深入浅出Java拆箱与装箱:理解自动类型转换与包装类的关系
“哥,听说 Java 的每个基本数据类型都对应了一个包装类型,比如说 int 的包装类型为 Integer,double 的包装类型为 Double,是这样吗?”从三妹这句话当中,能听得出来,她已经提前预习这块内容了。
“是的,三妹。”我接着三妹的问题回答说。
- Java 是面向对象的编程语言,但为了提升程序的运行效率,所以 Java 搞出来了基本数据类型这套东西,比如说 int、double、boolean 等等。后面我会讲为什么。
- 但是,基本数据类型又不能满足所有的应用场景,比如说,我们定义一个 int 类型的 ArrayList,你就只能用
List<Integer> list = new ArrayList<>();这种方式来定义,不能用List<int> list = new ArrayList<>();这种方式来定义,因为泛型不支持基本数据类型。后面我也会讲为什么。
那既然存在基本数据类型,又存在包装类型,它们之间肯定存在一些使用上的差异,以及在某些场景下需要进行类型转换。这就是今天我们要讲的拆箱和装箱。
拆箱就是将包装类型对象转换为其对应的基本数据类型,而装箱则是将基本数据类型转换为相应的包装类型对象。
示例代码如下:
Integer chenmo = new Integer(10); // 装箱
int wanger = chenmo.intValue(); // 拆箱包装类型和基本数据类型之间的区别
好,接下来我们先来介绍一下包装类型和基本数据类型之间的区别。
包装类型可以为 null,而基本数据类型不可以
别小看这一点区别,这使得包装类型可以应用于 POJO 中,而基本数据类型则不行。
POJO 是什么呢?
POJO 的英文全称是 Plain Ordinary Java Object,翻译一下就是,简单无规则的 Java 对象,只有字段以及对应的 setter 和 getter 方法。来看下面这段代码:
class Writer {
private Integer age;
private String name;
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}这就是一个非常纯粹,非常典型的 POJO,在我们编写的 Java 应用程序中会经常用到。
“哥,你说的 POJO 是不是就是 JavaBean 啊?”三妹这时候追问道。
“是的,如果定义没那么严格的话,JavaBean 也是一种 POJO。”
和 POJO 类似的,还有:
- 数据传输对象 DTO(Data Transfer Object,泛指用于展示层与服务层之间的数据传输对象)
- 视图对象 VO(View Object,把某个页面的数据封装起来)
- 持久化对象 PO(Persistant Object,可以看成是与数据库中的表映射的 Java 对象)。
技术派实战项目当中就有大量 POJO,我截图大家感受下,工作后其实会经常碰到。
只不过,我们不再写 setter 和 getter 方法,而是使用 Lombok 来自动生成。也就是上图当中的 @Data 注解。
“那为什么 POJO 的字段必须要用包装类型呢?”三妹又追问道。
“《阿里巴巴 Java 开发手册》上有详细的说明,你看。”我打开 PDF,并翻到了对应的内容,指着屏幕念道。
数据库的查询结果可能是 null,如果使用基本数据类型的话,因为要自动拆箱,就会抛出 NullPointerException 的异常。
“什么是自动拆箱呢?”
“自动拆箱指的是,将包装类型转为基本数据类型,比如说把 Integer 对象转换成 int 值;对应的,把基本数据类型转为包装类型,则称为自动装箱。”
“哦。”
包装类型可用于泛型,而基本数据类型不可以
“那接下来,我们来看第二点不同。包装类型可用于泛型,而基本数据类型不可以,否则就会出现编译错误。”一边说着,我一边在 Intellij IDEA 中噼里啪啦地敲了起来。
“三妹,你瞧,编译器提示错误了。”
List<int> list = new ArrayList<>(); // 提示 Syntax error, insert "Dimensions" to complete ReferenceType
List<Integer> list = new ArrayList<>();“为什么呢?”三妹及时地问道。
“因为泛型在编译时会进行类型擦除,最后只保留原始类型,而原始类型只能是 Object 类及其子类——基本数据类型是个例外。”
这个我们在讲泛型的时候,也有详细讲过,你应该还记得吧?
