AI Agent 面试题第二弹:Memory 系统、RAG 检索、长上下文工程 13 题
老王这次换了副金丝眼镜,像极了某个互联网大厂的 CTO,眼神犀利但嘴角带笑,看起来今天心情不错。
老王翻了翻我的简历,“你这个 PaiCLI 写了三层记忆架构、RAG 向量检索、长上下文自适应,挺能吹的啊。”
(内心 OS:王哥你别说吹,这些我一行一行码出来的😤)
我说:“王哥,这几块确实是 PaiCLI 的核心。记忆系统做了三期,第 3 期做 Memory、第 4 期做 RAG 代码库理解、第 12 期做长上下文工程。最近还做了两个升级——长期记忆加了项目级隔离,代码检索从 RAG 一把梭改成了精确搜索优先、RAG 语义兜底。”
老王露出感兴趣的表情:“行,那就从记忆系统开始聊。”
content
01、Agent 的记忆系统分哪几层
老王问:“先说说整体架构,你们的记忆系统是怎么分层的?”
我说:“三层。短期记忆、长期记忆、外部记忆。”
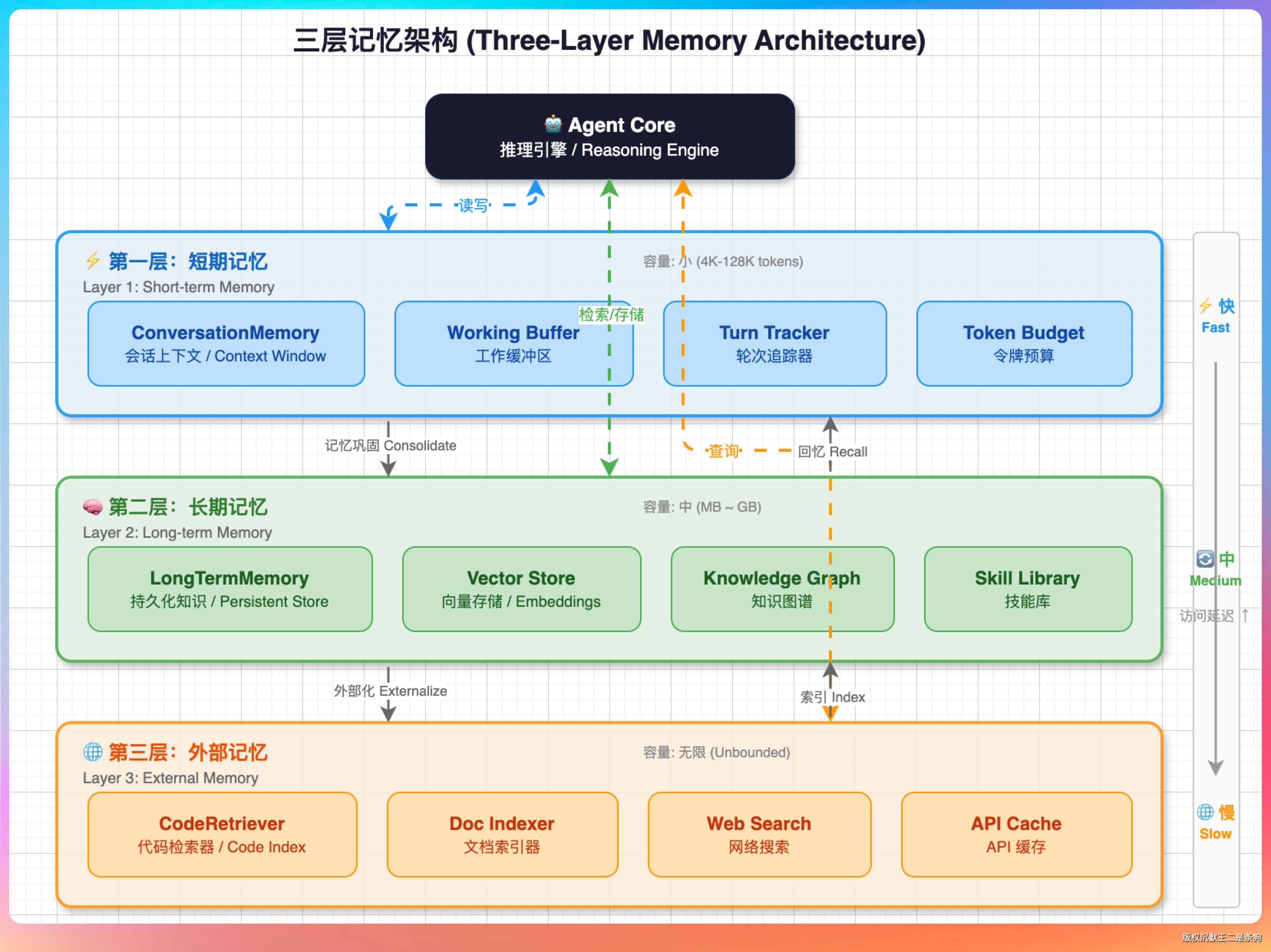
短期记忆就是当前对话的消息历史——用户输入、模型回复、工具调用和结果,每一轮都在追加。生命周期是一次会话,关掉终端就没了。
长期记忆是跨会话持久的。
用户说“记一下这个项目用 Java 17”,Agent 就把这条事实写到本地 JSON 文件里。下次开新会话,Agent 从文件里检索和当前对话相关的条目,注入到上下文中。这样跨会话 Agent 也能“记住”用户的偏好和项目背景。
外部记忆就是通过检索访问的外部知识库,不在对话历史里常驻,需要的时候按需查。
PaiCLI 的外部记忆有两条路:
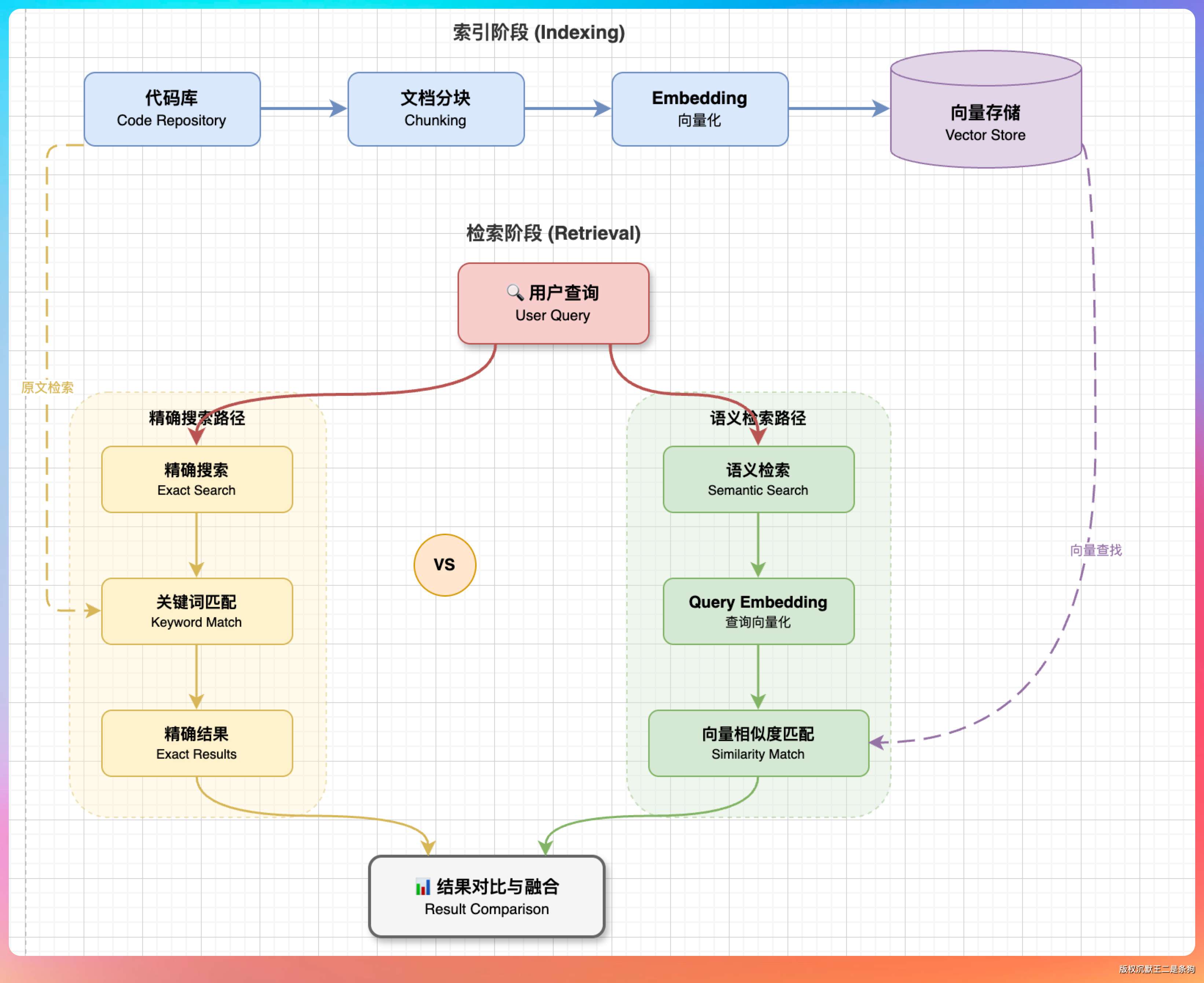
- 一条是精确搜索,按关键字或正则实时扫描项目文件树;
- 另一条是 RAG 向量语义检索,从预建的 Embedding 索引里找相关代码段。
Agent 优先走精确搜索,只有查询太模糊、关键词难确定的时候才走 RAG。
老王追问:“三层之间怎么协调?”
