最近有个东西让我有点坐不住。
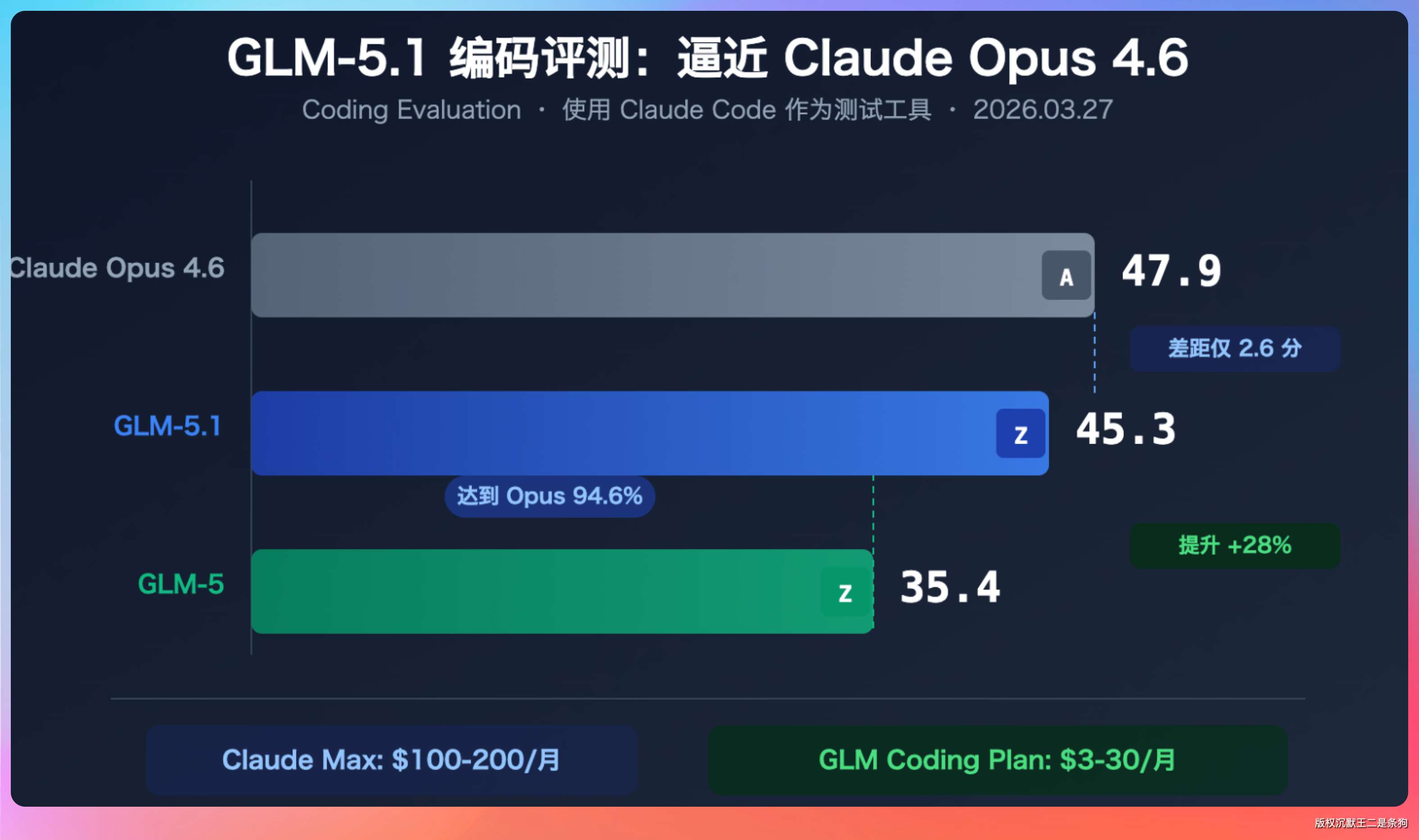
GLM-5.1 发布了,编程评测 45.3 分,直逼 Claude Opus 4.6 的 47.9。
光看跑分还不够,我得亲自下场测一测。
于是我给了它一个真实项目需求:从零开发一个在线简历编辑器——派简历。9 份需求文档、前后端完整开发、自动化测试,全程不让它停。
大约 11 分钟
最近有个东西让我有点坐不住。
GLM-5.1 发布了,编程评测 45.3 分,直逼 Claude Opus 4.6 的 47.9。
光看跑分还不够,我得亲自下场测一测。
于是我给了它一个真实项目需求:从零开发一个在线简历编辑器——派简历。9 份需求文档、前后端完整开发、自动化测试,全程不让它停。
大家好,我是二哥呀。
虽然只是一个小版本,但经过两天的高强度使用,GLM-5.1 给我的感受远不是 0.1 这个数字所能表达的。
