二哥修订版《30天速通Java》
二哥修订版《30天速通Java》
大家好,我是二哥呀。
GitHub 上有一个很知名的开源知识库《CS-Notes》,目前已有 173k 的 star 数,其中收录了不少我认为蛮不错的内容,比如说大家现在看到的《30天速通Java》——请原谅我起了一个噱头十足的名字😁。
一共五个章节,基础篇、IO 篇、容器篇、并发篇和 JVM篇,我结合《二哥的 Java 进阶之路》对内容做一些补充和优化,并导出了亮白版和暗黑版的 PDF 和 epub 版本,好方便大家在 30 天内真的速通 Java(减少大家学习的成本)。
- 由于时间仓促和个人能力有限,手册难免存在错误和疏漏,还请大家批评指正。微信 itwanger
- 该手册会持续更新,再次感谢原作者 CS-Notes,原文档地址:https://github.com/CyC2018/CS-Notes/
- 推荐:二哥的 Java 进阶之路:Java 最新学习路线
最新版 PDF 获取
讲个不好笑的笑话,PDF 内容没办法自动更新(😂),所以只能通过下面的方式:
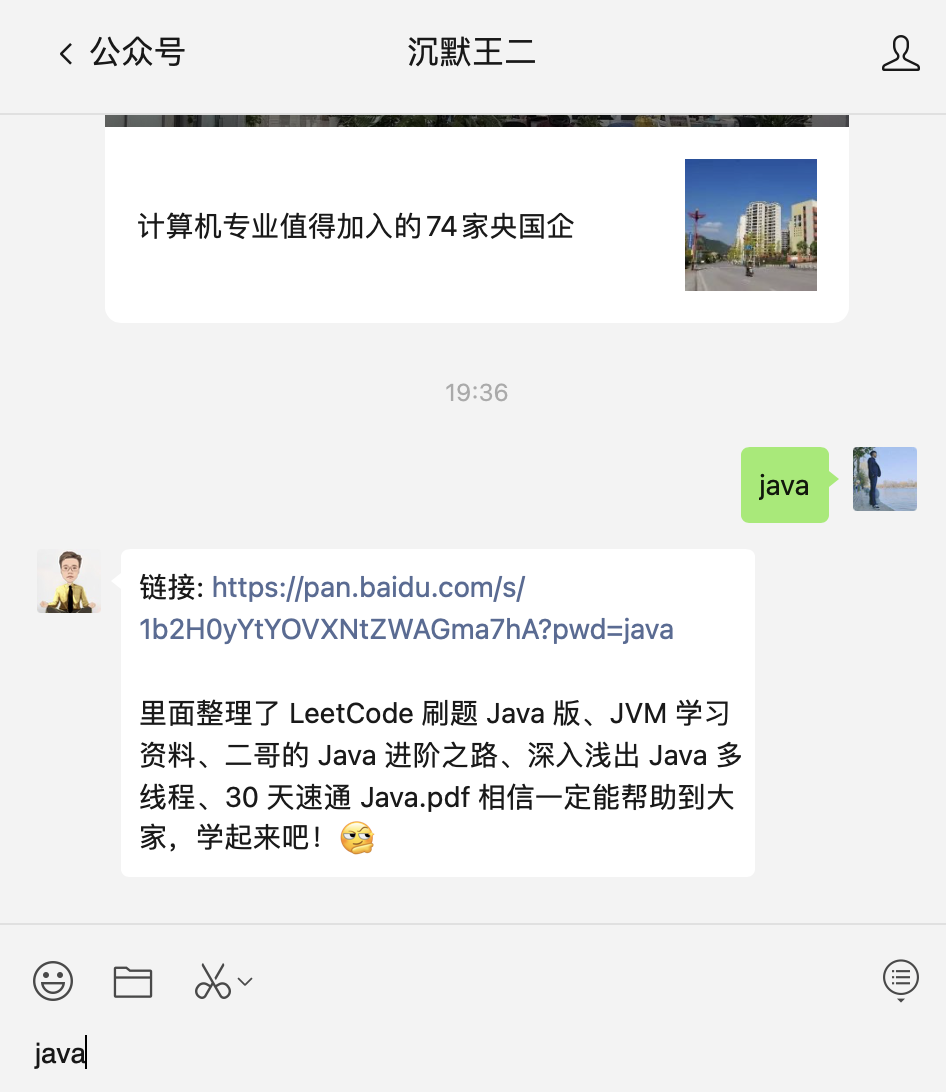
微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本(我会不定期更新)。

获取方式见下图(我用的 PC 端微信截图,手机端差不多):
附其他干货笔记下载地址:
- 二哥的 Linux 速查备忘手册 PDF 下载
- 阮一峰 C 语言入门教程 PDF 下载
- Java 核心知识点整理 PDF 下载
- 深入浅出 Java 多线程 PDF 下载
- Pro Git 中文版 PDF 下载
- 给操作系统捋条线 PDF 下载
第一章、Java基础篇
一、数据类型
基本类型
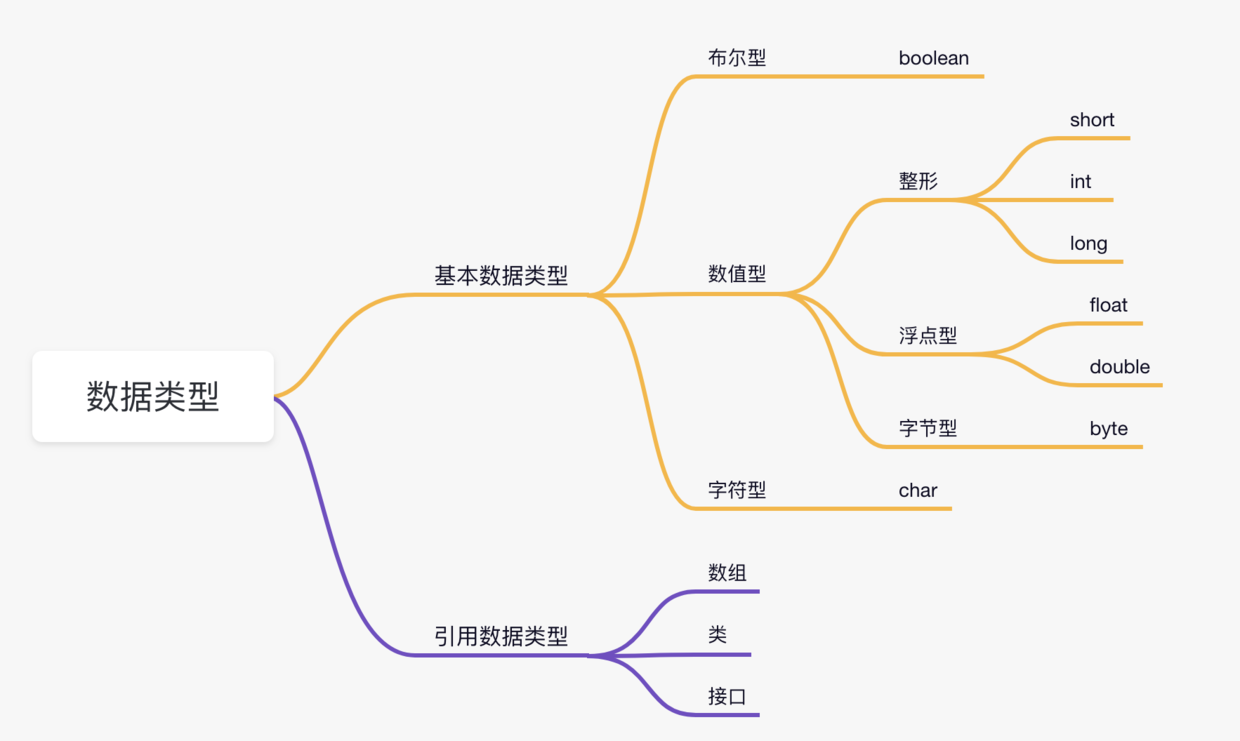
Java 基本数据类型的默认值和占用大小:
| 数据类型 | 默认值 | 大小 |
|---|---|---|
| boolean | false | 1 字节或 4 字节 |
| char | '\u0000' | 2 字节 |
| byte | 0 | 1 字节 |
| short | 0 | 2 字节 |
| int | 0 | 4 字节 |
| long | 0L | 8 字节 |
| float | 0.0f | 4 字节 |
| double | 0.0 | 8 字节 |
推荐阅读:二哥的 Java 进阶之路:Java 基本数据类型
包装类型
基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
Integer x = 2; // 装箱 调用了 Integer.valueOf(2)
int y = x; // 拆箱 调用了 X.intValue()推荐阅读:二哥的 Java 进阶之路:拆箱和装箱
缓存池
new Integer(123) 与 Integer.valueOf(123) 的区别在于:
new Integer(123)每次都会新建一个对象;Integer.valueOf(123)会使用缓存池中初始化好的对象。
Integer x = new Integer(123);
Integer y = new Integer(123);
System.out.println(x == y); // false
Integer z = Integer.valueOf(123);
Integer k = Integer.valueOf(123);
System.out.println(z == k); // truevalueOf() 方法的实现比较简单,先判断值是否在缓存池中,如果在的话就直接返回缓存池的对象。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
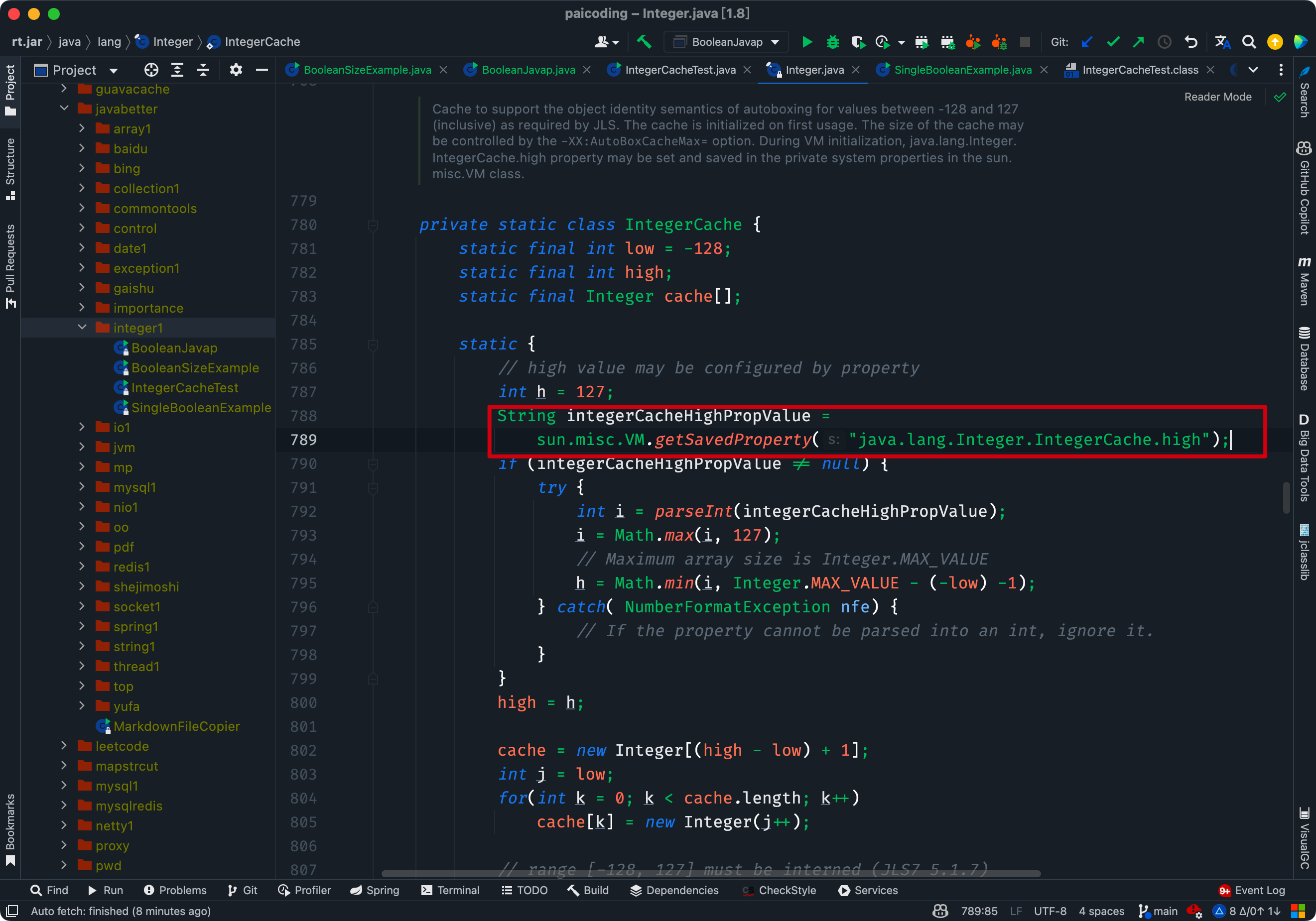
}在 Java 8 中,Integer 缓存池的大小默认为 -128~127。
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}编译器会在自动装箱过程调用 valueOf() 方法,也就是说,值相同且在缓存池内的 Integer 对象使用 == 来比较的时候会返回 true。
Integer m = 123;
Integer n = 123;
System.out.println(m == n); // true基本类型对应的缓冲池如下:
- boolean values true and false
- all byte values
- short values between -128 and 127
- int values between -128 and 127
- char in the range \u0000 to \u007F
在 Java 8 的数值类缓冲池中,Integer 的缓冲池 IntegerCache 很特殊,这个缓冲池的下界是 - 128,上界默认是 127,但是上界是可调的。
在启动 jvm 的时候,可以通过 -XX:AutoBoxCacheMax=<size> 来指定缓冲池的大小,该选项在 JVM 初始化的时候会设定一个名为 java.lang.IntegerCache.high 系统属性,然后 IntegerCache 初始化的时候就会读取该系统属性来决定上界。
二、String
概览
String 被声明为 final,因此它不能被继承。在 Java 8 中,String 内部使用 char 数组存储数据。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}但在 Java 9 之后,String 类的实现改用 byte 数组来存储字符串,同时使用 coder 来标识使用了哪种编码。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final byte[] value;
/** The identifier of the encoding used to encode the bytes in {@code value}. */
private final byte coder;
}value 数组被声明为 final,这意味着 value 变量在数组初始化之后就不能再引用其它数组对象了。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
字符串不可变的好处
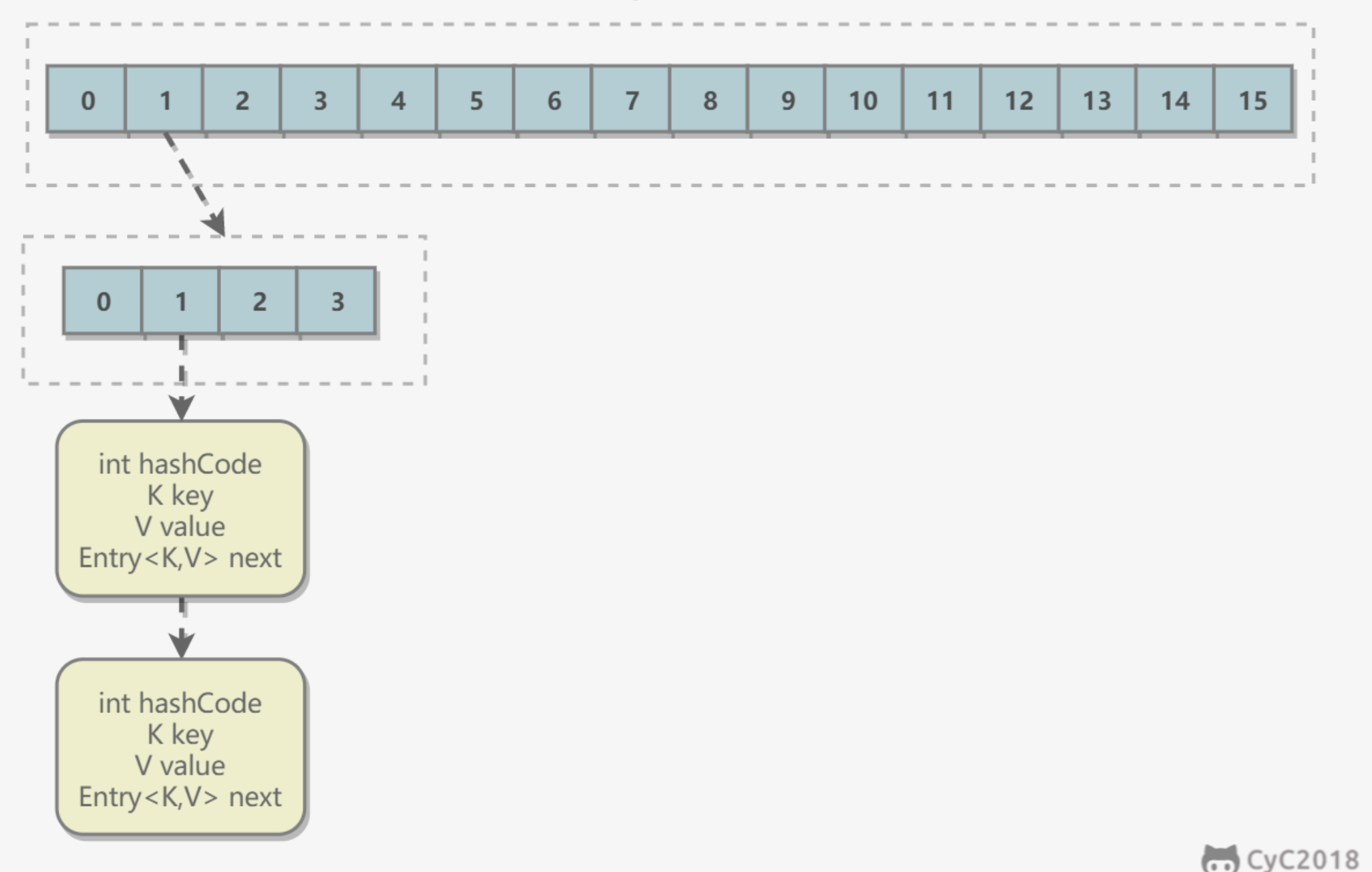
1. 可以用来作为 HashMap 的 key
HashMap 的底层数据结构是数组,其键值对在数组中的位置是通过 (n - 1) & hash 计算得到的,n 也就是数组的长度,hash 也就是键的哈希值。
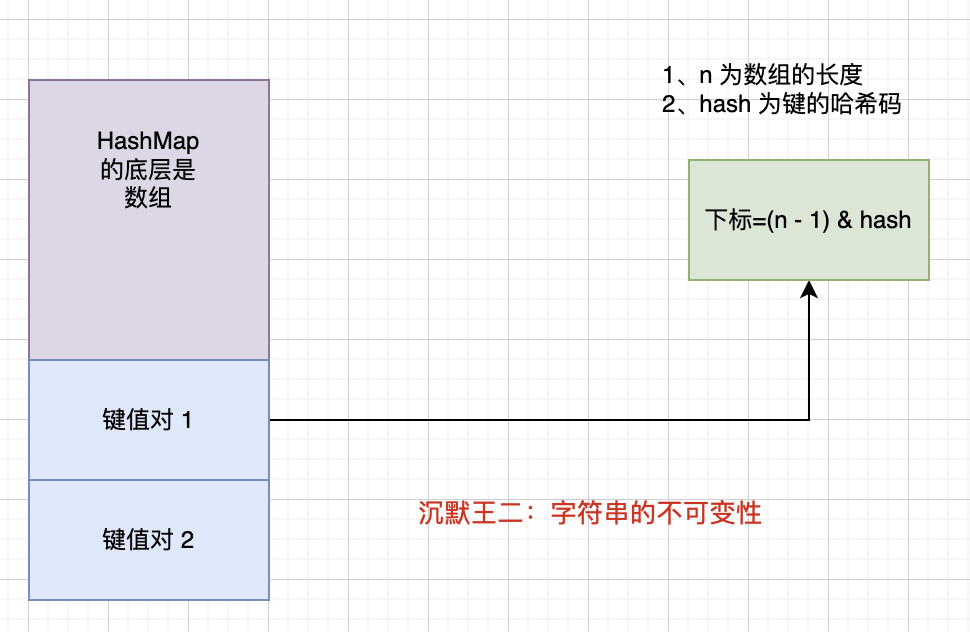
如果键是可变的,那么在计算键的哈希值时,哈希值也是不确定的,于是就无法准确地在数组中定位到键值对的位置。
推荐阅读:HashMap 的源码解读
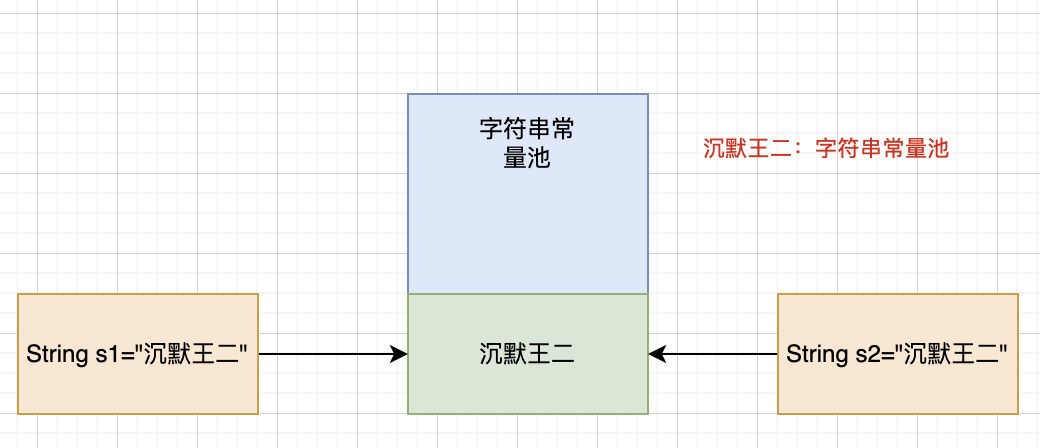
2. 字符串常量池的需要
因为字符串的使用频率非常高,所以 Java 设计者就决定将字符串常量放到一个公共的地方,这个地方叫做字符串常量池(String Pool)。
通过双引号创建的字符串(如 "沉默王二")都会被加入到字符串常量池中,这样就可以减少字符串的创建,节约内存空间。
推荐阅读:深入理解Java的字符串常量池
3. 安全性
String 经常作为参数进行传递,比如说数据库连接中的用户名和密码,如果 String 是可变的,那么在传递的过程中就会存在安全隐患。
推荐阅读:为什么 Java 字符串是不可变的?
String, StringBuffer 和 StringBuilder
1. 可变性
- String 不可变
- StringBuffer 和 StringBuilder 可变
2. 线程安全
- String 不可变,因此是线程安全的
- StringBuilder 不是线程安全的
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
推荐阅读:聊聊 Java StringBuilder和StringBuffer 两兄弟
字符串常量池
字符串常量池(String Pool)保存了所有字符串字面量(literal strings),也就是使用双引号 "" 创建的字符串对象。当然了,也可以使用 String 的 intern() 方法将字符串添加到字符串常量池中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同字符串,而 s3 和 s4 是通过 s1.intern() 和 s2.intern() 方法获取字符串的引用。
intern() 会从字符串常量池中返回这个字符串引用,因此 s3 和 s4 引用的是同一个字符串。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
String s4 = s2.intern();
System.out.println(s3 == s4); // true如果是采用 "bbb" 这种字面量的形式创建字符串,编译器会自动地将字符串放入 String Pool 中。
String s5 = "bbb";
String s6 = "bbb";
System.out.println(s5 == s6); // truenew String("abc")
使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 "abc" 字符串对象)。
- "abc" 属于字符串字面量,因此编译时会在 String Pool 中创建一个字符串对象;
- 使用 new 会在堆中创建一个新的字符串对象,这个新对象在创建的时候,会使用字符串常量池中 "abc" 作为构造方法的参数。
好,我们来创建一个测试类,main 方法中使用这种方式来创建字符串对象。
public class NewStringTest {
public static void main(String[] args) {
String s = new String("abc");
}
}使用 javap -verbose 进行反编译,得到以下内容:
// ...
Constant pool:
// ...
#2 = Class #18 // java/lang/String
#3 = String #19 // abc
// ...
#18 = Utf8 java/lang/String
#19 = Utf8 abc
// ...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=2, args_size=1
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String abc
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
// ...在 Constant Pool 中,#19 存储了字符串字面量 "abc",#3 是 String Pool 的字符串对象,它指向 #19 这个字符串字面量。
在 main 方法中,0: 行使用 new #2 在堆中创建了一个字符串对象,并且使用 ldc #3 将 String Pool 中的字符串对象作为 String 构造方法的参数。
以下是 String 构造方法的源码,可以看到,在将一个字符串对象作为另一个字符串对象的构造方法参数时,并不会复制 value 数组的内容,而是指向同一个 value 数组。
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本。
三、运算
参数传递
Java 的参数是以值传递的形式传入方法中的,而不是引用传递。
这是一个 Dog 类,有一个字段 name、一个构造方法、一个 getName 方法和一个 setName 方法,以及一个 getObjectAddress 方法,用来返回对象的地址。
public class Dog {
String name;
Dog(String name) {
this.name = name;
}
String getName() {
return this.name;
}
void setName(String name) {
this.name = name;
}
String getObjectAddress() {
return super.toString();
}
}然后我们在测试类的 main 方法中创建一个 Dog 对象 dog,并调用 func 方法,将 dog 对象作为参数传入。
class PassByValueExample {
public static void main(String[] args) {
Dog dog = new Dog("A");
func(dog);
System.out.println(dog.getName()); // B
}
private static void func(Dog dog) {
dog.setName("B");
}
}可以看到,dog 的 name 发生了改变,因为调用 func 方法时,传入的是 dog 对象的引用,也就是说,传入的是对象的地址,所以在 func 方法中对对象的字段进行修改,会影响到传入之前的对象。
但如果在方法中将变量引用到其它对象,那么此时方法里和方法外的两个引用其实指向了不同的对象,因此 func 方法中的 dog = new Dog("B") 并不会影响 main 方法中的 dog 对象。
public class PassByValueExample {
public static void main(String[] args) {
Dog dog = new Dog("A");
System.out.println(dog.getObjectAddress()); // Dog@4554617c
func(dog);
System.out.println(dog.getObjectAddress()); // Dog@4554617c
System.out.println(dog.getName()); // A
}
private static void func(Dog dog) {
System.out.println(dog.getObjectAddress()); // Dog@4554617c
dog = new Dog("B");
System.out.println(dog.getObjectAddress()); // Dog@74a14482
System.out.println(dog.getName()); // B
}
}因此,在将一个对象作为参数传入另外一个方法时,本质上是将对象的地址以值的方式传递到形参中。
推荐阅读:Java 到底是值传递还是引用传递
float 与 double
Java 不能隐式向下转型,因为这会使精度降低。
1.1 字面量属于 double 类型,不能直接将 1.1 赋值给 float 变量,因为这是向下转型。
// float f = 1.1;1.1f 字面量才是 float 类型。
float f = 1.1f;隐式类型转换
因为字面量 1 是 int 类型,它比 short 类型精度要高,因此不能隐式地将 int 类型向下转型为 short 类型。
short s1 = 1;
// s1 = s1 + 1;但是使用 += 或者 ++ 运算符会执行隐式类型转换。
s1 += 1;
s1++;上面的语句相当于将 s1 + 1 的计算结果进行了向下转型:
s1 = (short) (s1 + 1);推荐阅读:自动类型转换与强制类型转换
switch
从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象。
String s = "a";
switch (s) {
case "a":
System.out.println("aaa");
break;
case "b":
System.out.println("bbb");
break;
}推荐阅读:switch 语句的介绍
四、关键字
final
1.变量
使用 final 修饰的变量被称为常量,常量在定义时必须进行初始化,并且初始化后值不可改变。
- 对于基本数据类型,final 修饰后的变量值不可改变。
- 对于引用数据类型,final 修饰后的引用不变,也就事不能引用其它对象,但是被引用的对象本身是可以修改的。
final int x = 1;
// x = 2; // cannot assign value to final variable 'x'
final A y = new A();
y.a = 1;2.方法
final 修饰的方法不能被子类重写。
3. 类
final 修饰的类不允许被继承。
static
1.静态变量
- 静态变量:又称类变量,也就是通过 static 关键字修饰的变量,这个变量是属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问静态变量。静态变量在内存中只有一份。
- 实例变量:或者叫成员变量,每创建一个实例就会产生一个实例变量,它与该实例同生共死。
public class A {
private int x; // 实例变量
private static int y; // 静态变量
public static void main(String[] args) {
// int x = A.x; // Non-static field 'x' cannot be referenced from a static context
A a = new A();
int x = a.x;
int y = A.y;
}
}2.静态方法
static 修饰的方法被称为静态方法,它在类加载的时候就存在了,它不依赖于任何实例。
但 static 不能用来修饰抽象方法,因为 abstract 方法需要子类重写并提供具体实现,而 static 方法是静态的,无法被子类重写,这使得 static 和 abstract 修饰符是冲突的。
public abstract class A {
public static void func1(){
}
// public abstract static void func2(); // Illegal combination of modifiers: 'abstract' and 'static'
}静态方法只能访问所属类的静态字段和静态方法,并且静态方法中不能有 this 和 super 关键字,因为这两个关键字与具体的对象关联。
public class A {
private static int x;
private int y;
public static void func1(){
int a = x;
// int b = y; // Non-static field 'y' cannot be referenced from a static context
// int b = this.y; // 'A.this' cannot be referenced from a static context
}
}3.静态代码块
静态代码块在类初始化时运行一次。
public class A {
static {
System.out.println("123");
}
public static void main(String[] args) {
A a1 = new A();
A a2 = new A();
}
}可以用 static 代码块来初始化一些静态变量,它会优先于 main 方法执行。
1234.静态内部类
非静态内部类依赖于外部类的实例,也就是说需要先创建外部类的实例,才能用这个实例去创建非静态内部类。而静态内部类不需要,可以直接实例化。
public class OuterClass {
class InnerClass {
}
static class StaticInnerClass {
}
public static void main(String[] args) {
// InnerClass innerClass = new InnerClass(); // 'OuterClass.this' cannot be referenced from a static context
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
StaticInnerClass staticInnerClass = new StaticInnerClass();
}
}但静态内部类不能访问外部类的非静态变量和方法。
5.静态导包
在使用静态变量和静态方法时不用再指明 ClassName,从而简化代码,但可读性大大降低,不推荐。
import static com.xxx.ClassName.*6.代码的初始化顺序
静态变量和静态代码块优先于实例变量和普通代码块,而静态变量和静态代码块的初始化顺序取决于它们在代码中的顺序。
public static String staticField = "静态变量";
static {
System.out.println("静态语句块");
}
public String field = "实例变量";
{
System.out.println("普通语句块");
}最后才是构造方法的初始化。
public InitialOrderTest() {
System.out.println("构造方法");
}存在继承的情况下,初始化顺序为:
- 父类(静态变量、静态语句块)
- 子类(静态变量、静态语句块)
- 父类(实例变量、普通语句块)
- 父类(构造方法)
- 子类(实例变量、普通语句块)
- 子类(构造方法)
微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本。
五、Object 通用方法
概览
下面👇🏻这些方法都挺常用的,先看个大概,然后我们来挑一些使用频率非常高的方法做一个系统化地介绍。
public native int hashCode()
public boolean equals(Object obj)
protected native Object clone() throws CloneNotSupportedException
public String toString()
public final native Class<?> getClass()
protected void finalize() throws Throwable {}
public final native void notify()
public final native void notifyAll()
public final native void wait(long timeout) throws InterruptedException
public final void wait(long timeout, int nanos) throws InterruptedException
public final void wait() throws InterruptedExceptionequals()
1. 等价关系
两个对象具有等价关系,需要满足以下 4 个条件:
①、对称性
x.equals(y) == y.equals(x); // true②、传递性
if (x.equals(y) && y.equals(z))
x.equals(z); // true;③、一致性
多次调用 equals() 方法结果不变
x.equals(y) == x.equals(y); // true④、与 null 的比较
对任何不是 null 的对象 x 调用 x.equals(null) 结果都为 false
x.equals(null); // false;2. 等价与相等
- 对于基本数据类型,可以使用 == 判断两个值是否相等。
- 对于引用数据类型,可以使用 == 判断两个变量是否引用了同一个对象,而
equals()方法用于判断引用的对象是否等价。
Integer x = new Integer(1);
Integer y = new Integer(1);
System.out.println(x.equals(y)); // true
System.out.println(x == y); // false3. 如何实现equals方法
①、检查是否为同一个对象的引用,如果是直接返回 true;
②、检查是否是同一类型,如果不是,直接返回 false;
③、转型后判断关键字段是否相等。
public class EqualExample {
private int x;
private int y;
private int z;
public EqualExample(int x, int y, int z) {
this.x = x;
this.y = y;
this.z = z;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
EqualExample that = (EqualExample) o;
if (x != that.x) return false;
if (y != that.y) return false;
return z == that.z;
}
}hashCode()
hashCode() 方法用于返回对象的哈希值,而 equals() 用来判断两个对象是否等价。等价的两个对象哈希值一定相同,但是哈希值相同的两个对象不一定等价,因为哈希值的计算具有随机性,两个值不同的对象可能计算出相同的哈希值。
在重写 equals() 方法时应该重写 hashCode() 方法,保证等价的两个对象哈希值也相等。
HashSet 和 HashMap 等集合类使用了 hashCode() 方法来计算对象应该存储的位置(底层数据结构为数组),因此要将对象添加到这些集合类中,需要让对应的类实现 hashCode() 方法。
下面的代码中,新建了两个等价的对象,并将它们添加到 HashSet 中。我们希望将这两个对象当成一样的,只在集合中添加一个。但是 EqualExample 没有实现 hashCode() 方法,因此这两个对象的哈希值是不同的,最终导致集合添加了两个等价的对象。
EqualExample e1 = new EqualExample(1, 1, 1);
EqualExample e2 = new EqualExample(1, 1, 1);
System.out.println(e1.equals(e2)); // true
HashSet<EqualExample> set = new HashSet<>();
set.add(e1);
set.add(e2);
System.out.println(set.size()); // 2理想的哈希函数(方法/算法)应当具有均匀性,即不相等的对象应当均匀分布到所有可能的哈希值上。
这就要求了哈希函数要把所有域(字段)的值都考虑进来。可以将每个域都当成 R 进制的某一位,然后组成一个 R 进制的整数。
R 一般取 31,因为它是一个奇素数,如果是偶数的话,当出现乘法溢出,信息就会丢失,因为与 2 相乘相当于向左移一位,最左边的位丢失。
并且一个数与 31 相乘可以转换成移位和减法:31*x == (x<<5)-x,编译器会自动进行这个优化。
@Override
public int hashCode() {
int result = 17;
result = 31 * result + x;
result = 31 * result + y;
result = 31 * result + z;
return result;
}toString()
默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为哈希值(散列码)的无符号十六进制表示。
public class ToStringExample {
private int number;
public ToStringExample(int number) {
this.number = number;
}
}测试一下:
ToStringExample example = new ToStringExample(123);
System.out.println(example.toString());输出结果:
ToStringExample@4554617cclone()
1. cloneable 接口
clone() 是 Object 的 protected 方法,它不是 public,因此如果一个类没有显式重写 clone(),其它类就不能直接调用该类实例的 clone() 方法。
public class CloneExample {
private int a;
private int b;
}尝试直接调用 clone() 方法,编译器提示错误:
CloneExample e1 = new CloneExample();
// CloneExample e2 = e1.clone(); // 'clone()' has protected access in 'java.lang.Object'好,这次重写 clone() 方法:
public class CloneExample {
private int a;
private int b;
@Override
public CloneExample clone() throws CloneNotSupportedException {
return (CloneExample)super.clone();
}
}再次尝试调用 clone() 方法:
CloneExample e1 = new CloneExample();
try {
CloneExample e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}输出结果:
java.lang.CloneNotSupportedException: CloneExample哦哦,编译通过了,但运行时抛出 CloneNotSupportedException,这是因为 CloneExample 没有实现 Cloneable 接口。
需要注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的 protected 方法。
Cloneable 接口只是规定(约束),规定一个类如果没有实现 Cloneable 接口就直接调用了 clone() 方法,就会抛出 CloneNotSupportedException。
public class CloneExample implements Cloneable {
private int a;
private int b;
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}2. 浅拷贝
浅拷贝:复制对象的基本数据类型成员变量,和引用数据类型成员变量的引用,导致新对象和原对象共享同一引用对象。
public class ShallowCloneExample implements Cloneable {
private int[] arr;
public ShallowCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected ShallowCloneExample clone() throws CloneNotSupportedException {
return (ShallowCloneExample) super.clone();
}
}进行浅拷贝,改变 e1 的 arr 数组,e2 的 arr 数组也会改变。
ShallowCloneExample e1 = new ShallowCloneExample();
ShallowCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 2223. 深拷贝
深拷贝:不仅复制对象的基本数据类型成员变量,还递归复制引用类型成员变量所引用的对象,使得新对象和原对象完全独立。
public class DeepCloneExample implements Cloneable {
private int[] arr;
public DeepCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected DeepCloneExample clone() throws CloneNotSupportedException {
DeepCloneExample result = (DeepCloneExample) super.clone();
result.arr = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
result.arr[i] = arr[i];
}
return result;
}
}进行深拷贝,改变 e1 的 arr 数组,e2 的 arr 数组不会改变。
DeepCloneExample e1 = new DeepCloneExample();
DeepCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 24. clone() 的替代方案
使用 clone() 方法来拷贝一个对象既复杂又有风险,一需要类型转换,二可能抛出异常。
Effective Java 一书上讲到,最好不要去使用 clone(),可以使用拷贝构造方法或者拷贝工厂来拷贝一个对象。
public class CloneConstructorExample {
private int[] arr;
public CloneConstructorExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public CloneConstructorExample(CloneConstructorExample original) {
arr = new int[original.arr.length];
for (int i = 0; i < original.arr.length; i++) {
arr[i] = original.arr[i];
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
}使用拷贝构造方法来拷贝一个对象,简单高效。
CloneConstructorExample e1 = new CloneConstructorExample();
CloneConstructorExample e2 = new CloneConstructorExample(e1);
e1.set(2, 222);
System.out.println(e2.get(2)); // 2推荐阅读:深入理解Java浅拷贝与深拷贝
六、继承
访问权限
Java 中有三个访问权限修饰符:private、protected 以及 public,如果不加访问修饰符,表示包级可见。
可以对类或类中的成员(字段和方法)加上访问修饰符。
- 类可见表示其它类可以用这个类创建实例对象。
- 成员可见表示其它类可以用这个类的实例对象访问到该成员;
protected 用于修饰成员,表示在继承体系中成员对于子类可见,但是这个访问修饰符对于类没有意义。
设计良好的模块会隐藏所有的实现细节,把它的 API 与它的实现清晰地隔离开来。模块之间只通过它们的 API 进行通信,一个模块不需要知道其他模块的内部工作情况,这个概念被称为信息隐藏或封装。因此访问权限应当尽可能地使每个类或者成员不被外界访问。
如果子类的方法重写了父类的方法,那么子类中该方法的访问级别不允许低于父类的访问级别。这是为了确保可以使用父类实例的地方都可以使用子类实例去代替,也就是确保满足里氏替换原则。
字段决不能是公有的,因为这么做的话就失去了对这个字段修改行为的控制,客户端可以对其随意修改。
例如下面的例子中,AccessExample 拥有 id 公有字段,如果在某个时刻,我们想要使用 int 存储 id 字段,那么就需要修改所有的客户端代码。
public class AccessExample {
public String id;
}可以使用公有的 getter 和 setter 方法来替换公有字段,这样的话就可以控制对字段的修改行为。
public class AccessExample {
private int id;
public String getId() {
return id + "";
}
public void setId(String id) {
this.id = Integer.valueOf(id);
}
}但是也有例外,如果是包级私有的类或者私有的嵌套类,那么直接暴露成员不会有特别大的影响。
public class AccessWithInnerClassExample {
private class InnerClass {
int x;
}
private InnerClass innerClass;
public AccessWithInnerClassExample() {
innerClass = new InnerClass();
}
public int getValue() {
return innerClass.x; // 直接访问
}
}推荐阅读:Java访问权限修饰符
抽象类与接口
1. 抽象类
抽象类和抽象方法都使用 abstract 关键字进行声明。如果一个类中包含抽象方法,那么这个类必须声明为抽象类。
抽象类和普通类最大的区别是,抽象类不能被实例化,只能被继承。
public abstract class AbstractClassExample {
protected int x;
private int y;
public abstract void func1();
public void func2() {
System.out.println("func2");
}
}继承:
public class AbstractExtendClassExample extends AbstractClassExample {
@Override
public void func1() {
System.out.println("func1");
}
}抽象类不能被实例化。
// AbstractClassExample ac1 = new AbstractClassExample(); // 'AbstractClassExample' is abstract; cannot be instantiated
AbstractClassExample ac2 = new AbstractExtendClassExample();
ac2.func1();2. 接口
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类,让它们都实现新增的方法。
接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。从 Java 9 开始,允许将方法定义为 private,这样就能定义某些复用的代码又不会把方法暴露出去。
接口的字段默认都是 static 和 final 的。
public interface InterfaceExample {
void func1();
default void func2(){
System.out.println("func2");
}
int x = 123;
// int y; // Variable 'y' might not have been initialized
public int z = 0; // Modifier 'public' is redundant for interface fields
// private int k = 0; // Modifier 'private' not allowed here
// protected int l = 0; // Modifier 'protected' not allowed here
// private void fun3(); // Modifier 'private' not allowed here
}接口的实现:
public class InterfaceImplementExample implements InterfaceExample {
@Override
public void func1() {
System.out.println("func1");
}
}接口不能被实例化,但是可以使用接口引用来指向实现了该接口的类。
// InterfaceExample ie1 = new InterfaceExample(); // 'InterfaceExample' is abstract; cannot be instantiated
InterfaceExample ie2 = new InterfaceImplementExample();
ie2.func1();
System.out.println(InterfaceExample.x);3. 抽象类和接口比较
- 从设计层面上看,抽象类提供了一种 IS-A 的关系,需要满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
4. 抽象类和接口的使用选择
使用接口:
- 需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Comparable 接口中的
compareTo()方法; - 需要使用多重继承。
使用抽象类:
- 需要在几个相关的类中共享代码。
- 需要能控制继承来的成员访问权限,而不是都为 public。
- 需要继承非静态和非常量字段。
在很多情况下,接口优先于抽象类。因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
推荐阅读:
super 关键字
- 可以使用
super()访问父类的构造方法,从而委托父类完成一些初始化的工作。应该注意到,子类一定会调用父类的构造方法来完成初始化工作,一般是调用父类的默认构造方法,如果子类需要调用父类其它的构造方法,那么就可以使用super()。 - 访问父类的成员:如果子类重写了父类的某个方法,可以通过使用 super 关键字来引用父类的方法实现。
public class SuperExample {
protected int x;
protected int y;
public SuperExample(int x, int y) {
this.x = x;
this.y = y;
}
public void func() {
System.out.println("SuperExample.func()");
}
}使用 super() 调用父类的构造方法:
public class SuperExtendExample extends SuperExample {
private int z;
public SuperExtendExample(int x, int y, int z) {
super(x, y);
this.z = z;
}
@Override
public void func() {
super.func();
System.out.println("SuperExtendExample.func()");
}
}测试:
SuperExample e = new SuperExtendExample(1, 2, 3);
e.func();输出结果:
SuperExample.func()
SuperExtendExample.func()推荐阅读:this 和 super
重写与重载
1. 重写(Override)
重写存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的方法。
为了满足里式替换原则,重写有以下三个限制:
- 子类方法的访问权限必须大于等于父类方法;
- 子类方法的返回类型必须是父类方法返回类型或为其子类型。
- 子类方法抛出的异常类型必须是父类抛出异常类型或为其子类型。
使用 @Override 注解,可以让编译器帮忙检查是否满足上面的三个限制条件。
下面的示例中,SubClass 为 SuperClass 的子类,SubClass 重写了 SuperClass 的 func() 方法。其中:
- 子类方法访问权限为 public,大于父类的 protected。
- 子类的返回类型为 ArrayList<Integer>,是父类返回类型 List<Integer> 的子类。
- 子类抛出的异常类型为 Exception,是父类抛出异常 Throwable 的子类。
- 子类重写方法使用
@Override注解,从而让编译器自动检查是否满足限制条件。
class SuperClass {
protected List<Integer> func() throws Throwable {
return new ArrayList<>();
}
}
class SubClass extends SuperClass {
@Override
