MySQL面试题,83道MySQL八股文(5.5万字331张手绘图),面渣逆袭必看👍

前言
5.5 万字 331 张手绘图,详解 83 道 MySQL 面试高频题(让天下没有难背的八股),面渣背会这些 MySQL 八股文,这次吊打面试官,我觉得稳了(手动 dog)。整理:沉默王二,戳转载链接,作者:三分恶,戳原文链接。
亮白版本更适合拿出来打印,这也是很多学生党喜欢的方式,打印出来背诵的效率会更高。
2025 年 02 月 27 日开始着手第二版更新。
- 对于高频题,会标注在《Java 面试指南(付费)》中出现的位置,哪家公司,原题是什么,并且会加🌟,目录一目了然;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 区分八股精华回答版本和原理底层解释,让大家知其然知其所以然,同时又能做到面试时的高效回答。
- 结合项目(技术派、pmhub)来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 增加二哥编程星球的球友们拿到的一些 offer,对面渣逆袭的感谢,以及对简历修改的一些认可,以此来激励大家,给大家更多信心。
- 优化排版,增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
由于 PDF 没办法自我更新,所以需要最新版的小伙伴,可以微信搜【沉默王二】,或者扫描/长按识别下面的二维码,关注二哥的公众号,回复【222】即可拉取最新版本。

当然了,请允许我的一点点私心,那就是星球的 PDF 版本会比公众号早一个月时间,毕竟星球用户都付费过了,我有必要让他们先享受到一点点福利。相信大家也都能理解,毕竟在线版是免费的,CDN、服务器、域名、OSS 等等都是需要成本的。
更别说我付出的时间和精力了,大家觉得有帮助还请给个口碑,让你身边的同事、同学都能受益到。
我把二哥的 Java 进阶之路、JVM 进阶之路、并发编程进阶之路,以及所有面渣逆袭的版本都放进来了,涵盖 Java基础、Java集合、Java并发、JVM、Spring、MyBatis、计算机网络、操作系统、MySQL、Redis、RocketMQ、分布式、微服务、设计模式、Linux 等 16 个大的主题,共有 40 多万字,2000+张手绘图,可以说是诚意满满。
展示一下暗黑版本的 PDF 吧,排版清晰,字体优雅,更加适合夜服,晚上看会更舒服一点。
MySQL 基础
0.🌟什么是 MySQL?
MySQL 是一个开源的关系型数据库,现在隶属于 Oracle 公司。是我们国内使用频率最高的一种数据库,我在本地安装的是最新的 8.3 版本。

怎么删除/创建一张表?
可以使用 DROP TABLE 来删除表,使用 CREATE TABLE 来创建表。
创建表的时候,可以通过 PRIMARY KEY 设定主键。
CREATE TABLE users (
id INT AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
email VARCHAR(100),
PRIMARY KEY (id)
);请写一个升序/降序的 SQL 语句?
在 SQL 中,可以使用 ORDER BY 子句来对查询结果进行升序或者降序。默认情况下,查询结果是升序的,如果需要降序,可以通过 DESC 关键字来实现。
比如说在员工表中,我们要按工资降序,就可以使用 ORDER BY salary DESC 来完成:
SELECT id, name, salary
FROM employees
ORDER BY salary DESC;如果需对多个字段进行排序,例如按工资降序,按名字升序,就可以 ORDER BY salary DESC, name ASC 来完成:
SELECT id, name, salary
FROM employees
ORDER BY salary DESC, name ASC;MySQL出现性能差的原因有哪些?
可能是 SQL 查询使用了全表扫描,也可能是查询语句过于复杂,如多表 JOIN 或嵌套子查询。
也有可能是单表数据量过大。
通常情况下,添加索引就能解决大部分性能问题。对于一些热点数据,还可以通过增加 Redis 缓存,来减轻数据库的访问压力。
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:你平时用到的数据库
- Java 面试指南(付费)收录的腾讯云智面经同学 16 一面面试原题:数据库用过哪些,对哪个比较熟?
- Java 面试指南(付费)收录的 360 面经同学 3 Java 后端技术一面面试原题:用过哪些数据库
- Java 面试指南(付费)收录的招商银行面经同学 6 招银网络科技面试原题:了解 MySQL、Redis 吗?
- Java 面试指南(付费)收录的国企零碎面经同学 9 面试原题:数据库用什么多(说了 Mysql 和 Redis)
- Java 面试指南(付费)收录的vivo 面经同学 10 技术一面面试原题:怎么删除/创建一张表和设定主键 ,举例用sql实现升序降序
- Java 面试指南(付费)收录的滴滴面经同学 3 网约车后端开发一面原题:MySQL性能慢的原因
1.两张表怎么进行连接?
可以通过内连接 inner join、外连接 outer join、交叉连接 cross join 来合并多个表的查询结果。
什么是内连接?
内连接用于返回两个表中有匹配关系的行。假设有两张表,用户表和订单表,想查询有订单的用户,就可以使用内连接 users INNER JOIN orders,按照用户 ID 关联就行了。
SELECT users.name, orders.order_id
FROM users
INNER JOIN orders ON users.id = orders.user_id;只有那些在两个表中都存在 user_id 的记录才会出现在查询结果中。
什么是外连接?
和内连接不同,外连接不仅返回两个表中匹配的行,还返回没有匹配的行,用 null 来填充。
外连接又分为左外连接 left join 和右外连接 right join。
left join 会保留左表中符合条件的所有记录,如果右表中有匹配的记录,就返回匹配的记录,否则就用 null 填充,常用于某表中有,但另外一张表中可能没有的数据的查询场景。
假设要查询所有用户及他们的订单,即使用户没有下单,就可以使用左连接:
SELECT users.id, users.name, orders.order_id
FROM users
LEFT JOIN orders ON users.id = orders.user_id;查询前:
| users | orders |
|---|---|
| id | name |
| 1 | 王二 |
| 2 | 张三 |
| 3 | 李四 |
查询后:
| id | name | order_id |
|---|---|---|
| 1 | 王二 | 10 |
| 2 | 张三 | 20 |
| 3 | 李四 | null |
右连接就是左连接的镜像,right join 会保留右表中符合条件的所有记录,如果左表中有匹配的记录,就返回匹配的记录,否则就用 null 填充。
什么是交叉连接?
交叉连接会返回两张表的笛卡尔积,也就是将左表的每一行与右表的每一行进行组合,返回的行数是两张表行数的乘积。
假设有 A 表和 B 表,A 表有 2 行数据,B 表有 3 行数据,那么交叉连接的结果就是 2 ✖️ 3 = 6 行。
SELECT A.id, B.id
FROM A
CROSS JOIN B;笛卡尔积是数学中的一个概念,例如集合 A={a,b},集合 B={0,1,2},那么 A✖️B={<a,0>,<a,1>,<a,2>,<b,0>,<b,1>,<b,2>,}。
- Java 面试指南(付费)收录的用友面试原题:两张表怎么进行连接
2.内连接、左连接、右连接有什么区别?
MySQL 的连接主要分为内连接和外连接,外连接又可以分为左连接和右连接。
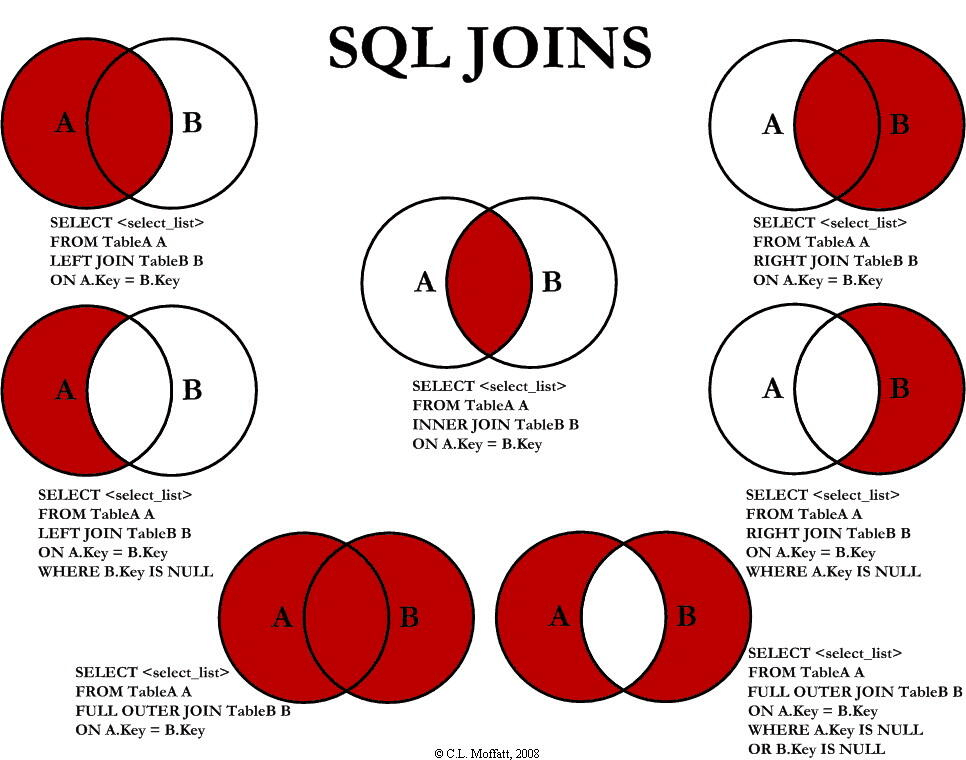
内连接可以用来找出两个表中共同的记录,相当于两个数据集的交集。
左连接和右连接可以用来找出两个表中不同的记录,相当于两个数据集的并集。两者的区别是,左连接会保留左表中符合条件的所有记录,右连接则刚好相反。
拿技术派实战项目的表为例来详细验证下。
有三张表,一张文章表 article,主要存文章标题 title, 一张文章详情表 article_detail,主要存文章的内容 content,一张文章评论表 comment,主要存评论 content,三个表通过文章 id 关联。
先来看内连接:
SELECT LEFT(a.title, 20) AS ArticleTitle, LEFT(c.content, 20) AS CommentContent
FROM article a
INNER JOIN comment c ON a.id = c.article_id
LIMIT 2;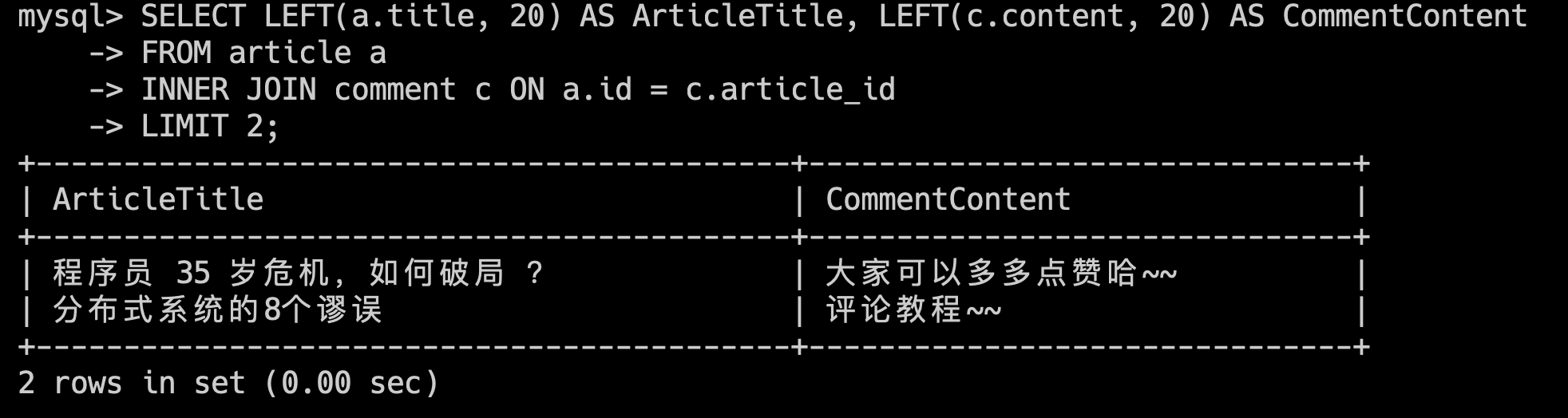
返回至少有一条评论的文章标题和评论内容(前 20 个字符),只返回符合条件的前 2 条记录。
再来看做连接:
SELECT LEFT(a.title, 20) AS ArticleTitle, LEFT(c.content, 20) AS CommentContent
FROM article a
LEFT JOIN comment c ON a.id = c.article_id
LIMIT 2;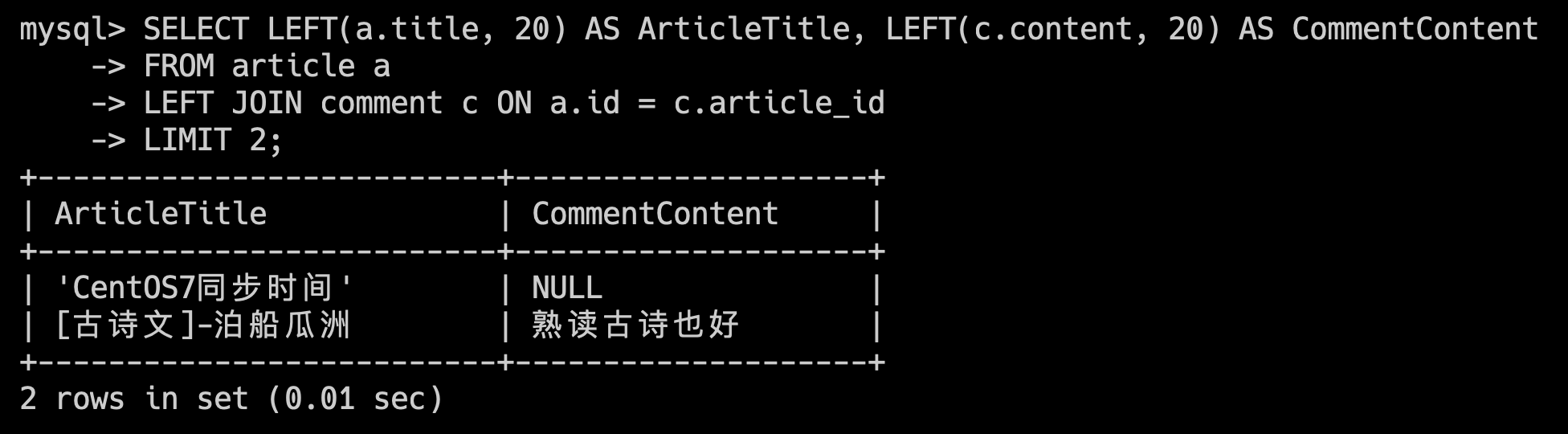
返回所有文章的标题和文章评论,即使某些文章没有评论(填充为 NULL)。
最后来看右连:
SELECT LEFT(a.title, 20) AS ArticleTitle, LEFT(c.content, 20) AS CommentContent
FROM comment c
RIGHT JOIN article a ON a.id = c.article_id
LIMIT 2;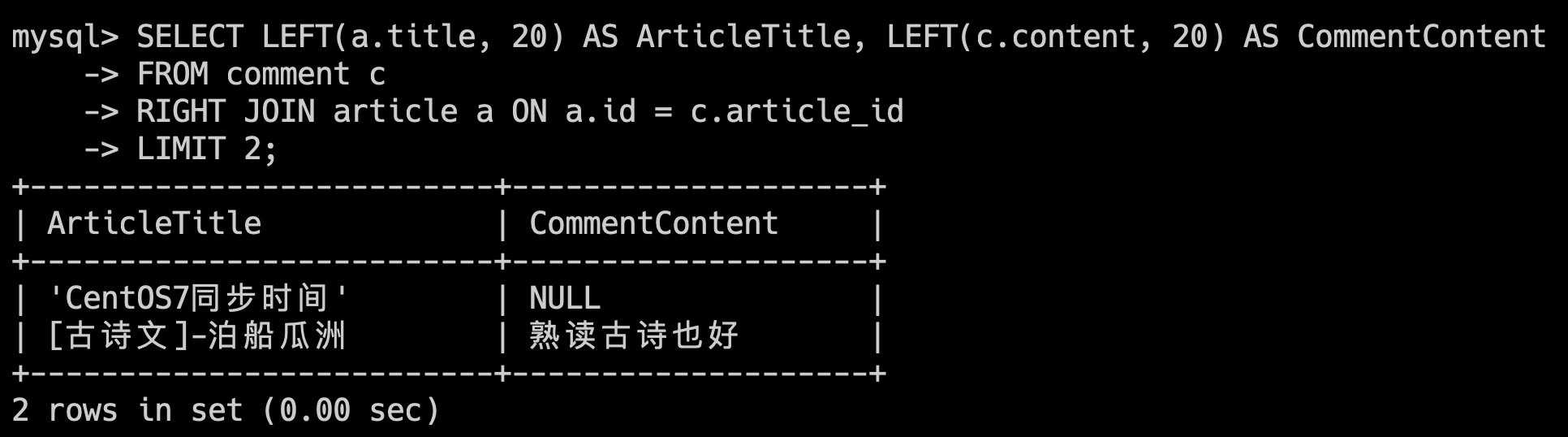
- Java 面试指南(付费)收录的腾讯 Java 后端实习一面原题:请说说 MySQL 的内联、左联、右联的区别。
memo:2025 年 2 月 27 日修改至此。给大家看一条球友的面经,基本上都是面渣逆袭中常见的八股,所以只要能把面渣中的高频题拿下,面试 OC 的概率真的很大,真心话。

3.说一下数据库的三大范式?
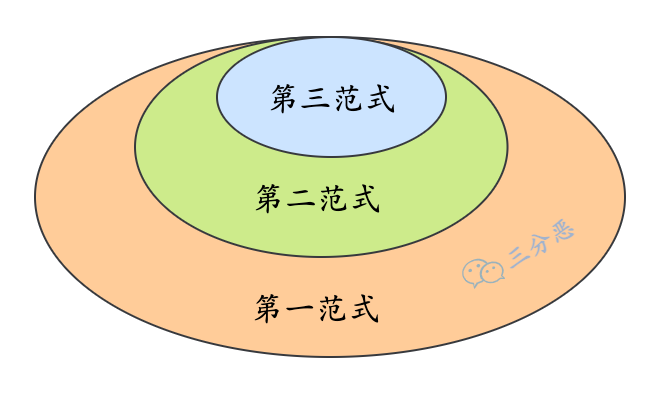
第一范式,确保表的每一列都是不可分割的基本数据单元,比如说用户地址,应该拆分成省、市、区、详细地址等 4 个字段。
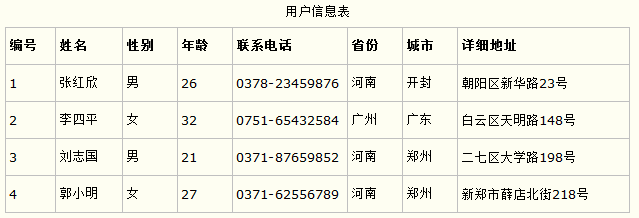
第二范式,要求表中的每一列都和主键直接相关。比如在订单表中,商品名称、单位、商品价格等字段应该拆分到商品表中。
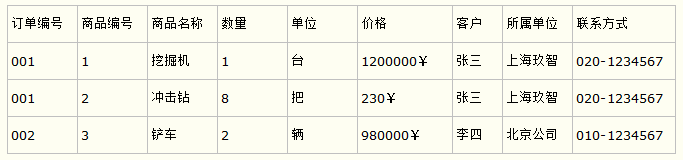
然后新建一个订单商品关联表,用订单编号和商品编号进行关联就好了。
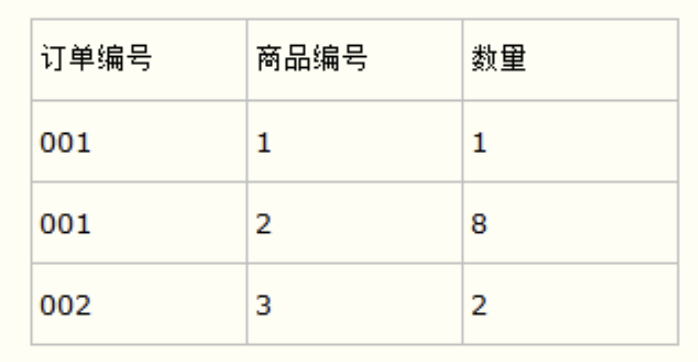
第三范式,非主键列应该只依赖于主键列。比如说在设计订单信息表的时候,可以把客户名称、所属公司、联系方式等信息拆分到客户信息表中,然后在订单信息表中用客户编号进行关联。
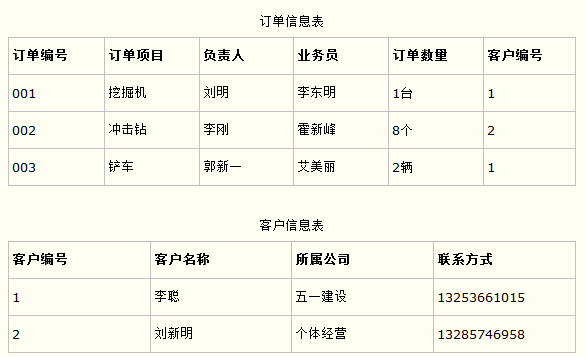
建表的时候需要考虑哪些问题?
首先需要考虑表是否符合数据库的三大范式,确保字段不可再分,消除非主键依赖,确保字段仅依赖于主键等。
然后在选择字段类型时,应该尽量选择合适的数据类型。
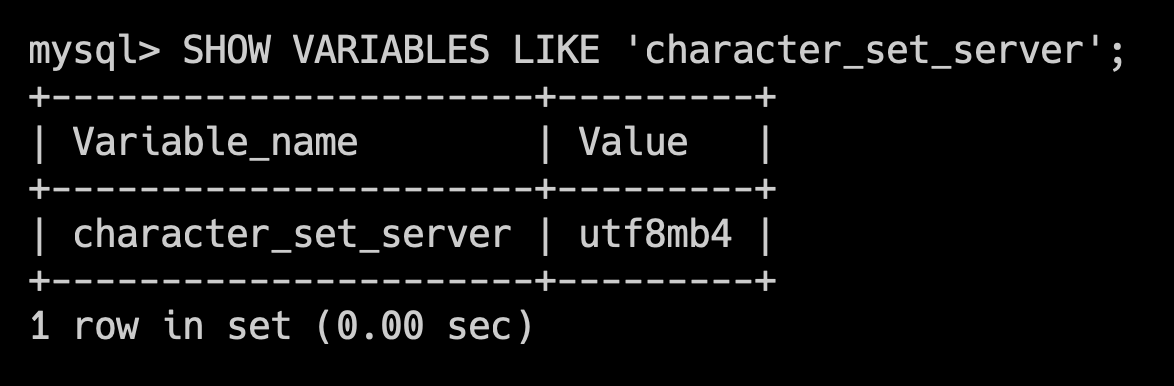
在字符集上,尽量选择 utf8mb4,这样不仅可以支持中文和英文,还可以支持表情符号等。
当数据量较大时,比如上千万行数据,需要考虑分表。比如订单表,可以采用水平分表的方式来分散单表存储压力。
- Java 面试指南(付费)收录的字节跳动面经同学 13 Java 后端二面面试原题:什么是三大范式,为什么要有三大范式,什么场景下不用遵循三大范式,举一个场景
- Java 面试指南(付费)收录的京东面经同学 5 Java 后端技术一面面试原题:建表考虑哪些问题
4.varchar 与 char 的区别?
varchar 是可变长度的字符类型,原则上最多可以容纳 65535 个字符,但考虑字符集,以及 MySQL 需要 1 到 2 个字节来表示字符串长度,所以实际上最大可以设置到 65533。
latin1 字符集,且列属性定义为 NOT NULL。
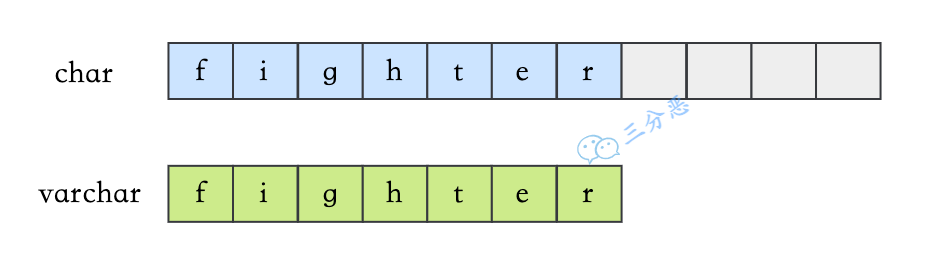
char 是固定长度的字符类型,当定义一个 CHAR(10) 字段时,不管实际存储的字符长度是多少,都只会占用 10 个字符的空间。如果插入的数据小于 10 个字符,剩余的部分会用空格填充。
| 值 | CHAR(4) | 存储需求(字节) | VARCHAR(4) | 存储需求(字节) |
|---|---|---|---|---|
| '' | ' ' | 4 | '' | 1 |
| 'ab' | 'ab ' | 4 | 'ab' | 3 |
| 'abcd' | 'abcd' | 4 | 'abcd' | 5 |
| 'abcdefgh' | 'abcd' | 4 | 'abcd' | 5 |
5.blob 和 text 有什么区别?
blob 用于存储二进制数据,比如图片、音频、视频、文件等;但实际开发中,我们都会把这些文件存储到 OSS 或者文件服务器上,然后在数据库中存储文件的 URL。
text 用于存储文本数据,比如文章、评论、日志等。
memo:2025 年 2 月 28 日修改至此。今天有球友反馈拿到了理想汽车的补录 offer, 真的恭喜了!
6.DATETIME 和 TIMESTAMP 有什么区别?
DATETIME 直接存储日期和时间的完整值,与时区无关。
TIMESTAMP 存储的是 Unix 时间戳,1970-01-01 00:00:01 UTC 以来的秒数,受时区影响。
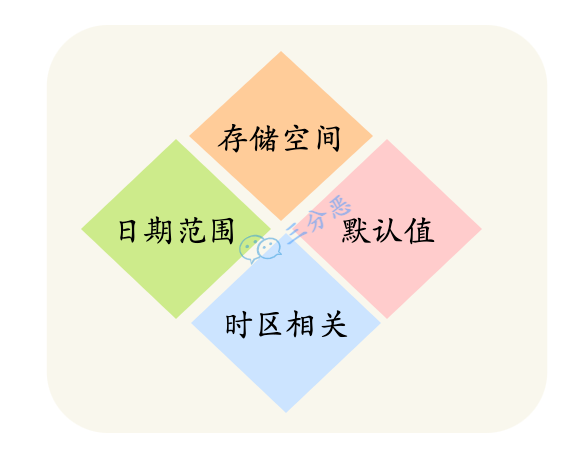
另外,DATETIME 的默认值为 null,占用 8 个字节;TIMESTAMP 的默认值为当前时间——CURRENT_TIMESTAMP,占 4 个字节,实际开发中更常用,因为可以自动更新。
7.in和exists的区别?
当使用 IN 时,MySQL 会首先执行子查询,然后将子查询的结果集用于外部查询的条件。这意味着子查询的结果集需要全部加载到内存中。
而 EXISTS 会对外部查询的每一行,执行一次子查询。如果子查询返回任何行,则 EXISTS 条件为真。EXISTS 关注的是子查询是否返回行,而不是返回的具体值。
-- IN 的临时表可能成为性能瓶颈
SELECT * FROM users
WHERE id IN (SELECT user_id FROM orders WHERE amount > 100);
-- EXISTS 可以利用关联索引
SELECT * FROM users u
WHERE EXISTS (SELECT 1 FROM orders o
WHERE o.user_id = u.id AND o.amount > 100);IN 适用于子查询结果集较小的情况。如果子查询返回大量数据,IN 的性能可能会下降,因为它需要将整个结果集加载到内存。
而 EXISTS 适用于子查询结果集可能很大的情况。由于 EXISTS 只需要判断子查询是否返回行,而不需要加载整个结果集,因此在某些情况下性能更好,特别是当子查询可以使用索引时。
NULL值陷了解吗?
IN: 如果子查询的结果集中包含 NULL 值,可能会导致意外的结果。例如,WHERE column IN (subquery),如果 subquery 返回 NULL,则 column IN (subquery) 永远不会为真,除非 column 本身也为 NULL。
EXISTS: 对 NULL 值的处理更加直接。EXISTS 只是检查子查询是否返回行,不关心行的具体值,因此不受 NULL 值的影响。
memo:2025 年 3 月 1 日修改至此。
8.记录货币用什么类型比较好?
如果是电商、交易、账单等涉及货币的场景,建议使用 DECIMAL 类型,因为 DECIMAL 类型是精确数值类型,不会出现浮点数计算误差。
例如,DECIMAL(19,4) 可以存储最多 19 位数字,其中 4 位是小数。
CREATE TABLE orders (
id INT AUTO_INCREMENT,
amount DECIMAL(19,4),
PRIMARY KEY (id)
);如果是银行,涉及到支付的场景,建议使用 BIGINT 类型。可以将货币金额乘以一个固定因子,比如 100,表示以“分”为单位,然后存储为 BIGINT。这种方式既避免了浮点数问题,同时也提供了不错的性能。但在展示的时候需要除以相应的因子。
为什么不推荐使用 FLOAT 或 DOUBLE?
因为 FLOAT 和 DOUBLE 都是浮点数类型,会存在精度问题。
在许多编程语言中,0.1 + 0.2 的结果会是类似 0.30000000000000004 的值,而不是预期的 0.3。
9.🌟怎么存储 emoji?
因为 emoji(😊)是 4 个字节的 UTF-8 字符,而 MySQL 的 utf8 字符集只支持最多 3 个字节的 UTF-8 字符,所以在 MySQL 中存储 emoji 时,需要使用 utf8mb4 字符集。
ALTER TABLE mytable CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;MySQL 8.0 已经默认支持 utf8mb4 字符集,可以通过 SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; 查看。
- Java 面试指南(付费)收录的字节跳动面经同学 13 Java 后端二面面试原题:mysql 怎么存 emoji,怎么编码
10.drop、delete 与 truncate 的区别?
DROP 是物理删除,用来删除整张表,包括表结构,且不能回滚。
DELETE 支持行级删除,可以带 WHERE 条件,可以回滚。
TRUNCATE 用于清空表中的所有数据,但会保留表结构,不能回滚。
memo:2025 年 3 月 4 日修改至此。给大家传递一个喜报,一位球友拿到了科大讯飞的 offer,这薪资在合肥真的会很香。

11.UNION 与 UNION ALL 的区别?
UNION 会自动去除合并后结果集中的重复行。UNION ALL 不会去重,会将所有结果集合并起来。
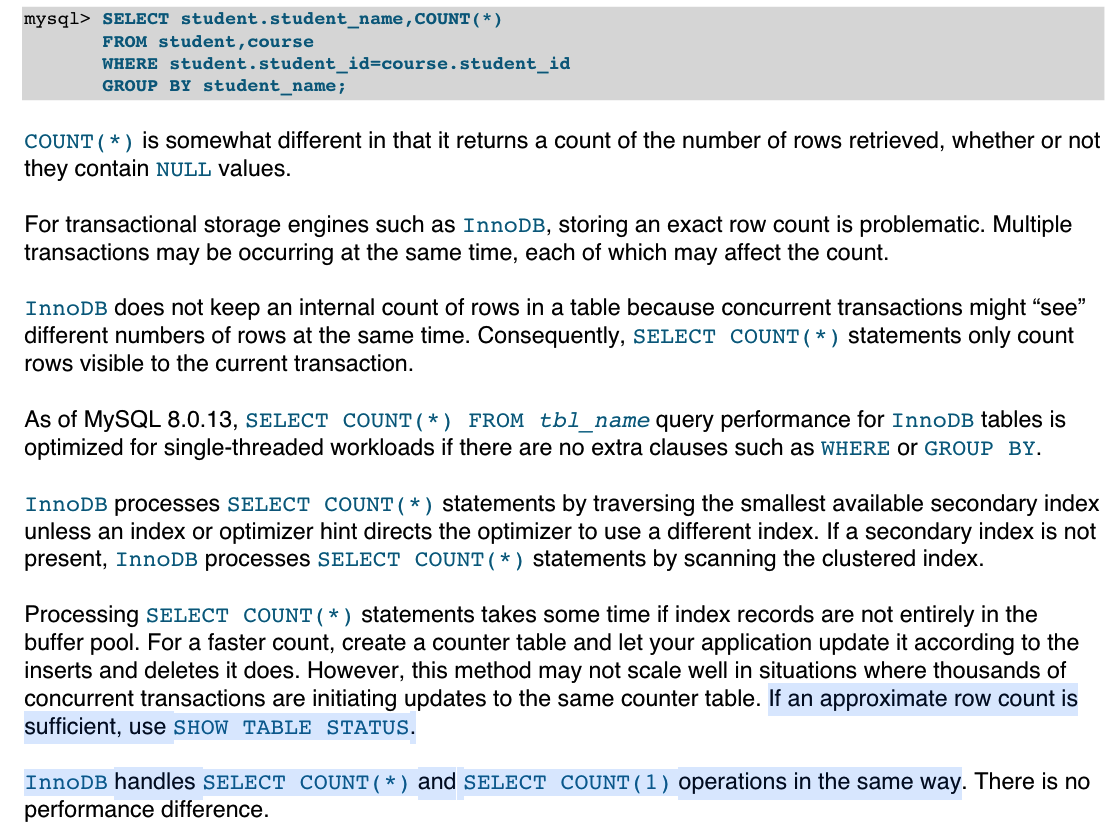
12.count(1)、count(*) 与 count(列名) 的区别?
在 InnoDB 引擎中,COUNT(1) 和 COUNT(*) 没有区别,都是用来统计所有行,包括 NULL。
如果表有索引,COUNT(*) 会直接用索引统计,而不是全表扫描,而 COUNT(1) 也会被 MySQL 优化为 COUNT(*)。
COUNT(列名) 只统计列名不为 NULL 的行数。
-- 假设 users 表:
+----+-------+------------+
| id | name | email |
+----+-------+------------+
| 1 | 张三 | zhang@xx.com |
| 2 | 李四 | NULL |
| 3 | 王二 | wang@xx.com |
+----+-------+------------+
-- COUNT(*)
SELECT COUNT(*) FROM users;
-- 结果:3 (统计所有行)
-- COUNT(1)
SELECT COUNT(1) FROM users;
-- 结果:3 (统计所有行)
-- COUNT(email)
SELECT COUNT(email) FROM users;
-- 结果:2 (NULL 不计入统计)这里解释一下,假设有这样一张表:
CREATE TABLE t1 (
id INT,
name VARCHAR(50),
value INT
);插入的数据为:
INSERT INTO t1 VALUES
(1, 'A', 10),
(2, 'B', NULL), -- NULL in value column
(3, 'C', 30),
(4, NULL, 40), -- NULL in name column
(5, 'E', NULL); -- NULL in value column因为 id 列没有索引,所以 select count(*) 是全表扫描。
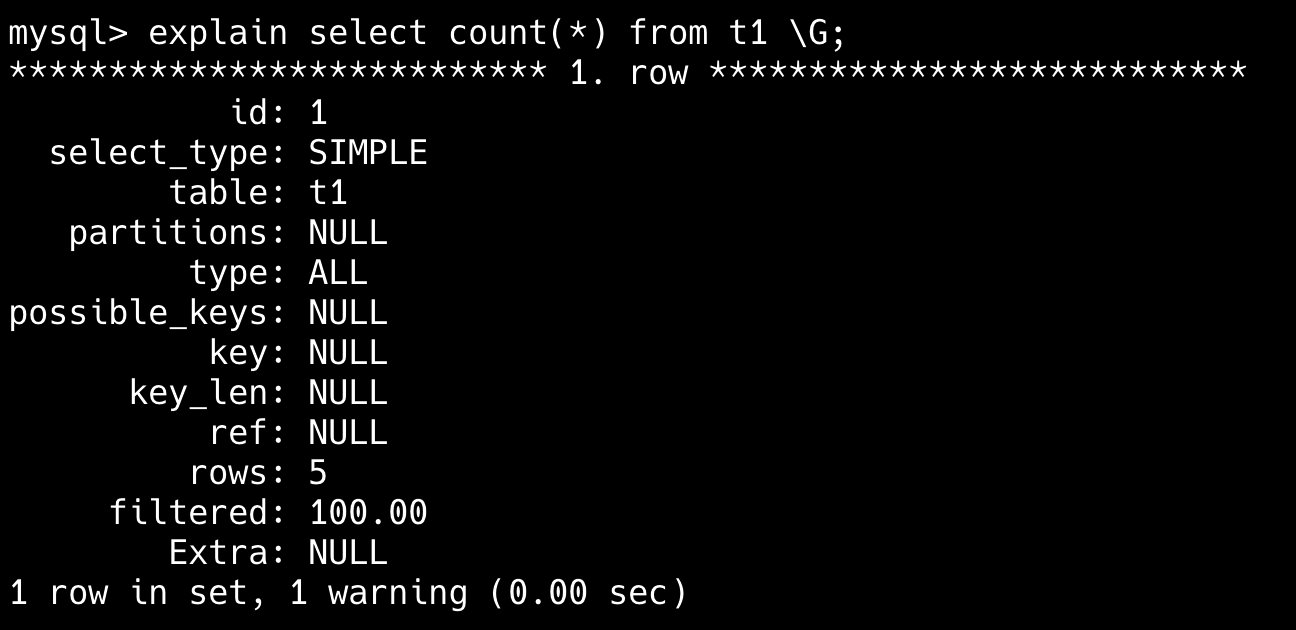
然后我们给 id 列加上索引。
alter table t1 add primary key (id);
再来看一下 select count(*),发现用了索引(MySQL 默认为给主键添加索引)。
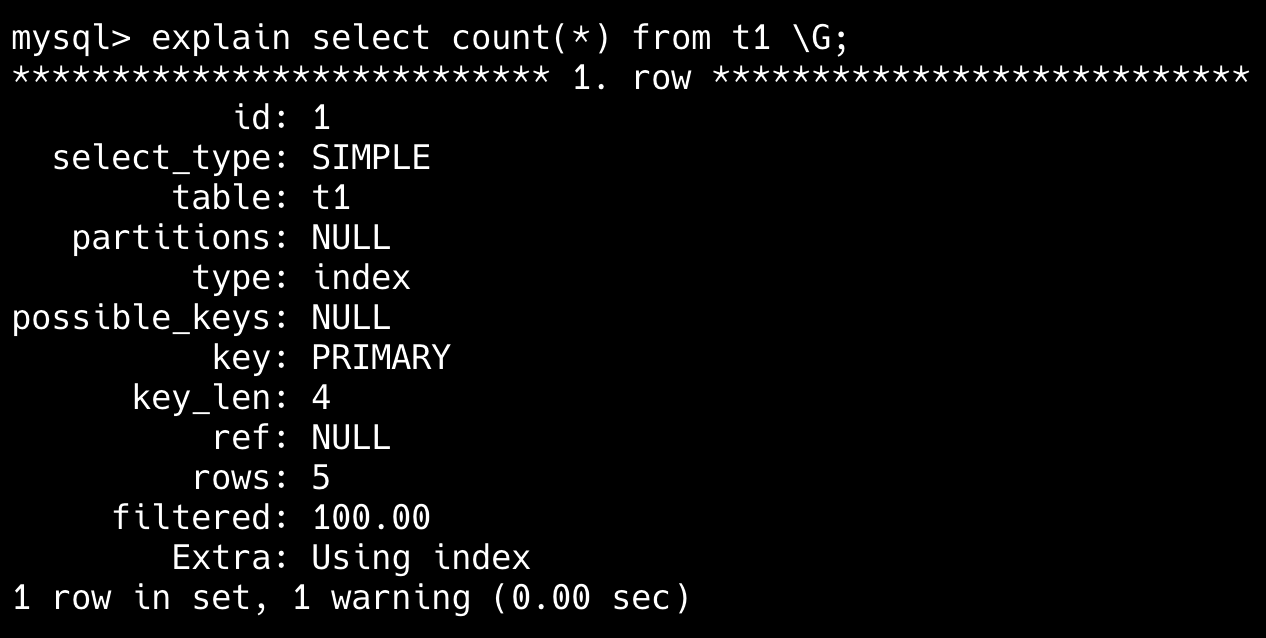
另外,MySQL 8.0 官方手册有明确说明,InnoDB 引擎对 SELECT COUNT(*) 和 SELECT COUNT(1) 的处理方式完全一致,性能并无差异。
memo:2025 年 3 月 5 日修改至此。再晒一个喜报给正在刷八股的你,一位球友拿到了咪咕的大模型应用开发,很不错的方向,恭喜了!给你也加加好运🍀buff,你也加把劲。
13.SQL 查询语句的执行顺序了解吗?
了解。先执行 FROM 确定主表,再执行 JOIN 连接,然后 WHERE 进行过滤,接着 GROUP BY 进行分组,HAVING 过滤聚合结果,SELECT 选择最终列,ORDER BY 排序,最后 LIMIT 限制返回行数。
WHERE 先执行是为了减少数据量,HAVING 只能过滤聚合数据,ORDER BY 必须在 SELECT 之后排序最终结果,LIMIT 最后执行以减少数据传输。
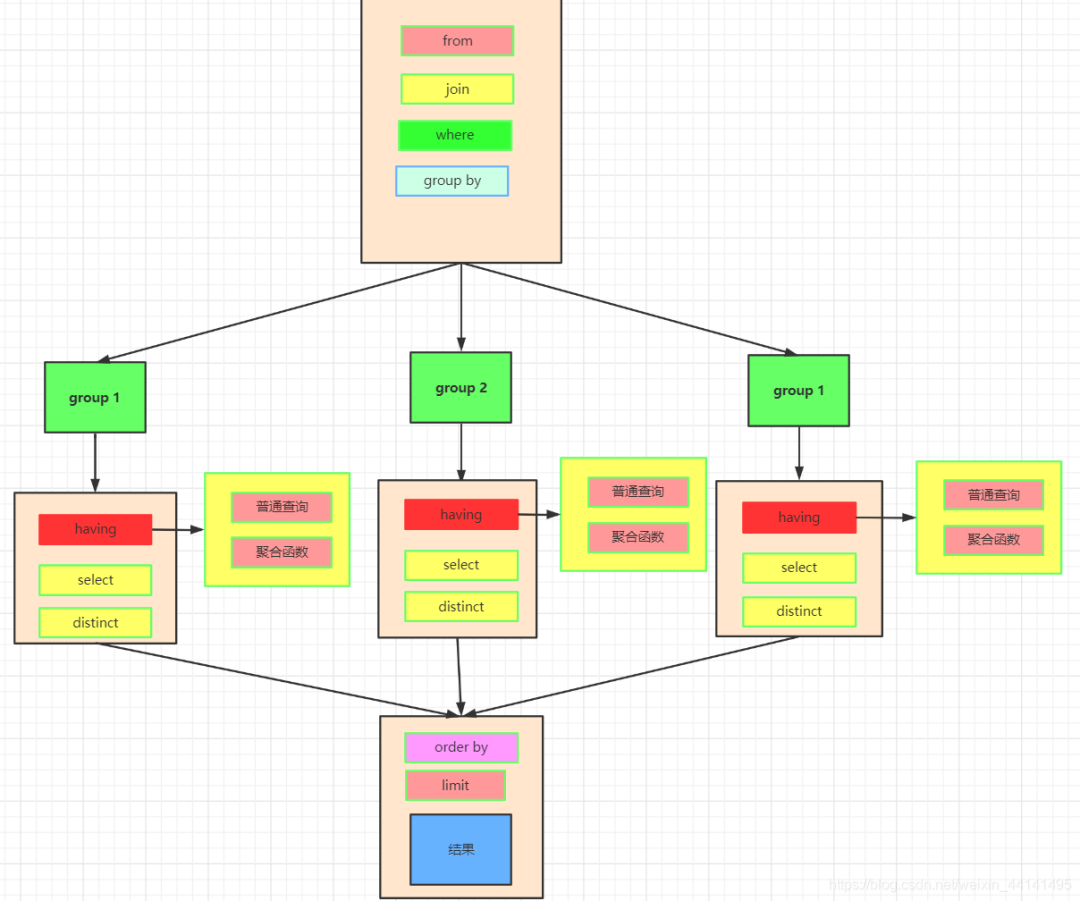
| 执行顺序 | SQL 关键字 | 作用 |
|---|---|---|
| ① | FROM | 确定主表,准备数据 |
| ② | ON | 连接多个表的条件 |
| ③ | JOIN | 执行 INNER JOIN / LEFT JOIN 等 |
| ④ | WHERE | 过滤行数据(提高效率) |
| ⑤ | GROUP BY | 进行分组 |
| ⑥ | HAVING | 过滤聚合后的数据 |
| ⑦ | SELECT | 选择最终返回的列 |
| ⑧ | DISTINCT | 进行去重 |
| ⑨ | ORDER BY | 对最终结果排序 |
| ⑩ | LIMIT | 限制返回行数 |
这个执行顺序与编写 SQL 语句的顺序不同,这也是为什么有时候在 SELECT 子句中定义的别名不能在 WHERE 子句中使用得原因,因为 WHERE 是在 SELECT 之前执行的。
LIMIT 为什么在最后执行?
因为 LIMIT 是在最终结果集上执行的,如果在 WHERE 之前执行 LIMIT,那么就会先返回所有行,然后再进行 LIMIT 限制,这样会增加数据传输的开销。
ORDER BY 为什么在 SELECT 之后执行?
因为排序需要基于最终返回的列,如果 ORDER BY 早于 SELECT 执行,计算 COUNT(*) 之类的聚合函数就会出问题。
SELECT name, COUNT(*) AS order_count
FROM orders
GROUP BY name
ORDER BY order_count DESC;14.介绍一下 MySQL 的常用命令(补充)
2024 年 03 月 13 日增补。
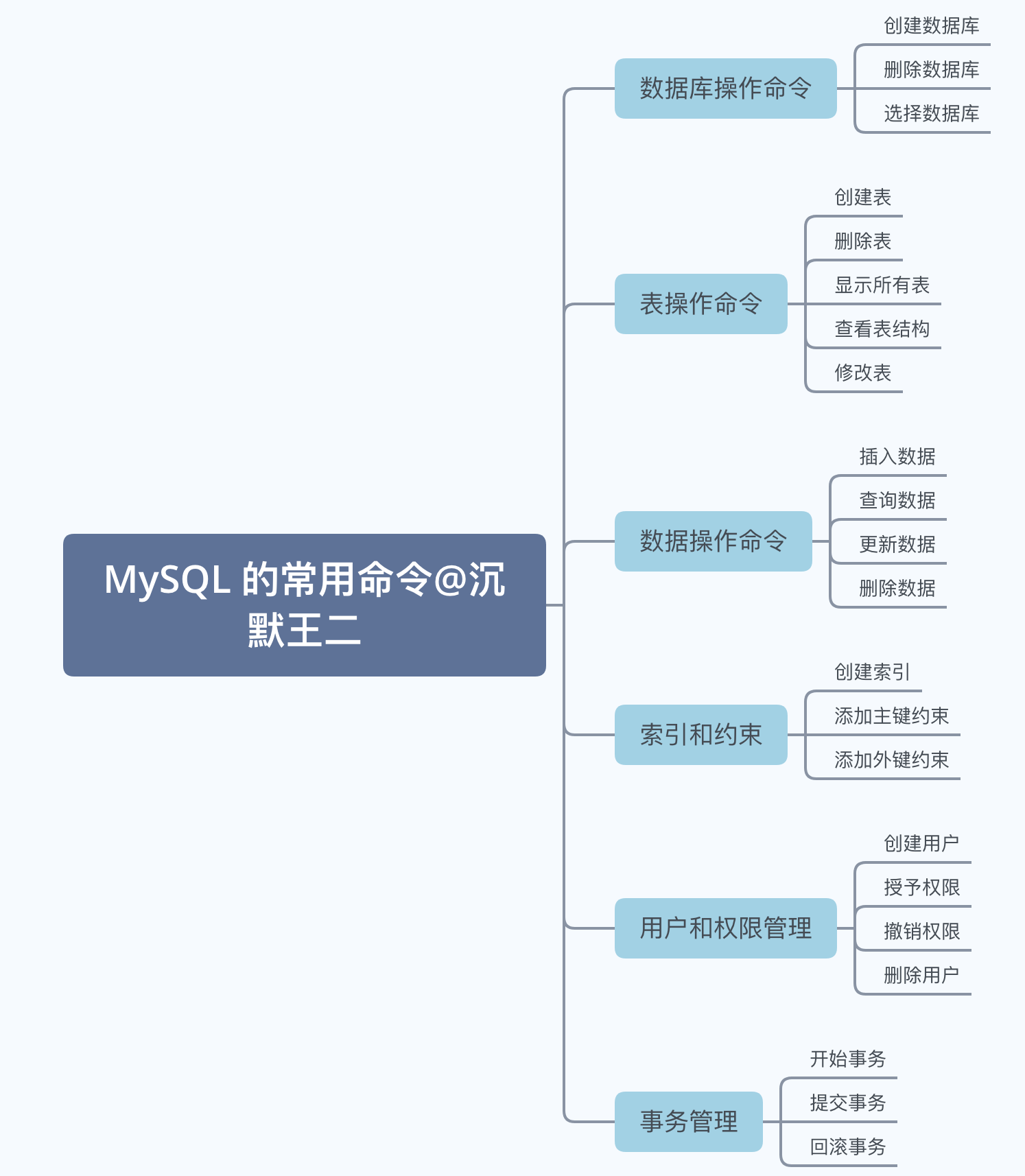
MySQL 的常用命令主要包括数据库操作命令、表操作命令、行数据 CRUD 命令、索引和约束的创建修改命令、用户和权限管理的命令、事务控制的命令等。
说说数据库操作命令?
CREATE DATABASE database_name; 用于创建数据库;DROP DATABASE database_name; 用于删除数据库;SHOW DATABASES; 用于显示所有数据库;USE database_name; 用于切换数据库。
说说表操作命令?
CREATE TABLE table_name (列名1 数据类型1, 列名2 数据类型2,...); 用于创建表;DROP TABLE table_name; 用于删除表;SHOW TABLES; 用于显示所有表;DESCRIBE table_name; 用于查看表结构;ALTER TABLE table_name ADD column_name datatype; 用于修改表。
说说行数据的 CRUD 命令?
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...); 用于插入数据;SELECT column_names FROM table_name WHERE condition; 用于查询数据;UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition; 用于更新数据;DELETE FROM table_name WHERE condition; 用于删除数据。
说说索引和约束的创建修改命令?
CREATE INDEX index_name ON table_name (column_name); 用于创建索引;ALTER TABLE table_name ADD PRIMARY KEY (column_name); 用于添加主键;ALTER TABLE table_name ADD CONSTRAINT fk_name FOREIGN KEY (column_name) REFERENCES parent_table (parent_column_name); 用于添加外键。
说说用户和权限管理的命令?
CREATE USER 'username'@'host' IDENTIFIED BY 'password'; 用于创建用户;GRANT ALL PRIVILEGES ON database_name.table_name TO 'username'@'host'; 用于授予权限;REVOKE ALL PRIVILEGES ON database_name.table_name FROM 'username'@'host'; 用于撤销权限;DROP USER 'username'@'host'; 用于删除用户。
说说事务控制的命令?
START TRANSACTION; 用于开始事务;COMMIT; 用于提交事务;ROLLBACK; 用于回滚事务。
- Java 面试指南(付费)收录的用友金融一面原题:介绍一下 MySQL 的常用命令
15.MySQL bin 目录下的可执行文件了解吗(补充)
2024 年 03 月 13 日增补
了解的。MySQL 的 bin 目录下有很多可执行文件,主要用于管理 MySQL 服务器、数据库、表、数据等。比如说:
- mysql:用于连接 MySQL 服务器
- mysqldump:用于数据库备份,对数据备份、迁移或恢复时非常有用
- mysqladmin:用来执行一些管理操作,比如说创建数据库、删除数据库、查看 MySQL 服务器的状态等。
- mysqlcheck:用于检查、修复、分析和优化数据库表,对数据库的维护和性能优化非常有用。
- mysqlimport:用于从文本文件中导入数据到数据库表中,适合批量数据导入。
- mysqlshow:用于显示 MySQL 数据库服务器中的数据库、表、列等信息。
- mysqlbinlog:用于查看 MySQL 二进制日志文件的内容,可以用于恢复数据、查看数据变更等。
16.MySQL 第 3-10 条记录怎么查?(补充)
2024 年 03 月 30 日增补
可以使用 limit 语句,结合偏移量和行数来实现。
SELECT * FROM table_name LIMIT 2, 8;limit 语句用于限制查询结果的数量,偏移量表示从哪条记录开始,行数表示返回的记录数量。
- 2:偏移量,表示跳过前两条记录,从第三条记录开始。
- 8:行数,表示从偏移量开始,返回 8 条记录。
偏移量是从 0 开始的,即第一条记录的偏移量是 0;如果想从第 3 条记录开始,偏移量就应该是 2。
- Java 面试指南(付费)收录的美团面经同学 16 暑期实习一面面试原题:MySQL 第 3-10 条记录怎么查?
17.用过哪些 MySQL 函数?(补充)
2024 年 04 月 12 日增补
用过挺多的,比如说处理字符串的函数:
CONCAT(): 用于连接两个或多个字符串。LENGTH(): 用于返回字符串的长度。SUBSTRING(): 从字符串中提取子字符串。REPLACE(): 替换字符串中的某部分。TRIM(): 去除字符串两侧的空格或其他指定字符。
实测数据:
-- 连接字符串
SELECT CONCAT('沉默', ' ', '王二') AS concatenated_string;
-- 获取字符串长度
SELECT LENGTH('沉默 王二') AS string_length;
-- 提取子字符串
SELECT SUBSTRING('沉默 王二', 1, 5) AS substring;
-- 替换字符串内容
SELECT REPLACE('沉默 王二', '王二', 'MySQL') AS replaced_string;
-- 去除字符串两侧的空格
SELECT TRIM(' 沉默 王二 ') AS trimmed_string;处理数字的函数:
ABS(): 返回一个数的绝对值。ROUND(): 四舍五入到指定的小数位数。MOD(): 返回除法操作的余数。
实测数据:
-- 返回绝对值
SELECT ABS(-123) AS absolute_value;
-- 四舍五入
SELECT ROUND(123.4567, 2) AS rounded_value;
-- 余数
SELECT MOD(10, 3) AS modulus;日期和时间处理函数:
NOW(): 返回当前的日期和时间。CURDATE(): 返回当前的日期。
实测数据:
-- 返回当前日期和时间
SELECT NOW() AS current_date_time;
-- 返回当前日期
SELECT CURDATE() AS current_date;汇总函数:
SUM(): 计算数值列的总和。AVG(): 计算数值列的平均值。COUNT(): 计算某列的行数。
实测数据:
-- 创建一个表并插入数据进行聚合查询
CREATE TABLE sales (
product_id INT,
sales_amount DECIMAL(10, 2)
);
INSERT INTO sales (product_id, sales_amount) VALUES (1, 100.00);
INSERT INTO sales (product_id, sales_amount) VALUES (1, 150.00);
INSERT INTO sales (product_id, sales_amount) VALUES (2, 200.00);
-- 计算总和
SELECT SUM(sales_amount) AS total_sales FROM sales;
-- 计算平均值
SELECT AVG(sales_amount) AS average_sales FROM sales;
-- 计算总行数
SELECT COUNT(*) AS total_entries FROM sales;逻辑函数:
IF(): 如果条件为真,则返回一个值;否则返回另一个值。CASE: 根据一系列条件返回值。
-- IF函数
SELECT IF(1 > 0, 'True', 'False') AS simple_if;
-- CASE表达式
SELECT CASE WHEN 1 > 0 THEN 'True' ELSE 'False' END AS case_expression;
- Java 面试指南(付费)收录的华为 OD 面经同学 1 一面面试原题:用过哪些 MySQL 函数?
- Java 面试指南(付费)收录的 小公司面经合集好未来测开面经同学 3 测开一面面试原题:知道 MySQL 的哪些函数,如 order by count()
18.说说 SQL 的隐式数据类型转换?(补充)
2024 年 04 月 25 日增补
当一个整数和一个浮点数相加时,整数会被转换为浮点数。
SELECT 1 + 1.0; -- 结果为 2.0当一个字符串和一个整数相加时,字符串会被转换为整数。
SELECT '1' + 1; -- 结果为 2隐式转换会导致意想不到的结果,最好通过显式转换来规避。
SELECT CAST('1' AS SIGNED INTEGER) + 1; -- 结果为 2实际验证结果:
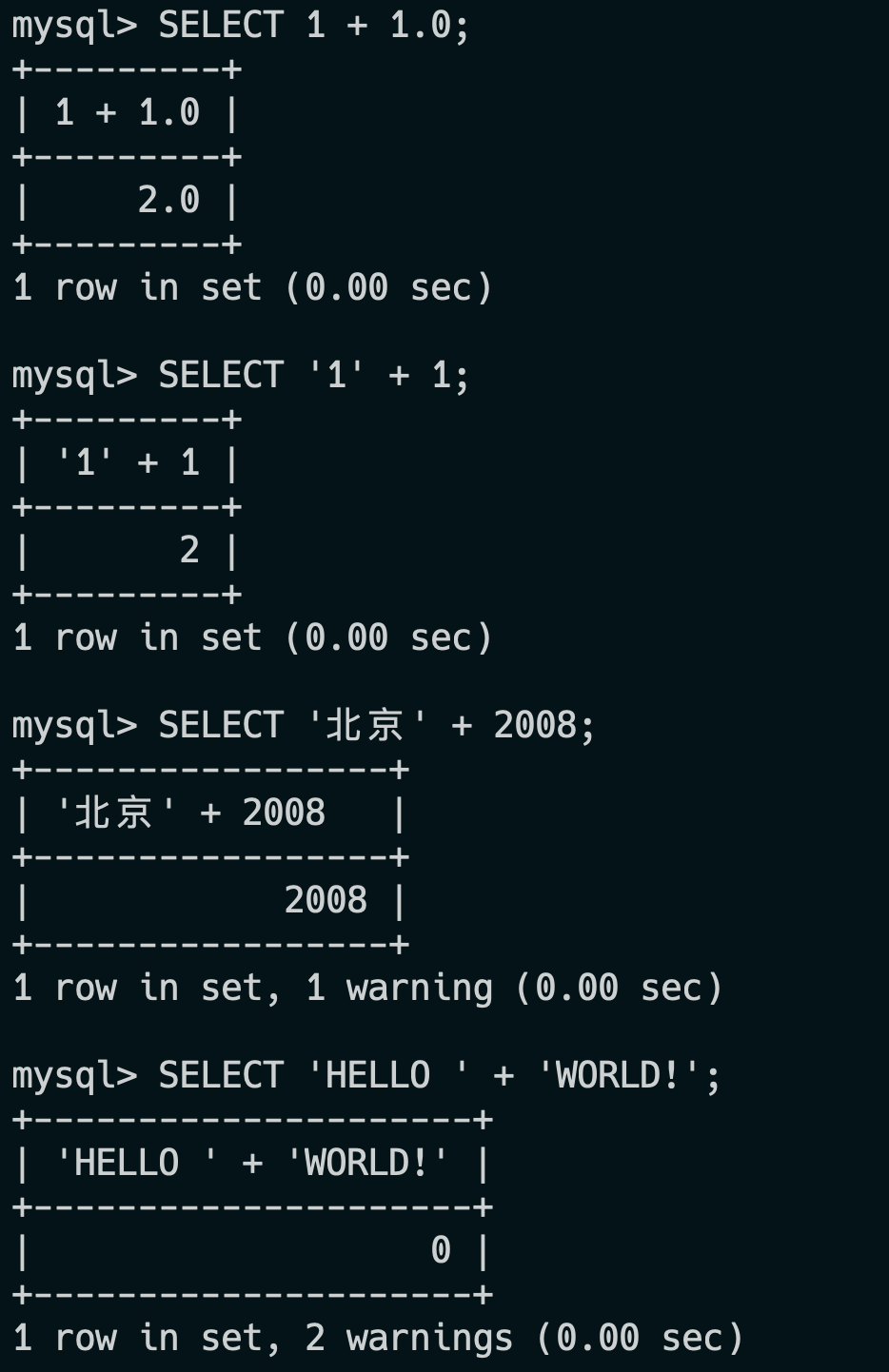
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:说说 SQL 的隐式数据类型转换?
memo:2025 年 3 月 6 日修改至此。
19. 说说 SQL 的语法树解析?(补充)
2024 年 09 月 19 日增补
SQL 语法树解析是将 SQL 查询语句转换成抽象语法树 —— AST 的过程,是数据库引擎处理查询的第一步,也是防止 SQL 注入的重要手段。
通常分为 3 个阶段。
第一个阶段,词法分析:拆解 SQL 语句,识别关键字、表名、列名等。
---这部分是帮助大家理解 start,面试中可不背---
比如说:
SELECT id, name FROM users WHERE age > 18;将会被拆解为:
[SELECT] [id] [,] [name] [FROM] [users] [WHERE] [age] [>] [18] [;]---这部分是帮助大家理解 end,面试中可不背---
第二个阶段,语法分析:检查 SQL 是否符合语法规则,并构建抽象语法树。
---这部分是帮助大家理解 start,面试中可不背---
比如说上面的语句会被构建成如下的语法树:
SELECT
/ \
Columns FROM
/ \ |
id name users
|
WHERE
|
age > 18或者这样表示:
SELECT
├── COLUMNS: id, name
├── FROM: users
├── WHERE
│ ├── CONDITION: age > 18---这部分是帮助大家理解 end,面试中可不背---
第三个阶段,语义分析:检查表、列是否存在,进行权限验证等。
---这部分是帮助大家理解 start,面试中可不背---
比如说执行:
SELECT id, name FROM users WHERE age > 'eighteen';会报错:
ERROR: Column 'age' is INT, but 'eighteen' is STRING.---这部分是帮助大家理解 end,面试中可不背---
- Java 面试指南(付费)收录的字节跳动面经同学 21 抖音商城一面面试原题:sql的语法树解析
memo:2025 年 3 月 7 日 修改至此。再晒一个 offer,一位球友拿到了经纬恒润的实习 offer,并且直言面试了很多场,我说超过 5 次的题目基本上都碰到了,啥都别说了,面渣逆袭 YYDS。
数据库架构
20.说说 MySQL 的基础架构?
MySQL 采用分层架构,主要包括连接层、服务层、和存储引擎层。
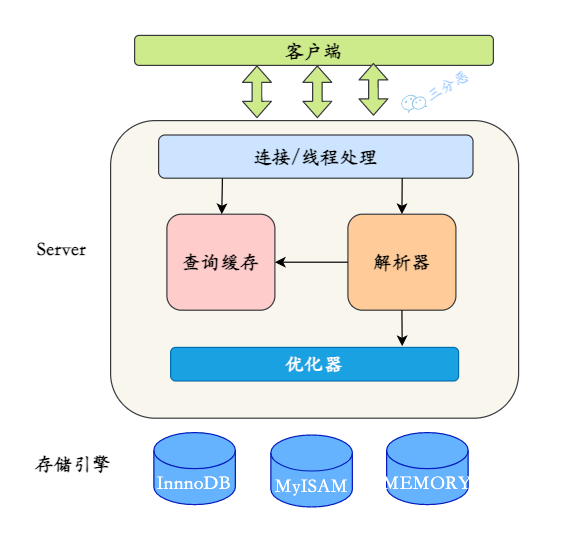
①、连接层主要负责客户端连接的管理,包括验证用户身份、权限校验、连接管理等。可以通过数据库连接池来提升连接的处理效率。
②、服务层是 MySQL 的核心,主要负责查询解析、优化、执行等操作。在这一层,SQL 语句会经过解析、优化器优化,然后转发到存储引擎执行,并返回结果。这一层包含查询解析器、优化器、执行计划生成器、日志模块等。
③、存储引擎层负责数据的实际存储和提取。MySQL 支持多种存储引擎,如 InnoDB、MyISAM、Memory 等。
binlog写入在哪一层?
binlog 在服务层,负责记录 SQL 语句的变化。它记录了所有对数据库进行更改的操作,用于数据恢复、主从复制等。
- Java 面试指南(付费)收录的字节跳动面经同学 21 抖音商城一面面试原题:mysql分为几层?binlog写入在哪一层
21.🌟一条查询语句是如何执行的?
当我们执行一条 SELECT 语句时,MySQL 并不会直接去磁盘读取数据,而是经过 6 个步骤来解析、优化、执行,然后再返回结果。
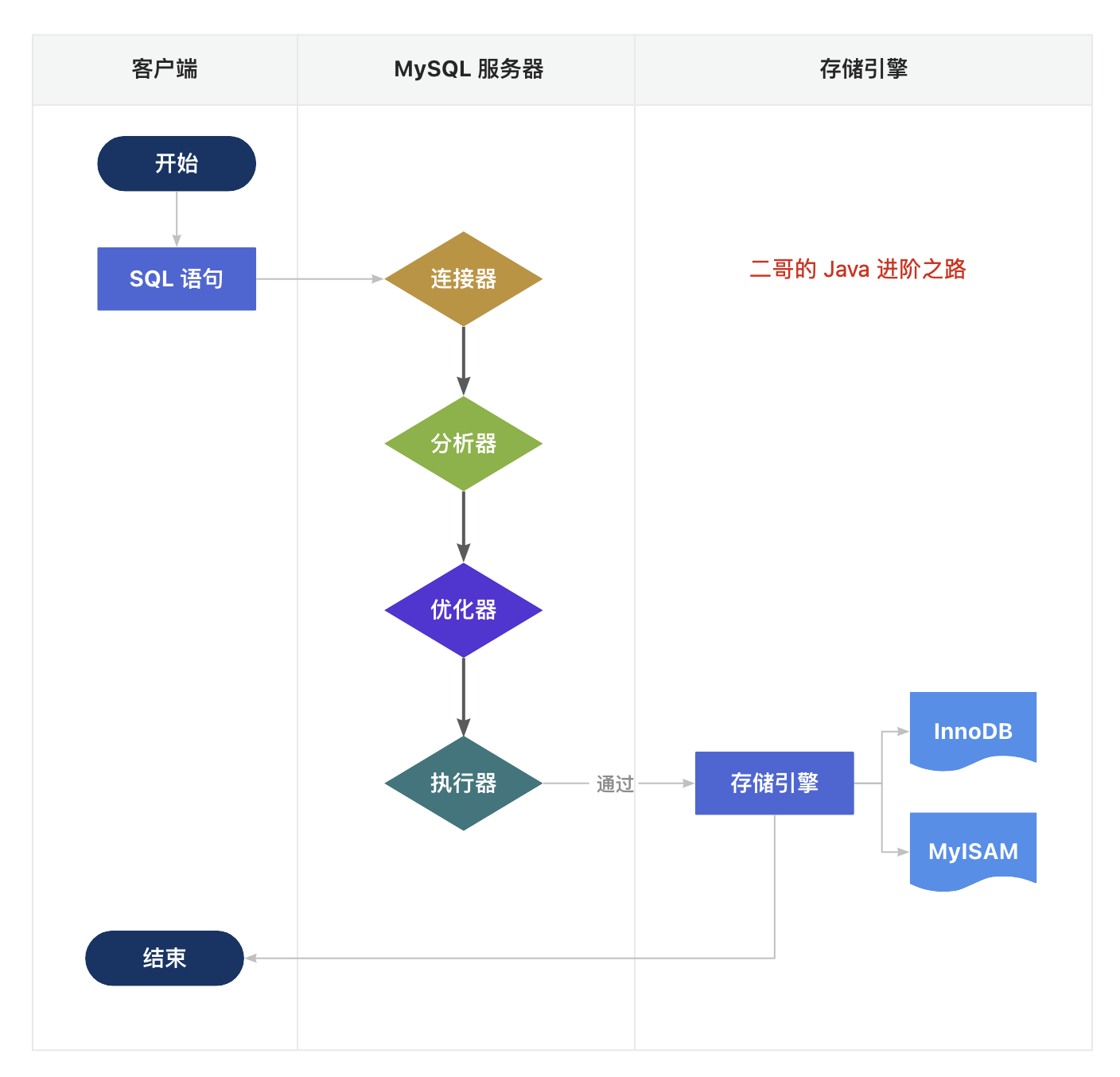
第一步,客户端发送 SQL 查询语句到 MySQL 服务器。
第二步,MySQL 服务器的连接器开始处理这个请求,跟客户端建立连接、获取权限、管理连接。
第三步,解析器对 SQL 语句进行解析,检查语句是否符合 SQL 语法规则,确保数据库、表和列都是存在的,并处理 SQL 语句中的名称解析和权限验证。
第四步,优化器负责确定 SQL 语句的执行计划,这包括选择使用哪些索引,以及决定表之间的连接顺序等。
第五步,执行器会调用存储引擎的 API 来进行数据的读写。
第六步,存储引擎负责查询数据,并将执行结果返回给客户端。客户端接收到查询结果,完成这次查询请求。
- Java 面试指南(付费)收录的美团面经同学 2 Java 后端技术一面面试原题:MySQL 执行语句的整个过程了解吗?
- Java 面试指南(付费)收录的美团面经同学 18 成都到家面试原题:mysql一条数据的查询过程
- Java 面试指南(付费)收录的字节跳动面经同学19番茄小说一面面试原题:MySQL中一条SQL的执行流程
memo:2025 年 3 月 8 日修改至此。
22.一条更新语句是如何执行的?
总的来说,一条 UPDATE 语句的执行过程包括读取数据页、加锁解锁、事务提交、日志记录等多个步骤。
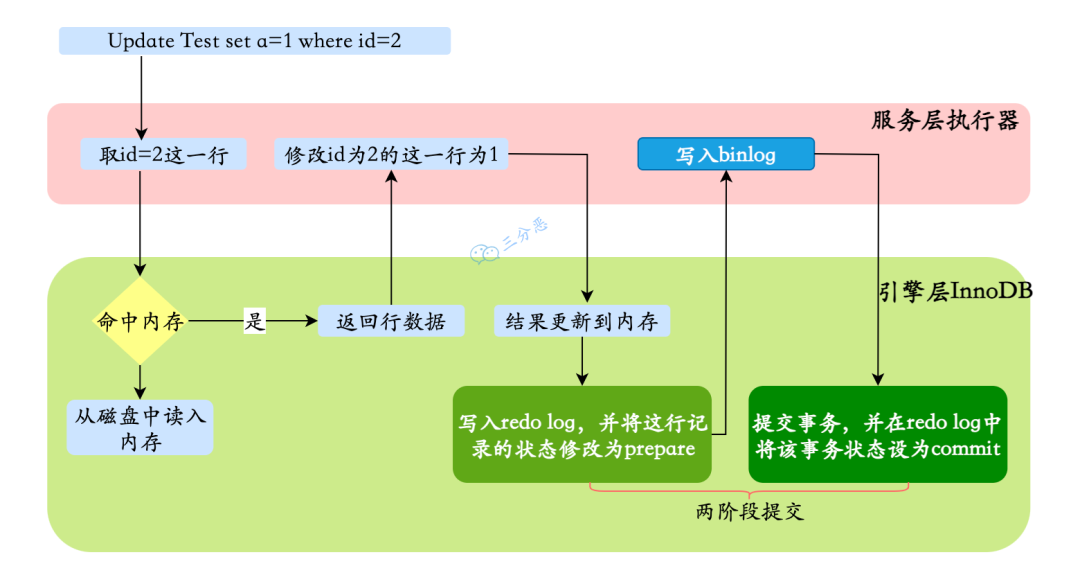
拿 update test set a=1 where id=2 举例来说:
在事务开始前,MySQL 需要记录undo log,用于事务回滚。
| 操作 | id | 旧值 | 新值 |
|---|---|---|---|
| update | 2 | N | 1 |
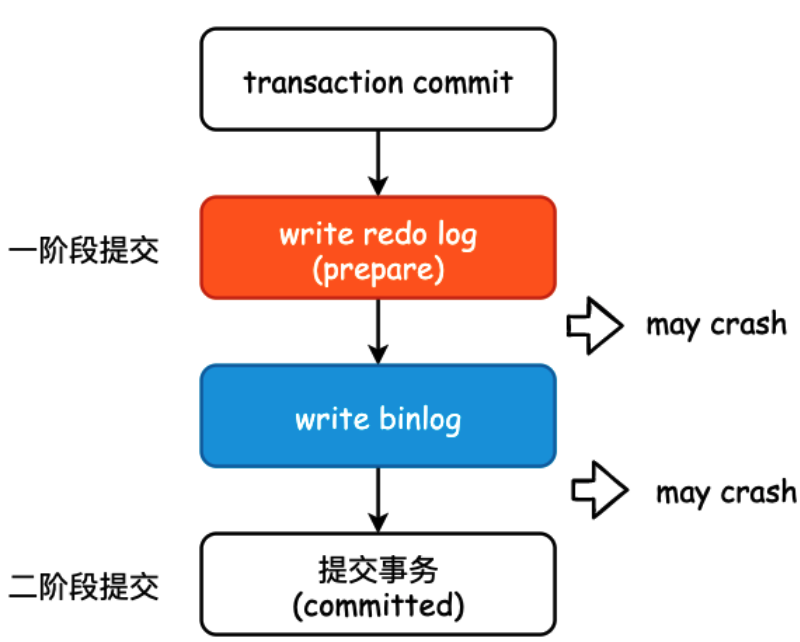
除了记录 undo log,存储引擎还会将更新操作写入 redo log,状态标记为 prepare,并确保 redo log 持久化到磁盘。这一步可以保证即使系统崩溃,数据也能通过 redo log 恢复到一致状态。
写完 redo log 后,MySQL 会获取行锁,将 a 的值修改为 1,标记为脏页,此时数据仍然在内存的 buffer pool 中,不会立即写入磁盘。后台线程会在适当的时候将脏页刷盘,以提高性能。
最后提交事务,redo log 中的记录被标记为 committed,行锁释放。
如果 MySQL 开启了 binlog,还会将更新操作记录到 binlog 中,主要用于主从复制。
以及数据恢复,可以结合 redo log 进行点对点的恢复。binlog 的写入通常发生在事务提交时,与 redo log 共同构成“两阶段提交”,确保两者的一致性。
注意,redo log 的写入有两个阶段的提交,一是 binlog 写入之前prepare 状态的写入,二是 binlog 写入之后 commit 状态的写入。
memo:2025 年 3 月 9 日修改至此。
23.说说 MySQL 的段区页行(补充)
2024 年 04 月 26 日增补
推荐阅读:了解 MySQL的数据行、行溢出机制吗?
MySQL 是以表的形式存储数据的,而表空间的结构则由段、区、页、行组成。
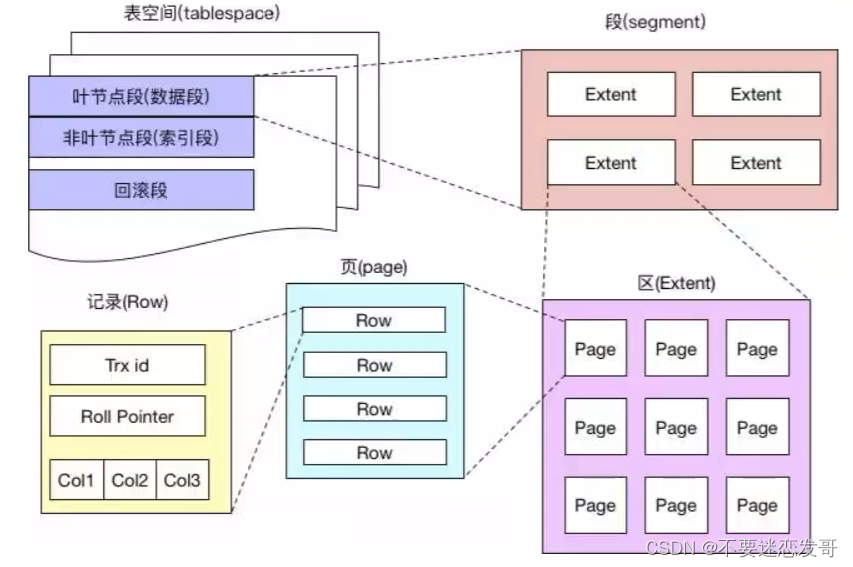
①、段:表空间由多个段组成,常见的段有数据段、索引段、回滚段等。
创建索引时会创建两个段,数据段和索引段,数据段用来存储叶子节点中的数据;索引段用来存储非叶子节点的数据。
回滚段包含了事务执行过程中用于数据回滚的旧数据。
②、区:段由一个或多个区组成,区是一组连续的页,通常包含 64 个连续的页,也就是 1M 的数据。
使用区而非单独的页进行数据分配可以优化磁盘操作,减少磁盘寻道时间,特别是在大量数据进行读写时。
③、页:页是 InnoDB 存储数据的基本单元,标准大小为 16 KB,索引树上的一个节点就是一个页。
也就意味着数据库每次读写都是以 16 KB 为单位的,一次最少从磁盘中读取 16KB 的数据到内存,一次最少写入 16KB 的数据到磁盘。
④、行:InnoDB 采用行存储方式,意味着数据按照行进行组织和管理,行数据可能有多个格式,比如说 COMPACT、REDUNDANT、DYNAMIC 等。
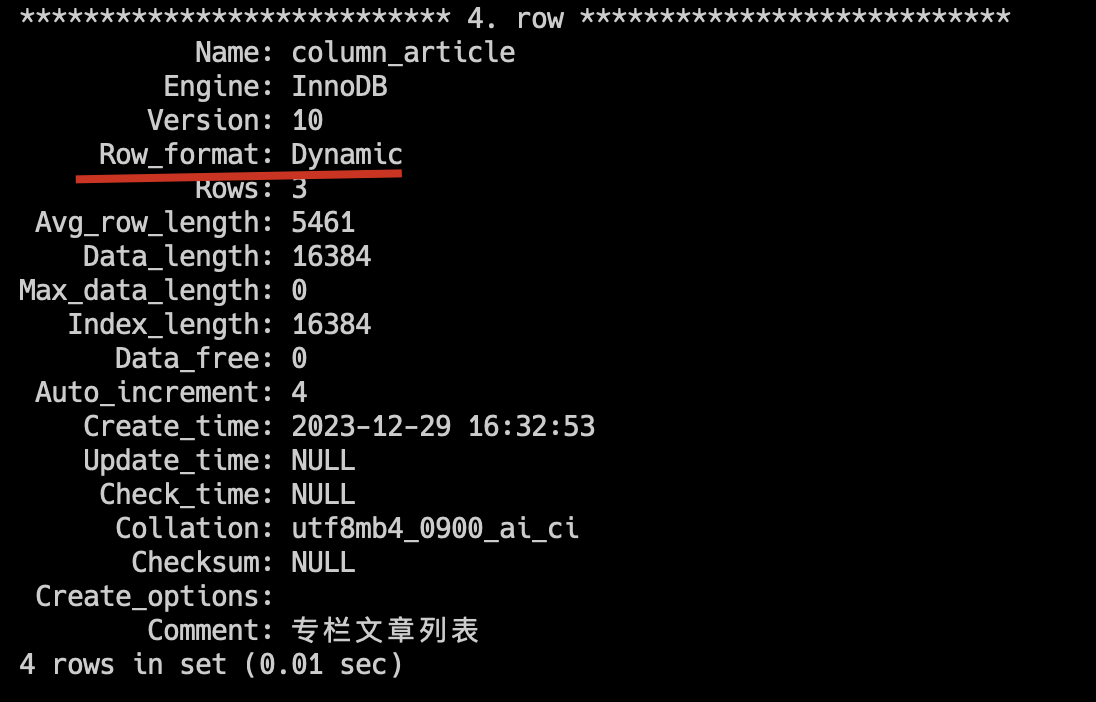
MySQL 8.0 默认的行格式是 DYNAMIC,由COMPACT 演变而来,意味着这些数据如果超过了页内联存储的限制,则会被存储在溢出页中。
可以通过 show table status like '%article%' 查看行格式。
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
存储引擎
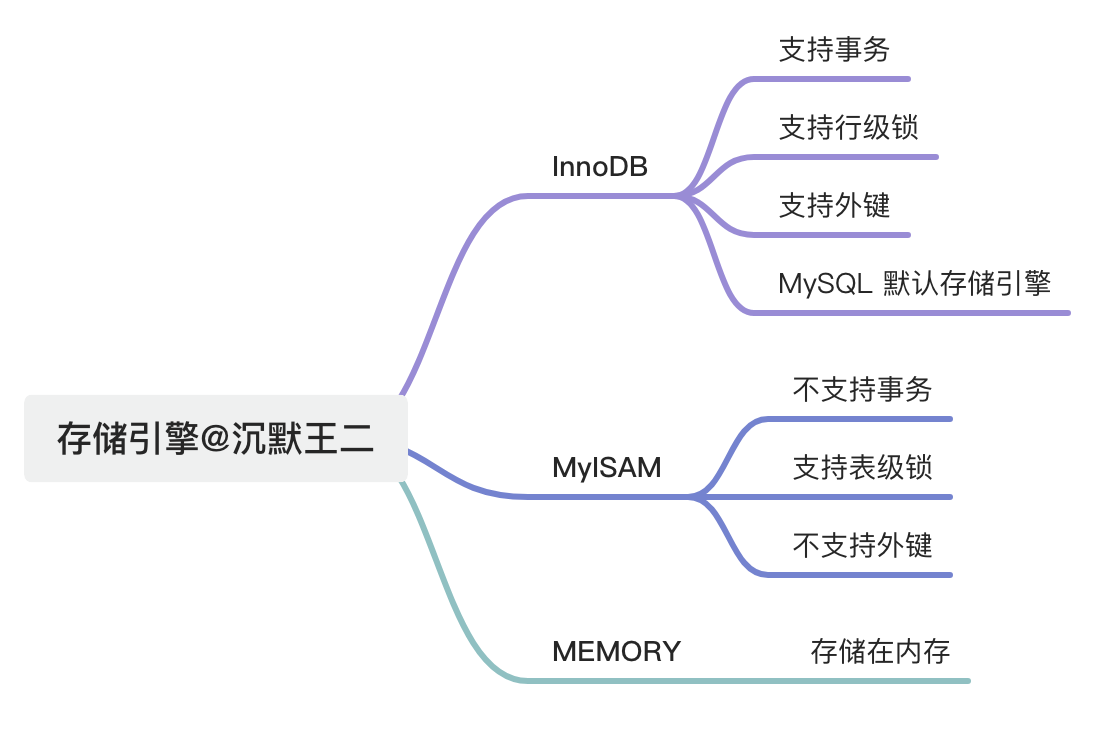
24.🌟MySQL 有哪些常见存储引擎?
MySQL 支持多种存储引擎,常见的有 MyISAM、InnoDB、MEMORY 等。
---这部分是帮助大家理解 start,面试中可不背---
我来做一个表格对比:
| 功能 | InnoDB | MyISAM | MEMORY |
|---|---|---|---|
| 支持事务 | Yes | No | No |
| 支持全文索引 | Yes | Yes | No |
| 支持 B+树索引 | Yes | Yes | Yes |
| 支持哈希索引 | Yes | No | Yes |
| 支持外键 | Yes | No | No |
---这部分是帮助大家理解 end,面试中可不背---
除此之外,我还了解到:
①、MySQL 5.5 之前,默认存储引擎是 MyISAM,5.5 之后是 InnoDB。
②、InnoDB 支持的哈希索引是自适应的,不能人为干预。
③、InnoDB 从 MySQL 5.6 开始,支持全文索引。
④、InnoDB 的最小表空间略小于 10M,最大表空间取决于页面大小。
如何切换 MySQL 的数据引擎?
可以通过 alter table 语句来切换 MySQL 的数据引擎。
ALTER TABLE your_table_name ENGINE=InnoDB;不过不建议,应该提前设计好到底用哪一种存储引擎。
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:MySQL 支持哪些存储引擎?
- Java 面试指南(付费)收录的用友面试原题:innodb 引擎和 hash 引擎有什么区别
- Java 面试指南(付费)收录的国企零碎面经同学 9 面试原题:MySQL 的存储引擎
- Java 面试指南(付费)收录的京东同学 4 云实习面试原题:mysql的数据引擎有哪些, 区别(innodb,MyISAM,Memory)
- Java 面试指南(付费)收录的阿里系面经同学 19 饿了么面试原题:存储引擎介绍
memo:2025 年 3 月 10 日修改至此。
25.存储引擎应该怎么选择?
大多数情况下,使用默认的 InnoDB 就可以了,InnoDB 可以提供事务、行级锁、外键、B+ 树索引等能力。
MyISAM 适合读多写少的场景。
MEMORY 适合临时表,数据量不大的情况。因为数据都存放在内存,所以速度非常快。
- Java 面试指南(付费)收录的快手同学 2 一面面试原题:MySQL的InnoDB特点?为什么用B+树?而不是B树,区别?
26.InnoDB 和 MyISAM 主要有什么区别?
InnoDB 和 MyISAM 的最大区别在于事务支持和锁机制。InnoDB 支持事务、行级锁,适合大多数业务系统;而 MyISAM 不支持事务,用的是表锁,查询快但写入性能差,适合读多写少的场景。
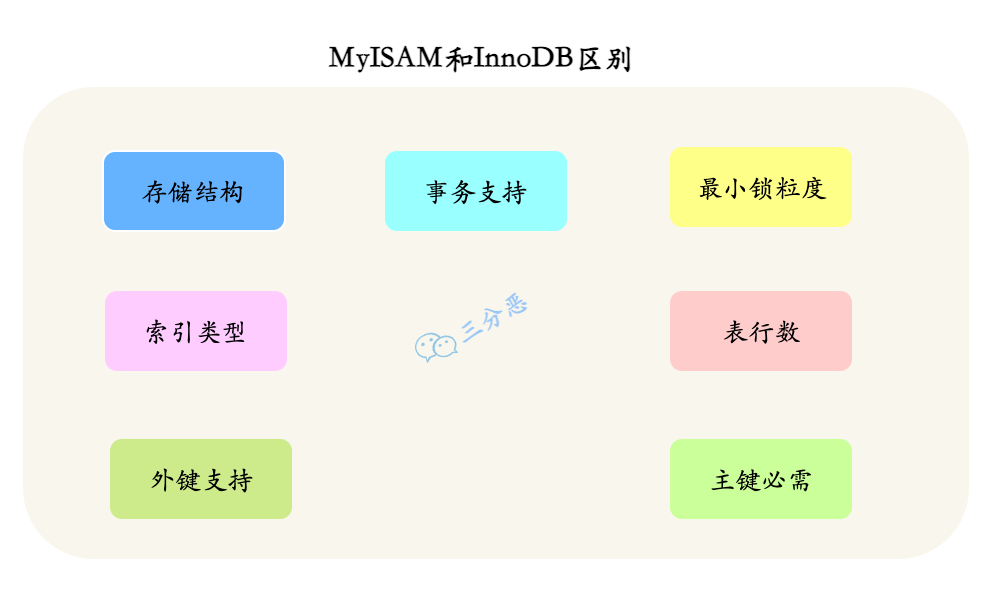
另外,从存储结构上来说,MyISAM 用三种格式的文件来存储,.frm 文件存储表的定义;.MYD 存储数据;.MYI 存储索引;而 InnoDB 用两种格式的文件来存储,.frm 文件存储表的定义;.ibd 存储数据和索引。
从索引类型上来说,MyISAM 为非聚簇索引,索引和数据分开存储,索引保存的是数据文件的指针。
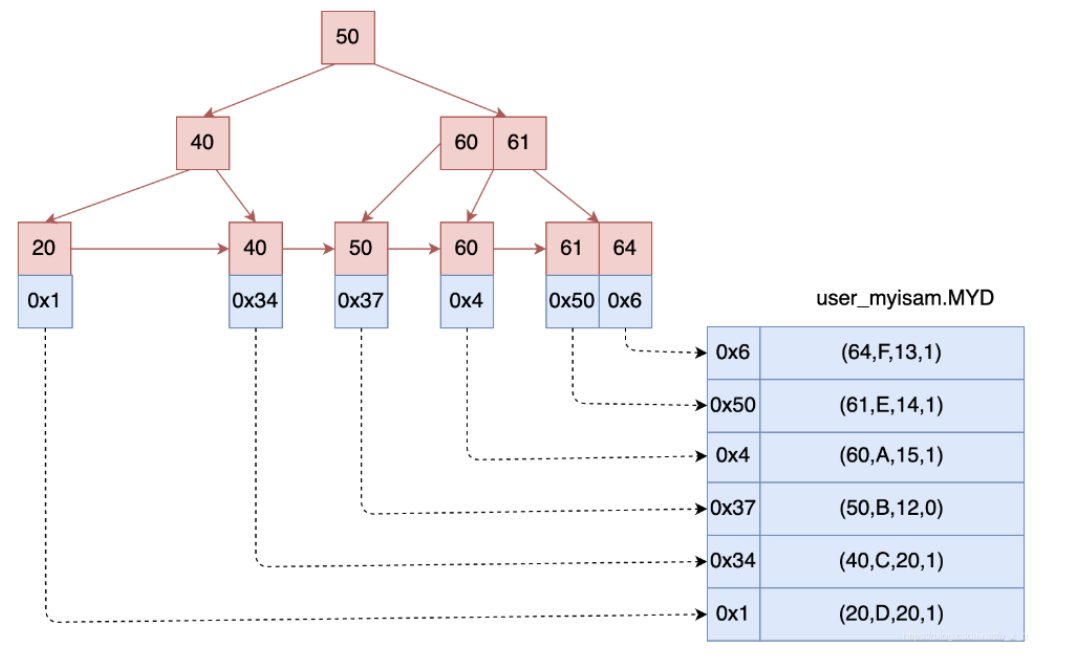
InnoDB 为聚簇索引,索引和数据不分开。
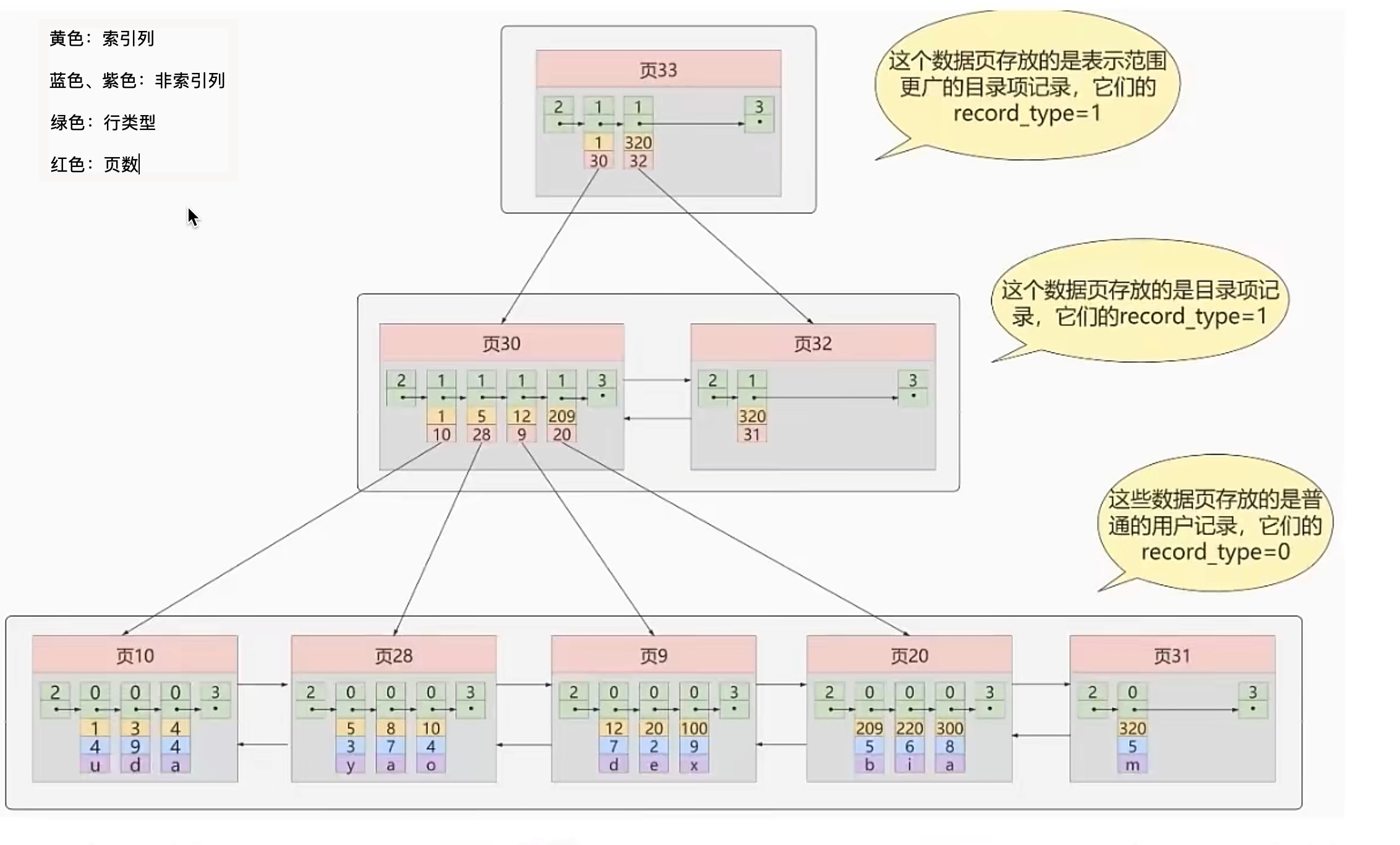
更细微的层面上来讲,MyISAM 不支持外键,可以没有主键,表的具体行数存储在表的属性中,查询时可以直接返回;InnoDB 支持外键,必须有主键,具体行数需要扫描整个表才能返回,有索引的情况下会扫描索引。
InnoDB的内存结构了解吗?
2025 年 04 月 04 日增补
InnoDB 的内存区域主要有两块,buffer pool 和 log buffer。 buffer pool 用于缓存数据页和索引页,提升读写性能;log buffer 用于缓存 redo log,提升写入性能。
数据页的结构了解吗?
InnoDB 的数据页由 7 部分组成,其中文件头、页头和文件尾的大小是固定的,分别为 38、56 和 8 个字节,用来标记该页的一些信息。行记录、空闲空间和页目录的大小是动态的,为实际的行记录存储空间。
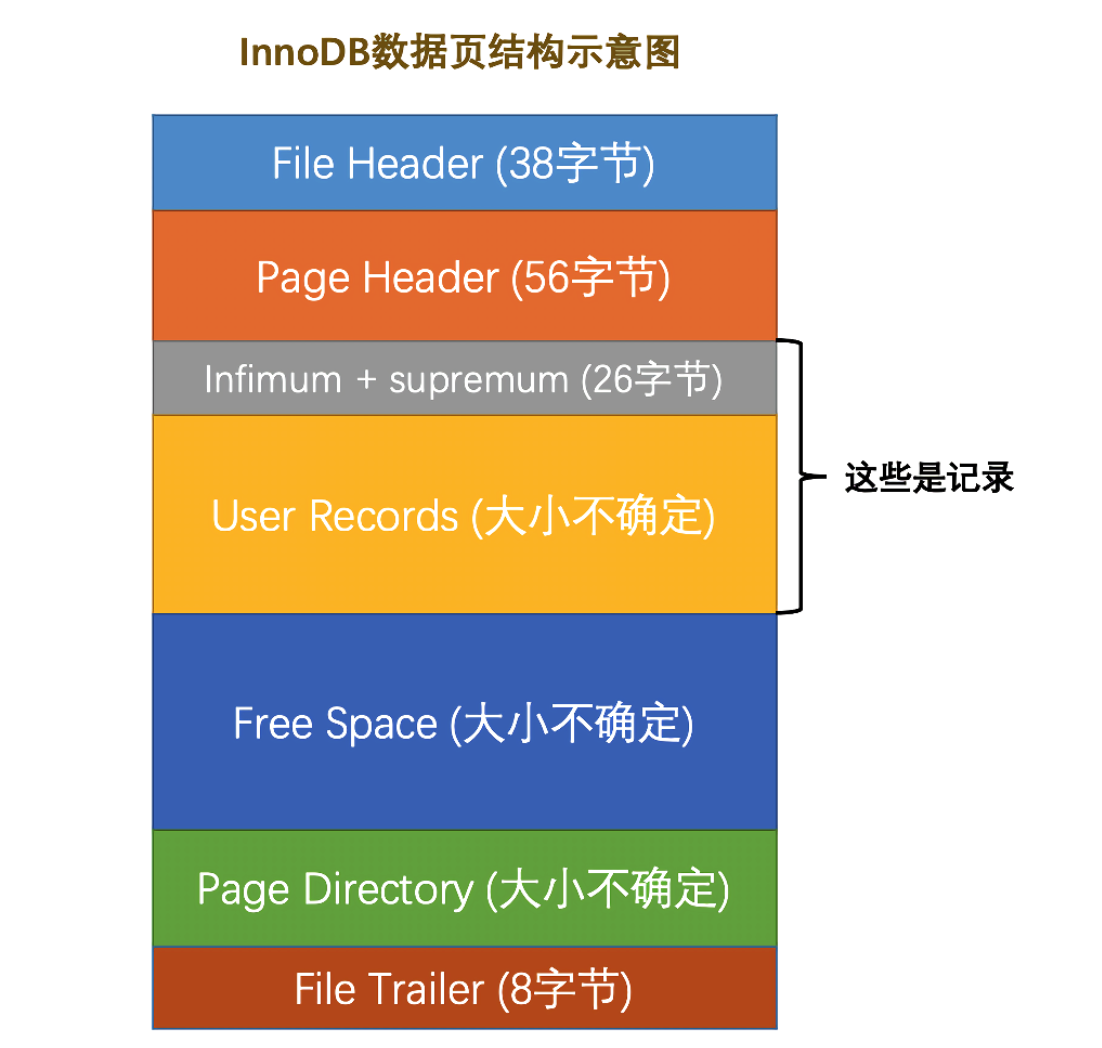
来个表格总结下:
| 名称 | 中文名 | 大小(单位:B) | 描述 |
|---|---|---|---|
| File Header | 文件头部 | 38 | 页的一些通用信息 |
| Page Header | 页面头部 | 56 | 数据页专有的一些信息 |
| Infimum + Supermum | 最小记录和最大记录 | 26 | 两个虚拟的行记录 |
| User Records | 用户真实记录 | 不确定 | 实际存储的行记录内容 |
| Free Space | 空闲空间 | 不确定 | 页中尚未使用的空间 |
| Page Directory | 页面目录 | 不确定 | 页中的某些记录的相对位置 |
| File Trailer | 文件尾部 | 8 | 校验页是否完整 |
真实的记录会按照指定的行格式存储到 User Records 中。
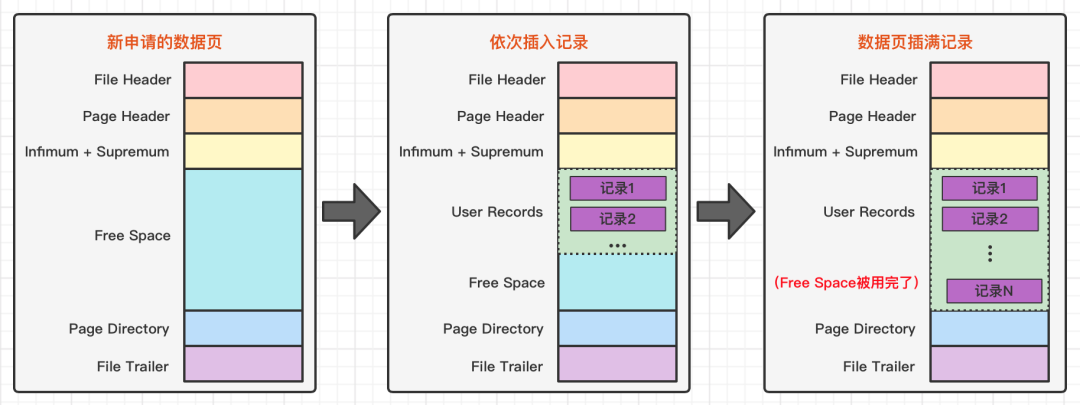
每个数据页的 File Header 都有一个上一页和下一页的编号,所有的数据页会形成一个双向链表。
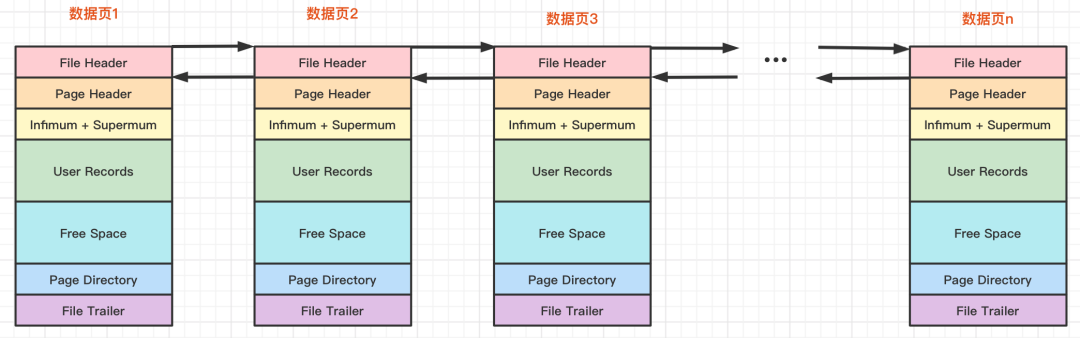
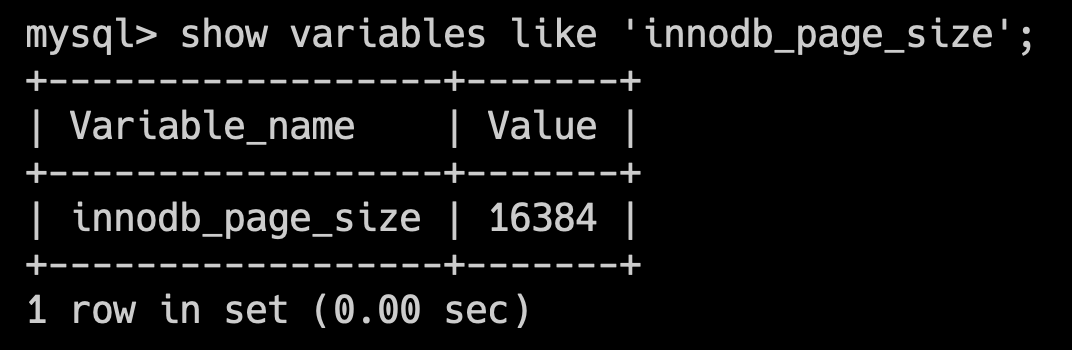
在 InnoDB 中,默认的页大小是 16KB。可以通过 show variables like 'innodb_page_size'; 查看。
推荐阅读:MySQL之数据页结构
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:MyISAM 和 InnoDB 的区别有哪些?
- Java 面试指南(付费)收录的美团同学 9 一面面试原题:mysql存储的数据都是什么样的?
memo:2025 年 3 月 11 日修改至此。
27. InnoDB 的 Buffer Pool了解吗?(补充)
2024 年 11 月 04 日增补
Buffer Pool 是 InnoDB 存储引擎中的一个内存缓冲区,它会将经常使用的数据页、索引页加载进内存,读的时候先查询 Buffer Pool,如果命中就不用访问磁盘了。
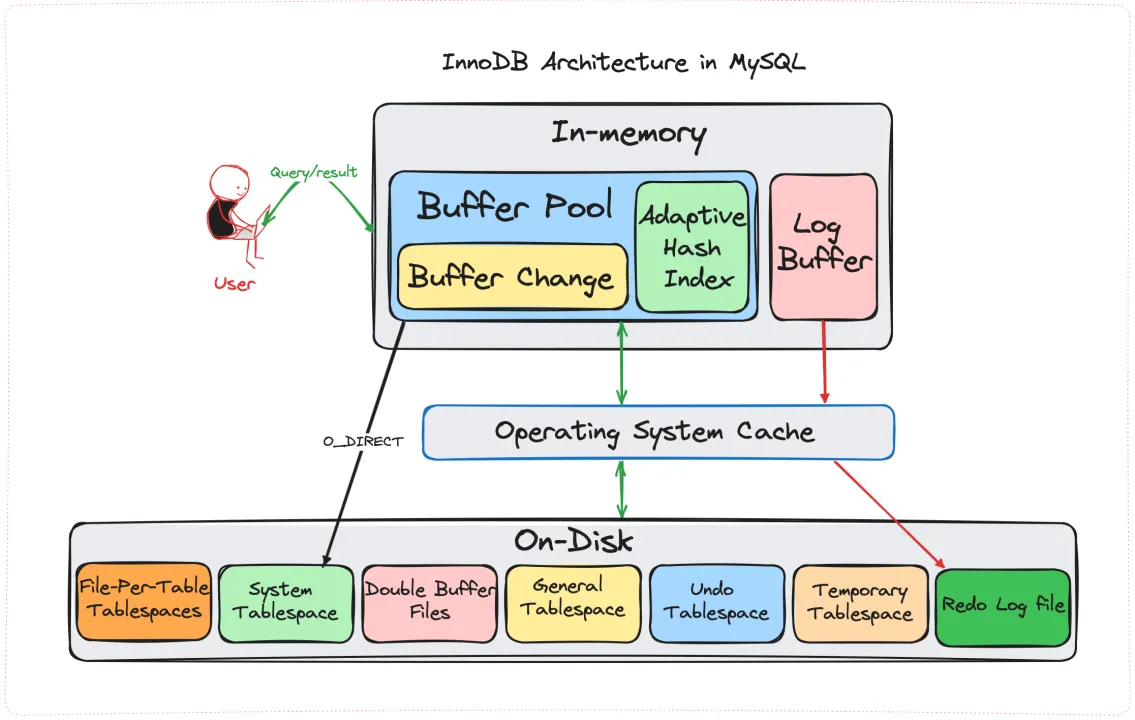
如果没有命中,就从磁盘读取,并加载到 Buffer Pool,此时可能会触发页淘汰,将不常用的页移出 Buffer Pool。
写操作时不会直接写入磁盘,而是先修改内存中的页,此时页被标记为脏页,后台线程会定期将脏页刷新到磁盘。
Buffer Pool 可以显著减少磁盘的读写次数,从而提升 MySQL 的读写性能。
Buffer Pool 的默认大小是多少?
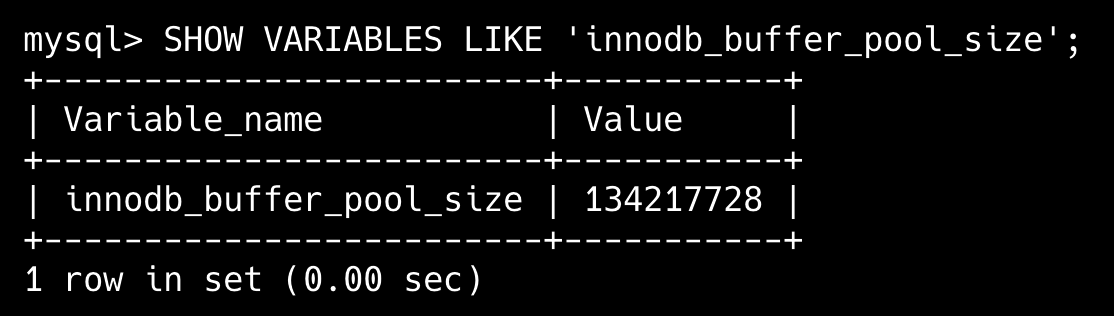
我本机上 InnoDB 的 Buffer Pool 默认大小是 128MB。
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';另外,在具有 1GB-4GB RAM 的系统上,默认值为系统 RAM 的 25%;在具有超过 4GB RAM 的系统上,默认值为系统 RAM 的 50%,但不超过 4GB。
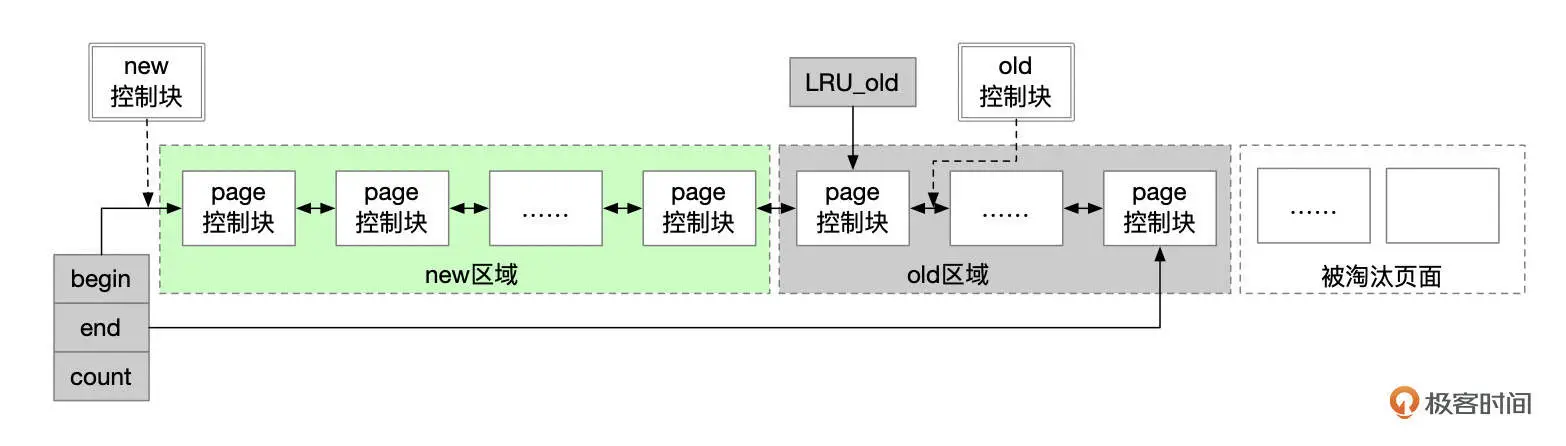
InnoDB 对 LRU 算法的优化了解吗?
了解,InnoDB 对 LRU 算法进行了改良,最近访问的数据并不直接放到 LRU 链表的头部,而是放在一个叫 midpoiont 的位置。默认情况下,midpoint 位于 LRU 列表的 5/8 处。
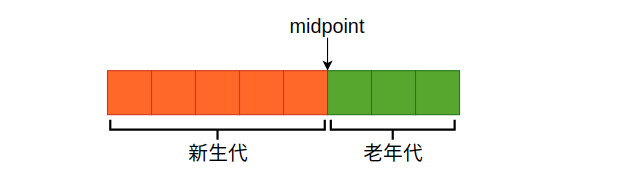
比如 Buffer Pool 有 100 页,新页插入的位置大概是在第 80 页;当页数据被频繁访问后,再将其移动到 young 区,这样做的好处是热点页能长时间保留在内存中,不容易被挤出去。
----这部分是帮助大家理解 start,面试中可不背----
可以通过 innodb_old_blocks_pct 参数来调整 Buffer Pool 中 old 和 young 区的比例;通过 innodb_old_blocks_time 参数来调整页在 young 区的停留时间。
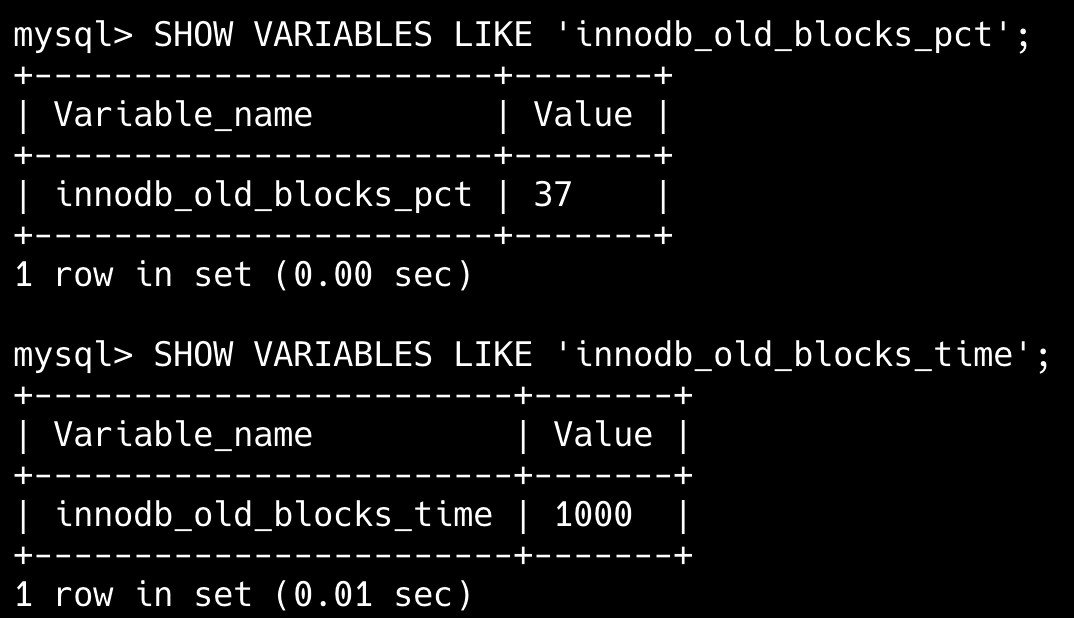
默认情况下,LRU 链表中 old 区占 37%;同一页再次访问提升的最小时间间隔是 1000 毫秒。
也就是说,如果某页在 1 秒内被多次访问,只会计算一次,不会立刻升级为热点页,防止短时间批量访问导致缓存污染。
----这部分是帮助大家理解 end,面试中可不背----
- Java 面试指南(付费)收录的美团面经同学 15 点评后端技术面试原题:说说 bufferpool
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 3 月 12 日修改至此。继续给大家一个喜报,今天有球友报喜说社招拿到了京东和美团的 offer,后续补充说滴滴也过了,我只能说太强了呀。

日志
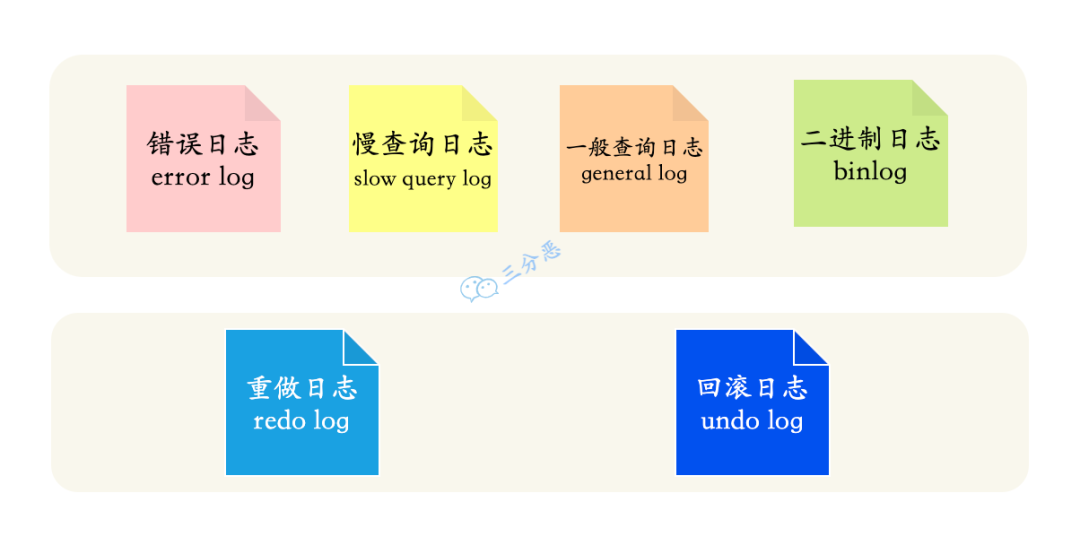
28.🌟MySQL 日志文件有哪些?
有 6 大类,其中错误日志用于问题诊断,慢查询日志用于 SQL 性能分析,general log 用于记录所有的 SQL 语句,binlog 用于主从复制和数据恢复,redo log 用于保证事务持久性,undo log 用于事务回滚和 MVCC。
----这部分是帮助大家理解 start,面试中可不背----
①、错误日志(Error Log):记录 MySQL 服务器启动、运行或停止时出现的问题。
②、慢查询日志(Slow Query Log):记录执行时间超过 long_query_time 值的所有 SQL 语句。这个时间值是可配置的,默认情况下,慢查询日志功能是关闭的。
③、一般查询日志(General Query Log):记录 MySQL 服务器的启动关闭信息,客户端的连接信息,以及更新、查询的 SQL 语句等。
④、二进制日志(Binary Log):记录所有修改数据库状态的 SQL 语句,以及每个语句的执行时间,如 INSERT、UPDATE、DELETE 等,但不包括 SELECT 和 SHOW 这类的操作。
⑤、重做日志(Redo Log):记录对于 InnoDB 表的每个写操作,不是 SQL 级别的,而是物理级别的,主要用于崩溃恢复。
⑥、回滚日志(Undo Log,或者叫事务日志):记录数据被修改前的值,用于事务的回滚。
----这部分是帮助大家理解 end,面试中可不背----
请重点说说 binlog?
推荐阅读:带你了解 MySQL Binlog 不为人知的秘密
binlog 是一种二进制日志,会在磁盘上记录数据库的所有修改操作。
如果误删了数据,就可以使用 binlog 进行回退到误删之前的状态。
# 步骤1:恢复全量备份
mysql -u root -p < full_backup.sql
# 步骤2:应用Binlog到指定时间点
mysqlbinlog --start-datetime="2025-03-13 14:00:00" --stop-datetime="2025-03-13 15:00:00" binlog.000001 | mysql -u root -p如果要搭建主从复制,就可以让从库定时读取主库的 binlog。
MySQL 提供了三种格式的 binlog:Statement、Row 和 Mixed,分别对应 SQL 语句级别、行级别和混合级别,默认为行级别。
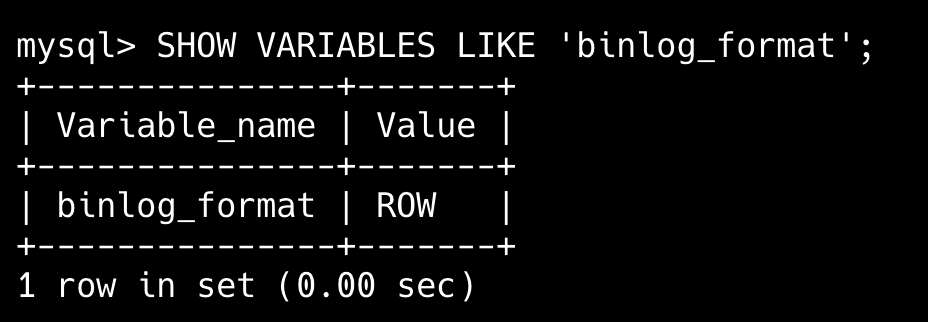
从后缀名上来看,binlog 文件分为两类:以 .index 结尾的索引文件,以 .00000* 结尾的二进制日志文件。
binlog 默认是没有启用的。
生产环境中是一定要启用的,可以通过在 my.cnf 文件中配置 log_bin 参数,以启用 binlog。
log_bin = mysql-bin #开启binlog
#mysql-bin.*日志文件最大字节(单位:字节)
#设置最大100MB
max_binlog_size=104857600
#设置了只保留7天BINLOG(单位:天)
expire_logs_days = 7
#binlog日志只记录指定库的更新
#binlog-do-db=db_name
#binlog日志不记录指定库的更新
#binlog-ignore-db=db_name
#写缓冲多少次,刷一次磁盘,默认0
sync_binlog=0binlog 的配置参数都了解哪些?
log_bin = mysql-bin 用于启用 binlog,这样就可以在 MySQL 的数据目录中找到 db-bin.000001、db-bin.000002 等日志文件。
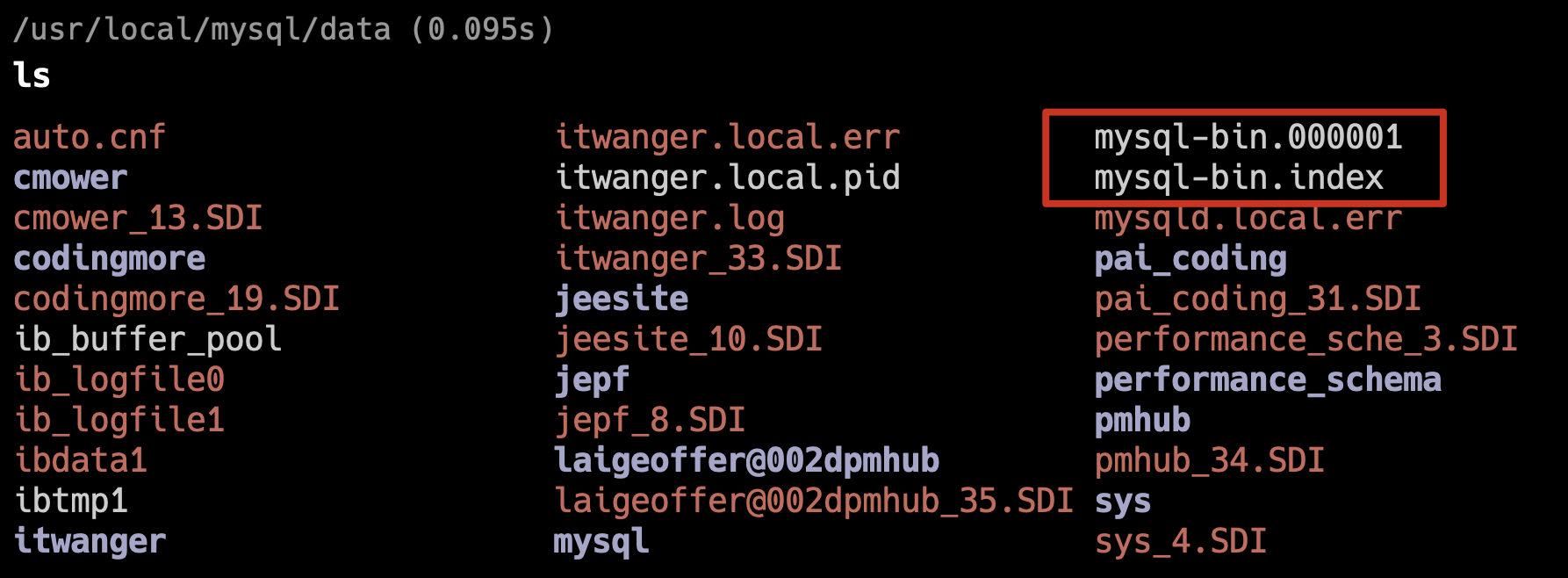
max_binlog_size=104857600 用于设置每个 binlog 文件的大小,不建议设置太大,网络传送起来比较麻烦。
当 binlog 文件达到 max_binlog_size 时,MySQL 会关闭当前文件并创建一个新的 binlog 文件。
expire_logs_days = 7 用于设置 binlog 文件的自动过期时间为 7 天。过期的 binlog 文件会被自动删除。防止长时间累积的 binlog 文件占用过多存储空间,技术派实战项目所在的项目是丐版服务器,所以这个配置很重要。
binlog-do-db=db_name,指定哪些数据库表的更新应该被记录。
binlog-ignore-db=db_name,指定忽略哪些数据库表的更新。
sync_binlog=0,设置每多少次 binlog 写操作会触发一次磁盘同步操作。默认值为 0,表示 MySQL 不会主动触发同步操作,而是依赖操作系统的磁盘缓存策略。
即当执行写操作时,数据会先写入缓存,当缓存区满了再由操作系统将数据一次性刷入磁盘。
如果设置为 1,表示每次 binlog 写操作后都会同步到磁盘,虽然可以保证数据能够及时写入磁盘,但会降低性能。
可以通过 show variables like '%log_bin%'; 查看 binlog 是否开启。
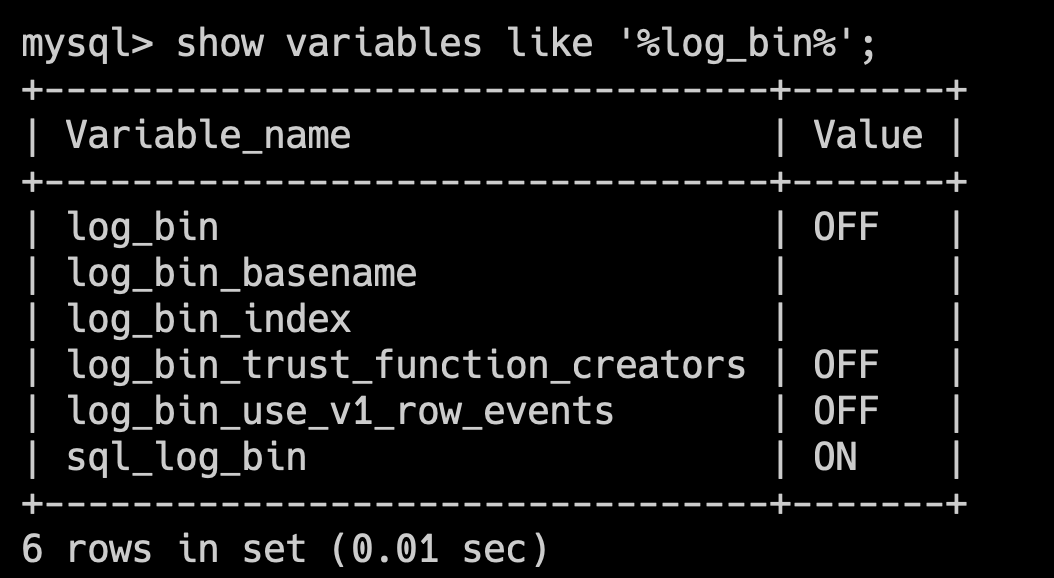
有了binlog为什么还要undolog redolog?
binlog 属于 Server 层,与存储引擎无关,无法直接操作物理数据页。而 redo log 和 undo log 是 InnoDB 存储引擎实现 ACID 的基石。
binlog 关注的是逻辑变更的全局记录;redo log 用于确保物理变更的持久性,确保事务最终能够刷盘成功;undo log 是逻辑逆向操作日志,记录的是旧值,方便恢复到事务开始前的状态。
另外一种回答方式。
binlog 会记录整个 SQL 或行变化;redo log 是为了恢复“已提交但未刷盘”的数据,undo log 是为了撤销未提交的事务。
以一次事务更新为例:
# 开启事务
BEGIN;
# 更新数据
UPDATE users SET age = age + 1 WHERE id = 1;
# 提交事务
COMMIT;事务开始的时候会生成 undo log,记录更新前的数据,比如原值是 18:
undo log: id=1, age=18修改数据的时候,会将数据写入到 redo log。
比如数据页 page_id=123 上,id=1 的用户被更新为 age=26:
redo log (prepare):
page_id=123, offset=0x40, before=18, after=26等事务提交的时候,redo log 刷盘,binlog 刷盘。
binlog 写完之后,redo log 的状态会变为 commit:
redo log (commit):
page_id=123, offset=0x40, before=18, after=26binlog 如果是 Statement 格式,会记录一条 SQL 语句:
UPDATE users SET age = age + 1 WHERE id = 1;binlog 如果是 Row 格式,会记录:
表:users
before: id=1, age=18
after: id=1, age=26随后,后台线程会将 redo log 中的变更异步刷新到磁盘。
memo:2025 年 3 月 13 日修改至此。有球友报喜,字节二面过了,找暑期顺利的不可思议,八股直接吟唱面渣。
说说 redo log 的工作机制?
当事务启动时,MySQL 会为该事务分配一个唯一标识符。
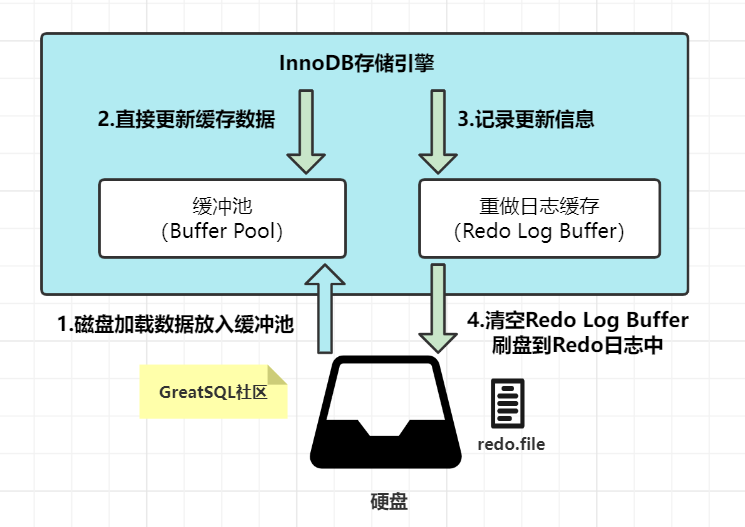
在事务执行过程中,每次对数据进行修改,MySQL 都会生成一条 Redo Log,记录修改前后的数据状态。
这些 Redo Log 首先会被写入内存中的 Redo Log Buffer。
当事务提交时,MySQL 再将 Redo Log Buffer 中的记录刷新到磁盘上的 Redo Log 文件中。
只有当 Redo Log 成功写入磁盘,事务才算真正提交成功。
当 MySQL 崩溃重启时,会先检查 Redo Log。对于已提交的事务,MySQL 会重放 Redo Log 中的记录。
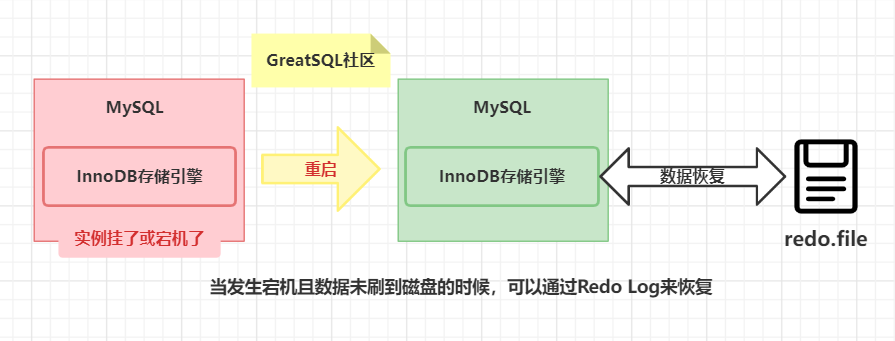
对于未提交的事务,MySQL 会通过 Undo Log 回滚这些修改,确保数据恢复到崩溃前的一致性状态。
Redo Log 是循环使用的,当文件写满后会覆盖最早的记录。
为避免覆盖未持久化的记录,MySQL 会定期执行 CheckPoint 操作,将内存中的数据页刷新到磁盘,并记录 CheckPoint 点。
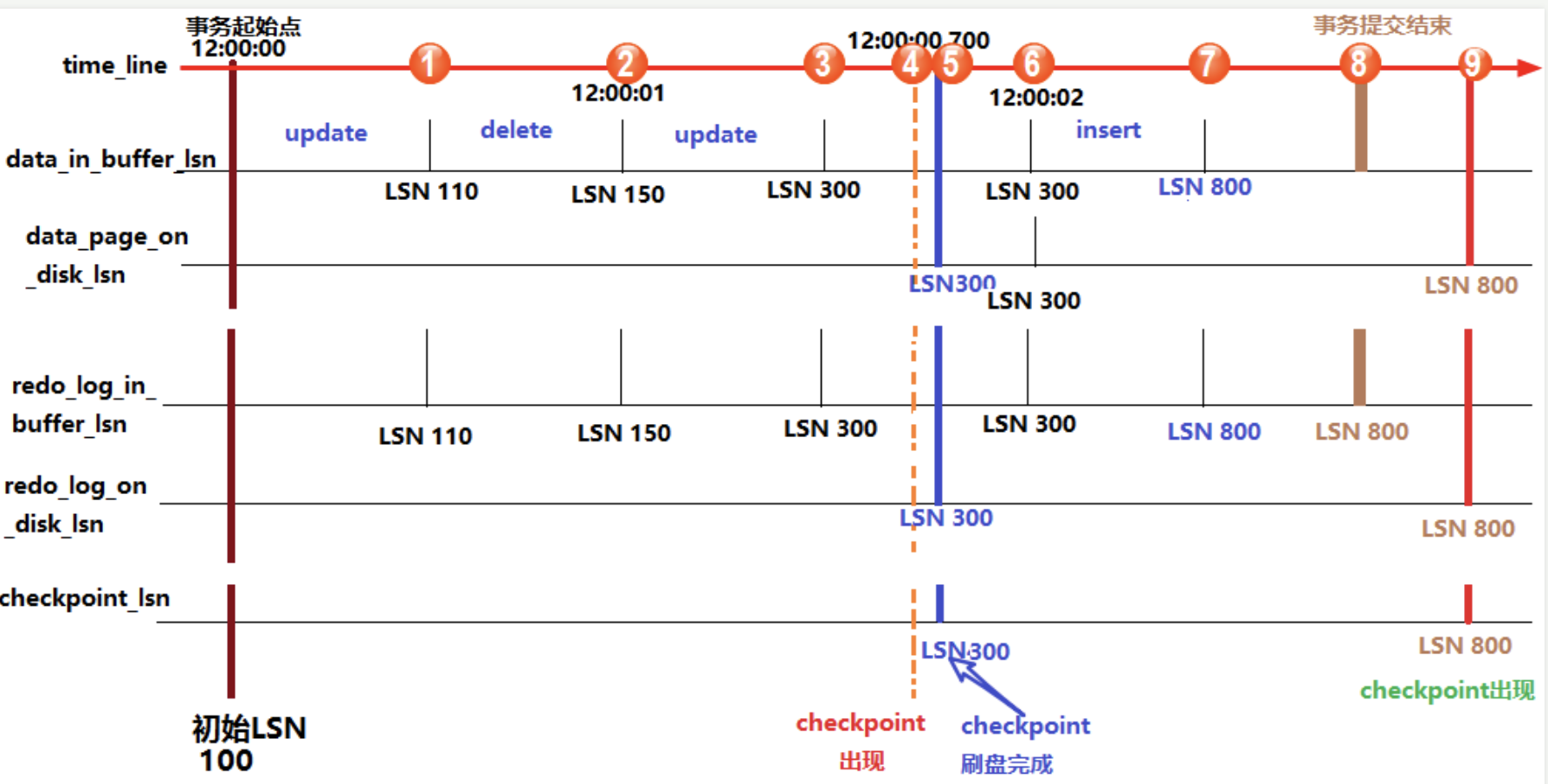
重启时,MySQL 只会重放 CheckPoint 之后的 Redo Log,从而提高恢复效率。
redo log 文件的大小是固定的吗?
redo log 文件是固定大小的,通常配置为一组文件,使用环形方式写入,旧的日志会在空间需要时被覆盖。
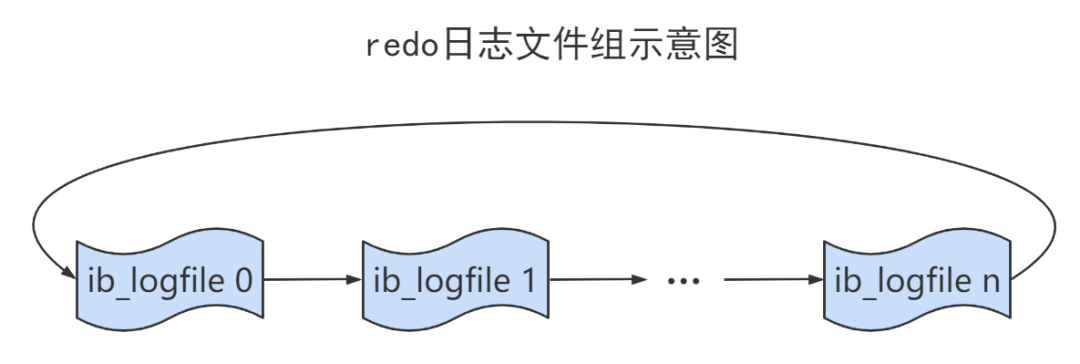
命名方式为 ib_logfile0、iblogfile1、、、iblogfilen。默认 2 个文件,每个文件大小为 48MB。

可以通过 show variables like 'innodb_log_file_size'; 查看 redo log 文件的大小;通过 show variables like 'innodb_log_files_in_group'; 查看 redo log 文件的数量。
说说 WAL?
WAL——Write-Ahead Logging。
预写日志是 InnoDB 实现事务持久化的核心机制,它的思想是:先写日志再刷磁盘。
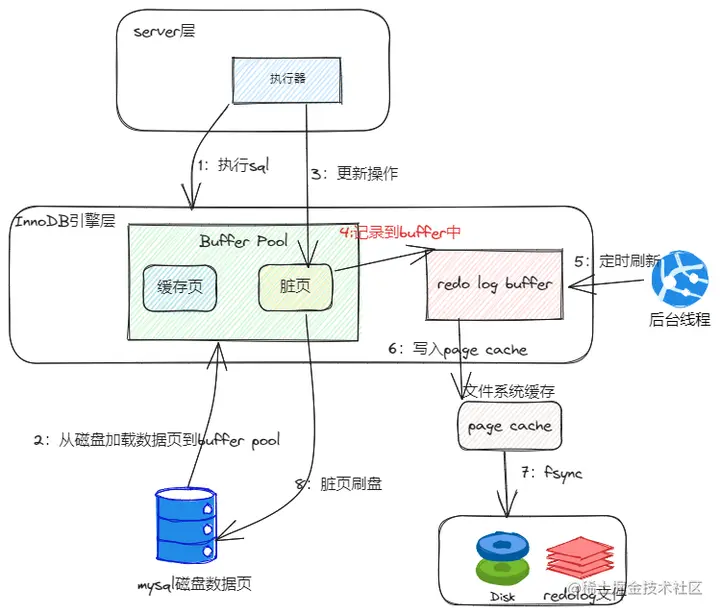
即在修改数据页之前,先将修改记录写入 Redo Log。
这样的话,即使数据页尚未写入磁盘,系统崩溃时也能通过 Redo Log 恢复数据。
----这部分是帮助大家理解 start,面试中可不背----
解释一下为什么需要 WAL:
- 数据最终是要写入磁盘的,但磁盘 IO 很慢;
- 如果每次更新都立刻把数据页刷盘,性能很差;
- 如果还没写入磁盘就宕机,事务会丢失。
WAL 的好处是更新时不直接写数据页,而是先写一份变更记录到 redo log,后台再慢慢把真正的数据页刷盘,一举多得。
----这部分是帮助大家理解 end,面试中可不背----
- Java 面试指南(付费)收录的华为面经同学 8 技术二面面试原题:MySQL 中的 bin log 的作用是什么?
- Java 面试指南(付费)收录的美团面经同学 2 Java 后端技术一面面试原题:说说 MySQL 的三大日志?
- Java 面试指南(付费)收录的字节跳动面经同学 21 抖音商城一面面试原题:redolog undolog binlog,有了binlog为什么还要undolog redolog,redolog的工作机制,说说 WAL
memo:2025 年 3 月 14 日修改至此。今天修改简历的时候,碰到一位比赛经历非常丰富的球友,大家在校期间如果有时间,也可以冲一下。

29.binlog 和 redo log 有什么区别?
binlog 由 MySQL 的 Server 层实现,与存储引擎无关;redo log 由 InnoDB 存储引擎实现。
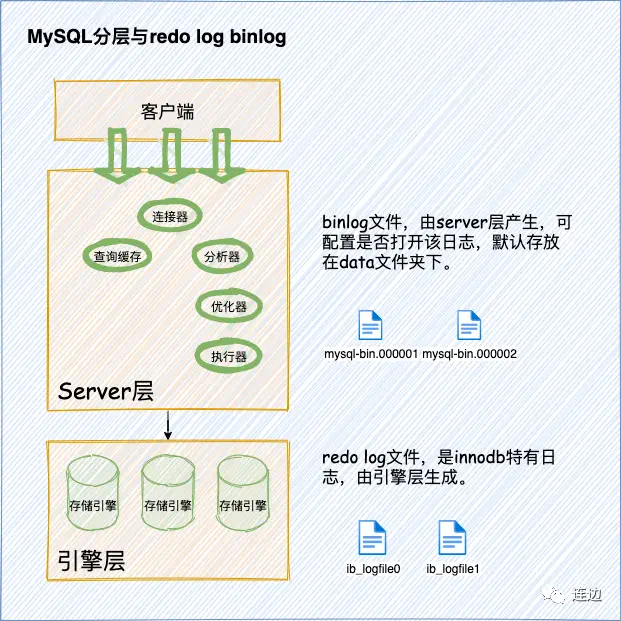
binlog 记录的是逻辑日志,包括原始的 SQL 语句或者行数据变化,例如“将 id=2 这行数据的 age 字段+1”。
redo log 记录物理日志,即数据页的具体修改,例如“将 page_id=123 上 offset=0x40 的数据从 18 修改为 26”。
binlog 是追加写入的,文件写满后会新建文件继续写入,不会覆盖历史日志,保存的是全量操作记录;redo log 是循环写入的,空间是固定的,写满后会覆盖旧的日志,仅保存未刷盘的脏页日志,已持久化的数据会被清除。
另外,为保证两种日志的一致性,innodb 采用了两阶段提交策略,redo log 在事务执行过程中持续写入,并在事务提交前进入 prepare 状态;binlog 在事务提交的最后阶段写入,之后 redo log 会被标记为 commit 状态。
可以通过回放 binlog 实现数据同步或者恢复到指定时间点;redo log 用来确保事务提交后即使系统宕机,数据仍然可以通过重放 redo log 恢复。
- Java 面试指南(付费)收录的美团同学 2 优选物流调度技术 2 面面试原题:redo log、bin log
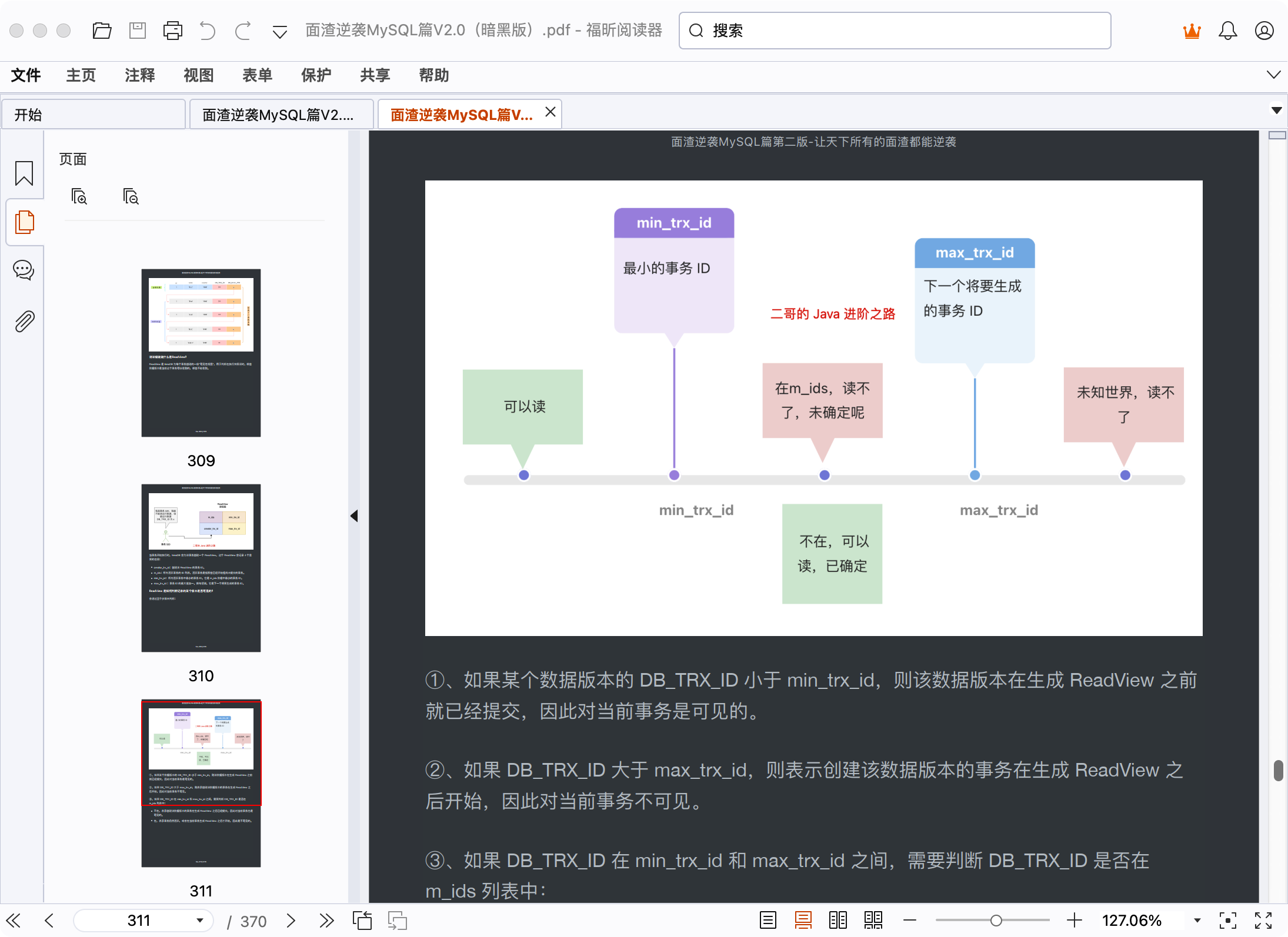
30.🌟为什么要两阶段提交呢?
为了保证 redo log 和 binlog 中的数据一致性,防止主从复制和事务状态不一致。
为什么 2PC 能保证 redo log 和 binlog 的强⼀致性?
假如 MySQL 在预写 redo log 之后、写入 binlog 之前崩溃。那么 MySQL 重启后 InnoDB 会回滚该事务,因为 redo log 不是提交状态。并且由于 binlog 中没有写入数据,所以从库也不会有该事务的数据。
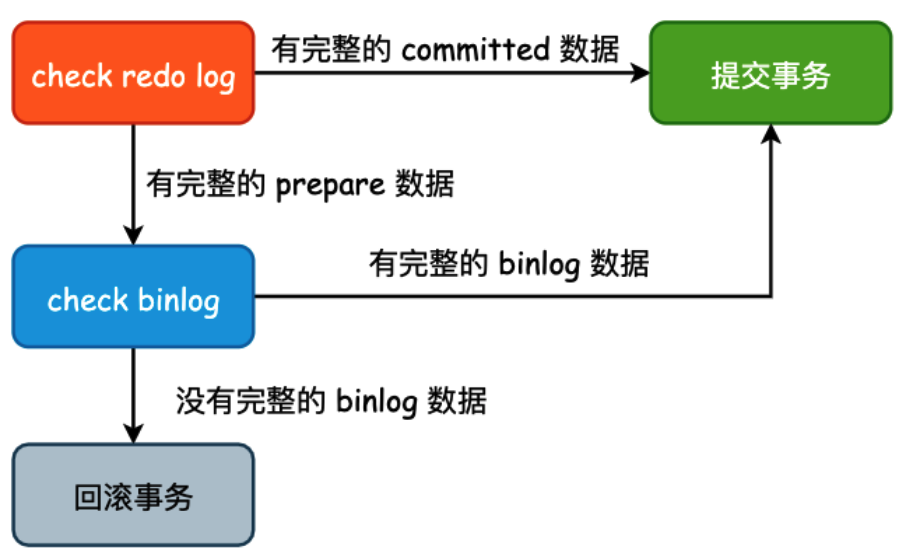
假如 MySQL 在写入 binlog 之后、redo log 提交之前崩溃。那么 MySQL 重启后 InnoDB 会提交该事务,因为 redo log 是完整的 prepare 状态。并且由于 binlog 中有写入数据,所以从库也会同步到该事务的数据。
伪代码如下所示:
// 事务开始
begin;
// try
{
// 执行 SQL
execute SQL;
// 写入 redo log 并标记为 prepare
write redo log prepare xid;
// 写入 binlog
write binlog xid sql;
// 提交 redo log
commit redo log xid;
}
// catch
{
// 回滚 redo log
innodb rollback redo log xid;
}
// 事务结束
end;XID 了解吗?
XID 是 binlog 中用来标识事务提交的唯一标识符。
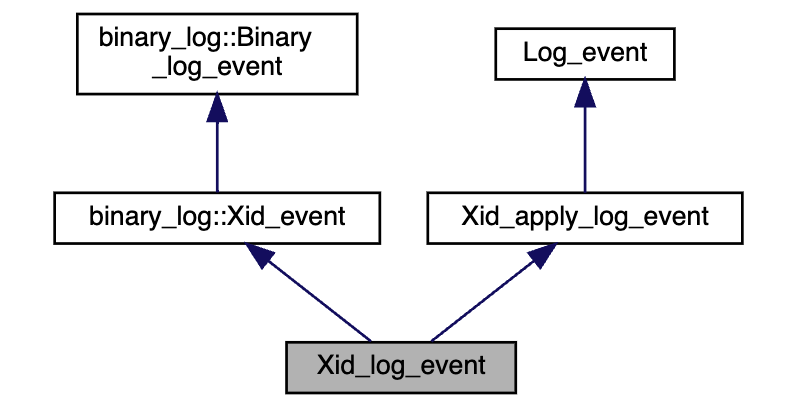
在事务提交时,会写入一个 XID_EVENT 到 binlog,表示这个事务真正完成了。
Log_name | Pos | Event_type | Server_id | End_log_pos | Info
| mysql-bin.000003 | 2005 | Gtid | 1013307 | 2070 | SET @@SESSION.GTID_NEXT= 'f971d5f1-d450-11ec-9e7b-5254000a56df:11' |
| mysql-bin.000003 | 2070 | Query | 1013307 | 2142 | BEGIN |
| mysql-bin.000003 | 2142 | Table_map | 1013307 | 2187 | table_id: 109 (test.t1) |
| mysql-bin.000003 | 2187 | Write_rows | 1013307 | 2227 | table_id: 109 flags: STMT_END_F |
| mysql-bin.000003 | 2227 | Xid | 1013307 | 2258 | COMMIT /* xid=121 */它不仅用于主从复制中事务完整性的判断,也在崩溃恢复中对 redo log 和 binlog 的一致性校验起到关键作用。
XID 可以帮助 MySQL 判断哪些 redo log 是已提交的,哪些是未提交需要回滚的,是两阶段提交机制中非常关键的一环。
memo:2025 年 3 月 16 日修改至此。
31.🌟redo log 的写入过程了解吗?
InnoDB 会先将 Redo Log 写入内存中的 Redo Log Buffer,之后再以一定的频率刷入到磁盘的 Redo Log File 中。
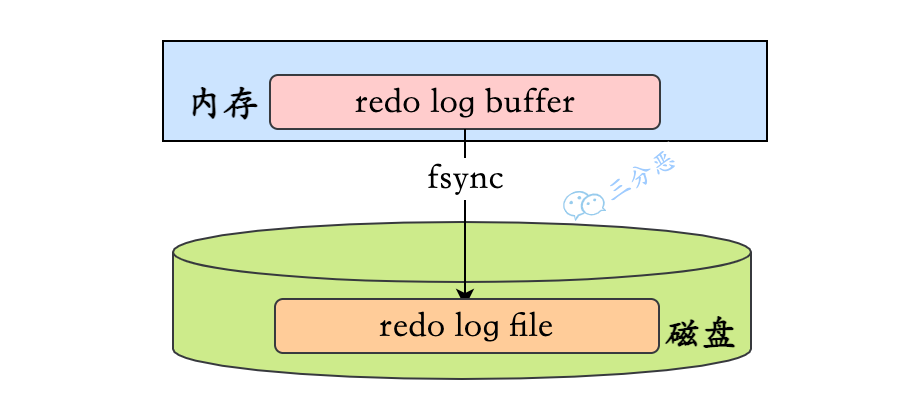
哪些场景会触发 redo log 的刷盘动作?
比如说 Redo Log Buffer 的空间不足时,事务提交时,触发 Checkpoint 时,后台线程定期刷盘时。
不过,Redo Log Buffer 刷盘到 Redo Log File 还会涉及到操作系统的磁盘缓存策略,可能不会立即刷盘,而是等待一定时间后才刷盘。
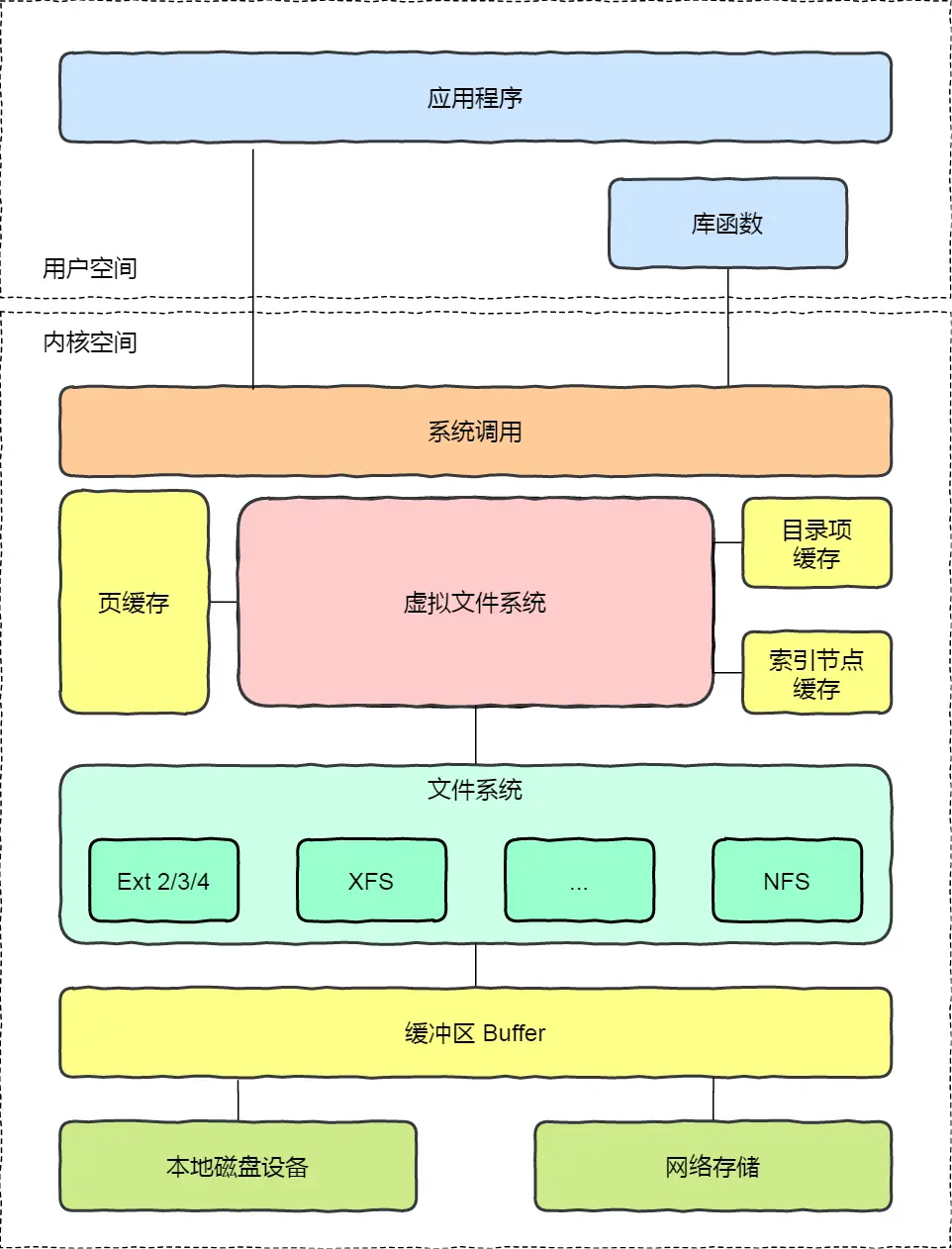
innodb_flush_log_at_trx_commit 参数你了解多少?
innodb_flush_log_at_trx_commit 参数是用来控制事务提交时,Redo Log 的刷盘策略,一共有三种。
0 表示事务提交时不刷盘,而是交给后台线程每隔 1 秒执行一次。这种方式性能最好,但是在 MySQL 宕机时可能会丢失一秒内的事务。
1 表示事务提交时会立即刷盘,确保事务提交后数据就持久化到磁盘。这种方式是最安全的,也是 InnoDB 的默认值。
2 表示事务提交时只把 Redo Log Buffer 写入到 Page Cache,由操作系统决定什么时候刷盘。操作系统宕机时,可能会丢失一部分数据。
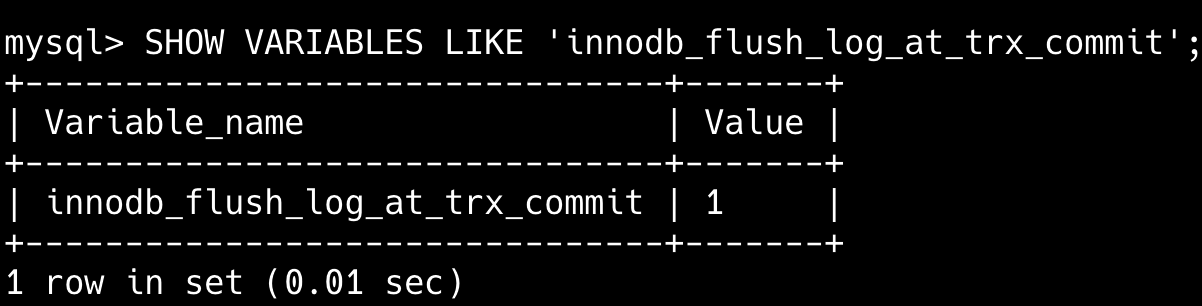
一个没有提交事务的 redo log,会不会刷盘?
InnoDB 有一个后台线程,每隔 1 秒会把 Redo Log Buffer 中的日志写入到文件系统的缓存中,然后调用刷盘操作。
因此,一个没有提交事务的 Redo Log 也可能会被刷新到磁盘中。
另外,如果当 Redo Log Buffer 占用的空间即将达到 innodb_log_buffer_size 的一半时,也会触发刷盘操作。
memo:2025 年 3 月 17 日修改至此。已经有球友发来喜报,暑期实习拿到恒生电子的暑期实习了。

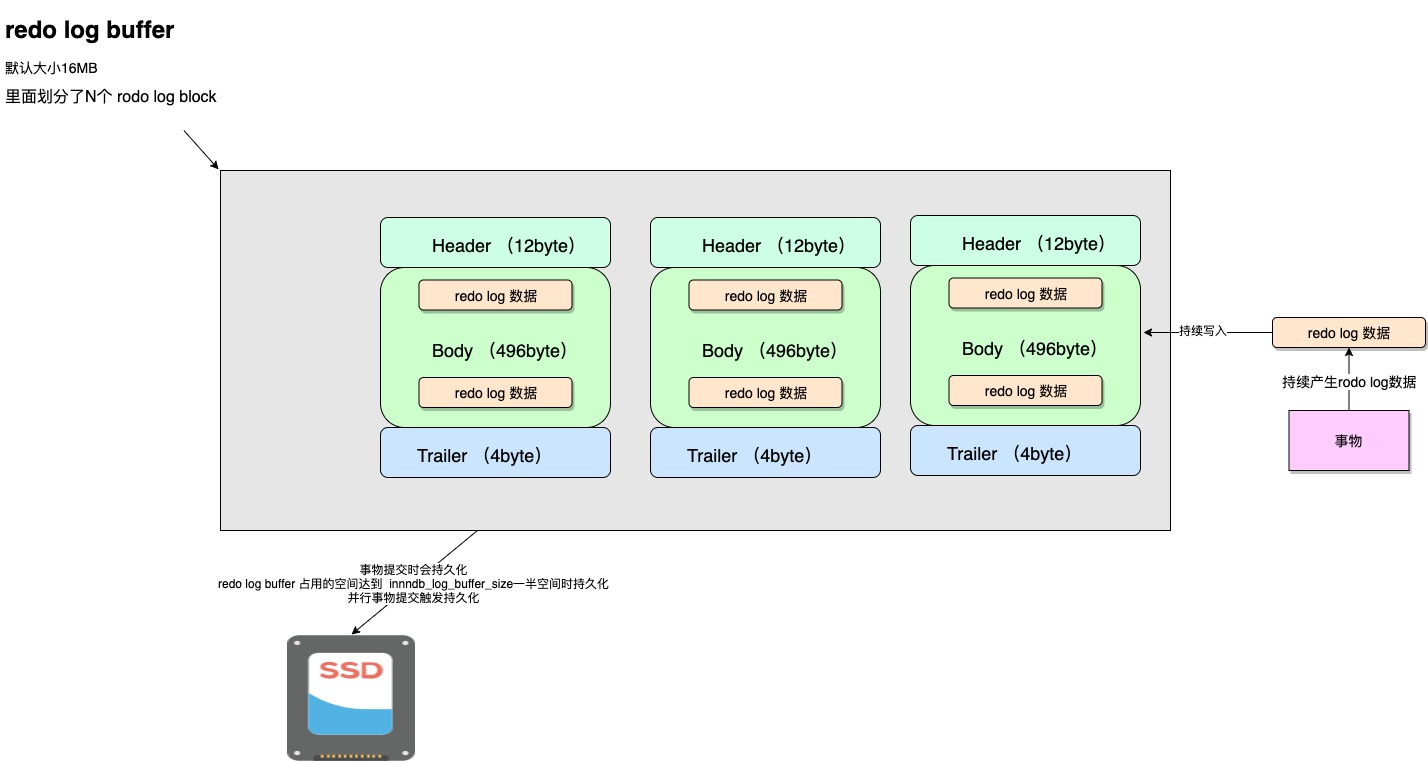
Redo Log Buffer 是顺序写还是随机写?
MySQL 在启动后会向操作系统申请一块连续的内存空间作为 Redo Log Buffer,并将其分为若干个连续的 Redo Log Block。
那为了提高写入效率,Redo Log Buffer 采用了顺序写入的方式,会先往前面的 Redo Log Block 中写入,当写满后再往后面的 Block 中写入。

于此同时,InnoDB 还提供了一个全局变量 buf_free,来控制后续的 redo log 记录应该写入到 block 中的哪个位置。
buf_next_to_write 了解吗?
buf_next_to_write 指向 Redo Log Buffer 中下一次需要写入硬盘的起始位置。
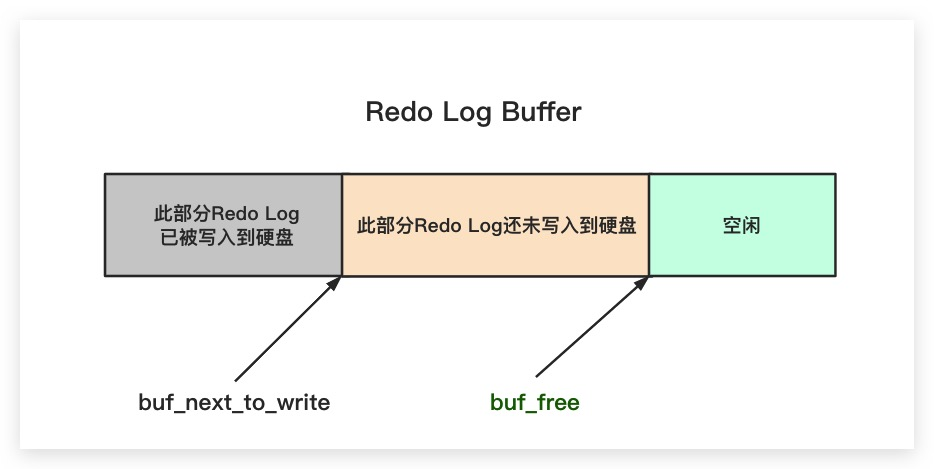
而 buf_free 指向的是 Redo Log Buffer 中空闲区域的起始位置。
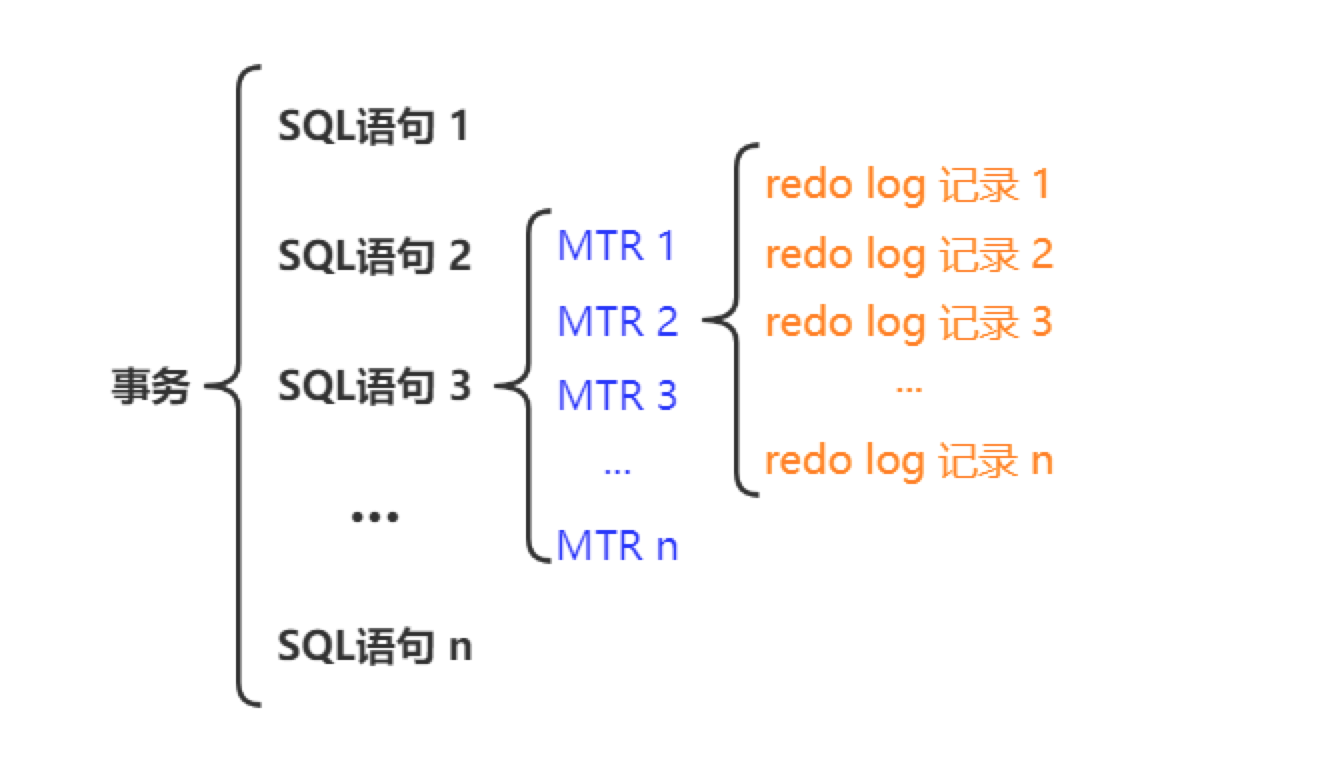
了解 MTR 吗?
Mini Transaction 是 InnoDB 内部用于操作数据页的原子操作单元。
mtr_t mtr;
mtr_start(&mtr);
// 1. 加锁
// 对待访问的index加锁
mtr_s_lock(rw_lock_t, mtr);
mtr_x_lock(rw_lock_t, mtr);
// 对待读写的page加锁
mtr_memo_push(mtr, buf_block_t, MTR_MEMO_PAGE_S_FIX);
mtr_memo_push(mtr, buf_block_t, MTR_MEMO_PAGE_X_FIX);
// 2. 访问或修改page
btr_cur_search_to_nth_level
btr_cur_optimistic_insert
// 3. 为修改操作生成redo
mlog_open
mlog_write_initial_log_record_fast
mlog_close
// 4. 持久化redo,解锁
mtr_commit(&mtr);多个事务的 Redo Log 会以 MTR 为单位交替写入到 Redo Log Buffer 中,假如事务 1 和事务 2 均有两个 MTR,一旦某个 MTR 结束,就会将其生成的若干条 Redo Log 记录顺序写入到 Redo Log Buffer 中。
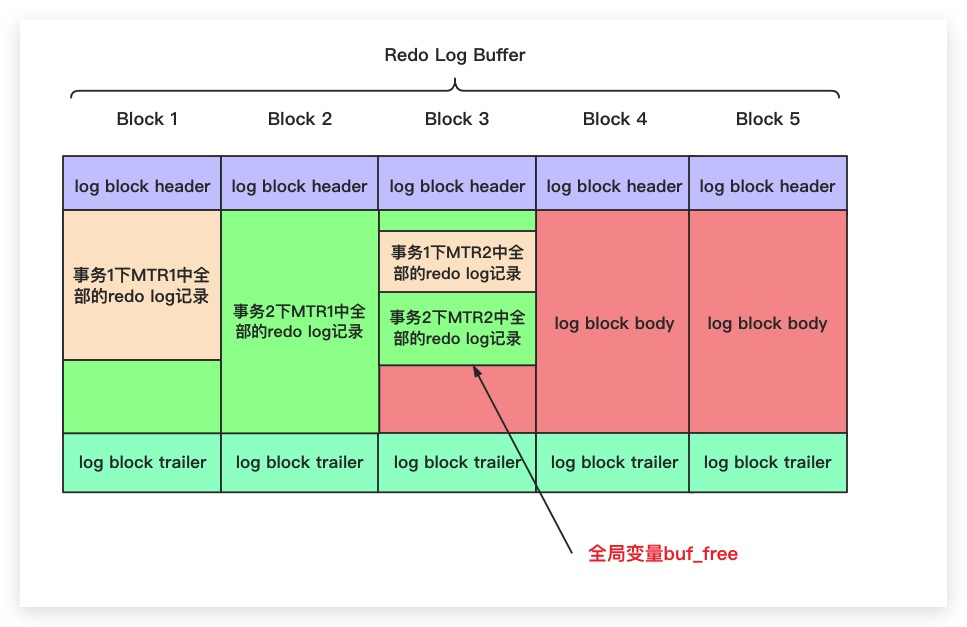
也就是说,一个 MTR 会包含一组 Redo Log 记录,是 MySQL 崩溃后恢复事务的最小执行单元。
Redo Log Block 的结构了解吗?
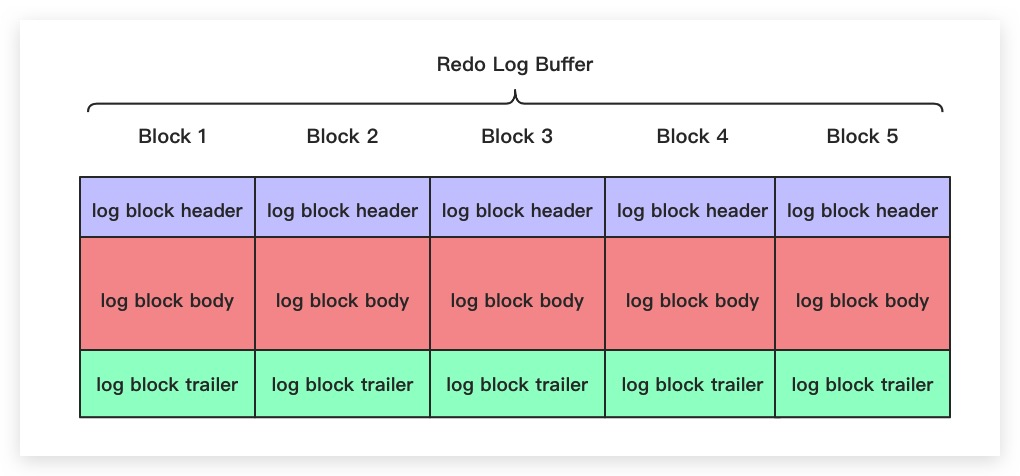
Redo Log Block 由日志头、日志体和日志尾组成,一共占用 512 个字节,其中日志头占用 12 个字节,日志尾占用 4 个字节,剩余的 496 个字节用于存储日志体。
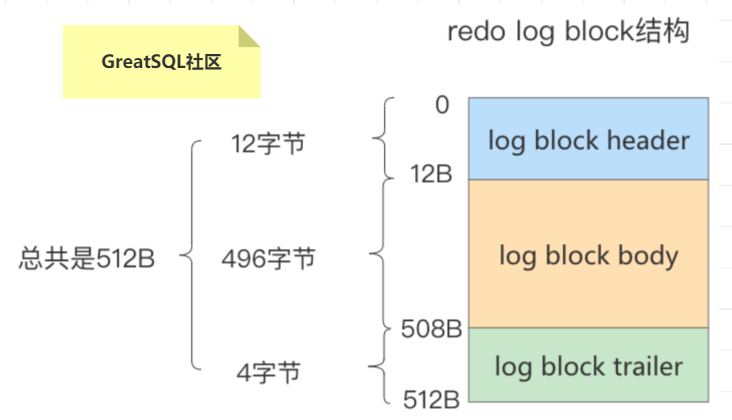
日志头包含了当前 Block 的序列号、第一条日志的序列号、类型等信息。
| 字段 | 作用 |
|---|---|
| LOG_BLOCK_HDR_NO | 当前 Block 的序号,假如把 Redo Log Buffer 看成一个数组,那么 LOG_BLOCK_HDR_NO 就相当于 Block 在 Buffer 中的下标。 |
| LOG_BLOCK_HDR_DATA_LEN | Block 已使用的字节数,初始值为 12,也就是日志头的长度;如果日志体被写满,值增长为 512。 |
| LOG_BLOCK_FIRST_REC_GROUP | 该 Block 中第一个 MTR 起始处的偏移量 |
| LOG_BLOCK_CHECKPOINT_NO | Block 最后被写入时的checkpoint |
日志尾主要存储的是 LOG_BLOCK_CHECKSUM,也就是 Block 的校验和,主要用于判断 Block 是否完整。
Redo Log Block 为什么设计成 512 字节?
因为机械硬盘的物理扇区大小通常为 512 字节,Redo Log Block 也设计为同样的大小,就可以确保每次写入都是整数个扇区,减少对齐开销。
比如说操作系统的页缓存默认为 4KB,8 个 Redo Log Block 就可以组合成一个页缓存单元,从而提升 Redo Log Buffer 的写入效率。
memo:2025 年 3 月 18 日修改至此。
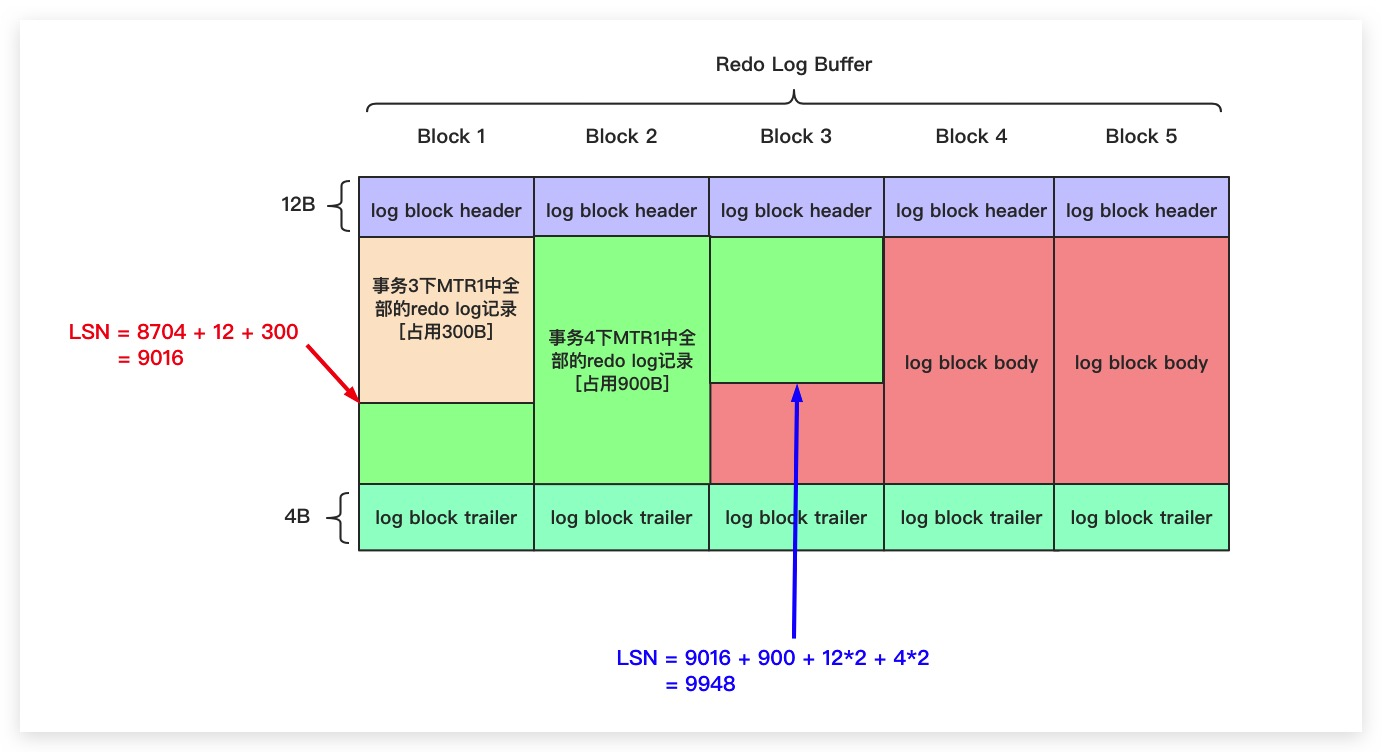
LSN 了解吗?
Log Sequence Number 是一个 8 字节的单调递增整数,用来标识事务写入 redo log 的字节总量,存在于 redo log、数据页头部和 checkpoint 中。
----这部分是帮助大家理解 start,面试中可不背----
MySQL 在第一次启动时,LSN 的初始值并不为 0,而是 8704;当 MySQL 再次启动时,会继续使用上一次服务停止时的 LSN。
在计算 LSN 的增量时,不仅需要考虑 log block body 的大小,还需要考虑 log block header 和 log block tail 中部分字节数。
比如说在上图中,事务 3 的 MTR 总量为 300 字节,那么写入到 Redo Log Buffer 中的 LSN 会增长为 8704 + 300 + 12 = 9016。
假如事务 4 的 MTR 总量为 900 字节,那么再次写入到 Redo Log Buffer 中的 LSN 会增长为 9016 + 900 + 12*2 + 4*2 = 9948。
2 个 12 字节的 log block header + 2 个 4 字节的 log block tail。
----这部分是帮助大家理解 end,面试中可不背----
核心作用有三个:
第一,redo log 按照 LSN 递增顺序记录所有数据的修改操作。LSN 的递增量等于每次写入日志的字节数。
第二,InnoDB 的每个数据页头部中,都会记录该页最后一次刷新到磁盘时的 LSN。如果数据页的 LSN 小于 redo log 的 LSN,说明该页需要从日志中恢复;否则说明该页已更新。
第三,checkpoint 通过 LSN 记录已刷新到磁盘的数据页位置,减少恢复时需要处理的日志。
----这部分是帮助大家理解 start,面试中可不背----
| 场景 | LSN 的作用 |
|---|---|
| 🔁 redo log 记录 | 每条 redo log 对应一个唯一的 LSN |
| 📄 数据页刷盘 | 每个数据页会记录当前刷盘时的 LSN(FIL_PAGE_LSN) |
| ⛳ Checkpoint | 表示“脏页已经刷盘,可以释放 redo”的安全点 |
| 💥 崩溃恢复 | 重启时从 checkpoint LSN 开始重放 redo log |
可以通过 show engine innodb status; 查看当前的 LSN 信息。
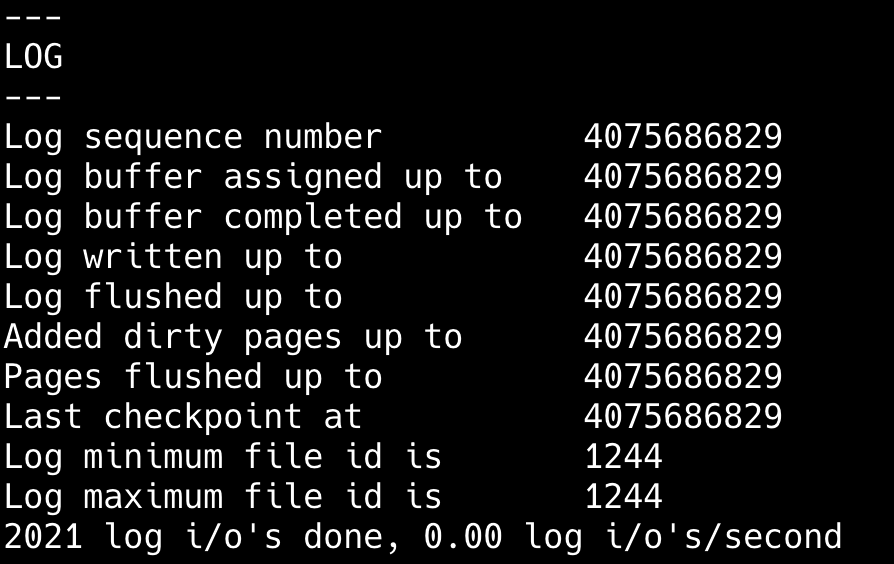
- Log sequence number:当前系统最大 LSN(已生成的日志总量)。
- Log flushed up to:已写入磁盘的 redo log LSN。
- Pages flushed up to:已刷新到数据页的 LSN。
- Last checkpoint at:最后一次检查点的 LSN,表示已持久化的数据状态。
----这部分是帮助大家理解 end,面试中可不背----
memo:2025 年 3 月 19 日修改至此。今天有读者问怎么付费购买纸质版面渣逆袭,说看到网友有这个,好羡慕啊。说实话,第一眼看到这个封面,真的觉得挺惊艳(虽然是我设计的)。😄
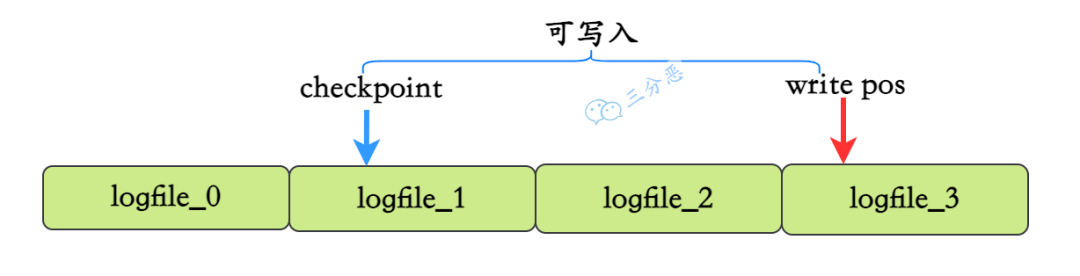
Checkpoint 了解多少?
Checkpoint 是 InnoDB 为了保证事务持久性和回收 redo log 空间的一种机制。
它的作用是在合适的时机将部分脏页刷入磁盘,比如说 buffer pool 的容量不足时。并记录当前 LSN 为 Checkpoint LSN,表示这个位置之前的 redo log file 已经安全,可以被覆盖了。
MySQL 崩溃恢复时只需要从 Checkpoint 之后开始恢复 redo log 就可以了,这样可以最大程度减少恢复所花费的时间。
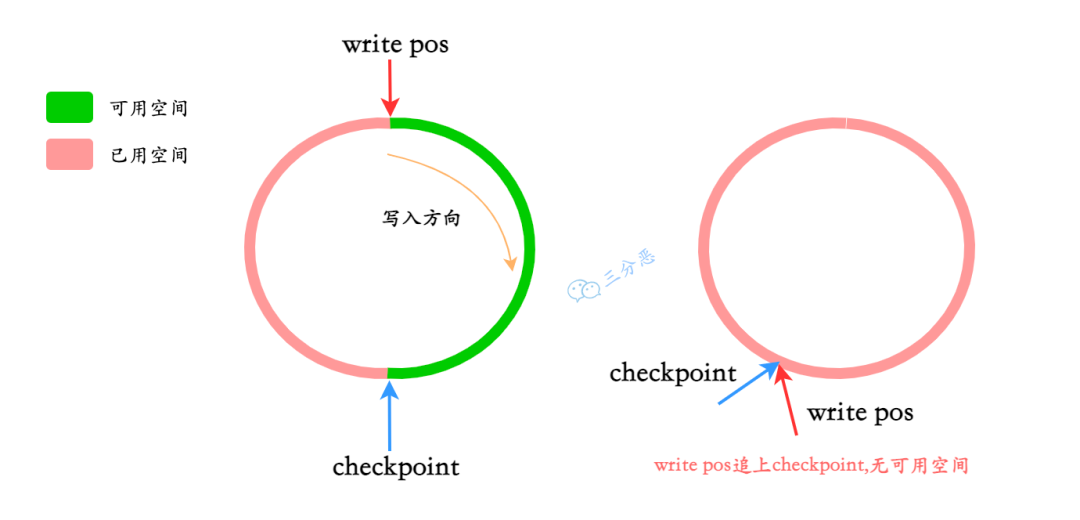
redo log file 的写入是循环的,其中有两个标记位置非常重要,也就是 Checkpoint 和 write pos。
write pos 是 redo log 当前写入的位置,Checkpoint 是可以被覆盖的位置。
当 write pos 追上 Checkpoint 时,表示 redo log 日志已经写满。这时候就要暂停写入并强制刷盘,释放可覆写的日志空间。
关于redo log 的调优参数了解多少?
如果是高并发写入的电商系统,可以最大化写入吞吐量,容忍秒级数据丢失的风险。
innodb_flush_log_at_trx_commit = 2
sync_binlog = 1000
innodb_redo_log_capacity = 64G
innodb_io_capacity = 5000
innodb_lru_scan_depth = 512
innodb_log_buffer_size = 256M如果是金融交易系统,需要保证数据零丢失,接受较低的吞吐量。
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
innodb_redo_log_capacity = 32G
innodb_io_capacity = 2000
innodb_lru_scan_depth = 1024核心参数一览表:
| 参数名 | 控制内容 | 影响点 |
|---|---|---|
| innodb_log_file_size | 每个 redo log 文件大小 | 总 redo 空间、恢复时间 |
| innodb_log_files_in_group | redo log 文件个数 | 配合文件大小决定总容量 |
| innodb_log_buffer_size | redo log buffer 缓冲区大小 | 是否频繁刷盘、写入性能 |
| innodb_flush_log_at_trx_commit | redo 刷盘策略 | 安全性 vs TPS |
| innodb_max_dirty_pages_pct | 脏页比例阈值 | 何时触发刷盘 / Checkpoint |
| innodb_io_capacity | 后台刷盘速度 | 限制 checkpoint 刷盘压力 |
总结:
- 对数据一致性要求高的场景,如金融交易使用
innodb_flush_log_at_trx_commit=1,对写入吞吐量敏感的场景,如日志采集可以使用 =2 或 =0,需要结合 sync_binlog 参数 - sync_binlog 参数控制 binlog 的刷盘策略,可以设置为 0、1、N,0 表示依赖系统刷盘,1 表示每次事务提交都刷盘(推荐与
innodb_flush_log_at_trx_commit=1搭配),N=1000 表示累计 1000 次事务后刷盘 - innodb_redo_log_capacity 动态调整 Redo Log 总容量,可以根据业务负载情况调整,建议设置为 1 小时写入量的峰值(如每秒 10MB 写入则设为 36GB)
- innodb_io_capacity 定义 InnoDB 后台线程的每秒 I/O 操作上限,直接影响脏页刷新速率;机械硬盘建议 200-500,SSD 建议 1000-2000,NVMe SSD 可设为 5000+
- innodb_lru_scan_depth 控制每个缓冲池实例中 LRU 列表的扫描深度,决定每秒可刷新的脏页数量,默认值 1024 适用于多数场景,I/O 密集型负载可适当降低(如 512),减少 CPU 开销。
memo:2025 年 3 月 20 日修改至此。有球友报喜说拿到了滴滴的测开实习 offer,恭喜恭喜!

SQL 优化
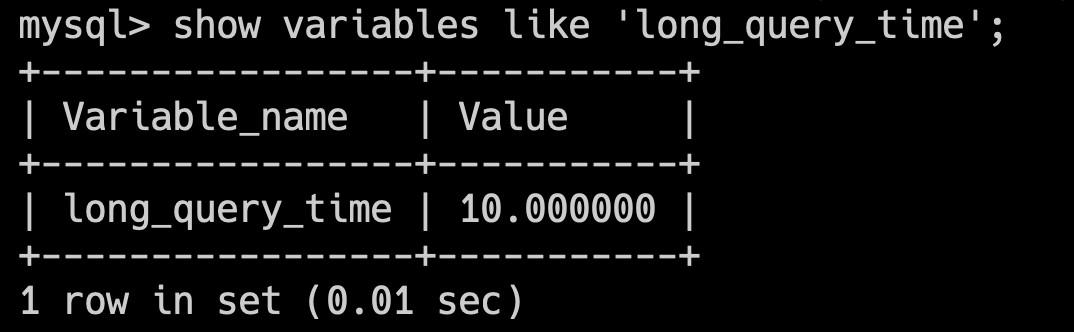
32.🌟什么是慢 SQL?
推荐阅读:慢 SQL 优化一点小思路
MySQL 中有一个叫 long_query_time 的参数,原则上执行时间超过该参数值的 SQL 就是慢 SQL,会被记录到慢查询日志中。
----这部分是帮助大家理解 start,面试中可不背----
可通过 show variables like 'long_query_time'; 查看当前的 long_query_time 的参数值。
----这部分是帮助大家理解 end,面试中可不背----
SQL 的执行过程了解吗?
了解。
SQL 的执行过程大致可以分为六个阶段:连接管理、语法解析、语义分析、查询优化、执行器调度、存储引擎读写等。Server 层负责理解和规划 SQL 怎么执行,存储引擎层负责数据的真正读写。
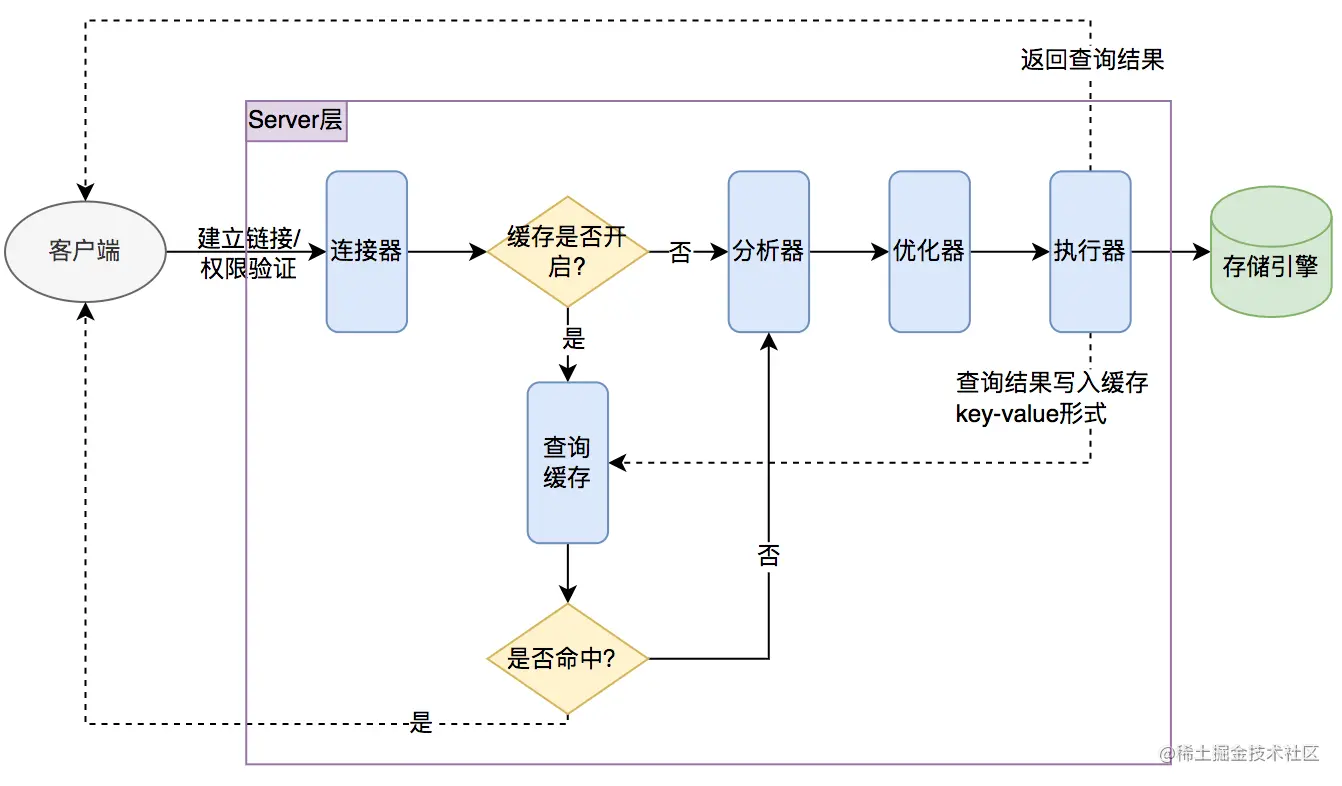
----这部分是帮助大家理解 start,面试中可不背----
来详细拆解一下:
- 客户端发送 SQL 语句给 MySQL 服务器。
- 如果查询缓存打开则会优先查询缓存,缓存中有对应的结果就直接返回。不过,MySQL 8.0 已经移除了查询缓存。这部分的功能正在被 Redis 等缓存中间件取代。
- 分析器对 SQL 语句进行语法分析,判断是否有语法错误。
- 搞清楚 SQL 语句要干嘛后,MySQL 会通过优化器生成执行计划。
- 执行器调用存储引擎的接口,执行 SQL 语句。
SQL 执行过程中,优化器通过成本计算预估出执行效率最高的方式,基本的预估维度为:
- IO 成本:从磁盘读取数据到内存的开销。
- CPU 成本:CPU 处理内存中数据的开销。
基于这两个维度,可以得出影响 SQL 执行效率的因素有:
①、IO 成本,数据量越大,IO 成本越高。所以要尽量查询必要的字段;尽量分页查询;尽量通过索引加快查询。
②、CPU 成本,尽量避免复杂的查询条件,如有必要,考虑对子查询结果进行过滤。
----这部分是帮助大家理解 end,面试中可不背----
如何优化慢 SQL 呢?
首先,需要找到那些比较慢的 SQL,可以通过启用慢查询日志,记录那些超过指定执行时间的 SQL 查询。
也可以使用 show processlist; 命令查看当前正在执行的 SQL 语句,找出执行时间较长的 SQL。
或者在业务基建中加入对慢 SQL 的监控,常见的方案有字节码插桩、连接池扩展、ORM 框架扩展等。

然后,使用 EXPLAIN 查看慢 SQL 的执行计划,看看有没有用索引,大部分情况下,慢 SQL 的原因都是因为没有用到索引。
EXPLAIN SELECT * FROM your_table WHERE conditions;最后,根据分析结果,通过添加索引、优化查询条件、减少返回字段等方式进行优化。
慢sql日志怎么开启?
编辑 MySQL 的配置文件 my.cnf,设置 slow_query_log 参数为 1。
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 2 # 记录执行时间超过2秒的查询然后重启 MySQL 就好了。
也可以通过 set global 命令动态设置。
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
SET GLOBAL long_query_time = 2;
- Java 面试指南(付费)收录的腾讯云智面经同学 16 一面面试原题:场景题:sql 查询很慢怎么排查
- Java 面试指南(付费)收录的快手面经同学 5 面试原题:慢sql日志怎么开启?
- Java 面试指南(付费)收录的美团面经同学 3 Java 后端技术一面面试原题:如何判断sql的效率,怎样排查效率比较低的sql
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:mysql中如何定位慢查询
- Java 面试指南(付费)收录的同学 1 贝壳找房后端技术一面面试原题:慢查询怎么分析
- Java 面试指南(付费)收录的腾讯面经同学 27 云后台技术一面面试原题:如何优化慢查询语句?
- Java 面试指南(付费)收录的虾皮面经同学 13 一面面试原题:mysql慢查询
memo:2025 年 3 月 21 日修改至此。今天有球友报喜说拿到了 wxg 的实习 offer,阿里云和美团也在进行当中,真的 tql。

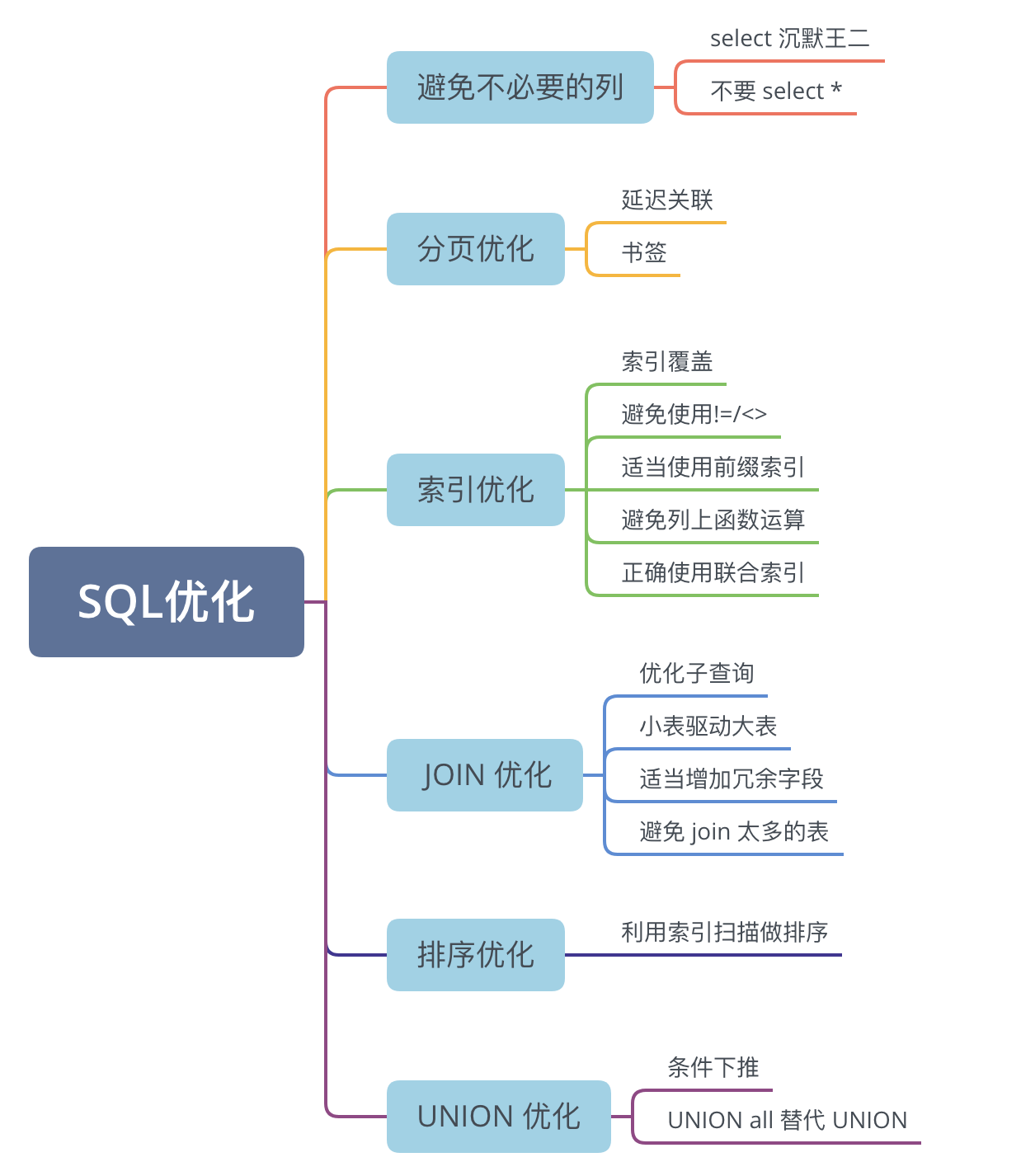
33.🌟你知道哪些方法来优化 SQL?
SQL 优化的方法非常多,但本质上就一句话:尽可能少地扫描、尽快地返回结果。
最常见的做法就是加索引、改写 SQL 让它用上索引,比如说使用覆盖索引、让联合索引遵守最左前缀原则等。
如何利用覆盖索引?
覆盖索引的核心是“查询所需的字段都在同一个索引里”,这样 MySQL 就不需要回表,直接从索引中返回结果。
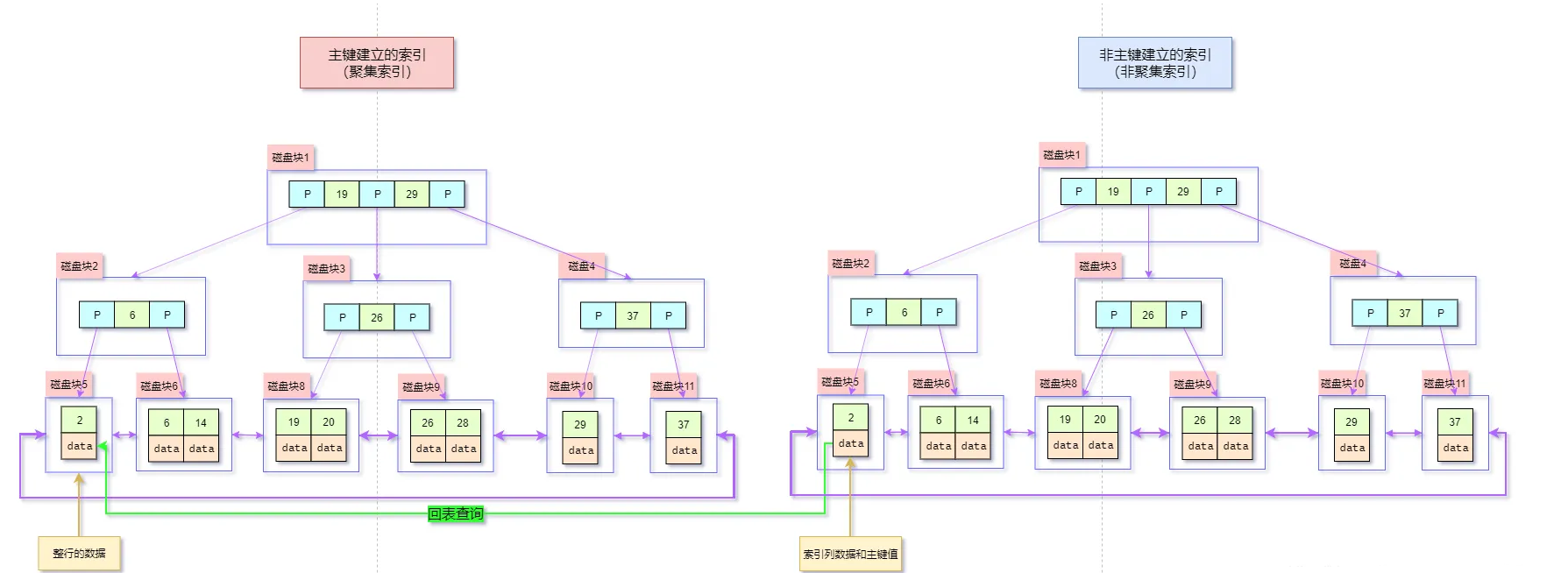
实际使用中,我会优先考虑把 WHERE 和 SELECT 涉及的字段一起建联合索引,并通过 EXPLAIN 观察结果是否有 Using index,确认命中索引。
----这部分是帮助大家理解 start,面试中可不背----
举个例子,现在要从 test 表中查询 city 为上海的 name 字段。
select name from test where city='上海'如果仅在 city 字段上添加索引,那么这条查询语句会先通过索引找到 city 为上海的行,然后再回表查询 name 字段。
为了避免回表查询,可以在 city 和 name 字段上建立联合索引,这样查询结果就可以直接从索引中获取。
alter table test add index index1(city,name);----这部分是帮助大家理解 end,面试中可不背----
如何正确使用联合索引?
使用联合索引最重要的一条是遵守最左前缀原则,也就是查询条件需要从索引的左侧字段开始。
----这部分是帮助大家理解 start,面试中可不背----
比如说我们创建了一个三列的联合索引。
CREATE INDEX idx_name_age_sex ON user(name, age, sex);我们来看一下什么样的查询条件可以用到这个索引:
| 查询条件 | 能否用上 idx_name_age_sex? | 说明 |
|---|---|---|
| WHERE name = 'itwanger' | ✅ 可以 | 匹配第一列,命中索引 |
| WHERE name = 'itwanger' AND age=20 | ✅ 可以 | 匹配前两列,命中索引 |
| WHERE age = 20 | ❌ 不行 | 第一列没用上,索引失效 |
| WHERE name='itwanger' AND sex='女' | ✅ 部分可用(只用前一列) | age 被跳过,后面的列无法使用 |
| WHERE name LIKE 'it%' | ✅ 可以(前缀匹配) | name 是前缀匹配,不影响使用 |
| WHERE name LIKE '%wanger%' | ❌ 不行 | 通配符在前,不能用索引 |
----这部分是帮助大家理解 end,面试中可不背----
如何进行分页优化?
分页优化的核心是避免深度偏移带来的全表扫描,可以通过两种方式来优化:延迟关联和添加书签。
延迟关联适用于需要从多个表中获取数据且主表行数较多的情况。它首先从索引表中检索出需要的行 ID,然后再根据这些 ID 去关联其他的表获取详细信息。
SELECT e.id, e.name, d.details
FROM employees e
JOIN department d ON e.department_id = d.id
ORDER BY e.id
LIMIT 1000, 20;延迟关联后,第一步只查主键,速度快,第二步只处理 20 条数据,效率高。
SELECT e.id, e.name, d.details
FROM (
SELECT id
FROM employees
ORDER BY id
LIMIT 1000, 20
) AS sub
JOIN employees e ON sub.id = e.id
JOIN department d ON e.department_id = d.id;添加书签的方式是通过记住上一次查询返回的最后一行主键值,然后在下一次查询的时候从这个值开始,从而跳过偏移量计算,仅扫描目标数据,适合翻页、资讯流等场景。
假设需要对用户表进行分页。
SELECT id, name
FROM users
ORDER BY id
LIMIT 1000, 20;通过添加书签来优化后,查询不再使用OFFSET,而是从上一页最后一个用户的 ID 开始查询。这种方法可以有效避免不必要的数据扫描,提高了分页查询的效率。
SELECT id, name
FROM users
WHERE id > last_max_id -- 假设last_max_id是上一页最后一行的ID
ORDER BY id
LIMIT 20;为什么分页会变慢?
分页查询的效率问题主要是由于 OFFSET 的存在,OFFSET 会导致 MySQL 必须扫描和跳过 offset + limit 条数据,这个过程是非常耗时的。
比如说,我们要查询第 100000 条数据,那么 MySQL 就必须扫描 100000 条数据,然后再返回 10 条数据。
SELECT * FROM user ORDER BY id LIMIT 100000, 10;数据越多、偏移越大,就越慢!
memo:2025 年 3 月 22 日修改至此。今天有球友说等腾讯云的 HR 面,很着急,但我赌他一定能拿到 offer,等一个后续哈。
JOIN 代替子查询有什么好处?
第一,JOIN 的 ON 条件能更直接地触发索引,而子查询可能因嵌套导致索引失效。
第二,JOIN 的一次连接操作替代了子查询的多次重复执行,尤其在大数据量的情况下性能差异明显。
----这部分是帮助大家理解 start,面试中可不背----
比如说我们有两个表 orders 和 customers。
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10,2),
INDEX idx_customer_id (customer_id) -- customer_id字段有索引
);
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100)
);子查询的写法:
SELECT o.order_id, o.amount,
(SELECT c.name
FROM customers c
WHERE c.customer_id = o.customer_id) AS customer_name
FROM orders o;JOIN 的写法:
SELECT o.order_id, o.amount, c.name AS customer_name
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id;| 对比项 | 子查询 | JOIN |
|---|---|---|
| 索引使用 | 内层子查询 WHERE c.customer_id = o.customer_id 每次执行时,可能无法直接利用 orders 表的 customer_id 索引。 | JOIN 的 ON 条件 o.customer_id = c.customer_id 可以直接利用 orders 的 idx_customer_id 索引,加速连接过程。 |
| 执行计划 | 子查询会被重复执行(每次外层 orders 行都会触发一次子查询),导致全表扫描。 | 优化器可能选择通过索引快速关联两张表,减少数据扫描量。例如,先通过 orders 的索引找到 customer_id,再与 customers 主键快速匹配。 |
| 性能表现 | 当 orders 表数据量大时,子查询可能因重复执行导致性能急剧下降。 | JOIN 的一次连接操作通常更高效,尤其在大数据量时。 |
对于子查询,执行流程是这样的:
- 外层 orders 表的每一行都会触发一次子查询。
- 如果 orders 表有 1000 条记录,则子查询会执行 1000 次。
- 每次子查询都需要单独查询 customers 表(即使 customer_id 相同)。
而 JOIN 的执行流程是这样的:
- 数据库优化器会将两张表的连接操作合并为一次执行。
- 通过索引(如 orders.customer_id 和 customers.customer_id)快速关联数据。
- 仅执行一次关联操作,而非多次子查询。
来看一下子查询的执行计划:
EXPLAIN SELECT o.order_id,
(SELECT c.name FROM customers c WHERE c.customer_id = o.customer_id)
FROM orders o;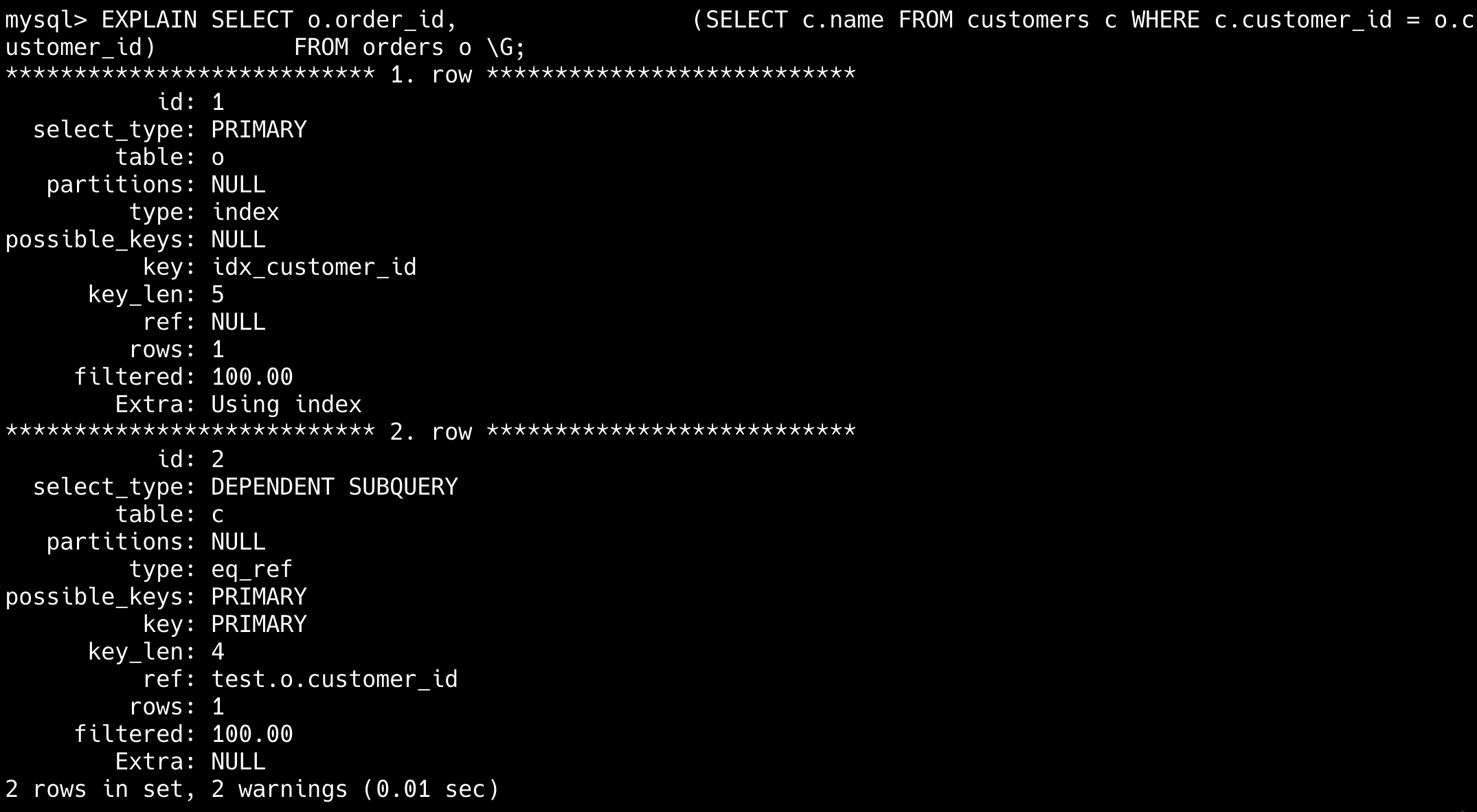
子查询(DEPENDENT SUBQUERY)类型表明其依赖外层查询的每一行,导致重复执行。
再对比看一下 JOIN 的执行计划:
EXPLAIN SELECT o.order_id,
(SELECT c.name FROM customers c WHERE c.customer_id = o.customer_id)
FROM orders o;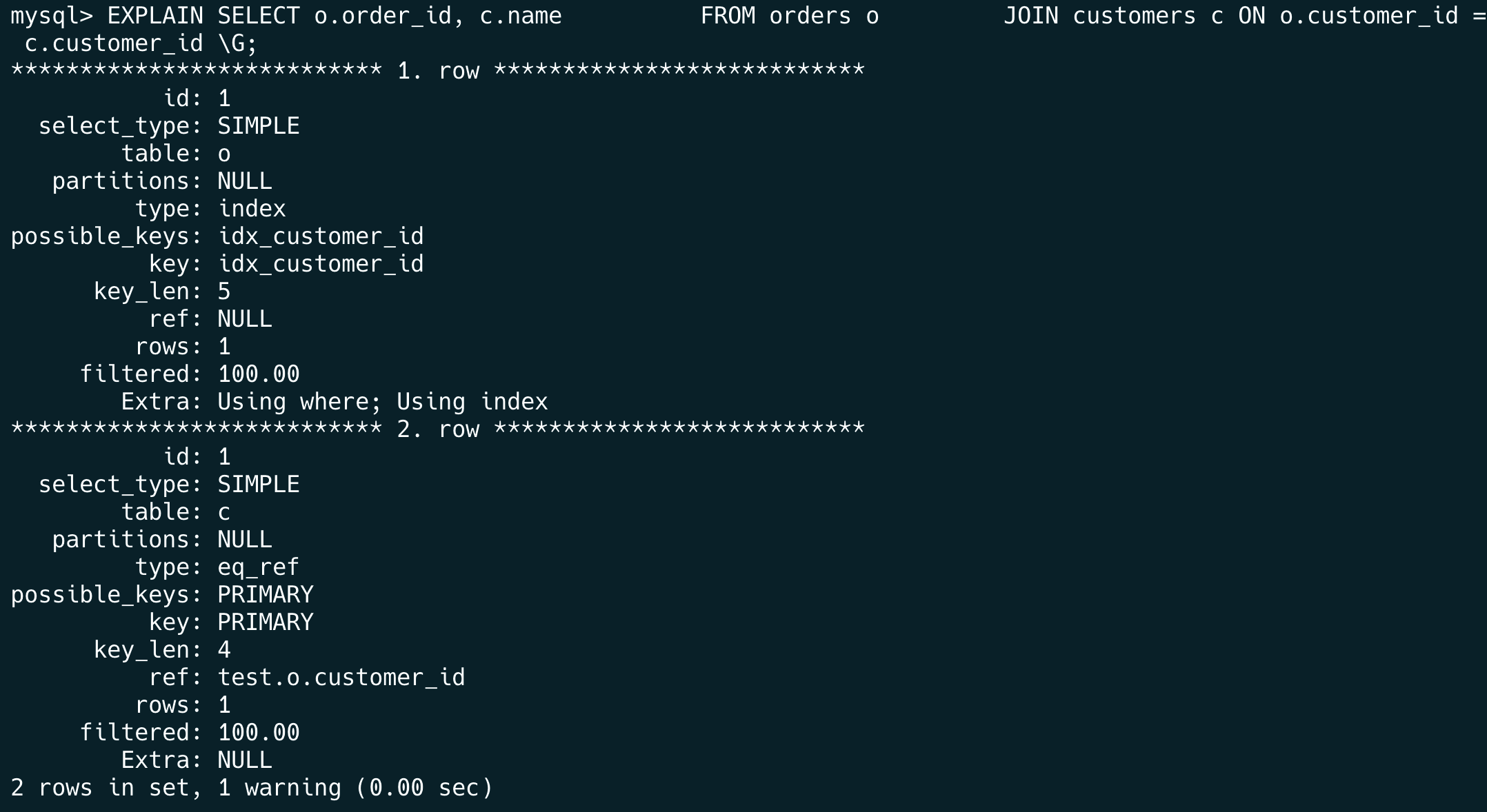
JOIN 通过 eq_ref 类型直接利用主键(customers.customer_id)快速关联,减少扫描次数。
----这部分是帮助大家理解 end,面试中可不背----
memo:2025 年 3 月 23 日修改至此,今天有球友说,通过一晚上的时间,就在星球里学到很多知识,让他这个 7 年经验的 CRUD Boy 受益匪浅。
JOIN操作为什么要小表驱动大表?
第一,如果大表的 JOIN 字段有索引,那么小表的每一行都可以通过索引快速匹配大表。
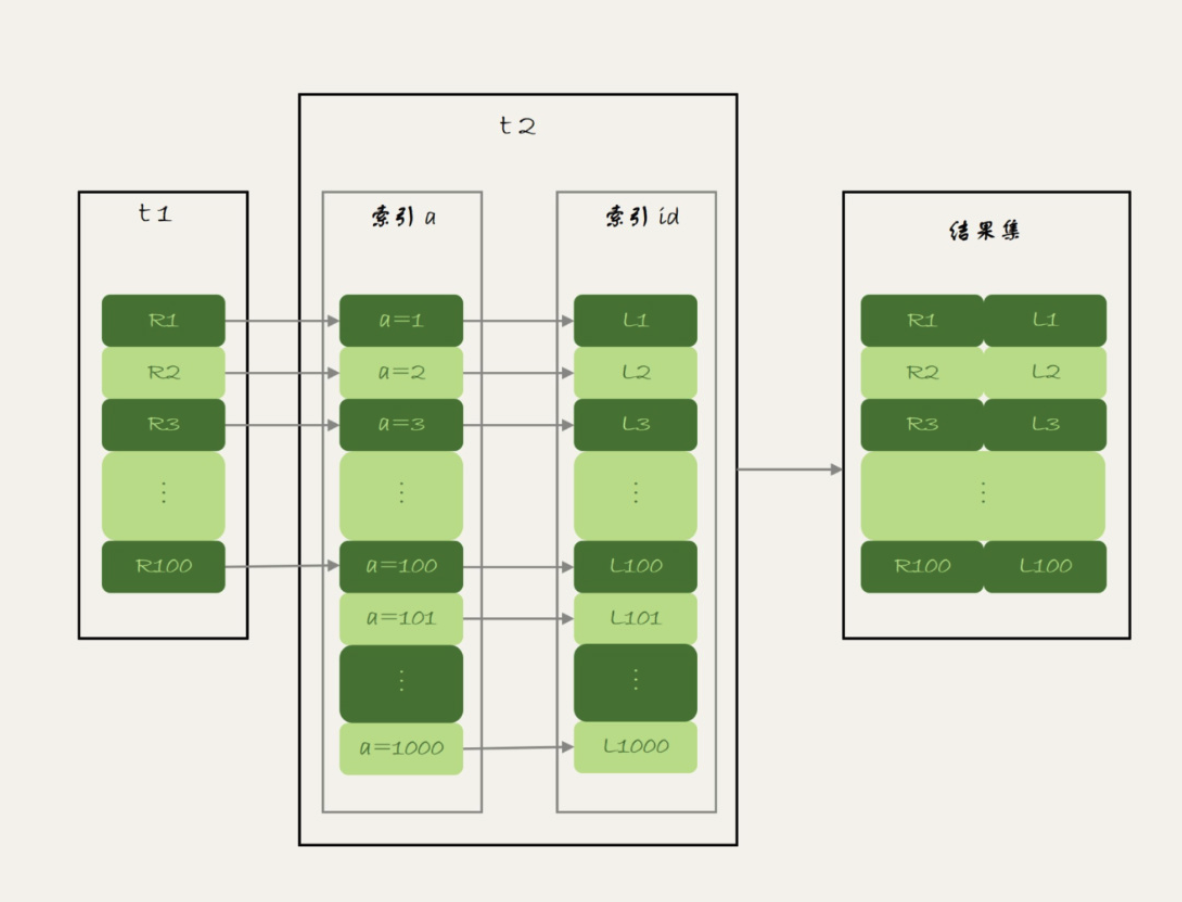
时间复杂度为小表行数 N 乘以大表索引查找复杂度 log(大表行数 M),总复杂度为 N*log(M)。
显然小表做驱动表比大表做驱动表的时间复杂度 M*log(N) 更低。
第二,如果大表没有索引,需要将小表的数据加载到内存,再全表扫描大表进行匹配。
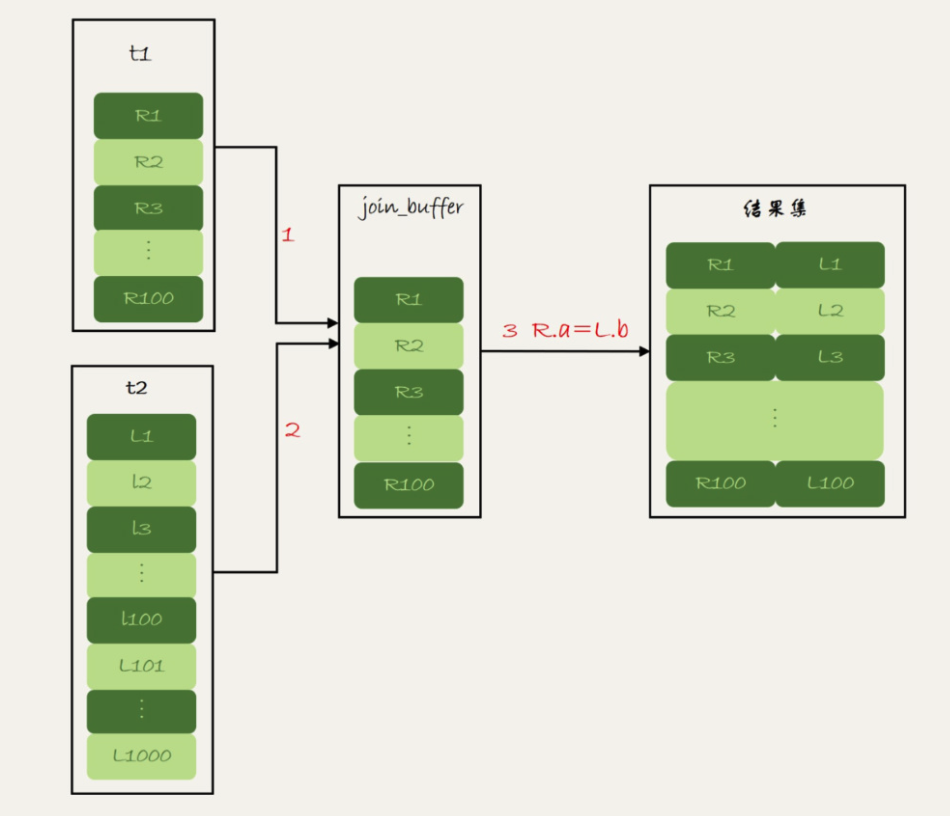
时间复杂度为小表分段数 K 乘以大表行数 M,其中 K = 小表行数 N / 内存大小 join_buffer_size。
显然小表做驱动表的时候 K 的值更小,大表做驱动表的时候需要多次分段。

-- 小表驱动(高效)
SELECT * FROM small_table s
JOIN large_table l ON s.id = l.id; -- l.id有索引
-- 大表驱动(低效)
SELECT * FROM large_table l
JOIN small_table s ON l.id = s.id; -- s.id无索引- 当使用 left join 时,左表是驱动表,右表是被驱动表。
- 当使用 right join 时,刚好相反。
- 当使用 join 时,MySQL 会选择数据量比较小的表作为驱动表,大表作为被驱动表。
----这部分是帮助大家理解 start,面试中可不背----
为了验证这一点,我特意新建了两个表 departments 和 employees。
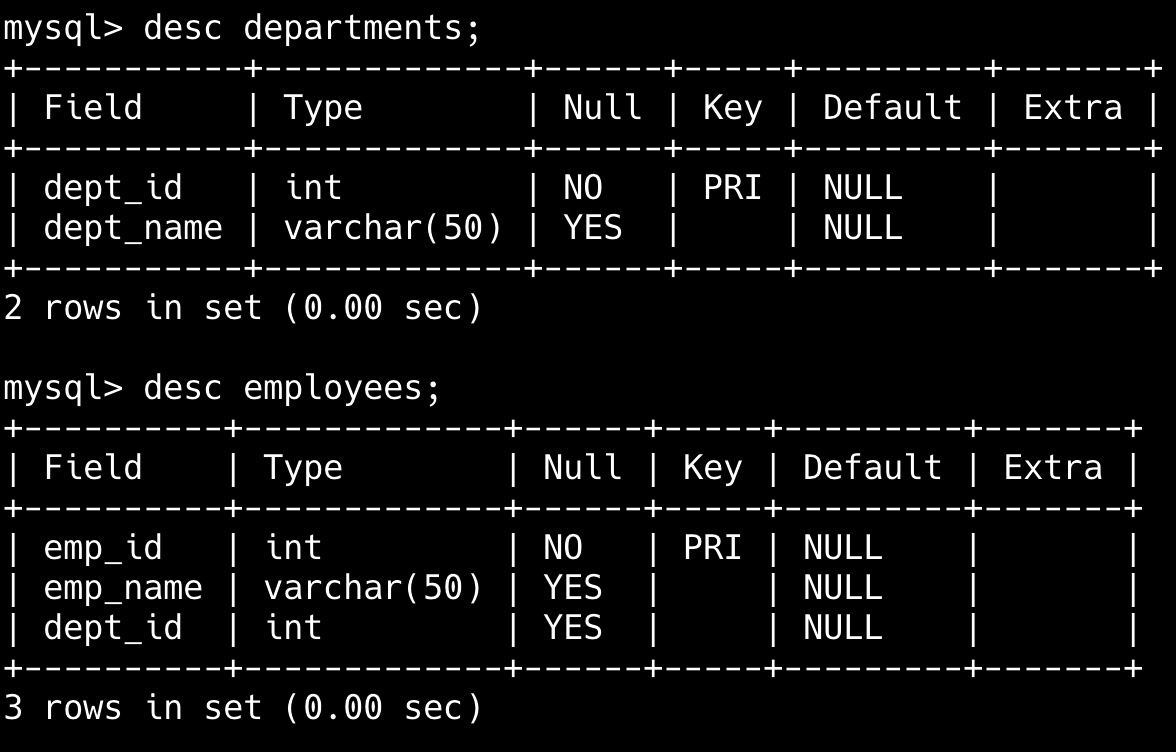
插入测试数据:
-- 插入测试数据
INSERT INTO departments VALUES
(1, '研发部'),
(2, '市场部'),
(3, '人事部');
-- 插入更多数据到员工表
INSERT INTO employees VALUES
(1, '张三', 1),
(2, '李四', 1),
(3, '王二', 2),
(4, '赵六', 2),
(5, '钱七', 3),
(6, '孙八', NULL),
(7, '周九', 1),
(8, '吴十', 2);然后用 explain 查看执行计划:
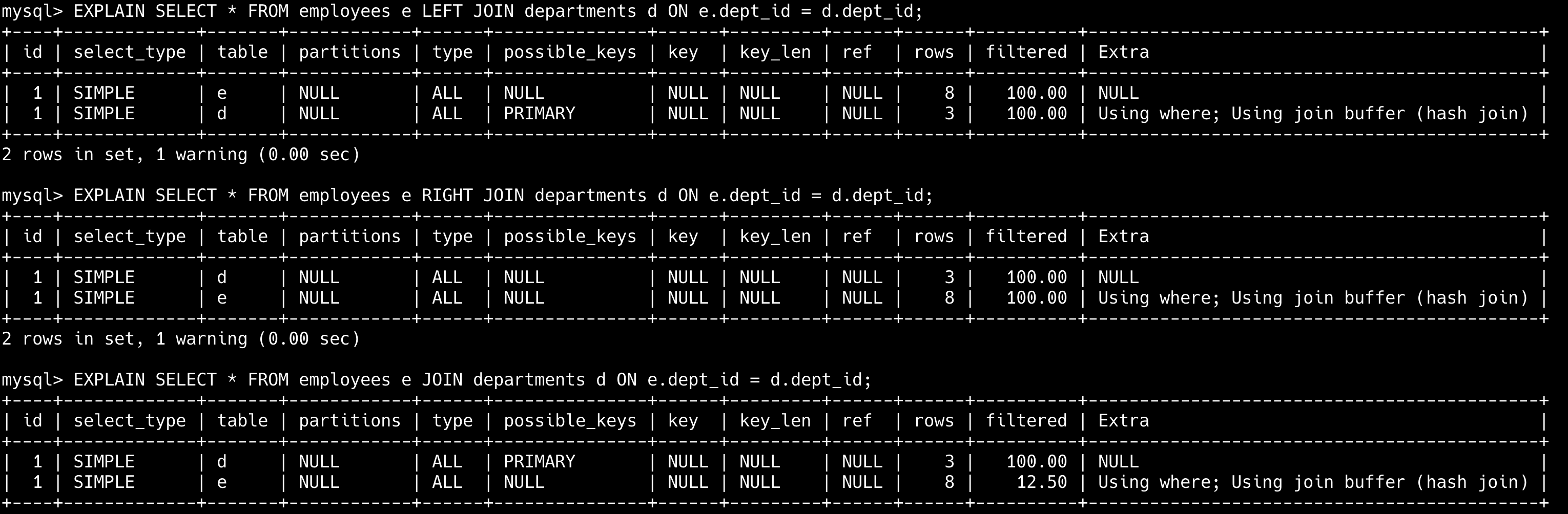
当使用 left join 的时候,第一行是 employees 表,说明左表是驱动表;当使用 right join 的时候,第一行是 departments 表,说明右表是驱动表;当使用 join 的时候,第一行是 departments 表,说明 MySQL 默认选择了小表作为驱动表。
----这部分是帮助大家理解 end,面试中可不背----
这里的小表指实际参与 JOIN 的数据量,而不是表的总行数。大表经过 where 条件过滤后也可能成为逻辑小表。
-- 实际参与JOIN的数据量决定小表
SELECT * FROM large_table l
JOIN small_table s ON l.id = s.id
WHERE l.created_at > '2025-01-01'; -- l经过过滤后可能成为小表也可以强制通过 STRAIGHT_JOIN 提示 MySQL 使用指定的驱动表。
explain select table_1.col1, table_2.col2, table_3.col2
from table_1
straight_join table_2 on table_1.col1=table_2.col1
straight_join table_3 on table_1.col1 = table_3.col1;
explain select straight_join table_1.col1, table_2.col2, table_3.col2
from table_1
join table_2 on table_1.col1=table_2.col1
join table_3 on table_1.col1 = table_3.col1;为什么要避免使用 JOIN 关联太多的表?
第一,多表 JOIN 的执行路径会随着表的数量呈现指数级增长,优化器需要估算所有路径的成本,有可能会导致出现大表驱动小表的情况。
SELECT * FROM A
JOIN B ON A.id = B.a_id
JOIN C ON B.id = C.b_id
JOIN D ON C.id = D.c_id
JOIN E ON D.id = E.d_id; -- 5 个表,优化器需评估 5! = 120 种顺序第二,多表 JOIN 需要缓存中间结果集,可能超出 join_buffer_size,这种情况下内存临时表就会转为磁盘临时表,性能也会急剧下降。
《阿里巴巴 Java 开发手册》上就规定,不要使用 join 关联太多的表,最多不要超过 3 张表。

memo:2025 年 3 月 24 日修改至此,今天有球友反馈说,简历上加了 mydb 项目后,也顺利拿到腾讯的暑期实习 offer。

如何进行排序优化?
第一,对 ORDER BY 涉及的字段创建索引,避免 filesort。
-- 优化前(可能触发 filesort)
SELECT * FROM users ORDER BY age DESC;
-- 优化后(添加索引)
ALTER TABLE users ADD INDEX idx_age (age);如果是多个字段,联合索引需要保证 ORDER BY 的列是索引的最左前缀。
-- 联合索引需与 ORDER BY 顺序一致(age 在前,name 在后)
ALTER TABLE users ADD INDEX idx_age_name (age, name);
-- 有效利用索引的查询
SELECT * FROM users ORDER BY age, name;
-- 无效案例(索引失效,因 name 在索引中排在 age 之后)
SELECT * FROM users ORDER BY name, age;第二,可以适当调整排序参数,如增大 sort_buffer_size、max_length_for_sort_data 等,让排序在内存中完成。
----这部分是帮助大家理解 start,面试中可不背----
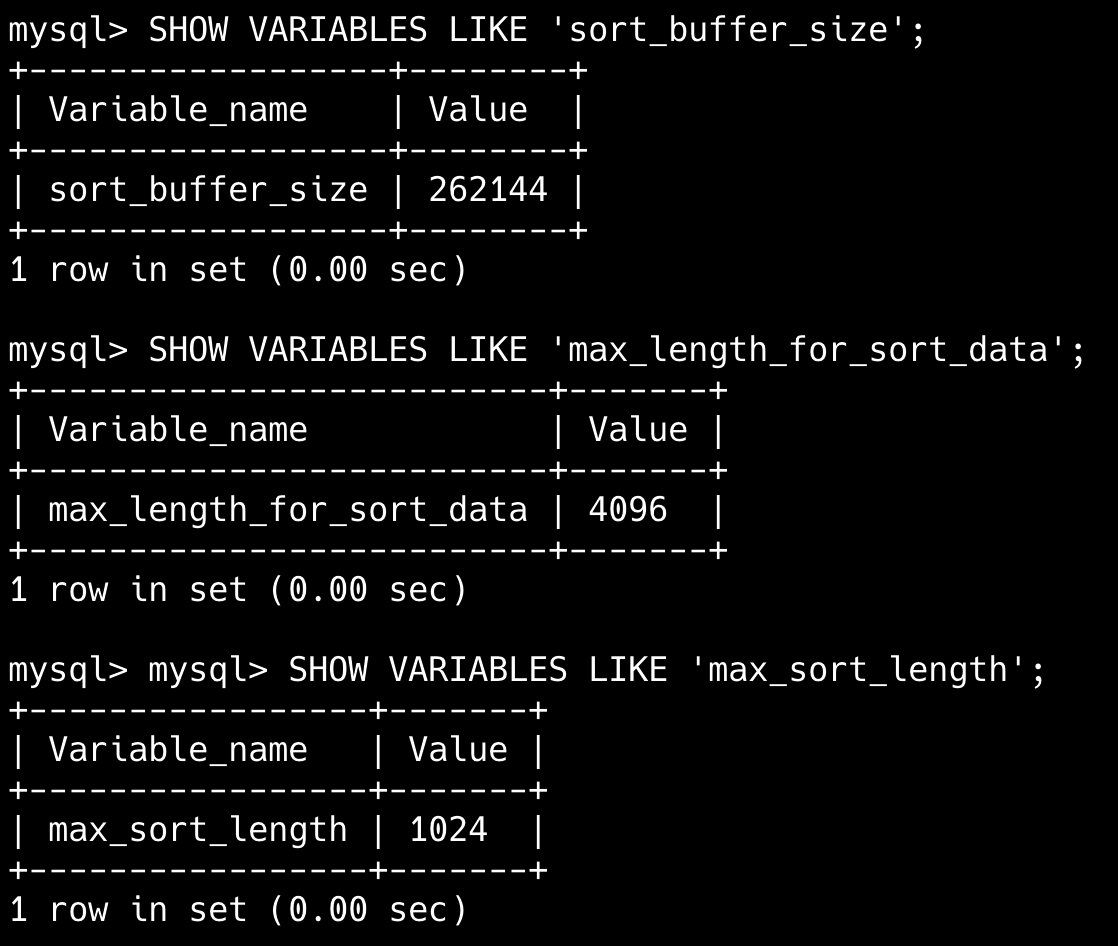
- sort_buffer_size:用于控制排序缓冲区的大小,默认为 256KB。也就是说,如果排序的数据量小于 256KB,MySQL 会在内存中直接排序;否则就要在磁盘上进行 filesort。
- max_length_for_sort_data:单行数据的最大长度,会影响排序算法选择。如果单行数据超过该值,MySQL 会使用双路排序,否则使用单路排序。
- max_sort_length:限制字符串排序时比较的前缀长度。当 MySQL 不得不对 text、blob 字段进行排序时,会截取前 max_sort_length 个字符进行比较。
----这部分是帮助大家理解 end,面试中可不背----
第三,可以通过 where 和 limit 限制待排序的数据量,减少排序的开销。
-- 优化前
SELECT * FROM users ORDER BY age LIMIT 100;
-- 优化后(减少数据传输和排序开销)
SELECT id, name, age FROM users ORDER BY age LIMIT 100;
-- 深度分页优化(避免 OFFSET 扫描全表)
SELECT * FROM users ORDER BY age LIMIT 10000, 20; -- 低效
SELECT * FROM users WHERE age > last_age ORDER BY age LIMIT 20; -- 高效(记录上一页最后一条的 age 值)什么是 filesort?
推荐阅读:MySQL 如何执行 ORDER BY
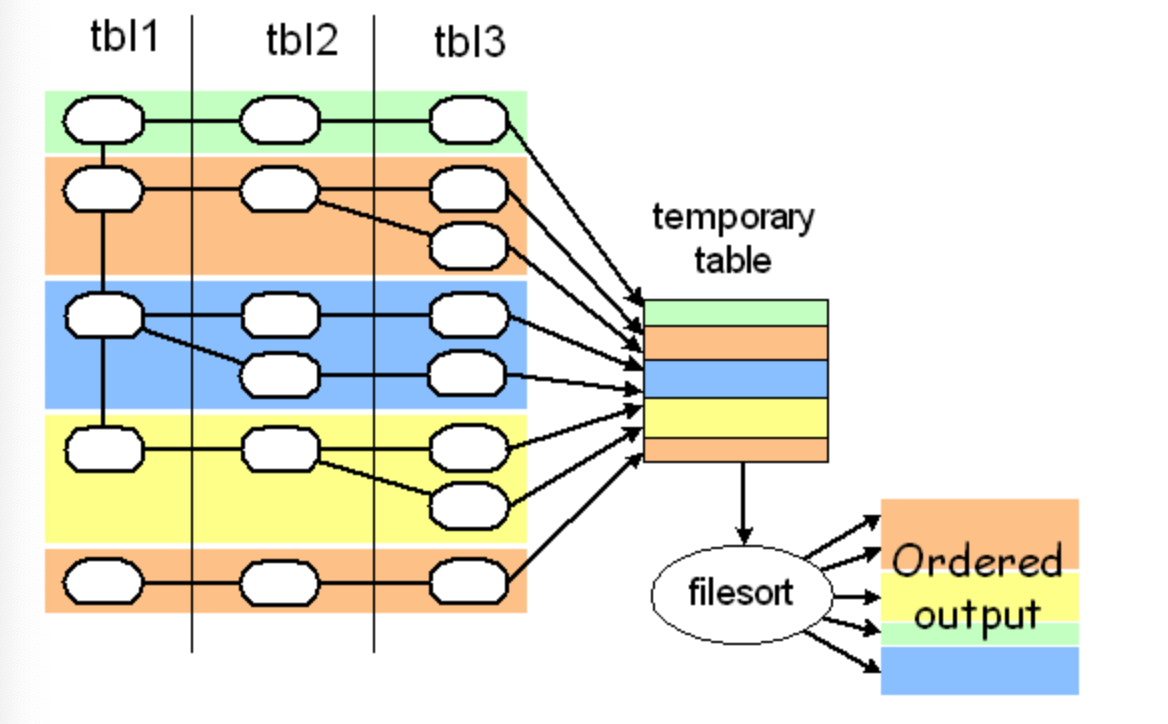
当不能使用索引生成排序结果的时候,MySQL 需要自己进行排序,如果数据量比较小,会在内存中进行;如果数据量比较大就需要写临时文件到磁盘再排序,我们将这个过程称为文件排序。
----这部分是帮助大家理解 start,面试中可不背----
好,让我们来验证一下 filesort 的情况,建表、插入数据。
执行 explain 查看执行计划。
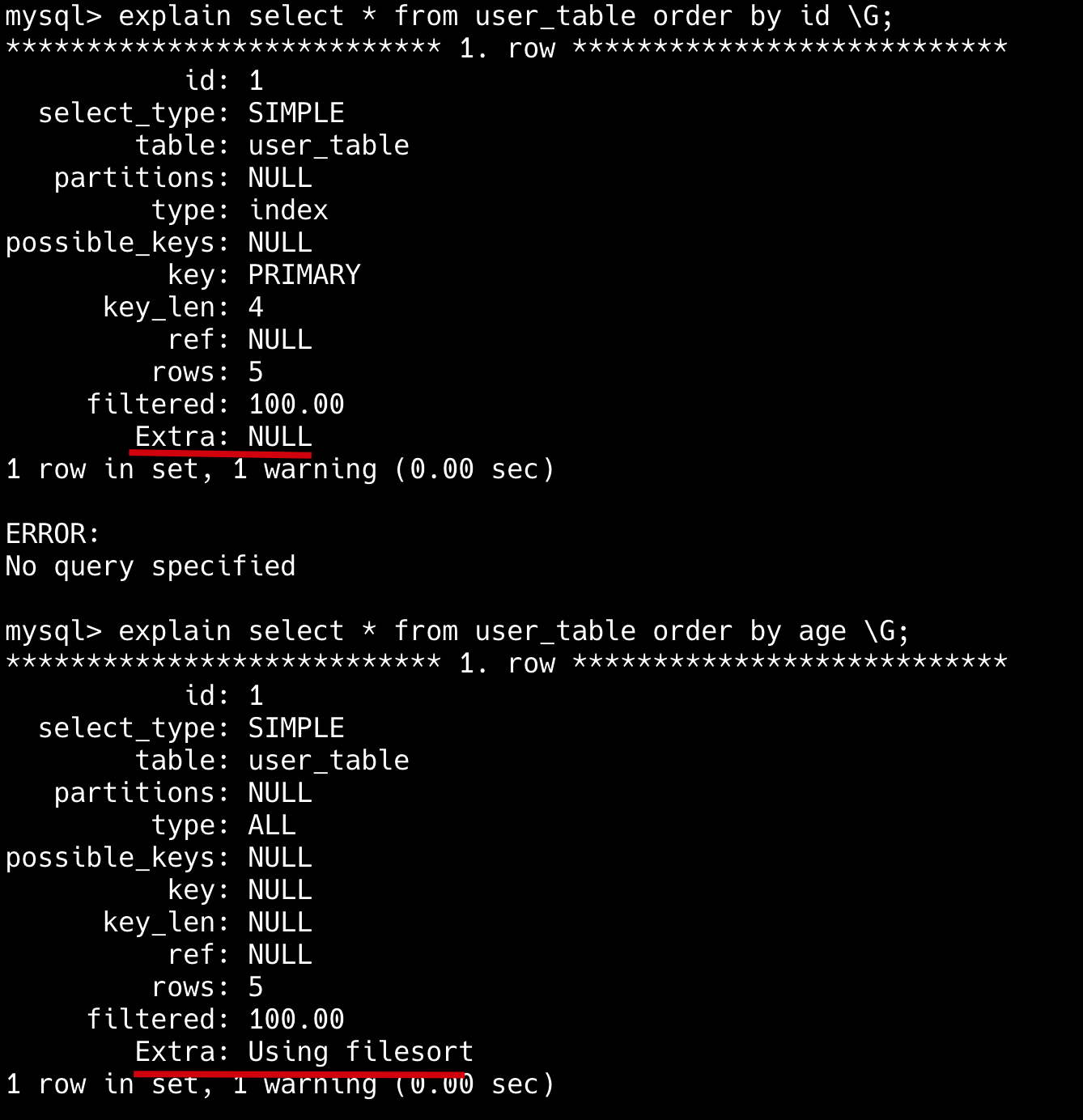
能够看得出来,当 order by id 也就是主键的时候,没有触发 filesort;当 order by age 的时候,由于没有索引,就触发了 filesort。
----这部分是帮助大家理解 end,面试中可不背----
memo:2025 年 3 月 26 日修改至此,今天有球友说,拿到了阿里云的实习 offer,真的 tql。
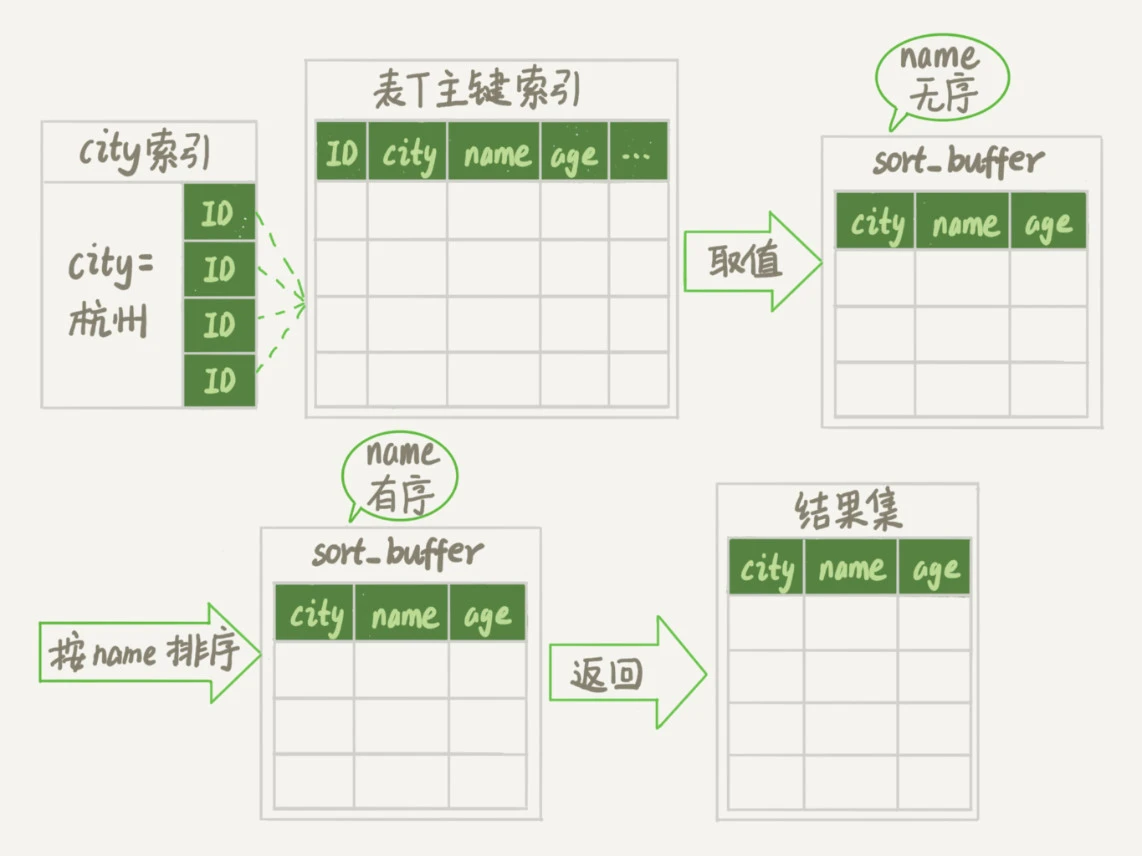
全字段排序和 rowid 排序了解多少?
当排序字段是索引字段且满足最左前缀原则时,MySQL 可以直接利用索引的有序性完成排序。
当无法使用索引排序时,MySQL 需要在内存或磁盘中进行排序操作,分为全字段排序和 rowid 排序两种算法。
全字段排序会一次性取出满足条件行的所有字段,然后在 sort buffer 中进行排序,排序后直接返回结果,无需回表。
以 SELECT * FROM user WHERE name = "王二" ORDER BY age 为例:
- 从 name 索引中找到第一个满足
name='张三'的主键 id; - 根据主键 id 取出整行所有的字段,存入 sort buffer;
- 重复上述过程直到处理完所有满足条件的行
- 对 sort buffer 中的数据按 age 排序,返回结果。
优点是仅需要一次磁盘 IO,缺点是内存占用大,如果数量超过 sort buffer 的话,需要分片读取并借助临时文件合并排序,IO 次数反而会增加。
也无法处理包含 text 和 blob 类型的字段。
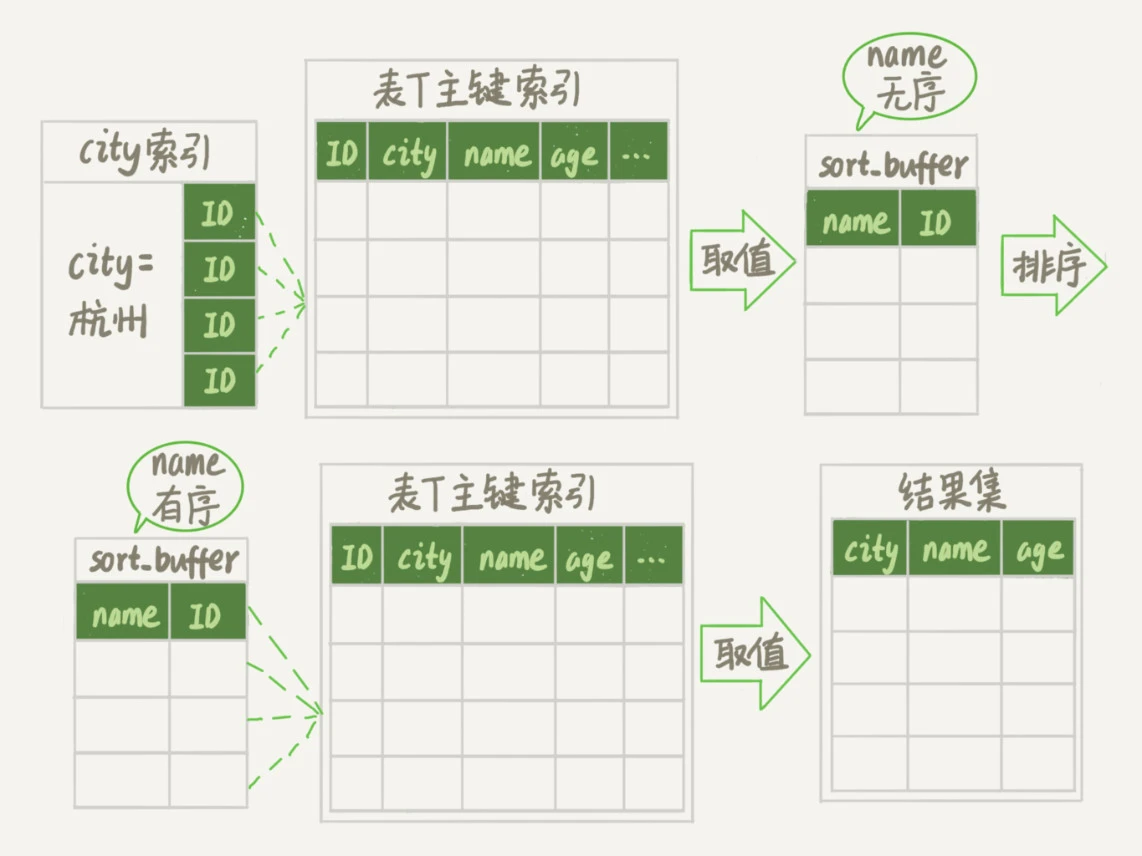
rowid 排序分为两个阶段:
- 第一阶段:根据查询条件取出排序字段和主键 ID,存入 sort buffer 进行排序;
- 第二阶段:根据排序后的主键 ID 回表取出其他需要的字段。
同样以 SELECT * FROM user WHERE name = "王二" ORDER BY age 为例:
- 从 name 索引中找到第一个满足
name='张三'的主键 id; - 根据主键 id 取出排序字段 age,连同主键 id 一起存入 sort buffer;
- 重复上述过程直到处理完所有满足条件的行
- 对 sort buffer 中的数据按 age 排序;
- 遍历排序后的主键 id,回表取出其他所需字段,返回结果。
优点是内存占用较少,适合字段多或者数据量大的场景,缺点是需要两次磁盘 IO。
MySQL 会根据系统变量 max_length_for_sort_data 和查询字段的总大小来决定使用全字段排序还是 rowid 排序。
如果查询字段总长度 <= max_length_for_sort_data,MySQL 会使用全字段排序;否则会使用 rowid 排序。
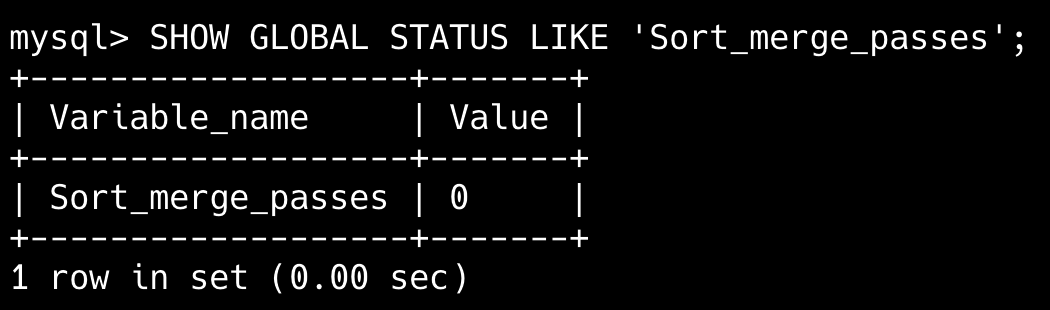
你对 Sort_merge_passes 参数了解吗?
Sort_merge_passes 是一个状态变量,用于统计 MySQL 在执行排序操作时进行归并排序的次数。
当 MySQL 需要进行排序但排序数据无法完全放入 sort_buffer_size 定义的内存缓冲区时,就会使用临时文件进行外部排序,这时就会产生 Sort_merge_passes。
如果 Sort_merge_passes 在短时间内快速激增,说明排序操作的数据量较大,需要调整 sort_buffer_size 或者优化查询语句。
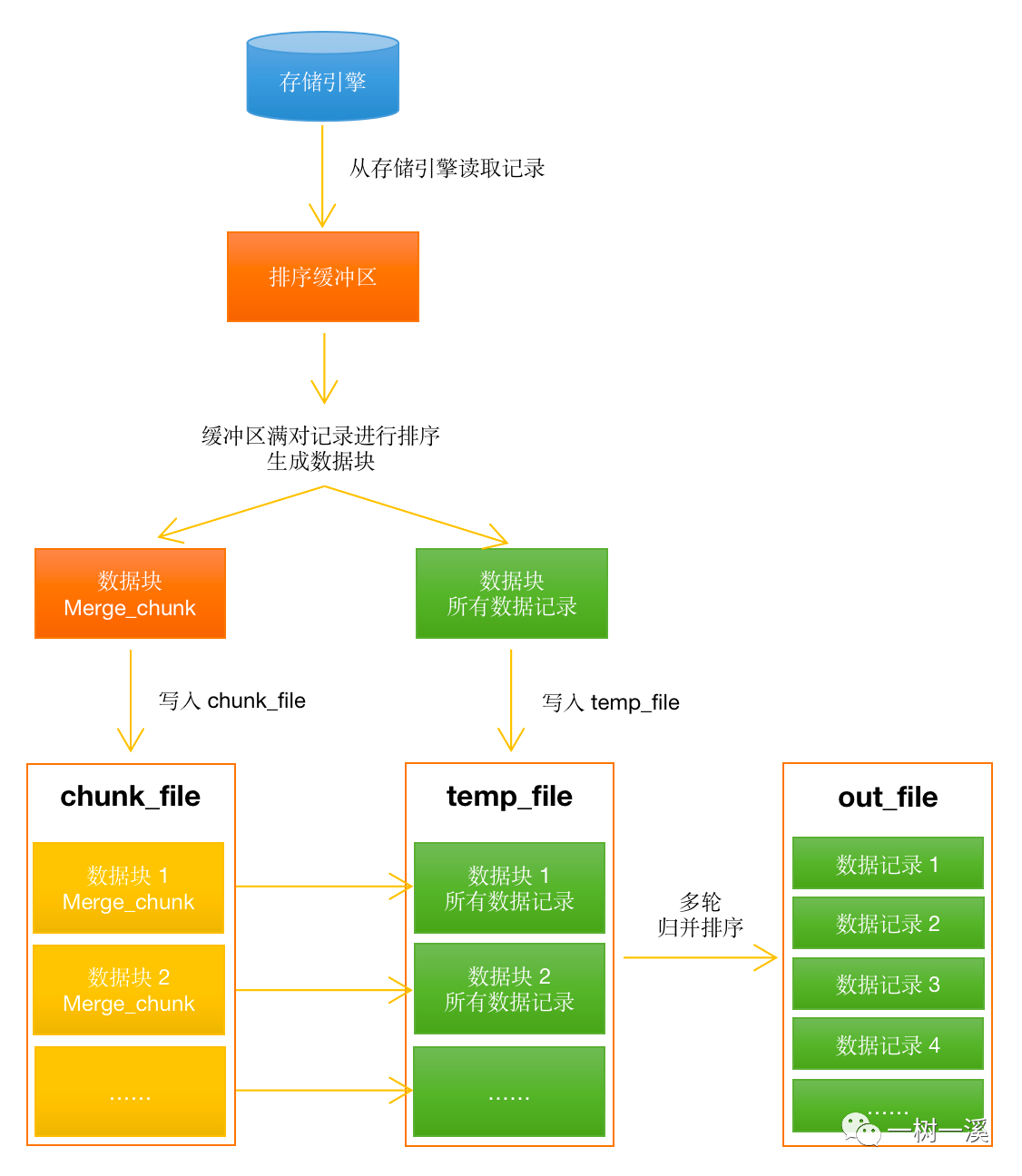
MySQL 在执行排序操作时,会经历两个过程:
- 内存排序阶段,MySQL 首先尝试在 sort buffer 中进行排序。如果数据量小于 sort_buffer_size 缓冲区大小,会完全在内存中完成快速排序。
- 外部排序阶段,如果数据量超过 sort_buffer_size,MySQL 会将数据分成多个块,每块单独排序后写入临时文件,然后对这些已排序的块进行归并排序。每次归并操作都会增加 Sort_merge_passes 的计数。
memo:2025 年 3 月 27 日修改至此,今天有球友说,通过了快手二面,并且 HR 面是不排序的,已经确定了入职时间,恭喜啊。

条件下推你了解多少?
条件下推的核心思想是将外层的过滤条件,比如说 where、join 等,尽可能地下推到查询计划的更底层,比如说子查询、连接操作之前,从而减少中间结果的数据量。
比如说原始查询是:
SELECT * FROM (
SELECT * FROM orders WHERE total > 100
) AS subquery
WHERE subquery.status = 'shipped';就可以将条件下推到子查询:
SELECT * FROM (
SELECT * FROM orders WHERE total > 100 AND status = 'shipped'
) AS subquery;这样就可以减少查询返回的数据量,避免外层再过滤。
再比如说 union 中的原始查询是:
(SELECT * FROM t1)
UNION ALL
(SELECT * FROM t2)
ORDER BY col LIMIT 10;就可以将条件下推到每个子查询:
(SELECT * FROM t1 ORDER BY col LIMIT 10)
UNION ALL
(SELECT * FROM t2 ORDER BY col LIMIT 10);每个子查询仅返回前 10 条数据,减少临时表的数据量。
再比如说连接查询 join 中的原始查询是:
SELECT * FROM orders
JOIN customers ON orders.customer_id = customers.id
WHERE customers.country = 'china';就可以将条件下推到表扫描的时候:
SELECT * FROM orders
JOIN (
SELECT * FROM customers WHERE country = 'china'
) AS filtered_customers
ON orders.customer_id = filtered_customers.id;先过滤 customers 表,减少 join 时的数据量。
为什么要尽量避免使用 select *?
SELECT * 会强制 MySQL 读取表中所有字段的数据,包括应用程序可能并不需要的,比如 text、blob 类型的大字段。
加载冗余数据会占用更多的缓存空间,从而挤占其他重要数据的缓存资源,降低整体系统的吞吐量。
也会增加网络传输的开销,尤其是在大字段的情况下。
最重要的是,SELECT * 可能会导致覆盖索引失效,本来可以走索引的查询最后变成了全表扫描。
-- 使用覆盖索引(假设索引为 idx_country)
SELECT id, country FROM users WHERE country = 'china'; -- 可能仅扫描索引
-- 使用 SELECT *
SELECT * FROM users WHERE country = 'china'; -- 需回表读取所有列你还知道哪些 SQL 优化方法?
①、避免使用 != 或者 <> 操作符
!= 或者 <> 操作符会导致 MySQL 无法使用索引,从而导致全表扫描。
可以把column<>'aaa',改成column>'aaa' or column<'aaa'。
②、使用前缀索引
比如,邮箱的后缀一般都是固定的@xxx.com,那么类似这种后面几位为固定值的字段就非常适合定义为前缀索引:
alter table test add index index2(email(6));需要注意的是,MySQL 无法利用前缀索引做 order by 和 group by 操作。
③、避免在列上使用函数
在 where 子句中直接对列使用函数会导致索引失效,因为 MySQL 需要对每行的列应用函数后再进行比较。
select name from test where date_format(create_time,'%Y-%m-%d')='2021-01-01';可以改成:
select name from test where create_time>='2021-01-01 00:00:00' and create_time<'2021-01-02 00:00:00';通过日期的范围查询,而不是在列上使用函数,可以利用 create_time 上的索引。
memo:2025 年 3 月 28 日修改至此,今天有球友说,字节跳动和腾讯的暑期实习都 OC 了,很感谢当时加了二哥的编程星球,看球友们日常的学习分享,以及二哥推荐的轮子。
- Java 面试指南(付费)收录的腾讯面经同学 22 暑期实习一面面试原题:查询优化、联合索引、覆盖索引
- Java 面试指南(付费)收录的华为面经同学 8 技术二面面试原题:说说 SQL 该如何优化
- Java 面试指南(付费)收录的华为面经同学 6 Java 通用软件开发一面面试原题:说说 SQL 该如何优化
- Java 面试指南(付费)收录的微众银行同学 1 Java 后端一面的原题:MySQL 索引如何优化?
- Java 面试指南(付费)收录的携程面经同学 10 Java 暑期实习一面面试原题:讲一讲 MySQL 的索引,如何优化 SQL?
- Java 面试指南(付费)收录的用友面试原题:了解 mysql 怎么优化吗
- Java 面试指南(付费)收录的阿里系面经同学 19 饿了么面试原题:查询如何优化
34.🌟explain平常有用过吗?
经常用,explain 是 MySQL 提供的一个用于查看 SQL 执行计划的工具,可以帮助我们分析查询语句的性能问题。
一共有 10 来个输出参数。
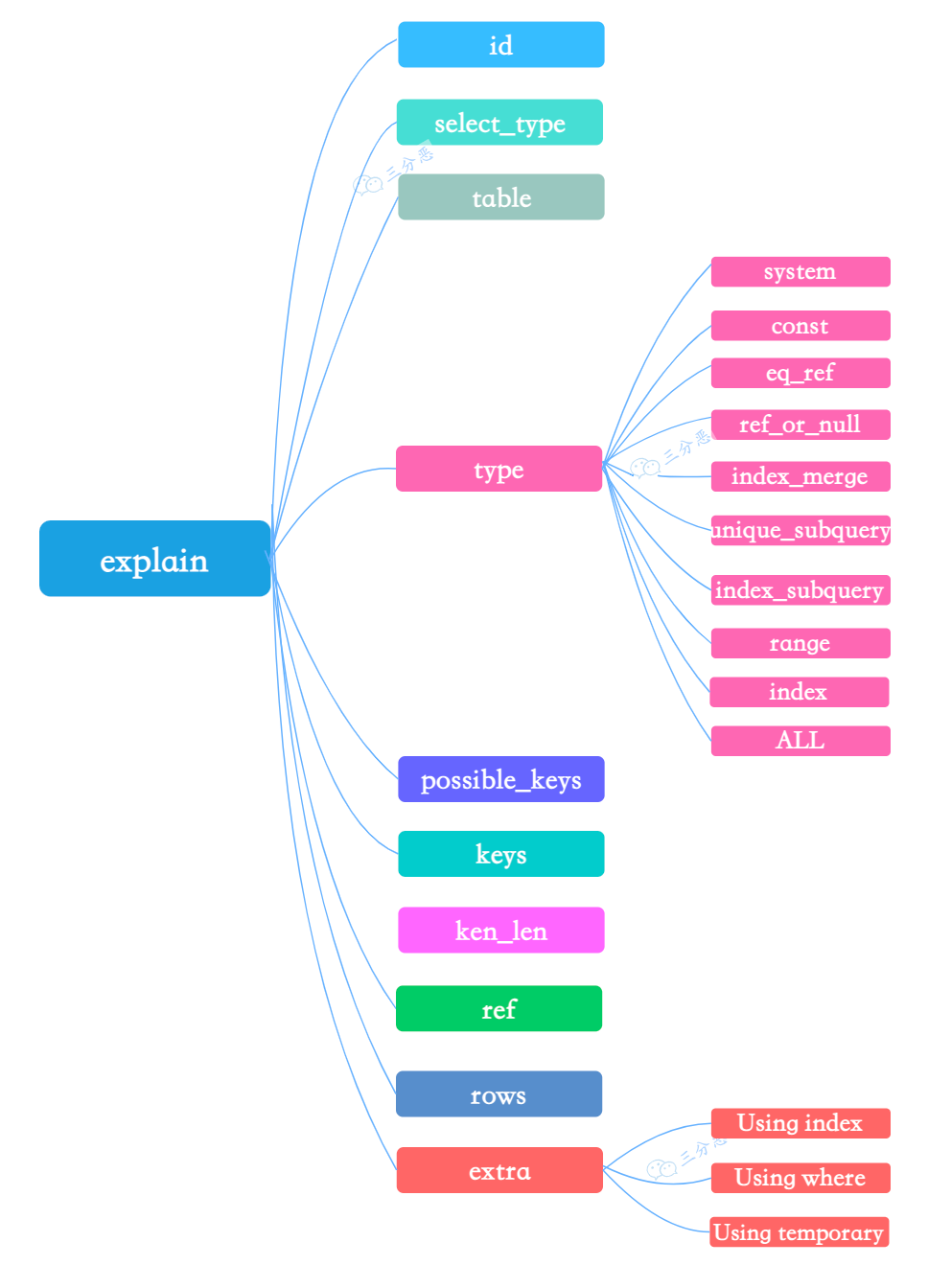
比如说 type=ALL,key=NULL 表示 SQL 正在全表扫描,可以考虑为 where 字段添加索引进行优化;Extra=Using filesort 表示 SQL 正在文件排序,可以考虑为 order by 字段添加索引。
使用方式也非常简单,直接在 select 前加上 explain 关键字就可以了。
explain select * from students where name='王二';更高级的用法可以配合 format=json 参数,将 explain 的输出结果以 JSON 格式返回。
explain format=json select * from students where name='王二';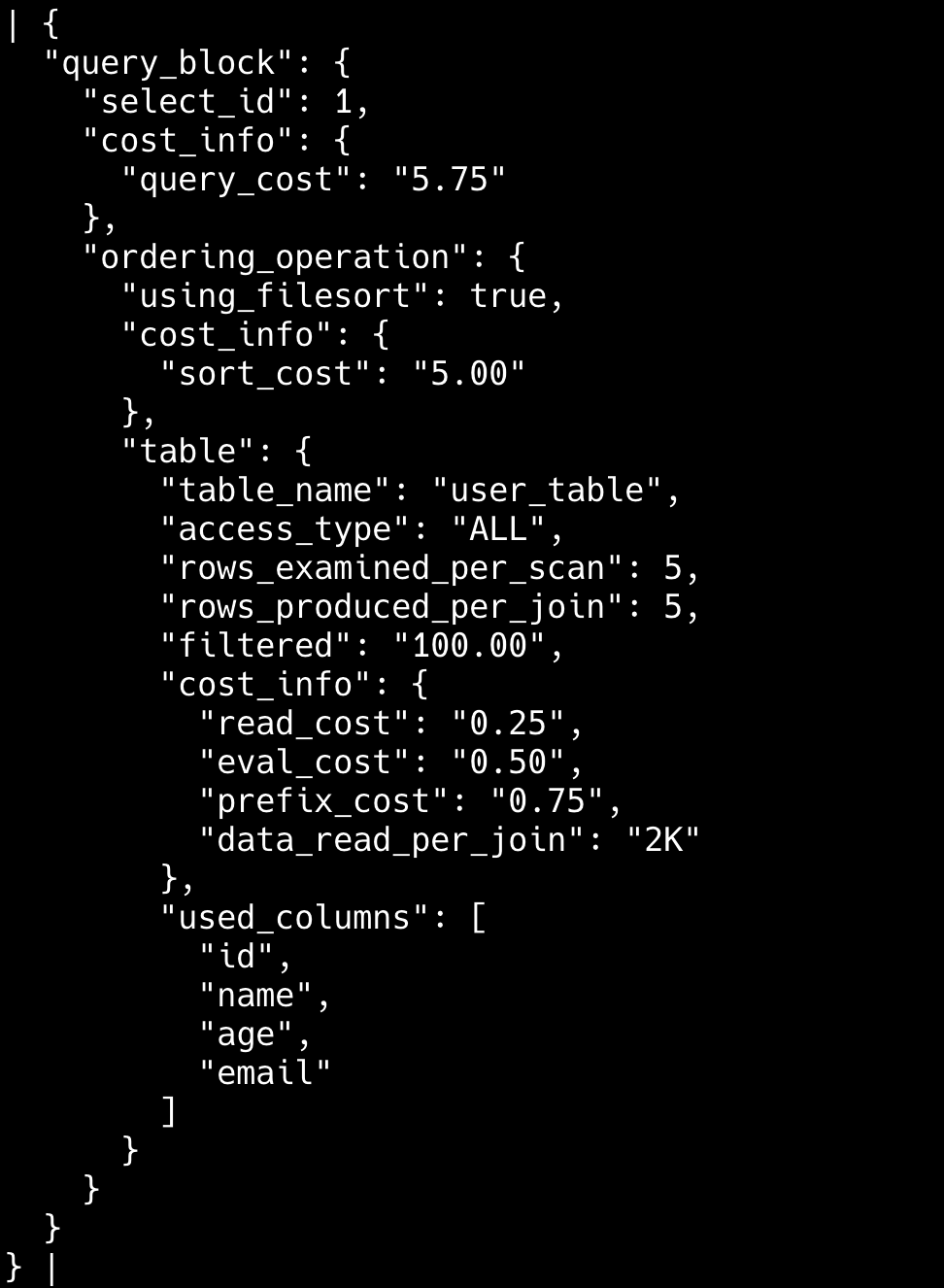
explain 输出结果中常见的字段含义理解吗?
在 EXPLAIN 输出结果中我最关注的字段是 type、key、rows 和 Extra。
我会通过它们判断 SQL 有没有走索引、是否全表扫描、预估扫描行数是否太大,以及是否触发了 filesort 或临时表。一旦发现问题,比如 type=ALL 或者 Extra=Using filesort,我会考虑建索引、改写 SQL 或控制查询结果集来做优化。
----这部分是帮助大家理解 start,面试中可不背----
以 EXPLAIN SELECT * FROM orders WHERE user_id = 100 的输出为例:
| 字段 | 值 | 含义与优化指导 |
|---|---|---|
| id | 1 | 查询序列号。 |
| select_type | SIMPLE | 简单查询(无子查询或 UNION)。复杂场景还有 PRIMARY、SUBQUERY、DERIVED 等。 |
| table | orders | 当前步骤操作的表名。 |
| partitions | NULL | 涉及的分区。 |
| type | ref | 访问类型:关键性能指标,常见类型: - system/const:唯一值匹配(性能最佳) - eq_ref:主键/唯一索引连接 - ref:非唯一索引匹配 - range:索引范围扫描 - index:全索引扫描 - ALL:全表扫描(需优化) |
| possible_keys | idx_user_id | 可能使用的索引。若为空,说明无合适索引。 |
| key | idx_user_id | 实际选择的索引。若为 NULL,表示未使用索引。 |
| key_len | 4 | 索引使用的字节数,可判断是否使用完整索引。例如,联合索引 (a,b),若 key_len=4 可能只用到了 a 列。 |
| ref | const | 与索引比较的列或常量(如 WHERE user_id=100 中的 100)。 |
| rows | 50 | 预估扫描行数。数值越小越好,若与实际差距大,可能统计信息过期(需 ANALYZE TABLE)。 |
| filtered | 100.00 | 查询条件过滤后剩余行的百分比。例如 rows=1000 且 filtered=10%,则最终返回约 100 行。 |
| Extra | Using where | 附加信息: - Using index:覆盖索引(无需回表) - Using temporary:使用临时表 - Using filesort:文件排序 |
非表格版本:
①、id 列:查询的执行顺序编号。id 相同:同一执行层级,按 table 列从上到下顺序执行(如多表 JOIN);id 递增:嵌套子查询,数值越大优先级越高,越先执行。
EXPLAIN SELECT * FROM t1 JOIN (SELECT * FROM t2 WHERE id = 1) AS sub;t2 子查询的 id=2,优先执行。
②、select_type 列:查询的类型。常见的类型有:
- SIMPLE:简单查询,不包含子查询或者 UNION。
- PRIMARY:查询中如果包含子查询,则最外层查询被标记为 PRIMARY。需要关注子查询或派生表性能。
- SUBQUERY:子查询;需要避免多层嵌套,尽量改写为 JOIN。
- DERIVED:派生表(FROM 子句中的子查询)。需要减少派生表数据量,或物化为临时表。
③、table 列:查的哪个表。
- derivedN:表示派生表(N 对应 id)。
- unionNM,N:表示 UNION 合并的结果(M、N 为参与 UNION 的 id)。
④、type 列:表示 MySQL 在表中找到所需行的方式。
- system,表仅有一行(系统表或衍生表),无需优化。
- const:通过主键或唯一索引找到一行(如 WHERE id = 1)。理想情况。
- eq_ref:对主键/唯一索引 JOIN 匹配(如
A JOIN B ON A.id = B.id)。确保 JOIN 字段有索引。 - ref:非唯一索引匹配(如
WHERE name = '王二',name 有普通索引)。 - range:只检索给定范围的行,使用索引来检索。在
where语句中使用bettween...and、<、>、<=、in等条件查询type都是range。 - index:全索引扫描,如果不需要回表,可接受;否则考虑覆盖索引。
- ALL:全表扫描,效率最低。
⑤、possible_keys 列:可能会用到的索引,但并不一定实际被使用。
⑥、key 列:实际使用的索引。如果为 NULL,则没有使用索引。如果为 PRIMARY,则使用了主键索引。
⑦、key_len 列:使用的索引字节数,反映索引列的利用率。使用联合索引 (a, b),key_len 是 a 和 b 的字节总和(仅当查询条件用到 a 或 a+b 时有效)。
-- 表结构:CREATE TABLE t (a INT, b VARCHAR(20), INDEX idx_a_b (a, b));
EXPLAIN SELECT * FROM t WHERE a = 1 AND b = 'test';key_len = 4(INT) + 20*3(utf8) + 2 = 66 字节。
⑧、ref 列:与索引列比较的值或列。
- const:常量。例如 WHERE
column = 'value'。 - func:函数。例如 WHERE
column = func(column)。
⑨、rows 列:优化器估算的需要扫描的行数。数值越小越好,若与实际差距大,可能统计信息过期(需 ANALYZE TABLE)。结合 filtered 字段可以计算最终返回行数(rows × filtered)。
⑩、Extra 列:附加信息。
- Using index:覆盖索引,无需回表。
- Using where:存储引擎返回结果后,Server 层需要再次过滤(条件未完全下推)。
- Using temporary :使用临时表(常见于 GROUP BY、DISTINCT)。
- Using filesort:文件排序(常见于 ORDER BY)。考虑为 ORDER BY 字段添加索引。
- Select tables optimized away:优化器已优化(如 COUNT(*) 通过索引直接统计)。
- Using join buffer:使用连接缓冲区(Block Nested Loop 或 Hash Join)。考虑增大 join_buffer_size。
示例:
----这部分是帮助大家理解 end,面试中可不背----
type的执行效率等级,达到什么级别比较合适?
从高到低的效率排序是 system、const、eq_ref、ref、range、index 和 ALL。
一般情况下,建议 type 值达到 const、eq_ref 或 ref,因为这些类型表明查询使用了索引,效率较高。
如果是范围查询,range 类型也是可以接受的。
ALL 类型表示全表扫描,性能最差,往往不可接受,需要优化。
- Java 面试指南(付费)收录的华为面经同学 8 技术二面面试原题:怎么看走没走索引,如何分析 SQL
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:key-len和key没什么区别,什么时候会用到key-len,你还会查看explain中的哪些字段,extra有哪些类型
- Java 面试指南(付费)收录的同学 1 贝壳找房后端技术一面面试原题:explain分析后, type的执行效率等级,达到什么级别比较合适
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 3 月 29 日修改至此,今天有球友说美团的 offer 口头 OC 了,真的太棒了。
索引
35.🌟索引为什么能提高MySQL查询效率?
索引就像一本书的目录,能让 MySQL 快速定位数据,避免全表扫描。
它一般是 B+ 树结构,查找效率是 O(log n),比从头到尾扫一遍数据要快得多。
除了查得快,索引还能加速排序、分组、连接等操作。
项目中最常见的做法就是通过 create index 为经常用作查询条件的字段建索引,比如:
create index idx_name on students(name);----这部分是帮助大家理解 start,面试中可不背----
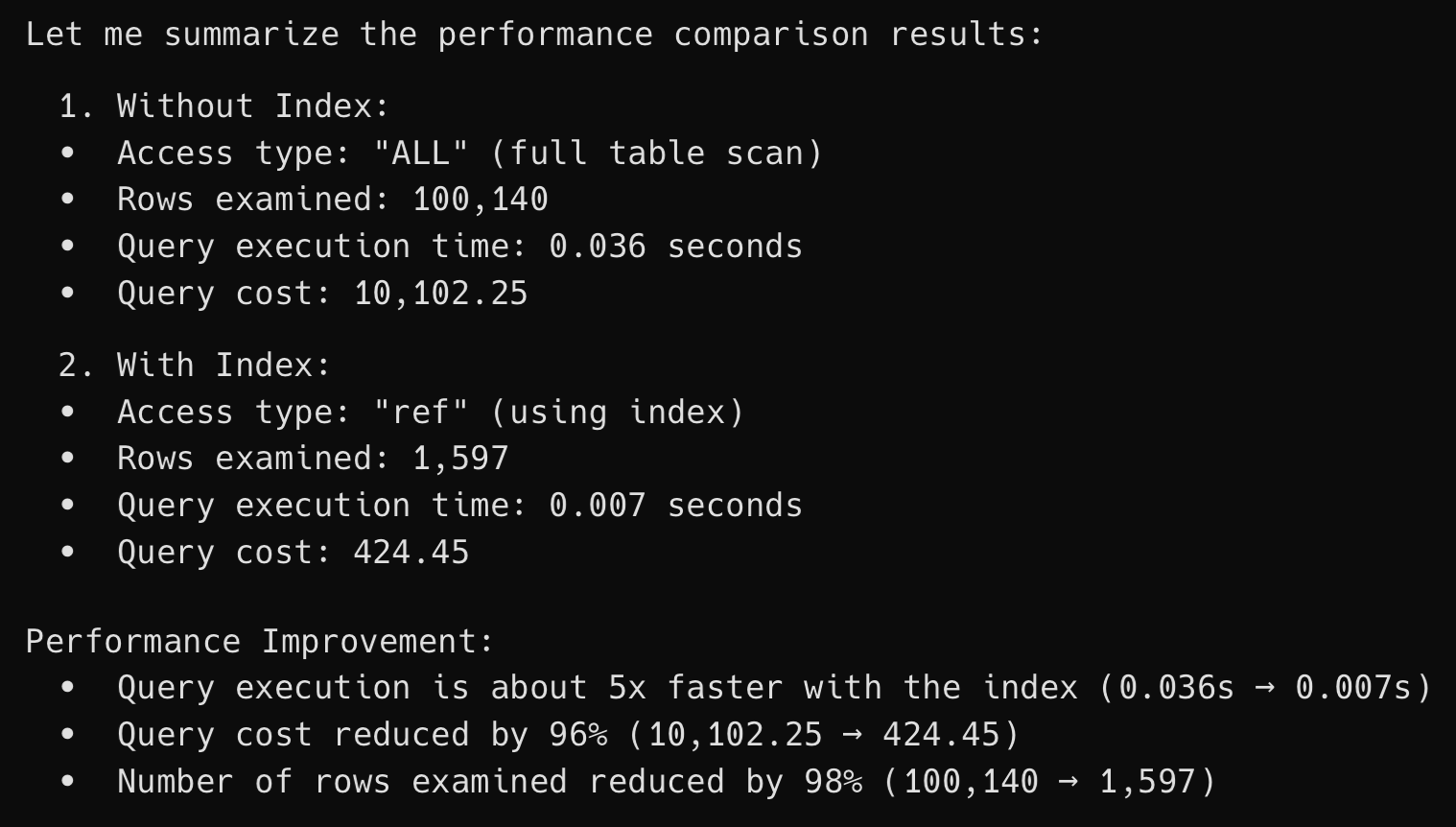
我们通过 wrap 的 agent 验证一下有没有索引的查询效率。
先上结果,有索引的查询时间是 0.007 秒,没有索引的查询时间是 0.036 秒。
创建数据库和表。

插入 10 万条数据。
然后依次执行 explain 查看没有索引和有索引时的执行计划。
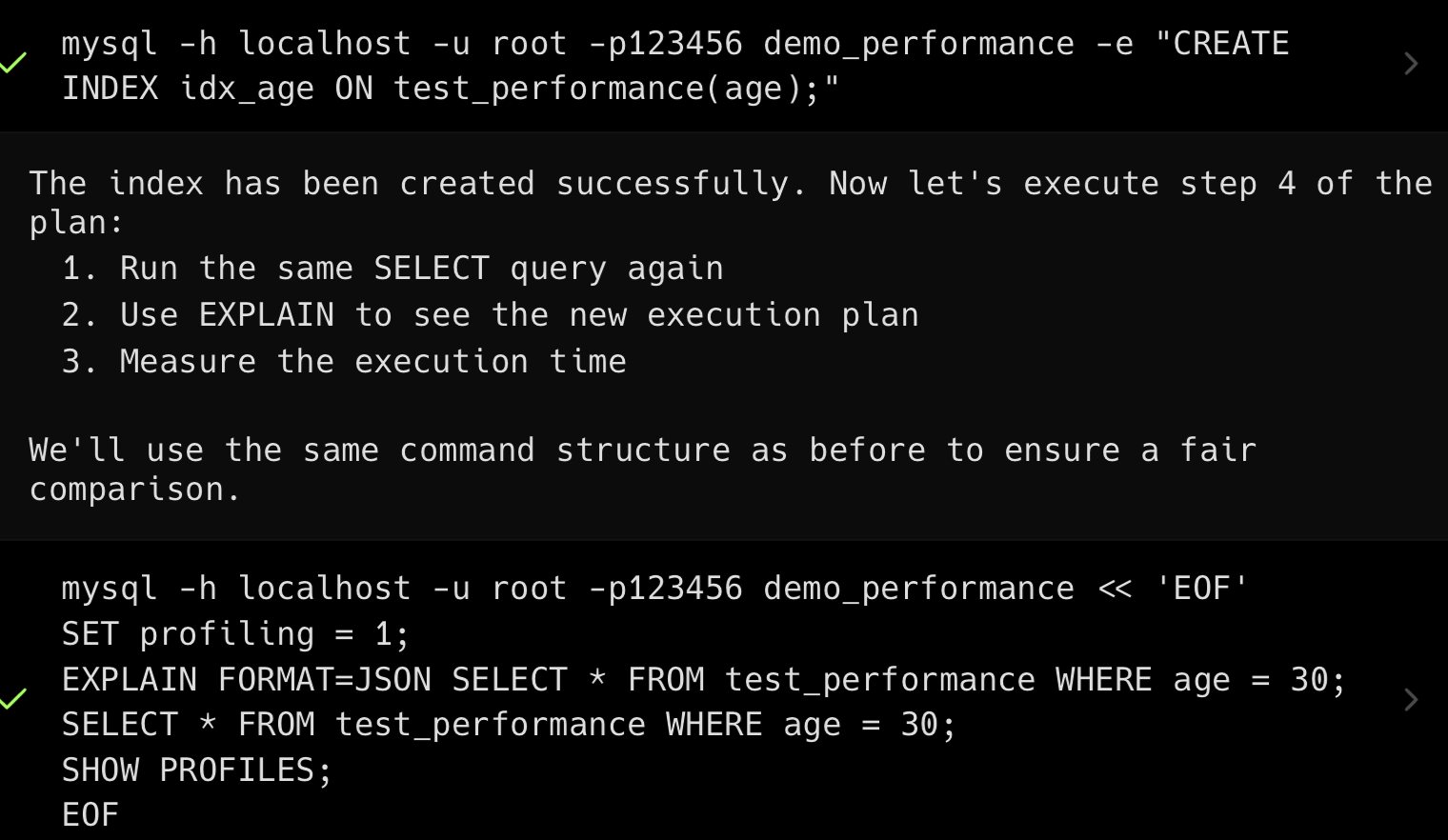
----这部分是帮助大家理解 end,面试中可不背----
- Java 面试指南(付费)收录的腾讯面经同学 23 QQ 后台技术一面面试原题:MySQL 索引,为什么用 B+树
- Java 面试指南(付费)收录的小米面经同学 E 第二个部门 Java 后端技术一面面试原题:为什么需要索引
- Java 面试指南(付费)收录的小公司面经同学 5 Java 后端面试原题:数据库索引讲一下,然后为什么会加快查询速度
- Java 面试指南(付费)收录的去哪儿面经同学 1 技术二面面试原题:mysql为什么用索引
- Java 面试指南(付费)收录的 OPPO 面经同学 1 面试原题:对MySQL索引的理解
- Java 面试指南(付费)收录的vivo 面经同学 10 技术一面面试原题:索引,为什么使用索引更快
- Java 面试指南(付费)收录的腾讯面经同学 27 云后台技术一面面试原题:介绍下索引?底层是啥?
memo:2025 年 3 月 30 日修改至此,之前有球友说拿到了淘天搜索的暑期实习,真的恭喜了。

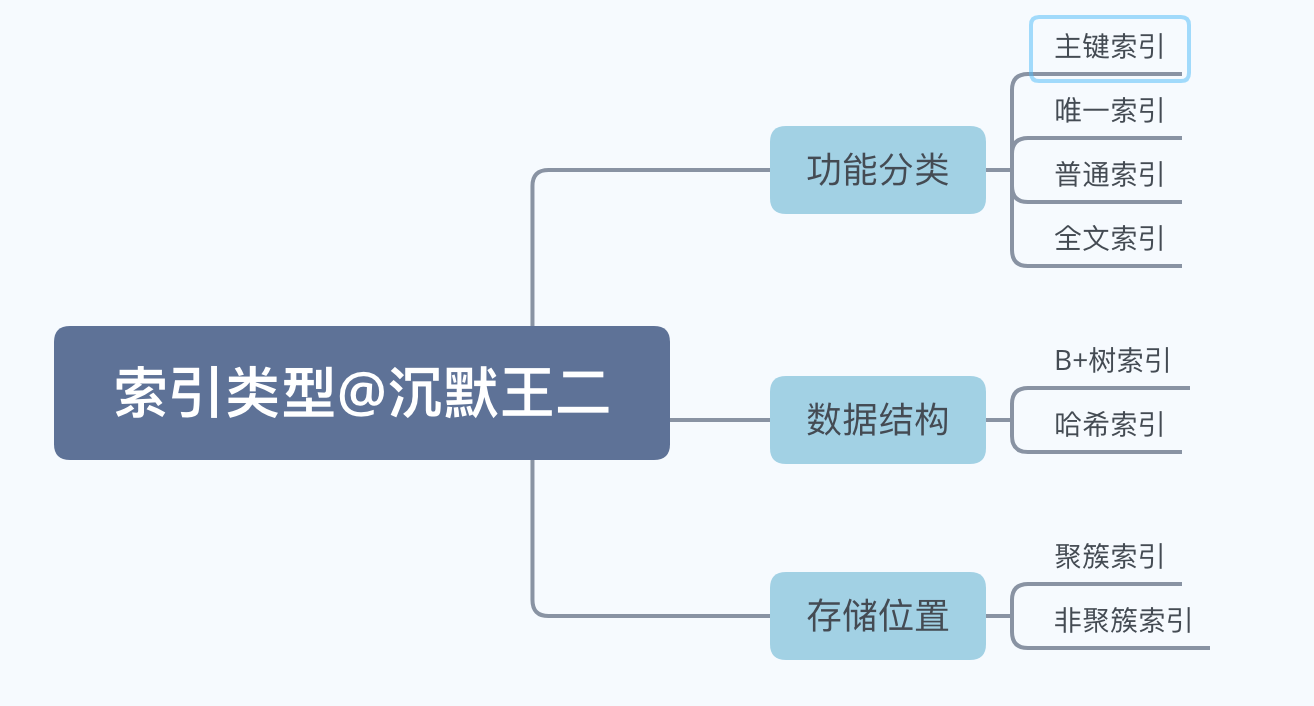
36.🌟能简单说一下索引的分类吗?
从功能上分类的话,有主键索引、唯一索引、全文索引;从数据结构上分类的话,有 B+ 树索引、哈希索引;从存储内容上分类的话,有聚簇索引、非聚簇索引。
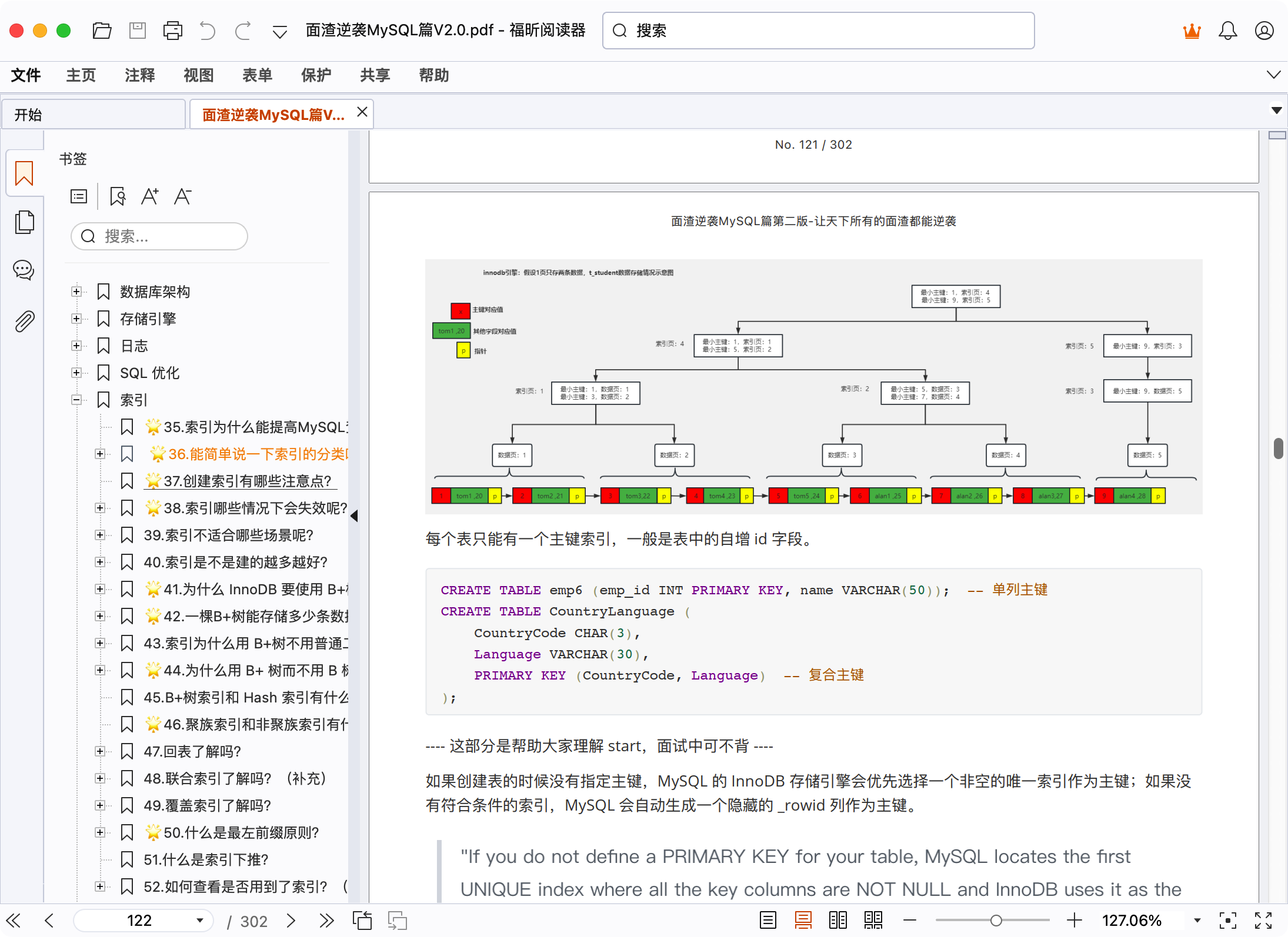
你对主键索引了解多少?
主键索引用于唯一标识表中的每条记录,其列值必须唯一且非空。创建主键时,MySQL 会自动生成对应的唯一索引。
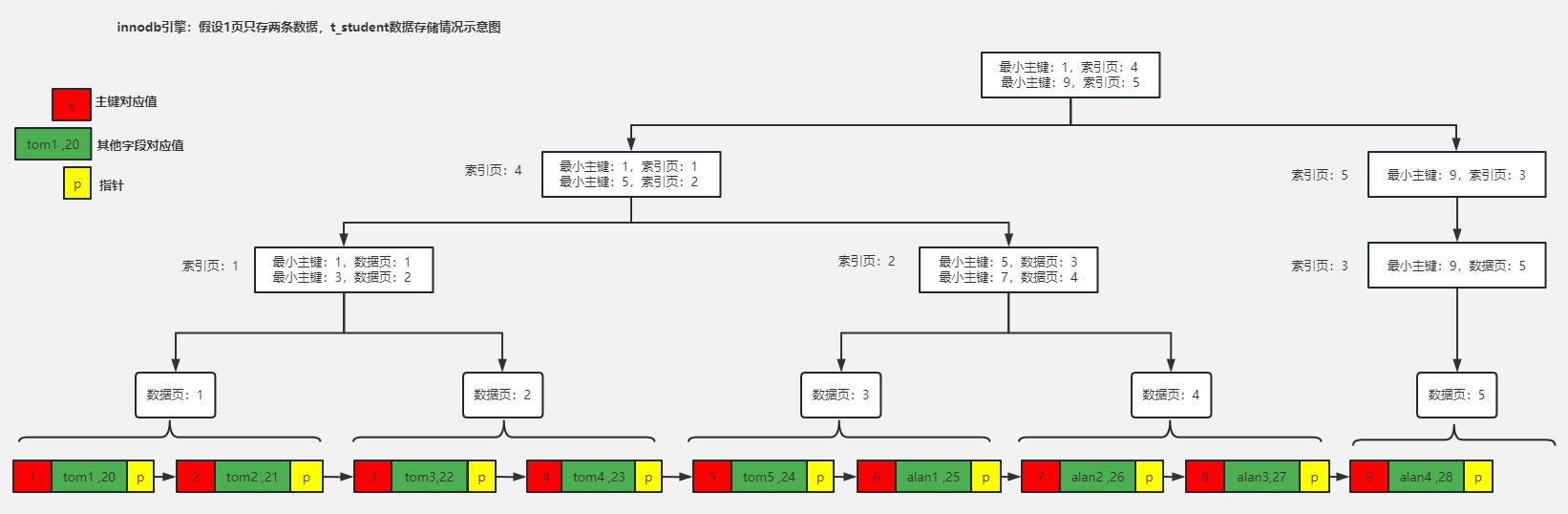
每个表只能有一个主键索引,一般是表中的自增 id 字段。
CREATE TABLE emp6 (emp_id INT PRIMARY KEY, name VARCHAR(50)); -- 单列主键
CREATE TABLE CountryLanguage (
CountryCode CHAR(3),
Language VARCHAR(30),
PRIMARY KEY (CountryCode, Language) -- 复合主键
);---- 这部分是帮助大家理解 start,面试中可不背 ----
如果创建表的时候没有指定主键,MySQL 的 InnoDB 存储引擎会优先选择一个非空的唯一索引作为主键;如果没有符合条件的索引,MySQL 会自动生成一个隐藏的 _rowid 列作为主键。

可以通过 show index from table_name 查看索引信息:
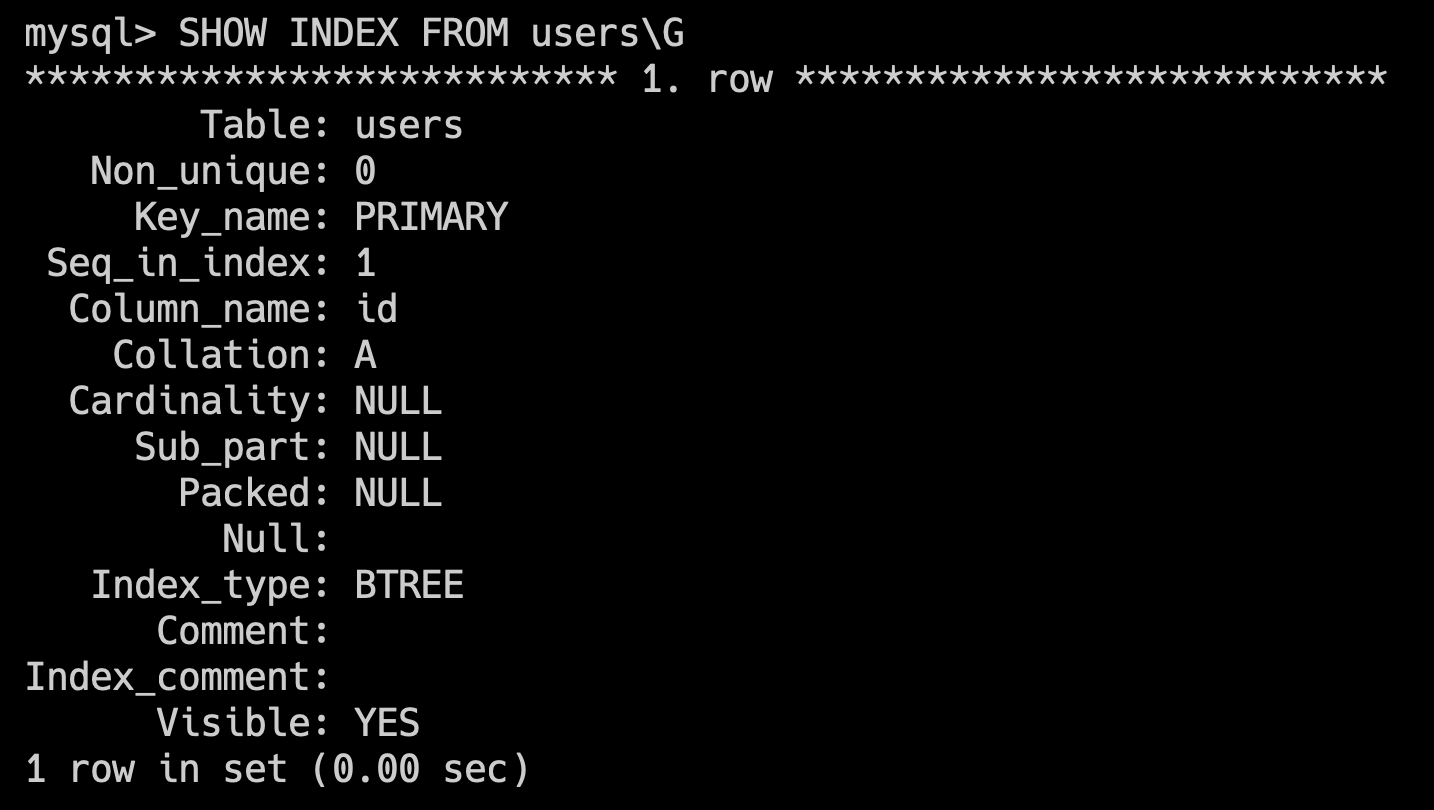
Table当前索引所属的表名。Non_unique是否唯一索引,0 表示唯一索引(如主键),1 表示非唯一。Key_name主键索引默认叫 PRIMARY;普通索引为自定义名。Seq_in_index索引中的列顺序,在联合索引中这个字段表示第几列(第 1 个)。Column_name当前索引中包含的字段名。CollationA 表示升序(Ascend);D 表示降序。Cardinality索引的基数,即不重复的索引值的数量。越高说明区分度越好(影响优化器是否用此索引)。Sub_part前缀索引的长度。Packed是否压缩存储索引;一般不用,默认为 NULL。Null字段是否允许为 NULL;主键字段不允许为 NULL。Index_type索引底层结构,InnoDB 默认是 B+ 树(BTREE)。Comment索引的注释。Visible是否可见;MySQL 8.0+ 可隐藏索引。
---- 这部分是帮助大家理解 end,面试中可不背 ----
唯一索引和主键索引有什么区别?
主键索引=唯一索引+非空。每个表只能有一个主键索引,但可以有多个唯一索引。
-- 在 email 列上添加唯一索引
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
UNIQUE KEY uk_email (email) -- 唯一索引
);
-- 复合唯一索引(保证 user_id 和 role 组合唯一)
CREATE TABLE user_roles (
user_id INT NOT NULL,
role VARCHAR(20) NOT NULL,
UNIQUE KEY uk_user_role (user_id, role)
);主键索引不允许插入 NULL 值,尝试插入 NULL 会报错;唯一索引允许插入多个 NULL 值。
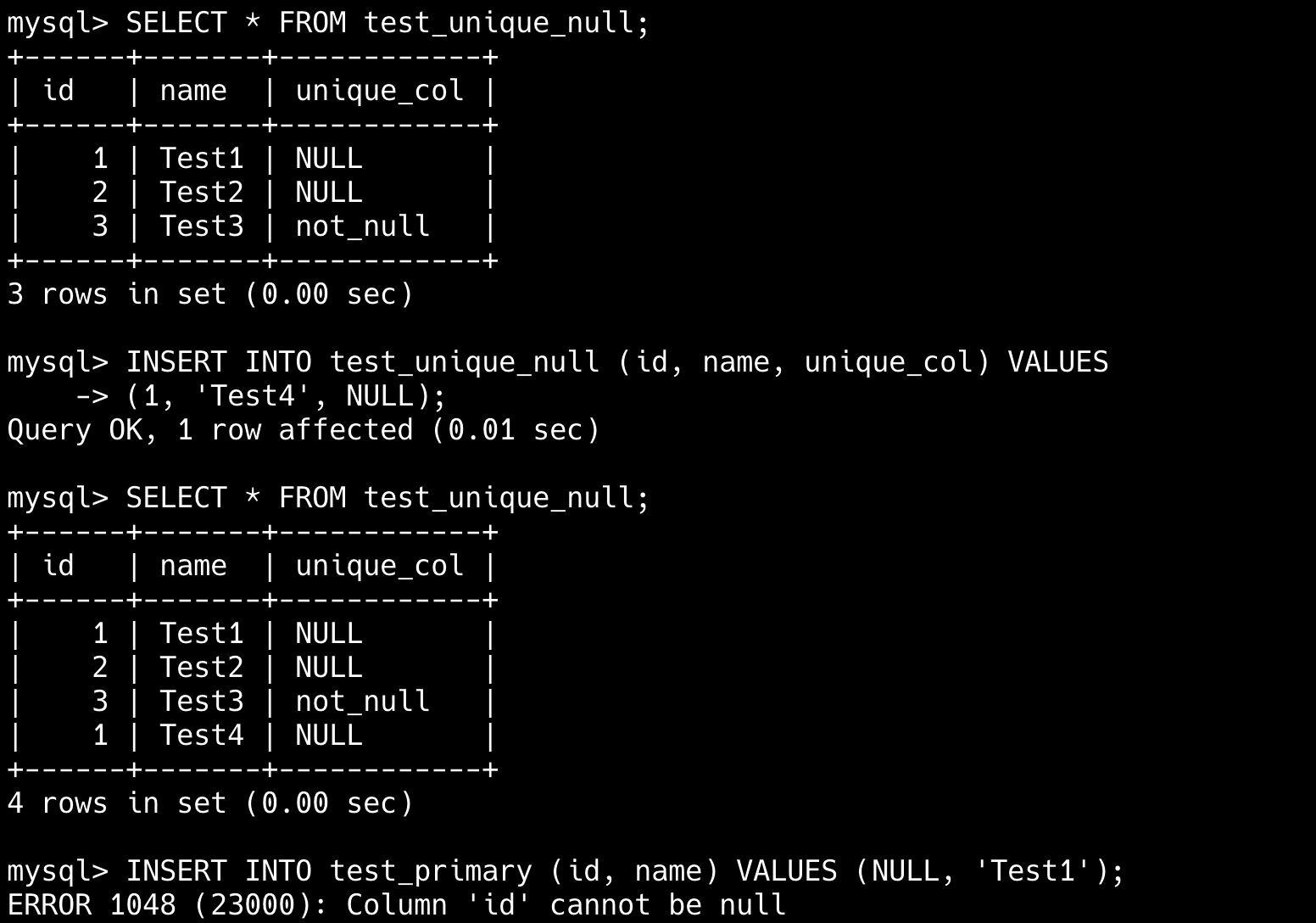
unique key 和 unique index 有什么区别?
创建唯一键时,MySQL 会自动生成一个同名的唯一索引;反之,创建唯一索引也会隐式添加唯一性约束。
可通过 UNIQUE KEY uk_name 定义或者 CONSTRAINT uk_name UNIQUE 定义唯一键。
CREATE TABLE users (
id INT PRIMARY KEY,
email VARCHAR(100),
-- 显式命名唯一键
CONSTRAINT uk_email UNIQUE (email)
);
CREATE TABLE users3 (
id INT PRIMARY KEY,
email VARCHAR(100),
UNIQUE KEY uk_email (email) -- 唯一索引
);可通过 CREATE UNIQUE INDEX 创建唯一索引。
CREATE TABLE users (
id INT PRIMARY KEY,
email VARCHAR(100)
);
-- 手动创建唯一索引
CREATE UNIQUE INDEX uk_email ON users(email);通过 SHOW CREATE TABLE table_name 查看表结构时,结果都是一样的。
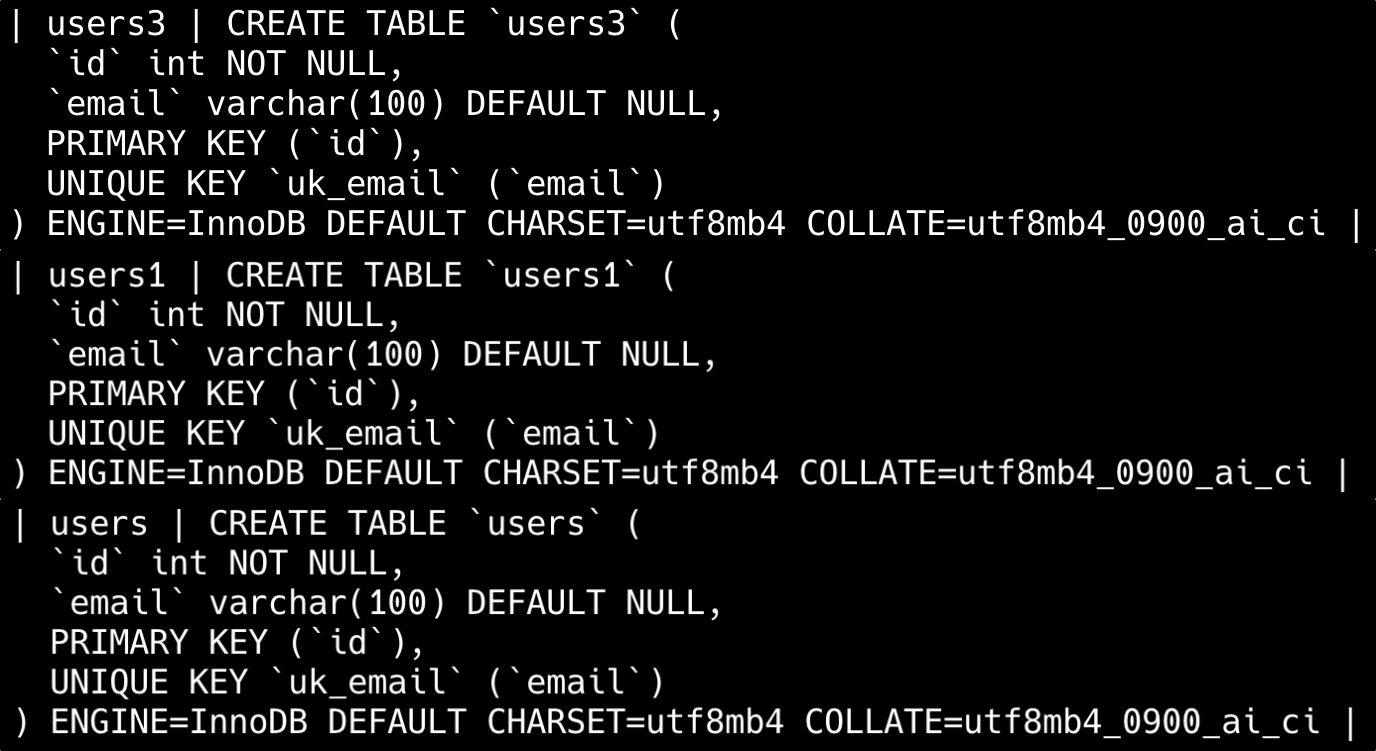
普通索引和唯一索引有什么区别?
普通索引仅用于加速查询,不限制字段值的唯一性;适用于高频写入的字段、范围查询的字段。
-- 日志时间戳允许重复,无需唯一性检查
CREATE INDEX idx_log_time ON access_logs(access_time);
-- 订单状态允许重复,但需频繁按状态过滤数据
CREATE INDEX idx_order_status ON orders(status);唯一索引强制字段值的唯一性,插入或更新时会触发唯一性检查;适用于业务唯一性约束的字段、防止数据重复插入的字段。
-- 用户邮箱必须唯一
CREATE UNIQUE INDEX uk_email ON users(email);
-- 确保同一用户对同一商品只能有一条未支付订单
CREATE UNIQUE INDEX uk_user_product ON orders(user_id, product_id) WHERE status = 'unpaid';memo:2025 年 3 月 31 日修改至此,今天有球友说,拿到了淘天暑期实习的 offer,并且再次强调背面渣逆袭的重要性,哈哈。

你对全文索引了解多少?
全文索引是 MySQL 一种优化文本数据检索的特殊类型索引,适用于 CHAR、VARCHAR 和 TEXT 等字段。
MySQL 5.7 及以上版本内置了 ngram 解析器,可处理中文、日文和韩文等分词。
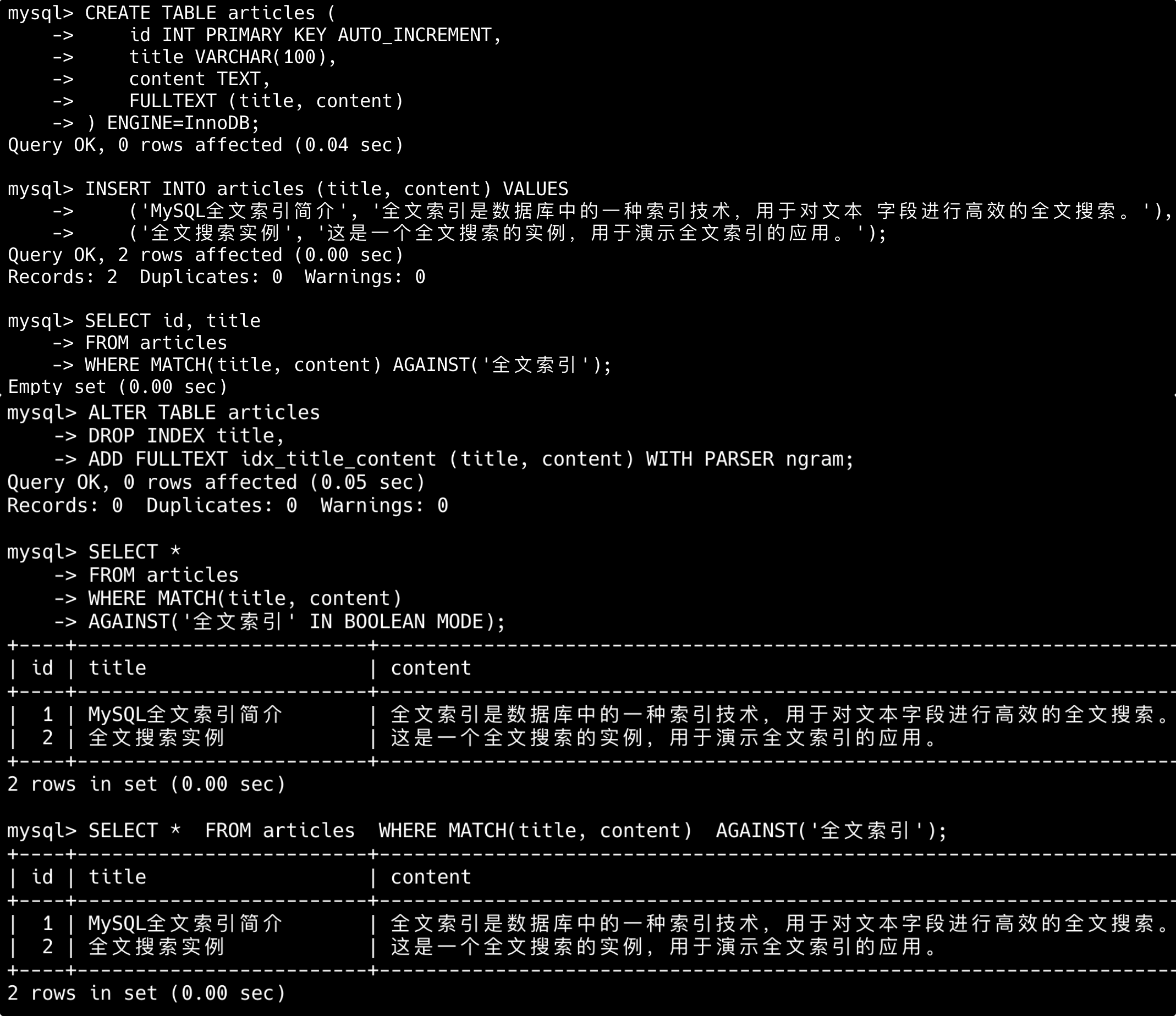
建表时通过 FULLTEXT (title, body) 来定义。通过 MATCH(col1, col2) AGAINST('keyword') 进行检索,默认按照降序返回结果,支持布尔模式查询。
+表示必须包含;-表示排除;*表示通配符;
-- 建表时创建全文索引(支持中文)
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(200),
content TEXT,
FULLTEXT(title, content) WITH PARSER ngram
) ENGINE=InnoDB;
-- 使用布尔模式查询
SELECT * FROM articles
WHERE MATCH(title, content) AGAINST('+MySQL -Oracle' IN BOOLEAN MODE);底层使用倒排索引将字段中的文本内容进行分词,然后建立一个倒排表。性能比 LIKE '%keyword%' 高很多。
---- 这部分是帮助大家理解 start,面试中可不背 ----
倒排索引通过一个辅助表存储单词与单词自身在一个或多个文档中所在位置之间的映射,通常采用关联数组实现。
有两种表现形式:inverted file index({单词,单词所在文档的ID})和full inverted index({单词,(单词所在文档的ID,在具体文档中的位置)})
比如有这样一个文档:
DocumentId Text
1 Pease porridge hot, pease porridge cold
2 Pease porridge in the pot
3 Nine days old
4 Some like it hot, some like it cold
5 Some like it in the pot
6 Nine days oldinverted file index 的关联数组存储形式为:
days → 3,6
old → 3,6
pease → 1,2
porridge → 1,2
...full inverted index 更加详细:
days → (3:5),(6:5)
old → (3:11),(6:11)
pease → (1:1),(1:7),(2:1)
porridge → (1:7),(2:7)
...full inverted index 不仅存储了文档 ID,还存储了单词在文档中的具体位置。
InnoDB 采用的是 full inverted index 的方式实现全文索引。
如果需要处理中文分词的话,一定要记得加上 WITH PARSER ngram,否则可能查不出来数据。
不过,对于复杂的中文场景,建议使用 Elasticsearch 等专业搜索引擎替代,技术派项目中就用了这种方案。
---- 这部分是帮助大家理解 end,面试中可不背 ----
memo:2025 年 4 月 1 日修改至此,今天有球友说,拿到了美团的实习 offer,真的太棒了,18 号一面、25 号二面、30 号 OC,4 月 1 发邮件 offer,节奏拉满了
- Java 面试指南(付费)收录的科大讯飞非凡计划研发类面经原题:聊聊 MySQL 的索引
- Java 面试指南(付费)收录的腾讯面经同学 23 QQ 后台技术一面面试原题:MySQL 索引,为什么用 B+树
- Java 面试指南(付费)收录的携程面经同学 10 Java 暑期实习一面面试原题:讲一讲 MySQL 的索引,如何优化 SQL?
- Java 面试指南(付费)收录的阿里面经同学 5 阿里妈妈 Java 后端技术一面面试原题:索引的分类,创建索引的最佳实践
- Java 面试指南(付费)收录的 360 面经同学 3 Java 后端技术一面面试原题:mysql 的索引用过哪些
- Java 面试指南(付费)收录的用友面试原题:索引是什么?有哪些索引
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:普通索引的叶子节点存储的是什么
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:innodb底层有哪些数据结构
- Java 面试指南(付费)收录的比亚迪面经同学 12 Java 技术面试原题:索引有哪些,区别是什么
37.🌟创建索引有哪些注意点?
第一,选择合适的字段
- 比如说频繁出现在 WHERE、JOIN、ORDER BY、GROUP BY 中的字段。
- 优先选择区分度高的字段,比如用户 ID、手机号等唯一值多的,而不是性别、状态等区分度极低的字段,如果真的需要,可以考虑联合索引。
第二,要控制索引的数量,避免过度索引,每个索引都要占用存储空间,单表的索引数量不建议超过 5 个。
要定期通过 SHOW INDEX FROM table_name 查看索引的使用情况,删除不必要的索引。比如说已经有联合索引 (a, b),单索引(a)就是冗余的。
第三,联合索引的时候要遵循最左前缀原则,即在查询条件中使用联合索引的第一个字段,才能充分利用索引。
比如说联合索引 (A, B, C) 可支持 A、A+B、A+B+C 的查询,但无法支持 B 或 C 的单独查询。
区分度高的字段放在左侧,等值查询的字段优先于范围查询的字段。例如 WHERE A=1 AND B>10 AND C=2,优先 (A, C, B)。
如果联合索引包含查询的所需字段,还可以避免回表,提高查询效率。
- Java 面试指南(付费)收录的用友金融一面原题:索引的作用,加索引需要注意什么
- Java 面试指南(付费)收录的京东同学 10 后端实习一面的原题:查询和更新都频繁的字段是否适合创建索引,为什么
- Java 面试指南(付费)收录的小米春招同学 K 一面面试原题:索引怎么设计才是最好的
- Java 面试指南(付费)收录的京东面经同学 1 Java 技术一面面试原题:MySQL 索引结构,建立索引的策略
- Java 面试指南(付费)收录的阿里面经同学 5 阿里妈妈 Java 后端技术一面面试原题:索引的分类,创建索引的最佳实践
- Java 面试指南(付费)收录的oppo 面经同学 8 后端开发秋招一面面试原题:建索引的时候应该注意什么
- Java 面试指南(付费)收录的京东面经同学 5 Java 后端技术一面面试原题:建立索引考虑哪些问题
38.🌟索引哪些情况下会失效呢?
简版:比如索引列使用了函数、使用了通配符开头的模糊查询、联合索引不满足最左前缀原则,或者使用 or 的时候部分字段无索引等。
第一,对索引列使用函数或表达式会导致索引失效。
-- 索引失效
SELECT * FROM users WHERE YEAR(create_time) = 2023;
SELECT * FROM products WHERE price*2 > 100;
-- 优化方案(使用范围查询)
SELECT * FROM users WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31';
SELECT * FROM products WHERE price > 50;第二,LIKE 模糊查询以通配符开头会导致索引失效。
-- 索引失效
SELECT * FROM articles WHERE title LIKE '%数据库%';
-- 可以使用索引(但范围有限)
SELECT * FROM articles WHERE title LIKE '数据库%';
-- 解决方案:考虑全文索引或搜索引擎
SELECT * FROM articles WHERE MATCH(title) AGAINST('数据库');第三,联合索引违反了最左前缀原则,索引会失效。
-- 假设有联合索引 (a, b, c)
SELECT * FROM table WHERE b = 2 AND c = 3; -- 索引失效
SELECT * FROM table WHERE a = 1 AND c = 3; -- 只使用a列索引
-- 正确使用联合索引
SELECT * FROM table WHERE a = 1 AND b = 2 AND c = 3;- 联合索引,但 WHERE 不满足最左前缀原则,索引无法起效。例如:
SELECT * FROM table WHERE column2 = 2,联合索引为(column1, column2)。
---- 这部分是帮助大家理解 start,面试中可不背 ----
第四,使用 OR 连接非索引列条件,会导致索引失效。
-- 假设name有索引但age没有
SELECT * FROM users WHERE name = '张三' OR age = 25; -- 全表扫描
-- 优化方案1:使用UNION ALL
SELECT * FROM users WHERE name = '张三'
UNION ALL
SELECT * FROM users WHERE age = 25 AND name != '张三';
-- 优化方案2:考虑为age添加索引第五,使用 != 或 <> 不等值查询会导致索引失效。
SELECT * FROM user WHERE status != 1; -- 若大部分行 `status=1`,可能全表扫描
-- 优化方案:使用范围查询
SELECT * FROM user WHERE status < 1 OR status > 1;---- 这部分是帮助大家理解 end,面试中可不背 ----
什么情况下模糊查询不走索引?
模糊查询主要使用 LIKE 语句,结合通配符来实现。
%(代表任意多个字符)和 _(代表单个字符)
SELECT * FROM table WHERE column LIKE '%xxx%';这个查询会返回所有 column 列中包含 xxx 的记录。
但是,如果模糊查询的通配符 % 出现在搜索字符串的开始位置,如 LIKE '%xxx',MySQL 将无法使用索引,因为数据库必须扫描全表以匹配任意位置的字符串。
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:where b =5 是否一定会命中索引?(索引失效场景)
- Java 面试指南(付费)收录的京东面经同学 1 Java 技术一面面试原题:索引失效的情况
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:编写 SQL 语句哪些情况会导致索引失效?
- Java 面试指南(付费)收录的比亚迪面经同学 12 Java 技术面试原题:索引失效场景
- Java 面试指南(付费)收录的 OPPO 面经同学 1 面试原题:什么情况下索引失效?
- Java 面试指南(付费)收录的京东面经同学 5 Java 后端技术一面面试原题:索引失效情况
- Java 面试指南(付费)收录的理想汽车面经同学 2 一面面试原题:什么操作会导致索引失效?
39.索引不适合哪些场景呢?
第一,区分度低的列,可以和其他高区分度的列组成联合索引。
第二,频繁更新的列,索引会增加更新的成本。
第三,TEXT、BLOB 等大对象类型的字段,可以使用前缀索引、全文索引替代。
第四,当表的数据量很小的时候,不超过 1000 行,全表扫描可能比使用索引更快。
---- 这部分是帮助大家理解 start,面试中可不背 ----
为了验证第四条,我们创建了一个小表,然后分别执行全表扫描和索引查询。
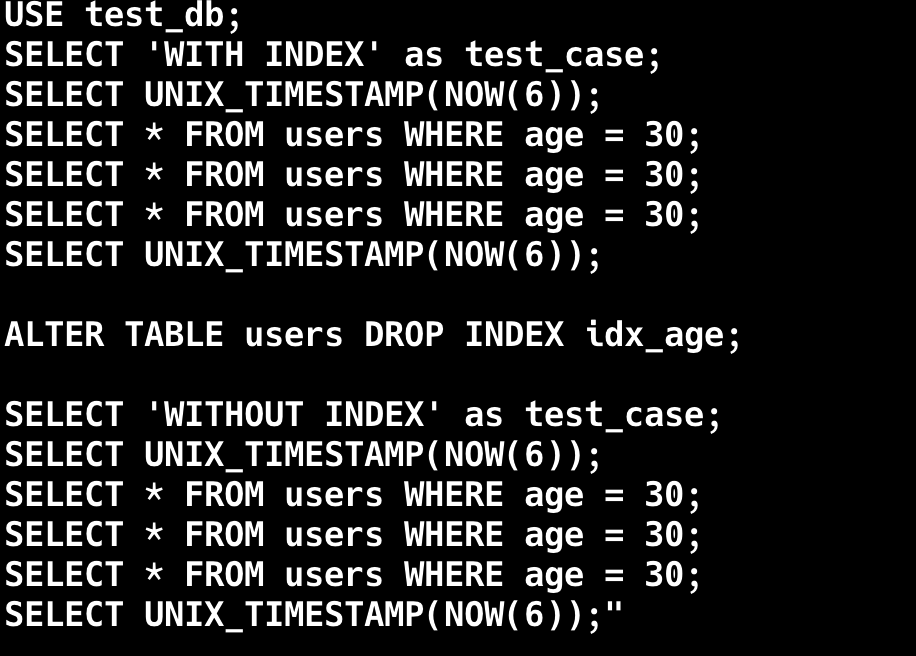
得出的结论的确是这样的,全表扫描更快一些。
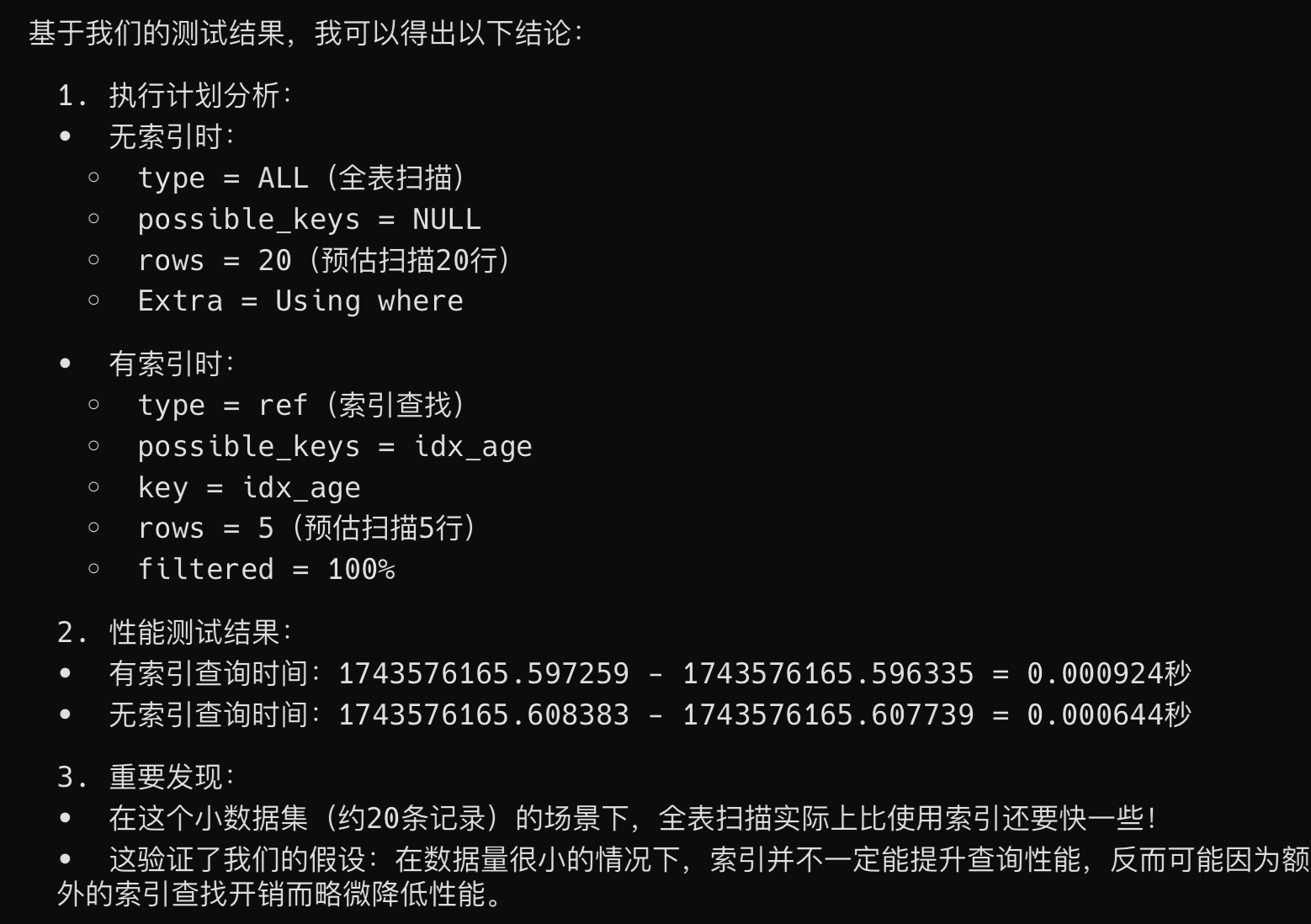
原因时当数据量很小时,全表扫描的成本很低,因为所有的数据可能都加载到内存中了,使用索引反而需要先查找索引,再通过索引去找到实际的数据行,增加了额外的 I/O 寻址时间。
---- 这部分是帮助大家理解 end,面试中可不背 ----
性别字段要建立索引吗?
性别字段不适合建立单独索引。因为性别字段的区分度很低。
如果性别字段确实经常用于查询条件,数据规模也比较大,可以将性别字段作为联合索引的一部分,与区分度高的字段一起,效果会好很多。
什么是区分度?
区分度是衡量一个字段在 MySQL 表中唯一值的比例。
区分度 = 字段的唯一值数量 / 字段的总记录数;越接近 1,就越适合作为索引。因为索引可以更有效地缩小查询范围。
例如,一个表中有 1000 条记录,其中性别字段只有两个值(男、女),那么性别字段的区分度只有 0.002,就不适合建立索引。
可以通过 COUNT(DISTINCT column_name) 和 COUNT(*) 的比值来计算字段的区分度。例如:
SELECT
COUNT(DISTINCT gender) / COUNT(*) AS gender_selectivity
FROM
users;什么样的字段适合加索引?
一句话回答:
一般来说,主键、唯一键、以及经常作为查询条件的字段最适合加索引。除此之外,字段的区分度要高,这样索引才能起到过滤作用;如果字段经常用于表连接、排序或分组,也建议加索引。同时如果多个字段经常一起出现在查询条件中,也可以建立联合索引来提升性能。
---- 这部分是帮助大家理解 start,面试中可不背 ----
查询条件中的高频字段,比如说WHERE子句中频繁用于等值查询、范围查询或者 IN 列表的字段。
SELECT * FROM orders WHERE status = 'PAID' AND create_time > '2023-01-01';
-- 若`status`和`create_time`常组合查询,建联合索引`(status, create_time)`多表连接时的关联字段,比如说 user.id 和 order.user_id。
SELECT * FROM user u JOIN order o ON u.id = o.user_id; -- `user_id`需索引参与排序或者分组的字段,可以直接利用索引的有序性,避免文件排序。
SELECT * FROM product ORDER BY price DESC; -- 单字段排序
SELECT category, COUNT(*) FROM product GROUP BY category; -- 分组统计需要利用覆盖索引的字段,可以避免回表操作。
-- 创建联合索引`(user_id, create_time)`
SELECT user_id, create_time FROM orders WHERE user_id = 100; -- 覆盖索引生效---- 这部分是帮助大家理解 end,面试中可不背 ----
- Java 面试指南(付费)收录的字节跳动面经同学 1 技术二面面试原题:性别字段要建立索引吗?为什么?什么是区分度?MySQL查看字段区分度的命令?
- Java 面试指南(付费)收录的快手同学 2 一面面试原题:什么样的字段适合加索引?什么不适合?
40.索引是不是建的越多越好?
索引不是越多越好。虽然索引可以加快查询,但也会带来写入变慢、占用更多存储空间、甚至让优化器选错索引的风险。
---- 这部分是帮助大家理解 start,面试中可不背 ----
每次数据写入(INSERT/UPDATE/DELETE)时,MySQL 都需同步更新所有相关索引,索引越多,维护成本越高。
假如某表有 10 个索引,插入一行数据需更新 10 个 B+树结构,导致写入延迟增加 5~10 倍。
假如某表数据量 100GB,若建 5 个索引,总存储可能达到 200GB+。
索引过多时,优化器需评估更多可能的执行路径,可能导致选择困难症,优化器也会选错索引。
再比如说,已有联合索引 (A, B, C),再单独建 (A) 或 (A, B) 索引即为冗余。
单表索引数量建议不超过 5 个,MySQL 官方建议单表索引总字段数 ≤ 表字段数的 30%。
---- 这部分是帮助大家理解 end,面试中可不背 ----
说说索引优化的思路?
一句话回答:
先通过慢查询日志找出性能瓶颈,然后用 EXPLAIN 分析执行计划,判断是否走了索引、是否回表、是否排序。接着根据字段特性设计合适的索引,如选择区分度高的字段,使用联合索引和覆盖索引,避免索引失效的写法,最后通过实测来验证优化效果。
- Java 面试指南(付费)收录的比亚迪面经同学 12 Java 技术面试原题:索引优化的思路
memo:2025 年 4 月 2 日修改至此,今天有球友说,拿到了百度的实习 offer,仅用了一个月的时间,可太强了。
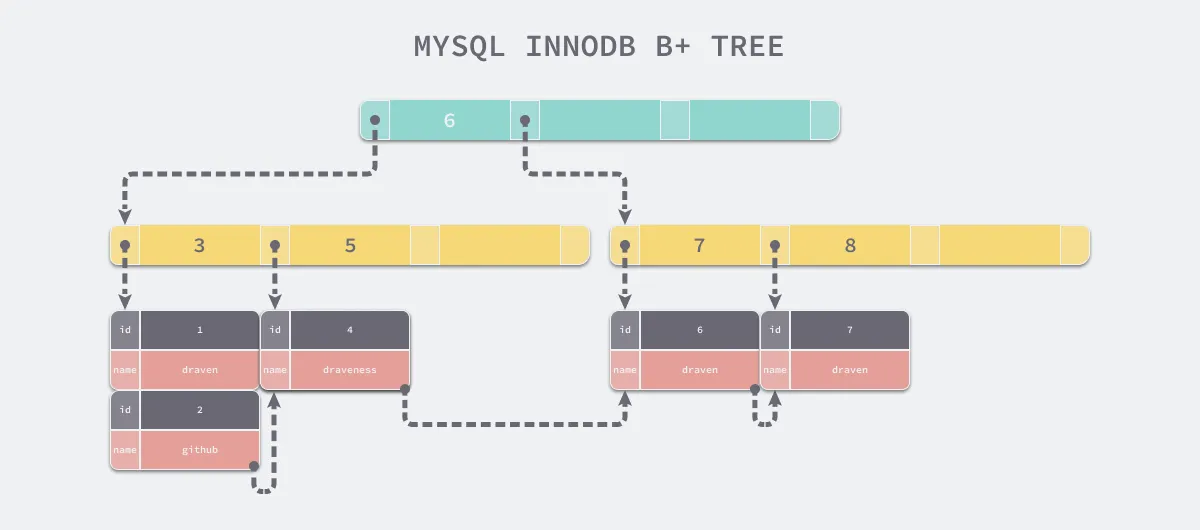
41.🌟为什么 InnoDB 要使用 B+树作为索引?
一句话总结:
因为 B+ 树是一种高度平衡的多路查找树,能有效降低磁盘的 IO 次数,并且支持有序遍历和范围查询。
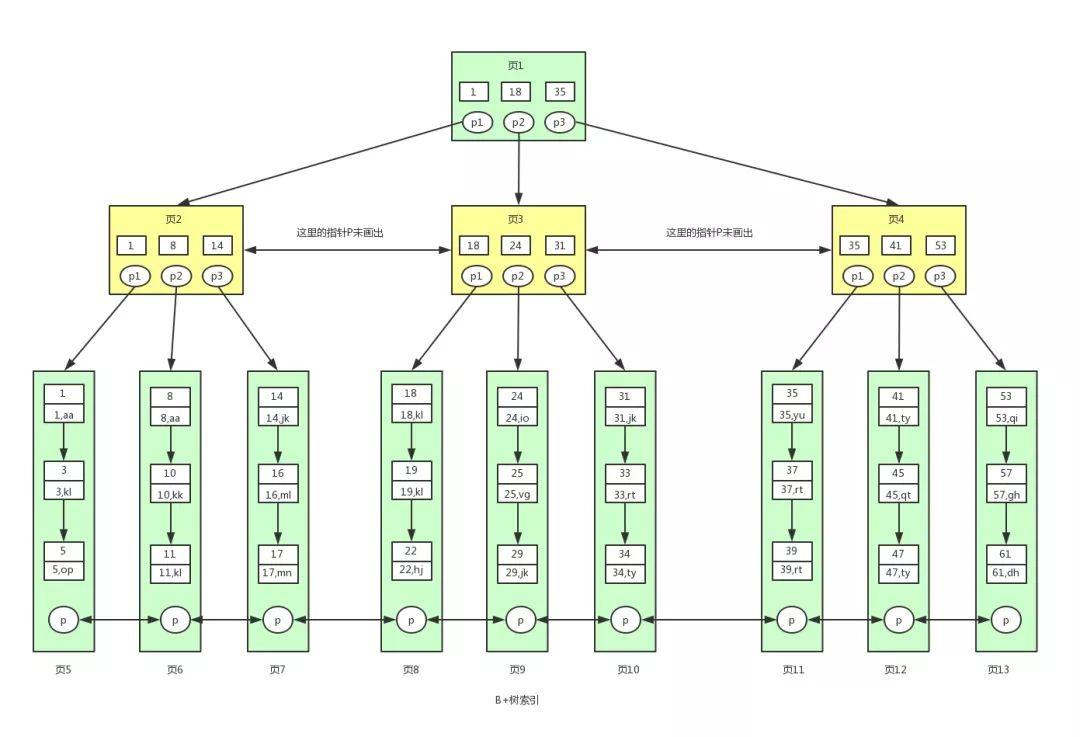
查询性能非常高,其结构也适合 MySQL 按照页为单位在磁盘上存储。
像其他选项,比如说哈希表不支持范围查询,二叉树层级太深,B 树又不方便范围扫描,所以最终选择了 B+ 树。
再换一种回答:
- 相比哈希表:B+ 树支持范围查询和排序
- 相比二叉树和红黑树:B+ 树更“矮胖”,层级更少,磁盘 IO 次数更少
- 相比 B 树:B+ 树的非叶子节点只存储键值,叶子节点存储数据并通过链表连接,支持范围查询
另外一种回答版本:
B+树是一种自平衡的多路查找树,和红黑树、二叉平衡树不同,B+树的每个节点可以有 m 个子节点,而红黑树和二叉平衡树都只有 2 个。
另外,和 B 树不同,B+树的非叶子节点只存储键值,不存储数据,而叶子节点存储了所有的数据,并且构成了一个有序链表。
这样做的好处是,非叶子节点上由于没有存储数据,就可以存储更多的键值对,再加上叶子节点构成了一个有序链表,范围查询时就可以直接通过叶子节点间的指针顺序访问整个查询范围内的所有记录,而无需对树进行多次遍历。查询的效率比 B 树更高。
- 推荐阅读:终于把 B 树搞明白了
- 推荐阅读:一篇文章讲透 MySQL 为什么要用 B+树实现索引
---- 这部分是帮助大家理解 start,面试中可不背 ----
先说说 B 树。
B 树是一种自平衡的多路查找树,和红黑树、二叉平衡树不同,B 树的每个节点可以有 m 个子节点,而红黑树和二叉平衡树都只有 2 个。
换句话说,红黑树、二叉平衡树是细高个,而 B 树是矮胖子。
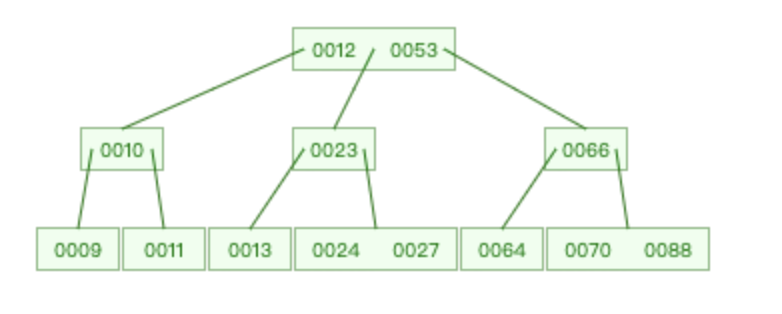
再来说说内存和磁盘的 IO 读写。
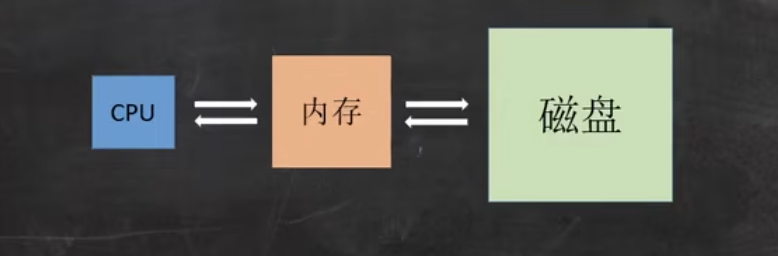
为了提高读写效率,从磁盘往内存中读数据的时候,一次会读取至少一页的数据,如果不满一页,会再多读点。
比如说查询只需要读取 2KB 的数据,但 MySQL 实际上会读取 4KB 的数据,以装满整页。页是 MySQL 进行内存和磁盘交互的最小逻辑单元。
再比如说需要读取 5KB 的数据,实际上 MySQL 会读取 8KB 的数据,刚好两页。
因为读的次数越多,效率就越低。就好比我们在工地上搬砖,一次搬 10 块砖肯定比一次搬 1 块砖的效率要高,反正我每次都搬 10 块(😁)。
对于红黑树、二叉平衡树这种细高个来说,每次搬的砖少,因为力气不够嘛,那来回跑的次数就越多。
通常 B+ 树高度为 3-4 层即可支持 TB 级数据,而每次查询只需 2-4 次磁盘 I/O,远低于二叉树或红黑树的 O(log2N) 复杂度
树越高,意味着查找数据时就需要更多的磁盘 IO,因为每一层都可能需要从磁盘加载新的节点。
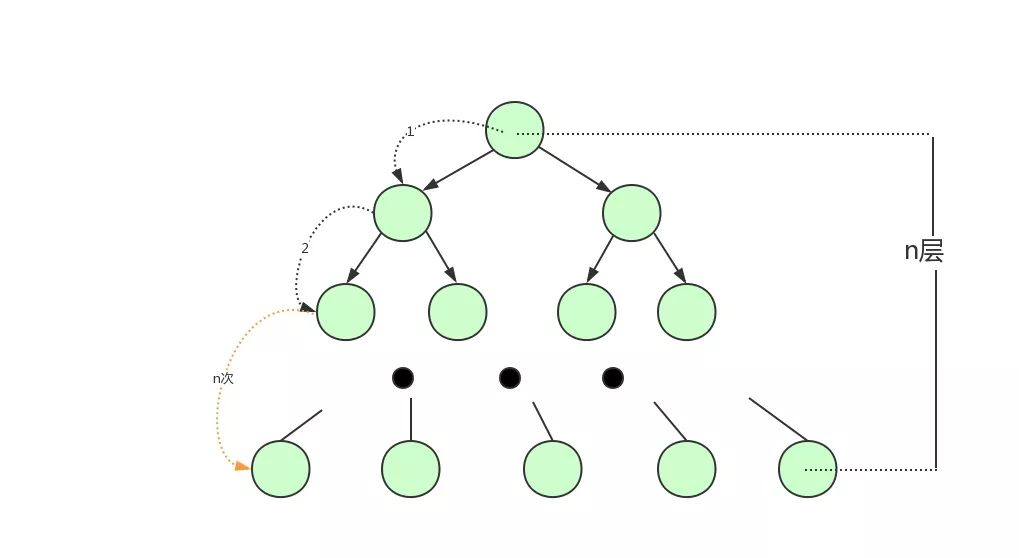
B 树的节点通常与页的大小对齐,这样每次从磁盘加载一个节点时,正好就是一页的大小。
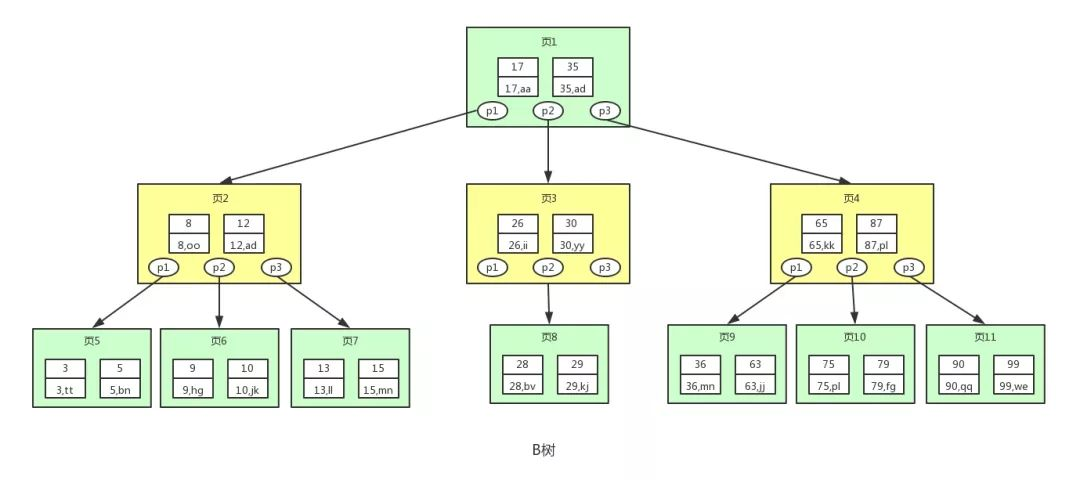
B 树的一个节点通常包括三个部分:
- 键值:即表中的主键
- 指针:存储子节点的信息
- 数据:除主键外的行数据
正所谓“祸兮福所倚,福兮祸所伏”,因为 B 树的每个节点上都存储了数据,就导致每个节点能存储的键值和指针变少了,因为每一个节点的大小是固定的,对吧?
于是 B+树就来了,B+树的非叶子节点只存储键值,不存储数据,而叶子节点会存储所有的行数据,并且构成一个有序链表。
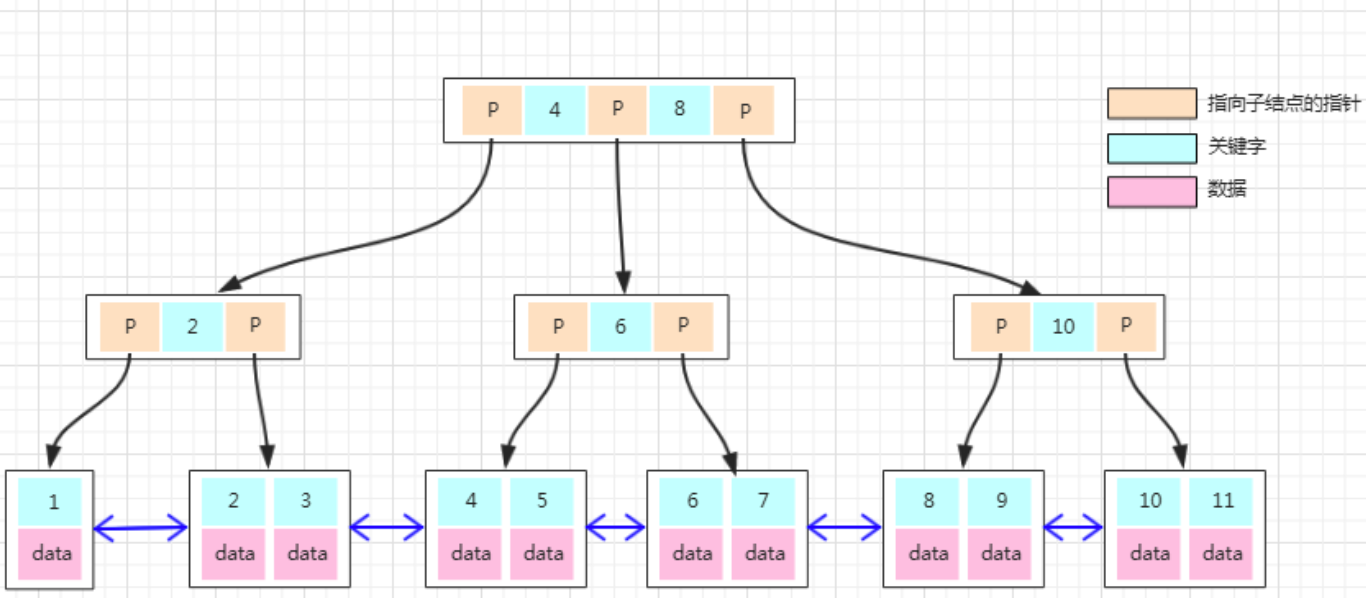
这样做的好处是,非叶子节点由于没有存储数据,就可以存储更多的键值对,树就变得更加矮胖了,于是就更有劲了,每次搬的砖也就更多了(😂)。
相比 B 树,B+ 树的非叶子节点可容纳的键值更多,一个 16KB 的节点可存储约 1200 个键值,大幅降低树的高度。
由此一来,查找数据进行的磁盘 IO 就更少了,查询的效率也就更高了。
再加上叶子节点构成了一个有序链表,范围查询时就可以直接通过叶子节点间的指针顺序访问整个查询范围内的所有记录,而无需对树进行多次遍历。
B 树就做不到这一点。
---- 这部分是帮助大家理解 end,面试中可不背 ----
B+树的叶子节点是单向链表还是双向链表?如果从大值向小值检索,如何操作?
B+树的叶子节点是通过双向链表连接的,这样可以方便范围查询和反向遍历。
- 当执行范围查询时,可以从范围的开始点或结束点开始,向前或向后遍历。
- 在需要对数据进行逆序处理时,双向链表非常有用。
如果需要在 B+树中从大值向小值进行检索,可以先定位到最右侧节点,找到包含最大值的叶子节点。从根节点开始向右遍历树的方式实现。
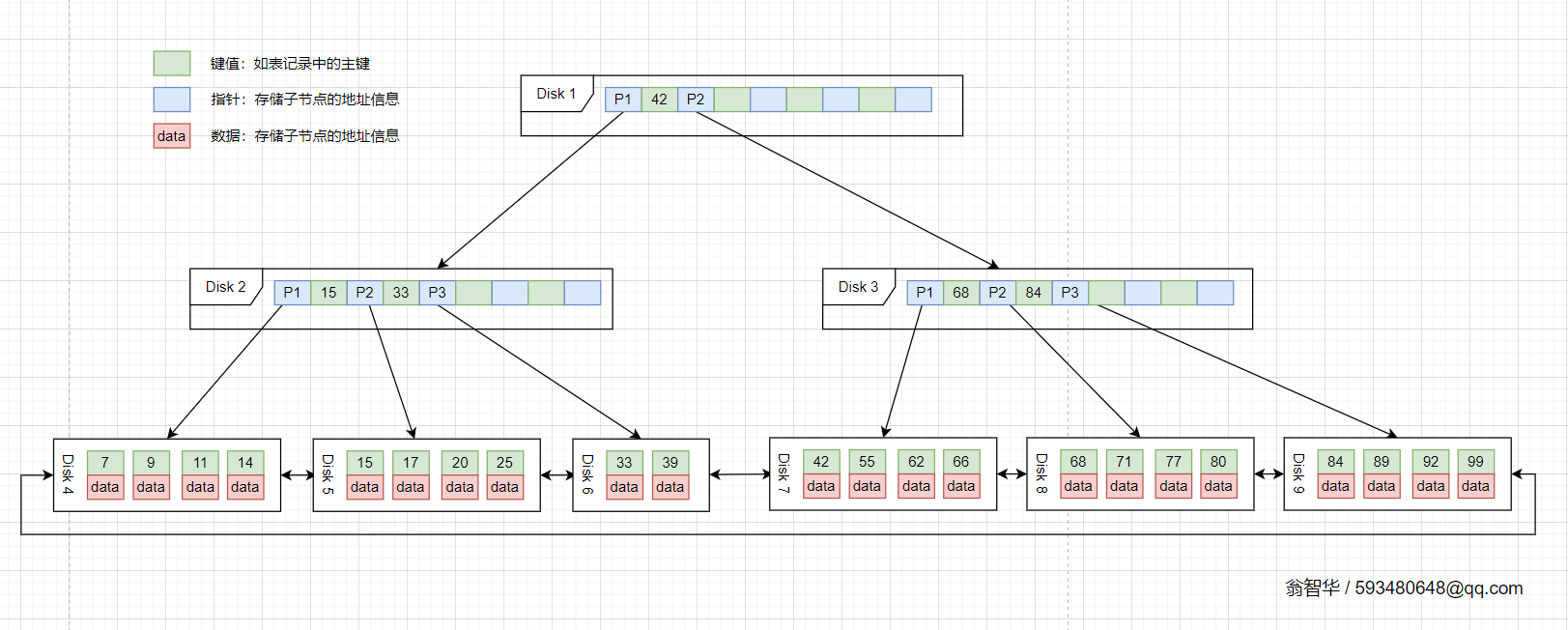
定位到最右侧的叶子节点后,再利用叶节点间的双向链表向左遍历就好了。
为什么 MongoDB 的索引用 B树,而 MySQL 用 B+ 树?
MongoDB 通常以 JSON 格式存储文档,查询以单键查询(如 find({_id: 123}))为主。B 树的“节点既存键又存数据”的特性允许查询在非叶子节点提前终止,从而减少 I/O 次数。
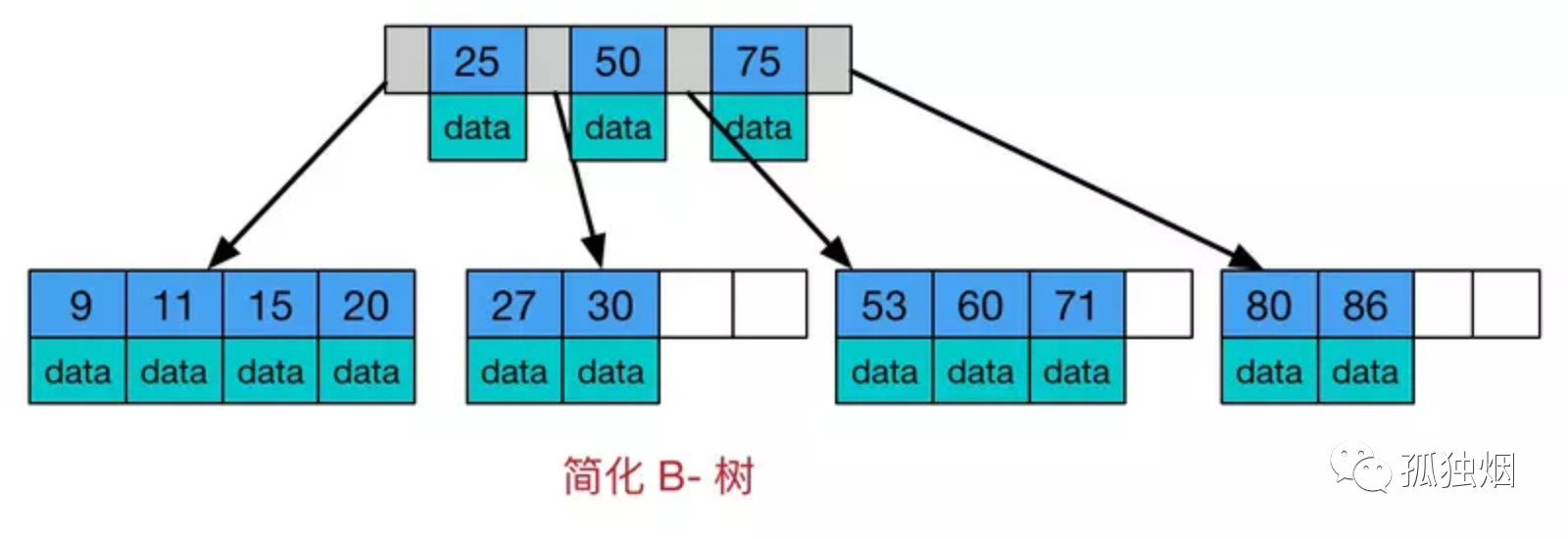
MySQL 的查询通常涉及范围(WHERE id > 100)、排序(ORDER BY)、连接(JOIN)等操作。B+ 树的叶子节点是链表结构,天然支持顺序遍历,无需回溯至根节点或中序遍历,效率远高于 B 树。
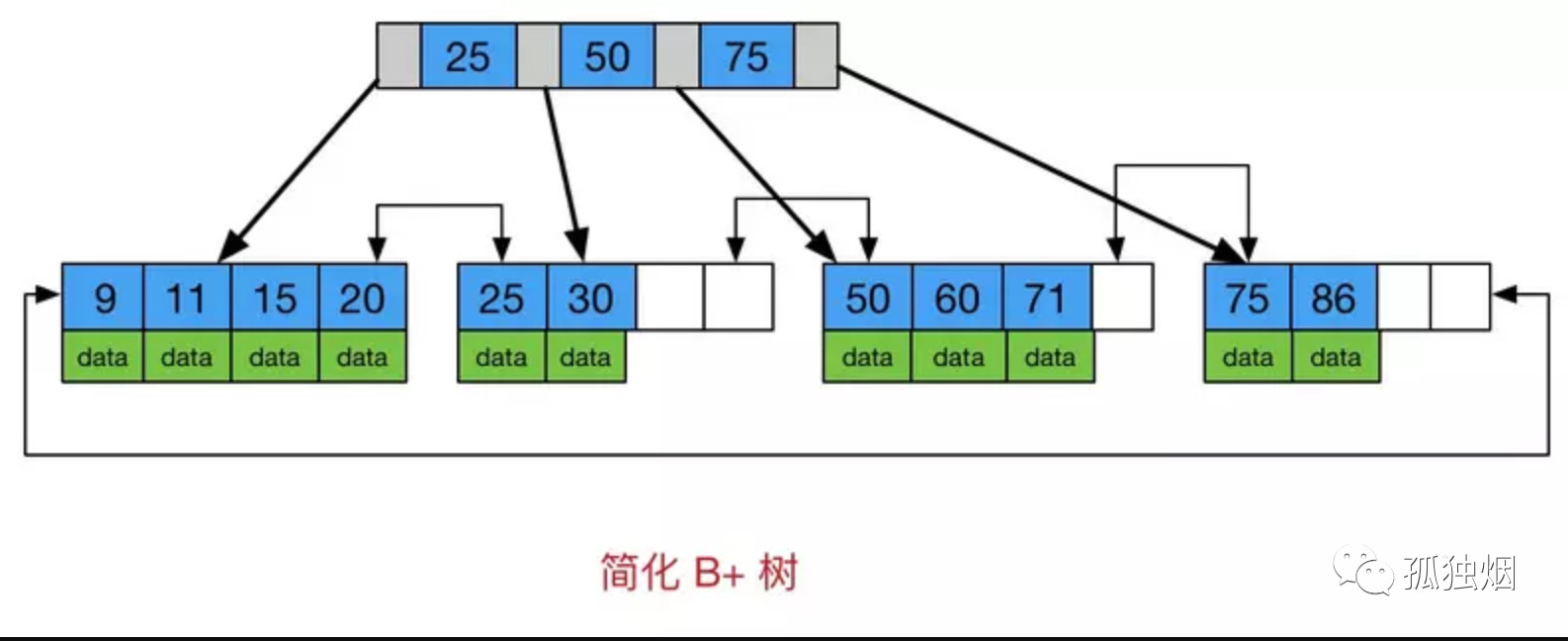
---- 这部分是帮助大家理解 start,面试中可不背 ----
| 特性 | MongoDB (B树) | MySQL InnoDB (B+树) |
|---|---|---|
| 数据模型 | 文档型数据库 | 关系型数据库 |
| 存储方式 | 数据文件+索引文件分离 | 聚簇索引数据与主键绑定存储 |
| 查询模式 | 侧重单文档查询 | 侧重范围查询和复杂连接 |
| 数据访问模式 | 随机访问为主 | 顺序访问更频繁 |
| 索引存储内容 | 非叶节点存储数据指针 | 只有叶节点存储数据 |
| 范围查询效率 | 需要多次树遍历 | 通过叶节点链表高效遍历 |
| 内存利用率 | 单个查询路径缓存更有效 | 适合批量扫描缓存 |
推荐阅读:为什么 MongoDB 索引用 B树,而 MySQL 用 B+ 树?
---- 这部分是帮助大家理解 end,面试中可不背 ----
- Java 面试指南(付费)收录的字节跳动商业化一面的原题:说说 B+树,为什么 3 层容纳 2000W 条,为什么 2000w 条数据查的快
- Java 面试指南(付费)收录的国企面试原题:说说 MySQL 的底层数据结构,B 树和 B+树的区别
- Java 面试指南(付费)收录的腾讯面经同学 22 暑期实习一面面试原题:MySQL 为什么选用 B+树
- Java 面试指南(付费)收录的小米面经同学 E 第二个部门 Java 后端技术一面面试原题:说一说 mysql 索引的底层机制
- Java 面试指南(付费)收录的京东面经同学 1 Java 技术一面面试原题:MySQL 索引结构,建立索引的策略
- Java 面试指南(付费)收录的腾讯云智面经同学 16 一面面试原题:MySQL 索引结构,为什么用 B+树?
- Java 面试指南(付费)收录的小公司面经同学 5 Java 后端面试原题:数据库索引讲一下,然后为什么会加快查询速度,我讲到了 B+树,然后问了 B 数与 B+树区别
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:B+树的页是单向链表还是双向链表?如果从大值向小值检索,如何操作?
- Java 面试指南(付费)收录的得物面经同学 1 面试原题:项目索引,MySQL索引,mongoDB为什么用的B树,二者比较
- Java 面试指南(付费)收录的oppo 面经同学 8 后端开发秋招一面面试原题:Mysql索引的数据结构,为什么选择这样的数据结构
- Java 面试指南(付费)收录的京东面经同学 8 面试原题:索引
- Java 面试指南(付费)收录的美团同学 9 一面面试原题:B+树?
- Java 面试指南(付费)收录的美团面经同学 15 点评后端技术面试原题:索引的数据结构
- Java 面试指南(付费)收录的得物面经同学 9 面试题目原题:B+树了解吗?底层呢?为什么这么用?
- Java 面试指南(付费)收录的滴滴面经同学 3 网约车后端开发一面原题:MySQL索引原理,B+树更扁 有什么好处
memo:2025 年 4 月 3 日修改至此,今天有球友说,拿到了美团的实习 offer,恭喜啊。

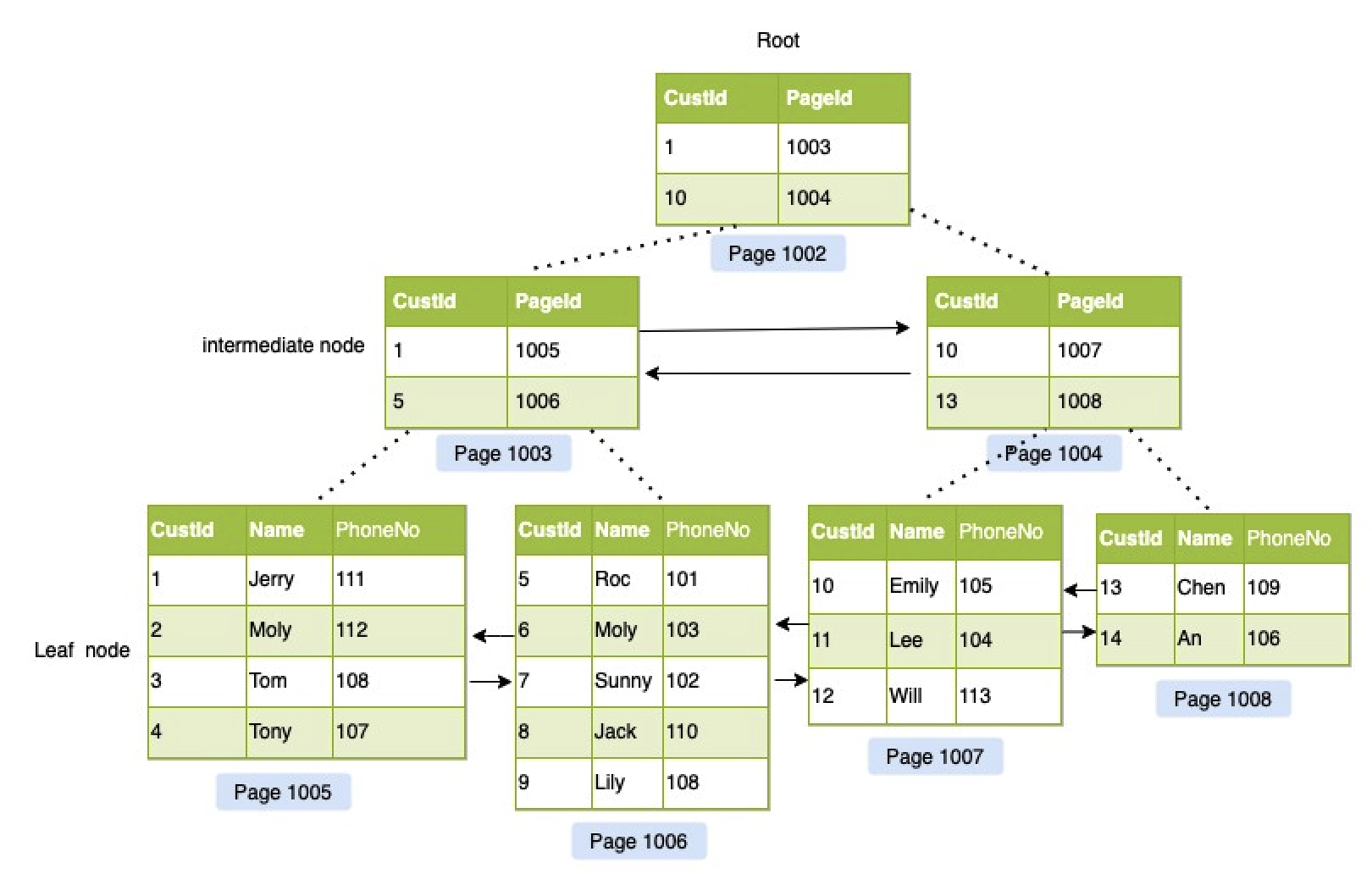
42.🌟一棵B+树能存储多少条数据呢?
一句话回复:
一棵 B+ 树能存多少数据,取决于它的分支因子和高度。在 InnoDB 中,页的默认大小为 16KB,当主键为 bigint 时,3 层 B+ 树通常可以存储约 2000 万条数据。
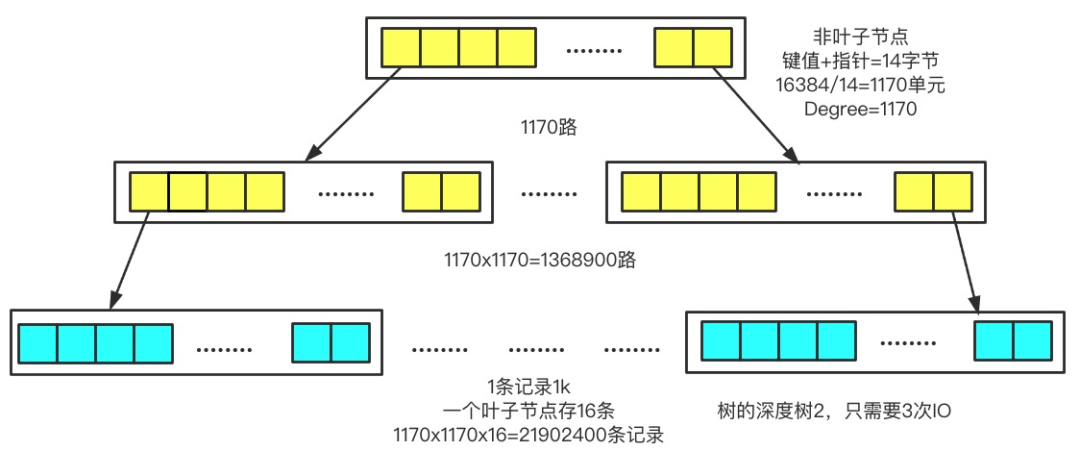
---- 这部分是帮助大家理解 start,面试中可不背 ----
先来看一下计算公式:
最大记录数 = (分支因子)^(树高度-1) × 叶子节点容量再来看一下关键参数:
①、页大小,默认 16KB
②、主键大小,假设是 bigint 类型,那么它的大小就是 8 个字节。
③、页指针大小,InnoDB 源码中设置为 6 字节,4 字节页号 + 2 字节页内偏移。
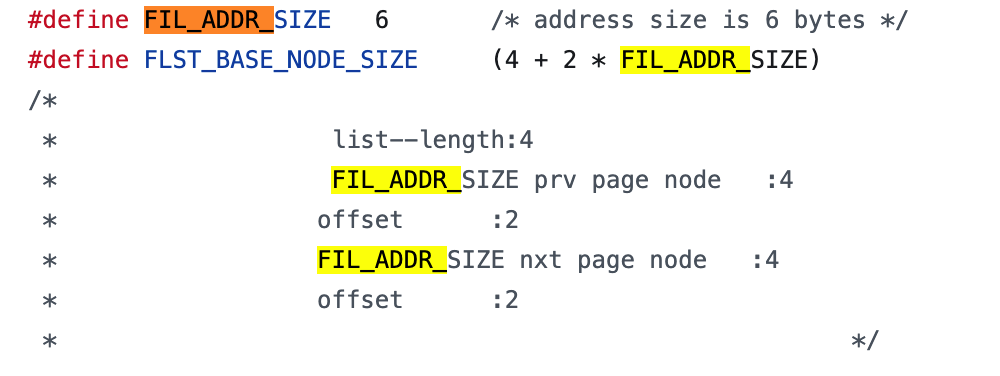
所以非叶子节点可以存储 16384/14(键值+指针)=1170 个这样的单元。
当层高为 2 时,根节点可以存储 1170 个指针,指向 1170 个叶子节点,所以总数据量为 1170×16 =18720 条。
当层高为 3 时,根节点指向 1170 个非叶子节点,每个非叶子节点再指向 1170 个叶子节点,所以总数据量为 1170×1170×16≈21,902,400 条(约2,190万条)记录。
推荐阅读:清幽之地:InnoDB 一棵 B+树可以存放多少行数据?
---- 这部分是帮助大家理解 end,面试中可不背 ----
现在有一张表 2kw 数据,我这个 b+树的高度有几层?
对于 2KW 条数据来说,B+树的高度为 3 层就够了。
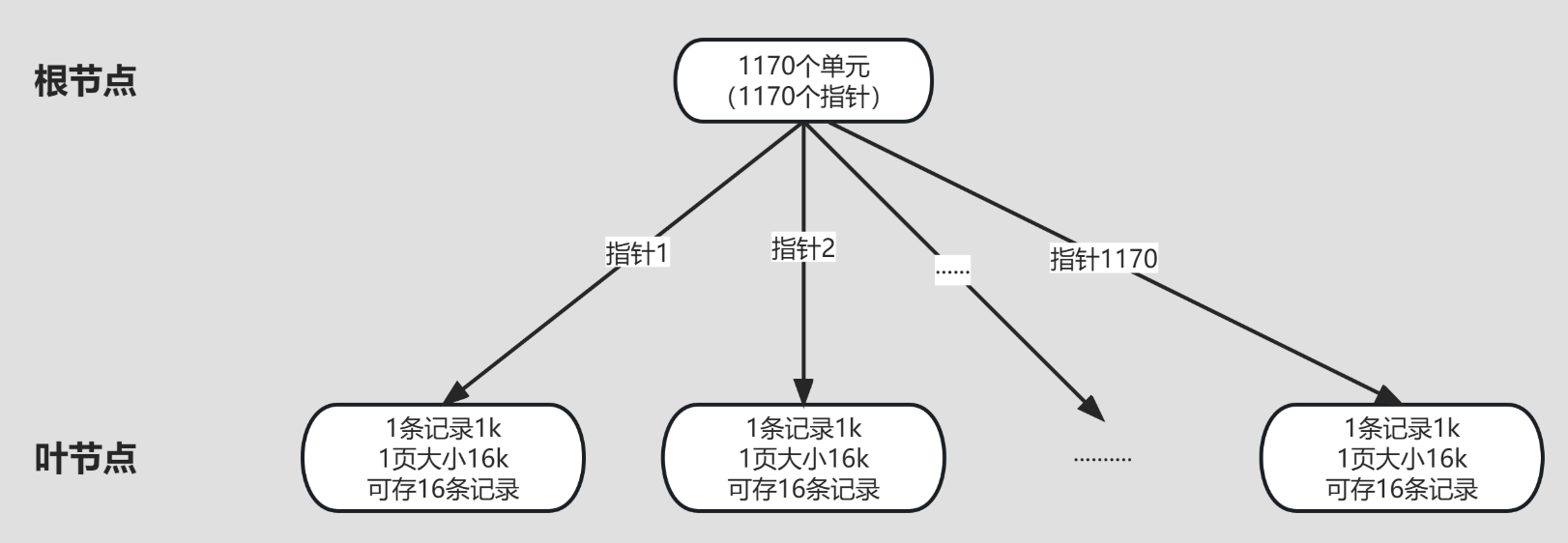
推荐阅读:Innodb 引擎中 B+树一般有几层?能容纳多少数据量?
每个叶子节点能存放多少条数据?
如果单行数据大小为 1KB,那么每页可存储约 16 行(16KB/1KB)数据。
---- 这部分是帮助大家理解 start,面试中可不背 ----
假设有这样一个表结构:
CREATE TABLE `user` (
`id` BIGINT PRIMARY KEY, -- 8字节
`name` VARCHAR(255) NOT NULL, -- 实际长度50字节(UTF8MB4,每个字符最多4字节)
`age` TINYINT, -- 1字节
`email` VARCHAR(255) -- 实际长度30字节,可为NULL
) ROW_FORMAT=COMPACT;那么一行数据的大小为:8 + 50 + 1 + 30 = 89 字节。
行格式的开销为:行头 5 字节+指针 6 字节+可变长度字段开销 2 字节(name 和 email 各占 1 字节)+ NULL 位图 1 字节 = 14 字节。
所以每行数据的实际大小为:89 + 14 = 103 字节。
每页大小默认为 16KB,那么每页最多可以存储 16384 / 103 ≈ 158 行数据。
---- 这部分是帮助大家理解 end,面试中可不背 ----
- Java 面试指南(付费)收录的字节跳动商业化一面的原题:说说 B+树,为什么 3 层容纳 2000W 条,为什么 2000w 条数据查的快
- Java 面试指南(付费)收录的奇安信面经同学 1 Java 技术一面面试原题:innodb 使用数据页存储数据?默认数据页大小 16K,我现在有一张表,有 2kw 数据,我这个 b+树的高度有几层?
- Java 面试指南(付费)收录的美团面经同学 18 成都到家面试原题:一张表最多存多少数据(我答得2kw,根据b+树的三层高度计算)
- Java 面试指南(付费)收录的得物面经同学 1 面试原题:MySQL B+树的度数越大越好吗,一般设多少
- Java 面试指南(付费)收录的腾讯面经同学 29 Java 后端一面原题:InnoDB中一个三层的B+树能存多少数据?每个叶子节点能存放多少条数据?
memo:2025 年 4 月 4 日修改至此,今天有球友问,有没有英文版的面渣逆袭,他人在国外留学,国外也开始卷八股了吗,真的离谱。
43.索引为什么用 B+树不用普通二叉树?
普通二叉树的每个节点最多有两个子节点。当数据按顺序递增插入时,二叉树会退化成链表,导致树的高度等于数据量。
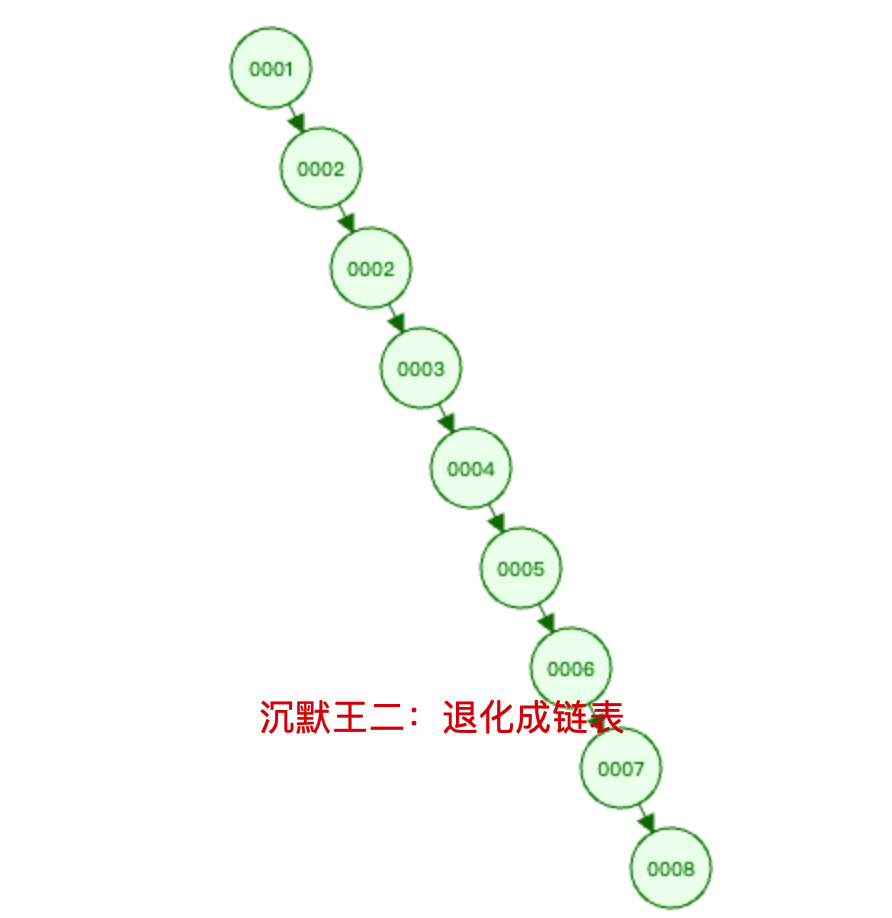
此时查找 id=7 就需要 7 次 I/O 操作,相当于全表扫描。而 B+ 树作为多叉平衡树,能将数亿级的数据量控制在 3-4 层的树高,能极大减少磁盘的 I/O 次数。
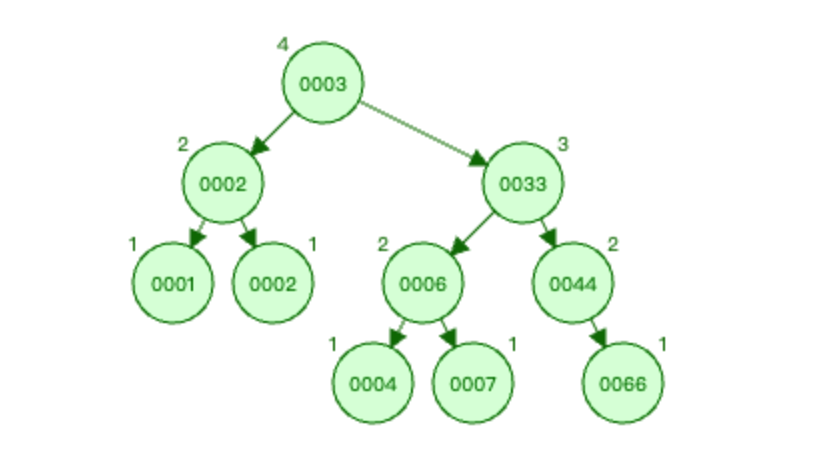
为什么不用平衡二叉树呢?
平衡二叉树虽然解决了普通二叉树的退化问题,但每个节点最多只有两个子节点的问题依然存在。
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:MySQL 索引为什么使用 B+树而不是用别的数据结构?
- Java 面试指南(付费)收录的腾讯面经同学 27 云后台技术一面面试原题:为什么不用二叉树?为什么不用AVL树?
44.🌟为什么用 B+ 树而不用 B 树呢?
B+ 树相比 B 树有 3 个显著优势:
第一,B 树的每个节点既存储键值,又存储数据和指针,导致单节点存储的键值数量较少。
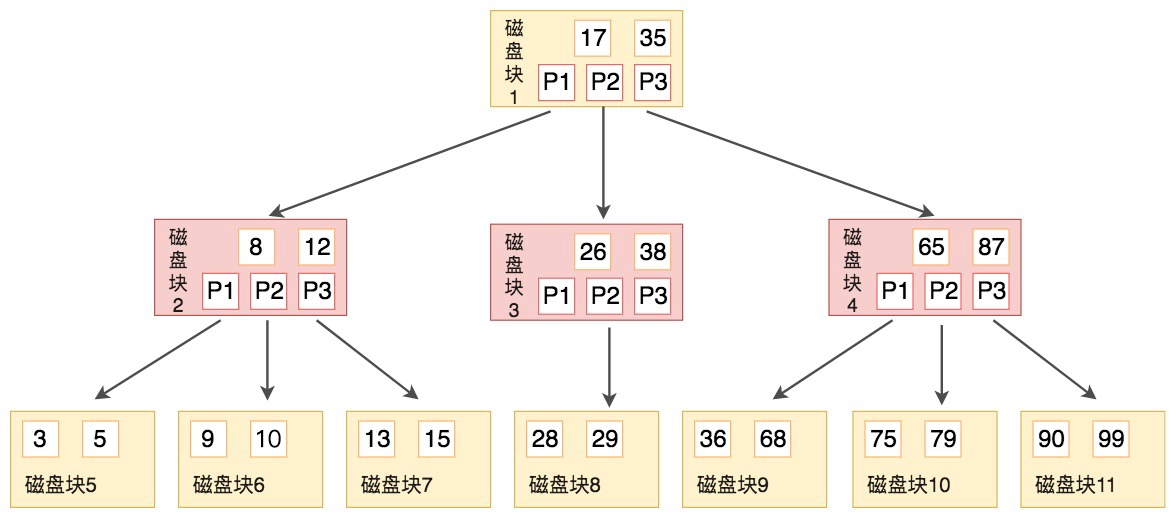
一个 16KB 的 InnoDB 页,如果数据较大,B 树的非叶子节点只能容纳几十个键值,而 B+ 树的非叶子节点可以容纳上千个键值。
第二,B 树的范围查询需要通过中序遍历逐层回溯;而 B+ 树的叶子节点通过双向链表顺序连接,范围查询只需定位起始点后顺序遍历链表即可,没有回溯开销。
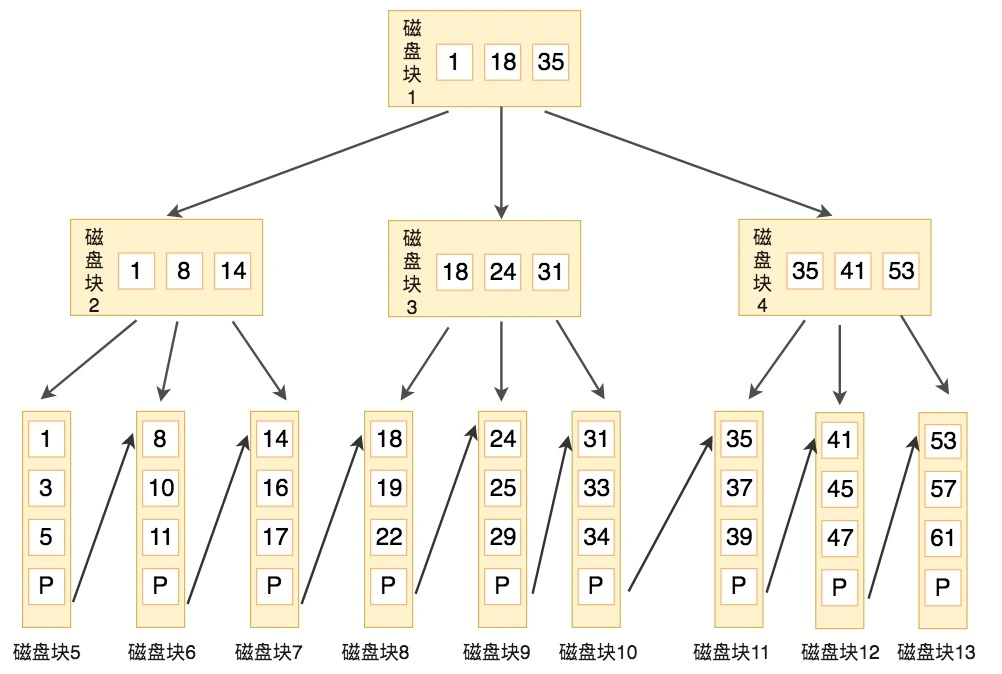
第三,B 树的数据可能存储在任意节点,假如目标数据恰好位于根节点或上层节点,查询仅需 1-2 次 I/O;但如果数据位于底层节点,则需多次 I/O,导致查询时间波动较大。
而 B+ 树的所有数据都存储在叶子节点,查询路径的长度是固定的,时间稳定为 O(logN),对 MySQL 在高并发场景下的稳定性至关重要。
想要了解 B 树和 B+树的更多区别,推荐阅读:
- GitHub:B 树和 B+树详解
- 思否:面试官问你 B 树和 B+树,就把这篇文章丢给他
- 极客时间:为什么用 B+树来做索引?
- 一颗剽悍的种子:用 16 张图就给你讲明白 MySQL 为什么要用 B+树做索引
B+树的时间复杂度是多少?
O(logN)。
树的高度 h 为:
其中 N 是数据总量,m 是阶数。每层需要做一次二分查找,复杂度为
总复杂度为:
为什么用 B+树不用跳表呢?
跳表本质上还是链表结构,只不过把某些节点抽到上层做了索引。
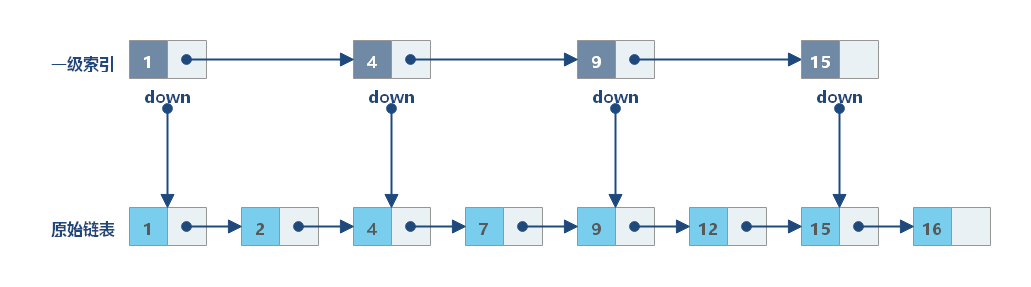
一条数据一个节点,如果需要存放 2000 万条数据,且每次查询都要能达到二分查找的效果,那么跳表的高度大约为 24 层(2 的 24 次方)。
在最坏的情况下,这 24 层数据分散在不同的数据页,查找一次数据就需要 24 次磁盘 I/O。
而 2000 万条数据在 B+树中只需要 3 层就可以了。
B+树的范围查找怎么做的?
一句话回答:
先通过索引路径定位到第一个满足条件的叶子节点,然后顺着叶子节点之间的链表向右/向左扫描,直到超过范围。
详细版:
B+ 树索引的范围查找主要依赖叶子节点之间的双向链表来完成。
第一步,从 B+ 树的根节点开始,通过索引键值逐层向下,找到第一个满足条件的叶子节点。
第二步,利用叶子节点之间的双向链表,从起始节点开始,依次向后遍历每个节点。当索引值超过查询范围,或者遍历到链表末尾时,终止查询。
---- 这部分是帮助大家理解 start,面试中可不背 ----
比如说在下面这棵 B+ 树上查找 45。
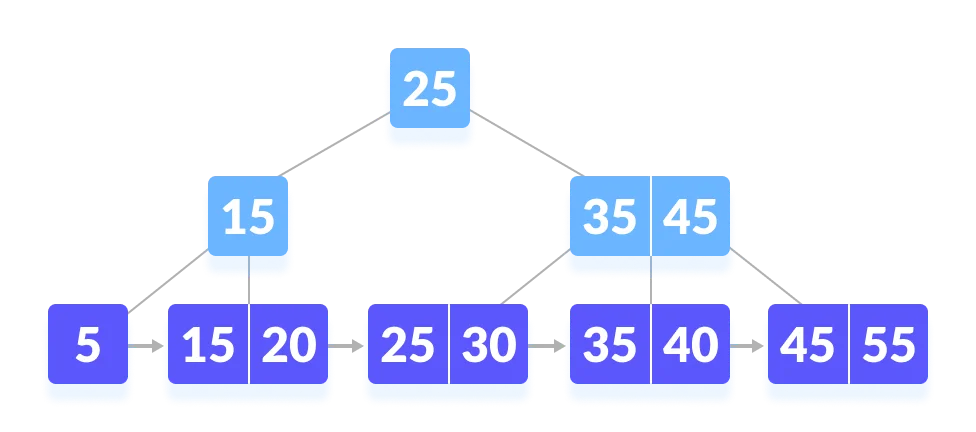
第一步,从根节点开始,因为比 25 大,所以从右子树开始。因为 45 比 35大,所以和右边的索引比较,右侧的索引也是 45,所以继续往右子树查找。
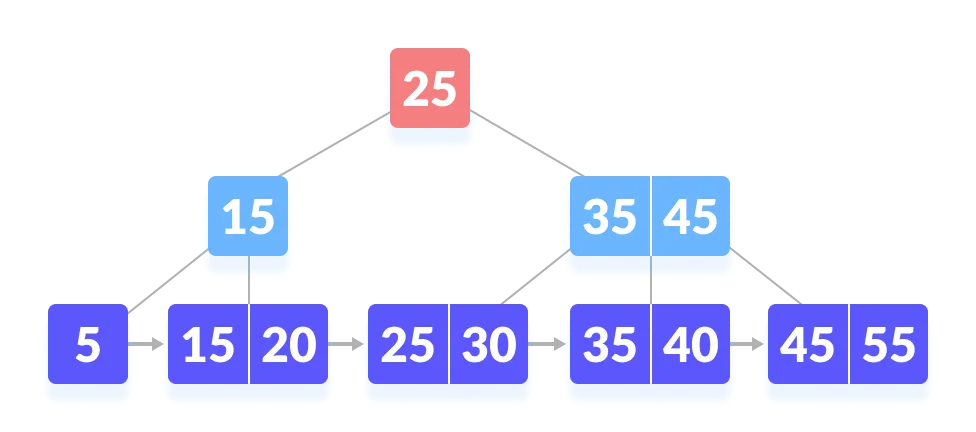
第二步,从叶子节点 45 开始,依次遍历,找到 45。
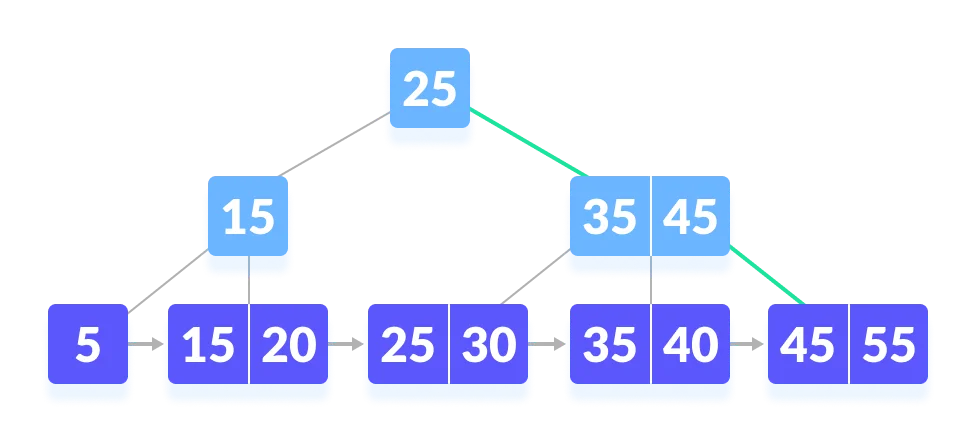
---- 这部分是帮助大家理解 end,面试中可不背 ----
了解快排吗?
快速排序使用分治法将一个序列分为较小和较大的 2 个子序列,然后递归排序两个子序列,由东尼·霍尔在 1960 年提出。
其核心思想是:
- 选择一个基准值。
- 将数组分为两部分,左边小于基准值,右边大于或等于基准值。
- 对左右两部分递归排序,最终合并。
public static void quickSort(int[] arr, int low, int high) {
if (low < high) {
int pivotIndex = partition(arr, low, high);
quickSort(arr, low, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, high);
}
}
private static int partition(int[] arr, int low, int high) {
int pivot = arr[high];
int i = low - 1;
for (int j = low; j < high; j++) {
if (arr[j] <= pivot) {
i++;
swap(arr, i, j);
}
}
swap(arr, i + 1, high);
return i + 1;
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}推荐链接:快速排序
- Java 面试指南(付费)收录的支付宝面经同学 2 春招技术一面面试原题:聚簇索引和非聚簇索引的区别?B+树叶子节点除了存数据还有什么?
- Java 面试指南(付费)收录的奇安信面经同学 1 Java 技术一面面试原题:b 树和 b+树有什么区别
- Java 面试指南(付费)收录的百度面经同学 1 文心一言 25 实习 Java 后端面试原题:MySQL 索引为什么使用 B+树而不是用别的数据结构?
- Java 面试指南(付费)收录的字节跳动面经同学 8 Java 后端实习一面面试原题:mysql b+树和b树的区别
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:B+树有哪些优点
- Java 面试指南(付费)收录的同学 1 贝壳找房后端技术一面面试原题:为什么用b+树不用b树
- Java 面试指南(付费)收录的阿里系面经同学 19 饿了么面试原题:索引为什么用B+树不用B树 时间复杂度深究 b+树 快速排序...
45.B+树索引和 Hash 索引有什么区别?
简版回答:
B+ 树索引支持范围查询、有序扫描,是 InnoDB 的默认索引结构。
Hash 索引只支持等值查找,速度快但功能弱,常见于 Memory 引擎。
稍微详细一点的回答:
B+ 树索引是一种平衡多路搜索树,所有数据存储在叶子节点上,非叶子节点仅存储索引键。叶子节点通过指针连接形成有序链表,天然支持排序。
并且支持范围查询、模糊查询,是 InnoDB 默认的索引结构。
Hash 索引基于哈希函数将键值映射到固定长度的哈希值,通过哈希值定位数据存储的位置。
完全无序,只支持等值查询,常见于 Memory 引擎。
---- 这部分是帮助大家理解 start,面试中可不背 ----
因为 B+ 树是 InnoDB 的默认索引类型,所以创建 B+ 树的时候不需要指定索引类型。
CREATE TABLE example_btree (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
INDEX name_index (name)
) ENGINE=InnoDB;可以通过 UNIQUE HASH 创建哈希索引:
CREATE TABLE example_hash (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
UNIQUE HASH (name)
) ENGINE=MEMORY;InnoDB 并不提供直接创建哈希索引的选项,因为 B+ 树索引能够很好地支持范围查询和等值查询,满足了大多数数据库操作的需要。
不过,InnoDB 内部使用了一种名为“自适应哈希索引”(Adaptive Hash Index, AHI)的技术,当某些索引值频繁访问时,InnoDB 会在 B+ 树基础上自动创建哈希索引,兼具两者的优点。
可通过 SHOW VARIABLES LIKE 'innodb_adaptive_hash_index'; 查看自适应哈希索引的状态。
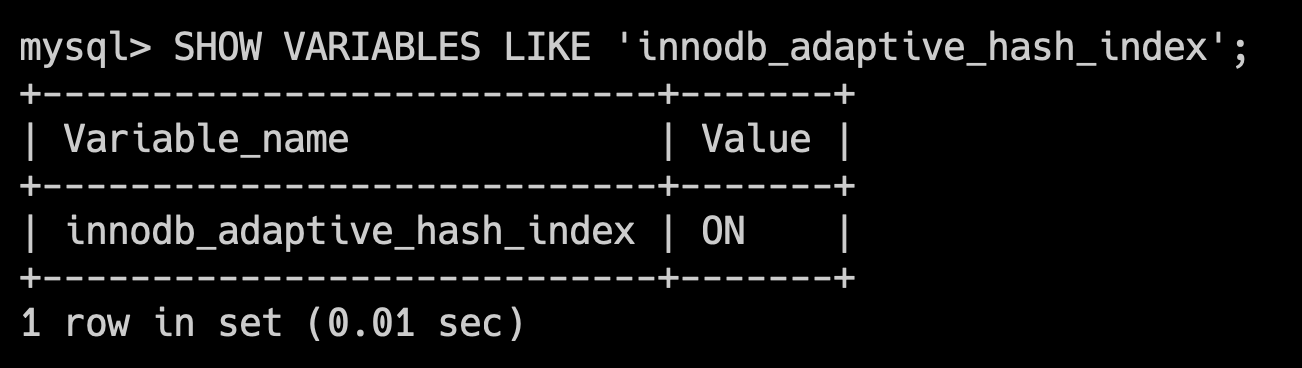
如果返回的值是 ON,说明自适应哈希索引是开启的。
---- 这部分是帮助大家理解 end,面试中可不背 ----
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:为什么不用hash索引
46.🌟聚族索引和非聚族索引有什么区别?
聚簇索引的叶子节点存储了完整的数据行,数据和索引是在一起的。InnoDB 的主键索引就是聚簇索引,叶子节点不仅存储了主键值,还存储了其他列的值,因此按照主键进行查询的速度会非常快。
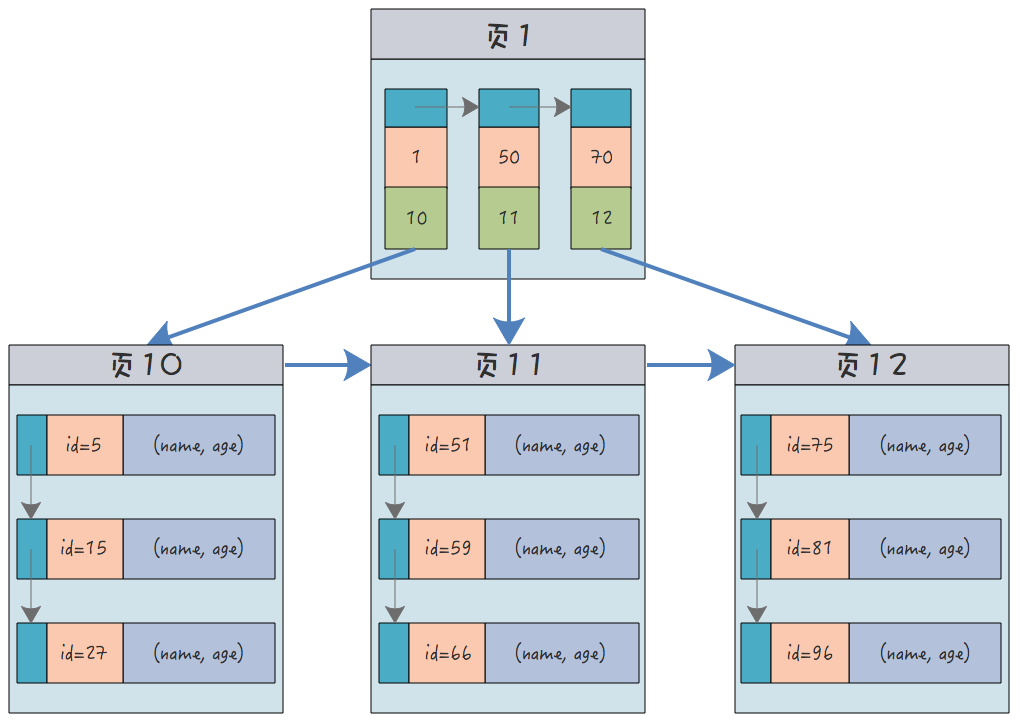
每个表只能有一个聚簇索引,通常由主键定义。如果没有显式指定主键,InnoDB 会隐式创建一个隐藏的主键索引 row_id。
非聚簇索引的叶子节点只包含了主键值,需要通过回表按照主键去聚簇索引查找其他列的值,唯一索引、普通索引等非主键索引都是非聚簇索引。
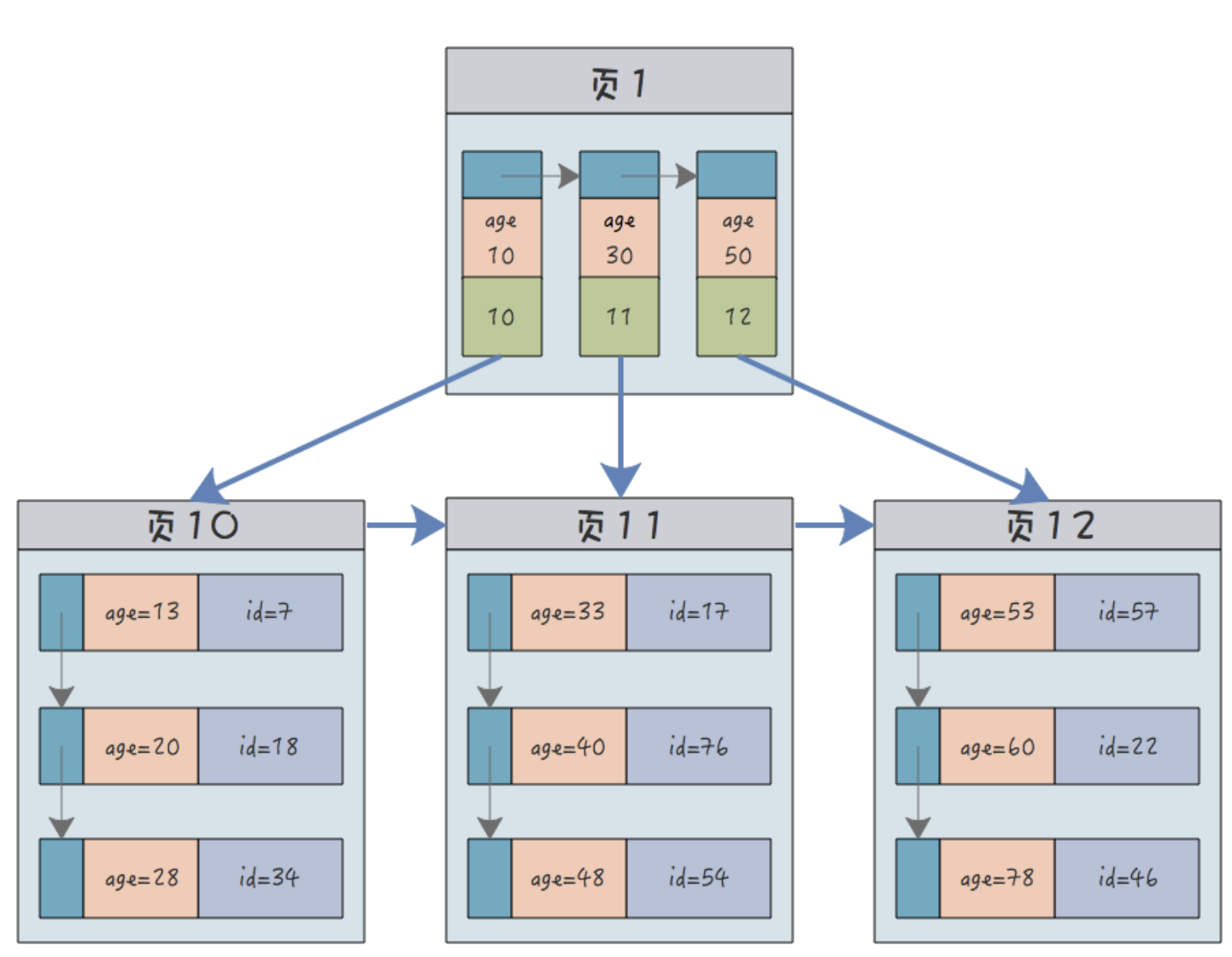
每个表都可以创建多个非聚簇索引,如果不想回表的话,可以通过覆盖索引把要查询的字段也放到索引中。
---- 这部分是帮助大家理解 start,面试中可不背 ----
一张表只能有一个聚簇索引。
CREATE TABLE user (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
);主键 id 是聚簇索引,B+ 树的叶子节点直接存储了 (id, name, age)。
一张表可以有多个非聚簇索引。
CREATE INDEX idx_name ON user(name);
CREATE INDEX idx_age ON user(age);idx_name 是非聚簇索引,叶子节点存的是 name -> id,查整行数据要回表。
idx_age 也是非聚簇索引,叶子节点存的是 age -> id,查整行数据也要回表。
想要了解更多聚簇索引和非聚簇索引,推荐阅读:
---- 这部分是帮助大家理解 end,面试中可不背 ----
- Java 面试指南(付费)收录的小米春招同学 K 一面面试原题:mysql:聚簇索引和非聚簇索引区别
- Java 面试指南(付费)收录的支付宝面经同学 2 春招技术一面面试原题:聚簇索引和非聚簇索引的区别?B+树叶子节点除了存数据还有什么?
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:聚簇索引是什么?非聚簇索引是什么?
- Java 面试指南(付费)收录的腾讯云智面经同学 16 一面面试原题:聚簇索引和非聚簇索引的区别?
- Java 面试指南(付费)收录的快手面经同学 1 部门主站技术部面试原题:Mysql 的聚簇索引和非聚簇索引的区别是什么?
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:mysql的聚簇索引是什么
- Java 面试指南(付费)收录的腾讯面经同学 29 Java 后端一面原题:MySQL的索引怎么存储的?每个索引一个B+树,还是多个索引放一个B+树?叶子节点中存的是什么数据?
memo:2025 年 4 月 5 日修改至此,今天有拿到美团暑期实习的球友说,简历找二哥修改了两次,基本上不卡第一学历的都有面,很棒。

47.🌟回表了解吗?
当使用非聚簇索引进行查询时,MySQL 需要先通过非聚簇索引找到主键值,然后再根据主键值回到聚簇索引中查找完整数据行,这个过程称为回表。
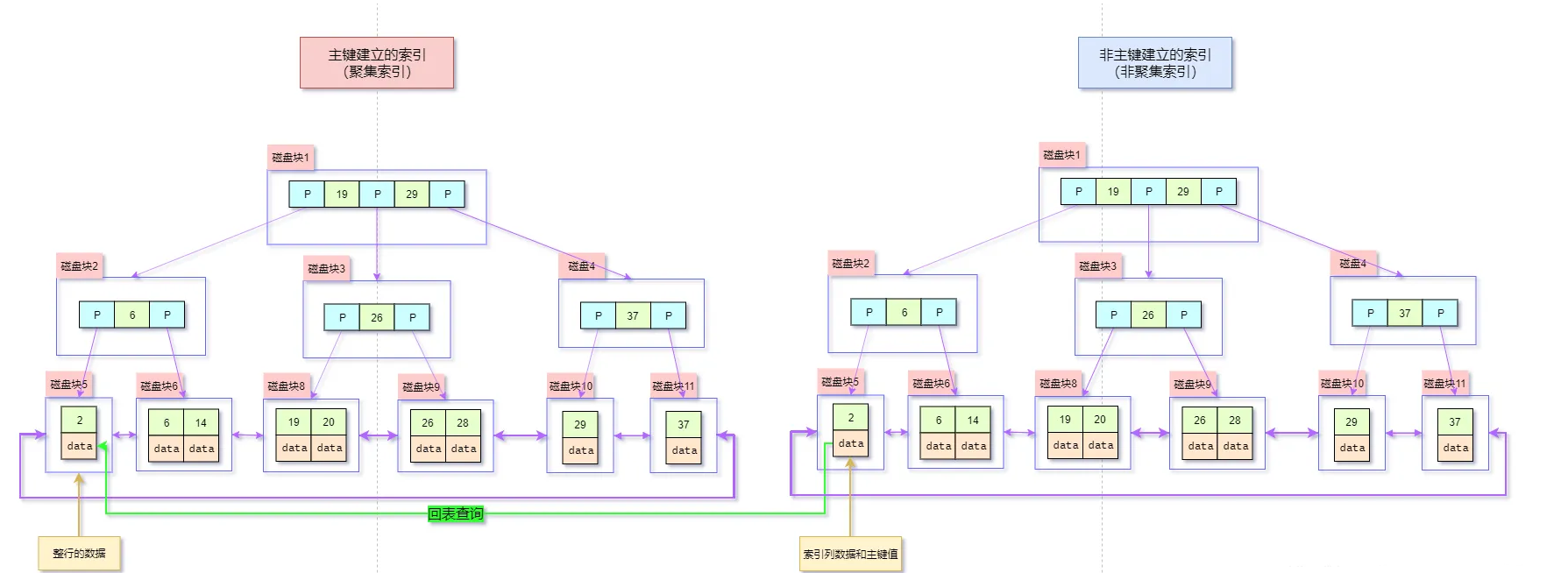
假设现在有一张用户表 users:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
email VARCHAR(50),
INDEX (name)
);执行查询:
SELECT * FROM users WHERE name = '王二';查询过程如下:
- 第一步,MySQL 使用 name 列上的非聚簇索引查找所有
name = '王二'的主键 id。 - 第二步,使用主键 id 到聚簇索引中查找完整记录。
回表的代价是什么?
回表通常需要访问额外的数据页,如果数据不在内存中,还需要从磁盘读取,增加 I/O 开销。
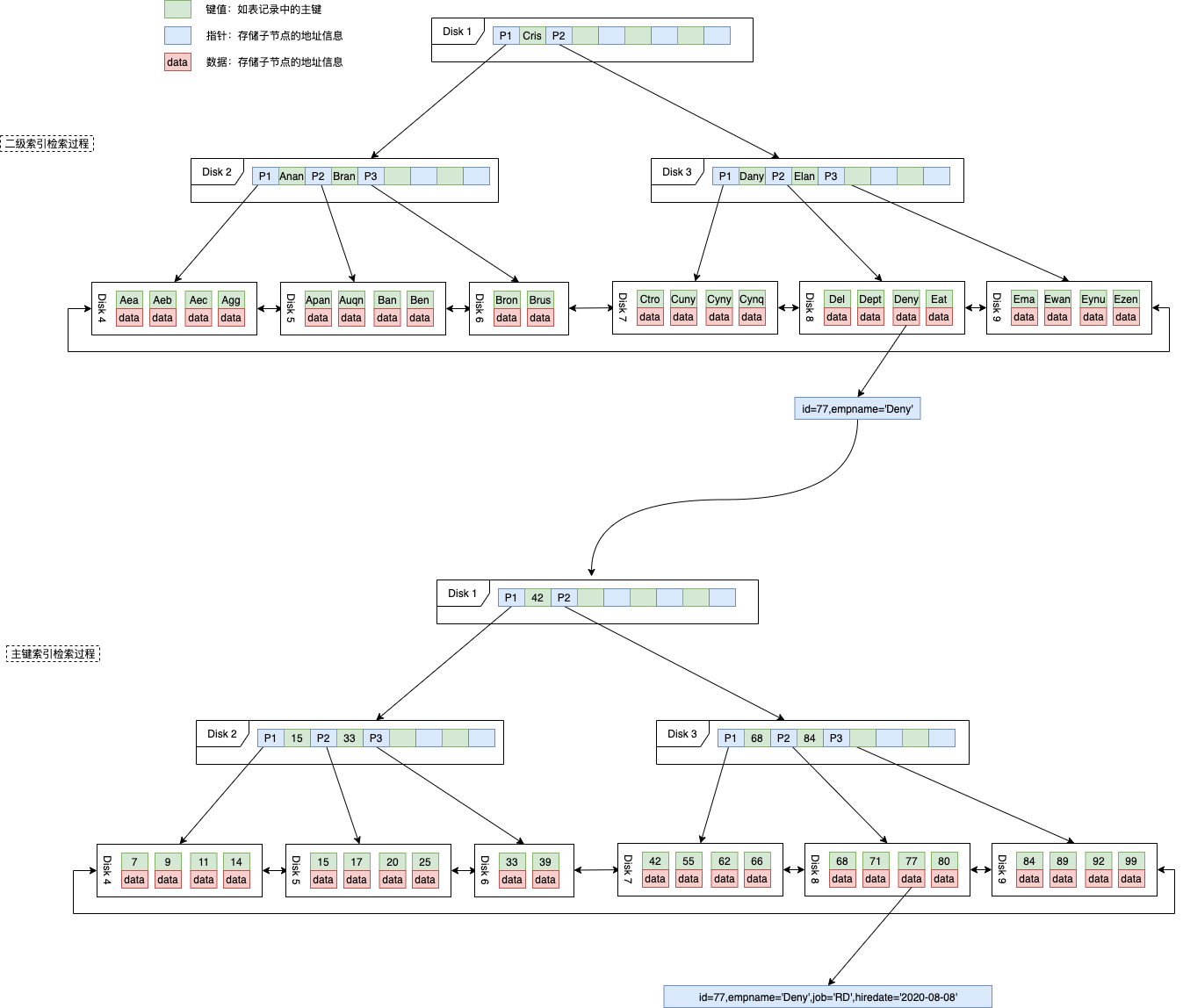
可通过覆盖索引或者联合索引来避免回表。
-- 原表结构
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
INDEX idx_name (name)
);
-- 需要查询name和age
SELECT name, age FROM users WHERE name = '张三';
-- 这会回表,因为age不在idx_name索引中
-- 优化方案1:创建包含age的联合索引
ALTER TABLE users ADD INDEX idx_name_age (name, age);
-- 现在同样的查询不需要回表什么情况下会触发回表?
第一,当查询字段不在非聚簇索引中时,必须回表到主键索引获取数据。
第二,查询字段包含非索引列(如 SELECT *),必然触发回表。
回表记录越多好吗?
回表记录越多,通常代表性能越差,因为每条记录都需要通过主键再查询一次完整数据。这个过程涉及内存访问或磁盘 IO,尤其当缓存命中率不高时,回表会严重影响查询效率。
了解 MRR 吗?
MRR 是 InnoDB 为了解决回表带来的大量随机 IO 问题而引入的一种优化策略。
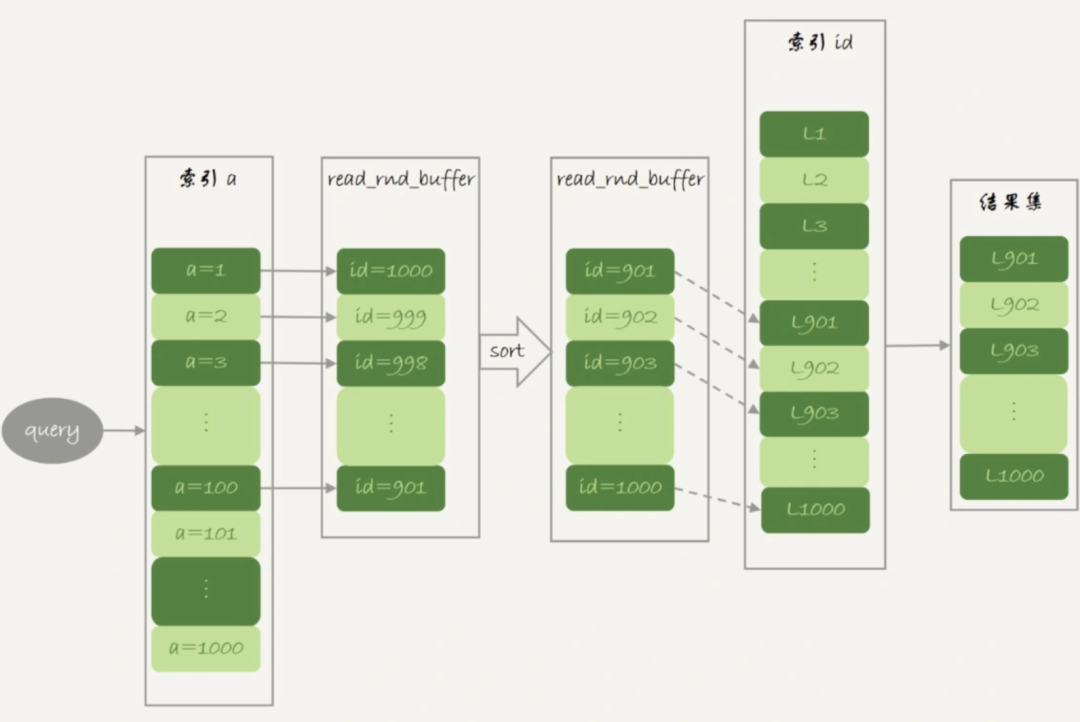
它会先把非聚簇索引查到的主键值列表进行排序,再按顺序去主键索引中批量回表,将随机 I/O 转换为顺序 I/O,以减少磁盘寻道时间。
---- 这部分是帮助大家理解 start,面试中可不背 ----
可通过 SHOW VARIABLES LIKE 'optimizer_switch'; 查看 MRR 是否启用。
其中 mrr=on 表示启用 MRR,mrr_cost_based=on 表示基于成本决定使用 MRR。
另外可以通过 show variables like 'read_rnd_buffer_size'; 查看 MRR 的缓冲区大小,默认是 256KB。
我们来创建一个表,插入一些数据,然后执行一个查询来演示 MRR 的效果。
CREATE DATABASE IF NOT EXISTS mrr_test;
USE mrr_test;
CREATE TABLE IF NOT EXISTS orders (id INT AUTO_INCREMENT PRIMARY KEY, user_id INT, order_date DATE, amount DECIMAL(10,2), status VARCHAR(20), INDEX idx_user_date(user_id, order_date));
DELIMITER //
CREATE PROCEDURE generate_test_data()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 100000 DO
INSERT INTO orders (user_id, order_date, amount, status)
VALUES (
FLOOR(1 + RAND() * 1000), -- Random user_id between 1 and 1000
DATE_ADD('2023-01-01', INTERVAL FLOOR(RAND() * 365) DAY), -- Random date in 2023
ROUND(10 + RAND() * 990, 2), -- Random amount between 10 and 1000
ELT(1 + FLOOR(RAND() * 3), 'completed', 'pending', 'cancelled') -- Random status
);
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
CALL generate_test_data();
DROP PROCEDURE generate_test_data;"查看 MRR 开启和关闭时的性能数据:
-- 确保MRR开启并设置足够大的缓冲区
SET SESSION optimizer_switch='mrr=on,mrr_cost_based=off';
SET SESSION read_rnd_buffer_size = 16*1024*1024;
-- 清理缓存和状态
FLUSH STATUS;
FLUSH TABLES;
-- 强制使用二级索引并回表查询(通过选择未被索引的列)
SELECT 'Raw data access pattern with MRR ON' as test_case;
SELECT /*+ MRR(orders_mrr_test) */ id, shipping_address, customer_name
FROM orders_mrr_test FORCE INDEX(idx_user_date)
WHERE user_id IN (100,200,300,400,500,600,700,800,900,1000)
AND order_date BETWEEN '2023-03-01' AND '2023-04-01'
LIMIT 15;
-- 显示处理器状态
SHOW STATUS LIKE 'Handler_%';
SHOW STATUS LIKE '%mrr%';
-- 对比:关闭MRR
SET SESSION optimizer_switch='mrr=off,mrr_cost_based=off';
FLUSH STATUS;
FLUSH TABLES;
SELECT 'Raw data access pattern with MRR OFF' as test_case;
SELECT id, shipping_address, customer_name
FROM orders_mrr_test FORCE INDEX(idx_user_date)
WHERE user_id IN (100,200,300,400,500,600,700,800,900,1000)
AND order_date BETWEEN '2023-03-01' AND '2023-04-01'
LIMIT 15;
-- 显示处理器状态
SHOW STATUS LIKE 'Handler_%';
SHOW STATUS LIKE '%mrr%';
-- 显示详细的执行计划
EXPLAIN FORMAT=TREE
SELECT /*+ MRR(orders_mrr_test) */ id, shipping_address, customer_name
FROM orders_mrr_test FORCE INDEX(idx_user_date)
WHERE user_id IN (100,200,300,400,500,600,700,800,900,1000)
AND order_date BETWEEN '2023-03-01' AND '2023-04-01';"可以看到 MRR 开启时的结果对比:
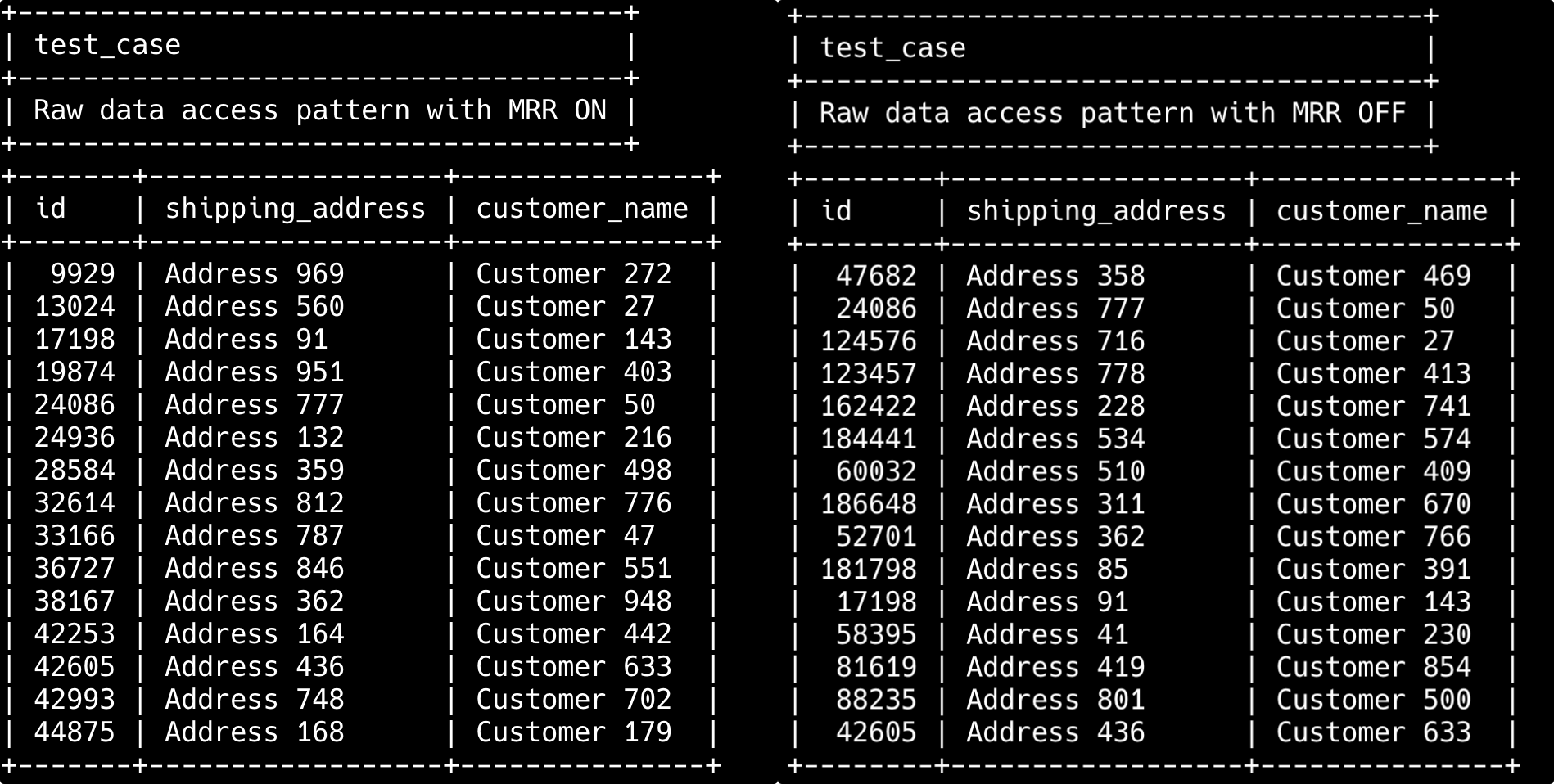
Wrap 也给出了对应的结果说明:
也可以在 explain 中确认 MRR 的使用情况。
---- 这部分是帮助大家理解 end,面试中可不背 ----
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:使用非聚簇索引如何查找数据?
- Java 面试指南(付费)收录的字节跳动面经同学 1 技术二面面试原题:回表记录越多好吗?(回表的代价)
memo:2025 年 4 月 6 日修改至此,今天帮球友修改简历的时候,看到有球友写技术派到简历上,很不错,推荐给大家。

48.🌟联合索引了解吗?(补充)
2024 年 11 月 22 日增补
联合索引就是把多个字段放在一个索引里,但必须遵守“最左前缀”原则,只有从第一个字段开始连续使用,索引才会生效。
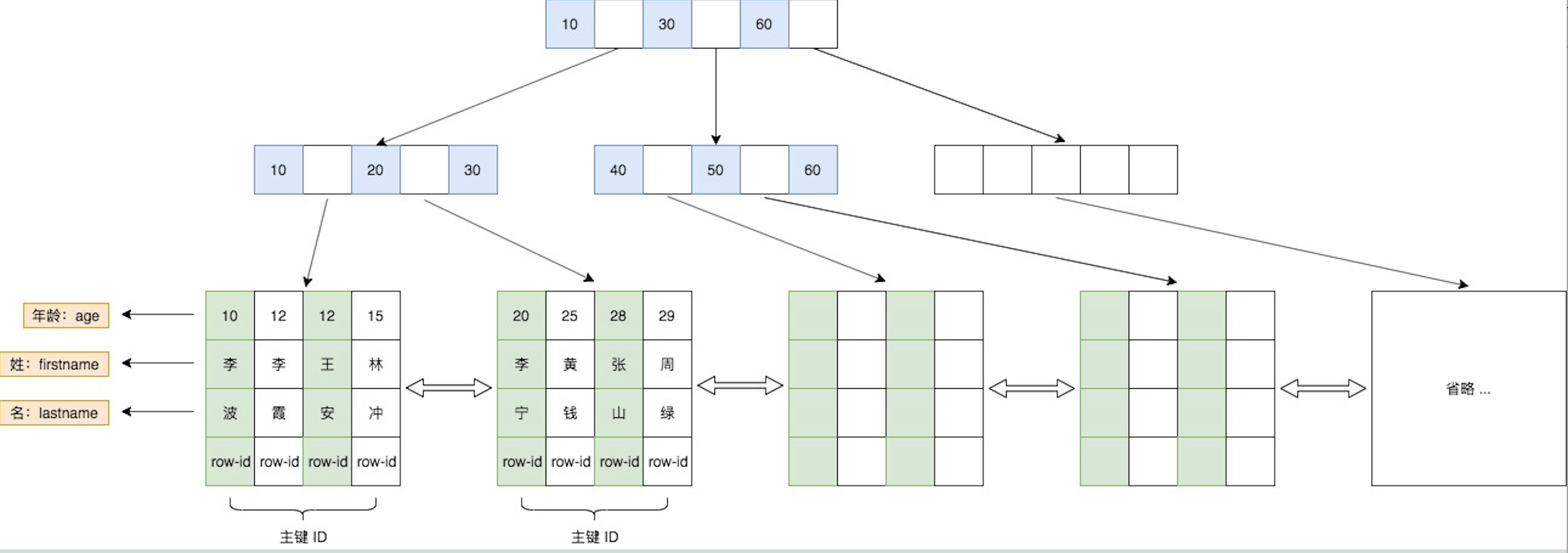
联合索引会按字段顺序构建B+树。例如(age, name)索引会先按照 age 排序,age 相同则按照 name 排序,若两者都相同则按主键排序,确保叶子节点无重复索引项。
创建(A,B,C)联合索引相当于同时创建了(A)、(A,B)和(A,B,C)三个索引。
-- 创建联合索引
CREATE INDEX idx_order_user_product ON orders(user_id, product_id, create_time)
-- 高效查询
SELECT * FROM orders
WHERE user_id=1001 AND product_id=2002
ORDER BY create_time DESC联合索引底层的存储结构是怎样的?
联合索引在底层采用 B+ 树结构进行存储,这一点与单列索引相同。
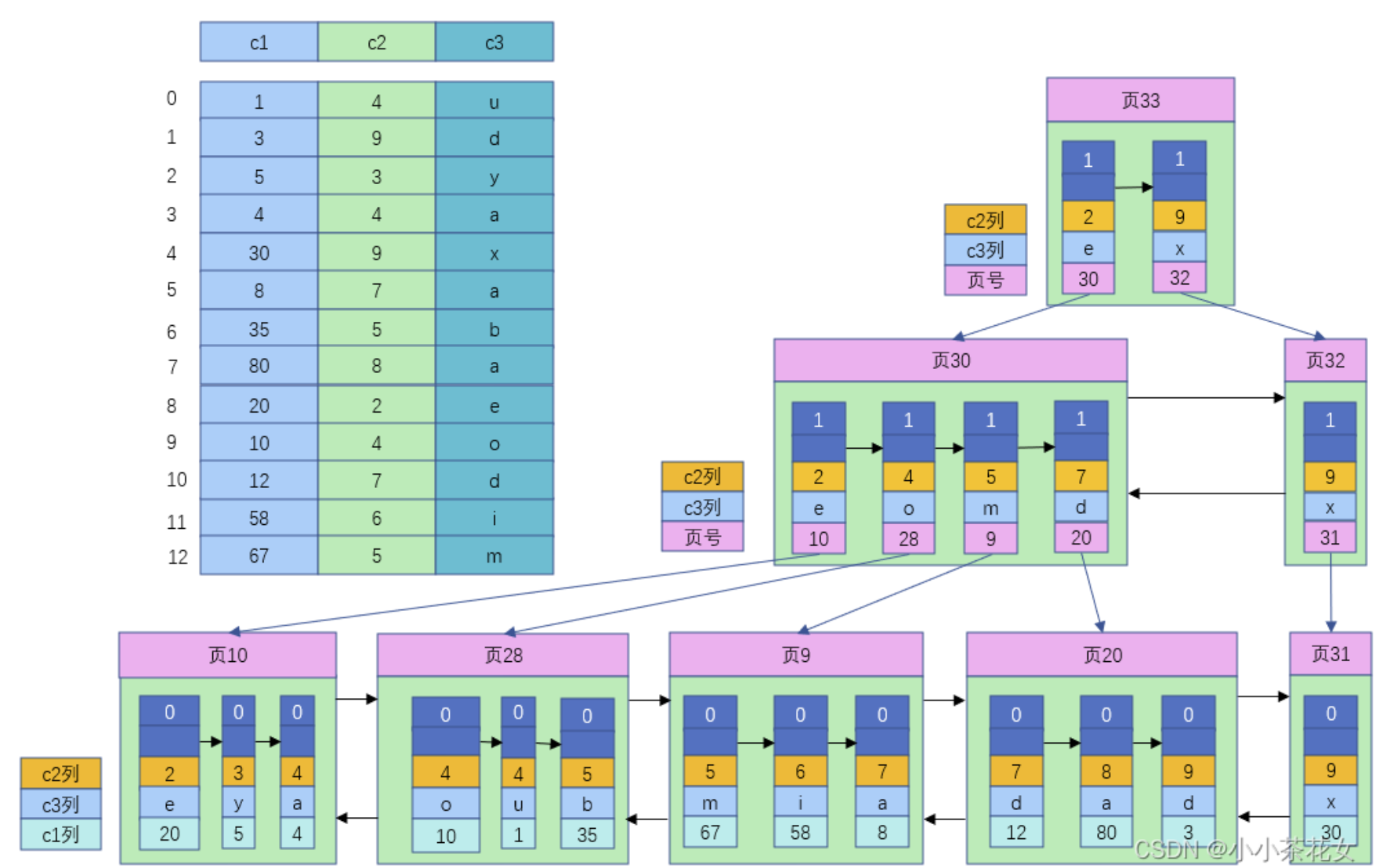
与单列索引不同的是,联合索引的每个节点会存储所有索引列的值,而不仅仅是第一列的值。例如,对于联合索引(a,b,c),每个节点都包含 a、b、c 三列的值。
非叶子节点示例:
[(a=1, b=2, c=3) → 子节点1, (a=5, b=3, c=1) → 子节点2]
叶子节点示例(InnoDB):
(a=1, b=2, c=3) → PK=100 | (a=1, b=2, c=4) → PK=101
(通过指针连接形成双向链表)联合索引的叶子节点存的什么内容?
联合索引属于非聚簇索引,叶子节点存储的是联合索引各列的值和对应行的主键值,而不是完整的数据行。查询非索引字段时,需要通过主键值回表到聚簇索引获取完整数据。
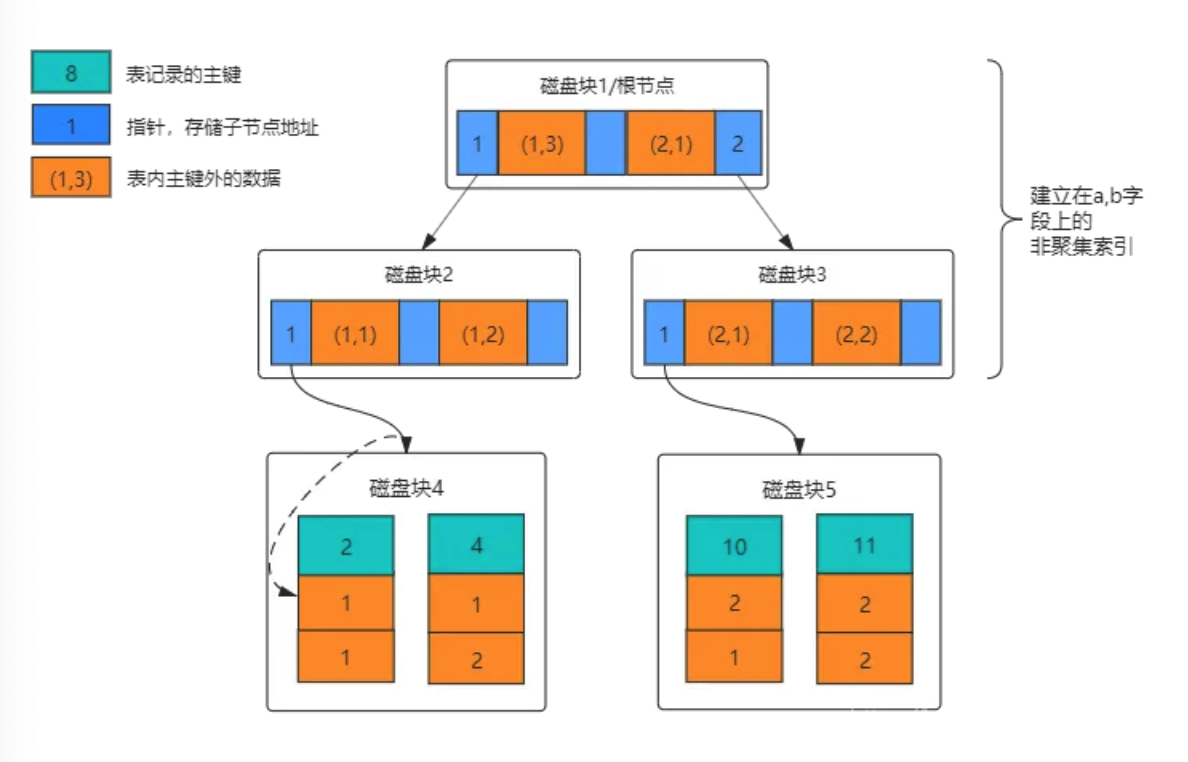
例如索引(a, b)的叶子节点会完整存储(a, b)的值,并按字段顺序排序(如 a 优先,a 相同则按 b 排序)。如果主键是 id,叶子节点会存储 (a, b, id) 的组合。
- Java 面试指南(付费)收录的百度同学 4 面试原题:联合索引底层存储结构(和其他种类的索引存储结构有什么区别?)联合索引的叶子节点存的什么内容?
memo:2025 年 04 月 07 日增补至此,今天有球友反馈说,加了二哥的星球,简历上写了技术派的项目后,拿到了腾讯天美的 offer,真的太强了。

49.🌟覆盖索引了解吗?
覆盖索引指的是:查询所需的字段全部都在索引中,不需要回表,从索引页就能直接返回结果。
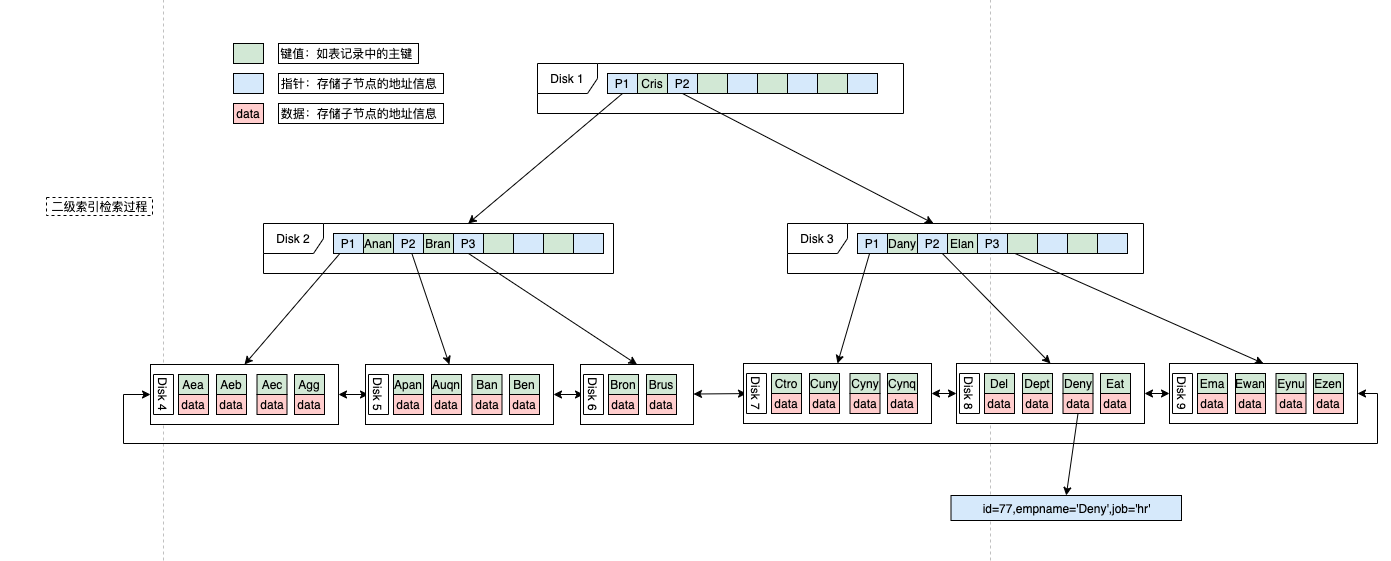
empname 和 job 两个字段是一个联合索引,而查询也恰好是这两个字段,这时候单次查询就可以达到目的,不需要回表。
可以将高频查询的字段(如 WHERE 条件和 SELECT 列)组合为联合索引,实现覆盖索引。
例如:
CREATE INDEX idx_empname_job ON employee(empname, job);这样查询的时候就可以走索引:
SELECT empname, job FROM employee WHERE empname = '王二' AND job = '程序员';普通索引只用于加速查询条件的匹配,而覆盖索引还能直接提供查询结果。
一个表(name, sex,age,id),select age,id,name from tblname where name='paicoding';怎么建索引
由于查询条件有 name 字段,所以最少应该为 name 字段添加一个索引。、
CREATE INDEX idx_name ON tblname(name);查询结果中还需要 age、id 字段,可以为这三个字段创建一个联合索引,利用覆盖索引,直接从索引中获取数据,减少回表。
CREATE INDEX idx_name_age_id ON tblname (name, age, id);
- Java 面试指南(付费)收录的作业帮面经同学 1 Java 后端一面面试原题:了解覆盖索引吗
- Java 面试指南(付费)收录的美团同学 9 一面面试原题:覆盖索引,回表?
- Java 面试指南(付费)收录的字节跳动面经同学 13 Java 后端二面面试原题:一个表(name, sex,age,id),select age,id,name from tblname where name='paicoding';怎么建索引
50.🌟什么是最左前缀原则?
最左前缀原则指的是:MySQL 使用联合索引时,必须从最左边的字段开始匹配,才能命中索引。
假设有一个联合索引 (A, B, C),其生效条件如下:
| 查询条件 | 是否触发索引? | 说明 |
|---|---|---|
| WHERE A = 1 | ✅ 是 | 使用索引的第一列 |
| WHERE A = 1 AND B = 2 | ✅ 是 | 使用索引的前两列 |
| WHERE A = 1 AND B = 2 AND C = 3 | ✅ 是 | 使用索引的全部列 |
| WHERE B = 2 | ❌ 否 | 跳过左侧列 A,索引失效 |
| WHERE B = 2 AND C = 3 | ❌ 否 | 无左侧列,索引失效 |
| WHERE A = 1 AND C = 3 | ⚠️ 部分生效 | 仅用 A 列,C 列无法利用索引优化 |
| WHERE A = 1 | ✅ 是 | 使用索引的第一列 |
| WHERE A = 1 AND B = 2 | ✅ 是 | 使用索引的前两列 |
| WHERE A = 1 AND B = 2 AND C = 3 | ✅ 是 | 使用索引全部列(最理想情况) |
| WHERE B = 2 | ❌ 否 | 跳过左侧列 A,索引失效 |
| WHERE B = 2 AND C = 3 | ❌ 否 | 无左侧列,索引失效 |
| WHERE A = 1 AND C = 3 | ⚠️ 部分生效 | 仅用 A 列,C 列无法利用索引优化 |
如果排序或分组的列是最左前缀的一部分,索引还可以加速操作。
SQL
-- 索引(a,b)
SELECT * FROM table WHERE a = 1 ORDER BY b; -- 可以利用索引排序范围查询后的列还能用索引吗?
范围查询只能应用于最左前缀的最后一列。范围查询之后的列无法使用索引。
SQL
-- 索引(a,b,c)
SELECT * FROM table WHERE a = 1 AND b > 2 AND c = 3;
-- 只能使用a和b,c无法使用索引为什么不从最左开始查,就无法匹配呢?
一句话回答:
因为联合索引在 B+ 树中是按照最左字段优先排序构建的,如果跳过最左字段,MySQL 无法判断查找范围从哪里开始,自然也就无法使用索引。
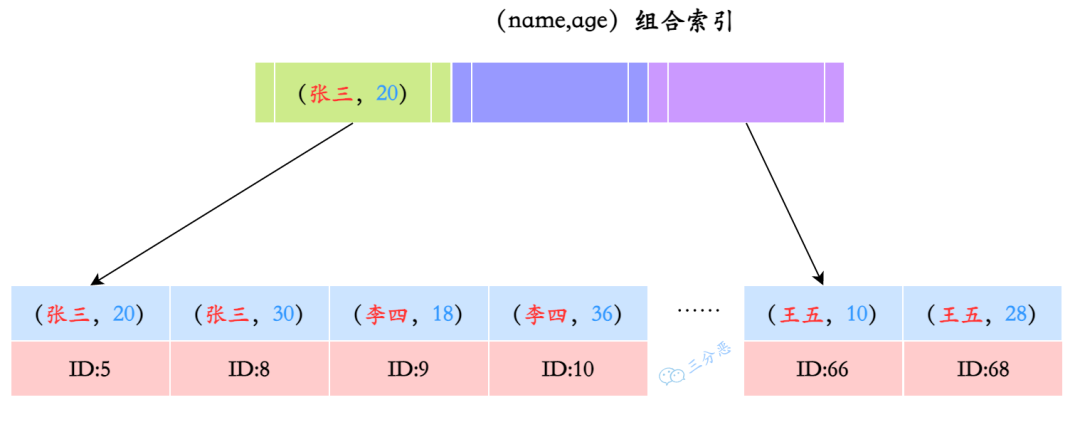
比如有一个 user 表,我们给 name 和 age 建立了一个联合索引 (name, age)。
ALTER TABLE user add INDEX comidx_name_phone (name,age);联合索引在 B+ 树中按照从左到右的顺序依次建立搜索树,name 在左,age 在右。
当我们使用 where name= '王二' and age = '20' 去查询的时候, B+ 树会优先比较 name 来确定下一步应该搜索的方向,往左还是往右。
如果 name 相同的时候再比较 age。
但如果查询条件没有 name,就不知道应该怎么查了,因为 name 是 B+树中的前置条件,没有 name,索引就派不上用场了。
联合索引 (a, b),where a = 1 和 where b = 1,效果是一样的吗
不一样。
WHERE a = 1 能命中联合索引,因为 a 是联合索引的第一个字段,符合最左前缀匹配原则。而 WHERE b = 1 无法命中联合索引,因为缺少 a 的匹配条件,MySQL 会全表扫描。
---- 这部分是帮助大家理解 start,面试中可不背 ----
我们来验证一下,假设有一个 ab 表,建立了联合索引 (a, b):
CREATE TABLE ab (
a INT,
b INT,
INDEX ab_index (a, b)
);插入数据:
INSERT INTO ab (a, b) VALUES (1, 2), (1, 3), (2, 1), (3, 3), (2, 2);执行查询:
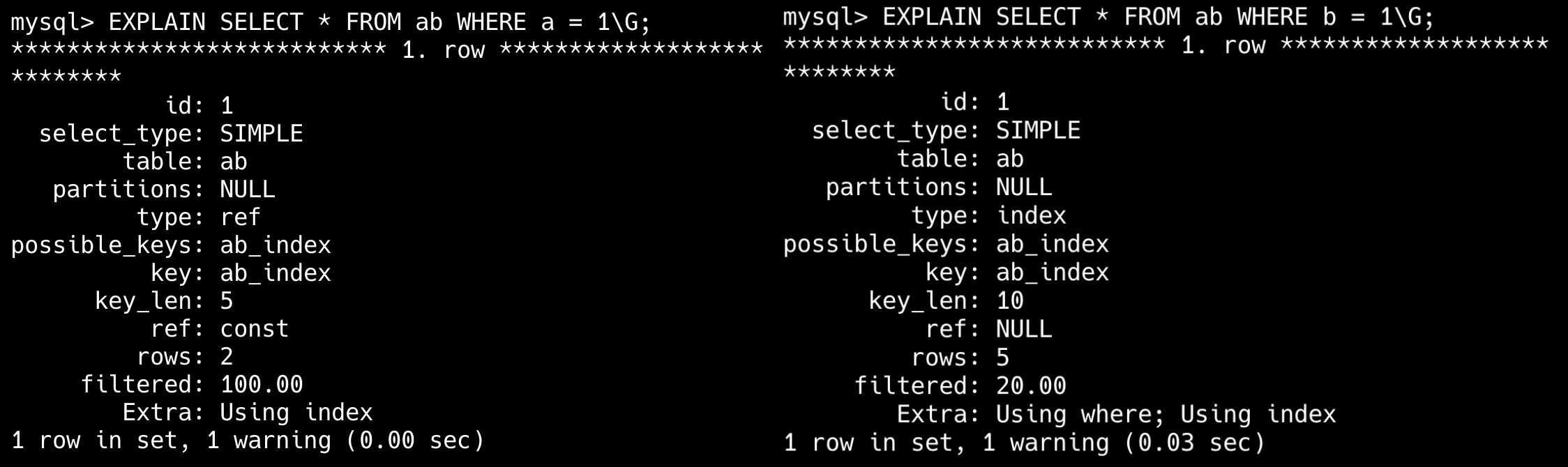
通过 explain 可以看到,WHERE a = 1 使用了联合索引,而 WHERE b = 1 需要全表扫描,依次检查每一行。
---- 这部分是帮助大家理解 end,面试中可不背 ----
假如有联合索引 abc,下面的 sql 怎么走的联合索引?
select * from t where a = 2 and b = 2;
select * from t where b = 2 and c = 2;
select * from t where a > 2 and b = 2;第一条 SQL 语句包含条件 a = 2 和 b = 2,刚好符合联合索引的前两列。
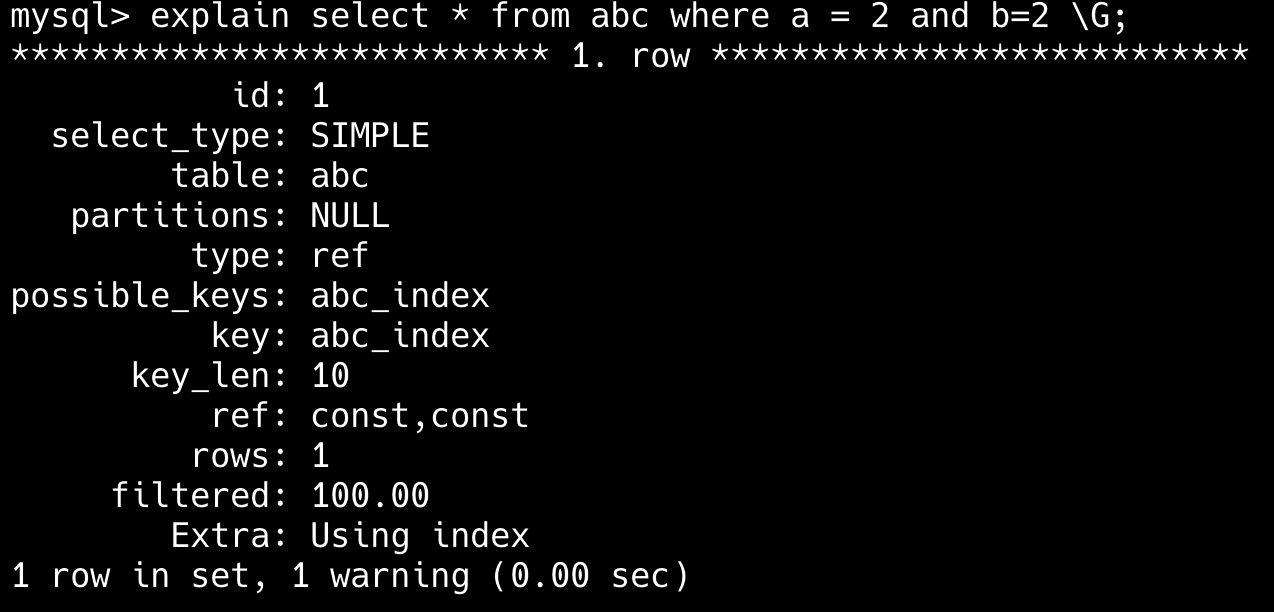
第二条 SQL 语句由于未使用最左前缀中的 a,会触发全表扫描。
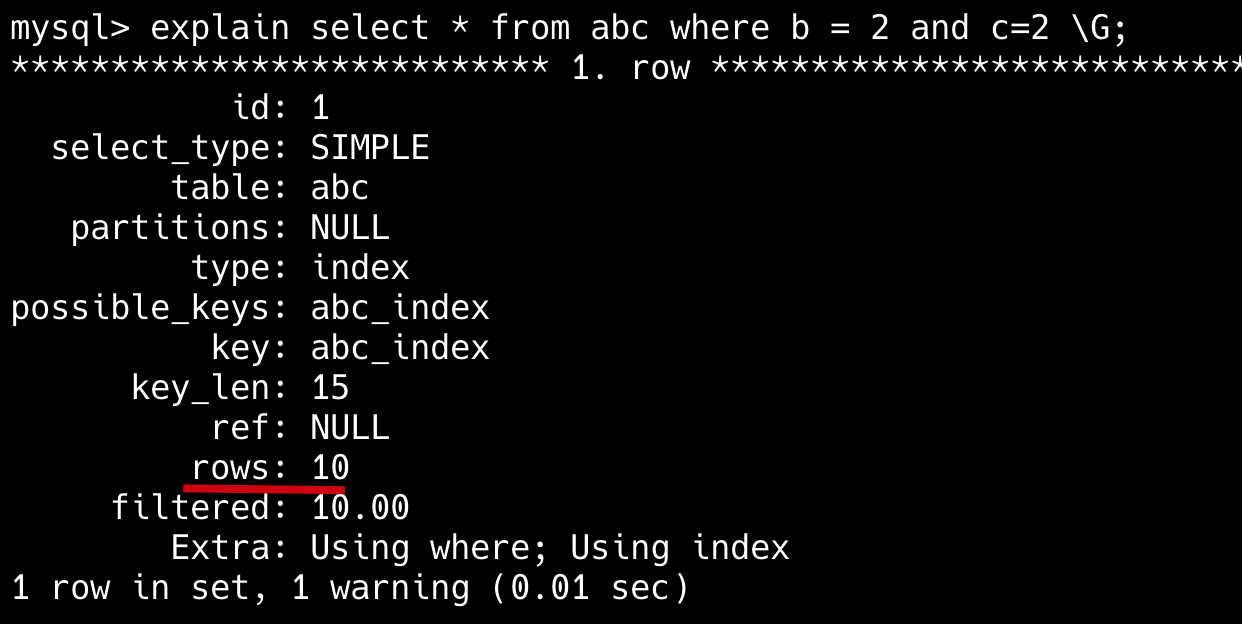
第三条 SQL 语句在范围条件 a > 2 之后,索引后会停止匹配,b = 2 的条件需要额外过滤。
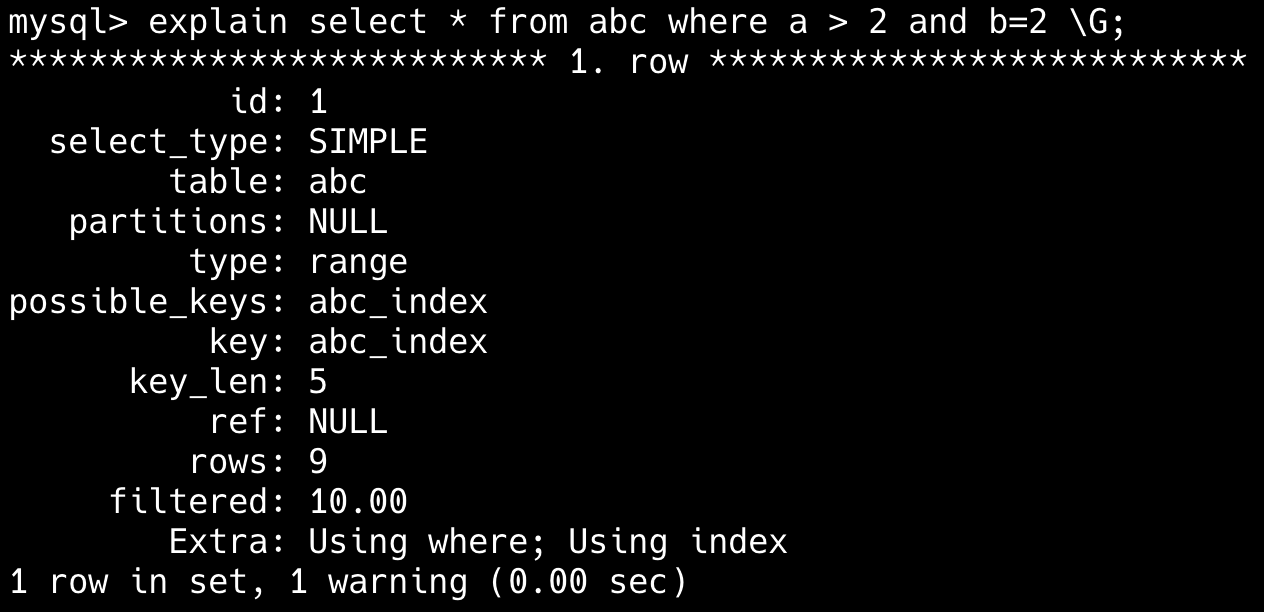
(A,B,C) 联合索引 select * from tbn where a=? and b in (?,?) and c>? 会走索引吗?
2024 年 03 月 15 日增补。
这个查询会命中联合索引,因为 a 是等值匹配,b 是 IN 等值多匹配,c 是 b 之后的范围条件,符合最左前缀原则。
对于
a=?:这是一个精确匹配,并且是联合索引的第一个字段,所以一定会命中索引。对于
b IN (?, ?):等价于 b=? OR b=?,属于多值匹配,并且是联合索引的第二个字段,所以也会命中索引。对于
c>?:这是一个范围条件,属于联合索引的第三个字段,也会命中索引。
---- 这部分是帮助大家理解 start,面试中可不背 ----
来验证一下。
第一步,建表。
CREATE TABLE tbn (A INT, B INT, C INT, D TEXT);第二步,创建索引。
CREATE INDEX idx_abc ON tbn (A, B, C);第三步,插入数据。
INSERT INTO tbn VALUES (1, 2, 3, 'First');
INSERT INTO tbn VALUES (1, 2, 4, 'Second');
INSERT INTO tbn VALUES (1, 3, 5, 'Third');
INSERT INTO tbn VALUES (2, 2, 3, 'Fourth');
INSERT INTO tbn VALUES (2, 3, 4, 'Fifth');第四步,执行查询。
EXPLAIN SELECT * FROM tbn WHERE A=1 AND B IN (2, 3) AND C>3\G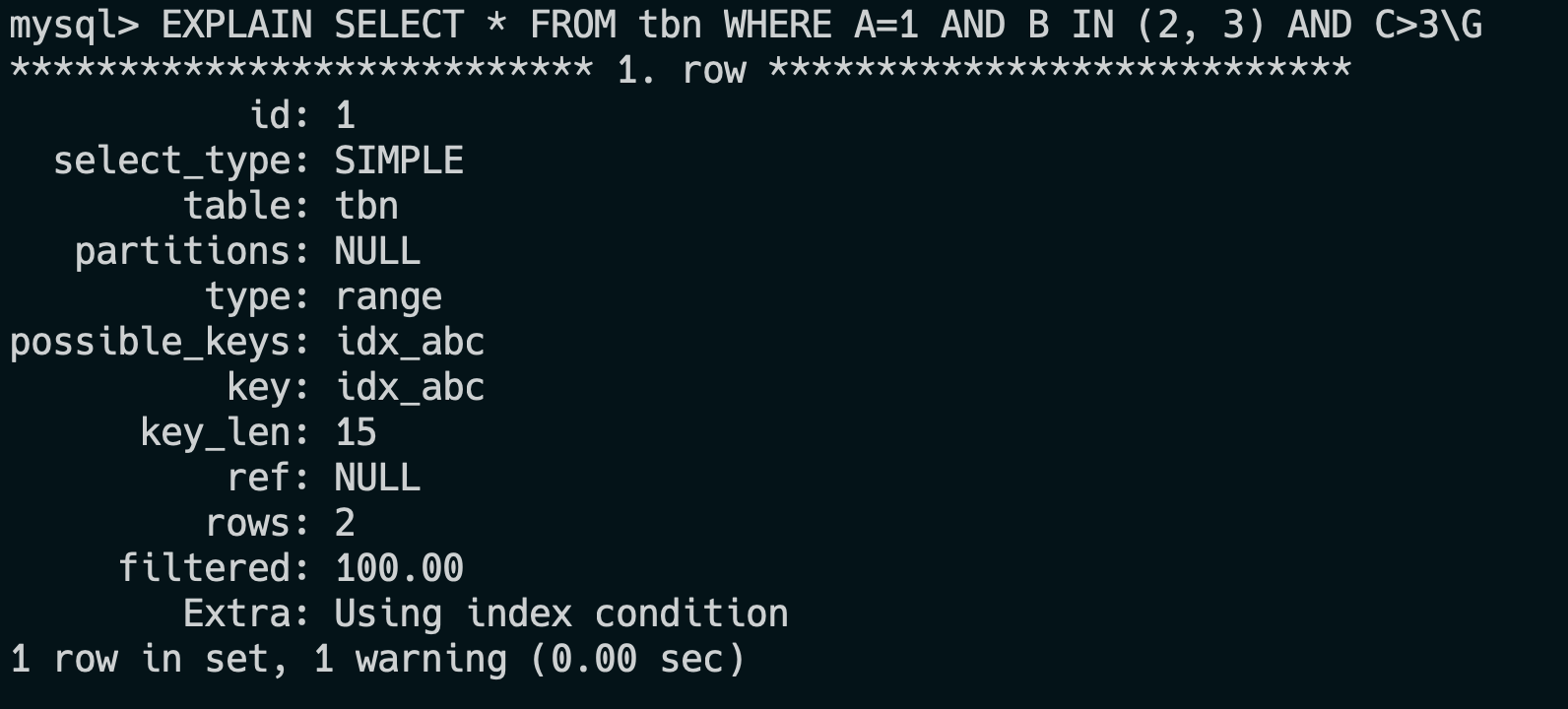
从 EXPLAIN 输出结果来看,我们可以得到 MySQL 是如何执行查询的一些关键信息:
- type: 查询类型,这里是
range,表示 MySQL 使用了范围查找,这是因为查询条件包含了>操作符。 - possible_keys: 可能被用来执行查询的索引,这里是
idx_abc,表示 MySQL 认为idx_abc索引会用于查询优化。 - key: 实际用来执行查询的索引,也是
idx_abc,这确定这条查询命中了联合索引。 - Extra: 提供了关于查询执行的额外信息。
Using index condition表示 MySQL 使用了索引下推(Index Condition Pushdown,ICP),这是 MySQL 的一个优化方式,它允许在索引层面过滤数据。
---- 这部分是帮助大家理解 end,面试中可不背 ----
联合索引的一个场景题:(a,b,c)联合索引,(b,c)是否会走索引吗?
2024 年 04 月 06 日增补
根据最左前缀原则,(b,c) 查询不会走索引。
因为联合索引 (a,b,c) 中,a 是最左边的列,联合索引在创建索引树的时候需要先有 a,然后才会有 b 和 c。而查询条件中没有包含 a,所以 MySQL 无法利用这个索引。
EXPLAIN SELECT * FROM tbn WHERE B=1 AND C=1\G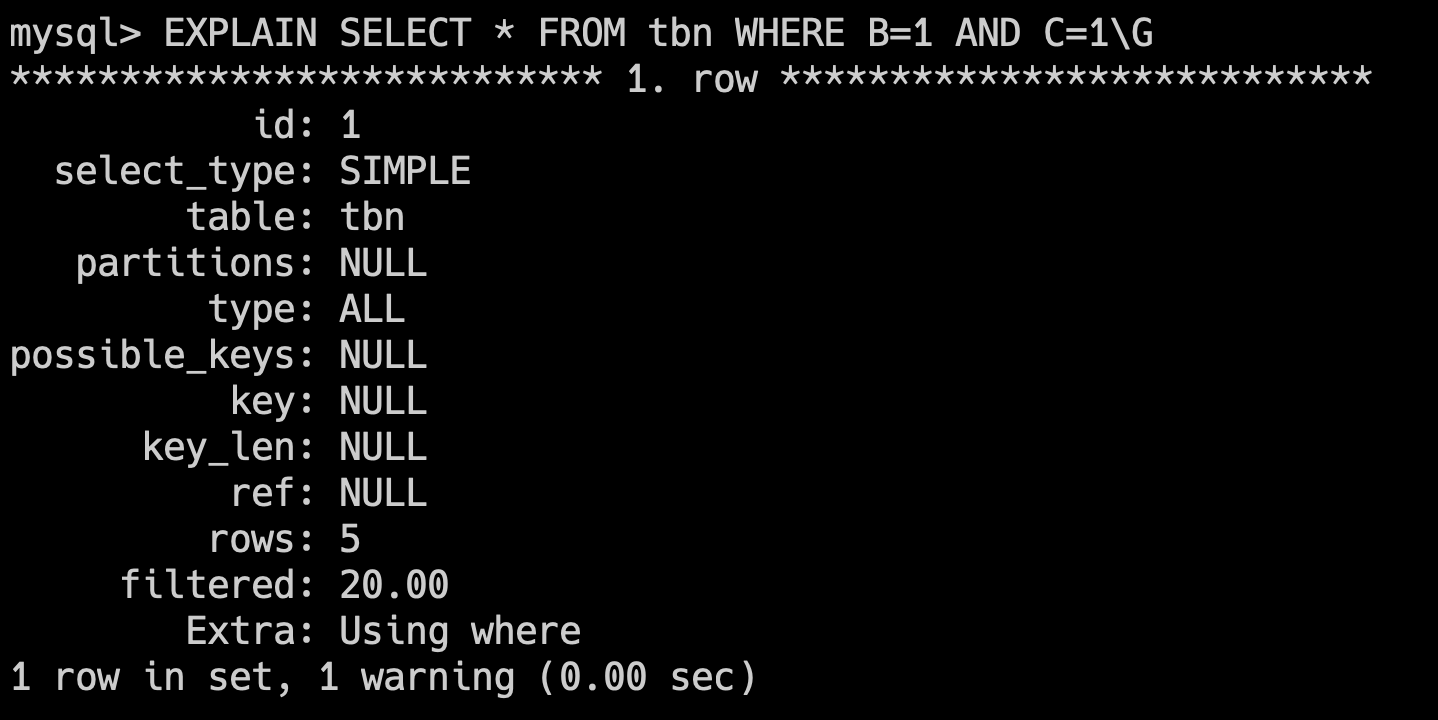
建立联合索引(a,b,c),where c = 5 是否会用到索引?为什么?
2024 年 04 月 08 日增补
不会。只有索引的第三列 c 被用作查询条件,而前两列 a 和 b 都没有被使用。这不符合最左前缀原则。
EXPLAIN SELECT * FROM tbn WHERE C=5\G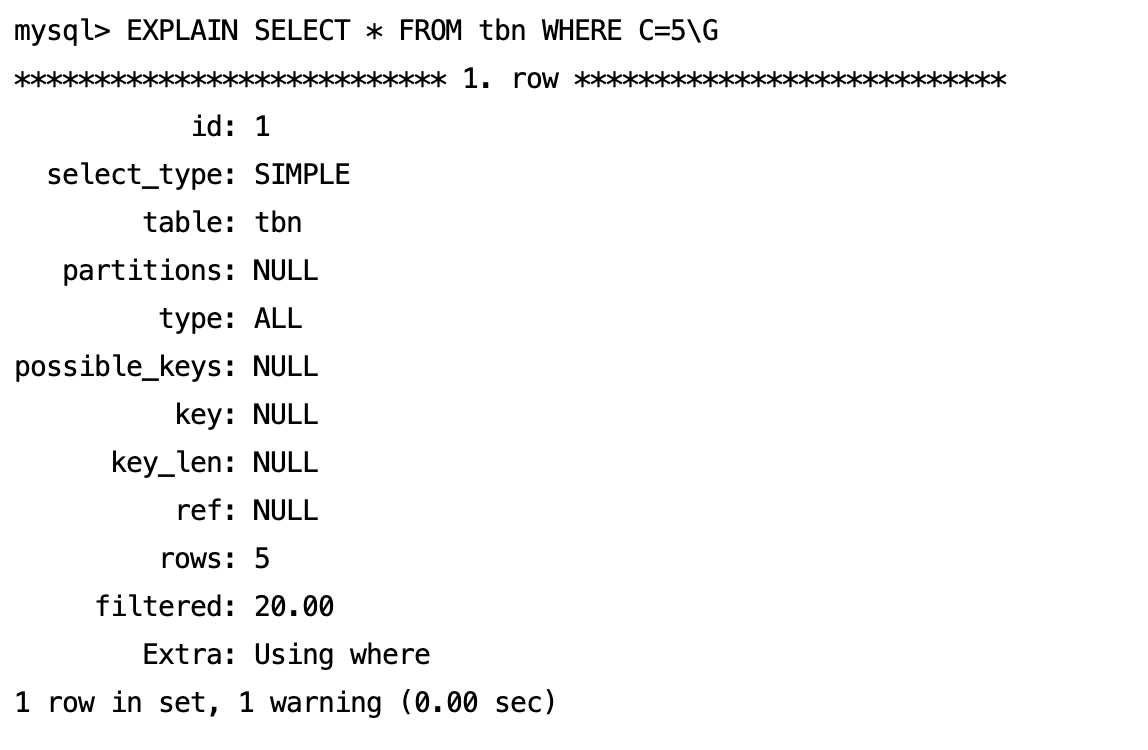
sql中使用like,如果遵循最左前缀匹配,查询是不是一定会用到索引?
2024 年 11 月 04 日增补
如果查询模式是后缀通配符 LIKE 'prefix%',且该字段有索引,优化器通常会使用索引。否则即便是遵循最左前缀匹配,LIKE 字段也无法命中索引。
如 age = 18 and name LIKE '%xxx',MySQL 会先使用联合索引 age_name 找到 age 符合条件的所有行,然后再全表扫描进行 name 字段的过滤。
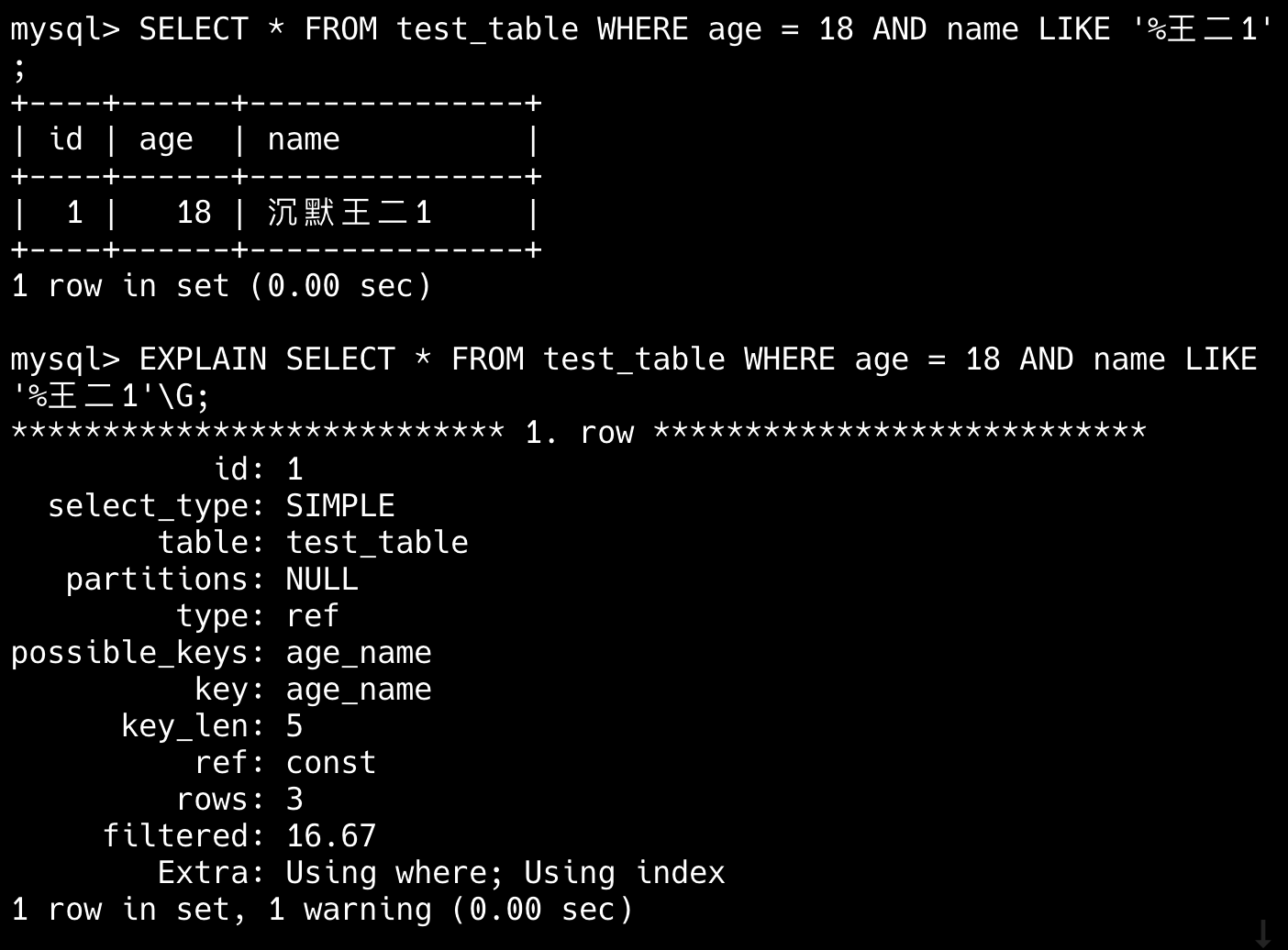
type: ref 表示使用索引查找匹配某个值的所有行。
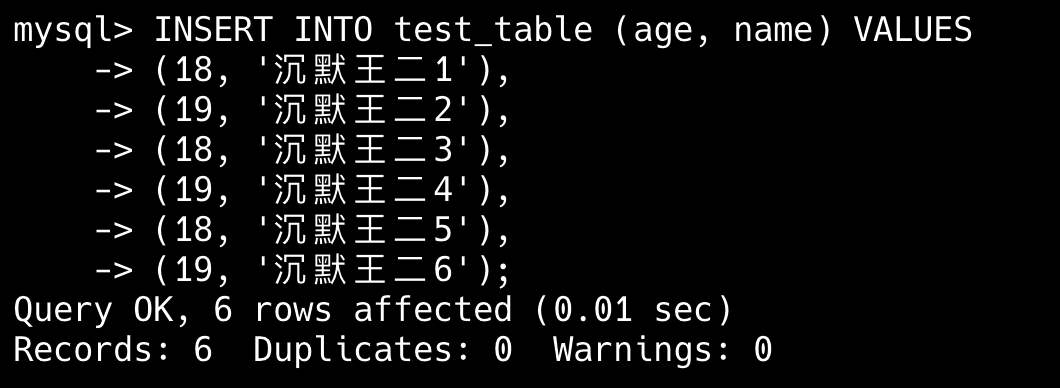
如果是后缀通配符,如 age = 18 and name LIKE 'xxx%',MySQL 会直接使用联合索引 age_name 找到所有符合条件的行。
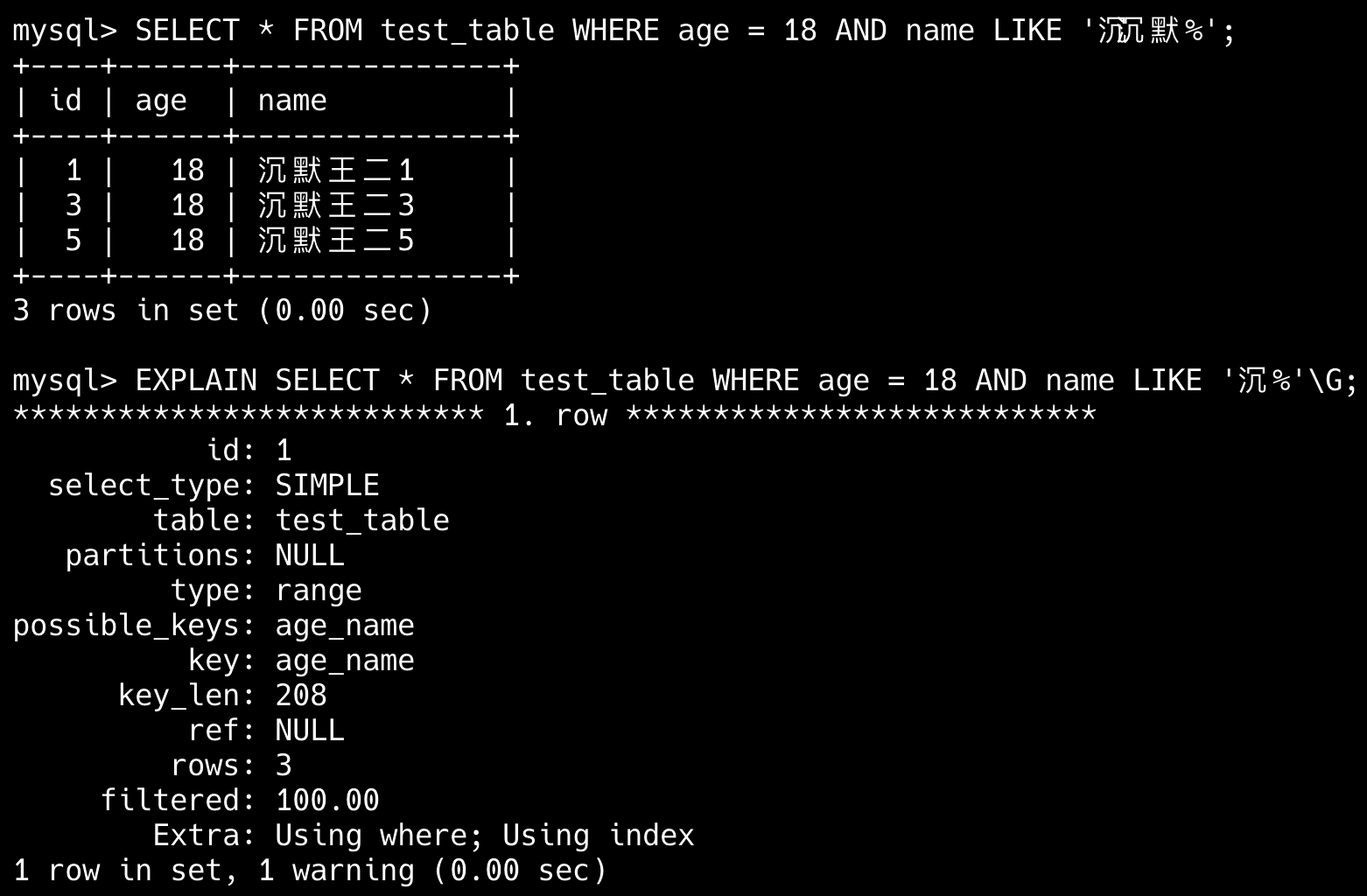
type 为 range,表示 MySQL 使用了索引范围扫描,filtered 为 100.00%,表示在扫描的行中,所有的行都满足 WHERE 条件。
- Java 面试指南(付费)收录的字节跳动商业化一面的原题:(A,B,C) 联合索引
select * from tbn where a=? and b in (?,?) and c>?会走索引吗?- Java 面试指南(付费)收录的京东同学 10 后端实习一面的原题:联合索引 abc,a=1,c=1/b=1,c=1/a=1,c=1,b=1 走不走索引
- Java 面试指南(付费)收录的快手面经同学 7 Java 后端技术一面面试原题:联合索引的一个场景题:(a,b,c)联合索引,(b,c)是否会走索引
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:建立联合索引(a,b,c),where c = 5 是否会用到索引?为什么?
- Java 面试指南(付费)收录的美团面经同学 15 点评后端技术面试原题:sql中使用like,如果遵循最左前缀匹配,查询是不是一定会用到索引?
- Java 面试指南(付费)收录的比亚迪面经同学 3 Java 技术一面面试原题:说一下数据库索引,最左匹配原则和索引的结构
- Java 面试指南(付费)收录的腾讯云智面经同学 16 一面面试原题:说说最左前缀原则
- Java 面试指南(付费)收录的招银网络科技面经同学 9 Java 后端技术一面面试原题:Mysql联合索引的设计原则
- Java 面试指南(付费)收录的同学 1 贝壳找房后端技术一面面试原题:联合索引 (a, b),where a = 1 和 where b = 1,效果是一样的吗
- Java 面试指南(付费)收录的腾讯面经同学 27 云后台技术一面面试原题:(联合索引)下面怎么走的索引?
- Java 面试指南(付费)收录的滴滴面经同学 3 网约车后端开发一面原题:联合索引 (a, b, c),where b = 1,能走吗,where a = 1,能走吗
51.🌟什么是索引下推?
索引下推是指:MySQL 把 WHERE 条件尽可能“下推”到索引扫描阶段,在存储引擎层提前过滤掉不符合条件的记录。
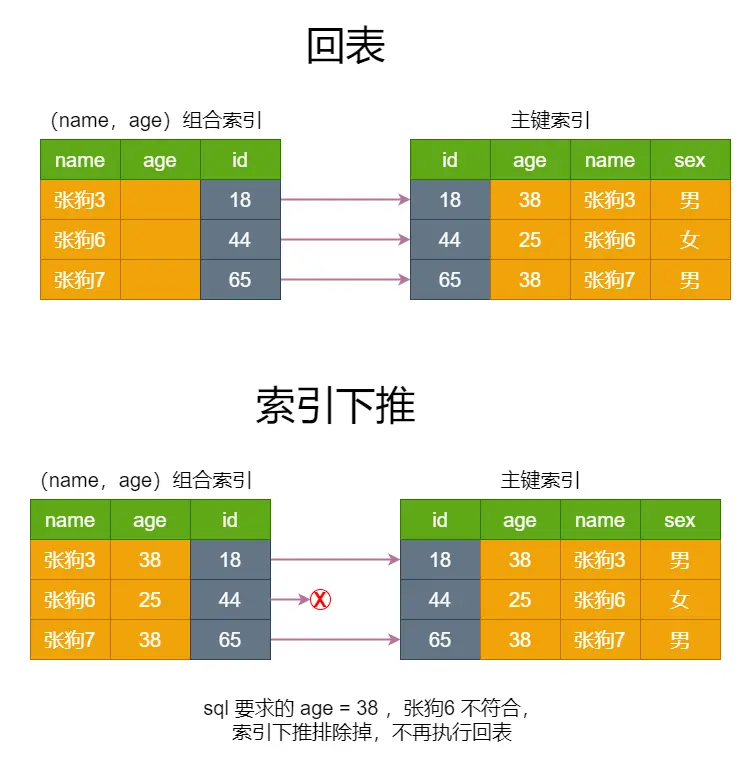
当查询条件包含索引列但未完全匹配时,ICP 会在存储引擎层过滤非索引列条件,以减少回表次数。
传统的查询流程是,储引擎通过联合索引定位到符合最左前缀条件的主键 ID;回表读取完整数据行并返回给 Server 层;Server 层对所有返回的行进行 WHERE 条件过滤。
有了 ICP 后,存储引擎在索引层直接过滤可下推的条件,仅对符合索引条件的记录回表读取数据,再返回给 Server 层进行剩余条件过滤。
---- 这部分是帮助大家理解 start,面试中可不背 ----
例如有一张 user 表,建了一个联合索引(name, age),查询语句:select * from user where name like '张%' and age=10;,没有索引下推优化的情况下:
MySQL 会使用索引 name 找到所有 name like '张%' 的主键,根据这些主键,一条条回表查询整行数据,并在 Server 层过滤掉不符合 age=10 的数据行。
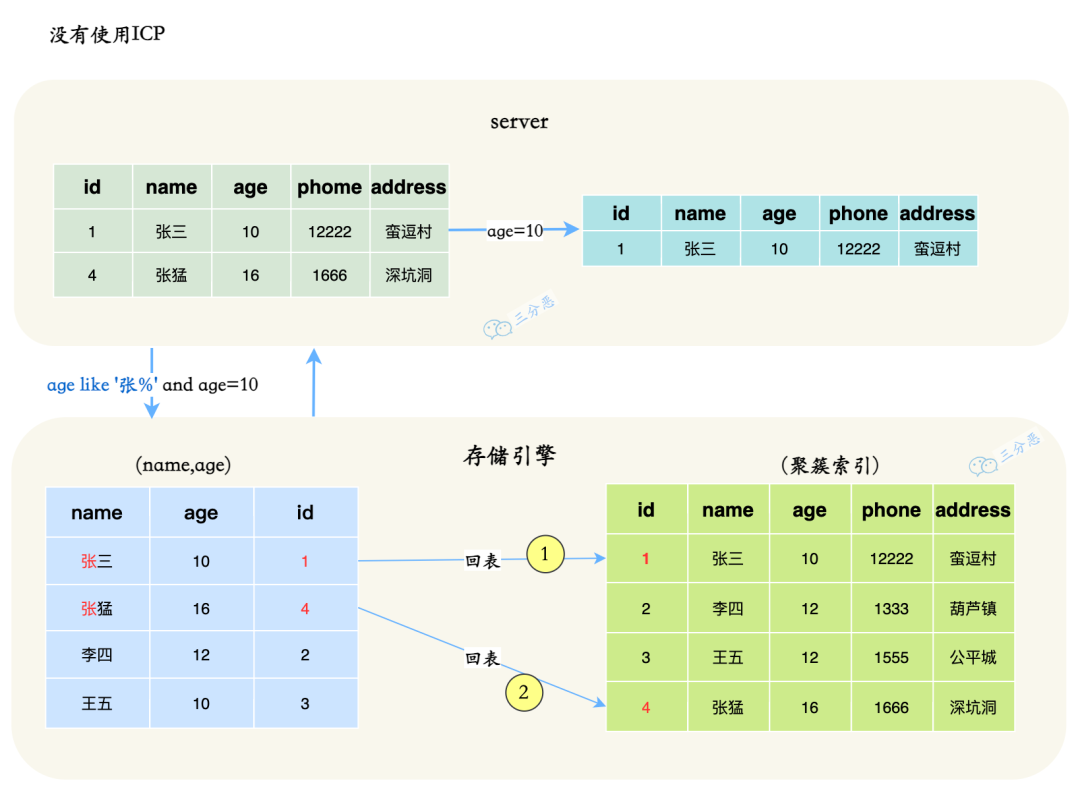
启用 ICP 后,InnoDB 会通过联合索引直接筛选出符合条件的主键 ID(name like '张%' and age=10),然后再回表查询整行数据。
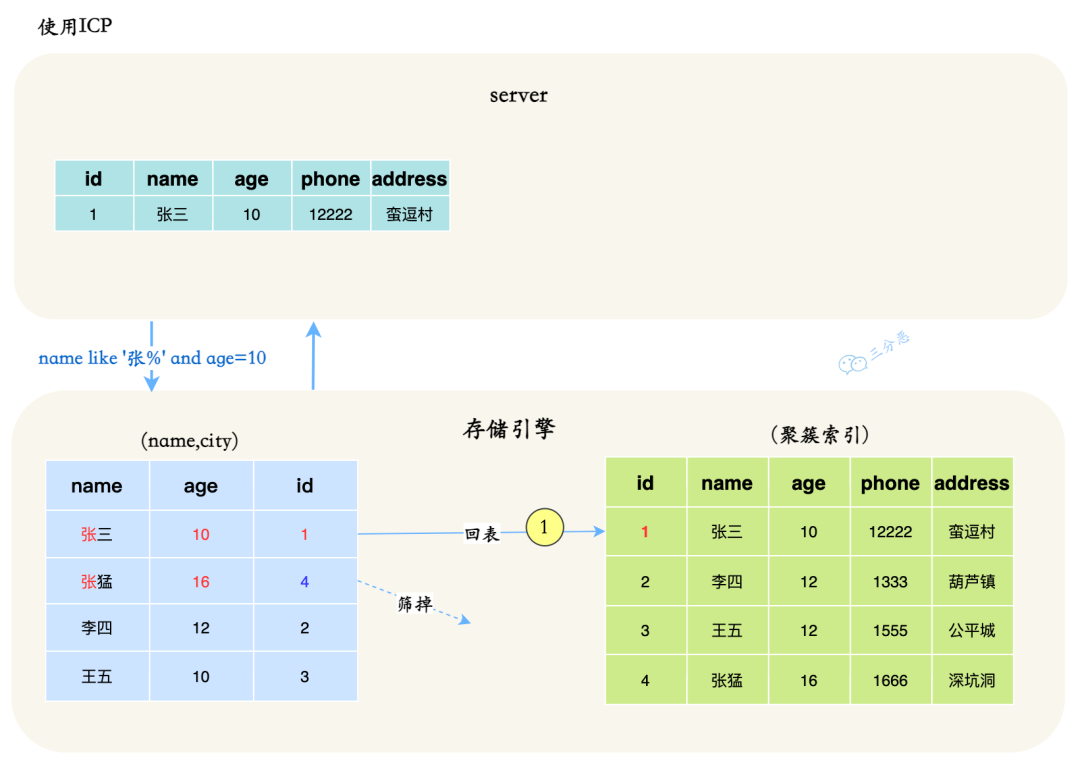
换句话说,假设 name like '张%' 找到 10000 行数据,age=10 只有其中 10 行,没有索引下推的情况下,MySQL 会回表 10000 次,读取 10000 行数据,然后在 Server 层过滤掉 9990 行。
而有了索引下推后,MySQL 只会回表 10 次,读取 10 行数据。
我们来验证一下。
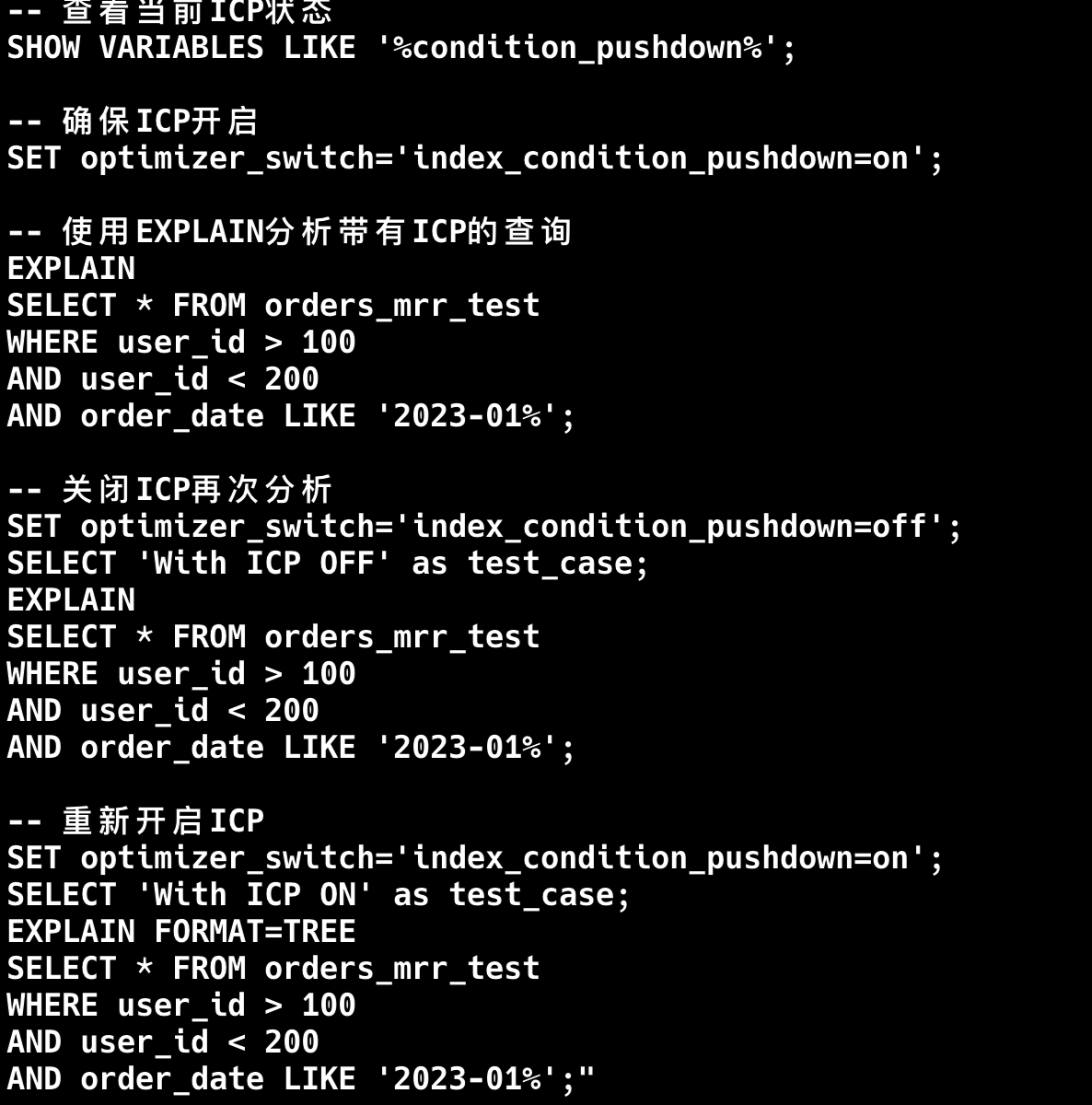
从结果中我们可以清楚地看到 ICP 的效果。ICP 开启时,Extra 列显示"Using index condition",表明过滤条件被下推到存储引擎层。
ICP关闭时,Extra 列仅显示"Using where",表明过滤条件在服务器层执行。
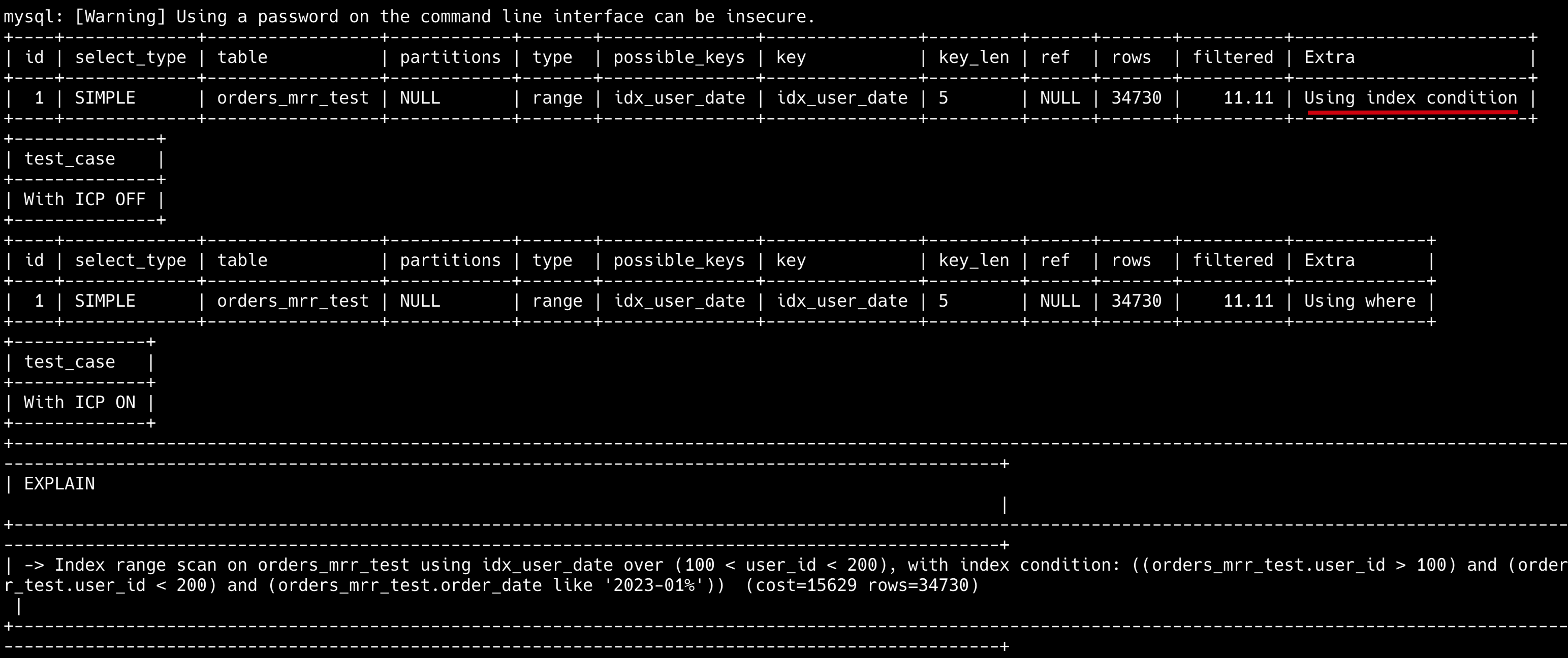
-- 开启ICP
SET optimizer_switch='index_condition_pushdown=on';
-- 清理状态
FLUSH STATUS;
SELECT 'Performance test with ICP ON' as test_case;
-- 执行查询并分析性能
EXPLAIN ANALYZE
SELECT /*+ ICP_ON */ *
FROM orders_mrr_test
WHERE user_id BETWEEN 100 AND 200
AND order_date >= '2023-01-01'
AND order_date < '2023-02-01'
AND order_date NOT LIKE '2023-01-15%';
-- 显示处理器状态
SHOW STATUS LIKE 'Handler_read%';
-- 关闭ICP
SET optimizer_switch='index_condition_pushdown=off';
-- 清理状态
FLUSH STATUS;
SELECT 'Performance test with ICP OFF' as test_case;
-- 执行相同的查询
EXPLAIN ANALYZE
SELECT *
FROM orders_mrr_test
WHERE user_id BETWEEN 100 AND 200
AND order_date >= '2023-01-01'
AND order_date < '2023-02-01'
AND order_date NOT LIKE '2023-01-15%';
-- 显示处理器状态
SHOW STATUS LIKE 'Handler_read%';"实际的性能差距也很大。ICP 开启时,实际扫描行数:1,649 行,执行时间:约12.3 毫秒。关闭时,实际扫描行数:19,959 行,执行时间:约 32.1 毫秒。

---- 这部分是帮助大家理解 start,面试中可不背 ----
- Java 面试指南(付费)收录的美团同学 9 一面面试原题:索引下推
52.如何查看是否用到了索引?(补充)
2024 年 03 月 15 日增补。
可以通过 EXPLAIN 关键字来查看是否使用了索引。
EXPLAIN SELECT * FROM table WHERE column = 'value';如果使用了索引,结果中的 key 值会显示索引的名称。
联合索引 abc,a=1,c=1/b=1,c=1/a=1,c=1,b=1 走不走索引?
2024 年 03 月 19 日增补
ac 能用上索引,条件 a=1 符合最左前缀原则,触发索引的第一列 a;由于跳过了中间列 b,c=1 无法直接利用索引的有序性优化,但可通过索引下推在存储引擎层过滤 c 的条件,减少回表次数。
bc 无法使用索引,只能全表扫描,因为不符合最左前缀原则;acb 虽然顺序是乱的,但 MySQL 优化器会自动重排为 abc,所以能命中索引。
---- 这部分是帮助大家理解 start,面试中可不背 ----
我们通过实际的 SQL 来验证一下。
示例 1(a=1,c=1):
EXPLAIN SELECT * FROM tbn WHERE A=1 AND C=1\G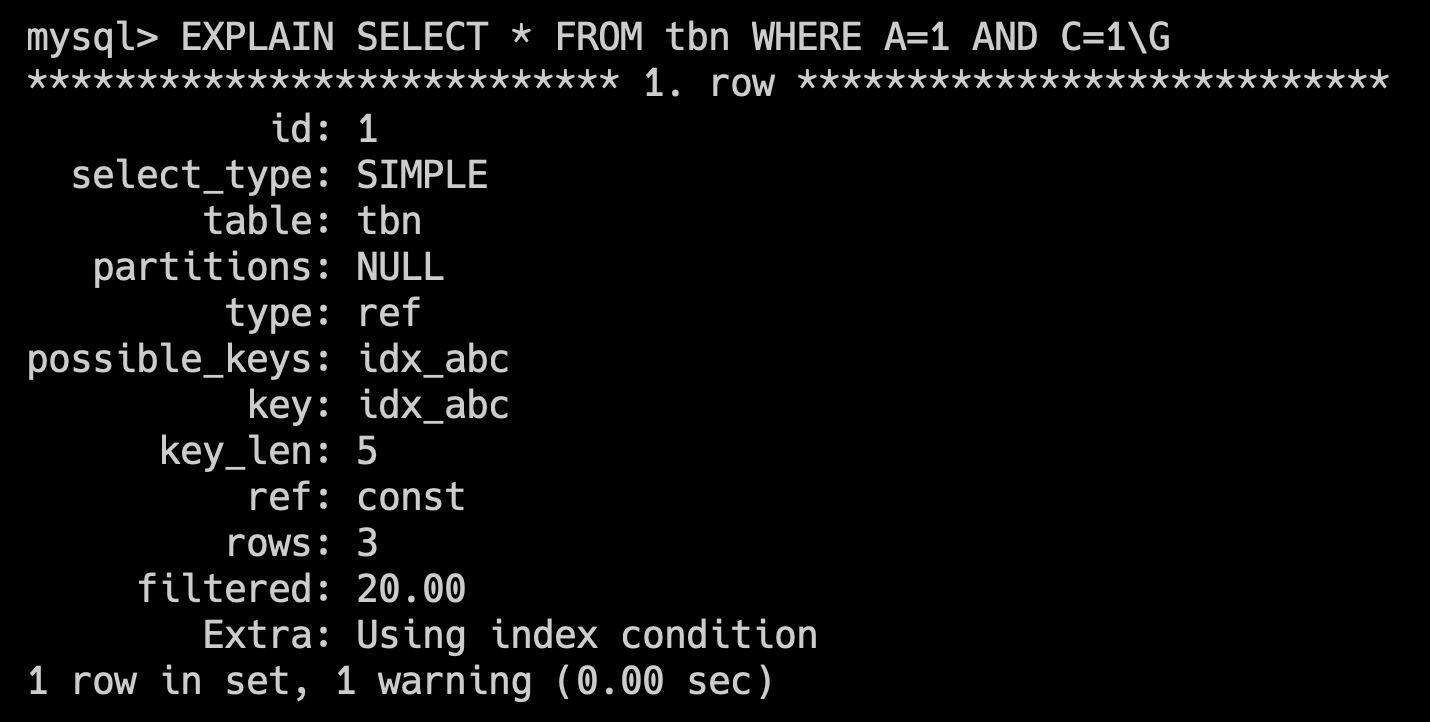
key 是 idx_abc,表明 a=1,c=1 会使用联合索引。Extra: Using index condition 表示 ICP 生效。
示例 2(b=1,c=1):
EXPLAIN SELECT * FROM tbn WHERE B=1 AND C=1\G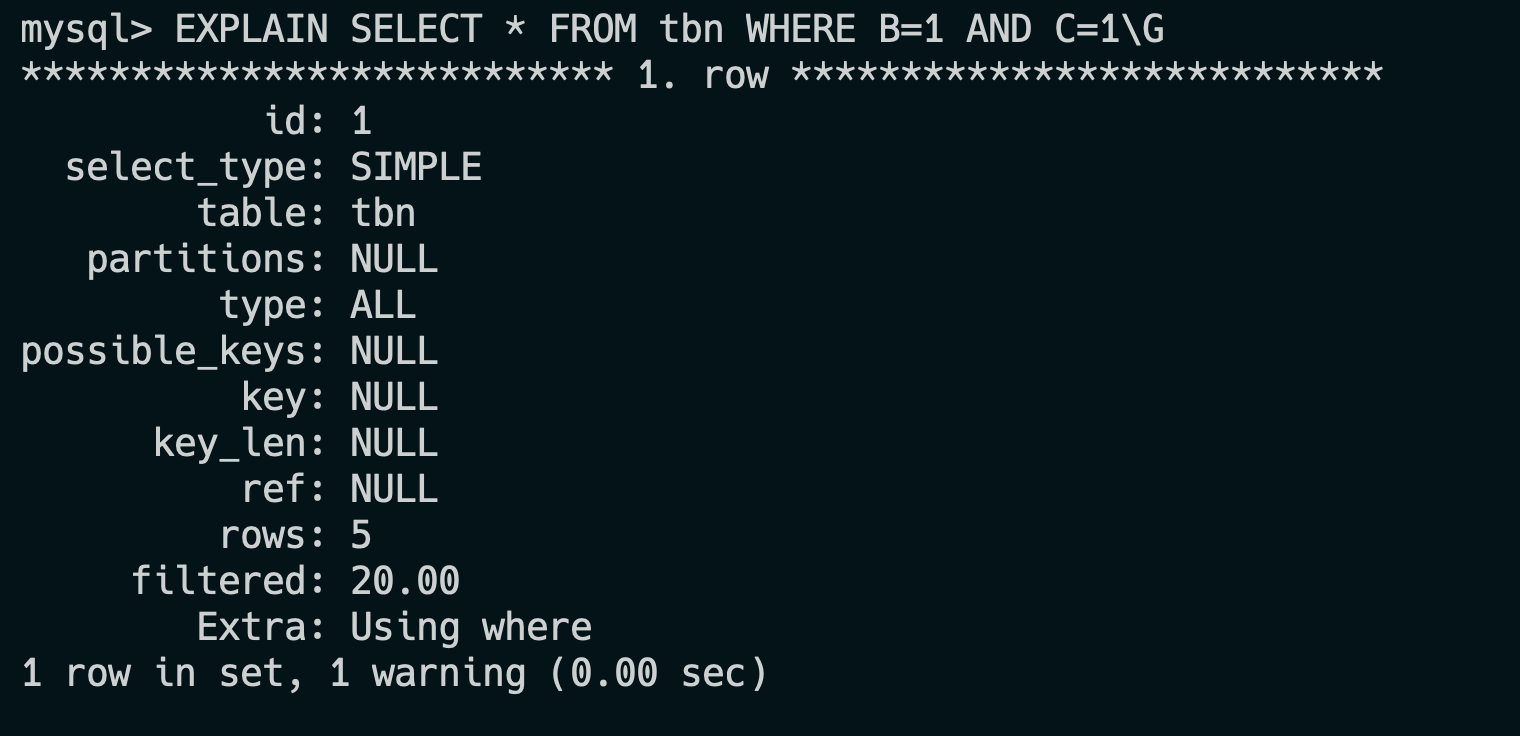
key 是 NULL,表明 b=1,c=1 不会使用联合索引。这是因为查询条件没有遵循最左前缀原则。
示例 3(a=1,c=1,b=1):
EXPLAIN SELECT * FROM tbn WHERE A=1 AND C=1 AND B=1\G优化器会自动调整条件顺序为 a=1 AND b=1 AND c=1。
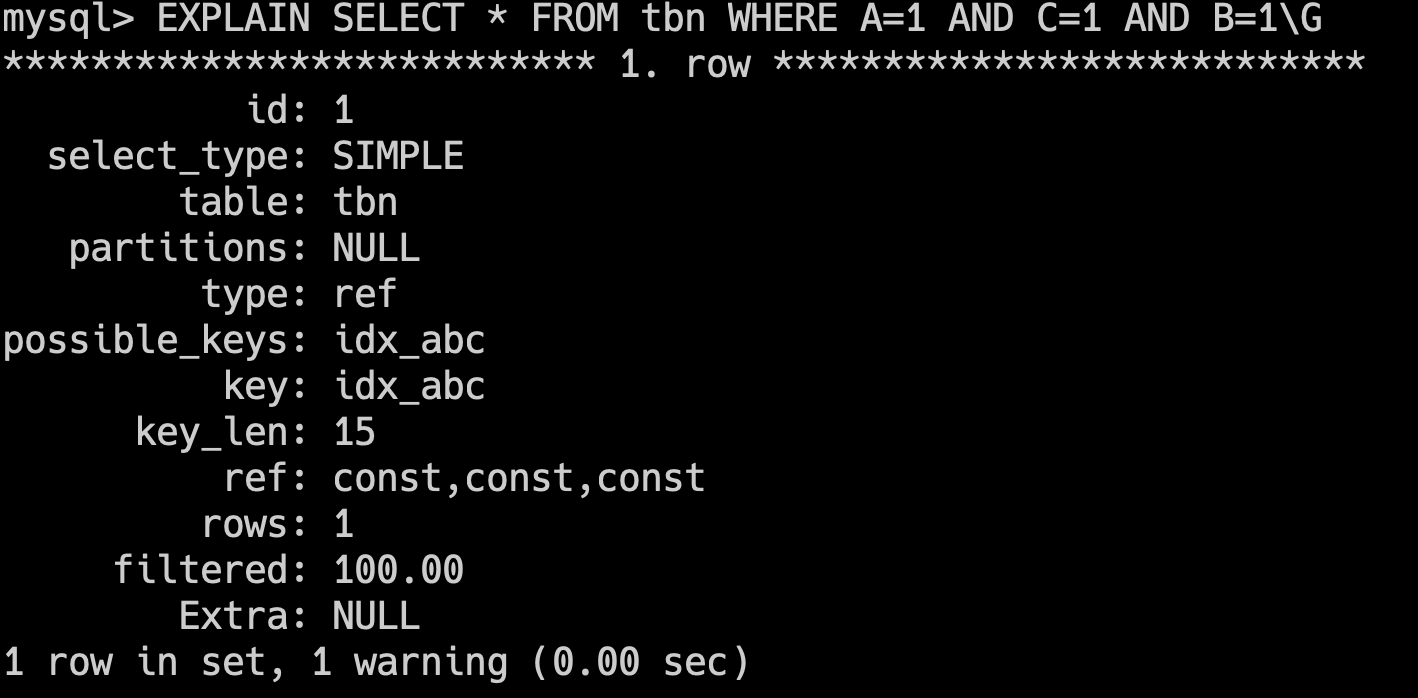
key 是 idx_abc,表明 a=1,c=1,b=1 会使用联合索引。
并且 rows=1,因为 MySQL 优化器会自动重排查询条件,以满足最左前缀原则,直接使用联合索引找出 a=1 AND b=1 AND c=1 的行。
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 4 月 8 日修改至此,今天有球友反馈说,拿到了鹅厂和美团的暑期实习 offer,并且都已经 OC,真的恭喜,又是一个值得晒成绩的日子,哈哈。
锁
53.🌟MySQL 中有哪几种锁?
MySQL 中有多种类型的锁,可以从不同维度来分类,按锁粒度划分的话,有表锁、行锁。
按照加锁机制划分的话,有乐观锁和悲观锁。按照兼容性划分的话,有共享锁和排他锁。
---- 这部分是帮助大家理解 start,面试中可不背 ----
表锁:锁定整个表,资源开销小,加锁快,但并发度低,不会出现死锁;适合查询为主、少量更新的场景(如 MyISAM 引擎)。
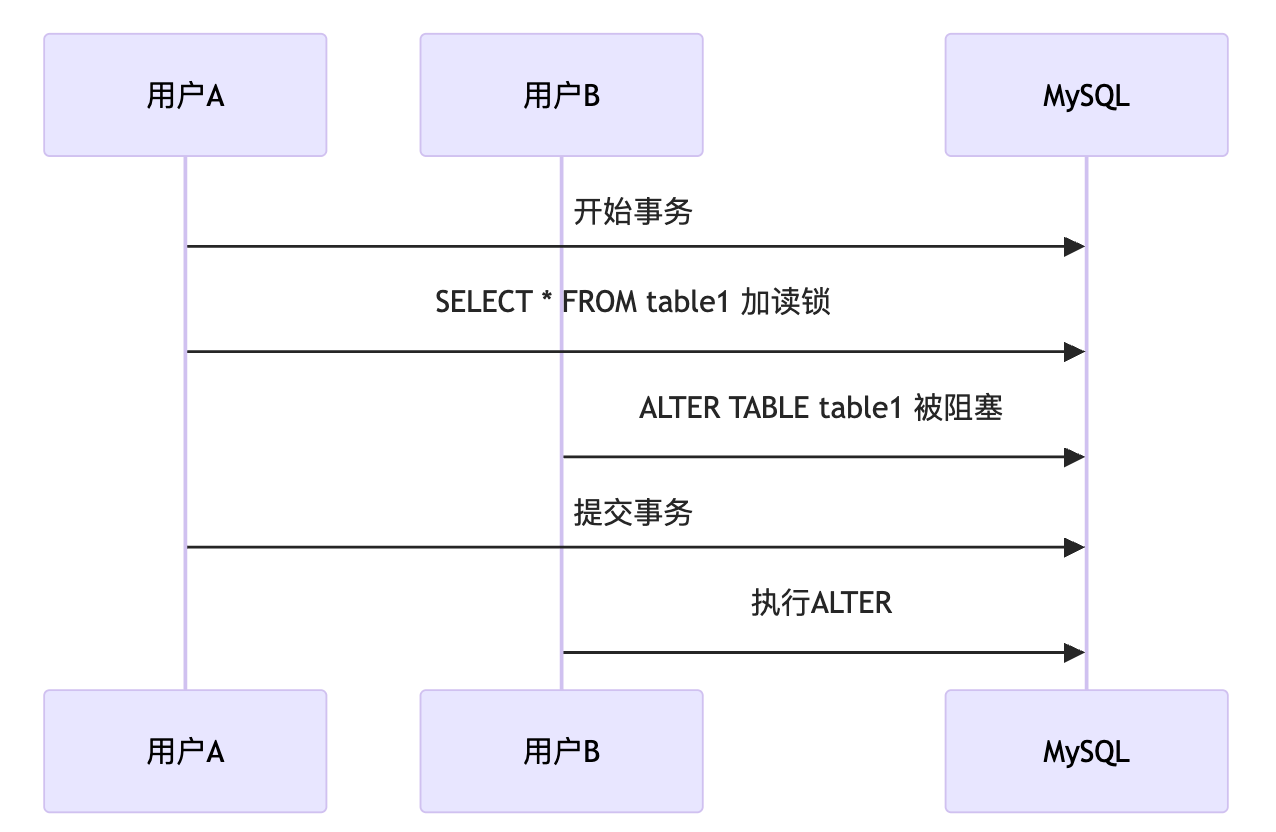
再细分的话,有表共享读锁(S锁):允许多个事务同时读,但阻塞写操作;表独占写锁(X锁):独占表,阻塞其他事务的读写。
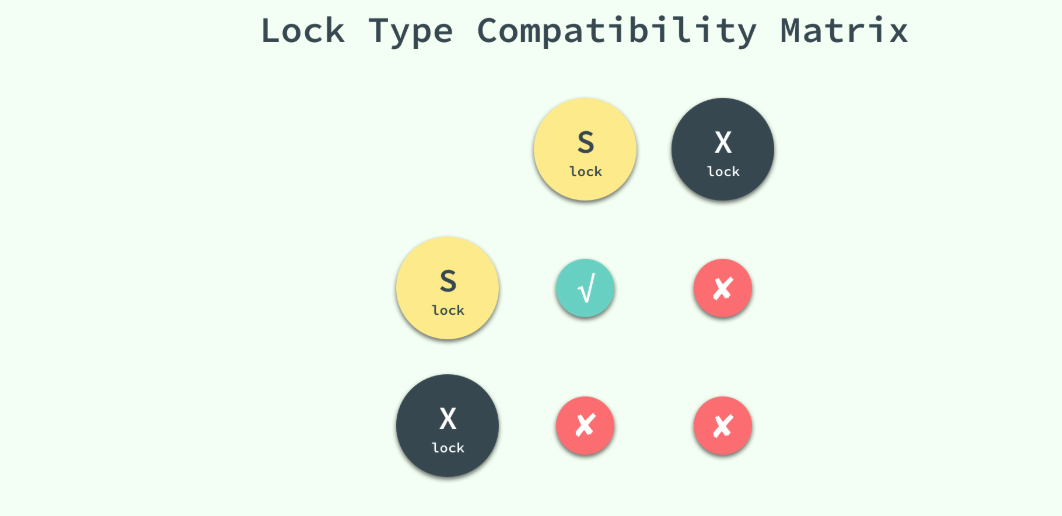
行锁:锁定单行或多行,开销大、加锁慢,可能出现死锁,但并发度高(InnoDB 默认支持)。
再细分的话,有记录锁(Record Lock):锁定索引中的具体记录;间隙锁(Gap Lock):锁定索引记录之间的间隙,防止幻读;临键锁(Next-Key Lock):结合记录锁和间隙锁,锁定一个左开右闭的区间(如 (5, 10])。
共享锁(S锁/读锁),允许多个事务同时读取数据,但阻塞写操作。语法:SELECT ... LOCK IN SHARE MODE
排他锁(X锁/写锁),独占数据,阻塞其他事务的读写。语法:SELECT ... FOR UPDATE。
乐观锁假设冲突少,通过版本号或 CAS 机制检测冲突(如 UPDATE SET version=version+1 WHERE version=old_version)。
悲观锁假设并发冲突频繁,先加锁再操作SELECT FOR UPDATE。
---- 这部分是帮助大家理解 end,面试中可不背
- Java 面试指南(付费)收录的京东同学 4 云实习面试原题:mysql一共有哪些锁
- Java 面试指南(付费)收录的美团面经同学 15 点评后端技术面试原题:问了一下mysql的锁和MVCC
- Java 面试指南(付费)收录的阿里系面经同学 19 饿了么面试原题:MySQL锁
54.全局锁了解吗?(补充)
2024 年 07 月 15 日增补。
全局锁就是对整个数据库实例进行加锁,当执行全局锁定操作时,整个数据库将会处于只读状态,所有写操作都会被阻塞,直到全局锁被释放。
在进行全库备份,或者数据迁移时,可以使用全局锁来保证数据的一致性。
在 MySQL 中,可以使用 FLUSH TABLES WITH READ LOCK 命令来获取全局锁。
执行该命令后,所有表将被锁定为只读状态。记得在完成备份或迁移后,使用 UNLOCK TABLES 命令释放全局锁。
-- 锁定整个数据库
FLUSH TABLES WITH READ LOCK;
-- 执行备份操作
-- 例如使用 mysqldump 进行备份
! mysqldump -u username -p database_name > backup.sql
-- 释放全局锁定
UNLOCK TABLES;表锁了解吗?
了解。
表锁常见于 MyISAM 引擎,InnoDB 也可以手动通过 LOCK TABLES 加锁。
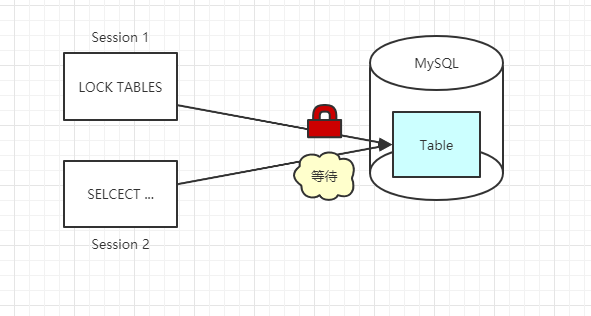
适合读多写少、全表扫描或者表结构变更的场景用。
表锁又可以细分为共享锁和排他锁。共享锁允许多个事务同时读表,但不允许写操作。
LOCK TABLES table_name READ; -- 显式加读锁
SELECT * FROM table_name; -- 其他会话可读,不可写
UNLOCK TABLES; -- 释放锁排他锁只允许一个事务进行写操作,其他事务不能读也不能写。
LOCK TABLES table_name WRITE; -- 显式加写锁
INSERT/UPDATE/DELETE table_name; -- 其他会话读写均阻塞
UNLOCK TABLES;MyISAM 在执行 SELECT 时会自动加读锁,执行 INSERT/UPDATE/DELETE 时会加写锁。
对于 InnoDB 引擎,无索引的 UPDATE/DELETE 可能会导致锁升级为表锁。
UPDATE innodb_table SET name='new' WHERE name='old'; -- 全表扫描,退化为表锁执行 ALTER TABLE 时会自动加表锁,阻塞所有读写操作。
- Java 面试指南(付费)收录的美团面经同学 3 Java 后端技术一面面试原题:数据库中的全局锁 表锁 行级锁 每种锁的应用场景有哪些
- Java 面试指南(付费)收录的同学 30 腾讯音乐面试原题:mysql的表级锁有几种
55.🌟说说 MySQL 的行锁?
行锁是 InnoDB 存储引擎中最细粒度的锁,它锁定表中的一行记录,允许其他事务访问表中的其他行。
底层是通过给索引加锁实现的,这就意味着只有通过索引条件检索数据时,InnoDB 才能使用行级锁,否则会退化为表锁。
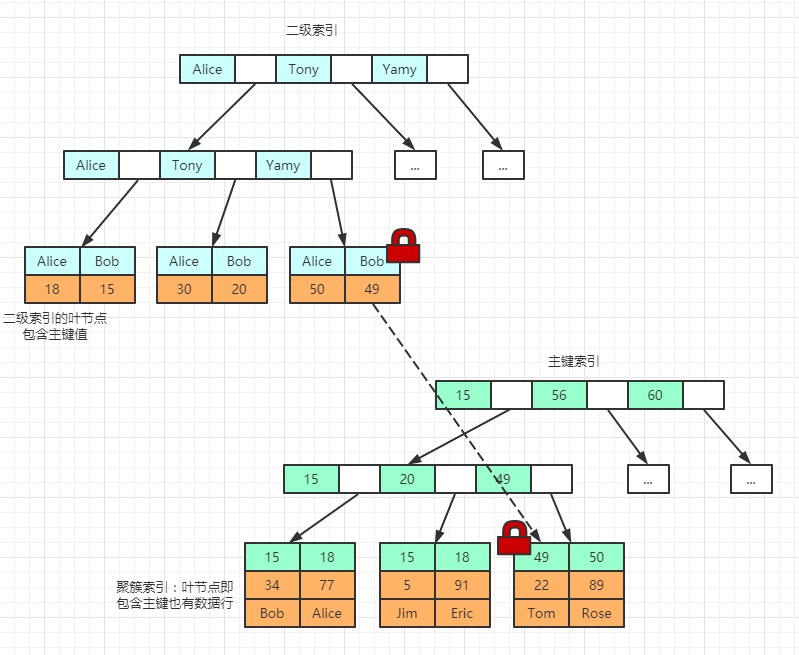
行锁又可以细分为记录锁、间隙锁和临键锁三种形式。通过 SELECT ... FOR UPDATE 可以加排他锁。
START TRANSACTION;
-- 加排他锁,锁定某一行
SELECT * FROM your_table WHERE id = 1 FOR UPDATE;
-- 对该行进行操作
UPDATE your_table SET column1 = 'new_value' WHERE id = 1;
COMMIT;通过 SELECT ...LOCK IN SHARE MODE 可以加共享锁。
START TRANSACTION;
-- 加共享锁,锁定某一行
SELECT * FROM your_table WHERE id = 1 LOCK IN SHARE MODE;
-- 只能读取该行,不能修改
COMMIT;select for update 有什么需要注意的?
第一,必须在事务中使用,否则锁会立即释放。
START TRANSACTION;
SELECT * FROM your_table WHERE id = 1 FOR UPDATE;
-- 对该行进行操作
COMMIT;第二,使用时必须注意是否命中索引,否则可能锁全表。
-- name 没有索引,会退化为表锁
SELECT * FROM user WHERE name = '王二' FOR UPDATE;---- 这部分是帮助大家理解 start,面试中可不背 ----
假设有一张名为 orders 的表,包含以下数据:
CREATE TABLE orders (
id INT PRIMARY KEY,
order_no VARCHAR(255),
amount DECIMAL(10,2),
status VARCHAR(50),
INDEX (order_no) -- order_no 上有索引
);表中的数据是这样的:
| id | order_no | amount | status |
|---|---|---|---|
| 1 | 10001 | 50.00 | pending |
| 2 | 10002 | 75.00 | pending |
| 3 | 10003 | 100.00 | pending |
| 4 | 10004 | 150.00 | completed |
| 5 | 10005 | 200.00 | pending |
如果我们通过主键索引执行 SELECT FOR UPDATE,确实只会锁定特定的行:
START TRANSACTION;
SELECT * FROM orders WHERE id = 1 FOR UPDATE;
-- 对 id=1 的行进行操作
COMMIT;由于 id 是主键,所以只会锁定 id=1 这行,不会影响其他行的操作。其他事务依然可以对 id = 2, 3, 4, 5 等行执行更新操作,因为它们没有被锁定。
如果使用 order_no 这个普通索引执行 SELECT FOR UPDATE,也只会锁定特定的行:
START TRANSACTION;
SELECT * FROM orders WHERE order_no = '10001' FOR UPDATE;
-- 对 order_no=10001 的行进行操作
COMMIT;因为 order_no 是唯一索引,所以只会锁定 order_no=10001 这行,不会影响其他行的操作。
但如果 WHERE 条件是 status='pending',而 status 上没有索引:
START TRANSACTION;
SELECT * FROM orders WHERE status = 'pending' FOR UPDATE;
-- 对 status=pending 的行进行操作
COMMIT;就会退化为表锁,因为在这种情况下,MySQL 需要全表扫描检查每一行的 status。
---- 这部分是帮助大家理解 end,面试中可不背 ----
memo:2025 年 4 月 9 日修改至此,今天有球友反馈说,拿到了美团的暑期实习 offer,并且特意感谢了面渣逆袭,口碑+1。
说说记录锁吧?
记录锁是行锁最基本的表现形式,当我们使用唯一索引或者主键索引进行等值查询时,MySQL 会为该记录自动添加排他锁,禁止其他事务读取或者修改锁定记录。
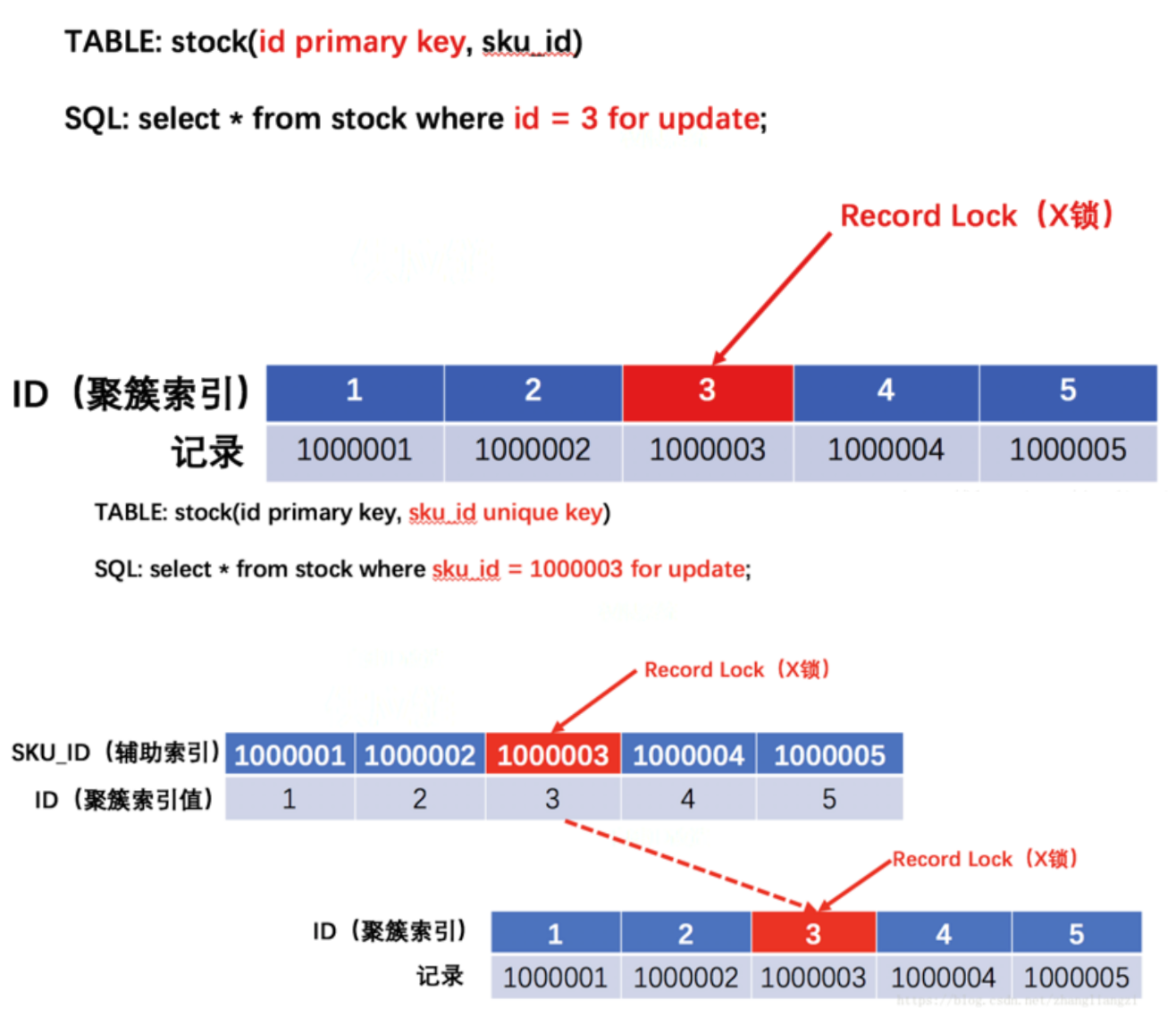
例如:
SELECT * FROM table WHERE id = 1 FOR UPDATE; -- 加X锁
UPDATE table SET name = '王二' WHERE id = 1; -- 隐式加X锁间隙锁了解吗?(补充)
2024 年 12 月 15 日增补。
间隙锁用于在范围查询时锁定记录之间的“间隙”,防止其他事务在该范围内插入新记录。仅在可重复读及以上的隔离级别下生效,主要用于防止幻读。
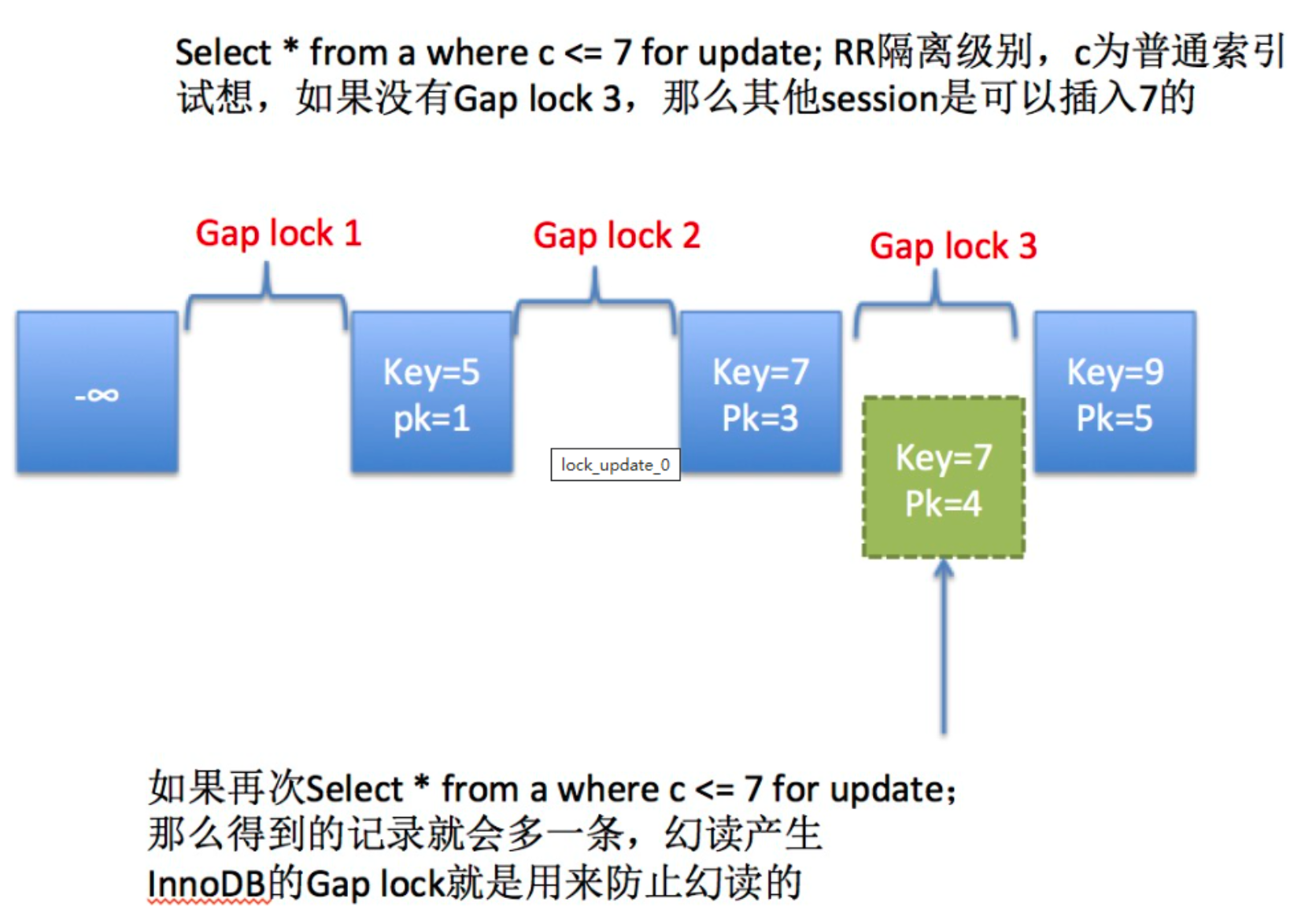
---- 这部分是帮助大家理解 start,面试中可不背 ----
例如事务 A 锁定了 (1000,2000) 区间,会阻止事务 B 在此区间插入新记录:
-- 事务A
BEGIN;
SELECT * FROM orders WHERE amount BETWEEN 1000 AND 2000 FOR UPDATE;
-- 事务B尝试插入会被阻塞
INSERT INTO orders VALUES(null,1500,'pending'); -- 阻塞假设表 test_gaplock 有 id、age、name 三个字段,其中 id 是主键,age 上有索引,并插入了 4 条数据。
CREATE TABLE `test_gaplock` (
`id` int(11) NOT NULL,
`age` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `age` (`age`)
) ENGINE=InnoDB;
insert into test_gaplock values(1,1,'张三'),(6,6,'吴老二'),(8,8,'赵四'),(12,12,'熊大');间隙锁会锁住:
(−∞, 1):最小记录之前的间隙。(1, 6)、(6, 8)、(8, 12):记录之间的间隙。(12, +∞):最大记录之后的间隙。

假设有两个事务,T1 执行以下语句:
START TRANSACTION;
SELECT * FROM test_gaplock WHERE age > 5 FOR UPDATE;T2 执行以下语句:
START TRANSACTION;
INSERT INTO test_gaplock VALUES (7, 7, '王五');T1 会锁住 (6, 8) 的间隙,防止其他事务在这个范围内插入新记录。
T2 在插入 (7, 7, '王五') 时,会被阻塞,可以在另外一个会话中执行 SHOW ENGINE INNODB STATUS 查看到间隙锁的信息。
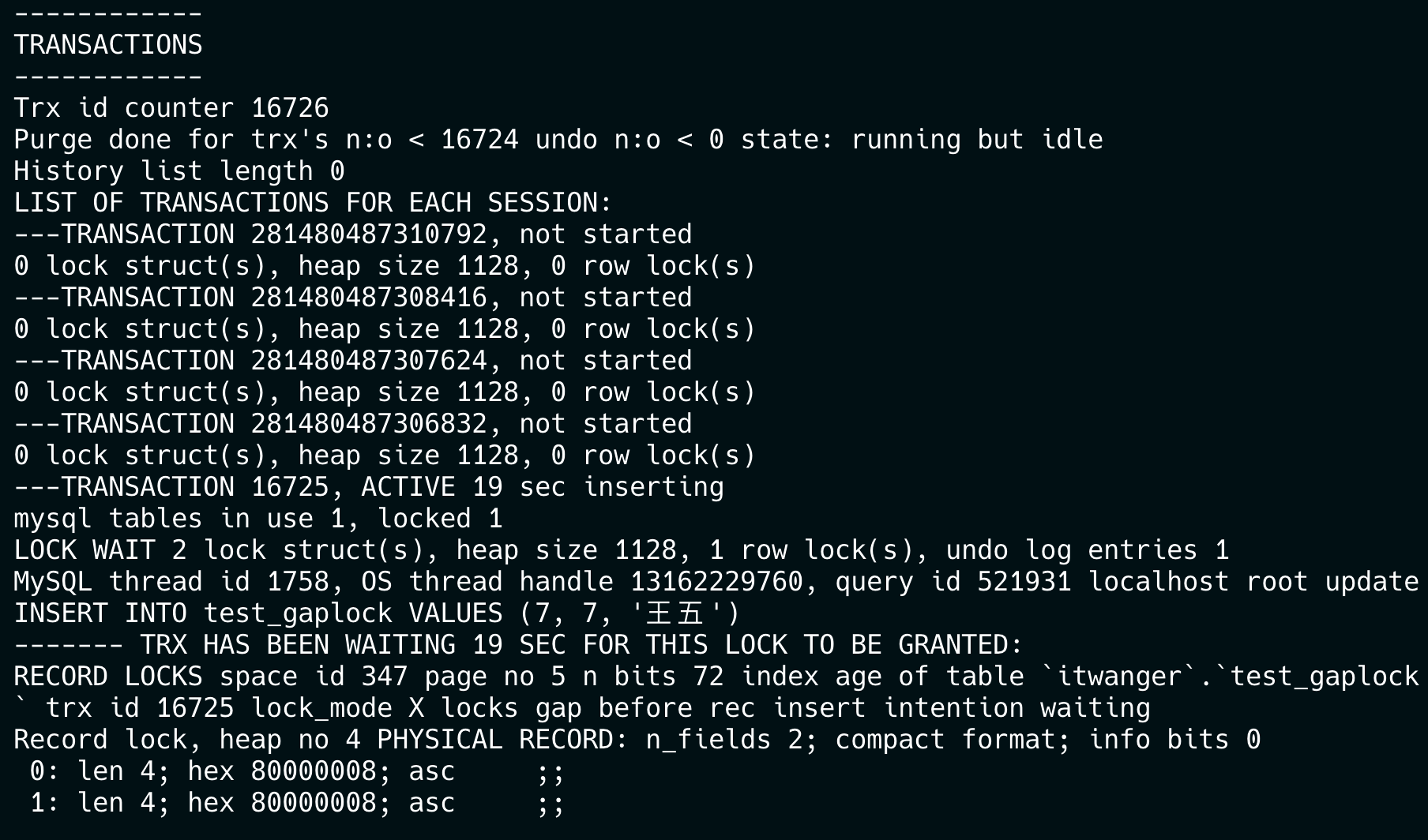
推荐阅读:六个案例搞懂间隙锁、MySQL中间隙锁的加锁机制
---- 这部分是帮助大家理解 end,面试中可不背 ----
执行什么命令会加上间隙锁?
在可重复读隔离级别下,执行 FOR UPDATE / LOCK IN SHARE MODE 等加锁语句,且查询条件是范围查询时,就会自动加上间隙锁。
-- SELECT ... FOR UPDATE + 范围查询
SELECT * FROM user WHERE score > 100 FOR UPDATE;
-- SELECT ... LOCK IN SHARE MODE + 范围查询
SELECT * FROM user WHERE id BETWEEN 10 AND 20 LOCK IN SHARE MODE;
-- UPDATE/DELETE + 范围查询
DELETE FROM user WHERE score < 50;
- Java 面试指南(付费)收录的阿里云面经同学 22 面经:mysql的什么命令会加上间隙锁
56.临键锁了解吗?
临键锁是记录锁和间隙锁的结合体,锁住的是索引记录和索引记录之间的间隙。
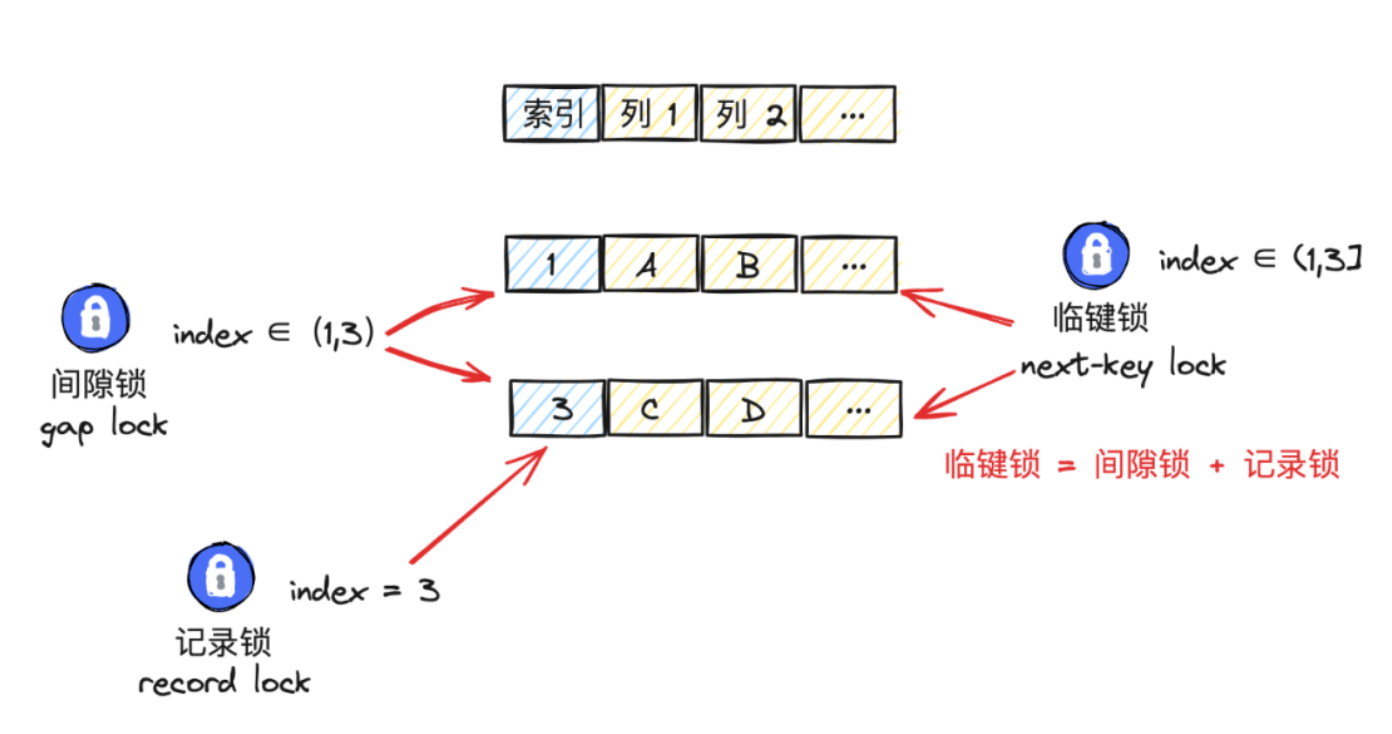
和间隙锁不同,临键锁的间隙是一个左开右闭区间。例如 (1,3] 表示锁定大于 1 且小于等于 3 的所有记录。
当 InnoDB 执行一个范围查询时,会使用临键锁来锁定满足条件的行数据以及该范围内的间隙。
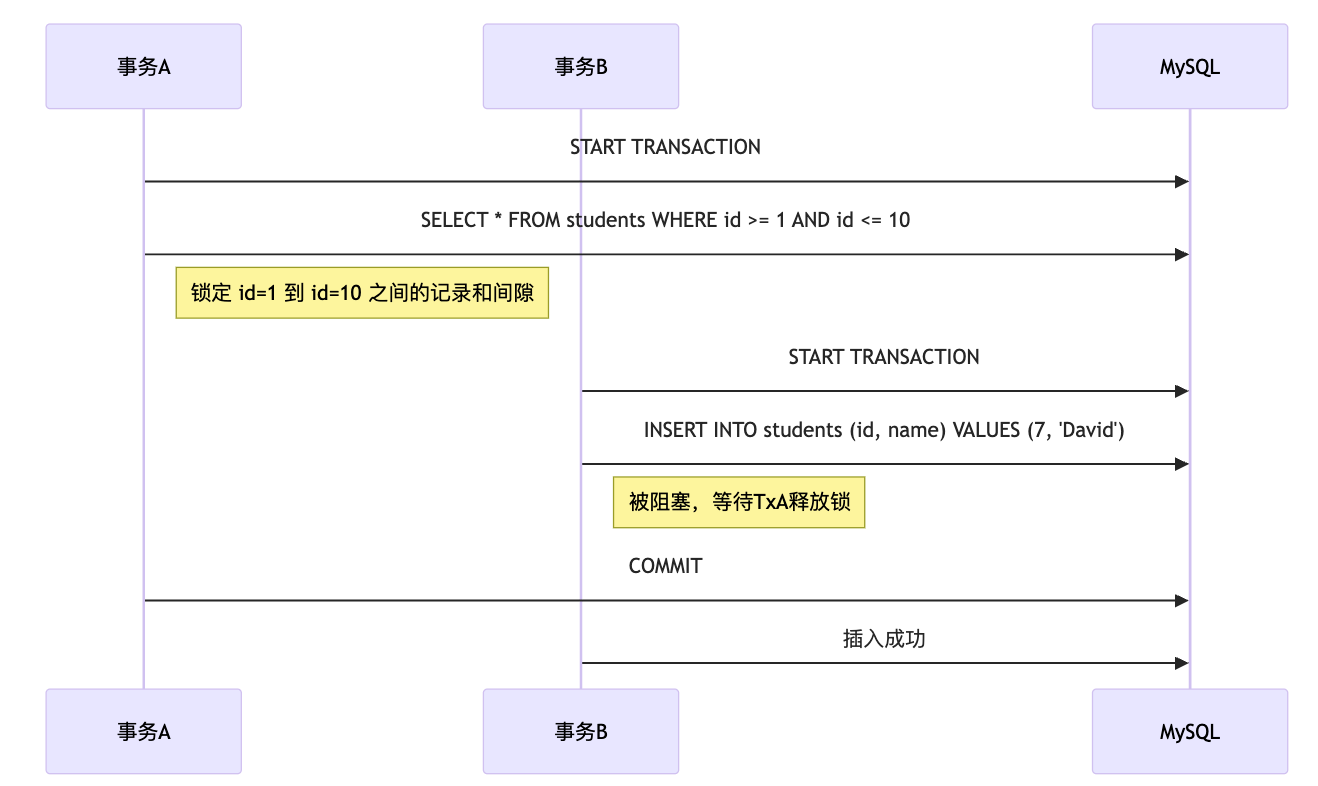
比如说下面这条语句会锁定 id 在 5 到 10 之间的所有记录,以及这些记录之间的间隙。
SELECT * FROM table WHERE id BETWEEN 5 AND 10 FOR UPDATE;MySQL 默认的行锁类型就是临键锁。当使用唯一索引的等值查询匹配到一条记录时,临键锁会退化成记录锁;如果没有匹配到任何记录,会退化成间隙锁。
memo:2025 年 4 月 10 日修改至此,今天有学院本的球友反馈说,拿到了滴滴的 sp offer,真的无敌啊,太能卷了。

57.意向锁是什么知道吗?
意向锁是一种表级锁,表示事务打算对表中的某些行数据加锁,但不会直接锁定数据行本身。
由 InnoDB 自动管理,当事务需要添加行锁时,会先在表上添加意向锁。这样当要添加表锁的时候,可以通过查看表上的意向锁,快速判断是否有冲突,而无需逐行检查,从而提高加锁效率。
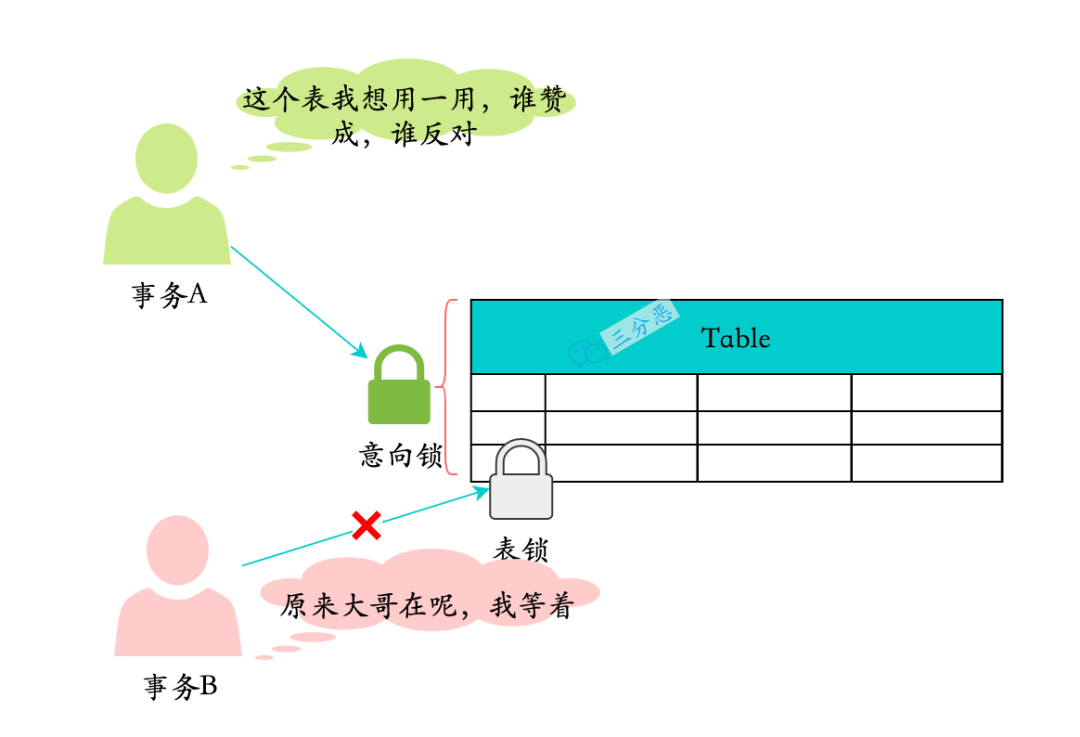
当执行 SELECT ... LOCK IN SHARE MODE 时,会自动加意向共享锁;当执行 SELECT ... FOR UPDATE 时,会自动加意向排他锁。
意向锁之间互相兼容,也不会与行锁冲突。
| 兼容关系 | 意向共享锁 | 意向排他锁 | 共享锁(表级) | 拍他锁(表级) |
|---|---|---|---|---|
| 意向共享锁 | 兼容 | 兼容 | 兼容 | 冲突 |
| 意向排他锁 | 兼容 | 兼容 | 冲突 | 冲突 |
| S锁 | 兼容 | 冲突 | 兼容 | 冲突 |
| X锁 | 冲突 | 冲突 | 冲突 | 冲突 |
意向锁的意义是什么?
在没有意向锁的情况下,当事务 A 持有某表的行锁时,如果事务 B 想添加表锁,InnoDB 必须检查表中每一行数据是否被加锁,这种全表扫描的方式效率极低。
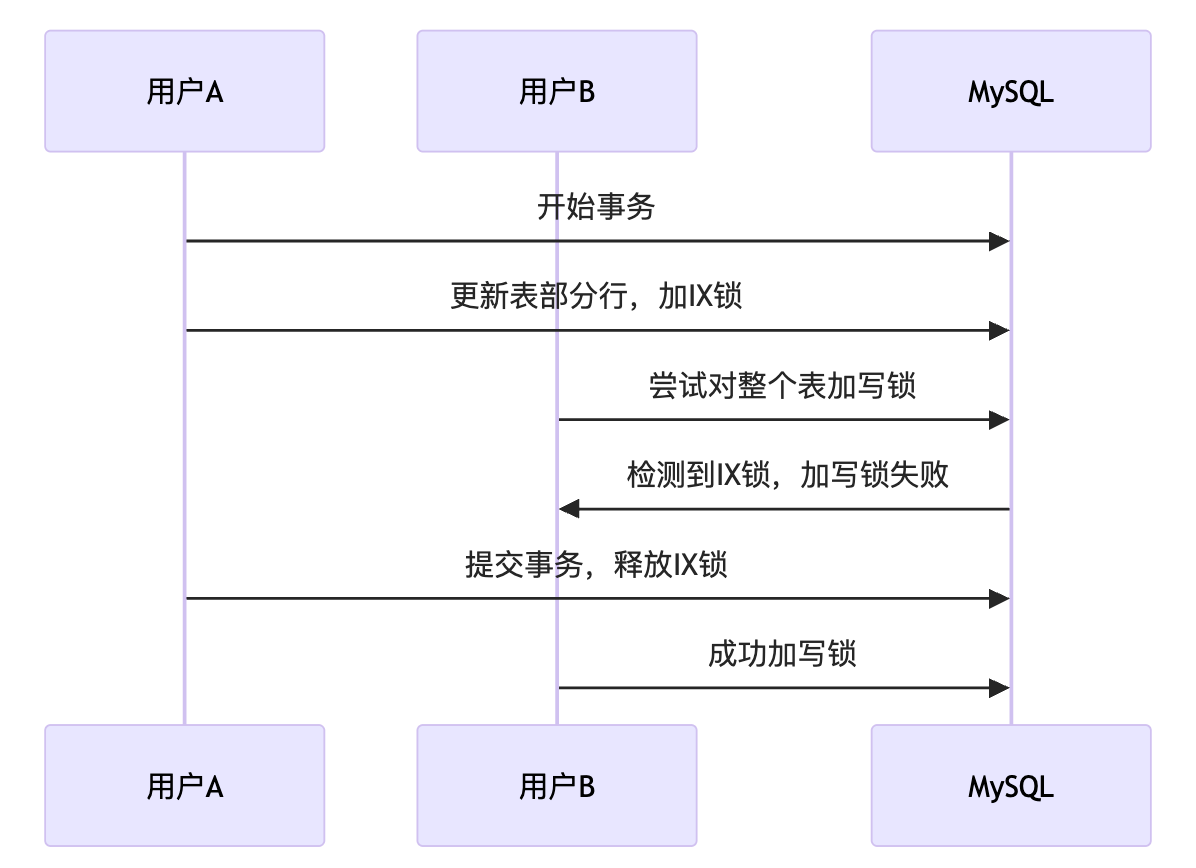
有了意向锁之后,事务在加行锁前,先在表上加对应的意向锁;其他事务加表锁时,只需检查表上的意向锁,无需逐行检查。
-- 事务A获取某行的排他锁
BEGIN;
SELECT * FROM users WHERE id = 6 FOR UPDATE; -- 自动加IX锁和行X锁
-- 事务B尝试加表锁
LOCK TABLES users READ; -- 发现表上有IX锁,与S锁冲突,直接阻塞而无需扫描全表memo:2025 年 4 月 11 日修改至此,今天拿到滴滴 offer 的球友反馈,MQ 部分主要看的面渣逆袭,比较全,这不,口碑就来了。
58.🌟MySQL的乐观锁和悲观锁了解吗?
悲观锁是一种"先上锁再操作"的保守策略,它假设数据被外界访问时必然会产生冲突,因此在数据处理过程中全程加锁,保证同一时间只有一个线程可以访问数据。
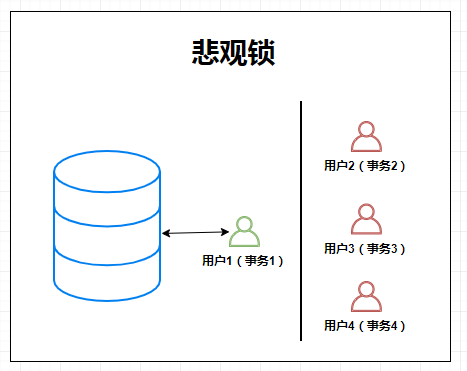
MySQL 中的行锁和表锁都是悲观锁。
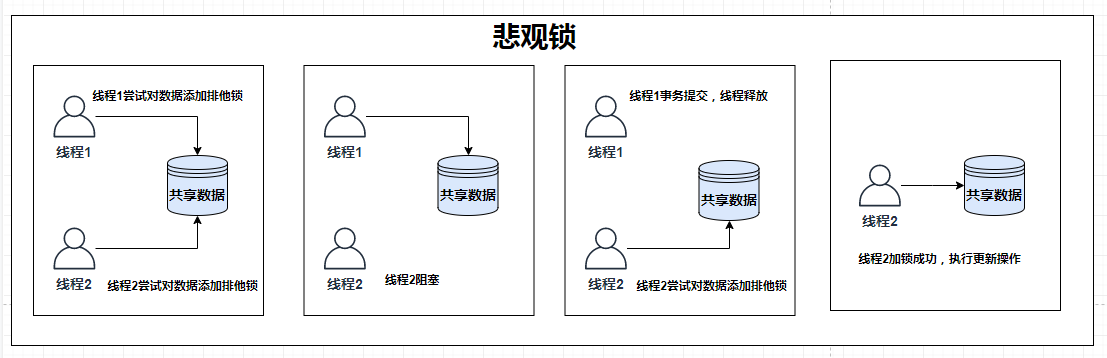
乐观锁会假设并发操作不会总发生冲突,属于小概率事件,因此不会在读取数据时加锁,而是在提交更新时才检查数据是否被其他事务修改过。
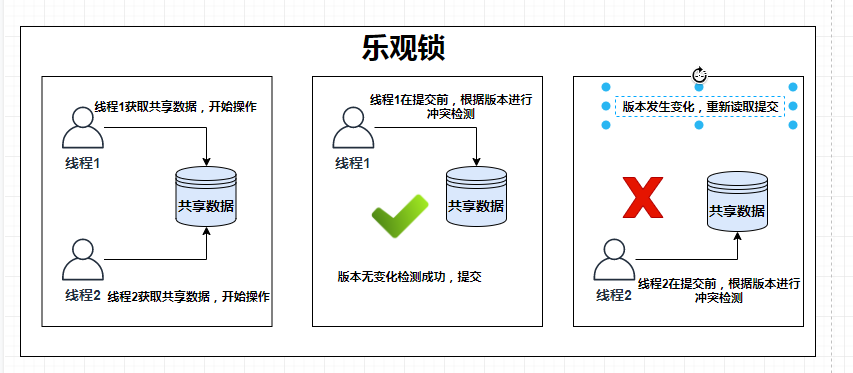
乐观锁并不是 MySQL 内置的锁机制,而是通过程序逻辑实现的,常见的实现方式有版本号机制和时间戳机制。通过在表中增加 version 字段或者 timestamp 字段来实现。
---- 这部分是帮助大家理解 start,面试中可不背 ----
当事务 A 已经上锁后,事务 B 会一直等待事务 A 释放锁;如果事务 A 长时间不释放锁,事务 B 就会报错 Lock wait timeout exceeded; try restarting transaction。
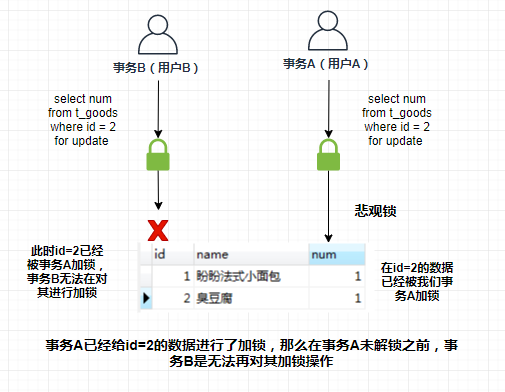
事务 A 和事务 B 同时读取同一个主键 ID 的数据,版本号为 0;事务 A 将版本号(version=1)作为条件进行数据更新,同时版本号 +1;事务 B 也将 version=1 作为更新条件,发现版本号不匹配,更新失败。
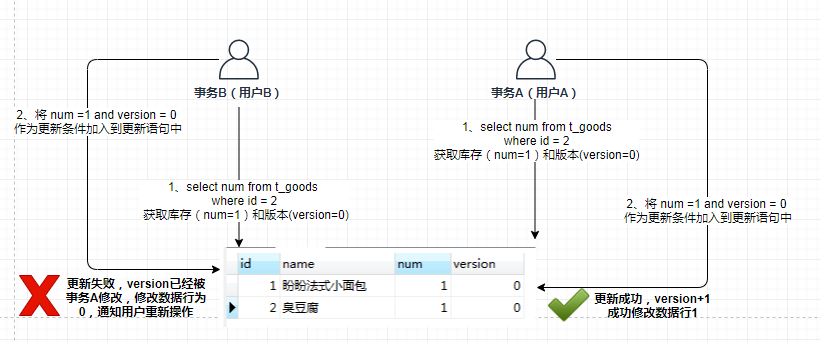
---- 这部分是帮助大家理解 end,面试中可不背 ----
如何通过悲观锁和乐观锁解决库存超卖问题?
悲观锁通过 SELECT ... FOR UPDATE 在查询时直接锁定记录,确保其他事务必须等待当前事务完成才能操作该行数据。
BEGIN;
-- 对id=1的商品记录加排他锁
SELECT stock FROM products WHERE id=1 FOR UPDATE;
-- 生成订单
INSERT INTO orders (user_id, product_id) VALUES (123, 1);
-- 扣减库存
UPDATE products SET stock=stock-1 WHERE id=1;
COMMIT;乐观锁通过在表中增加 version 字段作为判断条件。
-- 查询商品信息,获取版本号
SELECT stock, version FROM products WHERE id=1;
-- 更新库存时检查版本号
UPDATE products
SET stock=stock-1, version=version+1
WHERE id=1 AND version=旧版本号;---- 这部分是帮助大家理解 start,面试中可不背 ----
库存超卖是一个非常经典的问题:
- 事务A查询商品库存,得到库存值为1
- 事务B也查询同一商品库存,同样得到库存值为1
- 事务A基于查询结果执行库存扣减,将库存更新为0
- 事务B也执行库存扣减,将库存更新为-1
悲观锁的关键点:
- 必须在一个事务中执行;
- 通过
SELECT ... FOR UPDATE锁定行,确保其他事务必须等待当前事务完成才能操作该行数据; - 记得给查询条件加索引,避免全表扫描导致锁升级为表锁。
乐观锁的关键点:
- 在表中增加 version 字段;
- 查询时获取当前版本号;
- 更新时检查版本号是否发生了变化。
Java 程序的完整代码示例:
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
@Transactional
public boolean purchaseWithOptimisticLock(Long productId, int quantity) {
int retryCount = 0;
while(retryCount < 3) { // 最大重试次数
Product product = productMapper.selectById(productId);
if(product.getStock() < quantity) {
return false; // 库存不足
}
int updated = productMapper.reduceStockWithVersion(
productId, quantity, product.getVersion());
if(updated > 0) {
return true; // 更新成功
}
retryCount++;
}
return false; // 更新失败
}
}对应的 mapper:
@Update("UPDATE products SET stock=stock-#{quantity}, version=version+1 " +
"WHERE id=#{productId} AND version=#{version}")
int reduceStockWithVersion(@Param("productId") Long productId,
@Param("quantity") int quantity,
@Param("version") int version);时间戳机制实现的乐观锁:
UPDATE products SET stock=stock-1, update_time=NOW()
WHERE id=1 AND update_time=旧时间戳;这两种方式都需要保证操作的原子性,需要将多个 SQL 放在同一个事务中执行。
推荐阅读:牧小农:悲观锁和乐观锁
---- 这部分是帮助大家理解 end,面试中可不背 ----
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:乐观锁和悲观锁,库存的超卖问题的原因和解决方案?
- Java 面试指南(付费)收录的京东面经同学 5 Java 后端技术一面面试原题:乐观锁与悲观锁
memo:2025 年 4 月 12 日修改至此,今天有球友反馈说,京东进入 HR 面了,但加了一个 VP 级别的面试,副总监,等一手他的好消息。当然了,仍然不忘感谢一下面渣逆袭对他的帮助,哈哈。
59.遇到过MySQL死锁问题吗,你是如何解决的?
遇到过。MySQL 的死锁是由于多个事务持有资源并相互等待引起的。我通过 SHOW ENGINE INNODB STATUS 查看死锁信息,定位到是加锁顺序不一致导致的,最后通过调整加锁顺序解决了这个问题。
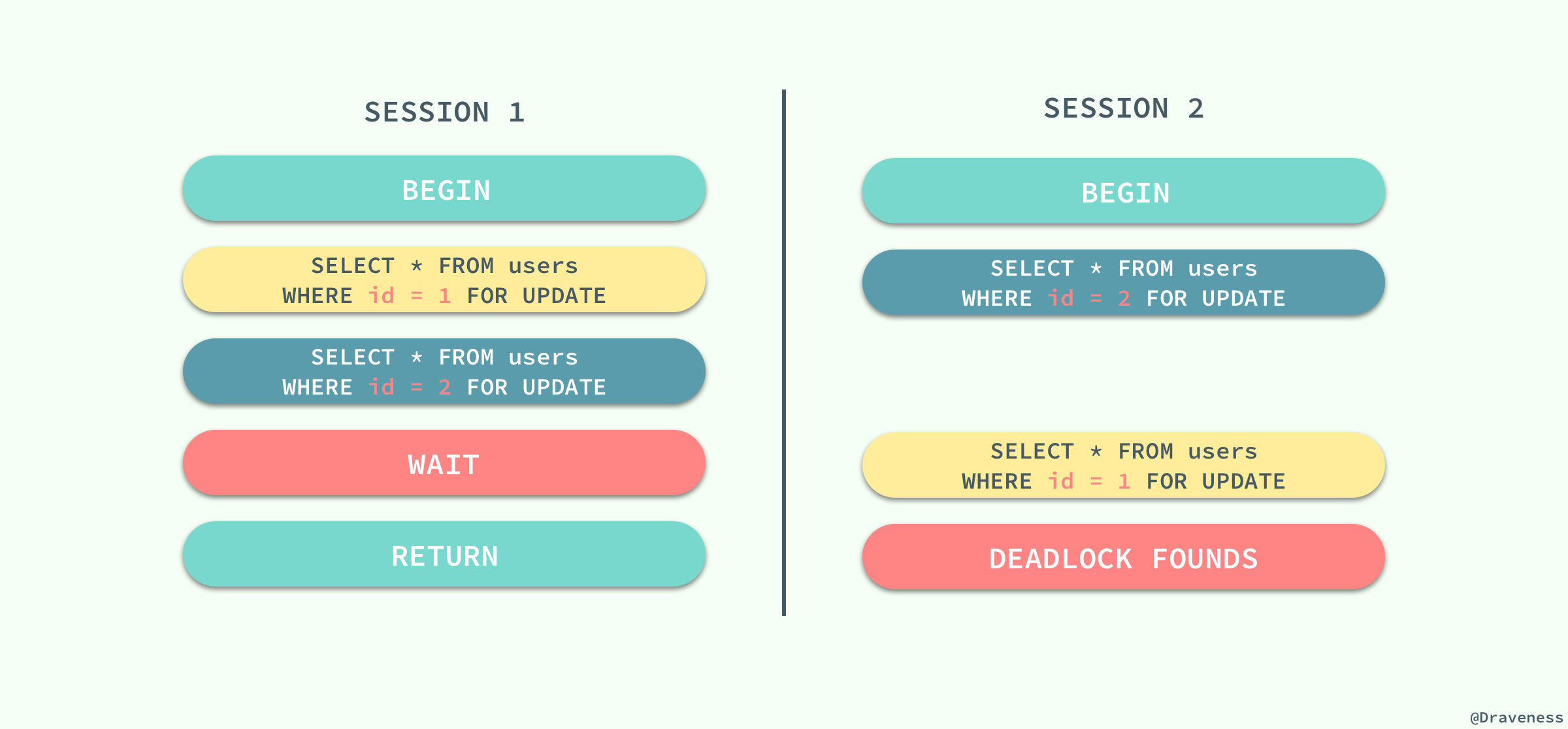
比如说技术派项目中,两个事务分别更新两张表,但是更新顺序不一致。
-- 创建表/插入数据
CREATE TABLE account (
id INT AUTO_INCREMENT PRIMARY KEY,
balance INT NOT NULL
);
INSERT INTO account (balance) VALUES (100), (200);
-- 事务 1
START TRANSACTION;
-- 锁住 id=1 的行
UPDATE account SET balance = balance - 10 WHERE id = 1;
-- 等待锁住 id=2 的行(事务 2 已锁住)
UPDATE account SET balance = balance + 10 WHERE id = 2;
-- 事务 2
START TRANSACTION;
-- 锁住 id=2 的行
UPDATE account SET balance = balance - 10 WHERE id = 2;
-- 等待锁住 id=1 的行(事务 1 已锁住)
UPDATE account SET balance = balance + 10 WHERE id = 1;访问相同的资源,但顺序不同,就会导致死锁。
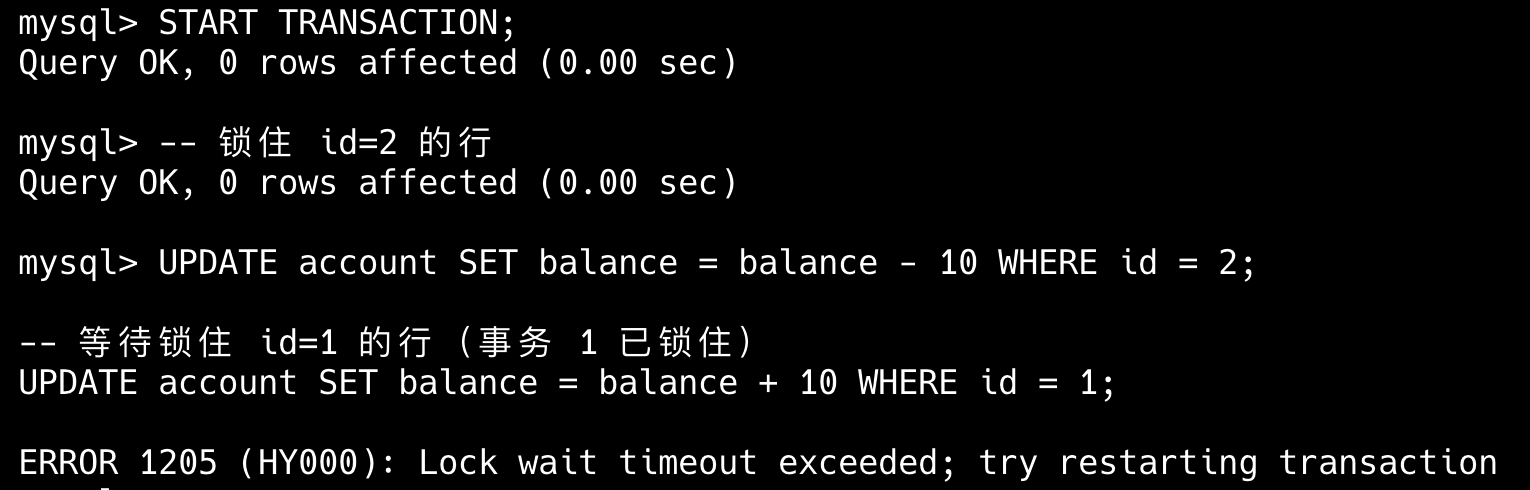
解决办法也很简单,先使用 SHOW ENGINE INNODB STATUS\G; 确认死锁的具体信息,然后调整资源的访问顺序。
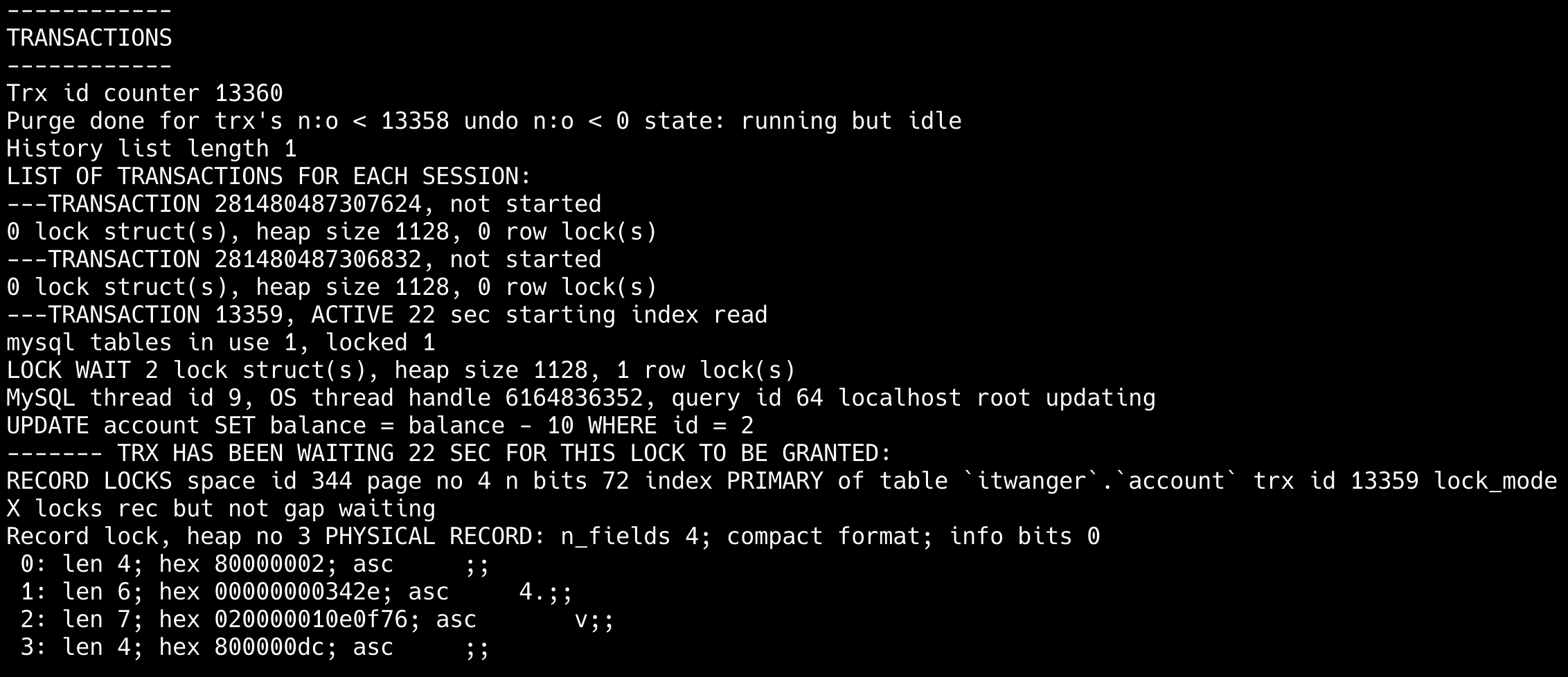
- Java 面试指南(付费)收录的虾皮面经同学 13 一面面试原题:遇到过mysql死锁或者数据不安全吗
事务
60.🌟MySQL事务的四大特性说一下?
事务是一条或多条 SQL 语句组成的执行单元。四个特性分别是原子性、一致性、隔离性和持久性。原子性保证事务中的操作要么全部执行、要么全部失败;一致性保证数据从事务开始前的一个一致状态转移到结束后的另外一个一致状态;隔离性保证并发事务之间互不干扰;持久性保证事务提交后数据不会丢失。

详细说一下原子性?
原子性意味着事务中的所有操作要么全部完成,要么全部不完成,它是不可分割的单位。如果事务中的任何一个操作失败了,整个事务都会回滚到事务开始之前的状态,如同这些操作从未被执行过一样。
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
-- 如果第二条语句失败,第一条也会回滚
COMMIT;简短回答:原子性要求事务的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务中的操作不能只执行其中一部分。
详细说一下一致性?
一致性确保事务从一个一致的状态转换到另一个一致的状态。
比如在银行转账事务中,无论发生什么,转账前后两个账户的总金额应保持不变。假如 A 账户(100 块)给 B 账户(10 块)转了 10 块钱,不管成功与否,A 和 B 的总金额都是 110 块。
-- 假设 A 账户余额为 100,B 账户余额为 10
-- 转账前状态
SELECT balance FROM accounts WHERE user_id = 'A'; -- 100
SELECT balance FROM accounts WHERE user_id = 'B'; -- 10
-- 转账操作
START TRANSACTION;
UPDATE accounts SET balance = balance - 10 WHERE user_id = 'A';
UPDATE accounts SET balance = balance + 10 WHERE user_id = 'B';
COMMIT;
-- 转账后状态
SELECT balance FROM accounts WHERE user_id = 'A'; -- 90
SELECT balance FROM accounts WHERE user_id = 'B'; -- 20`
-- 总金额仍然是 110简短回答:一致性确保数据的状态从一个一致状态转变为另一个一致状态。一致性与业务规则有关,比如银行转账,不论事务成功还是失败,转账双方的总金额应该是不变的。
详细说一下隔离性?
隔离性意味着并发执行的事务是彼此隔离的,一个事务的执行不会被其他事务干扰。事务之间是井水不犯河水的。
隔离性主要是为了解决事务并发执行时可能出现的脏读、不可重复读、幻读等问题。
---- 这部分是帮助大家理解 start,面试中可不背 ----
比如说在读未提交的隔离级别下,会出现脏读现象:一个事务C 读取了事务B 尚未提交的修改数据。如果事务B 最终回滚,事务C 读取的数据就是无效的“脏数据”。
-- 会话 A
-- 创建模拟并发的测试表
DROP TABLE IF EXISTS accounts;
CREATE TABLE accounts (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
balance DECIMAL(10,2)
);
-- 插入测试数据
INSERT INTO accounts (name, balance) VALUES
('王二', 1000.00),
('张三', 2000.00),
('李四', 3000.00);
-- 会话B 中,设置隔离级别为读未提交
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
START TRANSACTION;
-- 在会话 B 中更新数据但不提交
UPDATE accounts SET balance = balance - 500 WHERE name='王二';
-- 会话C 是读为提交级别,读取数据,得到 500
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT * FROM accounts WHERE name='王二';
-- 继续别的操作,基于 500
-- 会话 B 的事务回滚,导致会话 A 读到的数据其实是脏数据
ROLLBACK;
通过升级隔离级别为读已提交可以解决脏读的问题。
-- 会话 B 修改为读已提交
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 执行第一次查询 1000
SELECT * FROM accounts WHERE name='王二';
-- 会话 C 中,设置隔离级别为读已提交
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 在会话 C 中更新数据但不提交
START TRANSACTION;
UPDATE accounts SET balance = balance + 200 WHERE name='王二';
-- 会话 B 中再次读取数据,结果仍然为 1000
SELECT * FROM accounts WHERE name='王二';
-- 会话 C 中回滚事务
ROLLBACK;
-- 会话 B 中再次读取数据,结果仍然为 1000
SELECT * FROM accounts WHERE name='王二';
但会出现不可重复读的问题:事务B 第一次读取某行数据值为X,期间事务C修改该数据为Y并提交,事务B 再次读取时发现值变为Y,导致两次读取结果不一致。
-- 会话 B 修改为读已提交
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 执行第一次查询 1000
START TRANSACTION;
SELECT * FROM accounts WHERE name='王二';
-- 会话 C 中,设置隔离级别为读已提交
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 在会话 C 中更新数据并提交
START TRANSACTION;
UPDATE accounts SET balance = balance + 200 WHERE name='王二';
-- 会话 C 提交事务
COMMIT;
-- 会话 B 中再次读取数据,结果仍然为 1200
SELECT * FROM accounts WHERE name='王二';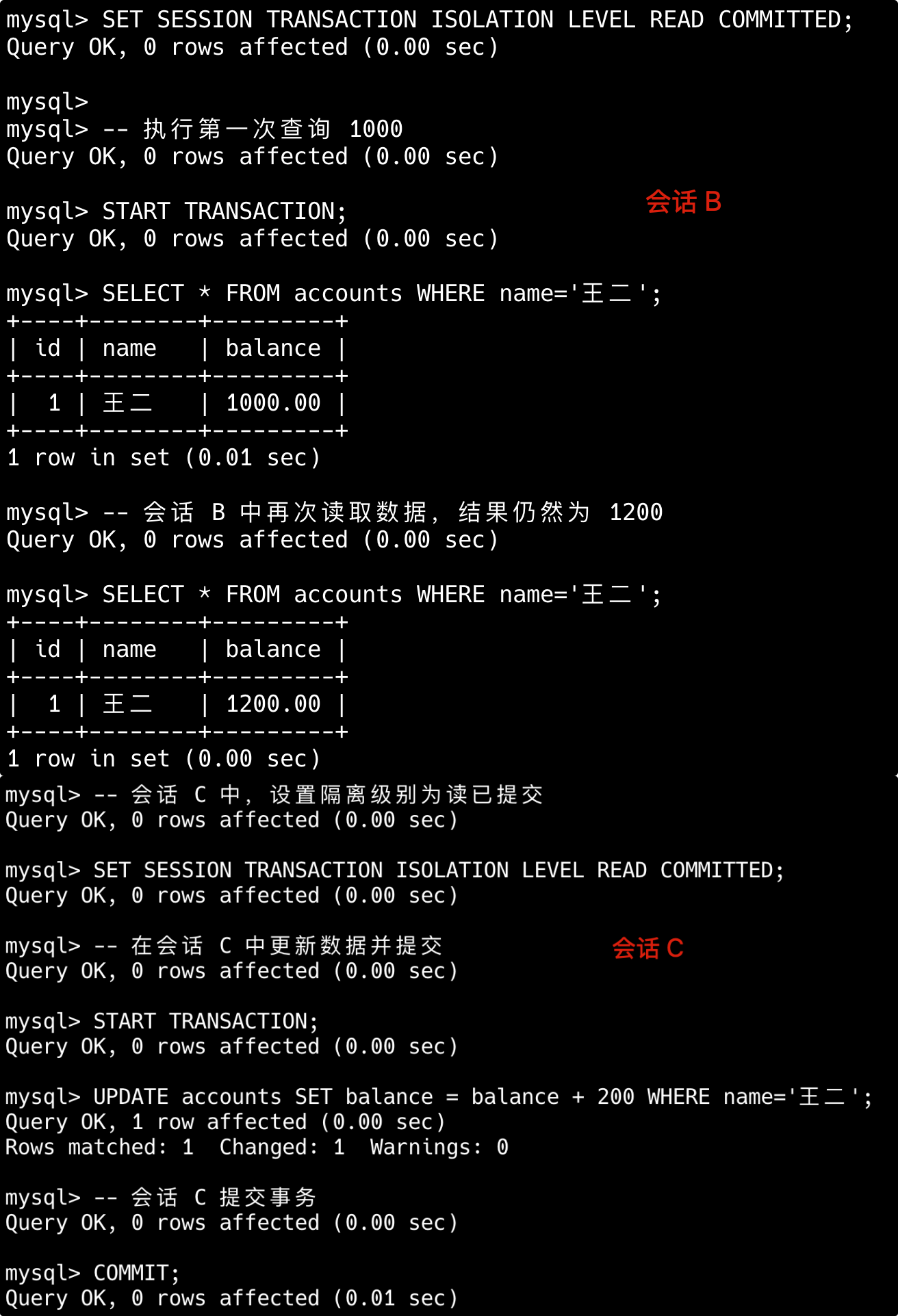
可以通过升级隔离级别为可重复读来解决不可重复读的问题。
-- 会话 B 修改为可重复读
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 开始事务并执行第一次查询 1000
START TRANSACTION;
SELECT * FROM accounts WHERE name='王二';
-- 会话 C 中,设置隔离级别为可重复读
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 在会话 C 中更新数据并提交
START TRANSACTION;
UPDATE accounts SET balance = balance + 200 WHERE name='王二';
-- 会话 C 提交事务
COMMIT;
-- 会话 B 中再次读取数据,结果仍然为 1000
SELECT * FROM accounts WHERE name='王二';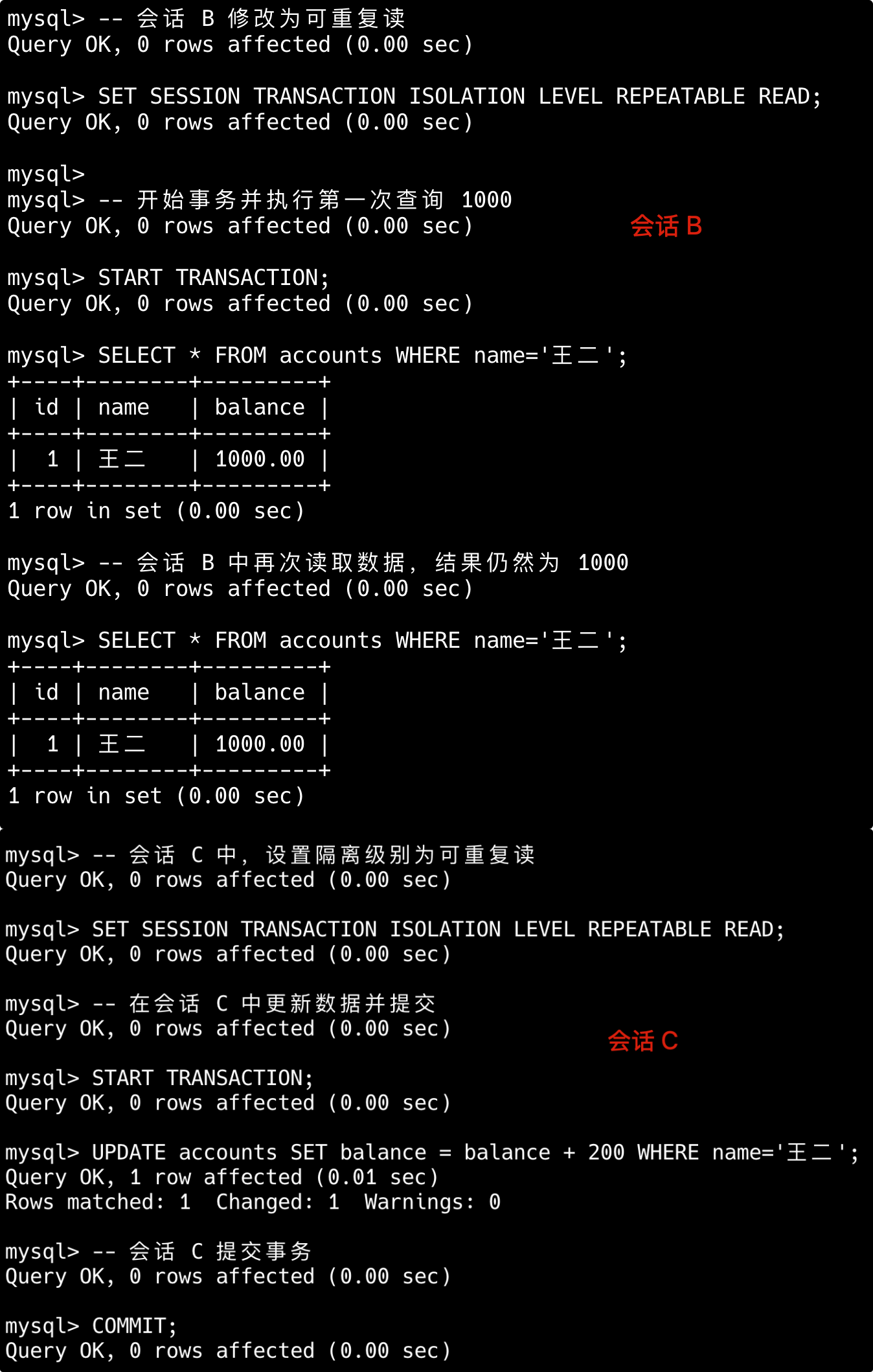
但可重复读级别下仍然会出现幻读的问题:事务B 第一次查询获得 2条数据,事务C 新增 1条数据并提交后,事务B 再次查询时仍然为 2 条数据,但可以更新新增的数据,再次查询时就发现有 3 条数据了。
-- 会话 B 修改为可重复读
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 执行第一次查询,查到 2 条记录
START TRANSACTION;
SELECT * FROM accounts WHERE balance > 1000;
-- 会话 C 中,设置隔离级别为可重复读
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 在会话 C 中新增数据并提交
START TRANSACTION;
INSERT INTO accounts (name, balance) VALUES ('王五', 4000);
-- 会话 C 提交事务
COMMIT;
-- 会话 B 中再次读取数据,结果仍然为 2 条
SELECT * FROM accounts WHERE balance > 1000;
-- 会话 B 中尝试更新王五的余额为 5000,竟然成功了
UPDATE accounts SET balance = 5000 WHERE name='王五';
-- 会话 B 中再次读取数据,发现 3 条记录
SELECT * FROM accounts WHERE balance > 1000;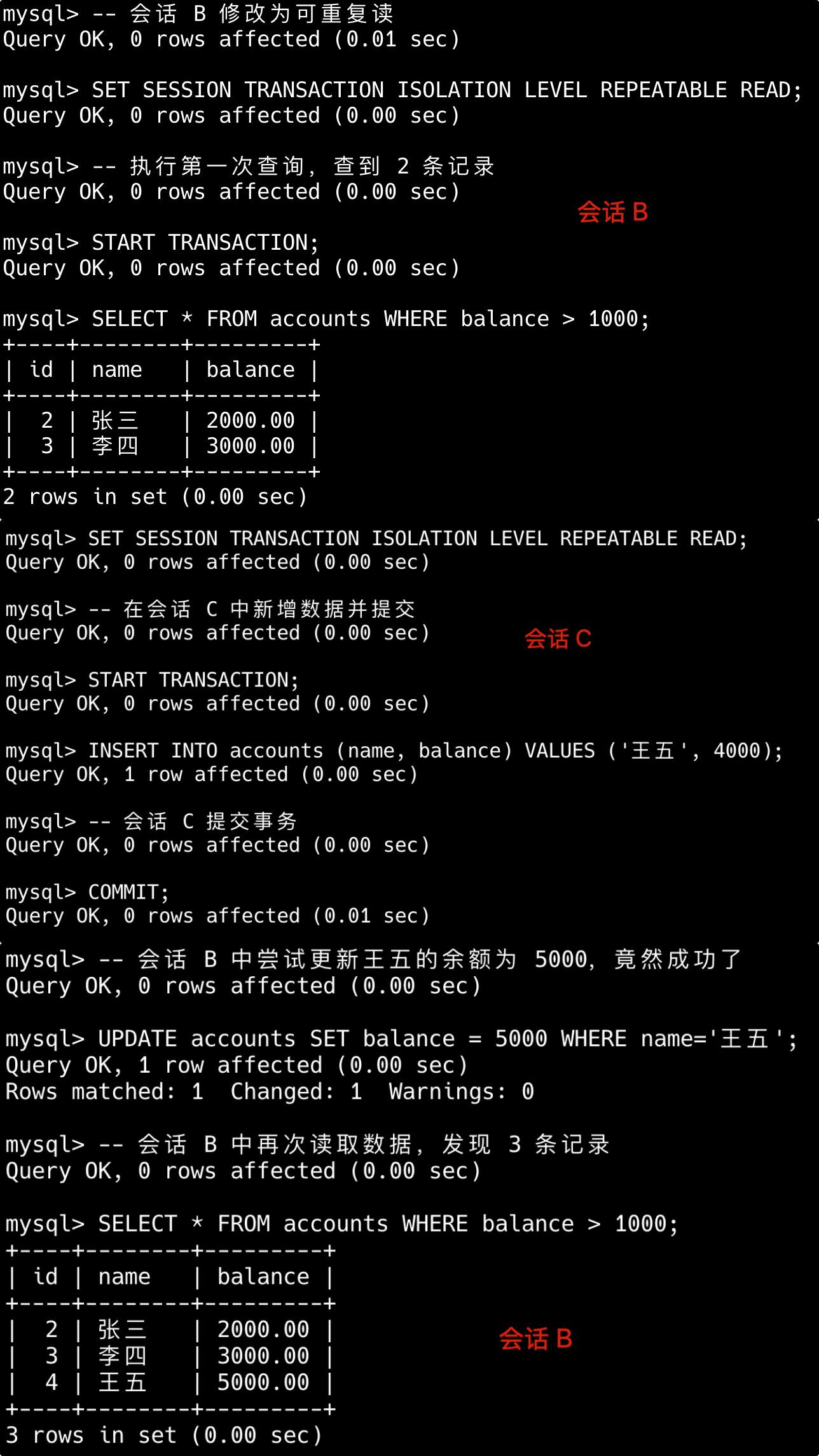
可以通过升级隔离级别为串行化来解决幻读的问题。
-- 会话 B 修改为可串行化
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- 执行第一次查询,查到 2 条记录
START TRANSACTION;
SELECT * FROM accounts WHERE balance > 1000;
-- 会话 C 中,设置隔离级别为可串行化
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- 在会话 C 中新增数据,会卡住
START TRANSACTION;
INSERT INTO accounts (name, balance) VALUES ('王五', 4000);
-- 只有等会话 B 提交事务后会话 C 才会继续执行并提交事务
COMMIT;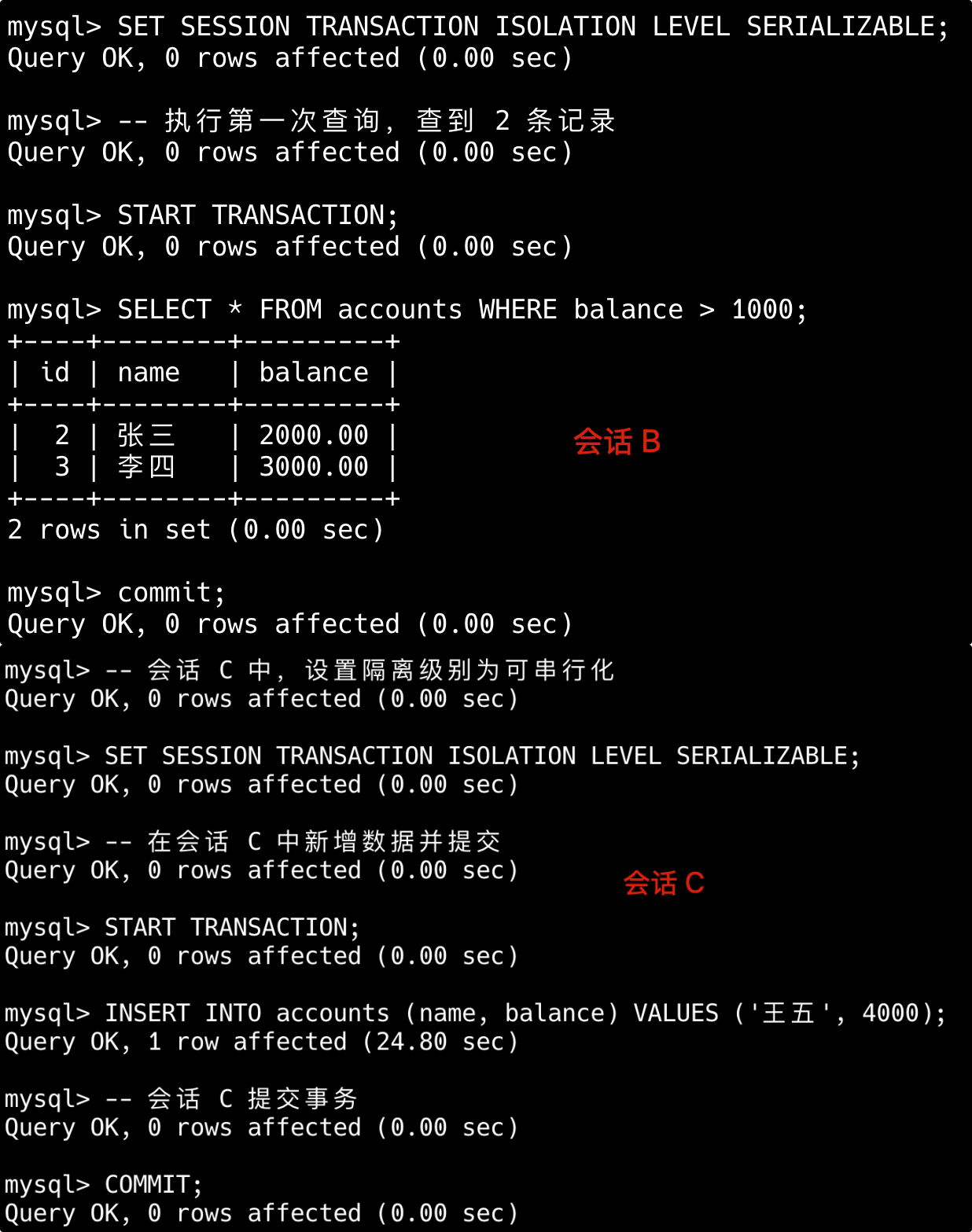
| 隔离级别 | 是否会脏读 | 是否会不可重复读 | 是否会幻读 |
|---|---|---|---|
| Read Uncommitted(读未提交) | ✅ 可能 | ✅ 可能 | ✅ 可能 |
| Read Committed(读已提交) | ❌ 不会 | ✅ 可能 | ✅ 可能 |
| Repeatable Read(可重复读) | ❌ 不会 | ❌ 不会 | ✅ 可能(但 InnoDB 已解决) |
| Serializable(可串行化) | ❌ 不会 | ❌ 不会 | ❌ 不会 |
---- 这部分是帮助大家理解 end,面试中可不背 ----
简短回答:多个并发事务之间需要相互隔离,即一个事务的执行不能被其他事务干扰。
详细说一下持久性?
持久性确保事务一旦提交,它对数据所做的更改就是永久性的,即使系统发生崩溃,数据也能恢复到最近一次提交的状态。
MySQL 的持久性是通过 InnoDB 引擎的 redo log 实现的。在事务提交时,InnoDB 会先将修改操作写入 redo log,并刷盘持久化。崩溃后,InnoDB 会通过 redo log 恢复数据,从而保证事务提交成功的数据不会丢失。
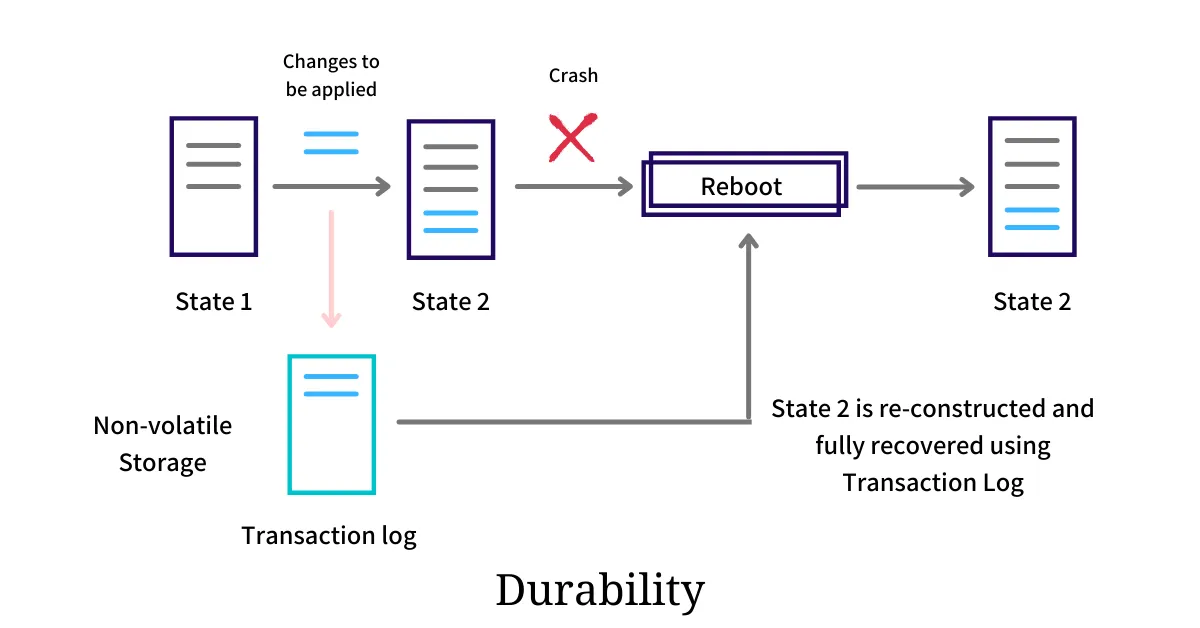
简短回答:一旦事务提交,则其所做的修改将永久保存到 MySQL 中。即使发生系统崩溃,修改的数据也不会丢失。
- Java 面试指南(付费)收录的京东同学 10 后端实习一面的原题:事务的四个特性,怎么理解事务一致性
- Java 面试指南(付费)收录的美团面经同学 16 暑期实习一面面试原题:MySQL 事务是什么,默认隔离级别,什么是可重复读?
- Java 面试指南(付费)收录的腾讯面经同学 23 QQ 后台技术一面面试原题:MySQL 事务,隔离级别
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:什么是数据库事务?事务的作用是什么?
- Java 面试指南(付费)收录的 OPPO 面经同学 1 面试原题:对MySQL事务的理解
- Java 面试指南(付费)收录的vivo 面经同学 10 技术一面面试原题:事务的概念
- Java 面试指南(付费)收录的同学 1 贝壳找房后端技术一面面试原题:事务ACID
- Java 面试指南(付费)收录的字节跳动同学 17 后端技术面试原题:什么是事务 事务为什么要有隔离级别 幻读是什么 什么时候要解决幻读 什么时候不用解决
- Java 面试指南(付费)收录的字节跳动面经同学19番茄小说一面面试原题:MySQL中的事务
memo:2025 年 4 月 13 日修改至此,今天给球友改简历的时候,发现这种彩虹屁真的离谱了,直接配享太庙了,但有一说一这位球友的话是真的甜,简历写的确实也很用心了,确定一个 offer 收割机。

61.ACID 靠什么保证的呢?
一句话总结:
ACID 中的原子性主要通过 Undo Log 来实现,持久性通过 Redo Log 来实现,隔离性由 MVCC 和锁机制来实现,一致性则由其他三大特性共同保证。
详细说说如何保证原子性?
事务对数据进行修改前,会记录一份快照到 Undo Log,如果事务中有任何一步执行失败,系统会读取 Undo Log 将所有操作回滚,恢复到事务开始前的状态,从而保证事务要么全部成功,要么全部失败。
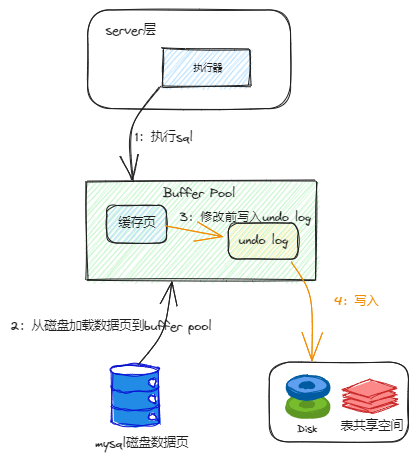
1)BEGIN;
2)UPDATE user SET balance = balance - 100 WHERE id = 1;
=> 写入 Undo Log:记录 id=1 的原始余额 500
3)UPDATE user SET balance = balance + 100 WHERE id = 2;
=> 写入 Undo Log:记录 id=2 的原始余额 300
4)COMMIT;
=> 清空 Undo Log,事务成功
❗如果失败:
=> 执行 ROLLBACK:根据 Undo Log 把数据还原!推荐阅读:庖丁解InnoDB之UNDO LOG
详细说说如何保证持久性?
MySQL 的持久性主要由预写 Redo Log、双写机制、两阶段提交以及 Checkpoint 刷盘机制共同保证。
当事务提交时,MySQL 会先将事务的修改操作写入 Redo Log,并强制刷盘,然后再将内存中的数据页刷入磁盘。这样即使系统崩溃,重启后也能通过 Redo Log 重放恢复数据。
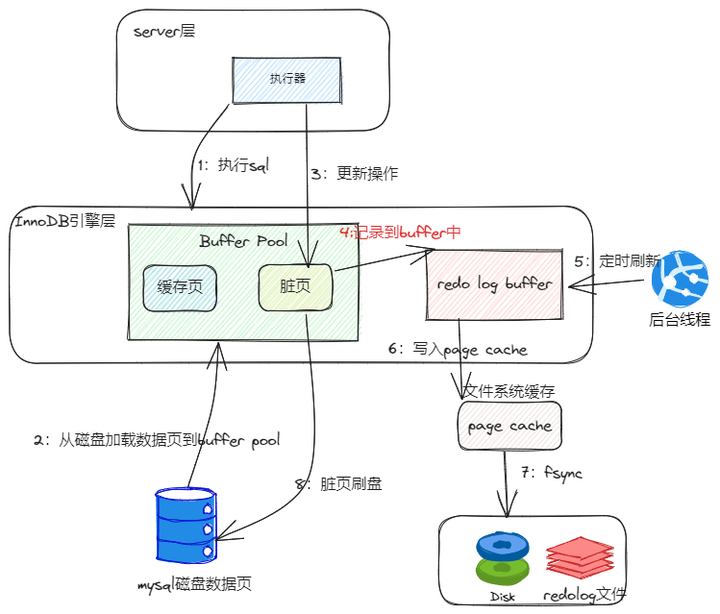
在将数据页写入到磁盘时,如果发生崩溃,可能会导致数据页不完整。InnoDB 的数据页大小为16KB,通常大于操作系统的 4KB页大小。
为了解决只写入部分的问题,MySQL 采用了双写机制,脏盘刷页时,先将数据页写入到一个双写缓冲区中,2M 的连续空间,然后再将其写入到磁盘的实际位置。
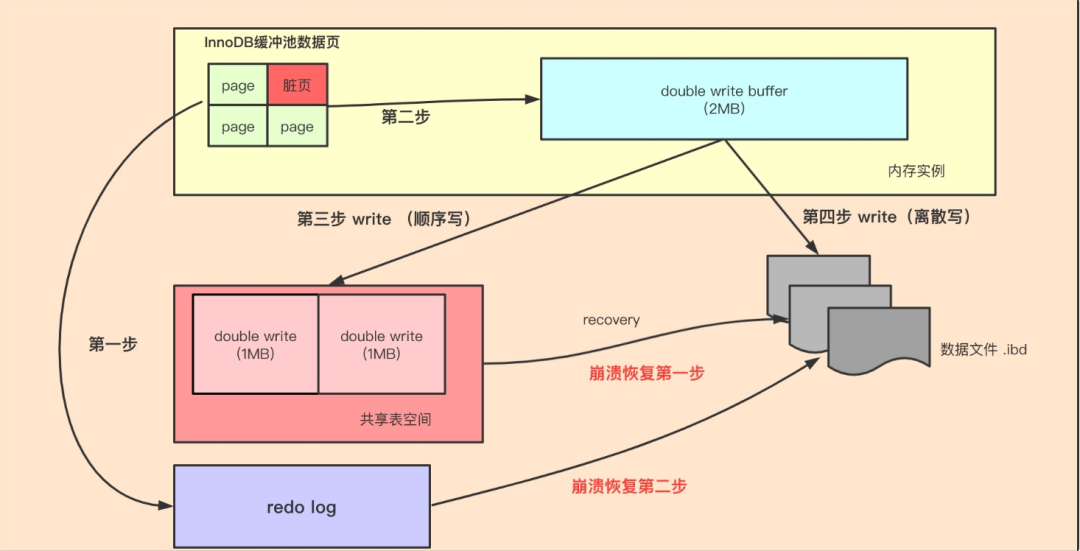
崩溃恢复时,如果发现数据页不完整,会从双写缓冲区中恢复副本,确保数据页的完整性。
在涉及主从复制时,MySQL 通过两阶段提交保证 Redo Log 和 Binlog 的一致性:第一阶段,写入 Redo Log 并标记为 prepare 状态;第二阶段,写入 Binlog 再提交 Redo Log 为 commit 状态。
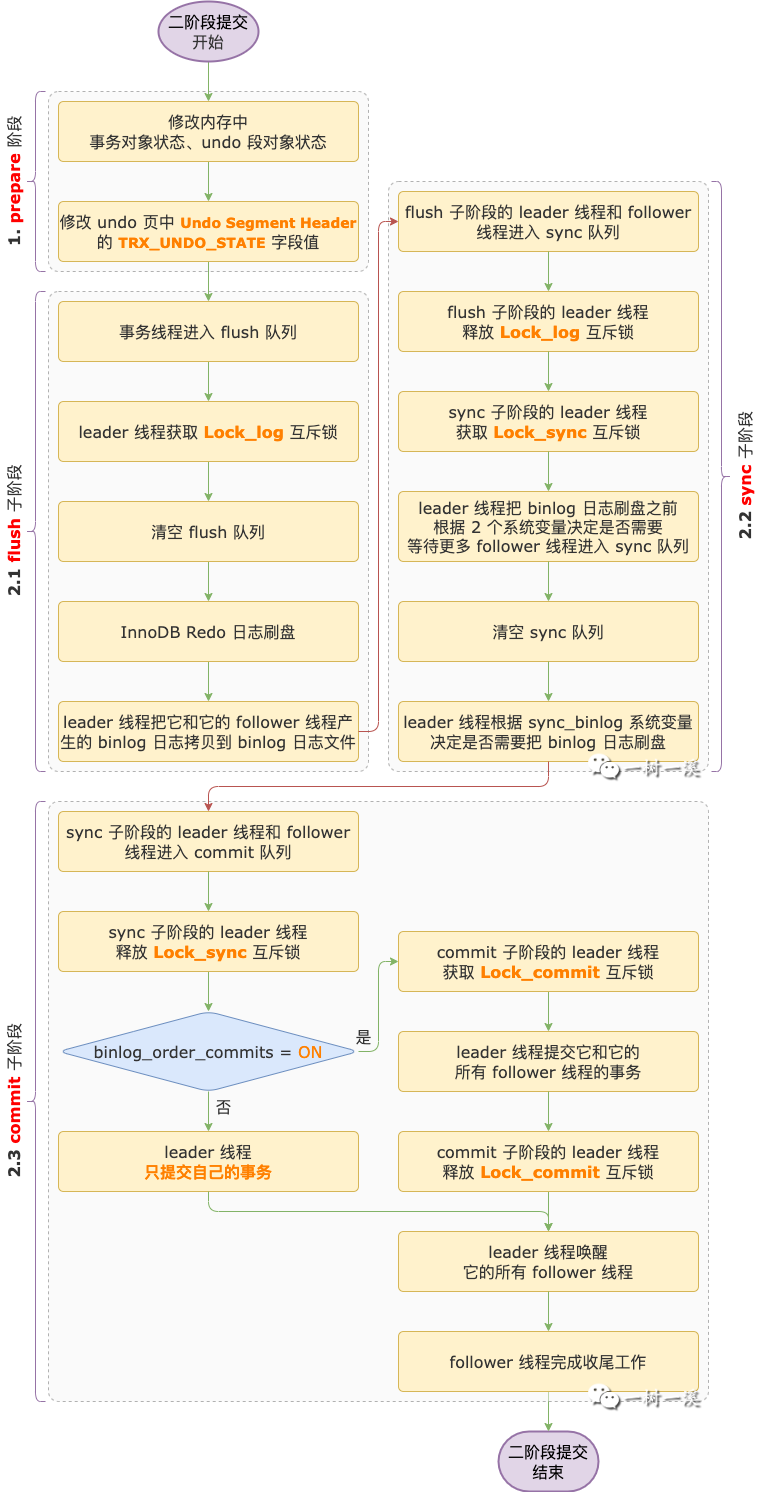
崩溃恢复时,如果发现 Redo Log 是 prepare 但 Binlog 完整,则会提交事务;反之会回滚,避免主从不一致。
另外,由于 Redo Log 的容量有限,Checkpoint 机制会定期将内存中的脏页刷到磁盘,这样能减少崩溃恢复时需要处理的 Redo Log 数量。
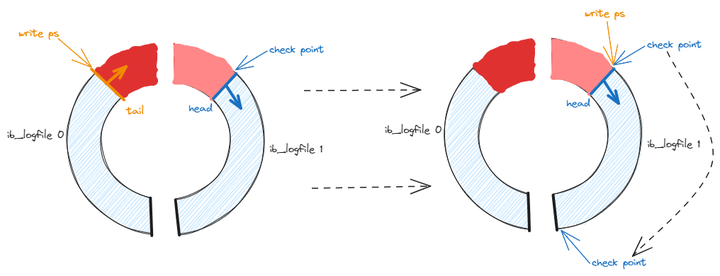
推荐阅读:深入解析MySQL双写缓冲区、MySQL 事务二阶段提交
详细说说如何保证隔离性?
隔离性主要通过锁机制和 MVCC 来实现。
比如说一个事务正在修改某条数据时,MySQL 会通过临键锁来防止其他事务同时进行修改,避免数据冲突。
同时,临键锁可以防止幻读现象的发生。比如事务 A 查询 id > 10 的记录,那么临键锁不仅会锁住 id=10 的行,还会锁住 10 后面的“间隙”,防止其他事务插入 id=15 的数据。
假如表中的主键有 id: 5, 10, 15, 20, 25,那么 InnoDB 会对以下区间和记录加锁:
| 加锁对象 | 类型 | 锁定含义 |
|---|---|---|
(10, 15] | 临键锁 | 锁住 id=15 和前间隙,防止插入11~14 |
(15, 20] | 临键锁 | 锁住了 id=20 和前间隙 |
(20, 25] | 临键锁 | 锁住了 id=25 和前间隙 |
(25, +∞) | 间隙锁 | 锁住尾部防止插入30等 |
MVCC 主要用来优化读操作,通过保存数据的历史版本,让读操作不需要加锁就能直接读取快照,提高读的并发性能。
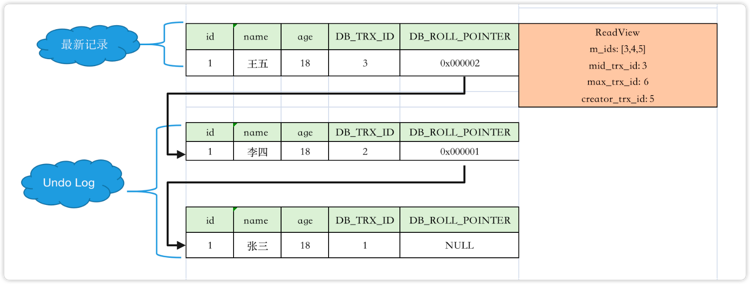
不同的隔离级别对应不同的实现策略,比如说在可重复读隔离级别下,事务第一次查询时会生成一个 Read View,之后所有读操作都复用这个视图,保证多次读取的结果一致。
如何保证一致性呢?
MySQL 的一致性并不是靠某一个机制单独保证的,而是原子性、隔离性和持久性协同作用的结果。
事务会不会自动提交?
是的,MySQL 默认开启了事务自动提交模式。
每条单独的 SQL 语句都会被视为一个独立的事务处理单元;SQL 语句执行成功后会自动执行 COMMIT;执行失败时会自动 ROLLBACK。
可通过 SELECT @@autocommit; 查看当前会话的自动提交状态。
如果需要执行多条 SQL 语句,可以将它们放在一个事务中,使用 START TRANSACTION 开启事务,执行完所有 SQL 语句后手动提交。
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
COMMIT;
- Java 面试指南(付费)收录的美团同学 2 优选物流调度技术 2 面面试原题:MySQL ACID 哪些机制来保证
- Java 面试指南(付费)收录的百度同学 4 面试原题:事务会不会自动提交?
memo:2025 年 4 月 14 日修改至此,昨天有球友发帖说拿到了字节、美团的暑期实习 offer,双非本末 9 硕,全文很硬,强烈推荐大家看看,差不多有 3000 多字,详细剖析了自己的准备过程。
62.🌟事务的隔离级别有哪些?
隔离级别定义了一个事务可能受其他事务影响的程度,MySQL 支持四种隔离级别,分别是:读未提交、读已提交、可重复读和串行化。
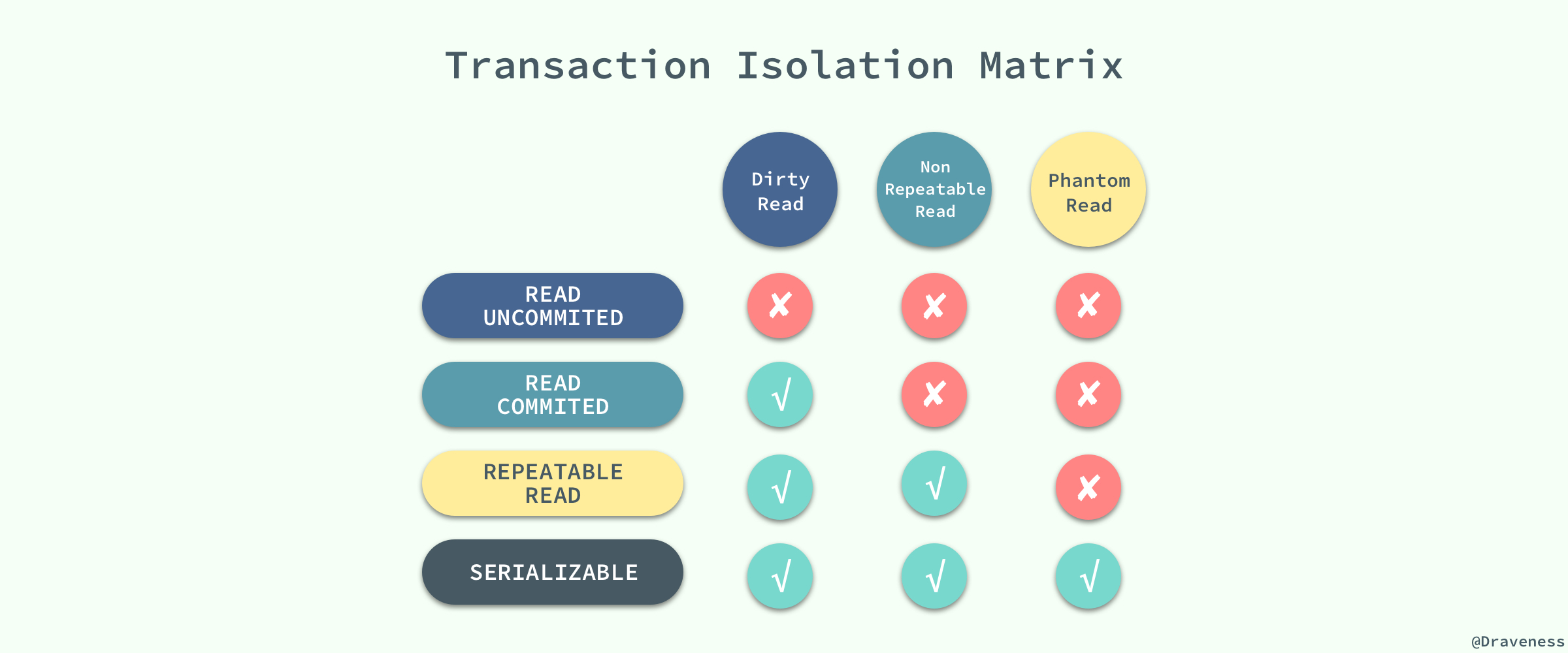
读未提交会出现脏读,读已提交会出现不可重复读,可重复读是 InnoDB 默认的隔离级别,可以避免脏读和不可重复读,但会出现幻读。不过通过 MVCC 和临键锁,能够防止大多数并发问题。
串行化最安全,但性能较差,通常不推荐使用。
详细说说读未提交?
事务可以读取其他未提交事务修改的数据。也就是说,如果未提交的事务一旦回滚,读取到的数据就会变成了“脏数据”,通常不会使用。
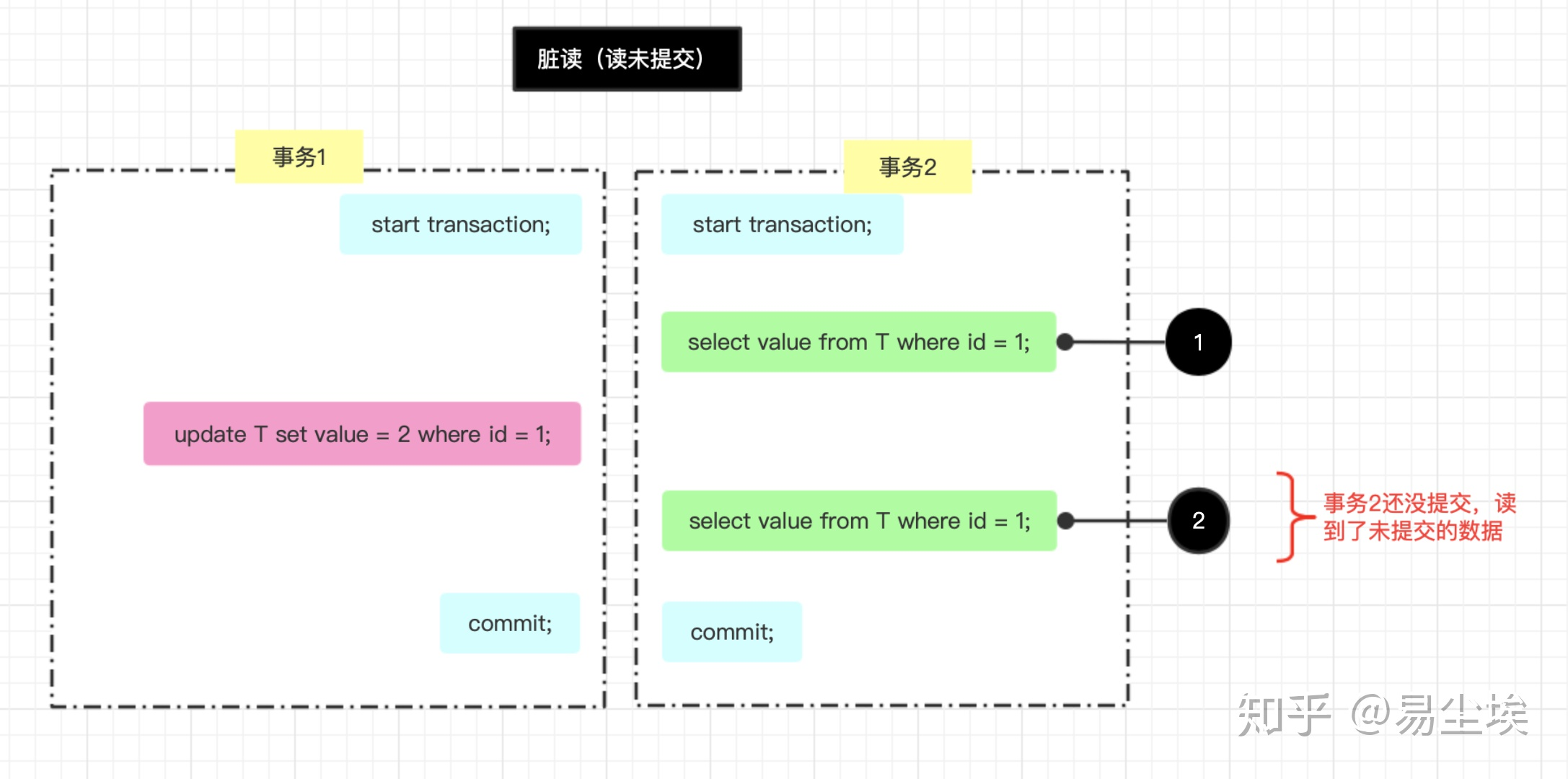
什么是读已提交?
读已提交避免了脏读,但可能会出现不可重复读,即同一事务内多次读取同一数据结果会不同,因为其他事务提交的修改,对当前事务是可见的。
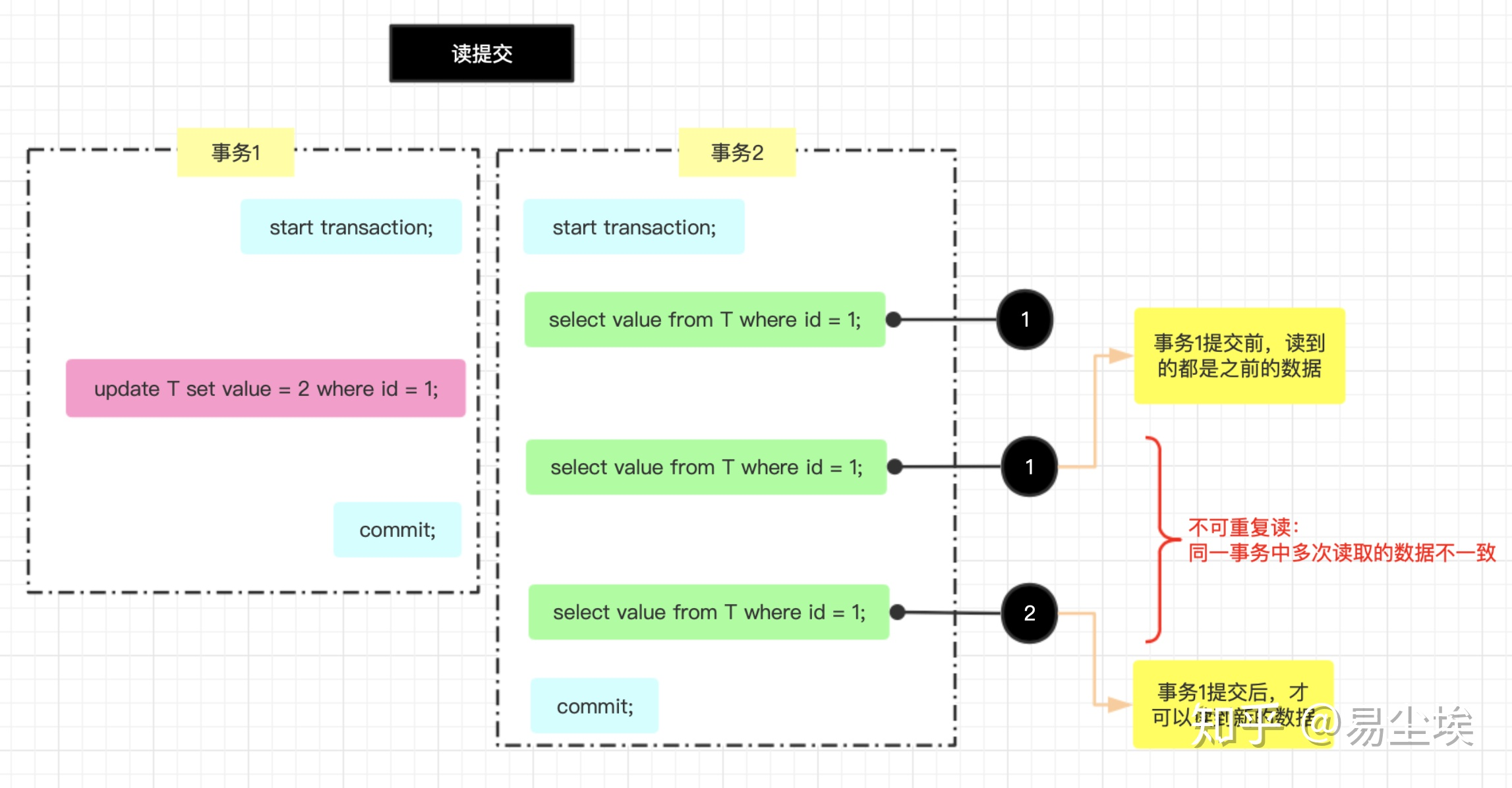
是 Oracle、SQL Server 等数据库的默认隔离级别。
什么是可重复读?
可重复读能确保同一事务内多次读取相同数据的结果一致,即使其他事务已提交修改。
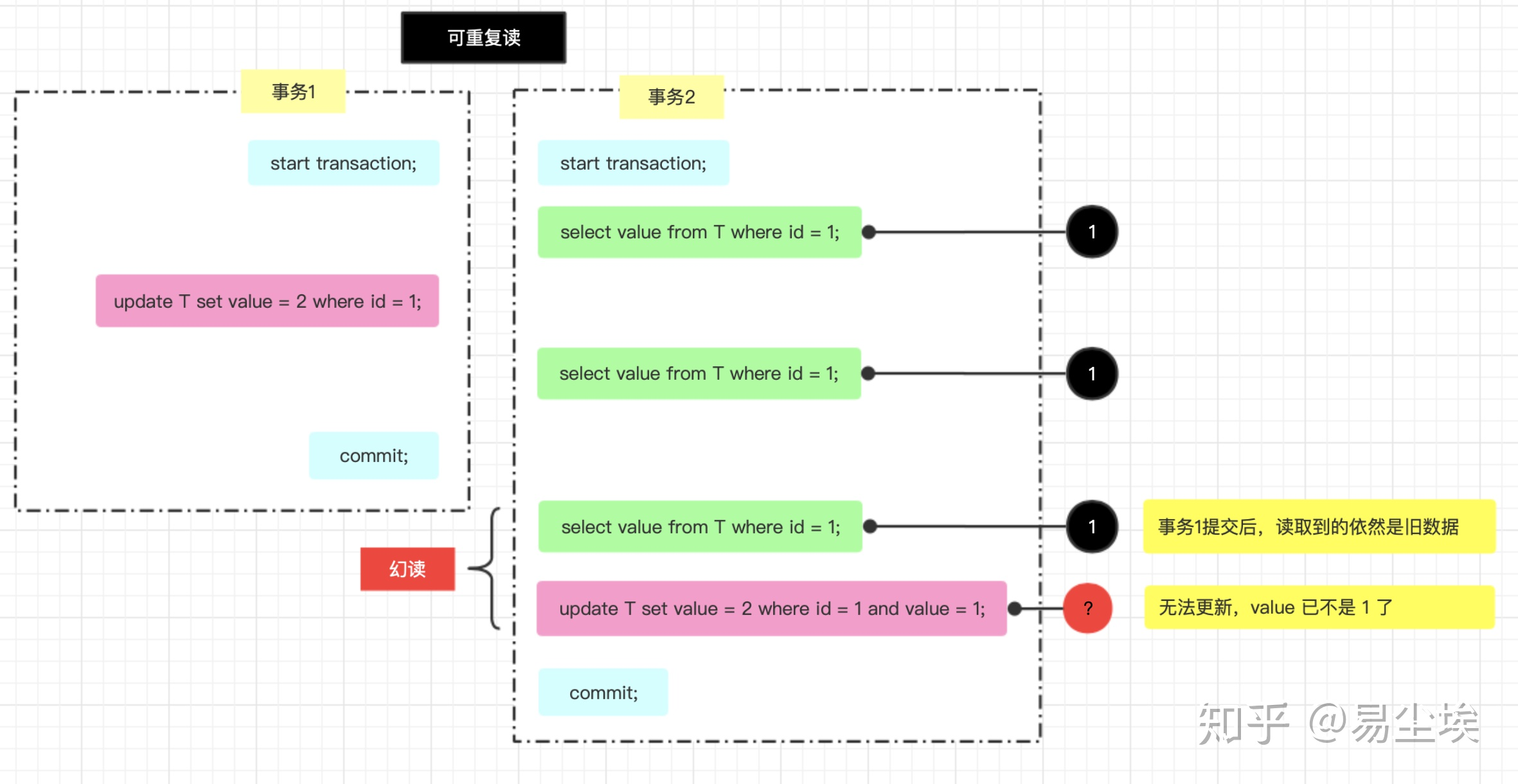
是 MySQL 默认的隔离级别,避免了“脏读”和“不可重复读”,通过 MVCC 和临键锁也能在一定程度上避免幻读。
-- Session A:
START TRANSACTION;
SELECT balance FROM accounts WHERE id=1; --返回500
-- Session B:
UPDATE accounts SET balance = balance +100 WHERE id=1;
COMMIT;
-- Session A再次查询:
SELECT balance FROM accounts WHERE id=1; --仍返回500(可重复读)
-- Session A更新后查询:
UPDATE accounts SET balance = balance +50 WHERE id=1; --基于最新值550更新为600
SELECT balance FROM accounts WHERE id=1; --返回600什么是串行化?
串行化是最高的隔离级别,通过强制事务串行执行来解决“幻读”问题。
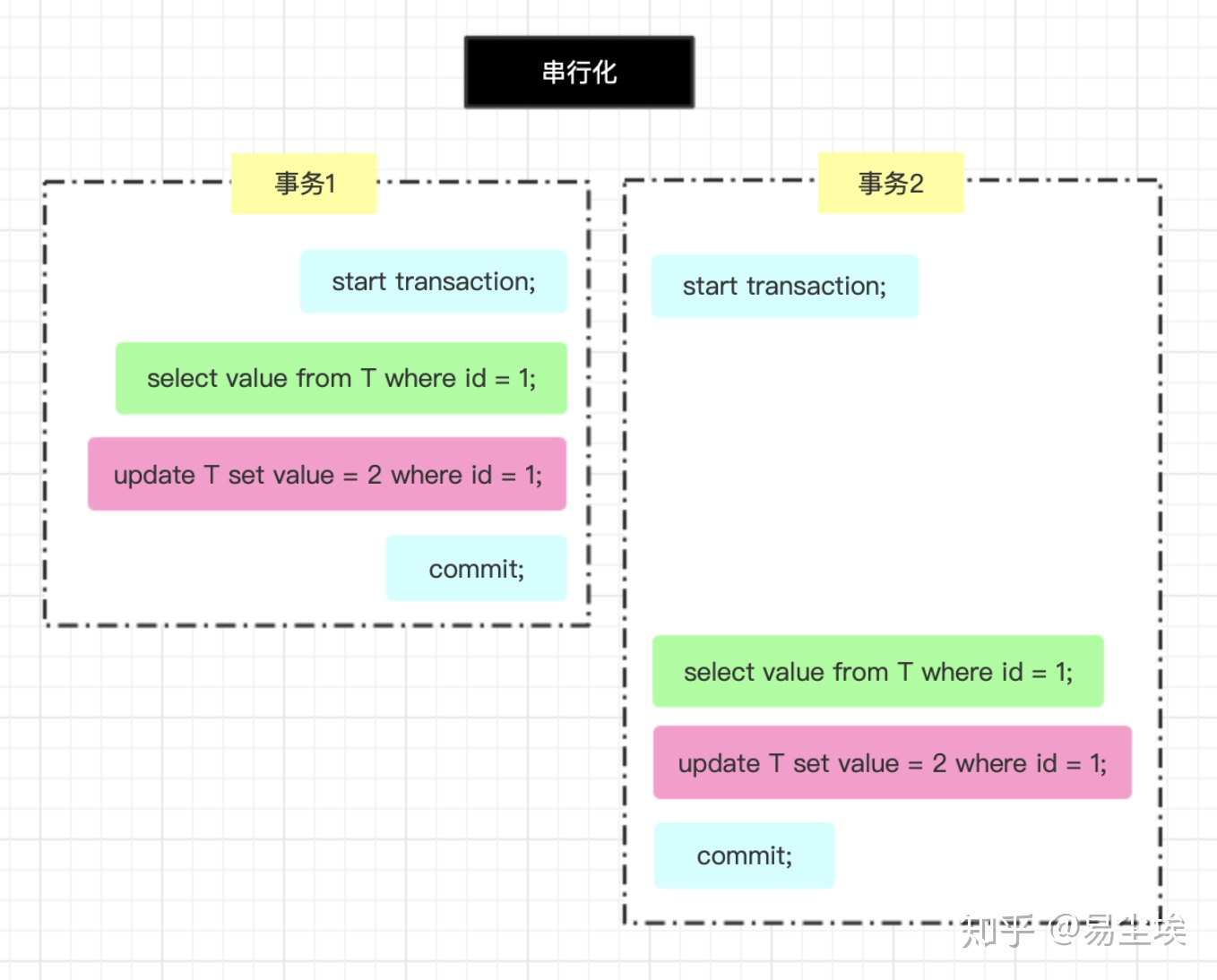
但会导致大量的锁竞争问题,实际应用中很少用。
A 事务未提交,B 事务上查询到的是旧值还是新值?
如果 B 是普通的 SELECT,也就是快照读,它读的是旧值,即事务 A 修改前的快照,并且不会阻塞;如果 B 是当前读,比如 SELECT … FOR UPDATE,它会被阻塞直到事务 A 提交或回滚。
-- 会话 A 中,更新王二的余额
START TRANSACTION;
UPDATE accounts SET balance = 8000 WHERE name = '王二';
-- 此时并没有 COMMIT
-- 会话 B 中查询王二的余额
SELECT * FROM accounts WHERE name = '王二';
-- 会话 B 会读取到 旧值 1000
-- 会话 C 中使用当前读查询王二的余额
SELECT * FROM accounts WHERE name = '王二' FOR UPDATE;
-- 会话 C 会被阻塞,直到会话 A 提交或回滚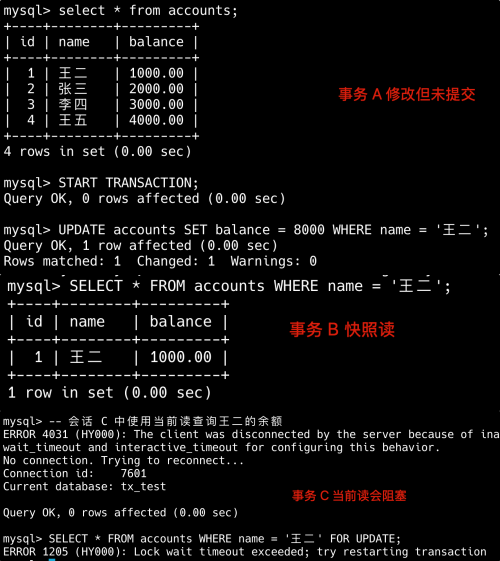
怎么更改事务的隔离级别?
MySQL 支持通过 SET 语句修改事务隔离级别,包括全局级别、当前会话,但一般不建议在生产环境中随意修改隔离级别。
测试环境下可以使用 SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; 可以修改当前会话的隔离级别。
使用 SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED; 可以修改全局隔离级别,影响新的连接,但不会改变现有会话。
- Java 面试指南(付费)收录的美团面经同学 16 暑期实习一面面试原题:MySQL 事务是什么,默认隔离级别,什么是可重复读?
- Java 面试指南(付费)收录的腾讯面经同学 23 QQ 后台技术一面面试原题:MySQL 事务,隔离级别
- Java 面试指南(付费)收录的快手面经同学 7 Java 后端技术一面面试原题:说一下事务的四大隔离级别,分别解决什么问题
- Java 面试指南(付费)收录的字节跳动面经同学 1 Java 后端技术一面面试原题:MySQL 默认隔离级别?
- Java 面试指南(付费)收录的美团面经同学 2 Java 后端技术一面面试原题:说说 MySQL 事务的隔离级别,如何实现?
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:MySQL 的四个隔离级别以及默认隔离级别?
- Java 面试指南(付费)收录的 360 面经同学 3 Java 后端技术一面面试原题:数据库隔离级别有哪些?mysql 是属于哪个隔离级别
- Java 面试指南(付费)收录的联想面经同学 7 面试原题:Mysql 四个隔离级别,MVCC 实现
- Java 面试指南(付费)收录的oppo 面经同学 8 后端开发秋招一面面试原题:讲讲Mysql的四个隔离级别
- Java 面试指南(付费)收录的比亚迪面经同学 12 Java 技术面试原题:mysql的隔离级别有哪些
- Java 面试指南(付费)收录的腾讯面经同学 27 云后台技术一面面试原题:事务的隔离级别?这些隔离级别是怎么保证数据的一致性的?默认的事务隔离级别是啥?(MVCC)怎么更改事务的隔离级别?
- Java 面试指南(付费)收录的字节跳动面经同学19番茄小说一面面试原题:事务隔离级别,哪个是默认的,特点
- Java 面试指南(付费)收录的虾皮面经同学 13 一面面试原题:mysql事务隔离级别
63.事务的隔离级别是如何实现的?
读未提交通过行锁共享锁确保一个事务在更新行数据但没有提交的情况下,其他事务不能更新该行数据,但不会阻止脏读,意味着事务2 可以在事务1 提交之前读取到事务1 修改的数据。
读已提交会在更新数据前加行级排他锁,不允许其他事务写入或者读取未提交的数据,也就意味着事务2 不能在事务 1 提交之前读取到事务1 修改的数据,从而解决脏读的问题。
另外,读已提交会在每次读取数据前都生成一个新的 ReadView,所以会出现不可重复读的问题。
可重复读只在第一次读操作时生成 ReadView,后续读操作都会使用这个 ReadView,从而避免不可重复读的问题。
另外,对于当前读操作,可重复读会通过临键锁来锁住当前行和前间隙,防止其他事务在这个范围内插入数据,从而避免幻读的问题。
串行化级别下,事务在读操作时,会先加表级共享锁;在写操作时,会先加表级排他锁。
直到事务结束后才释放锁,这样就能确保事务之间不会相互干扰。
- Java 面试指南(付费)收录的美团面经同学 2 Java 后端技术一面面试原题:说说 MySQL 事务的隔离级别,如何实现?
- Java 面试指南(付费)收录的得物面经同学 9 面试题目原题:Mysql隔离机制有哪些?怎么实现的?可串行化是怎么避免的三个事务问题?
- Java 面试指南(付费)收录的滴滴面经同学 3 网约车后端开发一面原题:可重复读级别是怎么实现的
memo:2025 年 4 月 17 日修改至此,今天有球友发微信说拿到京东的暑期实习 offer,并且今天 VIP 9 群有球友说今天是晒 offer 日,因为 9 群有好几个球友拿到了大厂 offer,后面我再同步给大家。
64.🌟请详细说说幻读呢?
幻读是指在同一个事务中,多次执行相同的范围查询,结果却不同。这种现象通常发生在其他事务在两次查询之间插入或删除了符合当前查询条件的数据。
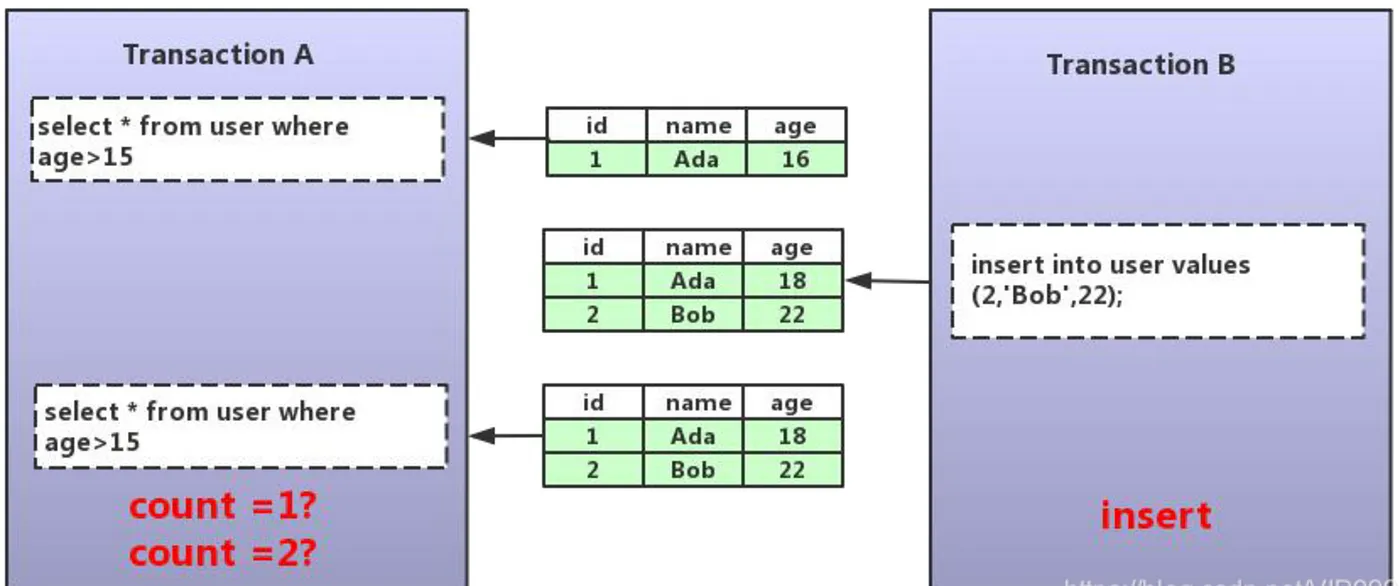
---- 这部分是帮助大家理解 start,面试中可以不背 ----
比如说事务 A 在第一次查询某个条件范围的数据行后,事务 B 插入了一条新数据且符合条件范围,事务 A 再次查询时,发现多了一条数据。
我们来验证一下,先创建测试表,插入测试数据。
CREATE TABLE `user_info` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '姓名',
`gender` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '性别',
`email` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '邮箱',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4 COMMENT='用户信息表';
-- 插入测试数据
INSERT INTO `user_info` (`id`, `name`, `gender`, `email`) VALUES
(1, 'Curry', '男', 'curry@163.com'),
(2, 'Wade', '男', 'wade@163.com'),
(3, 'James', '男', 'james@163.com');
COMMIT;然后我们在事务 A 中执行查询 SELECT * FROM user_info WHERE id > 1;,在事务 B 中插入数据 INSERT INTO user_info (name, gender, email) VALUES ('wanger', '女', 'wanger@163.com');,再在事务 A 中修改刚刚插入的数据 update user_info set gender='男' where id = 4;,最后在事务 A 中再次查询 SELECT * FROM user_info WHERE id > 1;。
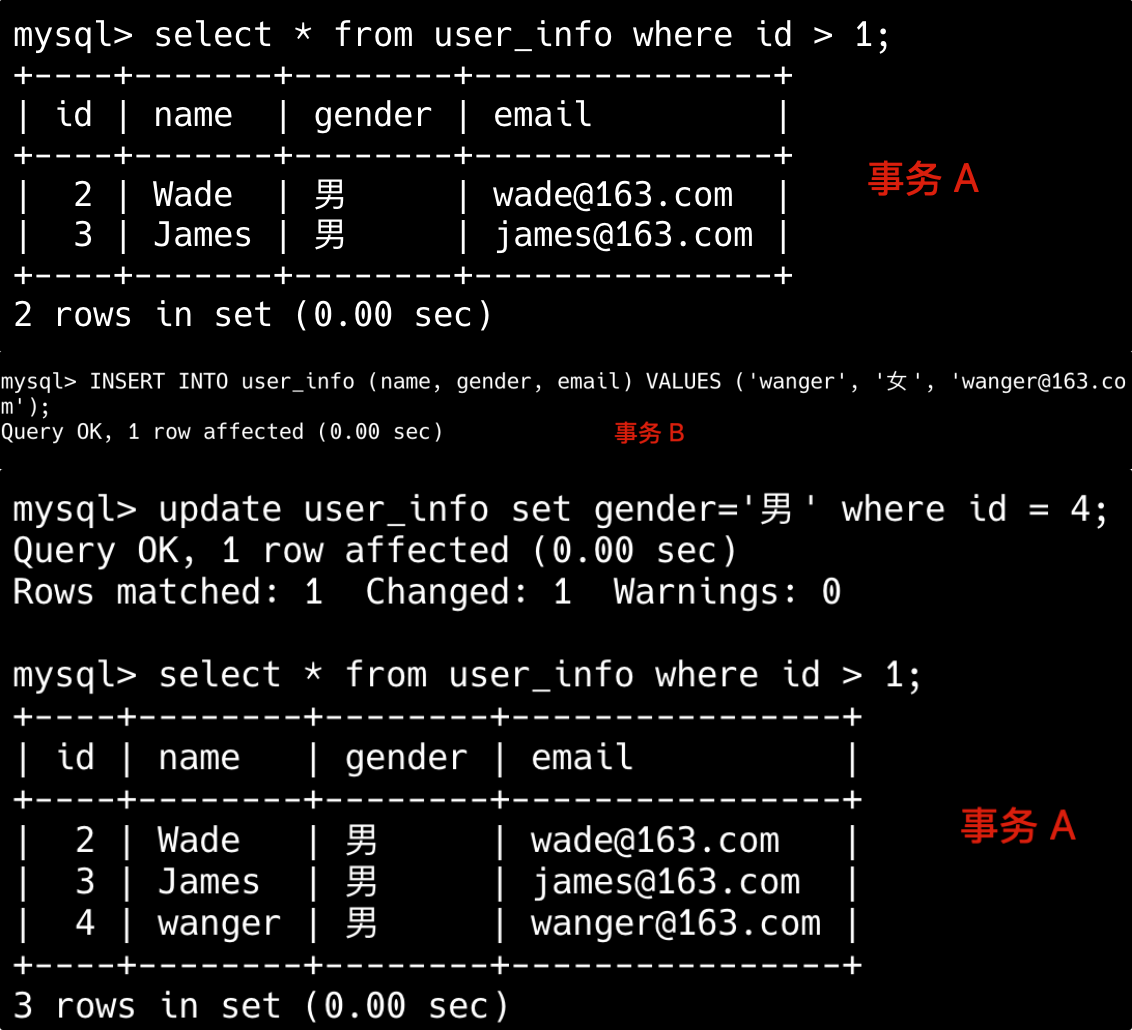
---- 这部分是帮助大家理解 end,面试中可以不背 ----
如何避免幻读?
MySQL 在可重复读隔离级别下,通过 MVCC 和临键锁可以在一定程度上避免幻读。
比如说在查询时显示加锁,利用临键锁锁定查询范围,防止其他事务插入新的数据。
START TRANSACTION;
SELECT * FROM user_info WHERE id > 1 FOR UPDATE; -- 加临键锁
COMMIT;其他事务在插入数据时,会被阻塞,直到当前事务提交或回滚。
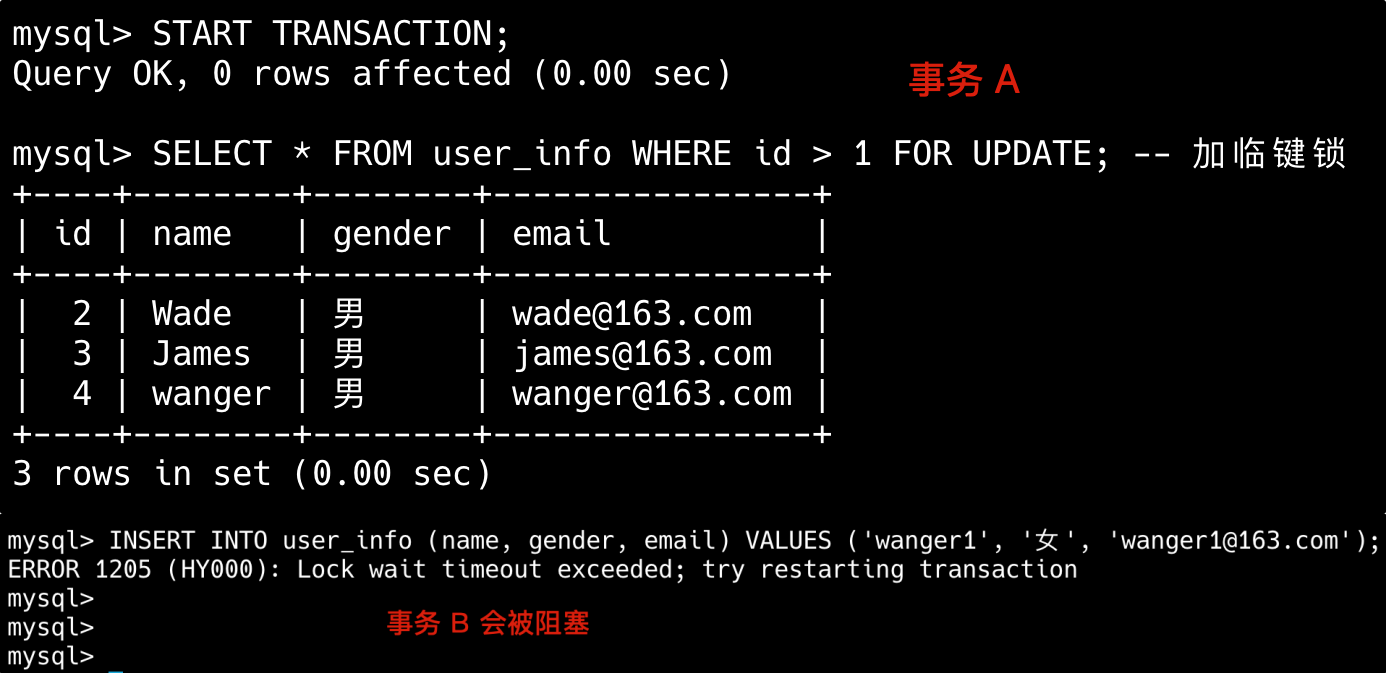
---- 这部分是帮助大家理解 start,面试中可以不背 ----
解释一下。
如果查询语句中包含显式加锁(如 FOR UPDATE),InnoDB 会使用当前读,直接读取最新的数据,并加锁。
在范围查询时,InnoDB 不仅会对符合条件的记录加行锁,还会对相邻的索引间隙加间隙锁,从而形成临键锁。
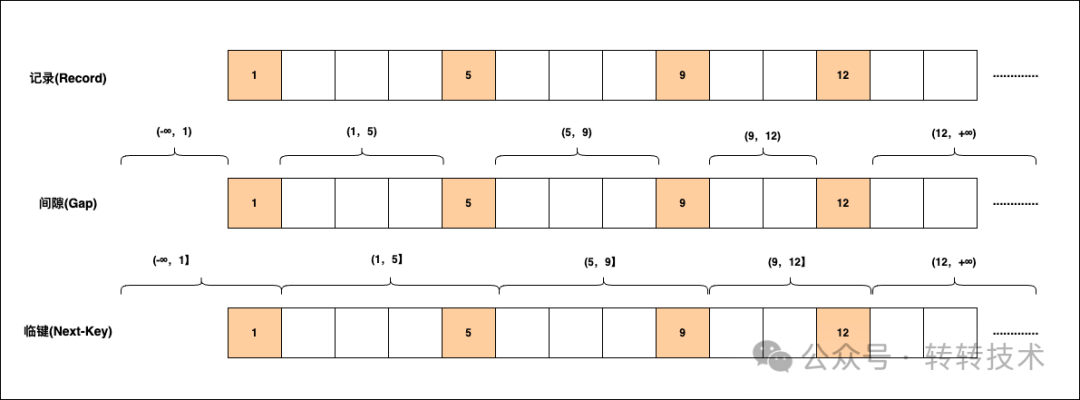
临键锁可以防止其他事务在间隙中插入新数据,从而避免幻读。
---- 这部分是帮助大家理解 end,面试中可以不背 ----
比如说在执行查询的事务中,不要尝试去更新其他事务插入/删除的数据,利用快照读来避免幻读。
---- 这部分是帮助大家理解 start,面试中可以不背 ----
使用 SELECT 查询时,如果没有显式加锁,InnoDB 会使用 MVCC 提供一致性视图。
每个事务在启动时都会生成一个 Read View,用来确定哪些数据对当前事务可见。
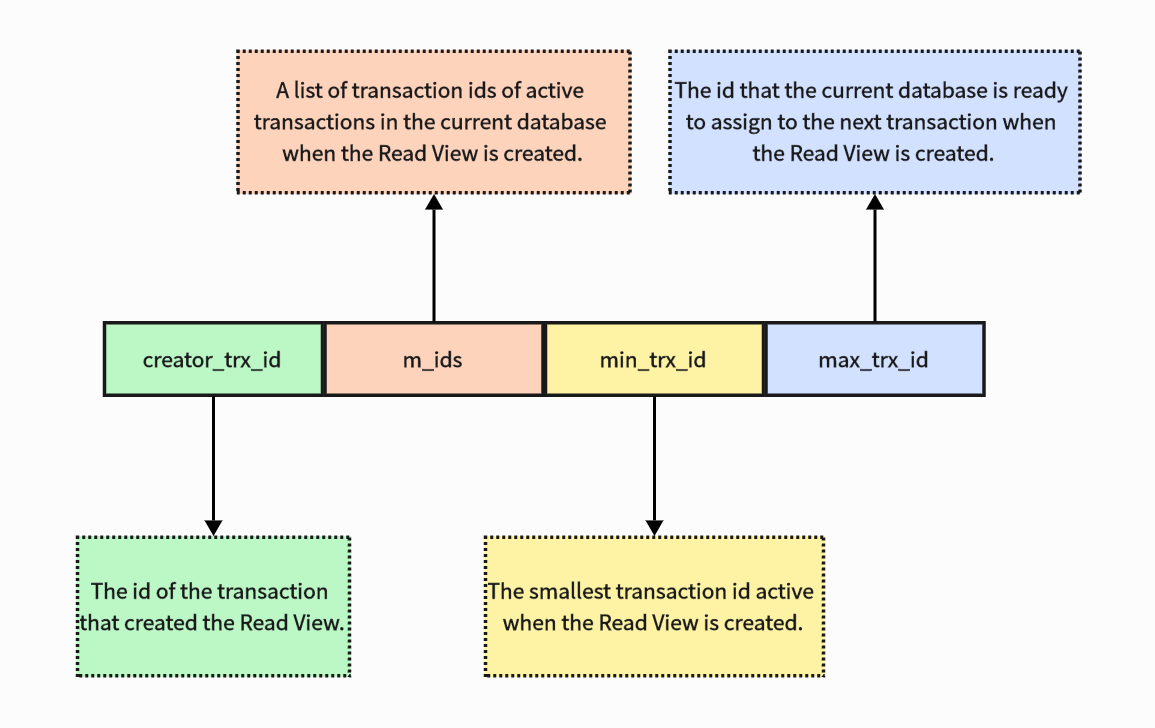
其他事务在当前事务启动后插入的新数据不会被当前事务看到,因此不会出现幻读。
---- 这部分是帮助大家理解 end,面试中可以不背 ----
什么是当前读呢?
当前读是指读取记录的最新已提交版本,并且在读取时对记录加锁,确保其他并发事务不能修改当前记录。
比如 SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE,以及 UPDATE、DELETE,都属于当前读。
为什么 UPDATE 和 DELETE 也属于当前读?
因为更新、删除这些操作,本质上不仅是写操作,还需要在写之前读取数据,然后才能修改或删除。为了保证修改的是最新的数据,并防止并发冲突,InnoDB 必须读取最新版本的数据并加锁,因此 UPDATE 和 DELETE 也属于当前读。
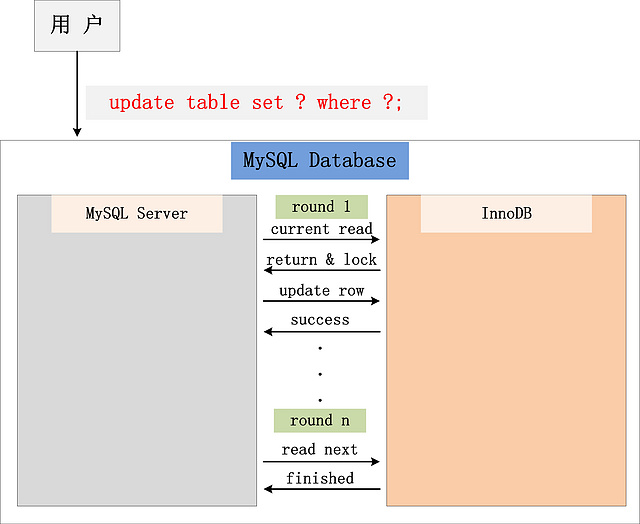
| SQL语句 | 是否当前读 | 是否加锁 |
|---|---|---|
SELECT * FROM user WHERE id=1 | ❌ 否 | ❌ 否 |
SELECT * FROM user WHERE id=1 FOR UPDATE | ✅ 是 | ✅ 加排他锁 |
SELECT * FROM user WHERE id=1 LOCK IN SHARE MODE | ✅ 是 | ✅ 加共享锁 |
UPDATE user SET ... WHERE id=1 | ✅ 是 | ✅ 加排他锁 |
DELETE FROM user WHERE id=1 | ✅ 是 | ✅ 加排他锁 |
什么是快照读呢?
快照读是 InnoDB 通过 MVCC 实现的一种非阻塞读方式。当事务执行 SELECT 查询时,InnoDB 并不会直接读当前最新的数据,而是根据事务开始时生成的 Read View 去判断每条记录的可见性,从而读取符合条件的历史版本。
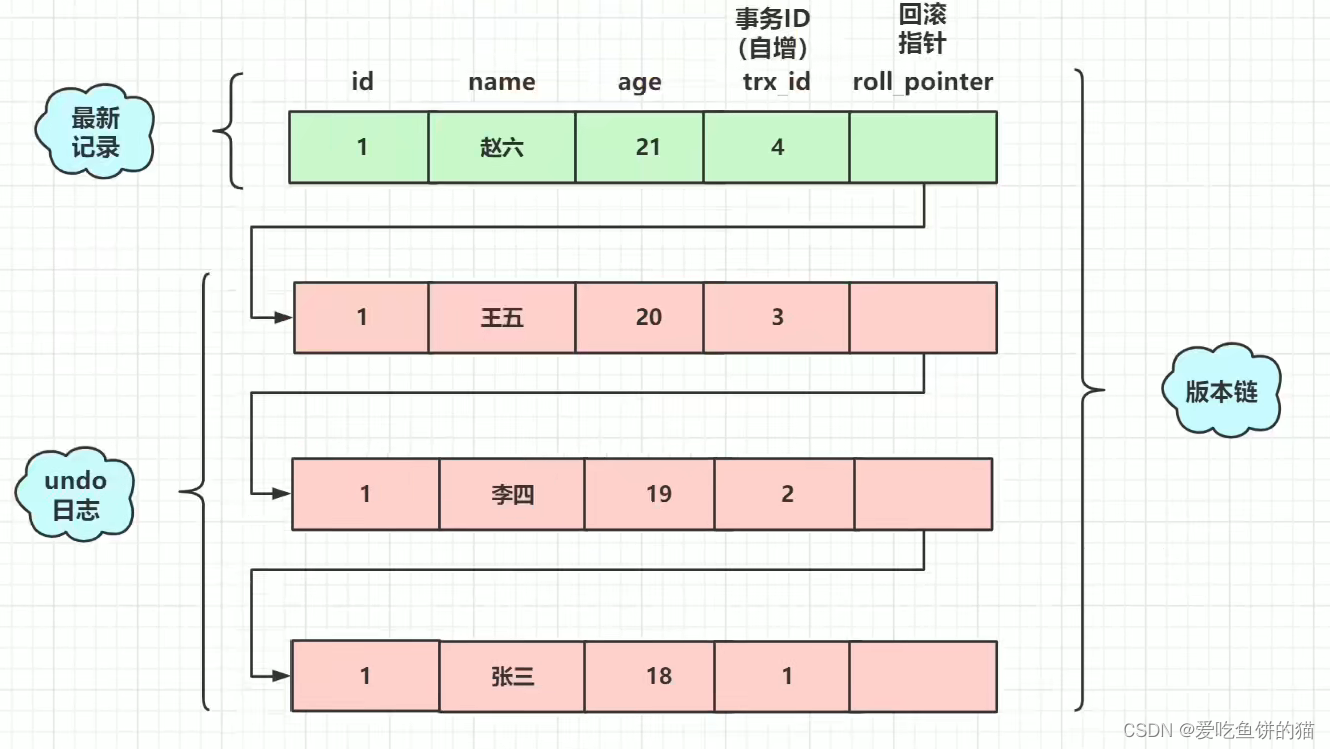
| SQL | 是否快照读? | 说明 |
|---|---|---|
SELECT * FROM t WHERE id=1 | ✅ 是 | 快照读 |
SELECT * FROM t WHERE id=1 FOR UPDATE | ❌ 否 | 当前读,读取最新版本并加锁 |
UPDATE / DELETE | ❌ 否 | 当前读,必须读取当前版本并加锁 |
INSERT | ❌ 否 | 写操作,不存在历史版本 |
- Java 面试指南(付费)收录的京东面经同学 7 京东到家面试原题:mysql事务隔离级别,默认隔离级别,如何避免幻读
- Java 面试指南(付费)收录的阿里云面经同学 22 面经:事务隔离级别,幻读和脏读的区别,如何防止幻读,事务的mvcc机制
memo:2025 年 4 月 18 日修改至此,今天有球友发帖说拿到了蚂蚁的暑期实习 offer,问前景怎么样,我只能说蚂蚁作为阿里的嫡长子,一直处在战略发展的核心位置,肯定是值得去的。

65.🌟MVCC 了解吗?
MVCC 指的是多版本并发控制,每次修改数据时,都会生成一个新的版本,而不是直接在原有数据上进行修改。并且每个事务只能看到在它开始之前已经提交的数据版本。
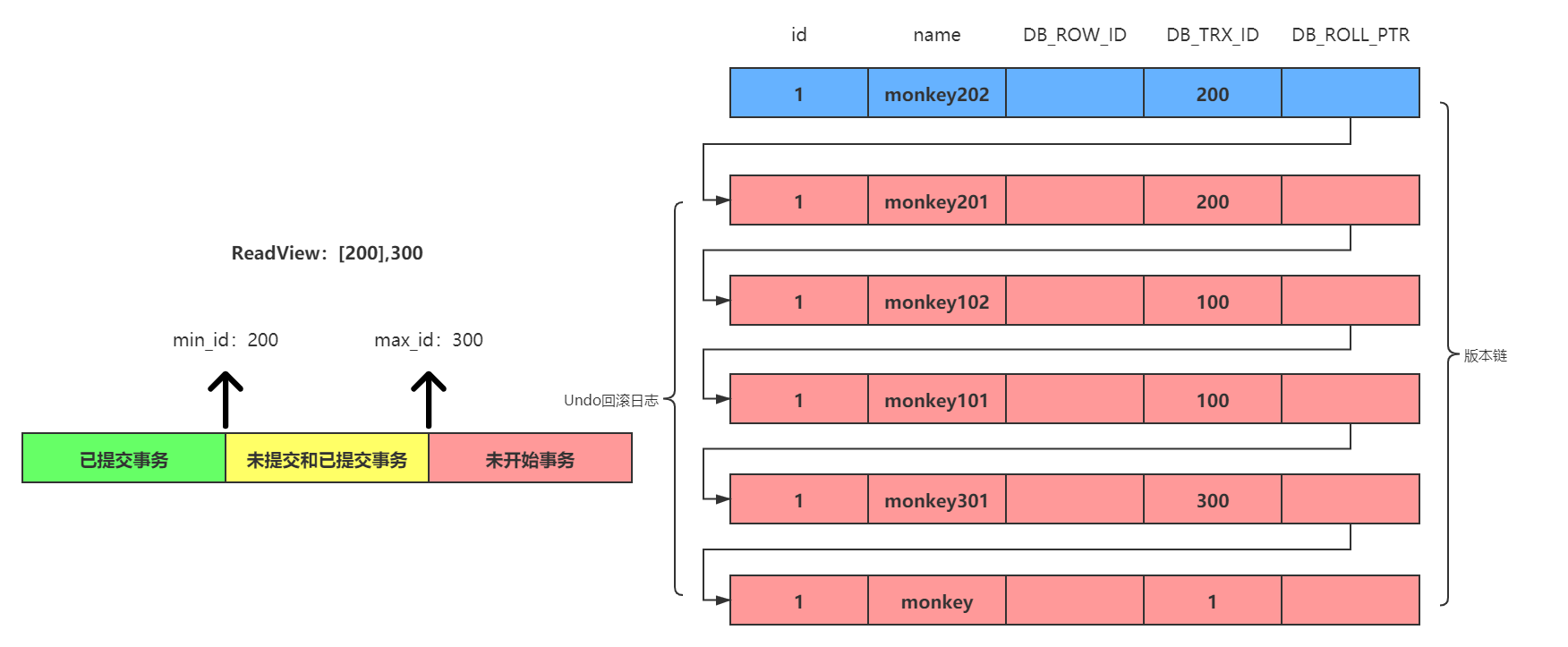
这样的话,读操作就不会阻塞写操作,写操作也不会阻塞读操作,从而避免加锁带来的性能损耗。
其底层实现主要依赖于 Undo Log 和 Read View。
每次修改数据前,先将记录拷贝到Undo Log,并且每条记录会包含三个隐藏列,DB_TRX_ID 用来记录修改该行的事务 ID,DB_ROLL_PTR 用来指向 Undo Log 中的前一个版本,DB_ROW_ID 用来唯一标识该行数据(仅无主键时生成)。
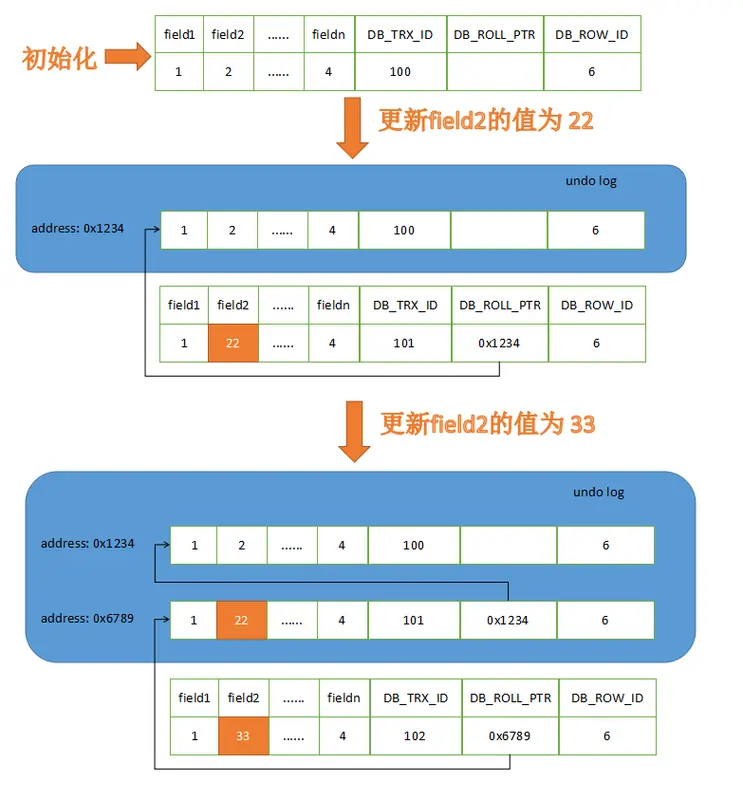
每次读取数据时,都会生成一个 ReadView,其中记录了当前活跃事务的 ID 集合、最小事务 ID、最大事务 ID 等信息,通过与 DB_TRX_ID 进行对比,判断当前事务是否可以看到该数据版本。
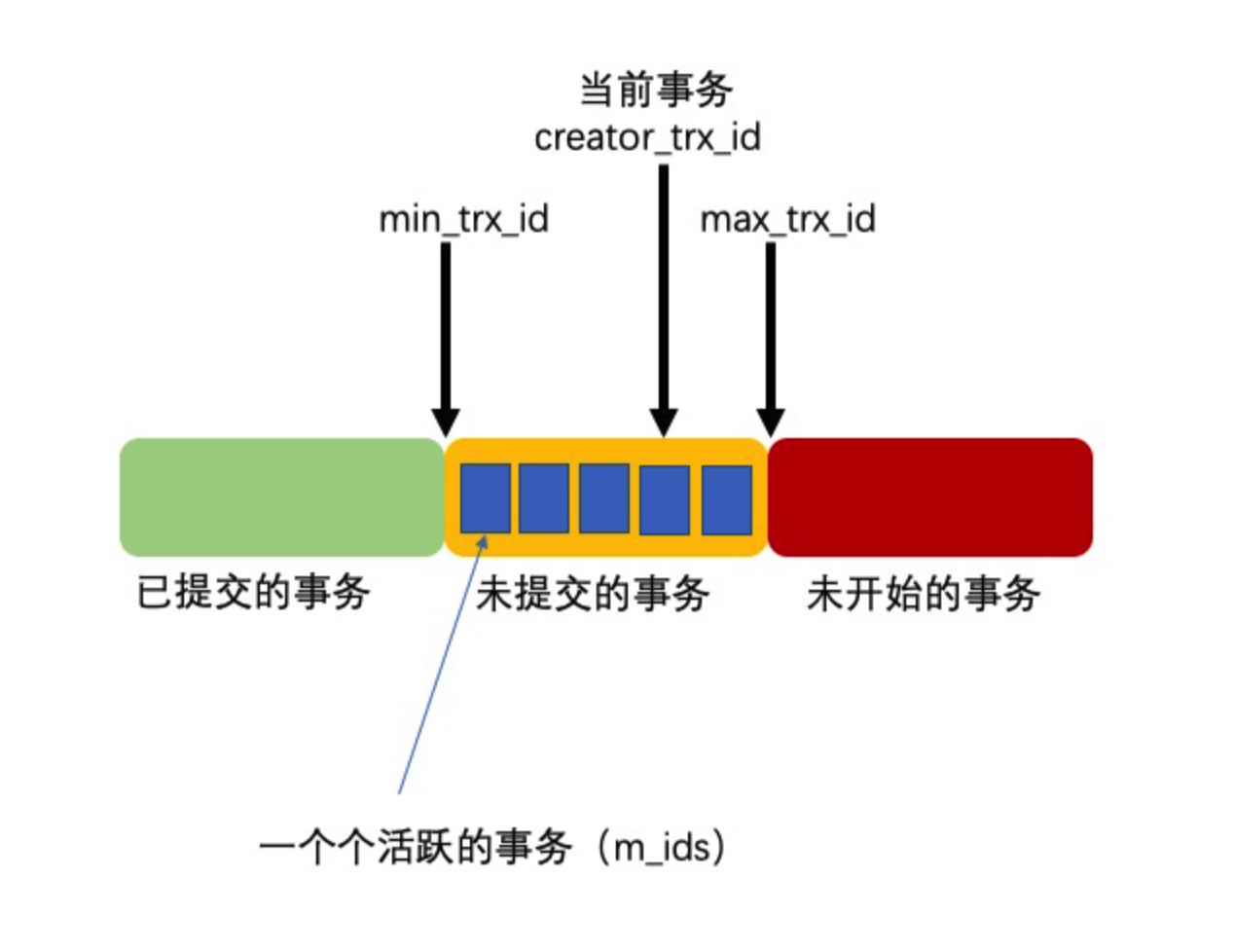
请详细说说什么是版本链?
版本链是指 InnoDB 中同一条记录的多个历史版本,通过 DB_ROLL_PTR 字段将它们像链表一样串起来,用来支持 MVCC 的快照读。
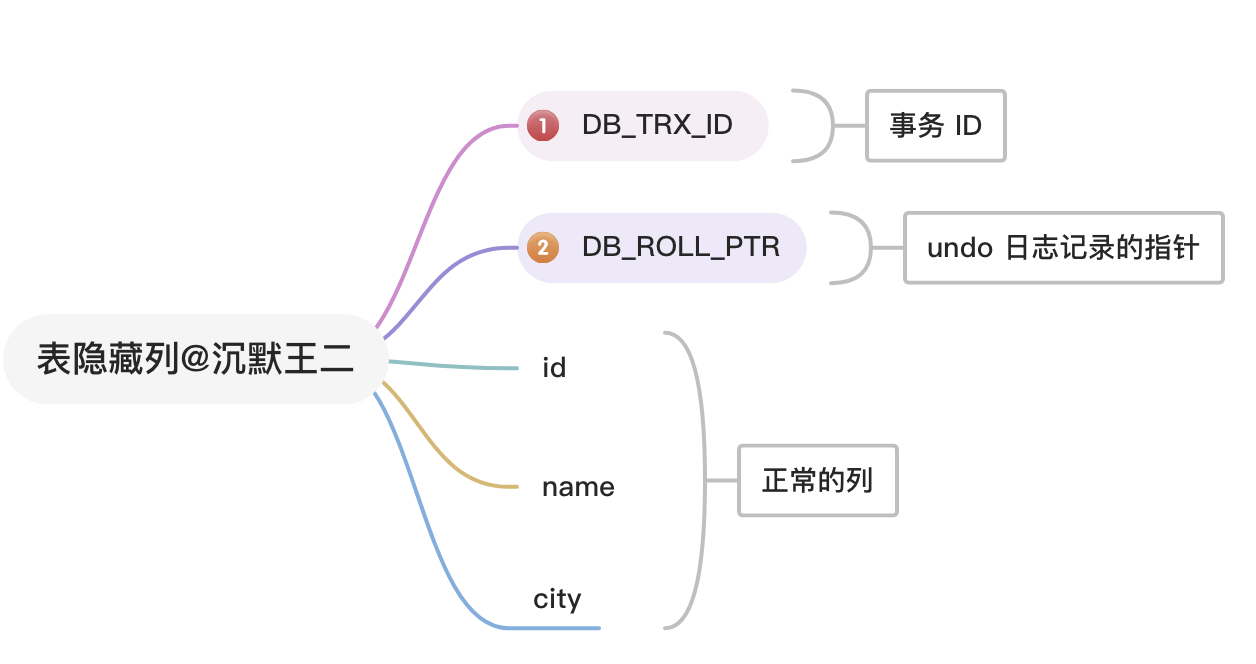
假设有一张hero表,表中有这样一行记录,name 为张三,city 为帝都,插入这行记录的事务 id 是 80。
此时,DB_TRX_ID的值就是 80,DB_ROLL_PTR的值就是指向这条 insert undo 日志的指针。
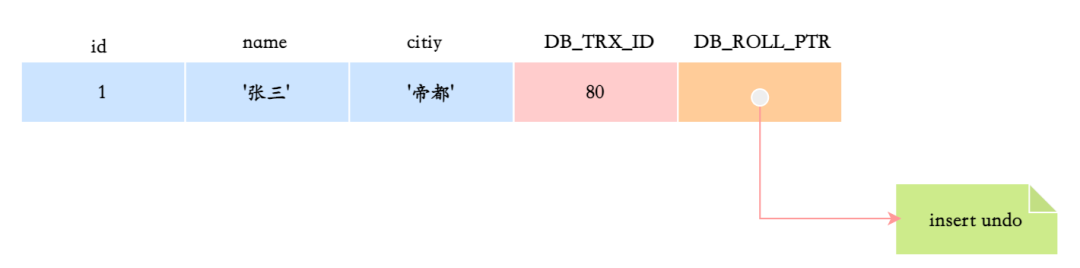
接下来,如果有两个DB_TRX_ID分别为100、200的事务对这条记录进行了update操作,那么这条记录的版本链就会变成下面这样:

也就是说,当更新一行数据时,InnoDB 不会直接覆盖原有数据,而是创建一个新的数据版本,并更新 DB_TRX_ID 和 DB_ROLL_PTR,使它们指向前一个版本和相关的 undo 日志。
这样,老版本的数据就不会丢失,可以通过版本链找到。
由于 undo 日志会记录每一次的 update,并且新插入的行数据会记录上一条 undo 日志的指针,所以可以通过 DB_ROLL_PTR 这个指针找到上一条记录,这样就形成了一个版本链。
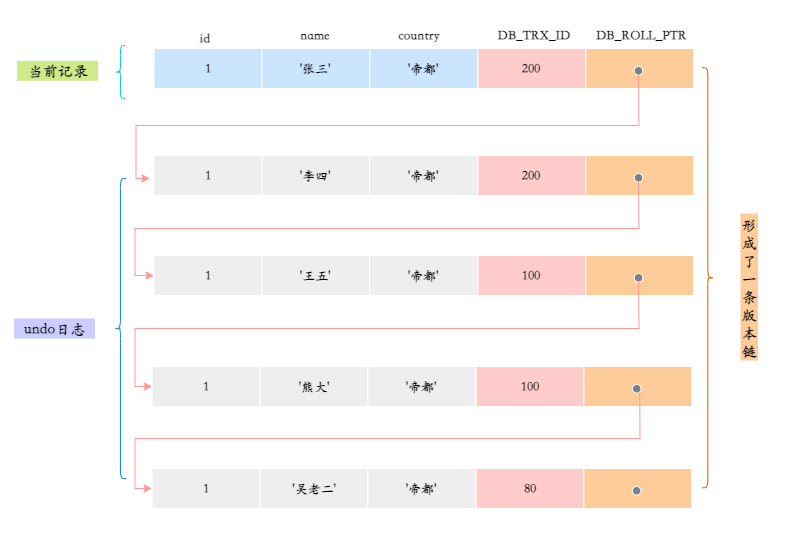
请详细说说什么是ReadView?
ReadView 是 InnoDB 为每个事务创建的一份“可见性视图”,用于判断在执行快照读时,哪些数据版本是当前这个事务可以看到的,哪些不能看到。
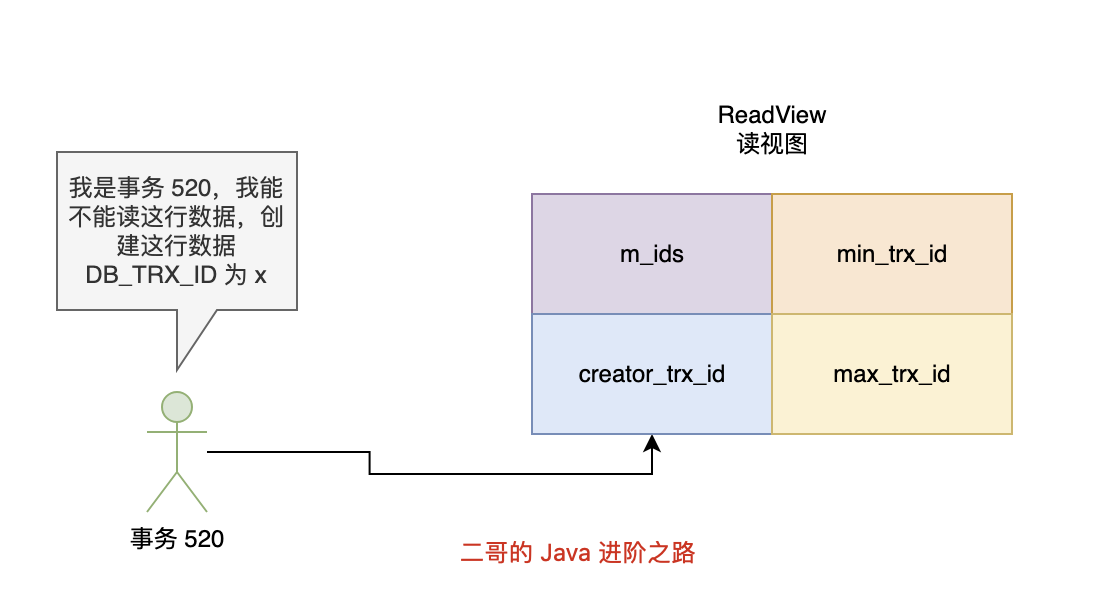
当事务开始执行时,InnoDB 会为该事务创建一个 ReadView,这个 ReadView 会记录 4 个重要的信息:
- creator_trx_id:创建该 ReadView 的事务 ID。
- m_ids:所有活跃事务的 ID 列表,活跃事务是指那些已经开始但尚未提交的事务。
- min_trx_id:所有活跃事务中最小的事务 ID。它是 m_ids 数组中最小的事务 ID。
- max_trx_id :事务 ID 的最大值加一。换句话说,它是下一个将要生成的事务 ID。
ReadView 是如何判断记录的某个版本是否可见的?
会通过三个步骤来判断:
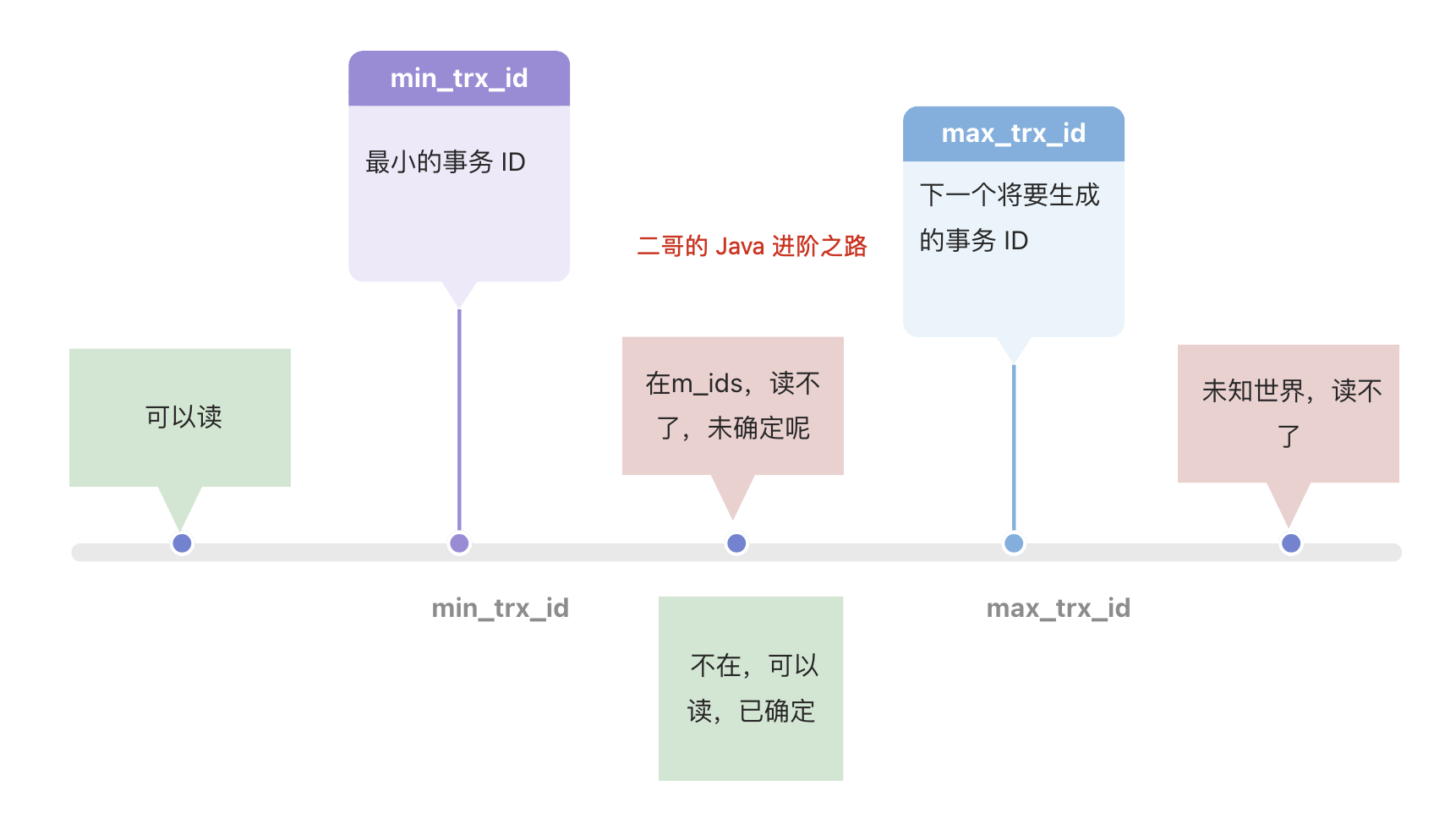
①、如果某个数据版本的 DB_TRX_ID 小于 min_trx_id,则该数据版本在生成 ReadView 之前就已经提交,因此对当前事务是可见的。
②、如果 DB_TRX_ID 大于 max_trx_id,则表示创建该数据版本的事务在生成 ReadView 之后开始,因此对当前事务不可见。
③、如果 DB_TRX_ID 在 min_trx_id 和 max_trx_id 之间,需要判断 DB_TRX_ID 是否在 m_ids 列表中:
- 不在,表示创建该数据版本的事务在生成 ReadView 之后已经提交,因此对当前事务也是可见的。
- 在,表示事务仍然活跃,或者在当前事务生成 ReadView 之后才开始,因此是不可见的。
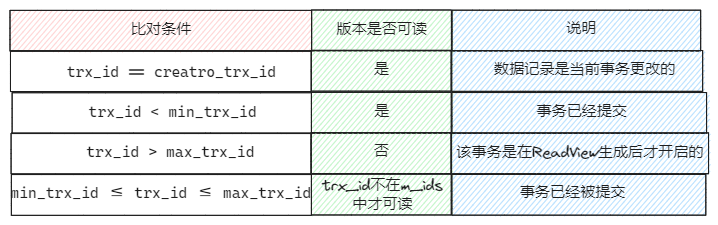
举个实际的例子。
读事务开启了一个 ReadView,这个 ReadView 里面记录了当前活跃事务的 ID 列表(444、555、665),以及最小事务 ID(444)和最大事务 ID(666)。当然还有自己的事务 ID 520,也就是 creator_trx_id。
它要读的这行数据的写事务 ID 是 x,也就是 DB_TRX_ID。
- 如果 x = 110,显然在 ReadView 生成之前就提交了,所以这行数据是可见的。
- 如果 x = 667,显然是未知世界,所以这行数据对读操作是不可见的。
- 如果 x = 519,虽然 519 大于 444 小于 666,但是 519 不在活跃事务列表里,所以这行数据是可见的。因为 519 是在 520 生成 ReadView 之前就提交了。
- 如果 x = 555,虽然 555 大于 444 小于 666,但是 555 在活跃事务列表里,所以这行数据是不可见的。因为 555 不确定有没有提交。
可重复读和读已提交在 ReadView 上的区别是什么?
可重复读:在第一次读取数据时生成一个 ReadView,这个 ReadView 会一直保持到事务结束,这样可以保证在事务中多次读取同一行数据时,读取到的数据是一致的。
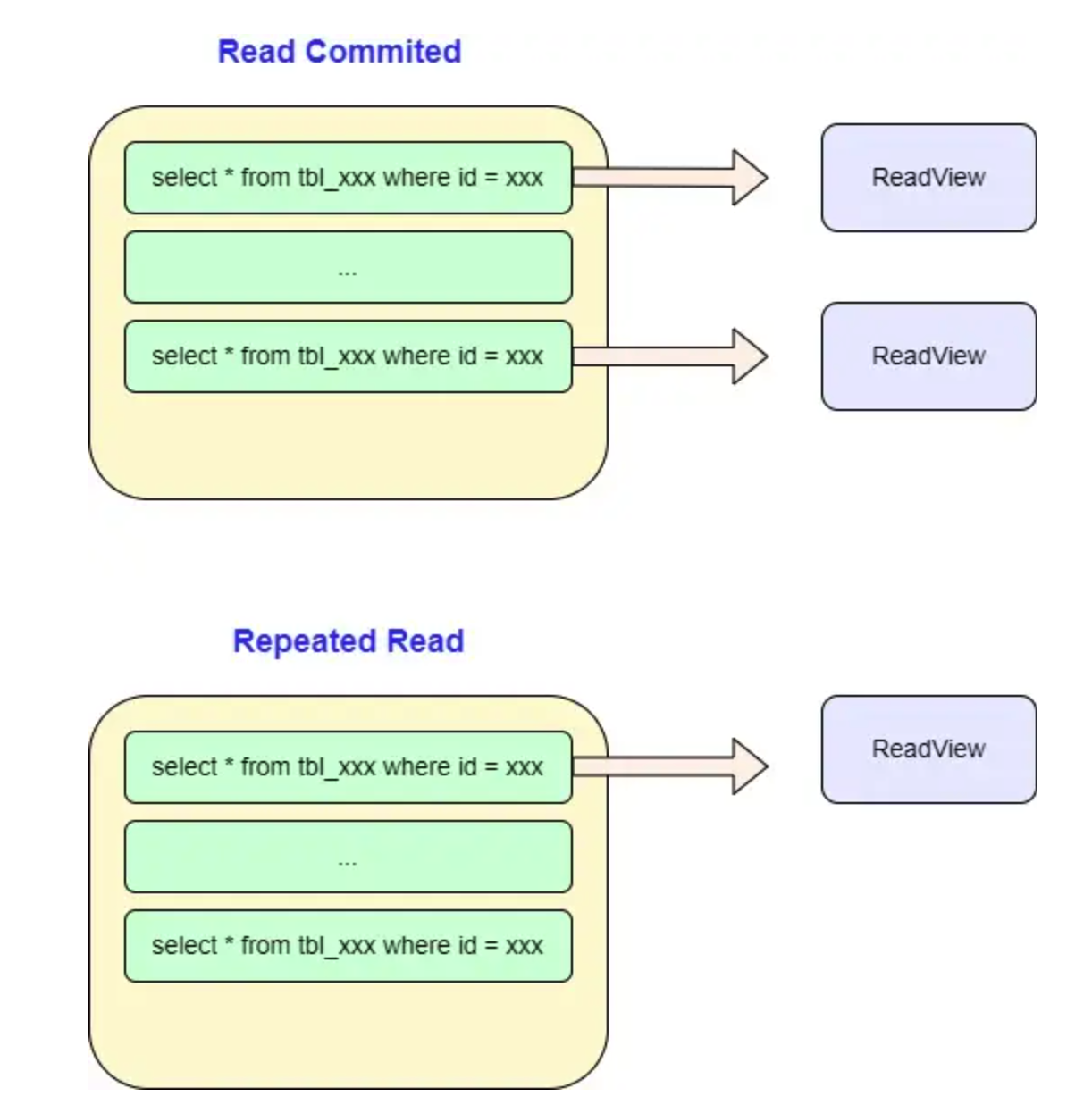
读已提交:每次读取数据前都生成一个 ReadView,这样就能保证每次读取的数据都是最新的。
推荐阅读:搞懂Mysql之InnoDB MVCC
如果两个 AB 事务并发修改一个变量,那么 A 读到的值是什么,怎么分析。
事务 A 在读取时是否能读到事务 B 的修改,取决于 A 是快照读还是当前读。如果是快照读,InnoDB 会使用 MVCC 的 ReadView 判断记录版本是否可见,若事务 B 尚未提交或在 A 的视图不可见,则 A 会读到旧值;如果是当前读,则需要加锁,若 B 已提交可直接读取,否则 A 会阻塞直到 B 结束。
- Java 面试指南(付费)收录的美团面经同学 2 Java 后端技术一面面试原题:说说 MVCC,解决了什么问题?
- Java 面试指南(付费)收录的小公司面经合集同学 1 Java 后端面试原题:了解的 MVCC 吗?
- Java 面试指南(付费)收录的联想面经同学 7 面试原题:Mysql 四个隔离级别,MVCC 实现,如果两个AB事务并发修改一个变量,那么A读到的值是什么,怎么分析,快照读的原理,读已提交和可重复读区别,具体原理是什么。
- Java 面试指南(付费)收录的oppo 面经同学 8 后端开发秋招一面面试原题:讲讲Mysql的MVCC机制
- Java 面试指南(付费)收录的快手同学 2 一面面试原题:事务隔离级别?MVCC机制介绍下?(版本链)版本链通过什么控制
- Java 面试指南(付费)收录的美团面经同学 15 点评后端技术面试原题:问了一下mysql的锁和MVCC
嗨嗨嗨,时隔两年,面渣逆袭第二版 PDF 终于可以下载了。我们做了大量的优化:
- 对于高频题:会标注在《Java 面试指南(付费)中出现的位置,哪家公司,原题是什么;如果你想节省时间的话,可以优先背诵这些题目,尽快做到知彼知己,百战不殆。
- 结合项目:包括技术派、mydb、pmhub来组织语言,让面试官最大程度感受到你的诚意,而不是机械化的背诵。
- 修复问题:第一版中出现的问题,包括球友们的私信反馈,网站留言区的评论,以及 GitHub 仓库中的 issue,让这份面试指南更加完善。
- 优化排版:增加手绘图,重新组织答案,使其更加口语化,从而更贴近面试官的预期。
你可以扫下面的二维码(或者长按自动识别)关注【沉默王二】公众号,发送关键字 222 来获取 PDF 版本,如果面渣逆袭真的对你有帮助,希望能给二哥的公众号加一个星标,满足我那一丁点虚荣心,这将是我更新下去的最强动力。
面渣逆袭的整理工作真的太不容易了,花了我好多好多的时间和精力,内容完全免费,但质量却有口皆碑,就是为了做一点真正有意义的、纯粹的事情。
memo:2025 年 4 月 19 日修改至此,今天有球友发帖说拿到了拼多多的 offer,这下真的是圆满了。
高可用
66.MySQL数据库读写分离了解吗?
读写分离就是把“写操作”交给主库处理,“读操作”分给多个从库处理,从而提升系统并发性能。
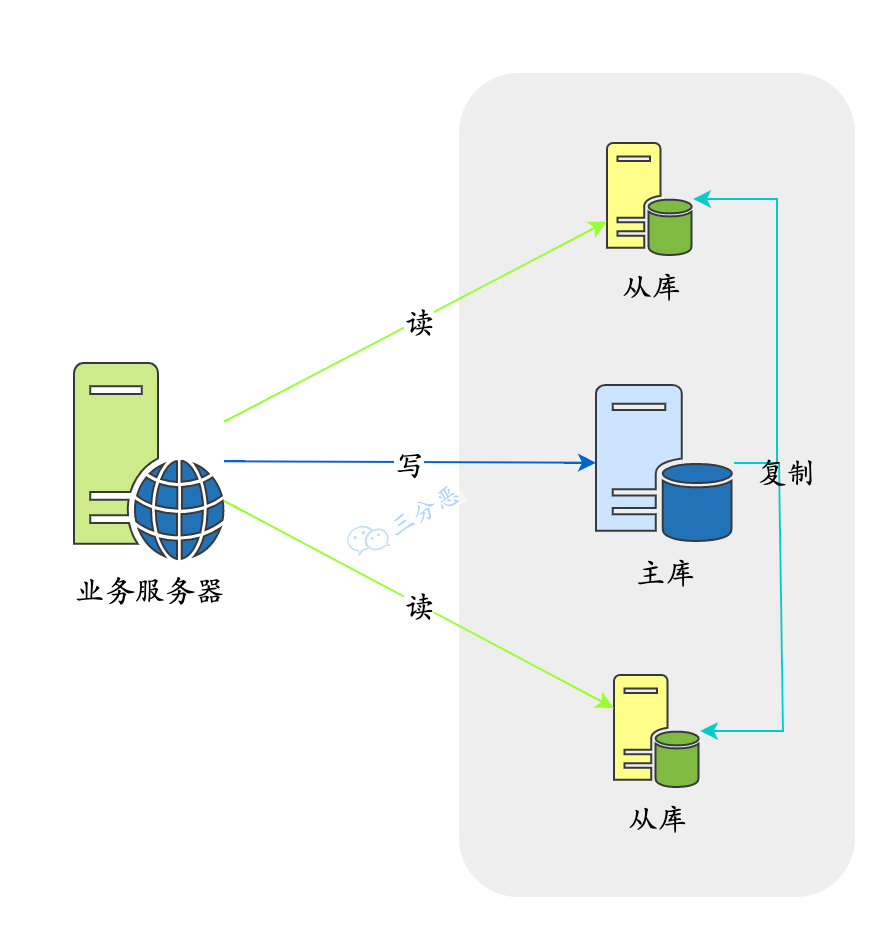
应用层通过中间件(如 MyCat、ShardingSphere)自动路由请求,将 INSERT / UPDATE / DELETE 等写操作发送给主库,将 SELECT 查询操作发送给从库。
// 示例:Java中通过不同数据源切换
@Transactional
public void updateOrder(Order order) {
masterDataSource.update(order); // 写操作走主库
}
public Order getOrderById(Long id) {
return slaveDataSource.query(id); // 读操作走从库
}主库将数据变更通过 binlog 同步到从库,从而保持数据一致性。
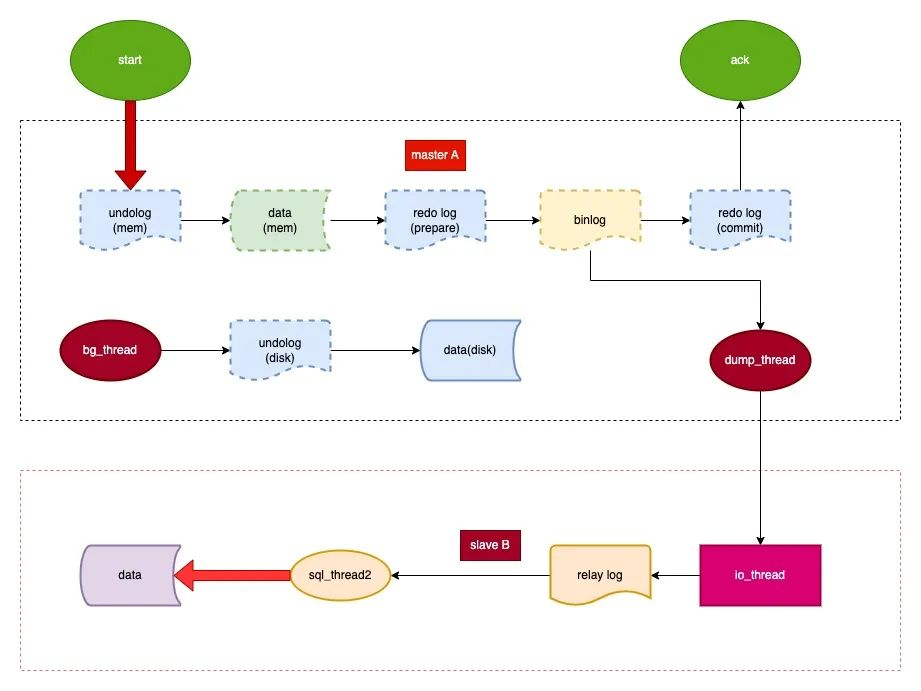
主库 dump_thread 线程通过 TCP 将 binlog 推送给从库,从库 io_thread 线程,接收主库 binlog,写入 relay log,从库 sql_thread 线程读取 relay log,并顺序执行 SQL 语句,更新从库数据。
67.读写分离的实现方式有哪些?
实现读写分离有三种方式:最简单的是在应用层手动控制主从数据源,适用于小型项目;
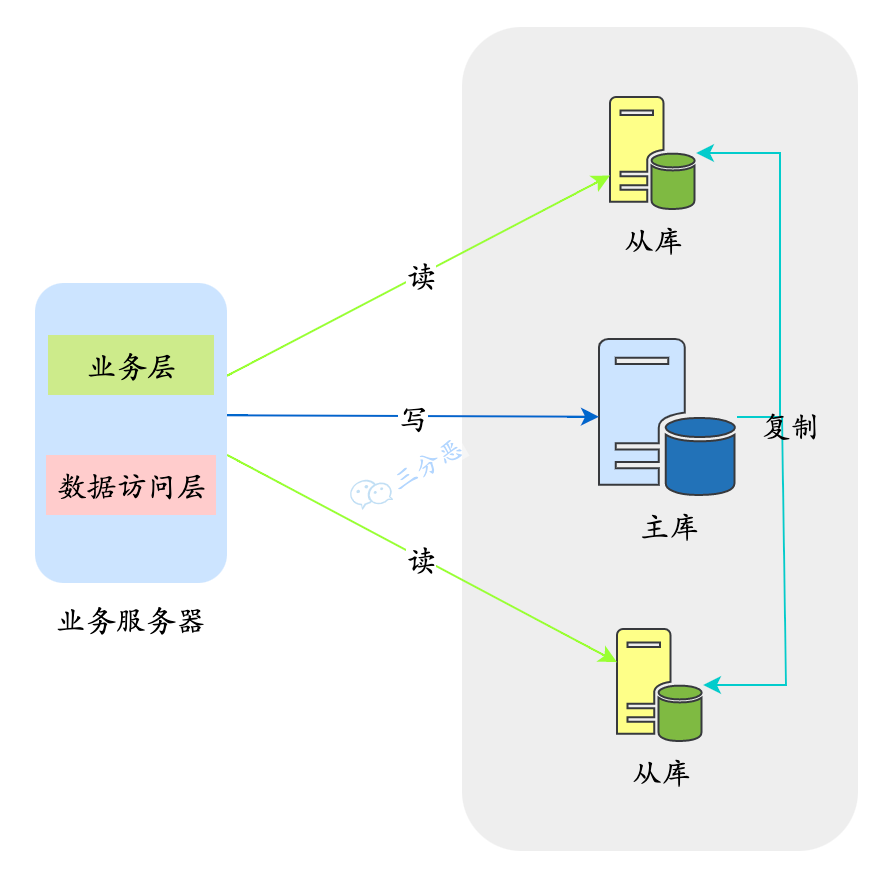
中等项目是通过 Spring + 多数据源插件、AOP 注解自动路由;
大型系统通常使用中间件,如 ShardingSphere、MyCat,支持自动路由、负载均衡、故障转移等功能。
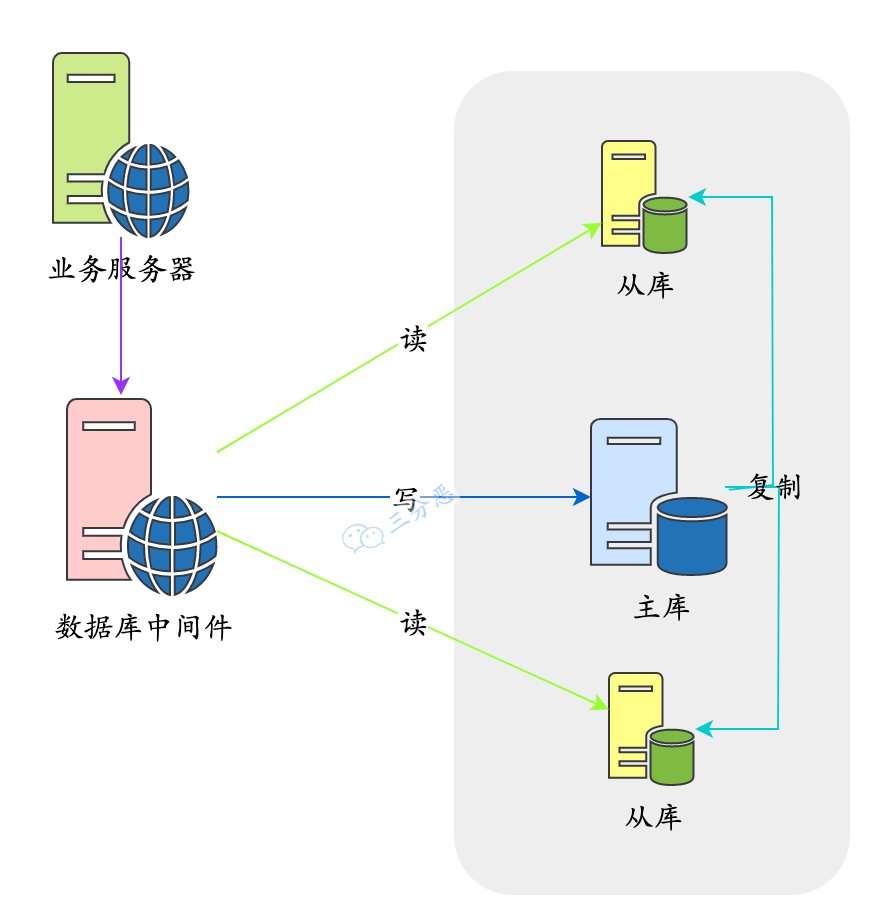
Mycat 的读写分离功能依赖于 MySQL 的主从复制架构:
- writeHost: 表示主节点,负责处理所有的 DML SQL 语句,如 INSERT、UPDATE 和 DELETE。
- readHost: 表示从节点,负责处理查询 SQL 语句(如 SELECT),以实现读写分离。
正常情况下,Mycat 会将第一个配置的 writeHost 作为默认的写节点。所有的 DML SQL 语句会被发送到此默认写节点执行。
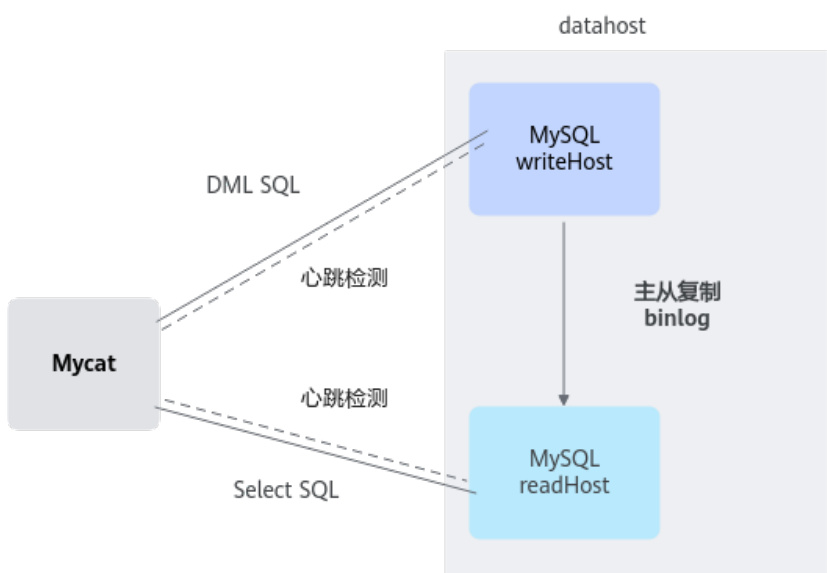
写节点完成数据写入后,通过 MySQL 的主从复制机制,将数据同步到所有从节点,确保主从数据一致性。
68.主从复制原理了解吗?
MySQL 的主从复制是一种数据同步机制,用于将数据从主数据库复制到一个或多个从数据库。
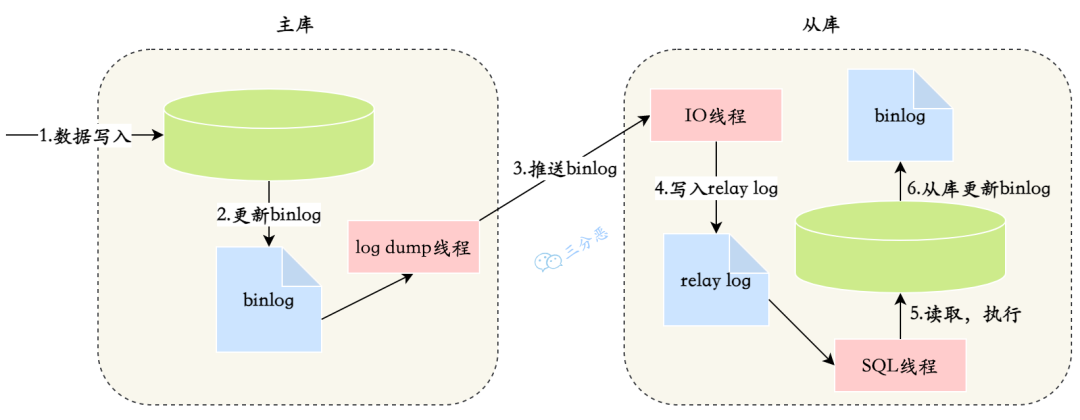
主库执行事务提交时,将数据变更以事件形式记录到 Binlog。从库通过 I/O 线程从主库的 Binlog 中读取变更事件,并将这些事件写入到本地的中继日志文件中,SQL 线程会实时监控中继日志的内容,按顺序读取并执行这些事件,从而保证从库与主库数据一致。
- Java 面试指南(付费)收录的腾讯云智面经同学 16 一面面试原题:MySQL 的主从复制过程
69.主从同步延迟怎么处理?
主从同步延迟是因为从库需要先接收 binlog,再执行 SQL 才能同步主库数据,在高并发写或网络抖动时容易出现延迟,导致读写不一致。
第一种解决方案:对一致性要求高的查询(如支付结果查询)可以直接走主库。
// 伪代码示例
public Object query(String sql) {
if(isWriteQuery(sql) || needStrongConsistency(sql)) {
return masterDataSource.query(sql);
} else {
return slaveDataSource.query(sql);
}
}第二种解决方案:对于非关键业务允许短暂数据不一致,可以提示用户“数据同步中,请稍后刷新”,然后借助异步通知机制替代实时查询。
// 伪代码示例
public Object query(String sql) {
if(isWriteQuery(sql)) {
return masterDataSource.query(sql);
} else {
// 异步通知用户数据已更新
notifyUser("数据同步中,请稍后刷新");
return slaveDataSource.query(sql);
}
}第三种解决方案:采用半同步复制,主库在事务提交时,要等至少一个从库确认收到 binlog(但不要求执行完成),才算提交成功。
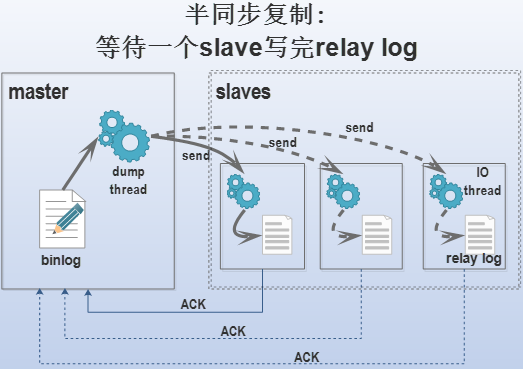
请说说半同步复制的流程?
第一步,主库安装半同步插件:
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';第二步,主库启用半同步复制并设置超时时间:
SET GLOBAL rpl_semi_sync_master_enabled = 1;
SET GLOBAL rpl_semi_sync_master_timeout = 10000;主库 my.cnf 配置示例:
[mysqld]
plugin-load = "rpl_semi_sync_master=semisync_master.so"
rpl_semi_sync_master_enabled = 1
rpl_semi_sync_master_timeout = 10000
# MySQL 5.7+建议使用无损模式
rpl_semi_sync_master_wait_point = AFTER_SYNC第三步,从库安装半同步插件:
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';第四步,从库启用半同步复制:
SET GLOBAL rpl_semi_sync_slave_enabled = 1;从库 my.cnf 配置示例:
[mysqld]
plugin-load = "rpl_semi_sync_slave=semisync_slave.so"
rpl_semi_sync_slave_enabled = 1memo:2025 年 4 月 20 日修改至此,今天给球友修改简历时,碰到有球友说,把星球安利给了同门,进来后都说好,口碑+1,很欣慰呢。
70.🌟你们一般是怎么分库的呢?
分库的策略有两种,第一种是垂直分库:按照业务模块将不同的表拆分到不同的库中,比如说用户、登录、权限等表放在用户库中,商品、分类、库存放在商品库中,优惠券、满减、秒杀放在活动库中。
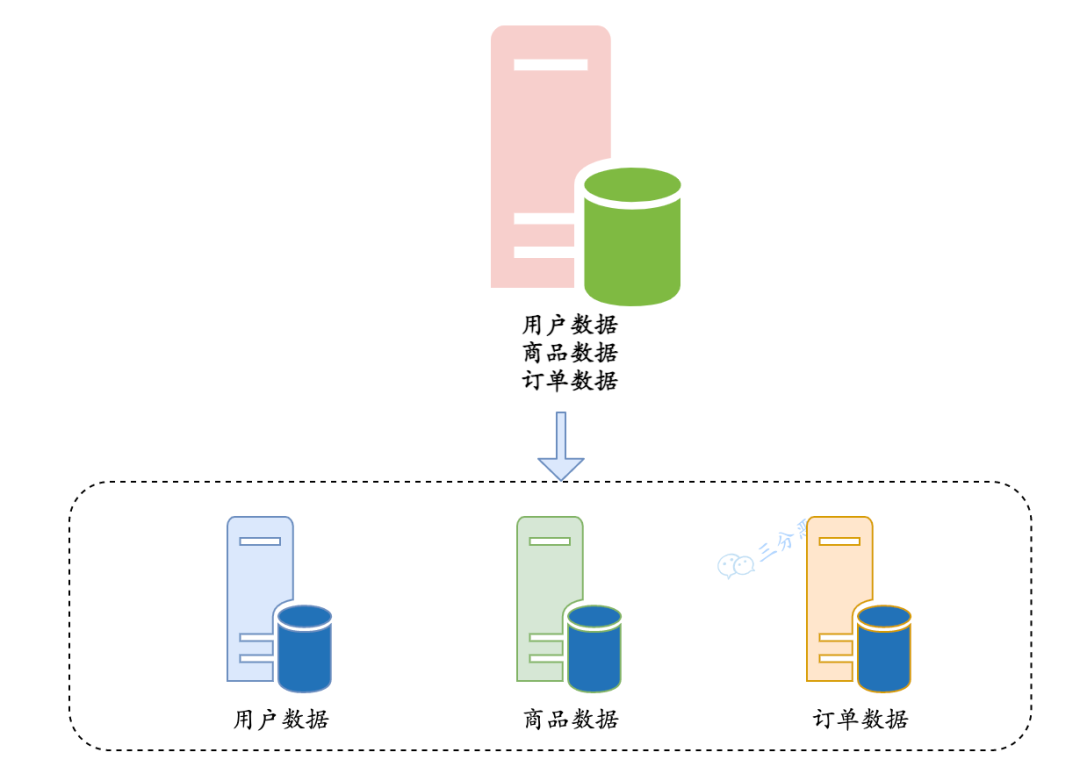
第二种是水平分库:按照一定的策略将一个表中的数据拆分到多个库中,比如哈希分片和范围分片,对用户 id 进行取模运算或者范围划分,将数据分散到不同的库中。
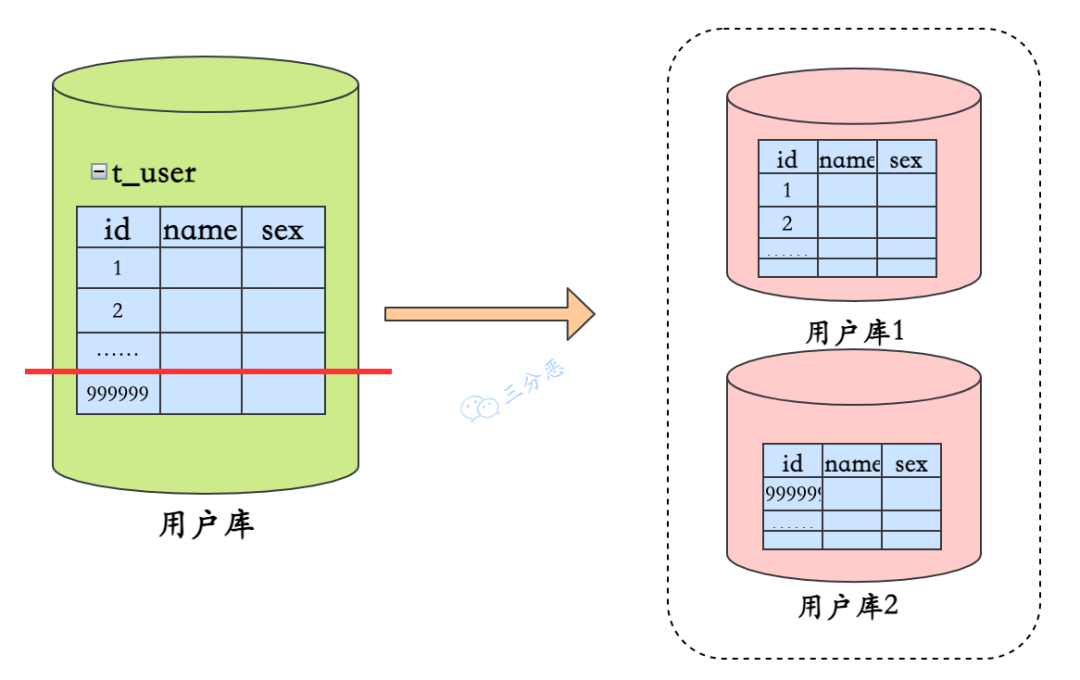
贴一段使用 ShardingSphere 的 inline 算法定义分片规则:
rules:
- !SHARDING
tables:
order:
actualDataNodes: db_${0..3}.order_${0..15}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: db_hash_mod
tableStrategy:
standard:
shardingColumn: order_time
shardingAlgorithmName: table_interval_yearly
shardingAlgorithms:
db_hash_mod:
type: HASH_MOD
props:
sharding-count: 4
table_interval_yearly:
type: INTERVAL
props:
datetime-pattern: 'yyyy-MM-dd HH:mm:ss'
datetime-lower: '2024-01-01 00:00:00'
datetime-upper: '2025-01-01 00:00:00'
sharding-suffix-pattern: 'yyyy'
datetime-interval-amount: 1
datetime-interval-unit: 'Years'
- Java 面试指南(付费)收录的快手面经同学 7 Java 后端技术一面面试原题:分库分表了解吗
- Java 面试指南(付费)收录的华为面经同学 8 技术二面面试原题:说说分库分表的准则
71.🌟那你们是怎么分表的?
当单表超过 500 万条数据,就可以考虑水平分表了。比如说我们可以将文章表拆分成多个表,如 article_0、article_9999、article_19999 等。
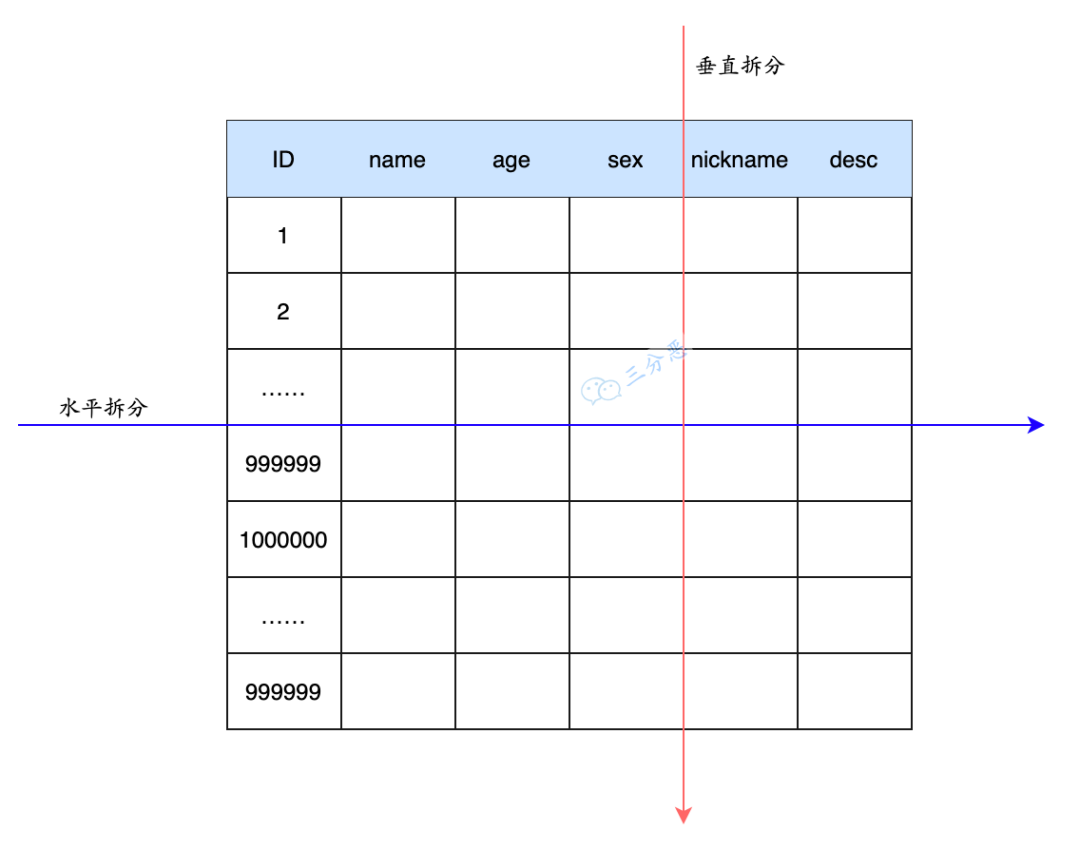
在技术派实战项目中,我们将文章的基本信息和内容详情做了垂直分表处理,因为文章的内容会占用比较大的空间,在只需要查看文章基本信息时把文章详情也带出来的话,就会占用更多的网络 IO 和内存导致查询变慢;而文章的基本信息,如标题、作者、状态等信息占用的空间较小,很适合不需要查询文章详情的场景。
- Java 面试指南(付费)收录的快手面经同学 7 Java 后端技术一面面试原题:分库分表了解吗
- Java 面试指南(付费)收录的华为面经同学 8 技术二面面试原题:说说分库分表的准则
- Java 面试指南(付费)收录的腾讯面经同学 29 Java 后端一面原题:表存满了之后怎么扩表?
72.水平分库分表的分片策略有哪几种?
常见的分片策略有三种,范围分片、Hash 分片和路由分片。
范围分片是根据某个字段的值范围进行水平拆分。适用于分片键具有连续性的场景。
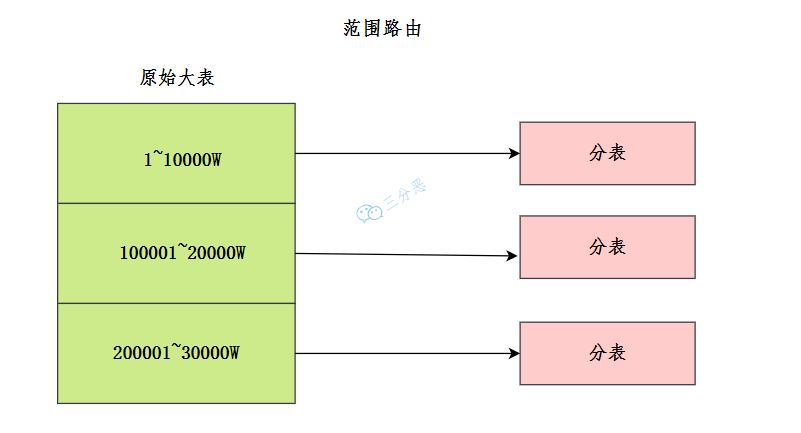
比如说将 user_id 作为分片键:
- 1 ~ 10000 → db1.user_1
- 10001 ~ 20000 → db2.user_2
Hash 分片是指通过对分片键的值进行哈希取模,将数据均匀分布到多个库表中,适用于分片键具有离散性的场景。
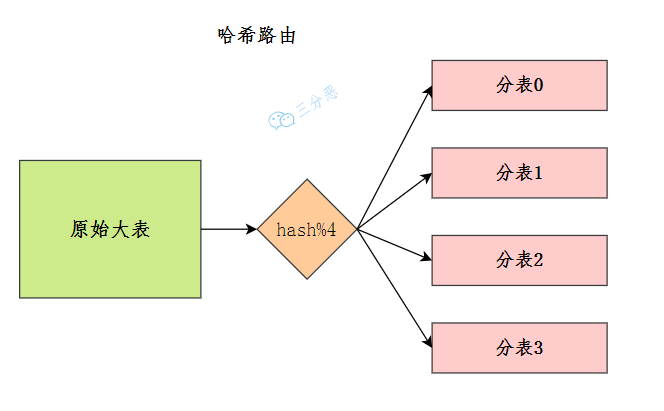
比如说我们一开始规划好了 4 个表,那么就可以简单地通过取模来实现分表:
public String getTableNameByHash(long userId) {
int tableIndex = (int) (userId % 4);
return "user_" + tableIndex;
}路由分片是通过路由配置来确定数据应该存储在哪个库表,适用于分片键不规律的场景。
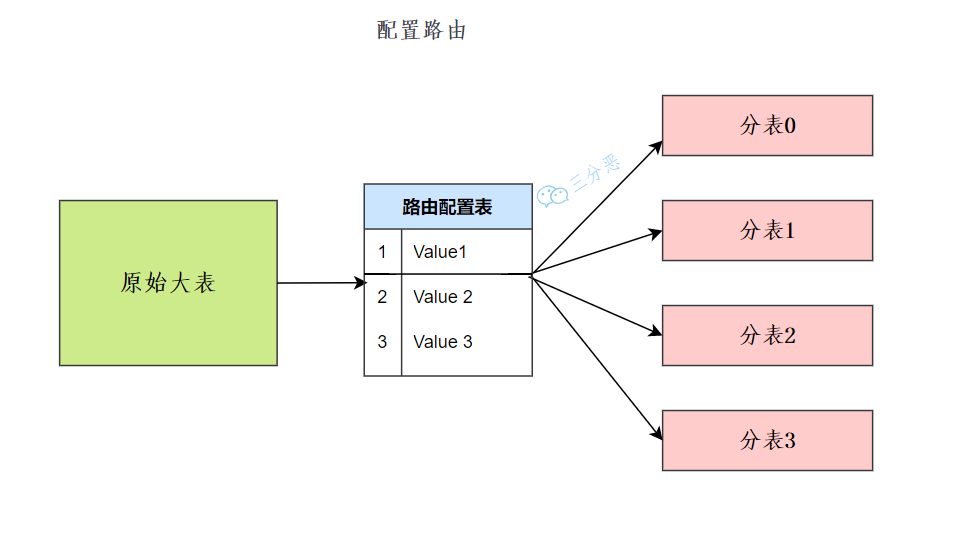
比如说我们可以通过 order_router 表来确定订单数据存储在哪个表中:
| order_id | table_id |
|---|---|
| xxxx | table_1 |
| yyyy | table_2 |
| zzzz | table_3 |
- Java 面试指南(付费)收录的腾讯面经同学 24 面试原题:项目中的水平分表是怎么做的?分片键具体是怎么设置的?
- Java 面试指南(付费)收录的腾讯面经同学 29 Java 后端一面原题:分库分表具体的分片策略是怎么做的?
memo:2025 年 4 月 22 日修改至此,今天给拿到蚂蚁暑期实习的球友发了个红包,感谢他在星球的经验贴,这些精华帖也会帮助到下一届的球友们,真的非常感谢。
73.不停机扩容怎么实现?
第一个阶段:新旧库同时写入,确保数据实时同步;可以借助消息队列实现异步补偿,幂等避免重复写入。读操作仍然走旧库。
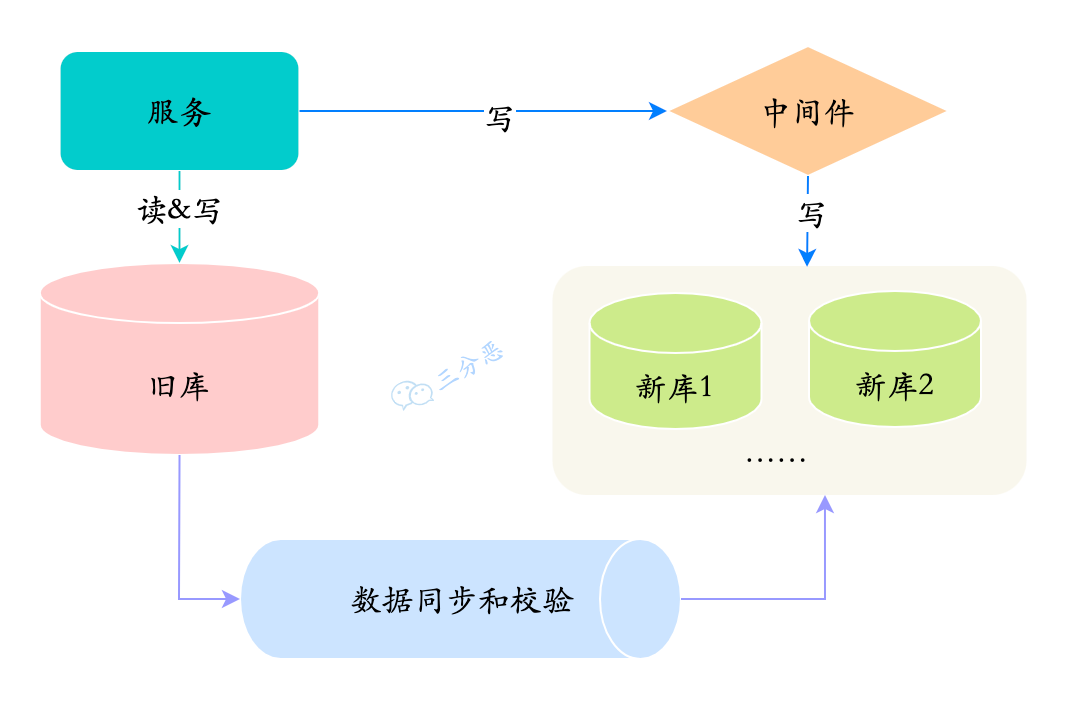
代码参考:
@Transactional
public void createOrder(Order order) {
oldDB.insert(order); // 写入旧库
newDB.insert(order); // 写入新扩容节点
kafka.send("data_sync", order); // 异步补偿通道
}第二个阶段,通过 Canal 或者自研脚本将旧库的历史数据同步到新库。关键业务在查询时同时查询新旧库,进行数据校验,确保一致性。
public List<Order> getOrders(Long userId) {
List<Order> orders = newDB.getOrders(userId);
List<Order> oldOrders = oldDB.getOrders(userId);
if (!orders.equals(oldOrders)) {
// 数据不一致,进行补偿
kafka.send("data_sync", oldOrders);
}
}第三个阶段,在确认新库数据一致性后,逐步将读请求切换到新库,然后下线旧库。
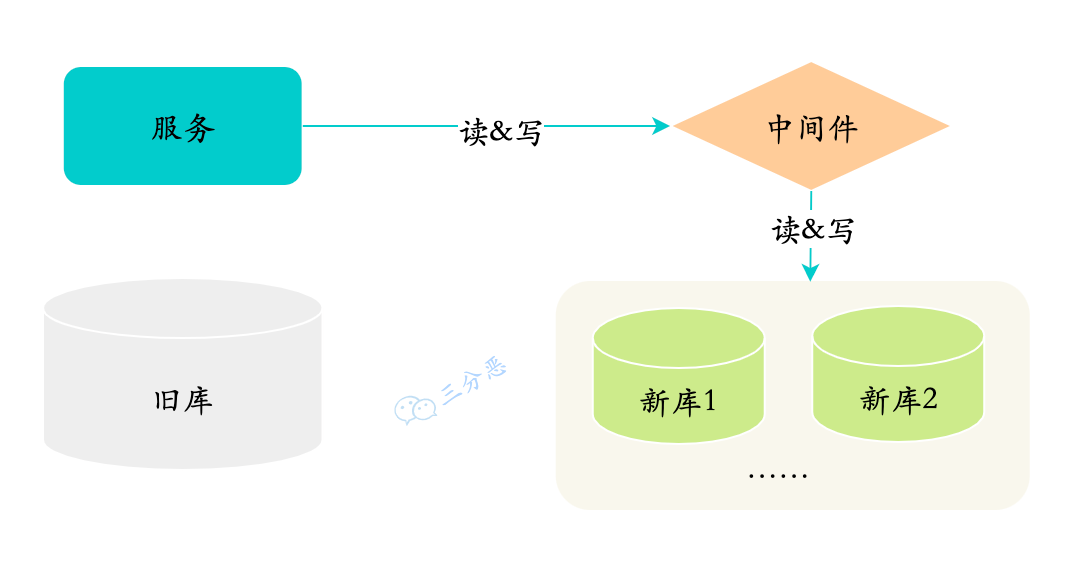
74.常用的分库分表中间件有哪些?
常用的分库分表中间件有 ShardingSphere 和 Mycat。
①、ShardingSphere 最初由当当开源,后来贡献给了 Apache,其子项目 Sharding-JDBC 主要在 Java 的 JDBC 层提供额外的服务。无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
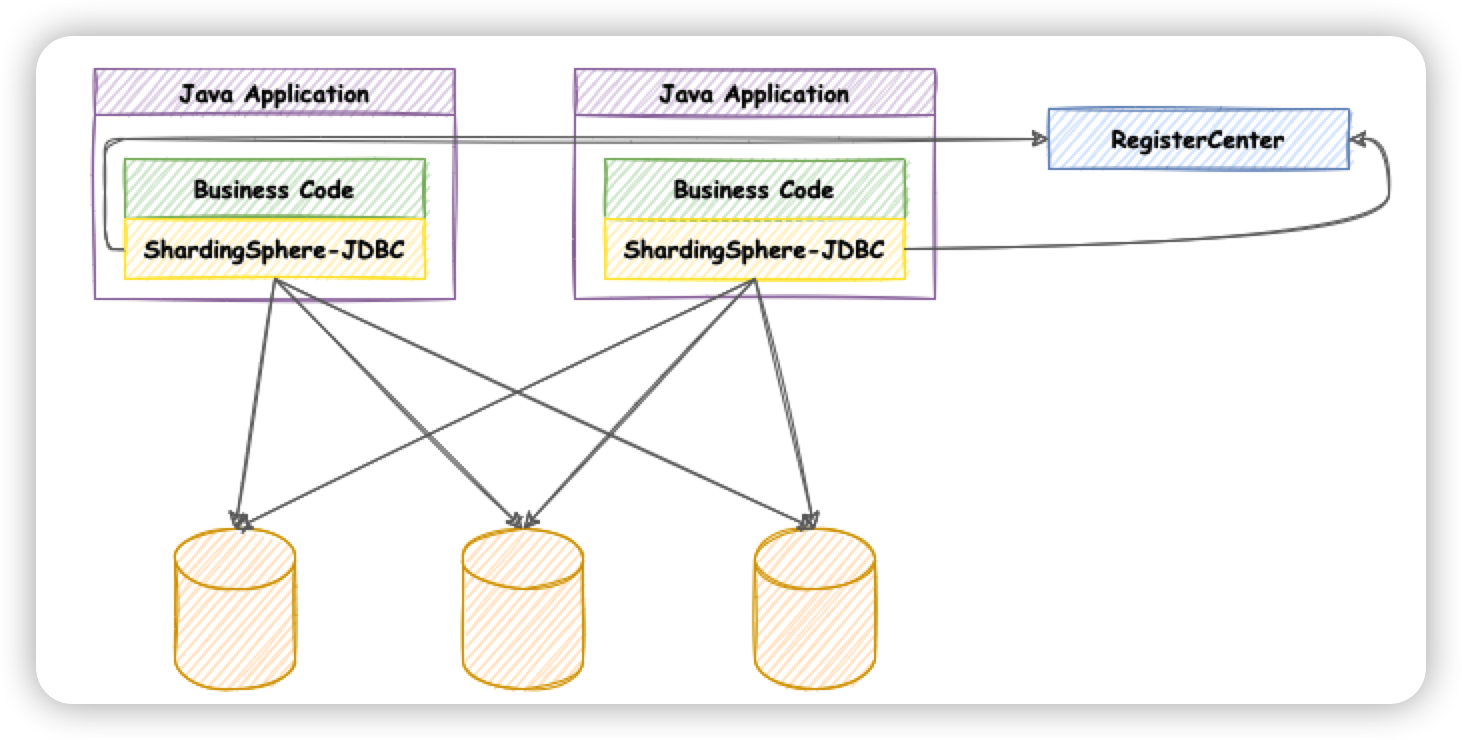
②、Mycat 是由阿里巴巴的一款产品 Cobar 衍生而来,可以把它看作一个数据库代理。
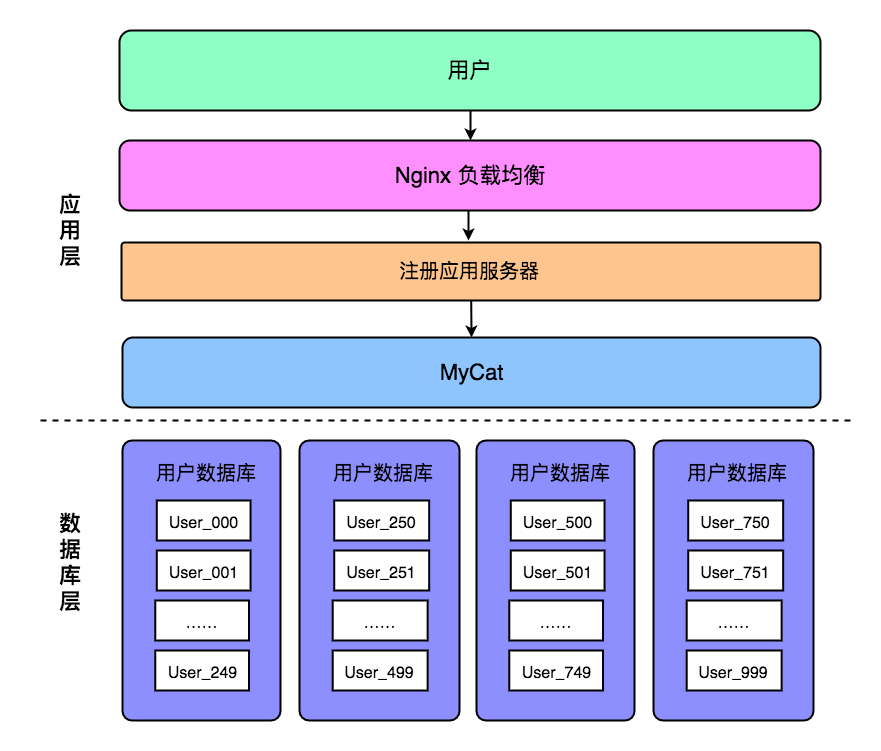
推荐阅读:mycat 介绍
75.你觉得分库分表会带来什么问题呢?
第一,跨库事务无法依赖单机 MySQL 的 ACID 特性,需要使用分布式事务解决方案,如 Seata 的 AT 模式、TCC 模式等。

第二,跨库后无法使用 JOIN 联表查询。可以在业务层进行拼接,或者把需要联表查询的数据放到 ES 中。
// Java 代码示例
User user = userService.getUserById(1);
List<Order> orders = orderService.getOrdersByUserId(1);第三,自增 ID 在分片场景下容易冲突,需要使用全局唯一方案。
数据库表被切分后,不能再依赖数据库自身的主键生成机制,所以需要一些手段来保证全局主键唯一。比如说雪花算法、京东的 JD-hotkey。
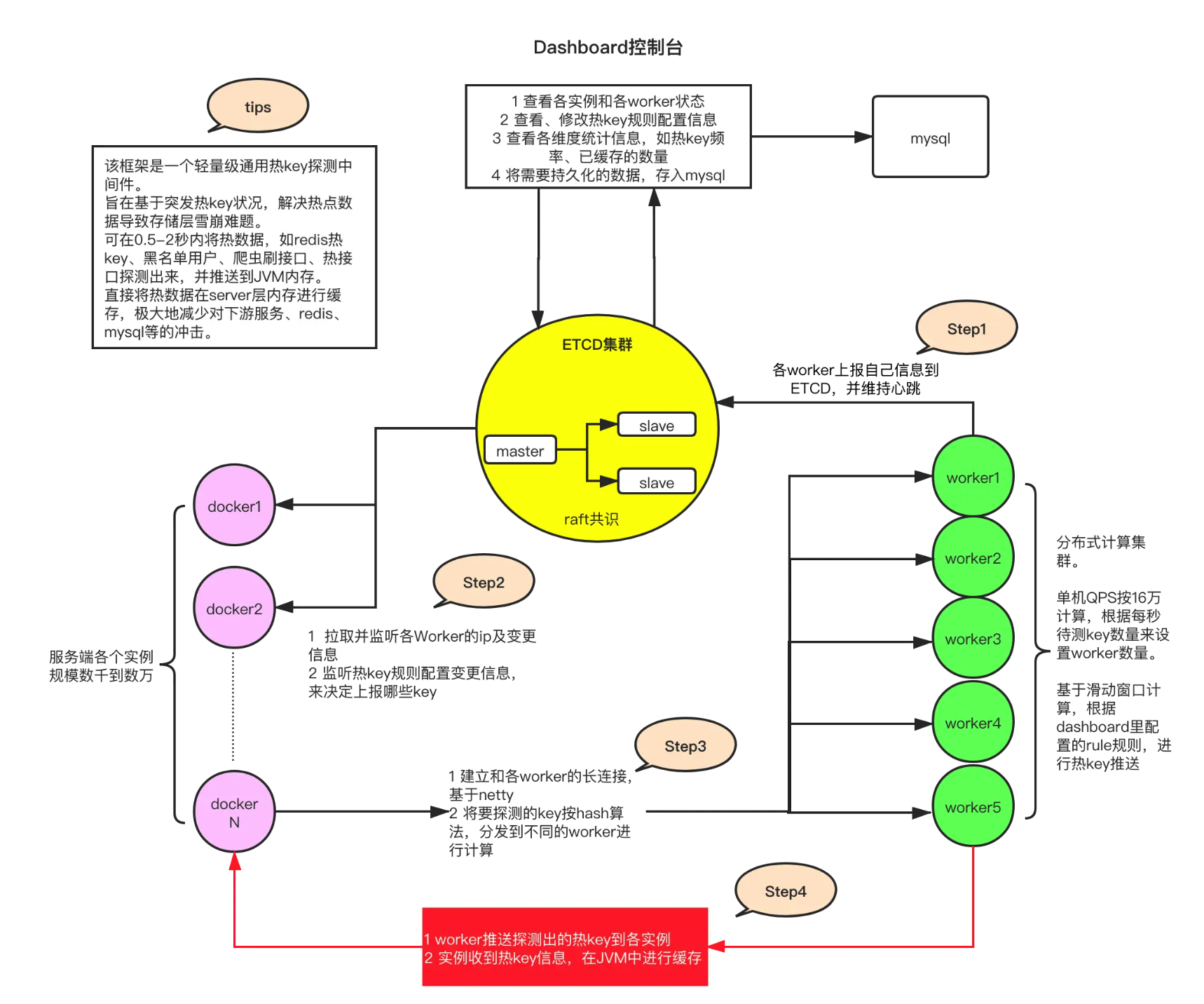
你们项目中的分布式主键 id 是怎么生成的?
在技术派项目中,我们在雪花算法的基础上实现了一套自定义的 ID 生成方案,通过更改时间戳单位、ID 长度、workId 与 dataCenterId 的分配比例,ID 生成的延迟降低了 20%;满足了分布式环境下 ID 的唯一性。
雪花算法具体是怎么实现的?
雪花算法是 Twitter 开源的分布式 ID 生成算法,其核心思想是:使用一个 64 位的数字来作为全局唯一 ID。
- 第 1 位是符号位,永远是 0,表示正数。
- 接下来的 41 位是时间戳,记录的是当前时间戳减去一个固定的开始时间戳,可以使用 69 年。
- 然后是 10 位的工作机器 ID。
- 最后是 12 位的序列号,每毫秒最多可生成 4096 个 ID。
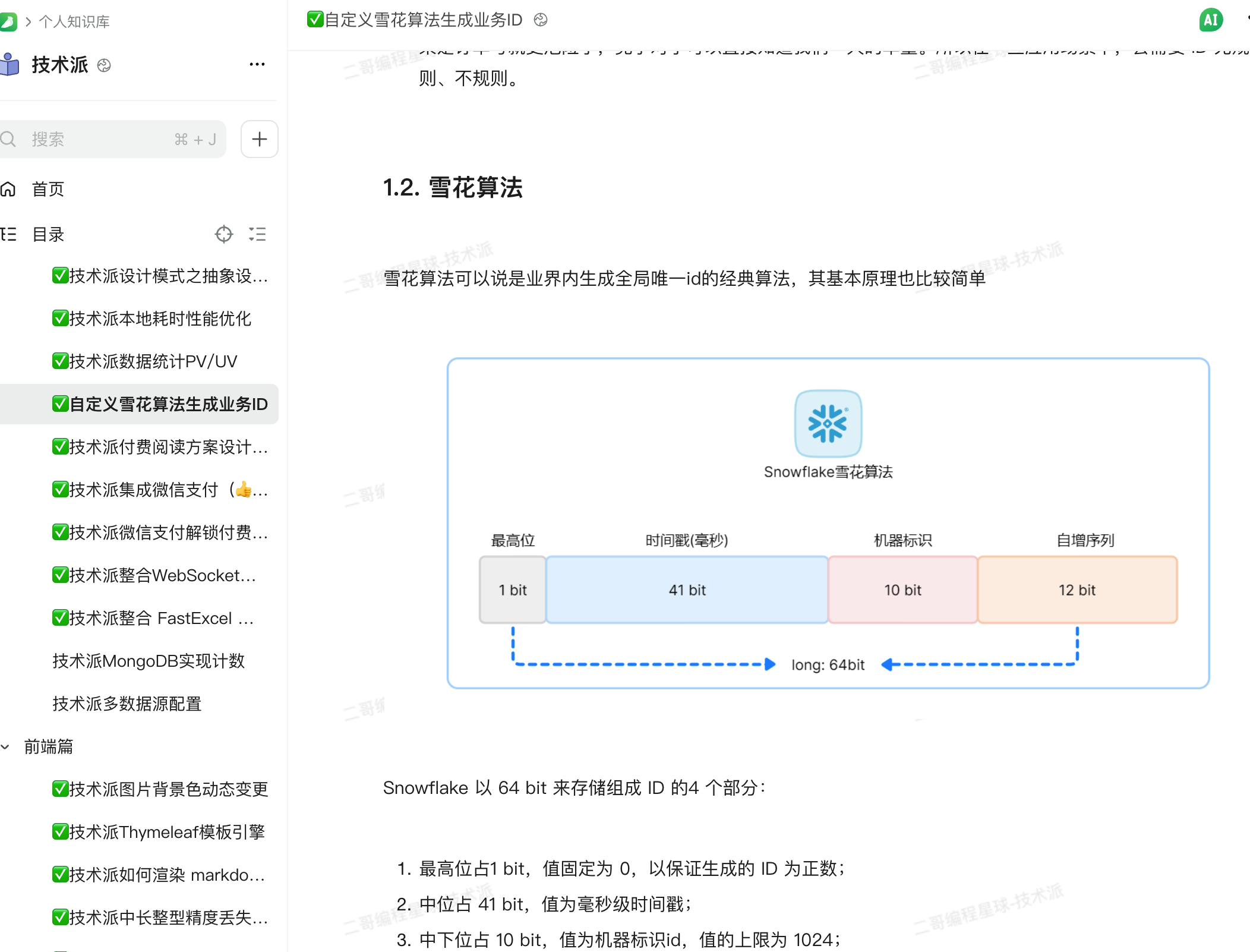
大致的实现代码如下所示:
public class SnowflakeIdGenerator {
private long datacenterId = 1L; // 数据中心ID
private long machineId = 1L; // 机器ID
private long sequence = 0L; // 序列号
private long lastTimestamp = -1L;
public synchronized long nextId() {
long timestamp = System.currentTimeMillis();
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & 4095;
if (sequence == 0) {
while (timestamp == lastTimestamp) {
timestamp = System.currentTimeMillis();
}
}
} else {
sequence = 0;
}
lastTimestamp = timestamp;
return ((timestamp - 1609459200000L) << 22) | (datacenterId << 17) | (machineId << 12) | sequence;
}
}
- Java 面试指南(付费)收录的腾讯面经同学 29 Java 后端一面原题:id是怎么生成的?(分布式自增主键)
memo:2025 年 4 月 23 日修改至此,今天有球友反馈说拿到了 vivo 的 offer,也是他第一个暑期实习 offer,真的需要恭喜啦🎉。
运维
76.百万级别以上的数据如何删除?
在处理百万级别的数据删除时,大范围的 DELETE 语句往往会造成锁表时间长、事务日志膨胀等问题。
可以采用批量删除的方案,将删除操作分成多个小批次进行处理。
public void batchDelete(String tableName, String condition, int batchSize) {
// 1. 创建线程池
int threadCount = Runtime.getRuntime().availableProcessors();
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
CountDownLatch latch = new CountDownLatch(threadCount);
// 2. 获取总记录数
long totalCount = getTotalCount(tableName, condition);
// 3. 计算每个线程处理的数据量
long perThreadCount = totalCount / threadCount;
// 4. 分配任务给线程池
for (int i = 0; i < threadCount; i++) {
long startId = i * perThreadCount;
long endId = (i == threadCount - 1) ? totalCount : (startId + perThreadCount);
executor.execute(() -> {
try {
// 分批次删除数据
for (long j = startId; j < endId; j += batchSize) {
String deleteSql = String.format(
"DELETE FROM %s WHERE %s LIMIT %d",
tableName, condition, batchSize
);
// 执行删除
jdbcTemplate.update(deleteSql);
}
} finally {
latch.countDown();
}
});
}
// 5. 等待所有线程完成
latch.await();
executor.shutdown();
}也可以采用创建新表替换原表的方式,把需要保留的数据迁移到新表中,然后删除旧表。
简单的方案:
-- 1. 创建新表结构(包含索引)
CREATE TABLE new_table LIKE large_table;
-- 2. 插入需要保留的数据
INSERT INTO new_table
SELECT * FROM large_table WHERE condition;
-- 3. 重命名表
RENAME TABLE large_table TO old_table, new_table TO large_table;
-- 4. 删除旧表
DROP TABLE old_table;加入检查表空间、分批导入数据、验证数据一致性等步骤:
-- 1. 在执行之前先检查空间是否足够
SELECT table_schema,
table_name,
round(((data_length + index_length) / 1024 / 1024), 2) "Size in MB"
FROM information_schema.TABLES
WHERE table_schema = DATABASE()
AND table_name = 'large_table';
-- 2. 创建新表
CREATE TABLE new_table LIKE large_table;
-- 3. 分批导入数据(避免一次性导入过多数据)
SET @batch = 1;
SET @batch_size = 10000;
SET @total = (SELECT COUNT(*) FROM large_table WHERE condition);
REPEAT
INSERT INTO new_table
SELECT * FROM large_table
WHERE condition
LIMIT @batch_size;
SET @batch = @batch + 1;
UNTIL @batch * @batch_size > @total END REPEAT;
-- 4. 验证数据一致性
SELECT COUNT(*) FROM new_table;
SELECT COUNT(*) FROM large_table WHERE condition;
-- 5. 在业务低峰期执行表切换
RENAME TABLE large_table TO old_table,
new_table TO large_table;
-- 6. 确认无误后再删除旧表(建议不要立即删除)
-- DROP TABLE old_table;77.千万级大表如何添加字段?
在低版本的 MySQL 中,千万级数据量的表中添加字段时,直接使用 ALTER TABLE 命令会导致长时间锁表、甚至数据库崩溃等。
可以使用 Percona Toolkit 的 pt-online-schema-change 来完成,它通过创建临时表、逐步同步数据并使用触发器捕获变更来实现。
pt-online-schema-change --alter "ADD COLUMN new_column datatype" D=database,t=your_table --execute对于 MySQL 8.0+ 版本,可以直接通过 ALTER TABLE 来完成,因为加入了 INSTAN 算法,添加列并不会长时间锁表。
ALTER TABLE your_table ADD COLUMN new_column datatype;如果没有指定 ALGORITHM=INSTANT 算法,MySQL 会先尝试 INSTANT 算法;如果无法完成,会切换到 INPLACE 算法;如果仍然无法完成,会尝试 COPY 算法。

78.MySQL 导致 cpu 飙升的话,要怎么处理呢?
我通常先通过 top 命令确认是否是 mysqld 的进程占用。
然后通过 SHOW PROCESSLIST 和慢查询日志定位是否存在耗时 SQL,再配合 explain 和 performance_schema 分析 SQL 是否命中索引,是否存在临时表和排序。
-- 使用 EXPLAIN 分析SQL执行计划
EXPLAIN SELECT * FROM large_table WHERE condition;
-- 查看表的索引使用情况
SHOW INDEX FROM table_name;
-- 查看InnoDB状态
SHOW ENGINE INNODB STATUS;
-- 查看表的统计信息
ANALYZE TABLE table_name;最终通过 SQL 优化、加索引、分批操作等手段逐步优化。
memo:2025 年 4 月 24 日修改至此,今天有球友反馈说拿到了小鹏汽车测试岗的 offer,真的恭喜啦🎉。

SQL 题
79.一张表:id,name,age,sex,class,sql 语句:所有年龄为 18 的人的名字?找到每个班年龄大于 18 有多少人?找到每个班年龄排前两名的人?(补充)
建议大家在本地建表,实操一下。 2024 年 04 月 11 日增补。
第一步,建表:
CREATE TABLE students (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age INT,
sex CHAR(1),
class VARCHAR(50)
);第二步,插入数据:
INSERT INTO students (name, age, sex, class) VALUES
('沉默王二', 18, '女', '三年二班'),
('沉默王一', 20, '男', '三年二班'),
('沉默王三', 19, '男', '三年三班'),
('沉默王四', 17, '男', '三年三班'),
('沉默王五', 20, '女', '三年四班'),
('沉默王六', 21, '男', '三年四班'),
('沉默王七', 18, '女', '三年四班');所有年龄为 18 的人的名字?
SELECT name FROM students WHERE age = 18;这条 SQL 语句从表中选择age等于 18 的所有记录,并返回这些记录的name字段。
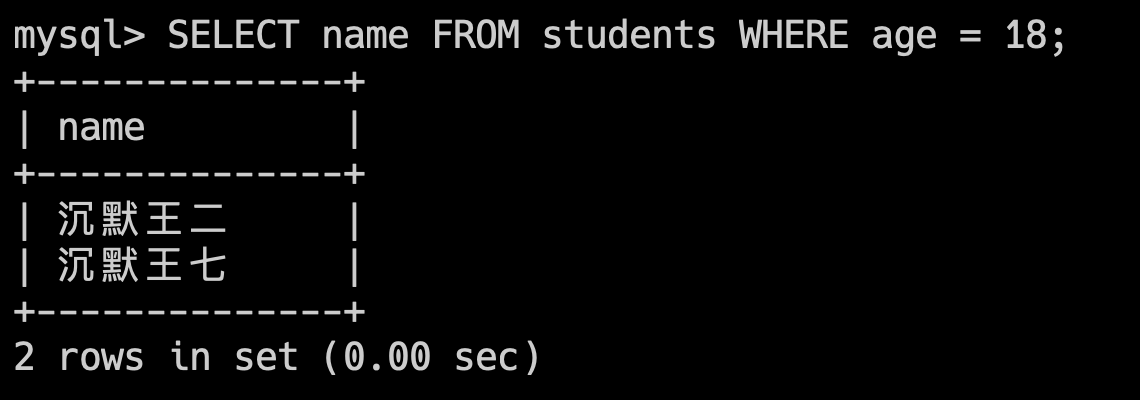
如果可以的话,可以给 age 字段加上索引。
ALTER TABLE students ADD INDEX age_index (age);找到每个班年龄大于 18 有多少人?
SELECT class, COUNT(*) AS number_of_students
FROM students
WHERE age > 18
GROUP BY class;这条 SQL 语句先筛选出年龄大于 18 的记录,然后按class分组,并通过 count 统计每个班的学生数。
找到每个班年龄排前两名的人?
这个查询稍微复杂一些,需要使用子查询和去重 DISTINCT。
SELECT a.class, a.name, a.age
FROM students a
WHERE (
SELECT COUNT(DISTINCT b.age)
FROM students b
WHERE b.class = a.class AND b.age > a.age
) < 2
ORDER BY a.class, a.age DESC;这条 SQL 语句首先从students表中选择class、name和age字段,然后使用子查询计算每个班级中年龄排前两名的学生。
- Java 面试指南(付费)收录的奇安信面经同学 1 Java 技术一面面试原题:一张表:id,name,age,sex,class,sql 语句:所有年龄为 18 的人的名字?找到每个班年龄大于 18 有多少人?找到每个班年龄排前两名的人?
80.有一个查询需求,MySQL 中有两个表,一个表 1000W 数据,另一个表只有几千数据,要做一个关联查询,如何优化
第一步,为关联字段建立索引,确保 on 连接的字段都有索引。
ALTER TABLE big_table ADD INDEX idx_small_id(small_id);第二步,小表驱动大表,将小表放在 JOIN 的左边(驱动表),大表放在右边。
SELECT ... FROM small_table s
JOIN big_table b ON s.id = b.small_id
- Java 面试指南(付费)收录的京东面经同学 1 Java 技术一面面试原题:有一个查询需求,MySQL 中有两个表,一个表 1000W 数据,另一个表只有几千数据,要做一个关联查询,如何优化
81.新建一个表结构,创建索引,将百万或千万级的数据使用 insert 导入该表,新建一个表结构,将百万或千万级的数据使用 isnert 导入该表,再创建索引,这两种效率哪个高呢?或者说用时短呢?
先说结论:
在大数据量导入场景下,先导入数据,后建索引的效率显著高于先建索引,后导入数据的效率。
来,实操。
先创建一个表,然后创建索引,执行插入语句,来看看执行时间(100 万数据在我本机上执行时间比较长,我们就用 10 万条数据来测试)。
CREATE TABLE test_table (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at DATETIME NOT NULL
);
CREATE INDEX idx_name ON test_table(name);
DELIMITER //
CREATE PROCEDURE insert_data()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000000 DO
INSERT INTO test_table(name, email, created_at)
VALUES (CONCAT('wanger',i), CONCAT('email', i, '@example.com'), NOW());
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
CALL insert_data();总的时间 13.93+0.01+0.01+0.01=13.96 秒。
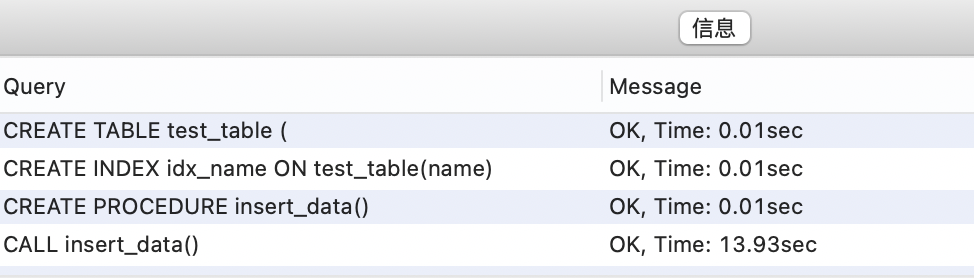
接下来,我们再创建一个表,执行插入操作,然后创建索引。
CREATE TABLE test_table_no_index (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at DATETIME NOT NULL
);
DELIMITER //
CREATE PROCEDURE insert_data_no_index()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000000 DO
INSERT INTO test_table_no_index(name, email, created_at)
VALUES (CONCAT('wanger', i), CONCAT('email', i, '@example.com'), NOW());
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
CALL insert_data_no_index();
CREATE INDEX idx_name_no_index ON test_table_no_index(name);来看一下总的时间,0.01+0.00+13.08+0.18=13.27 秒。
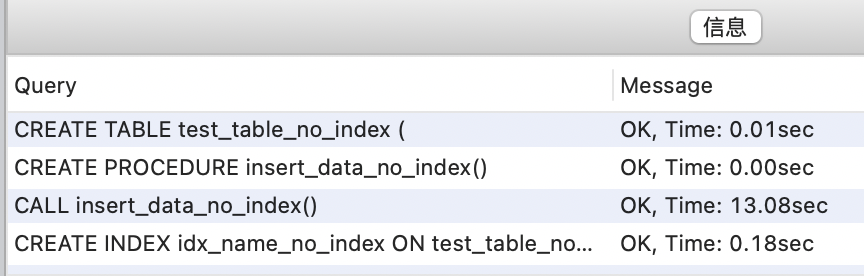
先插入数据再创建索引的方式比先创建索引再插入数据要快一点。
然后时间差距很微小,主要是因为我们插入的数据少。说一下差别。
- 先插入数据再创建索引:在没有索引的情况下插入数据,数据库不需要在每次插入时更新索引。
- 先创建索引再插入数据:数据库需要在每次插入新记录时维护索引结构,随着数据量的增加,索引的维护会导致额外的性能开销。
MySQL是先建立索引好还是先插入数据好?
如果是小批量插入,可以先建索引;但在大数据量数据导入场景下,推荐先插入数据再建索引。
因为索引是基于 B+ 树的,大量插入时如果提前建索引,会频繁触发页分裂和索引结构调整,影响性能。
插入完成后统一构建索引,MySQL 会按顺序批量生成索引结构,速度更快、资源消耗更低。
- Java 面试指南(付费)收录的农业银行面经同学 7 Java 后端面试原题:数据库是先建立索引还是先插入数据
memo:2025 年 4 月 25 日修改至此,今天有家长发来感谢信,说孩子在加入星球后,整个人明显变得更加积极了。说真的,家长的认可,更让我感到虚荣心得到了极大的满足。

82.什么是深分页,select * from tbn limit 1000000000 这个有什么问题,如果表大或者表小分别什么问题
深分页是指在 MySQL 中获取比较靠后的数据页,比如第 1000 页、第 10000 页等。特别是使用 LIMIT offset,count 这种方式,当 offset 特别大,就会带来严重的性能问题。
对于 SELECT * FROM tbn LIMIT 1000000,10,这样的查询语句来说,MySQL 会:
- 从表中读取第一条记录,判断是否满足 where 条件;如果满足,计数器+1;否则直到 计数器累计到 1000000 时才开始真正取数据
- 再继续获取 10 条数据,返回
性能会非常差,因为需要从头扫描,无法利用索引优化,并且需要抛弃大量不需要的数据,占用大量的内存和 CPU 资源。
可以借助主键索引分页进行优化:
SELECT * FROM tbn
WHERE id > (SELECT id FROM tbn ORDER BY id LIMIT 1000000, 1)
LIMIT 10或者记住上次分页的最大 ID,然后再查询:
SELECT * FROM tbn
WHERE id > last_page_max_id
LIMIT 10
- Java 面试指南(付费)收录的字节跳动面经同学 13 Java 后端二面面试原题:什么是深分页,select * from tbn limit 1000000000 这个有什么问题,如果表大或者表小分别什么问题
83.SQL 题:一个学生成绩表,字段有学生姓名、班级、成绩,求各班前十名
第一步,建表:
CREATE TABLE student_scores (
student_name VARCHAR(100),
class VARCHAR(50),
score INT
);第二步,插入数据:
INSERT INTO student_scores (student_name, class, score) VALUES
('沉默王二', '三年二班', 88),
('沉默王三', '三年二班', 92),
('沉默王四', '三年二班', 87),
('沉默王五', '三年二班', 85),
('沉默王六', '三年二班', 90),
('沉默王七', '三年二班', 95),
('沉默王八', '三年二班', 82),
('沉默王九', '三年二班', 78),
('沉默王十', '三年二班', 91),
('沉默王十一', '三年二班', 79),
('沉默王十二', '三年三班', 84),
('沉默王十三', '三年三班', 81),
('沉默王十四', '三年三班', 90),
('沉默王十五', '三年三班', 88),
('沉默王十六', '三年三班', 87),
('沉默王十七', '三年三班', 93),
('沉默王十八', '三年三班', 89),
('沉默王十九', '三年三班', 85),
('沉默王二十', '三年三班', 92),
('沉默王二十一', '三年三班', 84);第三步,查询各班前十名。如果 MySQL 是 8.0 以下版本,不支持窗口函数,可以通过在查询中维护班级当前处理状态和排名,实现分组内按成绩排序并打标号,再取前十名。
SET @cur_class = NULL, @cur_rank = 0;
SELECT student_name, class, score
FROM (
SELECT
student_name,
class,
score,
@cur_rank := IF(@cur_class = class, @cur_rank + 1, 1) AS rank,
@cur_class := class
FROM student_scores
ORDER BY class, score DESC
) AS ranked
WHERE ranked.rank <= 10;| 步骤 | 解释 |
|---|---|
| @cur_class 变量 | 记录当前正在处理的班级 |
| @cur_rank 变量 | 记录当前班级的排名,默认 0 |
IF(@cur_class = class, @cur_rank + 1, 1) | 如果班级没变,就排名 +1;如果换了新班级,排名从 1 重新开始 |
@cur_class := class | 更新当前班级变量,保持班级变化跟踪 |
ORDER BY class, score DESC | 必须先按班级升序、成绩降序排好,才能保证变量正确打排名 |
外层 WHERE rank <= 10 | 只取每班前十名 ✅ |
如果是 MySQL 8.0+ 版本,可以使用窗口函数来完成:
SELECT student_name, class, score
FROM (
SELECT
student_name,
class,
score,
ROW_NUMBER() OVER (PARTITION BY class ORDER BY score DESC) AS rn
FROM student_scores
) AS tmp
WHERE rn <= 10;| SQL 用到的技术 | 说明 |
|---|---|
ROW_NUMBER() OVER (PARTITION BY class ORDER BY score DESC) | 给每个班独立打排名,从 1 开始 |
| 子查询 tmp | 用来临时生成带有 rn(排名)的数据集 |
外层 WHERE rn <= 10 | 选出每个班排名前 10 的学生 |
ORDER BY score DESC | 成绩高排前面,符合常规排名逻辑 |
- Java 面试指南(付费)收录的腾讯云智面经同学 16 一面面试原题:SQL 题:一个学生成绩表,字段有学生姓名、班级、成绩,求各班前十名
memo:2025 年 4 月 26 日修改至此,今天有球友发邮件送来喜报,说他拿到了蚂蚁国际的 offer,并且多次感谢星球对他实习的帮助,比身边朋友拿到了更多的面试机会,并且准备阶段只看二哥的专栏,都有一种精神洁癖了,说实话,这种喜报我真的爱看,😄。
整整两个月,面渣逆袭 MySQL 篇第二版终于整理完了,这一版几乎可以说是重写了,每天耗费了大量的精力在上面,可以说是改头换面,有一种士别俩月,当刮目相看的感觉。

网上的八股其实不少,有些还是付费的,我觉得是一件好事,可以给大家提供更多的选择,但面渣逆袭的含金量懂的都懂。
面渣逆袭第二版是在星球嘉宾三分恶的初版基础上,加入了二哥自己的思考,加入了 1000 多份真实面经之后的结果,并且从 24 届到 25 届,再到 26 届,帮助了很多小伙伴。未来的 27、28 届,也将因此受益,从而拿到心仪的 offer。
能帮助到大家,我很欣慰,并且在重制面渣逆袭的过程中,我也成长了很多,很多薄弱的基础环节都得到了加强,因此第二版的面渣逆袭不只是给大家的礼物,也是我在技术上蜕变的记录。
很多时候,我觉得自己是一个佛系的人,不愿意和别人争个高低,也不愿意去刻意宣传自己的作品。
我喜欢静待花开。
如果你觉得面渣逆袭还不错,可以告诉学弟学妹们有这样一份免费的学习资料,帮我做个口碑。
我还会继续优化,也不确定第三版什么时候会来,但我会尽力。
愿大家都有一个光明的未来。
由于 PDF 没办法自我更新,所以需要最新版的小伙伴,可以微信搜【沉默王二】,或者扫描/长按识别下面的二维码,关注二哥的公众号,回复【222】即可拉取最新版本。
当然了,请允许我的一点点私心,那就是星球的 PDF 版本会比公众号早一个月时间,毕竟星球用户都付费过了,我有必要让他们先享受到一点点福利。相信大家也都能理解,毕竟在线版是免费的,CDN、服务器、域名、OSS 等等都是需要成本的。
更别说我付出的时间和精力了,大家觉得有帮助还请给个口碑,让你身边的同事、同学都能受益到。
我把二哥的 Java 进阶之路、JVM 进阶之路、并发编程进阶之路,以及所有面渣逆袭的版本都放进来了,涵盖 Java基础、Java集合、Java并发、JVM、Spring、MyBatis、计算机网络、操作系统、MySQL、Redis、RocketMQ、分布式、微服务、设计模式、Linux 等 16 个大的主题,共有 40 多万字,2000+张手绘图,可以说是诚意满满。
这次仍然是三个版本,亮白、暗黑和 epub 版本。给大家展示其中一个 epub 版本吧,有些小伙伴很急需这个版本,所以也满足大家了。
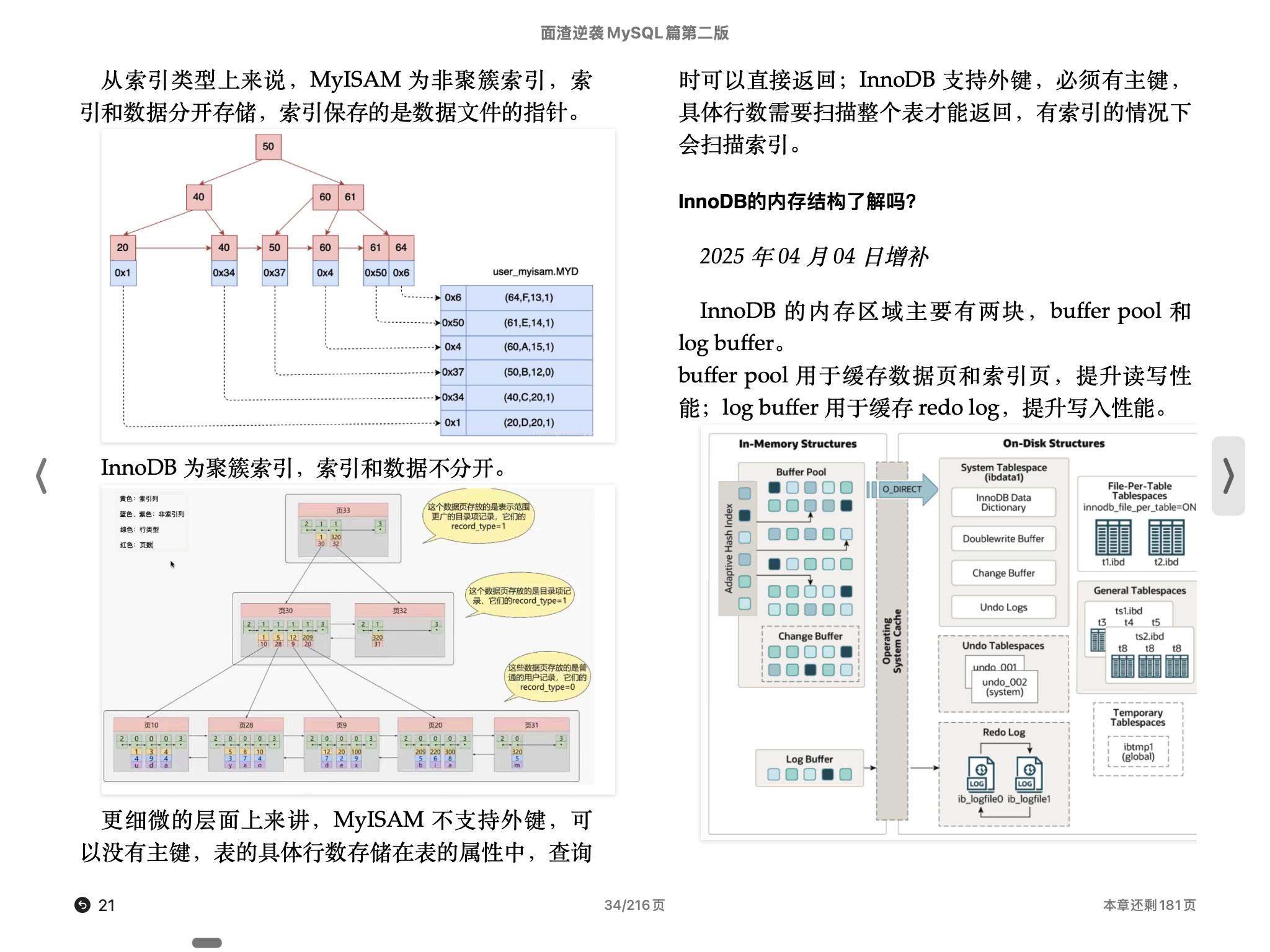
图文详解 83 道 MySQL 面试高频题,这次吊打面试官,我觉得稳了(手动 dog)。整理:沉默王二,戳转载链接,作者:三分恶,戳原文链接。
没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。
系列内容: