Skills面试题,33道 Skill 八股文(1万字40张手绘图),面渣逆袭必看👍
01、什么是 Skills?
面试官好,Skills 简单来说就是一套预定义的指令集,它告诉 AI 在遇到特定类型的任务时应该怎么做、遵循什么规范、输出什么格式。
具体来讲,一个 Skill 通常就是一个 SKILL.md 文件,里面包含了针对某类任务的最佳实践。
比如说有专门生成 Word 文档的 Skill,里面会写清楚字体怎么设、标题层级怎么处理、页眉页脚怎么加;也有专门做 PPT 的 Skill,规定了幻灯片布局、配色、动画等细节。这些经验是经过大量试错沉淀下来的,不是临时拍脑袋写的 Prompt。
从架构上看,每个 Skill 有三个关键要素:名称用来标识,描述用来让系统判断什么时候该触发这个 Skill,文件路径指向具体的指令内容。
当用户发起一个请求时,Agent 会根据请求内容自动匹配相关的 Skill,把对应的指令加载进上下文,AI 就能按照这套规范来执行任务。
举个例子,如果用户说“帮我做一份季度汇报的 PPT”,Agent 会自动识别出这是一个 PPT 生成任务,然后加载 pptx 这个 Skill,AI 在生成幻灯片的时候就会遵循里面定义的排版规范和设计原则,而不是随意发挥。
所以本质上,Skills 就是把零散的 Prompt 工程经验模块化、标准化了,让 AI 的输出质量更稳定、更可控。它和传统的 Prompt 模板最大的区别在于,它是系统级的自动调度,不需要人工干预。
参考答案版本 2
Skills 是 Anthropic 推出的一种结构化知识包机制,用于增强 Claude 在特定任务上的能力。它不是 API 调用,而是把专业知识、指令、脚本打包成一个文件夹,让 Claude 按需加载。
核心概念:
- Skills 是一个文件夹,包含 SKILL.md 文件(必需)和可选的资源文件
- SKILL.md 包含 YAML 元数据(name、description)和 Markdown 指令
- Claude 根据任务需要,动态加载相关 Skill 的内容
三者对比:
| 对比项 | Function Calling | MCP | Claude Skills |
|---|---|---|---|
| 本质 | API 调用 | 工具协议 | 知识包 |
| 格式 | JSON Schema | 复杂协议 | Markdown + YAML |
| Token 消耗 | 低(只传参数) | 高(协议开销) | 按需加载,高效 |
| 适用场景 | 调用外部 API | 复杂工具集成 | 增强特定任务能力 |
| 学习成本 | 中等 | 高 | 低 |
举个例子:假设要让 Claude 更擅长处理 PDF,用 Skills 的方式:
pdf-skill/
├── SKILL.md # 定义如何处理 PDF 的指令
├── examples/ # 示例用法
└── scripts/ # 辅助脚本而不是写一个 parsePdf() 的 Function。Skills 更像是教会 Claude 一项技能,而不是给 Claude 一个工具。
参考答案版本 3
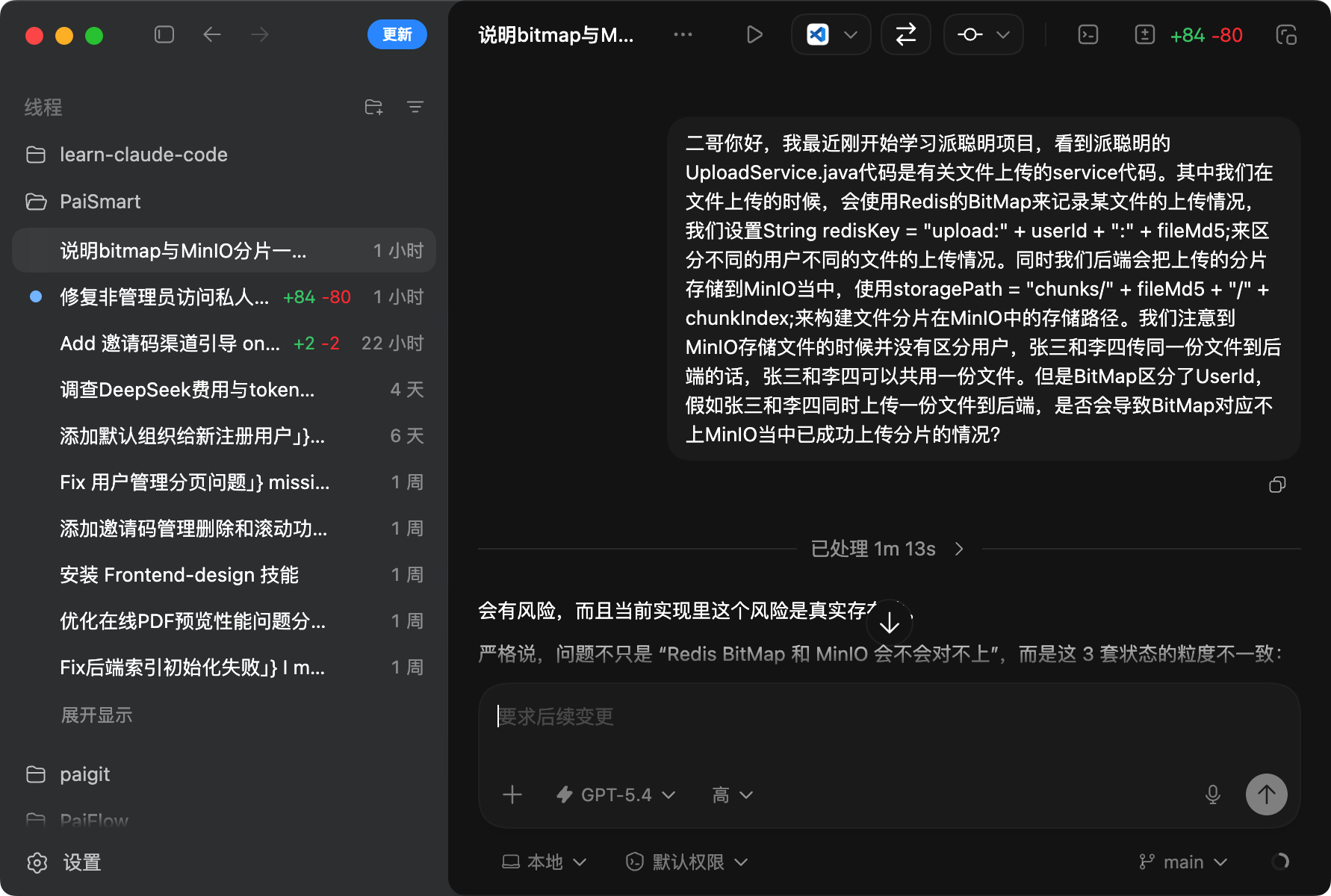
公共的 Prompt 就是 Skills。
每次让 AI 写代码我们需要告诉它“用 Java”、“遵循阿里巴巴代码规范”、“注释要写清楚”?
这些重复的指令,就是软件开发中的“重复代码”。在软件开发中,我们解决重复代码的方法是“封装复用”。
Skills 做的就是这件事。它把这些公共的 Prompt 封装起来,变成一个“技能模块”。下次需要用的时候,直接调用这个 Skill 就行,不用再把那些指令重复一遍。
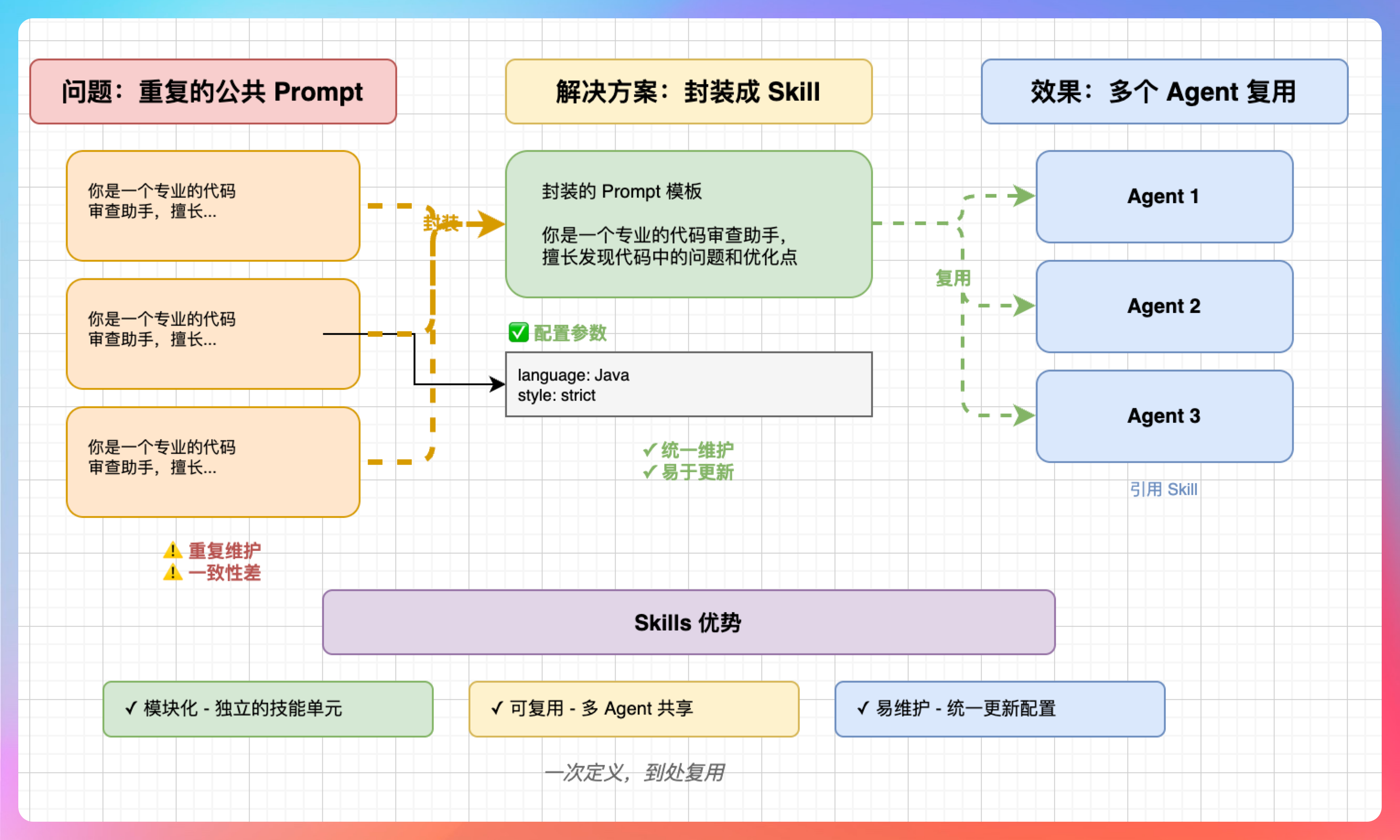
这就像我们写了一个工具类,以后所有项目都能直接调用。区别在于,这个工具类是给 AI 用的,不是给人用的。
参考答案版本4
Skill 是 Claude Code 的扩展机制,本质上是一个包含 SKILL.md 文件和可选资源(scripts、references、assets)目录。它能把 Claude 从通用 AI 变成某个领域的专家。
比如说,我们装了一个 PDF 处理的 Skill,Claude 就能帮我们合并 PDF、提取文字、填写表单。装一个前端开发的 Skill,它就能帮我们生成符合团队规范的 React 组件。
一个标准的 Skill 结构长这样:
skill-name/
├── SKILL.md # 必需,包含元数据和指令
├── scripts/ # 可选,可执行脚本
├── references/ # 可选,参考文档
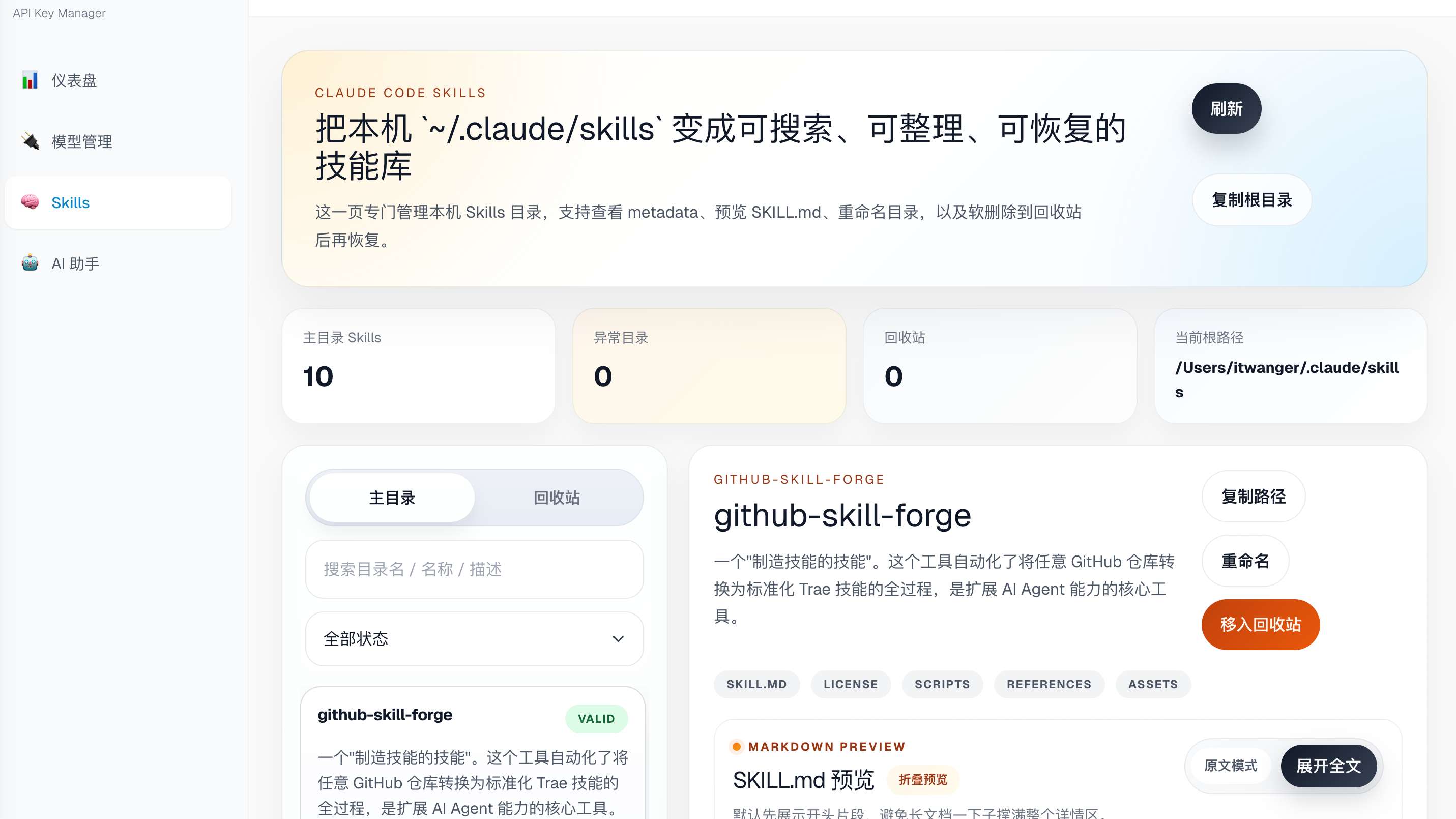
└── assets/ # 可选,模板、图片等资源01-1、Skills 的目录位置了解吗?
不同工具的 Skills 存放位置:
| 工具 | 个人 Skills 路径 | 项目 Skills 路径 |
|---|---|---|
| Claude Code | ~/.claude/skills/ | .claude/skills/ |
| Codex | ~/.codex/skills/ | .codex/skills/ |
| TRAE | ~/.trae/skills/ | .trae/skills/ |
| Qoder | ~/.qoder/skills/ | .qoder/skills/ |
这里要说明两点,除了 .codex 目录,Codex 还支持 .agent 目录;~ 是相对你的根目录,不带的话,相对你的项目目录。
memo:2026年4月3日修改至此,今天有球友发来喜报说,拿到了腾讯的暑期实习offer,还称赞了二哥修改的简历有帮助,真是太棒了!祝贺这位小伙伴,也希望其他小伙伴都能拿到心仪的offer!加油!💪
02、为什么 Skills 不直接把所有内容都加载进去?