public ArrayList<Integer> func() throws Exception {
return new ArrayList<>();
}
}在调用一个方法时,先从本类中查找是否有对应的方法,如果没有再到父类中查看,看是否从父类继承来。否则就要对参数进行转型,转成父类之后看是否有对应的方法。总的来说,方法调用的优先级为:
- this.func(this)
- super.func(this)
- this.func(super)
- super.func(super)
class A {
public void show(A obj) {
System.out.println("A.show(A)");
}
public void show(C obj) {
System.out.println("A.show(C)");
}
}
class B extends A {
@Override
public void show(A obj) {
System.out.println("B.show(A)");
}
}
class C extends B {
}
class D extends C {
}测试:
public static void main(String[] args) {
A a = new A();
B b = new B();
C c = new C();
D d = new D();
// 在 A 中存在 show(A obj),直接调用
a.show(a); // A.show(A)
// 在 A 中不存在 show(B obj),将 B 转型成其父类 A
a.show(b); // A.show(A)
// 在 B 中存在从 A 继承来的 show(C obj),直接调用
b.show(c); // A.show(C)
// 在 B 中不存在 show(D obj),但是存在从 A 继承来的 show(C obj),将 D 转型成其父类 C
b.show(d); // A.show(C)
// 引用的还是 B 对象,所以 ba 和 b 的调用结果一样
A ba = new B();
ba.show(c); // A.show(C)
ba.show(d); // A.show(C)
}2. 重载(Overload)
重载存在于同一个类中,指一个方法与已经存在的方法名称上相同,但是参数类型、个数、顺序至少有一个不同。
应该注意的是,返回值不同,其它都相同不算是重载。
class OverloadingExample {
public void show(int x) {
System.out.println(x);
}
public void show(int x, String y) {
System.out.println(x + " " + y);
}
}测试:
public static void main(String[] args) {
OverloadingExample example = new OverloadingExample();
example.show(1);
example.show(1, "2");
}推荐阅读:重载和重写
微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本。
七、反射
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
类加载相当于 Class 对象的加载,类在第一次使用时才动态加载到 JVM 中。也可以使用 Class.forName("com.mysql.jdbc.Driver") 这种方式来控制类的加载,该方法会返回一个 Class 对象。
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
- Field :可以使用
get()和set()方法读取和修改 Field 对象关联的字段; - Method :可以使用
invoke()方法调用与 Method 对象关联的方法; - Constructor :可以用 Constructor 的
newInstance()创建新的对象。
反射的优点:
- 可扩展性 :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
- 类浏览器和可视化开发环境 :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
- 调试器和测试工具 : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
反射的缺点:
尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
- 性能开销 :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
- 安全限制 :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
- 内部暴露 :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
推荐阅读:Java 反射详解
八、异常
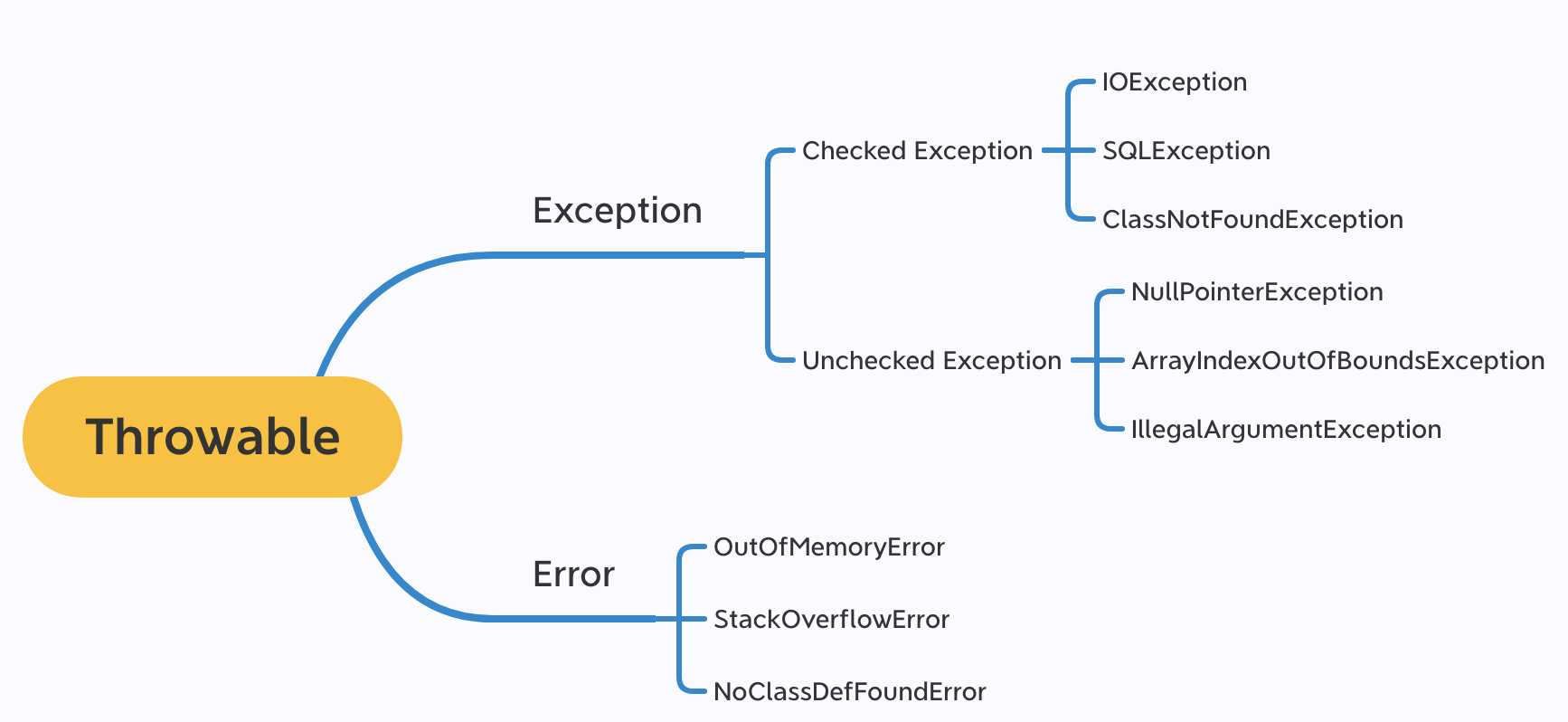
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: Error 和 Exception。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
- 受检异常 :需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
- 非受检异常 :程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
推荐阅读:一文彻底搞懂Java异常处理
九、泛型
public class Box<T> {
// T stands for "Type"
private T t;
public void set(T t) { this.t = t; }
public T get() { return t; }
}推荐阅读:Java 泛型深入解析
十、注解
Java 注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。
推荐阅读:深入理解Java中的注解
十一、特性
Java 各版本的新特性
New highlights in Java SE 8
- Lambda Expressions
- Pipelines and Streams
- Date and Time API
- Default Methods
- Type Annotations
- Nashhorn JavaScript Engine
- Concurrent Accumulators
- Parallel operations
- PermGen Error Removed
New highlights in Java SE 7
- Strings in Switch Statement
- Type Inference for Generic Instance Creation
- Multiple Exception Handling
- Support for Dynamic Languages
- Try with Resources
- Java nio Package
- Binary Literals, Underscore in literals
- Diamond Syntax
推荐阅读:
JRE or JDK
- JRE:Java Runtime Environment,Java 运行环境的简称,为 Java 的运行提供所需环境。它是一个 JVM 程序,主要包括了 JVM 的标准实现和一些 Java 基本类库。
- JDK:Java Development Kit,Java 开发工具包,提供了 Java 的开发及运行环境。JDK 是 Java 开发的核心,集成了 JRE 以及一些其它的工具,比如编译 Java 源码的编译器 javac 等。
参考资料
CS-Notes,原文档地址:https://github.com/CyC2018/CS-Notes/
花絮
该 PDF 文档是我在学习 CSNotes 时的一些优化和补充,加了很多二哥的 Java 进阶之路上的内容,可以进行很好的互补。整理不易,希望能帮助到大家(❤️)。
最新版更新完成后我会放到网盘中,微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《Java》即可获取最新的 PDF 版本。
附其他干货笔记下载地址:
- 二哥的 Linux 速查备忘手册 PDF 下载
- 阮一峰 C 语言入门教程 PDF 下载
- Java 核心知识点整理 PDF 下载
- 深入浅出 Java 多线程 PDF 下载
- Pro Git 中文版 PDF 下载
- 给操作系统捋条线 PDF 下载
第二章、IO 篇
一、概览
Java 的 I/O 大概可以分成以下几类:
- 磁盘操作:File
- 字节操作:InputStream 和 OutputStream
- 字符操作:Reader 和 Writer
- 对象操作:Serializable
- 网络操作:Socket
- 新的输入/输出:NIO
二、磁盘操作
File 类可以用于表示文件和目录的信息,但是它不表示文件的内容。
来看一个递归列出目录下所有文件的例子:
public static void listAllFiles(File dir) {
if (dir == null || !dir.exists()) {
return;
}
if (dir.isFile()) {
System.out.println(dir.getName());
return;
}
for (File file : dir.listFiles()) {
listAllFiles(file);
}
}从 Java 7 开始,可以使用 Paths 和 Files 代替 File。
推荐阅读:
三、字节操作
实现文件复制
public static void copyFile(String src, String dist) throws IOException {
FileInputStream in = new FileInputStream(src);
FileOutputStream out = new FileOutputStream(dist);
byte[] buffer = new byte[20 * 1024];
int cnt;
// read() 最多读取 buffer.length 个字节
// 返回的是实际读取的个数
// 返回 -1 的时候表示读到 eof,即文件尾
while ((cnt = in.read(buffer, 0, buffer.length)) != -1) {
out.write(buffer, 0, cnt);
}
in.close();
out.close();
}装饰者模式
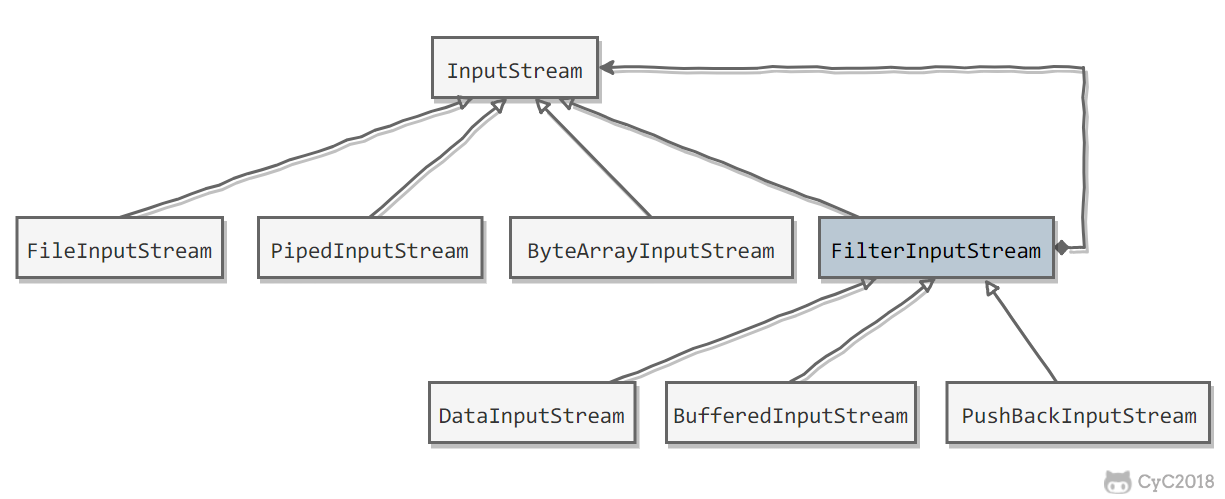
Java I/O 使用了装饰者模式来实现。
以 InputStream 为例:
- InputStream 是抽象组件;
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
- FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
FileInputStream fileInputStream = new FileInputStream(filePath);
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
四、字符操作
编码与解码
编码就是把字符转换为字节,而解码是把字节重新组合成字符。
如果编码和解码过程使用不同的编码方式那么就出现了乱码。
- GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
- UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
- UTF-16be 编码中,中文字符和英文字符都占 2 个字节。
UTF-16be 中的 be 指的是 Big Endian,也就是大端。相应地也有 UTF-16le,le 指的是 Little Endian,也就是小端。
Java 的内存编码使用双字节编码 UTF-16be,这不是指 Java 只支持这一种编码方式,而是说 char 这种类型使用 UTF-16be 进行编码。char 类型占 16 位,也就是两个字节,Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个 char 来存储。
推荐阅读:解决中文乱码:字符编码全攻略 - ASCII、Unicode、UTF-8、GB2312详解
String 的编码方式
String 可以看成一个字符序列,可以指定一个编码方式将它编码为字节序列,也可以指定一个编码方式将一个字节序列解码为 String。
String str1 = "中文";
byte[] bytes = str1.getBytes("UTF-8");
String str2 = new String(bytes, "UTF-8");
System.out.println(str2);在调用无参数 getBytes() 方法时,默认的编码方式不是 UTF-16be。双字节编码的好处是可以使用一个 char 存储中文和英文,而将 String 转为 bytes[] 字节数组就不再需要这个好处,因此也就不再需要双字节编码。getBytes() 的默认编码方式与平台有关,一般为 UTF-8。
byte[] bytes = str1.getBytes();Reader 与 Writer
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符。但是在程序中操作的通常是字符形式的数据,因此需要提供对字符进行操作的方法。
- InputStreamReader 实现从字节流解码成字符流;
- OutputStreamWriter 实现字符流编码成为字节流。
推荐阅读:Java 字符流:Reader和Writer的故事
实现逐行输出文本文件的内容
public static void readFileContent(String filePath) throws IOException {
FileReader fileReader = new FileReader(filePath);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
// 装饰者模式使得 BufferedReader 组合了一个 Reader 对象
// 在调用 BufferedReader 的 close() 方法时会去调用 Reader 的 close() 方法
// 因此只要一个 close() 调用即可
bufferedReader.close();
}微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本。
五、对象操作
序列化
序列化就是将一个对象转换成字节序列,方便存储和传输。
- 序列化:
ObjectOutputStream.writeObject() - 反序列化:
ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
推荐阅读:Java 序列流:Java 对象的序列化和反序列化
Serializable
序列化的类需要实现 Serializable 接口,它只是一个标准,没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
public static void main(String[] args) throws IOException, ClassNotFoundException {
A a1 = new A(123, "abc");
String objectFile = "file/a1";
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(objectFile));
objectOutputStream.writeObject(a1);
objectOutputStream.close();
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(objectFile));
A a2 = (A) objectInputStream.readObject();
objectInputStream.close();
System.out.println(a2);
}
private static class A implements Serializable {
private int x;
private String y;
A(int x, String y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return "x = " + x + " " + "y = " + y;
}
}推荐阅读:Java Serializable 接口:明明就一个空的接口嘛
transient
transient 关键字可以使一些属性(字段)不会被序列化。
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。
通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
private transient Object[] elementData;六、网络操作
Java 中的网络支持:
- InetAddress:用于表示网络上的硬件资源,即 IP 地址;
- URL:统一资源定位符;
- Sockets:使用 TCP 协议实现网络通信;
- Datagram:使用 UDP 协议实现网络通信。
InetAddress
没有公有的构造方法,只能通过静态方法来创建实例。
InetAddress.getByName(String host);
InetAddress.getByAddress(byte[] address);URL
可以直接从 URL 中读取字节流数据。
public static void main(String[] args) throws IOException {
URL url = new URL("https://www.javabetter.cn");
/* 字节流 */
InputStream is = url.openStream();
/* 字符流 */
InputStreamReader isr = new InputStreamReader(is, "utf-8");
/* 提供缓存功能 */
BufferedReader br = new BufferedReader(isr);
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}推荐阅读:Java网络编程的基础:计算机网络
Sockets
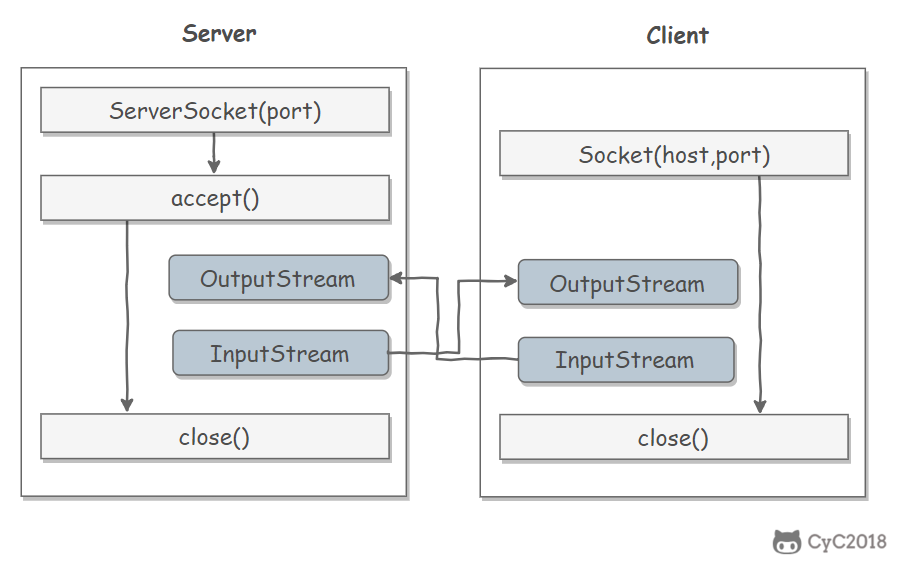
- ServerSocket:服务器端类
- Socket:客户端类
- 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
Datagram
- DatagramSocket:通信类
- DatagramPacket:数据包类
七、NIO
新的输入/输出 (NIO) 库是在 JDK 1.4 中引入的,弥补了原来 I/O 的不足,提供了高速的、面向块的 I/O。
流与块
I/O 与 NIO 最重要的区别是数据打包和传输的方式,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
面向流的 I/O 一次处理一个字节数据:一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。
面向块的 I/O 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
I/O 包和 NIO 已经很好地集成了,java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如,java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快。
通道与缓冲区
1. 通道
通道 Channel 是对原 I/O 包中流的模拟,可以通过它读取和写入数据。
通道与流的不同之处在于,流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),而通道是双向的,可以用于读、写或者同时用于读写。
通道包括以下类型:
- FileChannel:从文件中读写数据;
- DatagramChannel:通过 UDP 读写网络中数据;
- SocketChannel:通过 TCP 读写网络中数据;
- ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
2. 缓冲区
发送给通道的所有数据都必须首先放到缓冲区中,同样地,从通道中读取的任何数据都要先读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。
缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
缓冲区包括以下类型:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
缓冲区状态变量
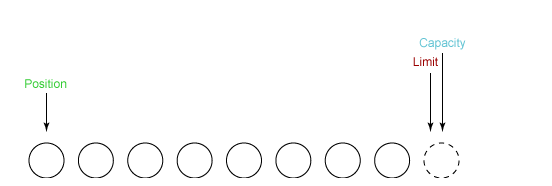
- capacity:最大容量;
- position:当前已经读写的字节数;
- limit:还可以读写的字节数。
状态变量的改变过程举例:
① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。
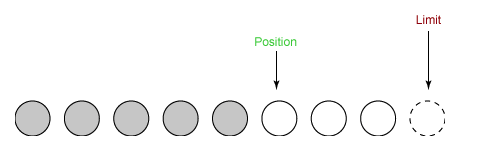
② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 为 5,limit 保持不变。
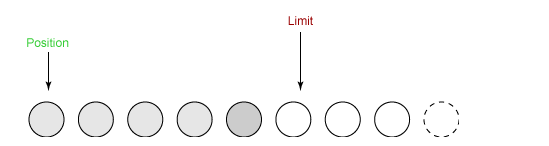
③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
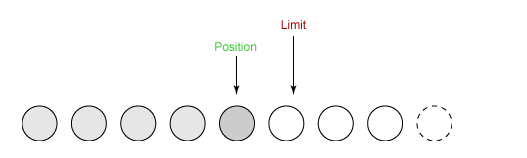
④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
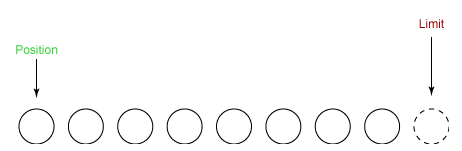
推荐阅读:详解Java NIO的Buffer缓冲区和Channel通道
文件 NIO 实例
以下展示了使用 NIO 快速复制文件的实例:
public static void fastCopy(String src, String dist) throws IOException {
/* 获得源文件的输入字节流 */
FileInputStream fin = new FileInputStream(src);
/* 获取输入字节流的文件通道 */
FileChannel fcin = fin.getChannel();
/* 获取目标文件的输出字节流 */
FileOutputStream fout = new FileOutputStream(dist);
/* 获取输出字节流的文件通道 */
FileChannel fcout = fout.getChannel();
/* 为缓冲区分配 1024 个字节 */
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
/* 从输入通道中读取数据到缓冲区中 */
int r = fcin.read(buffer);
/* read() 返回 -1 表示 EOF */
if (r == -1) {
break;
}
/* 切换读写 */
buffer.flip();
/* 把缓冲区的内容写入输出文件中 */
fcout.write(buffer);
/* 清空缓冲区 */
buffer.clear();
}
}选择器
NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。
NIO 实现了 IO 多路复用中的 Reactor 模型,一个线程 Thread 使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件,从而让一个线程就可以处理多个事件。
通过配置监听的通道 Channel 为非阻塞,那么当 Channel 上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它 Channel,找到 IO 事件已经到达的 Channel 执行。
因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件而不是一个线程处理一个事件,对于 IO 密集型的应用具有很好地性能。
应该注意的是,只有 SocketChannel 才能配置为非阻塞,FileChannel 不能,为 FileChannel 配置非阻塞也没有意义。
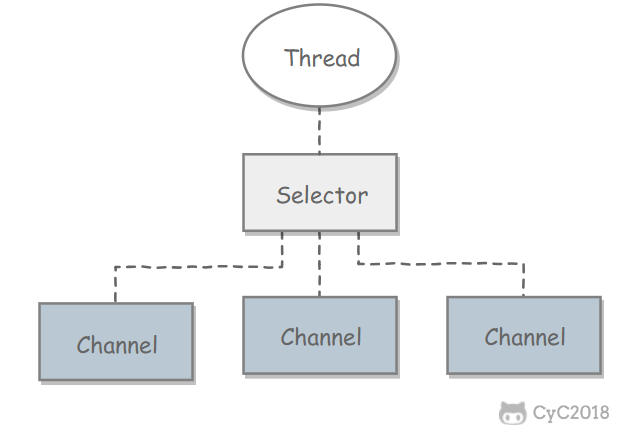
1. 创建选择器
Selector selector = Selector.open();2. 将通道注册到选择器上
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。
在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
- SelectionKey.OP_CONNECT
- SelectionKey.OP_ACCEPT
- SelectionKey.OP_READ
- SelectionKey.OP_WRITE
它们在 SelectionKey 的定义如下:
public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;3. 监听事件
int num = selector.select();使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
4. 获取到达的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}5. 事件循环
因为一次 select() 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
while (true) {
int num = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
}套接字 NIO 实例
public class NIOServer {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
ServerSocket serverSocket = ssChannel.socket();
InetSocketAddress address = new InetSocketAddress("127.0.0.1", 8888);
serverSocket.bind(address);
while (true) {
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel();
// 服务器会为每个新连接创建一个 SocketChannel
SocketChannel sChannel = ssChannel1.accept();
sChannel.configureBlocking(false);
// 这个新连接主要用于从客户端读取数据
sChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel sChannel = (SocketChannel) key.channel();
System.out.println(readDataFromSocketChannel(sChannel));
sChannel.close();
}
keyIterator.remove();
}
}
}
private static String readDataFromSocketChannel(SocketChannel sChannel) throws IOException {
ByteBuffer buffer = ByteBuffer.allocate(1024);
StringBuilder data = new StringBuilder();
while (true) {
buffer.clear();
int n = sChannel.read(buffer);
if (n == -1) {
break;
}
buffer.flip();
int limit = buffer.limit();
char[] dst = new char[limit];
for (int i = 0; i < limit; i++) {
dst[i] = (char) buffer.get(i);
}
data.append(dst);
buffer.clear();
}
return data.toString();
}
}客户端:
public class NIOClient {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 8888);
OutputStream out = socket.getOutputStream();
String s = "hello world";
out.write(s.getBytes());
out.close();
}
}推荐阅读:一文彻底理解Java IO模型
内存映射文件
内存映射文件 I/O 是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的 I/O 快得多。
向内存映射文件写入可能是危险的,只是改变数组的单个元素这样的简单操作,就可能会直接修改磁盘上的文件。修改数据与将数据保存到磁盘是没有分开的。
下面代码行将文件的前 1024 个字节映射到内存中,map() 方法返回一个 MappedByteBuffer,它是 ByteBuffer 的子类。因此,可以像使用其他任何 ByteBuffer 一样使用新映射的缓冲区,操作系统会在需要时负责执行映射。
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);对比
NIO 与普通 I/O 的区别主要有以下两点:
- NIO 是非阻塞的;
- NIO 面向块,I/O 面向流。
八、参考资料
https://github.com/CyC2018/CS-Notes/
微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本。
花絮
该 PDF 文档是我在学习 CSNotes 时的一些优化和补充,加了很多二哥的 Java 进阶之路上的内容,可以进行很好的互补。整理不易,希望能帮助到大家(❤️)。
最新版更新完成后我会放到网盘中,微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《Java》即可获取最新的 PDF 版本。
附其他干货笔记下载地址:
- 二哥的 Linux 速查备忘手册 PDF 下载
- 阮一峰 C 语言入门教程 PDF 下载
- Java 核心知识点整理 PDF 下载
- 深入浅出 Java 多线程 PDF 下载
- Pro Git 中文版 PDF 下载
- 给操作系统捋条线 PDF 下载
第三章、容器篇
一、概览
容器,也叫集合框架,主要包括 Collection 和 Map,Collection 又细分为 Set、List 和 Queue,Set 不常用,List 也就是列表,Queue 是队列;Map 是键值对集合。
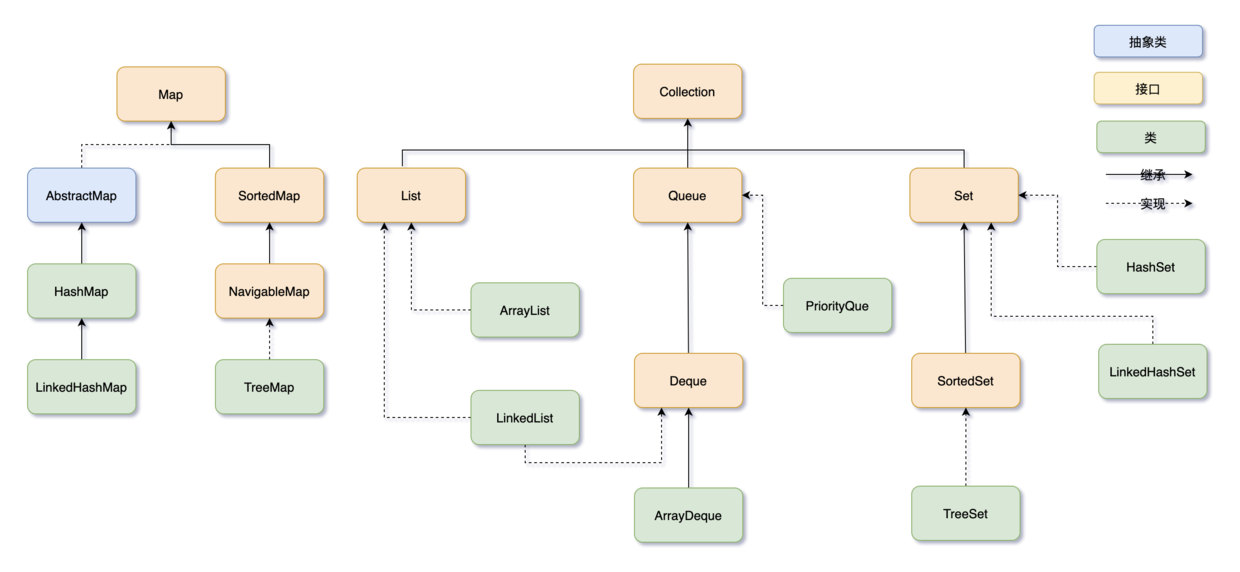
推荐阅读:Java集合框架全面解析
Collection
1. Set
- TreeSet:基于红黑树实现,支持有序操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为
O(1),TreeSet 则为O(logN)。 - HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
- LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
2. List
- ArrayList:基于动态数组实现,支持随机访问。
- Vector:和 ArrayList 类似,但它是线程安全的,几乎已淘汰。
- LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列。
3. Queue
- LinkedList:意不意外,LinkedList 也可以用它来实现双向队列。
- PriorityQueue:基于堆结构实现,可以用它来实现优先级队列。
- ArrayDeque:双端队列,可以用来取代以前的 Stack。
Map
- TreeMap:基于红黑树实现。
- HashMap:基于哈希表实现。
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程同时写入 HashTable 不会导致数据不一致。它是遗留类,已不推荐使用,替代品是 ConcurrentHashMap。
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
二、容器中的设计模式
迭代器模式
Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
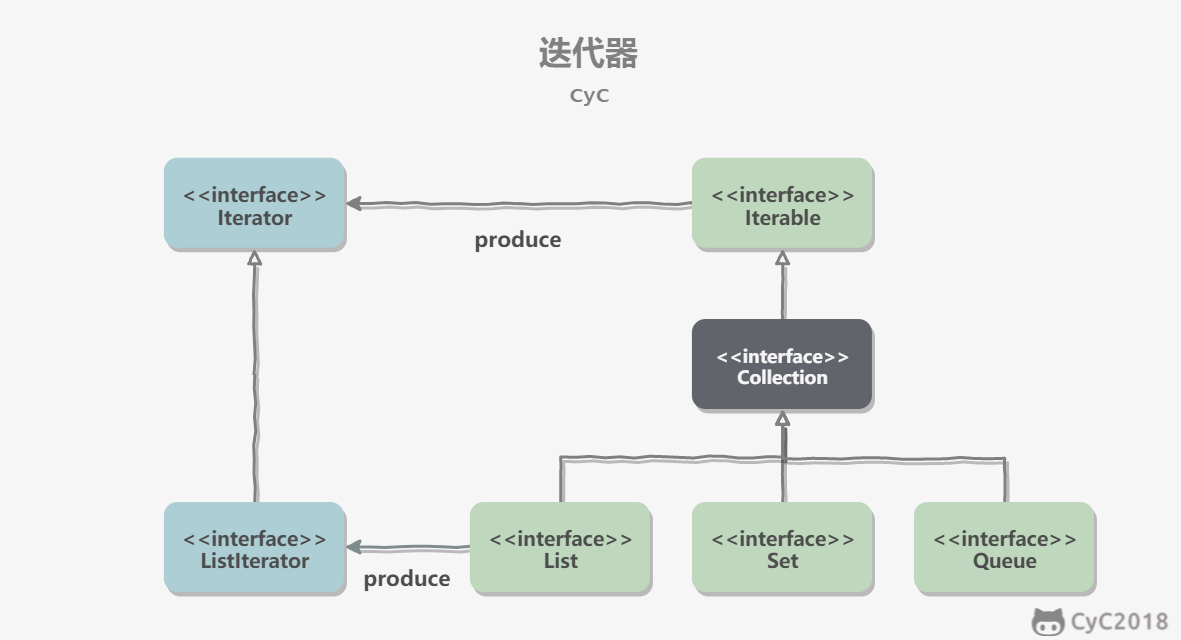
JDK 1.5 之后,可以使用 foreach 来遍历集合,非常方便。
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
for (String item : list) {
System.out.println(item);
}推荐阅读:Java迭代器Iterator和Iterable有什么区别?
适配器模式
java.util.Arrays#asList() 可以把数组类型转换为 List 类型。
@SafeVarargs
public static <T> List<T> asList(T... a)需要注意的是,asList() 的参数为泛型的变长参数,不能使用基本数据类型的数组作为参数,只能使用相应的包装器类型数组。
Integer[] arr = {1, 2, 3};
List list = Arrays.asList(arr);也可以使用以下方式调用 asList():
List list = Arrays.asList(1, 2, 3);微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本。
三、源码分析
如果没有特别说明,以下源码分析均基于 JDK 1.8。
ArrayList
1. 概览
因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识该类支持快速随机访问。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable数组的默认大小为 10。
private static final int DEFAULT_CAPACITY = 10;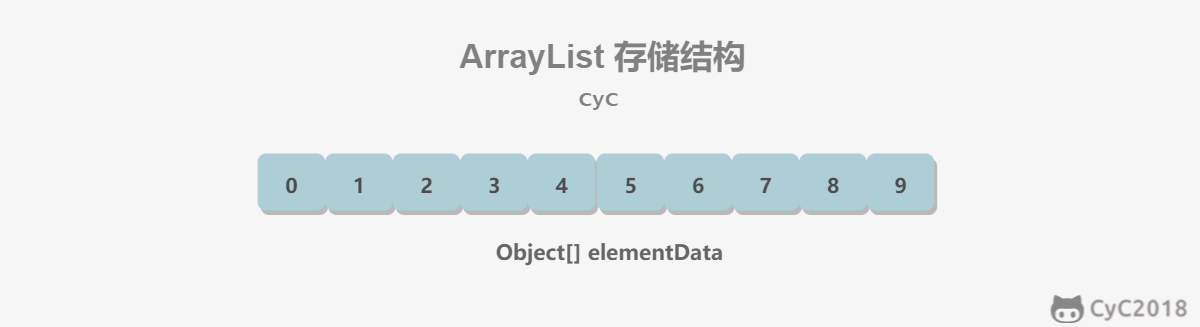
2. 扩容
添加元素时,ensureCapacityInternal() 方法会确认容量是否足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),即 oldCapacity+oldCapacity/2。
其中 oldCapacity >> 1 需要取整,所以新容量大约是旧容量的 1.5 倍左右。(oldCapacity 为偶数就是 1.5 倍,为奇数就是 1.5 倍-0.5)
扩容操作需要调用 Arrays.copyOf() 把原数组复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定恰当的容量大小,以减少扩容操作的次数。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}3. 删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素复制到 index 位置上,该操作的时间复杂度为 O(N),因此 ArrayList 删除元素的代价是非常高的。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}4. 序列化
ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没有必要全部进行序列化。
保存元素的数组 elementData 使用了 transient 关键字修饰,该关键字声明数组默认不会被序列化。
transient Object[] elementData; // non-private to simplify nested class accessArrayList 实现了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充的那部分内容。
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}序列化:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}序列化时需要使用 ObjectOutputStream 的 writeObject() 将对象转换为字节流并输出。而 writeObject() 方法在传入的对象存在 writeObject() 的时候会去反射调用该对象的 writeObject() 来实现序列化。反序列化使用的是 ObjectInputStream 的 readObject() 方法,原理类似。
ArrayList list = new ArrayList();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(list);推荐阅读:深入探讨 Java ArrayList
5. Fail-Fast
modCount 用来记录 ArrayList 结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了需要抛出 ConcurrentModificationException。代码参考上节序列化中的 writeObject() 方法。
推荐阅读:阿里Java开发规约:禁止在foreach里执行元素的删除操作
Vector
1. 同步
Vector 的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}2. 扩容
Vector 的构造方法可以传入 capacityIncrement 参数,它的作用是在扩容时使容量 capacity 增长 capacityIncrement。如果这个参数的值小于等于 0,扩容时每次都令 capacity 为原来的两倍。
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}调用没有 capacityIncrement 的构造函数时,capacityIncrement 值被设置为 0,也就是说默认情况下 Vector 每次扩容时容量都会翻倍。
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector() {
this(10);
}3. 与 ArrayList 的比较
- Vector 是同步的,因此开销比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,实际上 Vector 几乎已经不再使用了。
- Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
4. 替代方案
可以使用 Collections.synchronizedList(); 得到一个线程安全的 ArrayList。
List<String> list = new ArrayList<>();
List<String> synList = Collections.synchronizedList(list);也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
List<String> list = new CopyOnWriteArrayList<>();CopyOnWriteArrayList
1. 读写分离
写操作是在数组的拷贝上进行的,读操作还是在原始数组中进行,读写分离,互不影响。
写操作需要加锁,防止并发写入时数据丢失。写操作结束之后需要把原始数组指向新的复制数组。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}读:
@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
return (E) a[index];
}2. 适用场景
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
但是 CopyOnWriteArrayList 有其缺陷:
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
推荐阅读:吊打Java并发面试官之CopyOnWriteArrayList
LinkedList
1. 概览
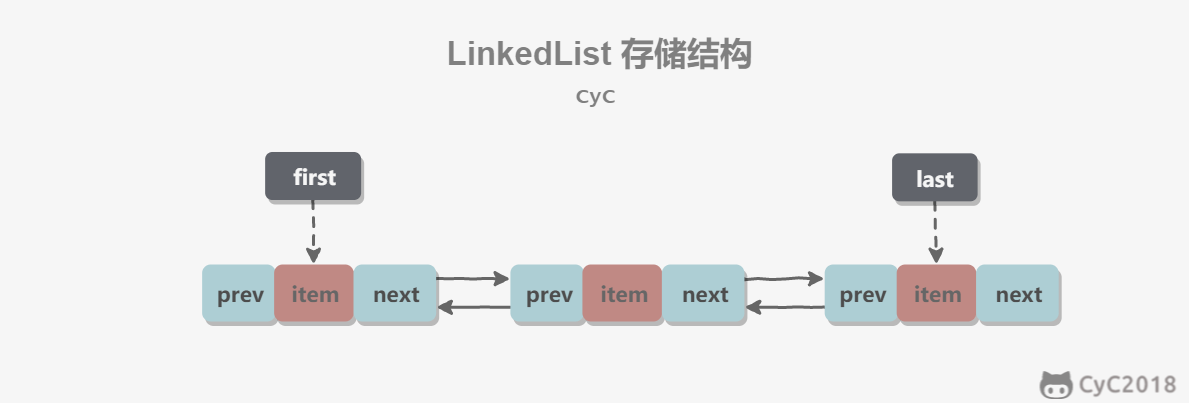
LinkedList 基于双向链表实现,使用 Node 存储链表节点信息。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}每个链表存储了 first 和 last 指针:
transient Node<E> first;
transient Node<E> last;2. 与 ArrayList 的比较
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现。ArrayList 和 LinkedList 的区别可以归结为数组和链表的区别:
- 数组支持随机访问,但插入和删除的代价很高,需要移动大量元素;
- 链表不支持随机访问,但插入删除只需要改变指针。
推荐阅读:深入探讨 Java LinkedList
HashMap
注意,为了便于理解,以下源码分析以 JDK 1.7 为主。
1. 存储结构
HashMap 内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。
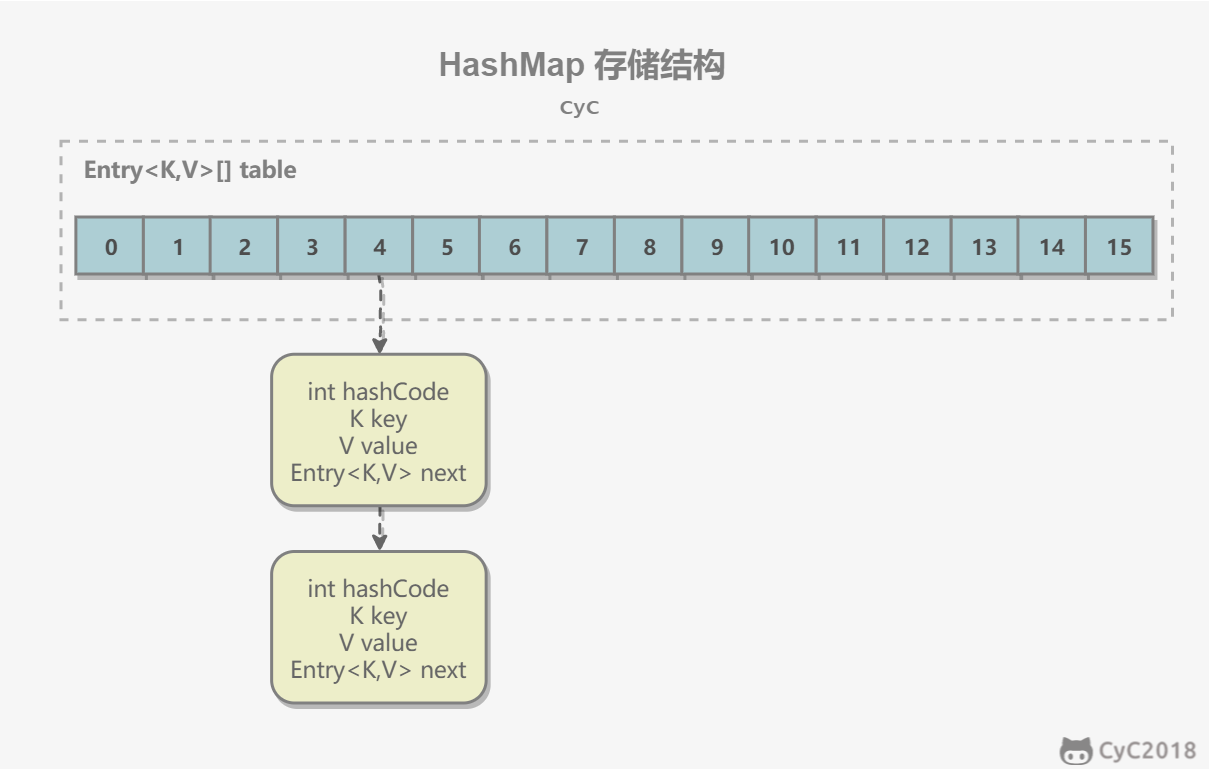
即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和数组长度取模运算结果相同的 Entry。
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}2. 拉链法的工作原理
HashMap<String, String> map = new HashMap<>();
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K3", "V3");- 新建一个 HashMap,默认大小为 16;
- 插入 <K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
- 插入 <K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
- 插入 <K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2> 的前面。
需要注意到,链表的插入是以头插法方式进行的,例如上面的 <K3,V3> 不是插在 <K2,V2> 后面,而是插入在链表头部。
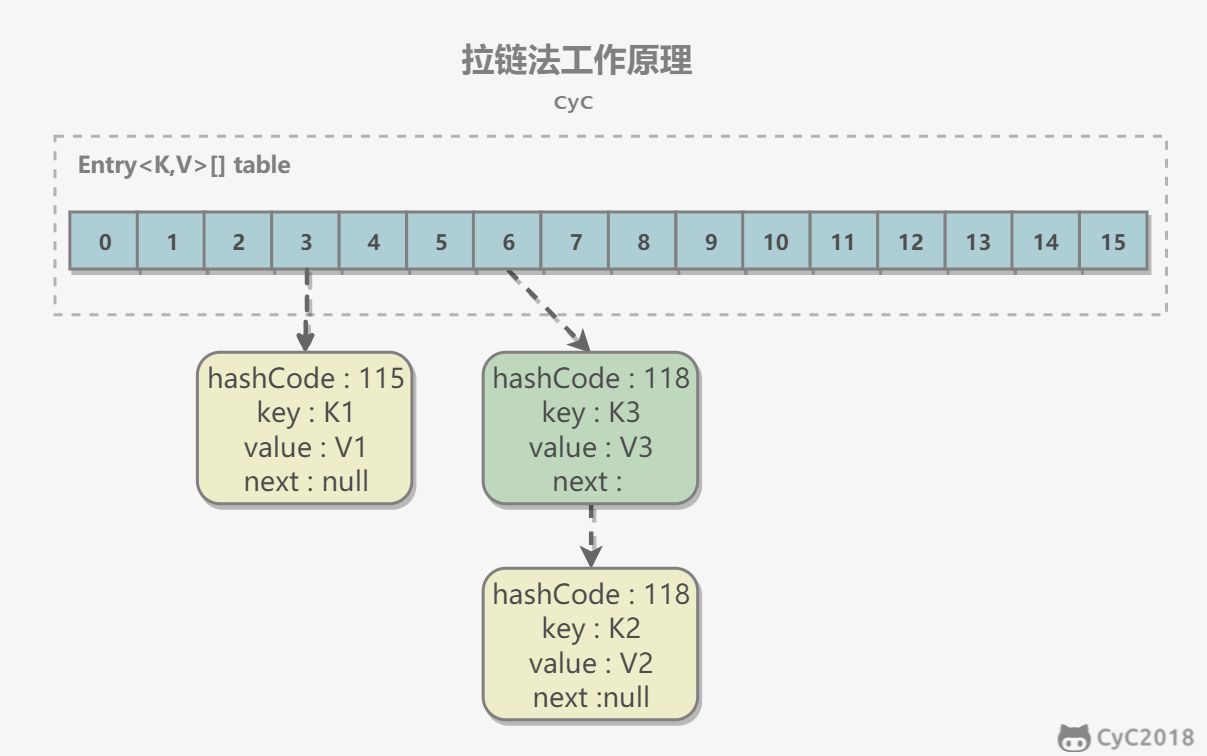
查找需要分成两步进行:
- 计算键值对所在的桶;
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比。
3. put 操作
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 键为 null 单独处理
if (key == null)
return putForNullKey(value);
int hash = hash(key);
// 确定桶下标
int i = indexFor(hash, table.length);
// 先找出是否已经存在键为 key 的键值对,如果存在的话就更新这个键值对的值为 value
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 插入新键值对
addEntry(hash, key, value, i);
return null;
}HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}使用链表的头插法,也就是新的键值对插在链表的头部,而不是链表的尾部。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
// 头插法,链表头部指向新的键值对
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}Entry 的构造方法:
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}4. 确定桶下标
很多操作都需要先确定一个键值对所在的桶下标。
int hash = hash(key);
int i = indexFor(hash, table.length);4.1 计算 hash 值
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}HashMap 的 hash 方法先获取一个 hashSeed,然后对 key 的 hashCode() 进行处理。如果 key 是字符串类型,就调用 sun.misc.Hashing.stringHash32() 方法计算字符串的 hash 值。
来看一下 Ojbect 的 hashCode() 方法:
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}4.2 取模
令 x = 1<<4,即 x 为 2 的 4 次方,它具有以下性质:
x : 00010000
x-1 : 00001111令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:
y : 10110010
x-1 : 00001111
y&(x-1) : 00000010这个性质和 y 对 x 取模效果是一样的:
y : 10110010
x : 00010000
y%x : 00000010我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能。
确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运算。
static int indexFor(int h, int length) {
return h & (length-1);
}5. 扩容-基本原理
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此查找的复杂度为 O(N/M)。
为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。
| 参数 | 含义 |
|---|---|
| capacity | table 的容量大小,默认为 16。需要注意的是 capacity 必须保证为 2 的 n 次方。 |
| size | 键值对数量。 |
| threshold | size 的临界值,当 size 大于等于 threshold 就必须进行扩容操作。 |
| loadFactor | 装载因子,table 能够使用的比例,threshold = (int)(capacity* loadFactor)。 |
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient Entry[] table;
transient int size;
int threshold;
final float loadFactor;
transient int modCount;从下面的添加元素代码中可以看出,当需要扩容时,令 capacity 为原来的两倍。
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}扩容使用 resize() 实现,需要注意的是,扩容操作同样需要把 oldTable 的所有键值对重新插入 newTable 中,因此这一步是很费时的。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}6. 扩容-重新计算桶下标
在进行扩容时,需要把键值对重新计算桶下标,从而放到对应的桶上。在前面提到,HashMap 使用 hash%capacity 来确定桶下标。HashMap capacity 为 2 的 n 次方这一特点能够极大降低重新计算桶下标操作的复杂度。
假设原数组长度 capacity 为 16,扩容之后 new capacity 为 32:
capacity : 00010000
new capacity : 00100000对于一个 Key,它的哈希值 hash 在第 5 位:
- 为 0,那么 hash%00010000 = hash%00100000,桶位置和原来一致;
- 为 1,hash%00010000 = hash%00100000 + 16,桶位置是原位置 + 16。
7. 计算数组容量
HashMap 构造方法允许用户传入的容量不是 2 的 n 次方,因为它可以自动地将传入的容量转换为 2 的 n 次方。
先考虑如何求一个数的掩码,对于 10010000,它的掩码为 11111111,可以使用以下方法得到:
mask |= mask >> 1 11011000
mask |= mask >> 2 11111110
mask |= mask >> 4 11111111mask+1 是大于原始数字的最小的 2 的 n 次方。
num 10010000
mask+1 100000000以下是 HashMap 中计算数组容量的代码:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}8. 链表转红黑树
从 JDK 1.8 开始,一个桶存储的链表长度大于等于 8 时会将链表转换为红黑树。
9. 与 Hashtable 的比较
- Hashtable 使用 synchronized 来进行同步。
- HashMap 可以插入键为 null 的 Entry。
- HashMap 的迭代器是 fail-fast 迭代器。
- HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
推荐阅读:Java HashMap详解
ConcurrentHashMap
1. 存储结构
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}ConcurrentHashMap 和 HashMap 实现上类似,最主要的差别是 ConcurrentHashMap 采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶,从而使其并发度更高(并发度就是 Segment 的个数)。
Segment 继承自 ReentrantLock。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}多个分段锁:
final Segment<K,V>[] segments;默认的并发级别为 16,也就是说默认创建 16 个 Segment。
static final int DEFAULT_CONCURRENCY_LEVEL = 16;2. size 操作
每个 Segment 维护了一个 count 变量来统计该 Segment 中的键值对个数。
/**
* The number of elements. Accessed only either within locks
* or among other volatile reads that maintain visibility.
*/
transient int count;在执行 size 操作时,需要遍历所有 Segment 然后把 count 累计起来。
ConcurrentHashMap 在执行 size 操作时先尝试不加锁,如果连续两次不加锁操作得到的结果一致,那么可以认为这个结果是正确的。
尝试次数使用 RETRIES_BEFORE_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。
如果尝试的次数超过 3 次,就需要对每个 Segment 加锁。
/**
* Number of unsynchronized retries in size and containsValue
* methods before resorting to locking. This is used to avoid
* unbounded retries if tables undergo continuous modification
* which would make it impossible to obtain an accurate result.
*/
static final int RETRIES_BEFORE_LOCK = 2;
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
// 超过尝试次数,则对每个 Segment 加锁
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 连续两次得到的结果一致,则认为这个结果是正确的
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}3. JDK 1.8 的改动
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发度与 Segment 数量相等。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
并且 JDK 1.8 的实现也在链表过长时会转换为红黑树。
推荐阅读:吊打Java并发面试官之ConcurrentHashMap
LinkedHashMap
存储结构
继承自 HashMap,因此具有和 HashMap 一样的快速查找特性。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>内部维护了一个双向链表,用来维护插入顺序或者 LRU 顺序。
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;accessOrder 决定了顺序,默认为 false,此时维护的是插入顺序。
final boolean accessOrder;LinkedHashMap 最重要的是用于维护顺序的方法,它们会在 put、get 等方法中被调用。
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }afterNodeAccess()
当一个节点被访问时,如果 accessOrder 为 true,则会将该节点移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表头部就是最近最久未使用的节点。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}afterNodeInsertion()
在 put 等操作之后执行,当 removeEldestEntry() 方法返回 true 时会移除最晚的节点,也就是链表头部节点 first。
evict 只有在构建 Map 的时候才为 false,在这里为 true。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}removeEldestEntry() 默认为 false,如果需要让它为 true,需要继承 LinkedHashMap 并且覆盖这个方法的实现,这在实现 LRU 的缓存中特别有用,通过移除最近最久未使用的节点,从而保证缓存空间足够,并且缓存的数据都是热点数据。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}LRU 缓存
以下是使用 LinkedHashMap 实现的一个 LRU 缓存:
- 设定最大缓存空间 MAX_ENTRIES 为 3;
- 使用 LinkedHashMap 的构造方法将 accessOrder 设置为 true,开启 LRU 顺序;
- 覆盖
removeEldestEntry()方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private static final int MAX_ENTRIES = 3;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
LRUCache() {
super(MAX_ENTRIES, 0.75f, true);
}
}来测试一下:
public static void main(String[] args) {
LRUCache<Integer, String> cache = new LRUCache<>();
cache.put(1, "a");
cache.put(2, "b");
cache.put(3, "c");
cache.get(1);
cache.put(4, "d");
System.out.println(cache.keySet());
}结果为:
[3, 1, 4]推荐阅读:Java LinkedHashMap详解
WeakHashMap
存储结构
WeakHashMap 的 Entry 继承自 WeakReference,被 WeakReference 关联的对象在下一次垃圾回收时会被回收。
WeakHashMap 主要用来实现缓存,通过使用 WeakHashMap 来引用缓存对象,由 JVM 对这部分缓存进行回收。
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V>推荐阅读:Java WeakHashMap详解(附源码分析)
ConcurrentCache
Tomcat 中的 ConcurrentCache 使用了 WeakHashMap 来实现缓存功能。
ConcurrentCache 采取的是分代缓存:
- 经常使用的对象放入 eden 中,eden 使用 ConcurrentHashMap 实现,不用担心会被回收(伊甸园);
- 不常用的对象放入 longterm,longterm 使用 WeakHashMap 实现,这些老对象会被垃圾收集器回收。
- 当调用
get()方法时,会先从 eden 区获取,如果没有找到的话再到 longterm 获取,当从 longterm 获取到就把对象放入 eden 中,从而保证经常被访问的节点不容易被回收。 - 当调用
put()方法时,如果 eden 的大小超过了 size,那么就将 eden 中的所有对象都放入 longterm 中,利用虚拟机回收掉一部分不经常使用的对象。
public final class ConcurrentCache<K, V> {
private final int size;
private final Map<K, V> eden;
private final Map<K, V> longterm;
public ConcurrentCache(int size) {
this.size = size;
this.eden = new ConcurrentHashMap<>(size);
this.longterm = new WeakHashMap<>(size);
}
public V get(K k) {
V v = this.eden.get(k);
if (v == null) {
v = this.longterm.get(k);
if (v != null)
this.eden.put(k, v);
}
return v;
}
public void put(K k, V v) {
if (this.eden.size() >= size) {
this.longterm.putAll(this.eden);
this.eden.clear();
}
this.eden.put(k, v);
}
}参考资料
https://github.com/CyC2018/CS-Notes/
花絮
该 PDF 文档是我在学习 CSNotes 时的一些优化和补充,加了很多二哥的 Java 进阶之路上的内容,可以进行很好的互补。整理不易,希望能帮助到大家(❤️)。
最新版更新完成后我会放到网盘中,微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《Java》即可获取最新的 PDF 版本。
附其他干货笔记下载地址:
- 二哥的 Linux 速查备忘手册 PDF 下载
- 阮一峰 C 语言入门教程 PDF 下载
- Java 核心知识点整理 PDF 下载
- 深入浅出 Java 多线程 PDF 下载
- Pro Git 中文版 PDF 下载
- 给操作系统捋条线 PDF 下载
第四章、并发篇
一、使用线程
有三种使用线程的方法:
- 实现 Runnable 接口;
- 实现 Callable 接口;
- 继承 Thread 类。
实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。可以理解为任务是通过线程驱动执行的。
实现 Runnable 接口
需要实现接口中的 run() 方法。
public class MyRunnable implements Runnable {
@Override
public void run() {
// ...
