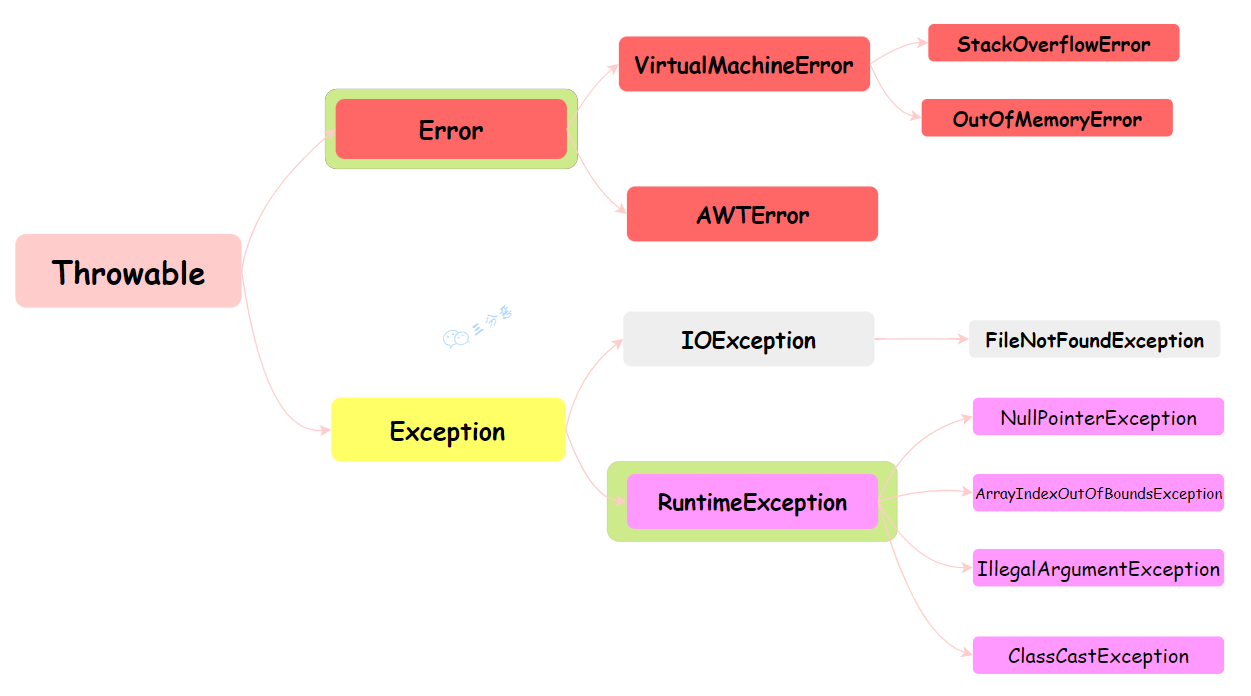
Spring面试题,41道Spring八股文(3.3万字180张手绘图),面渣逆袭必看👍

前言
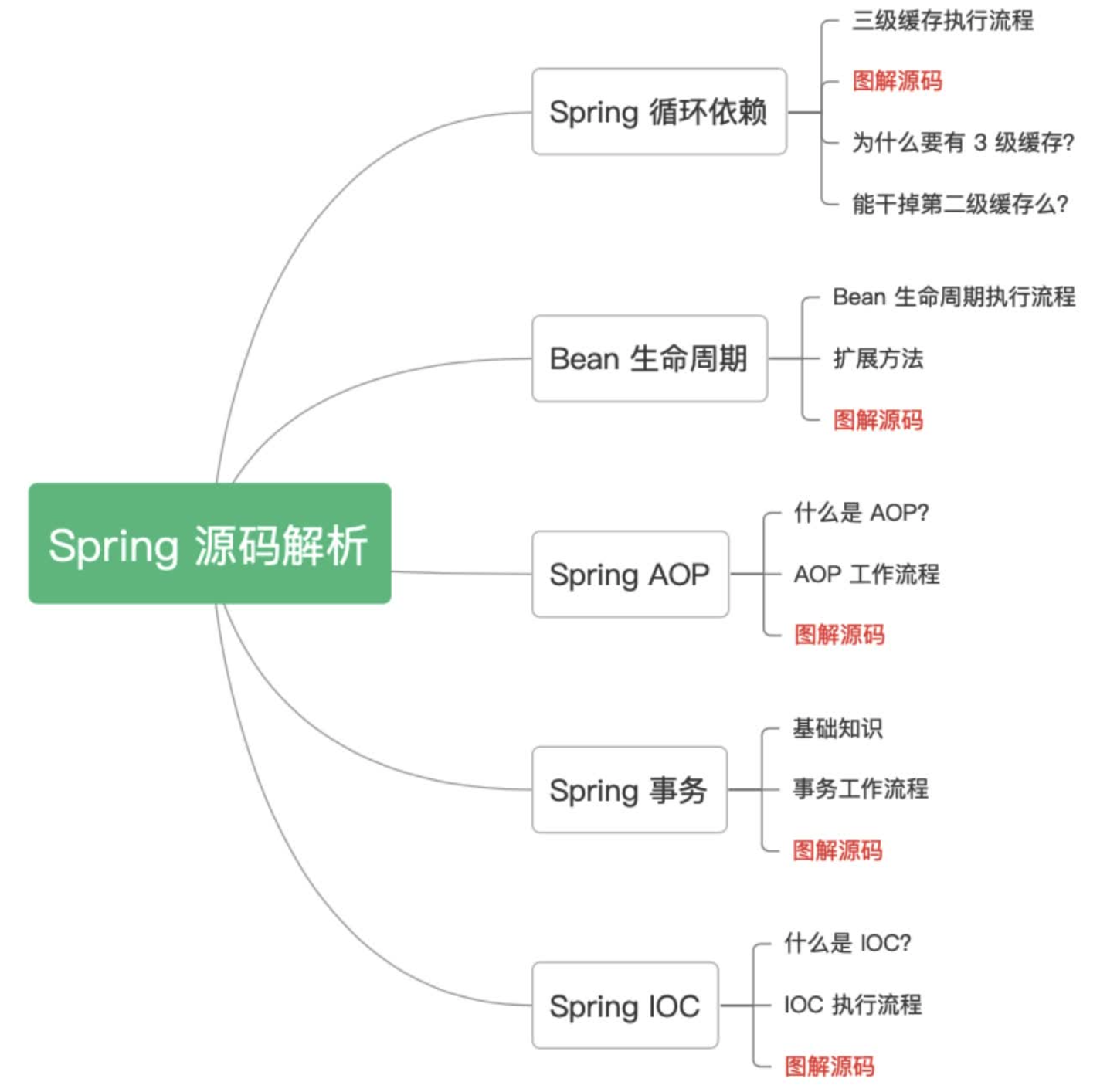
3.3 万字 180 张手绘图,详解 41 道 Spring 面试高频题(让天下没有难背的八股),面渣背会这些 Spring 八股文,这次吊打面试官,我觉得稳了(手动 dog)。整理:沉默王二,戳转载链接,作者:三分恶,戳原文链接。
亮白版本更适合拿出来打印,这也是很多学生党喜欢的方式,打印出来背诵的效率会更高。
2025 年 06 月 15 日开始着手第二版更新,历经两个月,主要是中间有段时间把精力放到了派聪明 RAG 这个项目的教程撰写上,第二版,我们升级了很多内容。
- 对于高频题,会标注在《Java 面试指南(付费)》中出现的位置,哪家公司,原题是什么,并且会加🌟,目录一目了然;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 区分八股精华回答版本和原理底层解释,让大家知其然知其所以然,同时又能做到面试时的高效回答。
- 结合项目(技术派、pmhub)来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 增加二哥编程星球的球友们拿到的一些 offer,对面渣逆袭的感谢,以及对简历修改的一些认可,以此来激励大家,给大家更多信心。
- 优化排版,增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
由于 PDF 没办法自我更新,所以需要最新版的小伙伴,可以微信搜【沉默王二】,或者扫描/长按识别下面的二维码,关注二哥的公众号,回复【222】即可拉取最新版本。

当然了,请允许我的一点点私心,那就是星球的 PDF 版本会比公众号早一个月时间,毕竟星球用户都付费过了,我有必要让他们先享受到一点点福利。相信大家也都能理解,毕竟在线版是免费的,CDN、服务器、域名、OSS 等等都是需要成本的。
更别说我付出的时间和精力了,大家觉得有帮助还请给个口碑,让你身边的同事、同学都能受益到。
我把二哥的 Java 进阶之路、JVM 进阶之路、并发编程进阶之路,以及所有面渣逆袭的版本都放进来了,涵盖 Java基础、Java集合、Java并发、JVM、Spring、MyBatis、计算机网络、操作系统、MySQL、Redis、RocketMQ、分布式、微服务、设计模式、Linux 等 16 个大的主题,共有 40 多万字,2000+张手绘图,可以说是诚意满满。
展示一下暗黑版本的 PDF 吧,排版清晰,字体优雅,更加适合夜服,晚上看会更舒服一点。
基础
1.Spring是什么?
Spring 是一个 Java 后端开发框架,其最核心的作用是帮我们管理 Java 对象。

其最重要的特性就是 IoC,也就是控制反转。以前我们要使用一个对象时,都要自己先 new 出来。但有了 Spring 之后,我们只需要告诉 Spring 我们需要什么对象,它就会自动帮我们创建好并注入到 Spring 容器当中。
比如我在一个 Service 类里需要用到 Dao 对象,只需要加个 @Autowired 注解,Spring 就会自动把 Dao 对象注入到 Spring 容器当中,这样就不需要我们手动去管理这些对象之间的依赖关系了。
另外,Spring 还提供了 AOP,也就是面向切面编程,在我们需要做一些通用功能的时候特别有用,比如说日志记录、权限校验、事务管理这些,我们不用在每个方法里都写重复的代码,直接用 AOP 就能统一处理。
Spring 的生态也特别丰富,像 Spring Boot 能让我们快速搭建项目,Spring MVC 能帮我们处理 web 请求,Spring Data 能帮我们简化数据库操作,Spring Cloud 能帮我们做微服务架构等等。
Spring有哪些特性?
Spring 的特性还是挺多的,我按照在实际工作/学习中用得最多的几个来说吧。
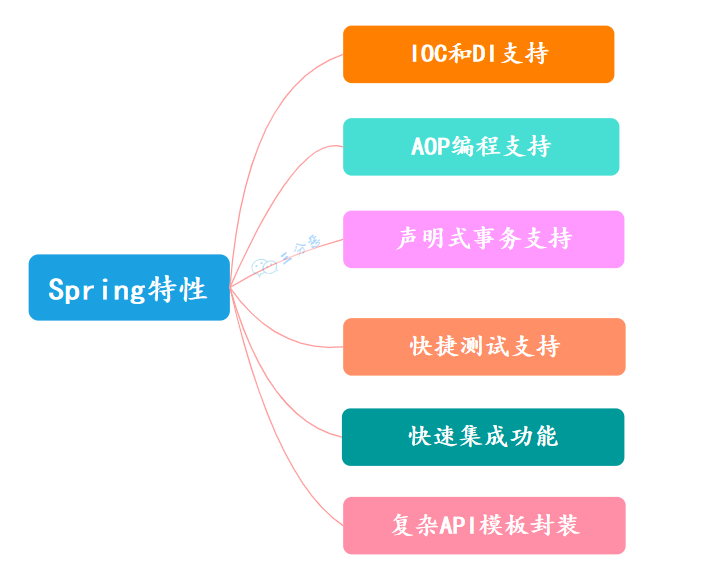
首先最核心的就是 IoC 控制反转和 DI 依赖注入,让 Spring 有能力帮我们管理对象的创建和依赖关系。
比如我写一个 UserService,需要用到 UserDao,以前得自己 new 一个 UserDao 出来,现在只要在 UserService 上加个 @Service 注解,在 UserDao 字段上加个 @Autowired,Spring 就会自动帮我们处理好这些依赖关系。
这样代码的耦合度就大大降低了,测试的时候也更容易 mock。
第二个就是 AOP 面向切面编程。这个在我们处理一些横切关注点的时候特别有用,比如说我们要给某些 Controller 方法都加上权限控制,如果没有 AOP 的话,每个方法都要写一遍加权代码,维护起来很麻烦。
用了 AOP 之后,我们只需要写一个切面类,定义好切点和通知,就能统一处理了。事务管理也是同样的道理,加个 @Transactional 注解就搞定了。
还有就是 Spring 对各种企业级功能的集成支持也特别好。比如数据库访问,不管我们用 JDBC、MyBatis-Plus 还是 Hibernate,Spring 都能很好地集成。消息队列、缓存、安全认证这些, Spring 都有对应的模块来支持。
另外 Spring 的配置也很灵活,既支持 XML 配置,也支持注解配置,现在我们基本都用注解了,写起来更简洁。Spring Boot 出来之后就更方便了,约定大于配置,很多东西都是开箱即用的。
简单说一下什么是AOP和IoC?
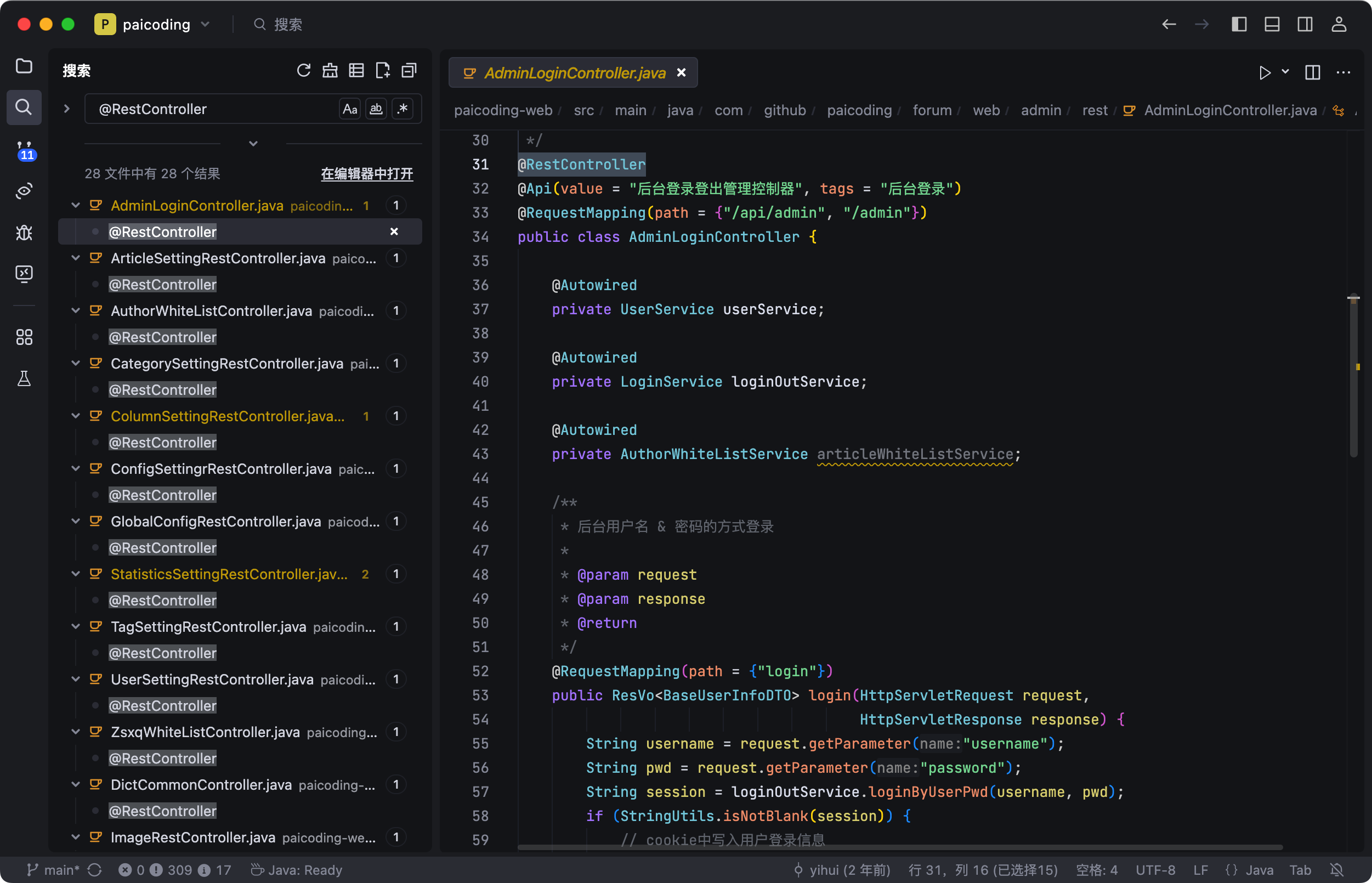
AOP 面向切面编程,简单点说就是把一些通用的功能从业务代码里抽取出来,统一处理。比如说技术派中的 @MdcDot 注解的作用是配合 AOP 在日志中加入 MDC 信息,方便进行日志追踪。
IoC 控制反转是一种设计思想,它的主要作用是将对象的创建和对象之间的调用过程交给 Spring 容器来管理。比如说在技术派项目当中,@PostConstruct 注解表明这个方法由 Spring 容器在 Bean 初始化完成后自动调用,我们不需要手动调用 init 方法。
Spring源码看过吗?
看过一些,主要是带着问题去看的,比如遇到一些技术难点或者想深入理解某个功能的时候。
我重点看过的是 IoC 容器的初始化过程,特别是 ApplicationContext 的启动流程。从 refresh() 方法开始,包括 Bean 的定义和加载、Bean 工厂的准备、Bean 的实例化和初始化这些关键步骤。
看源码的时候发现 Spring 用了很多设计模式,比如工厂模式、单例模式、模板方法模式等等,这对我平时写代码也很有启发。
还有就是 Spring 的 Bean 生命周期,从 BeanDefinition 的创建到 Bean 的实例化、属性注入、初始化回调,再到最后的销毁,整个过程还是挺复杂的。看了源码之后对 @PostConstruct、@PreDestroy 这些注解的执行时机就更清楚了。
不过说实话,Spring 的源码确实比较难啃,涉及的概念和技术点太多了。我一般是结合一些技术博客和 Claude 一起看,这样理解起来会相对容易一些。
PS:关于这份小册的 PDF 版本,目前只有星球的用户可以获取,后续会考虑开放给大家。
- Java 面试指南(付费)收录的京东面经同学 5 Java 后端技术一面面试原题:IOC与AOP
memo:2025 年 6 月 15 日修改至此,今天在帮球友们修改简历的时候,碰到一个中山大学本硕的球友,校园荣誉基本上拉满了,非常优秀,那我也希望能够帮助到更多的球友们,帮他们拿到更好的 offer。

2.Spring有哪些模块呢?
我按照平时工作/学习中接触的频率来说一下。
首先是 Spring Core 模块,这是整个 Spring 框架的基础,包含了 IoC 容器和依赖注入等核心功能。还有 Spring Beans 模块,负责 Bean 的配置和管理。这两个模块基本上是其他所有模块的基础,不管用 Spring 的哪个功能都会用到。
然后是 Spring Context 上下文模块,它在 Core 的基础上提供了更多企业级的功能,比如国际化、事件传播、资源加载这些。ApplicationContext 就是在这个模块里面的。
@SpringBootApplication
public class Application {
public static void main(String[] args) {
// Spring Boot会自动创建ApplicationContext
ApplicationContext context = SpringApplication.run(Application.class, args);
}
}Spring AOP 模块提供了面向切面编程的支持,我们用的 @Transactional、自定义切面这些都是基于这个模块。
Web 开发方面,Spring Web 模块提供了基础的 Web 功能,Spring WebMVC 就是我们常用的 MVC 框架,用来处理 HTTP 请求和响应。现在还有 Spring WebFlux,支持响应式编程。
比如说技术派项目中,GlobalExceptionHandler 类就使用了 @RestControllerAdvice 来实现统一的异常处理。
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(value = ForumAdviceException.class)
public ResVo<String> handleForumAdviceException(ForumAdviceException e) {
return ResVo.fail(e.getStatus());
}
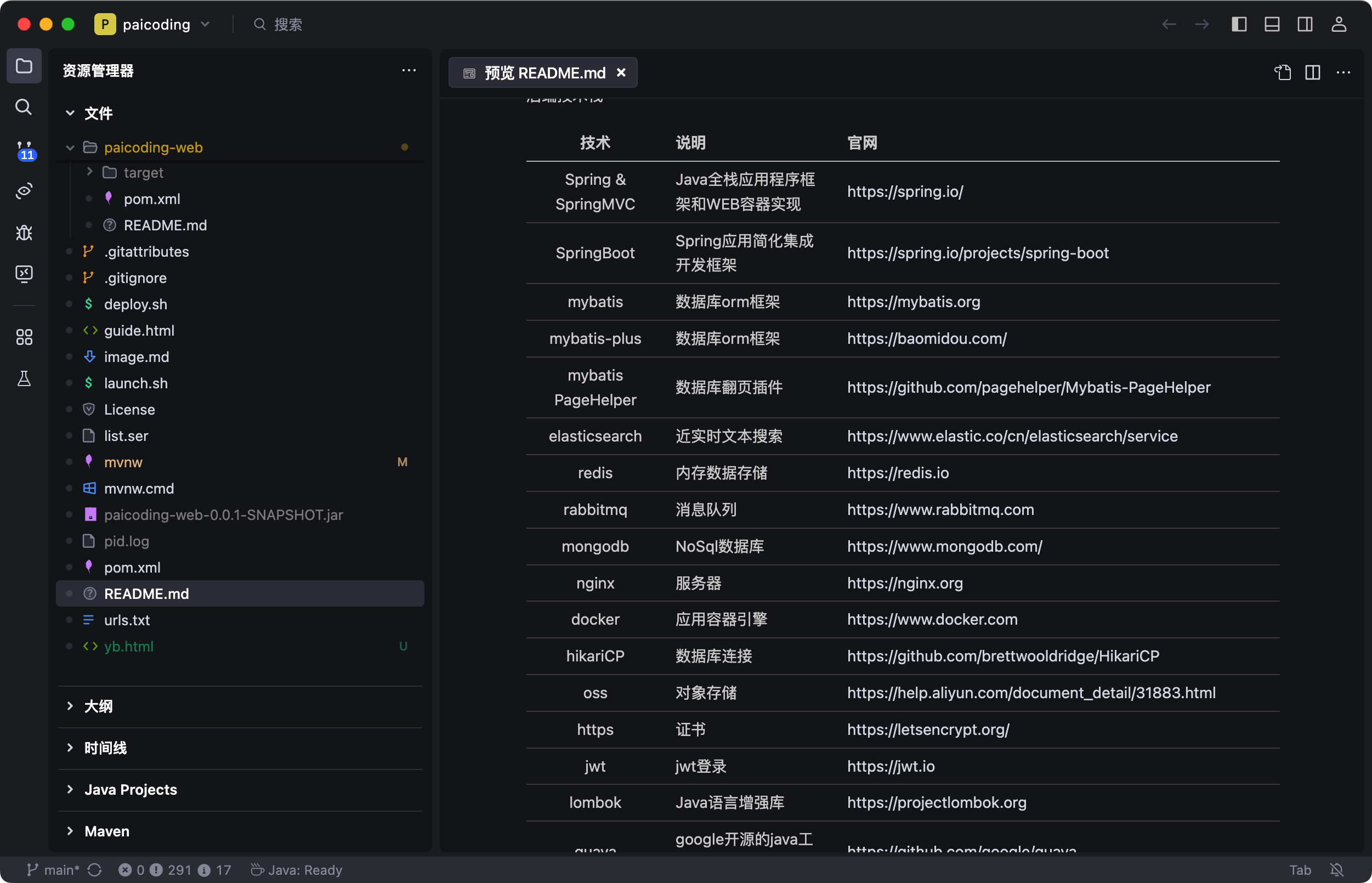
}数据访问方面,Spring JDBC 简化了 JDBC 的使用,在技术派项目中,我们就 JdbcTemplate 来检查表是否存在、执行数据库初始化脚本。
Spring ORM 提供了对 MyBatis-Plus 等 ORM 框架的集成支持。在技术派项目中,我们就用了 @TableName、@TableField 等注解进行对象关系映射,通过继承 BaseMapper 来获取通用的 CRUD 能力。
Spring Test 模块提供了测试支持,可以很方便地进行单元测试和集成测试。我们写测试用例的时候经常用 @SpringBootTest 这些注解。比如说在技术派项目中,我们就用 @SpringBootTest 注解来加载 Spring 上下文,进行集成测试。
@Slf4j
@SpringBootTest(classes = QuickForumApplication.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class BasicTest {
}还有一些其他的模块,比如 Spring Security 负责安全认证,Spring Batch 处理批处理任务等等。
现在我们基本都是用 Spring Boot 来开发,它把这些模块都整合好了,用起来更方便。
memo:2025 年 6 月 16 日修改至此,今天在帮球友们修改简历的时候,碰到一个大连海事大学硕河南理工大学本的球友,他荣誉奖项里提到的优秀研究生、奖学金、英语四六级,我希望看到的同学也都能争取一下,不要把这些荣誉拱手让人,或者压根就不知道,或者不屑于去参加,到时候你简历上这一栏就会比较苍白。

3.Spring有哪些常用注解呢?
Spring 的注解挺多的,我按照不同的功能分类来说一下平时用得最多的那些。
首先是 Bean 管理相关的注解。@Component 是最基础的,用来标识一个类是 Spring 组件。像 @Service、@Repository、@Controller 这些都是 @Component 的特化版本,分别用在服务层、数据访问层和控制器层。
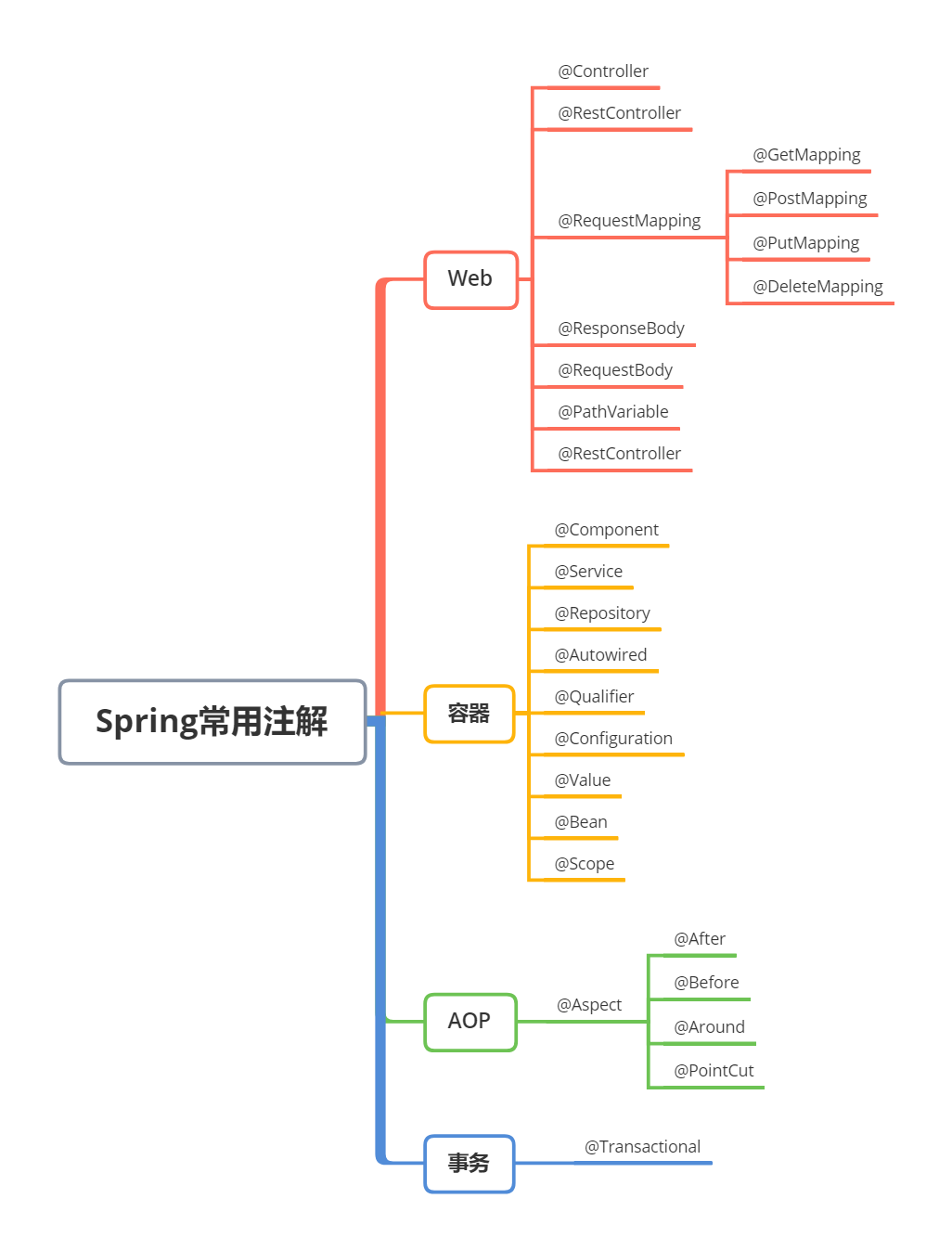
依赖注入方面,@Autowired 是用得最多的,可以标注在字段、setter 方法或者构造方法上。@Qualifier 在有多个同类型 Bean 的时候用来指定具体注入哪一个。@Resource 和 @Autowired 功能差不多,不过它是按名称注入的。
配置相关的注解也很常用。@Configuration 标识配置类,@Bean 用来定义 Bean,@Value 用来注入配置文件中的属性值。我们项目里的数据库连接信息、Redis 配置这些都是用 @Value 来注入的。@PropertySource 用来指定配置文件的位置。
Web 开发的注解就更多了。@RestController 相当于 @Controller 加 @ResponseBody,用来做 RESTful 接口。
@RequestMapping 及其变体@GetMapping、@PostMapping、@PutMapping、@DeleteMapping 用来映射 HTTP 请求。@PathVariable 获取路径参数,@RequestParam 获取请求参数,@RequestBody 接收 JSON 数据。
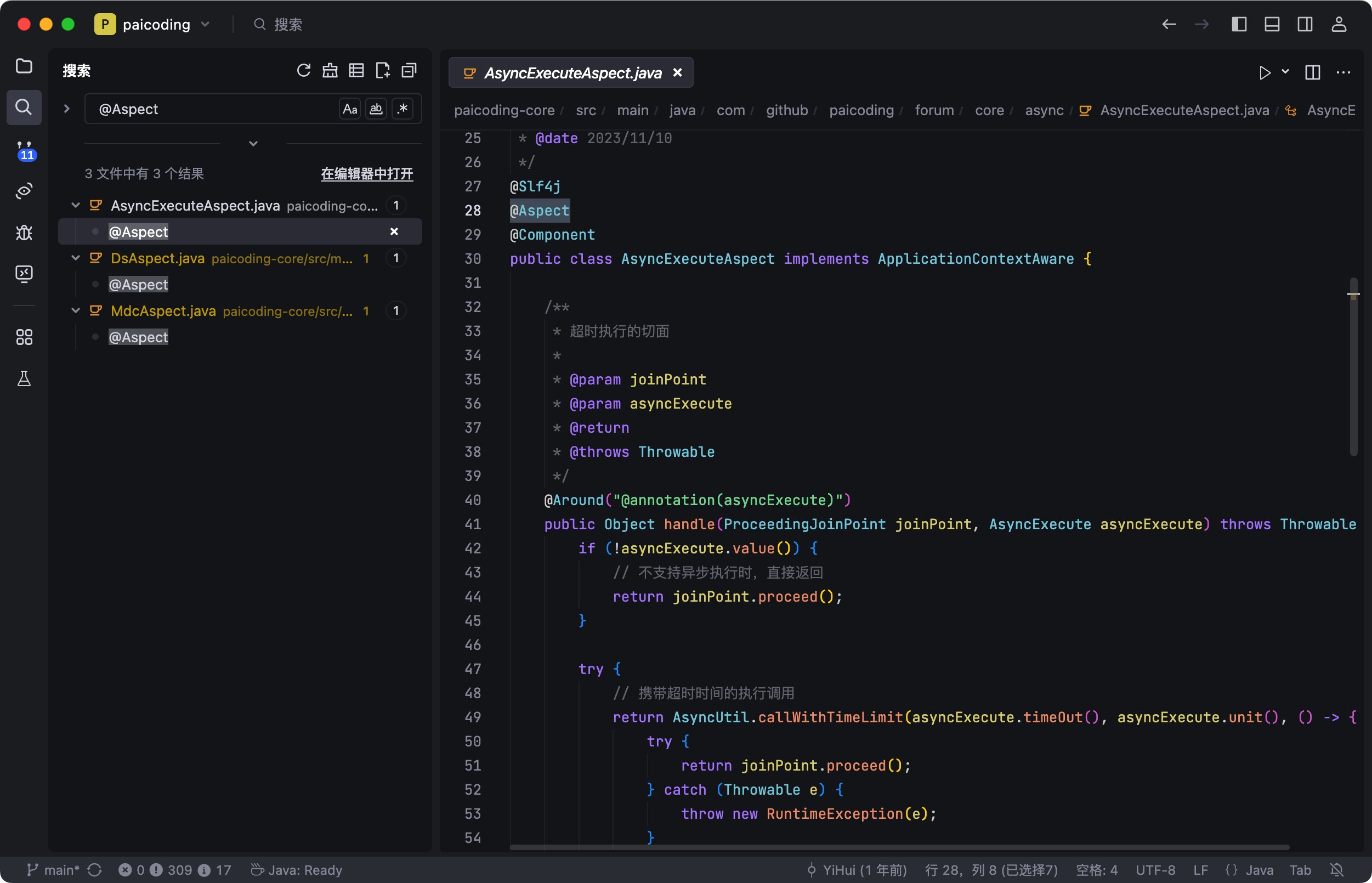
AOP 相关的注解,@Aspect 定义切面,@Pointcut 定义切点,@Before、@After、@Around 这些定义通知类型。
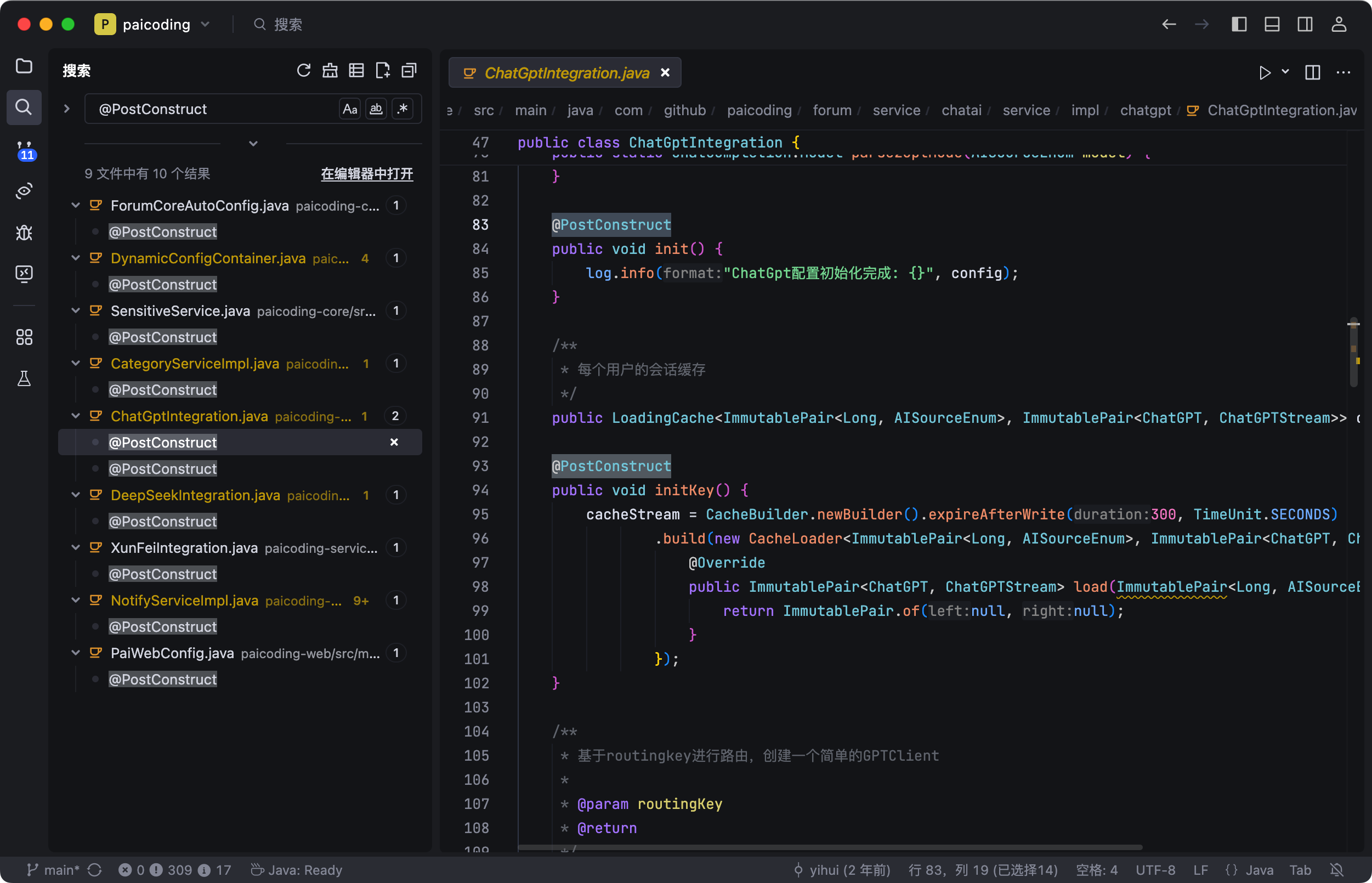
不过我们用得最多的还是@Transactional,基本上 Service 层需要保证事务原子性的方法都会加上这个注解。
生命周期相关的,@PostConstruct 在 Bean 初始化后执行,@PreDestroy 在 Bean 销毁前执行。测试的时候 @SpringBootTest 也经常用到。
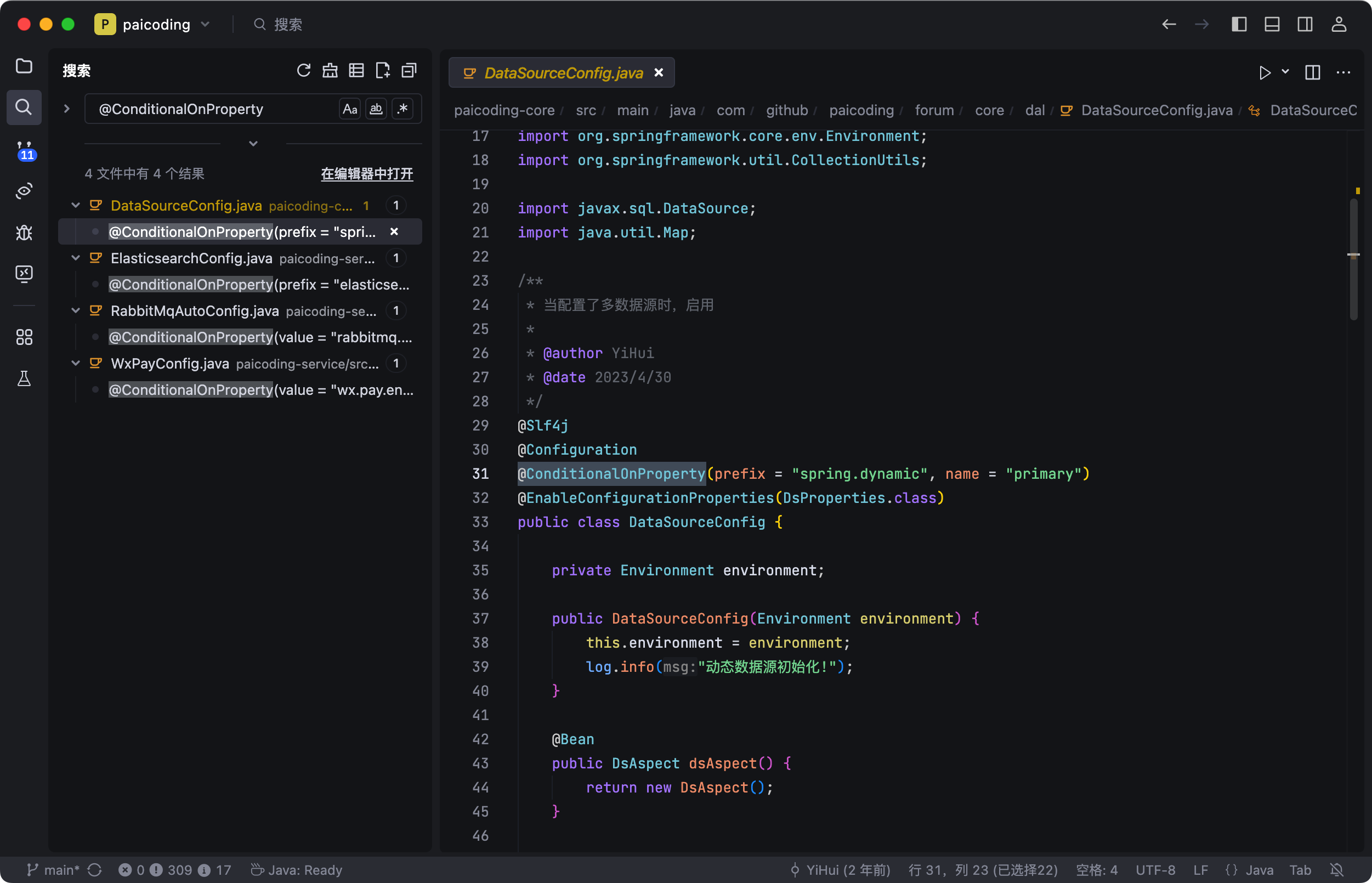
还有一些 Spring Boot 特有的注解,比如 @SpringBootApplication 这个启动类注解,@ConditionalOnProperty 做条件装配,@EnableAutoConfiguration 开启自动配置等等。
- Java 面试指南(付费)收录的微众银行同学 1 Java 后端一面的原题:说说 Spring 常见的注解?
memo:2025 年 6 月 17 日修改至此,今天在帮球友们修改简历的时候,碰到一个学院本的球友,他的荣誉奖项还是 OK的,态度也非常好,之前有学院本球友拿到滴滴 SP offer 的,希望这位球友也能够成为星球里新的榜样。

4.🌟Spring用了哪些设计模式?
Spring 框架里面确实用了很多设计模式,我从平时工作中能观察到的几个来说说。
首先是工厂模式,这个在 Spring 里用得非常多。BeanFactory 就是一个典型的工厂,它负责创建和管理所有的 Bean 对象。我们平时用的 ApplicationContext 其实也是 BeanFactory 的一个实现。当我们通过 @Autowired 获取一个 Bean 的时候,底层就是通过工厂模式来创建和获取对象的。
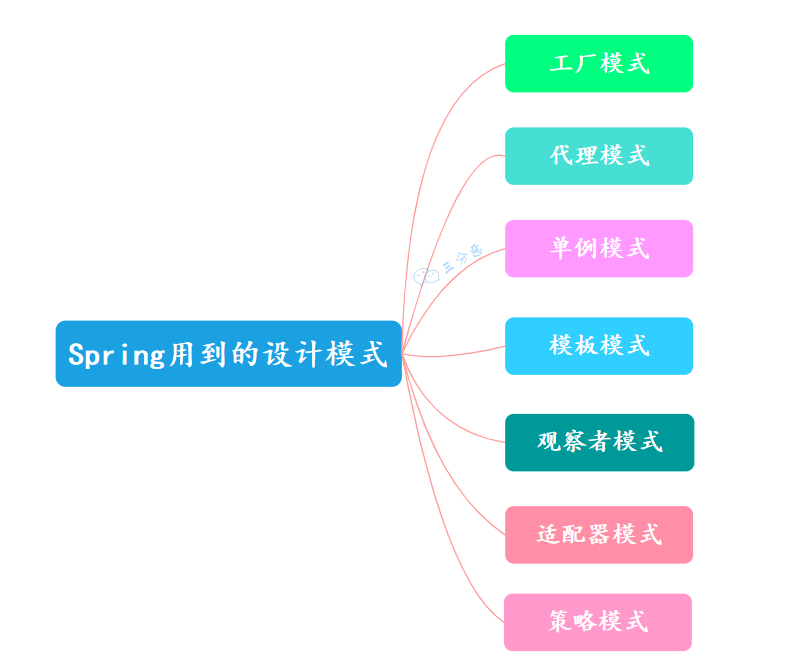
单例模式也是 Spring 的默认行为。默认情况下,Spring 容器中的 Bean 都是单例的,整个应用中只会有一个实例。这样可以节省内存,提高性能。当然我们也可以通过 @Scope 注解来改变 Bean 的作用域,比如设置为 prototype 就是每次获取都创建新实例。
代理模式在 AOP 中用得特别多。Spring AOP 的底层实现就是基于动态代理的,对于实现了接口的类用 JDK 动态代理,没有实现接口的类用 CGLIB 代理。比如我们用 @Transactional 注解的时候,Spring 会为我们的类创建一个代理对象,在方法执行前后添加事务处理逻辑。
模板方法模式在 Spring 里也很常见,比如 JdbcTemplate。它定义了数据库操作的基本流程:获取连接、执行 SQL、处理结果、关闭连接,但是具体的 SQL 语句和结果处理逻辑由我们来实现。
观察者模式在 Spring 的事件机制中有所体现。我们可以通过 ApplicationEvent 和 ApplicationListener 来实现事件的发布和监听。比如用户注册成功后,我们可以发布一个用户注册事件,然后有多个监听器来处理后续的业务逻辑,比如发送邮件、记录日志等。
这些设计模式的应用让 Spring 框架既灵活又强大,也让我在实际的开发中学到很多经典的设计思想。
Spring如何实现单例模式?
传统的单例模式是在类的内部控制只能创建一个实例,比如用 private 构造方法加 static getInstance() 这种方式。但是 Spring 的单例是容器级别的,同一个 Bean 在整个 Spring 容器中只会有一个实例。
具体的实现机制是这样的:Spring 在启动的时候会把所有的 Bean 定义信息加载进来,然后在 DefaultSingletonBeanRegistry 这个类里面维护了一个叫 singletonObjects 的 ConcurrentHashMap,这个 Map 就是用来存储单例 Bean 的。key 是 Bean 的名称,value 就是 Bean 的实例对象。
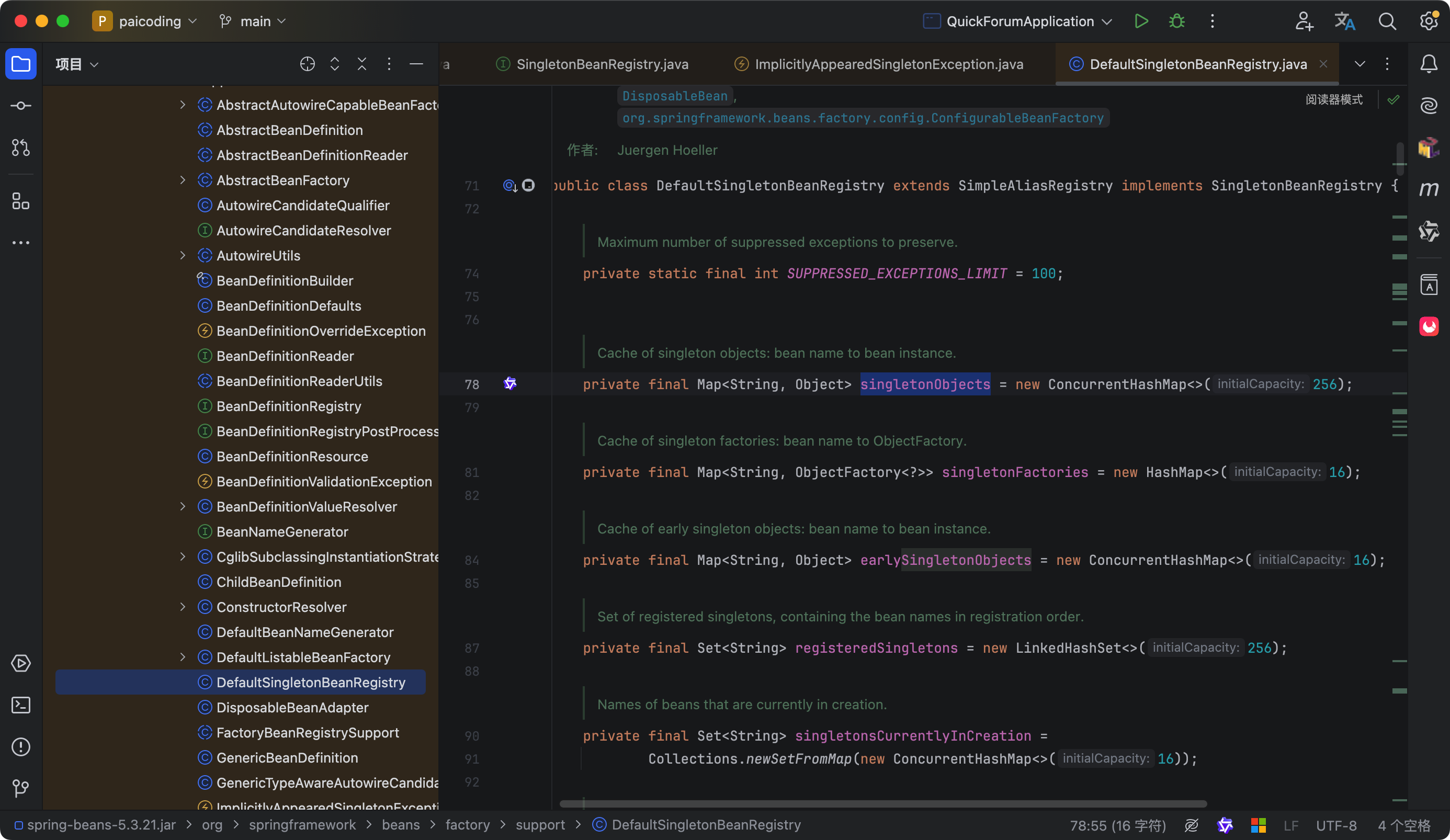
当我们第一次获取某个 Bean 的时候,Spring 会先检查 singletonObjects 这个 Map 里面有没有这个 Bean,如果没有就会创建一个新的实例,然后放到 Map 里面。后面再获取同一个 Bean 的时候,直接从 Map 里面取就行了,这样就保证了单例。
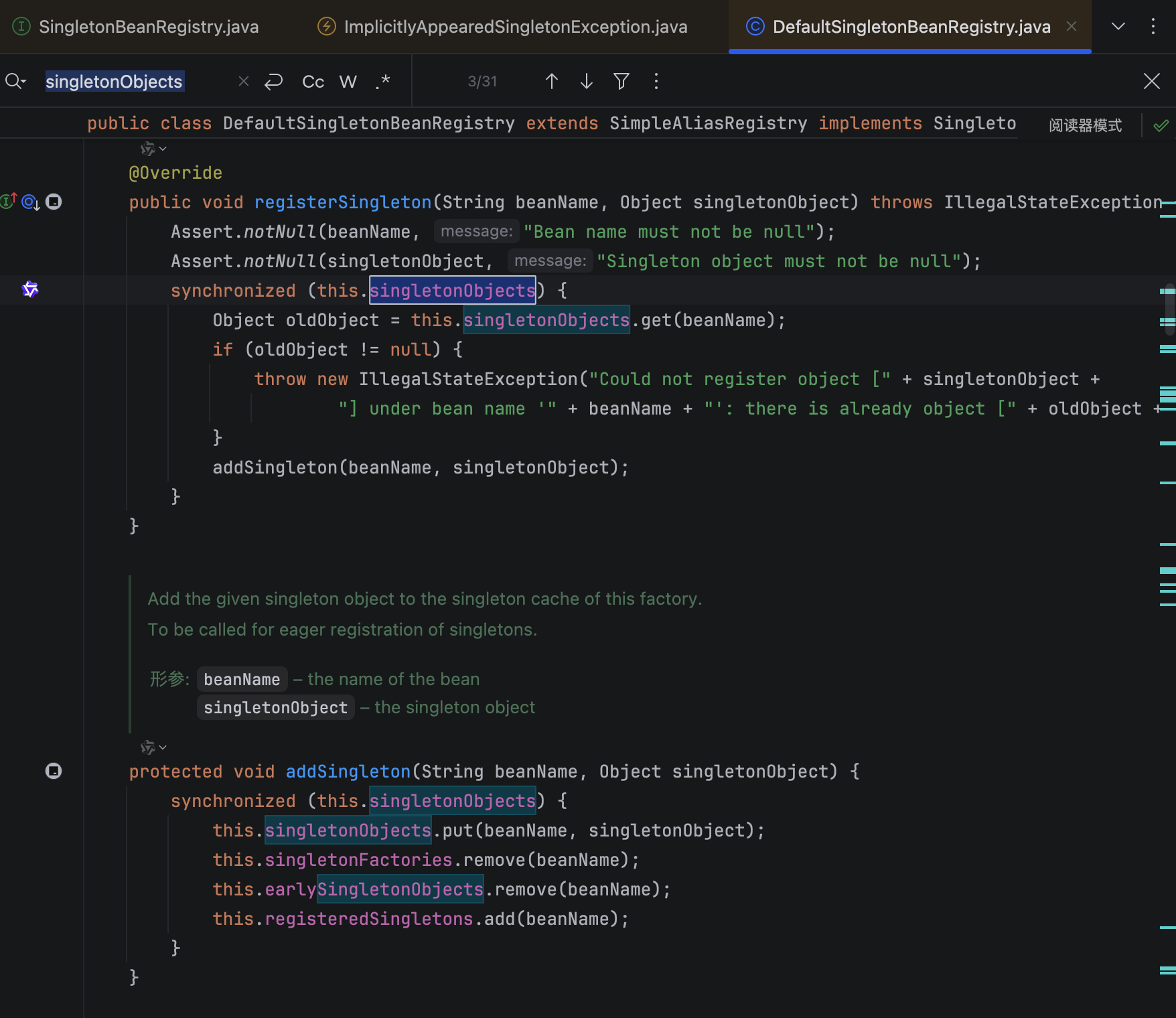
还有一个细节就是 Spring 为了解决循环依赖的问题,还用了三级缓存。除了 singletonObjects 这个一级缓存,还有 earlySingletonObjects 二级缓存和 singletonFactories 三级缓存。这样即使有循环依赖,Spring 也能正确处理。
而且 Spring 的单例是线程安全的,因为用的是 ConcurrentHashMap,多线程访问不会有问题。
- Java 面试指南(付费)收录的携程面经同学 10 Java 暑期实习一面面试原题:Spring IoC 的设计模式,AOP 的设计模式
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:Spring 框架使用到的设计模式?
- Java 面试指南(付费)收录的同学 1 贝壳找房后端技术一面面试原题:Spring用了什么设计模式?
- Java 面试指南(付费)收录的快手同学 4 一面原题:Spring中使用了哪些设计模式,以其中一种模式举例说明?Spring如何实现单例模式?
memo:2025 年 6 月 20 日修改至此,今天帮球友修改简历的时候,有碰到重庆邮电大学本,电子科技大学硕的球友,期间还有过清华大学科研项目的经历,基本上也是把学历这块拉的满中满了,那希望星球能帮助到更多院校的同学,不管是工作党还是学生党,都希望大家都拿到更好的 offer。

5.Spring容器和Web容器之间的区别知道吗?(补充)
2024 年 7 月 11 日增补
首先从概念上来说,Spring 容器是一个 IoC 容器,主要负责管理 Java 对象的生命周期和依赖关系。而 Web 容器,比如 Tomcat、Jetty 这些,是用来运行 Web 应用的容器,负责处理 HTTP 请求和响应,管理 Servlet 的生命周期。
/**
* SpringUtil.java
* 用于获取 Spring 容器中的 Bean,技术派源码:https://github.com/itwanger/paicoding
*/
@Component
public class SpringUtil implements ApplicationContextAware {
private volatile static ApplicationContext context;
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
SpringUtil.context = applicationContext;
}
public static <T> T getBean(Class<T> bean) {
return context.getBean(bean);
}
}从功能上看,Spring 容器专注于业务逻辑层面的对象管理,比如我们的 Service、Dao、Controller 这些 Bean 都是由 Spring 容器来创建和管理的。而 Web 容器主要处理网络通信,比如接收 HTTP 请求、解析请求参数、调用相应的 Servlet,然后把响应返回给客户端。
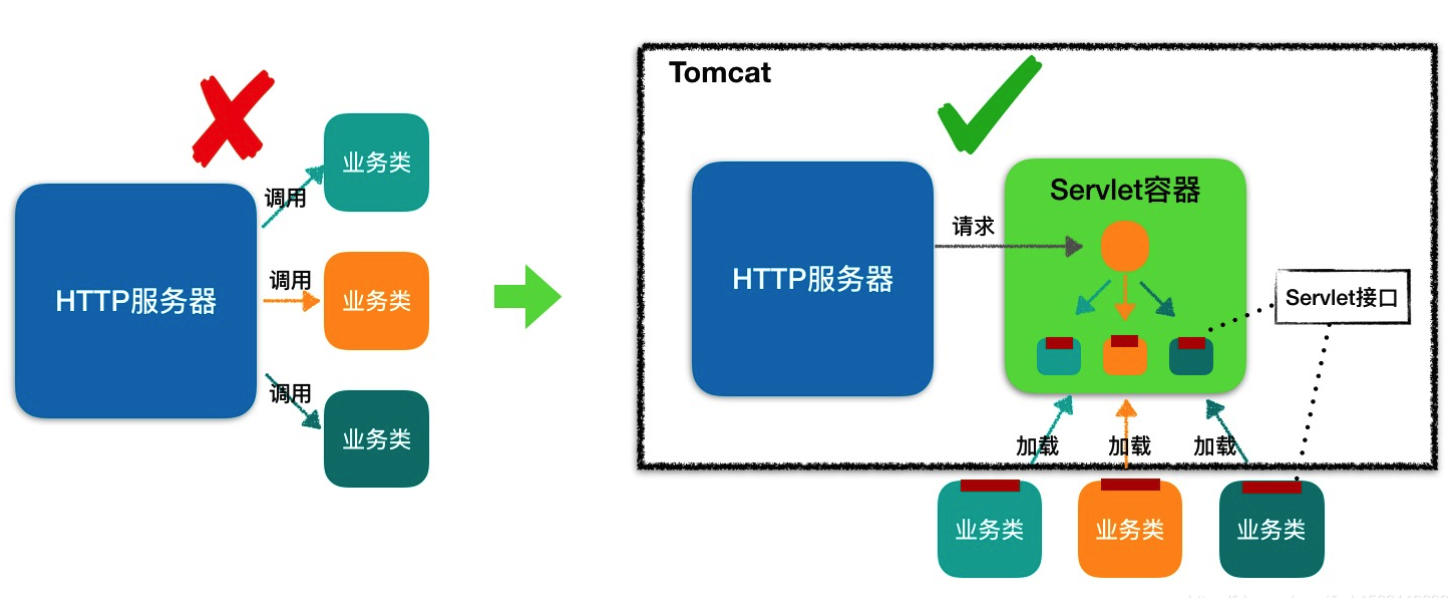
在实际项目中,这两个容器是相辅相成的。我们的 Web 项目部署在 Tomcat 上的时候,Tomcat 会负责接收 HTTP 请求,然后把请求交给 DispatcherServlet 处理,而 DispatcherServlet 又会去 Spring 容器中查找相应的 Controller 来处理业务逻辑。
/**
* GlobalViewInterceptor.java
* 用于全局拦截器,技术派源码:https://github.com/itwanger/paicoding
*/
@Component
public class GlobalViewInterceptor implements HandlerInterceptor {
@Autowired
private GlobalInitService globalInitService;
@Override
public boolean preHandle(HttpServletRequest request,
HttpServletResponse response,
Object handler) {
// Web 容器的 HTTP 请求 + Spring 容器的业务服务
}
}还有一个重要的区别是生命周期。Web 容器的生命周期跟 Web 应用程序的部署和卸载相关,而 Spring 容器的生命周期是在 Web 应用启动的时候初始化,应用关闭的时候销毁。
现在我们都用 Spring Boot 了,Spring Boot 内置了 Tomcat,把 Web 容器和 Spring 容器都整合在一起了,我们只需要运行一个 jar 包就可以了。
@SpringBootApplication
public class QuickForumApplication {
public static void main(String[] args) {
SpringApplication.run(QuickForumApplication.class, args);
}
}
- Java 面试指南(付费)收录的去哪儿同学 1 技术二面原题:spring的容器、web容器、springmvc的容器之间的区别
memo:2025 年 6 月 27 日修改至此,今天看到有球友发的 offer 选择提问贴,其中一个是杭州六小龙群核科技,我个人认为还是非常值得去的,毕竟是杭州的独角兽公司,薪资待遇都不错。
6.你是怎么理解Bean的?
在我看来,Bean 本质上就是由 Spring 容器管理的 Java 对象,但它和普通的 Java 对象有很大区别。普通的 Java 对象我们是通过 new 关键字创建的。而 Bean 是交给 Spring 容器来管理的,从创建到销毁都由容器负责。
从实际使用的角度来说,我们项目里的 Service、Dao、Controller 这些都是 Bean。比如 UserService 被标注了 @Service 注解,它就成了一个 Bean,Spring 会自动创建它的实例,管理它的依赖关系,当其他地方需要用到 UserService 的时候,Spring 就会把这个实例注入进去。
这种依赖注入的方式让对象之间的关系变得松耦合。
Spring 提供了多种 Bean 的配置方式,基于注解的方式是最常用的。
基于 XML 配置的方式在 Spring Boot 项目中已经不怎么用了。Java 配置类的方式则可以用来解决一些比较复杂的场景,比如说主从数据源,我们可以用 @Primary 注解标注主数据源,用 @Qualifier 来指定备用数据源。
@Configuration
public class AppConfig {
@Bean
@Primary // 主要候选者
public DataSource primaryDataSource() {
return new HikariDataSource();
}
@Bean
@Qualifier("secondary")
public DataSource secondaryDataSource() {
return new BasicDataSource();
}
}那在使用的时候,当我们直接用 @Autowired 注解注入 DataSource 时,Spring 默认会使用 HikariDataSource;当加上 @Qualifier("secondary") 注解时,Spring 则会注入 BasicDataSource。
@Autowired
private DataSource dataSource; // 会注入 primaryDataSource(因为有 @Primary)
@Autowired
@Qualifier("secondary")
private DataSource secondaryDataSource;@Component 和 @Bean 有什么区别?
首先从使用上来说,@Component 是标注在类上的,而 @Bean 是标注在方法上的。@Component 告诉 Spring 这个类是一个组件,请把它注册为 Bean,而 @Bean 则告诉 Spring 请将这个方法返回的对象注册为 Bean。
@Component // Spring自动创建UserService实例
public class UserService {
@Autowired
private UserDao userDao;
}
@Configuration
public class AppConfig {
@Bean // 我们手动创建DataSource实例
public DataSource dataSource() {
HikariDataSource ds = new HikariDataSource();
ds.setJdbcUrl("jdbc:mysql://localhost:3306/test");
ds.setUsername("root");
ds.setPassword("123456");
return ds; // 返回给Spring管理
}
}从控制权的角度来说,@Component 是由 Spring 自动创建和管理的。
而 @Bean 则是由我们手动创建的,然后再交给 Spring 管理,我们对对象的创建过程有完全的控制权。
- Java 面试指南(付费)收录的京东面经同学 9 面试原题:怎么理解spring的bean,@Component 和 @Bean 的区别
memo:2025 年 6 月 28 日修改至此,今天在帮球友修改简历的时候,又碰到一个杭电本硕的球友。我这里想说的一点是,杭电的计算机专业非常强,虽然他只是一所双非,如果能把项目经历、专业技能好好写的话,拿个大厂的顶级 offer 是完全没问题的。

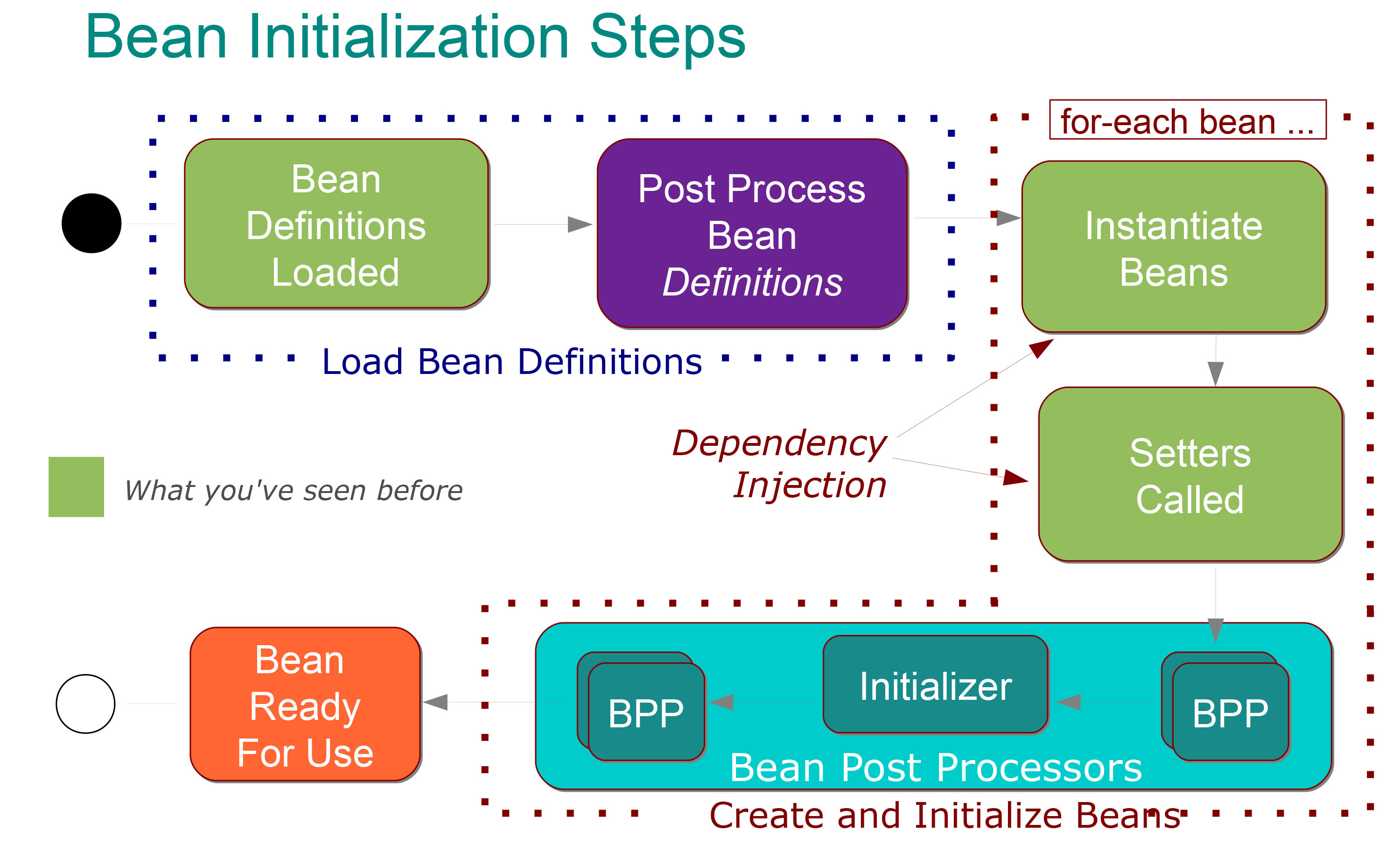
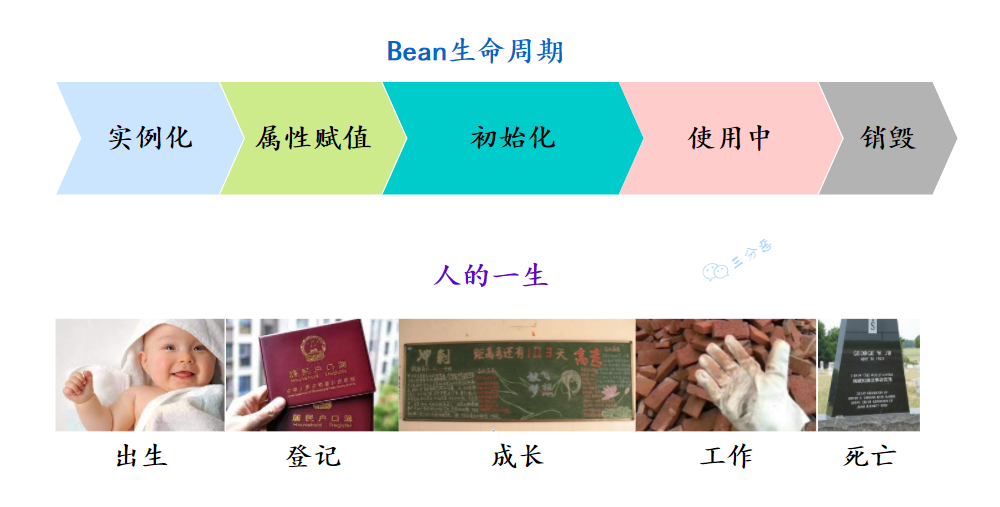
7.🌟能说一下Bean的生命周期吗?
推荐阅读:三分恶:Spring Bean 生命周期,好像人的一生
好的。
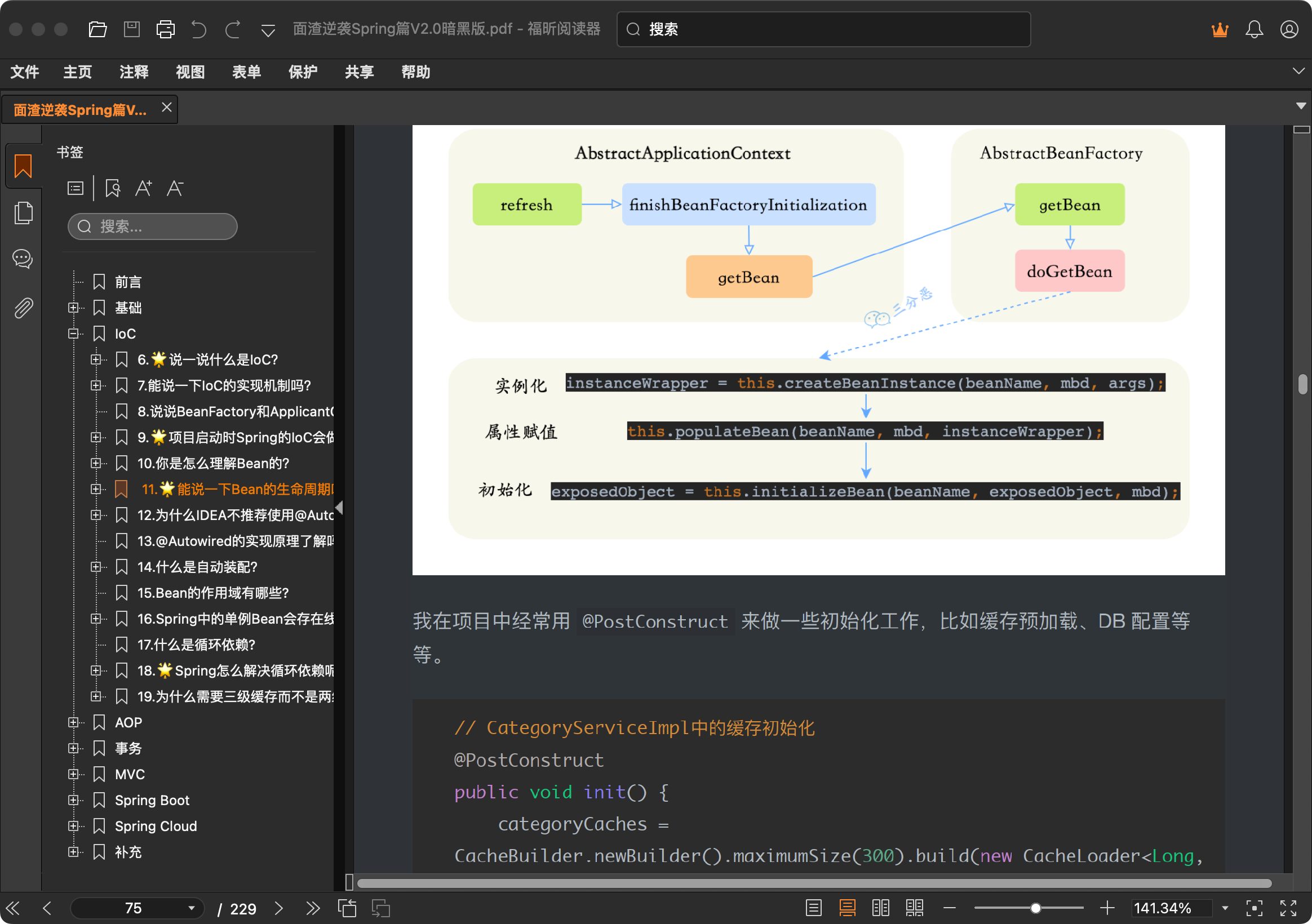
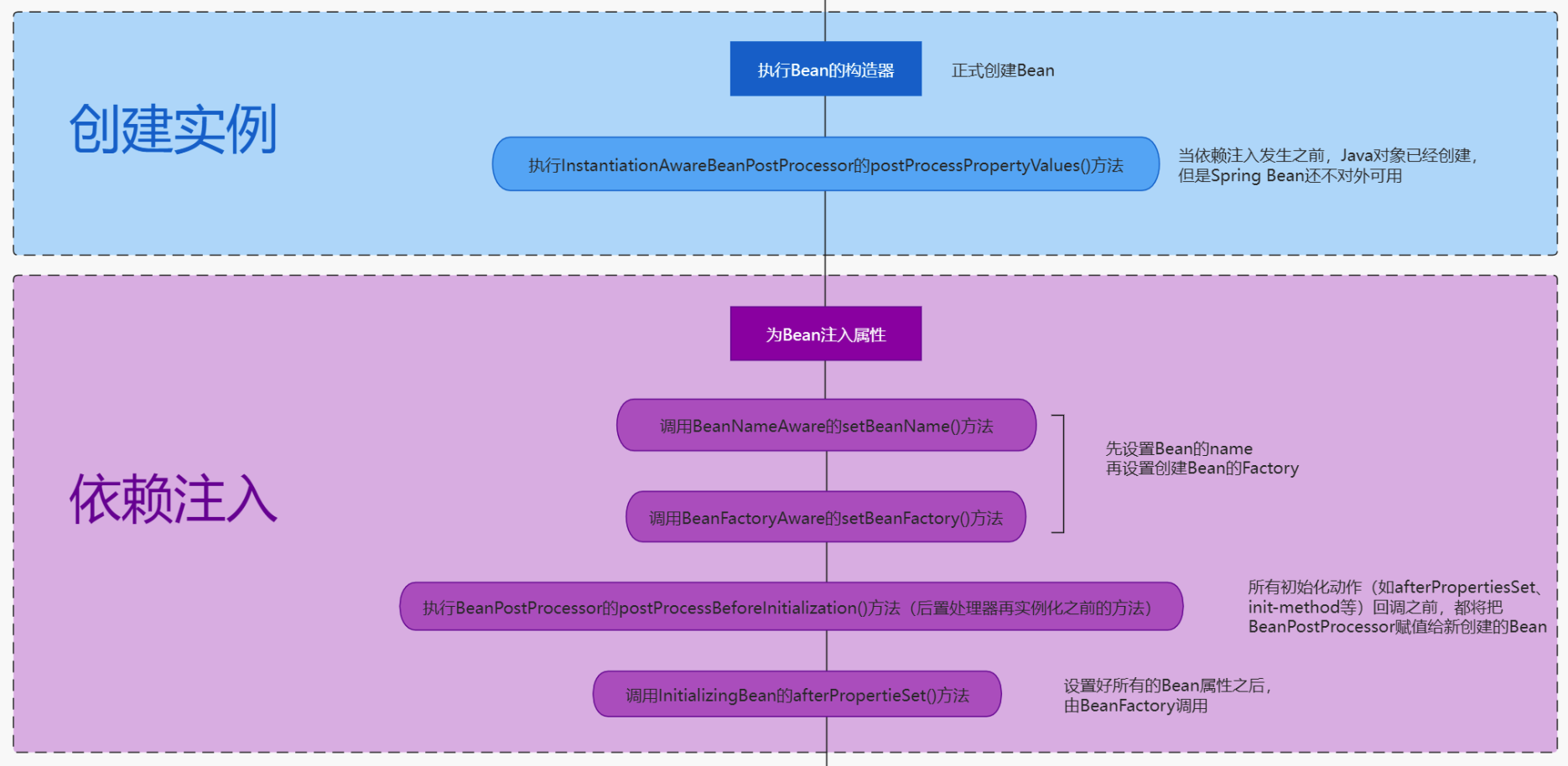
Bean 的生命周期可以分为 5 个主要阶段,我按照实际的执行顺序来说一下。
第一个阶段是实例化。Spring 容器会根据 BeanDefinition,通过反射调用 Bean 的构造方法创建对象实例。如果有多个构造方法,Spring 会根据依赖注入的规则选择合适的构造方法。
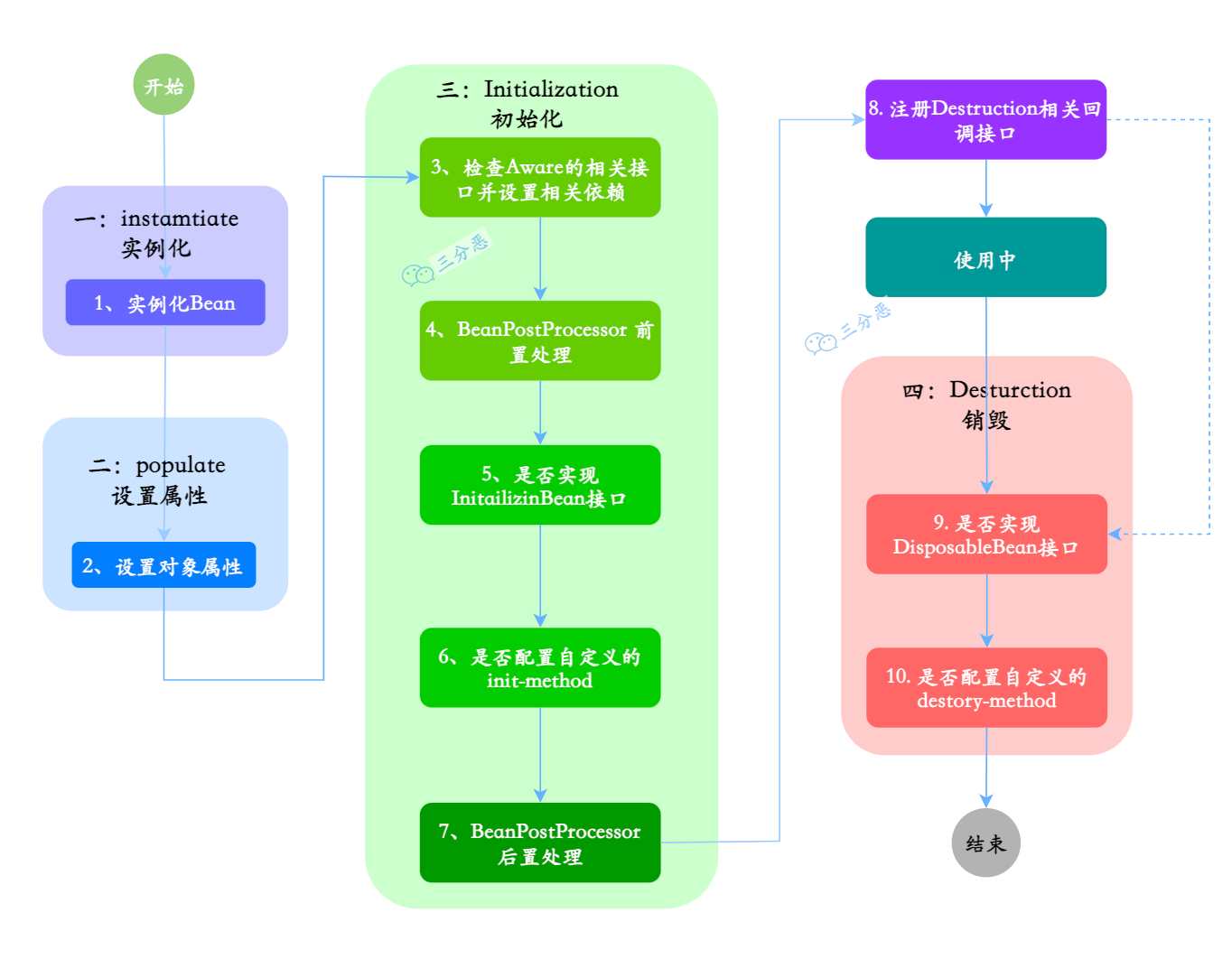
第二阶段是属性赋值。这个阶段 Spring 会给 Bean 的属性赋值,包括通过 @Autowired、@Resource 这些注解注入的依赖对象,以及通过 @Value 注入的配置值。
第三阶段是初始化。这个阶段会依次执行:
@PostConstruct标注的方法- InitializingBean 接口的 afterPropertiesSet 方法
- 通过
@Bean的 initMethod 指定的初始化方法
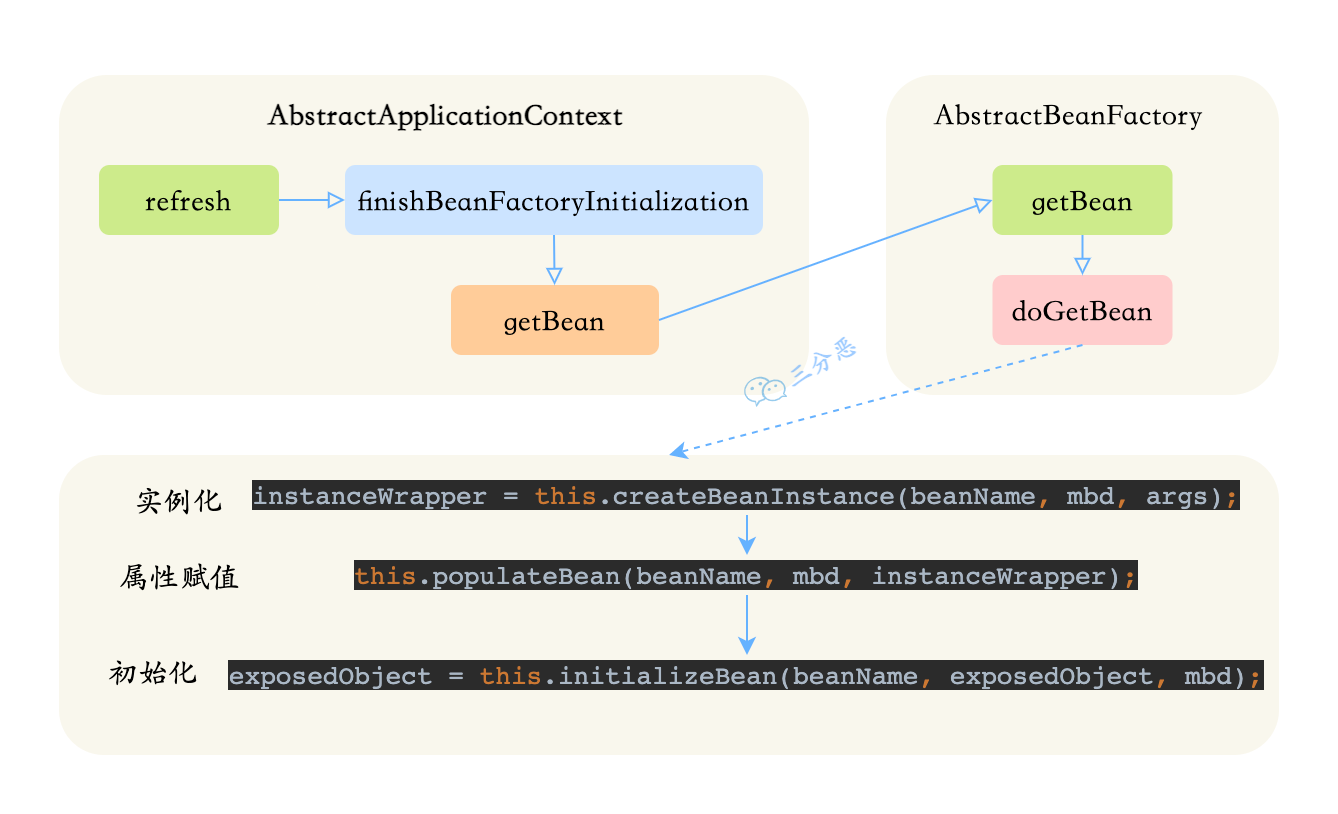
我在项目中经常用 @PostConstruct 来做一些初始化工作,比如缓存预加载、DB 配置等等。
// CategoryServiceImpl中的缓存初始化
@PostConstruct
public void init() {
categoryCaches = CacheBuilder.newBuilder().maximumSize(300).build(new CacheLoader<Long, CategoryDTO>() {
@Override
public CategoryDTO load(@NotNull Long categoryId) throws Exception {
CategoryDO category = categoryDao.getById(categoryId);
// ...
}
});
}
// DynamicConfigContainer中的配置初始化
@PostConstruct
public void init() {
cache = Maps.newHashMap();
bindBeansFromLocalCache("dbConfig", cache);
}初始化后,Spring 还会调用所有注册的 BeanPostProcessor 后置处理方法。这个阶段经常用来创建代理对象,比如 AOP 代理。
第五阶段是使用 Bean。比如我们的 Controller 调用 Service,Service 调用 DAO。
// UserController中的使用示例
@Autowired
private UserService userService;
@GetMapping("/users/{id}")
public UserDTO getUser(@PathVariable Long id) {
return userService.getUserById(id);
}
// UserService中的使用示例
@Autowired
private UserDao userDao;
public UserDTO getUserById(Long id) {
return userDao.getById(id);
}
// UserDao中的使用示例
@Autowired
private JdbcTemplate jdbcTemplate;
public UserDTO getById(Long id) {
String sql = "SELECT * FROM users WHERE id = ?";
return jdbcTemplate.queryForObject(sql, new Object[]{id}, new UserRowMapper());
}最后是销毁阶段。当容器关闭或者 Bean 被移除的时候,会依次执行:
@PreDestroy标注的方法- DisposableBean 接口的 destroy 方法
- 通过
@Bean的 destroyMethod 指定的销毁方法
Aware 类型的接口有什么作用?
Aware 接口在 Spring 中是一个很有意思的设计,它们的作用是让 Bean 能够感知到 Spring 容器的一些内部组件。
从设计理念来说,Aware 接口实现了一种“回调”机制。正常情况下,Bean 不应该直接依赖 Spring 容器,这样可以保持代码的独立性。但有些时候,Bean 确实需要获取容器的一些信息或者组件,Aware 接口就提供了这样一个能力。
我最常用的 Aware 接口是 ApplicationContextAware,它可以让 Bean 获取到 ApplicationContext 容器本身。
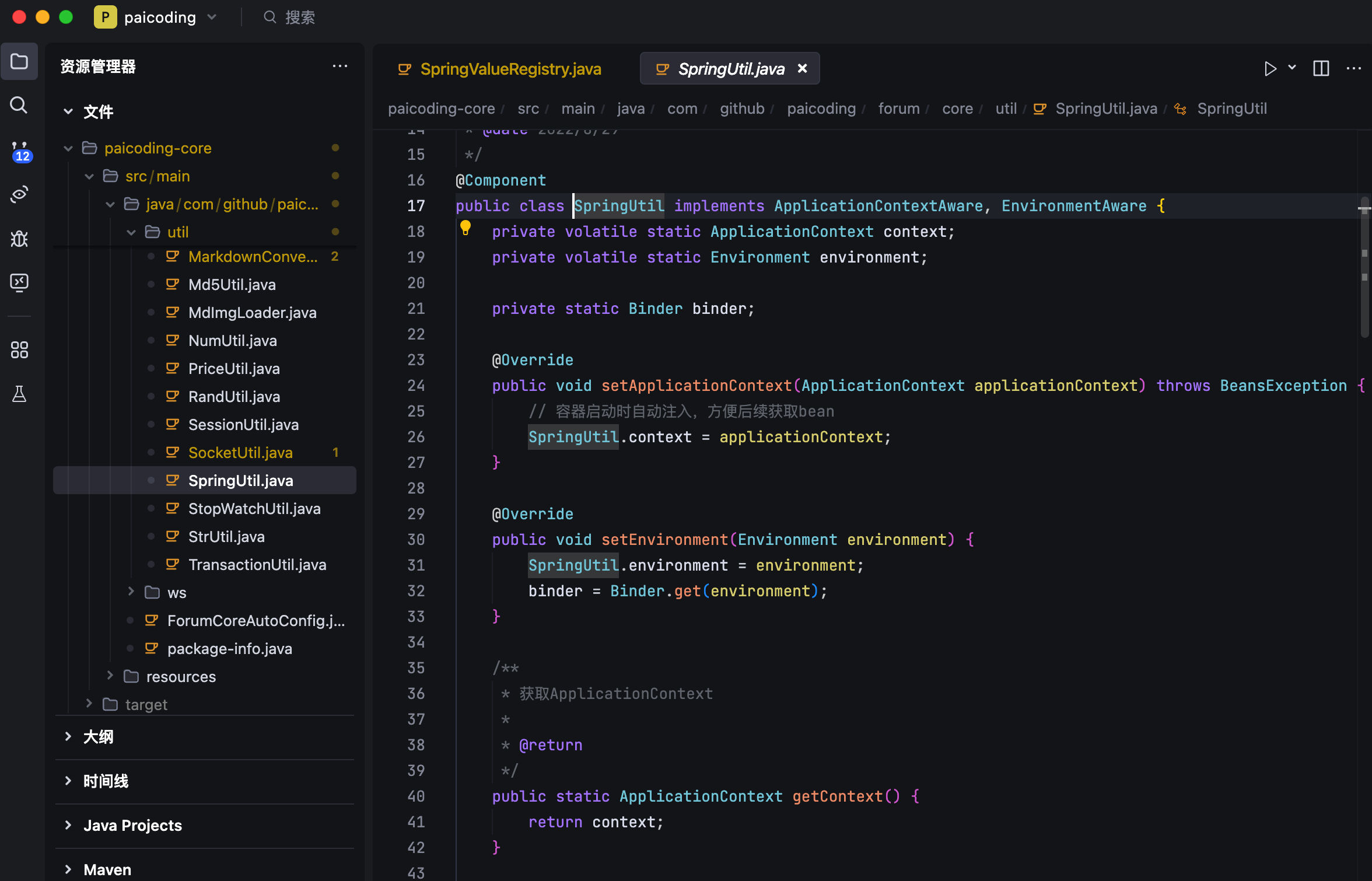
在技术派项目中,我就通过实现 ApplicationContextAware 和 EnvironmentAware 接口封装了一个 SpringUtil 工具类,通过 getBean 和 getProperty 方法来获取 Bean 和配置属性。
// 静态方法获取Bean,方便在非Spring管理的类中使用
public static <T> T getBean(Class<T> clazz) {
return context.getBean(clazz);
}
// 获取配置属性
public static String getProperty(String key) {
return environment.getProperty(key);
}如果配置了 init-method 和 destroy-method,Spring 会在什么时候调用其配置的方法?
init-method 指定的初始化方法会在 Bean 的初始化阶段被调用,具体的执行顺序是:
- 先执行
@PostConstruct标注的方法 - 然后执行 InitializingBean 接口的
afterPropertiesSet()方法 - 最后再执行 init-method 指定的方法
也就是说,init-method 是在所有其他初始化方法之后执行的。
@Component
public class MyService {
@Autowired
private UserDao userDao;
@PostConstruct
public void postConstruct() {
System.out.println("1. @PostConstruct执行");
}
public void customInit() { // 通过@Bean的initMethod指定
System.out.println("3. init-method执行");
}
}
@Configuration
public class AppConfig {
@Bean(initMethod = "customInit")
public MyService myService() {
return new MyService();
}
}destroy-method 会在 Bean 销毁阶段被调用。
@Component
public class MyService {
@PreDestroy
public void preDestroy() {
System.out.println("1. @PreDestroy执行");
}
public void customDestroy() { // 通过@Bean的destroyMethod指定
System.out.println("3. destroy-method执行");
}
}不过在实际开发中,通常用 @PostConstruct 和 @PreDestroy 就够了,它们更简洁。
- Java 面试指南(付费)收录的小米 25 届日常实习一面原题:说说 Bean 的生命周期
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:Spring中bean生命周期
- Java 面试指南(付费)收录的8 后端开发秋招一面面试原题:讲一下Spring Bean的生命周期
- Java 面试指南(付费)收录的同学 1 贝壳找房后端技术一面面试原题:bean生命周期
- Java 面试指南(付费)收录的快手同学 4 一面原题:介绍下Bean的生命周期?Aware类型接口的作用?如果配置了init-method和destroy-method,Spring会在什么时候调用其配置的方法?
memo:2025 年 6 月 30 日修改至此。昨天有读者发消息说有三个 offer 要选择,中科大读博、中海油、商飞北研,问我该怎么选择?说实话,这三个都是非常优质的选择,我个人的建议是优先考虑中科大读博,毕竟是国内顶尖学府,博士毕业后可以选择在高校任教,会更符合他的家庭条件,当然了,我深知,读博的产出压力非常大。
8.Bean的作用域有哪些?
Bean 的作用域决定了 Bean 实例的生命周期和创建策略,singleton 是默认的作用域。整个 Spring 容器中只会有一个 Bean 实例。不管在多少个地方注入这个 Bean,拿到的都是同一个对象。
@Component // 默认就是singleton
public class UserService {
// 整个应用中只有一个UserService实例
}生命周期和 Spring 容器相同,容器启动时创建,容器销毁时销毁。
实际开发中,像 Service、Dao 这些业务组件基本都是单例的,因为单例既能节省内存,又能提高性能。
当把 scope 设置为 prototype 时,每次从容器中获取 Bean 的时候都会创建一个新的实例。
@Component
@Scope("prototype")
public class OrderProcessor {
// 每次注入或获取都是新的实例
}当需要处理一些有状态的 Bean 时会用到 prototype,比如每个订单处理器需要维护不同的状态信息。
需要注意的是,在 singleton Bean 中注入 prototype Bean 时要小心,因为 singleton Bean 只创建一次,所以 prototype Bean 也只会注入一次。这时候可以用 @Lookup 注解或者 ApplicationContext 来动态获取。
@Component
public class SingletonService {
// 错误的做法,prototypeBean只会注入一次
@Autowired
private PrototypeBean prototypeBean;
// 正确的做法,每次调用都获取新实例
@Lookup
public PrototypeBean getPrototypeBean() {
return null; // Spring会重写这个方法
}
}除了 singleton 和 prototype,Spring 还支持其他作用域,比如 request、session、application 和 websocket。
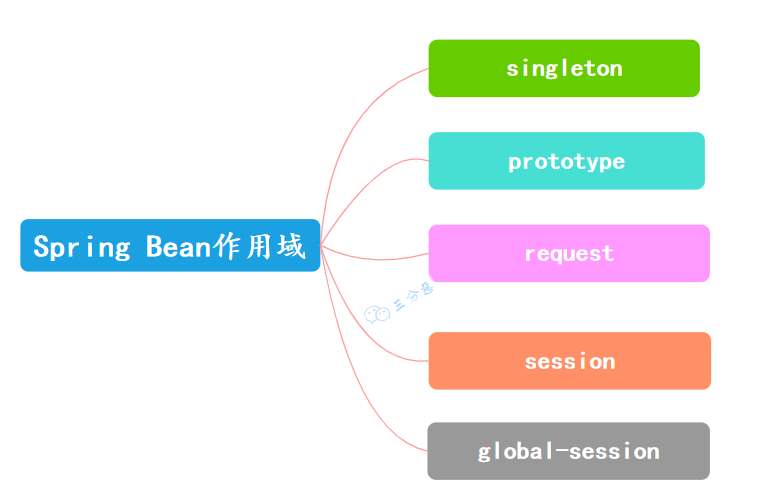
如果作用于是 request,表示在 Web 应用中,每个 HTTP 请求都会创建一个新的 Bean 实例,请求结束后 Bean 就被销毁。
@Component
@Scope("request")
public class RequestContext {
// 每个HTTP请求都有自己的实例
}如果作用于是 session,表示在 Web 应用中,每个 HTTP 会话都会创建一个新的 Bean 实例,会话结束后 Bean 被销毁。
@Component
@Scope("session")
public class UserSession {
// 每个用户会话都有自己的实例
}典型的使用场景是购物车、用户登录状态这些需要在整个会话期间保持的信息。
application 作用域表示在整个应用中只有一个 Bean 实例,类似于 singleton,但它的生命周期与 ServletContext 绑定。
@Component
@Scope("application")
public class AppConfig {
// 整个应用中只有一个实例
}websocket 作用域表示在 WebSocket 会话中每个连接都有自己的 Bean 实例。WebSocket 连接建立时创建,连接关闭时销毁。
@Component
@Scope("websocket")
public class WebSocketHandler {
// 每个WebSocket连接都有自己的实例
}
- Java 面试指南(付费)收录的同学 1 贝壳找房后端技术一面面试原题:bean是单例还是多例的,具体怎么修改
memo:2025 年 7 月 3 日修改至此,今天在帮球友修改简历的时候,碰到一个郑州大学硕,河北师范大学本的球友,整体在校的经历非常出色,奖学金、论文期刊基本上都拉满了。那这么多优秀的球友选择来到这里,也是对星球的又一次认可和肯定,我也一定会继续努力,提供更多优质的内容和服务。