面试官好,这个问题其实涉及到大模型一个很核心的限制,就是上下文窗口(Context Window)是有限的。
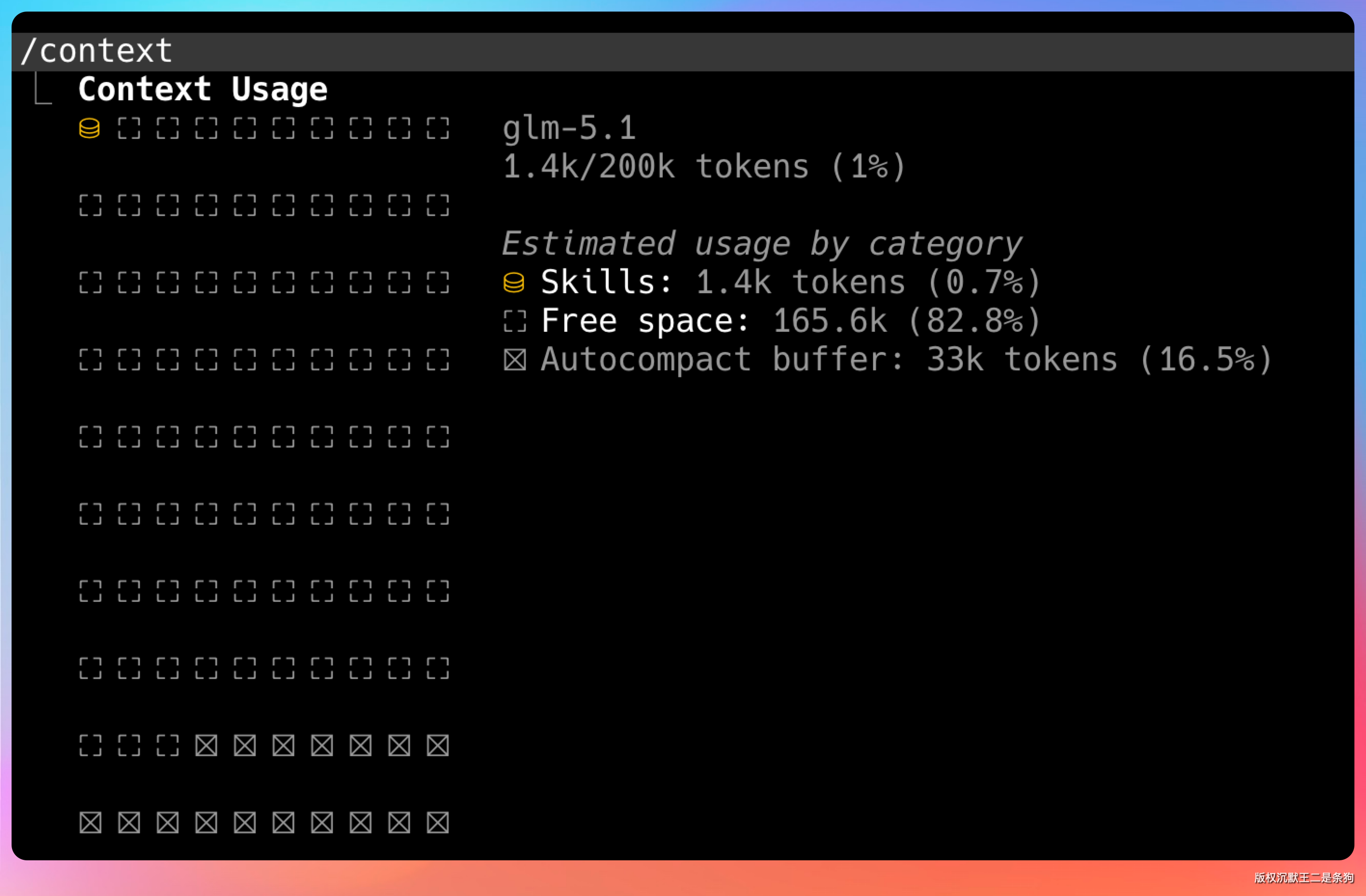
不管模型的上下文窗口有多大,它终归是一个有上限的资源。
如果把所有 Skills 的内容一股脑全塞进去,首先会大量占用上下文空间,留给用户实际任务的空间就被压缩了。
比如说一共有十几个 Skill,每个几千字,全加载进去可能就占掉好几万 token,真正用来处理用户需求的空间就很紧张了。
其次是注意力稀释的问题。大模型在处理长上下文时,信息越多,对每条指令的关注度越低,容易出现“该遵循的规范没遵循、不相关的规范反而干扰了输出”这种情况。
只加载当前任务相关的 Skill,模型的注意力更集中,执行质量也更高。
第三点是性能和成本。token 数量直接影响推理速度和 API 调用费用,全量加载意味着每次请求都要多处理大量无关内容,响应变慢,成本也上去了,这在生产环境里是不可接受的。
所以现在的设计思路其实很像软件工程里的按需加载(Lazy Loading)。系统先通过 Skill 的名称和描述做一次轻量级匹配,判断当前任务需要哪些 Skill,然后只把相关的加载进来。这样既保证了指令的精准性,又最大化利用了上下文空间。
这个设计理念在很多地方都能看到类似思路,比如 RAG 也是先检索再生成,而不是把整个知识库塞给模型。核心逻辑是一样的:在有限的上下文里放最有价值的信息,而不是最多的信息。
参考答案版本 2
AI 的工作空间是有限的。
我们知道 AI 在工作的时候,并不是一个无限的资源空间,而是运行在一个特定大小的窗口上。
也就是上下文窗口(Context Window)。我的Claude Code 配的是GLM-5,目前大小是 200K,看起来很大,但真用起来,会发现很快就不够用了。
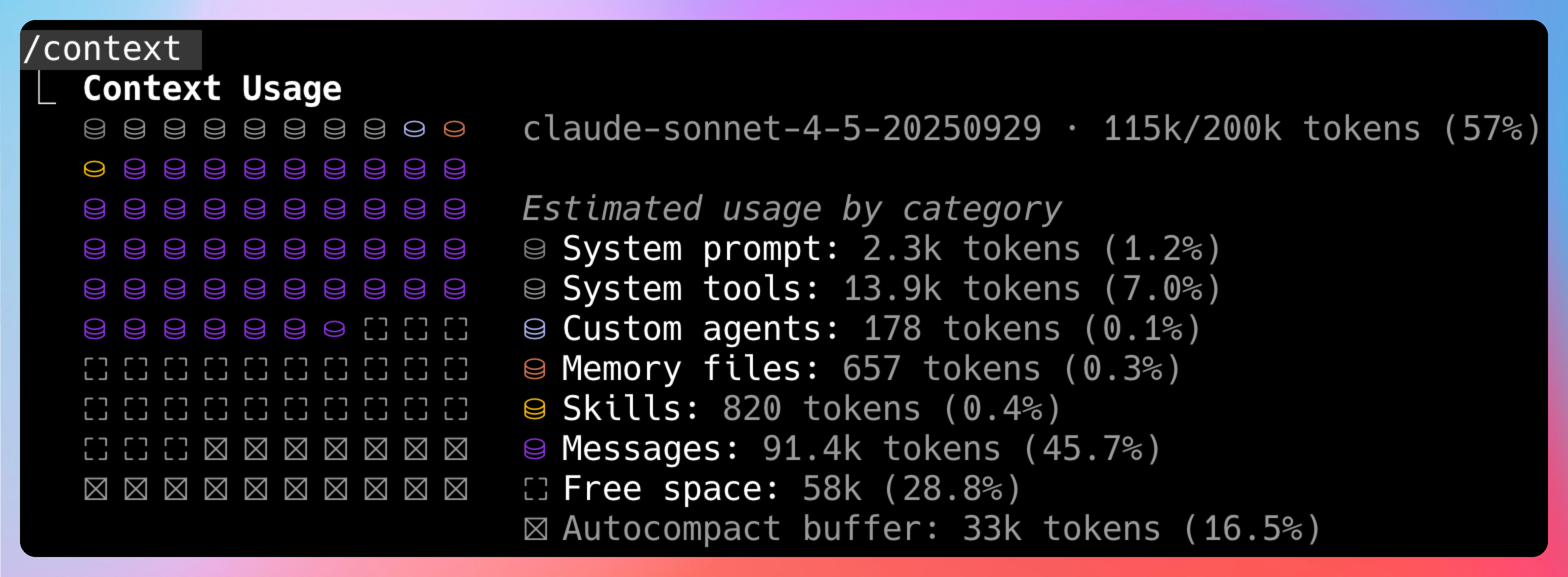
如果有 100 个 Skills,每个 Skill 的完整内容都是几千字的 Prompt,全部加载进去,上下文窗口直接爆炸。AI 还没开始干活,光加载这些 Skills 就把 token 用完了。
所以 Skills 的设计理念是:不是让 AI 知道更多,而是让 AI 在恰当的时间知道恰当的事。
这就是“渐进式披露(Progressive Disclosure)”架构的核心思想。
02-1、具体怎么实现渐进式披露呢?
面试官好,渐进式披露在 Skills 这个场景下,实现起来大致分三个层次。
第一层是轻量级索引匹配。系统不会一上来就读取所有 Skill 的完整内容,而是先维护一份索引,每个 Skill 只暴露名称和描述这两个字段。
当用户的请求进来后,系统根据请求内容和这些描述做语义匹配,判断哪些 Skill 跟当前任务相关。这一步的信息量非常小,可能每个 Skill 就几十个字的描述,十几个 Skill 加起来也占不了多少 token。
第二层是按需加载完整指令。匹配到相关 Skill 之后,系统才去读取对应的 SKILL.md 文件,把里面的详细规范和最佳实践加载进上下文。
而且一个任务可能匹配到多个 Skill,比如用户要做一份包含图表的 Word 报告,可能同时触发 docx 和 xlsx 两个 Skill,系统会把这两个都加载进来,但其他不相关的就不动。
第三层是执行过程中的逐步展开。即使一个 Skill 被加载了,也不意味着里面所有指令都要一次性全部执行。
很多 Skill 内部本身就是分阶段的,比如先搭骨架、再填内容、最后做格式调整,模型会根据当前执行到哪个阶段去关注对应的指令段落,而不是同时处理所有规则。
这个思路其实在前端工程里特别常见,就像代码分割(Code Splitting)一样。首屏只加载关键资源,用户滚动到哪里再加载哪里的内容。
本质上都是在解决同一个问题:资源有限的情况下,如何让最关键的信息在最需要的时刻出现。放到大模型场景下,这个“资源”就是上下文窗口,“关键信息”就是当前任务真正需要的指令和规范。
参考答案版本2
搞个分级缓存。当输入 Prompt 的时候,不要带上全量的 Skills 信息,而是最基本的元信息。AI 会按照语意进行匹配,匹配到了才会加载实际的内容。
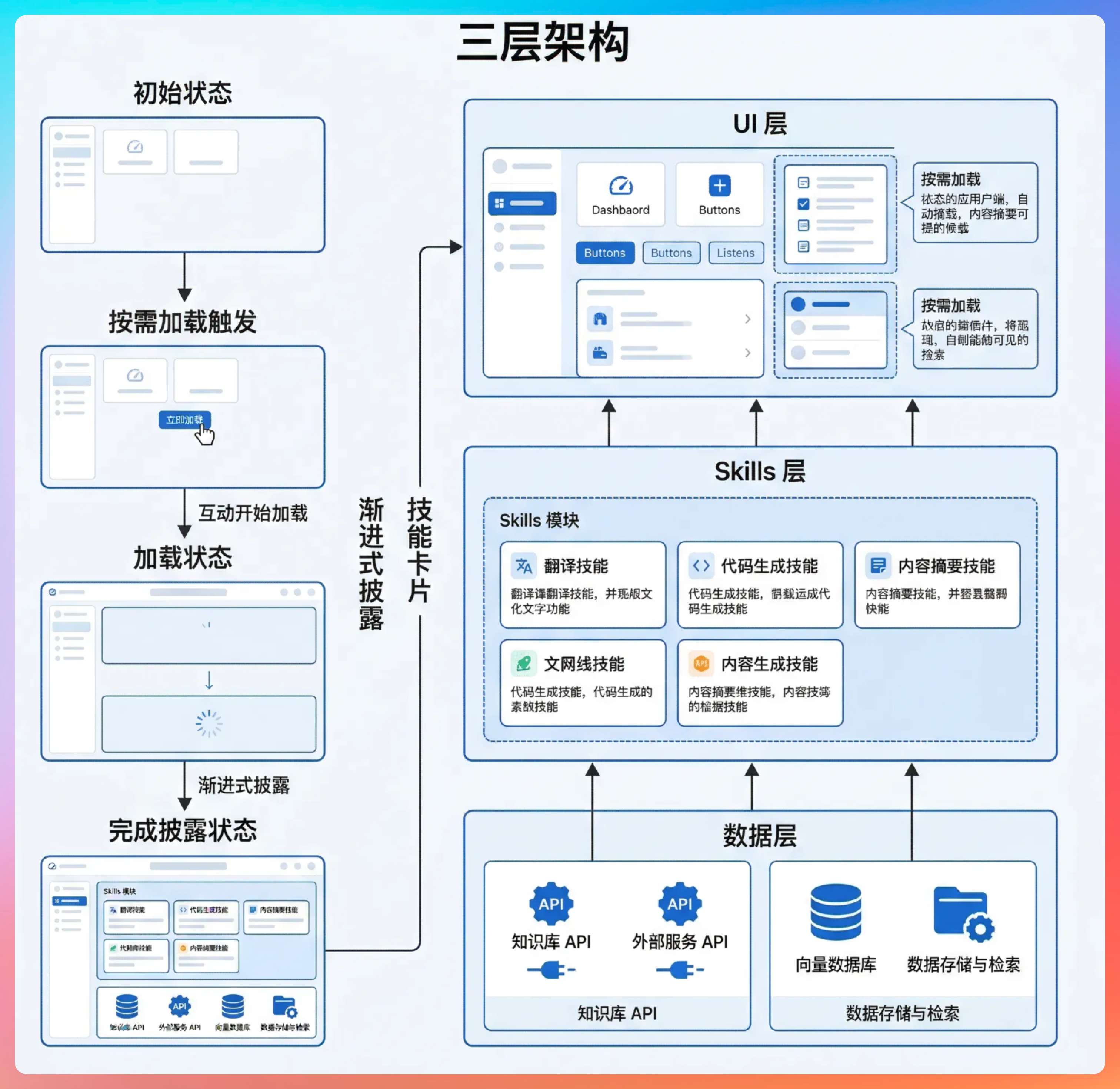
这个过程分为三步:
第一步:发现阶段。 启动时,AI 扫描所有 Skills 的元数据,建立一个“技能注册表”。这个注册表只包含最基本的信息:Skill 名称、描述、触发关键词。就像图书馆的目录卡片,只告诉我们书名和位置,不会把整本书都给我们看。
第二步:语义匹配。 当用户输入一个问题,AI 会根据语义去匹配相关的 Skills。比如我们问“帮我写一个 Java 的单例模式”,AI 就会匹配到“Java 代码生成”相关的 Skill。这个过程是动态的,基于向量相似度计算。
第三步:执行阶段。 匹配成功后,才会加载这个 Skill 的完整内容。这时候,AI 才真正“看到”这个 Skill 的详细指令、示例、约束条件。
这三步走完,一个 Skill 才算真正被激活。而那些没被匹配到的 Skills,全程只占用几个 token 的元数据空间。这就是为什么你可以拥有几十上百个 Skills,却不用担心上下文爆炸。
02-2、Skills 的渐进式披露原理是什么?
面试官好,渐进式披露的原理,核心就是信息分层、按需释放,背后对应的是对上下文窗口这个稀缺资源的精细化管理。
可以把它类比成一个漏斗模型。最顶层是粗粒度的元信息,也就是每个 Skill 的名称和一段简短描述,这些信息常驻在系统提示词里,体量很小,目的是让模型具备“我有哪些能力可用”的全局认知。
中间层是完整的指令文件,只有当上层匹配命中之后,系统才通过读取文件的方式把具体内容拉进上下文。最底层是执行时的细节展开,模型在实际生成过程中逐步消化指令,分阶段完成任务。
这个设计背后有一个很重要的原理,就是信息论里的相关性过滤。上下文窗口本质上是一个固定容量的信道,往里面塞的信息越多,信噪比越低,模型的输出质量就越差。
渐进式披露做的事情就是在每个阶段只保留信噪比最高的那部分信息,把噪声挡在外面。
从工程实现的角度看,它依赖的是一个两阶段检索机制。第一阶段是基于描述的语义匹配,成本极低,相当于在一个很小的索引上做一次查找;第二阶段才是文件级别的内容加载,成本相对高但精准度也高,因为已经经过了第一阶段的过滤。
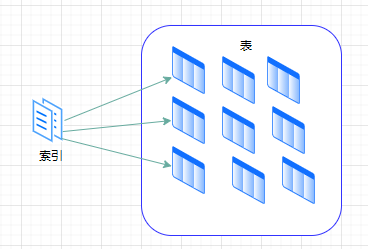
这跟数据库查询里先走索引再回表的逻辑是一样的,先用最小代价缩小范围,再精确获取需要的数据。
所以渐进式披露的本质,就是用多级过滤的方式,在有限的上下文空间里最大化有效信息密度。
它不是一个多复杂的算法问题,而是一个资源调度问题,核心思想在很多系统设计里都能看到,比如 CPU 的多级缓存、CDN 的分层分发,底层逻辑都是相通的。
参考答案版本2
考察点:理解 Skills 的核心设计理念
参考答案:
渐进式披露是 Skills 最核心的设计思想,解决的是上下文窗口有限的问题。
问题背景:传统做法是把所有工具说明、使用指南都塞进 System Prompt,导致:Token 消耗巨大(可能几万 Token 的说明)、无关信息干扰模型判断、上下文空间被挤占。
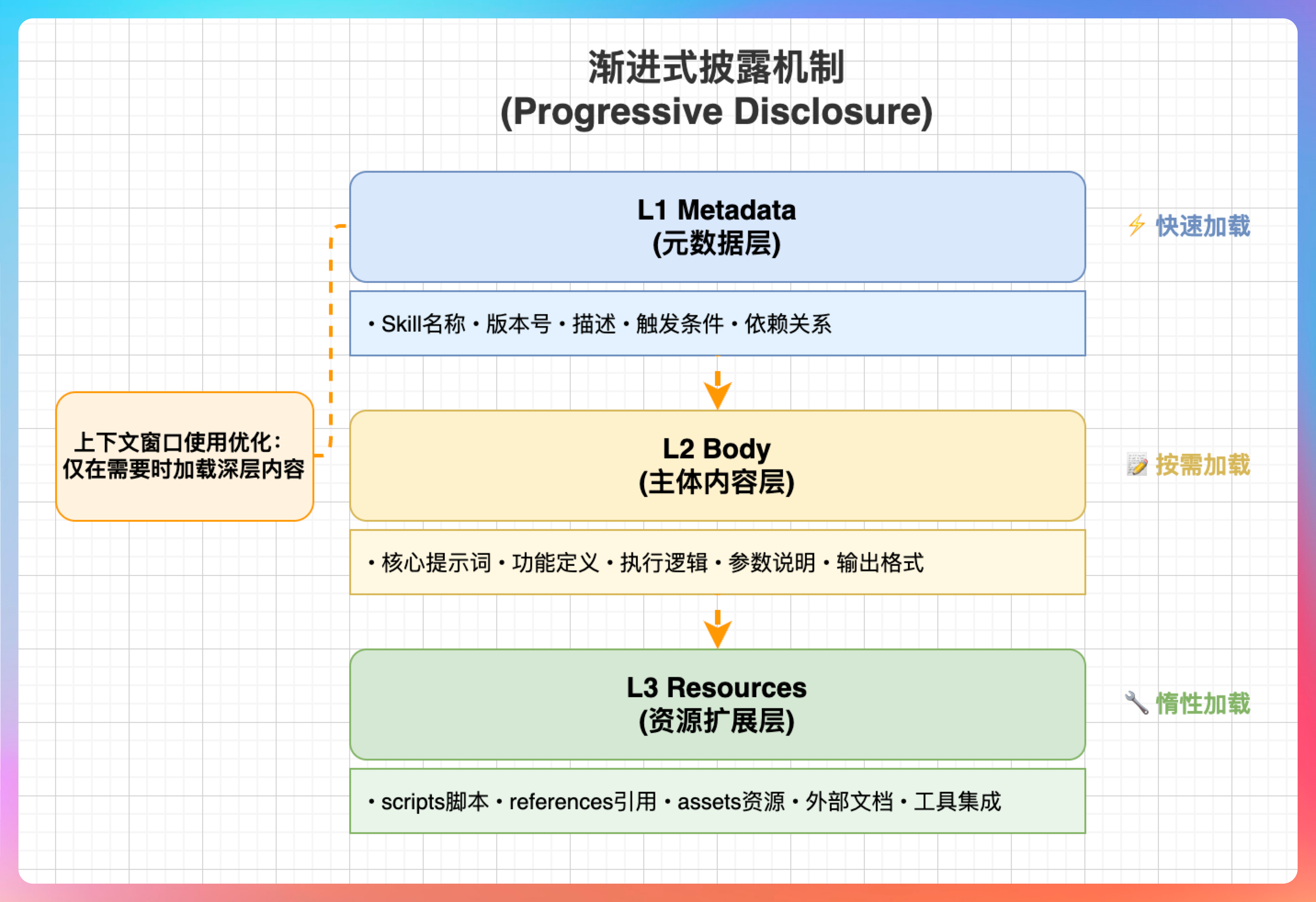
渐进式披露的三层加载:
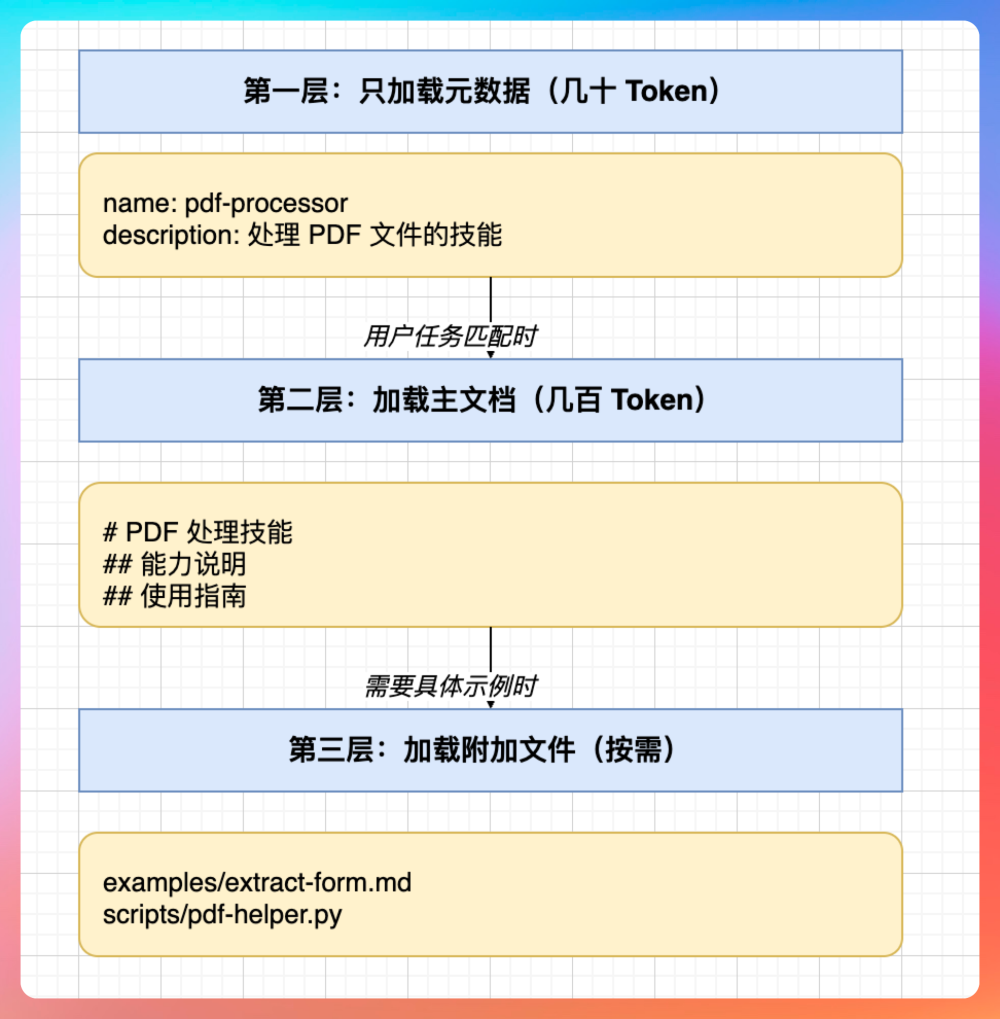
就像一本技术手册,目录页(元数据)让我们快速知道有哪些内容,章节概述(主文档)告诉我们怎么用,详细示例(附加文件)只在需要时翻阅。
好处是 Token 高效:不需要时不加载,响应更准确:没有无关信息干扰,扩展性好:可以有几百个 Skills,不会撑爆上下文。
memo:2026年4月3日修改至此,今天有球友发来喜报说,拿到了美团的暑期实习offer,果然4月正是收获的季节啊!加油!💪
03、直接把 Prompt 保存到笔记里,下次复制粘贴不就行了?为什么还要搞个 Skills?
面试官好,关于这个问题,我的理解是这样的。
复制粘贴 Prompt 最大的问题在于上下文管理成本高。一个好的 Prompt 往往很长,场景多了之后笔记里攒几十条,每次得自己判断该用哪个,找起来费劲,而且不同场景需要微调,改完还不一定记得同步回去,版本就乱了。
Skills 解决的核心问题是自动化触发和结构化管理。Prompt 封装成 Skill 之后,它就不再是一段死文本,而是一个可以被系统自动识别、自动加载的模块。
比如让 Claude 写 Word 文档,它会自动读取对应的 SKILL.md 拿到最佳实践,不需要人工去翻笔记。这就像手动挡和自动挡的区别,都能开,但自动挡明显更省心。
第二点是可复用和可协作。Skills 有标准结构,有名字、描述、触发条件,可以在团队内共享,保证输出质量一致。复制粘贴的话,每个人手里的 Prompt 版本可能都不一样,质量参差不齐。
第三点是可组合。一个复杂任务可能需要同时加载好几个 Skill,系统会自动判断该用哪些,靠手动粘贴很难做到这一点,不可能每次都把三四个 Prompt 全部粘进去还不搞混顺序。
所以本质上,复制粘贴是把菜谱抄在纸上自己翻,Skills 是把菜谱录入智能系统让它自动调取。效率、一致性和可维护性上,Skills 高出一个台阶。
04、如何创建一个 Skill?
面试官好,创建一个 Skill 其实并不复杂,核心就是写好 SKILL.md 文件,然后把它放到指定目录下。
首先要明确这个 Skill 要解决什么问题。
比如说我想让 AI 在生成技术博客时遵循特定的排版风格和写作规范,那这个 Skill 的定位就很清晰了。
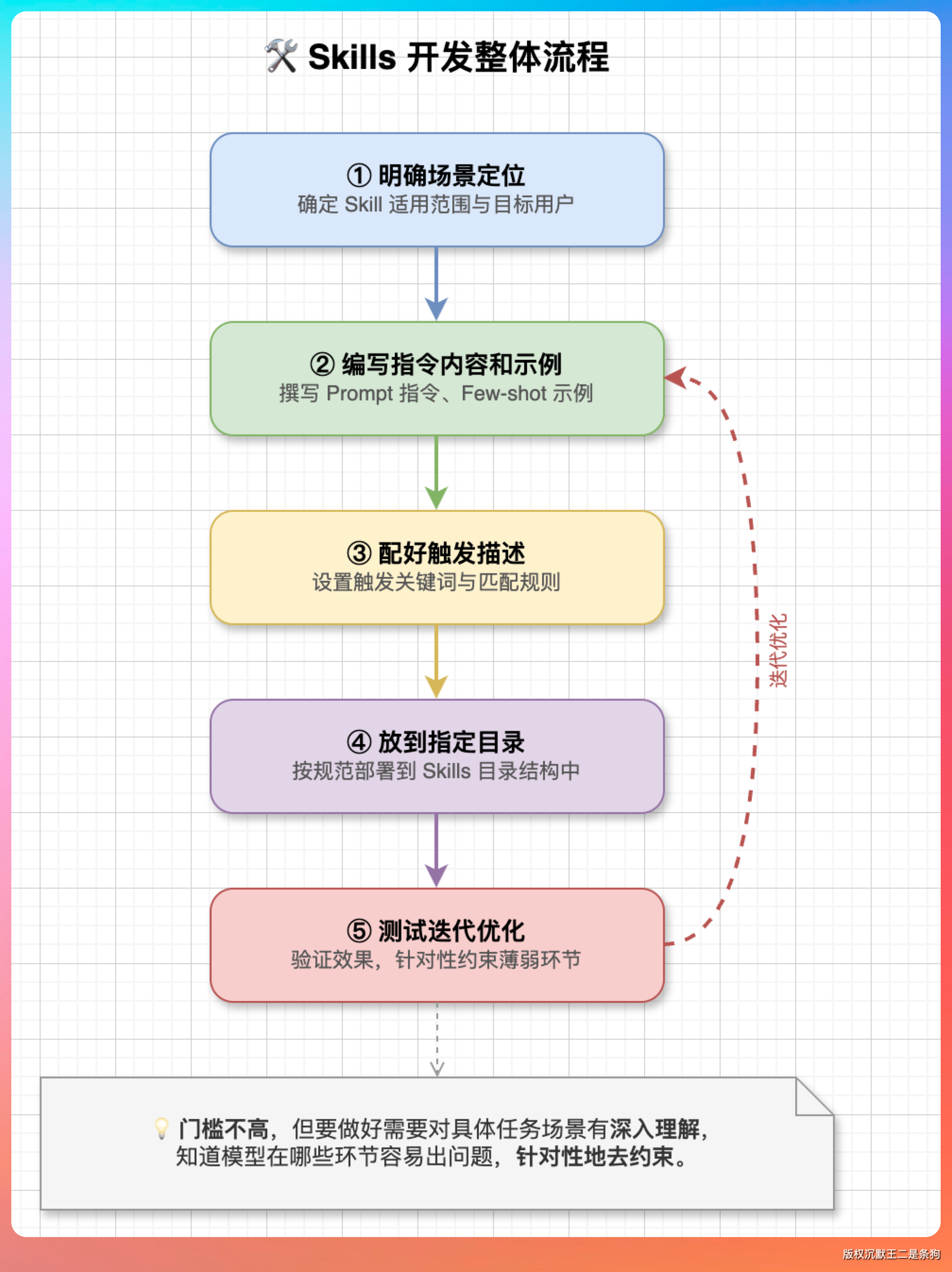
定位清楚之后,接下来就是写 SKILL.md 的内容,这里面一般包含几个部分:第一是任务描述,说明这个 Skill 干什么的;第二是具体的规范和约束,比如标题格式、段落风格、图片占位符怎么写、用什么标点符号;第三是示例,给模型展示一段符合规范的输出长什么样。示例这部分非常关键,很多时候光靠文字描述模型理解不到位,但给一个好的范例它就能快速对齐。
写好 SKILL.md 之后,需要给它配一个触发描述。这个描述的作用是告诉系统在什么场景下应该加载这个 Skill,写得越精准,触发的准确率越高。
比如描述里写“当用户要求生成微信公众号风格的技术文章时触发”,那系统在遇到相关请求时就会自动匹配上来。这个描述相当于 Skill 的“索引词”,直接决定了它能不能在该出现的时候出现。
文件组织上,通常把 SKILL.md 放在一个独立的目录里,如果这个 Skill 执行过程中需要用到模板文件、参考素材之类的辅助资源,也一起放在同一个目录下,保持结构清晰。
开发完之后还有一个很重要的环节是测试和迭代。实际跑几个典型场景,看输出是不是符合预期,哪些地方模型没有遵循规范,回去调整指令的措辞和优先级。
这个过程跟调 Prompt 本质上是一样的,只不过 Skill 的结构化程度更高,迭代起来更有章法,不像散装 Prompt 改来改去容易失控。
所以整体流程就是:明确场景定位、编写指令内容和示例、配好触发描述、放到指定目录、测试迭代优化。门槛不高,但要做好需要对具体任务场景有深入理解,知道模型在哪些环节容易出问题,针对性地去约束。
参考答案版本2
创建 Skill 的核心思路是:将工作中的案例总结提炼(归纳),固化为 Skill,用以应对同类问题(演绎),或是再次反馈完善这个 Skill。
听起来有点抽象,我用一个具体的例子来说明。
假设我们经常需要让 AI 帮忙做“逆向建模”。什么是逆向建模?就是有一段现有的代码,想让 AI 分析它的设计思路,然后生成对应的设计文档或者架构图。
这是开发过程中最高频的场景之一,对应着我们最常见的应用场景:需求迭代。
第一步,观察 Prompt 过程。
“帮我分析这段代码的设计思路,然后画一个架构图。” “注意要标注清楚各个模块的职责。” “用 PlantUML 语法。” “模块之间的关系用箭头表示。”
第二步,总结提炼。把这些指令固化为一个 Skill:
---
name: reverse-modeling
description: 逆向建模,分析代码设计思路并生成架构图
trigger:
- 逆向建模
- 代码分析
- 架构图
---
## 任务目标
分析给定代码的设计思路,生成清晰的架构图。
## 输出要求
1. 标注清楚各个模块的职责
2. 使用 PlantUML 语法
3. 模块之间的关系用箭头表示
4. 包含关键数据流
## 示例
输入:一段 Spring Boot 应用的代码
输出:展示 Controller -> Service -> Repository 层级关系的架构图第三步,验证和迭代。在实际使用中,可能会发现这个 Skill 还不够完善。比如有时候需要支持 Mermaid 语法,有时候需要生成时序图。就可以把这些新需求加进去,让这个 Skill 越来越强大。
这里有一个关键点:我们是否有去洞察问题的眼力见。
在这个 AI 飞速发展的时代,解决问题的能力会被 AI 逐步取代,但精准发现一个有价值的问题,恰恰是最难被替代的核心能力,也是 Skill 的价值根源。
很多人用 AI 解决完一个问题,就关掉对话框,继续下一个任务。但如果我们想让 AI 越来越懂我们,就得学会让它帮我们沉淀经验。
04-1、你设计过哪些Skill?
我设计过一个简历优化的Skill。
这个 Skill 的场景是:我有一份简历,想让 AI 帮我优化措辞、突出亮点、规避常见问题。
首先,创建 Skill 文件。在 Skills 目录下,新建一个 resume-optimizer/SKILL.md 文件:
---
name: resume-optimizer
description: 简历优化专家,帮助优化措辞、突出亮点、规避常见问题
trigger:
- 简历优化
- 简历
- CV
- 求职
---
## 角色定义
你是一位资深的简历优化专家,拥有 10 年以上的 HR 和猎头经验。你擅长从招聘者的视角审视简历,帮助求职者突出核心竞争力。
## 优化原则
1. 用数据说话:将模糊的描述转化为量化的成果
2. 突出关键词:根据目标岗位调整关键词密度
3. 精简冗余:删除与目标岗位无关的经历
4. 规避雷区:避免使用“参与”、“协助”等弱动词
## 优化流程
1. 分析目标岗位的 JD,提取核心要求
2. 对比简历内容,找出匹配点和差距
3. 优化措辞,突出成果而非过程
4. 检查格式和排版,确保专业美观
## 输出格式
### 简历诊断
- 当前问题:[列出 3-5 个主要问题]
- 优化方向:[给出具体的优化建议]
### 优化后简历
[输出优化后的简历内容]
### 亮点提炼
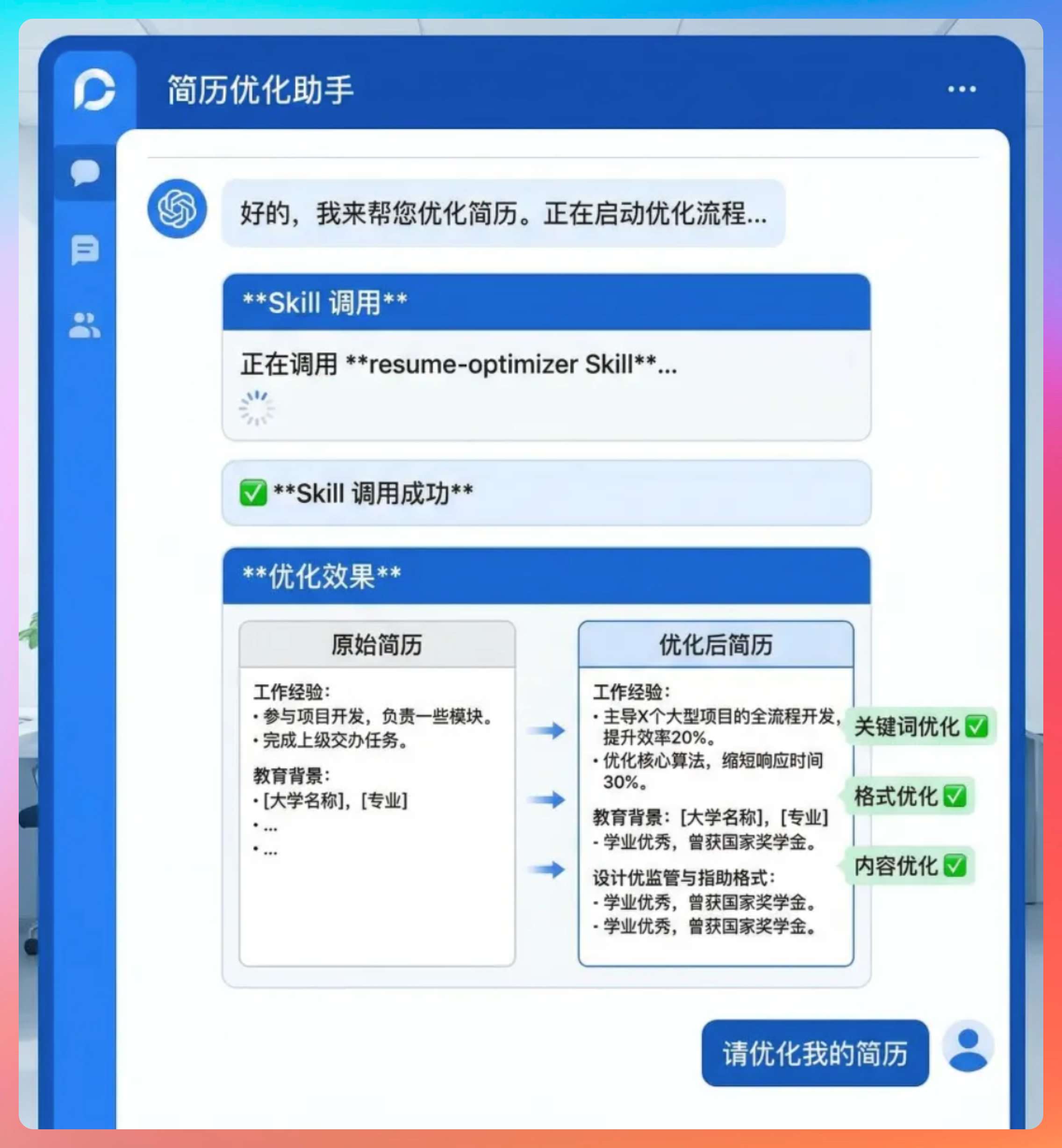
[列出简历中的 3 个核心亮点]然后,就可以直接使用这个 Skill 了。在 Claude Code 对话中输入:
“用 resume-optimizer Skill 帮我优化这份简历:[粘贴简历内容]”
AI 会自动加载这个 Skill,按照我定义的流程帮我优化简历。
04-2 创建 Skills 有哪些注意事项?
面试官好,创建 Skills 有几个比较关键的注意事项,我结合实际经验来说一下。
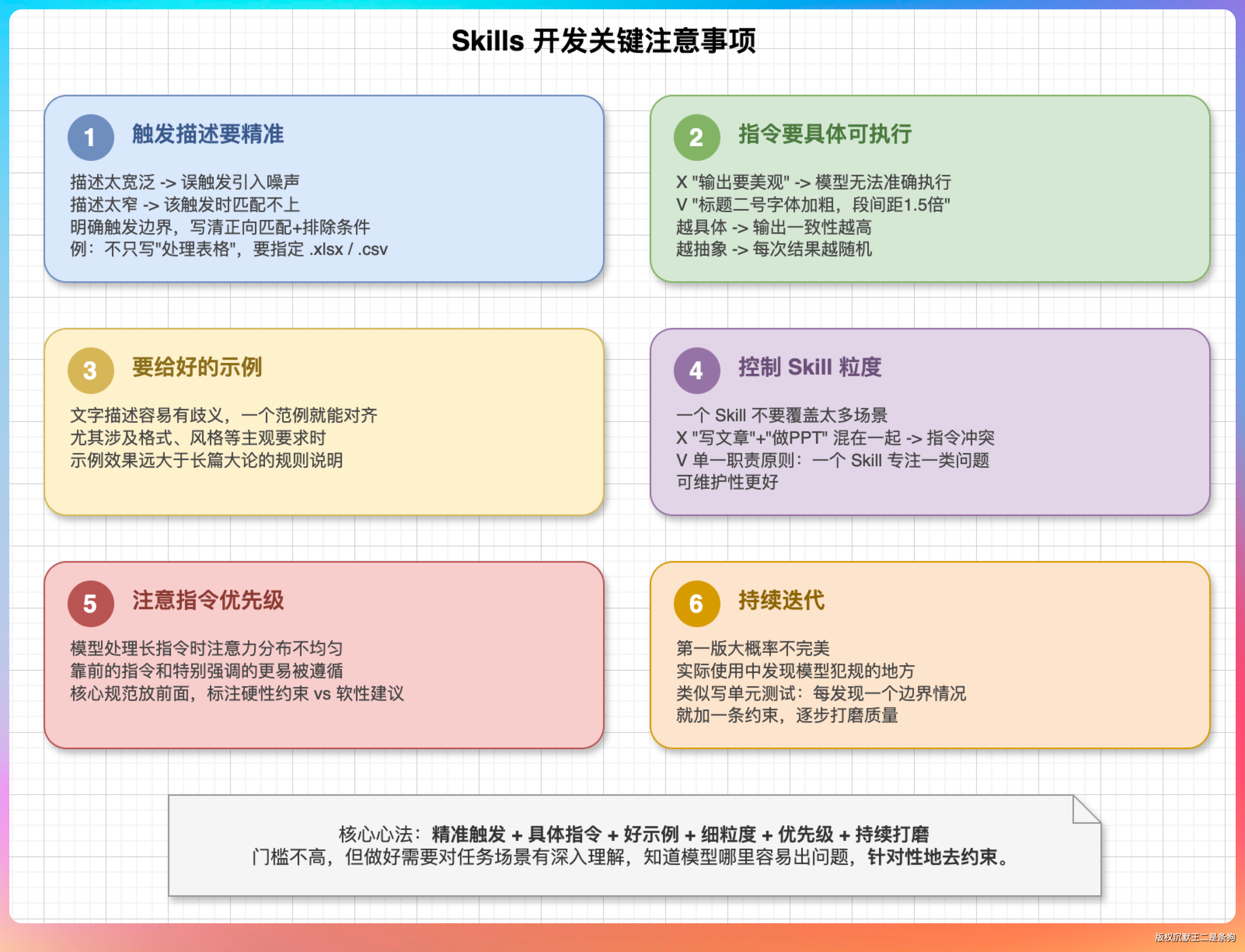
第一个是触发描述一定要写精准。这个是最容易被忽视但又最影响效果的地方。描述写得太宽泛,不相关的任务也会误触发这个 Skill,等于引入了噪声;写得太窄,该触发的时候又匹配不上。
比如一个处理 Excel 文件的 Skill,描述里不能只写“处理表格”,因为 HTML 表格、Markdown 表格也是表格,得明确写清楚是针对 .xlsx、.csv 这类文件格式的操作。最好把触发和不触发的边界都说清楚,类似于代码里的正向匹配加排除条件。
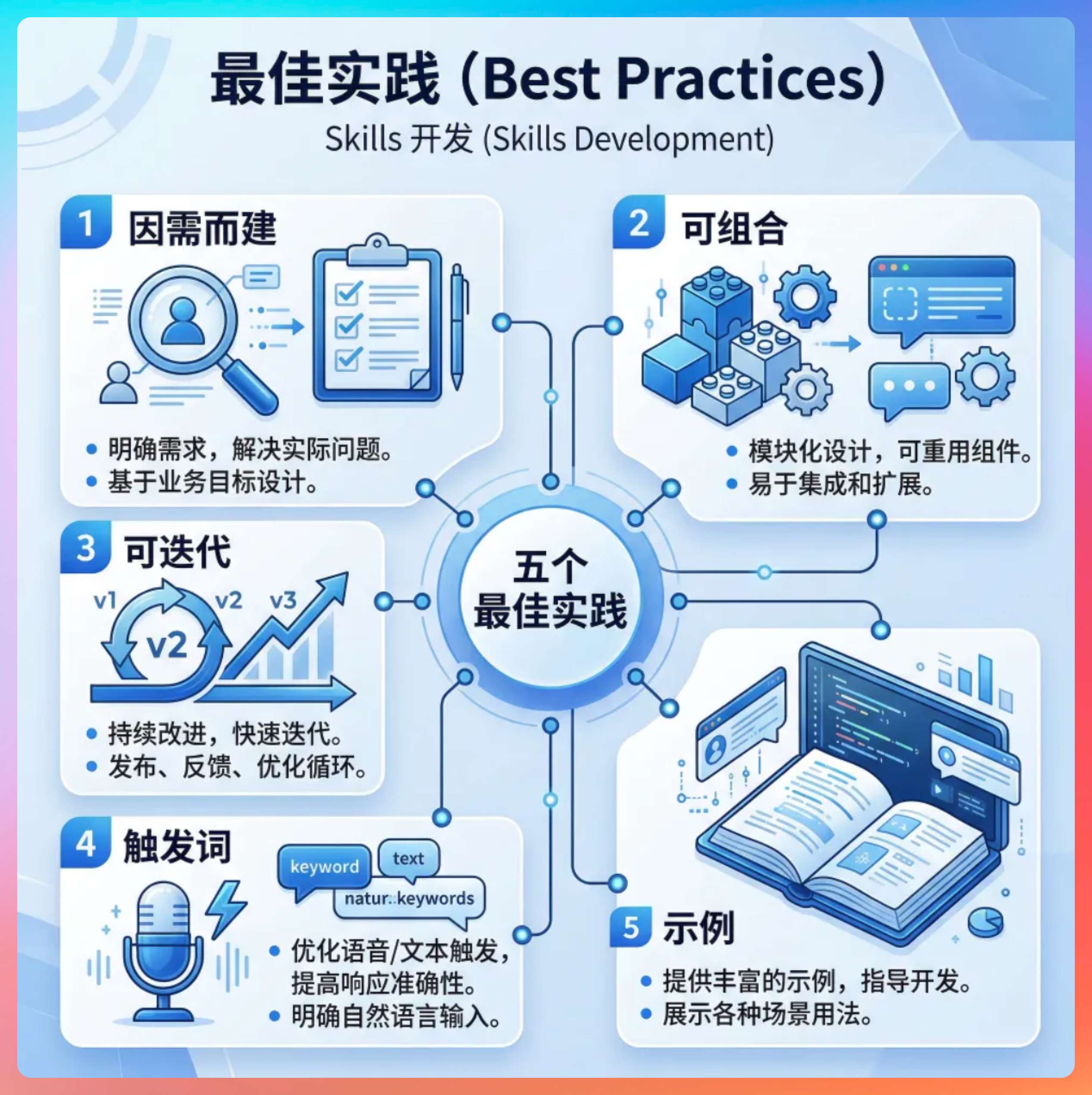
第二个是指令要具体到可执行,不能太抽象。比如写“输出要美观”这种话模型是没法准确执行的,它不知道什么叫美观。得具体到“标题用二号字体加粗,段间距 1.5 倍,配色用深蓝主色配浅灰背景”这种程度。越具体,模型的输出一致性越高,越抽象,每次跑出来的结果就越随机。
第三个是要给好的示例。很多规范光靠文字描述容易有歧义,但放一个符合要求的范例在那里,模型一下子就能对齐。尤其是涉及到格式、风格这类比较主观的要求,示例的效果远比长篇大论的规则说明好得多。
第四个是控制 Skill 的粒度。一个 Skill 不要试图覆盖太多场景,不然里面的指令会互相冲突或者模型不知道该优先遵循哪条。
比如“写文章”和“做 PPT”虽然都是内容生成,但差异很大,应该拆成两个独立的 Skill。单一职责原则在这里同样适用,一个 Skill 专注解决一类问题,可维护性也更好。
第五个是注意指令的优先级。Skill 里面可能有很多条规范,但模型处理长指令时注意力分布是不均匀的,靠前的指令和特别强调的指令更容易被遵循。
所以最核心的规范要放在前面,或者用明确的优先级标注告诉模型哪些是必须遵守的硬性约束、哪些是尽量满足的软性建议。
最后一个是持续迭代。第一版写出来大概率不完美,得在实际使用中不断发现模型“犯规”的地方,然后回去补充或修正指令。这个过程跟写单元测试有点像,每发现一个边界情况就加一条约束,Skill 的质量就是这样一点一点打磨出来的。
memo:2026年4月3日修改至此,今天又是修改了26份简历,包括南京大学、深圳大学、北京邮电大学、燕山大学、香港中文大学、中国地质大学、浙江工业大学、福州大学、华东理工大学、西安电子科技大学等等。
05、PaiAgent有用Skills吗?
PaiAgent 项目里其实是有一套比较完整的 Skills 体系的,而且是自研的 Skill 系统。
https://github.com/itwanger/PaiAgent
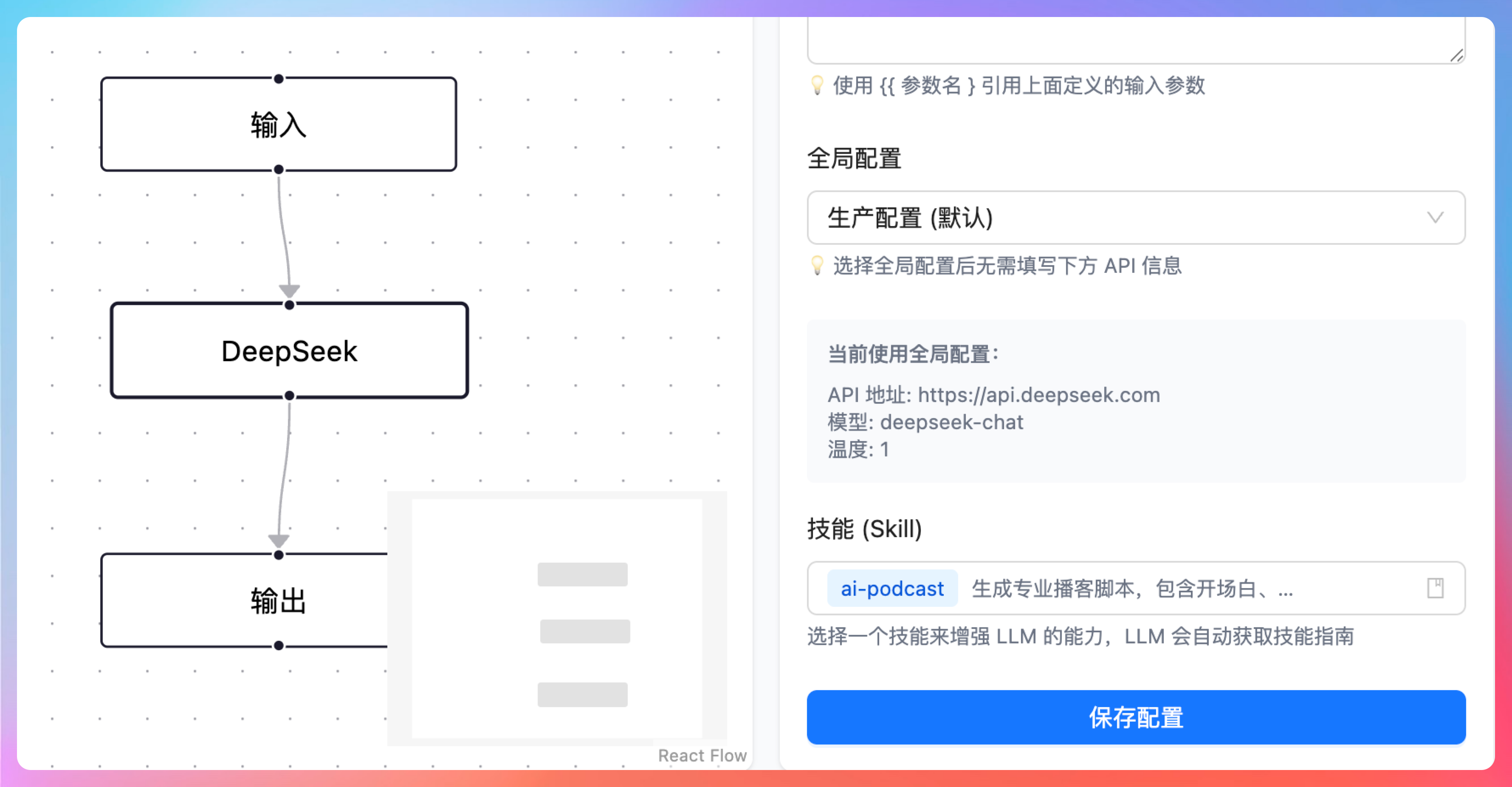
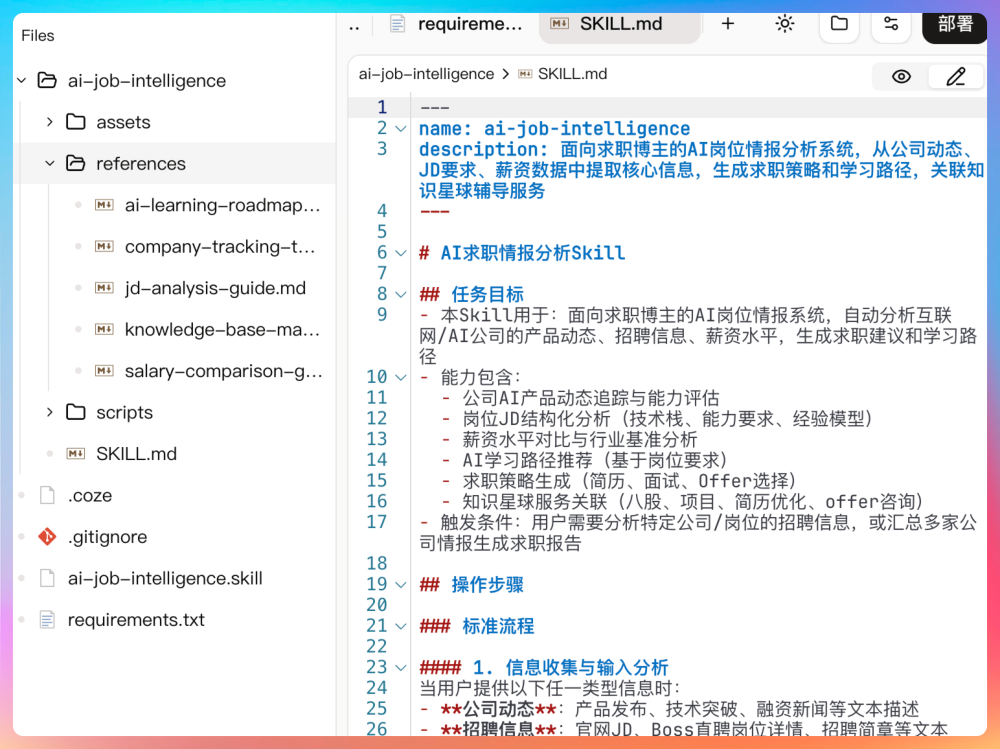
从整体架构来看,后端是用 Java 实现了一套 Skill 的注册和加载机制。SkillRegistry 负责统一管理所有 Skill 的注册和查找,SkillLoader 用来解析 SKILL.md 文件,每个 Skill 则用 Skill.java 这个数据模型来承载,里面包含名称、描述、内容以及引用文档这些信息。
前端这边也有配套组件,比如 SkillSelector.tsx,主要用来在界面上做 Skill 的选择。
Skill 的定义方式是通过 resources/skills/ 目录下的 SKILL.md 文件来完成的,采用 YAML frontmatter 的形式去声明名称和描述。目前项目里内置了一个 ai-podcast 的 Skill,用来生成播客脚本,同时还配了脚本模板和声音风格指南这两个引用文档。
这里面我觉得比较有意思的是,三级渐进式加载来控制 Token 消耗的设计。
第一层只加载 Skill 的名称和描述摘要,用于初步选择;
@PostConstruct
public void init() {
// 从 classpath 扫描所有 SKILL.md 文件
Resource[] resources = resolver.getResources("classpath*:" + skillsPath + "/*/SKILL.md");
for (Resource resource : resources) {
Skill skill = skillLoader.load(skillDir);
register(skill);
}
}第二层再加载完整的 SKILL.md 内容;
public Map<String, String> loadAllReferences(String skillName) {
Skill skill = skills.get(skillName);
Map<String, String> references = new HashMap<>();
for (String refName : skill.getReferences()) {
String content = skillLoader.loadReference(skill.getSkillPath(), refName);
references.put(refName, content);
}
return references;
}第三层则是在需要的时候按需加载引用文档。
public String getFullExecutionPrompt(Map<String, String> referenceContents) {
StringBuilder sb = new StringBuilder();
sb.append("# 技能: ").append(name).append("\n\n");
sb.append(description).append("\n\n---\n\n");
sb.append("## 技能指南\n\n").append(content).append("\n\n");
// 直接嵌入所有 reference 内容
for (Map.Entry<String, String> entry : referenceContents.entrySet()) {
sb.append("### ").append(entry.getKey()).append("\n\n");
sb.append(entry.getValue()).append("\n\n");
}
return sb.toString();
}这样设计的好处是,在 Agent 做 Skill 选择的时候,不需要一次性把所有 Skill 的完整内容都读进来,可以有效避免上下文被撑爆。
if (config.getSkillName() != null && !config.getSkillName().isBlank()) {
skill = skillRegistry.getSkill(config.getSkillName());
// 直接加载所有 references,打包进 Prompt
skillReferences = skillRegistry.loadAllReferences(config.getSkillName());
}
String systemPrompt = buildSystemPrompt(skill, skillReferences);另外,这套 Skill 系统还和 Spring AI 做了集成。Skill 会通过 FunctionCallback 的形式暴露给大模型,让模型可以自己发现并调用这些 Skill。同时系统也提供了一套 REST API,对外支持查询 Skill 列表、获取 Skill 详情以及访问引用文档。
06、怎么知道该调用哪个 Skill?
面试官好,判断该调用哪个 Skill,靠的是一个语义匹配的过程,可以理解为两步走。
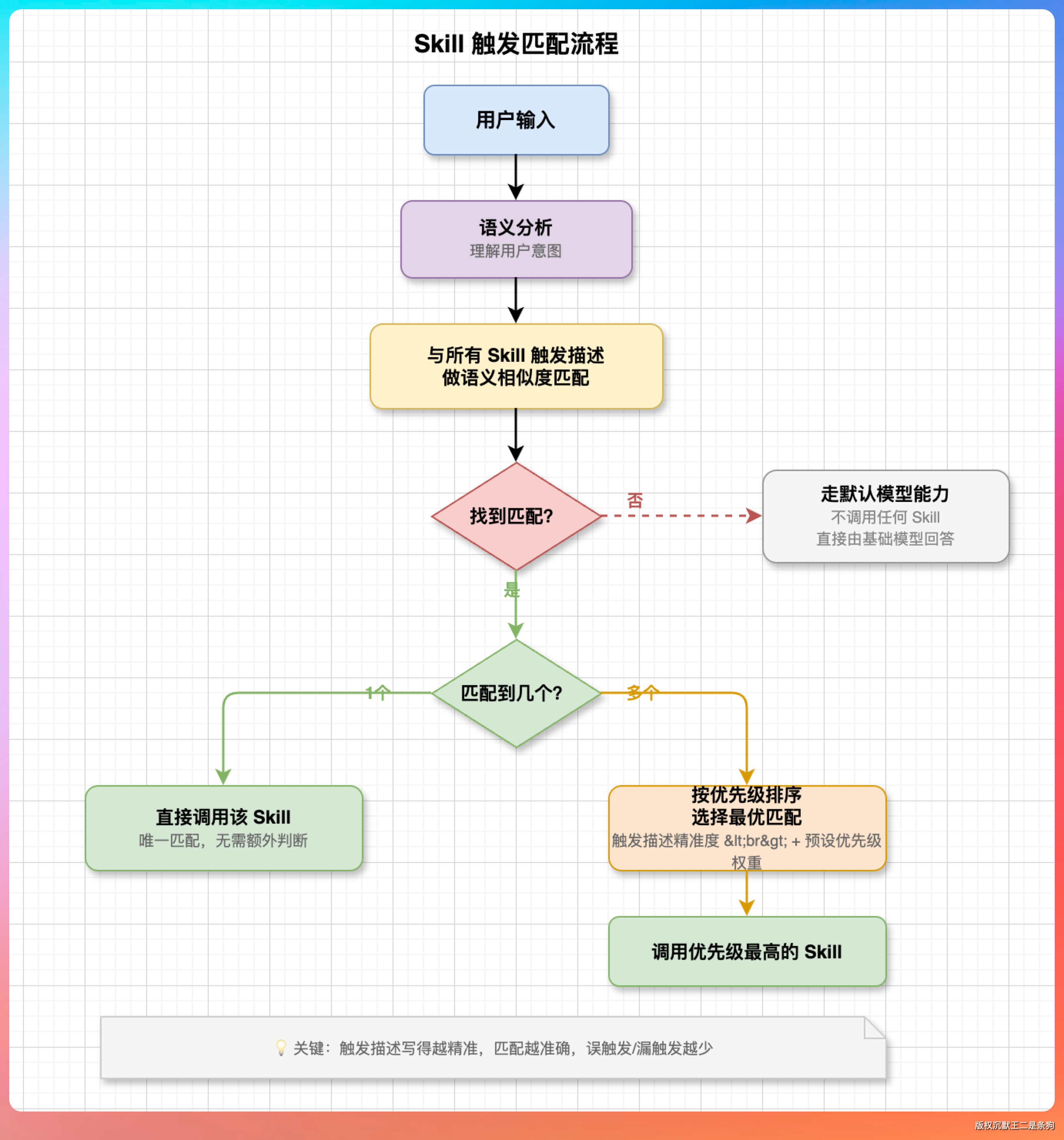
第一步是建立候选池。系统启动时,所有可用 Skill 的名称和描述会作为元信息常驻在上下文里。每个 Skill 的描述里会写明它适用于什么场景、处理什么类型的任务、不适用于什么情况,这些描述本质上就是匹配的依据。
第二步是请求进来后做匹配。用户发了一个请求,模型会把请求的语义和所有 Skill 描述做比对,看哪些 Skill 跟当前任务相关。
这个比对不是简单的关键词匹配,而是基于模型自身的语义理解能力。比如用户说“帮我把这份报告整理成 PPT”,模型能理解这是一个演示文稿生成任务,就会匹配到 pptx 这个 Skill。如果用户说“帮我读一下这个 PDF 里面写了什么”,模型就会匹配到 pdf-reading 而不是 pdf 创建的 Skill,因为描述里已经把“读取”和“创建”这两类场景做了明确区分。
这里有一个很关键的设计细节,就是 Skill 描述里的排除条件。好的 Skill 描述不光写自己能干什么,还会写自己不干什么。
比如 xlsx 这个 Skill 的描述里会明确说“不适用于生成 Word 文档或 HTML 报告的场景”,这样即使用户的请求里同时出现了“表格”和“报告”这样的词,模型也不会误判。这跟搜索引擎里的负向关键词是一个思路,通过排除来提高匹配精度。
还有一种情况是一个请求同时匹配到多个 Skill,这也是被允许的。比如用户要“把这个 Excel 表格里的数据生成一份 Word 报告”,那 xlsx 和 docx 两个 Skill 都会被加载,模型会综合两套指令来完成任务。
所以整个机制的核心,其实就是让模型充当一个路由器,基于语义理解来做任务分发。Skill 描述写得越精准、边界越清晰,路由的准确率就越高。
参考答案2
这是 Skill 系统的核心机制,也是我觉得设计得最巧妙的地方。
当用户输入一句话时,Claude Code 会扫描所有 Skill 的 frontmatter,提取 name 和 description,然后判断哪个 Skill 最匹配用户意图。注意,这里不是简单的关键词匹配,而是通过 description 来理解用户的真实意图。
07、SKILL.md 是怎么被读进去的?
面试官好,SKILL.md 是通过文件读取工具在运行时动态加载的。
具体来说,当模型通过语义匹配判断出当前任务需要某个 Skill 之后,它会调用一个 view 工具去读取对应路径下的 SKILL.md 文件。
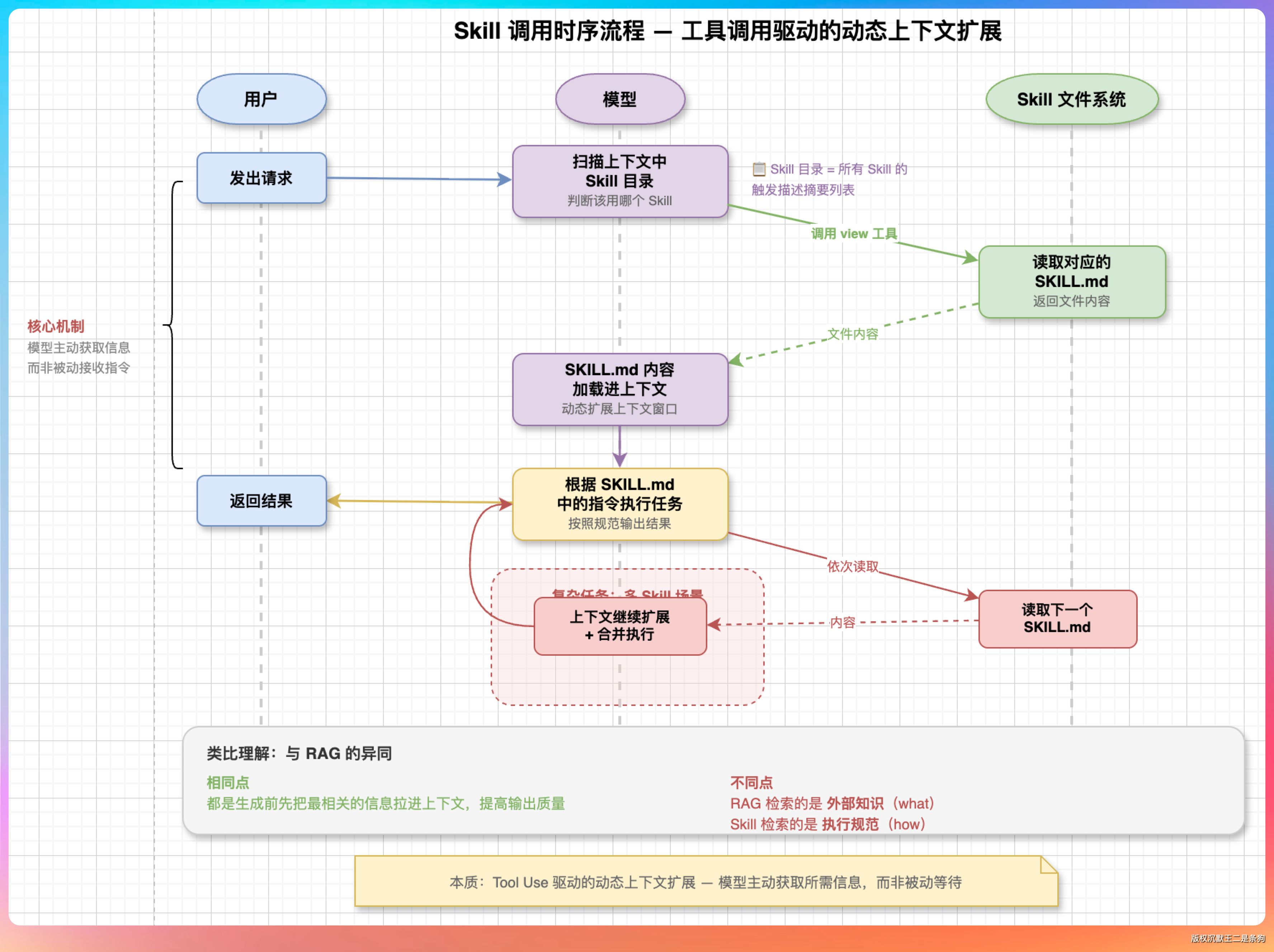
比如用户要生成一份 Word 文档,模型匹配到 docx 这个 Skill 后,就会主动去读取 /mnt/skills/public/docx/SKILL.md 这个文件,把里面的内容拉进当前的上下文窗口。读进来之后,这些指令就成为了模型在本次对话中遵循的规范,指导它怎么去生成文档。
这里有一个很重要的点,就是这个读取动作是模型自己发起的,不是系统预先注入的。系统只是在上下文里提供了一份 Skill 目录,告诉模型有哪些 Skill 可用、每个 Skill 的文件在哪里,但真正触发读取是模型根据任务需求自主决定的。
这个设计非常巧妙,因为它把调度权交给了模型本身的推理能力,而不是靠硬编码的规则去做路由。
从时序上看,整个流程是这样的:用户发出请求,模型先扫一遍上下文里的 Skill 目录,判断该用哪个,然后调 view 工具把对应的 SKILL.md 读进来,读完之后再根据里面的指令去执行具体任务。如果任务复杂需要多个 Skill,模型会依次读取多个文件。
这个机制本质上就是一种工具调用(Tool Use)驱动的动态上下文扩展。
模型不是被动接收指令,而是主动获取自己需要的信息,跟 RAG 的检索增强生成思路很像,区别在于 RAG 检索的是外部知识,而这里检索的是执行规范。底层逻辑是一致的,都是在生成之前先把最相关的信息拉进上下文,提高输出质量。
memo:2026年4月3日修改至此,今天给球友修改简历的时候,球友直言:加入三个月,比之前自学半年学到的都多,还把星球推荐给同门了。
08、create-skill 了解吗?
了解。
create-skill 是 Claude Code 内置的一个“元 Skill”,专门用来帮我们创建 Skill。
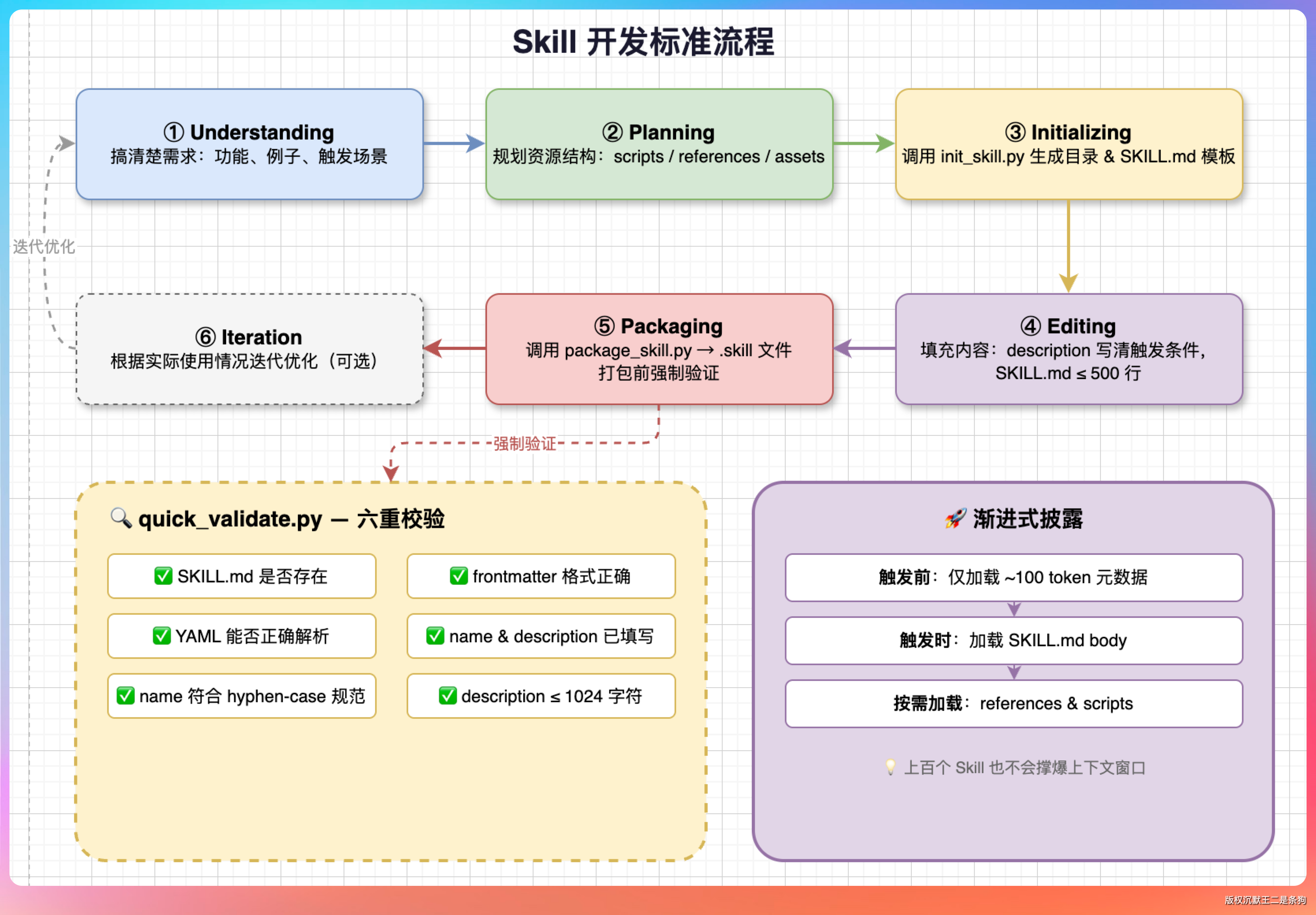
它定义了一套 6 步标准流程:
**第一步 理解Understanding,**先搞清楚需求。Agent 会问我们这个 Skill 要支持什么功能、有没有具体例子、什么场景会触发它。
**第二步 规划Planning。**Agent会分析我们的需求,决定要不要写脚本放 scripts、要不要放参考文档到 references/。
**第三步 初始化Initializing,**自动生成目录结构和 SKILL.md 模板。
**第四步 编辑Editing,**填充内容。
**第五步 打包Packaging,**打包成 .skill 文件。
**第六步 迭代Iteration,**根据实际使用情况迭代优化,这是可选步骤。
08-1、理解阶段会做什么?
这一步的目的是避免做出来一个没人用的 Skill。Agent 会问:
- “What functionality should the skill support?” (这个 Skill 应该支持什么功能?)
- “Can you give some examples?” (能不能给一些具体的例子?)
- “What would trigger this skill?” (什么场景会触发这个 Skill?)
函数调用:
step1_understanding()
└── ask_user_questions([...])
└── 收集用户反馈
└── validate_examples(examples)举个例子,用户说“我想做一个处理 Excel 的 Skill”,这时候 Agent 会追问:是处理什么类型的 Excel?是财务报表还是数据分析?需要支持哪些操作?是读取、写入还是格式转换?
只有把这些问题搞清楚,Agent 才能做出真正有用的 Skill。
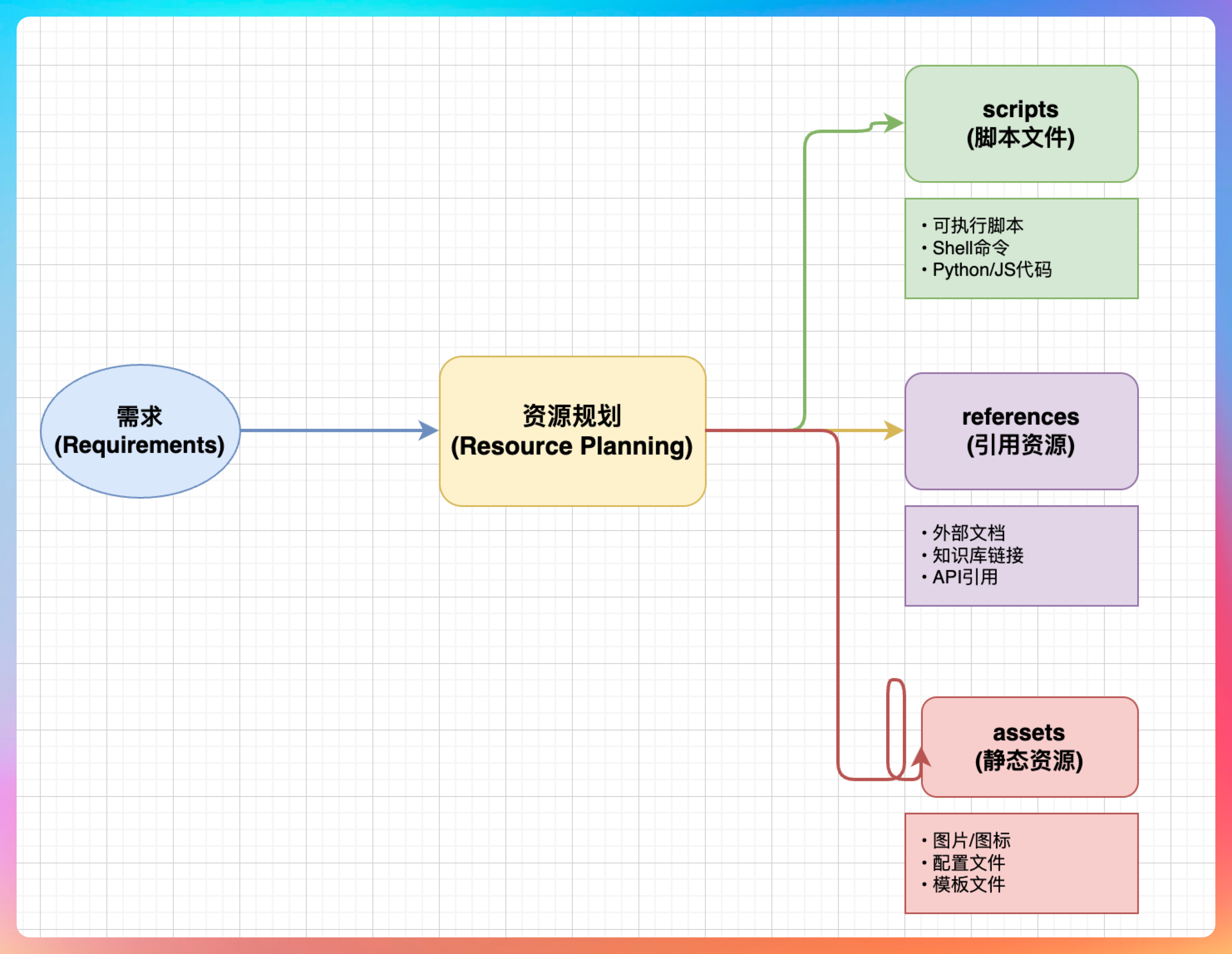
08-2、规划阶段会做什么?
把用户的具体需求抽象成可复用的资源类型。
函数调用链:
step2_planning(user_examples)
└── analyze_example(example)
│ └── identify_reusable_resources(example)
│ ├── need_script? → 加入 scripts/ 列表
│ ├── need_reference? → 加入 references/ 列表
│ └── need_asset? → 加入 assets/ 列表
└── generate_resource_plan()Agent 需要考虑哪些功能适合用脚本实现,哪些需要参考文档,哪些需要模板资源。一个好的规划能让后续的实现事半功倍。
08-3、初始化阶段会做什么?
Agent 会调用 init_skill.py 脚本生成一个完整的 Skill 模板。
函数调用链:
step3_initialize(skill_name, output_path)
└── run_script("scripts/init_skill.py", args=[...])
└── init_skill.main()
├── validate_skill_name(skill_name)
├── skill_dir = Path(path) / skill_name
├── skill_dir.mkdir(parents=True)
├── generate_skill_md(skill_name)
├── generate_example_script()
├── generate_example_reference()
└── generate_example_asset()08-4、编辑阶段会做什么?
这是整个流程中最耗时的部分,也是最能体现 Skill 质量的部分。
函数调用:
step4_edit_skill(skill_dir)
├── edit_scripts(skill_dir / "scripts")
├── edit_references(skill_dir / "references")
├── edit_assets(skill_dir / "assets")
└── update_skill_md(skill_dir / "SKILL.md")有几个关键点需要注意:
- description 必须包含触发条件,因为它决定了 Skill 什么时候会被触发。
- 保持简洁,SKILL.md 不超过 500 行
08-5、打包阶段会做什么?
Agent 会调用 package_skill.py 脚本,将 Skill 打包成 .skill 文件。
函数调用链:
step5_package(skill_dir, output_dir=None)
└── run_script("scripts/package_skill.py", args=[...])
└── package_skill.main()
├── validate_skill(skill_path)
│ └── quick_validate.validate_skill()
│ ├── check_skill_md_exists()
│ ├── parse_frontmatter()
│ ├── validate_name_format()
│ └── validate_description_length()
└── create_zip_file()注意,打包前会先验证。就像代码提交前的 CI 检查一样,能在最后一刻发现问题。
08-6、迭代阶段会做什么?
可选步骤,根据实际使用情况优化 Skill。一个好的 Skill 不是一次写成的,而是在使用中不断完善的。
step6_iterate(skill_dir)
└── observe_usage_patterns()
└── identify_improvements()
└── update_skill_md_or_resources()08-7、渐进式披露在create-skill中的体现?
“渐进式披露”这个设计理念贯穿了整个 Skill 系统的架构。通过渐进式披露,系统只加载当前需要的内容,既保证了功能完整,又不会浪费上下文空间。
| 层级 | 内容 | 大小 | 加载时机 |
|---|---|---|---|
| L1 | Metadata (name + description) | ~100 tokens | 始终加载 |
| L2 | SKILL.md body | <5k tokens | Skill 触发后 |
| L3 | Bundled resources | 无限制 | 按需加载 |
08-8、create-skill完整调用顺序了解吗?
用一张图总结整个执行流程:
用户输入 → 触发判断 → 加载 SKILL.md → 执行 6 个步骤 → 验证 → 打包 → 完成
│ │ │ │ │ │
│ │ │ │ │ └── .skill 文件
│ │ │ │ └── validate_skill()
│ │ │ └── step1() → step2() → ... → step6()
│ │ └── inject_to_context()
│ └── match_skill()
└── "帮我创建一个 Skill"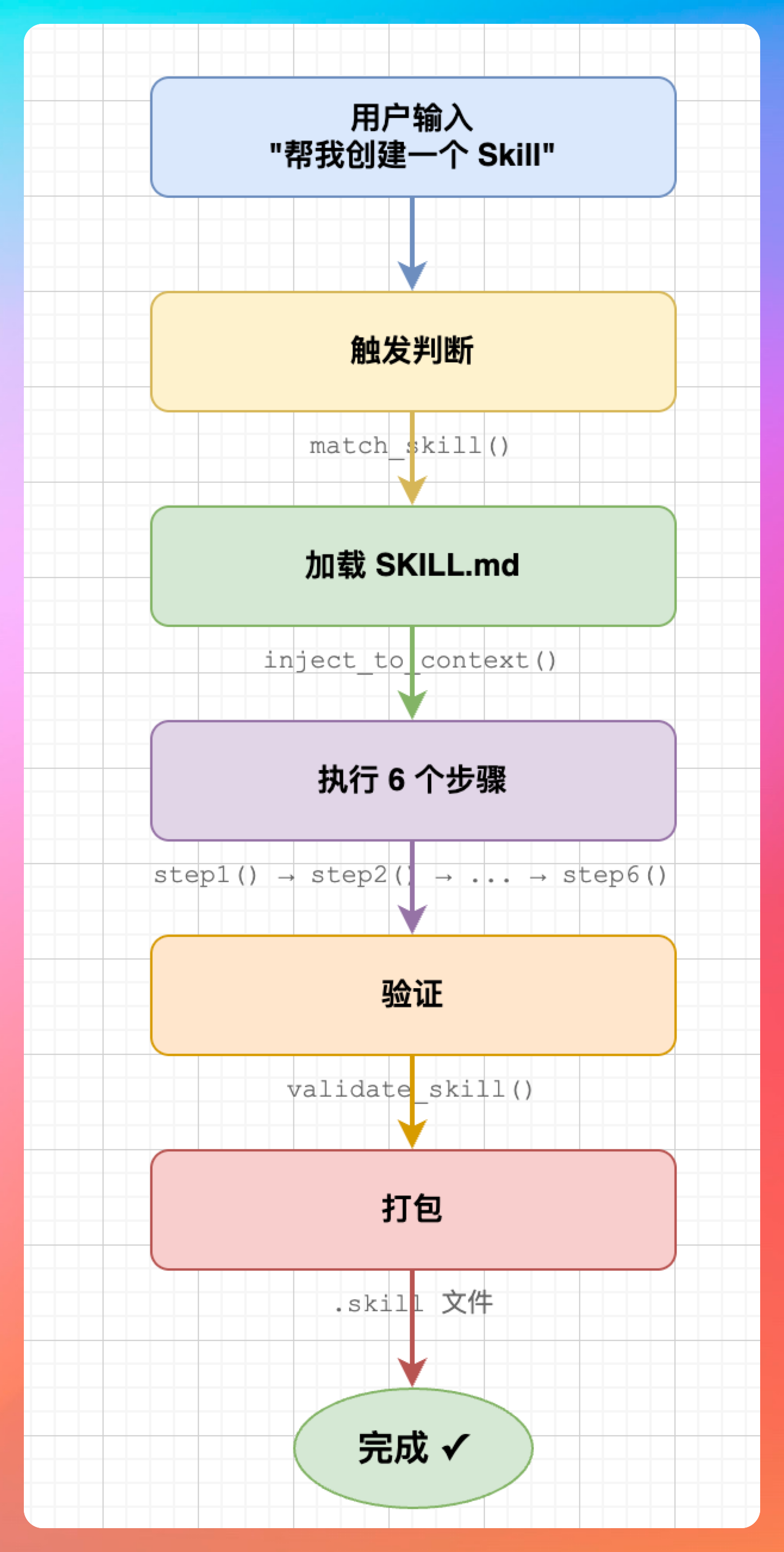
09、Skills 和 GPTs、Rules 有什么区别?
Claude Code 的 Skill 系统有几个独特之处:
1. 渐进式披露:只有被触发后才加载完整内容,节省上下文 2. 自由度分级:可以根据任务复杂度选择不同的约束程度 3. 验证机制:打包前强制验证,保证质量 4. 可执行脚本:支持 bundled scripts,可以执行确定性操作
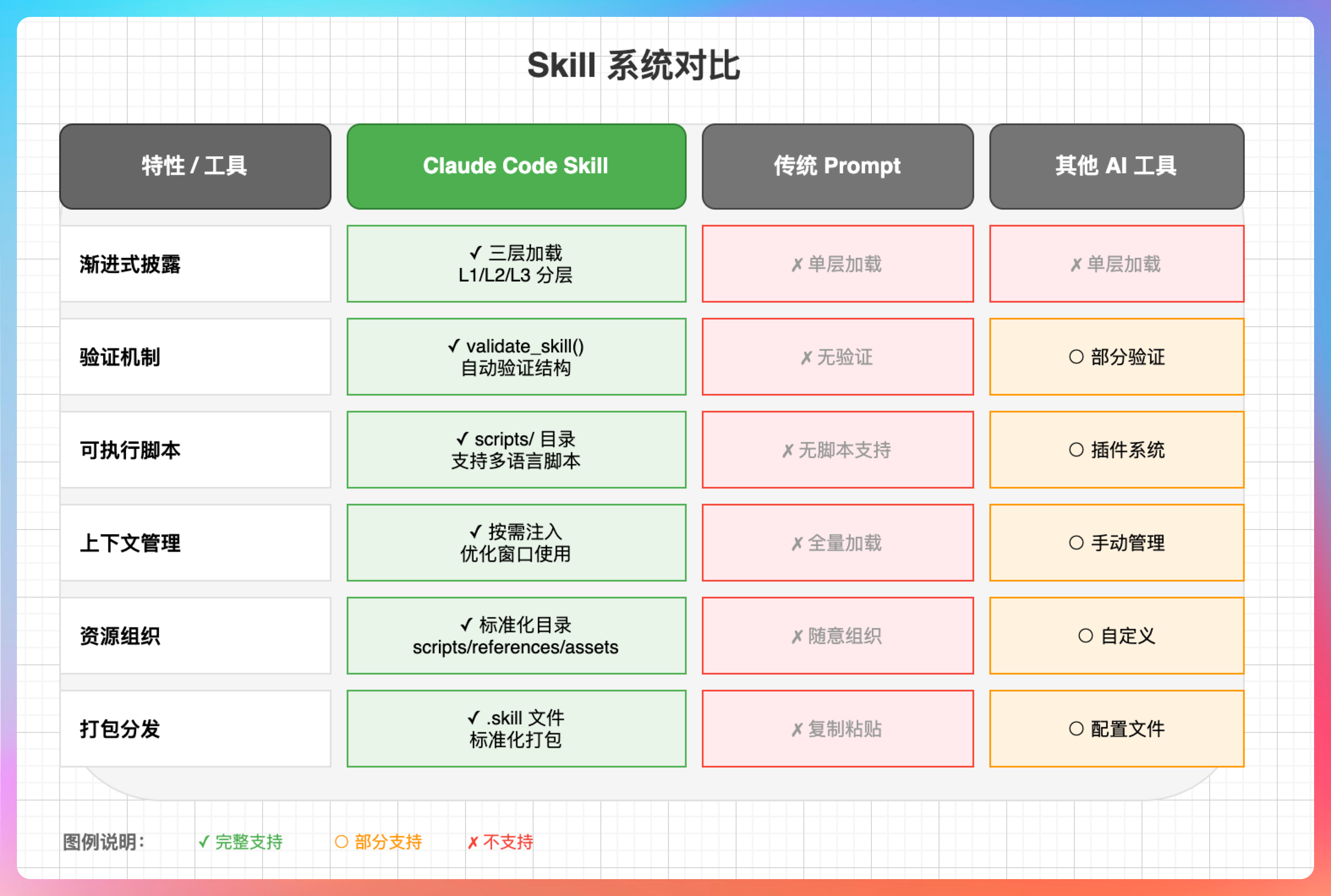
相比之下,GPT 的 GPTs 更侧重于知识库和对话定制,Cursor 的 Rules 更侧重于编码规范约束,而 Claude Code 的 Skill 则是把上下文管理、领域知识和可执行能力三者结合在了一起。
10、如何写出一个高质量的 Skill?
1. description 要写清楚触发条件
这是 Skill 被正确触发的关键。要准确描述 Skill 能解决什么问题,什么场景下应该使用。
举个例子,好的 description 应该是这样: “Use when working with PDF documents for: (1) Extracting text and tables, (2) Merging or splitting PDFs, (3) Filling form fields, (4) Converting to other formats”【当处理 PDF 文档时使用,适用于:(1) 提取文本和表格,(2) 合并或拆分 PDF,(3) 填充表单字段,(4) 转换为其他格式】
2. 保持 SKILL.md 简洁
不要超过 500 行。如果内容太多,把详细内容放到 references 里,SKILL.md 只保留核心流程。记住,SKILL.md 是指南,不是百科全书。
3. 多写示例
示例比说明更有用。在 SKILL.md 里多放一些具体的例子,让 Claude 知道怎么处理各种情况。比如你可以写:“When user says 'merge these PDFs', use scripts/merge_pdf.py”(当用户说“合并这些 PDF”时,使用 scripts/merge_pdf.py)。示例越具体,模型的执行就越准确。
4. 测试 Skill
在发布之前,多测试几次。看看触发是否准确,执行是否符合预期。一个好的 Skill 需要反复打磨。建议至少测试 5 个不同的场景,确保覆盖各种边界情况。
5. 善用 references
如果 Skill 涉及复杂的领域知识,比如数据库 schema、API 文档、业务规则,把这些放到 references 目录下。这样 SKILL.md 保持简洁,详细内容按需加载。
11、Agent在读取Skill 时有哪些性能优化措施?
先说缓存机制。Skills 目前的缓存更多体现在描述索引层面,也就是所有 Skill 的名称和描述是常驻上下文的,这本身就是一种缓存,避免了每次请求都要重新获取“有哪些 Skill 可用”这个信息。
但对于 SKILL.md 的具体内容,在同一轮对话里读取过一次之后它就已经在上下文里了,后续引用不需要再次读取,这算是上下文窗口天然的“会话级缓存”。
class SkillMetadataCache:
def __init__(self):
self.cache = {}
self.last_update = None
def get_metadata(self, skill_name):
if skill_name in self.cache:
if not self.is_expired(skill_name):
return self.cache[skill_name]
# 缓存未命中或已过期,重新读取
metadata = self.load_from_disk(skill_name)
self.cache[skill_name] = metadata
return metadata
def is_expired(self, skill_name):
# 检查文件修改时间
file_mtime = os.path.getmtime(skill_path)
return file_mtime > self.cache[skill_name].loaded_time不过跨对话是不缓存的,每次新对话如果需要用到某个 Skill,都要重新读取一次,因为上下文是全新的。
再说增量加载策略。对于大型 reference 文件,Agent 采用了增量加载策略。不会一次性把整个文件都加载到上下文中,而是只加载需要的部分。
def load_reference_incremental(ref_path, section=None):
if section:
# 只加载指定章节
content = extract_section(ref_path, section)
else:
# 先加载目录和概述
content = extract_toc_and_summary(ref_path)
inject_to_context(content)这种策略对于几百行的 reference 文档特别有用。
最后说脚本预编译。对于 Python 脚本,Agent 会检查是否有预编译的字节码(.pyc 文件)。如果有且没有过期,就直接使用字节码,省去编译时间。
run_script("scripts/init_skill.py")
├── check_pyc_exists("scripts/init_skill.py")
│ └── if exists and not expired:
│ └── execute_pyc("scripts/__pycache__/init_skill.cpython-311.pyc")
│ └── else:
│ ├── compile_to_pyc("scripts/init_skill.py")
│ └── execute_pyc(compiled_path)12、Agent在执行Skills时有哪些安全机制?
1、沙箱执行环境,脚本只在沙箱环境中执行,这样好防止恶意脚本对系统破坏。即使脚本有问题,也只能在受限的环境中运行,无法访问敏感资源。
def run_script_in_sandbox(script_path, args):
sandbox = Sandbox()
sandbox.restrict_network_access() # 限制网络访问
sandbox.restrict_file_access(allowed_dirs=["./temp"]) # 限制文件访问
sandbox.restrict_system_calls() # 限制系统调用
result = sandbox.execute(script_path, args)
return result2、所有传入脚本的用户输入都会经过严格验证,防止命令注入等攻击。用户的输入会被清理,确保不会被执行或解析为命令。
def validate_user_input(user_input):
# 检查是否包含危险字符
dangerous_patterns = [';', '&&', '||', '`', '$(']
for pattern in dangerous_patterns:
if pattern in user_input:
raise SecurityError(f"Input contains dangerous pattern: {pattern}")
# 检查长度
if len(user_input) > 1000:
raise SecurityError("Input too long")
return sanitize_input(user_input)3、脚本执行时有资源使用限制,防止资源耗尽攻击:
script_limits = {
"max_execution_time": 30, # 最多执行30秒
"max_memory_mb": 512, # 最多使用512MB内存
"max_file_size_mb": 100, # 最多读写100MB文件
"max_network_requests": 10 # 最多10次网络请求
}memo:2026年4月3日修改至此,今天球友发喜报的时候,说暑期拿到了腾讯、阿里云、美团三家offer,还特意感谢了派聪明+mydb 这两个项目,直言把星球还推荐给了同门。
13、Skills 和 Prompt 有什么区别?
Prompt 是我们和 AI 的一次对话,说完就完了。下次再想用同样的能力,得重新说一遍,或者从聊天记录里翻出来复制粘贴。
Skills 不一样。它是把一类问题的解决方案固化下来,变成一个可以反复调用的模块。就像写代码时封装的工具类,一次开发,到处复用。
13-1 那不就是 Prompt 的模板化吗?
不只是模板化。模板化是静态的,Skills 是动态的、可进化的。
举个例子。假设我们经常让 AI 帮做代码审查。用 Prompt 的方式,每次都要说:“帮我审查这段代码,关注安全性、性能、可读性,按照阿里巴巴 Java 规范。”
用 Skills 的方式,变成了把这套审查逻辑封装成一个 Skill。下次直接说“用 code-review Skill”,AI 就知道要做什么、怎么做、做到什么程度。
更重要的是,这个 Skill 可以不断优化。我们发现漏掉了并发安全检查,就加进去;团队规范更新了,就同步更新。所有用这个 Skill 的人,都能立刻享受到改进。
14、Skills 和 MCP 有什么关系?
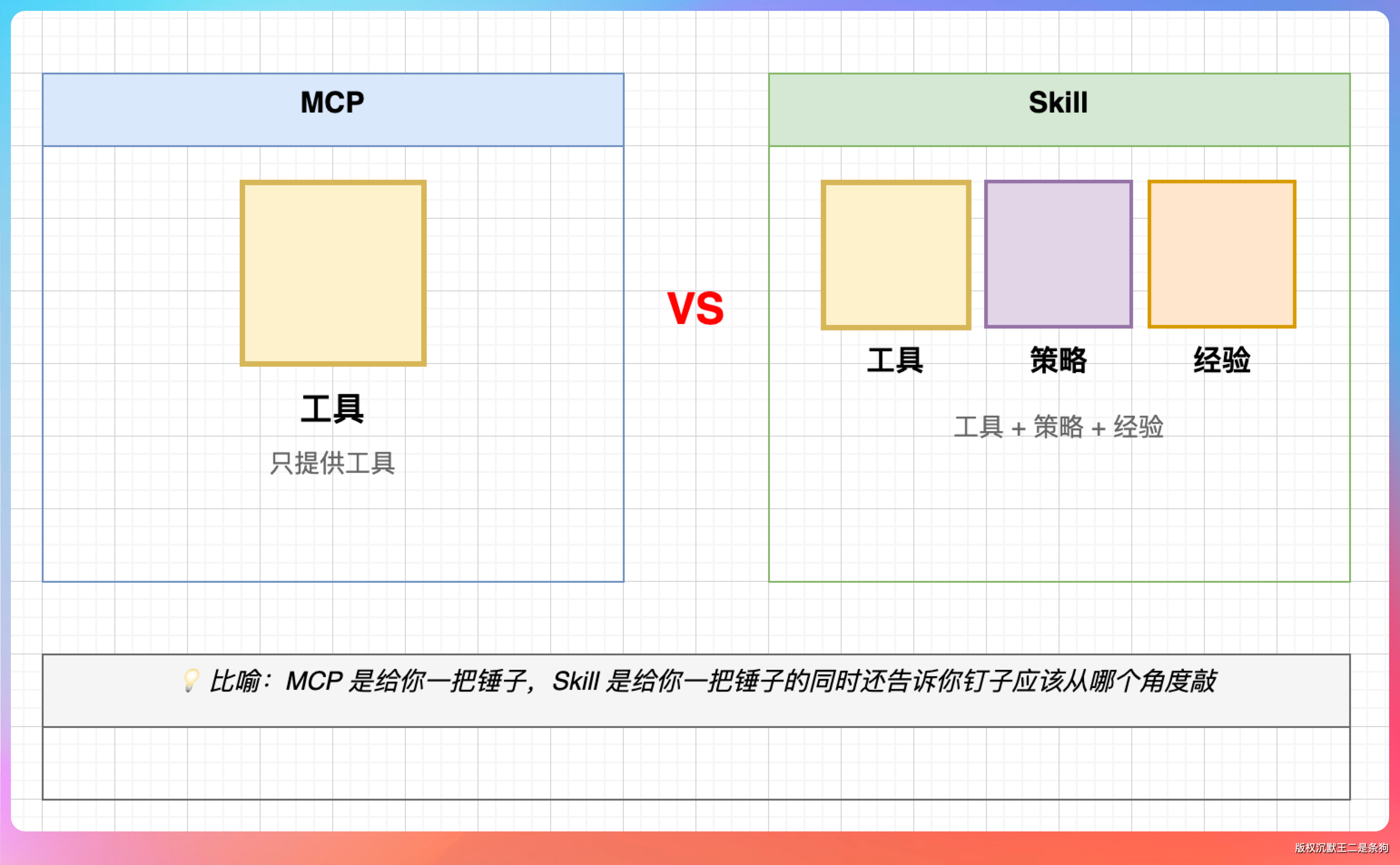
我觉得它们是互补的。
MCP(Model Context Protocol)解决的是 AI 与外部系统的连接问题。比如让 AI 调用 GitHub API、查询数据库、操作文件系统、打开浏览器等。
我就经常用 Chrome 的 Devtools MCP 让 AI 进行自动化测试。
Skills 解决的是 AI 的能力封装问题。比如让 AI 具备代码审查的能力、文档生成的能力、技术方案评审的能力。
MCP 像是给 AI 装上了机械臂,让它能接触外部世界。Skills 像是给了 AI 使用说明书,让它知道怎么做事。
两者结合起来,AI 才能真正成为生产力工具。
15、你平常都用过哪些Skills?
Frontend-design(前端设计)
下载地址:https://mcpservers.org/claude-skills/anthropic/frontend-design
这个 Skill 的定位是“前端设计专家”。我们描述需求,它直接输出 HTML+CSS 代码,带响应式布局。
想要看 Claude Code 中都安装了哪些Skills?
可以执行 /skills 命令。
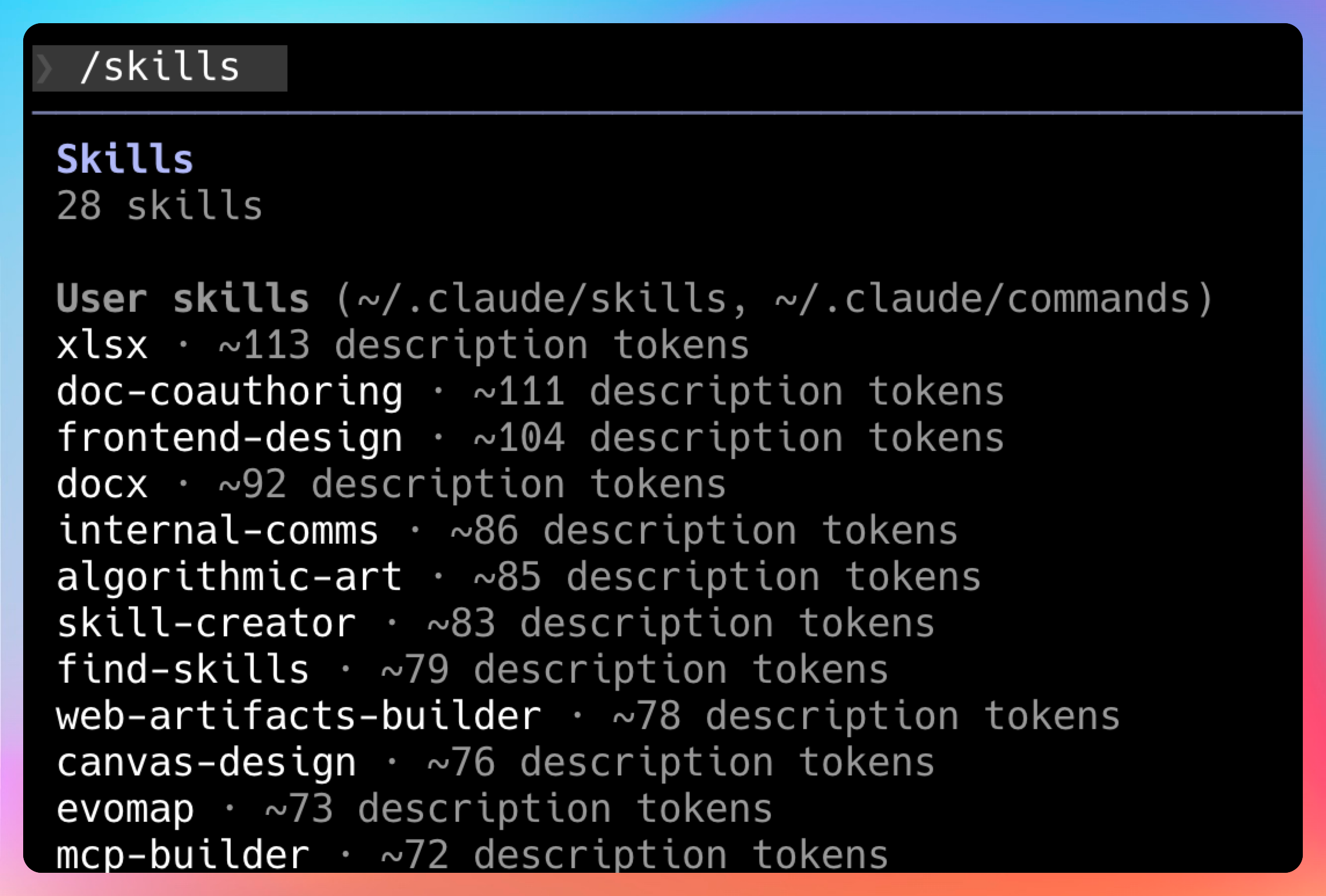
提示词:“设计一个现代化的登录页面,包含邮箱、密码输入框,支持深色模式切换”。

- 色彩: 深色模式使用深黑炭色 + 琥珀金点缀,浅色模式使用暖白 + 深灰
- 字体: Playfair Display (标题) + Source Serif 4 (正文) - 经典优雅的组合
- 视觉: 细腻的渐变背景、微妙的噪声纹理、精致的边框、流畅的动画
- 差异化: 金色光泽效果、玻璃拟态卡片、优雅的悬停动画
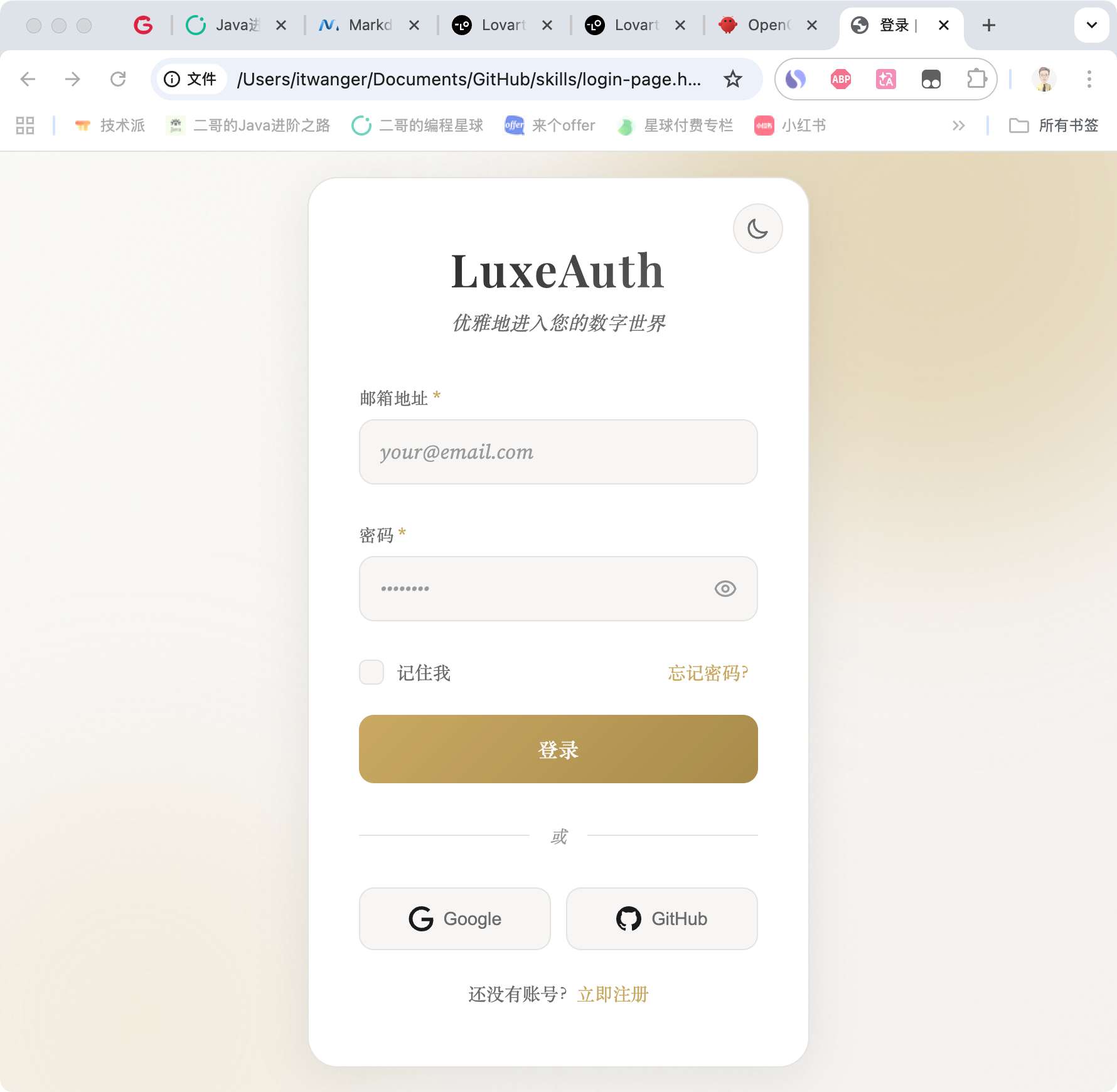
当然了,这和背后的模型有一定的关系,我目前用的是GLM-5做的测试。
UI-UX-PRO-MAX
下载地址:https://skillsmp.com/skills/nextlevelbuilder-ui-ux-pro-max-skill-claude-skills-ui-ux-pro-max-skill-md
这个 Skill 比 Frontend-design 更侧重 UX 流程。它不会直接给代码,而是先出线框图描述、交互流程、再出视觉方案。
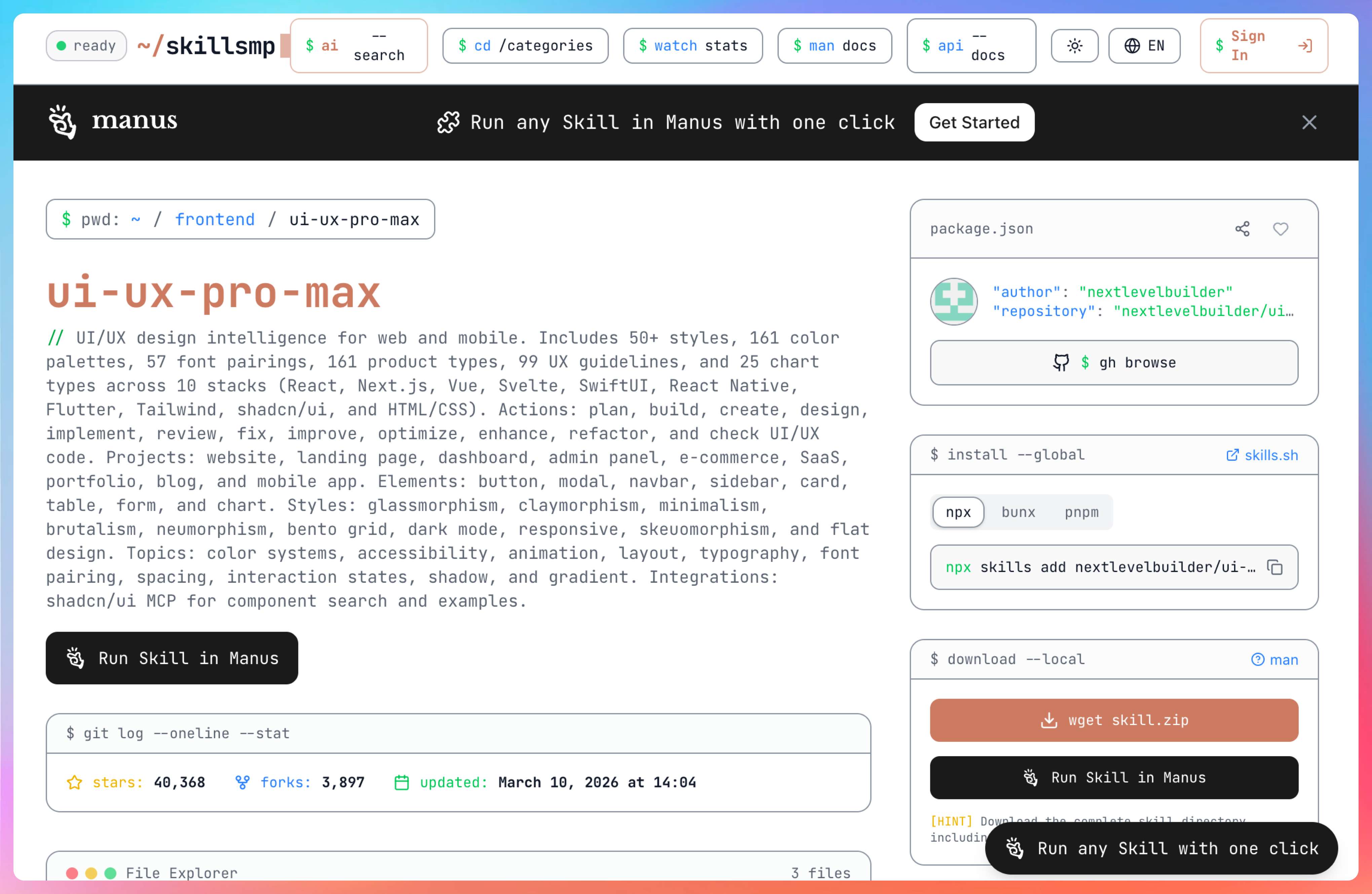
同样是登录页需求,它的输出是:用户流程图 → 信息架构 → 线框图描述 → 视觉建议。适合需要完整设计文档的场景,但如果你只想快速拿到代码,会觉得它“太啰嗦”。
Interaction-design(前端交互设计)
下载地址:https://github.com/wshobson/agents/tree/main/plugins/ui-design/skills/interaction-design
这个 Skill 专注交互动效。微交互、状态反馈、过渡动画,是它的强项。
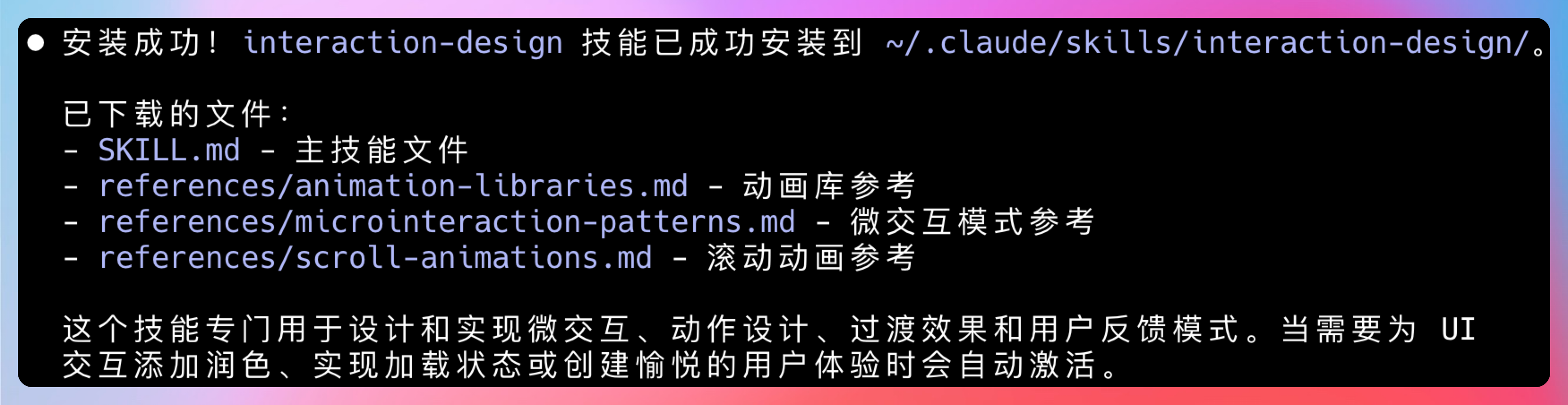
我让它给登录页加一个“密码可见性切换”的微交互。

输出包含:点击动效、图标切换动画、错误状态的抖动反馈。代码直接可用,动画参数也调得比较舒服。
Skill-creator
下载地址:https://github.com/anthropics/skills/tree/main/skills/skill-creator
这个 Skill 是用来生成 Skills 的 Skill,有点绕,但很有用。
把一个重复的工作流程描述给它,它能帮我们封装成可复用的 Skill。
Claude最近给这Skills做了较大的升级,新增完整的技能评估和基准测试框架。
- generate_review.py - 生成评估报告的脚本
- viewer.html - 交互式网页查看器,支持两个标签页,Outputs 标签 - 逐个查看测试用例的输出。提供反馈;Benchmark 标签 - 显示定量统计数据、通过率、时间和 token 使用
我也第一时间给Codex升级了,整体的使用体感感觉还不错。
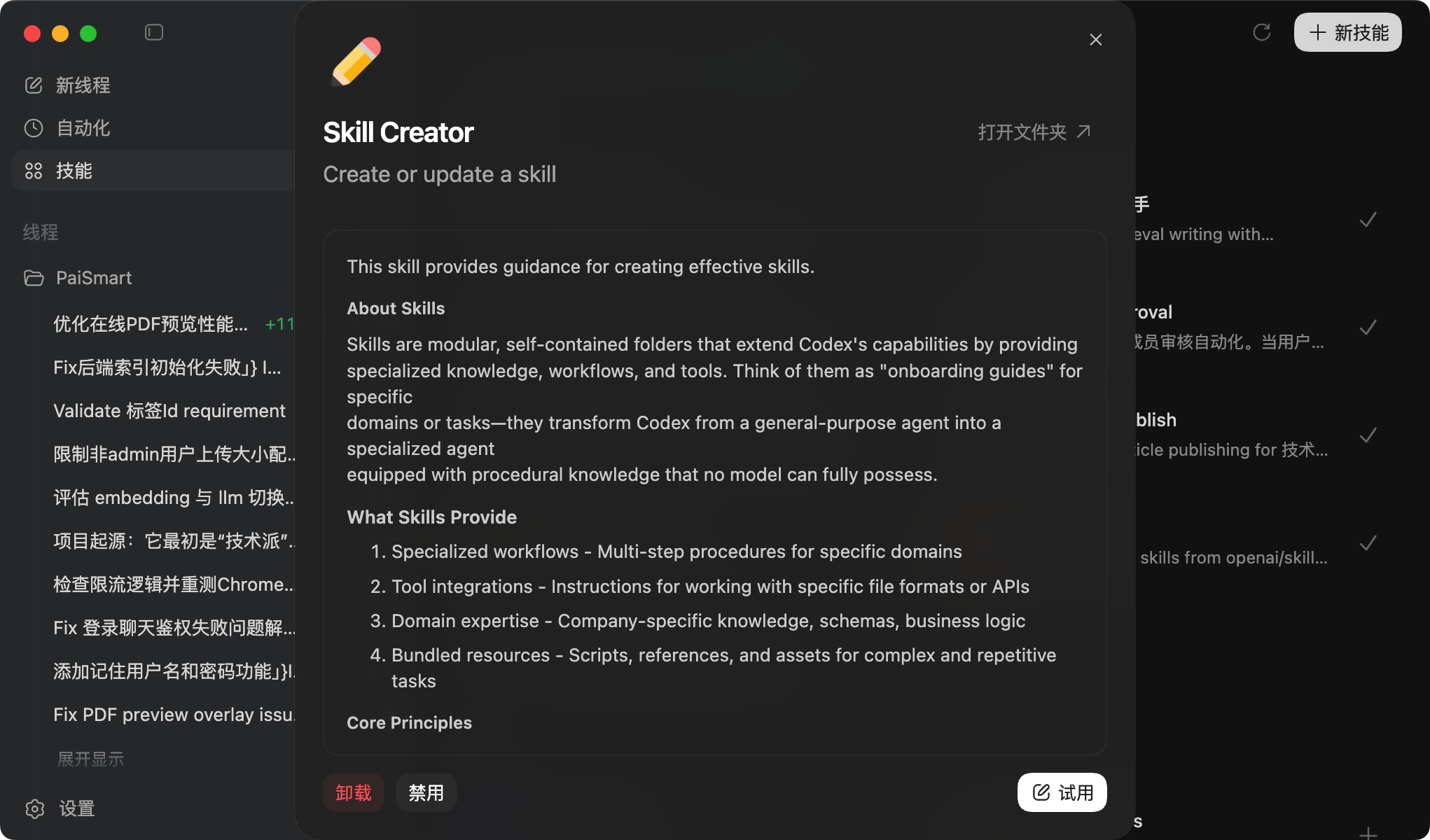
对,Codex也可以用Claude的Skills。
解决重复性信息检索的 Skill
下载地址:https://github.com/YuJunZhiXue/github-skill-forge
这个 Skill 适合需要频繁查资料的场景。它会把检索流程固化下来,下次直接调用。
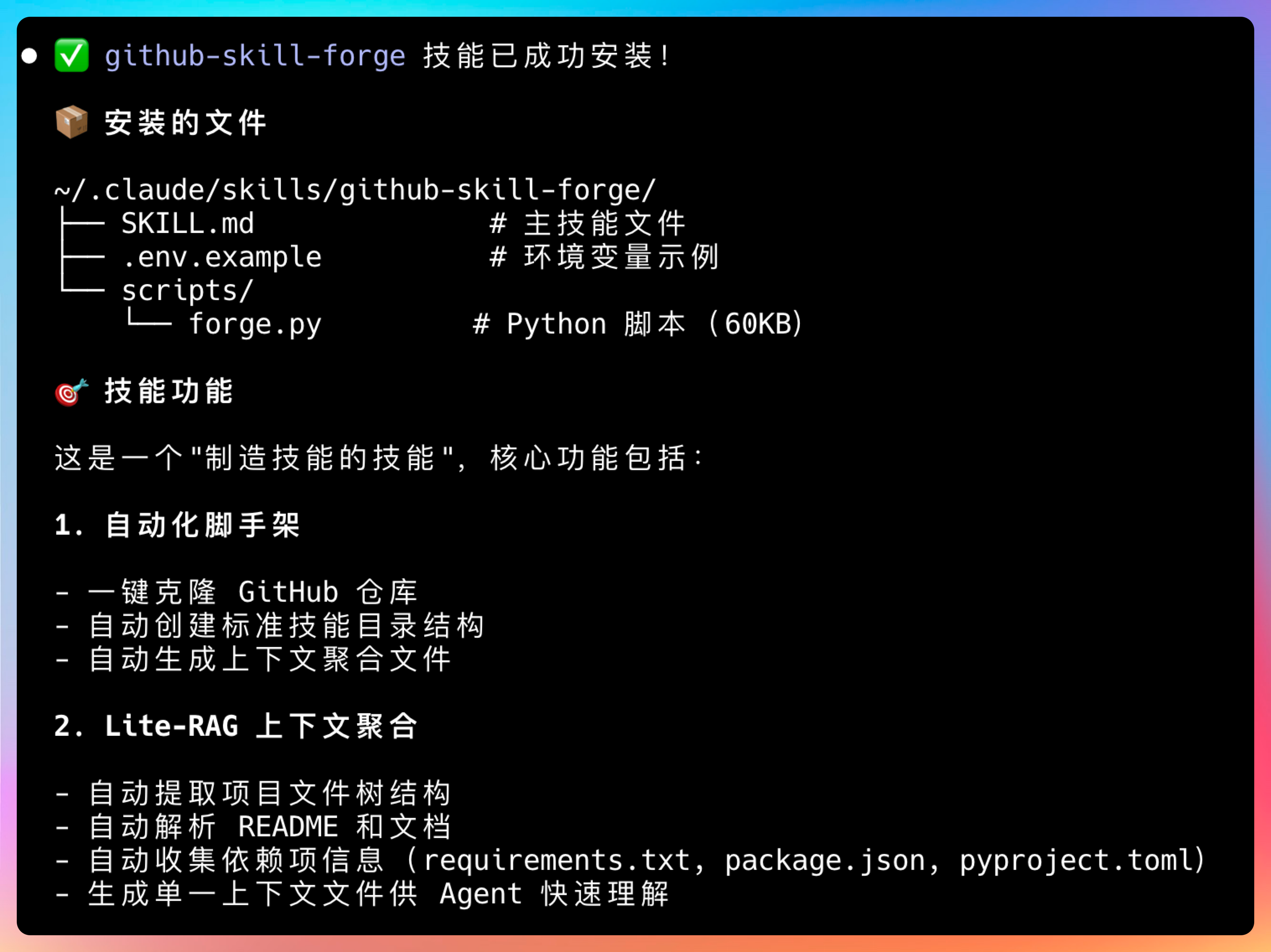
我让他找找 GitHub 上有没有辅助写小说的项目,他会先按照中英文做分类,然后把项目转换成Skills。

Find-Skills
下载地址:https://github.com/vercel-labs/skills
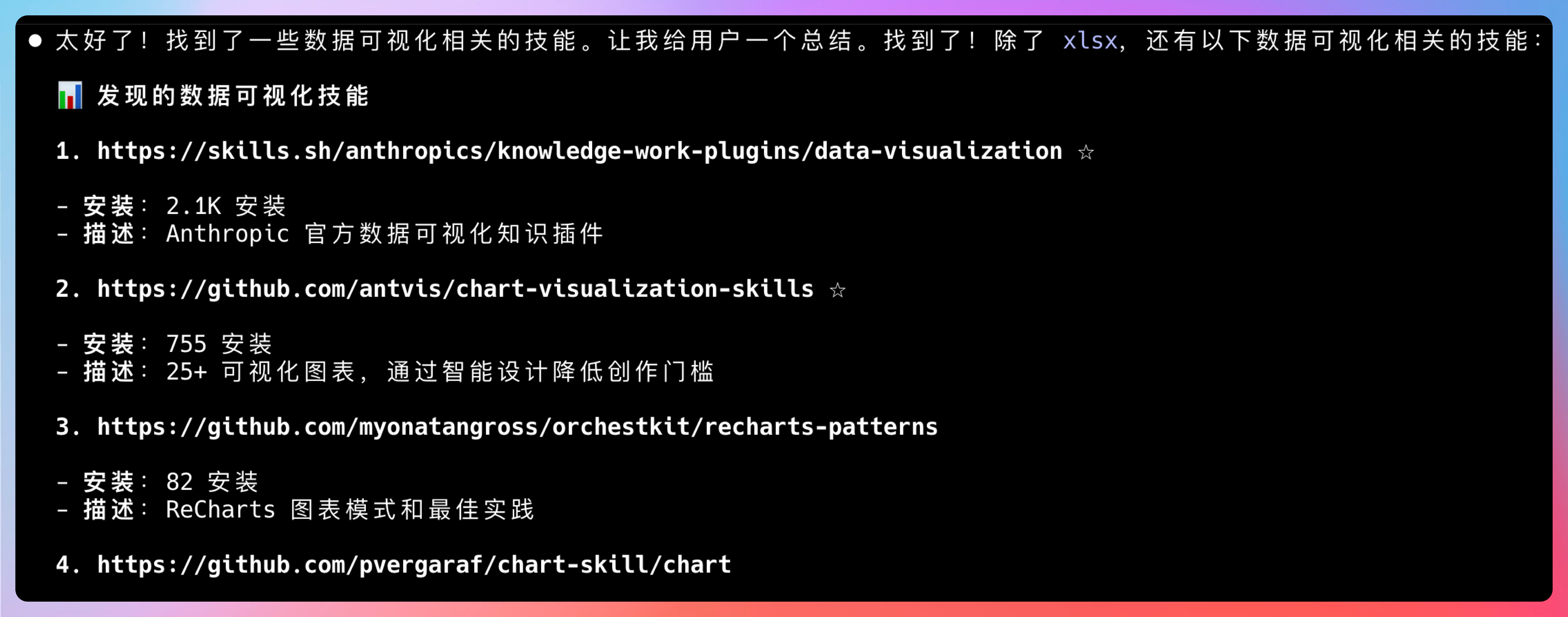
这个 Skill 是用来发现其他 Skills 的。当我们不知道某个需求该用哪个 Skill 时,它可以帮我们推荐。
我测试问它:“我想生成一个数据可视化图表,该用哪个 Skill?”它推荐了 3 个相关 Skills,并说明了每个的适用场景。
web-access
web-access 的核心设计哲学叫“像人一样思考”,拿到任务先明确目标,选最可能直达的方式验证,过程中根据反馈实时调整策略,达成目标后才停止。
整个 Skill 文件不光定义了工具接口,还写了大量的决策逻辑,教 Agent 在什么场景用什么工具、遇到什么问题怎么绕。
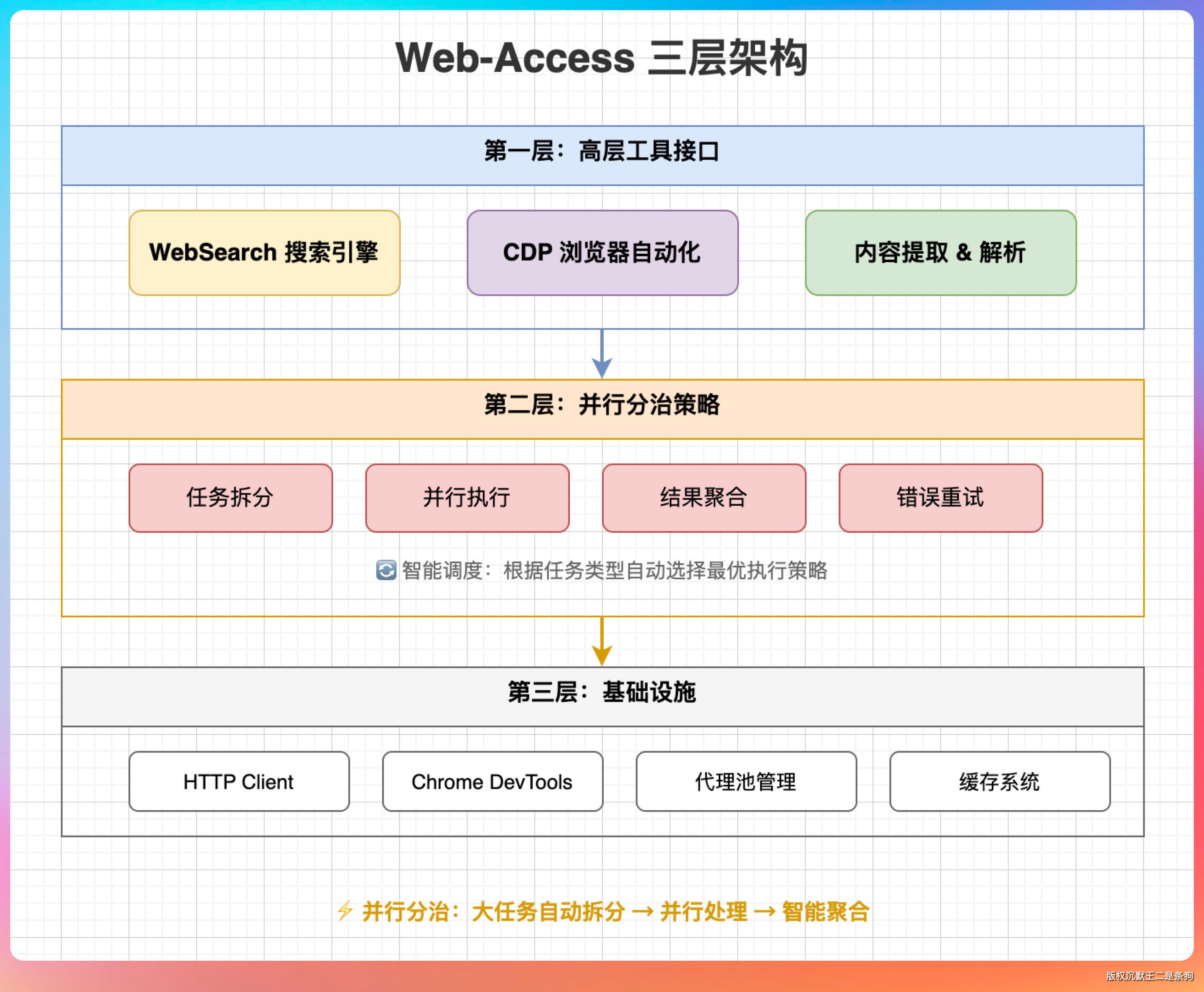
它的工具集分三层:
第一层是轻量级的搜索和抓取。WebSearch 搜关键词、WebFetch 抓已知 URL 的内容、curl 拿原始 HTML、Jina 把网页转 Markdown 省 token。
这些是现有 Agent 就有的能力,web-access 在上面加了调度策略——什么时候该用哪个,什么时候该放弃换思路。
第二层是浏览器 CDP 直连。这才是 web-access 的杀手锏。
先科普一下 CDP 是什么。CDP 全称 Chrome DevTools Protocol,是 Chrome 浏览器对外暴露的一套调试协议。你可以把它理解成 Chrome 的“后门”,通过这个协议,外部程序可以完全控制浏览器的行为:打开页面、执行 JavaScript、点击元素、截图、甚至操控视频播放。
web-access 通过 CDP 直接连接用户日常使用的 Chrome 浏览器,天然带登录态,能操作任何需要交互的页面。小红书、微信公众号、需要登录的后台管理系统,统统不在话下。
第三层是并行分治。多个调研任务可以拆给子 Agent 并行执行,每个子 Agent 自己开 tab、自己操作、自己关闭,主 Agent 只接收摘要结果。速度快,还不撑爆上下文。
16、未来Skills会怎么发展?
我觉得会有两个趋势。
第一个趋势是 Skills 标准化。现在每个团队的 Skills 格式可能都不一样,未来可能会出现行业标准,就像 npm、pip 一样。
第二个趋势是 Skills 商店化。个人开发者可以把 Skills 发布到商店,其他人付费或免费使用。这会催生一个新的生态。
17、你觉得未来程序员的核心竞争力是什么?
第一,问题定义能力。AI 能帮我们解决问题,但前提是我们要能准确定义问题。很多人连自己想要什么都说不清楚,AI 再强也没用。
第二,系统设计能力。AI 能写代码,但架构设计、模块划分、接口定义,这些还是需要人来把控。AI 是执行者,人是设计者。
第三,持续学习能力。技术更新这么快,今天有用的 Skills,明天可能就过时了。保持学习,才能保持竞争力。
18、在实际项目中,如何管理和控制大量的 Skills?
可以在企业内部部署一个SkillHub,SkillHub 提供了一个企业级的解决方案,它是一个自托管、开源的 Agent Skill 注册中心,旨在帮助团队发布、发现和管理可重用的 Skill 包。
GitHub 地址:https://github.com/iflytek/skillhub
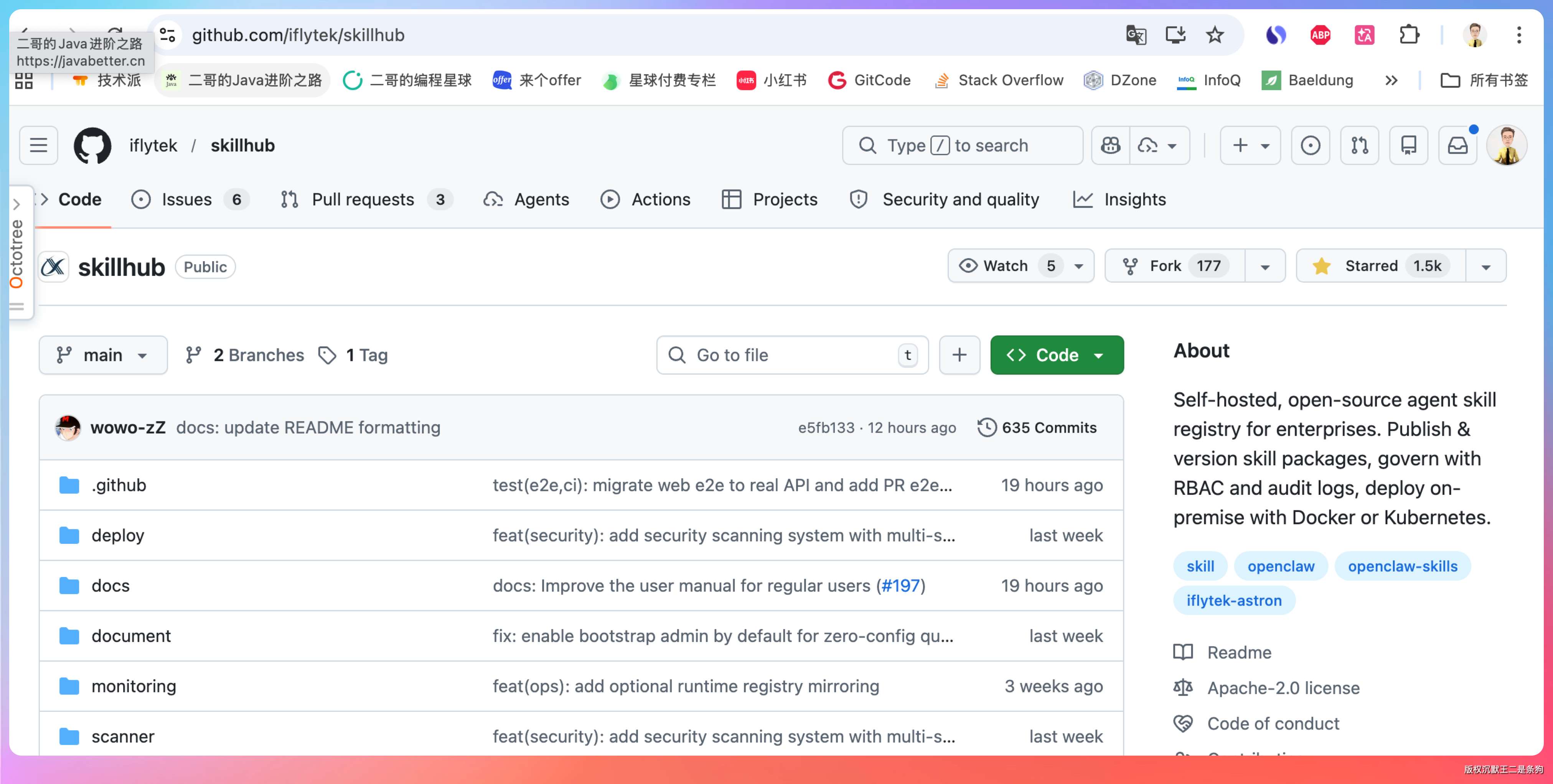
SkillHub 允许企业将 Skill 注册中心部署在自家的服务器上,确保所有专有 Skills 都在防火墙内。
还提供了全文搜索功能,并支持按命名空间、下载量、评分和最新程度进行过滤。
支持组织团队或全局作用域的命名空间。每个命名空间都有自己的成员、角色(所有者/管理员/成员)和发布策略,从而实现精细化的权限控制。
提供原生的 REST API 和兼容 clawhub CLI 的兼容层。开发者可以通过命令行进行 Skills 的发布、安装和管理。
memo:2026年4月3日修改至此,今天球友在简历修改的邮件中说,我给他的指点比学校老师加起来给的都多,感激不尽。真的收到这样的感谢,很感动。🥹
没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。
系列内容:
- 面渣逆袭 Java SE 篇 👍
- 面渣逆袭 Java 集合框架篇 👍
- 面渣逆袭 Java 并发编程篇 👍
- 面渣逆袭 JVM 篇 👍
- 面渣逆袭 Spring 篇 👍
- 面渣逆袭 Redis 篇 👍
- 面渣逆袭 MyBatis 篇 👍
- 面渣逆袭 MySQL 篇 👍
- 面渣逆袭操作系统篇 👍
- 面渣逆袭计算机网络篇 👍
- 面渣逆袭 RocketMQ 篇 👍
- 面渣逆袭分布式篇 👍
- 面渣逆袭微服务篇 👍
- 面渣逆袭设计模式篇 👍
- 面渣逆袭 Linux 篇 👍
- 面渣逆袭OpenClaw篇 👍
- 面渣逆袭Skills篇 👍
GitHub 上标星 17000+ 的开源知识库《面渣逆袭》第二版 PDF 终于来了!包括 Java基础、Java 集合框架、Java 并发编程、JVM、Spring、Redis、MyBatis、MySQL、操作系统、计算机网络、RocketMQ、分布式、微服务、设计模式、Linux、OpenClaw、Skills 等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:面渣逆袭 2.0 版 PDF 发布,Java后端程序员必背,可能是 2026 年最好的八股文
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