}
}使用 Runnable 实例再创建一个 Thread 实例,然后调用 Thread 实例的 start() 方法来启动线程。
public static void main(String[] args) {
MyRunnable instance = new MyRunnable();
Thread thread = new Thread(instance);
thread.start();
}实现 Callable 接口
与 Runnable 相比,Callable 可以有返回值,返回值通过 FutureTask 进行封装。
public class MyCallable implements Callable<Integer> {
public Integer call() {
return 123;
}
}来看测试类:
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyCallable mc = new MyCallable();
FutureTask<Integer> ft = new FutureTask<>(mc);
Thread thread = new Thread(ft);
thread.start();
System.out.println(ft.get());
}继承 Thread 类
同样也是需要实现 run() 方法,因为 Thread 类也实现了 Runable 接口。
当调用 start() 方法启动一个线程时,虚拟机会将该线程放入就绪队列中等待被调度,当一个线程被调度时会执行该线程的 run() 方法。
public class MyThread extends Thread {
public void run() {
// ...
}
}启动线程类:
public static void main(String[] args) {
MyThread mt = new MyThread();
mt.start();
}实现接口 VS 继承 Thread
实现接口会更好一些,因为:
- Java 不支持多重继承,因此继承了 Thread 类就无法继承其它类,但是可以实现多个接口;
- 类可能只需要可执行就行,继承整个 Thread 类开销过大。
二、基础线程机制
Executor
Executor 用来管理多个异步任务的执行,这里的异步是指多个任务的执行互不干扰,不需要进行同步操作。
主要有三种 Executor:
- CachedThreadPool:一个任务创建一个线程;
- FixedThreadPool:所有任务只能使用固定大小的线程;
- SingleThreadExecutor:相当于大小为 1 的 FixedThreadPool。
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
executorService.execute(new MyRunnable());
}
executorService.shutdown();
}Daemon
守护线程是程序运行时在后台提供服务的线程,不属于程序中不可或缺的部分。
当所有非守护线程结束时,程序也就终止,同时会杀死所有守护线程。
main() 属于非守护线程。
在线程启动之前使用 setDaemon() 方法可以将一个线程设置为守护线程。
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.setDaemon(true);
}sleep()
Thread.sleep(millisec) 方法会休眠当前正在执行的线程,millisec 单位为毫秒。
sleep() 可能会抛出 InterruptedException,因为异常不能跨线程传播回 main() 中,因此必须在本地进行处理。线程中抛出的其它异常也同样需要在本地进行处理。
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}yield()
调用静态方法 Thread.yield() 意味着当前线程已经走完了生命周期中最重要的阶段,可以切换给其它线程来执行了。该方法只是对线程调度器提供一个建议,而且也只是建议具有相同优先级的其它线程可以运行。
public void run() {
Thread.yield();
}三、中断
一个线程执行完毕之后会自动结束,如果在运行过程中发生异常也会提前结束。
InterruptedException
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
对于以下代码,在 main() 中启动一个线程之后再中断它,由于线程中调用了 Thread.sleep() 方法,因此会抛出一个 InterruptedException,从而提前结束线程,不执行之后的语句。
public class InterruptExample {
private static class MyThread1 extends Thread {
@Override
public void run() {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}执行 main 方法:
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new MyThread1();
thread1.start();
thread1.interrupt();
System.out.println("Main run");
}执行结果:
Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at InterruptExample.lambda$main$0(InterruptExample.java:5)
at InterruptExample$$Lambda$1/713338599.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)interrupted()
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
但是调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true。因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程。
public class InterruptExample {
private static class MyThread2 extends Thread {
@Override
public void run() {
while (!interrupted()) {
// ..
}
System.out.println("Thread end");
}
}
}执行 main 方法:
public static void main(String[] args) throws InterruptedException {
Thread thread2 = new MyThread2();
thread2.start();
thread2.interrupt();
}输出结果:
Thread endExecutor 的中断操作
调用 Executor 的 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用了每个线程的 interrupt() 方法。
以下使用 Lambda 创建线程,相当于创建了一个匿名内部线程。
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.shutdownNow();
System.out.println("Main run");
}测试结果:
Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at ExecutorInterruptExample.lambda$main$0(ExecutorInterruptExample.java:9)
at ExecutorInterruptExample$$Lambda$1/1160460865.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)如果只想中断 Executor 中的一个线程,可以通过使用 submit() 方法来提交一个线程,它会返回一个 Future<?> 对象,通过调用该对象的 cancel(true) 方法就可以中断线程。
Future<?> future = executorService.submit(() -> {
// ..
});
future.cancel(true);四、互斥同步
Java 提供了两种锁机制来控制多个线程对共享资源的互斥访问,第一个是 JVM 实现的 synchronized,另一个是 JDK 实现的 ReentrantLock。
synchronized
1. 同步一个代码块
public void func() {
synchronized (this) {
// ...
}
}它只作用于同一个对象,如果调用两个对象上的同步代码块,就不会进行同步。
对于以下代码,使用 ExecutorService 执行了两个线程,由于调用的是同一个对象的同步代码块,因此这两个线程会进行同步,当一个线程进入同步语句块时,另一个线程就必须等待。
public class SynchronizedExample {
public void func1() {
synchronized (this) {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
}
}
}执行 main 方法:
public static void main(String[] args) {
SynchronizedExample e1 = new SynchronizedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> e1.func1());
executorService.execute(() -> e1.func1());
}输出结果:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9对于以下代码,两个线程调用了不同对象的同步代码块,因此这两个线程就不需要同步。从输出结果可以看出,两个线程交叉执行。
public static void main(String[] args) {
SynchronizedExample e1 = new SynchronizedExample();
SynchronizedExample e2 = new SynchronizedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> e1.func1());
executorService.execute(() -> e2.func1());
}输出结果:
0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 92. 同步一个方法
public synchronized void func () {
// ...
}它和同步代码块一样,作用于同一个对象。
3. 同步一个类
public void func() {
synchronized (SynchronizedExample.class) {
// ...
}
}作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
public class SynchronizedExample {
public void func2() {
synchronized (SynchronizedExample.class) {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
}
}
}执行 main 方法:
public static void main(String[] args) {
SynchronizedExample e1 = new SynchronizedExample();
SynchronizedExample e2 = new SynchronizedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> e1.func2());
executorService.execute(() -> e2.func2());
}输出结果:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 94. 同步一个静态方法
public synchronized static void fun() {
// ...
}作用于整个类。
ReentrantLock
ReentrantLock 是 java.util.concurrent(J.U.C)包中的锁。
public class LockExample {
private Lock lock = new ReentrantLock();
public void func() {
lock.lock();
try {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
} finally {
lock.unlock(); // 确保释放锁,从而避免发生死锁。
}
}
}执行 main 方法:
public static void main(String[] args) {
LockExample lockExample = new LockExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> lockExample.func());
executorService.execute(() -> lockExample.func());
}输出结果:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9推荐阅读:ReentrantLock 源码分析
比较
1. 锁的实现
synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
2. 性能
新版本 Java 对 synchronized 进行了很多优化,例如自旋锁,synchronized 与 ReentrantLock 的性能大致相同。
3. 等待可中断
当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
ReentrantLock 可中断,而 synchronized 不行。
4. 公平锁
公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
5. 锁绑定多个条件
一个 ReentrantLock 可以同时绑定多个 Condition 对象。
使用选择
除非需要使用 ReentrantLock 的高级功能,否则优先使用 synchronized。这是因为 synchronized 是 JVM 实现的一种锁机制,不需要手动释放锁,而 ReentrantLock 是 JDK 实现的,需要手动释放锁🔒。
意味着 synchronized 是自动的智能锁,而 ReentrantLock 还是手工上锁和解锁的,如果没有及时释放锁,那么就可能造成死锁。
五、线程之间的协作
当多个线程可以一起工作去解决某个问题时,如果某些部分必须在其它部分之前完成,那么就需要对线程进行协调。
join()
在线程中调用另一个线程的 join() 方法,会将当前线程挂起,直到目标线程结束。
对于以下代码,虽然 b 线程先启动,但是因为在 b 线程中调用了 a 线程的 join() 方法,b 线程会等待 a 线程结束才继续执行,因此最后能够保证 a 线程的输出先于 b 线程的输出。
public class JoinExample {
private class A extends Thread {
@Override
public void run() {
System.out.println("A");
}
}
private class B extends Thread {
private A a;
B(A a) {
this.a = a;
}
@Override
public void run() {
try {
a.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("B");
}
}
public void test() {
A a = new A();
B b = new B(a);
b.start();
a.start();
}
}执行 main 方法:
public static void main(String[] args) {
JoinExample example = new JoinExample();
example.test();
}输出结果:
A
Bwait() notify() notifyAll()
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。
它们都属于 Object 的一部分,而不属于 Thread。
只能在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateException。
使用 wait() 挂起期间,线程会释放锁。这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。
public class WaitNotifyExample {
public synchronized void before() {
System.out.println("before");
notifyAll();
}
public synchronized void after() {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("after");
}
}执行 main 方法:
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
WaitNotifyExample example = new WaitNotifyExample();
executorService.execute(() -> example.after());
executorService.execute(() -> example.before());
}输出结果:
before
afterwait() 和 sleep() 的区别
wait()是 Object 的方法,而sleep()是 Thread 的静态方法;wait()会释放锁,sleep()不会。
await() signal() signalAll()
java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。
相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
使用 Lock 来获取一个 Condition 对象。
public class AwaitSignalExample {
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void before() {
lock.lock();
try {
System.out.println("before");
condition.signalAll();
} finally {
lock.unlock();
}
}
public void after() {
lock.lock();
try {
condition.await();
System.out.println("after");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}执行 main 方法:
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
AwaitSignalExample example = new AwaitSignalExample();
executorService.execute(() -> example.after());
executorService.execute(() -> example.before());
}输出结果:
before
after微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本。
六、线程状态
一个线程只能处于一种状态,并且这里的线程状态特指 Java 虚拟机的线程状态,不能反映线程在特定操作系统下的状态。
新建(NEW)
创建后尚未启动。
可运行(RUNABLE)
正在 Java 虚拟机中运行。但是在操作系统层面,它可能处于运行状态,也可能等待资源调度(例如处理器资源),资源调度完成就进入运行状态。所以该状态的可运行是指可以被运行,具体有没有运行要看底层操作系统的资源调度。
阻塞(BLOCKED)
请求获取 monitor lock 从而进入 synchronized 方法或者代码块,但是其它线程已经占用了该 monitor lock,所以处于阻塞状态。要结束该状态进入 RUNABLE 需要其他线程释放 monitor lock。
无限期等待(WAITING)
等待其它线程显式地唤醒。
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取 monitor lock。而等待是主动的,通过调用 Object.wait() 等方法进入。
| 进入方法 | 退出方法 |
|---|---|
| 没有设置 Timeout 参数的 Object.wait() 方法 | Object.notify() / Object.notifyAll() |
没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
LockSupport.park() 方法 | LockSupport.unpark(Thread) |
限期等待(TIMED_WAITING)
无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
| 进入方法 | 退出方法 |
|---|---|
| Thread.sleep() 方法 | 时间结束 |
| 设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
| 设置了 Timeout 参数的 Thread.join() 方法 | 时间结束 / 被调用的线程执行完毕 |
| LockSupport.parkNanos() 方法 | LockSupport.unpark(Thread) |
| LockSupport.parkUntil() 方法 | LockSupport.unpark(Thread) |
调用 Thread.sleep() 方法使线程进入限期等待状态时,常常用“使一个线程睡眠”进行描述。调用 Object.wait() 方法使线程进入限期等待或者无限期等待时,常常用“挂起一个线程”进行描述。睡眠和挂起是用来描述行为,而阻塞和等待用来描述状态。
死亡(TERMINATED)
可以是线程结束任务之后自己结束,或者产生了异常而结束。
推荐阅读:
七、J.U.C - AQS
java.util.concurrent(J.U.C)大大提高了并发性能,AQS 被认为是 J.U.C 的核心。
CountDownLatch
CountDownLatch用来控制一个或者多个线程等待多个线程。
维护了一个计数器 cnt,每次调用 countDown() 方法会让计数器的值减 1,减到 0 的时候,那些因为调用 await() 方法而在等待的线程就会被唤醒。
public class CountdownLatchExample {
public static void main(String[] args) throws InterruptedException {
final int totalThread = 10;
CountDownLatch countDownLatch = new CountDownLatch(totalThread);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < totalThread; i++) {
executorService.execute(() -> {
System.out.print("run..");
countDownLatch.countDown();
});
}
countDownLatch.await();
System.out.println("end");
executorService.shutdown();
}
}输出结果:
run..run..run..run..run..run..run..run..run..run..endCyclicBarrier
CyclicBarrier用来控制多个线程互相等待,只有当多个线程都到达时,这些线程才会继续执行。
和 CountdownLatch 相似,都是通过维护计数器来实现的。线程执行 await() 方法之后计数器会减 1,并进行等待,直到计数器为 0,所有调用 await() 方法而在等待的线程才能继续执行。
CyclicBarrier 和 CountdownLatch 的一个区别是,CyclicBarrier 的计数器通过调用 reset() 方法可以循环使用,所以它才叫做循环屏障。
CyclicBarrier 有两个构造方法,其中 parties 指示计数器的初始值,barrierAction 在所有线程都到达屏障的时候会执行一次。
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties;
this.barrierCommand = barrierAction;
}
public CyclicBarrier(int parties) {
this(parties, null);
}
public class CyclicBarrierExample {
public static void main(String[] args) {
final int totalThread = 10;
CyclicBarrier cyclicBarrier = new CyclicBarrier(totalThread);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < totalThread; i++) {
executorService.execute(() -> {
System.out.print("before..");
try {
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
System.out.print("after..");
});
}
executorService.shutdown();
}
}输出结果:
before..before..before..before..before..before..before..before..before..before..after..after..after..after..after..after..after..after..after..after..Semaphore
Semaphore 类似于操作系统中的信号量,可以控制对互斥资源的访问线程数。
以下代码模拟了对某个服务的并发请求,每次只能有 3 个客户端同时访问,请求总数为 10。
public class SemaphoreExample {
public static void main(String[] args) {
final int clientCount = 3;
final int totalRequestCount = 10;
Semaphore semaphore = new Semaphore(clientCount);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < totalRequestCount; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
System.out.print(semaphore.availablePermits() + " ");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
});
}
executorService.shutdown();
}
}输出结果:
2 1 2 2 2 2 2 1 2 2推荐阅读:Java并发编程通信工具类
八、J.U.C - 其它组件
FutureTask
在介绍 Callable 时我们知道它可以有返回值,返回值通过 Future<V> 进行封装。FutureTask 实现了 RunnableFuture 接口,该接口继承自 Runnable 和 Future<V> 接口,这使得 FutureTask 既可以当做一个任务执行,也可以有返回值。
public class FutureTask<V> implements RunnableFuture<V>RunnableFuture:
public interface RunnableFuture<V> extends Runnable, Future<V>FutureTask 可用于异步获取执行结果或取消执行任务的场景。当一个计算任务需要执行很长时间,那么就可以用 FutureTask 来封装这个任务,主线程在完成自己的任务之后再去获取结果。
public class FutureTaskExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> futureTask = new FutureTask<Integer>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int result = 0;
for (int i = 0; i < 100; i++) {
Thread.sleep(10);
result += i;
}
return result;
}
});
Thread computeThread = new Thread(futureTask);
computeThread.start();
Thread otherThread = new Thread(() -> {
System.out.println("other task is running...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
otherThread.start();
System.out.println(futureTask.get());
}
}输出结果:
other task is running...
4950推荐阅读:获取 Java 线程执行结果
BlockingQueue
java.util.concurrent.BlockingQueue 接口有以下阻塞队列的实现:
- FIFO 队列 :LinkedBlockingQueue、ArrayBlockingQueue(固定长度)
- 优先级队列 :PriorityBlockingQueue
提供了阻塞的 take() 和 put() 方法:如果队列为空 take() 将阻塞,直到队列中有内容;如果队列为满 put() 将阻塞,直到队列有空闲位置。
使用 BlockingQueue 实现生产者消费者问题
public class ProducerConsumer {
private static BlockingQueue<String> queue = new ArrayBlockingQueue<>(5);
private static class Producer extends Thread {
@Override
public void run() {
try {
queue.put("product");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.print("produce..");
}
}
private static class Consumer extends Thread {
@Override
public void run() {
try {
String product = queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.print("consume..");
}
}
}执行 main 方法:
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
Producer producer = new Producer();
producer.start();
}
for (int i = 0; i < 5; i++) {
Consumer consumer = new Consumer();
consumer.start();
}
for (int i = 0; i < 3; i++) {
Producer producer = new Producer();
producer.start();
}
}输出结果:
produce..produce..consume..consume..produce..consume..produce..consume..produce..consume..推荐阅读:吊打Java面试官之阻塞队列BlockingQueue
ForkJoin
主要用于并行计算中,和 MapReduce 原理类似,都是把大的计算任务拆分成多个小任务并行计算。
public class ForkJoinExample extends RecursiveTask<Integer> {
private final int threshold = 5;
private int first;
private int last;
public ForkJoinExample(int first, int last) {
this.first = first;
this.last = last;
}
@Override
protected Integer compute() {
int result = 0;
if (last - first <= threshold) {
// 任务足够小则直接计算
for (int i = first; i <= last; i++) {
result += i;
}
} else {
// 拆分成小任务
int middle = first + (last - first) / 2;
ForkJoinExample leftTask = new ForkJoinExample(first, middle);
ForkJoinExample rightTask = new ForkJoinExample(middle + 1, last);
leftTask.fork();
rightTask.fork();
result = leftTask.join() + rightTask.join();
}
return result;
}
}执行 main 方法:
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinExample example = new ForkJoinExample(1, 10000);
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future result = forkJoinPool.submit(example);
System.out.println(result.get());
}ForkJoin 使用 ForkJoinPool 来启动,它是一个特殊的线程池,线程数量取决于 CPU 核数。
public class ForkJoinPool extends AbstractExecutorServiceForkJoinPool 实现了工作窃取算法来提高 CPU 的利用率。
每个线程都维护了一个双端队列,用来存储需要执行的任务。工作窃取算法允许空闲的线程从其它线程的双端队列中窃取一个任务来执行。窃取的任务必须是最晚的任务,避免和队列所属线程发生竞争。
例如下图中,Thread2 从 Thread1 的队列中拿出最晚的 Task1 任务,Thread1 会拿出 Task2 来执行,这样就避免发生竞争。但是如果队列中只有一个任务时还是会发生竞争。
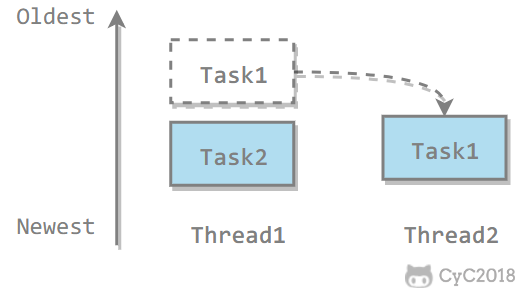
九、线程不安全示例
如果多个线程对同一个共享数据进行访问而不采取同步操作的话,那么操作的结果会不一致。
以下代码演示了 1000 个线程同时对 cnt 执行自增操作,操作结束之后它的值有可能小于 1000。
public class ThreadUnsafeExample {
private int cnt = 0;
public void add() {
cnt++;
}
public int get() {
return cnt;
}
}执行 main 方法:
public static void main(String[] args) throws InterruptedException {
final int threadSize = 1000;
ThreadUnsafeExample example = new ThreadUnsafeExample();
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < threadSize; i++) {
executorService.execute(() -> {
example.add();
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println(example.get());
}输出结果:
997微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本。
十、Java 内存模型
Java 内存模型试图屏蔽各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。
主内存与工作内存
处理器上的寄存器读写速度比内存快几个数量级,为了解决这种速度矛盾,在它们之间加入了高速缓存。
加入高速缓存带来了一个新的问题:缓存一致性。如果多个缓存共享同一块主内存区域,那么多个缓存的数据可能会不一致,需要一些协议来解决这个问题。
所有的变量都存储在主内存中,每个线程还有自己的工作内存,工作内存存储在高速缓存或者寄存器中,保存了该线程使用的变量的主内存副本拷贝。
线程只能操作工作内存中的变量,不同线程之间的变量值传递需要通过主内存来完成。
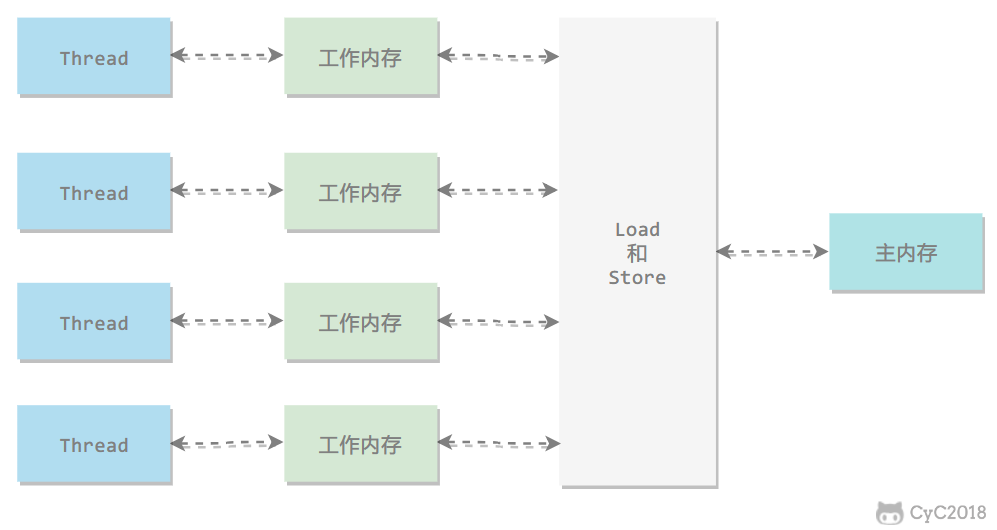
内存间交互操作
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作。
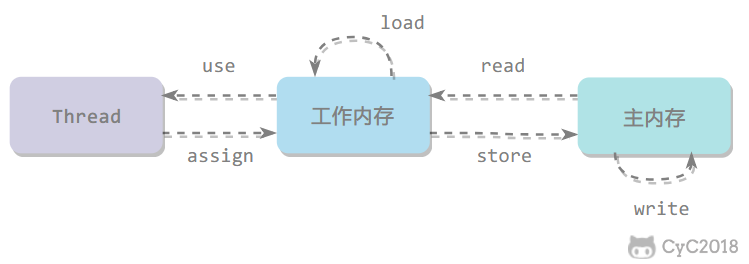
- read:把一个变量的值从主内存传输到工作内存中
- load:在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
- use:把工作内存中一个变量的值传递给执行引擎
- assign:把一个从执行引擎接收到的值赋给工作内存的变量
- store:把工作内存的一个变量的值传送到主内存中
- write:在 store 之后执行,把 store 得到的值放入主内存的变量中
- lock:作用于主内存的变量
内存模型三大特性
1. 原子性
Java 内存模型保证了 read、load、use、assign、store、write、lock 和 unlock 操作具有原子性。
例如对一个 int 类型的变量执行 assign 赋值操作,这个操作就是原子性的。
但是 Java 内存模型允许虚拟机将没有被 volatile 修饰的 64 位数据(long,double)的读写操作划分为两次 32 位的操作来进行,即 load、store、read 和 write 操作可以不具备原子性。
有一个错误认识就是,int 等原子性的类型在多线程环境中不会出现线程安全问题。前面的线程不安全示例代码中,cnt 属于 int 类型变量,1000 个线程对它进行自增操作之后,得到的值为 997 而不是 1000。
为了方便讨论,将内存间的交互操作简化为 3 个:load、assign、store。
下图演示了两个线程同时对 cnt 进行操作,load、assign、store 这一系列操作整体上看不具备原子性,那么在 T1 修改 cnt 并且还没有将修改后的值写入主内存,T2 依然可以读入旧值。
可以看出,这两个线程虽然执行了两次自增运算,但是主内存中 cnt 的值最后为 1 而不是 2。因此对 int 类型读写操作满足原子性只是说明 load、assign、store 这些单个操作具备原子性。
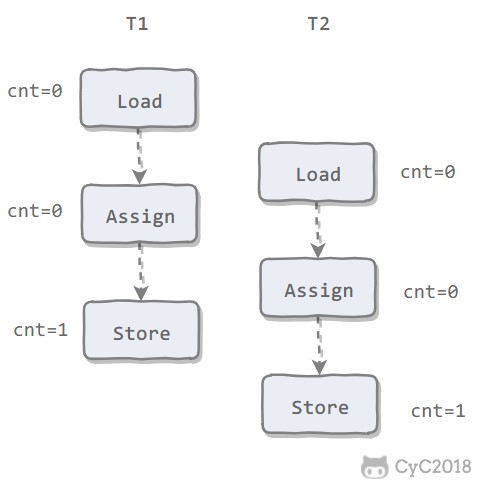
AtomicInteger 能保证多个线程修改的原子性。
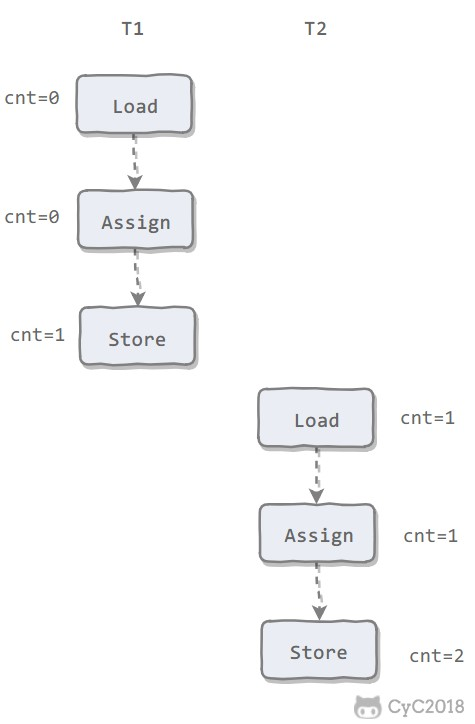
使用 AtomicInteger 重写之前线程不安全的代码:
public class AtomicExample {
private AtomicInteger cnt = new AtomicInteger();
public void add() {
cnt.incrementAndGet();
}
public int get() {
return cnt.get();
}
}执行 main 方法:
public static void main(String[] args) throws InterruptedException {
final int threadSize = 1000;
AtomicExample example = new AtomicExample(); // 只修改这条语句
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < threadSize; i++) {
executorService.execute(() -> {
example.add();
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println(example.get());
}输出结果:
1000除了使用原子类之外,也可以使用 synchronized 互斥锁来保证操作的原子性。它对应的内存间交互操作为:lock 和 unlock,在虚拟机实现上对应的字节码指令为 monitorenter 和 monitorexit。
public class AtomicSynchronizedExample {
private int cnt = 0;
public synchronized void add() {
cnt++;
}
public synchronized int get() {
return cnt;
}
}执行 main 方法:
public static void main(String[] args) throws InterruptedException {
final int threadSize = 1000;
AtomicSynchronizedExample example = new AtomicSynchronizedExample();
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < threadSize; i++) {
executorService.execute(() -> {
example.add();
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println(example.get());
}输出结果:
10002. 可见性
可见性指当一个线程修改了共享变量的值,其它线程能够立即得知这个修改。Java 内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值来实现可见性的。
主要有三种实现可见性的方式:
- volatile
- synchronized,对一个变量执行 unlock 操作之前,必须把变量值同步回主内存。
- final,被 final 关键字修饰的字段在构造方法中一旦初始化完成,并且没有发生 this 逃逸(其它线程通过 this 引用访问到初始化了一半的对象),那么其它线程就能看见 final 字段的值。
对前面的线程不安全示例中的 cnt 变量使用 volatile 修饰,不能解决线程不安全问题,因为 volatile 并不能保证操作的原子性。
3. 有序性
有序性是指:在本线程内观察,所有操作都是有序的。在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序。
在 Java 内存模型中,允许编译器和处理器对指令进行重排序,重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
volatile 关键字通过添加内存屏障的方式来禁止指令重排,即重排序时不能把后面的指令放到内存屏障之前。
也可以通过 synchronized 来保证有序性,它保证每个时刻只有一个线程执行同步代码,相当于是让线程顺序执行同步代码。
先行发生原则
上面提到了可以用 volatile 和 synchronized 来保证有序性。除此之外,JVM 还规定了先行发生原则,让一个操作无需控制就能先于另一个操作完成。
1. 单一线程原则
Single Thread rule
在一个线程内,在程序前面的操作先行发生于后面的操作。
2. 管程锁定规则
Monitor Lock Rule
一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
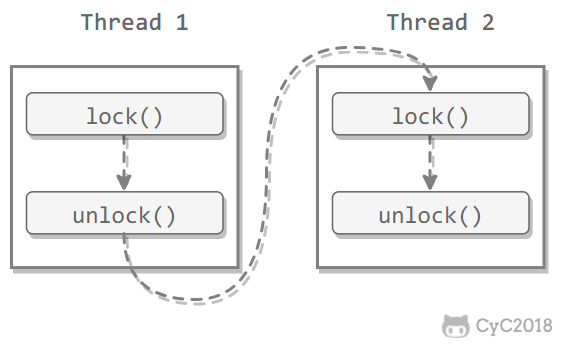
3. volatile 变量规则
Volatile Variable Rule
对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。
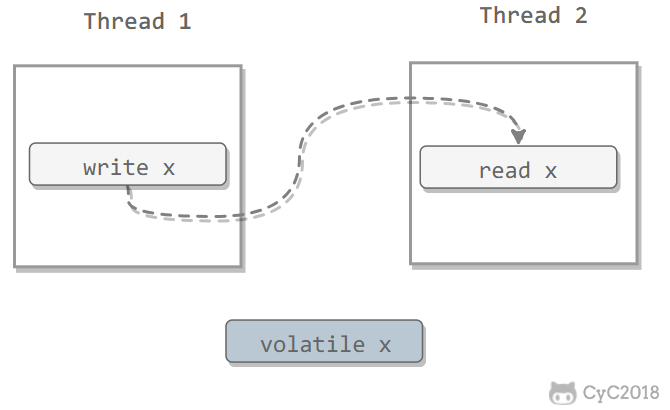
4. 线程启动规则
Thread Start Rule
Thread 对象的 start() 方法调用先行发生于此线程的每一个动作。
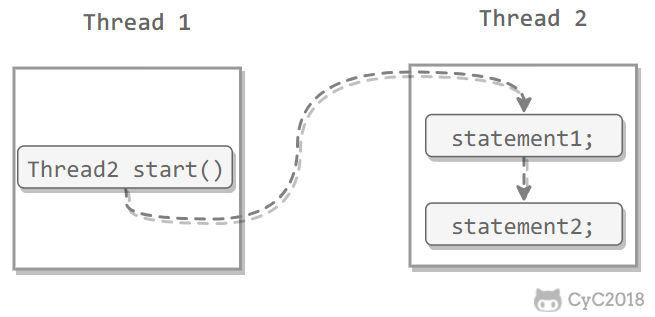
5. 线程加入规则
Thread Join Rule
Thread 对象的结束先行发生于 join() 方法返回。
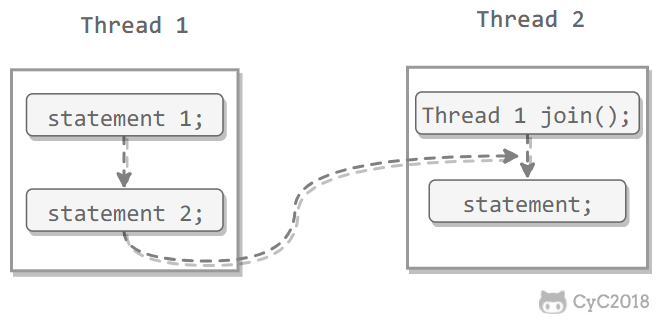
6. 线程中断规则
Thread Interruption Rule
对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 interrupted() 方法检测到是否有中断发生。
7. 对象终结规则
Finalizer Rule
一个对象的初始化完成(构造方法执行结束)先行发生于它的 finalize() 方法的开始。
8. 传递性
Transitivity
如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。
推荐阅读:说说Java的内存模型(JMM)
十一、线程安全
多个线程不管以何种方式访问某个类,并且在主调代码中不需要任何额外的同步或协调,这个类都能表现出正确的行为,那么就称这个类是线程安全的。
主调代码就是在应用程序中使用线程安全类的代码。例如,一个Java应用程序中,创建线程安全类的实例并调用其方法的代码段。主调代码不需要显式地使用同步块或其他并发控制机制来确保线程安全。
线程安全有以下几种实现方式:
不可变
不可变(Immutable)的对象一定是线程安全的,不需要再采取任何的线程安全保障措施。只要一个不可变的对象被正确地构建出来,永远也不会看到它在多个线程之中处于不一致的状态。多线程环境下,应当尽量使对象成为不可变,来满足线程安全。
不可变的类型:
- final 关键字修饰的基本数据类型
- String
- 枚举类型
- Number 部分子类,如 Long 和 Double 等数值包装类型,BigInteger 和 BigDecimal 等大数据类型。但同为 Number 的原子类 AtomicInteger 和 AtomicLong 则是可变的。
对于集合类型,可以使用 Collections.unmodifiableXXX() 方法来获取一个不可变的集合。
public class ImmutableExample {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
Map<String, Integer> unmodifiableMap = Collections.unmodifiableMap(map);
unmodifiableMap.put("a", 1);
}
}输出结果:
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.Collections$UnmodifiableMap.put(Collections.java:1457)
at ImmutableExample.main(ImmutableExample.java:9)Collections.unmodifiableXXX() 先对原始的集合进行拷贝,需要对集合进行修改的方法都直接抛出异常。
public V put(K key, V value) {
throw new UnsupportedOperationException();
}互斥同步
synchronized 和 ReentrantLock。
非阻塞同步
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略:先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
1. CAS
乐观锁需要操作、冲突检测这两个步骤具备原子性,这里就不能再使用互斥同步来保证了,只能靠硬件来完成。
硬件支持的原子性操作最典型的是:比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个操作数,分别是内存地址 V、旧的预期值 A 和新值 B。当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
推荐阅读:一文彻底搞清楚Java实现CAS的原理
2. AtomicInteger
J.U.C 包里面的整数原子类 AtomicInteger 的方法调用了 Unsafe 类的 CAS 操作。
以下代码使用了 AtomicInteger 执行了自增的操作。
private AtomicInteger cnt = new AtomicInteger();
public void add() {
cnt.incrementAndGet();
}以下代码是 incrementAndGet() 的源码,它调用了 Unsafe 的 getAndAddInt() 。
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}以下代码是 getAndAddInt() 源码,var1 指示对象内存地址,var2 指示该字段相对对象内存地址的偏移,var4 指示操作需要加的数值,这里为 1。
通过 getIntVolatile(var1, var2) 得到旧的预期值,通过调用 compareAndSwapInt() 来进行 CAS 比较,如果该字段内存地址中的值等于 var5,那么就更新内存地址为 var1+var2 的变量为 var5+var4。
可以看到 getAndAddInt() 在一个循环中进行,发生冲突的做法是不断的进行重试。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}3. ABA
如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过。
J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference 来解决这个问题,它可以通过控制变量值的版本来保证 CAS 的正确性。大部分情况下 ABA 问题不会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
无同步方案
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。
1. 栈封闭
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
public class StackClosedExample {
public void add100() {
int cnt = 0;
for (int i = 0; i < 100; i++) {
cnt++;
}
System.out.println(cnt);
}
}执行 main 方法:
public static void main(String[] args) {
StackClosedExample example = new StackClosedExample();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> example.add100());
executorService.execute(() -> example.add100());
executorService.shutdown();
}输出结果:
100
1002. 线程本地存储(Thread Local Storage)
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
符合这种特点的应用并不少见,大部分使用消费队列的架构模式(如“生产者-消费者”模式)都会将产品的消费过程尽量在一个线程中消费完。其中最重要的一个应用实例就是经典 Web 交互模型中的“一个请求对应一个服务器线程”(Thread-per-Request)的处理方式,这种处理方式的广泛应用使得很多 Web 服务端应用都可以使用线程本地存储来解决线程安全问题。
可以使用 java.lang.ThreadLocal 类来实现线程本地存储功能。
对于以下代码,thread1 中设置 threadLocal 为 1,而 thread2 设置 threadLocal 为 2。过了一段时间之后,thread1 读取 threadLocal 依然是 1,不受 thread2 的影响。
public class ThreadLocalExample {
public static void main(String[] args) {
ThreadLocal threadLocal = new ThreadLocal();
Thread thread1 = new Thread(() -> {
threadLocal.set(1);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadLocal.get());
threadLocal.remove();
});
Thread thread2 = new Thread(() -> {
threadLocal.set(2);
threadLocal.remove();
});
thread1.start();
thread2.start();
}
}输出结果:
1为了理解 ThreadLocal,先看以下代码:
public class ThreadLocalExample1 {
public static void main(String[] args) {
ThreadLocal threadLocal1 = new ThreadLocal();
ThreadLocal threadLocal2 = new ThreadLocal();
Thread thread1 = new Thread(() -> {
threadLocal1.set(1);
threadLocal2.set(1);
});
Thread thread2 = new Thread(() -> {
threadLocal1.set(2);
threadLocal2.set(2);
});
thread1.start();
thread2.start();
}
}它所对应的底层结构图为:

每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象。
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;当调用一个 ThreadLocal 的 set(T value) 方法时,先得到当前线程的 ThreadLocalMap 对象,然后将 ThreadLocal->value 键值对插入到该 Map 中。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}get() 方法类似。
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}ThreadLocal 从理论上讲并不是用来解决多线程并发问题的,因为根本不存在多线程竞争。
在一些场景 (尤其是使用线程池) 下,由于 ThreadLocal.ThreadLocalMap 的底层数据结构导致 ThreadLocal 有内存泄漏的情况,应该尽可能在每次使用 ThreadLocal 后手动调用 remove(),以避免出现 ThreadLocal 经典的内存泄漏甚至是造成自身业务混乱的风险。
推荐阅读:Java并发编程之ThreadLocal
3. 可重入代码(Reentrant Code)
这种代码也叫做纯代码(Pure Code),可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误。
可重入代码有一些共同的特征,例如不依赖存储在堆上的数据和公用的系统资源、用到的状态量都由参数中传入、不调用非可重入的方法等。
十二、锁优化
这里的锁优化主要是指 JVM 对 synchronized 的优化。
自旋锁
互斥同步进入阻塞状态的开销很大,应该尽量避免。在许多应用中,共享数据的锁定状态只会持续很短的一段时间。自旋锁的思想是让一个线程在请求一个共享数据的锁时执行忙循环(自旋)一段时间,如果在这段时间内能获得锁,就可以避免进入阻塞状态。
自旋锁虽然能避免进入阻塞状态从而减少开销,但是它需要进行忙循环操作占用 CPU 时间,它只适用于共享数据的锁定状态很短的场景。
在 JDK 1.6 中引入了自适应的自旋锁。自适应意味着自旋的次数不再固定了,而是由前一次在同一个锁上的自旋次数及锁的拥有者的状态来决定。
锁消除
锁消除是指对于被检测出不可能存在竞争的共享数据的锁进行消除。
锁消除主要是通过逃逸分析来支持,如果堆上的共享数据不可能逃逸出去被其它线程访问到,那么就可以把它们当成私有数据对待,也就可以将它们的锁进行消除。
对于一些看起来没有加锁的代码,其实隐式的加了很多锁。例如下面的字符串拼接代码就隐式加了锁:
public static String concatString(String s1, String s2, String s3) {
return s1 + s2 + s3;
}String 是一个不可变的类,编译器会对 String 的拼接自动优化。在 JDK 1.5 之前,会转化为 StringBuffer 对象的连续 append() 操作:
public static String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}每个 append() 方法中都有一个同步块。虚拟机观察变量 sb,很快就会发现它的动态作用域被限制在 concatString() 方法内部。也就是说,sb 的所有引用永远不会逃逸到 concatString() 方法之外,其他线程无法访问到它,因此可以进行消除。
锁粗化
如果一系列的连续操作都是对同一个对象反复加锁和解锁,频繁的加锁操作就会导致性能损耗。
上一节的示例代码中连续的 append() 方法就属于这类情况。如果虚拟机探测到由这样的一串零碎的操作都对同一个对象加锁,将会把加锁的范围扩展(粗化)到整个操作序列的外部。对于上一节的示例代码就是扩展到第一个 append() 操作之前直至最后一个 append() 操作之后,这样只需要加锁一次就可以了。
轻量级锁
JDK 1.6 引入了偏向锁和轻量级锁,从而让锁拥有了四个状态:无锁状态(unlocked)、偏向锁状态(biasble)、轻量级锁状态(lightweight locked)和重量级锁状态(inflated)。
以下是 HotSpot 虚拟机对象头的内存布局,这些数据被称为 Mark Word。其中 tag bits 对应了五个状态,这些状态在右侧的 state 表格中给出解释。除了 marked for gc 状态,其它四个状态已经在前面介绍过了。
下图左侧是一个线程的虚拟机栈,其中有一部分称为 Lock Record 的区域,这是在轻量级锁运行过程创建的,用于存放锁对象的 Mark Word。而右侧就是一个锁对象,包含了 Mark Word 和其它信息。
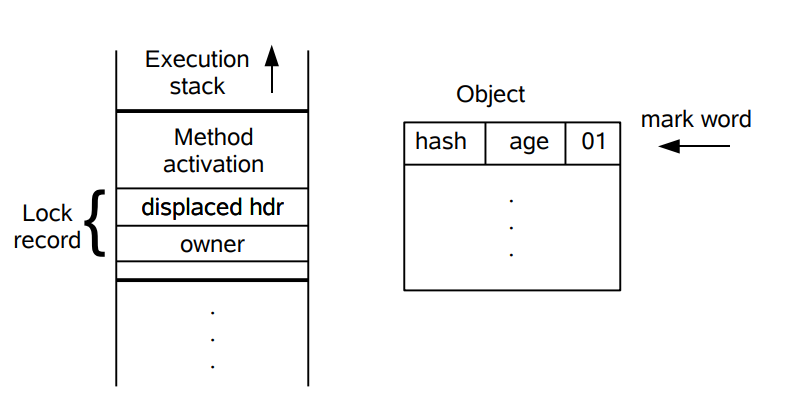
轻量级锁是相对于传统的重量级锁而言,它使用 CAS 操作来避免重量级锁使用互斥量的开销。对于绝大部分的锁,在整个同步周期内都是不存在竞争的,因此也就不需要都使用互斥量进行同步,可以先采用 CAS 操作进行同步,如果 CAS 失败了再改用互斥量进行同步。
当尝试获取一个锁对象时,如果锁对象标记为 0 01,说明锁对象的锁未锁定(unlocked)状态。此时虚拟机在当前线程的虚拟机栈中创建 Lock Record,然后使用 CAS 操作将对象的 Mark Word 更新为 Lock Record 指针。如果 CAS 操作成功了,那么线程就获取了该对象上的锁,并且对象的 Mark Word 的锁标记变为 00,表示该对象处于轻量级锁状态。
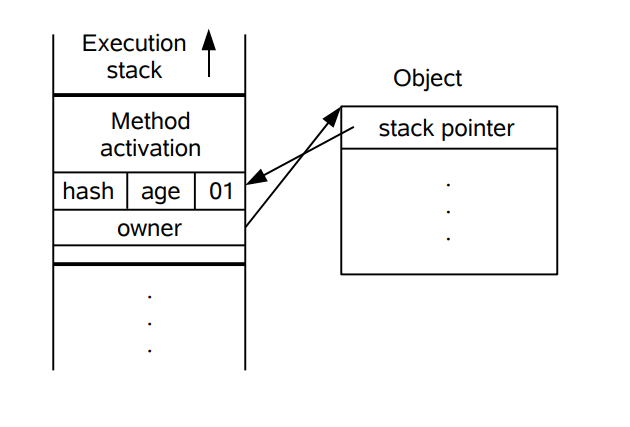
如果 CAS 操作失败了,虚拟机首先会检查对象的 Mark Word 是否指向当前线程的虚拟机栈,如果是的话说明当前线程已经拥有了这个锁对象,那就可以直接进入同步块继续执行,否则说明这个锁对象已经被其他线程线程抢占了。如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁。
偏向锁
偏向锁的思想是偏向于让第一个获取锁对象的线程,这个线程在之后获取该锁就不再需要进行同步操作,甚至连 CAS 操作也不再需要。
当锁对象第一次被线程获得的时候,进入偏向状态,标记为 1 01。同时使用 CAS 操作将线程 ID 记录到 Mark Word 中,如果 CAS 操作成功,这个线程以后每次进入这个锁相关的同步块就不需要再进行任何同步操作。
当有另外一个线程去尝试获取这个锁对象时,偏向状态就宣告结束,此时撤销偏向(Revoke Bias)后恢复到未锁定状态或者轻量级锁状态。
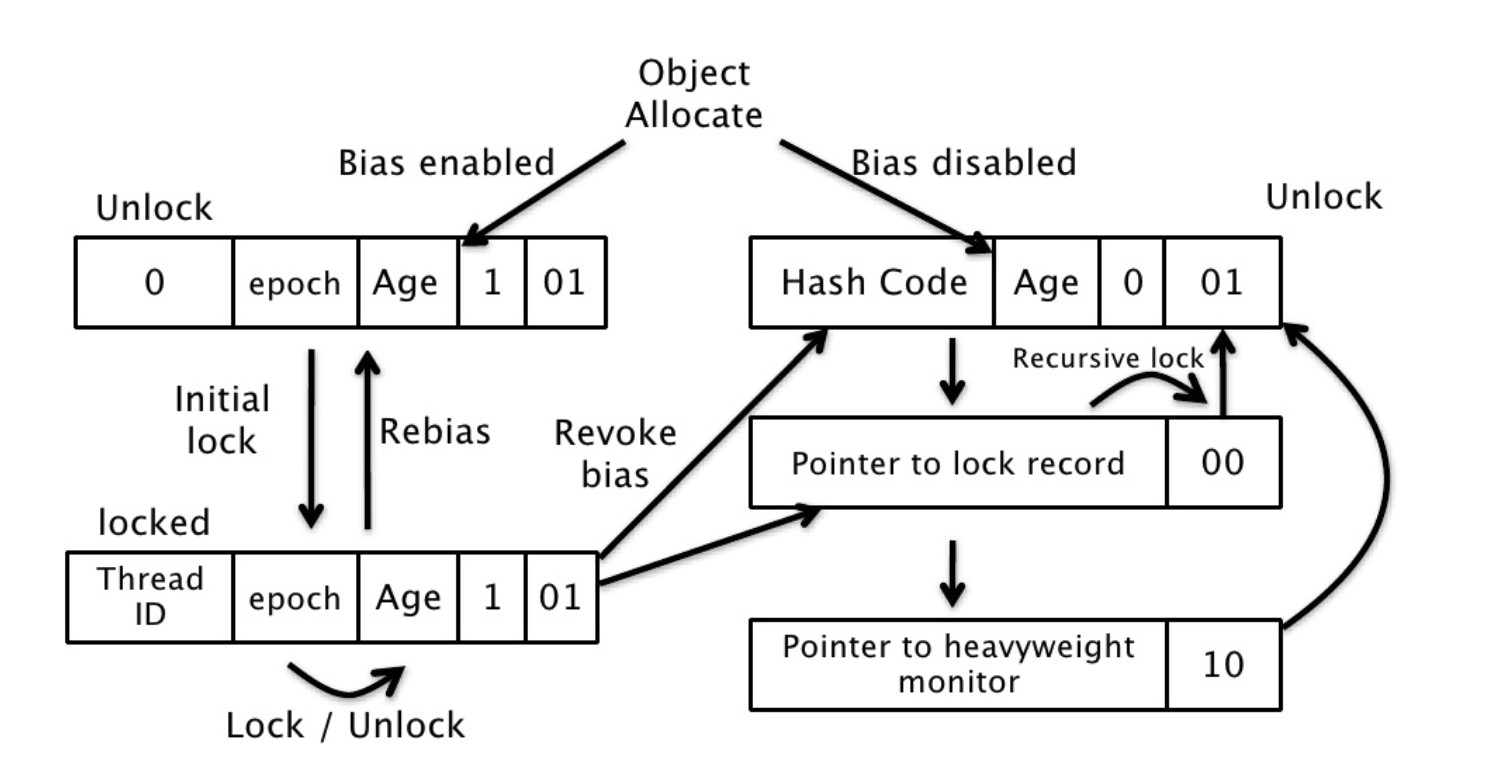
推荐阅读:synchronized到底锁的什么?偏向锁、轻量级锁、重量级锁到底是什么?
十三、多线程开发良好的实践
- 给线程起个有意义的名字,这样可以方便找 Bug。
- 缩小同步范围,从而减少锁争用。例如对于 synchronized,应该尽量使用同步块而不是同步方法。
- 多用同步工具少用
wait()和notify()。首先,CountDownLatch, CyclicBarrier, Semaphore 和 Exchanger 这些同步类简化了编码操作,而用wait()和notify()很难实现复杂控制流;其次,这些同步类是由最好的企业编写和维护,在后续的 JDK 中还会不断优化和完善。 - 使用 BlockingQueue 实现生产者消费者问题。
- 多用并发集合少用同步集合,例如应该使用 ConcurrentHashMap 而不是 Hashtable。
- 使用本地变量和不可变类来保证线程安全。
- 使用线程池而不是直接创建线程,这是因为创建线程代价很高,线程池可以有效地利用有限的线程来启动任务。
参考资料
CS-Notes,原文档地址:https://github.com/CyC2018/CS-Notes/
花絮
该 PDF 文档是我在学习 CSNotes 时的一些优化和补充,加了很多二哥的 Java 进阶之路上的内容,可以进行很好的互补。整理不易,希望能帮助到大家(❤️)。
最新版更新完成后我会放到网盘中,微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《Java》即可获取最新的 PDF 版本。
附其他干货笔记下载地址:
- 二哥的 Linux 速查备忘手册 PDF 下载
- 阮一峰 C 语言入门教程 PDF 下载
- Java 核心知识点整理 PDF 下载
- 深入浅出 Java 多线程 PDF 下载
- Pro Git 中文版 PDF 下载
- 给操作系统捋条线 PDF 下载
第五章、JVM 篇
一、运行时数据区域
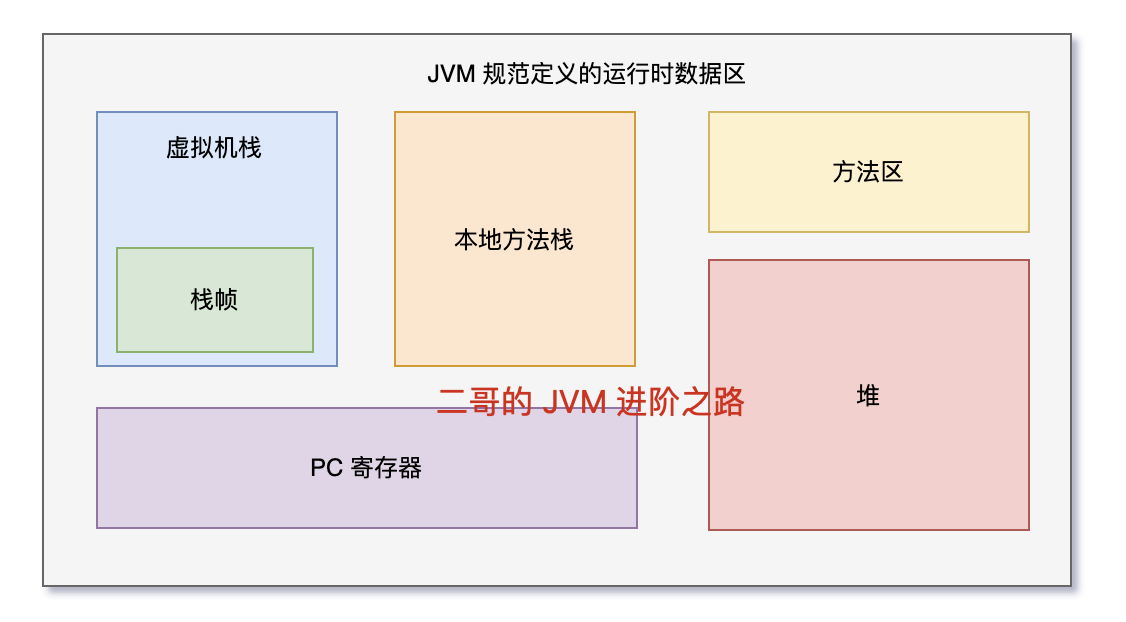
程序计数器
记录正在执行的虚拟机字节码指令的地址(如果正在执行的是本地方法则为空)。
Java 虚拟机栈
每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
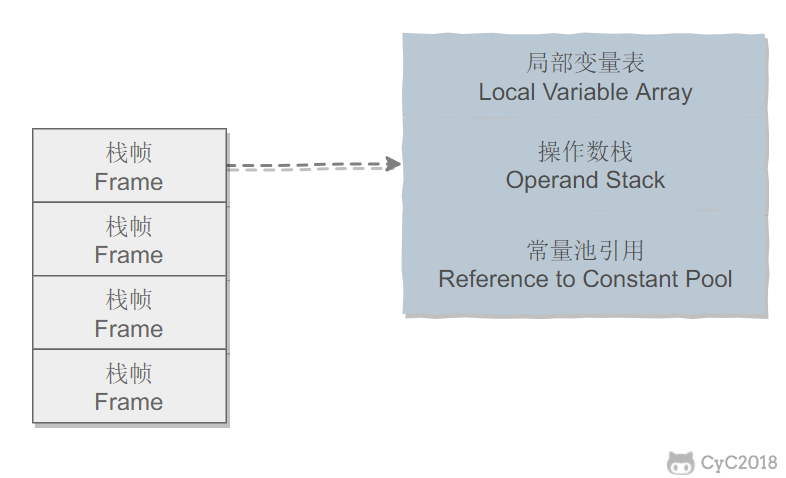
该区域可能抛出以下异常:
- 当线程请求的栈深度超过最大值,会抛出 StackOverflowError 异常;
- 栈进行动态扩展时如果无法申请到足够内存,会抛出 OutOfMemoryError 异常。
本地方法栈
本地方法栈与 Java 虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务。
本地方法一般是用其它语言(C、C++ 或汇编语言等)编写的,并且被编译为基于本机硬件和操作系统的程序,对待这些方法需要特别处理。
堆
所有对象都在这里分配内存,是垃圾收集的主要区域("GC 堆")。
现代垃圾收集器基本都是采用分代收集算法,其主要的思想是针对不同类型的对象采取不同的垃圾回收算法。可以将堆分成两块:
- 新生代(Young Generation)
- 老年代(Old Generation)
堆不需要连续内存,并且可以动态增加其内存,增加失败会抛出 OutOfMemoryError 异常。
方法区
方法区并不真实存在,属于 Java 虚拟机规范中的一个定义。
用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
和堆一样不需要连续的内存,并且可以动态扩展,动态扩展失败一样会抛出 OutOfMemoryError 异常。
对这块区域进行垃圾回收的主要目标是对常量池的回收和对类的卸载,但是一般比较难实现。
HotSpot 虚拟机把它当成永久代来进行垃圾回收。但很难确定永久代的大小,因为它受到很多因素影响,并且每次 Full GC 之后永久代的大小都会改变,所以经常会抛出 OutOfMemoryError 异常。为了更容易管理方法区,从 JDK 1.8 开始,移除永久代,并把方法区移至元空间,它位于本地内存中,而不是虚拟机内存中。
方法区是一个 JVM 规范,永久代与元空间都是其一种实现方式。在 JDK 1.8 之后,原来永久代的数据被分到了堆和元空间中。元空间存储类的元信息,静态变量和常量池等放入堆中。
运行时常量池
运行时常量池是方法区的一部分。
Class 文件中的常量池(编译器生成的字面量和符号引用)会在类加载后被放入这个区域。
除了在编译期生成的常量,还允许动态生成,例如 String 类的 intern()。
直接内存
JDK 1.4 新引入了 NIO 类,它可以使用 Native 函数库直接分配堆外内存,然后通过 Java 堆里的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在堆内存和堆外内存来回拷贝数据。
推荐阅读:深入理解JVM的运行时数据区
二、垃圾收集
垃圾收集主要是针对堆和方法区进行。程序计数器、虚拟机栈和本地方法栈这三个区域属于线程私有的,只存在于线程的生命周期内,线程结束之后就会消失,因此不需要对这三个区域进行垃圾回收。
判断一个对象是否可被回收
1. 引用计数算法
为对象添加一个引用计数器,当对象增加一个引用时计数器加 1,引用失效时计数器减 1。引用计数为 0 的对象可被回收。
在两个对象出现循环引用的情况下,引用计数器永远不为 0,导致无法对它们进行回收。正是因为循环引用的存在,Java 虚拟机就没法使用引用计数算法。
public class Test {
public Object instance = null;
public static void main(String[] args) {
Test a = new Test();
Test b = new Test();
a.instance = b;
b.instance = a;
a = null;
b = null;
doSomething();
}
}在上述代码中,a 与 b 引用的对象实例互相持有对象的引用,因此当我们把对 a 对象与 b 对象的引用去除之后,由于两个对象还存在互相之间的引用,导致两个 Test 对象无法被回收。
2. 可达性分析算法
以 GC Roots 为起始点进行搜索,可达的对象都是存活的,不可达的对象可被回收。
Java 虚拟机使用该算法来判断对象是否可被回收,GC Roots 一般包含以下内容:
- 虚拟机栈中局部变量表中引用的对象
- 本地方法栈中 JNI 中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中的常量引用的对象
3. 方法区的回收
因为方法区主要存放永久代对象,而永久代对象的回收率比新生代低很多,所以在方法区上进行回收性价比不高。主要是对常量池的回收和对类的卸载。
为了避免内存溢出,在大量使用反射和动态代理的场景都需要虚拟机具备类卸载功能。
类的卸载条件很多,需要满足以下三个条件,并且满足了条件也不一定会被卸载:
- 该类所有的实例都已经被回收,此时堆中不存在该类的任何实例。
- 加载该类的 ClassLoader 已经被回收。
- 该类对应的 Class 对象没有在任何地方被引用,也就无法在任何地方通过反射访问该类方法。
4. finalize()
类似 C++ 的析构函数,用于关闭外部资源。但是用 try-finally 可以做得更好,并且 finalize 方法运行代价很高,不确定性大,无法保证各个对象的调用顺序,因此最好不要使用。
当一个对象可被回收时,如果需要执行该对象的 finalize() 方法,那么就有可能在该方法中让对象重新被引用,从而实现自救。自救只能进行一次,如果回收的对象之前调用了 finalize() 方法自救,后面回收时不会再调用该方法。
引用类型
无论是通过引用计数算法判断对象的引用数量,还是通过可达性分析算法判断对象是否可达,判定对象是否可被回收都与引用有关。Java 提供了四种强度不同的引用类型。
1. 强引用
被强引用关联的对象不会被回收。
使用 new 一个新对象的方式来创建强引用。
Object obj = new Object();2. 软引用
被软引用关联的对象只有在内存不够的情况下才会被回收。使用 SoftReference 类来创建软引用。
Object obj = new Object();
SoftReference<Object> sf = new SoftReference<Object>(obj);
obj = null; // 使对象只被软引用关联3. 弱引用
被弱引用关联的对象一定会被回收,也就是说它只能存活到下一次垃圾回收发生之前。使用 WeakReference 类来创建弱引用。
Object obj = new Object();
WeakReference<Object> wf = new WeakReference<Object>(obj);
obj = null;4. 虚引用
又称为幽灵引用或者幻影引用,一个对象是否有虚引用的存在,不会对其生存时间造成影响,也无法通过虚引用得到一个对象。
为一个对象设置虚引用的唯一目的是能在这个对象被回收时收到一个系统通知。使用 PhantomReference 来创建虚引用。
Object obj = new Object();
PhantomReference<Object> pf = new PhantomReference<Object>(obj, null);
obj = null;垃圾收集算法
1. 标记 - 清除
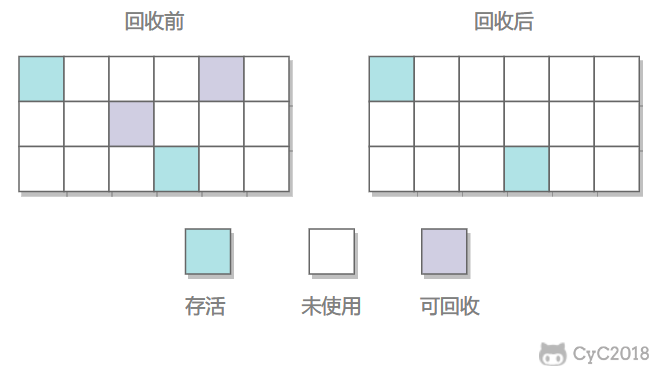
在标记阶段,程序会检查每个对象是否为活动对象,如果是活动对象,则程序会在对象头部打上标记。
在清除阶段,会进行对象回收并取消标志位,另外,还会判断回收后的分块与前一个空闲分块是否连续,若连续,会合并这两个分块。回收对象就是把对象作为分块,连接到被称为 “空闲链表” 的单向链表,之后进行分配时只需要遍历这个空闲链表,就可以找到分块。
在分配时,程序会搜索空闲链表寻找空间大于等于新对象大小 size 的块 block。如果它找到的块等于 size,会直接返回这个分块;如果找到的块大于 size,会将块分割成大小为 size 与 (block - size) 的两部分,返回大小为 size 的分块,并把大小为 (block - size) 的块返回给空闲链表。
不足:
- 标记和清除过程效率都不高;
- 会产生大量不连续的内存碎片,导致无法给大对象分配内存。
2. 标记 - 整理
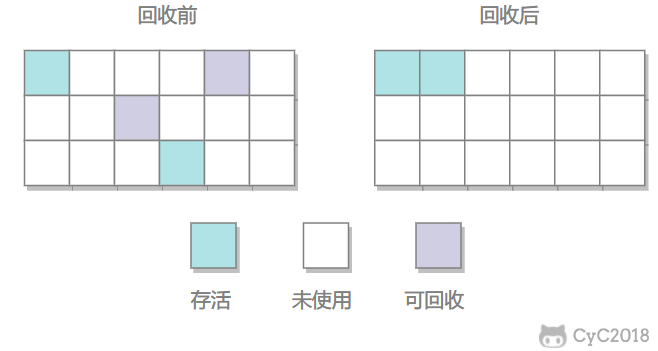
让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
优点: 不会产生内存碎片
不足: 需要移动大量对象,处理效率比较低。
3. 复制
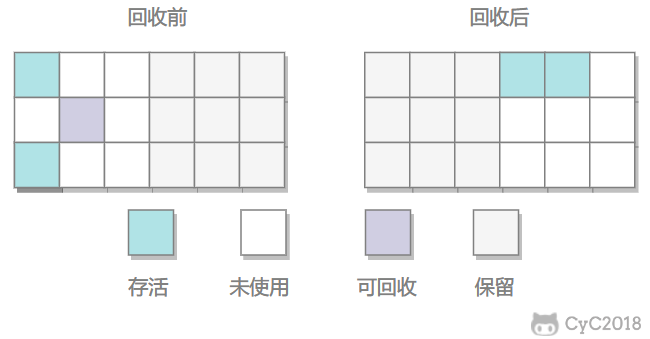
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
不足是只使用了内存的一半。
现在的商业虚拟机都采用这种收集算法回收新生代,但是并不是划分为大小相等的两块,而是一块较大的 Eden 空间和两块较小的 Survivor 空间,每次使用 Eden 和其中一块 Survivor。在回收时,将 Eden 和 Survivor 中还存活着的对象全部复制到另一块 Survivor 上,最后清理 Eden 和使用过的那一块 Survivor。
HotSpot 虚拟机的 Eden 和 Survivor 大小比例默认为 8:1,保证了内存的利用率达到 90%。如果每次回收有多于 10% 的对象存活,那么一块 Survivor 就不够用了,此时需要依赖于老年代进行空间分配担保,也就是借用老年代的空间存储放不下的对象。
4. 分代收集
现在的商业虚拟机采用分代收集算法,它根据对象存活周期将内存划分为几块,不同块采用适当的收集算法。一般将堆分为新生代和老年代。
- 新生代使用:复制算法
- 老年代使用:标记 - 清除 或者 标记 - 整理 算法
垃圾收集器
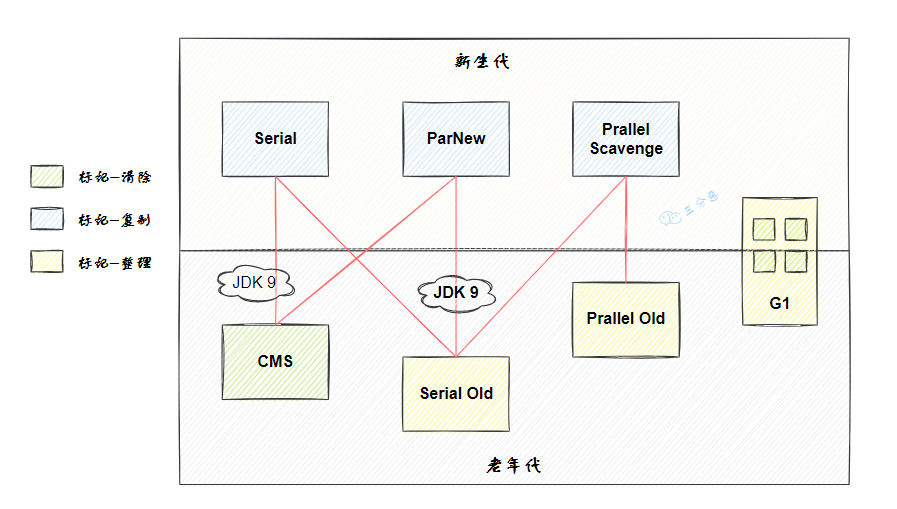
以上是 HotSpot 虚拟机中的 7 个垃圾收集器,连线表示垃圾收集器可以配合使用。
- 单线程与多线程:单线程指的是垃圾收集器只使用一个线程,而多线程使用多个线程;
- 串行与并行:串行指的是垃圾收集器与用户程序交替执行,这意味着在执行垃圾收集的时候需要停顿用户程序;并行指的是垃圾收集器和用户程序同时执行。除了 CMS 和 G1 之外,其它垃圾收集器都是以串行的方式执行。
1. Serial 收集器
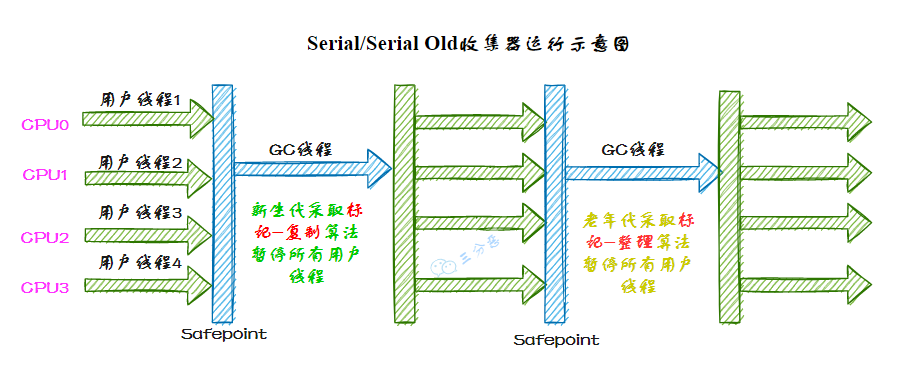
Serial 翻译为串行,也就是说它以串行的方式执行。它是单线程的收集器,只会使用一个线程进行垃圾收集工作。
优点是简单高效,在单个 CPU 环境下,由于没有线程交互的开销,因此拥有最高的单线程收集效率。
它是 Client 场景下的默认新生代收集器,因为在该场景下内存一般来说不会很大。它收集一两百兆垃圾的停顿时间可以控制在一百多毫秒以内,只要不是太频繁,这点停顿时间是可以接受的。
2. ParNew 收集器
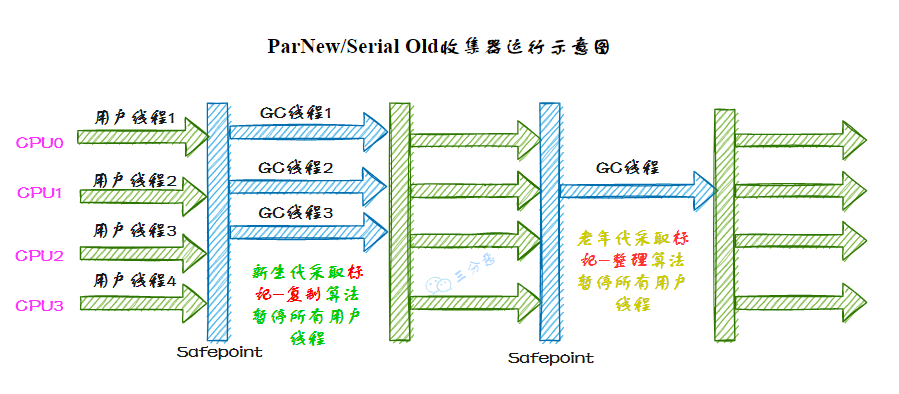
它是 Serial 收集器的多线程版本。
它是 Server 场景下默认的新生代收集器,除了性能原因外,主要是因为除了 Serial 收集器,只有它能与 CMS 收集器配合使用。
3. Parallel Scavenge 收集器
与 ParNew 一样是多线程收集器。
其它收集器目标是尽可能缩短垃圾收集时用户线程的停顿时间,而它的目标是达到一个可控制的吞吐量,因此它被称为“吞吐量优先”收集器。这里的吞吐量指 CPU 用于运行用户程序的时间占总时间的比值。
停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验。而高吞吐量则可以高效率地利用 CPU 时间,尽快完成程序的运算任务,适合在后台运算而不需要太多交互的任务。
缩短停顿时间是以牺牲吞吐量和新生代空间来换取的:新生代空间变小,垃圾回收变得频繁,导致吞吐量下降。
可以通过一个开关参数打开 GC 自适应的调节策略(GC Ergonomics),就不需要手工指定新生代的大小(-Xmn)、Eden 和 Survivor 区的比例、晋升老年代对象年龄等细节参数了。虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量。
4. Serial Old 收集器
是 Serial 收集器的老年代版本,也是给 Client 场景下的虚拟机使用。如果用在 Server 场景下,它有两大用途:
- 在 JDK 1.5 以及之前版本(Parallel Old 诞生以前)中与 Parallel Scavenge 收集器搭配使用。
- 作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用。
5. Parallel Old 收集器
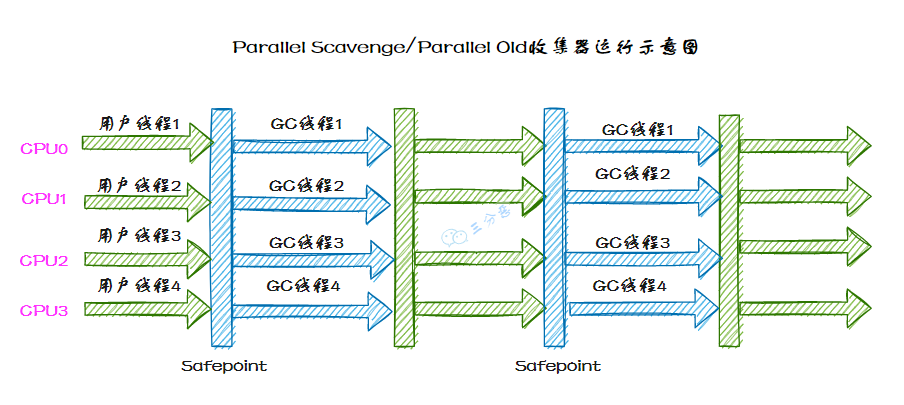
是 Parallel Scavenge 收集器的老年代版本。
在注重吞吐量以及 CPU 资源敏感的场合,都可以优先考虑 Parallel Scavenge 加 Parallel Old 收集器。
6. CMS 收集器
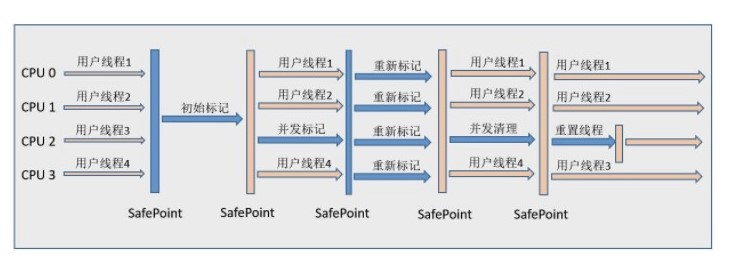
CMS(Concurrent Mark Sweep),Mark Sweep 指的是标记 - 清除算法。
分为以下四个流程:
- 初始标记:仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,需要停顿。
- 并发标记:进行 GC Roots Tracing 的过程,它在整个回收过程中耗时最长,不需要停顿。
- 重新标记:为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,需要停顿。
- 并发清除:不需要停顿。
在整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,不需要进行停顿。
具有以下缺点:
- 吞吐量低:低停顿时间是以牺牲吞吐量为代价的,导致 CPU 利用率不够高。
- 无法处理浮动垃圾,可能出现 Concurrent Mode Failure。浮动垃圾是指并发清除阶段由于用户线程继续运行而产生的垃圾,这部分垃圾只能到下一次 GC 时才能进行回收。由于浮动垃圾的存在,因此需要预留出一部分内存,意味着 CMS 收集不能像其它收集器那样等待老年代快满的时候再回收。如果预留的内存不够存放浮动垃圾,就会出现 Concurrent Mode Failure,这时虚拟机将临时启用 Serial Old 来替代 CMS。
- 标记 - 清除算法导致的空间碎片,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象,不得不提前触发一次 Full GC。
7. G1 收集器
G1(Garbage-First),它是一款面向服务端应用的垃圾收集器,在多 CPU 和大内存的场景下有很好的性能。HotSpot 开发团队赋予它的使命是未来可以替换掉 CMS 收集器。
堆被分为新生代和老年代,其它收集器进行收集的范围都是整个新生代或者老年代,而 G1 可以直接对新生代和老年代一起回收。
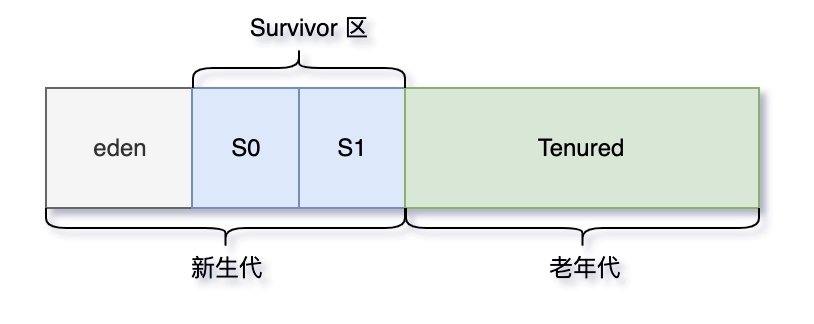
G1 把堆划分成多个大小相等的独立区域(Region),新生代和老年代不再物理隔离。
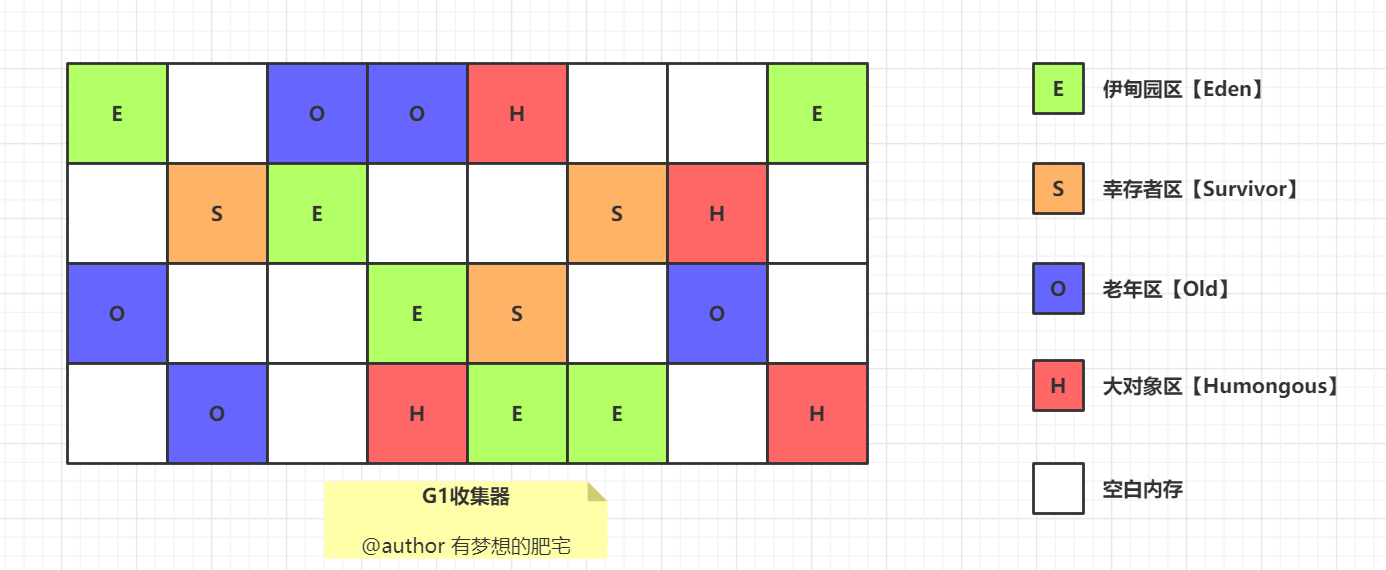
通过引入 Region 的概念,从而将原来的一整块内存空间划分成多个的小空间,使得每个小空间可以单独进行垃圾回收。
这种划分方法带来了很大的灵活性,使得可预测的停顿时间模型成为可能。通过记录每个 Region 垃圾回收时间以及回收所获得的空间(这两个值是通过过去回收的经验获得),并维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region。
每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region。通过使用 Remembered Set,在做可达性分析的时候就可以避免全堆扫描。
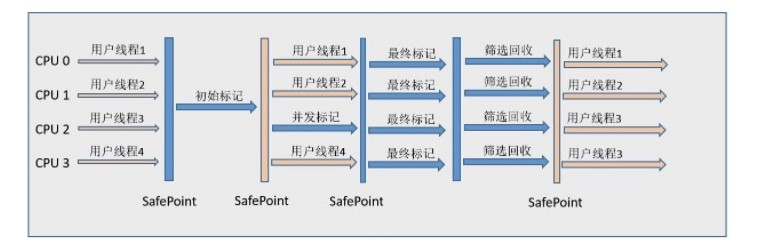
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
- 初始标记
- 并发标记
- 最终标记:为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中。这阶段需要停顿线程,但是可并行执行。
- 筛选回收:首先对各个 Region 中的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
具备如下特点:
- 空间整合:整体来看是基于“标记 - 整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
- 可预测的停顿:能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒。
微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《java》即可获取最新的 PDF 版本。
三、内存分配与回收策略
Minor GC 和 Full GC
Minor GC:回收新生代,因为新生代对象存活时间很短,因此 Minor GC 会频繁执行,执行的速度一般也会比较快。
Full GC:回收老年代和新生代,老年代对象存活时间长,因此 Full GC 很少执行,执行速度会比 Minor GC 慢很多。
内存分配策略
1. 对象优先在 Eden 分配
大多数情况下,对象在新生代 Eden 上分配,当 Eden 空间不够时,发起 Minor GC。
2. 大对象直接进入老年代
大对象是指需要连续内存空间的对象,最典型的大对象是那种很长的字符串以及数组。
经常出现大对象会提前触发垃圾收集以获取足够的连续空间分配给大对象。
-XX:PretenureSizeThreshold,大于此值的对象直接在老年代分配,避免在 Eden 和 Survivor 之间的大量内存复制。
3. 长期存活的对象进入老年代
为对象定义年龄计数器,对象在 Eden 出生并经过 Minor GC 依然存活,将移动到 Survivor 中,年龄就增加 1 岁,增加到一定年龄则移动到老年代中。
-XX:MaxTenuringThreshold 用来定义年龄的阈值。
4. 动态对象年龄判定
虚拟机并不是永远要求对象的年龄必须达到 MaxTenuringThreshold 才能晋升老年代,如果在 Survivor 中相同年龄所有对象大小的总和大于 Survivor 空间的一半,则年龄大于或等于该年龄的对象可以直接进入老年代,无需等到 MaxTenuringThreshold 中要求的年龄。
5. 空间分配担保
在发生 Minor GC 之前,虚拟机先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果条件成立的话,那么 Minor GC 可以确认是安全的。
如果不成立的话虚拟机会查看 HandlePromotionFailure 的值是否允许担保失败,如果允许那么就会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次 Minor GC;如果小于,或者 HandlePromotionFailure 的值不允许冒险,那么就要进行一次 Full GC。
Full GC 的触发条件
对于 Minor GC,其触发条件非常简单,当 Eden 空间满时,就将触发一次 Minor GC。而 Full GC 则相对复杂,有以下条件:
1. 调用 System.gc()
只是建议虚拟机执行 Full GC,但是虚拟机不一定真正去执行。不建议使用这种方式,而是让虚拟机管理内存。
2. 老年代空间不足
老年代空间不足的常见场景为前文所讲的大对象直接进入老年代、长期存活的对象进入老年代等。
为了避免以上原因引起的 Full GC,应当尽量不要创建过大的对象以及数组。除此之外,可以通过 -Xmn 虚拟机参数调大新生代的大小,让对象尽量在新生代被回收掉,不进入老年代。还可以通过 -XX:MaxTenuringThreshold 调大对象进入老年代的年龄,让对象在新生代多存活一段时间。
3. 空间分配担保失败
使用复制算法的 Minor GC 需要老年代的内存空间作担保,如果担保失败会执行一次 Full GC。具体内容请参考上面的第 5 小节。
4. JDK 1.7 及以前的永久代空间不足
在 JDK 1.7 及以前,HotSpot 虚拟机中的方法区是用永久代实现的,永久代中存放的为一些 Class 的信息、常量、静态变量等数据。
当系统中要加载的类、反射的类和调用的方法较多时,永久代可能会被占满,在未配置为采用 CMS GC 的情况下也会执行 Full GC。如果经过 Full GC 仍然回收不了,那么虚拟机会抛出 java.lang.OutOfMemoryError。
为避免以上原因引起的 Full GC,可采用的方法为增大永久代空间或转为使用 CMS GC。
5. Concurrent Mode Failure
执行 CMS GC 的过程中同时有对象要放入老年代,而此时老年代空间不足(可能是 GC 过程中浮动垃圾过多导致暂时性的空间不足),便会报 Concurrent Mode Failure 错误,并触发 Full GC。
四、类加载机制
类是在运行期间第一次使用时动态加载的,而不是一次性加载所有类。因为如果一次性加载,会占用很多的内存。
类的生命周期
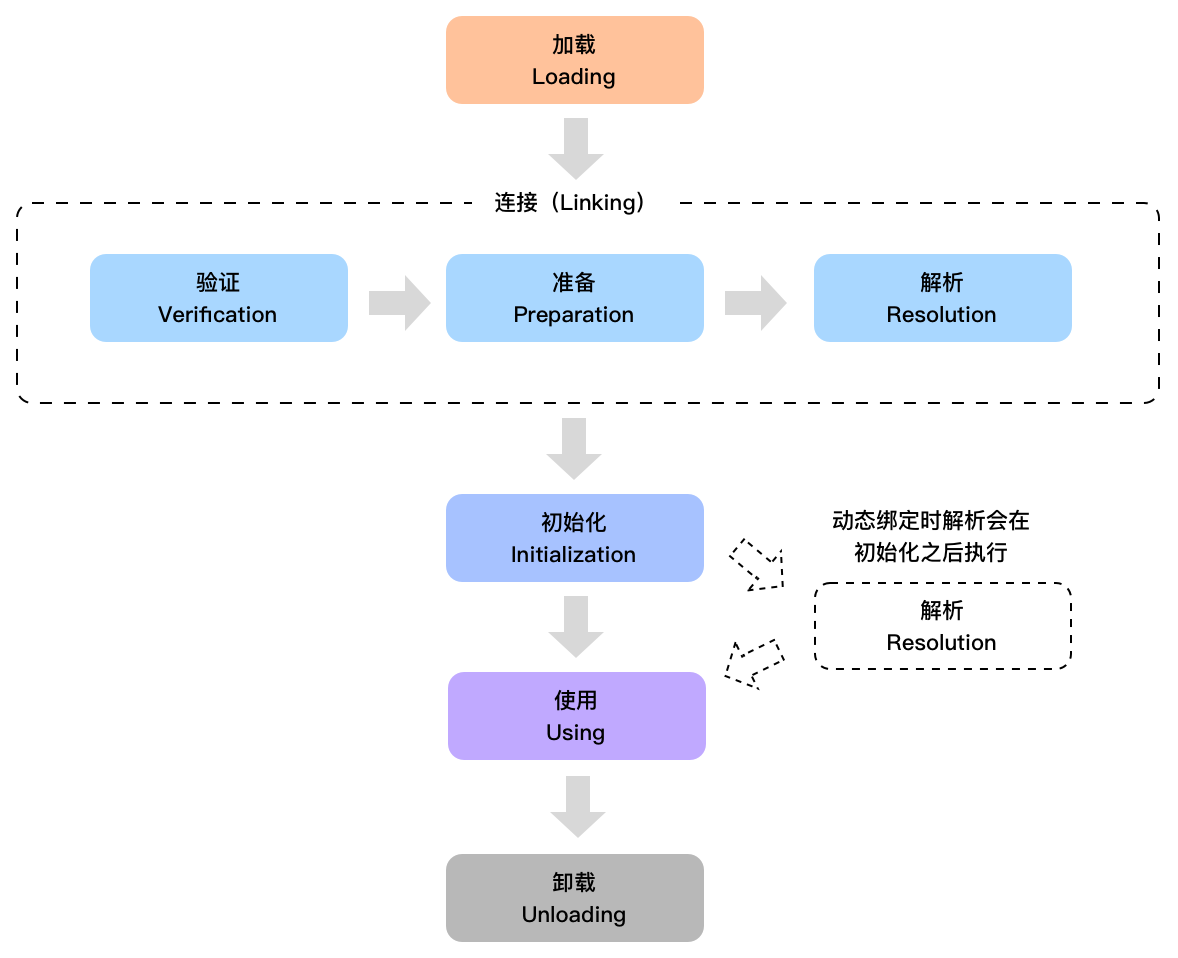
包括以下 7 个阶段:
- 加载(Loading)
- 验证(Verification)
- 准备(Preparation)
- 解析(Resolution)
- 初始化(Initialization)
- 使用(Using)
- 卸载(Unloading)
类加载过程
包含了加载、验证、准备、解析和初始化这 5 个阶段。
1. 加载
加载是类加载的一个阶段,注意不要混淆。加载过程完成以下三件事:
- 通过类的完全限定名称获取定义该类的二进制字节流。
- 将该字节流表示的静态存储结构转换为方法区的运行时存储结构。
- 在内存中生成一个代表该类的 Class 对象,作为方法区中该类各种数据的访问入口。
其中二进制字节流可以从以下方式中获取:
- 从 ZIP 包读取,成为 JAR、EAR、WAR 格式的基础。
- 从网络中获取,最典型的应用是 Applet。
- 运行时计算生成,例如动态代理技术,在 java.lang.reflect.Proxy 使用 ProxyGenerator.generateProxyClass 的代理类的二进制字节流。
- 由其他文件生成,例如由 JSP 文件生成对应的 Class 类。
2. 验证
确保 Class 文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
3. 准备
类变量是被 static 修饰的变量,准备阶段为类变量分配内存并设置初始值,使用的是方法区的内存。
实例变量不会在这阶段分配内存,它会在对象实例化时随着对象一起被分配在堆中。
应该注意到,实例化不是类加载的一个过程,类加载发生在所有实例化操作之前,并且类加载只进行一次,实例化可以进行多次。
初始值一般为 0 值,例如下面的类变量 value 被初始化为 0 而不是 123。
public static int value = 123;如果类变量是常量,那么它将初始化为表达式所定义的值而不是 0。例如下面的常量 value 被初始化为 123 而不是 0。
public static final int value = 123;4. 解析
将常量池的符号引用替换为直接引用的过程。
其中解析过程在某些情况下可以在初始化阶段之后再开始,这是为了支持 Java 的动态绑定。
5. 初始化
初始化阶段才真正开始执行类中定义的 Java 程序代码。初始化阶段是虚拟机执行类构造器 <clinit>() 方法的过程。在准备阶段,类变量已经赋过一次系统要求的初始值,而在初始化阶段,根据程序员通过程序制定的主观计划去初始化类变量和其它资源。
<clinit>() 是由编译器自动收集类中所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序由语句在源文件中出现的顺序决定。特别注意的是,静态语句块只能访问到定义在它之前的类变量,定义在它之后的类变量只能赋值,不能访问。例如以下代码:
public class Test {
static {
i = 0; // 给变量赋值可以正常编译通过
System.out.print(i); // 这句编译器会提示“非法向前引用”
}
static int i = 1;
}由于父类的 <clinit>() 方法先执行,也就意味着父类中定义的静态语句块的执行要优先于子类。例如以下代码:
static class Parent {
public static int A = 1;
static {
A = 2;
}
}
static class Sub extends Parent {
public static int B = A;
}
public static void main(String[] args) {
System.out.println(Sub.B); // 2
}接口中不可以使用静态语句块,但仍然有类变量初始化的赋值操作,因此接口与类一样都会生成 <clinit>() 方法。
但接口与类不同的是,执行接口的 <clinit>() 方法不需要先执行父接口的 <clinit>() 方法。只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也一样不会执行接口的 <clinit>() 方法。
虚拟机会保证一个类的 <clinit>() 方法在多线程环境下被正确的加锁和同步,如果多个线程同时初始化一个类,只会有一个线程执行这个类的 <clinit>() 方法,其它线程都会阻塞等待,直到活动线程执行 <clinit>() 方法完毕。
如果在一个类的 <clinit>() 方法中有耗时的操作,就可能造成多个线程阻塞,在实际过程中此种阻塞很隐蔽。
类初始化时机
1. 主动引用
虚拟机规范中并没有强制约束何时进行加载,但是规范严格规定了有且只有下列五种情况必须对类进行初始化(加载、验证、准备都会随之发生):
遇到 new、getstatic、putstatic、invokestatic 这四条字节码指令时,如果类没有进行过初始化,则必须先触发其初始化。最常见的生成这 4 条指令的场景是:使用 new 关键字实例化对象的时候;读取或设置一个类的静态字段(被 final 修饰、已在编译期把结果放入常量池的静态字段除外)的时候;以及调用一个类的静态方法的时候。
使用 java.lang.reflect 包的方法对类进行反射调用的时候,如果类没有进行初始化,则需要先触发其初始化。
当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
当虚拟机启动时,用户需要指定一个要执行的主类(包含
main()方法的那个类),虚拟机会先初始化这个主类;当使用 JDK 1.7 的动态语言支持时,如果一个 java.lang.invoke.MethodHandle 实例最后的解析结果为 REF_getStatic, REF_putStatic, REF_invokeStatic 的方法句柄,并且这个方法句柄所对应的类没有进行过初始化,则需要先触发其初始化;
2. 被动引用
以上 5 种场景中的行为称为对一个类进行主动引用。除此之外,所有引用类的方式都不会触发初始化,称为被动引用。被动引用的常见例子包括:
- 通过子类引用父类的静态字段,不会导致子类初始化。
System.out.println(SubClass.value); // value 字段在 SuperClass 中定义- 通过数组定义来引用类,不会触发此类的初始化。该过程会对数组类进行初始化,数组类是一个由虚拟机自动生成的、直接继承自 Object 的子类,其中包含了数组的属性和方法。
SuperClass[] sca = new SuperClass[10];- 常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
System.out.println(ConstClass.HELLOWORLD);类与类加载器
两个类相等,需要类本身相等,并且使用同一个类加载器进行加载。这是因为每一个类加载器都拥有一个独立的类名称空间。
这里的相等,包括类的 Class 对象的 equals() 方法、isAssignableFrom() 方法、isInstance() 方法的返回结果为 true,也包括使用 instanceof 关键字做对象所属关系判定结果为 true。
类加载器分类
从 Java 虚拟机的角度来讲,只存在以下两种不同的类加载器:
启动类加载器(Bootstrap ClassLoader),使用 C++ 实现,是虚拟机自身的一部分;
所有其它类的加载器,使用 Java 实现,独立于虚拟机,继承自抽象类 java.lang.ClassLoader。
从 Java 开发人员的角度看,类加载器可以划分得更细致一些:
启动类加载器(Bootstrap ClassLoader)此类加载器负责将存放在 <JRE_HOME>\lib 目录中的,或者被 -Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar,名字不符合的类库即使放在 lib 目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被 Java 程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给启动类加载器,直接使用 null 代替即可。
扩展类加载器(Extension ClassLoader)这个类加载器是由 ExtClassLoader(sun.misc.Launcher$ExtClassLoader)实现的。它负责将 <JAVA_HOME>/lib/ext 或者被 java.ext.dir 系统变量所指定路径中的所有类库加载到内存中,开发者可以直接使用扩展类加载器。
应用程序类加载器(Application ClassLoader)这个类加载器是由 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的。由于这个类加载器是 ClassLoader 中的
getSystemClassLoader()方法的返回值,因此一般称为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
双亲委派模型
应用程序是由三种类加载器互相配合从而实现类加载,除此之外还可以加入自己定义的类加载器。
下图展示了类加载器之间的层次关系,称为双亲委派模型(Parents Delegation Model)。该模型要求除了顶层的启动类加载器外,其它的类加载器都要有自己的父类加载器。这里的父子关系一般通过组合关系(Composition)来实现,而不是继承关系(Inheritance)。
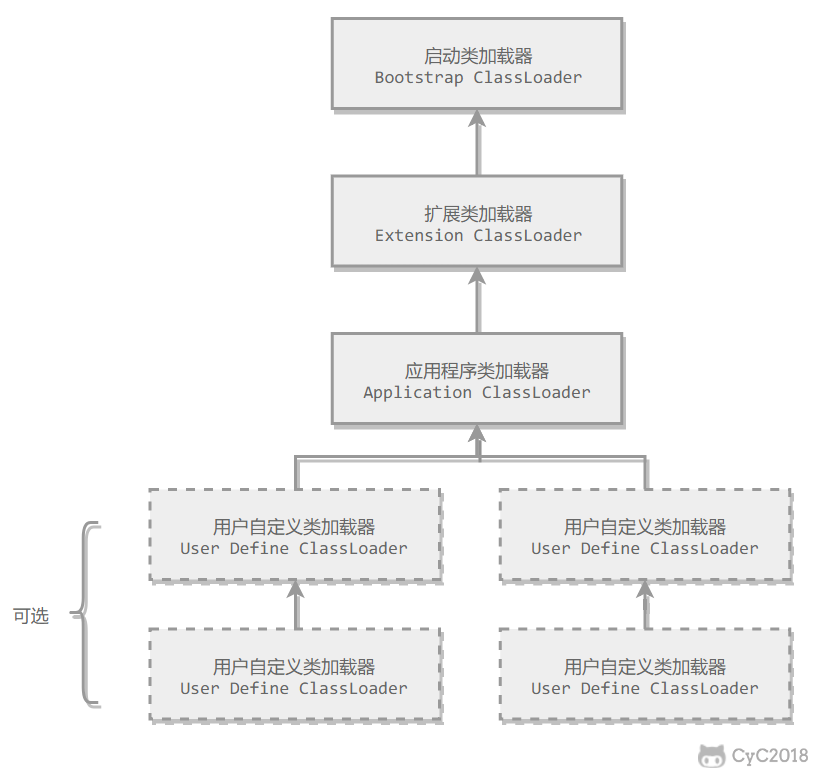
1. 工作过程
一个类加载器首先将类加载请求转发到父类加载器,只有当父类加载器无法完成时才尝试自己加载。
2. 好处
使得 Java 类随着它的类加载器一起具有一种带有优先级的层次关系,从而使得基础类得到统一。
例如 java.lang.Object 存放在 rt.jar 中,如果编写另外一个 java.lang.Object 并放到 ClassPath 中,程序可以编译通过。
由于双亲委派模型的存在,所以在 rt.jar 中的 Object 比在 ClassPath 中的 Object 优先级更高,这是因为 rt.jar 中的 Object 使用的是启动类加载器,而 ClassPath 中的 Object 使用的是应用程序类加载器。rt.jar 中的 Object 优先级更高,那么程序中所有的 Object 都是这个 Object。
3. 实现
以下是抽象类 java.lang.ClassLoader 的代码片段,其中的 loadClass() 方法运行过程如下:先检查类是否已经加载过,如果没有则让父类加载器去加载。当父类加载器加载失败时抛出 ClassNotFoundException,此时尝试自己去加载。
public abstract class ClassLoader {
// The parent class loader for delegation
private final ClassLoader parent;
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
}自定义类加载器实现
以下代码中的 FileSystemClassLoader 是自定义类加载器,继承自 java.lang.ClassLoader,用于加载文件系统上的类。它首先根据类的全名在文件系统上查找类的字节代码文件(.class 文件),然后读取该文件内容,最后通过 defineClass() 方法来把这些字节代码转换成 java.lang.Class 类的实例。
java.lang.ClassLoader 的 loadClass() 实现了双亲委派模型的逻辑,自定义类加载器一般不去重写它,但是需要重写 findClass() 方法。
public class FileSystemClassLoader extends ClassLoader {
private String rootDir;
public FileSystemClassLoader(String rootDir) {
this.rootDir = rootDir;
}
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] classData = getClassData(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
return defineClass(name, classData, 0, classData.length);
}
}
private byte[] getClassData(String className) {
String path = classNameToPath(className);
try {
InputStream ins = new FileInputStream(path);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int bufferSize = 4096;
byte[] buffer = new byte[bufferSize];
int bytesNumRead;
while ((bytesNumRead = ins.read(buffer)) != -1) {
baos.write(buffer, 0, bytesNumRead);
}
return baos.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
private String classNameToPath(String className) {
return rootDir + File.separatorChar
+ className.replace('.', File.separatorChar) + ".class";
}
}推荐阅读:一文彻底搞懂 Java 类加载机制
参考资料
CS-Notes,原文档地址:https://github.com/CyC2018/CS-Notes/
花絮
该 PDF 文档是我在学习 CSNotes 时的一些优化和补充,加了很多二哥的 Java 进阶之路上的内容,可以进行很好的互补。整理不易,希望能帮助到大家(❤️)。
最新版更新完成后我会放到网盘中,微信搜索《沉默王二》或者微信扫下面的二维码,关注后回复《Java》即可获取最新的 PDF 版本。
附其他干货笔记下载地址: