派聪明 RAG 知识库项目:企业级 AI 知识库实战教程
大家好,我是二哥呀。
每次修改简历,看到不少球友还在点评和外卖上努力雕花,就有一种无力感。不是说这俩项目不好,这俩项目足够优秀,就是用的太多了。
如果不是 92 本硕这种头部选手,我是不建议用的,毕竟站在面试官的立场,他看多了也会头皮发麻。大家可以想想是不是这个道理。😄
当然了,说外卖和点评烂大街,我肯定是要提供一些解决方案的。
这不,历经 4 个月,派聪明 RAG 知识库项目终于完工(包括源码和教程,全部交付给大家)!
不容易啊。
派聪明是 2025年 9 月份上线的,截止到目前,已经取得了非常瞩目的成绩,我这里晒一下哈。
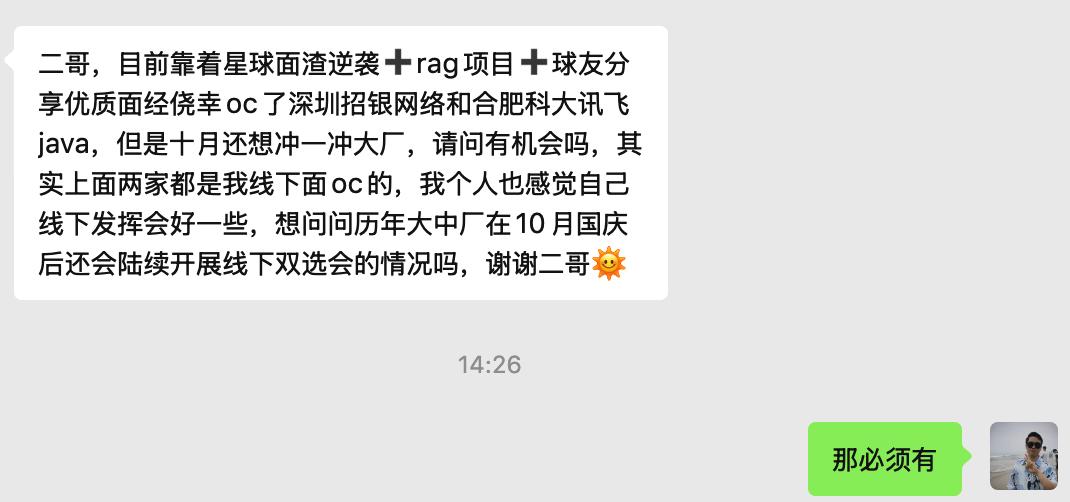
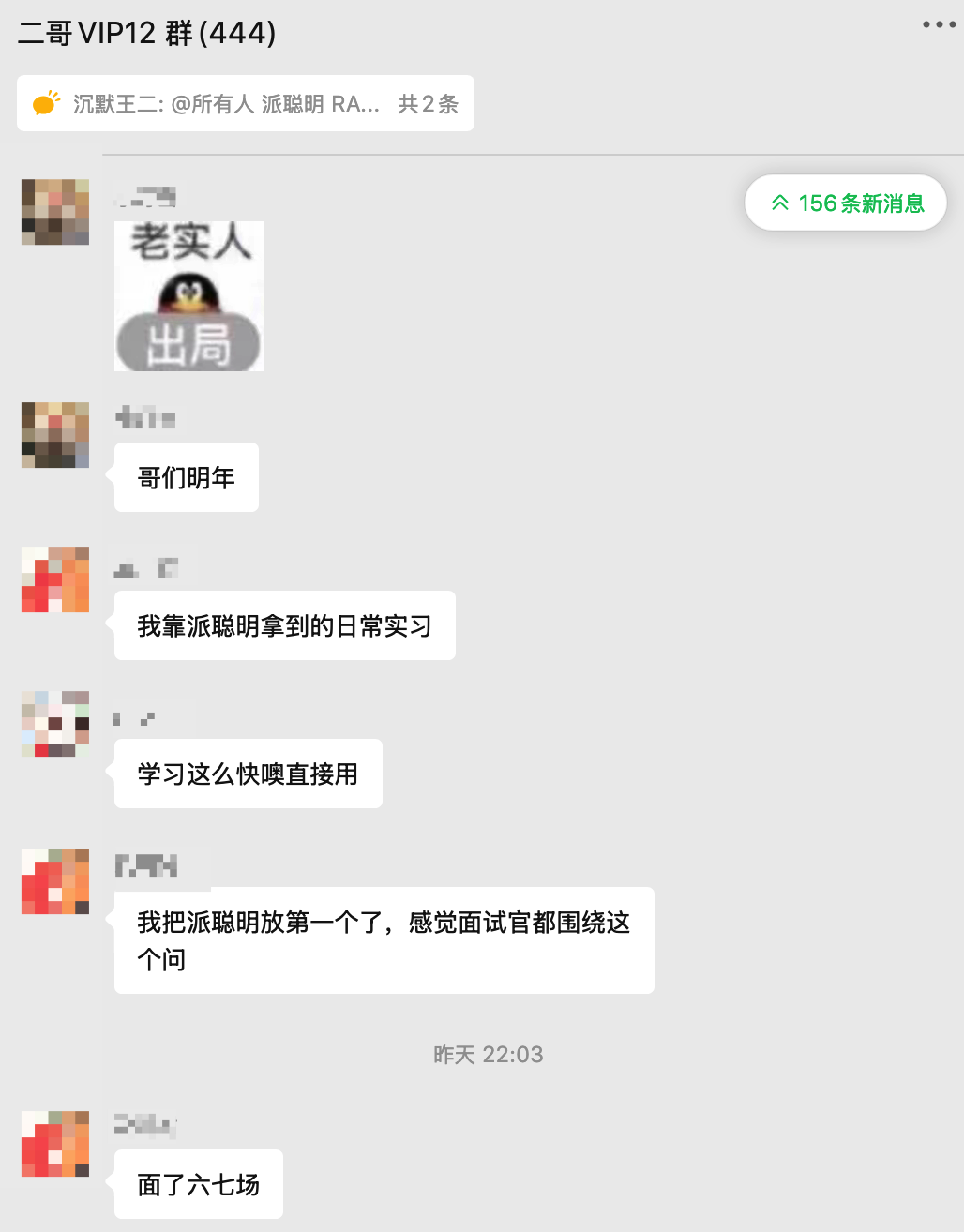
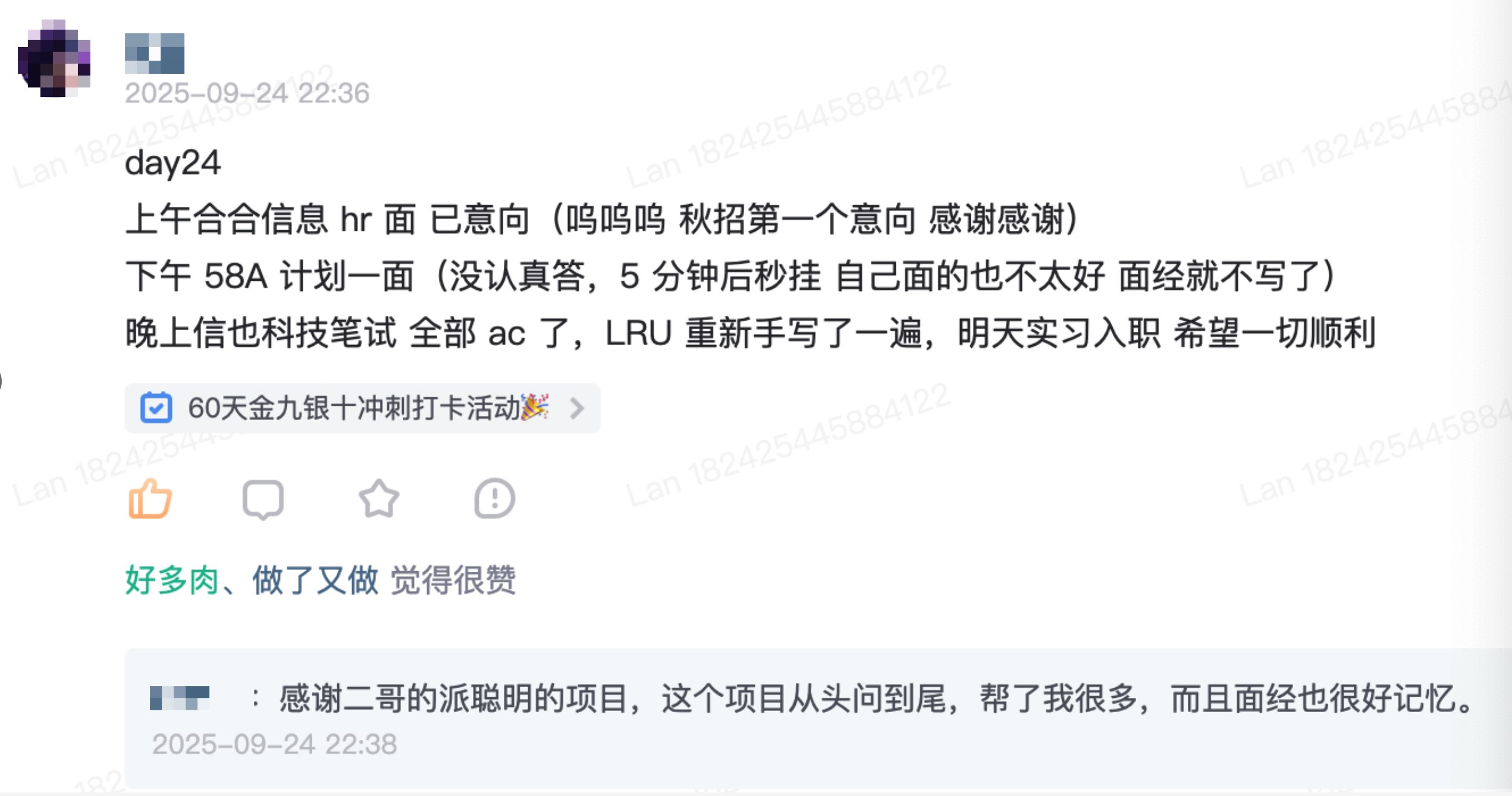


说句真心话,看到这,就可以无脑冲这个项目了,因为这些,还只是冰山一角。扫下面的优惠券(或者长按自动识别)解锁派聪明源码和教程吧,星球目前定价 169 元/年,优惠完只需要 139 元,每天不到 0.38 元,绝对的超值。
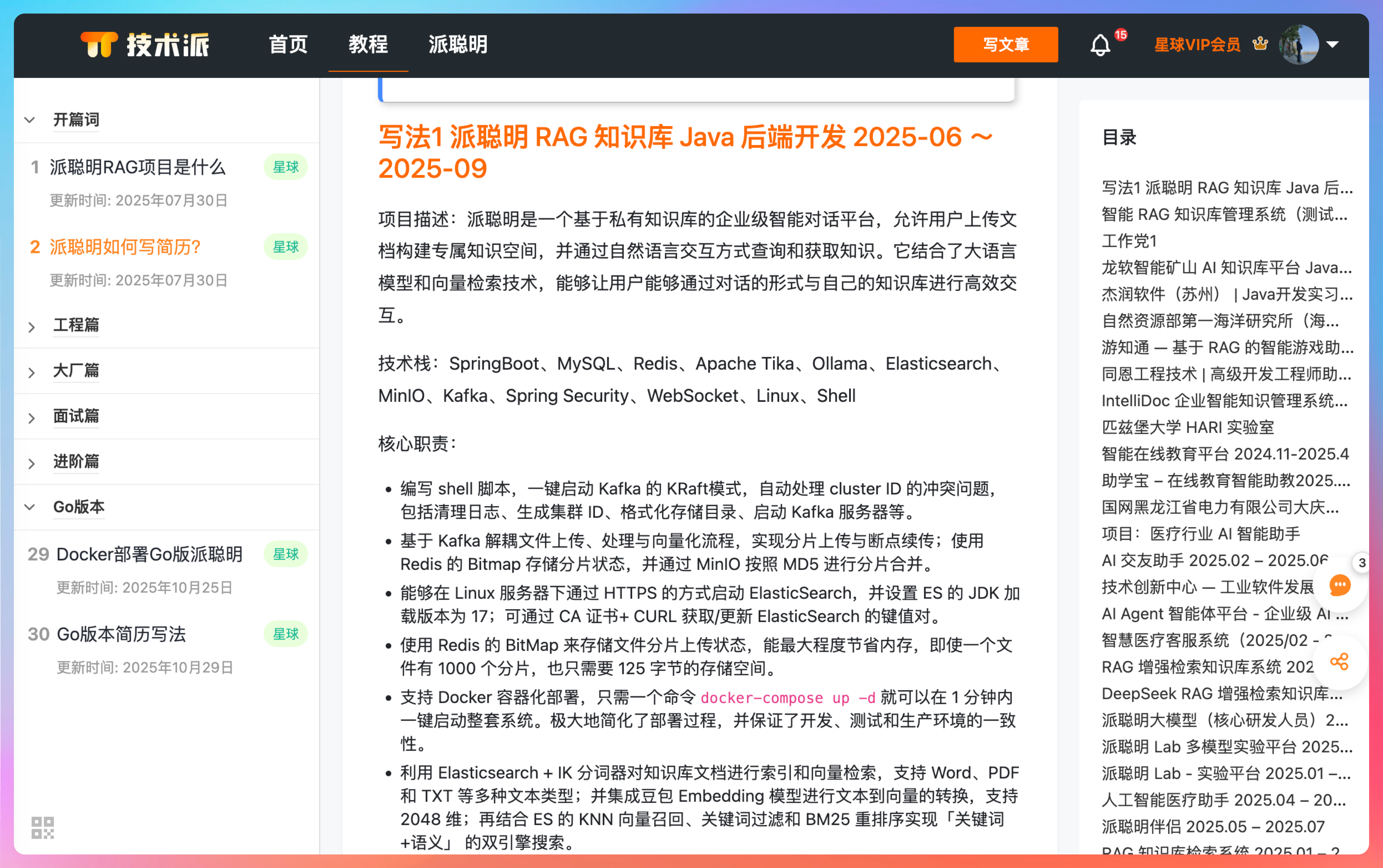
派聪明如何写到简历上:https://paicoding.com/column/10/2
这篇内容我先带大家了解一下什么是派聪明,我为什么要做派聪明这个企业级的 RAG 知识库?派聪明这个 AI 项目能让大家学到什么?以及如何解锁派聪明的源码仓库和教程?

一、派聪明的起源
了解技术派的球友应该知道,派聪明最初是技术派实战项目中一部分,主打的服务是和 AI 大模型进行聊天对话(没有检索增强生成)。
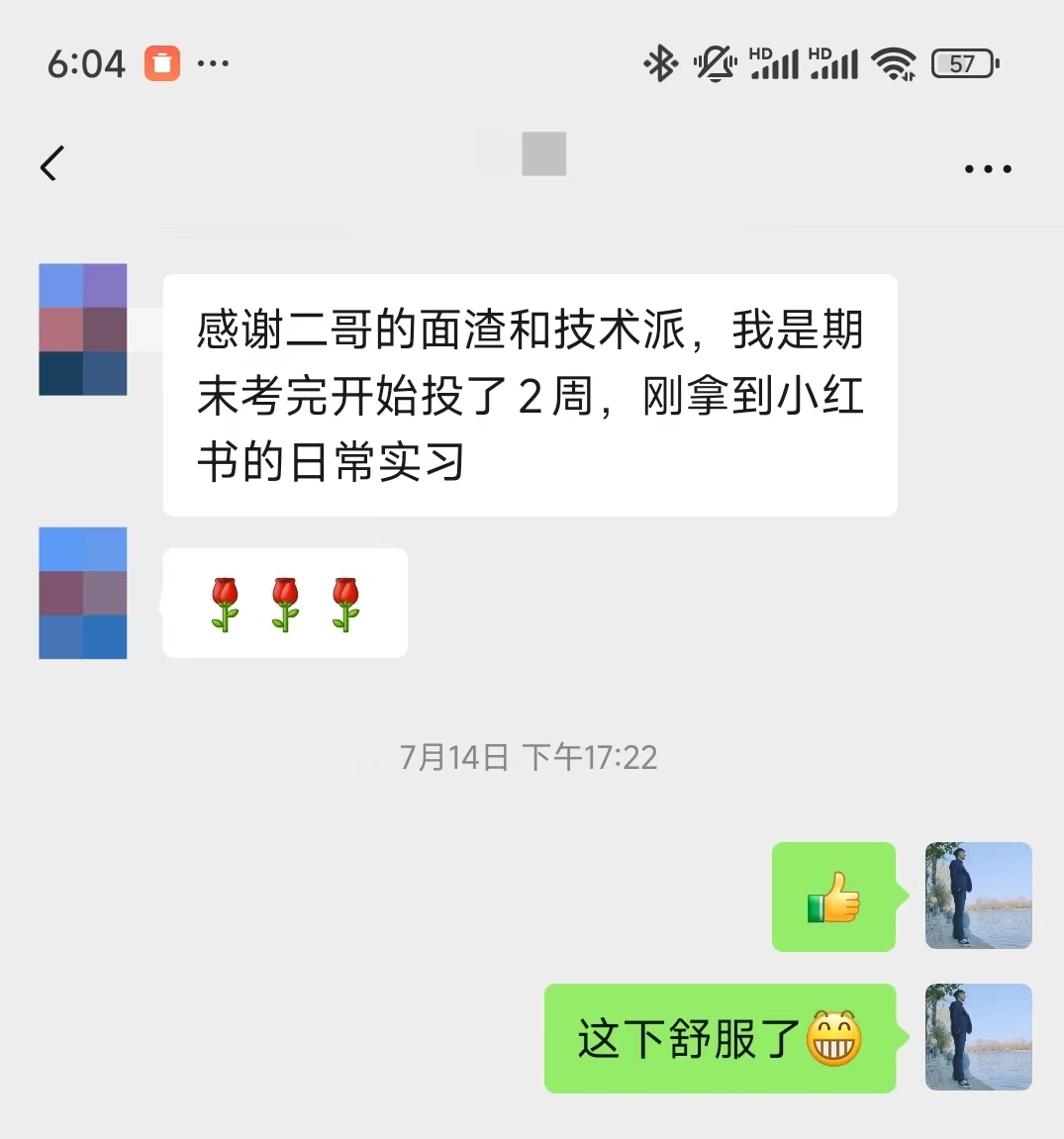
技术派这个项目也是非常经典,帮助 24、25 届,以及 26 届同学斩获了很多超出预期的 offer,我们这里就不多讲了,只贴一个喜报,一位球友靠技术派和面渣逆袭,投了两周拿下小红书的日常实习。
技术派这个项目如果你能认真学完,会收获非常非常多,基本上一个企业级的 Web 开发项目用到的技术栈,技术派都覆盖到了。

那为了延续正宗的皇家血脉,我把派聪明这三个字延续到了新的 RAG 项目,也就是大家目前看到的这个派聪明 AI 知识库项目(界面还是非常清爽的 😄)。
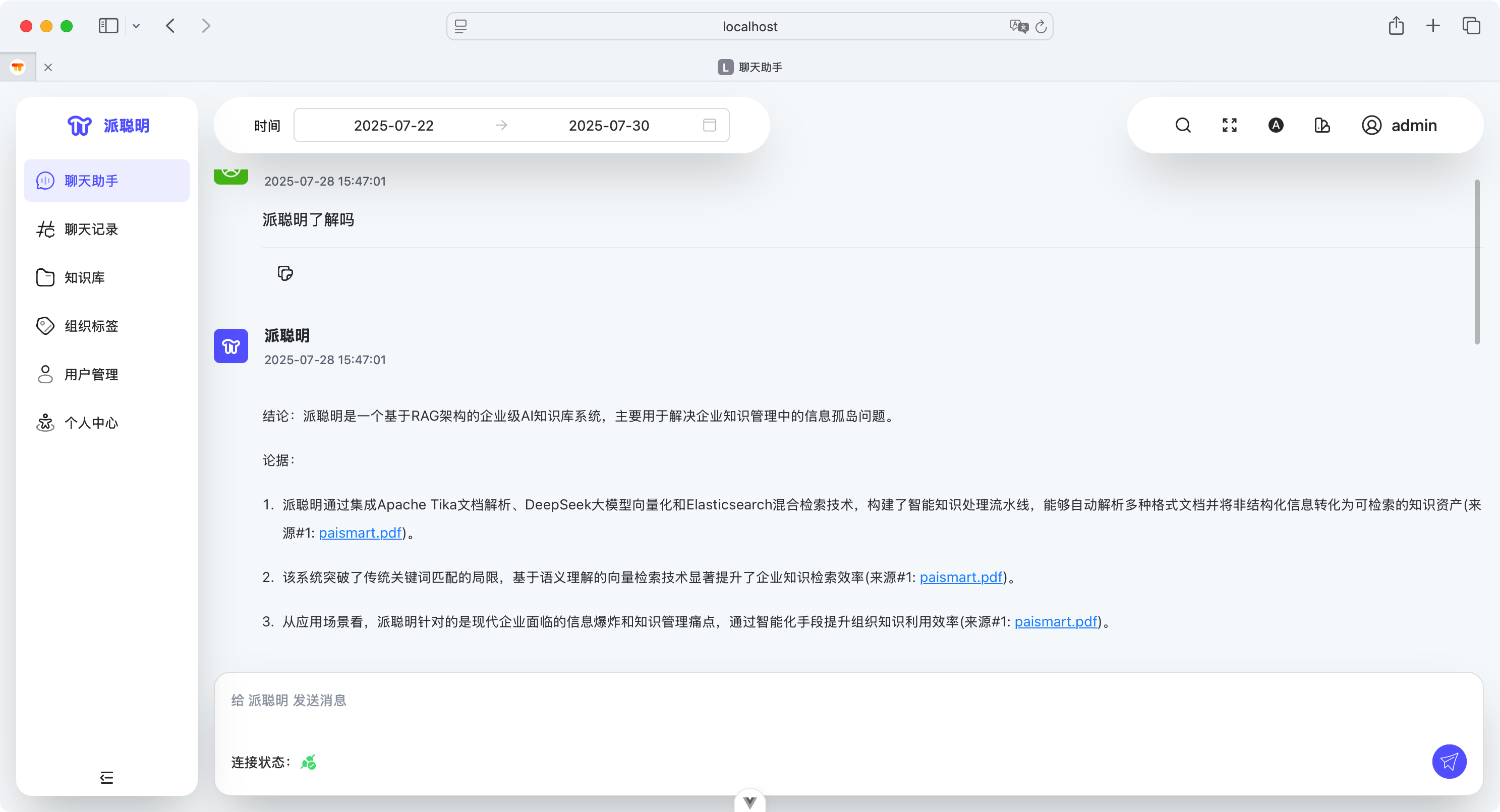
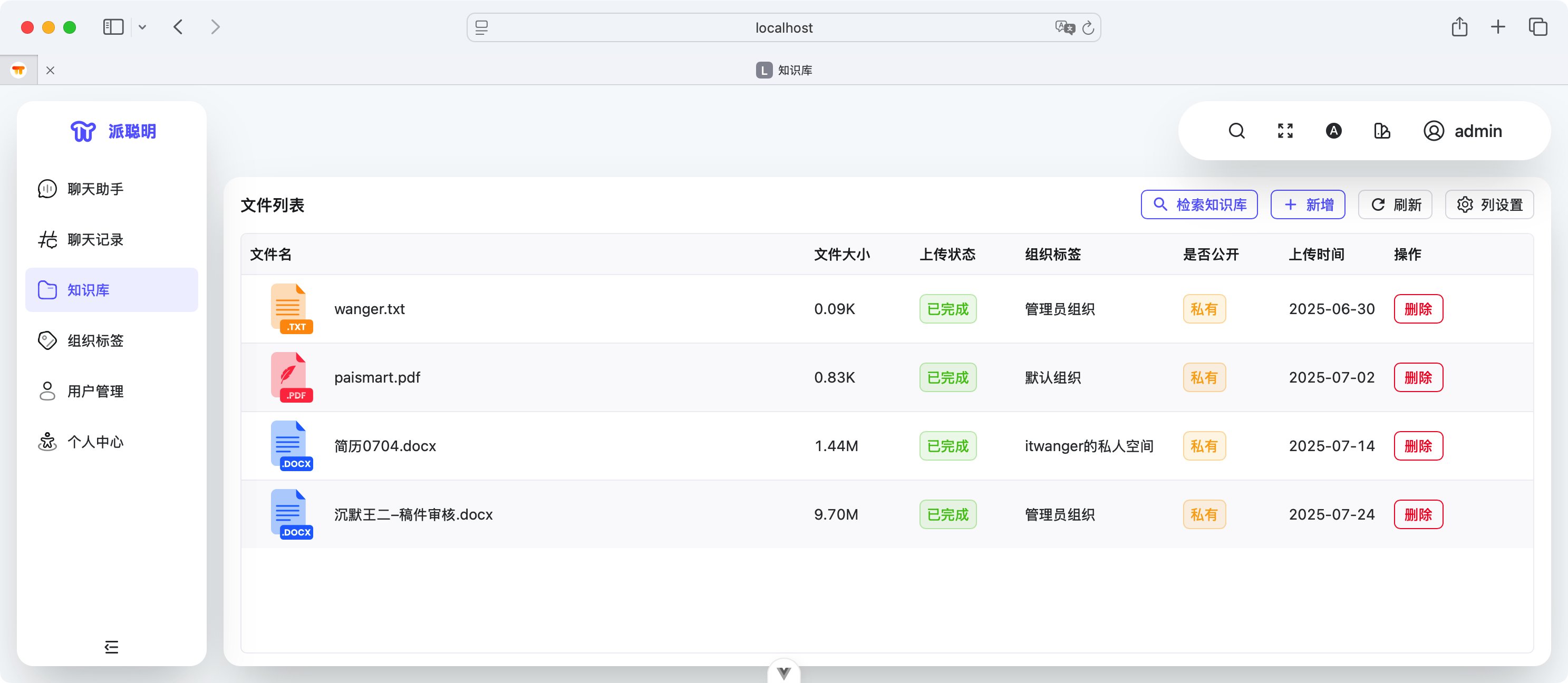
做 AI 知识库的起源,当然还是 DeepSeek 刚出来那会,我在本地用 Ollama+DeepSeek+Anythingllm 搭了一个本地的面渣逆袭知识库,当时觉得这玩意挺有意思的。刚好星球球友 Lan 来找我说,要不一起做点事吧,我就把我这个想法交给他去落实了。
当时我没有抱很大的期待,因为从一个 idea 萌芽到开花结果,真的很难,但 Lan 信守承诺,很快就把后端搭建好了。用了很多我觉得对大家求职很有帮助的技术栈,比如说 JDK17、ElasticSearch、MySQL、Redis、MinIO、Kafka 等等,并且涉及到了很多 AI 的知识,比如说目前很火的 RAG 技术。
2025年4 月份的时候,机缘巧合,我和朋友【我糖呢】闲聊,就讲起这个项目,他已经悄咪咪的成为一名前端大佬,于是索性我就喊他来做前端,就这样,我们的派聪明团队就算是正式成立了。
下个项目校招派,我打算把 MCP 和 Agent 也加进来。所以,这个项目在 AI 时代,绝对是一个明星级、现象级的实战项目。
二、派聪明的技术栈
先说后端的:
- 框架/依赖管理 : Spring Boot 3.4.2 (Java 17)+Maven
- 数据库 : MySQL 8.0 + Spring Data JPA
- 缓存 : Redis
- 搜索引擎 : Elasticsearch 8.10.0
- 消息队列 : Apache Kafka
- 文件存储/解析 : MinIO + Apache Tika
- 安全认证 : Spring Security + JWT
- AI 集成 : DeepSeek API/本地 Ollama+豆包 Embedding
- 实时通信 : WebSocket
- 响应式编程 : WebFlux
后端的整体项目结构:
src/main/java/com/yizhaoqi/smartpai/
├── SmartPaiApplication.java # 主应用程序入口
├── client/ # 外部API客户端
├── config/ # 配置类
├── consumer/ # Kafka消费者
├── controller/ # REST API端点
├── entity/ # 数据实体
├── exception/ # 自定义异常
├── handler/ # WebSocket处理器
├── model/ # 领域模型
├── repository/ # 数据访问层
├── service/ # 业务逻辑
└── utils/ # 工具类前端其实用到的技术栈也非常新,包括:
- 框架 : Vue 3 + TypeScript
- 构建工具 : Vite
- UI 组件 : Naive UI
- 状态管理 : Pinia
- 路由 : Vue Router
- 样式 : UnoCSS + SCSS
- 图标 : Iconify
- 包管理 : pnpm
前端的整体项目结构:
frontend/
├── packages/ # 可重用模块
├── public/ # 静态资源
├── src/ # 主应用程序代码
│ ├── assets/ # SVG图标,图片
│ ├── components/ # Vue组件
│ ├── layouts/ # 页面布局
│ ├── router/ # 路由配置
│ ├── service/ # API集成
│ ├── store/ # 状态管理
│ ├── views/ # 页面组件
│ └── ... # 其他工具和配置
└── ... # 构建配置文件三、派聪明的技术架构
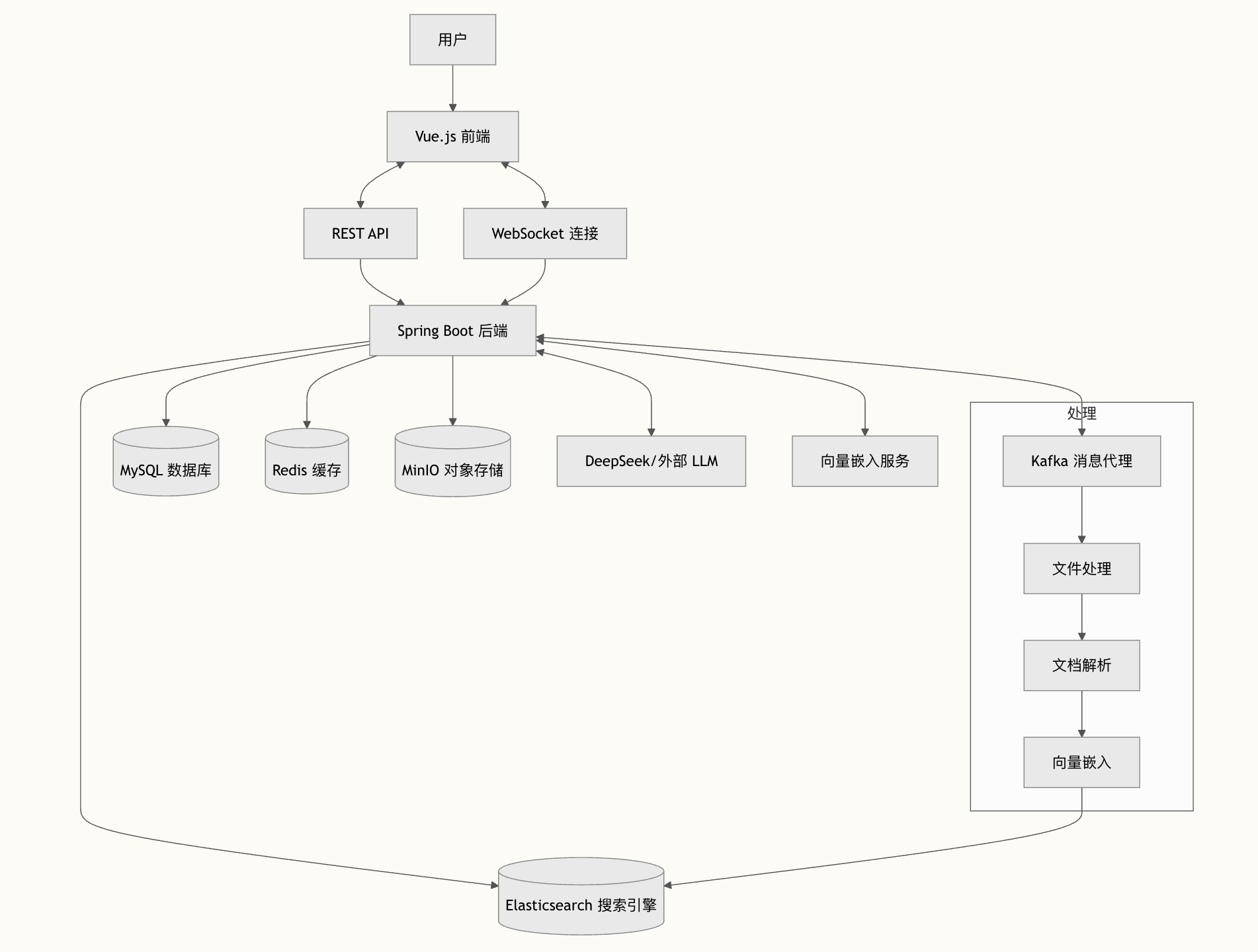
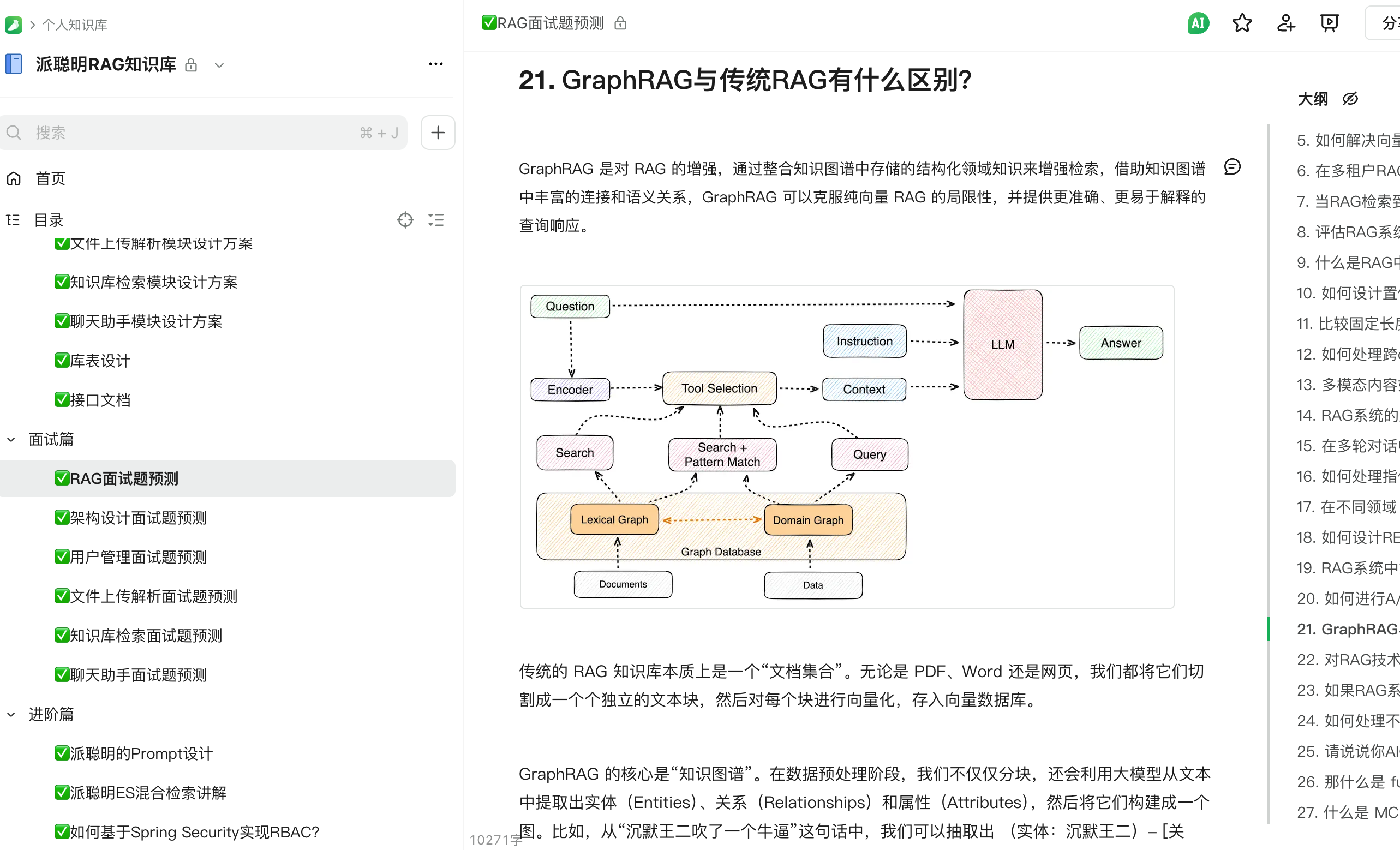
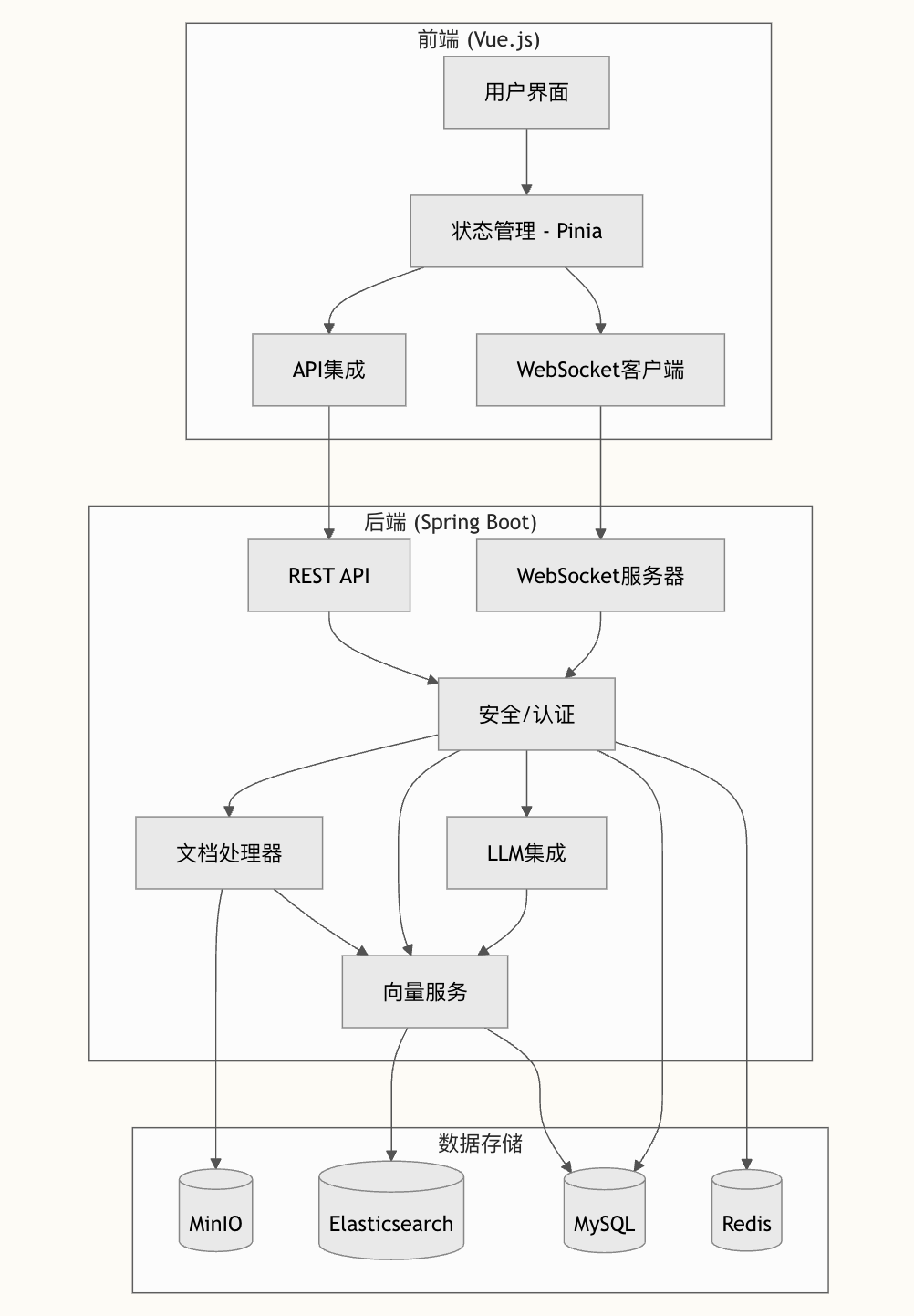
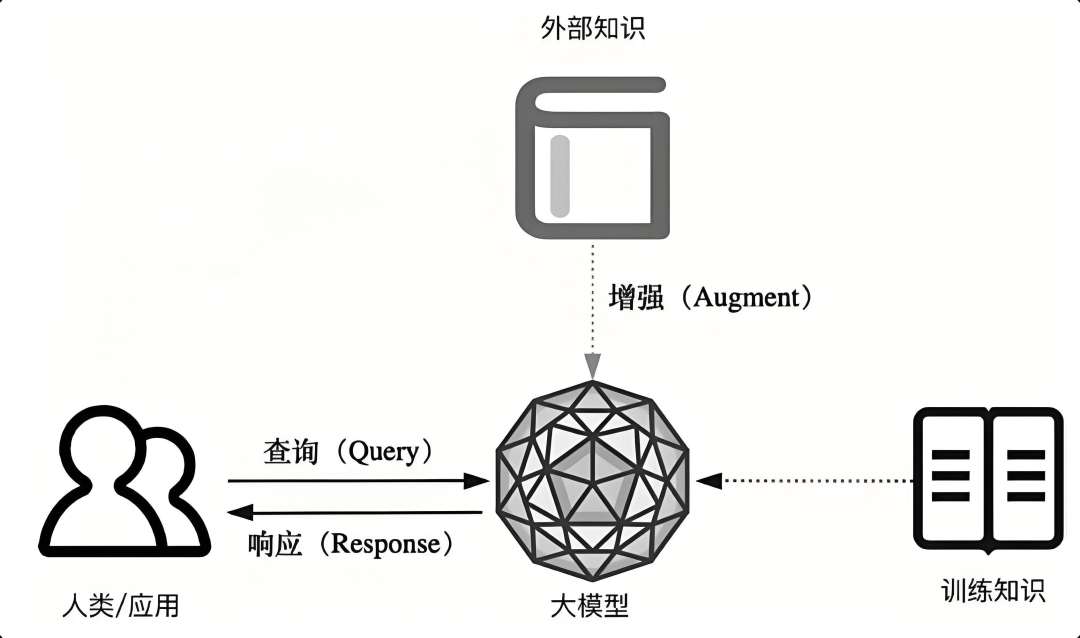
看到一张图,和派聪明 RAG 知识库是比较吻合的,我直接贴出来,方便大家一睹为快。
底层大模型我们用的是 DeepSeek。上层的业务是,当你把企业私有的 Word、PDF、txt 丢给派聪明,他就会自动进行向量化处理,支持大文件的断点续传和分片上传,分片状态使用 Redis 的 BitMap 进行保存,文件本身通过 MinIO 进行存储。
具体来说,系统会使用 Apache Tika 从文档中提取出纯文本信息,然后将长文档智能切分成多个语义完整的文本块。
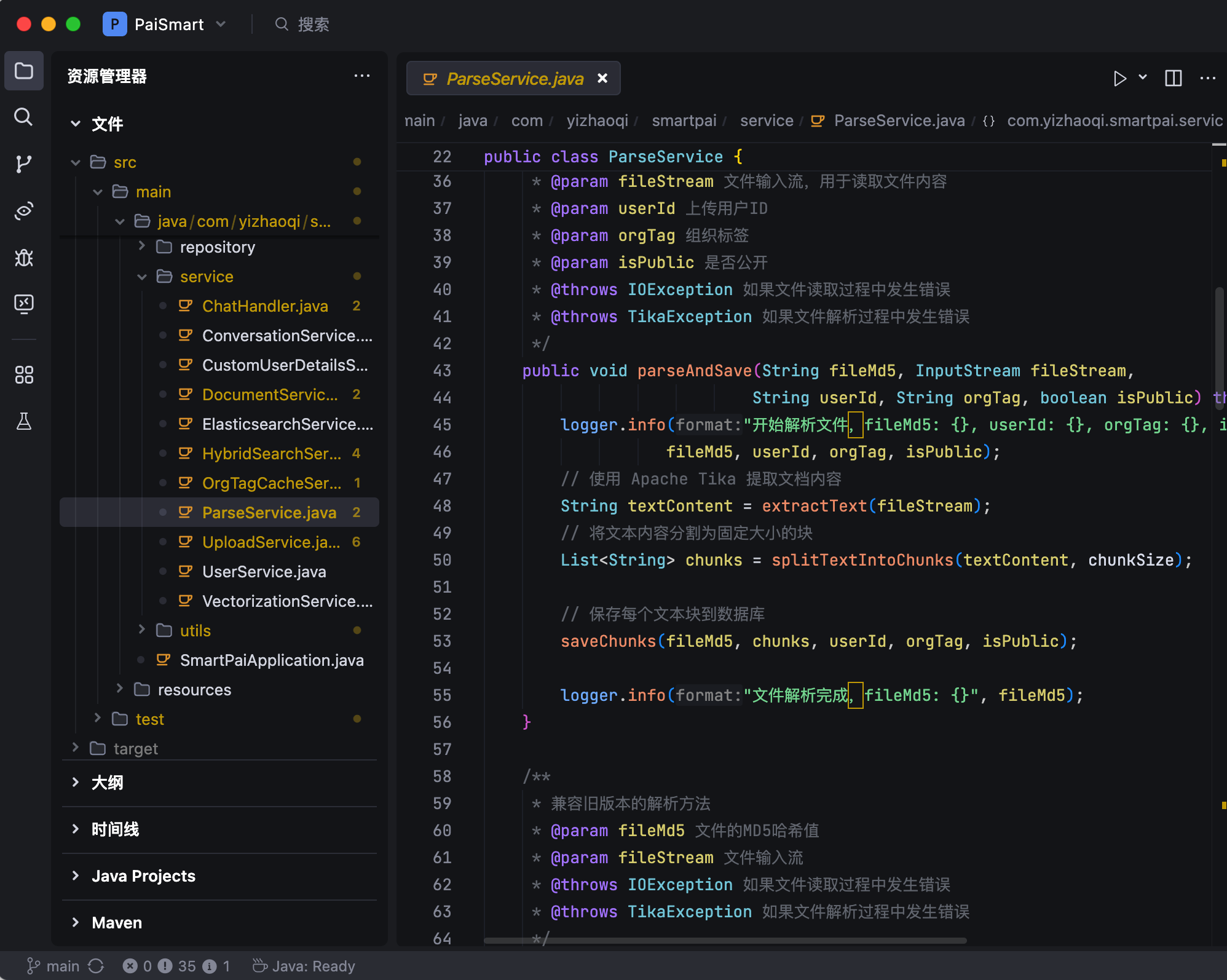
接下来调用阿里的 Embedding 模型,将文本块转换成 2048 维的向量表示,这些向量能够捕捉文本的深层语义信息。然后,会将所有的向量数据和原始文本存入到 Elasticsearch 中,形成一个强大的知识库索引。
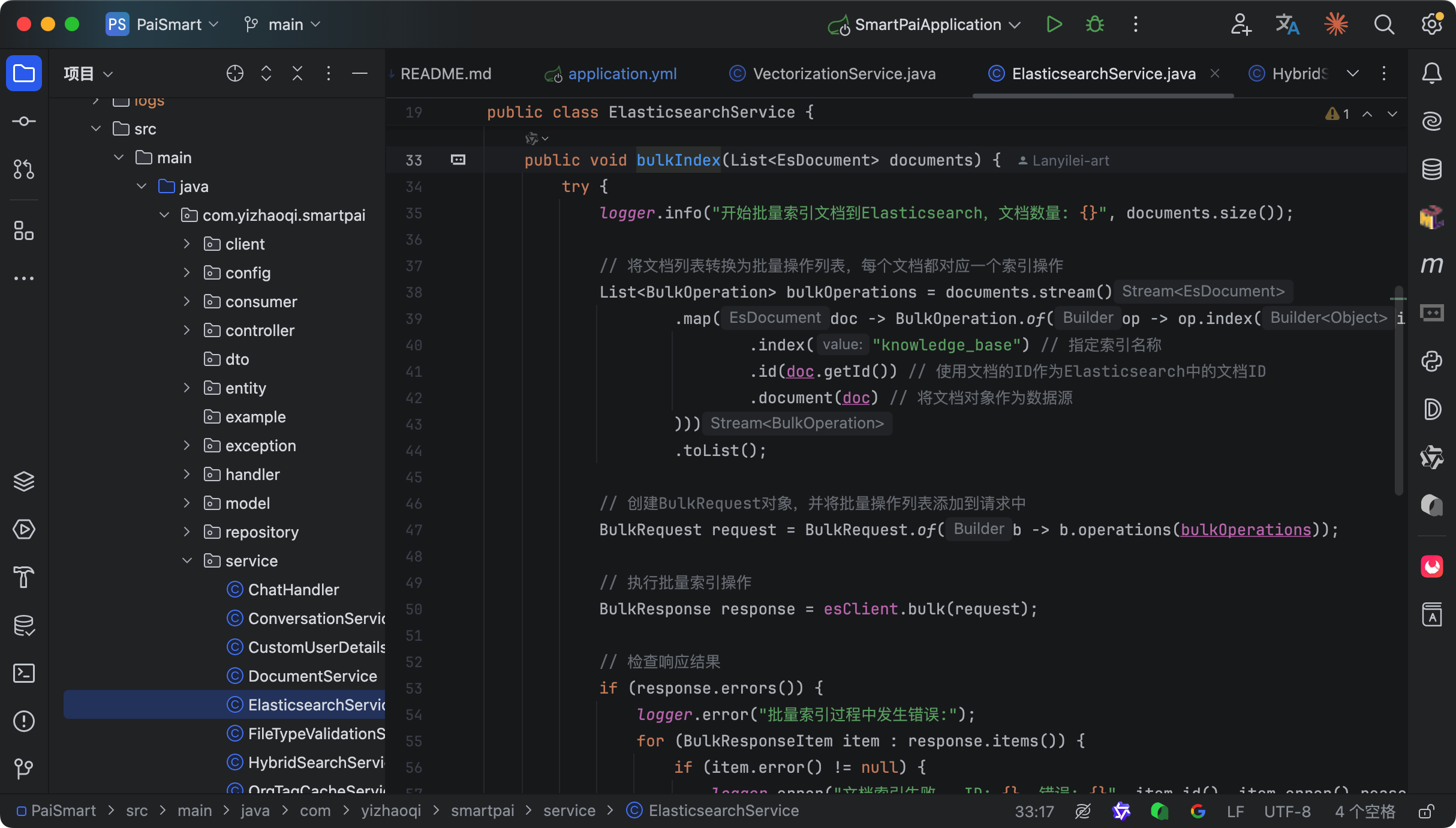
当用户提出问题后,派聪明会通过 ElasticSearch 进行混合检索:先进行语义的向量搜索,再进行关键词的精排。同时,会根据用户的组织权限,自动过滤出用户有权访问的文档内容。
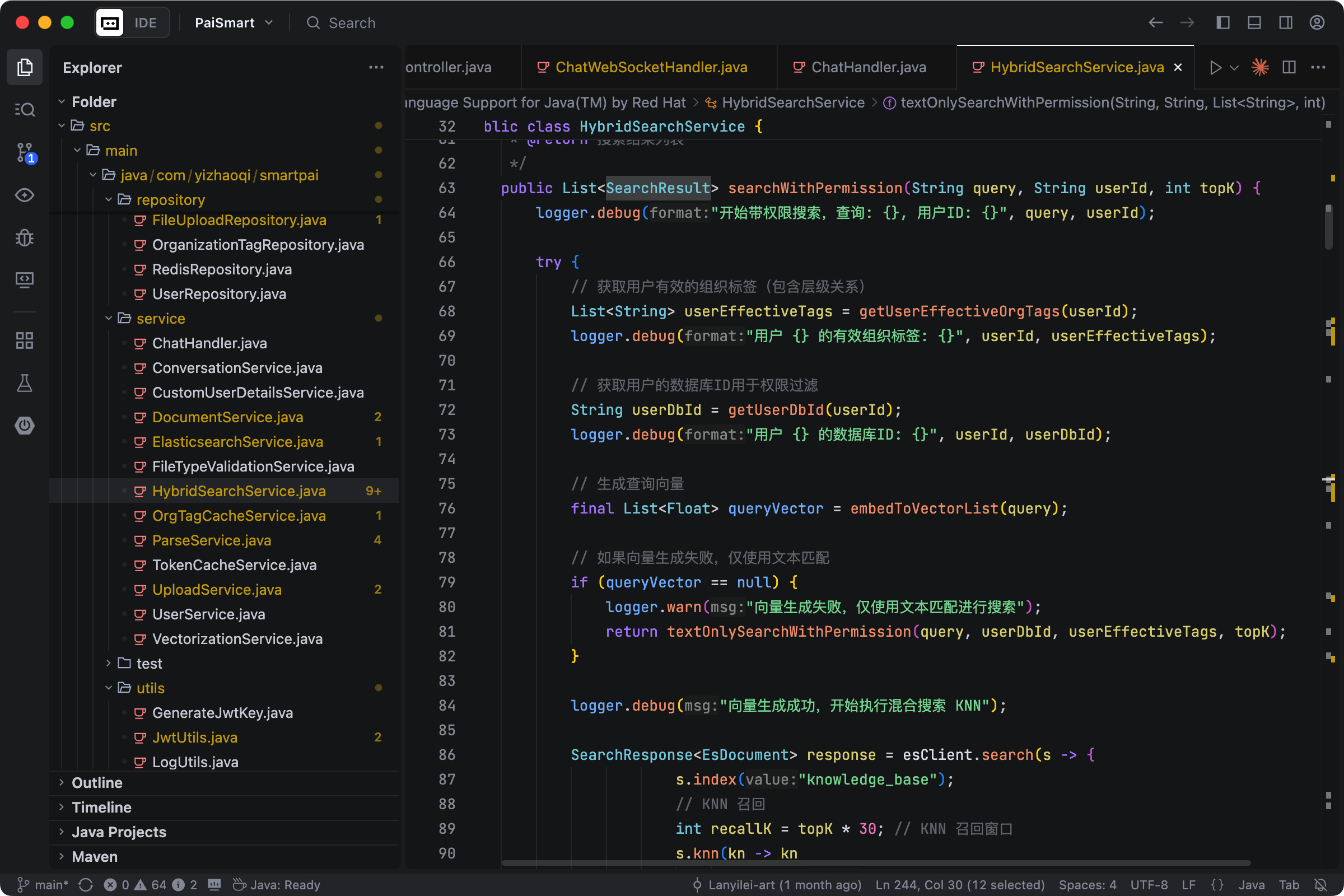
之后,系统会将这些信息作为上下文,连同用户的问题一起发送给 DeepSeek。DeepSeek 会基于我们封装好的 Prompt,生成准确、相关的回答。整个对话过程采用流式输出,用户可以实时看到 AI 的回答过程,体验非常流畅。
四、为什么要学习派聪明?
在大模型席卷全球的今天,掌握主流 Java 技术栈和 AI 工程化能力已成为学生党和工作党在求职中脱颖而出的关键。
在阿里实习的球友直言,现在没有 RAG 简历都过不去,有关 AI 大模型的项目现在真的非常吃香。并且部门的 HR 也说了,要招聘懂点大模型的人。
星球里也非常多球友在迫切地等待派聪明这个 RAG 项目,相信不用我过多的刻画,大家也都知道 AI 项目现在有多吃香。

那经过 4 个多月的打磨和沉淀,派聪明的代码和文档在 2025 年 7 月 29 日这天算是告一段落了。
我相信,派聪明这个项目一定能解决大家的燃眉之急;我也相信,大家会在接下来的求职当中大展拳脚。
星球已经有了前后端分离项目技术派(里面也有 AI 的聊天对话服务),还有微服务项目 PmHub,以及轮子项目 mydb、涉及到 Spring AI 和 Agent 的校招派(同时进行的另外一个项目)等,这些就足够让大家“喝一壶”的了,教程和源码的获取方式可以查看 👉 星球的第一个置顶帖球友必看。
派聪明主打的技术栈和以上这些项目的技术栈也是完全不重叠的,尤其是 RAG 涉及到的一系列 AI 相关的内容,会让大家在 AI 时代吃进红利。
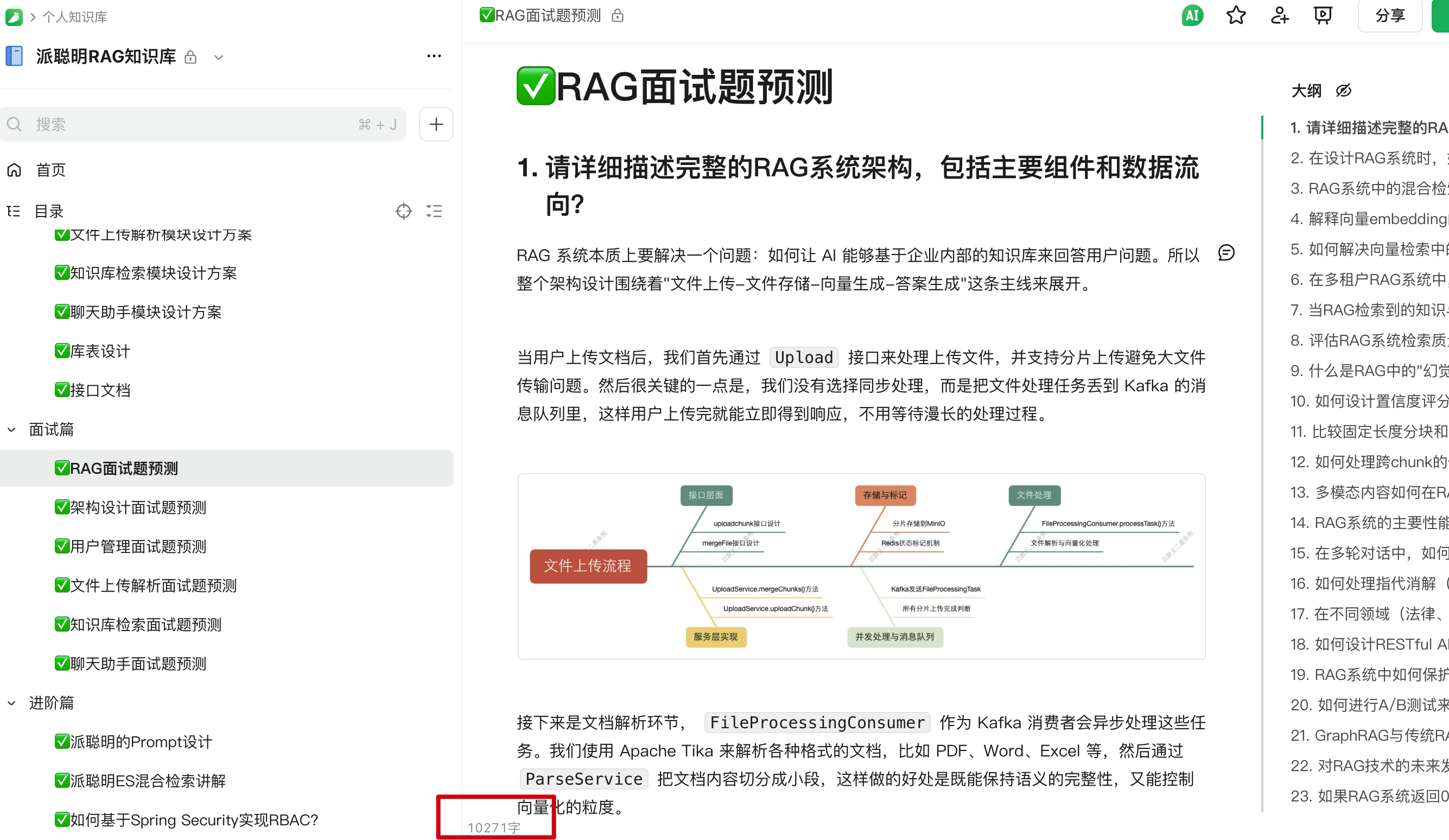
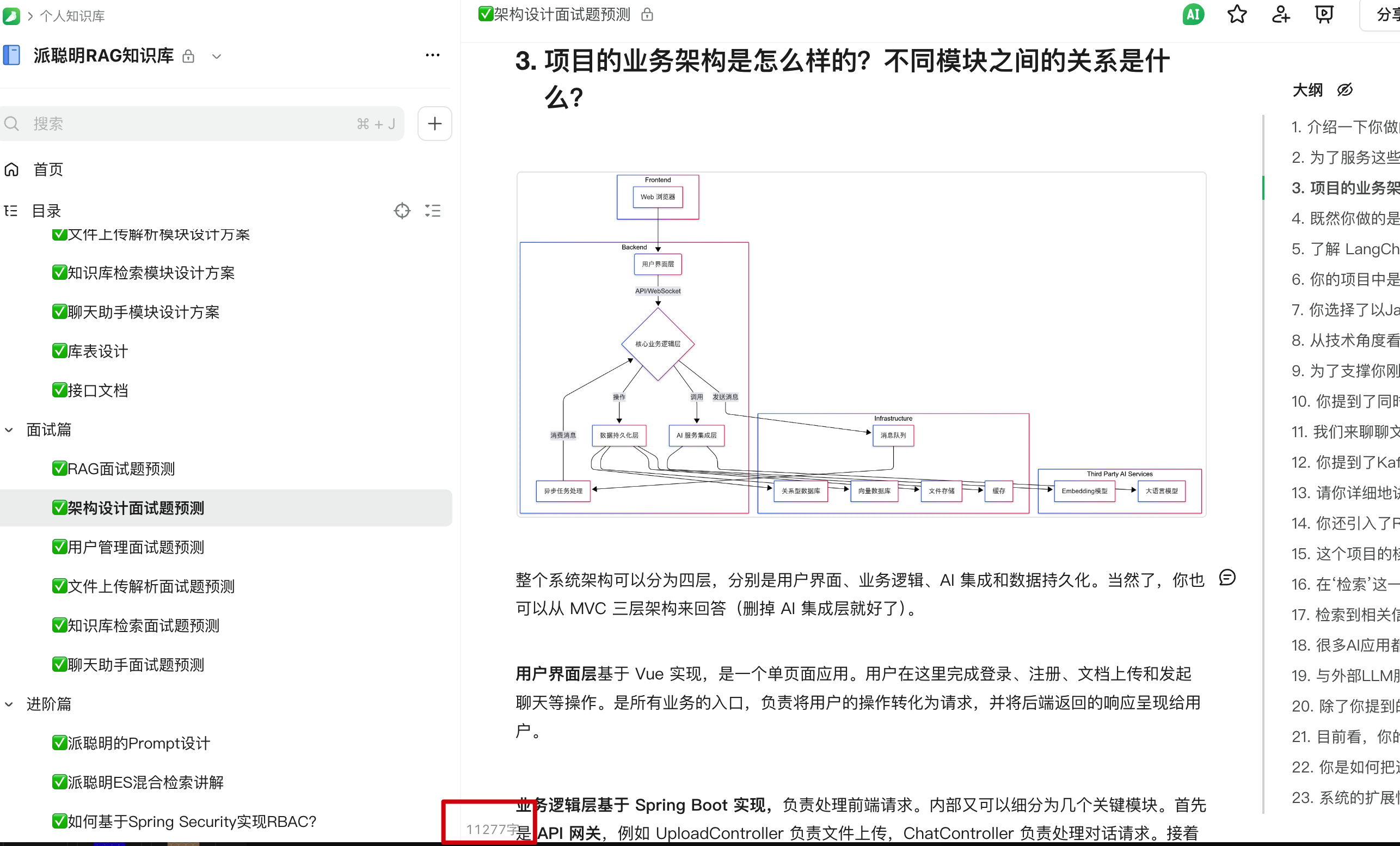
来看看每篇教程的字数吧,RAG 面试题 27 道,一共 10271 字,还有我亲自负责的手绘图;架构设计篇 25 道面试题,一共 11277 字,市面上能做到这种程度的教程,我敢拍着胸脯说,绝对对得起 100 多块钱的门票。
看到这就想迫不及待地解锁派聪明源码和教程的同学,请扫下面的优惠券(或者长按自动识别)加入我们吧,星球目前定价 159 元/年,优惠完只需要 139 元,每天不到 0.38 元,绝对的超值。
超超超低价给到大家,你去其他机构/社群对比一下,这种硬核的教程和源码最起码要价 1999 元,我们现在只要一百多,为的就是尽量减轻大家的钱包负担,我希望用自己最大的诚意,去俘获大家发自内心的口碑。
五、如何给面试官介绍派聪明?
答:
派聪明作为一个基于 RAG 架构的企业级 AI 知识库系统,其核心意义在于解决现代企业知识管理的痛点,推动组织智能化转型。在信息爆炸的时代,企业积累了大量文档资料,但传统的文件管理方式导致知识孤岛现象严重,员工难以快速获取所需信息,严重影响工作效率。
派聪明通过集成 Apache Tika 文档解析、豆包 Embedding 向量模型、Elasticsearch 混合检索技术和 DeepSeek API,构建了一套完整的智能知识处理流水线。
系统能够自动解析 Word、PDF、TXT 等文档,将非结构化信息转化为可检索的知识资产。更重要的是,基于语义理解的向量检索技术突破了传统关键词匹配的局限,用户通过自然语言描述就能够获得要检索的相关内容。
与依赖预训练的模型不同,RAG 能够实时检索最新的企业内部知识,避免模型幻觉,保持回答的准确性。除此之外,派聪明还实现了细粒度的多租户权限控制,确保不同部门和层级的用户只能访问授权范围内的知识。流式的 AI 聊天功也能让知识获取更加自然和高效。
那假如面试官继续追问:你对 RAG 技术了解多少?你可以这样作答。
RAG,也就是检索增强生成,是当前 AI 领域的一项重要技术,它巧妙地结合了信息检索和文本生成两大能力。简单来说,RAG 就是让 AI 在回答问题时,先去“查资料”,然后基于查到的相关信息来生成回答,而不是仅凭训练时的记忆来“凭空想象”。这种方式能有效解决大语言模型的幻觉问题。
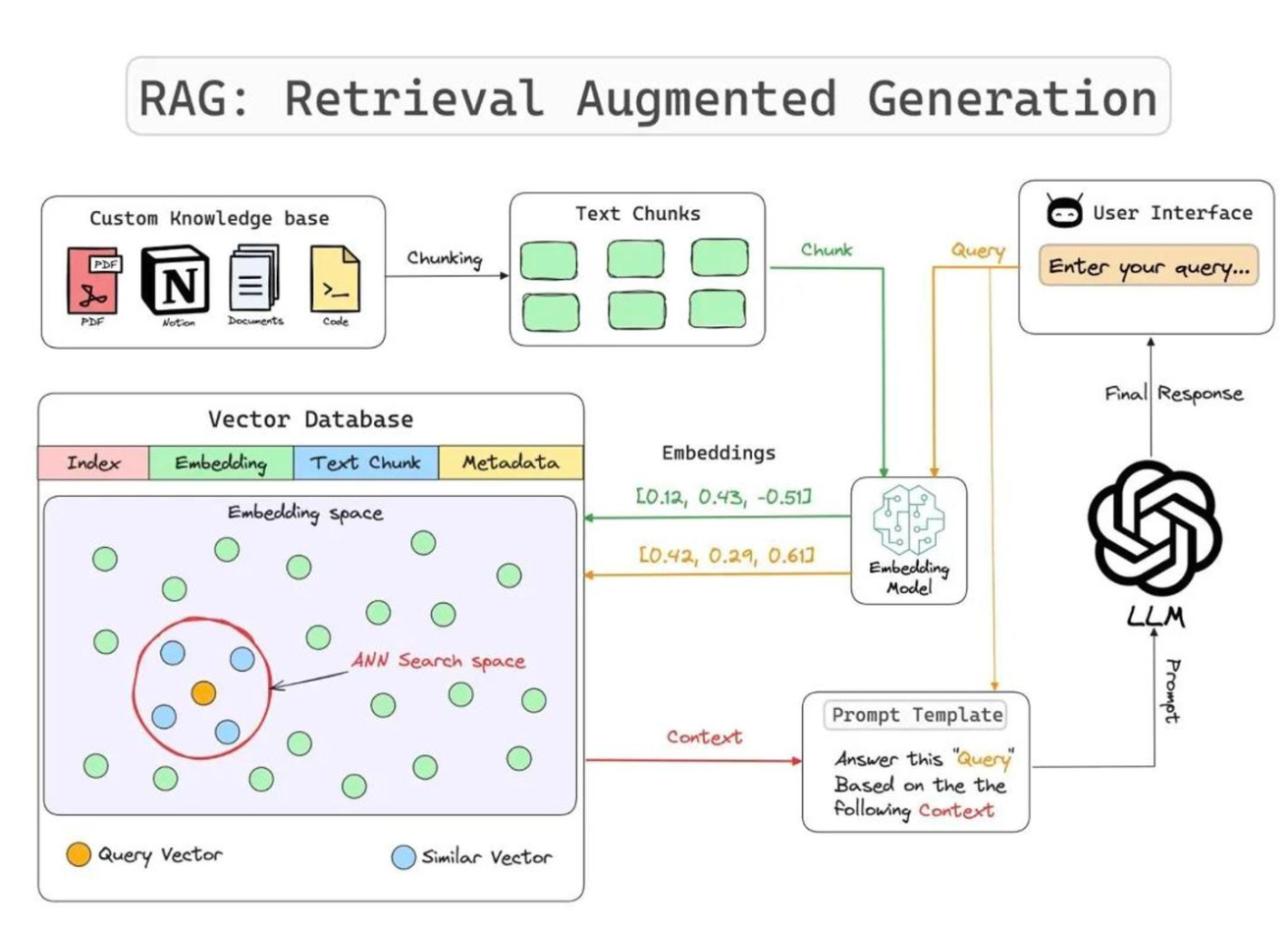
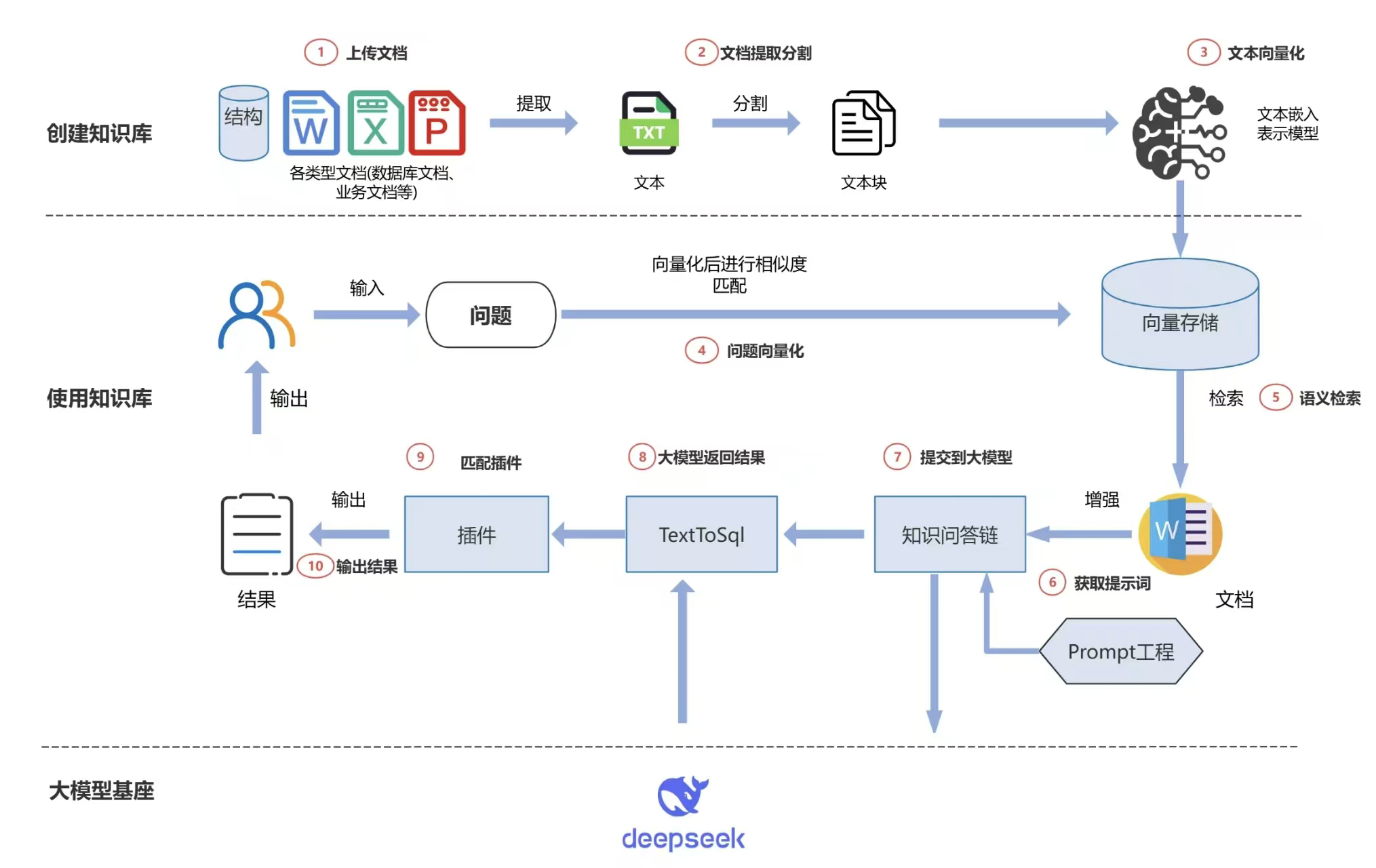
在我参与的派聪明项目中,我们深度实践了 RAG 的技术架构。具体来说,我们的系统分为三个核心环节:
- 首先是知识入库阶段,我们使用 Apache Tika 解析各种格式的企业文档,然后调用豆包的 Embedding 模型将文本转换为向量表示,并存储到 Elasticsearch。
- 其次是检索阶段,当用户提问时,我们同样将问题向量化,然后在 Elasticsearch 中进行混合检索,既包括传统的关键词匹配,也包括基于向量相似度的语义搜索,确保能找到最相关的知识片段。
- 最后是生成阶段,我们将检索到的相关文档作为上下文,连同用户问题一起发送给 DeepSeek,让 AI 基于真实的企业知识来生成准确的回答。
通过派聪明项目的实践,我深刻体会到 RAG 技术的价值所在。它不仅解决了大模型知识更新滞后的问题,更重要的是为企业级 AI 应用提供了可靠的技术路径。这种“有据可查”的 AI 问答方式,让企业用户能够放心地将 RAG 系统应用到实际业务场景中,真正实现 AI 技术的落地。
六、派聪明提供了哪些大模型开发经验?
01、RAG
派聪明最核心的能力就是 RAG,后面还打算增加 MCP 和 Agent 能力,可以说覆盖了整个大模型应用开发的落地经验,并且我们会围绕 RAG 把 AI 相关的一些高频面试题全部讲透。
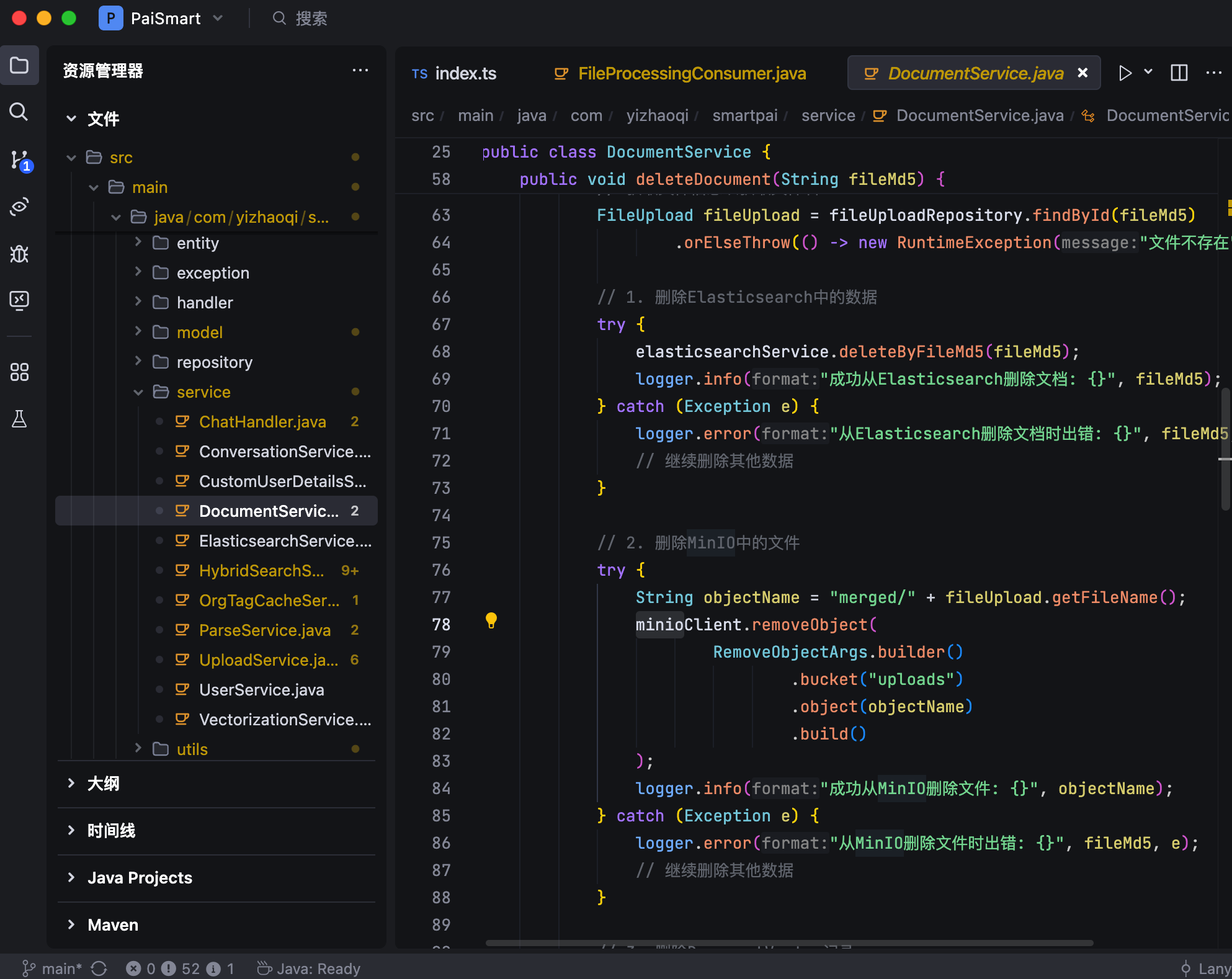
02、文档上传和解析
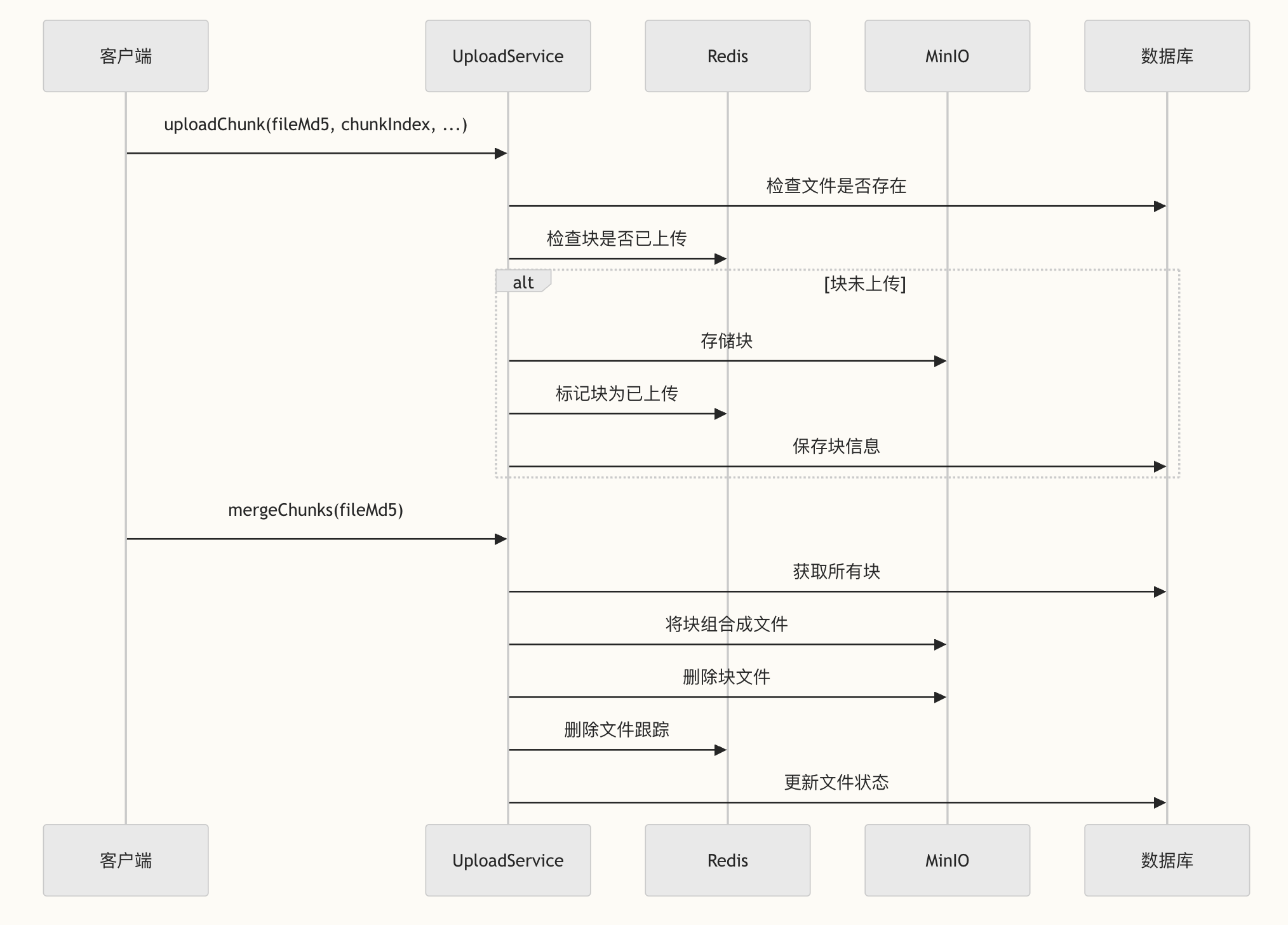
如何上传文档?包括断点续传和分片上传。
如何将用户上传的文档转化为可检索的语义向量?
如何通过 ElasticSearch 实现混合检索,包括关键词搜索与语义搜索?
都是 RAG 非常核心的内容模块。
// 文档处理流程:解析 -> 分块 -> 向量化 -> 存储
public void vectorizeFile(MultipartFile file, String userId, String orgTag, boolean isPublic) {
// 1. 文档解析和分块
List<String> chunks = fileParsingService.parseAndChunk(file);
// 2. 批量向量化
List<float[]> vectors = embeddingClient.batchEmbedding(chunks);
// 3. 构建文档对象
List<EsDocument> documents = buildDocuments(chunks, vectors, metadata);
// 4. 批量存储
elasticsearchService.bulkIndex(documents);
}传统的数据库内容查询主要依赖“关键字匹配”,比如说 MySQL 经常用到的 like xxx%,这种对查询的精确度要求很高,假如我们查询的是“如何提供编程技术”,那么数据库只有“Java、Python 等编程语言的教程”,那么就无法搜索到任何内容。
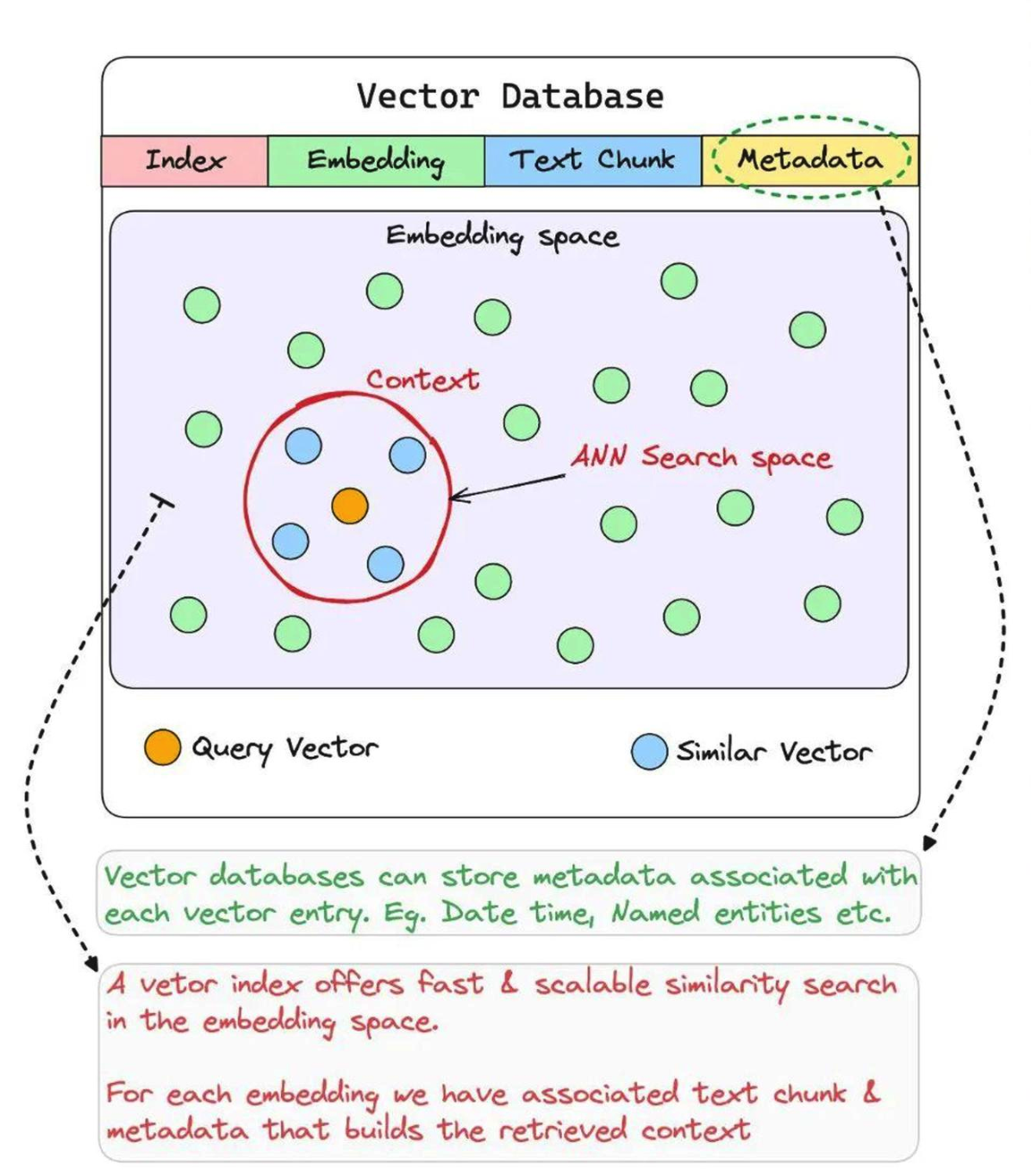
但向量数据库就可以有效解决这个问题,它会把各种知识都转成一组组数据(vector),这些 vector 可以代表知识的内容和特点,当我们在 RAG 知识库中输入要查找的信息时,系统能将输入信息也转成一组组数据,然后找出最相关的知识,从而实现“语义检索”。
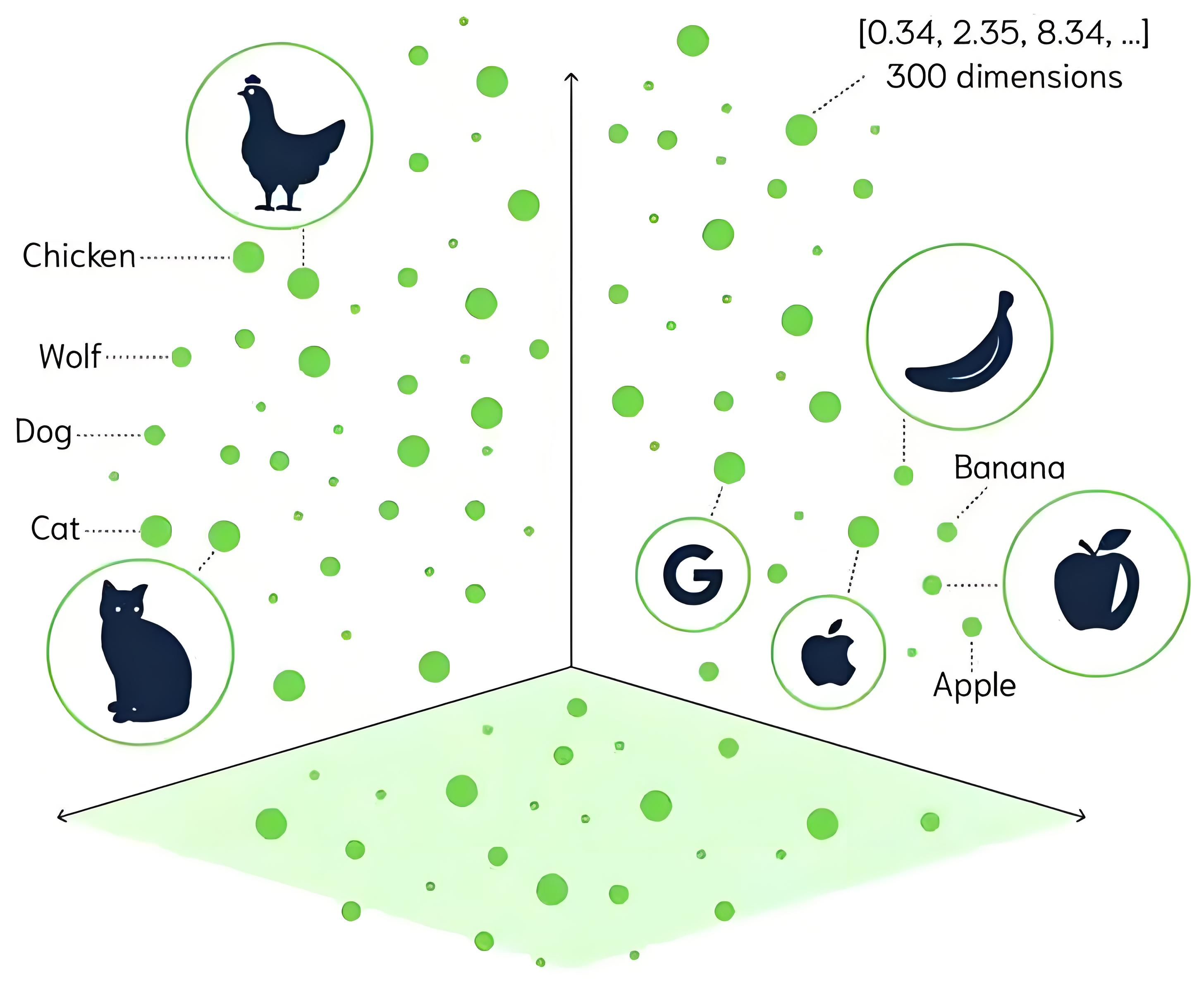
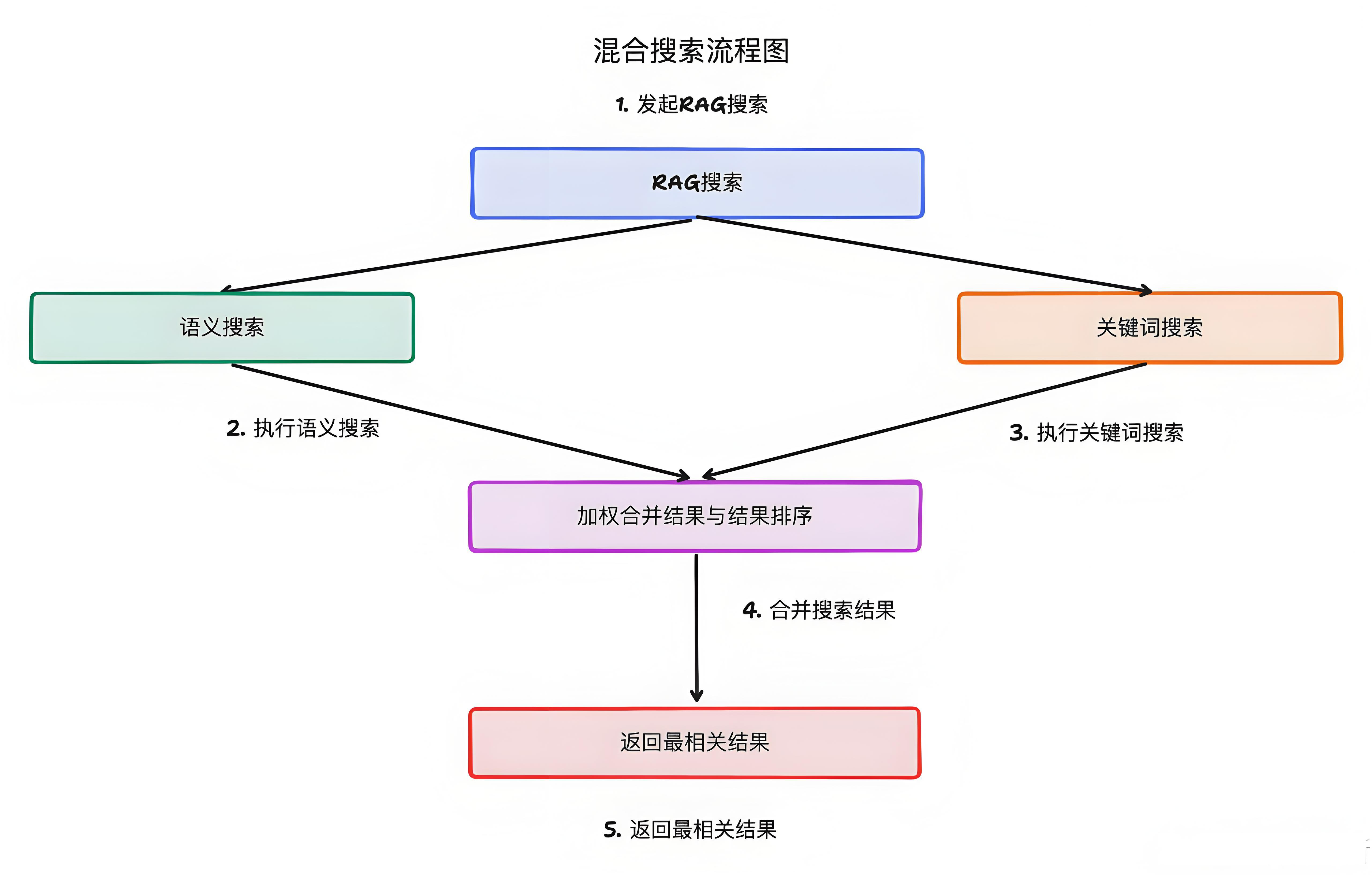
那基于向量知识库的语义检索,虽然解决了传统关键词匹配的局限性,但显然关键词搜索这种场景还是需要的,所以派聪明兼具了关键词检索和语义检索两种能力。
03、集成 DeepSeek 和豆包 Embedding
集成大模型 API 的工程实践,比如说如何集成 DeepSeek,实现流式响应与多轮对话?
如何集成豆包 Embedding 进行文档分块的语义转化?
再比如说如何通过 WebSocket 实现实时通信,逐步推送生成内容?
如何通过 Redis 实现的多轮的对话记忆?
都是 AI 时代非常关键的技术能力。那除了调用 DeepSeek API,我们还支持本地私有的 DeepSeek R1 模型部署。
七、派聪明提供了哪些企业级技术栈?
01、Spring Boot 3.4.2+JDK17
派聪明基于 Spring Boot 3.4.2 版本,使用 Java 17 作为开发语言。
这次真的不用 JDK 8 了,🤣
02、Kafka+Redis+MinIO
派聪明通过 Kafka 实现异步任务调度,使用 Redis 缓存优化对话上下文管理,基于 MinIO 实现大文件分片上传与断点续传。
Redis 的八股就不用多说了,有面渣逆袭 Redis 篇,技术派和 PmHub 中都没有用 Kafka,用的的 RabbitMQ 和 RocketMQ,这次把消息队列中的 Kafka 直接补齐,从此以后再也不用担心 MQ 没有落地经验了(齐活)。
MinIO 的话,在处理文件的时候也经常用到,编程喵当时有讲到,但技术派和 PmHub 中都没有应用,这次派聪明我们也一并补齐了。
03、ElasticSearch
集成 Elasticsearch,实现「关键词+语义」的双引擎搜索。目前已经通过 ES 的 bool should 查询实现了关键词+语义的搜索方式。

04、Vue 3+TypeScript+Vite
派聪明全面采用了 Vue 3 的 Composition API,技术派当时用的是 React,等于说前端的三驾马车就只剩下了 Angular。
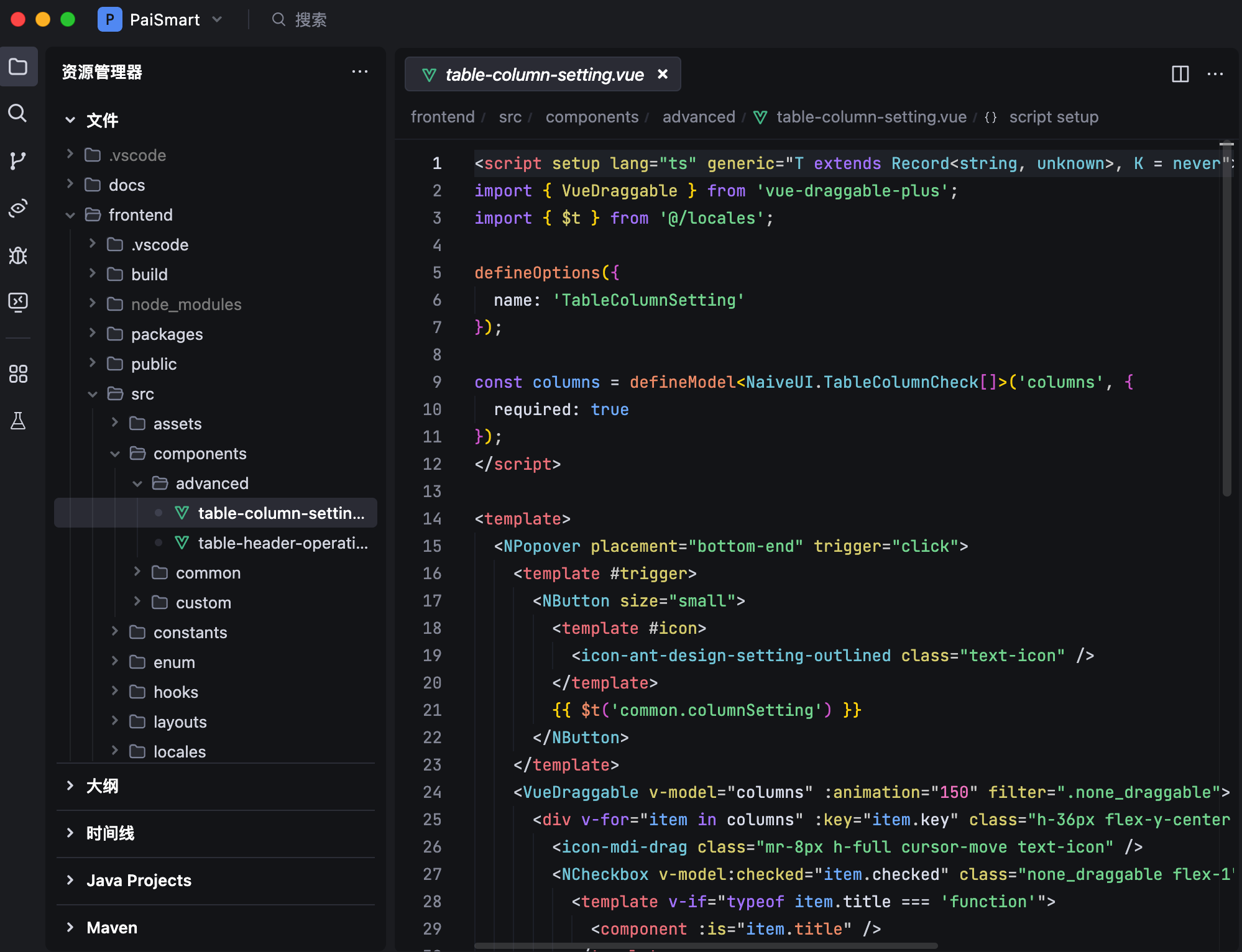
状态管理采用了 Pinia 这一 Vue 3 官方推荐的状态管理库,相比 Vuex 具有更好的 TypeScript 支持和更简洁的 API 设计。状态管理的模块包含主题管理(theme)、路由管理(route)、标签页管理(tab)、认证管理(auth)、应用状态(app)等。
在 vite.config.ts 中,派聪明配置了完整的开发和生产环境构建策略。Vite 的配置支持环境变量加载( loadEnv ),实现了不同环境下的差异化配置,如开发环境的代理设置、生产环境的优化策略等。
整个前端采用了 Monorepo 架构,在 frontend/packages 目录下组织了多个独立的功能包,包括 axios 封装、颜色工具、hooks 库、UI 组件、工具函数等。特别值得关注的是 index.ts 中的 HTTP 客户端封装,项目基于 axios 实现了企业级的请求库,支持请求/响应拦截、错误处理、请求取消、重试机制等高级功能。

05、JWT+Spring Security+RBAC
基于 JWT+Spring Security 实现的多租户认证授权体系。当用户登录时,系统会从数据库查询用户信息,然后将用户 ID、角色、组织标签(orgTags)和主组织标签(primaryOrg)等关键信息都打包到 Token 中。
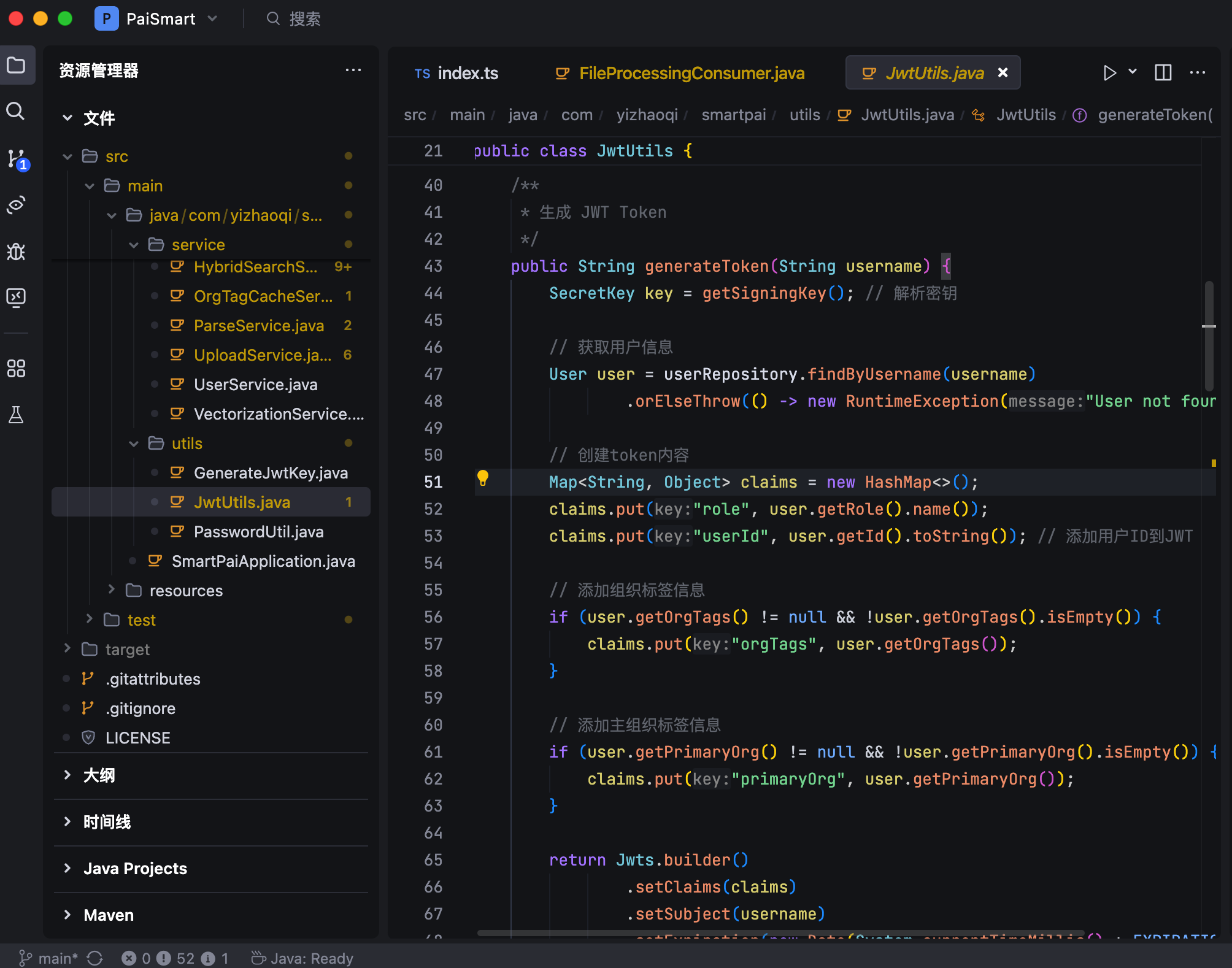
派聪明的多租户权限控制设计了三个层级,非常贴合企业的实际需求。第一层是私人空间权限,以“PRIVATE_”前缀标识的组织标签,只有资源的创建者才能访问,保证用户个人数据的绝对安全。第二层是组织权限,同一个组织标签下的用户可以共享资源,满足团队协作的需求。第三层是公开权限,标记为公开的资源所有用户都能访问,适用于公司公告、共享文档等场景。

06、Mockito+TDD
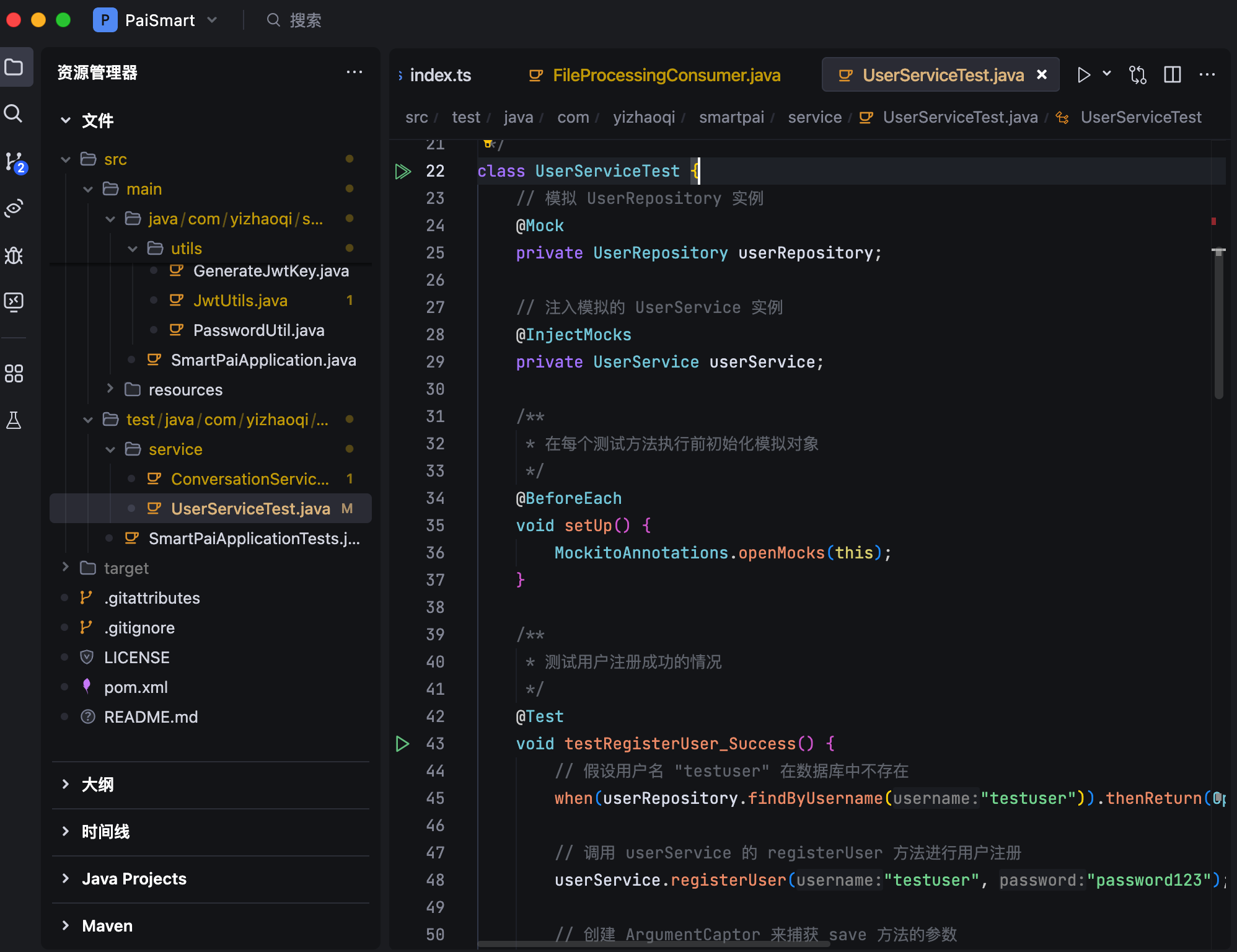
项目采用了 Mockito 注解驱动的测试模式,践行测试驱动开发(TDD)的理念,每个业务功能都有对应的测试用例,包括正常流程和异常流程。通过 @Mock 注解创建模拟对象,比如 UserRepository,这样就不需要真实的数据库连接,@InjectMocks 注解则自动将模拟对象注入到被测试的服务类当中,这种依赖注入的方式让测试变得非常干净和独立。
八、解锁派聪明源码+教程
那这次为了避免盗版,这次的代码仓库采用的是邀请制,加入星球后,在星球第一个置顶帖【球友必看】中获取邀请链接,审核通过后即可查看。
派聪明的教程,这次托管在技术派教程上,之前只要在技术派上绑定过星球的成员编号,均可以解锁查看。
并且了照顾大家的阅读习惯,我们也会在星球里第一时间同步。
加入「二哥的编程星球」后,你还可以享受以下专属内容服务:
- 1、付费文档: PaiFlow工作流Agent、派聪明 RAG、微服务 PmHub、前后端分离技术派、轮子 MYDB、入门编程喵、Agent+MCP 的校招派、类 dify 工作流 PaiAgent、派简历等项目配套的 60 万+ 字教程查看权限
- 2、简历修改: 提供价值超 600 元的简历修改服务,附赠星球 5000+优质简历模板可供参考
- 3、专属问答: 向二哥和星球嘉宾发起 1v1 提问,内容不限于 offer 选择、学习路线、职业规划等
- 4、面试指南: 获取针对校招、社招的 40 万+字面试求职攻略《Java 面试指南》,以及二哥的 LeetCode 刷题笔记、一灰的职场进阶之路、华为 OD 题库
- 5、学习环境: 打造一个沉浸式的学习环境,有一种高考冲刺、大学考研的氛围
截止到 2026 年 02 月 22 日,已经有 13000+ 球友加入星球了,很多同学在认真学习项目之后,都成功拿到了心仪的校招或者社招 offer,我就随便举两个例子。
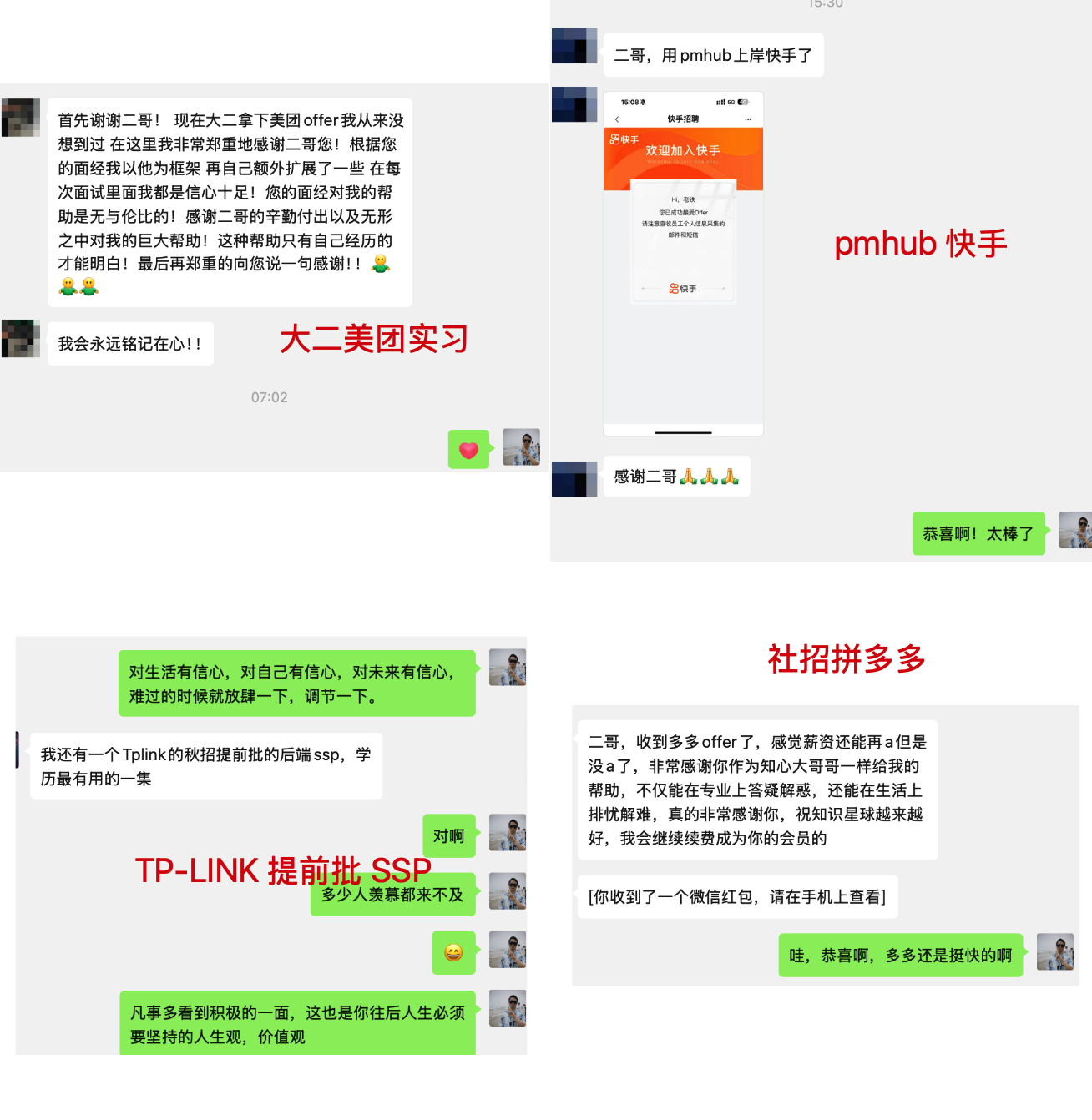
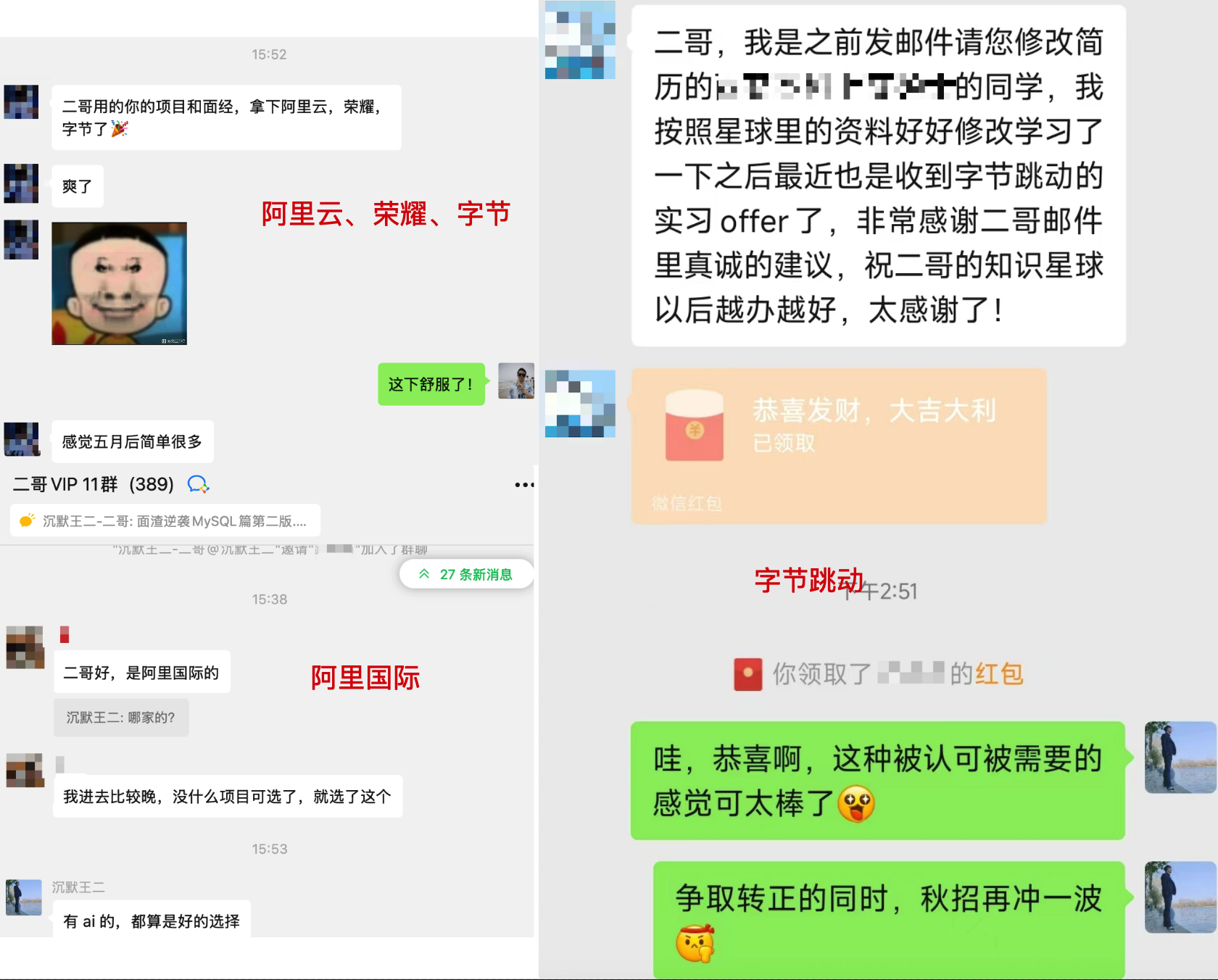
目前,派聪明这个项目也完结了,大家可以放心冲 😊。26 届秋招可以说发了大力。
并且一次购买不需要额外付费,即可获取星球的所有付费资料,帮助你少走弯路,提高学习的效率。直接微信扫下面这个优惠券即可加入。
步骤 ①:微信扫描上方二维码,点击「加入知识星球」按钮 步骤 ②:访问星球置顶帖球友必看:https://t.zsxq.com/11rEo9Pdu,获取项目的源码和配套教程
加入星球需要多少钱呢?星球目前定价 169 元,限时优惠 30 元,目前只需要 139 元就可以加入。
0 人的时候优惠完 69 元,1000 人的时候 79 元,2000 人的时候 89 元,3000 人的时候 99 元,5000 人的时候是 119 元,后面肯定还会继续涨。
付费社群我加入了很多,但从未见过比这更低价格,提供更多服务的社群,光派聪明这个项目的就能让你值回票价。
多说一句,任何时候,技术都是我们程序员的安身立命之本,如果你能认认真真跟完派聪明的源码和教程,相信你的编程功底会提升一大截。
再给大家展示一下派聪明教程的部分目录吧,真的是满满的诚意和干货。
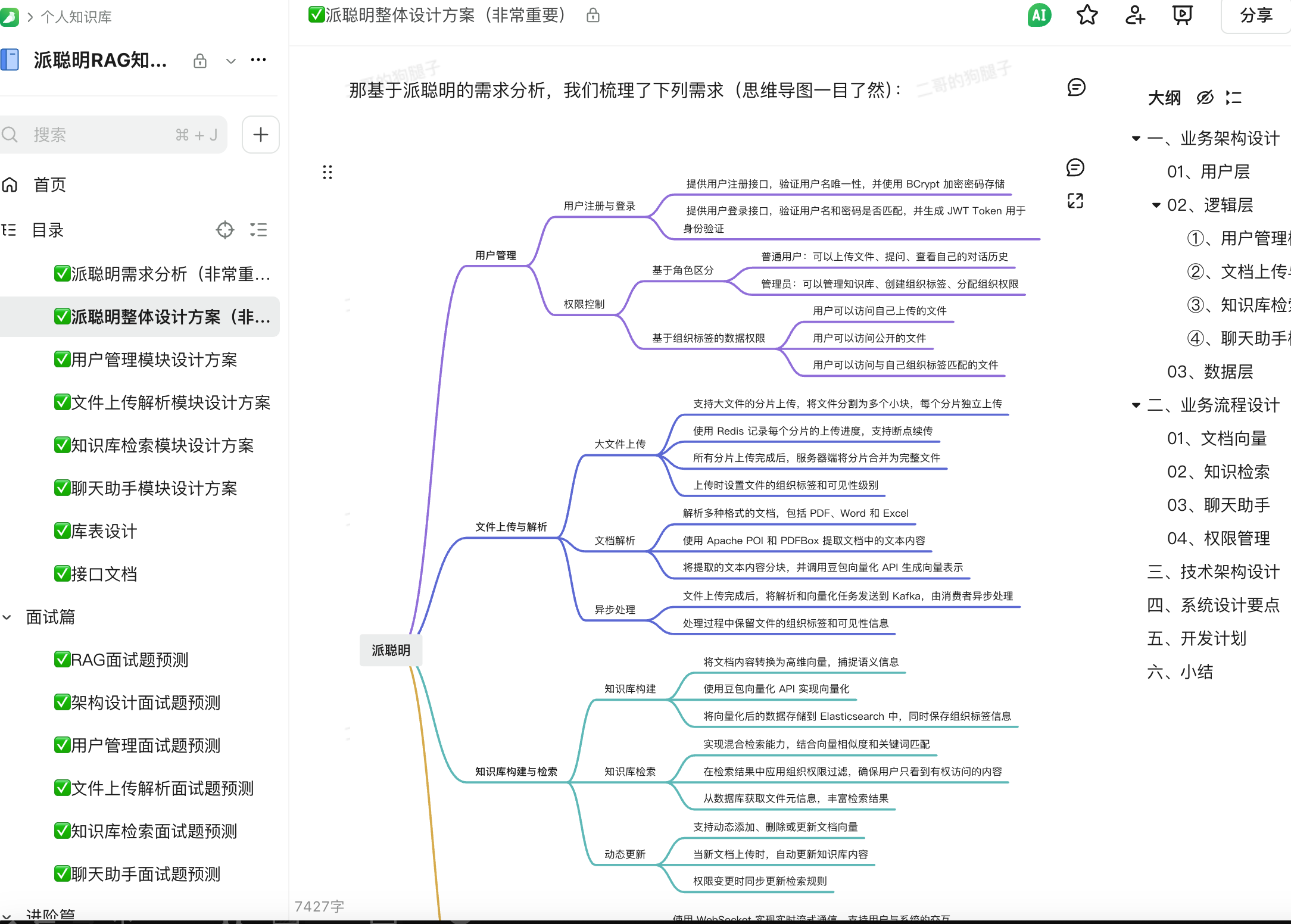
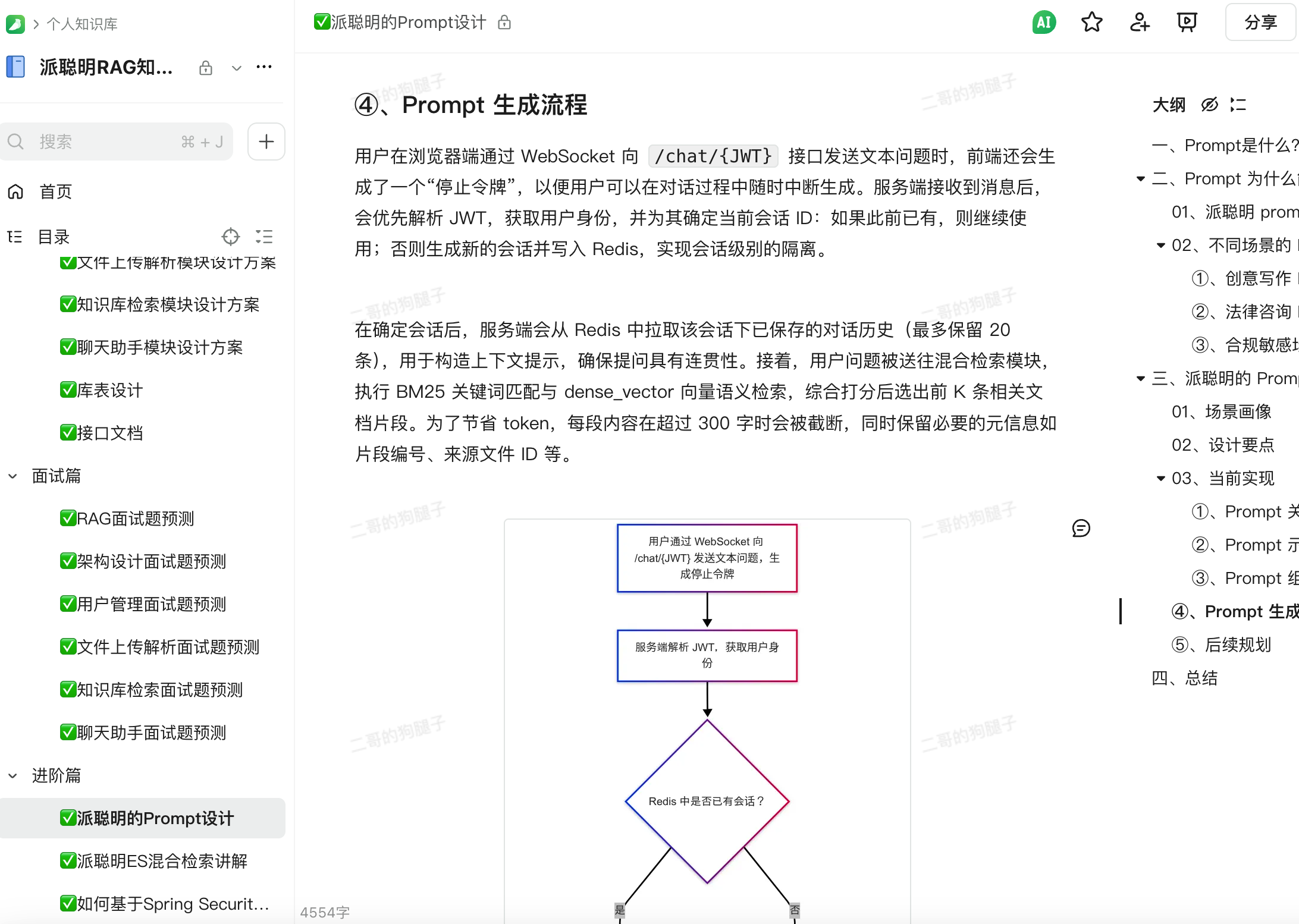

之前就有球友反馈说,“二哥,你这套教程如果让培训机构来卖,1999 元都算少!
讲真心话,这个价格也不会持续很久,星球已经 13000+ 人了,后面还会迎来一波新的涨价(179 元),所以早买早享受,不要等,想好了就去冲,错过不能说后悔一辈子,但至少会有遗憾。
我们的代码,严格按照大厂的标准来,无论是整体的架构,还是具体的细节,都是无可挑剔的学习对象。
之前曾有球友问我:“二哥,你的星球怎么不定价 199、299、399 啊,我感觉星球提供的价值远超这个价格啊。”
答案很明确,我有自己的原则,拒绝割韭菜,用心做内容,能帮一个是一个。
不为别的,为的就是给所有人提供一个可持续的学习环境。当然了,随着人数的增多,二哥付出的精力越来越多,星球也会涨价,今天这批 30 元的优惠券不仅是 2026 年最大的优惠力度,也是 2027 年最大的优惠力度,现在入手就是最划算的,再犹豫就只能等着涨价了。
想想,QQ 音乐听歌连续包年需要 88 元,腾讯视频连续包年需要 178 元,腾讯体育包年 233 元。我相信,二哥编程星球回馈给你的,将是 10 倍甚至百倍的价值。
最后,希望同学们,能紧跟我们的步伐!不要掉队。今年,和二哥一起翻身、一起逆袭、一起晋升、一起拿高薪 offer!
那无论你是社招还是校招,我们都希望你通过派聪明这个项目,能提升自己的简历含金量,拿到更好的 offer,也能更加从容的应对面试中各种 AI 相关的考察。
冲。