9.Spring中的单例Bean会存在线程安全问题吗?
首先要明确一点。Spring 容器本身保证了 Bean 创建过程的线程安全,也就是说不会出现多个线程同时创建同一个单例 Bean 的情况。但是 Bean 创建完成后的使用过程,Spring 就不管了。
换句话说,单例 Bean 在被创建后,如果它的内部状态是可变的,那么在多线程环境下就可能会出现线程安全问题。
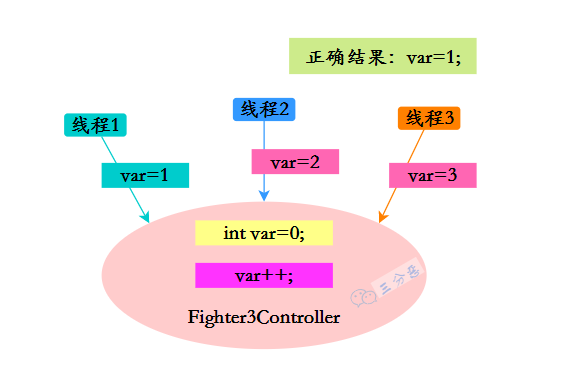
比如说在技术派项目中,有一个敏感词过滤的 Bean,我们就需要使用 volatile 关键字来保证多线程环境下的可见性。
@Service
public class SensitiveService {
private volatile SensitiveWordBs sensitiveWordBs; // 使用volatile保证可见性
@PostConstruct
public void refresh() {
// 重新初始化sensitiveWordBs
}
}如果 Bean 中没有成员变量,或者成员变量都是不可变的,final 修饰的,那么就不存在线程安全问题。
@Service
public class UserServiceImpl implements UserService {
@Resource
private UserDao userDao;
@Autowired
private CountService countService;
// 只有依赖注入的无状态字段
}
@Service
public class ConfigService {
private final String appName; // final修饰,不可变
public ConfigService(@Value("${app.name}") String appName) {
this.appName = appName;
}
}单例Bean的线程安全问题怎么解决呢?
第一种,使用局部变量,也就是使用无状态的单例 Bean,把所有状态都通过方法参数传递:
@Service
public class UserService {
@Autowired
private UserDao userDao;
// 无状态方法,所有数据通过参数传递
public User processUser(Long userId, String operation) {
User user = userDao.findById(userId);
// 处理逻辑...
return user;
}
}第二种,当确实需要维护线程相关的状态时,可以使用 ThreadLocal 来保存状态。ThreadLocal 可以保证每个线程都有自己的变量副本,互不干扰。
@Service
public class UserContextService {
private static final ThreadLocal<User> userThreadLocal = new ThreadLocal<>();
public void setCurrentUser(User user) {
userThreadLocal.set(user);
}
public User getCurrentUser() {
return userThreadLocal.get();
}
public void clear() {
userThreadLocal.remove(); // 防止内存泄漏
}
}第三种,如果需要缓存数据或者计数,使用 JUC 包下的线程安全类,比如说 AtomicInteger、ConcurrentHashMap、CopyOnWriteArrayList 等。
@Service
public class CacheService {
// 使用线程安全的集合
private final ConcurrentHashMap<String, Object> cache = new ConcurrentHashMap<>();
private final AtomicLong counter = new AtomicLong(0);
public void put(String key, Object value) {
cache.put(key, value);
counter.incrementAndGet();
}
}第四种,对于复杂的状态操作,可以使用 synchronized 或 Lock:
@Service
public class CacheService {
private final Map<String, Object> cache = new HashMap<>();
private final ReentrantLock lock = new ReentrantLock();
public void put(String key, Object value) {
lock.lock();
try {
cache.put(key, value);
} finally {
lock.unlock();
}
}
}第五种,如果 Bean 确实需要维护状态,可以考虑将其改为 prototype 作用域,这样每次注入都会创建一个新的实例,避免了多线程共享同一个实例的问题。
@Service
@Scope("prototype") // 每次注入都创建新实例
public class StatefulService {
private String state; // 现在每个实例都有独立状态
public void setState(String state) {
this.state = state;
}
}或者使用 request 作用域,这样每个 HTTP 请求都会创建一个新的实例。
@Service
@Scope("request")
public class RequestScopedService {
private String requestData;
// 每个请求都有独立的实例
}
- Java 面试指南(付费)收录的阿里面经同学 1 闲鱼后端一面的原题:spring的bean的并发安全问题
memo:2025 年 7 月 4 日修改至此,今天在帮球友修改简历的时候,碰到一个武汉理工大学本硕的球友。说真的,和武汉理工大学挺有缘的,2023 年去武汉,就线下见了一名武理的球友,他当时签约的是小米,非常优秀。

10.为什么IDEA不推荐使用@Autowired注解注入Bean?
前情提要:当使用 @Autowired 注解注入 Bean 时,IDEA 会提示“Field injection is not recommended”。
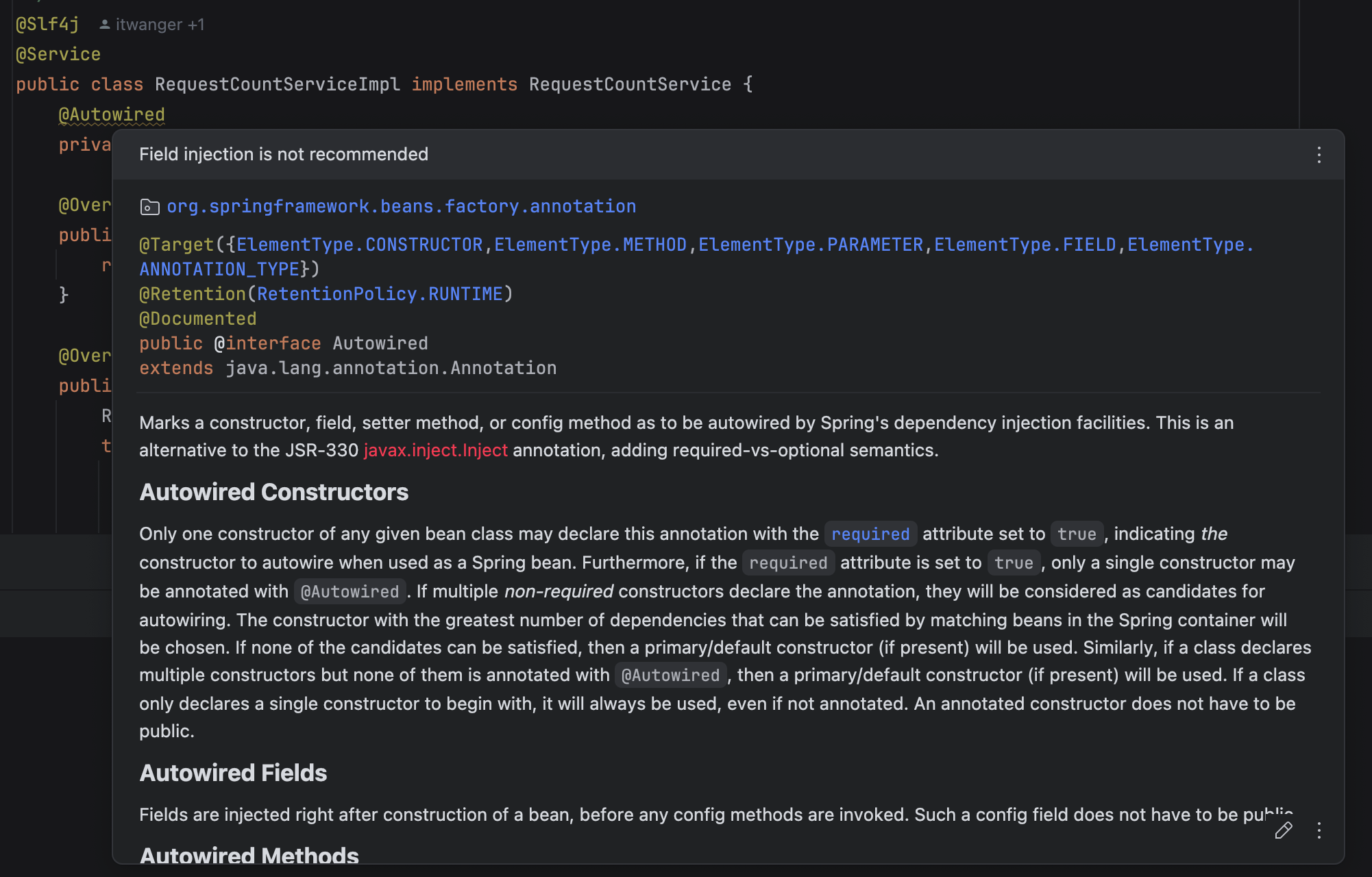
面试回答:
主要有几个原因。
第一个是字段注入不利于单元测试。字段注入需要使用反射或 Spring 容器才能注入依赖,测试更复杂;而构造方法注入可以直接通过构造方法传入 Mock 对象,测试起来更简单。
// 字段注入的测试困难
@Test
public void testUserService() {
UserService userService = new UserService();
// 无法直接设置userRepository,需要反射或Spring容器
// userService.userRepository = Mockito.mock(UserRepository.class);
// 需要手动设置依赖,测试不方便
ReflectionTestUtils.setField(userService, "userRepository", Mockito.mock(UserRepository.class));
userService.doSomething();
// ...
}
// 构造方法注入的测试简单
@Test
public void testUserService() {
UserRepository mockRepository = Mockito.mock(UserRepository.class);
UserService userService = new UserService(mockRepository); // 直接注入
}第二个是字段注入会隐藏循环依赖问题,而构造方法注入会在项目启动时就去检查依赖关系,能更早发现问题。
第三个是构造方法注入可以使用 final 字段确保依赖在对象创建时就被初始化,避免了后续修改的风险。
在技术派项目中,我们已经在使用构造方法注入的方式来管理依赖关系。
不过话说回来,@Autowired 的字段注入方式在一些简单的场景下还是可以用的,主要看团队的编码规范吧。
@Autowired 和 @Resource 注解的区别?
首先从来源上说,@Autowired 是 Spring 框架提供的注解,而 @Resource 是 Java EE 标准提供的注解。换句话说,@Resource 是 JDK 自带的,而 @Autowired 是 Spring 特有的。
虽然 IDEA 不推荐使用 @Autowired,但对 @Resource 注解却没有任何提示。
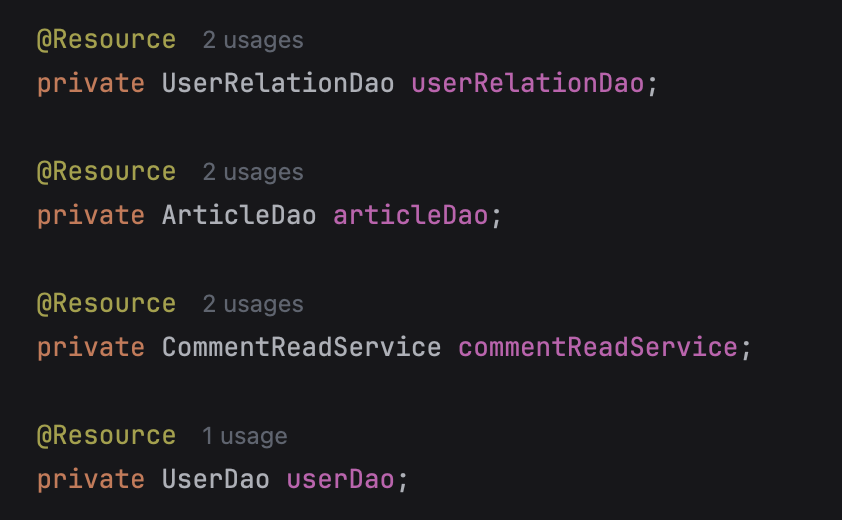
从注入方式上说,@Autowired 默认按照类型,也就是 byType 进行注入,而 @Resource 默认按照名称,也就是 byName 进行注入。
当容器中存在多个相同类型的 Bean, 比如说有两个 UserRepository 的实现类,直接用 @Autowired 注入 UserRepository 时就会报错,因为 Spring 容器不知道该注入哪个实现类。
@Component
public class UserRepository21 implements UserRepository2 {}
@Component
public class UserRepository22 implements UserRepository2 {}
@Component
public class UserService2 {
@Autowired
private UserRepository2 userRepository; // 冲突
}这时候,有两种解决方案,第一种是使用 @Autowired + @Qualifier 指定具体的 Bean 名称来解决冲突。
@Component("userRepository21")
public class UserRepository21 implements UserRepository2 {
}
@Component("userRepository22")
public class UserRepository22 implements UserRepository2 {
}
@Autowired
@Qualifier("userRepository22")
private UserRepository2 userRepository22;第二种是使用 @Resource 注解按名称进行注入。
@Resource(name = "userRepository21")
private UserRepository2 userRepository21;
- Java 面试指南(付费)收录的京东面经同学 9 面试原题:依赖注入的时候,直接Autowired比较直接,为什么推荐构造方法注入呢
memo:2025 年 7 月 1 日修改至此,今天在帮球友修改简历的时候,碰到一个郑州大学本硕的球友,这也是我们河南省最好的大学了,但也仅仅是一所 211,所以希望所有河南的同学都能加把劲,证明自己的实力,去拿到更好的 offer,为校争光。

11.@Autowired的实现原理了解吗?
@Autowired 是 Spring 实现依赖注入的核心注解,其实现原理基于反射机制和 BeanPostProcessor 接口。
整个过程分为两个主要阶段。第一个阶段是依赖收集阶段,发生在 Bean 实例化之后、属性赋值之前。Autowired 的 Processor 会扫描 Bean 的所有字段、方法和构造方法,找出标注了 @Autowired 注解的地方,然后把这些信息封装成 Injection 元数据对象缓存起来。这个过程用到了大量的反射操作,需要分析类的结构、注解信息等等。
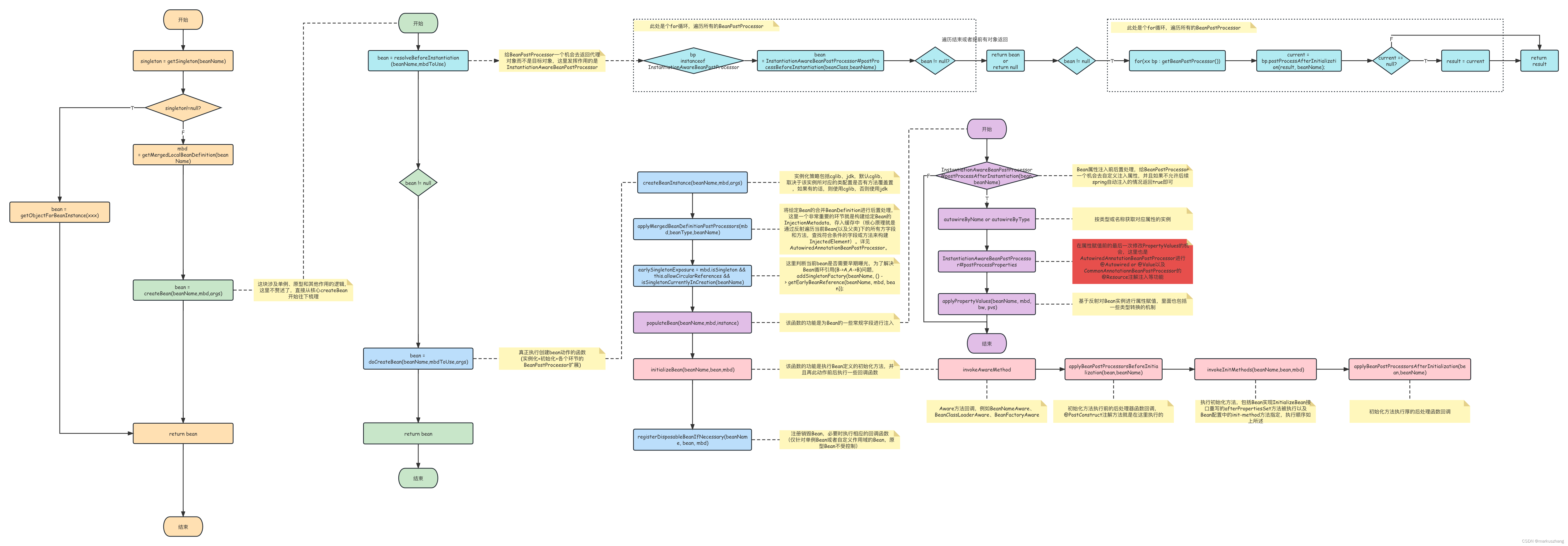
第二个阶段是依赖注入阶段,Spring 会取出之前缓存的 Injection 元数据对象,然后逐个处理每个注入点。对于每个 @Autowired 标注的字段或方法,Spring 会根据类型去容器中查找匹配的 Bean。
// 1. 按类型查找(byType)
Map<String, Object> matchingBeans = BeanFactoryUtils.beansOfTypeIncludingAncestors(
this.beanFactory, type);
// 2. 如果找到多个候选者,按名称筛选(byName)
String autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
// 3. 考虑@Primary和@Priority注解
// 4. 最后按照字段名或参数名匹配在具体的注入过程中,Spring 会使用反射来设置字段的值或者调用 setter 方法。比如对于字段注入,会调用 Field.set() 方法;对于 setter 注入,会调用 Method.invoke() 方法。
12.什么是自动装配?
自动装配的本质就是让 Spring 容器自动帮我们完成 Bean 之间的依赖关系注入,而不需要我们手动去指定每个依赖。简单来说,就是“我们不用告诉 Spring 具体怎么注入,Spring 自己会想办法找到合适的 Bean 注入进来”。
自动装配的工作原理简单来说就是,Spring 容器在启动时自动扫描 @ComponentScan 指定包路径下的所有类,然后根据类上的注解,比如 @Autowired、@Resource 等,来判断哪些 Bean 需要被自动装配。
@Configuration
@ComponentScan("com.github.paicoding.forum.service")
@MapperScan(basePackages = {
"com.github.paicoding.forum.service.article.repository.mapper",
"com.github.paicoding.forum.service.user.repository.mapper"
// ... 更多包路径
})
public class ServiceAutoConfig {
// Spring自动扫描指定包下的所有组件并注册为Bean
}之后分析每个 Bean 的依赖关系,在创建 Bean 的时候,根据装配规则自动找到合适的依赖 Bean,最后根据反射将这些依赖注入到目标 Bean 中。
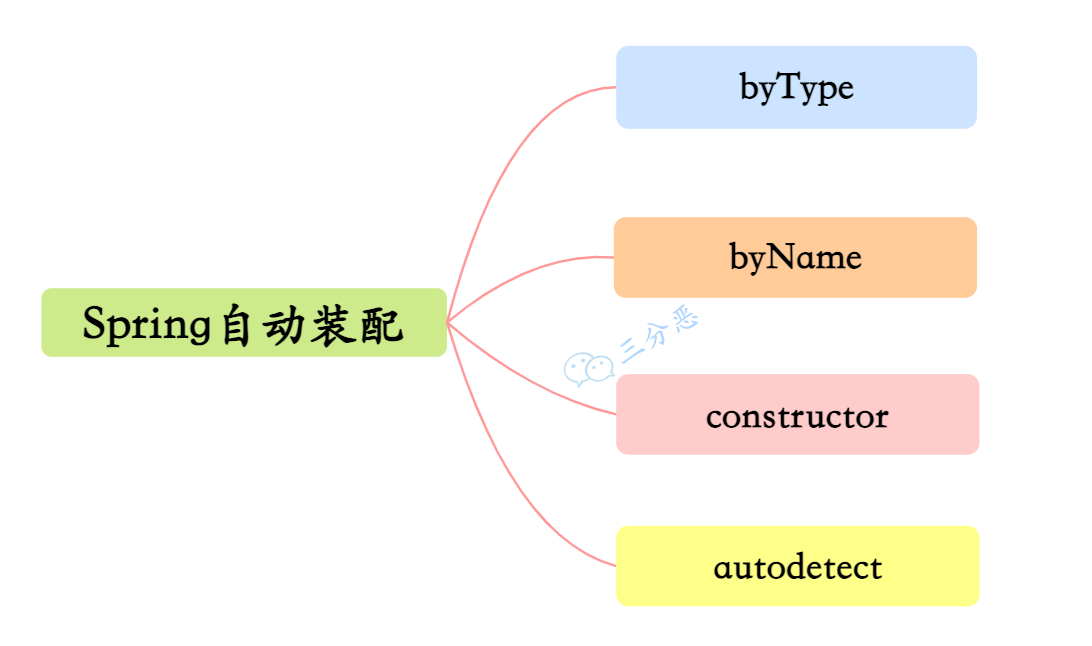
Spring提供了哪几种自动装配类型?
Spring 的自动装配方式有好几种,在 XML 配置时代,主要有 byName、byType、constructor 和 autodetect 四种方式。
到了注解驱动时代,用得最多的是 @Autowired 注解,默认按照类型装配。
@Service
public class UserService {
@Autowired // 按类型自动装配
private UserRepository userRepository;
}其次还有 @Resource 注解,它默认按照名称装配,如果找不到对应名称的 Bean,就会按类型装配。
Spring Boot 的自动装配还有一套更高级的机制,通过 @EnableAutoConfiguration 和各种 @Conditional 注解来实现,这个是框架级别的自动装配,会根据 classpath 中的类和配置来自动配置 Bean。
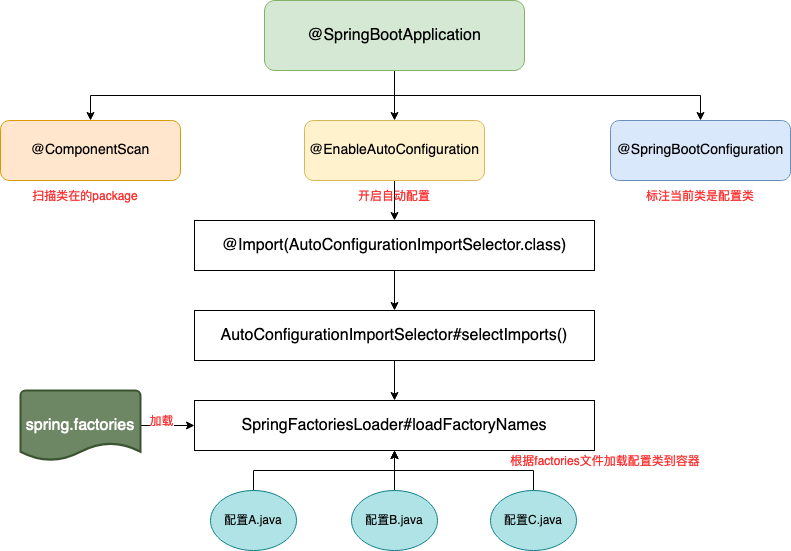
- Java 面试指南(付费)收录的 oppo 面经同学 15 技术面试原题:spring自动装配原理、启动原理,要在启动阶段自定义逻辑该怎么做?
memo:2025 年 7 月 2 日修改至此,今天在帮球友修改简历的时候,碰到一个北京航空航天大学的球友,他在邮件中说到:在星球里学到了好多东西,目前正在准备技术派和 MYDB,打算好好冲秋招,能帮助到大家我真的很欣慰。
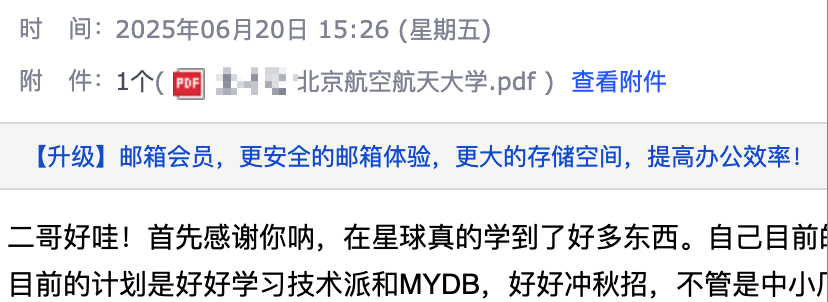
13.什么是循环依赖?
简单来说就是两个或多个 Bean 相互依赖,比如说 A 依赖 B,B 依赖 A,或者 C 依赖 C,就成了循环依赖。
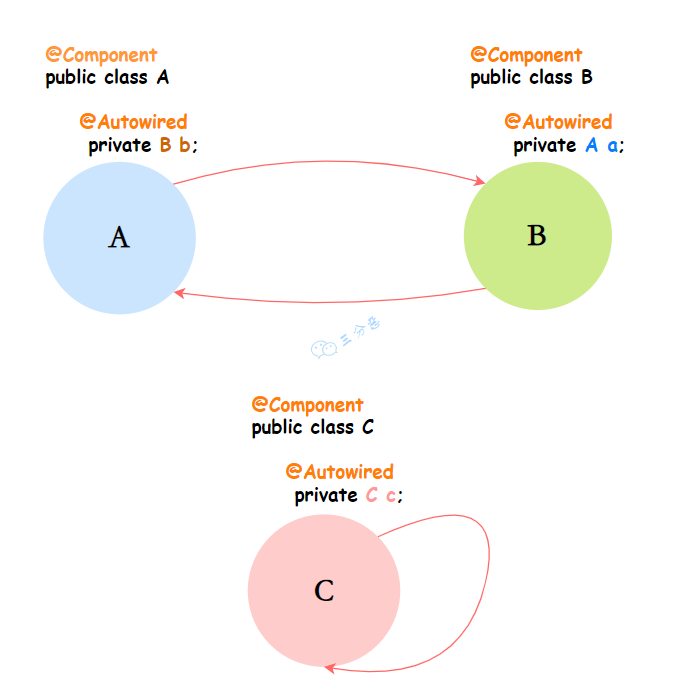
14.🌟Spring怎么解决循环依赖呢?
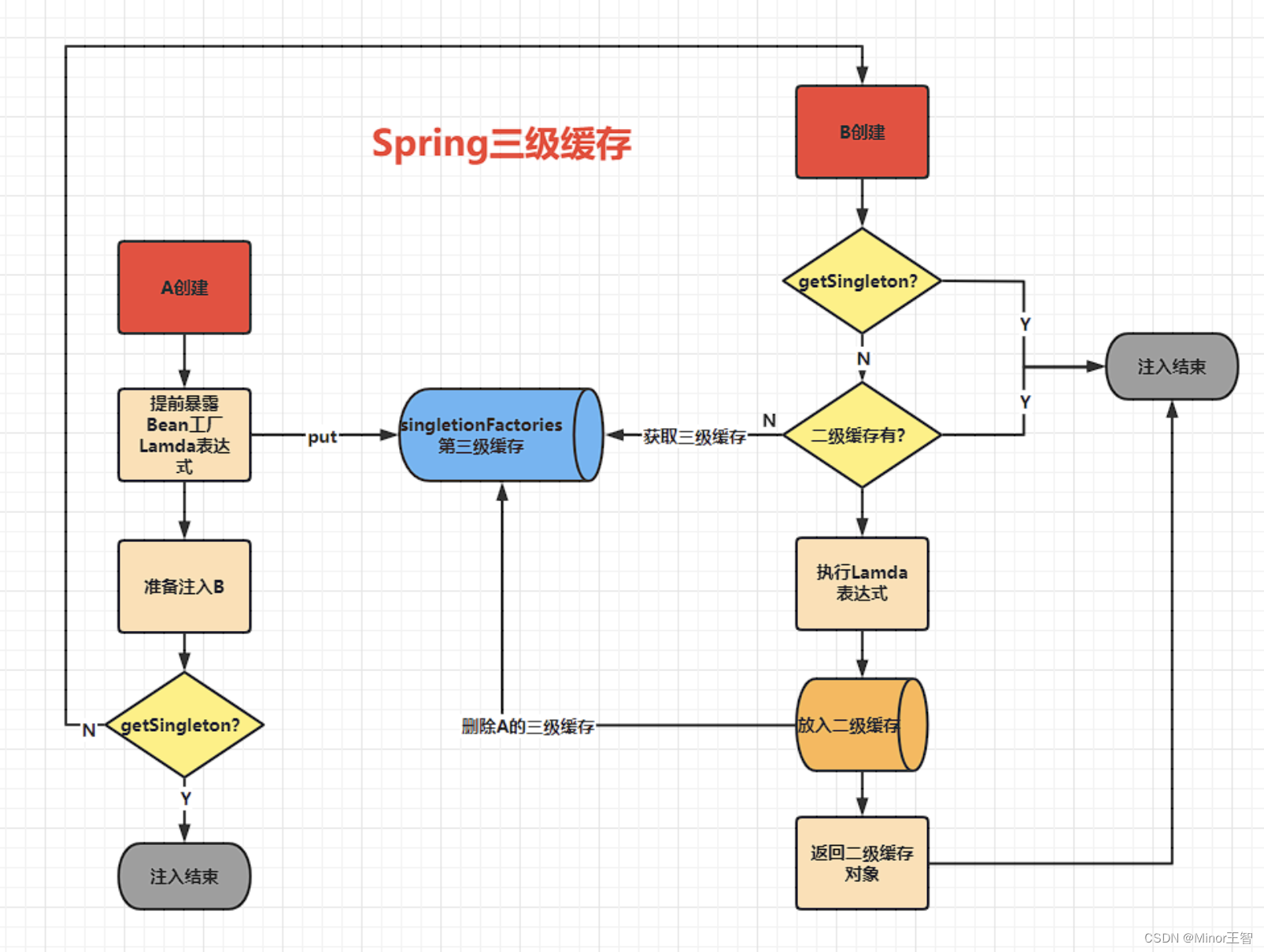
Spring 通过三级缓存机制来解决循环依赖:
- 一级缓存:存放完全初始化好的单例 Bean。
- 二级缓存:存放提前暴露的 Bean,实例化完成,但未初始化完成。
- 三级缓存:存放 Bean 工厂,用于生成提前暴露的 Bean。
以 A、B 两个类发生循环依赖为例:
第 1 步:开始创建 Bean A。
- Spring 调用 A 的构造方法,创建 A 的实例。此时 A 对象已存在,但 b属性还是 null。
- 将 A 的对象工厂放入三级缓存。
- 开始进行 A 的属性注入。
第 2 步:A 需要注入 B,开始创建 Bean B。
- 发现需要 B,但 B 还不存在,所以开始创建 B。
- 调用 B 的构造方法,创建 B 的实例。此时 B 对象已存在,但 a 属性还是 null。
- 将 B 的对象工厂放入三级缓存。
- 开始进行 B 的属性注入。
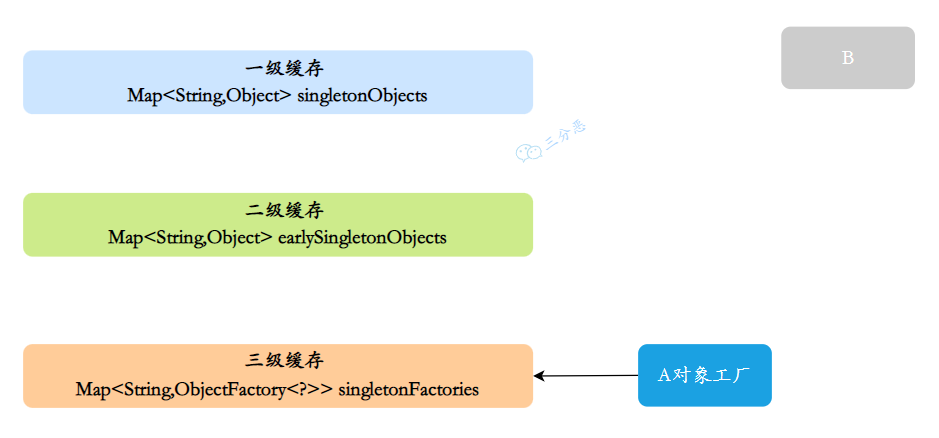
第 3 步:B 需要注入 A,从缓存中获取 A。
- B 需要注入 A,先从一级缓存找 A,没找到。
- 再从二级缓存找 A,也没找到。
- 最后从三级缓存找 A,找到了 A 的对象工厂。
- 调用 A 的对象工厂得到 A 的实例。这时 A 已经实例化了,虽然还没完全初始化。
- 将 A 从三级缓存移到二级缓存。
- B 拿到 A 的引用,完成属性注入。
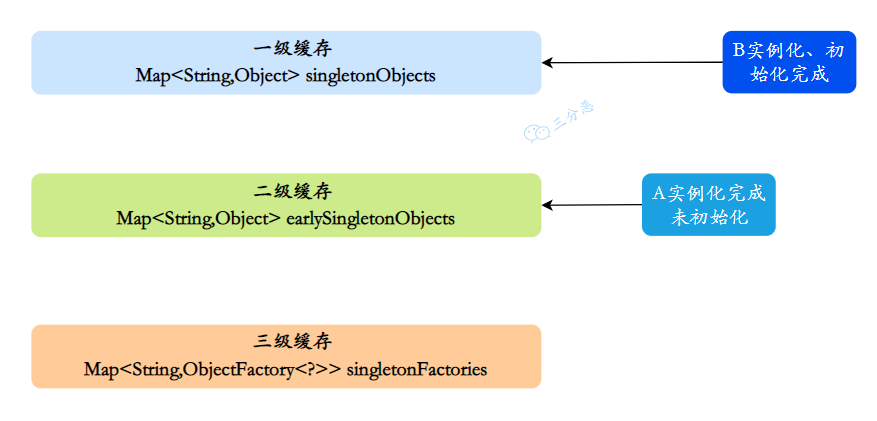
第 4 步:B 完成初始化。
- B 的属性注入完成,执行
@PostConstruct等初始化逻辑。 - B 完全创建完成,从三级缓存移除,放入一级缓存。
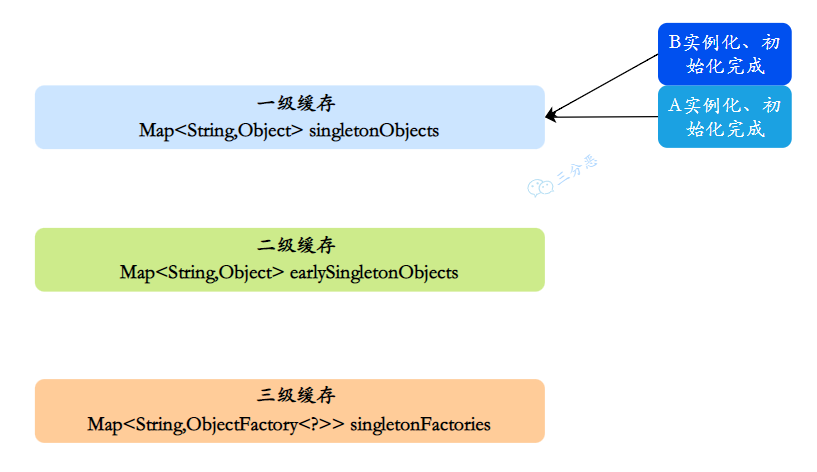
第 5 步:A 完成初始化。
- 回到 A 的创建过程,A 拿到完整的 B 实例,完成属性注入。
- A 执行初始化逻辑,创建完成。
- A 从二级缓存移除,放入一级缓存。
用代码来模拟这个过程,是这样的:
// 模拟Spring的解决过程
public class CircularDependencyDemo {
// 三级缓存
Map<String, Object> singletonObjects = new HashMap<>();
Map<String, Object> earlySingletonObjects = new HashMap<>();
Map<String, ObjectFactory> singletonFactories = new HashMap<>();
public Object getBean(String beanName) {
// 先从一级缓存获取
Object bean = singletonObjects.get(beanName);
if (bean != null) return bean;
// 再从二级缓存获取
bean = earlySingletonObjects.get(beanName);
if (bean != null) return bean;
// 最后从三级缓存获取
ObjectFactory factory = singletonFactories.get(beanName);
if (factory != null) {
bean = factory.getObject();
earlySingletonObjects.put(beanName, bean); // 移到二级缓存
singletonFactories.remove(beanName); // 从三级缓存移除
}
return bean;
}
}哪些情况下Spring无法解决循环依赖?
Spring 虽然能解决大部分循环依赖问题,但确实有几种情况是无法处理的,我来详细说说。

第一种,构造方法的循环依赖,这种情况 Spring 会直接抛出 BeanCurrentlyInCreationException 异常。
@Component
public class A {
private B b;
public A(B b) { // 构造方法注入
this.b = b;
}
}
@Component
public class B {
private A a;
public B(A a) { // 构造方法注入
this.a = a;
}
}因为构造方法注入发生在实例化阶段,创建 A 的时候必须先有 B,但创建 B又必须先有 A,这时候两个对象都还没创建出来,无法提前暴露到缓存中。
第二种,prototype 作用域的循环依赖。prototype 作用域的 Bean 每次获取都会创建新实例,Spring 无法缓存这些实例,所以也无法解决循环依赖。
----面试中可以不背,方便大家理解 start----
我们来看一个实例,先是 PrototypeBeanA:
@Component
@Scope("prototype")
public class PrototypeBeanA {
private final PrototypeBeanB prototypeBeanB;
@Autowired
public PrototypeBeanA(PrototypeBeanB prototypeBeanB) {
this.prototypeBeanB = prototypeBeanB;
}
}然后是 PrototypeBeanB:
@Component
@Scope("prototype")
public class PrototypeBeanB {
private final PrototypeBeanA prototypeBeanA;
@Autowired
public PrototypeBeanB(PrototypeBeanA prototypeBeanA) {
this.prototypeBeanA = prototypeBeanA;
}
}再然后是测试:
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Bean
CommandLineRunner commandLineRunner(ApplicationContext ctx) {
return args -> {
// 尝试获取PrototypeBeanA的实例
PrototypeBeanA beanA = ctx.getBean(PrototypeBeanA.class);
};
}
}运行结果:
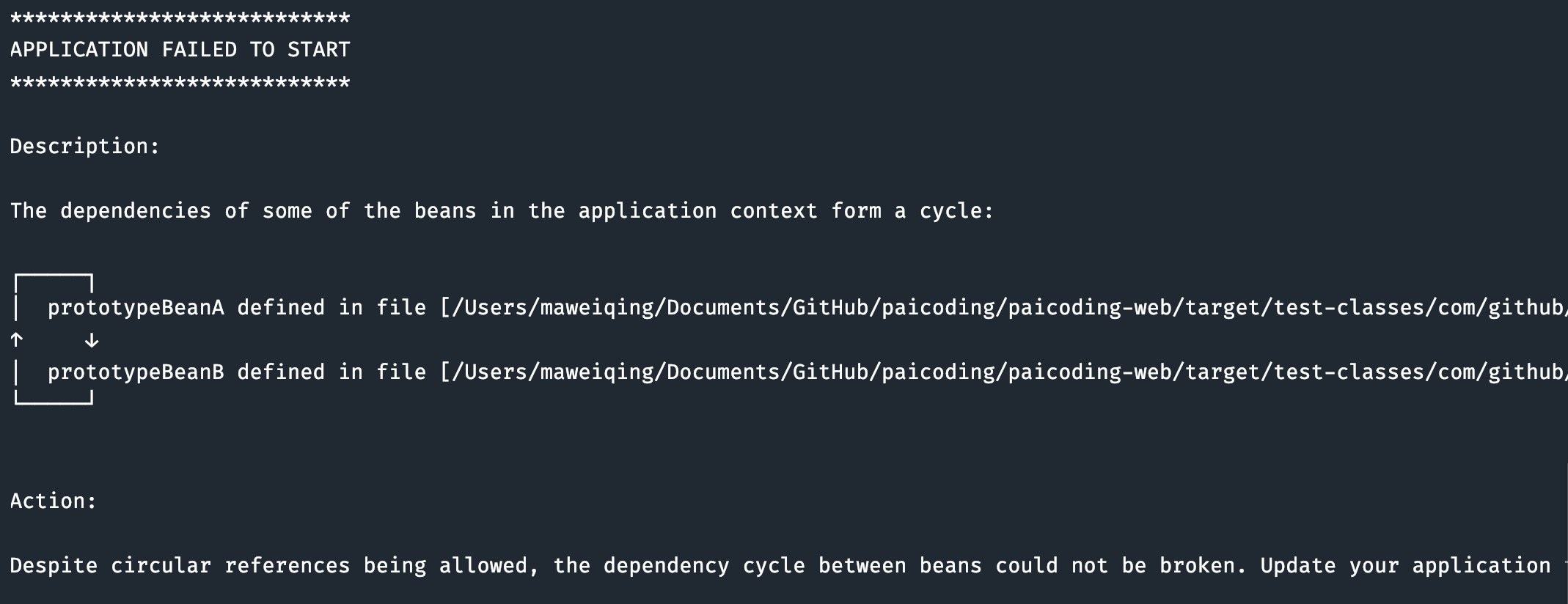
----面试中可以不背,方便大家理解 end----
- Java 面试指南(付费)收录的小米 25 届日常实习一面原题:如何解决循环依赖?
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:Spring如何解决循环依赖?
- Java 面试指南(付费)收录的得物面经同学 9 面试题目原题:Spring源码看过吗?Spring的三级缓存知道吗?
- Java 面试指南(付费)收录的阿里云面经同学 22 面经:spring三级缓存解决循环依赖问题
memo:2025 年 7 月 5 日修改至此。今天 VIP 群来了非常多的球友,不知不觉我们已经 21 群了,也是一个大家庭了,希望大家都能在这里找到自己的归属感,我们一起学习,一起进步。

15.为什么需要三级缓存而不是两级?
Spring 设计三级缓存主要是为了解决 AOP 代理的问题。
我举个具体的例子来说明一下。假设我们有 A 和 B 两个类相互依赖,A 的某个方法上面还标注了 @Transactional 注解,这意味着 A 最终需要被 Spring 创建成一个代理对象。
@Component
public class A {
@Autowired
private B b;
@Transactional // A需要被AOP代理
public void doSomething() {
// 业务逻辑
}
}
@Component
public class B {
@Autowired
private A a;
}如果只有二级缓存的话,当创建 A 的时候,我们需要把 A 的原始对象提前放到缓存里面,然后 B 在创建的时候从缓存中拿到 A 的原始对象。
// 假设只有两级缓存
Map<String, Object> singletonObjects = new HashMap<>(); // 完整Bean
Map<String, Object> earlySingletonObjects = new HashMap<>(); // 半成品Bean但是问题来了,A 完成初始化后,由于有 @Transactional 注解,Spring 会把 A 包装成一个代理对象放到容器中。这样就出现了一个很严重的问题:B 里面持有的是 A 的原始对象,而容器中存的是 A 的代理对象,同一个 Bean 居然有两个不同的实例,这肯定是不对的。

三级缓存就是为了解决这个问题而设计的。三级缓存里面存放的不是 Bean 的实例,而是一个对象工厂,这是一个函数式接口。
当 B 需要 A 的时候,会调用这个对象工厂的 getObject 方法,这个方法里面会判断 A 是否需要被代理。如果需要代理,就创建 A 的代理对象返回给 B;如果不需要代理,就返回 A 的原始对象。这样就保证了 B 拿到的 A 和最终放入容器的 A 是同一个对象。
Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>();
// Spring源码中的逻辑
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
// 关键:如果需要代理,这里会创建代理对象
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}简单来说,三级缓存的核心作用就是延迟决策。它让 Spring 在真正需要 Bean 的时候才决定返回原始对象还是代理对象,这样就避免了对象不一致的问题。如果没有三级缓存,Spring 要么无法在循环依赖的情况下支持 AOP,要么就会出现同一个 Bean 有多个实例的问题,这些都是不可接受的。
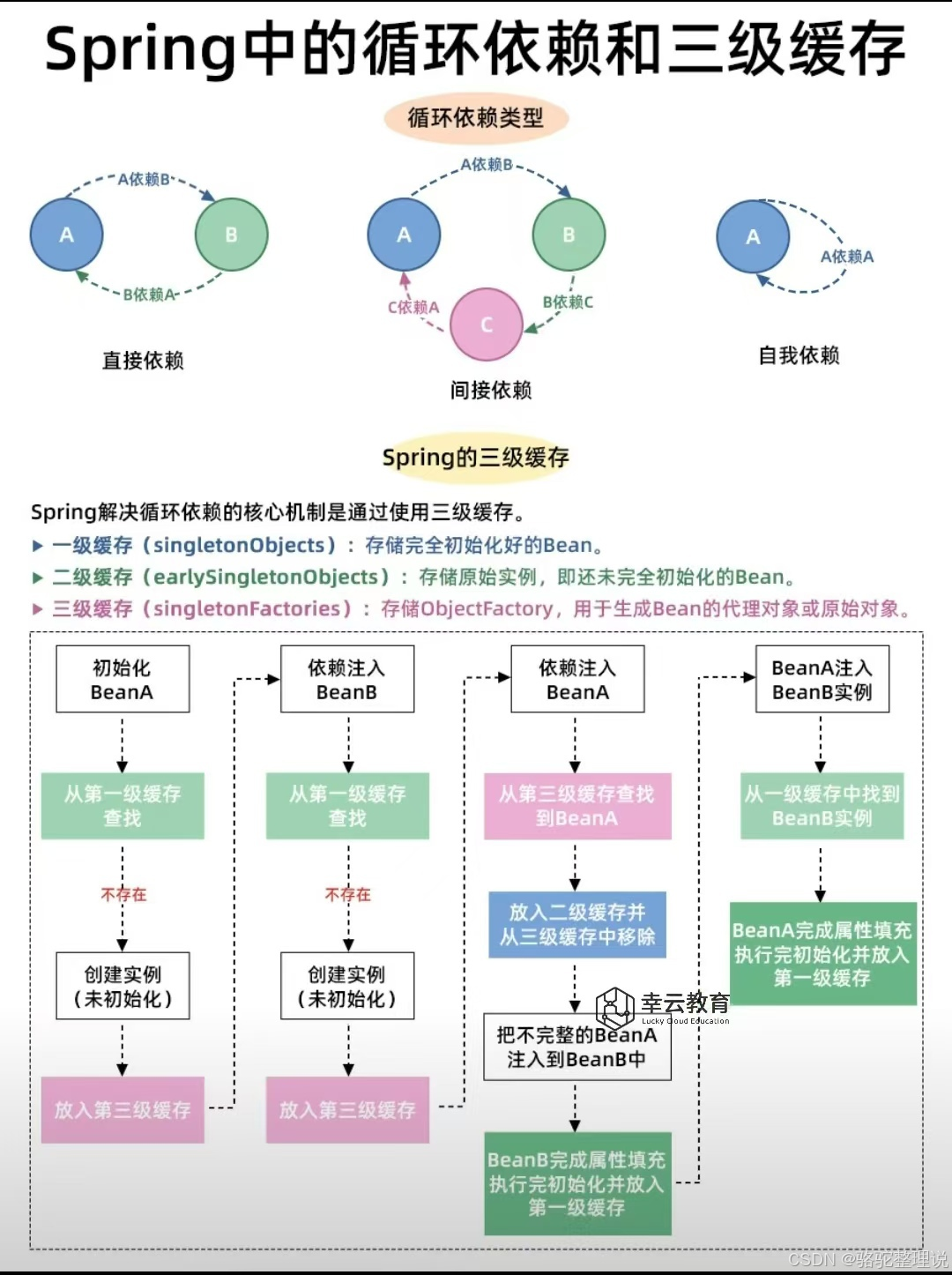
如果缺少二级缓存会有什么问题?
二级缓存 earlySingletonObjects 主要是用来存放那些已经通过三级缓存的对象工厂创建出来的早期 Bean 引用。
假设我们有 A、B、C 三个 Bean,A 依赖 B 和 C,B 和 C 都依赖 A,形成了一个复杂的循环依赖。在没有二级缓存的情况下,每次 B 或者 C 需要获取 A 的时候,都需要调用三级缓存中 A 的 ObjectFactory.getObject() 方法。这意味着如果 A 需要被代理的话,代理对象可能会被重复创建多次,这显然是不合理的。
// 没有二级缓存的伪代码
public Object getSingleton(String beanName) {
Object singletonObject = singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 直接从三级缓存获取
ObjectFactory<?> singletonFactory = singletonFactories.get(beanName);
if (singletonFactory != null) {
return singletonFactory.getObject(); // 每次都会创建新的代理对象!
}
}
return singletonObject;
}我举个具体的例子。比如 A 有 @Transactional 注解需要被 AOP 代理,B 在初始化的时候需要 A,会调用一次对象工厂创建 A 的代理对象。接着 C 在初始化的时候也需要 A,又会调用一次对象工厂,可能又创建了一个 A 的代理对象。这样 B 和 C 拿到的可能就是两个不同的 A 代理对象,这就违反了单例 Bean 的语义。
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB;
@Transactional // 需要 AOP 代理
public void methodA() {
// 业务逻辑
}
}
@Service
public class ServiceB {
@Autowired
private ServiceA serviceA; // 获得代理对象 A1
@Autowired
private ServiceC serviceC;
}
@Service
public class ServiceC {
@Autowired
private ServiceA serviceA; // 可能获得代理对象 A2
}二级缓存就是为了解决这个问题。当第一次通过对象工厂创建了 A 的早期引用之后,就把这个引用放到二级缓存中,同时从三级缓存中移除对象工厂。
// 第一次获取 A
ObjectFactory<A> factory = singletonFactories.get("serviceA");
Object proxyA = factory.getObject(); // 创建代理
earlySingletonObjects.put("serviceA", proxyA); // 缓存代理
singletonFactories.remove("serviceA");
// 第二次获取 A
Object cachedA = earlySingletonObjects.get("serviceA"); // 直接返回缓存的代理
// proxyA == cachedA ✓后续如果再有其他 Bean 需要 A,就直接从二级缓存中获取,不需要再调用对象工厂了。
- Java 面试指南(付费)收录的快手同学 4 一面原题:循环依赖有了解过吗?出现循环依赖的原因?三大缓存存储内容的区别?如何解决循环依赖?如果缺少第二级缓存会有什么问题?
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2024 年 7 月 11 日修改至此,今天在帮球友们修改简历的时候,碰到北京交通大学本,北京航空航天大学硕的球友,她的简历上有很多校园荣誉奖项,像优秀学生、奖学金、英语四六级等,这些都是非常好的加分项。

IoC
16.🌟说一说什么是IoC?
推荐阅读:IoC 扫盲
IoC 的全称是 Inversion of Control,也就是控制反转。这里的“控制”指的是对象创建和依赖关系管理的控制权。
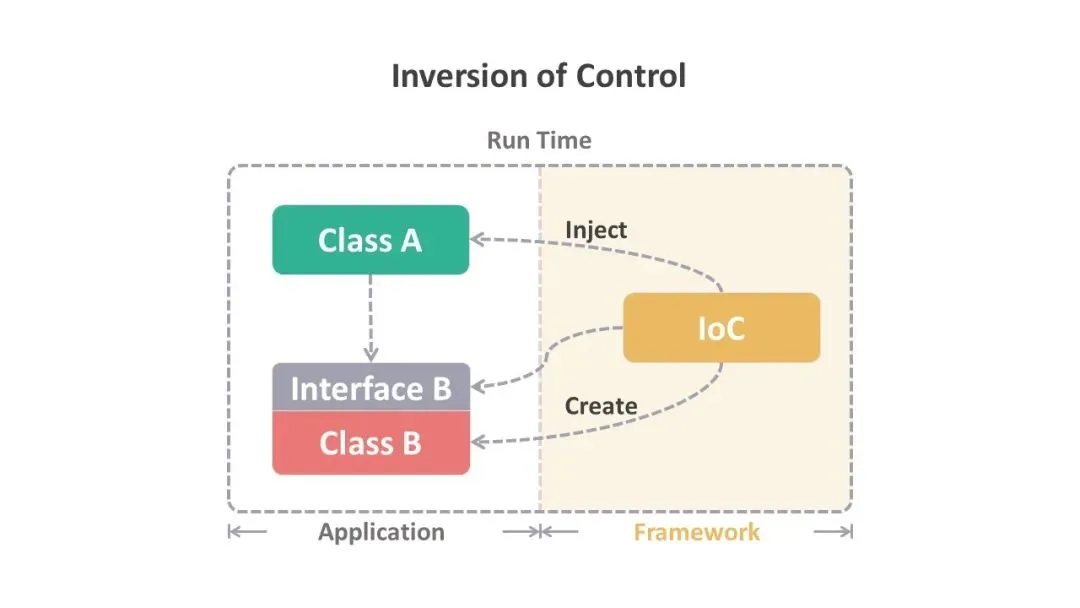
以前我们写代码的时候,如果 A 类需要用到 B 类,我们就在 A 类里面直接 new 一个 B 对象出来,这样 A 类就控制了 B 类对象的创建。
// 传统方式:对象主动创建依赖
public class UserService {
private UserDao userDao;
public UserService() {
// 主动创建依赖对象
this.userDao = new UserDaoImpl();
}
}有了 IoC 之后,这个控制权就“反转”了,不再由 A 类来控制 B 对象的创建,而是交给外部的容器来管理。
/**
* 使用 Spring IoC 容器来管理 UserDao 的创建和注入
* 技术派源码:https://github.com/itwanger/paicoding
*/
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;
// 不需要主动创建 UserDao,由 Spring 容器注入
public BaseUserInfoDTO getAndUpdateUserIpInfoBySessionId(String session, String clientIp) {
// 直接使用注入的 userDao
return userDao.getBySessionId(session);
}
}----这部分面试中可以不背 start----
没有 IoC 之前:
我需要一个女朋友,刚好大街上突然看到了一个小姐姐,人很好看,于是我就自己主动上去搭讪,要她的微信号,找机会聊天关心她,然后约她出来吃饭,打听她的爱好,三观。。。
有了 IoC 之后:
我需要一个女朋友,于是我就去找婚介所,告诉婚介所,我需要一个长的像赵露思的,会打 Dota2 的,于是婚介所在它的人才库里开始找,找不到它就直接说没有,找到它就直接介绍给我。
婚介所就相当于一个 IoC 容器,我就是一个对象,我需要的女朋友就是另一个对象,我不用关心女朋友是怎么来的,我只需要告诉婚介所我需要什么样的女朋友,婚介所就帮我去找。

----这部分面试中可以不背 end----
DI和IoC的区别了解吗?
IoC 的思想是把对象创建和依赖关系的控制权由业务代码转移给 Spring 容器。这是一个比较抽象的概念,告诉我们应该怎么去设计系统架构。

而 DI,也就是依赖注入,它是实现 IoC 这种思想的具体技术手段。在 Spring 里,我们用 @Autowired 注解就是在使用 DI 的字段注入方式。
@Service
public class ArticleReadServiceImpl implements ArticleReadService {
@Autowired
private ArticleDao articleDao; // 字段注入
@Autowired
private UserDao userDao;
}从实现角度来看,DI 除了字段注入,还有构造方法注入和 Setter 方法注入等方式。在做技术派项目的时候,我就尝试过构造方法注入的方式。
当然了,DI 并不是实现 IoC 的唯一方式,还有 Service Locator 模式,可以通过实现 ApplicationContextAware 接口来获取 Spring 容器中的 Bean。
之所以 ID 后成为 IoC 的首选实现方式,是因为代码更清晰、可读性更高。
IoC(控制反转)
├── DI(依赖注入) ← 主要实现方式
│ ├── 构造器注入
│ ├── 字段注入
│ └── Setter注入
├── 服务定位器模式
├── 工厂模式
└── 其他实现方式为什么要使用 IoC 呢?
在日常开发中,如果我们需要实现某一个功能,可能至少需要两个以上的对象来协助完成,在没有 Spring 之前,每个对象在需要它的合作对象时,需要自己 new 一个,比如说 A 要使用 B,A 就对 B 产生了依赖,也就是 A 和 B 之间存在了一种耦合关系。
// 传统方式:对象自己创建依赖
public class UserService {
private UserDao userDao = new UserDaoImpl(); // 硬编码依赖
public User getUser(Long id) {
return userDao.findById(id);
}
}有了 Spring 之后,创建 B 的工作交给了 Spring 来完成,Spring 创建好了 B 对象后就放到容器中,A 告诉 Spring 我需要 B,Spring 就从容器中取出 B 交给 A 来使用。
// IoC 方式:依赖由外部注入
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao; // 依赖注入,不关心具体实现
public User getUser(Long id) {
return userDao.findById(id);
}
}至于 B 是怎么来的,A 就不再关心了,Spring 容器想通过 newnew 创建 B 还是 new 创建 B,无所谓。
这就是 IoC 的好处,它降低了对象之间的耦合度,让每个对象只关注自己的业务实现,不关心其他对象是怎么创建的。
- Java 面试指南(付费)收录的小米 25 届日常实习一面原题:说说你对 AOP 和 IoC 的理解。
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:介绍 Spring IoC 和 AOP?
- Java 面试指南(付费)收录的招商银行面经同学 6 招银网络科技面试原题:SpringBoot框架的AOP、IOC/DI?
- Java 面试指南(付费)收录的京东面经同学 8 面试原题:IOC,AOP
- Java 面试指南(付费)收录的快手同学 4 一面原题:解释下什么是IOC和AOP?分别解决了什么问题?IOC和DI的区别?
memo:2025 年 6 月 22 日修改至此,今天有球友发喜报说拿到了两个 offer,一个是做 B 端电商的,另一个是外企,主要做 Power BI 的低代码开发,我的建议是去外企,因为实习最重要的是混个 title,有更多的时间,可以去学习星球里的项目,其实会更实在。

17.能说一下IoC的实现机制吗?
好的,Spring IoC 的实现机制还是比较复杂的,我尽量用比较通俗的方式来解释一下整个流程。
第一步是加载 Bean 的定义信息。Spring 会扫描我们配置的包路径,找到所有标注了 @Component、@Service、@Repository 这些注解的类,然后把这些类的元信息封装成 BeanDefinition 对象。
// Bean定义信息
public class BeanDefinition {
private String beanClassName; // 类名
private String scope; // 作用域
private boolean lazyInit; // 是否懒加载
private String[] dependsOn; // 依赖的Bean
private ConstructorArgumentValues constructorArgumentValues; // 构造参数
private MutablePropertyValues propertyValues; // 属性值
}第二步是 Bean 工厂的准备。Spring 会创建一个 DefaultListableBeanFactory 作为 Bean 工厂来负责 Bean 的创建和管理。
第三步是 Bean 的实例化和初始化。这个过程比较复杂,Spring 会根据 BeanDefinition 来创建 Bean 实例。
对于单例 Bean,Spring 会先检查缓存中是否已经存在,如果不存在就创建新实例。创建实例的时候会通过反射调用构造方法,然后进行属性注入,最后执行初始化回调方法。
// 简化的Bean创建流程
public class AbstractBeanFactory {
protected Object createBean(String beanName, BeanDefinition bd) {
// 1. 实例化前处理
Object bean = resolveBeforeInstantiation(beanName, bd);
if (bean != null) {
return bean;
}
// 2. 实际创建Bean
return doCreateBean(beanName, bd);
}
protected Object doCreateBean(String beanName, BeanDefinition bd) {
// 2.1 实例化
Object bean = createBeanInstance(beanName, bd);
// 2.2 属性填充(依赖注入)
populateBean(beanName, bd, bean);
// 2.3 初始化
Object exposedObject = initializeBean(beanName, bean, bd);
return exposedObject;
}
}依赖注入的实现主要是通过反射来完成的。比如我们用 @Autowired 标注了一个字段,Spring 在创建 Bean 的时候会扫描这个字段,然后从容器中找到对应类型的 Bean,通过反射的方式设置到这个字段上。
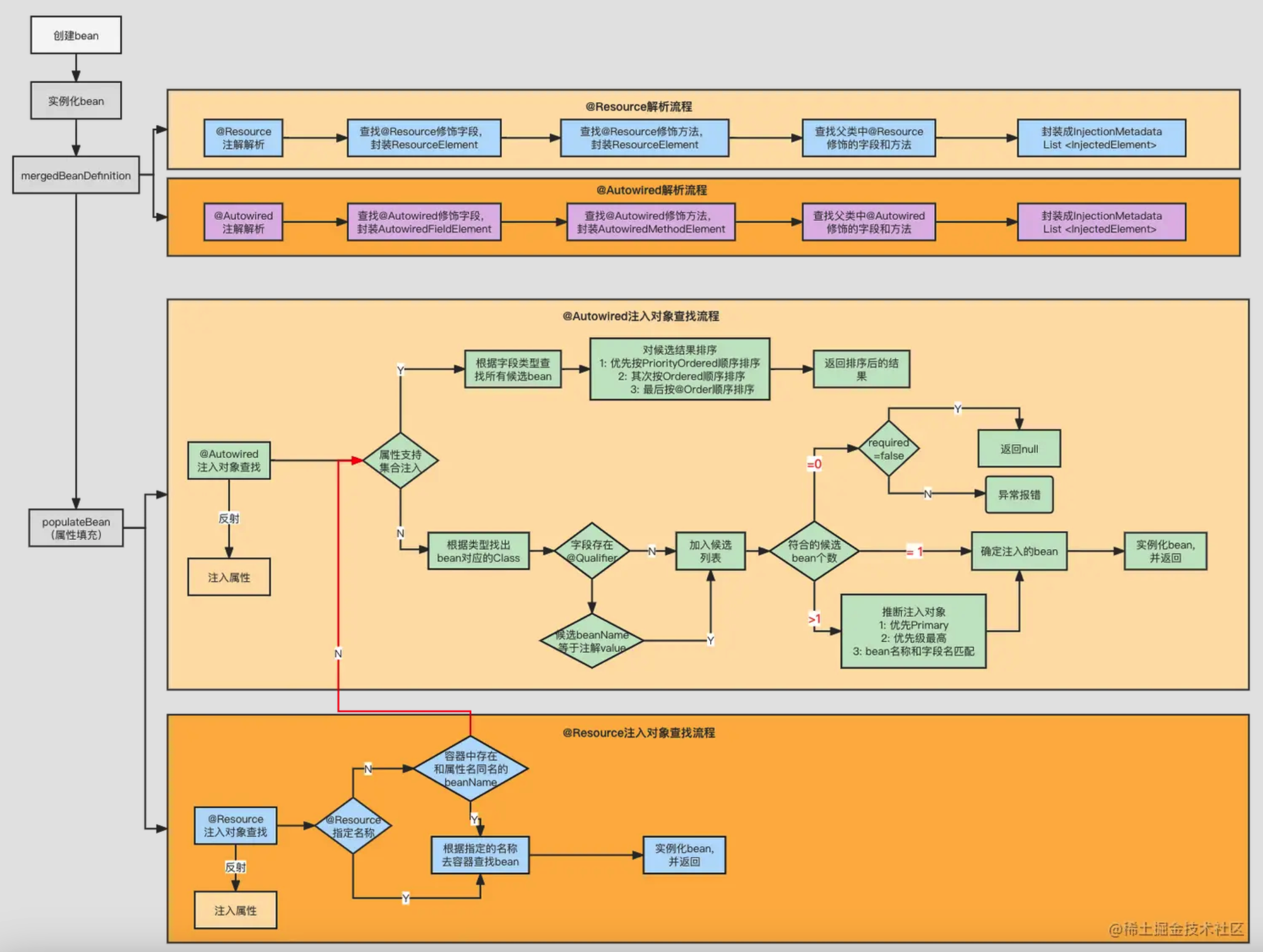
你是怎么理解 Spring IoC 的?
IoC 本质上一个超级工厂,这个工厂的产品就是各种 Bean 对象。
我们通过 @Component、@Service 这些注解告诉工厂:“我要生产什么样的产品,这个产品有什么特性,需要什么原材料”。
然后工厂里各种生产线,在 Spring 中就是各种 BeanPostProcessor。比如 AutowiredAnnotationBeanPostProcessor 专门负责处理 @Autowired 注解。
工厂里还有各种缓存机制用来存放产品,比如说 singletonObjects 是成品仓库,存放完工的单例 Bean;earlySingletonObjects 是半成品仓库,用来解决循环依赖问题。
// Spring单例Bean注册表
public class DefaultSingletonBeanRegistry {
// 一级缓存:完成初始化的单例Bean
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存:早期暴露的单例Bean(解决循环依赖)
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
// 三级缓存:单例Bean工厂
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
public Object getSingleton(String beanName) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
return singletonObject;
}
}最有意思的是,这个工厂还很智能,它知道产品之间的依赖关系。它会根据依赖关系来决定 Bean 的创建顺序。如果发现循环依赖,它还会用三级缓存机制来巧妙地解决。
能手写一个简单的 IoC 容器吗?
1、首先定义基础的注解,比如说 @Component、@Autowired 等。
// 组件注解
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Component {
}
// 自动注入注解
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Autowired {
}2、核心的 IoC 容器类,负责扫描包路径,创建 Bean 实例,并处理依赖注入。
public class SimpleIoC {
// Bean容器
private Map<Class<?>, Object> beans = new HashMap<>();
/**
* 注册Bean
*/
public void registerBean(Class<?> clazz) {
try {
// 创建实例
Object instance = clazz.getDeclaredConstructor().newInstance();
beans.put(clazz, instance);
} catch (Exception e) {
throw new RuntimeException("创建Bean失败: " + clazz.getName(), e);
}
}
/**
* 获取Bean
*/
@SuppressWarnings("unchecked")
public <T> T getBean(Class<T> clazz) {
return (T) beans.get(clazz);
}
/**
* 依赖注入
*/
public void inject() {
for (Object bean : beans.values()) {
injectFields(bean);
}
}
/**
* 字段注入
*/
private void injectFields(Object bean) {
Field[] fields = bean.getClass().getDeclaredFields();
for (Field field : fields) {
if (field.isAnnotationPresent(Autowired.class)) {
try {
field.setAccessible(true);
Object dependency = getBean(field.getType());
field.set(bean, dependency);
} catch (Exception e) {
throw new RuntimeException("注入失败: " + field.getName(), e);
}
}
}
}
}3、使用示例,定义一些 Bean 类,并注册到 IoC 容器中。
// DAO层
@Component
class UserDao {
public void save(String user) {
System.out.println("保存用户: " + user);
}
}
// Service层
@Component
class UserService {
@Autowired
private UserDao userDao;
public void createUser(String name) {
userDao.save(name);
System.out.println("用户创建完成");
}
}
// 测试
public class Test {
public static void main(String[] args) {
SimpleIoC ioc = new SimpleIoC();
// 注册Bean
ioc.registerBean(UserDao.class);
ioc.registerBean(UserService.class);
// 依赖注入
ioc.inject();
// 使用
UserService userService = ioc.getBean(UserService.class);
userService.createUser("王二");
}
}4、可以加上组件扫描。
import java.lang.reflect.Field;
import java.util.*;
public class SimpleIoC {
private Map<Class<?>, Object> beans = new HashMap<>();
/**
* 扫描并注册组件
*/
public void scan(String packageName) {
// 简化版:手动添加需要扫描的类
List<Class<?>> classes = getClassesInPackage(packageName);
for (Class<?> clazz : classes) {
if (clazz.isAnnotationPresent(Component.class)) {
registerBean(clazz);
}
}
// 依赖注入
inject();
}
/**
* 获取包下的类(简化实现)
*/
private List<Class<?>> getClassesInPackage(String packageName) {
// 面试时可以说:"实际实现需要扫描classpath,这里简化处理"
return Arrays.asList(UserDao.class, UserService.class);
}
private void registerBean(Class<?> clazz) {
try {
Object instance = clazz.getDeclaredConstructor().newInstance();
beans.put(clazz, instance);
} catch (Exception e) {
throw new RuntimeException("创建Bean失败", e);
}
}
@SuppressWarnings("unchecked")
public <T> T getBean(Class<T> clazz) {
return (T) beans.get(clazz);
}
private void inject() {
for (Object bean : beans.values()) {
Field[] fields = bean.getClass().getDeclaredFields();
for (Field field : fields) {
if (field.isAnnotationPresent(Autowired.class)) {
try {
field.setAccessible(true);
Object dependency = getBean(field.getType());
field.set(bean, dependency);
} catch (Exception e) {
throw new RuntimeException("注入失败", e);
}
}
}
}
}
}IoC 容器的核心是管理对象和依赖注入,首先定义注解,然后实现容器的三个核心方法:注册Bean、获取Bean、依赖注入;关键是用反射创建对象和注入依赖。
memo:2025 年 6 月 23 日修改至此,今天有球友发喜报说拿到了京东的社招 offer,这真的要恭喜他,也希望所有看到这里的小伙伴都能有一个好的结果。
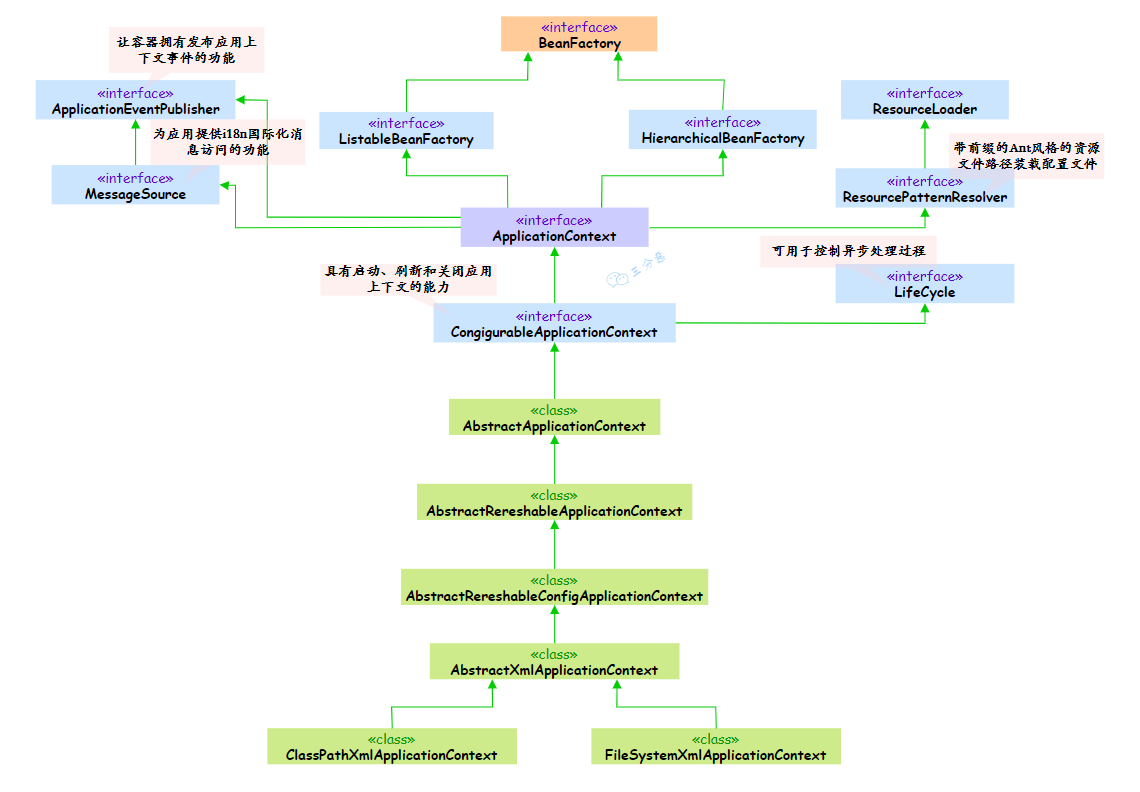
18.说说BeanFactory和ApplicantContext的区别?
BeanFactory 算是 Spring 的“心脏”,而 ApplicantContext 可以说是 Spring 的完整“身躯”。
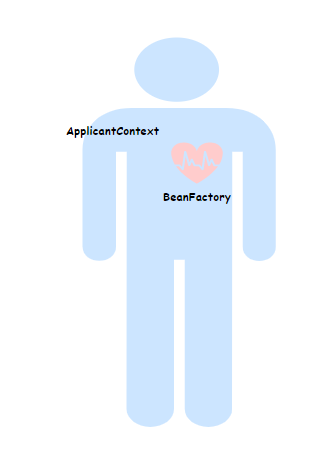
BeanFactory 提供了最基本的 IoC 能力。它就像是一个 Bean 工厂,负责 Bean 的创建和管理。他采用的是懒加载的方式,也就是说只有当我们真正去获取某个 Bean 的时候,它才会去创建这个 Bean。
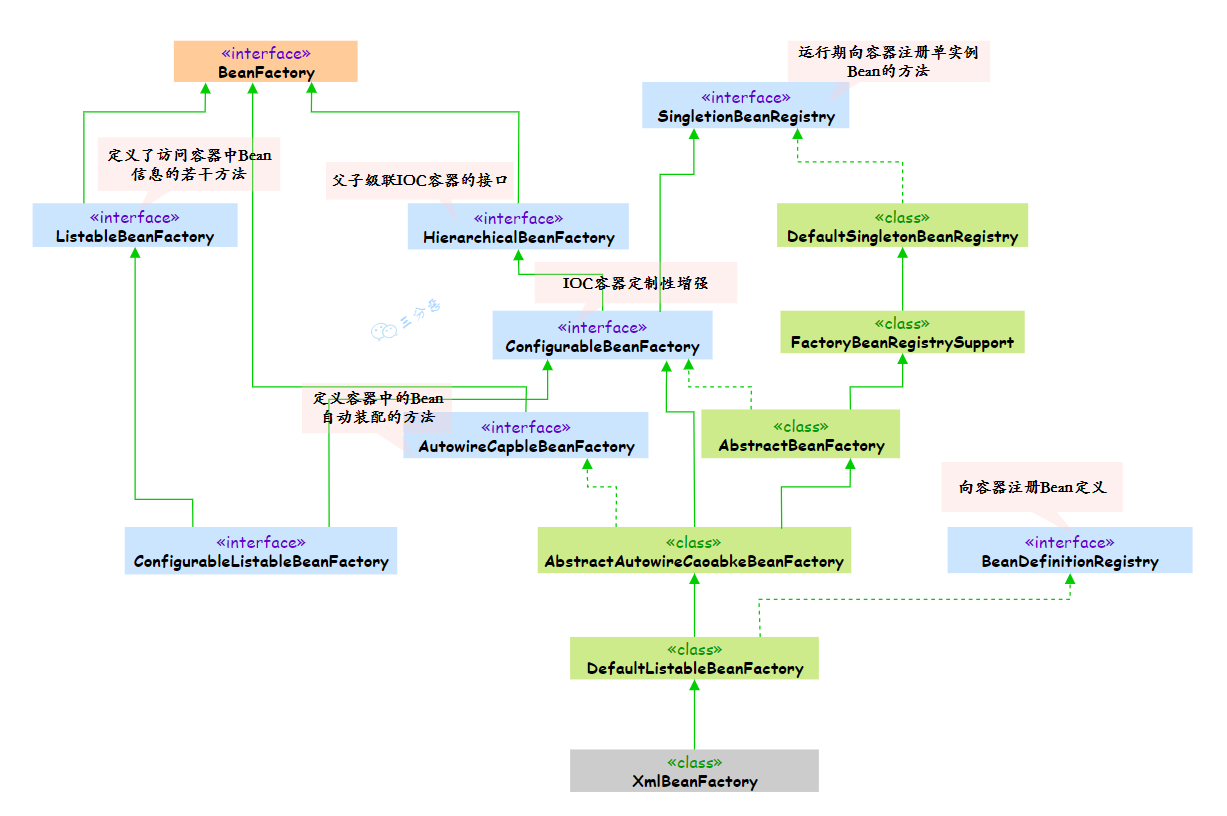
它最主要的方法就是 getBean(),负责从容器中返回特定名称或者类型的 Bean 实例。
public class BeanFactoryExample {
public static void main(String[] args) {
// 创建 BeanFactory
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
// 手动注册 Bean 定义
BeanDefinition beanDefinition = new RootBeanDefinition(UserService.class);
beanFactory.registerBeanDefinition("userService", beanDefinition);
// 懒加载:此时才创建 Bean 实例
UserService userService = beanFactory.getBean("userService", UserService.class);
}
}ApplicationContext 是 BeanFactory 的子接口,在 BeanFactory 的基础上扩展了很多企业级的功能。它不仅包含了 BeanFactory 的所有功能,还提供了国际化支持、事件发布机制、AOP、JDBC、ORM 框架集成等等。
ApplicationContext 采用的是饿加载的方式,容器启动的时候就会把所有的单例 Bean 都创建好,虽然这样会导致启动时间长一点,但运行时性能更好。
@Configuration
public class AppConfig {
@Bean
public UserService userService() {
return new UserService();
}
}
public class ApplicationContextExample {
public static void main(String[] args) {
// 创建 ApplicationContext,启动时就创建所有 Bean
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
// 获取 Bean
UserService userService = context.getBean(UserService.class);
// 发布事件
context.publishEvent(new CustomEvent("Hello World"));
}
}从使用场景来说,实际开发中用得最多的是 ApplicationContext。像 AnnotationConfigApplicationContext、WebApplicationContext 这些都是 ApplicationContext 的实现类。
另外一个重要的区别是生命周期管理。ApplicationContext 会自动调用 Bean 的初始化和销毁方法,而 BeanFactory 需要我们手动管理。
在 Spring Boot 项目中,我们可以通过 @Autowired 注入 ApplicationContext,或者通过实现 ApplicationContextAware 接口来获取 ApplicationContext。
- Java 面试指南(付费)收录的美团同学 2 优选物流调度技术 2 面面试原题:BeanFactory和ApplicationContext
memo:2025 年 6 月 25 日修改至此,今天给一个华科本硕研 0 的球友修改简历后,发来这样的感慨,要是早点知道你的网站和星球就好了,技术派不比外卖强多了?再次感谢二哥。
19.🌟项目启动时Spring的IoC会做什么?
第一件事是扫描和注册 Bean。IoC 容器会根据我们的配置,比如 @ComponentScan 指定的包路径,去扫描所有标注了 @Component、@Service、@Controller 这些注解的类。然后把这些类的元信息包装成 BeanDefinition 对象,注册到容器的 BeanDefinitionRegistry 中。这个阶段只是收集信息,还没有真正创建对象。
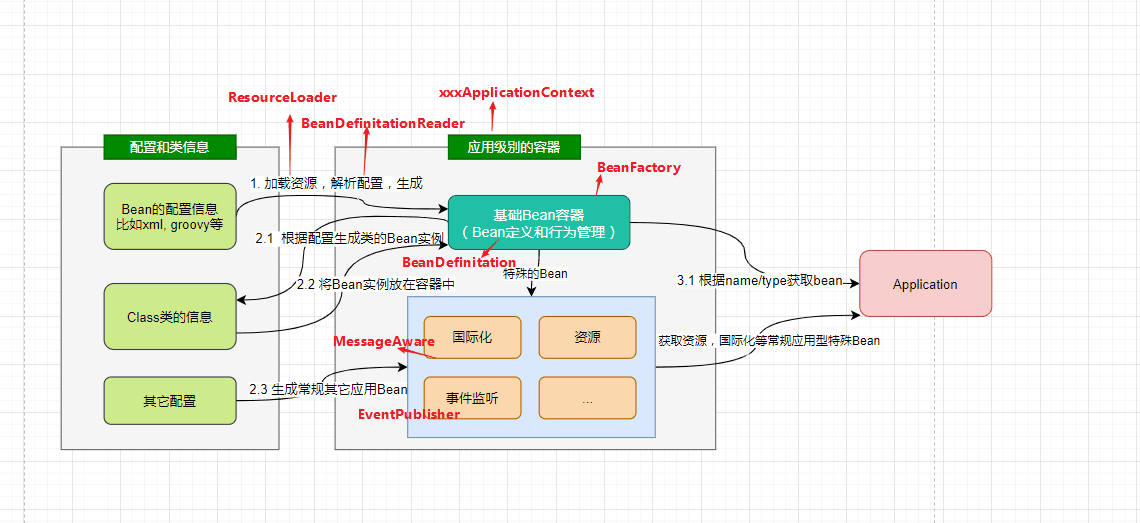
第二件事是 Bean 的实例化和注入。这是最核心的过程,IoC 容器会按照依赖关系的顺序开始创建 Bean 实例。对于单例 Bean,容器会通过反射调用构造方法创建实例,然后进行属性注入,最后执行初始化回调方法。
在依赖注入时,容器会根据 @Autowired、@Resource 这些注解,把相应的依赖对象注入到目标 Bean 中。比如 UserService 需要 UserDao,容器就会把 UserDao 的实例注入到 UserService 中。
说说Spring的Bean实例化方式?
Spring 提供了 4 种方式来实例化 Bean,以满足不同场景下的需求。
第一种是通过构造方法实例化,这是最常用的方式。当我们用 @Component、@Service 这些注解标注类的时候,Spring 默认通过无参构造器来创建实例的。如果类只有一个有参构造方法,Spring 会自动进行构造方法注入。
@Service
public class UserService {
private UserDao userDao;
public UserService(UserDao userDao) { // 构造方法注入
this.userDao = userDao;
}
}第二种是通过静态工厂方法实例化。有时候对象的创建比较复杂,我们会写一个静态工厂方法来创建,然后用 @Bean 注解来标注这个方法。Spring 会调用这个静态方法来获取 Bean 实例。
@Configuration
public class AppConfig {
@Bean
public static DataSource createDataSource() {
// 复杂的DataSource创建逻辑
return new HikariDataSource();
}
}第三种是通过实例工厂方法实例化。这种方式是先创建工厂对象,然后通过工厂对象的方法来创建Bean:
@Configuration
public class AppConfig {
@Bean
public ConnectionFactory connectionFactory() {
return new ConnectionFactory();
}
@Bean
public Connection createConnection(ConnectionFactory factory) {
return factory.createConnection();
}
}第四种是通过 FactoryBean 接口实例化。这是 Spring 提供的一个特殊接口,当我们需要创建复杂对象的时候特别有用:
@Component
public class MyFactoryBean implements FactoryBean<MyObject> {
@Override
public MyObject getObject() throws Exception {
// 复杂的对象创建逻辑
return new MyObject();
}
@Override
public Class<?> getObjectType() {
return MyObject.class;
}
}在实际工作中,用得最多的还是构造方法实例化,因为简单直接。工厂方法一般用在需要复杂初始化逻辑的场景,比如数据库连接池、消息队列连接这些。FactoryBean 主要是在框架开发或者需要动态创建对象的时候使用。
Spring 在实例化的时候会根据 Bean 的定义自动选择合适的方式,我们作为开发者主要是通过注解和配置来告诉 Spring 应该怎么创建对象。
- Java 面试指南(付费)收录的华为面经同学 8 技术二面面试原题:说说 Spring 的 Bean 实例化方式
- Java 面试指南(付费)收录的美团同学 2 优选物流调度技术 2 面面试原题:bean加工有哪些方法?
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 7 月 6 日修改至此,今天在星球里看到一个球友的秋招打卡,已经持续 30 天了,按照他这个节奏下去,互联网大厂的 offer 基本上就算是锁定了。并且还有准备 RAG MCP 的八股,很棒。

AOP
20.🌟说说什么是 AOP?
AOP,也就是面向切面编程,简单点说,AOP 就是把一些业务逻辑中的相同代码抽取到一个独立的模块中,让业务逻辑更加清爽。
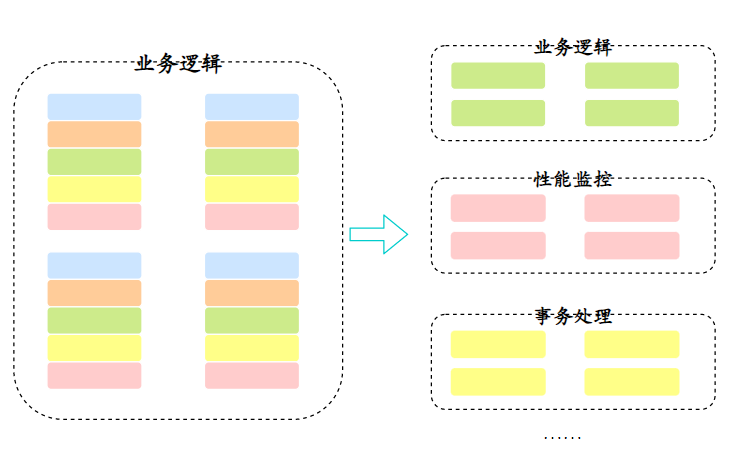
----这部分面试中可以不背,方便大家理解 start----
举个简单的例子,假设我们有很多个 Service 方法,每个方法都需要记录执行日志、检查权限、管理事务等等。如果没有 AOP 的话,我们可能需要在每个方法里都写这样的代码:
public void createUser(User user) {
log.info("开始执行createUser方法");
// 权限检查
if (!hasPermission()) {
throw new SecurityException("无权限");
}
// 开启事务
transactionManager.begin();
try {
// 真正的业务逻辑
userDao.save(user);
transactionManager.commit();
log.info("createUser方法执行成功");
} catch (Exception e) {
transactionManager.rollback();
log.error("createUser方法执行失败", e);
throw e;
}
}如果每个方法都这样写,代码就会变得非常臃肿,AOP 就是为了解决这个问题,它可以让我们把这些横切关注点(如日志、权限、事务等)从业务代码中抽取出来。
这样,我们就可以定义一个切面,在切面中统一处理这些横切关注点:
@Aspect
@Component
public class LoggingAspect {
@Before("execution(* com.example.service.*.*(..))")
public void logBefore(JoinPoint joinPoint) {
log.info("开始执行方法: " + joinPoint.getSignature().getName());
}
@AfterReturning("execution(* com.example.service.*.*(..))")
public void logAfterReturning(JoinPoint joinPoint) {
log.info("方法执行成功: " + joinPoint.getSignature().getName());
}
@AfterThrowing(pointcut = "execution(* com.example.service.*.*(..))",
throwing = "ex")
public void logAfterThrowing(JoinPoint joinPoint, Throwable ex) {
log.error("方法执行失败: " + joinPoint.getSignature().getName(), ex);
}
}然后,业务代码就变得非常干净了:
public void createUser(User user) {
// 只需要关注业务逻辑,不需要关心日志、权限、事务等
userDao.save(user);
}----面试中可以不背,方便大家理解 end----
从技术实现上来说,AOP 主要是通过动态代理来实现的。如果目标类实现了接口,就用 JDK 动态代理;如果没有实现接口,就用 CGLIB 来创建子类代理。代理对象会在方法执行前后插入我们定义的切面逻辑。
Spring AOP 有哪些核心概念?
Spring AOP 是 AOP 的一个具体实现,我按照在工作/学习中理解的重要程度来说一下:
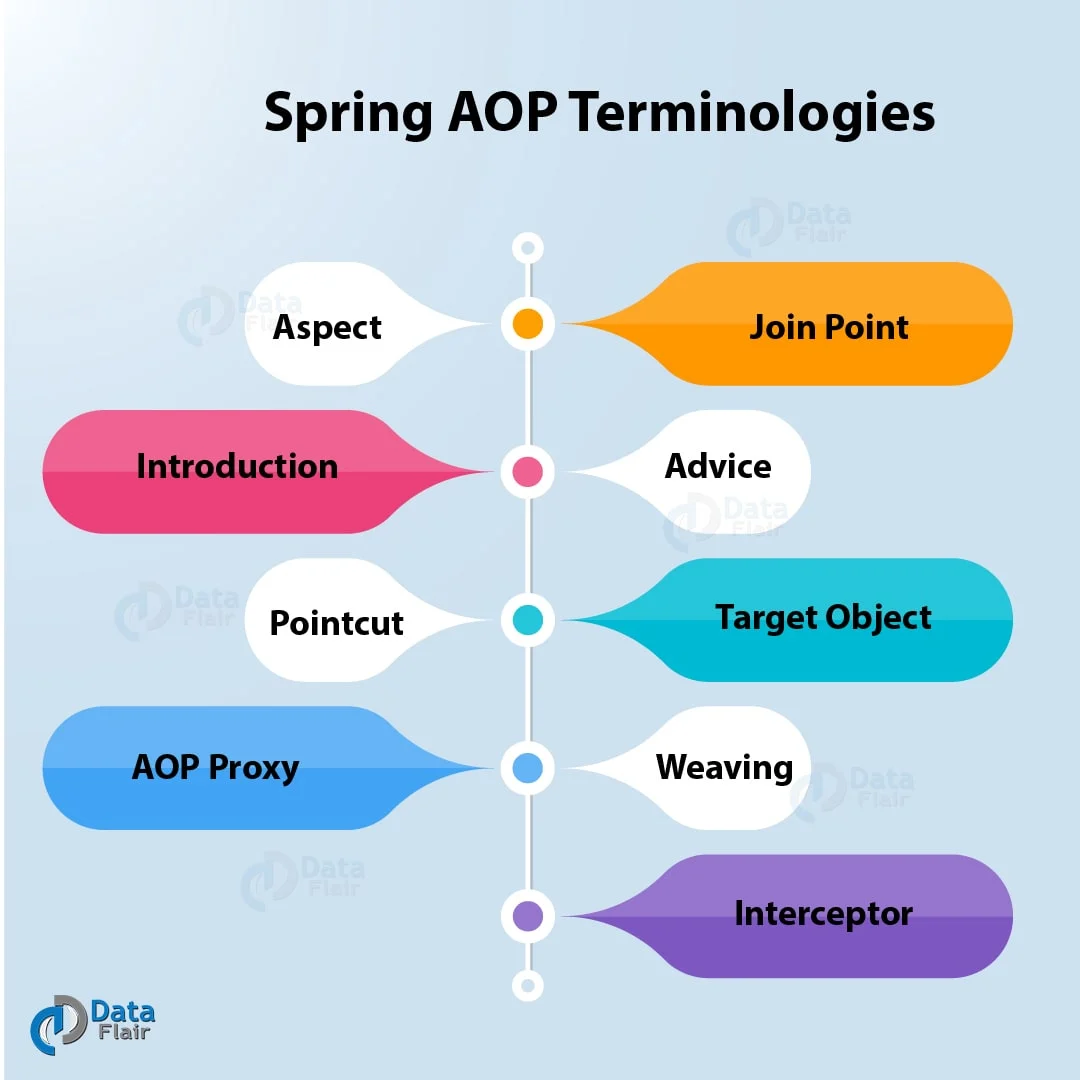
①、切面:我们定义的一个类,包含了要在什么时候、什么地方执行什么逻辑。比如我们定义一个日志切面,专门负责记录方法的执行情况。在 Spring 中,我们会用 @Aspect 注解来标识一个切面类。
②、切点:定义了在哪些地方应用切面逻辑。说白了就是告诉 Spring,我这个切面要在哪些方法上生效。比如我们可以定义一个切点表达式,让它匹配所有 Service 层的方法,或者匹配某个特定包下的所有方法。在 Spring 中用 @Pointcut 注解来定义,通常会写一些表达式,比如 execution( com.example.service..*(..)) 这样的。
③、通知:是切面中具体要执行的代码逻辑。它有几种类型:@Before 是在方法执行前执行,@After 是在方法执行后执行,@Around 是环绕通知,可以在方法执行前后都执行,@AfterReturning 是在方法正常返回后执行,@AfterThrowing 是在方法抛出异常后执行。我一般用得最多的是 @Around,因为它最灵活,可以控制方法是否执行,也可以修改参数和返回值。
④、连接点:被拦截到的点,因为 Spring 只支持方法类型的连接点,所以在 Spring 中,连接点指的是被拦截到的方法,实际上连接点还可以是字段或者构造方法。
⑤、织入:是把切面逻辑应用到目标对象的过程。Spring AOP 是在运行时通过动态代理来实现织入的,当我们从 Spring 容器中获取 Bean 的时候,如果这个 Bean 需要被切面处理,Spring 就会返回一个代理对象给我们。
⑥、目标对象:被切面处理的对象,也就是我们平时写的 Service、Controller 等类。Spring AOP 会在目标对象上织入切面逻辑。
它们之间的逻辑关系图是这样的:
切面(Aspect)
├── 切入点(Pointcut)─── 定义在哪里执行
└── 通知(Advice) ─── 定义何时执行什么
├── @Before
├── @After
├── @AfterReturning
├── @AfterThrowing
└── @Around
目标对象(Target)──→ 代理对象(Proxy)──→ 织入(Weaving)
↑ ↓
连接点(Join Point) 客户端调用Spring AOP 织入有哪几种方式?
织入有三种主要方式,我按照它们的执行时机来说一下。
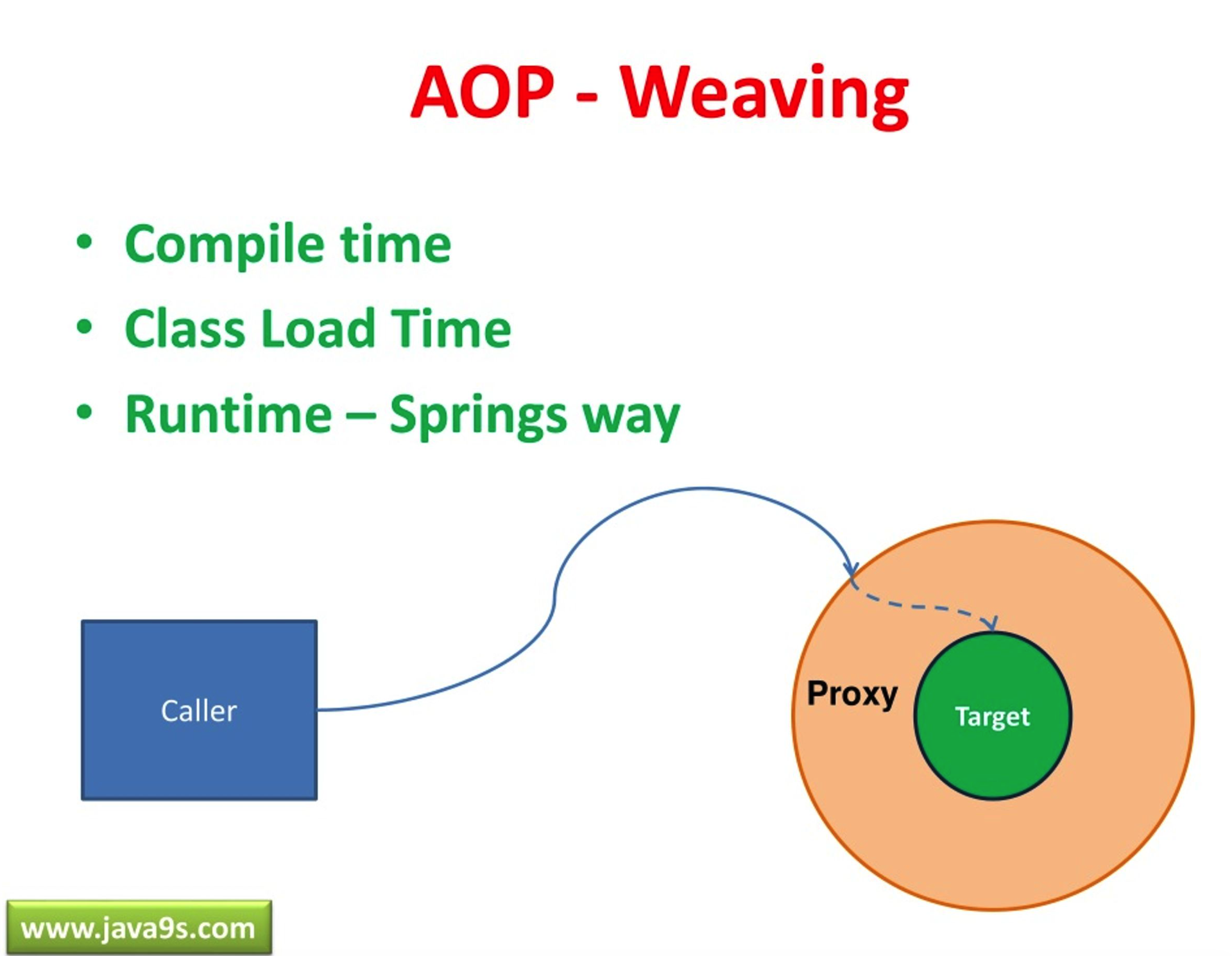
编译期织入是在编译 Java 源码的时候就把切面逻辑织入到目标类中。这种方式最典型的实现就是 AspectJ 编译器。它会在编译的时候直接修改字节码,把切面的逻辑插入到目标方法中。
// 源代码
@Aspect
public class LoggingAspect {
@Before("execution(* com.example.service.*.*(..))")
public void logBefore(JoinPoint joinPoint) {
System.out.println("方法执行前: " + joinPoint.getSignature().getName());
}
}
@Service
public class UserService {
public void saveUser(String username) {
System.out.println("保存用户: " + username);
}
}这样生成的 class 文件就已经包含了切面逻辑,运行时不需要额外的代理机制。
// 编译器自动生成的代码
public class UserService {
public void saveUser(String username) {
// 织入的切面代码
System.out.println("方法执行前: saveUser");
// 原始业务代码
System.out.println("保存用户: " + username);
}
}编译期织入的优点是性能最好,因为没有代理的开销,但缺点是需要使用特殊的编译器,而且比较复杂,在 Spring 项目中用得不多。
类加载期织入是在 JVM 加载 class 文件的时候进行织入。这种方式通过 Java 的 Instrumentation API 或者自定义的 ClassLoader 来实现,在类被加载到 JVM 之前修改字节码。
public class WeavingClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] classBytes = loadClassBytes(name);
// 在这里进行字节码织入
byte[] wovenBytes = weaveAspects(classBytes);
return defineClass(name, wovenBytes, 0, wovenBytes.length);
}
private byte[] weaveAspects(byte[] classBytes) {
// 使用 ASM 或其他字节码操作库进行织入
return classBytes;
}
}AspectJ 的 Load-Time Weaving 就是这种方式的典型实现。它比编译期织入更灵活一些,但是配置相对复杂,需要在 JVM 启动参数中指定 Java agent,在 Spring 中也有支持,但用得不是特别多。
# JVM 启动参数
java -javaagent:aspectjweaver.jar -jar myapp.jar运行时织入是我们在 Spring 中最常见的方式,也就是通过动态代理来实现。Spring AOP 采用的就是这种方式。当 Spring 容器启动的时候,如果发现某个 Bean 需要被切面处理,就会为这个 Bean 创建一个代理对象。如果目标类实现了接口,Spring 会使用 JDK 的动态代理技术。
// 接口
public interface UserService {
void saveUser(String username);
}
// 实现类
@Service
public class UserServiceImpl implements UserService {
@Override
public void saveUser(String username) {
System.out.println("保存用户: " + username);
}
}
// Spring 自动创建的代理(伪代码)
public class UserServiceProxy implements UserService {
private UserService target;
private List<Advisor> advisors;
@Override
public void saveUser(String username) {
// 执行前置通知
for (Advisor advisor : advisors) {
if (advisor.getPointcut().matches(this.getClass().getMethod("saveUser", String.class))) {
advisor.getAdvice().before();
}
}
// 执行目标方法
target.saveUser(username);
// 执行后置通知
for (Advisor advisor : advisors) {
advisor.getAdvice().after();
}
}
}如果目标类没有实现接口,就会使用 CGLIB 来创建一个子类作为代理。运行时织入的优点是实现简单,不需要特殊的编译器或 JVM 配置,缺点是有一定的性能开销,因为每次方法调用都要经过代理。
// 没有接口的类
@Service
public class OrderService {
public void createOrder(String orderId) {
System.out.println("创建订单: " + orderId);
}
}
// CGLIB 生成的代理子类(伪代码)
public class OrderService$$EnhancerByCGLIB$$12345 extends OrderService {
private MethodInterceptor interceptor;
@Override
public void createOrder(String orderId) {
// 通过 MethodInterceptor 执行切面逻辑
interceptor.intercept(this, getMethod("createOrder"), new Object[]{orderId},
new MethodProxy() {
@Override
public Object invokeSuper(Object obj, Object[] args) {
return OrderService.super.createOrder((String) args[0]);
}
});
}
}Spring AOP 默认的织入方式就是运行时织入,使用起来非常简单,只需要加个 @Aspect 注解和相应的通知注解就可以了。虽然性能上不如编译期织入,但是对于大部分业务场景来说,这点性能开销是完全可以接受的。
// Spring AOP 的代理创建过程
@Configuration
@EnableAspectJAutoProxy // 启用 AOP 自动代理
public class AopConfig {
}
// Spring 内部的代理创建逻辑(简化版)
public class DefaultAopProxyFactory implements AopProxyFactory {
@Override
public AopProxy createAopProxy(AdvisedSupport config) {
if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
// 使用 CGLIB 代理
return new CglibAopProxy(config);
} else {
// 使用 JDK 动态代理
return new JdkDynamicAopProxy(config);
}
}
}AspectJ 是什么?
AspectJ 是一个 AOP 框架,它可以做很多 Spring AOP 干不了的事情,比如说编译时、编译后和类加载时织入切面。并且提供了很多复杂的切点表达式和通知类型。
Spring AOP 只支持方法级别的拦截,而且只能拦截 Spring 容器管理的 Bean。但是 AspectJ 可以拦截任何 Java 对象的方法调用、字段访问、构造方法执行、异常处理等等。
// Spring AOP 只能做到这些
@Aspect
@Component
public class SpringAopAspect {
// ✅ 可以拦截:public 方法调用
@Around("execution(public * com.example.service.*.*(..))")
public Object aroundPublicMethod(ProceedingJoinPoint pjp) {
return pjp.proceed();
}
// ❌ 无法拦截:字段访问
// ❌ 无法拦截:构造函数
// ❌ 无法拦截:私有方法
// ❌ 无法拦截:静态方法
}Spring AOP 有哪些通知方式?
Spring AOP 提供了多种通知方式,允许我们在方法执行的不同阶段插入逻辑。常用的通知方式有:
- 前置通知 (@Before)
- 返回通知 (@AfterReturning)
- 异常通知 (@AfterThrowing)
- 后置通知 (@After)
- 环绕通知 (@Around)
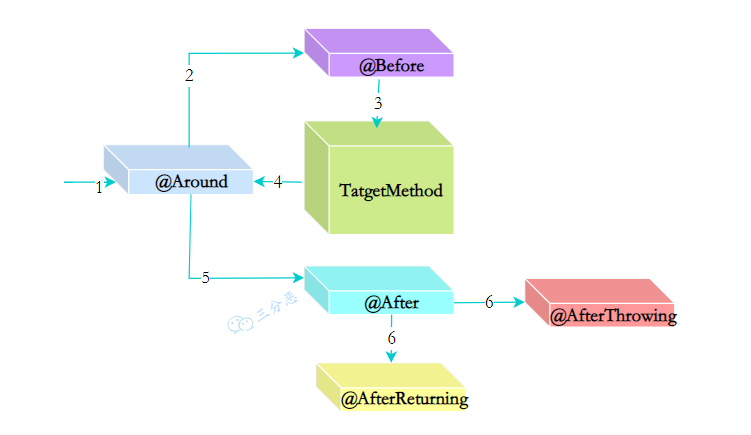
前置通知是在目标方法执行之前执行的通知。这种通知比较简单,主要用来做一些准备工作,比如参数校验、权限检查、记录方法开始执行的日志等等。前置通知无法阻止目标方法的执行,也无法修改方法的参数,它只能在方法执行前做一些额外的操作。我们在项目中经常用它来记录操作日志,比如记录谁在什么时候调用了什么方法。
@Aspect
@Component
public class LoggingAspect {
@Before("execution(* com.example.service.*.*(..))")
public void logBefore(JoinPoint joinPoint) {
// 打印方法名和参数
System.out.println("调用方法: " + joinPoint.getSignature().getName());
System.out.println("参数: " + Arrays.toString(joinPoint.getArgs()));
}
}后置通知是在目标方法执行完成后执行的,不管方法是正常返回还是抛出异常都会执行。这种通知主要用来做一些清理工作,比如释放资源、记录方法执行完成的日志等等。需要注意的是,后置通知拿不到方法的返回值,也捕获不到异常信息,它就是纯粹的在方法执行后做一些收尾工作。
@Aspect
@Component
public class LoggingAspect {
@After("execution(* com.example.service.*.*(..))")
public void logAfter(JoinPoint joinPoint) {
// 打印方法执行完成的日志
System.out.println("方法执行完成: " + joinPoint.getSignature().getName());
}
}返回通知是在目标方法正常返回后执行的。这种通知可以获取到方法的返回值,我们可以在注解中指定 returning 参数来接收返回值。返回通知经常用来做一些基于返回结果的后续处理,比如缓存方法的返回结果、根据返回值发送通知等等。如果方法抛出异常的话,返回通知是不会执行的。
@Aspect
@Component
public class LoggingAspect {
@AfterReturning(pointcut = "execution(* com.example.service.*.*(..))", returning = "result")
public void logAfterReturning(JoinPoint joinPoint, Object result) {
// 打印方法执行完成的日志
System.out.println("方法执行完成: " + joinPoint.getSignature().getName());
// 打印方法返回值
System.out.println("返回值: " + result);
}
}异常通知是在目标方法抛出异常后执行的。我们可以在注解中指定 throwing 参数来接收异常对象。异常通知主要用来做异常处理和记录,比如记录错误日志、发送告警、异常统计等等。需要注意的是,异常通知不能处理异常,异常还是会继续向上抛出。
@Aspect
@Component
public class LoggingAspect {
@AfterThrowing(pointcut = "execution(* com.example.service.*.*(..))",
throwing = "ex")
public void logAfterThrowing(JoinPoint joinPoint, Throwable ex) {
// 打印方法名和异常信息
System.out.println("方法执行异常: " + joinPoint.getSignature().getName());
System.out.println("异常信息: " + ex.getMessage());
}
}环绕通知是最强大也是我们用得最多的一种通知。它可以在方法执行前后都执行逻辑,而且可以控制目标方法是否执行,还可以修改方法的参数和返回值。环绕通知的方法必须接收一个 ProceedingJoinPoint 参数,通过调用其 proceed() 方法来执行目标方法。
技术派 项目中就主要是通过环绕通知来实现切面。
如果有多个切面,还可以通过 @Order 注解指定先后顺序,数字越小,优先级越高。代码示例如下:
@Aspect
@Component
public class WebLogAspect {
private final static Logger logger = LoggerFactory.getLogger(WebLogAspect.class);
@Pointcut("@annotation(cn.fighter3.spring.aop_demo.WebLog)")
public void webLog() {}
@Before("webLog()")
public void doBefore(JoinPoint joinPoint) throws Throwable {
// 开始打印请求日志
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
// 打印请求相关参数
logger.info("========================================== Start ==========================================");
// 打印请求 url
logger.info("URL : {}", request.getRequestURL().toString());
// 打印 Http method
logger.info("HTTP Method : {}", request.getMethod());
// 打印调用 controller 的全路径以及执行方法
logger.info("Class Method : {}.{}", joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName());
// 打印请求的 IP
logger.info("IP : {}", request.getRemoteAddr());
// 打印请求入参
logger.info("Request Args : {}",new ObjectMapper().writeValueAsString(joinPoint.getArgs()));
}
@After("webLog()")
public void doAfter() throws Throwable {
// 结束后打个分隔线,方便查看
logger.info("=========================================== End ===========================================");
}
@Around("webLog()")
public Object doAround(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
//开始时间
long startTime = System.currentTimeMillis();
Object result = proceedingJoinPoint.proceed();
// 打印出参
logger.info("Response Args : {}", new ObjectMapper().writeValueAsString(result));
// 执行耗时
logger.info("Time-Consuming : {} ms", System.currentTimeMillis() - startTime);
return result;
}
}Spring AOP 发生在什么时候?
Spring AOP 是在 Bean 的初始化阶段发生的,具体来说是在 Bean 生命周期的后置处理阶段。
在 Bean 实例化完成、属性注入完成之后,Spring 会调用所有 BeanPostProcessor 的 postProcessAfterInitialization 方法,AOP 代理的创建就是在这个阶段完成的。
简单总结一下 AOP
AOP,也就是面向切面编程,是一种编程范式,旨在提高代码的模块化。比如说可以将日志记录、事务管理等分离出来,来提高代码的可重用性。
AOP 的核心概念包括切面、连接点、通知、切点和织入等。
① 像日志打印、事务管理等都可以抽离为切面,可以声明在类的方法上。像 @Transactional 注解,就是一个典型的 AOP 应用,它就是通过 AOP 来实现事务管理的。我们只需要在方法上添加 @Transactional 注解,Spring 就会在方法执行前后添加事务管理的逻辑。
② Spring AOP 是基于代理的,它默认使用 JDK 动态代理和 CGLIB 代理来实现 AOP。
③ Spring AOP 的织入方式是运行时织入,而 AspectJ 支持编译时织入、类加载时织入。
AOP和 OOP 的关系?
AOP 和 OOP 是互补的编程思想:
- OOP 通过类和对象封装数据和行为,专注于核心业务逻辑。
- AOP 提供了解决横切关注点(如日志、权限、事务等)的机制,将这些逻辑集中管理。
- Java 面试指南(付费)收录的腾讯 Java 后端实习一面原题:说说 AOP 的原理。
- Java 面试指南(付费)收录的小米 25 届日常实习一面原题:说说你对 AOP 和 IoC 的理解。
- Java 面试指南(付费)收录的快手面经同学 7 Java 后端技术一面面试原题:说一下 Spring AOP 的实现原理
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:介绍 Spring IoC 和 AOP?
- Java 面试指南(付费)收录的招商银行面经同学 6 招银网络科技面试原题:SpringBoot框架的AOP、IOC/DI?
- Java 面试指南(付费)收录的美团面经同学 4 一面面试原题:Spring AOP发生在什么时候
- Java 面试指南(付费)收录的理想汽车面经同学 2 一面面试原题:Spring AOP的概念了解吗?AOP和 OOP 的关系?
memo:2025 年 7 月 7 日修改至此,有球友提问要一个详细版的学习计划表,我用了一个早上的时间整理了一个三个月的冲刺计划,包括八股、算法、项目的安排,已经放在了 Java 面试指南中,需要的小伙伴可以自取做个参考。
21.🌟AOP的应用场景有哪些?
答:AOP 在实际工作/编码学习中有很多应用场景,我按照使用频率来说说几个主要的。
事务管理是用得最多的场景,基本上每个项目都会用到。只需要在 Service 方法上加个 @Transactional 注解,Spring 就会自动帮我们管理事务的开启、提交和回滚。
日志记录也是一个很常见的应用。在技术派实战项目中,就利用了 AOP 来打印接口的入参和出参日志、执行时间,方便后期 bug 溯源和性能调优。
----这部分面试可以不背,方便大家理解 start----
第一步,定义 @MdcDot 注解:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface MdcDot {
String bizCode() default "";
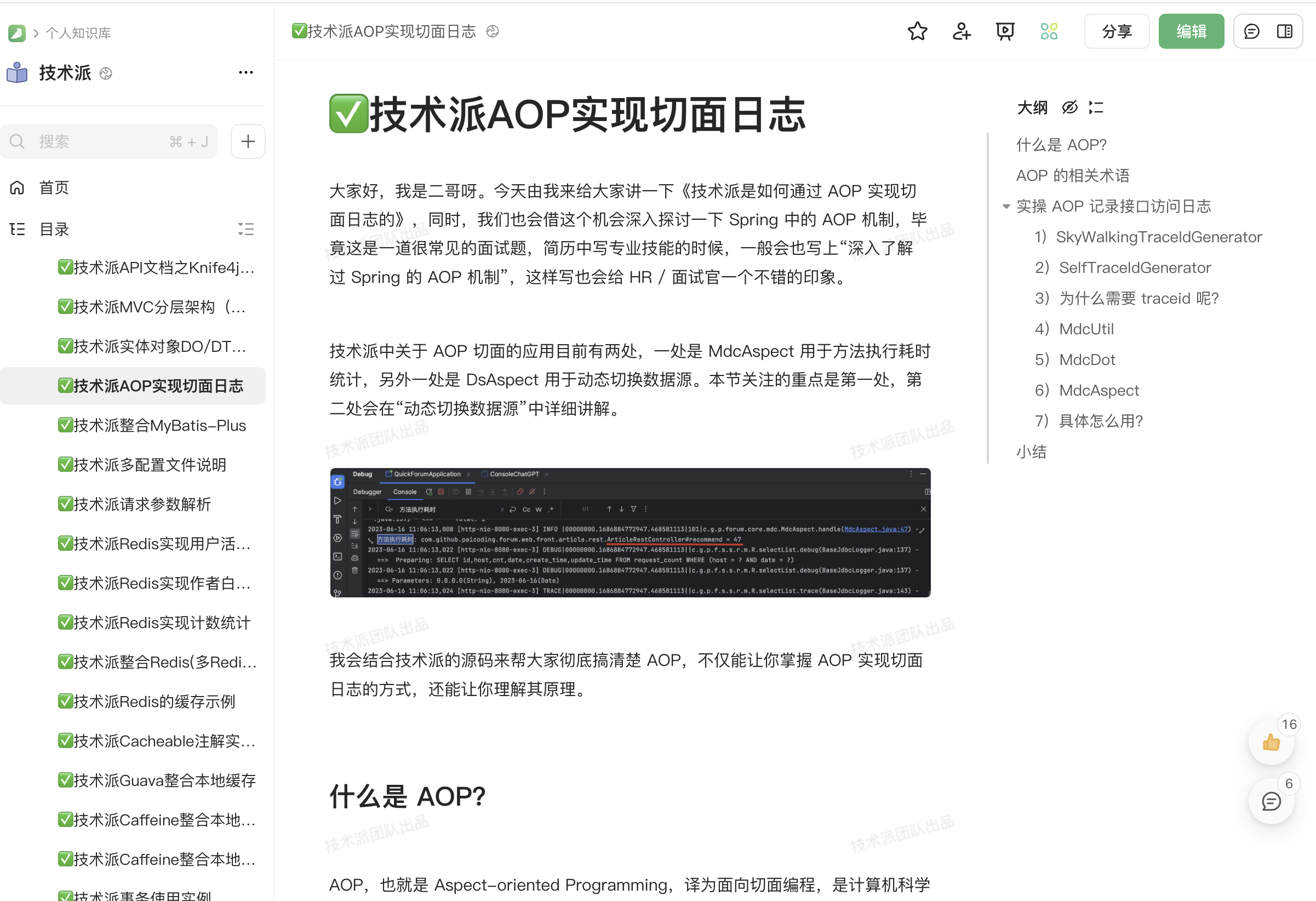
}第二步,配置 MdcAspect 切面,拦截带有 @MdcDot 注解的方法或类,在方法执行前后进行 MDC 操作,记录方法执行耗时。
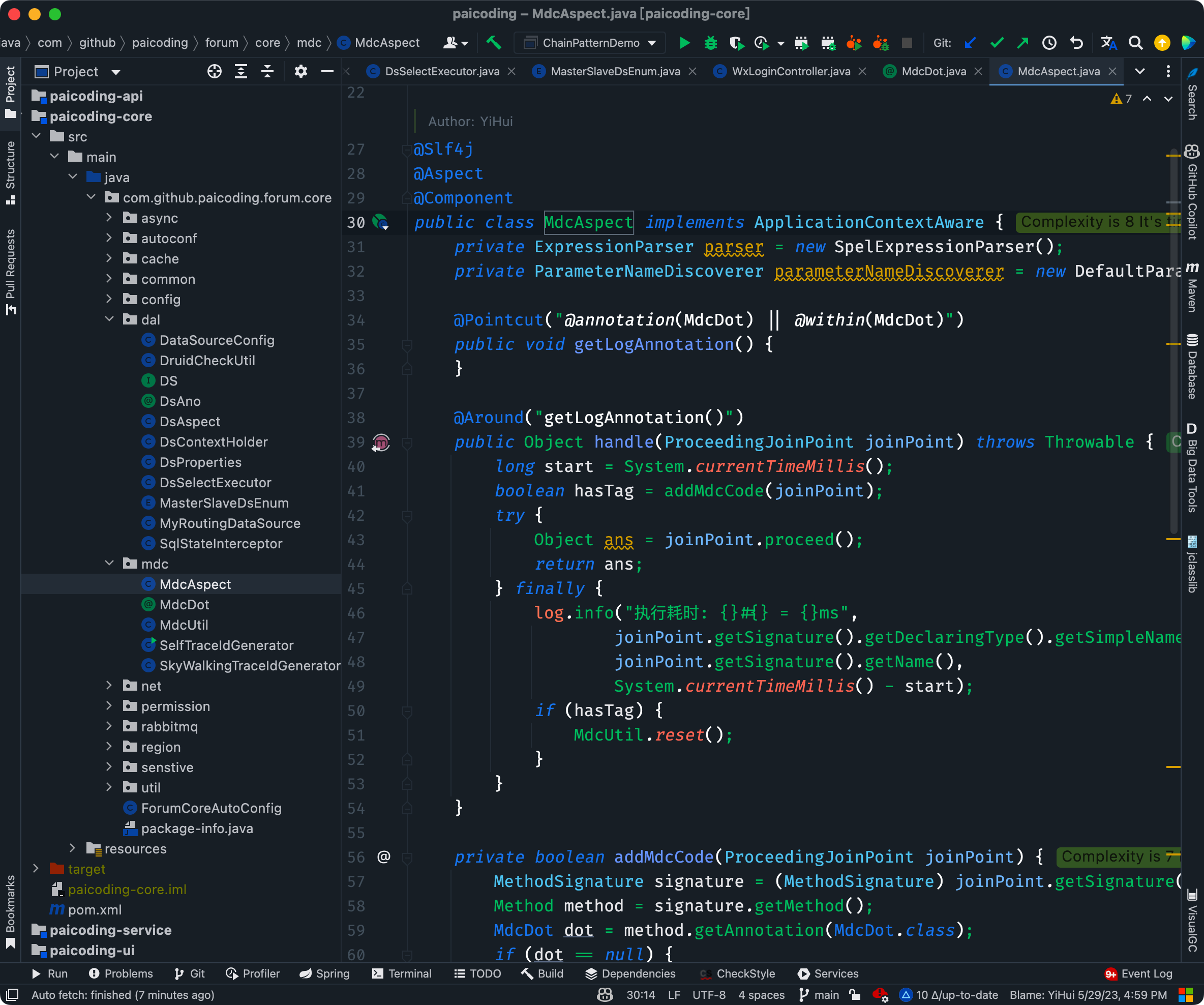
第三步,在需要的地方加上 @MdcDot 注解。
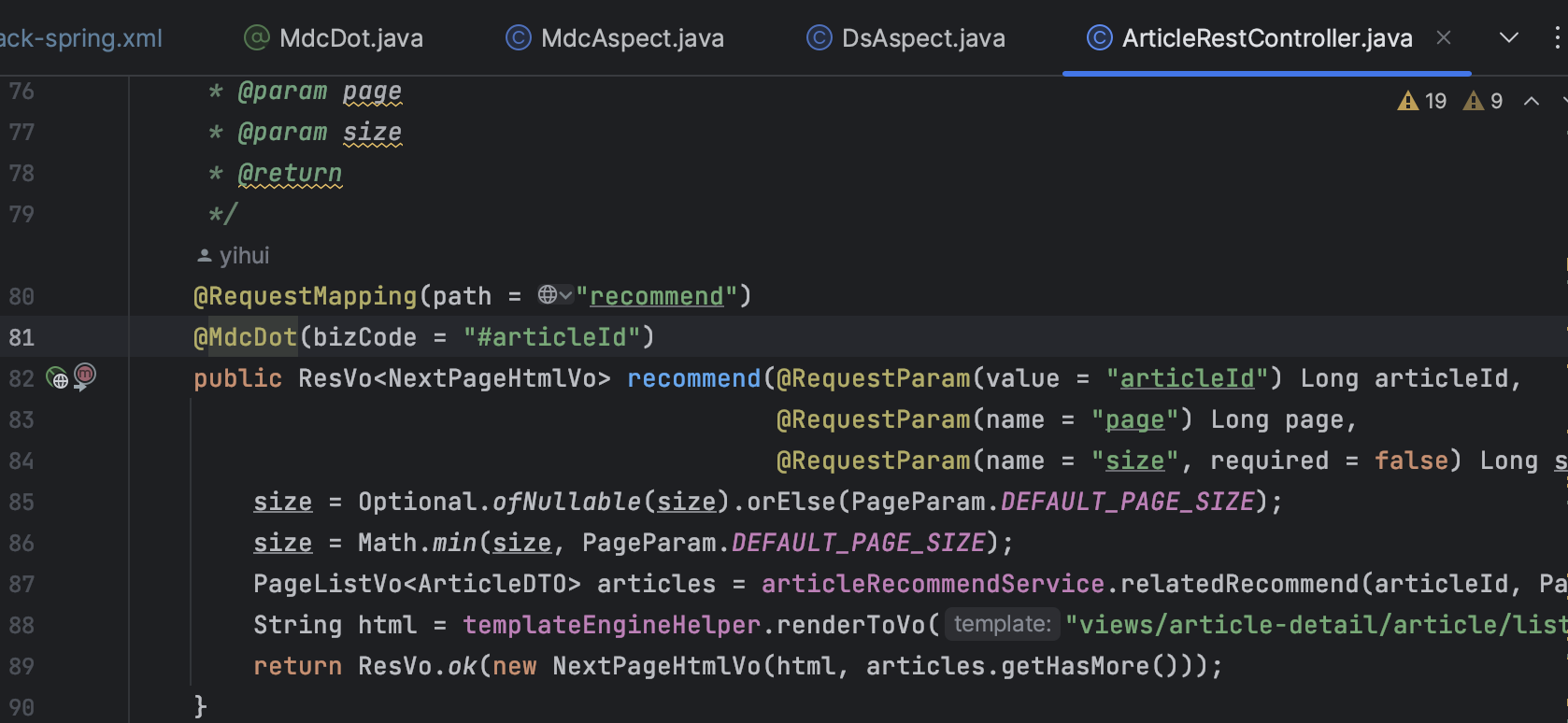
第四步,当接口被调用时,就可以看到对应的执行日志。
2023-06-16 11:06:13,008 [http-nio-8080-exec-3] INFO |00000000.1686884772947.468581113|101|c.g.p.forum.core.mdc.MdcAspect.handle(MdcAspect.java:47) - 方法执行耗时: com.github.paicoding.forum.web.front.article.rest.ArticleRestController#recommend = 47----面试可以不背,方便大家理解 end----
除此之外,还有权限控制、性能监控、缓存处理等场景。总的来说,任何需要在多个地方重复执行的通用逻辑,都可以考虑用 AOP 来实现。
- Java 面试指南(付费)收录的京东面经同学 5 Java 后端技术一面面试原题:AOP应用场景
- Java 面试指南(付费)收录的理想汽车面经同学 2 一面面试原题:AOP的使用场景有哪些?
- Java 面试指南(付费)收录的京东面经同学 9 面试原题:项目中的AOP是怎么用到的
memo:2025 年 7 月 8 日修改至此,今天在星球的 VIP 群里又看到在吹面渣逆袭的,球友说美团、小红书八股都没问题,看二哥的足够。
22.说说 Spring AOP 和 AspectJ 区别?
Spring AOP 只支持方法级别的织入,而且只能拦截 Spring 容器管理的 Bean。但是 AspectJ 几乎可以织入任何地方,包括方法、字段、构造方法、异常处理等等。
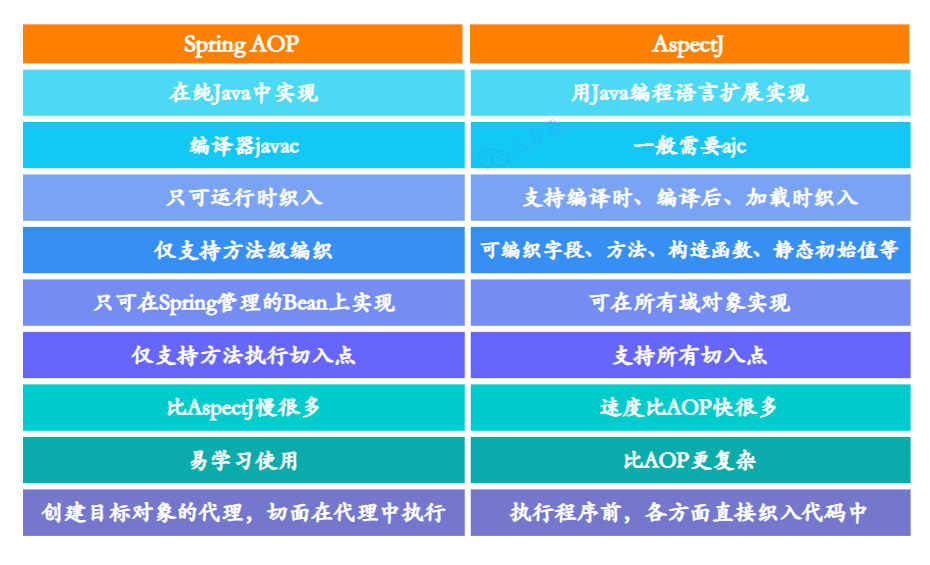
从实现机制上来说,Spring AOP 是基于动态代理实现的,在运行时为目标对象创建代理,通过代理来执行切面逻辑。而 AspectJ 是通过字节码织入来实现的,它直接修改目标类的字节码,把切面逻辑编织到目标方法中。
在实际项目中,我们大部分时候用的都是 Spring AOP,因为它能满足绝大多数需求,而且使用简单。只有在遇到 Spring AOP 无法解决的问题时,比如需要织入第三方 jar 包中的方法,或者监控字段才会考虑引入 AspectJ。
Spring AOP 借鉴了很多 AspectJ 的概念和注解,我们在 Spring 中使用的 @Aspect、@Pointcut 这些注解,其实都是 AspectJ 定义的。
23.说说 AOP 和反射的区别?(补充)
2024 年 7 月 27 日增补。
反射主要是为了让程序能够检查和操作自身的结构,比如获取类的信息、调用方法、访问字段等等。而 AOP 则是为了在不修改业务代码的前提下,动态地为方法添加额外的行为,比如日志记录、事务管理等。
从技术实现来说,反射是 Java 语言本身提供的功能,通过 java.lang.reflect 包下的 API 来实现。而 AOP 通常需要框架支持,比如 Spring AOP 是通过动态代理实现的,而动态代理又是基于反射实现的。
- Java 面试指南(付费)收录的得物面经同学 9 面试题目原题:抛开Spring,讲讲反射和动态代理?那三种代理模式怎么实现的?
AOP 和装饰器模式有什么区别?
AOP 和装饰器模式都是为了在不修改原有代码的情况下,动态地为对象添加额外的行为。
装饰器模式是通过创建一个包装类来实现的,这个包装类持有被装饰对象的引用,并在调用方法时添加额外的逻辑。装饰器模式通常需要手动编写包装类,适用于单个对象的增强。
// 基础组件接口
interface Component {
void operation();
}
// 具体组件
class ConcreteComponent implements Component {
public void operation() {
System.out.println("执行基本操作");
}
}
// 装饰器基类
abstract class Decorator implements Component {
protected Component component;
public Decorator(Component component) {
this.component = component;
}
public void operation() {
component.operation();
}
}
// 具体装饰器
class ConcreteDecorator extends Decorator {
public ConcreteDecorator(Component component) {
super(component);
}
public void operation() {
addedBehavior();
super.operation();
addedBehavior();
}
private void addedBehavior() {
System.out.println("添加的新功能");
}
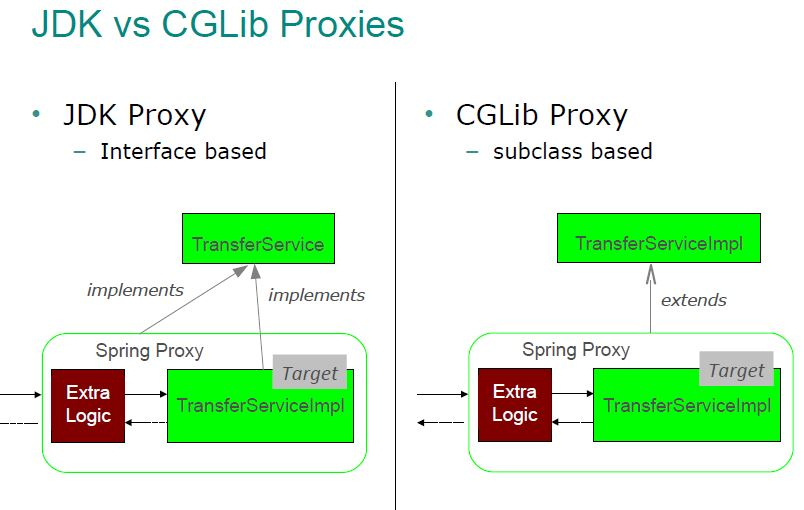
}24.🌟说说JDK动态代理和CGLIB代理的区别?
JDK 动态代理和 CGLIB 代理是 Spring AOP 用来创建代理对象的两种方式。
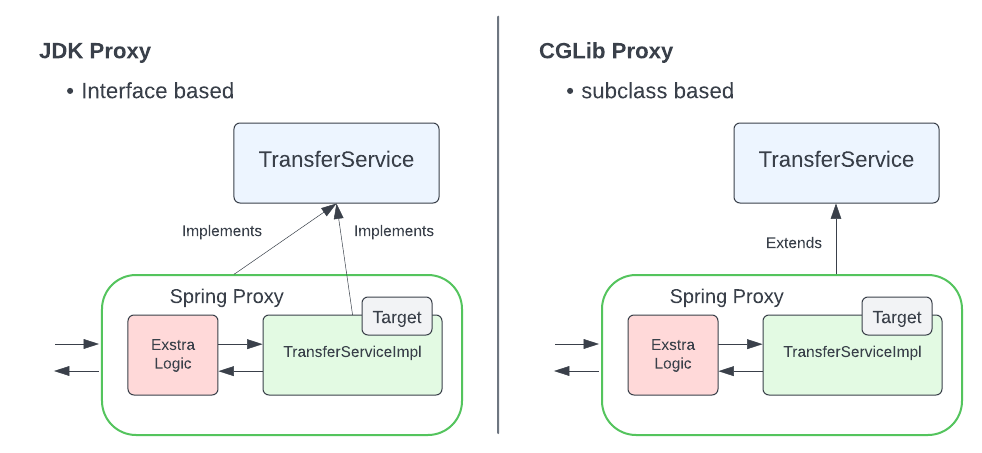
从使用条件来说,JDK 动态代理要求目标类必须实现至少一个接口,因为它是基于接口来创建代理的。而 CGLIB 代理不需要目标类实现接口,它是通过继承目标类来创建代理的。
这是两者最根本的区别。比如我们有一个 TransferService 接口和 TransferServiceImpl 实现类,如果用 JDK 动态代理,创建的代理对象会实现 TransferService 接口;
如果用 CGLIB,代理对象会继承 TransferServiceImpl 类。
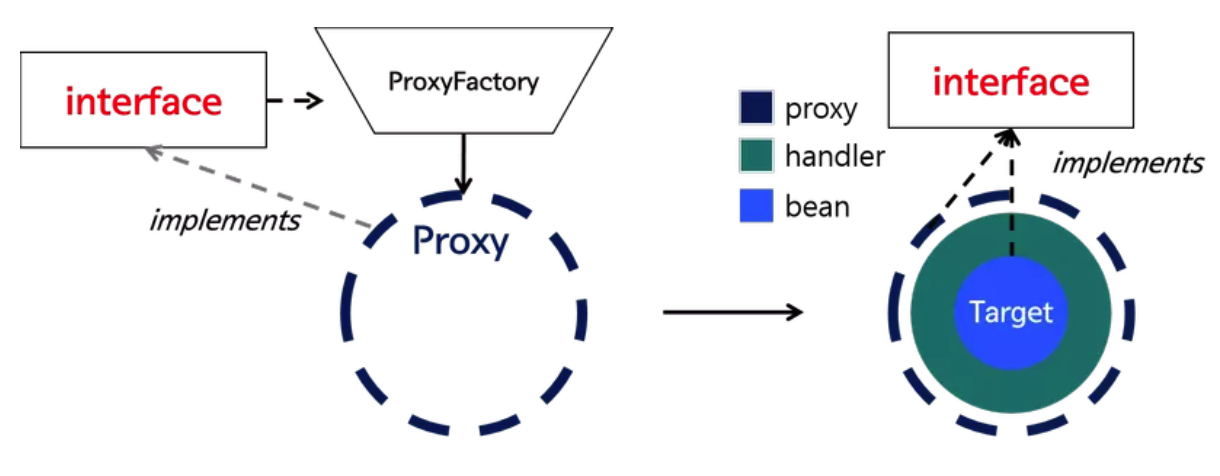
从实现原理来说,JDK 动态代理是 Java 原生支持的,它通过反射机制在运行时动态创建一个实现了指定接口的代理类。当我们调用代理对象的方法时,会被转发到 InvocationHandler 的 invoke 方法中,我们可以在这个方法里插入切面逻辑,然后再通过反射调用目标对象的真实方法。
public class JdkProxyExample {
public static void main(String[] args) {
UserService target = new UserServiceImpl();
UserService proxy = (UserService) Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),
(proxy1, method, args1) -> {
System.out.println("Before method: " + method.getName());
Object result = method.invoke(target, args1);
System.out.println("After method: " + method.getName());
return result;
}
);
proxy.findUser(1L);
}
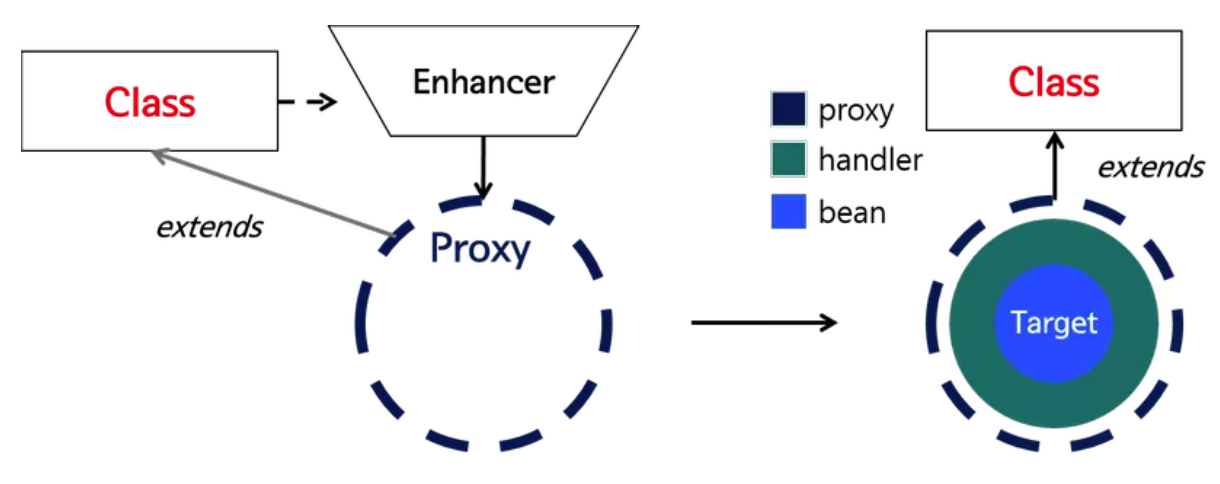
}CGLIB 则是一个第三方的字节码生成库,它通过 ASM 字节码框架动态生成目标类的子类,然后重写父类的方法来插入切面逻辑。
public class CglibProxyExample {
public static void main(String[] args) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(UserController.class);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Before method: " + method.getName());
Object result = proxy.invokeSuper(obj, args);
System.out.println("After method: " + method.getName());
return result;
}
});
UserController proxy = (UserController) enhancer.create();
proxy.getUser(1L);
}
}选择 CGLIB 还是 JDK 动态代理?
如果目标对象没有实现任何接口,就只能使用 CGLIB 代理,就比如说 Controller 层的类。
// 没有实现接口的Controller
@RestController
public class ArticleController {
@MdcDot(bizCode = "article.create")
public ResponseVo<String> create(@RequestBody ArticleReq req) {
// 业务逻辑
}
}如果目标对象实现了接口,通常首选 JDK 动态代理,比如说 Service 层的类,一般都会先定义接口,再实现接口。
// 接口定义
public interface ArticleService {
void saveArticle(Article article);
}
// 实现类
@Service
public class ArticleServiceImpl implements ArticleService {
@Transactional(rollbackFor = Exception.class)
@Override
public void saveArticle(Article article) {
// 业务逻辑
}
}在 Spring Boot 2.0 之后,Spring AOP 默认使用 CGLIB 代理。这是因为 Spring Boot 作为一个追求“约定优于配置”的框架,选择 CGLIB,可以简化开发者的心智负担,避免因为忘记实现接口而导致 AOP 不生效的问题。
你会用 JDK 动态代理吗?
会的。
假设我们有这样一个小场景,客服中转,解决用户问题:
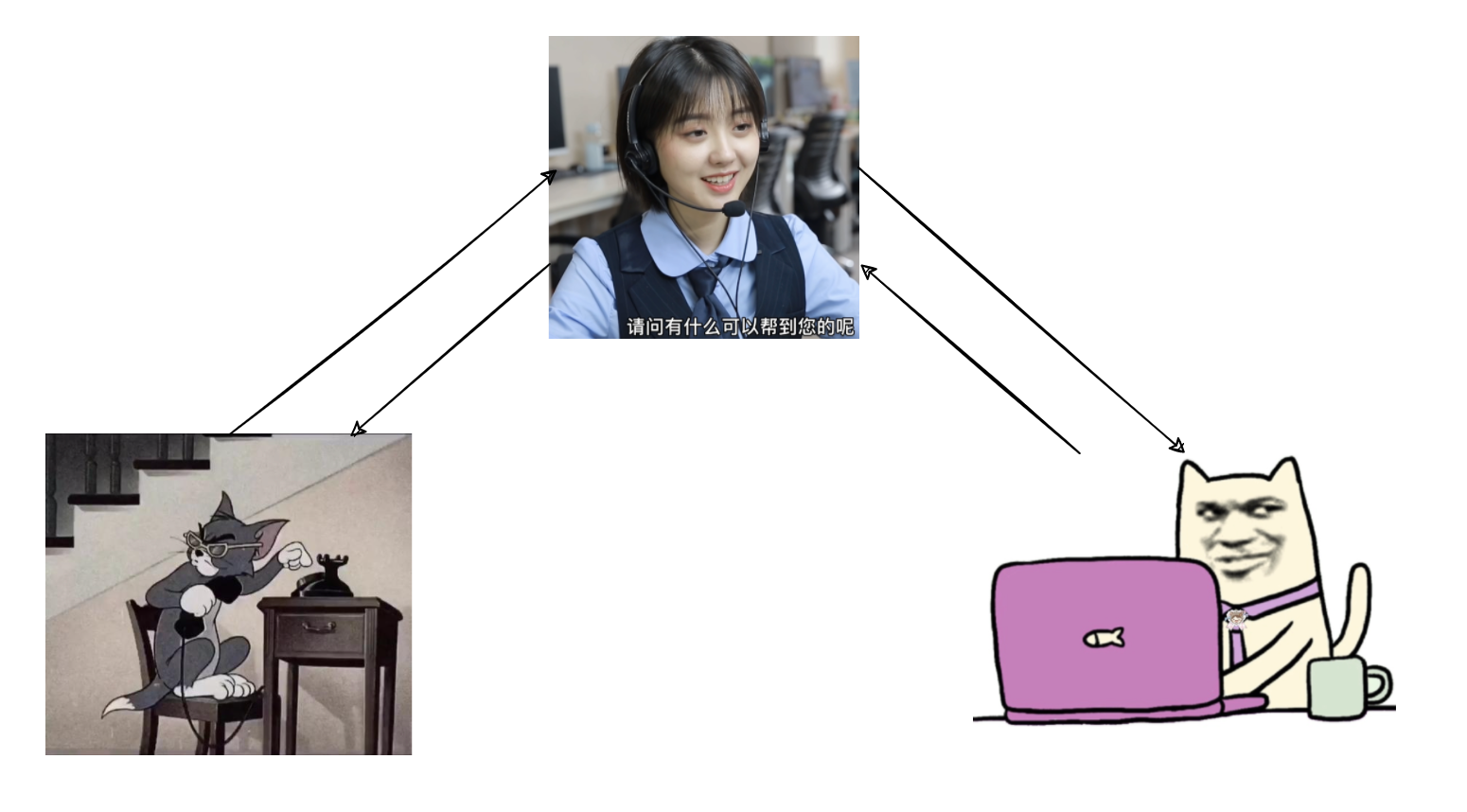
我们可以用 JDK 动态代理来实现这个场景。JDK 动态代理的核心是通过反射机制在运行时创建一个实现了指定接口的代理类。
第一步,创建接口。
public interface ISolver {
void solve();
}第二步,实现接口。
public class Solver implements ISolver {
@Override
public void solve() {
System.out.println("疯狂掉头发解决问题……");
}
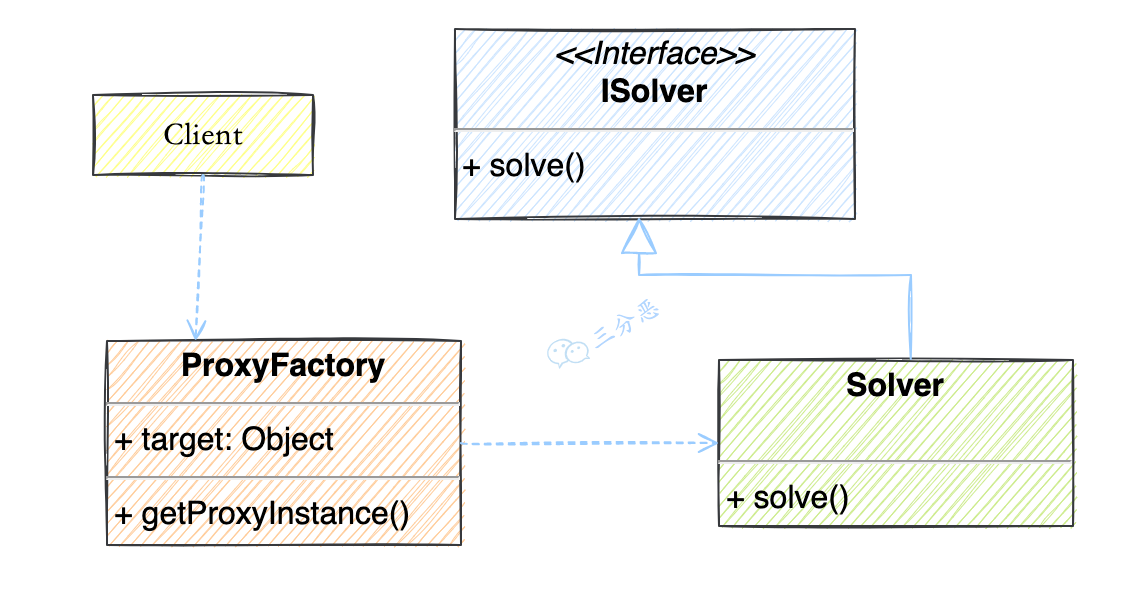
}第三步,使用用反射生成目标对象的代理,这里用了一个匿名内部类方式重写 InvocationHandler 方法。
public class ProxyFactory {
// 维护一个目标对象
private Object target;
public ProxyFactory(Object target) {
this.target = target;
}
// 为目标对象生成代理对象
public Object getProxyInstance() {
return Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(),
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("请问有什么可以帮到您?");
// 调用目标对象方法
Object returnValue = method.invoke(target, args);
System.out.println("问题已经解决啦!");
return null;
}
});
}
}第四步,生成一个代理对象实例,通过代理对象调用目标对象方法。
public class Client {
public static void main(String[] args) {
//目标对象:程序员
ISolver developer = new Solver();
//代理:客服小姐姐
ISolver csProxy = (ISolver) new ProxyFactory(developer).getProxyInstance();
//目标方法:解决问题
csProxy.solve();
}
}你会用 CGLIB 动态代理吗?
会的。
第一步:定义目标类 Solver,定义 solve 方法,模拟解决问题的行为。目标类不需要实现任何接口,这与 JDK 动态代理的要求不同。
public class Solver {
public void solve() {
System.out.println("疯狂掉头发解决问题……");
}
}第二步:创建代理工厂 ProxyFactory,使用 CGLIB 的 Enhancer 类来生成目标类的子类(代理对象)。CGLIB 允许我们在运行时动态创建一个继承自目标类的代理类,并重写目标方法。
public class ProxyFactory implements MethodInterceptor {
//维护一个目标对象
private Object target;
public ProxyFactory(Object target) {
this.target = target;
}
//为目标对象生成代理对象
public Object getProxyInstance() {
//工具类
Enhancer en = new Enhancer();
//设置父类
en.setSuperclass(target.getClass());
//设置回调函数
en.setCallback(this);
//创建子类对象代理
return en.create();
}
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("请问有什么可以帮到您?");
// 执行目标对象的方法
Object returnValue = method.invoke(target, args);
System.out.println("问题已经解决啦!");
return null;
}
}第三步:创建客户端 Client,获取代理对象并调用目标方法。
public class Client {
public static void main(String[] args) {
//目标对象:程序员
Solver developer = new Solver();
//代理:客服小姐姐
Solver csProxy = (Solver) new ProxyFactory(developer).getProxyInstance();
//目标方法:解决问题
csProxy.solve();
}
}
- Java 面试指南(付费)收录的帆软同学 3 Java 后端一面的原题:cglib 的原理
- Java 面试指南(付费)收录的腾讯面经同学 22 暑期实习一面面试原题:Spring AOP 实现原理
- Java 面试指南(付费)收录的小米面经同学 F 面试原题:两种动态代理的区别
- Java 面试指南(付费)收录的字节跳动面经同学 8 Java 后端实习一面面试原题:spring的aop是如何实现的
- Java 面试指南(付费)收录的腾讯云智面经同学 20 二面面试原题:spring aop的底层原理是什么?
- Java 面试指南(付费)收录的美团面经同学 3 Java 后端技术一面面试原题:java的反射机制,反射的应用场景AOP的实现原理是什么,与动态代理和反射有什么区别
- Java 面试指南(付费)收录的比亚迪面经同学 12 Java 技术面试原题:代理介绍一下,jdk和cglib的区别
- Java 面试指南(付费)收录的快手同学 4 一面原题:Spring AOP的实现原理?JDK动态代理和CGLib动态代理的各自实现及其区别?现在需要统计方法的具体执行时间,说下如何使用AOP来实现?
- Java 面试指南(付费)收录的理想汽车面经同学 2 一面面试原题:了解AOP底层是怎么做的吗?
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 7 月 10 日修改至此,今天在给球友修改简历的时候碰到一个对星球非常认可的球友,他在我的帮助下也顺利找到了实习,并且大家也可以看到,他提到的这些路线规划问题、简历书写问题、秋招准备问题、项目问题,都可以在星球里找到答案。

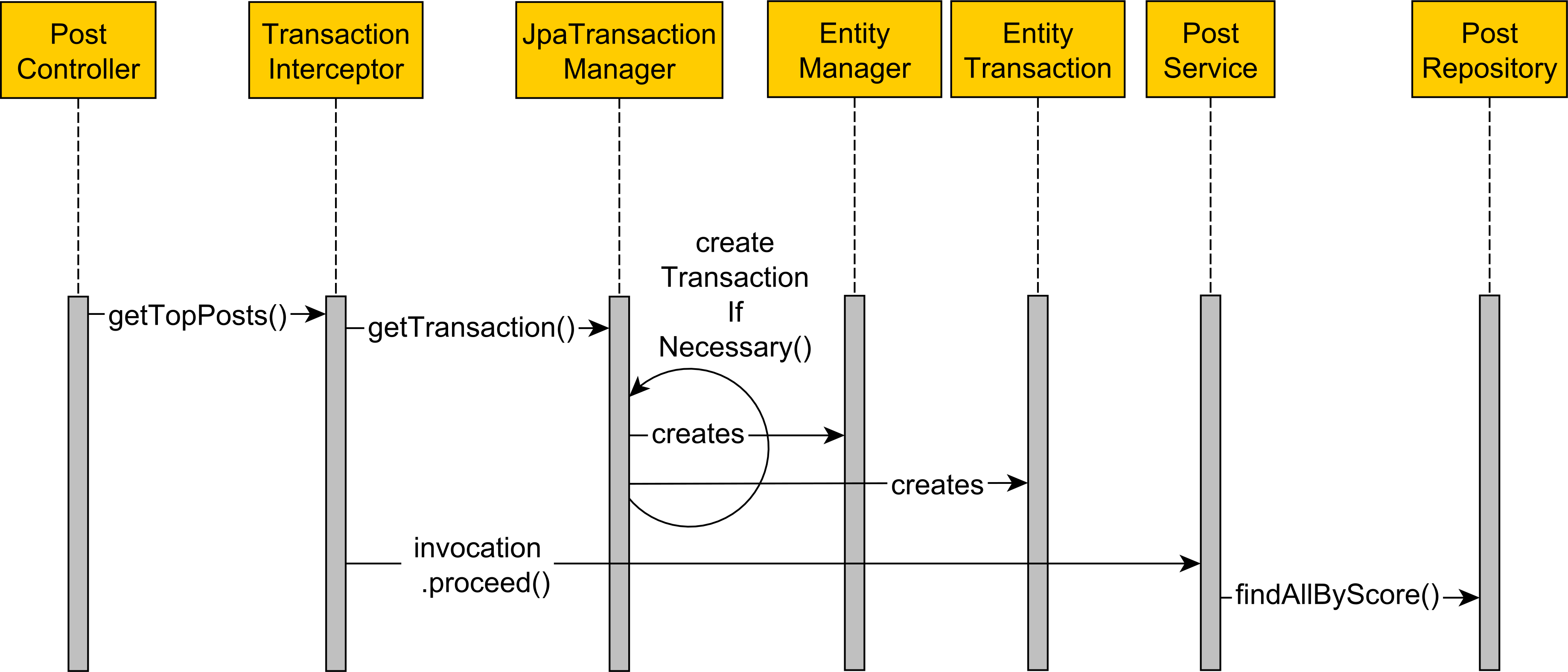
事务
25.🌟说说你对Spring事务的理解?
Spring 提供了两种事务管理方式,编程式事务和声明式事务。编程式事务就是我们要手动调用事务的开始、提交、回滚这些操作,虽然灵活但是代码比较繁琐。声明式事务只需要在需要事务的方法上加上 @Transactional 注解就好了,Spring 会帮我们自动处理事务的整个生命周期。
----这部分可以不背,方便大家理解 start----
编程式事务可以使用 TransactionTemplate 和 PlatformTransactionManager 来实现,允许我们在代码中直接控制事务的边界。
public class AccountService {
private TransactionTemplate transactionTemplate;
public void setTransactionTemplate(TransactionTemplate transactionTemplate) {
this.transactionTemplate = transactionTemplate;
}
public void transfer(final String out, final String in, final Double money) {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus status) {
// 转出
accountDao.outMoney(out, money);
// 转入
accountDao.inMoney(in, money);
}
});
}
}----这部分可以不背,方便大家理解 end----
Spring 事务的底层实现是通过 AOP 来完成的。当我们在方法上加 @Transactional 注解后,Spring 会为这个 Bean 创建代理对象,在方法执行前开启事务,方法正常返回时提交事务,如果方法抛出异常就回滚事务。
声明式事务的优点是不需要在业务逻辑代码中掺杂事务管理的代码,缺点是,最细粒度只能到方法级别,无法到代码块级别。
@Service
public class AccountService {
@Autowired
private AccountDao accountDao;
@Transactional
public void transfer(String out, String in, Double money) {
// 转出
accountDao.outMoney(out, money);
// 转入
accountDao.inMoney(in, money);
}
}
- Java 面试指南(付费)收录的京东同学 10 后端实习一面的原题:Spring 事务怎么实现的
- Java 面试指南(付费)收录的农业银行面经同学 7 Java 后端面试原题:Spring 如何保证事务
- Java 面试指南(付费)收录的比亚迪面经同学 12 Java 技术面试原题:Spring的事务用过吗,在项目里面怎么使用的
- Java 面试指南(付费)收录的虾皮面经同学 13 一面面试原题:spring事务
- Java 面试指南(付费)收录的阿里云面经同学 22 面经:如何使用spring实现事务
memo:2025 年 7 月 11 日修改至此,今天有球友在 VIP 群里讲,面渣逆袭的 Redis、MySQL、JVM 篇非常强;另外一个球友也是继续口碑说,面过几次全包过。😄
26.声明式事务的实现原理了解吗?
Spring 的声明式事务管理是通过 AOP 和代理机制实现的,大致可以分为两个阶段。
第一个阶段发生在 Spring 容器启动时,它会扫描所有的 Bean。如果发现某个 Bean 的方法上标注了 @Transactional 注解,Spring 不会直接返回这个原始的 Bean 实例。而是为这个 Bean 创建一个代理对象。这个代理对象拥有和原始对象完全相同的方法,但在内部悄悄地包裹了事务处理的逻辑。
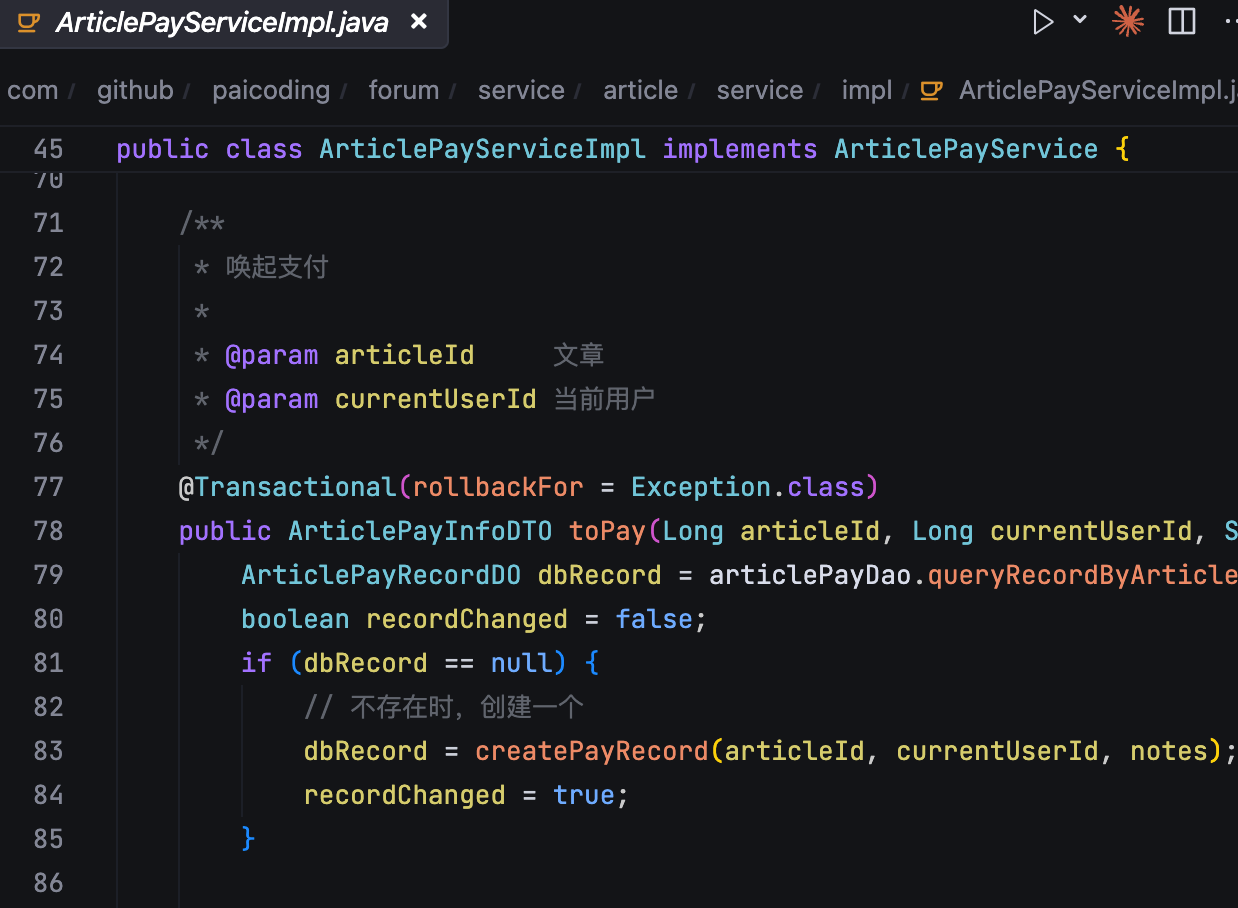
第二个阶段发生在方法调用的运行阶段,当我们的代码调用那个被 @Transactional 注解修饰的方法时,实际上调用的是 Spring 创建的那个代理对象的方法。
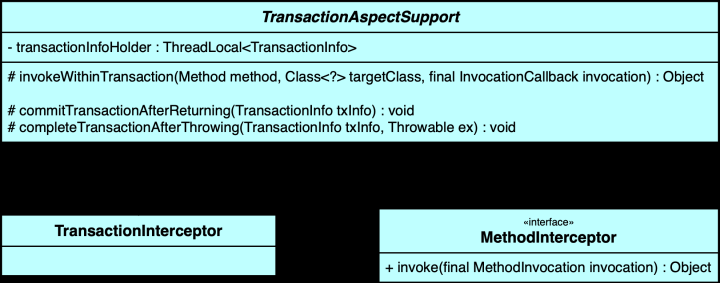
事务拦截器会在代理对象执行真正的业务逻辑之前,根据 @Transactional 注解的配置获取事务属性,比如传播行为、隔离级别等,然后通过事务管理器来开启一个新的事务。并从数据库连接池获取一个连接,关闭其自动提交。
public class TransactionInterceptor implements MethodInterceptor {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
// 获取事务属性
TransactionAttribute txAttr = getTransactionAttribute(invocation.getMethod(), invocation.getThis().getClass());
// 开始事务
TransactionStatus status = transactionManager.getTransaction(txAttr);
try {
// 执行目标方法
Object retVal = invocation.proceed();
// 提交事务
transactionManager.commit(status);
return retVal;
} catch (Throwable ex) {
// 回滚事务
transactionManager.rollback(status);
throw ex;
}
}
}接着,代理对象会调用原始 Bean 实例中真正的业务方法,如果业务方法顺利执行完毕,没有抛出任何异常,那么拦截器就会通过事务管理器提交事务,将之前的所有数据库操作永久保存。
如果业务方法抛出了异常,拦截器会捕获到这个异常,并通过事务管理器回滚事务,将之前的所有数据库操作撤销。
最后,无论事务是提交还是回滚,拦截器都会释放数据库连接。
- Java 面试指南(付费)收录的京东同学 10 后端实习一面的原题:Spring 事务怎么实现的
memo:2025 年 7 月 15 日修改至此,今天在给球友修改简历时,看到球友说简历修改后拿到了星环科技内推的实习机会,也学到了很多,并且真诚的感谢了 Java 方面的八股面试题对他的帮助。讲真,能看到大家最真实的反馈,我挺开心的。
27.@Transactional在哪些情况下会失效?
@Transactional 虽然用起来很方便,但确实有一些“坑”,如果使用不当是会导致事务失效的。根据我的理解和实践,主要有以下几种常见情况:
第一种,@Transactional 注解用在非 public 修饰的方法上。
Spring 的 AOP 代理机制决定了它无法代理 private 方法。因为 private 方法在子类中是不可见的,代理类无法覆盖它。因此,在 private 方法上加 @Transactional 注解是完全无效的。同理,protected 和 default 权限的方法也应避免使用。
protected TransactionAttribute computeTransactionAttribute(Method method,
Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
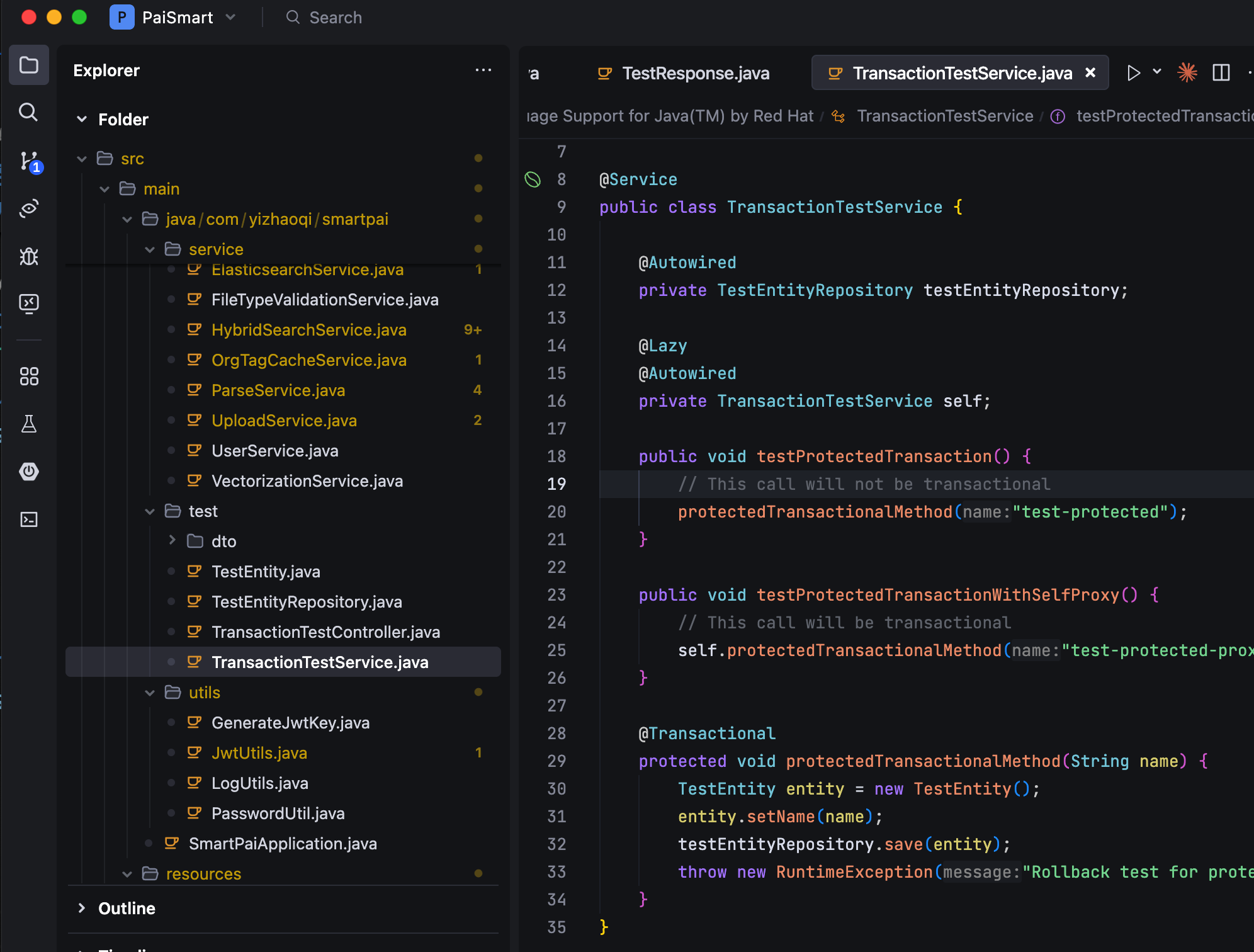
}第二种,方法内部调用,这也是最容易被忽略的一种失效场景。如果在一个类的方法 A 中,直接调用本类的另外一个加了 @Transactional 的方法 B,那么方法 B 的事务是不会生效的。
这是因为方法 A 调用方法 B 时,使用的是 this 引用,直接访问原始对象的方法,绕过了 Spring 的代理对象,也就导致代理对象中的事务逻辑没有机会执行。
public class UserService {
@Transactional
public void createUser(User user) {
// 直接调用本类的另一个方法,事务不会生效
saveUser(user);
}
private void saveUser(User user) {
// 保存用户逻辑
}
}解决方法是把当前类作为一个 Bean 注入到自己中,然后通过这个注入的 Bean 来调用方法 B。
第三种,如果在事务方法内部用 try-catch 捕获了异常,但没有在 catch 块中将异常重新抛出,或者抛出一个新的能触发回滚的异常,那么 Spring 的事务拦截器就无法感知到异常的发生,也就没办法回滚。
@Transactional
public void process() {
try {
// 业务逻辑
} catch (Exception e) {
// 捕获异常但没有重新抛出
// 事务不会回滚
}
}第四种,Spring 事务默认只对 RuntimeException 和 Error 类型的异常进行回滚。如果在代码中抛出的是一个Checked Exception,是 Exception 的子类但不是 RuntimeException 的子类,又没有通过 @Transactional(rollbackFor = Exception.class) 指定事务回归的异常类型,那么事务同样不会回滚。
@Transactional
public void process() throws Exception {
// 抛出一个 Checked Exception
throw new SQLException("This is a checked exception");
}
- Java 面试指南(付费)收录的小米春招同学 K 一面面试原题:事务传播,protected 和 private 加事务会生效吗,还有那些不生效的情况
memo:2025 年 7 月 16 日修改至此,今天在给球友修改简历时,看到一个中国海洋大学本,四川大学硕的球友,非常优秀,基本上校园经历和荣誉奖项算是拉满了。能帮助到这么多优秀的球友,我也很开心。

28.说说Spring事务的隔离级别?
事务的隔离级别定义了一个事务可以受其他并发事务影响的程度。SQL 标准定义的四个隔离级别,Spring 都支持,定义在 TransactionDefinition 接口中。
Spring 在标准的隔离级别上定义了五个隔离级别:
其中 DEFAULT 表示使用底层数据库的默认隔离级别。比如说对于 MySQL 来说,默认的隔离级别是可重复读,那就用可重复读;对于 Oracle 来说,默认是读已提交,那就用读已提交。在实际项目中,我们也通常都用 DEFAULT,让数据库自己决定合适的隔离级别。
读未提交是最低的隔离级别,允许读取未提交的数据。这种级别会出现脏读问题,也就是一个事务可能会读到另一个事务还没提交的数据。比如 A 事务修改了一条数据但还没提交,B 事务就能读到这个修改后的值,如果 A 事务后来回滚了,B 事务读到的就是脏数据。这个级别在实际项目中基本不会使用,因为数据一致性无法保证。
读已提交解决了脏读问题,但会出现不可重复读问题,也就是在同一个事务中多次读取同一条数据,可能得到不同的结果。比如 A 事务先读了一条数据,然后 B 事务修改并提交了这条数据,A 事务再次读取时就会发现数据变了。
可重复读保证在同一个事务中多次读取同一条数据的结果是一致的,解决了不可重复读问题。但是会出现幻读问题,也就是在同一个事务中多次执行同一个查询,可能会看到不同数量的记录。比如 A 事务查询某个条件的记录数是 10 条,然后 B 事务插入了一条符合条件的记录并提交,A 事务再次查询时可能会看到 11 条记录。MySQL 的 InnoDB 存储引擎通过临键锁在很大程度上解决了幻读问题。
串行化是最高的隔离级别,完全串行化执行事务,可以解决所有并发问题,包括脏读、不可重复读和幻读。但是性能是最差的,因为事务基本上是排队执行的。在实际项目中很少使用,除非对数据一致性有极高的要求。
在 Spring 中设置隔离级别也很简单,可以在 @Transactional 注解中通过 isolation 属性来指定。
@Transactional(isolation = Isolation.READ_UNCOMMITTED)
public void someMethod() {
// 业务逻辑
}不过在实际项目中,我们很少手动设置隔离级别,通常都是使用数据库的默认级别,只有在遇到特定的并发问题时才会考虑调整。
- Java 面试指南(付费)收录的华为面经同学 8 技术二面面试原题:Spring 中的事务的隔离级别,事务的传播行为?
- Java 面试指南(付费)收录的小米面经同学 E 第二个部门 Java 后端技术一面面试原题:spring 的隔离机制,默认是哪一种
memo:2025 年 7 月 13 日修改至此,今天在帮球友修改简历时,碰到一个电子科技大学硕士、华中科技大学本的球友,他说到,自己也在推荐星球给师弟们,真的非常欣慰,能有这样的口碑,很感动,必须要感谢球友们的支持。
29.🌟说说Spring的事务传播机制?
简单来说,当一个事务方法 A 调用另一个事务方法 B 时,方法 B 的事务应该如何运行?是加入方法 A 的现有事务,还是开启一个新事务,或者以非事务方式运行?这就是事务传播机制要解决的问题。
Spring 定义了七种事务传播行为,其中 REQUIRED 是默认的传播行为,表示如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。

比如说在技术派实战项目中,一个用户解锁付费文章的操作,会涉及到创建支付订单、更新订单状态等好几个数据库操作。
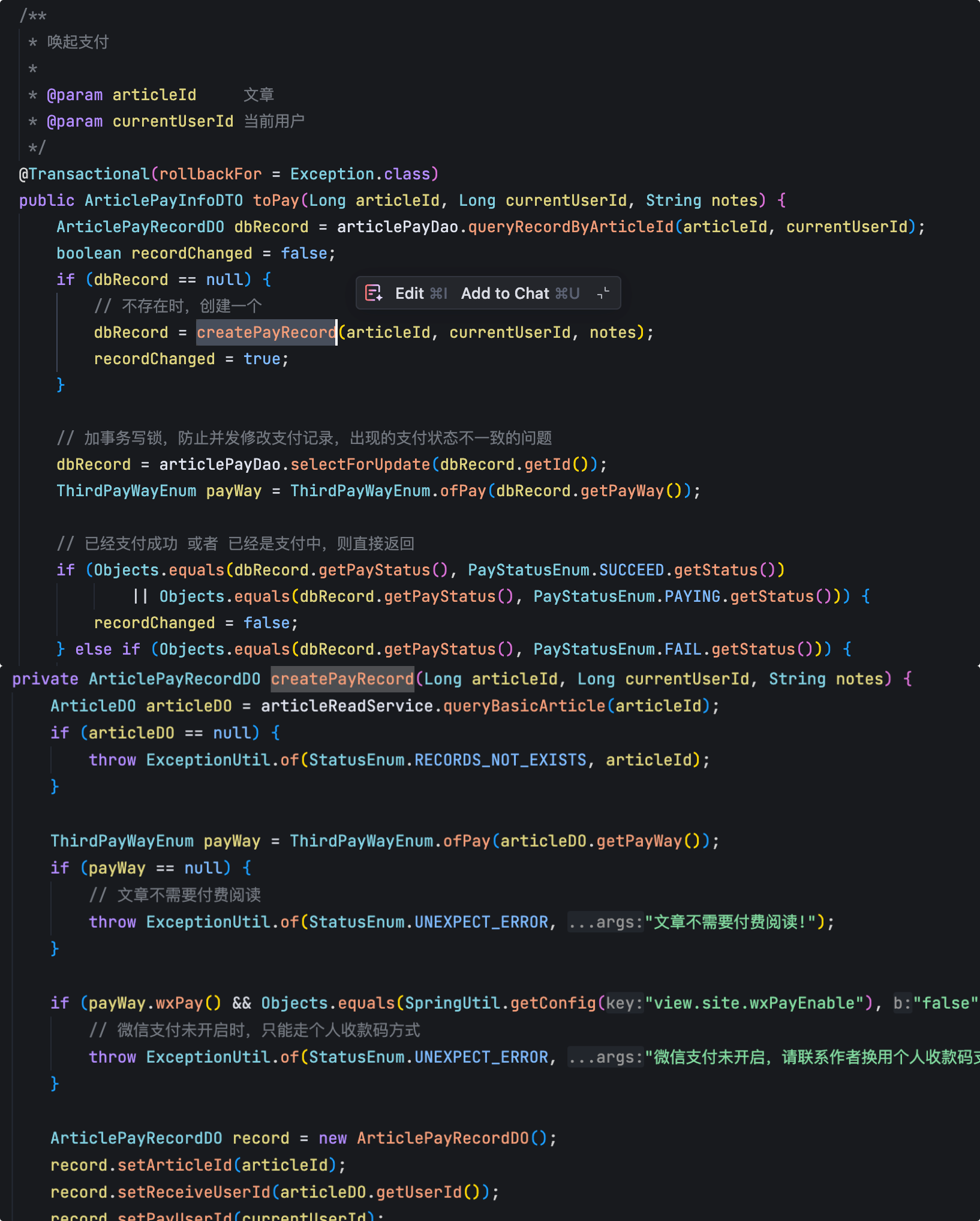
这些不同操作的方法就可以放在一个 @Transactional 注解的方法里,它们就自动在同一个事务里了,要么一起成功,要么一起失败。
当然,还有一些特殊情况。比如,我们希望记录一些操作日志,但不想因为主业务失败导致日志回滚。这时候 REQUIRES_NEW 就派上用场了。它不管当前有没有事务,都重新开启一个全新的、独立的事务来执行。这样,日志保存的事务和主业务的事务就互不干扰,即使主业务失败回滚,日志也能妥妥地保存下来。
另外,还有像 SUPPORTS、 NOT_SUPPORTED 这些。SUPPORTS 比较佛系,有事务就用,没事务就不用,适合一些不重要的更新操作。而 NOT_SUPPORTED 则更干脆,它会把当前的事务挂起,以非事务的方式去执行。比如说我们的事务里需要调用一个第三方的、响应很慢的接口,如果这个调用也包含在事务里,就会长时间占用数据库连接。把它用 NOT_SUPPORTED 包起来,就可以避免这个问题。
@Transactional(propagation = Propagation.NOT_SUPPORTED)
public void callExternalApi() {
// 调用第三方接口
}最后还有一个比较特殊的 NESTED,嵌套事务。它有点像 REQUIRES_NEW,但又不完全一样。NESTED 是父事务的一个子事务,父事务回滚,它肯定也得回滚。但它自己回滚,却不会影响到父事务。这个特性在处理一些批量操作,希望能部分回滚的场景下特别有用。不过它需要数据库支持 Savepoint 功能,MySQL 就支持。
事务能在新线程中传播吗?
事务传播机制是通过 ThreadLocal 实现的,所以,如果调用的方法是在新线程中,事务传播就会失效。
@Transactional
public void parentMethod() {
new Thread(() -> childMethod()).start();
}
public void childMethod() {
// 这里的操作将不会在 parentMethod 的事务范围内执行
}protected 和 private 方法加事务会生效吗?
我的理解是:在 private 方法上加事务是肯定不会生效的,而 protected 方法在特定的代理模式下是可能生效的,但这两种用法都应该避免,不是推荐的使用方式。
这背后涉及到 Spring AOP 的代理机制。
我先说一下 JDK 动态代理,它要求目标类必须实现一个或者多个接口。也就意味着代理只能拦截接口中声明的方法,而 protected 和 private 方法并不能在接口中声明,因此在 JDK 动态代理下,这些方法的事务注解是会被直接忽略的。
那 Spring Boot 2.0 之后,Spring AOP 默认使用的是 CGLIB 代理。CGLIB 代理是通过继承目标类来创建代理对象的。
那对于 private 方法来说,由于无法被子类重写,所以 CGLIB 代理也无法拦截,事务也就无法生效。对于 protected 方法来说,因为它可以被子类重写,所以理论上事务是生效的。
----这部分可以不背,方便大家理解 start----
我们创建一个 protected 方法,名为 protectedTransactionalMethod ,它被 @Transactional 注解标记。这个方法会先向数据库中插入一条记录(一个 TestEntity 实例)。紧接着,它会立即抛出一个 RuntimeException 。
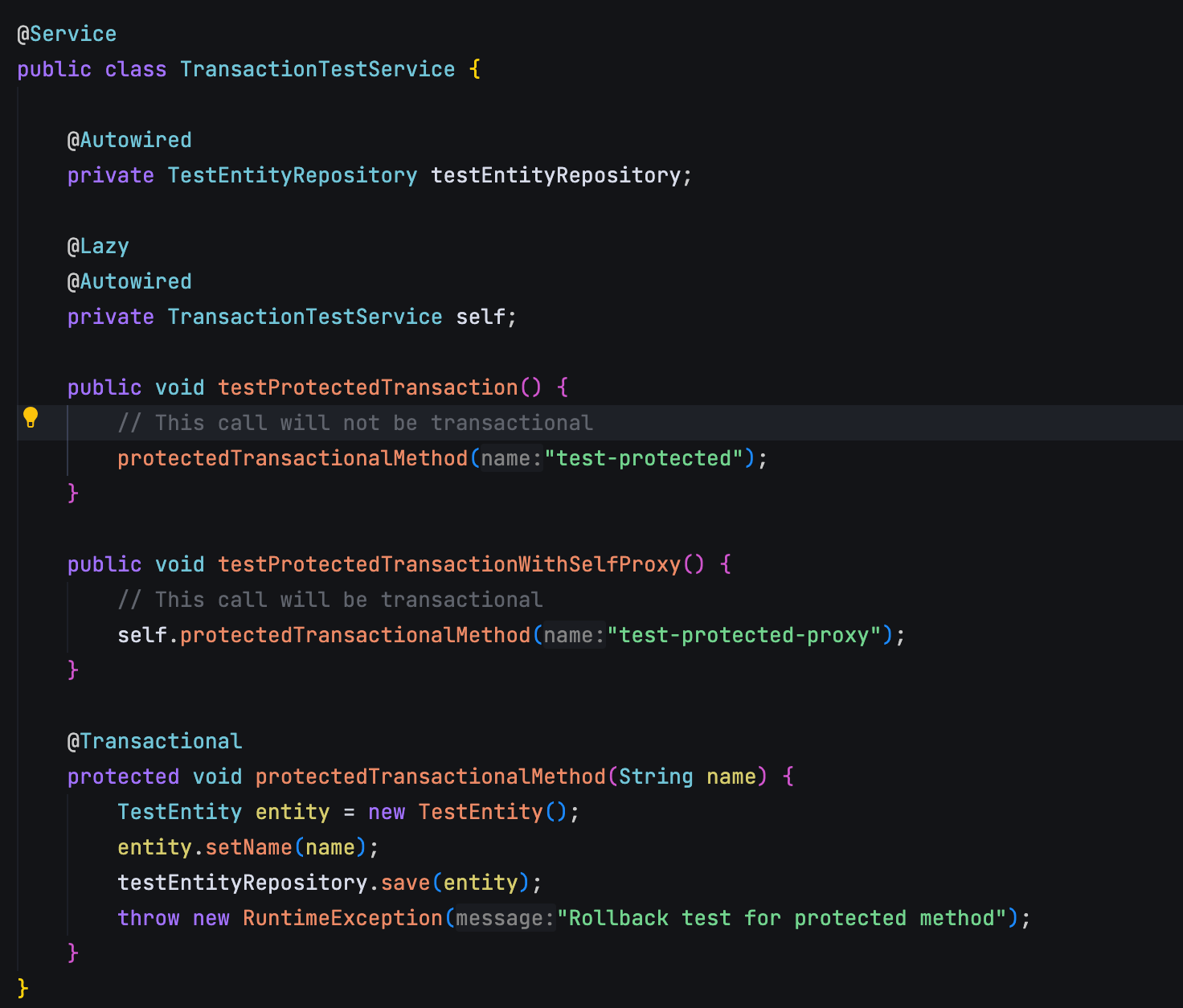
- 如果事务生效:当 RuntimeException 抛出时,Spring 的事务管理器会捕获它,并触发事务回滚。这意味着,之前插入数据库的那条记录会被撤销。最终,数据库里不会留下这条记录。
- 如果事务失效:即使 RuntimeException 被抛出,由于没有事务管理,已经执行的数据库插入操作不会被撤销。最终,数据库里会留下这条记录。
我们创建了一个 public 方法 testProtectedTransaction ,它通过 this.protectedTransactionalMethod() 的方式直接调用了那个 protected 方法。接着我们访问 /api/v1/test/transaction/protected 来触发这个调用。
结果:数据库中会留下一条名为 'test-protected' 的记录。这证明了由于是内部调用,绕过了 Spring AOP 代理,@Transactional 注解没有生效。
我们创建了另一个 public 方法 testProtectedTransactionWithSelfProxy。在这个方法里,我们通过一个“自注入”的代理对象 self 来调用 self.protectedTransactionalMethod()。接着我们通过访问 /api/v1/test/transaction/protected/proxy 来触发这个调用。
结果:数据库中不会留下名为 'test-protected-proxy' 的记录。这证明通过代理对象的调用,Spring AOP 成功拦截并开启了事务,最终在异常发生时正确地回滚了事务。
----这部分可以不背,方便大家理解 end----
- Java 面试指南(付费)收录的京东同学 10 后端实习一面的原题:事务的传播机制
- Java 面试指南(付费)收录的小米春招同学 K 一面面试原题:事务传播,protected 和 private 加事务会生效吗,还有那些不生效的情况
- Java 面试指南(付费)收录的华为面经同学 8 技术二面面试原题:Spring 中的事务的隔离级别,事务的传播行为?
- Java 面试指南(付费)收录的oppo 面经同学 8 后端开发秋招一面面试原题:讲一下Spring事务传播机制
- Java 面试指南(付费)收录的阿里云面经同学 22 面经:介绍事务传播模型
memo:2025 年 7 月 14 日修改至此,今天在帮球友修改简历时,一个浙江大学硕士的球友不仅拿到了腾讯 WXG 的实习 offer,秋招也开始同步进行了,我只能说优秀的球友真的赶早不赶晚啊!
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
MVC
30.Spring MVC 的核心组件有哪些?
Spring MVC 作为 Spring 框架中处理 Web 请求的核心模块,它的设计遵循了经典的 MVC 模式,根据我的理解,它的核心组件主要包括:
前端控制器 DispatcherServlet,这是 Spring MVC 的入口和核心调度器。当一个 HTTP 请求到达服务器时,首先由 DispatcherServlet 接收。它负责将请求分发到合适的处理器,也就是 Controller 中的方法,并协调其他组件的工作。
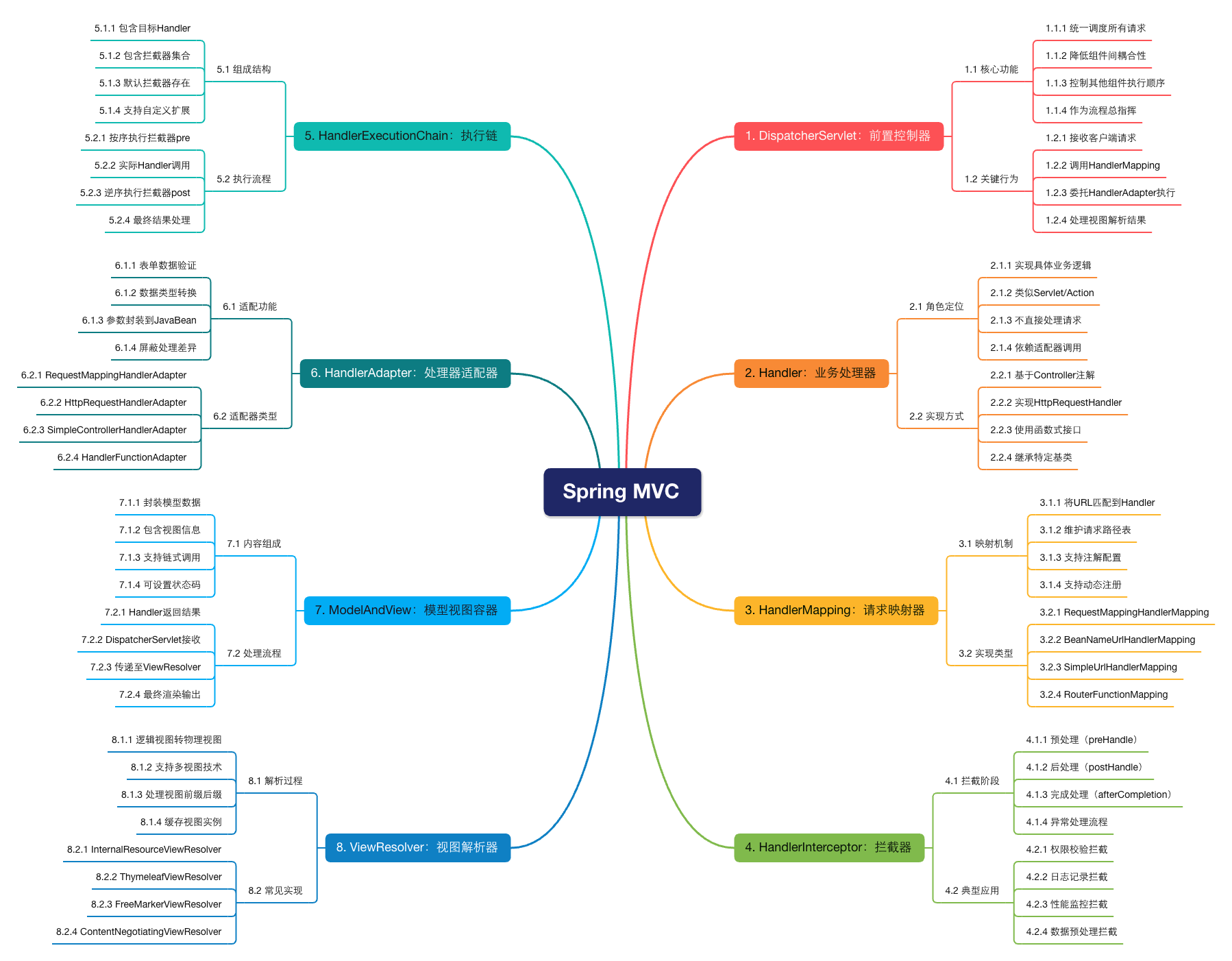
在 Spring Boot 项目中,DispatcherServlet 的启动是通过自动配置完成的。Spring Boot 会自动注册一个默认的 DispatcherServlet,并将其映射到 /。
@Bean
public ServletRegistrationBean<DispatcherServlet> dispatcherServletRegistration(DispatcherServlet dispatcherServlet) {
ServletRegistrationBean<DispatcherServlet> registration = new ServletRegistrationBean<>(dispatcherServlet, "/"); // 默认映射路径为 "/"
registration.setName("dispatcherServlet");
return registration;
}处理器映射 HandlerMapping,当一个请求进来时,前端控制器会询问处理器映射:“这个 URL 应该由哪个 Controller 的哪个方法来处理?”然后它就会根据 @RequestMapping、@GetMapping 这些注解来匹配请求。
处理器 Handler,实际上就是我们写的 Controller 方法,这是真正处理业务逻辑的地方。
处理器适配器 HandlerAdapter,负责调用该处理器的方法,并处理参数绑定、类型转换等。因为处理器可能有不同的类型,比如注解方式、实现接口方式等,处理器适配器就是为了统一调用方式。
视图解析器 ViewResolver,处理完业务逻辑后,如果需要渲染视图,ViewResolver 会根据返回的视图名称解析实际的视图对象,比如 Thymeleaf。在前后端分离的项目中,这个组件更多用于返回 JSON 数据。
异常处理器 HandlerExceptionResolver,捕获并处理请求处理过程中抛出的异常。通常,我们可以通过 @ControllerAdvice 和 @ExceptionHandler 来自定义异常处理逻辑,确保返回友好的错误响应。
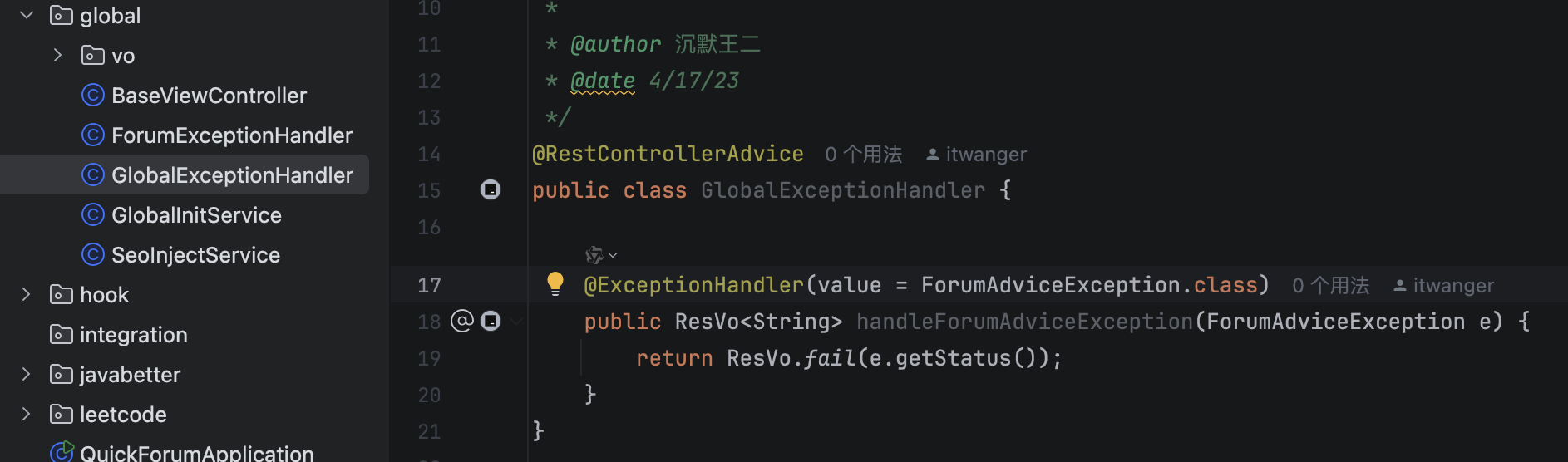
除此之外,还有文件上传解析器 MultipartResolver,用于处理文件上传请求;拦截器 HandlerInterceptor,用于在请求处理前后执行一些额外的逻辑,比如权限校验、日志记录等。
memo:2025 年 7 月 17 日修改至此,昨天有球友说手写了一个 Redis 的轮子项目,用的 Go 语言,我今天去看了一下 doc 和代码,写得非常好,代码注释很清晰,doc 写得很详细,能看得出球友的用心。手写轮子是非常考验一个人的能力的,我看他实现的功能有:字符串和散列的数据类型、RESP 协议解析器、使用goroutine 来同时处理多个连接、持久化 AOF 协议等,非常强。
31.🌟Spring MVC 的工作流程了解吗?
简单来说,Spring MVC 是一个基于 Servlet 的请求处理框架,核心流程可以概括为:请求接收 → 路由分发 → 控制器处理 → 视图解析。
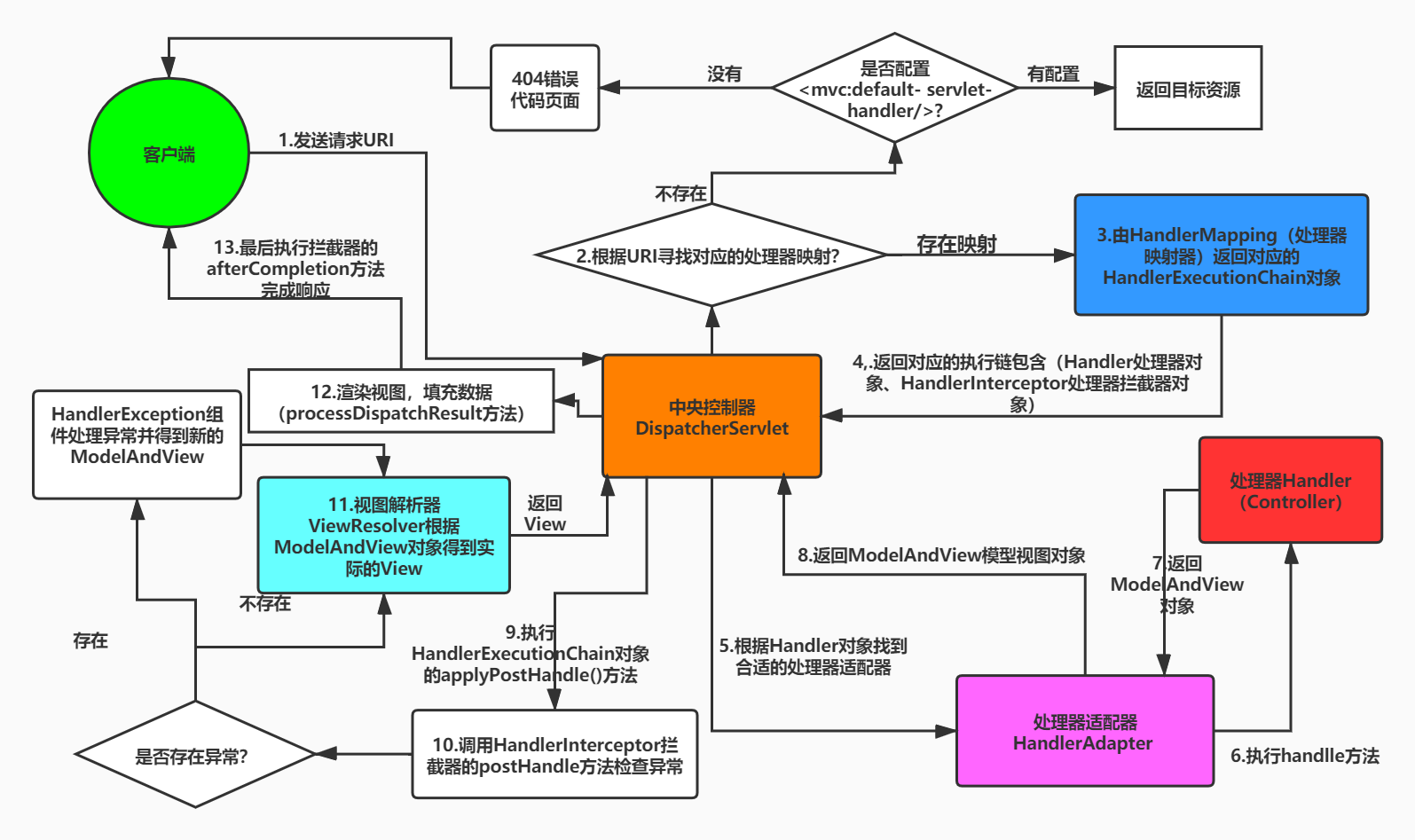
用户发起的 HTTP 请求,首先会被 DispatcherServlet 捕获,这是 Spring MVC 的“前端控制器”,负责拦截所有请求,起到统一入口的作用。
DispatcherServlet 接收到请求后,会根据 URL、请求方法等信息,交给 HandlerMapping 进行路由匹配,查找对应的处理器,也就是 Controller 中的具体方法。
找到对应 Controller 方法后,DispatcherServlet 会委托给处理器适配器 HandlerAdapter 进行调用。处理器适配器负责执行方法本身,并处理参数绑定、数据类型转换等。在注解驱动开发中,常用的是 RequestMappingHandlerAdapter。这一层会把请求参数自动注入到方法形参中,并调用 Controller 执行实际的业务逻辑。
Controller 方法最终会返回结果,比如视图名称、ModelAndView 或直接返回 JSON 数据。
当 Controller 方法返回视图名时,DispatcherServlet 会调用 ViewResolver 将其解析为实际的 View 对象,比如 Thymeleaf 页面。在前后端分离的接口项目中,这一步则通常是返回 JSON 数据。
最后,由 View 对象完成渲染,或者将 JSON 结果直接通过 DispatcherServlet 返回给客户端。
为什么还需要 HandlerAdapter?
Spring MVC 支持多种风格的处理器,比如基于 @Controller 注解的处理器、实现了 Controller 接口的处理器等。如果没有处理器适配器,DispatcherServlet 就需要硬编码每种处理器的调用方式,框架就会变得非常僵硬——新增一种 Controller 类型,就必须改 DispatcherServlet 的代码。
因此,Spring 引入了 HandlerAdapter 作为适配器,屏蔽不同控制器的差异,给 DispatcherServlet 提供一个统一的调用入口。
比如说,如果是实现了 Controller 接口的处理器,DispatcherServlet 会使用 SimpleControllerHandlerAdapter 来适配它。
public class SimpleControllerHandlerAdapter implements HandlerAdapter {
@Override
public boolean supports(Object handler) {
return (handler instanceof Controller);
}
@Override
@Nullable
public ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
return ((Controller) handler).handleRequest(request, response);
}
// ... 省略一个无关方法 ...
}如果是使用 @RequestMapping 注解的处理器,DispatcherServlet 则会使用 RequestMappingHandlerAdapter 来适配。
public class RequestMappingHandlerAdapter implements HandlerAdapter {
@Override
public boolean supports(Object handler) {
return (handler instanceof HandlerMethod);
}
@Override
@Nullable
public ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
HandlerMethod handlerMethod = (HandlerMethod) handler;
// 执行方法并返回 ModelAndView
return invokeHandlerMethod(handlerMethod, request, response);
}
}
- Java 面试指南(付费)收录的腾讯 Java 后端实习一面原题:说说前端发起请求到 SpringMVC 的整个处理流程。
- Java 面试指南(付费)收录的国企面试原题:说说 SpringMVC 的流程吧
- Java 面试指南(付费)收录的小公司面经同学 5 Java 后端面试原题:springMVC 工作流程 我大概就是按面渣逆袭里答的,答到一半打断我:然后会有个 Handler,这个 Handler 是什么东西啊。前面 Handler 不是已经知道 controller 了吗,我直接执行不就行了,为什么还要 Adapter 呢。
- Java 面试指南(付费)收录的京东面经同学 8 面试原题:SpringMVC框架
- Java 面试指南(付费)收录的字节跳动同学 17 后端技术面试原题:springmvc执行流程
memo:2025 年 7 月 18 日修改至此,今天在帮球友修改简历时,碰到一个荣誉奖项基本拉满的球友,国家励志奖学金、省级比赛、校级三好学生等,那这里也是温馨提醒一下大家,学校的荣誉奖项如果你有能力争取,有时间争取,还是尽量争取一下的,尤其是求职央国企的时候,会非常有用。

32.SpringMVC Restful 风格的接口流程是什么样的呢?
在传统的 MVC 中,Controller 方法通常返回一个视图名称或者 ModelAndView 对象,然后由视图解析器 ViewResolver 解析并渲染成 HTML 页面。但在 RESTful 架构中,通常返回的是 JSON 或 XML,不再是一个完整的页面。
其中很重要的两个注解:@RestController 相当于 @Controller 和 @ResponseBody 的结合。当在一个类上使用 @RestController 时,它会告诉 Spring 这个类中所有方法的返回值都应该被直接写入 HTTP 响应体中,而不再被解析为视图。
@ResponseBody 可以用在方法级别,作用相同。它标志着该方法的返回值将作为响应体内容,Spring 会跳过视图解析的步骤。
HttpMessageConverter 是实现 RESTful 风格的关键。当 Spring 检测到 @ResponseBody 注解时,它会使用 HttpMessageConverter 来将 Controller 方法返回的 Java 对象序列化成指定的格式,如 JSON。
默认情况下,如果类路径下有 Jackson 库,Spring Boot 会自动配置 MappingJackson2HttpMessageConverter 来处理 JSON 的转换。相应的,对于带有 @RequestBody 注解的方法参数,它也会用这个转换器将请求体中的 JSON 数据反序列化成 Java 对象。
所以,RESTful 接口的流程可以概括为:请求到达前端控制器 DispatcherServlet → 通过 HandlerMapping 找到对应的 Controller 方法 → 执行方法并返回数据 → 使用 HttpMessageConverter 将数据转换为 JSON 或 XML 格式 → 直接写入 HTTP 响应体。
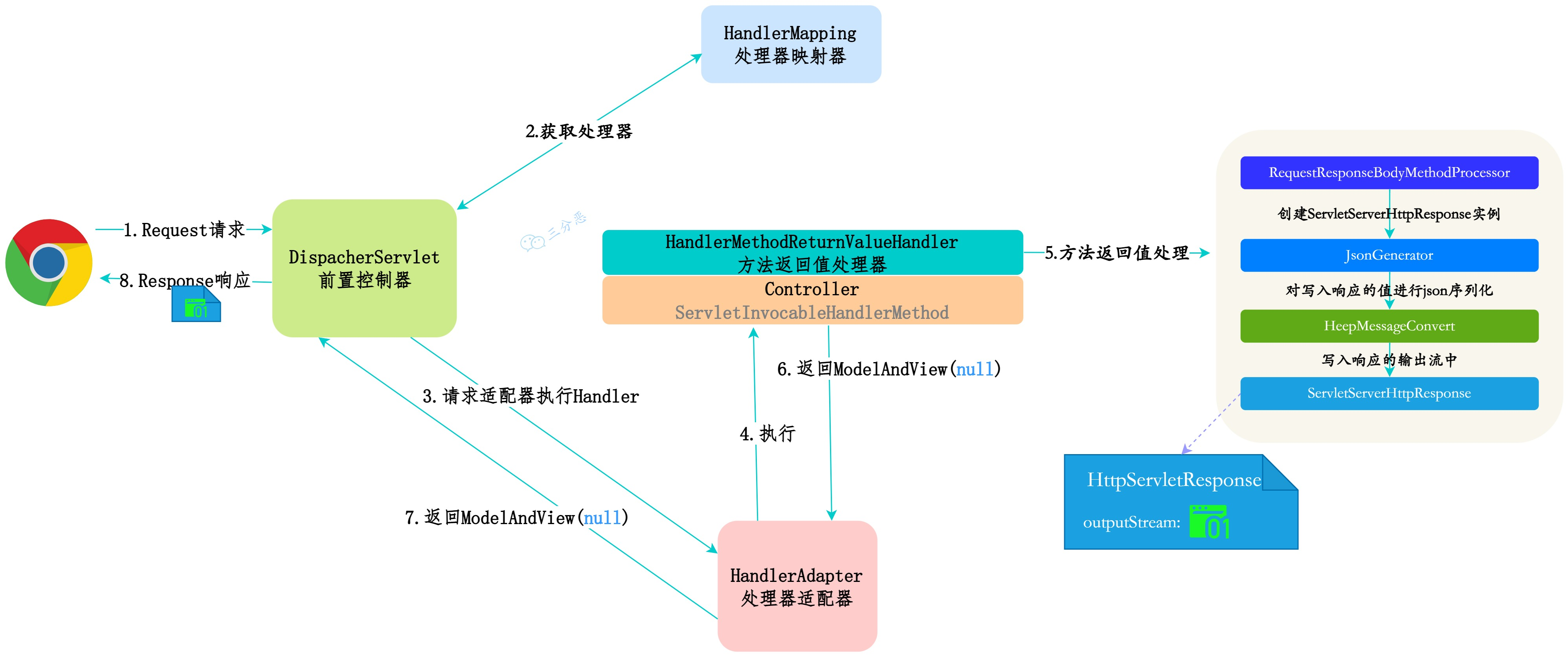
总结来说,RESTful 接口的流程通过 @RestController 和 HttpMessageConverter “抄了近道”,省略了 ViewResolver 和 View 的渲染过程,直接将数据转换为指定的格式返回,非常适合前后端分离的应用场景。
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 7 月 19 日修改至此,今天有球友私信我说,拿到了京东的实习 offer,问接下来的秋招该怎么准备?那 7 月份实习 Offer 确实会比较少,但仍然有一部分,如果这个阶段还想要冲实习的话,确实可以捡漏。

Spring Boot
33.🌟介绍一下 SpringBoot?
Spring Boot 可以说是 Spring 生态的一个重大突破,它极大地简化了 Spring 应用的开发和部署过程。

以前我们用 Spring 开发项目的时候,需要配置一大堆 XML 文件,包括 Bean 的定义、数据源配置、事务配置等等,非常繁琐。而且还要手动管理各种 jar 包的依赖关系,很容易出现版本冲突的问题。部署的时候还要单独搭建 Tomcat 服务器,整个过程很复杂。Spring Boot 就是为了解决这些痛点而生的。
“约定大于配置”是 Spring Boot 最核心的理念。它预设了很多默认配置,比如默认使用内嵌的 Tomcat 服务器,默认的日志框架是 Logback 等等。这样,我们开发者就只需要关注业务逻辑,不用再纠结于各种配置细节。
自动装配也是 Spring Boot 的一大特色,它会根据项目中引入的依赖自动配置合适的 Bean。比如说,我们引入了 Spring Data JPA,Spring Boot 就会自动配置数据源;比如说,我们引入了 Spring Security,Spring Boot 就会自动配置安全相关的 Bean。
Spring Boot 还提供了很多开箱即用的功能,比如 Actuator 监控、DevTools 开发工具、Spring Boot Starter 等等。Actuator 可以让我们轻松监控应用的健康状态、性能指标等;DevTools 可以加快开发效率,比如自动重启、热部署等;Spring Boot Starter 则是一些预配置好的依赖集合,让我们可以快速引入某些常用的功能。
Spring Boot常用注解有哪些?
Spring Boot 的注解很多,我就挑两个说一下吧。
@SpringBootApplication:这是 Spring Boot 的核心注解,它是一个组合注解,包含了@Configuration、@EnableAutoConfiguration和@ComponentScan。它标志着一个 Spring Boot 应用的入口。@SpringBootTest:用于测试 Spring Boot 应用的注解,它会加载整个 Spring 上下文,适合集成测试。
- Java 面试指南(付费)收录的华为 OD 面经中出现过该题:讲讲 Spring Boot 的特性。
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:SpringBoot基本原理
- Java 面试指南(付费)收录的国企零碎面经同学 9 面试原题:Springboot基于Spring的配置有哪几种
- Java 面试指南(付费)收录的阿里云面经同学 22 面经:springboot常用注解
memo:2025 年 7 月 20 日修改至此,今天又有球友发私信说,后悔没有早一点加入星球,加入星球后,才发现大家早早就为自己的未来去拼搏了。很真实,好吧,这就是星球的价值所在,100 多块钱的门票就能提供学校几万学费给你不了的东西。

34.🌟Spring Boot的自动装配原理了解吗?
在 Spring Boot 中,开启自动装配的注解是@EnableAutoConfiguration。这个注解会告诉 Spring 去扫描所有可用的自动配置类。
Spring Boot 为了进一步简化,把这个注解包含到了 @SpringBootApplication 注解中。也就是说,当我们在主类上使用 @SpringBootApplication 注解时,实际上就已经开启了自动装配。
当 main 方法运行的时候,Spring 会去类路径下找 spring.factories 这个文件,读取里面配置的自动配置类列表。比如在我们的技术派项目中,paicoding-core 和 paicoding-service 模块里都有 spring.factories,分别注册了 ForumCoreAutoConfig 和 ServiceAutoConfig,这两个配置类就会在项目启动的时候被自动加载。
然后每个自动配置类内部,通常会有一个 @Configuration 注解,同时结合各种 @Conditional 注解来做条件控制。像技术派的 RabbitMqAutoConfig 类,就用了 @ConditionalOnProperty 注解来判断配置文件里有没有开启 rabbitmq.switchFlag,来决定是否初始化 RabbitMQ 消费线程。
另外一个常见的场景是自动注入 Bean,比如技术派的 ServiceAutoConfig 中就用了 @ComponentScan 来扫描 service 包,@MapperScan 扫描 MyBatis 的 mapper 接口,实现业务层和 DAO 层的自动装配。
具体的执行过程可以总结为:Spring Boot 项目在启动时加载所有的自动配置类,然后逐个检查它们的生效条件,当条件满足时就实例化并创建相应的 Bean。
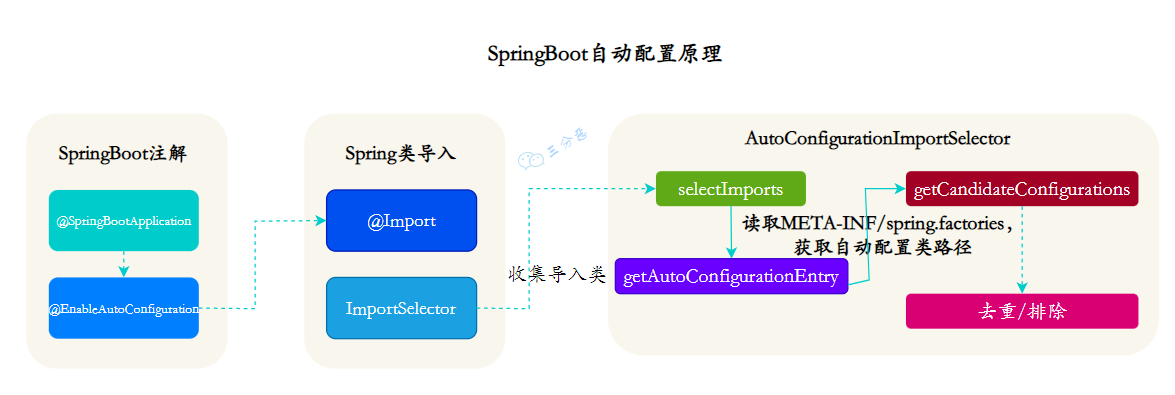
自动装配的执行时机是在 Spring 容器启动的时候。具体来说是在 ConfigurationClassPostProcessor 这个 BeanPostProcessor 中处理的,它会解析 @Configuration 类,包括通过 @Import 导入的自动配置类。
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {
// 检查自动配置是否启用。如果@ConditionalOnClass等条件注解使得自动配置不适用于当前环境,则返回一个空的配置条目。
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
// 获取启动类上的@EnableAutoConfiguration注解的属性,这可能包括对特定自动配置类的排除。
AnnotationAttributes attributes = getAttributes(annotationMetadata);
// 从spring.factories中获取所有候选的自动配置类。这是通过加载META-INF/spring.factories文件中对应的条目来实现的。
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
// 移除配置列表中的重复项,确保每个自动配置类只被考虑一次。
configurations = removeDuplicates(configurations);
// 根据注解属性解析出需要排除的自动配置类。
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
// 检查排除的类是否存在于候选配置中,如果存在,则抛出异常。
checkExcludedClasses(configurations, exclusions);
// 从候选配置中移除排除的类。
configurations.removeAll(exclusions);
// 应用过滤器进一步筛选自动配置类。过滤器可能基于条件注解如@ConditionalOnBean等来排除特定的配置类。
configurations = getConfigurationClassFilter().filter(configurations);
// 触发自动配置导入事件,允许监听器对自动配置过程进行干预。
fireAutoConfigurationImportEvents(configurations, exclusions);
// 创建并返回一个包含最终确定的自动配置类和排除的配置类的AutoConfigurationEntry对象。
return new AutoConfigurationEntry(configurations, exclusions);
}
- Java 面试指南(付费)收录的滴滴同学 2 技术二面的原题:SpringBoot 启动时为什么能够自动装配
- Java 面试指南(付费)收录的腾讯面经同学 22 暑期实习一面面试原题:Spring Boot 如何做到启动的时候注入一些 bean
- Java 面试指南(付费)收录的比亚迪面经同学 3 Java 技术一面面试原题:说一下 Spring Boot 的自动装配原理
- Java 面试指南(付费)收录的农业银行同学 1 面试原题:spring boot 的自动装配
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:SpringBoot如何实现自动装配
- Java 面试指南(付费)收录的 OPPO 面经同学 1 面试原题:自动配置怎么实现的?
memo:2025 年 7 月 21 日修改至此,今天有球友发私信说,拿到了亚信科技+新石器无人车的 offer,问我该如何选择,如果是你,你会如何选择呢?
35.🌟如何自定义一个 SpringBoot Starter?
第一步,SpringBoot 官方建议第三方 starter 的命名格式是 xxx-spring-boot-starter,所以我们可以创建一个名为 my-spring-boot-starter 的项目,一共包括两个模块,一个是 autoconfigure 模块,包含自动配置逻辑;一个是 starter 模块,只包含依赖声明。
<properties>
<spring.boot.version>2.3.1.RELEASE</spring.boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
<version>${spring.boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>${spring.boot.version}</version>
</dependency>
</dependencies>第二步,创建一个自动配置类,通常在 autoconfigure 包下,该类的作用是根据配置文件中的属性来创建和配置 Bean。
@Configuration
@EnableConfigurationProperties(MyStarterProperties.class)
public class MyServiceAutoConfiguration {
@Bean
@ConditionalOnMissingBean
public MyService myService(MyStarterProperties properties) {
return new MyService(properties.getMessage());
}
}第三步,创建一个配置属性类,用于读取配置文件中的属性。通常使用 @ConfigurationProperties 注解来标记这个类。
@ConfigurationProperties(prefix = "mystarter")
public class MyStarterProperties {
private String message = "二哥的 Java 进阶之路不错啊!";
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
}第四步,创建一个简单的服务类,用于提供业务逻辑。
public class MyService {
private final String message;
public MyService(String message) {
this.message = message;
}
public String getMessage() {
return message;
}
}第五步,在 src/main/resources/META-INF 目录下创建一个名为 spring.factories 文件,告诉 SpringBoot 在启动时要加载我们的自动配置类。
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.itwanger.mystarter.autoconfigure.MyServiceAutoConfiguration第六步,使用 Maven 打包这个项目。
mvn clean install第七步,在其他的 Spring Boot 项目中,通过 Maven 来添加这个自定义的 Starter 依赖,并通过 application.properties 配置信息:
mystarter.message=javabetter.cn然后就可以在 Spring Boot 项目中注入 MyStarterProperties 来使用它。
启动项目,然后在浏览器中输入 localhost:8081/hello,就可以看到返回的内容是 javabetter.cn,说明我们的自定义 Starter 已经成功工作了。
Spring Boot Starter 的原理了解吗?
Starter 的核心思想是把相关的依赖打包在一起,让开发者只需要引入一个 starter 依赖,就能获得完整的功能模块。
当我们在 pom.xml 中引入一个 starter 时,Maven 就会自动解析这个 starter 的依赖树,把所有需要的 jar 包都下载下来。
每个 starter 都会包含对应的自动配置类,这些配置类通过条件注解来判断是否应该生效。比如当我们引入了 spring-boot-starter-web,它会自动配置 Spring MVC、内嵌的 Tomcat 服务器等。
spring.factories 文件是 Spring Boot 自动装配的核心,它位于每个 starter 的 META-INF 目录下。这个文件列出了所有的自动配置类,Spring Boot 在启动时会读取这个文件,加载对应的配置类。
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.example.demo.autoconfigure.DemoAutoConfiguration,\
com.example.demo.autoconfigure.AnotherAutoConfiguration
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:你封装过 springboot starter 吗?
- Java 面试指南(付费)收录的腾讯云智面经同学 20 二面面试原题:Spring Boot Starter 的原理了解吗?
- Java 面试指南(付费)收录的快手同学 4 一面原题:为什么使用SpringBoot?SpringBoot自动装配的原理及流程?@Import的作用?如果想让SpringBoot对自定义的jar包进行自动配置的话,需要怎么做?
memo:2025 年 7 月 22 日修改至此,今天有球友在 VIP 群里聊天,发现两个人都在小红书,有缘分的很,那能去小红书实习,基本上秋招就算是稳如老狗了😄,这家独角兽的实习含金量还是非常高的。
36.🌟Spring Boot 启动原理了解吗?
Spring Boot 的启动主要围绕两个核心展开,一个是 @SpringBootApplication 注解,一个是 SpringApplication.run() 方法。
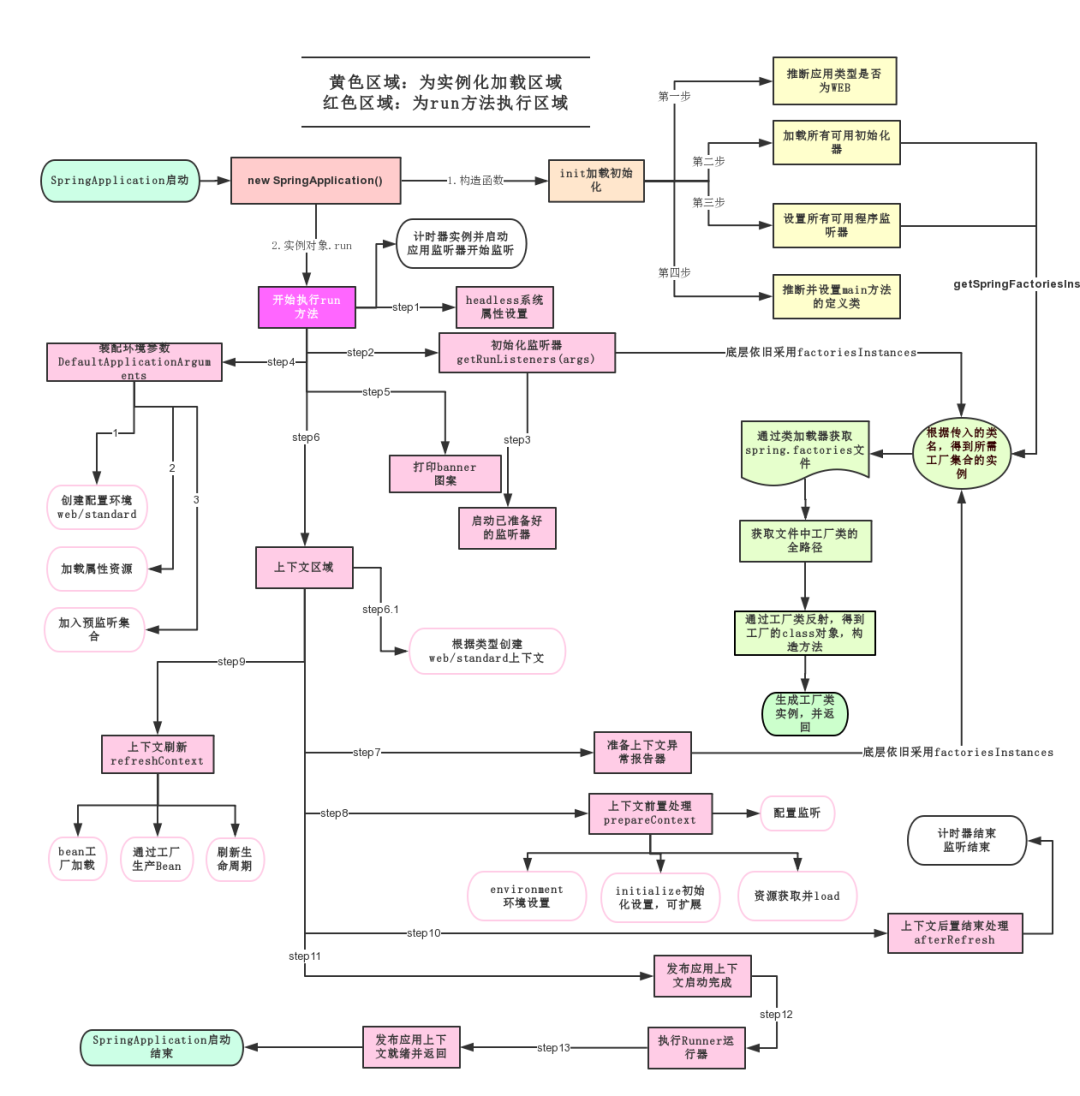
我先说一下 @SpringBootApplication 注解,它是一个组合注解,包含了 @SpringBootConfiguration、@EnableAutoConfiguration 和 @ComponentScan,这三个注解的作用分别是:
@SpringBootConfiguration:标记这个类是一个 Spring Boot 配置类,相当于一个 Spring 配置文件。@EnableAutoConfiguration:告诉 Spring Boot 可以进行自动配置。比如说,项目引入了 Spring MVC 的依赖,那么 Spring Boot 就会自动配置 DispatcherServlet、HandlerMapping 等组件。@ComponentScan:扫描当前包及其子包下的组件,注册为 Bean。
好,接下来我再说一下 SpringApplication.run() 方法,它是 Spring Boot 项目的启动入口,内部流程大致可以分为 5 个步骤:
①、创建 SpringApplication 实例,并识别应用类型,比如说是标准的 Servlet Web 还是响应式的 WebFlux,然后准备监听器和初始化监听容器。
②、创建并准备 ApplicationContext,将主类作为配置源进行加载。
③、刷新 Spring 上下文,触发 Bean 的实例化,比如说扫描并注册 @ComponentScan 指定路径下的 Bean。
④、触发自动配置,在 Spring Boot 2.7 及之前是通过 spring.factories 加载的,3.x 是通过读取 AutoConfiguration.imports,并结合 @ConditionalOn 系列注解依据条件注册 Bean。
⑤、如果引入了 Web 相关依赖,会创建并启动 Tomcat 容器,完成 HTTP 端口监听。
关键的代码逻辑如下:
public ConfigurableApplicationContext run(String... args) {
// 1. 创建启动时的监听器并触发启动事件
SpringApplicationRunListeners listeners = getRunListeners(args);
listeners.starting();
// 2. 准备运行环境
ConfigurableEnvironment environment = prepareEnvironment(listeners);
configureIgnoreBeanInfo(environment);
// 3. 创建上下文
ConfigurableApplicationContext context = createApplicationContext();
try {
// 4. 准备上下文
prepareContext(context, environment, listeners, args);
// 5. 刷新上下文,完成 Bean 初始化和装配
refreshContext(context);
// 6. 调用运行器
afterRefresh(context, args);
// 7. 触发启动完成事件
listeners.started(context);
} catch (Exception ex) {
handleRunFailure(context, ex, listeners);
}
return context;
}要在启动阶段自定义逻辑该怎么做?
可以通过实现 ApplicationRunner 接口来完成启动后的自定义逻辑。
比如说在技术派项目中,我们就在 run 方法中追加了:JSON 类型转换配置和动态设置应用访问地址等。
为什么 Spring Boot 在启动的时候能够找到 main 方法上的@SpringBootApplication 注解?
其实 Spring Boot 并不是自己找到 @SpringBootApplication 注解的,而是我们通过程序告诉它的。
@SpringBootApplication
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}我们把 Application.class 作为参数传给了 run 方法。这个 Application 类标注了 @SpringBootApplication 注解,用来告诉 Spring Boot:请用这个类作为配置类来启动。
然后,SpringApplication 在运行时就会把这个类注册到 Spring 容器中。
Spring Boot 默认的包扫描路径是什么?
Spring Boot 默认的包扫描路径是主类所在的包及其子包。
比如说在技术派实战项目中,启动类QuickForumApplication所在的包是com.github.paicoding.forum.web,那么 Spring Boot 默认会扫描com.github.paicoding.forum.web包及其子包下的所有组件。
- Java 面试指南(付费)收录的滴滴同学 2 技术二面的原题:为什么 Spring Boot 启动时能找到 Main 类上面的注解
- Java 面试指南(付费)收录的腾讯面经同学 22 暑期实习一面面试原题:Spring Boot 默认的包扫描路径?
- Java 面试指南(付费)收录的微众银行同学 1 Java 后端一面的原题:@SpringBootApplication 注解了解吗?
- Java 面试指南(付费)收录的国企零碎面经同学 9 面试原题:Springboot的工作原理?
- Java 面试指南(付费)收录的京东面经同学 5 Java 后端技术一面面试原题:SpringBoot启动流程(忘了)
- Java 面试指南(付费)收录的哔哩哔哩同学 1 二面面试原题:springBoot启动机制,启动之后做了哪些步骤
memo:2025 年 8 月 10 日修改至此,今天在修改球友简历的时候,很感动,因为有球友说,他给周围很多人安利了二哥的编程星球,并且反向很不错。真的很感谢,球友们的口碑,没有大家,真走不到现在。
37.说一下 SpringBoot 和 SpringMVC 的区别?(补充)
2024 年 04 月 04 日增补
SpringMVC 是 Spring 的一个模块,专门用来做 Web 开发,处理 HTTP 请求和响应。而Spring Boot 的目标是简化 Spring 应用的开发过程,可以通过 starter 的方式快速集成 SpringMVC。
传统的 Web 项目通常需要手动配置很多东西,比如 DispatcherServlet、ViewResolver、HandlerMapping 等等。而 Spring Boot 则通过自动装配的方式,帮我们省去了这些繁琐的配置。
Spring Boot 还内置了一个嵌入式的 Servlet 容器,比如 Tomcat,这样我们就不需要像传统的 Web 项目那样需要配置 Tomcat 容器,然后导出 war 包再运行。只需要打包成一个 JAR 文件,就可以直接通过 java -jar 命令运行。
- Java 面试指南(付费)收录的滴滴同学 2 技术二面的原题:SpringBoot 和 SpringMVC 的区别
- Java 面试指南(付费)收录的京东面经同学 5 Java 后端技术一面面试原题:SpringBoot与SpringMVC区别
38.Spring Boot 和 Spring 有什么区别?(补充)
2024 年 07 月 09 日新增
从定位上来说,Spring 是一个完整的应用开发框架,提供了 IoC 容器、AOP 等各种功能模块。Spring Boot 不是一个独立的框架,而是基于 Spring 框架的脚手架,它的目标是让 Spring 应用的开发和部署变得简单高效。
Spring 项目需要我们手动管理每个 jar 包的版本,经常会遇到版本冲突的问题。比如我们要用 Spring MVC,需要引入 spring-webmvc、jackson-databind、hibernate-validator 等一堆依赖,还要确保版本兼容。Spring Boot 通过 starter 机制解决了这个问题,只需要引入 spring-boot-starter-web 这一个依赖就可以了,它包含了所有相关的 jar 包,而且版本都是测试过的,可以兼容的。
- Java 面试指南(付费)收录的小米同学 F 面试原题:Spring Boot 和 Spring 的区别
- Java 面试指南(付费)收录的 OPPO 面经同学 1 面试原题:说一下Spring和Springboot之间有什么差异?
memo:2025 年 8 月 11 日修改至此,今天有球友在 VIP 群里交流说,用二哥的项目,轻松过大厂的简历初筛,包括小米和美团。
Spring Cloud
39.对 SpringCloud 了解多少?
Spring Cloud 其实是一套基于 Spring Boot 的微服务全家桶,帮我们把分布式系统里的基础设施做了一个“拿来即用”的封装,比如服务注册与发现、配置管理、负载均衡、熔断限流、链路追踪这些。
我自己用得比较多的是 Spring Cloud Alibaba 这一套,PmHub 这个项目就是一个例子,比如:
- 我们使用 Nacos 做服务注册和配置中心,并且将配置信息持久化到了 MySQL 中,这样就可以统一管理注册信息和配置信息,还支持动态刷新配置。
- 使用 Gateway 做 API 网关,支持路由转发、全局过滤器、限流等功能。
- 使用 Sentinel 做熔断、限流、降级策略,结合业务自定义规则比较方便。
- 使用 OpenFeign 做服务间的声明式调用,比 RestTemplate 更省代码,也更清晰可维护。
- 使用 Seata 处理分布式事务,这个在订单、支付、审批流场景中用得比较多。
我觉得 Spring Cloud 最大的价值是统一了技术栈和编程模型,不需要我们去自己从零实现注册中心、熔断器这些基础设施。
什么是微服务?
微服务就是把一个大的、复杂的单体应用,拆成一个个围绕业务功能独立部署的小服务,每个服务维护自己的数据和逻辑,服务之间通过轻量级的通信机制(比如 gRPC)来协作。
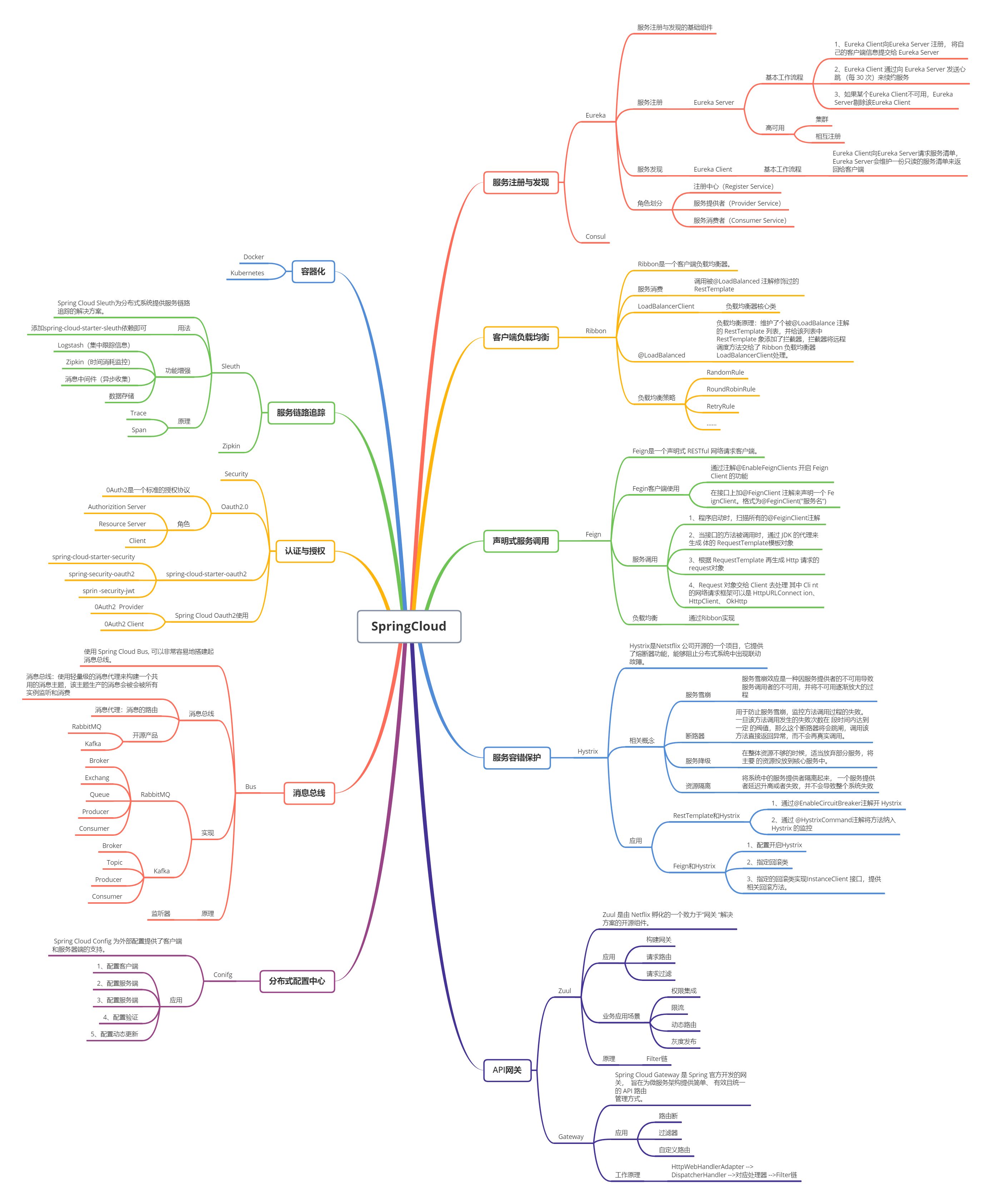
微服务的核心价值我认为是:业务之间的边界更清晰了,不同团队可以独立开发、部署、扩展某个功能,不会因为一个小的改动就要把整套系统重新上线。
像 PmHub 这个项目 就是从单体拆分成微服务的,包括启动网关、认证、流程、项目管理、代码生成等多个服务。
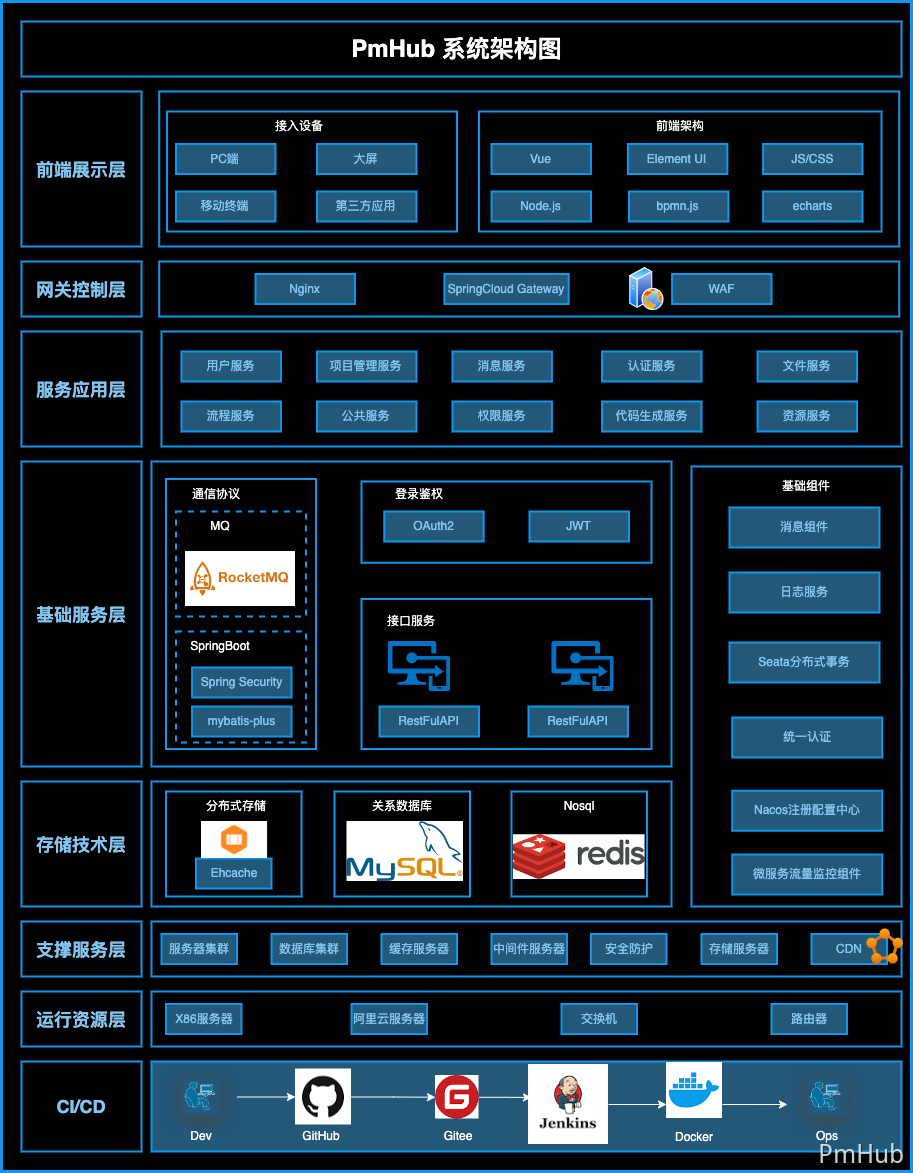
- Java 面试指南(付费)收录的比亚迪同学 1 面试原题:SpringCloud 了解多少?
memo:2025 年 8 月 12 日修改至此,今天帮球友修改简历的时候,碰到一个球友说:感谢二哥对我简历的修改,没有二哥绝对进不了字节。看完后真的非常感动,觉得自己做的事情确实有意义。

补充
40.SpringTask 了解吗?
SpringTask 是 Spring 框架提供的一个轻量级的任务调度框架,它允许我们开发者通过简单的注解来配置和管理定时任务。
使用起来也非常方便,首先使用 @EnableScheduling 开启定时任务的支持。
然后在需要定时任务的方法上加上 @Scheduled 注解,支持 fixedRate、fixedDelay 和 cron 表达式。技术派实战项目中,就使用过 cron 表达式在每天凌晨定时刷新文章的 sitemap。
@Scheduled(cron = "0 15 5 * * ?")
public void autoRefreshCache() {
log.info("开始刷新sitemap.xml的url地址,避免出现数据不一致问题!");
refreshSitemap();
log.info("刷新完成!");
}用SpringTask资源占用太高,有什么其他的方式解决?(补充)
2024年05月27日新增
首先我们需要分析一下 SpringTask 资源占用高的原因。
默认情况下,SpringTask 会使用单线程执行所有定时任务,如果某个任务执行时间长或者任务数量多,就会造成阻塞。而且它是基于内存的,所有任务信息都保存在 JVM 中,应用重启后任务状态就丢失了。
那我们可以通过配置线程池来解决这个问题。
@Configuration
@EnableScheduling
public class ScheduleConfig implements SchedulingConfigurer {
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
taskRegistrar.setScheduler(Executors.newScheduledThreadPool(10));
}
}另外,就是可以将 SpringTask 迁移到其他的任务调度框架,比如 Quartz、XXL-JOB 等。
Quartz 功能更强大,支持集群、持久化、灵活的调度策略。还可以把任务信息持久化到数据库,支持集群部署,一个节点挂了其他节点可以接管任务。
使用 XXL-JOB 是分布式场景下更彻底的解决方案,有独立的调度中心,任务配置和执行可以分离;支持分片执行,大任务可以拆分成多个子任务并行处理。
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片参数
int shardIndex = com.xxl.job.core.context.XxlJobHelper.getShardIndex();
int shardTotal = com.xxl.job.core.context.XxlJobHelper.getShardTotal();
logger.info("分片广播任务开始执行,当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
// 业务逻辑处理,根据分片参数处理不同的数据
for (int i = shardIndex; i < 100; i += shardTotal) {
logger.info("第{}片, 处理数据: {}", shardIndex, i);
// 模拟处理数据的时间
TimeUnit.MILLISECONDS.sleep(100);
}
logger.info("分片广播任务执行完成");
}
- Java 面试指南(付费)收录的微众银行同学 1 Java 后端一面的原题:SpringTask 了解吗?
- Java 面试指南(付费)收录的阿里面经同学 1 闲鱼后端一面的原题:订单超时,用springtask资源占用太高,有什么其他的方式解决?
memo:2025 年 8 月 16 日修改至此,今天帮球友修改简历的时候,碰到一个球友说:暑期实习的时候使用了技术派,也找二哥修改了简历,最后拿到了哈啰的实习,非常感谢。那说实话每次碰到球友这样的反馈,都挺开心的。
41.Spring Cache 了解吗?
Spring Cache 是 Spring 框架提供的一套缓存抽象,它通过提供统一的接口来支持多种缓存实现,如 Redis、Caffeine 等。
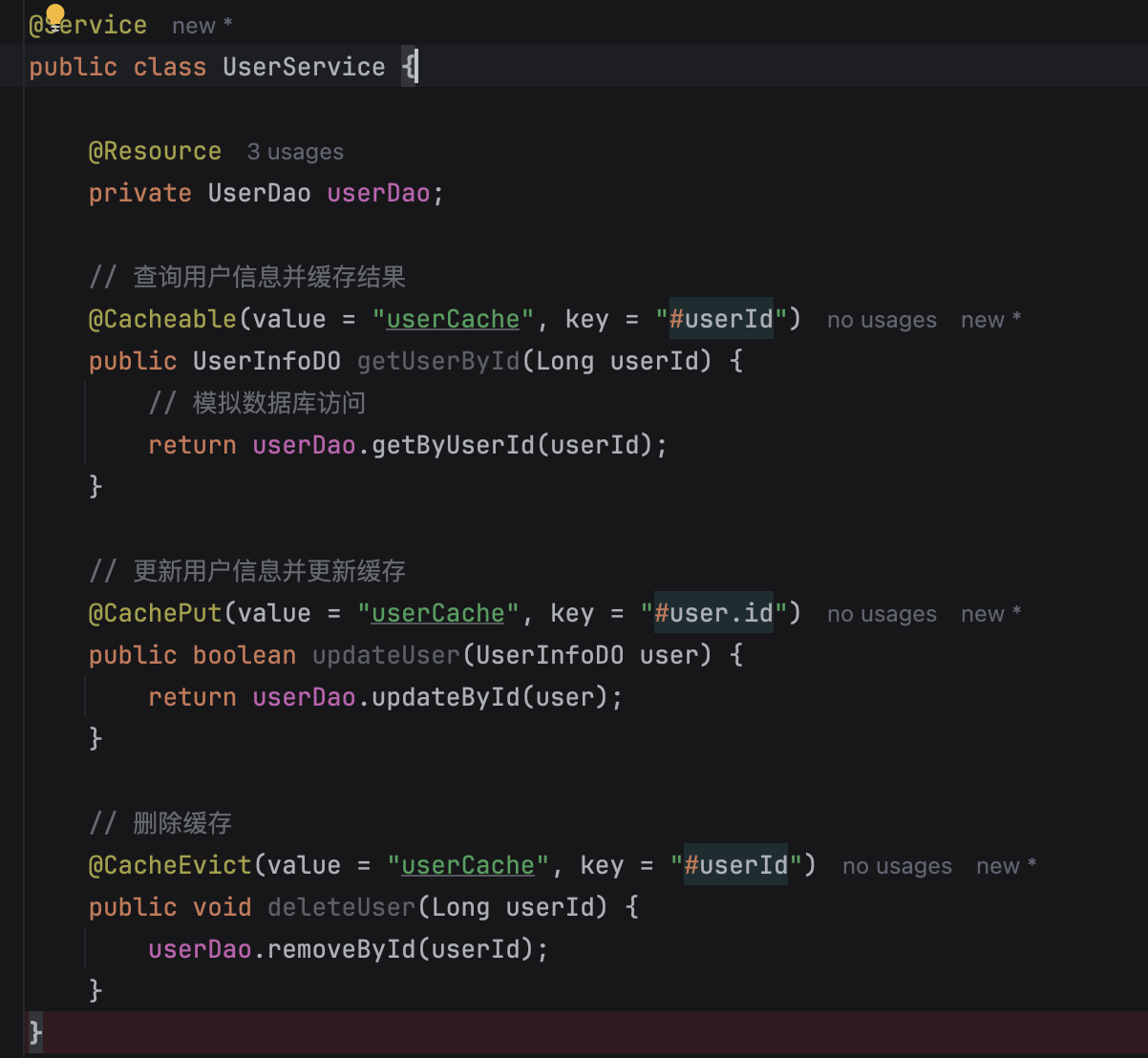
我们只需要在方法上加几个注解,Spring 就会自动处理缓存的存取,这种声明式的缓存使用方式让业务代码和缓存逻辑能够完全分离。
最常用的注解是 @Cacheable,用来标识方法的返回值需要被缓存。
@Cacheable(value = "users", key = "#id")
public User getUserById(Long id) {
return userDao.findById(id);
}方法在第一次执行后会把结果缓存起来,后续的调用就直接从缓存中返回,不再执行方法体。
还有 @CacheEvict 注解,用于在方法执行前或执行后清除缓存。
@CacheEvict(value = "users", key = "#id")
public void deleteUserById(Long id) {
userDao.deleteById(id);
}Spring Cache 是基于 AOP 实现的,通过拦截方法调用,在调用前后插入缓存逻辑。需要我们在配置中先启用缓存功能。
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
RedisCacheManager.Builder builder = RedisCacheManager
.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory())
.cacheDefaults(cacheConfiguration());
return builder.build();
}
}Spring Cache 和 Redis 有什么区别?
Spring Cache 和 Redis 的区别其实是抽象层和具体实现的区别。Spring Cache 只是提供了一套统一的接口和注解来管理缓存,本身并不提供缓存能力,而 Redis 是具体的缓存实现。
在使用层面上,Spring Cache 更简单,只需要在方法上添加注解就行,框架会帮我们自动处理。
@Cacheable("users")
public User getUser(Long id) {
return userDao.findById(id);
}如果用 Redis 则需要我们手动处理缓存逻辑:
public User getUser(Long id) {
String key = "user:" + id;
User user = (User) redisTemplate.opsForValue().get(key);
if (user == null) {
user = userDao.findById(id);
redisTemplate.opsForValue().set(key, user, 30, TimeUnit.MINUTES);
}
return user;
}在实际的项目当中,我通常会选择使用 Spring Cache 来处理一些简单的缓存业务,但对于一些复杂的业务场景,对于复杂的业务逻辑,比如分布式锁、计数器、排行榜等,我会直接用 Redis。
有了 Redis 为什么还需要 Spring Cache?
虽然 Redis 非常强大,但 Spring Cache 可以简化缓存的管理。我们直接在方法上加注解就能实现缓存逻辑,减少了手动操作 Redis 的代码量。
@Cacheable("users")
public User getUser(Long id) {
return userDao.findById(id);
}此外,Spring Cache 还能灵活切换底层的缓存实现,比如说从 Redis 切换到 Caffeine。
说说 Spring Cache 的底层原理?
Spring Cache 的底层是通过 AOP 实现的。当我们在方法上标注了 @Cacheable 注解时,Spring 会在项目启动的时候扫描这些注解,并创建代理对象。代理对象会拦截所有的方法调用,在方法执行前后插入缓存相关的逻辑。
具体的执行流程是这样的:
当用户调用一个被缓存注解标注的方法时,实际上调用的是代理对象而不是原始对象。
代理对象中的 CacheInterceptor 拦截器会先解析方法上的缓存注解,获取缓存名称、key 生成规则、过期时间这些配置信息。然后根据注解的类型执行不同的缓存策略,比如 @Cacheable 会先去缓存中查找数据,如果找到就直接返回,不执行原方法;如果没找到,就执行原方法获取结果,然后将结果存入缓存再返回。
缓存 key 的生成是通过 KeyGenerator 组件完成的,默认情况下会根据方法的参数来生成 key。如果我们在注解中指定了 key 属性,Spring 会使用 SpEL 表达式引擎来解析这个表达式,结合方法参数、返回值等上下文信息计算出具体的 key 值。
底层的缓存存储是通过 CacheManager 和 Cache 这两个抽象接口来管理的。CacheManager 负责管理多个缓存区域,每个 Cache 实例对应一个具体的缓存区域。
不管我们使用 Redis、Caffeine 还是其他缓存技术,都需要实现这两个接口。这样 Spring Cache 就能以统一的方式操作不同的缓存实现,实现了很好的解耦。
- Java 面试指南(付费)收录的美团同学 9 一面面试原题:介绍一下springcache 和redis?Spring cache和redis之间的各应用在什么场景?有了redis为什么还要用springcahe?springcache 底层原理,基于什么实现的?
memo:今天在给球友们修改简历的时候,有球友说,找实习的时候也找二哥修改了简历,最后也顺利找到了,我很喜欢这种反馈,说明我付出的心血是有回报的,也感谢同学们每一次的口碑。

整整两个月,面渣逆袭 Spring 篇第二版终于整理完了,这一版几乎可以说是重写了,每天耗费了大量的精力在上面,可以说是改头换面,有一种士别俩月,当刮目相看的感觉(从 1.3 万字暴涨到 3.4 万字,加餐的同时区分高频低频版)。

网上的八股其实不少,有些还是付费的,我觉得是一件好事,可以给大家提供更多的选择,但面渣逆袭的含金量懂的都懂。
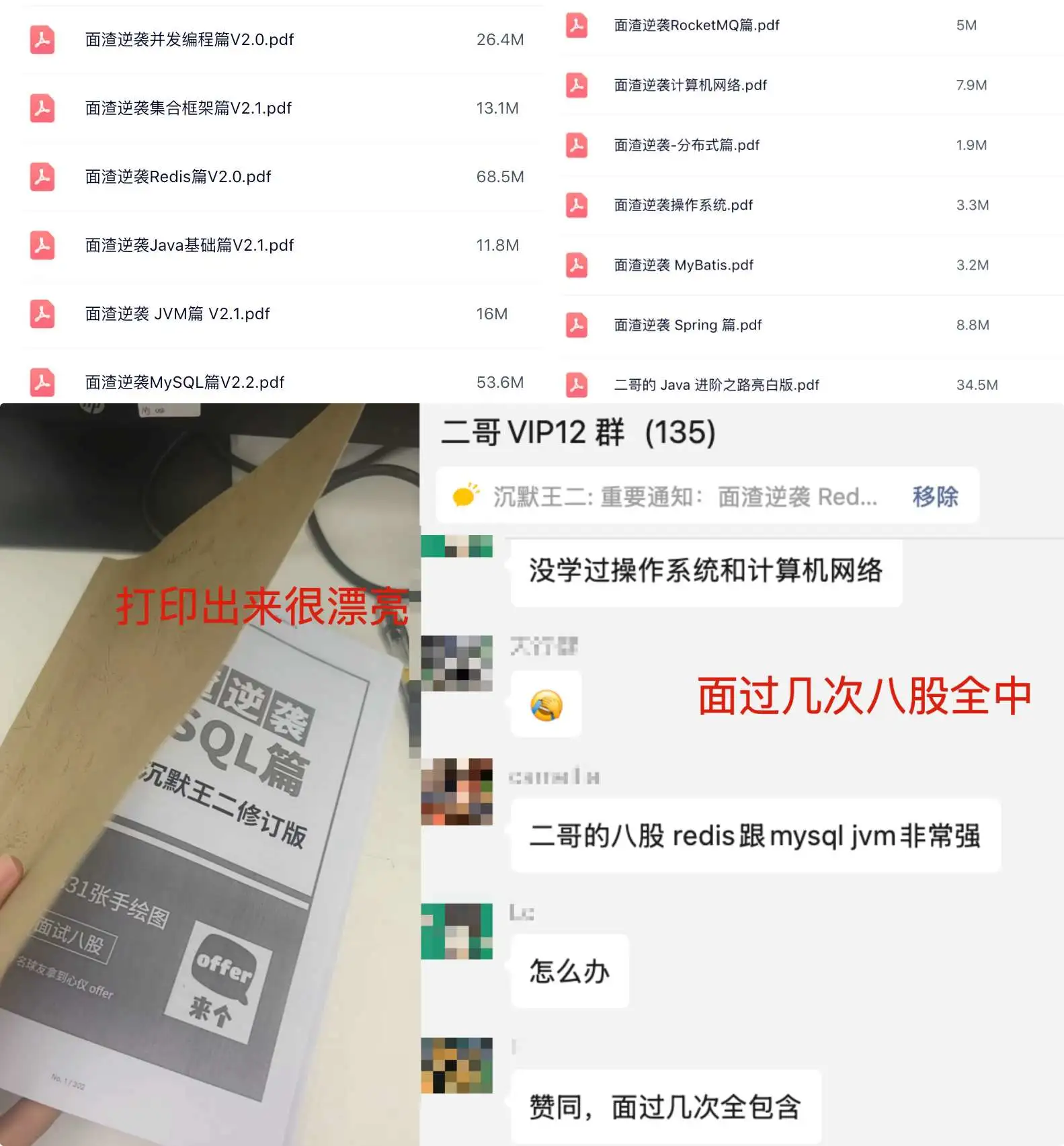
面渣逆袭第二版是在星球嘉宾三分恶的初版基础上,加入了二哥自己的思考,加入了 1000 多份真实面经之后的结果,并且从 24 届到 25 届,再到 26 届,帮助了很多小伙伴。未来的 27、28 届,也将因此受益,从而拿到心仪的 offer。
能帮助到大家,我很欣慰,并且在重制面渣逆袭的过程中,我也成长了很多,很多薄弱的基础环节都得到了加强,因此第二版的面渣逆袭不只是给大家的礼物,也是我在技术上蜕变的记录。
很多时候,我觉得自己是一个佛系的人,不愿意和别人争个高低,也不愿意去刻意宣传自己的作品。
我喜欢静待花开。
如果你觉得面渣逆袭还不错,可以告诉学弟学妹们有这样一份免费的学习资料,帮我做个口碑。
我还会继续优化,也不确定第三版什么时候会来,但我会尽力。
愿大家都有一个光明的未来。
由于 PDF 没办法自我更新,所以需要最新版的小伙伴,可以微信搜【沉默王二】,或者扫描/长按识别下面的二维码,关注二哥的公众号,回复【222】即可拉取最新版本。
当然了,请允许我的一点点私心,那就是星球的 PDF 版本会比公众号早一个月时间,毕竟星球用户都付费过了,我有必要让他们先享受到一点点福利。相信大家也都能理解,毕竟在线版是免费的,CDN、服务器、域名、OSS 等等都是需要成本的。
更别说我付出的时间和精力了,大家觉得有帮助还请给个口碑,让你身边的同事、同学都能受益到。
我把二哥的 Java 进阶之路、JVM 进阶之路、并发编程进阶之路,以及所有面渣逆袭的版本都放进来了,涵盖 Java基础、Java集合、Java并发、JVM、Spring、MyBatis、计算机网络、操作系统、MySQL、Redis、RocketMQ、分布式、微服务、设计模式、Linux 等 16 个大的主题,共有 40 多万字,2000+张手绘图,可以说是诚意满满。
这次仍然是三个版本,亮白、暗黑和 epub 版本。给大家展示其中一个 epub 版本吧,有些小伙伴很急需这个版本,所以也满足大家了。

图文详解 41 道 Spring 面试高频题,这次吊打面试官,我觉得稳了(手动 dog)。整理:沉默王二,戳转载链接,作者:三分恶,戳原文链接。
没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。
系列内容: