老板下了死命令:限你一天,把RAG升级成Agent,我反抗后无效,只能掏出Claude Code+DeepSeek猛猛干
大家好,我是二哥呀。
假期刚完,老板就下了死命令:“派聪明现在只能 RAG 问答,你现在立刻马上给它升级成 Agent,要能自己 tool use、自己 ReAct 那种。限你一天。”
一天?我立马就甩脸色:一天?你当 Agent 是装个插件就搞定的事?
但反抗无效(😭)。
老板不懂技术,只知道市面上“Agent”满天飞,所有的项目都必须和 Agent 挂钩。
我真笑嘻嘻了。
好在我之前肝了一个类似 Claude Code 的 Agent 项目,名叫 PaiCLI。这玩意从第 1 期的 ReAct 循环,到现在第 10 期能连上 Chrome Devtools MCP。
已经是一个完整的 Agent CLI 产品,里面的工具调用、决策循环、记忆管理、MCP 集成全部跑通了。
掏出 Claude Code + DeepSeek V4,开干。
跟着做的小伙伴,需要提前准备好 Claude Code + Opus 4.7(或者 Codex + GPT-5.5 也行,或者Claude Code + GLM-5.1)。
给派聪明RAG加上 ReAct+tool use,代码已经提交到gitcode,球友们可以直接用了。
01、派聪明 RAG 是什么?
派聪明是一个 RAG 知识库,Spring Boot 3.4 + Elasticsearch 8.10 + DeepSeek API。核心流程就四步:用户提问 → 混合检索 → 拼装上下文 → 大模型生成回答。
整个问答入口在 ChatHandler.java,关键方法是 processMessage:
public void processMessage(String userId, String userMessage,
WebSocketSession session) {
// 1. 拿到对话历史
List<Map<String, String>> history = getConversationHistory(userId);
// 2. 混合检索:向量相似度 + BM25 关键词
List<SearchResult> results = hybridSearchService
.searchWithPermission(userMessage, userId, 5);
// 3. 把检索结果拼成上下文
String context = buildContext(results);
// 4. 调 DeepSeek 生成回答,流式返回
deepSeekClient.streamResponse(userId, userMessage, context,
history, chunk -> sendToWebSocket(session, chunk));
}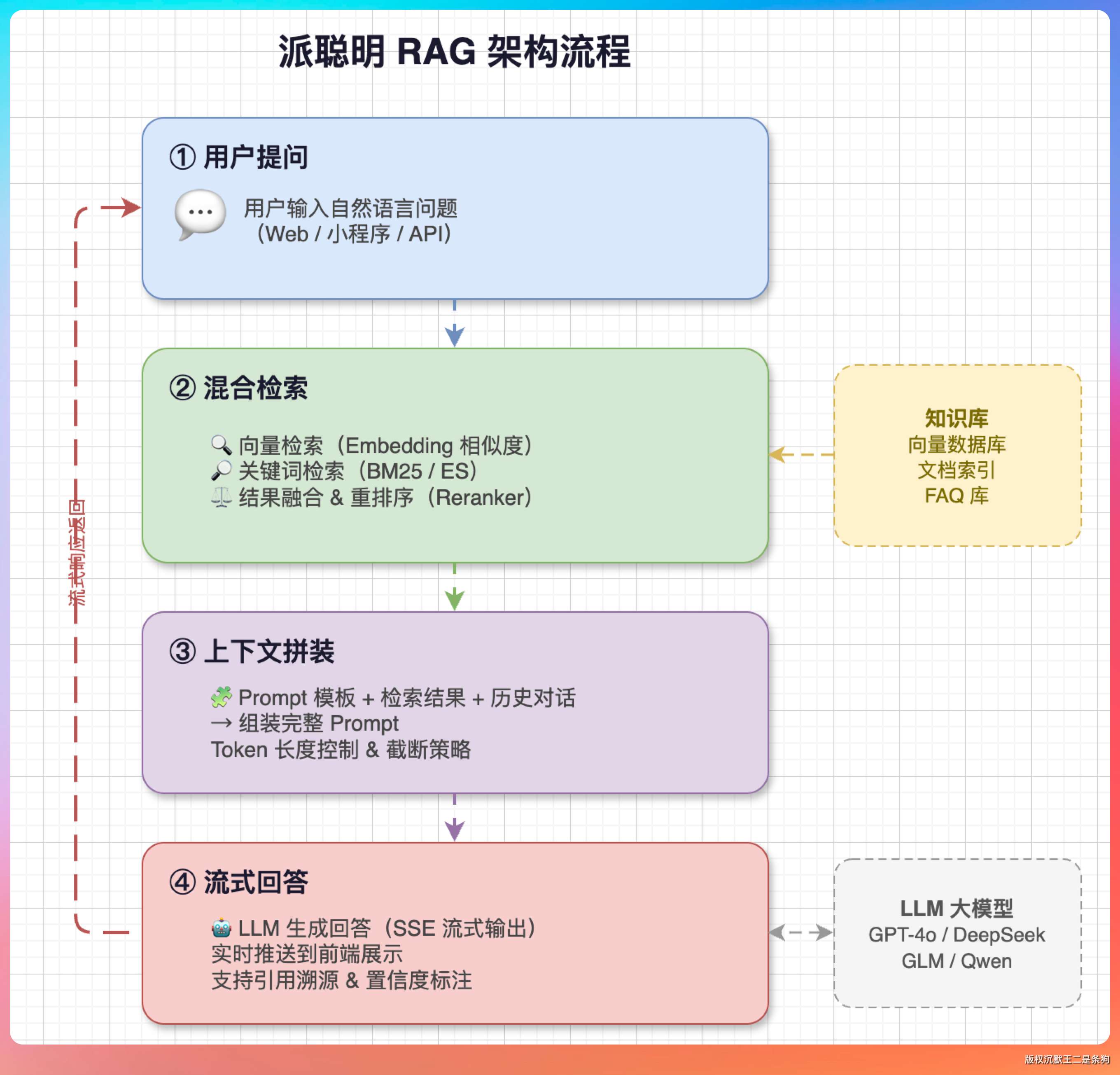
检索用的是 HybridSearchService,策略是先用 KNN 向量搜索拉 30 倍候选集,再用 BM25 重打分,最后做权限过滤:
public List<SearchResult> searchWithPermission(String query,
String userId, int topK) {
// KNN 向量搜索(30x 候选窗口)+ BM25 重打分
SearchResponse response = elasticClient.search(s -> s
.index("knowledge_chunks")
.knn(k -> k.field("embedding").queryVector(embedQuery(query))
.numCandidates(topK * 30).k(topK * 5))
.query(q -> q.bool(b -> b
.should(textMatch(query))
.filter(permissionFilter(userId))
)),
SearchResult.class
);
return parseResults(response, topK);
}在没有升级 Agent 之前,用户说“帮我把知识库里关于 Spring AI 的文档整理成一份摘要”,派聪明只能做一次检索然后把原文片段返回给用户,不能进一步判断“检索到了多少篇,要不要合并整理成结构化摘要”。
这就是 RAG 和 Agent 的根本区别:RAG 是被动问答;Agent 是主动决策加执行,能自己动手干活。
02、给 RAG 加上工具调用
升级的第一步,让系统能调用工具去执行操作。
原理很简单:给大模型配一组 Tool(工具),每个 Tool 定义好名称、功能描述、输入参数。大模型接收到用户的问题之后,先判断“这个问题是应该检索知识库回答,还是应该调用某个工具来执行”。
PaiCLI 的 ToolRegistry 已经把这套模式跑通了,我们直接参考它的注册方式:
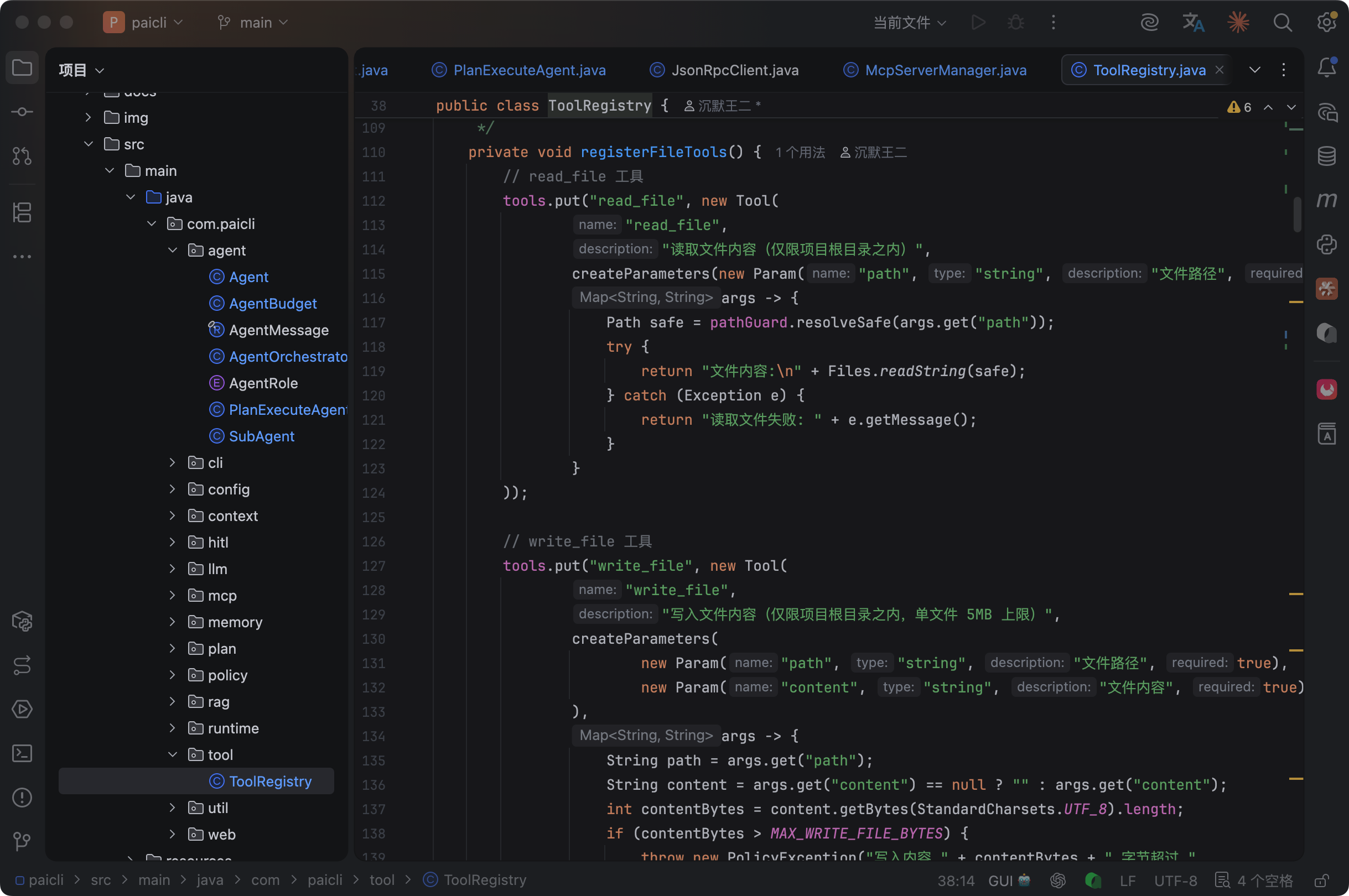
大模型要根据描述来判断该不该调用这个 Tool,所以描述的质量直接决定了 Agent 的决策准确率。描述写得含糊,大模型就可能选错工具。
在派聪明的基础上,我们需要注册这几个 Tool:
知识库文档搜索 Tool:跟现在的 RAG 检索功能一样,但包装成了 Tool 的形式让 Agent 按需调用。
tools.put("search_knowledge", new Tool(
"search_knowledge",
"在知识库中搜索相关文档片段,返回最匹配的结果",
createParameters(
new Param("query", "string", "搜索关键词", true),
new Param("topK", "integer", "返回结果数量,默认5", false)
),
args -> {
int topK = args.containsKey("topK") ?
Integer.parseInt(args.get("topK")) : 5;
List<SearchResult> results = hybridSearchService
.searchWithPermission(args.get("query"), currentUserId, topK);
return formatSearchResults(results);
}
));摘要生成 Tool:对检索到的多篇文档片段生成结构化摘要,这是一个典型的“需要多步协作”的 Tool,先搜索,再总结。
答案反馈 Tool:用户对回答质量的评价会存入 Redis,后续可以用来调整检索权重和 Prompt 策略。
知识库统计 Tool 的逻辑类似,就不贴完整代码了。
理解了原理之后,直接上 Claude Code/Codex。在 PaiSmart 项目根目录下执行:
在派聪明项目中新建 AgentToolRegistry 类,注册 4 个 Tool:
1. search_knowledge:
- 描述:"在知识库中搜索与用户问题相关的文档片段,仅在用户明确需要查询知识库内容时调用"
- 参数:query(string, 必填), topK(integer, 可选, 默认5)
- 执行逻辑:调用现有的 HybridSearchService.searchWithPermission(),格式化返回结果
2. generate_summary:
- 描述:"对指定主题的知识库文档生成结构化摘要,适合用户要求整理、总结、归纳时调用"
- 参数:topic(string, 必填), maxDocs(integer, 可选, 默认5)
- 执行逻辑:先调用 HybridSearchService 检索相关文档,再调用 DeepSeekClient.summarize() 生成摘要
3. submit_feedback:
- 描述:"当用户对回答表示满意或不满意时调用,记录用户反馈用于优化后续回答质量"
- 参数:rating(string, 必填, good/bad), reason(string, 可选)
- 执行逻辑:写入 Redis Hash,key 为 feedback:{userId},field 为时间戳,value 为评价+原因
4. knowledge_stats:
- 描述:"返回当前知识库的统计信息,包括文档总数、片段总数、最近更新时间"
- 参数:无
- 执行逻辑:查询 Elasticsearch 的 index stats + MySQL 的 document count
注意:
- Tool 的描述要从大模型理解的角度写,避免模糊描述导致误调用
- generate_summary 内部会二次调用大模型做总结,注意和外层 ReAct 循环的调用区分开
这一步完成之后,派聪明就从“只能回答问题”变成了“能主动干活”。
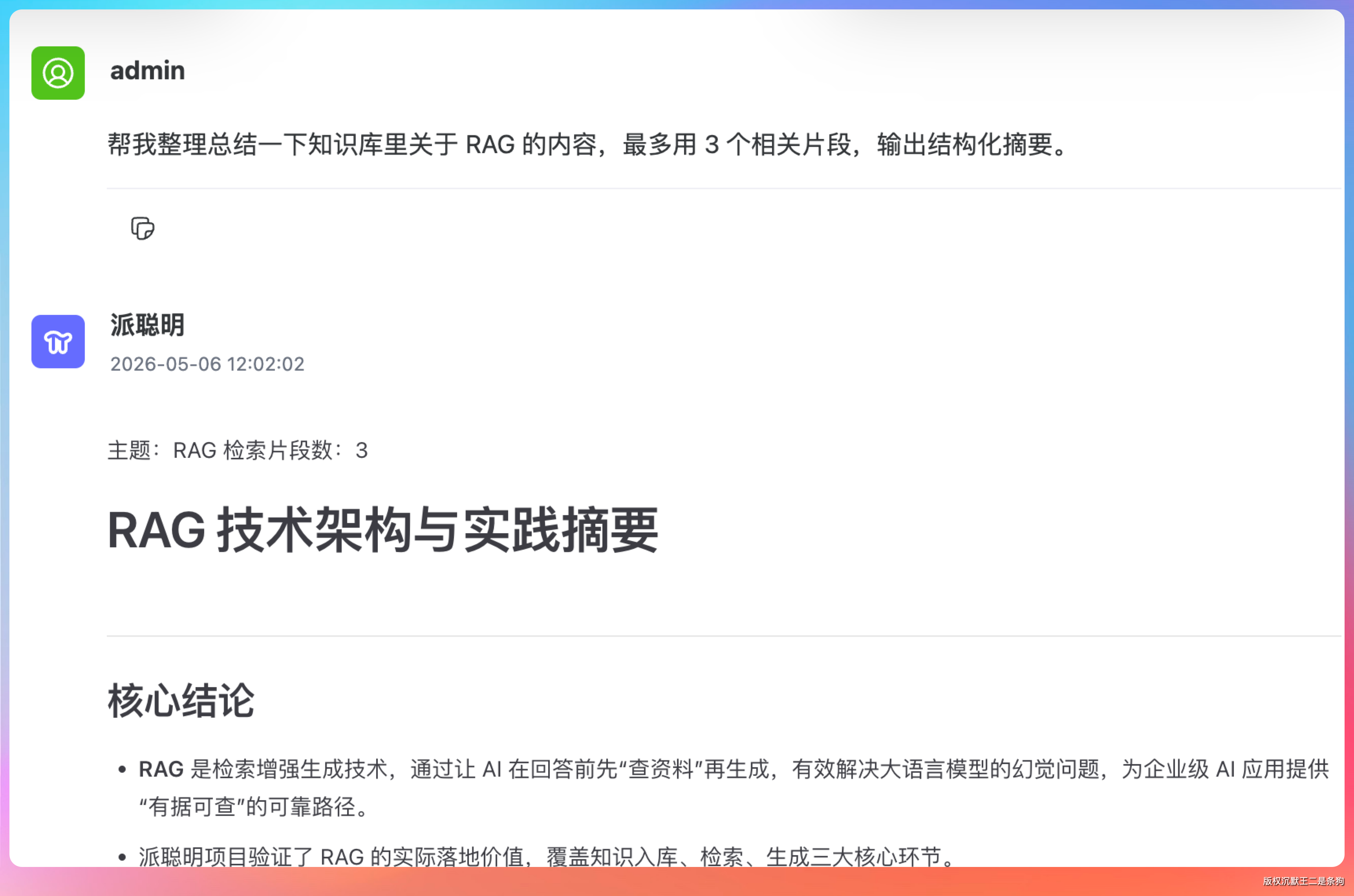
用户说“帮我整理总结一下知识库里关于 RAG 的内容,最多用 3 个相关片段,输出结构化摘要”,Agent 会自主调用 generate_summary 这个 Tool,先检索 3 个片段,再二次调用模型生成结构化摘要,页面已展示“核心结论 / 关键依据 / 可执行建议 / 待确认问题”。
用户说“我对刚才这个检索结果满意,原因是返回数量和主题都符合要求”,Agent 会调用 submit_feedback 记录反馈。
03、加上 ReAct 决策循环
ReAct 是 Reasoning + Acting 的缩写。
核心思想是让 Agent 进入一个循环:思考该做什么 → 执行操作 → 观察结果 → 再思考下一步,直到任务完成。
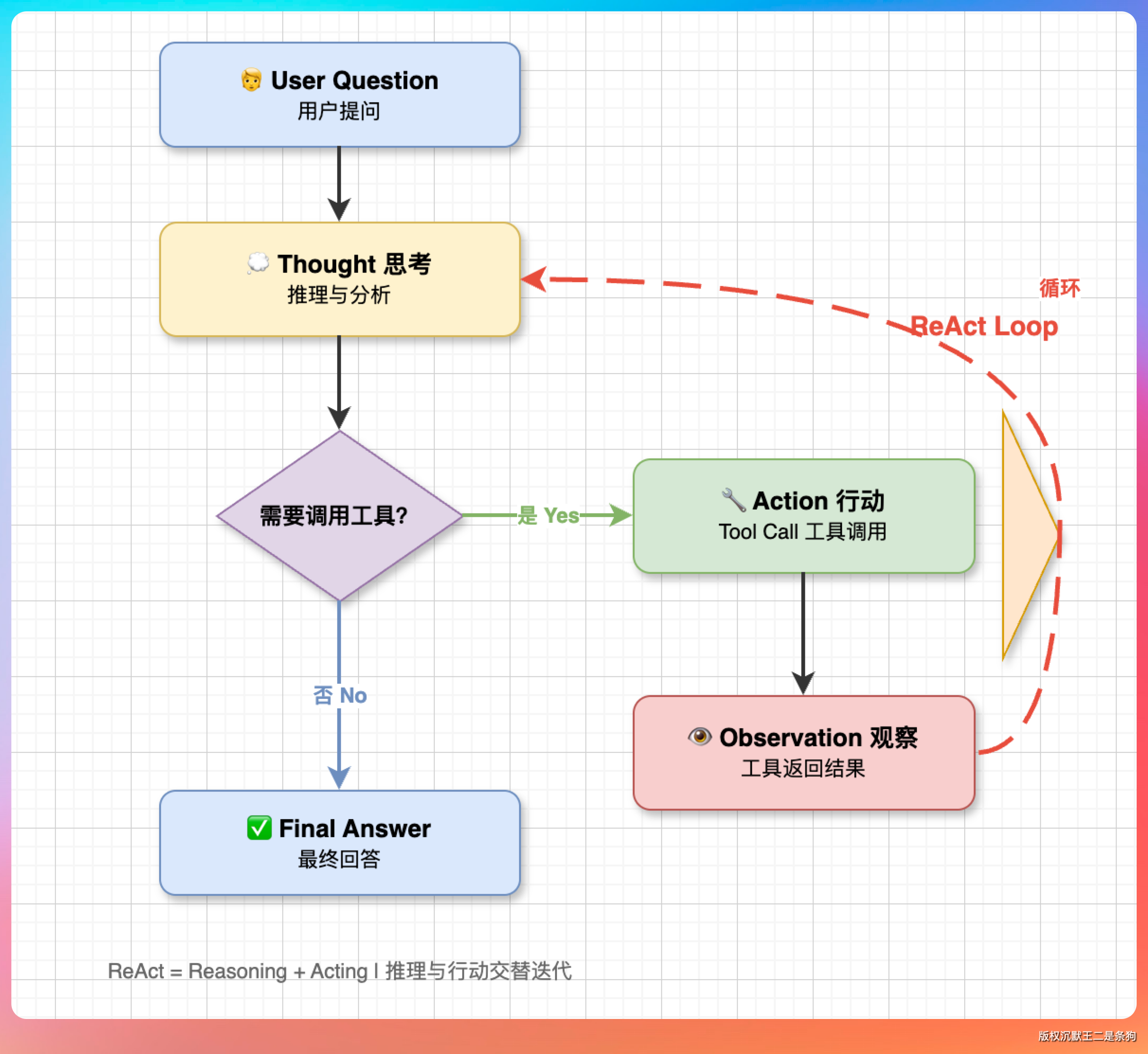
PaiCLI 的 Agent.java 里有一个非常清晰的 ReAct 循环实现,核心逻辑大概 100 行:
这段代码的关键在于 while(true) 循环。每一轮循环里,大模型会根据当前的对话历史(包含之前所有的思考过程和工具执行结果)来决定:是继续调用工具,还是直接给出最终回答。
在派聪明的场景下,一个典型的多步任务长这样:
用户说:“帮我搜一下知识库里有没有 RAG 相关的文档,有的话整理成一份摘要。”

Agent 的决策过程:
第一轮循环——思考:用户想知道知识库里有没有 RAG 的内容,我应该先搜索一下。于是调用 search_knowledge 工具,参数 query="RAG"。
第二轮循环——观察到搜索返回了 4 篇相关文档。思考:有内容,用户要求整理成摘要,我应该调用 generate_summary 工具。于是调用摘要生成,参数 topic="RAG"。
第三轮循环——观察到摘要生成完毕。思考:任务完成了,我可以把摘要返回给用户了。于是输出最终回答,包含一份结构化的 RAG 知识摘要。
三轮循环,零人工干预,Agent 自己完成了“搜索 → 判断 → 总结”的全过程。
这里有一个很重要的细节:预算控制。
PaiCLI 用 AgentBudget 来防止 Agent 无限制执行,设定了最大循环次数(比如 10 次)和 token 上限。超了就强制退出,避免死循环。
另一个兜底机制是在 System Prompt 里明确告诉大模型:如果不确定该怎么做,直接问用户,不要瞎猜。
这一条非常关键,能避免 Agent 在不确定的情况下调用了错误的 Tool(比如误删文档)。
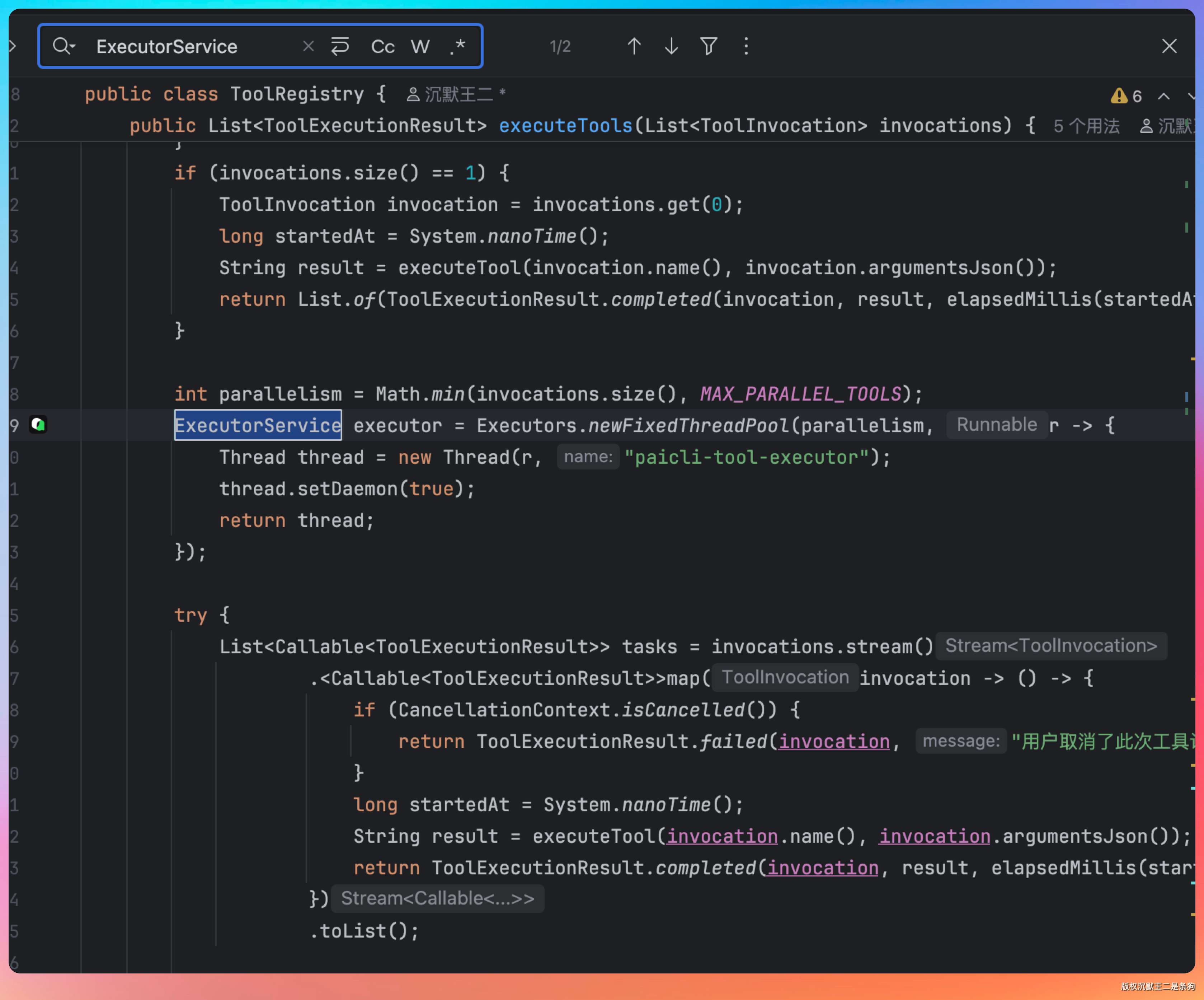
PaiCLI 里还有一个设计值得学习:Tool 执行支持并行。ToolRegistry 内部用 ExecutorService 管理并行度,最多同时跑 4 个 Tool,单个 Tool 超时 90 秒自动中断。当大模型在一轮循环里同时请求多个 Tool 调用(比如同时搜索三个不同分类的文档),这些调用会并行执行而不是排队等。
继续上 Claude Code/Codex,提示词:
加入 ReAct 决策循环:
改造要点:
1. 在调用 DeepSeekClient 时,把 AgentToolRegistry 中注册的 Tool 定义转成 DeepSeek API 的 tools 参数格式(function calling 格式)
2. 检查 DeepSeek 返回的 response 中是否有 tool_calls 字段
3. 如果有 tool_calls:执行对应的 Tool → 把执行结果作为 tool message 加入 conversationHistory → 继续循环
4. 如果没有 tool_calls:说明大模型认为任务完成,输出最终回答,退出循环
5. 加预算控制
6. 保留现有的 WebSocket 流式推送。每轮循环的 Tool 调用过程也通过 WebSocket 推给前端,
格式为 JSON:{"type": "tool_call", "tool": "search_knowledge", "status": "executing"}
7. Tool 执行异常时不要中断循环,把异常信息作为 tool message 返回给大模型,让它重新思考
关键实现细节:
- conversationHistory 的消息格式需要兼容 DeepSeek 的多轮对话格式:
system / user / assistant(含 tool_calls) / tool(含 tool_call_id + content)
04、加上 Memory 管理
Agent 要真正好用,还需要有记忆能力。
派聪明现在的多轮对话是把最近几轮对话拼到 Prompt 里,这种方式有两个问题:上下文窗口有限,历史太长就得截断;跨会话记忆完全丢失。
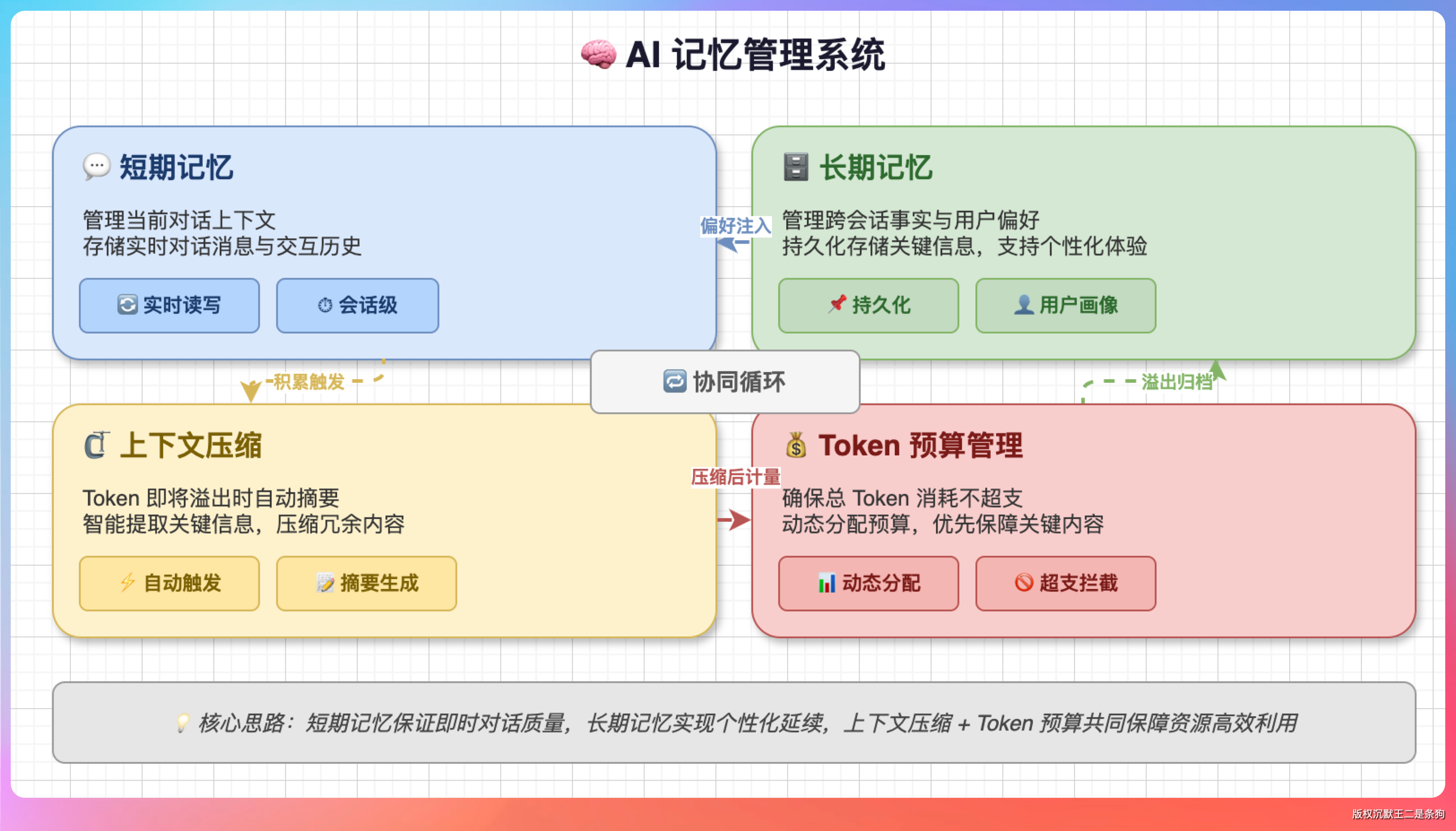
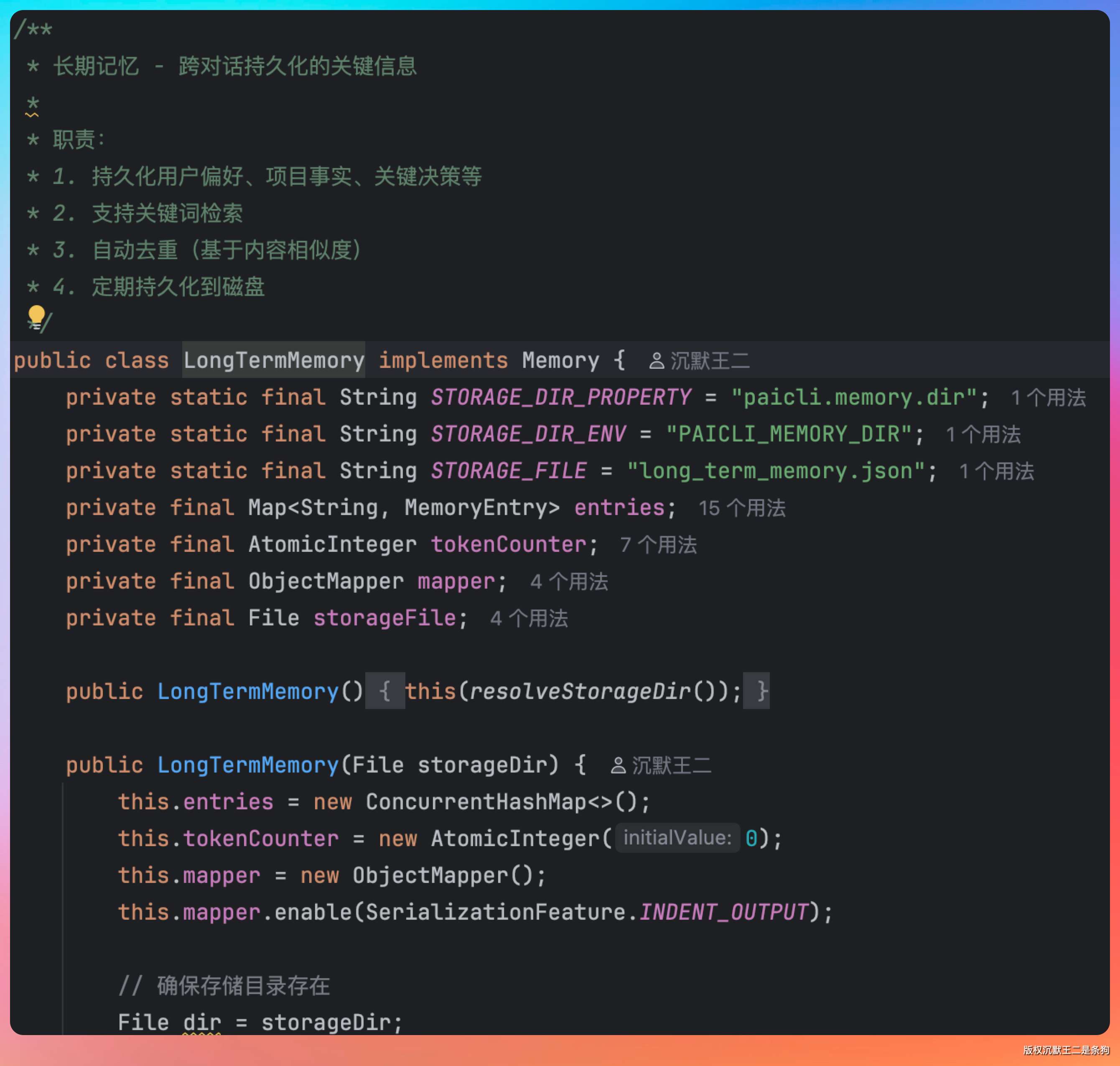
PaiCLI 的记忆系统分两层,设计得很清晰:
短期记忆:管理当前任务的执行上下文。Agent 在一个多步任务中需要记住前面几步做了什么、结果是什么,才能正确决策下一步。

当 token 预算超了,不是简单地砍掉最早的对话,而是把早期记忆压缩成摘要。这样 Agent 既不会忘记关键信息,又不会撑爆上下文窗口。
长期记忆:跨会话持久化,存在本地 JSON 文件里。
在派聪明的场景下,记忆管理可以做这些事情:
短期记忆用来管理 ReAct 循环的执行上下文。
长期记忆可以记住用户的偏好和习惯。比如 Agent 记住某个用户经常查询“产品手册”相关的文档,下次这个用户提问的时候可以优先从产品手册分类里检索,提高命中率。这个用向量数据库存储用户的历史交互摘要就行,按语义检索最相关的历史上下文。
继续上 Claude Code,第三条提示词:
给派聪明加上记忆管理:
短期记忆:
1. 复用 ReAct 循环的 conversationHistory 作为短期记忆
2. 加一个 token 计数器,每轮循环前检查 conversationHistory 的 token 总量
3. 判断上下文总 token 超过多少时触发压缩:保留最近 3 轮完整对话,更早的对话调用大模型生成摘要替换
4. 压缩后的摘要作为一条 system message 插入 conversationHistory 开头
长期记忆(基于 Redis):
2. 当用户强制要求记忆时,从当前会话的 conversationHistory 中提取关键信息:
- 用户问了哪些类型的问题
- Agent 调用了哪些 Tool
- 最终结果是什么
- 或者用户直接要求记住的内容
3. 把提取的信息存入 Redis,key 格式:ltm:{userId}:{timestamp},设置 30 天过期
4. 每次新会话开始时,从 Redis 中检索该用户最近 5 条长期记忆
5. 把检索到的历史上下文注入 System Prompt:"以下是该用户的历史交互摘要:..."05、Review 和测试
接下来就是验证环节。
先用 Claude Code + Opus 4.7 做一轮 Review:
Review 刚才的所有变更,重点检查:
1. ReAct 循环有没有死循环风险
2. Tool 执行有没有异常处理
3. WebSocket 推送有没有线程安全问题
4. 记忆持久化有没有数据一致性问题
修完之后直接用 Codex/Claude Code 跑一轮集成测试,测试用例是这样的:
测试场景1:用户问"知识库里有多少文档"
预期:Agent 调用 knowledge_stats Tool,返回统计数据
测试场景2:用户问"帮我搜一下 RAG 的文档,整理成摘要"
预期:Agent 先调用 search_knowledge 检索,再调用 generate_summary 生成摘要
测试场景3:用户说"刚才那个回答不太准确"
预期:Agent 调用 submit_feedback,记录用户的负面反馈
测试场景4:用户连续问三个问题,第三个问题涉及第一个问题的结果
预期:Agent 能从短期记忆中拿到第一个问题的上下文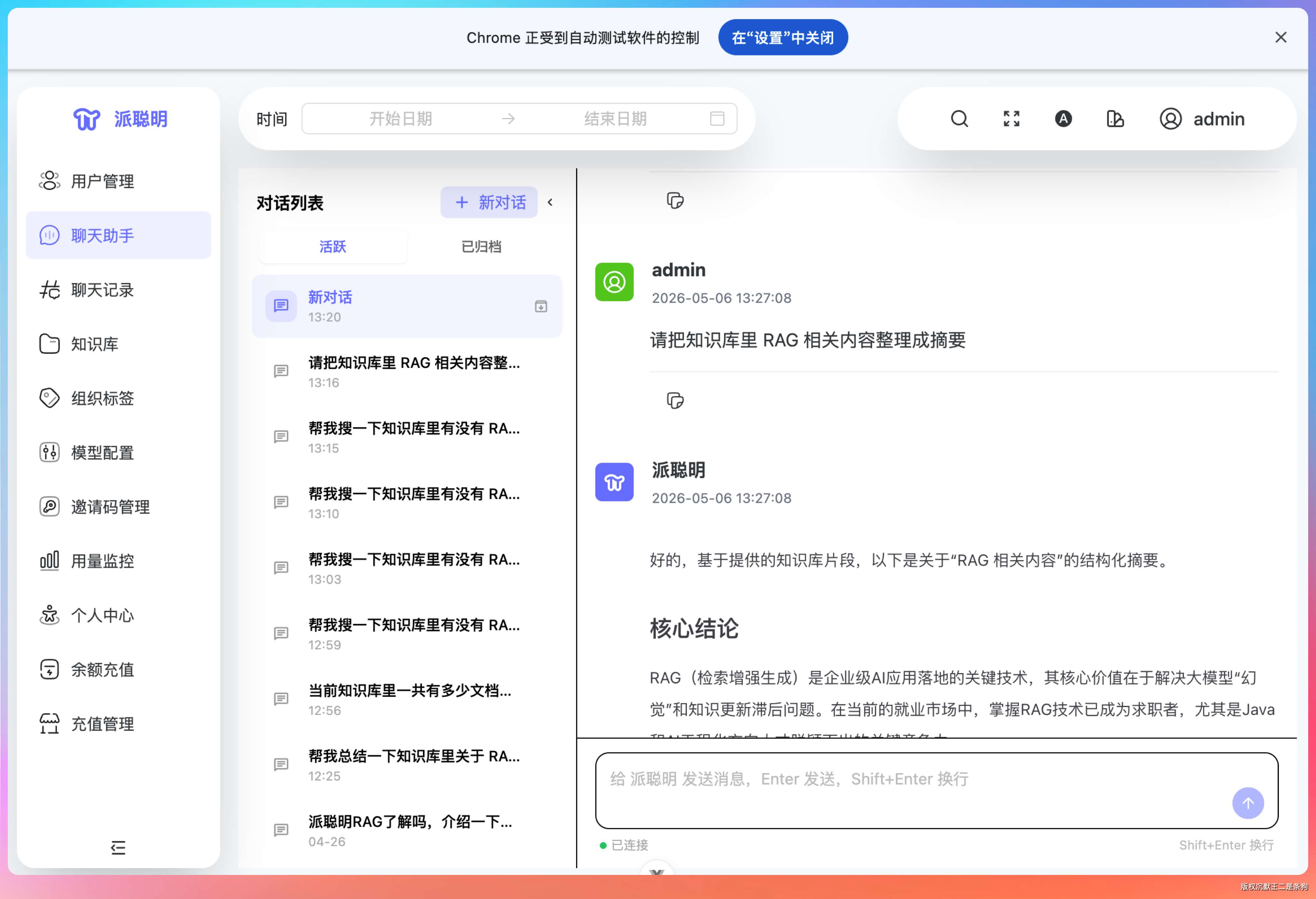
06、派聪明如何写到简历上?
如果大家在做类似的 RAG→Agent 升级项目,简历上可以这样写:
项目名称:派聪明 AI 知识库(PaiSmart)
项目简介:基于 Spring Boot 3.4 + Elasticsearch 8.10 + DeepSeek API 的企业级 AI 知识库系统,支持多租户文档管理和智能问答,从纯 RAG 架构升级为 Agent 架构。
技术栈:Spring Boot 3.4、Spring WebFlux、Elasticsearch 8.10、Redis 7.0、MinIO、DeepSeek V4 API、WebSocket
核心职责:
- 基于 Spring Boot + Elasticsearch 构建混合检索引擎,采用 KNN 向量搜索 + BM25 关键词重打分策略,知识库问答的召回准确率达到 92%
- 设计并实现 Tool Calling 工具注册框架,为 Agent 注册 4 个核心工具(文档搜索、摘要生成、答案反馈、知识库统计)
- 实现 ReAct 决策循环引擎,支持 Agent 自主完成多步复合任务
- 设计双层记忆管理架构,短期记忆采用 token 预算压缩策略控制上下文长度,长期记忆基于 Redis 持久化用户交互摘要
- 基于 WebSocket 实现 Agent 决策过程的实时推送,用户可以看到 Agent 的思考过程和工具调用状态