“嗯,我记得。”
基本数据类型比包装类型更高效
“哥,你之前说到,Java 搞出来了基本数据类型这套东西,是为了提升程序的运行效率,为什么呢?”三妹又追问道。
那这里其实就是为了讲这个问题。
“好,接下来,我们来说第三点,基本数据类型比包装类型更高效。”我喝了一口布丁奶茶后继续说道。
“作为局部变量时,基本数据类型在栈中直接存储的具体数值,而包装类型则存储的是堆中的引用。”我一边说着,一边打开 draw.io 画起了图。
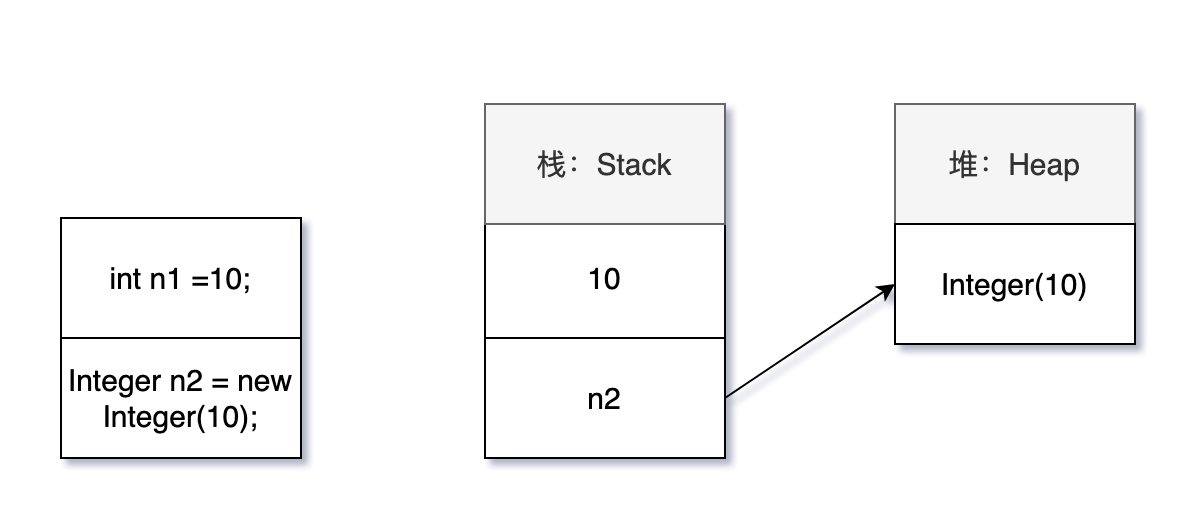
关于堆和栈的知识,我们会在讲 JVM 运行时数据区的时候详细讲解。
很显然,相比较于基本类型而言,包装类型需要占用更多的内存空间。
- 基本数据类型:仅占用足够存储其值的固定大小的内存。例如,一个 int 值占用 4 字节。
- 包装类型:占用的内存空间要大得多,因为它们是对象,并且要存储对象的元数据。例如,一个 Integer 对象占用 16 字节。
并且不仅要存储对象,还要存储引用。假如没有基本数据类型的话,对于数值这类经常使用到的数据来说,每次都要通过 new 一个包装类型就显得非常笨重。
我们通过一个简单的例子来印证这一点:
public class MemoryUsageTest {
public static void main(String[] args) {
Runtime runtime = Runtime.getRuntime();
long memoryBefore, memoryAfter;
int size = 1000000;
// 测试基本类型 int 的内存占用
runtime.gc();
memoryBefore = runtime.totalMemory() - runtime.freeMemory();
int[] intArray = new int[size];
memoryAfter = runtime.totalMemory() - runtime.freeMemory();
System.out.println("基本数据类型数组占用内存: " + (memoryAfter - memoryBefore));
// 测试包装类型 Integer 的内存占用
runtime.gc();
memoryBefore = runtime.totalMemory() - runtime.freeMemory();
Integer[] integerArray = new Integer[size];
for (int i = 0; i < size; i++) {
integerArray[i] = i; // 自动装箱
}
memoryAfter = runtime.totalMemory() - runtime.freeMemory();
System.out.println("包装类型数组占用内存空间: " + (memoryAfter - memoryBefore));
}
}创建 100万个数组,一个用基本数据类型,一个用包装类型,然后比较它们的内存占用情况。
基本数据类型数组占用内存: 5342192
包装类型数组占用内存空间: 22790672可以看得出来,基本数据类型数组占用的内存空间比包装类型的少了一个数量级。当然了,这种方法没那么严谨,但多少能说明一些问题。
不同类型数据存储的位置
“三妹,你想知道程序运行时,数据都存储在什么地方吗?”
“嗯嗯,哥,你说说呗。”
“通常来说,有 4 个地方可以用来存储数据。”
1)寄存器。这是最快的存储区,因为它位于 CPU 内部,用来暂时存放参与运算的数据和运算结果。
2)栈。位于 RAM(Random Access Memory,也叫主存,与 CPU 直接交换数据的内部存储器)中,速度仅次于寄存器。但是,在分配内存的时候,存放在栈中的数据大小与生存周期必须在编译时是确定的,缺乏灵活性。基本数据类型的值和对象的引用通常存储在这块区域。
3)堆。也位于 RAM 区,可以动态分配内存大小,编译器不必知道要从堆里分配多少存储空间,生存周期也不必事先告诉编译器,Java 的垃圾收集器会自动收走不再使用的数据,因此可以得到更大的灵活性。但是,运行时动态分配内存和销毁对象都需要占用时间,所以效率比栈低一些。new 创建的对象都会存储在这块区域。
4)磁盘。如果数据完全存储在程序之外,就可以不受程序的限制,在程序没有运行时也可以存在。像文件、数据库,就是通过持久化的方式,让对象存放在磁盘上。当需要的时候,再反序列化成程序可以识别的对象。
“能明白吗?三妹?”
“这节讲完后,我再好好消化一下。”
“别担心,后面讲 JVM 运行时数据区的时候也会重新讲到。”
包装类型的值可以相同,但却不相等
“那好,我们来说第四点,两个包装类型的值可以相同,但却不相等。”
Integer chenmo = new Integer(10);
Integer wanger = new Integer(10);
System.out.println(chenmo == wanger); // false
System.out.println(chenmo.equals(wanger )); // true“两个包装类型在使用“==”进行判断的时候,判断的是其指向的地址是否相等,由于是两个对象,所以地址是不同的。”
“而 chenmo.equals(wanger) 的输出结果为 true,是因为 equals() 方法内部比较的是两个 int 值是否相等。”
private final int value;
public int intValue() {
return value;
}
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}虽然 chenmo 和 wanger 的值都是 10,但他们并不相等。换句话说就是:将“==”操作符应用于包装类型比较的时候,其结果很可能会和预期的不符。
自动装箱和自动拆箱
“三妹,瞧,((Integer)obj).intValue() 这段代码就是用来拆箱的。不过这种属于手动拆箱,对应的还有一种自动拆箱,我们来详细地解释下。”
既然有基本数据类型和包装类型,肯定有些时候要在它们之间进行转换。把基本数据类型转换成包装类型的过程叫做装箱(boxing)。反之,把包装类型转换成基本数据类型的过程叫做拆箱(unboxing)。
在 Java 1.5 之前,开发人员要手动进行装拆箱,比如说:
Integer chenmo = new Integer(10); // 手动装箱
int wanger = chenmo.intValue(); // 手动拆箱Java 1.5 为了减少开发人员的工作,提供了自动装箱与自动拆箱的功能。这下就方便了。
Integer chenmo = 10; // 自动装箱
int wanger = chenmo; // 自动拆箱来看一下反编译后的代码。
Integer chenmo = Integer.valueOf(10);
int wanger = chenmo.intValue();也就是说,自动装箱是通过 Integer.valueOf() 完成的;自动拆箱是通过 Integer.intValue() 完成的。
“嗯,三妹,给你出一道面试题吧。”
// 1)基本数据类型和包装类型
int a = 100;
Integer b = 100;
System.out.println(a == b);
// 2)两个包装类型
Integer c = 100;
Integer d = 100;
System.out.println(c == d);
// 3)
c = 200;
d = 200;
System.out.println(c == d);“给你 3 分钟时间,你先思考下,我去抽根华子,等我回来,然后再来分析一下为什么。”
。。。。。。
“嗯,哥,你过来吧,我说一说我的想法。”
第一段代码,基本数据类型和包装类型进行 == 比较,这时候 b 会自动拆箱,直接和 a 比较值,所以结果为 true。
第二段代码,两个包装类型都被赋值为了 100,这时候会进行自动装箱,按照你之前说的,将“==”操作符应用于包装类型比较的时候,其结果很可能会和预期的不符,我想结果可能为 false。
第三段代码,两个包装类型重新被赋值为了 200,这时候仍然会进行自动装箱,我想结果仍然为 false。
“嗯嗯,三妹,你分析的很有逻辑,但第二段代码的结果为 true,是不是感到很奇怪?”
“为什么会这样呀?”三妹急切地问。
IntegerCache
“你说的没错,自动装箱是通过 Integer.valueOf() 完成的,我们来看看这个方法的源码就明白为什么了。”
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}是不是看到了一个之前见过的类——IntegerCache?
“难道说是 Integer 的缓存类?”三妹做出了自己的判断。
“是的,来看一下 IntegerCache 的源码吧。”
private static class IntegerCache {
// 缓存的最小值,默认为 -128
static final int low = -128;
// 缓存的最大值,默认为 127,但可以通过 JVM 参数配置
static final int high;
static final Integer cache[];
static {
// 默认情况下 high 值为 127
int h = 127;
// 通过系统属性获取用户可能配置的更高的缓存上限
// integerCacheHighPropValue 是一个字符串,代表配置的高值
int i = parseInt(integerCacheHighPropValue);
// 确保缓存的最高值至少为 127
i = Math.max(i, 127);
// 设置 high 的值,但不能超过 Integer.MAX_VALUE - (-low) - 1
h = Math.min(i, Integer.MAX_VALUE - (-low) - 1);
high = h;
// 初始化缓存数组,大小为 high - low + 1
cache = new Integer[(high - low) + 1];
// 填充缓存,从 low 开始,为每个值创建一个 Integer 对象
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// 断言确保 high 的值至少为 127,这是 Java 语言规范要求的
assert IntegerCache.high >= 127;
}
}大致瞟一下这段代码你就全明白了。-128 到 127 之间的数会从 IntegerCache 中取,然后比较,所以第二段代码(100 在这个范围之内)的结果是 true,而第三段代码(200 不在这个范围之内,所以 new 出来了两个 Integer 对象)的结果是 false。
“三妹,看完上面的分析之后,我希望你记住一点:当需要进行自动装箱时,如果数字在 -128 至 127 之间时,会直接使用缓存中的对象,而不是重新创建一个对象。”
自动拆箱的注意事项
“自动装拆箱是一个很好的功能,大大节省了我们开发人员的精力,但也会引发一些麻烦,比如下面这段代码,性能就很差。”
long t1 = System.currentTimeMillis();
Long sum = 0L;
for (int i = 0; i < Integer.MAX_VALUE;i++) {
sum += i;
}
long t2 = System.currentTimeMillis();
System.out.println(t2-t1);“知道为什么吗?三妹。”
“难道是因为 sum 被声明成了包装类型 Long 而不是基本数据类型 long。”三妹若有所思。
“是滴,由于 sum 是个 Long 型,而 i 为 int 类型,sum += i 在执行的时候,会先把 i 强转为 long 型,然后再把 sum 拆箱为 long 型进行相加操作,之后再自动装箱为 Long 型赋值给 sum。”
等后面你学了 javap 命令之后,就可以通过 javap -v xxx.class 命令来查看这段代码的执行过程。
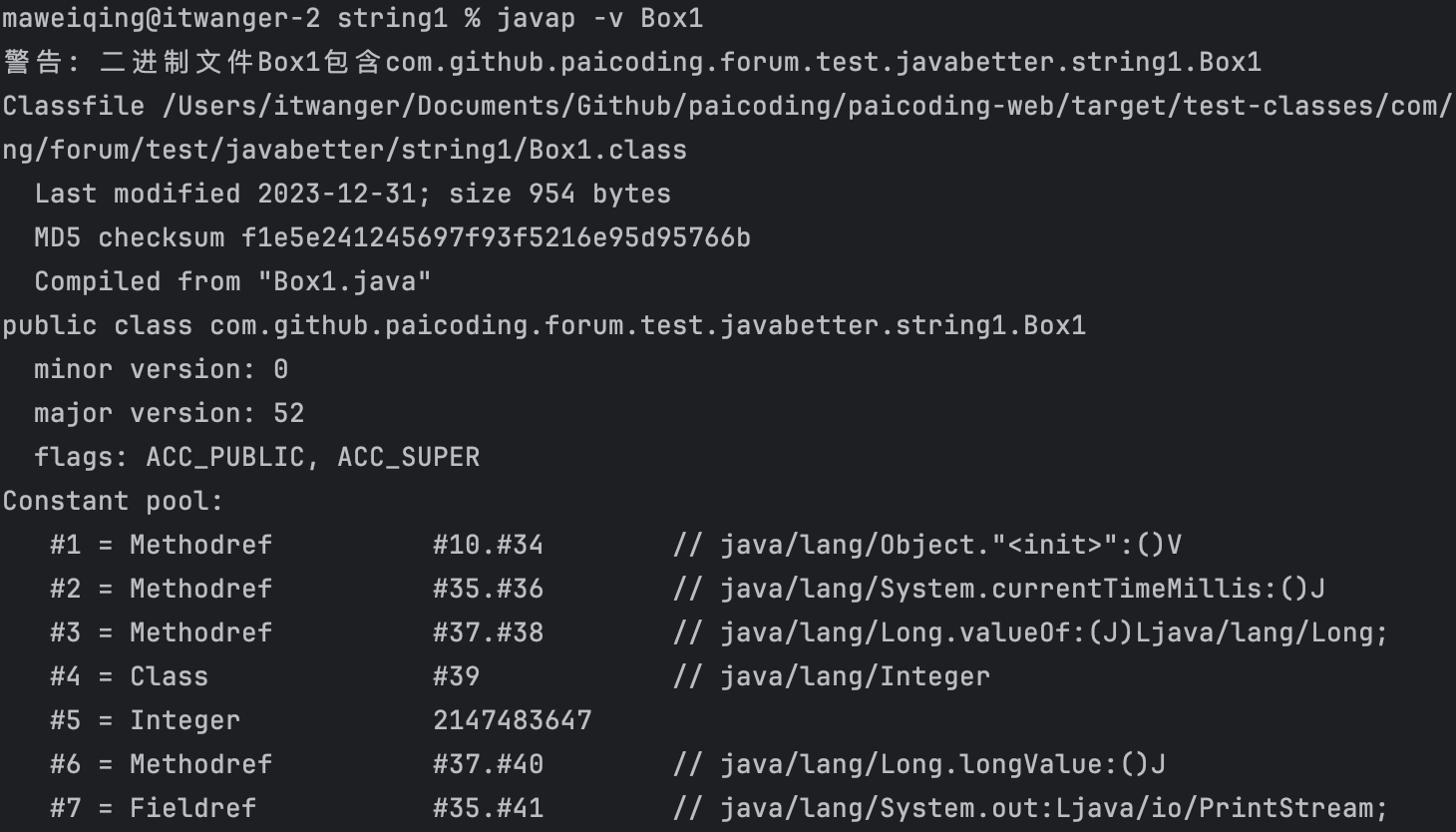
从这里面,你应该能看到 Long.valueOf() 和 Long.longValue() 的身影。它们分别对应了自动装箱和自动拆箱。
“三妹,你可以试一下,把 sum 换成 long 型比较一下它们运行的时间。”
。。。。。。
“哇,sum 为 Long 型的时候,足足运行了 5825 毫秒;sum 为 long 型的时候,只需要 679 毫秒。”
“好了,三妹,今天的主题就先讲到这吧。我再去来根华子。”
总结
今天我们讲了拆箱和装箱的概念,以及包装类型和基本数据类型之间的区别。最后,我们还讲了自动装箱和自动拆箱的原理,以及自动拆箱的注意事项。
GitHub 上标星 17000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 17000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
