一文彻底搞懂 Java 类加载机制
上一节在讲 JVM 运行 Java 代码的时候,我们提到,JVM 需要将编译后的字节码文件加载到其内部的运行时数据区域中进行执行。这个过程涉及到了 Java 的类加载机制(面试常问的知识点),所以我们来详细地讲一讲。
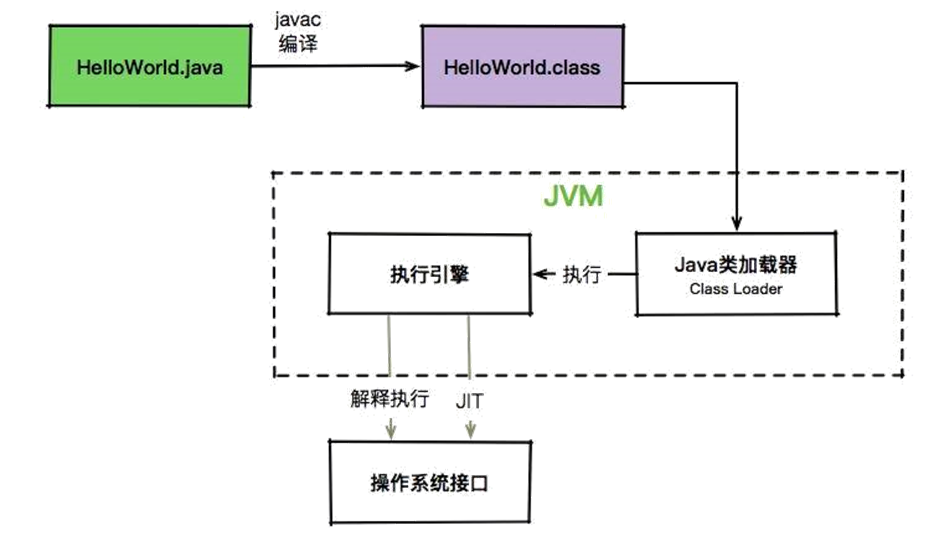
字节码我们上一节也讲过,它和类的加载机制息息相关,相信大家都还有印象。
这里再给大家普及一个小技巧,可以通过 xxd 命令来查看字节码文件,先看下面这段代码。
public class Test {
public static void main(String[] args) {
System.out.println("沉默王二");
}
}代码编译通过后,在命令行执行 xxd Test.class(macOS 用户可以直接执行,Windows 用户可以戳这个链接获取替代品)就可以快速查看字节码的十六进制内容。
xxd 是一个用于在终端中创建十六进制转储(hex dump)或将十六进制转回二进制的工具。可通过维基百科了解更多信息。
00000000: cafe babe 0000 0034 0022 0700 0201 0019 .......4."......
00000010: 636f 6d2f 636d 6f77 6572 2f6a 6176 615f com/cmower/java_
00000020: 6465 6d6f 2f54 6573 7407 0004 0100 106a demo/Test......j
00000030: 6176 612f 6c61 6e67 2f4f 626a 6563 7401 ava/lang/Object.
00000040: 0006 3c69 6e69 743e 0100 0328 2956 0100 ..<init>...()V..
00000050: 0443 6f64 650a 0003 0009 0c00 0500 0601 .Code...........
00000060: 000f 4c69 6e65 4e75 6d62 6572 5461 626c ..LineNumberTabl这里只说一点,这段字节码中的 cafe babe 被称为“魔数”,是 JVM 识别 .class 文件(字节码文件)的标志,相信大家都知道,Java 的 logo 是一杯冒着热气的咖啡,是不是又关联上了?

文件格式的定制者可以自由选择魔数值(只要没用过),比如说 .png 文件的魔数是
8950 4e47。
至于字节码文件中的其他内容,暂时先不用去管,我们后面会详细讲解。
类加载过程
知道什么是 Java 字节码后,我们来聊聊 Java 的类加载过程。
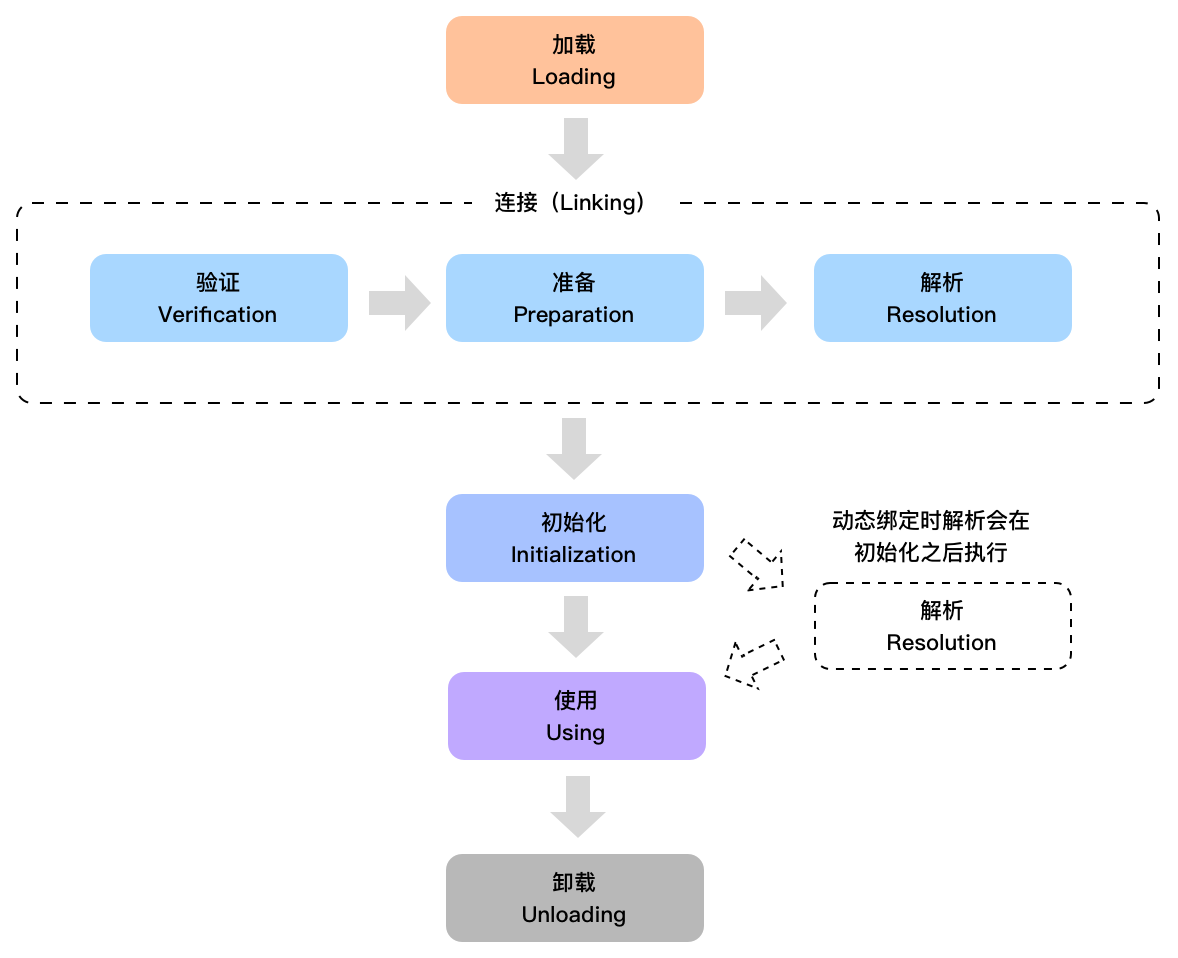
类从被加载到 JVM 开始,到卸载出内存,整个生命周期分为七个阶段,分别是加载、验证、准备、解析、初始化、使用和卸载。其中验证、准备和解析这三个阶段统称为连接。
除去使用和卸载,就是 Java 的类加载过程。这 5 个阶段一般是顺序发生的,但在动态绑定的情况下,解析阶段发生在初始化阶段之后(我们随后来解释)。
1)Loading(载入)
JVM 在该阶段的目的是将字节码从不同的数据源(可能是 class 文件、也可能是 jar 包,甚至网络)转化为二进制字节流加载到内存中,并生成一个代表该类的 java.lang.Class 对象(在学反射的时候有讲过)。
2)Verification(验证)
JVM 会在该阶段对二进制字节流进行校验,只有符合 JVM 字节码规范的才能被 JVM 正确执行。该阶段是保证 JVM 安全的重要屏障,下面是一些主要的检查。
读者飞 2025 年 2 月 22 日 提供的修改建议。
- 确保二进制字节流格式符合预期(比如说是否以
cafe babe开头,前面提到过)。 - 是否所有方法都遵守访问控制关键字的限定,protected、private 那些。
- 方法调用的参数个数和类型是否正确。
- 确保变量在使用之前被正确初始化了。
- 检查变量是否被赋予恰当类型的值。
- 还有更多。
3)Preparation(准备)
JVM 会在该阶段对类变量(也称为静态变量,static 关键字修饰的)分配内存并初始化,对应数据类型的默认初始值,如 0、0L、null、false 等。
也就是说,假如有这样一段代码:
public String chenmo = "沉默";
public static String wanger = "王二";
public static final String cmower = "沉默王二";chenmo 不会被分配内存,而 wanger 会;但 wanger 的初始值不是“王二”而是 null。
需要注意的是,static final 修饰的变量被称作为常量,和类变量不同(这些在讲 static 关键字就讲过了)。常量一旦赋值就不会改变了,所以 cmower 在准备阶段的值为“沉默王二”而不是 null。
4)Resolution(解析)
该阶段将常量池中的符号引用转化为直接引用。
what?符号引用,直接引用?
符号引用以一组符号(任何形式的字面量,只要在使用时能够无歧义的定位到目标即可)来描述所引用的目标。
在编译时,Java 类并不知道所引用的类的实际地址,因此只能使用符号引用来代替。比如 com.Wanger 类引用了 com.Chenmo 类,编译时 Wanger 类并不知道 Chenmo 类的实际内存地址,因此只能使用符号 com.Chenmo。
直接引用通过对符号引用进行解析,找到引用的实际内存地址。我们再来对比说明一下。
符号引用
- 定义:包含了类、字段、方法、接口等多种符号的全限定名。
- 特点:在编译时生成,存储在编译后的字节码文件的常量池中。
- 独立性:不依赖于具体的内存地址,提供了更好的灵活性。
直接引用
- 定义:直接指向目标的指针、相对偏移量或者能间接定位到目标的句柄。
- 特点:在运行时生成,依赖于具体的内存布局。
- 效率:由于直接指向了内存地址或者偏移量,所以通过直接引用访问对象的效率较高。
下面通过一张简化的图来描述它们的区别:
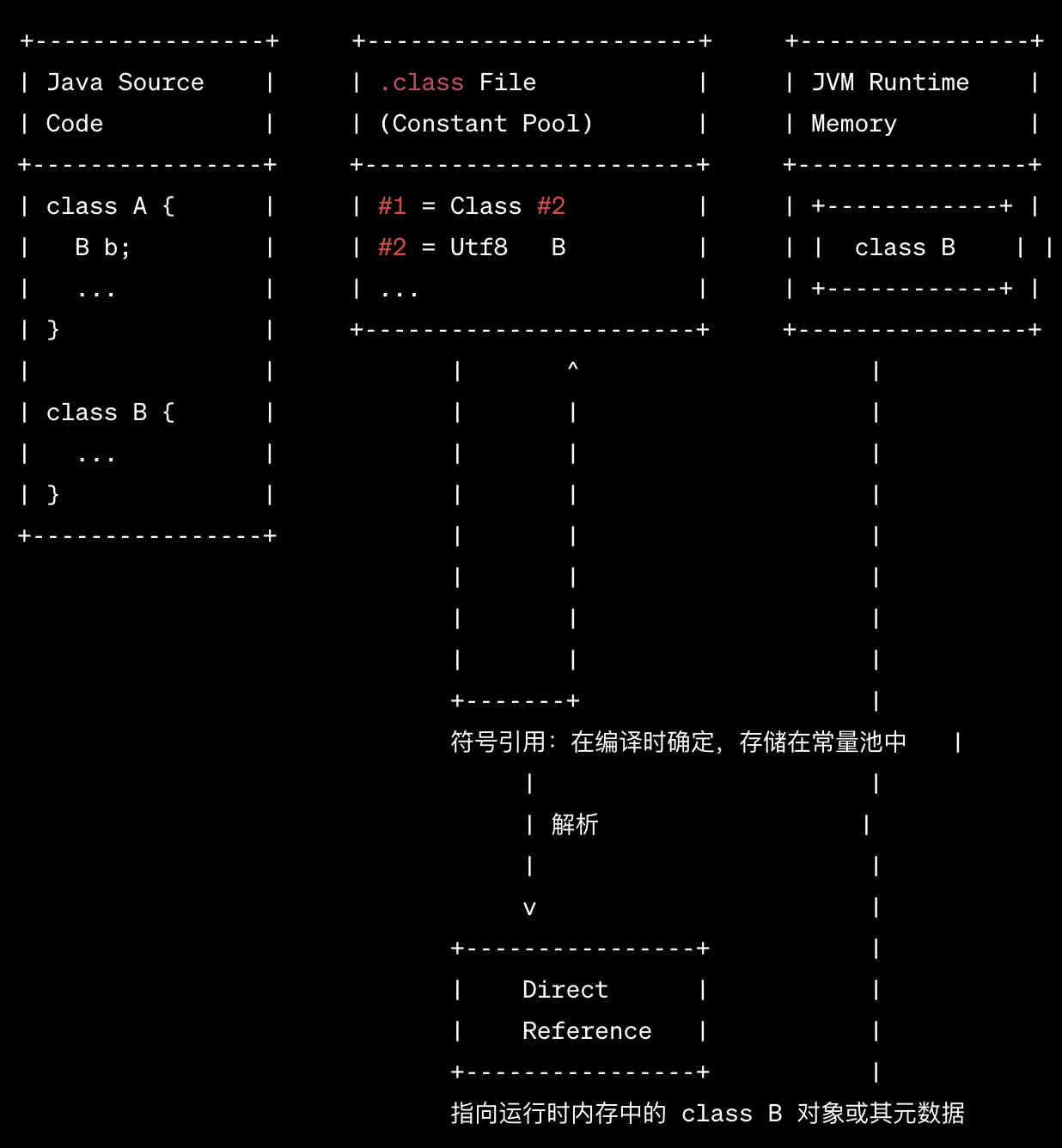
在上面的例子中:
class A引用了class B。- 在编译时,这个引用变成了符号引用,存储在
.class文件的常量池中。 - 在运行时,当
class A需要使用class B的时候,JVM 会将符号引用解析为直接引用,指向内存中的class B对象或其元数据。
通过这种方式,Java 程序能够在编译时和运行时具有更高的灵活性和解耦性,同时在运行时也能获得更好的性能。
Java 本身是一个静态语言,但后面又加入了动态加载特性,因此我们理解解析阶段需要从这两方面来考虑。
如果不涉及动态加载,那么一个符号的解析结果是可以缓存的,这样可以避免多次解析同一个符号,因为第一次解析成功后面多次解析也必然成功,第一次解析异常后面重新解析也会是同样的结果。
如果使用了动态加载,前面使用动态加载解析过的符号后面重新解析结果可能会不同。使用动态加载时解析过程发生在在程序执行到这条指令的时候,这就是为什么前面讲的动态加载时解析会在初始化后执行。
整个解析阶段主要做了下面几个工作:
- 类或接口的解析
- 类方法解析
- 接口方法解析
- 字段解析
5)Initialization(初始化)
该阶段是类加载过程的最后一步。在准备阶段,类变量已经被赋过默认初始值,而在初始化阶段,类变量将被赋值为代码期望赋的值。换句话说,初始化阶段是执行类构造器方法(javap 中看到的 <clinit>() 方法)的过程。
上面这段话可能说得很抽象,不好理解,我来举个例子。
String cmower = new String("沉默王二");上面这段代码使用了 new 关键字来实例化一个字符串对象,那么这时候,就会调用 String 类的构造方法对 cmower 进行实例化。
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}初始化时机包括以下这些:
- 创建类的实例时。
- 访问类的静态方法或静态字段时(除了 final 常量,它们在编译期就已经放入常量池)。
- 使用 java.lang.reflect 包的方法对类进行反射调用时。
- 初始化一个类的子类(首先会初始化父类)。
- JVM 启动时,用户指定的主类(包含 main 方法的类)将被初始化。
类加载器
聊完类加载过程,就不得不聊聊类加载器。
一般来说,Java 程序员并不需要直接同类加载器进行交互。JVM 默认的行为就已经足够满足大多数情况的需求了。不过,如果遇到了需要和类加载器进行交互的情况,而对类加载器的机制又不是很了解的话,就不得不花大量的时间去调试 ClassNotFoundException 和 NoClassDefFoundError 等异常(前面讲过)。
对于任意一个类,都需要由它的类加载器和这个类本身一同确定其在 JVM 中的唯一性。也就是说,如果两个类的加载器不同,即使两个类来源于同一个字节码文件,那这两个类就必定不相等(比如两个类的 Class 对象不 equals)。
来通过一段简单的代码了解下。
/**
* @author 微信搜「沉默王二」,回复关键字 PDF
*/
public class Test {
public static void main(String[] args) {
ClassLoader loader = Test.class.getClassLoader();
while (loader != null) {
System.out.println(loader);
loader = loader.getParent();
}
}
}每个 Java 类都维护着一个指向定义它的类加载器的引用,通过 类名.class.getClassLoader() 可以获取到此引用;然后通过 loader.getParent() 可以获取类加载器的上层类加载器。
上面这段代码的输出结果如下:
jdk.internal.loader.ClassLoaders$AppClassLoader@512ddf17
jdk.internal.loader.ClassLoaders$PlatformClassLoader@2d209079第一行输出为 Test 的类加载器,即应用类加载器,它是 jdk.internal.loader.ClassLoaders$AppClassLoader 类的实例;第二行输出为平台类加载器,是 jdk.internal.loader.ClassLoaders$PlatformClassLoader 类的实例。那启动类加载器呢?
按理说,扩展类加载器的上层类加载器是启动类加载器,但启动类加载器是虚拟机的内置类加载器,通常表示为 null。
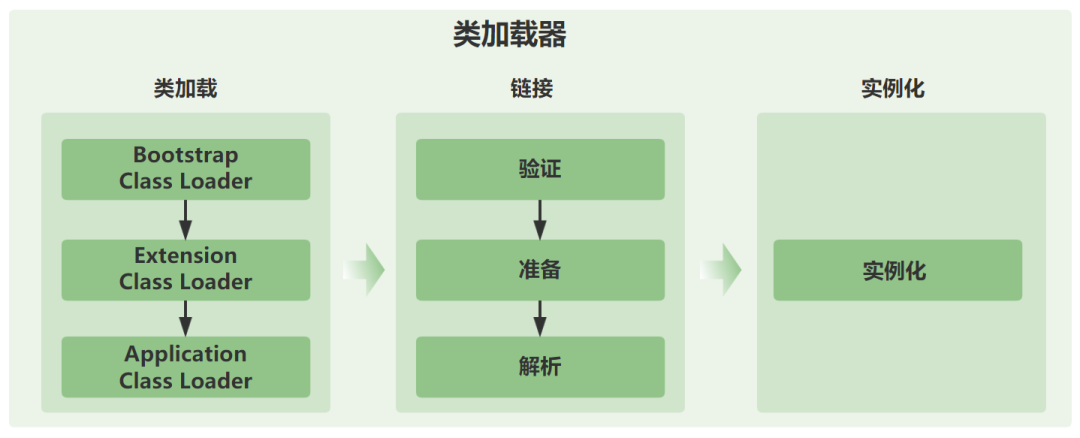
也就是说,类加载器可以分为四种类型:
①、引导类加载器(Bootstrap ClassLoader):负责加载 JVM 基础核心类库,如 rt.jar、sun.boot.class.path 路径下的类。
②、扩展类加载器(Extension ClassLoader):负责加载 Java 扩展库中的类,例如 jre/lib/ext 目录下的类或由系统属性 java.ext.dirs 指定位置的类。
③、系统(应用)类加载器(System ClassLoader):负责加载系统类路径 java.class.path 上指定的类库,通常是你的应用类和第三方库。
④、用户自定义类加载器:Java 允许用户创建自己的类加载器,通过继承 java.lang.ClassLoader 类的方式实现。这在需要动态加载资源、实现模块化框架或者特殊的类加载策略时非常有用。
import java.io.*;
public class CustomClassLoader extends ClassLoader {
private String pathToBin;
public CustomClassLoader(String pathToBin) {
this.pathToBin = pathToBin;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
try {
byte[] classData = loadClassData(name);
return defineClass(name, classData, 0, classData.length);
} catch (IOException e) {
throw new ClassNotFoundException("Class " + name + " not found", e);
}
}
private byte[] loadClassData(String name) throws IOException {
String file = pathToBin + name.replace('.', File.separatorChar) + ".class";
InputStream is = new FileInputStream(file);
ByteArrayOutputStream byteSt = new ByteArrayOutputStream();
int len = 0;
while ((len = is.read()) != -1) {
byteSt.write(len);
}
return byteSt.toByteArray();
}
}这个自定义类加载器做了以下几件事情:
- 构造器:接受一个字符串参数,这个字符串指定了类文件的存放路径。
- 覆写 findClass 方法:当父类加载器无法加载类时,findClass 方法会被调用。在这个方法中,首先使用 loadClassData 方法读取类文件的字节码,然后调用 defineClass 方法来将这些字节码转换为 Class 对象。
- loadClassData 方法:读取指定路径下的类文件内容,并将内容作为字节数组返回。
双亲委派模型
双亲委派模型(Parent Delegation Model)是 Java 类加载器使用的一种机制,用于确保 Java 程序的稳定性和安全性。在这个模型中,类加载器在尝试加载一个类时,首先会委派给其父加载器去尝试加载这个类,只有在父加载器无法加载该类时,子加载器才会尝试自己去加载。
委派给父加载器:当一个类加载器接收到类加载的请求时,它首先不会尝试自己去加载这个类,而是将这个请求委派给它的父加载器。
递归委派:这个过程会递归向上进行,从启动类加载器(Bootstrap ClassLoader)开始,再到扩展类加载器(Extension ClassLoader),最后到系统类加载器(System ClassLoader)。
加载类:如果父加载器可以加载这个类,那么就使用父加载器的结果。如果父加载器无法加载这个类(它没有找到这个类),子加载器才会尝试自己去加载。
安全性和避免重复加载:这种机制可以确保不会重复加载类,并保护 Java 核心 API 的类不被恶意替换。
类加载器的层级结构如下图所示:
Bootstrap ClassLoader
↑
│
Extension ClassLoader
↑
│
System/Application ClassLoader
↑
│
Custom ClassLoader这种层次关系被称作为双亲委派模型:如果一个类加载器收到了加载类的请求,它会先把请求委托给上层加载器去完成,上层加载器又会委托上上层加载器,一直到最顶层的类加载器;如果上层加载器无法完成类的加载工作时,当前类加载器才会尝试自己去加载这个类。
PS:双亲委派模型突然让我联想到朱元璋同志,这个同志当上了皇帝之后连宰相都不要了,所有的事情都亲力亲为,只有自己没精力没时间做的事才交给大臣们去干。
使用双亲委派模型有一个很明显的好处,那就是 Java 类随着它的类加载器一起具备了一种带有优先级的层次关系,这对于保证 Java 程序的稳定运作很重要。
上文中曾提到,如果两个类的加载器不同,即使两个类来源于同一个字节码文件,那这两个类就必定不相等——双亲委派模型能够保证同一个类最终会被特定的类加载器加载。
小结
Java 的类加载机制通过类加载器和类加载过程的合作,确保了 Java 程序的动态加载、灵活性和安全性。双亲委派模型进一步增强了这种机制的安全性和类之间的协调性。
学习就是这样,只要你敢于挑战自己,就能收获知识——就像山就在那里,只要你肯攀登,就能到达山顶。
参考链接:详解 Java 类加载过程
GitHub 上标星 17000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括 Java 基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM 等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 17000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