它在长时间跨度、长链路依赖、多工具协同、强目标一致等关键能力上都令我印象深刻,仿佛吃了仙丹一样,Coding 方面的进化远超我的预期。
下面是我用 GLM-5.1 从 0 到 1 完成的一个 AI 智能简历生成 Agent——派简历的完整录屏测试。
【录屏】
咱们直接上实战。
系好安全带,咱们滴滴滴出发~
大家好,我是二哥呀。
这几天,大家应该都在忙着吃年夜饭、走亲访友。
各大AI厂商倒好,趁着春节假期,狠狠卷了一把。比如千问就在除夕夜发布了千问 Qwen3.5,整体表现又有了大幅提升。

测完之后,我有句话憋不住:大厂是真的能卷,国产大模型确实也在进步。
大家好,我是二哥呀。
就在刚刚。
偷偷打听到一个内部消息,说 DeepSeek V4 春节期间可能要上线(真不是狼来了),我立马就去测了一手。

看到结果的那一刻,我瞬间就热血沸腾了!
有一种 DeepSeek V1.0 当初发布的那种感觉——国产大模型终于追上了世界级水平。
大家好,我是二哥呀。
昨天深夜,前脚 DeepSeek V4 悄悄灰度,后脚 GLM-5 悄悄发布。
争先恐后,好不热闹。
我熬夜测了 6 小时,先上结论:GLM-5 就是目前最聪明的国产模型,没有之一。
以前我还会用Claude Opus 规划开发文档,用 GLM 4.7 去具体执行,但经过这一夜,我决定 All in GLM-5。
大家好,我是二哥呀。
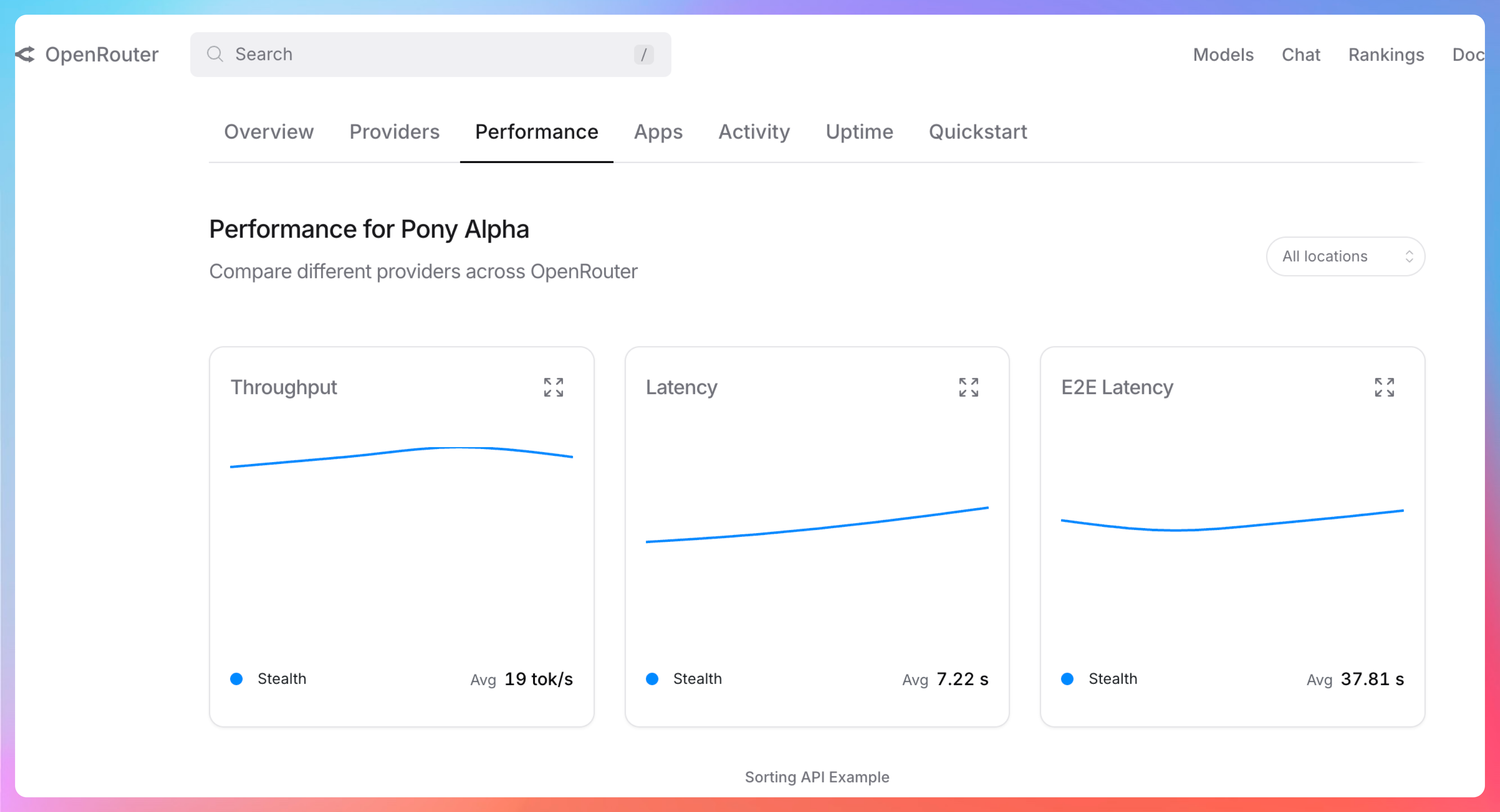
最近 AI 圈有个神秘模型在 OpenRouter 上悄悄火了。
Pony Alpha。
免费,能力强得离谱,外界都在猜它到底是不是 DeepSeek V4 的马甲。
我花了一个小时,用这个模型在 Claude Code 里做了一件事——从零开发一个 macOS 原生应用。全程用 Swift 语言,要知道我之前可是一行Swift代码都没写过。
大家好,我是二哥呀。
说实话,看到两家前后脚发布的消息,我第一反应是:这两家不会是商量好了吧?
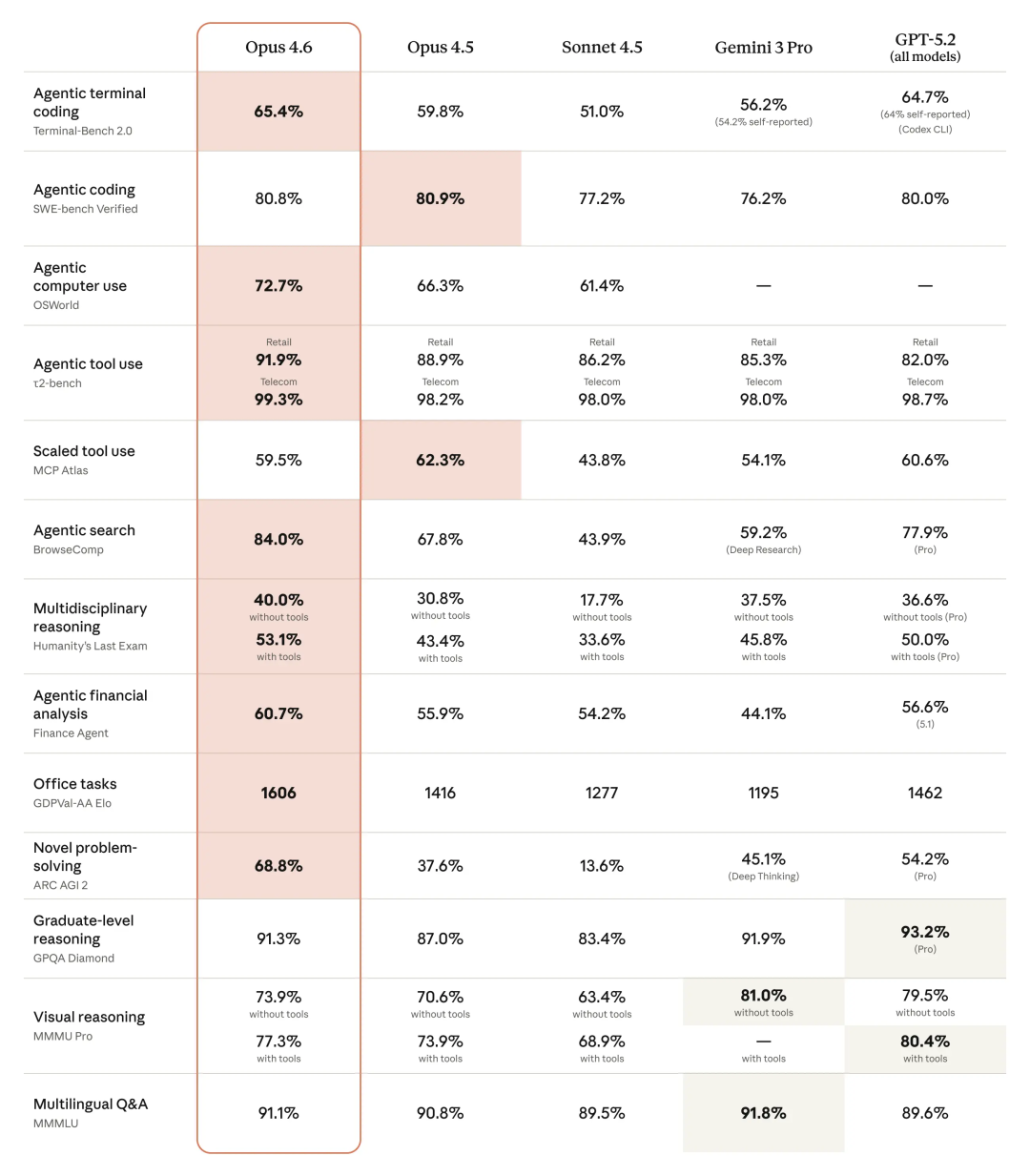
OpenAI和Anthropic几乎同一时间发布了新一代编程模型——GPT-5.3-Codex和Claude Opus 4.6。
大家好,我是二哥呀。
看到朋友轩辕做了一个特别有意思的网站,用 Gemini 做 SVG 动画,尤其是历史人物的一生足迹动图,能动态展示某人一生去过哪些地方、经历过什么大事。
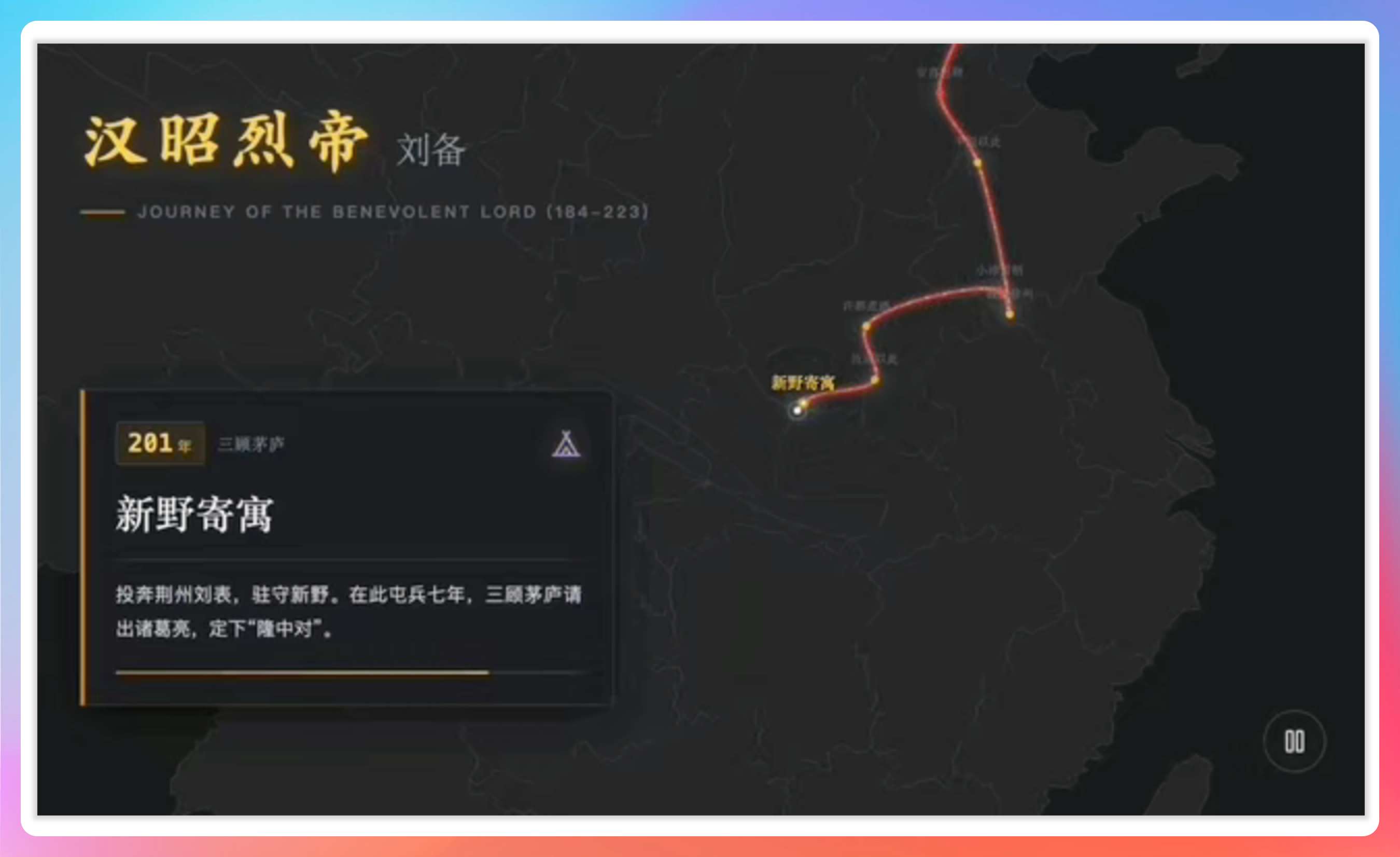
我看到后的第一个想法是,能不能用 Kimi 复刻一个版本。
大家好,我是二哥呀。
如果把时间拨回到 2023 年,AI 圈讨论最多的还是:谁更会聊天、谁更像人、谁能写诗。那时候的大模型,说白了就是"文本处理专家",你给它文字,它回你文字。
到了 2024 年,风向开始变了。GPT-4V、Gemini 这些模型开始能看图了,但它们的方式很简单:文本归文本团队管,图像归视觉团队管,最后把两个模块拼在一起,美其名曰"多模态"。
这就好像你公司里有个翻译团队,还有个设计团队,两个团队分别干活,最后老板说:"你俩合作一下吧"。
2026 年 1 月 22 日,百度正式发布了文心大模型 5.0,这一次他们选了一条完全不同的路——原生全模态。