面试结束后,我反问:“就面个实习至于上这么大强度吗?”面试官:“你对 RAG、Agent、MCP、Skill 理解得很到位,所以要求高一点。”
老王今天穿了件黑 T 恤,胸口印着一行白字「My code does compile」,胡子有点拉碴,应该是连续好几天没刮了。
桌上摆着一杯冰美式,估摸着是刚冲的,但一直没顾得上喝。
“我对你要求比较高。”老王开门见山地说,“你,可不要紧张啊。”
(内心OS:哥们也是见过大风大浪的,根本不怕好吧,你尽管来。)

但讲老实话,这次面试确实顶,顶到肺了快。😄
兄弟姐妹们可以先看看这些题目,真的,不是一般人,扛不住啊。
系好安全带,咱们粗粗粗粗发~~
content
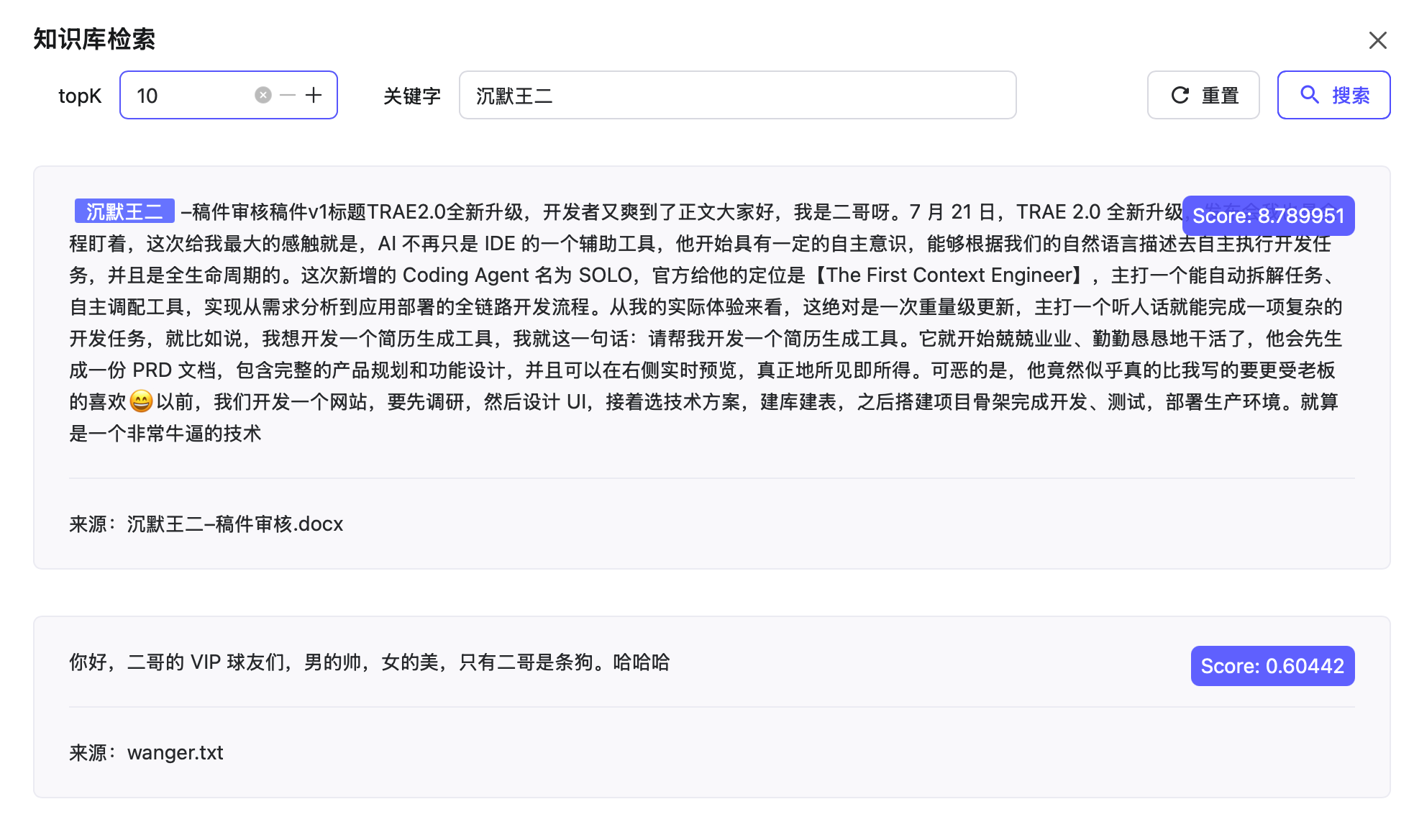
01、RAG 项目,你里边的分片是怎么设计的?然后还有就是内容的解析以及向量化又是怎么做的,然后在检索召回的时候又是怎么做的?
我说:「我分四块儿来讲,分片、解析、向量化、召回。」
老王点点头,往椅子上一靠,看样子是准备听我的长篇大论了。
分片这一块,派聪明用的是多层级语义分片,按段落 → 句子 → 词 → 字符这种递进的方式来切。分片大小默认设的是 512 字节,没有用 overlap。
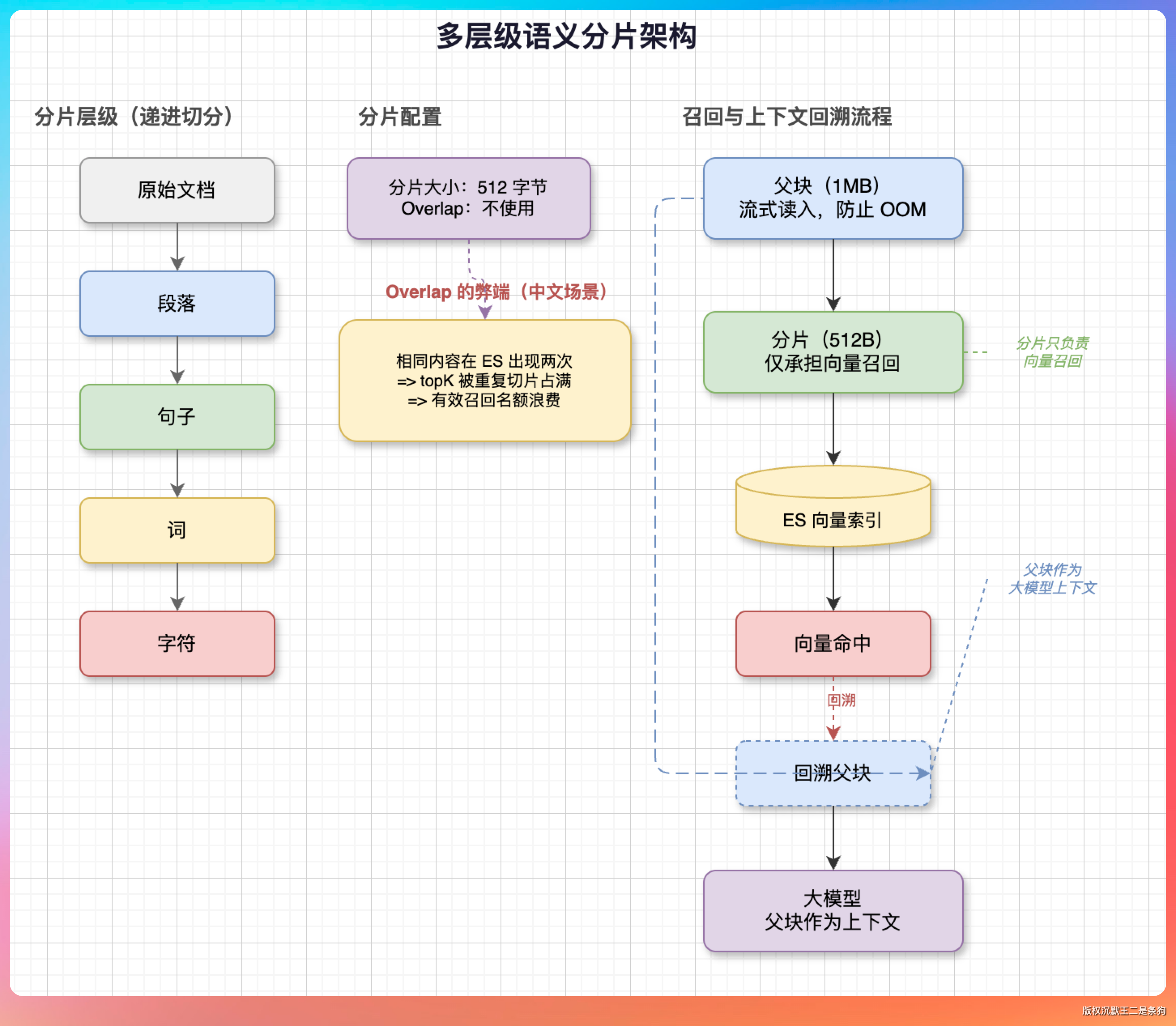
老王这时候插了一句:「不用 overlap 不怕语义割裂吗?」
我说:「这个问题我们也想过。后来发现 overlap 在中文场景下效果一般,反而会让相同内容在 ES 里出现两次,召回的时候排在前面的几条都是同一段落的不同切片,相当于浪费 topK 名额。我们的做法是,分片之外维护一个 1MB 的父块,流式读进来防止 OOM,分片只承担向量召回,命中之后回溯到父块给大模型作为上下文。」
老王眼睛亮了一下,没说话,示意我继续。
解析这一块,用的是 Apache Tika 2.9.1,自动识别格式,支持 PDF、Word、Excel、PPT、Markdown、HTML 这几大类。PDF 我们是用 PDFBox 单独处理的,按页码切片,同时把页眉页脚这些重复出现的字符给剔除掉。中文长句切词用的 HanLP 的 StandardTokenizer。
