AI Agent 面试题第七弹:多模型适配、运行时切换、成本控制 12 题
老王这次没废话,直接开问:“PaiCLI 接了几家大模型?”
“目前支持 GLM、DeepSeek、Kimi、StepFun。”
“那你 API 调用的代码是不是写了四遍?”老王的语气里带着一点挑衅。
我笑了:“那不至于,一个基类搞定,每个 Provider 实现就二三十行。”
01、怎么设计一个支持多模型的 LLM 客户端接口?
策略模式。定义一个统一接口,每个模型的 Provider 自己实现差异化逻辑。
接口需要声明两组能力。
第一组是行为能力,也就是对话方法。一般设计两个 chat 方法,一个带流式监听器参数,一个不带。不带监听器的方法内部调用带监听器的。
第二组是声明式能力。包括模型名称、Provider 名称、最大上下文窗口、是否支持提示词缓存、缓存模式等等。
public interface LlmClient {
ChatResponse chat(List<Message> messages, List<Tool> tools) throws IOException;
ChatResponse chat(List<Message> messages, List<Tool> tools,
StreamListener listener) throws IOException;
String getModelName();
String getProviderName();
default int maxContextWindow() { return 128_000; }
default boolean supportsPromptCaching() { return false; }
default String promptCacheMode() { return "none"; }
}为什么要把能力声明放在接口里?
因为上下文管理模块需要根据模型能力做策略调整。
短期记忆预算、压缩触发阈值、MCP 资源索引,这些参数全部可以从上下文窗口大小推导出来。
接口声明了这些能力后,上层不需要写 if-else 判断“当前是哪个模型”,直接读接口方法的返回值就行。
四个 Provider 实现类共享一个基类,负责通用的 SSE 解析和 HTTP 请求逻辑,每个子类只覆盖 API 地址、默认模型名、API Key 来源这几个差异点。
02、模板方法模式在多模型适配里怎么用?
都兼容 OpenAI 协议。
就是把相同的部分提到基类里,子类只覆盖差异点。
基类的 chat 方法定义了完整的 SSE 请求-响应流程:构建请求体、发送 HTTP 请求、逐行解析 SSE 流、合并增量 tool_calls、提取 usage 统计、返回最终响应等。
所有 Provider 都是一样的。
子类只需要覆盖三个抽象方法:API 端点地址、默认模型名、API Key。
拿 DeepSeek 的实现来说,整个类不到 60 行代码,SSE 解析、tool_calls 合并、HTTP 超时处理一行没写,全在基类里。
// DeepSeek 的实现,继承基类后只需覆盖差异点
protected String getApiUrl() { return "https://api.deepseek.com/chat/completions"; }
protected String getModel() { return "deepseek-v4-flash"; }
protected String getApiKey() { return apiKey; }
public int maxContextWindow() { return 1_000_000; }
public boolean supportsPromptCaching() { return true; }
public String promptCacheMode() { return "automatic-prefix-cache"; }03、OpenAI 兼容协议是什么?为什么大家都兼容它?
OpenAI 兼容协议就是 OpenAI Chat Completions API 的请求和响应格式,分三层。
- 请求层:核心字段是 model、messages(每条包含 role 和 content)、tools(名称、描述、JSON Schema 参数定义)、stream 布尔值。
- 非流式响应层:返回 choices 数组,每个 choice 包含 message 对象,里面有 content 和 tool_calls。
- 流式响应层:SSE 格式,每个 chunk 包含
choices[0].delta,增量返回 content 和 tool_calls 片段。
为什么大家都兼容它?
- 生态效应:OpenAI 是第一个大规模商用的 LLM API,全球最多的 SDK、框架、工具链都围绕这套格式构建。兼容它,用户的已有代码换个 URL 就能跑。
- 标准化收益:Agent 框架只需要实现一套协议适配就能接入多家模型。
- 迁移成本低:GLM、DeepSeek、Kimi、StepFun 都兼容这套协议,差异主要在特有字段(比如 DeepSeek 的 reasoning_content、GLM 的 Coding 端点分离)、计费字段(缓存命中 token 的字段名不统一)和 Rate limit 响应头格式等。
04、运行时切换模型是怎么实现的?
靠工厂方法。
用户输入切换命令后,工厂方法接收 Provider 名称和配置,创建一个新的客户端实例。
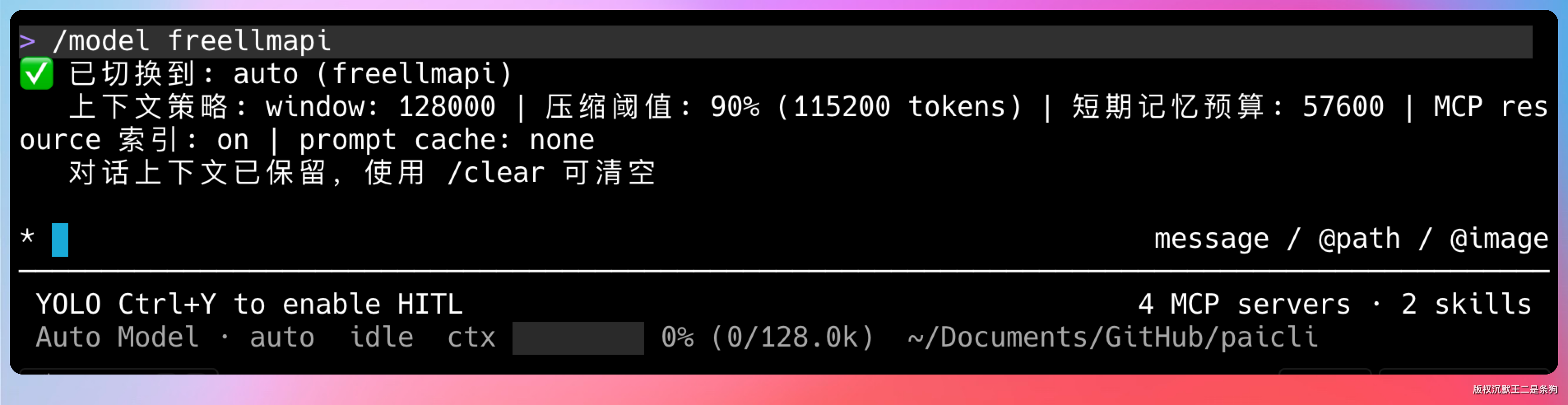
切换流程分四步。
- 第一步,工厂创建新的客户端实例。
- 第二步,Agent 持有的客户端引用指向新实例。
- 第三步,上下文管理模块根据新模型的最大上下文窗口重新计算所有策略参数,包括短期记忆预算、压缩阈值、MCP 索引开关等。
- 第四步,把用户的选择持久化到配置文件,下次启动自动使用新模型。
如果用户没有配置默认的 Provider,工厂会按 glm、deepseek、step、kimi 的顺序扫描,哪个有 API Key 就用哪个。保证“配了 Key 就能用”。
切换模型后对话历史怎么处理
对话历史保持不变。但有几个变化。
Token 预算会重新计算。比如从 200k 窗口的模型切到 1M 窗口的模型,可用预算自动提升。
工具定义不变,所有模型共用同一套工具注册表。reasoning_content 的兼容也需要处理。历史中包含 DeepSeek 生成的 reasoning_content 字段,切到 GLM 后这些字段不会被发送给 GLM,除非目标模型声明了需要接收。
05、不同模型的 Token 计费差异有多大?怎么估算成本?
以 2026 年 5 月 30 日核对到的官方公开定价为例(每百万 token)。美元报价保留官方币种,括号内人民币只做粗略折算:
| 模型 | 输入价格 | 输出价格 | 缓存命中输入 | 窗口 |
|---|---|---|---|---|
| StepFun Step-3.5 Flash | $0.10(约 0.7 元) | $0.30(约 2.1 元) | $0.02(约 0.14 元) | 256k |
| DeepSeek V4 Flash | $0.14(约 1.0 元) | $0.28(约 2.0 元) | $0.0028(约 0.02 元) | 1M |
| DeepSeek V4 Pro | $0.435(约 3.1 元,限时折扣) | $0.87(约 6.2 元,限时折扣) | $0.003625(约 0.03 元,限时折扣) | 1M |
| Kimi K2.6 | $0.95(约 6.8 元) | $4.00(约 28.6 元) | $0.16(约 1.1 元) | 256k |
| GLM-5.1 [0, 32k) | 6 元 | 24 元 | 1.3 元 | 200k |
| GLM-5.1 [32k, 200k] | 8 元 | 28 元 | 2 元 | 200k |
官方来源:DeepSeek Models & Pricing、StepFun Pricing and Rate Limits、Kimi K2.6 Pricing、智谱价格页。
DeepSeek V4 Pro 当前表格使用的是官方 75% off 限时折扣价,折扣结束时间是 2026-05-31 15:59 UTC;后续会调整为原价四分之一的正式价格。
2026 年,国产模型的定价分化非常明显。DeepSeek V4 Flash 和 StepFun 走性价比路线,日常开发拿来当默认模型完全够用。
Kimi K2.6 和 GLM-5.1 的输出价格明显高于 DeepSeek V4 Flash 和 StepFun Step-3.5 Flash。GLM-5.1 还有输入长度分档,[32k, 200k] 档的输入和输出价格都会上调,Agent 长上下文场景很容易落到高价档。
选模型时成本意识很重要,简单任务和复杂任务的模型选择可能差出 10 倍以上的费用。
怎么估算?
靠 Token 消耗统计。
每次 LLM 调用后记录三个数值:输入 token 数、输出 token 数、命中缓存的输入 token 数。调用次数也要累计。
单轮成本的计算公式:input_tokens 乘以输入单价再除以一百万,加上 output_tokens 乘以输出单价除以一百万,再减去缓存命中输入 token 数乘以(输入单价减去缓存单价)除以一百万。不同 Provider 的缓存命中字段名不同,客户端需要先统一抽象成 cacheHitInputTokens 之类的内部字段。
Prompt Caching 缓存命中的输入 token 会按更低价格计费,但不同 Provider 的折扣差异很大:DeepSeek V4 Flash 的缓存命中价格约为未命中价格的 2%,StepFun 约为 20%,Kimi K2.6 约为 17%,GLM-5.1 约为 22% 到 25%。
假如一个 Agent session 有 50 轮对话,每轮的 system prompt 加工具定义大概有 3000 token 是重复的,稳定前缀命中缓存后可以显著降低输入成本。具体能省多少,取决于 Provider 的缓存折扣和实际命中率。
每轮对话结束后在状态栏输出 token 统计,让用户实时感知到消耗。
怎么判断什么时候需要压缩上下文
当对话历史的 token 占用达到可用预算的 90% 时触发压缩。
可用预算等于总窗口大小减去系统提示预留(约 500 token)、工具定义预留(约 800 token)和回复预留(约 2000 token)。剩下的才是对话历史可以使用的空间。
为什么是 90% 而不是 100%?
因为需要留一段缓冲区。如果等到 100% 才压缩,最后一轮的输入可能已经超出窗口了,模型会直接报错。90% 这个阈值给压缩操作留出了大约 10% 窗口的安全余量。
06、Prompt Caching 在不同 Provider 之间有什么差异?
各家的缓存机制差异不小,但有一个共同趋势:国产模型基本都走自动前缀缓存了。
- DeepSeek:服务端自动前缀缓存,客户端不需要做任何操作。服务端自动检测多次请求的公共前缀并持久化到硬盘,缓存命中后 usage 里返回
prompt_cache_hit_tokens和prompt_cache_miss_tokens。 - GLM:也是自动上下文缓存,客户端不需要手动配置。GLM-5.1 按输入长度分两档计费,
[0, 32k)档缓存命中 1.3 元/百万 token,[32k, 200k]档缓存命中 2 元/百万 token。 - StepFun:自动前缀缓存,输入超过 256 token 自动启用,缓存命中按原价 20% 计费,用 LRU 策略淘汰。
- Kimi:K2.5/K2.6 官方文档明确支持自动上下文缓存。Moonshot/Kimi 历史上也提供过显式 Context Caching API,可以通过
role="cache"引用已创建缓存,但 PaiCLI 当前按自动缓存处理即可。 - Claude:需要在 message 里显式加 cache_control 标记,指定哪些内容需要缓存。
对 Agent 客户端来说,国产四家都不需要在请求里注入缓存相关参数,只需要在 prompt 布局上保持“不变的在前面”原则,让服务端自动匹配前缀。

为什么 Prompt 布局要“不变的在前面”?
这和 LLM 推理时的 KV Cache 机制有关。
LLM 在推理时会把 prompt 里的每个 token 计算出 Key 和 Value 向量,缓存下来用于后续生成。
如果连续两次请求的 prompt 前缀完全相同,服务端可以直接复用上次计算好的 KV Cache,跳过重复计算。
所以 prompt 的组装顺序非常重要。
系统提示词放最前面,几乎不变;个性化提示词紧随其后;然后是项目上下文;Skill 按需加载;最后是交接信息和对话历史,每轮都不同。
这样稳定前缀越长,越容易持续命中缓存。如果把动态内容放到前面,每次都变化,前缀缓存收益就会明显下降。
07、上下文策略是怎么根据模型能力自动调整的?
全模型走同一套逻辑,只是窗口大小不同导致触发时机和容量不同。公式很简单:
- Agent 单次运行预算 = 窗口 × 0.8
- 短期记忆预算 = 窗口 × 0.45
- 压缩触发比例 = 固定 0.9
- 记忆注入上限 = 窗口 / 200,封顶 5000 token
- MCP 资源索引 = 窗口 ≥ 32k 时才开启
举个具体例子。
从 GLM-5.1(200k 窗口)切到一个 32k 窗口的小模型,短期记忆预算从 90k 降到 14.4k,压缩触发阈值从 180k 降到 28.8k,MCP 资源索引刚好卡在开启的边界上。这些调整全部自动完成,不需要用户干预。
08、流式响应(SSE)的增量 tool_calls 合并是怎么做的?
LLM 的流式响应会把一个 tool_call 拆成多个 SSE chunk 返回。
比如调用 read_file 工具,第一个 chunk 可能只包含函数名的前半部分 read_,第二个 chunk 接上 file,第三个 chunk 返回参数 JSON 的前半段 {"pa,第四个 chunk 补上 th":"pom.xml"}。如果不做合并就直接解析参数 JSON,会解析失败。
解决方案是用累加器模式。
为每个 tool_call 维护一个累加器,里面有三个 StringBuilder,分别存 id、函数名和参数 JSON。每收到一个 SSE chunk,就根据 chunk 里的 index 字段找到对应的累加器,把增量内容 append 上去。多个并行的 tool_call 通过 index 区分,互不干扰。
有一个关键点:流式过程中只做累加,不做解析。
等 SSE 流彻底结束了,再把攒好的函数名和参数 JSON 拼成正式的工具调用对象。省掉在中间状态尝试解析不完整 JSON 的麻烦。
chunk 1: tool_calls[0].function.name = "read_" → StringBuilder.append("read_")
chunk 2: tool_calls[0].function.name = "file" → StringBuilder.append("file")
chunk 3: tool_calls[0].function.arguments = '{"pa' → StringBuilder.append('{"pa')
chunk 4: tool_calls[0].function.arguments = 'th":"x"}' → StringBuilder.append('th":"x"}')
流结束 → 拼出完整的 name="read_file", arguments='{"path":"x"}'
如果 LLM 返回的 arguments JSON 被截断了怎么办
偶尔会发生这种情况。
LLM 的 max_tokens 限制或者网络中断都可能导致参数 JSON 不完整。
处理策略是在流结束后、实际执行工具之前做 JSON 解析校验。如果参数 JSON 解析失败,Agent 不会执行工具,而是构造一条错误的 tool message 发回给 LLM,告诉它“你的参数 JSON 格式有误,请重新输出”。LLM 看到这条错误信息后,在下一轮对话中会自行修正参数格式重新调用工具。
09、API Key 的读取优先级是怎么设计的?
四级优先级,从高到低依次是:配置文件中对应 Provider 的 apiKey、环境变量(GLM_API_KEY / DEEPSEEK_API_KEY 等)、项目目录下的 .env 文件、用户主目录下的 .env 文件。
为什么这样排序?
- 配置文件最高:通过命令设置的 Key 是用户最明确的意图表达,应该覆盖其他来源
- 环境变量次之:CI/CD 和 Docker 环境通常通过环境变量注入 Key
- .env 最低:本地开发的便利性,不需要 export 环境变量就能用
如果用户没有配默认 Provider,工厂方法会按 glm、deepseek、step、kimi 的顺序扫描,哪个有可用的 Key 就用哪个作为默认模型。
安全上有什么注意事项
.env文件绝对不能提交到 Git,.gitignore里必须有.env这一行- 配置文件存放在用户主目录的隐藏文件夹下(比如
~/.paicli/),不在项目目录内,不会被 Git 追踪 - Key 在日志输出时做脱敏处理,只显示前后各 4 位字符,中间用星号替代
10、如果模型不支持 Function Calling 怎么办?
碰到不支持的模型,业界有两种常见的适配方式。
第一种是 Prompt 注入法。在 system prompt 里用自然语言描述工具的使用格式,约定一种标记语法(比如 XML 标签或 JSON 代码块),让 LLM 在回复文本里按这个格式输出工具调用。客户端用正则表达式匹配标记,解析出工具名和参数,执行后再把结果放回对话历史。

比如在 system prompt 里告诉模型:“当你需要读文件时,请输出 <tool_call>{"name": "read_file", "arguments": {"path": "xxx"}}</tool_call>”。客户端匹配 <tool_call>...</tool_call> 标签提取 JSON,解析执行。
第二种是中间层适配。在客户端和模型 API 之间加一个适配层,对上游完全透明,Agent 以为自己在和一个支持 Function Calling 的模型对话。适配层负责把 tools 定义转成 prompt 文本注入,再从模型的文本输出中解析出工具调用转成标准的 tool_calls 结构。
PaiCLI 目前只接入支持 Function Calling 的模型,没做 Prompt 注入适配。但面试时了解这个思路很重要,如果面试官追问“怎么扩展到不支持 FC 的模型”,你可以说出 Prompt 注入法并分析其局限:解析成功率依赖 LLM 的格式遵循能力,比原生 Function Calling 低;多个工具并行调用时格式更容易出错;LLM 可能在工具调用标记外还输出一段解释文字,增加了解析复杂度。
11、Agent 的总成本怎么估算?有哪些优化手段?
Agent 的成本等于所有 LLM 请求的 token 费用之和。一个复杂任务可能涉及 20 到 50 轮 LLM 调用,每轮都有输入和输出的费用。
每次 session 结束后输出完整统计:调用次数、总输入 token、总输出 token、缓存命中 token、平均每轮输入 token、剩余预算。
优化手段按效果排序:
- Prompt Caching(效果最大):把不变的 system prompt 和工具定义放在 prompt 最前面,让服务端自动缓存前缀。长 session 里 cached token 比例可能很高,输入成本会随缓存命中率和 Provider 折扣下降。
- 减少轮次:好的 system prompt 能让 LLM 一次做对,减少重试。Multi-Agent 架构下 Reviewer 的重试也要有上限。
- 工具结果裁剪:工具返回的内容不要全量塞进 prompt。比如说列目录只保留前 100 个,加一句“还有 900 个未显示”。大段代码只返回关键部分。
- 选对模型:DeepSeek V4 Flash 输入 $0.14(约 1.0 元)每百万、StepFun Step-3.5 Flash 输入 $0.10(约 0.7 元)每百万,日常开发拿来当默认模型绰绰有余。遇到复杂架构分析再切到 DeepSeek V4 Pro 或 Claude,运行时切换在这里就体现出价值了。
- 长上下文取舍:大窗口模型单 token 不便宜,但省掉了摘要压缩那次额外的 LLM 调用。摘要压缩本身也消耗 token,频繁压缩的累计成本可能比用大窗口模型更高。
- 历史裁剪:定期清理对话历史中的大块内容,比如旧截图的 base64 编码(单张几千 token)、超长的工具结果。把历史图片替换成一行文字描述就能省出大量空间。
12、面试官问“你用过哪些模型?各自的优缺点?”怎么回答?
DeepSeek V4 Flash 是性价比之王。1M 超大窗口加自动前缀缓存,输入只要 $0.14(约 1.0 元)每百万 token。分析大型代码库时优势很明显,不需要做 RAG 分块就能把大量代码直接塞进上下文。
StepFun Step-3.5 Flash 更便宜,输入 $0.10(约 0.7 元)每百万,响应速度快,适合快速原型和简单任务。
GLM-5.1 有专门的 Coding 版本,200k 上下文和中文生成质量是它的优势。它采用输入长度分档计价,[0, 32k) 为 6 元输入 / 24 元输出,[32k, 200k] 为 8 元输入 / 28 元输出,适合对中文生成质量和 Agentic Coding 表现要求较高的场景。
Kimi K2.6 的长文本理解和长程 Agent 能力强,官方案例里有 5 天自主运行的工程工作流。但它的单价明显高于 DeepSeek V4 Flash 和 StepFun Step-3.5 Flash,适合对长程稳定性、工具调用和多模态能力要求更高的场景。
Claude 的工具调用最稳定,推理能力强,适合复杂推理和架构设计。GPT-5 系列多模态强,生态最大。
回答时抓住三个要点:
- 场景驱动:不要只说优缺点,要说在什么场景下用了什么模型、为什么选它。比如“DeepSeek V4 Flash 分析大型代码库时,1M 窗口的优势很明显,省去了 RAG 的复杂度”。
- 运行时切换:日常开发用 DeepSeek Flash 或 StepFun 省成本,遇到复杂架构问题切到 DeepSeek Pro 或 Claude。
- 成本意识:StepFun 和 DeepSeek V4 Flash 这类低价模型适合承担日常开发和快速验证任务,复杂架构分析再切到更强模型更合理。
面试官追问怎么做模型评估
- 准确率:给一组标准任务(读文件、改代码、搜索),看各模型的完成率和所需轮次。完成率高、轮次少的在这个任务类型上更合适。
- 稳定性:同一任务跑 10 次,看输出是否一致、工具调用是否正确。有些模型偶尔会生成格式错误的 tool_calls 参数,执行失败要重试。
- 性价比:完成同一任务的 token 消耗和费用。每次 session 结束时的统计报告天然提供了这个维度的数据,拿来做横向对比就行。
简历参考
项目名称:PaiCLI - Java AI Agent CLI
项目简介:对标 Claude Code 的 Java 实现 AI Agent CLI,支持多模型适配、ReAct/Plan-and-Execute/Multi-Agent 多种推理模式、MCP 协议集成、长上下文管理和流式终端渲染。
技术栈:Java 17、OkHttp(SSE 流式通信)、Jackson(JSON 解析)、JGit(快照管理)、SQLite(任务持久化)、JLine/Lanterna(终端 TUI)
核心职责(多模型与成本方向):
- 设计并实现了基于策略模式 + 模板方法模式的多模型 LlmClient 抽象层,通过公共基类复用 SSE 解析和 tool_calls 合并逻辑
- 实现运行时模型切换机制,基于工厂模式创建新实例,上下文策略根据模型窗口大小自动调整,无 if-else 分支
- 统一处理四家 Provider(GLM、DeepSeek、Kimi、StepFun)的 Prompt Caching 差异,通过声明式适配不同 Provider 的自动前缀缓存能力和 usage 字段解析
- 实现 Token 预算管理和成本估算,结合 Prompt 布局优化(“稳定在前”原则)提升长 session 中的 cached token 比例