手机用的大模型开源了,MiniCPM-V 4.6 真的顶。
大家好,我是二哥呀。
手机跑大模型这件事,之前一直有点像“概念车”——发布会上很酷,日常生活中压根用不上。不是模型太大手机塞不下,主要是跑起来太慢。
但最近面壁智能开源的 MiniCPM-V 4.6 让我改变了看法。
1.3B 参数,能看图能理解视频,在自己手机上跑,速度非常快。更离谱的是,这么小的一个模型,多模态综合能力居然这么强。
今天这篇文章,我打算把 MiniCPM-V 4.6 从里到外扒一遍。
不光看跑分,还要聊明白几个大家可能好奇但又搞不太清楚的事儿:
- 手机 8GB 内存到底能跑多大的模型?
- 量化到底是怎么回事?
- 为什么 1B 到 2B 可能是端侧模型的甜点?
弄明白这些,再看这个 1.3B 小钢炮的厉害之处,感受完全不一样。
01、MiniCPM-V的成绩
MiniCPM-V 4.6 提供了 Instruct 和 Thinking 两种使用/评测模式。
综合能力上,在大部分图文理解任务里,4.6 超过了 Qwen3.5-0.8B;OpenBMB 的项目页还提到,它在性能上超过了更大的 Gemma4-E2B-it。
不是某一项强,是综合起来强。
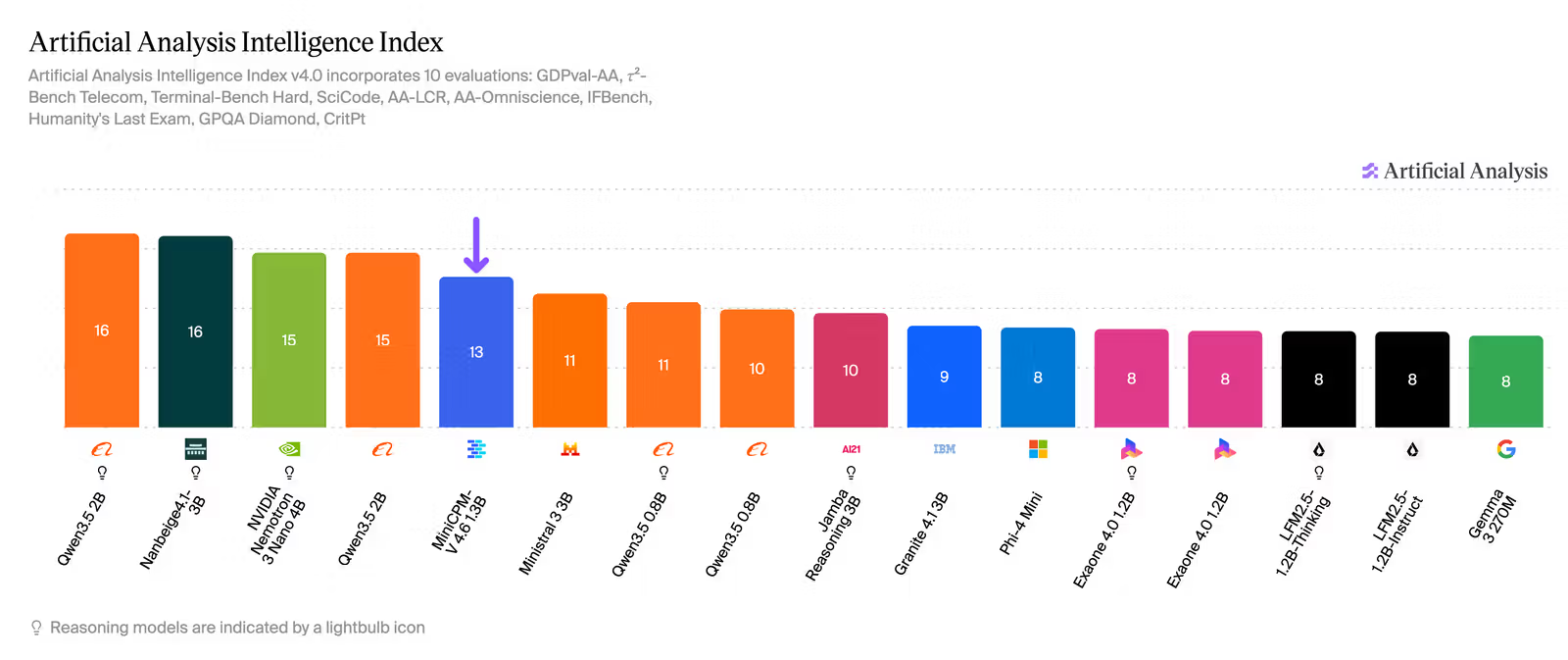
在 Artificial Analysis Intelligence Index 这个基准上,MiniCPM-V 4.6 拿了 13 分,Qwen3.5-0.8B 拿了 10 分。
更具体一点,在 OpenCompass、RefCOCO、HallusionBench、MUIRBench、OCRBench 这些 benchmark 上,4.6 摸到了 Qwen3.5 2B 版本的部分能力区间。注意,是部分视觉语言任务接近 2B 档,不等于它所有能力都压过 2B。
Artificial Analysis 的原文还有一个很有意思的细节:跑完整个 Intelligence Index,MiniCPM-V 4.6 Instruct 只用了 5.4M output tokens,而 Qwen3.5-0.8B 非推理版本用了 101M,Thinking 版本用了 233M。
这说明什么?
不是说大家日常用它每次都会少花 19 倍 token,而是说在同一套评测里,它用更短的输出拿到了更高的分数。对端侧和高并发场景来说,这个指标很关键,因为 token 少,通常就意味着延迟、算力、功耗都会更好看。
首响延迟也值得说一下。
处理 3136×3136 分辨率的高清大图,首次响应只需要 75.7ms,比 Qwen3.5-0.8B 快 2.2 倍。最让我意外的是,官方图里的分辨率-延迟曲线非常平,分辨率提高后,TTFT 没有跟着暴涨。这个特性对实际应用来说非常关键,用户不管传什么尺寸的图,体验都更可控。
02、手机能跑多大的模型
模型训练完之后,默认用 16 位浮点数(FP16)存储。
对于纯粹的语言模型,一个参数占 2 个字节,1.3B 参数就是 2.6GB,8B 参数就是 16GB。像 DeepSeek R1 那样的 671B 模型,原始状态需要 1342GB 内存,但之前很多人拿着 192GB 的 Mac 就跑起来了,靠的就是量化。
量化是什么呢?
就是减少每个参数的存储位数,把模型权重压小。
FP16 用 16 位存一个小数,能表示 65536 种不同的值。压到 8 位(Q8 或 INT8),只能表示 256 种值,存储空间减半。压到 4 位(Q4 或 INT4),只能表示 16 种值,空间再减半。
代价是什么?精度下降,模型会变笨。
Q4、INT4、AWQ、GPTQ,看着像四种完全不同的东西,其实都可以落到 4-bit 量化这个大类里。只是它们不能直接画等号,因为量化粒度、校准方法、权重格式、推理框架都不一样。
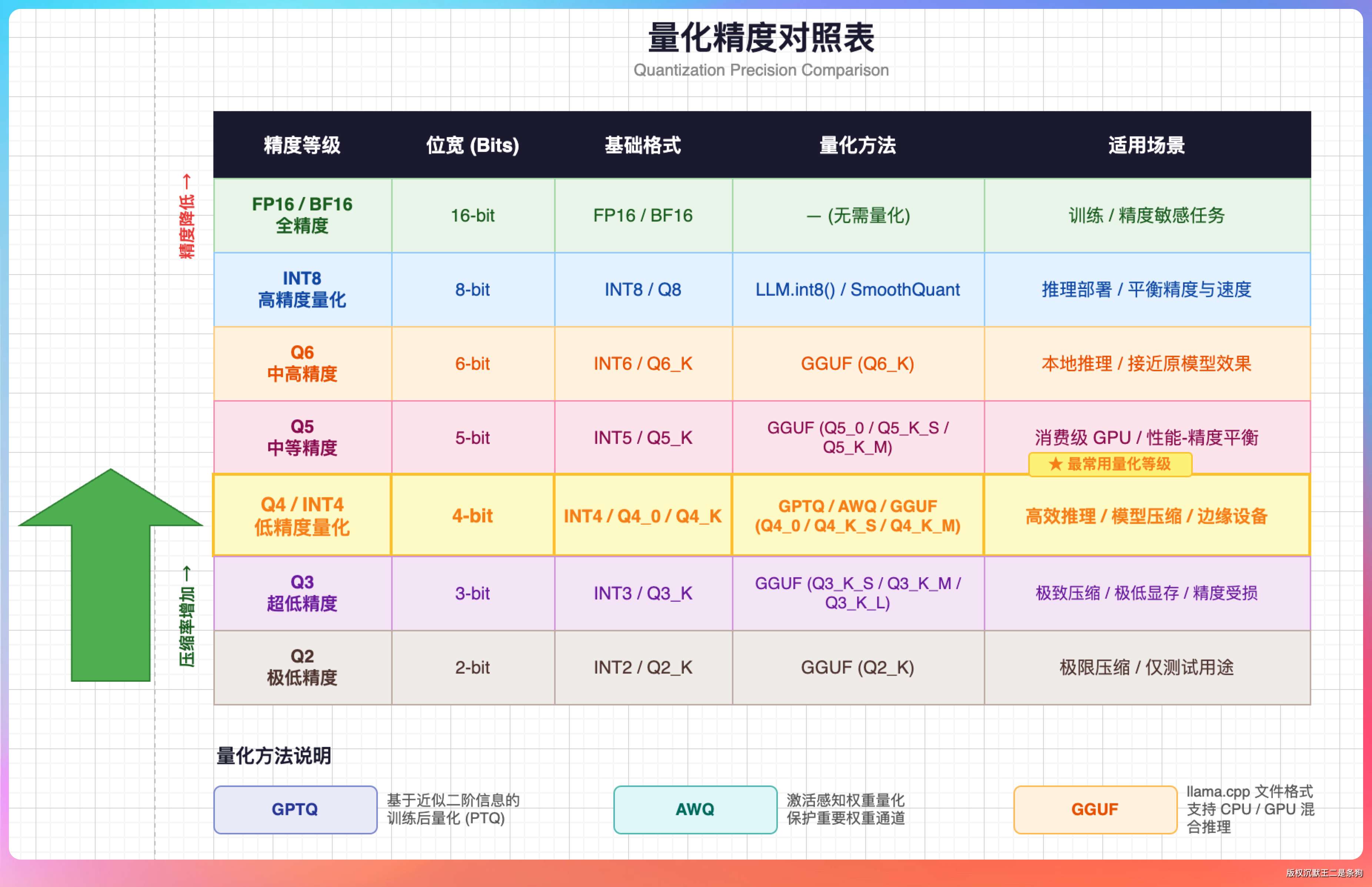
我整理一下:
- Q 系列(Q2、Q3、Q4、Q5、Q8)是 llama.cpp 和 Ollama 用的 GGUF 格式,手机和 PC 本地部署走这条路。
- INT 系列(INT4、INT8)是 vLLM 和 TensorRT 用的标准整数量化,云端部署走这个。
- Q4_K_M、Q8_0 是 GGUF 里常见的量化类型,分别属于 4-bit 和 8-bit 这一类。
- AWQ 和 GPTQ 也是常见的 4-bit 量化方案,但它们是不同的后训练量化方法,不能简单说精度一定等同于某个 Q4 格式。
搞清楚了量化,我们回到核心问题:主流手机 8GB 内存,到底能跑多大的模型?
答案可能比大家想的要小。
系统和常驻 App 通常会吃掉一部分内存,真正留给大模型的空间没有参数表上看起来那么宽裕。在 INT4 量化下,1.3B 纯语言模型的权重可以粗略压到 GB 级以内,但 MiniCPM-V 是多模态模型,还要算视觉编码器、视觉 token、KV Cache 和推理框架本身的开销。
所以我更愿意把它理解成一个工程甜蜜点:1.3B 足够小,小到有机会塞进手机和车机;同时又不是那种只能玩玩简单问答的玩具模型,它还能看图、看视频、做 OCR 和多图理解。
对于中端手机只有 6GB RAM 的情况,1B 可能就是唯一的选择了。

顺带举个具体的例子,大家感受一下。
只按参数权重粗算,1.3B 模型做 4-bit 量化时,权重体积大概是 0.65GB 这个量级。但这只是一个帮助大家建立直觉的估算,不等于真实 App 运行时只需要这么多内存。
真实推理还要加上 KV Cache、视觉编码器、视觉 token、框架缓冲区、系统调度开销。一个 8B 模型即便做 4-bit,光权重就可能到 4GB 量级,再加上下文和运行时开销,对 8GB 内存手机就很不友好了。这里不是不能跑,而是跑起来很容易牺牲上下文长度、速度和稳定性。
说到内存,还得补充一个概念:KV Cache。
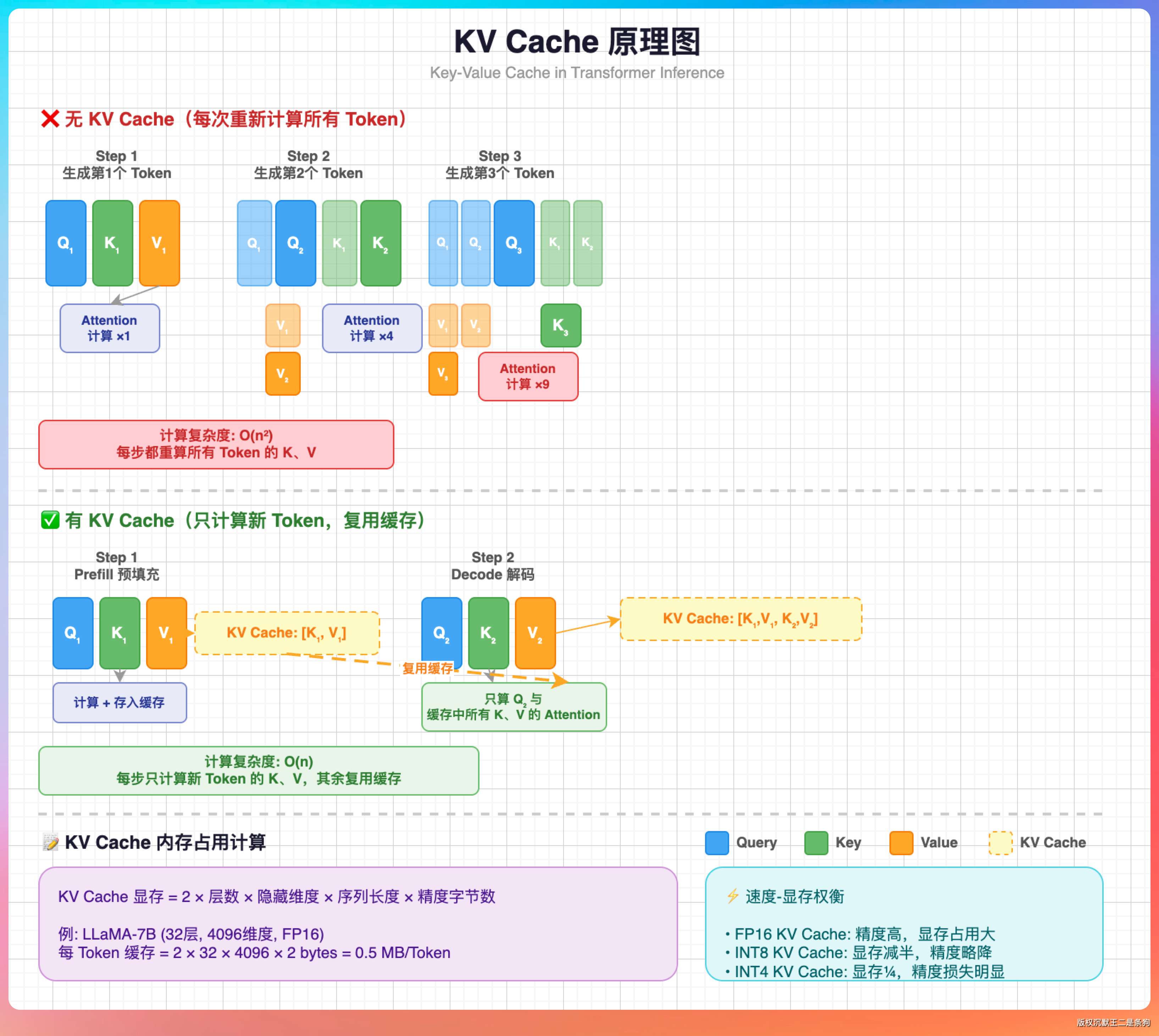
模型跑起来之后,所有的上下文信息都会以 token 的形式在内存里存一份 Key 和一份 Value,用来做注意力计算,不断推导出下一个 Token 是什么。上下文越长,KV Cache 占的内存就越大。
这就是为什么很多模型有“最大上下文”的限制,为什么有些平台在上下文过长时会额外收费。
多模态模型还有一笔额外开销:视觉 token。
图片在进入模型之前会被编码成一组 token,和文本一样占 KV Cache,数量取决于图片分辨率和压缩方式。分辨率越高,视觉 token 越多,内存占用越大。这也是为什么 MiniCPM-V 4.6 在视觉 token 压缩上下了这么大功夫。
03、MiniCPM-V 4.6为什么这么快
MiniCPM-V 4.6 跑得快,背后有两个关键的技术创新。
第一个是 LLaVA-UHD v4 架构。
传统多模态模型处理高清图片时,视觉 token 会随着分辨率增加而快速变多,视觉编码器里的注意力计算也会被拖慢。之前很多方案是在 ViT(Vision Transformer,视觉编码器)之后做 Token 压缩。问题是这只减轻了下游语言模型的负担,视觉编码器内部的计算量一点没少。
LLaVA-UHD v4 的思路反过来了:把 Token 压缩前移到 ViT 内部的浅层。越早压缩,后面需要处理的 Token 越少,整体计算量就越低。
这个设计思路实现起来有个技术难点:ViT 的浅层已经学到了大量视觉表征,直接插入随机初始化的下采样模块,会破坏这些已经学好的表征,导致训练代价非常高。
OpenBMB/面壁团队相关论文(arXiv: 2605.08985)里给出了一个巧妙的方案:不用随机初始化,而是把压缩模块的注意力投影和 MLP 权重从相邻的预训练层拷贝过来。这样压缩模块从第一步训练开始就在预训练的表征流形上工作,不需要完全从零学习。

结果就是视觉编码阶段的浮点运算量从 3555G 降到 1573G,降了 55.8%,同时尽量保持效果。叠加 4 倍的 post-ViT MLP 压缩之后,总共是 16 倍压缩。
第二个创新是 4 倍/16 倍混合压缩。
之前的版本只能在 4 倍和 16 倍之间二选一,4.6 版本把两个都做进去了。要精度用 4 倍压缩,要速度用 16 倍压缩。一个模型两种模式,在云端能以极低成本承接高并发流量。