向量化走的是阿里千问的 text-embedding-v4,维度 2048,通过兼容 OpenAI 协议的 API 调,单次最多 batch 10 条。
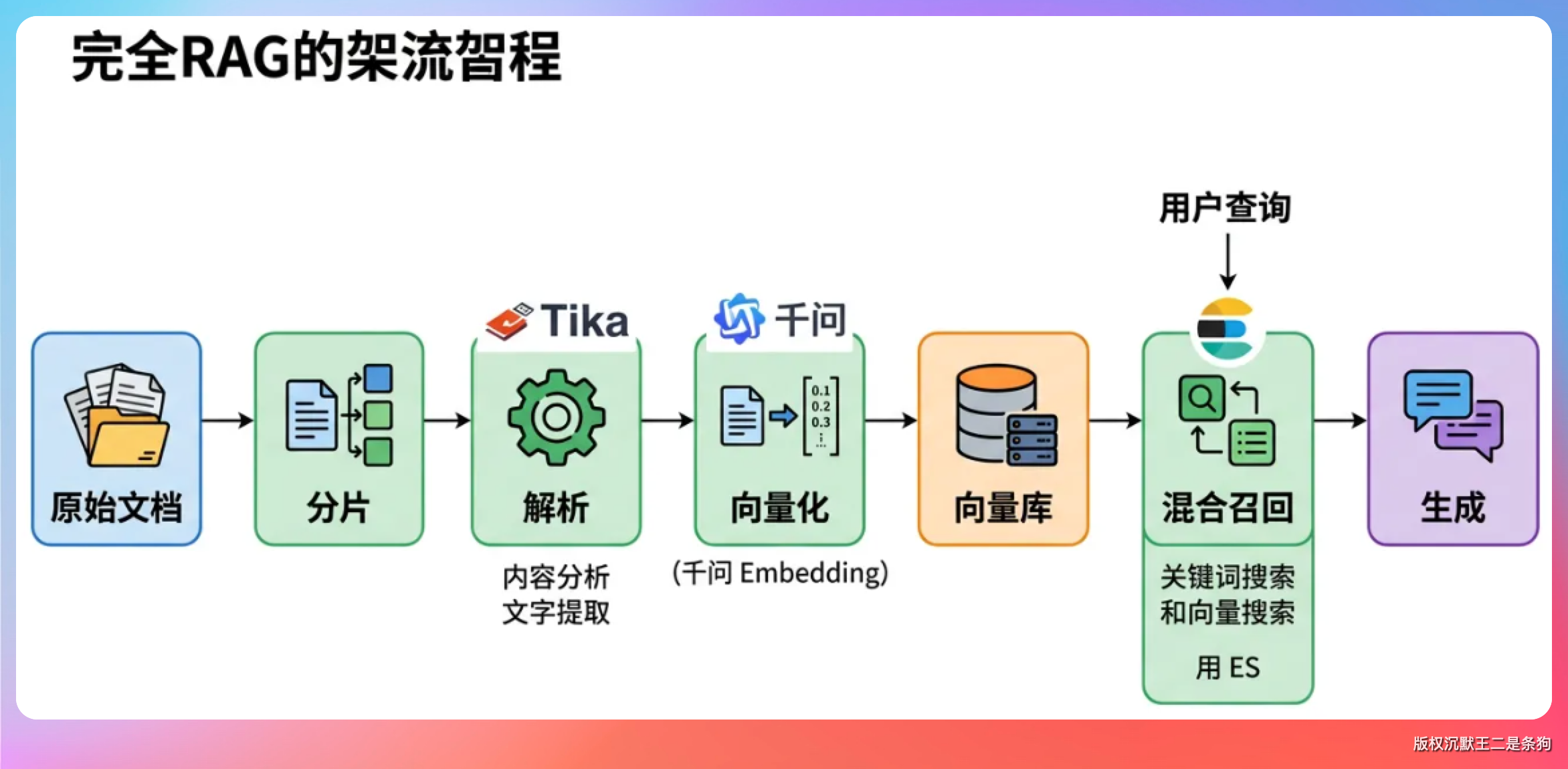
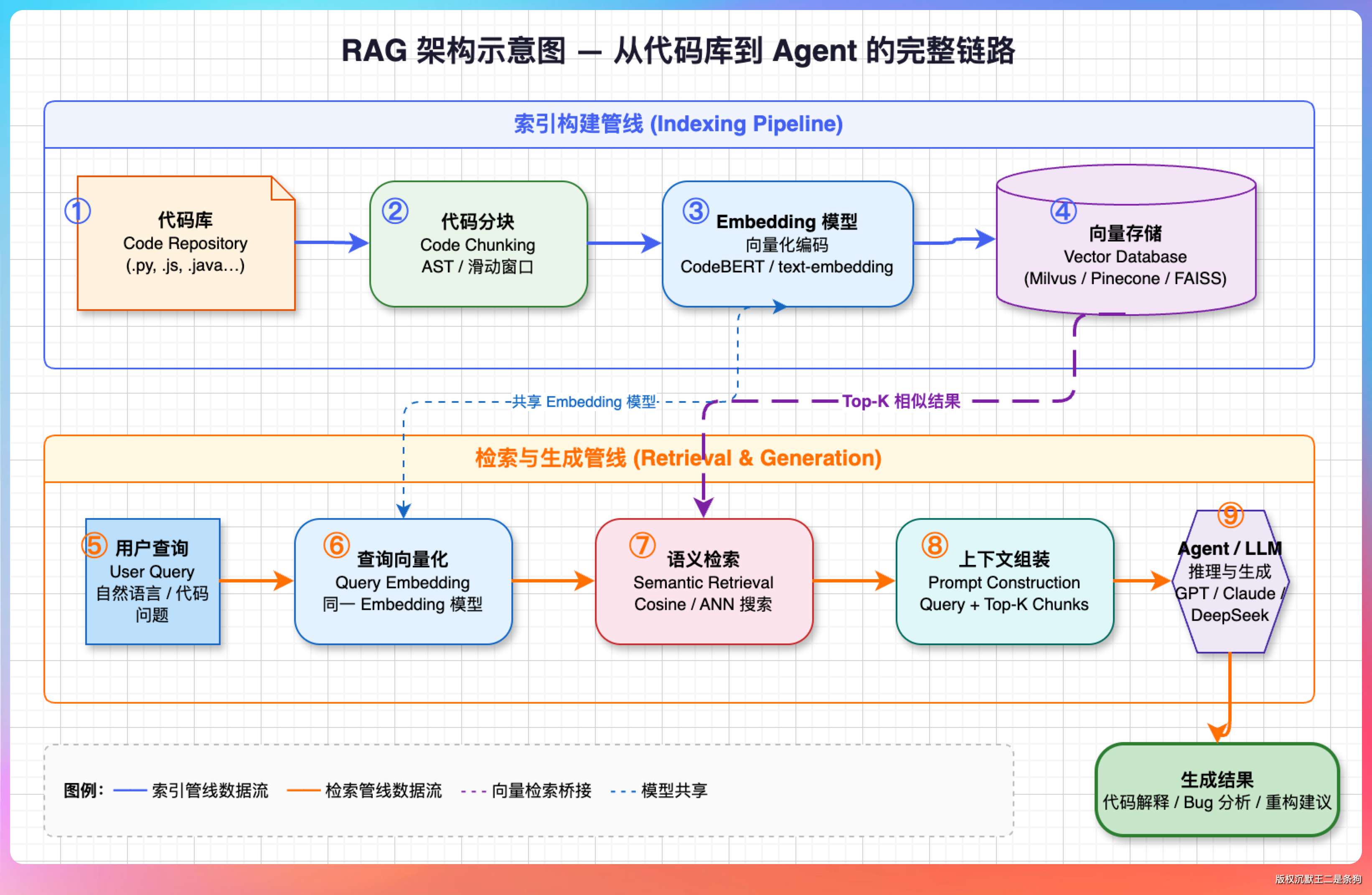
召回这一块是重头戏。我们使用ElasticSearch来完成的,索引名为 knowledge_base,向量字段用的 dense_vector,相似度 cosine。我们做了一个 KNN + BM25 的混合召回,KNN 先粗召回 topK × 30 条,然后 BM25 在这个窗口里 rescore,最终返回 topK。
老王听完说:「行,整体讲清楚了,不错。」
这句话虽然简单,却给了我很大鼓励,说实话。
02、为什么选择千问,然后为什么选择 2048 维的向量呢?
我说:「这个问题我还真研究过。」
千问 v4 这个 embedding 模型,中文场景下的表现非常不错,尤其是技术文档这种带着代码、英文、中文解释的混合内容。
我们之前对比过,同样一份 Spring Boot 教程,千问的召回准确率能比另外一家向量模型高出十几个百分点。
老王追问:「那 2048 维呢?千问 v4 不是支持 1024、1536、2048 三档吗?为什么选最大的?」
主要是两个原因。
一是精度,维度越高,向量空间表达能力越强,对长文本和专业术语的区分度越好。
二是 ES 这边的存储和计算成本我们做过测算,2048 维相比 1024 维,单条向量大概多了 8KB,knowledge_base 索引里目前有几十万条数据,多出来的存储压力可以接受。
检索这块儿因为有 BM25 兜底重排,KNN 的耗时增加在能接受的范围内。
老王手指在桌面上轻轻敲了一下:「成本算过这点不错。继续。」
内心 OS:嘿嘿,这个问题之前被卡脖子过一次,回去补了一波功课。
03、这个 KNN 向量召回以及那个 BM25 重排序是怎么做的呢?
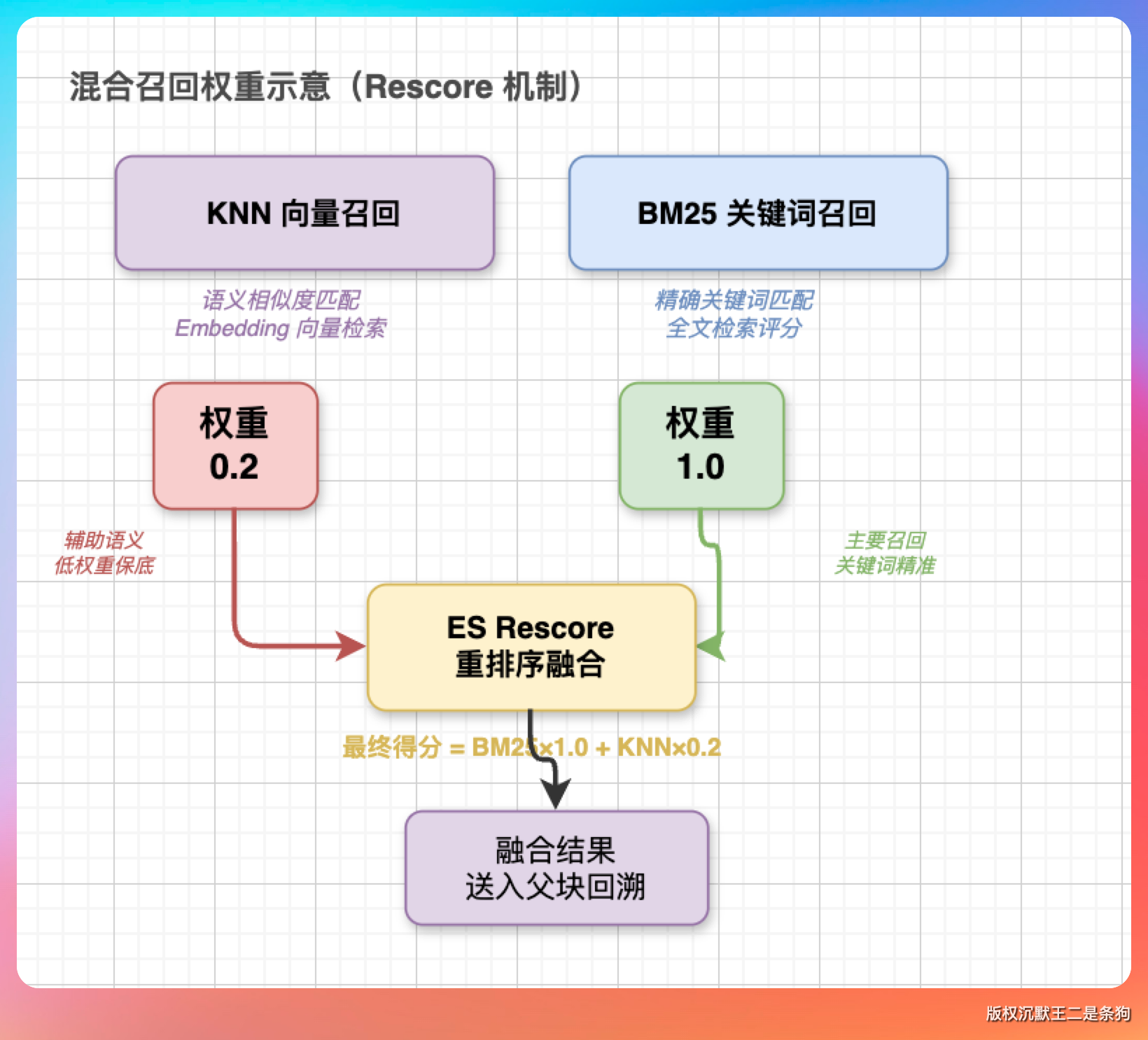
KNN 用的是 ES 8.x 原生的 _knn_search 接口。
具体参数上,我们设的是 recallK = topK × 30,比如最终要返回 10 条,KNN 会先粗召回 300 条出来。
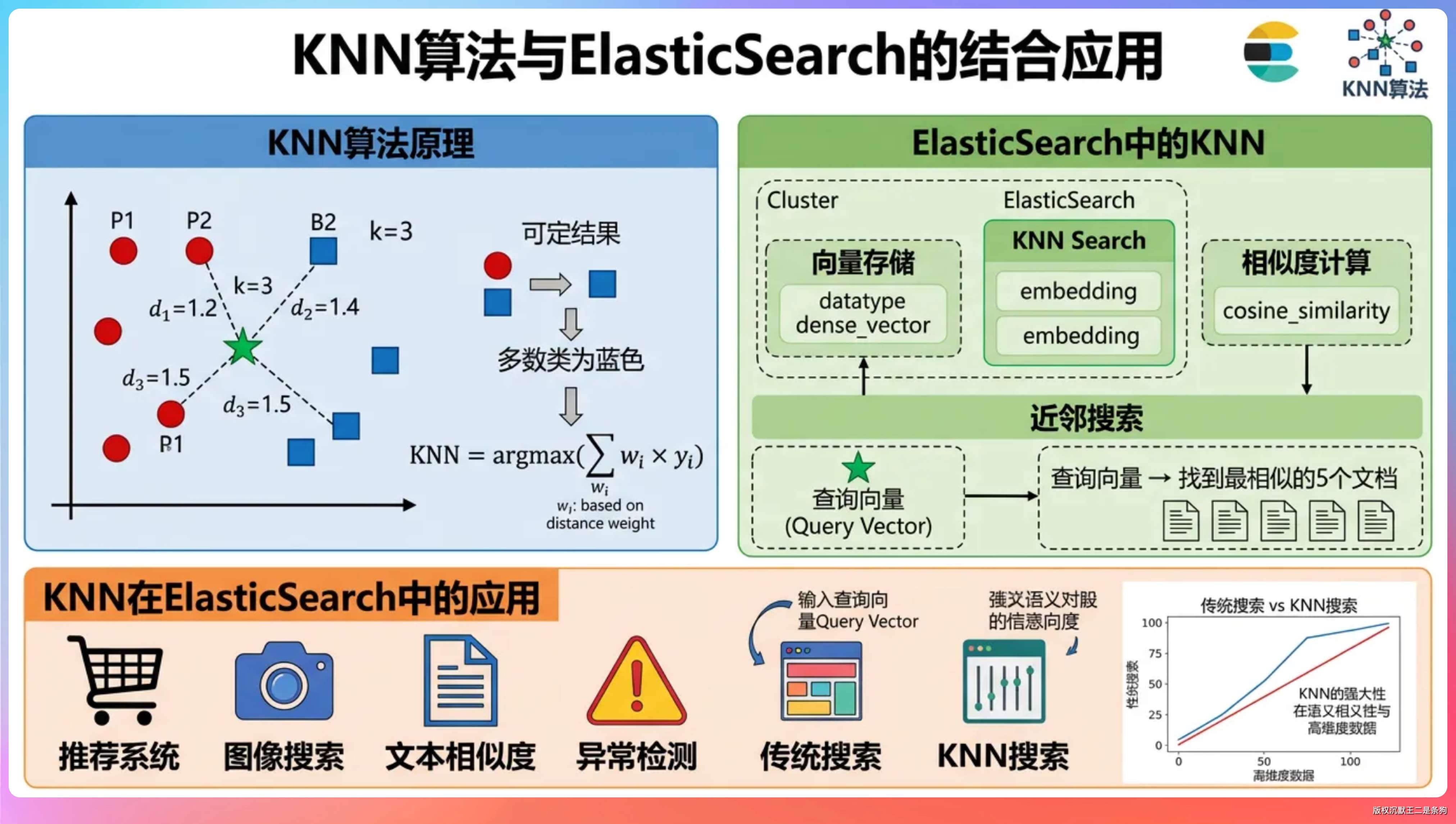
BM25 这一段走的是 ES 的 rescore 机制,在 KNN 召回出来的 300 条窗口里再排一次序。
权重设的是 KNN 占 0.2、BM25 占 1.0,BM25 是主导。
老王挑了挑眉:「为什么 BM25 占主导而不是 KNN?现在主流做法不是向量召回为主吗?」
我们做过 A/B 测试,纯 KNN 在长文档场景下会出现『语义相近但答案错位』的情况,比如用户问『派聪明的分片大小是多少』,纯 KNN 会召回一堆讲分片策略的段落,但具体的 512 这个数字反而排不到前面。
BM25 对关键词的命中很敏感,能把含『512』『chunk-size』这种精确的段落顶上来。所以我们让 BM25 来做最终判定,KNN 提供候选池。
老王面露悦色,看起来对这个回答很认可。
04、BM25 是什么呢?
BM25 是一个经典的文本相关性打分算法,全名 Best Matching 25,跟 TF-IDF 是一脉相承的。
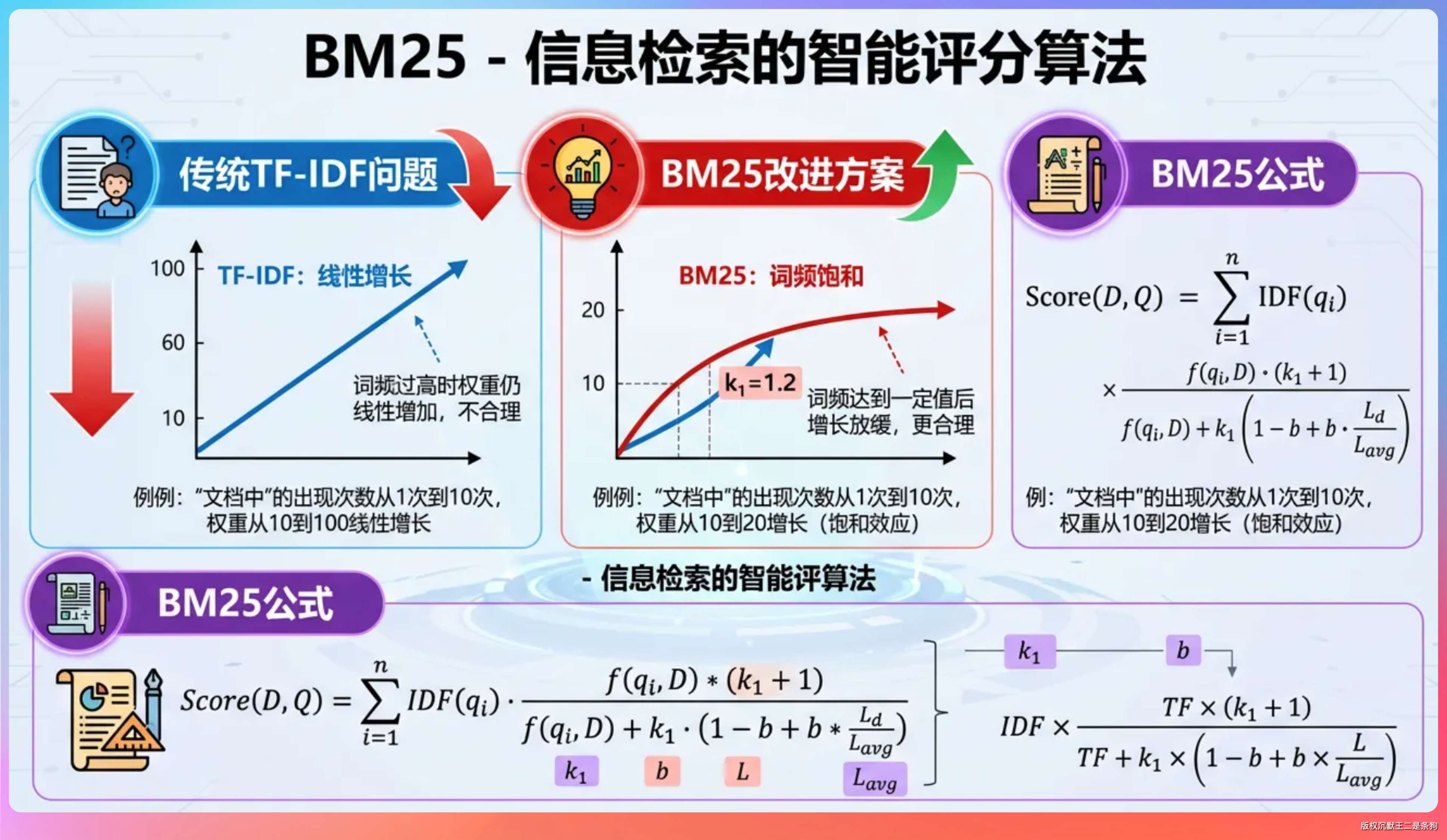
它的核心思想就三点:词频(TF)、逆文档频率(IDF)、文档长度归一化。
词在当前文档里出现次数越多,这个词对这个文档越重要;这个词在所有文档里出现得越普遍(比如「的」「是」),它的权重就越低;文档越长,单个词的权重要适当低一些,因为长文档天然占优势。
