Redis面试题,57道Redis八股文(4.6万字286张手绘图),面渣逆袭必看👍

前言
4.6 万字 286 张手绘图,详解 57 道 Redis 面试高频题(让天下没有难背的八股),面渣背会这些 Redis 八股文,这次吊打面试官,我觉得稳了(手动 dog)。整理:沉默王二,戳转载链接,作者:三分恶,戳原文链接。
亮白版本更适合拿出来打印,这也是很多学生党喜欢的方式,打印出来背诵的效率会更高。
2025 年 04 月 27 日开始着手第二版更新。
- 对于高频题,会标注在《Java 面试指南(付费)》中出现的位置,哪家公司,原题是什么,并且会加🌟,目录一目了然;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 区分八股精华回答版本和原理底层解释,让大家知其然知其所以然,同时又能做到面试时的高效回答。
- 结合项目(技术派、pmhub)来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 增加二哥编程星球的球友们拿到的一些 offer,对面渣逆袭的感谢,以及对简历修改的一些认可,以此来激励大家,给大家更多信心。
- 优化排版,增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
由于 PDF 没办法自我更新,所以需要最新版的小伙伴,可以微信搜【沉默王二】,或者扫描/长按识别下面的二维码,关注二哥的公众号,回复【222】即可拉取最新版本。

当然了,请允许我的一点点私心,那就是星球的 PDF 版本会比公众号早一个月时间,毕竟星球用户都付费过了,我有必要让他们先享受到一点点福利。相信大家也都能理解,毕竟在线版是免费的,CDN、服务器、域名、OSS 等等都是需要成本的。
更别说我付出的时间和精力了,大家觉得有帮助还请给个口碑,让你身边的同事、同学都能受益到。
我把二哥的 Java 进阶之路、JVM 进阶之路、并发编程进阶之路,以及所有面渣逆袭的版本都放进来了,涵盖 Java基础、Java集合、Java并发、JVM、Spring、MyBatis、计算机网络、操作系统、MySQL、Redis、RocketMQ、分布式、微服务、设计模式、Linux 等 16 个大的主题,共有 40 多万字,2000+张手绘图,可以说是诚意满满。
展示一下暗黑版本的 PDF 吧,排版清晰,字体优雅,更加适合夜服,晚上看会更舒服一点。
基础
1.🌟说说什么是 Redis?
Redis 是一种基于键值对的 NoSQL 数据库。
它主要的特点是把数据放在内存当中,相比直接访问磁盘的关系型数据库,读写速度会快很多,基本上能达到微秒级的响应。
所以在一些对性能要求很高的场景,比如缓存热点数据、防止接口爆刷,都会用到 Redis。
不仅如此,Redis 还支持持久化,可以将内存中的数据异步落盘,以便服务宕机重启后能恢复数据。
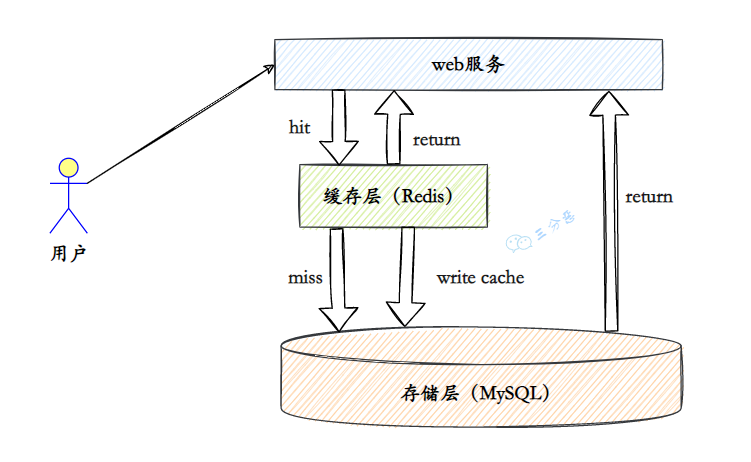
Redis 和 MySQL 的区别?
Redis 属于非关系型数据库,数据是通过键值对的形式放在内存当中的;MySQL 属于关系型数据库,数据以行和列的形式存储在磁盘当中。
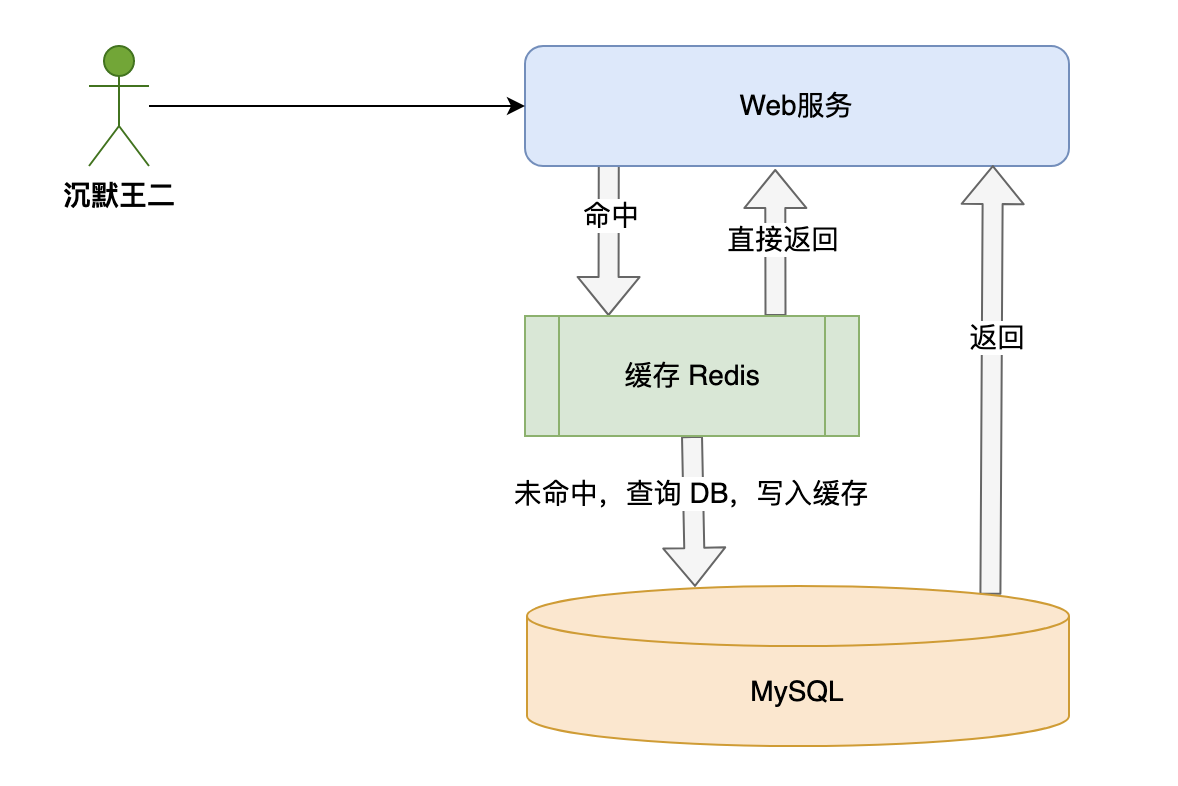
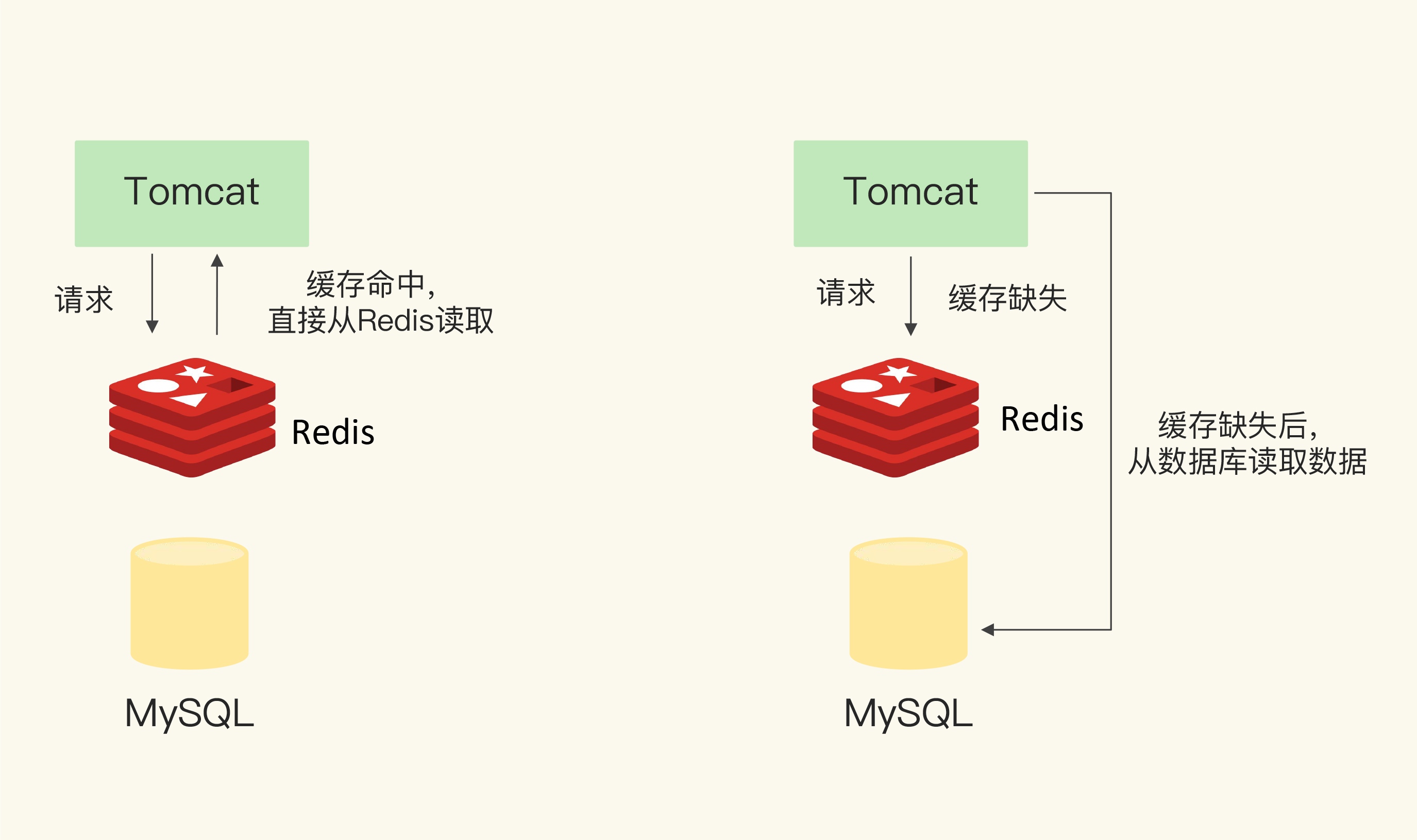
实际开发中,会将 MySQL 作为主存储,Redis 作为缓存,通过先查 Redis,未命中再查 MySQL 并写回Redis 的方式来提高系统的整体性能。
项目里哪里用到了 Redis?
在技术派实战项目当中,有很多地方都用到了 Redis,比如说用户活跃排行榜用到了 zset,作者白名单用到了 set。
还有用户登录后的 Session、站点地图 SiteMap,分别用到了 Redis 的字符串和哈希表两种数据类型。
其中比较有挑战性的一个应用是,通过 Lua 脚本封装 Redis 的 setnex 命令来实现分布式锁,以保证在高并发场景下,热点文章在短时间内的高频访问不会击穿 MySQL。
部署过 Redis 吗?
第一种回答版本:
我只在本地部署过单机版,下载 Redis 的安装包,解压后运行 redis-server 命令即可。
第二种回答版本:
我有在生产环境中部署单机版 Redis,从官网下载源码包解压后执行 make && make install 编译安装。然后编辑 redis.conf 文件,开启远程访问、设置密码、限制内存、设置内存过期淘汰策略、开启 AOF 持久化等:
bind 0.0.0.0 # 允许远程访问
requirepass your_password # 设置密码
maxmemory 4gb # 限制内存,避免 OOM
maxmemory-policy allkeys-lru # 内存淘汰策略
appendonly yes # 开启 AOF 持久化第三种回答版本:
我有使用 Docker 拉取 Redis 镜像后进行容器化部署。
docker run -d --name redis -p 6379:6379 redis:7.0-alpineRedis 的高可用方案有部署过吗?
有部署过哨兵机制,这是一个相对成熟的高可用解决方案,我们生产环境部署的是一主两从的 Redis 实例,再加上三个 Sentinel 节点监控它们。Sentinel 的配置相对简单,主要设置了故障转移的判定条件和超时阈值。
主节点配置:
port 6379
appendonly yes从节点配置:
replicaof 192.168.1.10 6379哨兵节点配置:
sentinel monitor mymaster 192.168.1.10 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1当主节点发生故障时,Sentinel 能够自动检测并协商选出新的主节点,这个过程大概需要 10-15 秒。
另一个大型项目中,我们使用了 Redis Cluster 集群方案。该项目数据量大且增长快,需要水平扩展能力。我们部署了 6 个主节点,每个主节点配备一个从节点,形成了一个 3主3从 的初始集群。Redis Cluster 的设置比 Sentinel 复杂一些,需要正确配置集群节点间通信、分片映射等。
redis-server redis-7000.conf
redis-server redis-7001.conf
...
# 使用 redis-cli 创建集群
# Redis 会自动将 key 哈希到 16384 个槽位
# 主节点均分槽位,从节点自动跟随
redis-cli --cluster create \
127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 \
127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1Redis Cluster 最大的优势是数据自动分片,我们可以通过简单地增加节点来扩展集群容量。此外,它的故障转移也很快,通常在几秒内就能完成。
对于一些轻量级应用,我也使用过主从复制加手动故障转移的方案。主节点负责读写操作,从节点负责读操作。手动故障转移时,我们会先将从节点提升为主节点,然后重新配置其他从节点。
# 1. 取消从节点身份
redis-cli -h <slave-ip> slaveof no one
# 2. 将其他从节点指向新的主节点
redis-cli -h <other-slave-ip> slaveof <new-master-ip> <port>用过哪些缓存数据库,除redis以外?
技术派实战项目中还用到了 Guava Cache 和 Caffeine 作为本地缓存,Guava Cache 适合小规模缓存,Caffeine 性能更好,支持更多高级特性。
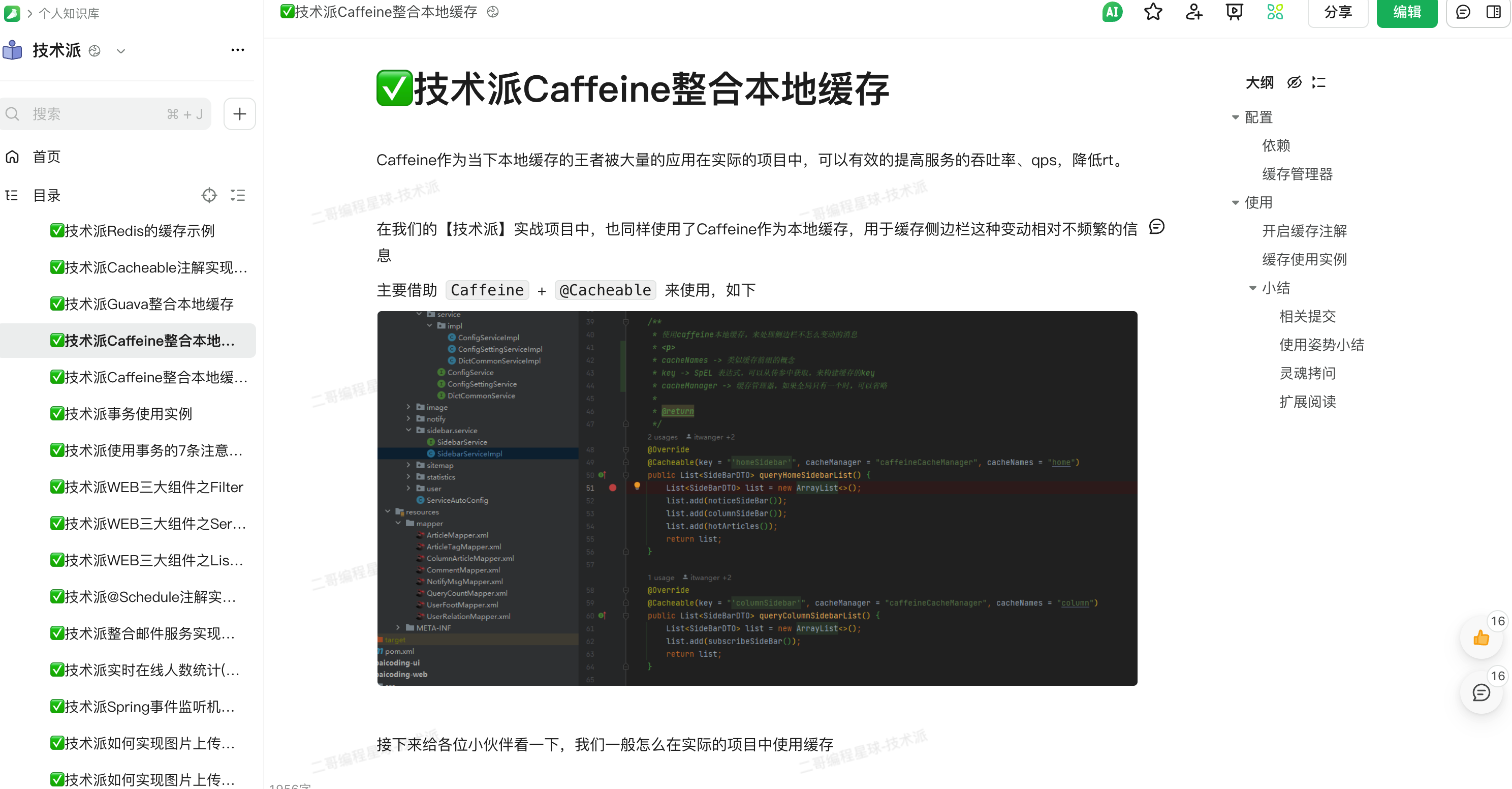
Caffeine 通常用来作为二级缓存来使用,主要用于存储一些不经常变动的数据,以减轻 Redis 的压力。
- Java 面试指南(付费)收录的华为一面原题:说下 Redis 和 HashMap 的区别
- Java 面试指南(付费)收录的字节跳动商业化一面的原题:Redis 和 MySQL 的区别
- Java 面试指南(付费)收录的农业银行面经同学 7 Java 后端面试原题:Redis 相关的基础知识
- Java 面试指南(付费)收录的华为 OD 面经同学 1 一面面试原题:Redis 的了解, 部署方案?
- Java 面试指南(付费)收录的农业银行面经同学 3 Java 后端面试原题:项目里哪里用到了 Redis
- Java 面试指南(付费)收录的 360 面经同学 3 Java 后端技术一面面试原题:用过 redis 吗 用来干什么
- Java 面试指南(付费)收录的招商银行面经同学 6 招银网络科技面试原题:了解 MySQL、Redis 吗?
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:项目中什么地方使用了 redis 缓存,redis 为什么快?
- Java 面试指南(付费)收录的国企零碎面经同学 9 面试原题:数据库用什么多(说了 Mysql 和 Redis)
- Java 面试指南(付费)收录的荣耀面经同学 4 面试原题:Redis和MySQL的区别?
- Java 面试指南(付费)收录的海康威视同学 4面试原题:Redis部署
- Java 面试指南(付费)收录的华为 OD 面经同学 1 一面面试原题:Redis 的了解, 部署方案?
- Java 面试指南(付费)收录的同学 30 腾讯音乐面试原题:redis的部署方式都有哪些呢,各自有什么优缺点?
memo:2025 年 9 月 23 日修改至此,今天帮球友修改简历的时候,收到一位球友的反馈说,从 8.16 加入星球以来,每天都在星球里充电学习,学到了很多东西。对于这种正反馈我是非常开心的。

2.Redis 可以用来干什么?
Redis 可以用来做缓存,比如说把高频访问的文章详情、商品信息、用户信息放入 Redis 当中,并通过设置过期时间来保证数据一致性,这样就可以减轻数据库的访问压力。
Redis 的 Zset 还可以用来实现积分榜、热搜榜,通过 score 字段进行排序,然后取前 N 个元素,就能实现 TOPN 的榜单功能。

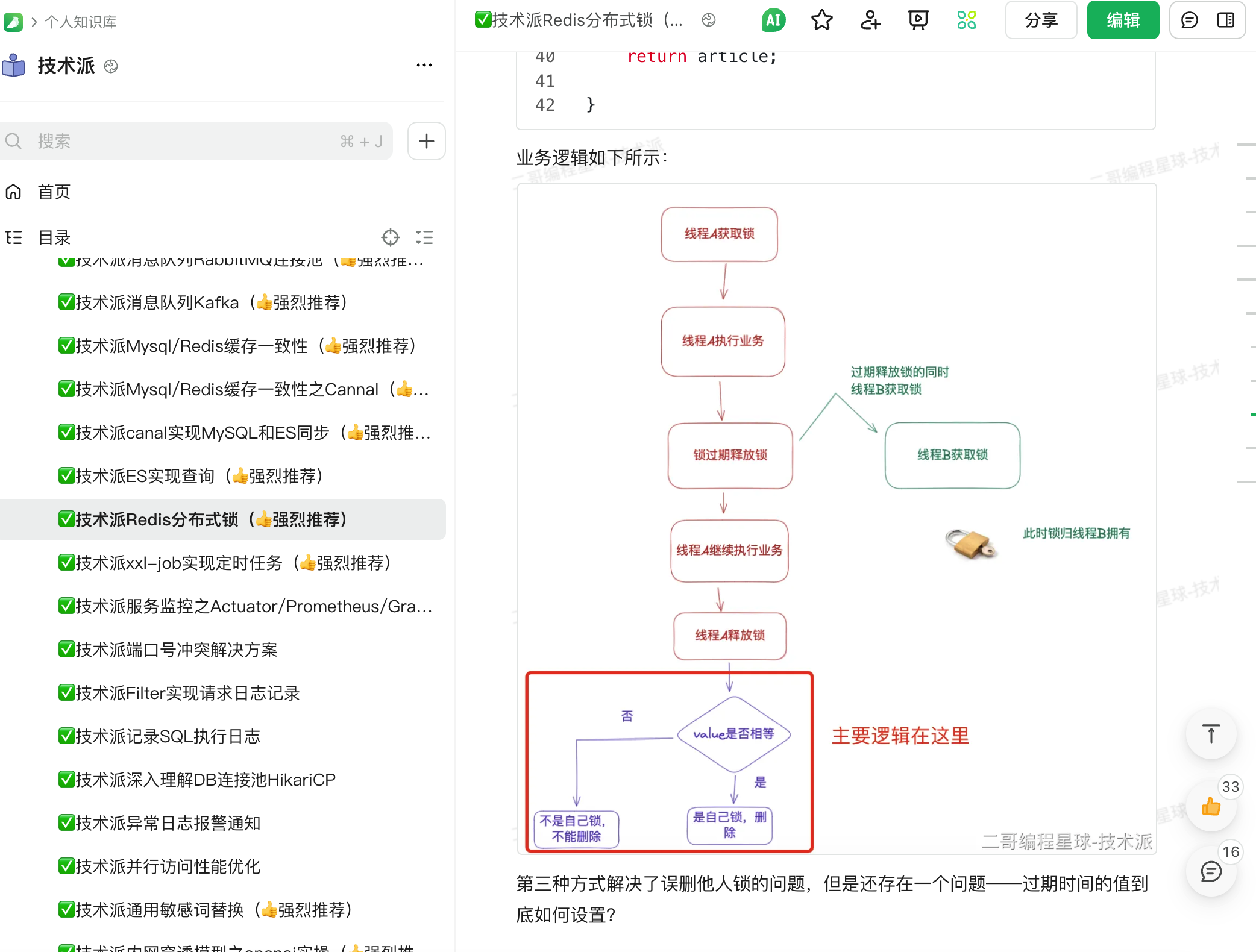
利用 Redis 的 SETNX 命令或者 Redisson 还可以实现分布式锁,确保同一时间只有一个节点可以持有锁;为了防止出现死锁,可以给锁设置一个超时时间,到期后自动释放;并且最好开启一个监听线程,当任务尚未完成时给锁自动续期。
如果是秒杀接口,还可以使用 Lua 脚本来实现令牌桶算法,限制每秒只能处理 N 个请求。
-- KEYS[1]: 令牌桶的key
-- ARGV[1]: 桶容量
-- ARGV[2]: 令牌生成速率(每秒)
-- ARGV[3]: 当前时间戳(秒)
local bucket = redis.call('HMGET', KEYS[1], 'tokens', 'timestamp')
local tokens = tonumber(bucket[1]) or ARGV[1]
local last_time = tonumber(bucket[2]) or ARGV[3]
local rate = tonumber(ARGV[2])
local capacity = tonumber(ARGV[1])
local now = tonumber(ARGV[3])
-- 计算新令牌数
local delta = math.max(0, now - last_time)
local add_tokens = delta * rate
tokens = math.min(capacity, tokens + add_tokens)
last_time = now
local allowed = 0
if tokens >= 1 then
tokens = tokens - 1
allowed = 1
end
redis.call('HMSET', KEYS[1], 'tokens', tokens, 'timestamp', last_time)
redis.call('EXPIRE', KEYS[1], 3600) -- 过期时间可自定义
return allowed在 Java 中调用 Lua 脚本:
// 令牌桶参数
int capacity = 10; // 桶容量
int rate = 2; // 每秒2个令牌
long now = System.currentTimeMillis() / 1000;
String key = "token_bucket:user:123";
// 调用 Lua 脚本,返回 1 表示通过,0 表示被限流
Long allowed = (Long) redis.eval(luaScript, 1, key, String.valueOf(capacity), String.valueOf(rate), String.valueOf(now));redis做缓存要考虑哪些问题,在业务方面呢
一类是经典的缓存系统设计问题(穿透、击穿、雪崩),另一类是与业务逻辑紧密相关的业务缓存问题(数据一致性、缓存粒度等)。
当修改了数据库的数据后,如何保证缓存里的数据也同步更新?如果处理不好,用户就会看到“脏数据”。
另外就是我们应该缓存一个完整的、包含各种关联信息的复杂对象,还是只缓存那些最常用的基础字段?
- Java 面试指南(付费)收录的农业银行面经同学 7 Java 后端面试原题:Redis 相关的基础知识
- Java 面试指南(付费)收录的字节跳动同学 7 Java 后端实习一面的原题:讲一下为什么要用 Redis 去存权限列表?
- Java 面试指南(付费)收录的字节跳动同学 20 测开一面的原题:redis 有什么好处,为什么用 redis
memo:2025 年 4 月 28 日修改至此,今天帮球友修改简历的时候,碰到一位东南大学本硕连读的球友,星球能来这么多优秀的球友,真的很开心啊。

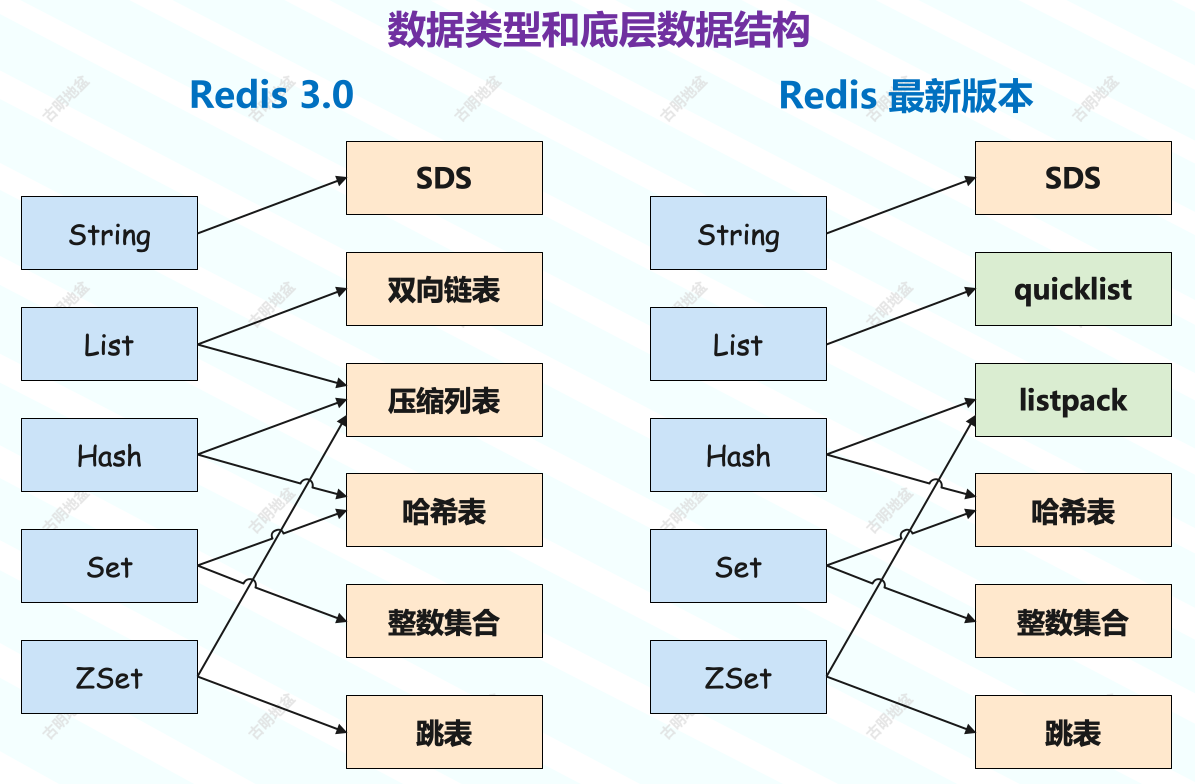
3.🌟Redis有哪些数据类型?
Redis 支持五种基本数据类型,分别是字符串、列表、哈希、集合和有序集合。
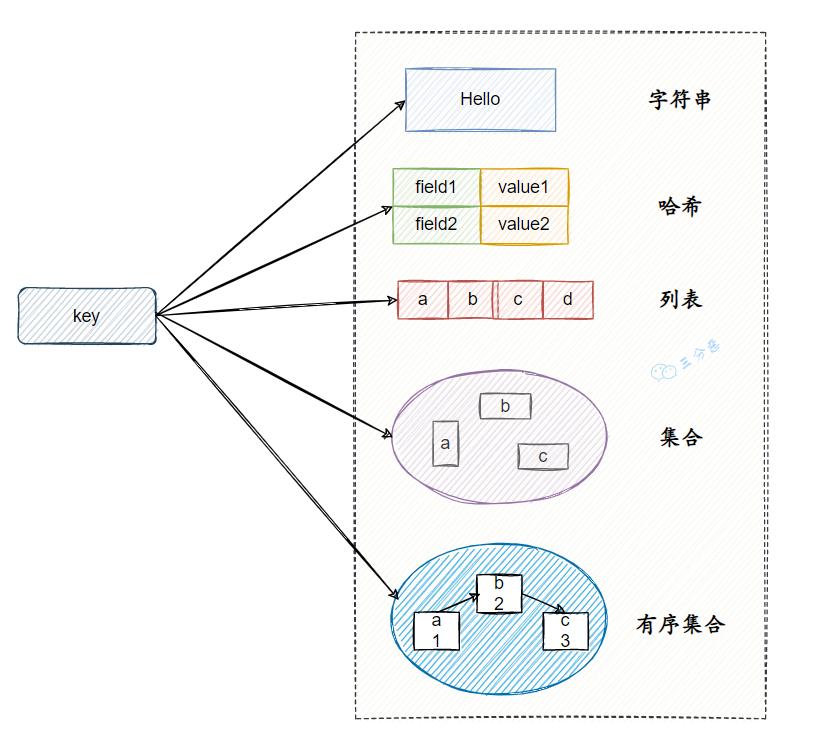
还有三种扩展数据类型,分别是用于位级操作的 Bitmap、用于基数估算的 HyperLogLog、支持存储和查询地理坐标的 GEO。
详细介绍下字符串?
字符串是最基本的数据类型,可以存储文本、数字或者二进制数据,最大容量是 512 MB。
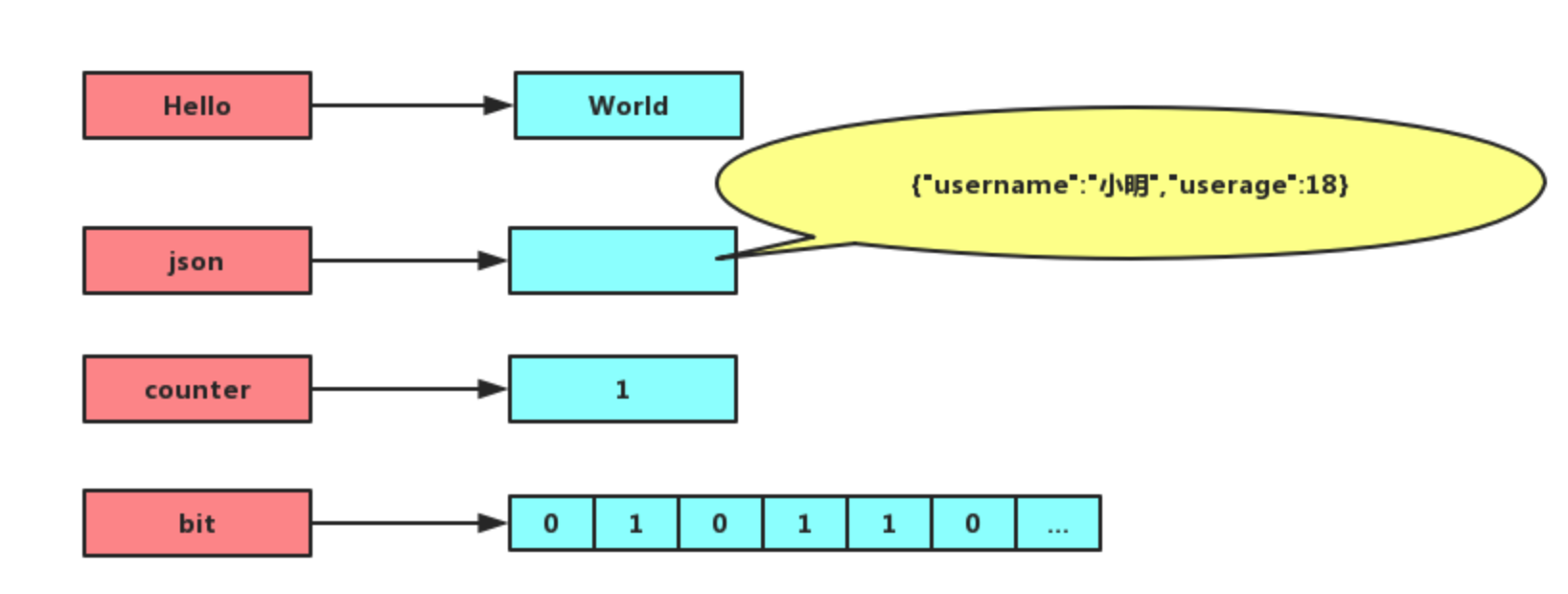
适合缓存单个对象,比如验证码、token、计数器等。
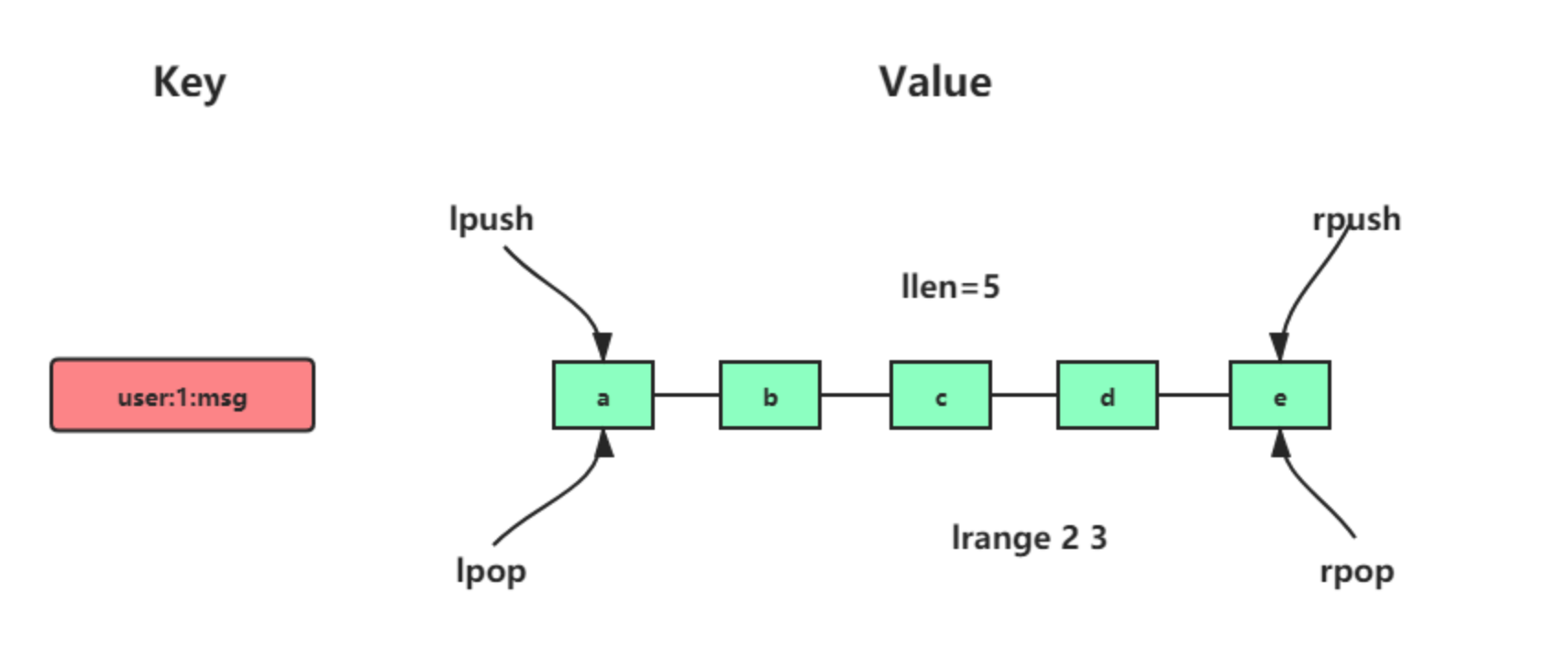
详细介绍下列表?
列表是一个有序的元素集合,支持从头部或尾部插入/删除元素,常用于消息队列或任务列表。
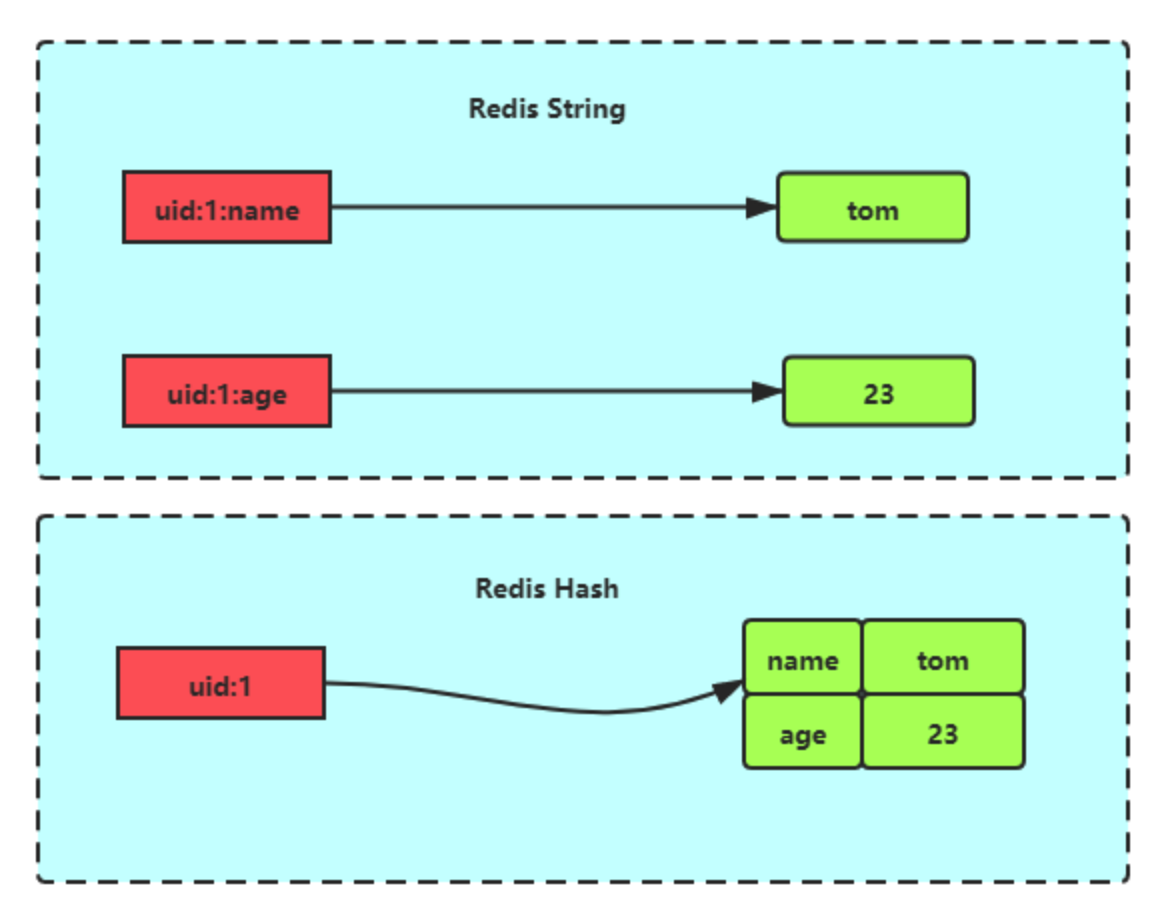
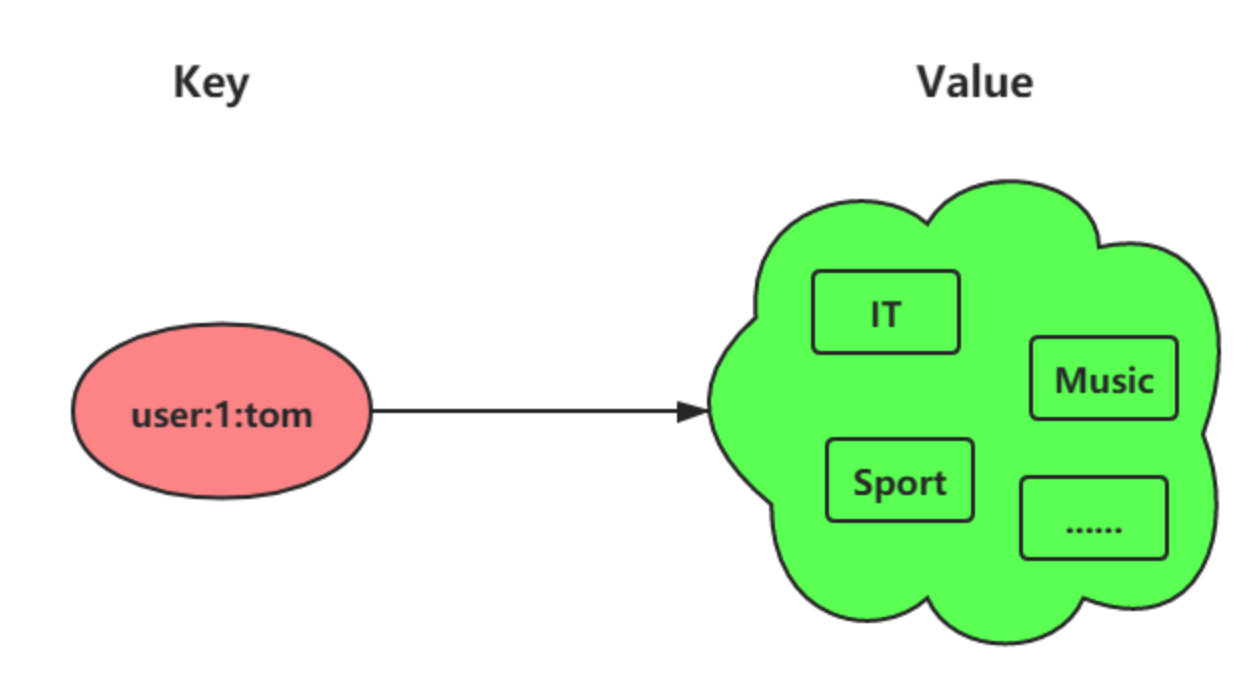
详细介绍下哈希?
哈希是一个键值对集合,适合存储对象,如商品信息、用户信息等。比如说 value = {name: '沉默王二', age: 18}。
详细介绍下集合?
集合是无序且不重复的,支持交集、并集操作,查询效率能达到 O(1) 级别,主要用于去重、标签、共同好友等场景。
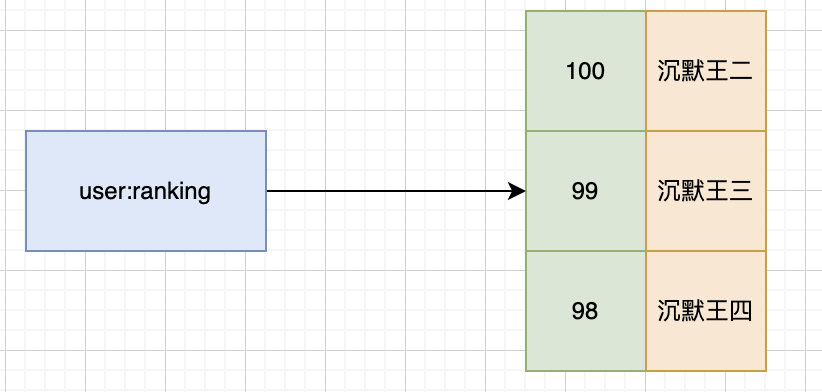
详细介绍下有序集合?
有序集合的元素按分数进行排序,支持范围查询,适用于排行榜或优先级队列。
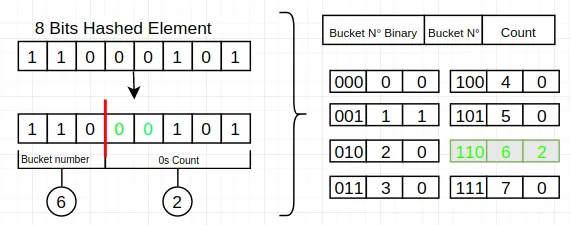
详细介绍下Bitmap?
Bitmap 可以把一组二进制位紧凑地存储在一块连续内存中,每一位代表一个对象的状态,比如是否签到、是否活跃等。
比如用户 0 的已签到 1、用户 1 未签到 0、用户 2 已签到,Redis 就会把这些状态放进一个连续的二进制串 101,1 亿用户签到仅需 100,000,000 / 8 / 1024 ≈ 12MB 的空间,真的省到离谱。
详细介绍下HyperLogLog?
HyperLogLog 是一种用于基数统计的概率性数据结构,可以在仅有 12KB 的内存空间下,统计海量数据集中不重复元素的个数,误差率仅 0.81%。
底层基于 LogLog 算法改进,先把每个元素哈希成一个二进制串,然后取前 14 位进行分组,放到 16384 个桶中,记录每组最大的前导零数量,最后用一个近似公式推算出总体的基数。
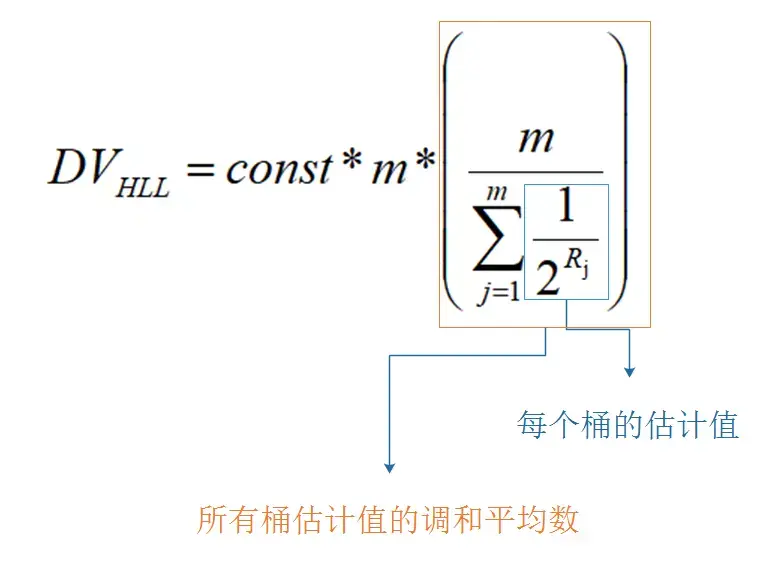
个桶,每个桶 6 Bit,刚好 16384 * 6 /8 / 1024 K = 12KB,8 bit = 1 byte。
举个超简单的例子,假设有一个神奇的哈希函数,可以把元素散列成一个二进制数,比如:
| 元素 | 哈希值 | 前导零个数 |
|---|---|---|
| userA | 000100101… | 3 |
| userB | 001010011… | 2 |
| userC | 000000101… | 6 |
可以发现,哈希值越长前导零越多,也就说明集合里的元素越多。
大型网站 UV 统计系统示例:
public class UVCounter {
private Jedis jedis;
public void recordVisit(String date, String userId) {
String key = "uv:" + date;
jedis.pfadd(key, userId);
}
public long getUV(String date) {
return jedis.pfcount("uv:" + date);
}
public long getUVBetween(String startDate, String endDate) {
List<String> keys = getDateKeys(startDate, endDate);
return jedis.pfcount(keys.toArray(new String[0]));
}
}详细介绍下GEO?
GEO 用于存储和查询地理位置信息,可以用来计算两点之间的距离,查找某位置半径内的其他元素。
常见的应用场景包括:附近的人或者商家、计算外卖员和商家的距离、判断用户是否进入某个区域等。
底层基于 ZSet 实现,通过 Geohash 算法把经纬度编码成 score。
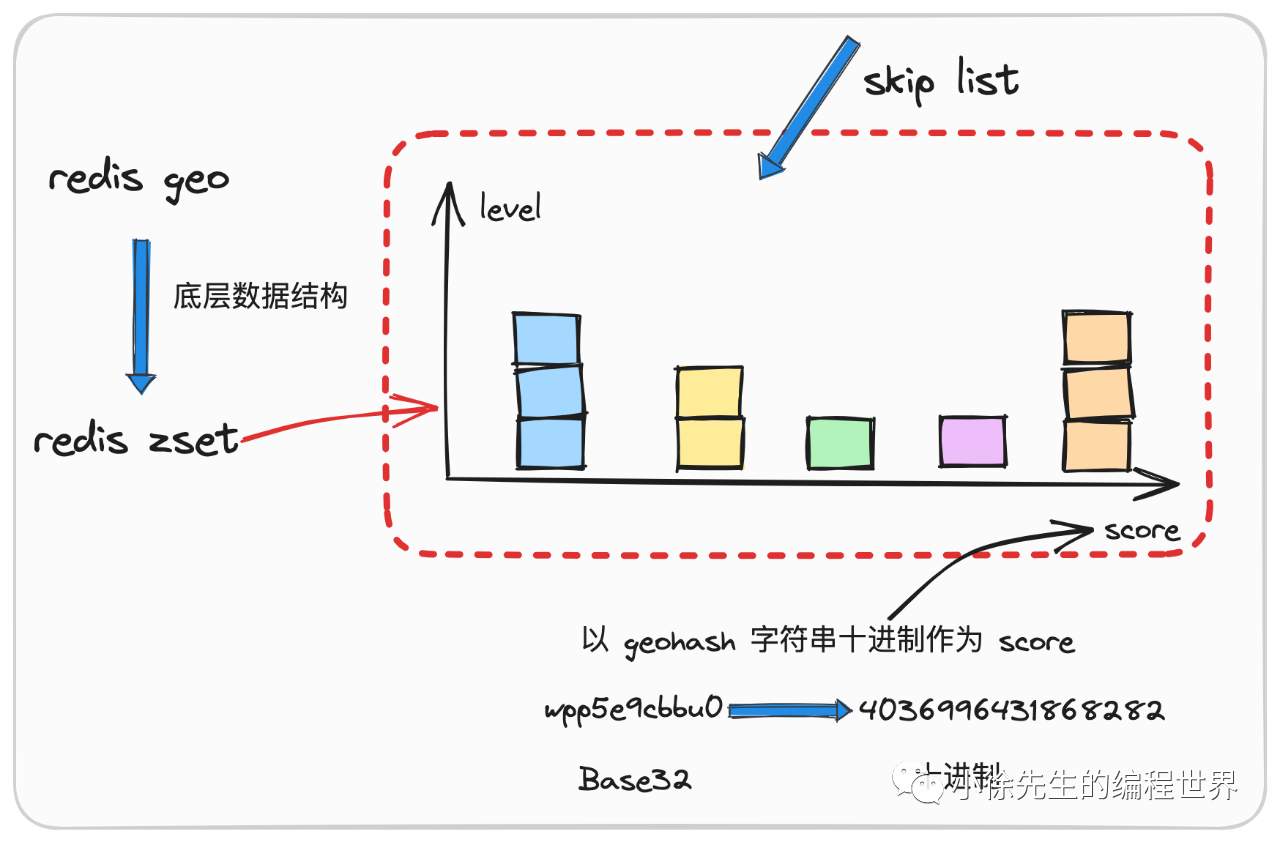
比如说查询附近的商家时,Redis 会根据中心点经纬度反推可能的 Geohash 范围, 在 ZSet 上做范围查询,拿到候选点后,用 Haversine 公式精确计算球面距离,筛选出最终符合要求的位置。
public class NearbyShopService {
private Jedis jedis;
private static final String SHOP_KEY = "shops:geo";
// 添加商铺
public void addShop(String shopId, double longitude, double latitude) {
jedis.geoadd(SHOP_KEY, longitude, latitude, shopId);
}
// 查询附近的商铺
public List<GeoRadiusResponse> getNearbyShops(
double longitude,
double latitude,
double radiusKm) {
return jedis.georadius(SHOP_KEY,
longitude,
latitude,
radiusKm,
GeoUnit.KM,
GeoRadiusParam.geoRadiusParam()
.withCoord()
.withDist()
.sortAscending()
.count(20));
}
// 计算两个商铺之间的距离
public double getShopDistance(String shop1Id, String shop2Id) {
return jedis.geodist(SHOP_KEY,
shop1Id,
shop2Id,
GeoUnit.KILOMETERS);
}
}为什么使用 hash 类型而不使用 string 类型序列化存储?
Hash 可以只读取或者修改某一个字段,而 String 需要一次性把整个对象取出来。
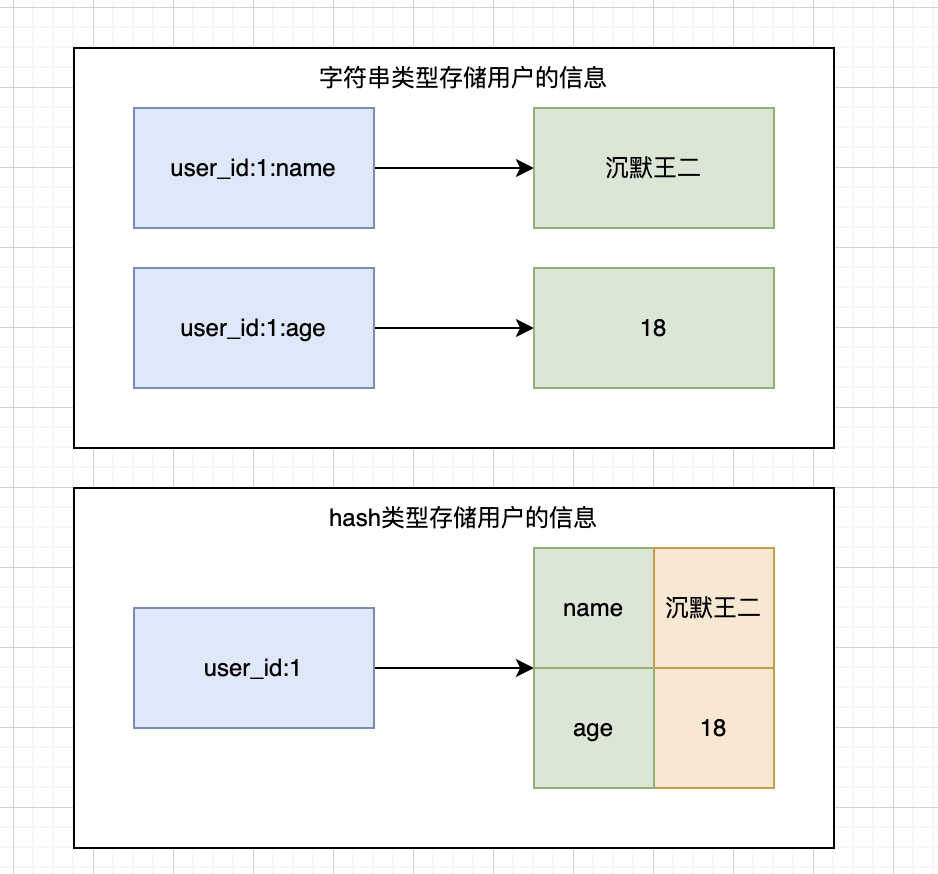
比如说有一个用户对象 user = {name: '沉默王二', age: 18},如果使用 Hash 存储,可以直接修改 age 字段:
redis.hset("user:1", "age", 19);如果使用 String 存储,需要先取出整个对象,修改后再存回去:
String userJson = redis.get("user:1");
User user = JSON.parseObject(userJson, User.class);
user.setAge(19);
redis.set("user:1", JSON.toJSONString(user));
- Java 面试指南(付费)收录的字节跳动商业化一面的原题:说说 Redis 的 zset,什么是跳表,插入一个节点要构建几层索引
- Java 面试指南(付费)收录的字节跳动面经同学 9 飞书后端技术一面面试原题:Redis 的数据类型,ZSet 的实现
- Java 面试指南(付费)收录的小米暑期实习同学 E 一面面试原题:你对 Redis 了解多少,说说常见的数据结构和应用场景
- Java 面试指南(付费)收录的腾讯面经同学 23 QQ 后台技术一面面试原题:Redis 的数据类型
- Java 面试指南(付费)收录的快手面经同学 7 Java 后端技术一面面试原题:说一下 Redis 常用的数据结构
- Java 面试指南(付费)收录的农业银行面经同学 7 Java 后端面试原题:Redis 相关的基础知识
- Java 面试指南(付费)收录的华为面经同学 11 面试原题:项目中使用了 redis,redis 有哪些数据类型?分别使用的场景是什么?什么使用 hash 类型而不使用 string 类型序列化存储?
- Java 面试指南(付费)收录的 OPPO 面经同学 1 面试原题:Redis常见数据结构
- Java 面试指南(付费)收录的美团同学 9 一面面试原题:redis的数据结构类型?
- Java 面试指南(付费)收录的阿里云面经同学 22 面经:redis高级数据结构的使用场景
- Java 面试指南(付费)收录的腾讯面经同学 29 Java 后端一面原题:Redis保证incr命令原子性的原理是什么?
memo:2025 年 4 月 29 日修改至此,今天有球友发信息说拿到了亚马逊的 offer,工资还给的很高,问我要不要选? 真的恭喜了🎉。
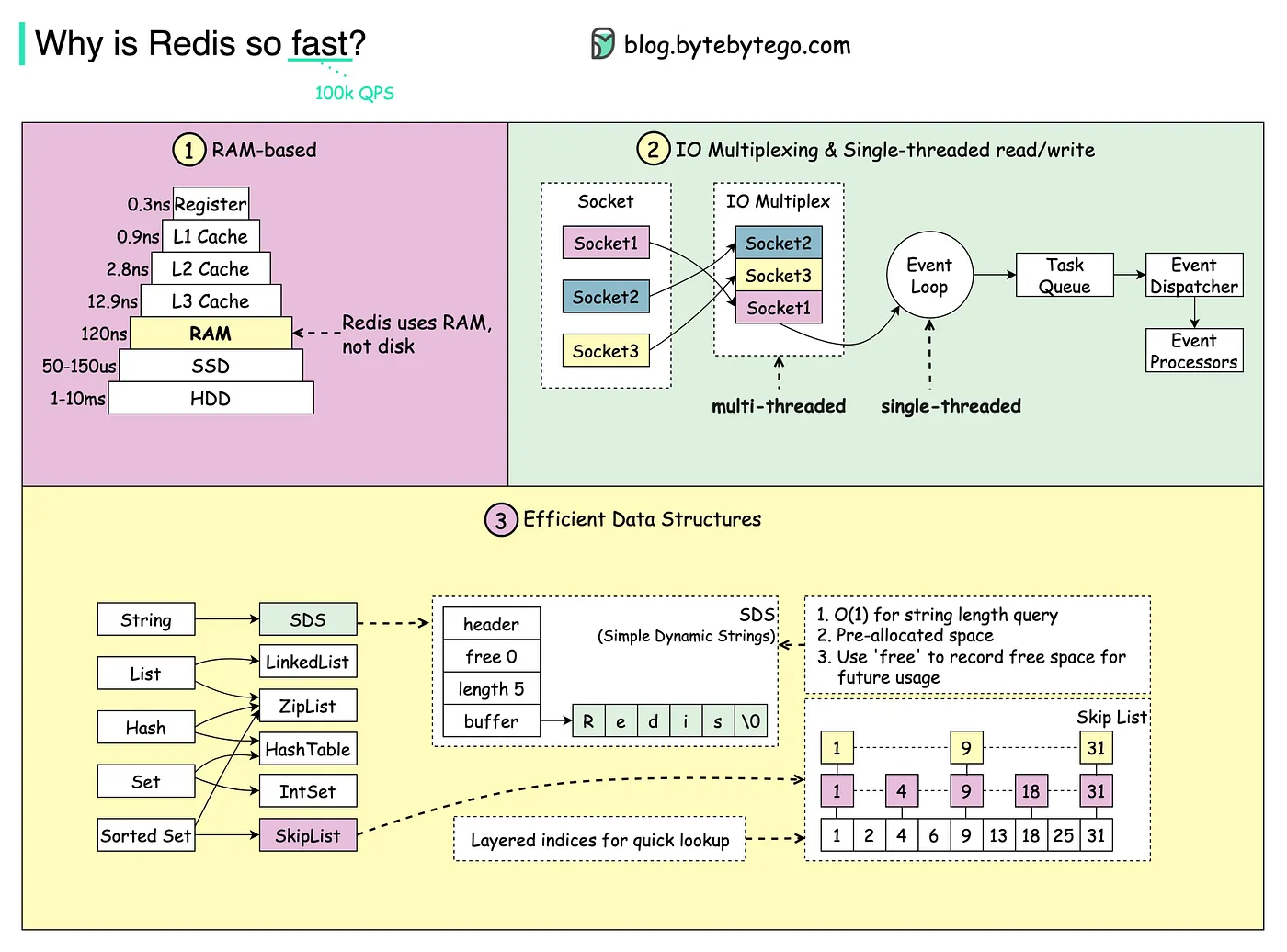
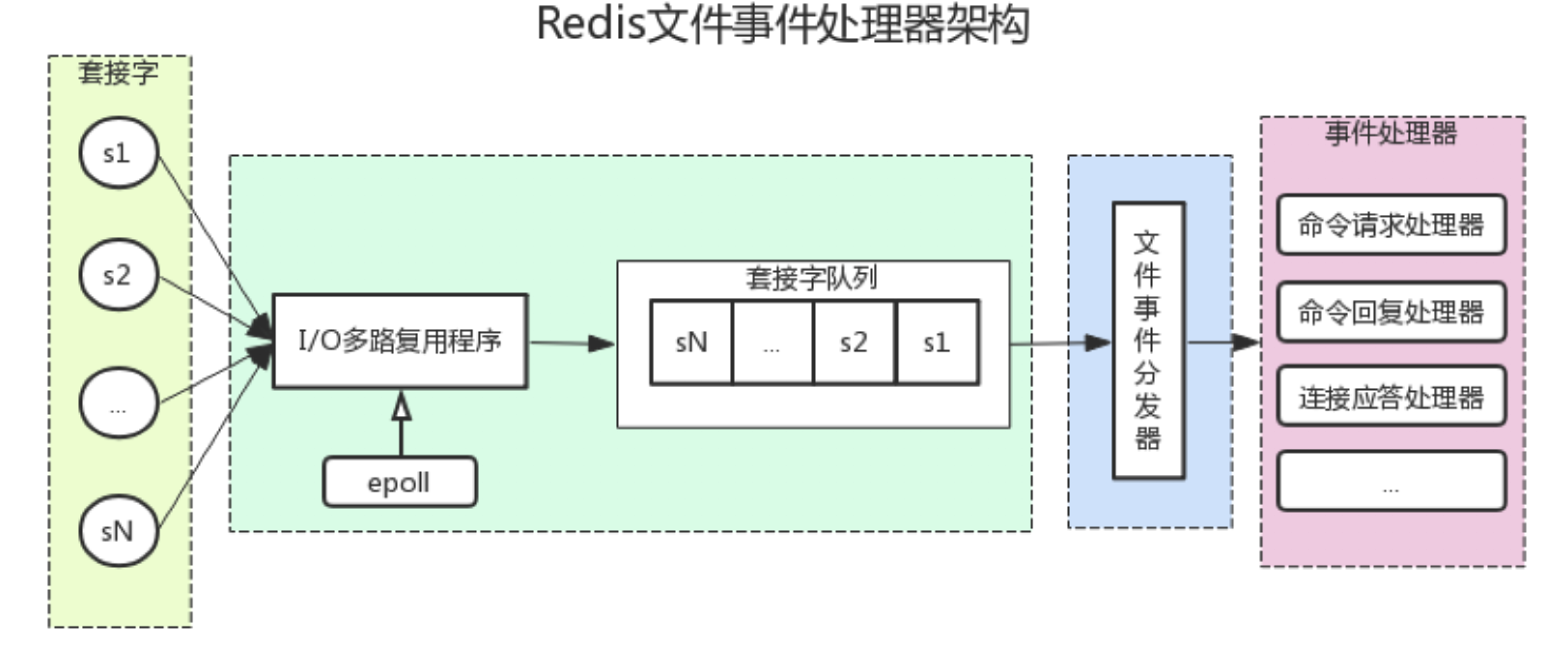
4.🌟Redis 为什么快呢?
第一,Redis 的所有数据都放在内存中,而内存的读写速度本身就比磁盘快几个数量级。
第二,Redis 采用了基于 IO 多路复用技术的事件驱动模型来处理客户端请求和执行 Redis 命令。
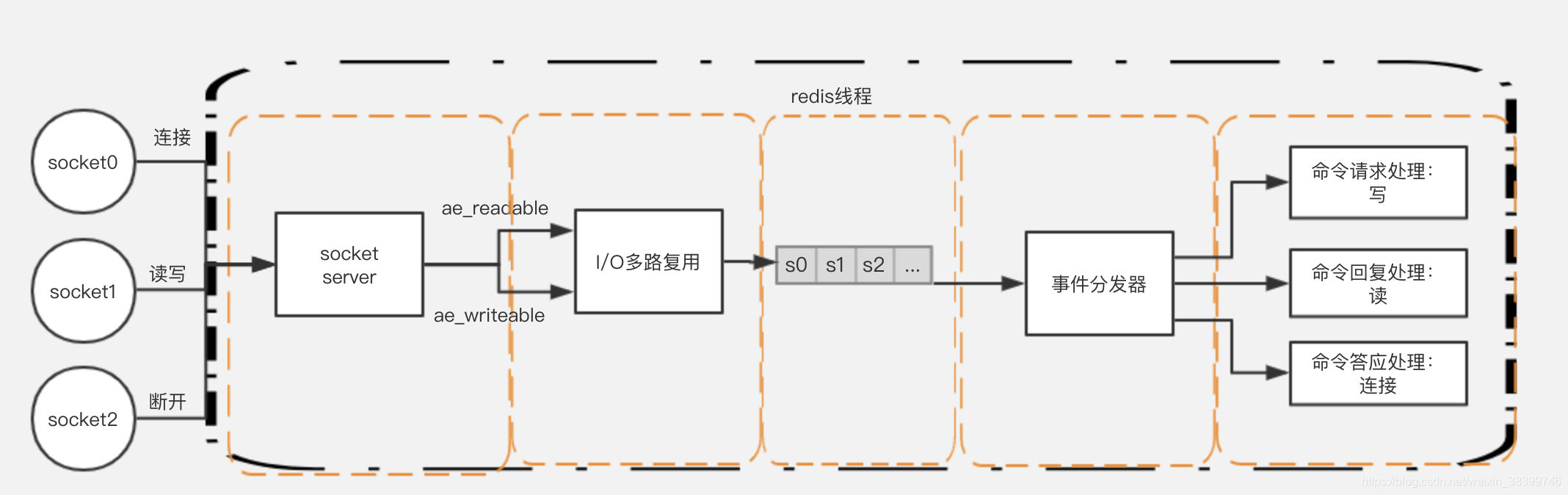
其中的 IO 多路复用技术可以在只有一个线程的情况下,同时监听成千上万个客户端连接,解决传统 IO 模型中每个连接都需要一个独立线程带来的性能开销。
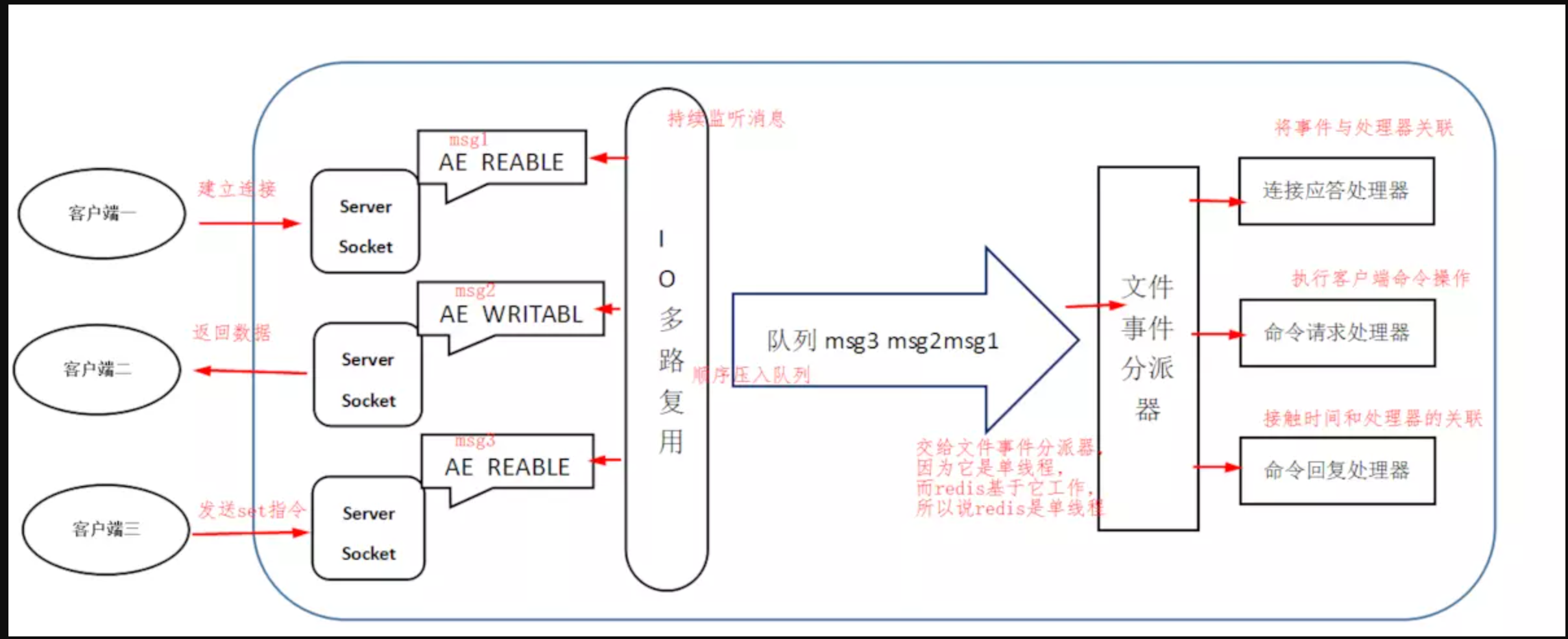
IO 多路复用会持续监听请求,然后把准备好的请求压入到一个队列当中,并将其有序地传递给文件事件分派器,最后由事件处理器来执行对应的 accept、read 和 write 请求。
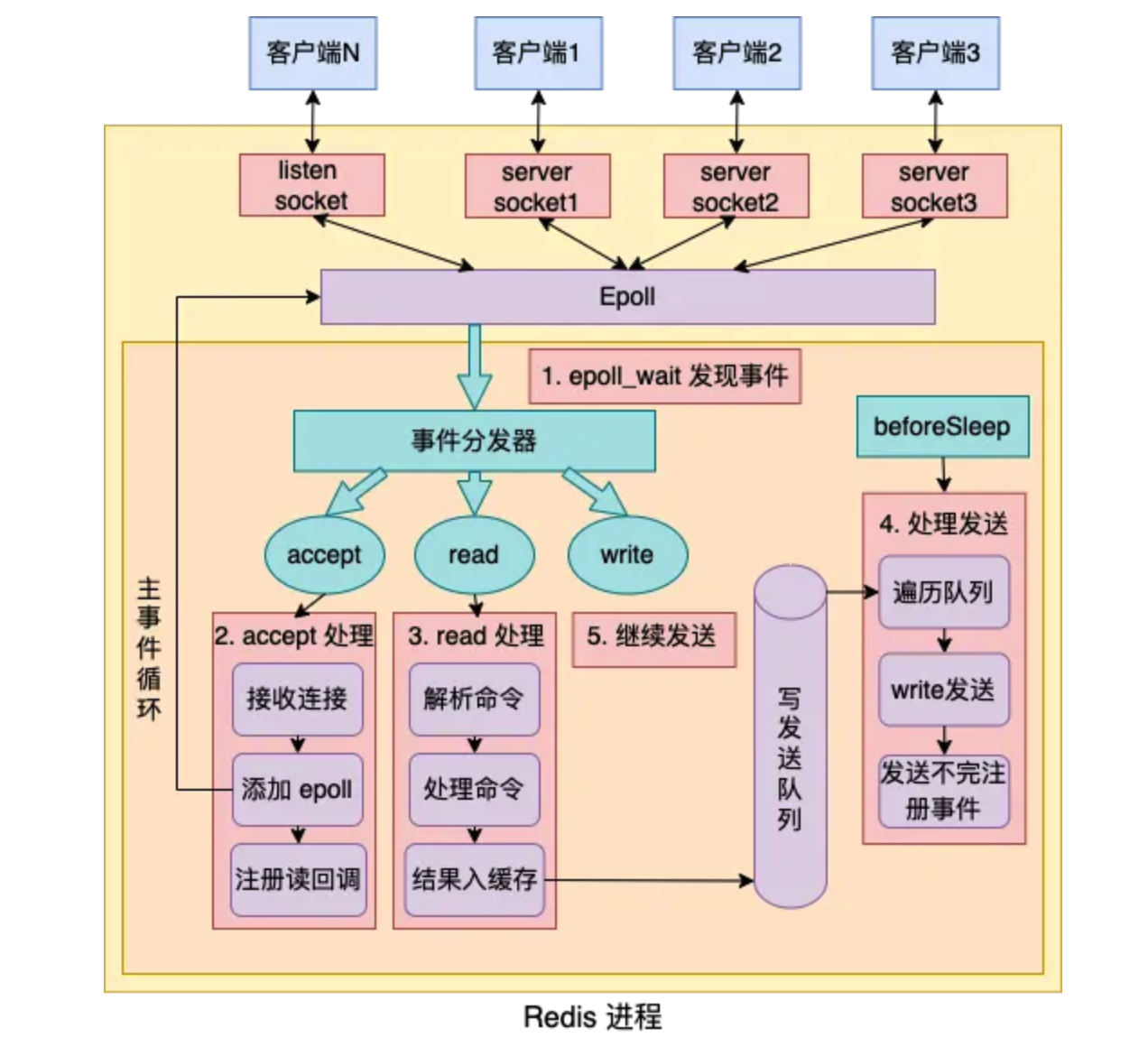
Redis 会根据操作系统选择最优的 IO 多路复用技术,比如 Linux 下使用 epoll,macOS 下使用 kqueue 等。
// epoll 的创建和使用
int epfd = epoll_create(1024); // 创建 epoll 实例
struct epoll_event ev, events[MAX_EVENTS];
// 添加监听事件
ev.events = EPOLLIN;
ev.data.fd = listen_sock;
epoll_ctl(epfd, EPOLL_CTL_ADD, listen_sock, &ev);
// 等待事件发生
while (1) {
int nfds = epoll_wait(epfd, events, MAX_EVENTS, -1);
for (int i = 0; i < nfds; i++) {
// 处理就绪的文件描述符
}
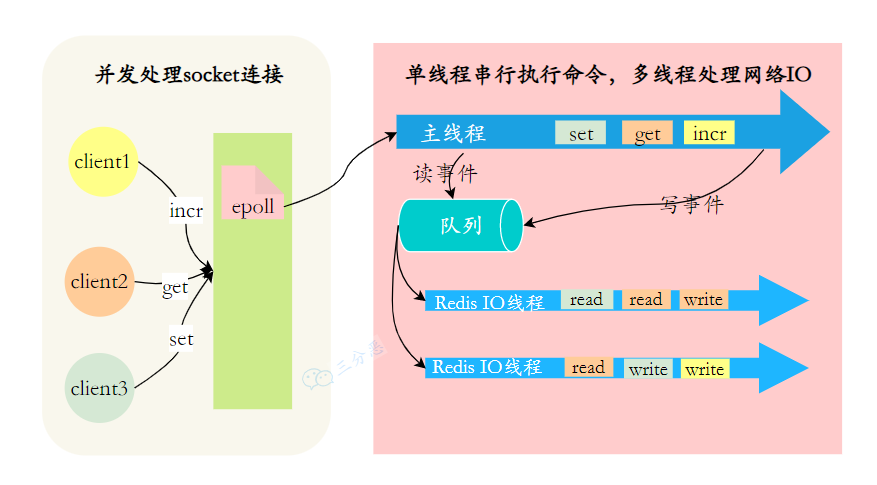
}在 Redis 6.0 之前,包括连接建立、请求读取、响应发送,以及命令执行都是在主线程中顺序执行的,这样可以避免多线程环境下的锁竞争和上下文切换,因为 Redis 的绝大部分操作都是在内存中进行的,性能瓶颈主要是内存操作和网络通信,而不是 CPU。
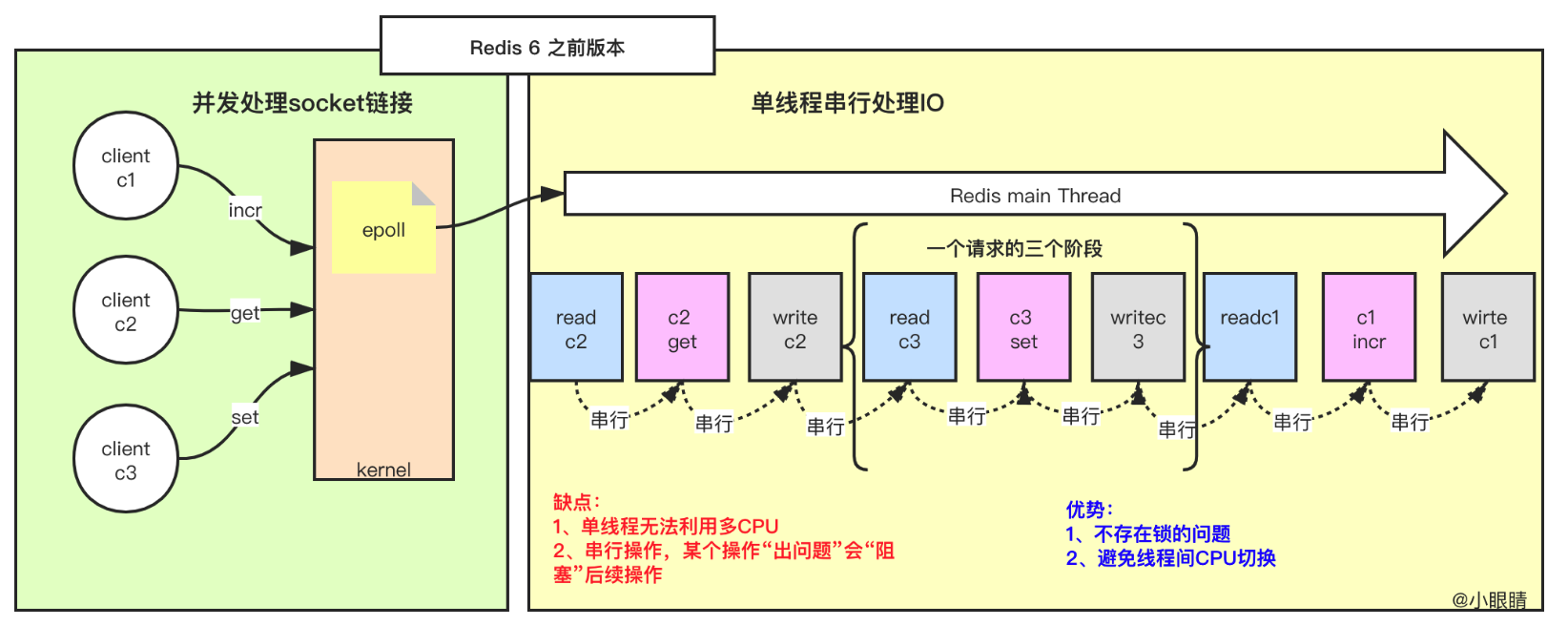
为了进一步解决网络 IO 的性能瓶颈,Redis 6.0 引入了多线程机制,把网络 IO 和命令执行分开,网络 IO 交给线程池来处理,而命令执行仍然在主线程中进行,这样就可以充分利用多核 CPU 的性能。
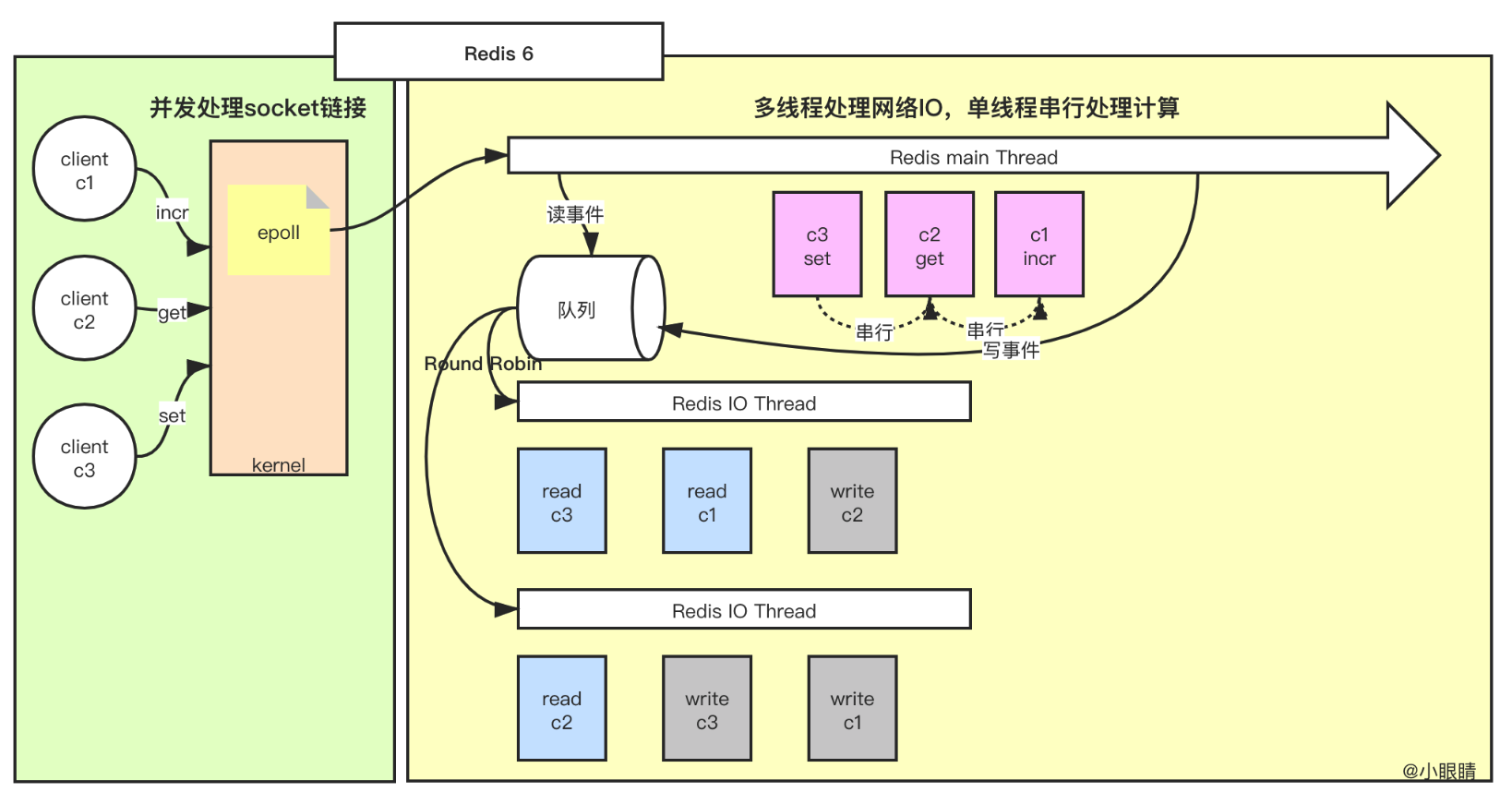
主线程专注于命令执行,网络IO 由其他线程分担,在多核 CPU 环境下,Redis 的性能可以得到显著提升。
第三,Redis 对底层数据结构做了极致的优化,比如说 String 的底层数据结构动态字符串支持动态扩容、预分配冗余空间,能够减少内存碎片和内存分配的开销。
总结:
- Java 面试指南(付费)收录的腾讯 Java 后端实习一面原题:Redis 为什么读写性能高?
- Java 面试指南(付费)收录的小米春招同学 K 一面面试原题:为什么 redis 快,淘汰策略 持久化
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:单线程的 Redis 为什么这么快?
- Java 面试指南(付费)收录的微众银行同学 1 Java 后端一面的原题:Redis 为什么这么快?
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:项目中什么地方使用了 redis 缓存,redis 为什么快?
- Java 面试指南(付费)收录的得物面经同学 8 一面面试原题:Redis 为什么快
- Java 面试指南(付费)收录的字节跳动面经同学 21 抖音商城一面面试原题:redis为什么能处理高并发
memo:2025 年 4 月 30 日修改至此,今天有球友发信息说拿到了滴滴的实习 offer,真的恭喜了🎉。

5.能详细说一下IO多路复用吗?
IO 多路复用是一种允许单个进程同时监视多个文件描述符的技术,使得程序能够高效处理多个并发连接而无需创建大量线程。
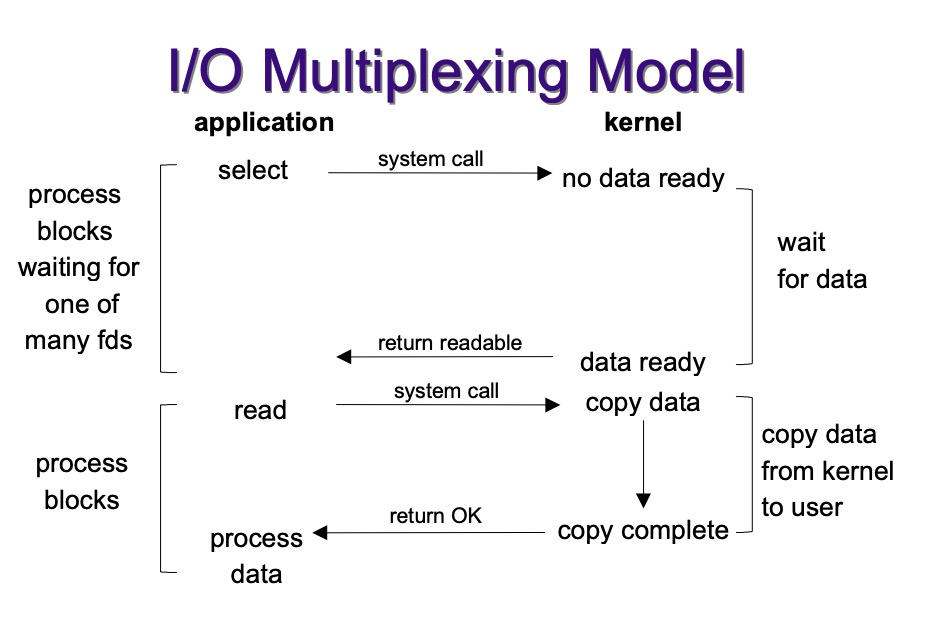
IO 多路复用的核心思想是:让单个线程可以等待多个文件描述符就绪,然后对就绪的描述符进行操作。这样可以在不使用多线程或多进程的情况下处理并发连接。
主要的实现机制包括 select、poll、epoll、kqueue 和 IOCP 等。
请说说 select、poll、epoll、kqueue 和 IOCP 的区别?
select 的缺点是单个进程能监视的文件描述符数量有限,一般为 1024 个,且每次调用都需要将文件描述符集合从用户态复制到内核态,然后遍历找出就绪的描述符,性能较差。
// select 的基本使用
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
// 示例代码
fd_set readfds;
FD_ZERO(&readfds); // 清空集合
FD_SET(sockfd, &readfds); // 添加监听套接字
select(sockfd + 1, &readfds, NULL, NULL, NULL);
if (FD_ISSET(sockfd, &readfds)) { // 检查是否就绪
// 处理读事件
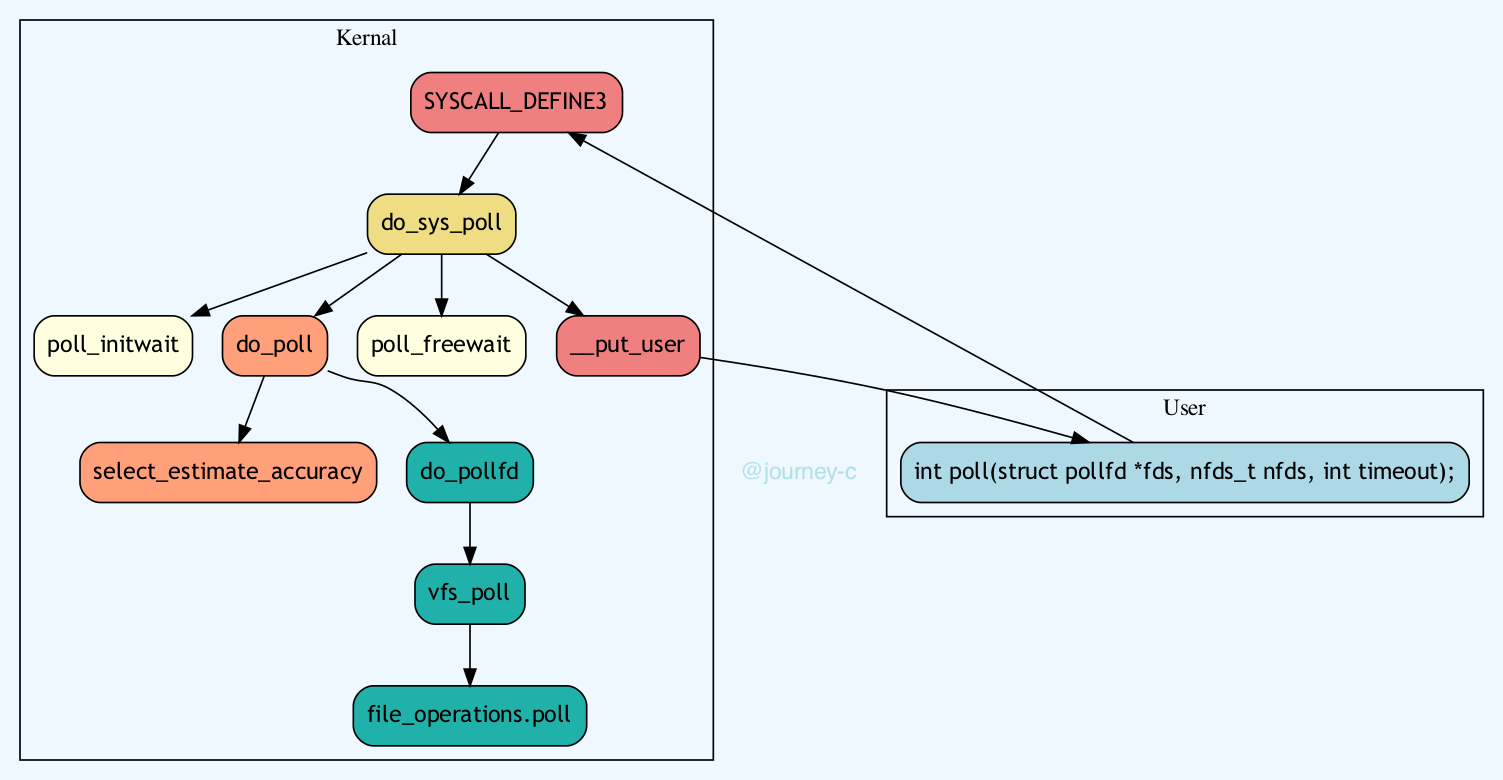
}poll 的优点是没有最大文件描述符数量的限制,但是每次调用仍然需要将文件描述符集合从用户态复制到内核态,依然需要遍历,性能仍然较差。
// poll 的基本使用
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
// 示例代码
struct pollfd fds[MAX_EVENTS];
fds[0].fd = sockfd;
fds[0].events = POLLIN; // 监听读事件
poll(fds, 1, -1);
if (fds[0].revents & POLLIN) {
// 处理读事件
}epoll 是 Linux 特有的 IO 多路复用机制,支持大规模并发连接,使用事件驱动模型,性能更高。其工作原理是将文件描述符注册到内核中,然后通过事件通知机制来处理就绪的文件描述符,不需要轮询,也不需要数据拷贝,更没有数量限制,所以性能非常高。
// epoll 的基本使用
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
// 示例代码
int epfd = epoll_create(1);
struct epoll_event ev, events[MAX_EVENTS];
ev.events = EPOLLIN;
ev.data.fd = sockfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &ev);
while (1) {
int nfds = epoll_wait(epfd, events, MAX_EVENTS, -1);
for (int i = 0; i < nfds; i++) {
if (events[i].data.fd == sockfd) {
// 处理读事件
}
}
}kqueue 是 BSD/macOS 系统下的 IO 多路复用机制,类似于 epoll,支持大规模并发连接,使用事件驱动模型。
int kqueue(void);
int kevent(int kq, const struct kevent *changelist, int nchanges, struct kevent *eventlist, int nevents, const struct timespec *timeout);IOCP 是 Windows 系统下的 IO 多路复用机制,使用使用完成端口模型而非事件通知。
HANDLE CreateIoCompletionPort(HANDLE FileHandle, HANDLE ExistingCompletionPort, ULONG_PTR CompletionKey, DWORD NumberOfConcurrentThreads);举个例子说一下 IO 多路复用?
比如说我是一名数学老师,上课时提出了一个问题:“今天谁来证明一下勾股定律?”
同学小王举手,我就让小王回答;小李举手,我就让小李回答;小张举手,我就让小张回答。
这种模式就是 IO 多路复用,我只需要在讲台上等,谁举手谁回答,不需要一个一个去问。
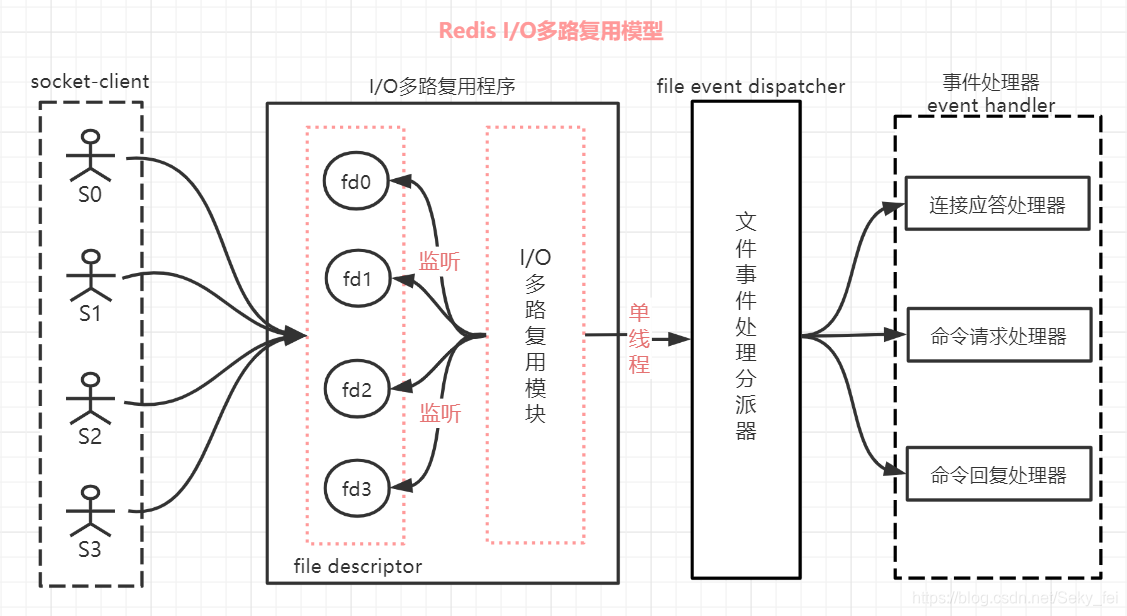
Redis 就是使用 epoll 这样的 IO 多路复用机制,在单线程模型下实现高效的网络 IO,从而支持高并发的请求处理。
举例子说一下阻塞 IO和 IO 多路复用的差别?
假设我是一名老师,让学生解答一道题目。
我的第一种选择:按顺序逐个检查,先检查 A同学,然后是 B,之后是 C、D。。。这中间如果有一个学生卡住,全班都会被耽误。
这种就是阻塞 IO,不具有并发能力。
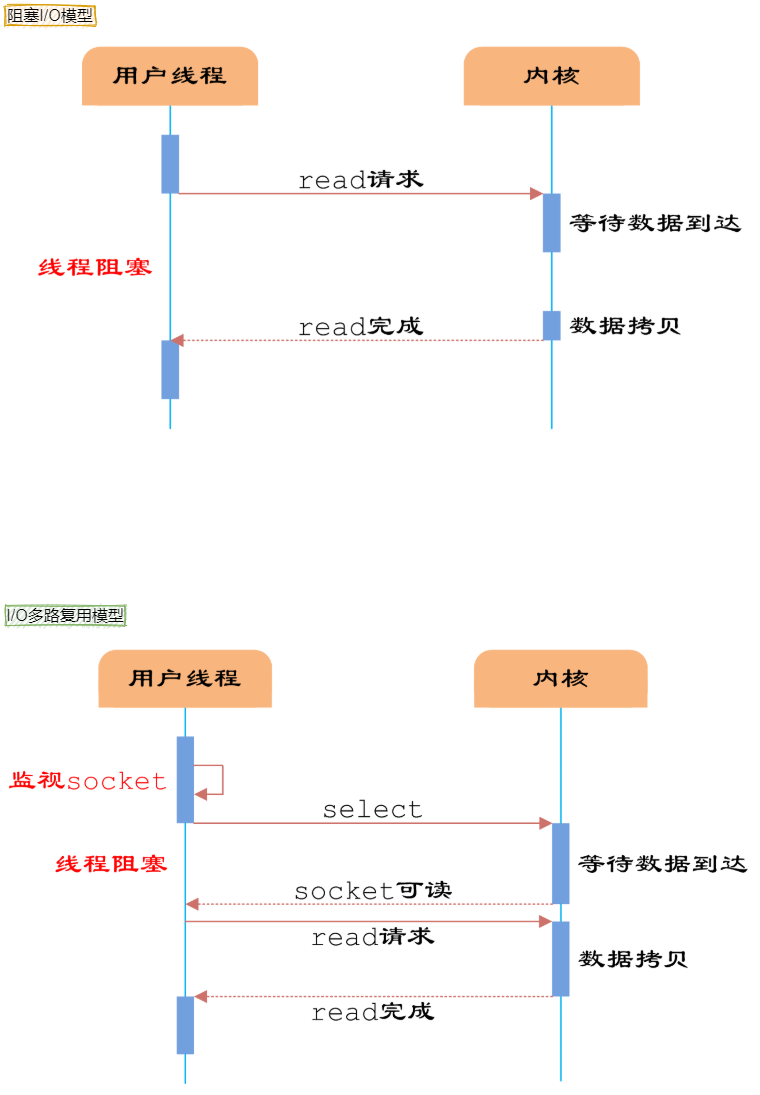
我的第二种选择,我站在讲台上等,谁举手我去检查谁。C、D 举手,我去检查 C、D 的答案,然后继续回到讲台上等。此时 E、A 又举手,然后去处理 E 和 A。
select、poll 和 epoll 的实现原理?
select 和 poll 都是通过把所有文件描述符传递给内核,由内核遍历判断哪些就绪。
select 将文件描述符 FD 通过 BitsMap 传入内核,轮询所有的 FD,通过调用 file->poll 函数查询是否有对应事件,没有就将 task 加入 FD 对应 file 的待唤醒队列,等待事件来临被唤醒。
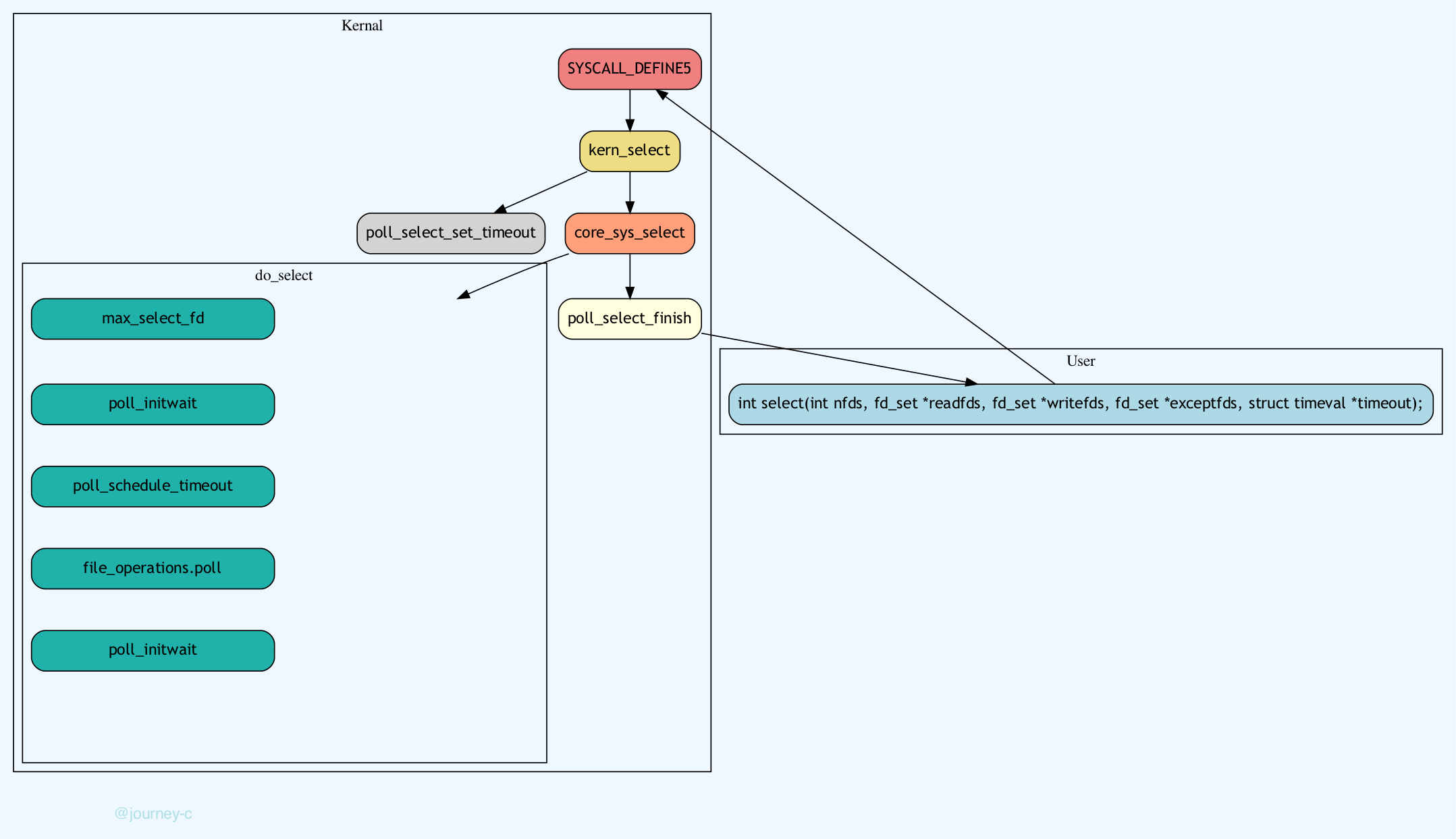
poll 改进了连接数上限问题,不再用 BitsMap 来传入 FD,取而代之的是动态数组 pollfd,但本质上仍是线性遍历,性能没有提升太多。
select和poll的模式都是,一次将参数拷贝到内核空间,等有结果了再一次拷贝出去。
epoll 将监听的 FD 注册进内核的红黑树,由内核在事件触发时将就绪的 FD 放入 ready list。应用程序通过 epoll_wait 获取就绪的 FD,从而避免遍历所有连接的开销。
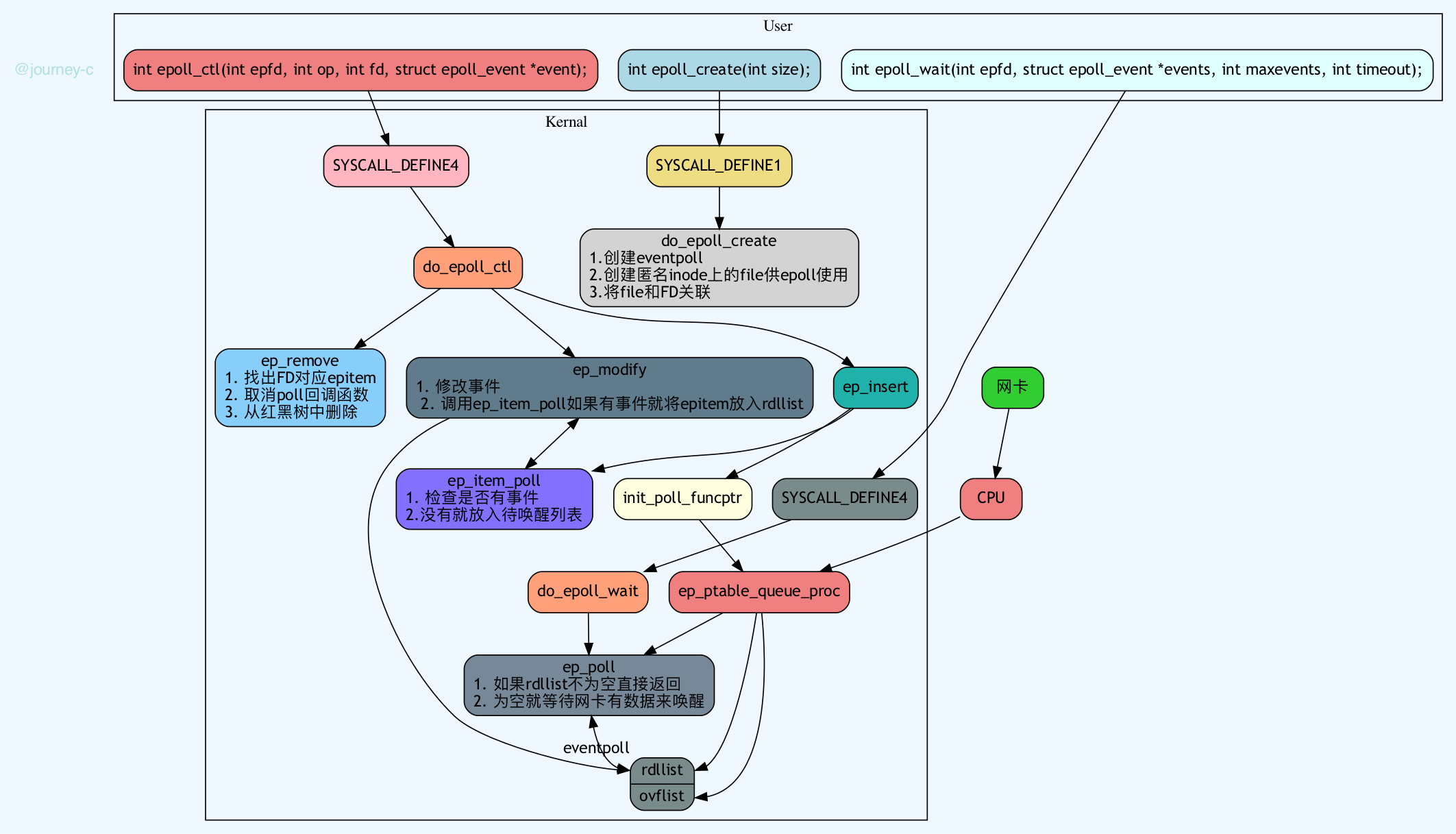
epoll 最大的优点是:支持事件驱动 + 边缘触发,ADD 时拷贝一次,epoll_wait 时利用 MMAP 和用户共享空间,直接拷贝数据到用户空间,因此在高并发场景下性能远高于 select 和 poll。
- Java 面试指南(付费)收录的字节跳动面经同学 21 抖音商城一面面试原题:io多路复用了解吗?
- Java 面试指南(付费)收录的快手同学 4 一面原题:IO多路复用中select/poll/epoll各自的实现原理和区别?
- Java 面试指南(付费)收录的字节跳动面经同学19番茄小说一面面试原题:Linux中的IO多路复用
memo:2025 年 5 月 1 日修改至此,今天帮球友修改简历时 时,碰到一名北京交通大学的同学,又一所 211 院校,星球真的是人才济济,大家一起加油吧(骄傲)。

6.Redis为什么早期选择单线程?
第一,单线程模型不需要考虑复杂的锁机制,不存在多线程环境下的死锁、竞态条件等问题,开发起来更快,也更容易维护。
第二,Redis 是IO 密集型而非 CPU 密集型,主要受内存和网络 IO 限制,而非 CPU 的计算能力,单线程可以避免线程上下文切换的开销。
哪怕我们在一个普通的 Linux 服务器上启动 Redis 服务,它也能在 1s 内处理 1000000 个用户请求。
第三,单线程可以保证命令执行的原子性,无需额外的同步机制。

Redis 虽然最初采用了单线程设计,但后续的版本中也在特定方面引入了多线程,比如说 Redis 4.0 就引异步多线程,用于清理脏数据、释放无用连接、删除大 Key 等。
/* 从数据库中删除一个键、值以及相关的过期条目(如果有的话)。
* 如果释放值对象需要大量的内存分配操作,该对象可能会被放入
* 延迟释放列表中,而不是同步释放。延迟释放列表将在
* bio.c 的另一个线程中进行回收。 */
#define LAZYFREE_THRESHOLD 64
int dbAsyncDelete(redisDb *db, robj *key) {
/* 从过期字典中删除条目不会释放键的 sds,
* 因为它与主字典共享。 */
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
/* 如果值对象只包含少量的内存分配,使用延迟释放方式
* 实际上会更慢... 所以在一定阈值以下,我们就直接
* 同步释放对象。 */
dictEntry *de = dictUnlink(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
// 计算value的回收收益
size_t free_effort = lazyfreeGetFreeEffort(val);
/* 如果释放对象的工作量太大,就通过将对象添加到延迟释放列表
* 在后台进行处理。
* 注意,如果对象是共享的,现在就回收它是不可能的。这种情况
* 很少发生,但是有时 Redis 核心的某些实现部分可能会调用
* incrRefCount() 来保护对象,然后调用 dbDelete()。在这种
* 情况下,我们会继续执行并到达 dictFreeUnlinkedEntry()
* 调用,这相当于仅仅调用 decrRefCount()。 */
// 只有回收收益超过一定值,才会执行异步删除,否则还是会退化到同步删除
if (free_effort > LAZYFREE_THRESHOLD && val->refcount == 1) {
atomicIncr(lazyfree_objects,1);
bioCreateBackgroundJob(BIO_LAZY_FREE,val,NULL,NULL);
dictSetVal(db->dict,de,NULL);
}
}
/* 释放键值对,如果我们将 val 字段设置为 NULL 以便稍后
* 延迟释放,那么就只释放键。 */
if (de) {
dictFreeUnlinkedEntry(db->dict,de);
if (server.cluster_enabled) slotToKeyDel(key->ptr);
return 1;
} else {
return 0;
}
}官方解释:https://redis.io/topics/faq
memo:2025 年 5 月 2 日修改至此,今天帮球友修改简历时 时,碰到一名同济大学的同学,让感觉自己的付出正在越来越多被更多人看到,真的很开心。

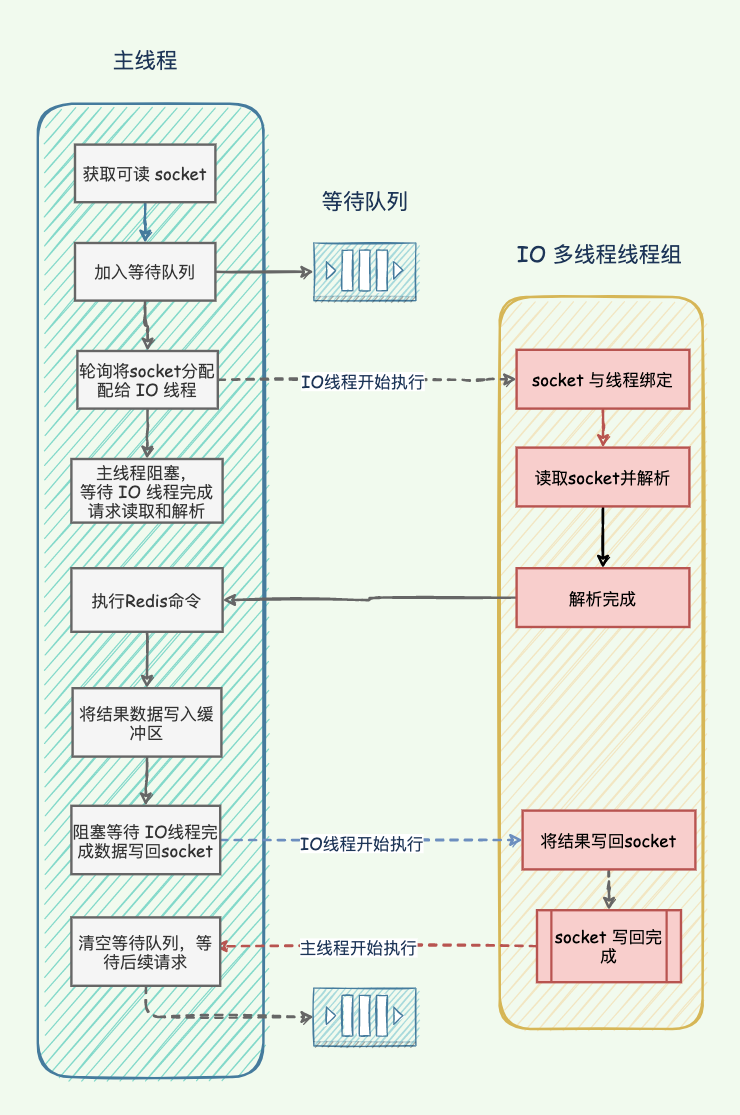
7.Redis 6.0 使用多线程是怎么回事?
Redis 6.0 的多线程仅用于处理网络 IO,包括网络数据的读取、写入,以及请求解析。
│ 单线程执行命令 │
│ ↑ ↓ │
┌─────────┐ ┌─┴────────────┴──┐
│ I/O线程1 │ ←→ │ │
├─────────┤ │ │
│ I/O线程2 │ ←→ │ 主线程 │
├─────────┤ │ │
│ I/O线程3 │ ←→ │ │
└─────────┘ └─────────────────┘而命令的执行依然是单线程,这种设计被称为“IO 线程化”,能够在高负载的情况下,最大限度地提升 Redis 的响应速度。
---- 这部分面试中可以不背,方便大家理解 start ----
这一变化主要是因为随着网络带宽和服务器性能的提升,Redis 的瓶颈从 CPU 逐渐转移到了网络 IO:
- 带宽从 10Gbps 提升到 100Gbps,甚至更高。
- 请求的并发数从几千到几万,甚至几十万。
单线程在高负载场景下处理网络 IO 出现了明显的性能瓶颈,Redis 的开发团队通过研究发现,在处理大数据包时,单线程 Redis 有超过 80% 的 CPU 时间花在网络 IO 上,而实际命令执行仅占 20% 左右。
Redis 6.0 的多线程 IO 模型主要包含三个核心步骤:
- 仍然由主线程负责接收客户端的连接请求。
- 主线程将连接请求分发给多个 IO 线程进行处理,主线程负责解析和执行命令。
- 命令执行完毕后,由多个 IO 线程将结果返回给客户端。
// Redis 主事件循环(简化版)
void beforeSleep(struct aeEventLoop *eventLoop) {
// 1. 主线程分派读任务给 I/O 线程
handleClientsWithPendingReadsUsingThreads();
// 2. 等待 I/O 线程完成读取
waitForIOThreads();
// 3. 主线程处理命令
processInputBuffer();
// 4. 主线程分派写任务给 I/O 线程
handleClientsWithPendingWritesUsingThreads();
}Redis 6.0 默认仍然使用单线程模式,但可以通过配置文件或命令行参数启用多线程模式。
# 启用多线程模式
io-threads 4
# 启用多线程写入(Redis 6.0 默认只开启多线程读取)
io-threads-do-reads yes建议将 IO 线程数设置为 CPU 核心数的一半,一般不建议超过 8 个。
经过多次测试,Redis 6.0 在处理 1-200 字节的小数据包时,性能提升 1.5-2 倍;在处理 1KB 以上的大数据包时提升约 3-5 倍。
----这部分面试中可以不背,方便大家理解 end ----
- Java 面试指南(付费)收录的同学 30 腾讯音乐面试原题:redis6.0引入的多线程用作什么地方
8.说说 Redis 的常用命令(补充)
2024 年 04 月 11 日增补
一句话回答(也不用全部都背,挑三个就行):
Redis 支持多种数据结构,常用的命令也比较多,比如说操作字符串可以用 SET/GET/INCR,操作哈希可以用 HSET/HGET/HGETALL,操作列表可以用 LPUSH/LPOP/LRANGE,操作集合可以用 SADD/SISMEMBER,操作有序集合可以用 ZADD/ZRANGE/ZINCRBY等,通用命令有 EXPIRE/DEL/KEYS 等。
----这部分面试中可以不背,方便大家理解 start----
①、操作字符串的命令有:
| 命令 | 作用 | 示例 |
|---|---|---|
SET key value | 设置字符串键值 | SET name jack |
GET key | 获取字符串值 | GET name |
INCR key | 数值自增 1 | INCR count |
DECR key | 数值自减 1 | DECR stock |
INCRBY key N | 增加 N | INCRBY views 10 |
APPEND key value | 追加字符串 | APPEND log "done" |
GETRANGE key start end | 获取子串 | GETRANGE name 0 3 |
MSET k1 v1 k2 v2 | 批量设置多个键值 | MSET a 1 b 2 |
②、操作列表的命令有:
LPUSH key value:将一个值插入到列表 key 的头部。RPUSH key value:将一个值插入到列表 key 的尾部。LPOP key:移除并返回列表 key 的头元素。RPOP key:移除并返回列表 key 的尾元素。LRANGE key start stop:获取列表 key 中指定范围内的元素。
③、操作集合的命令有:
SADD key member:向集合 key 添加一个元素。SREM key member:从集合 key 中移除一个元素。SMEMBERS key:返回集合 key 中的所有元素。
④、操作有序集合的命令有:
ZADD key score member:向有序集合 key 添加一个成员,或更新其分数。ZRANGE key start stop [WITHSCORES]:按照索引区间返回有序集合 key 中的成员,可选 WITHSCORES 参数返回分数。ZREVRANGE key start stop [WITHSCORES]:返回有序集合 key 中,指定区间内的成员,按分数递减。ZREM key member:移除有序集合 key 中的一个或多个成员。
⑤、操作哈希的命令有:
HSET key field value:向键为 key 的哈希表中设置字段 field 的值为 value。HGET key field:获取键为 key 的哈希表中字段 field 的值。HGETALL key:获取键为 key 的哈希表中所有的字段和值。HDEL key field:删除键为 key 的哈希表中的一个或多个字段。
详细说说 set 命令?
SET 命令用于设置字符串的 key,支持过期时间和条件写入,常用于设置缓存、实现分布式锁、延长 Session 等场景。
SET key value [EX seconds | PX milliseconds | EXAT timestamp | PXAT timestamp-milliseconds | KEEPTTL] [NX | XX] [GET]默认情况下,SET 会覆盖键已有的值。
支持多种设置过期时间的方式,比如说 EX 设置秒级过期时间,PX 设置毫秒过期时间。
支持条件写入,使其可以实现原子性操作,比如说 NX 仅在键不存在时设置值,XX 仅在键存在时设置值。
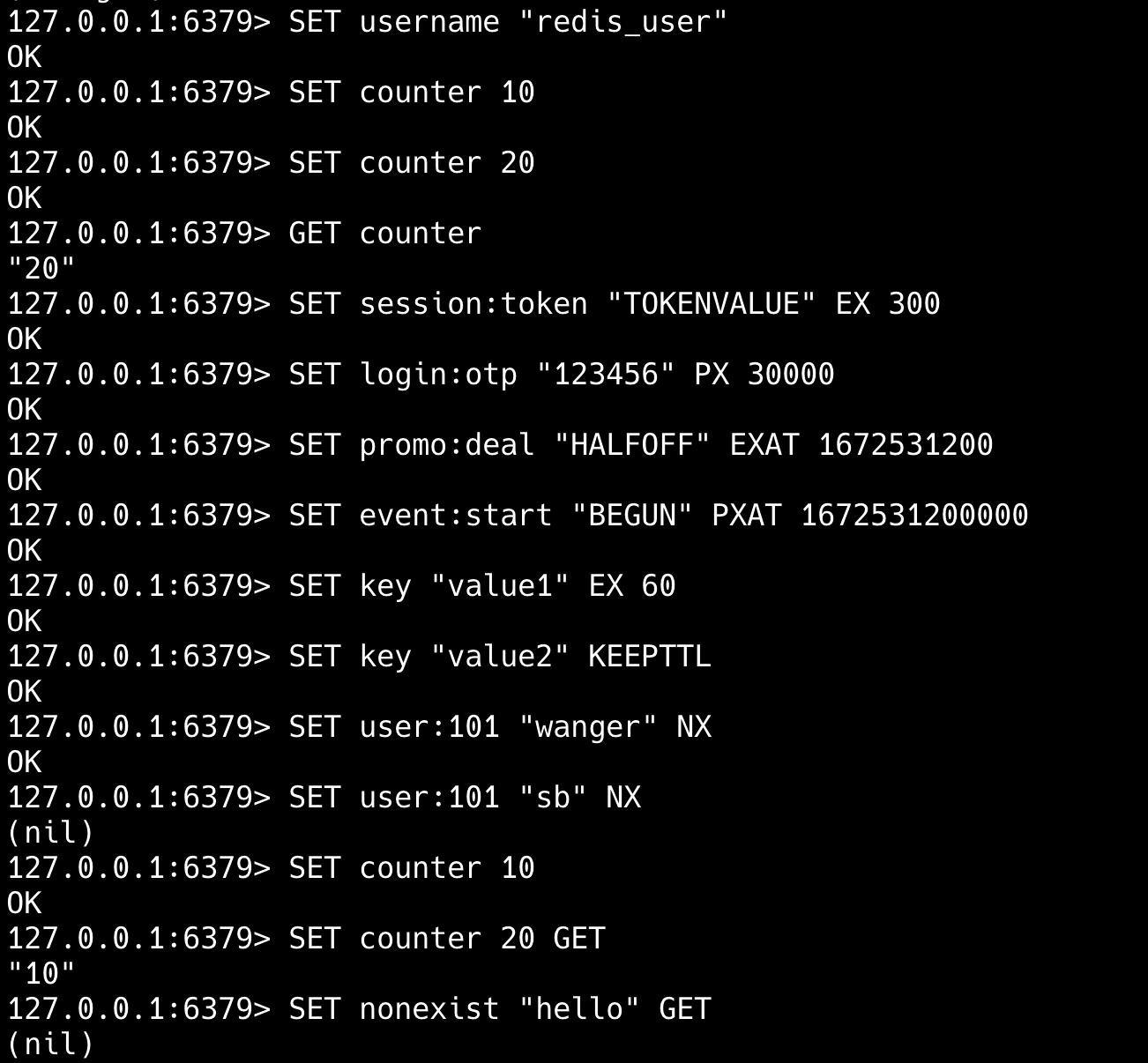
缓存实现:
SET user:profile:{userid} {JSON数据} EX 3600 # 存储用户资料,并设置1小时过期实现分布式锁:
SET lock:resource_name {random_value} EX 10 NX # 获取锁,10秒后自动释放存储 Session:
SET session:{sessionid} {session_data} EX 1800 # 存储用户会话,30分钟过期sadd 命令的时间复杂度是多少?
SADD 支持一次添加多个元素,返回值为实际添加成功的元素数量,时间复杂度为 O(N)。
redis-cli SADD myset "apple" "banana" "orange"incr命令了解吗?
INCR 是一个原子命令,可以将指定键的值加 1,如果 key 不存在,会先将其设置为 0,再执行加 1 操作。
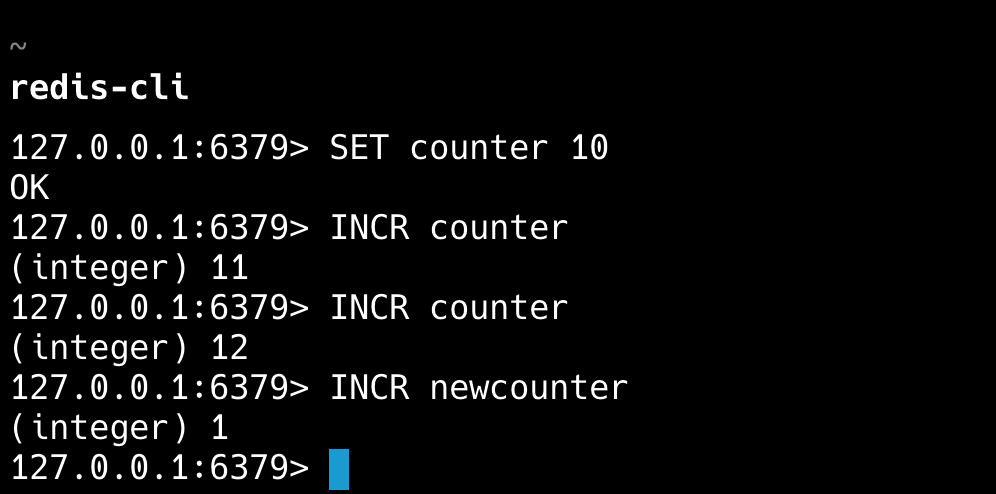
常用于网站访问量、文章点赞数等计数器的实现;结合过期时间实现限流器;生成分布式唯一 ID;库存扣减等。
# 限制用户每分钟最多访问10次
FUNCTION limit_api_call(user_id)
current = INCR("rate:"+user_id)
IF current == 1 THEN
EXPIRE("rate:"+user_id, 60)
END
IF current > 10 THEN
RETURN false # 超出限制
ELSE
RETURN true # 允许访问
END
END
- Java 面试指南(付费)收录的京东面经同学 1 Java 技术一面面试原题:说说 Redis 常用命令
- Java 面试指南(付费)收录的农业银行面经同学 3 Java 后端面试原题:说的那么好,Redis 设置 key value 的函数是啥
- Java 面试指南(付费)收录的快手面经同学 1 部门主站技术部面试原题:Redis 的 sadd 命令时间复杂度是多少?
memo:2025 年 5 月 3 日修改至此,今天有球友发信息说拿到了美的的软开暑期实习 offer,虽然他自己不满意,但暂时没有其他更好的,我建议他先去试一下🎉。
9.单线程的Redis QPS 能到多少?(补充)
2024 年 4 月 14 日增补
根据官方的基准测试,一个普通服务器的 Redis 实例通常可以达到每秒十万左右的 QPS。
----这部分面试中可以不背,方便大家理解 start ----
Redis 的 QPS(每秒请求数)性能取决于多种因素,包括硬件配置、网络延迟、数据结构、命令类型等。
可以通过 redis-benchmark 命令进行基准测试:
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000-h:指定 Redis 服务器的地址,默认是 127.0.0.1。-p:指定 Redis 服务器的端口,默认是 6379。-c:并发连接数,即同时有多少个客户端在进行测试。-n:请求总数,即测试过程中总共要执行多少个请求。
2023 年前,我用的是一台 macOS,4 GHz 四核 Intel Core i7,32 GB 1867 MHz DDR3,测试结果如下:
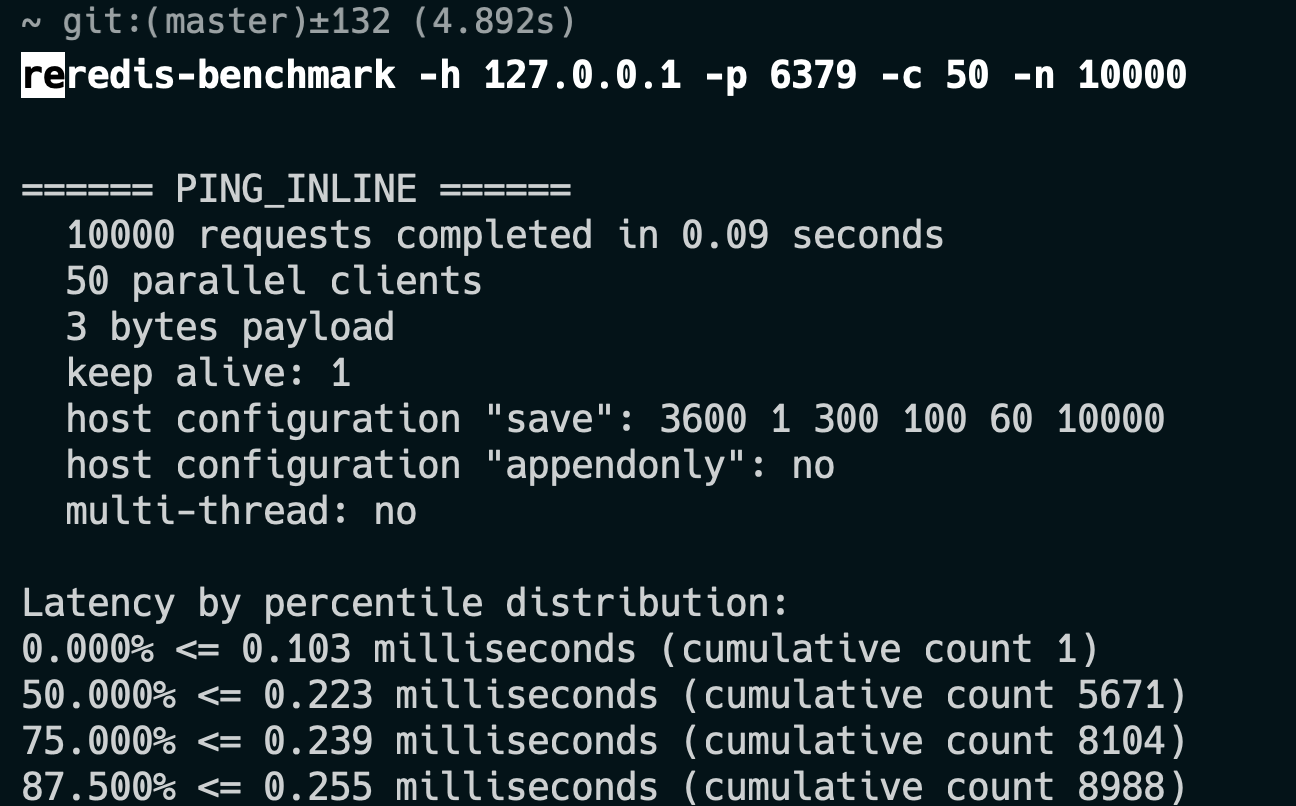
可以看得出,每秒能处理超过 10 万次请求。
QPS = 总请求数 / 总耗时 = 10000 / 0.09 ≈ 111111 QPS延迟也非常低,99% 的请求都在 0.3ms 以内完成了。
----这部分面试中可以不背,方便大家理解 end ----
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:单线程 Redis 的 QPS 是多少?
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
持久化
10.🌟Redis的持久化方式有哪些?
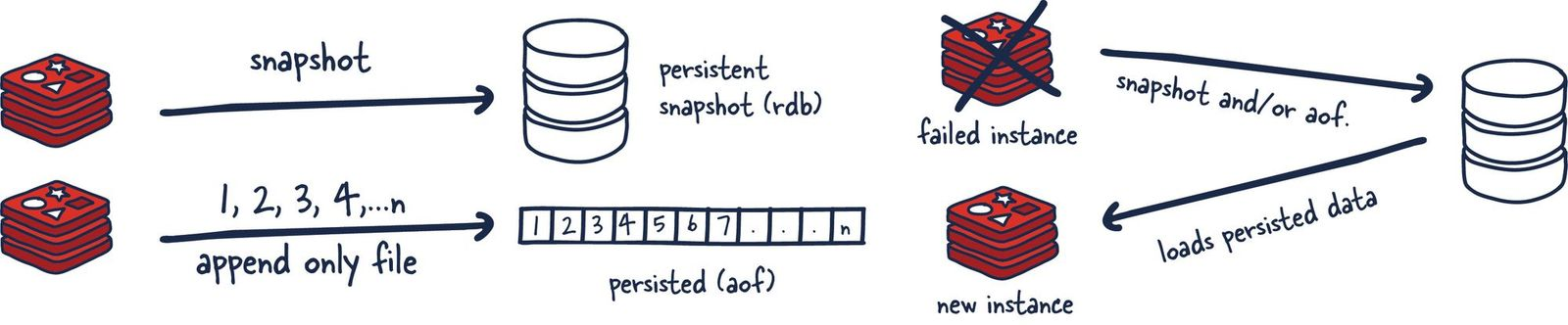
主要有两种,RDB 和 AOF。RDB 通过创建时间点快照来实现持久化,AOF 通过记录每个写操作命令来实现持久化。
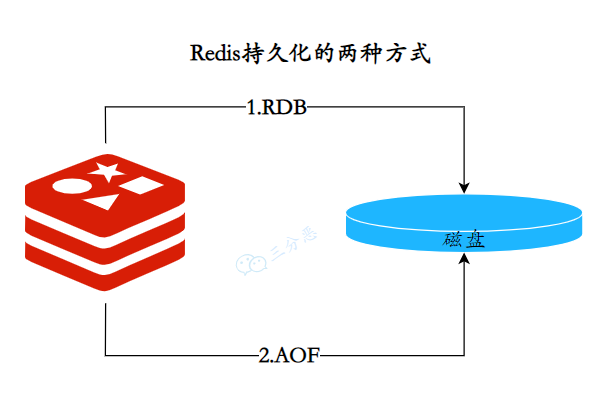
这两种方式可以单独使用,也可以同时使用。这样就可以保证 Redis 服务器在重启后不丢失数据,通过 RDB 和 AOF 文件来恢复内存中原有的数据。
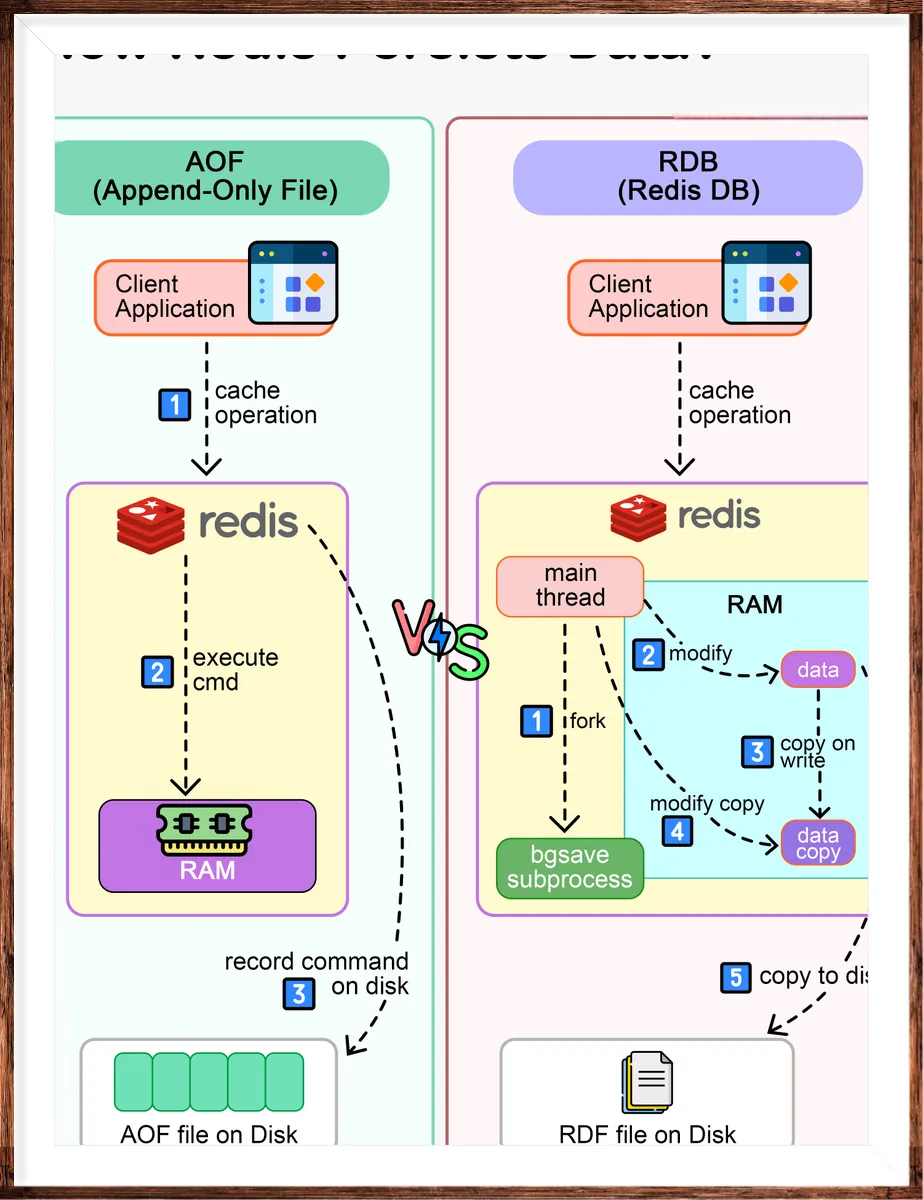
详细说一下 RDB?
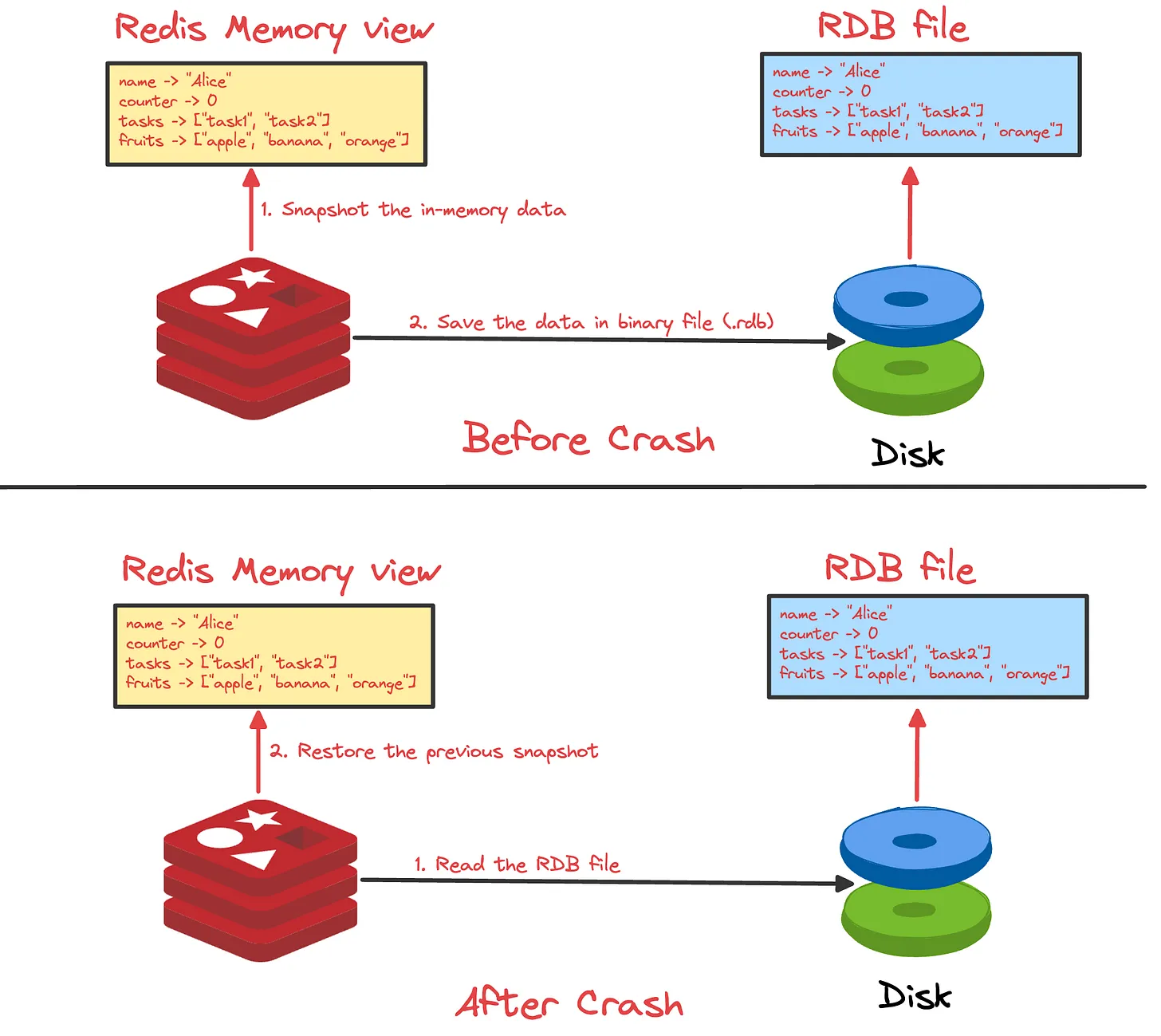
RDB 持久化机制可以在指定的时间间隔内将 Redis 某一时刻的数据保存到磁盘上的 RDB 文件中,当 Redis 重启时,可以通过加载这个 RDB 文件来恢复数据。
RDB 持久化可以通过 save 和 bgsave 命令手动触发,也可以通过配置文件中的 save 指令自动触发。
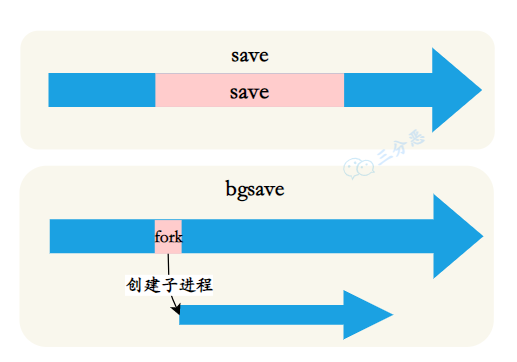
save 命令会阻塞 Redis 进程,直到 RDB 文件创建完成。
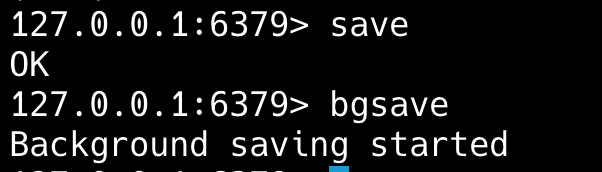
bgsave 命令会在后台 fork 一个子进程来执行 RDB 持久化操作,主进程不会被阻塞。
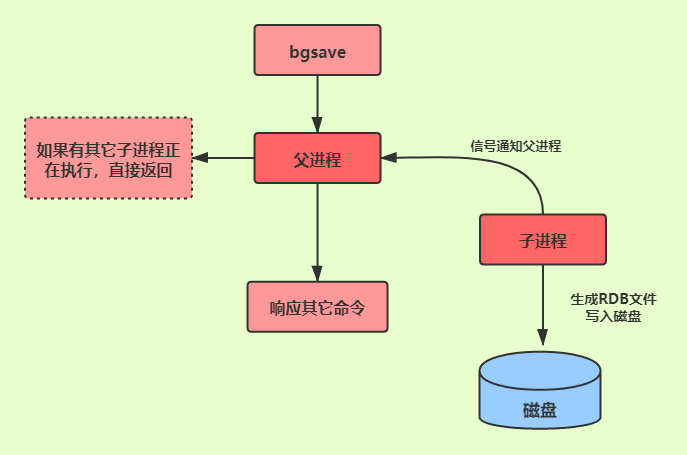
什么情况下会自动触发 RDB 持久化?
第一种,在 Redis 配置文件中设置 RDB 持久化参数 save <seconds> <changes>,表示在指定时间间隔内,如果有指定数量的键发生变化,就会自动触发 RDB 持久化。
save 900 1 # 900 秒(15 分钟)内有 1 个 key 发生变化,触发快照
save 300 10 # 300 秒(5 分钟)内有 10 个 key 发生变化,触发快照
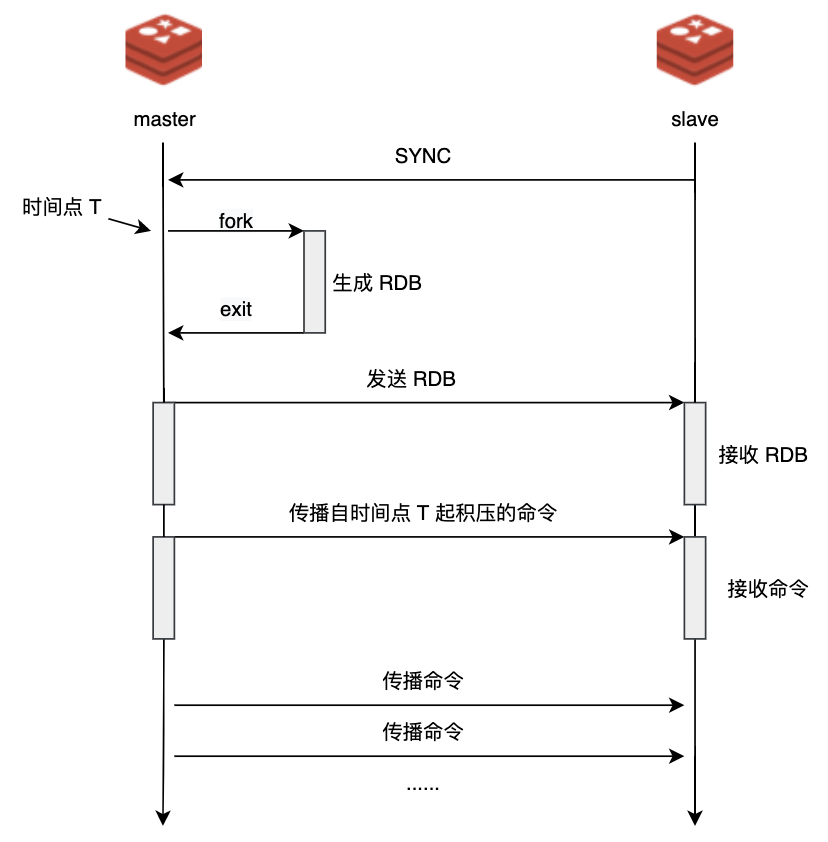
save 60 10000 # 60 秒内有 10000 个 key 发生变化,触发快照第二种,主从复制时,当从节点第一次连接到主节点时,主节点会自动执行 bgsave 生成 RDB 文件,并将其发送给从节点。
第三种,如果没有开启 AOF,执行 shutdown 命令时,Redis 会自动保存一次 RDB 文件,以确保数据不会丢失。
详细说一下 AOF?
AOF 通过记录每个写操作命令,并将其追加到 AOF 文件来实现持久化,Redis 服务器宕机后可以通过重新执行这些命令来恢复数据。
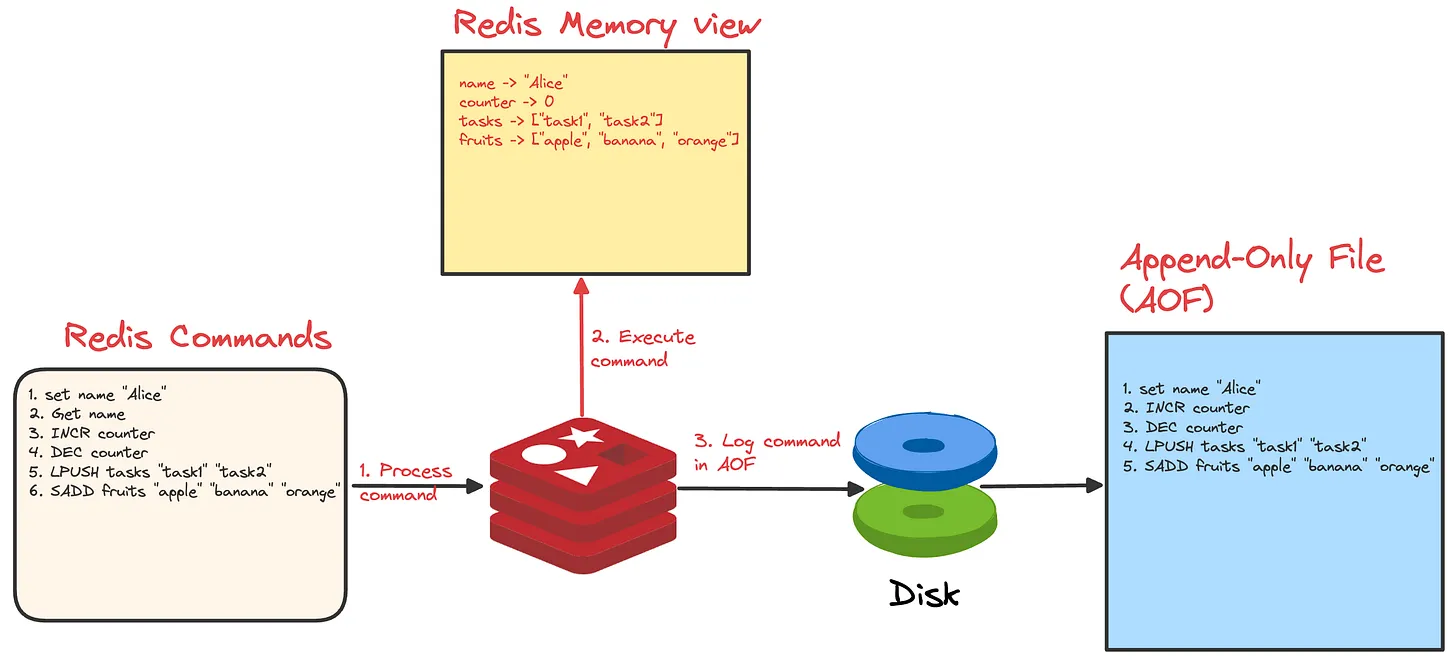
当 Redis 执行写操作时,会将写命令追加到 AOF 缓冲区;Redis 会根据同步策略将缓冲区的数据写入到 AOF 文件。
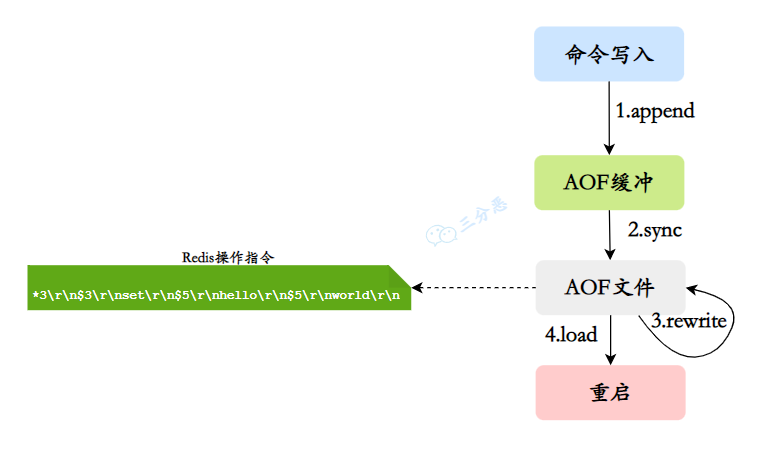
当 AOF 文件过大时,Redis 会自动进行 AOF 重写,剔除多余的命令,比如说多次对同一个 key 的 set 和 del,生成一个新的 AOF 文件;当 Redis 重启时,读取 AOF 文件中的命令并重新执行,以恢复数据。
AOF 的刷盘策略了解吗?
Redis 将 AOF 缓冲区的数据写入到 AOF 文件时,涉及两个系统调用:write 将数据写入到操作系统的缓冲区,fsync 将 OS 缓冲区的数据刷新到磁盘。
这里的刷盘涉及到三种策略:always、everysec 和 no。
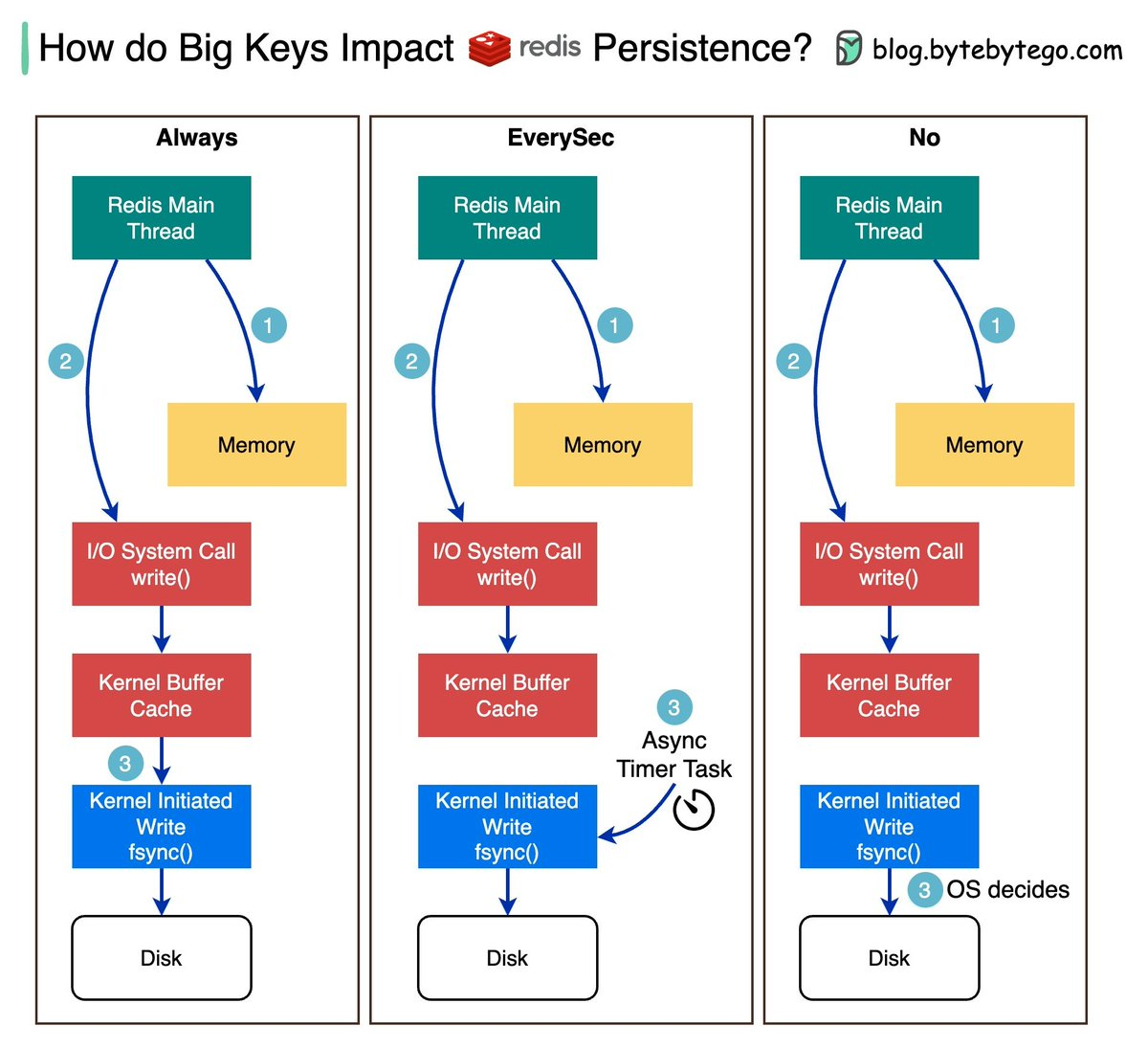
- always:每次写命令执行完,立即调用 fsync 同步到磁盘,这样可以保证数据不丢失,但性能较差。
- everysec:每秒调用一次 fsync,将多条命令一次性同步到磁盘,性能较好,数据丢失的时间窗口为 1 秒。
- no:不主动调用 fsync,由操作系统决定,性能最好,但数据丢失的时间窗口不确定,依赖于操作系统的缓存策略,可能会丢失大量数据。
可以通过配置文件中的 appendfsync 参数进行设置。
appendfsync everysec # 每秒 fsync 一次说说AOF的重写机制?
由于 AOF 文件会随着写操作的增加而不断增长,为了解决这个问题, Redis 提供了重写机制来对 AOF 文件进行压缩和优化。
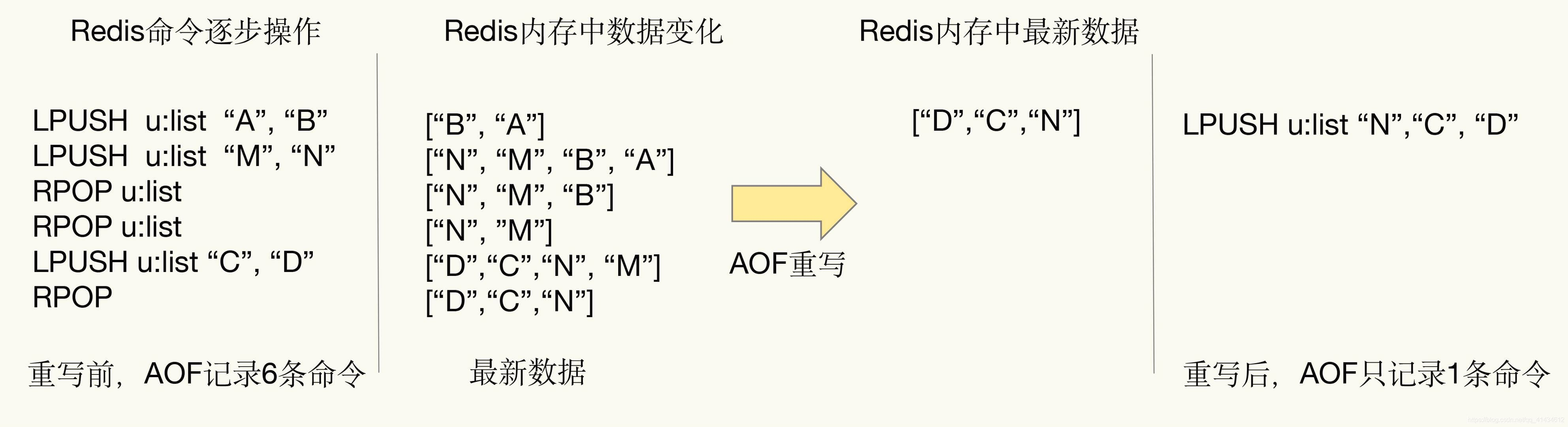
AOF 重写可以通过两种方式触发,第一种是手动执行 BGREWRITEAOF 命令,适用于需要立即减小AOF文件大小的场景。
第二种是在 Redis 配置文件中设置自动重写参数,比如说 auto-aof-rewrite-percentage 和 auto-aof-rewrite-min-size,表示当 AOF 文件大小超过指定值时,自动触发重写。
auto-aof-rewrite-percentage 100 # 默认值100,表示当前AOF文件大小相比上次重写后大小增长了多少百分比时触发重写
auto-aof-rewrite-min-size 64mb # 默认值64MB,表示AOF文件至少要达到这个大小才会考虑重写AOF 重写的具体过程是怎样的?
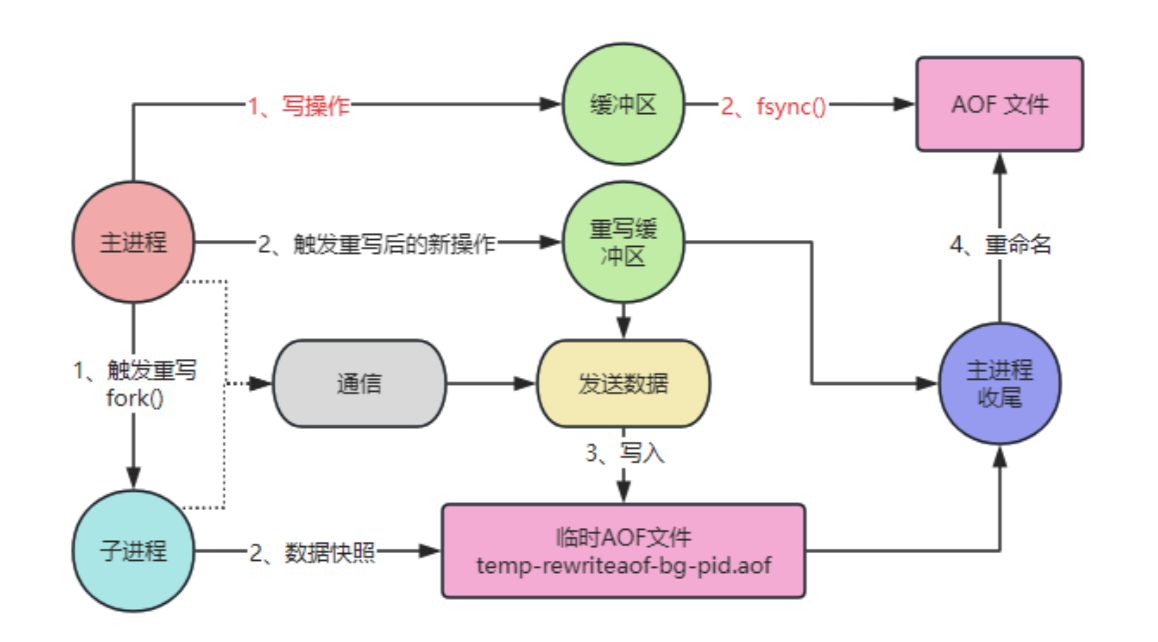
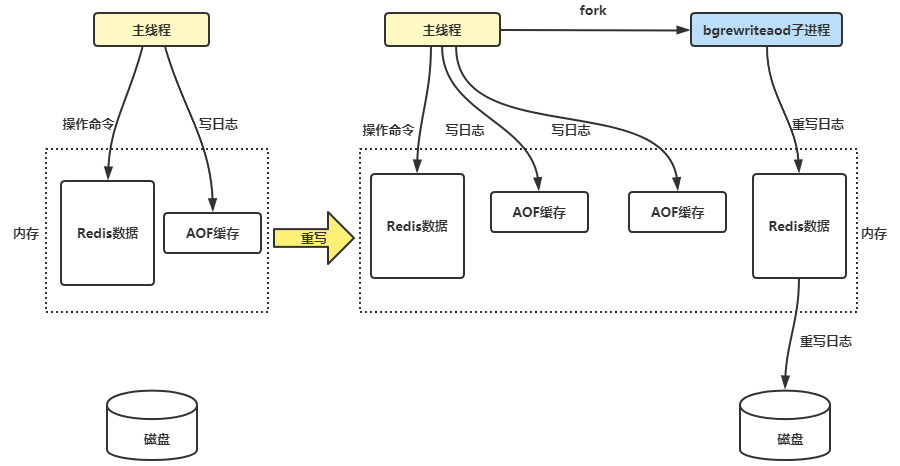
Redis 在收到重写指令后,会创建一个子进程,并 fork 一份与父进程完全相同的数据副本,然后遍历内存中的所有键值对,生成重建它们所需的最少命令。
比如说多个 RPUSH 命令可以合并为一个带有多个参数的 RPUSH;
比如说一个键被设置后又被删除,这个键的所有操作都不会被写入新 AOF。
比如说使用 SADD key member1 member2 member3 代替多个单独的 SADD key memberX。
子进程在执行 AOF 重写的同时,主进程可以继续处理来自客户端的命令。
为了保证数据一致性,Redis 使用了 AOF 重写缓冲区机制,主进程在执行写操作时,会将命令同时写入旧的 AOF 文件和重写缓冲区。
等子进程完成重写后,会向主进程发送一个信号,主进程收到后将重写缓冲区中的命令追加到新的 AOF 文件中,然后调用操作系统的 rename,将旧的 AOF 文件替换为新的 AOF 文件。
主进程(fork)
│
├─→ 子进程(生成新的 AOF 文件)
│ │
│ ├─→ 内存快照
│ ├─→ 写入临时 AOF 文件
│ ├─→ 通知主进程完成
│
├─→ 主进程(追加缓冲区到新 AOF 文件)
├─→ 替换旧 AOF 文件
├─→ 重写完成AOF 重写期间,Redis 服务器会处于特殊状态:
- aof_child_pid 不为 0,表示有子进程在执行 AOF 重写
- aof_rewrite_buf_blocks 链表不为空,存储 AOF 重写缓冲区内容
如果在配置文件中设置 no-appendfsync-on-rewrite 为 yes,那么重写期间可能会暂停 AOF 文件的 fsync 操作。
appendonly yes # 开启AOF
appendfilename "appendonly.aof" # AOF文件名
appendfsync everysec # 写入磁盘策略
no-appendfsync-on-rewrite no # 重写期间是否临时关闭fsync
auto-aof-rewrite-percentage 100 # AOF文件增长到原来多少百分比时触发重写
auto-aof-rewrite-min-size 64mb # AOF文件最小多大时才允许重写AOF 文件存储的是什么类型的数据?
AOF 文件存储的是 Redis 服务器接收到的写命令数据,以 Redis 协议格式保存。
这种格式的特点是,每个命令以*开头,后跟参数的数量,每个参数前用$符号,后跟参数字节长度,然后是参数的实际内容。
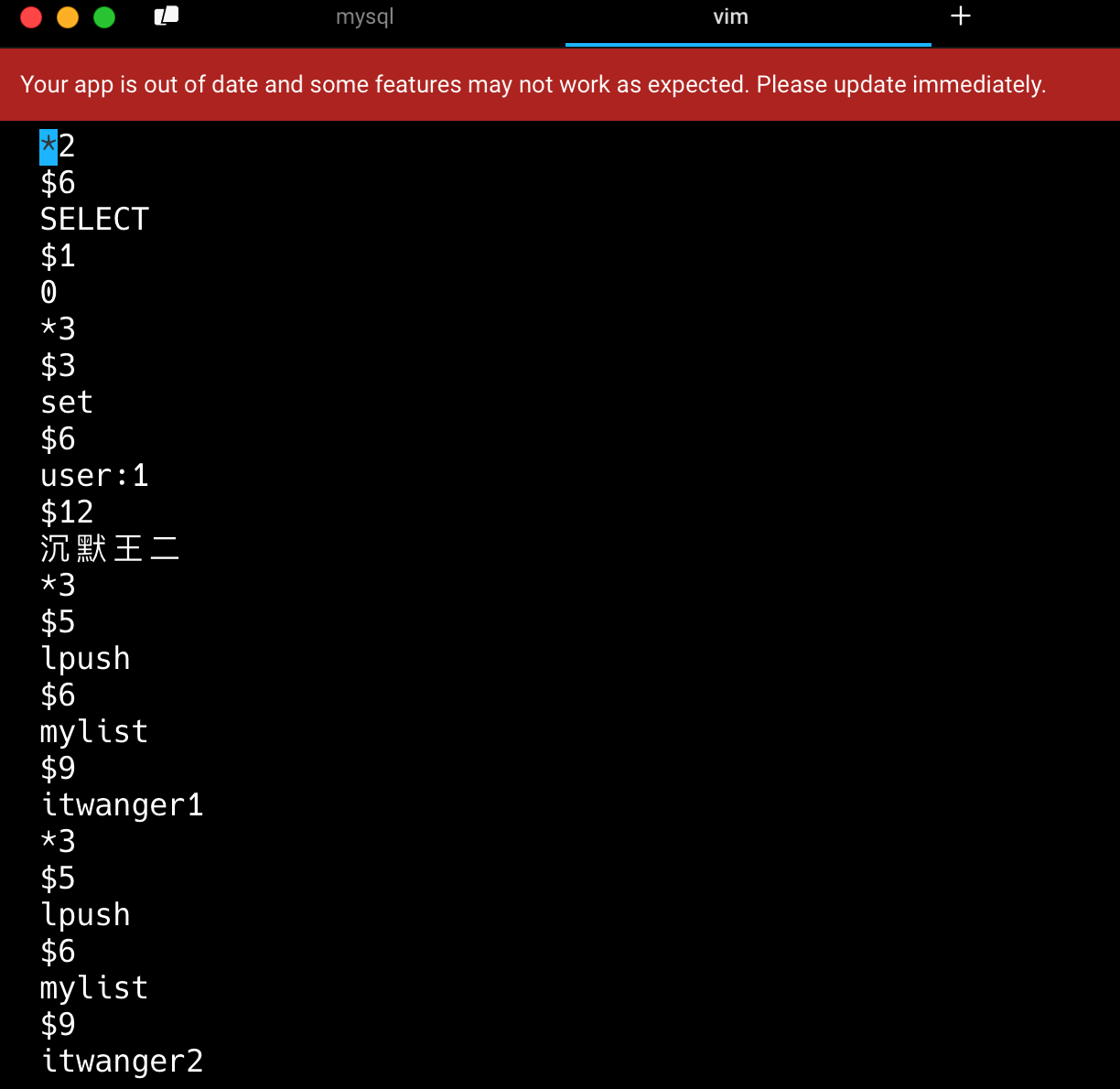
AOF重写期间命令可能会写入两次,会造成什么影响?
AOF 重写期间命令会同时写入现有AOF文件和重写缓冲区,这种机制是有意设计的,并不会导致数据重复或不一致问题。
因为新旧文件是分离的,现有命令写入当前 AOF 文件,重写缓冲区的命令最终写入新的 AOF 文件,完成后,新文件通过原子性的 rename 操作替换旧文件。两个文件是完全分离的,不会导致同一个 AOF 文件中出现重复命令。
- Java 面试指南(付费)收录的小米春招同学 K 一面面试原题:为什么 redis 快,淘汰策略 持久化
- Java 面试指南(付费)收录的快手面经同学 7 Java 后端技术一面面试原题:说一下 Redis 的持久化方式
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:Redis 的持久化方式?RDB 和 AOF 的区别?Redis 宕机哪种恢复的比较快?
- Java 面试指南(付费)收录的美团面经同学 18 成都到家面试原题:redis 持久化
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:redis持久化机制
- Java 面试指南(付费)收录的 OPPO 面经同学 1 面试原题:Redis持久化方案
- Java 面试指南(付费)收录的得物面经同学 9 面试题目原题:Redis的基本数据类型?Redis的持久化呢?有何优缺点?
- Java 面试指南(付费)收录的滴滴面经同学 3 网约车后端开发一面原题:Redis持久化
- Java 面试指南(付费)收录的快手面经同学 1 部门主站技术部面试原题:Redis数据的可靠性怎么保证?AOF重写期间命令可能会写入两次,会造成什么影响?
memo:2025 年 5 月 4 日修改至此,今天有球友发信息说把并发编程和 JVM 的面渣逆袭都打印成纸质版了,说实话,这个封面的颜值我也很喜欢,哈哈。
11.RDB 和 AOF 各自有什么优缺点?
RDB 通过 fork 子进程在特定时间点对内存数据进行全量备份,生成二进制格式的快照文件。其最大优势在于备份恢复效率高,文件紧凑,恢复速度快,适合大规模数据的备份和迁移场景。
缺点是可能丢失两次快照期间的所有数据变更。
AOF 会记录每一条修改数据的写命令。这种日志追加的方式让 AOF 能够提供接近实时的数据备份,数据丢失风险可以控制在 1 秒内甚至完全避免。
缺点是文件体积较大,恢复速度慢。
来个表格对比一下:
| 对比项 | RDB(快照) | AOF(命令日志) |
|---|---|---|
| 数据完整性 | ❌ 可能丢失几分钟数据 | ✅ 最多丢 1 秒数据 |
| 恢复速度 | ✅ 快(直接加载二进制快照) | ❌ 慢(逐条 replay) |
| 文件大小 | ✅ 小(压缩后) | ❌ 大(命令追加) |
| 性能影响 | ✅ 低(fork 后保存) | ❌ 较高(每次写都记录) |
| 写入方式 | 定期全量写 | 每次写命令就记录 |
| 适用场景 | 冷备份,灾难恢复 | 实时持久化,数据安全 |
| 默认状态 | 默认启用 | Redis 7 默认也启用 |
| 重写机制 | 无 | 有(BGREWRITEAOF) |
| 混合支持 | Redis 4.0 后支持结合使用(aof-use-rdb-preamble) |
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:Redis 的持久化方式?RDB 和 AOF 的区别?Redis 宕机哪种恢复的比较快?
12.RDB 和 AOF 如何选择?
在选择 Redis 持久化方案时,我会从业务需求和技术特性两个维度来考虑。
如果是缓存场景,可以接受一定程度的数据丢失,我会倾向于选择 RDB 或者完全不使用持久化。RDB 的快照方式对性能影响小,而且恢复速度快,非常适合这类场景。
但如果是处理订单或者支付这样的核心业务,数据丢失将造成严重后果,那么 AOF 就成为必然选择。通过配置每秒同步一次,可以将潜在的数据丢失风险限制在可接受范围内。
在实际的项目当中,我更偏向于使用 RDB + AOF 的混合模式。
appendonly yes # 开启 AOF
appendfsync everysec # 每秒刷盘一次
aof-use-rdb-preamble yes # 开启混合持久化,重启时优先加载 RDB,RDB 作为冷备,AOF 作为实时同步
- Java 面试指南(付费)收录的美团面经同学 18 成都到家面试原题:什么时候用 rdb 什么时候用 aof
13.Redis如何恢复数据?
当 Redis 服务重启时,它会优先查找 AOF 文件,如果存在就通过重放其中的命令来恢复数据;如果不存在或未启用 AOF,则会尝试加载 RDB 文件,直接将二进制数据载入内存来恢复。
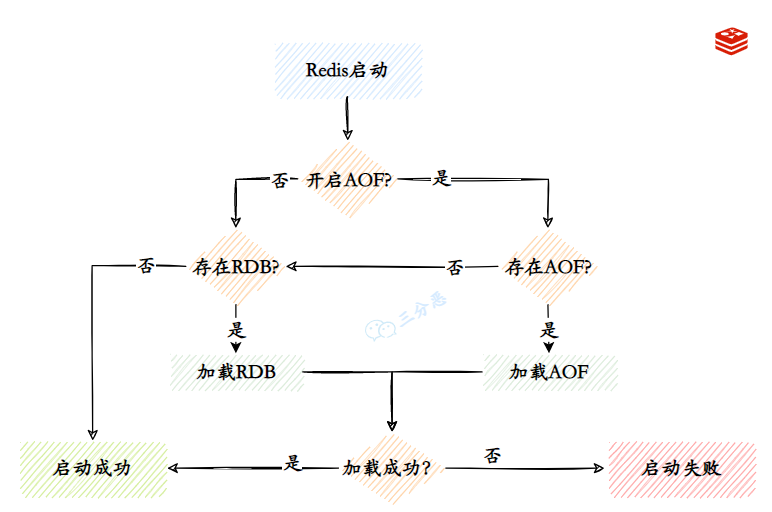
如果 AOF 文件损坏的话,Redis 会尝试通过 redis-check-aof 工具来修复 AOF 文件,或者直接使用 --repair 参数来修复。
redis-check-aof --repair appendonly.aof虽然 Redis 还提供了 redis-check-rdb 工具来检查 RDB 文件的完整性,但它并不支持修复 RDB 文件,只能用来验证文件的完整性。
redis-check-rdb dump.rdb
- Java 面试指南(付费)收录的美团面经同学 4 一面面试原题:Redis 内存中数据丢失怎么解决
memo:2025 年 5 月 5 日修改至此,今天给球友修改简历时,碰到一个华科本硕的球友,985 高校又+1,目前国内的 985 高校有 39 所,希望不久的将来,能全部集齐。😄

14.🌟Redis 4.0 的混合持久化了解吗?
是的。
混合持久化结合了 RDB 和 AOF 两种方式的优点,解决了它们各自的不足。在 Redis 4.0 之前,我们要么面临 RDB 可能丢失数据的风险,要么承受 AOF 恢复慢的问题,很难两全其美。
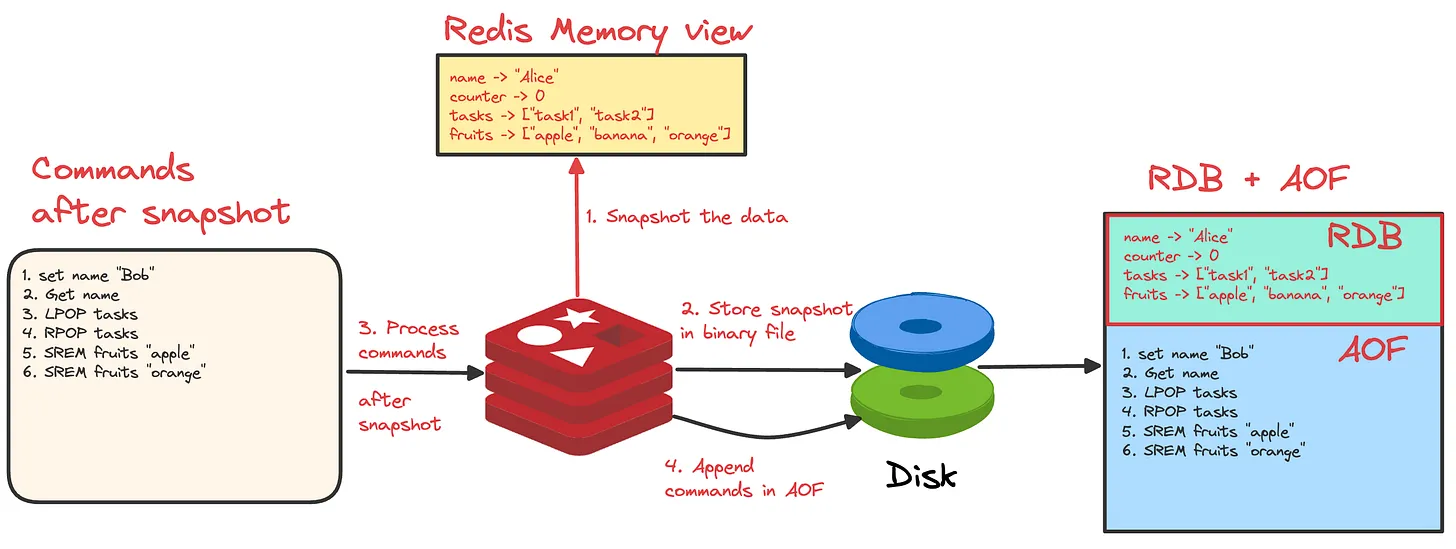
混合持久化的工作原理非常巧妙:在 AOF 重写期间,先以 RDB 格式将内存中的数据快照保存到 AOF 文件的开头,再将重写期间的命令以 AOF 格式追加到文件末尾。
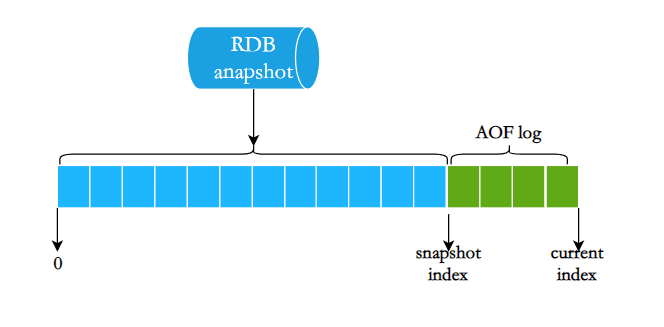
这样,当需要恢复数据时,Redis 先加载 RDB 格式的数据来快速恢复大部分的数据,然后通过重放命令恢复最近的数据,这样就能在保证数据完整性的同时,提升恢复速度。
如何设置持久化模式?
启用混合持久化的方式非常简单,只需要在配置文件中设置 aof-use-rdb-preamble yes 就可以了。
aof-use-rdb-preamble yes你在开发中是怎么配置 RDB 和 AOF 的?
对于大多数生产环境,我倾向于使用混合持久化方式,结合 RDB 和 AOF 的优点。
# 启用AOF
appendonly yes
# 使用混合持久化
aof-use-rdb-preamble yes
# 每秒同步一次AOF,平衡性能和安全性
appendfsync everysec
# AOF重写触发条件:文件增长100%且至少达到64MB
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# RDB备份策略
save 900 1 # 15分钟内有1个修改
save 300 10 # 5分钟内有10个修改
save 60 10000 # 1分钟内有10000个修改对于单纯的缓存场景,或者本地开发,我会只启用 RDB,关闭 AOF:
# 禁用AOF
appendonly no
# 较宽松的RDB策略
save 3600 1 # 1小时内有1个修改
save 300 100 # 5分钟内有100个修改而对于金融类等高一致性的系统,我通常会在关键时间窗口动态将 appendfsync 设置为 always:
# 启用AOF
appendonly yes
# 使用混合持久化
aof-use-rdb-preamble yes
# 每个命令都同步(谨慎使用,性能影响大)
# 通常我会在关键时间窗口动态修改为always
appendfsync always
# 更频繁的RDB快照
save 300 1 # 5分钟内有1个修改
save 60 100 # 1分钟内有100个修改另外,对于高并发场景,应该设置no-appendfsync-on-rewrite yes,避免 AOF 重写影响主进程性能;对于大型实例,也应该设置 rdb-save-incremental-fsync yes 来减少大型 RDB 保存对性能的影响。
# AOF重写期间不fsync,AOF 重写期间,主进程不会对新写入的 AOF 缓冲区执行 fsync 操作(即不强制刷盘),而是等重写结束后再统一刷盘。
no-appendfsync-on-rewrite yes
# RDB 快照保存时采用增量 fsync,即每写入一定量的数据就执行一次 fsync,将数据分批同步到磁盘。
rdb-save-incremental-fsync yes
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:Redis 的持久化机制?
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:Redis 宕机哪种恢复的比较快?
- Java 面试指南(付费)收录的美团面经同学 18 成都到家面试原题:如何设置持久化模式
- Java 面试指南(付费)收录的美团面经同学 4 一面面试原题:业界使用哪一种数据持久化,两种持久化方法的优缺点
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:两种 Redis持久化机制可以混合使用吗
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 5 月 6 日修改至此,今天在修改球友简历时,碰到一个东北大学硕合肥工业大学本的球友,真的非常优秀,也希望大家能够通过星球这个平台彼此激励,共同进步。

高可用
15.主从复制了解吗?
主从复制允许从节点维护主节点的数据副本。在这种架构中,一个主节点可以连接多个从节点,从而形成一主多从的结构。主节点负责处理写操作,从节点自动同步主节点的数据变更,并处理读请求,从而实现读写分离。
主从复制的主要作用是什么?
第一,主节点负责处理写请求,从节点负责处理读请求,从而实现读写分离,减轻主节点压力的同时提升系统的并发能力。
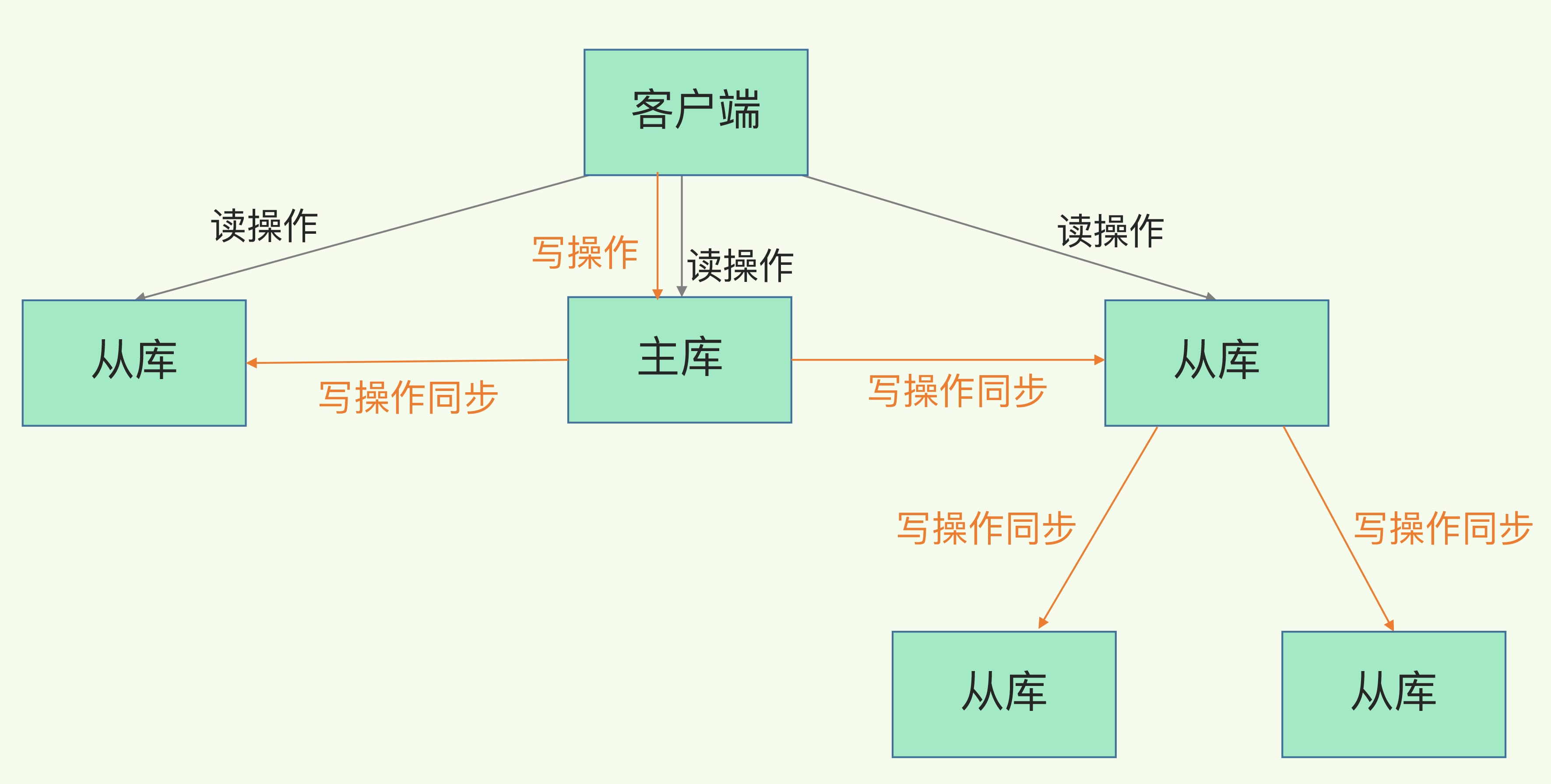
第二,从节点可以作为主节点的数据备份,当主节点发生故障时,可以快速将从节点提升为新的主节点,从而保证系统的高可用性。
什么情况下会出现主从复制数据不一致?
Redis 的主从复制是异步进行的,因此在主节点宕机、网络波动或复制延迟较高时会出现从节点数据不同步的情况。
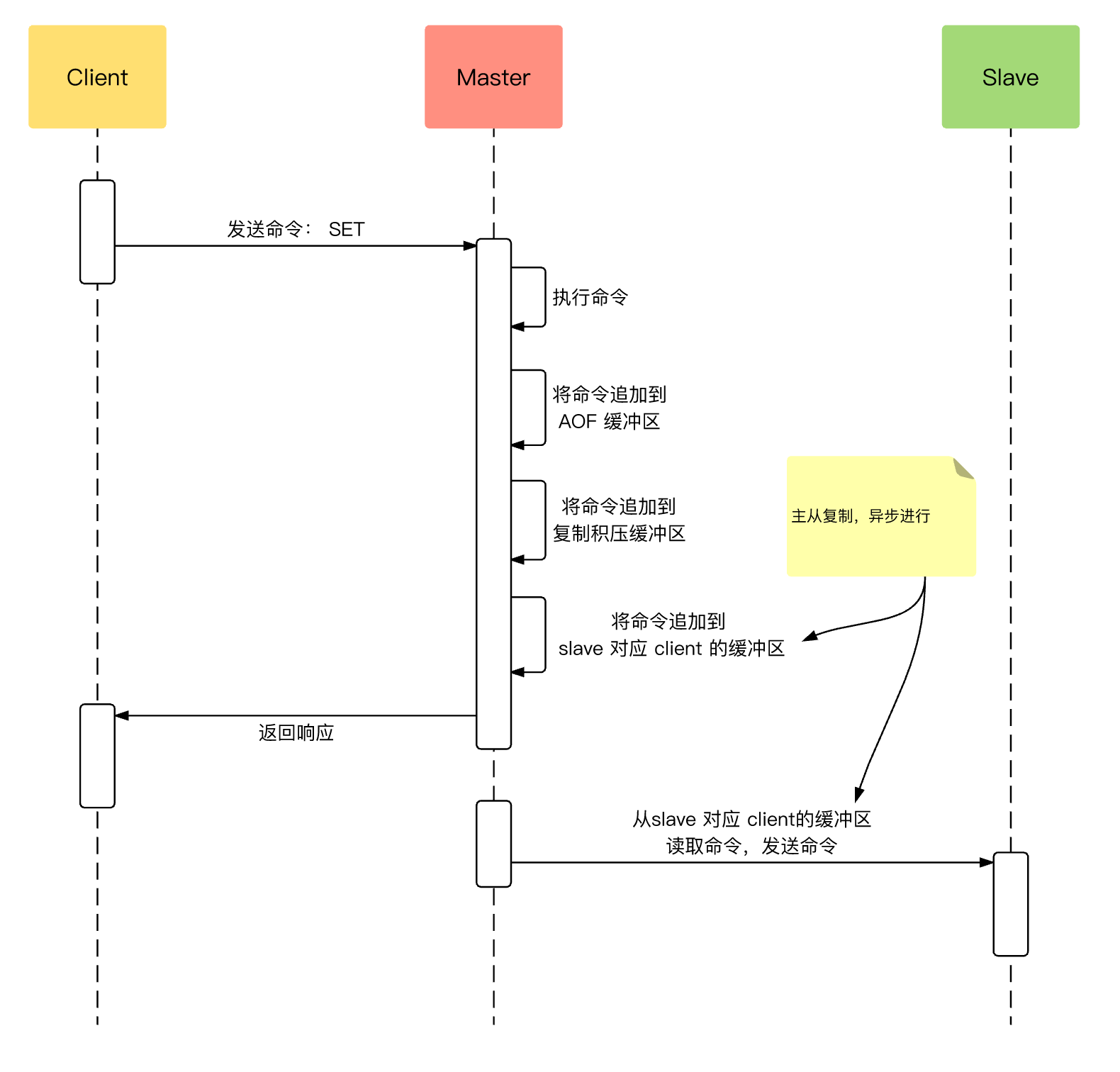
比如主节点写入数据后宕机,但从节点还未来得及复制,就会出现数据不一致。
时间线:→
客户端 → 向主节点 SET user:1 二哥 → 主节点处理成功 ✅
↓
正准备推送给从节点(异步复制)... 但还没推送完 ❌
↓
—— 突然主节点宕机(机器死机、断网) 💥 ——
↓
Sentinel 监测到故障,failover:将从节点提升为新主节点 🧠
↓
客户端继续请求:GET user:1 ❓→ 从节点返回:空 ❌(数据没同步过来)另一个容易被忽视的因素是主节点内存压力。当主节点内存接近上限并启用了淘汰策略时,某些键可能被自动删除,而这些删除操作如果未能及时同步,就会造成从节点保留了主节点已经不存在的数据。
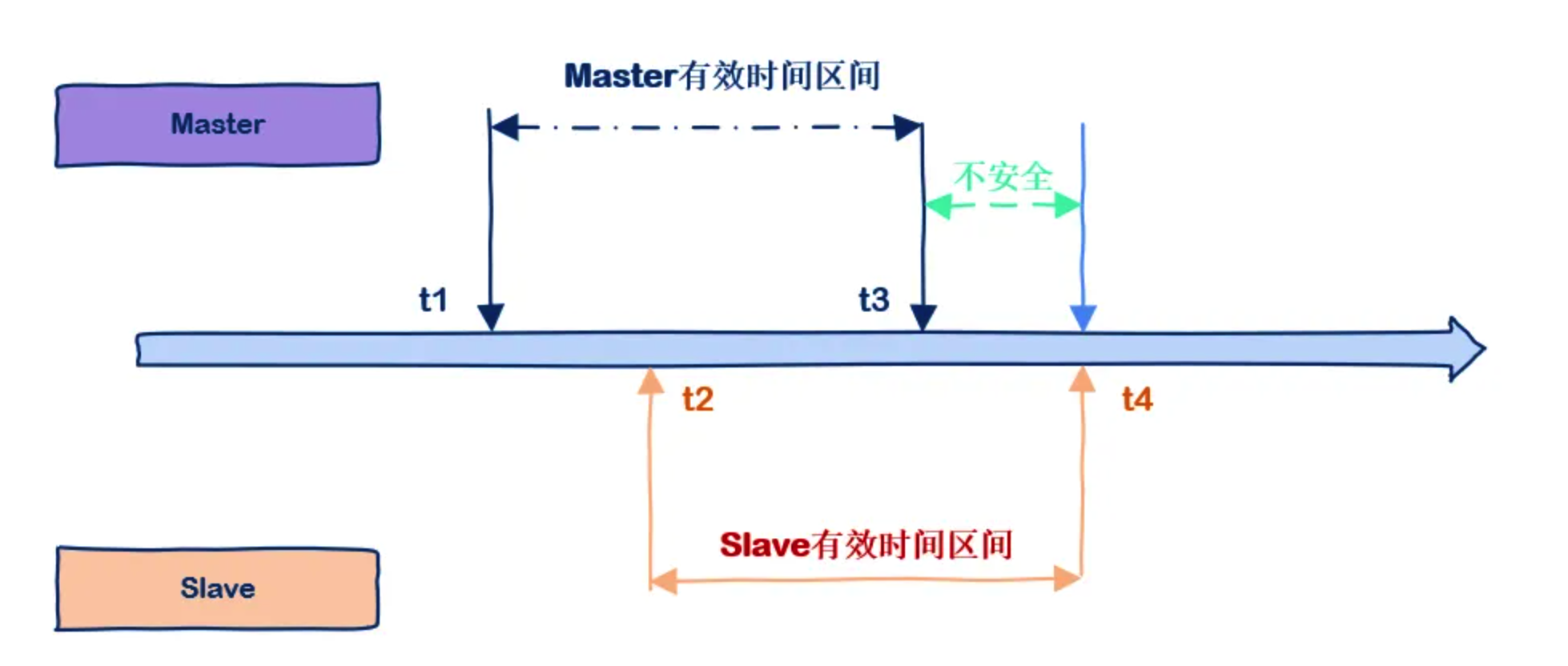
主从复制数据不一致的解决方案有哪些?
首先是网络层面的优化,理想情况下,主从节点应该部署在同一个网络区域内,避免跨区域的网络延迟。
其次是配置层面的调整,比如说适当增大复制积压缓冲区的大小和存活时间,以便从节点重连后进行增量同步而不是全量同步,以最大程度减少主从同步的延迟。
repl-backlog-size 1mb # 默认值 1MB,表示主节点的复制缓冲区大小
repl-backlog-ttl 3600 # 默认值 3600 秒,表示主节点的复制缓冲区存活时间第三是引入监控和自动修复机制,定期检查主从节点的数据一致性。
比如说通过比较主从的 offset 差值判断从库是否落后。一旦超过设定阈值,就将从节点剔除,并重新进行全量同步。
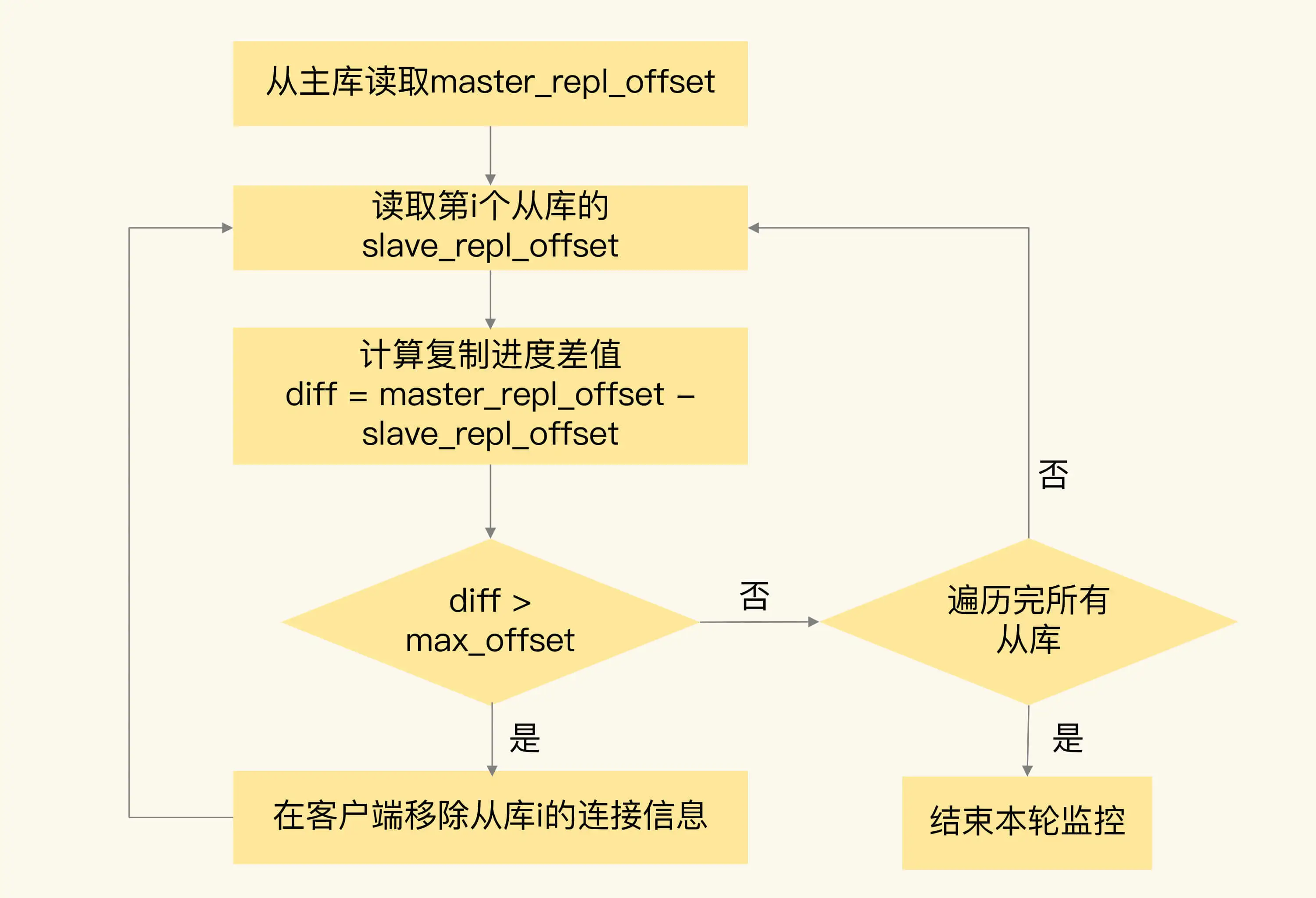
- Java 面试指南(付费)收录的得物面经同学 1 面试原题:Redis 分布式,主从,一个节点挂掉怎么办
- Java 面试指南(付费)收录的小米面经同学 F 面试原题:redis 的主从架构和主从哨兵区别
- Java 面试指南(付费)收录的收钱吧面经同学 1 Java 后端一面面试原题:Redis解决单点故障主要靠什么?主从模式用的是异步还是同步?
memo:2025 年 5 月 7 日修改至此,今天在修改球友简历时,收到了球友对简历修改的认可:“现在这份简历应该比较完美了”,完美这个词我觉得褒奖的有点多了,哈哈,不过我还是很开心的。
16.Redis主从有几种常见的拓扑结构?
主要有三种。
最基础的是一主一从,这种模式适合小型项目。一个主节点负责写入,一个从节点负责读和数据备份。这种结构虽然简单,但维护成本低。
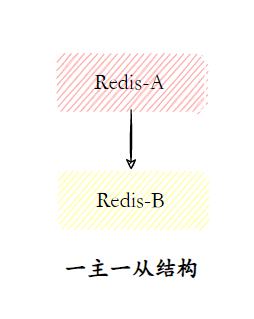
随着业务增长,读请求增多,可以考虑扩展为一主多从结构。主节点负责写入,多个从节点还可以分摊压力。
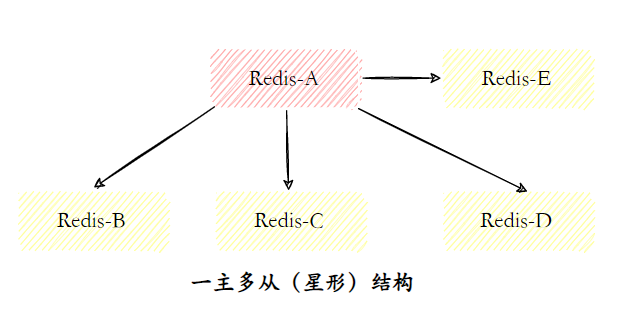
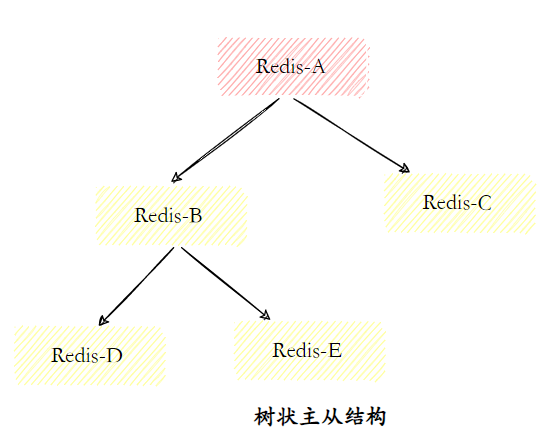
在跨地域部署场景中,树状主从结构可以有效降低主节点负载和需要传送给从节点的数据量。通过引入复制中间层,从节点不仅可以复制主节点数据,同时可以作为其他从节点的主节点继续向下层复制。
17.Redis的主从复制原理了解吗?
了解。
Redis 的主从复制是指通过异步复制将主节点的数据变更同步到从节点,从而实现数据备份和读写分离。这个过程大致可以分为三个阶段:建立连接、同步数据和传播命令。

在建立连接阶段,从节点通过执行 replicaof 命令连接到主节点。连接建立后,从节点向主节点发送 psync 命令,请求数据同步。这时主节点会为该从节点创建一个连接和复制缓冲区。
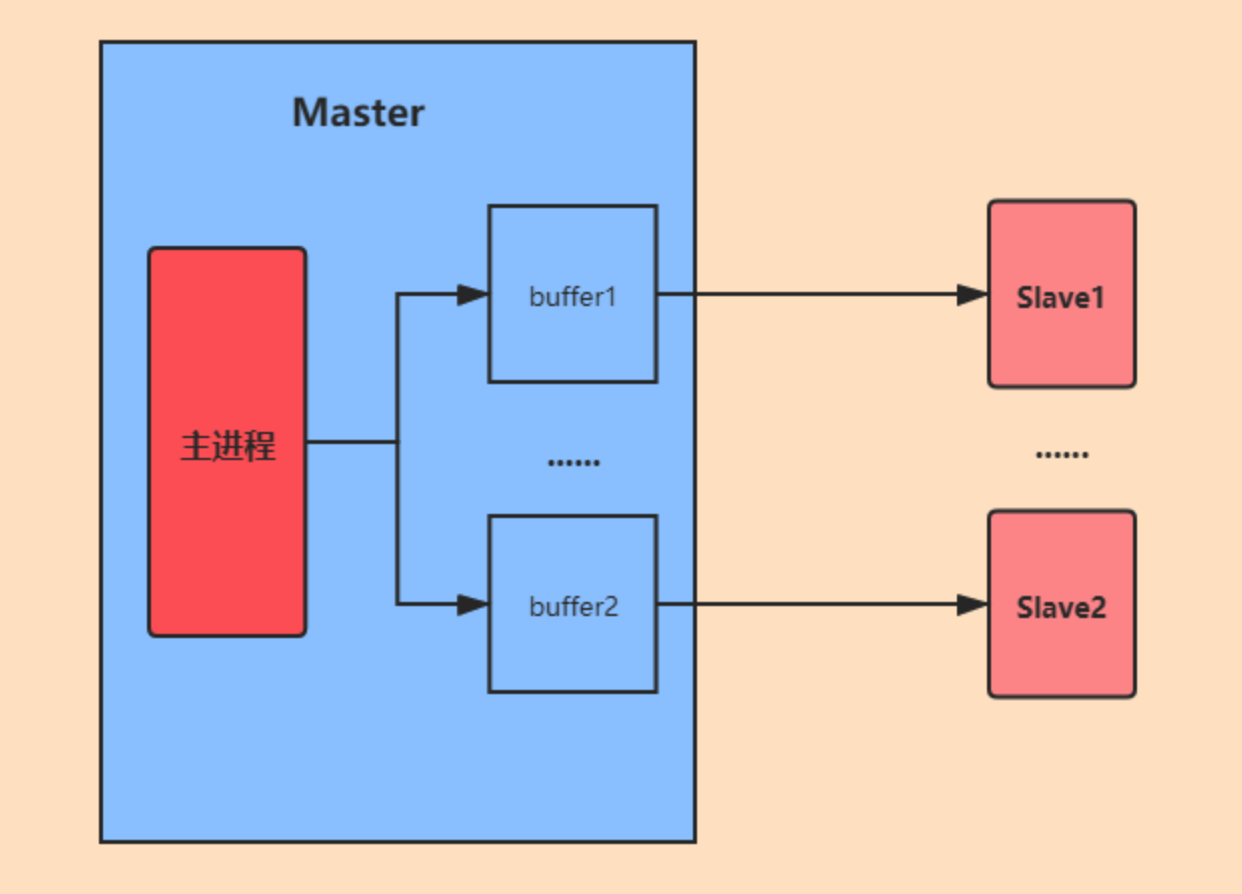
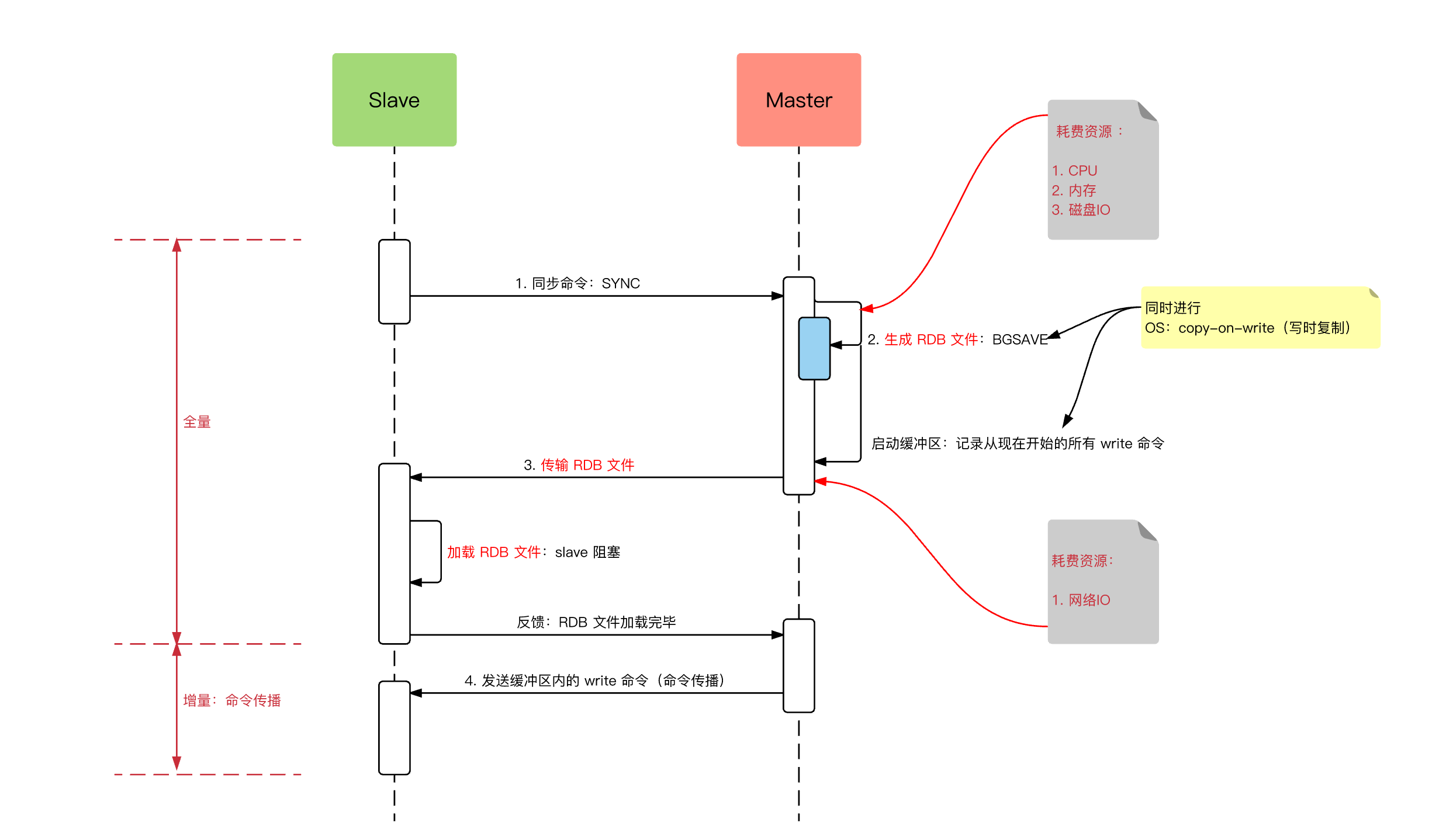
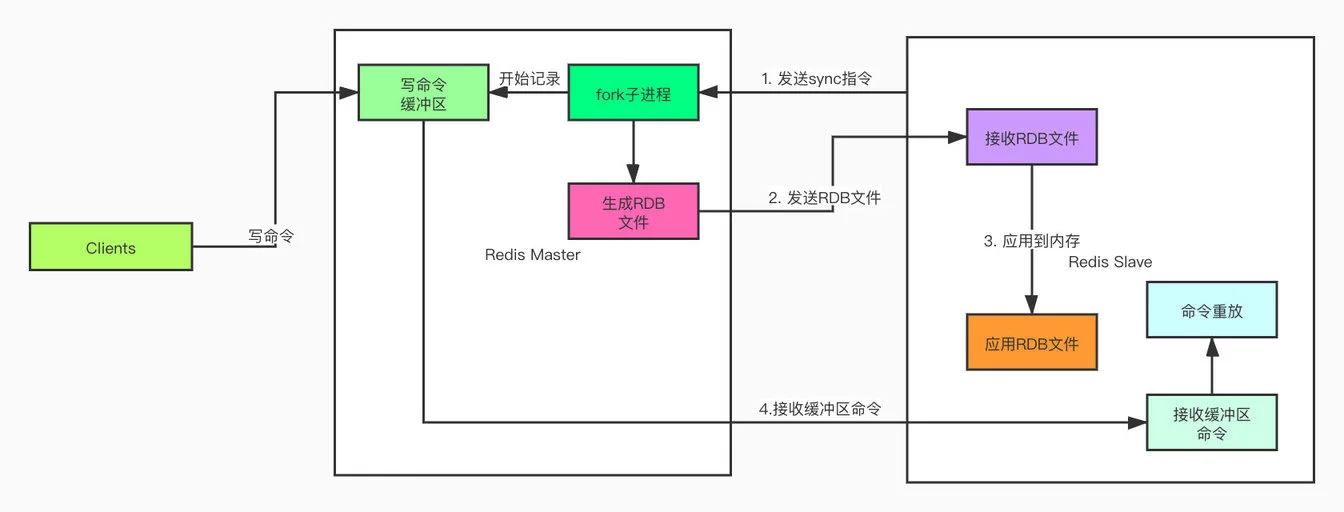
同步数据阶段分为全量同步和增量同步。当从节点首次连接主节点时,会触发全量同步。
在这个过程中,主节点会 fork 一个子进程生成 RDB 文件,同时将文件生成期间收到的写命令缓存到复制缓冲区。然后将 RDB 文件发送给从节点,从节点清空自己的数据并加载这个 RDB 文件。等 RDB 传输完成后,主节点再将缓存的写命令发送给从节点执行,确保数据完全一致。
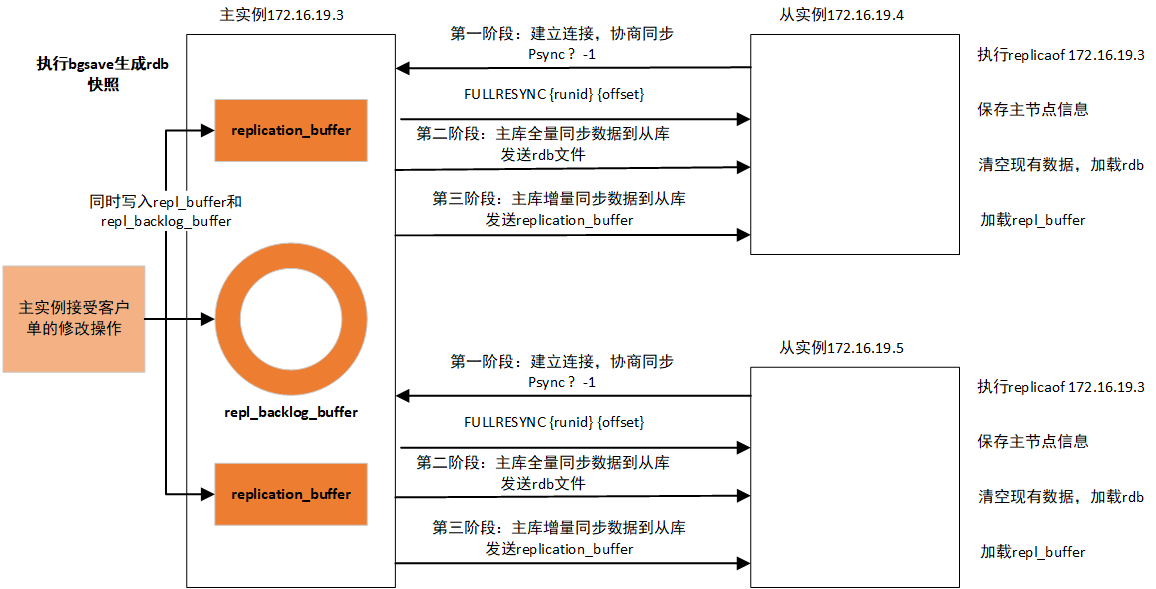
主从完成全量同步后,主要依靠传播命令阶段来保持数据的增量同步。主节点会将每次执行的写命令实时发送给所有从节点。
Redis 2.8 版本后,主节点会为每个从节点维护一个复制积压缓冲区,用于存储最近的写命令。
增量复制时,主节点会把要同步的写命令暂存一份到复制积压缓冲区。这样当从节点和主节点发生网络断连,从节点重新连接后,可以从复制积压缓冲区中复制尚未同步的写命令。
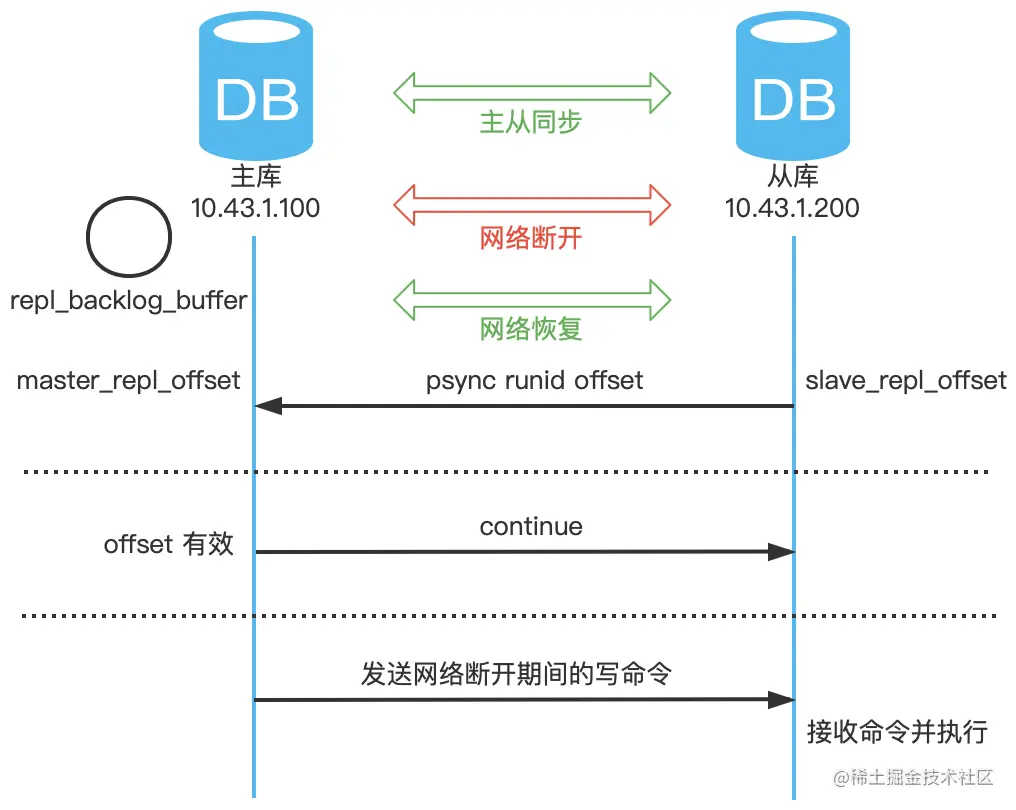
memo:2025 年 5 月 8 日修改至此,今天有球友在星球里发帖说拿到了腾讯的实习 offer,真的要恭喜了。面经,我看题目主要集中在技术派项目和MySQL、计算机网络的八股上。

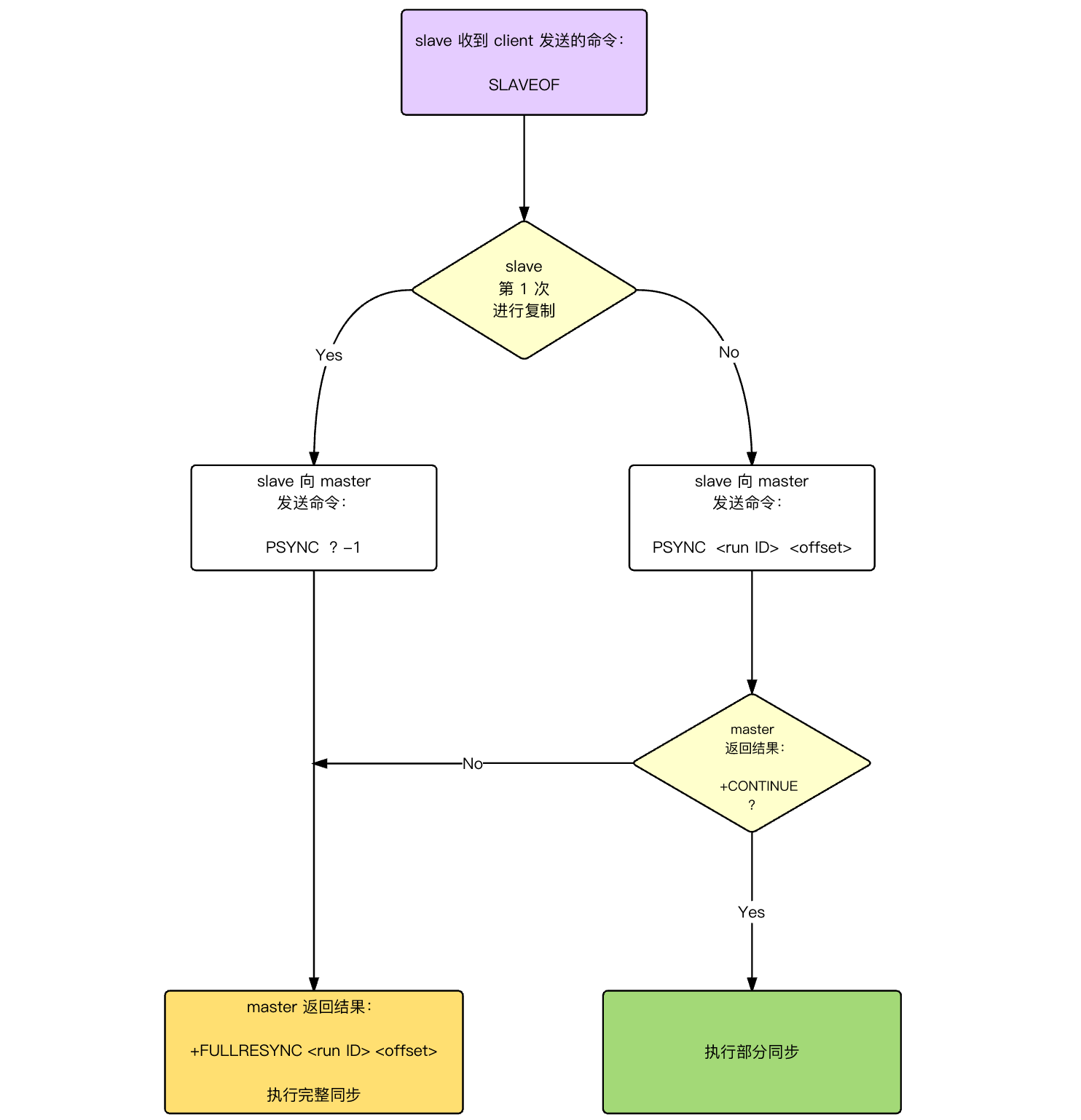
18.详细说说全量同步和增量同步?
全量同步会将主节点的完整数据集传输给从节点,通常发生在从节点首次连接主节点时。
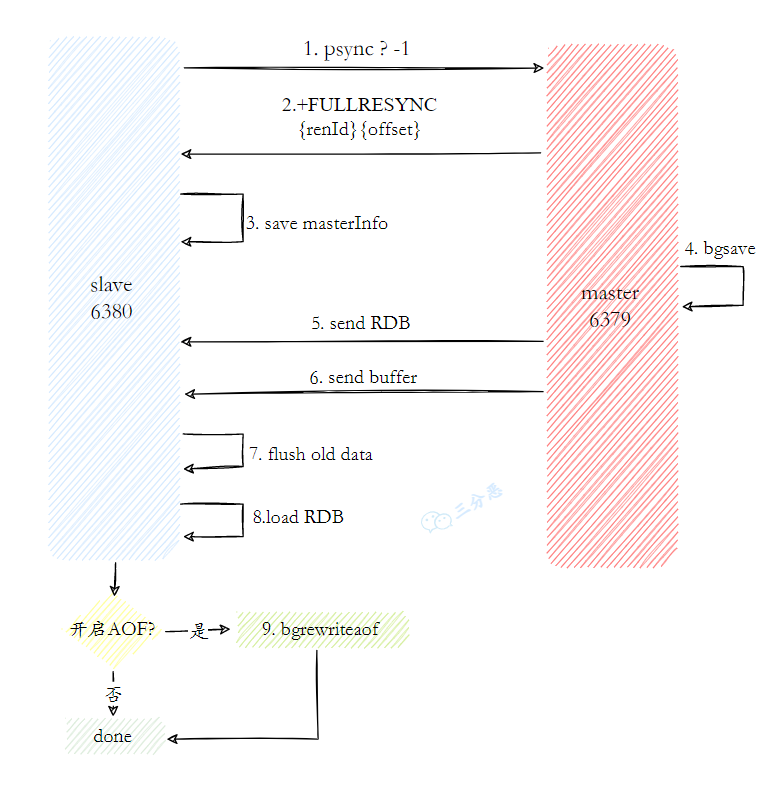
此时,从节点发送 psync ? -1 命令请求同步。? 表示从节点没有主节点 ID,-1 表示没有偏移量。主节点收到后会回复 FULLRESYNC响应从节点。同时也会包含主库 runid 和复制偏移量 offset 两个参数。
然后 fork 一个子进程生成 RDB 文件,并将新的写命令存入复制缓冲区。
从库收到 RDB 文件后,清空旧数据并加载新的 RDB 文件。加载完成后,从节点会向主节点回复确认消息,主节点再将复制缓冲区中的数据发送给从节点,确保从节点的数据与主节点一致。
全量同步的代价很高,因为完整的 RDB 文件在生成时会占用大量的 CPU 和磁盘 IO;在网络传输时还会消耗掉不少带宽。
于是 Redis 在 2.8 版本后引入了增量同步的概念,目的是在断线重连后避免全量同步。
增量依赖三个关键要素:
①、复制偏移量:主从节点分别维护一个复制偏移量,记录传输的字节数。主节点每传输 N 个字节数据,自身的复制偏移量就会增加 N;从节点每收到 N 个字节数据,也会相应增加自己的偏移量。
②、主节点 ID:每个主节点都有一个唯一 ID,即复制 ID,用于标识主节点的数据版本。当主节点发生重启或者角色变化时,ID 会改变。
③、复制积压缓冲区:主节点维护的一个固定长度的先进先出队列,默认大小为 1M。主节点在向从节点发送命令的同时,也会将命令写入这个缓冲区。
当从节点与主节点断开重连后,会发送 psync{runId}{offset} 命令,带上之前记录的主节点 ID 和复制偏移量。
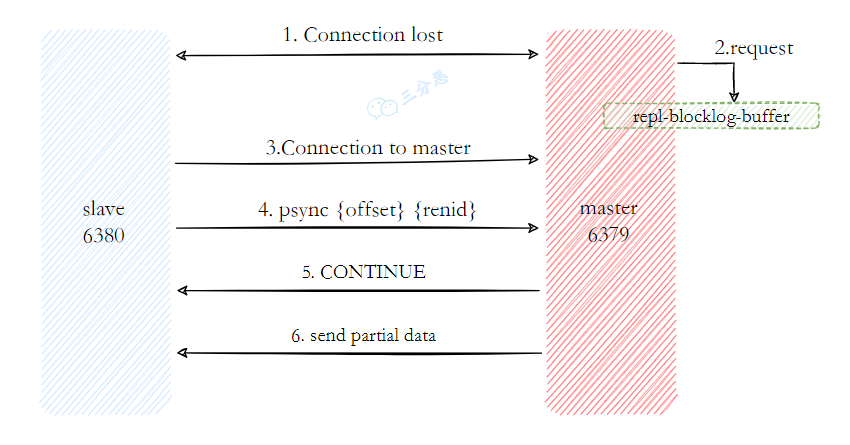
主节点收到这个命令后,会检查 runId 和 offset:
如果主节点 ID 与从节点提供的 runId 不匹配,说明主节点已经变化,必须进行全量同步。
如果 ID 匹配,主节点会查找从节点请求的偏移量之后的数据是否还在复制积压缓冲区。
如果在,只发送从该偏移量开始的增量数据,这就是增量同步;否则说明断线时间太长,积压缓冲区已经覆盖了这部分数据,需要全量同步。
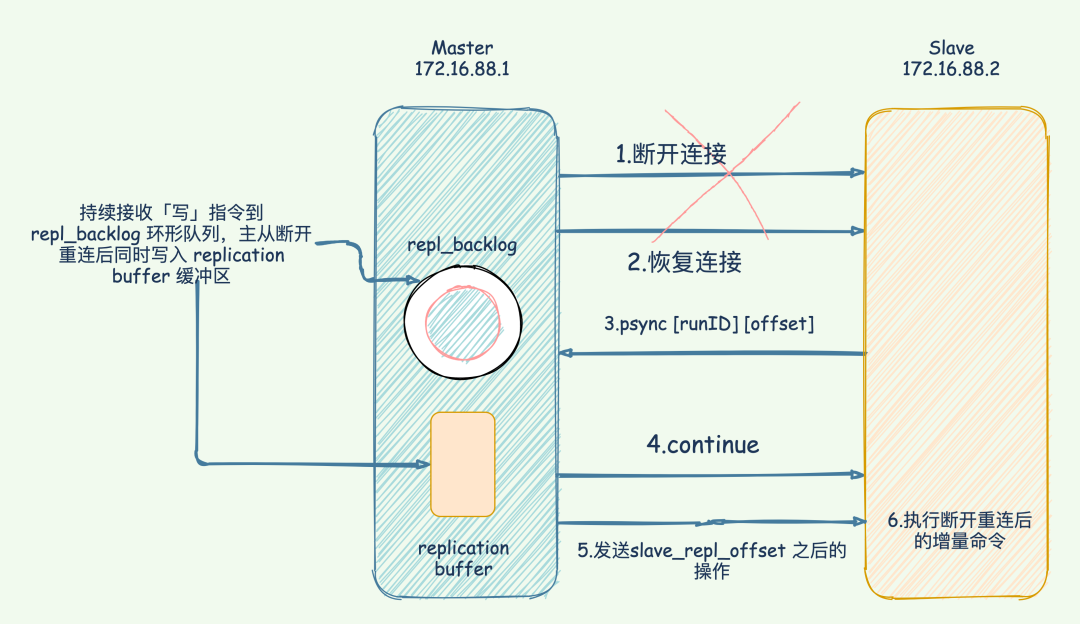
增量同步的优势显而易见:只传输断线期间的命令数据,大大减少了网络传输量和主从节点的负载,从节点也不需要清空重载数据,能更快地跟上主节点状态。
对于写入频繁或网络不稳定的环境,应该增大复制积压缓冲区的大小,确保短时间断线后能进行增量同步而不是全量同步。
repl-backlog-size 1mb # 默认值 1MB,表示主节点的复制缓冲区大小
repl-backlog-ttl 3600 # 默认值 3600 秒,表示主节点的复制缓冲区存活时间memo:2025 年 5 月 9 日修改至此,今天在修改球友简历时,碰到一个河北大学硕东华理工大学本的球友,希望这个大家庭能给大家带来更多的帮助和支持。