这里有个论文里的重要发现:切片编码比全局编码更好。在做了大量对照实验后,研究团队发现全局编码下,文字、图表这类精细元素容易被全局信息稀释。切片编码让编码器专注于每个小区域内的细粒度模式,分辨率越高优势越大。
04、消费级显卡也能微调
微调框架支持 ms-swift 和 LLaMA-Factory,推理部署支持 vLLM、SGLang、llama.cpp、Ollama。主流框架全覆盖,准备好数据,改几行配置就能开始训练。
这里我得把话说严谨一点。
“消费级显卡能微调”,不等于“随便一张 4090 就能全参微调”。全参微调还要看 batch size、上下文长度、图片分辨率、优化器状态、是否开 ZeRO、是否用梯度检查点。稍微不注意,显存就爆了。
但 LoRA、QLoRA 这类轻量微调就现实很多。比如我们只想让它适配某个垂直场景:识别工单截图、理解车机界面、读票据、看商品图、做一套企业内部表单 OCR。这个时候没必要把所有参数都重新训练一遍,只要挂一个低秩适配层,让模型学会这类图片和指令的表达方式就够了。
小模型的优势就在这里。
同样是做行业定制,大模型当然能力更强,但训练、部署、迭代成本也更高。MiniCPM-V 4.6 这种 1.3B 模型,适合的不是“拿来替代云端最强模型”,而是放在端侧和私有环境里,把高频、低延迟、隐私敏感的视觉任务先吃掉。
面壁还贴心地提供了多种量化格式的预量化模型和部署教程:
- vLLM 部署:github.com/OpenSQZ/MiniCPM-V-CookBook/.../vllm
- llama.cpp 部署:github.com/OpenSQZ/MiniCPM-V-CookBook/.../llama.cpp
- Ollama 部署:github.com/OpenSQZ/MiniCPM-V-CookBook/.../ollama
模型本身采用 Apache-2.0 开源协议,商用也没问题。
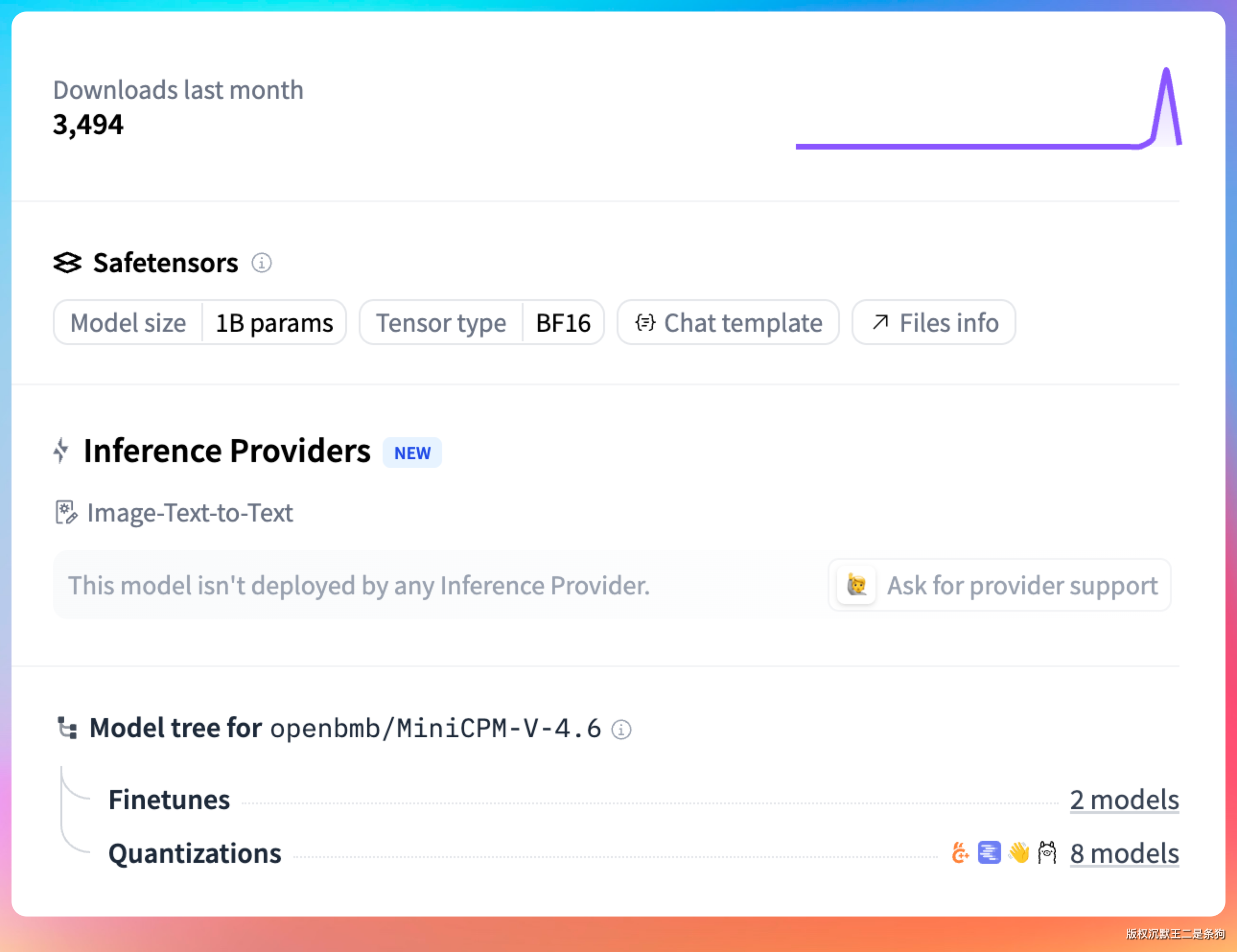
HuggingFace 上的模型格式是 Safetensors,支持 BF16 精度,同时提供 GGUF、BNB、AWQ、GPTQ 多种量化版本。截至 2026 年 5 月 14 日,HuggingFace openbmb/MiniCPM-V-4.6 模型页面显示月下载量为 3494 次,GitHub OpenBMB/MiniCPM-V 仓库显示 Star 约 24.8k。
05、从快手到车机
光看跑分和论文数据,可能还是觉得有点“实验室味”。那我们看看实际落地的情况。
快手 OneRec 推荐模型在处理短视频的封面图、字幕、OCR、ASR 这些多模态信息时,用到了上一代 MiniCPM-V-8B。公开的 OneRec 技术资料里提到,OneRec 在线上主场景承接了约 25% QPS。
这件事能说明一个问题:MiniCPM-V 这条路线不是只停留在 demo 里。短视频推荐这种场景,对吞吐、稳定性、成本都很敏感,能被放进这种链路里,本身就说明小模型的工程价值不是“参数小所以便宜”这么简单。
除了快手,MiniCPM 这套模型在车机领域也有公开落地报道。公开报道里提到过吉利、长安、大众等车企或相关车型对端侧多模态模型的接入。这里不展开做车企案例考据,大家把它理解成端侧模型的一个重要落地方向就行。
车机对模型的要求和手机很像:内存有限、算力有限、网络不稳定,很多交互还希望尽量本地完成。比如识别仪表盘状态、理解中控屏内容、结合语音做多轮交互、在弱网环境下继续响应用户,这些都不适合完全依赖云端。
我觉得 MiniCPM-V 4.6 的价值恰恰在这里。
它不是宣传一个“手机上也能跑大模型”的噱头,而是把多模态模型往真实硬件限制里压:参数要小,视觉 token 要少,延迟要稳,部署框架要全,许可证还得宽松。少一个条件,开发者都很难真正用起来。