食堂打饭时,同事问:你们天天说的 Embedding、Rerank 到底是啥?打饭阿姨抢着说:就是让LLM听懂人话。佩服佩服啊。
大家好,我是二哥呀。
不管是 Claude Code 还是 Codex,它们在读项目源码/读知识库的时候都很无敌,随便问一个问题,都能精准定位到对应的代码块/文档。
这是怎么做到的呢?
背后离不开 Embedding 的功劳。
今天这篇,我们从 Embedding 和 Rerank 的原理讲起,结合派聪明 RAG 和 PaiCLI Agent 两个项目的真实实现,把这两块知识彻底讲透。
01、为什么需要 RAG?
现在的模型能力已经非常强了,不管是 GPT-5.5 还是 Opus 4.7。
基本上日常的 Coding 和部分的文本都可以交给他们来完成了。
并且质量很高。
但有两个问题是 LLM 很难解决的。
第一个是知识截止。
模型训练完之后,它的知识就定格在那个时间点了。2026 年 5 月发生的事,一个 2025 年训练完的模型是不可能知道的。
第二个是私有数据盲区。
公司内部的文档、代码仓库、客户资料,这些没出现在训练数据里的东西,模型统统不认识。
解决办法目前有两个,一个是联网搜索,让 Agent 即时获取最新的知识。
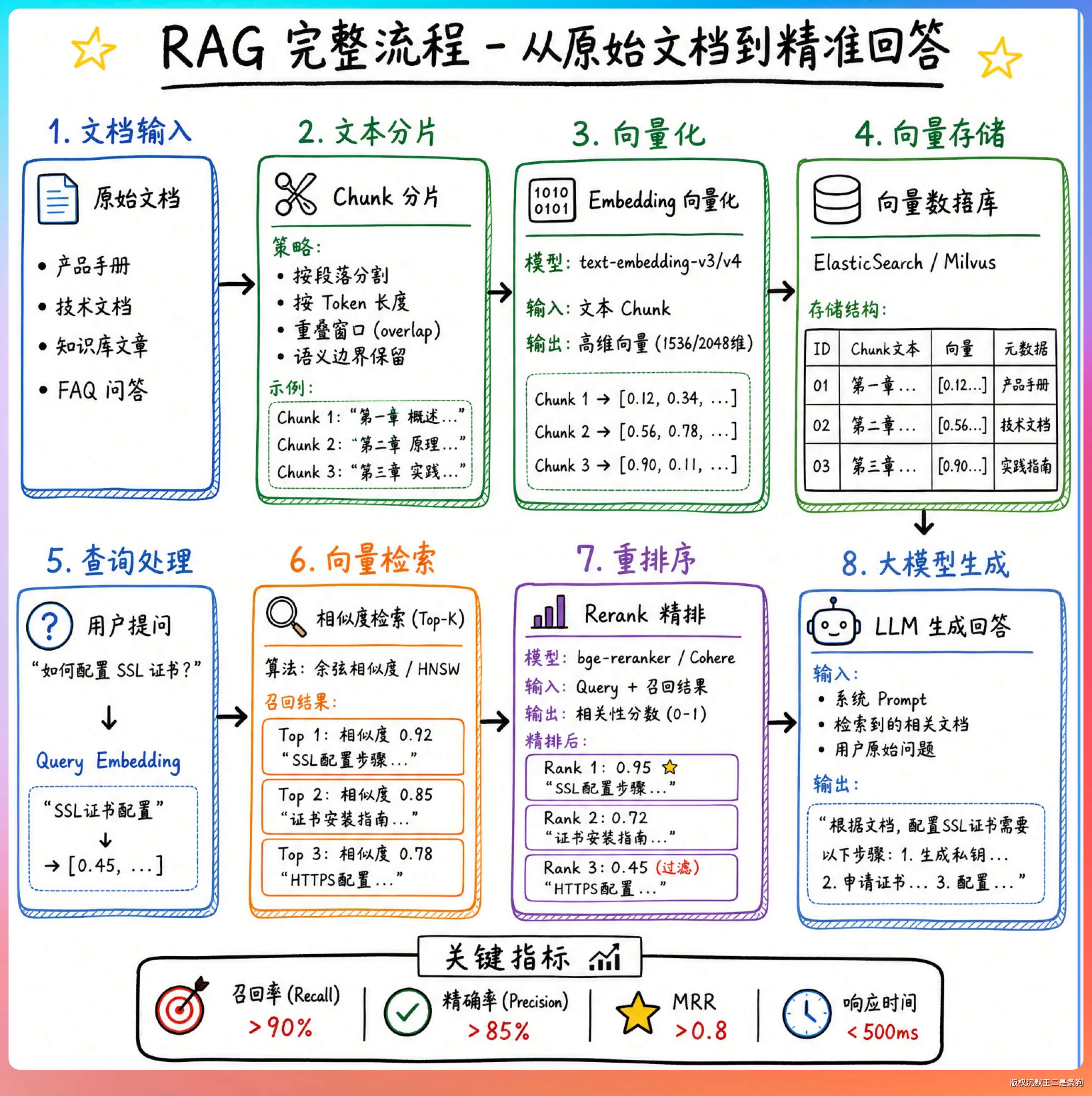
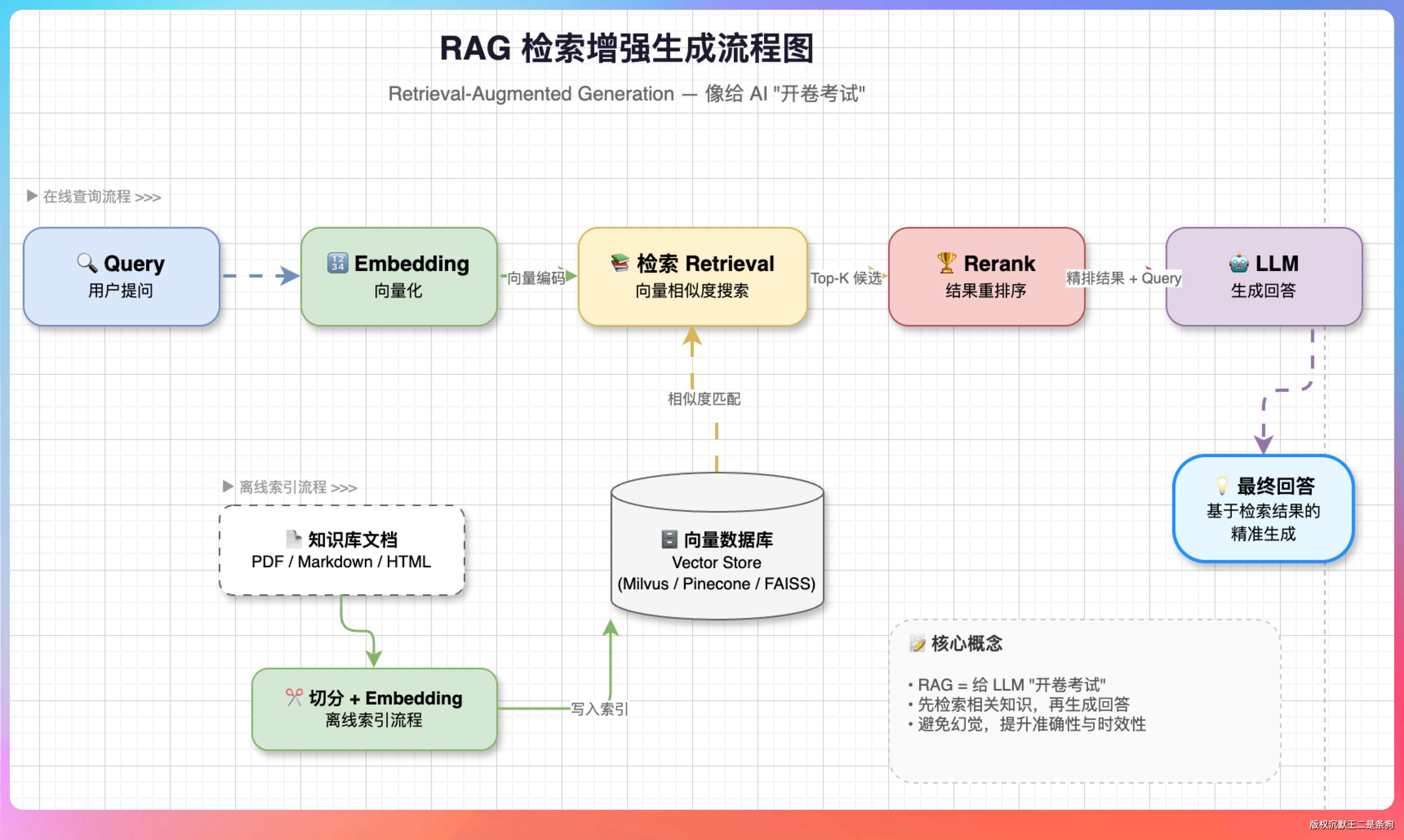
另外一个就是 RAG。思路很简单:问问题之前,先从知识库里把相关的内容检索出来,塞到 LLM 的上下文里,让它"开卷考试"。
这个检索过程的核心技术就是 Embedding。
02、Embedding 是什么?
Embedding 就是把文本变成一组向量,让计算机能用数学方式理解语义。
举个例子,王二是个沙雕和王二很可能不正常,在语义上是完全一样的。
Embedding 做的就是这件事,把这两句话各自变成一个 2048 维的向量(一组 2048 个浮点数),然后通过计算这两个向量之间的余弦相似度,得出它们"有多像"。
向量空间里,语义相近的文本会聚集在一起,语义不同的文本会远离。"苹果手机"和"iPhone"的向量距离很近,而"苹果手机"和"母猪会上树"的向量距离很远。
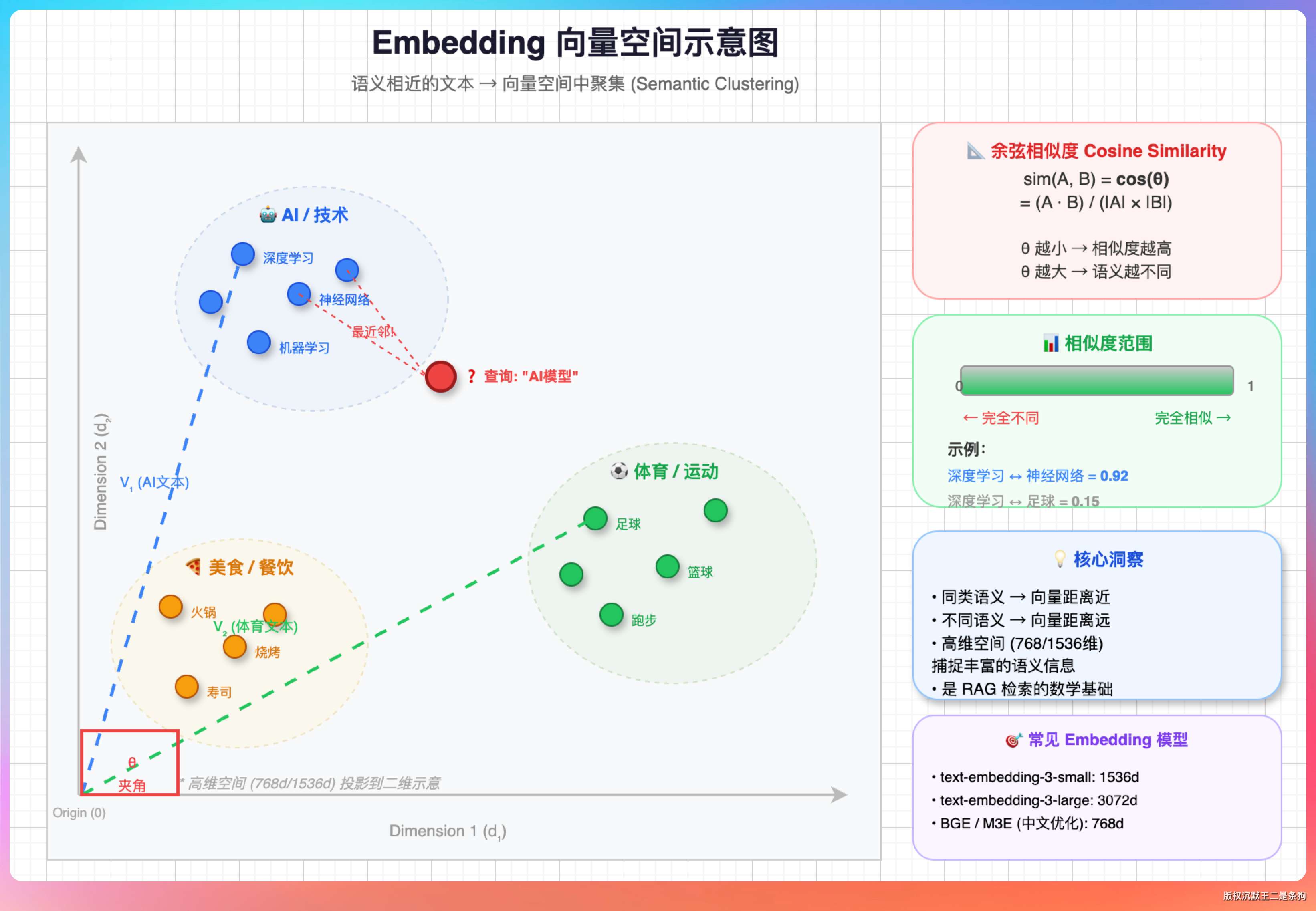
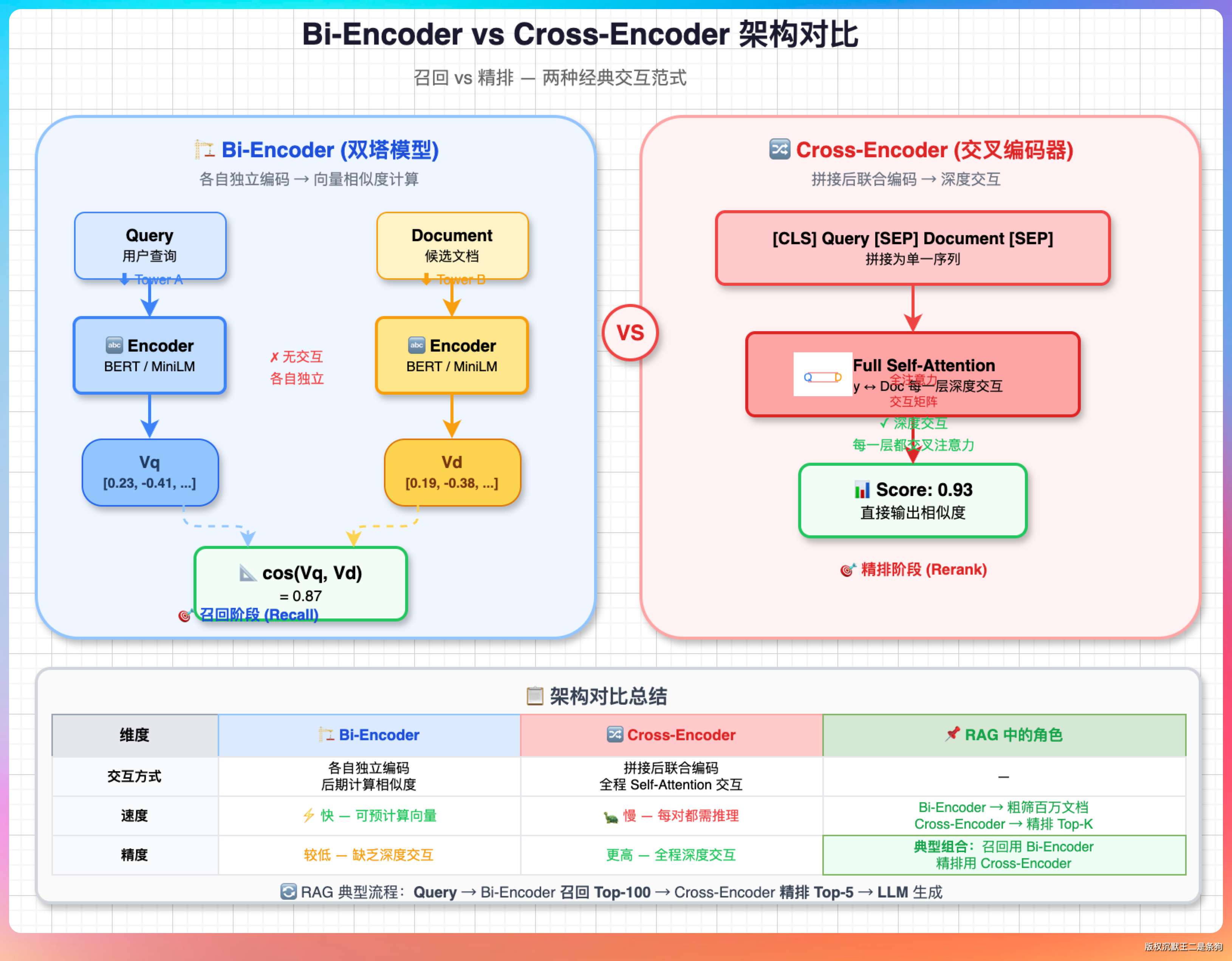
Embedding 模型用的是双塔架构(Bi-Encoder)。
Query 和文档各自独立编码成向量,两边互不干扰。
这种架构有一个巨大的好处:文档的向量可以提前算好存起来,查询的时候只需要算 Query 的向量然后做相似度比较就行了。
几百万条文档的检索,毫秒级完成。
03、如何做好 Chunk?
Embedding 模型有输入长度限制(一般 8192 个 token),不可能把一篇几万字的文档一口气塞进去。所以需要先把文档切成小块(Chunk),每块单独做 Embedding。
Chunk 切得好不好,直接决定了检索质量。
切太大,一个 Chunk 里混了好几个话题,检索的时候会带一堆无关信息。切太小,上下文断裂,LLM 拿到的片段前后不搭。
派聪明(PaiSmart)的分块策略采用了语义感知切分,默认 chunk 大小 512 字符,重叠 100 字符。切分的时候不是机械地按字数截断,而是用 HanLP 做中文分词,尽量在句子边界处切割。
具体来说分了四个层级:
- 第一层先按段落切(双换行符
\n\n) - 第二层如果段落太长就按句子切
- 第三层用 HanLP 分词器在词的边界处切
- 第四层实在没办法了才按字符切。
这样切出来的每个 Chunk 都是语义完整的。
重叠区域(Overlap)也很讲究。派聪明不是简单地取前一个 Chunk 的最后 100 个字符,而是做了语义感知的重叠,用 HanLP 的分词结果找到合适的句子边界,保证重叠部分不会把一个词从中间劈开。
PaiCLI 的分块策略完全不同,因为它处理的是代码而不是文档。
代码有天然的结构,文件、类、方法,这些结构本身就是最好的分块边界。PaiCLI 用 JavaParser 做 AST 解析,把 Java 代码切成三个层级:文件级(整个文件太大时不用)、类级(类声明加上前几行)、方法级(每个方法单独一块)。非 Java 文件按 2000 字符切。
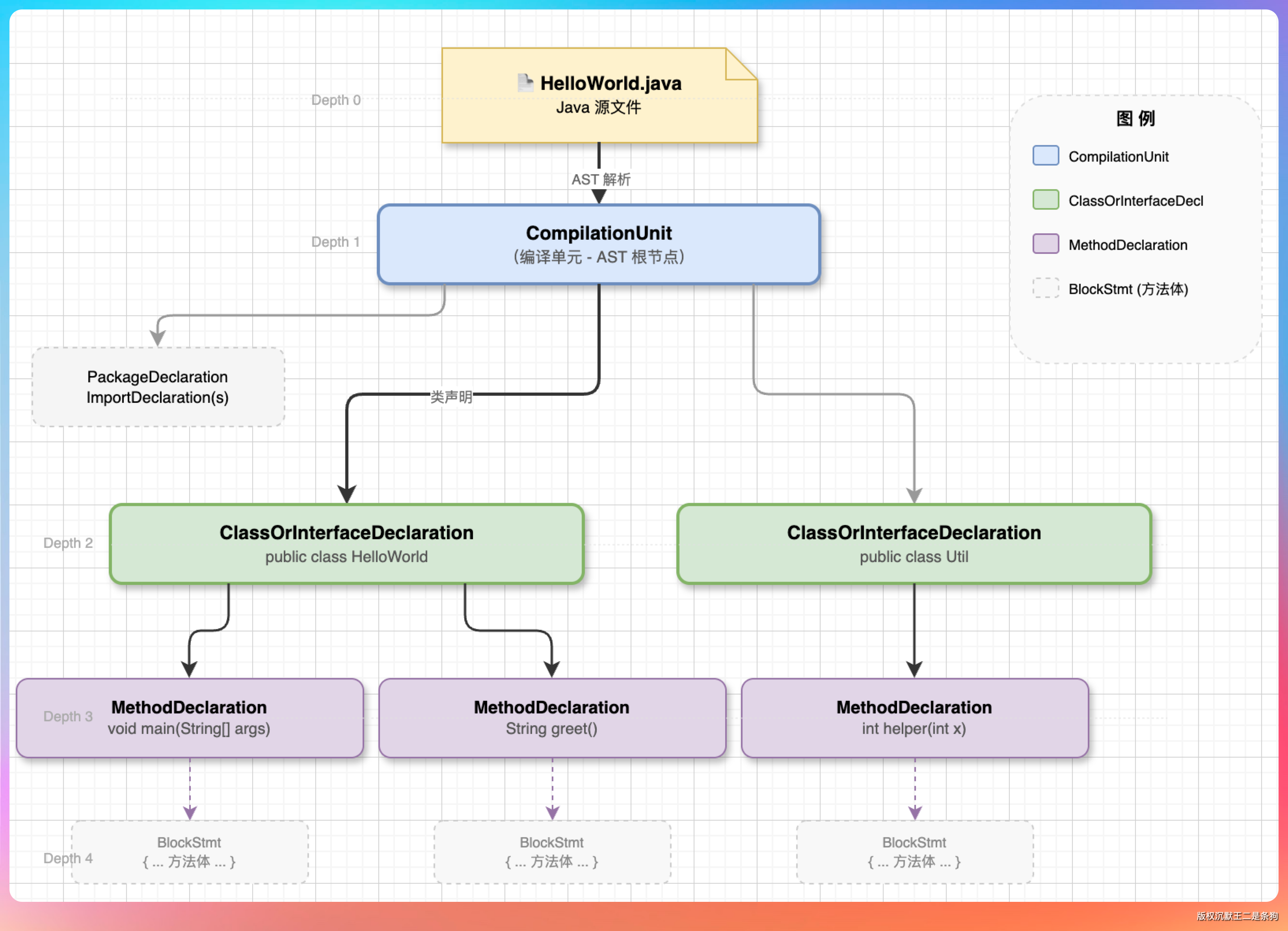
这种基于 AST 的分块比按行数切要精准得多。一个方法就是一个完整的语义单元,不会出现"上半截是 if 判断、下半截是 else 分支"这种割裂的情况。
04、派聪明中的 Embedding
派聪明是我们做的一个 RAG 知识库产品,用户上传文档后可以用自然语言提问,系统从文档中检索相关片段传给 LLM 生成回答。
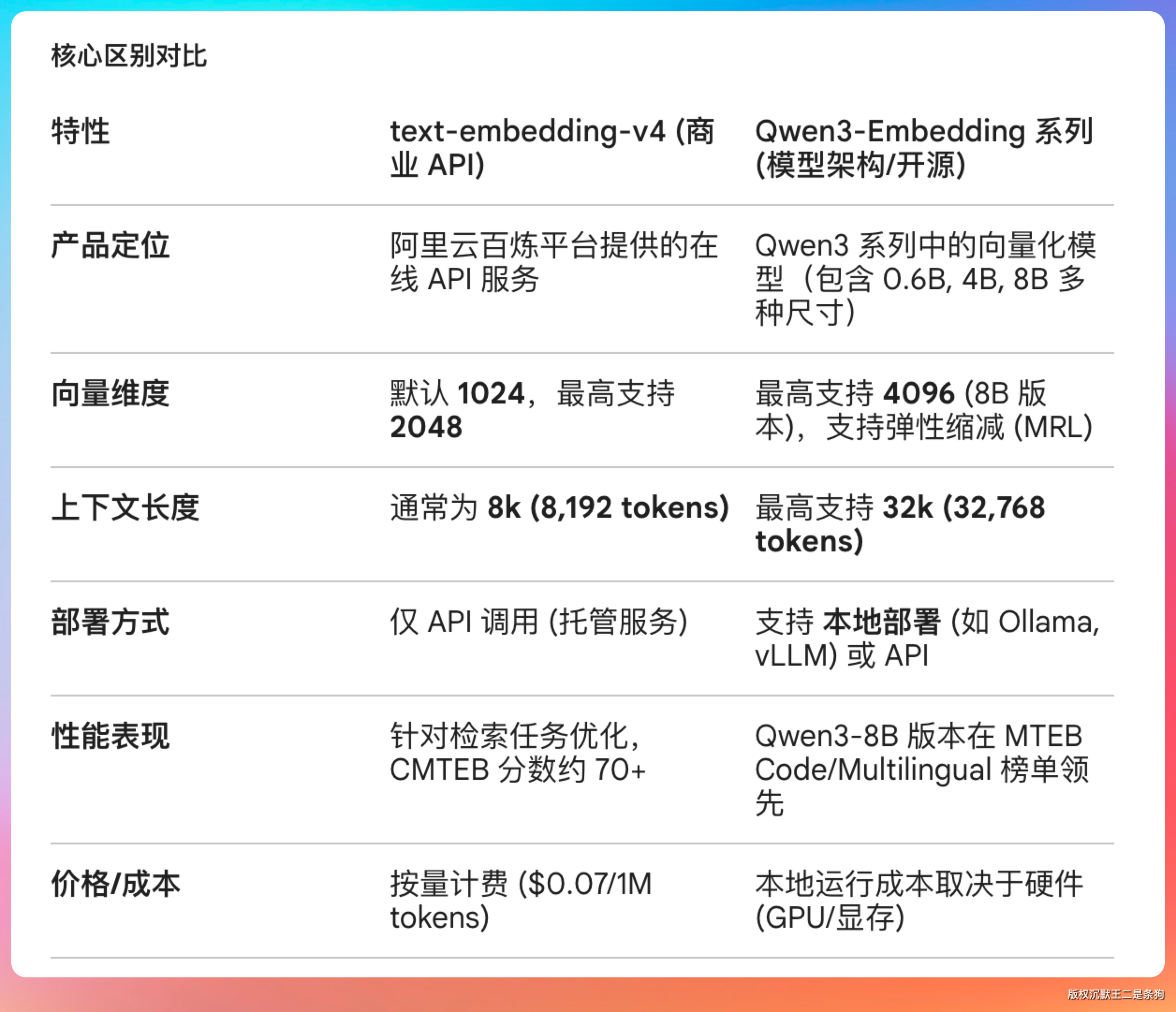
Embedding 这块,派聪明默认用的是阿里千问的 text-embedding-v4 模型,向量维度 2048,通过 OpenAI 兼容接口调用。同时支持切换到智谱的 embedding-3 模型,也是 2048 维。
调用方式是批量的。
EmbeddingClient 会把文本按批次(默认 10 条)发给 API,带有自动重试机制(3 次重试,每次间隔 1 秒),还有速率限制(60 次/分钟)和用量配额跟踪。
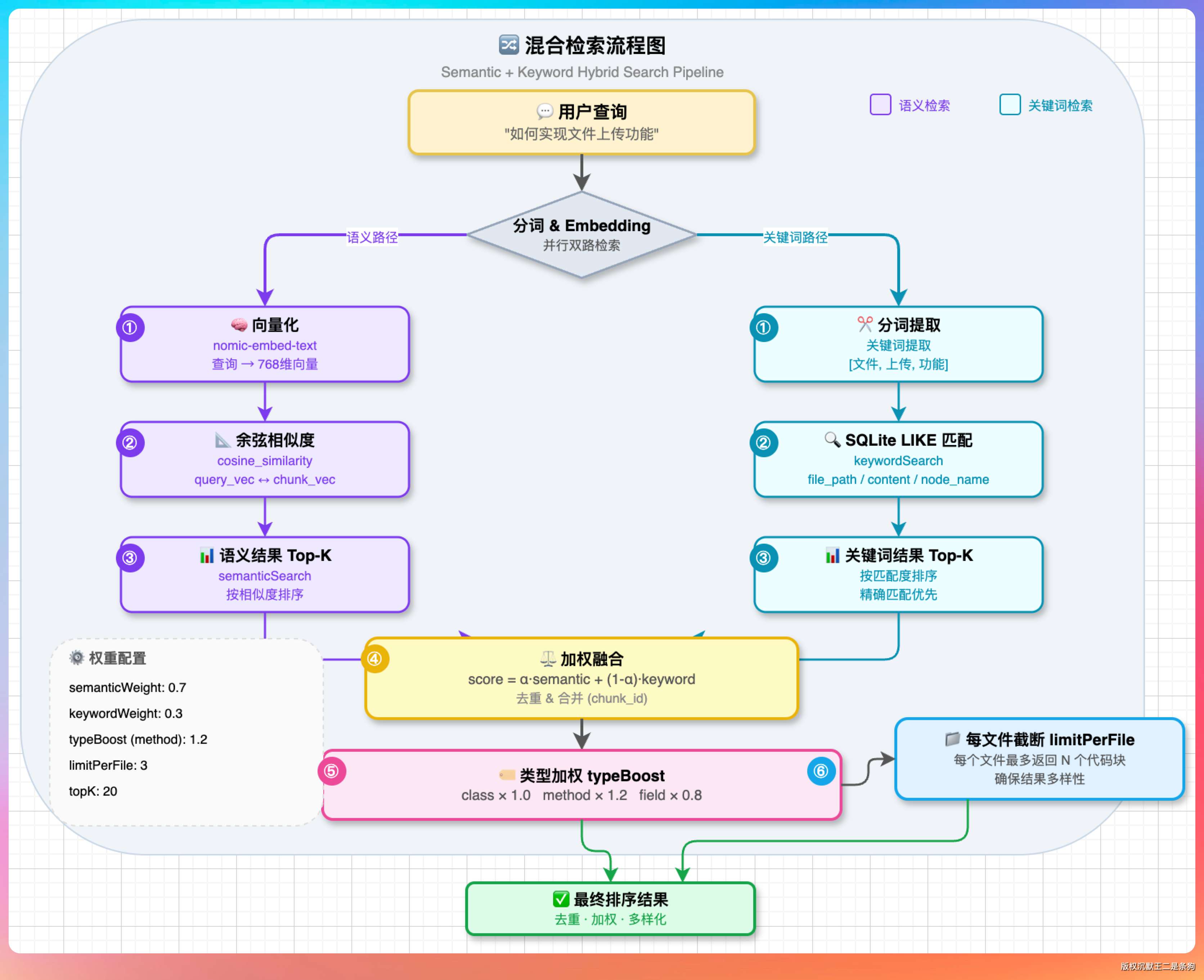
向量存储用的是 Elasticsearch。
每个 Chunk 生成的 2048 维向量存到 ES 的 knowledge_base 索引里,查询时走 KNN 搜索。ES 的好处是天然支持混合检索,可以同时做向量相似度搜索(KNN)和关键词匹配(BM25),两路结果融合排序。
这套混合检索的具体实现在 HybridSearchService 里。
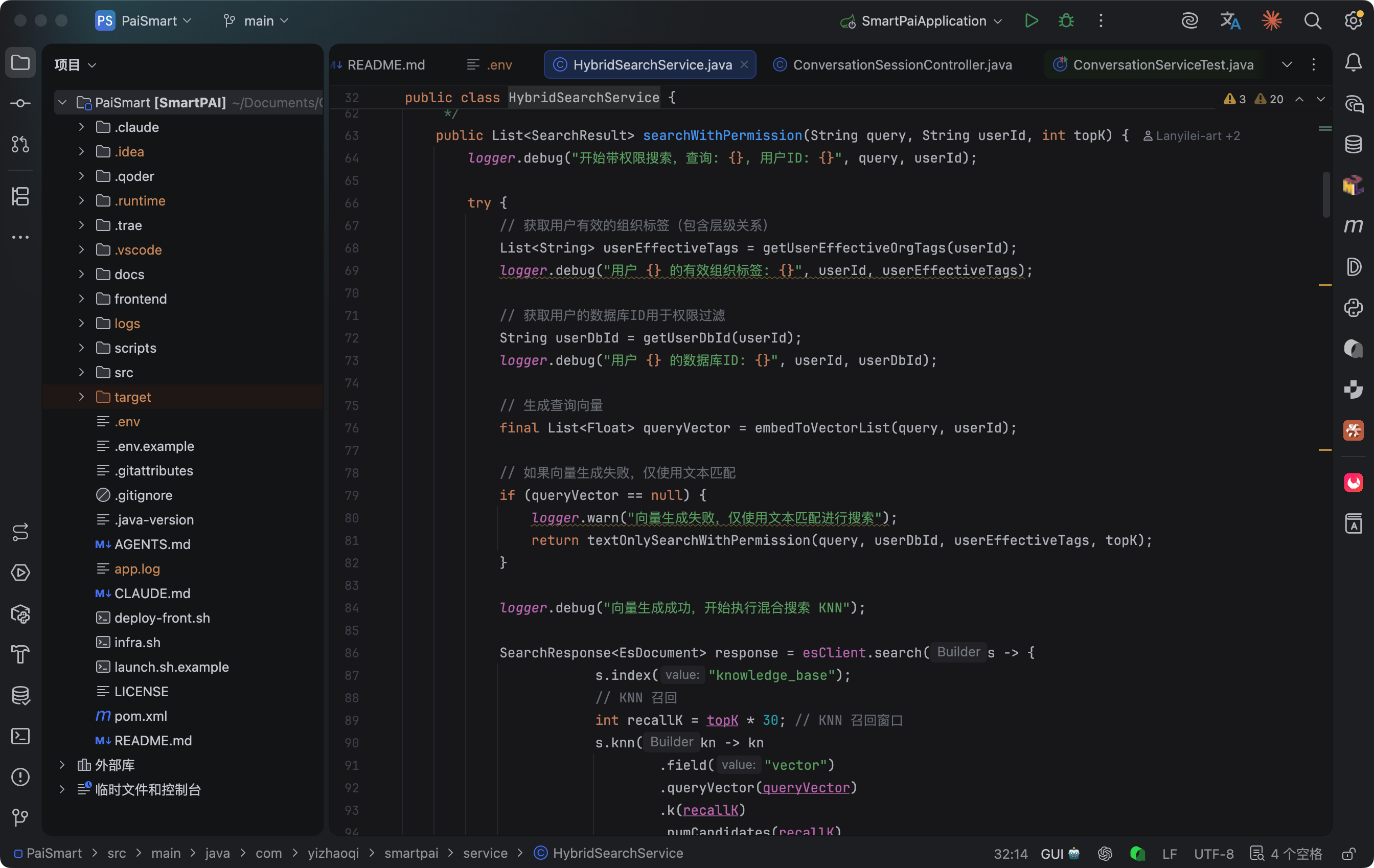
先用 KNN 召回 topK × 30 个候选(比如 topK=5 就召回 150 个),然后用 BM25 做 rescore 重新排序。KNN 的权重设为 0.2,BM25 的权重设为 1.0,也就是说最终排序以关键词匹配为主、语义相似度为辅。
为什么关键词匹配权重这么高?
因为在中文场景下,用户的提问往往包含很明确的关键词(比如"退款流程""审批权限"),这些关键词精确匹配到的文档片段往往就是最相关的。纯语义搜索反而可能被一些"意思差不多但不是在说这件事"的片段干扰。
05、PaiCLI 中的 Embedding
PaiCLI 是我们做的 Agent CLI 工具,内置了代码语义搜索功能。用自然语言描述想找的代码,它就能从整个项目里找到最相关的代码块。
和派聪明不同,PaiCLI 用的是本地 Embedding 模型,通过 Ollama 运行 nomic-embed-text。
使用前需要先索引项目:
> /index
🔍 开始索引: /Users/itwanger/Documents/GitHub/paicli
📁 发现 42 个文件待索引
进度: 10/42 (Main.java)
...
✅ 索引完成:238 个代码块,156 条关系索引完成后就可以用自然语言搜索了:
Agent的ReAct循环是怎么实现的
底层实现是这样的:每个代码块经过 Embedding 后生成一个向量,存在本地的 SQLite 数据库里(JSON 序列化存储)。搜索时把查询文本也做 Embedding,然后遍历所有代码块的向量算余弦相似度,取 topK 个结果。
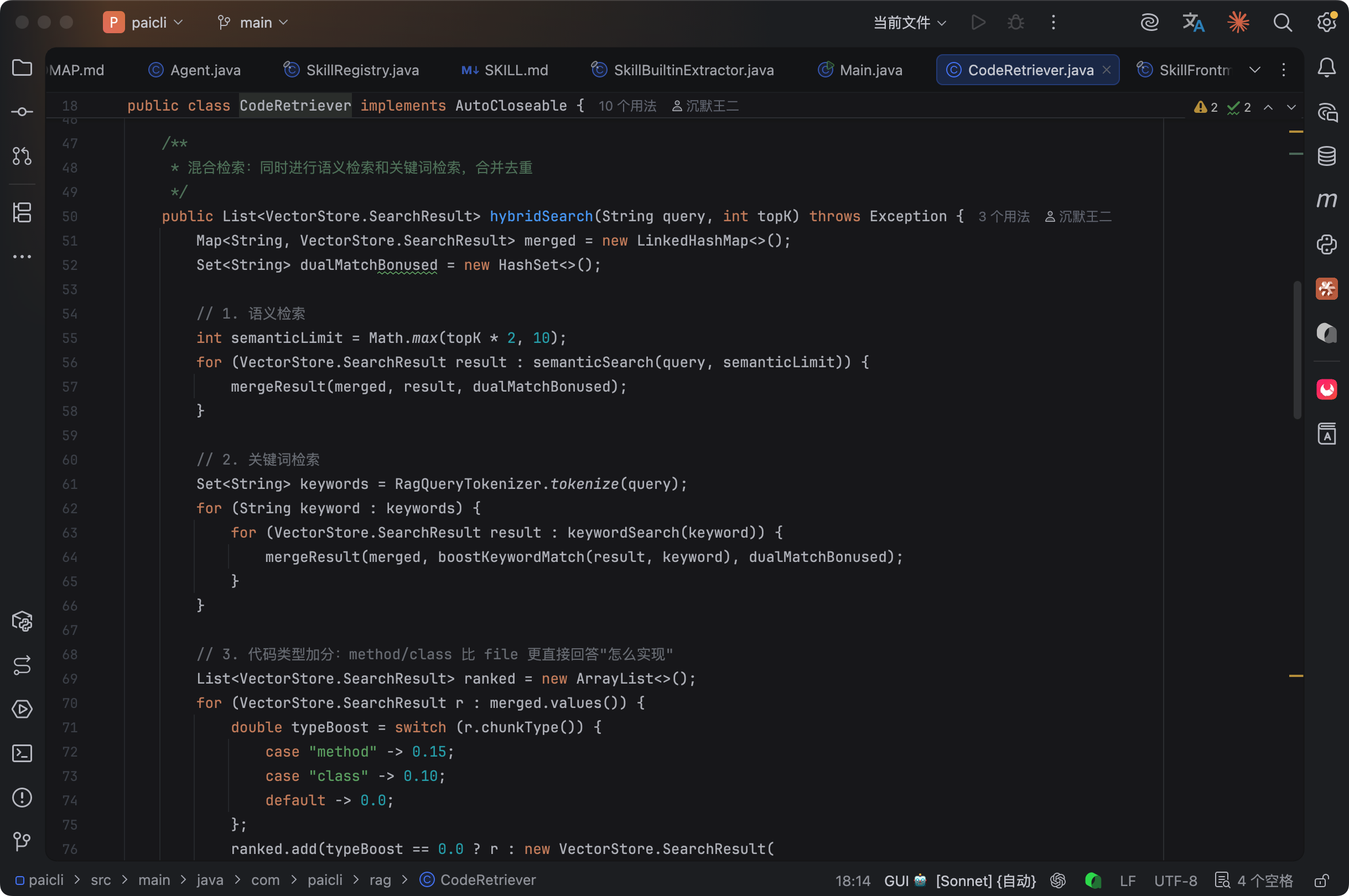
CodeRetriever 里实现了混合搜索,不只是语义搜索,还有关键词搜索加分。如果代码块的类名或方法名里包含查询关键词,给 +0.3 的加分。如果文件路径里包含关键词,给 +0.1。如果是方法级的代码块(最直接的答案),再给 +0.15 的加分。如果语义搜索和关键词搜索都命中了同一个代码块,再给 +0.1 的双匹配奖励。
这套多阶段 Boost 机制虽然没有用专门的 Rerank 模型,但在代码搜索场景下效果很好。因为代码的命名本身就是强语义信号,一个方法叫 runReactLoop,搜"ReAct 循环"的时候关键词直接命中。
06、千问 Embedding
派聪明默认用的千问 text-embedding-v4,聊聊为什么选它。
千问 Embedding 走的是 OpenAI 兼容接口。
2048 维的向量在精度和存储成本之间取得了不错的平衡。维度越高语义表达越丰富,但存储和计算成本也越高。2048 维是目前中文 Embedding 的主流选择。
Qwen3-Embedding 是 text-embedding-v4 的开源版本,在 MMTEB 多语言检索子榜上表现很强。搭配 Qwen3-Reranker-4B 可以组成"高效召回+精准重排"的组合,多轮检索准确率比单一模型提升 15%-20%。
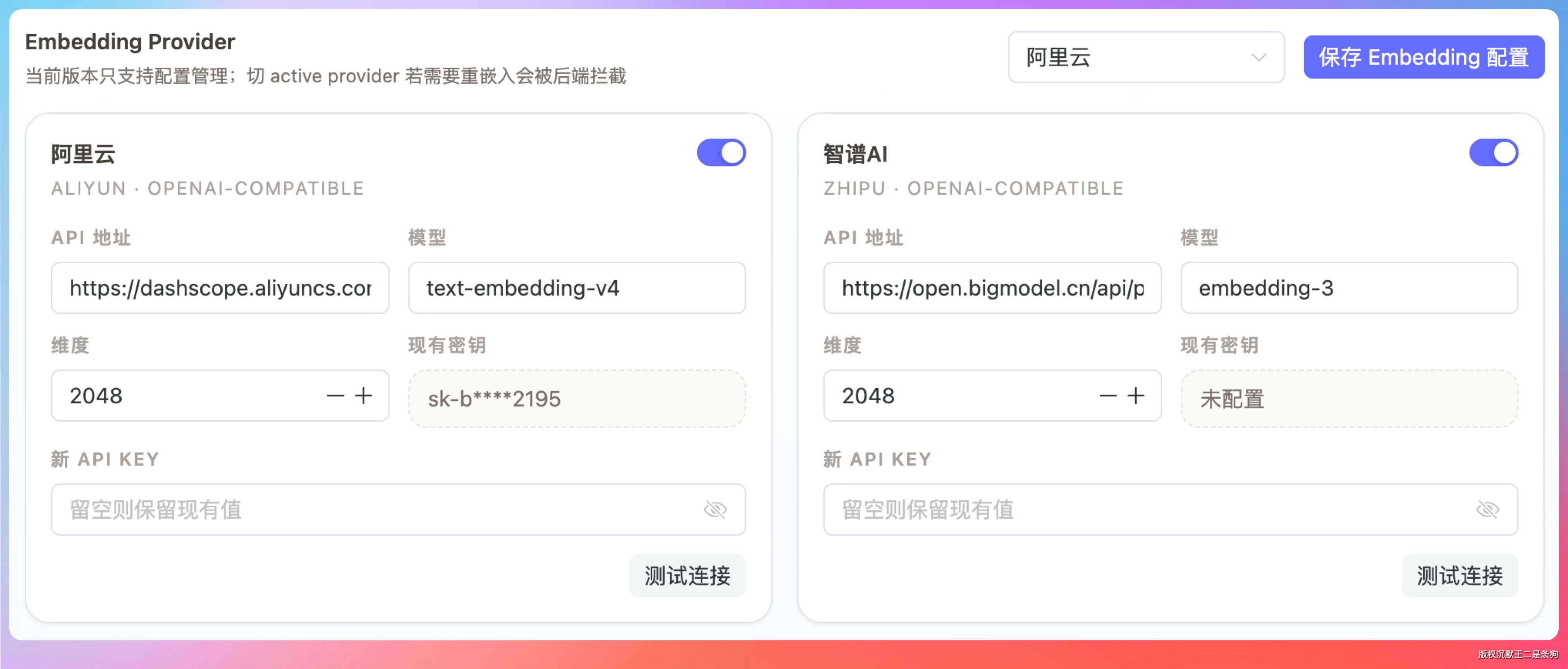
派聪明也支持动态切换 Embedding 提供商。
在 ModelProviderConfigService 里配置了阿里云和智谱 AI 两个选项,运行时可以切换。
但有一点要注意:换了 Embedding 模型之后,原来的向量全部作废,必须对所有文档重新做 Embedding 重建索引。因为不同模型生成的向量处于不同的语义空间,直接混用会导致检索结果乱套。
07、Ollama nomic-embed-text
PaiCLI 选 nomic-embed-text 的原因很简单:免费、本地、快。
nomic-embed-text 是 Nomic AI 开源的 Embedding 模型,Apache 2.0 协议,可以商用。通过 Ollama 一行命令就能跑起来:
ollama pull nomic-embed-text最新的 V2 版本用了 MoE(混合专家)架构,总参数 475M,活跃参数只有 137M,小到可以在 CPU 上跑。支持 Matryoshka 表示学习,向量维度可以从 768 压缩到 256 甚至 64,在损失很小的情况下大幅降低存储成本。
它支持 100 多种编程语言的 Embedding,对代码场景的支持比通用文本模型好不少。PaiCLI 选它就是看中了这个代码理解能力。
不过 nomic-embed-text 有一个局限:长文本性能会下降。根据 Milvus 的评测(2026 年),超过 4000 字符(约 1000 个 token)后检索质量明显降低。PaiCLI 做了对应的处理,把每个 Chunk 的输入限制在 2000 字符以内。
如果场景需要更强的长文本能力,可以通过环境变量切换到 OpenAI 或者智谱的 Embedding 模型:
EMBEDDING_PROVIDER=openai
EMBEDDING_MODEL=text-embedding-3-large
EMBEDDING_BASE_URL=https://api.openai.com/v1
EMBEDDING_API_KEY=sk-xxx08、Embedding 和 Rerank 的区别?
这是很多小伙伴容易搞混的两个概念。
Embedding 负责召回,从几十万条文档里快速找出 top-50 个可能相关的片段。速度是第一优先级,毫秒级完成。
Rerank 负责精排,从 Embedding 召回的 top-50 里精选出真正最相关的 top-5 传给 LLM。精度是第一优先级,可以慢一点。
架构上两者完全不同。
Embedding 用的是 Bi-Encoder(双塔模型),Query 和文档各自独立编码。Rerank 用的是 Cross-Encoder(交叉编码器),把 Query 和候选文档拼在一起联合输入模型,让模型看到两者之间的细粒度交互。
打个比方。
Embedding 像是在图书馆用搜索系统搜关键词,几秒钟找出 50 本可能相关的书。Rerank 像是把这 50 本书都拿到桌上,一本本翻开目录和摘要,挑出真正和问题最相关的 5 本。搜索系统很快但不一定准,人工挑选很准但很慢。
目前主流的 Rerank 模型有 jina-rerank-v3(Jina AI 出品,专为 Agentic-RAG 优化)、Qwen3-Reranker-4B(阿里千问,中文语义理解精度领先,MMTEB-R 72.74)、bge-reranker-v2-m3(智源 BAAI,量化后不到 200MB,适合边缘部署)。
派聪明目前没有用独立的 Rerank 模型,而是用 Elasticsearch 的 BM25 rescore 来做重排序。KNN 先召回候选,BM25 再根据关键词匹配重新打分。
这种方式在中文场景下效果不错,但如果要进一步提升精度,下一步计划接入 Qwen3-Reranker。
PaiCLI 用的是多阶段 Boost 机制来替代 Rerank,在代码搜索场景下足够用了。
09、中文如何做 Embedding?
中文没有天然的空格分词,一个"苹果"到底是水果还是手机品牌,需要上下文才能判断。
通用的多语言模型对中文的语义捕捉能力明显弱于专门训练过的中文模型。
选中文 Embedding 模型,首先看 MTEB(Massive Text Embedding Benchmark)的中文检索子榜 CMTEB-R。这是 HuggingFace 上专门评估 Embedding 模型检索能力的排行榜,按语言和任务类型细分。
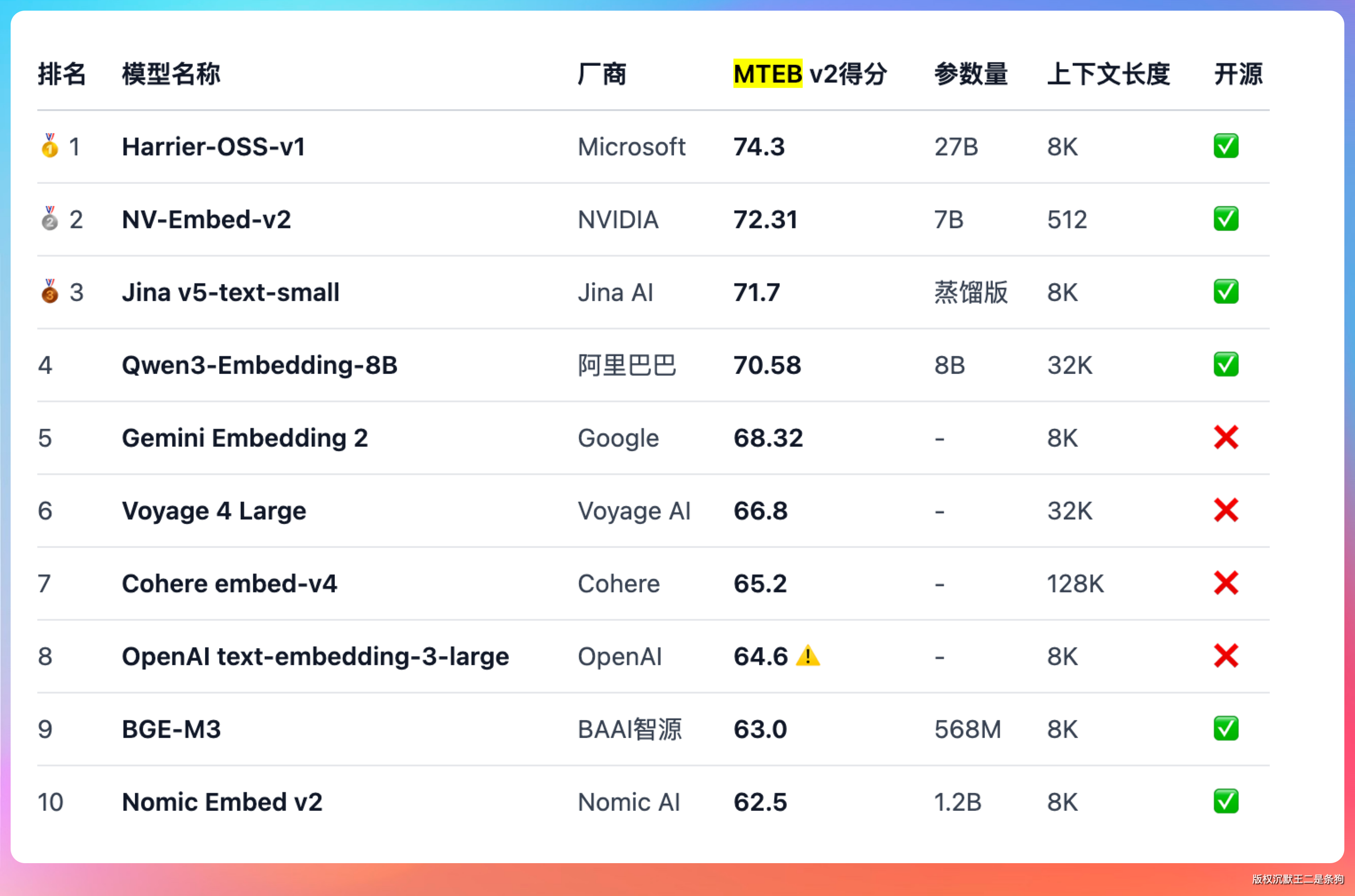
目前在开源中文 Embedding 模型里,Qwen3-Embedding 表现非常不错。
10、Code 如何做 Embedding?
代码和自然语言差别很大。自然语言的语义在句子里,代码的语义在结构里。
PaiCLI 的做法是先用 AST 把代码拆成有意义的结构单元,再对每个单元做 Embedding。CodeChunk 有一个 toEmbeddingText() 方法,会在代码内容前面加上类型标注:
[method:Agent.runReactLoop()] ReAct 循环:读取用户输入...这个 [method:Agent.runReactLoop()] 前缀很关键。它告诉 Embedding 模型"这是一个方法,名字叫 runReactLoop",让模型更好地理解代码块的角色。
除了代码块本身,PaiCLI 还会提取代码之间的关系:extends(继承)、implements(实现)、imports(导入)、calls(调用)、contains(包含)。
这些关系存在 SQLite 的 code_relations 表里,搜索时可以用来做关系图扩展。找到一个类之后,顺着关系图把它的父类、实现的接口、调用的方法也拉出来。
对于代码 Embedding 模型的选择,Nomic 专门出了一个 Nomic Embed Code,支持 100 多种编程语言,比通用的 text embedding 模型在代码检索任务上表现好不少。Jina 也有一个 Jina Code V2 专门做代码 Embedding。
11、面试题快问快答
准备 AI 面试的小伙伴,这 10 道题覆盖了 Embedding 和 Rerank 的核心知识点。
Q1:Embedding 和 Rerank 的区别是什么?
Embedding 用 Bi-Encoder 双塔架构做召回,Query 和文档独立编码成向量,速度快但精度一般。
Rerank 用 Cross-Encoder 交叉编码器做精排,Query 和文档拼在一起联合编码,精度高但速度慢。
RAG 系统里一般先 Embedding 召回 top-50,再 Rerank 精排出 top-5。
Q2:top-K 怎么选?
Embedding 召回的 top-K 不是越大越好。
K 太小容易漏掉正确答案,K 太大会引入噪音拉低 Rerank 的精度。
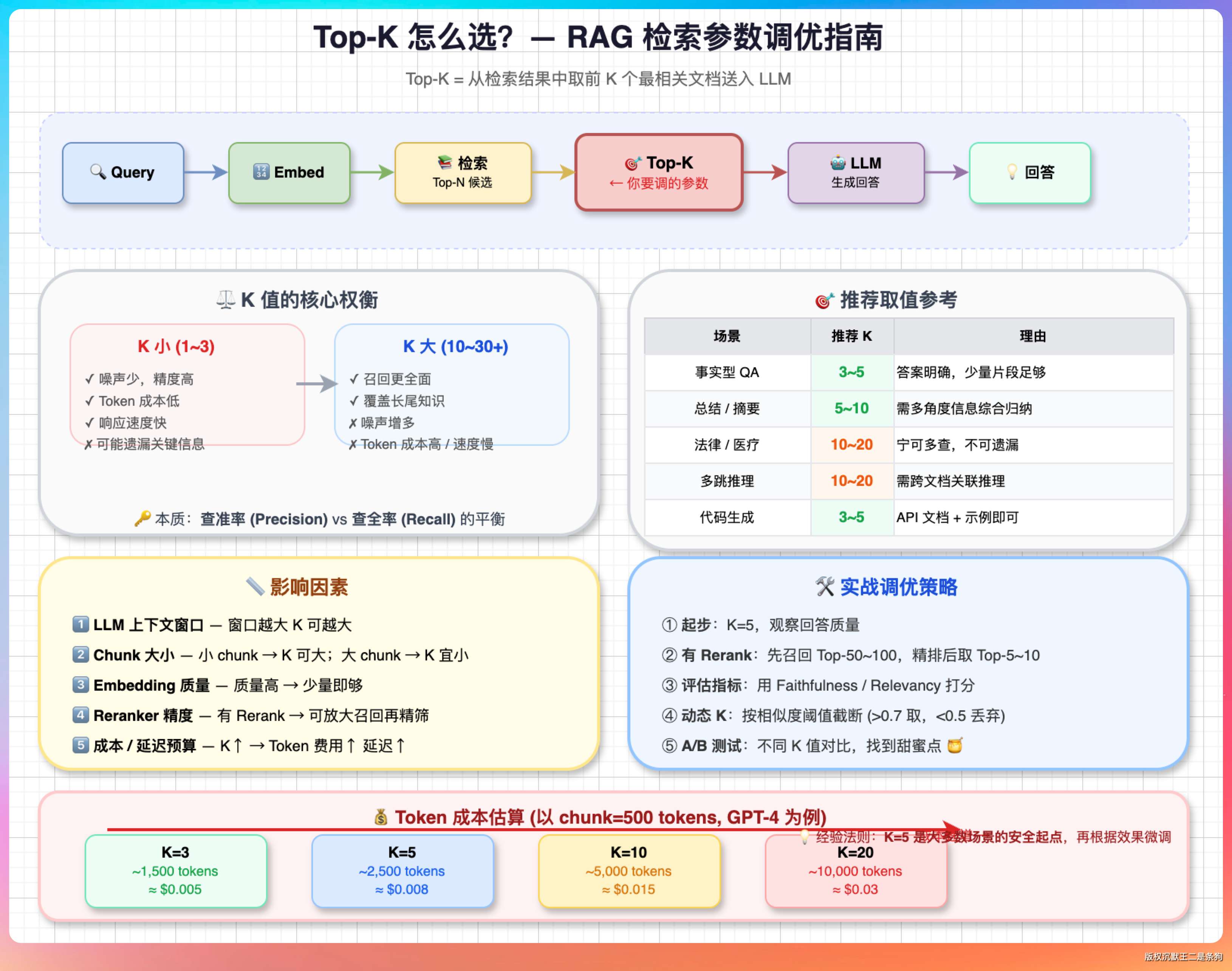
一般经验是:有 Rerank 的情况下 K=20-50,没有 Rerank 的情况下 K=5-10。派聪明设的是 topK × 30 做召回窗口,然后 BM25 rescore 重排后取 topK 个。
Q3:Rerank 模型的打分机制是什么?
Cross-Encoder 把 Query 和文档拼成一个输入 [CLS] query [SEP] document [SEP],模型输出一个 0-1 之间的相关性分数。
这个分数是模型看到 Query 和文档全部内容后给出的,比 Embedding 的余弦相似度更可靠。
Q4:Chunk 大小怎么定?
需要在检索粒度和上下文完整性之间平衡。一般 300-800 字符比较合适,加上 50-150 字符的重叠区域。
派聪明用 512 + 100 overlap,PaiCLI 用方法级切分(天然的语义边界)。
Q5:为什么换了 Embedding 模型要重建索引?
不同模型生成的向量处于不同的语义空间。
模型 A 觉得"苹果"和"水果"的向量距离是 0.1,模型 B 可能觉得是 0.5。如果索引里的向量用 A 生成的,查询向量用 B 生成的,余弦相似度的计算结果没有意义。
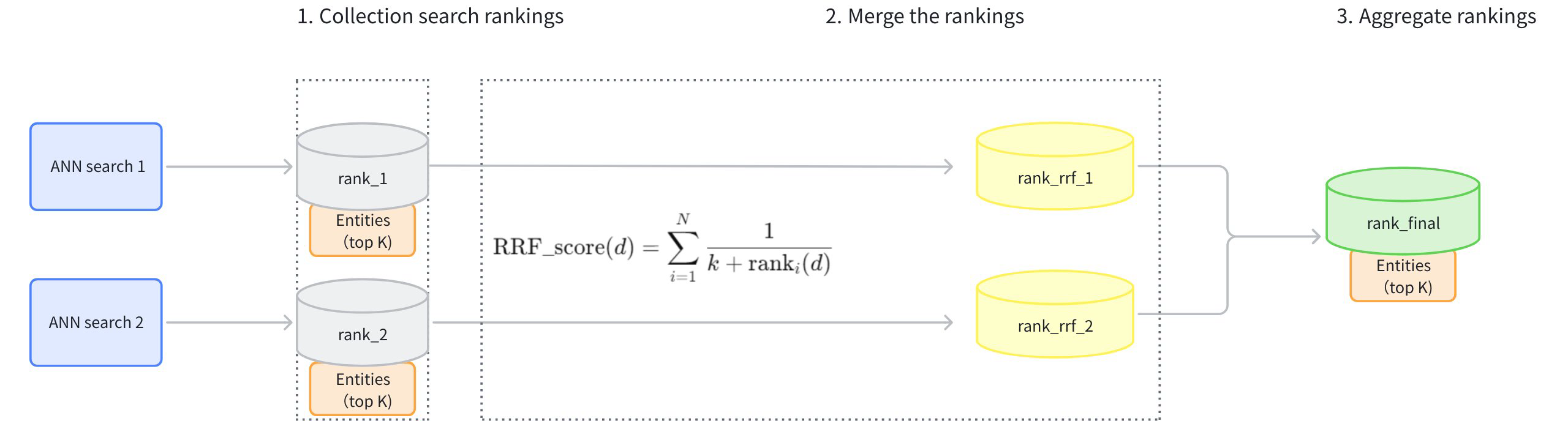
Q6:混合检索怎么做?
向量检索(KNN)和关键词检索(BM25)同时跑,两路结果融合排序。
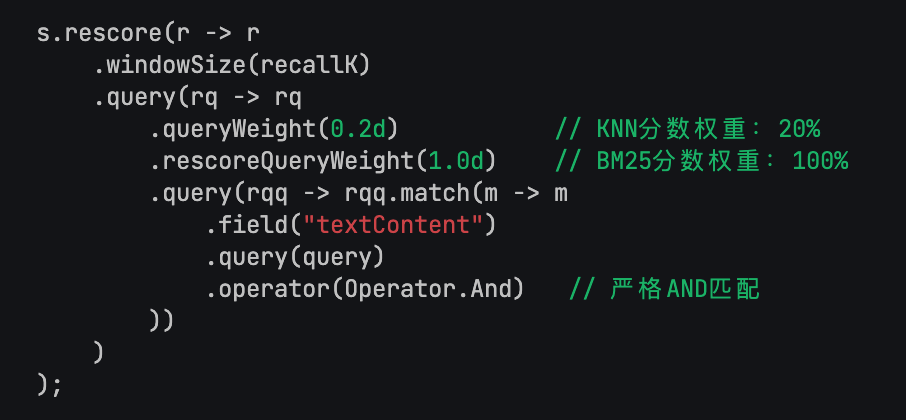
常见的融合方式有加权求和(派聪明:KNN 权重 0.2 + BM25 权重 1.0)和 RRF(Reciprocal Rank Fusion)。
Q7:中文 Embedding 有什么特殊考虑?
中文没有空格分词,通用多语言模型对中文的语义捕捉弱于专门训练的模型。选模型看 MTEB 中文检索子榜(CMTEB-R),目前 Qwen3-Embedding 表现很好。分块阶段要用中文分词器保证 Chunk 边界。
Q8:代码 Embedding 和文本 Embedding 有什么不同?
代码的语义在结构里(类名、方法名、调用关系),文本的语义在句子里。
代码 Embedding 最好先做 AST 解析,按结构单元切分,然后在 Embedding 输入里加上结构类型标注(比如 [method:xxx])。专用代码 Embedding 模型(Nomic Embed Code、Jina Code V2)比通用模型效果好。
Q9:Embedding 的向量维度怎么选?
维度越高语义表达越丰富,但存储和计算成本也越高。目前主流选择:768(轻量级,适合本地部署)、1024-1536(平衡型)、2048-3072(高精度,适合企业级 RAG)。
Q10:什么时候该加 Rerank,什么时候不需要?
当发现 Embedding 召回的 top-50 里有正确答案但 top-5 里没有,说明需要 Rerank。
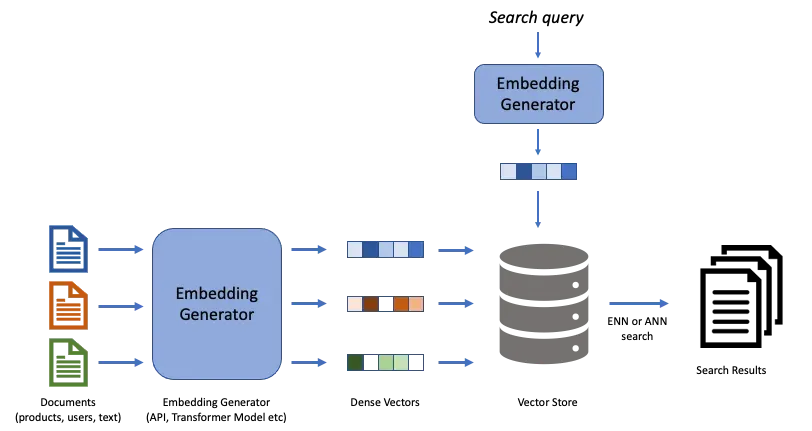
如果文档量不大(几百到几千个 Chunk),或者查询关键词非常明确(比如搜代码的类名方法名),Embedding + 关键词加分就够了,不需要额外的 Rerank 模型。