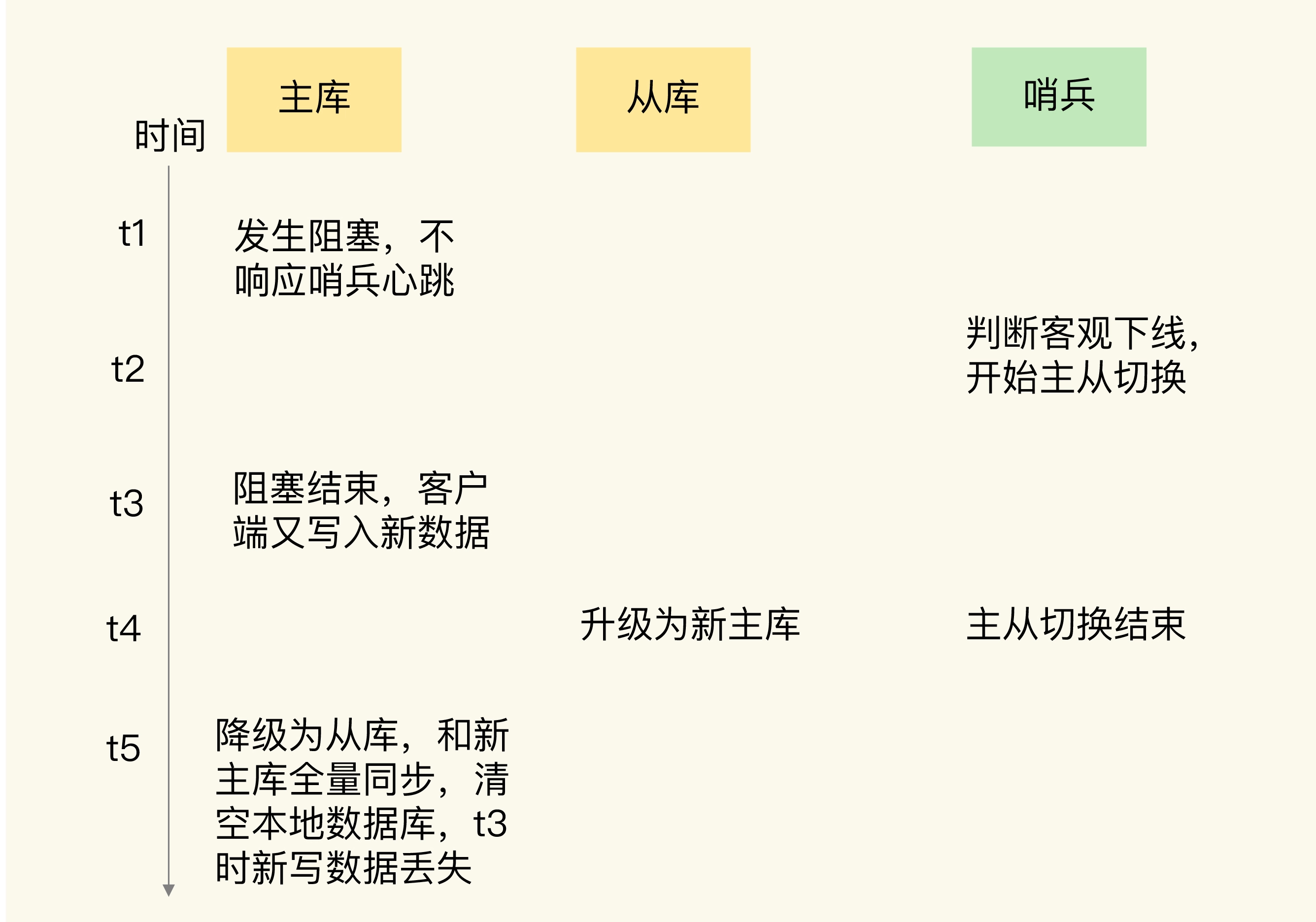
19.主从复制存在哪些问题呢?
Redis 主从复制的最大挑战来自于它的异步特性,主节点处理完写命令后会立即响应客户端,而不会等待从节点确认,这就导致在某些情况下可能出现数据不一致。
另一个常见问题是全量同步对系统的冲击。全量同步会占用大量的 CPU 和 IO 资源,尤其是在大数据量的情况下,会导致主节点的性能下降。
脑裂问题了解吗?
在 Redis 的哨兵架构中,脑裂的典型表现为:主节点与哨兵、从节点之间的网络发生故障了,但与客户端的连接是正常的,就会出现两个“主节点”同时对外提供服务。
哨兵认为主节点已经下线了,于是会将一个从节点选举为新的主节点。但原主节点并不知情,仍然在继续处理客户端的请求。
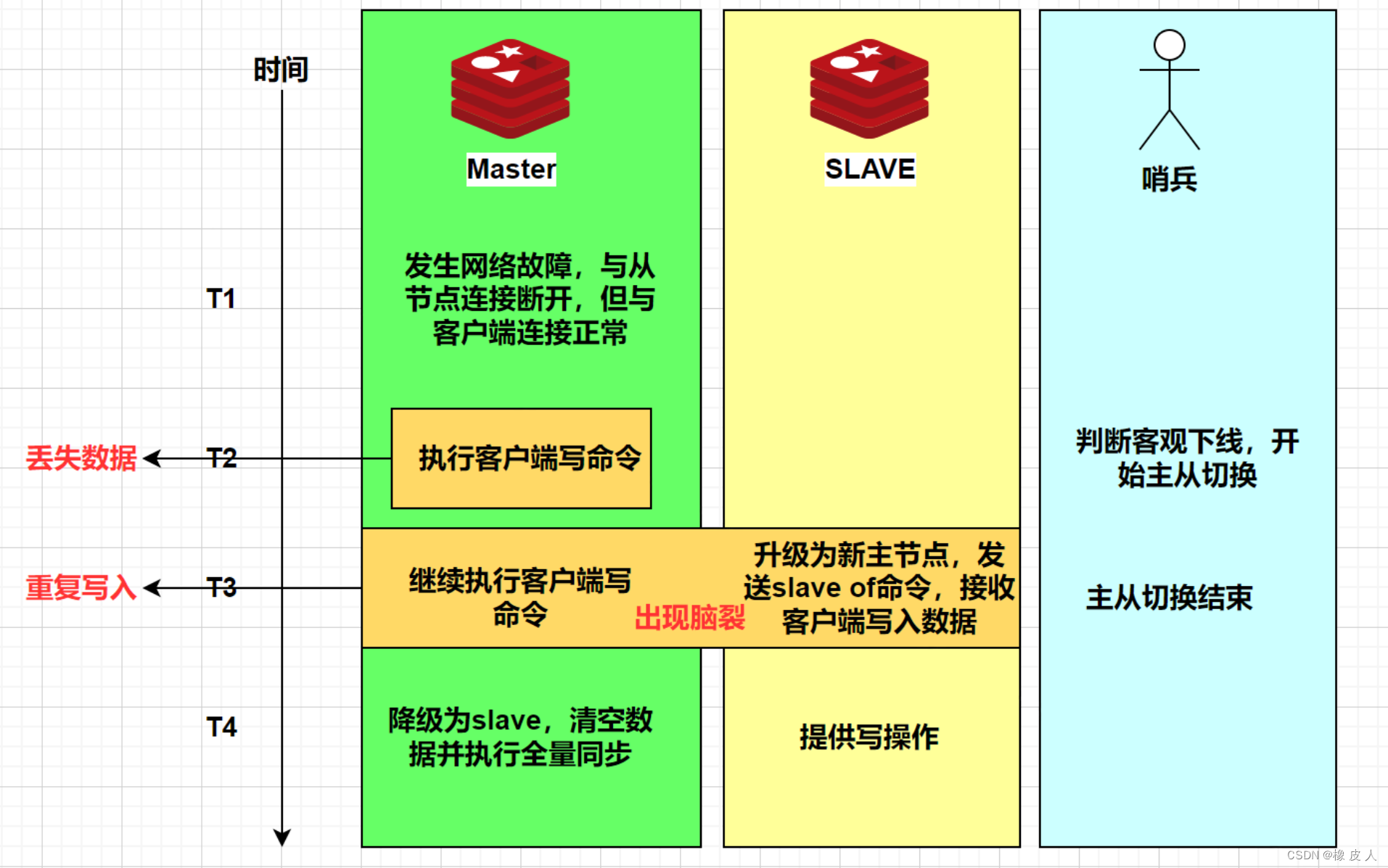
等主节点网络恢复正常了,发现已经有新的主节点了,于是原主节点会自动降级为从节点。在降级过程中,它需要与新主节点进行全量同步,此时原主节点的数据会被清空。导致客户端在原主节点故障期间写入的数据全部丢失。
为了防止这种数据丢失,Redis 提供了 min-slaves-to-write 和 min-slaves-max-lag 参数。
这两个参数可以设置最少需要多少个从节点在线,以及从节点的最大延迟时间。
# 设置主节点能进行数据同步的最少从节点数量
min-slaves-to-write 1
# 设置主从节点间进行数据同步时,从节点给主节点发送 ACK 消息的最大延迟(以秒为单位)
min-slaves-max-lag 10设置这两个参数后,如果主节点连接不到指定数量的从节点,或者从节点响应超时,主节点会拒绝写入请求,从而避免脑裂期间的数据冲突。
具体来说,当网络分区发生,主节点与从节点、哨兵之间的连接断开,但主节点与客户端的连接正常时,由于主节点无法再连接到任何从节点,或者延迟超过了设定值,比如说配置了min-slaves-to-write 1,主节点就会自动拒绝所有写请求。
同时在网络的另一侧,哨兵会检测到主节点"下线",选举一个从节点成为新的主节点。由于原主节点已经停止接受写入,所以不会产生新的数据变更,等网络恢复后,即使原主节点降级为从节点并进行全量同步,也不会丢失网络分区期间的写入数据,因为根本就没有新的写入发生。
- Java 面试指南(付费)收录的同学 30 腾讯音乐面试原题:主从复制有什么缺点呢?redis的脑裂问题
memo:2025 年 5 月 10 日今天把新项目的前置环境也配的七七八八了,还差一个 Kafka 的安装教程。日拱一卒,争取秋招前给大家球友们见面。
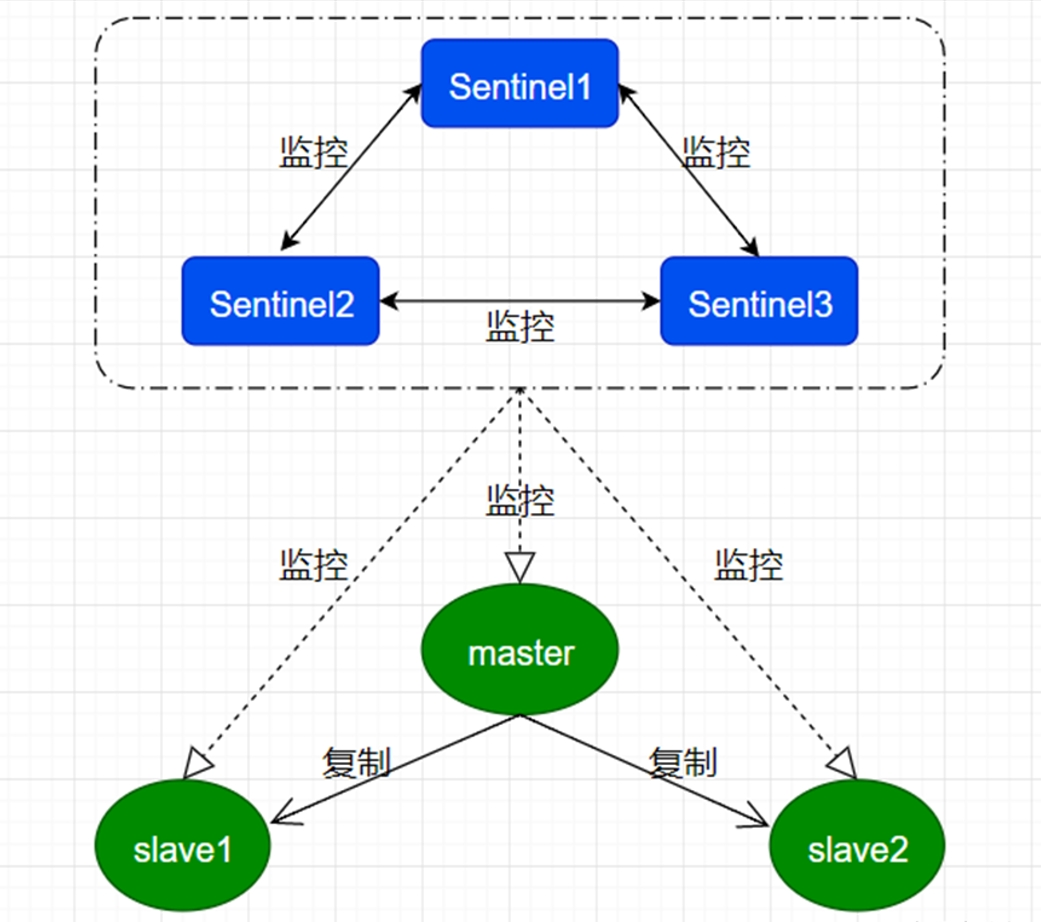
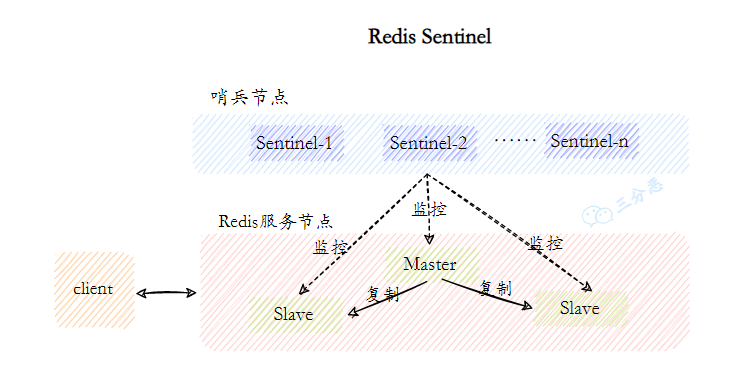
20.Redis哨兵机制了解吗?
Redis 中的哨兵用于监控主从集群的运行状态,并在主节点故障时自动进行故障转移。
核心功能包括监控、通知和自动故障转移。哨兵会定期检查主从节点是否按预期工作,当检测到主节点故障时,就在从节点中选举出一个新的主节点,并通知客户端连接到新的主节点。
# 监控的主节点信息 + 多少个哨兵同意才算宕机
sentinel monitor mymaster 127.0.0.1 6379 2
# 多久不响应就标记为“主观下线”
sentinel down-after-milliseconds mymaster 5000
# 故障转移超时时间
sentinel failover-timeout mymaster 60000
# 同时允许多少个从节点同步新主节点数据
sentinel parallel-syncs mymaster 1
- Java 面试指南(付费)收录的比亚迪面经同学 1 面试原题:Redis 的哨兵机制了解吗?
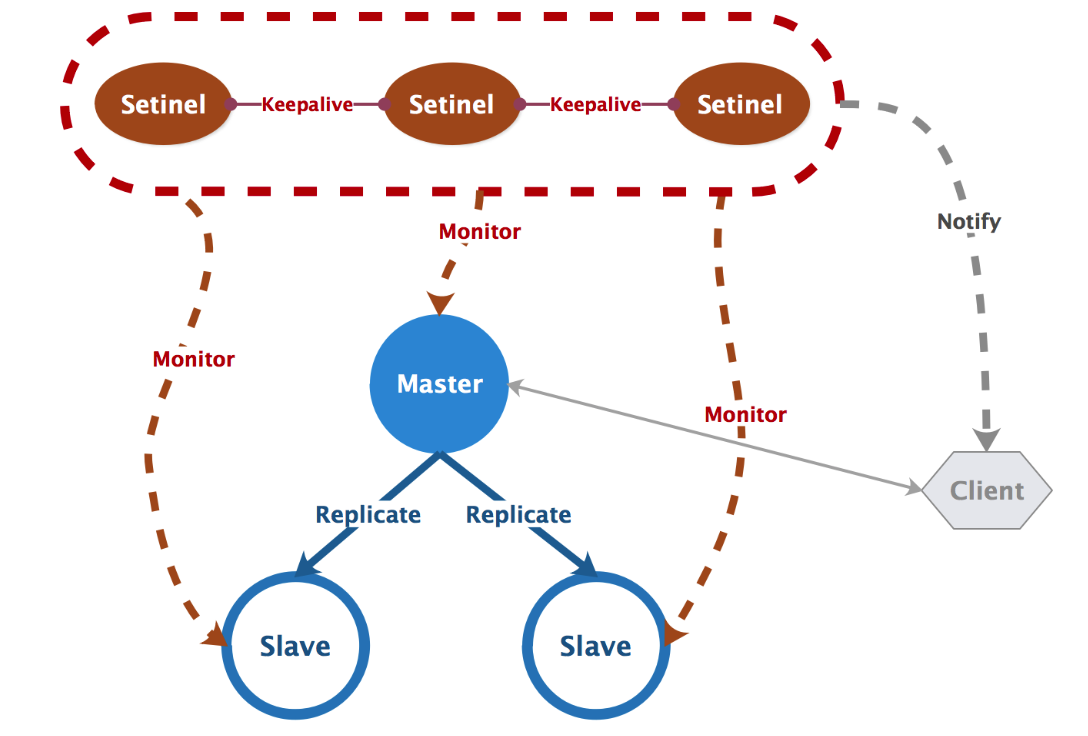
21.Redis哨兵的工作原理知道吗?
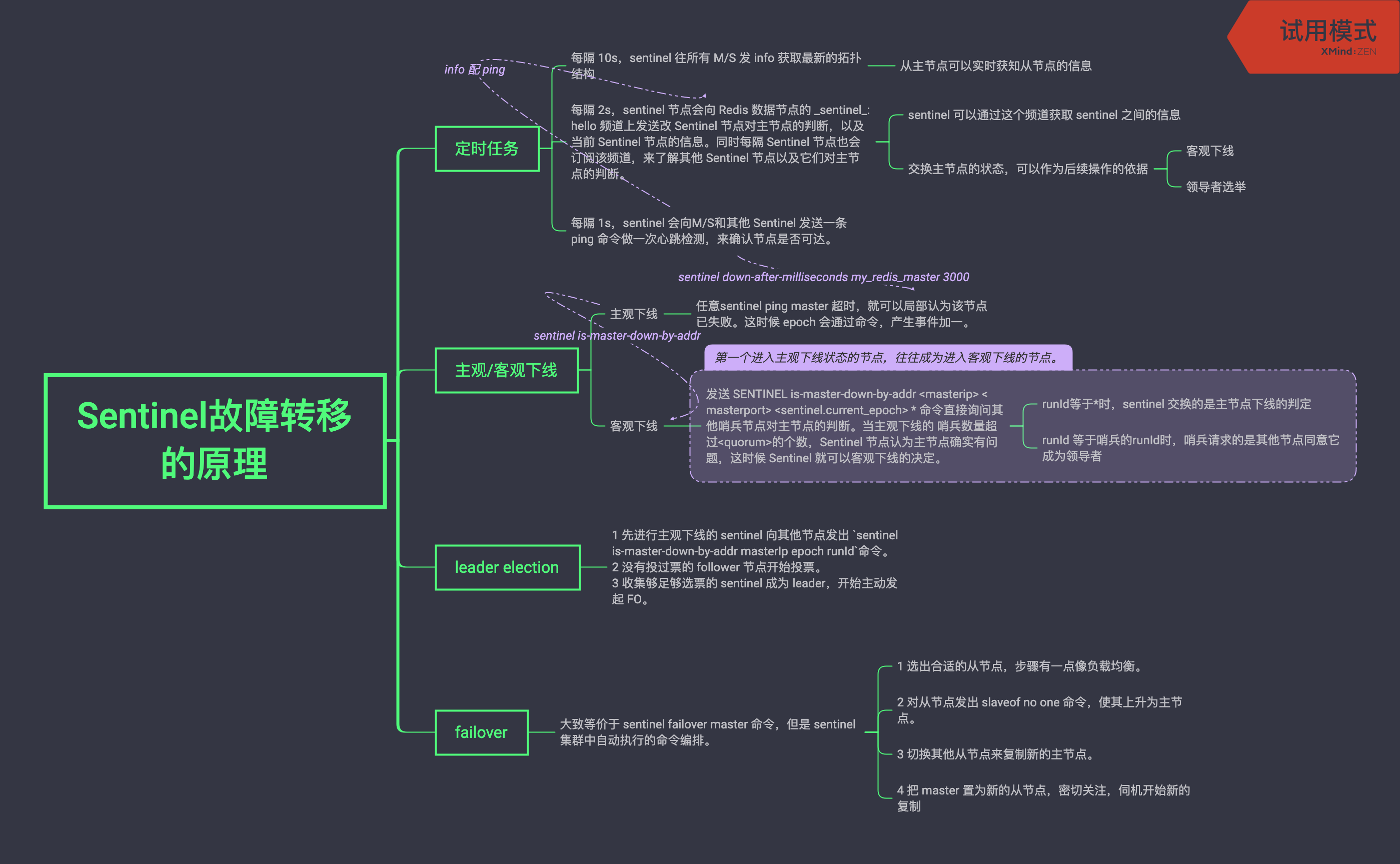
哨兵的工作原理可以概括为 4 个关键步骤:定时监控、主观下线、领导者选举和故障转移。
首先,哨兵会定期向所有 Redis 节点发送 PING 命令来检测它们是否可达。如果在指定时间内没有收到回复,哨兵会将该节点标记为“主观下线”。
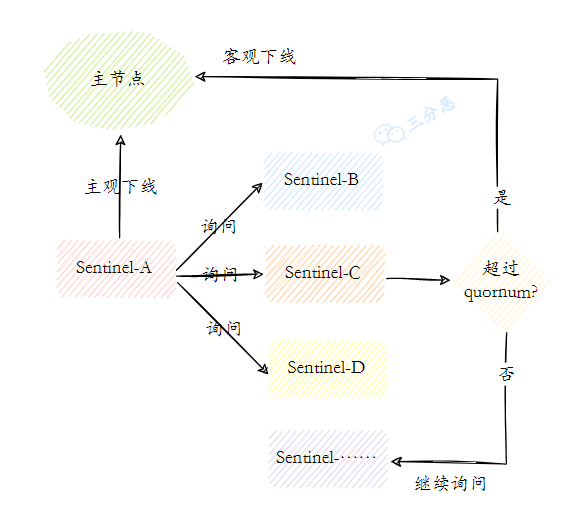
当一个哨兵判断主节点主观下线后,会询问其他哨兵的意见,如果达到配置的法定人数,主节点会被标记为“客观下线”。
然后开始故障转移,这个过程中,哨兵会先选举出一个领导者,领导者再从从节点中选择一个最适合的节点作为新的主节点,选择标准包括复制偏移量、优先级等因素。
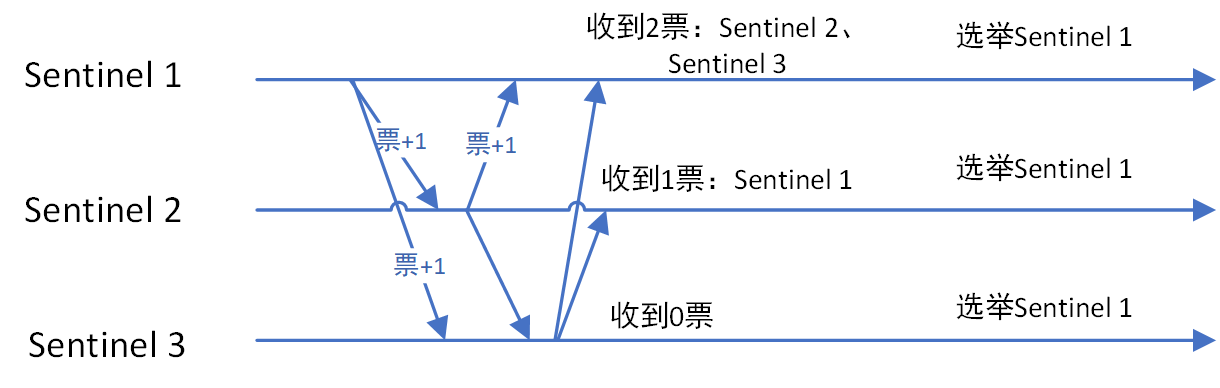
确定新主节点后,哨兵会向其发送 SLAVEOF NO ONE 命令使其升级为主节点,然后向其他从节点发送 SLAVEOF 命令指向新主节点,最后通过发布/订阅机制通知客户端主节点已经发生变化。
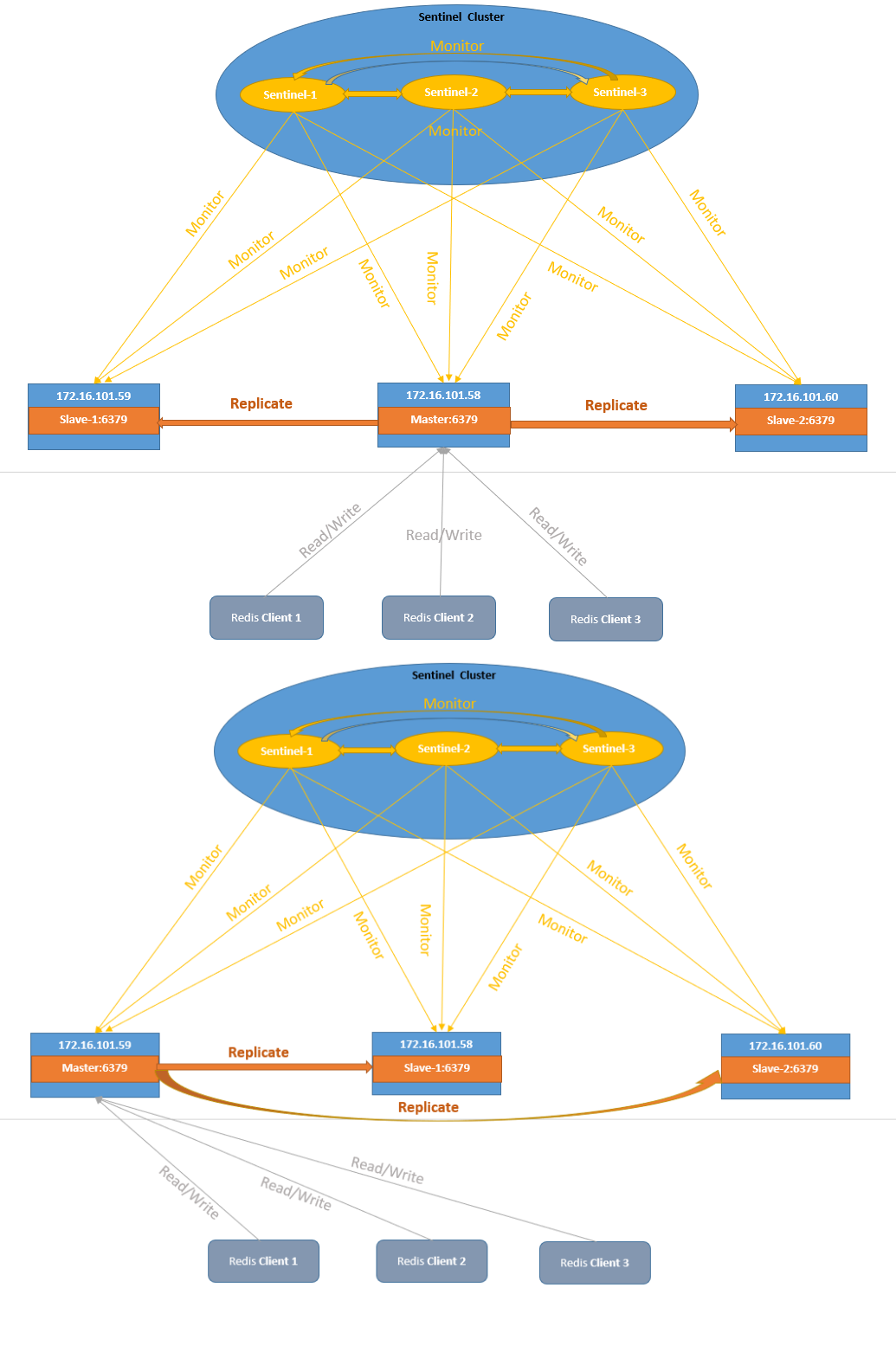
在实际部署中,为了保证哨兵机制的可靠性,通常建议至少部署三个哨兵节点,并且这些节点应分布在不同的物理机器上,降低单点故障风险。
同时,法定人数的设置也非常关键,一般建议设置为哨兵数量的一半加一,既能确保在少数哨兵故障时系统仍能正常工作,又能避免网络分区导致的脑裂问题。
- Java 面试指南(付费)收录的 OPPO 面经同学 1 面试原题:Redis的Sentinel和Cluster怎么理解?说一下大概原理
memo:贴一个读者对 Java 进阶之路的美赞吧,我也是人,也需要大家的情绪共鸣,哈哈,就让赞美多一点吧😄
22.Redis领导者选举了解吗?
Redis 使用 Raft 算法实现领导者选举,目的是在主节点故障时,选出一个哨兵来负责执行故障转移操作。
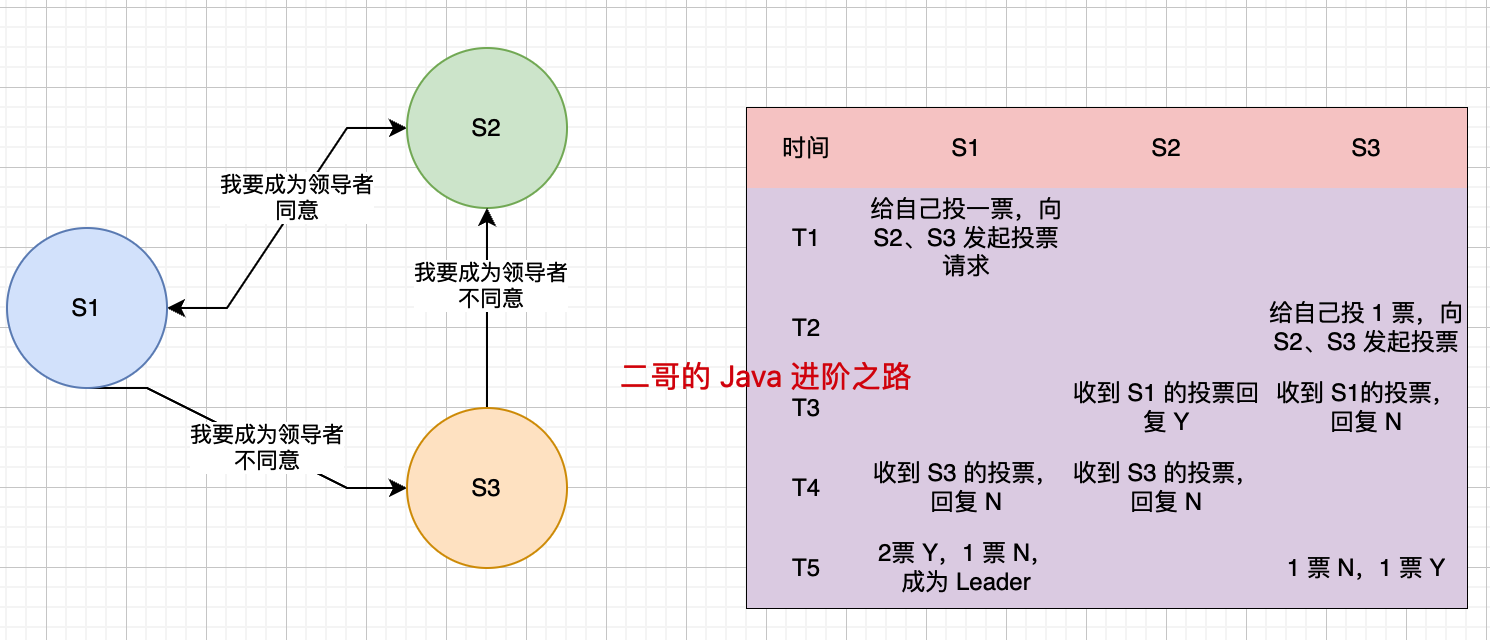
选举过程是这样的:
①、当一个哨兵确认主节点客观下线后,会向其他哨兵节点发送请求,表明希望由自己来执行主从切换,并让所有其他哨兵进行投票。候选者会先给自己先投 1 票,然后等待其他哨兵节点的投票结果。
// sentinel.c中的sentinelAskMasterStateToOtherSentinels函数
void sentinelAskMasterStateToOtherSentinels(sentinelRedisInstance *master) {
dictIterator *di;
dictEntry *de;
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *sentinel = dictGetVal(de);
int retval;
// 只有在进入领导者选举阶段才发送投票请求
if (master->failover_state == SENTINEL_FAILOVER_STATE_SELECT_LEADER) {
// 发送特殊的is-master-down-by-addr命令请求投票
retval = redisAsyncCommand(sentinel->cc,
sentinelReceiveVoteFromSentinel, sentinel,
"SENTINEL is-master-down-by-addr %s %d %llu %s",
master->addr->ip, master->addr->port,
(unsigned long long)master->failover_epoch,
// 这里发送自己的runid请求投票
sentinelGetMyRunID());
} else {
// 否则只询问主节点状态,不请求投票
retval = redisAsyncCommand(sentinel->cc,
sentinelReceiveIsMasterDownReply, sentinel,
"SENTINEL is-master-down-by-addr %s %d %llu *",
master->addr->ip, master->addr->port,
(unsigned long long)0);
}
}
dictReleaseIterator(di);
}②、收到请求的哨兵节点进行判断,如果候选者的日志和自己的一样新,任期号也小于自己,且之前没有投票过,就会投同意票 Y。否则回复 N。
// sentinel.c中的sentinelCommand函数部分(处理SENTINEL命令)
// 处理is-master-down-by-addr命令
else if (!strcasecmp(c->argv[1]->ptr,"is-master-down-by-addr")) {
/* SENTINEL IS-MASTER-DOWN-BY-ADDR <ip> <port> <current-epoch> <runid> */
sentinelRedisInstance *ri;
char *master_ip = c->argv[2]->ptr;
int master_port = atoi(c->argv[3]->ptr);
long long req_epoch = strtoull(c->argv[4]->ptr,NULL,10);
char *req_runid = c->argv[5]->ptr;
int isdown = 0;
char *leader = "*";
long long leader_epoch = -1;
ri = sentinelGetMasterByAddress(master_ip, master_port);
if (ri) {
isdown = ri->flags & SRI_S_DOWN;
// 判断是否是投票请求
if (req_runid[0] != '*') {
// 检查是否已经在当前配置纪元中投过票
if (req_epoch > sentinel.current_epoch) {
// 更新自己的配置纪元
sentinel.current_epoch = req_epoch;
}
// 如果我们觉得主节点下线了,且在这个epoch还没投过票,则投票
if (isdown && sentinel.current_epoch == req_epoch &&
sentinel.leader_epoch < req_epoch)
{
// 记录投票信息
sentinel.leader_epoch = req_epoch;
sentinel.leader = sdsnew(req_runid);
leader = req_runid;
leader_epoch = req_epoch;
}
}
}
// 返回投票结果
addReplyMultiBulkLen(c,3);
addReplyLongLong(c, isdown);
addReplyBulkCString(c, leader);
addReplyLongLong(c, leader_epoch);
}③、候选者收到投票后会统计自己的得票数,如果获得了集群中超过半数节点的投票,它就会当选为领导者。
// sentinel.c中的sentinelReceiveVoteFromSentinel函数
void sentinelReceiveVoteFromSentinel(redisAsyncContext *c, void *reply, void *privdata) {
sentinelRedisInstance *sentinel = privdata;
sentinelRedisInstance *master = sentinel->master;
redisReply *r = reply;
char *leader = NULL;
// 处理回复
if (r->type == REDIS_REPLY_ARRAY && r->elements == 3) {
// 解析回复中的leader信息
if (r->element[1]->type == REDIS_REPLY_STRING)
leader = r->element[1]->str;
// 检查是否投给了我们
if (leader && strcmp(leader, sentinelGetMyRunID()) == 0) {
// 记录获得一票
dictAdd(master->sentinels_voted, sdsnew(sentinel->runid), sentinel);
}
}
// 检查是否获得多数票
if (master->failover_state == SENTINEL_FAILOVER_STATE_SELECT_LEADER) {
int voters = dictSize(master->sentinels) + 1; // +1是因为包括自己
int votes = dictSize(master->sentinels_voted) + 1; // 自己也算一票
// 如果获得多数票(大于一半)
if (votes >= voters/2+1) {
// 成为领导者,开始执行故障转移
sentinelEvent(LL_WARNING, "+elected-leader", master, "%@");
master->failover_state = SENTINEL_FAILOVER_STATE_FAILOVER_IN_PROGRESS;
sentinelFailoverSelectSlave(master);
}
}
}④、如果没有哨兵在这一轮投票中获得超过半数的选票,这次选举就会失败,然后进行下一轮的选举。为了防止无限制的选举失败,每个哨兵都会有一个选举超时时间,且是随机的。
// sentinel.c中的sentinelFailoverSelectLeader函数
void sentinelFailoverSelectLeader(sentinelRedisInstance *master) {
// 检查选举是否超时
mstime_t election_timeout = SENTINEL_ELECTION_TIMEOUT * 2;
if (mstime() - master->failover_start_time > election_timeout) {
// 选举超时,重置状态
sentinelEvent(LL_WARNING, "-failover-abort-timeout", master, "%@");
sentinelAbortFailover(master);
return;
}
// ... 其他选举逻辑 ...
// 如果没有足够票数且未超时,则继续等待
}这里 SENTINEL_ELECTION_TIMEOUT_MIN 通常为 0,SENTINEL_ELECTION_TIMEOUT_MAX 通常为 2000 毫秒。这样每个哨兵会在 0-2 秒的随机时间后开始选举,减少选举冲突。
推荐阅读:Raft算法的选主过程详解
- Java 面试指南(付费)收录的8 后端开发秋招一面面试原题:raft主节点挂了怎么选从节点
memo:2025 年 5 月 12 日修改至此,今天有球友发微信说拿到了三个大厂的 offer,分别是蚂蚁、美团和腾讯,真的是太优秀了呀。
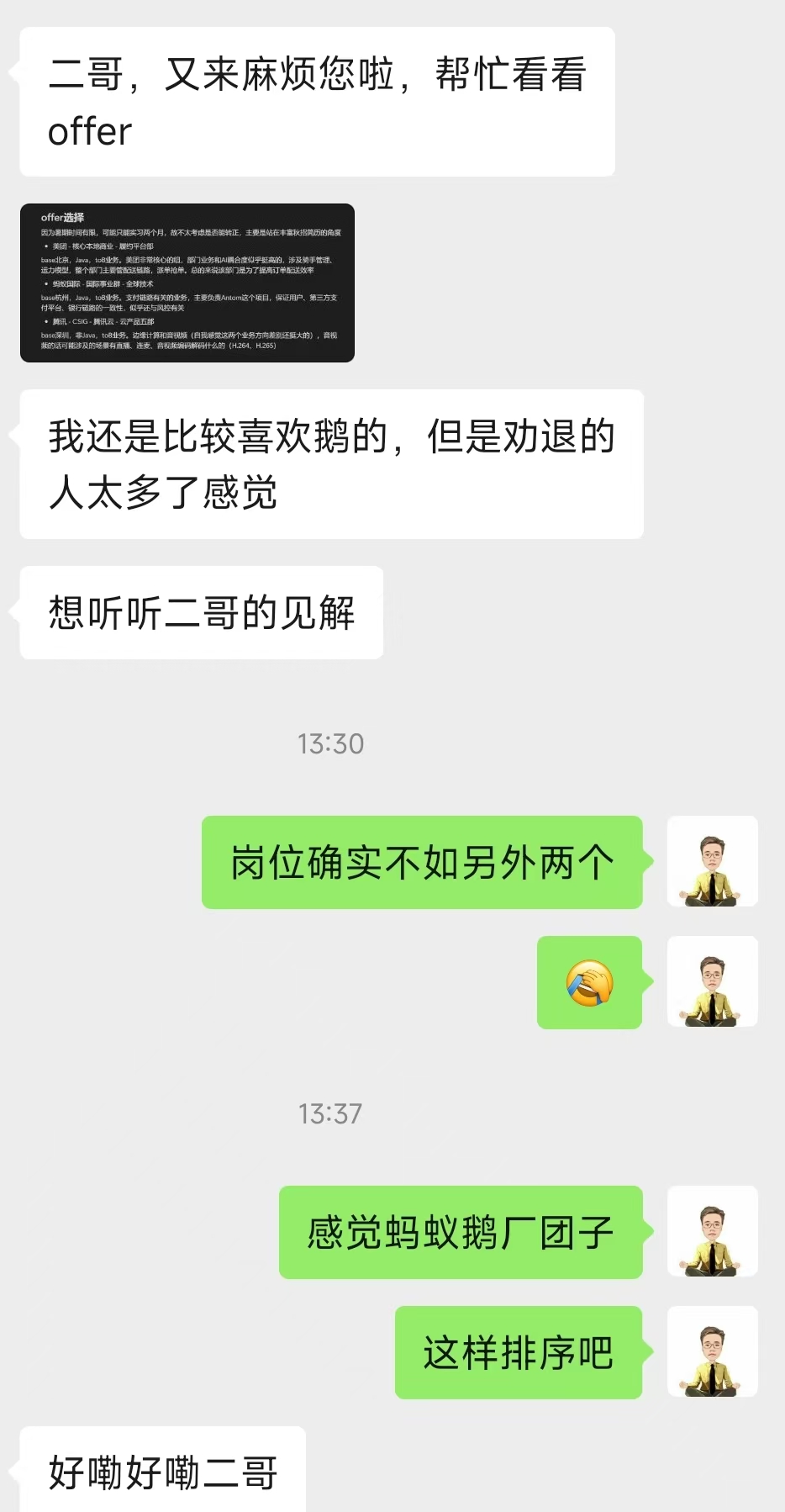
23.新的主节点是怎样被挑选出来的?
哨兵在挑选新的主节点时,非常精细化。
首先,哨兵会对所有从节点进行一轮基础筛选,排除那些不满足基本条件的节点。比如说已下线的节点、网络连接不稳定的节点,以及优先级设为 0 明确不参与挑选的节点。
// 第一轮筛选:排除不满足基本条件的从节点
for (int i = 0; i < numslaves; i++) {
sentinelRedisInstance *slave = slaves[i];
// 排除已下线的从节点
if (slave->flags & (SRI_S_DOWN|SRI_O_DOWN)) continue;
// 排除断开连接的从节点
if (slave->link->disconnected) continue;
// 排除近期(5秒内)断过连的从节点
if (mstime() - slave->link->last_avail_time > 5000) continue;
// 排除未建立主从复制的节点
if (slave->slave_priority == 0) continue;
// 找到第一个满足条件的从节点
selected = i;
break;
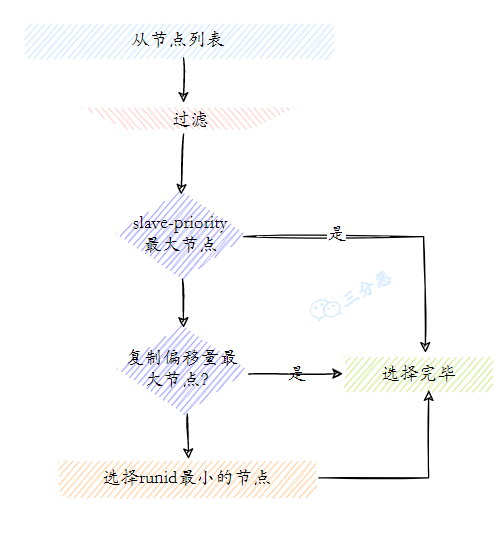
}然后,哨兵会对剩下的从节点进行排序,选出最合适的主节点。
// sentinel.c中的compareSlaves函数
int compareSlaves(sentinelRedisInstance *a, sentinelRedisInstance *b) {
// 1. 首先比较用户设置的优先级,值越小优先级越高
if (a->slave_priority != b->slave_priority)
return (a->slave_priority < b->slave_priority) ? 1 : 2;
// 2. 如果优先级相同,比较复制偏移量,偏移量越大数据越新
if (a->slave_repl_offset > b->slave_repl_offset) return 1;
else if (a->slave_repl_offset < b->slave_repl_offset) return 2;
// 3. 如果复制偏移量也相同,比较运行ID的字典序
return (strcmp(a->runid, b->runid) < 0) ? 1 : 2;
}排序的标准有三个:
①、从节点优先级: slave-priority 的值越小优先级越高,优先级为 0 的从节点不会被选中。
②、复制偏移量: 偏移量越大意味着从节点的数据越新,复制的越完整。
③、运行 ID: 如果优先级和偏移量都相同,就比较运行 ID 的字典序,字典序小的优先。
选出新主节点后,哨兵会向其发送 SLAVEOF NO ONE 命令将其提升为主节点。
// sentinel.c中的sentinelFailoverPromoteSlave函数
void sentinelFailoverPromoteSlave(sentinelRedisInstance *master) {
// ... 选择最佳从节点的逻辑 ...
// 向选中的从节点发送SLAVEOF NO ONE命令,使其成为主节点
retval = redisAsyncCommand(slave->link->cc,
sentinelReceivePromotionResponseFromSlave, master,
"SLAVEOF NO ONE");
// 更新状态
master->promoted_slave = slave;
slave->flags |= SRI_PROMOTED;
// 记录日志
sentinelEvent(LL_WARNING, "+promoted-slave", slave, "%@");
sentinelEvent(LL_WARNING, "+failover-state-wait-promotion", master, "%@");
}之后,哨兵会等待新主节点的角色转换完成,通过发送 INFO 命令检查其角色是否已变为 master 来确认。确认成功后,会更新所有从节点的复制目标,指向新的主节点。
SLAVEOF new-master-ip new-master-portmemo:2025 年 5 月 13 日,今天有球友发微信说拿到了携程的 offer,携程现在也是第二梯队的互联网大厂了,值得一手恭喜啊。

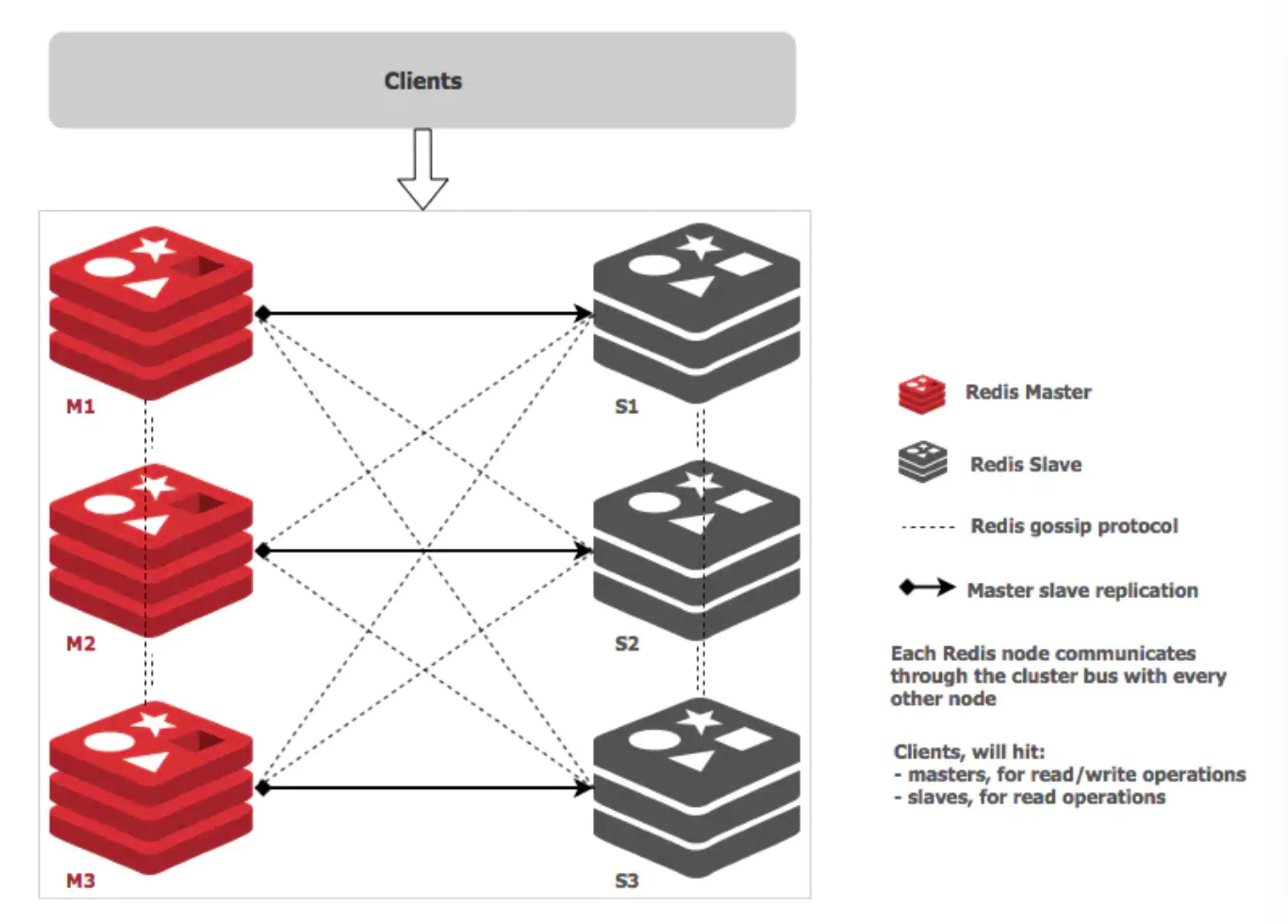
24.Redis集群了解吗?
主从复制实现了读写分离和数据备份,哨兵机制实现了主节点故障时自动进行故障转移。
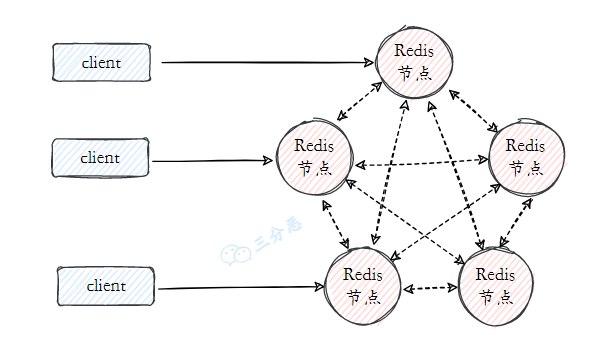
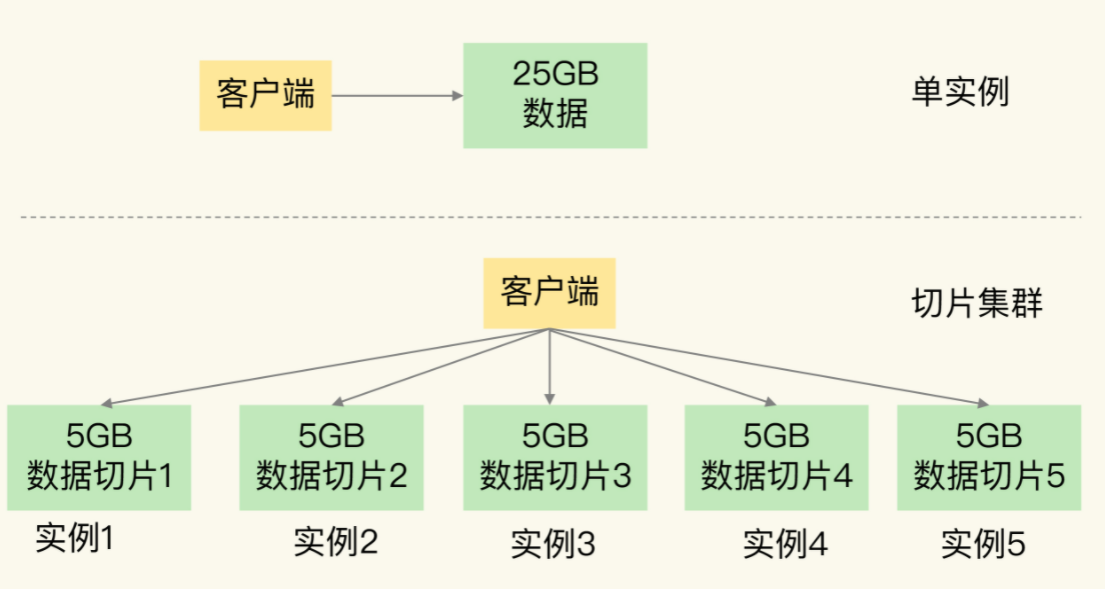
集群架构是对前两种方案的进一步扩展和完善,通过数据分片解决 Redis 单机内存大小的限制,当用户基数从百万增长到千万级别时,我们只需简单地向集群中添加节点,就能轻松应对不断增长的数据量和访问压力。
比如说我们可以将单实例模式下的数据平均分为 5 份,然后启动 5 个 Redis 实例,每个实例保存 5G 的数据,从而实现集群化。
25.请详细说一说Redis Cluster?(补充)
2024 年 04 月 26 日新增
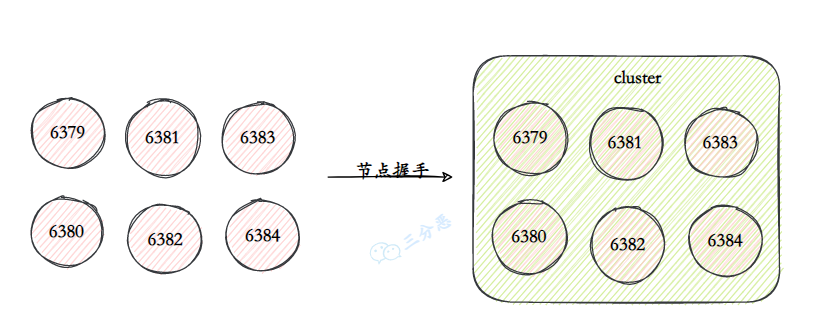
Redis Cluster 是 Redis 官方提供的一种分布式集群解决方案。其核心理念是去中心化,采用 P2P 模式,没有中心节点的概念。每个节点都保存着数据和整个集群的状态,节点之间通过 gossip 协议交换信息。
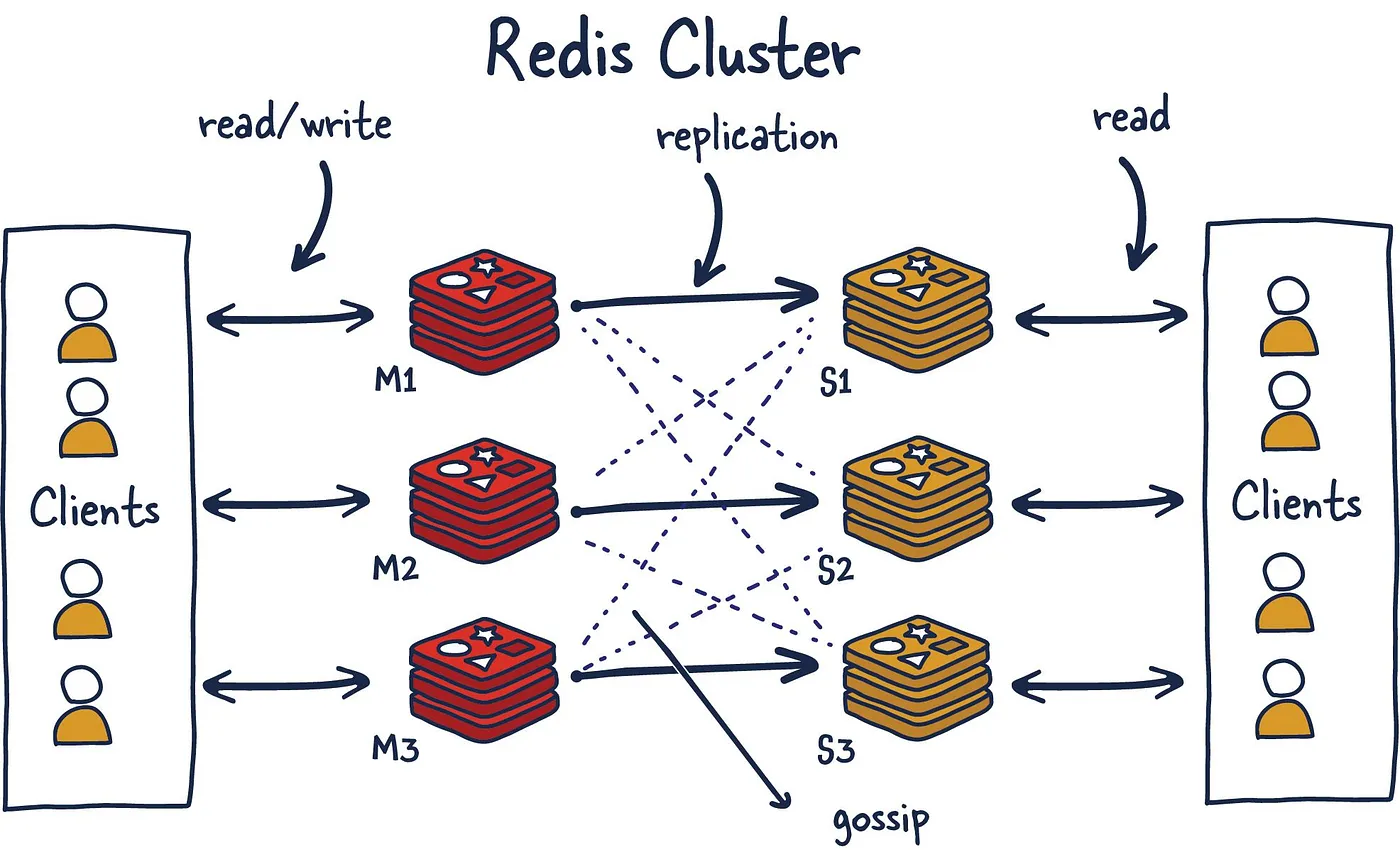
在数据分片方面,Redis Cluster 使用哈希槽机制将整个集群划分为 16384 个单元。
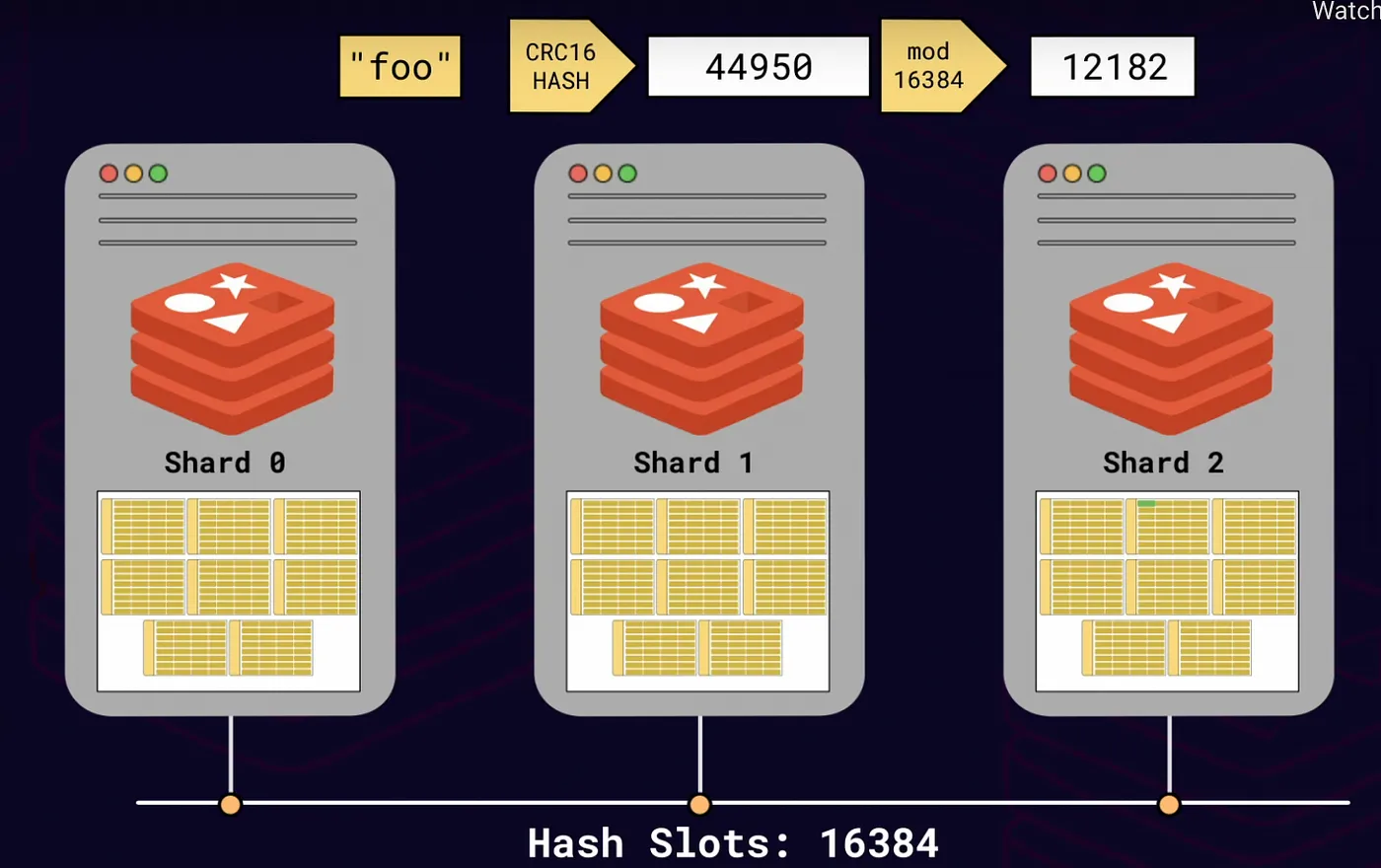
例如,如果我们有 4 个 Redis 实例,那么每个实例会负责 4000 多个哈希槽。
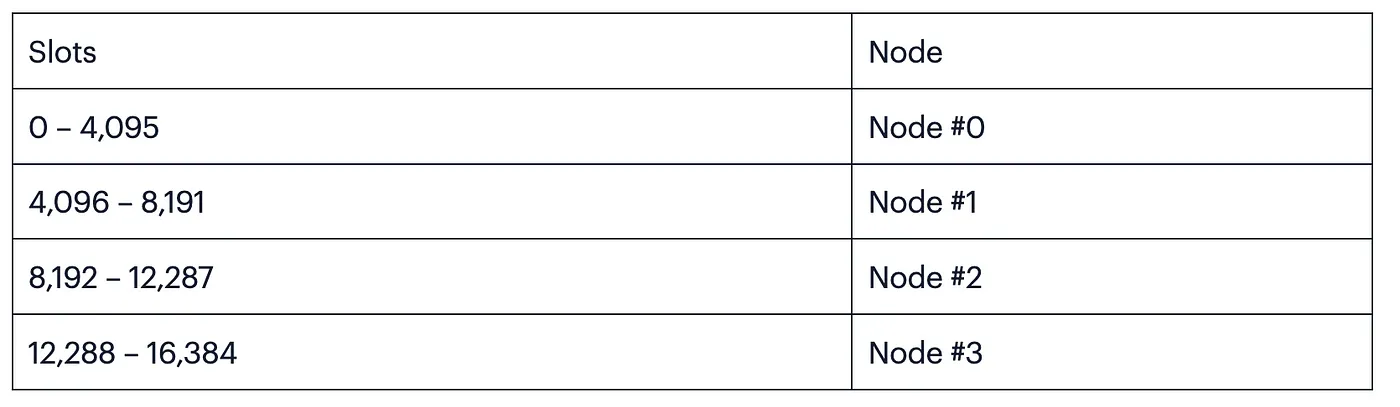
在计算哈希槽编号时,Redis Cluster 会通过 CRC16 算法先计算出键的哈希值,再对这个哈希值进行取模运算,得到一个 0 到 16383 之间的整数。
slot = CRC16(key) mod 16384这种方式可以将数据均匀地分布到各个节点上,避免数据倾斜的问题。
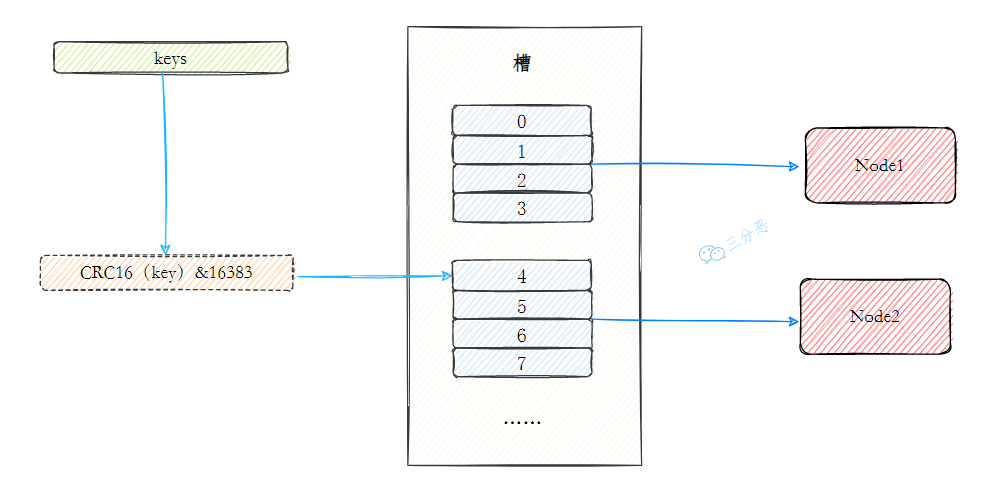
当需要存储或查询一个键值对时,Redis Cluster 会先计算这个键的哈希槽编号,然后根据哈希槽编号找到对应的节点进行操作。
推荐阅读:Redis Cluster
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:Redis 切片集群?数据和实例之间的如何进行映射?
- Java 面试指南(付费)收录的快手面经同学 1 部门主站技术部面试原题:Redis 的 cluster 集群如何实现?
memo:2025 年 5 月 14 日,今天有球友发微信说拿到了百度和美团的暑期实习 offer,果然五月也是一个开花结果的季节。
26.集群中数据如何分区?
常见的数据分区有三种:节点取余、一致性哈希和哈希槽。
节点取余分区简单明了,通过计算键的哈希值,然后对节点数量取余,结果就是目标节点的索引。
target_node = hash(key) % N // N为节点数量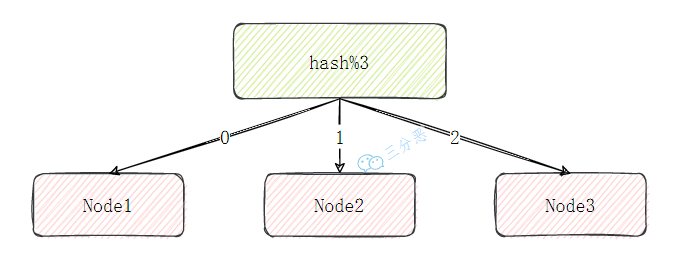
缺点是增加一个新节点后,节点数量从 N 变为 N+1,几乎所有的取余结果都会改变,导致大部分缓存失效。
为了解决节点变化导致的大规模数据迁移问题,一致性哈希分区出现了:它将整个哈希值空间想象成一个环,节点和数据都映射到这个环上。数据被分配到顺时针方向上遇到的第一个节点。
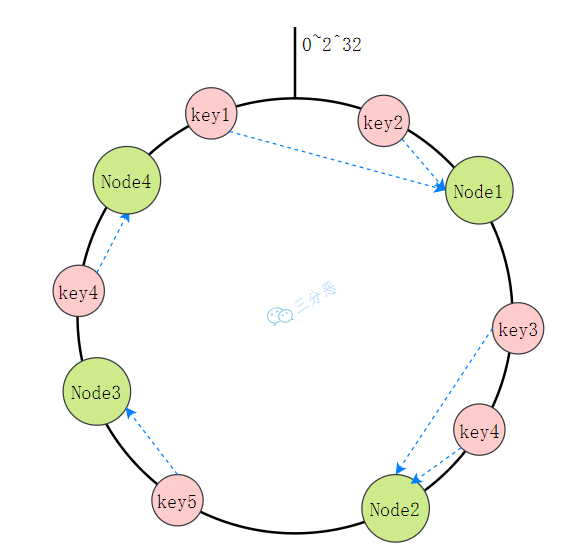
这种设计的巧妙之处在于,当节点数量变化时,只有部分数据需要重新分配。比如说我们从 5 个节点扩容到 8 个节点,理论上只有约 3/8 的数据需要迁移,大大减轻了扩容时的系统压力。
但一致性哈希仍然有一个问题:数据分布不均匀。比如说在上面的例子中,节点 1 和节点 2 的数据量差不多,但节点 3 的数据量却远远小于它们。
Redis Cluster 的哈希槽分区在一致性哈希和节点取余的基础上,做了一些改进。
它将整个哈希值空间划分为 16384 个槽位,每个节点负责一部分槽,数据通过 CRC16 算法计算后对 16384 取模,确定它属于哪个槽。
slot = CRC16(key) % 16384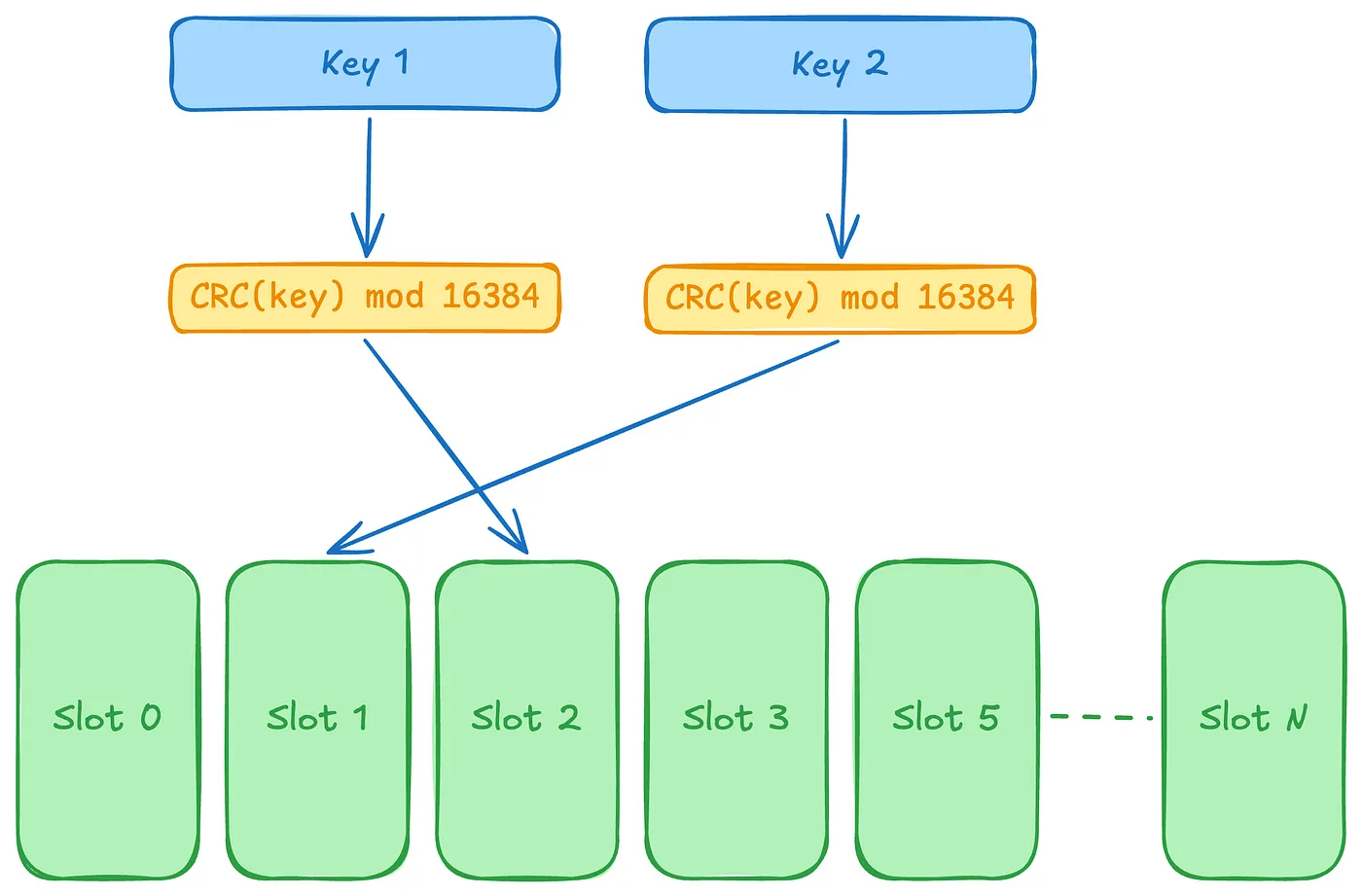
假设系统中有 4 个节点,为其分配了 16 个槽(0-15);
- 槽 0-3 位于节点 node1;
- 槽 4-7 位于节点 node2;
- 槽 8-11 位于节点 node3;
- 槽 12-15 位于节点 node4。
如果此时删除 node2,只需要将槽 4-7 重新分配即可,例如将槽 4-5 分配给 node1,槽 6 分配给 node3,槽 7 分配给 node4,数据在节点上的分布仍然较为均衡。
如果此时增加 node5,也只需要将一部分槽分配给 node5 即可,比如说将槽 3、槽 7、槽 11、槽 15 迁移给 node5,节点上的其他槽位保留。
因为槽的个数刚好是 2 的 14 次方,和 HashMap 中数组的长度必须是 2 的幂次方有着异曲同工之妙。它能保证扩容后,大部分数据停留在扩容前的位置,只有少部分数据需要迁移到新的槽上。
- Java 面试指南(付费)收录的小米暑期实习同学 E 一面面试原题:你知道 Redis 的一致性 hash 吗
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:Redis 扩容之后,哈希槽的位置是否发生变化?
- Java 面试指南(付费)收录的字节跳动面经同学 8 Java 后端实习一面面试原题:redis 分片集群,如何分片的,有什么好处
memo:2025 年 5 月 15 日,今天有球友发微信说加了星球后,算一算,踩着点拿到了滴滴的实习 offer,我看了一下时间线,也就一个月时间不到,真的太强了。

27.能说说 Redis 集群的原理吗?
Redis 集群的搭建始于节点的添加和握手。每个节点通过设置 cluster-enabled yes 来开启集群模式。然后通过 CLUSTER MEET 进行握手,将对方添加到各自的节点列表中。
这个过程设计的非常精巧:节点 A 发送 MEET 消息,节点 B 回复 PONG 并发送 PING,节点 A 回复 PONG,于是双向的通信链路就建立完成了。
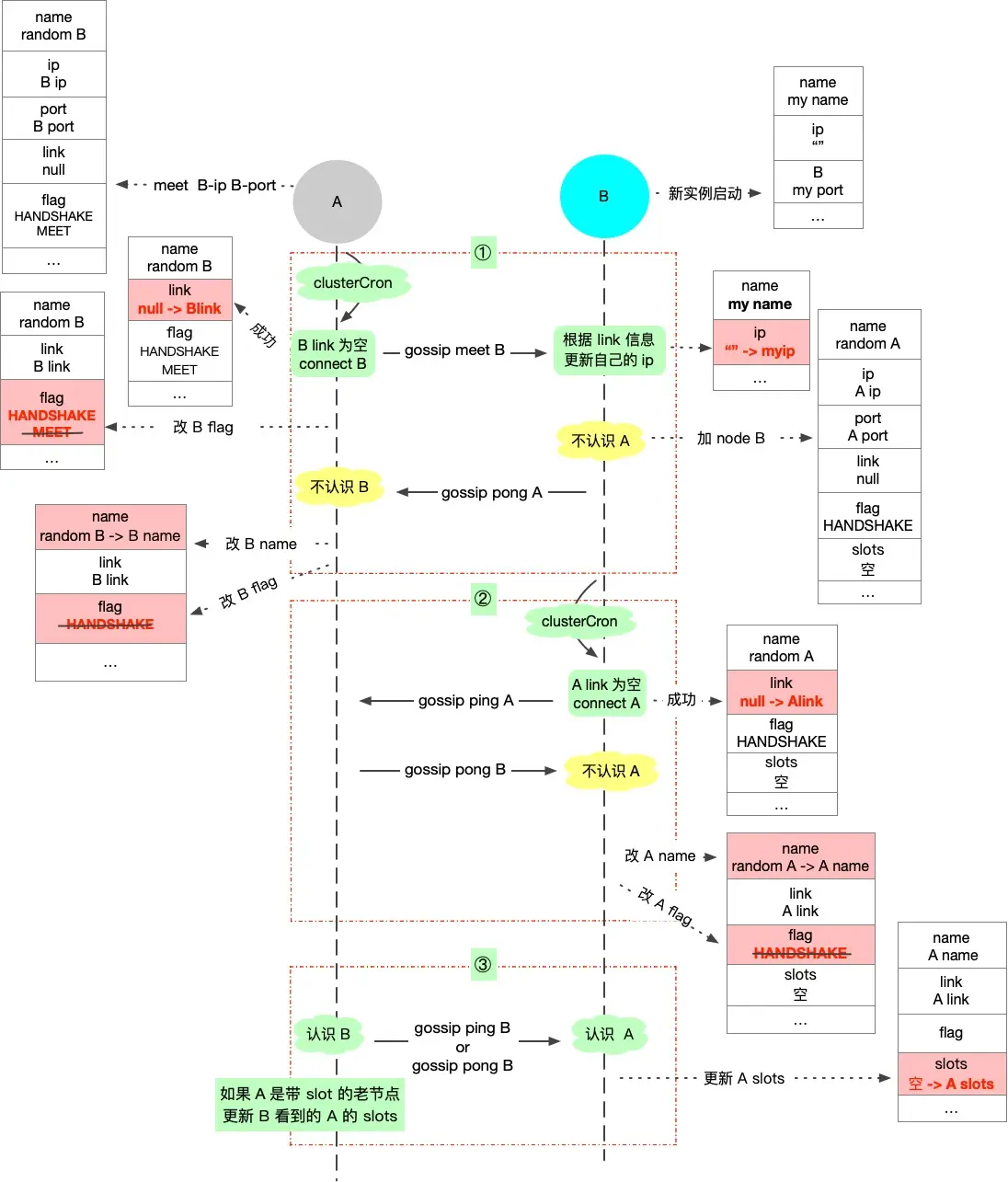
有趣的是,由于采用了 Gossip 协议,我们不需要让每对节点都执行握手。在一个多节点集群的部署中,仅需要让第一个节点与其他节点握手,其余节点就能通过信息传播自动发现并连接彼此。
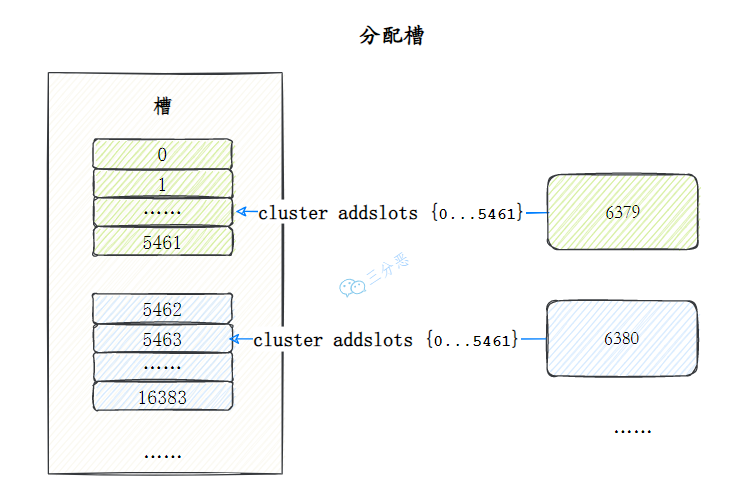
握手完成后,可以通过 CLUSTER ADDSLOTS 命令为主节点分配哈希槽。当 16384 个槽全部分配完毕,集群正式进入就绪状态。
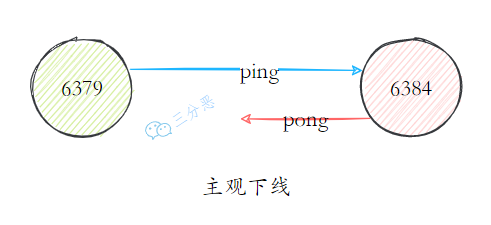
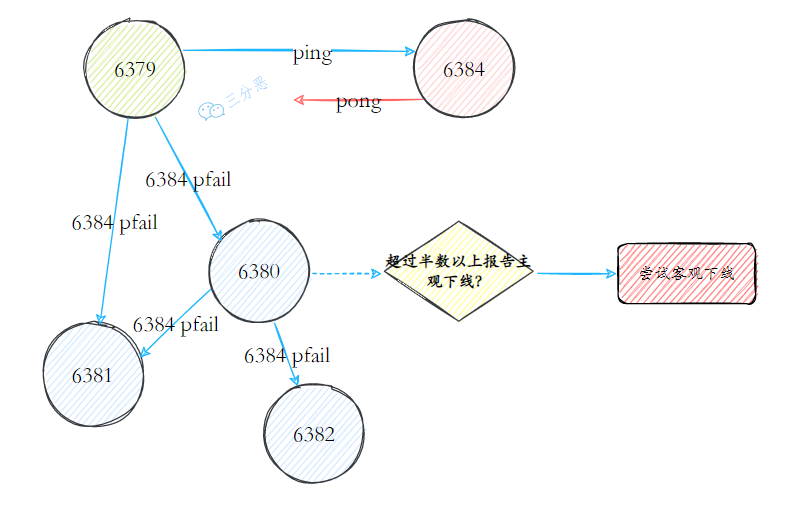
故障检测和恢复是保障 Redis 集群高可用的关键。每秒钟,节点会向一定数量的随机节点发送 PING 消息,当发现某个节点长时间未响应 PING 消息,就会将其标记为主观下线。
当半数以上的主节点都认为某节点主观下线时,这个节点就会被标记为“客观下线”。
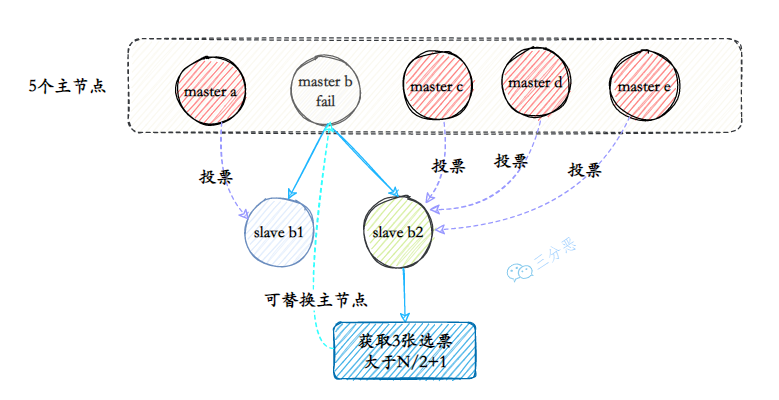
如果下线的是主节点,它的从节点之一将被选举为新的主节点,接管原主节点负责的哈希槽。
部署 Redis 集群至少需要几个物理节点?
部署一个生产环境可用的 Redis 集群,从技术角度来说,至少需要 3 个物理节点。
这个最小节点数的设定并非 Redis 技术上的硬性要求,而是基于高可用原则的实践考量。
从实践角度看,最经典的 Redis 集群配置是 3 主 3 从,共 6 个 Redis 实例。考虑到需要 3 个主节点和 3 个从节点,并且每对主从不能在同一物理机上,那么至少需要 3 个物理节点,每个物理节点上运行 1 个主节点和另一个主节点的从节点。
- 物理节点1:主节点A + 从节点B'
- 物理节点2:主节点B + 从节点C'
- 物理节点3:主节点C + 从节点A'
这种交错部署方式可以确保任何一个物理节点故障时,最多只影响一个主节点和一个不同主节点的从节点。
memo:2025 年 5 月 16 日,今天在修改简历的时候,碰到一个河南理工本科,郑州大学硕士的球友,也是希望这个社群能够帮助到更多的同学,无论来自哪里,都能在这里找回那个渴望进步,渴望拿到优质 offer 的自己。

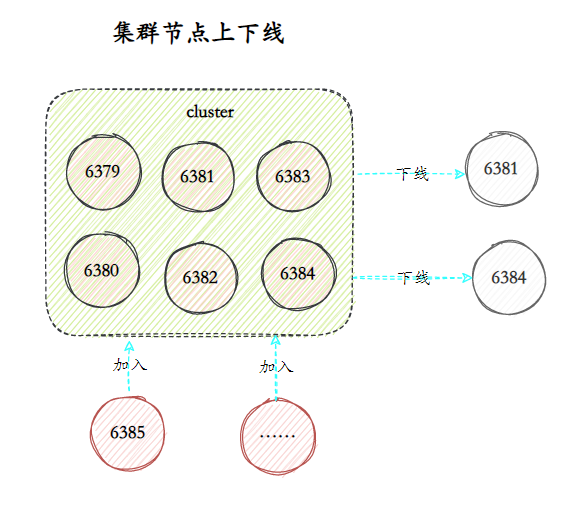
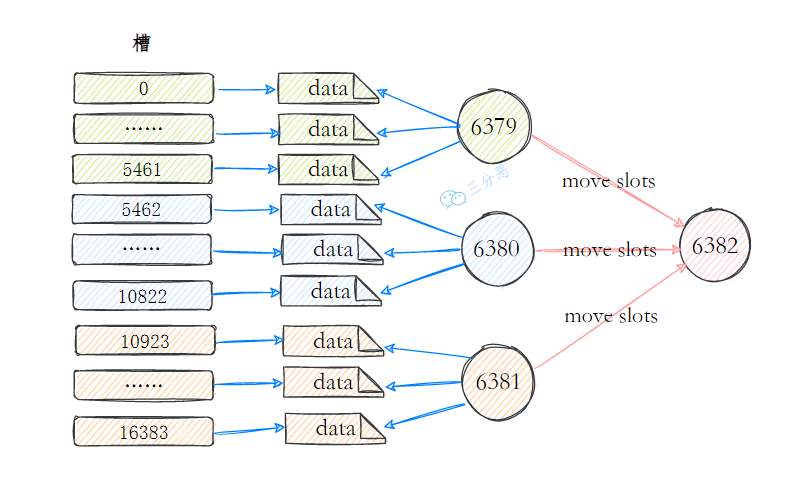
28.说说Redis集群的动态伸缩?
Redis 集群动态伸缩的核心机制是通过重新分配哈希槽实现的。
当需要扩容时,首先通过 CLUSTER MEET 命令将新节点加入集群;然后使用 reshard 命令将部分哈希槽重新分配给新节点。
----这部分面试中可以不背start----
准备新的节点:
# redis.conf
port 6382
cluster-enabled yes
cluster-config-file nodes-6382.conf
cluster-node-timeout 5000
appendonly yes然后启动新的节点:
redis-server /path/to/redis-6382.conf接下来,使用 CLUSTER MEET 命令将新节点加入集群:
redis-cli -p 6379 cluster meet 127.0.0.1 6382检查新节点是否加入:
redis-cli -p 6379 cluster nodes然后,重新分配哈希槽:
redis-cli --cluster reshard 127.0.0.1:6379在提示中输入要迁移的哈希槽范围。
# 输入要迁移的槽数量,比如 4096(平均分配的话,16384/4=4096)。
How many slots do you want to move (from 16384 total slots)? 4096
# 输入 6382 节点的 ID(可通过 cluster nodes 命令查到)。
What is the receiving node ID? <6382的节点ID>
# 输入 all(表示从所有节点平均迁移)。
Source node IDs? all
# 输入 yes(表示确认迁移)。
Do you want to proceed with the proposed reshard plan (yes/no)? yes检查检查槽分配情况:
redis-cli -p 6379 cluster slots验证集群的状态:
redis-cli -p 6382 cluster info也可以直接一步到位:
redis-cli --cluster reshard 127.0.0.1:6379 --cluster-from all --cluster-to <6382的节点ID> --cluster-slots 4096 --cluster-yes----这部分面试中可以不背end----
缩容则是反向操作:先将要下线节点负责的所有槽迁移到其他节点,再通过 CLUSTER FORGET 命令将节点从集群中移除。
整个伸缩过程支持在线操作,无需停机,得益于 Redis 集群的 MOVED 和 ASK 重定向机制。当客户端访问的键不在当前节点时,会收到重定向响应,指引它连接到正确的节点。
MOVED 和 ASK 重定向的区别?
MOVED 重定向反映的是哈希槽的永久性变更。当客户端请求一个键,但键所在的槽不在当前节点时,节点会返回 MOVED 响应,告诉客户端这个槽现在归属于哪个节点。通常发生在集群完成重新分片后,槽的分配关系已经稳定。
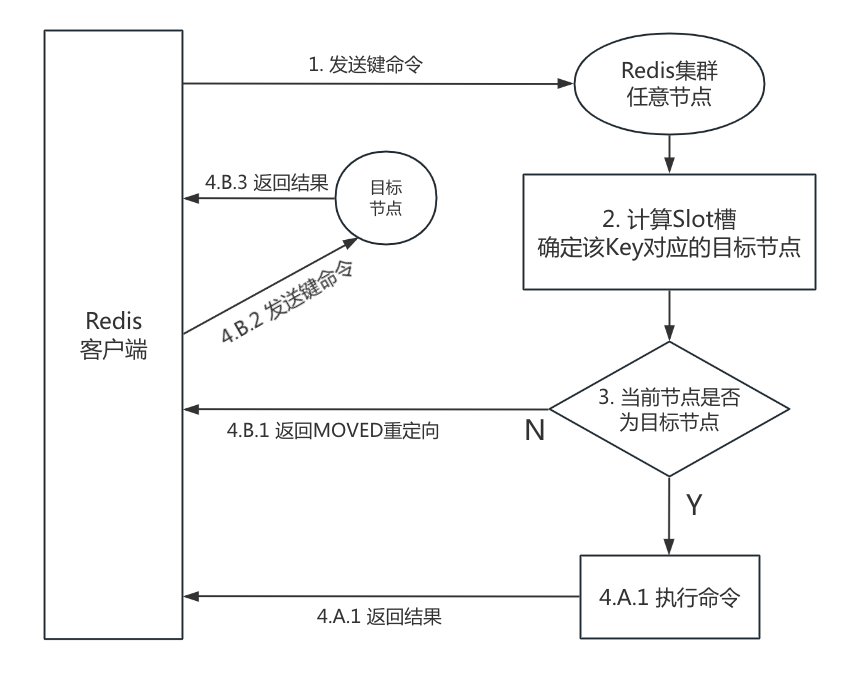
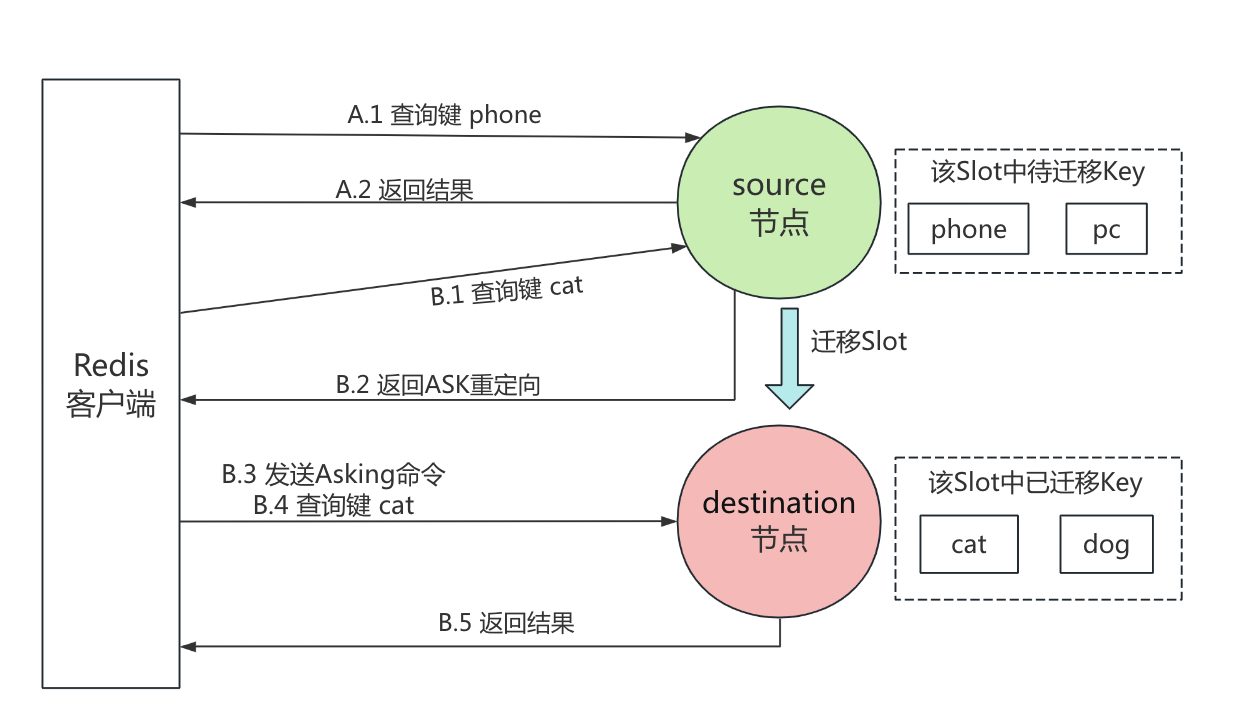
比如说某个槽从节点 A 移动到节点 B 后,如果客户端仍向节点 A 请求该槽中的键,会收到 MOVED 响应,提示应该连接节点 B。
ASK 重定向出现在槽迁移过程中,表示请求的键可能已经从源节点迁移到了目标节点,但迁移尚未完成。
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 5 月 17 日,今天有球友发微信说拿到了一个国企子公司的 Java 后端开发和一个小米安卓的 offer,问我该怎么选择?
缓存设计
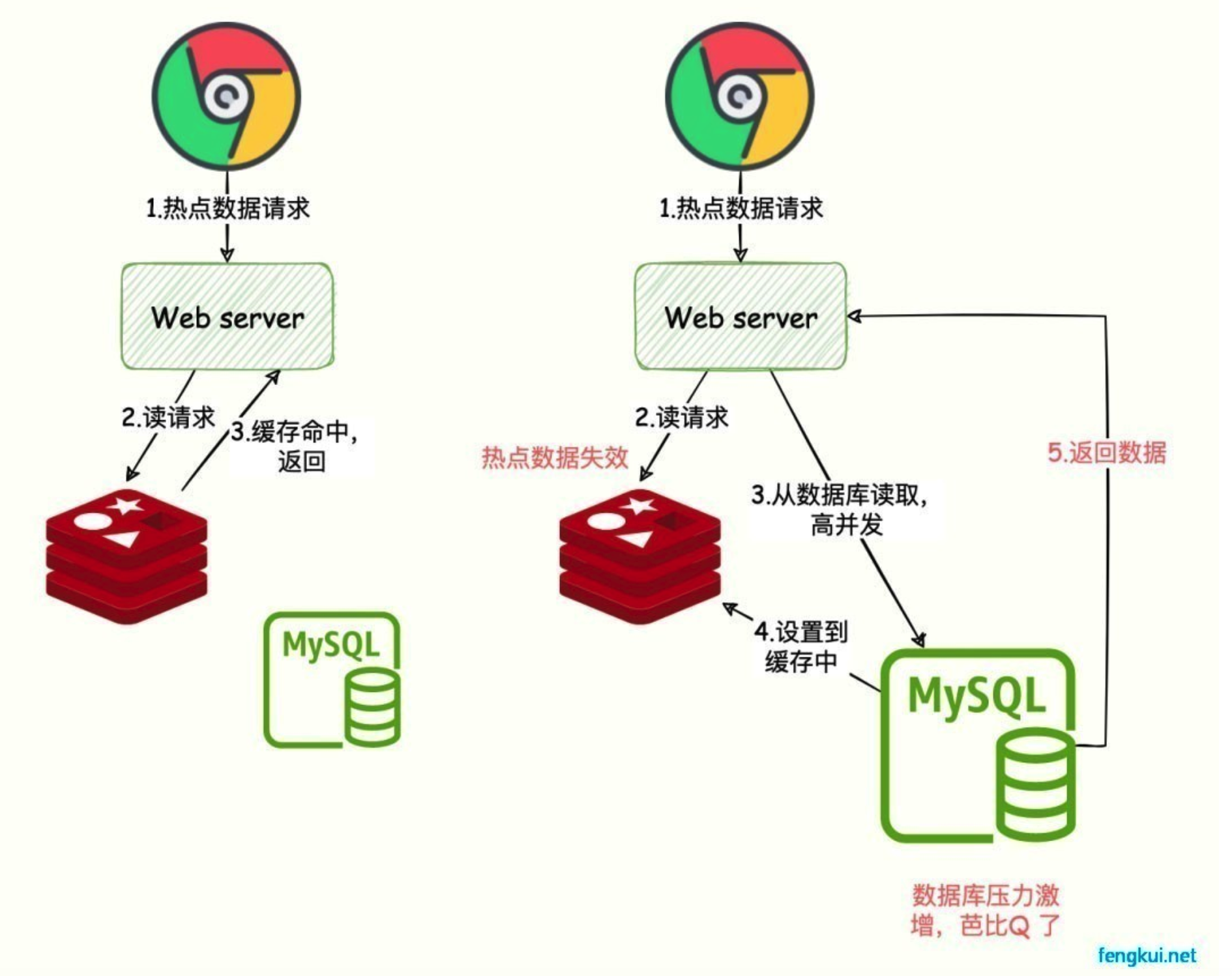
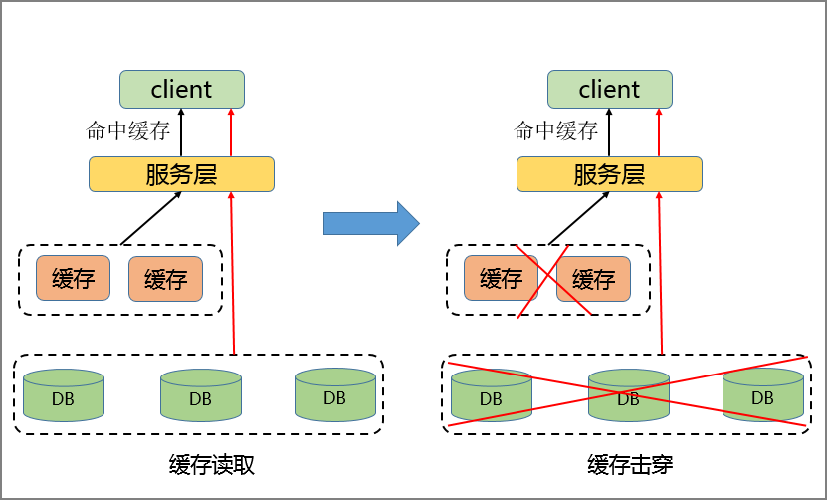
29.🌟什么是缓存击穿?
缓存击穿是指某个热点数据缓存过期时,大量请求就会穿透缓存直接访问数据库,导致数据库瞬间承受的压力巨大。
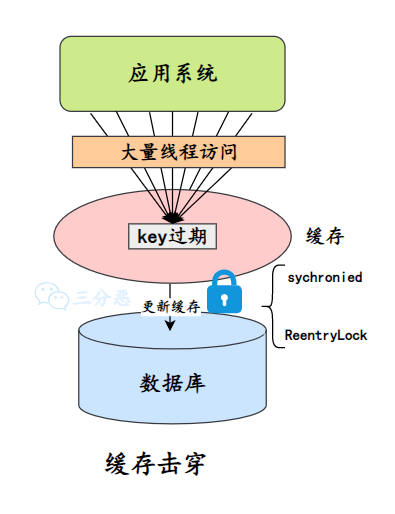
解决缓存击穿有两种常用的策略:
第一种是加互斥锁。当缓存失效时,第一个访问的线程先获取锁并负责重建缓存,其他线程等待或重试。
这种策略虽然会导致部分请求延迟,但实现起来相对简单。在技术派实战项目中,我们就使用了 Redisson 的分布式锁来确保只有一个服务实例能更新缓存。
String cacheKey = "product::" + productId;
RLock lock = redissonClient.getLock("lock::" + productId);
if (lock.tryLock(10, TimeUnit.SECONDS)) {
try {
String result = cache.get(cacheKey);
if (result == null) {
result = database.queryProductById(productId);
cache.set(cacheKey, result, 60 * 1000); // 设置缓存
}
} finally {
lock.unlock();
}
}第二种是永不过期策略。缓存项本身不设置过期时间,也就是永不过期,但在缓存值中维护一个逻辑过期时间。当缓存逻辑上过期时,返回旧值的同时,异步启动一个线程去更新缓存。
public String getData(String key) {
CacheItem item = cache.get(key);
if (item == null) {
// 缓存不存在,同步加载
String data = db.query(key);
cache.set(key, new CacheItem(data, System.currentTimeMillis() + expireTime));
return data;
} else if (item.isLogicalExpired()) {
// 逻辑过期,异步刷新
asyncRefresh(key);
// 返回旧数据
return item.getData();
}
return item.getData();
}
// 异步刷新缓存
private void asyncRefresh(final String key) {
threadPool.execute(() -> {
// 重新查询数据库
String newData = db.query(key);
// 更新缓存
cache.set(key, new CacheItem(newData, System.currentTimeMillis() + expireTime));
});
}memo:2025 年 5 月 18 日修改至此,今天给球友改简历时,碰到一个西北工业大学的球友,这又是一所 985 院校,希望这个社群能把所有的 985 院校集齐,也希望去帮助到更多院校的同学,希望大家都能拿到一个满意的 offer。

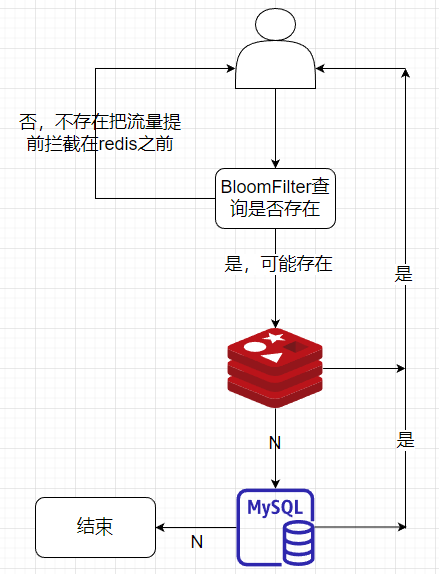
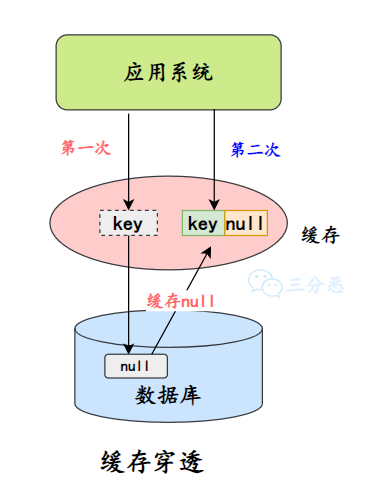
什么是缓存穿透?
缓存穿透是指查询的数据在缓存中没有命中,因为数据压根不存在,所以请求会直接落到数据库上。如果这种查询非常频繁,就会给数据库造成很大的压力。
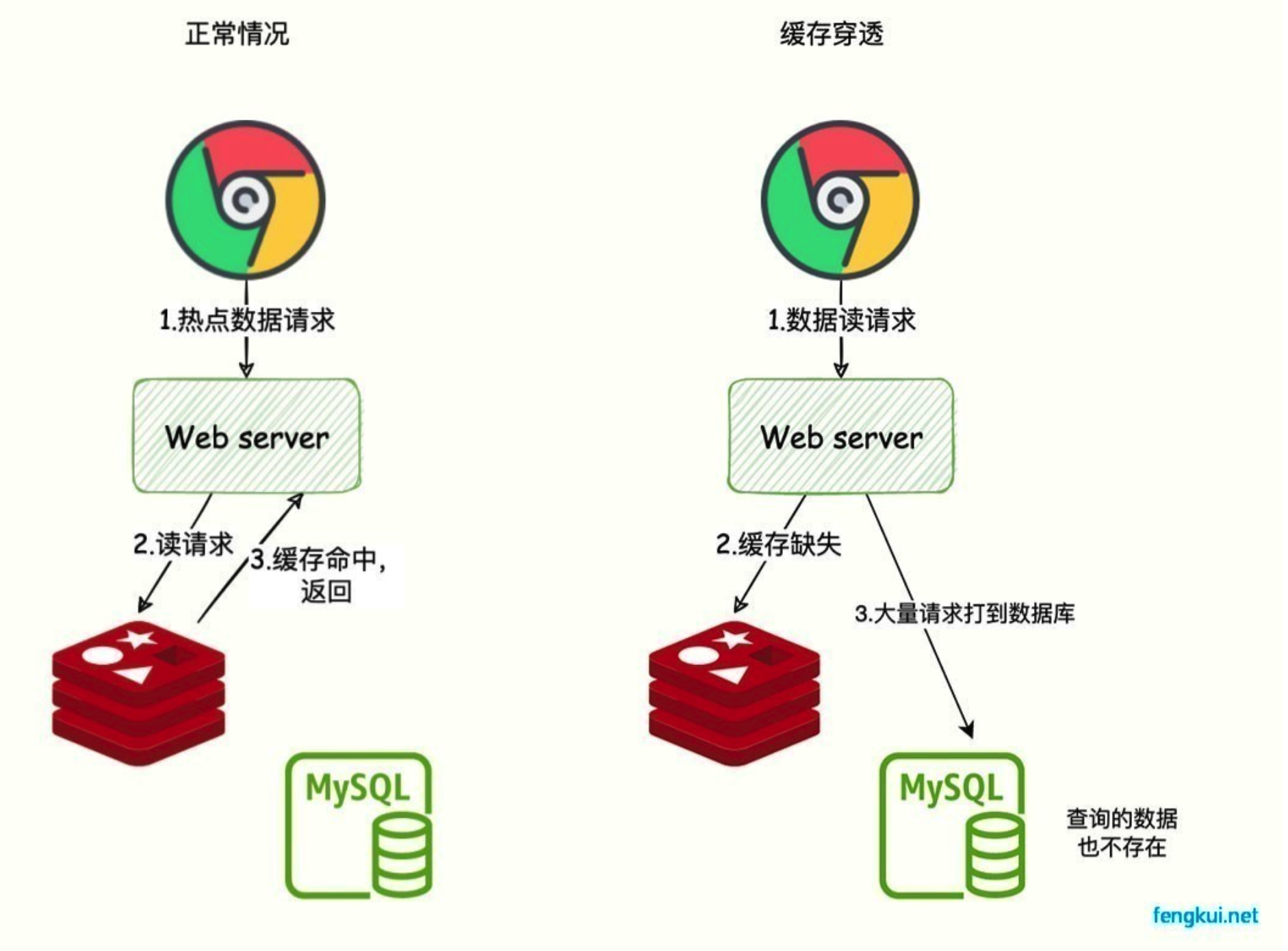
缓存击穿是因为单个热点数据缓存失效导致的,而缓存穿透是因为查询的数据不存在,原因可能是自身的业务代码有问题,或者是恶意攻击造成的,比如爬虫。
常用的解决方案有两种:第一种是布隆过滤器,它是一种空间效率很高的数据结构,可以用来判断一个元素是否在集合中。
我们可以将所有可能存在的数据哈希到布隆过滤器中,查询时先检查布隆过滤器,如果布隆过滤器认为该数据不存在,就直接返回空;否则再去查询缓存,这样就可以避免无效的缓存查询。
代码示例:
public String getData(String key) {
// 缓存中不存在该key
String cacheResult = cache.get(key);
if (cacheResult != null) {
return cacheResult;
}
// 布隆过滤器判断key是否可能存在
if (!bloomFilter.mightContain(key)) {
return null; // 一定不存在,直接返回
}
// 可能存在,查询数据库
String dbResult = db.query(key);
// 将结果放入缓存,包括空值
cache.set(key, dbResult != null ? dbResult : "", expireTime);
return dbResult;
}布隆过滤器存在误判,即可能会认为某个数据存在,但实际上并不存在。但绝不会漏判,即如果布隆过滤器认为某个数据不存在,那它一定不存在。因此它可以有效拦截不存在的数据查询,减轻数据库压力。
第二种是缓存空值。对于不存在的数据,我们将空值写入缓存,并设置一个合理的过期时间。这样下次相同的查询就能直接从缓存返回,而不再访问数据库。
代码示例:
public String getData(String key) {
String cacheResult = cache.get(key);
// 缓存命中,包括空值
if (cacheResult != null) {
// 特殊值表示空结果
if (cacheResult.equals("")) {
return null;
}
return cacheResult;
}
// 缓存未命中,查询数据库
String dbResult = db.query(key);
// 写入缓存,空值也缓存,但设置较短的过期时间
int expireTime = dbResult == null ? EMPTY_EXPIRE_TIME : NORMAL_EXPIRE_TIME;
cache.set(key, dbResult != null ? dbResult : "", expireTime);
return dbResult;
}缓存空值的方法实现起来比较简单,但需要给空值设置一个合理的过期时间,以免数据库中新增了这些数据后,缓存仍然返回空值。
在实际的项目当中,还需要在接口层面做一些处理,比如说对参数进行校验,拦截明显不合理的请求;或者对疑似攻击的 IP 进行限流和封禁。
memo:2025 年 5 月 19 日,今天有球友发微信说拿到了滴滴的测开实习 offer,目前还想继续找,问我该继续学点什么,我的回复说,暑期能拿到 offer,秋招继续就行了,加上滴滴的实习经历就很硬核了。大家在准备暑期和秋招的时候,也不要太焦虑,保持一个好的学习习惯,秋招没问题的。
什么是缓存雪崩?
缓存雪崩是指在某一时间段,大量缓存同时失效或者缓存服务突然宕机了,导致大量请求直接涌向数据库,导致数据库压力剧增,甚至引发系统崩溃的现象。
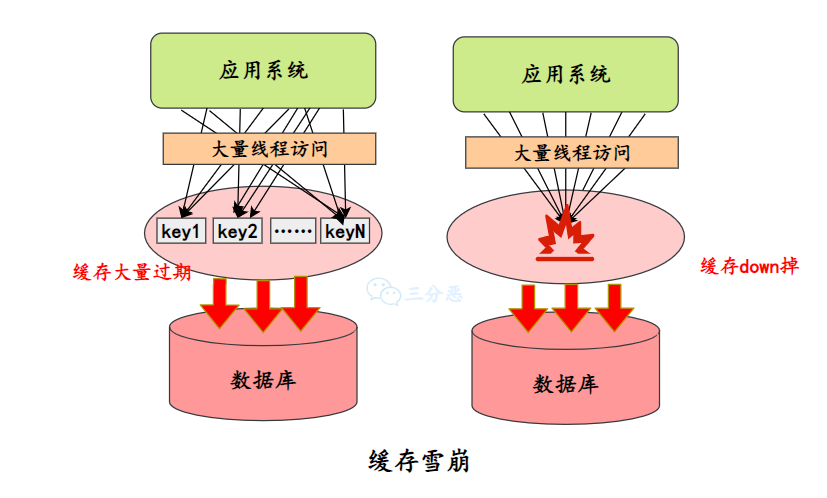
缓存击穿是单个热点数据失效导致的,缓存穿透是因为请求不存在的数据,而缓存雪崩是因为大范围的缓存失效。
缓存雪崩主要有三种成因和应对策略。
第一种,大量缓存同时过期,解决方法是添加随机过期时间。
public void setCache(String key, String value) {
// 基础过期时间,例如30分钟
int baseExpireSeconds = 1800;
// 增加随机过期时间,范围0-300秒
int randomSeconds = new Random().nextInt(300);
// 最终过期时间为基础时间加随机时间
cache.set(key, value, baseExpireSeconds + randomSeconds);
}第二种,缓存服务崩溃,解决方法是使用高可用的缓存集群。
比如说使用 Redis Cluster 构建多节点集群,确保数据在多个节点上有备份,并且支持自动故障转移。
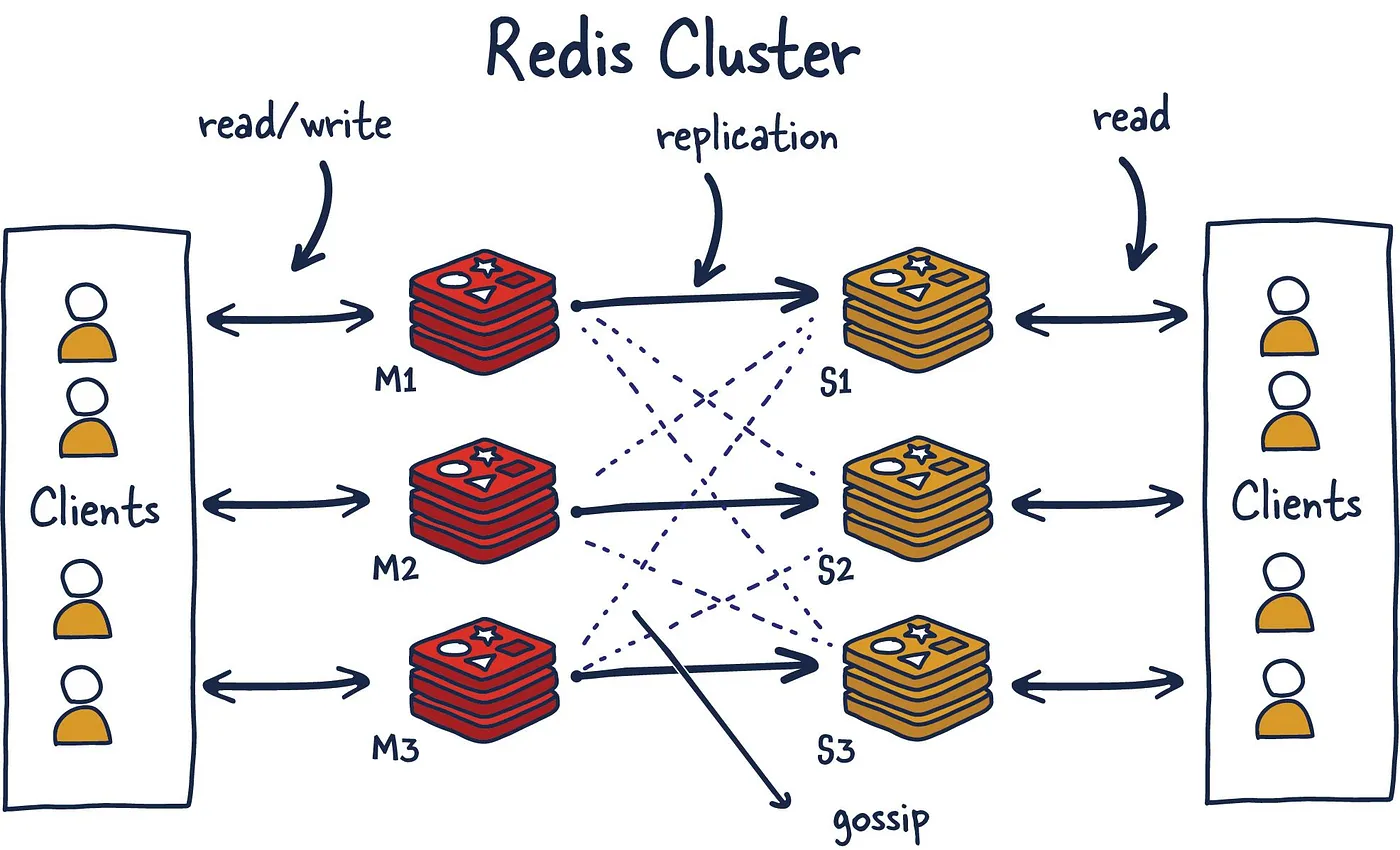
对于一些高频关键数据,可以配置本地缓存作为二级缓存,缓解 Redis 的压力。在技术派实战项目中,我们就采用了多级缓存的策略,其中就包括使用本地缓存 Caffeine 来作为二级缓存,当 Redis 出现问题时自动切换到本地缓存。
这个过程称为“缓存降级”,保证 Redis 发生故障时,系统能够继续提供服务。
LoadingCache<String, UserPermissions> permissionsCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(this::loadPermissionsFromRedis);
public UserPermissions loadPermissionsFromRedis(String userId) {
try {
return redisClient.getPermissions(userId);
} catch (Exception ex) {
// Redis 异常处理,尝试从本地缓存获取
return permissionsCache.getIfPresent(userId);
}
}第三种,缓存服务正常但并发请求量超过了缓存服务的承载能力,这种情况下可以采用限流和降级措施。
public String getData(String key) {
try {
// 尝试从缓存获取数据
return cache.get(key);
} catch (Exception e) {
// 缓存服务异常,触发熔断
if (circuitBreaker.shouldTrip()) {
// 直接从数据库获取,并进入降级模式
circuitBreaker.trip();
return getFromDbDirectly(key);
}
throw e;
}
}
private String getFromDbDirectly(String key) {
// 实施限流保护
if (!rateLimit.tryAcquire()) {
// 超过限流阈值,返回兜底数据或默认值
return getDefaultValue(key);
}
// 限流通过,从数据库查询
return db.query(key);
}
- Java 面试指南(付费)收录的腾讯面经同学 22 暑期实习一面面试原题:缓存雪崩,如何解决
- Java 面试指南(付费)收录的快手面经同学 7 Java 后端技术一面面试原题:说一下 缓存穿透、缓存击穿、缓存雪崩
- Java 面试指南(付费)收录的字节跳动同学 7 Java 后端实习一面的原题:Redis 宕机会不会对权限系统有影响?
- Java 面试指南(付费)收录的字节跳动同学 7 Java 后端实习一面的原题:说一下 Redis 雪崩、穿透、击穿等场景的解决方案
- Java 面试指南(付费)收录的小米同学 F 面试原题:缓存常见问题和解决方案(引申到多级缓存),多级缓存(redis,nginx,本地缓存)的实现思路
- Java 面试指南(付费)收录的TP联洲同学 5 Java 后端一面的原题:如何解决缓存穿透
- Java 面试指南(付费)收录的理想汽车面经同学 2 一面面试原题:如何理解缓存雪崩、缓存击穿和缓存穿透?
memo:2025 年 5 月 20 日,今天有球友发微信说项目用的技术派,八股背的面渣,春招拿到了四个 offer,其中包括泰隆银行和交通银行,问我该怎么选择,说实话我看完后觉得挺难选的,😄不过还是值得恭喜一手。大家在准备春招的时候也不要着急,付出总会有回报的。

30.🌟能说说布隆过滤器吗?
布隆过滤器是一种空间效率极高的概率性数据结构,用于快速判断一个元素是否在一个集合中。它的特点是能够以极小的内存消耗,判断一个元素“一定不在集合中”或“可能在集合中”,常用来解决 Redis 缓存穿透的问题。
----这部分面试中可以不背start----
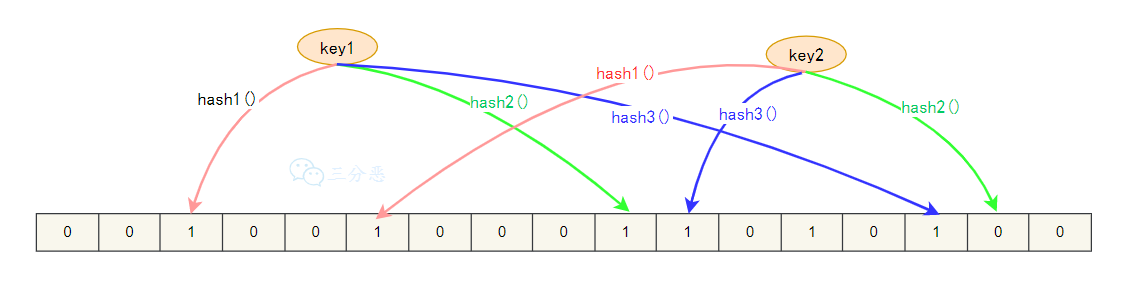
布隆过滤器的核心由一个很长的二进制向量和一系列哈希函数组成。
- 初始化的时候,创建一个长度为 m 的位数组,初始值全为 0,同时选择 k 个不同的哈希函数
- 当添加一个元素时,用 k 个哈希函数计算出 k 个哈希值,然后对 m 取模,得到 k 个位置,将这些位置的二进制位都设为 1
- 当需要判断一个元素是否在集合中时,同样用 k 个哈希函数计算出 k 个位置,如果这些位置的二进制位有任何一个为 0,该元素一定不在集合中;如果全部为 1,则该元素可能在集合中
public class BloomFilter<T> {
private BitSet bitSet;
private int bitSetSize;
private int numberOfHashFunctions;
public BloomFilter(double falsePositiveProbability, int expectedNumberOfElements) {
// 根据预期元素数量和期望的误判率,计算最优的位数组大小和哈希函数个数
this.bitSetSize = calculateOptimalBitSetSize(expectedNumberOfElements, falsePositiveProbability);
this.numberOfHashFunctions = calculateOptimalNumberOfHashFunctions(expectedNumberOfElements, bitSetSize);
this.bitSet = new BitSet(bitSetSize);
}
public void add(T element) {
int[] hashes = createHashes(element);
for (int hash : hashes) {
bitSet.set(Math.abs(hash % bitSetSize), true);
}
}
public boolean mightContain(T element) {
int[] hashes = createHashes(element);
for (int hash : hashes) {
if (!bitSet.get(Math.abs(hash % bitSetSize))) {
return false; // 如果任何一位为0,元素一定不存在
}
}
return true; // 所有位都为1,元素可能存在
}
// 其他辅助方法,如计算哈希值,计算最优参数等
}----这部分面试中可以不背end----
布隆过滤器存在误判吗?
是的,布隆过滤器存在误判。它可能会错误地认为某个元素在集合中,而元素实际上并不在集合中。
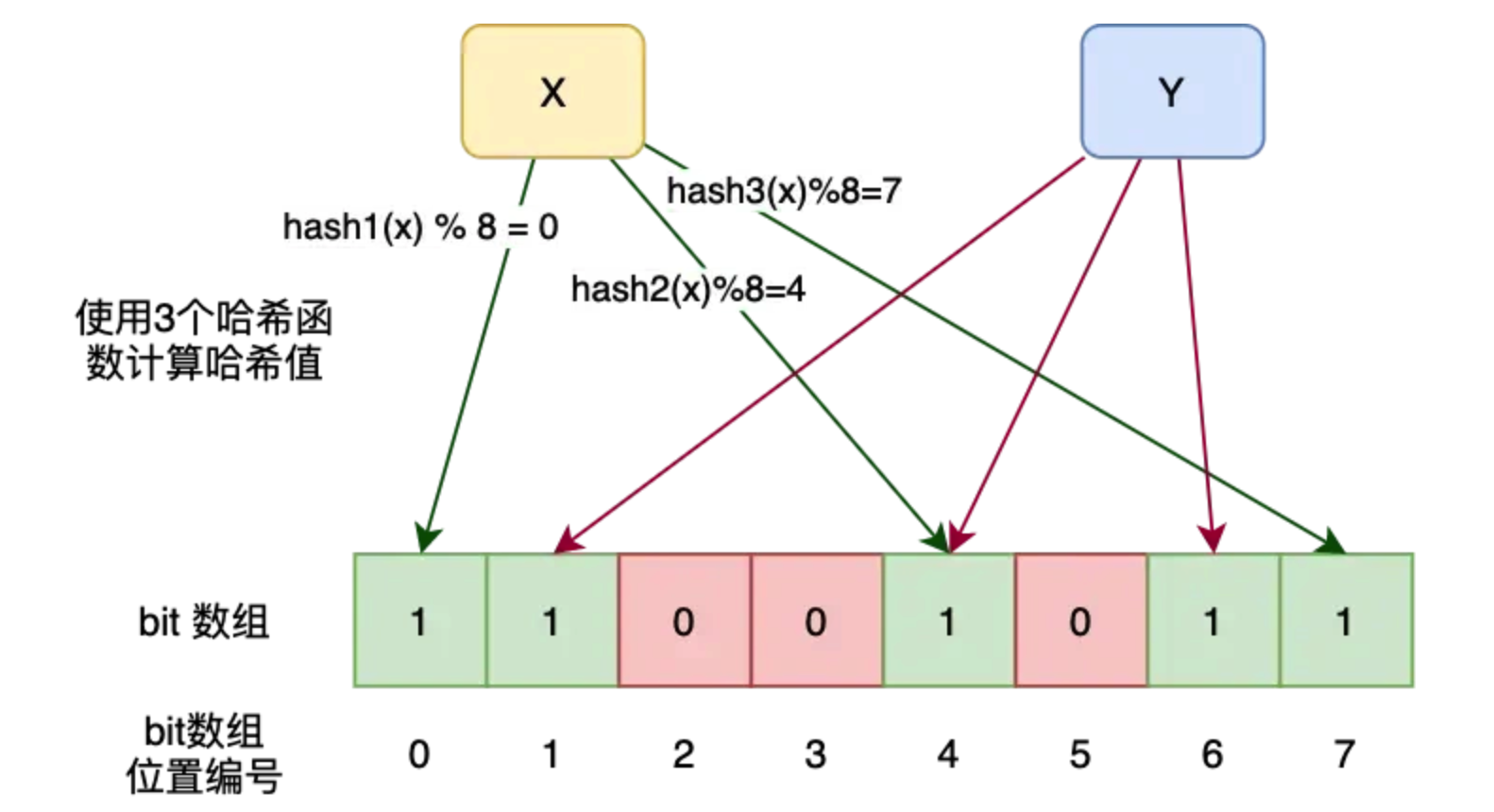
但如果布隆过滤器认为某个元素不存在于集合中,那么它一定不存在。
误判产生的原因是因为哈希冲突。在布隆过滤器中,多个不同的元素可能映射到相同的位置。随着向布隆过滤器中添加的元素越来越多,位数组中的 1 也越来越多,发生哈希冲突的概率随之增加,误判率也就随之上升。
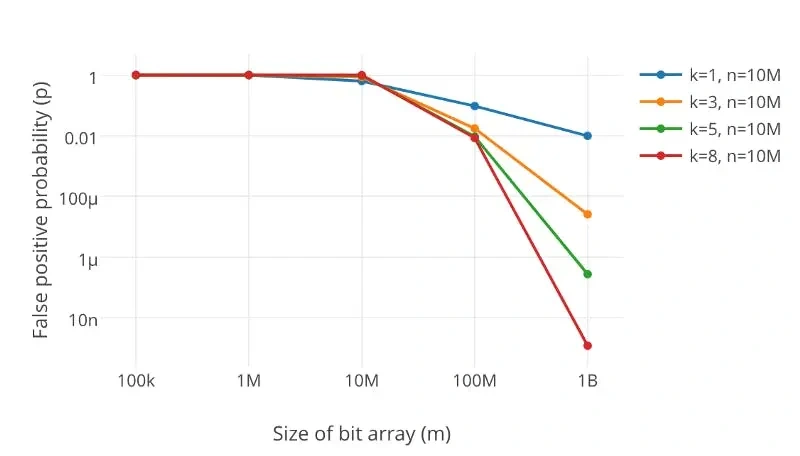
误判率取决于以下 3 个因素:
- 位数组的大小(m):m 决定了可以存储的标志位数量。如果位数组过小,那么哈希碰撞的几率就会增加,从而导致更高的误判率。
- 哈希函数的数量(k):k 决定了每个元素在位数组中标记的位数。哈希函数越多,碰撞的概率也会相应变化。如果哈希函数太少,过滤器很快会变得不精确;如果太多,误判率也会升高,效率下降。
- 存入的元素数量(n):n 越多,哈希碰撞的几率越大,从而导致更高的误判率。
要降低误判率,可以增加位数组的大小或者减少插入的元素数量。
要彻底解决布隆过滤器的误判问题,可以在布隆过滤器返回"可能存在"时,再通过数据库进行二次确认。
布隆过滤器支持删除吗?
布隆过滤器并不支持删除操作,这是它的一个重要限制。
当我们添加一个元素时,会将位数组中的 k 个位置设置为 1。由于多个不同元素可能共享相同的位,如果我们尝试删除一个元素,将其对应的 k 个位重置为 0,可能会错误地影响到其他元素的判断结果。
例如,元素 A 和元素 B 都将位置 5 设为 1,如果删除元素 A 时将位置 5 重置为 0,那么对元素 B 的查询就会产生错误的"不存在"结果,这违背了布隆过滤器的基本特性。
如果想要实现删除操作,可以使用计数布隆过滤器,它在每个位置上存储一个计数器而不是单一的位。这样可以通过减少计数器的值来实现删除操作,但会增加内存开销。
public class CountingBloomFilter<T> {
private int[] counters;
private int size;
private int hashFunctions;
public CountingBloomFilter(int size, int hashFunctions) {
this.size = size;
this.hashFunctions = hashFunctions;
this.counters = new int[size];
}
public void add(T element) {
int[] positions = getHashPositions(element);
for (int position : positions) {
counters[position]++;
}
}
public void remove(T element) {
int[] positions = getHashPositions(element);
for (int position : positions) {
if (counters[position] > 0) {
counters[position]--;
}
}
}
public boolean mightContain(T element) {
int[] positions = getHashPositions(element);
for (int position : positions) {
if (counters[position] == 0) {
return false;
}
}
return true;
}
private int[] getHashPositions(T element) {
// 计算哈希位置的代码
}
}为什么不能用哈希表而是用布隆过滤器?
布隆过滤器最突出的优势是内存效率。
假如我们要判断 10 亿个用户 ID 是否曾经访问过特定页面,使用哈希表至少需要 10G 内存(每个 ID 至少需要8字节),而使用布隆过滤器只需要 1.2G 内存。
m ≈ -n*ln(p)/ln(2)² ≈ -10⁹*ln(0.01)/ln(2)² ≈ 9.6 billion bits ≈ 1.2GB
- Java 面试指南(付费)收录的字节跳动同学 7 Java 后端实习一面的原题:有了解过布隆过滤器吗?
- Java 面试指南(付费)收录的TP联洲同学 5 Java 后端一面的原题:布隆过滤器原理,这种方式下5%的错误率可接受?
- Java 面试指南(付费)收录的美团同学 9 一面面试原题:布隆过滤器?布隆过滤器优点?为什么不能用哈希表要用布隆过滤器?
- Java 面试指南(付费)收录的理想汽车面经同学 2 一面面试原题:追问:说明一下布隆过滤器
memo:2025 年 5 月 20 日,今天有球友发贴说拿到了滴滴的暑期 offer,特意来感谢了一下面渣逆袭。
31.🌟如何保证缓存和数据库的数据⼀致性?
在技术派实战项目中,对于文章标签这种允许短暂不一致的数据,我会采用 Cache Aside + TTL 过期机制来保证缓存和数据库的一致性。

具体做法是读取时先查 Redis,未命中再查 MySQL,同时为缓存设置一个合理的过期时间;更新时先更新 MySQL,再删除 Redis。
这种方式简单有效,适用于读多写少的场景。TTL 过期时间也能够保证即使更新操作失败,未能及时删除缓存,过期时间也能确保数据最终一致。
// 读取逻辑
public UserInfo getUser(String userId) {
// 先查缓存
UserInfo user = cache.get("user:" + userId);
if (user != null) {
return user;
}
// 缓存未命中,查数据库
user = database.selectUser(userId);
if (user != null) {
// 放入缓存,设置合理的过期时间
cache.set("user:" + userId, user, 3600);
}
return user;
}
// 更新逻辑
public void updateUser(UserInfo user) {
// 先更新数据库
database.updateUser(user);
// 删除缓存
cache.delete("user:" + user.getId());
}那再来说说为什么要删除缓存而不是更新缓存?
最初设计缓存策略时,我也考虑过直接更新缓存,但通过实践发现,删除缓存是更优的选择。
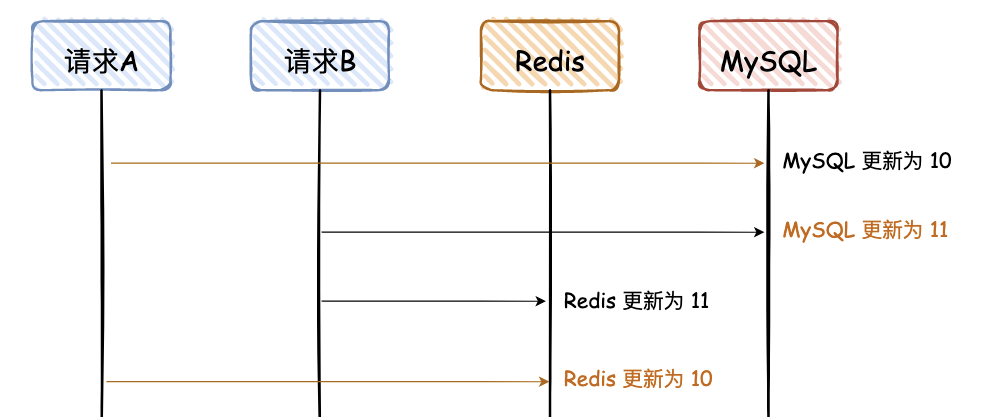
最主要的原因是在并发环境下,假设我们有两个并发的更新操作,如果采用更新缓存的策略,就可能出现这样的时序问题:
- 操作 A 和操作 B 同时发生,A 先更新 MySQL 将值改为 10,B 后更新 MySQL 将值改为 11。但在缓存更新时,可能 B 先执行将缓存设为 11,然后 A 才执行将缓存设为10。这样就会造成 MySQL 是 11 但 Redis 是 10 的不一致状态。
而采用删除策略,无论 A 和 B 谁先删除缓存,后续的读取操作都会从 MySQL 获取最新值。
另外,相对而言,删除缓存的速度比更新缓存的速度快得多。
因为删除操作只是简单的 DEL 命令,而更新可能需要重新序列化整个对象再写入缓存。
那再说说为什么要先更新数据库,再删除缓存?
这个操作顺序的选择也是我在实际项目中踩过坑才深刻理解的。假设我们采用先删缓存再更新数据库的策略,在高并发场景下就可能出现这样的问题:
- 线程 A 要更新用户信息,先删除了缓存
- 线程 B 恰好此时要读取该用户信息,发现缓存为空,于是查询数据库,此时还是旧值
- 线程 B 将查到的旧值重新放入缓存
- 线程 A 完成数据库更新
结果就是数据库是新的值,但缓存中还是旧值。
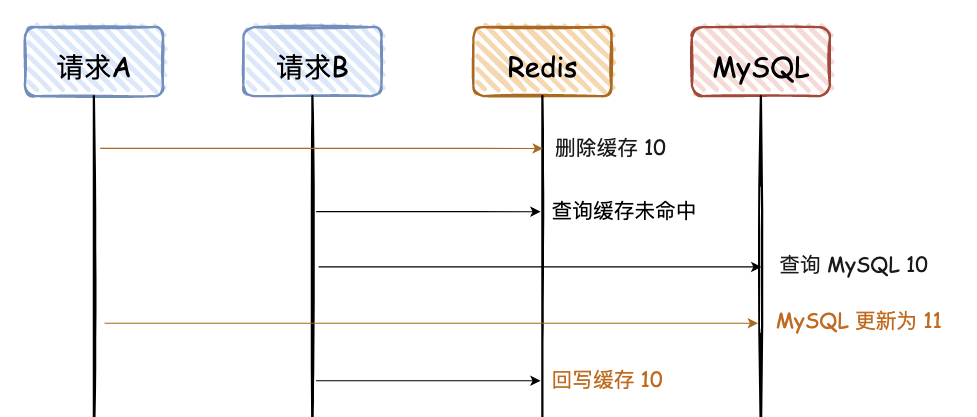
而采用先更新数据库再删缓存的策略,即使出现类似的并发情况,最坏的情况也只是短暂地从缓存中读取到了旧值,但缓存删除后的请求会直接从数据库中获取最新值。
另外,如果先删缓存再更新数据库,当数据库更新失败时,缓存已经被删除了。这会导致短期内所有读请求都会穿透到数据库,对数据库造成额外的压力。
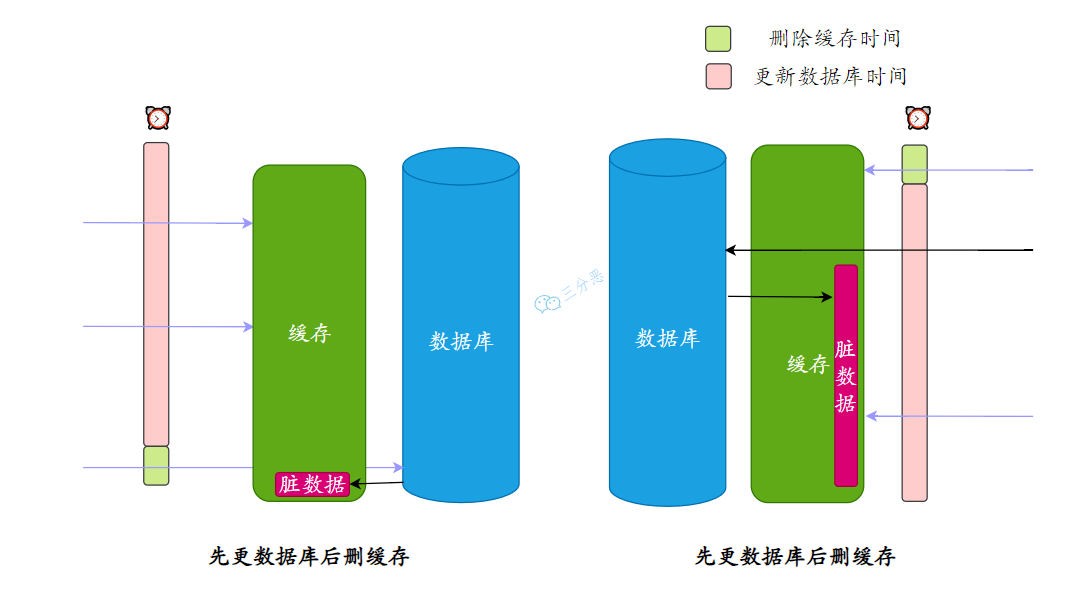
而先更新数据库再删缓存,如果数据库更新失败,缓存保持原状,系统仍然能继续正常提供服务。
public void updateUser(User user) {
try {
// 先更新数据库
database.updateUser(user);
// 再删除缓存
cache.delete("user:" + user.getId());
} catch (DatabaseException e) {
// 数据库更新失败,缓存保持原状,系统仍可正常提供服务
log.error("Database update failed", e);
throw e;
} catch (CacheException e) {
// 缓存删除失败,数据库已更新,数据会在TTL后自动一致
log.warn("Cache deletion failed, will be eventually consistent", e);
// 可以选择不抛异常,因为有TTL兜底
}
}memo:2025 年 5 月 22 日,今天给球友修改简历时,碰到一个西北工业大学本、电子科技大学硕的球友,一下子 985 高校又集齐了两所。如果球友们在星球里有所收获,也请给学弟学妹们一个口碑,让大家都能因此受益,拿到更好的 offer。

那假如对缓存数据库一致性要求很高,该怎么办呢?
当业务对缓存与数据库的一致性要求很高时,比如支付系统、库存管理等场景,我会采用多种策略来保证强一致性。
第一种,引入消息队列来保证缓存最终被删除,比如说在数据库更新的事务中插入一条本地消息记录,事务提交后异步发送给 MQ 进行缓存删除。
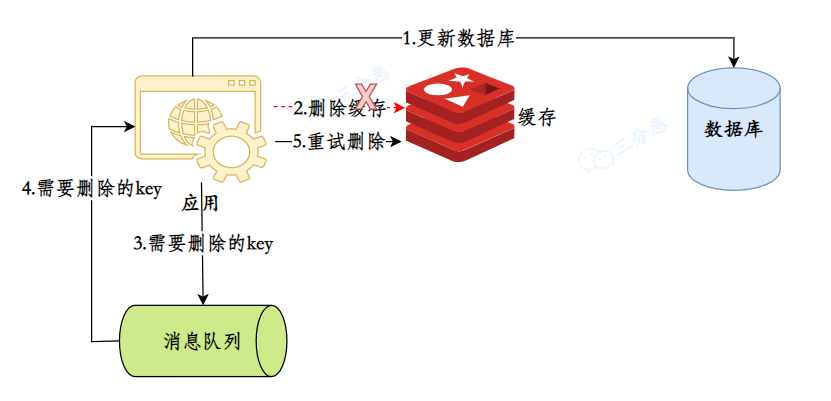
即使缓存删除失败,消息队列的重试机制也能保证最终一致性。
@Transactional
public void updateUser(UserInfo user) {
// 在事务中更新数据库
database.updateUser(user);
// 在同一事务中记录需要删除的缓存信息
LocalMessage message = new LocalMessage("CACHE_DELETE", "user:" + user.getId());
database.insertLocalMessage(message);
// 显式发布事件,供监听器捕获
eventPublisher.publishEvent(new UserUpdateEvent(this, "user:" + user.getId()));
}
// 事务提交后发送MQ消息
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void sendCacheDeleteMessage(UserUpdateEvent event) {
messageQueue.send("cache-delete-topic", event.getCacheKey());
}第二种,使用 Canal 监听 MySQL 的 binlog,在数据更新时,将数据变更记录到消息队列中,消费者消息监听到变更后去删除缓存。
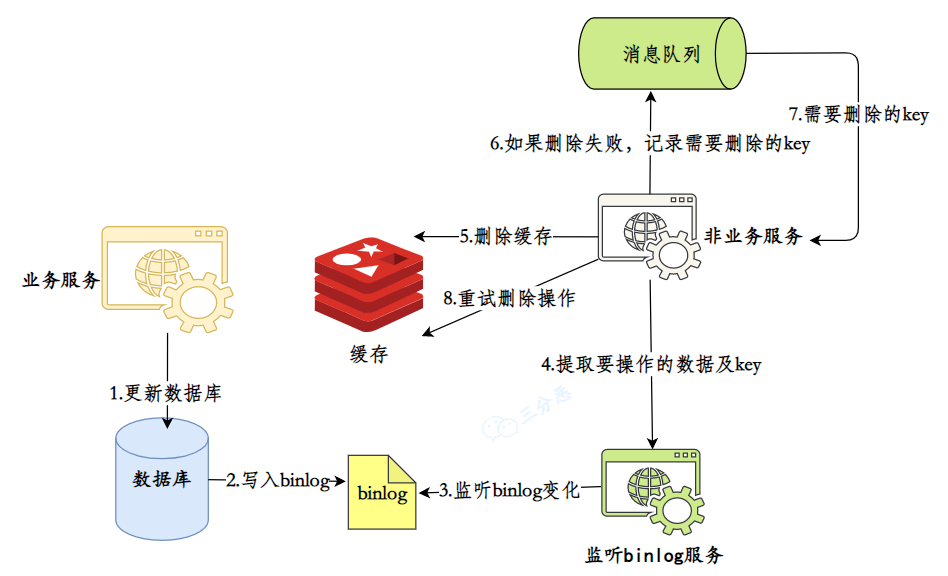
这种方案的优势是完全解耦了业务代码和缓存维护逻辑。
@CanalListener
public class CacheUpdateListener {
@EventHandler
public void handleUserUpdate(UserUpdateEvent event) {
// 从binlog事件中提取变更信息
String userId = event.getUserId();
// 发送缓存删除消息
CacheDeleteMessage message = new CacheDeleteMessage();
message.setCacheKey("user:" + userId);
messageQueue.send("cache-delete-topic", message);
}
}
// 消费者监听消息队列
@KafkaListener(topics = "cache-delete-topic")
public void handleCacheDeleteMessage(CacheDeleteMessage message) {
// 删除缓存
cache.delete(message.getCacheKey());
}当然了,如果说业务比较简单,不需要上消息队列,可以通过延迟双删策略降低缓存和数据库不一致的时间窗口,在第一次删除缓存之后,过一段时间之后,再次尝试删除缓存。
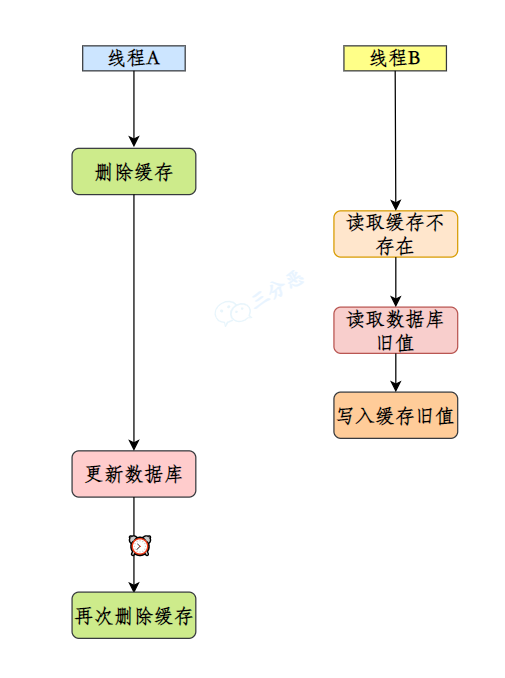
这种方式主要针对缓存不存在,但写入了脏数据的情况。
public void updateUser(UserInfo user) {
// 第一次删除缓存,减少不一致时间窗口
cache.delete("user:" + user.getId());
// 更新数据库
database.updateUser(user);
// 立即删除缓存
cache.delete("user:" + user.getId());
// 延时删除,应对可能的并发读取
CompletableFuture.runAsync(() -> {
try {
Thread.sleep(1000); // 延时时间根据主从同步延迟调整
cache.delete("user:" + user.getId());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}最后,无论采用哪种策略,最好为缓存设置一个合理的过期时间作为最后的保障。即使所有的主动删除机制都失败了,TTL 也能确保数据最终达到一致:
// 根据数据的重要程度设置不同的TTL
public void setCache(String key, Object value, DataImportance importance) {
int ttl;
switch (importance) {
case HIGH: // 关键数据,短TTL
ttl = 300; // 5分钟
break;
case MEDIUM: // 一般数据
ttl = 1800; // 30分钟
break;
case LOW: // 不太重要的数据
ttl = 3600; // 1小时
break;
}
cache.setWithTTL(key, value, ttl);
}这种方式虽然简单,但能确保即使出现极端情况,数据不一致的影响也是可控的。
- Java 面试指南(付费)收录的华为面经同学 8 技术二面面试原题:怎样保证数据的最终一致性?
- Java 面试指南(付费)收录的腾讯面经同学 23 QQ 后台技术一面面试原题:数据一致性问题
- Java 面试指南(付费)收录的微众银行同学 1 Java 后端一面的原题:MySQL 和缓存一致性问题了解吗?
- Java 面试指南(付费)收录的美团面经同学 3 Java 后端技术一面面试原题:如何保证 redis 缓存与数据库的一致性,为什么这么设计
- Java 面试指南(付费)收录的比亚迪面经同学 12 Java 技术面试原题:怎么解决redis和mysql的缓存一致性问题
- Java 面试指南(付费)收录的字节跳动同学 17 后端技术面试原题:双写一致性怎么解决的
- Java 面试指南(付费)收录的京东面经同学 9 面试原题:redis的数据和缓存不一致应该处理
memo:2025 年 5 月 23 日修改至此,今天在修改球友简历时,看到一条非常温暖的感谢信,球友说改完后的简历,每一句都比之前的好很多,真的很欣慰,感觉自己的付出得到了回报。😄

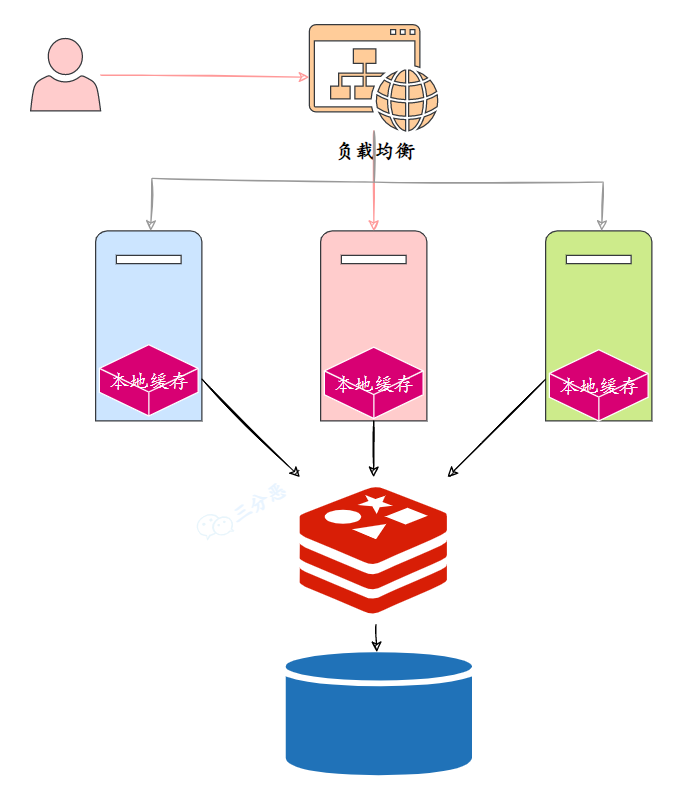
32.如何保证本地缓存和分布式缓存的一致?
在技术派实战项目中,为了减轻 Redis 的负载压力,我又追加了一层本地缓存 Caffeine。
为了保证 Caffeine 和 Redis 缓存的一致性,我采用的策略是当数据更新时,通过 Redis 的 pub/sub 机制向所有应用实例发送缓存更新通知,收到通知后的实例立即更新或者删除本地缓存。
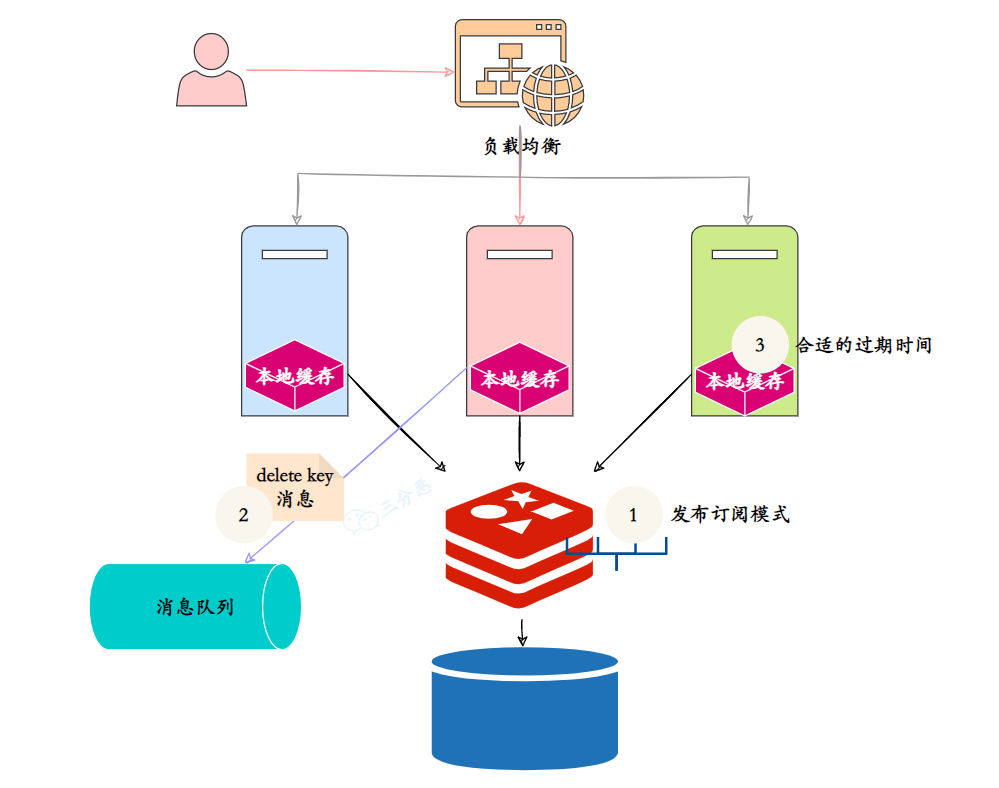
@Service
public class CacheService {
private final RedisTemplate redisTemplate;
private final CaffeineCache localCache;
public void updateData(String key, Object value) {
// 更新数据库
database.update(key, value);
// 更新分布式缓存
redisTemplate.opsForValue().set(key, value, 30, TimeUnit.MINUTES);
// 发送缓存更新通知
CacheUpdateMessage message = new CacheUpdateMessage(key, "UPDATE", value);
redisTemplate.convertAndSend("cache-update-channel", message);
}
@EventListener
public void handleCacheUpdate(CacheUpdateMessage message) {
if ("UPDATE".equals(message.getAction())) {
localCache.put(message.getKey(), message.getValue());
} else if ("DELETE".equals(message.getAction())) {
localCache.invalidate(message.getKey());
}
}
}考虑到消息可能丢失,我还会引入版本号机制作为补充。每次从 Redis 获取数据时添加一个最新的版本号。从本地缓存获取数据前,先检查自己的版本号是否是最新的,如果发现版本落后,就主动从 Redis 中获取最新数据。
@Component
public class VersionBasedCacheManager {
@Autowired
private StringRedisTemplate redisTemplate;
// 使用 Caffeine 构建本地缓存:最多 1000 项,写入后 10 分钟过期
private final Cache<String, VersionedData> localCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build();
/**
* 获取缓存数据,优先使用本地缓存,必要时从 Redis 加载
*/
public Object get(String key) {
VersionedData cached = localCache.getIfPresent(key); // 从本地缓存取出
// 从 Redis 获取版本号
String versionStr = redisTemplate.opsForValue().get(key + ":version");
// 如果 Redis 中没找到版本号,说明可能数据已失效,强制刷新
if (versionStr == null) {
return loadAndCache(key);
}
long remoteVersion = Long.parseLong(versionStr);
// 如果本地没有缓存,或版本落后于 Redis,强制刷新
if (cached == null || cached.getVersion() < remoteVersion) {
return loadAndCache(key);
}
// 命中本地缓存且版本最新,直接返回
return cached.getData();
}
/**
* 从 Redis 加载数据和版本,并写入本地缓存
*/
private Object loadAndCache(String key) {
Object data = redisTemplate.opsForValue().get(key);
String versionStr = redisTemplate.opsForValue().get(key + ":version");
if (data != null && versionStr != null) {
long version = Long.parseLong(versionStr);
localCache.put(key, new VersionedData(data, version));
}
return data;
}
}如果在项目中多个地方都要使用到二级缓存的逻辑,如何设计这一块?
我的思路是将二级缓存抽象成一个统一的组件。设计一个 CacheManager 作为核心入口,提供 get、put、evict 等基本操作,执行先查本地缓存,再查分布式缓存,最后查数据库的完整流程。
public class CacheManager {
private final LocalCache localCache;
private final RedisCache redisCache;
private final Database database;
public CacheManager(LocalCache localCache, RedisCache redisCache, Database database) {
this.localCache = localCache;
this.redisCache = redisCache;
this.database = database;
}
public Object get(String key) {
// 先查本地缓存
Object value = localCache.get(key);
if (value != null) {
return value;
}
// 再查分布式缓存
value = redisCache.get(key);
if (value != null) {
// 更新本地缓存
localCache.put(key, value);
return value;
}
// 最后查数据库
value = database.get(key);
if (value != null) {
// 更新分布式缓存和本地缓存
redisCache.put(key, value);
localCache.put(key, value);
}
return value;
}
}本地缓存和 Redis 的区别了解吗?
Redis 可以部署在多个节点上,支持数据分片、主从复制和集群。而本地缓存只能在单个服务器上使用。
对于读取频率极高、数据相对稳定、允许短暂不一致的数据,我优先选择本地缓存。比如系统配置信息、用户权限数据、商品分类信息等。
而对于需要实时同步、数据变化频繁、多个服务需要共享的数据,我会选择 Redis。比如用户会话信息、购物车数据、实时统计信息等。
- Java 面试指南(付费)收录的字节跳动同学 7 Java 后端实习一面的原题:怎么保证二级缓存和 Redis 缓存的数据一致性?
- Java 面试指南(付费)收录的华为面经同学 11 面试原题:使用的 guava cache 和 redis 是如何组合使用的?如果在项目中多个地方都要使用到二级缓存的逻辑,如何设计这一块?
- Java 面试指南(付费)收录的去哪儿同学 1 技术二面的原题:redis 和本地缓存的区别,哪个效率高
- Java 面试指南(付费)收录的拼多多面经同学 8 一面面试原题:缓存一致性如何保证
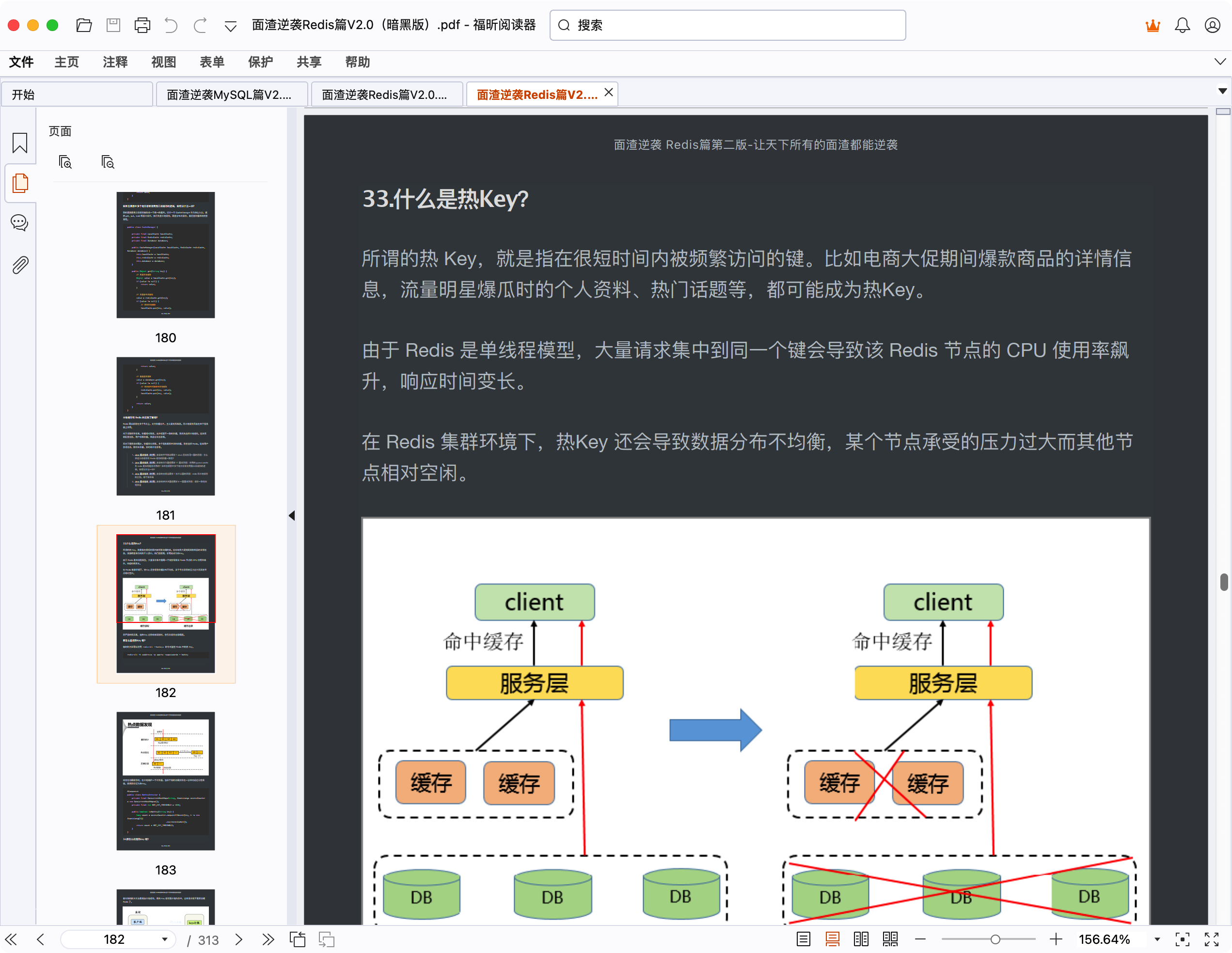
33.什么是热Key?
所谓的热 Key,就是指在很短时间内被频繁访问的键。比如电商大促期间爆款商品的详情信息,流量明星爆瓜时的个人资料、热门话题等,都可能成为热Key。
由于 Redis 是单线程模型,大量请求集中到同一个键会导致该 Redis 节点的 CPU 使用率飙升,响应时间变长。
在 Redis 集群环境下,热Key 还会导致数据分布不均衡,某个节点承受的压力过大而其他节点相对空闲。
更严重的情况是,当热Key 过期或被误删时,会引发缓存击穿问题。
那怎么监控热Key 呢?
临时的方案可以使用 redis-cli --hotkeys 命令来监控 Redis 中的热 Key。
redis-cli -h <address> -p <port> -a<password> — hotkey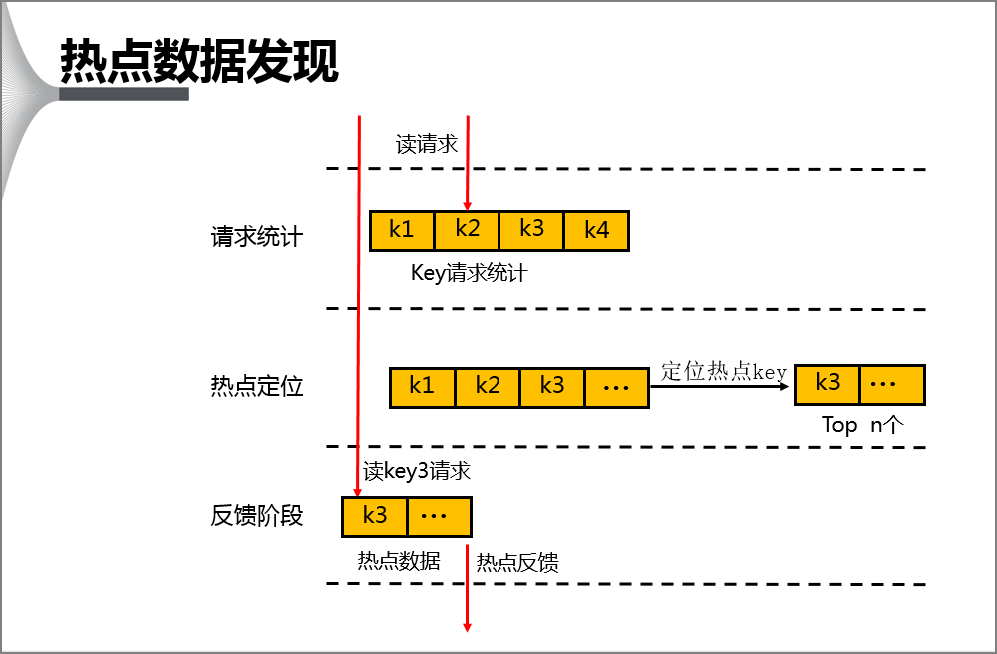
或者在访问缓存时,在本地维护一个计数器,当某个键的访问次数在一分钟内超过设定阈值,就将其标记为热Key。
@Component
public class HotKeyDetector {
private final ConcurrentHashMap<String, AtomicLong> accessCounter = new ConcurrentHashMap<>();
private final int HOT_KEY_THRESHOLD = 1000;
public boolean isHotKey(String key) {
long count = accessCounter.computeIfAbsent(key, k -> new AtomicLong(0))
.incrementAndGet();
return count > HOT_KEY_THRESHOLD;
}
}34.那怎么处理热Key 呢?
最有效的解决方法是增加本地缓存,将热 Key 缓存到本地内存中,这样请求就不需要访问 Redis 了。
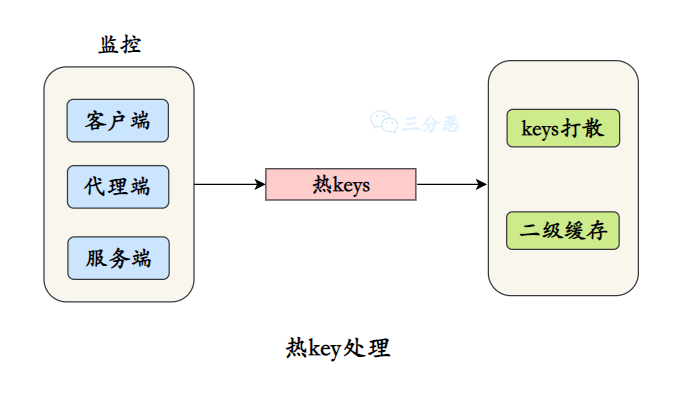
对于一些特别热的 Key,可以将其拆分成多个子 Key,然后随机分布到不同的 Redis 节点上。比如将 hot_product:12345 拆分成 hot_product:12345:1、hot_product:12345:2 等多个副本,读取时随机选择其中一个。
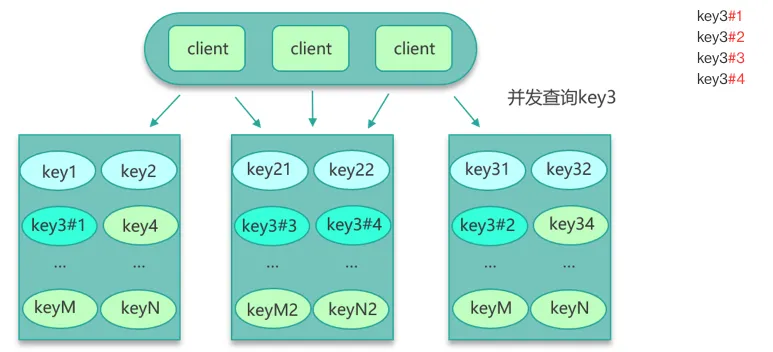
public String getHotData(String key) {
if (isHotKey(key)) {
// 随机选择一个副本
int replica = ThreadLocalRandom.current().nextInt(HOT_KEY_REPLICAS);
return redis.get(key + ":" + replica);
}
return redis.get(key);
}35.怎么处理大 Key 呢?
大Key 是指占用内存空间较大的缓存键,比如超过 10M 的键值对。常见的大Key 类型包括:包含大量元素的 List、Set、Hash 结构,存储大文件的 String 类型,以及包含复杂嵌套对象的 JSON 数据等。
在内存有限的情况下,可能导致 Redis 内存不足。另外,大Key 还会导致主从复制同步延迟,甚至引发网络拥塞。
可以通过 redis-cli --bigkeys 命令来监控 Redis 中的大 Key。
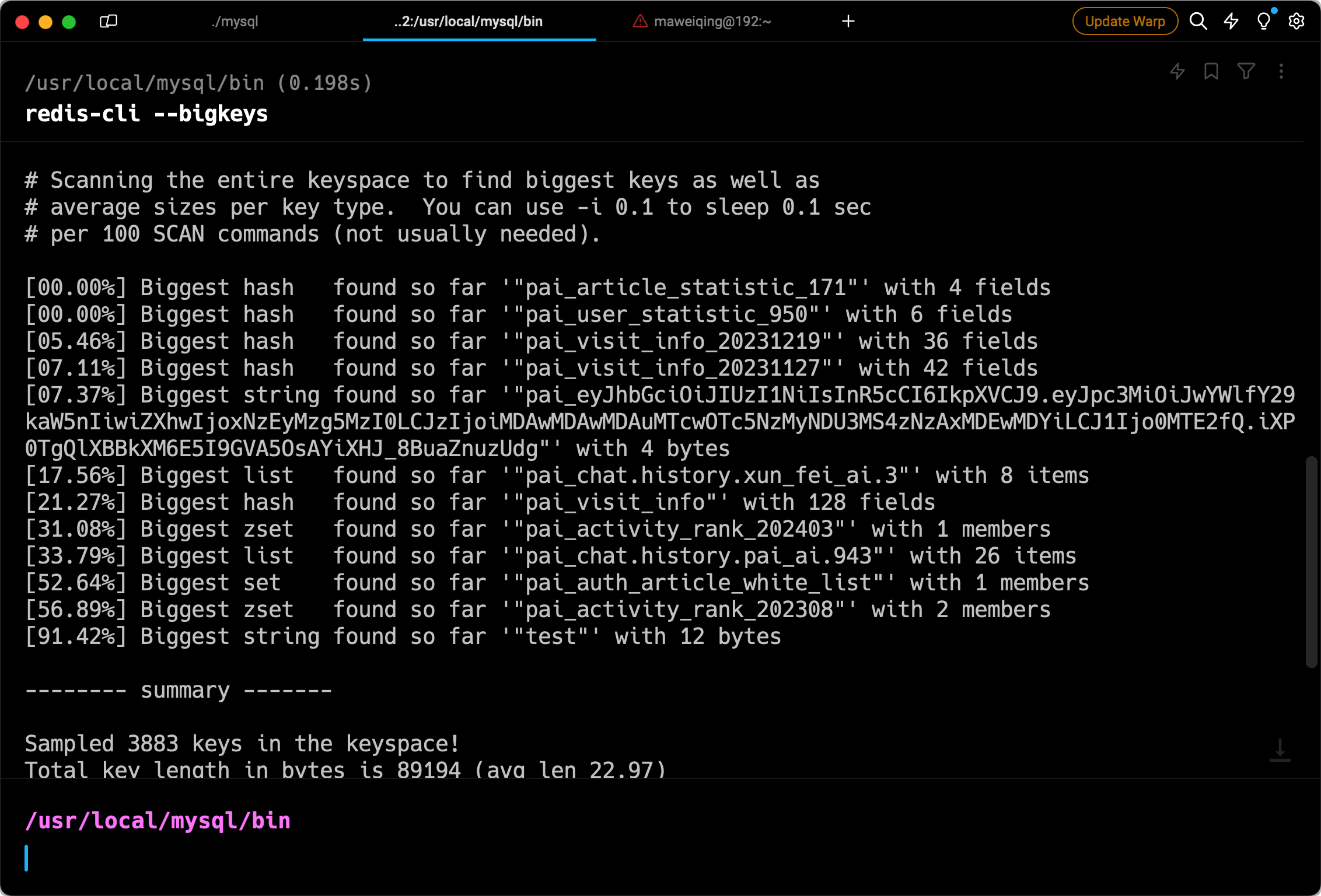
或者编写脚本进行全量扫描:
@Component
public class BigKeyScanner {
private final RedisTemplate redisTemplate;
private final int BIG_KEY_THRESHOLD = 1024 * 1024; // 1MB
public List<BigKeyInfo> scanBigKeys() {
List<BigKeyInfo> bigKeys = new ArrayList<>();
// 使用SCAN命令遍历所有键
ScanOptions options = ScanOptions.scanOptions().count(1000).build();
Cursor<byte[]> cursor = redisTemplate.executeWithStickyConnection(
connection -> connection.scan(options)
);
while (cursor.hasNext()) {
String key = new String(cursor.next());
long memory = getKeyMemoryUsage(key);
if (memory > BIG_KEY_THRESHOLD) {
bigKeys.add(new BigKeyInfo(key, memory, getKeyType(key)));
}
}
return bigKeys;
}
private long getKeyMemoryUsage(String key) {
// 使用MEMORY USAGE命令获取键的内存占用
return redisTemplate.execute((RedisCallback<Long>) connection ->
connection.memoryUsage(key.getBytes())
);
}
}对于大 Key 问题,最根本的解决方案是拆分大 Key,将其拆分成多个小 Key 存储。比如将一个包含大量用户信息的 Hash 拆分成多个小 Hash。
public void splitBigKey(String bigKey) {
Map<String, String> bigData = redisTemplate.opsForHash().entries(bigKey);
// 将大 Key 拆分成多个小 Key
for (Map.Entry<String, String> entry : bigData.entrySet()) {
String smallKey = bigKey + ":" + entry.getKey();
redisTemplate.opsForValue().set(smallKey, entry.getValue());
}
// 删除原始大 Key
redisTemplate.delete(bigKey);
}另外,对于 JSON 数据,可以进行 Gzip 压缩后再存储,虽然会增加一些 CPU 开销,但在内存敏感的场景在是值得的。
public void setCompressedData(String key, Object data) {
try {
String json = objectMapper.writeValueAsString(data);
byte[] compressed = compress(json.getBytes());
redisTemplate.opsForValue().set(key, compressed);
} catch (Exception e) {
log.error("Failed to compress data", e);
}
}
private byte[] compress(byte[] data) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
try (GZIPOutputStream gzip = new GZIPOutputStream(out)) {
gzip.write(data);
}
return out.toByteArray();
}推荐阅读:
- Java 面试指南(付费)收录的华为 OD 的面试中出现过该题:讲一讲 Redis 的热 Key 和大 Key
memo:2025 年 5 月 24 日,今天球友发私信说,拿到了荣耀通软的实习 offer,恭喜他!🎉

36.缓存预热怎么做呢?
缓存预热是指在系统启动或者特定时间点,提前将热点数据加载到缓存中,避免冷启动时大量请求直接打到数据库。
缓存预热的方法有多种,在技术派实战项目中,我会在项目启动时将热门文章提前加载到 Redis 中,在每天凌晨定时将最新的站点地图更新到 Redis中,以确保用户在第一次访问时就能获取到缓存数据,从而减轻数据库的压力。
/**
* 采用定时器方案,每天5:15分刷新站点地图,确保数据的一致性
*/
@Scheduled(cron = "0 15 5 * * ?")
public void autoRefreshCache() {
log.info("开始刷新sitemap.xml的url地址,避免出现数据不一致问题!");
refreshSitemap();
log.info("刷新完成!");
}
@Override
public void refreshSitemap() {
initSiteMap();
}
private synchronized void initSiteMap() {
long lastId = 0L;
RedisClient.del(SITE_MAP_CACHE_KEY);
while (true) {
List<SimpleArticleDTO> list = articleDao.getBaseMapper().listArticlesOrderById(lastId, SCAN_SIZE);
// 刷新站点地图信息,放到 Redis 当中
Map<String, Long> map = list.stream().collect(Collectors.toMap(s -> String.valueOf(s.getId()), s -> s.getCreateTime().getTime(), (a, b) -> a));
RedisClient.hMSet(SITE_MAP_CACHE_KEY, map);
if (list.size() < SCAN_SIZE) {
break;
}
lastId = list.get(list.size() - 1).getId();
}
}
- Java 面试指南(付费)收录的字节跳动面经同学 1 技术二面面试原题:什么是缓存预热?如何解决?
37.无底洞问题听说过吗?如何解决?
无底洞问题的核心在于,随着缓存节点数量的增加,虽然总的存储容量和理论吞吐量都在增长,但是单个请求的响应时间反而变长了。
这个问题的根本原因是网络通信开销的增加。当节点数量从几十个增长到几千个时,客户端需要与更多的节点进行通信。
其次就是数据分布的碎片化。随着节点增多,数据分散得更加细碎,原本可以在一个节点获取的相关数据,现在可能分散在多个节点上。
针对这个问题,可以采取以下几种解决方案:
第一,可以将同一节点的多个请求合并成一个批量请求,减少网络往返次数。
public Map<String, Object> batchGet(List<String> keys) {
// 按节点分组keys
Map<String, List<String>> nodeKeysMap = groupKeysByNode(keys);
Map<String, Object> results = new ConcurrentHashMap<>();
// 并发访问各个节点
List<CompletableFuture<Void>> futures = nodeKeysMap.entrySet().stream()
.map(entry -> CompletableFuture.runAsync(() -> {
String node = entry.getKey();
List<String> nodeKeys = entry.getValue();
// 批量获取该节点的数据
Map<String, Object> nodeResults = getFromNode(node, nodeKeys);
results.putAll(nodeResults);
}))
.collect(Collectors.toList());
// 等待所有请求完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
return results;
}第二,可以使用一致性哈希算法来优化数据分布,减少数据迁移和重分布的开销。
public class LocalityAwareSharding {
public String getNodeForKey(String key, String category) {
// 相同类别的数据尽量分配到相同节点
String shardKey = category + ":" + (key.hashCode() % SHARDS_PER_CATEGORY);
return consistentHash.getNode(shardKey);
}
// 用户相关数据尽量在同一个节点
public String getUserDataNode(String userId) {
return "user_cluster_" + (userId.hashCode() % USER_CLUSTERS);
}
}嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
Redis 运维
38.Redis 报内存不足怎么处理?
Redis 报内存不足时,通常是因为 Redis 占用的物理内存已经接近或者超过了配置的最大内存限制。这时可以采取以下几种步骤来处理:
第一,使用 INFO memory 命令查看 Redis 的内存使用情况,看看是否真的达到了最大内存限制。
redis-cli INFO memory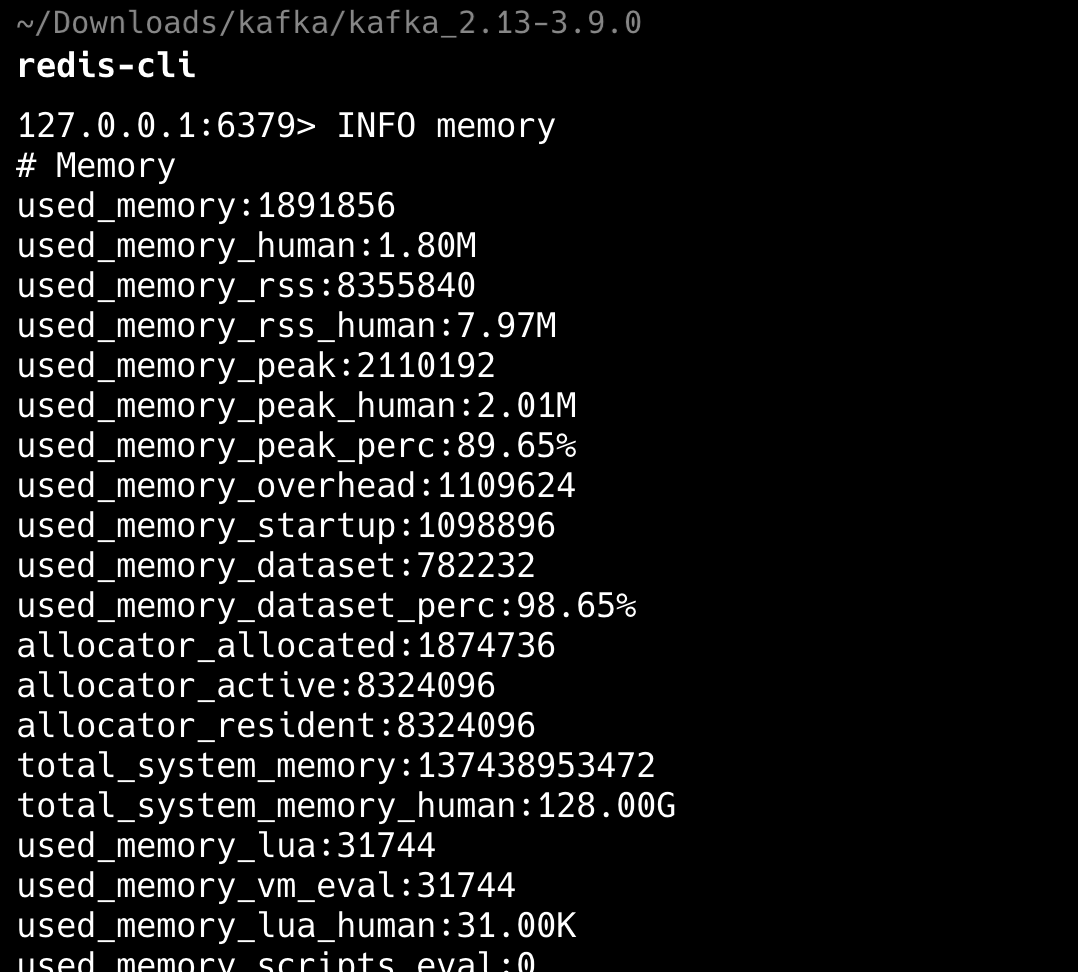
第二,如果服务器还有可用内存的话,修改 redis.conf 中的 maxmemory 参数,增加 Redis 的最大内存限制。比如将最大内存设置为 8GB:
maxmemory 8gb第三,修改 maxmemory-policy 参数来调整内存淘汰策略。比如可以选择 allkeys-lru 策略,让 Redis 自动删除最近最少使用的键。
maxmemory-policy allkeys-lrumemo:2025 年 5 月 25 日修改至此,今天在修改球友简历时,碰到一个西安交通大学本、上海交通大学硕的球友,985 本硕学历真的非常顶了,我会竭尽所能去帮助他,在秋招中斩获一个 SSP offer,冲!

39.Redis key过期策略有哪些?
Redis 主要采用了两种过期删除策略来保证过期的 key 能够被及时删除,包括惰性删除和定期删除。
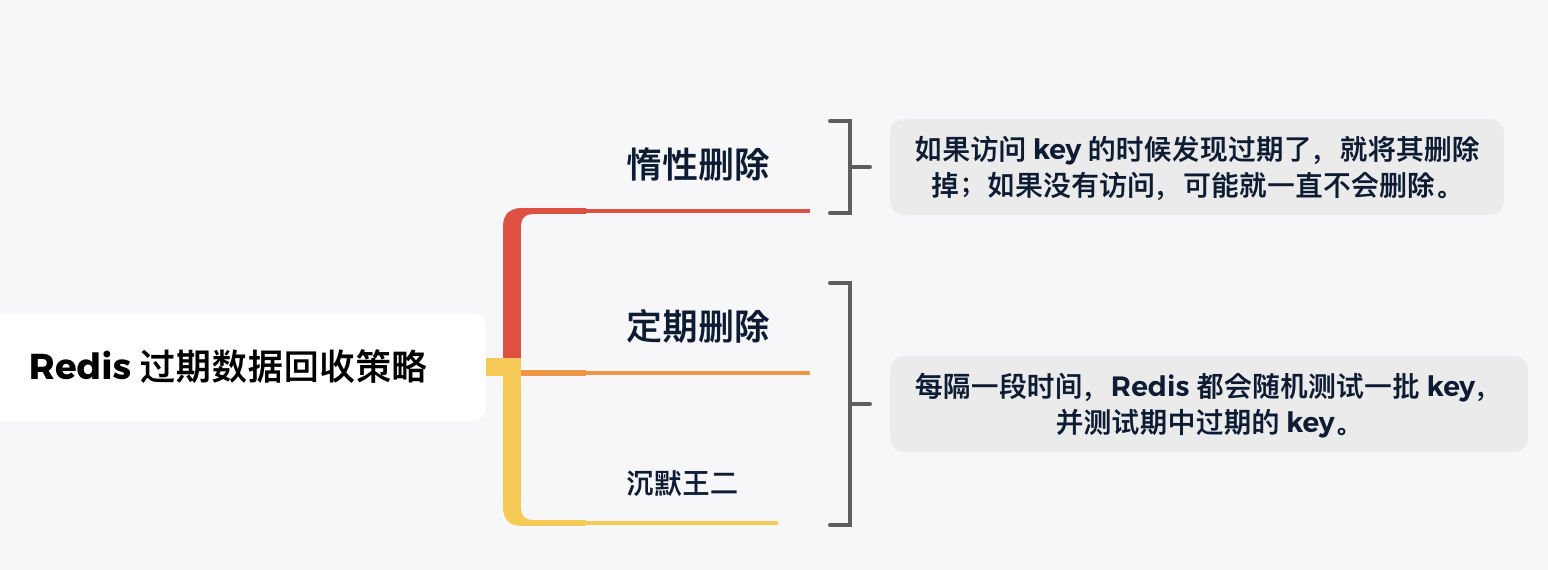
惰性删除是最基本的策略,当客户端访问一个 key 时,Redis 会检查该 key 是否已过期,如果过期就会立即删除并返回 nil。
// 模拟惰性删除的逻辑
public Object get(String key) {
RedisKey redisKey = getKeyFromMemory(key);
if (redisKey != null && isExpired(redisKey)) {
// key已过期,删除并返回null
deleteKey(key);
return null;
}
return redisKey != null ? redisKey.getValue() : null;
}这种策略的优点是不会有额外的 CPU 开销,只在访问 key 时才检查。但问题是如果一个过期的 key 永远不被访问,它就会一直占用内存。
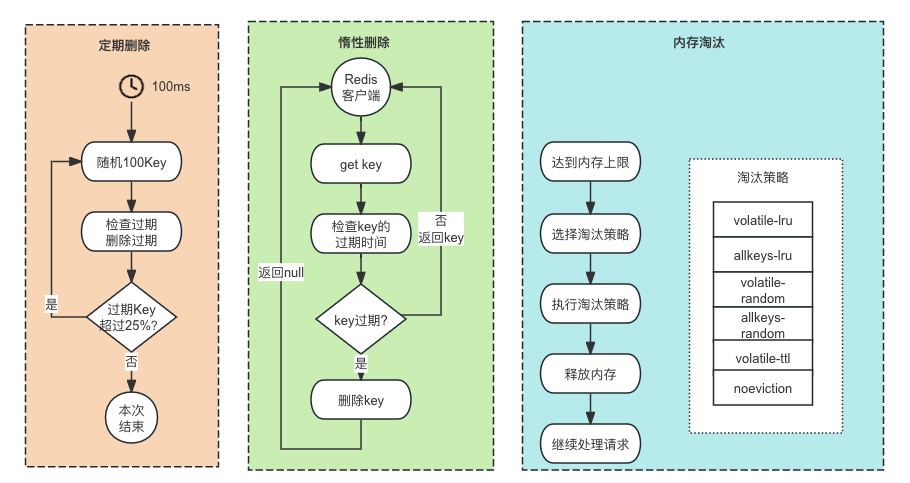
于是就有了定期删除策略,Redis 会定期随机选择一些设置了过期时间的 key 进行检查,删除其中已过期的 key。这个过程默认每秒执行 10 次,每次随机选择 20 个 key 进行检查。
----这部分面试中可以不背 start----
可以通过 config get hz 命令查看 Redis 内部定时任务的频率。
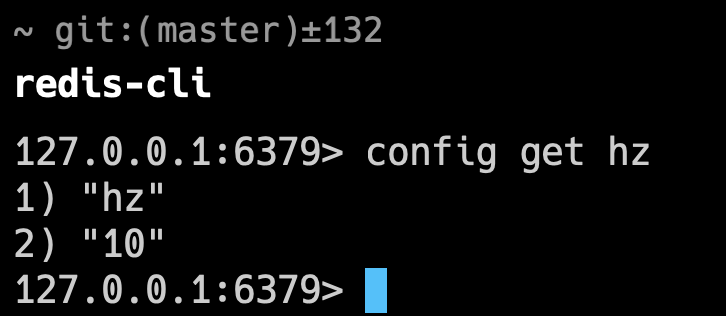
hz 的值为“10”意味着 Redis 每秒执行 10 次定时任务 。可以通过 CONFIG SET hz 20 进行调整。
----这部分面试中可以不背 end----
- Java 面试指南(付费)收录的腾讯面经同学 22 暑期实习一面面试原题:Redis key 删除策略
- Java 面试指南(付费)收录的去哪儿面经同学 1 技术 2 面面试原题:redis 内存淘汰和过期策略
- Java 面试指南(付费)收录的京东面经同学 5 Java 后端技术一面面试原题:redis key过期策略
40.🌟Redis有哪些内存淘汰策略?
当内存使用接近 maxmemory 限制时,Redis 会依据内存淘汰策略来决定删除哪些 key 以缓解内存压力。
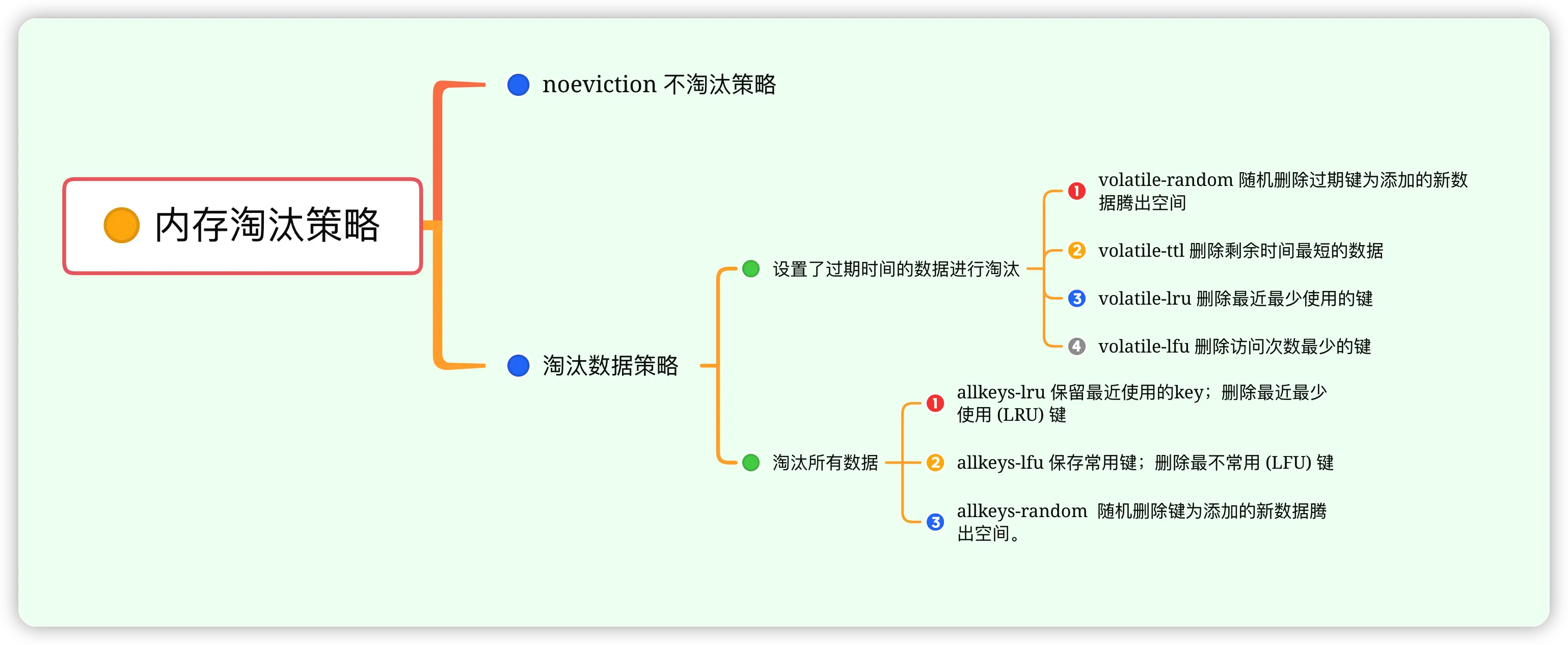
常用的内存淘汰策略有八种,分别是默认的 noeviction,内存不足时不会删除任何 key,直接返回错误信息,生产环境下基本上不会使用。
然后是针对所有 key 的 allkeys-lru、allkeys-lfu 和 allkeys-random。lru 会删除最近最少使用的 key,在纯缓存场景中最常用,能自动保留热点数据;lfu 会删除访问频率最低的 key,更适合长期运行的系统;random 会随机删除一些 key,一般不推荐使用。
其次是针对设置了过期时间的 key,有 volatile-lru、volatile-lfu、volatile-ttl 和 volatile-random。
lru 在混合存储场景中经常使用。
@Service
public class HybridStorageService {
// 重要数据不设置过期时间,临时数据设置过期时间
public void storeData(String key, Object data, DataImportance importance) {
if (importance == DataImportance.HIGH) {
// 重要数据不设置过期时间,在volatile-*策略下不会被淘汰
redisTemplate.opsForValue().set(key, data);
} else {
// 临时数据设置过期时间,可以被volatile-*策略淘汰
redisTemplate.opsForValue().set(key, data, Duration.ofHours(1));
}
}
}lfu 适合需要保护某些重要数据不被淘汰的场景;ttl 优先删除即将过期的 key,在用户会话管理系统中推荐使用;random 仍然很少用。
- Java 面试指南(付费)收录的小米春招同学 K 一面面试原题:为什么 redis 快,淘汰策略 持久化
- Java 面试指南(付费)收录的去哪儿面经同学 1 技术 2 面面试原题:redis 内存淘汰和过期策略
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:redis内存淘汰策略
41.LRU 和 LFU 的区别是什么?
LRU 是 Least Recently Used 的缩写,基于时间维度,淘汰最近最少访问的键。
LFU 是 Least Frequently Used 的缩写,基于次数维度,淘汰访问频率最低的键。
假设缓存中有三个数据 A、B、C,在 LRU 场景下,如果访问顺序是 A→B→C→A,那么此时的 LRU 顺序是B→C→A,如果需要淘汰,会先删除 B。
但在 LFU 场景下,如果 A 被访问了 5 次,B 被访问了 2 次,C 被访问了 1 次,那么无论最近的访问顺序如何,都会优先淘汰 C,因为它的访问频率最低。
LRU 更适合有明显时间局部性的场景,比如在新闻网站中,用户更关心最新的新闻,而昨天的新闻访问量会急剧下降。这种情况下,LRU 能很好地保留用户当前关心的热点内容。
LFU 则更适合有长期访问模式的场景,更强调“热度”,比如在电商平台中,某些商品可能长期保持热销状态,即使它们的访问时间间隔较长,但由于访问频率高,LFU 会优先保留这些商品的信息。
- Java 面试指南(付费)收录的阿里系面经同学 19 饿了么面试原题:redis内存淘汰机制 延伸到LRU LFU
memo:2025 年 5 月 27 日,今天球友发私信说,拿到了哈啰和得物的实习 offer,恭喜他!🎉 还特意感谢了一下之前对他简历的修改和学习上的建议。

42.Redis发生阻塞了怎么解决?
Redis 发生阻塞在生产环境中是比较严重的问题,当发现 Redis 变慢时,我会先通过 monitor 命令查看当前正在执行的命令,或者使用 slowlog 命令查看慢查询日志。
# 查看当前正在执行的命令
redis-cli MONITOR
# 查看慢查询日志
redis-cli SLOWLOG GET 10
# 检查客户端连接状况
redis-cli CLIENT LIST通常情况下,大Key 是导致 Redis 阻塞的主要原因之一。比如说直接 DEL 一个包含几百万个元素的 Set,就会导致 Redis 阻塞几秒钟甚至更久。
这时候可以用 UNLINK 命令替代 DEL 来异步删除,避免阻塞主线程。
# 使用 UNLINK 异步删除大 Key
redis-cli UNLINK big_key对于非常大的集合,可以使用 SCAN 命令分批删除。
public void safeBatchProcess(String key) {
ScanOptions options = ScanOptions.scanOptions().count(1000).build();
Cursor<String> cursor = redisTemplate.opsForSet().scan(key, options);
while (cursor.hasNext()) {
String member = cursor.next();
// 分批处理,避免阻塞
processElement(member);
}
}另外,当 Redis 使用的内存超过物理内存时,操作系统会将部分内存交换到磁盘,这时候会导致 Redis 响应变慢。我的处理方式是:
使用 free -h 检查内存的使用情况 ;确认 Redis 的 maxmemory 设置是否合理;如果发生了内存交换,立即调整 maxmemory 并清理一些不重要的数据。
大量的客户端连接也可能会导致阻塞,这时候最好检查一下连接池的配置。
@Configuration
public class RedisConnectionConfig {
@Bean
public JedisConnectionFactory jedisConnectionFactory() {
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(200); // 最大连接数
poolConfig.setMaxIdle(50); // 最大空闲连接
poolConfig.setMinIdle(10); // 最小空闲连接
poolConfig.setMaxWaitMillis(3000); // 获取连接最大等待时间
poolConfig.setTestOnBorrow(true); // 获取连接时检测有效性
return new JedisConnectionFactory(poolConfig);
}
}嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
Redis 应用
43.Redis如何实现异步消息队列?
Redis 实现异步消息队列是一个很实用的技术方案,最简单的方式是使用 List 配合 LPUSH 和 RPOP 命令。
@Service
public class SimpleRedisQueue {
private final RedisTemplate<String, Object> redisTemplate;
// 生产者:向队列发送消息
public void sendMessage(String queueName, Object message) {
redisTemplate.opsForList().leftPush(queueName, message);
}
// 消费者:从队列获取消息
public Object receiveMessage(String queueName) {
return redisTemplate.opsForList().rightPop(queueName);
}
// 阻塞式消费,避免轮询
public Object blockingReceive(String queueName, int timeoutSeconds) {
List<Object> result = redisTemplate.opsForList()
.rightPop(queueName, timeoutSeconds, TimeUnit.SECONDS);
return result != null && !result.isEmpty() ? result.get(0) : null;
}
}另外就是用 Redis 的 Pub/Sub 来实现简单的消息广播和订阅。
@Service
public class RedisPubSubService {
private final RedisTemplate<String, Object> redisTemplate;
// 发布消息到指定频道
public void publish(String channel, Object message) {
redisTemplate.convertAndSend(channel, message);
}
// 订阅频道
@PostConstruct
public void subscribe() {
redisTemplate.setMessageListener((message, pattern) -> {
System.out.println("Received message: " + message);
});
redisTemplate.getConnectionFactory().getConnection().subscribe(
new ChannelTopic("myChannel").getTopic().getBytes()
);
}
}发布者将消息发布到指定的频道,订阅该频道的客户端就能收到消息。
但是这两种方式都是不可靠的,因为没有 ACK 机制所以不能保证订阅者一定能收到消息,也不支持消息持久化。
44.Redis如何实现延时消息队列?
延时消息队列在实际业务中很常见,比如订单超时取消、定时提醒等场景。Redis 虽然不是专业的消息队列,但可以很好地实现延时队列功能。
核心思路是利用 ZSet 的有序特性,将消息作为 member,把消息的执行时间作为 score。这样消息就会按照执行时间自动排序,我们只需要定期扫描当前时间之前的消息进行处理就可以了。

@Service
public class DelayedMessageQueue {
private final RedisTemplate<String, Object> redisTemplate;
// 发送延时消息
public void sendDelayedMessage(String queueName, Object message, long delaySeconds) {
// 计算消息的执行时间
long executeTime = System.currentTimeMillis() + (delaySeconds * 1000);
// 将消息加入ZSet,以执行时间作为score
redisTemplate.opsForZSet().add(queueName, message, executeTime);
log.info("发送延时消息: {}, 延时: {}秒", message, delaySeconds);
}
// 消费延时消息
@Scheduled(fixedDelay = 1000) // 每秒扫描一次
public void consumeDelayedMessages() {
String queueName = "delayed:queue";
long currentTime = System.currentTimeMillis();
// 获取已到期的消息(score <= 当前时间)
Set<Object> messages = redisTemplate.opsForZSet()
.rangeByScore(queueName, 0, currentTime);
for (Object message : messages) {
try {
// 处理消息
processMessage(message);
// 处理成功后从队列中移除
redisTemplate.opsForZSet().remove(queueName, message);
log.info("处理延时消息成功: {}", message);
} catch (Exception e) {
log.error("处理延时消息失败: {}", message, e);
// 可以实现重试机制
handleFailedMessage(queueName, message);
}
}
}
}具体实现上,我会在生产者发送延时消息时,计算消息应该执行的时间戳,然后用 ZADD 命令将消息添加到 ZSet 中。
ZADD delay_queue 1617024000 task1消费者通过定时任务,使用 ZRANGEBYSCORE 命令获取当前时间之前的所有消息。
ZREMRANGEBYSCORE delay_queue -inf 1617024000处理完成后再用 ZREM 删除消息。
ZREM delay_queue task1在技术派实战项目中,我就用这种方式实现了文章定时发布的功能。作者在发布文章时,可以选择一个未来的时间节点,比如说 30 分钟后,系统就会向延时队列发送一条延时消息,然后定时任务就会在 30 分钟后将这条消息从延时队列中取出并发布文章。
- Java 面试指南(付费)收录的腾讯面经同学 23 QQ 后台技术一面面试原题:Redis 实现延迟队列
- Java 面试指南(付费)收录的字节跳动面经同学 8 Java 后端实习一面面试原题:redis 数据结构,用什么结构实现延迟消息队列
memo:2025 年 5 月 28 日修改至此,今天有球友在 VIP群里发消息说拿到了荣耀的暑期实习 offer,虽然时间节点已经不早了,但越是到这个时候,确实容易捡漏。
45.🌟Redis支持事务吗?
是的,Redis 支持简单的事务,可以将 multi、exec、discard 和 watch 命令打包,然后一次性的按顺序执行。
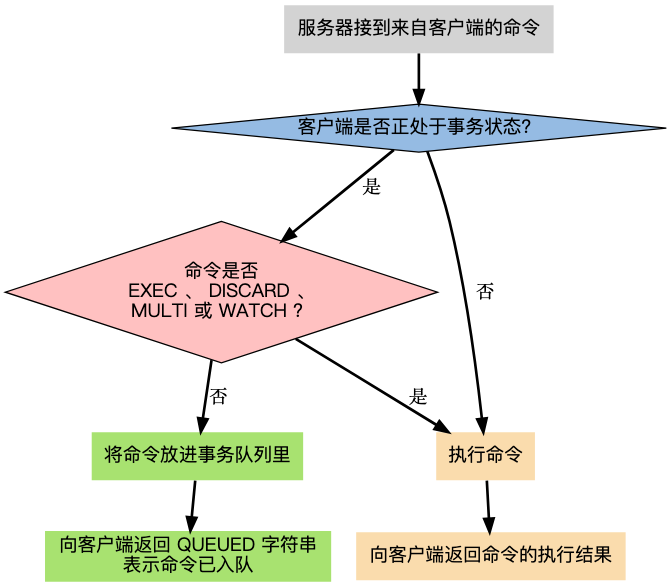
基本流程是用 multi 开启事务,然后执行一系列命令,最后用 exec 提交。这些命令会被放入队列,在 exec 时批量执行。
当客户端处于非事务状态时,所有发送给 Redis 服务的命令都会立即执行;但当客户端进入事务状态之后,这些命令会被放入一个事务队列中,然后立即返回 QUEUED,表示命令已入队。
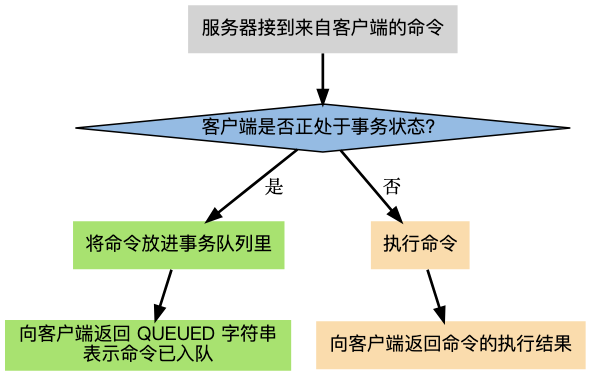
当 exec 命令执行时,Redis 会将事务队列中的所有命令按先进先出的顺序执行。当事务队列里的命令全部执行完毕后,Redis 会返回一个数组,包含每个命令的执行结果。
discard 命令用于取消一个事务,它会清空事务队列并退出事务状态。
watch 命令用于监视一个或者多个 key,如果这个 key 在事务执行之前 被其他命令改动,那么事务将会被打断。
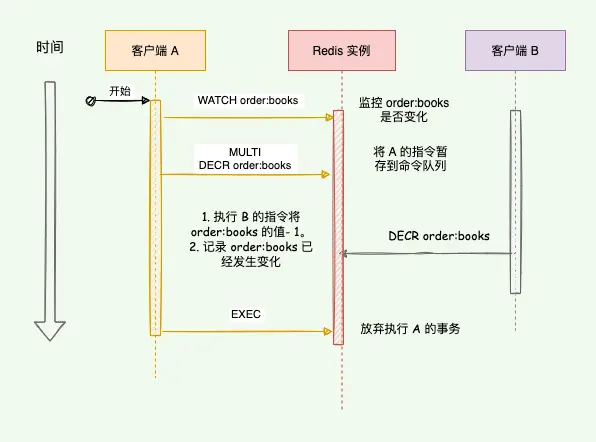
但 Redis 的事务与 MySQL 的有很大不同,它并不支持回滚,也不支持隔离级别。
说一下 Redis 事务的原理?
Redis 事务的原理并不复杂,核心就是一个"先排队,后执行"的机制。
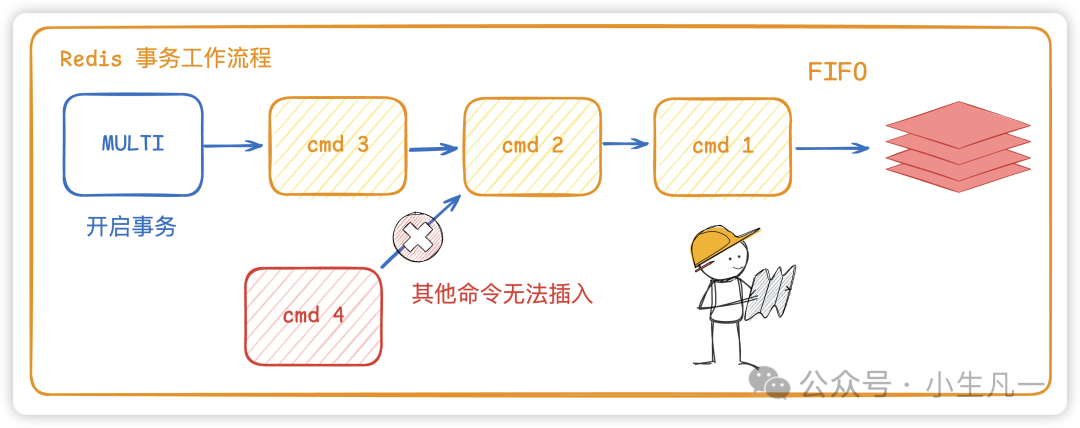
当执行 MULTI 命令时,Redis 会给这个客户端打一个事务的标记,表示这个客户端后面发送的命令不会被立即执行,而是被放到一个队列里排队等着。
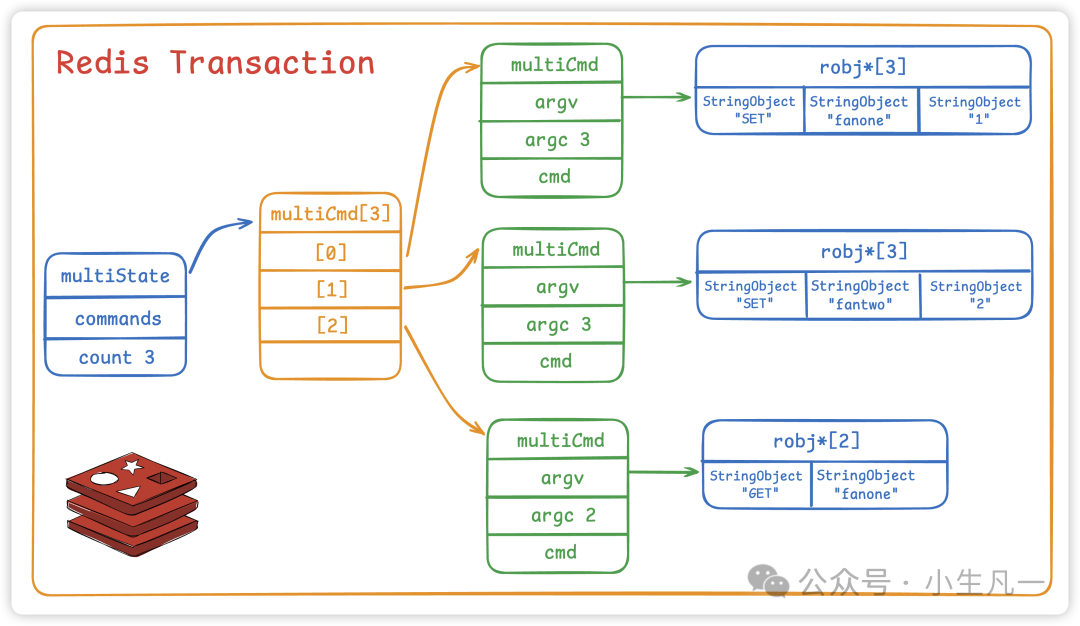
当 Redis 收到 EXEC 命令时,它会把队列里的命令一个个拿出来执行。因为 Redis 是单线程的,所以这个过程不会被其他命令打断,这就保证了Redis 事务的原子性。
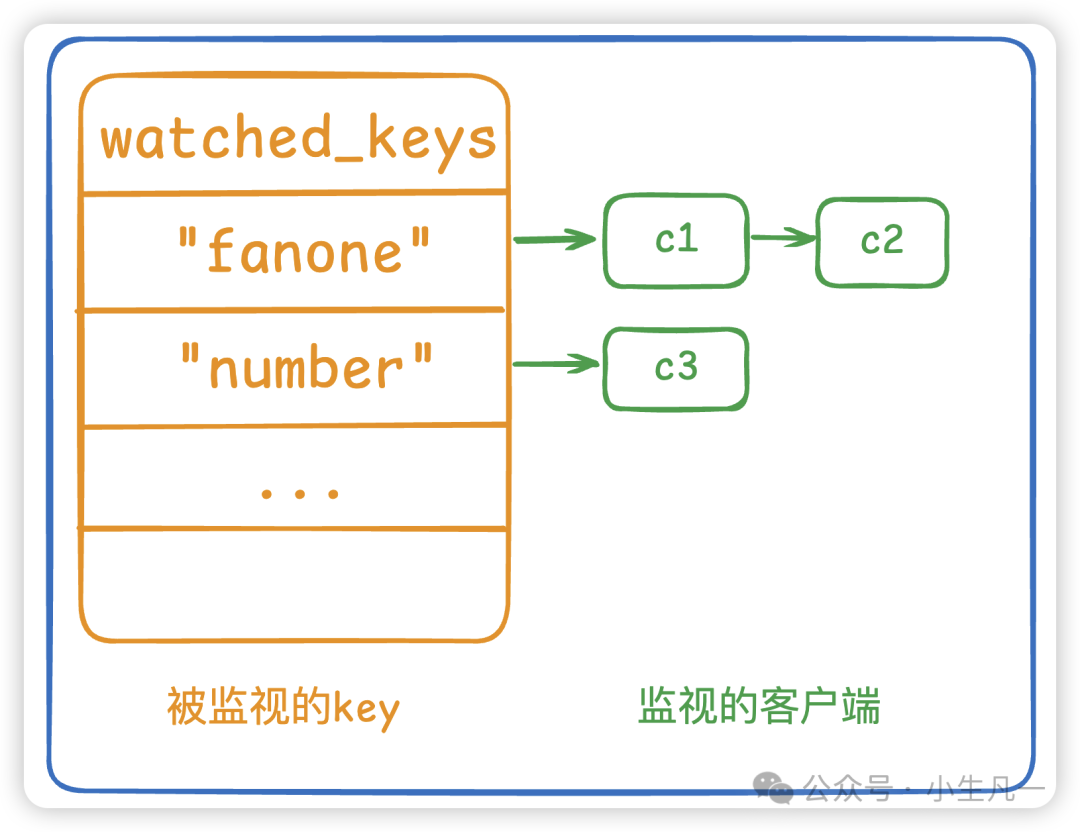
当执行 WATCH 命令时,Redis 会将 key 添加到全局监视字典中;只要这些 key 在 EXEC 前被其他客户端修改,Redis 就会给相关客户端打上脏标记,EXEC 时发现事务已被干扰就会直接取消整个事务。
// 全局监视字典
dict *watched_keys;
typedef struct watchedKey {
robj *key;
redisDb *db;
} watchedKey;DISCARD 做的事情很简单直接,首先检查客户端是否真的在事务状态,如果不在就报错;如果在事务状态,就清空事务队列并退出事务状态。
void discardCommand(client *c) {
if (!(c->flags & CLIENT_MULTI)) {
addReplyError(c,"DISCARD without MULTI");
return;
}
discardTransaction(c);
addReply(c,shared.ok);
}Redis 事务有哪些注意点?
最重要的的一点是,Redis 事务不支持回滚,一旦 EXEC 命令被调用,所有命令都会被执行,即使有些命令可能执行失败。
Redis事务为什么不支持回滚?
Redis 的核心设计理念是简单、高效,而不是完整的 ACID 特性。而实现回滚需要在执行过程中保存大量的状态信息,并在发生错误时逆向执行命令以恢复原始状态。这会增加 Redis 的复杂性和性能开销。

Redis事务满足原子性吗?要怎么改进?
Redis 的事务不能满足标准的原子性,因为它不支持事务回滚,也就是说,假如某个命令执行失败,整个事务并不会自动回滚到初始状态。
// 一个转账事务
redisTemplate.multi();
redisTemplate.opsForValue().decrement("user:1:balance", 100); // 成功
redisTemplate.opsForList().leftPush("user:1:balance", "log"); // 类型错误,失败
redisTemplate.opsForValue().increment("user:2:balance", 100); // 还是会执行
List<Object> results = redisTemplate.exec();
// 结果:用户1被扣了钱,用户2也收到了钱,但中间的日志操作失败了
// 这符合Redis的原子性定义,但不符合业务期望可以使用 Lua 脚本来替代事务,脚本运行期间,Redis 不会处理其他命令,并且我们可以在脚本中处理整个业务逻辑,包括条件检查和错误处理,保证要么执行成功,要么保持最初的状态,不会出现一个命令执行失败、其他命令执行成功的情况。
@Service
public class ImprovedTransactionService {
public boolean atomicTransfer(String fromUser, String toUser, int amount) {
String luaScript =
"local from_key = KEYS[1] " +
"local to_key = KEYS[2] " +
"local amount = tonumber(ARGV[1]) " +
// 检查转出账户余额
"local from_balance = redis.call('GET', from_key) " +
"if not from_balance then return -1 end " +
"from_balance = tonumber(from_balance) " +
"if from_balance < amount then return -2 end " +
// 检查转入账户是否存在
"if redis.call('EXISTS', to_key) == 0 then return -3 end " +
// 所有检查通过,执行转账
"redis.call('DECRBY', from_key, amount) " +
"redis.call('INCRBY', to_key, amount) " +
// 记录转账日志
"local log = from_key .. ':' .. to_key .. ':' .. amount " +
"redis.call('LPUSH', 'transfer:log', log) " +
"return 1";
DefaultRedisScript<Long> script = new DefaultRedisScript<>();
script.setScriptText(luaScript);
script.setResultType(Long.class);
Long result = redisTemplate.execute(script,
Arrays.asList("user:" + fromUser + ":balance", "user:" + toUser + ":balance"),
amount);
return result != null && result == 1;
}
}Redis 事务的 ACID 特性如何体现?
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务在执行过程中如果某个命令失败了,其他命令还是会继续执行,不会回滚。
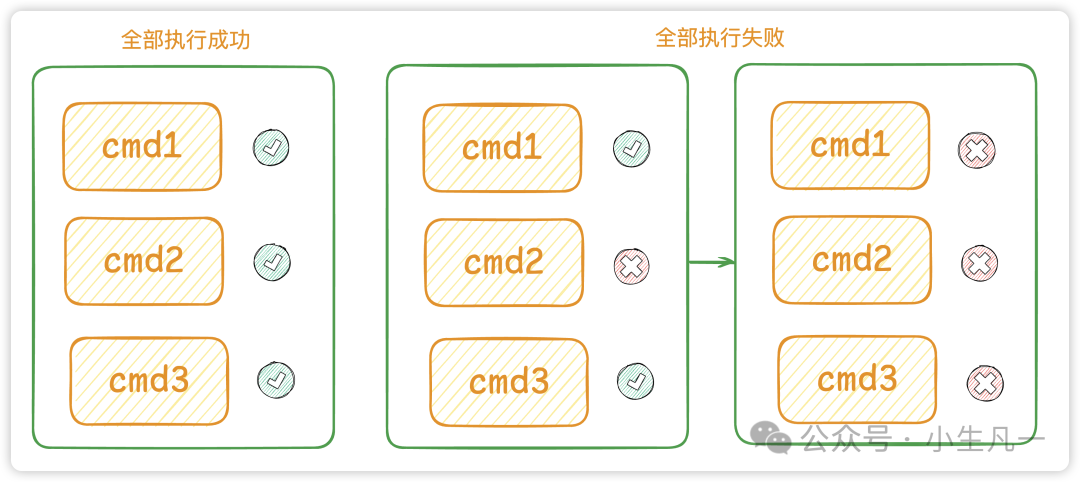
一致性指的是,如果数据在执行事务之前是一致的,那么在事务执行之后,无论事务是否执行成功,数据也应该是一致的。但 Redis 事务并不保证一致性,因为如果事务中的某个命令失败了,其他命令仍然会执行,就会出现数据不一致的情况。
Redis 是单线程执行事务的,并且不会中断,直到执行完所有事务队列中的命令为止。因此,我认为 Redis 的事务具有隔离性的特征。
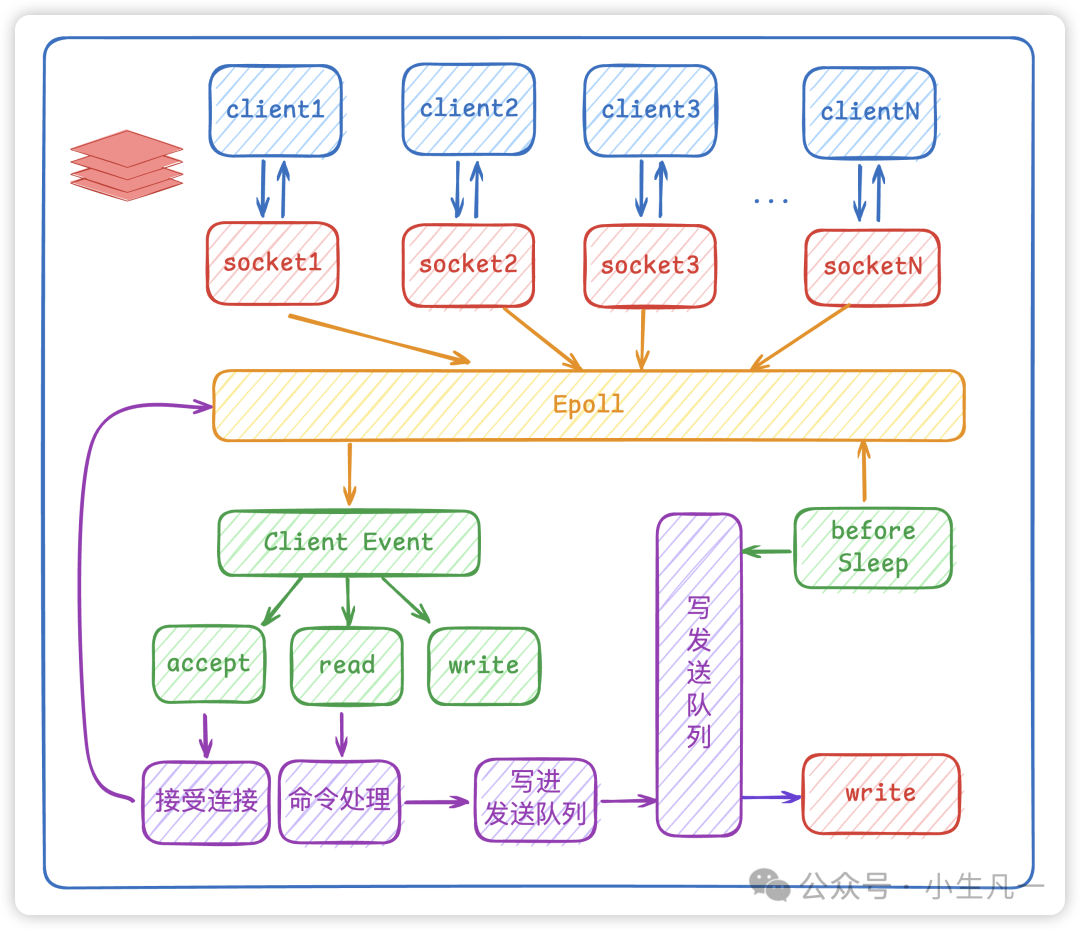
Redis 事务的持久性完全依赖于 Redis 本身的持久化机制,如果开启了 AOF,那么事务中的命令会作为一个整体记录到 AOF 文件中,当然也要看 AOF 的 fsync 策略。
如果只开启了 RDB,事务中的命令可能会在下次快照前丢失。如果两个都没有开启,肯定是不满足持久性的。
- Java 面试指南(付费)收录的华为一面原题:说下 Redis 事务
- 二哥编程星球球友枕云眠美团 AI 面试原题:什么是 redis 的事务,它的 ACID 属性如何体现
- Java 面试指南(付费)收录的快手同学 4 一面原题:Redis事务满足原子性吗?要怎么改进?
memo:2025 年 5 月 29 日,今天给球友修改简历时,碰到一个东南大学本硕博 3 985 的球友,这也是我已知信息中学历最高的球友了。
46.有Lua脚本操作Redis的经验吗?
Lua 脚本是处理 Redis 复杂操作的首选方案,比如说原子扣减库存、分布式锁、限流等业务场景,都可以通过 Lua 脚本来实现。
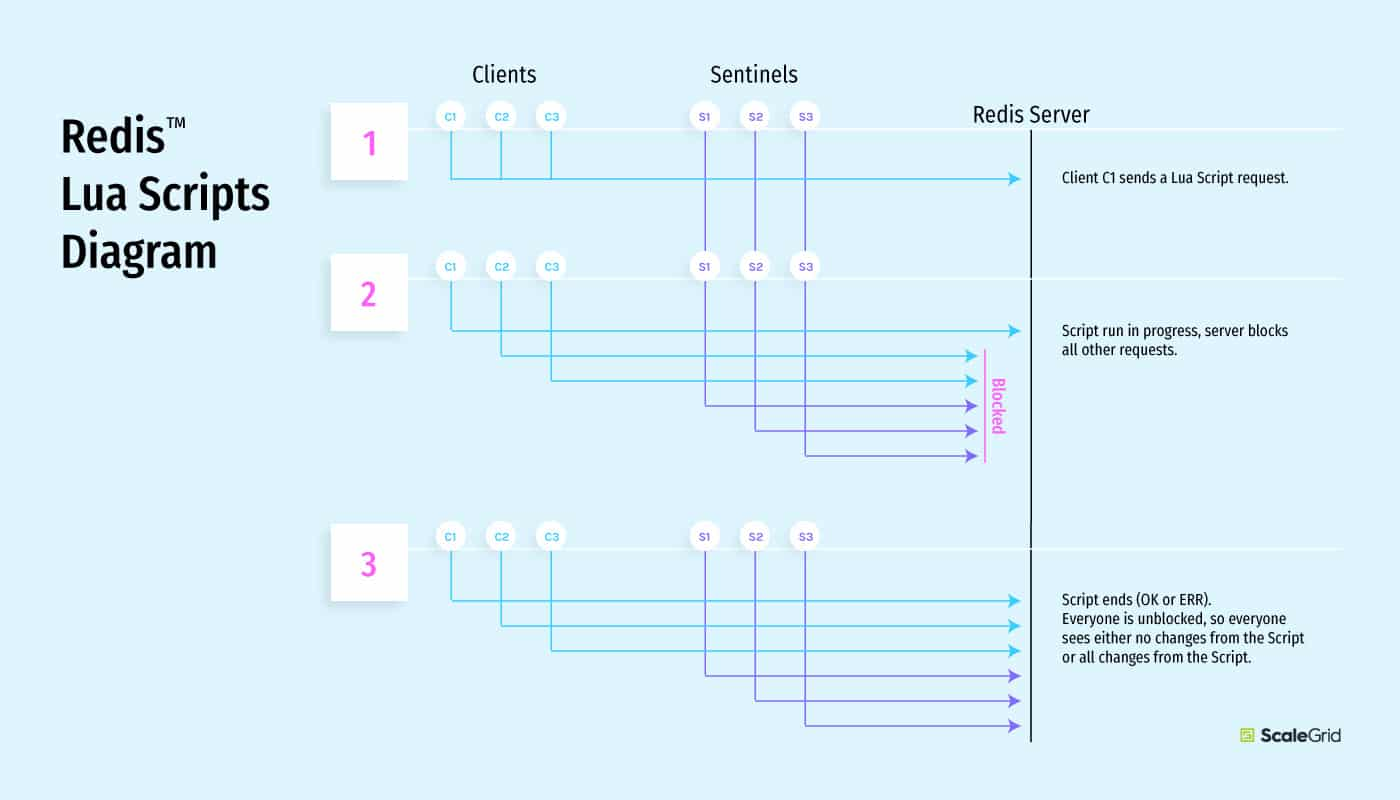
在秒杀场景下,可以用 Lua 脚本把所有检查逻辑都写在一起:先看库存够不够,再看用户有没有买过,所有条件都满足才扣减库存。因为整个脚本是原子执行的,Redis 在执行期间不会处理其他命令,所以可以彻底解决超卖问题。
// 这个秒杀脚本救了我的命
String luaScript =
"local stock = redis.call('GET', KEYS[1]) " +
"if not stock or tonumber(stock) < tonumber(ARGV[2]) then " +
" return -1 " + // 库存不足
"end " +
"if redis.call('SISMEMBER', KEYS[2], ARGV[1]) == 1 then " +
" return -2 " + // 重复购买
"end " +
"redis.call('DECRBY', KEYS[1], ARGV[2]) " +
"redis.call('SADD', KEYS[2], ARGV[1]) " +
"return 1";在分布式锁场景下,我一开始用的 SETNX 命令来实现,结果发现如果程序异常退出,锁就死掉了。后来加了过期时间,但又发现可能误删其他线程的锁。最后还是用 Lua 脚本彻底解决了这个问题,确保只有锁的持有者才能释放锁。
// 解锁脚本特别重要,必须验证是自己的锁才能删
private final String UNLOCK_SCRIPT =
"if redis.call('GET', KEYS[1]) == ARGV[1] then " +
" return redis.call('DEL', KEYS[1]) " +
"else " +
" return 0 " +
"end";甚至还可以用 Lua脚本实现滑动窗口限流器,一次性完成过期数据清理、计数检查、新记录添加三个操作,而且完全原子化。
// 滑动窗口限流,逻辑清晰,性能还好
String luaScript =
"local key = KEYS[1] " +
"local now = tonumber(ARGV[1]) " +
"local window = tonumber(ARGV[2]) " +
"local limit = tonumber(ARGV[3]) " +
// 先清理过期记录
"redis.call('ZREMRANGEBYSCORE', key, 0, now - window) " +
// 检查当前请求数
"local current = redis.call('ZCARD', key) " +
"if current < limit then " +
" redis.call('ZADD', key, now, now) " +
" return 1 " +
"else " +
" return 0 " +
"end";memo:2025 年 5 月 30 日,今天有球友在星球里发消息说拿到了金山办公的 offer,问我该选 cpp 还是go,我的建议大家可以看看符合是否合理,不管如何选择,真的恭喜球友!
47.Redis的管道Pipeline了解吗?
了解,Pipeline 允许客户端一次性向 Redis 服务器发送多个命令,而不必等待一个命令响应后才能发送下一个。Redis 服务器会按照命令的顺序依次执行,并将所有结果打包返回给客户端。
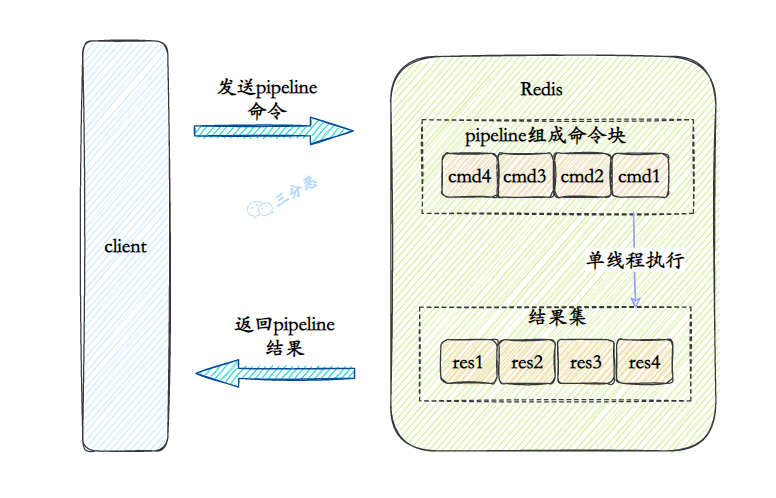
正常情况下,每执行一个 Redis 命令都需要一次网络往返:发送命令 -> 等待响应 -> 发送下一个命令。
客户端 Redis服务器
| |
|------- SET key1 val1 ---->|
|<------ OK ---------------|
|------- SET key2 val2 ---->|
|<------ OK ---------------|
|------- GET key1 -------->|
|<------ val1 -------------|如果大量请求依次发送,网络延迟会显著增加请求的总执行时间,假如一次 RTT 的时间是 1 毫秒,3 个就是 3 毫秒。有了 Pipeline 后,可以一次性发送 3 个命令,总时间就只需要 1 毫秒。
@Service
public class RedisBatchService {
public void batchInsertUsers(List<User> users) {
// 不用Pipeline的错误做法 - 很慢
// for (User user : users) {
// redisTemplate.opsForValue().set("user:" + user.getId(), user);
// }
// 使用Pipeline的正确做法
redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
for (User user : users) {
String key = "user:" + user.getId();
byte[] keyBytes = key.getBytes();
byte[] valueBytes = serialize(user);
connection.set(keyBytes, valueBytes);
}
return null; // Pipeline不需要返回值
}
});
}
}当然了,Pipeline 不是越大越好,太大会占用过多内存,通常建议每个 Pipeline 包含 1000 到 5000 个命令。可以根据实际情况调整。
public void smartBatchInsert(List<String> data) {
int batchSize = 1000; // 经验值,根据数据大小调整
for (int i = 0; i < data.size(); i += batchSize) {
List<String> batch = data.subList(i, Math.min(i + batchSize, data.size()));
redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
for (String item : batch) {
connection.set(item.getBytes(), item.getBytes());
}
return null;
}
});
}
}什么场景下适合使用 Pipeline呢?
需要批量插入、更新或删除数据,或者需要执行大量相似的命令时。比如:系统启动时的缓存预热 -> 批量加载热点数据;比如统计数据的批量更新;比如大批量数据的导入导出;比如批量删除过期或无效的缓存。
有了解过 Pipeline 的底层原理吗?
有,其实就是缓冲的思想。在技术派实战项目中,我就在 RedisClient 类中封装了一个 PipelineAction 内部类,用来缓存命令。
add 方法将命令包装成 Runnable 对象,放入 List 中。当执行 execute 方法时,再调用 RedisTemplate 的 executePipelined 方法开启管道模式将多个命令发送到 Redis 服务端。
Redis 服务端从输入缓冲区读到命令后,会按照 RESP 协议进行命令拆解,再依次执行这些命令。执行结果会写入到输出缓冲区,最后再将所有结果一次性返回给客户端。
typedef struct client {
sds querybuf; // 输入缓冲区
list *reply; // 输出缓冲区链表
unsigned long reply_bytes; // 输出缓冲区大小
} client;
- Java 面试指南(付费)收录的京东面经同学 8 面试原题:对pipeline的理解,什么场景适合使用pipeline?有了解过pipeline的底层?
memo:2025 年 6 月 1 日,今天有球友在星球里发消息说拿到了百得思维的offer,他是民办二本,对这个结果很满意,也很感谢面渣逆袭和星球的实战项目,让他摆脱了浑浑噩噩的日子。恭喜他!

48.🌟Redis能实现分布式锁吗?
分布式锁是一种用于控制多个不同进程在分布式系统中访问共享资源的锁机制。它能确保在同一时刻,只有一个节点可以对资源进行访问,从而避免分布式场景下的并发问题。
可以使用 Redis 的 SETNX 命令实现简单的分布式锁。比如 SET key value NX PX 3000 就创建了一个锁名为 key 的分布式锁,锁的持有者为 value。NX 保证只有在 key 不存在时才能创建成功,EX 设置过期时间用以防止死锁。
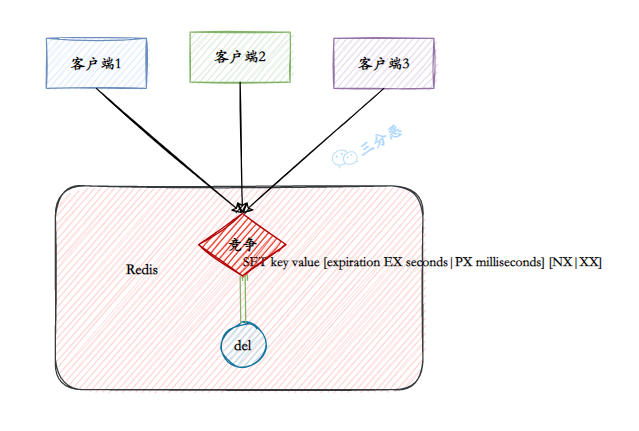
Redis如何保证 SETNX 不会发生冲突?
当我们使用 SET key value NX EX 30 这个命令进行加锁时,Redis 会把整个操作当作一个原子指令来执行。因为 Redis 的命令处理是单线程的,所以在同一时刻只能有一个命令在执行。
比如说两个客户端 A 和 B 同时请求同一个锁:
客户端A: SET lock_key uuid_a NX EX 30
客户端B: SET lock_key uuid_b NX EX 30虽然这两个请求可能几乎同时到达 Redis 服务器,但 Redis 会严格按照到达的先后顺序来处理。假设 A 的请求先到,Redis 会先执行 A 的 SET 命令,这时 lock_key 被设置为 uuid_a。
当处理 B 的请求时,因为 lock_key 已经存在了,NX 条件不满足,所以 B 的 SET 命令会失败,返回 NULL。这样就保证了只有 A 能获取到锁。
关键点在于 NX 的语义:NOT EXISTS,只有在 key 不存在的时候才会设置成功。Redis 在执行这个命令时,会先检查 key 是否存在,如果不存在才会设置值,这整个过程是原子的,不会被其他命令打断。
SETNX有什么问题,如何解决?
使用 SETNX 创建分布式锁时,虽然可以通过设置过期时间来避免死锁,但会误删锁。比如线程 A 获取锁后,业务执行时间比较长,锁过期了。这时线程 B 获取到锁,但线程 A 执行完业务逻辑后,会尝试删除锁,这时候删掉的其实是线程 B 的锁。
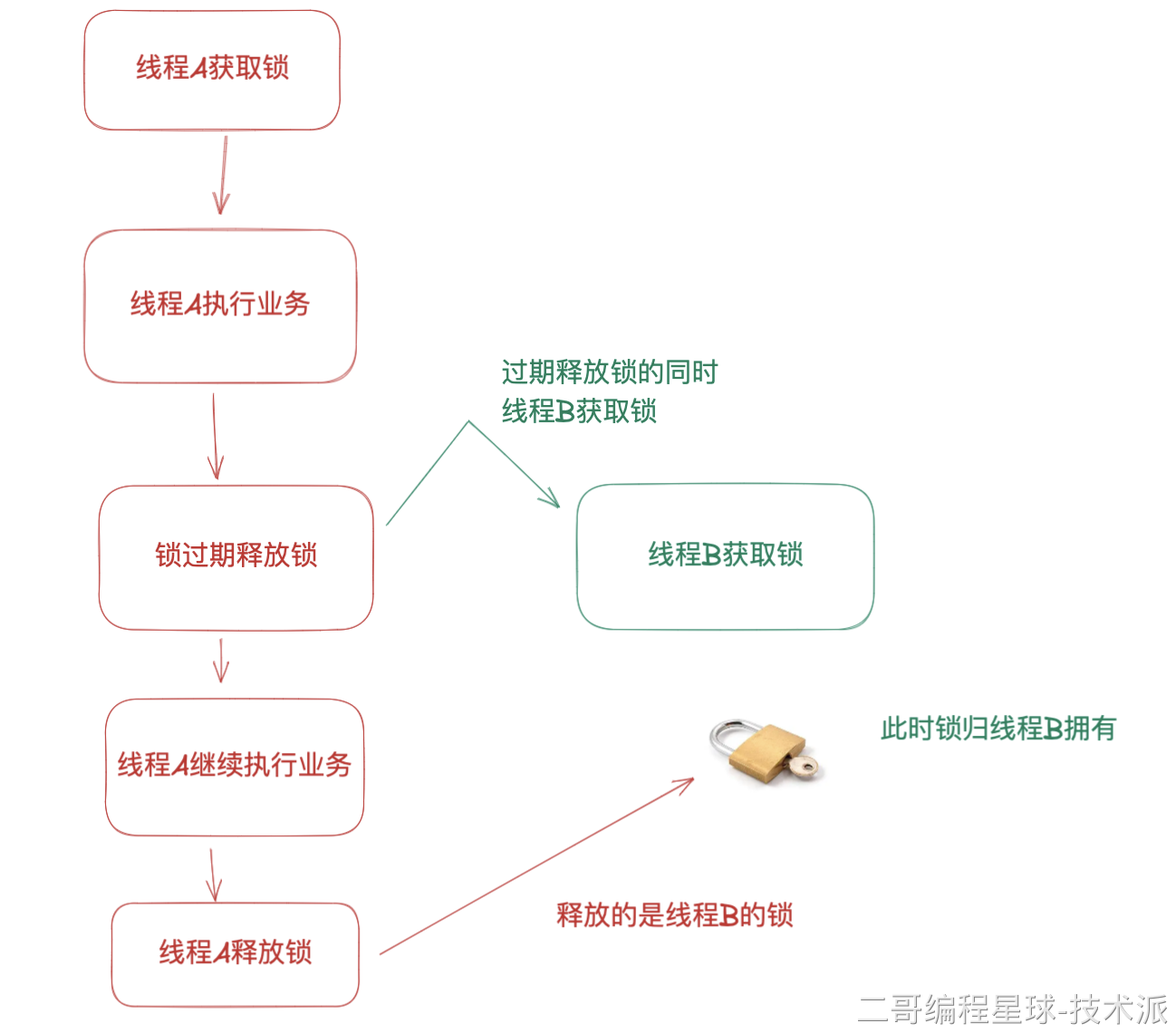
可以通过锁的自动续期机制来解决锁过期的问题,比如 Redisson 的看门狗机制,在后台启动一个定时任务,每隔一段时间就检查锁是否还被当前线程持有,如果是就自动延长过期时间。这样既避免了死锁,又防止了锁被提前释放。
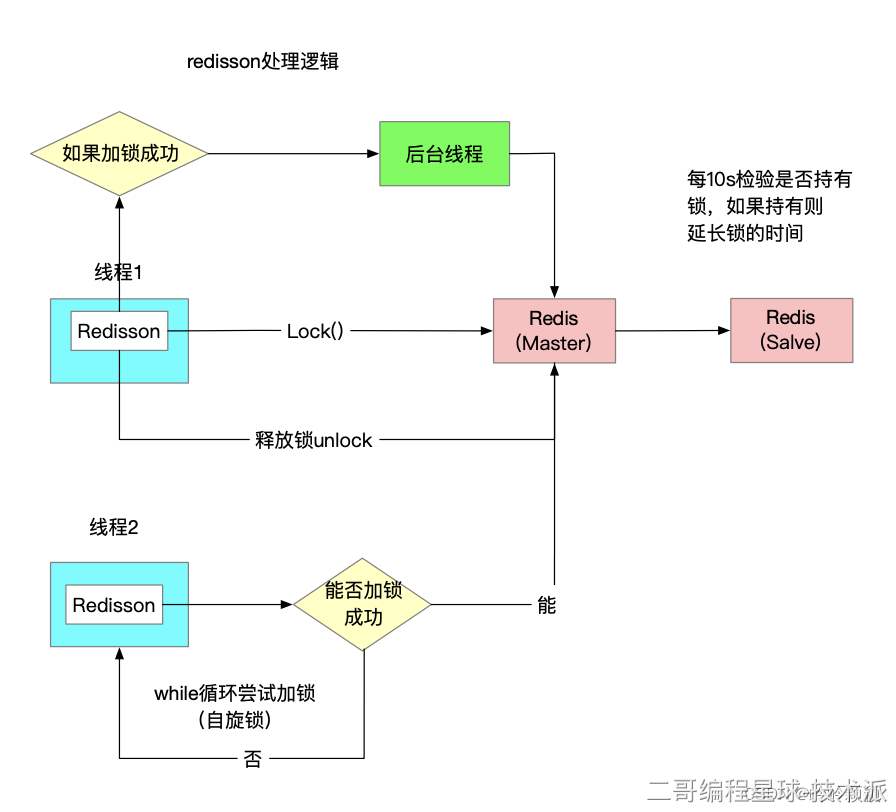
memo:2025 年 6 月 2 日修改至此,今天在帮一个学院本球友分析 offer 选择后,他又回复说多亏了星球才能一路走到现在,很满足这个结果。看多了拿大厂 offer 球友的感谢,看到学院本也能取得满意的成绩,我也很开心。
Redisson了解多少?
Redisson 是一个基于 Redis 的 Java 客户端,它不只是对 Redis 的操作进行简单地封装,还提供了很多分布式的数据结构和服务,比如最常用的分布式锁。
RLock lock = redisson.getLock("lock");
lock.lock();
try {
// do something
} finally {
lock.unlock();
}Redisson 的分布式锁比 SETNX 完善的得多,它的看门狗机制可以让我们在获取锁的时候省去手动设置过期时间的步骤,它在内部封装了一个定时任务,每隔 10 秒会检查一次,如果当前线程还持有锁就自动续期 30 秒。
private Long tryAcquire(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
return get(tryAcquireAsync(waitTime, leaseTime, unit, threadId));
}
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
RFuture<Long> ttlRemainingFuture;
if (leaseTime != -1) {
// 手动设置过期时间
ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
// 启用看门狗机制,使用默认的30秒过期时间
ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
}
// 处理获取锁成功的情况
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// 如果获取锁成功且启用看门狗机制
if (ttlRemaining == null) {
if (leaseTime != -1) {
internalLockLeaseTime = unit.toMillis(leaseTime);
} else {
scheduleExpirationRenewal(threadId); // 启动看门狗
}
}
});
return ttlRemainingFuture;
}另外,Redisson 还提供了分布式限流器 RRateLimiter,基于令牌桶算法实现,用于控制分布式环境下的访问频率。
// API 接口限流
@RestController
public class ApiController {
@Autowired
private RedissonClient redissonClient;
@GetMapping("/api/data")
public ResponseEntity<?> getData() {
RRateLimiter limiter = redissonClient.getRateLimiter("api.data");
limiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.MINUTES);
if (limiter.tryAcquire()) {
// 处理请求
return ResponseEntity.ok(processData());
} else {
// 限流触发
return ResponseEntity.status(429).body("Rate limit exceeded");
}
}
}详细说说Redisson的看门狗机制?
Redisson 的看门狗机制是一种自动续期机制,用于解决分布式锁的过期问题。
基本原理是这样的:当调用 lock() 方法加锁时,如果没有显式设置过期时间,Redisson 会默认给锁加一个 30 秒的过期时间,同时启用一个名为“看门狗”的定时任务,每隔 10 秒(默认是过期时间的 1/3),去检查一次锁是否还被当前线程持有,如果是,就自动续期,将过期时间延长到 30 秒。
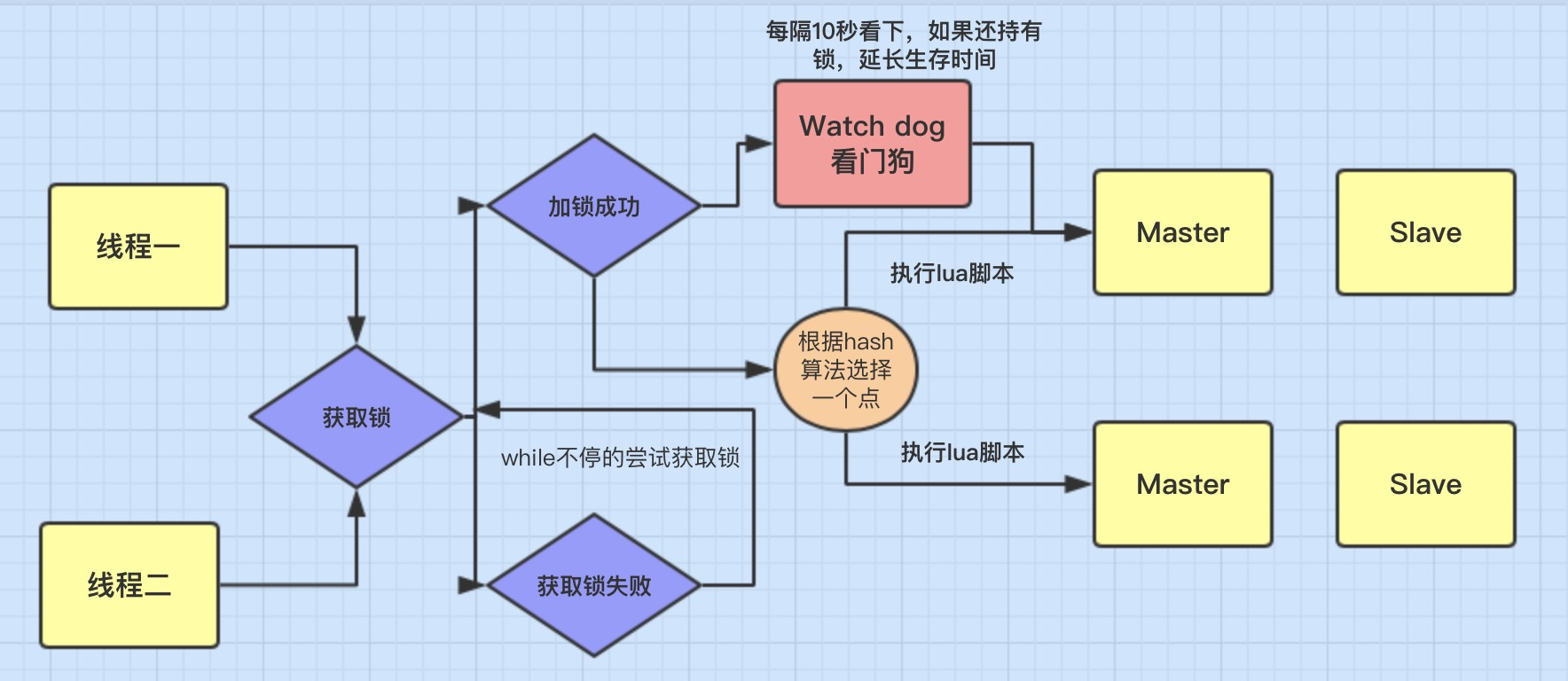
// 伪代码展示核心逻辑
private void renewExpiration() {
Timeout task = commandExecutor.getConnectionManager()
.newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) {
// 用 Lua 脚本检查并续期
if (redis.call("get", lockKey) == currentThreadId) {
redis.call("expire", lockKey, 30);
// 递归调用,继续下一次续期
renewExpiration();
}
}
}, 10, TimeUnit.SECONDS);
}续期的 Lua 脚本会检查锁的 value 是否匹配当前线程,如果匹配就延长过期时间。这样就能保证只有锁的真正持有者才能续期。
当调用 unlock() 方法时,看门狗任务会被取消。或者如果业务逻辑执行完但忘记 unlock 了,看门狗也会帮我们自动检查锁,如果锁已经不属于当前线程了,也会自动停止续期。
这样我们就不用担心业务执行时间过长导致锁被提前释放,也避免了手动估算过期时间的麻烦,同时也解决了分布式环境下的死锁问题。
看门狗机制中的检查锁过程是原子操作吗?
是的,Redisson 使用了 Lua 脚本来保证锁检查的原子性。
Redis 在执行 Lua 脚本时,会把整个脚本当作一个命令来处理,期间不会执行其他命令。所以 hexists 检查和 expire 续期是原子执行的。
Redlock你了解多少?
Redlock 是 Redis 作者 antirez 提出的一种分布式锁算法,用于解决单个 Redis 实例作为分布式锁时存在的单点故障问题。
Redlock 的核心思想是通过在多个完全独立的 Redis 实例上同时获取锁来实现容错。
minLocksAmount 方法返回的 locks.size()/2 + 1,正是 Redlock 算法要求的少数服从多数原则。failedLocksLimit 方法会计算允许失败的锁数量,确保即使部分实例失败,只要成功的实例数量超过一半就认为获取锁成功。
红锁会尝试依次向所有 Redis 实例获取锁,并记录成功获取的锁数量,当数量达到 minLocksAmount 时就认为获取成功,否则释放已获取的锁并返回失败。
虽然 Redlock 存在一些争议,比如说时钟漂移问题、网络分区导致的脑裂问题,但它仍然是一个相对成熟的分布式锁解决方案。
红锁能不能保证百分百上锁?
不能,Redlock 无法保证百分百上锁成功,这是由分布式系统的本质特性决定的。
当有网络分区时,客户端可能无法与足够数量的 Redis 实例通信。比如在 5 个 Redis 实例的部署中,如果网络分区导致客户端只能访问到 2 个实例,那么无论如何都无法满足红锁要求的少数服从多数原则,获取锁的时候必然失败。
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
// ...
for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {
RLock lock = iterator.next();
boolean lockAcquired;
try {
lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);
} catch (RedisResponseTimeoutException e) {
lockAcquired = false; // 网络超时导致失败
} catch (Exception e) {
lockAcquired = false; // 其他异常导致失败
}
// 如果剩余可尝试的实例数量不足以达到多数派,直接退出
if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {
break;
}
}
// 检查是否达到多数派要求
if (acquiredLocks.size() >= minLocksAmount(locks)) {
return true;
} else {
unlockInner(acquiredLocks);
return false; // 未达到多数派,获取失败
}
}时钟漂移也会影响成功率。即使所有实例都可达,如果各个 Redis 实例之间存在明显的时钟漂移,或者客户端在获取锁的过程中耗时过长,比如网络延迟、GC 停顿等,都可能会导致锁在获取完成前就过期,从而获取失败。
在实际应用中,可以通过重试机制来提高锁的成功率。
for (int i = 0; i < maxRetries; i++) {
if (redLock.tryLock(waitTime, leaseTime, TimeUnit.MILLISECONDS)) {
return true;
}
Thread.sleep(retryDelay);
}
return false;项目中有用到分布式锁吗?
在PmHub项目中,我有使用 Redission 的分布式锁来确保流程状态的更新按顺序执行,且不被其他流程服务干扰。
- Java 面试指南(付费)收录的腾讯 Java 后端实习一面原题:分布式锁用了 Redis 的什么数据结构
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:Redisson 的底层原理?以及与 SETNX 的区别?
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:redis 分布式锁的实现原理?setnx?
- Java 面试指南(付费)收录的小米同学 F 面试原题:自己实现 redis 分布式锁的坑(主动提了 Redission)
- Java 面试指南(付费)收录的腾讯云智面经同学 20 二面面试原题:redission 的原理是什么? setnx + lua 脚本?
- Java 面试指南(付费)收录的收钱吧面经同学 1 Java 后端一面面试原题:系统里面分布式锁是怎么做的?你提到了redlock,那它机制是怎么样的?红锁能不能保证百分百上锁?
- Java 面试指南(付费)收录的字节跳动面经同学 21 抖音商城一面面试原题:加分布式锁时redis如何保证不会发生冲突?分布式锁过期怎么办?
- Java 面试指南(付费)收录的拼多多面经同学 8 一面面试原题:Redis分布式锁如何实现的
- Java 面试指南(付费)收录的百度同学 4 面试原题:Setnx,知道吗? 用这个加锁有什么问题吗?怎么解决?
- Java 面试指南(付费)收录的阿里系面经同学 19 饿了么面试原题:分布式锁用redis实现思路
- Java 面试指南(付费)收录的京东面经同学 9 面试原题:redis的分布式锁有了解过吗
- Java 面试指南(付费)收录的同学 30 腾讯音乐面试原题:redis锁有几种实现方式
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 6 月 3 日修改至此,今天在修改球友的简历时,碰到一个 211 本科、北京大学软微学院的球友,我只能说,星球的球友真是人才济济啊!祝大家都有一个美好的未来。

底层结构
49.🌟Redis都有哪些底层数据结构?
Redis 之所以快,除了基于内存读写之外,还有很重要的一点就是它精心设计的底层数据结构。Redis 总共有 8 种核心的底层数据结构,我按照重要程度来说一下。
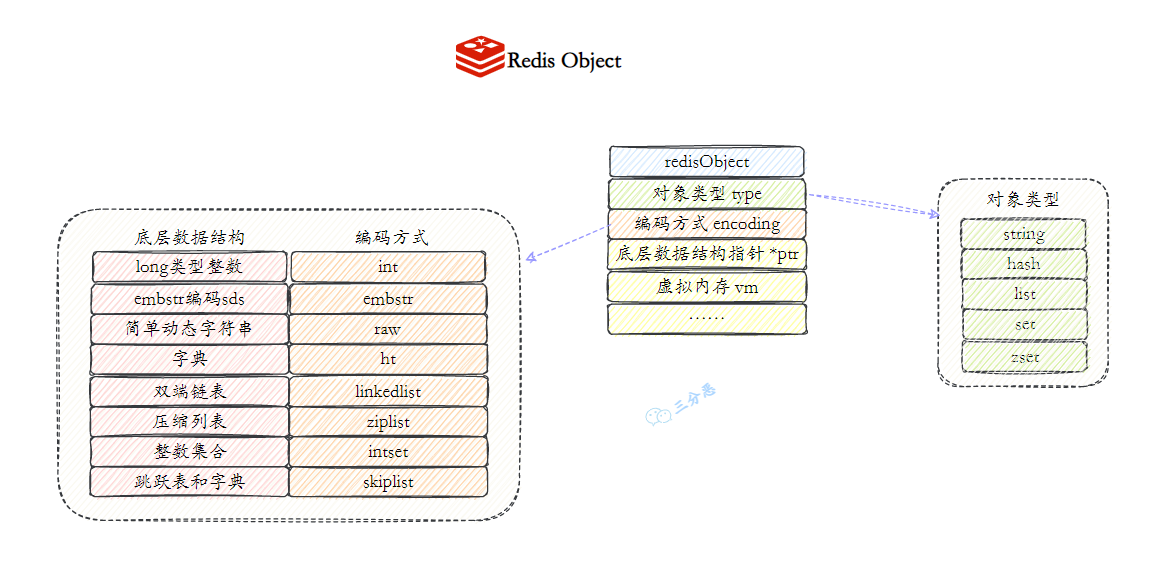
首先是 SDS,这是 Redis 自己实现的动态字符串,它保留了 C 语言原生的字符串长度,所以获取长度的时间复杂度是 O(1),在此基础上还支持动态扩容,以及存储二进制数据。
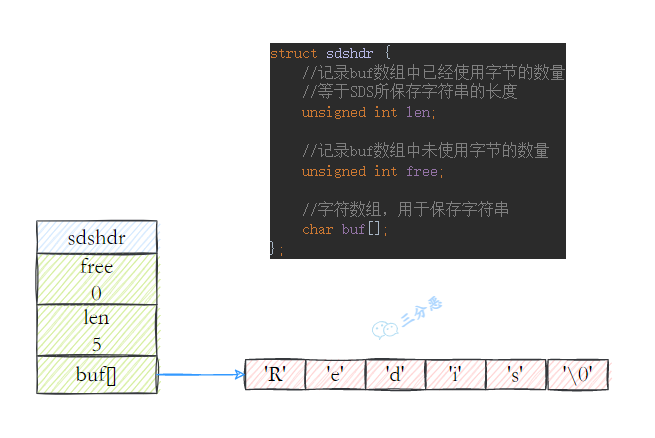
然后是字典,更底层是用数组+链表实现的哈希表。它的设计很巧妙,用了两个哈希表,平时用第一个,rehash 的时候用第二个,这样可以渐进式地进行扩容,不会阻塞太久。
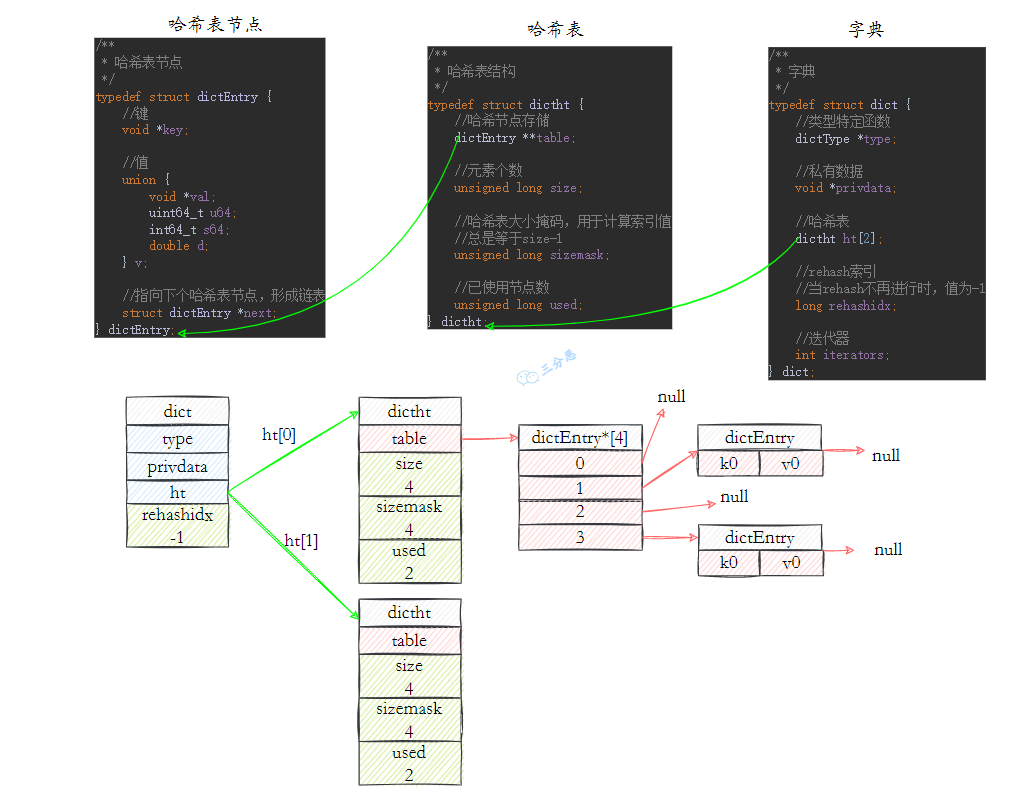
接下来压缩列表 ziplist,这个设计很有意思。Redis 为了节省内存,设计了这种紧凑型的数据结构,把所有元素连续存储在一块内存里。但是它有个致命问题叫"连锁更新",就是当我们修改一个元素的时候,可能会导致后面所有的元素都要重新编码,性能会急剧下降。
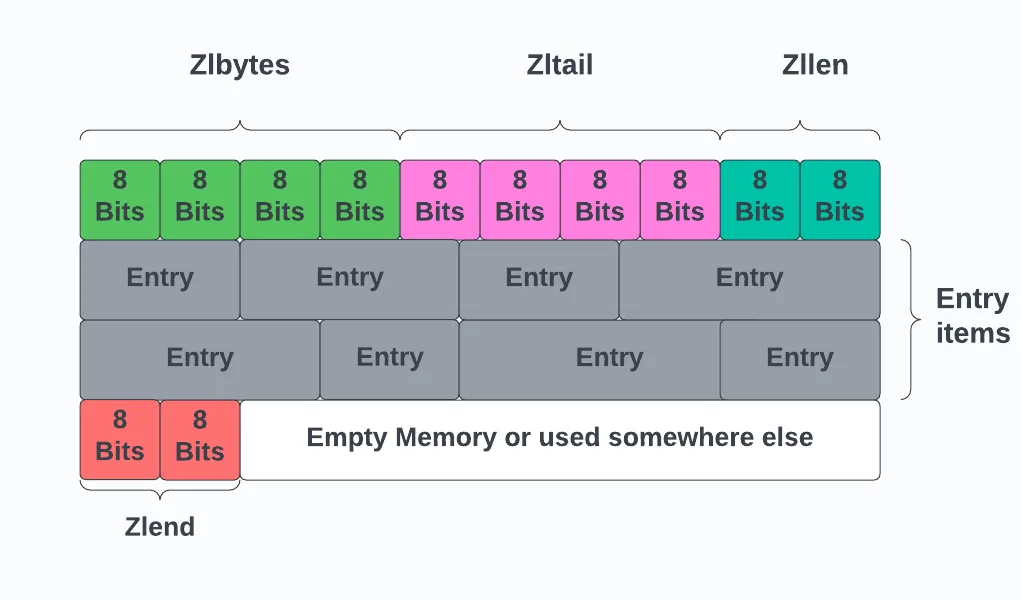
为了解决压缩列表的问题,Redis 后来设计了 quicklist。这个设计思路很聪明,它把 ziplist 拆分成小块,然后用双向链表把这些小块串起来。这样既保持了 ziplist 节省内存的优势,又避免了连锁更新的问题,因为每个小块的 ziplist 都不会太大。
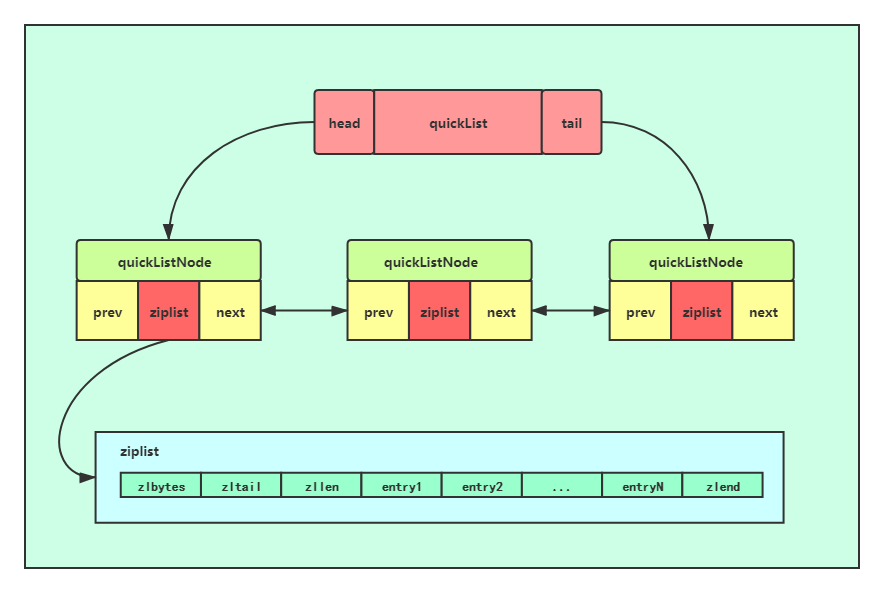
再后来,Redis 又设计了 listpack,这个可以说是 ziplist 的完美替代品。它最大的特点是每个元素只记录自己的长度,不记录前一个元素的长度,这样就彻底解决了连锁更新的问题。Redis 5.0 已经用 listpack 替换了 ziplist。
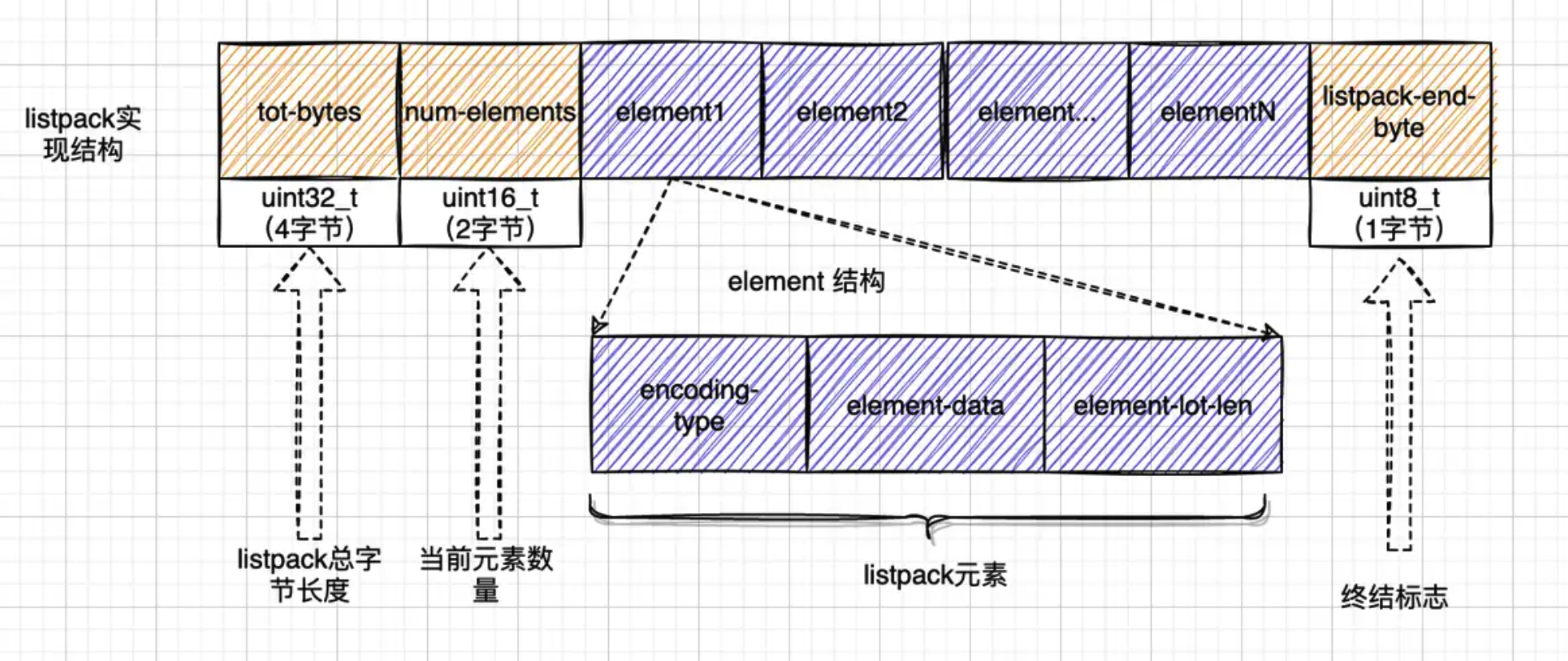
跳表skiplist 主要用在 ZSet 中。它的设计很巧妙,通过多层指针来实现快速查找,平均时间复杂度是 O(log N)。相比红黑树,跳表的实现更简单,而且支持范围查询,这对 Redis 的有序集合来说很重要。
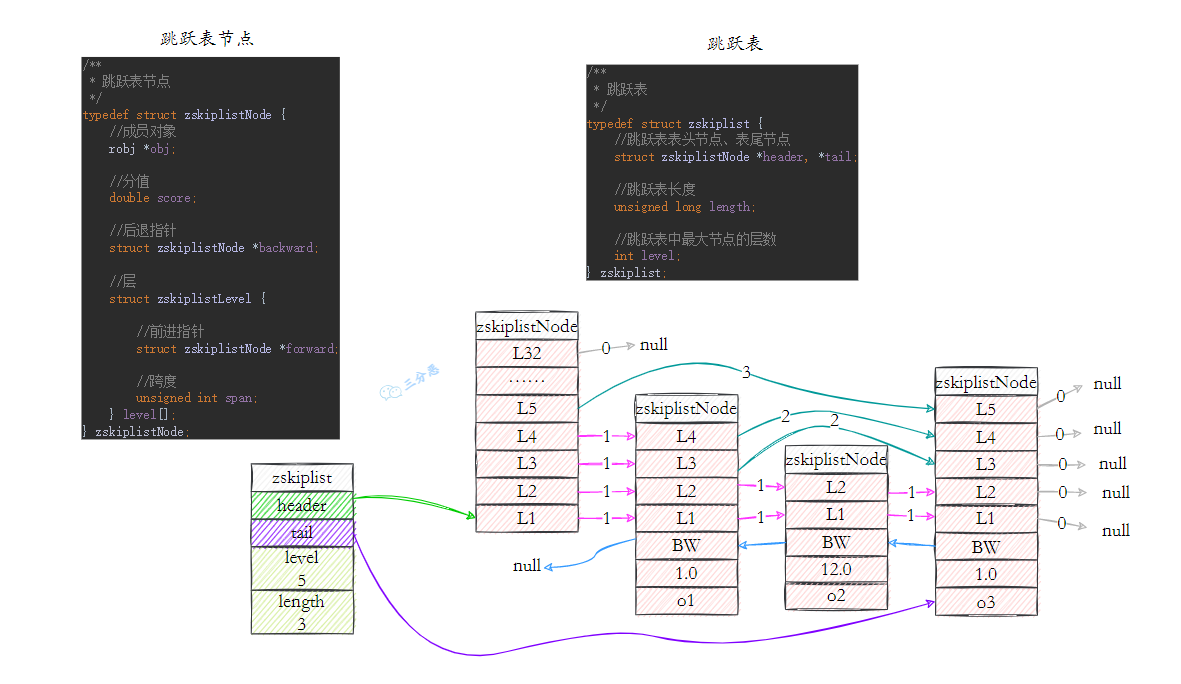
还有整数集合intset,当 Set 中都是整数且元素数量较少时使用,内部是一个有序数组,查找用的二分法。
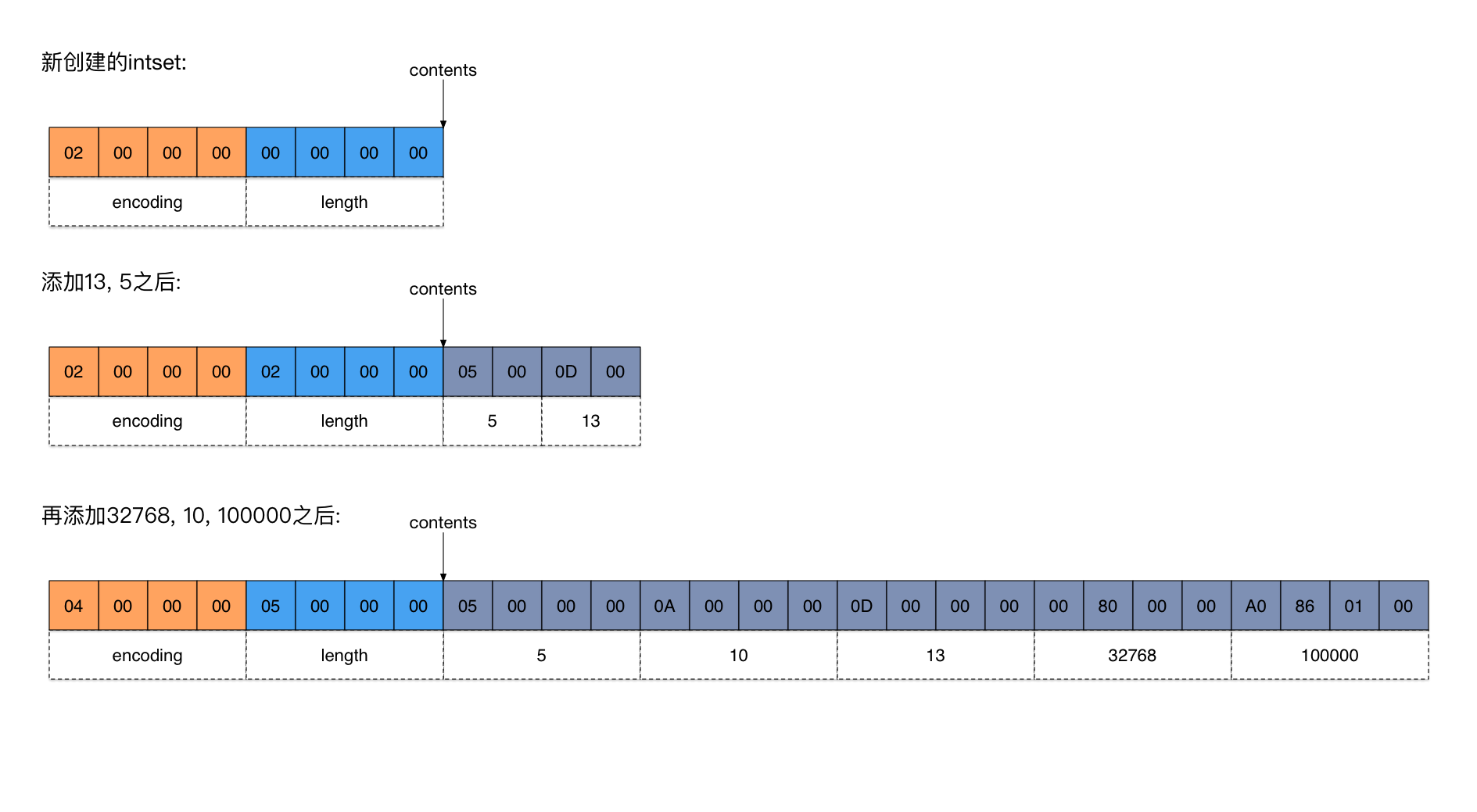
最后是双向链表LinkedList,早期版本的 Redis 会在 List 中用到,但 Redis 3.2 后就被 quicklist 替代了,因为纯链表的问题是内存不连续,影响 CPU 缓存性能。
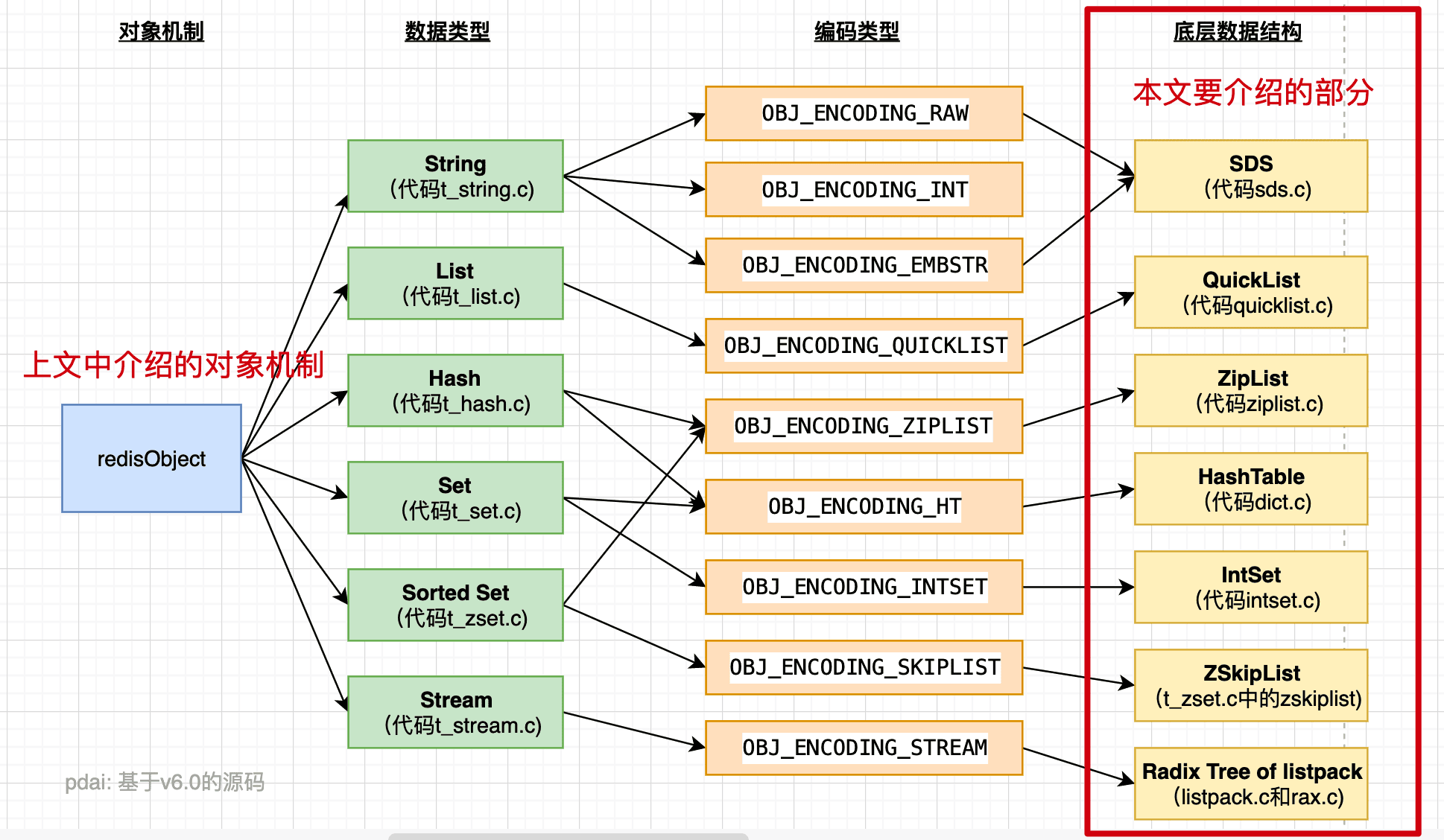
memo:2025 年 6 月 4 日,今天有球友发喜报说拿到了京东零售的实习 offer,并且部门和业务还是挺不错的,恭喜他!6 月份还有机会,冲。
简单介绍下链表?
Redis 的 linkedlist 是⼀个双向⽆环链表结构,和 Java 中的 LinkedList 类似。
节点由 listNode 表示,每个节点都有指向其前置节点和后置节点的指针,头节点的前置和尾节点的后置均指向 null。
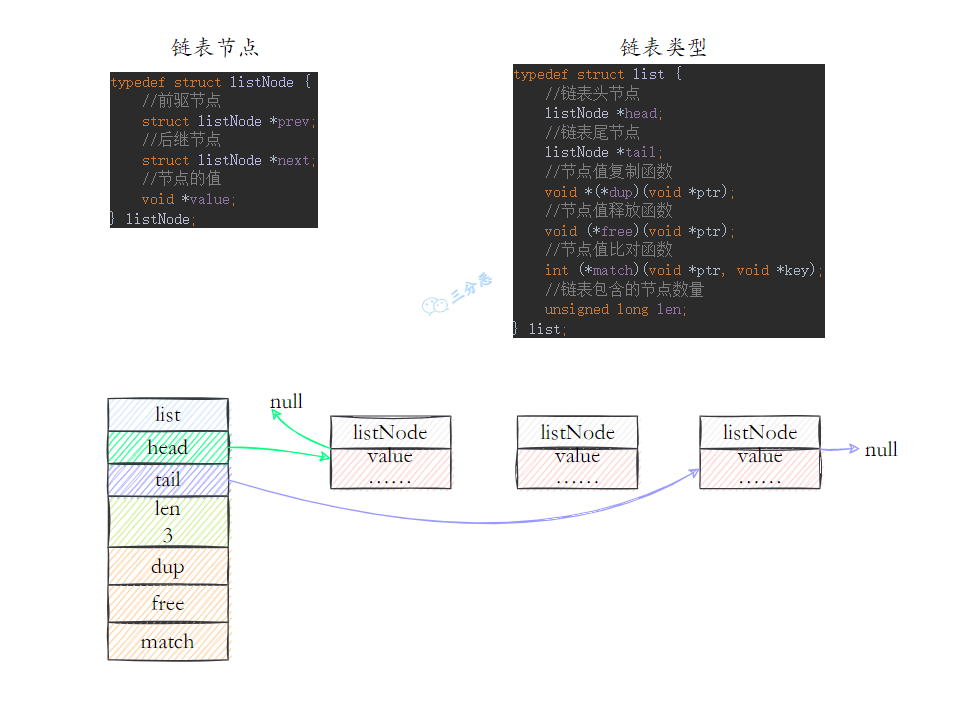
关于整数集合,能再详细说说吗?
整数集合是 Redis 中一个非常精巧的数据结构,当一个 Set 只包含整数元素,并且数量不多时,默认不超过 512 个,Redis 就会用 intset 来存储这些数据。
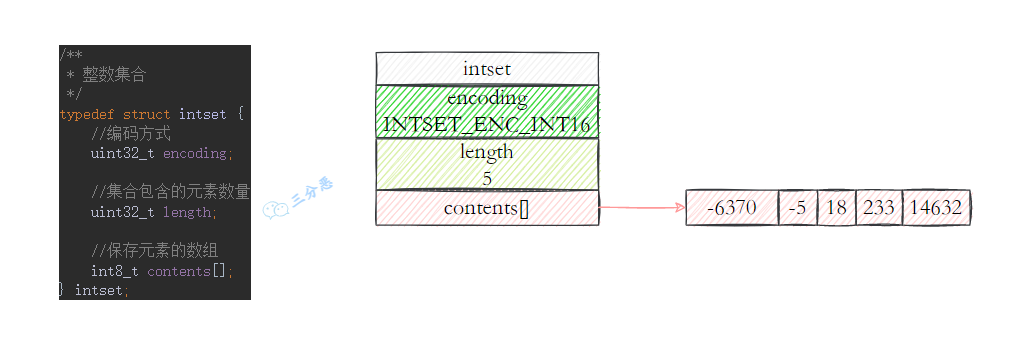
intset 最有意思的地方是类型升级机制。它有三种编码方式:16位、32位和 64位,会根据存储的整数大小动态调整。比如原来存的都是小整数,用 16 位编码就够了,但突然插入了一个很大的数,超出了 16 位的范围,这时整个数组会升级到 32 位编码。
typedef struct intset {
uint32_t encoding; // 编码方式:16位、32位或64位
uint32_t length; // 元素数量
int8_t contents[]; // 保存元素的数组
} intset;当然了,这种升级是有代价的,因为需要重新分配内存并复制数据,并且是不可逆的,但它的好处是可以节省内存空间,特别是在存储大量小整数时。
另外,所有元素在数组中按照从小到大的顺序排列,这样就可以使用二分查找来定位元素,时间复杂度为 O(log N)。
说一下zset 的底层原理?
ZSet 是 Redis 最复杂的数据类型,它有两种底层实现方式:压缩列表和跳表。
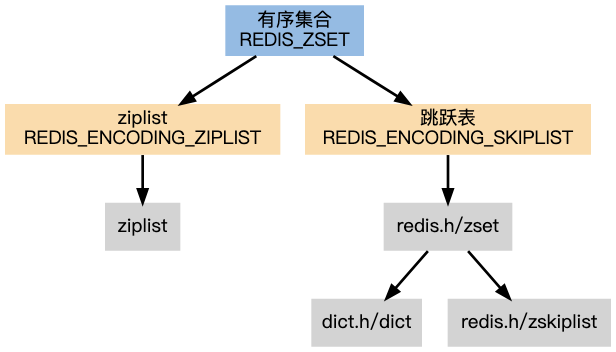
当保存的元素数量少于 128 个,且保存的所有元素大小都小于 64 字节时,Redis 会采用压缩列表的编码方式;否则就用跳表。
当然,这两个条件都可以通过参数进行调整。
选择压缩列表作为底层实现时,每个元素会使用两个紧挨在一起的节点来保存:第一个节点保存元素的成员,第二个节点保存元素的分值。
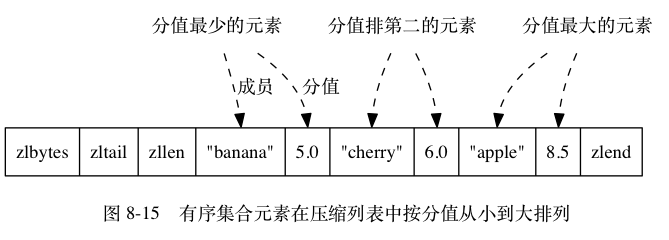
所有元素按分值从小到大有序排列,小的放在靠近表头的位置,大的放在靠近表尾的位置。
但跳表的缺点是查找只能按顺序进行,时间复杂度为 O(N),而且在最坏的情况下,插入和删除操作还可能会引起连锁更新。
当元素数量较多或元素较大时,Redis 会使用 skiplist 的编码方式;这个设计非常的巧妙,同时使用了两种数据结构:
typedef struct zset {
zskiplist *zsl; // 跳跃表
dict *dict; // 字典
} zset;跳表按分数有序保存所有元素,且支持范围查询(如 ZRANGE、ZRANGEBYSCORE),平均时间复杂度为 O(log N)。而哈希表则用来存储成员和分值的映射关系,查找时间复杂度为 O(1)。
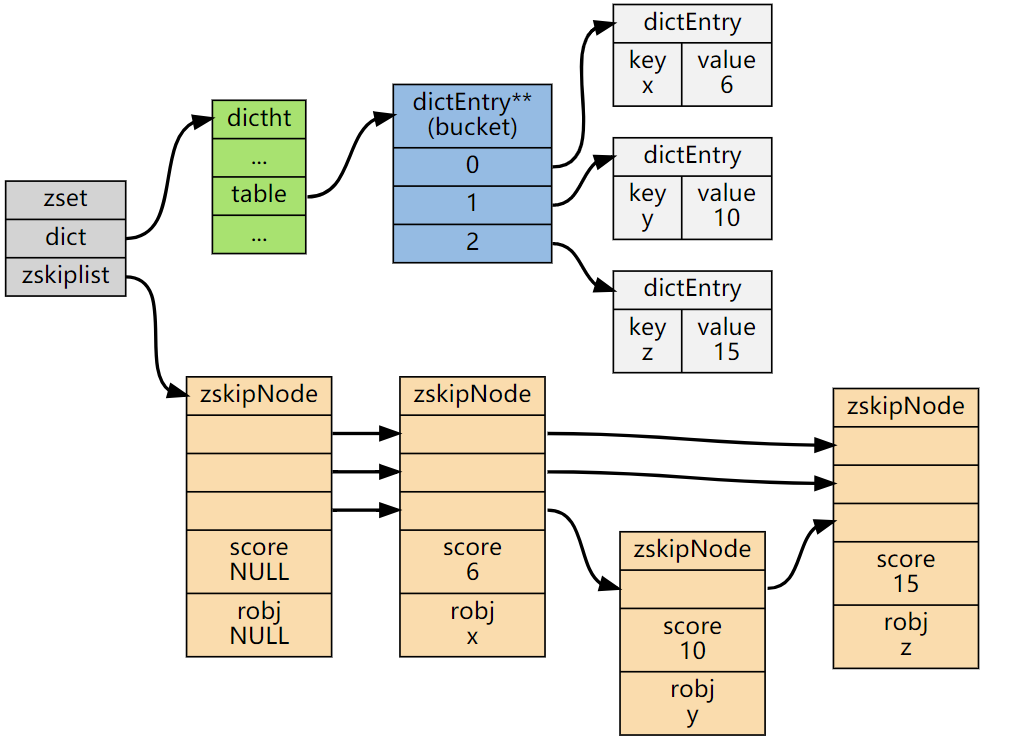
虽然同时使用两种结构,但它们会通过指针来共享相同元素的成员和分值,因此不会浪费额外的内存。
你知道为什么Redis 7.0要用listpack来替代ziplist吗?
答:主要是为了解决压缩列表的一个核心问题——连锁更新。在压缩列表中,每个节点都需要记录前一个节点的长度信息。
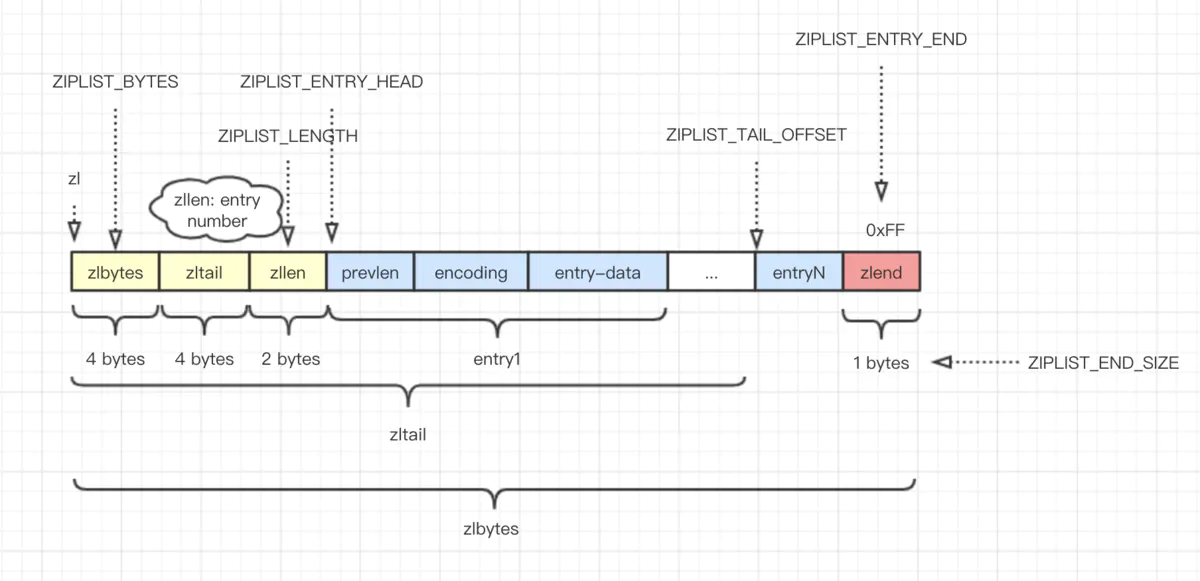
当插入或删除一个节点时,如果这个操作导致某个节点的长度发生了变化,那么后续的节点可能都需要更新它们存储的"前一个节点长度"字段。最坏的情况下,一次操作可能触发整个链表的更新,时间复杂度会从 O(1)退化到 O(n²)。
而 listpack 的设计理念完全不同。它让每个节点只记录自己的长度信息,不再依赖前一个节点的长度。这样就从根本上避免了连锁更新的问题。
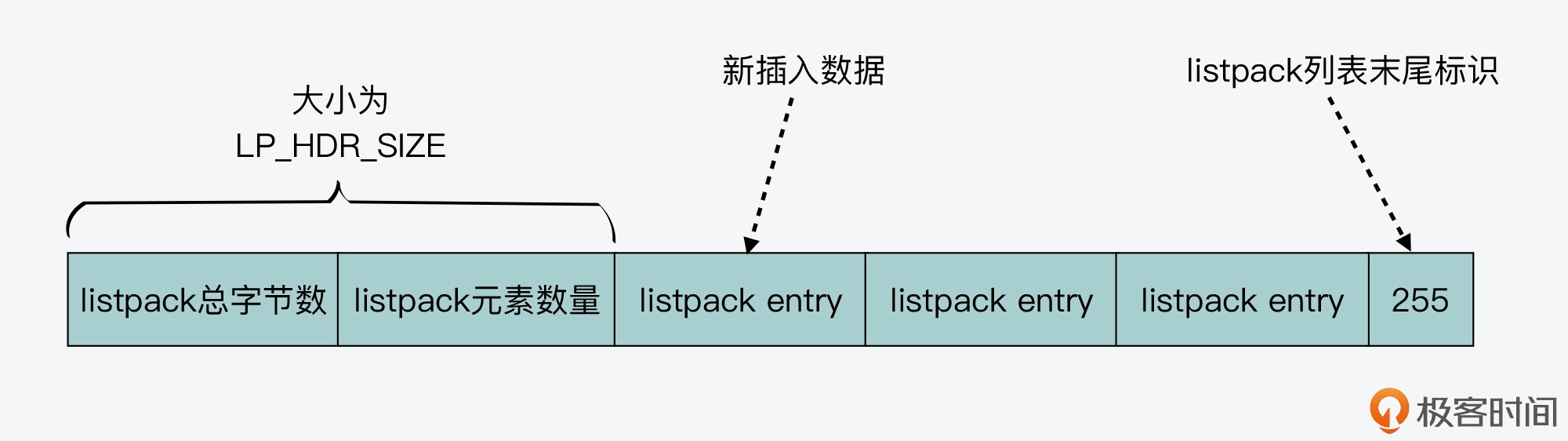
listpack 中的节点不再保存其前一个节点的长度,而是保存当前节点的编码类型、数据和长度。
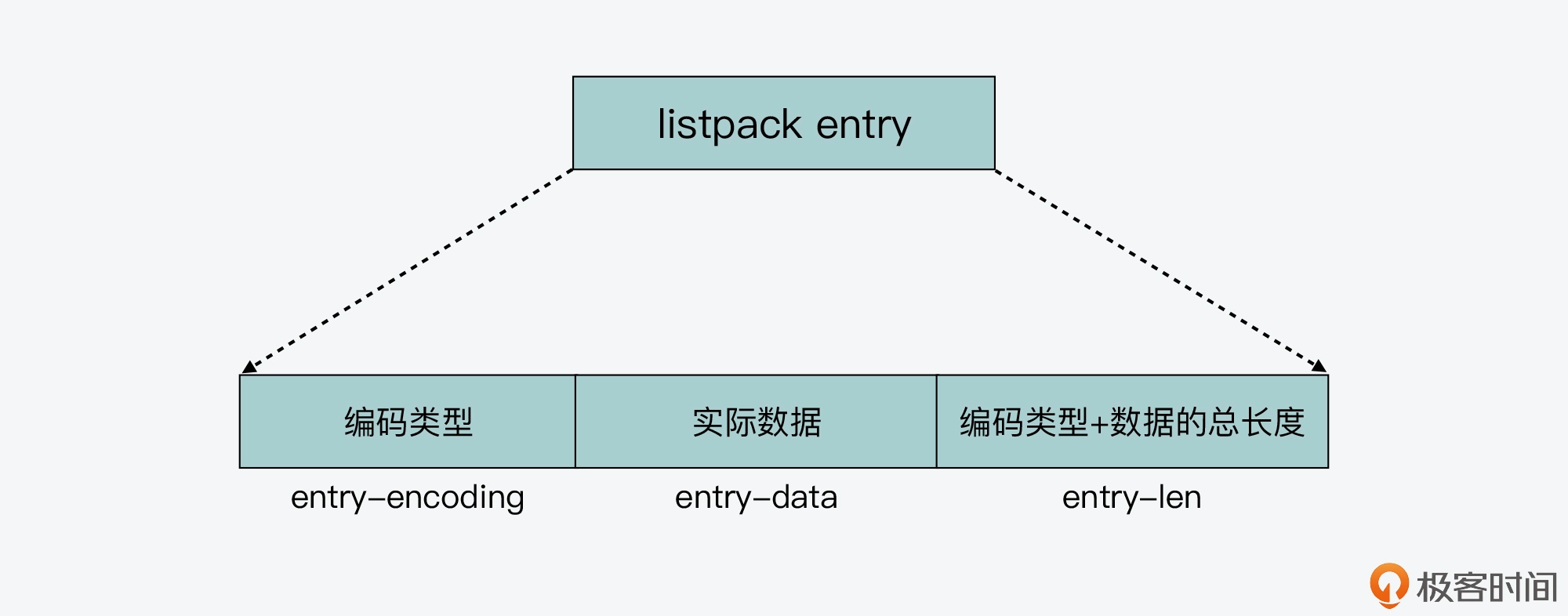
连锁更新是怎么发生的?
比如说我们有一个压缩列表,其中有几个节点的长度都是 253 个字节。在 ziplist 的编码中,如果前一个节点的长度小于 254 字节,我们只需要 1 个字节来存储这个长度信息。

但如果在这些节点前面插入一个长度为 254 字节的节点,那么原来只需要 1 个字节存储长度的节点现在需要 5 个字节来存储长度信息。这就会导致后续所有节点的长度信息都需要更新。
- Java 面试指南(付费)收录的字节跳动商业化一面的原题:说说 Redis 的 zset,什么是跳表,插入一个节点要构建几层索引
- Java 面试指南(付费)收录的字节跳动面经同学 9 飞书后端技术一面面试原题:Redis 的数据类型,ZSet 的实现
- Java 面试指南(付费)收录的小米暑期实习同学 E 一面面试原题:你知道 Redis 的 zset 底层实现吗
- Java 面试指南(付费)收录的腾讯面经同学 23 QQ 后台技术一面面试原题:zset 的底层原理
- Java 面试指南(付费)收录的快手面经同学 7 Java 后端技术一面面试原题:说一下 ZSet 底层结构
- Java 面试指南(付费)收录的美团同学 9 一面面试原题:redis的数据结构底层原理?
- Java 面试指南(付费)收录的腾讯面经同学 27 云后台技术一面面试原题:Zset的底层实现?
- Java 面试指南(付费)收录的得物面经同学 9 面试题目原题:Zset的底层如何实现?
memo:2025 年 6 月 5 日,今天有球友在VIP群里咨询 offer 的选择,一个拼多多,一个快手,真让人羡慕的要死啊,😄
50.Redis 为什么不用 C 语言的原生字符串?
第一,C 语言的字符串其实就是字符数组,以 \0 结尾,这意味着如果数据本身包含 \0 字节,就会被误认为字符串结束。但 Redis 需要存储各种类型的数据,包括图片、序列化对象等二进制数据,这些数据中很可能包含 \0。
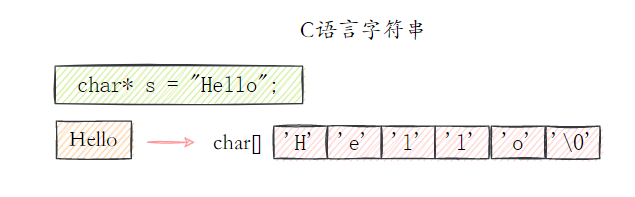
第二,如果需要获取字符串长度,C 语言只能调用 strlen() 函数,时间复杂度是 O(N),因为要遍历整个字符串直到遇到 \0。
第三,C 语言的字符串不会自动检查边界,如果往一个字符数组里写入超过其容量的数据,就会出现缓冲区溢出。
第四,C 语言的字符串不支持动态扩容,如果需要修改内容,就必须重新分配内存并复制数据,开销很大。
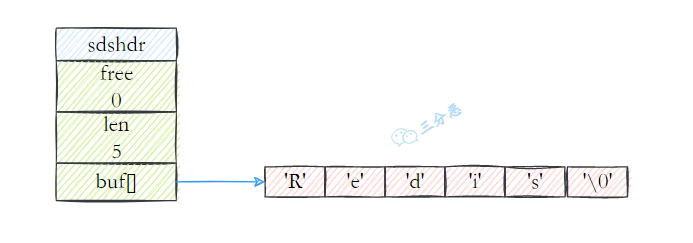
Redis 设计的 SDS 完美解决了这些问题,获取长度可以直接通过 len 字段,时间复杂度为 O(1);free 字段会记录剩余空间,因此 Redis 可以根据预分配策略动态扩容,不用在追加数据时重新分配内存;并且不依赖于 \0 结尾,可以存储任意二进制数据。
struct sds {
int len; // 字符串长度
int free; // 剩余空间
char buf[]; // 字符数组
}51.你研究过 Redis 的字典源码吗?
是的,有研究过。Redis 的字典分为三层,最外层是一个 dict 结构,包含两个哈希表 ht[0] 和 ht[1],用于存储键值对。每个哈希表由一个数组和链表组成,数组用于快速定位,链表用于解决哈希冲突。
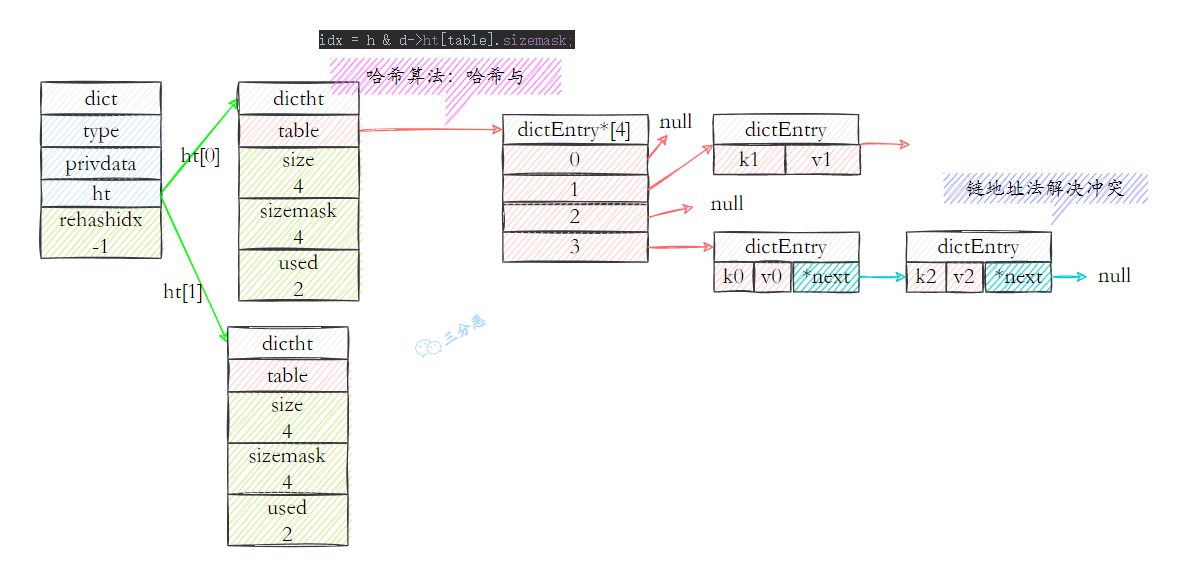
// 最外层的字典结构
typedef struct dict {
dictht ht[2]; // 两个哈希表!这是关键
long rehashidx; // rehash索引,-1表示没有进行rehash
// ...
} dict;
// 哈希表结构
typedef struct dictht {
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表大小
unsigned long sizemask; // 哈希表大小掩码,用于计算索引值
unsigned long used; // 该哈希表已有节点的数量
} dictht;
// 哈希表节点
typedef struct dictEntry {
void *key; // 键
v; // 值
struct dictEntry *next; // 指向下个哈希表节点,形成链表
} dictEntry;字典最核心的特点是渐进式 rehash,这是我觉得最精彩的部分。传统的哈希表扩容都是一次性完成的,但 Redis 不是这样的。
当负载因子触发 rehash 条件时,Redis 会为哈希表1 分配新的空间,通常是哈希表 0 的两倍大小,然后将 rehashidx 设置为 0。
接下来的关键是,Redis 不会一次性把所有数据从哈希表0 迁移到哈希表1,而是每次操作字典时,顺便迁移哈希表0 中 rehashidx 位置上的所有键值对。迁移完一个槽位后,rehashidx 递增,直到整个哈希表0 迁移完毕。
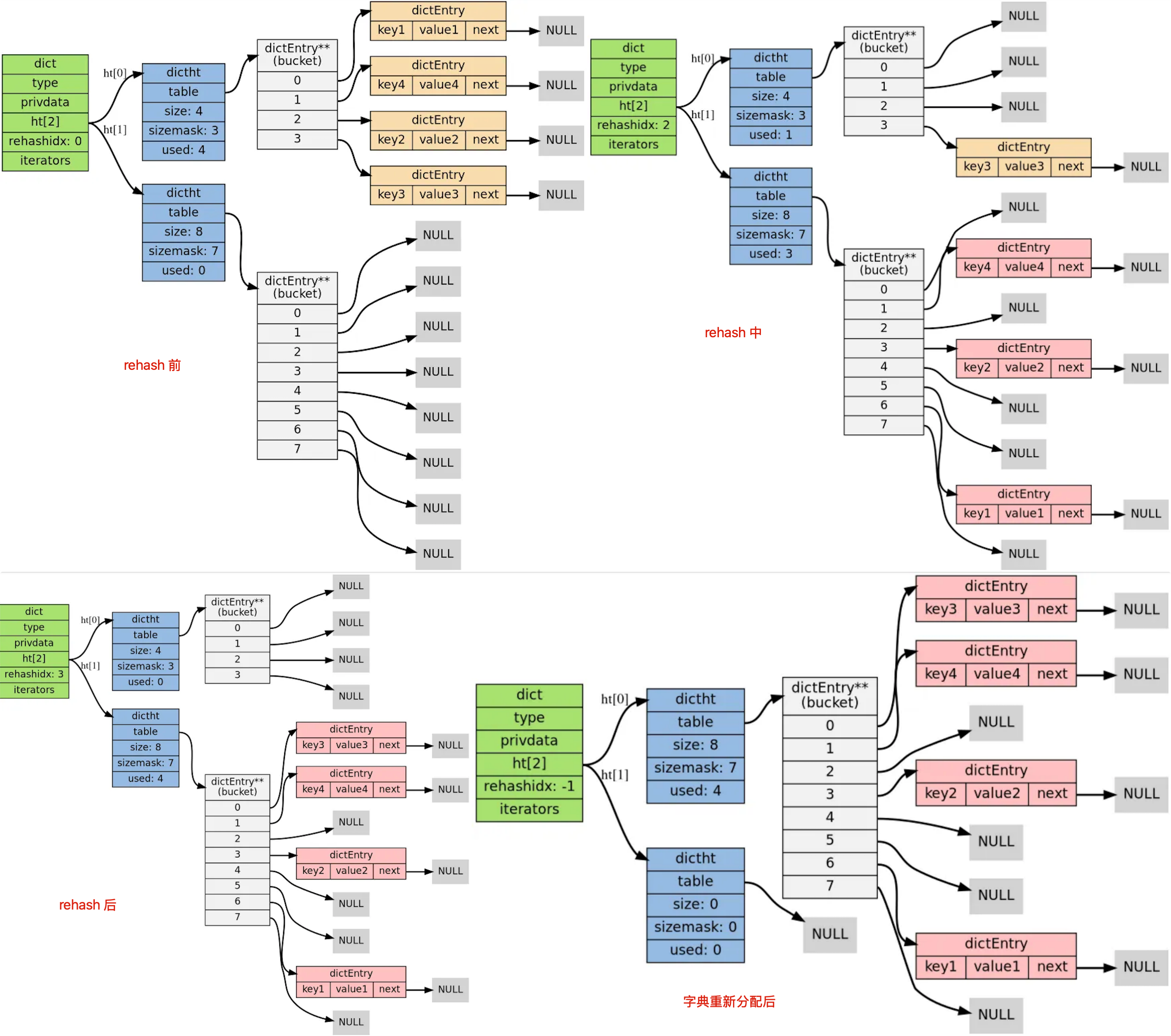
这种设计的巧妙之处在于把 rehash 的开销分摊到了每次操作中。假设有一个几百万键的哈希表,如果一次性 rehash 可能需要几百毫秒,这对单线程的 Redis 来说是灾难性的。但通过渐进式 rehash,每次操作只增加很少的额外开销,用户基本感觉不到延迟。
在 rehash 期间,查找操作会先查 哈希表 0,没找到再查哈希表 1;但是新插入的数据只会放到哈希表 1 中。这样既可以保证数据的完整性,又能避免数据的重复。
遇到哈希冲突怎么办?
Redis 是通过链地址法来解决哈希冲突的,每个哈希表的槽位实际上是一个链表的头指针,当多个键的哈希值映射到同一个槽位时,这些键会以链表的形式串联起来。
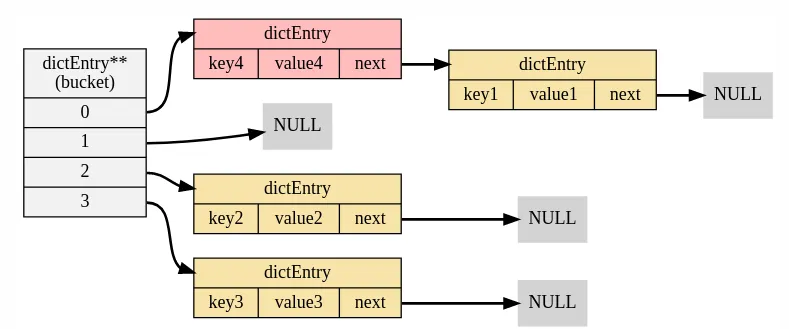
具体实现上,Redis 会通过哈希表节点的 next 指针,指向下一个具有相同哈希值的节点。当发生冲突时,新的键值对会插入到链表的头部,时间复杂度是 O(1)。查找时需要遍历整个链表,最坏的情况下时间复杂度为 O(n),但通常链表都比较短。
另外,Redis 设计的哈希函数在分布上也比较均匀,能够有效减少哈希冲突的发生。
/* MurmurHash2, by Austin Appleby
* Note - This code makes a few assumptions about how your machine behaves -
* 1. We can read a 4-byte value from any address without crashing
* 2. sizeof(int) == 4
*
* And it has a few limitations -
*
* 1. It will not work incrementally.
* 2. It will not produce the same results on little-endian and big-endian
* machines.
*/
unsigned int dictGenHashFunction(const void *key, int len) {
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len;
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}memo:2025 年 6 月 6 日,今天有球友咨询去金山办公暑期实习,要提前学点什么?又一个凭借 Java 这个载体拿到 Go offer 的球友,说明大家在求职 Go 岗的时候,也不用说非要提前刻意去学习 Go,当然有一些基础是最好的,我之前也整理过 Go 的学习路线在 Java 进阶之路上。
52.🌟你了解跳表吗?
跳表是一种非常巧妙的数据结构,它在有序链表的基础上建立了多层索引,最底层包含所有数据,每往上一层,节点数量就减少一半。

它的核心思想是"用空间换时间",通过多层索引来跳过大量节点,从而提高查找效率。
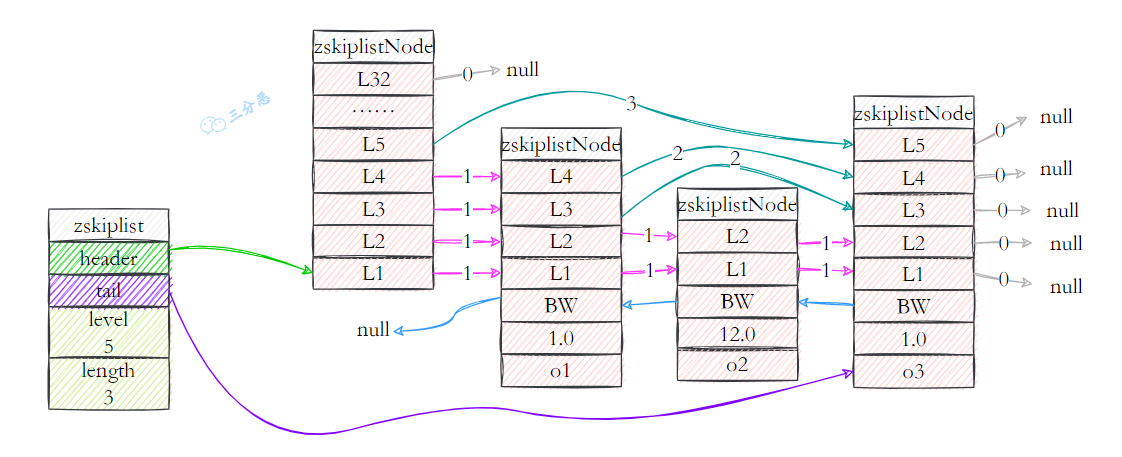
每个节点有 50% 的概率只在第 1 层出现,25% 的概率在第 2 层出现,依此类推。查找的时候从最高层开始水平移动,当下一个节点值大于目标时,就向下跳一层,直到找到目标节点。
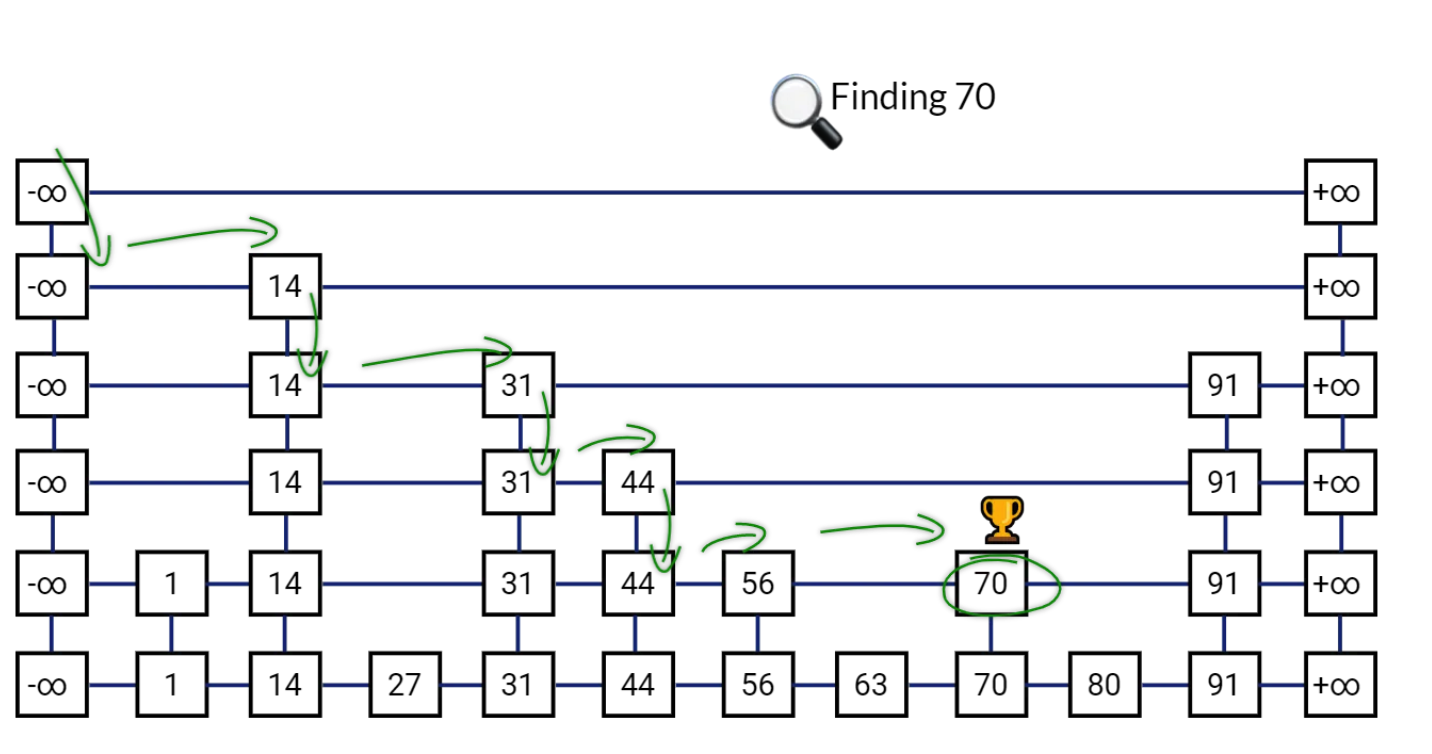
怎么往跳表插入节点呢?
首先是找到插入位置,从最高层的头节点开始,在每一层都找到应该插入位置的前驱节点,用一个 update 数组把这些前驱节点记录下来。这个查找过程和普通查找一样,在每层向右移动直到下个节点的值大于要插入的值,然后下降到下一层。
// 记录每层的插入位置
zskiplistNode *update[ZSKIPLIST_MAXLEVEL];
zskiplistNode *x;
int i, level;
// 从最高层开始查找
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
// 在当前层水平移动,找到插入位置
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele, ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x; // 记录每层的前驱节点
}接下来随机生成新节点的层数。通常用一个循环,每次有 50% 的概率继续往上,直到随机失败或达到最大层数限制。
// Redis 中的随机层数生成
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level < ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
// 生成新节点的层数
level = zslRandomLevel();创建新节点后,从底层开始到新节点的最高层,在每一层都进行标准的链表插入操作。这一步要利用之前记录的 update 数组,将新节点插入到正确位置,然后更新前后指针的连接关系。
// 更新前进指针
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
// 更新跨度信息
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
// 更新未涉及层的跨度
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 更新后退指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
// 更新跳表长度
zsl->length++;我们来模拟一个跳表的插入过程,假设插入的数据依次是 22、19、7、3、37、11、26。
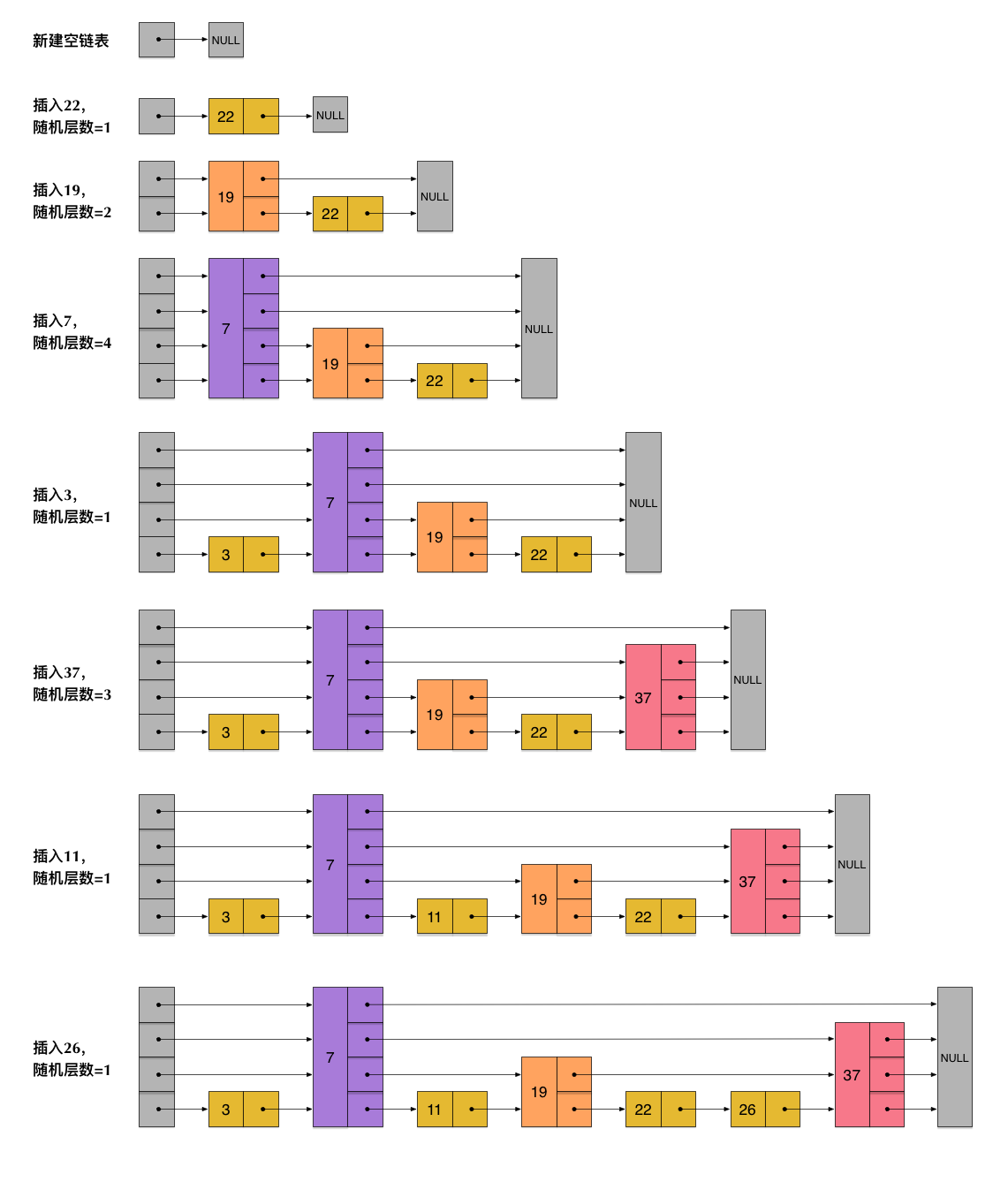
那假如我们在一个已经分布了 1、14、27、31、44、56、63、70、80、91 的跳表中插入一个 67 的节点,插入过程是这样的:
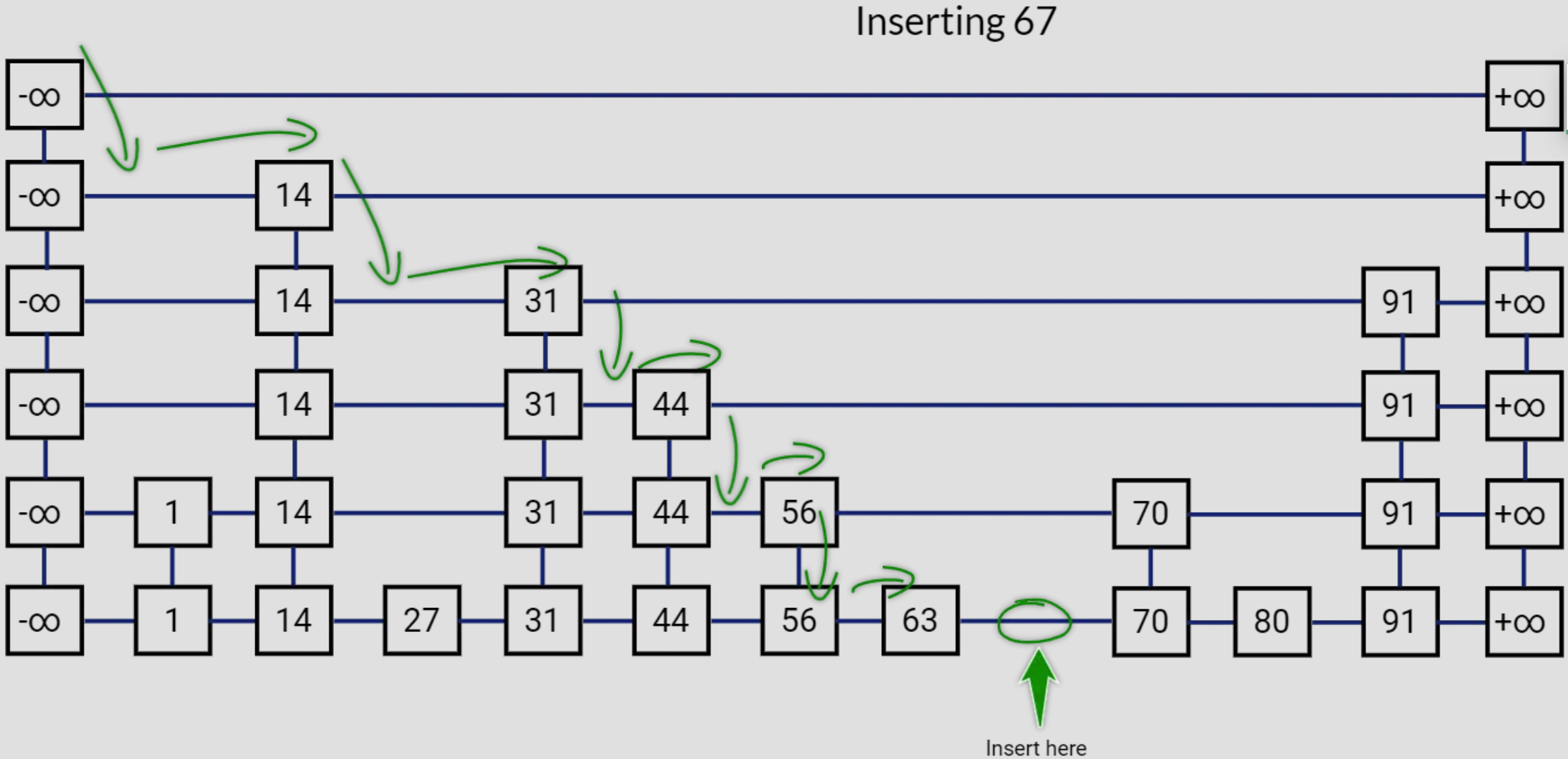
zset为什么要使用跳表呢?
第一,跳表天然就是有序的数据结构,查找、插入和删除都能保持 O(log n) 的时间复杂度。
第二,跳表支持范围查询,找到起始位置后可以直接沿着底层链表顺序遍历,满足 ZRANGE 按排名获取元素,或者 ZRANGEBYSCORE 按分值范围获取元素。
memo:2025 年 6 月 7 日,今天给一个学院本球友修改简历的时候,他提到实习的同事,都拿到了 20k 以上的 offer,甚至还有 25k 携程 offer 的,自己并不比他们差,问在实习、项目和能力上还能怎么提高?

我想说的是,这就是为什么很多人选择跑来卷互联网开发的原因啊,上线比其他行业高太多了,虽然互联网开发的工作强度也大,但最起码能劳有所获。
跳表是如何定义的呢?
跳表本质上是一个多层链表,底层是一个包含所有元素的有序链表,上一层作为索引层,包含了下一层的部分节点;层数通过随机算法确定,理论上可以无限高。
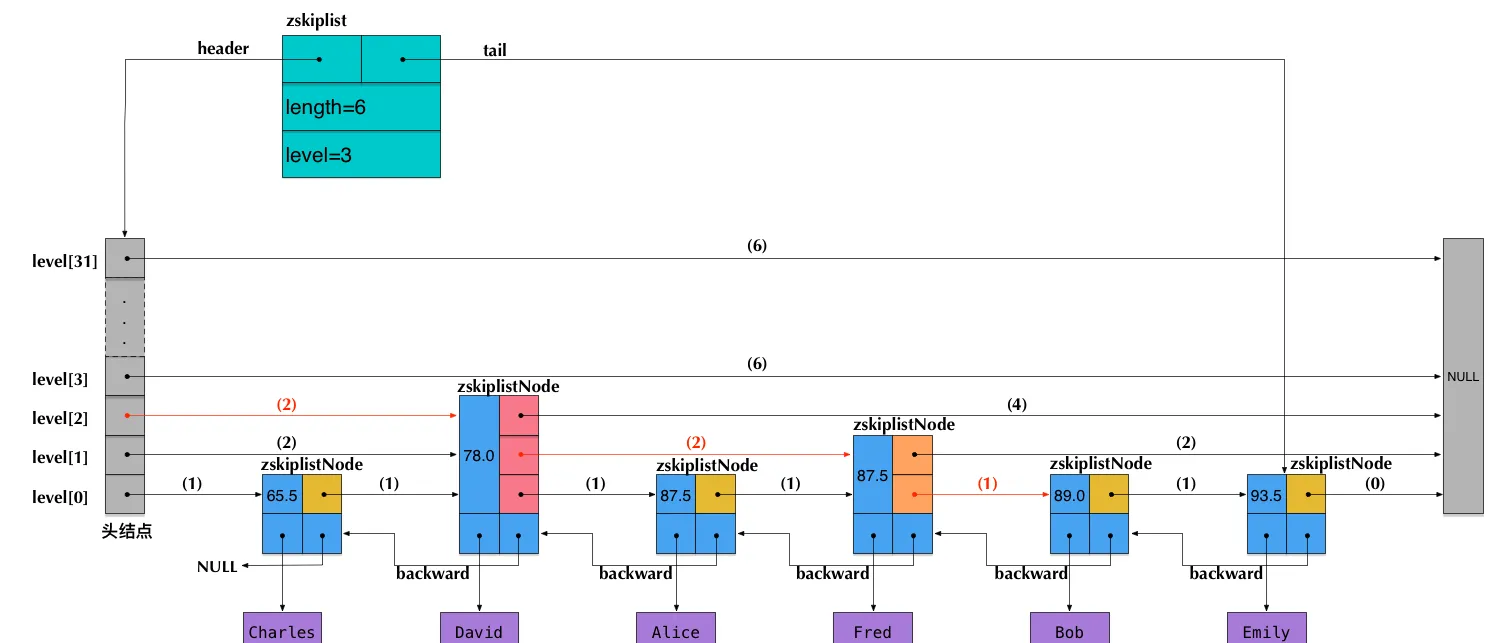
跳表节点包含分值 score、成员对象 obj、一个后退指针 backward,以及一个层级数组 level。每个层级包含 forward 前进指针和 span 跨度信息。
typedef struct skiplistNode {
double score; // 分值(用于排序)
robj *obj; // 数据对象
struct skiplistNode *backward; // 后退指针
struct skiplistLevel {
struct skiplistNode *forward; // 前进指针
unsigned int span; // 跨度(到下个节点的距离)
} level[]; // 层级数组
} skiplistNode;跳表本身包含头尾节点指针、节点总数 length 和当前最大层数 level。
typedef struct skiplist {
struct skiplistNode *header, *tail; // 头尾节点
unsigned long length; // 节点数量
int level; // 最大层数
} skiplist;span 跨度有什么用?
span 记录了当前节点到下一节点之间,底层到底跨越了几个节点,它的主要作用是快速找到 ZSet 中某个分值的排名。
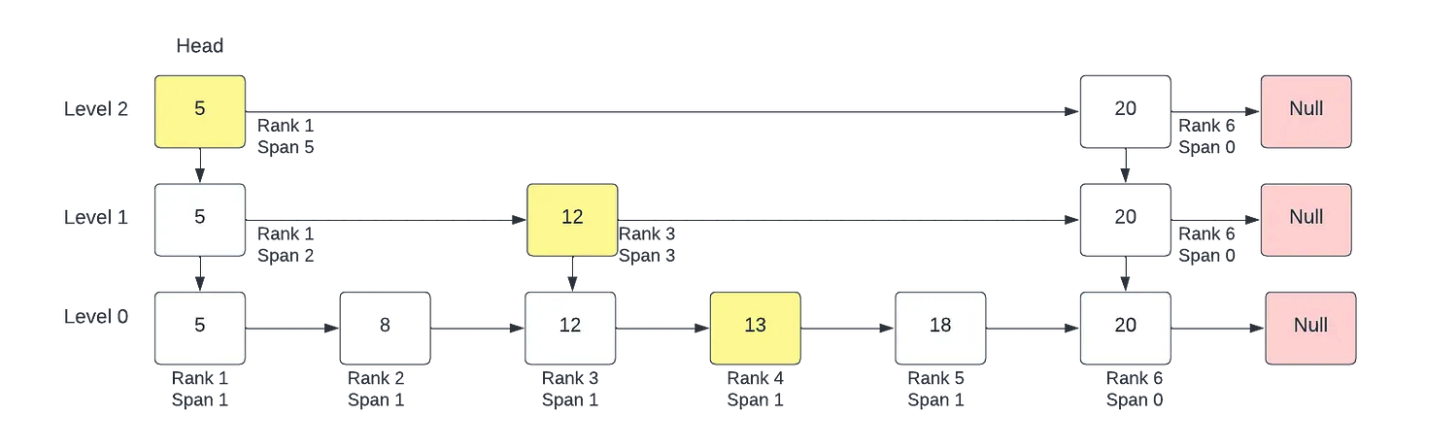
比如说我们执行 ZRANK 命令时,如果没有 span,就需要从头节点开始遍历每个节点,直到找到目标分值,这样时间复杂度是 O(n)。
// 没有span的排名查询 - O(n)
int getRankWithoutSpan(skiplist *zsl, double score, robj *obj) {
skiplistNode *x = zsl->header->level[0].forward;
int rank = 0;
while (x) {
if (x->score == score && equalStringObjects(x->obj, obj)) {
return rank + 1; // 排名从1开始
}
rank++;
x = x->level[0].forward;
}
return 0;
}但有了 span,我们在从高层往低层搜索的时候,可以直接跳过一些节点,快速定位到目标分值所在的范围。这样就能把时间复杂度降到 O(log n)。
long skiplistGetRank(skiplist *zsl, double score, robj *obj) {
skiplistNode *x = zsl->header;
unsigned long rank = 0;
// 从最高层开始查找
for (int i = zsl->level - 1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
compareStringObjects(x->level[i].forward->obj, obj) < 0))) {
rank += x->level[i].span; // 累加跨度
x = x->level[i].forward;
}
// 找到目标节点
if (x->level[i].forward &&
x->level[i].forward->score == score &&
equalStringObjects(x->level[i].forward->obj, obj)) {
rank += x->level[i].span;
return rank;
}
}
return 0;
}为什么跳表的范围查询效率比字典高?
字典是通过哈希函数将键值对分散存储的,元素在内存中是无序分布的,没有任何顺序关系。而跳表本身就是有序的数据结构,所有元素按照分值从小到大排列。
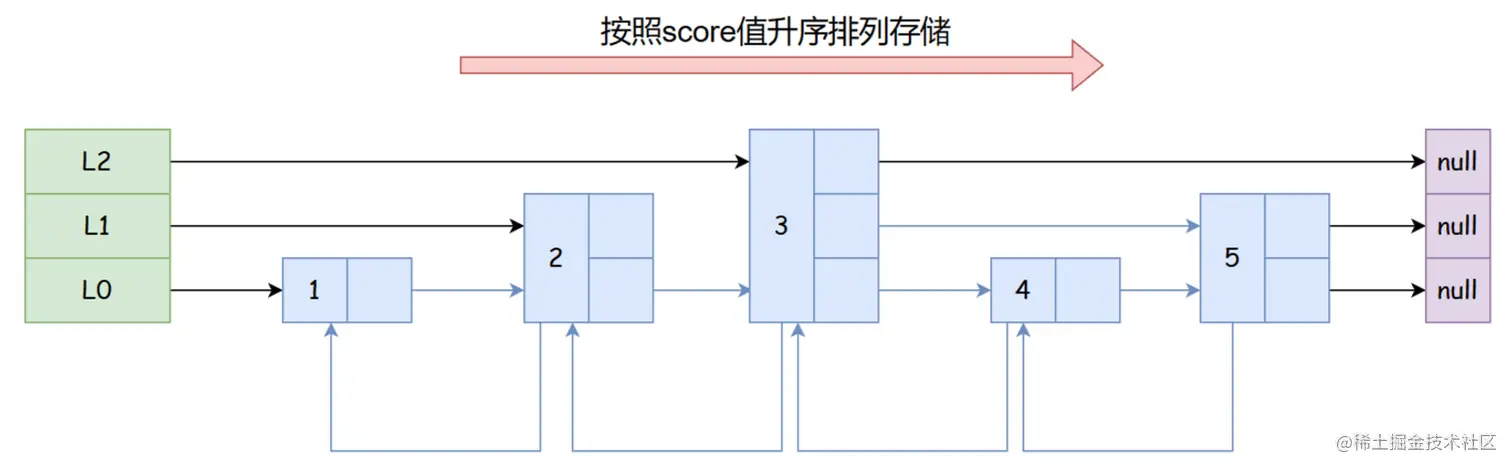
当需要进行范围查询时,字典必须遍历所有元素,逐个检查每个元素是否在指定范围内,时间复杂度是 O(n)。比如要找分值在 60 到 80 之间的所有元素,字典只能把整个哈希表扫描一遍,因为它无法知道符合条件的元素在哪里。
而跳表的范围查询就高效多了。首先用 O(log n) 时间找到范围的起始位置,然后沿着底层的有序链表顺序遍历,直到超出范围为止。总时间复杂度是 O(log n + k),其中 k 是结果集的大小。这种效率差异在数据量大的时候非常明显。
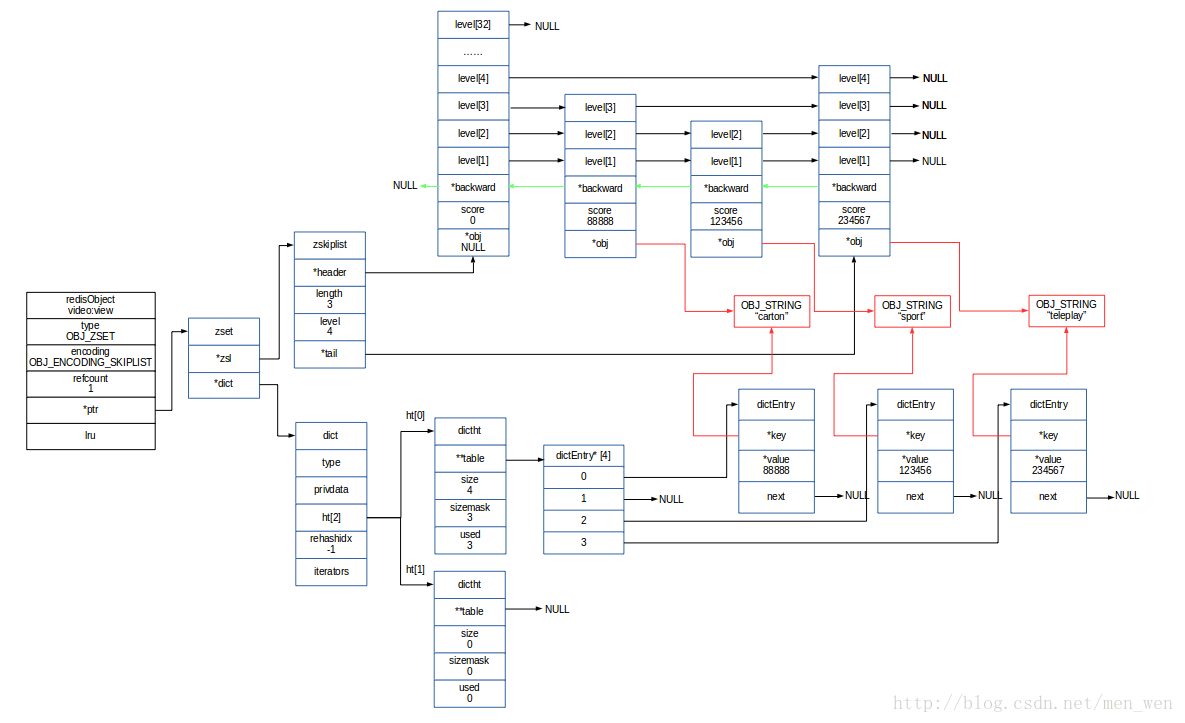
这也是为什么 Redis 的 zset 要用跳表而不是纯哈希表的重要原因,因为 zset 经常需要 ZRANGE、ZRANGEBYSCORE 这类范围操作。实际上 Redis 的 zset 是跳表和哈希表的组合:跳表保证有序性支持范围查询,哈希表保证 O(1) 的单点查找效率,两者互补。
- Java 面试指南(付费)收录的小米暑期实习同学 E 一面面试原题:为什么 hash 表范围查询效率比跳表低
- Java 面试指南(付费)收录的得物面经同学 8 一面面试原题:跳表的结构
- Java 面试指南(付费)收录的美团面经同学 4 一面面试原题:Redis 跳表
- Java 面试指南(付费)收录的阿里系面经同学 19 饿了么面试原题:跳表了解吗
memo:2025 年 6 月 8 日,今天有球友发信息称赞 Java 进阶之路的内容写得好,说实话,我是有这个自信的,基本上所写的内容也都是我这些年从读到的所有书籍、视频、教程中提炼到的精华,把一些难懂晦涩的知识都用通俗易懂的语言表达出来,配合手绘图,能让人更容易理解。

53.压缩列表了解吗?
答:压缩列表是 Redis 为了节省内存而设计的一种紧凑型数据结构,它会把所有数据连续存储在一块内存当中。
整个结构包含头部信息,如总的字节数、尾部偏移量、节点数量,以及连续的节点数据。

当 list、hash 和 set 的数据量较小且值都不大时,底层会使用压缩列表来实现。

通常情况在,每个节点包含三个部分:前一个节点的长度、编码类型和实际的数据。
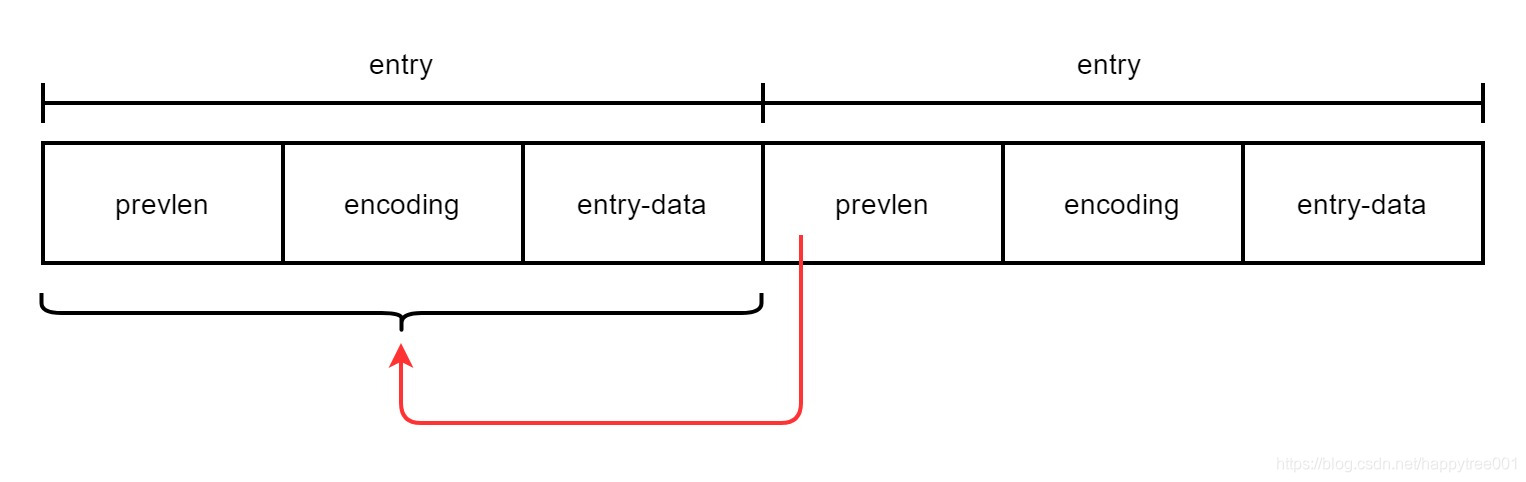
前一个节点的长度是为了支持从后往前遍历;当前一个节点的长度小于 254 字节时,使用 1 字节存储;否则用 5 字节存储,第一个字节设置为 254,后四个字节存储实际长度。
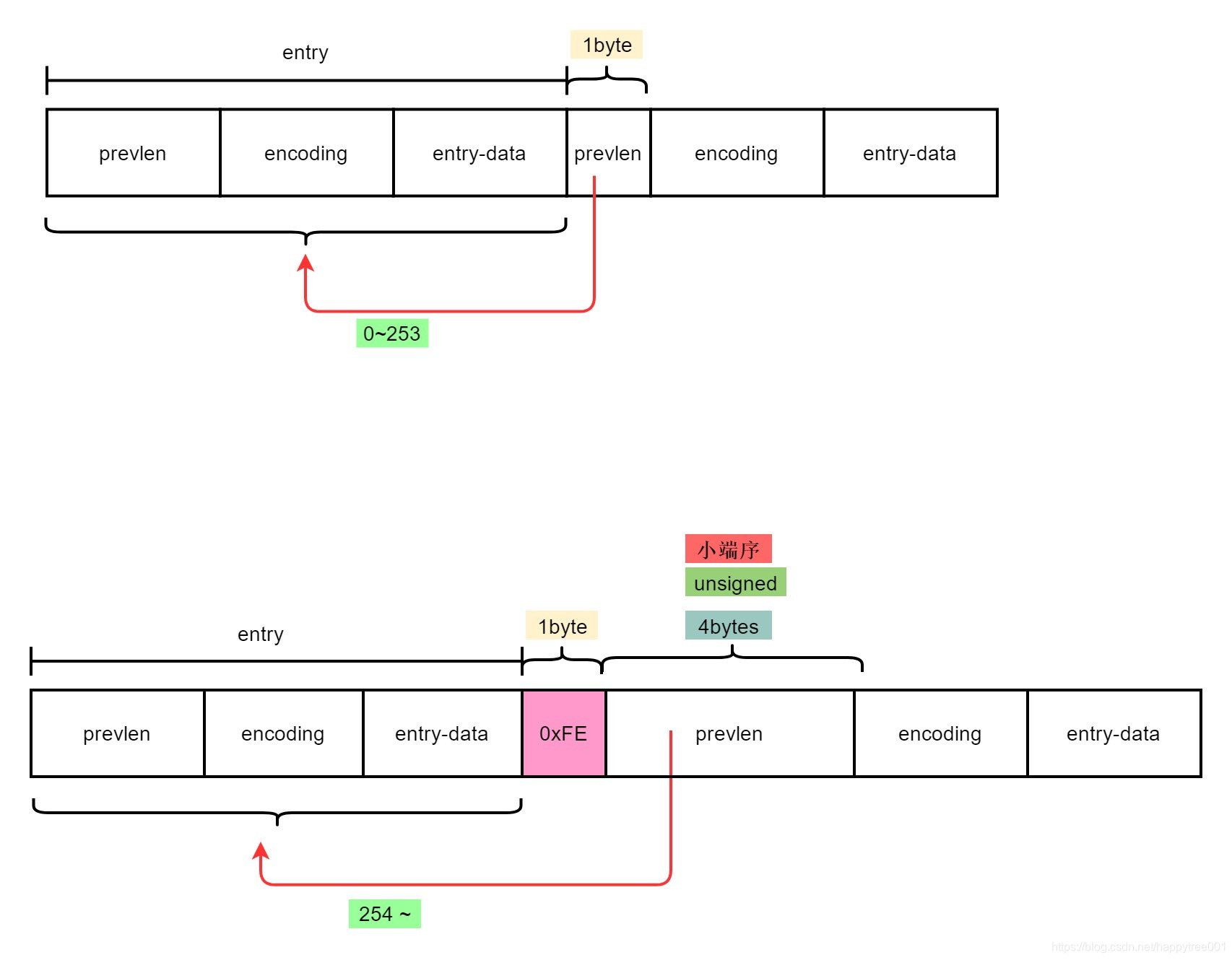
编码类型会根据数据的实际情况选择最紧凑的存储方式。

但压缩列表有个致命问题,就是连锁更新。当插入或删除节点导致某个节点长度发生变化时,可能会影响后续所有节点存储的“前一个节点长度”字段,最坏情况下时间复杂度会退化到 O(n²)。
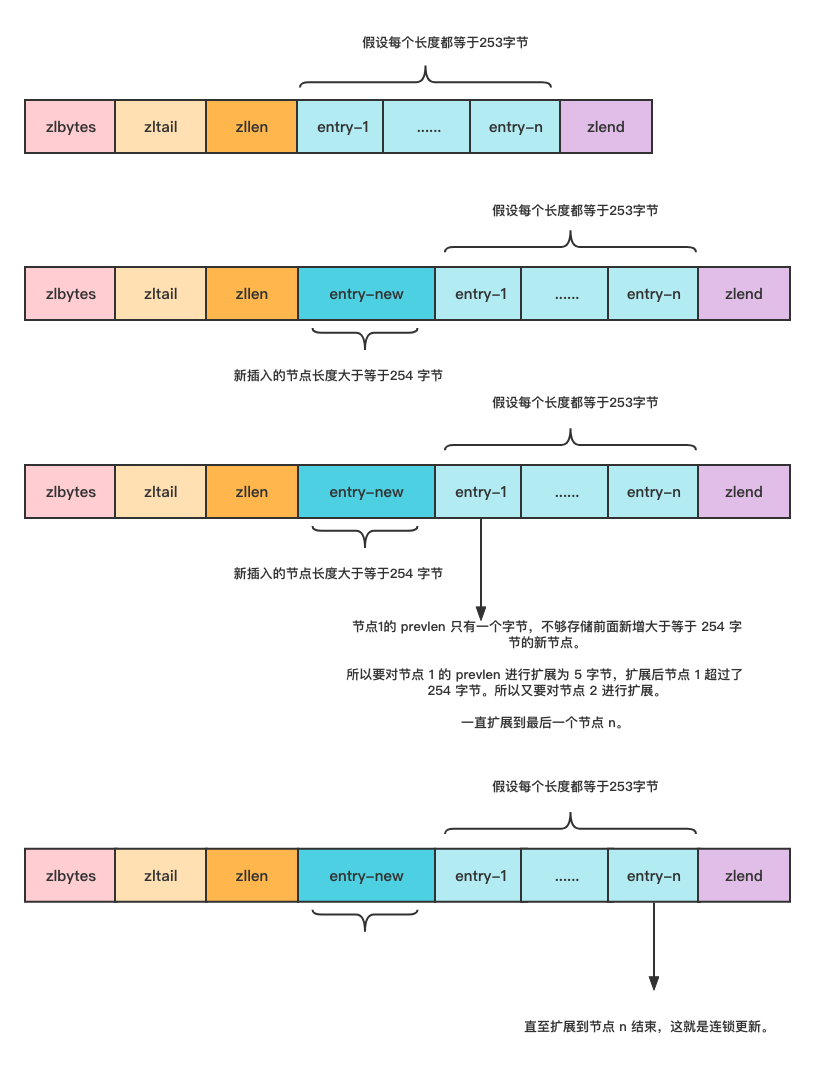
ziplist 的节点数量会超过 65535 吗?
不会。
Zllen 字段的类型是 uint16_t,最大值为 65535,也就是 2 的 16次方,所以压缩列表的节点数量不会超过 65535。
当节点数量小于 65535 时,该字段会存储实际的数量;否则该字段就固定为 65535,实际存储的数量需要逐个遍历节点来计算。
ziplist 的编码类型了解多少?
ziplist 的编码类型设计得很精巧,主要分为字符串编码和整数编码两大类,目的是用最少的字节存储数据。
比如 0 到 12 这些小整数直接编码在 type 字段中,只需要 1 个字节。
| 编码 | 长度 | 描述 |
|---|---|---|
| 11000000 | 1字节 | int16_t类型整数,2 字节 |
| 11010000 | 1字节 | int32_t类型整数,4 字节 |
| 11100000 | 1字节 | int64_t类型整数,8 字节 |
| 11110000 | 1字节 | 24位有符号整数 ,3 字节 |
| 1111xxxx | 1字节 | 数据范围在[0-12],数据包含在编码中 |
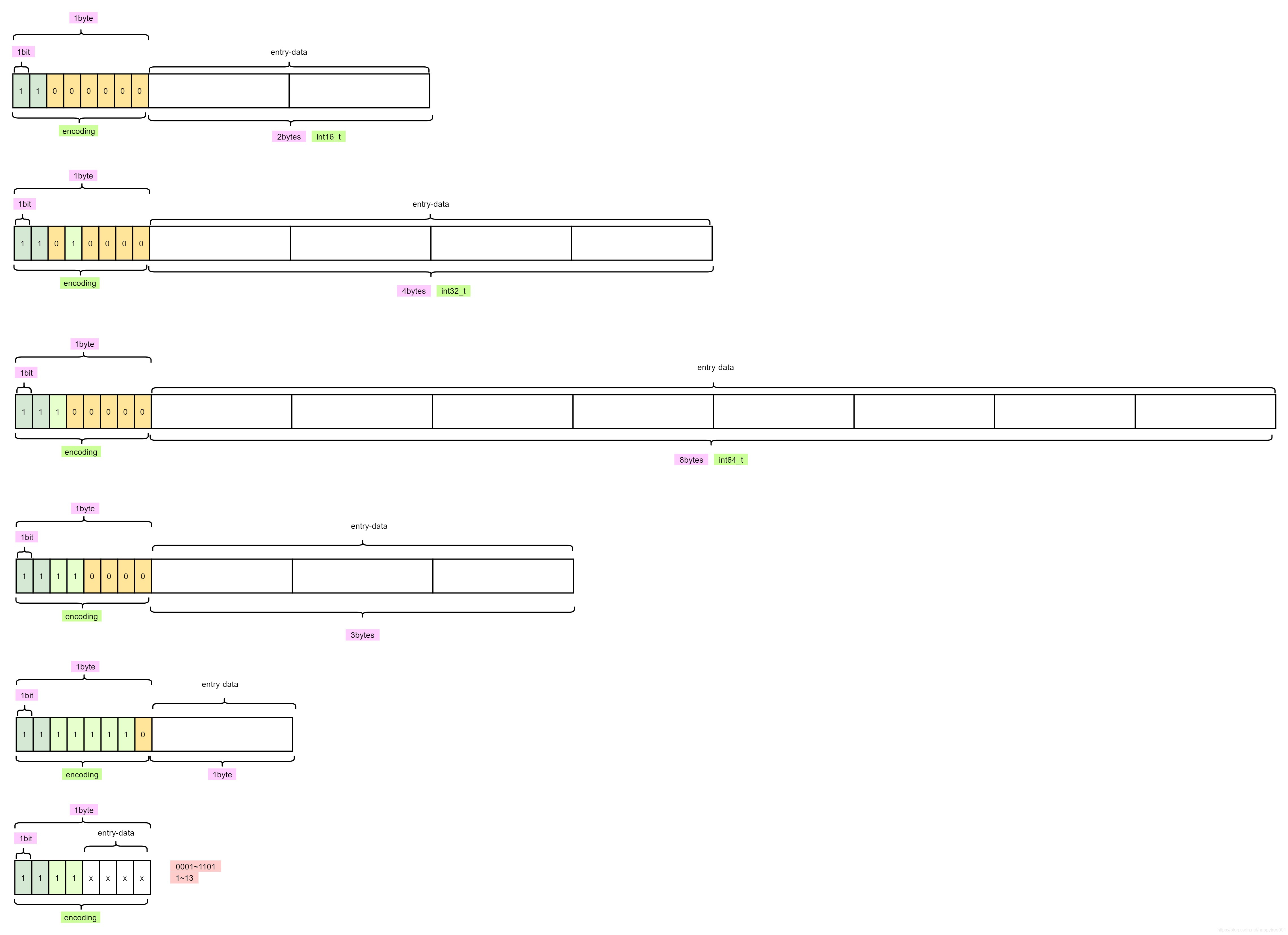
对于字符串编码,根据字符串长度有三种格式。长度小于 63 字节的用 00 开头的单字节编码,剩余 6 位存储长度。长度在 63 到 16383 之间的用 01 开头的双字节编码,剩余 14 位存储长度。超过 16383 字节的用 10 开头,后面跟 4 字节存储长度。
| 编码 | 长度 | 描述 |
|---|---|---|
| 00pppppp | 1字节 | 0-63 字节的字符串 |
| 01pppppp qqqqqqqq | 2字节 | 64-16383字节的字符串 |
| 10______ qqqqqqqq rrrrrrrr ssssssss tttttttt | 5字节 | 16384-4294967295字节的字符串 |
- Java 面试指南(付费)收录的同学 30 腾讯音乐面试原题:什么情况下使用压缩列表
memo:2025 年 6 月 9 日修改至此,今天有球友特意发私信,感谢面渣逆袭对他的帮助。对,这么棒的内容,我依然选择了免费,因为我相信知识是有价值的,只有诚恳的分享出来才能让更多人受益。
54.quicklist 了解吗?
quicklist 是 Redis 在 3.2 版本时引入的,专门用于 List 的底层实现,它实际上是一个混合型数据结构,结合了压缩列表和双向链表的优点。
在早期的版本中,List 会根据元素的数量和大小采用两种不同的底层数据结构,当元素较少或者较小时,会使用压缩列表;否则用双向链表。
但这种设计有个问题,就是当 List 中的元素数量较多时,压缩列表会因为连锁更新导致性能下降,而双向链表又会占用更多内存。
quicklist 通过将 List 拆分为多个小的 ziplist,再通过指针链接成一个双向链表,巧妙的解决了这个问题。
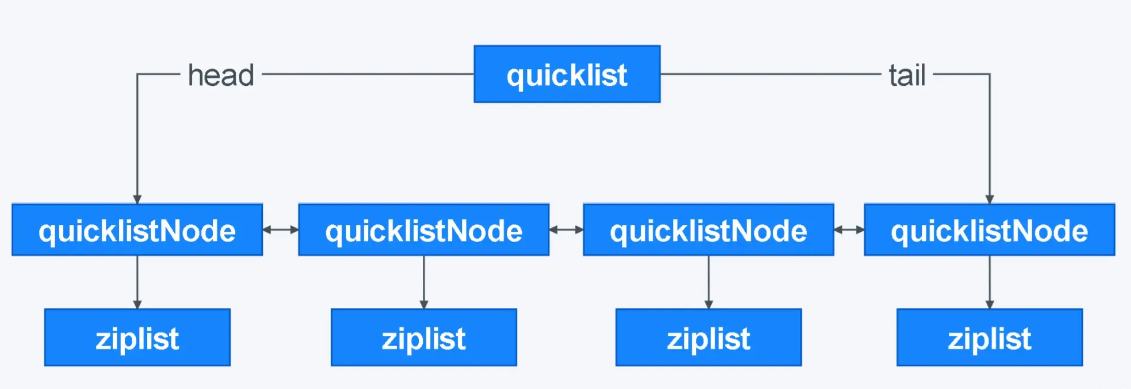
默认情况下,每个 ziplist 可以存储 8KB 的数据,假如每个元素的大小恰好是 1KB,那么一个 quicklist 就可以存储 8 个元素。80 个这样的元素就会被分成 10 个 ziplist。
这样既保留了压缩列表的内存紧凑性,又减少了双向链表指针的数量,进一步降低了内存开销。
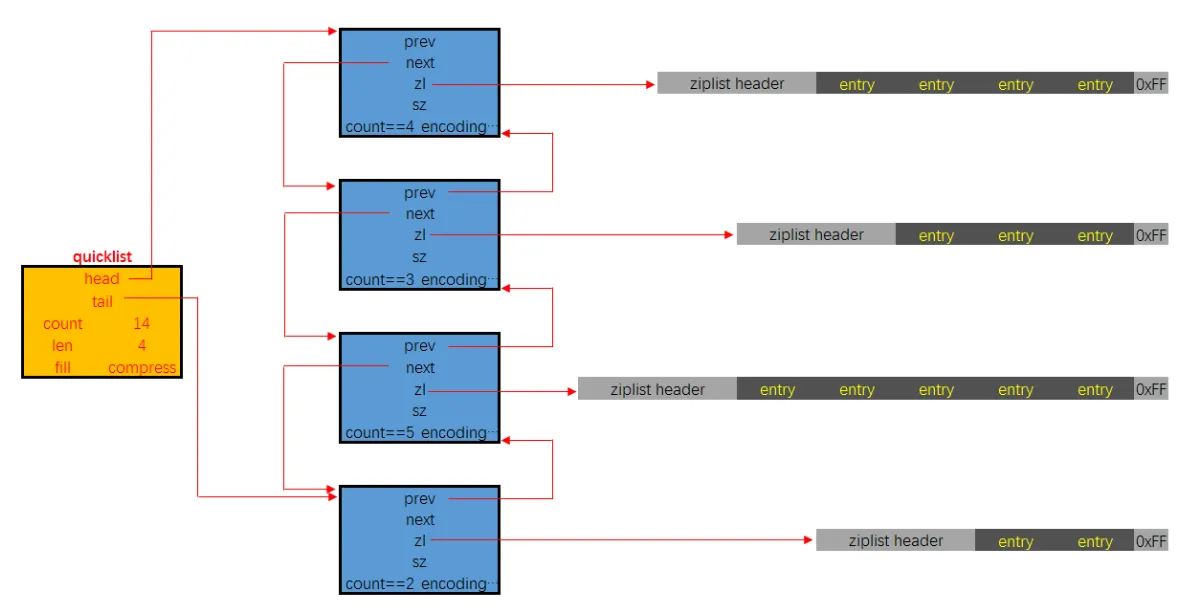
除此之外,quicklist 还有一个重要的特性,就是它的可配置性,可以通过填充因子控制每个 ziplist 节点的大小。当填充因子为正数时,它还可以限制每个 ziplist 最多包含的元素数量。
# 填充因子,默认 -2(8KB)
list-max-ziplist-size 10如果想进一步节省内存,quicklist 还支持对中间节点进行 LZF 压缩,压缩深度为 1 时,表示除了首尾各 1 个节点不压缩外,其他节点都压缩。
# 压缩深度,默认 0(不压缩)
list-compress-depth 1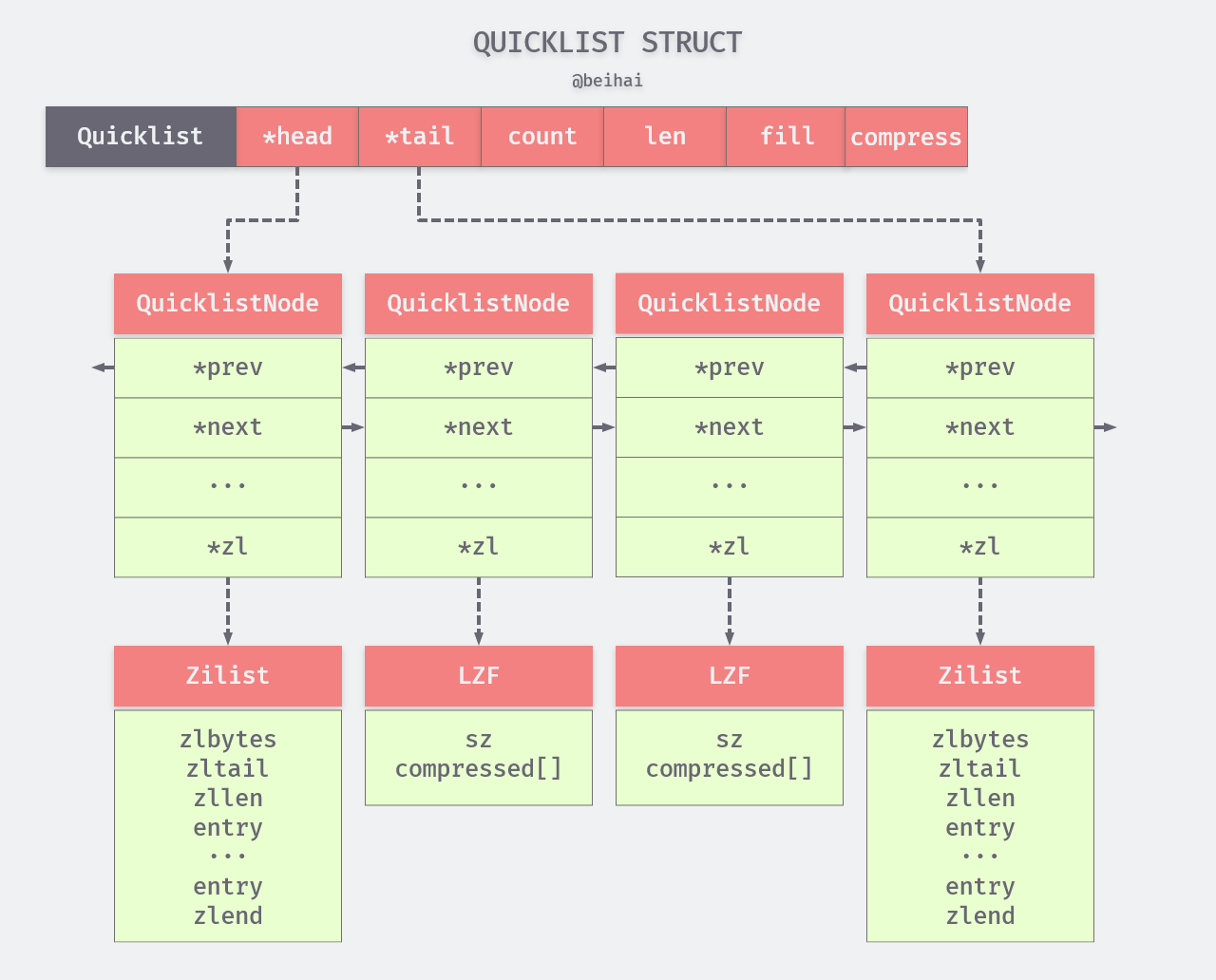
LZF 压缩算法了解吗?
LZF 是一种快速的无损压缩算法,主要用于减少数据存储空间。它的核心思想是通过查找重复数据来实现压缩,通过一个滑动窗口来查找重复的字节序列,并将这些序列替换为更短的引用。
输入数据: "hello world hello redis"
步骤1: 处理 "hello world "
- 建立字典,记录字节序列位置
步骤2: 遇到重复的 "hello"
- 在字典中找到之前的 "hello" 位置
- 用 (距离, 长度) 对替换: (12, 5)
输出: "hello world " + (12,5) + " redis"嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 6 月 10 日,今天有球友发信息说找我修改了简历后,又按照星球的学习资料好好学了一下之后,拿到了字节跳动的 offer,并特意发了一个大红包来感谢。这种被认可被需要的感觉,真好!

补充
55.假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如何将它们全部找出来?
我会使用 SCAN 命令配合 MATCH 参数来解决。
比如要找以 user: 开头的 key,可以执行 SCAN 0 MATCH user:* COUNT 1000。
SCAN 的优势在于它是基于游标的增量迭代,每次只返回一小批结果,不会阻塞服务器。可以从游标 0 开始,每次处理返回的 key 列表,然后用返回的下一个游标继续扫描,直到游标回到 0 表示扫描完成。
使用 Spring Data Redis 的代码示例:
@Service
public class RedisKeyService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public List<String> scanKeysByPrefix(String prefix, int batchSize) {
List<String> keys = new ArrayList<>();
ScanOptions options = ScanOptions.scanOptions()
.match(prefix + "*")
.count(batchSize)
.build();
try (Cursor<String> cursor = redisTemplate.scan(options)) {
while (cursor.hasNext()) {
keys.add(cursor.next());
}
}
return keys;
}
}千万不要用 KEYS 命令,因为 KEYS 会阻塞 Redis 服务器直到遍历完所有 key,在生产环境中对 1 亿个 key 执行 KEYS 是非常危险的。
memo:2025 年 6 月 11 日修改至此,今天有读者留言说,找实习的时候背了一个月的面渣逆袭,然后快手和美团都拿到 offer 了。能帮助到大家,也是我做技术博主最开心的一件事情了,也感谢读者给的口碑。
56.Redis在秒杀场景下可以扮演什么角色?
秒杀是一种非常特殊的业务场景,它的特点是在极短时间内会有大量用户涌入系统,对系统的并发处理能力、响应速度和数据一致性都提出了极高的要求。在这种场景下,Redis 作为一种高性能的内存数据库,能够发挥多方面的关键作用。
比如说在秒杀开始前,我们可以将商品信息、库存数据等预先加载到 Redis 中,这样大量的用户读请求就可以直接从 Redis 中获取响应,而不必每次都去访问数据库,这样就能大大减轻数据库的访问压力。
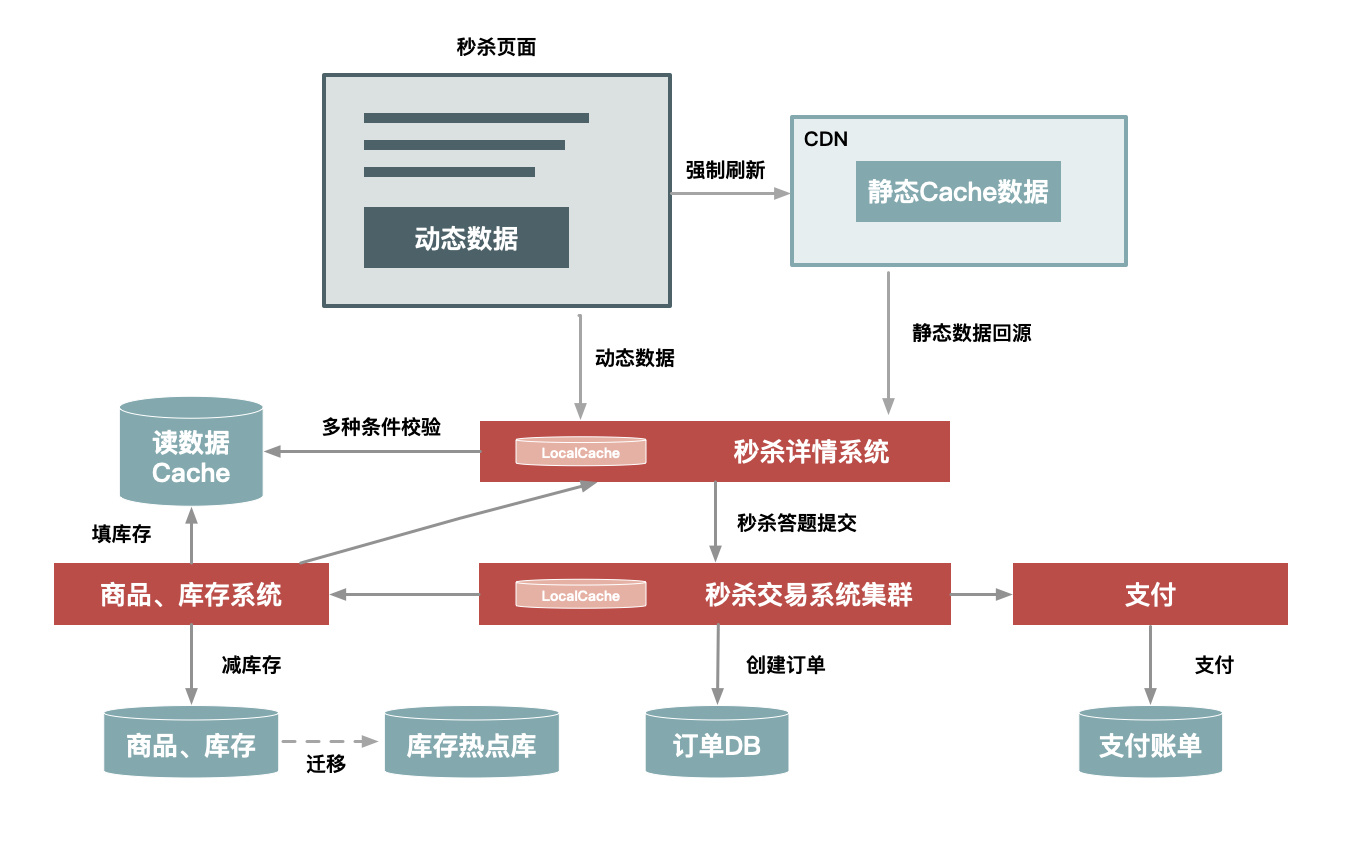
其次,Redis 在库存控制方面具有得天独厚的优势。秒杀最核心的问题之一就是容易发生超卖。Redis 提供的原子操作如 DECR、DECRBY 等命令,可以确保在高并发环境下库存计数的准确性。
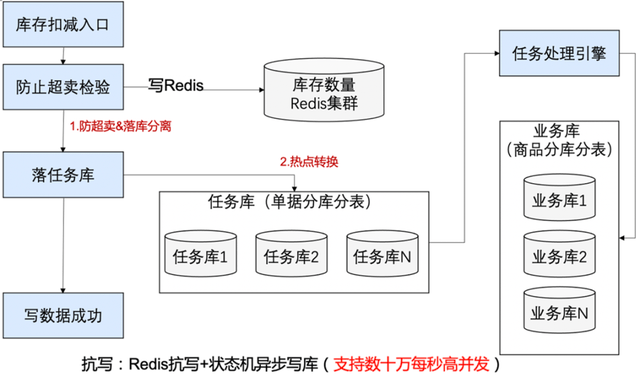
更复杂的逻辑,可以通过 Lua 脚本来实现,因为 Lua 脚本在 Redis 中是原子执行的,所以可以包含复杂的判断和操作逻辑,比如先检查库存是否充足,再进行扣减,这整个过程是不会被其他操作打断的。
第三点,Redis 的分布式锁可以确保多个用户同时抢购同一件商品时的操作是互斥的,保证数据一致性的同时,还可以用来防止用户重复下单。
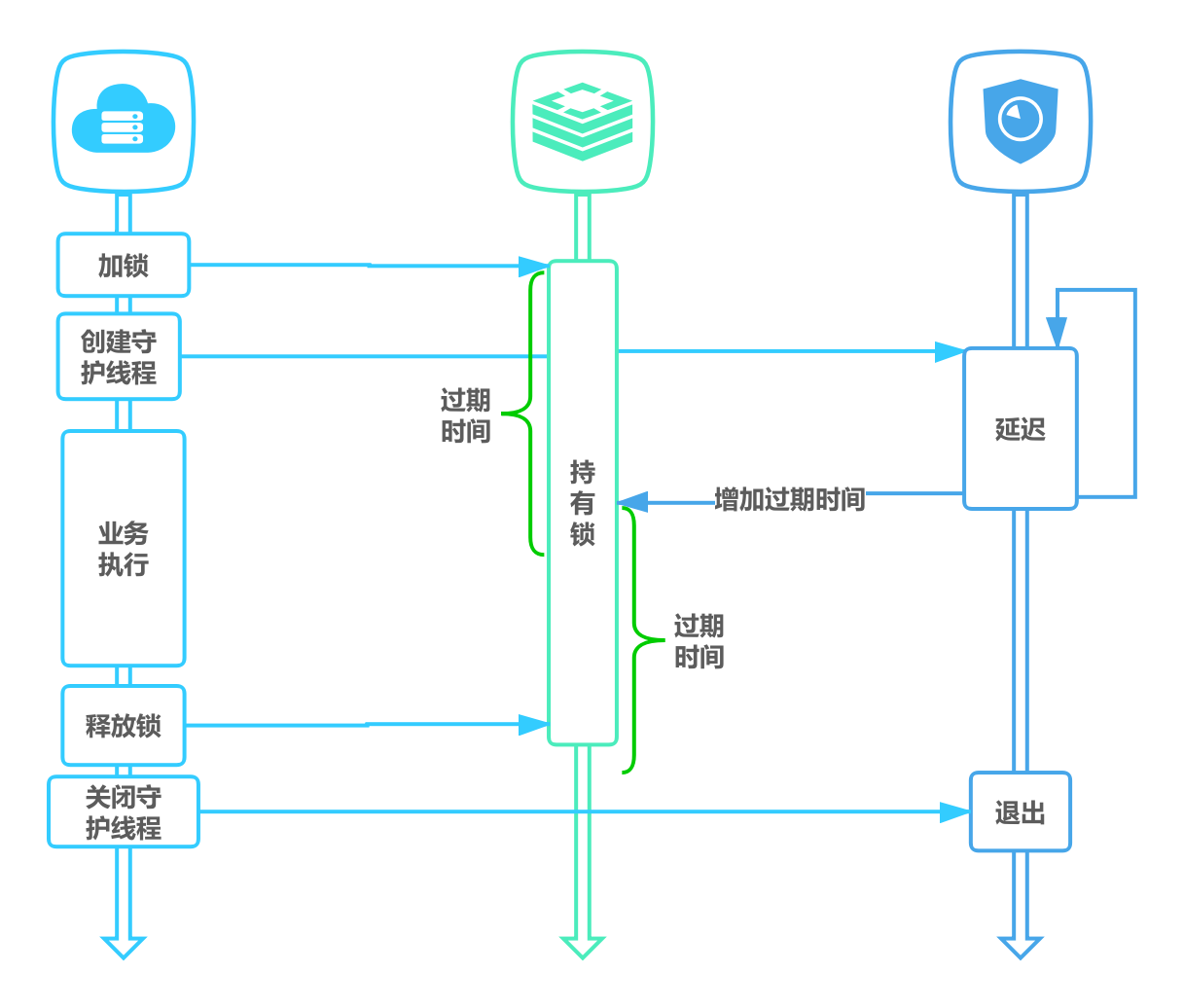
第四点,限流削峰。秒杀开始的瞬间,可能会有成千上万的请求同时到达,如果不加控制,很容易导致系统崩溃。Redis 可以实现多种限流算法,比如简单的计数器限流、令牌桶或漏桶算法等。
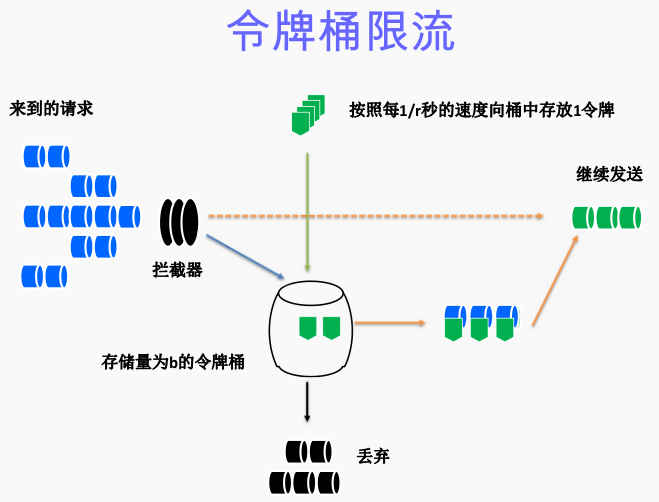
通过限流算法我们可以控制单位时间内系统能够处理的请求数量,超出部分可以排队或者直接拒绝,从而保护系统的稳定运行。
memo:2025 年 6 月 12 日修改至此,今天有球友发信息说,大二就拿下了美团的实习 offer,特意发来感谢,说我的付出对他有着巨大的帮助,真的很感动,每一个懂得感恩的球友,你们也是我坚持下去的最强动力。
Redis具体如何实现削峰呢?
削峰的本质是将瞬时的高流量请求缓冲起来,通过排队、限流等机制,使系统以一个可承受的速度来处理请求。
那第一步就是缓存预热。在秒杀活动开始前,先把商品信息这些热点数据提前加载到 Redis 中。这样用户访问商品页面时,可以直接从 Redis 读取,数据库基本上不会有压力。
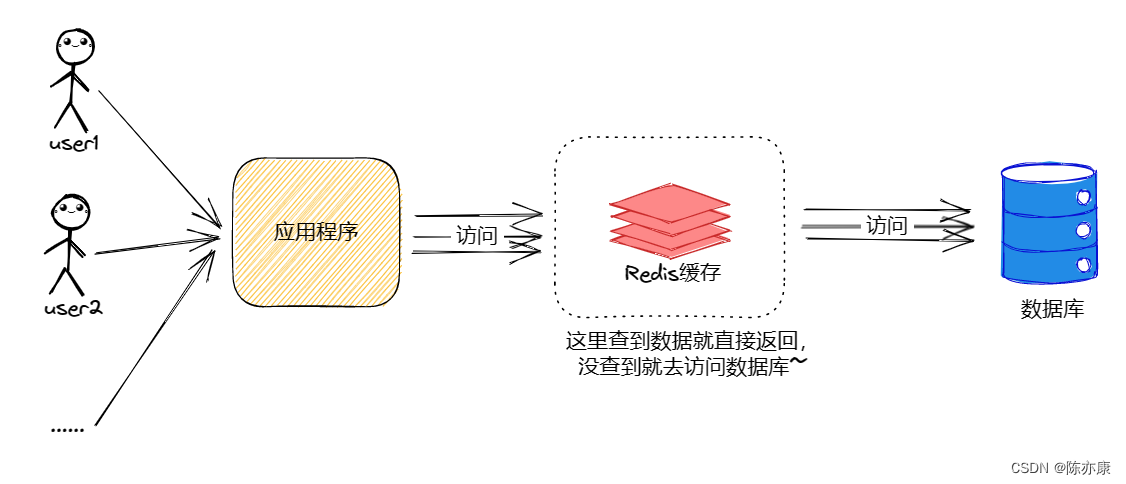
第二步是引入消息队列,特别是下单这种写操作,不能让用户等太久,但后端处理订单、扣库存这些操作又比较重。所以可以用 Redis 的 List 做了个队列,或者直接用 RocketMQ 这种标准的消息中间件,用户下单后立即返回"订单提交成功",然后把订单数据丢到队列里,后台服务慢慢消费。这样既保证了用户体验,又避免了系统被瞬时写请求压垮。
第三步,可以在秒杀活动中加入答题环节,只有答对题目的用户才能参与秒杀活动,这样可以最大程度减少无效请求。
一个比较完整的秒杀削峰处理方案:
@Service
public class SeckillServiceImpl implements SeckillService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
private OrderService orderService;
@Autowired
private CommodityService commodityService;
/**
* 秒杀请求入口
*/
public Result seckill(Long userId, Long commodityId) {
// 1. 用户请求频率限制
if (!countRateLimit("user:" + userId, 5, 60)) {
return Result.error("请求过于频繁");
}
// 2. 商品是否在秒杀时间内
if (!isInSeckillTime(commodityId)) {
return Result.error("秒杀未开始或已结束");
}
// 3. 是否还有库存(快速失败)
String stockKey = "seckill:stock:" + commodityId;
Integer stock = Integer.valueOf(redisTemplate.opsForValue().get(stockKey));
if (stock != null && stock <= 0) {
return Result.error("商品已售罄");
}
// 4. 全局限流
if (!acquireToken("global", 1000, 100)) {
// 系统负载过高,将请求放入队列延迟处理
enqueueDelayedRequest(userId, commodityId);
return Result.success("秒杀请求已受理,排队处理中");
}
// 5. 检查用户是否已购买
if (hasUserBought(userId, commodityId)) {
return Result.error("您已经购买过该商品");
}
// 6. 将请求放入队列,返回排队状态
String requestId = generateRequestId(userId, commodityId);
enqueueRequest(userId, commodityId, requestId);
return Result.success("秒杀请求已提交,请等待结果", requestId);
}
/**
* 异步处理秒杀请求
*/
@Scheduled(fixedRate = 50) // 每50ms处理一批
public void processSeckillQueue() {
String queueKey = "seckill:queue";
// 批量处理,控制处理速度
for (int i = 0; i < 10; i++) {
String requestJson = redisTemplate.opsForList().leftPop(queueKey);
if (requestJson == null) {
break;
}
SeckillRequest request = JSON.parseObject(requestJson, SeckillRequest.class);
try {
// 执行秒杀核心逻辑
boolean success = doSeckill(request.getUserId(), request.getCommodityId());
// 更新请求状态,便于用户查询
String statusKey = "seckill:status:" + request.getRequestId();
redisTemplate.opsForValue().set(statusKey, success ? "SUCCESS" : "FAILED", 1, TimeUnit.HOURS);
} catch (Exception e) {
log.error("处理秒杀请求失败", e);
// 记录失败状态
String statusKey = "seckill:status:" + request.getRequestId();
redisTemplate.opsForValue().set(statusKey, "ERROR", 1, TimeUnit.HOURS);
}
}
}
/**
* 秒杀核心逻辑
*/
private boolean doSeckill(Long userId, Long commodityId) {
// 使用Lua脚本保证原子性操作
String script =
"-- 检查库存\n" +
"local stockKey = KEYS[1]\n" +
"local stock = tonumber(redis.call('get', stockKey))\n" +
"if stock == nil or stock <= 0 then\n" +
" return 0\n" +
"end\n" +
"\n" +
"-- 检查是否重复购买\n" +
"local boughtKey = KEYS[2]\n" +
"local hasBought = redis.call('sismember', boughtKey, ARGV[1])\n" +
"if hasBought == 1 then\n" +
" return -1\n" +
"end\n" +
"\n" +
"-- 扣减库存并记录购买\n" +
"redis.call('decr', stockKey)\n" +
"redis.call('sadd', boughtKey, ARGV[1])\n" +
"\n" +
"-- 返回成功\n" +
"return 1";
String stockKey = "seckill:stock:" + commodityId;
String boughtKey = "seckill:bought:" + commodityId;
Long result = (Long) redisTemplate.execute(
new DefaultRedisScript<>(script, Long.class),
Arrays.asList(stockKey, boughtKey),
userId.toString()
);
if (result == 1) {
// 创建订单(可以进一步异步化)
createOrder(userId, commodityId);
return true;
}
return false;
}
// 其他辅助方法...
}Redis如何做限流呢?
限流是为了控制系统的请求速率,防止系统被过多的请求压垮。
Redis 实现限流最简单的方法是基于计数器的固定窗口限流。比如限制用户每分钟最多访问 100 次,我们就用 INCR 命令给每个用户设个计数器,key 是 rate_limit:用户ID:分钟时间戳,每次请求就加 1,同时设置 60 秒过期。如果计数超过 100 就拒绝请求。
// 伪代码
String key = "rate_limit:" + userId;
// 尝试获取当前计数
Long count = redis.get(key);
// 如果key不存在,设置为1并设置过期时间
if (count == null) {
redis.setex(key, 60, "1"); // 60秒窗口期
return true; // 允许访问
}
// 如果计数未超过限制
if (count < maxRequests) {
redis.incr(key);
return true; // 允许访问
}
return false; // 拒绝访问这种方法简单粗暴,但有个问题就是临界时间会有突刺,比如用户在第 59 秒访问了 100 次,第 61 秒又访问 100 次,相当于 2 秒内访问了 200 次。
第二种就是滑动窗口限流,通过 Redis 的 ZSET 来实现,把每次请求的时间戳作为 score 存进去,然后用 ZREMRANGEBYSCORE 删除窗口外的旧数据,再用 ZCARD 统计当前窗口内的请求数。这样限流就比较均匀了。
// 伪代码
String key = "sliding_window:" + userId;
long now = System.currentTimeMillis();
// 添加当前请求到有序集合,score为当前时间戳
redis.zadd(key, now, String.valueOf(now));
// 移除时间窗口之前的请求数据
redis.zremrangeByScore(key, 0, now - windowSize);
// 设置key过期时间,避免冷用户持续占用内存
redis.expire(key, windowSize / 1000 + 1);
// 获取当前窗口的请求数
Long count = redis.zcard(key);
return count <= maxRequests;在实际开发中,通常会采用令牌桶算法,它就像在帝都/魔都买车,摇到号才有资格,没摇到就只能等下一次(😁)。
可以在 Redis 里存两个值,一个是令牌数量,一个是上次更新时间。每次请求时用 Lua 脚本计算应该补充多少令牌,然后判断是否有足够的令牌。
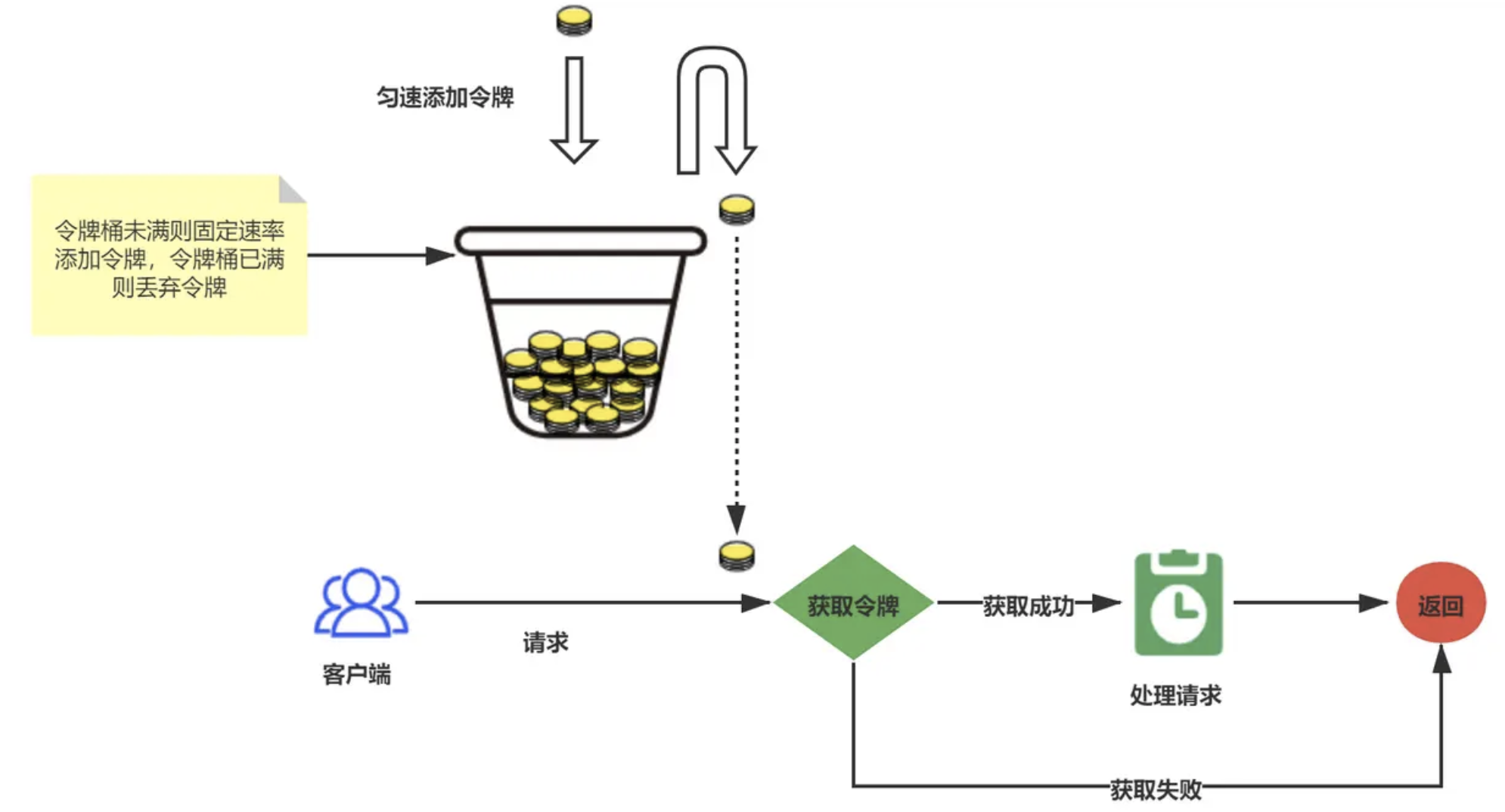
-- Redis Lua脚本实现令牌桶算法
local key = KEYS[1] -- 限流的key
local max_permits = tonumber(ARGV[1]) -- 最大令牌数
local permits_per_second = tonumber(ARGV[2]) -- 每秒产生的令牌数
local required_permits = tonumber(ARGV[3]) -- 请求的令牌数
-- 获取当前时间
local time = redis.call('time')
local now_micros = tonumber(time[1]) * 1000000 + tonumber(time[2])
-- 获取上次更新的时间和当前存储的令牌数
local last_micros = tonumber(redis.call('hget', key, 'last_micros') or 0)
local stored_permits = tonumber(redis.call('hget', key, 'stored_permits') or 0)
-- 计算时间间隔内新产生的令牌数
local interval_micros = now_micros - last_micros
local new_permits = interval_micros * permits_per_second / 1000000
stored_permits = math.min(max_permits, stored_permits + new_permits)
-- 判断令牌是否足够
local result = 0
if stored_permits >= required_permits then
-- 令牌足够,更新令牌数和时间
stored_permits = stored_permits - required_permits
result = 1
end
-- 更新Redis中的数据
redis.call('hset', key, 'last_micros', now_micros)
redis.call('hset', key, 'stored_permits', stored_permits)
redis.call('expire', key, 10) -- 设置过期时间,避免长期占用内存
return result
- Java 面试指南(付费)收录的农业银行面经同学 3 Java 后端面试原题:秒杀问题(错峰、削峰、前端、流量控制)
- Java 面试指南(付费)收录的滴滴面经同学 3 网约车后端开发一面原题:限流算法
memo:2025 年 6 月 13 日修改至此,今天在修改简历的过程中,碰到一位西安交通大学的球友,他整个校园经历是比较丰富的,先去了新加坡国立大学做暑期交换生,然后又去了加州大学伯克利分校做学期交换生,希望大家也都能在学校阶段尽量丰富自己的经历,争取多拿一些奖学金、实习经历,这样才能在毕业时有更强的竞争力。

57.客户端宕机后 Redis 服务端如何感知到?
TCP 的 keepalive 是 Redis 用来检测客户端连接状态的主要机制,默认值为 300 秒。
# 针对低延迟场景,设置为60秒,表示每60秒发送一次keepalive探测
config set tcp-keepalive 60当客户端与服务器在指定时间内没有任何数据交互时,Redis 服务器会发送 TCP ACK 探测包,如果连续多次没有收到响应,TCP 协议栈会通知 Redis 服务端连接已断开,之后,Redis 服务端会清理相关的连接资源,释放连接。
另外还有一个 timeout 参数,用来控制客户端连接的空闲超时时间。
# 表示600秒内没有任何命令则断开连接
config set timeout 600默认值为 0,表示永不断开连接;当设置为非零值时,如果客户端在指定时间内没有发送任何命令,服务端会主动断开连接。
Redis 服务器会定期检查空闲连接是否超时,检查频率由 hz 参数控制;这将有助于释放那些客户端异常退出但 TCP 连接未正常关闭的资源。
不同的连接池也会有自己的连接检测机制,比如 Jedis 连接池可以通过设置 testOnBorrow 和 testWhileIdle 来启用连接检测。
# 是否启用连接池
spring.redis.jedis.pool.enabled=true
# 连接池最大连接数(使用负值表示没有限制)
spring.redis.jedis.pool.max-active=200
# 连接池最大空闲连接数
spring.redis.jedis.pool.max-idle=200
# 连接池最小空闲连接数
spring.redis.jedis.pool.min-idle=50
# 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.jedis.pool.max-wait=3000
# 空闲连接检查间隔(毫秒)
spring.redis.jedis.pool.time-between-eviction-runs=60000
- Java 面试指南(付费)收录的字节跳动面经同学 21 抖音商城一面面试原题:如果客户端宕机服务器如何感知?
memo:2025 年 6 月 14 日修改至此,今天有球友在 VIP 群里发消息说,快手oc 了,恭喜他。球友们都太有实力了。
整整一个半月,面渣逆袭 Redis 篇第二版终于整理完了,这一版几乎可以说是重写了,每天耗费了大量的精力在上面,可以说是改头换面,有一种士别俩月,当刮目相看的感觉(从 1.8 万字暴涨到 4.6 万字,加餐的同时区分高频低频版)。
网上的八股其实不少,有些还是付费的,我觉得是一件好事,可以给大家提供更多的选择,但面渣逆袭的含金量懂的都懂。
面渣逆袭第二版是在星球嘉宾三分恶的初版基础上,加入了二哥自己的思考,加入了 1000 多份真实面经之后的结果,并且从 24 届到 25 届,再到 26 届,帮助了很多小伙伴。未来的 27、28 届,也将因此受益,从而拿到心仪的 offer。
能帮助到大家,我很欣慰,并且在重制面渣逆袭的过程中,我也成长了很多,很多薄弱的基础环节都得到了加强,因此第二版的面渣逆袭不只是给大家的礼物,也是我在技术上蜕变的记录。
很多时候,我觉得自己是一个佛系的人,不愿意和别人争个高低,也不愿意去刻意宣传自己的作品。
我喜欢静待花开。
如果你觉得面渣逆袭还不错,可以告诉学弟学妹们有这样一份免费的学习资料,帮我做个口碑。
我还会继续优化,也不确定第三版什么时候会来,但我会尽力。
愿大家都有一个光明的未来。
由于 PDF 没办法自我更新,所以需要最新版的小伙伴,可以微信搜【沉默王二】,或者扫描/长按识别下面的二维码,关注二哥的公众号,回复【222】即可拉取最新版本。
当然了,请允许我的一点点私心,那就是星球的 PDF 版本会比公众号早一个月时间,毕竟星球用户都付费过了,我有必要让他们先享受到一点点福利。相信大家也都能理解,毕竟在线版是免费的,CDN、服务器、域名、OSS 等等都是需要成本的。
更别说我付出的时间和精力了,大家觉得有帮助还请给个口碑,让你身边的同事、同学都能受益到。
我把二哥的 Java 进阶之路、JVM 进阶之路、并发编程进阶之路,以及所有面渣逆袭的版本都放进来了,涵盖 Java基础、Java集合、Java并发、JVM、Spring、MyBatis、计算机网络、操作系统、MySQL、Redis、RocketMQ、分布式、微服务、设计模式、Linux 等 16 个大的主题,共有 40 多万字,2000+张手绘图,可以说是诚意满满。
这次仍然是三个版本,亮白、暗黑和 epub 版本。给大家展示其中一个 epub 版本吧,有些小伙伴很急需这个版本,所以也满足大家了。
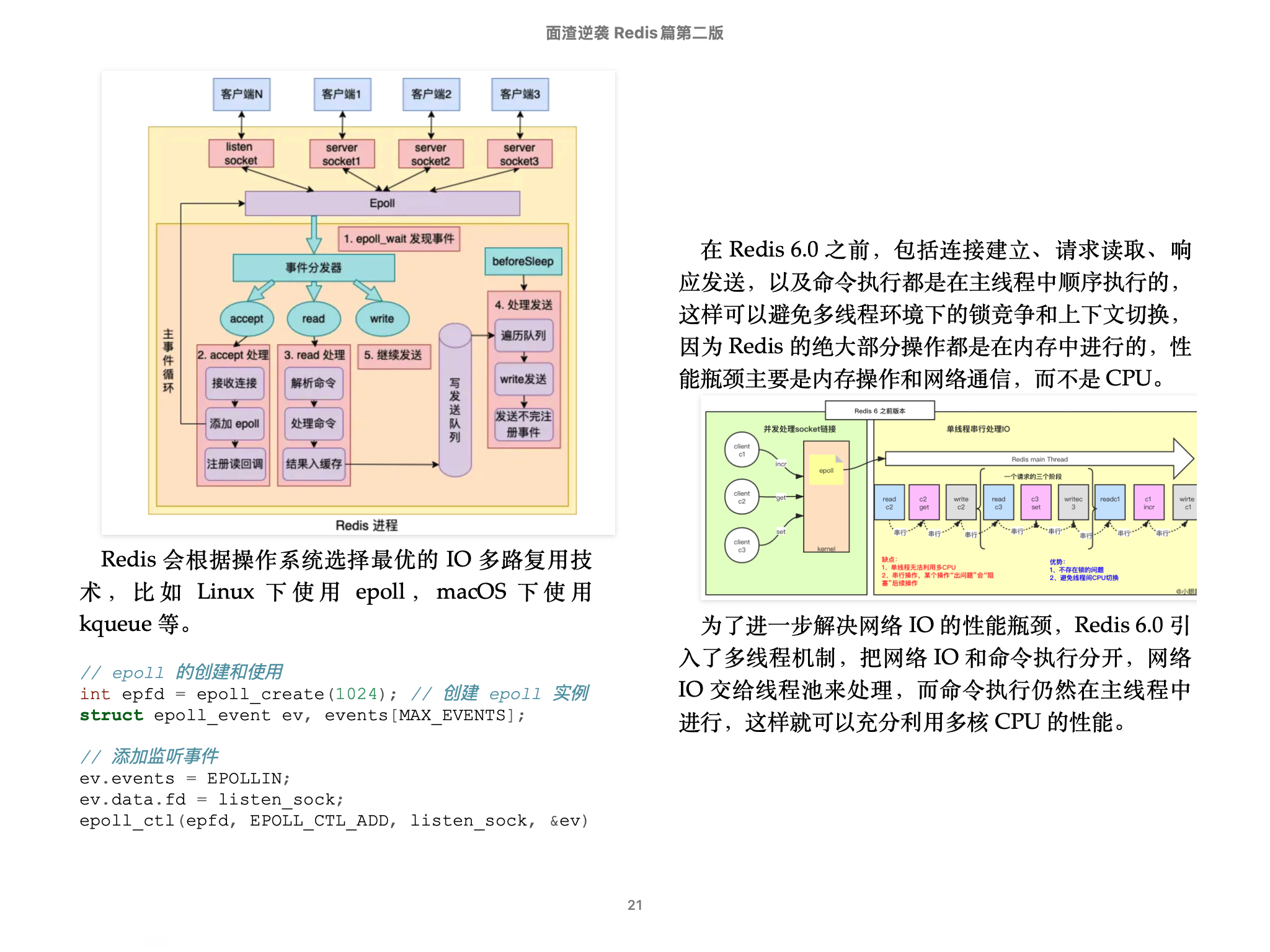
图文详解 57 道 Redis 面试高频题,这次吊打面试官,我觉得稳了(手动 dog)。整理:沉默王二,戳转载链接,作者:三分恶,戳原文链接。
没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。
系列内容: