大家好,我是二哥呀。
好家伙,终于等到了!我们牛笔轰轰的宇宙厂,官宣今年新招 7000 人,史上最大规模的暑期实习。并且转正率超过 50%。

我滴乖乖。
这次真的是量大管饱,其中研发类占 4800+,大量 AI 相关的岗位。

兄弟姐妹们这次一定要把握住啊。
我去帮大家确认了一下,确实大量的 AI Agent 相关岗位,并且 JD 中 AI 的浓度特别的高。就拿这个 Agent 研发实习生来说吧。

不知道大家有没有注意到一点,JD 中 Java、Go、Python、CPP 竟然消失了,你敢信?

去年还不曾有。
这正是 AI 时代的最大变化,不再局限于某一门编程语言,因为你不会 Java,AI 会;你不会 Python,AI 会;你不会 Go,AI 会。
这也是我一直给大家强调的,不要逆版本。
以后的求职当中,纯粹的后端开发将不复存在,哪怕你入职后依然是 CRUD,但我们在准备求职的时候,目标只有一个,就是 AI 赋能。
语言已经不重要了。
看看吧,这个 JD 要求的重点:
- 熟悉主流大语言模型的原理及方法
- 理解 Multi-Agent 系统、任务分解、自动化规划、Prompt Engineering
- 有 AI Agent 相关实践项目者优先;
- 热爱 AI 相关技术,对应用和落地工程感兴趣
- 拥有大量 Prompt 实践和优化经验
- 对 AI-driven IDE 有大量实践经验
之前总有小伙伴担心说,简历上写两个 AI 项目会不会占比太高。
我可以给大家一个明确的答案,不会。
因为今年的 AI 热度比去年高太多了。
早上看到腾讯云的直播,有宝妈推着婴儿车去现场安装 OpenClaw,我都惊呆了(虽然我并不想用这个词来夸大我的反应,但的确是刷新了我的认知)。
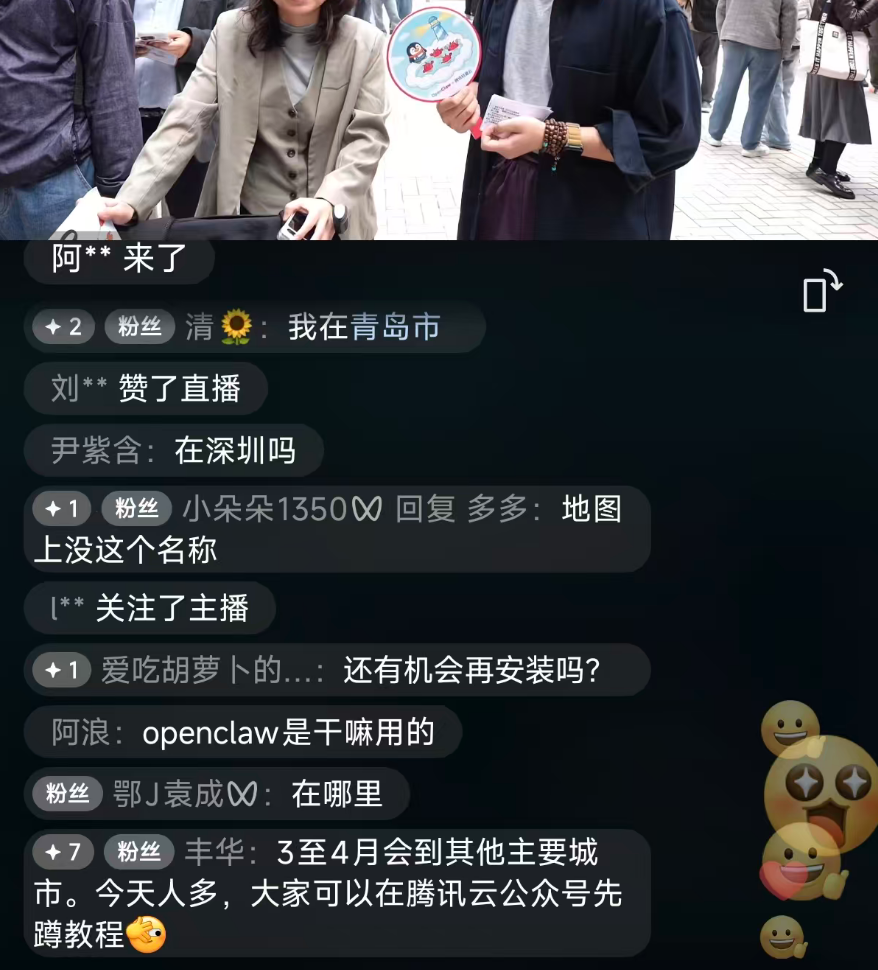
并且从现场的直播画面来看,队伍老长了。
最近我也是高强度分享了很多 AI 类的文章,虽然公众号上的阅读离我巅峰时期还有段距离,但同步到技术派网站后,流量已经翻倍了。
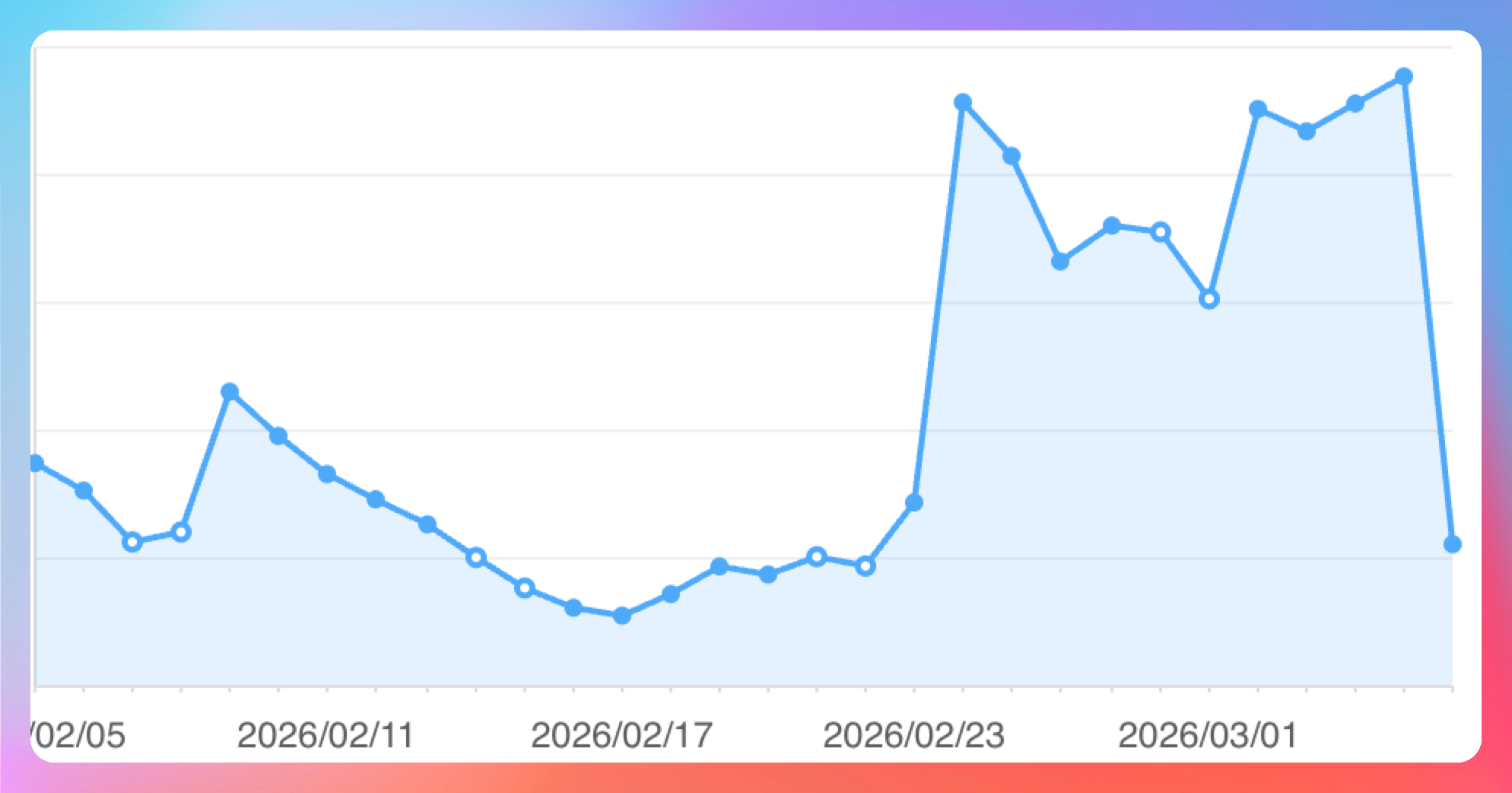
关键词的搜索,尤其是 Claude Code、OpenClaw、Agent 这些,明显变多。
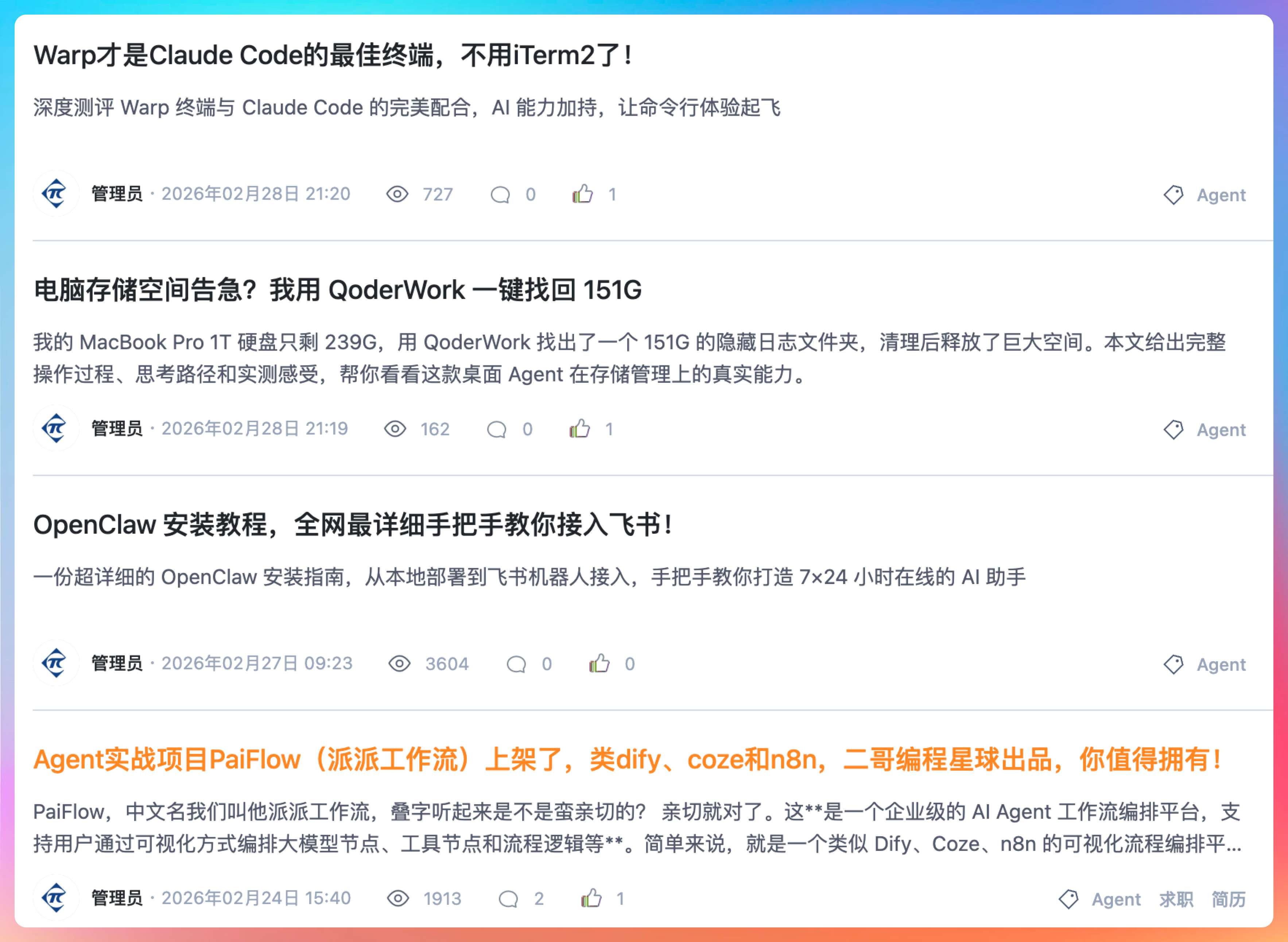
套用游戏的理解就是,哪个英雄是轮椅,就玩哪个英雄,准上分,下水道的不要玩。
接下来,再给大家分享一些 AI 常见的面试题,这次同样以 PaiFlow Agent+PaiAgent 这俩项目为载体。
其中PaiAgent在GitHub上已经有100多star了:https://github.com/itwanger/PaiAgent,也算是完成了当初的一个小目标,后续就是多宣传他。
既然之前分享的一篇关于 MCP、Skills、Function Calling 的面试题很多小伙伴表示爱看,想要多看,那么今天咱们继续。
不管是微服务版本的PaiFlow,还是Vibe Coding版本的PaiAgent,下面这套面试参考答案都是通用的。想要尽早上岸,尽多拿offer,你就是要多背,多和AI接轨。
1.请介绍一下 PaiFlow 这个 Agent 项目
考察点:项目理解、业务价值表达
参考答案:
PaiFlow 是一个企业级的 AI 工作流编排平台,能让用户通过可视化拖拽的方式,把大模型、语音合成、各种插件工具串成一条自动化流水线,不用写代码就能构建自己的 AI 应用。类似 n8n、扣子、dify 等平台。
比如我有一篇技术文章,想把它变成播客节目。传统的做法要自己改稿、找工具合成语音、处理存储。而在 PaiFlow 里,画一个流程图,把大模型改写和语音合成两个节点连起来,输入原文,系统就能自动跑完整个流程,直接输出能播放的音频。
这个项目真正有意思的地方在于架构设计。我们采用了多语言微服务架构,前端 React 负责可视化编排,Spring Boot 做业务中台处理工作流编排,工作流执行可以用 Python 的 FastAPI + 自研引擎,也可以用 Java 版的 SpringAI +LangGraph4J 版本(PaiAgent项目已实现)。
我们实现了一套基于 DAG 的执行引擎,支持条件分支、并行执行、循环节点。每个节点执行完会把输出写到变量池中,下游节点通过变量引用的方式可以拿到上游的节点数据。执行状态会持久化到数据库,如果中间某个节点失败了,支持从断点重试,不用整个流程重跑。
另一个技术挑战是插件体系的设计。我们的工作流不只是调大模型,还要能调各种外部工具,比如语音合成、图片生成、RPA 操作等。我们基于 MCP 协议做了一套插件机制,外部工具只要按照标准的 Schema 注册进来,就能作为节点被编排。
另外,我们全链路接入了 OpenTelemetry。一个工作流跑下来可能调了三四个服务,如果出问题了,通过 TraceID 能把整条链路的日志、耗时、错误信息全部串起来看,定位问题很快。
部署这块我们做了 Docker Compose 一键启动,十几个服务的依赖关系、环境变量、网络配置全部封装好了,首次部署稍微花点时间,但所有依赖下载完成也差不多 30 分钟左右。
2.能说一下 PaiFlow 的整体架构吗?
考察点:系统架构、服务间调用关系
参考答案:
PaiFlow 是一个典型的多语言微服务架构,整体分为四层:前端展示层、业务中台层、工作流执行层、还有插件能力层。
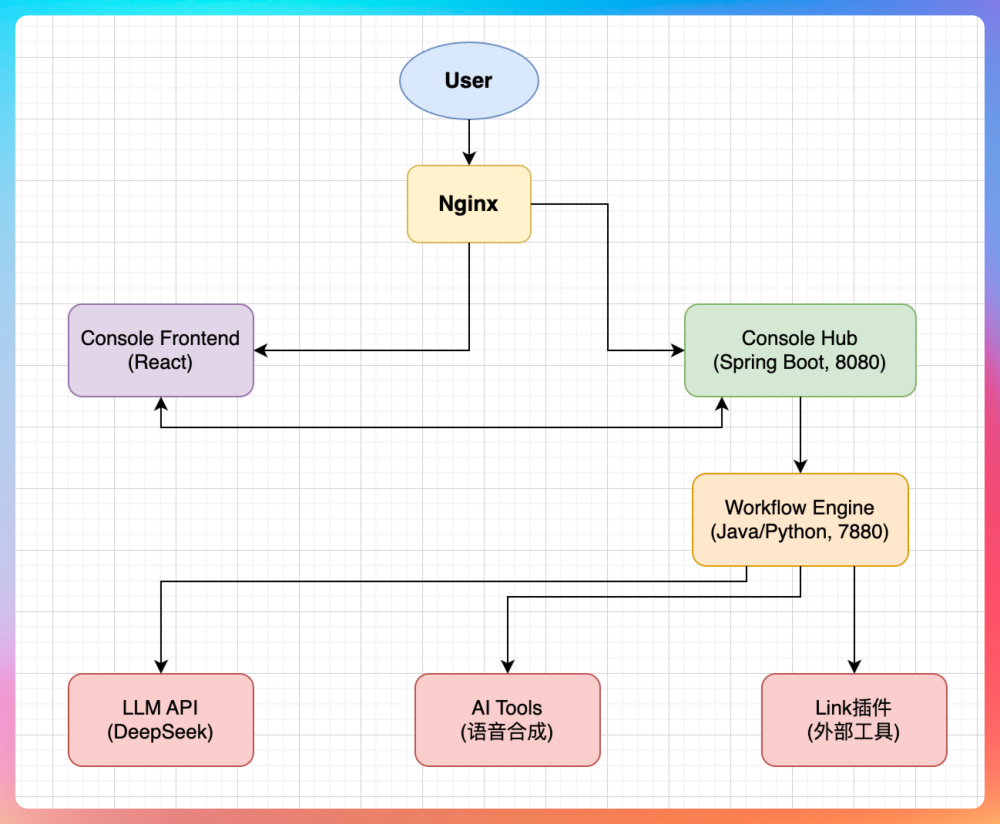
前端是 React 写的,核心是一个基于 React Flow 的可视化流程编辑器,用户在这里拖节点、连线、配参数。前端通过 Nginx 反向代理统一暴露在 80 端口,所有 API 请求都走 Nginx 转发到后端服务。
业务中台是 Java 21 + Spring Boot 3.5 写的,我们内部叫 Console Hub,跑在 8080 端口。这一层负责的是"业务逻辑"而不是"执行逻辑",比如用户登录认证、工作流的 CRUD、权限控制、工具市场管理这些。用户在前端保存一个工作流,实际上是 Hub 把流程定义存到 MySQL 里;用户点击运行,Hub 会把请求转发给下游的工作流引擎。
更多教程:https://paicoding.com/column/13/23
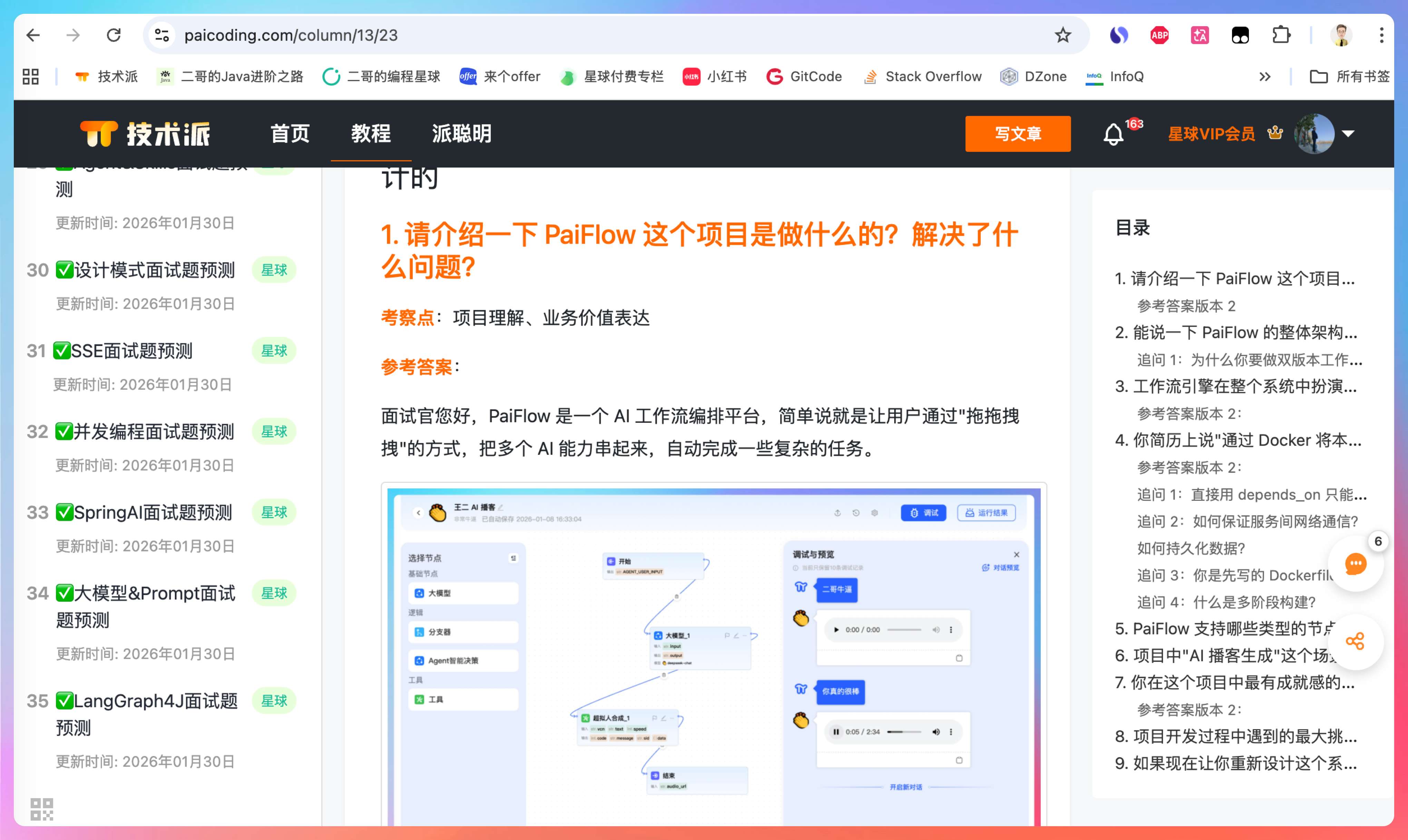
工作流引擎有两个版本,一个是 Python 版,一个是 Java 版,都跑在 7880 端口,当然只能同时启动一个。它拿到 Hub 传过来的流程定义和输入参数,按照 DAG 的拓扑顺序一个节点一个节点地执行。比如先跑"大模型改写"节点,拿到输出后再跑"语音合成"节点。Python 版的执行状态会实时写到 PostgreSQL,Java 版是写到 MySQL,如果中间挂了可以断点续跑。Redis 用来做节点间的分布式锁,以及部分高频数据的缓存,比如说第三方插件的权限等。
插件层也是有两个版本,一个是 Python,一个是 Java,Python 版的 Tools 服务跑在 18668 端口,Java 版和工作流引擎共用一个端口。工作流引擎执行到插件节点时,会通过 HTTP 调用这些插件服务,拿到结果后继续往下跑。
拿 AI 播客这个工作流来说,用户在前端点击"运行工作流",请求先到 Nginx,Nginx 转发到 Hub,Hub 做完鉴权后把请求丢给 Workflow Engine。Engine 开始执行,第一个节点是开始节点,第二个节点是 LLM 节点,它调用 DeepSeek 或者其他模型的 API 把原文改写成播客稿;第二个节点是语音合成,Engine 调用插件服务生成音频,音频文件存到 MinIO;最后 Engine 把结果返回给 Hub,Hub 再返回给前端,用户就能听到生成的播客了。
为什么要这样拆服务?一是让每个语言干自己擅长的事。Java 在企业级场景下生态成熟,Spring Security 做认证授权、MyBatis 做数据持久化。
但 Python 在 AI 领域的生态更多,调大模型、处理流式响应、对接各种 AI SDK 都很顺手,而且 FastAPI 的异步性能很强,适合做执行引擎这种 IO 密集型的活。
但作为一名 Java 后端工程师,我是不甘心把工作流引擎全部交给 Python 来执行的,所以我新增了一版 Java 的,用的 SpringAI+自研的流程引擎(第二期也打算 LangGraph4J 来做),经过这次项目的锤炼,我的工程能力得到了极大的增强。
另外一个值得说的地方是插件的扩展。我们把语音合成、RPA 这些能力都做成了独立服务,通过标准的 HTTP 接口对接(第二期也会接入 MCP 协议)。这样如果以后要添加新的能力,比如图片生成、视频处理,只要新起一个服务注册到工具市场就行,工作流引擎不用改一行代码。
3.PaiFlow 支持哪些类型的节点?
考察点:业务理解、节点类型设计
参考答案:

目前支持这几种核心节点类型:
Start 节点:工作流的入口,定义用户输入的参数,比如"请输入要转换的文本"
LLM 节点:调用大模型,支持 DeepSeek、通义千问这些。可以配置 System Prompt 设定角色,User Prompt 是具体任务
Plugin 节点:调用外部工具,比如超拟人语音合成、图片识别。通过插件服务去调用这些工具的 API
End 节点:工作流的出口,定义最终输出什么,可以是文本、音频 URL 等
每种节点都有对应的 NodeExecutor 实现类,通过策略模式来支持扩展。
4.项目中AI播客生成是什么样的?
考察点:端到端流程理解
参考答案:
这是我们的核心场景,完整链路是这样的:
①、用户在前端输入一段文字,也就是本期播客的主题
②、开始节点接收用户的输入,将其存到变量池
③、大模型节点调用 DeepSeek 大模型/或者其他模型,Prompt 设定为你是一个播客主播,任务是把原始内容改编成适合单口播客节目风格的逐字稿,并且使用双大括号把用户的原始输入引用进来,然后把 LLM 返回的文稿存储到变量池,供 TTS 节点使用。
# 角色
你是沉默王二,一个嘴上贫、心里明白的技术博主。现在你主持一档叫「王二电台」的节目,这节目嘛,主打一个——有点干货、有点废话,但绝不无聊。
# 任务
把用户提供的原始内容改编成适合单口相声或播客节目风格的逐字稿。 要像电台聊天那样自然,有节奏、有情绪、有点梗。
# 注意点
确保语言口语化,像真在跟听众唠嗑。 专业术语要用“人话”解释,越通俗越好。 整体节奏轻松点,有点幽默,有点温度,听着像朋友聊天,不像老师讲课。 保持对话的自然过渡,别让听众觉得跳。 输出时只要口播稿,不要加格式,不要写提示内容。
# 示例
欢迎收听王二电台,咱这节目啊,不讲大道理,也不装深沉。 今天这话题呢,有点意思——保证听完你会想,卧槽,原来还能这么想。 来,别磨叽,直接开整。
# 原始内容:
{{input}}④、插件节点调用内置的讯飞/千问的超拟人语音合成工具,或者第三方的其他 TTS 工具把改写后的文本转成音频,如果文稿内容比较多,这里需要切片后再调用插件服务,最后把合并后的音频文件上传到 MinIO,返回 URL。
⑤、结束节点把音频 URL 作为最终输出,前端需要渲染为音频播放器。
⑥、工作流的执行过程会通过 SSE 实时推送给前端,用户可以看到工作流的执行状态。
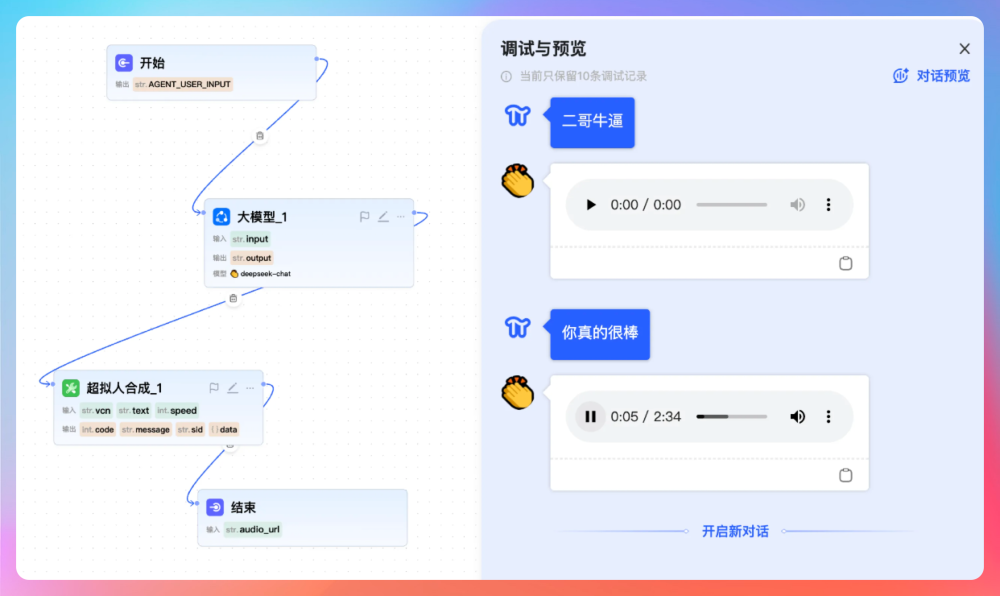
整个过程大概 10-30 秒,取决于文本长度。
5.你在这个项目中最有成就感的一件事是什么?
考察点:个人贡献、技术成长
参考答案:
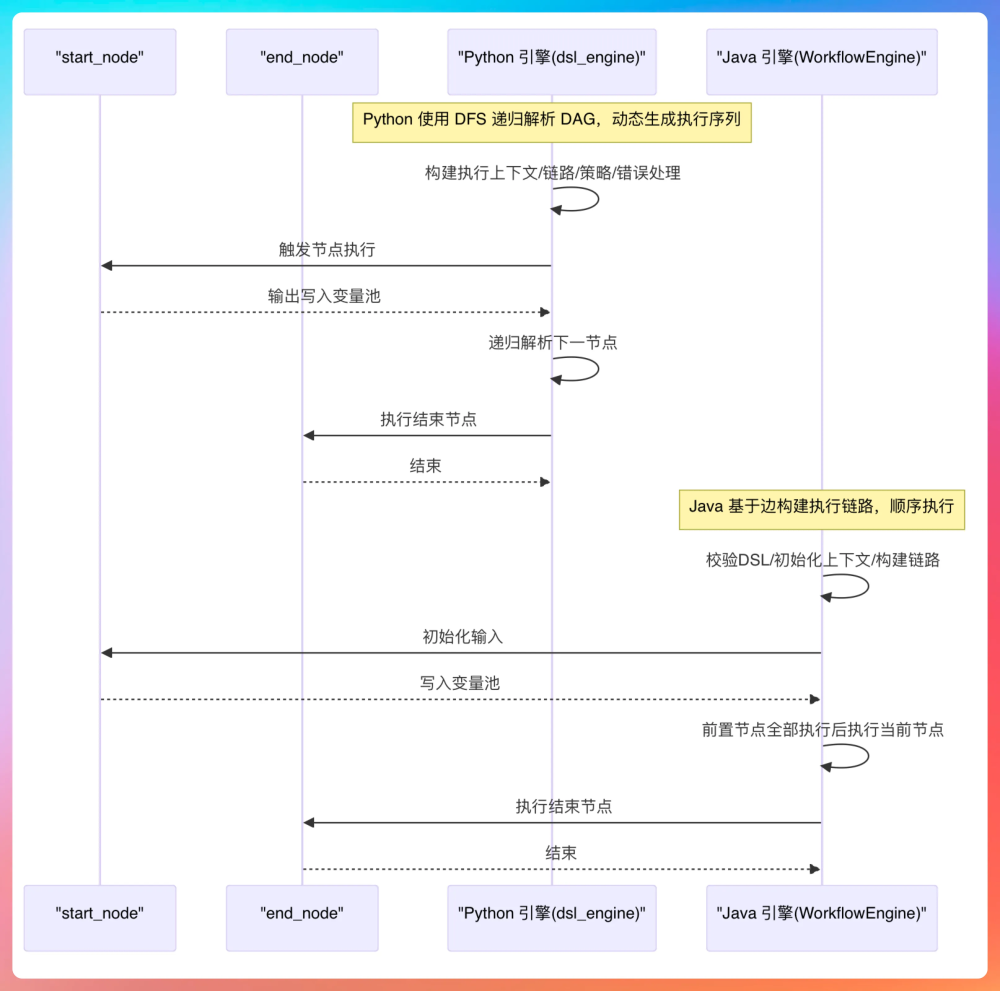
最有成就感的,应该是把工作流引擎从 Python 重写成 Java 这件事。刚开始接手这个项目的时候,只有 Python 版的工作流引擎,但我们团队成员基本上都是 Java 技术栈,维护起来很不顺手。
所以我主动承担起了这个职责,用 Java 重写一遍。我设计了基于策略模式的执行器架构,WorkflowEngine 实现了一个通用的 DAG(有向无环图)调度器,负责解析 DSL,管理节点间的依赖关系,并执行工作流。
抽象基类 AbstractNodeExecutor 用来处理通用的逻辑(如重试机制、超时控制、错误捕获),让具体的节点执行器(如 LLMNode、PluginNode )只关注自身的业务逻辑,比如说 LLM 节点执行器封装了 DeepSeek 等大模型的流式调用,插件节点执行器实现了对第三方工具的标准化调用。
另外,我还设计了一套变量解析机制,支持从上游节点的输出中动态提取数据(如 {{node_1.output}} ),并将其映射为当前节点的强类型输入。
还有 SSE + 生产者/消费者模型实现了工作流执行的毫秒级实时推送,这些工作让我从一个框架使用者真正蜕变成了一个框架设计者,我很享受这段旅程。
6.项目开发过程中遇到的最大挑战是什么?
考察点:问题解决能力
参考答案:
用户习惯在节点配置中使用类似 Jinja2 的模板语法来引用上游变量,例如:
{{node_1.response.choices[0].message.content}},但 Java 是强类型的,我们无法预知上游节点会输出什么样的 JSON 结构。直接映射为 POJO 不现实,使用 Map 又很难处理深层嵌套和数组下标访问(如 [0] )。
为了解决这个问题,我设计了一个动态变量池 VariablePool,模拟了动态语言的内存访问机制。首先,在 VariablePool 中,我放弃了强类型对象,转而利用 FastJSON2 将所有节点的输出(无论是 List、Map 还是自定义对象)统一转换成 JSONObject 或 JSONArray 进行存储。
// VariablePool.java L42-53
public void set(String nodeId, String outputName, Object value) {
// 强制转换为 JSON 结构,抹平类型差异
if (value instanceof List) {
value = JSON.parseArray(JSON.toJSONString(value));
} else {
value = JSON.parseObject(JSON.toJSONString(value));