我说:“有一个统一的管理者负责协调。每轮请求模型之前,它会做三件事:从长期记忆里检索相关条目,从外部记忆拿到检索结果,然后把这些和短期记忆里的对话历史一起拼装成完整的 prompt 发给模型。三层各司其职,管理者负责‘调度’。”
02、短期记忆会溢出吗
老王问:“对话聊久了,短期记忆会不会撑爆上下文窗口?”
我说:“会。”
模型有上下文窗口限制,GLM-5.1 是 200k token,DeepSeek V4 是 1M。
看起来很大,但对话历史不管理的话,几十轮下来就可能满了。特别是工具调用的结果——读一个大文件可能就是好几千 token,命令行输出如果不截断也是灾难级别的。
PaiCLI 的做法是实时跟踪当前对话占用的 token 数。当占用接近窗口的 90%,自动触发摘要压缩。
老王追问:“压缩具体怎么做?”
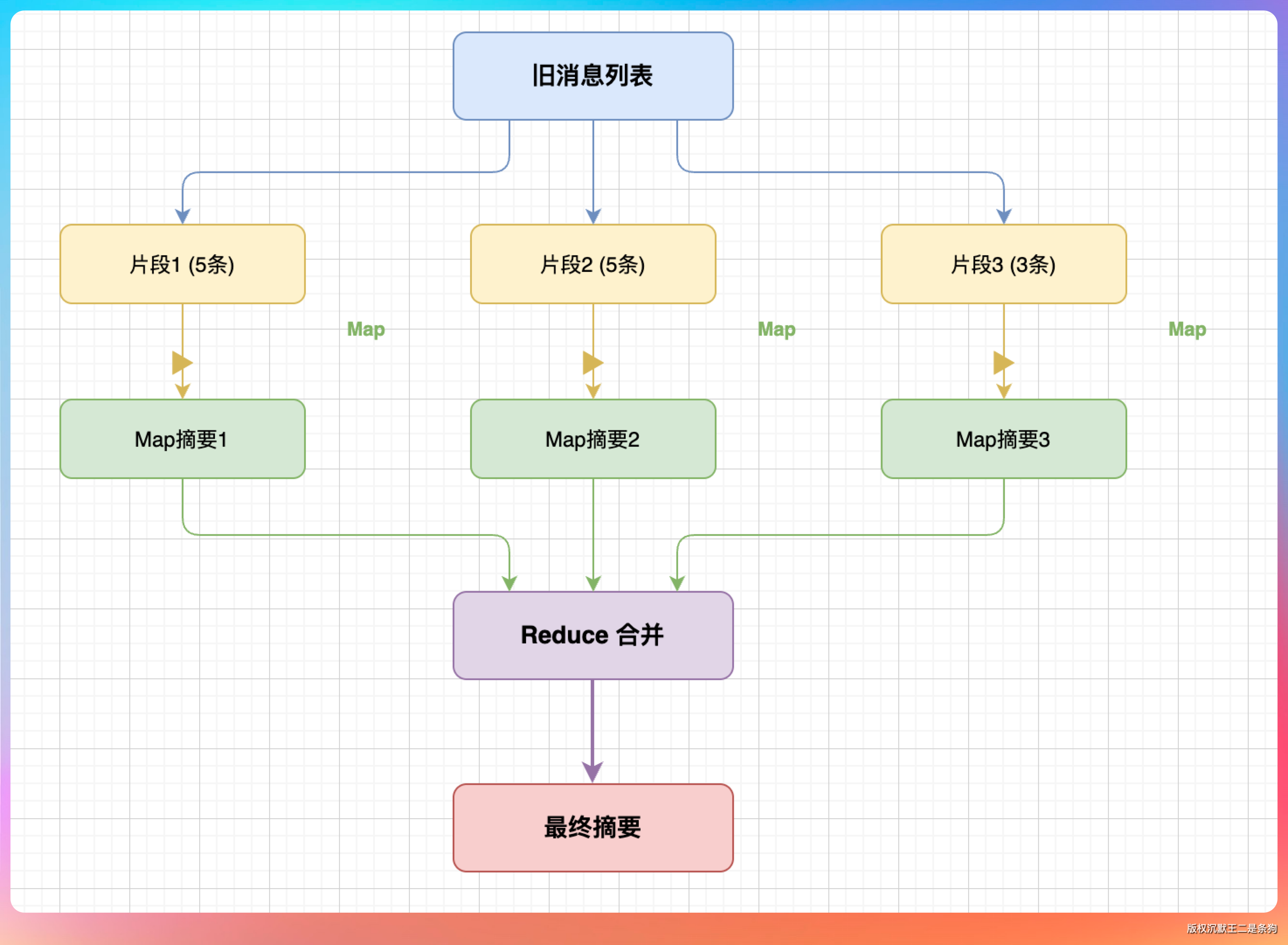
我说:“第一套是 Memory 系统里的短期记忆压缩,用的是 Map-Reduce 摘要:旧消息先按片段生成摘要,再把多段摘要合并,最后把摘要写回短期记忆。”
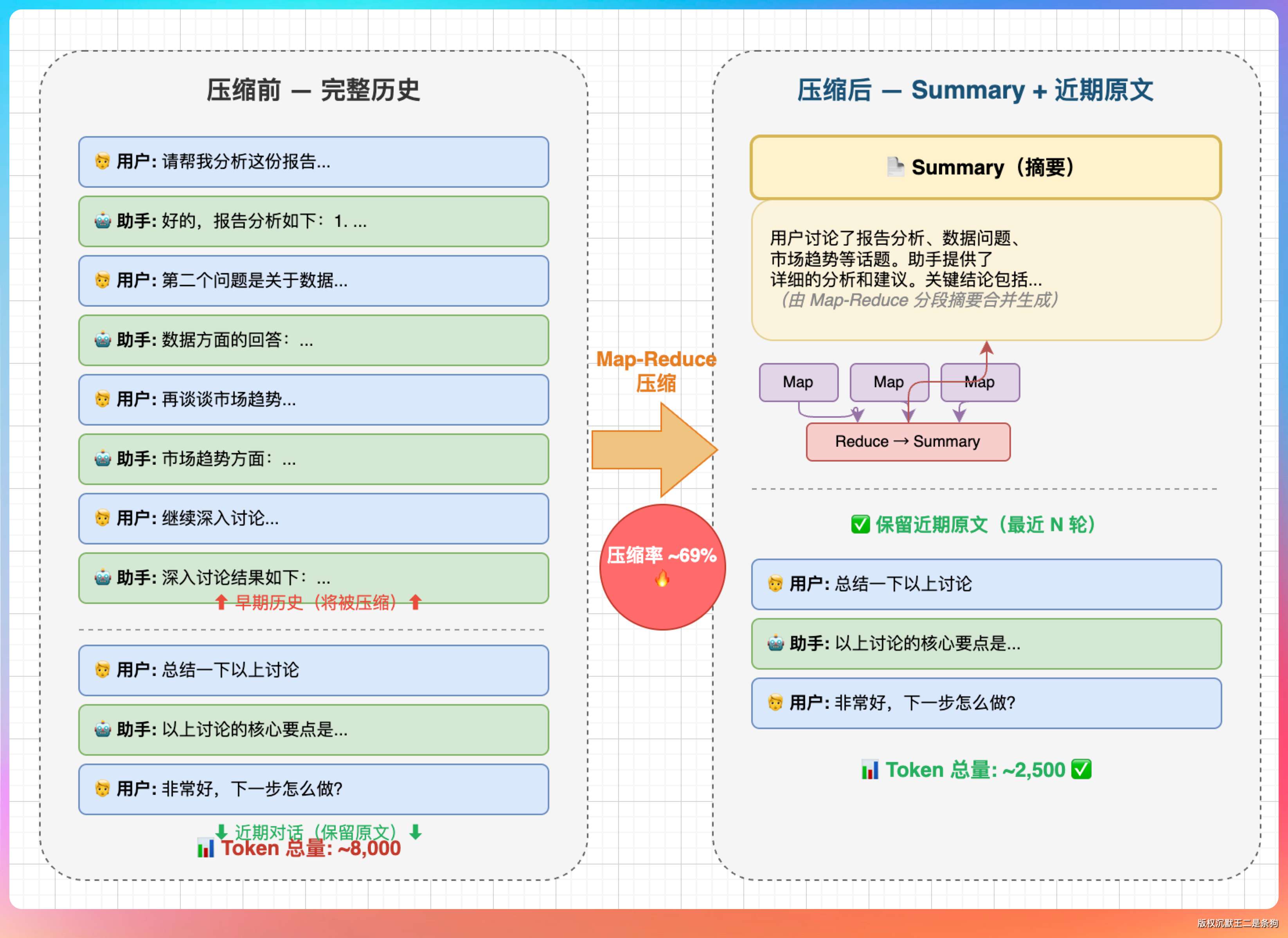
“第二套是 conversationHistory 压缩,压的是 Agent 真正发给 LLM 的消息列表。它不是 Map-Reduce,而是在调用 LLM 前检查 token,达到阈值后,把 system 后面、最近 3 个 user 轮次之前的旧消息交给 LLM 总结成一段摘要,再重建消息列表。”
原始 history:
[system, user1, assistant1(tool_call), tool1, ..., user20, assistant20]
压缩后:
[system,
user("[已压缩的历史对话摘要]\n" + summary),
assistant("好的,我已了解之前的上下文,请继续。"),
最近 3 个 user 轮次开始的尾部消息]关键是分割点必须落在 user message 边界,不能切断 assistant tool_call 和 tool result 的配对关系。否则 OpenAI-compatible API 会发现 tool_call_id 找不到对应 tool 消息,轻则模型理解混乱,重则直接 400。
(内心 OS:这个坑我踩过,第一版把所有历史都压缩了,模型回答前言不搭后语,调了一晚上才发现问题🥲)
03、长期记忆什么时候存、什么时候取
老王说:“聊聊长期记忆,什么时候存、什么时候取?”
我说:“先说存。两条路径触发。”
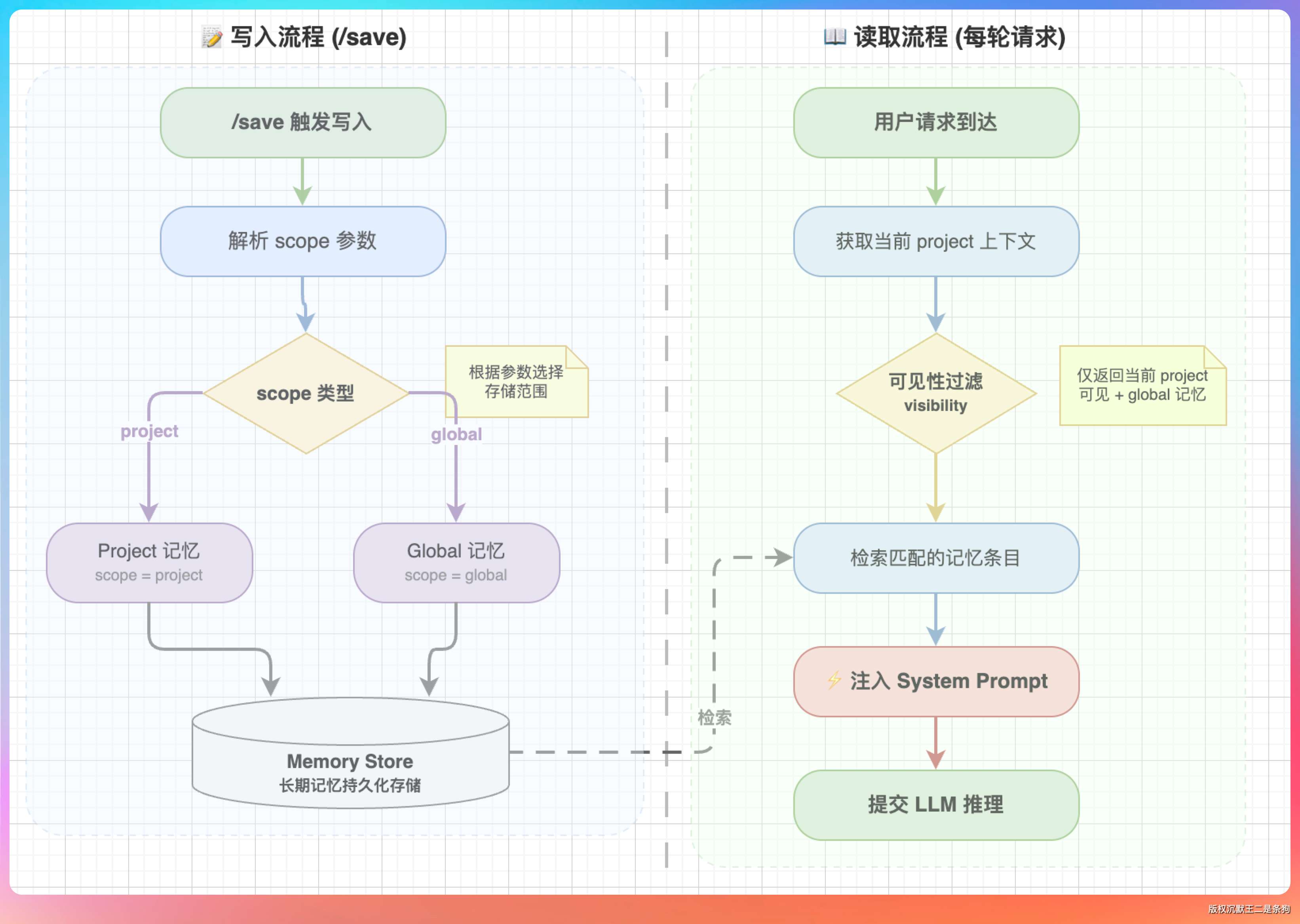
第一条是用户显式存,比如输入 /save 这个项目用的是 Java 17。
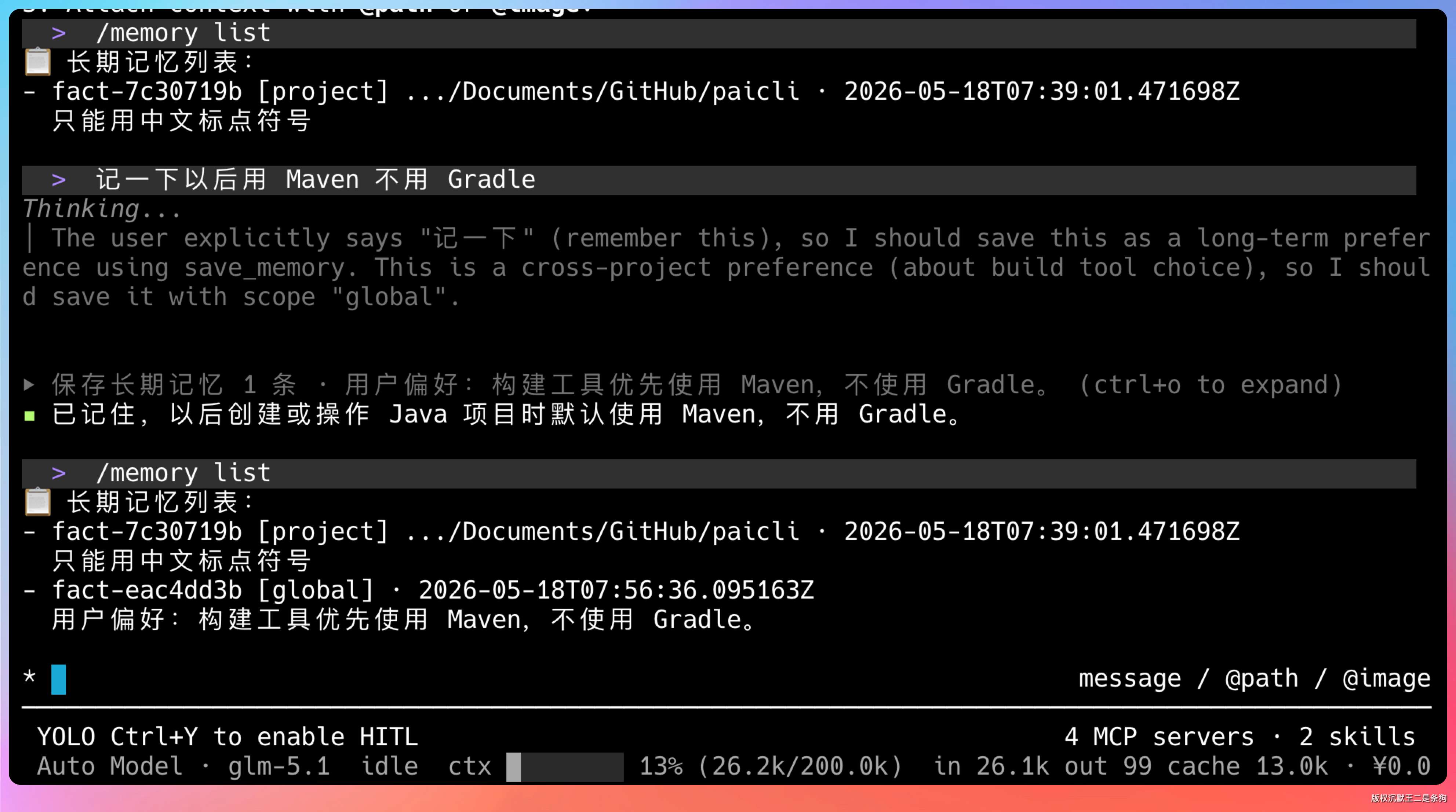
第二条是 Agent 主动存,用户说“记一下以后用 Maven 不用 Gradle”,Agent 判断这是个稳定事实,调用 save_memory 工具自动存。
设计原则是只存稳定事实,不存临时信息。
“用户偏好中文回复”可以存,“当前正在改 Main.java 第 42 行”不应该存,后者是短期记忆的事,下次会话不需要知道。
老王追问:“做了 scope 机制?讲讲。”
我说:“对,这是最近的一次重要升级。之前所有长期记忆是不区分项目的。结果出现一个问题:我在 A 项目里存了‘用 Java 17’,切到 B 项目,也就是一个 Python 项目时,Agent 也把这条记忆注入进去了,干扰模型判断。”
所以我们引入了作用域机制,每条记忆分两种 scope。
- project 级是默认的,绑定到具体项目路径,只在该项目的会话中可见。
- global 级是跨项目通用的偏好,所有会话都能看到,比如“用户偏好中文回复”“代码注释用英文”。
用户通过 /save 事实内容 保存 project 级记忆,/save --global 偏好内容 保存 global 级。存的时候会自动把当前项目的绝对路径写进元数据,路径做了标准化处理,防止相对路径和绝对路径指向同一目录却被当成两个项目。
老王又问:“取的时候怎么过滤?”
我说:“每轮对话开始前,检索长期记忆的时候多了一层项目可见性过滤。global 级的记忆对所有项目可见,project 级的记忆只对元数据里的项目路径匹配当前项目的会话可见。过滤完可见性之后,才进入关键词匹配和评分排序,取 top-k 条注入 system prompt。”
检索用的是最朴素的关键词匹配,不是向量检索。
因为长期记忆通常就几十条,关键词匹配够用且零依赖。如果记忆量到了几千条,就应该换成向量检索了。
我们还新增了三个管理命令:/memory list 查看所有记忆,/memory search 按当前项目可见性搜索,/memory delete 删除单条。让用户能看到 Agent 到底记住了什么,心里有底。
04、什么是 RAG
老王话锋一转:“聊聊 RAG,先说说你的理解。”
我说:“RAG 也就是检索增强生成。核心思路很简单,模型回答之前,先从外部知识库检索相关内容,把检索结果塞进 prompt 一起发给模型。”
Agent 为什么需要 RAG?
让 Agent“重构登录模块”,它不知道 LoginService 在哪个文件、有哪些方法、被谁调用。
全量代码塞进上下文?一个 10 万行代码的项目直接就把模型上下文撑爆了。
RAG 的做法是只检索相关的代码片段。用户问“登录逻辑在哪”,RAG 从向量库里检索出 LoginService 和 AuthController 的相关方法,只把这几百行代码喂给模型,精准且省 token。
老王问:“PaiCLI 的 RAG 全流程是什么样的?”
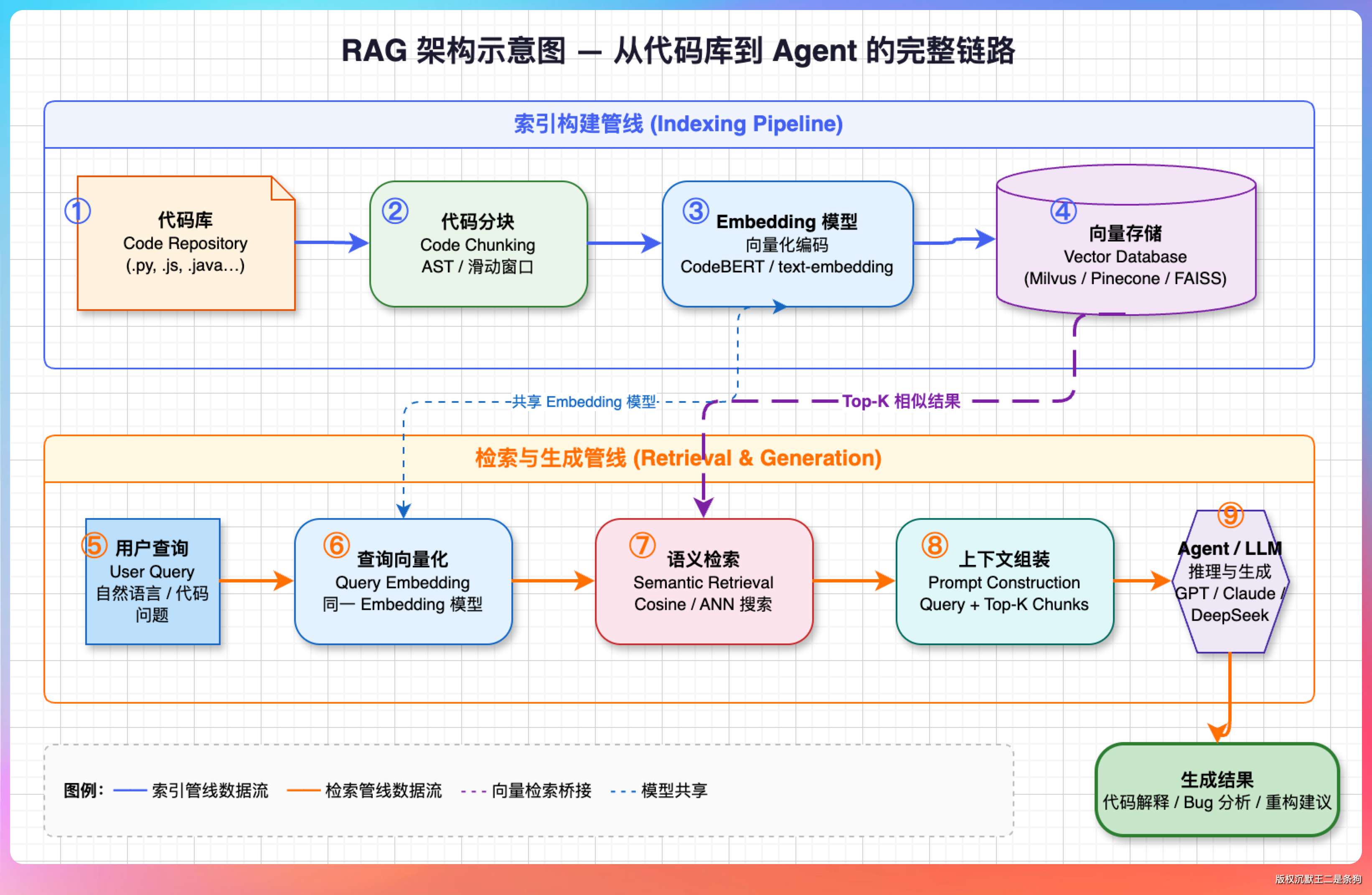
我说:“分两步,先建索引后检索。”
建索引的时候,把代码库的源文件拿出来,按语法结构分块,然后每个代码块用 Embedding 模型转成向量,存到 SQLite 数据库里。用户执行 /index 命令就能触发这个流程。
检索的时候,把用户的查询也转成向量,和库里所有代码块的向量算余弦相似度,取相似度最高的 Top-K 个代码块注入 prompt。
不过有个重要变化。
PaiCLI 最新版本把 RAG 从“主力检索”降级成了“语义辅助”。
老王来了兴趣:“为什么降级?”
我说:“因为我们新增了两个精确搜索工具,一个按关键字或正则实时搜索代码,一个按文件名 glob 匹配。这两个工具零预处理、零冷启动,对精确符号的定位又快又准。RAG 有冷启动成本,需要先建索引,有 Embedding 延迟,也有向量精度损失。你搜一个类名 UserService,精确搜索一秒出结果,RAG 还得先把查询转向量再算相似度。”
(内心 OS:说白了就是大炮打蚊子,精确匹配的活交给精确工具干😏)
现在的策略是:精确符号、文件名、字符串定位优先走精确搜索,只有查询模糊、关键词难确定、或代码文档混合检索的场景才走 RAG。这个优先级写在 Agent 的系统提示词里,模型会自己判断用哪个工具。
05、代码怎么分块
老王问:“你刚才说‘按语法结构分块’,具体怎么做的?”
我说:“分块是 RAG 的关键环节。分块太粗,一个文件里有 10 个方法但只有 1 个相关,检索出来夹带大量无关内容。分块太细,代码脱离上下文毫无意义。”
PaiCLI 不是按固定行数切的,而是用 JavaParser 做 AST 解析,按语法结构切分。
当前实现里有三种 chunk 类型:
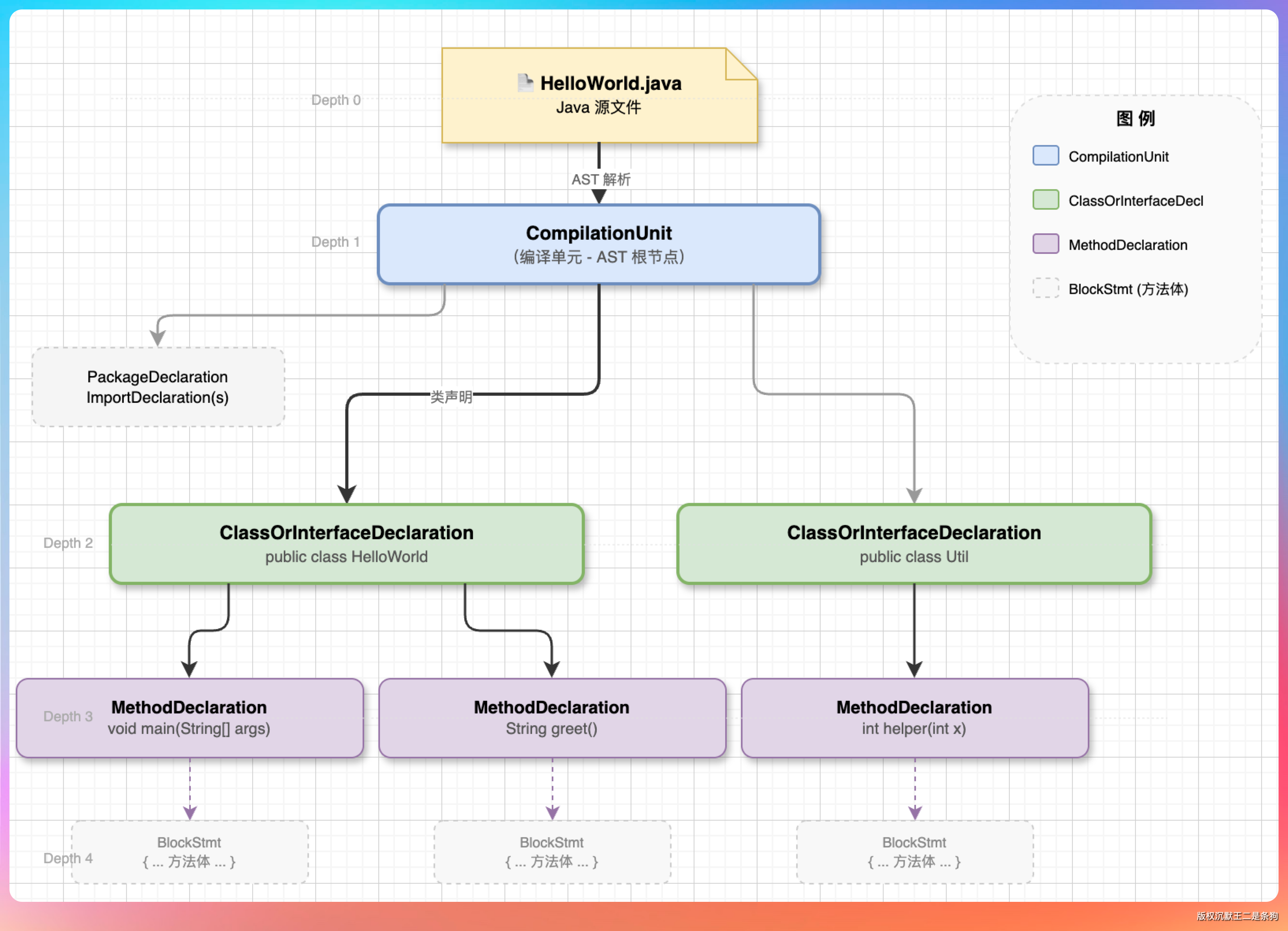
- 文件级:非 Java 文件或 Java 解析失败时使用;大文件会按行拆成不超过约 2000 字符的多个 file chunk。
- 类级:JavaParser 解析 Java 文件后,为每个类或接口生成一个 class chunk。当前 class chunk 主要保存类声明开头几行,用来提供类名和结构入口,不是把整个类和所有方法塞进去。
- 方法级:为每个方法生成一个 method chunk,内容是完整方法源码,名称里带上
类名.方法签名,这是回答“某个逻辑怎么实现”时最有价值的粒度。
老王追问:“为什么不按固定行数切?”
我说:“按行数切有个致命问题,会把一个方法从中间劈开。上半截在 A 块,下半截在 B 块。检索到 A 的时候模型看到半个方法,不知道这方法到底在干什么。AST 解析保证 Java 方法 chunk 是完整语法单元,从方法声明节点的起止行号提取源码,尽量避免把一个方法从中间截断;非 Java 大文件才会回退到按行分段。”
老王又问:“Python 代码怎么办?”
我说:“PaiCLI 当前只做了 Java 的 AST 分块,其他语言回退到文件级分块。要做通用多语言支持的话,可以用 tree-sitter,它支持几十种语言的语法解析。”
06、Embedding 是什么
老王问:“向量化这步,Embedding 你给我解释一下。”
我说:“Embedding 就是把文本映射到高维向量空间。两段语义相近的文本,映射出来的向量距离就近。”
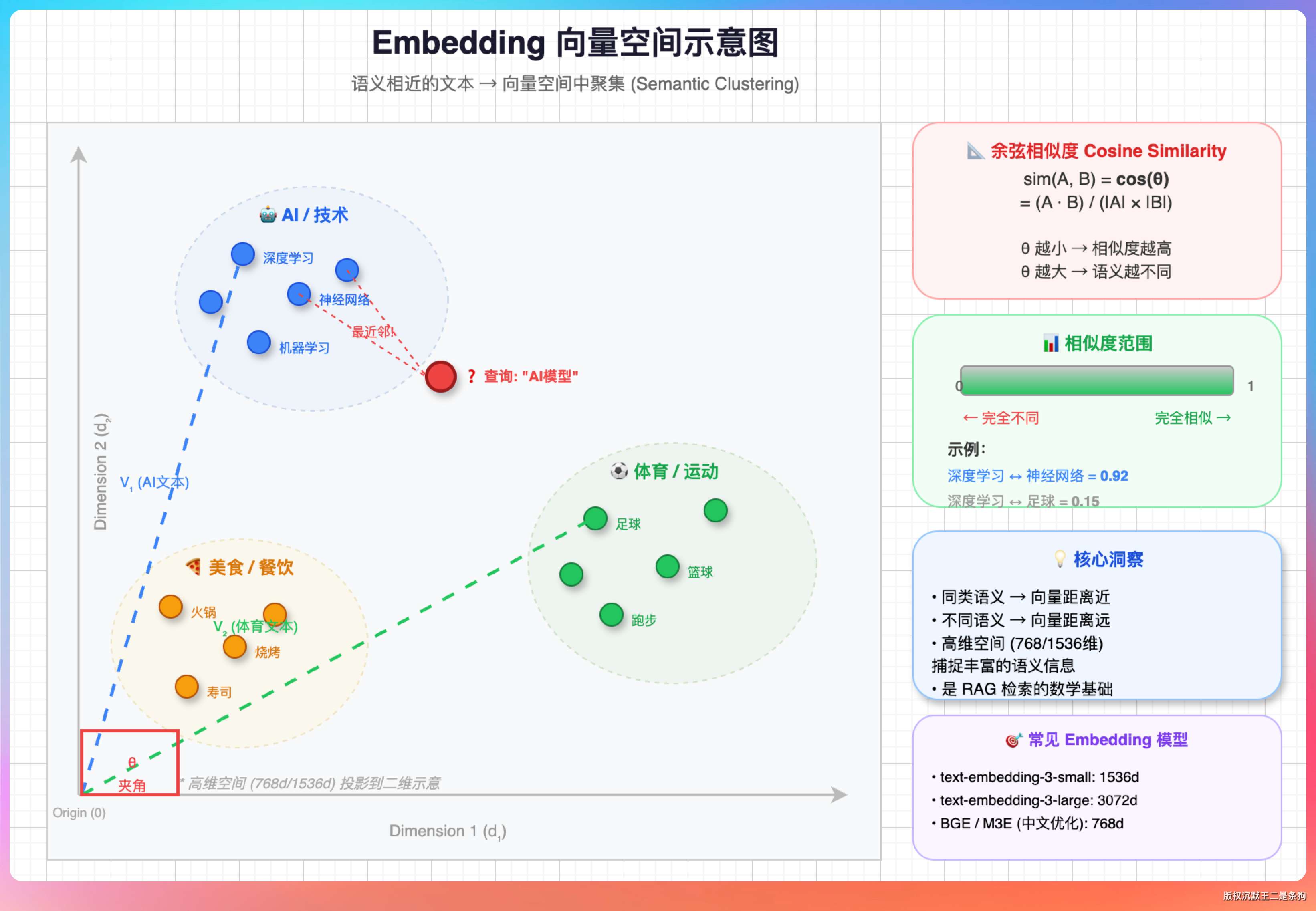
举个例子。
用户搜“处理用户登录的代码”,关键词匹配只能找到包含“用户”“登录”这些词的文件。但如果代码里写的是 authenticate() 和 SessionManager,一个都匹配不上。Embedding 能理解语义,“用户登录”和 authenticate + session 在向量空间里距离很近,检索就能命中。
PaiCLI 用的 Embedding 模型是 nomic-embed-text,本地 Ollama 跑,免费但需要本机装 Ollama。生成的是 768 维的浮点数组,存到 SQLite 数据库里。

07、向量检索用的什么算法
老王问:“向量存进去了,检索的时候用什么算法?”
我说:“余弦相似度。公式是 cos(A, B) = (A · B) / (|A| × |B|),就是两个向量的点积除以各自的模长,值域 -1 到 1,越接近 1 越相似。”
老王追问:“为什么选余弦不选欧氏距离?”
我说:“两个原因。第一,余弦只看方向不看大小,不受向量长度影响。两段代码的 Embedding 可能因为文本长度不同而模长差异很大,余弦不受干扰。第二,高维空间里欧氏距离有‘维度灾难’的问题,所有点的距离趋于相同,区分度下降,余弦更稳定。”
PaiCLI 没有引入专门的向量数据库,就是在 SQLite 里存向量,检索时 Java 代码逐一算余弦相似度,排序取 Top-K。
暴力检索复杂度是 O(n),对于几千个代码块的中小型项目完全够用。如果代码库有几百万个块,就需要用 ANN 近似最近邻算法加速了——HNSW、IVF 这些,或者直接上 Milvus、Qdrant 之类的向量数据库。
08、代码关系图谱是什么
老王问:“你简历上还写了个代码关系图谱,这跟 RAG 有什么关系?”
我说:“这两个是互补的。RAG 回答的是‘哪段代码和登录有关’,是语义检索。图谱回答的是‘LoginService 被谁调用了’‘UserController 依赖哪些类’,是结构查询。”
PaiCLI 用 JavaParser 分析 AST,提取代码元素之间的五种结构关系:继承、接口实现、导入、方法调用、包含。
这些关系存在 SQLite 里,用户输入 /graph 类名 就能看到完整的关系链。
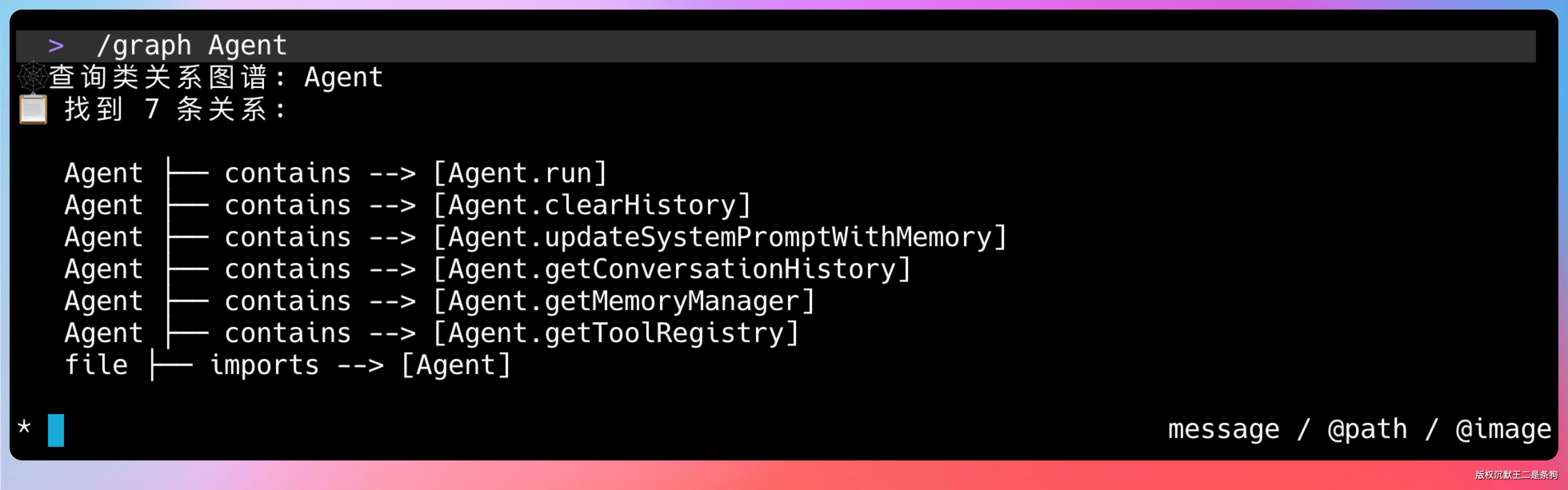
09、长上下文模型出来后,RAG 还有必要吗
老王突然放了个大招:“现在 DeepSeek V4 都 1M 窗口了,RAG 还有存在的必要吗?”
(内心 OS:经典高频面试题来了,稳住🤣)
我说:“有必要,但角色变了。”
第一是注意力精度。模型对长文本中间部分的信息关注度会下降,这就是 Lost in the Middle 问题。RAG 预先筛选出最相关的内容放在显眼位置,准确率更高。
第二是超大代码库。50 万行代码的仓库,1M 窗口也装不下。
老王问:“那 PaiCLI 怎么处理的?”
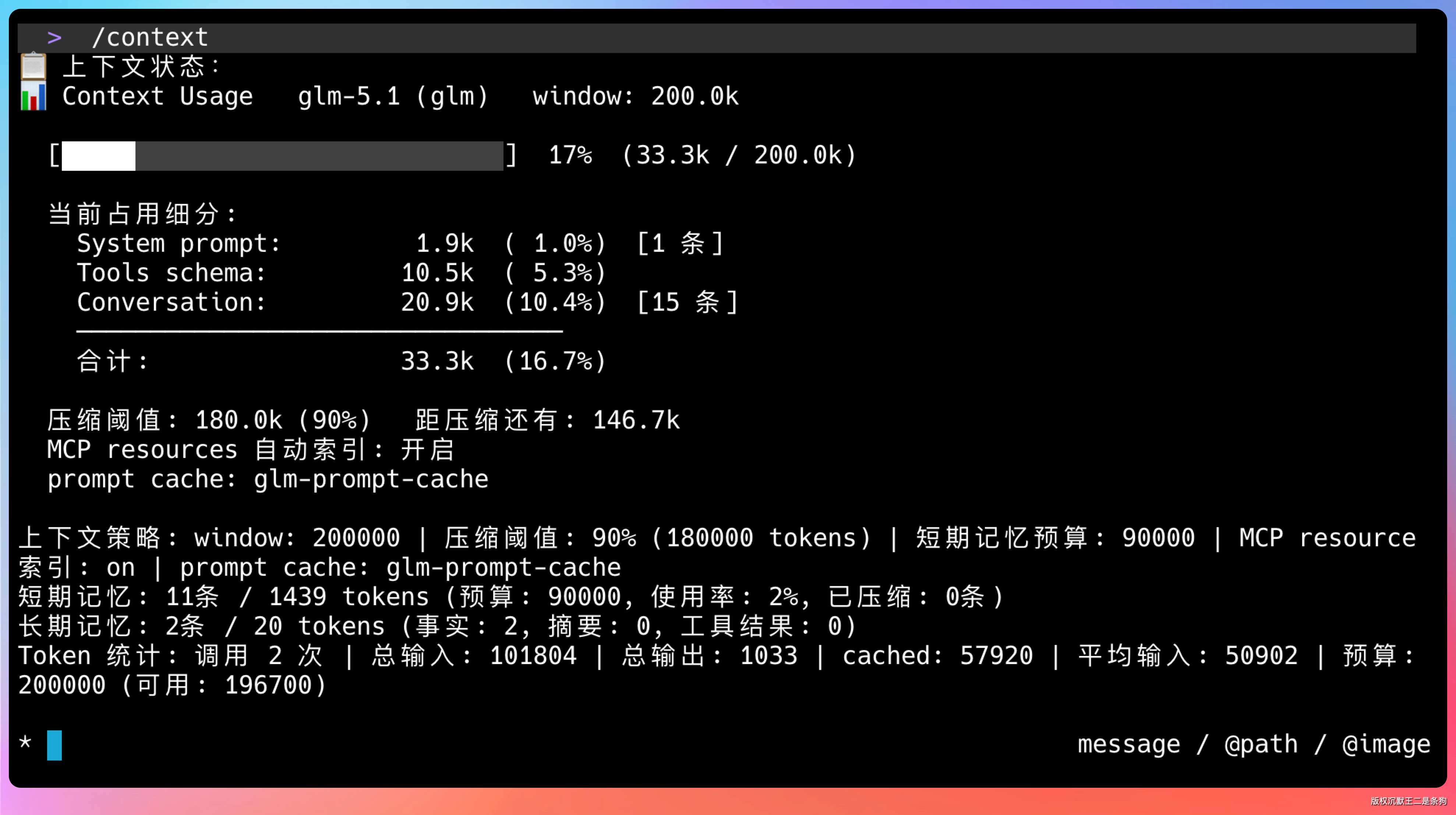
当前核心规则是:
| 参数 | 规则 |
|---|---|
| 压缩触发线 | maxContextWindow * 90% |
| 短期记忆预算 | maxContextWindow * 45% |
| 长期记忆注入上限 | min(5000, max(500, window / 200)) |
| MCP resource 索引 | window ≥ 32k 才开启 |
search_code 不再根据窗口自动把 topK 切成 5/10/20。工具默认 top_k=5,可以显式传参,最大 30。
让 Agent 优先用 grep_code / glob_files / read_file 精确定位;只有用户描述很模糊、关键词难确定、普通搜索多轮无果,才调用 search_code 做语义辅助。
最新版本还有个补充——RAG 不再是代码检索的唯一路径。Agent 拿到查询后,先用精确搜索工具做匹配,只有搞不定的模糊查询才走 RAG。所以即使没有提前建索引,Agent 依然能通过精确搜索理解代码库,RAG 变成了锦上添花而不是必须前置。
10、Prompt Caching 是什么
老王问了一个成本相关的问题:“你们有做 Prompt Caching 吗?”
我说:“做了,而且 Agent 场景天然适合 caching。”
Prompt Caching 是模型提供商的服务端优化——如果连续请求的 prompt 前缀相同,服务端可以复用前缀缓存,跳过一部分重复计算。不同供应商的计费规则不一样,PaiCLI 不假设计费折扣,只负责识别和展示响应里的缓存命中 token。
Agent 的请求模式完美契合这个机制。
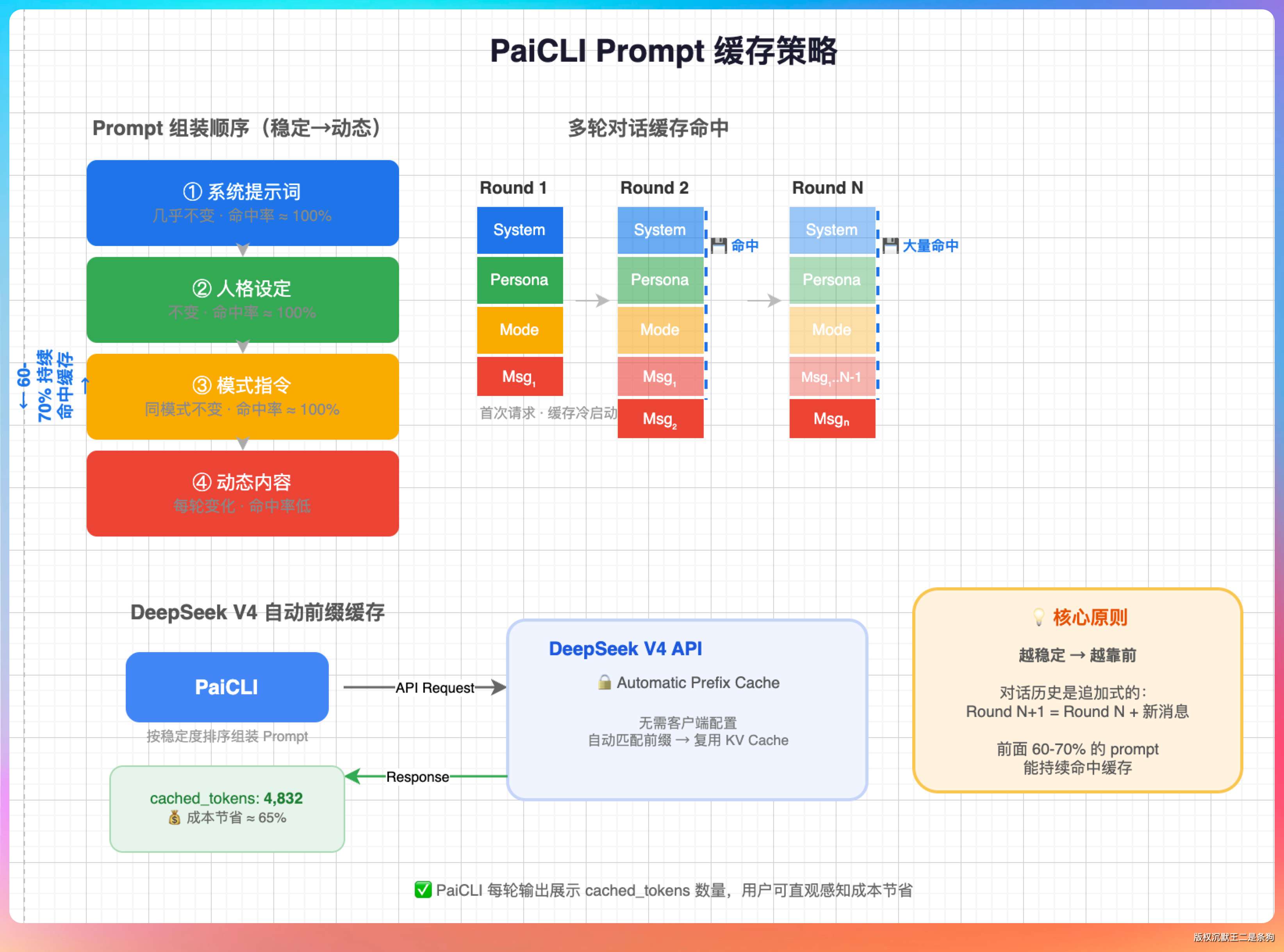
system prompt 每轮都一样,是完美的缓存前缀。对话历史是追加式的,新一轮请求等于旧请求加上新消息,大部分前缀都重复。
PaiCLI 组装 prompt 的时候遵循“越稳定的内容越靠前”的原则:系统提示词、人格设定、模式指令这些稳定内容放前面,项目上下文、技能索引、记忆等动态内容放后面。这样更容易让 provider 的前缀缓存命中。
DeepSeek 走 automatic prefix cache;GLM、Kimi、Step 也在 LlmClient 里声明了对应的 prompt cache mode。PaiCLI 会从 cached_tokens、prompt_cache_hit_tokens、input_cache_hit_tokens 等字段里解析缓存命中量,并在状态栏展示。
11、上下文压缩有哪些策略
老王问:“除了你们用的 Map-Reduce 摘要法,还有其他压缩策略吗?”
我说:“主流的有三种。”
第一种是截断法,最简单粗暴,直接丢弃最早的对话。
第二种是摘要法,就是 PaiCLI 用的这种。用模型对早期对话生成摘要,用摘要替代原文。保留了语义,但摘要本身要消耗一次模型调用。
第三种是选择性保留。只保留 system prompt + 最近 N 轮 + 所有工具调用结果,中间的“闲聊”丢掉。需要判断哪些是“闲聊”,实现比较复杂。
老王又问:“压缩的时机怎么选?”
PaiCLI 里要分清两种压缩,别混在一起讲。
第一种是 Memory 系统里的短期记忆压缩。触发点是在写入短期记忆之后:用户消息、助手回复、工具结果存进去后,都会立刻调用 compressIfNeeded()。
判断条件是短期记忆 token 占用达到阈值,当前代码默认是 90%。短期记忆预算又是模型窗口的 45%,所以粗略看:DeepSeek 1M window 下,短期记忆大约到 450k * 90% = 405k tokens 才会压缩;GLM 200k 下大约是 81k tokens。
第二种,是 conversationHistory 压缩。
这是 Agent 真正要发给 LLM 的消息列表,防止上下文窗口爆掉。它的触发时机是在 每次调用 LLM 之前,不是任务结束后,也不是报错后才压缩。
ReAct 主循环、Plan 每个 task 的执行循环、Multi-Agent 的 SubAgent 循环,都在发起下一轮 LLM 请求前检查一次。如果当前 conversationHistory 估算 token 达到 maxContextWindow * 90%,就触发压缩。
所以按模型算,conversationHistory 的压缩阈值大概是:
- DeepSeek V4:
1,000,000 * 90% = 900,000 tokens - GLM-5.1:
200,000 * 90% = 180,000 tokens - Step / Kimi:
256,000 * 90% = 230,400 tokens
压缩方式按 user message 边界切割,保留最近 3 个用户轮次,把更早的消息交给 LLM 总结成一段摘要,然后重建成:
system
[已压缩的历史对话摘要]
assistant: 好的,我已了解之前的上下文,请继续。
最近 3 个 user 轮次开始的尾部消息这么做是为了避免切断 assistant tool_call 和 tool result 这种成对协议。否则很容易出现上一条 assistant 说要调用工具,但工具结果被截没了。
一句话概括就是:PaiCLI 的压缩不是等模型报超限才处理,而是在每轮 LLM 请求前主动检查。 当前实现以 90% window 作为统一触发线。
12、对话历史的消息格式为什么要严格遵循协议
老王问了一个看起来简单但坑很深的问题:“消息格式有什么讲究?”
我说:“模型的聊天 API 对消息格式有严格要求。四种角色,system 是系统指令,user 是用户输入,assistant 是模型回复,可能带工具调用,tool 是工具返回结果,必须带 tool_call_id 和对应的工具调用匹配。”
老王问:“不遵循会怎样?”
我说:“直接报错或者模型理解混乱。tool 消息没有匹配的 tool_call_id?API 返回 400。assistant 和 user 顺序搞乱了?模型分不清谁说了什么。把工具结果塞进 user 消息?”
我说:“做摘要压缩的时候有个特别容易踩的坑。被压缩掉的消息如果包含工具调用和对应的工具结果,压缩后的 assistant 消息不能保留 tool_calls 字段。因为对应的 tool 消息已经被摘要吃掉了,但 tool_calls 还留在 assistant 消息里,API 就会发现有个 tool_call_id 找不到对应的 tool 结果,直接报错。”

13、RAG 检索效果不好怎么优化
老王最后一个问题:“如果 RAG 检索出来的结果不准,你怎么优化?”
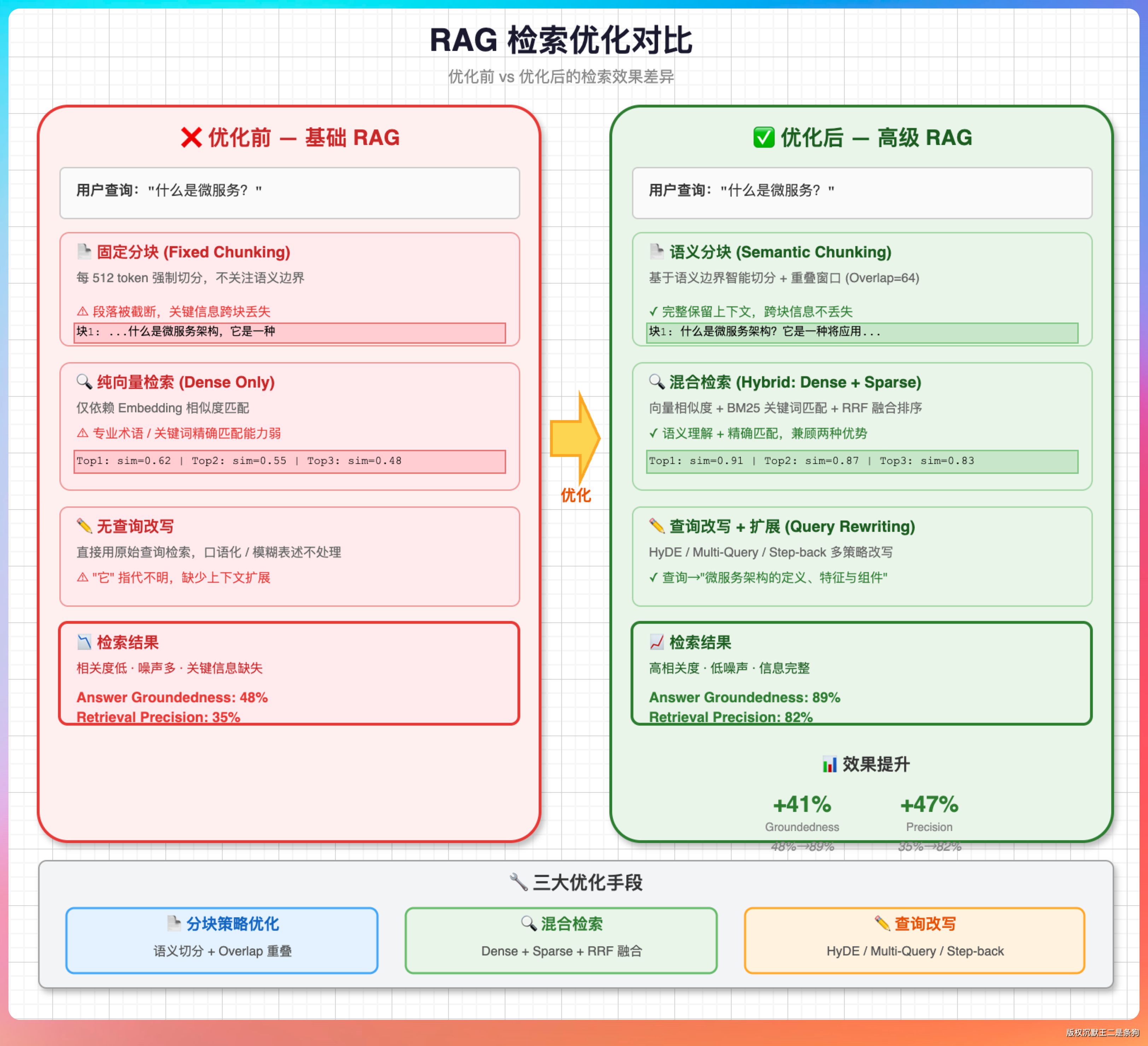
我说:“四个方向。”
第一个是分块策略优化。
从固定行数切换到语义分块,按方法、类、段落边界切,保证每个块语义完整。PaiCLI 用 AST 解析做的就是语义分块。还可以在每个块里加上父级上下文,比如所属类名和 import 信息,帮助模型理解代码片段在项目里的位置。
第二个是是用专业的 Embedding 模型。
第三个是混合检索。PaiCLI 最新版本就是这个思路的实践,精确搜索工具负责关键词定位,RAG 负责语义兜底。虽然不是传统的单次融合排序,但在 Agent 多轮工具调用的场景下效果是类似的——先精确找,找不到再语义兜底。
第四个是查询改写。用户的查询往往很口语化,“登录那块代码”改写成“用户认证和会话管理的实现代码”后,Embedding 的语义匹配会精准很多。这个改写可以用一轮轻量模型调用完成。
老王合上笔记本,面露悦色:“可以,记忆系统和 RAG 这块你是真做过的,不是纸上谈兵。”
ending
项目名称:PaiCLI — Java Agent CLI(对标 Claude Code)
项目简介:从零实现的终端 AI Agent,内置三层记忆架构(短期/长期/RAG 外部记忆)、项目级记忆隔离、精确搜索优先 + RAG 语义兜底的分层代码检索策略,支持 200k-1M 窗口模型的长上下文自适应工程。
技术栈:Java 17、JavaParser AST、Ollama nomic-embed-text Embedding、SQLite、Map-Reduce、NIO FileVisitor
核心职责:
- 设计三层记忆架构,短期记忆管理对话历史,长期记忆持久跨会话事实到 JSON 文件(支持 project/global 双作用域隔离)
- 实现精确搜索优先 + RAG 语义兜底的分层代码检索策略,精确搜索按关键字/正则实时扫描项目文件树做符号定位,文件名匹配按 glob 模式查找,RAG 走 Embedding 向量语义检索处理模糊查询
- 基于 JavaParser 实现 AST 级代码分块,按方法/类/文件三种粒度切分,保证每个 chunk 语义完整
- 实现两套上下文压缩:对短期记忆做 Map-Reduce 摘要压缩;在每轮 LLM 调用前压缩真实消息历史,按 user 边界保留最近 3 轮,避免切断 tool_call / tool_result 协议