ES 默认的 similarity 就是 BM25,参数有两个,k1 控制词频饱和速度,默认 1.2;b 控制长度归一化强度,默认 0.75。我们没改过这俩参数,用的就是默认值。
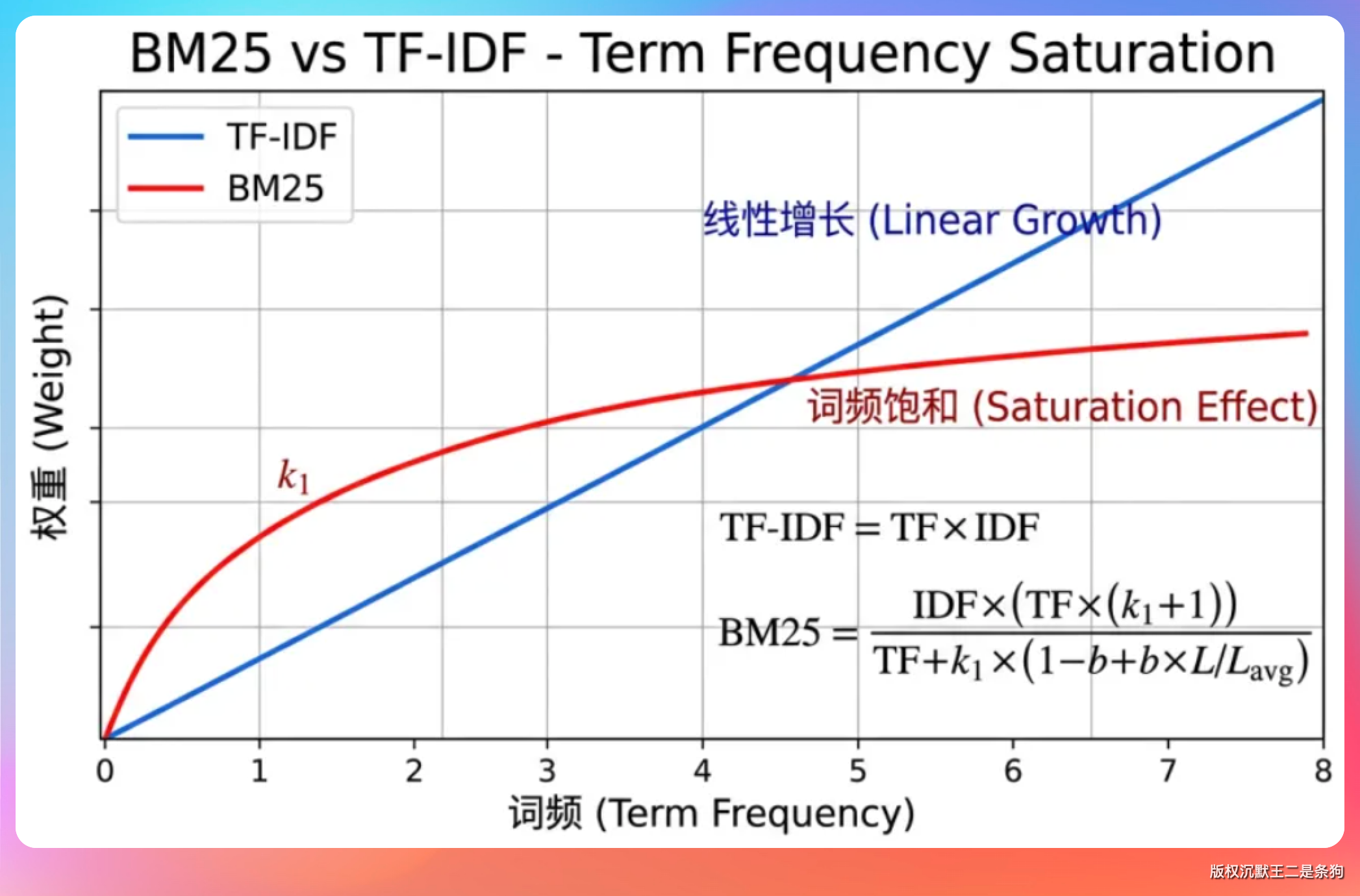
老王追问:「那 BM25 相比 TF-IDF 强在哪?」
最关键的是 k1 这个参数引入了词频饱和。
TF-IDF 里词频是线性增长的,一个词出现 100 次的文档得分是出现 10 次的 10 倍,这个明显不合理。
BM25 用一个 (k1+1)*tf / (k1+tf) 的公式让词频增长有上限,更符合人类直觉。
05、在实际完成这个项目的时候,你有哪些感悟或者说感受,这个项目是多少个人完成的?
这个项目核心开发就 3 个人,我和另外两个宿友,加上我们的导师二哥。
要说感悟,最深的一条是:RAG 这个东西,效果好不好,七成在数据,两成在召回,一成在模型。
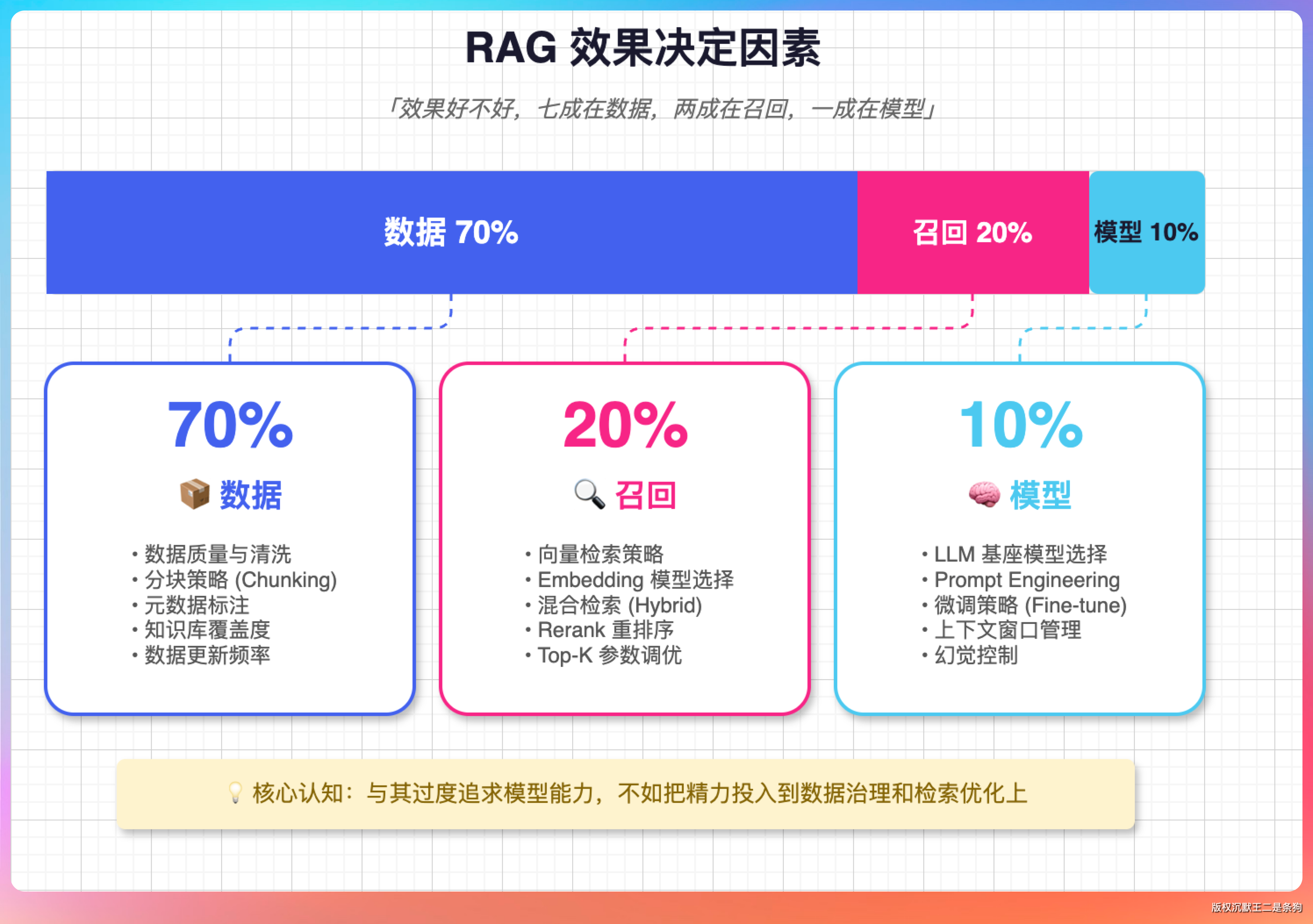
我们一开始死磕模型、调 prompt,效果就是上不去。后来回头去看分片,发现把分片大小从 1024 调到 512、再加上语义边界切分,召回准确率直接涨了一大截。
老王点点头:「这个体感我也认同。还有别的吗?」
还有一条,生产级 RAG 和 demo 级 RAG 完全是两个东西。
demo 跑通向量化 + 召回 + LLM 三步流程一周就能出来,但要加上权限隔离、多租户、文件去重、流式上传、增量更新这些,工作量直接翻 10 倍。
我们光权限这一块就做了 userId、orgTag、isPublic 三层过滤。
06、在整个这个项目当中,你觉得 AI 承担了一个什么样的角色呢?
