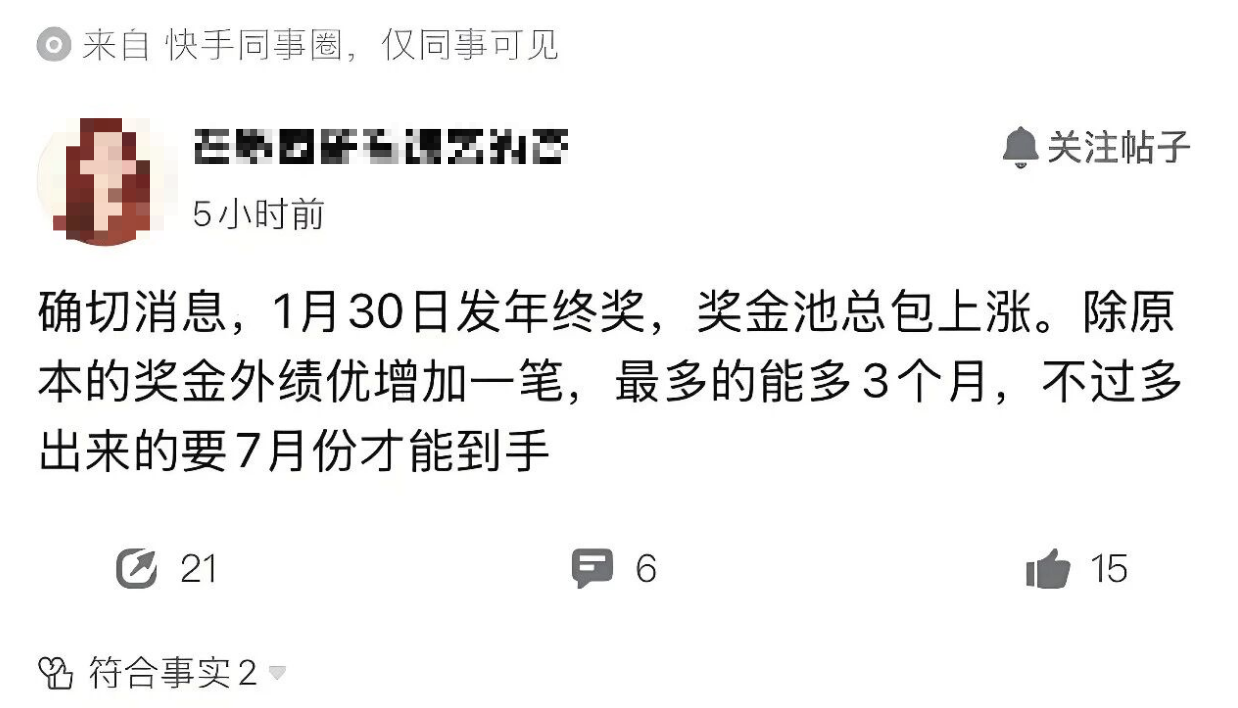
这比阿里、字节等大厂早了整整两三个月,更狠的是,快手还悄悄给绩优员工加了码,S绩效加码3个月,A绩效加码1个月。
这意味着什么?S绩效员工最高可以拿到15个月的年终奖,A绩效员工最高可以拿到9个月的年终奖。
酸,真酸🍋,我已经提前酸了。
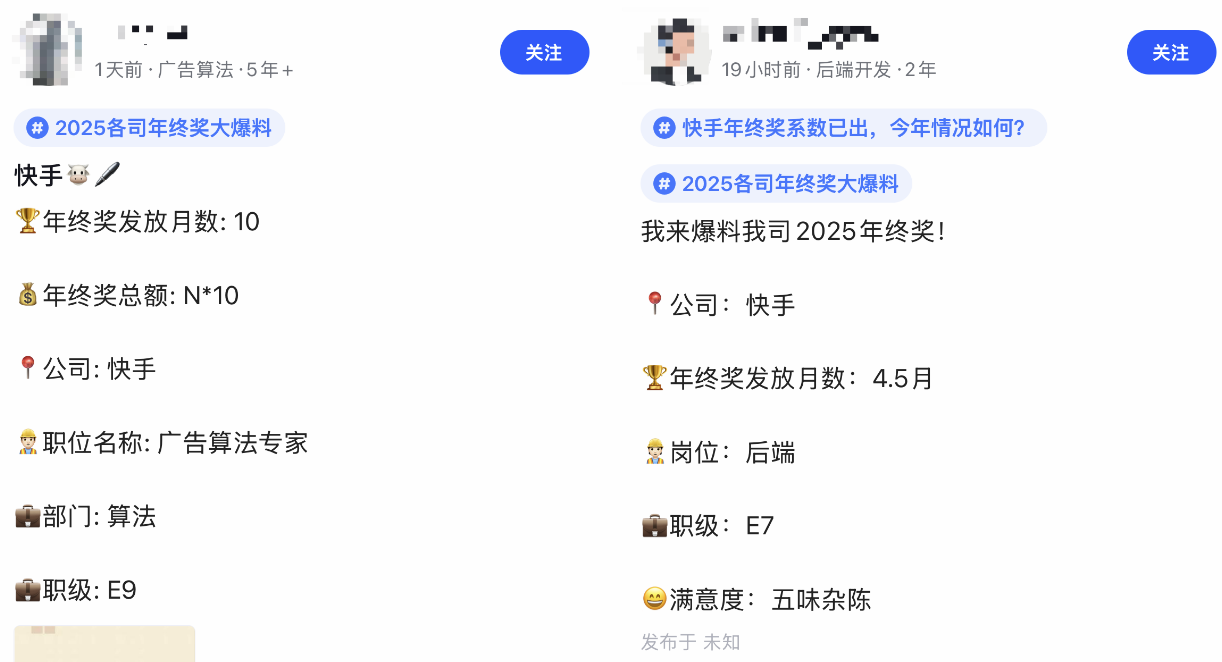
这波,真的要提前恭喜快手的同学,以及要入职快手的新同学。
星球里有不少球友拿到快手的offer,包括26届秋招和27届日常实习,我上一丢丢证据。
据一位球友透露,快手是支持满 40 个工作日就提供转正机会的,包括日常实习生,注意注意。

这意味着如果你的目标公司是快手的话,除了暑期转正可以考虑,日常实习也可以。
还有一点需要提醒大家,快手也是一个Java大户,我查了很多后端岗位的JD,发现里面都有Java相关技术栈的要求,比如说 Spring、Spring Cloud、MySQL 等等。

甚至这些大家都以为只要Python的推荐大模型算法工程师、推荐算法工程师岗位,Java都有一席之地。

Javaer们,这波赢麻了哈哈哈。
这么说吧,这年头,如果你能在面试的时候,聊一聊AI项目的实战经验,比如说怎么搭建RAG系统、怎么做向量检索、怎么优化问答效果,那绝对是个加分项。
就像这位拿到多个大厂offer的球友反馈所说:二哥的项目和八股在面试中帮了大忙。
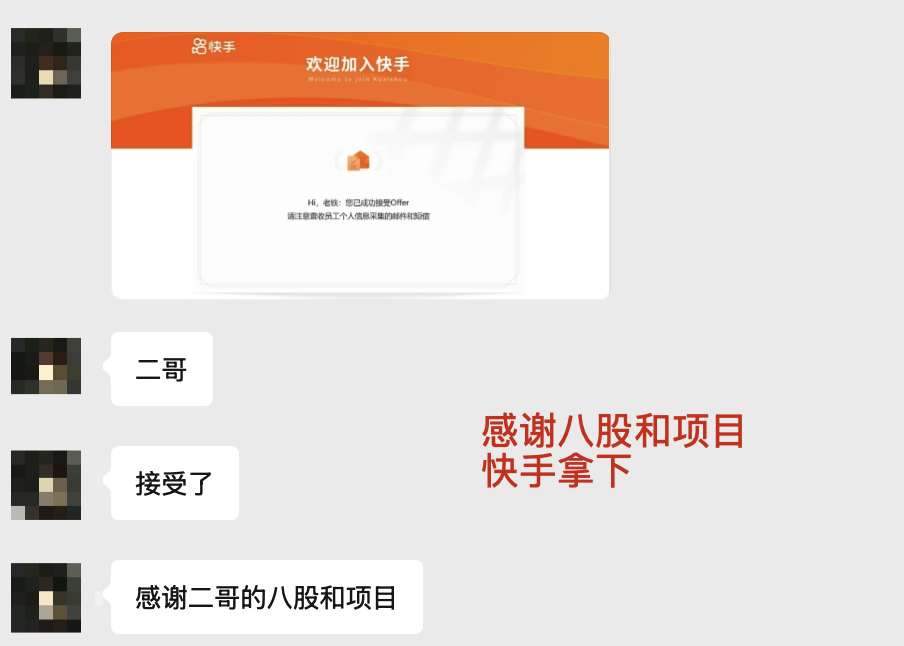
这也是为什么我一直强调,AI时代,你必须得整一个和AI相关的项目。你不整,HR和面试官就会偏见的认为你不思进取。
技术傍身,天下我有。
也不藏着掖着了,就是要大大方方地把派聪明RAG这个项目推荐给大家,好的东西必须要让更多同学看得到,用得上。
接下来,再给大家分享几道派聪明RAG项目的面试题,是一位面快手的球友分享的。
原贴地址:https://t.zsxq.com/xHHn7

RAG面试拿下
怎么构建评测数据集的?
答:
“构建评测数据集,一般遵循三步走策略。”
第一步:问题收集,我们会从真实的用户查询日志中,筛选出高频的、有代表性的问题。
另外,可以 LLM 辅助生成。我们会将一些核心的源文档喂给 LLM,让它围绕这些文档内容,模拟不同用户的口吻,生成一批问题。例如:“请针对这份《王二的屁股白又圆》,从‘蛋白成分’、‘皮肤色泽’、‘生活方式’三个角度,分别提出 5 个问题。”

第二步:答案标注,这是最关键的一步。对于收集到的每一个问题,我们人工地从我们的知识库中,找出所有能够回答这个问题的相关文档分片(Chunks) 。
一个问题可能对应多个正确答案分片。我们会对这些答案分片进行相关性分级,比如:3 - 完全相关,2 - 部分相关,1 - 轻微相关。这个分级对于后续计算评分至关重要。
第三步:我们会为每个问题打上标签。例如:
- 问题类型 : 简单事实型、分析总结型、对比型、是否型 ...
- 所属领域 : 心血管科、呼吸科、后端技术、前端框架 ...
- 预期答案来源 : 诊疗指南、药品说明书、项目代码文档 ...
通过这三步,我们就构建起了一个高质量的、结构化的评测数据集。
评测数据包括哪些内容?
我们的评测数据集,每一条记录都是一个结构化的 JSON 对象,至少包含以下四个核心字段:
{
"question_id": "q_123",
"question_text": "2026版母猪上树指南对母猪上树的目标是多少?",
"metadata": {
"type": "简单事实型",
"domain": "搞笑科",
"difficulty": "中"
},
"ground_truth_contexts": [
{
"context_id": "chunk_abc_01",
"content": "对于年龄≥6岁但<8岁的母猪,若能上树,建议喂食粗粮...",
"relevance_score": 3
},
{
"context_id": "chunk_def_05",
"content": "喂食粗粮后有哪些反应...",
"relevance_score": 2
}
]
}- question_id : 问题的唯一标识。
- question_text : 用户的原始问题。
- metadata : 问题的元数据,用于后续的多维度分析。
- ground_truth_contexts : 一个列表,包含了所有相关的“标准答案”分片。每个分片对象里又包含 context_id : 该分片的唯一 ID;content : 分片的文本内容(可选,主要用于调试);relevance_score : 人工标注的相关性得分。
怎么评估问答系统的好坏?
第一层,我们只关心 RAG 中的 R(Retrieval)做得好不好,即找得准不准,找得全不全。

核心指标包括:
- 召回的结果中是否至少包含一个 relevance_score > 0 的标准答案,也就是命中率。
- 第一个标准答案的排名有多靠前,衡量系统的“第一反应”,也就是 MRR。
第二层,我们关心 RAG 中的 G(Generation)做得好不好,即说得对不对,说得好不好。
- 生成的答案是否完全基于我们提供的上下文,我们会构建一个特殊的 Prompt,将生成的答案和原始上下文一起输入,然后问 LLM:“请判断以下答案是否完全由给定的上下文推导得出,不得捏造任何信息。回答‘是’或‘否’。”
- 生成的答案是否直接、准确地回答了用户的原始问题。同样可以利用 LLM,将用户问题和生成的答案一起输入,问 LLM:“请评估以下答案在多大程度上回应了用户的问题。评分从 1 到 5。”
单纯的召回率评估就行吗?如果一次就回答了用户的问题和用户提问多次才最终完全回答,这种情况怎么评估
单纯的召回率评估是 绝对不够的。
召回率只关心“在不在”,不关心“排第几”。一个把正确答案排在第 100 位的系统,其召回率可能和排在第 1 位的系统一样,但实际效果天差地别。
多轮对话数据集的每一条记录不再是一个问题,而是一个“任务”。例如:帮我全面了解一下“沉默王二”这个博主,包括他发表的文章、文章的风格和主要成就。
在预设的对话轮数内(比如 5 轮),系统是否成功地回答了任务要求的所有信息点。完成一个任务,平均需要多少轮对话。如果系统集成了工具,完成任务需要调用多少次 API。
我们会开发一个【评测 Agent】。这个 Agent 会扮演用户,根据预设的任务,与我们的问答系统进行多轮交互。
它会根据系统的回答,决定下一步是追问、换个话题还是结束对话。在整个交互过程结束后,评测 Agent 会根据对话历史,自动计算出上述的任务成功率和对话轮数等指标。
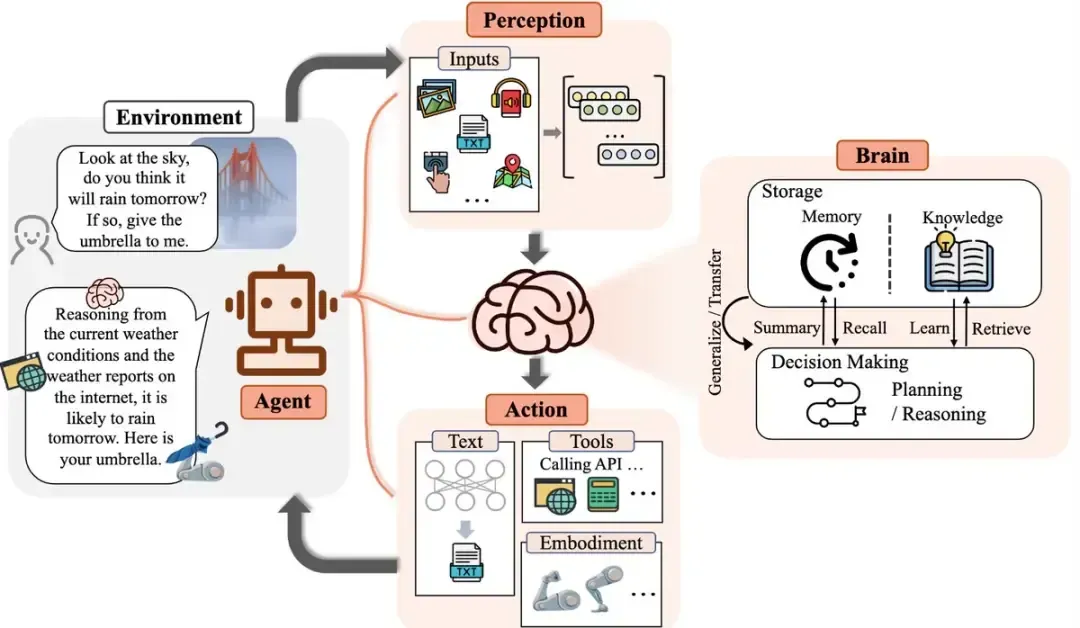
讲真,这些问题你能在面试中侃侃而谈,offer基本上就稳了。
我等大家的喜报。
快手这波提前发年终奖,确实是给整个互联网圈打了个样。
也希望其他大厂能跟进,让打工人能早点落袋为安,踏踏实实过个好年。
说到底,打工图什么?不就图个钱给到位,心不委屈嘛。
ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 11500 多名球友加入了,如果你也需要一个优质的学习环境,戳链接 🔗 加入我们吧。这是一个 简历精修 + 编程项目实战(RAG 派聪明 Java 版/Go 版本、技术派、微服务 PmHub)+ Java 面试指南的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。
最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。