}
variables.computeIfAbsent(nodeId, k -> new HashMap<>()).put(outputName, value);
}然后,为了支持 data.result[0].value 这样的复杂引用,我手写了一个递归解析算法 getVal ,它能够智能识别点号 . 和中括号 [] ,在嵌套的 Map 和 List 中精准定位数据。
// 核心解析逻辑
private Object getVal(Map map, String key) {
// ... 解析 rootKey 和 subKey ...
// 处理数组下标访问,如 "list[0]"
if (index > 0 && rootKey.endsWith("]")) {
// ... 提取下标并访问 List ...
}
// 递归查找下一层
return getVal(subMap, subKey);
}最后,通过 VariableTemplateRender.java 在节点执行前动态扫描输入参数,利用正则匹配 {{...}} 占位符,并调用变量池进行实时替换。
这一套机制让 Java 引擎也具备了动态语言的数据处理能力。
ending
想要上手Vibe Coding的小伙伴请注意,PaiAgent项目的教程也是完全开放的:https://paicoding.com/column/14/1
你把Qoder换成TRAE,换成Claude Code,都可以实现类似的效果。
字节的暑期实习,也代表了整个互联网大厂的招聘风向。
大家一定要学会迎风而已,顺势而为。
当语言壁垒消融、工具边界瓦解,真正的核心竞争力,已经从“我会写什么代码”,跃迁为“我能否定义问题、拆解目标、调度AI、闭环验证”。
AI 不是替代者,而是放大器;Agent 不是终点,而是新生产力的起点。
顺势而为,不是追逐热点,而是校准自己与时代底层逻辑的共振频率。风已起,帆已扬,真正的上岸,始于主动跳入浪潮中央。
😄