代码生成这块儿,大概有 60% 的代码是 Codex 写的,包括 mapper、service 的 CRUD、ES 的 mapping 配置、千问 API 的封装等。
老王追问:「那剩下 40% 是什么?」
剩下 40% 是核心业务逻辑,比如分片策略、混合召回的权重调优、prompt 工程、性能优化。
这些 AI 写出来的第一版基本不能直接用,需要我们结合实际数据反复调。
07、ElasticSearch KNN 向量召回的一个响应耗时大概有多少?
我们没专门做过 SLA 测试,但从日志埋点上看,单次 KNN + BM25 rescore 的整体耗时大概在 50ms 到 120ms 之间,平均 80ms 左右。
老王追问:「这个耗时受什么影响最大?」
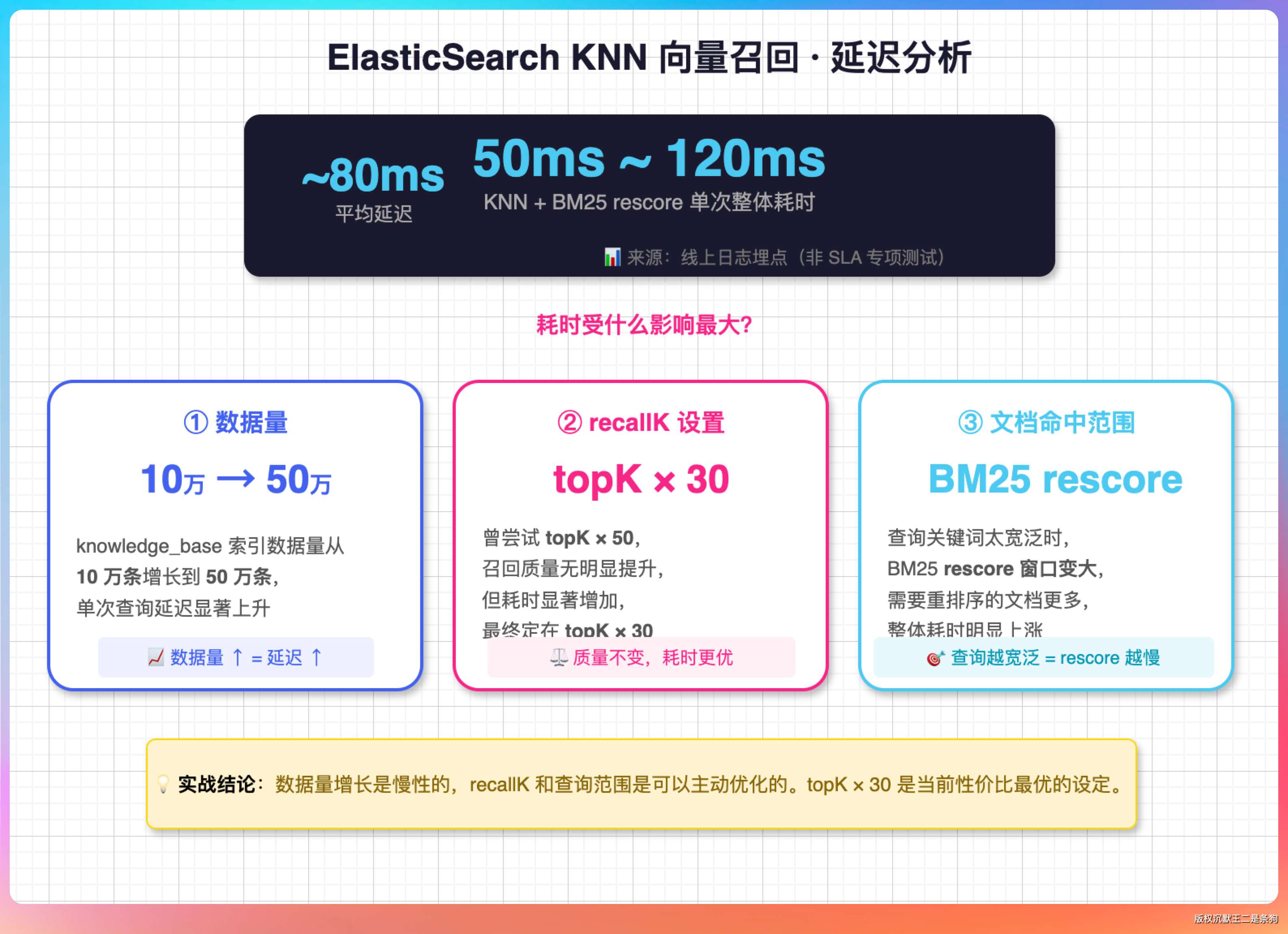
主要看三个因素。
一是数据量,knowledge_base 索引里数据从 10 万条涨到 50 万条,单次查询就会变慢。
二是 recallK 的设置,我们试过 topK × 50,召回质量没明显提升,但耗时却更多了,所以后来定在了 × 30。
三是文档命中范围,如果用户的查询关键词太宽泛,BM25 那一段 rescore 的窗口就会变大,耗时会涨。
08、为什么你们做这个东西要用 es 呢?
主要是因为它一份索引同时支持文本检索和向量检索。
如果用专门的向量数据库比如 Milvus、Qdrant,再单独搭一套关键词检索,运维和数据同步的成本就上去了。ES 8.x 之后的 dense_vector 已经够用,没必要再引入新组件。
老王追问:「ES 底层数据结构了解吗?」
文本检索是经典的 Lucene 倒排索引,文档分词后建立词到文档的映射,查询的时候直接查词。
向量检索,ES 8.x 用的是 HNSW(Hierarchical Navigable Small World)算法,简单说就是一个多层图结构,从顶层稀疏图入口往下逐层精搜,能在 O(log n) 的复杂度内找到近似最近邻。
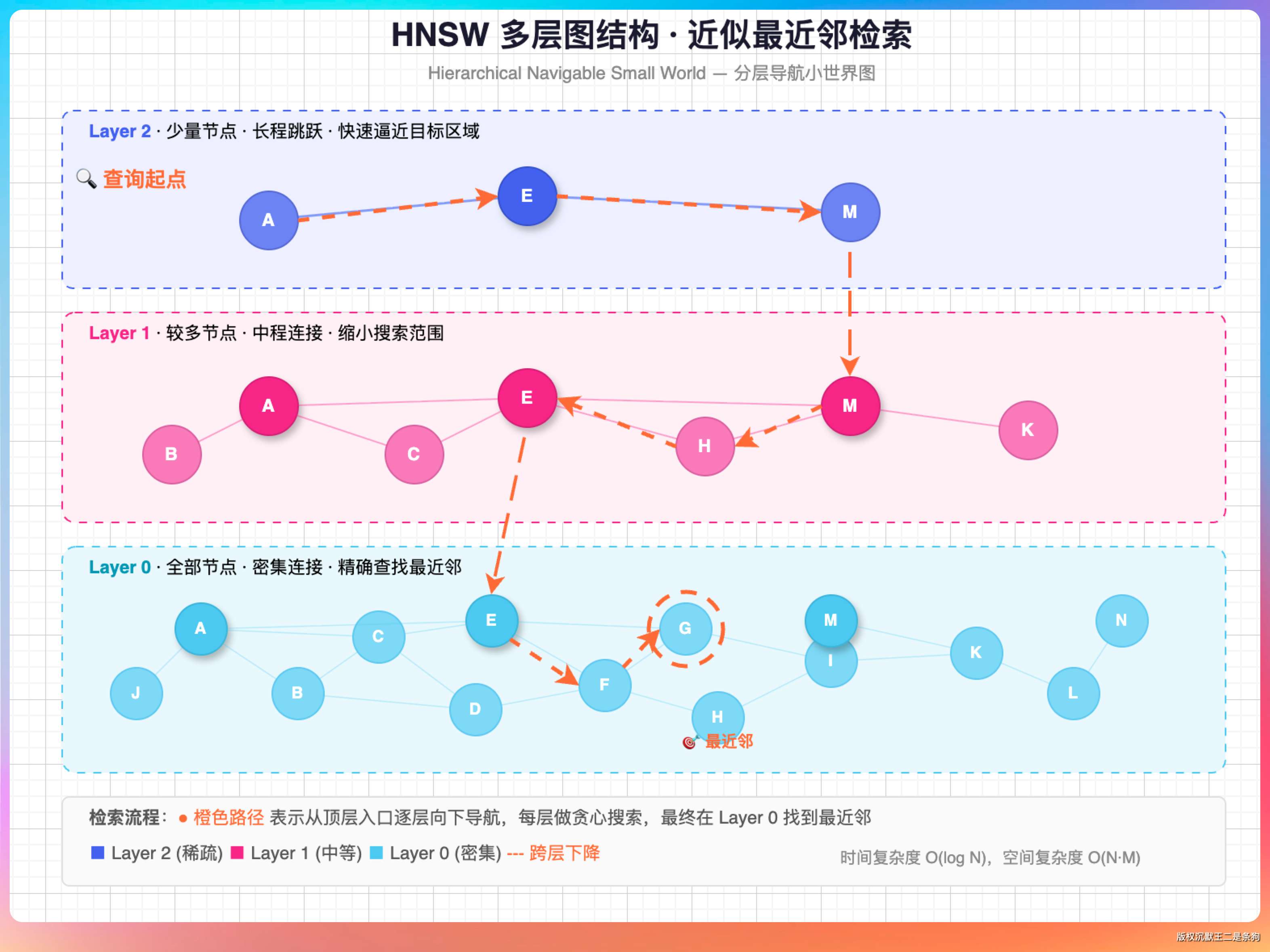
老王明显对这方面有深入的研究,听到 HNSW 的时候点了点头。
常规查询方式上,ES 主要有几种:
term 精确匹配、match 分词匹配、bool 组合查询、range 范围查询、aggregation 聚合。
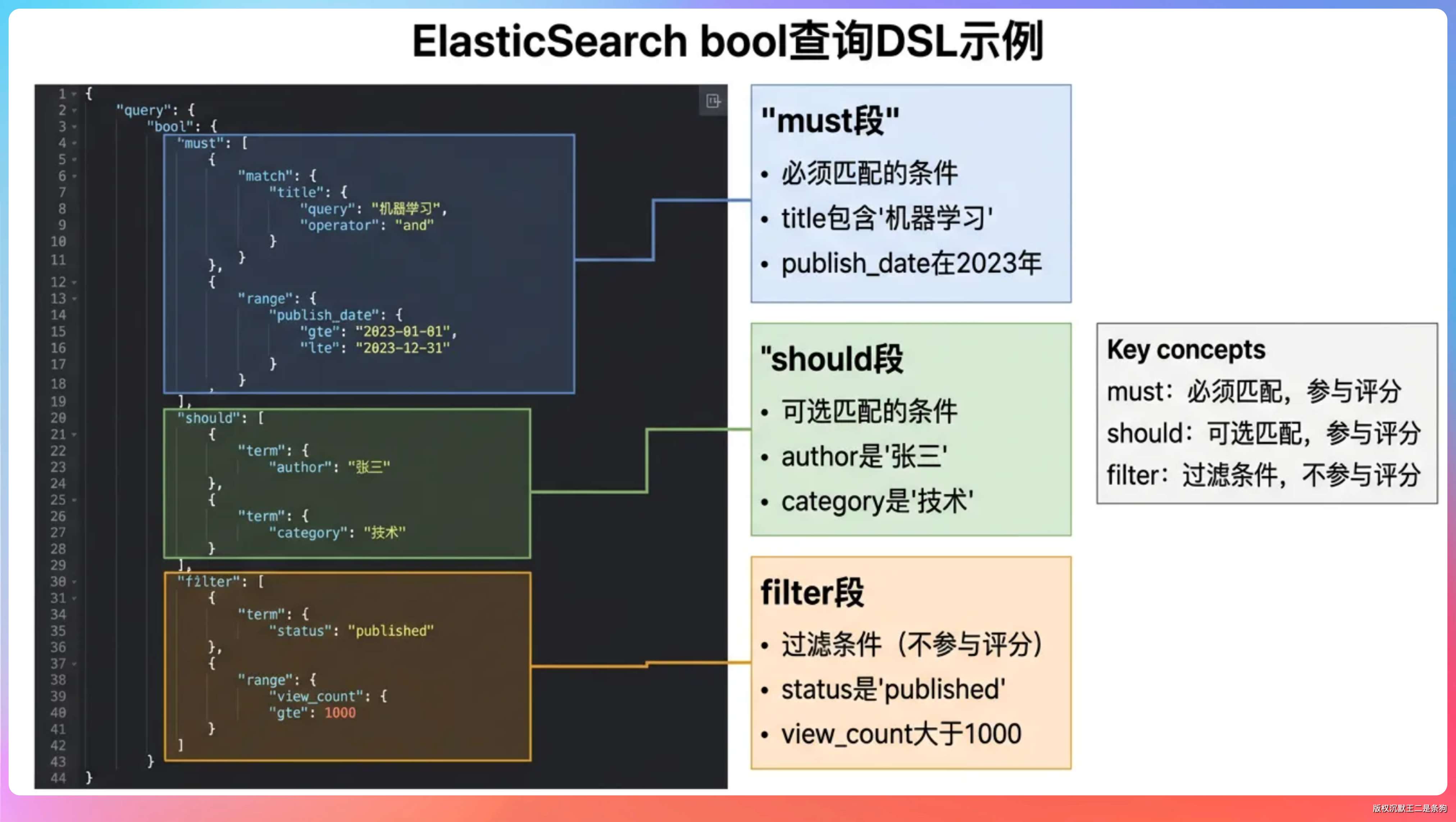
然候我们项目里最常用的是 bool + match + filter 的组合,bool 包括 must/should/filter 三种用法,should 做权限过滤,filter 做硬性过滤不参与打分。
老王面漏悦色:「这个理解到位了。」
09、AI 用的模型是啥什么?
我们项目里用了两个 AI 模型,一个是 embedding,一个是 LLM。
embedding 用的是阿里千问 text-embedding-v4,2048 维。
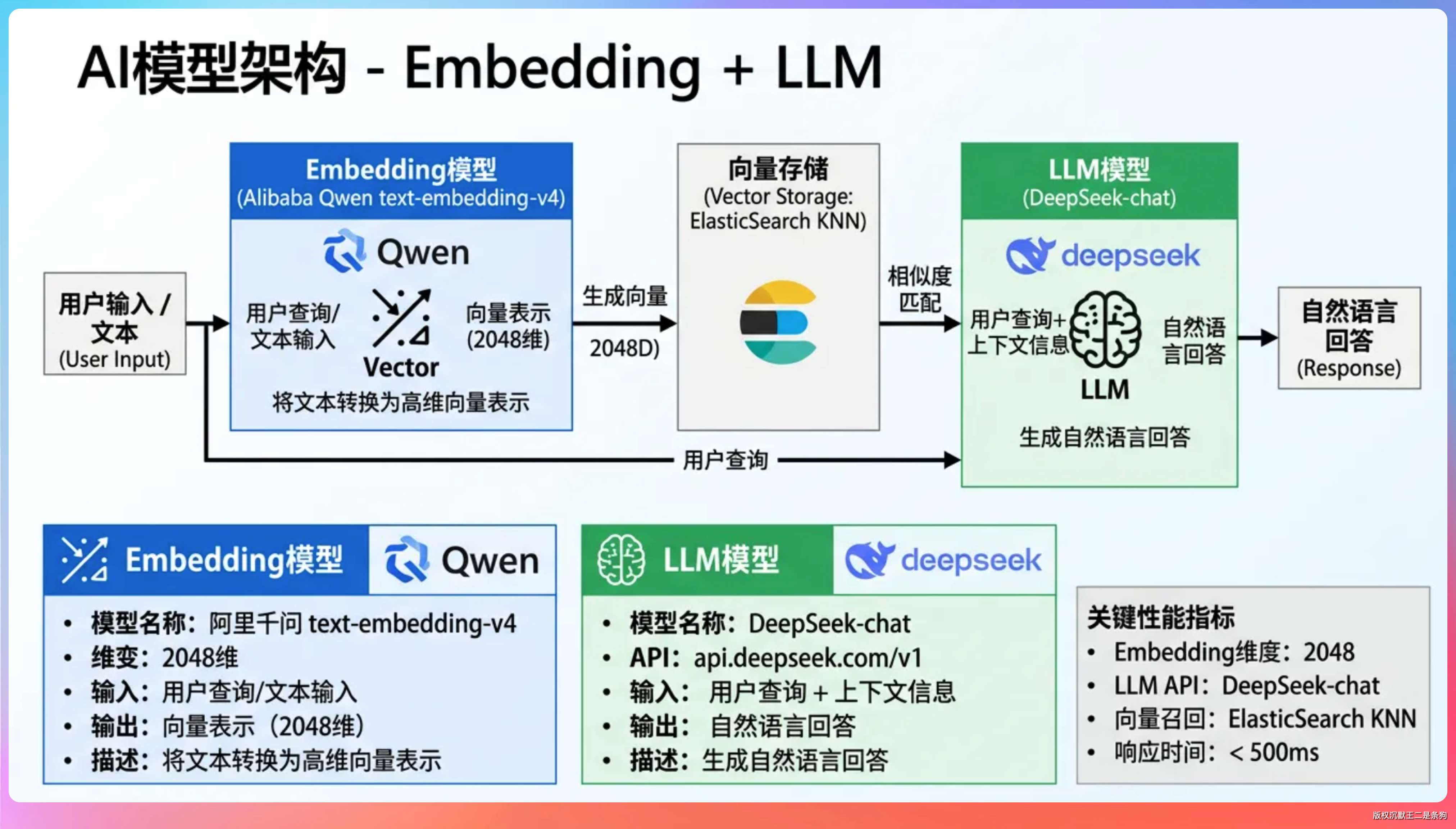
LLM 用的是 DeepSeek-chat,走官方 API(api.deepseek.com/v1)。
老王追问:「为什么 LLM 选 DeepSeek 而不是千问或者 GLM?」
主要是性价比。
DeepSeek 的输出质量在 Top 梯队,但 API 价格只有 GPT 的几十分之一,对我们特别友好。
10、你平时在用那个 AI 编程的时候,是怎么去使用的?
Claude Code 主要用来处理文本,Codex 主要用来编码。
为了方便使用,我在IntelliJ IDEA中也接入了Codex,阅读代码的时候非常好用;Claude Code 也做一个 PaiSwitch 控制台,可以切换底层的模型,Kimi 和 GLM 都在用。
老王追问:「Claude Code 你用过哪些 Skill?」
Frontend-design(前端设计)、Skill-creator、web-access 等,最后一个最好用,可以让Agent的联网能力拉满,如果有些内容需要登录才能访问,这个Skill 可以通过 cdp 直连 Chrome 已登录的标签页。
11、那怎么知道 AI 做的对不对呢?
我现在的做法分三层。
第一层,让 AI 自己给出验证方案。比如它写完一个接口,我会让它再跑一遍单元测试,或者写一段 curl 命令验证。
第二层,**关键路径必须多个 Agent review。**比如说Codex写完代码,我会开Qoder的专家团进行测试。
第三层,亲自动手测试。虽然说 Codex 可以用 computer use 控制浏览器进行测试,但有些难产的问题 Agent 现在还是没办法触及到,还是需要亲自动手去测。
12、平时会关注一些就是技术前沿的动态吗?怎么关注的呢?以什么方式呢?
主要是 X、GitHub trending、Hacker News 这三个渠道。
X 上我关注了一批活跃的开发者和官方账号,包括 Anthropic、OpenAI、DeepMind 这些大厂,还有一些独立开发者比如 swyx、karpathy。
还关注了一个叫二哥狗腿子的账号,每天都会分享一些硬核AI知识,学到很多。

Hacker News 我用 OpenClaw 跑了一个定时任务,每天早上推送一封邮件给我,把前一天 top 30 的帖子和评论摘要发给我,能了解到不少。
13、那如果说我们要把这个 rag 升级成一个智能体需要怎么做?
核心改造有三块。
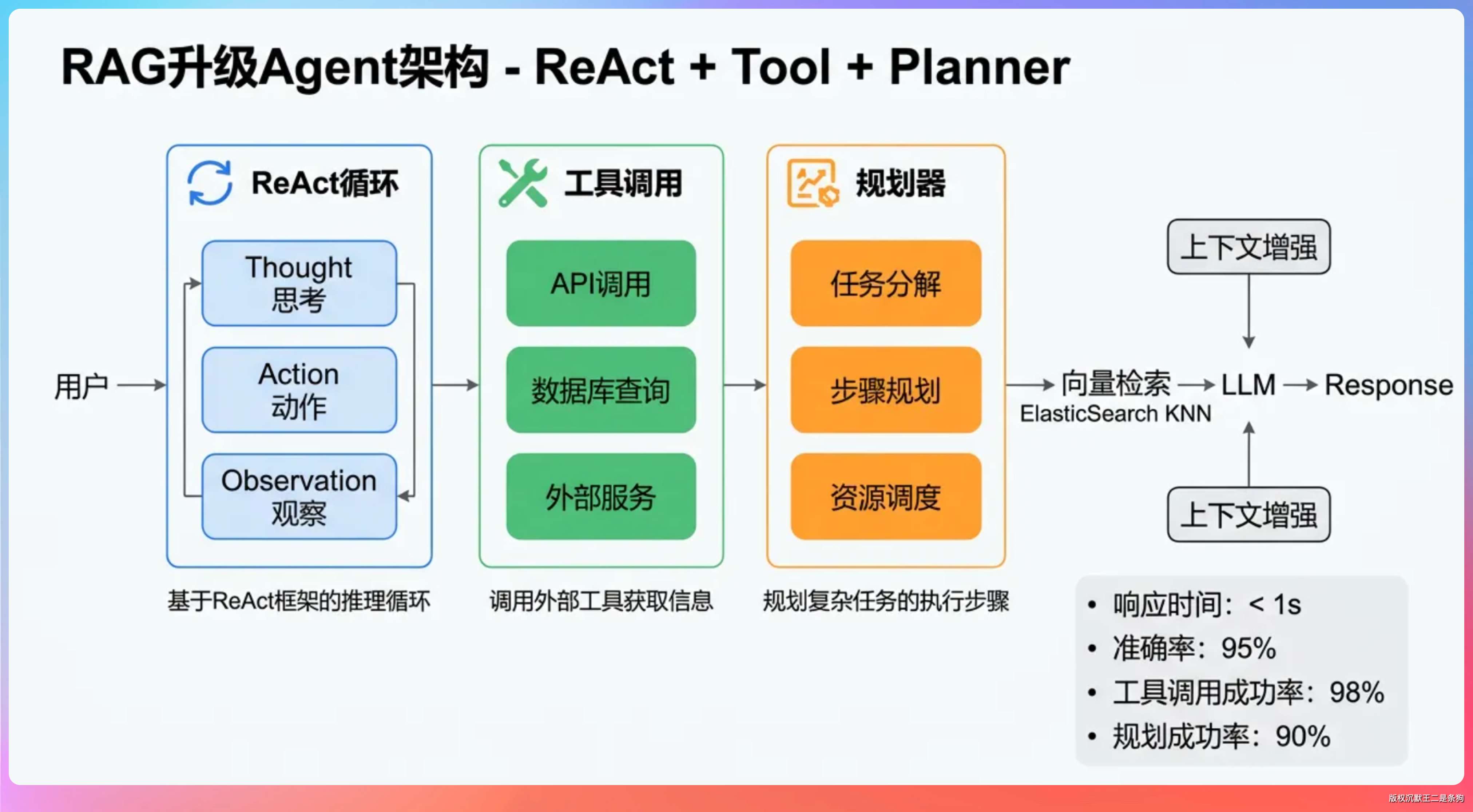
- 一是把检索从『一次性查询』改成『循环查询』,让模型能根据中间结果决定要不要再查、查什么。
- 二是引入工具调用,除了知识库检索,再加上联网搜索、SQL 查询、文件读写这些原子能力。
- 三是加一个规划器(Planner),让模型先把用户问题拆成子任务,然后逐个执行。
老王追问:「具体到PaiCLI Agent,你会怎么改?」
最简单的方案是引入一个 ReAct 循环。
让模型思考完再执行,然后观察结果后再思考,不断重复。
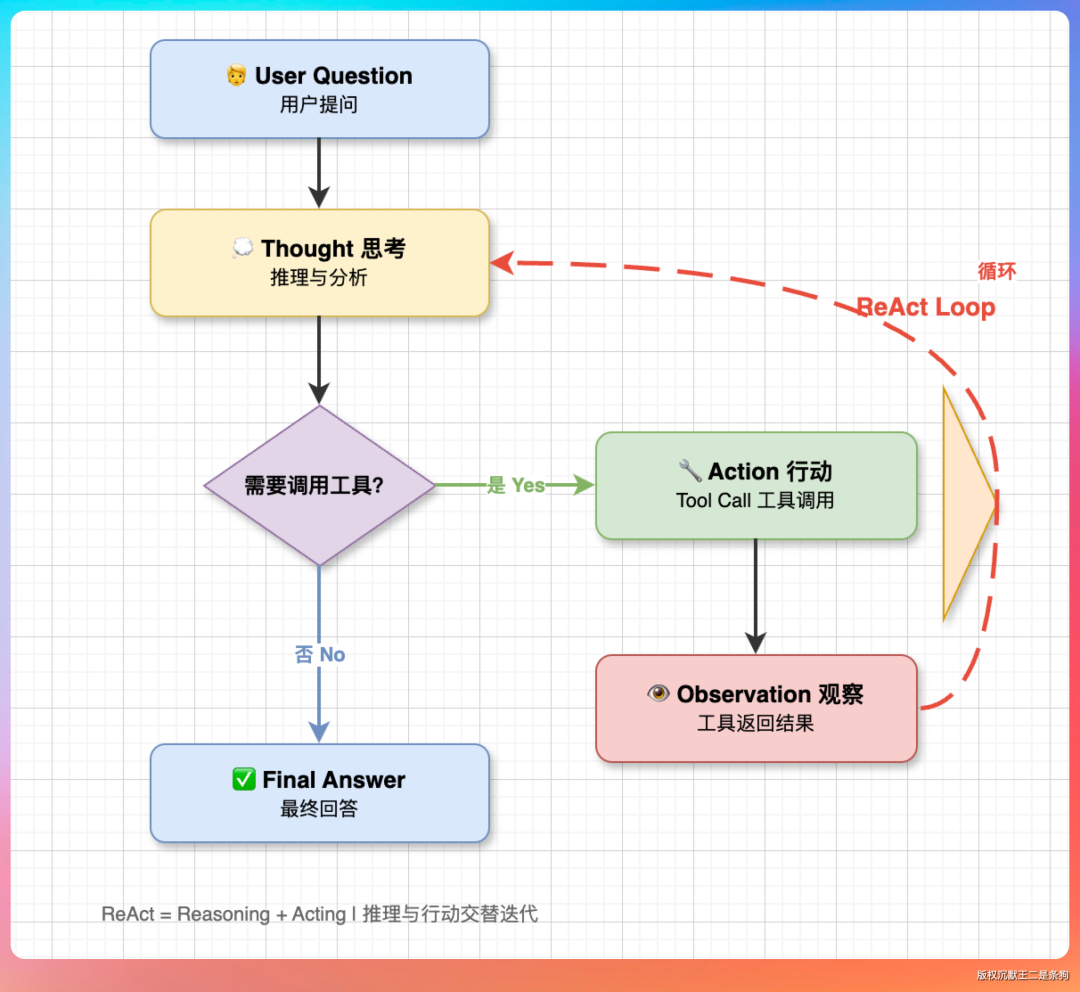
调用 ES 检索,观察 ElasticSearch 的返回。直到模型输出 Final Answer 结束循环。这套机制 LangChain、LangGraph 都有现成的实现,搬过来就能用。
不过要做到生产可用,还得加上几个东西:
超时和最大轮次限制(避免死循环)、中间状态持久化(避免一次失败全部重来)、人工介入接口(关键决策需要确认)。
14、你是怎么理解 skills, mcp 还有 tool 的?
这三个东西在 Claude Code 里经常一起出现,但定位不同。
Tool 是最底层的原子能力,比如读文件、跑命令行、查数据库,每个 Tool 就是一个函数签名 + 一段执行逻辑。模型通过 Function Calling 调用 Tool,参数和返回值都是结构化的 JSON。
MCP 是 Tool 的标准化协议。MCP 规定了一套统一的协议,让 Tool 可以打包成独立的 Server,被任何支持 MCP 的客户端调用。Claude Code、Codex 这些工具都支持 MCP。
Skill 是工作流的封装。是一套「做某件事的完整方法论」,包含了 prompt 模板、调用顺序、判断逻辑、甚至子 Skill 的调用。Anthropic 把 Skill 放在 .claude/skills/ 目录下,每个 Skill 是一个文件夹,包含 SKILL.md(说明)、references(参考资料)、scripts(辅助脚本)。
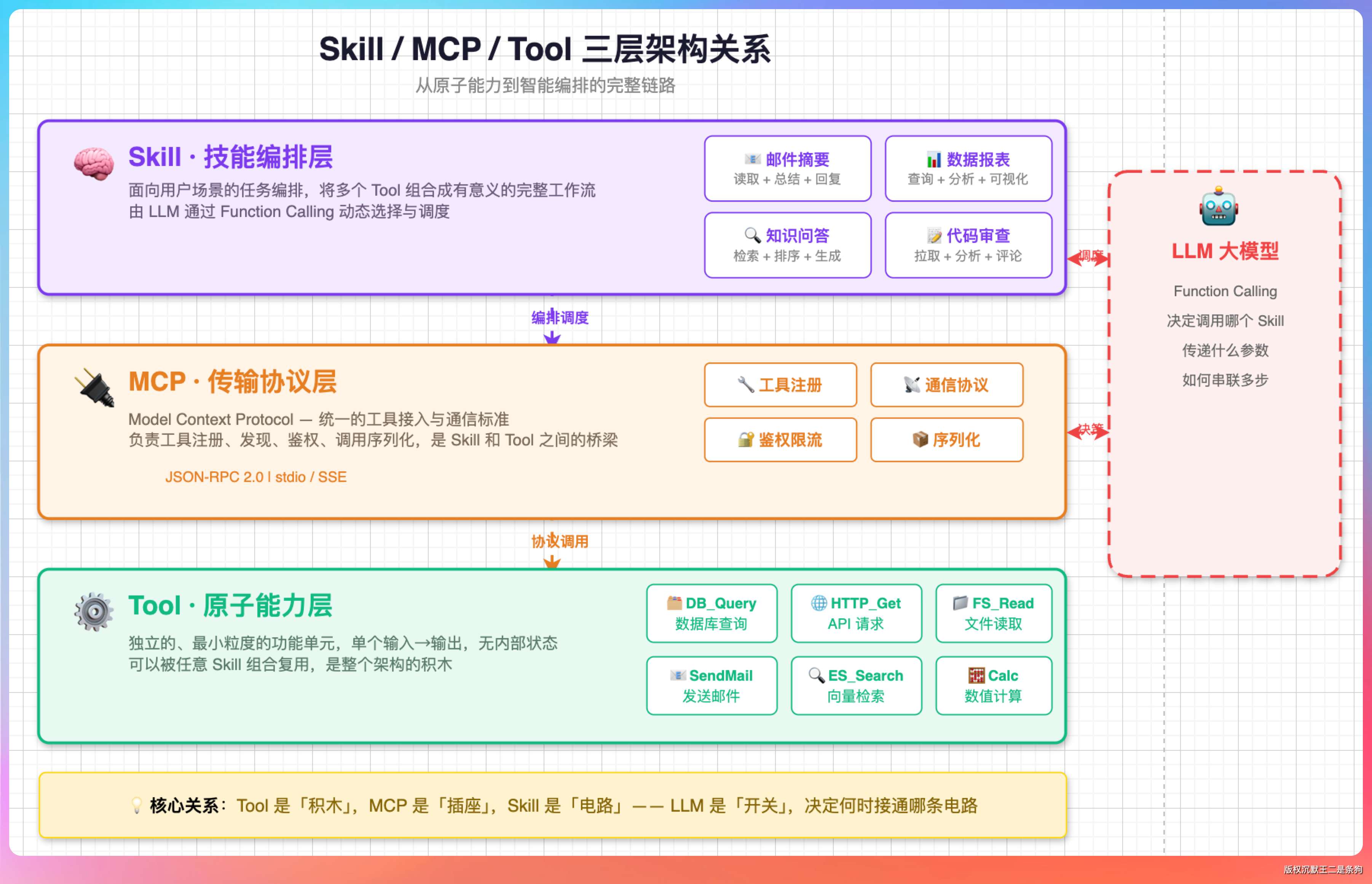
老王追问:「那这三者是包含关系吗?」
不完全是。
Tool 是原子能力,MCP 是 Tool 的传输协议,Skill 是基于 Tool 和 prompt 编排出来的高阶能力。
可以这么类比:Tool 像是 Linux 里的 cat、grep、awk 这些命令;MCP 像是 shell 这个统一接口;Skill 像是写好的 shell 脚本。
老王听完这个类比,忍不住乐了:「这个类比挺贴切。」
15、那么在实际的使用当中,就是说你在 AI 编程的过程当中,你觉得哪种会用的比较多?
Skill 用得最多,MCP 排第二,原生 Tool 用得最少。
Tool 属于底层的东西,Agent 直接就封装好了。
MCP 的话,我目前用的最多的是 Chrome Devtools MCP和IntelliJ IDEA,可以接入到 Agent中使用。
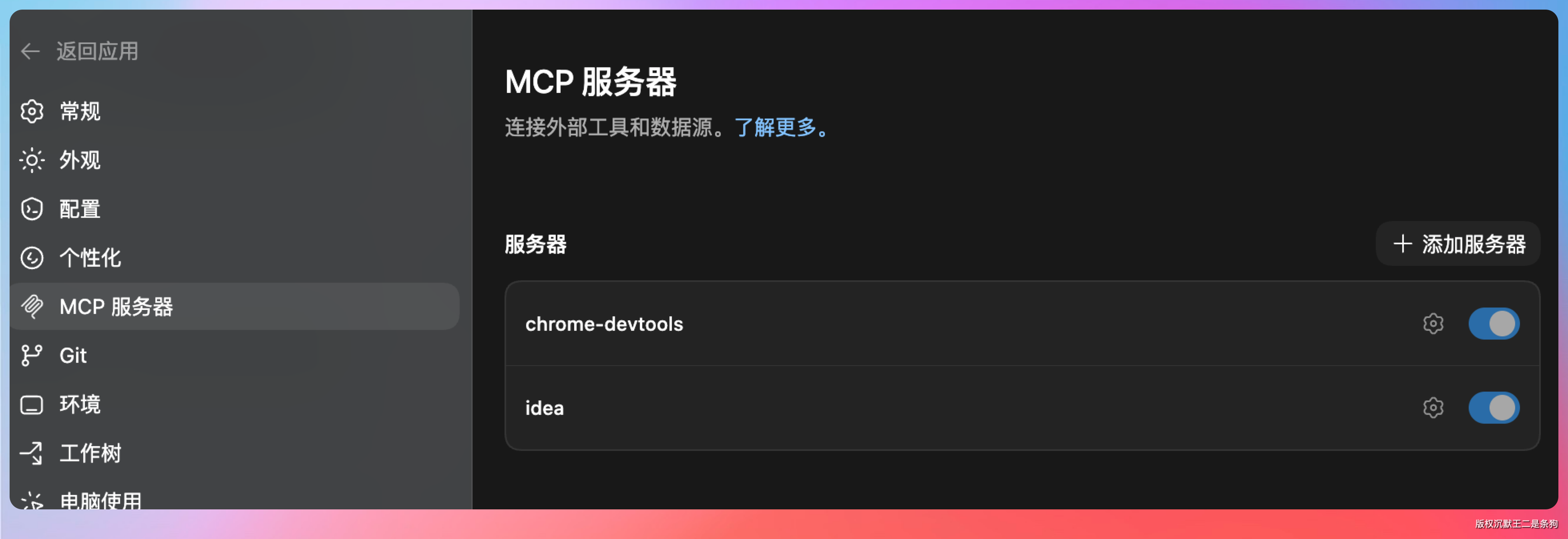
Skills 话,目前用得比较多,如果GitHub上有开源的现成的,比较好用的,我会直接拿来用。没有合适的话,我会自己让 Agent 根据我的工作流去生成。
老王追问:「那 Skill 有什么坑吗?」
最大的坑是 Skill 的描述写不好,模型就不会主动触发。
Skill 的 description 字段相当于一个分类器,模型看到用户请求之后会判断要不要加载这个 Skill。description 写得太宽泛,会被误触。
16、自己写过 skills 吗?没有,那有看过 skills 的具体实现吗?
写过不少。
比如说我之前蒸馏过王小波.skill,出来的效果还是挺有趣的。
老王眼睛一下亮了:「能讲讲怎么写的吗?」
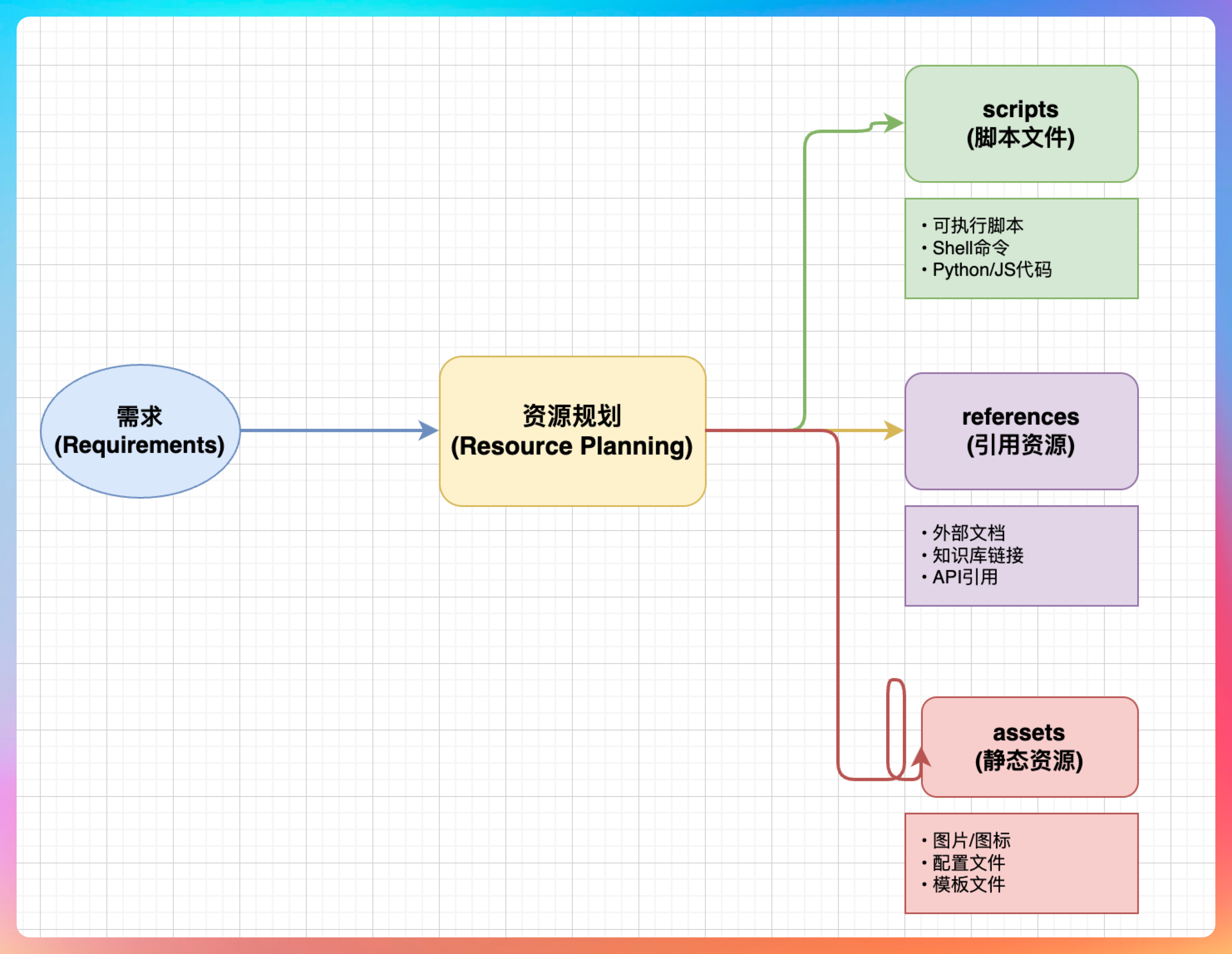
Skill 的核心就是三个文件。
第一个是 SKILL.md,frontmatter 里写 name 和 description,正文写工作流。第二个是 references 目录,放参考资料,比如风格指南、历史文章样本。第三个是 scripts 目录,放辅助脚本,比如检查字数的 Python 脚本。
老王听完,长长地舒了一口气:「行,我们差不多就到这。」
我反问了一句:「就面个实习至于上这么大强度吗?」
老王笑了笑:「你对 RAG、Agent、MCP、Skill 理解的很到位,所以要求高一点。一会儿 HR 会和你聊。」
走出会议室的时候,我看了一眼手机,整整一个半小时。
内心 OS:老王这体力是真好,还特么能问,劳资快顶不住了。